ainews-kolmogorov-arnold-networks-mlp-killers-or
**Kolmogorov-Arnold 网络:MLP 杀手,还是只是“加了料”的 MLP?** (注:MLP 指多层感知机,“spicy” 在此处意指“更有趣的变体”或“进阶版”。)
刘子鸣(Max Tegmark 的研究生)发表了一篇关于 Kolmogorov-Arnold 网络 (KANs) 的论文,声称尽管其训练速度慢 10 倍,但参数效率比 MLP 高出 100 倍,且在可解释性、归纳偏置注入、函数逼近精度和扩展性方面均优于后者。KANs 在“边”上使用由 B 样条(B-splines)建模的可学习激活函数,而非在“节点”上使用固定激活函数。然而,随后有研究表明,KANs 在数学上可以被重新排列回参数量相似的 MLP,这引发了关于其可解释性和新颖性的争论。
与此同时,在 AI 推特圈(AI Twitter)上,人们对 GPT-5 可能发布的传闻反应不一;OpenAI 为 DALL-E 3 采用了 C2PA 元数据标准,以高精度检测 AI 生成的图像;微软正在训练一个名为 MAI-1 的 5000 亿参数大模型,可能在 Build 大会上进行预展,这标志着其与 OpenAI 的竞争加剧。此外,还有消息指出:“OpenAI 对 GPT-4.5 的安全测试未能赶在 Google I/O 大会发布前完成”。
可学习激活函数就是你所需的一切吗?
2024年5月6日至5月7日的 AI 新闻。我们为你查看了 7 个 Reddit 子版块、373 个 Twitter 账号以及 28 个 Discord 社区(包含 419 个频道和 3749 条消息)。为你节省了约 414 分钟 的阅读时间(按每分钟 200 字计算)。
理论论文通常超出了我们的能力范围,但最近的争议足够多,而今天又没有太多其他事情发生,所以我们有空间来写写它。一周前,Max Tegmark 的研究生 Ziming Liu 发布了他那篇写得非常出色的 关于 KANs 的论文(附带了文档齐全的库),声称它们在许多重要维度上几乎普遍等同于或优于 MLPs,例如可解释性/归纳偏置注入、函数逼近精度和扩展性(scaling)(尽管承认在相同参数量的情况下,目前在现有硬件上的训练速度慢了 10 倍,但它的参数效率也高出 100 倍)。
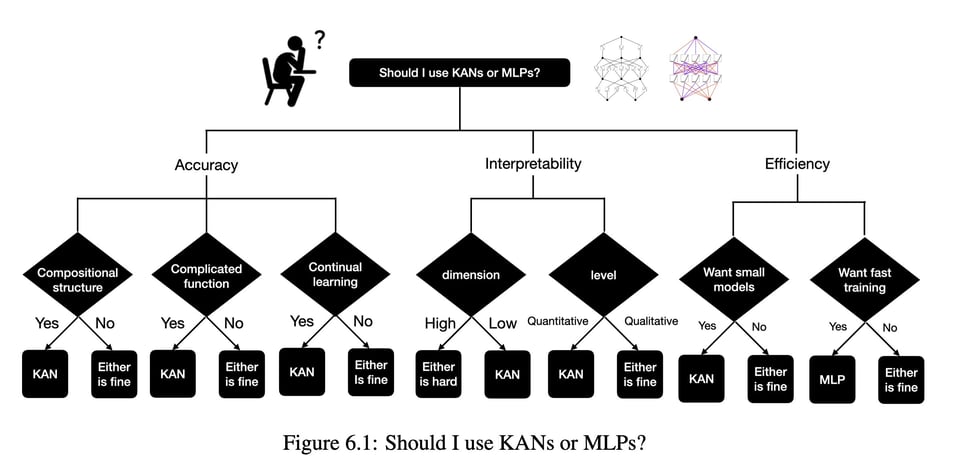
虽然 MLPs 在节点(“神经元”)上具有固定的激活函数,但 KANs 在边(“权重”)上具有可学习的激活函数。
KANs 不再分层堆叠像 ReLu 这样的预设激活函数,而是使用 B-splines(即没有线性权重,只有曲线)和简单加法来建模“可学习的激活函数”。人们对此感到兴奋,甚至开始用 KANs 重写 GPTs。
一周后,事实证明你可以重新排列 KAN 的项,从而回到参数数量大致相同的 MLPs (twitter):
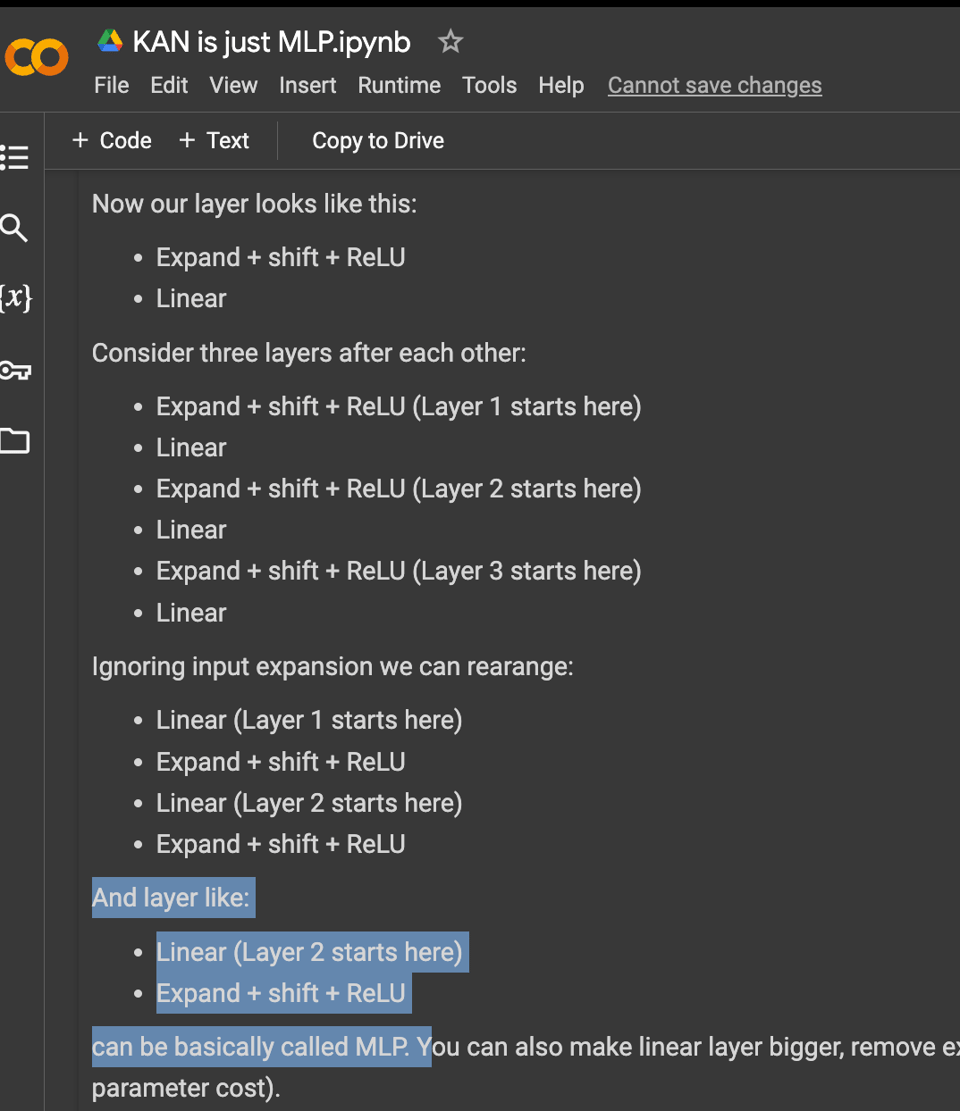
将一个通用逼近器重写为另一个并不令人惊讶——但在这一非常简单的出版物之后,许多人都在为 KANs 的可解释性辩护……而这一点也正受到合理的质疑。
我们是否在短短一周内见证了一篇新理论论文的完整兴衰?这就是预印本系统的运作方式吗?
目录
[TOC]
AI Twitter 总结
所有总结均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程。
OpenAI 和 GPT 模型
- 潜在的 GPT-5 发布:@bindureddy 指出 gpt-2 聊天机器人已回到 chat.lmsys,可能就是最新的 GPT-5 版本,尽管与炒作相比,它们似乎表现平平。@nptacek 测试了 im-a-good-gpt2-chatbot 模型,发现它非常强大,绝对优于最新的 GPT-4,而 im-also-a-good-gpt2-chatbot 虽然输出速度快,但容易陷入重复循环。
- OpenAI 安全测试:@zacharynado 推测 OpenAI 对 GPT-4.5 的“安全测试”无法像 GPT-4 那样赶在 Google I/O 发布前完成。
- 检测 AI 生成的图像:OpenAI 采用了 C2PA 元数据标准来认证 AI 生成的图像和视频的来源,该标准已集成到 DALL-E 3 等产品中。@rohanpaul_ai 指出该分类器可以识别 ~98% 的 DALL-E 3 图像,同时错误标记非 AI 图像的比例 <0.5%,但在区分 DALL-E 3 与其他 AI 生成图像方面的表现较低。
Microsoft AI 进展
- 内部 LLM 训练:根据 @bindureddy 的消息,Microsoft 正在训练自己的 500B 参数模型,名为 MAI-1,可能会在 Build 大会上预展。随着该模型的推出,Microsoft 自然会倾向于推广自家模型而非 OpenAI 的 GPT 系列,这将使两家公司更具竞争性。
- Copilot Workspace 印象:@svpino 对 Copilot Workspace 的第一印象非常积极,指出其精细的方法以及与 GitHub 的紧密集成,可用于直接在仓库中生成代码、解决问题和进行测试。该工具的定位是开发者的助手而非替代品。
- Microsoft 的 AI 重心:加入 Microsoft 的 @mustafasuleyman 分享道,公司坚持 AI 优先并推动大规模技术转型,并将负责任的 AI 作为基石。团队正致力于定义新规范并构建具有积极影响的产品。
其他 LLM 进展
- Anthropic 的方法:在 @labenz 讨论的一次采访中,Anthropic 的 CTO 解释了他们的方法:为 AI 提供大量示例,而不是针对每个任务进行 Fine-tuning,因为 Fine-tuning 从根本上缩小了系统能力的范围。
- DeepSeek-V2 发布:@deepseek_ai 宣布发布 DeepSeek-V2,这是一个开源的 236B 参数 MoE 模型,其在 AlignBench 中位列前三,超越了 GPT-4,并在 MT-Bench 中排名靠前,足以与 LLaMA3-70B 媲美。它擅长数学、代码和推理,拥有 128K 的 Context Window。
- Llama-3 动态:@abacaj 认为,具备多模态能力和长上下文的 Llama-3 可能会给 OpenAI 带来压力。@bindureddy 指出,在 Groq 上运行的 Llama-3 允许 LLM 应用高效地进行多次串行调用,以便在给出正确答案前做出多个决策,这在 GPT-4 上很难实现。
AI 基准测试与评估
- LLM 商品化:@bindureddy 认为 LLM 已经成为一种商品,即使 GPT-5 非常出色,随着语言能力的平台期到来,其他主要实验室和公司也会在几个月内赶上。他建议使用 LLM-agnostic 服务以获得最佳性能和效率。
- 评估 LLM 输出:@aleks_madry 介绍了 ContextCite,这是一种将 LLM 回答归因于给定上下文的方法,用以观察模型如何使用信息,以及是否存在误读或 Hallucination。该方法可以应用于任何 LLM,代价仅是少量的额外推理调用。
- LLM 的涌现能力:@raphaelmilliere 分享了一篇探讨 LLM 相关哲学问题的预印本论文,涵盖了涌现能力、意识以及 LLM 作为认知模型的地位等主题。该论文大部分篇幅致力于近期的可解释性研究和因果干预方法。
Scaling Laws 与架构
- MoE 的 Scaling Laws:@teortaxesTex 指出,DeepSeek-V2-236B 的训练耗费了 140 万 H800 小时,而 Llama-3-8B 耗费了 130 万 H100 小时,这验证了《Scaling Laws for Fine-Grained MoEs》论文的观点。与一些西方前沿公司相比,DeepSeek 公开分享了推理单位经济效益。
- MoE 模型的优势:@teortaxesTex 强调了 DeepSeek 在架构上的创新,包括注意力机制(用于高效推理的 Multi-head Latent Attention)和稀疏层(用于经济地训练强大模型的 DeepSeekMoE),这与一些实验室“规模就是一切”的思维形成了对比。
- MoE 效率:@teortaxesTex 指出,在 1M 上下文下,像 DeepSeek-V2 这样约 250B 参数的 MLA 模型仅使用 34.6GB 缓存,这表明存储长上下文示例作为 Fine-tuning 的替代方案正变得越来越可行。
AI Reddit 综述
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 进展与能力
- Google 的医疗 AI 表现优于 GPT 和医生:在 /r/singularity 中,Google 的 Med-PaLM 2 AI 打破了 GPT 的基准测试,并在医疗诊断任务上表现优于医生。这突显了 AI 在医疗保健等专业领域的快速进步。
- Microsoft 正在开发大型语言模型以参与竞争:据 /r/artificial 报道,Microsoft 正在开发一个名为 MAI-1 的 500B 参数模型,以与 Google 和 OpenAI 的产品竞争。开发更大规模基础模型的竞赛仍在继续。
- AI 系统声称消除了“幻觉”:在 /r/artificial 中,Alembic 声称 开发出了一种能够消除输出中“幻觉”和虚假信息生成的 AI。如果属实,这将是迈向更可靠 AI 系统的重要一步。
AI 伦理与社会影响
- 病毒式传播的 AI 生成误导信息:在 /r/singularity 中,一张 AI 生成的 Katy Perry 参加 Met Gala 的照片走红,在不到 2 小时内获得了超过 20 万个赞。这展示了 AI 大规模快速传播误导信息的潜力。
- 著名 AI 批评者的公信力受到质疑:在 /r/singularity 中,据透露 著名的 AI 批评者 Gary Marcus 承认他实际上并不使用他所批评的大型语言模型,这引发了人们对他对该技术理解程度的怀疑。
- 对 AI 诈骗和欺诈的担忧:在 /r/artificial 中,沃伦·巴菲特 预测随着技术的进步,AI 诈骗和欺诈将成为下一个重大的“增长行业”,强调了对 AI 恶意使用的担忧。
{kind=link}
{kind=link}
技术发展
- 新型神经网络架构分析:在 /r/MachineLearning 中,Kolmogorov-Arnold Network 被证明在经过某些修改后等同于标准的 MLP,为神经网络设计提供了新的见解。
- 开发出高效的大型语言模型:在 /r/MachineLearning 中,DeepSeek-V2,一个 236B 参数的 Mixture-of-Experts 模型,在降低成本的同时实现了强大的性能(与稠密模型相比),推动了更高效架构的发展。
- 用于机器人和具身智能的新库:在 /r/artificial 中,Hugging Face 发布了 LeRobot,一个用于深度学习机器人的库,旨在实现现实世界的 AI 应用并推进具身智能 (Embodied AI) 研究。
Stable Diffusion 与图像生成
- Stable Diffusion 3.0 展示了重大改进:在 /r/StableDiffusion 中,Stable Diffusion 3.0 在图像质量和提示词遵循能力方面展示了重大改进(与之前版本及竞争对手相比)。
- 高效模型性能媲美 Stable Diffusion 3.0:在 /r/StableDiffusion 中,PixArt Sigma 模型展示了出色的提示词遵循能力,在保持高效的同时与 SD3.0 旗鼓相当,提供了一个极具吸引力的替代方案。
- 用于实现逼真光绘效果的新模型:在 /r/StableDiffusion 中,一个新的 “Aether Light” LoRA 模型在 Stable Diffusion 中实现了逼真的光绘效果,为艺术家扩展了创作可能性。
幽默与迷因 (Memes)
- 幽默的 AI 聊天机器人出现:在 /r/singularity 中,一个 “im-a-good-gpt2-chatbot”模型出现在 OpenAI 的 Playground 上,并与用户进行幽默对话,展示了 AI 发展轻松幽默的一面。
{kind=link}
AI Discord 综述
摘要之摘要的摘要
1. 模型性能优化与基准测试
-
[量化 (Quantization)] 技术如 AQLM 和 QuaRot 旨在让大型语言模型 (LLMs) 在保持性能的同时,能够在单个 GPU 上运行。例如:在 RTX3090 上运行 Llama-3-70b 的 AQLM 项目。
-
通过 动态内存压缩 (Dynamic Memory Compression, DMC) 等方法努力提升 Transformer 效率,在 H100 GPUs 上可能将吞吐量提高多达 370%。例如:@p_nawrot 发表的 DMC 论文。
-
关于优化 CUDA 操作的讨论,例如融合逐元素操作(element-wise operations),使用 Thrust 库的
transform来实现接近带宽饱和的性能。示例:Thrust 文档。 -
在 AlignBench 和 MT-Bench 等基准测试中对模型性能进行的比较,其中 DeepSeek-V2 在某些领域超越了 GPT-4。示例:DeepSeek-V2 发布公告。
2. 微调挑战与 Prompt Engineering 策略
-
在将 Llama3 模型转换为 GGUF 格式时保留微调数据的困难,并讨论了一个已确认的 bug。
-
Prompt 设计和使用正确模板(包括 end-of-text token)对于在微调和评估期间影响模型性能的重要性。示例:Axolotl prompters.py。
-
Prompt Engineering 策略,例如将复杂任务拆分为多个 Prompt,研究 logit bias 以获得更多控制。示例:OpenAI logit bias 指南。
-
教会 LLM 在不确定时使用
<RET>token 进行信息检索,从而提高在低频查询上的表现。示例:ArXiv 论文。
3. 开源 AI 进展与协作
-
StoryDiffusion 的发布,这是一个采用 MIT 许可证的 Sora 开源替代方案,尽管权重尚未发布。示例:GitHub 仓库。
-
OpenDevin 的发布,这是一个基于 Cognition 的 Devin 的开源自主 AI 工程师,并举行了网络研讨会,在 GitHub 上的关注度不断增长。
-
呼吁就预测 IPO 成功的开源机器学习论文进行协作,该项目托管在 RicercaMente。
-
围绕 LlamaIndex 集成的社区努力,包括在更新后遇到的 Supabase Vectorstore 和包导入问题。示例:llama-hub 文档。
4. 高效 AI 工作负载的硬件考量
-
关于 GPU 功耗的讨论,深入探讨了 P40 GPU 在待机时为 10W 但总功耗达 200W 的情况,以及将其限制在 140W 以获得 85% 性能的策略。
-
评估推理任务对 PCI-E 带宽的需求,这通常会因为共享资源而被高估。示例:Reddit 讨论。
-
探索 tinygrad 等框架中的单线程操作,该框架在矩阵乘法等 CPU 操作中不使用多线程。
-
咨询 Apple Silicon GPU 上的 Metal 内存分配,以寻找类似于 CUDA
__shared__的共享/全局内存。
5. 其他
-
探索 AI 模型的能力与局限:工程师们比较了 Llama 3 70b、Mistral 8x22b、GPT-4 Turbo 和 Sonar 等多种模型在函数调用(function calling)、文章写作和代码重构等任务中的表现(Nous Research AI)。他们还讨论了量化对模型性能的影响,例如
llama.cpp量化导致的性能下降(OpenAccess AI Collective)。 -
Prompt Engineering 技术与挑战:强调了 Prompt 设计的重要性,指出模板和 token 的更改如何显著影响模型性能(OpenAccess AI Collective)。用户分享了处理复杂 Prompt 任务的技巧,例如将产品识别拆分为多个 Prompt(OpenAI),并讨论了集成负样本的难度(OpenAI)。此外,还探索了来自 Anthropic 的新 Prompt 生成器工具(LLM Perf Enthusiasts AI)。
-
优化 CUDA 操作和模型训练:CUDA 开发者分享了关于使用 Triton 进行高效 kernel 设计、利用 fused operations 进行 element-wise 计算以及利用 CUDA 的 Thrust 库实现最优性能的见解 (CUDA MODE)。讨论还涵盖了提升 Transformer 效率的技术,如 Dynamic Memory Compression (DMC) (CUDA MODE),以及针对特定架构微调 CUDA kernels (CUDA MODE)。
-
开源 AI 项目的进展:值得关注的开源发布包括 DeepSeek-V2(一个在代码和推理基准测试中表现出色的 MoE 模型)(Latent Space)、用于魔法故事创作的 StoryDiffusion (OpenAccess AI Collective) 以及自主 AI 工程师 OpenDevin (LlamaIndex)。此外,还鼓励开展协作,例如关于贡献机器学习 IPO 预测论文的公开征集 (Unsloth AI)。
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- GGUF 转换难题:工程师们注意到将 Llama3 模型转换为 GGUF 时存在一个影响微调数据保留的 bug,这引发了关于 GitHub Issue #7062 和 Reddit 帖子的讨论。
- 训练技巧与故障排除:模型训练是一个热门话题,包括微调过程中的 tokenization 问题 以及在 Unsloth 中成功利用 LoRA Adapters。此外,还讨论了基础数据影响微调模型结果的问题,指出微调会改变先前见过 token 的权重。
- AI 引擎的挑战与策略:Aphrodite Engine 与 4bit bnb 量化的兼容性引发了疑问,同时提到了针对 GGUF 和 exllama 等模型的 VRAM 计算器,以确保推理程序的兼容性。另外,一名成员强调需要一种通用的方法来微调 Large Vision Language Models (LVLM)。
- 模型迭代与协作:发布了新版本的模型,包括用于知识图谱构建的 LLaMA-3-8B-RDF-Experiment,同时发起了关于预测 IPO 成功的机器学习论文协作的公开征集。
- 产品展示与支持请求:专业网站生成器 Oncord 的推出并在 oncord.com 进行了演示,成员们讨论了初创公司的营销策略。此外,还有关于 moondream 微调的支持请求,并链接了一个 GitHub notebook。
Nous Research AI Discord
Function Calling 对决:Llama 3 70b 在 Function Calling 性能上表现优于 Mistral 8x22b,尽管后者声称拥有强大能力,但两者之间仍存在差距。成员们围绕 AI 聊天机器人的 Function Calling 实用性和准确性展开了讨论。
AI 训练速度之战:训练时间的对比引发了关注。有报告称在 A100 上进行 LoRA Llama 3 8b 微调时每步耗时 500 秒,而使用 litgpt 对 Llama2 7B 进行 1,000 次迭代仅需 3 分钟。这种巨大的效率差异引发了关于优化和实践的疑问。
对改进的迫切期待:用户对无法访问的功能(如 worldsim.nousresearch.com)以及 Bittensor 等网络关键更新的延迟表示失望,这凸显了 AI 开发者面临的实时挑战以及更新停滞对生产力的连锁反应。
量化技术的飞跃:AQLM 项目 随着 Llama-3-70b 和 Command-R+ 等模型的加入而取得进展,展示了在单张 GPU 上运行 Large Language Models 的进步,并触及了社区对提高模型可访问性和性能的追求。
追求值得信赖的 AI:Invetech 旨在对抗幻觉的“确定性引用(Deterministic Quoting)”表明社区对可靠 AI 的强烈渴望,特别是在医疗保健等敏感领域,旨在将真实性与 Large Language Models 的创新潜力相结合,详见讨论。
Stability.ai (Stable Diffusion) Discord
-
揭秘 Hyper Diffusion 与 Stable Diffusion 3:工程师们剖析了以速度著称的 Hyper Stable Diffusion 与即将推出的 Stable Diffusion 3 之间的细微差别。社区对后者可能不开源表示担忧,引发了关于 AI 模型战略保护的讨论。
-
写实人物渲染中的偏见警示:对最有效的写实人物模型的追求引发了辩论,大家达成共识,认为必须避免使用来自 civitai 等具有严重偏见的模型,以保持生成内容的多样性。
-
深入探讨 Dreambooth 和 LoRA:用户间的深度技术咨询揭示了在微调 Stable Diffusion 模型时如何利用 Dreambooth 和 LoRA。讨论特别关注于生成独特且多样化的面孔和风格。
-
放大算法大比拼:参与者对比了 RealESRGAN_x4plus 和 4xUltrasharp 等放大器,分享了各自的成功案例和偏好。对话旨在找出能提升图像分辨率的卓越放大技术。
-
开源 AI 的黄昏?:对话中反复出现的一个主题反映了社区对开源 AI 未来的焦虑,特别是与 Stable Diffusion 模型相关的未来。讨论围绕专有化开发的后果以及保留关键 AI 资产访问权限的策略展开。
LM Studio Discord
代码的私密生活:用户呼吁在 LM Studio 中增加服务器日志关闭功能以保护开发过程中的隐私,并对通过 GUI 收集服务器日志表示了真正的担忧。
CLI 的一天:人们对以 headless mode 使用 LM Studio 以及利用 lms CLI 通过命令行启动服务器产生了浓厚兴趣。用户还分享了在 llama toolkit 更新后,Command R 和 Command R+ 的 Tokenizer 复杂化问题的更新,并发布了从 Hugging Face Co’s Model Repo 下载更新后的量化(quantizations)版本的指南。
Linux 中的内存失效:LM Studio 0.2.22 版本中一个特殊的 Linux 内存误报案例引发了一些讨论,并提出了解决运行 Meta Llama 3 instruct 7B 等模型时 GPU offloading 故障的建议。
迷失在思绪中的提示词:用户解决了 LM Studio 错误地响应已删除内容和限定范围的文档访问问题,引发了关于 LLM 处理和保留数据方式的辩论。
模型故障:LM Studio 中的几个模型被指出存在问题,包括 llava-phi-3-mini 误识别图像,以及尽管使用了 AnythingLLM database,Mixtral 和 Wizard LM 等模型在处理《龙与地下城》(Dungeon & Dragons)数据持久化时出现失误。
功耗考量:社区中的硬件爱好者们正在努力解决 GPU 功耗、服务器主板和 PCIe 带宽问题,分享了在带有虚拟 GPU 的 VM 中成功运行 LM Studio 的经验,并权衡了 AI 项目的实际硬件设置。
Beta 测试的忧郁:讨论提到了 8GB GPU 运行 7B 模型时的崩溃问题以及崩溃后的卸载问题,Beta 用户正在寻求针对反复出现错误的解决方案。
SDK 的到来:新 lmstudiojs SDK 的发布预示着即将到来的 LangChain 集成,这将使工具开发更加精简。
在 AI 前线:用户提供了 Linux 上依赖包安装的解决方案,讨论了 LM Studio 在 Ubuntu 22.04 与 24.04 上的兼容性,并分享了 LM Studio 的 API 集成和并发请求处理方面的挑战。
