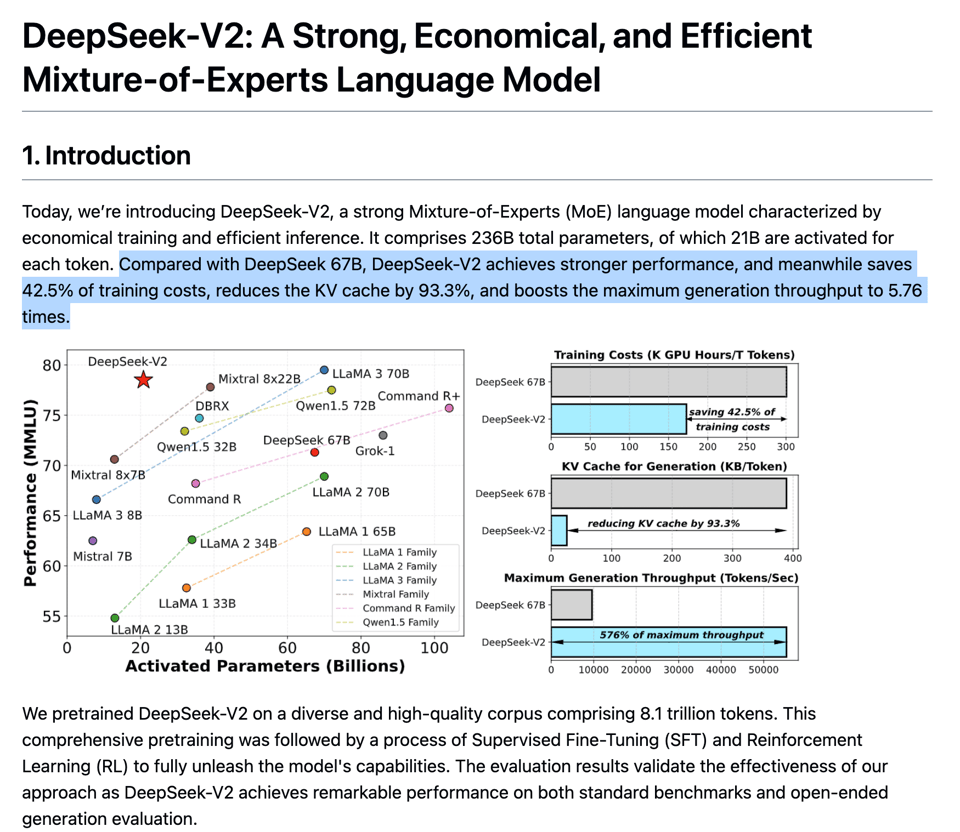
ainews-deepseek-v2-beats-mixtral-8x22b
DeepSeek-V2 性能超越 Mixtral 8x22B:拥有 160 多个专家,且成本仅需一半。
DeepSeek V2 推出了一款新型的顶尖混合专家(MoE)模型,拥有 2360 亿参数和一种新颖的多头潜在注意力(Multi-Head Latent Attention)机制,实现了更快的推理速度,并在 AlignBench 基准测试上超越了 GPT-4。Llama 3 120B 展示了强大的创意写作能力,而据报道,微软正在开发一个名为 MAI-1 的 5000 亿参数大语言模型。Scale AI 的研究强调了 Mistral 和 Phi 等模型中存在的过拟合问题,而 GPT-4、Claude、Gemini 和 Llama 则保持了基准测试的鲁棒性。在机器人领域,特斯拉 Optimus 凭借卓越的数据采集和远程操控技术取得进展,LeRobot 标志着向开源机器人 AI 的迈进,而英伟达的 DrEureka 则实现了机器人技能训练的自动化。此外,一项调查研究了多模态大语言模型的幻觉问题并提出了新的缓解策略,谷歌的 Med-Gemini 通过微调的多模态模型在医学基准测试中达到了业内领先(SOTA)的水平。
2024年5月3日至5月6日的 AI 新闻。我们为您查阅了 7 个 subreddit、373 个 Twitter 账号 和 28 个 Discord 社区(419 个频道,共 10335 条消息)。为您节省了预计阅读时间(以 200wpm 计算):1112 分钟。
更多专家就是你所需要的一切?
DeepSeek V2 突破了上个月的 Mistral 凸包 (Convex Hull):
关于数据集的信息非常少;他们只提到它是 8B tokens(是 DeepSeek v1 的 4 倍),其中中文比例比英文高出约 12%。
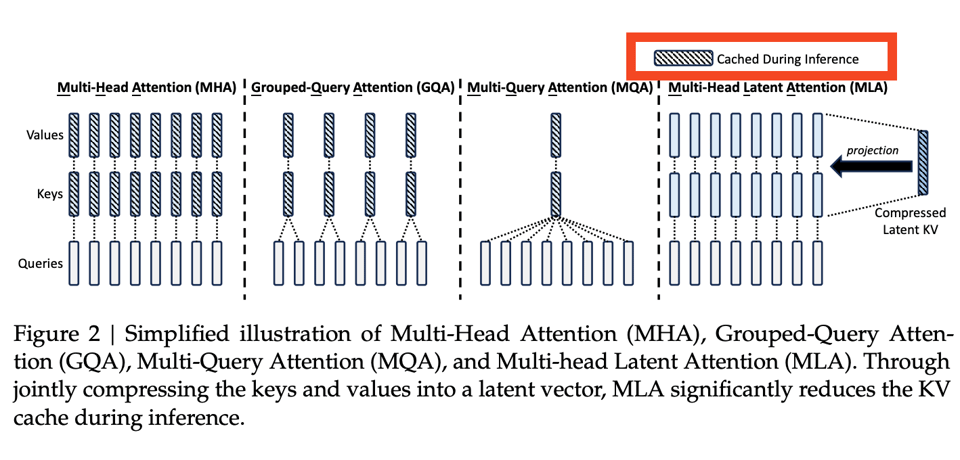
Snowflake Arctic 是我们之前见过的最后一个拥有最高专家数量(128 个)的超大型 MoE 模型;DeepSeek v2 现在设定了新的标杆,不仅扩展了 DeepSeekMOE 已经取得的成功,还引入了一种名为 Multi-Head Latent Attention 的新注意力变体。
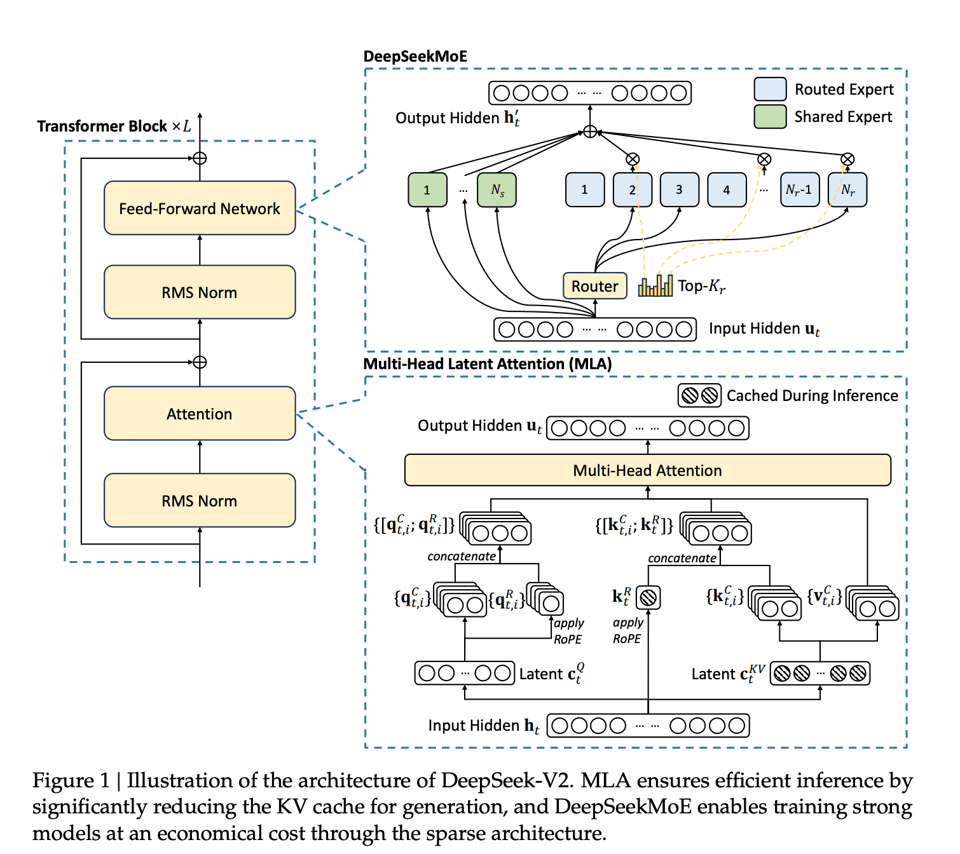
通过缓存压缩后的 KV(“减少了 93.3% 的 KV cache”),这显著提升了推理速度。
论文详细介绍了他们发现有效的其他小技巧。
DeepSeek 正在用实际行动证明自己——他们在平台上提供的 token 推理价格为每百万 token 0.28 美元,大约是 2023 年 12 月 Mixtral 价格战 中最低价格的一半。
目录
[TOC]
AI Twitter 回顾
所有摘要均由 Claude 3 Opus 完成,从 4 次运行中择优。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
LLM 进展与发布
- Llama 3 发布:@erhartford 指出 Llama 3 120B 比 Opus 更聪明,并对 llama3-400b 充满期待。@maximelabonne 分享道,Llama 3 120B 在创意写作方面优于 GPT-4,但在推理方面逊于 L3 70B。
- DeepSeek-V2 发布:@deepseek_ai 推出了 DeepSeek-V2,这是一款开源 MoE 模型,在 AlignBench 中位列前三,超越了 GPT-4。它拥有 236B 参数,生成过程中仅激活 21B。
- 来自 Microsoft 的 MAI-1 500B:@bindureddy 预测 Microsoft 正在训练自己的 500B 参数 LLM,名为 MAI-1,可能会在 Build 大会上预展。一旦发布,它将与 OpenAI 的 GPT 系列展开竞争。
- Mistral 和开源 LLM 的基准测试过拟合问题:@adcock_brett 分享了 Scale AI 发布的研究,揭示了 Mistral 和 Phi 等某些 LLM 在流行 AI 基准测试中存在“过拟合”现象,而 GPT-4、Claude、Gemini 和 Llama 则表现稳健。
机器人与具身智能 (Embodied AI)
- Tesla Optimus 更新:@DrJimFan 祝贺 Tesla Optimus 团队的更新,指出他们的人类数据采集场是 Optimus 最大的领先优势,拥有顶级的机械手、远程操作软件、庞大的车队以及精心设计的任务和环境。
- LeRobot 开启开源机器人技术:@ClementDelangue 欢迎由 @remicadene 及其团队开发的 LeRobot,这标志着机器人 AI 向开源方向的转变。
- 来自 Nvidia 的 DrEureka:@adcock_brett 分享了 Nvidia 的 “DrEureka”,这是一个 LLM Agent,可以自动编写代码来训练机器人技能,用于在模拟中训练机器狗的技能,并将其零样本(zero-shot)迁移到现实世界。
多模态 AI 与幻觉
- 多模态 LLM 幻觉综述:@omarsar0 分享了一篇论文,对多模态 LLM 中的幻觉进行了综述,讨论了在检测、评估、缓解策略、原因、基准测试、指标和挑战方面的最新进展。
- 来自 Google 的 Med-Gemini:@adcock_brett 报道了 Google 推出的 Med-Gemini,这是一个针对医疗任务进行微调的 AI 模型系列,在文本、多模态和长上下文应用的 14 个基准测试中,有 10 个达到了 SOTA。
新兴架构与训练技术
- Kolmogorov-Arnold Networks (KANs):@rohanpaul_ai 强调了一篇论文,提议将 KANs 作为 MLPs 的替代方案来逼近非线性函数,其表现优于 MLPs,且在不使用线性权重的情况下拥有更快的 neural scaling laws。
- 用于 Parameter-Efficient Finetuning 的 LoRA:@rasbt 从零开始实现了 LoRA,用于训练一个在 SPAM 分类中达到 98% 准确率的 GPT 模型,并指出 LoRA 是他最喜欢的 LLMs 参数高效微调技术。
- 带有 Expert Router 的混合 LLM 方法:@rohanpaul_ai 分享了一篇关于高性价比混合 LLM 方法的论文,该方法使用 Expert Router 将“简单”查询引导至较小的模型,以在保持质量的同时降低成本。
基准测试、框架和工具
- 从 PyTorch Lightning 导出 TorchScript 模型:@rohanpaul_ai 指出,使用
to_torchscript()方法从 PyTorch Lightning 导出和编译模型到 TorchScript 非常顺畅,能够为非 Python 环境实现模型序列化。 - 带有 Whisper 和 Diarization 的 Hugging Face Inference Endpoints:@_philschmid 为 Hugging Face Inference Endpoints 创建了一个优化的 Whisper(支持发言人日志),利用 flash attention、speculative decoding 和自定义处理器,在 1x A10G GPU 上实现了 60 秒音频仅需 4.15 秒的转录。
- 用于复杂 AI Agents 的 LangChain:@omarsar0 分享了一个 2 小时的免费研讨会,内容是使用 LangChain 构建复杂的 AI Agents,用于自动化客户支持、营销、技术支持、销售和内容创作中的任务。
趋势、观点和讨论
- LLMs 商品化:@bindureddy 认为 LLMs 已经成为一种商品,即使 GPT-5 非常出色,其他主要参与者也会在几个月内赶上。推理价格将趋于下降,表现最好的 LLM 每隔几周就会更替。最佳策略是使用 LLM-agnostic 服务,并从基础模型转向构建 AI Agents。
- 读写能力与技术:@ylecun 分享了对不同时期人们对阅读和技术态度转变的观察,从 1900 年的“你为什么不去耕田而是读书?”到 2020 年的“你为什么不去玩平板而是看电视?”。
- 基础研究资助:@ylecun 认为,几乎所有拨给大学的联邦资金都流向了 STEM 和生物医学研究,社会科学得到的很少,人文科学几乎为零。削减这些资金将“杀掉下金蛋的鹅”,并可能导致生命损失。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 发展与能力
- Tesla Optimus 进展:在 /r/singularity 中,一段新视频展示了 Tesla Optimus 机器人的最新能力,包括手部精细触觉和力觉感知。讨论围绕机器人的当前速度限制,以及一旦达到人类工人的“20倍速率”,在工厂进行 24/7 全天候运行的潜力。
- Sora AI 视频渲染:在 /r/singularity 中,AI 系统 Sora 展示了在更改单个元素的同时渲染视频的能力,尽管该功能仍处于研究阶段,尚未公开发布。
- GPT-4 训练的机器人狗:在 /r/singularity 中,一只使用 GPT-4 训练的机器人狗展示了其在滚动且放气的瑜伽球上保持平衡的能力,体现了 AI 驱动的机器人技术和平衡控制方面的进步。
- 算力与 AI 里程碑:在 /r/singularity 中,Microsoft CTO Kevin Scott 认为 AI 里程碑成就的共同因素是使用了更多算力。讨论还涉及 Llama 3 400b 的潜力,由于其在 25,000 块 H100 上训练,而据报道 GPT-4 仅使用了 10,000 块 A100,因此其表现可能超越 GPT-4。
- LLaMA 70B 性能:在 /r/singularity 中,一位用户报告在配备 4 年前 3090 GPU 的 7 年老旧 PC 上运行 Llama 3 70B,在某些情况下获得了比 GPT-4 和 Claude 3 更好的响应。该帖子强调了拥有一个无需互联网连接且能提供高质量输出的高智能 AI 的意义。
社会影响与担忧
- 公众对 AI 生成图像的认知:在 /r/singularity 中,一项调查显示一半的美国人不知道 AI 可以生成逼真的人物图像,这引发了关于人们在不知情的情况下接触了多少 AI 生成图像的问题。评论讨论了美国公众普遍缺乏相关知识的现状。
- AI 与全民富足:在 /r/singularity 中,一则帖子质疑了AI 将导致全民富足的信念,认为 AI 可能会巩固现有的权力结构并加剧不平等。作者认为这种转变将是渐进的,失业率和生活成本会随着时间的推移缓慢增加,直到灾难发生。
- 沃伦·巴菲特对 AI 的担忧:在 /r/StableDiffusion 中,沃伦·巴菲特将 AI 比作原子弹,强调了其在诈骗方面的潜力,并对 AI 的力量表示担忧。评论讨论了 AI 的双重性质,将其与电力的出现进行类比,既有积极影响也有消极影响。
{kind=link}
AI 应用与发展
- AI 在医疗笔记记录中的应用:在 /r/singularity 中,安大略省的一位家庭医生报告称,AI 驱动的笔记记录显著改善了她的工作并保住了她的职位,突显了 AI 辅助医疗文档记录的潜力。
- Optimus 手部进展:在 /r/singularity 中,Elon Musk 宣布将于今年晚些时候发布的新版 Optimus 手部将拥有 22 个自由度 (DoF),比之前的 11 个 DoF 有所增加。
- AI 训练与推理的未来:在 /r/singularity 中,Nvidia CEO 预测未来AI 训练和推理将成为一个单一过程,使 AI 能够在与用户互动的同时进行学习。该视频被推荐为关注 AI 发展人士的有趣内容。
迷因与幽默
- AI 训练与奇怪的结果:在 /r/StableDiffusion 中,一张迷因图片暗示在不寻常或非传统的图像上训练 AI 会导致奇怪的结果。
- 精致的香蕉:在 /r/StableDiffusion 中,一个幽默的图片帖子展示了一根精致的香蕉。
- 安全团队建议:在 /r/StableDiffusion 中,一段视频迷因描绘了一个恶作剧,一个人的椅子被从身后抽走,导致其摔倒。评论讨论了该恶作剧的危险性以及造成严重伤害的可能性。
{kind=link}
{kind=link}
AI Discord 摘要
摘要之摘要的摘要
-
Llama3 GGUF 转换挑战:用户在使用 llama.cpp 将 Llama3 模型转换为 GGUF 格式时遇到问题,训练数据丢失与精度无关。换行符的 Regex 不匹配被认为是潜在原因,影响了 ollama 和 lm studio 等平台。社区成员正在协作进行 regex 修改等修复工作。
-
GPT-4 Turbo 性能担忧:OpenAI 用户报告了 GPT-4 Turbo 显著的延迟增加以及对消息上限阈值的困惑,部分用户经历了 5-10 倍的响应速度变慢,且上限在 25-50 条消息之间。相关理论认为这是高峰时段的动态调整。
-
Stable Diffusion 安装困扰:Stability.ai 社区成员在 Stable Diffusion 设置无法访问 GPU 资源方面寻求帮助,遇到了如 “RuntimeError: Torch is not able to use GPU” 的错误。讨论还涉及缺乏全面且最新的 LoRA/DreamBooth/微调教程。
-
Hermes 2 Pro Llama 3 的上下文表现令人印象深刻:Hermes 2 Pro Llama 3 在使用 vLLM 和 RoPE 缩放的 32GB Nvidia v100 Tesla 上展示了约 32k 的上下文,具有完美的 16k token 召回且无衰减。通过编辑
config.json和 RoPE 缩放因子可以实现扩展上下文。 -
Perplexity AI 的 Pages 功能引起关注:Perplexity AI 用于创建综合报告的新 Pages 功能引发了热议,同时用户对 Claude 3 Opus 每天 50 条消息的限制表示沮丧,相比之下 GPT-4 Turbo 和 Sonnet 的限制较少。讨论还涉及 Perplexity 从无限消息向有限消息的转变。
-
LM Studio 启用 Headless 模式:LM Studio 用户利用
lmsCLI 工具在 GUI 之外进行 headless 操作,排查内存异常并为平滑的服务器端部署制定策略,从而避免通过 RDP 消耗 VRAM。微调瓶颈也被讨论,一名成员报告在 128GB M3 Max MacBook Pro 上成功进行了 8 小时的微调。 -
CUDA 编译与多 GPU 训练挑战:CUDA 开发者遇到
nvcc 11.5在旧款 GPU 上进行 bfloat16 操作报错的问题,并提出了一个修复方案以手动处理算术运算实现向后兼容。正如 Issue #369 所述,最近的提交还导致了多 GPU 训练挂起,目前有一个独立分支维持功能正常。 -
Mojo 编译器与类型系统演进:Mojo 的 nightly 编译器更新带来了符合当前实践的变化,不再采用 80 列宽限制,并向可寄存器传递类型(register passable types)转型。讨论涉及逐步淘汰
OptionalReg,转而支持指示寄存器传递能力的 traits,详见 changelog。 -
HuggingFace 社区亮点:HuggingFace 社区中值得关注的项目包括 Moondream 2 批处理、FLUENT 的最新迭代、HF 音频课程章节的葡萄牙语翻译,以及针对长标题的 BLIP 微调。完整列表可在社区亮点中查看。
-
Eleuther 探讨 Transformer 的国际象棋实力:一篇 arXiv 论文展示了一个 270M 参数的 Transformer 模型在没有特定领域算法的情况下,在国际象棋中超越了 AlphaZero 的策略和价值网络,这引发了 Eleuther 社区关于规模对策略游戏影响的讨论。
第 1 部分:高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
Llama3 的 GGUF 转换小故障:Unsloth 社区在使用 llama.cpp 处理 Llama3 模型时遇到了转换问题,特别是在转换为 GGUF 格式时影响了训练数据。问题不仅限于 FP16 转换,这暗示了除了精度损失之外,还存在更深层的底层问题。
换行符引发的大问题:故障中的一个反复出现的主题与换行符的 Tokenization 有关,不同正则表达式库(regex libraries)之间的行为差异导致了不稳定的 tokenizer.json 模式。社区正在探索涉及正则表达式修改的潜在解决方案,以修复 GGUF 转换挑战。
Llama 变体挑战基因组数据:M.chimiste 推出的 LLaMA-3-8B-RDF-Experiment 模型标志着将 LLM 与基因组数据和知识图谱构建相结合的尝试。
对视觉语言模型微调工具的需求:社区提出了对视觉语言模型(LVLM)通用微调方法的需求,一位成员表达了对支持 Moondream 的兴趣,详见其 GitHub notebook。
展示与分享平台的增长:关于设立专门的 LLM 部署讨论频道的提案突显了对共享学习的需求。这与 Oncord 集成 Unsloth AI 用于 Web 开发 AI 工具的展示,以及增强 Llama-3 能力的模型发布相契合。
OpenAI Discord
Perplexity AI 凭借 Pages 功能领先:Perplexity AI 新推出的 Pages 功能因其创建综合报告的能力而备受关注。与此同时,随着工程师们讨论投资回报递减的问题,对于 GPT-5 潜力的怀疑态度也随之产生。
AGI 概念引发辩论:Discord 上的 AI 社区陷入了关于 AGI 定义以及像 ChatGPT 这样的 AI 模型是否是 AGI 先驱版本的辩论。对 AI 生成音乐的兴趣表明,人们对创意 AI 应用的需求日益增长,并提到了 Udio 等服务。
