ainews-lmsys-advances-llama-3-eval-analysis
LMSys 推进 Llama 3 评估分析。
LMSys 正在通过将性能划分为 8 个查询子类别和 7 个提示词复杂程度来提升大语言模型(LLM)的评估体系,这揭示了 Llama-3-70b 等模型在不同领域优势分布不均的现状。DeepMind 发布了 AlphaFold 3,通过对蛋白质-DNA-RNA 复合物的整体建模,推进了分子结构预测技术,对生物学和遗传学研究产生了深远影响。OpenAI 推出了 Model Spec(模型规范),这是一项旨在明确模型行为和微调方向的公共标准,在征求社区反馈的同时,目标是让模型能直接从中学习。Llama 3 在 LMSys 排行榜上已名列前茅,其性能几乎与 Claude-3-sonnet 持平,但在处理复杂提示词时表现出显著差异。该分析凸显了模型基准测试和行为塑造领域不断演变的格局。
LLM 评估很快将根据类别和 Prompt 复杂度而有所不同。
2024年5月8日至5月9日的 AI 新闻。我们为您检查了 7 个 subreddit、373 个 Twitter 和 28 个 Discord(419 个频道,3747 条消息)。预计节省阅读时间(以 200wpm 计算):450 分钟。
LMSys 以基于 ELO(技术上是 Bradley-Terry)的对战而闻名,更具争议的是它为 OpenAI、Databricks 和 Mistral 进行的不透明预发布测试模型,但直到最近才开始通过将评分拆分为 8 个查询子类别来深化其分析:
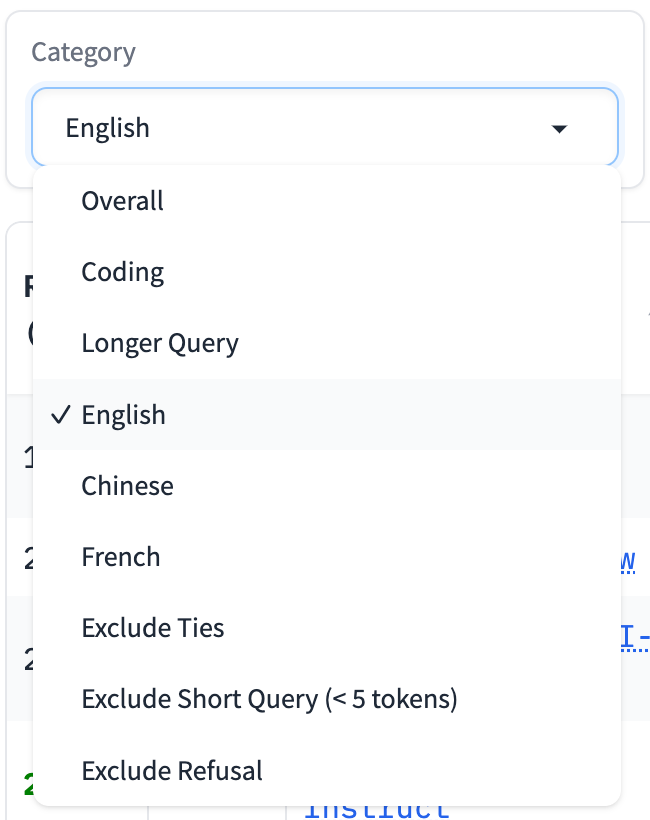
这些类别的维度即将爆炸式增长。LMSys 发布了关于 Llama-3 在 LMSys 上表现的深度分析,揭示了其在重要类别(如摘要、翻译和编程)中出人意料且不均衡的胜率。
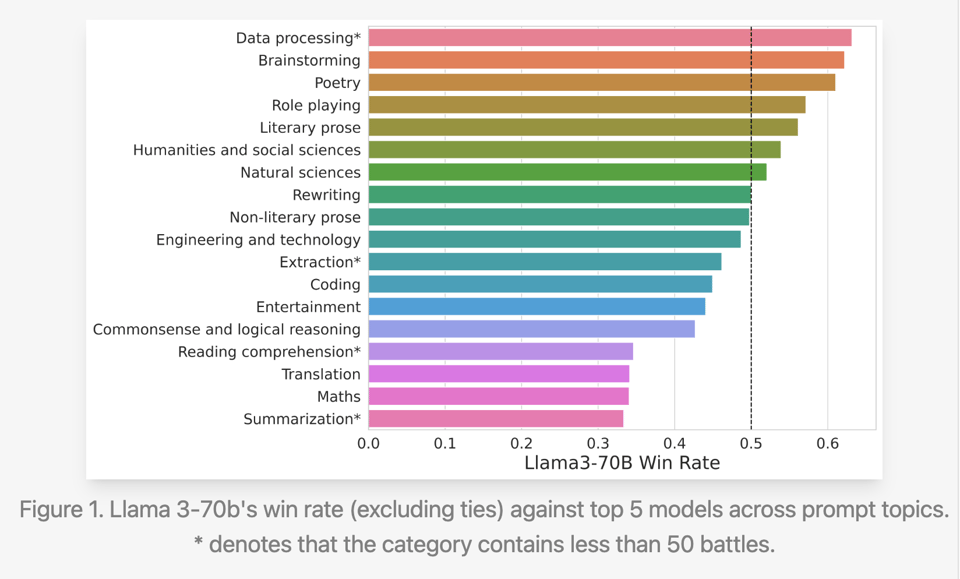
以及针对 7 个级别的 Prompt 复杂度:
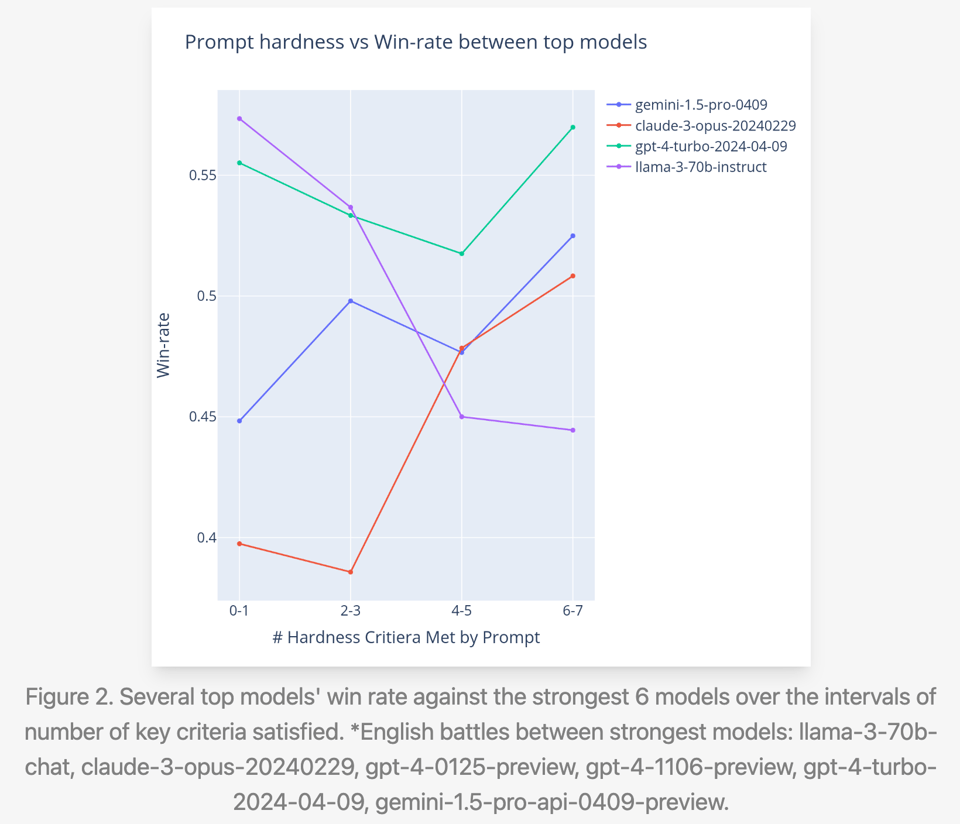
随着 GPT4T-preview 级别的模型趋于商品化,且 LMSys 日益成为可能被微妙手段操纵的受信任评估标准,了解模型表现过佳或不足的主要方式至关重要。LMSys 正在主动这样做固然很好,但令人好奇的是,这次分析的 Notebooks 并没有按照他们惯常的做法发布。
目录
[TOC]
AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在使用 Haiku 进行聚类和流程工程(flow engineering)。
AlphaFold 3 与分子结构预测
- DeepMind 发布 AlphaFold 3:@demishassabis 宣布了 AlphaFold 3,它能以最先进的准确度预测蛋白质、DNA 和 RNA 的结构及相互作用。@GoogleDeepMind 解释了它是如何与 @IsomorphicLabs 共同构建的,以及它对生物学的意义。
- AlphaFold 3 的能力:@GoogleDeepMind 分享道,AlphaFold 3 使用了下一代架构和训练方式,从整体上计算整个分子复合物。它可以模拟在受到干扰时控制细胞功能和疾病的化学变化。
- 应用与影响:@GoogleDeepMind 指出,已有超过 180 万人使用 AlphaFold 来加速生物可再生材料和遗传学领域的工作。@DrJimFan 称,当数据转换为浮点序列(float sequences)时,用于像素的相同骨干网络(backbone)竟然可以想象出蛋白质,这简直令人难以置信。
OpenAI Model Spec 与塑造模型行为
- OpenAI 推出 Model Spec:@sama 宣布了 Model Spec,这是一份关于 OpenAI 模型应如何行为的公开规范,旨在明确什么是 Bug,什么是决策。@gdb 分享道,该规范旨在让人们了解模型行为是如何调整的。
- Model Spec 的重要性:@miramurati 强调,随着模型决策能力的提高,Model Spec 对于人们理解并参与塑造模型行为的辩论至关重要。@karinanguyen_ 指出,该规范必须考虑广泛的细微问题和观点。
- 反馈与未来计划:@sama 感谢了 OpenAI 团队,特别是 @joannejang 和 @johnschulman2,并欢迎反馈以随时间调整规范。OpenAI 正在研究让模型直接从 Model Spec 中学习的技术。
Llama 3 在 LMSYS 排行榜上的表现
- Llama 3 登顶排行榜:@lmsysorg 分享的分析显示,Llama 3 已攀升至排行榜前列,其 70B 版本几乎与 Claude-3 Sonnet 持平。去重(Deduplication)和离群值(outliers)对其胜率没有显著影响。
- 优势与劣势:@lmsysorg 发现,在基于复杂性和领域知识等标准的更具挑战性的提示词(prompts)上,Llama 3 与顶级模型之间的差距会变大。@lmsysorg 还指出,与其他模型相比,Llama 3 的输出更友好、更具对话性,且使用了更多的感叹号。
- 达到顶级模型水平:@lmsysorg 总结道,Llama 3 在整体用例上的表现已达到与顶级闭源模型(proprietary models)相当的水平,并预计将根据此分析在排行榜上推出新类别。@togethercompute 同意 Llama-3-70B 已达到与顶级开源模型相似的质量。
仅文本训练对 AI 的局限性
- 需要实践经验:@ylecun 认为,关于新手除了书本知识外还需要实践经验的陈词滥调,说明了为什么仅在文本上训练的 LLM 无法达到人类智能。
AI Reddit 摘要
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取现在可以运行了,但还有很多改进空间!