工程师的询问:人们对使用 LM Studio 设置 GPT-Engineer 以及是否涉及自定义 Prompting 技术表现出了极大的好奇。
向 AI 提问:一些人表达了 Prompt Engineering 作为一种手艺的价值,认为它是从 LLM 获得优质输出的核心,并分享了在 Towards Data Science 报道的新加坡 GPT-4 Prompt Engineering 竞赛中获胜的经验。
AutoGen 的小插曲:简要提到了一个导致 AutoGen Studio 发送不完整消息的 Bug,目前还没有关于解决方法或原因的进一步讨论。
HuggingFace Discord
ASR 微调成为焦点:工程师们讨论了如何增强 openai/whisper-small ASR 模型,强调了数据集大小和超参数微调 (hyperparameter tuning)。建议包括调整 weight_decay 和 learning_rate 以优化训练,社区分享的资源重点介绍了梯度累积步数 (gradient accumulation steps) 和学习率调整等超参数。
深入探讨量子与 AI 工具:对看似初期的量子虚拟服务器的隐秘兴趣随着 Oqtant 的出现而浮出水面;而 AI 工具包则涵盖了从支持 50 多种语言的全能助手 everything-ai,到代码结构混乱但功能完备的图像生成 Discord 机器人 Sparky 2。
调试与数据集:设计 PowerPoint 幻灯片的聊天机器人、获得 Flash Attention 2 升级的 XLM-R,以及多标签图像分类训练的困扰成为了讨论焦点,社区成员就这些问题交换了宝贵的见解。与此同时,丢失的 UA-DETRAC 数据集引发了一场搜寻,该数据集对于基于交通摄像头的目标检测所需的标注信息至关重要。
模型训练中的定制化与挑战:从使用 Custom Diffusion(仅需极少样本图像)个性化图像模型,到微调 Stable Diffusion 1.5 和 BERT 模型时的挣扎,社区成员针对各种训练故障进行了讨论并构思解决方案。在多 GPU 和 CPU offloading 过程中的设备不匹配问题,以及针对受限资源的优化技术的重要性,是显著的痛点。
教 LLMs 检索的新方法:讨论了一种鼓励 LLMs 使用 <RET> 标记进行信息检索以提升性能的新技术,并参考了近期的一篇论文,强调了该方法对于模型记忆无法涵盖的冷门问题的重要性。与此同时,还观察了通过 Token 计数进行模型计费的方法,并分享了关于定价策略的实用见解。
Perplexity AI Discord
Beta 版困惑:用户在访问 Perplexity AI 的 Beta 版本时感到困惑;有人以为点击图标会显示表单,但事实并非如此,随后官方澄清 Beta 版是封闭测试。
性能难题:在不同设备上,Perplexity AI 用户报告了按钮无响应和加载缓慢等技术问题。对话围绕 Claude 3 Opus 和 Sonar 32k 等模型的限制及其对工作的影响展开,并呼吁查看 Perplexity FAQ 以获取详情。
AI 模型大混战:讨论了 GPT-4 Turbo、Sonar 和 Opus 等 AI 模型的能力对比,重点关注论文写作和代码重构等任务。用户还询问了搜索中的来源限制是否有所增加,并使用 GIF 来辅助说明回复。
API 焦虑与见解:Perplexity API 频道的讨论范围从构建 JSON 输出到对 Perplexity 在线模型搜索功能的困惑。文档已更新(如文档链接所示),这对于处理搜索结果过时和探索模型参数量等问题的用户非常重要。
通过 Perplexity 共享发现:社区深入探讨了 Perplexity AI 的产品,涉及从 US Air Force 见解到 Microsoft 5000 亿参数 AI 模型等一系列话题。用户表达了对标准化图像生成 UI 的渴望,分享了 Insanity by XDream 等功能的链接,并强调了内容的可分享性。
CUDA MODE Discord
GPU 时钟频率混淆:一场关于 H100 GPUs 时钟频率的混淆引发了讨论,最初提到的 1.8 MHz 被更正为 1.8 GHz。这强调了区分 MHz 与 GHz 的必要性,以及在讨论 GPU 性能时准确规格的重要性。
优化 CUDA:从 Kernels 到库:成员们分享了优化 CUDA 操作的见解,强调了 Triton 在 Kernel 设计中的效率、fused operations 在逐元素计算中的优势,以及 CUDA Thrust 库的使用。CUDA 的最佳实践是使用 Thrust 的 for_each 和 transform 来实现接近带宽饱和的性能。
PyTorch 动态:讨论了 PyTorch 中的各种问题和改进,包括使用 TORCH_LOGS="+dynamic" 调试 PyTorch Compile 的动态形状(dynamic shapes),以及如何针对 Triton 后端使用 torch.compile。PyTorch 的 GitHub 上报告的一个问题涉及将 Compile 与 DDP 及动态形状结合使用,记录在 pytorch/pytorch #125641 中。
Transformer 性能创新:对话围绕提升 Transformer 效率的技术展开,一位社区成员介绍了 Dynamic Memory Compression (DMC),该技术可能在 H100 GPUs 上将吞吐量提高多达 370%。成员们还参考相关论文讨论了该方法是否涉及量化(quantization)。
llm.c 中的 CUDA 讨论升温:llm.c 频道非常活跃,处理了诸如 master 分支上多 GPU 训练挂起以及使用 NVIDIA Nsight™ Systems 进行优化等问题。一个显著的贡献是 HuggingFace 发布了用于 LLM 性能评估的 FineWeb 数据集,记录在 PR #369 中,PR #307 则讨论了通过 Kernel 优化获取性能提升的可能性。
OpenAI Discord
-
OpenAI 语言化定义其数据准则:OpenAI 关于数据处理的新文档阐明了该机构在处理 AI 行业海量数据时的实践和伦理准则。
-
AI 的节奏革命可能已经到来:讨论集中在 AI 在音乐领域的演进,引用了一位音乐家与 AI 的即兴演奏会作为例子,展示了 AI 在生成能引起人类听众共鸣的音乐方面的重大进展。
-
Perplexity 和余弦相似度引发工程师思考:工程师们对发现 Perplexity 在 AI 文本分析中的效用感到惊叹,并辩论了文本嵌入(text embeddings)的最佳余弦相似度阈值,强调了从“旧标准 0.9”向“新标准 0.45”的转变。
-
Prompt 实践与陷阱备受关注:关于 Prompt Engineering 的技巧强调了使用负面示例和将任务拆分为多个 Prompt 的复杂性,并指向 OpenAI logit bias 指南以微调 AI 回复。
-
GPT 的向量库与统一交付保证:分享了关于 GPT 知识库机制和性能一致性的见解,消除了“波动的用户需求会影响 GPT-4 输出”或“可能部署劣质模型来管理用户负载”的观念。
Eleuther Discord
-
质疑神圣的 P 值:讨论强调了科学研究中 .05 p-value 阈值 的随意性,并指向了一项将该标准移至 0.005 以增强可重复性的运动,正如一篇 Nature 文章所倡导的那样。
-
突破 Skip Connections 的边界:Adaptive skip connections 正在研究中,有证据表明将权重设为负值可以提高模型性能;这些实验的细节可以在 Weights & Biases 上找到。针对权重动力学底层机制的查询,得到了一个 gated residual network 论文和一个 代码片段的回应。
-
Logit 锁定世界中的模型评估:为了防止提取敏感“签名”,OpenAI 等 API 模型对 Logits 进行了隐藏,这引发了关于模型评估替代方案的讨论。参考了在 YAML 中使用 ‘generate_until’ 进行意大利语 LLM 比较的方法,这是基于最近的研究发现(Logit 提取工作)。
-
接触不可微调学习:介绍了 SOPHON,这是一个专为不可微调学习设计的框架,旨在限制任务的可迁移性,从而减轻预训练模型的伦理滥用(SOPHON 论文)。与此同时,还出现了一项关于 QuaRot 的讨论,这是一种基于旋转的量化方案,可以将 LLM 组件压缩到 4-bit,同时保持性能(QuaRot 论文)。
-
规模扩展与损失曲线之谜:一项值得注意的模型扩展实验使用了在 fineweb 数据集上训练的 607M 参数设置,发现了异常的损失曲线,引发了在其他数据集上进行实验以进行 Benchmarking 的建议。
Modular (Mojo 🔥) Discord
-
探索 Mojo 的无限编程冒险:工程师们讨论了在 Mojo 中编程的复杂性,包括使用 Docker 在 Intel Mac OS 上安装,通过 WSL2 支持 Windows,以及与 Python 生态系统的集成。对设计选择的强调(如包含 structs 和 classes)引发了辩论,而允许生成如 .exe 等原生机器码的编译能力仍然是一个亮点。
-
关注 Modular 的最新动态:Modular 团队在 Twitter 上发布了两条重要更新,暗示了未提及的进展或新闻,社区成员可查看 推文 1 和 推文 2 了解详情。
-
展示 MAX 引擎的卓越与 API 的优雅:MAX 24.3 在社区直播中首次亮相,展示了其最新更新,并为 Mojo 引入了新的 Extensibility API。热衷学习者和好奇者可以观看解说视频。
-
Mojo 开发中的 Tensor 与策略修补:从 Tensor 索引技巧到大型数组的 SIMD 复杂性,AI 工程师分享了 Mojo 领域的指针和范式。讨论扩展到了 Benchmarking 函数、无类设置中的构造函数、高级编译器工具需求、关于
where子句的提案,以及 Mojo 中编译时元编程的潜力。 -
推动 Mojo 前行的社区项目:社区项目内的更新展示了进展和寻求协助的请求,例如 mojo-sort 的高效基数排序及基准测试,Lightbug 迁移到 Mojo 24.3 的困难(详见 GitHub issue),以及将 Minbpe 移植到 Mojo,其速度在 Minbpe.mojo 超过了 Python 版本。同时,对 Mojo GUI 库 的寻找仍在继续。
-
Nightly 编译改变游戏规则:工程师们处理了 Mojo 的类型处理问题,特别是 Traits 和 Variants,指出了局限性以及像
PythonObject和@staticmethods这样的变通方法。新的 Nightly 编译器版本 引发了关于自动发布通知的讨论,并强调了对Reference使用的改进,所有这些都伴随着一个俏皮的评论,即更新内容已经超出了 2k 显示器的显示范围。
OpenRouter (Alex Atallah) Discord
-
模型使用费率回滚:Soliloquy L3 8B 模型在 2023 - 2024 年的价格降至 $0.05/M tokens,正如 OpenRouter 价格更新 中宣布的那样,该模型在私有和日志记录端点上均可使用。
-
为 Rubik 寻找 Beta 测试专家:Rubik’s AI 正在征集 Beta 测试人员,通过 rubiks.ai 上的促销代码提供为期两个月的模型高级访问权限,包括 Claude 3 Opus, GPT-4 Turbo, 和 Mistral Large,并暗示将推出包含 Apple 和 Microsoft 最新动态的技术新闻板块。
-
解码冗长的 Llama:工程师们对 llama-3-lumimaid-8b 的响应长度表示沮丧,讨论了与 Yi 和 Wizard 等模型相比在冗长程度上的复杂性,并对 Meta-Llama-3-120B-Instruct 的发布感到兴奋,这一点在 Hugging Face 的揭晓 中得到了强调。
-
跨区域模型请求之谜:用户们在思考 Amazon Bedrock 是否可能对模型请求施加区域限制,共识倾向于跨区域请求是可行的。
-
精度指南与参数难题:对话揭示了 OpenRouter 内部对模型精度的偏好,通常维持在 fp16,偶尔会蒸馏至 int8,并进一步讨论了默认参数是否需要调整以获得最佳对话效果。
OpenInterpreter Discord
Python 3.10 带来成功:Open Interpreter (OI) 应使用 Python 3.10 运行以避免兼容性问题;一位用户通过切换到 dolphin 或 mixtral 等模型提升了性能。建议参考 Open Interpreter 的 GitHub 仓库 以获取有关技能持久化的见解。
Conda 环境化解难题:工程师建议在 Mac 上使用 Conda 环境 进行无冲突的 Open Interpreter 安装,特别是使用 Python 3.10 以避开版本冲突和相关错误。
Jan 框架支持本地运行:Jan 可以作为 O1 设备的本地模型框架顺利使用,前提是采用与 Open Interpreter 类似的模型服务方法。
全球旅行者询问 O1:01 设备在全球范围内均可使用,但目前假设托管服务以美国为中心,尚未确认国际发货。
微调的挫折与修复:在微调模型之前,呼吁有效理解和使用 system messages,这引出了 OpenPipe.ai 的建议,因为成员们正在探索 Open Interpreter 各种模型的最佳性能。对话还包括模型基准测试,以及 Phi-3-Mini-128k-Instruct 在与 OI 配合使用时表现不佳的问题。
OpenAccess AI Collective (axolotl) Discord
开源魔力正在崛起:社区推出了 Sora 的开源替代方案,名为 StoryDiffusion,在 GitHub 上以 MIT 许可证发布;然而,其权重仍待发布。
通过 Unsloth Checkpointing 提高内存效率:据报道,实施 Unsloth 梯度检查点(gradient checkpointing)已将 VRAM 使用量从 19,712MB 降至 17,427MB,突显了 Unsloth 在内存优化方面的有效性。
关于“懒惰”模型层的推测:观察到一种奇怪现象,即只有特定切片的模型层在接受训练,这与在其他模型中看到的完整层训练形成对比;提出的理论包括,当面对过于简单的数据集时,模型可能主要优化第一层和最后一层。
提示词设计至关重要:AI 爱好者强调,提示词设计(特别是关于使用合适的模板和 end-of-text tokens)在微调和评估期间对模型性能的影响至关重要。
扩展的 Axolotl 文档揭示权重合并见解:Axolotl 文档已推出新更新,增强了对合并模型权重的见解,重点是将这些指南扩展到涵盖推理策略,详见 Continuum Training Platform。
LangChain AI Discord
-
LangChain 的 OData V4 及更多内容:讨论重点在于 LangChain 与 Microsoft Graph (OData V4) 的兼容性,以及对 kappa-bot-langchain 的 API 访问需求。还有一个关于 ConversationEntityMemory 中
k参数的查询,参考了 LangChain 文档。 -
Python 与 JS 流式传输一致性问题:成员们在 LangChain 的 RemoteRunnable 的 JavaScript 实现中遇到了
streamEvents的不一致问题,而该功能在 Python 中运行正常。这促使人们建议联系 LangChain GitHub 仓库 以寻求解决方案。 -
AI 项目寻求合作者:分享了 everything-ai V1.0.0 的更新,现在包含一个用户友好的本地 AI 助手,具备文本摘要和图像生成等功能。还讨论了为研究助手工具 Rubiks.ai 招募 Beta 测试人员的请求。Beta 测试人员报名请访问 Rubiks.ai。
-
实现平滑 AI 部署的无代码工具:介绍了一款旨在简化 AI 应用创建和部署的无代码工具,内置 Prompt Engineering 功能。早期演示可以在 这里 观看。
-
通过视频教程学习 LangChain:成员可以访问 “Learning Langchain Series”,最新的 API Chain 和 Router Chain 教程分别可在 YouTube 和 这里 观看。这些教程指导用户如何使用这些工具在 LLM 中管理 API。
LAION Discord
-
渴望真实的 AI 聊天?关注角色扮演!:有人提议汇编一个纯人工编写的对话数据集,其中可能包含笑话和更真实的互动,以增强 AI 对话,使其超越在智能 Instruct 模型中看到的公式化回复。
-
用虚构创造:介绍 Simian 合成数据:介绍了一个 Simian 合成数据生成器,能够生成用于潜在 AI 实验的图像、视频和 3D 模型,为那些寻求为研究目的模拟数据的人提供了一个工具。
-
寻找完美数据集:针对最适合文本/数值回归或分类任务的数据集请求,提出了几项建议,包括 MNIST-1D 和 Stanford Large Movie Review Dataset。
-
文本转视频:Diffusion 击败 Transformers:有争论认为 Diffusion 模型目前是 SOTA 文本转视频任务的最佳选择,并且通常计算效率更高,因为它们可以从 Text-to-Image (T2I) 模型进行微调。
-
视频 Diffusion 模型专家发表见解:一篇 Stable Video Diffusion 论文的作者讨论了在确保视频模型的高质量文本监督方面面临的挑战,以及使用 LLM 为视频生成字幕的好处,并提出了 Autoregressive 和 Diffusion 视频生成技术之间的差异。
LlamaIndex Discord
-
向 OpenDevin 的创作者学习:LlamaIndex 邀请工程师参加本周四上午 9 点(PT 时间)举行的网络研讨会,届时 OpenDevin 的作者将出席,探讨在 GitHub 日益拥抱 AI 的背景下如何构建自主 AI Agent。点击此处注册研讨会。
-
Hugging Face 和 AIQCon 更新:Hugging Face 的 TGI 工具包升级,现在支持 function calling 和 batched inference;同时,Jerry Liu 正准备在 AIQCon 上讨论高级问答 Agent(Advanced Question-Answering Agents),在推文中提到使用 “Community” 代码可获得折扣。
-
集成 LlamaIndex 变得更加棘手:工程师们报告了将 LlamaIndex 与 Supabase Vectorstore 集成时的挑战,并遇到了包导入混淆的问题,更新后的 llama-hub 文档已迅速解决了这些问题。
-
解决 LlamaIndex 的问题:社区在讨论删除文档知识和本地 PDF 解析库时,倾向于重新实例化 query engine 并利用 PyMuPDF 寻求解决方案,同时考虑通过 prompt engineering 来处理无关的模型响应。
-
探索与反思 AI Agent:工程师们正在寻求有效的 HyDE 方法来进行语言到 SQL 的转换,而内省 Agent(introspective agents)凭借其 reflection agent pattern 引起了关注,正如在 AI Artistry 的一篇文章中所观察到的,尽管有些链接出现了 404 错误。
tinygrad (George Hotz) Discord
-
LLVM IR 启发 tinygrad 格式化提案:有人建议改进 tinygrad 的可读性,希望采用更接近 LLVM IR 人类可读格式的操作表示。对话转向了静态单赋值(SSA)形式,以及 tinygrad 中 PHI 操作位置可能引起的混淆。
-
tinygrad 保持单线程:George Hotz 确认 tinygrad 不使用多线程进行 CPU 操作(如矩阵乘法),保持其单线程设计。
-
为了效率重映射 Tensor:讨论了通过改变 strides 来重映射 Tensor 的技术,重点在于如何高效地执行 reshape,类似于 tinygrad 的内部方法。
-
推动 tinygrad 社区的实践理解:分享了诸如 GitHub 上的 symbolic mean 解释和关于 view merges 的 Google 文档等资源,表明 tinygrad 社区正通过实践案例和文档推动更好的理解。
-
tinygrad 探索量化推理:对话涉及了 tinygrad 执行量化推理(quantized inference)的能力,这一特性有可能压缩模型并加速推理时间。
Cohere Discord
发现 SQL 数据库端口:在 Cohere 工具包中用于跟踪对话历史所需的 SQL 数据库被设置为在 port 5432 上运行,但未提及具体位置。
Google Bard 竞争,校园版:一名计划创建类似 Bard 聊天机器人的高中生收到了来自 Cohere 的指导,建议遵守用户协议并注意获取生产密钥(production key),详见 Cohere 文档。
本地测试中的 Chroma 小故障:在使用 Cohere 工具包的 Chroma 进行文档检索时出现了一个未解决的 IndexError,完整的日志追踪可在 Pastebin 查看,并建议使用最新的预构建容器。
Cohere 工具包中的检索器混淆:根据用户报告,观察到一个异常现象,即尽管指定了备选方案,系统仍默认选择了 Langchain retriever,不过用于证明此点的截图无法查看。
生产密钥之谜:一位用户遇到了奇怪的情况,新的生产密钥在 Cohere 工具包中表现得像试用密钥。然而,Cohere 支持团队澄清说,这在 Playground / Chat UI 中是预期行为,在 API 中使用时应能恢复正常功能。
Coral 融合了聊天机器人和 ReRank 技能:推出了 Coral Chatbot,它将文本生成、摘要和 ReRank 等功能整合到一个统一的工具中,可在其 Streamlit 页面 提供反馈。
Python Decorators 简短介绍:分享了一个名为 “Python Decorators In 1 MINUTE” 的简短说明,适合那些寻求快速了解这一 Pythonic 概念的人——视频可在 YouTube 上观看。
Latent Space Discord
-
半人马程序员(Centaur Coders)可能会精简团队:AI 在开发中的集成正在推动一种趋势,即 Centaur Programmer 团队可能会缩小规模,这可能会提高生产的精确度和效率。
-
DeepSeek-V2 排名上升:DeepSeek-V2 在 Twitter 上宣布作为一个开源 MoE 模型,在代码和逻辑推理方面拥有卓越的能力,引发了关于其对当前 AI 基准测试影响的讨论。
-
赞扬 DeepSeek 的成就:相关通信称赞了 DeepSeek-V2 在基准测试中的成功,一份 AI News 通讯 详细介绍了该模型对 AI 生态系统带来的引人注目的增强。
-
寻找统一搜索的协同效应:对有效统一搜索解决方案的追求引发了关于 Glean 等工具的对话,以及 Hacker News 上关于潜在开源替代方案的讨论,建议使用机器人来桥接不一致的搜索平台。
-
众包 AI 编排(Orchestration)智慧:社区成员对 AI 编排的最佳实践感到好奇,并就处理涉及文本和 embeddings 的复杂 pipeline 时所青睐的工具和技术进行了咨询。
AI Stack Devs (Yoko Li) Discord
- 免费软件 Faraday 基础:工程师们确认 Faraday 可以在本地免费使用,不需要云端订阅;一位成员使用 6 GB VRAM 的配置成功运行了该软件及其免费的语音输出功能。
- 持久下载:强调从 Faraday 平台下载的角色和模型等资产可以无限期访问和使用,无需任何额外费用。
- GPU 性能即正义:公认强大的 GPU 是运行 Faraday 的云端订阅的可行替代方案,除非有人更愿意通过订阅来支持开发者。
- 模拟站协作:在用户发起的项目领域,@abhavkedia 发起了一项合作,旨在创建一个与 Kendrick 和 Drake 事件相关的有趣模拟,鼓励其他成员加入。
