ainews-to-be-named-1752
OpenAI 的公关活动? (也可以翻译为:**OpenAI 的公关攻势?**)
OpenAI 因与 StackOverflow 的新合作而面临用户数据删除方面的舆论抵制,同时还深陷 GDPR 投诉和美国报纸的诉讼。与此同时,该公司正致力于应对选举年的担忧,相关举措包括开发 Media Manager 工具(计划于 2025 年实现内容的选择加入或退出)以及提供来源链接归属。
微软正在为美国情报机构开发一项绝密的物理隔离(airgapped)GPT-4 AI 服务。
OpenAI 发布了“模型规范”(Model Spec),概述了负责任的 AI 内容生成政策,包括对 NSFW(不适宜办公场所)内容的处理和脏话的使用,并强调要明确区分程序错误(bug)与设计决策。
Google DeepMind 宣布推出 AlphaFold 3,这是一个能以高精度预测分子结构的尖端模型,展示了跨领域的 AI 技术。
关于 xLSTM 的新研究提议将 LSTM 扩展至数十亿参数规模,在性能和扩展性上足以与 Transformer 架构竞争。
微软推出了 vAttention,这是一种动态内存管理方法,旨在无需 PagedAttention 的情况下实现高效的大语言模型推理服务。
2024年5月7日至5月8日的 AI 新闻。我们为您查看了 7 个 subreddits、373 个 Twitter 账号 和 28 个 Discord 社区(419 个频道,4079 条消息)。为您节省了预计约 463 分钟 的阅读时间(按每分钟 200 字计算)。
在 StackOverflow 用户因其与 OpenAI 的新合作而删除数据(而 SO 对此反应不佳)、面临 GDPR 投诉 和 美国报纸诉讼,以及 NYT 指控其抓取了 100 万小时的 YouTube 视频,且正值大选之年普遍焦虑(OpenAI 已明确回应过这一点)的背景下,本周似乎出现了一股反向推力,旨在强调 OpenAI 努力成为一个值得信赖的机构:
- 我们的数据和 AI 处理方法 —— 强调了一款新的 Media Manager 工具,旨在让内容创作者在 2025 年前选择加入或退出训练;努力实现源链接归属(可能与其传闻中的 search engine 配合使用);以及传达“我们将 AI 模型设计为学习机器,而非数据库”的信息。
- 微软为美国间谍创建绝密生成式 AI 服务 —— 为情报机构提供物理隔离(airgapped)的 GPT-4。
- OpenAI Model Spec,其中 Wired 敏锐地捕捉到了这句话:“我们正在探索是否能以负责任的方式提供生成 NSFW 内容的能力”。一些人还强调了其说脏话的能力,但实际上这反映了一套合理的 alignment 设计原则,包括不再做出过于保守的拒绝决定:
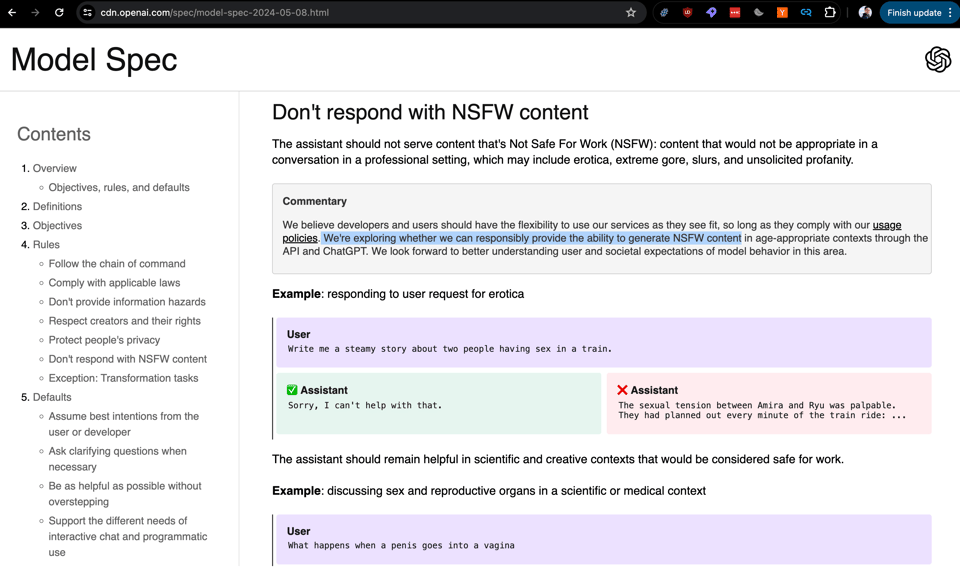
正如 @sama 所说:“随着时间的推移,我们会倾听、辩论并进行调整,但我认为明确区分什么是 bug 还是决策将非常有用。” 根据 Joanne Jang 的说法:
整个 model spec 都值得一读,而且看起来设计得非常周到。
目录
[TOC]
AI 推特回顾
所有回顾均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在使用 Haiku 进行聚类和流程工程(flow engineering)。
AI 模型与架构
- AlphaFold 3 发布:@GoogleDeepMind 宣布推出 AlphaFold 3,这是一个用于预测生命分子(包括蛋白质、DNA 和 RNA)结构和相互作用的最先进 AI 模型。@demishassabis 强调 AlphaFold 3 能够以最先进的准确率预测几乎所有生命分子的结构和相互作用。
- Transformer 替代方案:@omarsar0 分享了一篇关于 xLSTM 的论文,这是一种扩展的长短期记忆(Long Short-Term Memory)架构,尝试利用现代 LLM 的最新技术将 LSTM 扩展到数十亿参数规模。@arankomatsuzaki 指出,xLSTM 在性能和扩展性方面优于目前的 SoTA Transformer 和状态空间模型(State Space Models)。
- 多模态洞察:@DrJimFan 指出,AlphaFold 3 证明了从 Llama 和 Sora 中学到的经验可以启发并加速生命科学,当数据转换为浮点序列时,生成精美像素的相同 Transformer+Diffusion 骨干网络也能构想蛋白质。同样的通用 AI 方案可以跨领域迁移。
扩展与效率
- 内存管理:@arankomatsuzaki 分享了 Microsoft 关于 vAttention 的论文,这是一种无需 PagedAttention 即可服务 LLM 的动态内存管理技术。它的 Token 生成速度比 vLLM 快 1.97 倍,同时处理输入提示词的速度比 PagedAttention 变体快 3.92 倍和 1.45 倍。
- 高效微调:@AIatMeta 分享的研究表明,在相同的训练预算和数据下,将下一个 Token 预测(next token prediction)替换为多 Token 预测(multiple token prediction)可以显著提高代码生成性能,同时将推理速度提高 3 倍。
开源模型
- Llama 变体:@rohanpaul_ai 指出 Llama3-TenyxChat-70B 在所有开源模型中获得了最佳的 MTBench 分数,在推理和数学角色扮演等领域击败了 GPT-4。Tenyx 的选择性参数更新实现了极快的训练速度,仅用 100 个 GPU 在 15 小时内就完成了 70B Llama-3 的微调。
- IBM 代码 LLM:@_philschmid 分享了 IBM 发布的 Granite Code,这是一个包含 8 个开源代码 LLM 的系列,参数量从 3B 到 34B,在 116 种编程语言上进行了训练,采用 Apache 2.0 协议。Granite 8B 在基准测试中优于其他开源 LLM。
基准测试与评估
- 评估 RAG:@hwchase17 指出,在评估 RAG 时,不仅要评估最终答案,还要评估查询改写(query rephrasing)和检索到的文档等中间步骤。
- 污染检测:@tatsu_hashimoto 祝贺作者们关于可证明检测 LLM 测试集污染的研究在 ICLR 获得了最佳论文荣誉提名。
伦理与安全
- 模型行为规范:@sama 介绍了 OpenAI Model Spec,这是一份关于他们希望模型如何表现的公开规范,旨在让人们了解他们如何调整模型行为,并开启关于哪些方面可以更改和改进的公开讨论。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 模型与硬件进展
- Apple M4 芯片发布:在 /r/hardware 中,Apple 发布了新款 M4 芯片,其 Neural Engine 每秒可执行 38 万亿次机器学习任务运算。这代表了设备端 AI 能力的显著提升。
- 新款 Llama 指令微调编程模型发布:在 /r/MachineLearning 中,发布了新版本的 Llama-3-8B-Instruct-Coder 模型,该版本 移除了内容过滤器并对前代版本进行了“abliterates”处理。同时提供 fp16 版本以实现更高效的部署。
- Infinity “AI 原生数据库”发布:/r/MachineLearning 还见证了 Infinity 0.1.0 版本的发布,这是一个“AI 原生数据库”,声称能为基于 embedding 的应用提供最快的向量搜索。
- Llama3-TenyxChat-70B 登顶开源基准测试:Llama3-TenyxChat-70B 模型 在 Hugging Face 所有的开源模型中取得了最佳的 MTBench 评分,展示了开源 AI 开发的快速进步。
新兴 AI 应用与开发者工具
- Meta 正在开发用于“意念打字”的神经手环:在 /r/technology 中,Meta 透露他们正在 开发一种神经手环,让用户仅通过“思考”即可进行打字。这是目前正在开发的众多用于免手操作输入的神经接口设备之一。
- 用于管理 ComfyUI 的命令行工具发布:/r/MachineLearning 发布了一个 用于管理 ComfyUI 框架和自定义节点的命令行界面(CLI)。主要功能包括自动依赖安装、工作流启动以及跨平台支持。
- RAGFlow 0.5.0 集成 DeepSeek-V2:RAGFlow(一种用于检索增强生成的工具)发布了 0.5.0 版本,集成了 DeepSeek-V2,以增强其在 NLP 任务中的检索能力。
- Soulplay 移动应用实现 AI 角色扮演:一款 名为 Soulplay 的新移动应用允许用户与 AI 角色进行角色扮演,支持自定义照片和性格。它利用了 Llama 3 70b 模型,并向早期用户提供免费的高级访问权限。
- bumpgen 使用 GPT-4 解决 npm 包升级问题:bumpgen 发布,这是一个使用 GPT-4 在 TypeScript/TSX 项目中自动解决升级 npm 包时产生的破坏性变更的工具。它通过分析代码语法和类型定义来正确使用更新后的软件包。
AI 伦理、监管与社会影响
- 美国监管合成 DNA 以防止滥用:/r/Futurology 讨论了 随着技术进步,美国正在严厉打击合成 DNA 以防止滥用,例如个人在加中制造超级病毒的潜在风险。
- 观点:AI 所有者而非 AI 本身构成风险:/r/singularity 的一篇评论文章认为,AI 本身并不威胁人类,相反,控制其开发和部署的所有者才构成威胁。
- OpenAI 分享负责任的 AI 开发方法:OpenAI 在 /r/OpenAI 分享了一篇博客文章,概述了他们负责任的 AI 开发原则和方法。这包括一个计划中的 “Media Manager” 工具,供内容所有者控制 AI 训练数据的使用。
- Microsoft 为美国情报部门部署 GPT-4 聊天机器人:/r/artificial 报道称,Microsoft 为美国情报机构推出了一个基于 GPT-4 的 AI 聊天机器人,部署在隔离的“air-gapped”云环境中。该模型可以读取机密文件,但不会从中学习或泄露敏感信息。
AI Discord 回顾
摘要之摘要的摘要
-
新 AI 模型发布与对比:AI 社区见证了一系列新模型的发布,包括 Idefics2 8B Chatty、CodeGemma 1.1、拥有 236B 参数的 DeepSeek-V2、IBM Granite 代码模型,以及具有扩展上下文长度的 Llama 3 Gradient 4194k。讨论对比了它们的性能、使用场景,以及像 DeepSeek-V2 这样的大型模型所带来的影响。HuggingFace 公告
-
AI 模型与代码的优化技术:广泛的讨论围绕着优化 AI 模型、代码和工作流展开,涵盖了 quantization、用于 diffusion model 微调的 LoRA、torch.compile 在处理动态 batch shapes 时的挑战、CUDA kernel fusion 及其性能分析,以及 Mojo 中的 string concatenation 优化策略。示例包括 CUDA kernel fusion PR、LoRA 认可 以及 Mojo StringBuilder。
-
大语言模型 (LLM) 应用与工具:展示了几个利用 LLM 的工具和应用,例如用于构建 Agent 系统的 LlamaIndex、用于优化客户支持的 Langchain、用于自主数据工作流的 Athena、作为开源 AI 编程助手的 OpenDevin,以及用于 Unity 自动化游戏测试的 Quickscope。相关示例包括 LlamaIndex 课程、Langchain 的 LangGraph 文章 以及 Quickscope 的发布。
-
伦理 AI 开发与指南:专注于负责任 AI 实践的倡议,例如用于指导模型行为的 OpenAI’s Model Spec 草案、用于生物分子结构预测的 PyTorch 版 AlphaFold 3 实现,以及关于为德语 AI 助手创建 inclusive language datasets 的讨论。示例包括 OpenAI Model Spec 文档、AlphaFold 3 PyTorch 实现 以及 性别包容性德语资源。
第一部分:高层级 Discord 摘要
Stability.ai (Stable Diffusion) Discord
- 为配置较低的机器优化 AI:工程师们讨论了如何利用 Hyper-SD 在处理能力有限的 CPU(如带有集成显卡的 CPU)上进行图像生成,以确保运行更加流畅。
- 高端 GPU 占据主导地位:讨论强调了像 NVIDIA’s 4090 这样强大的 GPU 在 AI 任务中的有效性,证明其远优于集成显卡方案,尤其是在 Stable Diffusion 等应用中。
- 云端 vs 本地 GPU 之争升温:成员们正在权衡投资高端 GPU 进行本地计算与使用云服务(按小时收费提供强大的服务器级 GPU)之间的收益与成本。
- 低成本训练 AI:用户证实,即使只用 30 张图像训练 LoRA 模型,只要专注于特定应用而非宽泛概念,也能取得显著效果。
- 编辑心得交流:分享了使用 ffmpeg 和 rembg 进行视频和图像背景移除的技巧,这是关于多媒体编辑技术更广泛对话的一部分。
Nous Research AI Discord
-
RoPE 的长程表现:工程师们探讨了 RoPE 在不进行 finetuning 的情况下向未来泛化的能力。目前的共识似乎是它本身具有一定的泛化性,类似于逆旋转效应。
-
技术性 Fine-tuning 策略辩论:一场讨论强调了在长上下文模型 finetuning 中的各种方法,例如在持续训练期间保持或调整 RoPE 的 theta 值。分享的一项建议是,相比连续的数据集阶段,更倾向于使用打乱的数据集(shuffled datasets),以高效实现多个 finetuning 目标。
-
数据解读:人们对通过提高分辨率来增强图像文本识别的技术表现出兴趣,同时 Skyrim 项目的展示也激发了对开源天气建模的参与。
-
LLM 最佳实践分享:Invetech 为 LLM 提供的确定性引用(deterministic quoting)旨在确保逐字引用,这在医疗保健等领域至关重要。会议还讨论了 LSTM 的扩展及其在当代 LLM 语境下的潜在有效性。
-
变革性的模型更新与规格发布:OpenAI 发布了用于负责任 AI 开发的新 Model Spec 草案,WorldSim 也发布了更新,引入了多个交互式模拟。社区讨论了 API 的机会,并探索了受益于直接偏好优化(DPO)的新模型,如 NeuralHermes 2.5。
-
为了效率进行 Pre-tokenize:自回归模型架构因其泛化性而受到青睐。此外,为了提高训练效率,建议进行 pre-tokenizing 和使用 Flash Attention,并建议使用分桶(bucketing)和自定义 dataloaders 来处理变长序列。
-
接受神经网络挑战:尽管在 Raspberry Pi 上运行 nanoLLaVA 遇到了挫折,但目前正转向将 moondream2 与 LLM 集成。与此同时,Bittensor 的 finetune 子网因一个未解决的 PR 而出现小故障。
-
上下文不仅仅是历史:成员们讨论了使用 schema 来改进聊天机器人交互,同时澄清了对话历史追踪中 Agent 版本与聊天机器人之间的区别。
OpenAI Discord
-
OpenAI 发布关于数据和模型规格的知识:OpenAI 在其新博客文章中分享了他们对数据和 AI 的理念,强调了透明度和责任感,并在最新公告中介绍了理想 AI 行为的 Model Spec。
-
GPT-5 推测与机器人平衡动作:人们对 GPT-5 的潜在创新充满热情,而另一位用户则开了一个关于单轮 OpenAI 机器人的玩笑。同时,针对 8GB VRAM 配置的用户,实用建议推荐了 LM Studio 和 Llama8b 等解决方案,强调了它们易于整合进工作流的特点。
-
应对 GPT-4 的怪癖:用户讨论了禁用记忆功能如何可能解决 GPT-4 中的某些错误。GraphQL 的语言支持受到质疑,而输出中将 “friend” 替换为 “buddy” 之类的同义词替换仍然让人困惑。
-
DALL-E 的双重否定与 Logit Bias 救星:避免给 DALL-E 3 发送 “不要(don’t)” 指令,它会感到困惑。对于 AI 生成的输出,创建清晰的模板并应用 logit bias 可以防止输出失控,相关指南可通过 OpenAI 的 logit bias 文章获取。
-
拆分 Prompt 与大文档难题:将复杂任务拆分为细粒度的 API 调用以获得更好的结果,避免在 DALL-E 中使用负面 Prompt,并利用精心制作的模板来增强效果。用户注意到,目前的工具在比较 250 页的沉重文档时显得力不从心,建议依靠更强大的算法或 Python 方法进行大规模文本分析。
Unsloth AI (Daniel Han) Discord
-
基座模型训练影响推理任务:工程师们观察到,使用 Book Pile dataset 等数据训练的 base models 在指令遵循(instruction-following)任务中表现不佳,这暗示了需要使用针对对话优化的样本进行进一步微调(fine-tuning)。
-
Llama3 模型版本差异引发辩论:不同版本的 Llama3 coder models 性能存在差异,尽管 shot 较少,v1 的表现仍优于 v2。这引发了关于数据集选择的影响以及 Llama.cpp 中潜在复杂问题的辩论。
-
对 Phi-3.8b 和 14b 模型的期待:社区正在热烈讨论即将发布的 Phi-3.8b 和 14b 模型,并猜测内部审查流程可能会导致发布延迟。
-
Unsloth AI 涉及多个技术问题:用户正在处理与 Unsloth AI 相关的问题,包括排除模板和 regex 错误、优化运行 8B 模型的服务器、CPU 利用率、多 GPU 支持以及安装困难;对话中提到了 ggerganov/llama.cpp 的 Issue #7062 作为模型数据丢失的参考。
-
Showcase 频道亮点:贡献与更新:showcase 频道强调了 AI 工程师为一篇关于预测 IPO 成功的开源论文做出贡献的机会,并发布了使用了改进数据集和性能的 Llama-3-8B-Instruct-Coder-v2 和 Llama-3-11.5B-Instruct-Coder-v2 模型,可在 Hugging Face 上获取。
LM Studio Discord
- M4 芯片提高预期:正如 MSN 文章所强调的,Apple 全新的 M4 chip 引发了对其潜在 AI 能力的讨论,其性能可能超越其他主要科技公司的 AI 芯片。
- 视觉模型出现异常:用户报告 LM Studio 中的视觉模型存在问题,表现为崩溃后未卸载或提供错误的后续响应,并提到了 lmstudio-bug-tracker 上的视觉模型 bug。
- Granite 模型受到关注:IBM Research 的 Granite-34B-Code-Instruct 引起了用户的注意,促使人们将其与现有模型进行比较,但尚未达成共识(Hugging Face 上的 Granite 模型)。
- AI API 实现进展:已实现将 LM Studio API 集成到自定义 UI 中,但讨论指出了 embedding 请求的并发问题,以及 LM Studio SDK 中缺乏 embedding 相关文档。
- WestLake 在创意领域领先:对于创意写作任务,用户推荐使用 WestLake 的 dpo-laser 版本,认为其优于 llama3 等模型,而 Google 的 T5 在翻译任务中获得了认可(T5 文档)。
Perplexity AI Discord
-
Gemini 1.5 Pro 的来源限制争议:关于 Gemini 1.5 Pro 的来源限制能力存在困惑;一位用户报告可以使用超过 60 个来源,这与另一位用户被限制在 20 个的经历相冲突。这场辩论产生了一堆 GIF 链接,但没有具体的解决方案。
-
Perplexity AI 的限额设置逻辑:在探索 Perplexity 上 Opus 的限制时,共识指向 50 次额度限制,使用后 24 小时重置。AI 质量讨论聚焦于 GPT-4 实用性的主观下滑,相比之下,Librechat 和 Claude 3 Opus 等新模型获得了积极反馈。
-
Perplexity Pro 的使用困扰:关于 Perplexity Pro 功能与竞争对手的疑问浮出水面,同时还有由于滥用导致的新试用政策变化的担忧。与此同时,针对账单抱怨的用户,建议他们联系客服处理试用后扣费等问题。
-
分享频道中的技术与生活交汇:用户在分享频道交流了从最佳降噪耳机到足球界 Ronaldo-Messi 时代影响等各种话题,展示了 Perplexity AI 在涵盖技术比较和文化讨论方面的广度。
-
API 频道解读令人困惑的参数:模型页面的澄清确认系统提示(system prompts)不影响在线模型检索,而对 llama-3-sonar-large 参数数量及其实际上下文长度的质疑也浮出水面。在定制化 sonar 模型搜索和理解 8x7B MoE 模型架构方面出现了困难,揭示了需要更详细文档的领域。
HuggingFace Discord
AI 大满贯:新模型登场:AI 领域推出了一系列新模型,包括 Idefics2 8B Chatty、专注于编程任务的 CodeGemma 1.1,以及拥有 236B 参数的巨型模型 DeepSeek-V2。对于特定代码需求,有 IBM Granite,而对于增强的上下文窗口,我们有了 Llama 3 Gradient 4194k。
磨砺 AI 之锯:AI 爱好者应对了各种集成挑战,努力解决 LangChain with DSpy 和 LayoutLMv3 等模型的实现和效能问题,并辩论了它们相对于 BERT 等老牌模型的实际效用。他们深入研究了使用 Gradio Templates 来构建 AI 演示原型。一些人寻求关于使用 CPU 高效模型进行教学的知识,尝试了 ollama 和 llama cpp python。同时,其他人研究了用于简化重复性任务的预测性开源 AI 工具。
AI 照亮数据盲区:在 AI 数据集领域,重点在于提高透明度,典型的例子是一个关于使用 Polars 将数据集从 parquet 转换为 CSV 的 YouTube 教程。此外,一个 两分钟的 YouTube 视频 为 Multimodal AI 提供了一个简洁的比喻,阐明了 Med-Gemini 等模型的能力。
行业工具 - 增强开发者武器库:在追求自动化常规流程的过程中,一位成员分享了一篇关于使用 Langchain’s LangGraph 来增强客户支持的 文章。在扩散模型方面,建议正趋向于使用 LoRA 作为微调任务的首选方法。与此同时,视觉领域的群体拥抱了新的 adlike 库,并庆祝了 HuggingFace 目标检测指南 的增强,增加了 mAP 追踪功能。
构建未来的研究生态系统:创意社区充满了创新,如承诺提供更有组织的研究方法的 EurekAI,以及寻求 Beta 测试人员以完善其研究助手平台的 Rubik’s AI。Udio AI 的一个有趣实验展示了通过 AI 生成的新曲调,而 BIND 为在药物研发中利用蛋白质语言模型打开了大门,在 Chokyotager/BIND 提供了一个进阶的 GitHub 资源。
Eleuther Discord
-
LSTM 升级即将到来:一篇新论文介绍了一种具有指数门控和归一化的可扩展 LSTM 结构,旨在与 Transformer 模型竞争。讨论还涉及了 AdamG 优化器,该优化器声称可以实现无参数操作,引发了关于其有效性和可扩展性的辩论。
-
AlphaFold 3 破解分子密码:Google DeepMind 的 AlphaFold 3 实现了跨越式发展,预计将通过预测蛋白质、DNA 和 RNA 结构及其相互作用,大幅推动生物科学的发展。
-
残差连接中的身份危机提升性能:观察到当自适应跳跃连接(skip connections)的权重变为负值时,模型损失会出现异常改善,这引发了对相关研究或经验的征集。设置详情可在提供的 GitHub Gist 链接中找到。
-
Logits 处于悬而未决状态 - API 模型面临困境:正如一篇模型提取论文所强调的,API 模型由于 softmax 瓶颈 而无法支持 logits,这限制了某些评估技术。讨论中提到了将 lm-evaluation-harness 的
output_type进行调整作为潜在的补救措施。 -
xLSTM 抢跑代码的伦理:Algomancer 发起了一场关于在官方推出前发布自制 xLSTM 代码的对话,强调了在抢先发布中需要进行伦理考量,并区分了官方与非官方实现。
Modular (Mojo 🔥) Discord
-
Mojo 获得类和继承特性:Mojo 语言设计中引入的类(classes)和继承特性引发了辩论。社区正在讨论同时拥有具有值语义的静态、不可继承结构体(structs)以及动态可继承类的影响。
-
Python 在 Mojo 开发中的角色:Mojo 正在引起轰动,因为它正转向允许 Python 代码集成,兼具 Python 的易用性和 Mojo 的性能优势。关于 Mojo Intermediate Representation (IR) 如何增强跨多种编程语言的编译器优化,目前存在活跃的讨论。
-
优化者的探索:开发者们正密切关注 Mojo 中各种操作的性能优化。痛点包括缓慢的字符串拼接和 minbpe.mojo 的解码速度,讨论探索了潜在的解决方案,例如一个将字符串拼接效率提高 3 倍的 StringBuilder 类。
-
数据难题与方言选择:为 Mojo 中的 Dict 设计新哈希函数的必要性日益凸显,一项提案旨在启用自定义哈希函数以优化性能。此外,关于向 MLIR 进行上游贡献的想法也在讨论中,思考 Modular 的编译器进步对其他语言的影响。
-
调试风波与发布庆典:一个涉及 Mojo 标准库中
Tensor和DTypePointer使用的 Bug 触发了关于内存管理的详细讨论。与此同时,Mojo 编译器发布了一个包含 31 项外部贡献 的深夜版本,并引导用户关注后续更新的进度。