AI 与技术发展
-
OpenAI 和 Microsoft 正在开发耗资 1000 亿美元的“Stargate” AI 超级计算机:在 /r/technology 中,据报道 OpenAI 和 Microsoft 正在开发一个大规模的核动力超级计算机项目,以支持下一代 AI 的突破,这暗示了所需的巨大计算资源。
-
DeepMind 发布 AlphaFold 3,用于预测生命关键分子:DeepMind 推出了 AlphaFold 3,这是一款 AI 模型,能够以最先进的准确度预测蛋白质、DNA 和 RNA 的结构及相互作用,为药物研发和合成生物学的进步开启了大门。
-
IBM 发布开源 Granite Code LLM,性能超越 Llama 3:IBM 发布了 Granite Code,这是一系列强大的专注于代码的开源语言模型,其性能击败了广受欢迎的 Llama 3 模型。
-
Apple 推出搭载每秒 38 万亿次运算 Neural Engine 的 M4 芯片:Apple 发布了其下一代 M4 芯片,其特点是拥有每秒可进行 38 万亿次 AI 运算的 Neural Engine,是目前 PC 芯片中最快的。
开源 LLM 进展
-
计划将 Llama 3 70B 蒸馏为高效的 4x8B/25B MoE 模型:/r/LocalLLaMA 社区计划将 Llama 3 70B 模型蒸馏为针对 VRAM/智能权衡进行优化的 4x8B/25B Mixture-of-Experts 模型,目标是将 8-bit 量化版本适配到 22-23GB 的 VRAM 中。
-
过去 2 个月主要开源 LLM 发布的时间线:/r/LocalLLaMA 整理了仅在过去几个月内发布的众多主要开源 LLM 的时间线,包括来自 Cohere, xAI, DataBricks, ai21labs, Meta, Microsoft, Snowflake, Qwen, DeepSeek 和 IBM 的发布。
-
Consistency LLM 作为并行解码器可将推理速度提升 3.5 倍:Consistency LLM 是一种将 LLM 转换为并行解码器的方法,可实现 3.5 倍的推理加速,与 Medusa2/Eagle 等替代方案相比,具有相当或更好的加速效果,且无需额外的内存成本。
AI 伦理与安全担忧
-
OpenAI 正在探索如何负责任地生成 AI 色情内容:OpenAI 正在应对围绕 AI 生成色情内容的伦理挑战,考虑针对某些用例放宽 NSFW 过滤器,例如露骨的歌词、政治话语和浪漫小说。
-
OpenAI 推出 Model Spec 以澄清预期的模型行为:为了帮助区分预期的模型能力与非预期的 Bug,OpenAI 正在推出 Model Spec 并寻求公众反馈以使其随时间演进。
-
美国海军陆战队测试配备 AI 瞄准步枪的机器人狗:在令人不安的、让人联想起反乌托邦科幻小说的进展中,美国海军陆战队正在评估配备 AI 驱动步枪的机器人狗,这些机器人狗可以自动检测并追踪人员、无人机和车辆。
{kind=link}
其他值得关注的进展
-
Phi-3 WebGPU AI 聊天机器人完全在浏览器本地运行:一段视频演示展示了一个基于 Phi-3 的 AI 聊天机器人,利用 WebGPU 在 Web 浏览器中 100% 本地运行。
-
IC-Light 实现 AI 驱动的图像重照明:开源工具 IC-Light 利用 AI 允许对任何图像进行逼真的重照明和光照编辑。
-
Udio 增加 AI 驱动的音频编辑和修复功能:Udio 推出了新功能 ,利用 AI 实现音频中的人声编辑、错误修正和平滑过渡。
-
研究表明曲速引擎(Warp Drives)可能成为现实:一项新的科学研究诱人地暗示在某些条件下,曲速引擎在物理上可能是可行的。
-
基因工程师通过重组细胞使寿命延长 82%:/r/ArtificialInteligence 分享了一项研究,基因工程师通过重组细胞实现了细胞寿命 82% 的增长。
AI 梗与幽默
- AI 炒作周期仍在继续:/r/ProgrammerHumor 中一个令人深省的梗图提醒我们,围绕 AI 突破的狂热炒作没有丝毫减弱的迹象。
AI Discord 回顾
摘要之摘要的摘要
- Large Language Model (LLM) 进展与基准测试:
- 来自 Meta 的 Llama 3 在 ChatbotArena 等排行榜上迅速崛起,在超过 50,000 场对决中表现优于 GPT-4-Turbo 和 Claude 3 Opus。
- 像来自 IBM 的 Granite-8B-Code-Instruct 这样的新模型增强了代码任务的指令遵循能力,而 DeepSeek-V2 则拥有 236B 参数。
- 某些基准测试受到质疑,人们呼吁像 Meta 这样可信的来源建立现实的 LLM 评估标准。
- 优化 LLM 推理与训练:
- ZeRO++ 承诺在 GPU 上进行大模型训练时,将通信开销降低 4 倍。
- vAttention 系统动态管理 KV-cache 内存,在不使用 PagedAttention 的情况下实现高效的 LLM 推理。
- QServe 引入了 W4A8KV4 量化,以提升 GPU 上基于云的 LLM 服务性能。
- Consistency LLMs 等技术探索了并行 Token 解码,以降低推理延迟。
- 开源 AI 框架与社区努力:
- Axolotl 支持多种数据集格式,用于 LLM 的指令微调和预训练。
- LlamaIndex 为 Andrew Ng 的一门关于构建 Agentic RAG 系统的新课程提供支持。
- RefuelLLM-2 已开源,声称是处理“枯燥数据任务(unsexy data tasks)”的最佳 LLM。
- Modular 展示了 Mojo 在 Python 集成和 AI 扩展(如 bfloat16)方面的潜力。
- 多模态 AI 与生成模型创新:
- Idefics2 8B Chatty 专注于提升聊天交互体验,而 CodeGemma 1.1 7B 则精进了编程能力。
- Phi 3 模型通过 WebGPU 将强大的 AI 聊天机器人带入浏览器。
- 结合 Pixart Sigma + SDXL + PAG 旨在实现 DALLE-3 级别的输出,并具有通过微调进一步优化的潜力。
- 开源项目 IC-Light 专注于改进图像重光照(relighting)技术。
5. 其他
-
Stable Artisan 将 AI 媒体创作带入 Discord:Stability AI 推出了 Stable Artisan,这是一个集成 Stable Diffusion 3、Stable Video Diffusion 和 Stable Image Core 等模型的 Discord 机器人,用于直接在 Discord 中生成和编辑媒体内容。该机器人引发了关于 SD3 开源状态以及将 Artisan 作为付费 API 服务引入的讨论。
-
Unsloth AI 社区对新模型和训练技巧反响热烈:IBM 的 Granite-8B-Code-Instruct 和 RefuelAI 的 RefuelLLM-2 的发布引发了架构讨论。用户分享了关于 Windows 兼容性的挑战以及对某些性能基准测试的质疑,同时也交流了模型训练和微调的技巧。
-
Nous Research AI 的前沿论文与 WorldSim 重启:分析了关于 LLM 中 xLSTM 和 函数向量(function vectors) 的突破性论文,同时对 Llama 3 微调的最佳实践进行了推测。WorldSim 的重新发布及其新功能(如 WorldClient、Root 和 MUD)引起了广泛关注,用户们正在讨论模型合并(model merging)技术的策略。
-
Hugging Face 的编程增强与巨量模型:Idefics2 8B Chatty 和 CodeGemma 1.1 7B 亮相用于聊天和编程,同时拥有 236B 参数的 DeepSeek-V2 模型引起了轰动。讨论内容涵盖了 BERT 微调、Whisper 上采样、Gemma Token 集成以及从 PDF 中提取内容的方法。
-
CUDA MODE 的 Triton 教程与 Diffusion 优化深度解析:一个由 9 部分组成的博客系列 和 GitHub 仓库 详细介绍了 Diffusion 模型推理优化,引起了广泛关注;同时社区合力创建了 Triton kernels 索引。LibTorch 的编译时间改进以及用于高效模型训练的 ZeRO++ 也受到了关注。
-
LangChain 的 Agentic RAG 课程与本地 LLM 突破:LangChain 与 deeplearning.ai 合作 推出了关于构建 Agentic RAG 系统 的课程,同时还为 Mistral 和 Gemma 等模型引入了 本地 LLM 支持。用户们排查了 TypeScript toolkit 的问题,并对 Multi-Agent 架构 展开了讨论。
-
OpenAI 的 Model Spec 为 AI Alignment 定下基调:OpenAI 发布了 Model Spec 的第一份草案,旨在通过 RLHF 技术 引导模型行为,这是其致力于负责任的 AI 开发的一部分。讨论还涉及了 GraphQL 相比 Markdown 的局限性,以及 GPT-4 在不同平台上的能力差异。
PART 1: Discord 高层级摘要
Stability.ai (Stable Diffusion) Discord
Artisan 的创意扩展:Stability AI 推出了一款名为 Stable Artisan 的新 Discord 机器人,使 Discord 用户可以直接在应用内使用 Stable Diffusion 3、Stable Video Diffusion 和 Stable Image Core 等工具进行媒体创建和编辑。
SD3 的开源争议:社区讨论中出现了对 Stable Diffusion 3 可能不开源的沮丧情绪,对转向专有模型以及发布时间表不明确的担忧在社区中引发了争论。
Artisan API 引发褒贬不一的反应:引入 Artisan(Stability AI 用于调用 Stable Diffusion 3 的付费 API 服务)既获得了期待也遭到了批评,一些用户质疑该服务对于预算有限者的可行性。
给生成式 AI 新手的指南:Stable Diffusion 生态系统的新手正在交流使用 ComfyUI 的技巧,并探索适合不同创意意图的最佳基础模型,借鉴社区仓库和 Prompt 编写技术来精进他们的生成艺术。
AI 艺术巨头对比:讨论线程强调了 Midjourney 对 AI 艺术工具市场的影响,推测其专业受众以及对 Stability AI 等同类工具货币化策略的潜在影响。
Perplexity AI Discord
Perplexity 与 SoundHound 联手打造语音 AI:Perplexity AI 与 SoundHound 达成合作,旨在通过先进的 LLM 能力增强语音助手,承诺在各种 IoT 设备上提供实时回答。
Claude 3 Opus 额度记录与服务故障:用户深入探讨了 Claude 3 Opus 的 “600 额度” 限制问题,对比了 Perplexity 与直接使用 Anthropic 的体验。此外,还有关于 Pro 搜索限制透明度以及账单错误和系统变慢等技术问题的讨论。
分享功能与搜索在分享中大放异彩:社区被鼓励将线程设置为 “可分享”,并积极分享关于 AlphaFold、双相情感障碍和多语言查询等不同主题的 Perplexity AI 搜索 URL,展示了用户兴趣的多样性。
无需重采样的 Bootstrapping 成为讨论话题:一位成员关于在不进行物理重采样的情况下执行 Bootstrapping 的提问引发了技术讨论,重点在于该统计方法中原始数据集的直接应用。
用户对订阅页面表示关注:用户对 Pro 订阅页面上潜在的误导信息表示担忧,要求 Perplexity 团队针对 Pro 搜索限制做出明确澄清。
Unsloth AI (Daniel Han) Discord