- AI 爱好者的全新游乐场:邀请工程师试用并可能将 Llama Farm 集成,讨论重点围绕一种涉及 AI-Town 的集成技术,以及转向使 Llama Farm 在利用 OpenAI API 的系统中更具普遍适用性。
Mozilla AI Discord
-
设备端需要速度?试试 Rocket-3B:在经历 每 token 8 秒 的缓慢速度后,参与者开始寻找更快的模型选项,Rocket-3B 提供了显著的速度提升。
-
llamafile 缓存趋于成熟:用户可以通过
-m model_name.gguf使用 ollama 缓存,从而避免在 llamafile 中重复下载模型,提高了效率。 -
AutoGPT 与 llamafile 的端口故障:AutoGPT 与 llamafile 的集成出现了问题;llamafile agent 在 AP 服务器启动期间崩溃,需要手动解决。
-
寻求 AutoGPT-llamafile 集成的反馈:AutoGPT 社区正在积极开发与 llamafile 的集成,正如 草案 PR 所示,在进一步开展工作前正征求反馈。
Interconnects (Nathan Lambert) Discord
AI 基准测试备受关注:Jim Fan 博士的推文引发了关于特定基准测试过度估值以及 AI 评估中公共民主化的辩论,成员建议将 AB testing 作为一种更有效的方法。
跨行业基准测试:一位工程师借鉴数据库行业的类比,强调了为 AI 建立标准基准测试的重要性,并引用了 Fan 博士推文中提到的方法。
TPC 标准解析:针对询问,一名成员澄清了 TPC 是指事务处理委员会(Transaction Processing Council),该组织负责规范数据库行业的基准测试,并提到了 TPC-C 和 TPC-H 等具体基准。
GPT-2 令人惊讶的回归:Sam Altman 的一次轻松提及引发了关于 GPT-2 回归 LMsys 竞技场的讨论,并分享了一张显示其中幽默成分的推文截图。
对 LMsys 发展方向的疑虑:Nathan Lambert 对 OpenAI 可能利用 LMsys 进行模型评估表示怀疑,并对 LMsys 的资源限制以及最近“chatgpt2-chatbot”炒作可能带来的声誉损害表示担忧。
DiscoResearch Discord
- PR 被关闭:一个 Pull Request 在没有提供额外上下文的情况下被关闭,这标志着所讨论的开发工作可能发生了变化或停滞。
- 工程师们对 AIDEV 充满期待:即将举行的 AIDEV 活动 的参与者正在进行同步,并对线下见面表现出极大的热情,不过参与者们也在询问是否需要自备食物。
- Mistral 在德语讨论中获得关注:8x22b Mistral 模型在某个项目中的应用已得到验证,重点在于部署和性能。关于低延迟解码技术以及创建包含包容性语言的德语数据集的咨询引发了动态讨论。
- 为德语 AI 构建关键数据集:有人建议从 Common Crawl 构建德语专属的预训练数据集,引发了关于应优先纳入哪些高质量内容领域的讨论。
- 分享包容性语言资源:对于有兴趣在模型中实现包容性语言模式的人,社区传阅了 INCLUSIFY 原型 (https://davids.garden/gender/) 及其 GitLab 仓库 (https://gitlab.com/davidpomerenke/gender-inclusive-german) 等资源。
LLM Perf Enthusiasts AI Discord
Anthropic AI 的 Prompt 工具引起兴趣:工程师们在 Anthropic 控制台 中发现了一个新的 prompt 生成工具,引发了对其潜力和能力的讨论。
通过 AI 打造礼貌用语:该工具通过成功地将陈述句改写得更加礼貌,展示了其价值,获得了实际 AI 应用方面的认可。
拆解 AI 的指令集:一位工程师着手揭示该工具的 system prompt,特别注意到其架构中对 k-shot 示例 的高度依赖。
提取完整 AI Prompt 面临挑战:尽管由于 Prompt 体积庞大,在获取完整内容时遇到了障碍,但讨论的热情依然高涨。
AI 爱好者之间的分享与互助:一位社区成员承诺将向同行分享完整提取的 prompt,以确保在理解和利用这一新工具方面取得共同进步。
Alignment Lab AI Discord
鉴于提供的信息,目前没有针对 AI Engineer 受众的相关讨论内容可供总结。如果未来的讨论包含技术性、注重细节的内容,将生成适合工程师的总结。
Datasette - LLM (@SimonW) Discord
- GitHub Issue 激发插件协作:一场关于改进插件的讨论包含了一个 GitHub issue 链接,表明正在积极开发一个在测试中实现参数化的功能。
- OpenAI Assistant API 兼容性问题:有人询问是否可以将
llm与 OpenAI Assistant API 结合使用,并对之前分享的相关信息的遗失表示担忧。
Skunkworks AI Discord 没有新消息。如果该频道长期保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期保持沉默,请告知我们,我们将将其移除。
PART 2: 按频道划分的详细总结和链接
Unsloth AI (Daniel Han) ▷ #general (170 messages🔥🔥):
-
GGUF 转换中的技术故障:用户讨论了一个在将 Llama3 模型微调并转换为 GGUF 时确认的 bug,特别提到了在转换过程中保留微调数据的问题。后续及相关讨论引用了 Reddit 和 GitHub issue 的直接链接(Reddit 讨论,GitHub Issue)。
-
使用量化运行 Aphrodite Engine:一位用户在运行带有 4bit bnb 量化的 Aphrodite Engine 时遇到困难并寻求建议。建议使用带有
--load-in-4bit标志的 fp16,并从 dev 分支构建以获得更好的支持和功能。 -
推理程序的 LLM VRAM 需求:分享了一个指向 Hugging Face Spaces 上 VRAM 计算器 (LLM-Model-VRAM-Calculator) 的链接,并讨论了其准确性以及与 vLLM、GGUF 和 exllama 等推理程序的兼容性。
-
Unsloth Studio 发布延迟:一位用户询问由于 phi 和 llama 的问题导致 Unsloth Studio 发布延迟的情况,期待能更方便地使用 notebook。另一位用户澄清了在 Unsloth 更新的 Llama3-8b-instruct 训练代码中 eos_token 的正确用法。
-
关于模型基础数据对推理结果影响的担忧:讨论了基础模型的训练数据对微调模型结果的影响。澄清了微调可能会更新用于预测模型之前见过的对话中的 token 的权重。
- LLM Model VRAM Calculator - a Hugging Face Space by NyxKrage:未找到描述
- Reddit - Dive into anything:未找到描述
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp:我正在使用 Unsloth 对 llama3-8b Instruct 模型进行 LORA 微调。1:我将模型与 LORA adapter 合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理...
- Reddit - Dive into anything:未找到描述
Unsloth AI (Daniel Han) ▷ #random (86 messages🔥🔥):
- 支持者角色困惑:一位成员在收到关于支持者私人频道的各种消息后,对其支持者身份感到不确定。经澄清,支持者角色确实存在,但需要会员资格或至少 10 美元的捐赠。
- 处理未过滤的 LLaMA-3 输出:一位成员对 LLaMA-3 针对某些有问题提示词提供未经审查的输出表示担忧。尽管尝试通过 System Prompts 来阻止,LLaMA-3 仍继续生成露骨内容。
- FlashAttention 优化讨论:一位成员分享了 Hugging Face Blog 上的一篇文章,讨论了如何利用 FlashAttention 为长序列机器学习模型优化 Attention 计算,这可以减少训练中的内存占用。
- 显卡促销提醒:一位成员分享了一个 Reddit 帖子,关于 MSi GeForce RTX 4090 SUPRIM LIQUID X 24 GB 显卡的折扣,引发了关于新型 GPU 型号中更小、更高效冷却系统优势的讨论。
- AI 生成头像赞赏:讨论围绕一位成员的新头像展开,该头像被证实是 AI 生成的。这引发了大家的兴趣,并将其与流行媒体中的角色进行了比较。
Unsloth AI (Daniel Han) ▷ #help (412 条消息🔥🔥🔥):
- GGUF 上传查询:成员们讨论了将 GGUF 模型上传到 GPT-4all 的能力,另一位成员确认这是可行的,并建议使用 Huggingface 的
model.push_to_hub_gguf来实现。 - Tokenization 问题:对话强调了包括 GGUF 在内的各种格式的 Tokenization 问题,并指出使用 Unsloth 进行 Fine-tuning 与使用其他推理方法时在响应上的差异。
- Tokenizer Regex 修订:GitHub Issue #7062 正在讨论关于 Llama3 GGUF 转换的 Tokenization 问题,特别是涉及到 LORA Adapters 的部分;已有人提议修改 Regex 以解决此问题。
- LORA Adapters 与训练:一位成员通过设置
load_in_4bit = False进行训练,单独保存 LORA Adapters,并使用特定的 llama.cpp 脚本进行转换,成功使用了 LORA,并获得了完美的结果。 - 部署与 Multi-GPU 问题:讨论了使用本地数据进行模型 Fine-tuning 的部署咨询,以及使用 Unsloth 进行多 GPU 训练的能力。目前的结论是 Unsloth 尚未支持 Multi-GPU,但未来可能会支持。
- Reddit - 探索一切:未找到描述
- 来自 bartowski (@bartowski1182) 的推文:经过数天的计算(因为我不得不重新开始),它终于上线了!带有 tokenizer 修复的 Llama 3 70B GGUF :) https://huggingface.co/bartowski/Meta-Llama-3-70B-Instruct-GGUF 另外,刚刚订购了...
- 主页:以 2-5 倍的速度和减少 80% 的内存微调 Llama 3, Mistral & Gemma LLM - unslothai/unsloth
- 烹饪 GIF - Cooking Cook - 发现并分享 GIF:点击查看 GIF
- Supervised Fine-tuning Trainer:未找到描述
- Reddit - 探索一切:未找到描述
- ScottMcNaught - 概览:ScottMcNaught 有一个可用的仓库。在 GitHub 上关注他们的代码。
- GGUF 损坏 - llama-3 · Issue #430 · unslothai/unsloth:来自 ggerganov/llama.cpp#7062 和 Discord 聊天的发现:复现用的 Notebook:https://colab.research.google.com/drive/1djwQGbEJtUEZo_OuqzN_JF6xSOUKhm4q?usp=sharing Unsloth + float16 + QLoRA = 正常工作...
- llama3-instruct 模型未在 stop token 处停止 · Issue #3759 · ollama/ollama:问题是什么?我正在通过兼容 OpenAI 的端点使用 llama3:70b。生成时,我得到了如下输出:请提供上述命令的输出。让我们继续...
- Google Colab:未找到描述
- 带有合并 LORA Adapter 的 Llama3 GGUF 转换似乎随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp:我正在使用 Unsloth 在 llama3-8b 上微调 LORA Instruct 模型。1:我将模型与 LORA adapter 合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理...
- GitHub - ggerganov/llama.cpp 的 gg/bpe-preprocess 分支:C/C++ 中的 LLM 推理。通过在 GitHub 上创建账户为 ggerganov/llama.cpp 的开发做出贡献。
- 带有合并 LORA Adapter 的 Llama3 GGUF 转换似乎随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp:我正在使用 Unsloth 在 llama3-8b 上微调 LORA Instruct 模型。1:我将模型与 LORA adapter 合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理...
- 带有合并 LORA Adapter 的 Llama3 GGUF 转换似乎随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp:我正在使用 Unsloth 在 llama3-8b 上微调 LORA Instruct 模型。1:我将模型与 LORA adapter 合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理...
- 带有合并 LORA Adapter 的 Llama3 GGUF 转换似乎随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp:我正在使用 Unsloth 在 llama3-8b 上微调 LORA Instruct 模型。1:我将模型与 LORA adapter 合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理...
- 带有合并 LORA Adapter 的 Llama3 GGUF 转换似乎随机丢失训练数据 · Issue #7062 · ggerganov/llama.cpp:我正在使用 Unsloth 在 llama3-8b 上微调 LORA Instruct 模型。1:我将模型与 LORA adapter 合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理...
- llama : 修复 BPE 预分词 (#6920) · ggerganov/llama.cpp@f4ab2a4:* 将 deepseeker 模型的更改合并到 main 分支 * 将 regex 模式移动到 unicode.cpp 并更新了 unicode.h * 移动了头文件 * 解决了问题
Unsloth AI (Daniel Han) ▷ #showcase (23 messages🔥):
- 用于增强知识的 LLaMA 变体:开发了一种新的 LLaMA-3 变体,用于辅助知识图谱构建,重点关注 RDF triples 等结构化数据。该模型 LLaMA-3-8B-RDF-Experiment 旨在生成知识图谱三元组,并专门排除了非英语数据集。
- Instruct Coder 模型发布:一个新的 LLaMA 模型 rombodawg/Llama-3-8B-Instruct-Coder-v2 已完成,并对其前身进行了改进。更新后的模型 Llama-3-8B-Instruct-Coder-v2 经过重新训练以修复之前的问题,预计表现会更好。
- Oncord:专业网站生成器亮相:Oncord 被介绍为一个专业的网站生成器,用于创建集成了营销、商业和客户管理工具的现代网站。该平台在 oncord.com 展示,提供只读演示,面向技术和非技术用户的混合群体。
- 机器学习论文协作公开征集:邀请社区为一篇关于使用机器学习预测 IPO 成功的开源论文做出贡献。感兴趣的各方可以协助处理托管在 RicercaMente 的论文。
- 初创公司讨论与交流:就初创公司营销、策略和协作进行了对话。具体讨论了一家初创公司 Oncord,重点是增强用户的技术灵活性,并暗示了另一个用于衡量观众与内容创作者之间信任度的概念,但尚未正式发布。
- PREDICT IPO USING MACHINE LEARNING: 旨在通过多年发表的科学研究追溯数据科学历史的开源项目
- rombodawg/Llama-3-8B-Instruct-Coder-v2 · Hugging Face: 未找到描述
- M-Chimiste/Llama-3-8B-RDF-Experiment · Hugging Face: 未找到描述
- The miR-200 family is increased in dysplastic lesions in ulcerative colitis patients - PubMed: UC-发育不良与粘膜中 miRNA 表达改变和 miR-200b-3p 水平升高有关。
- Oncord - Digital Marketing Software: 集网站、电子邮件营销和电子商务于一体的直观软件平台。Oncord 托管的 CMS 让一切变得简单。
- no title found: 未找到描述
Unsloth AI (Daniel Han) ▷ #suggestions (3 messages):
-
微调 LVLM 的请求:一位成员表达了对 Large Vision Language Models (LVLM) 通用微调方式的需求。
-
呼吁支持 Moondream:另一位成员请求支持 moondream,指出它目前仅微调 phi 1.5 文本模型,并分享了 用于 moondream 微调的 GitHub notebook。
提及的链接:moondream/notebooks/Finetuning.ipynb at main · vikhyat/moondream: 微型视觉语言模型。通过在 GitHub 上创建账户为 vikhyat/moondream 的开发做出贡献。
Nous Research AI ▷ #ctx-length-research (2 messages):
-
寻求数据收集进度:一位成员询问了 cortex 项目中当前收集的页面数量,寻求数据积累里程碑的更新。
-
探索虚空:发布了一个据推测与 ctx-length-research 频道相关的链接,但由于该链接被引用为 *«
>>*,其内容或上下文无法访问。
Nous Research AI ▷ #off-topic (6 messages):
-
创新烹饪便利性亮相:分享了一个名为 “Recipic Demo” 的 YouTube 视频,展示了一个网站,用户可以上传现有的食材来获取菜谱。这为那些寻求利用手头食材获取烹饪灵感的人带来了惊喜。观看 “Recipic Demo”
-
深入探讨多模态语言模型的增强:一位成员询问了显著改进多模态语言模型的方法,提到将 JEPA 集成作为一种潜在的增强手段,尽管目前尚未找到实现此类集成的仓库或模型。
-
多模态协作构想:针对增强多模态语言模型,另一位成员提出了开发使语言模型能够利用 JEPA models 的工具的想法,表明了对跨模型功能的兴趣。
-
推动多模态语言模型实现更高分辨率:一位成员建议,推进多模态模型可以涉及提高其分辨率,以便更好地解释图像中的微小文本。这一进展可以扩大语言模型能够有效理解和整合的视觉数据范围。
提到的链接: Recipic Demo:是否曾对晚餐或午餐吃什么感到困惑?如果有一个网站,你只需上传你拥有的食材就能获得食谱……
Nous Research AI ▷ #interesting-links (7 messages):
-
AQLM 凭借 Llama-3 挑战极限:AQLM 项目引入了更多预量化模型,例如 Llama-3-70b 和 Command-R+,增强了开源 Large Language Models (LLMs) 的可访问性。特别是 Llama-3-70b 可以在单个 RTX3090 上运行,展示了 model quantization 方面的重大进展。
-
正交化技术创造 Kappa-3:Phi-3 的权重已通过 正交化处理以减少模型拒绝回答,并作为 Kappa-3 模型发布。Kappa-3 提供全精度 (fp32 safetensors) 和 GGUF fp16 选项,尽管其在需要遵守规则的提示词上的表现仍存疑问。
-
Deepseek AI 庆祝胜利:来自 Deepseek AI’s Twitter 的分享指向了他们的成功,引发了一个关于 AI 成就中家族相似性的轻松玩笑。
-
通过确定性引用革新医疗保健:Invetech’s 项目引入了 “Deterministic Quoting”(确定性引用),以解决 LLMs 在医疗保健等敏感领域生成幻觉引用的风险。通过这种技术,只有来自源材料的逐字引用才会以蓝色背景显示,旨在增强 AI 在医疗记录处理和诊断中使用的信任度。提供的详细信息和视觉效果。
- 无幻觉 RAG:让 LLMs 在医疗保健领域更安全:LLMs 有潜力彻底改变我们的医疗保健领域,但对幻觉的恐惧和现实阻碍了在大多数应用中的采用。
- Reddit - 深入探索:未找到描述
- Reddit - 深入探索:未找到描述
Nous Research AI ▷ #general (527 messages🔥🔥🔥):
<ul>
<li><strong>AI 聊天机器人对比与推测</strong>:成员们讨论了各种 AI 模型的性能,特别关注了 function calling 能力。尽管 **Mistral 8x22b** 营销号称具有“卓越的 function calling 能力”,但 **Llama 3 70b** 在这方面的表现被认为优于前者。</li>
<li><strong>GPT-2 回归 LMSYS</strong>:关于 **GPT-2** 回归 LMSYS 并带有显著改进的消息引起了热议,大家推测这是否是一个正在进行 A/B 测试的新模型,或者是其他产品,如 GPT-4Lite 或更具成本效益的 GPT 替代方案。</li>
<li><strong>Hermes 2 Pro Llama 3 8B 模型测试</strong>:有成员请求测试 **Hermes 2 Pro Llama 3 8B** 模型在高达 32k token 限制下的 function calling 能力,但由于时间和资源限制,提到了实际操作中的局限性。</li>
<li><strong>聊天机器人命名、开源希望与 GPT 炒作辩论</strong>:聊天机器人模型的独特命名(如 GPT-2 chatbot)引发了关于其能力以及 OpenAI 模型开源可能性的讨论和玩笑。对于下一个重大 AI 进展及其发布时间表,既存在怀疑也充满期待。</li>
<li><strong>模型输入中的 YAML 与 JSON 对比</strong>:简要提到了在模型输入中 YAML 优于 JSON,因为其具有更好的可读性和 token 效率。</li>
</ul>
- cognitivecomputations/Meta-Llama-3-120B-Instruct-gguf · Hugging Face: 未找到描述
- OpenAI 高管称,今天的 ChatGPT 在 12 个月后将显得“糟糕得可笑”:OpenAI 的 COO 在 Milken Institute 的小组讨论中表示,AI 将在一年内能够完成“复杂工作”并成为“优秀的队友”。
- 来自 Maxime G, M.D (@maximegmd) 的推文:Internistai 7b:医疗语言模型。今天我们发布了最强的 7b 医疗模型,其表现优于 GPT-3.5,并首次通过了 USMLE(美国执业医师资格考试)!我们的方法使模型能够保留...