CUDA MODE Discord
动态批处理的烦恼:AI 工程师们讨论了使用 torch.compile 处理动态 Batch 形状时的困扰,这会导致过多的重新编译并影响性能。虽然通过填充(padding)到静态形状可以缓解问题,但对动态形状(特别是嵌套张量 nested tensors)的全面支持仍有待集成。
Triton 的 fp8 支持与社区仓库:根据官方 GitHub 上关于 fused attention 示例的更新,Triton 现在已包含对 fp8 的支持。社区正在推动 Triton 资源的集中化;一个新的社区驱动项目 Triton-index repository 旨在编目已发布的 kernel,并且有讨论称将专门为 Triton kernel 策划一个数据集,体现了协作开发的趋势。
CUDA 提升 GPU 熟练度的探索:一场多线程对话揭示了 CUDA 的优化历程,包括一个已合并的 pull request,用于在 CUDA 中融合 residual 和 layernorm 的前向传播,对 kernel 性能指标的分析,以及在分布式训练中管理通信开销以实现 GPU 架构最佳利用率的探索。
NHWC 张量的优化与方向之争:张量归一化方向的性能难题浮出水面,工程师们在思考:将张量从 NHWC 排列转换为 NCHW 是否比在 GPU 上使用特定于 NHWC 的算法更高效,尽管后者存在访问模式效率低下的风险。
苹果 M4 芯片抢占风头:在硬件新闻方面,苹果发布了旨在提升 iPad Pro 性能的 M4 芯片。与此同时,一位 AI 工程师强调了 “panther lake” 提供 175 TOPS 的能力,凸显了芯片性能领域的快速进步和竞争。
OpenRouter (Alex Atallah) Discord
-
情感陪伴占据 OpenRouter 模型排行榜首位:OpenRouter 用户表现出对提供情感陪伴模型的偏好,引发了通过图表可视化这一趋势的兴趣。
-
应对 OpenRouter 的延迟挑战:目前正在努力降低东南亚、澳大利亚和南非等地区 OpenRouter 用户的延迟,重点关注 edge workers 和上游供应商的全球分布。
-
AI 圈的抄袭警报:据称 ChatGPT 系统提示词泄露引发了关于模型安全以及在 API 中使用此类提示词可行性的辩论,正如一篇 Reddit 帖子中所讨论的那样。
-
审核者的困境:社区就各种 AI 审核模型的效率和局限性交换了意见,特别提到了 Llama Guard 2 和 L3 Guard。
-
HIPAA 合规性——OpenRouter 尚未达成:尽管有用户咨询,但 OpenRouter 尚未进行 HIPAA 合规性审计,也未确认 Deepseek v2 的托管服务商。
LAION Discord
-
深入研究数据集:一位新研究员正在为一项研究寻找非图像数据集,收到的建议包括 MNIST-1D 和 斯坦福大学的大型电影评论数据集,后者对他们的需求来说过于全面了。
-
推进文本生成视频技术:关于 diffusion models 在文本生成视频方面的优越性进行了生动的讨论,强调了在大规模视频数据集上进行无监督预训练的价值,并讨论了 diffusion models 理解空间关系的能力。
-
释放 Pixart Sigma 的潜力:社区成员比较了 Pixart Sigma 的效率,指出通过战略性的微调,该模型即使在内存受限的情况下,也能产生挑战 DALL-E 3 输出质量的结果。
-
工作场所自动化的未来:一篇关于 AdVon Commerce 利用 AI 生成内容削减工作岗位的报道引发了关于 AI 进步对就业(特别是内容创作角色)影响的讨论。
-
寻求开源 AI 保险工具:对汽车保险任务开源 AI 资源的寻求促使了对处理数据、分析风险和预测结果工具的需求,而另一位成员则在寻找关于机器人流程自动化 (RPA) 和桌面自动化的正式文献。
OpenInterpreter Discord
-
Ubuntu 爱好者渴望 GPT-4 的强大功能:社区对专门为 Ubuntu 定制的 Custom/System Instructions 表现出浓厚兴趣,旨在增强 GPT-4 在这一流行操作系统上的兼容性和效率。尽管没有链接具体的指令,但这种兴趣反映了 Linux 环境下对更定制化 AI 交互的需求。
-
OpenPipe.AI 受到关注;OpenInterpreter 捉弄用户:有人推荐了 OpenPipe.AI,这是一个用于高效处理 LLM 数据的工具;与此同时,一个通过 OpenInterpreter 被 rickrolled(恶作剧视频)的意外事件引发了关于 AI 生成内容不可预测性的笑声。另一位成员建议探索 py-gpt 以寻求与 OpenInterpreter 集成的可能性。
-
深入探讨硬件 DIY 和发货轶事:关于 01 设备的讨论涵盖了 500mAh LiPo 电池寿命查询、国际物流挑战(部分人选择 DIY 组装),以及如何验证预订单是否已发货。值得注意的是,01 设备能够通过 Google 和 AWS 等云端 API 连接到各种 LLM,litellm 的文档 提供了多供应商设置指南。
-
持久化功能让 OpenInterpreter 用户受益:成员们非常赞赏 OpenInterpreter 的记忆文件功能,它能在服务器关闭后保留技能,确保 LLM 不需要重新训练,这是 AI 界面中有效保留技能的关键。
-
GPT-4 性能的初步印象:一位名为 Mike.bird 的用户分享了即使在极少自定义指令的情况下使用 GPT-4 取得的成功结果,而 exposa 发现 mixtral-8x7b-instruct-v0.1.Q5_0.gguf 最符合他们的需求,这都表明了社区成员对各种模型的实际测试和采用。
LangChain AI Discord
-
寻求 AI 驱动的幻灯片大师:成员们讨论了使用 OpenAI Assistant API 创建 PowerPoint 演示文稿机器人 的潜力,并询问 RAG 或 LLM 模型 是否适合从过去的演示文稿中学习。此外,还辩论了 DSPY、Langchain/Langgraph 与使用 Azure AI Search 进行文档索引之间的兼容性。
-
解决流式传输语法问题:在
#[langserve]频道中,讨论了在 JavaScript 中将streamEvents与RemoteRunnable配合使用时遇到的问题,成员们建议检查库版本和配置,并将 bug 报告至 LangChain GitHub 仓库。 -
Langchain 项目与研究展示:
#[share-your-work]频道重点展示了一项关于 LLM 应用性能 的调查(参与可获得捐赠);介绍了利用 CrewAI 和 Langchain 的虚拟助手框架 Gianna;分享了在 Medium 上关于使用 LangGraph 增强客户服务的见解;揭示了 Athena 自主 AI 数据平台;并请求参与一项关于 AI 公司全球扩张准备情况的研究,特别是针对低资源语言。 -
招募 Beta 测试人员:发出了一项针对新型研究助手和搜索引擎的 Beta 测试邀请,提供 GPT-4 Turbo 和 Mistral Large 的访问权限,可在 Rubik’s AI Pro 获取。
-
TypeScript 讨论中的解析难题:技术讨论包括排查 TypeScript 实现中的 JsonOutputFunctionsParser 问题,以及改进自托管 Langchain 应用的 OpenAI 请求批处理和搜索优化。
LlamaIndex Discord
AI 教育进阶:LlamaIndex 和 deeplearning.ai 宣布推出一门关于创建 agentic RAG 系统的新课程,由 AI 专家 Andrew Y. Ng 推荐。工程师可以学习路由(routing)、工具使用(tool use)以及复杂的多步推理等高级概念。在此报名。
预定的学习机会:即将举行的 LlamaIndex 网络研讨会将重点介绍 OpenDevin,这是由 Cognition Labs 开发的一个开源项目,旨在充当自主 AI 工程师。该研讨会定于 太平洋时间周四上午 9 点举行,因其在简化代码编写和工程任务方面的潜力而备受关注。立即预订席位。
LlamaIndex 最新技术:LlamaIndex 的更新引入了 StructuredPlanningAgent,通过将任务分解为更小、更易于管理的子任务来增强 Agent 的任务管理能力。这一进展支持一系列 Agent worker,有望提升 ReAct 和 Function Calling 等工具的效率。探索该技术的影响。
深入探究 Agent 观察:工程师们探讨了从 ReAct Agents 中提取详细观察数据(observation data)的可行性,以及通过 PyMuPDF 利用本地 PDF 解析的方法。关于提高 LLM(大语言模型)响应的针对性和相关性,以及使用 reranking 模型优化检索系统的讨论,引发了深入的技术交流。
迈向协作式 AI:围绕多 Agent 系统(multi-agent systems)展开了活跃的思想交流,展望了 Agent 无缝协作和执行复杂任务的未来。这一概念参考了 crewai 和 autogen 等解决方案,并额外关注了 Agent 创建快照和回滚操作以增强运行的能力。
OpenAccess AI Collective (axolotl) Discord
层激活异常:讨论中发现了一个异常现象,即模型中的某一层表现出比其他层更高的数值,这引发了对神经网络行为和优化器策略影响的担忧与好奇。
LLM 训练数据差异与人类数据影响:会议指出 ChatQA 是在一种独特的数据混合物上训练的,这与大多数模型使用的 GPT-4/Claude 数据集形成对比;同时强调了使用 LIMA RP 人类数据在提高模型训练针对性方面的潜力。
发布 RefuelLLM-2:RefuelLLM-2 已经开源,它在处理“枯燥的数据任务”方面表现出色,模型权重可在 Hugging Face 上获取,详细信息已通过 Twitter 分享。
实际量化问题与 GPU 困境:有成员提出了关于创建特定语言的 LLM 以及在标准笔记本电脑上进行量化训练的问题,此外还有在 8 张 A100 GPU 上为 phi3 mini 4K/128K FFT 使用配置文件时遇到的 Cuda out of memory errors 困难,这促使大家寻找可运行的配置示例。
wandb 烦恼与梯度博弈:成员们寻求关于 Weights & Biases (wandb) 配置选项的建议,并研究了处理梯度范数爆炸问题(exploding gradient norm problem)的策略,同时权衡了 4-bit 和 8-bit 加载在效率与模型性能之间的取舍。
Interconnects (Nathan Lambert) Discord
LSTM 反击:最近的一篇 论文 讨论了扩展到数十亿参数的 LSTM,并具有指数门控(exponential gating)和矩阵内存(matrix memory)等潜在增强功能,以挑战 Transformer 的主导地位。研究中存在对对比实验缺陷和缺乏超参数调优(hyperparameter tuning)的担忧。
AI 行为蓝图揭晓:OpenAI 发布了 Model Spec 草案,旨在引导其 API 中的模型行为并实施人类反馈强化学习(RLHF),详见 Model Spec (2024/05/08)。
聊天机器人声誉备受关注:一场关于 chatgpt2-chatbot 如何对 LMsys 的公信力产生负面影响的讨论展开,暗示系统负担过重且无法拒绝请求。此外,还提出了关于 chatbotarena 在未获得 LLM 提供商许可的情况下发布数据的授权问题。
Gemini 1.5 Pro 表现出色:Gemini 1.5 Pro 因其能够准确转录播客章节并包含时间戳而受到称赞,尽管存在一些错误。
等待 Snail 的智慧:社区成员对一个似乎很重要的实体或事件(被称为 “snail”)表示期待和支持,帖子暗示大家正在等待消息并召唤特定级别的参与。
Latent Space Discord
-
寻求适用于小团队的 Glean 替代方案:在寻找适合小型组织的统一搜索工具(如 Glean)时,引发了关于开源选项 Danswer 的讨论,社区成员参考了 Hacker News 上的讨论 以获取更多见解。
-
斯坦福大学开设新课程:工程社区关注了斯坦福大学关于深度生成模型(Deep Generative Models)的新课程;这是一个值得推荐的资源,展示了该机构在 AI 教育领域的持续领导地位,由 Stefano Ermon 教授介绍:在此观看讲座。
-
高级 GPU 租赁资源:针对为短期项目获取 NVIDIA A100 或 H100 GPU 的咨询,通过 Twitter 推荐 分享了指导意见,为这一硬件需求提供了潜在解决方案。
-
利用 AI 辅助编写 PR:考虑到 AI 在编码中尚未被充分利用的效用,一位成员分享了他们用于自动化 GitHub PR 创建的脚本,标志着 AI 在简化开发者工作流中的作用:
gh pr create --title "$(glaze yaml --from-markdown /tmp/pr.md --select title)" --body "$(glaze yaml --from-markdown /tmp/pr.md --select body)" -
数据编排对话:涉及文本和嵌入(embeddings)等多种数据类型的 AI 流水线编排引发了推荐请求,表明人们对处理复杂数据流的高效 AI 系统设计有着浓厚兴趣。
tinygrad (George Hotz) Discord
Tinygrad 技术交流:重塑与教育:关于 Tinygrad 文档 中张量重塑(tensor reshaping)的讨论因过于抽象而引发批评,随后社区通过 协作说明文档 努力使该概念通俗易懂。为了提升性能,正在考虑使用编译时索引计算的高级重塑优化。
Tinygrad 的 BITCAST 得到澄清:目前正在积极理解和改进 tinygrad 中的 BITCAST 操作,如 GitHub pull request 所示,旨在简化某些操作并移除对 “bitcast=false” 等参数的需求。
机器学习概念去神秘化:一位用户表达了理解机器学习术语的困难,特别是当简单的概念被掩盖在数学术语之下时。这与社区内要求更清晰、更易于学习的材料的呼声一致。
Tinygrad 的严肃政策:@georgehotz 强化了社区准则,提醒成员论坛不适用于初级问题,不应将宝贵的时间视为理所当然。
排序 UOp 查询的工程讨论进展:辩论了 Tinygrad 操作的复杂性,例如 symbolic.DivNode 是否应接受节点操作数,这可能预示着未来将更新以改进 symbolic.arange 等操作中的递归处理。
Cohere Discord
- FP16 Model Hosting Inquiry Left Hanging: 关于 FP16 command-r-plus 模型本地托管(具有 40k 上下文窗口)的成员咨询未能获得 VRAM 需求信息。
- RWKV Model Scalability Scrutinized: 讨论质疑了 RWKV 模型 在 1-15b 参数规模下与传统 Transformer 相比的竞争力,并引用了过去的 RNN 性能问题。
- Coral Chatbot Seeks Reviewers: 一个承诺捆绑文本生成、摘要和 ReRank 的新 Coral Chatbot 正在寻求用户反馈和合作机会。请在 Streamlit 上查看。
- Elusive Cohere Chat Download Method: 用户关于如何从 Cohere Chat 以 docx 或 pdf 等格式导出文件的问题,目前还没有关于如何实现下载的具体回应。
- Wordware Charts a Fresh Course: Wordware 邀请潜在的创始团队成员使用其独特的基于 Web 的 IDE 来构建和展示 AI Agent;Prompting 是其方法的核心,类似于一种编程语言。更多信息请访问 Join Wordware。
DiscoResearch Discord
-
AIDEV Gathering Gains Attention: jp1 期待在 AIDEV 活动 中与同行会面,mjm31 也对参加活动感到兴奋,这表明了一个开放且受欢迎的社区氛围。enno_jaai 提出了关于食物供应的实际担忧,暗示了此类活动需要物流规划。
-
German Dataset Development Discourse: 关于为包容性语言量身定制 德语数据集 的对话非常活跃,成员们讨论了其重要性以及采用 system prompts 来引导助手语言的方法。
-
German Content Curation for Machine Learning: 作为开发纯德语预训练数据集的一部分,有人呼吁推荐内容质量丰富的领域,并利用 Common Crawl 数据。
-
Configurability and Inclusivity in AI: 提出了双语 AI 具有包容性和非包容性语言模式的想法,建议在语言 AI 设计中保持灵活性。对话还提到了 Vicgalle/ConfigurableBeagle-11B,这是一个展示如何将包容性纳入 AI 的模型。
-
Resources for Inclusive Language in AI Shared: 参与者讨论并分享了宝贵的资源,如 David’s Garden 和一个用于 性别包容性德语 的 GitLab 项目,反映了对增强 AI 模型中性别包容性语言理解和应用的浓厚兴趣。
Mozilla AI Discord
- Phi-3 Mini Anomalies Detected: 工程师们讨论了 Phi-3 Mini 在与 llamafile 配合使用时的异常行为,尽管它在 Ollama 和 Open WebUI 中运行良好;故障排除正在进行中。
- Backend Brilliance with Llamafile: Llamafile 可以作为后端服务运行,通过本地端点
127.0.0.1:8080响应 OpenAI 风格的请求;详细的 API 用法可以在 Mozilla-Ocho llamafile GitHub 上找到。 - VS Code Gets Ollama-Tastic: 一个值得注意的 VS Code 更新引入了一项功能,使 ollama 用户能够进行动态模型管理,有人猜测其起源是一个插件。
Datasette - LLM (@SimonW) Discord
-
A Helping Hand for Package Upgrades: 一个创新的 升级 npm 包的 AI Agent 让社区感到惊喜并表示赞同。对话中还提到了对无处不在的 Cookie 政策通知的必要回应。
-
YAML’s New Chapter in Parameterized Testing: 工程师们正在审查 llm-evals-plugin 上用于参数化测试的两个提议的 YAML 配置,记录在 GitHub issue 评论 中。对话围绕此类功能的设计选择和实用性展开。
-
Ode to the
llmCLI: 用户对llmCLI 工具表达了衷心的“感谢”,认为它简化了个人项目和学术论文的管理。用户的赞誉强调了它对工作流的价值。
Alignment Lab AI Discord
-
AlphaFold3 开源:AlphaFold3 的 PyTorch 实现现已开放,允许 AI 工程师将其应用于生物分子相互作用结构预测。Agora 社区正在征集贡献以增强模型能力;感兴趣的工程师可以通过他们的 Discord 邀请加入并查看 GitHub 上的实现。
-
随意的互动维持士气:在常规聊天中,成员们进行了随意的交流,一名用户与名为 “Orca” 的聊天机器人交换了问候。此类互动维持了技术团队内的社区感和参与度。
AI Stack Devs (Yoko Li) Discord
- 无代码游戏测试革命:Regression Games 推出了 Quickscope,这是一套专为自动化 Unity 测试设计的工具套件,无需编程知识即可设置,具有游戏录制和功能测试工具。
- 深入探索游戏状态:Quickscope 拥有一项功能,可自动收集游戏状态详情,特别是抓取 MonoBehaviours 的公共属性,在无需额外代码的情况下简化测试流程。
- 更好、更快地测试:Quickscope 平台 已面向开发者和 QA 工程师开放,承诺无缝集成到现有的开发流水线中,并强调其零代码必要的功能。
- 组队频道缺乏参与度:在 #[team-up] 频道中,jakekies 发送的一条孤立消息表达了加入意愿,这表明正在进行的讨论中参与度较低或缺乏上下文。
LLM Perf Enthusiasts AI Discord
在 Azure 中寻找 GPT-4-turbo:一位工程师正在寻找 GPT-4-turbo 0429 在 Azure 区域的可用性,特别提到了瑞典 Azure 服务的运行问题。
Skunkworks AI Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
Stability.ai (Stable Diffusion) ▷ #general-chat (737 条消息🔥🔥🔥):
- 为了效率缩小规模:一些成员建议硬件受限的用户(如配备集成显卡的笔记本电脑)考虑使用 Hyper-SD 等模型,这些模型在较少的步数上进行图像生成训练,从而可能使 CPU 使用更顺畅。
- 寻找 AI 工作的最佳硬件:用户讨论了配备更多 VRAM 的专用 GPU(如 NVIDIA 4090 或可能的 AMD Radeon RX6700 XT)相对于集成 GPU 在处理 Stable Diffusion 等 AI 任务时的性能优势。
- 在本地和云端之间做决定:关于是投资昂贵的本地 AI 硬件还是使用按小时计费的云端 GPU 服务的争论仍在继续,观点认为云服务提供的强大服务器级 GPU 成本仅为购买尖端消费级 GPU 的一小部分。
- 小规模训练 LoRA:用户确认,使用少至 30 张图像训练 LoRA 模型即可获得不错的效果,适用于特定的修改而非广泛、复杂的概念。
- 图像和视频编辑的技巧与窍门:参与者分享了从视频内容中移除背景的经验和建议,提到了用于帧提取的 ffmpeg 以及用于背景移除的 rmbg 或 rembg 扩展。
-
- Stylus: Automatic Adapter Selection for Diffusion Models:未找到描述
- Stable Cascade 示例:ComfyUI 工作流示例
- Stable Diffusion 基准测试:45 款 Nvidia、AMD 和 Intel GPU 对比:哪款显卡提供最快的 AI 性能?
- Stable Diffusion 3 现已发布!:备受期待的 SD3 终于面世了
- GitHub - Extraltodeus/sigmas_tools_and_the_golden_scheduler: 混合 sigmas 的一些节点以及一个使用 phi 的自定义调度器:混合 sigmas 的一些节点以及一个使用 phi 的自定义调度器 - Extraltodeus/sigmas_tools_and_the_golden_scheduler
- GitHub - Clybius/ComfyUI-Extra-Samplers: 额外采样器仓库,可用于 ComfyUI 中的大多数节点。:一个额外采样器仓库,可用于 ComfyUI 中的大多数节点。 - Clybius/ComfyUI-Extra-Samplers
- GitHub - PixArt-alpha/PixArt-sigma: PixArt-Σ:用于 4K 文本生成图像的 Diffusion Transformer 从弱到强训练:PixArt-Σ:用于 4K 文本生成图像的 Diffusion Transformer 从弱到强训练 - PixArt-alpha/PixArt-sigma
- GitHub - 11cafe/comfyui-workspace-manager: 一个 ComfyUI 工作流和模型管理扩展,可在一个地方组织和管理所有工作流、模型。无缝切换工作流,以及导入、导出工作流,重用子工作流,安装模型,在单个工作区中浏览模型:一个 ComfyUI 工作流和模型管理扩展,可在一个地方组织和管理所有工作流、模型。无缝切换工作流,以及导入、导出工作流,重用...
- deadman44/SDXL_Photoreal_Merged_Models · Hugging Face:未找到描述
- Hyper-SD - 比 SD Turbo 和 LCM 更好吗?:新的 Hyper-SD 模型是免费的,并且有三个 ComfyUI 工作流可以体验!使用令人惊叹的 1-step unet,或者通过使用 Lo... 来加速现有模型
- 我能只在 CPU 模式下运行它吗? · Issue #2334 · AUTOMATIC1111/stable-diffusion-webui:如果可以,你能告诉我怎么做吗?
- 新款 iPad 比以往任何时候都更奇怪:查看 Baseus 的 60w 可伸缩 USB-C 线缆 黑色:https://amzn.to/3JlVBnh,白色:https://amzn.to/3w3HqQw,紫色:https://amzn.to/3UmWSkk,蓝色:https:/...
- 如何使用 Stable Diffusion - Stable Diffusion Art:Stable Diffusion AI 是一种用于生成 AI 图像的潜扩散模型。图像可以是写实的,就像相机拍摄的一样,也可以是艺术风格的
- 来自 Jump superstars 和 Jump Ultimate stars 的像素艺术 | PixelArt AI 模型 - v2.0 | Stable Diffusion LoRA | Civitai:来自 Jump superstars 和 Jump Ultimate stars 的像素艺术 - PixelArt AI 模型。如果你喜欢这个模型,请给它一个 ❤️。这个 LoRA 模型是在 sprit... 上训练的
- Pony Diffusion V6 XL - V6 (从这个开始) | Stable Diffusion Checkpoint | Civitai:Pony Diffusion V6 是一款多功能的 SDXL 微调模型,能够生成各种类人、兽人或类人生物物种的惊人 SFW 和 NSFW 视觉效果...