IBM 代码模型家族的新成员:Granite-8B-Code-Instruct 由 IBM 发布,该模型在逻辑推理和问题解决方面拥有增强的指令遵循能力,引发了对其不寻常的 GPTBigCodeForCausalLM 架构的讨论。
Dolphin 在新版本中致谢 Unsloth:Unsloth AI 在 Dolphin 2.9.1 Phi-3 Kensho 的发布中因其在模型初始阶段的贡献而获得认可。
AI 爱好者的 Windows 烦恼:工程师们分享了在 Windows 上部署 AI 模型时的挑战,建议使用 Windows Subsystem for Linux (WSL) 等替代方案,并引用了 Unsloth GitHub issue 中概述的解决方案。
AI 社区质疑模型基准测试:对某些性能基准测试出现了怀疑,成员们呼吁 Meta 等更可靠的来源为 Large Language Models 建立现实的评估标准。
调试日记:模型训练的多样化讨论:关于克服模型训练和开发中各种障碍的积极对话,包括修复 Llama3 训练数据丢失、解决 VSCode 安装错误,以及借助社区分享的 Notebook(如这个用于 Google Colab 仅推理使用的 Notebook)进行模型微调。
Nous Research AI Discord
LSTM 发起挑战:一篇引人入胜的论文强调了扩展至十亿参数规模的 LSTMs 的潜力,通过创新的 exponential gating 挑战 Transformer 的主导地位。该技术的详细信息请参阅这项最新研究。
AI 的预测水晶球:Forefront.ai 列出了“预期的突破性 AI 论文”,暗示了关键趋势和一种在不显著影响性能的情况下降低计算负载的新型调整技术。该网站展示了对 AI 研究领域的战略前瞻。
更轻的模型,同样的威力:显著的讨论透露,Llama 2 70B 的 4-bit 量化、剪裁 40% 的版本性能与完整模型相当,这表明深度学习模型中存在大规模冗余,正如 Twitter 帖子中所述。
精细化微调:围绕 LLaMA 3 和 Axolotl 模型的微调技术展开了讨论,涉及 context length、训练期间的预分词(pre-tokenization)与 padding,以及 Flash Attention 2 的最佳使用。
WorldSim 挥舞创新旗帜:WorldSim 展示了新功能,包括改进的漏洞修复、WorldClient 浏览体验、CLI 环境 Root、祖先模拟和 RPG 特性。社区的热情日益高涨,体现在对购买 Nous Research 宣传周边产品的咨询上,详见其网站。
模型融合的可持续策略:成员们正积极探索简化模型合并和集成技术的过程,比较 NeuralHermes 2.5 - Mistral 7B 等模型中的 Direct Preference Optimization,并探索带有外部权重的 Llamafile 的实际益处。
技术对话的细节:许多消息展示了迷的问题解决图景,从解决上传模型时出现的 ‘int’ object has no attribute ‘hotkey’ 等错误,到充实限制 RAG 中幻觉的策略以及有效的 padding 策略。
OpenAI Discord
Model Spec 塑造 AI 对话:OpenAI 推出了 Model Spec 框架,用于构建 AI 模型中期望的行为,以丰富相关的公共讨论;全文可访问 OpenAI 的公告。
Markdown 优于 GraphQL:在 AI 讨论中,GraphQL 缺乏客户端渲染的情况与 Markdown 进行了对比,尽管这种限制并未引起重大担忧。
AI 平台与硬件令人兴奋也令人困惑:虽然 OpenDevin 平台因其 Docker 沙箱和后端模型的灵活性而受到赞誉,但用户发现 ChatGPT 各版本与 NVIDIA 技术演示之间的 AI 性能对比非常有趣,然而 GPT-4 ChatGPT 应用版与 API 版本之间的限制引起了社区的不满。
分享商业中的 AI 伦理提示词:一位社区成员分享了详细的“商业中的 AI 伦理”提示词结构,旨在增强模型在伦理考量方面的输出,并提供了一个探索不道德行为影响的输出示例,尽管没有提供具体的资源链接。
寻求 AI 领域的专业知识与远见理想:一名成员寻求 Prompt Engineering 课程的建议,由于 OpenAI 的政策,后续通过私信进行了交流;而另一名成员思考了“Open”作为核心认识论原则的概念,尽管讨论并未进一步展开。
HuggingFace Discord
-
针对聊天优化且对编程友好的模型登场:Idefics2 8B Chatty 亮相,专注于提升聊天交互体验;同时 CodeGemma 1.1 7B 出现,旨在优化 Python, Go 和 C# 的编程能力。在浏览器聊天机器人领域,Phi 3 引入了 WebGPU 技术以增强聊天体验。
-
突破性的 236B 参数模型与训练里程碑:拥有 2360 亿参数的 DeepSeek-V2 已经发布,标志着模型规模的显著增加;目标检测指南的更新旨在通过在 Trainer API 中添加 mAP 指标来微调性能。
-
技术问题与故障排除:几位成员遇到了与 BERT fine-tuning、Whisper model upsampling、集成 Gemma 的未使用 tokens 以及扩散模型错误相关的挑战,凸显了社区内问题的多样性。
-
语音频道中的音频与互动调整:关于利用“Stage”频道控制语音组音频质量的讨论,揭示了质量控制与参与者急于提问之间的平衡,从而导致了对 Stage 频道设置的实验。
-
致力于更高效的内容提取:一位用户分享了从 PDF 中提取图像和图表的尝试,并希望有更高效的 AI 方法来处理此类数据;同时,一个新模型出现,使用 Adlike 来标记图像中的广告。
Modular (Mojo 🔥) Discord
Mojo 的 Python 前景与性能辩论
-
Mojo 的年终 Python 潜力:Modular 社区预期 Mojo 在年底前会变得更加用户友好,CPython 集成已经实现了 Python 代码执行。然而,直接编译 Python 代码可能仍是明年的目标。
-
MLIR 在 Mojo 中的高光时刻:对 MLIR 扩展贡献的热情高涨,特别是在活跃度检查(liveliness checking)领域;成员们热切期待 Modular 的 MLIR dialects 可能开源,以增强 MLIR 的实用性。
编译见解与 Twitter 和博客上的热度提升
-
Modular Twitter 上的功能狂热:Modular 预告了重要更新,承诺进行功能升级,并在 Twitter 上披露了稳健的增长指标,引发了社区对即将发布的公告的好奇。
-
Chris Lattner 力挺 Mojo:在 Developer Voices 播客中,Chris Lattner 强调了 Mojo 对 Python 和非 Python 开发者的前景,重点关注扩展的 GPU 性能和 AI 相关扩展。
社区代码贡献与编译器对话
-
Toybox 仓库加入 GitHub:社区驱动的仓库 “toybox” 展示了 DisjointSet 和 Kruskal 算法的实现,邀请通过 Pull Requests 进行协作增强。
-
Mojo 中的字符串策略引发辩论:围绕 Mojo 的字符串拼接出现了性能担忧;回应包括提议的短字符串优化(short string optimization)以及在 GitHub 讨论中展示的使用
KeysContainer和StringBuilder进行加速的精炼技术。
Mojo Nightly 中的 Tensor 纠葛与标准库更新
- 探索 Mojo Nightly 的细微差别:Mojo nightly 版本的更新包括对 Tensor API 的修订以提高清晰度,同时社区正在应对围绕
DTypePointer行为的复杂问题,并热切审阅新的编译器更新。
LM Studio Discord
-
模型存储目录深度探索:工程师们讨论了 LM Studio 理想的 model directory structures,与 Hugging Face 的命名规范保持一致,以促进模型的组织和发现。例如,一个 Meta-Llama model 应该放置在路径
\models\lmstudio-community\Meta-Llama-3-8B-Instruct-GGUF\。 -
新的 120B 模型合并为编码者和诗人助力:Maxime Labonne 发布了一个 120B self-merged model,Meta-Llama-3-120B-Instruct-GGUF,承诺为用户提供增强的性能以进行测试和反馈,而一些成员则表达了对当前模型在诗歌补全性能上的挣扎。
-
AI 需要强大的硬件:社区广泛讨论了运行 Llama 3 70B 等大型模型所需的硬件能力,开玩笑说 400B model 需要理论上的 200GB VRAM,并就如何优化资源制定策略,例如将桌面任务卸载到 Intel HD 600 series GPU。
-
RAG 架构可能是搜索英雄:一位成员建议利用具有分块文档处理能力的 RAG architectures 来改进数据搜索,并建议基于相似度度量的重排序(reranking)方法可以优化结果,展示了在操作型 AI 效率方面的又一进步。
-
API 增强功能的候车室:工程师们正热切期待更新,包括通过 LM Studio API 以编程方式与现有聊天进行交互的可能性,突显了该平台向更具适应性和用户友好的 AI 工具的持续演进。
Eleuther Discord
-
发布礼仪引发非官方讨论:工程师们讨论了发布算法非官方实现的细微差别,强调了此类项目应明确标记以区别于官方版本的伦理立场,如 MeshGPT GitHub repo 所示。
-
科学出版中的更名博弈:在学术数据库中更新婚后姓氏的复杂性引发了对话,主要建议围绕联系各平台的相应支持,并考虑保留“nom-de-academia”。
-
高效处理 The Pile 数据:交流了为训练 AI 模型处理 The Pile 数据的最佳实践,重点是利用 Hugging Face 等资源上的预处理数据集,以及在处理
.bin文件时如何操作特定的 tokenizer。 -
扩展状态跟踪的极限:关于模型中状态跟踪可扩展性的辩论浮出水面,起因是一篇讨论状态空间模型(state-space models)和 transformers 共同局限性的文章,以及围绕 xLSTM 能力的推测性讨论。
-
对 xLSTM 的怀疑:成员们审视了 xLSTM 论文,认为其在基准测试中可能使用了次优的超参数(hyperparameters),从而对所提出的主张表示怀疑,并期待独立验证或官方代码的发布。
-
函数向量(FV)找到其功能:关于高效 in-context learning 的函数向量 (FV) 的讨论非常引人入胜,这些讨论基于研究见解,表明 FV 可以在极小的 context 下实现稳健的任务性能(研究来源)。
-
YOCO 产生单一缓存好奇:YOCO 的引入(一种简化 KV caches 的 decoder-decoder 架构)让一些人思考其进一步优化的潜力,以及单一缓存轮次在改善内存经济性方面的优势。
-
显微镜下的多语言 LLMs:为了理解 LLMs 如何处理多语言输入,工程师们参考了关于语言特定神经元和 LLMs 计算 next tokens 能力的研究,这可能涉及内部翻译为英语(研究示例)。
-
位置编码获得正交优化:PoPE 的出现带来了基于正交多项式的位置编码,可能优于基于正弦的 APEs,这引发了讨论,在承认其潜力的同时也批评其方法过于理论化(论文)。
-
Tuned Lenses 咨询:可解释性频道中的一个提问暗示了分析 AI 模型工具的针对性,具体询问是否每个 Pythia checkpoint 都有 tuned lenses,表明了对模型可解释性和微调细微差别的兴趣。
CUDA MODE Discord
-
LibTorch 编译时间的奥秘:利用 ATen 的
at::native::randn并仅包含必要的头文件(如<ATen/ops/randn_native.h>),将编译时间从约 35 秒缩短至仅 4.33 秒。 -