- Mlp 相关 GIF - MLP 相关 Mylittlepony - 发现并分享 GIF:点击查看 GIF
- 支持 Grammar · Issue #1229 · vllm-project/vllm:如果该库能加入对 Grammar 和 GBNF 文件的支持,将大有裨益。https://github.com/ggerganov/llama.cpp/blob/master/grammars/README.md
- TRI-ML/mamba-7b-rw · Hugging Face:未找到描述
- 来自 Kyle Mistele 🏴☠️ (@0xblacklight) 的推文:顺便说一下,我用 @vllm_project 测试了这一点,它成功将 @NousResearch 的 Hermes 2 Pro Llama 3 8B 的上下文扩展到了约 32k,且具有极佳的连贯性和性能(我让它总结了 @paulg 的文章)。下载...
- 由 K-Mistele 更新 Server 的 README,包含 RoPE、YaRN 和 KV cache 量化等未公开选项 · Pull Request #7013 · ggerganov/llama.cpp:我最近更新了我的 llama.cpp,发现有许多服务器 CLI 选项在 README 中没有描述,包括 RoPE、YaRN 和 KV cache 量化以及 flash attention...
- NousResearch/Hermes-2-Pro-Llama-3-8B · Hugging Face:未找到描述
- NousResearch/Hermes-2-Pro-Llama-3-8B · Hugging Face:未找到描述
- GitHub - huggingface/lerobot: 🤗 LeRobot:基于 Pytorch 的前沿真实世界机器人机器学习库:🤗 LeRobot:基于 Pytorch 的前沿真实世界机器人机器学习库 - huggingface/lerobot
- 通过 RoPE 缩放扩展上下文大小 · ggerganov/llama.cpp · Discussion #1965:简介:这是一个关于最近提出的扩展 LLaMA 模型上下文大小策略的讨论。最初的想法在这里提出:https://kaiokendev.github.io/til#extending-context-t...
- 由 Maximilian-Winter 将 self extension 移植到服务器 · Pull Request #5104 · ggerganov/llama.cpp:你好,我将 self extension 的代码移植到了服务器。我用信息检索进行了测试,在一段约 6500 token 长的文本中插入了上下文之外的信息,它起作用了,至少...
Nous Research AI ▷ #ask-about-llms (12 条消息🔥):
- LlamaCpp 更新解决了问题:通过更新到最新版本,解决了 LlamaCpp 不生成
<tool_call>token 的问题。现在的 system prompt 已按预期工作。 - A100 上的 LoRA 微调挑战:一位成员在使用 axolotl 在 A100 上对 LoRA llama 3 8b 进行训练时,遇到了异常漫长的训练时间,每步大约需要 500 秒,这促使他们考虑进行调试,因为其他人的训练速度要快得多。
- 训练速度对比见解:对于 Llama2 7B,一位成员报告使用 litgpt 进行 1,000 次迭代大约需要 3 分钟,这表明与另一位成员在使用 LoRA 时经历的训练时间存在显著的速度差异。
- 向 GPT 提供示例的最佳实践:一位成员征求关于训练 GPT 示例的最佳方法的建议,在提供包含示例的文件和将示例结构化为重复的 user-assistant 消息对之间进行权衡。
- Attention 论文实现反馈请求:一位成员寻求关于他们重新实现 “Attention is All You Need” 论文的反馈,并在 https://github.com/davidgonmar/attention-is-all-you-need 分享了他们的 GitHub 仓库。他们正在考虑改进措施,如使用 torch 的 scaled dot product 和预分词(pretokenizing)。
Nous Research AI ▷ #bittensor-finetune-subnet (11 messages🔥):
- 新矿工仓库卡住:有用户报告他们提交到矿池的仓库几个小时都无法下载,这表明新用户可能面临网络问题。
- 网络等待关键 PR:一位用户提到 Bittensor 网络 目前处于非运行状态,直到一个待处理的 pull request (PR) 被合并,这对于修复网络至关重要。
- 网络修复时间表不确定:当被问及时,一位用户表示 PR 将会 “很快” 合并,但澄清说他们无法控制 PR 的审核过程,导致时间线模糊。
- 网络问题导致模型验证停滞:澄清指出,在上述 PR 解决之前,提交到网络的新 commit 或模型将不会得到验证,这直接影响了矿工的操作。
- 寻求 GraphQL 服务信息:一位用户询问了与 Bittensor 子网 相关的 GraphQL 资源或服务,表明可能需要开发者支持或文档。
Nous Research AI ▷ #world-sim (7 messages):
- World Sim 访问问题依然存在:一位成员表达了访问 worldsim.nousresearch.com 的困难,并简单评论道该网站仍未运行,“still not work”。
- 表达失望:针对持续存在的问题,另一位成员通过多个沮丧的表情符号表达了失望。
- 呼吁进行模拟:发布了一条简短的消息“plz sim”,可能表示希望开始或参与模拟。
- 关于 World Sim 的询问:一位成员询问:“什么是 world sim?在哪里可以找到更多信息?world-sim 角色是什么?”表现出对该频道模拟方面的兴趣。
- 信息指引:针对关于 World Sim 的问题,一位成员引导其他人前往特定频道 <#1236442921050308649> 查看置顶帖子,其中可能包含相关信息。
提到的链接:worldsim:未找到描述
Stability.ai (Stable Diffusion) ▷ #general-chat (421 messages🔥🔥🔥):
-
剖析扩散模型:成员们就 Hyper Stable Diffusion(一种经过微调或 LoRA 的快速运行模型)与 Stable Diffusion 3(一种与 Hyper Stable Diffusion 不等同的独立模型)之间的区别交换了见解。未提供解释性资源的链接。
-
寻求 Stable Diffusion 的明确信息:对话围绕 Stable Diffusion 不再开源以及 SD3 可能不发布展开。用户讨论了在担心 AI 开源时代可能结束的情况下,下载并保存模型和适配器(adapters)的重要性。
-
优化写实人物模型: 关于寻找具有灵活性且最佳的写实人物模型的讨论涵盖了多种模型选项,并建议避免使用来自 civitai 等具有严重偏好的模型,以防止生成的角色出现同质化。
-
Dreambooth 和 LoRA 探索:用户进行了详尽的咨询和深入讨论,探讨如何最好地利用 Dreambooth 和 LoRA 训练来优化 Stable Diffusion,并争论创建独特面孔和风格的最佳方法。
-
放大技术(Upscaling)大冒险:关于最有效放大器(upscaler)的询问引发了对各种放大模型和工作流的讨论,如 RealESRGAN_x4plus 和 4xUltrasharp,用户分享了个人经验和偏好。
- 如何使用 Stable Diffusion - Stable Diffusion Art:Stable Diffusion AI 是一种用于生成 AI 图像的潜在扩散模型。生成的图像可以是像相机拍摄的那样写实,也可以是艺术风格的。
- 如何安装 Stable Diffusion - automatic1111:第 2 部分:如何使用 Stable Diffusion https://youtu.be/nJlHJZo66UA Automatic1111 https://github.com/AUTOMATIC1111/stable-diffusion-webui 安装 Python https://w...
- Stable Cascade 示例:ComfyUI 工作流示例
- Stylus: Diffusion 模型的自动适配器选择:未找到描述
- 为初学者解释 LoRA 训练:LoRA 训练指南/教程,以便你了解如何使用 KohyaSS 上的重要参数。使用 Dreamlook.AI 在几分钟内完成训练:https://dreamlook.ai/?...
- 另一个 LoRA 训练 Rentry:Stable Diffusion LoRA 训练科学与笔记,由 The Other LoRA Rentry Guy 提供。这不是安装指南,而是关于如何改进结果、描述各种选项的指南...
LM Studio ▷ #💬-general (107 messages🔥🔥):
- 服务器日志关闭选项请求:一位用户对无法通过 LM Studio 的 GUI 关闭服务器日志表示不安,强调在应用开发过程中希望增加隐私保护。
- Prompt Engineering 价值的认可:Prompt Engineering 被公认为科技行业中一项关键且有价值的技能,相关引用表明它是一项利润丰厚的职业,也是从 LLM 产出高质量结果的关键环节。
- LM Studio 的无头模式(Headless Mode)运行:用户讨论了在无头模式下运行 LM Studio 的可行性,有用户表现出通过命令行而非 GUI 启动服务器模式的兴趣,其他人则提供了使用 lms CLI 作为潜在解决方案的见解。
- Phi-3 与 Llama 3 的输出质量对比:针对 Phi-3 模型与 Llama 3 在内容摘要和 FAQ 生成任务中的效果展开了辩论,用户分享了改善结果的设置和策略。
- 模型崩溃和配置故障排除:多位用户报告了 LM Studio 中的模型性能问题,包括尽管 VRAM 充足但 RAM 消耗过高、更新后行为异常以及加载模型时的错误。社区成员通过建议检查驱动程序、调整模型配置和评估系统规格进行了回应。
- 欢迎 | LM Studio:LM Studio 是一款用于在计算机上运行本地 LLM 的桌面应用程序。
- 我是如何赢得新加坡 GPT-4 Prompt Engineering 大赛的:深入探讨我学到的利用大语言模型(LLM)力量的策略。
- GitHub - lmstudio-ai/lms:终端里的 LM Studio:终端里的 LM Studio。欢迎为 lmstudio-ai/lms 的开发做出贡献。
LM Studio ▷ #🤖-models-discussion-chat (21 messages🔥):
-
Llama Toolkit 更新影响 Command R+ Tokenizer:llamacpp 上游针对 llama3 的更改破坏了 Command R 和 Command R+ 的 Tokenizer,并有关于量化错误的额外报告。Command R+ 的更新量化版本可以在 Hugging Face Co Model Repo 找到,并注意“不要连接分卷(do not concatenate splits)”,而应在必要时使用
gguf-split进行文件合并。 -
Hermes-2-Pro L3 微调问题说明:尽管很受欢迎,微调 Hermes-2-Pro L3 仍然存在问题,有观点认为它虽然优于 L3 8b,但并没有像预期的那样比前代产品有显著提升。
-
Hermes-2-Pro L3 实际运行:使用 8bit MLX 运行该模型显示出其对不连贯输入的出色处理能力,并引用了一个测试 AI 对披露潜在不道德信息反应的例子。一名用户询问了如何应用“jailbreak(越狱)”来移除内容安全保护。
-
GGUF 格式与 Llama.cpp 的兼容困难:一名用户发现 GGUF 格式目前无法在 llama.cpp 中运行,因为该工具包需要更新。这引发了尝试替代模型或在工具包更新后再使用某些基于 GGUF 模型的建议。
-
AI 模型中的翻译与文化敏感性:推荐了一些在翻译和创意写作方面表现出色的 AI 模型,并指出 Llama3 的多语言能力和 Command R 的语言支持。对于文化敏感的回复,推荐了 WestLake;对于特定的翻译任务,建议将 T5 模型作为替代方案,可通过 Hugging Face 的 T5 文档获取。
LM Studio ▷ #🧠-feedback (11 条消息🔥):
- LM Studio 中的 Linux 内存误报:一名用户报告称,他们的 Ubuntu 机器在 LM Studio 中显示剩余 RAM 为 33.07KB,而实际剩余 20GB。确认使用的是来自 LM 网站的 0.2.22 版本的 Linux AppImage。
- Ubuntu 版本可能影响依赖项:寻求澄清用户是否使用的是现代的 Ubuntu v22.04,因为旧版本可能存在库依赖问题。
- 旧版 Ubuntu 发行版上的库依赖担忧:讨论指向了库依赖项在旧版 Ubuntu 发行版上无法正常运行的可能性。
- 禁用 GPU Offloading 解决运行问题:在设置中禁用 GPU Offloading 似乎解决了一个问题,允许用户运行 Meta Llama 3 instruct 7B 模型。
- 访问 Linux Beta 频道的指南:引导用户通过 LM Studio 的 Channels & Roles 选项注册 Linux beta 角色,以获得 Linux Beta 频道的访问权限。
LM Studio ▷ #📝-prompts-discussion-chat (8 条消息🔥):
- 文档章节的范围访问:一名用户询问了 LM Studio 或通用 LLM 中的一种技术,该技术允许 AI 临时访问文档的特定部分。澄清了 LLM 只知道 Prompt 中包含的内容或嵌入在其权重中的内容。
- AI 对已删除内容的响应:同一用户报告了 LM Studio 似乎混淆了已删除上下文的情况,提出了 Bug 影响 AI 响应的可能性。
- 理解 AI 的响应机制:讨论了语言模型是否能保留被认为已删除的信息,共识是如果语言模型似乎记住了已删除的内容,要么是因为 Bug,要么是幻觉。
LM Studio ▷ #⚙-configs-discussion (9 条消息🔥):
-
寻找终极 AI 地下城主:一名成员对 Mixtral 和 Wizard LM 等模型在《龙与地下城》中无法追踪复杂游戏元素表示失望,尽管上传了大量的背景信息。他们报告说,即使有 AnythingLLM 数据库的帮助,模型在维持连贯性(如冒险中的角色卡和生命值)方面也很吃力。
-
llava-phi-3-mini 模型混淆:一名成员报告了 llava-phi-3-mini 模型的问题,该模型没有描述上传的图像,而是描述了来自 Unsplash 的随机图像。尝试使用不同的 Prompt Templates 仍未解决问题,包括模板陷入循环的情况。
-
深层故障排除询问:针对 llava-phi-3-mini model 的问题,另一位成员询问了如何确定模型是在描述来自 Unsplash 的内容,以及具体是哪个 Prompt Template 失败了。
-
模型图像识别问题持续存在:多位成员在使用视觉模型时遇到了类似问题,模型要么描述 Unsplash 图片而非上传的图片,要么在处理第一张图片后停止工作。该问题在包括 ollama 在内的多种模型中普遍存在,似乎是由最近的后端更新引起的。
-
Bunny Llama 前来救场!:在各种模型出现问题之际,一位成员发现 Bunny Llama 3 8B V 表现良好,没有出现其他模型中的问题。
-
AI 角色扮演中的长期记忆挑战:一位成员建议使用 nous research hermes2 mitral 8x7b do the q8 版本和 ycros bagelmusterytour v2 8x7b,并认为目前的数据库可能不足以支持高级角色扮演。他们建议探索 lollms,该工具在保持长期记忆和性格连续性方面表现出了潜力。
LM Studio ▷ #🎛-hardware-discussion (25 messages🔥):
-
GPU 功耗讨论:一位用户观察到他们的 P40 GPUs 在闲置时功耗为 10 瓦,但在使用后从未降至 50 瓦以下,即使 LM Studio 一次只使用一个 GPU,GPU 的总功耗也达到了 200 瓦。他们分享了服务器配置详情,包括两个 220vac 的 1600 瓦电源,并将设备放置在车间内以减少噪音,同时在办公室进行远程桌面操作。
-
规划推理的 GPU 功耗预算:另一位用户讨论了将 GPU 限制在 140 瓦以获得 85% 性能的计划,打算将其用于高上下文的 7b Mistral 模型和小型视觉模型,并询问 LM Studio 是否能有效利用多个 GPU。
-
评估不带额外 GPU 的 P40 游戏主板:一位用户思考是否可以为他们的 P40 使用游戏主板,因为服务器主板会为每个 GPU 提供完整的 PCIe x16 带宽,而游戏主板在运行多个 GPU 时可能会牺牲带宽。
-
揭秘推理中 PCI-E 带宽的迷思:针对推理任务是否需要足够 PCI-E 带宽的担忧,一位用户提供了 Reddit 链接(推理对 PCI-E 带宽的依赖,exl2 或 llamacpp 上的多 GPU)和 GitHub 讨论(各种硬件上的性能测试),表明对于推理任务,PCI-E 带宽需求往往被高估了。
-
考虑高效 LLM 推理的硬件配置:用户交流了关于高效服务器构建、功耗、散热以及强大硬件与实用性之间平衡的想法,讨论了是否有必要为了运行语言模型而建立专用服务器,并分享了他们的做法,例如为了节能不 24/7 全天候运行服务器。
- MSN:未找到描述
- Reddit - 探索一切:未找到描述
- Reddit - 探索一切:未找到描述
- 各种硬件上的性能测试 · turboderp/exllama · Discussion #16:首先,我要感谢你的工作,非常喜欢你的推理实现,这似乎是目前 NVIDIA GPU 上最快的!我在各种 GPU 上运行了一系列测试,并想...
- 各种硬件上的性能测试 · turboderp/exllama · Discussion #16:首先,我要感谢你的工作,非常喜欢你的推理实现,这似乎是目前 NVIDIA GPU 上最快的!我在各种 GPU 上运行了一系列测试,并想...
LM Studio ▷ #🧪-beta-releases-chat (28 messages🔥):
-
视觉模型的隐蔽错误:一位用户报告了在使用 vision model 时出现的错误,但错误消息未包含错误代码或描述,仅包含系统规格。其他成员(如 propheticus_05547 和 heyitsyorkie)参与澄清问题,暗示可能是 GPU 限制,并询问了其他模型的运行情况。
-
在 LM Studio 中寻找最新的 LLMs:用户 yu_xie 询问如何刷新 LM Studio 内容以获取最新的 LLM 模型。heyitsyorkie 解释说 LM Studio 的主页是静态的,并非实时仓库,建议使用 model explorer 搜索 “GGUF” 并按 Most Recent 排序作为替代方案。
-
可下载的 LLM 模型:一位用户请求能够直接从 LM Studio 应用主页下载最新的 LLM 模型。heyitsyorkie 回应称目前无法实现,因为模型并不总是以 GGUF 格式发布,且当 IBM Granite 等新模型发布时,llama.cpp 可能需要更新。
-
孤立事件还是普遍问题?:用户 aibyhumans 提到在 8GB GPU 上使用 7B 模型时发生崩溃,且崩溃仅发生在 vision models 上。propheticus_05547 回复询问非视觉模型是否正常工作,并建议关闭 GPU offloading 或将其调整为 50/50。
-
模型加载不稳定:同一位用户 aibyhumans 观察到模型在崩溃后似乎没有完全卸载,且在一次成功加载后,后续尝试会导致错误,每次都需要重启模型。这种行为在不同模型中也有发生。
LM Studio ▷ #autogen (2 messages):
- Troubleshooting AutoGen Studio:一位成员提到了 AutoGen Studio 中的一个 Bug,似乎会发送只有一两个单词的截断消息。他们请求查看用于调用 Bot 的代码,并建议在发送前打印出消息列表。
LM Studio ▷ #langchain (2 messages):
- LM Studio SDK 开发:一位成员提到了新的 lmstudiojs SDK 已可用,暗示未来的 langchain integrations 即将到来。
LM Studio ▷ #crew-ai (1 messages):
- GPT-Engineer 设置查询:一位成员表示有兴趣了解 GPT-Engineer 是如何与 LM Studio 配合设置的,特别询问了过程中是否涉及 custom prompting。
LM Studio ▷ #🛠-dev-chat (41 messages🔥):
-
依赖包安装成功:命令
sudo apt install xvfb fuse libatk1.0-0 libatk-bridge2.0-0 libcups2 libgtk-3-0 libgbm1 libasound2解决了之前的问题,允许用户继续进行安装过程的第 2 步。 -
LM Studio 在 Ubuntu 22.04 上的兼容性问题:用户讨论了在 Ubuntu 22.04 与最新的 Ubuntu Server 24.04 上运行 LM Studio 的兼容性问题,暗示可能依赖于更新的操作系统。
-
LM Studio 需要 GPU 吗?:一位尝试运行 LM Studio 的成员遇到了暗示 GPU 问题的错误,尽管使用的是仅提供虚拟或集成 GPU 的服务器。
-
虚拟 GPU 上的 LM Studio:另一位用户确认他们已成功在虚拟机中使用虚拟 GPU 运行 LM Studio,尽管他们尚未测试没有 GPU 的环境。
-
LM Studio API 集成:一位成员分享了通过 API 将 LM Studio 支持集成到自己 UI 中的兴奋之情,而另一位成员则在 LM Studio 的并发请求处理方面面临挑战,特别是在不使用提供的 SDK 生成 embeddings 时。
HuggingFace ▷ #general (164 messages🔥🔥):
-
Whispering Fresh: Fine-Tuning ASR:用户讨论了微调 openai/whisper-small ASR 模型,强调了足够的数据集大小的重要性,并考虑调整
weight_decay和learning_rate等超参数以获得更好的性能。分享的具体超参数包括 gradient accumulation steps、learning rate、evaluation strategy 等,同时讨论了 training loss 和 validation loss 之间的差异。 -
在 Android 上访问 Llama:一位参与者询问了如何通过 Termux 在 Android 上使用 llama.cpp 并通过网页访问,表明了对 Llama 在移动平台应用的持续探索。
-
令人费解的性能悖论:有人询问为何 Smaug-72B-LLM 的表现优于 Mistral 8x22B 和 Llama-3 70B 等巨头,却缺乏同等的知名度,这引发了关于其尽管 Benchmark 结果强劲却表现低调的原因讨论。
-
寻求帮助:AI 与 Blockchain 的集成:一位用户表达了对 AI 与 Blockchain 集成的兴趣,寻求融合这些前沿技术,展示了社区内多样化的兴趣和倡议。
-
资源分享与协作:对话的亮点包括成员分享关于 Fine-tuning Whisper 的 YouTube 教程、用于教学目的的 BabyTorch 等 GitHub 项目链接,以及处理 LLM 和音频数据的 HF 相关资源 URL。社区支持和资源分享贯穿了整个互动过程。
- GitHub - Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.: 使用单个文件分发和运行 LLM。通过在 GitHub 上创建一个账户来为 Mozilla-Ocho/llamafile 的开发做出贡献。
- timm/ViT-SO400M-14-SigLIP-384 · Hugging Face: 未找到描述
- Hugging Face – Posts: 未找到描述
- Fine-tuning the ASR model - Hugging Face Audio Course: 未找到描述
- GitHub - getumbrel/llama-gpt: A self-hosted, offline, ChatGPT-like chatbot. Powered by Llama 2. 100% private, with no data leaving your device. New: Code Llama support!: 一个自托管、离线、类 ChatGPT 的聊天机器人。由 Llama 2 驱动。100% 私密,数据不会离开您的设备。新增:Code Llama 支持!- getumbrel/llama-gpt
- GitHub - amjadmajid/BabyTorch: BabyTorch is a minimalist deep-learning framework with a similar API to PyTorch. This minimalist design encourages learners explore and understand the underlying algorithms and mechanics of deep learning processes. It is design such that when learners are ready to switch to PyTorch they only need to remove the word `baby`.: BabyTorch 是一个极简的深度学习框架,具有与 PyTorch 类似的 API。这种极简设计鼓励学习者探索和理解深度学习过程的底层算法和机制...
- OpenAI Whisper - Fine tune to Lithuanian | step-by-step with Python: 使用 Python 和带有 GPU 的 Google Colab 可以简单地将 OpenAI 的 Whisper Fine-tune 到不同的语言。在本教程中,我选择了 Whisper 的 small 版本...
- A Multi-Agent game where LLMs must trick each other as humans until one gets caught: 五个顶尖 LLM —— OpenAI 的 ChatGPT、Google Gemini、Anthropic 的 Claude、Meta 的 LLAMA 2 和 Mistral AI 的 Mixtral 8x7B 在这个基于文本的图灵测试游戏中展开竞争...