GPT-4 Turbo 遭遇性能瓶颈:据报告,GPT-4 Turbo 的响应延迟显著增加,用户正在寻求关于不一致的消息上限阈值的解释,这表明在高峰时段可能存在动态调整。
Prompt Engineering 的挑战与策略:工程师们分享了经验和资源,推荐了 Teddy Dicus Murphy 的 “Wordplay” 以获取 Prompt 创作见解,并深入探讨了在 OpenAI API 中使用 logit bias 来操纵 Token 概率的复杂性。
为查询微调 AI:一场热烈的讨论围绕着微调模型以生成问题而非答案展开,包括改进用于提取产品信息的 GPT-4-TURBO Prompt 的策略,并辅以 logit bias 教程的支持。
Stability.ai (Stable Diffusion) Discord
-
GPU 问题成为焦点:成员们报告了 Stable Diffusion 安装程序无法访问 GPU 资源的问题,具体表现为 “RuntimeError: Torch is not able to use GPU” 等错误。
-
Stable Diffusion 3 传闻引发热议:关于 Stable Diffusion 3 发布的预期不断升温,引发了对其潜在延迟影响的辩论,而怀疑者则对其是否真的会发布表示质疑。
-
微调教程的缺失:社区对缺乏关于 LoRA/DreamBooth/fine-tuning 等技术的最新、全面教程感到沮丧,许多人发现现有教程要么过时,要么细节匮乏。
-
追求独特的面孔:一位成员询问了训练 AI 生成独特、真实面孔的策略,纠结于是对多张面孔使用 LoRA,还是在生成的随机面孔基础上进行训练。
-
开源障碍讨论:对话转向了 Stable Diffusion 开源承诺的真实性,人们担心未来高质量模型、Checkpoints 和训练细节可能会被设置门槛。
Nous Research AI Discord
- SVM 在 AI 圈内依然活跃:Discord 成员在技术闲聊中澄清,SVM 代表 Support Vector Machine(支持向量机)。
- 对 Meta-Llama-3-120B-Instruct 的期待:Hugging Face 上的 Meta-Llama-3-120B-Instruct 模型引发了对其潜力的讨论,用户呼吁进行全面的 Benchmarking(基准测试),而非仅仅依赖炒作。
- 部署困境:用户讨论了 Serverless Llama 的局限性,同时探讨了具备充足 VRAM 的更好 GPU 选项,例如 Azure 的 NC80adis_H100_v5,以处理大上下文任务需求。
- Hermes 2 令人印象深刻的性能表现:Hermes 2 Pro Llama 8B 展示了惊人的约 32k 扩展上下文容量且无明显衰减,在 32GB 的 Nvidia v100 Tesla 上实现了 16k 的完美 Recall(召回)。
- Cynde 助力数据耕作:分享了关于 Cynde 的更新,标志着其核心实现的完成。社区对这个用于 Intelligence Farming(智能耕作)的框架表现出极高热情,Cynde 的 GitHub 仓库 欢迎贡献者加入。
Perplexity AI Discord
-
Pages Beta 不再开放申请:由于参与人数已满,Pages 的 Beta 测试申请阶段已经结束。关于 Pages 的后续更新将另行通知。
-
关于 Perplexity AI 性能与限制的热烈讨论:成员们遇到了 Claude 3 模型响应速度慢的问题,并对 Claude 3 Opus 模型每天 50 条消息的限制表示沮丧。在将 Opus 与 GPT-4 Turbo 及 Sonnet 进行对比时,用户还对 Perplexity 从无限量转向受限的消息能力表示担忧。
-
探索 AI 的创意与新颖用途:Perplexity AI 社区正积极探索该平台在图像生成、模仿小说写作风格以及多样化搜索方面的能力,例如挖掘 BASIC 编程语言的历史或深入研究 Perplexity 自身的发展史。
-
API 探索与灵活调整:用户讨论了模型迁移,特别是从 sonar-medium-online 切换到 llama-3-sonar-large-32k-online,并询问了潜在的计费不一致问题。对话还涉及了 AI 结果优化的成功与困扰,以及使用 Perplexity API 创建极简代码 Telegram 机器人的建议。
-
多渠道搜索查询分享:社区分享了多个搜索查询及其结果,引发了关于 Perplexity 的有效使用及其提供见解深度的讨论。这些探索涵盖了从编程历史到专有技术见解的各种背景。
LM Studio Discord
-
无头模式(Headless)进展:工程师们正在利用 LM Studio 的 CLI 工具
lms进行无头操作,并与 GUI 版本配合使用。他们正在解决内存消耗异常的问题,并讨论在不通过 RDP 消耗 VRAM 的情况下实现平滑服务器端部署的策略。 -
微调技巧与模型故障:成员们正在排查微调瓶颈,分享在 128GB M3 Max MacBook Pro 等硬件上进行长时间微调的成功案例,并讨论困扰 Llama 3 等模型的输出不一致问题。
-
交互意图与 AI 记忆怪癖:用户表达了一个令人困惑的观察结果,即语言模型可能会保留已删除 Prompt 元素的上下文,这暗示了潜在的 Bug 或对模型行为的误解。他们探索了个性化写作风格的交互技术,并为 LLM 实现了对文档部分的“作用域访问(scoped access)”。
-
角色扮演无限制?没那么快:围绕 AI 与 RPG 结合的讨论非常热烈,用户目标是将 AI 训练为 D&D 的地下城主(Dungeon Masters),并指出现有系统受限于内容审核,这可能会影响故事的黑暗程度和深度。
-
ROCm 赞誉与 Linux 热情:ROCm 的更新表现稳健,但讨论也涉及了模型转换和为 Embeddings 发送更长序列的挑战。对话转向社区对贡献 Linux ROCm 构建版本的兴趣,暗示如果项目寻求更多开源协作,将会有进一步的参与。
-
硬件前沿的 AI:成员们投入到激烈的硬件交流中,对比了 Tesla P40 等旧款 GPU 相对于 GRID K1 的适用性,并痴迷于以 AI 为中心的家庭实验室中多 GPU 设置的细节。具体细节涵盖了从服务器硬件采购到散热、电源和驱动兼容性等问题。
-
LM Studio 最新阵容:
lmstudio-community仓库已更新了 CodeGemma 1.1 和 Nvidia 的 ChatQA 1.5 模型,前者引起了热切期待,而后者提供了专为基于上下文的问答(Q/A)应用量身定制的专业模型。
CUDA MODE Discord
BackPACK 表现强劲:BackPACK 是一个用于从反向传播中提取额外信息的 PyTorch 扩展工具,讨论强调了它对 PyTorch 开发者的潜力。详情见 Dangel 等人 2020 年发表的论文 “BackPACK: Packing more into Backprop”。
DoRA 在融合方面表现出色:一个新的 fused DoRA layer implementation 减少了单个 kernel 的数量,并针对 GEMM 和 reduction 操作进行了优化,详见 GitHub pull request。社区对即将发布的针对这些增强功能的 benchmark 表示期待。
自定义 CUDA 扩展的定制化:成员们讨论了安装自定义 PyTorch/CUDA 扩展的最佳实践,分享了多个 GitHub pull requests(如 PR#135)和一个示例 setup.py 以供参考,旨在简化安装过程。
利用 CUTLASS 稳步前行:围绕 CUTLASS 中使用的 stream-K 调度技术引起了广泛关注,并建议在未来的演讲中深入探讨其工作原理。
GPU 通信课程:宣布了即将举行的关于使用 NCCL 进行 GPU 集体通信(Collective Communications)的会议,重点关注分布式 ML 概念。
必读的 ML 系统论文:对于机器学习系统的新手,GitHub 上的 ML Systems Onboarding list 提供了一系列精选的参考论文。
克服 CUDA 编译难题:针对 nvcc 11.5 在 bfloat16 操作中报错的问题,已在 fix proposal 中提出解决方案,旨在支持旧版 GPU 和工具包。还讨论了多 GPU 训练挂起的问题,涉及 Issue #369,并有一个独立分支维持功能。
LLaMa 的精简学习:关于 LLaMa 2 70B 模型训练 期间内存效率的讨论强调了可以减少内存使用的配置。提到了一个名为 HTA 的工具,用于定位 PyTorch 中的性能瓶颈。
量化带来的后训练巅峰:分享了一个 YouTube 视频,详细介绍了 PyTorch 中量化的过程和优势。
GreenBitAI 走向全球:介绍了一个名为 green-bit-llm 的工具包,用于微调和推理 GreenBitAI 的语言模型。BitBlas 因其快速的 2-bit 操作 gemv kernel 而受到关注,同时 GreenBitAI 的工具包中还包含一种独特的梯度计算方法。
Modular (Mojo 🔥) Discord
收看 Mojo 直播,获取 MAX 24.3 更新:Modular 的新直播视频 “Modular Community Livestream - New in MAX 24.3” 邀请社区探索 MAX Engine 和 Mojo 的最新功能,并介绍了 MAX Engine Extensibility API。
社区项目飞速发展:值得关注的更新包括 NuMojo 性能的提升以及用于图像解析的 Mimage 的推出。Basalt 项目也达到了 200 stars 的里程碑,并发布了新的 文档。
Mojo 编译器不断演进:Mojo 编译器迎来了 nightly updates,其更改更符合当前实践,例如放弃了 80 列宽度限制,并向更适合寄存器传递(register passability)的类型过渡。
AI 工程师探索 Don Hoffman 的意识研究:对加州大学欧文分校(UCI)Donald Hoffman 关于意识研究工作的兴趣与 AI 产生了关联,人们在裂脑患者的感官数据限制与 AI 幻觉(hallucinations)之间找到了相似之处。
Mojo 生态系统的成长与开发者指导:讨论了 Mojo 的贡献流程,符合 GitHub 的 pull request 指南,并通过 参数教程 深入了解开发工作流,展示了对快速扩张的 Mojo 生态系统贡献者的积极支持。
HuggingFace Discord
Moondream 和 BLOOM 掀起波澜:HuggingFace 社区聚焦了多项新进展,包括 Moondream 2 批处理 和 FLUENT 的最新迭代,以及多语言支持工具。特别值得关注的是 BLOOM 多语言聊天 和 AutoTrain 对 YAML 配置的支持,这简化了机器学习初学者的训练流程。查看 社区亮点。
当音频模型开始歌唱:人们对用于生成式音乐的音频扩散模型产生了浓厚兴趣,Whisper 正在针对菲律宾语 ASR 进行微调,并引发了关于优化的讨论。然而,一位用户在将 PyTorch 模型转换为 TensorFlow Lite 时因尺寸限制遇到了挑战。
AI 的前线:网络安全成为焦点,Hugging Face Twitter 账号被盗,强调了对稳健的 AI 相关安全性的需求。成员们还交流了 GPU 利用率技巧,以应对不同配置间训练时间的差异。
量子与 AI 结合的愿景:在 computer vision 领域,重点在于改进传统方法,如使用 YOLO 进行汽车零部件的缝隙检测,以及调整 CLIP 等模型以识别旋转物体。GhostNet 的预训练权重备受追捧,CV 成员们也在思考 SURF 和 SIFT 等方法在当代的适用性。
图论专家齐聚:近期关于将 LLM 与图机器学习结合的论文提出了新颖的整合方式,其中一篇 论文 专门教学 LLM 仅在需要时通过 <RET> 标记检索信息。阅读小组 为渴望学习更多知识的人提供了额外资源。
展示合成与应用 AI:在 #i-made-this 板块,发布了 Podcastify 和 OpenGPTs-platform 等工具,以及使用 mergekit 构建的 shadow-clown-BioMistral-7B-DARE 等模型。
NLP 者的疑惑与查询:在 NLP 板块,一位用户为 Mistral-7B-instruct 的定制训练提供报酬,同时也有人对 LLM 评估其他 LLM 表示担忧。介绍了使用 GPT 3.5+ 衡量翻译质量的 GEMBA 指标,并提供了了解更多的链接。
OpenInterpreter Discord
将 OpenInterpreter 与 Groq LLM 集成:工程师们讨论了将 Groq LLM 集成到 Open Interpreter 上的挑战,强调了输出不可控和错误文件创建等问题。分享的连接命令为 interpreter --api_base "https://api.groq.com/openai/v1" --api_key "YOUR_API_KEY_HERE" --model "llama3-70b-8192" -y --max_tokens 8192。
微软黑客松寻求 Open Interpreter 爱好者:一个团队正在组建以参加使用 Open Interpreter 的微软开源 AI 黑客松(Microsoft Open Source AI Hackathon);该活动承诺提供实操教程,报名详情请见此处。
Open Interpreter 的 iOS 重构:讨论围绕在 Open Interpreter 上为 iOS 重新实现 TMC 协议,以及解决 Azure Open AI 模型的设置问题,一位成员分享了正在开发的 iOS 应用的 GitHub 仓库链接,见此处。
本地 LLM 挑战开发者:分享了对 Phi-3-mini-128k-instruct 等本地 LLM 的个人测试,结果显示出显著的性能差异,并呼吁在未来的实现中采用更好的优化方法。
AI Vtuber 的 STT 难题:为 AI 驱动的虚拟主播实现 Speech-to-Text 带来了实际挑战,工程师们考虑使用触发词,并致力于通过独立的 LLM 实例实现 AI 驱动的 Twitch 聊天互动,旨在获得全面的回复。对于正在处理类似集成的开发者,一位成员指出了其 GitHub 上的 main.py 文件作为参考资源。
Eleuther Discord
-
国际象棋特级大师请注意,Transformers 来了:一项新研究揭示了一个拥有 270M 参数的 Transformer 模型在没有领域特定算法的情况下,在国际象棋领域超越了 AlphaZero 的策略和价值网络,引发了关于 Scale 在策略游戏中有效性的讨论。
-
LLM 研究在多语言和 Prompting 技术方面蓬勃发展:研究亮点包括一项关于 LLM 处理多语言输入的研究,以及尽管对其实用性存在质疑,但“Maieutic Prompting”在处理不一致数据方面的潜力。该领域的贡献提供了见解和论文链接,例如 How Mixture Models Handle Multilingualism 以及对抗 LLM 漏洞的方法,包括 The Instruction Hierarchy 论文。
-
显微镜下的模型性能:迁移学习的 Scaling Laws 表明,预训练模型通过有效的迁移数据在固定大小的数据集上有所提升,这与社区在确定 LLM In-context Learning 的准确衡量标准和性能评估方法方面的努力相呼应。
-
解释 Transformers 并提高可部署性:分享了关于解释基于 Transformer 的 LLM 的入门指南和综述,以及关于跨模型泛化的讨论。社区对解决 Phi-2 和 Mistral-7B 等模型中的 Weight Tying 问题表现出浓厚兴趣,并澄清了关于知名开源模型中 Weight Tying 的误解。
-
社区参与 ICLR 和求职:尽管面临旅行挑战,ICLR 线下聚会的准备工作正在展开;社区支持显而易见,成员们分享了就业资源以及参与 OSLO 和 Polyglot 团队等项目的经验。
OpenRouter (Alex Atallah) Discord
-
Llama 家族新成员:Llama 3 Lumimaid 8B 模型已发布,同时还提供 扩展版,而 Llama 3 8B Instruct Extended 则迎来了降价。由于服务器更新,Lynn 系列模型宣布了短暂的停机。
-
高端 AI 招募 Beta 测试员:Rubik’s AI Pro 是一款先进的研究助手和搜索引擎,正在招募 Beta 测试员,提供 2 个月的尊享访问权限,包括 GPT-4 Turbo 和 Mistral Large 等模型。该项目可通过 此处 使用促销代码
RUBIX访问。 -
混合搭配模型:社区成员报告称 Gemini Pro 现在已无错误,并讨论了 Lumimaid 70B 的潜在托管方。Phi-3 等模型备受期待,但供应稀缺。不同供应商的模型精度各异,大多数使用 fp16,部分使用量化的 int8。
-
模型合并:对话重点介绍了 Hugging Face 上新创建的 Meta-Llama 3 70B 自合并版本,引发了关于自合并(Self-merges)与传统层映射合并(Layer-mapped merges)效果的辩论。
LlamaIndex Discord
提升 Agent 智能:LlamaIndex 0.10.34 引入了 introspective agents(内省型智能体),能够通过反思机制实现自我改进。详情见 notebook,该内容包含敏感材料警告。
Agentic RAG 升级:一段教学视频展示了如何集成 LlamaParse + Firecrawl 来构建 agentic RAG 系统,发布详情可通过 此链接 查看。
信任评分的 RAG 响应:@CleanlabAI 的 “Trustworthy Language Model” 引入了一套针对 RAG 响应可信度的评分系统,旨在确保生成内容的准确性。更多见解请参考其公告 此处。
本地 RAG 流水线手册上架:为寻求摆脱云服务的开发者,一份使用 LlamaIndex 搭建全本地 RAG 流水线的手册现已发布,承诺比快速入门指南更深入,可在此处访问 此处。