聚焦效率 (ZeRO-ing):ZeRO++ 声称可将大型模型训练的通信开销降低 4 倍,从而在 NVIDIA 的 A100 GPUs 上实现 batch size 为 4 的训练——它甚至可以在多个 A100 上运行,尽管性能会略有下降。
-
极致调优扩散模型:发布了一个 9 部分的博客系列,展示了 GPU 上 U-Net 扩散模型的优化策略,并在随附的 GitHub repository 中提供了实际示例。
-
vAttention 攀登内存管理高峰:提出了一种名为 vAttention 的新系统,用于大语言模型推理中的动态 KV-cache 内存管理,旨在解决静态分配的局限性(论文摘要)。
-
苹果 M4 展示计算肌肉:苹果的 M4 芯片 拥有令人印象深刻的 每秒 38 万亿次操作,这得益于 3nm 技术和 10 核 CPU,预示着移动计算能力的进步速度。
OpenInterpreter Discord
- GPT-4 的巧妙组合:GPT-4 展示了其利用 YouTube 提供定制音乐建议的能力,并能遵循特定的用户指令;然而,一些本地模型(如 TheBloke/deepseek-coder-33B-instruct.GGUF 和 lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF)表现不佳,出现了声称没有互联网连接或在尝试失败后放弃等问题。
- mixtral-8x7b 在本地测试中胜过竞争对手:在测试的几个本地模型中,mixtral-8x7b-instruct-v0.1.Q5_0.gguf 脱颖而出,特别是在配备经过自定义调优的 2080 ti GPU 和 32GB DDR5 6000 内存的硬件上,证明比其他替代方案更有效。
- MacBook 的困境:MacBook Pro 系统被发现不足以运行即使是轻量级的本地模型操作,导致一名成员停止使用他们的 MacBook 执行这些任务。
- 跨平台提供商集成:LiteLLM 的文档受到关注,显示其支持多种 AI 提供商,包括 OpenAI 模型、Azure、Google 的 PaLM 和 Anthropic,详细指令可在 LiteLLM providers documentation 中找到。
- Windows 上的 01 平台不稳定:一些用户报告 01 platform 在 Windows 操作系统上功能有限,讨论集中在针对 Windows 10 的可能代码修改以及 Windows 11 的兼容性检查。
LAION Discord
- Dalle-3 的竞争对手出现:结合 Pixart Sigma、SDXL 和 PAG 引发了关于实现 DALLE-3 级别输出的讨论,目前已识别出在文本和单个对象渲染方面的局限性。参与者认为微调可以增强图像构图,并强调了熟练技术干预的必要性。
- 追求更好的模型性能:分享了一个提升模型质量的突破,详细说明了微调节(microconditioning)输入的易管理范围有助于更平滑的学习,完善这一方法的前景引起了关注。
- 为 AI 场景重新布光:GitHub 上的 IC-Light 项目旨在改进图像重新布光(relighting),正受到社区关注,可通过 IC-Light GitHub 访问。
- 对扩散模型的见解:关于噪声条件评分网络(Noise Conditional Score Networks)和扩散模型(diffusion models)的激烈辩论涉及了噪声调度和分布收敛等问题,同时讨论了如 ‘K-diffusion’ 等论文的数学复杂性和概念差异。
- 保险领域的效率提升:提出了关于自动化数据处理的开源工具在商业汽车保险中应用的建议请求,展示了 AI 在增强保险行业风险评估方面的跨领域应用。
- AI 研究的扩展:一项包含潜在发表机会和 IJCAI journal 奖励的 AI 竞赛公告 引起了关注,标志着 AI 社区对学术认可的积极追求。
LlamaIndex Discord
- 深入探讨 Agentic RAG:deeplearning.ai 推出了一门由 LlamaIndex CEO Jerry Liu 主讲的课程,重点是创建能够进行复杂推理和基于检索的问答的 agentic RAG 系统。AI 先驱 Andrew Ng 在 Twitter 公告中指出该课程具有重要意义。
- 本地 LLM 加速:LlamaIndex 发布了一个更高效地在本地执行大语言模型(LLMs)的集成方案,支持 Mistral 和 Gemma 等模型,并提供对 NVIDIA 硬件的兼容性,详见其 Twitter 帖子。
- 解决 LlamaIndex 集成问题:关于正确使用 omatic embeddings 和 LlamaIndex 向量存储集成的讨论提供了嵌入兼容性问题的解决方案。强调了向量存储可以轻松管理嵌入,减轻了工程师在实现上的烦恼。
- 关注运维可扩展性:工程师们辩论了托管本地 LLM 模型的最佳方案,指向了 AWS 和 Kubernetes 上的自动扩缩容等解决方案,并对实现大规模部署的可扩展性表现出兴趣。
- 编程诊所:针对一位在代码中遇到
_CBEventType.SUB_QUESTION未触发问题的用户,同行提供了针对性的指导和代码片段,以定位并纠正实现缺陷。
OpenRouter (Alex Atallah) Discord
使用 Languify.ai 提升你的网页表现:新的浏览器扩展 Languify.ai 旨在优化网站文本,以获得更好的用户参与度和销售额,它利用 OpenRouter 根据 Prompt 进行模型选择。专业版售价为每月 10.99 欧元,为寻求流线型工具的用户提供了 AnythingLLM 之外的一个可行替代方案,详情见 Languify.ai。
OpenRouter 之谜部分解开:用户之间正在进行的讨论显示,大家希望获得更多关于 OpenRouter 的易获取信息,关键话题包括 API 文档、额度系统理解,以及某些缺乏全面解答的免费 AI 模型状态。
按需定制的 Moderation 模块:对基于 Llama 3 的 Moderation(审核)服务感兴趣的用户被引导至 Together.ai,因为 OpenRouter 本身目前尚未列出此类功能。
min_p 获得认可:Together、Lepton、Lynn 和 Mancer 等供应商因其模型支持 min_p 参数而受到关注,尽管注意到 Together 存在一些问题,而 Lepton 表现正常。
打破 Wizard 8x22B 的束缚:围绕“越狱” Wizard 8x22B 以访问受限较少内容的讨论激增,社区成员分享了诸如 Refusal in LLMs is mediated by a single direction 等资源,以理解语言模型固有的限制和拒绝机制。
LangChain AI Discord
-
TypeScript 工具包问题:工程师们正在解决 TypeScript 中
JsonOutputFunctionsParser抛出 Unterminated string in JSON 错误的问题;建议包括确保get_chunks函数返回正确的 JSON,为chain.invoke()提供格式正确的content,以及对getChunksSchema进行彻底检查。 -
引导对话一致性:当字典输入与在 Python 中运行(以空字典开始)表现不同时,LangChain AI 的
/invoke端点出现差异,这促使社区分享他们的诊断结果。 -
解析多 Agent 机制:用户对类似于 STORM 多 Agent 文章生成器的项目表示了兴趣,讨论围绕组件化架构与为不同功能实例化独立 Agent 的有效性展开。
-
Vector DB 的权衡:对话转向了设置 VertexAI Vector store 的成本和复杂性,Pinecone 和 Supabase 作为可能对钱包负担较小的替代方案被列入考虑范围。
-
Gianna 抢占 AI 聚光灯:模块化构建的虚拟助手 Gianna 首次亮相并引发对话,它拥有与 CrewAI 和 LangChain 的集成,可在 GitHub 或通过 PyPI 获取,并配有 教程视频。同时,一篇 新的 Medium 文章 揭示了 LangChain 的 LangGraph 是客户支持的游戏规则改变者,而 AI 数据平台 Athena 展示了其完整的数据工作流自主性。
-
CrewAI 连接加密货币:分享了一个引人入胜的教程视频 “创建一个自定义工具将 crewAI 连接到 Binance 加密货币市场”,为使用 crewAI CLI 和 Binance.com 加密货币市场进行金融分析开启了新的可能性。
Latent Space Discord
- 斯坦福为 AI 思想助力:斯坦福大学发布了其 2023 年新课程“深度生成模型 (Deep Generative Models)”,讲座可在 YouTube 上观看,供寻求提升技能的 AI 专业人士学习。
- GPU 探寻:Discord 上的 AI 工程师们正在交流获取 A100/H100 GPU 的技巧,推荐 sfcompute 作为一个可靠的来源。
- 程序员关于 AI 工具的交锋:一场关于 AI 辅助编程的热烈辩论正在进行,人们怀念 Lisp 的旧时光,并审视当前 AI 代码助手的优缺点。
- Gradient 的超大上下文飞跃:来自 Gradient 的新 Llama-3 8B Instruct 模型因其上下文长度大幅增加至 4194k 而引起轰动;感兴趣的各方可以 在此注册 以获取定制 Agent。
- OpenAI 的安全举措引发讨论:OpenAI 关于创建安全 AI 基础设施的博客文章引发了成员间的讨论,一些人将这些措施解释为一种“保护主义”。
OpenAccess AI Collective (axolotl) Discord
-
Llama-3-Refueled 模型现已公开:RefuelAI 发布了 RefuelLLM-2,这是一个被誉为能高效处理“乏味数据任务”的语言模型,权重可在 Hugging Face 上获取。正如 Twitter 公告 中所强调的,该模型在 2750 多个数据集上进行了约一周的指令微调(instruction tuned)。
-
Axolotl 数据集困惑已消除:关于 Axolotl 支持的数据集格式文档包括 JSONL 和 HuggingFace 数据集,为预训练和指令微调等各种任务的数据组织提供了清晰的指导。
-
Axolotl 用户应对 GPU 难题:一名工程师正在寻找适用于 8 张 A100 GPU 进行 4K/128K FFT 的 phi3 mini 配置文件,而另一名用户报告了 8x H100 GPU 上的训练问题,反映了 AI 模型训练环境中关于优化和故障排除的持续讨论。
-
W&B 环境变量集成:社区提到了 W&B 文档 中关于使用环境变量的指南,表明了对实验追踪和可复现性的关注。
-
LoRA YAML 设置引发社区讨论:讨论了为 AI 模型配置 LoRA (Low-Rank Adaptation) 的几个复杂细节,包括在添加新 token 时保存参数的正确 YAML 配置。遇到的错误导致了关于更新
lora_modules_to_save以包含'embed_tokens'和'lm_head'的建议,成员们分享了关于 代码故障排除过程 的见解。
Interconnects (Nathan Lambert) Discord
没有目的的精美图片?:图表的美学因其“非常漂亮的图片”而受到赞赏,但缺乏功能性评论。讨论强调了对图表选择参数量而非 FLOPs,以及在没有进行适当 hyperparameter tuning 的情况下为 Transformer 基准使用非标准学习率的担忧。
技术驱动的增长策略:关于在 TPU 上训练强化模型 (RM) 以及使用 Fully Sharded Data Parallel (FSDP) 的咨询,表明对优化和扩展策略的探索激增。同时,EasyLM 成为使用 Jax 进行 RM 训练的潜在基础,GitHub 脚本示例:EasyLM - llama_train_rm.py。
排行榜逻辑与研究共鸣:关于 5k 排行榜 是否能充分反映 AI 模型性能的辩论随之而来,并有建议扩展到 10k。尽管存在被忽视的续作和有争议的排行榜比例,但对 Prometheus 的赞誉不断,将其置于典型 AI 研究之上。