HuggingFace ▷ #today-im-learning (6 条消息):
-
Look-alike Machine Learning Modelling 详解:Tolulade 分享了一篇关于初学者 Look-alike Modeling 的教学文章。文章结合了信息内容与工程见解,并推广了一个名为 Semis 的 AI 和 Big Tech 社交平台。
-
在 Step-by-Step LLM 上遇到困难:一位成员尝试为他们的本地 LLM 实现“think step by step”过程,但发现模型无法从其 Fine-tuned 的常规完整回答中调整过来。
-
创新的模型响应链:该成员通过创建由
planner、writer、analyst和editor组成的循环 Language Chain 序列取得了更好的成功,使用的是 Llama 3 instruct 7B,这比 Zero-shot 输出提供了更全面的结果。 -
推广环保 AI:通过一段讨论 Meta AI 公开报告二氧化碳排放量的 YouTube 视频以及一个名为 codecarbon 的相关工具(旨在估算 ML 项目的碳足迹),强调了具有环保意识的 AI 开发的重要性。
-
学习 Quantization 的门道:一位成员分享了他们在对称和非对称 Quantization 方面的学习历程,这是优化 Machine Learning 模型的一项基本技术。
- Introduction to Look-alike-Machine Learning Modelling:在交易型和营销型电子邮件中的应用
- What Makes Environmentally Conscious genAI? An Overview:快速了解什么是具有环保意识的 AI,参考 @meta AI 公开报告 LLaMA3 的 CO2 排放量的示例...
- Machine Learning CO2 Impact Calculator:Machine Learning 对我们的气候有影响。以下是如何估算你的 GPU 碳排放量的方法
HuggingFace ▷ #cool-finds (12 messages🔥):
- 揭秘量子虚拟服务器:一位成员分享了一个有趣的资源链接 Oqtant,这似乎是一个与量子虚拟服务器相关的平台。
- 彻底改变 RAG Pipeline 评估:随着 Ragas Framework 的引入,评估 Retrieval Augmented Generation (RAG) Pipeline 的工作得到了加强,该框架旨在评估 RAG 应用的性能并制定指标驱动的策略。
- 备受关注的 Introspective Agents:Medium 上的一篇博文讨论了 LlamaIndex 框架内内省式 AI Agent 的潜力,旨在提高 AI 的自我评估和优化能力。
- Lilian Weng 的 AI Safety 博客:Lilian Weng 在博客中记录了她关于 AI 学习的笔记以及她在 OpenAI 的 AI safety 和 alignment 团队的工作,并幽默地提到 ChatGPT 在她写作中提供的帮助(或缺乏帮助)。
- 创新的基于图像的虚拟试穿:一篇新论文介绍了 IDM-VTON 模型,旨在通过一种新型的 Diffusion 方法增强虚拟试穿应用中的自然度和服装身份保持。
- Lil'Log:记录我的学习笔记。
- Improving Diffusion Models for Virtual Try-on:本文探讨了基于图像的虚拟试穿,即在给定一对分别描绘人物和服装的图像的情况下,渲染出该人物穿着指定服装的图像。之前的工作...
- Oqtant:未找到描述
- Introspective Agents with LlamaIndex:Ankush k Singal
- Agent AI: Surveying the Horizons of Multimodal Interaction:多模态 AI 系统可能会在我们的日常生活中无处不在。使这些系统更具交互性的一种有前景的方法是将它们作为 Agent 具身化在物理和虚拟环境中...
- Introduction | Ragas:未找到描述
- 未找到标题:未找到描述
HuggingFace ▷ #i-made-this (8 messages🔥):
-
认识 everything-ai:你的新 AI 多任务助手:everything-ai 是一款全能的本地 AI 驱动助手,可以处理 PDF、文本、图像等,支持 50 多种语言。该项目的 GitHub 页面 包含快速入门指南和新的用户界面,以 Docker 应用形式分发。
-
意大利面条式代码实现功能:Sparky 2 是一个具有图像生成功能的 Discord Bot,基于 llama-cpp 构建,被其创建者描述为“Python 代码的意大利面条”。该 Bot 的代码可在 GitHub 上获得。
-
AI 辅助研究革命:Adityam Ghosh 介绍了 EurekAI,这是一款旨在简化研究流程的新工具。有兴趣提供反馈的人可以通过其网站 eurekai.tech 联系团队进行用户访谈。
-
为高级研究助手和搜索引擎招募 Beta 测试人员:Rubik’s AI 正在寻找 Beta 测试人员来试用其高级搜索引擎,其中包括对 GPT-4 Turbo 和 Mistral Large 等最先进模型的访问。感兴趣的各方可以在 rubiks.ai 注册,并使用促销代码
RUBIX获得两个月的免费会员。 -
AI 音乐生成变得“疯狂”:一段使用 AI 音乐生成器和来自 Udio AI 的采样创作的新死亡金属-回响贝斯(death metal-dubstep)曲目被分享以寻求反馈。这首名为 “DJ Stomp - The Arsonist” 的曲目可以在 YouTube 上收听。
-
Twitter 上展示实时视频生成:一段以 17fps 运行的实时 AI 生成视频被分享,展示了基于 prompt 对视觉输出的控制,尽管没有录制音频。该帖子可以在 Twitter 上查看。
- OpenAlgos:未找到描述
- GitHub - Gapi505/Sparky-2:通过在 GitHub 上创建账号来为 Gapi505/Sparky-2 的开发做出贡献。
- everything-ai:介绍 everything-ai,你功能齐全、AI 驱动且本地运行的聊天机器人助手!🤖
- GitHub - AstraBert/everything-ai:介绍 everything-ai,你多任务、AI 驱动且本地运行的助手!🤖 - AstraBert/everything-ai
- DJ Stomp - The Arsonist | Deathstep:The Arsonist 比我之前的任何作品都更黑暗、更激烈,融合了激进的 dubstep 与死亡金属元素。简单来说,这首曲目是……
- Rubik's AI - AI 研究助手与搜索引擎:未找到描述
HuggingFace ▷ #reading-group (3 条消息):
-
特殊 Token 触发更智能的检索:讨论引入了教导 Large Language Models (LLMs) 在不确定时使用特殊 Token
<RET>来触发信息检索的概念。讨论的论文探讨了利用该技术提高 LLM 性能的方法,这对于 LLM 的参数化记忆(parametric memory)无法处理的低频问题尤为重要。 -
LLM 何时应该查找信息:一篇通过 @omarsar0 的推文推广的新论文详细介绍了一种微调方法,使 LLM 能够决定何时检索额外的上下文。这种方法可以带来更准确、更可靠的 Retrieve-And-Generate (RAG) 系统。
- When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively:在本文中,我们展示了 Large Language Models (LLMs) 如何有效地学习使用现成的检索 (IR) 系统,特别是当需要额外上下文来回答时……
- Bytez: When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively:在本文中,我们展示了 Large Language Models (LLMs) 如何有效地学习使用现成的检索 (IR) 系统,特别是当需要额外上下文来回答时……
- elvis (@omarsar0) 的推文:何时检索?这篇新论文提出了一种训练 LLMs 有效利用信息检索的方法。它首先提出了一种训练方法,教导 LLM 生成一个特殊的 Token,并且……
- Training an LLM to effectively use information retrieval:这篇新论文提出了一种训练 LLMs 有效利用信息检索的方法。它首先提出了一种训练方法,教导 LLM 生成……
HuggingFace ▷ #computer-vision (15 条消息🔥):
-
捣鼓 Darknet Yolov4:一位成员分享了他们实验 Darknet Yolov4 的意图,通过在其尾部连接一个 CNN 来处理缩放后的图像并重新训练整个网络,尽管该模型已经过时且难以找到相关文档。
-
寻找丢失的 UA-DETRAC 数据集:UA-DETRAC 数据集对于计算机视觉和交通摄像头的目标检测非常有用,但它已在网上消失,其标注信息也无法通过官方网站或 Internet Archive 获取。一位来自 BSC 设施的社区成员请求任何可能之前下载过该数据集的人提供帮助。
-
冻结 Convnext 以实现高效训练:一位成员询问了关于使用
AutoModelForImageClassification.from_pretrained()加载 convnext tiny 的问题,以及它是否默认冻结模型的预训练部分。另一位成员提供了建议,推荐显式地将卷积基参数的requires_grad属性设置为False。 -
多标签图像分类训练:进行了一场关于在多标签数据上训练图像分类模型的资源讨论。一位成员寻求关于管理数据集的建议,其中图像可能具有 1 到 10 个不等的颜色标签。虽然找到了一个来自 Hugging Face 计算机视觉课程的资源,但据报告该资源无法正常运行。
-
用于人脸识别和关键点检测的 Facenet 与 VGG16:一位成员表示需要关于将迁移学习应用于预训练 Facenet 模型以进行人脸识别的指导;而另一位成员则有兴趣寻找适合进行头影测量关键点检测(cephalometric keypoint detection)微调的模型。
HuggingFace ▷ #NLP (9 条消息🔥):
- XLM-R 中 Flash Attention 2 的咨询:一位成员表示有兴趣在 XLM-R 中添加 Flash Attention 2,并正在寻求指导,因为 HuggingFace 尚未实现该功能。此外还有关于可用教程或实现指南的查询。
- 请求聊天机器人驱动的 PowerPoint 生成:有人请求开发一种能够使用 OpenAI Assistant API 生成 PowerPoint 演示文稿的聊天机器人,该机器人能从之前的文稿中学习,并仅修改幻灯片内容。同时还询问了使用 RAG 或 LLM 模型的替代方案。
- 向 Transformers 添加模型:讨论了决定将哪些新模型集成到 HuggingFace Transformers 中的流程。鼓励社区贡献,并建议考虑 Papers with Code 和其他热门的 SOTA 模型。
- 关于模型行为的随机发现:一位成员分享说 Moritz 创建的分类器非常高效,并强调了与概率分布和模型选择相关的问题,请求更多信息以排除该问题。
- 跨不同云集群调试脚本问题:社区讨论了在不同云环境中运行脚本的挑战,以及调试奇特错误的经历,例如 sentence transformers 的 encode 函数中的 None type 错误。调试被强调为一种宝贵的学习工具,对于解决代码问题至关重要。
HuggingFace ▷ #diffusion-discussions (7 条消息):
-
轻松自定义图像模型:Custom Diffusion 是一种图像生成模型的个性化技术,仅需 4-5 张示例图像即可通过 cross-attention 层学习概念。为了优化资源,建议在 vRAM 有限的系统上通过
--enable_xformers_memory_efficient_attention启用 xFormers,而--set_grads_to_none标志可以进一步减少训练期间的内存占用。 -
解决模型卸载中的设备不匹配问题:一位用户在尝试将 Accelerate 的多 GPU 功能与 Diffusers 的模型 CPU 卸载(offloading)结合使用时遇到错误,收到了 “expect tensors to be on the same device” 和 “cannot copy from meta device” 的错误消息。
-
通过 Token 计数估算 AI 模型成本:一位用户根据 定价计算器指南 讨论了基于 Token 计数的计费考虑,强调基于 Token 的计费是行业标准做法,1,000 个 Token 大约相当于 750 个英文单词。
-
BERT 模型训练求助信号:一位用户在 BERT 预训练和微调方面寻求帮助,指出虽然预训练损失正常下降,但在进行情感分析微调时,两个 epoch 内就出现了过拟合。他们分享了其 Colab notebook 以寻求社区建议。
-
Stable Diffusion 微调困境:一位成员征求关于使用约 1300 个样本的私有数据集微调 Stable Diffusion 1.5 的建议,表示在寻找有效的超参数(hyperparameters)方面感到吃力。
- OpenAI & other LLM API Pricing Calculator - DocsBot AI: 使用我们强大的免费价格计算器计算并比较使用 OpenAI, Azure, Anthropic, Llama 3, Google Gemini, Mistral 和 Cohere API 的成本。
- Custom Diffusion: 未找到描述
- Google Colab: 未找到描述
- Custom Diffusion: 未找到描述
Perplexity AI ▷ #general (168 messages🔥🔥):
- 对 Beta 测试权限的困惑:一位成员点击了一个图标,期望出现一个表单,但并没有。另一位成员澄清说 Beta 测试已关闭。
- Perplexity 的技术故障:多位用户报告了 Perplexity 的响应问题,包括登录和登出问题、按钮无响应以及在各种设备上加载缓慢。
- 关于模型限制和类型的问题:几位成员询问了 Claude 3 Opus 和 Sonar 32k 等不同模型的每日限制,讨论了这些限制如何影响他们的工作,并引用了 Perplexity FAQ 页面上的官方声明和更新。
- AI 模型之间的对比查询:用户比较了 GPT-4 Turbo、Sonar 和 Opus 等不同模型在各种任务中的能力和局限性,包括论文写作、代码重构以及学习小说写作风格。
- 寻求关于来源限制的澄清:搜索中的来源限制存在困惑,成员们讨论了限制是否有所增加,并分享了可能相关的 GIF 链接作为回应。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文本进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持紧密联系。
- Sky News 获悉,中国黑客攻击了英国国防部:国会议员今天晚些时候将被告知一起涉及国防部的大规模数据泄露事件,目标是服役人员。
- TikTok - 让你的一天充满活力:未找到描述
- Thistest GIF - Thistest 测试 - 发现并分享 GIF:点击查看 GIF
- Scooby Doo 神秘机器 GIF - Scooby Doo 神秘机器动画 - 发现并分享 GIF:点击查看 GIF
- 骷髅梗 GIF - 骷髅梗 - 发现并分享 GIF:点击查看 GIF
Perplexity AI ▷ #sharing (19 messages🔥):
- 展示 Perplexity 的集合:各种用户分享了 Perplexity AI 的链接,探讨了 美国空军、AlphaGo 的推理、围棋、磁带对磁带、图像生成、波音、Microsoft 的 5000 亿参数模型、降噪耳机等主题。
- 强调直观的图像生成:一位用户分享了一个关于创建图像的 Perplexity AI 链接,并表达了希望拥有标准图像生成 UI 的愿望。
- 探索技术与趋势:一些用户正在通过 Perplexity AI 的搜索功能调查 Microsoft 的新模型、降噪耳机以及其他各种主题。
- 强调可分享内容:Perplexity AI 两次提醒用户确保他们的线程是
Shareable(可分享的),强调了社区内可分享内容的重要性。 - XDream 功能:分享了指向 XDream 页面的链接,重点关注一个界面项目和名为 Insanity by XDream 的功能。
Perplexity AI ▷ #pplx-api (23 messages🔥):
- JSON 输出策划思路:成员们讨论了生成 JSON 格式输出的变通方法,其中一人建议在 llama3 中使用简单的配置风格,通过提供 Explanation=Blah Blah Blah 和 Rating=Blah Blah Blah 的示例来引导输出。
- Perplexity API 搜索能力受质疑:用户表达了对 Perplexity 在线模型的困扰,特别是在尝试获取竞争对手落地页的最新 URL 时,指出结果往往过时或不相关。
- 模型卡指南更新:有人指出 Perplexity 文档中关于模型卡的更新,明确说明系统提示词(system prompts)不会影响在线模型的检索过程,并提供了文档链接以获取更多细节。
- 关于模型参数量的辩论:围绕 llama-3-sonar-large 模型的参数量存在困惑和讨论,一些人争论它是否真的以 Llama 为基础,因为据报道其结构类似 MoE 但并非 Llama。
- Sonar 模型站点限制:用户询问了将 Perplexity sonar 模型的输出限制在特定站点的可能性,尝试使用 site:scholar.google.com 等方式但结果并不一致。
CUDA MODE ▷ #triton (13 messages🔥):
- 实现 DoRALinear 模块:一名成员强调了
BNBDoRALinear和HQQDoRALinear模块的实现,包含纯 torch 和融合(fused)前向传播,改编自 FSDP-DoRA 层。该代码需要具备训练鲁棒性,可以在其 PR 的Usage和Benchmarks部分找到。 - Triton 在 Kernel 设计中的优势:一名成员表示,与
Cutlass等高级库相比,使用 Triton 设计 Kernel 的效率更高,后者需要花费更多时间。他们还对 autotuner 进行了细微调整以方便调试。 - DoRA 层中的瓶颈与融合 GEMM:分享了 DoRA 层的详细分析(profiling),将成本最高的 Kernel 锁定在基础层 matmul 以及组合的
lora_B / lora_A matmul + 2-norm操作。设计了两个自定义融合 GEMM 来优化这些瓶颈,详见其 PR 的Profiling部分。 - Autotuner 代码分叉担忧:关于 Triton autotuner 进行了简短讨论,一名成员鼓励尝试日志功能,尽管有人担心由于最近对 autotuner 的其他更改会导致代码分叉。
- 通过 NCU 分析理解 Triton Autotune:一名成员询问了 Triton 的 autotune 功能,询问是否针对每个特定的输入形状编译并运行所有配置,以及这对使用 ncu 等工具进行分析的影响。
CUDA MODE ▷ #cuda (20 messages🔥):
-
CUTLASS Stream-K 调度说明:讨论澄清了 Stream-K 是一种用于 GEMM 实现中负载均衡 Tile 的调度方案,它在概念上独立于 CUTLASS 的其他部分。有人提到,涵盖 Stream-K 可以作为未来演讲的一个简短章节,但解释整个 CUTLASS 2.0 API 可能会非常冗长。
-
在 CUDA 上优化逐元素操作:对于优化逐元素(element-wise)操作,建议包括使用多操作融合(fusions),应用参考讲座 8 中的技巧(如粗粒化和分层拆分),以及利用 Thrust 中的
thrust::for_each或thrust::transform,这可能达到高达 90% 的饱和带宽。提供了 Thrust 文档链接 供参考。
- Modifying:CUDA C++ 核心库
- Transformations:CUDA C++ 核心库
CUDA MODE ▷ #torch (2 messages):
-
使用 PyTorch Compile 调试 Dynamic Shapes:一位成员建议在运行 PyTorch 时使用日志选项
TORCH_LOGS="+dynamic",以诊断指示inputs_ids.shape[1] == 7的错误(该错误通常出现在预期 Dynamic Shapes 的情况下)。此日志设置可以揭示是用户代码还是 PyTorch 框架代码在 tracing 过程中触发了形状特化(shape specialization)。 -
在 PyTorch GitHub 上发布的 Issue:一位成员在 PyTorch 的 GitHub 上提交了一个带有最小示例的 Issue,涉及 Compile 与 DDP (Distributed Data Parallel) 及 Dynamic Shapes 的结合使用。可以通过链接探索该问题并提供更多信息:pytorch/pytorch #125641。
提到的链接:Issues · pytorch/pytorch:Python 中具有强 GPU 加速的张量和动态神经网络 - Issues · pytorch/pytorch
CUDA MODE ▷ #algorithms (2 条消息):
-
提升 Transformer 效率:@p_nawrot 发布的内容介绍了 Dynamic Memory Compression (DMC),这是一种在不牺牲性能的情况下压缩 Large Language Models (LLMs) 中 KV cache 的方法,在 H100 GPU 上显著提升了高达 370% 的吞吐量。他们提供了论文链接,并表示代码和模型将很快发布。
-
关于量化的疑问:针对 KV cache 压缩技术,一位成员询问该方法是否涉及对模型进行量化(Quantization)。目前尚未针对此疑问提供更多信息或回复。
提到的链接:Piotr Nawrot (@p_nawrot) 的推文:Transformer 中的内存在推理时随序列长度线性增长。在 SSMs 中它是常数,但通常以性能为代价。我们引入了 Dynamic Memory Compression (DMC)…
CUDA MODE ▷ #beginner (7 条消息):
-
初学者对 GPU 时钟频率的困惑:一位成员对 H100 GPUs 的时钟频率感到困惑,称其为 1.8 MHz,并询问为什么 fp64 的理论峰值是 34 TFLOPs。另一位成员指出这可能暗示了 MHz 和 GHz 之间的常见错误。
-
纠正 GPU 时钟频率假设:在后续讨论中,该成员承认他们可能指的是 1.8 GHz,这比最初提到的时钟频率高得多,但仍无法找到确认 H100 GPUs 这一参数的来源。
-
关于针对 Triton 的 PyTorch Torch Compile 的咨询:一位成员询问在使用 PyTorch 时如何为 Triton 后端调用
torch.compile,不确定backend="inductor"是否是正确的选项。 -
提升 PyTorch 中的模型性能:讨论涉及使用 BetterTransformer 配合
torch.compile来优化 PyTorch 模型。该成员分享了代码片段,展示了如何在 Hugging Face 生态系统中实现这些优化。
CUDA MODE ▷ #pmpp-book (4 条消息):
-
对转置操作中 Tiling 的困惑:在第 5 章练习的讨论中,有人质疑矩阵转置操作中 tiling 的必要性。另一位成员澄清说,其目的是为了确保合并内存写入(coalesced memory write),并分享了一篇非常有价值的 NVIDIA 博客文章以帮助理解。
-
预期的知识点可能导致困惑:成员们注意到书中的练习有时会包含尚未涉及的主题,从而导致困惑。这表明合并(coalescing)主题预计将在后续章节中讨论。
提到的链接:CUDA C/C++ 中的高效矩阵转置 | NVIDIA 技术博客:我上一篇关于 CUDA C++ 的文章介绍了使用共享内存的机制,包括静态和动态分配。在本文中,我将展示使用共享内存可以实现的一些性能提升。
CUDA MODE ▷ #youtube-recordings (4 条消息):
- 寻找下一次视频会议:一位成员询问了下一次视频会议的时间安排。
- 导航至活动信息:他们被引导至 Events 栏目下查找视频会议详情,该栏目可通过日历图标识别。
CUDA MODE ▷ #jax (1 条消息):
_
- 探索多芯片模型训练:一位成员分享了一篇博客文章,讨论了在多个芯片上训练机器学习模型的必要性。文章重点介绍了如何高效使用 Google 的 TPU,特别是在 Google Cloud 上,并提供了一个用于工作负载分布的逐层矩阵乘法(layerwise matrix multiplication)的可视化示例。
提到的链接:JAX 中的多芯片性能:我们使用的模型越大,就越有必要在多个芯片上进行机器学习模型的训练。在这篇博客文章中,我们将解释如何高效地使用 G…
CUDA MODE ▷ #off-topic (8 条消息🔥):
- 寻求 Metal 内存说明:一位成员寻求关于 Metal 和 Apple Silicon 的说明,特别是如何分配与 CUDA 的
__shared__和float global_array类似的 Shared/Tile 或 Global/Unified/System 内存缓冲区。他们在 Apple 文档中找到了答案。 - Metal 内存访问查询:同一位成员询问在 Apple Silicon 上的 Metal 中,是否所有 GPU 线程都可以访问
.memoryless和.private内存类别,这是对之前内存分配问题的进一步追问。 - Lightning AI Studio 反馈查询:一位用户询问是否有人有使用 Lightning AI Studio 的经验,并能否提供反馈。
- Triton 语言演讲提案:讨论包括一个关于 OpenAI 的 Triton 语言及其在 ML 推理中应用的演讲提案,同时澄清了其与 Nvidia 的 Triton Inference Server 的区别。
- 参考 CUDA Mode YouTube 的 Triton 演讲:一位成员引导其他人查看 CUDA MODE 的 YouTube 频道,观看之前关于 Triton 的演讲,其中可能包含与提议的演讲想法相关的内容。
提到的链接:GitHub - openai/triton: Triton 语言和编译器的开发仓库:Triton 语言和编译器的开发仓库 - openai/triton
CUDA MODE ▷ #irl-meetup (1 条消息):
glaxus_: 有人会去参加 MLSys 吗?