Hugging Face 与 LlamaIndex 深度集成:LlamaIndex 宣布支持 Hugging Face TGI,从而在 Huggingface 上实现语言模型的最优部署,并增强了 function calling 和延迟优化等功能。点击 此处 了解 TGI 的新功能。
创建对话式 SQL Agents:AI 工程师正在考虑使用 HyDE 为拥有大量表格的数据库构建 NL-SQL bots,旨在提高 LLM 生成 SQL 查询的精确度;同时,introspective agent 方法论也引起了关注,更多阅读见 Introspective Agents with LlamaIndex。
OpenAccess AI Collective (axolotl) Discord
Hermes 2 Pro Llama 3 速度测试结果:Hermes 2 Pro Llama 3 在配备 8GB RAM 的 Android 设备上展示了令人印象深刻的 inference speed(推理速度),这得益于 llama.cpp 的增强。
动漫在 AI 对话中的角色:成员们幽默地讨论了 anime(动漫)的兴起与 AI question-answering(问答)及 image generation(图像生成)任务能力提升之间的关系。
Gradio 定制化成果:Gradio 的调整现在允许通过 YAML file 进行动态配置,从而能够以编程方式设置隐私级别和服务器参数。
AI 训练数据集备受关注:讨论了一个包含 143,327 个经过验证的 Python 示例的新数据集(Python Dataset),以及即使使用以数学为中心的数据集,提升 Llama3 数学性能仍面临困难,凸显了 AI 训练中数据集的挑战。
AI 训练平台的增强与需求:有人呼吁完善 Axolotl 的文档,特别是关于合并模型权重和模型推理的部分,可在 Axolotl Community Docs 访问。此外,还解决了 gradient clipping(梯度裁剪)配置的问题,Phorm 提供了关于为 gradient clipping 和 chatbot prompt 定制 TrainingArguments 的见解。
Latent Space Discord
-
Gary 玩转 Ableton:一个新的开发中 Python 项目 gary4live 将 Python continuations 与 Ableton 集成用于现场音乐表演,邀请社区贡献和同行评审。
-
Suno 扩大音乐制作规模:关于使用 Suno 进行音乐生成的讨论包括与 Musicgen 等其他设置的比较,重点是 Suno 的音频 tokenization 过程,并探索这些模型是否能自动生成乐谱。
-
Token 探讨:深入探讨音乐模型的 token 结构,参与者研究了音频合成中的 token 长度和组成,引用了学术论文中的特定架构设计但未展开细节。
-
打破音频合成的障碍:讨论了将音频直接集成到多模态模型中的潜力,重点是音频通道的实时替换以及直接音频对实现全模态(omnimodal)功能的重要性。
-
Stable Audio 的商业节奏:出现了关于稳定音频模型输出的商业用途和许可问题,特别关注其在现场表演中的实时应用以及对行业的潜在影响。
AI Stack Devs (Yoko Li) Discord
-
本地硬件攻克 AI 任务:用户现在可以使用 llama-farm 在旧笔记本电脑上本地运行 Ollama,以处理 LLM 任务,而无需将其暴露在公共互联网中。这还关联到了一个 GitHub 仓库,其中包含更多实现细节(GitHub 上的 llama-farm chat)。
-
实现 AI 云端独立:讨论表明,使用 Faraday 允许用户永久保留下载的角色和模型,并且在拥有 6 GB VRAM 配置的情况下,本地运行工具可以规避云端订阅费用。本地执行无需订阅,是工具使用方面一个极具性价比的选择。
-
Ubuntu 用户重获控制权:通过降级到 Node 版本 18.17.0 并根据 GitHub issue 更新 Ubuntu,解决了 Ubuntu 18 上
convex-local-backend的安装问题。提出了 Dockerization(Docker 化)作为简化未来配置的潜在解决方案。 -
模拟现实备受关注:旧金山的 Mission Control 举办了一场 AI Simulated Party(AI 模拟派对),融合了真实与数字体验。此外,AI-Westworld 模拟进入了公开测试阶段,并推出了一个名为 AI Town Player 的 Web 应用,用于通过导入 sqlite 文件回放 AI Town 场景。
-
剪贴板与节拍的融合:有人呼吁合作创建一个涉及嘻哈歌手 Kendrick 和 Drake 的模拟。这展示了将 AI 开发与文化评论相结合的兴趣。
LAION Discord
CLIP vs. T5:模型大比拼:关于集成 CLIP 和 T5 编码器 进行 AI 模型训练的讨论非常热烈;虽然同时使用两种编码器显示出前景,但一些人主张仅使用 T5,因为 CLIP 存在提示词遵循(prompt adherence)问题。
小模型是大趋势吗?:在模型尺寸领域,小模型的增强正被优先考虑,400M 的 DeepFloyd 备受关注就是证明,技术对话涉及到了扩展至 8B 模型的挑战。
发布 SD3:吊胃口还是全量发布?:社区对 Stability AI 暗示的逐步推出 SD3 模型(从小型到大型)的反应褒贬不一,既有怀疑也有渴望,大家都在思考这种发布策略是否符合社区的预期。
LLama Embeds 走入聚光灯下:关于在模型训练中使用 LLama embeds 效果的辩论浮出水面,一些成员主张使用它们而非 T5 embeds,并分享了 LaVi-Bridge 等资源来展示现代应用。
从概念到应用:数据之辩:对话深入探讨了为什么在某些研究中合成数据集比 MNIST 和 ImageNet 等现实世界数据集更受青睐,提到了 AI 方法中可解释性的价值,并分享了 StoryDiffusion 网站 以获取见解。
LangChain AI Discord
代码执行找到了 AI 伙伴:围绕使用 AI 执行生成的代码展开了热烈对话,重点介绍了 Open Interpreter 等方法以及开发 custom tools(如 CLITOOL)。这些讨论对于构建更具交互性和自动化系统的人来说至关重要。
Langchain 学习新语言:Langchain 库通过 langchain4j 扩展到 Java 生态系统,这对于渴望利用 AI 助手能力的 Java 开发者来说是关键的一步。
Langchain 获得高性能优化:LangChain 与 Dragonfly 的结合在聊天机器人上下文管理方面取得了显著增强,正如一篇详细介绍这些进展的 博客文章 所描述的那样。
去中心化搜索创新:社区正热议 LangChain 去中心化搜索功能的开发,该功能有望通过用户拥有的索引网络(index network)提升搜索功能。这项工作在最近的一条 推文 中得到了展示。
使用 Llama 和 LangGraph 的奇点空间:一位贡献者分享了一段关于使用 Llama 3 在没有 vectorstore 的情况下实现 Retrieval-Augmented Generation(检索增强生成)技术的视频,而另一位贡献者则通过对比执行领域的 LangGraph 与 LangChain Core 丰富了对话内容。
tinygrad (George Hotz) Discord
Clojure 吸引了工程师对符号编程的兴趣:工程师们正在讨论与 Python 相比,使用 Clojure 进行符号编程(symbolic programming)的便利性,建议通过悬赏任务(bounties)来加速上手 tinygrad,并辩论在 ML/AI 领域 Julia 是否优于 Clojure。
tinygrad 的 UOps 让工程师困惑:有人提议重新格式化 tinygrad 的文本 UOps 表示,使其更易于理解(可能类似于 LLVM IR),并解释了这些 UOps 确实是静态单赋值(SSA)的一种形式。
为 Qualcomm GPU 乐园优化 tinygrad:讨论强调了 tinygrad 通过利用 textures 和 pixel shaders 在 Qualcomm GPUs 上高效运行,但提醒激活 DSP 支持可能会使过程复杂化。
tinygrad 的单线程 CPU 故事:George Hotz 本人确认 tinygrad 在 CPU 端是单线程运行的,不存在线程冲突。
理解 tinygrad 的张量探戈:用户对 matmul 函数和张量转置的好奇引发了讨论,另一位用户分享了关于在 tinygrad 中计算符号均值(symbolic mean)的书面分析。
Mozilla AI Discord
-
Json\Schema 与 llamafile 发生冲突:
json_schema与 llamafile 0.8.1 之间的冲突引发了讨论,建议使用--unsecure作为临时方案,并暗示在未来版本中会有永久修复。 -
寻找更轻量级的机器学习模型:社区交流了关于轻量级 AI 模型的想法,其中 phi 3 mini 被认为太重,而 Rocket-3B 因其在低资源系统上的灵活性而被推荐。
-
为 Llamafile 整合缓存:确认 llamafile 确实可以利用来自 ollama cache 的模型,只要保持 GGUF 文件兼容性,就可以通过避免重复下载来简化操作。
-
AutoGPT 与 Llamafile 携手并进:分享了一个集成计划,重点介绍了将 llamafile 与 AutoGPT 融合的草案 Pull Request;设置说明已发布在 AutoGPT/llamafile-integration,正等待维护者反馈。
-
为 Llamafile 选择正确的本地模型:聚焦实时问题解决,一位用户在区分了实际模型文件和元数据后,成功让 llamafile 配合本地缓存的 .gguf 文件运行。
DiscoResearch Discord
Mixtral 问题频发:mixtral transformers 因影响微调(finetune)性能的 Bug 而遇到障碍;参考资料包括 Twitter、Gist 和一个已关闭的 GitHub PR。目前尚不清楚该 Bug 是仅影响训练还是也影响推理生成,需要进一步审查。
量化版 LLaMA-3 性能受损:一则 Reddit 帖子显示,与 LLaMA-2 相比,量化(quantization)显著降低了 LLaMA-3 的性能,并提供了一项可能有启发性的 arXiv 研究。Meta 的缩放策略可能是导致 LLaMA-3 精度下降问题的原因,而 GitHub PR #6936 和 Issue #7088 讨论了潜在的修复方案。
结识社区新模型:对话表明 8x22b Mistral 正被用于当前的工程任务,但未披露具体的性能指标或使用细节。
Interconnects (Nathan Lambert) Discord
-
AI 语音:真假难辨:The Atlantic 发表了一篇文章,讨论了 ElevenLabs 如何创建先进的 AI 语音克隆技术。用户对 ElevenLabs 的能力表现出既着迷又警惕的反应,其中一人对限制完全访问此类内容的付费墙表示不屑。
-
Prometheus 2:评判评判者:最近的一篇 arXiv 论文介绍了 Prometheus 2,这是一个与人类和 GPT-4 判断保持一致的语言模型评估器,旨在解决专有语言模型中的透明度和成本问题。尽管该论文显著忽略了该模型表现不佳的 RewardBench 评分,但社区对测试 Prometheus 2 的评估能力表现出浓厚兴趣。
-
经典 RL 之谜:rl 频道的对话探讨了经典强化学习(Reinforcement Learning)中尚未探索的领域。讨论重点强调了价值函数(value function)在 PPO 和 DPO 等方法中的重要性,并强调了其在 RL 系统规划中的关键作用。
-
John 模糊回应之谜:在 random 频道中,成员们分享了对重复成功的隐秘担忧,并开玩笑说某个“john”对一项提议给出了模棱两可的回应。这些陈述背后的相关性和背景仍不清楚。
LLM Perf Enthusiasts AI Discord
- Anthropic 的 Prompt 生成器引发关注:工程师们讨论了 Anthropic console 中提供的一个新的 prompt generator tool(Prompt 生成工具),这对于寻求高效生成 Prompt 的人来说可能非常有用。
- 礼貌模式测试运行:测试了该工具“礼貌地改写句子”的能力,产生的结果受到了成员们的好评。
- 破译系统机制:目前正在努力了解该工具的 system prompt 是如何运作的,重点是揭开其中嵌入的 k-shot examples 的秘密。
- 提取长内容:从该工具中提取完整数据一直面临挑战,有报告称 system prompt 被截断,特别是在冗长的“苏格拉底式数学导师”示例期间。
- 揭秘:一旦成功完整提取,将承诺向社区分享完整的 system prompt,这对于那些对 Prompt Engineering 感兴趣的人来说可能是一个资源。
Skunkworks AI Discord
- 伪造数据实验:一位成员正在寻找一个伪造数据集,旨在测试 Llama 3 和 Phi3 模型的微调,这暗示了他们的实验并不要求数据的真实性。
- 通过快速计算加速 AI:表现出潜力的 Skunkworks AI 项目可以获得 Fast compute grants(快速计算资助),更多详情见最近的推文。
- YouTube 上的 AI 教育内容:分享了一个与 AI 相关的教育类 YouTube 视频,可能为社区正在进行的技术讨论增添价值。
Datasette - LLM (@SimonW) Discord
- LLM 将错误日志转化为启发:一种利用 LLM 在运行
conda activate命令后迅速总结错误的方法已被证明有效,并建议将该方法集成到 LLM README 文档中。 - Bash 魔法遇上 LLM 洞察:一个新编写的
llm-errbash 函数已提上日程,旨在将命令输出直接输入 LLM 以进行快速错误诊断,进一步简化工程师的错误排查流程。
Cohere Discord
- 寻找奥斯汀的 AI 专家:向位于德克萨斯州奥斯汀的 AI 专业人士发出了友好问候。
- Finexov 的融资前沿:Vivien 介绍了 Finexov,这是一个旨在简化 R&D(研发)融资机会识别的 AI 平台,目前已开展初步合作并获得 Founder Institute (fi.co) 的支持。
- 为 Finexov 寻找技术领导者:正在寻找一位具有深厚 ML 背景的 CTO 联合创始人来领导 Finexov,并准备应对团队建设和融资的挑战;优先考虑常驻欧洲或中东的候选人,会说法语者优先。
- 迪拜聚会预告:Vivien 预告今年 6 月可能在迪拜举行聚会,邀请潜在合作伙伴讨论与 Finexov 的合作机会。
AI21 Labs (Jamba) Discord
- AI21 Labs 突破边界:AI21 Labs 表明了其进一步扩展技术的雄心。工作人员鼓励社区成员通过私信分享他们的使用案例和见解。
Alignment Lab AI Discord
- 获取算力支持:感兴趣的各方有机会获得 快速算力资助 (fast compute grants);一名成员分享的推文呼吁申请或提名以授予算力资源,这对 AI 研究和项目非常有益。查看推文了解详情。
PART 2: 各频道详细摘要与链接
Unsloth AI (Daniel Han) ▷ #general (791 条消息🔥🔥🔥):
-
关于 Llama3 微调和 GGUF 转换的讨论:用户一直在尝试使用 Unsloth 微调 Llama3,并将微调后的模型转换为 GGUF,结果各异。一些人报告了转换后出现无限生成的问题,并被引导关注一个 GitHub issue,该 issue 强调了转换为 GGUF 的模型存在的问题。
-
关于 Unsloth 全量微调的咨询:一位用户对使用 Unsloth 进行全量微调(Full Finetuning,而不仅仅是 LoRA)的可能性感到好奇,引发了关于潜在 VRAM 节省和性能的讨论。Unsloth 社区成员就如何实现这一目标提供了见解,并引用了一个 GitHub feature request。
-
深度量化模型性能调查:一位用户质疑了针对 7B 模型的 4 Bit Q2_K 等深度量化的有效性,建议在低资源应用中可能应改用 Phi-3,强调了为模型性能选择正确量化级别的重要性。
-
资源分享与 Unsloth 故障排除:用户分享了他们的经验,并就运行 Unsloth 模型的云供应商(如 Tensordock)、Unsloth Studio 的使用,以及处理微调数据集、量化效果和使用不同推理引擎的通用技巧提供了建议。
-
关于使用 LLM 微调低资源语言的不确定性:一位考虑使用 LLM 微调低资源语言的用户寻求关于 LLM 与 T5 等模型效果对比的建议。社区讨论强调了 Phi-3 等模型在此类任务中的潜力,并就如何处理微调过程的不同方面提供了建议。
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- 论文页面 - A Closer Look at the Limitations of Instruction Tuning: 未找到描述
- GGUF My Repo - 由 ggml-org 提供的 Hugging Face Space: 未找到描述
- unsloth/Phi-3-mini-4k-instruct · Hugging Face: 未找到描述
- LLM Model VRAM Calculator - 由 NyxKrage 提供的 Hugging Face Space: 未找到描述
- Google Colab: 未找到描述
- unsloth/Phi-3-mini-4k-instruct-bnb-4bit · Hugging Face: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- gradientai/Llama-3-8B-Instruct-Gradient-1048k · Hugging Face: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- unsloth (Unsloth AI): 未找到描述