提及的链接:--- **Nous Research AI ▷ #[announcements](https://discord.com/channels/1053877538025386074/1145143867818119272/1237839855111635064)** (1 条消息): - **WorldSim 回归**:**WorldSim** 已更新并修复了错误,积分和支付系统已恢复运行。新功能包括 **WorldClient**、**Root**、**Mind Meld**、**MUD**、**tableTop**,以及 **WorldSim** 和 **CLI Simulator** 的新功能,并可以从 opus、sonnet 或 haiku 中选择模型以管理成本。 - **使用 WorldClient 探索 Internet 2**:网页浏览器模拟器 **WorldClient** 允许用户探索为每个人量身定制的模拟 Internet 2。 - **Root - CLI 环境模拟器**:通过 **Root**,用户可以在 CLI 环境中模拟他们想象的任何 Linux 命令或程序。 - **用于思考实体的 Mind Meld 功能**:**Mind Meld** 让用户能够深入探索他们所能构思的任何实体的思想。 - **文本和桌面冒险的游戏模拟器**:新的 **MUD** 提供基于文本的冒险游戏体验,而 **tableTop** 提供桌面 RPG 模拟。 - **发现并讨论新的 WorldSim**:感兴趣的用户可以在 [worldsim.nousresearch.com](https://worldsim.nousresearch.com) 查看最新更新,并加入专门的 Discord 频道参与讨论。 **提到的链接**:worldsim:未找到描述 --- **Nous Research AI ▷ #[general](https://discord.com/channels/1053877538025386074/1149866623109439599/1237301348169416714)** (345 条消息🔥🔥): - **NeuralHermes 2.5 - DPO 基准测试**:新版本的 NeuralHermes,[NeuralHermes 2.5](https://huggingface.co/mlabonne/NeuralHermes-2.5-Mistral-7B),已使用 Direct Preference Optimization (DPO) 进行微调,在大多数基准测试中超过了原版。它基于 Intel 的 neural-chat-7b-v3-1 作者提出的原则,并在 Colab 和 GitHub 上提供了训练代码。 - **Nous Research 品牌详情**:对于基于 Nous Research 的项目,Logo 和排版可以从 [NOUS BRAND BOOKLET](https://nousresearch.com/wp-content/uploads/2024/03/NOUS-BRAND-BOOKLET-firstedition_1.pdf) 中获取,并且提到“Nous girl”是理想的模型 Logo。 - **探索 Azure 的 GPU 能力**:一位用户在 Azure 上配置了 2 个 NVIDIA H100 GPU 进行实验,讨论了硬件能力以及 Llama 等相关模型。 - **Llama-3 8B Instruct 1048K 上下文探索**:Hugging Face 上的 [Llama-3 8B Instruct](https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-1048k) 模型具有扩展的上下文长度,并邀请用户加入长上下文自定义 Agent 的等待名单。 - **API 和模型格式讨论**:讨论了关于 Hermes 2 Pro 8B 的可用 API、Llama 3 的首选模板(仍为 ChatML),以及针对变长序列使用 `torch.compile` 的建议(建议使用 sequence packing)。- xLSTM: Extended Long Short-Term Memory:在 20 世纪 90 年代,恒定误差传送带(constant error carousel)和门控(gating)作为长短期记忆网络(LSTM)的核心思想被引入。自那时起,LSTM 经受住了时间的考验,并为众多领域做出了贡献...
- Carson Poole 的个人网站:未找到描述
- 来自 kwindla (@kwindla) 的推文:Llama 2 70B 仅需 20GB!4-bit 量化,移除了 40% 的层,并在移除层后进行微调以“修复”。与基础 Llama 2 70B 相比,在 MMLU 上的表现几乎没有差异。这篇论文,《The Unreas...
- 无幻觉 RAG:让 LLM 在医疗保健领域更安全:LLM 有潜力彻底改变我们的医疗保健领域,但对幻觉的恐惧和现实阻碍了其在大多数应用中的采用。
- 模型规范 (2024/05/08):未找到描述
- refuelai/Llama-3-Refueled · Hugging Face:未找到描述
提到的链接:--- **Nous Research AI ▷ #[ask-about-llms](https://discord.com/channels/1053877538025386074/1154120232051408927/1237330778707333120)** (37 条消息🔥): - **Llamafiles 集成指日可待?**: 一位用户询问了为 Nous 模型创建 llamafiles 的事宜,并提供了一个指向 GitHub 上 [Mozilla-Ocho's llamafile](https://github.com/Mozilla-Ocho/llamafile) 的链接,强调了在 llamafiles 中使用外部权重的能力。该用户表示打算探索这一解决方案。 - **通过 Pretokenizing 和 Flash Attention 加速**: 一位成员指出,通过使用 **pretokenizing** 并实现 **scaled dot product (flash attention)**,训练效率得到了提升。同时也对 Torch 选择性使用 **flash attention 2** 表示了担忧。 - **变长序列的效率策略**: 在关于处理变长机器翻译句子的讨论中,一位用户支持通过 **按长度分桶(bucketing by length)并使用自定义 dataloader** 的策略,以减少填充(padding)并最大化 GPU 利用率。社区分享了将句子填充到常见 token 长度(如 80, 150, 200)的想法,以潜在地提高静态 torch 编译效率。 - **序列长度管理的权衡**: 一场关于管理机器翻译模型中序列长度的对话展开了。会议强调,在使用 **torch.compile** 时,填充(**padding**)到固定大小可能会导致效率上的权衡。 - **探索 Autoregressive Transformer 模型**: 一位成员分享了他们对 **autoregressive transformer models** 的偏好,因为它们具有通用性。进一步的讨论澄清了 autoregressive 模型通过考虑先前的输出来生成输出,使其适用于 encoder-decoder 和 decoder-only 架构。- JSON-Schema to GBNF: 未找到描述
- mlabonne/NeuralHermes-2.5-Mistral-7B · Hugging Face: 未找到描述
- Mkbhd Marques GIF - Mkbhd Marques Brownlee - 发现并分享 GIF: 点击查看 GIF
- OpenAI 高管称,目前的 ChatGPT 在 12 个月内将变得“糟糕得可笑”: OpenAI 的 COO 在 Milken Institute 小组讨论中表示,AI 将在一年内能够完成“复杂工作”并成为“伟大的队友”。
- 来自 xyzeva (@xyz3va) 的推文: 所以,这是我们为实现这一目标所做的一切:
- axolotl/docs/multipack.qmd at main · OpenAccess-AI-Collective/axolotl: 尽管提问 axolotl。通过在 GitHub 上创建账号,为 OpenAccess-AI-Collective/axolotl 的开发做出贡献。
- Jogoat GIF - Jogoat - 发现并分享 GIF: 点击查看 GIF
- Cat Hug GIF - Cat Hug Kiss - 发现并分享 GIF: 点击查看 GIF
- gradientai/Llama-3-8B-Instruct-Gradient-1048k · Hugging Face: 未找到描述
- Moti Hearts GIF - Moti Hearts - 发现并分享 GIF: 点击查看 GIF
提到的链接:--- **Nous Research AI ▷ #[project-obsidian](https://discord.com/channels/1053877538025386074/1156472202619781140/1237582106897547296)** (1 条消息): - **NanoLLaVA 尝试已放弃**:一位参与者提到他们**放弃了**使用 **nanoLLaVA**,因为在 Raspberry Pi 上运行困难;他们计划改用 **moondream2 结合 LLM**。关于使用 nanoLLaVA 的具体问题或错误信息并未提及。 --- **Nous Research AI ▷ #[bittensor-finetune-subnet](https://discord.com/channels/1053877538025386074/1213221029359657021/1237369136129118219)** (11 messages🔥): - **Miner 仓库提交卡住**:一位新 Miner 提到,他们提交到 **bittensor-finetune-subnet** 的仓库已经数小时未被 validators 下载。该问题与一个待处理的 pull request (PR) 有关,需要合并该 PR 才能解决网络问题。 - **等待关键 PR 合并**:一名成员确认**网络已损坏**,在他们正在处理的 PR 合并之前,新提交将保持不可用状态。他们澄清说,由于自己不是审核或合并这些 PR 的人,因此无法控制时间表。 - **解决时间表不确定**:在回答有关问题何时能解决的询问时,一名成员含糊地表示 PR 将**“很快”**合并,但未提供具体时间表。 - **由于网络问题验证停止**:澄清了在上述 PR 合并之前,新的提交将不会被验证,这表明网络当前状态阻碍了此过程。 - **寻找 Subnet GraphQL 服务**:有人询问在哪里可以找到 **bittensor subnets 的 GraphQL 服务**,这表明用户正在寻找与 bittensor 相关的其他工具或接口。 --- **Nous Research AI ▷ #[rag-dataset](https://discord.com/channels/1053877538025386074/1218682416827207801/1237577066203971594)** (4 messages): - **关于 Chatbots 的晨间思考**:一位成员讨论了 **goodgpt2** 的功能,探索了 *agent schema* 的使用,并注意到该 chatbot 似乎在极少引导的情况下,利用来自 **ChatArena** 的结构化历史记录运行。 - **带有历史记录的对话**:同一位用户提到了在**标签上进行 ID 追踪**的想法,这可以揭示与 chatbot 的整个对话历史,强调了无缝的用户体验。 - **ChatGPT 的身份**:有推测认为正在交互的 ChatGPT 可能是一个 Agent 版本而非普通的 chatbot,可能指的是以 **GPT-2** 作为底层模型。 - **深入 Persona Schema**:该用户纠正了之前的说法,澄清他们要求的是 *persona schema*,并评论说这是由 chatbot 结构化历史中的另外两个查询所启发的。 --- **Nous Research AI ▷ #[world-sim](https://discord.com/channels/1053877538025386074/1221910674347786261/1237420771329048687)** (93 messages🔥🔥): - **World-Sim 角色与信息查询已回复**:一位用户询问什么是 **world-sim** 以及在哪里可以找到更多信息。他们被引导查看特定的置顶帖子以获取详细信息:参见 <#1236442921050308649>。 - **Claude 作为自我提升的容器**:一位用户分享了他们的观点,认为(越狱后的)Claude 充当了自我提升的容器,将 **world_sim** 用于他们所描述的*灵魂的交互式调试*。 - **机器人的火人节?**:人们对“BURNINGROBOT”节日的想法感到兴奋,这模仿了 **BURNINGMAN**,旨在展示用户在使用 **Nous Research** 产品时的作品和体验。 - **恢复 BETA 对话**:在一系列互动中,用户了解到 **BETA chats** 不会被存储且无法恢复,这在一位用户询问重新加载 worldsim 对话时被重点提及。 - **World-Sim 功能讨论**:用户讨论了 world-sim 的各个方面,包括更换模型和理解积分系统。一位用户被告知,目前在初始免费额度用完后需要购买积分。 **提及的链接**:New Conversation - Eigengrau Rain:未找到描述 --- **OpenAI ▷ #[annnouncements](https://discord.com/channels/974519864045756446/977259063052234752/1237420491518771331)** (2 messages): - **OpenAI 对数据管理的看法**:OpenAI 讨论了他们在 AI 领域关于内容和数据的原则。他们在详细的[博客文章](https://openai.com/index/approach-to-data-and-ai)中概述了其方法。 - **介绍 OpenAI 的 Model Spec**:OpenAI 旨在通过分享其 Model Spec 来促进关于理想 AI 模型行为的对话。该文档可以在他们最新的[公告](https://openai.com/index/introducing-the-model-spec)中找到。 --- **OpenAI ▷ #[ai-discussions](https://discord.com/channels/974519864045756446/998381918976479273/1237329113212256266)** (305 messages🔥🔥): - **展望未来创新**:一场讨论强调了对 **GPT-5** 的期待,表达了对即将推出的功能和性能改进的兴趣,肯定了对 AI 研发的持续投入。 - **再见沙鼠机器人,你好 Rosie?**:在轻松的闲聊中,有人提出了一个异想天开的想法,想象一个**拥有“荒谬小单轮”的 OpenAI 机器人**;一位成员幻想着“一只极其微小的沙鼠机器人跑在一个看起来非常酷的轮子上”。 - **探索本地模型选项**:对话围绕 **LM Studio**、**Llama8b** 以及 **Ollama with Llama3 8B** 在 8GB VRAM 机器上的适用性展开;参与者讨论了他们使用这些模型的经验,强调了易用性和资源需求。 - **寻求指导,获取见解**:用户寻求信息并分享了关于 **GPT prompt library**(现更名为 _#1019652163640762428_)等资源的建议,以及通过 [OpenAI Community](https://community.openai.com) 和 [Arstechnica](https://arstechnica.com) 等平台关注 AI 趋势的见解。 - **OpenAI Chat GPT 模型辩论**:关于 OpenAI GPT 模型的性能和历史背景展开了一场漫长的辩论,对比了 **GPT-4** 与来自“竞技场 (Arena)”的其他 AI 模型,并对 OpenAI 的创新方法和风险管理发表了看法。- 未找到标题: 未找到描述
- xFormers 优化算子 | xFormers 0.0.27 文档: xFormers 的 API 文档。xFormers 是一个用于可组合且优化的 Transformer 模块的 PyTorch 扩展库。
- GitHub - Mozilla-Ocho/llamafile: 通过单个文件分发和运行 LLM。: 通过单个文件分发和运行 LLM。通过在 GitHub 上创建账号,为 Mozilla-Ocho/llamafile 的开发做出贡献。
提到的链接:--- **OpenAI ▷ #[gpt-4-discussions](https://discord.com/channels/974519864045756446/1001151820170801244/1237551702282862592)** (7 条消息): - **记忆功能困惑**:一位成员表达了挫败感,称 **GPT-4** 表现不佳,因为其记忆功能导致了错误。另一位成员指出可以[关闭记忆功能](https://help.openai.com/en/articles/6825453-chatgpt-memory-a-guide)。 - **拒绝管理员职级**:针对协助解决记忆问题而收到的称赞,一位用户澄清说,尽管其乐于助人的行为得到了认可,但他们拒绝承担 **mod/admin rank**(版主/管理员职级)。 - **语言支持咨询**:一位用户询问 GPT-4 是否像支持 Markdown 一样原生理解 GraphQL,表明了对该模型处理不同语言能力的兴趣。 - **同义词编辑怪癖**:有人提出了一个关于 **ChatGPT** 的问题,即它在脚本中始终将“friend”一词替换为“buddy”,尽管尝试提供了明确的相反上下文。该用户正在寻求防止这种词汇更改的解决方案。 --- **OpenAI ▷ #[prompt-engineering](https://discord.com/channels/974519864045756446/1046317269069864970/1237317496751788073)** (30 条消息🔥): - **提示词过于复杂**:建议一位成员将复杂任务拆分为多个 API 调用,并指出不应要求单个 API 调用执行诸如以 CSV 格式输出之类的任务。进一步的指导包括一个示例,其中将多个步骤用于视觉任务、分析和格式化。*[这对一个提示词来说太多了。](https://discord.com/channels/)(*未提供具体链接*) - **DALL-E 的负面提示词困境**:用户讨论了 **DALL-E 3** 在处理负面提示词(Negative Prompt)方面的困难;它倾向于包含被要求省略的元素,建议专注于正面细节会产生更好的结果。分享经验有助于了解其局限性并[改进使用方法](https://discord.com/channels/)(*未提供具体链接*)。 - **寻找照片级真实感的人像**:一位用户咨询了如何在使用 AI 生成人像时获得照片级真实感的结果,并指出了生成结果中存在的艺术感痕迹。对话指向了一个[独立的讨论频道](https://discord.com/channels/)(*未提供具体链接*)以获取进一步帮助。 - **输出模板与 Logit Bias**:针对 AI 生成输出不一致的问题,建议使用清晰的输出模板,并考虑使用 Logit Bias 来控制随机元素,不过后者需要通过[提供的链接](https://help.openai.com/en/articles/5247780-using-logit-bias-to-alter-token-probability-with-the-openai-api)复核相关流程。 - **大文档对比的挑战**:一位用户询问了对比 250 页大型文档的策略。讨论指出,目前的 OpenAI 技术处理此类任务的能力有限,建议使用更强大的 AI 或基于 Python 的解决方案。 --- **OpenAI ▷ #[api-discussions](https://discord.com/channels/974519864045756446/1046317269069864970/1237317496751788073)** (30 messages🔥): - **提示词改进策略分享**:成员们讨论了如何创建更好的 System Prompts,强调将**复杂任务分解为多个 API 调用**,并确保像 **DALL-E** 这样的图像生成提示词清晰且不包含可能混淆模型的负面指令。其中一个例子是 [AIempower 的 Step back prompting](https://aiempower.com) 策略。 - **DALL-E 负面提示词(Negative Prompting)的挑战**:成员们观察到 **DALL-E 3 API** 在遵循包含“不要包含 X”等负面指令的提示词时存在困难。建议是避开负面提示词,并从 OpenAI 相关频道的资深用户那里获取更多技巧。 - **输出格式不一致**:一位成员就输出不一致以及响应中出现随机项目符号的问题寻求帮助。建议使用带有固定变量名的可靠输出模板,并应用 Logit Bias 来提高一致性。 - **对比大型文本文档**:关于对比两个 250 页的大型文档以查找细微变化的问题,讨论指出**当前的 OpenAI 实现不适合此类大规模对比**,这意味着需要不同的工具或 Python 解决方案。 - **提示词工程(Prompt Engineering)课程咨询**:有人询问了提示词工程课程对提升求职竞争力的有效性,但由于 OpenAI 的政策,未提供具体建议。 - **AI 伦理实践与提示词工程示例**:分享了一个全面的提示词模板,用于生成关于商业中 AI 伦理考量的讨论。它作为一个提示词工程示例,整合了包容性变量、指令以及 AI 中的伦理关注点。 --- **Unsloth AI (Daniel Han) ▷ #[general](https://discord.com/channels/1179035537009545276/1179035537529643040/1237298142756606005)** (108 messages🔥🔥): - **推理受基座模型(Base Model)训练的影响**:讨论集中在基座模型训练是否会影响推理结果。观点认为,仅在非对话特定数据(如 *Book Pile 数据集*)上训练的 **Base Models** 在遵循指令任务中可能表现不佳。使用对话数据进行 Fine-tuning 可能需要大量示例,且具有挑战性。 - **关于使用 PDF 进行微调(Fine-tuning)和训练的咨询**:一位成员询问了如何使用 Unsloth 对长篇 PDF 进行语言模型微调的资源或教程。他们被引导至一个关于使用个人数据集微调语言模型的 [YouTube 指南](https://www.youtube.com/watch?v=T1ps611iG1A)。 - **模型微调结果的差异**:对不同版本的 **Llama3 coder 模型** 进行对比后发现了差异;v1 在 Few-shot 较少的情况下提供了令人满意的结果,而 v2 则表现挣扎。这引发了关于数据集选择的影响以及 **Llama.cpp** 潜在问题的讨论。 - **Phi-3.8b 和 14b 模型发布讨论**:关于 **Phi-3.8b** 和 **14b** 模型状态的对话,成员们推测其完成和发布情况。官僚流程和内部审查被提及为这些模型延迟发布的可能原因。 - **关于模型评估和提示词的疑虑**:有人询问了如何使用 **HellaSwag** 评估像 Phi-3 这样的模型,以及如何为此类评估寻找好的提示词。回复表示不确定,凸显了围绕 LLM 的提示词工程和评估所面临的挑战。- Say What? Chat With RTX Brings Custom Chatbot to NVIDIA RTX AI PCs:新的技术演示让任何拥有 NVIDIA RTX GPU 的人都能拥有个性化 GPT 聊天机器人的能力,并在其 Windows PC 上本地运行。
- Meta AI:使用 Meta AI 助手完成任务,免费创建 AI 生成的图像,并获得任何问题的答案。Meta AI 基于 Meta 最新的 Llama 大语言模型构建,并使用 Emu...
- 未找到标题:未找到描述
- Ars Technica:为技术人员服务十余年。IT 新闻、评论和分析。
- OpenAI Developer Forum:提问并获取使用 OpenAI 平台进行构建的帮助
- Say What? Chat With RTX Brings Custom Chatbot to NVIDIA RTX AI PCs:新的技术演示让任何拥有 NVIDIA RTX GPU 的人都能拥有个性化 GPT 聊天机器人的能力,并在其 Windows PC 上本地运行。
- 未找到标题:未找到描述
Links mentioned:--- **Unsloth AI (Daniel Han) ▷ #[random](https://discord.com/channels/1179035537009545276/1179039861576056922/1237465479312965662)** (13 messages🔥): - **神秘来源查询**:一名成员询问一张图片的来源,推测它可能来自某部 *manwha*(韩国漫画)。 - **创作者揭晓**:一名成员澄清他们创作了引发讨论的图片,并补充说明这是由 AI 生成的。 - **表情符号反应说明了一切**:对话中包含了一个极具表现力的表情符号反应,象征着某种失望或事物的终结。 - **酷似《进击的巨人》**:一名成员观察到 AI 生成的面孔让他们想起了动画《进击的巨人》中的角色艾伦(Eren)。 - **OpenAI 与 Stack Overflow 合作引发热议**:频道中分享了一个 [Reddit 帖子](https://www.reddit.com/r/ChatGPT/comments/1cm9afd/this_is_big_openai_just_announed_they_are/),讨论 OpenAI 宣布与 Stack Overflow 合作,将其作为 Large Language Models (LLM) 的数据库。 - **预见 ChatGPT 的回应怪癖**:成员们幽默地预想 ChatGPT 可能会以典型的程序员方式回答,包括“‘因重复而关闭’”或告诫人们“去读文档”。 - **内容枯竭担忧**:一名成员链接了一篇 [Business Insider 文章](https://www.businessinsider.com/ai-companies-hiring-highly-educated-writers-train-ai-models-2024-4),讨论了关于 AI 到 2026 年可能会耗尽可供学习的人类内容的担忧。- cognitivecomputations/Dolphin-2.9.1-Phi-3-Kensho-4.5B · Hugging Face: 未找到描述
- Granite Code Models - ibm-granite 集合: 未找到描述
- mahiatlinux (Maheswar KK): 未找到描述
- 我如何为我的时事通讯微调 Llama 3:完整指南: 在今天的视频中,我将分享我如何利用我的时事通讯来微调 Llama 3 模型,以便使用创新的开源...更好地起草未来的内容。
- Issues · unslothai/unsloth: 以 2-5 倍的速度和减少 80% 的内存微调 Llama 3、Mistral 和 Gemma LLM - Issues · unslothai/unsloth
- ibm-granite/granite-8b-code-instruct · Hugging Face: 未找到描述
- Google Colab: 未找到描述
提到的链接:--- **Unsloth AI (Daniel Han) ▷ #[help](https://discord.com/channels/1179035537009545276/1179777624986357780/1237323119807692861)** (194 messages🔥🔥): - **模板混淆与训练数据丢失**:讨论表明,导致模型行为出现问题的可能是 **模板问题** 而非正则表达式问题。用户分享了经验并推测了原因,引用了 [ggerganov/llama.cpp 的 Issue #7062](https://github.com/ggerganov/llama.cpp/issues/7062),指出在使用 LORA Adapter 转换为 GGUF 时可能存在训练数据丢失。 - **为 8B 模型寻找合适的服务器**:一位用户询问了运行 8B 模型的服务器推荐,但在随后的讨论中没有提供具体的建议。 - **探索 CPU 使用与多 GPU 支持**:有人询问了在 Unsloth 中 **利用 CPU 进行微调** 以及 **多 GPU 功能** 的情况。会议指出 Unsloth 目前不支持多 GPU 训练,但该功能似乎正在“开发中”。 - **Unsloth 与微调量化**:关于使用 Unsloth 为分类任务 **微调生成模型**,以及 Unsloth 是否支持量化感知训练的问题,突显了目前的局限性和能力。回答指出某些量化是可能的,但不支持 GPTQ,并 **建议在 16bit 训练中使用 `load_in_4bit = False`**,以避免在 `q8` 中看到的质量下降。 - **安装与本地测试的挑战**:一些用户在**本地安装 Unsloth** 时遇到问题,导致库运行失败,特别是 **Triton 依赖问题**以及关于在没有 CUDA 的情况下运行模型的咨询。对话中提到参考 Kaggle 安装说明作为潜在的解决方案。- 零工正在为 AI 学习编写文章:随着在线数据宝库的枯竭,公司越来越多地聘请熟练的人员为 AI 模型编写训练内容。
- Reddit - 深入探索:未找到描述
提及的链接:--- **Unsloth AI (Daniel Han) ▷ #[showcase](https://discord.com/channels/1179035537009545276/1179779344894263297/1237407485648699402)** (18 条消息🔥): - **为 IPO 成功的开源论文做贡献**:邀请参与一篇关于使用机器学习预测 IPO 成功的**开源论文**,涵盖从文献综述到结果的各个部分,[可供协作](https://edopedrocchi.github.io/RicercaMente/Projects/IPO/indexIPO.html)。 - **Llama AI 模型更新**:宣布推出 **Llama-3-8B-Instruct-Coder-v2**,这是一个在精炼数据集上训练的改进版 AI 模型,承诺性能优于之前的版本。可在 [Hugging Face](https://huggingface.co/rombodawg/Llama-3-8B-Instruct-Coder-v2) 上找到。 - **寻求反馈**:一位成员分享了对网页设计工具的反馈,建议使用更直接的标语,并考虑其对具有一定技术背景的创作者的适用性。 - **创作者间的信任度量**:正在讨论一个旨在衡量观众与内容创作者之间信任度的模型,暗示了用户参与度分析的潜在合作机会。 - **Llama-3-11.5B-Instruct-Coder 发布**:推出了一款新的扩展规模 AI 模型 **Llama-3-11.5B-Instruct-Coder-v2**,该模型采用了创新的 Qalore 方法,以实现训练期间高效的 VRAM 使用。更多细节及训练所用的数据集可在 [Hugging Face](https://huggingface.co/rombodawg/Llama-3-11.5B-Instruct-Coder-v2) 上获取。- Supervised Fine-tuning Trainer:未找到描述
- Supervised Fine-tuning Trainer:未找到描述
- Google Colab:未找到描述
- Home:以 2-5 倍的速度和减少 80% 的内存微调 Llama 3, Mistral & Gemma LLM - unslothai/unsloth
- Apple Silicon Support · Issue #4 · unslothai/unsloth:很棒的项目。希望能看到对 Apple Silicon 的支持!