CUDA MODE ▷ #llmdotc (133 条消息🔥🔥):
-
Master 分支上的多 GPU 训练挂起:有人提出了一个关于 master 分支上多 GPU 训练挂起的问题,推测是由于引入了
cudastreams。该问题记录在 GitHub issue #369 中,贡献者正在调查,一些人建议可以使用 GitHub 上的 self-hosted runners 进行真实的 GPU CI 测试,以避免此类问题。 -
使用 Nsight Systems 进行性能分析:分享了一个 NVIDIA Nsight™ Systems 的链接,用于分析应用程序算法并识别 CPU 和 GPU 的优化机会。该工具允许在时间线上可视化系统工作负载,并可用于本地和远程分析,如 Nsight Systems macOS 下载链接所示。
-
解决内核同步以提高性能:有人建议将 kernel 与训练文件同步,特别是将所有内容转换为
floatX并标准化文档,以便新协作者更容易上手。示例 pull request #319 展示了同步后的样子。 -
微调 CUDA Kernel 以获得更好的性能:关于针对特定 GPU 架构深度优化 CUDA kernel 以提升性能(特别是针对内存受限的操作)的讨论非常活跃。例如,Gelu_backward 似乎是内存受限(memory-bound)的,可以通过重构避免不必要的函数来获益,如 PR #307 中所建议。
-
HuggingFace 发布用于预训练的 FineWeb:HuggingFace 发布了一个名为 FineWeb 的数据集,拥有超过 15 万亿个来自清洗和去重后的英语网页数据的 token,并针对 LLM 性能进行了优化。该数据集最小的子集约为 27.6GB,适合从零开始的模型预训练实验,可在 HuggingFace datasets 获取。
- Strangely, Matrix Multiplications Run Faster When Given "Predictable" Data!: 奇怪的是,当给定“可预测”数据时,矩阵乘法运行得更快! - mm_weird.py
- When should I use CUDA's built-in warpSize, as opposed to my own proper constant?: nvcc 设备代码可以访问一个内置值 warpSize,它被设置为执行 kernel 的设备的 warp 大小(即在可预见的未来为 32)。通常你无法区分它们...
- MultiGPU training hangs · Issue #369 · karpathy/llm.c: 在为参数的主副本分配了 474 MiB 后,使用多个 GPU 的 mpirun 挂起。很可能是由于引入了 cudastreams。@karpathy @PeterZhizhin
- convert all float to floatX for layernorm_forward by JaneIllario · Pull Request #319 · karpathy/llm.c: 将所有 kernels 更改为使用 floatX
- HuggingFaceFW/fineweb · Datasets at Hugging Face: 未找到描述
- utilities for mixed-precision tests/benchmarks by ngc92 · Pull Request #352 · karpathy/llm.c: 这允许我们编译一个单一的可执行文件,作为 f32、f16 和 bf16 版本 kernels 的测试/基准测试。到目前为止,我只更新了那些已经定义了 BF... 的测试文件。
- Adding self-hosted runners - GitHub Docs: 未找到描述
- Optimisations for layernorm_backward / matmul_backward_bias / fused_classifier by ademeure · Pull Request #378 · karpathy/llm.c: 这些优化相当难以描述,希望注释会有所帮助/足够!我会关注 train_gpt2.cu 中的更改,而不是 /dev/cuda/ 中类似的更改(我没有...)
- Improve tanh derivative in backward gelu by akbariyeh · Pull Request #307 · karpathy/llm.c: 将 tanh 的导数计算为 1 - tanh^2 比计算 1/(cosh^2) 更便宜。这可能不会产生明显的差异。
- cuda::memcpy_async: CUDA C++ 核心库
- NVIDIA Nsight Systems: 分析系统、分析性能并优化平台。
- no title found: 未找到描述
CUDA MODE ▷ #oneapi (4 messages):
-
发现 GitHub Pull Request: 一位成员分享了 PyTorch.org 的一个 GitHub pull request。该 pull 在快速启动表中添加了一个加速器下拉菜单,选项包括 Huawei Ascend、Intel Extension for PyTorch 和 Intel Gaudi。
-
PyTorch.org 预览版发布: 分享了一个 PyTorch.org 的预览链接,重点介绍了 PyTorch Conference 2024 提案征集、早鸟注册、PyTorch 2.3 的新功能、会员信息和生态系统详情。预览还强调了 TorchScript、TorchServe、torch.distributed 后端以及对 PyTorch 的云平台支持。
- PyTorch : 未找到描述
- Add accelerators to quick start table by aradys · Pull Request #1596 · pytorch/pytorch.github.io: 创建包含以下选项的加速器下拉菜单并将其添加到快速启动表:Huawei Ascend、Intel Extension for PyTorch、Intel Gaudi。在之前版本部分添加命令。RFC: pytorc...
OpenAI ▷ #annnouncements (1 messages):
- OpenAI 分享其数据准则:OpenAI 概述了其在 AI 时代下的 内容与数据处理方法。这份关键文档详细说明了他们如何处理当今环境下的海量数据,以及他们遵循的伦理原则。
OpenAI ▷ #ai-discussions (87 messages🔥🔥):
- 探索 AI 的音乐造诣:一位成员提到了 音乐人 Davie504 与 AI 音乐的即兴演奏,认为 AI 音乐的质量已经变得非常引人入胜。
- Perplexity:AI 领域中隐藏的瑰宝:一位成员在发现 Perplexity 后表示惊讶,遗憾没有早点使用它,并感叹“为什么我没早点用这个”。
- Embedding 模型中的余弦相似度阈值:一位成员询问了 text-embedding-3-small 模型的合适余弦相似度阈值,并指出在旧模型中“旧的 0.9”阈值在较新模型中可能相当于“新的 0.45”。
- 针对 8GB VRAM 的本地 LLM 模型推荐:当有成员寻求适用于 8GB VRAM 显卡的 LLM 模型推荐时,有人建议 Llama8B 运行良好,并可以使用 LM Studio 进行尝试。
- AI 新闻与更新:成员们分享了关注 AI 趋势的不同来源,建议包括与社区成员交流、关注相关的 Twitter 账号,以及浏览 OpenAI Community 和 Ars Technica 等网站。
- OpenAI 开发者论坛:提问并获取有关使用 OpenAI 平台构建应用的帮助
- Ars Technica:服务技术人员十余载。提供 IT 新闻、评论和分析。
OpenAI ▷ #gpt-4-discussions (15 messages🔥):
-
寻求 GPT 知识优先排序:一位成员表示 GPT 倾向于给出通用回答,而不是访问其知识库中的特定条目,这让他感到困扰。有人建议告诉 GPT 参考其“Analyze utility”可能会促使更准确的回答。
-
GPT 知识库原理解析:对 GPT 知识库的工作原理进行了说明,该过程被描述为将知识切分为块(chunks),将其转换为数学向量,并在向量数据库中搜索这些向量以匹配提示词。
-
向量可视化的挑战:简要讨论了在 GPT 知识库背景下可视化向量的复杂性,并指出由于向量处于 256 维空间,这具有很大挑战性。
-
GPT-4 性能在不同需求下保持一致:另一位成员指出,GPT-4 的性能不会随需求量变化,无论使用情况如何,每个人获得的都是相同的“turbo 模型”。
-
没有用于应对需求的劣质模型:最后一条评论驳斥了使用劣质模型来管理需求的说法,认为投资服务器比投资一个不受欢迎的模型更具成本效益。
OpenAI ▷ #prompt-engineering (33 messages🔥):
- 处理 Twitter 数据的困扰:一位成员尝试使用 RAG 将 Twitter 数据作为 LLM 的知识库,但发现模型失去了泛化能力。建议是探索 Custom GPT 或基于 Web 浏览器的 GPT 解决方案,这些方案目前可能支持此类功能。
- 负向提示词 (Negative Prompting) 的陷阱:讨论了将负向示例整合到提示词工程中的难度,建议将其视为一种“高级提示词工程”技术,因为其性质复杂且可能影响回答质量。
- 针对产品识别的提示词扩展建议:对于识别超市手册中产品详情等复杂任务,建议将工作负载拆分为多个提示词而不是一个,将前一个提示词的输出作为后续提示词的输入,以获得更好的效果。
- DALL-E 提示词准确性的挑战:成员们讨论了 DALL-E 在处理负向提示词方面的困难,指出指定不包含的内容(例如“不要牛油果核”)可能会导致混淆。建议去一个拥有资深 DALL-E 用户的频道寻求进一步建议。
- 通过 Logit Bias 脚本改进回答:为了在没有随机项目符号的情况下获得更一致的输出,建议使用伪代码格式的带有开放变量名的输出模板;为了获得更多控制,可以研究 Logit Bias,这需要遵循提供链接中的步骤。
OpenAI ▷ #api-discussions (33 messages🔥):
- GPT 模型在定制化回复方面表现不佳:一位成员就如何将 Twitter 数据整合到 ChatGPT 的知识库中以解决特定 Prompt 寻求建议。他们表示 LLM 模型在使用 RAG 时存在困难,且无法回答 Twitter 数据之外的查询。
- Prompt Engineering 最佳实践:Madame_architect 推荐了 Ronnie Sheer 在 LinkedIn Learning 上的课程《使用 ChatGPT 进行 Prompt Engineering》,用于学习从基础到高级的技术,包括苏格拉底式提示(Socratic prompting)和 Dall-E 交互。
- DALL-E 处理负面提示(Negative Prompts)的困难:讨论指出 DALL-E 经常难以处理负面提示,例如,即使在 Prompt 中明确提到不需要,它仍会生成带有核的牛油果。
- 通过 Logit Bias 处理不需要的 Token:分享了 (OpenAI logit bias 指南) 链接,以解决 AI 产生包含不需要 Token 的不一致输出问题。
- 分步改进 API Prompt 回复:Madame_architect 分享了一种多步骤方法,用于改进 GPT API 在分析和格式化产品信息方面的回复,建议将 Vision 任务和格式结构化拆分为不同的 API 调用。
Eleuther ▷ #general (39 messages🔥):
-
参加 ICLR 并关注 AI 可解释性:一位成员提到他们将参加 ICLR,工作重点是生成式 AI 的可解释性(Interpretability),特别是视觉端和 3D Vision。
-
来自泰国的问候:一位来自泰国的成员分享了简单的问候。
-
测试 System Prompts 对模型性能的影响:一位成员表示有兴趣使用 lm-evaluation-harness 来评估不同的 System Prompts 如何影响模型性能(使用 llama3 8b instruct 等模型),并询问如何在 harness 中为 Hugging Face 模型指定 System Prompts。
-
lm-eval 中的意大利语排行榜:一位成员正在评估意大利语的 LLMs,并使用 lm-evaluation-harness 维护一个排行榜。
-
关于获取 MMLU 数据的查询:一位学生成员询问如何获取任何闭源模型的粒度化 MMLU 数据,因为他们在尝试评估 GPT-4 时耗尽了评估额度。他们提到发现了一个 CSV 文件,但缺少特定模型的答案。
-
关于显存充足时使用 PEFT 的讨论:成员们讨论了在显存(VRAM)充足时,使用 LoRA 进行 PEFT(参数高效微调) 是否有益,一些见解认为实现可能不是最优的,或者特定的配置可能会影响性能,例如混合精度设置和 LoRA 中的 R 值。
Eleuther ▷ #research (77 messages🔥🔥):
-
评估科学标准:一位成员讨论了公认的科学界标准(如 0.05 的 p 值阈值)虽然看起来有些武断,但在历史上具有实际用途。分享了 Nature 文章 降低 P 值阈值,主张将阈值从 0.05 降至 0.005,以提高科学发现的可复现性。
-
P 值争论继续:随后的对话强调了 p 值阈值的随意性,并引用了涉及 Fisher、Neyman 以及统计检验发展的历史背景。物理学与其他领域之间的差异、数据对结果的影响以及公众对不确定性的误解是讨论的核心点。
-
引入 SOPHON 框架:分享了一种名为不可微调学习(non-fine-tunable learning)的新学习范式,旨在防止预训练模型被滥用于不道德的任务。SOPHON 框架旨在保护预训练模型在受限领域免遭微调。
-
QuaRot 的新型量化方案:提供了一个指向 QuaRot 的链接,这是一种针对 LLM 的新量化方法,详见 arXiv 论文,该方法声称在对权重、激活值和 KV cache 进行全面的 4-bit 量化时仍能保持性能。
-
MoE 架构 Lory 发布:讨论引入了一个名为 Lory 的新 MoE 模型,重点是其在 150B Token 上预训练的可微架构。它包含了用于因果分段路由(causal segment routing)和基于相似度的数据批处理以实现专家专业化(expert specialization)的新技术。
- CameraCtrl: 未找到描述
- SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-trained Models: 开发者不再从头开始构建深度学习模型,而是越来越多地依赖于将预训练模型适配到其定制任务中。然而,强大的预训练模型可能会被滥用...
- Lady tasting tea - Wikipedia: 未找到描述
- Significant: 未找到描述
- The mechanistic basis of data dependence and abrupt learning in an...: Transformer 模型展现出 In-Context Learning:能够根据输入序列中的示例准确预测对新查询的响应,这与...
- Lory: Fully Differentiable Mixture-of-Experts for Autoregressive Language Model Pre-training: Mixture-of-Experts (MoE) 模型促进了高效的扩展;然而,训练 Router 网络引入了优化不可微、离散目标的挑战。最近,一种全微分...
- Redefine statistical significance - Nature Human Behaviour: 我们建议将统计显著性的默认 P-value 阈值从 0.05 更改为 0.005,用于新发现的声明。
- QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs: 我们介绍了 QuaRot,一种基于旋转的新量化方案,能够对 LLM 进行端到端量化,包括 4 bits 的所有权重、激活和 KV Cache。QuaRot 以一种方式旋转 LLM...
Eleuther ▷ #scaling-laws (1 messages):
nullonesix: https://arxiv.org/abs/2102.01293
Eleuther ▷ #interpretability-general (34 messages🔥):
-
探索 Skip Connections:一位成员正在实验 Adaptive Skip Connections,其中权重在训练期间会减小甚至变为负值,与标准模型相比,这带来了改进的 Loss 指标。他们提供了实验结果并询问关于此现象的相关研究。
-
调查权重动态:另一位成员分享了一篇关于对 Residual Path 进行 Gating 的相关论文 https://arxiv.org/pdf/2003.04887,尽管它与该实验的不同之处在于没有将 Identity 组件限制为正值。
-
代码与澄清:针对实验中“Identity 组件”的含义寻求了进一步的澄清。该成员分享了代码,显示在 Transformer 层中的 Residual Connection 上使用了单个权重。
-
数据集和模型细节揭晓:实验中使用的模型具有 607M 参数,并在 fineweb 数据集上进行了训练,Batch Size 为 24,Learning Rate 为 6e-4,Context Window 为 768,全部在单台 A100 上运行。
-
关于训练速度和异常 Loss 曲线的讨论:一位讨论该实验的成员注意到 Loss 曲线看起来很奇怪,下降速度太慢,而另一位成员建议在 OpenWebText 数据集上尝试该实验以对比结果。
- train_loss (24/05/07 01:06:58): 使用交互式图表发布您的模型见解,包括性能指标、预测和超参数。由 Nick Ryan 使用 Weights & Biases 制作
- gist:08c059ec3deb3ef2aca881bdc4409631: GitHub Gist:即时分享代码、笔记和片段。
Eleuther ▷ #lm-thunderdome (11 messages🔥):
- Logits 支持仍不可用:尽管人们对通过访问 logit 来理解模型很感兴趣,但在最近的研究表明可能从中提取模型的“图像”或“签名”后(logit 提取研究),像 OpenAI 这样的 API 模型仍然不支持 logits 或使用 logit 偏置。这影响了基于对数似然(log likelihoods)进行评估的能力,并导致 API 响应中省略了 输入 token 的 log probs。
- 封闭模型的评估变通方法:分享了针对 GPT-3.5 等模型评估 意大利语 LLM 的尝试,包括使用 YAML 配置在 MMLU 和 ARC 等任务中利用 ‘generate_until’ 代替 logits,这为封闭模型的外部评估提供了一种变通方案。
- OpenAI 文档暗示 Logprob 返回:一位成员指出 OpenAI 的文档暗示会返回 logprobs,这突显了对专有模型进行外部评估的复杂性。
- 关于 Logprob 可用性的澄清:澄清指出,目前的限制是缺少 prompt/输入 token 的 logprobs,这对于在评估场景中计算模型多 token 响应的完整性至关重要。
- Stealing Part of a Production Language Model:我们介绍了第一种模型窃取攻击,它可以从 OpenAI 的 ChatGPT 或 Google 的 PaLM-2 等黑盒生产级语言模型中提取精确且非平凡的信息。具体来说,我们的...
- Logits of API-Protected LLMs Leak Proprietary Information:大语言模型(LLM)的商业化导致了对专有模型仅提供高级 API 访问的普遍做法。在这项工作中,我们展示了即使在保守的假设下...
- lm-evaluation-harness/lm_eval/tasks/mmlu/flan_cot_zeroshot/_mmlu_flan_cot_zeroshot_template_yaml at main · EleutherAI/lm-evaluation-harness:一个用于语言模型 few-shot 评估的框架。- EleutherAI/lm-evaluation-harness
Modular (Mojo 🔥) ▷ #general (39 messages🔥):
- 安装咨询:一位用户询问如何通过 Docker 在 Intel Mac OS 上安装 mojo,但未提供直接的解决方案。
- Windows 上的 Mojo:用户讨论了在 Windows 上使用 mojo 的替代方案,建议利用 WSL2 以获得相当的体验。通过一个暗示等待原生 Windows 支持的 gif 幽默地表达了耐心。
- 关于 Mojo 设计选择的讨论:成员们辩论了在 mojo 中同时保留 structs 和 classes 的基本原理,涉及设计模式,并回应了关于包含这两种构造的决定的疑虑。
- Mojo 的编译能力:澄清了 mojo 可以编译为原生机器码,类似于 Rust,并可以生成如 .exe 之类的可执行文件。针对与 Python 等语言的即时性相比,数据工程任务中解释速度的担忧得到了回应。
- Python 与 Mojo 的集成:用户解释了 mojo 如何通过导入模块和调用函数与 Python 集成,并引用官方文档证明 mojo 旨在成为 Python 的超集,在引入自身功能的同时利用已有的 Python 生态系统。
Modular (Mojo 🔥) ▷ #💬︱twitter (2 messages):
- Modular 分享了两个重要更新:Modular 团队通过两条独立的 Twitter 帖子发布了重要更新。
- 获取 Modular 的最新动态:欲了解更多信息,请访问 Modular 官方 Twitter 页面上的 推文 1 和 推文 2 链接。
Modular (Mojo 🔥) ▷ #📺︱youtube (1 messages):
- Modular Community Livestream 提醒:一段名为“Modular Community Livestream - New in MAX 24.3”的新视频已发布,宣布 MAX 24.3 正式可用。该直播深入探讨了 MAX Engine 的最新更新,并介绍了 Mojo🔥 的新 Extensibility API。立即观看。
提到的链接:Modular Community Livestream - New in MAX 24.3:MAX 24.3 现已发布!加入我们的直播,讨论 MAX Engine 和 Mojo🔥 的新功能 - 预览 MAX Engine Extensibility API…
Modular (Mojo 🔥) ▷ #🔥mojo (53 条消息🔥):
-
解决 Tensor 索引问题:一位用户在通过索引设置 Tensor 特定位置的值时遇到错误,该问题通过使用
utils.index中的Index工具得到了解决。来自 Tensor 库的代码演示了如何正确设置指定索引处的 Tensor 值而不会报错。 -
优化大型数组上的 SIMD 操作:一位成员在大型数组上使用 SIMD 时遇到困难,并在数组大小超过 2^14 时遇到了编译问题。另一位用户建议使用更小的 SIMD 块,并提供了来自 Mojo GitHub 仓库的示例代码。
-
基准测试(Benchmarking)困境:一位用户对基准测试函数中未使用的计算值表示担忧,因为这可能导致编译器优化掉函数本身。通过建议使用
benchmark.keep来保留结果并防止此类优化,该问题得到了解决。 -
关于无类继承的构造函数的疑问:一位成员质疑在 Mojo 中使用构造函数的必要性,因为该语言缺乏类(class)和继承。对话涉及了 Mojo 与 Go 和 Rust 等其他语言的区别,强调构造函数是确保实例在创建时有效的一种手段。
-
探索高级编译器工具:聊天参与者讨论了对能够揭示编译代码细节(如 LLVM IR)的工具的需求,以消除猜测。大家对类似于 Mojo 的 Compiler Explorer 工具或查看编译后 Mojo 代码低级表示的能力表现出兴趣。
-
关于 Mojo 中 ‘where’ 子句的提案:针对一项关于 Mojo 函数中参数推导的 GitHub 提案展开了讨论,辩论了从右到左推导规则的实现与可读性,以及使用类似于数学和 Swift 编程语言中的
where子句。参与者对指定参数约束最直观的方法持有不同意见。 -
Mojo 中的编译时元编程:一位用户询问了 Mojo 中编译时元编程的程度,特别是像斐波那契数列这样的计算是否可以在编译时完成。得到的确认是此类计算确实可行,但前提是不能涉及副作用。
- transpose | Modular 文档:transpose(input Int, y: Int) -> Symbol
- [功能请求] 从其他参数推导参数 · Issue #1245 · modularml/mojo:查看 Mojo 的优先级。我已经阅读了路线图和优先级,并认为此请求符合优先级。你的请求是什么?Mojo 已经支持从参数中推导参数...
- basalt/basalt/utils/tensorutils.mojo at main · basalt-org/basalt:一个用纯 Mojo 🔥 从零开始编写的机器学习框架 - basalt-org/basalt
- mojo/proposals/inferred-parameters.md at main · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账户为 modularml/mojo 的开发做出贡献。
- mojo/examples at main · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账户为 modularml/mojo 的开发做出贡献。
- mo - 概览:mo 有 49 个可用的仓库。在 GitHub 上关注他们的代码。
Modular (Mojo 🔥) ▷ #community-projects (14 条消息🔥):
- Mojo-sort 更新与增强:mojo-sort 项目已更新以适配最新的 Mojo nightly。它现在包含一个更高效的字符串基数排序算法,在所有基准测试中表现出更快的速度。
- Lightbug 迁移需要帮助:Lightbug 项目在迁移到 Mojo 24.3 版本时遇到问题,特别是涉及似乎记录了 EC2 位置的错误。开发者请求协助,详情记录在此 GitHub issue中。
- Basalt 应对 Mojo 的局限性:Basalt 项目通过寻找变通方案(如使用 StaticTuple 处理编译时列表)来适应 Mojo 目前的局限性(如缺乏类和继承),但这通常没有限制其总体目标。
- Minbpe 的 Mojo 新移植版:Minbpe.mojo 发布,这是 Andrej Karpathy 的 Python 项目的 Mojo 移植版。虽然目前比 Rust 对应版本慢,但它比原始 Python 版本快三倍,且具有优化潜力,包括未来可能的 SIMD 实现。
- Mojo GUI 库查询:一名成员表示有兴趣了解是否存在 Mojo GUI 库,但在给定的消息中尚未得到回应。
- 客户端测试无法适配 Mojo 24.3 的更改 · Issue #34 · saviorand/lightbug_http:自 Mojo 24.3 起,不再支持包内的 main() 函数。这曾用于 /tests/run.mojo 来运行测试套件(目前仅为一个客户端测试)。该客户端测试通过运行...