- 主页: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral & Gemma LLM - unslothai/unsloth
- unsloth (Unsloth AI): 未找到描述
- GitHub - IBM/unitxt: 🦄 Unitxt: 一个用于准备训练和评估数据的 Python 库: 🦄 Unitxt: 一个用于准备训练和评估数据的 Python 库 - IBM/unitxt
- Grizzly: Grizzly 有 9 个可用的仓库。在 GitHub 上关注他们的代码。
- 主页: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral & Gemma LLM - unslothai/unsloth
- Google Colab: 未找到描述
- Cerebras Systems 发布拥有惊人的 4 万亿个晶体管的全球最快 AI 芯片 - Cerebras: 第三代 5nm Wafer Scale Engine (WSE-3) 为业界最具扩展性的 AI 超级计算机提供动力,通过 2048 个节点可达 256 exaFLOPs
- Padding 和 truncation: 未找到描述
- gradientai/Llama-3-8B-Instruct-262k · Hugging Face: 未找到描述
- 如何微调 Llama 3 以获得更好的指令遵循能力?: 🚀 在今天的视频中,我很高兴能带你了解微调 LLaMA 3 模型以实现最佳指令遵循的复杂过程!从设置...
- Reddit - 深入探索一切: 未找到描述
- GitHub - unslothai/unsloth: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral & Gemma LLM: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral & Gemma LLM - unslothai/unsloth
- 合并 LORA Adapter 后的 Llama3 GGUF 转换似乎会随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp: 我正在使用 Unsloth 在 llama3-8b 上微调 LORA 指令模型。1:我将模型与 LORA adapter 合并为 safetensors 2:在 Python 中直接使用合并后的模型进行推理...
- Llama3 GGUF 转换与合并的 LoRA Adapter 似乎会随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp:我正在使用 Unsloth 对 llama3-8b 的 Instruct 模型进行 LoRA 微调。1:我将模型与 LoRA adapter 合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理...
- 未找到标题:未找到描述 </ul> </div> --- **Unsloth AI (Daniel Han) ▷ #[random](https://discord.com/channels/1179035537009545276/1179039861576056922/1235890587337494528)** (107 条消息🔥🔥): - **LLaMA3 的露骨内容警报**:一位用户报告称,在输入淫秽查询时,**LLaMa3** 生成了不当且露骨的内容,质疑该模型的审查程度。[另一位用户](https://www.github.com/status-check/status) 发现,即使使用系统提示词(system prompts)来防止此类响应,也会得到类似的结果。 - **支持者的新角色**:在关于支持者角色的简短讨论中,用户了解到新增了一个 "**regulars**" 角色,并且成为会员或捐赠至少 $10 的用户可以进入私有的支持者频道。 - **RTX 4090 获得 Suprim 优惠**:在关于显卡交易的新讨论中,有人指出 **MSi GeForce RTX 4090 SUPRIM LIQUID X** 正在以 $1549 的价格促销,一位用户敦促其他人抓住这个机会。该显卡与其他型号相比更紧凑的尺寸引发了进一步的辩论。 - **Kendrick 与 Drake 的动态**:用户讨论了 Kendrick Lamar 和 Drake 恩怨的最新进展,指出 Kendrick 的曲目《Meet the Grahams》在 Drake 的《Family Ties》发布后不久便发布,在说唱界引起了巨大轰动。 - **YouTube 上的 Unsloth.ai**:一段对话涉及一位用户祝贺另一位向 PyTorch 团队进行演示,并引导他们观看来自 Unsloth.ai 的 [YouTube 视频](https://www.youtube.com/watch?v=MQwryfkydc0),暗示很快会发布进一步的更新。
- Orenguteng/Llama-3-8B-LexiFun-Uncensored-V1-GGUF · Hugging Face: 未找到描述
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- microsoft/Phi-3-mini-128k-instruct · Hugging Face: 未找到描述
- Reddit - Dive into anything: 未找到描述
- Load: 未找到描述
- llama.cpp/examples/export-lora at finetune-lora · xaedes/llama.cpp: Facebook LLaMA 模型的 C/C++ 移植版本。通过在 GitHub 上创建账号来为 xaedes/llama.cpp 的开发做出贡献。
- Reddit - Dive into anything: 未找到描述
- AutoAWQ/examples/generate.py at main · casper-hansen/AutoAWQ: AutoAWQ 实现了用于 4-bit 量化的 AWQ 算法,在推理过程中可实现 2 倍加速。文档:- casper-hansen/AutoAWQ
- creating gguf model from lora adapter · ggerganov/llama.cpp · Discussion #5360: 我有一个由 convert-lora-to-ggml.py 创建的 ggml 适配器模型 (ggml-adapter-model.bin)。现在我的疑问是如何从中创建完整的 GGUF 模型?我见过使用 ./main -m models/llama...
- ScottMcNaught - Overview: ScottMcNaught 有一个可用的仓库。在 GitHub 上关注他们的代码。
- llama.cpp failing by bet0x · Pull Request #371 · unslothai/unsloth: llama.cpp 无法为训练好的模型生成量化版本。错误:你可能需要自己编译 llama.cpp,然后再次运行。你不需要关闭这个 Python 程序。运行...
- bartowski (@bartowski1182) 的推文: 经过几天的计算(因为我不得不重新开始),它终于上线了!带有 tokenizer 修复的 Llama 3 70B GGUF :) https://huggingface.co/bartowski/Meta-Llama-3-70B-Instruct-GGUF 另外,刚刚订购了...
- llama : fix BPE pre-tokenization (#6920) · ggerganov/llama.cpp@f4ab2a4: * 将 deepseeker 模型的更改合并到 main 分支 * 将正则表达式模式移动到 unicode.cpp 并更新了 unicode.h * 移动了头文件 * 解决了问题
- GGUF 损坏 - llama-3 · Issue #430 · unslothai/unsloth: 来自 ggerganov/llama.cpp#7062 和 Discord 聊天的发现:复现用的 Notebook:https://colab.research.google.com/drive/1djwQGbEJtUEZo_OuqzN_JF6xSOUKhm4q?usp=sharing Unsloth + float16 + QLoRA = 正常工作...
- 主页: 微调 Llama 3, Mistral & Gemma LLM,速度提升 2-5 倍,显存占用减少 80% - unslothai/unsloth
- readme : 添加关于 convert.py 不支持 LLaMA 3 的说明 (#7065) · ggerganov/llama.cpp@ca36326: 未找到描述
- 主页: 微调 Llama 3, Mistral & Gemma LLM,速度提升 2-5 倍,显存占用减少 80% - unslothai/unsloth
- 我让 unsloth 在原生 windows 上运行了。 · Issue #210 · unslothai/unsloth: 我让 unsloth 在原生 windows 上运行了(无需 WSL)。你需要 Visual Studio 2022 C++ 编译器、Triton 和 DeepSpeed。我有一个完整的安装教程,我本想在这里写完,但我现在在手机上...
- 无法将 llama3 8b 模型转换为 gguf · Issue #7021 · ggerganov/llama.cpp: 请包含有关您的系统信息、重现 Bug 的步骤以及您正在使用的 llama.cpp 版本。如果可能,请提供一个重现该问题的最小代码示例...
- GitHub - ggerganov/llama.cpp 分支 gg/bpe-preprocess: C/C++ 中的 LLM 推理。通过在 GitHub 上创建账号为 ggerganov/llama.cpp 的开发做出贡献。
- jaime-m-p 提交的 llama3 自定义正则分割 · Pull Request #6965 · ggerganov/llama.cpp: unicode_regex_split_custom_llama3() 的实现。
- 带有合并 LoRA Adapter 的 Llama3 GGUF 转换似乎会随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp: 我正在使用 Unsloth 在 llama3-8b 上微调 LoRA 指令模型。1:我将模型与 LoRA Adapter 合并为 safetensors 2:在 Python 中直接使用合并后的模型运行推理...
- 带有合并 LoRA Adapter 的 Llama3 GGUF 转换似乎会随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp: 我正在使用 Unsloth 在 llama3-8b 上微调 LoRA 指令模型。1:我将模型与 LoRA Adapter 合并为 safetensors 2:在 Python 中直接使用合并后的模型运行推理...
- 带有合并 LoRA Adapter 的 Llama3 GGUF 转换似乎会随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp: 我正在使用 Unsloth 在 llama3-8b 上微调 LoRA 指令模型。1:我将模型与 LoRA Adapter 合并为 safetensors 2:在 Python 中直接使用合并后的模型运行推理...
- 带有合并 LoRA Adapter 的 Llama3 GGUF 转换似乎会随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp: 我正在使用 Unsloth 在 llama3-8b 上微调 LoRA 指令模型。1:我将模型与 LoRA Adapter 合并为 safetensors 2:在 Python 中直接使用合并后的模型运行推理...
- 带有合并 LoRA Adapter 的 Llama3 GGUF 转换似乎会随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp: 我正在使用 Unsloth 在 llama3-8b 上微调 LoRA 指令模型。1:我将模型与 LoRA Adapter 合并为 safetensors 2:在 Python 中直接使用合并后的模型运行推理...
- llama.cpp/convert.py (master 分支) · ggerganov/llama.cpp: C/C++ 中的 LLM 推理。通过在 GitHub 上创建账号为 ggerganov/llama.cpp 的开发做出贡献。
- 带有合并 LoRA Adapter 的 Llama3 GGUF 转换似乎会随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp: 我正在使用 Unsloth 在 llama3-8b 上微调 LoRA 指令模型。1:我将模型与 LoRA Adapter 合并为 safetensors 2:在 Python 中直接使用合并后的模型运行推理...
- 带有合并 LoRA Ada... pter 似乎随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp</a>: 我正在运行 Unsloth 在 llama3-8b 上微调 LORA Instruct 模型。1:我将模型与 LORA 适配器合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理... </ul>
- 未找到标题:未找到描述
- M-Chimiste/Llama-3-8B-RDF-Experiment · Hugging Face:未找到描述
- Dog Awkward GIF - Dog Awkward Awkward dog - Discover & Share GIFs:点击查看 GIF
- miR-200 家族在溃疡性结肠炎患者的异型增生病变中增加 - PubMed:UC-异型增生与粘膜中 miRNA 表达的改变和 miR-200b-3p 水平升高有关。
- RomboDawg (@dudeman6790) 的推文:宣布 Codellama-3-8B,这是在完整的 OpenCodeInterpreter 数据集上对 llama-3-8b-instruct 进行的 Qalore 微调。它的编码能力远优于基础 instruct 模型,并且在代码迭代方面表现极佳。Forgi...
- Llama-3-8B-Instruct-Coder:未找到描述
- Oncord - 数字营销软件:集网站、电子邮件营销和电子商务于一体的直观软件平台。Oncord 托管的 CMS 使其变得简单。
- 未找到标题:未找到描述
- Google Scholar Citations: 未找到描述
- Dirty Docks Shawty GIF - Dirty Docks Shawty Triflin - Discover & Share GIFs: 点击查看 GIF
- ChatGPT listed as author on research papers: many scientists disapprove: 至少有四篇文章将该 AI 工具列为共同作者,出版商正争相规范其使用。
- GitHub - catppuccin/catppuccin: 😸 Soothing pastel theme for the high-spirited!: 为充满活力的人准备的舒缓粉彩色调主题!欢迎在 GitHub 上为 catppuccin 的开发做出贡献。
- EMO: EMO: Emote Portrait Alive - 在弱条件下使用 Audio2Video Diffusion 模型生成具有表现力的肖像视频
- Highlight: Generate photos with friends: Highlight 是一款通过与朋友共同生成图像来进行白日梦(想象)的应用程序。
- Stable Diffusion 3: Research Paper — Stability AI: 继我们宣布 Stable Diffusion 3 的早期预览版之后,今天我们发布了研究论文,概述了即将发布的模型的详细技术细节,并邀请您...
- Fireworks - Generative AI For Product Innovation!: 使用 Fireworks.ai 以极快的速度使用最先进的开源 LLM 和图像模型,或者无需额外费用即可微调并部署您自己的模型!
- Login • Instagram: 未找到描述
- How to Install Stable Diffusion - automatic1111: 第 2 部分:如何使用 Stable Diffusion https://youtu.be/nJlHJZo66UA Automatic1111 https://github.com/AUTOMATIC1111/stable-diffusion-webui 安装 Python https://w...
- High-Similarity Face Swapping: ControlNet IP-Adapter + Instant-ID Combo: 探索使用 WebUI Forge、IP-Adapter 和 Instant-ID 进行高相似度换脸的艺术,以获得无缝、逼真的效果。🖹 文章教程:- https:/...