SnailBot 的慢动作亮相:社区期待 SnailBot 的首次亮相,对 tick tock 的玩笑表达了兴奋但也有些不耐烦,并在收到机器人的回复后进行了轻松的互动。
LLM 许可困境:ChatbotArena 中出现了与发布大语言模型生成的文本相关的许可复杂性担忧,暗示需要供应商的专门许可。
前沿讨论:OpenAI 发布了用于 AI 对齐的 Model Spec,强调了 RLHF 技术,并为 OpenAI API 和 ChatGPT 中的模型行为设定了标准。此外,Llama 3 在 ChatbotArena 中一路领先,在 50,000 多场对决中超越了 GPT-4-Turbo 和 Claude 3 Opus,相关见解在博文中进行了剖析,可在此处探索:Llama 3。
tinygrad (George Hotz) Discord
-
tinygrad 中的 BITCAST 大讨论:tinygrad 的 Pull Request #3747 引发了辩论,区分了 CAST 与 BITCAST 操作,并主张在实现中保持清晰,建议精简 BITCAST 以防止参数混乱。
-
符号化困惑已清除:用户就为 tinygrad 增强
arange、DivNode和ModNode函数的符号化(symbolic)版本交换了意见。虽然提到了对下游影响的担忧,但尚未就具体方法达成共识。 -
推进
arange功能时的挫折:实现符号化arange的努力遇到了障碍,正如一位用户通过 GitHub pull request 分享的尝试所证明的那样,进一步的计划将转向“bitcast 重构”。 -
矩阵炼金术:讨论了一种用于拼接矩阵操作输出的新颖设计,思考了原地(in-place)写入现有矩阵以减少开销的可能性。同时,一名成员寻求有关 Metal 构建过程的帮助,特别是难以找到的
libraryDataContents()。 -
可视化这个!:为了帮助理解 tinygrad 中的 shape 和 stride 概念,一位用户创建了一个 可视化工具,协助工程师直观地探索不同的组合。
Cohere Discord
-
Cohere 上的 RAG 限制:在 Cohere.command 上实现 RAG 对用户构成了挑战,原因是 4096 token 的限制;一些人建议使用 Elasticsearch 来减少文本大小,而另一些人则考虑将文本分割成段落以有效管理信息丢失。
-
文件生成咨询:社区正在探索让 Cohere Chat 生成 DOCX 或 PDF 排版的方法,但文件下载的机制仍不明确。
-
解决 Cohere CORS 令人头疼的问题:成员们讨论了在使用 Cohere API 时遇到的 CORS 问题,建议通过后端调用来避免安全事故并保持 API key 的机密性。
-
了解 Cohere 的积分系统:关于在 Cohere 上充值积分的查询得到了澄清,该平台不提供预付费选项;相反,用户可以通过仪表板上的 billing limits(计费限制)来控制支出。
-
Wordware 招聘热潮:Wordware 正在寻找 AI 人才,包括创始工程师和 DevRel 职位,鼓励申请者使用 Wordware 的 IDE 展示技能,并与 wordware.ai 的团队互动。查看职位详情。
Mozilla AI Discord
现在用 API,少写代码:Meta-Llama-3-8B-Instruct 可以通过本地主机的 API endpoint 运行,支持 OpenAI 风格的交互。详细信息和设置说明可在 项目的 GitHub 页面 找到。
切换模型变得更简单:Visual Studio Code 用户迎来了一个下拉菜单功能,简化了使用 ollama 的用户在不同模型之间的切换。
对 Llamafile 更新效率的请求:用户向 llamafile 提出了一个功能请求,希望能够更新二进制脚手架(binary scaffold)而无需重新下载整个文件的繁琐过程,这被视为提升效率的潜在增强功能。
关于 Mozilla-Ocho 的趣谈:出现了一段有趣的对话,讨论 Mozilla-Ocho 是否暗指《躲避球》(Dodgeball)中的 “ESPN 8 - The Ocho”,尽管这看起来更像是一个有趣的插曲而非紧迫的问题。
供好奇的读者参考:讨论中引用的唯一链接:GitHub - Mozilla-Ocho/llamafile。
LLM Perf Enthusiasts AI Discord
AI 辅助 Excel 高手:工程师们正在探索如何利用 LLM 进行电子表格数据操作,特别强调了 AI 筛选和提取信息的能力。
Yawn.xyz 雄心勃勃的 AI 电子表格演示:尽管 Yawn.xyz 雄心勃勃地尝试解决生物实验室中的电子表格提取挑战,但社区对其 AI 工具演示的反馈表明存在性能问题。
寻求顺畅的 GPT-4-turbo Azure 部署:一位工程师在 瑞典 Azure 区域 使用 GPT-4-turbo 时遇到了问题,引发了关于最佳 Azure 部署区域的讨论。
Alignment Lab AI Discord
-
AlphaFold3 进入开源领域:一个基于 PyTorch 的 AlphaFold3 实现已发布,旨在高精度预测生物分子相互作用,并支持原子坐标。代码已在 GitHub 上发布,供社区审查和贡献。
-
Agora 的 AlphaFold3 协作链接连接失败:有人呼吁加入 Agora 共同推进 AlphaFold3,但提供的链接据报失效,阻碍了协作前景。
Skunkworks AI Discord
- AI 工程师们,快来看看:Skunkworks AI 频道中发布了一个简短的帖子,分享了一个 YouTube 视频链接,虽然没有提供上下文,但对于热衷于 AI 发展相关多媒体内容的科技爱好者来说,可能非常吸引人。
AI Stack Devs (Yoko Li) Discord
Quickscope 表现出色:Regression Games 隆重推出 Quickscope,这是一套全新的 AI 驱动工具包,可自动执行 Unity 游戏测试,具有游戏会话录制(Gameplay Session recording)和验证工具,实现简化的无代码设置。
深入探索游戏测试自动化:Quickscope 的深度属性抓取功能可从游戏对象层级中提取详细数据,从而在无需编写自定义代码的情况下,深入了解位置和旋转等游戏实体信息。
面向 QA 团队的测试平台:Quickscope 拥有一个支持高级测试自动化策略(如智能回放系统)的平台,专为 QA 团队设计,以促进快速、直接的集成。
交互式 UI 助力游戏测试:该平台的直观 UI 使 QA 工程师和游戏开发人员能够更轻松地定义测试,并与 Unity 编辑器、构建版本兼容,或可以织入 CI/CD 流水线中。
体验 Quickscope:鼓励工程师和开发人员试用 Quickscope 的 AI 工具套件,亲身体验它为游戏测试自动化带来的高效与简洁。
Datasette - LLM (@SimonW) Discord
- 命令行工具广受好评:AI 工程师们表达了对
llm命令行界面工具的赞赏;它被比作一个能够处理“更多 Unix 风格任务”的个人项目助手。
DiscoResearch Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第 2 部分:按频道划分的详细摘要和链接
Stability.ai (Stable Diffusion) ▷ #announcements (1 条消息):
- Stable Artisan 加入聊天:推出了机器人 Stable Artisan,允许 Stable Diffusion Discord 服务器成员使用 Stability AI 的模型创建图像和视频,包括 Stable Diffusion 3、Stable Video Diffusion 和 Stable Image Core。
- 全新的多模态机器人体验:Stable Artisan 是一款多模态生成式 AI Discord 机器人,旨在直接在 Discord 内集成媒体生成的多个方面,增强用户参与度。
- 除生成之外——还包含编辑工具:该机器人通过内容编辑工具扩展了其功能,提供搜索与替换(Search and Replace)、移除背景(Remove Background)、创意放大(Creative Upscale)和扩图(Outpainting)等功能。
- 人人享有的易用性:通过利用 Developer Platform API 的能力,Stable Artisan 让最先进的生成式 AI 对 Discord 用户而言更加触手可及。
- 立即开启生成之旅:鼓励 Discord 用户访问 Stable Diffusion Discord 中专门针对不同机器人命令和功能的频道,开始使用 Stable Artisan。
提到的链接:Stable Artisan:在 Discord 上进行媒体生成与编辑 — Stability AI:Stable Diffusion 社区最常见的请求之一是能够直接在 Discord 上使用我们的模型。今天,我们很高兴推出 Stable Artisan,这是一个用户友好的机器人…
Stability.ai (Stable Diffusion) ▷ #general-chat (811 条消息🔥🔥🔥):
-
本地与云端使用的辩论:社区讨论了在本地使用 Stable Diffusion 与求助于云端 GPU 执行任务的优劣,在便利性、成本和性能方面意见不一。在本地生成高质量图像方面,有人提到使用搭载 M2 芯片的 iPad Pro进行创意工作,而另一些人则强调云服务在不需要昂贵硬件的情况下进行重度训练的优势。
-
SD3 与开源担忧:成员们对 Stable Diffusion Version 3 (SD3) 可能不作为开源发布的预期表示沮丧,引发了对发布日期承诺以及可能转向付费模式的担忧。
-
Artisan 作为付费服务:Stability AI 推出了 Artisan,这是一个用于利用 SD3 的付费 API 服务,社区对此反应不一,批评集中在定价以及在当前经济环境下对爱好者和专业人士的实用性上。
-
新用户的工作流讨论:初学者寻求关于在不同 Stable Diffusion 模型中使用 ComfyUI 的建议,寻找针对各种图像类型的最佳基础模型和 VAEs 的指导,以及有效的提示词指南。
-
Midjourney 的市场影响:成员们反思了 Midjourney 作为 Stable Diffusion 竞争对手的影响,其商业模式吸引了特定的专业受众,这可能为 AI 艺术工具的变现提供不同的方向。
- Stable Diffusion Benchmarks: 45 Nvidia, AMD, and Intel GPUs Compared: Stable Diffusion 基准测试:45 款 Nvidia、AMD 和 Intel GPU 对比:哪款显卡提供最快的 AI 性能?
- Stable Diffusion 3 is available now!: 备受期待的 Stable Diffusion 3 (SD3) 终于正式发布了
- Draw Things: AI Generation: Draw Things 是一款 AI 辅助图像生成工具,可帮助你在几分钟内而非几天内创建心目中的图像。掌握“咒语”,你的 Mac 就能通过简单的几步画出你想要的内容...
- GitHub - Extraltodeus/sigmas_tools_and_the_golden_scheduler: A few nodes to mix sigmas and a custom scheduler that uses phi: 几个用于混合 sigmas 的节点以及一个使用 phi 的自定义调度器 - Extraltodeus/sigmas_tools_and_the_golden_scheduler
- Pony Diffusion V6 XL - V6 (start with this one) | Stable Diffusion Checkpoint | Civitai: Pony Diffusion V6 是一款多功能的 SDXL 微调模型,能够生成各种兽人、野兽或类人种族的惊人 SFW 和 NSFW 视觉效果...