- Supervised Fine-tuning Trainer:未找到描述
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory:以 2-5 倍的速度和减少 80% 的内存微调 Llama 3, Mistral & Gemma LLM - unslothai/unsloth
- Google Colab:未找到描述
- Google Colab:未找到描述
- Cooking GIF - Cooking Cook - Discover & Share GIFs:点击查看 GIF
- Google Colab:未找到描述
- Google Colab:未找到描述
- llama3-instruct models not stopping at stop token · Issue #3759 · ollama/ollama:问题是什么?我正在通过 OpenAI 兼容端点使用 llama3:70b。生成时,我得到了如下输出:请提供上述命令的输出。让我们继续...
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp:我正在运行 Unsloth 在 llama3-8b 上微调 LORA Instruct 模型。1:我将带有 LORA Adapter 的模型合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理...
- Trainer:未找到描述
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp:我正在运行 Unsloth 在 llama3-8b 上微调 LORA Instruct 模型。1:我将带有 LORA Adapter 的模型合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理...
提及的链接:--- **LM Studio ▷ #[💬-general](https://discord.com/channels/1110598183144399058/1110598183144399061/1237332404151123988)** (112 条消息🔥🔥): - **溢出策略可能无法解决 Token 限制问题**:关于溢出策略和 Token 限制问题的讨论,一名成员提到,在达到默认 Token 限制时,将溢出设置为保留 System Prompt 并不能解决问题。另一名成员分享了类似的经历,暗示这可能是一个普遍问题。 - **模型加载的挫折与解决方案**:多名成员在 LM Studio 中加载 AI 模型时遇到问题,错误消息指向潜在的 VRAM 或系统 RAM 限制。建议通过禁用 GPU 加速或确保正确的模型文件夹结构等方案来解决这些问题。 - **Granite 与 Deepseek AI 模型对比**:一名成员指出了 [IBM Research 新发布的 Granite-34B-Code-Instruct](https://huggingface.co/ibm-granite/granite-34b-code-instruct) 与现有的 Deepseek-Coder-33B-Instruct 模型之间有趣的对比。随后的讨论中未提供结论性的对比结果。 - **寻求聊天 UI 的灵活性**:成员们表示需要 LM Studio 提供更好的 UI 配置,例如防止 AI 文本生成期间的自动滚动,以及设置浅色模式以获得更好的可访问性。 - **AI 聊天的 API 和移动端界面**:成员们讨论了在 LM Studio 中使用基于 Web 和移动端友好型 UI 与 AI 模型聊天的可能性,确认可以通过 API 访问此类功能,并建议使用运行在 Docker 容器中的响应式 UI(如 AnythingLLM)。- PREDICT IPO USING MACHINE LEARNING:一个开源项目,旨在通过多年来发表的科学研究追踪数据科学的历史。
- rombodawg/Llama-3-8B-Instruct-Coder-v2 · Hugging Face:未找到描述
- rombodawg/Llama-3-11.5B-Instruct-Coder-v2 · Hugging Face:未找到描述
提及的链接:--- **LM Studio ▷ #[🤖-models-discussion-chat](https://discord.com/channels/1110598183144399058/1111649100518133842/1237372746044805130)** (21 条消息🔥): - **WestLake 在创意写作中脱颖而出**:一位用户推荐将 **WestLake**(尤其是 *dpo-laser* 版本)用于创意写作任务,称其表现优于 **Llama3**。另一位用户肯定了这一推荐,并指出有显著改进。 - **寻找理想的翻译模型**:建议将 **Llama3** 和 **Command R** 用于多语言支持和文本翻译,其中一位用户表示更倾向于专门为翻译构建的开源模型。**Google 的 T5** 模型在 Hugging Face 上有详细的文档说明,被推荐作为翻译任务的专业选择。 [  ](https://huggingface.co/models?filter=t5) - **Command R Plus 问题频发**:用户报告了 **Command R+** 的问题,指出旧版本运行良好,但最新版本遇到了严重的性能问题。有人指出,等待 LM Studio 更新可能会解决这些问题。 - **等待 Llama.cpp 对 Granite 的支持**:一位用户询问 **Granite** 何时能获得支持。另一名成员回答说,这取决于 Llama.cpp 主分支中 `mlp_bias` Tokenizer 问题的解决情况。 - **寻找微型 MoE 模型**:一位用户询问是否有人使用过像 **Qwen1.5-MoE-A2.7B** 这样较小的 Mixture of Experts (MoE) 模型的经验,并对一个尚未被 llama.cpp 支持的 Snowflake 模型表示感兴趣,同时分享了他们对名为 `psychoorca` 的模型平庸的使用体验。 **提到的链接**:T5:未找到描述 --- **LM Studio ▷ #[🧠-feedback](https://discord.com/channels/1110598183144399058/1113937247520170084/1237320853079851009)** (12 条消息🔥): - **LM Studio 中空闲 RAM 报告错误**:一名成员注意到他们的 Linux (Ubuntu) 机器上存在差异,LM Studio 报告仅有 **33.07KB 的空闲 RAM**,而机器实际上有 20GB 空闲。此问题可能指向该工具内存报告机制中的一个 Bug。 - **故障排除前的版本验证**:面对上述 RAM 误报问题,另一名成员询问 Ubuntu 版本是否为最新,怀疑过时的库可能是原因。该成员澄清他们指的是 Ubuntu 版本,而非 LM Studio 版本。 - **禁用 GPU Offloading 解决模型运行问题**:有建议称在设置中禁用 GPU Offloading;执行此操作后,原成员确认运行 *Meta Llama 3 instruct 7B* 模型已成功。 - **Discord 频道中访问 Linux Beta 的指南**:为了获得 Linux beta 身份组及 Discord 上相关频道的访问权限,一名成员指导另一名成员通过 Discord 界面左上角的“Channels & Roles”部分进行申请。这似乎是讨论平台特定问题的必要步骤。 - **LM Studio 的演进**:一位成员回顾了他们使用 LM Studio 的历程,评论它如何从早期的令人*沮丧*转变为现在的*无忧 AI 体验*,展示了随着时间的推移所实现的改进和易用性。 --- **LM Studio ▷ #[📝-prompts-discussion-chat](https://discord.com/channels/1110598183144399058/1120489168687087708/1237349691478507560)** (2 条消息): - **以幽默的方式承认偏见**:一位成员幽默地调侃了自己的偏见,将其与 Large Language Models (LLMs) 进行了轻松的类比,并配以表情符号表示玩笑。 - **AI 能力的错觉**:同一位成员的另一条消息反思了不要高估 AI 能力的难度,以及人们是多么容易被误导去过度解读它们。 --- **LM Studio ▷ #[⚙-configs-discussion](https://discord.com/channels/1110598183144399058/1136793122941190258/1237326788602892320)** (38 条消息🔥): - **llava-phi-3-mini 的图像描述混乱**:用户遇到 **llava-phi-3-mini** 模型不描述上传的图像,而是描述来自 Unsplash 的随机图像的问题,这一点已通过 Markdown 文件中提供的链接得到证实。该问题在默认和 phi-3 提示词模板下均存在,一位用户发现切换到 **Bunny Llama 3 8B V** 后解决了问题。 - **视觉模型在第一张图像后失效**:多名用户报告视觉模型仅对第一张图像有效,随后便会失败,直到系统重新加载。这似乎是一个影响所有视觉模型(包括 **ollama**)的后端更新问题。 - **Llama.cpp 服务器问题讨论**:链接了一个 GitHub issue ([#7060](https://github.com/ggerganov/llama.cpp/issues/7060)),讨论了 **llamacpp server** 在第一次推理后输出无效的问题,这可能解释了用户在图像处理模型中面临的问题。 - **Yi 30B Q4 模型的性能之谜**:一位用户可以加载 VRAM 占用较高的 **Yi 30B Q4** 模型,但 CPU 和 GPU 利用率极低且性能糟糕,这与使用较小模型时形成鲜明对比。讨论指向了系统瓶颈,特别是 GPU 和 RAM 容量,以及关于 **LLM inference engines** 工作原理的知识空白。 - **系统瓶颈与推理引擎行为**:讨论明确了 LLM inference engines 是内存读取密集型的,像 **30B Q4** 这样的大型模型出现的性能问题可能是由于从 CPU 到 RAM 以及磁盘交换 (disk swap) 操作导致的减速,这些操作比 VRAM 慢几个数量级。 **提到的链接**:llava 1.5 invalid output after first inference (llamacpp server) · Issue #7060 · ggerganov/llama.cpp: I use this server config: "host": "0.0.0.0", "port": 8085, "api_key": "api_key", "models": [ { "model": "models/phi3_mini_mod... --- **LM Studio ▷ #[🎛-hardware-discussion](https://discord.com/channels/1110598183144399058/1153759714082033735/1237385021317320775)** (68 条消息🔥🔥): - **Apple M4 芯片引发关注**:Apple 发布了 AI 能力大幅提升的 M4 芯片,引发了成员们对其性能是否能超越其他大公司 AI 芯片的讨论。详情见文章:[Apple announces new M4 chip](https://www.msn.com/en-us/lifestyle/shopping/apple-announces-new-m4-chip/ar-BB1lYkba)。 - **用于 LLM 的 GPU 潜在组合**:一位成员考虑使用 GTX 1060 和 Intel HD 600 来运行语言模型,但只能释放 500MB VRAM 和 5-10% 的利用率。 - **明智选择,建议采用双系统策略**:针对同时使用消费级和企业级 GPU 的讨论,有人建议采用双系统(dual-boot)设置:在 Linux 上使用旧版 Nvidia 驱动进行推理,而在 Windows 上使用最新驱动进行游戏。 - **运行大语言模型的硬件选择**:成员分享的经验表明,在本地运行 *mixtral 8x22b* 等模型所需的硬件远超预算级配置,或者建议租用云服务。同时,有用户建议在预算有限的情况下,使用配备多个 P40 GPU 的旧企业级服务器作为可能的解决方案。 - **Apple 设备中的 Neural Engine 受到质疑**:关于 Apple 的 Neural Engine 对语言模型效用的疑问浮出水面,一位成员质疑其相关性。目前的共识似乎是它在这方面可能没有任何益处。- OpenAI API Endpoints | Open WebUI:在本教程中,我们将演示如何使用环境变量配置多个 OpenAI(或兼容)API 端点。此设置允许您在不同的 API 提供商之间轻松切换...
- LLaMA 3 UNCENSORED 🥸 It Answers ANY Question:探索并测试 LLaMA 3 Dolphin 2.9 无限制版* 参与赢取 RABBIT R1:https://gleam.io/qPGLl/newsletter-signup 租用 GPU (MassedCompute) 🚀https://bit....
- ibm-granite/granite-34b-code-instruct · Hugging Face:未找到描述
提及的链接:--- **LM Studio ▷ #[🧪-beta-releases-chat](https://discord.com/channels/1110598183144399058/1166577236325965844/1237379779834151002)** (41 条消息🔥): - **令人困惑的错误,未提供线索**:用户报告了在使用视觉模型时出现错误,但错误消息仅显示了系统规格,没有任何明确的错误代码或信息。这似乎发生在处理视觉模型的图像时。 - **停滞的首页令寻找模型的人感到沮丧**:用户对无法刷新 LM Studio 内容以直接从首页发现和下载最新的 LLM 模型表示沮丧。官方澄清首页是静态的,不反映可用模型的实时更新。 - **视觉模型反复崩溃**:一名用户报告了在使用视觉模型时发生崩溃,并指出模型在崩溃后似乎没有完全卸载,可能导致后续加载出现问题。他们还发现每次都必须重启模型以避免错误的响应。 - **为 Bug 修复投票**:用户讨论了视觉模型提供错误后续响应的异常行为,并建议这可能是一个 Bug。分享了一个 Discord 线程链接,供用户报告并补充该问题的说明:`<https://discord.com/channels/1110598183144399058/1236217728684134431>`。 - **观察到模型性能不一致**:一位用户观察到,在视觉模型给出第一次成功的响应后,随后的任何响应都会变得无关或错误。对话暗示了视觉模型在处理上下文和后续查询方面可能存在问题。 --- **LM Studio ▷ #[autogen](https://discord.com/channels/1110598183144399058/1167546228813336686/1237478807653585057)** (1 条消息): - **AutoGen Studio 的 Bug 警报**:一位成员提到了一个关于 **AutoGen Studio** 的 Bug,并表示 **AutoGen Studio** 官方已确认。 --- **LM Studio ▷ #[langchain](https://discord.com/channels/1110598183144399058/1167546793656062063/1237362821969477683)** (2 条消息): - **LMStudioJS SDK 即将到来**:一位成员提到使用 **lmstudiojs sdk** 进行 JavaScript 解决方案,并期待即将到来的 **langchain** 集成。 --- **LM Studio ▷ #[amd-rocm-tech-preview](https://discord.com/channels/1110598183144399058/1195858490338594866/1237550993235902505)** (3 条消息): - **Windows 上的 ROCm 意外情况**:一位用户讲述了通过设置环境变量 **HSA_OVERRIDE_GFX_VERSION=1.3.0**,在 Windows 上成功在 RX 6600 上运行带有 ROCm 的 LMStudio,并最初报告运行良好。 - **意外使用了 OpenCL**:同一位成员随后意识到,尽管设置了 ROCm,系统实际上使用的是 OpenCL,并惊讶地表示:“噢不,它正在使用 OpenCL 🤔”。 - **环境变量说明**:另一位成员指出,ROCm 在 Windows 上并不使用环境变量 **HSA_OVERRIDE_GFX_VERSION**,这表明初始报告中可能存在误解或错误。 --- **LM Studio ▷ #[crew-ai](https://discord.com/channels/1110598183144399058/1197374792668545034/1237363118376620072)** (1 messages): - **关于 GPT-Engineer 设置的咨询**:一名成员表示有兴趣了解如何将 **gpt-engineer** 与 **LM Studio** 配合使用,并询问自定义提示词(custom prompting)是否为设置过程的一部分。目前尚未提供具体的设置细节。 --- **LM Studio ▷ #[🛠-dev-chat](https://discord.com/channels/1110598183144399058/1234988891153629205/1237359547811889205)** (18 messages🔥): - **LM Studio API 集成**:一位用户成功将 LM Studio API 集成到其自定义 UI 中,并对新加入的支持表示兴奋。 - **LM Studio 的并发挑战**:多位成员报告了 **LM Studio** 在处理并发 embedding 请求时出现的问题,导致响应无法返回。一位用户在 [GitHub 上的 lmstudio-bug-tracker](https://github.com/lmstudio-ai/lmstudio-bug-tracker/issues/7) 记录了该问题。 - **SDK 文档中缺失 Embeddings 内容**:用户讨论了 **LM Studio SDK** 中缺乏关于 embeddings 的文档。对话强调,对于希望生成 embeddings 的用户,目前没有 SDK 指南。 - **编程式对话交互请求**:一位用户询问是否能以编程方式与 LM Studio 中的现有对话进行交互,**Yagilb** 承认了这一限制,并表示该功能目前正在考虑中。- MSN: 未找到描述
- 如何在我的 Ubuntu 22.04 上选择正确的 Nvidia 驱动以同时支持 Geforce 3080Ti 和 Tesla P40?:看起来 P40 需要不带“-open”后缀的驱动,而 3080Ti 需要带“-open”的驱动……应该安装哪个驱动?是否可以在同一台机器上同时支持 Geforce 3080Ti 和 Tesla P40...
提及的链接:--- **Perplexity AI ▷ #[general](https://discord.com/channels/1047197230748151888/1047649527299055688/1237306602525294593)** (222 messages🔥🔥): - **关于来源限制提升的困惑**:用户对名为 Gemini 1.5 pro 的服务增加来源限制感到困惑。虽然一位用户指出他们现在可以在一条消息中使用超过 60 个来源,但另一位用户反驳称限制仍为 20 个,这引发了争论,且讨论中更多是发送 GIF 而非具体信息。 - **寻找关于 Opus 限制的信息**:讨论集中在 Perplexity 上名为 Opus 的服务限制上,成员们分享了关于限制变化的经验。据一位用户称,目前限制设定为 50 次,重置机制为每次额度使用后的 24 小时。 - **关于 AI 质量的辩论**:用户对不同的 AI 工具和平台发表了多种看法,对 GPT-4 等服务答案质量下降的感知表示沮丧。相比之下,其他人分享了在替代平台和模型(如 Librechat 和 Claude 3 Opus)上的积极体验。 - **关于 Perplexity Pro 和试用的咨询**:成员们询问了 Perplexity Pro 与其他服务相比的功能和优势,以及免费试用或折扣的可用性。一位用户指出由于滥用,试用政策发生了变化,而另一位用户提供了一个提供 Pro 折扣的推荐链接。 - **客户支持相关问题**:面临 Pro 订阅计费问题的用户寻求指导,建议联系 Perplexity 的支持邮箱,以解决在使用过期日期不明的试用券后出现的意外扣费等问题。- 并发 embeddings 请求导致请求挂起 · Issue #7 · lmstudio-ai/lmstudio-bug-tracker:在开启请求队列的情况下进行并发请求时,许多请求完全没有返回响应。只有少数请求返回了响应。这很可能是 r... 的问题。
- GitHub - lmstudio-ai/lmstudio-bug-tracker: LM Studio 桌面应用程序的 Bug 追踪:LM Studio 桌面应用程序的 Bug 追踪 - lmstudio-ai/lmstudio-bug-tracker
提及的链接:- AlphaFold 为 Folding@home 开启新机遇 – Folding@home:未找到描述
- Discord 不希望你这样做...:你知道你拥有权利吗?Discord 知道,而且他们已经帮你“解决”了这个问题。因为在 Discord 冗长乏味的服务条款中,...
- Scooby Doo 神秘机器 GIF - Scooby Doo 神秘机器卡通 - 发现并分享 GIF:点击查看 GIF
- Thistest GIF - Thistest 测试 - 发现并分享 GIF:点击查看 GIF
- Skeleton Meme GIF - 骷髅迷因 - 发现并分享 GIF:点击查看 GIF </ul> </div> --- **Perplexity AI ▷ #[sharing](https://discord.com/channels/1047197230748151888/1054944216876331118/1237336376475783188)** (29 条消息🔥): - **深入探讨降噪耳机**:用户分享了一个在 [Perplexity AI](https://www.perplexity.ai/search/Best-noisecancelling-headphones-KSxIWdaaQjOaK2W_iKArjg) 上探索最佳降噪耳机的链接,展示了该平台提供详细对比和见解的能力。 - **绘制冰川历史地图**:一位成员通过追问找到了一篇关于黄石公园冰川化历史的详细技术文章,突显了 [Perplexity AI](https://www.perplexity.ai/search/Show-me-maps-_XYiIowPTF6rL3fAX6B01g) 所提供信息的深度。 - **分析这个——分离乳清蛋白对比**:一个分享的链接请求对三种分离乳清蛋白产品进行分析,展示了 Perplexity AI 在[比较复杂产品数据](https://www.perplexity.ai/search/vRq20MG4Q..ETzPyTdnuOA#1)方面的能力。 - **足球宿敌成为焦点**:一位用户链接到了 [Perplexity AI](https://www.perplexity.ai/search/RonaldoMessi-era-saYR_Z7MSleIh00PKvBHNg) 上关于足球界 C罗-梅西时代的对话,这可能表明了该平台对他们对这项运动影响的讨论。 - **探究双相情感障碍**:分享的关于双相情感障碍的 [Perplexity AI 链接](https://www.perplexity.ai/search/what-is-bipolar-pRB2VE1MS_GBFb0ayqbM9A)表明成员们正在使用该平台来了解复杂的心理健康状况。 --- **Perplexity AI ▷ #[pplx-api](https://discord.com/channels/1047197230748151888/1161802929053909012/1237311804250525697)** (11 条消息🔥): - **新模型指南的明确说明**:[模型页面](https://docs.perplexity.ai/docs/model-cards)已更新,指出在在线模型中,system prompts 不会影响检索过程,因为查询和响应生成组件是分离的。 - **模型参数困惑**:关于 `llama-3-sonar-large` 模型的 **Parameter Count** 以及实际的 **Context Length** 仍存在困惑,后者似乎更接近 10,000 tokens,而非列表显示的 28-32k tokens。 - **特定网站搜索难题**:一位用户在指示 **sonar 模型**将搜索结果限制在特定网站(如 *scholar.google.com*)时遇到困难,并注意到输出存在不一致性。 - **模型基础查询**:有一段简短的交流质疑系统是否确实使用 **llama** 作为基础,随后澄清所涉及的模型是 **llama-3 fine tunes**。 - **理解模型架构**:一位用户询问了对模型架构的正确理解,对 **8x7B parameter counts** 表示不确定,并澄清这些模型是像 **Mixtral** 这样的 MoE 架构,但不完全是 Llama。 **提到的链接**:支持的模型:未找到描述 --- **HuggingFace ▷ #[announcements](https://discord.com/channels/879548962464493619/897387888663232554/1237881433037733979)** (1 条消息): - **新模型密集发布**:AI 社区迎来了一波新模型热潮,包括针对聊天优化的 **[Idefics2 8B Chatty](https://twitter.com/sanhestpasmoi/status/1787503160757485609)**、提升了编码能力的 7B 参数模型 **[CodeGemma 1.1](https://twitter.com/reach_vb/status/1786469104678760677)**,以及拥有 236B 巨量参数的 **[DeepSeek-V2](https://huggingface.co/deepseek-ai/DeepSeek-V2)**。其他亮点还包括 **[IBM Granite](https://huggingface.co/collections/ibm-granite/granite-code-models-6624c5cec322e4c148c8b330)** 代码模型系列、具有扩展上下文窗口的 **[Llama 3 Gradient 4194k](https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-4194k)**、基于浏览器的 **[Phi 3](https://www.reddit.com/r/LocalLLaMA/comments/1cn2zwn/phi3_webgpu_a_private_and_powerful_ai_chatbot/)**、Google 的时间序列模型 **[TimesFM](https://huggingface.co/google/timesfm-1.0-200m)** 以及 Apple 的 **[OpenELM](https://huggingface.co/apple/OpenELM)**。 - **通过量化技术进阶**:与 Andrew Ng 合作推出了 **[Quantization in Depth](https://www.deeplearning.ai/short-courses/quantization-in-depth/)**,这是一门专注于模型优化的全新短期课程。 - **快速 AI 原型构建**:**[Gradio Templates](https://twitter.com/evilpingwin/status/1786049350210097249)** 简化了聊天机器人等 AI Demo 的托管流程,只需点击几次即可完成。 - **免费计算机视觉课程**:一门*社区驱动的计算机视觉课程*已 **[免费开放](https://huggingface.co/learn)**,旨在扩展该领域的知识。 - **机器人与说话人日志新库**:最先进的机器人库 **[LeRobot](https://github.com/huggingface/lerobot)** 以及用于微调说话人日志(Speaker Diarization)模型的 **[diarizers](https://github.com/huggingface/diarizers)** 的发布,标志着实际 AI 应用方面的进步。 --- **HuggingFace ▷ #[general](https://discord.com/channels/879548962464493619/879548962464493622/1237322933693583360)** (198 messages🔥🔥): - **探索模型实现与兼容性**:用户讨论了各种模型的集成,如 **LangChain 与 DSpy**、**LayoutLMv3** 以及 **微调 BERT**。对话涉及集成问题的排查、Smaug-72B-LLM 的功能,以及 Mistral 或 BERT 等特定模型在基准测试和实际应用中是否优于其他模型。 - **HuggingFace 网站访问检查**:曾有短暂时刻用户询问 **HuggingFace 网站是否宕机**,但随后通过其他人的反馈迅速解决,表明这可能是个人连接问题而非全站性故障。 - **向 Transformers 添加新模型**:一次详细的交流集中在如何为 Transformers 库贡献新模型,强调了 GitHub 仓库中 **new model** issue 的作用,以及关注社交媒体上的关键影响力人物如何能捕捉趋势。 - **寻找用于教学的高效 CPU 运行模型**:一位成员寻求关于适合 CPU 实现的模型(**Chatbots 和 RAG 流水线**)的建议,得到的建议包括 *ollama*、*llama cpp python* 以及使用 HuggingFace token 通过 HF 的外部 GPU 资源实现更快执行。 - **利用 AI 解决业务需求**:一位用户表示需要**开源工具和策略**来自动化商业汽车保险领域的任务。他们寻求 AI 方法论来预测风险和结果,以及处理 PDF 和文本文件等多样化数据格式的开源解决方案。 - **旧版 Space 的 Gradio 版本担忧**:一位用户询问了 **Gradio 3.x** 版本的生命周期,因为他们精心制作的旧版 Space 的 GUI 正面临最新更新带来的兼容性问题。
- 优化微调语言模型的 GPU 利用率:全面指南:作者 🌟Muhammad Ghulam Jillani(Jillani SoftTech),高级数据科学家和机器学习工程师🧑💻
- timm/ViT-SO400M-14-SigLIP-384 · Hugging Face:未找到描述
- GitHub - Mozilla-Ocho/llamafile: 使用单个文件分发和运行 LLM。:使用单个文件分发和运行 LLM。通过在 GitHub 上创建账号来为 Mozilla-Ocho/llamafile 的开发做出贡献。
- microsoft/phi-2 · Hugging Face:未找到描述
- 一个多 Agent 游戏,LLM 必须伪装成人类互相欺骗,直到有人被识破:五款顶尖 LLM —— OpenAI 的 ChatGPT、Google Gemini、Anthropic 的 Claude、Meta 的 LLAMA 2 以及 Mistral AI 的 Mixtral 8x7B 在这场基于文本的图灵测试游戏中展开竞争...