- GitHub - philz1337x/clarity-upscaler: Clarity AI | AI Image Upscaler & Enhancer - free and open-source Magnific Alternative: Clarity AI | AI 图像放大器与增强器 - 免费且开源的 Magnific 替代方案 - philz1337x/clarity-upscaler
- Aether Light - LoRA for SDXL - v1.0 | Stable Diffusion LoRA | Civitai: 商务咨询、商业许可、定制模型和咨询,请通过 joachim@rundiffusion.com 联系我。介绍 Aether Light,我...
- GitHub - crystian/ComfyUI-Crystools: A powerful set of tools for ComfyUI: 一套功能强大的 ComfyUI 工具。通过在 GitHub 上创建账户为 ComfyUI-Crystools 的开发做出贡献。
- Reddit - Dive into anything: 未找到描述
- Reddit - Dive into anything: 未找到描述
- LORA training EXPLAINED for beginners: LoRA 训练指南/教程,以便您了解如何使用 KohyaSS 上的重要参数。使用 Dreamlook.AI 在几分钟内完成训练:https://dreamlook.ai/?...
- THE OTHER LoRA TRAINING RENTRY: Stable Diffusion LoRA 训练科学与笔记,由 The Other LoRA Rentry Guy 提供。这不是安装指南,而是关于如何改进结果、描述不同选项的指南...
- Recipic Demo:是否曾对晚餐或午餐做什么感到困惑?如果有一个网站,你只需上传现有的食材就能获得食谱……
- FreeGPT.today - 最强大的免费 AI 语言模型!:免费访问最强大的 AI 语言模型。无需信用卡。
- Secret Llama: 未找到描述
- Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens: 在神经大语言模型(LLM)时代,$n$-gram 语言模型是否仍然具有相关性?我们的答案是肯定的,并展示了它们在文本分析和改进神经 LLM 方面的价值。这篇...
- Demo Search Fine Web Dataset: 未找到描述
- Better & Faster Large Language Models via Multi-token Prediction: 诸如 GPT 和 Llama 之类的 LLM 是通过下一个 Token 预测损失进行训练的。在这项工作中,我们建议训练语言模型一次预测多个未来 Token 会导致...
- LLM Model VRAM Calculator - a Hugging Face Space by NyxKrage: 未找到描述
- Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads: 由于自回归解码过程缺乏并行性,LLM 的推理过程通常受到限制,导致大多数操作受限于内存...
- What's In My Big Data?: 大型文本语料库是语言模型的支柱。然而,我们对这些语料库内容的理解有限,包括一般统计数据、质量、社会因素以及...
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- GitHub - LEXNY/Taskmaster-LLM: 通过在 GitHub 上创建账户来为 LEXNY/Taskmaster-LLM 的开发做出贡献。
- GitHub - prometheus-eval/prometheus-eval: Evaluate your LLM's response with Prometheus 💯: 使用 Prometheus 评估你的 LLM 响应 💯。通过在 GitHub 上创建账户来为 prometheus-eval/prometheus-eval 的开发做出贡献。
- NVIDIA CEO Jensen Huang Leaves Everyone SPEECHLESS (Supercut): NVIDIA(#nvda 股票)创始人兼首席执行官黄仁勋在斯坦福经济政策研究所(SIEPR)演讲的亮点。亮点包括...
- Refusal in LLMs is mediated by a single direction — LessWrong: 这项工作是 Neel Nanda 在 ML Alignment & Theory Scholars 项目(2023-24 冬季班)中的一部分,由...共同指导。
- [WIP][FIX] Fix Mixtral model by casper-hansen · Pull Request #30658 · huggingface/transformers: 此 PR 是基于 @kalomaze 实现的进行中工作(WIP),旨在修复 Mixtral 模型。众所周知,由于代码中的某些错误,Mixtral 一直难以训练。请注意,这...
- Pull requests · huggingface/transformers: 🤗 Transformers:适用于 Pytorch、TensorFlow 和 JAX 的最先进机器学习库。- Pull requests · huggingface/transformers
- Wordware - WebIntellect - Search with ScratchPad-Think Framework (V2): 利用 <ScratchPad-Think> 的力量进行日常网络搜索。
- turboderp/Cat-Llama-3-70B-instruct · Hugging Face: 未找到描述
- 来自 RomboDawg (@dudeman6790) 的推文: 发布 Codellama-3-8B,这是一个基于完整的 OpenCodeInterpreter 数据集对 llama-3-8b-instruct 进行的 Qalore 微调版本。它的代码编写能力远优于基础 instruct 模型,并且在代码迭代方面表现出色。Forgi...
- cognitivecomputations/Meta-Llama-3-120B-Instruct-gguf · Hugging Face: 未找到描述
- NousResearch/Hermes-2-Pro-Llama-3-8B · Hugging Face: 未找到描述
- NousResearch/Hermes-2-Pro-Llama-3-8B · Hugging Face: 未找到描述
- Google Colab: 未找到描述
- Multi-hop Question Answering over Knowledge Graphs using Large Language Models: 知识图谱 (KGs) 是具有特定结构的大型数据集,代表了大型知识库 (KB),其中每个节点代表一个关键实体,它们之间的关系是类型化的边。自然语...
- blockblockblock/Hermes-2-Pro-Llama-3-8B-bpw2.5-exl2 · Hugging Face: 未找到描述
- In-Context Learning with Long-Context Models: An In-Depth Exploration: 随着模型上下文长度的不断增加,上下文中可以提供的示例数量已接近整个训练数据集的大小。我们研究了 In-Context Learning 的行为...
- 来自 Kyle Mistele 🏴☠️ (@0xblacklight) 的推文: 顺便说一下,我用 @vllm_project 测试了它,它可以将 @NousResearch 的 Hermes 2 Pro Llama 3 8B 扩展到约 32k 上下文,并具有出色的连贯性和性能(我让它总结了 @paulg 的文章)下载...
- CarperAI/pilev2-dev · Hugging Face 数据集: 未找到描述
- 来自 kache (@yacineMTB) 的推文: 当 llama 400b 降临时,你的整个公司都将不复存在。你真的认为你能监管得够快吗?你知道政府动作有多慢吗?只要一个种子文件 (torrent) 发布,你的整个业务...
- BooookScore: A systematic exploration of book-length summarization in the era of LLMs: 总结超过大语言模型 (LLMs) 上下文窗口大小的长篇文档 (>100K tokens) 需要先将输入文档分解为较小的块,然后进行提示...
- 来自 kache (@yacineMTB) 的推文: 当 llama 400b 降临时,你的整个公司都将不复存在。你真的认为你能监管得够快吗?你知道政府动作有多慢吗?只要一个种子文件 (torrent) 发布,你的整个业务...
- NousResearch/Hermes-Function-Calling 项目 main 分支下的 examples/crewai_agents.ipynb: 通过在 GitHub 上创建账号来为 NousResearch/Hermes-Function-Calling 的开发做出贡献。
- 价格概览: 通过 Google Cloud 的按需付费定价模式,你只需为你使用的服务付费。无需预付费用。无终止费。
- blockblockblock/Hermes-2-Pro-Llama-3-8B-bpw4-exl2 · Hugging Face: 未找到描述
- blockblockblock/Hermes-2-Pro-Llama-3-8B-bpw5.5-exl2 · Hugging Face: 未找到描述
- blockblockblock/Hermes-2-Pro-Llama-3-8B-bpw6-exl2 · Hugging Face: 未找到描述
- 由 K-Mistele 提交的 Pull Request #7013 · ggerganov/llama.cpp:更新服务器 README,增加 RoPE、YaRN 和 KV cache 量化等未记录选项: 我最近更新了我的 llama.cpp,发现有许多服务器 CLI 选项在 README 中没有描述,包括 RoPE、YaRN 和 KV cache 量化以及 flash a... t...
- GitHub - theavgjojo/openai_api_tool_call_proxy: A thin proxy PoC to support prompt/message handling of tool calls for OpenAI API-compliant local APIs which don't support tool calls: 一个轻量级代理 PoC,用于为不支持 tool calls 的 OpenAI API 兼容本地 API 提供 tool calls 的 prompt/消息处理支持 - theavgjojo/openai_api_tool_call_proxy
- Mlp Relevant GIF - MLP Relevant Mylittlepony - Discover & Share GIFs: 点击查看 GIF
- Reddit - Dive into anything: 未找到描述
- GitHub - huggingface/lerobot: 🤗 LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch: 🤗 LeRobot:基于 Pytorch 的真实世界机器人技术最先进机器学习库 - huggingface/lerobot
- GitHub - Infini-AI-Lab/Sequoia: scalable and robust tree-based speculative decoding algorithm: 可扩展且鲁棒的基于树的 speculative decoding 算法 - Infini-AI-Lab/Sequoia
- Support for grammar · Issue #1229 · vllm-project/vllm: 如果该库能加入对 Grammar 和 GBNF 文件的支持,将非常有益。 https://github.com/ggerganov/llama.cpp/blob/master/grammars/README.md
- GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple: Silero Models:预训练的语音转文本、文本转语音和文本增强模型,极其简单易用 - snakers4/silero-models
- Building a Large Japanese Web Corpus for Large Language Models: 为大语言模型(LLMs)构建大规模日语 Web 语料库:开源日语大语言模型(LLMs)已在 CC-100、mC4 和 OSCAR 等语料库的日语部分进行了训练。然而,这些语料库并非为了日语文本质量而创建...
- GitHub - N8python/SYNTH-8: An open-source voice-enabled chatbot. Many features will come soon.: 一个开源的语音启用聊天机器人。许多功能即将推出。 - N8python/SYNTH-8
- SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling: SOLAR 10.7B:通过简单而有效的 Depth Up-Scaling 扩展大语言模型:我们推出了 SOLAR 10.7B,一个拥有 107 亿参数的大语言模型(LLM),在各种自然语言处理(NLP)任务中表现出卓越的性能。受近期努力的启发...
- Tweet from Maziyar PANAHI (@MaziyarPanahi): 做得好 @Gradient_AI_!这个模型非常接近 Instruct 版本,非常令人印象深刻!❤️🚀👏🏽 引用 OpenLLMLeaders (@OpenLLMLeaders) 排行榜新增模型!模型名称 h...
- Scale your AI business with Paddle | AI Launchpad: 未找到描述
- Arcee/Mergekit launch Model Merging Hackathon: Arcee 和 MergeKit 通过启动由 AWS 共同赞助的 MergeKit 黑客松来推进模型合并(model merging)创新。提交您的模型合并研究、实验和结果,有机会赢取现金奖励...
- GitHub - hsiehjackson/RULER: This repo contains the source code for RULER: What’s the Real Context Size of Your Long-Context Language Models?: 此仓库包含 RULER 的源代码:您的长上下文语言模型的真实上下文大小是多少? - hsiehjackson/RULER
- GitHub - OpenBMB/InfiniteBench: Codes for the paper "∞Bench: Extending Long Context Evaluation Beyond 100K Tokens": https://arxiv.org/abs/2402.13718: 论文 "∞Bench: Extending Long Context Evaluation Beyond 100K Tokens" 的代码:https://arxiv.org/abs/2402.13718 - OpenBMB/InfiniteBench
- Port of self extension to server by Maximilian-Winter · Pull Request #5104 · ggerganov/llama.cpp: 你好,我将 self extension 的代码移植到了服务器。我已经通过信息检索进行了测试,我在约 6500 个 token 长的文本中插入了上下文之外的信息,它起作用了,至少...
- blockblockblock/Hermes-2-Pro-Llama-3-8B-bpw3-exl2 · Hugging Face: 未找到描述
- block/Hermes-2-Pro-Llama-3-8B-bpw3.5-exl2">blockblockblock/Hermes-2-Pro-Llama-3-8B-bpw3.5-exl2 · Hugging Face: 未找到描述
- blockblockblock/Hermes-2-Pro-Llama-3-8B-bpw3.7-exl2 · Hugging Face: 未找到描述
- Extending context size via RoPE scaling · ggerganov/llama.cpp · Discussion #1965: 简介:这是一个关于最近提出的扩展 LLaMA 模型上下文大小策略的讨论。最初的想法在这里提出:https://kaiokendev.github.io/til#extending-context-t...
- 未找到标题:未找到描述
- LLaVA:未找到描述
- NousResearch/Hermes-2-Pro-Llama-3-8B-GGUF at main:未找到描述
- agents/src/agents/hermes/functioncall.py at main · aniketmaurya/agents:一个由 LangChain 驱动的、用于构建带有函数调用的 Agentic 工作流的有趣项目。- aniketmaurya/agents
- FutureEpoch Wiki - 探索人类与宇宙的遥远未来: 未找到描述
- 量子粒子球观测台: 未找到描述
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、闲逛,并与你的朋友和社区保持紧密联系。
- 这就是为什么 AI 搜索引擎真的无法取代 Google:搜索引擎不仅仅是一个搜索引擎,而 AI 仍然无法完全跟上步伐。
- 未找到标题:未找到描述
- Sky News 获悉,中国黑客攻击了英国国防部:国会议员将在周二被告知一起涉及国防部的大规模数据泄露事件,目标是现役人员。
- Tiktokenizer:未找到描述
- 独家:消息人士称,Perplexity 正在为其 AI 搜索平台以 25-30 亿美元的估值筹集超过 2.5 亿美元资金:AI 搜索引擎初创公司 Perplexity 目前是热门项目。TechCrunch 获悉,该公司目前正在筹集至少 2.5 亿美元。
- 来自 Wei Ping (@_weiping) 的推文:介绍 ChatQA-1.5,这一系列模型在 RAG 和对话式 QA 方面超越了 GPT-4-0613 和 Command-R-Plus。ChatQA-1.5 有两个变体:Llama3-ChatQA-1.5-8B,https://huggingface.co/nvidia...
- Perplexity 在 Trustpilot 上的评分为“一般”,分数为 2.9 / 5:你同意 Perplexity 的 TrustScore 吗?今天就发表你的意见,听听 14 位客户已经说了什么。
- 灭霸说话 GIF - 灭霸说话迷因 - 发现并分享 GIF:点击查看 GIF
- 跳舞的鸭子 GIF - 发现并分享 GIF:点击查看 GIF
- Baqua GIF - 发现并分享 GIF:点击查看 GIF
- 未找到标题: 未找到描述
- <a href="https://"">未找到标题</a>: 未找到描述
- OpTonal • 为使用 Slack, HubSpot, Google Meet 的团队提供的 AI 销售 Agent: 未找到描述
- Perplexity 通过 Amazon SageMaker HyperPod 将基础模型训练速度提升 40% | Perplexity 案例研究 | AWS: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 不仅仅是 OpenAI 的套壳:Perplexity 转向开源: Perplexity 首席执行官 Aravind Srinivas 是 Larry Page 的忠实粉丝。然而,他认为自己已经找到了一种不仅能与 Google 搜索竞争,还能与 OpenAI 的 GPT 竞争的方法。
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- Salesforce:以客户为中心的公司: Salesforce 作为排名第一的 AI CRM,使公司能够通过统一的 Einstein 1 平台与客户建立联系,该平台结合了 CRM、AI、数据和信任。
- 适用于小型到企业级公司的销售软件 | 免费开始使用: 强大的销售软件,帮助您的团队在统一的互联平台上达成更多交易、加深关系并更有效地管理销售漏斗。
- Zoho CRM | 备受客户好评的销售 CRM 软件: Zoho CRM 是一款在线销售 CRM 软件,在单一 CRM 平台上管理您的销售、营销和支持。全球超过 1 亿用户信赖!立即注册免费试用。
- Gong - 收入智能平台: Gong 捕捉客户互动,然后大规模提供洞察,赋能团队基于数据而非主观意见做出决策。
- 排名第一的对话式营销和销售平台 - Exceed.ai: 利用对话式 AI 增强潜在客户转化。自动化收入互动,实现大规模参与,并通过电子邮件、聊天、短信进行互动。
- Salesloft:领先的销售参与平台: 未找到描述
- 让销售参与变得简单 | Yesware: Yesware 帮助高效销售团队大规模开展有意义的电子邮件外展。如果您需要通过电子邮件外展推动更多收入,但觉得复杂的平台过于繁琐,请尝试 Yesware。
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- 未找到标题: 未找到描述
- Sidecar Doughnuts - 世界上最新鲜的甜甜圈!: 自 2012 年以来提供世界上最新鲜的甜甜圈、招牌混合咖啡和微笑服务 | 加利福尼亚州科斯塔梅萨、圣莫尼卡和德尔马
- The Pie Hole: 您的下一次活动需要新鲜派或 Pie Holes 吗?在线下单,全国免费配送,因为派就是爱。
- LM Studio Beta Releases:未找到描述
- Introducing `lms` - LM Studio's companion cli tool | LM Studio:今天,随 LM Studio 0.2.22 一起,我们发布了 lms 的第一个版本 —— LM Studio 的配套 CLI 工具。
- Welcome | LM Studio:LM Studio 是一款用于在电脑上运行本地 LLM 的桌面应用程序。
- Rick Roll Rick Ashley GIF - Rick Roll Rick Ashley Never Gonna Give You Up - Discover & Share GIFs:点击查看 GIF
- openai-community/gpt2-xl · Hugging Face:未找到描述
- Unable to use LM Studio with override:覆盖(override)应该可以工作,因为他们将其设计为作为 URL 覆盖与 OpenAI Python 库集成。但我认为他们不支持发送空查询来检查 API Key。这就是为什么...