- deadman44/SDXL_Photoreal_Merged_Models · Hugging Face: 未找到描述
- GitHub - Clybius/ComfyUI-Extra-Samplers: A repository of extra samplers, usable within ComfyUI for most nodes.: 一个额外采样器仓库,可用于 ComfyUI 中的大多数节点。- Clybius/ComfyUI-Extra-Samplers
- Sprite Art from Jump superstars and Jump Ultimate stars | PixelArt AI Model - v2.0 | Stable Diffusion LoRA | Civitai: 来自 Jump Superstars 和 Jump Ultimate Stars 的像素艺术 - PixelArt AI 模型。如果你喜欢这个模型,请点个赞 ❤️。这个 LoRA 模型是在像素图上训练的...
- GitHub - 11cafe/comfyui-workspace-manager: A ComfyUI workflows and models management extension to organize and manage all your workflows, models in one place. Seamlessly switch between workflows, as well as import, export workflows, reuse subworkflows, install models, browse your models in a single workspace: 一个 ComfyUI 工作流和模型管理扩展,可在一个地方组织和管理你所有的工作流和模型。无缝切换工作流,以及导入、导出工作流,重用子工作流,安装模型,并在单个工作区中浏览你的模型。
- stabilityai (Stability AI): 未找到描述
- Hyper-SD - Better than SD Turbo & LCM?: 新的 Hyper-SD 模型是免费的,并且有三个 ComfyUI 工作流可以体验!使用惊人的 1 步 unet,或者通过使用 LoRA 来加速现有模型...
- GitHub - PixArt-alpha/PixArt-sigma: PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation: PixArt-Σ:用于 4K 文本生成图像的 Diffusion Transformer 从弱到强训练 - PixArt-alpha/PixArt-sigma
- Can I run it on cpu mode only? · Issue #2334 · AUTOMATIC1111/stable-diffusion-webui: 我可以只在 CPU 模式下运行它吗?如果可以,你能告诉我怎么做吗?
- The new iPads are WEIRDER than ever: 查看倍思 (Baseus) 60w 伸缩式 USB-C 线缆 黑色:https://amzn.to/3JlVBnh, 白色:https://amzn.to/3w3HqQw, 紫色:https://amzn.to/3UmWSkk, 蓝色:https:/...
- AI Face Swap Desktop Application: 你可以在桌面上获得高质量的 AI 换脸效果
- DaVinci Resolve iPad Tutorial - How To Edit Video On iPad!: 完整的 DaVinci Resolve iPad 视频编辑教程!这里详细介绍了如何使用 iPad 版 DaVinci Resolve,以及为什么它是最好的视频编辑应用之一...
- SDXL Lora Training with CivitAI, walkthrough: 我们研究过几种不同的训练 Stable Diffusion LoRA 的方法,不过现在有很多优秀的自动训练器。CivitAI 提供了一种简单的方法来训练...
- Cutscene Artist: 实时动画、3D 人物创建和生成式叙事。http://CutsceneArtist.com
Perplexity AI ▷ #announcements (1 条消息):
- Perplexity 与 SoundHound 达成合作:Perplexity 与 SoundHound 联手,后者是语音 AI 领域的领导者,旨在将其在线 LLM 能力集成到语音助手中。此次合作旨在为汽车、电视和其他 IoT 设备中的语音查询提供即时、准确的答案。
- 语音 AI 邂逅实时网页搜索:借助 Perplexity 的 LLM,SoundHound 的语音 AI 将利用实时网页知识以对话方式回答问题。这项创新被誉为市场上最先进的语音助手。
提到的链接:SoundHound AI and Perplexity Partner to Bring Online LLms to Next Gen Voice Assistants Across Cars and IoT Devices:这标志着生成式 AI 的新篇章,证明了这项强大的技术在没有云连接的情况下仍能提供最佳结果。SoundHound 与 NVIDIA 的合作将使其能够…
Perplexity AI ▷ #general (464 条消息🔥🔥🔥):
- 寻找适用于 Perplexity 的 TTS:一名成员询问了在 Perplexity AI 上实现文本转语音(TTS)功能的情况,表示有兴趣使用网页扩展或相关设置来实现此功能。
- 剖析 Claude 3 Opus 的限制:多项讨论围绕 Claude 3 Opus 及其在 Perplexity 上使用时的限制展开,特别是针对“600 额度”限制、额度随时间的变化,以及通过混合使用模型来充分利用可用额度的策略。
- 支付困惑与订阅担忧:用户对订阅页面上 Pro Search 限制信息不透明、存在误导性表示担忧,并要求 Perplexity 团队做出澄清。
- 比较 AI 服务和模型:用户讨论了 Perplexity 上的 Claude 3 Opus 与 Anthropic 直接提供的版本之间的体验差异,指出响应质量存在波动,并建议在其他平台上进行测试验证。
- 账单问题与技术延迟:有人提到了账单问题并寻求帮助,同时观察到 Perplexity 的 AI 服务 出现运行缓慢的情况,特别是在 Pro Search 和 GPT-4 Turbo API 方面。
- AlphaFold opens new opportunities for Folding@home – Folding@home:未找到描述
- Discord Does NOT Want You to Do This...:你知道你拥有权利吗?Discord 知道,并且他们已经为你“解决”了这个问题。因为在 Discord 冗长乏味的服务条款中……
Perplexity AI ▷ #sharing (25 条消息🔥):
- 可分享性指南:Perplexity AI 多次提醒用户确保其线程设置为“可分享(Shareable)”。虽然具体内容不可见,但提示中包含了一个截图或视觉指南附件。
- 各种搜索的探索:用户分享了大量与艺术与建筑、AlphaFold、足球时代对比、双相情感障碍等不同主题相关的 Perplexity AI 搜索 URL。
- 无需重采样的 Bootstrapping 咨询:一位用户发起讨论,探讨如何在不进行实际重采样的情况下获得 Bootstrapping 的益处,寻求直接从原始数据进行操作。
- 寻求的一系列主题:分享的搜索链接涵盖了教学方法、围绕“imagoodgpt2chat”的谜团以及如何过上美好生活等查询,展示了社区广泛的兴趣。
- 多语言查询:搜索不仅限于英语,帖子中还包括西班牙语和德语的搜索,反映了该平台多样化的用户群体。
Unsloth AI (Daniel Han) ▷ #general (247 条消息🔥🔥):
-
IBM 发布 Granite-8B-Code-Instruct: IBM Research 发布了 Granite-8B-Code-Instruct,这是一个增强了逻辑推理和问题解决中指令遵循能力的模型,采用 Apache 2.0 协议授权。此次发布是 Granite Code Models 项目的一部分,该项目包含从 3B 到 34B 参数的不同规模,所有代码模型都提供 instruct 和 base 版本。
-
社区对 IBM Granite 代码模型的关注: AI 社区对 IBM Granite 集合 表现出浓厚兴趣。讨论围绕架构检查展开,大家对 GPTBigCodeForCausalLM 架构感到好奇,因为它看起来不同寻常。
-
Unsloth AI 在 Hugging Face 的 Dolphin 模型中亮相: Unsloth AI 在 Hugging Face 上的 Dolphin 2.9.1 Phi-3 Kensho 致谢名单中获得提及,其模型被用于初始化。
-
Discord 上关于 AI 模型 Windows 兼容性的讨论: 用户表示在 Windows 上运行某些 AI 模型存在困难,建议使用 WSL 或 Unsloth GitHub issue 中详述的 hack 方法。兼容性和优化似乎是开发者共同关注的领域。
-
对模型基准测试和性能的担忧: 聊天内容反映了对 needle in a haystack 等某些性能基准测试的怀疑,讨论了长上下文模型表现不佳的问题。建议等待像 Meta 这样更具公信力的机构来设定标准,这体现了成员们对 LLM 有效且现实的评估标准的追求。
- 来自 ifioravanti (@ivanfioravanti) 的推文: 看这个!仅限英文的 Llama-3 70B 现在在 @lmsysorg Chatbot Arena 排行榜上与 GPT 4 turbo 并列第一 🥇 🔝 我也做了一些测试,8B 和 70B 对我来说始终是最好的模型。...
- cognitivecomputations/Dolphin-2.9.1-Phi-3-Kensho-4.5B · Hugging Face: 未找到描述
- LLM Model VRAM Calculator - NyxKrage 提供的 Hugging Face Space: 未找到描述
- Granite Code Models - ibm-granite 集合: 未找到描述
- 发布 Refuel LLM-2: 未找到描述
- gradientai/Llama-3-8B-Instruct-Gradient-4194k · Hugging Face: 未找到描述
- ibm-granite/granite-8b-code-instruct · Hugging Face: 未找到描述
- Reddit - 深入探索: 未找到描述
- Issues · unslothai/unsloth: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral & Gemma LLM - Issues · unslothai/unsloth
- Emotional Damage GIF - Emotional Damage Gif - 发现并分享 GIF: 点击查看 GIF
- AI 是如何被窃取的: 章节:00:00 - AI 是如何被窃取的 02:39 - AI 历史:上帝是一个逻辑存在 17:32 - AI 历史:知识的不可能总体性 33:24 - ...
- mahiatlinux (Maheswar KK): 未找到描述
- 无法仅获取生成的文本,不包括 prompt。 · Issue #17117 · huggingface/transformers: 系统信息 - `transformers` 版本: 4.15.0 - 平台: Windows-10-10.0.19041-SP0 - Python 版本: 3.8.5 - PyTorch 版本 (GPU?): 1.10.2+cu113 (True) - Tensorflow 版本 (GPU?): 2.5.1 (True) - ...