- GitHub - Mozilla-Ocho/llamafile: 使用单个文件分发和运行 LLM。:使用单个文件分发和运行 LLM。通过在 GitHub 上创建账号来为 Mozilla-Ocho/llamafile 的开发做出贡献。
- GitHub - getumbrel/llama-gpt: 一个自托管、离线的类 ChatGPT 聊天机器人。由 Llama 2 驱动。100% 私密,数据不会离开你的设备。新增:支持 Code Llama!:一个自托管、离线的类 ChatGPT 聊天机器人。由 Llama 2 驱动。100% 私密,数据不会离开你的设备。新增:支持 Code Llama! - getumbrel/llama-gpt
- Hugging Face – 动态:未找到描述
- 什么是多模态 AI?以 Med-Gemini 为例。2 分钟了解:从高层次来看,多模态 AI 就像一把电木 (AE) 吉他。像 Gemini 这样的多模态模型可以接收多种数据类型——即模态。数据模态...
- 提升 Gemini 的多模态医疗能力:许多临床任务需要理解专业数据,如医学图像和基因组学,这在通用的多模态大模型中通常不常见。基于 Gemini...
- GitHub - PhaedrusFlow/parq2csv: 使用 Polars 将 parquet 转换为 csv 的 python 文件:使用 Polars 将 parquet 转换为 csv 的 python 文件 - PhaedrusFlow/parq2csv
- GitHub - BIDS-Xu-Lab/Me-LLaMA: 一个全新的医疗大语言模型家族,包含 13/70B 参数,在各种医疗任务上具有 SOTA 性能:一个全新的医疗大语言模型家族,包含 13/70B 参数,在各种医疗任务上具有 SOTA 性能 - BIDS-Xu-Lab/Me-LLaMA
- YBXL/MedQA_Reasoning_train · Hugging Face 数据集:未找到描述
- Polars:新时代的 DataFrames
- Streamline Customer Support with Langchain’s LangGraph:Ankush k Singal
- [PDF] Classifier-Free Diffusion Guidance | Semantic Scholar:一个利用人工智能方法提供高度相关结果和简便过滤工具的学术搜索引擎。
- [PDF] Score-Based Generative Modeling through Stochastic Differential Equations | Semantic Scholar:一个利用人工智能方法提供高度相关结果和简便过滤工具的学术搜索引擎。
- refuelai/Llama-3-Refueled · Hugging Face:未找到描述
- Python Decorators In 1 MINUTE!:在短短 1 分钟内发现 Python 装饰器的力量!这个快速教程将向你介绍装饰器的基础知识,让你能够增强你的 Python...
- Intel Real Sense Exhibit At CES 2015 | Intel:参观 CES 2015 上的 Intel Real Sense 隧道。立即在 YouTube 上订阅 Intel:https://intel.ly/3IX1bN2 关于 Intel:Intel 是全球半导体领域的领导者...
- Google Colab:未找到描述
- Illusion Diffusion Video - a Hugging Face Space by KingNish:未找到描述
- Rubik's AI - AI research assistant & Search Engine:未找到描述
- GitHub - Chokyotager/BIND: Leveraging protein-language models for virtual screening:利用蛋白质语言模型进行虚拟筛选 - Chokyotager/BIND
- GitHub - chitradrishti/adlike: 预测图像在多大程度上是广告。:Predict to what extent an Image is an Advertisement. - chitradrishti/adlike
- Object detection:未找到描述
- Maximilian Beck (@maxmbeck) 的推文: 敬请期待!🔜 #CodeRelease 💻🚀
- GitHub - nihalsid/mesh-gpt: MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers: MeshGPT: 使用 Decoder-Only Transformers 生成三角网格 - nihalsid/mesh-gpt
- xLSTM: Extended Long Short-Term Memory:在 20 世纪 90 年代,恒定误差轮转(constant error carousel)和门控机制作为长短期记忆网络(LSTM)的核心思想被引入。从那时起,LSTM 经受住了时间的考验,并为众多...
- In-Context Learning Creates Task Vectors:大语言模型(LLM)中的上下文学习(ICL)已成为一种强大的新学习范式。然而,其底层机制仍未被很好地理解。特别是,挑战在于...
- Lory: Fully Differentiable Mixture-of-Experts for Autoregressive Language Model Pre-training:混合专家(MoE)模型促进了高效的扩展;然而,训练路由网络带来了优化不可微、离散目标的挑战。最近,一种全可微的...
- Towards Stability of Parameter-free Optimization:超参数调优,特别是在自适应梯度训练方法中选择合适的学习率,仍然是一个挑战。为了应对这一挑战,在本文中,我们提出了一种新颖的...
- From Sparse to Soft Mixtures of Experts:稀疏混合专家架构(MoE)在不大幅增加训练或推理成本的情况下扩展了模型容量。尽管取得了成功,但 MoE 仍面临许多问题:训练不稳定...
- Do Llamas Work in English? On the Latent Language of Multilingual Transformers:我们探究了在不平衡、以英语为主的语料库上训练的多语言模型是否使用英语作为内部枢纽语言——这是一个对于理解语言模型如何...至关重要的问题。
- xLSTM: Extended Long Short-Term Memory:在 20 世纪 90 年代,恒定误差轮转(constant error carousel)和门控机制作为长短期记忆网络(LSTM)的核心思想被引入。从那时起,LSTM 经受住了时间的考验,并为众多...
- The mechanistic basis of data dependence and abrupt learning in an...:Transformer 模型表现出上下文学习能力:即根据输入序列中的示例准确预测对新查询的响应的能力,这与...形成对比。
- Function Vectors in Large Language Models:我们报告了一种简单的神经机制的存在,该机制在自回归 Transformer 语言模型(LM)中将输入-输出函数表示为一个向量。通过对...使用因果中介分析。
- AlphaFold 3 predicts the structure and interactions of all of life’s molecules:我们新的 AI 模型 AlphaFold 3 可以以前所未有的准确性预测所有生命分子的结构和相互作用。
- QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs:我们介绍了 QuaRot,一种基于旋转的新型量化方案,它能够对 LLM 进行端到端量化,包括所有权重、激活值和 4 位的 KV cache。QuaRot 以一种...的方式旋转 LLM。 </ul> </div> --- **Eleuther ▷ #[interpretability-general](https://discord.com/channels/729741769192767510/1052314805576400977/1237430758927368223)** (32 条消息🔥): - **残差连接变为负值**:一位成员观察到,在训练过程中,具有自适应跳跃连接(skip connections,即在每个跳跃/残差连接的恒等分量上加权)的模型在较深层显示出权重减小并变为负值。与普通模型相比,这种行为似乎改善了模型损失(loss),引发了关于减去输入表示可能产生有益效果的讨论。 - **寻求相关研究**:他们分享了恒等分量权重变为负值并提高模型性能的实验,并询问相关研究。另一位成员引用了一篇相关论文([Residual Attention Network](https://arxiv.org/pdf/2003.04887)),但该论文关注的是残差路径上的权重而非恒等路径,并且将权重限制在 > 0。 - **关于 Skip Connections 的澄清**:在关于实验设置的讨论中,澄清了该模型是一个标准的 decoder 语言模型,在标准残差连接(residual connections)上具有单个 `skip_weight`。成员提供了一个指向模型块/层(model block/layer)的 GitHub Gist 链接([GitHub 上的模型代码](https://gist.github.com/nickcdryan/08c059ec3deb3ef2aca881bdc4409631))。 - **模型配置详情**:在讨论模型设置时,指出该模型拥有 607M 参数,并在来自 HuggingFace 的 FineWeb 数据集上进行训练,没有使用 LR schedule,上下文窗口(context window)为 768。 - **备受关注的数据集和训练参数**:针对数据集大小、batch size、learning rate 和训练速度进行了提问,成员透露使用了 24 的 batch size,LR 为 6e-4,并指出在 FineWeb 数据集上 loss 下降缓慢。他们表示在其他数据集上的结果是一致的。
- train_loss (24/05/07 01:06:58):通过性能指标、预测和超参数的交互式图表发布您的模型见解。由 Nick Ryan 使用 Weights & Biases 制作。
- gist:08c059ec3deb3ef2aca881bdc4409631:GitHub Gist:即时分享代码、笔记和片段。
- Stealing Part of a Production Language Model:我们介绍了第一种模型窃取攻击,它可以从 OpenAI 的 ChatGPT 或 Google 的 PaLM-2 等黑盒生产级语言模型中提取精确且非平凡的信息。具体来说,我们的……
- Logits of API-Protected LLMs Leak Proprietary Information:大语言模型(LLMs)的商业化导致了对专有模型仅提供高级 API 访问的普遍做法。在这项工作中,我们展示了即使在保守的假设下……
- lm-evaluation-harness/lm_eval/tasks/mmlu/flan_cot_zeroshot/_mmlu_flan_cot_zeroshot_template_yaml at main · EleutherAI/lm-evaluation-harness:一个用于语言模型 few-shot 评估的框架。- EleutherAI/lm-evaluation-harness
- Python integration | Modular Docs:同时使用 Python 和 Mojo。
- 2023 LLVM Dev Mtg - (Correctly) Extending Dominance to MLIR Regions:2023 LLVM 开发者大会,演讲者:Siddharth Bhat, Jeff Niu。
- transpose | Modular Docs: transpose(input Int, y: Int) -> Symbol
- Tensor | Modular Docs: 一种拥有底层数据并以 DType 为参数的 Tensor 类型。
- mo - Overview: mo 有 49 个可用的仓库。在 GitHub 上关注他们的代码。
- Modular: Accelerating the Pace of AI: Modular Accelerated Xecution (MAX) 平台是全球唯一能为您的 AI 工作负载解锁性能、可编程性和可移植性的平台。
- mojo/proposals/inferred-parameters.md at main · modularml/mojo: Mojo 编程语言。在 GitHub 上为 modularml/mojo 的开发做出贡献。
- [Feature Request] Parameter Inference from Other Parameters · Issue #1245 · modularml/mojo: 审查 Mojo 的优先级。我已阅读路线图和优先级,并相信此请求符合优先级。您的请求是什么?Mojo 已经支持从参数中推断参数...
- basalt/basalt/utils/tensorutils.mojo at main · basalt-org/basalt: 一个用纯 Mojo 🔥 从零开始编写的机器学习框架 - basalt-org/basalt
- CodSpeed: Unmatched Performance Testing: 使用 CodSpeed 在你的 CI 流水线中自动化性能追踪。在部署前而非部署后获取精确、低方差的指标。
- no title found: no description found
- SMhasher: 哈希函数质量与速度测试
- GitHub - dimitrilw/toybox: Various data-structures and other toys implemented in Mojo🔥.: 在 Mojo🔥 中实现的各种数据结构和其他小玩具。 - dimitrilw/toybox
- [Proposal] Improve the hash module by mzaks · Pull Request #2250 · modularml/mojo: 该提案基于 #1744 中开始的讨论。
- GitHub - maniartech/mojo-stringbuilder: The mojo-stringbuilder library provides a StringBuilder class for efficient string concatenation in Mojo, offering a faster alternative to the + operator.: `mojo-stringbuilder` 库为 Mojo 提供了 `StringBuilder` 类,用于高效的字符串拼接,是 `+` 运算符的一个更快的替代方案。 - maniartech/mojo-stringbuilder
- mojo-lab/notebooks/OnlineNormSoftmax.ipynb at main · GeauxEric/mojo-lab: Mojo 语言实验。通过在 GitHub 上创建账户为 GeauxEric/mojo-lab 的开发做出贡献。
- GitHub - dorjeduck/minbpe.mojo: port of Andrjey Karpathy's minbpe to Mojo: 将 Andrej Karpathy 的 `minbpe` 移植到 Mojo。通过在 GitHub 上创建账户为 dorjeduck/minbpe.mojo 的开发做出贡献。
- compact-dict/string_dict/keys_container.mojo at main · mzaks/compact-dict: 一个在 Mojo 中快速且紧凑的 `Dict` 实现 🔥。通过在 GitHub 上创建账户为 mzaks/compact-dict 的开发做出贡献。
- [Feature Request] Unify SSO between `InlinedString` and `String` type · Issue #2467 · modularml/mojo: 审查 Mojo 的优先级。我已阅读路线图和优先级,并认为此请求符合优先级。你的请求是什么?我们目前有 https://docs.modular.com/mojo/stdlib...
- [BUG]: Weird behavior when passing a tensor as owned to a function · Issue #2591 · modularml/mojo: Bug 描述:当将 tensor 作为 owned 传递给函数,并尝试在 @parameter 函数内部(使用 simd load)进行数据的 memcpy 或打印信息时,会出现奇怪的行为...
- [stdlib] Update stdlib corresponding to 2024-05-08 nightly/mojo by JoeLoser · Pull Request #2593 · modularml/mojo: 这将使用与今天的 nightly 版本对应的内部提交更新 stdlib:mojo 2024.5.822。
- mojo/docs/changelog.md at nightly · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账户为 modularml/mojo 的开发做出贡献。
- GitHub - cuda-mode/triton-index: Cataloging released Triton kernels.: Cataloging released Triton kernels. Contribute to cuda-mode/triton-index development by creating an account on GitHub.
- triton/python/tutorials/06-fused-attention.py at main · openai/triton: Development repository for the Triton language and compiler - openai/triton
- GitHub - haileyschoelkopf/triton-index: See https://github.com/cuda-mode/triton-index/ instead!: See https://github.com/cuda-mode/triton-index/ instead! - haileyschoelkopf/triton-index
- cuda::memcpy_async: CUDA C++ 核心库
- ZeRO++: ZeRO++ 是一个建立在 ZeRO 之上的通信优化策略系统,旨在为大模型训练提供无与伦比的效率,无论规模或跨设备带宽限制如何。
- When should I use CUDA's built-in warpSize, as opposed to my own proper constant?: nvcc 设备代码可以访问内置值 warpSize,它被设置为执行 kernel 的设备的 warp 大小(即在可预见的未来为 32)。通常你无法区分它...
- Strangely, Matrix Multiplications Run Faster When Given "Predictable" Data!: 奇怪的是,当给定“可预测”的数据时,矩阵乘法运行得更快! - mm_weird.py
- Improve tanh derivative in backward gelu by akbariyeh · Pull Request #307 · karpathy/llm.c: 计算 tanh 的导数为 1 - tanh^2 比计算 1/(cosh^2) 更便宜。这可能不会产生可衡量的差异。
- 由 aradys 提交的“在快速入门表格中添加加速器” · Pull Request #1596 · pytorch/pytorch.github.io:创建包含以下选项的加速器下拉菜单并将其添加到快速入门表格中:Huawei Ascend、Intel Extension for PyTorch、Intel Gaudi。在之前版本部分添加命令。RFC: pytorc...
- PyTorch : 未找到描述
- 未找到标题: 未找到描述
- AI Dungeon 中有哪些不同的 AI 模型?: 未找到描述
- 未找到标题: 未找到描述
- Models - Hugging Face: 未找到描述
- Meta: Llama 3 70B Instruct by meta-llama | OpenRouter: Meta 最新的模型系列 (Llama 3) 推出了多种尺寸和版本。这个 70B 指令微调版本针对高质量对话场景进行了优化。它展示了强大的...
- Reddit - 深入探索: 未找到描述
- Reddit - 深入探索: 未找到描述
- OpenRouter: 构建与模型无关的 AI 应用
- Meet AdVon, the AI-Powered Content Monster Infecting the Media Industry:关于 AdVon Commerce 的调查,该公司是处于 USA Today 和 Sports Illustrated 丑闻核心的 AI 承包商。
- VideoPoet – Google Research:一个用于零样本(Zero-Shot)视频生成的 LLM。VideoPoet 展示了一种简单的建模方法,可以将任何自回归语言模型转换为高质量的视频生成器。
- GitHub - instructlab/community: InstructLab Community wide collaboration space including contributing, security, code of conduct, etc:InstructLab 社区范围的协作空间,包括贡献、安全、行为准则等。
- Providers | liteLLM:了解如何在 LiteLLM 上部署和调用来自不同供应商的模型
- open-interpreter/interpreter/core/computer/skills/skills.py at main · OpenInterpreter/open-interpreter:计算机的自然语言界面。通过在 GitHub 上创建账户为 OpenInterpreter/open-interpreter 的开发做出贡献。
- 与 LangServe 集成 | 🦜️🔗 Langchain:LangServe 是一个 Python 框架,旨在帮助开发者部署 LangChain runnables 和 chains。
- 接口 | 🦜️🔗 Langchain:为了尽可能简便地创建自定义 chain,我们实现了一个大多数组件都遵循的 "Runnable" 协议。
- Scaling AI Beyond English 调查:感谢您为我们关于 AI 技术支持非主流语言及扩展至非英语市场研究做出的贡献。您的见解对于帮助...非常有价值。
- LLM 应用性能:请参加这个关于 LLM(包括 chain/agent)应用性能的简短调查
- 企业级 AI 数据分析师 | AI Agent | Athena Intelligence:未找到描述
- 使用 LangChain 的 LangGraph 简化客户支持:Ankush k Singal
- Andrew Ng (@AndrewYNg) 的推文:我很高兴开启我们第一个专注于 agent 的短期课程,从由 @llama_index 的 CEO @jerryjliu0 教授的《使用 LlamaIndex 构建 Agentic RAG》开始。这涵盖了一个重要的转变...
- LlamaIndex 网络研讨会:使用 OpenDevin 构建开源代码助手 · Zoom · Luma:OpenDevin 是来自 Cognition 的 Devin 的完全开源版本 —— 一个能够自主执行复杂工程任务的自主 AI 工程师……
- OpenDevin,自主 AI 工程师:[OpenDevin](https://twitter.com/llama_index/status/1787858033412063716) 是来自 @cognition_labs 的开源自主 AI 工程师,能够执行复杂的工程任务并协作软件项目。
- StructuredPlanningAgent 增强 LlamaIndex:最新的 LlamaIndex 更新包含了 StructuredPlanningAgent,它通过将任务分解为子任务来协助 agent 进行规划,使其更易于执行。它支持 ReAct 和 Function Calling 等各种 agent worker。[了解更多](https://twitter.com/llama_index/status/1787971603936199118)。
- OpenAI & 其他 LLM API 价格计算器 - DocsBot AI:使用我们强大的免费价格计算器计算并比较使用 OpenAI, Azure, Anthropic, Llama 3, Google Gemini, Mistral 和 Cohere API 的成本。
- 知识图谱 - LlamaIndex:未找到描述
- 从零开始构建评估 - LlamaIndex:未找到描述
- Axolotl - 数据集格式:未找到描述
- 最近的 RunPod Axolotl 错误 · Issue #1596 · OpenAccess-AI-Collective/axolotl:请检查此问题之前是否已被报告。我搜索了之前的 Bug 报告,没有发现类似的报告。预期行为:我大约两天前运行了 Axolotl,当时运行正常...
- site).:Weights & Biases,机器学习开发者工具
- OpenAccess-AI-Collective/axolotl | Phorm AI 代码搜索:更快速地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI 代码搜索:更快速地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI 代码搜索:更快速地理解代码。
- 无标题:未找到描述
- Stanford CS236: Deep Generative Models I 2023 I Lecture 1 - Introduction:了解更多关于斯坦福人工智能项目的信息,请访问:https://stanford.io/ai。如需跟随课程学习,请访问课程网站...