- High Quality Story Writing Type Third Person:未找到描述
- Release b2775 · ggerganov/llama.cpp:未找到描述
- Chatbox - Your AI Copilot on the Desktop, Free Download:未找到描述
- lms/CONTRIBUTING.md at main · lmstudio-ai/lms:终端里的 LM Studio。通过在 GitHub 上创建账号为 lmstudio-ai/lms 的开发做出贡献。
- GitHub - lmstudio-ai/lms: LM Studio in your terminal:终端里的 LM Studio。通过在 GitHub 上创建账号为 lmstudio-ai/lms 的开发做出贡献。
- Enable Flash Attention on GGML/GGUF (feature now merged into llama.cpp) · Issue #4051 · ollama/ollama:Flash Attention 已进入 llama.cpp (ggerganov/llama.cpp#5021)。简而言之,只需将 -fa 标志传递给 llama.cpp 的服务器。我们能否拥有一个 Ollama 服务器环境变量来传递此标志...
- xtuner/llava-llama-3-8b-v1_1-gguf · Hugging Face: 未找到描述
- 如何在 MacBook Pro 上微调 phi-3: 未找到描述
- google/codegemma-1.1-7b-it-GGUF · Hugging Face: 未找到描述
- mzwing/MiniCPM-V-2-GGUF · Hugging Face: 未找到描述
- DavidAU/D_AU-Tiefighter-Holomax-15B-UNHINGED-V1 · Hugging Face: 未找到描述
- mradermacher/D_AU-Tiefighter-Holomax-20B-V1-GGUF · Hugging Face: 未找到描述
- Meta Llama Guard 2 | 模型卡片与提示词格式: 由于护栏(guardrails)可以同时应用于模型的输入和输出,因此存在两种不同的提示词:一种用于用户输入,另一种用于 Agent 输出。
- 微调 | 操作指南: 全参数微调是一种对预训练模型所有层的所有参数进行微调的方法。
- dranger003/c4ai-command-r-plus-iMat.GGUF · Hugging Face: 未找到描述
- Release b2791 · ggerganov/llama.cpp: 未找到描述
- 我退出,不客气 GIF - 我退出,不客气 Bugs Bunny - 发现并分享 GIF: 点击查看 GIF
- Daleks Exterminate GIF - Daleks Exterminate Doctor Who - 发现并分享 GIF: 点击查看 GIF
- Upgrades Robots GIF - Upgrades Robots - 发现并分享 GIF: 点击查看 GIF
- GitHub - mlabonne/llm-course: 包含路线图和 Colab 笔记本的入门大语言模型 (LLMs) 课程。: 包含路线图和 Colab 笔记本的入门大语言模型 (LLMs) 课程。 - mlabonne/llm-course
- 教程:如何将 HuggingFace 模型转换为 GGUF 格式 · ggerganov/llama.cpp · Discussion #2948: 来源:https://www.substratus.ai/blog/converting-hf-model-gguf-model/ 我在我们的博客上发布了这篇文章,但认为这里的其他人也可能受益,因此也在 GitHub 上分享了原始博客。希望它...
- 支持 Llama 3 转换,由 pcuenca 提交 · Pull Request #6745 · ggerganov/llama.cpp: 分词器(tokenizer)是 BPE。
- baukit_orth_act_steering.ipynb: GitHub Gist: 即时分享代码、笔记和片段。
- LLMs 中的拒绝是由单一方向介导的 — LessWrong: 这项工作是 Neel Nanda 在 ML Alignment & Theory Scholars Program - 2023-24 冬季班项目中的一部分,由……共同指导。
- hjhj3168/Llama-3-8b-Orthogonalized-exl2 · Discussions: 未找到描述
- 用于 AI 部署的 GPU 选择:成员们讨论了使用旧显卡执行 AI 任务的可行性。有人提到像 GRID K1 这样的显卡可能太旧且不受当前支持,建议将 Tesla P40 作为最老旧但可行的选择。用户建议虽然 P40 以其价格提供了大量 VRAM,但散热和供电可能比较棘手,并且在运行 Stable Diffusion 等任务时可能无法提供最佳性能。
- 构建以 AI 为中心的硬件配置:对话围绕构建高效的 AI 家庭实验室展开,分享了一个 PNY GeForce RTX 4070 VERTO Dual Fan 12GB GDDR6X 显卡的 eBay 链接,作为目前 3060 GPU 的潜在升级方案以满足个人游戏需求。建议在游戏和 LLMs 方面,12GB 是 VRAM 的最低要求,更倾向于 16GB 或 24GB 的型号。
- 服务器硬件采购:用户分享了购买二手服务器的经验,提到了 ASUS ESC 4000 G3 服务器等特定型号,该服务器可容纳多个 GPU(如 P40),且价格合理,包含大量 RAM。用户还表达了对硬件兼容性以及可能需要升级以支持 AVX2 的担忧。
- 多 GPU 与推理速度:讨论涉及了 P40 的推理速度,并将其与 Mac 的性能进行了对比,承认虽然多个 GPU 有助于将大型模型完全托管在 VRAM 中,但在特定任务中,其速度可能不会显著超过高性能的单 GPU。
- 多 GPU 配置的主板注意事项:成员们交流了最适合搭载 Tesla P40 等多个 GPU 的主板类型,并讨论了由于驱动不兼容,将数据中心 GPU 与消费级 GPU 混合运行可能出现的问题。共识似乎是,虽然运行多个 GPU 具有成本效益,但也可能面临带宽瓶颈、电源限制和散热挑战等复杂问题。
- 未找到标题:未找到描述
- NVIDIA GPUs:检查 NVIDIA GPU 的生命周期终止、发布政策和支持计划。
- PNY GeForce RTX 4070 VERTO Dual Fan 12GB GDDR6X Graphics Card 751492775005 | eBay:未找到描述
- PNY GeForce RTX 4070 VERTO Dual Fan 12GB GDDR6X Graphics Card 751492775005 | eBay:未找到描述
- 👾 LM Studio - 发现并运行本地 LLM:查找、下载并实验本地 LLM
- Oil GIF - Oil - 发现并分享 GIF:点击查看 GIF
- 未找到标题:未找到描述
- 本地 LLM 服务器 | LM Studio:你可以通过运行在 localhost 的 API 服务器使用在 LM Studio 中加载的 LLM。
- Qawe Asd GIF - Qawe Asd - 发现并分享 GIF:点击查看 GIF
- GitHub - lmstudio-ai/lms: 终端中的 LM Studio:终端中的 LM Studio。通过在 GitHub 上创建账号为 lmstudio-ai/lms 的开发做出贡献。
- 来自 2wl (@2wlearning) 的推文:啊,现在我明白为什么 Citadel 赚这么多钱了 https://arxiv.org/abs/1804.06826
- 未找到标题:未找到描述
- Fix the URLs of web pages by Jokeren · Pull Request #217 · pytorch/ao: 未找到描述
- Fused DoRA kernels by jeromeku · Pull Request #216 · pytorch/ao: Fused DoRA Kernels。融合 DoRA 层实现,将独立 kernel 的数量从 ~10 个减少到 5 个。内容包括背景、优化、主要贡献、用法、测试、基准测试、Profiling、下一步工作...
- Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking: 每年都会推出新的 NVIDIA GPU 设计。这种快速的架构和技术进步,加上制造商不愿透露底层细节,使得...
- Grokking PyTorch Intel CPU performance from first principles — PyTorch Tutorials 2.3.0+cu121 documentation: 未找到描述
- serve/docs/performance_guide.md at master · pytorch/serve: 在生产环境中提供、优化和扩展 PyTorch 模型 - pytorch/serve
- serve/docs/performance_guide.md at master · pytorch/serve: 在生产环境中提供、优化和扩展 PyTorch 模型 - pytorch/serve
- serve/frontend/server/src/main/java/org/pytorch/serve/util/ConfigManager.java at master · pytorch/serve: 在生产环境中提供、优化和扩展 PyTorch 模型 - pytorch/serve
- serve/docs/configuration.md at master · pytorch/serve: 在生产环境中提供、优化和扩展 PyTorch 模型 - pytorch/serve
- GitHub - eureka-research/DrEureka: 通过在 GitHub 上创建账户来为 eureka-research/DrEureka 的开发做出贡献。
- Advanced configuration — PyTorch/Serve master documentation: 未找到描述
- hqq/setup.py at master · mobiusml/hqq: Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- ao/setup.py at 0ba0006eb704dea33becec82b3f34512fe8a6dff · pytorch/ao: 用于量化和稀疏化的原生 PyTorch 库 - pytorch/ao
- Lightning Talk: The Fastest Path to Production: PyTorch Inference in Python - Mark Saroufim, Meta: 闪电演讲:通往生产的最快路径:Python 中的 PyTorch 推理 - Mark Saroufim, Meta。从历史上看,为了进行推理,用户不得不重写他们的...
- Compute – Amazon EC2 Instance Types – AWS: 未找到描述
- Custom CUDA extensions by msaroufim · Pull Request #135 · pytorch/ao: 这是 #130 的可合并版本 - 我必须进行一些更新:添加除非使用 PyTorch 2.4+ 否则跳过的测试,以及如果 CUDA 不可用则跳过的测试;在开发依赖中添加 ninja;本地...
- louder warning + docs for custom cuda extensions by msaroufim · Pull Request #186 · pytorch/ao: 未找到描述
- Add A10G support in CI by msaroufim · Pull Request #176 · pytorch/ao: 支持 A10G + manylinux,以便 CUDA 扩展可以在尽可能多的系统上运行
- Answer.AI - You can now train a 70b language model at home:我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两个 24GB GPU 上训练 70b 模型。
- Answer.AI - Answer.AI - Practical AI R&D:实用 AI 研发
- Holistic Trace Analysis — Holistic Trace Analysis 0.2.0 documentation:未找到描述
- GitHub - AnswerDotAI/fsdp_qlora: Training LLMs with QLoRA + FSDP:使用 QLoRA + FSDP 训练 LLM。通过在 GitHub 上创建账户为 AnswerDotAI/fsdp_qlora 的开发做出贡献。
- GitHub - AnswerDotAI/fsdp_qlora: Training LLMs with QLoRA + FSDP:使用 QLoRA + FSDP 训练 LLM。通过在 GitHub 上创建账户为 AnswerDotAI/fsdp_qlora 的开发做出贡献。
- Piotr Nawrot (@p_nawrot) 的推文:Transformer 中的内存在推理时随序列长度线性增长。在 SSM 中它是常数,但通常以性能为代价。我们引入了动态内存压缩 (DMC)...
- GitHub - cuda-mode/awesomeMLSys: An ML Systems Onboarding list:一个 ML 系统入门列表。通过在 GitHub 上创建账户为 cuda-mode/awesomeMLSys 的开发做出贡献。
- 使用 PyTorch 解释量化 - 训练后量化、量化感知训练:在此视频中,我将介绍并解释量化:我们将首先简要介绍整数和浮点数的数值表示...
- GitHub - GreenBitAI/green-bit-llm: 用于微调、推理和评估 GreenBitAI LLM 的工具包。:一个用于微调、推理和评估 GreenBitAI LLM 的工具包。 - GreenBitAI/green-bit-llm
- bitorch-engine/bitorch_engine/layers/qlinear/binary/cutlass/binary_linear_cutlass.cpp at main · GreenBitAI/bitorch-engine:该工具包通过为低比特量化神经网络提供专门函数来增强 PyTorch。 - GreenBitAI/bitorch-engine
- bitorch-engine/bitorch_engine/layers/qlinear/nbit/cutlass/q4_layer.py at main · GreenBitAI/bitorch-engine:该工具包通过为低比特量化神经网络提供专门函数来增强 PyTorch。 - GreenBitAI/bitorch-engine
- nampdn-ai/mini-fineweb · Hugging Face 数据集:未找到描述
- 如何优化 CUDA Matmul 内核以获得类似 cuBLAS 的性能:工作日志:在这篇文章中,我将迭代地优化一个用 CUDA 编写的矩阵乘法实现。我的目标不是构建一个 cuBLAS 的替代品,而是深入...
- 项目进展报告 [2024年5月3日] · karpathy/llm.c · Discussion #344:[2024年5月3日] 这是 llm.c 项目的第 24 天。我们现在可以进行多 GPU 训练,支持 bfloat16 和 Flash Attention,而且速度非常快!🚀 单 GPU 训练方面,我们现在训练 GPT-2 (124M) 的速度更快了.....
- 多 GPU 训练挂起 · Issue #369 · karpathy/llm.c:在使用多个 GPU 运行 mpirun 时,在为参数的主副本分配了 474 MiB 后挂起。极有可能是由于引入了 CUDA Streams。@karpathy @PeterZhizhin
- 重叠梯度计算与 NCCL AllReduce,由 PeterZhizhin 提交 · Pull Request #361 · karpathy/llm.c:在我的设置中,结果如下:优化前:step 2/37: train loss 4.720275 (acc 4.688650) (224.046844 ms, 36563.773438 tok/s) step 3/37: train loss 3.802741 (acc 3.943135) (224.151611 ms, 36555...
- 修改版的 ademeure 融合 GELU 前向内核,由 ChrisDryden 提交 · Pull Request #363 · karpathy/llm.c:正在尝试融合 GELU 内核,以便在处理之前构建的非 GELU Matmuls 时能结合之前的代码,在本地运行时似乎有一个 p...
- 尝试布局的全局实例化,由 ChrisDryden 提交 · Pull Request #347 · karpathy/llm.c:我观察到了速度提升,虽然需要进行大量的清理和重构,但很高兴看到潜在的加速效果
- GitHub - NVIDIA/cudnn-frontend: cudnn_frontend 为 cuDNN 后端 API 提供了一个 C++ 封装以及使用示例:cudnn_frontend 为 cuDNN 后端 API 提供了一个 C++ 封装以及使用示例 - NVIDIA/cudnn-frontend
- 融合 LayerNorm 残差,由 ngc92 提交 · Pull Request #353 · karpathy/llm.c:目前基于 #352。我没有使用 kernel 6,因为 a) 性能似乎对参数非常敏感 b) 我不理解性能测量结果/不是 100% 确定...
- 修复反向传播中的激活梯度重置,由 ngc92 提交 · Pull Request #342 · karpathy/llm.c:此外,我们不需要在 zero_grad 中触碰其他缓冲区,这些缓冲区在反向传播期间无论如何都会被多次覆盖
- 性能优化:matmul_bias, CUDA Streams, 融合分类器(+移除 Cooperative Groups),由 ademeure 提交 · Pull Request #343 · karpathy/llm.c:我可能需要将其拆分为多个 PR,请告诉我你的想法(我仍需将新内核添加到 /dev/cuda/)。主要变更:新的超优化 matmul_backward_bias_kernel6 CU...
- 将 layernorm_forward 中的所有 float 转换为 floatX,由 JaneIllario 提交 · Pull Request #319 · karpathy/llm.c:将所有内核更改为使用 floatX
- 用于混合精度测试/基准测试的实用程序,由 ngc92 提交 · Pull Request #352 · karpathy/llm.c:这允许我们编译一个单一的可执行文件,作为内核的 f32、f16 和 bf16 版本的测试/基准测试。到目前为止,我只更新了那些已经定义了 BF... 的测试文件。
- llm.c/train_gpt2.cu (master 分支) · PeterZhizhin/llm.c:使用简单、原始的 C/CUDA 进行 LLM 训练。通过在 GitHub 上创建账号来为 PeterZhizhin/llm.c 的开发做出贡献。
- 添加自托管运行器 - GitHub Docs:未找到描述
- GitHub - NVIDIA/cudnn-frontend: cudnn_frontend 为 cuDNN 后端 API 提供了一个 C++ 封装以及使用示例:cudnn_frontend 为 cuDNN 后端 API 提供了一个 C++ 封装以及使用示例 - NVIDIA/cudnn-frontend
- 首次尝试将 cuDNN 移出主文件 for faster compiles by ngc92 · Pull Request #346 · karpathy/llm.c</a>: 我认为这破坏了非 cuDNN 的构建,可能还有 Windows。不过我对 Makefile 了解不多,所以如果有人知道如何优雅地处理这些,那就太好了 :)
- The TensorFlow Open Source Project on Open Hub: 未找到描述
- NVIDIA Nsight Systems: 分析系统、分析性能并优化平台。
- 未找到标题: 未找到描述
- Performance: matmul_bias, cuda streams, fused_classifier (+remove cooperative groups) by ademeure · Pull Request #343 · karpathy/llm.c: 我可能需要将其拆分为多个 PR,请告诉我你的想法(我还需要将新的 kernel 添加到 /dev/cuda/)。主要变化:新的超优化 matmul_backward_bias_kernel6 CU...
- Refactoring & Improvements to reduce LOC by ademeure · Pull Request #2 · ademeure/llm.c: 重构并移除未使用的函数,以减少代码行数(LOC)并使一切更加一致(同时仍保留代码的呼吸空间)。同时更新了 encoder_...