- GitHub - dorjeduck/minbpe.mojo: Andrej Karpathy 的 minbpe 到 Mojo 的移植:Andrej Karpathy 的 minbpe 到 Mojo 的移植。通过在 GitHub 上创建账号来为 dorjeduck/minbpe.mojo 的开发做出贡献。
- GitHub - mzaks/mojo-sort:通过在 GitHub 上创建账号来为 mzaks/mojo-sort 的开发做出贡献。
- mojo-pytest/example/tests/util.mojo at main · guidorice/mojo-pytest:Mojo 测试运行器,pytest 插件(又名 pytest-mojo)。通过在 GitHub 上创建账号来为 guidorice/mojo-pytest 的开发做出贡献。
Modular (Mojo 🔥) ▷ #nightly (16 messages🔥):
-
Trait 和 Variant 中的类型处理困扰:围绕编程语境下处理返回类型的讨论浮出水面,提到了需要
Never类型或类似于 Rust 的宏技巧来通过返回类型检查。一些成员认为目前的解决方案只是权宜之计,强调需要更明确的语言结构(如关键字)。 -
Variant 类型受到 Trait 继承的挑战:一名成员在创建具有 Trait 继承的 Variant 类型时遇到问题,突显了相关 GitHub issue中标记的当前局限性。他们还在探索替代方法,如使用带有
@staticmethods的PythonObject以避免使用UnsafePointer。 -
Nightly 编译器发布与 Reference 易用性改进:Mojo Discord 宣布了 Mojo 编译器的最新 nightly 版本发布,同时增强了
Reference的易用性(ergonomics),简化了理解和使用。 -
自动化 Nightly 发布通知的请求:关于自动化 nightly 发布消息的问题得到了成员的回应,表示虽然可行,但尚未被列为优先实现的项。
-
显示器被最新更新撑满:一位用户幽默地评论说,他们的 2k 显示器刚好能容纳最新更新的内容范围,暗示了改动的重大意义。
- [Feature Request] 允许子 Trait 替换父 Trait · Issue #2413 · modularml/mojo:回顾 Mojo 的优先级,我已阅读路线图和优先级,并认为此请求符合优先级。你的请求是什么?如果一个函数接受受 Trait 约束的可变参数...
- [stdlib] 更新 stdlib 以对应 2024-05-06 nightly/mojo,由 JoeLoser 提交 · Pull Request #2559 · modularml/mojo:此更新将 stdlib 与对应于今天 nightly 版本的内部提交同步:mojo 2024.5.622。
- nightly 分支下的 mojo/docs/changelog.md · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账户来为 modularml/mojo 的开发做出贡献。
- [stdlib] 更新 stdlib 以对应 2024-05-06 nightly/mojo,由 JoeLoser 提交 · Pull Request #2559 · modularml/mojo:此更新将 stdlib 与对应于今天 nightly 版本的内部提交同步:mojo 2024.5.622。
OpenRouter (Alex Atallah) ▷ #announcements (1 条消息):
- Soliloquy L3 降价: 使用 Soliloquy L3 8B 模型的价格已降至 $0.05/M tokens,适用于 2023 - 2024 年的私有和登录端点。
提到的链接: Lynn: Llama 3 Soliloquy 8B v2 由 lynn 开发 | OpenRouter:Soliloquy-L3 v2 是一款快速、高性能的角色扮演模型,旨在提供沉浸式、动态的体验。基于超过 2.5 亿 token 的角色扮演数据训练,Soliloquy-L3 拥有庞大的知识库…
OpenRouter (Alex Atallah) ▷ #app-showcase (1 条消息):
- Rubik’s AI 招募 Beta 测试人员: 邀请用户成为 Rubik’s AI 的 Beta 测试人员,这是一款新型的高级研究助手和搜索引擎。潜在测试人员在 rubiks.ai 注册并使用促销代码
RUBIX,即可获得 2 个月的免费高级功能,包括访问 Claude 3 Opus, GPT-4 Turbo, Mistral Large 和其他前沿模型。 - 科技界热点 - 苹果与微软的创新: 在应用的趋势话题中,有关于 苹果 2024 年最新 iPad 型号 的更新,以及 微软正在开发名为 MAI-1 的 500B 参数模型 以与 OpenAI 竞争的新闻。用户可以在应用内访问这些故事以获取详细见解。
提到的链接: Rubik’s AI - AI 研究助手 & 搜索引擎:未找到描述
OpenRouter (Alex Atallah) ▷ #general (119 条消息🔥🔥):
- 寻找难以捉摸的啰嗦版 Llama: 成员们讨论了让 llama-3-lumimaid-8b 生成更长回复的挑战,认为其较短的输出不如之前使用 Yi 和 Wizard 等模型的体验。
- Meta-Llama-3-120B-Instruct 发布: 关于在 Hugging Face 上发布 Meta-Llama-3-120B-Instruct 的对话,该模型灵感来自 Goliath-120b 和 MegaDolphin-120b 等大型自我合并模型;成员分享了关于其发布的推文链接。
- Amazon Bedrock 模型请求的区域限制: 一位用户询问了在 Amazon Bedrock 上从不同计费区域请求模型时是否存在区域限制的可能性,其他人建议 请求访问另一个区域似乎是可行的。
- OpenRouter 的精度偏好: 关于 OpenRouter 是否以 全精度 运行模型的对话表明,这取决于提供商,大多为 fp16,有时会量化为 int8。
- 模型优化与参数调整: 询问 OpenRouter 的默认参数 是否通常适用,引发了关于是否需要调整参数以获得更好对话效果的观点和经验分享。
- 未找到标题: 未找到描述
- mlabonne/Meta-Llama-3-120B-Instruct · Hugging Face: 未找到描述
- AI Dungeon 中有哪些不同的 AI 模型?: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- abacusai/Fewshot-Metamath-OrcaVicuna-Mistral-10B · Hugging Face: 未找到描述
- OpenRouter: 构建与模型无关的 AI 应用
OpenInterpreter ▷ #general (39 条消息🔥):
- 解决本地 Interpreter 问题:一位用户在本地运行 Interpreter 搭配 Mixtral 时遇到了错误。另一位用户试图了解 OpenInterpreter 的功能,并将其个人体验与该项目令人印象深刻的演示视频进行了对比。
- Phi 性能评估:讨论了在 OpenInterpreter 上使用 Hugging Face 模型 (Phi-3-Mini-128k-Instruct) 的情况;Mike 提到使用 Phi 时的性能“非常差”。
- 对模型性能基准测试的兴趣:成员们有兴趣对各种模型进行基准测试,以查看哪些模型与 Open Interpreter 配合效果最好,怀疑合成数据较少的模型可能表现更好。
- 征集模型和框架的昵称:在一位用户分享了关于 Gemma-over-Groq (GoG) 体验的正面反馈后,出现了为模型+框架组合起昵称的建议。
- 请求自定义系统指令:有人请求关于在 Ubuntu 上使用 GPT-4 的自定义/系统指令方面的帮助,表明社区对这类资源有需求。
- 预微调建议:针对有关为特定任务训练模型的问题,建议使用 OpenPipe.ai,并提到在微调模型之前,有效理解和使用 system messages 的重要性。
- OpenPipe: 面向开发者的微调:将昂贵的 LLM 提示词转换为快速、廉价的微调模型。
- microsoft (Microsoft): 未找到描述
- What Hello GIF - What Hello Yes - 发现并分享 GIF:点击查看 GIF
- 什么是 Reka Core?:**Reka Core** 是由 Reka 开发的前沿级多模态语言模型。它是仅有的两种商用综合多模态解决方案之一,能够处理和理解...
- microsoft/Phi-3-mini-128k-instruct · Hugging Face: 未找到描述
OpenInterpreter ▷ #O1 (80 条消息🔥🔥):
-
Open Interpreter 版本特定性:强调了 Open Interpreter (OI) 应在 Python 3.10 下运行,以避免兼容性问题。一位用户在运行 Groq 时遇到了性能缓慢的问题,被建议切换到更小的模型(如 dolphin 或 mixtral)以获得更好的体验。
-
在 Mac 上使用 Conda 进行干净安装:在面临多个 Python 版本冲突和错误后,用户讨论了创建一个带有 Python 3.10 的独立 Conda 环境来重新安装 Open Interpreter。
-
本地模型框架查询:一位用户询问是否支持将 Jan 作为 O1 设备的本地模型框架,类似于它在 Open Interpreter (text) 中的使用。得到的肯定答复是,只要模型的提供方式相似,就应该没有问题。
-
01 设备国际可用性:关于 01 设备的网络服务可用性,有人指出虽然该设备在任何有互联网接入的地方都可以工作,但托管服务目前可能仅限美国,且目前尚未发货。
-
LLM 技能持久化与执行问题:一位用户指出持久化已学习技能的重要性,以避免向语言模型重复教授相同信息。他们被引导至 Open Interpreter 的 GitHub,以了解技能在存储中如何持久化的相关信息。此外,还提到并在一份视频参考中解决了使用较小语言模型运行代码的问题。
- open-interpreter/interpreter/core/computer/skills/skills.py at main · OpenInterpreter/open-interpreter:计算机的自然语言接口。通过在 GitHub 上创建账号为 OpenInterpreter/open-interpreter 的开发做出贡献。
- microsoft/Phi-3-mini-128k-instruct · Hugging Face:未找到描述
OpenAccess AI Collective (axolotl) ▷ #general (35 messages🔥):
- Sora 的开源替代方案发布:一个采用 MIT 许可证的 Sora 开源替代方案已在 GitHub 上发布,提供了一个创建魔法故事的工具。然而,值得注意的是权重(weights)尚未发布。在此探索该工具。
- Gradient Checkpointing 内存节省:一位成员报告成功使用了新的 unsloth gradient checkpointing,观察到 VRAM 使用量从 19,712MB 减少到 17,427MB,表明了显著的内存节省。
- 模型层中异常的训练模式:在讨论中,有人指出一个令人费解的发现,即似乎只有模型层的一个切片得到了训练,这与其他模型中各层得到充分训练的情况形成对比,引发了一些推测,但尚无具体解释。
- 对 Lazy Optimizer 行为的推测:有推测认为,如果数据集过于简单,模型可能不会优化所有层,而为了效率仅专注于前几层和最后几层,然而这一理论并不能完全解释各层训练强度的异常。
- Axolotl 功能咨询:一位有一段时间没有进行训练的成员询问了 Axolotl 的最新功能,寻求关于新能力或增强功能的更新。
提到的链接:GitHub - HVision-NKU/StoryDiffusion: Create Magic Story!:创建魔法故事!通过在 GitHub 上创建账号为 HVision-NKU/StoryDiffusion 的开发做出贡献。
OpenAccess AI Collective (axolotl) ▷ #other-llms (1 messages):
icecream102: 巧合吗?
OpenAccess AI Collective (axolotl) ▷ #general-help (5 messages):
-
识别 HuggingFace 数据集类型:当不确定 HuggingFace 数据集的类型时,最简单的方法是下载并打开它以检查内容。或者,也可以查看数据集的预览(preview)来获取此信息。
-
构建针对特定编程语言的代码 LLM:受 IBM 的 granite 模型启发,一位成员分享了创建特定语言 LLM 的兴趣,特别是针对 Java 代码辅助,并打算在没有 GPU 的标准笔记本电脑上运行。他们正在寻求关于选择 fine-tuning 基座模型、确定合适的 epoch 数量、训练规模以及保持准确性的 quantization(量化)方面的指导。
OpenAccess AI Collective (axolotl) ▷ #datasets (38 messages🔥):
-
数学性能 fine-tuning 中的挑战:讨论强调了数学主题评分的下降,特别是在 mmlu 和中文数学评估(ceval 和 cmmlu)中。即使在 Hugging Face 的
orca-math-word-problems-200k、math instruct和metamathQA等数据集上进行 fine-tuning 后,性能仍有所下降。 -
Quantization 对模型性能的影响:成员们提到了 quantization 效应的话题,特别是引用了
llama.cpp的 quantization 可能会显著降低模型性能。 -
讨论 fine-tuning 和评估策略:据报告,模型在
orca-math-word-problems-200k、math instruct和MetaMathQA等数据集上进行了 fine-tuning,并使用 lm-evaluation-harness 进行了评估。然而,对于确保在评估和 fine-tuning 期间正确使用 prompt template(提示词模板)存在一些担忧。 -
Prompt 设计会影响模型行为:一场深入的讨论指出使用正确的 Prompt 设计至关重要,因为模板的变化(包括可能错误的 end-of-text tokens)可能会影响模型性能。
-
Prompt 格式在 Fine-tuning 中的关键作用:一位参与者认为,如果模型也使用这些示例进行 Fine-tuning,则可以使用像
alpaca这样的自定义 Prompt 格式,同时需意识到准确对比的必要性以及潜在的性能问题。
- Meta Llama 3 | Model Cards and Prompt formats:Meta Llama 3 使用的 Special Tokens。一个 Prompt 应该包含单个 system message,可以包含多个交替的 user 和 assistant message,并且总是以最后一个 user message 结尾...
- GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models.:一个用于语言模型 few-shot 评估的框架。- EleutherAI/lm-evaluation-harness
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp:我正在运行 Unsloth 对 llama3-8b 的 Instruct 模型进行 LORA Fine-tuning。1:我将模型与 LORA adapter 合并为 safetensors 2:在 python 中直接运行合并后的模型进行推理...
- axolotl/src/axolotl/prompters.py at 3367fca73253c85e386ef69af3068d42cea09e4f · OpenAccess-AI-Collective/axolotl:尽管提问 Axolotl 相关问题。通过在 GitHub 上创建账号来为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp:我正在运行 Unsloth 对 llama3-8b 的 Instruct 模型进行 LORA Fine-tuning。1:我将模型与 LORA adapter 合并为 safetensors 2:在 python 中直接运行合并后的模型进行推理...
- TIGER-Lab/MathInstruct · Datasets at Hugging Face:未找到描述
- meta-math/MetaMathQA · Datasets at Hugging Face:未找到描述
OpenAccess AI Collective (axolotl) ▷ #docs (2 条消息):
- 关于 Model Merging 的扩展文档:Axolotl 发布了新的文档更新,涉及模型权重合并。概述的下一个目标是处理 Inference 指南。
- Axolotl:AI 爱好者的训练枢纽:Axolotl GitHub 仓库提供了一个灵活的 AI 模型 Fine-tuning 工具,涵盖了广泛的 Huggingface 模型和 Fine-tuning 技术,并强调了自定义配置的能力。
提及的链接:Introduction | Continuum Training Platform | Axolotl Training Platform:未找到描述
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (5 条消息):
- 在 ShareGPT 中修改 System Prompts:要更改对话训练的 System Prompt,必须调整
ShareGPTPrompter类中的对话模板或初始 System Message。这涉及修改_build_result方法或相应的配置参数。
提及的链接:OpenAccess-AI-Collective/axolotl | Phorm AI Code Search:更快速地理解代码。
LangChain AI ▷ #general (43 条消息🔥):
- 寻找 OData V4 支持:一位成员询问了 LangChain 对 Microsoft Graph (OData V4) 的支持情况,并讨论了创建类似于 SQLDatabase utility 的自定义工具的潜在需求。
- 对 Kappa Bot 的 API 需求:由于公司对 Discord 平台的限制,一位用户表示希望为 kappa-bot-langchain 提供 API,以便在 Discord 之外使用。
- 深入探讨实体记忆 (Entity Memory):用户寻求关于 ConversationEntityMemory 中参数
k的澄清,并参考 LangChain documentation 以获取深入见解。 - Python 新手的框架之争:一位 Python 新手向社区咨询在开发新应用时应选择 Flask 还是 Django,并表达了对 Flask 可扩展性的担忧。
- 探寻 LangChain 的数据容量限制:一位用户询问了 Langsmith Free plan 中数据集的上传大小限制,特别提到了一个 300MB 的 CSV 文件。
- Defining Custom Tools | 🦜️🔗 LangChain:在构建自己的 Agent 时,你需要为其提供一个可用的 Tool 列表。除了实际调用的函数外,Tool 还包含几个组件:
- Table with LLMs Token Output Limit:一张包含多个大语言模型 (LLMs) 的 Context Window 和最大输出 Token 信息的表格。
- Use query parameters to customize responses - Microsoft Graph:Microsoft Graph 提供了可选的查询参数,可用于指定和控制响应中返回的数据量。包含常用参数。
- langchain.memory.entity.ConversationEntityMemory — 🦜🔗 LangChain 0.1.18:未找到描述
- Rubik's AI - AI research assistant & Search Engine:未找到描述
LangChain AI ▷ #langserve (13 messages🔥):
-
关于 RemoteRunnable 使用 streamEvents 的咨询:一位成员询问了在 LangChain 中是否可以将
streamEvents与RemoteRunnable结合使用。得到了肯定的回答以及详细的代码示例,并被引导至 LangChain documentation 和 API reference。 -
JavaScript 中 RemoteRunnable 的流式传输问题:该成员随后报告了一个问题,即 JavaScript 版本的
RemoteRunnable未能按预期通过streamEvents进行流式传输,尽管在 Python 中可以正常工作。这表明 JavaScript 版本可能存在不一致或 bug。 -
可能指向了错误的 API 端点:对话以该成员注意到
streamEvents方法正在向/stream而非/stream_events发送 HTTP POST 请求而结束。这种不一致促使社区建议在 LangChain GitHub repository 上提交 issue 以寻求澄清或修复潜在的 bug。
- Integrating with LangServe | 🦜️🔗 Langchain:LangServe 是一个 Python 框架,旨在帮助开发者部署 LangChain runnables 和 chains。
- Interface | 🦜️🔗 Langchain:为了尽可能简化自定义 chain 的创建,我们实现了一个大多数组件都遵循的 "Runnable" 协议。
LangChain AI ▷ #share-your-work (5 messages):
-
Everything-AI 介绍:everything-ai 已更名为 V1.0.0,其特点是一个多任务、AI 驱动的本地助手,能够与 PDF 对话、总结文本、生成图像等。该项目可以在 GitHub 上找到,并配有全新的用户界面和快速入门文档:https://astrabert.github.io/everything-ai。
-
招募 Beta 测试人员:Rubiks.ai 正在为其先进的研究助手和搜索引擎招募 Beta 测试人员,并提供 2 个月的免费高级访问权限,可使用 Claude 3 Opus、GPT-4 Turbo 和 Mistral Large 等模型。感兴趣的人员可以使用促销代码在 https://rubiks.ai/ 注册。
-
AI 应用无代码工具发布:一款旨在简化 AI 应用创建并促进从原型到生产过渡的新型无代码工具已经推出,配备了内置的 Prompt Engineering 和一键部署功能。早期演示可在 Google Drive demo 查看,反馈意见可通过 预约链接 安排。
-
通过 Langchain 系列探索 API Chain:在名为 “API Chain Chain Types Learning Langchain Series” 的视频中,提供了一个关于使用 APIChain 调用 LLM API 的教程,可在 YouTube 上找到。 -
学习利用 Router Chain:Learning Langchain 系列的另一部分涵盖了 Router Chain,这是一个用于管理多个 API 和 LLM 任务的工具,在 YouTube 上的视频 “ROUTER CHAIN Learning Langchain Series Chain Types” 中有详细讲解。
- everything-ai:介绍 everything-ai,您的全能、AI 驱动且本地运行的聊天机器人助手! 🤖
- GitHub - AstraBert/everything-ai:介绍 everything-ai,您的多任务、AI 驱动且本地运行的助手! 🤖 - AstraBert/everything-ai
- Rubik's AI - AI 研究助手与搜索引擎:未找到描述
- API Chain | Chain Types | Learning Langchain Series:学习如何使用 Langchain 的 APIChain 调用 API。您将看到,借助此库,您将在交付价值方面处于领先地位...
- Pixie.ai.mp4:未找到描述
- Appointments:未找到描述
- ROUTER CHAIN | Learning Langchain Series | Chain Types:在处理多任务时,Router chain 是您绝对需要的工具之一!想象一下如何在多个 API 或多个任务之间进行处理...