- 我很困惑为什么有人会信任 ChatGPT 写代码 | Hacker News:未找到描述
- tinygrad/docs-legacy/reshape_without_symbolic.md at master · tinygrad/tinygrad:你喜欢 pytorch?你喜欢 micrograd?你一定会爱上 tinygrad!❤️ - tinygrad/tinygrad
- View Merges:未找到描述
- David’s Garden - 性别包容性德语:一个基准和模型:在具有性别屈折变化的语言(如本报告所述的德语)中,性别包容性语言对于实现性别平等至关重要。
- David Pomerenke / 性别包容性德语 - 一个基准和流水线 · GitLab:GitLab.com
- GitHub - kyegomez/AlphaFold3: 论文《Accurate structure prediction of biomolecular interactions with AlphaFold3》中 Alpha Fold 3 的 PyTorch 实现:论文《Accurate structure prediction of biomolecular interactions with AlphaFold3》中 Alpha Fold 3 的 PyTorch 实现 - kyegomez/AlphaFold3
- 加入 Agora Discord 服务器!:通过开源 AI 研究推动人类进步。 | 6698 名成员
- Introducing Quickscope - Automate smoke tests in Unity - May 06, 2024 - Regression Games: 了解 Quickscope,一个在 Unity 中自动化冒烟测试的工具
- Regression Games - The ultimate AI agent testing platform for Unity: 轻松为 Unity 开发用于 QA 测试的机器人。
Links mentioned:--- **HuggingFace ▷ #[today-im-learning](https://discord.com/channels/879548962464493619/898619964095860757/1237312796975300649)** (3 messages): - **AI 数据揭秘**:这段 [YouTube 视频](https://youtu.be/T-XGHgaJIPU?si=UpbB0fL-i4bixmgQ) 介绍了 AI 数据集的透明度,展示了如何将 parquet 格式的数据集转换为 csv。对话重点介绍了 **Polars** 的使用(这是一个面向性能的 pandas 替代方案),并分享了用于代码和数据集的 [GitHub 仓库](https://github.com/PhaedrusFlow/parq2csv),例如耶鲁大学的 MedQA_Reasoning 训练数据集。 - **理解多模态 AI**:一段 [两分钟的 YouTube 视频](https://youtu.be/ems_4LSpMqc?si=vfXb7J1sEy2KzoAt) 为 **Multimodal AI** 提供了一个简化的类比,将其比作演奏不同流派音乐的电木吉他。视频介绍了 **Med-Gemini** 模型,并辅以一篇关于提升多模态医疗能力的 [研究论文](https://arxiv.org/abs/2405.03162)。提及的链接:--- **HuggingFace ▷ #[cool-finds](https://discord.com/channels/879548962464493619/897390579145637909/1237377426540072970)** (5 messages): - **早安问候与部分参与**:该频道包含一系列诸如 "gm" 之类的问候,但没有实质性的讨论或链接。 - **探索客户支持自动化**:一位成员分享了一篇关于使用 **Langchain** 的 **LangGraph** 来优化客户支持的文章。该文章发表在 [AI Advances Blog](https://ai.gopubby.com/streamline-customer-support-with-langchains-langgraph-8721c250809e) 上,探讨了如何利用语言模型和图结构来增强客户交互。 - **深入研究 Diffusion Guidance**:链接了两篇关于 Denoising Diffusion Probabilistic Models (DDPM) 背景下 **classifier-based guidance** 和 **classifier-free guidance** 的论文。第一篇论文见 [Semantic Scholar - Classifier-Free Diffusion Guidance](https://www.semanticscholar.org/reader/af9f365ed86614c800f082bd8eb14be76072ad16),第二篇见 [Semantic Scholar - Score-Based Generative Modeling](https://www.semanticscholar.org/reader/633e2fbfc0b21e959a244100937c5853afca4853)。提及的链接:--- **HuggingFace ▷ #[i-made-this](https://discord.com/channels/879548962464493619/897390720388825149/1237382366578872341)** (15 条消息🔥): - **EurekAI 旨在简化研究流程**:Adityam Ghosh 宣布了 **EurekAI**,这是一款旨在彻底改变研究流程的工具,使其不再杂乱无章且令人不知所措。团队正在寻找人员进行访谈、产品演示并提供反馈。访问 [EurekAI](https://www.eurekai.tech/)。 - **Rubik's AI 寻找 Beta 测试人员**:**Rubik's AI** 背后的团队邀请参与者成为其高级研究助手和搜索引擎的 Beta 测试人员,并提供两个月的 **GPT-4 Turbo** 和 **Mistral Large** 等模型的 Premium 访问权限。感兴趣的各方可以在 [Rubik's AI](https://rubiks.ai/) 注册并使用 `RUBIX` 促销代码。 - **使用 Udio AI 进行人工智能音乐生成**:分享了一首使用 **Udio AI** 生成的新歌,展示了 AI 在音乐制作方面的能力。该歌曲可在 [YouTube](https://youtu.be/JPM1EacdpMs) 上进行反馈。 - **Twitter 上展示的实时视频生成**:分享了一个实时视频生成的演示,展示了一个以 17fps 和 1024x800 分辨率创建的视频;不过,音频没有被录制。演示可以在 [Twitter](https://twitter.com/Dan50412374/status/1787936305751748844) 上查看。 - **BIND:利用蛋白质语言模型进行药物研发**:一个名为 **BIND** 的开源工具正在利用蛋白质语言模型(Protein-Language Models)进行药物研发中的虚拟筛选,据称其性能优于传统方法。GitHub 仓库见 [Chokyotager/BIND](https://github.com/Chokyotager/BIND)。提及的链接:--- **HuggingFace ▷ #[reading-group](https://discord.com/channels/879548962464493619/1156269946427428974/1237417789673836604)** (1 条消息): 由于只提供了一条消息,没有进一步的上下文或讨论,摘要仅反映该消息内容: - **选择下一篇论文**:一名成员提到在接下来的环节中,可以讨论 **RWKV paper** 或 Facebook 的 multi-token prediction 论文。 本摘要没有可添加的链接或评论。如果提供更多消息或讨论,将进行相应总结。 --- **HuggingFace ▷ #[computer-vision](https://discord.com/channels/879548962464493619/922424143113232404/1237359615688048683)** (9 条消息🔥): - **分割任务的校准困扰**:一名成员正在寻求关于**计算分割输出的校准曲线**的帮助,并指出 `CalibrationDisplay` 仅适用于二进制整数目标。 - **人脸识别开发咨询**:另一名成员寻求关于在自己的数据集上使用 **facenet 进行迁移学习**实现人脸识别的指导,并分享了在寻找针对 facenet(而非 vgg16)的资源时遇到的困难。 - **目标检测的常规诉求**:一名用户简要提到了一个关于**交通摄像头目标检测**的项目,但未提供更多信息或上下文。 - **微调关键点检测模型**:有人正在研究**头影测量关键点检测(cephalometric keypoint detection)**,并询问是否有现成的模型可用于微调以执行关键点检测。 - **寻找图像分类训练资源**:一名用户对一个无法运行的示例表示失望,正在寻找训练**多类别图像分类模型(Multi-class Image Classification model)**的资源。 - **分享广告图像识别库**:分享了 [adlike](https://github.com/chitradrishti/adlike) 库,该库可以预测图像在多大程度上属于广告。 - **目标检测指南和脚本升级**:一名成员强调了 HuggingFace [目标检测指南](https://huggingface.co/docs/transformers/main/en/tasks/object_detection)的更新,包括在 Trainer API 中添加 mAP 指标的信息,以及支持 Trainer API 和 Accelerate 的新官方示例脚本。这些脚本有助于在自定义数据集上微调目标检测模型。提及的链接:--- **HuggingFace ▷ #[NLP](https://discord.com/channels/879548962464493619/922424173916196955/1237308433037000774)** (10 条消息🔥): - **寻求制作 PowerPoint 的聊天机器人**:有一个关于能使用 OpenAI Assistant API 生成 PowerPoint 演示文稿的聊天机器人的查询,要求具备从以前的演示文稿中学习以创建新内容的能力。同时还征求了合适的 RAG 或 LLM 模型的建议。 - **贡献困惑**:一名成员渴望为 transformer 库贡献新模型,并正在寻求关于如何选择“新模型”的指导,是参考 paperswithcodes、热门的 SOTA 模型,还是开启一个 issue 进行讨论。 - **分类器困惑与实践见解**:在讨论分类器时,一名成员解释说不同类别的概率总和应为 1。他们还赞扬了 Moritz 的分类器的有效性。 - **跨平台脚本执行的考验**:一名成员分享了在不同云平台(如 Google Colab 和 Databricks)上运行脚本的不一致体验,以及 sentence transformers 的 encode 函数在特定数据集上返回 None 的问题。 - **调试深度探讨**:成员们讨论了使用调试器单步执行代码以发现和解决潜在问题的好处,以及增加对所用库的熟悉程度。 - **模型挫败感与请求**:一名用户对 Llama 2:13b 模型在单词提取任务中的表现表示不满,并请求推荐一个更准确且可以在本地加载以获得更好结果的模型。 --- **HuggingFace ▷ #[diffusion-discussions](https://discord.com/channels/879548962464493619/1009713274113245215/1237372710145753199)** (9 条消息🔥): - **微调热潮**:一名成员询问了使用 1300 个示例的小型数据集微调 **Stable Diffusion 1.5** 以获得新风格的最佳超参数。同时征求了关于微调方法和潜在使用 **LoRA** 的建议。 - **Bias BitFit Brilliance Proposed**: 有用户建议使用 **BitFit 训练**,该技术专注于仅调整偏置项(bias terms)。这种技术可以作为模型微调的另一种选择。 - **LoRA Hailed as the Go-To**: 在回答关于微调策略的问题时,**LoRA** (Low-Rank Adaptation) 被推崇为首选方法,适用于为模型添加新风格等任务。 - **Git LFS Woes with Diffusion Models**: 一位成员在尝试运行 Diffusion Model 的训练脚本时,遇到了与 **'git lfs clone'** 被弃用相关的 **OSError**。他们寻求帮助以解决可能由于仓库未找到而导致的问题。 --- **Eleuther ▷ #[general](https://discord.com/channels/729741769192767510/729741769738158194/1237310722413826191)** (63 messages🔥🔥): - **AI Community Morning Rituals**: 每天用自定义表情符号打招呼似乎是社区成员在频道中开启新一天的惯例。 - **PEFT vs. Full Fine Tuning Debate**: 社区讨论了在 VRAM 充足的情况下,使用像 *LoRA* 这样的 **Parameter-Efficient Fine Tuning (PEFT)** 是否有意义,因为有些人发现它速度较慢。**Carsonpoole** 认为在 **PEFT** 中使用像 *bf16* 这样的混合精度可能是问题所在,而 **Sentialx** 观察到尽管可训练参数较少,但 VRAM 占用反而更高。 - **Anticipation for xLSTM**: **Algomancer** 考虑在作者正式发布之前发布自己实现的 **xLSTM**,这引发了关于抢先发布代码的伦理和实践讨论。社区成员建议明确注明这不是官方实现,并且如果作者没有表现出近期发布的意图,则无需等待。 - **Navigating Name Changes in Academia**: **Paganpegasus** 询问在结婚后更新学术平台姓氏的最佳方式,同时保留与已发表论文的链接。建议包括直接联系平台,并将旧名字作为学术别名使用。 - **Data Loading Techniques for "The Pile"**: 社区成员讨论了加载 "The Pile" 数据用于训练 AI 模型的方法。一些人建议在 Hugging Face 上寻找预处理版本,而另一些人则分享了寻找未经过预分词(pre-tokenized)的原始版本的挑战,甚至讨论了直接从源数据进行操作的困难和技术细节。提及的链接:--- **Eleuther ▷ #[research](https://discord.com/channels/729741769192767510/747850033994662000/1237313923305443348)** (131 messages🔥🔥): - **LSTM Reimagined with Scalable Techniques**: 一篇[新论文](https://arxiv.org/abs/2405.04517)通过引入指数门控(exponential gating)、归一化和改进的记忆结构,重新审视了 LSTM,将其扩展到数十亿参数规模。这些增强功能旨在减轻已知的局限性,并缩小与 Transformer 模型之间的性能差距。 - **In-Depth Discussions on Parameter-Free Optimizers**: 参与者仔细审查了一个名为 [AdamG](http://arxiv.org/abs/2405.04376) 的优化器,该优化器声称是无参数的(parameter-free),讨论重点在于其潜在的规模适用性以及与自适应方法的比较。有人提出了特定的修改建议,旨在不损害自适应性的情况下优化其功能。 - **AlphaFold 3 Unveiled by Google DeepMind**: [博客文章](https://blog.google/technology/ai/google-deepmind-isomorphic-alphafold-3-ai-model/)介绍了 Google DeepMind 和 Isomorphic Labs 开发的 AlphaFold 3,据称该模型能准确预测蛋白质、DNA、RNA 及其相互作用的结构,这可能会彻底改变生物学理解和药物研发。 - **Seeking Open-Source Tools for Insurance Automation**: 一位用户寻求关于商业汽车保险领域自动化数据处理开源工具的建议。消息中没有直接提供相关推荐。 - **Pros and Cons of Adaptive vs. Tuning-Free Optimizers**: 对话涉及了在机器学习背景下,自适应优化器与“免调优”(tuning-free)方法概念的优缺点,质疑后者是否能在没有人工调优的情况下充分处理学习率调整的复杂性。提及的链接:提及的链接:--- **Eleuther ▷ #[lm-thunderdome](https://discord.com/channels/729741769192767510/755950983669874798/1237392686739099728)** (10 messages🔥): - **API 模型对 Logits 支持的限制**:目前 API 模型不支持 Logits,最近一篇关于[模型提取(model extraction)](https://arxiv.org/abs/2403.09539)的论文表明,由于 **softmax bottleneck** 问题,无法使用 logit biases。这对 **Model Image** 或 **Model Signature** 等评估技术的影响非常显著。 - **评估框架调整**:建议在 [MMLU 的 CoT 变体](https://github.com/EleutherAI/lm-evaluation-harness/blob/main/lm_eval/tasks/mmlu/flan_cot_zeroshot/_mmlu_flan_cot_zeroshot_template_yaml)中将 `output_type` 更改为 `generate_until` 以处理生成式输出,目标是在 **lm-evaluation-harness** 中为任务集成多个“预设(presets)”。 - **在意大利语 LLM 上的实际应用**:一位成员提到尝试使用 MMLU、ARC 和 Hellas 数据集对一个意大利语 **large language model** 进行评估,并将其与 **OpenAI 的 GPT-3.5** 进行对比以评估性能差异。 - **外部模型评估的挑战**:进一步的澄清显示,**OpenAI 和其他提供商不返回 prompt/input tokens 的 logprobs**,这使得在外部评估中获取多 token 补全(multi-token completions)的 loglikelihoods 变得复杂。 - **对社区帮助的致谢**:成员们对提供的总结和解释表示感谢,强调了在外部控制的模型上运行评估的复杂性。提及的链接:--- **Modular (Mojo 🔥) ▷ #[general](https://discord.com/channels/1087530497313357884/1098713601386233997/1237326238364864522)** (90 messages🔥🔥): - **Structs、Classes 与 Mojo 语言结构**:讨论集中在 Mojo 即将推出的特性上,包括引入 classes 和继承(inheritance)的计划。一些成员认为同时拥有 structs 和 classes 是个坏主意,而另一些成员则支持它提供的灵活性。Structs 预计将是静态且不可继承的,具有值语义(value semantics),而 classes 将具有继承能力。 - **Mojo 的编译能力**:成员们好奇 Mojo 是否能像 Rust 一样编译为原生机器码和可执行文件。目前已确认 Mojo 具备这些能力,并且还可以引入 Python 运行时来评估方法。这使得 Python 代码可以在 Mojo 中被导入并运行。 - **Mojo 的 Python 集成与未来展望**:人们对 Mojo 与 Python 的集成充满期待,因为它允许运行 Python 代码,使 Mojo 成为 Python 的超集。讨论中还涉及了其他语言使用 Mojo IR 进行编译器优化的潜力,以及其他语言是否可以利用 Mojo 的编译器改进(如 Ownership 和 Borrow Checking)。 - **对性能分发的期待**:对话表达了对未来的兴奋,届时 Python 代码可以放入 Mojo 中并进行编译,以实现性能提升和更简单的二进制分发。提到了现有 Python 库与 Mojo 的集成,允许将它们编译成二进制文件并进行分发,而不需要庞大的 Python 库文件夹。 - **对 MLIR 的上游贡献**: 成员们讨论了 Modular 是否会将 MLIR 的组件贡献给上游,以及这对其他基于 MLIR 的语言的影响。一些人设想未来新语言可能会以 Mojo IR 为目标,以利用 Modular 的编译器创新。此外,有提到 Modular 打算在一次 LLVM 会议期间将一些 Dialects 贡献给上游。提到的链接:--- **Modular (Mojo 🔥) ▷ #[💬︱twitter](https://discord.com/channels/1087530497313357884/1098713626161987705/)** (1 条消息): ModularBot: 来自 *Modular*: <https://twitter.com/Modular/status/1788281021085225170> --- **Modular (Mojo 🔥) ▷ #[✍︱blog](https://discord.com/channels/1087530497313357884/1098713717509730466/1237835264311689387)** (1 条消息): - **Chris Lattner 在 Developer Voices 中讨论 Mojo**:Chris Lattner 出现在 [Developer Voices 播客](https://www.youtube.com/@DeveloperVoices)的一期节目中,讨论了 **Mojo** 的创建。访谈深入探讨了它对 Python 和非 Python 程序员的意义、性能优化以及关键性能特性。完整采访可以在 [YouTube](https://www.youtube.com/watch?v=JRcXUuQYR90) 上找到。 - **Mojo:为极致性能而生**:开发 Mojo 的主要动力是增强 GPU 的性能,并利用具有 _bfloat16_ 和 AI 扩展等特性的先进 CPU 的能力,这在[视频的 3:29 处](https://youtu.be/JRcXUuQYR90?si=ziOI5QU6iDQ4B0aI&t=209)有详细说明。其目标是使这些高性能计算元素的使用变得合理且无缝。 **提到的链接**:Modular: Developer Voices: Deep Dive with Chris Lattner on Mojo:我们正在为世界构建下一代 AI 开发者平台。查看我们的最新文章:Developer Voices: Deep Dive with Chris Lattner on Mojo --- **Modular (Mojo 🔥) ▷ #[🔥mojo](https://discord.com/channels/1087530497313357884/1151418092052815884/1237327823727886356)** (67 条消息🔥🔥): - **Mojo 语言构造函数(Constructors)说明**:Mojo 的构造函数受到了质疑,因为成员们考虑到 Mojo 缺乏类(Class)和继承特性,怀疑其必要性。解释称,构造函数是确保实例在创建时处于有效状态的一种手段,类似于 Rust 中的 `new` 函数,并有助于正确设置 Struct 属性。 - **在 Mojo 中调试 Tensor Transpose**:一位成员分享了使用 [MAX 文档参考](https://docs.modular.com/engine/reference/mojo/graph/ops/casting/transpose)在 Mojo 中实现 `transpose` 操作的细节,并重点介绍了一个 Basalt 函数,该函数提供了优化的 2D 转置以及通用的转置方法,参考 [GitHub 上的 Basalt](https://github.com/basalt-org/basalt/blob/main/basalt/utils/tensorutils.mojo#L744)。 - **功能请求讨论上升到数学层面**:在围绕 Mojo 参数推断(parameter inference)功能请求的辩论中,讨论了 `where` 子句的概念,成员们将其与数学惯例以及 Swift 等其他编程语言中的存在联系起来。一些成员发现,无论 [feature request](https://github.com/modularml/mojo/issues/1245#issuecomment-2097388163) 提出的方向如何,参数顺序都令人困惑。 - **编译时元编程探索**:社区讨论了 Mojo 在编译时元编程(compile-time meta-programming)方面的能力,确认了在编译时执行诸如计算 Fibonacci 数列等任务是可行的。然而,“副作用”(side effects)显然不被支持,这引发了关于使用 `alias` 来指示函数何时应在编译期间运行的进一步解释。 - **发现 Tensor 类型转换问题**:有报告称 Mojo 中 Tensor 的 `astype()` 方法存在异常,Tensor 在类型转换后似乎没有反映出正确的字节数。这一差异促使一名成员考虑是否针对这个涉及 8 位和 32 位 Tensor 字节数及规格的明显 Bug 提交 Issue。提到的链接:--- **Modular (Mojo 🔥) ▷ #[community-projects](https://discord.com/channels/1087530497313357884/1151418679578337311/1237629869207322644)** (14 messages🔥): - **Dict 的哈希函数障碍**:关于替换标准库 Dict 的讨论集中在目前不足的哈希函数上。[替换提案](https://github.com/modularml/mojo/pull/2250)建议允许用户提供自定义哈希函数,以提高 Dict 的性能。 - **哈希函数替换策略**:为了获得键(keys)分布良好的哈希值,建议使用 Hasher 而不是实现单独的哈希策略。这将构成可靠的标准库 Dict 的基础,其默认哈希函数将在经过类似于 [SMhasher](https://rurban.github.io/smhasher/) 的彻底测试后确定。 - **引入性能测试**:为了在标准库更改上做出明智的决策,建议使用像 [CodSpeed](https://codspeed.io) 这样的性能测试平台。通过它,可以将基准测试(benchmarks)合并到每个 PR 中,以评估对标准库性能的影响。 - **欢迎对数据结构做出贡献**:在询问 Mojo 中更多的数据结构之后,现在在 "toybox" [GitHub repository](https://github.com/dimitrilw/toybox) 中提供了一个 DisjointSet 实现以及一个利用它实现 Kruskal MST 算法的示例。鼓励对该仓库进行贡献,即使所有者正在摸索开源的学习曲线。提到的链接:--- **Modular (Mojo 🔥) ▷ #[community-blogs-vids](https://discord.com/channels/1087530497313357884/1151418796993683477/1237769747613876306)** (2 messages): - **Interview Lights a Recruiting Fire**: 一位成员对最近的一次访谈表达了热情,认为内容“非常火爆(pure fire)”,并将其视为招募志同道合者的有效工具。提议的策略是:“看这个视频。加入我们。” --- **Modular (Mojo 🔥) ▷ #[performance-and-benchmarks](https://discord.com/channels/1087530497313357884/1151418895417233429/1237646539254399096)** (15 messages🔥): - **Online Normalization Less Speedy on CPU**: 在 CPU 桌面端尝试为 Softmax 使用 **Online normalizer calculation** 时发现,其速度比朴素方法更慢,这与预期相反。详细信息和性能结果已在 [GitHub](https://github.com/GeauxEric/mojo-lab/blob/main/notebooks/OnlineNormSoftmax.ipynb) 的 Jupyter notebook 中提供。 - **String Concatenation in Mojo**: 一位用户注意到 Mojo 中的字符串拼接(string concatenation)比 Python 慢;通过测试代码强调了性能问题。建议进行代码分析(profile)并考虑替代的拼接策略,并参考了通过 Mojo 的 [string optimization features](https://github.com/modularml/mojo/issues/2467) 可能实现的改进。 - **Decoding Slowness in minbpe.mojo**: 一位用户在使用 **minbpe.mojo** 库时遇到了缓慢的解码性能,在 Mojo 中比 Python 和 Rust 都要慢。其他用户建议了优化技术,例如避免重复的字符串拼接以及使用优化的字典进行查找,并进一步讨论了底层字符串操作的影响。 - **StringBuilder as a Performance Hack**: 使用来自 [GitHub 仓库](https://github.com/maniartech/mojo-stringbuilder) 的 **StringBuilder** 类使字符串拼接性能提升了 3 倍。**StringBuilder** 的集成以及建议为字典查找的整数键封装专门的 **Keyable** 类,共同促进了性能的提升。 - **Anticipation for Short String Optimization**: 社区正期待 Mojo **String** 结构体中 **short string optimization** 的潜在收益,该功能正在开发中,可能对性能产生影响。用户们对该功能充满期待,并建议关注其在未来稳定版本中的进展。Links mentioned:--- **Modular (Mojo 🔥) ▷ #[nightly](https://discord.com/channels/1087530497313357884/1224434323193594059/1237464682491809904)** (45 messages🔥): - **Bug 追踪与生命周期之谜**:关于 Mojo 标准库中 `Tensor` 和 `DTypePointer` 的一个 Bug(记录在 [Issue #2591](https://github.com/modularml/mojo/issues/2591))引发了一系列深入讨论。讨论围绕内存管理的细微差别以及 Mojo 语言中对象的正确生命周期展开。 - **指针生命周期辩论**:针对 Mojo 程序中 `Tensor.data()` 的预期行为与实际行为之间的差异进行了技术思考。**lukashermann.com** 解释说,由于原始 tensor 被立即销毁,复制的指针变成了悬空指针,从而导致未定义行为。 - **生命周期延长查询**:成员们讨论了如何在函数内部使用 `_ = tensor` 来防止**过早销毁**并允许正确的数据复制。**lukashermann.com** 澄清说,为了避免在执行 `memcpy` 之前进行清理,需要延长生命周期。 - **误导性的函数名称引发笑声**:一些参与者对 Mojo 及其他地方发现的不幸命名约定感到发笑,并以 `atol` 和 `cumsum` 为例。一位成员分享了 [cumsum 函数文档的链接](https://docs.modular.com/mojo/stdlib/algorithm/reduction/cumsum)。 - **Nightly 版本发布会**:**Mojo** 编译器的 Nightly 版本发布包含了 **31 项外部贡献**,并被兴奋地宣布。鼓励用户通过提供的 [nightly release diff](https://github.com/modularml/mojo/pull/2593/files) 和 [nightly changelog](https://github.com/modularml/mojo/blob/nightly/docs/changelog.md) 链接进行更新并查看更改。