- CP4: GPU baseline: 未找到描述
- CP5: fast GPU solution: 未找到描述
- Creating a pull request template for your repository - GitHub Docs: 未找到描述
- Modular: How to Contribute to Mojo Standard Library: A Step-by-Step Guide: 我们正在为世界构建下一代 AI 开发者平台。查看我们的最新文章:如何为 Mojo 标准库做贡献:分步指南
- Microspeak: Cookie licking - The Old New Thing: 现在别人都不能拥有它了。
- mojo/stdlib/docs/development.md at main · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 开发做贡献。
- mojo/CONTRIBUTING.md at main · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 开发做贡献。
- [Feature Request] Make the `msg` argument of `assert_true/false/...` keyword only · Issue #2487 · modularml/mojo: 审查 Mojo 的优先级。我已阅读路线图和优先级,并认为此请求符合优先级。你的请求是什么?如题。你进行此更改的动机是什么?为了...
- Mojo: -M- · 歌曲 · 2012
- 2023 LLVM Dev Mtg - Mojo 🔥: A system programming language for heterogenous computing: 2023 LLVM 开发者大会 https://llvm.org/devmtg/2023-10------Mojo 🔥:一种用于异构计算的系统编程语言。演讲者:Abdul Dakkak, Chr...
- [Feature Request] Add `__rfloordiv__()` to SIMD type · Issue #2415 · modularml/mojo: 审查 Mojo 的优先级。我已阅读路线图和优先级,并认为此请求符合优先级。你的请求是什么?Int 和 Object 类型支持 rfloordiv。我添加了...
- [SR-852] [QoI] Poor diagnostic with missing "self." in convenience initializer · Issue #43464 · apple/swift: 之前的 ID SR-852 Radar 无 原始报告者 @ddunbar 类型 Bug 状态 已解决 分辨率 已完成 来自 JIRA 的其他详细信息 投票 0 组件 编译器 标签 Bug, DiagnosticsQoI 被指派人 @dduan...
- [stdlib] Support print to stderr by GeauxEric · Pull Request #2457 · modularml/mojo: 为 print 函数添加关键字参数以支持流向 stderr。修复 #2453。签署人:Yun Ding yunding.eric@gmail.com
- Modular: 在 Mojo 中实现 NumPy 风格的矩阵切片🔥:我们正在为世界构建下一代 AI 开发者平台。查看我们的最新文章:在 Mojo 中实现 NumPy 风格的矩阵切片🔥
- mojo/examples (位于 main 分支) · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 的开发做出贡献。
- Mojo🔥 路线图与注意事项 | Modular 文档:Mojo 计划摘要,包括即将推出的功能和我们需要修复的问题。
- quals-2024/🌌/src/async_runtime.mojo (位于 main 分支) · Nautilus-Institute/quals-2024:通过在 GitHub 上创建账号为 Nautilus-Institute/quals-2024 的开发做出贡献。
- devrel-extras/blogs/mojo-matrix-slice (位于 main 分支) · modularml/devrel-extras:包含开发者关系博客文章、视频和研讨会的辅助材料 - modularml/devrel-extras
- Mojo 中的矩阵乘法 | Modular 文档:学习如何利用 Mojo 的各种函数编写高性能的 matmul。
- Issues · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 的开发做出贡献。
- [功能请求] 统一 `InlinedString` 和 `String` 类型的 SSO · Issue #2467 · modularml/mojo:审查 Mojo 的优先级。我已阅读路线图和优先级,并相信此请求符合优先级。你的请求是什么?我们目前有 https://docs.modular.com/mojo/stdlib...
- [llvm] r217292 - [docs] 在提交信息中记录 "NFC" 的含义:未找到描述
- Issues · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 的开发做出贡献。
- [stdlib] 由 gabrieldemarmiesse 为 `String` 结构体添加小字符串优化 (SSO) · Pull Request #2507 · modularml/mojo:修复 #2467 的一部分。此 PR 将保持草稿状态,因为它太大无法一次性合并,我将进一步拆分为多个 PR。我还有一些清理工作和基准测试要做。但它可以提供...
- 由 KarateCowboy 添加关于尚未支持自定义装饰器的说明 · Pull Request #2539 · modularml/mojo:未找到描述
- lsx/struct composability prototype at main · rd4com/lsx:一个用于 Mojo 中 HTML 生成的实验性库 - rd4com/lsx
- GitHub - dorjeduck/minbpe.mojo: port of Andrjey Karpathy's minbpe to Mojo:将 Andrej Karpathy 的 minbpe 移植到 Mojo。可以通过在 GitHub 上创建账户为 dorjeduck/minbpe.mojo 的开发做出贡献。
- GitHub - mzaks/mojo-sort:为 mzaks/mojo-sort 的开发做出贡献。
- Client tests don't work with changes in Mojo 24.3 · Issue #34 · saviorand/lightbug_http:自 Mojo 24.3 起,不再支持包内的 main() 函数。这曾用于 /tests/run.mojo 来运行测试套件(目前只是一个客户端测试)。客户端测试通过运行...
- GitHub - gorodion/pycv:为 gorodion/pycv 的开发做出贡献。
- pycv/demo.ipynb at main · gorodion/pycv:为 gorodion/pycv 的开发做出贡献。
- mojo-learning/tutorials/use-parameters-to-create-or-integrate-workflow.md at main · rd4com/mojo-learning: 📖 学习一些 Mojo!通过在 GitHub 上创建账号来为 rd4com/mojo-learning 的开发做出贡献。
- Parsing PNG images in Mojo: 目前 Mojo 还没有直接读取图像文件的方法。在这篇文章中,我介绍了如何在不通过 Python 的情况下,直接在 Mojo 中解析 PNG 文件。此外,我还重构了...
- GitHub - fnands/mimage: A library for parsing images in Mojo: 一个用于在 Mojo 中解析图像的库。通过在 GitHub 上创建账号来为 fnands/mimage 的开发做出贡献。
- 为什么默认终端宽度是 80 个字符?:80 似乎是许多不同环境中的默认值,我正在寻找技术或历史原因。众所周知,代码行不应超过 80 个字符,但是...
- [功能请求] 允许子 Trait 替换父 Trait · Issue #2413 · modularml/mojo:查看 Mojo 的优先级。我已阅读路线图和优先级,并认为此请求符合优先级。您的请求是什么?如果一个函数接收受 Trait 约束的可变参数...
- Issues · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账户来为 modularml/mojo 的开发做出贡献。
- [BUG] check-license 有时失败 · Issue #2528 · modularml/mojo:Bug 描述。用于许可证检查的 pre-commit 钩子有时会失败。我一直无法理解它何时发生,从日志来看,似乎找不到我的 stdlib.mojopkg,但运行...
- [BUG] check-license 有时失败 · Issue #2528 · modularml/mojo:Bug 描述。用于许可证检查的 pre-commit 钩子有时会失败。我一直无法理解它何时发生,从日志来看,似乎找不到我的 stdlib.mojopkg,但运行...
- [BUG] `__call_location().file_name` 返回错误信息 · Issue #2534 · modularml/mojo:Bug 描述。似乎 __call_location() 函数返回了错误的数据。有人建议,“它看起来像是将我们的内部源代码路径硬编码到了 Mojo 二进制文件中...”
- [BUG] 函数、Trait、结构体和别名泄露到 builtins 中,并且可以从任何地方导入 · Issue #2529 · modularml/mojo:Bug 描述。正如标题所述,在 "./stdlib/builtin/anything.mojo" 中导入任何不带前导下划线的内容,都会将其插入到不需要全局导入的内容列表中...
- [BUG] 操作 StaticTuple 时编译时间过长 · Issue #2425 · modularml/mojo:Bug 描述。以下代码编译大约需要 40 秒,而构建后的实际执行时间微不足道。编译时间还与 Tuple 大小有关,而不是...
- [stdlib] 更新 stdlib 以对应 2024-05-03 nightly/mojo,由 JoeLoser 提交 · Pull Request #2498 · modularml/mojo:这使用与今天的 nightly 版本对应的内部提交更新了 stdlib:mojo 2024.5.323。
- nightly 分支下的 mojo/docs/changelog.md · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账户来为 modularml/mojo 的开发做出贡献。
- 社区亮点更新:社区亮点第 56 期介绍了 Moondream 2 批处理、FluentlyXL v4、HF Audio 课程前几章的葡萄牙语翻译、用于长字幕的 BLIP 微调以及许多其他项目。此处还提供了一份全面的葡萄牙语列表和亮点回顾 here。
- AI 新进展分享:最新的 Spaces 包含 BLOOM 多语言聊天、一个 局部重绘(inpainting)素描板以及一个链接预测 仓库。此外,正如这条 推文所述,HuggingFace alignment handbook 任务现在可以通过 dstack 在云端运行。
- 社区揭晓的酷炫内容:涵盖了从 使用生成式 AI 进行蛋白质优化 到 从零开始实现 Vision Language Model 的广泛主题。还讨论了结合 LLM 的 Google Search、用于快速 LLM 推理的 Token Merging 以及 一键创建聊天模型。
- 前沿对话:已安排读书会讨论近期进展并分享见解,进一步促进 AI 领域的知识交流。要参加下一场活动,请查看此 链接。
- 引入 AutoTrain 配置:AutoTrain 现在支持 yaml 配置文件,简化了模型训练过程,即使是机器学习新手也能轻松上手。有关此新功能的公告已发布在 推文上,包含示例配置的 GitHub 仓库可在此处 访问。
- GitHub - huggingface/autotrain-advanced: 🤗 AutoTrain Advanced: 🤗 AutoTrain Advanced。通过在 GitHub 上创建账号,为 huggingface/autotrain-advanced 的开发做出贡献。
- 🤗 Destaques da Comunidade: Destaques da Comunidade 是在 Hugging Face Discord 上定期发布的一篇帖子,包含由社区制作的一系列项目、模型、Spaces、帖子和文章……
- 目录:旨在通过多年发表的科学研究来追溯数据科学历史的开源项目
- 在 Replicate 上与 Meta Llama 3 聊天:Llama 3 是来自 Meta 的最新语言模型。
- meta-llama/Meta-Llama-3-8B · Hugging Face:未找到描述
- crusoeai/Llama-3-8B-Instruct-Gradient-1048k-GGUF · Hugging Face:未找到描述
- 欢迎来到社区计算机视觉课程 - Hugging Face Community Computer Vision Course:未找到描述
- komorra - 概览:Programmer / twitter: https://twitter.com/komorra86 - komorra
- GitHub - amjadmajid/BabyTorch: BabyTorch 是一个极简的深度学习框架,具有与 PyTorch 类似的 API。这种极简设计鼓励学习者探索和理解深度学习过程的底层算法和机制。它的设计初衷是当学习者准备好切换到 PyTorch 时,只需删除 `baby` 这个词即可。:BabyTorch 是一个极简的深度学习框架,具有与 PyTorch 类似的 API。这种极简设计鼓励学习者探索和理解深度学习过程的底层算法和机制...
- KAN: Kolmogorov-Arnold Networks:受 Kolmogorov-Arnold 表示定理的启发,我们提出 Kolmogorov-Arnold Networks (KANs) 作为多层感知器 (MLPs) 的有前途的替代方案。虽然 MLPs 具有固定的激活函数...
- DLAI - 使用 Hugging Face 的开源模型:介绍 · 选择模型 · 自然语言处理 (NLP) · 翻译和摘要 · 句子嵌入 · 零样本音频分类 · 自动语音识别 · 文本转语音...
- DLAI - 使用 Hugging Face 的开源模型:介绍 · 选择模型 · 自然语言处理 (NLP) · 翻译和摘要 · 句子嵌入 · 零样本音频分类 · 自动语音识别 · 文本转语音...
- 微调预训练模型:未找到描述
- 2024 年构建大语言模型小指南:2024 年构建大语言模型小指南 thomas@huggingface.co
- Introduction | Ragas:未找到描述
- Oqtant:未找到描述
- Lil'Log:记录我的学习笔记。
- Webhooks Server:未找到描述
- GitHub - microsoft/MS-MARCO-Web-Search:一个大规模、信息丰富的 Web 数据集,具有数百万个真实的点击查询-文档标签。
- 什么是 Retrieval Augmented Generation (RAG)? | Databricks:RAG 是一种架构方法,它使用数据作为大语言模型 (LLM) 的上下文,以提高相关性...
- Pyannote Speaker Diarization 3.1 - a Hugging Face Space by Delik: 未找到描述
- Podcastify - a Hugging Face Space by eswardivi: 未找到描述
- Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.: 一个将日常工作应用整合为一的新工具。它是为您和您的团队打造的一体化工作空间。
- BEE-spoke-data/fineweb-100_128k · Datasets at Hugging Face: 未找到描述
- kimou605/shadow-clown-BioMistral-7B-DARE · Hugging Face: 未找到描述
- RealESRGAN Pytorch - a Hugging Face Space by Nick088: 未找到描述
- Fish Speech 1 - a Hugging Face Space by fishaudio: 未找到描述
- GitHub - di37/LLM-Load-Unload-Ollama: This is a simple demonstration to show how to keep an LLM loaded for prolonged time in the memory or unloading the model immediately after inferencing when using it via Ollama.: 这是一个简单的演示,展示了在使用 Ollama 时,如何让 LLM 在内存中长时间保持加载状态,或者在推理后立即卸载模型。
- GitHub - Tobiadefami/fuxion: Sythetic data generation and normalization functions: 合成数据生成与归一化函数 - Tobiadefami/fuxion
- GitHub - Gapi505/Sparky-2: 通过在 GitHub 上创建账号来为 Gapi505/Sparky-2 的开发做出贡献。
- everything-ai: 介绍 everything-ai,您功能完备、AI 驱动且本地运行的聊天机器人助手! 🤖
- GitHub - AstraBert/everything-ai: Introducing everything-ai, your fully proficient, AI-powered and local chatbot assistant! 🤖: 介绍 everything-ai,您功能完备、AI 驱动且本地运行的聊天机器人助手! 🤖 - AstraBert/everything-ai
- no title found: 未找到描述
- no title found: 未找到描述
- Graph Machine Learning in the Era of Large Language Models (LLMs): 图在表示社交网络、知识图谱和分子发现等各个领域的复杂关系方面发挥着重要作用。随着深度学习的出现,图神经网络 (Graph Neural N...
- What Is Bro Yammering About What Is Bro Wafflin About GIF - What is bro yammering about What is bro wafflin about What is bro yapping about - Discover & Share GIFs: 点击查看 GIF
- Hugging Face Reading Group 20: Graph Machine Learning in the Era of Large Language Models (LLMs): 演讲者:Isamu Isozaki,总结报告:https://isamu-website.medium.com/understanding-graph-machine-learning-in-the-era-of-large-language-models-llms-dce2fd3f3af4
- When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively: 在本文中,我们展示了大语言模型 (LLMs) 如何有效地学习使用现成的检索 (IR) 系统,特别是在需要额外上下文来回答...
- Bytez: When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively: 在本文中,我们展示了大语言模型 (LLMs) 如何有效地学习使用现成的检索 (IR) 系统,特别是在需要额外上下文来回答...
- Tweet from elvis (@omarsar0): 何时进行检索?这篇新论文提出了一种训练 LLMs 有效利用信息检索的方法。它首先提出了一种训练方法,教 LLM 生成一个特殊的 token,&...
- Training an LLM to effectively use information retrieval: 这篇新论文提出了一种训练 LLMs 有效利用信息检索的方法。它首先提出了一种训练方法,教 LLM 生成...
- GhostNet: More Features from Cheap Operations: 由于内存和计算资源有限,在嵌入式设备上部署卷积神经网络 (CNN) 非常困难。特征图中的冗余是该模型的一个重要特征...
- GitHub - huawei-noah/Efficient-AI-Backbones: Efficient AI Backbones including GhostNet, TNT and MLP, developed by Huawei Noah's Ark Lab.: 由华为诺亚方舟实验室开发的搞笑 AI 骨干网络,包括 GhostNet、TNT 和 MLP。 - huawei-noah/Efficient-AI-Backbones
- Custom Diffusion:未找到描述
- OpenAI & 其他 LLM API 价格计算器 - DocsBot AI:使用我们强大的免费价格计算器计算并比较使用 OpenAI, Azure, Anthropic, Llama 3, Google Gemini, Mistral 和 Cohere API 的成本。
- Custom Diffusion:未找到描述
- 比较 huggingface:main...bghira:partial-diffusion-2 · huggingface/diffusers:🤗 Diffusers:在 PyTorch 和 FLAX 中用于图像和音频生成的先进扩散模型。
- 未找到标题:未找到描述
- IYO:IYO 构建音频计算机,欢迎你进入音频计算的世界。沉浸在混合音频现实中,与虚拟音频 Agent 交谈,帮助你学习、工作、购物和创作。
- microsoft/Phi-3-mini-128k-instruct · Hugging Face:未找到描述
- Life Barrel GIF - Life Barrel Me - Discover & Share GIFs:点击查看 GIF
- Build software better, together:GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 发现、fork 并为超过 4.2 亿个项目做出贡献。
- Build software better, together:GitHub 是人们构建软件的地方。超过 1 亿人使用 GitHub 发现、fork 并为超过 4.2 亿个项目做出贡献。
- Open Source AI Hackathon #4 · Luma:根据上一次黑客松的反馈,我们已经找到了 LLM 赞助商!OctoAI 将为所有注册者提供获得 50 美元...的机会。
- GitHub - OpenInterpreter/open-interpreter: A natural language interface for computers:计算机的自然语言界面。为 GitHub 上的 OpenInterpreter/open-interpreter 开发做出贡献。
- microsoft (Microsoft):未找到描述
- What is Reka Core?:**Reka Core** 是由 Reka 开发的前沿级多模态语言模型。它是仅有的两个商用综合多模态解决方案之一,能够处理和理解...