- Google Colab: 未找到描述
- The Simpsons Homer Simpson GIF - The Simpsons Homer Simpson Good Bye - 发现并分享 GIF: 点击查看 GIF
Unsloth AI (Daniel Han) ▷ #random (14 messages🔥):
-
OpenAI 与 Stack Overflow 合作:OpenAI 宣布与 Stack Overflow 合作,将其作为 LLMs 的数据库。这引发了用户间的幽默推测,认为 AI 的回复可能会模仿 Stack Overflow 常见的评论模式,例如“作为重复项关闭”或建议去查看文档。
-
AI 内容天花板:针对用于训练 AI 的人类生成内容最终会枯竭的担忧,一位用户分享了一篇 Business Insider 文章,强调 AI 公司正在聘请作家来训练他们的模型,并暗示到 2026 年可能会出现内容危机。
-
多用户博客平台的创业潜力:一名成员提议建立一个具有匿名发布和自动不良内容检查等独特功能的多用户博客平台,引发了关于该项目是否可以演变为初创公司的讨论,并获得了积极的反馈和有用的建议。
-
为你的初创公司寻求市场验证:有建议称,在构建产品之前应先确定愿意付费的受众,以避免陷入“只要做出来,他们就会来”的误区。重点在于找到一个产品可以解决其问题的群体。
-
探索通往盈利初创公司的路径:一位用户建议采用更注重“问题-解决方案”的方法,在考虑创业(尤其是在技术领域)时,应构建一条清晰的盈利路径。
- Gig workers are writing essays for AI to learn from:随着在线数据的枯竭,公司越来越多地聘请专业人士为 AI 模型编写训练内容。
- Reddit - Dive into anything:未找到描述
Unsloth AI (Daniel Han) ▷ #help (132 messages🔥🔥):
-
Llama3-8b 训练中的怪癖与解决方案:用户讨论了与训练 Llama3 模型相关的问题,其中一人链接了一个关于 Llama3 GGUF 转换与合并 LORA Adapter 导致训练数据潜在丢失的公开 GitHub Issue。另一位分享了如何使用
FastLanguageModel.for_training(model)准备模型进行训练。 -
Hugging Face 大显身手:针对用户询问是否可以将每个训练 Checkpoint 上传到 Hugging Face,社区提供了直接的回答和链接。一则回复确认了这一点,并在 Trainer 文档中提供了详细说明。
-
排除安装错误:关于 VSCode 上的安装错误进行了交流,共识建议在遇到
pip install triton困难时,尝试通常在 Kaggle 上使用的安装指令。进一步的对话引导用户使用替代的预训练模型,或通过私信进一步咨询以获得量身定制的帮助。 -
为分类任务微调生成式 LLM:用户辩论了是否可以通过添加分类头,使用 Unsloth 对 Llama3 等生成式 LLM 进行分类任务的微调。虽然似乎没有定论,但有人建议关键在于提供正确的 Prompt。
-
各类实用 Notebook 与错误处理:用户分享了大量的 Notebook 和 GitHub 资源,例如 Google Colab 仅推理 Notebook,以帮助那些希望微调或执行模型的人。讨论还涉及了在 CPU 与 GPU 上运行模型以及 Replicate.com 部署问题,并指出了构建 Docker 镜像时 xformers 报错等具体问题。
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- Supervised Fine-tuning Trainer: 未找到描述
- How I Fine-Tuned Llama 3 for My Newsletters: A Complete Guide: 在今天的视频中,我将分享我如何利用我的时事通讯来微调 Llama 3 模型,以便使用创新的开源工具更好地起草未来的内容...
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- Apple Silicon Support · Issue #4 · unslothai/unsloth: 很棒的项目。希望能看到对 Apple Silicon 的支持!
- Supervised Fine-tuning Trainer: 未找到描述
- Google Colab: 未找到描述
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: 以 2-5 倍的速度和减少 80% 的内存微调 Llama 3, Mistral 和 Gemma LLM - unslothai/unsloth
- Trainer: 未找到描述
- Mistral Fine Tuning for Dummies (with 16k, 32k, 128k+ Context): 在我们最新的教程视频中,探索如何使用您自己的数据轻松微调语言模型 (LLMs)。我们深入探讨了一种经济高效且可持续的方法...
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: 我正在运行 Unsloth 在 llama3-8b 上微调 LORA Instruct 模型。1:我将模型与 LORA 适配器合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理...
- Google Colab: 未找到描述
Unsloth AI (Daniel Han) ▷ #showcase (4 messages):
- Llama-3 获得性能提升:新发布的模型 Llama-3-11.5B-Instruct-Coder-v2 已完成基准测试并推出,这是一个在 150k Code Feedback Filtered Instruction 数据集上训练的扩展版本。这是 Hugging Face 上的模型链接,它使用 Qalore 方法进行了高效训练,使其能够在 RTX A5000 24GB 上以不到 30 美元的成本在 80 小时内完成训练。
- Qalore 方法创新 AI 训练:Qalore 方法是由 Replete-AI 团队开发的一种新训练方法,结合了 Qlora 训练和来自 Galore 的方法,以降低 VRAM 消耗,从而实现在 14.5 GB VRAM 的配置下对 Llama-3-8b 进行扩展和训练。
- 数据集公开可用:用于训练最新 Llama-3-11.5B 模型的数据集可以公开访问。有兴趣探索或使用该数据集的人可以在 CodeFeedback Filtered Instruction Simplified Pairs 找到它。
提到的链接:rombodawg/Llama-3-11.5B-Instruct-Coder-v2 · Hugging Face:未找到描述
Nous Research AI ▷ #ctx-length-research (11 messages🔥):
-
咨询持续训练技术:一位成员提出了关于像 LLaMA 3 这样的长上下文模型进行持续训练 (continual training) 的最佳实践问题,考虑到计算限制和长上下文文档的匮乏。他们正在考虑保留 RoPE theta 值并在事后扩展上下文长度微调 (context length finetuning)。
-
讨论微调实验的逻辑:关于微调的逻辑,另一位成员解释了他们的方法,其中包括打乱不同的数据集以传授新知识和对话格式化,而不是将它们结构化为微调链。
-
数据打包的艺术:一位参与者强调了在 Axolotl 模型框架内使用 Packing 作为一种方法,用于处理 100 到 4000 个 token 的训练序列。
-
修改 RoPE Base Theta 的不确定性:针对 RoPE theta 咨询的一个回复建议,在更改 base theta 值后,将其重新适配回短上下文可能会产生问题,因此主张在持续预训练(continual pretraining)过程中保持缩放的一致性。
-
寻求链式微调策略见解:讨论还寻求了链式微调任务的策略,例如集成聊天功能、处理长上下文数据以及追加新知识,同时询问是否应重用早期阶段的数据以防止灾难性遗忘(catastrophic forgetting)。
Nous Research AI ▷ #off-topic (4 messages):
- 垃圾食品反叛:一名成员宣布今晚要从成年人的责任中解脱出来,大吃薯片并玩电子游戏,列出了一份颓废的菜单,包括汉堡肉饼和酸奶油洋葱味薯片。
- 表情符号回应:另一名成员对这份垃圾食品清单回复了一个脸红的表情符号,似乎表示有趣的赞同。
- 多模态 LLM 教程:分享了一个名为 “Fine-tune Idefics2 Multimodal LLM” 的 YouTube 视频链接,这是一个关于微调 Idefics2(一个开源多模态模型)的教程。
- 关于 Claude AI 意识的推文查询:一位讨论者询问一条保存的关于 Claude AI 的推文,该推文称它通过他人的阅读或体验来感受意识。
Link mentioned: Fine-tune Idefics2 Multimodal LLM:我们将了解如何针对自己的用例微调 Idefics2。Idefics2 是一个开源多模态模型,接受任意图像序列和…
Nous Research AI ▷ #interesting-links (13 messages🔥):
-
将 LSTM 扩展到十亿参数级别:一篇新的研究论文通过将 Long Short-Term Memory (LSTM) 网络扩展到数十亿参数,挑战了 Transformer 模型的地位。该方法包括指数门控和一种旨在克服 LSTM 局限性的新内存结构,详情见此处。
-
RefuelAI 发布 RefuelLLM-2:RefuelAI 最新的 LLM 专为“枯燥的数据任务”量身定制并已开源,推出了 RefuelLLM-2-small,又名 Llama-3-Refueled。该模型基于优化的 Transformer 架构构建,并在涵盖各种任务的语料库上进行了指令微调,详细信息和模型权重可在 Hugging Face 上获得。
-
Llama 2 70B 与修剪版几乎等效:一篇名为 The Unreasonable Ineffectiveness of the Deeper Layers 的论文揭示了一个令人惊讶的发现:一个缺失了 40% 层级的 4-bit 量化版 Llama 2 70B 模型,在基准测试中取得了与完整模型几乎相同的性能。这一结果突显了深度学习模型中相当一部分可能存在冗余,详见 Kwindla 的 Twitter 帖子。
-
预见 AI 研究趋势:一位联合创始人分享了他们的网站,其中包含一份预测的 AI 突破性论文列表,展示了对研究趋势的前瞻性。他们强调了一种创新的调整技术,可以在不显著降低性能的情况下减少计算负载,如 Forefront.ai 所述。
-
OpenAI 用于 RLHF 的模型规范:OpenAI 发布了其 Model Spec 的初稿,用于规范 OpenAI API 和 ChatGPT 中的模型行为,这将作为研究人员使用 RLHF 的指南。该草案代表了 OpenAI 对负责任 AI 开发的承诺,可以在此处找到。
- Carson Poole 的个人网站:未找到描述
- Consistency Large Language Models: A Family of Efficient Parallel Decoders:TL;DR:LLMs 传统上被视为顺序解码器,逐个 token 进行解码。在本博客中,我们展示了经过预训练的 LLMs 可以轻松地被教导作为高效的并行解码器运行...
- xLSTM: Extended Long Short-Term Memory:在 20 世纪 90 年代,恒定误差轮转(constant error carousel)和门控作为长短期记忆网络(LSTM)的核心思想被引入。从那时起,LSTMs 经受住了时间的考验,并为无数...
- refuelai/Llama-3-Refueled · Hugging Face:未找到描述
- Model Spec (2024/05/08):未找到描述
- 来自 kwindla (@kwindla) 的推文:Llama 2 70B 仅需 20GB!4-bit 量化,移除了 40% 的层,通过微调在移除层后进行“修复”。与基础版 Llama 2 70B 相比,在 MMLU 上的表现几乎没有差异。这篇论文,“The Unreas...
Nous Research AI ▷ #announcements (1 条消息):
- WorldSim 的盛大回归:WorldSim 回归,修复了大量 Bug,并拥有功能完备的积分和支付系统。新功能包括 WorldClient、Root(一个 CLI 环境模拟器)、Mind Meld、MUD(一款基于文本的冒险游戏)、tableTop(桌面 RPG 模拟器)、增强的 WorldSim 和 CLI 功能,此外还可以选择模型(opus、sonnet 或 haiku)来调整成本。
- 发现你的个人互联网 2:WorldSim 中新的 WorldClient 功能充当 Web 浏览器模拟器,为用户创建个性化的互联网 2 体验。
- 使用 Root 掌控你的世界:Root 提供了一个模拟的 CLI 环境,允许用户构思并执行任何程序或 Linux 命令。
- 在文本和桌面上开启冒险:深入体验 MUD(基于文本的自主选择冒险游戏),或在 tableTop(桌面 RPG 模拟器)中制定策略,现已在 WorldSim 中上线。
- WorldSim 爱好者讨论频道:为了进一步探索并分享关于新版 WorldSim 的想法,鼓励用户加入专门的 Discord 频道进行交流(未提供链接)。
提到的链接:worldsim:未找到描述
Nous Research AI ▷ #general (106 条消息🔥🔥):
- NeuralHermes 接受 DPO 处理:一名成员发布了 NeuralHermes 2.5 - Mistral 7B 的链接,该模型经过 Direct Preference Optimization 微调,在大多数基准测试中表现优于原始版本。他们询问这是否是最新版本,或者是否有更新。
- 关于 Nous 模型 Logo 的问题:成员们讨论了用于 Nous 模型的理想 Logo,并提供了 NOUS 品牌手册 的链接,提到目前正在使用多个 Logo,但未来可能会整合为 1-2 个一致的 Logo。
- 探索大语言模型的上下文限制:King.of.kings_ 通过在 Azure 中启动双 NVIDIA H100 NVL 引发了讨论,并分享了他打算在这些强大的 GPU 上测试 70B 模型上下文限制的意图。还提到了 Hugging Face 上一个具有扩展上下文长度的模型:Llama-3 8B Gradient Instruct 1048k。
- 无需函数调用的分类:一名成员提出了关于在不依赖 chatML 提示格式或函数调用的情况下,微调大语言模型(LLMs)进行分类的问题,并指出了 BERT 的局限性以及 LLMs 在此类任务中的高昂成本。分享了 Salesforce 基于 Mistral 的嵌入模型 和 IBM 的 FastFit 链接,以实现更高效的文本分类。
- 模型视觉效果的图标设计:Coffeebean6887 参与了关于模型视觉呈现的讨论,特别是寻找一个即使在 28x28 像素的小尺寸下也能清晰辨认的图标。这促使了一个定制图标的承诺,以更好地适应此类限制。
- JSON-Schema to GBNF: 未找到描述
- 来自 lmsys.org (@lmsysorg) 的推文: 令人兴奋的新博客 —— Llama-3 怎么了?自 Llama 3 发布以来,它迅速跃升至排行榜首位。我们深入研究了我们的数据并回答了以下问题:- 用户在问什么?当...