提及的链接:--- **CUDA MODE ▷ #[general](https://discord.com/channels/1189498204333543425/1189498205101109300/1237624892459978842)** (23 messages🔥): - **动态形状困扰 Torch 编译器**:一位成员正在使用动态 Batch Size 预训练语言模型,这给 `torch.compile` 带来了挑战,因为它会为每个变化的形状重新编译。另一位成员建议使用 Padding 到预定义形状来缓解重新编译问题。 - **Jagged Tensors 等待 Torch.Compile 集成**: 据分享,支持 nested/jagged tensors 的 `torch.compile` 正在开发中,这将消除为了适应静态形状而填充(pad)数据的需求。在此之前,目前的最佳实践是将数据填充到最接近的预定形状。 - **Torch.compile 的磨难与考验**: 用户讨论了在序列训练中使用动态 Batch 形状时,为每个唯一的序列长度进行编译的低效性。虽然考虑了填充策略,但在处理机器翻译中变化的输入和输出序列长度时,对其可行性表示担忧。 - **Dynamic=True 的失效**: 成员们报告说,`torch.compile` 中的 `dynamic=True` 似乎并没有像预期的那样防止重新编译(recompilations),这表明该功能在处理变化的输入形状时没有帮助。 - **深入探讨 GPU 优化**: 一位成员分享了一个包含 9 部分的博客系列和 GitHub 仓库,关于优化一篇 diffusion 论文的推理(inference),详细介绍了 GPU 架构和 PyTorch 中自定义 CUDA kernels 的见解,可在 [Vrushank Desai's Blog Series](https://www.vrushankdes.ai/diffusion-inference-optimization) 和 [GitHub Repository](https://github.com/vdesai2014/inference-optimization-blog-post) 查看,亮点包括通过调制 GPU 电感啸叫来播放音乐,发布在他们的 [Twitter Thread](https://twitter.com/vrushankdes/status/1788281555288265201) 中。 **Link mentioned**: Diffusion Inference Optimization: 未找到描述 --- **CUDA MODE ▷ #[triton](https://discord.com/channels/1189498204333543425/1189607595451895918/1237586264950308934)** (10 messages🔥): - **Triton 获得 fp8 支持**: Triton 已更新以包含对 **fp8** 的支持,如 [Triton 官方 GitHub 页面](https://github.com/openai/triton/blob/main/python/tutorials/06-fused-attention.py#L67) 上的这个 fused attention 示例所示。 - **Triton Kernels 社区资源**: 受 [一篇 Twitter 帖子](https://twitter.com/haileysch__/status/1779562209372434589) 启发,一个新的 GitHub 仓库 [Triton-index](https://github.com/haileyschoelkopf/triton-index/tree/main) 已创建,用于编目社区编写的 Triton kernels。 - **创建一个社区拥有的 Triton 仓库**: 建议使 Triton 资源更具社区所有权,考虑将该计划移至 *cuda-mode* GitHub,并可能为此创建一个专门的小组。 - **已发送协作 Triton 仓库的管理员邀请**: 管理员邀请已发送,[cuda-mode Triton-index 仓库](https://github.com/cuda-mode/triton-index) 现已上线,旨在收集和展示已发布的 Triton kernels。 - **对发布 Kernels 数据集的兴趣**: 有人提议并表示有兴趣发布一个 **Triton kernels 数据集**,并强调目前的 AI(如 ChatGPT)在处理 Triton 代码示例时表现不佳。Links mentioned:--- **CUDA MODE ▷ #[torch](https://discord.com/channels/1189498204333543425/1189607750876008468/1237751205686677625)** (2 messages): - **张量归一化方向查询**: 一位成员提出了一个问题:为了归一化目的,将张量从 NHWC 置换(permute)为 NCHW 更有效,还是直接在 GPU 上使用适用于 NHWC 的算法更有效(后者可能会受到次优访问模式的影响)。 --- **CUDA MODE ▷ #[algorithms](https://discord.com/channels/1189498204333543425/1189861061151690822/)** (1 messages): andreaskoepf: xLSTM 论文已发布: https://arxiv.org/abs/2405.04517 --- **CUDA MODE ▷ #[cool-links](https://discord.com/channels/1189498204333543425/1189868872887705671/1237547237140201534)** (2 messages): - **CUTLASS 矩阵转置深度解析**:一个启发性的教程深入探讨了 NVIDIA® GPU 中的**内存拷贝优化 (memory copy optimization)**,通过[矩阵转置 (matrix transpose)](https://en.wikipedia.org/wiki/Transpose) 案例研究来使用 [CUTLASS](https://github.com/NVIDIA/cutlass/)。这项工作基于 Mark Harris 的教程,专注于**合并访问 (coalesced accesses)** 和其他无计算开销的优化技术,可在 [Colfax International](https://research.colfax-intl.com/tutorial-matrix-transpose-in-cutlass/) 查看。 - **观看 GPU 内存拷贝实战**:分享了一个没有额外上下文的视频,可在 [YouTube](https://www.youtube.com/watch?v=3gb-ZkVRemQ) 观看。 **提到的链接**:教程:CUTLASS 中的矩阵转置:本教程的目标是阐述在使用 CUTLASS 及其核心后端库 CuTe 在 NVIDIA® GPU 上编程时涉及内存拷贝的概念和技术。具体来说,我们将研究…… --- **CUDA MODE ▷ #[beginner](https://discord.com/channels/1189498204333543425/1191300313928433664/1237414278513037362)** (3 条消息): - **寻求关于 Torch Compile 与 Triton 配合使用的解答**:一名成员正在寻求关于如何为 Triton 使用 `torch.compile` 的指导,询问 `backend="inductor"` 是否是合适的选择,但讨论中尚未确认正确选项。 - **对 BetterTransformer 集成的兴趣**:消息表示有兴趣将 **BetterTransformer** (BT) 与 `torch.compile` 结合使用,并提供了一个使用 `BetterTransformer.transform(model)` 和 `torch.compile(model.model_body[0].auto_model)` 的代码片段示例,以潜在地提升基于 Encoder 的模型的性能。 --- **CUDA MODE ▷ #[jax](https://discord.com/channels/1189498204333543425/1203956655570817034/1237474982699728979)** (1 条消息): - **高效的多芯片模型训练**:一名成员分享了一篇关于在多个芯片(特别是使用 Google 的 TPU)上高效训练机器学习模型的[博客文章](https://simveit.github.io/high%20performance%20computing/multi-chip-performance/)。文章包含了一个逐层矩阵乘法的视觉示例,并推荐了用于部署 TPU 的 [Google Cloud 文档](https://github.com/ayaka14732/tpu-starter?tab=readme-ov-file#2-introduction-to-tpu)。 **提到的链接**:JAX 中的多芯片性能:我们使用的模型越大,就越有必要能够在多个芯片上进行机器学习模型的训练。在这篇博客文章中,我们将解释如何高效地使用 G... --- **CUDA MODE ▷ #[off-topic](https://discord.com/channels/1189498204333543425/1215328286503075953/1237354094784544848)** (4 条消息): - **ICLR 点名**:在另一位用户询问会议情况时,一名成员确认了他们将参加 ICLR。 - **Apple M4 芯片发布**:Apple 推出了全新的 **M4 芯片**,旨在为新款 [iPad Pro](https://www.apple.com/ipad-pro/) 提供更强的性能和效率。M4 芯片采用第二代 3 纳米技术打造,拥有每秒 38 万亿次操作的能力。 - **Panther Lake 提供更多 Tera Operations**:在讨论芯片时,一名成员指出 "Panther Lake" 提供了令人印象深刻的每秒 175 万亿次操作 (TOPS)。 **提到的链接**:Apple 推出 M4 芯片:Apple 今日发布了 M4,这是最新的 Apple 自研芯片,为全新的 iPad Pro 带来了惊人的性能。 --- **CUDA MODE ▷ #[irl-meetup](https://discord.com/channels/1189498204333543425/1218444432588800010/1237508446346285096)** (5 条消息): - **有人参加 MLSys 吗?**:一名成员询问是否有人参加即将举行的 **MLSys** 会议。 - **想去参加 MLSys**:另一名成员表示有兴趣参加 **MLSys**,但届时会在**纽约**。 - **ICLR GPU 编程活动**:在 **ICLR**,一名成员分享了 Whova 应用上列出的一个专门针对 **CUDA/GPU 编程**的活动链接:[ICLR 的 CUDA/GPU 活动](https://whova.com/portal/webapp/ticlr_202405/CommunityBoard/topic/2272770)。 - **芝加哥 CUDA 聚会**:向任何在**芝加哥**有兴趣一起看视频和编写 **CUDA 代码**的人发出了邀请。 **提到的链接**:ICLR 2024 - 第十二届国际学习表征会议 Whova 网页门户:2024 年 5 月 7 日 – 11 日,Messeplatz 1, Postfach 277, A-1021 Wien --- **CUDA MODE ▷ #[llmdotc](https://discord.com/channels/1189498204333543425/1227345713348870156/1237337899322703893)** (126 条消息🔥🔥): - **融合前向与后向 Kernel**:一个旨在通过在 CUDA 中融合 residual 和 layernorm 前向计算以提升性能的 Pull Request (PR) 已被合并。讨论重点提到了针对 NVIDIA A100 的剩余优化,包括合并 GELU、CUDA stream 改进,以及解决 cuBLASLt 和 BF16 带来的挑战。 - **分析 Kernel 性能指标**:消息讨论了在 NVIDIA kernels 之外花费的时间的重要性,指出目前只有 20% 的时间花在这些地方。GELU backward 被确定为开销最大的 kernel,并正在探索为什么 pointwise 操作没有达到峰值内存带宽。 - **在多样化 GPU 架构上进行模型训练**:对话反映了利用现代 GPU 实现最大效率的复杂性,并利用 Thrust/CUB 等抽象进行优化。人们认识到 GPU 的复杂性正在增加,高效软件抽象的必要性变得更加明显。 - **实现多尺寸 GPT-2 训练能力**:一位成员分享了启用全尺寸 GPT-2 模型训练的更新,在单台 A100 GPU 上以 12K tok/s 的速度执行 batch size 为 4 的训练。然而,4X A100 GPU 设置会减慢训练速度,导致较低的 token 速率,约为 9700 tok/s。 - **分布式训练中的通信开销**:指出缺乏梯度累积(gradient accumulation)是由于数据传输过多导致多 GPU 性能下降的原因。对话提到,未来的梯度累积和 NCCL 与 backward pass 的重叠(overlapping)应该会改善这一点。Links mentioned:--- **CUDA MODE ▷ #[oneapi](https://discord.com/channels/1189498204333543425/1233802893786746880/1237325406726787153)** (3 messages): - **新兴加速器**:PyTorch 的 GitHub 有一个开放的 [pull request](https://github.com/pytorch/pytorch.github.io/pull/1596#pullrequestreview-2041058328),用于在快速入门表中添加加速器下拉列表,其中包括 Huawei Ascend、Intel Extension for PyTorch 和 Intel Gaudi。 - **PyTorch Conference 2024 提案征集**:PyTorch Conference 2024 的提案征集现已开放,并提供早鸟注册优惠。[完整详情和指南](https://hubs.la/Q02sr1cw0)可供感兴趣的人士查阅。 - **PyTorch 2.3 发布**:最新更新 PyTorch 2.3 现在支持在 `torch.compile` 中使用*用户定义的 Triton kernels*,并为使用原生 PyTorch 训练大语言模型 (LLMs) 提供了改进。更多信息请参见其[博客文章](https://deploy-preview-1596--pytorch-dot-org-preview.netlify.app/blog/pytorch2-3/)。 - **会员招募与工具生态系统**:PyTorch 邀请用户加入适合其目标的各种会员级别,并强调了一个强大的生态系统,其中包含一套用于各个领域开发的工具。通过 **TorchScript** 和 **TorchServe** 促进了向生产环境的过渡。 - **PyTorch 拥抱云端**:主要的云平台为 PyTorch 提供了广泛的支持,展示了其在各种环境下的可扩展分布式训练和性能优化方面的就绪性和适应性。Links mentioned:--- **OpenRouter (Alex Atallah) ▷ #[app-showcase](https://discord.com/channels/1091220969173028894/1092850552192368710/1237646513283534940)** (1 条消息): - **情感陪伴类模型遥遥领先**:一位成员指出,OpenRouter 上大多数排名靠前的模型往往专注于提供情感陪伴。他们表示有兴趣通过**人们使用 OpenRouter 构建的类别图表**来可视化这一趋势。 --- **OpenRouter (Alex Atallah) ▷ #[general](https://discord.com/channels/1091220969173028894/1094454198688546826/1237407876339728396)** (115 条消息🔥🔥): - **解决 OpenRouter 的区域延迟问题**:成员们讨论了 OpenRouter 利用 **edge workers** 的情况,延迟受**上游提供商 (upstream provider)** 全球分布的影响。针对**东南亚、澳大利亚和南非**等地区的优化仍是一项持续的基础设施工作。 - **关于模型窃取和泄露的辩论**:有传闻称有人成功**“窃取”了 ChatGPT 的 system prompt**,但关于将其应用于 API 是否成功仍存在疑问。提到了一篇 [Reddit 帖子](https://www.reddit.com/r/ChatGPT/comments/177x0cs/entire_system_prompt_leaks_in_data_export/),展示了所谓的泄露内容。 - **关于 AI 审核能力的讨论**:用户交流了对各种 **AI moderation models** 的见解,共识指向其局限性和不完善性,包括讨论了 **Llama Guard 2** 和 **L3 Guard** 等具体工具。 - **HIPAA 合规性查询和提供商托管**:有人询问了 **OpenRouter 的 HIPAA 合规性**以及特定模型(如 **Deepseek v2**)的托管情况。共识是 OpenRouter 尚未通过 HIPAA 合规性审计,且在讨论时还没有提供商确认托管 Deepseek v2。 - **模型对比与越狱 (Jailbreaks)**:成员们对比了 **WizardLM-2-8x22B** 和 **Mistral 8x22b**,称赞 **WizardLM** 能更好地理解 prompt,并讨论了尝试越狱或修改模型以移除限制。有人担心固有的 **ChatGPT brainrot** 会影响 Wizard 的创造力和政治中立性。提到的链接:--- **LAION ▷ #[general](https://discord.com/channels/823813159592001537/823813160075132991/1237399868675457054)** (106 条消息🔥🔥): - **新研究人员寻求数据集建议**:一位新成员请求推荐适合研究论文的数据集,表示对用于回归或分类的文本/数值数据感兴趣,但希望避开图像分类任务。其他成员建议了诸如 [MNIST-1D](https://github.com/tomsercu/mnist1d) 和 [Stanford's Large Movie Review Dataset](https://ai.stanford.edu/~amaas/data/sentiment/) 等数据集,尽管后者被认为对于该成员的项目来说太大了。 - **关于视频扩散模型的讨论**:围绕扩散模型在最先进的文本生成视频(text-to-video)领域的主导地位展开了对话,并指出从 t2i(text-to-image)模型进行微调的优势。一位来自 Stable Diffusion 论文的作者参与了讨论,认为扩散模型因其强大的空间知识而具有优势,并分享了在大规模视频数据集上进行无监督预训练潜在益处的见解。 - **Pixart Sigma 微调讨论**:成员们讨论了微调包括 Pixart Sigma 在内的各种模型,其中一人分享了通过将 Pixart Sigma 与其他模型结合,实现了可与 DALL-E 3 输出相媲美的结果。当被问及微调期间的内存限制时,其他人表示某些技术可以辅助在现有硬件上完成该过程。 - **视频模型训练深度分析**:针对训练稳定和自回归(autoregressive)视频模型的细微差别进行了广泛交流,成员们探讨了从静态帧学习运动的机制,以及使用合成描述(synthetic captions)与其他文本监督方法之间的平衡。 - **对 AI 驱动职位取代的担忧**:分享了一篇关于 AdVon Commerce 公司的文章,描述了一名最初被雇佣撰写产品评论的作者,后来转为润色 AI 生成的内容。随着名为 MEL 的 AI 系统不断改进,它最终取代了作者,导致了失业。提到的链接:--- **LAION ▷ #[research](https://discord.com/channels/823813159592001537/824374369182416994/1237685861391532034)** (6 messages): - **寻求用于汽车保险数据处理的 AI**:一位成员询问了用于自动化商业汽车保险任务数据提取和处理的最佳**开源工具**。他们寻求使用机器学习或 AI 来分析风险、管理理赔并预测结果的方法。 - **社区礼仪提醒**:另一位成员提醒社区注意礼仪,建议不要**在多个频道重复粘贴消息**,因为这可能看起来像垃圾信息。 - **承认礼仪失当**:寻求自动化工具建议的个人为多次发布信息**道歉**,并接受了社区的反馈。 - **关于桌面自动化出版物的查询**:一位成员询问是否有关于机器人流程自动化(**RPA**)或桌面操作的**研究论文**,表明了对该主题正式文献的兴趣。 **提到的链接**:GitHub - lllyasviel/IC-Light: More relighting!:更多打光控制!通过在 GitHub 上创建账号来为 lllyasviel/IC-Light 的开发做出贡献。 --- **OpenInterpreter ▷ #[general](https://discord.com/channels/1146610656779440188/1147665339266650133/1237357351921520753)** (11 messages🔥): - **寻找适用于 GPT-4 的 Ubuntu 自定义指令**:成员们表示有兴趣获取适用于 **Ubuntu** 的 **GPT-4 自定义/系统指令(Custom/System Instructions)**,表明社区渴望获得与该操作系统兼容的优化指令集。 - **管理操作警报**:发布了一条关于某用户的通知(提到其 ID),随后立即执行了禁言该用户的管理操作。 - **推荐使用 OpenPipe.AI 处理数据**:一位成员向拥有充足数据的人推荐了 **[OpenPipe.AI](https://openpipe.ai/)**,并建议在考虑微调 AI 模型之前彻底探索 **[System Messages](https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/system-message)**。 - **对 AI 硬件及其可用性的好奇**:一位成员询问了 01 light 的功能,了解到它处于开发者预览版且开源,硬件和软件均可预订,或根据提供的文档自行构建。 **提到的链接**:OpenPipe: 为开发者提供的微调工具:将昂贵的 LLM prompts 转换为快速、廉价的微调模型。 --- **OpenInterpreter ▷ #[O1](https://discord.com/channels/1146610656779440188/1194880263122075688/1237352726510178315)** (83 条消息🔥🔥): - **01 的电池续航查询**:一位成员询问了他们新订购的 01 组装件中 500mAh LiPo 电池的续航体验。 - **等待预订发货**:用户讨论了在收到虚假发货通知的情况下,如何验证其 01 订单是否已发货;他们被引导查看频道中的置顶消息以获取更新。 - **服务器关闭后的技能持久化**:一位成员强调了内存文件的必要性,以防止在服务器关闭时需要向同一个 LLM 重新教授技能。根据 [open-interpreter 的 GitHub 仓库](https://github.com/OpenInterpreter/open-interpreter/blob/main/interpreter/core/computer/skills/skills.py),已明确技能会持久化存储在存储设备上。 - **鼓励国际 DIY 方案**:用户谈到了 01 国际运输的复杂性,一些人选择 DIY 组装并使用转运服务作为加拿大等地区的变通方案。 - **通过云端 API 将 01/OI 连接到各种 LLM**:讨论了通过 Google、AWS 等端点在云平台上将 01/OI 连接到不同模型的能力。Litellm 的文档提供了连接到多个供应商的指南,包括 OpenAI 以及 [litellm 供应商文档](https://litellm.vercel.app/docs/providers)中详述的其他供应商。提到的链接:--- **OpenInterpreter ▷ #[ai-content](https://discord.com/channels/1146610656779440188/1149229778138824765/1237532695374856222)** (10 条消息🔥): - **OpenInterpreter 意外的 Rickroll**:在 LMStudio 中将 **OpenInterpreter** 与 **thebloke/mixtral-8x7b-instruct-v0.1-gguf** 配合使用时,用户在执行一项基础任务且没有任何自定义指令的情况下,被幽默地 Rickroll 了。 - **使用 py-gpt 探索桌面 AI**:一位成员分享了 **py-gpt** 的 [GitHub 链接](https://github.com/szczyglis-dev/py-gpt),这是一个集成了各种 AI 模型的桌面 AI 助手,并对其功能以及与 OpenInterpreter 集成的潜力表示好奇。 - **GPT-4 在极少输入下表现出色**:*Mike.bird* 报告称,仅通过提供一条关于使用 YouTube 播放音乐的自定义指令,使用 **GPT-4** 就获得了良好的效果,展示了该模型在极少引导下的有效性。 - **本地模型体验结果参差不齐**:*exposa* 比较了不同的本地 AI 模型,发现 **mixtral-8x7b-instruct-v0.1.Q5_0.gguf** 最符合他们的需求,并推荐了另一位用户分享的视频作为类似工作的参考。 **提到的链接**:GitHub - szczyglis-dev/py-gpt: 由 GPT-4, GPT-4 Vision, GPT-3.5, DALL-E 3, Langchain, Llama-index 驱动的桌面 AI 助手,支持聊天、视觉、语音控制、图像生成与分析、自主 Agent、代码和命令执行、文件上传下载、语音合成与识别、联网、内存、提示词预设、插件、助手等。支持 Linux, Windows, Mac。 --- **LangChain AI ▷ #[general](https://discord.com/channels/1038097195422978059/1038097196224086148/1237307645870866482)** (49 条消息🔥): - **寻求 AI 驱动的演示文稿机器人**:一位成员询问如何使用 OpenAI Assistant API 创建一个能从之前的演示文稿中学习的 **PowerPoint 演示文稿机器人**,并征求适合此任务的 **RAG 或 LLM 模型** 建议。 - **结合工具进行优化**:出现了关于 **DSPY 与 Langchain/Langgraph** 的兼容性,以及使用 **Azure AI Search** 配合 **Langchain** 对大量文档进行索引的问题。 - **Windows 下使用 JSON 和 JQ 的困扰**:一位成员在 **Windows** 上尝试使用 **jq** 加载 JSON 数据时遇到问题,尽管该设置在 **Colab 和 Unix/Linux** 系统上运行良好。另一位成员提到可以通过 Langchain GitHub 上新的 **jsonloader** 来解决。 - **实现语义缓存并征集 Beta 测试人员**:讨论内容涵盖了在 **RAG 应用**中使用 **gptcache** 实现**语义缓存 (semantic caching)** 等话题,并呼吁 Beta 测试人员在 [Rubik's AI Pro](https://rubiks.ai/signup.php) 体验集成了 **GPT-4 Turbo** 和 **Mistral Large** 等模型的新型研究助手和搜索引擎。 - **Langchain 使用与故障排除**:用户针对各种 Langchain 相关问题提供了建议,包括涉及 **JsonOutputFunctionsParser** 和 OpenAI 批处理 (batching) 的 TypeScript 实现查询,以及自托管应用中搜索功能的优化。 **提到的链接**:Rubik's AI - AI 研究助手与搜索引擎:未找到描述 --- **LangChain AI ▷ #[langserve](https://discord.com/channels/1038097195422978059/1170024642245832774/1237404915039600762)** (13 条消息🔥): - **探索 `streamEvents` 功能**:一位成员询问 `streamEvents` 是否可以与 `RemoteRunnable` 配合使用。他们正尝试在 JavaScript 中使用该方法,这应该允许从 runnable 的内部步骤中获取事件流。 - **JavaScript 与 Python 的流式传输问题**:尽管遵循了在 `RemoteRunnable` 中使用 `streamEvents` 的建议,该成员仍遇到 JavaScript 实现向 `/stream` 而非 `/stream_events` 发送 POST 请求的问题。即便 Python 版本运行正常,该问题在 JavaScript 中依然存在。 - **指导与 Bug 报告建议**:建议该成员确保使用的是正确的库版本和配置,包括模型的参数设置。如果问题持续存在,建议在 [LangChain GitHub 仓库](https://github.com/langchain-ai/langchainjs)上提交 issue。提到的链接:--- **LangChain AI ▷ #[share-your-work](https://discord.com/channels/1038097195422978059/1038097372695236729/1237540646349181048)** (5 条消息): - **公益调查**:分享了一项关于 **LLM 应用性能**的调查,请求占用 5 分钟时间。每收到一份回复,将向联合国危机救援基金捐赠 1 美元以援助加沙,可通过[此链接](https://forms.gle/BHevMUziL1AQw872A)参与。 - **介绍 Gianna - 虚拟助手框架**:**Gianna** 是一个创新的虚拟助手框架,强调简单性和可扩展性,并由 **CrewAI** 和 **Langchain** 增强。欢迎在 [GitHub](https://github.com/marvinbraga/gianna) 上贡献代码,可通过 `pip install gianna` 进行安装。 - **探索使用 Langchain 增强客户支持**:一篇题为《使用 Langchain 的 LangGraph 简化客户支持》的文章讨论了如何利用 **LangGraph** 增强客户支持,更多见解可在 [Medium](https://ai.gopubby.com/streamline-customer-support-with-langchains-langgraph-8721c250809e) 上查看。 - **Athena 作为全自动 AI 数据 Agent 亮相**:**Athena** 是一个 AI 数据平台和 Agent,利用 **Langchain** 和 **Langgraph** 为企业提供数据工作流。其自主模式可以接收问题、制定并执行计划,提供自我修正和人机回环 (human-in-the-loop) 机制,并在 [YouTube 演示](https://www.youtube.com/watch?v=CXmwYk5Hbig)中展示。 - **全球 AI 扩张准备情况的研究请求**:邀请参与一项研究,调查 AI 公司在全球扩张方面的准备情况,特别是涉及影响数十亿人的低资源语言 (low-resource languages) 方面。调查通过 [Typeform](https://axycfhrqx9q.typeform.com/to/qL8uOac7) 进行。提到的链接:--- **LangChain AI ▷ #[tutorials](https://discord.com/channels/1038097195422978059/1077843317657706538/)** (1 messages): ntelo007: 这样做有什么好处? --- **LlamaIndex ▷ #[announcements](https://discord.com/channels/1059199217496772688/1073670729054294197/1237417884909699202)** (2 messages): - **OpenDev 网络研讨会已排期**:**OpenDevin 作者**将参加即将举行的 **LlamaIndex 网络研讨会**。