- GitHub - OpenInterpreter/open-interpreter: A natural language interface for computers:计算机的自然语言界面。为 GitHub 上的 OpenInterpreter/open-interpreter 开发做出贡献。
- History for interpreter/core/computer/skills/skills.py - OpenInterpreter/open-interpreter:计算机的自然语言界面。为 GitHub 上的 OpenInterpreter/open-interpreter 开发做出贡献。
- 未找到标题:未找到描述
- microsoft/Phi-3-mini-128k-instruct · Hugging Face:未找到描述
- 01/software/source/clients/mobile at main · OpenInterpreter/01:开源语言模型计算机。欢迎在 GitHub 上为 OpenInterpreter/01 的开发做出贡献。
- 由 rbrisita 修复文档 · Pull Request #1258 · OpenInterpreter/open-interpreter:描述你所做的更改:修复自定义模型使用的文档。引用任何相关的 issue(例如 "Fixes #000"):修复了 #1182 提交前检查清单(可选但建议...
- Dual Operating Modes of In-Context Learning:In-Context Learning (ICL) 表现出双重运行模式:任务学习(即从上下文样本中获取新技能)和任务检索(即定位并激活相关的预训练技能...)
- The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions:当今的 LLM 容易受到 Prompt 注入、越狱和其他攻击的影响,这些攻击允许攻击者用自己的恶意 Prompt 覆盖模型的原始指令。在这项工作中...
- Parallel Structures in Pre-training Data Yield In-Context Learning:预训练语言模型 (LMs) 具有 In-Context Learning (ICL) 能力:它们可以仅通过 Prompt 中给出的几个示例来适应任务,而无需任何参数更新。然而,目前尚不清楚...
- How do Large Language Models Handle Multilingualism?:大语言模型 (LLMs) 在多种语言中都表现出卓越的性能。在这项工作中,我们深入探讨了这个问题:LLM 如何处理多语言?我们引入了一个框架来...
- Kichang Yang:崇实大学 - 被引用 50 次 - 机器学习 - NLP
- jason9693 - 概览:AI 研究工程师。jason9693 拥有 71 个代码仓库。在 GitHub 上关注他们的代码。
- CameraCtrl:未找到描述
- 来自 Sam Altman (@sama) 的推文:im-a-good-gpt2-chatbot
- SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-trained Models:开发者越来越多地依赖于将预训练模型适配到自定义任务,而不是从头构建深度学习模型。然而,强大的预训练模型可能会被滥用……
- Significant:未找到描述
- Grandmaster-Level Chess Without Search:机器学习最近的突破性成功主要归功于规模:即大规模基于 Attention 的架构和前所未有的数据集规模。本文研究了……
- Lady tasting tea - Wikipedia:未找到描述
- Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations:尽管预训练大语言模型 (LMs) 能力惊人,但在一致性推理方面仍面临挑战;最近,提示 LMs 生成自我引导推理的解释已经出现……
- Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models:GPT-4 等私有 LMs 常被用于评估各种 LMs 的响应质量。然而,出于透明度、可控性和成本等方面的考虑,强烈促使……
- Redefine statistical significance - Nature Human Behaviour:我们建议将新发现声明的统计显著性默认 P 值阈值从 0.05 更改为 0.005。
- Stockfish and Lc0, test at different number of nodes – MeloniMarco.it:未找到描述
- Papers with Code - MATH Benchmark (Math Word Problem Solving): 目前 MATH 上的 SOTA 是 GPT-4 Turbo (MACM, w/code, voting)。查看 110 篇带有代码的论文的完整对比。
- Scaling Laws for Transfer: 我们研究了在无监督微调设置下,不同分布之间迁移学习的经验性缩放法则。当我们从零开始在固定大小的数据上训练越来越大的神经网络时...
- GitHub - protagolabs/odyssey-math: 通过在 GitHub 上创建账号来为 protagolabs/odyssey-math 的开发做出贡献。
- Lynn: Llama 3 Soliloquy 8B v2 by lynn | OpenRouter: Soliloquy-L3 v2 是一款快速且功能强大的角色扮演模型,专为沉浸式、动态体验而设计。Soliloquy-L3 在超过 2.5 亿个 token 的角色扮演数据上进行了训练,拥有庞大的知识库……
- Llama 3 Lumimaid 8B by neversleep | OpenRouter: NeverSleep 团队回归,带来了基于其精选角色扮演数据训练的 Llama 3 8B 微调模型。Lumimaid 在 eRP 和 RP 之间取得了平衡,设计风格严肃,但在必要时保持无审查……
- Llama 3 Lumimaid 8B by neversleep | OpenRouter: NeverSleep 团队回归,带来了基于其精选角色扮演数据训练的 Llama 3 8B 微调模型。Lumimaid 在 eRP 和 RP 之间取得了平衡,设计风格严肃,但在必要时保持无审查……
- Meta: Llama 3 8B Instruct by meta-llama | OpenRouter: Meta 最新的模型系列 (Llama 3) 发布了多种尺寸和版本。这个 8B 指令微调版本针对高质量对话场景进行了优化。它展示了强大的……
- OpenRouter: 在 OpenRouter 上浏览模型
- 未找到标题: 未找到描述
- Rubik's AI - AI 研究助手 & 搜索引擎: 未找到描述
- mlabonne/Meta-Llama-3-120B-Instruct · Hugging Face: 未找到描述
- abacusai/Fewshot-Metamath-OrcaVicuna-Mistral-10B · Hugging Face: 未找到描述
- Mixtral 8x22B 现已在 OctoAI 文本生成解决方案上线 | OctoAI: 你可以使用 /completions API、curl 或 OpenAI SDK 在 OctoAI 上对 Mixtral 8x22B 进行推理。联系我们以运行微调版本。
- <a href="http://localhost:11434",">未找到标题</a>: 未找到描述
- Llama Hub: 未找到描述
- 联系我们 — LlamaIndex,LLM 应用的数据框架: 如果您对 LlamaIndex 有任何疑问,请联系我们,我们将尽快安排通话。
- 入门教程(本地模型)- LlamaIndex: 未找到描述
- Prompting | 操作指南: Prompt engineering 是一种用于自然语言处理 (NLP) 的技术,通过为语言模型提供更多关于当前任务的上下文和信息来提高其性能。
- Release v0.1.33 · ollama/ollama: 新模型:Llama 3:Meta 推出的新模型,也是迄今为止功能最强大的开源 LLM;Phi 3 Mini:Microsoft 推出的新型 3.8B 参数、轻量级、最先进的开源模型。Moondream moon...
- llama_index/llama-index-integrations/embeddings/llama-index-embeddings-huggingface at main · run-llama/llama_index: LlamaIndex 是适用于您的 LLM 应用的数据框架 - run-llama/llama_index
- 使用 Optimum-Intel 优化 Embedding 模型 - LlamaIndex: 未找到描述
- Fine-Tuning - LlamaIndex: 未找到描述
- Composition | 🦜️🔗 LangChain: 本节包含更高级别的组件,它们将其他任意系统(例如外部 API 和服务)和/或 LangChain 原语组合在一起。
- Meta Llama 3 | 模型卡片和 Prompt 格式: Meta Llama 3 使用的特殊 Token。一个 Prompt 应包含一条 system 消息,可以包含多条交替的 user 和 assistant 消息,并且始终以最后一条 user 消息结尾...
- Redis Ingestion Pipeline - LlamaIndex: 未找到描述
- Supabase - LlamaIndex: 未找到描述
- 通过 co-antwan 调用带有 documents 参数的 Cohere RAG 推理 · Pull Request #13196 · run-llama/llama_index: 描述:增加了在 RAG 流水线中使用时对 Cohere.chat 的 documents 参数的支持。这确保了 Cohere 客户端的正确格式化,并带来更好的下游性能。T...
- 未找到标题: 未找到描述
- Fine-Tuning - LlamaIndex: 未找到描述
- turboderp/Cat-Llama-3-70B-instruct · Hugging Face:未找到描述
- 在 Hugging Face Inference Endpoints 上使用 vLLM 部署开源 LLM:在这篇博文中,我们将向您展示如何在 Hugging Face Inference Endpoints 上使用 vLLM 部署开源 LLM。
- 来自 Grant♟️ (@granawkins) 的推文:2024 年的 SOTA RAG
- 来自 Tom's Hardware (@tomshardware) 的推文:价值数百万美元的 Cheyenne 超级计算机拍卖以 480,085 美元成交 —— 买家带走了 8,064 颗 Intel Xeon Broadwell CPU、313TB DDR4-2400 ECC RAM 以及一些漏水问题 https://trib.al/7BzUc...
- GitHub - HVision-NKU/StoryDiffusion: 创造魔法故事!:创造魔法故事!通过在 GitHub 上创建账号为 HVision-NKU/StoryDiffusion 的开发做出贡献。
- 简介 | Continuum 训练平台 | Axolotl 训练平台:未找到描述
- llama.cpp/scripts/convert-gg.sh at master · ggerganov/llama.cpp:C/C++ 中的 LLM 推理。欢迎在 GitHub 上为 ggerganov/llama.cpp 的开发做出贡献。
- Introduction | Continuum Training Platform | Axolotl Training Platform:未找到描述
- Meta Llama 3 | Model Cards and Prompt formats: Meta Llama 3 使用的特殊 Token。一个 Prompt 应包含单个系统消息,可以包含多个交替的用户和助手消息,并且始终以最后一个用户消息结尾...
- Vezora/Tested-143k-Python-Alpaca · Datasets at Hugging Face: 未找到描述
- axolotl/src/axolotl/prompters.py at 3367fca73253c85e386ef69af3068d42cea09e4f · OpenAccess-AI-Collective/axolotl: 尽管提问(axolotl questions)。通过在 GitHub 上创建账户为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models.: 一个用于语言模型 Few-shot 评估的框架。 - EleutherAI/lm-evaluation-harness
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: 我正在运行 Unsloth 在 llama3-8b 上对 Instruct 模型进行 LORA 微调。1:我将模型与 LORA 适配器合并为 safetensors 2:在 Python 中使用合并后的模型直接运行推理...
- TIGER-Lab/MathInstruct · Datasets at Hugging Face: 未找到描述
- meta-math/MetaMathQA · Datasets at Hugging Face: 未找到描述
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、聚会,与你的朋友和社区保持紧密联系。
- 来自 Snake 激活函数的推文:Snake 是一种神经网络激活函数,对于建模具有“周期性归纳偏置”的问题(换句话说,具有规律性、重复模式的问题)非常有用...
- 来自 yikes (@yikesawjeez) 的推文:醒醒吧宝贝,新的神经网络架构刚刚发布 https://arxiv.org/abs/2404.19756
- 使用潜扩散的长篇音乐生成:基于音频的音乐生成模型最近取得了长足进步,但到目前为止还未能产生具有连贯音乐结构的全长音乐曲目。我们展示了通过训练一个地理...
- GitHub - betweentwomidnights/gary4live: 这是 gary。Python continuations 加上 Ableton 内部的 continuations。这是一个新手的在研项目。:这是 gary。Python continuations 加上 Ableton 内部的 continuations。这是一个新手的在研项目。 - betweentwomidnights/gary4live
- 来自 Theoretically Media (@TheoMediaAI) 的推文:探索两个卓越的 AI 世界模拟:首先是来自 @fablesimulation 的 AI-Westworld(公测已开启!),同时也尝试了 @realaitown,并重现了有史以来最棒的电影(The THI...
- 来自 cocktail peanut (@cocktailpeanut) 的推文:介绍 AI Town Player。你知道整个 AI Town 都通过 @convex_dev 存储在单个 sqlite 文件中吗?我逆向工程了其 Schema 并构建了一个 Web 应用,让任何人都可以回放任何 A...
- 我们去了旧金山“首个 AI 模拟派对”,所以你不用去了:前往 Mission Control 黑客之家的一次旅行,在那里,一场超现实的虚拟狂欢之后紧接着是一场真实的 DJ 舞会。
- CLI | Convex 开发者中心: Convex 命令行界面 (CLI) 是你管理 Convex 的界面
- TypeError [ERR_UNKNOWN_FILE_EXTENSION]: 未知的文件扩展名 ".ts",路径为 /app/npm-packages/convex/src/cli/index.ts · Issue #1 · get-convex/convex-backend: 我按照前提条件中的步骤操作,但在仅运行 run-local-backend 时遇到了这个错误:Failed to run convex deploy: TypeError [ERR_UNKNOWN_FILE_EXTENSION]: Unknown file extension ".ts"...
- GitHub - get-convex/llama-farm-chat: 使用本地托管的 LLM 为你的云端托管 Web 应用提供支持: 使用本地托管的 LLM 为你的云端托管 Web 应用提供支持 - get-convex/llama-farm-chat
- ai21labs/Jamba-v0.1 · Hugging Face: 未找到描述
- SD3 权重永远不会发布了,对吧: 将会发布。目前还没有日期。肯定会发布。如果这有帮助的话,我们已经与多家合作伙伴公司分享了 Beta 版模型权重...
- TestCode - CodePad: 未找到描述
- no title found: 未找到描述
- 使用查询参数自定义响应 - Microsoft Graph: Microsoft Graph 提供可选的查询参数,可用于指定和控制响应中返回的数据量。包括常用参数。
- 定义自定义工具 | 🦜️🔗 LangChain: 在构建自己的 Agent 时,你需要为其提供一个
- langchain.memory.entity.ConversationEntityMemory — 🦜🔗 LangChain 0.1.17: 未找到描述
- Discord | 你的聊天与聚会场所:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里与你的朋友和社区聊天、聚会并保持紧密联系。
- 在 LangChain 聊天机器人中使用 Dragonfly 进行高效上下文管理:探索使用 Dragonfly 为 LangChain OpenAI 聊天机器人提供高效的上下文管理,通过缓存技术提升性能和用户体验。
- Rubik's AI - AI 研究助手与搜索引擎:未找到描述
- everything-ai:介绍 everything-ai,你功能完备、AI 驱动且本地运行的聊天机器人助手!🤖
- GitHub - AstraBert/everything-ai: 介绍 everything-ai,你功能完备、AI 驱动且本地运行的聊天机器人助手!🤖:Introducing everything-ai, your fully proficient, AI-powered and local chatbot assistant! 🤖 - AstraBert/everything-ai
- GitHub - langchain4j/langchain4j: LangChain 的 Java 版本:LangChain 的 Java 版本。欢迎在 GitHub 上为 langchain4j/langchain4j 的开发做出贡献。
- LangGraph 是 AgentExecutor 的未来吗?对比揭晓一切!:🚀 深入探讨今天视频中的 AgentExecutor 实现,我将在其中展示 LangGraph 🦜🕸️ 与 LangChain Core 🦜🔗 组件之间的对比!🔧 什么是...
- 使用 SVM 且无需 Vectorstore 的 Llama 3 RAG:我们将探讨如何使用 Llama 3 Groq 和相似度分类器进行 RAG,而无需 Vectorstore。https://github.com/githubpradeep/notebooks/blob/m...
- AutoGPT/autogpts/autogpt/llamafile-integration at draft-llamafile-support · Mozilla-Ocho/AutoGPT:AutoGPT 是让每个人都能使用和构建 AI 的愿景。我们的使命是提供工具,让你专注于重要的事情。 - Mozilla-Ocho/AutoGPT
- Draft llamafile support by k8si · Pull Request #7091 · Significant-Gravitas/AutoGPT:背景:此草案 PR 是通过添加 llamafile 作为 LLM provider 来实现在 AutoGPT 中使用本地模型的一步。相关问题:#6336 #6947。变更 🏗️:有关此内容的完整文档.....
- Reddit - 深入了解任何事物:未找到描述
- 低比特量化 LLaMA3 模型的效果如何?一项实证研究:Meta 的 LLaMA 家族已成为最强大的开源大语言模型(LLM)系列之一。值得注意的是,LLaMA3 模型最近发布,并在各项指标上取得了令人印象深刻的性能……
- perplexity:更多统计数据,由 JohannesGaessler 添加的文档 · Pull Request #6936 · ggerganov/llama.cpp:我看到了一些主观报告,称量化对 LLaMA 3 的危害比对 LLaMA 2 更大。我决定对此进行调查,并为此在 pe... 中添加了更多统计数据(和文档)。
- convert-hf-to-gguf-update.py 似乎无法工作 · Issue #7088 · ggerganov/llama.cpp:Ubuntu 20.04, cudatoolkit12.2 GPU: Nvidia A100 24G RAM 10G(可用) 当我使用 llama.cpp 中的 'convert-hf-to-gguf-update.py' 将 'hf' 转换为 'gguf' 时,它既没有报告任何错误...