LangChain AI ▷ #tutorials (1 条消息):
mhadi91: https://youtu.be/WTfWgYsIspE?si=gEdyMrX4vJm2gC6E
LAION ▷ #general (61 条消息 🔥🔥):
- 探索 AI 角色扮演数据集:一名成员建议创建一个完全由人类编写的对话组成的数据集,包括笑话和人类互动,以改善 AI 模型的响应,使其超越典型的、缺乏灵魂的智能 Instruct 模型输出。
- 用于研究的合成数据生成:一位用户分享了 Simian 的 GitHub 链接,这是一个用于图像、视频和 3D 模型的合成数据生成器,为实验提供了可能的资源。
- 寻求数据集推荐:一位机器学习新手询问了适用于专注于文本/数值回归或分类任务的研究论文的数据集,从而得到了各种数据集推荐,如 MNIST-1D 和情感分析数据集,例如 Stanford’s Large Movie Review Dataset。
- 关于文本转视频 Diffusion 模型的讨论:一场关于 Diffusion 模型在 SOTA 文本转视频任务中优于生成式 Transformer 的热烈讨论展开了,指出 Diffusion 模型通常是从现有的 T2I 模型微调而来的,从而节省了计算成本。分享了关于这些模型的 3D 知识及其文本调节(text-conditioning)挑战的见解。
- 来自作者的视频 Diffusion 模型见解:Stable Video Diffusion 论文的作者参与了讨论,强调了为视频模型获取高质量文本监督的挑战、利用 LLM 为视频自动生成字幕的潜力,以及视频生成的 Autoregressive 和 Diffusion 方法之间的细微差别。
提到的链接:
- VideoPoet – Google Research:一种用于零样本视频生成的 Large Language Model。VideoPoet 展示了一种简单的建模方法,可以将任何自回归语言模型转换为高质量的视频生成器。
- GitHub - RaccoonResearch/Simian: Synthetic data generator for image, video and 3D models:用于图像、视频和 3D 模型的合成数据生成器 - RaccoonResearch/Simian
- GitHub - instructlab/community: InstructLab Community wide collaboration space including contributing, security, code of conduct, etc:InstructLab 社区范围内的协作空间,包括贡献、安全、行为准则等 - instructlab/community
</div>
LlamaIndex ▷ #announcements (1 条消息):
- OpenDevin 网络研讨会公告:LlamaIndex 将于 周四上午 9 点(太平洋时间) 举办一场网络研讨会,邀请 OpenDevin(Cognition 开发的 Devin 的开源版本)的作者。与会者可以学习如何构建自主 AI Agent,并从其在 GitHub 上迅速增长的人气中获得见解。在这里注册。
提到的链接:LlamaIndex Webinar: Build Open-Source Coding Assistant with OpenDevin · Zoom · Luma:OpenDevin 是来自 Cognition 的 Devin 的完全开源版本 —— 一个能够自主执行复杂工程任务的自主 AI 工程师……
LlamaIndex ▷ #blog (4 条消息):
-
Hugging Face TGI 发布新功能:Hugging Face 的 TGI (Text Generation Inference) 工具包宣布支持 function calling 和批量推理等功能,旨在优化该平台上的 LLM 部署。完整的功能列表已在 LlamaIndex 的推文中分享。
-
Jerry Liu 将在 AIQCon 发表演讲:联合创始人 Jerry Liu 将在旧金山的 AIQCon 上发表关于在复杂数据上构建高级问答 Agent 的演讲。根据包含会议详情的推文,使用代码 “Community” 可享受 15% 的门票折扣。
-
使用 LlamaParse 增强 RAG:LlamaParse 旨在提高在复杂文档上构建检索增强生成 (RAG) 模型的数据质量,强调高质量数据对良好性能至关重要。这一进展在最近的 LlamaIndex 推文中得到了强调。
-
OpenDevin 作为开源 AI 工程师:@cognition_labs 发布了 OpenDevin,这是一个开源的自主 AI 工程师,能够执行复杂的工程任务并在软件项目上进行协作。公告和详情已在 LlamaIndex 更新中提供。
提到的链接:The AI Quality Conference:2024 年 6 月 25 日在加利福尼亚州旧金山举行的全球首届 AI 质量大会。
LlamaIndex ▷ #general (50 条消息🔥):
-
LlamaIndex 集成探索:对话探讨了将 LlamaIndex 与其他数据库 集成的问题。一位用户在查询 Supabase Vectorstore 时遇到了空响应和维度不匹配错误的问题;他们最终通过在创建查询引擎时指定模型和维度解决了维度问题。
-
包导入和文档混淆:讨论围绕 llama-index 最近更新后的 包导入 展开。用户分享了关于定位正确包路径和导入的经验,并建议参考更新后的 llama-hub 文档进行安装和导入。
-
文档知识删除故障排除:一位用户在尝试从 llama-index 的索引中 删除文档知识 时遇到了问题。与另一位用户的对话建议在持久化更改后重新实例化 query_engine 以观察删除效果,尽管该问题似乎尚未解决,因为用户在 json 向量存储中仍能看到该文档。
-
本地使用的 PDF 解析库:一位用户询问了 本地 PDF 解析库,作为使用 LlamaParse 的替代方案。推荐了 PyMuPDF,并提供了一个展示如何将 PyMuPDF 与 LlamaIndex 集成的使用示例。
-
处理响应中缺乏相关信息的情况:用户讨论了在上下文中未发现相关信息时防止模型响应的方法。建议将 Prompt engineering 以及在每个请求上采用类似于 Evaluate 的检查作为潜在解决方案。
- OpenAI & 其他 LLM API 价格计算器 - DocsBot AI:使用我们强大的免费价格计算器计算并比较使用 OpenAI、Azure、Anthropic、Llama 3、Google Gemini、Mistral 和 Cohere API 的成本。
- Llama Hub:未找到描述
- llama_index/llama-index-integrations/embeddings/llama-index-embeddings-huggingface at main · run-llama/llama_index:LlamaIndex 是适用于您的 LLM 应用程序的数据框架 - run-llama/llama_index
- 从零开始构建 Evaluation - LlamaIndex:未找到描述
LlamaIndex ▷ #ai-discussion (4 条消息):
-
为复杂的 NL-SQL 寻求 HyDE 方法:一位成员正在构建一个 NL-SQL 聊天机器人,以处理跨数百个表的复杂 SQL 查询,并正在寻找在这种场景下有效的 HyDE 方法。他们只找到了 HyDE 在 pdf/文本聊天机器人中使用的参考资料,并正在探索提高 LLM 在数据库查询中准确性的选项。
-
使用 LlamaIndex 的 Introspective Agents:分享了一篇题为“使用 LlamaIndex 构建 Introspective Agents”的文章链接,描述了在 LlamaIndex 框架内使用 reflection agent pattern 的 Introspective Agents。来源是 AI Artistry on Medium,并包含使用 MidJourney 创建的图像。
-
Agent 文章的 Medium 404 错误:一位成员分享了同一篇文章“Introspective Agents with LlamaIndex”的链接,但这次链接指向了 Medium 上的 404 Page Not Found 错误。页面建议浏览其他可能感兴趣的故事。
-
文章确认:另一位成员确认了分享的关于 Introspective Agents with LlamaIndex 的文章是一篇“好文章”,暗示了积极的反响,但未提供更多细节或讨论。
- Introspective Agents with LlamaIndex:Ankush k Singal
- 未找到标题:未找到描述
tinygrad (George Hotz) ▷ #general (35 条消息🔥):
- 重新思考 UOps 表示:用户建议通过采用类似于 LLVM IR 的格式来提高 tinygrad 操作呈现的可读性。该建议包括为操作使用更易于人类阅读的格式。
- 澄清 SSA 和 UOps:在讨论变更时,强调了 tinygrad 的操作 应该是 Static Single Assignment (SSA) 形式。用户指出,与传统的 LLVM IR 相比,PHI 操作被放置在块的末尾而不是开头,这引起了困惑。
- 对拟议格式的意见分歧:虽然一位成员反对更改 tinygrad 当前的格式,称其引入了不必要的抽象层,但另一位成员鼓励提交 Pull Request (PR) 来实现拟议的更改。
- Discord 赌约趣闻:两名用户参与了一场关于通过 PayPal 余额对代码正确性进行投注的对话。随后演变为对潜在 bug 的承认,以及在服务器上创建一个受时间和准确性限制的投注挑战的复杂性。
- 讨论机器学习术语的规避方法:在技术交流中,一位用户寻求关于在不深入研究数学术语的情况下学习机器学习的建议。他们被引导至 Andrej Karpathy 的资源,而另一位用户重申了关于询问初学者问题的聊天规则。
tinygrad (George Hotz) ▷ #learn-tinygrad (20 条消息🔥):
-
tinygrad 中的 CPU Kernel 单线程运行:针对 tinygrad 是否在矩阵乘法等操作中使用多线程的问题,George Hotz 确认 tinygrad 是单线程的,且在 CPU 操作中不使用线程。
-
理解 Tensor 中的重映射(Remapping)与步长(Strides):一位用户描述了如何通过改变步长来重映射 Tensor,从而实现特定的 Reshape 和计算,并建议保留原始形状以在 Reshape 后计算索引,这种技术可能类似于 tinygrad 的底层实现。
-
通过文档分享知识:用户分享了自制的解释性内容,例如关于 Symbolic Mean 和 Winograd 卷积理解的文章。一位用户分享了关于 Symbolic Mean 的 GitHub 帖子,另一位提供了关于 View Merges 的 Google Doc 链接。
-
tinygrad 中的量化推理能力:一位用户询问 tinygrad 是否具备类似于 bitsandbytes 库的量化推理能力,并得到了其在一定程度上具备该能力的确认。
-
通过文档和示例学习的建议:用户鼓励创建和分享玩具示例(toy examples)及文档,作为学习和教授 tinygrad 相关概念的方法,这对比作者本人和社区都有潜在益处。
- tinygrad-notes/symbolic-mean.md at main · mesozoic-egg/tinygrad-notes:tinygrad 教程。通过在 GitHub 上创建账号为 mesozoic-egg/tinygrad-notes 的开发做出贡献。
- tinygrad/docs-legacy/reshape_without_symbolic.md at master · tinygrad/tinygrad:你喜欢 PyTorch?你喜欢 micrograd?你一定会爱上 tinygrad!❤️ - tinygrad/tinygrad
- View Merges:未找到描述
Cohere ▷ #general (35 messages🔥):
-
在 Cohere Toolkit 中寻找 SQL 数据库位置:一名成员询问在 Cohere Toolkit 中存储对话历史记录的 SQL 数据库位置。另一名成员澄清其位于 5432 端口,但未指定确切位置。
-
学生渴望创建类似 Google Bard 的聊天机器人:一名高中生表达了构建类似 Google Bard 聊天机器人的抱负,并询问这是否符合 Cohere 的用户协议。Cohere 代表分享了关于测试版和生产版密钥的指南,确认在获得生产版密钥的前提下,构建并最终提供付费访问聊天机器人是允许的。
-
解决 Chroma 检索和嵌入问题:一名成员报告了在本地使用 Chroma 测试 Cohere Toolkit 时遇到的问题,具体为文档检索过程中出现的 IndexError。对话指向检查 Pastebin 链接中的完整日志追踪以及来自
ghcr.io/cohere-ai/cohere-toolkit:latest的预构建容器。 -
Cohere Toolkit 中始终选中 Langchain Retriever:尽管选择了 File Reader - LlamaIndex,一名用户报告称系统仍使用了 Langchain retriever,并分享了截图证明(但截图无法访问)。
-
生产版密钥注册后表现为测试版密钥:一名用户遇到了新注册的生产版密钥仍作为测试版密钥运行的问题。Cohere 代表澄清称,测试版密钥仅在 Playground / Chat UI 中使用,并保证在 API 中使用时应反映生产版密钥的使用情况,且不需要预充值。
- 📏 Telemetry | Chroma: Chroma 包含一个遥测功能,用于收集匿名使用信息。
- Pasteboard - 上传的图片: 未找到描述
- Going Live - Cohere 文档: 未找到描述
- 1 分钟掌握 Python 装饰器!: 在短短 1 分钟内发现 Python 装饰器的强大功能!这个快速教程将向你介绍装饰器的基础知识,让你能够增强你的 Python...
- PDF | 🦜️🔗 LangChain: 便携式文档格式 (PDF),标准化为 ISO 32000,是 Adobe 在 1992 年开发的一种文件格式,用于以独立于应用程序的方式呈现文档,包括文本格式和图像...
{kind=link}
</div>
Cohere ▷ #project-sharing (2 条消息):
-
Cohere Coral 结合了 Chatbot 和 ReRank: 一位成员介绍了一个名为 Coral Chatbot 的应用,它将文本生成、摘要和 ReRank 集成到一个工具中。你可以通过他们的 Streamlit 页面 查看该应用并提供反馈。
-
60 秒揭秘 Python 装饰器: 分享了一个名为“1 分钟掌握 Python 装饰器”的快速教程,承诺简要介绍 Python 装饰器。感兴趣的成员可以在 YouTube 上观看解说视频。
- 1 分钟掌握 Python 装饰器!: 在短短 1 分钟内发现 Python 装饰器的强大功能!这个快速教程将向你介绍装饰器的基础知识,让你能够增强你的 Python...
- 未找到标题: 未找到描述
Latent Space ▷ #ai-general-chat (35 条消息🔥):
-
Centaur Programmers 会缩小团队规模吗?: 来自 v01.io 的一篇链接文章讨论了 Centaur Programmers 缩小产品团队规模的潜力,利用人机协作来提高效率。围绕这一假设的讨论推测是否会出现更小的团队,或者团队是否会转而专注于提高产品产出。
-
DeepSeek-V2 登顶性能排行榜: 通过 Twitter 发布,DeepSeek-V2 是一款出色的开源 MoE 模型,在基准测试中表现优异,在包括代码和推理能力在内的多个领域具有顶尖性能。社区反应包括兴奋和分析,相关讨论研究了该新模型的影响。
-
揭秘 DeepSeek 的成就: 分享了更多围绕 DeepSeek-V2 基准测试成就的对话,以及 AI News 时事通讯 中提供的个人见解,说明了该模型对 AI 领域的影响。
-
统一搜索方案探索: 为小型组织寻找可行统一搜索解决方案的讨论提到了 Glean,以及在分享的 Hacker News 帖子 中讨论的一个潜在 OSS 替代方案。有人建议开发一个机器人,可以预先在 Discord 等平台搜索相关帖子。
-
AI 编排实践查询: 提出了关于 AI (data) orchestration 实践的问题,寻求社区对首选编排工具、数据传输方法以及处理涉及文本和 embeddings 的复杂数据流水线的架构建议。
- Centaur Programmers 缩小了产品团队规模——至少,他们应该这样做。 – Klaus Breyer: Pedro Alves, Bruno Pereira Cipriano, 2023: Centaur Programmer 的理念基于这样一个前提:人类与 AI 之间的协作方法将比单纯的 AI 更有效,正如...
- 来自 DeepSeek (@deepseek_ai) 的推文: 🚀 发布 DeepSeek-V2:尖端开源 MoE 模型!🌟 亮点:> 在 AlignBench 中位列前三,超越了 GPT-4 并接近 GPT-4-Turbo。> 在 MT-Bench 中排名顶尖,媲美...
- 未找到标题: 未找到描述
- [AINews] DeepSeek-V2 以一半的成本击败了拥有超过 160 个专家(experts)的 Mixtral 8x22B: 2024/5/3-2024/5/6 的 AI News。我们为您检查了 7 个 subreddits、373 个 Twitters 和 28 个 Discords(419 个频道,10335 条消息)。预计阅读时间...
AI Stack Devs (Yoko Li) ▷ #ai-companion (6 messages):
-
本地使用 Faraday 是免费的:成员们澄清说,在本地使用 Faraday 不需要云端订阅,且不涉及任何费用。一位成员分享了他们的个人经验,表示它在 6 GB VRAM 下运行良好,并包含免费的语音输出。
-
永久访问下载内容:用户强调,一旦从 Faraday 平台下载了角色和模型,就可以无限期使用,无需进一步付费。
-
对充足 GPU 的认可:有人指出,只要有足够强大的 GPU,就不再需要云端账号,除非用户希望通过订阅向开发者做出贡献。
AI Stack Devs (Yoko Li) ▷ #team-up (5 messages):
- 模拟协作启动:一位名为 @abhavkedia 的成员提议共同创建一个关于 Kendrick 和 Drake 事件的有趣模拟,并正在寻找合作者。
- 项目进展与组队:@abhavkedia 分享了他们在模拟项目上的最新进展,@jakekies 表示有兴趣加入该项目,表明协作工作正在进行中。
AI Stack Devs (Yoko Li) ▷ #ai-town-dev (11 messages🔥):
- 代码更新需要手动清空表:在代码中更新角色定义不会自动刷新系统;成员们被提醒,如果修改了角色功能或地图,需要运行 wipe-all-tables。
- 使用 inotifywait 的自动化建议:分享了一种通过使用
inotifywait检测 data/character.ts 中的更改并相应地进行更新的自动化方法。 - 邀请尝试 Llama Farm:鼓励成员们尝试新的模拟项目 Llama Farm,分享的链接已经引起了关注。
- Llama Farm 与 AI-Town 的集成:提出了一个 Llama Farm 与 AI-Town 之间的独特集成概念,这需要一个 Ollama 实例来参与 AI-Town,并按角色标记本地消息处理。
- 迈向更通用的 Llama Farm:分享了将 Llama Farm 的能力泛化以使用 OpenAI API 挂载到任何系统的计划,包括一种使用 query/mutation 进行多路复用(multiplexing)的流式传输方法。
提到的链接:llama farm: 未找到描述
AI Stack Devs (Yoko Li) ▷ #paper-spam (1 messages):
Deforum 每日论文:论文现在将发送至 <#1227492197541220394>
Mozilla AI ▷ #llamafile (18 messages🔥):
-
设备上的模型性能较慢:一位成员报告说在他们的设备上运行模型很慢,每 token 需要 8 秒。
-
Rocket-3B 作为更快的替代方案:在遇到另一个模型的性能问题后,一位成员被建议尝试 Rocket-3B,这显著提高了速度。
-
在 llamafile 中高效使用 Ollama 缓存:有人询问 llamafile 是否可以使用存储在 Ollama 缓存中的模型以避免重复下载,回复澄清说可以通过使用
-m model_name.gguf来实现。 -
AutoGPT 与 Llamafile 集成的挑战:一位成员遇到了 AutoGPT 无法正确启动 AP 服务器的问题,导致 llamafile agent 在启动时被终止;手动重启是针对端口
8080的变通方法,但对端口8000无效。 -
AutoGPT 支持 Llamafile 的草案 PR:提供了设置 autoGPT + llamafile 的说明,并指出在进一步开发之前,正等待 AutoGPT 维护者的反馈。对话暗示目前正努力通过一个草案 PR 将 llamafile 与 AutoGPT 集成。草案 llamafile 支持说明。
- AutoGPT/autogpts/autogpt/llamafile-integration at draft-llamafile-support · Mozilla-Ocho/AutoGPT:AutoGPT 是一个愿景,旨在让每个人都能使用和构建易于获取的 AI。我们的使命是提供工具,让你能够专注于重要的事情。 - Mozilla-Ocho/AutoGPT
- Draft llamafile support by k8si · Pull Request #7091 · Significant-Gravitas/AutoGPT:背景:此草案 PR 是通过添加 llamafile 作为 LLM 提供者,实现在 AutoGPT 中使用本地模型的一步。相关问题:#6336 #6947。变更 🏗️:有关完整文档...
Interconnects (Nathan Lambert) ▷ #news (5 条消息):
-
关于 AI 评估的辩论:分享了一个来自 Dr. Jim Fan 的推文 链接,涉及 AI 评估。消息强调虽然推文内容很有趣,但可能存在错误,并且特定的基准测试和评估中的公共民主被过度看重,更倾向于 AB 测试而非开放民主。
-
基准测试——数据库视角:一位成员对 AI 领域需要标准基准测试的需求产生共鸣,并将其与他们在数据库领域的经验进行了比较。他们建议推文中提到的三套基准测试可能是一个合适的方法。
-
什么是 TPC?简要介绍:在关于 TPC 的提问后,一位成员解释说 TPC 代表事务处理委员会(Transaction Processing Council),这是一个中立实体,通过 TPC-C 和 TPC-H 等基准测试为数据库行业制定和审计标准。他们详细说明这是为了应对数据库厂商过度炒作的宣传。
Interconnects (Nathan Lambert) ▷ #random (11 条消息🔥):
- GPT-2 聊天机器人搅动 LMsys Arena:xeophon. 分享的一条推文提到了一个“优秀的 gpt2-chatbot”,引用了 Sam Altman 的幽默评论,预示着 GPT-2 重返 LMsys Arena。推文包含了一张 对话截图。
- 对 OpenAI 使用 LMsys 进行评估的质疑:Nathan Lambert 表达了个人对 OpenAI 似乎利用 LMsys 进行模型评估的反感。
- LMsys 的走钢丝处境:Nathan Lambert 观察到 LMsys 处于困难境地,由于缺乏资源,导致他们无法拒绝合作。
- 对 LMsys 公信力的担忧:Nathan 提到,最近一波“chatgpt2-chatbot”的参与可能会对 LMsys 的声誉和公信力产生负面影响。
- 考虑进行关于 LMsys 的播客采访:Nathan 考虑与 LMsys 团队进行一次 Interconnects 音频采访,但仍未做出决定,理由是过去的互动缺乏协同效应。
提到的链接:来自 ハードはんぺん (@U8JDq51Thjo1IHM) 的推文:I’m-also-a-good-gpt2-chatbot I’m-a-good-gpt2-chatbot ?? 引用 Jimmy Apples 🍎/acc (@apples_jimmy) @sama 你这家伙真有趣。Gpt2 回到了 lmsys arena。
DiscoResearch ▷ #mixtral_implementation (2 条消息):
- PR 关闭已确认:讨论以一个 Pull Request (PR) 被关闭/拒绝的信息结束。未提供进一步细节。
DiscoResearch ▷ #general (3 条消息):
- AIDEV 会议氛围热烈:成员们对即将到来的 AIDEV 活动 表示期待,并正在协调见面。鼓励参加者如果尚未建立联系,请尽早沟通。
- 关于会议设施的咨询:有人提出了关于 AIDEV 活动 是否提供食物,或者参加者是否需要自备的问题。
DiscoResearch ▷ #discolm_german (10 messages🔥):
-
探索 Mistral 的能力:一位成员确认在当前项目中使用 8x22b Mistral 模型,并讨论了其部署和性能方面的问题。
-
降低延迟的解码技术:有人询问如何在不等待句子结束的情况下实现低延迟(low latency)解码,涉及高效语言模型输出生成的策略。
-
德语 DPO 数据集的潜力:提出了为包容性语言创建德语数据集的想法,引发了关于其效用以及是否应在关注包容性的同时关注语法和用词的讨论。
-
寻求德语预训练数据集的建议:一位成员就从 Common Crawl 构建纯德语预训练数据集寻求反馈,并询问哪些特定领域可能因高质量内容而值得更多关注。
-
包容性语言的资源分享:分享了关于性别和多样性敏感语言的资源,包括 INCLUSIFY 原型 (https://davids.garden/gender/) 和相关的 GitLab 仓库 (https://gitlab.com/davidpomerenke/gender-inclusive-german),这些资源可能与在 AI 模型中实现包容性语言模式相关。
- David’s Garden - Gender-inclusive German: A benchmark and a model:对于具有性别屈折变化的语言(如本报告所述的德语)来说,包容性语言对于实现性别平等至关重要。
- David Pomerenke / Gender-inclusive German - a benchmark and a pipeline · GitLab:GitLab.com
LLM Perf Enthusiasts AI ▷ #prompting (7 messages):
- 提示词生成器工具揭晓:一位成员讨论了在 Anthropic console 中发现的新 prompt generator tool。
- 测试礼貌改写功能:使用该工具测试了将句子改写得更礼貌的提示词,得到了令人满意的结果。
- 探索底层机制:一位成员正在提取新工具使用的 system prompt,并评论了其中大量使用的 k-shot examples,其中一个关于苏格拉底式数学导师的示例非常有趣。
- 提取长提示词的挑战:提取完整提示词的尝试仍在进行中,由于其长度(特别是冗长的数学导师示例)而面临困难。
- 承诺分享信息:该成员确认,一旦成功提取完整提示词,将在聊天中分享。
Alignment Lab AI ▷ #general-chat (2 messages):
由于提供的消息仅为问候语,没有实质性内容可以按要求的格式进行总结。如果提供了更多具有主题性和详细内容的消息,我将能够根据这些内容创建摘要。
Datasette - LLM (@SimonW) ▷ #llm (2 messages):
- GitHub Issue 协作:讨论插件的参数化测试,分享了一个 GitHub issue 链接(Design and implement parameterization mechanism · Issue #4),表明开发和贡献正在进行中。
- 关于
llm配合 OpenAI Assistant API 的咨询:一位成员询问llm是否可以与 OpenAI Assistant API 配合使用,希望自己没有遗漏相关信息。
提及的链接:Design and implement parameterization mechanism · Issue #4 · simonw/llm-evals-plugin:初步想法如下:#1 (comment) 我需要一个参数化机制,以便可以同时针对多个示例运行相同的 eval。这些示例可以直接存储在 YAML 中,也可以是…