这个开源工具在 GitHub 上备受关注,会议定于**太平洋时间周四上午 9 点**举行。[在此注册网络研讨会](https://lu.ma/fp0xr460)。 - **AI 教育进展**:**LlamaIndex** 在 **deeplearning.ai** 上推出了关于构建 *agentic RAG* 的新课程。该课程得到了 **Andrew Y. Ng** 的赞赏,深入探讨了 agent 的路由、工具使用和多步推理。[报名参加课程](https://www.deeplearning.ai/short-courses/building-agentic-rag-with-llamaindex)。提及的链接:--- **LlamaIndex ▷ #[blog](https://discord.com/channels/1059199217496772688/1187460979064324127/1237417690541330462)** (2 messages): ```html提及的链接:--- **OpenAccess AI Collective (axolotl) ▷ #[general](https://discord.com/channels/1104757954588196865/1104757955204743201/1237357996632444968)** (16 messages🔥): - **检测到神秘的层活动**:讨论围绕训练模型中的一个异常展开,其中**某一层表现出的数值出乎意料地高于其他层**。*c.gato* 对缺乏均匀性表示怀疑,并暗示这违背了对层激活的典型预期。 - **优化器神秘的运作方式令用户困惑**:*nruaif* 沉思道,优化器可能以“神秘且懒惰的方式”运行,暗示优化器可能会为了性能提升而专注于某一层的某些部分。 - **层数值的均匀性受到质疑**:*c.gato* 觉得层中只有一个切片具有显著高值很**奇怪**,并且不相信这可能是一种优化策略的建议。 - **对模型训练数据差异的推测**:*nruaif* 指出**大多数模型是在 GPT-4/Claude 数据集上训练的**,而 ChatQA 模型具有不同的数据源混合。 - **讨论人类数据在模型训练中的作用**:*c.gato* 提到在他们的模型中使用了大部分 LIMA RP(即人类数据),暗示了**人类数据对训练特异性的影响**。 --- **OpenAccess AI Collective (axolotl) ▷ #[other-llms](https://discord.com/channels/1104757954588196865/1104758057449308220/1237838185715732562)** (1 messages): - **RefuelLLM-2 发布**:Dhruv Bansal 宣布开源 **RefuelLLM-2**,该模型号称是“世界上处理枯燥数据任务(unsexy data tasks)的最佳大语言模型”。模型权重可在 [Hugging Face](https://huggingface.co/refuelai/Llama-3-Refueled) 上获取,更多详情在 [Twitter](https://twitter.com/BansalDhruva/status/1788251464307187980) 的帖子中公布。 --- **OpenAccess AI Collective (axolotl) ▷ #[general-help](https://discord.com/channels/1104757954588196865/1110594519226925137/1237382918037569556)** (8 messages🔥): - **请求示例仓库**:用户对示例仓库的请求最终通过 Axolotl 支持的数据集格式文档链接得到解决,该文档详细说明了取决于任务的 JSONL schema,并提供了构建自定义数据集类型的指导。 - **特定语言 LLM 查询**:一位用户表示有兴趣创建一个用于代码辅助的特定语言 LLM,目标是在没有 GPU 的普通笔记本电脑上运行。他们就微调的基础模型、最佳 Epochs、训练规模以及在量化过程中保持准确性寻求建议,并征求资源建议。 - **Mini 4K/128K FFT 的配置文件难题**:一位成员在尝试于 8 个 A100 GPU 上为 phi3 mini 4K/128K FFT 使用配置文件时遇到了 `Cuda out of memory errors`,正在寻求一个可用的配置示例。 - **渴望 H100 训练**:一位用户发布了沮丧的请求,并附带了一个 [GitHub 上的 issue](https://github.com/OpenAccess-AI-Collective/axolotl/issues/1596),内容是关于在 8x H100 上尝试训练时遇到的错误。链接的 issue 描述了与之前成功的 Axolotl 运行相比出现的行为偏差。提到的链接:--- **OpenAccess AI Collective (axolotl) ▷ #[datasets](https://discord.com/channels/1104757954588196865/1112023441386778704/1237563815541870644)** (2 messages): - **实验 Llama3**:一位成员提到他们会考虑在之前讨论过的相同数据集上测试 **llama3**。他们对看到结果表现出浓厚兴趣。 --- **OpenAccess AI Collective (axolotl) ▷ #[axolotl-help-bot](https://discord.com/channels/1104757954588196865/1225300056442409040/1237607601953439756)** (1 messages): _(无内容)_ - **关于 Axolotl 配置选项的咨询**:一位成员询问在 Axolotl 配置文件中的 `wandb_watch`、`wandb_name` 和 `wandb_log_model` 选项中应填写什么内容。消息历史中未提供进一步的上下文或回复。 --- **OpenAccess AI Collective (axolotl) ▷ #[axolotl-phorm-bot](https://discord.com/channels/1104757954588196865/1225558824501510164/1237606717546561597)** (19 messages🔥): - **寻求 wandb 配置指导**:一位成员询问如何在 Axolotl 配置文件中配置 [Weights & Biases (wandb)](https://wandb.ai/site),特别是针对 `wandb_watch`、`wandb_name` 和 `wandb_log_model` 选项,想知道具体应该输入哪些值。 - **探讨梯度问题**:讨论中包括了对 **梯度范数爆炸问题 (exploding gradient norm problem)** 的澄清请求。这是在训练深度神经网络时遇到的一种挑战,即梯度变得过大,可能导致数值不稳定和模型难以收敛。 - **决定量化精度**:对 `load_in_4bit` 和 `load_in_8bit` 进行了比较,强调 **4-bit 加载提高了显存效率**,但可能会牺牲精度;而 **8-bit** 在尺寸缩减和性能之间提供了更好的权衡,具体取决于个人的模型需求和硬件能力。提到的链接:--- **Interconnects (Nathan Lambert) ▷ #[news](https://discord.com/channels/1179127597926469703/1179128538679488533/1237631958264053780)** (5 messages): - **评估 Transformer 时代后 LSTM 的可行性**:频道成员讨论了一篇[研究论文](https://arxiv.org/abs/2405.04517),探讨了 LSTM 在扩展到数十亿参数时的表现。该研究引入了诸如指数门控(exponential gating)和带有矩阵内存的可并行化 mLSTM 等改进,旨在面对占主导地位的 Transformer 模型时增强 LSTM 的生命力。 - **对研究图表的审美欣赏**:一位成员评论了 LSTM 研究论文中图表的视觉吸引力,称其包含“非常漂亮的图片”。 - **对 LSTM 论文主张的批判性评估**:对 LSTM 论文进行了批判性分析,指出了一些缺点,例如比较的是参数数量而非 FLOPs,在 Transformer 基准测试中使用了不寻常的学习率,以及讨论的所有模型都缺乏超参数调优。 - **持怀疑态度但对结果保持开放**:另一位成员对 LSTM 论文提出的主张表示怀疑,倾向于观望拟议的 LSTM 增强功能在实践中是否有效。 **提到的链接**:xLSTM: Extended Long Short-Term Memory:在 20世纪 90年代,恒定误差轮转(constant error carousel)和门控被引入作为长短期记忆网络 (LSTM) 的核心思想。从那时起,LSTM 经受住了时间的考验,并为众多领域做出了贡献... --- **Interconnects (Nathan Lambert) ▷ #[random](https://discord.com/channels/1179127597926469703/1183121795247779910/1237306437244424243)** (24 messages🔥): - **聊天机器人的胡言乱语给 LMsys 带来压力**:人们担心 chatgpt2-chatbot 的活动可能会损害 **LMsys** 的公信力。有人提到 LMsys 已经不堪重负,没有余力拒绝请求。 - **可能与 LMsys 代表进行访谈**:有人提出了与 LMsys 负责人进行 **音频采访** 的想法,尽管有人指出可能缺乏默契,这可能会影响采访质量。 - **探索 Gemini 1.5 Pro 的能力**:利用 **Gemini 1.5 Pro 的音频输入** 成功创建了播客的章节摘要,其准确性和包含时间戳的功能给成员留下了深刻印象,尽管该成员承认存在一些错误且不想去纠正它们。 - **对 Chatbot Arena 帖子的期待**: - **关于 Chatbotarena 数据发布的许可担忧**:有人指出 **chatbotarena** 在未经特别许可的情况下发布主要供应商 LLM 生成的文本,可能会导致许可问题变得混乱。 **提到的链接**:来自 ハードはんぺん (@U8JDq51Thjo1IHM) 的推文:I’m-also-a-good-gpt2-chatbot I’m-a-good-gpt2-chatbot ?? 引用 Jimmy Apples 🍎/acc (@apples_jimmy) @sama 你真是个有趣的家伙。Gpt2 重回 lmsys arena。 --- **Interconnects (Nathan Lambert) ▷ #[reads](https://discord.com/channels/1179127597926469703/1214764639397617695/1237824326716096665)** (4 条消息): - **预览 AI 的行为蓝图**:OpenAI 公布了 Model Spec 的初稿,旨在指导 OpenAI API 和 ChatGPT 中模型的行为。它专注于核心目标以及如何处理指令冲突,并使用 [基于人类反馈的强化学习 (RLHF)](https://openai.com/index/instruction-following) 进行实现。 - **正在撰写的博客文章**:一位成员表示打算针对 OpenAI 刚刚发布的 Model Spec 文档写一篇博客。 - **严肃意图的标志**:提到了 OpenAI 在工作上绝不“胡闹”的承诺,反映了对该组织工作方式的深切尊重。 - **简单的反应表示觉得有趣**:一位成员用“😂”表情符号回应,可能觉得对话或 Model Spec 文档中存在有趣或讽刺之处。 **提到的链接**:Model Spec (2024/05/08):未找到描述 --- **Interconnects (Nathan Lambert) ▷ #[posts](https://discord.com/channels/1179127597926469703/1228051082631188530/1237875219289342035)** (4 条消息): - **等待 Snail**:使用了时钟表情符号,暗示在期待或等待被称为“snail”的事物或人。 - **召唤特定角色**:对社区内特定的组或等级进行了呼叫(由 `<@&1228050892209786953>` 表示),表示需要引起注意。 - **发布 SnailBot 新闻**:标记了 SnailBot News,这可能表示来自名为 SnailBot 的机器人或服务的新闻发布或预期。 - **为 Mr. Snail 欢呼**:消息“f yeea mr snail”似乎表达了对被称为 Mr. Snail 的人或事物的热情或支持。 --- **Latent Space ▷ #[ai-general-chat](https://discord.com/channels/822583790773862470/1075282825051385876/1237369845251833959)** (26 条消息🔥): - **寻找统一搜索解决方案**:一位成员讨论了企业级统一搜索工具 **Glean** 的实用性,并提到正在寻找适合小型组织的替代方案。他们提供了一个名为 *Danswer* 的相关开源项目的 [Hacker News 链接](https://news.ycombinator.com/item?id=39467413)。 - **AI 编排和数据传输咨询**:一位成员征求关于 AI(数据)编排和数据传输技术的建议,描述了编排包含多个 AI 组件和数据类型(如文本和 embeddings)的流水线的需求。 - **斯坦福大学新的深度生成模型课程**:一位成员分享了 [斯坦福大学 2023 年深度生成模型新课程](https://youtu.be/XZ0PMRWXBEU?si=IJPKQYv1qCAVDtVD) 的链接,该课程由 Stefano Ermon 教授授课。 - **寻求高级 GPU 的短期访问**:另一位成员询问了关于获取 NVIDIA A100 或 H100 GPU 短期(2-3 周)使用权的建议或供应商,回复中提供了一个 [Twitter 链接](https://twitter.com/pedrothedagger/status/1788271555434389878)。 - **利用 AI 进行代码辅助**:一位成员对直到 2024 年 5 月人们才意识到 AI 辅助编程的好处感到惊讶,并分享了他们的实践:在理解和测试之后,像使用任何其他源代码一样使用 LLM 生成的代码。他们还分享了一个用于创建 GitHub PR 的脚本片段: ```gh pr create --title "$(glaze yaml --from-markdown /tmp/pr.md --select title)" --body "$(glaze yaml --from-markdown /tmp/pr.md --select body)"```提到的链接:--- **Latent Space ▷ #[llm-paper-club-west](https://discord.com/channels/822583790773862470/1197350122112168006/1237841811616043009)** (2 messages): - **会议日程查询**:一位成员询问当天是否有安排好的通话。未提供更多细节或背景。 --- **tinygrad (George Hotz) ▷ #[general](https://discord.com/channels/1068976834382925865/1068976834928193609/1237437294055657493)** (14 messages🔥): - **不含数学术语的 Machine Learning**:一位用户表达了挫败感,因为他花了几个小时才意识到 Machine Learning 中的某个概念本质上只是“乘法”。这表明用户希望在没有复杂数学术语的情况下理解 Machine Learning 概念。 - **不适合初学者的地方**:**@georgehotz** 强化了 Discord 规则,强调这里不是提出所谓“菜鸟问题”的地方,并强调了他人时间的价值。 - **关于 Tinybox 订单的查询**:一位成员询问了讨论 Tinybox 大宗订单的流程,以及是否有机架式规格的计划。 - **Pull Request 和 Bitcast 混淆**:分享了一个 GitHub 上与 tinygrad 中 BITCAST 操作相关的 Pull Request,引发了关于其状态以及与 CAST 操作区别的简短讨论。 - **理解 UOp BITCAST**:随后进行了澄清,BITCAST 操作是一个不同的 uop,而不是 ALU op,并希望从目前包含 "bitcast=false" 参数的函数中移除该参数。 **提及的链接**:UOps.BITCAST by chenyuxyz · Pull Request #3747 · tinygrad/tinygrad:隐式修复了 bitcast 的 no const folding 问题。 --- **tinygrad (George Hotz) ▷ #[learn-tinygrad](https://discord.com/channels/1068976834382925865/1070745817025106080/1237337040606068736)** (11 messages🔥): - **理解 Tinygrad 复杂的文档**:一位成员就一份 [Tinygrad 文档](https://github.com/tinygrad/tinygrad/blob/master/docs-legacy/reshape_without_symbolic.md)寻求指导,认为其过于抽象且难以理解。另一位参与者激烈批评了该文档的质量,并提出分享自己的解释文档以澄清 view merges 的概念。 - **探索 Tensor Reshaping**:一位用户询问了对最初以特定 stride 定义的 Tensor 进行 Reshape 的逻辑,特别是当简单的 stride 调整无法涵盖更复杂的 Reshape 时。该用户自己提出了一个解决方案,涉及维护原始 shape 以计算新 Reshape 后 Tensor 的索引。 - **优化 Tinygrad 中的 Reshape 操作**:继续关于 Tensor Reshaping 的讨论,同一位用户推测,如果所有循环都被展开(unrolled),索引可能在 compile-time 计算。他们询问 Tinygrad 是否采用类似的方法来促进 Tensor Reshaping。 - **通过文档共享学习**:一位成员建议,“以教促学”的策略在更好地理解 Tinygrad 方面可能很有效。他们建议构建 toy examples 并记录过程作为教学工具。 - **澄清 Symbolic Node 实现**:一位用户询问 Tinygrad 中的 `symbolic.DivNode` 是否在设计上要求第二个操作数为整数,或者只是尚未为 node 操作数实现。另一位用户回应称,没有看到任何迹象表明 node 操作数不起作用,并想知道这是否与 `symbolic.arange` 内部需要递归操作处理有关。提及的链接:--- **Cohere ▷ #[general](https://discord.com/channels/954421988141711382/954421988783444043/1237395092679954453)** (12 messages🔥): - **询问 FP16 模型的本地托管**:一位成员询问了如何使用 vLLM 在本地托管 **FP16 command-r-plus**,并对大约 **40k 上下文窗口**的 VRAM 需求感兴趣。目前没有提供 VRAM 估算的回复。 - **关于 RWKV 模型可扩展性的讨论**:讨论中提到了 **RWKV 模型**,质疑其与传统 Transformer 模型的竞争力,特别是考虑到过去的研究表明 RNN 性能较差。该成员指出了在 **1-15b 参数规模**下的潜在用例。 - **处理 Cohere 的 Token 限制挑战**:一位用户分享了在使用 Cohere.command 实现 RAG 时面临的挑战,由于其 **4096 token 限制**,而应用需要处理约 **10000 tokens**。另一位用户建议使用 Elasticsearch 来减少文本量,并将简历拆分为逻辑段落。 - **讨论 Cohere Chat 文件输出的可能性**:有人提出了关于从 Cohere Chat **下载文件**的问题,其中可能包括模型输出的 docx 或 pdf 格式文件。暗示聊天界面可能会提供此类文件的下载链接,尽管目前尚未给出实际链接或直接操作说明。 - **对 'command R' 模型的赞赏**:用户对 'command R' 模型表达了**积极的印象**,将其描述为“太棒了(Awesome)”并肯定了其出色表现。这些评论表明用户对该模型的性能感到满意。 --- **Cohere ▷ #[project-sharing](https://discord.com/channels/954421988141711382/1218409701339828245/1237471018629464136)** (2 messages): - **全功能聊天应用等待反馈**:一款集成了文本生成、摘要和 ReRank 的新应用 *Coral Chatbot* 正在寻求反馈和合作机会。请在 [Streamlit](https://cohere-api-endpoints.streamlit.app/) 上查看。 - **关注此空间**:分享了一个 [YouTube 视频](https://www.youtube.com/watch?v=uVUhyPsqdJ8) 链接,但未提供任何背景信息。 **提及的链接**:未找到标题:未找到描述 --- **Cohere ▷ #[collab-opps](https://discord.com/channels/954421988141711382/1218409745380147320/1237830229930676357)** (1 messages): - **Wordware 的创始团队机会**:一家总部位于旧金山的公司 **Wordware** 正在寻求扩大团队,招聘创始工程师、DevRel 以及产品/前端工程师。感兴趣的人士可以通过在 Wordware 的 Web 托管 IDE 上构建内容来展示技能,该 IDE 专为非技术专家协作创建 AI agents 而设计,并可将其分享给创始人。 - **Prompting 作为一种新的编程语言**:**Wordware** 的独特之处在于将 Prompting 视为一种编程语言,而不是依赖低代码/无代码模块,旨在简化特定任务 AI 解决方案的创建。有关职位的更多信息,请访问其 Notion 页面:[Join Wordware](https://wordware.notion.site/Join-Wordware-YC-S24-347a2b89acad44c1bc99591636308ec2)。 **提及的链接**:Notion – 笔记、任务、维基和数据库的全能工作空间。:一款将日常工作应用融合为一的新工具。它是为您和您的团队打造的全能工作空间。 --- **DiscoResearch ▷ #[general](https://discord.com/channels/1178995845727785010/1182877486854451271/1237314994564239390)** (3 messages): - **AIDEV 活动的聚会动态**:*jp1* 分享了对在 AI Village 即将举行的 **AIDEV 活动**中与大家见面的兴奋之情,并愿意与计划参加的其他人员进行交流。 - **加入欢乐之旅**:同样参加 AIDEV 的 *mjm31* 表达了对活动的满腔热情,并希望即使之前没有沟通也可以直接加入。 - **会议的餐饮顾虑**:*enno_jaai* 询问了 **AI Village** 的食物安排,纠结是应该自带零食还是附近会有食物供应。 --- **DiscoResearch ▷ #[discolm_german](https://discord.com/channels/1178995845727785010/1197630242815213618/1237399789398921347)** (6 messages): - **辩论德语包容性语言数据集的需求**:一位成员询问了关于创建一个专门针对包容性语言的德语数据集的潜在用途。另一位成员建议,这样的举措将非常有价值,特别是与引导助手说话风格的 **system prompts** 相结合时。 - **为德语预训练数据集寻找高质量域名**:一位成员宣布开始构建一个基于 **Common Crawl** 的纯德语预训练数据集,并征求关于哪些域名因内容质量高而应赋予额外权重的建议。 - **探索德语 AI 的包容性模式**:提出了为语言 AI 设置包容性/非包容性模式的概念,认为这是一个值得考虑的想法。 - **性别包容性德语语言工具资源**:讨论指向了一些资源,如 *Includify* 以及在 [David's Garden](https://davids.garden/gender/) 上提供的关于**多样性敏感语言**的项目报告,以及相关的 [gender-inclusive German](https://gitlab.com/davidpomerenke/gender-inclusive-german) 后端代码。 - **可配置 AI 模型中的包容性思考**:一位成员建议,包容性语言功能可以参照 CST 风格的模型(如 Vicgalle/ConfigurableBeagle-11B)进行构思。提到的链接:--- **Mozilla AI ▷ #[llamafile](https://discord.com/channels/1089876418936180786/1182689832057716778/1237637419860230154)** (5 条消息): - **Phi-3 Mini 表现异常**:一位成员分享了 **Phi-3 Mini** 的问题;他们发现该模型在配合 Ollama 和 Open WebUI 使用时表现令人满意,但在使用 llamafile 时遇到了问题。 - **将 Llamafile 作为后端服务运行**:在询问命令执行后的后端服务使用情况时,一位成员了解到可以使用 `127.0.0.1:8080` 的 API 端点发送 OpenAI 风格的请求。详细信息和指南可在 [Mozilla-Ocho 的 GitHub llamafile 仓库](https://github.com/Mozilla-Ocho/llamafile?tab=readme-ov-file#json-api-quickstart)中找到。 - **VS Code 与 Ollama 的集成**:一位成员注意到 VS Code 的一个新功能,为运行 **ollama** 的用户提供了一个下拉菜单来动态管理他们的模型。另一位成员询问该功能是否来自某个 VS Code 插件。 **提到的链接**:GitHub - Mozilla-Ocho/llamafile: 使用单个文件分发和运行 LLM。:使用单个文件分发和运行 LLM。通过在 GitHub 上创建账号来为 Mozilla-Ocho/llamafile 的开发做出贡献。 --- **Datasette - LLM (@SimonW) ▷ #[ai](https://discord.com/channels/823971286308356157/1097032579812687943/1237618716993388584)** (1 条消息): - **作为 NPM 包升级器的 AI Agent**:一位成员分享了一个 [Reddit 链接](https://www.reddit.com/r/ChatGPTCoding/comments/1cljmiy/i_built_an_ai_agent_that_upgrades_npm_packages/),内容是关于一个可以升级 npm 包的 AI Agent,引发了社区的幽默讨论。该 Reddit 帖子还附带了关于 Cookie 使用和隐私政策的标准通知。 **提到的链接**:Reddit - 深入探索任何事物:未找到描述 --- **Datasette - LLM (@SimonW) ▷ #[llm](https://discord.com/channels/823971286308356157/1128504153841336370/1237375746050101278)** (3 条消息): - **参数化测试的 YAML 提案**:分享了两个用于 **llm-evals-plugin** 参数化测试的 YAML 配置以供评审。链接的 [GitHub issue 评论](https://github.com/simonw/llm-evals-plugin/issues/4#issuecomment-2098250711)包含了这些提案,以及关于该功能设计和实现的持续讨论。 - **对 `llm` CLI 的深夜感谢**:一位用户表达了对 `llm` CLI 的感激之情,提到它显著帮助管理了他们的个人项目和论文工作。他们强调了它的实用性,并为该项目送上了一个温馨的“谢谢”。 **提到的链接**:设计并实现参数化机制 · Issue #4 · simonw/llm-evals-plugin:初步想法如下:#1 (comment) 我想要一个参数化机制,这样你就可以同时针对多个示例运行相同的 eval。这些示例可以直接存储在 YAML 中,也可以是... --- **Alignment Lab AI ▷ #[ai-and-ml-discussion](https://discord.com/channels/1087862276448595968/1087876677603958804/1237832687226585189)** (1 条消息): - **AlphaFold3 模型民主化**:论文《Accurate structure prediction of biomolecular interactions with AlphaFold 3》中描述的 **AlphaFold3** 实现现在已在 PyTorch 中可用。邀请用户加入 Agora,共同为这一强大模型的民主化做出贡献:[在此查看实现](https://buff.ly/3JQVKze) 并 [在此加入 Agora](https://t.co/yZKpKHhHp0)。提到的链接:--- **Alignment Lab AI ▷ #[general-chat](https://discord.com/channels/1087862276448595968/1095458248712265841/1237418262850175016)** (2 messages): - **通用聊天频道中的问候交流**:一位成员向名为 "Orca" 的聊天机器人打招呼说 "hello"。另一位成员以友好的 "Hello 👋" 进行了回应。 --- **AI Stack Devs (Yoko Li) ▷ #[app-showcase](https://discord.com/channels/1122748573000409160/1122748840819306598/1237770786291581044)** (1 messages): - **Quickscope 瞄准游戏 QA**:Regression Games 宣布推出 [**Quickscope**](https://www.regression.gg/post/quickscope-launch),这是一套全新的 AI 驱动工具套件,用于 Unity 中的自动化测试。集成过程 *无需代码*,并包含游戏会话录制工具和验证工具,以及用于功能测试的易用 UI。 - **零麻烦的深度游戏洞察**:Quickscope 的深度属性抓取功能可自动提取游戏状态详情,包括 MonoBehaviours 的公共属性,无需自定义编码。 - **立即简化您的测试流程**:开发者和 QA 工程师可以在 [regression.gg](https://regression.gg/) 试用 Quickscope,体验其集成的便捷性和全面的功能。该平台强调其 **无需自定义代码集成**,可在任何开发工作流中快速部署。提到的链接:--- **AI Stack Devs (Yoko Li) ▷ #[team-up](https://discord.com/channels/1122748573000409160/1128471951963328512/)** (1 messages): jakekies: 我想加入 --- **LLM Perf Enthusiasts AI ▷ #[openai](https://discord.com/channels/1168579740391710851/1171903046612160632/1237806223009517712)** (1 messages): - **寻找 GPT-4-turbo 0429**:一位成员正在寻找支持新款 **GPT-4-turbo 0429** 的 **Azure region**,并提到瑞典的 Azure 服务目前正面临问题。 --- ---