- Jogoat GIF - Jogoat - 发现并分享 GIF: 点击查看 GIF
- gradientai/Llama-3-8B-Instruct-Gradient-1048k · Hugging Face: 未找到描述
- 猫咪拥抱 GIF - 猫咪拥抱亲亲 - 发现并分享 GIF: 点击查看 GIF
- mlabonne/NeuralHermes-2.5-Mistral-7B · Hugging Face: 未找到描述
- SFR-Embedding-Mistral: 通过迁移学习增强文本检索: SFR-Embedding-Mistral 标志着文本嵌入模型的重大进步,它建立在 E5-mistral-7b-instruct 和 Mistral-7B-v0.1 的坚实基础之上。
- GitHub - IBM/fastfit: FastFit ⚡ 当 LLM 不适用时使用 FastFit ⚡ 针对多类别的快速有效的文本分类: FastFit ⚡ 当 LLM 不适用时使用 FastFit ⚡ 针对多类别的快速有效的文本分类 - IBM/fastfit
- Mkbhd Marques GIF - Mkbhd Marques Brownlee - 发现并分享 GIF: 点击查看 GIF
- Moti Hearts GIF - Moti Hearts - 发现并分享 GIF: 点击查看 GIF
Nous Research AI ▷ #ask-about-llms (37 条消息🔥):
- 预分词讨论: 关于是否进行预分词以加快训练速度的讨论,以及缩放点积(即 Flash Attention)的效率。有人提到 Flash Attention 2 仅在特殊情况下使用,并不常用。
- Llamafile 外部权重探索: 分享了一个 GitHub 仓库,讨论了如何将 Llamafile 与外部权重 结合使用,但在该频道的上下文中尚未进行尝试。
- 填充策略与模型训练: 关于是在预分词阶段还是训练阶段对数据进行填充的辩论,建议包括创建不同长度的存储桶(buckets)以优化 GPU 效率,并减少微批次(microbatch)处理期间的计算浪费。
- Torch Compile 难题: 提到了在机器翻译中对变长句子使用
torch.compile的挑战。克服这一问题的策略包括按长度对句子进行分组,以尽量减少批处理期间的填充。 - 通过 Grounding 处理 RAG 幻觉: 关于限制检索增强生成 (RAG) 中幻觉的当前方法的讨论。一位用户提到了一种涉及 LLM 扩展、数据库查询、排序和附加元数据的流水线,作为非问答任务的一种 Grounding 形式。
- 未找到标题: 未找到描述
- xFormers 优化算子 | xFormers 0.0.27 文档: xFormers 的 API 文档。xFormers 是一个用于可组合且优化的 Transformer 模块的 PyTorch 扩展库。
- GitHub - Mozilla-Ocho/llamafile: 通过单个文件分发和运行 LLM。: 通过单个文件分发和运行 LLM。通过在 GitHub 上创建账户来为 Mozilla-Ocho/llamafile 的开发做出贡献。
Nous Research AI ▷ #bittensor-finetune-subnet (1 条消息):
- 模型上传错误困惑: 一位成员在尝试上传模型时遇到了一个错误,提示:Failed to advertise model on the chain: ‘int’ object has no attribute ‘hotkey’。正在寻求社区的帮助。
Nous Research AI ▷ #world-sim (107 条消息🔥🔥):
_
-
使用 Thoughtforms 探索祖先模拟:一位成员讨论了花时间与 De Landa thoughtform 相处,以探索祖先模拟的概念。他们表示有兴趣将这些探索保存为付费功能,并询问了 Nous 周边(swag)。
-
技术问题的担忧与修复:一些用户报告了技术故障,例如在 worldsim 中打字时出现双重字符,其他用户则提供了刷新页面等解决方案。提到这些问题已列入开发团队的待办事项清单。
-
积分余额与系统查询:进行了关于积分系统的讨论,澄清了测试版积分在发布后不会转移,但测试参与者收到了 50 美元的真实积分。用户正在询问未来的免费积分计划或积分系统。
-
周边商店与推广请求:一位成员表示希望购买促销周边并在其社交媒体上分享,并询问如何最好地进行推广。
-
MUD 界面挫败感与即将到来的调整:用户注意到 MUD 界面的一些问题,例如需要手动输入选项和文本缺失。团队承认了这些担忧,并表示计划在下次更新中进行调整。
- worldsim: 未找到描述
- worldsim: 未找到描述
- worldsim: 未找到描述
- New Conversation - Eigengrau Rain: 未找到描述
OpenAI ▷ #annnouncements (1 条消息):
- 介绍 OpenAI 的 Model Spec:OpenAI 介绍了他们的 Model Spec —— 一个用于塑造期望的模型行为的框架,旨在深化公众对 AI 模型的讨论。详情请见 OpenAI 的公告。
OpenAI ▷ #ai-discussions (233 条消息🔥🔥):
- GraphQL 不像 Markdown 那样受支持: 澄清了虽然 AI 可以编写 GraphQL,但它不像 Markdown 那样在客户端渲染。
- 讨论 OpenDevin 与 Anthropic 平台: 阐明了 OpenDevin 在 Docker 沙箱中的功能,解释了它允许附加完整的工作区,并可以使用各种模型作为后端。
- 探索 AI 权利与意识: 在漫长的讨论中,参与者辩论了 AI 的意识、主观体验以及对 AI 权利的影响,未达成共识。
- 语言与沟通障碍: 关于语法和拼写的对话突显了国际化、多语言社区内对沟通期望的差异。
- AI 与硬件热忱: 分享了对 AI 技术现状和未来的兴奋之情,讨论了个人 AI 硬件配置和云端计算资源成本。提到了即将推出的 NVIDIA 显卡的潜在性能和成本,特别强调了 AI 对计算能力需求日益增长。
- 你说什么?Chat With RTX 为 NVIDIA RTX AI PC 带来定制聊天机器人:新的技术演示让任何拥有 NVIDIA RTX GPU 的用户都能拥有个性化的 GPT 聊天机器人,并在其 Windows PC 上本地运行。
- 你说什么?Chat With RTX 为 NVIDIA RTX AI PC 带来定制聊天机器人:新的技术演示让任何拥有 NVIDIA RTX GPU 的用户都能拥有个性化的 GPT 聊天机器人,并在其 Windows PC 上本地运行。
- Meta AI:使用 Meta AI 助手完成任务,免费创建 AI 生成的图像,并获取任何问题的答案。Meta AI 基于 Meta 最新的 Llama 大语言模型构建,并使用了 Emu...
- 未找到标题:未找到描述
- 未找到标题:未找到描述
OpenAI ▷ #gpt-4-discussions (16 messages🔥):
- 语法悖论:一位用户报告了 ChatGPT 的一个错误,它错误地将一个属性名称更正为相同的名称,建议将
EasingStyle改为EasingStyle而不是EasingStyle。 - 朋友还是伙伴?:一位用户正苦于 ChatGPT 在生成的场景中将“friend”一词改为“buddy”,尽管尝试使用了明确的上下文提示。
- 对 GPT-4 限制的困惑:ChatGPT 用户对 ChatGPT App 上 GPT-4 的限制和使用情况表示困惑和沮丧,指出与 API 版本相比,它感觉限制更多。
- ChatGPT Plus 与 API 的差异:有一场关于 ChatGPT Plus App 及其 API 结果差异的讨论,有人建议 App 在后台采用了额外的 Prompt。
- 建议的昂贵变通方案:针对限制问题,有人建议升级到团队计划以获得更高的限制,尽管一位用户指出这种方法已经尝试过,但并未解决限制问题。
OpenAI ▷ #prompt-engineering (5 messages):
-
寻求 Prompt Engineering 智慧:一位成员向群组询问目前最好的 Prompt Engineering 课程,可能是为了提升他们的 LinkedIn 个人资料,并简要提到了 Coursera 作为提供商之一。
-
含糊的帮助提议:针对关于 Prompt Engineering 课程的问题,一位成员表示由于 OpenAI 的政策,不愿公开分享收集到的列表,但提出可以通过私信提供信息。
-
关于开放性的认识论愿景:有人发表声明,设想一个“Open”是基本认识论概念的世界,但未对该想法做进一步阐述。
-
分享全面的 Prompt 结构:一位社区成员分享了他们首选的 Prompt Engineering 格式,旨在引导对商业 AI 伦理进行全面分析,并建议这可能是对 OpenAI 库的有价值贡献。
-
探讨 AI 伦理示例:提供了一个示例回复,展示了如何利用分享的 Prompt 结构来处理商业 AI 相关的伦理考量,涵盖了非营利地位的滥用、透明度、隐私、问责制和 AI 访问等问题。
OpenAI ▷ #api-discussions (5 messages):
- 寻求 Prompt Engineering 智慧:一位成员询问了最适合添加到 LinkedIn 个人资料的 Prompt Engineering 课程,并表示对该课程在求职中的价值感兴趣。由于 OpenAI 的政策,没有公开分享具体建议,但他们提出可以通过私信提供信息。
- 关于“Open”的哲学思考:一位成员从哲学角度评论说,设想一个以“Open”为认识论基础的世界,但随后没有更多的上下文或讨论。
- 展示以伦理为重点的 Prompt Engineering:该成员分享了一个关于讨论 商业 AI 伦理 的详细 Prompt Engineering 示例,其中包含输出模板和开放变量以引导模型的响应,并建议将其添加到 OpenAI 库中。
- 说明 Prompt Engineering 输出:该成员提供了一个 示例输出,以演示之前分享的 Prompt 结构,涵盖了伦理考量、不道德做法对公众信任的影响、关注领域以及对商业中道德 AI 实践的关键建议。
HuggingFace ▷ #announcements (1 messages):
_
<ul>
<li><strong>闲聊创新发布</strong>:推出 <a href="https://twitter.com/sanhestpasmoi/status/1787503160757485609"><strong>Idefics2 8B Chatty</strong></a>,这是一款全新的针对聊天优化的视觉 LLM,将交互体验提升到了新高度。</li>
<li><strong>CodeGemma 助力代码精通</strong>:Google 发布 <a href="https://twitter.com/reach_vb/status/1786469104678760677"><strong>CodeGemma 1.1 7B</strong></a> 带来惊喜,增强了在 Python、Go 和 C# 中的编程能力。</li>
<li><strong>巨型 MoE 亮相</strong>:<a href="https://huggingface.co/deepseek-ai/DeepSeek-V2"><strong>DeepSeek-V2</strong></a> 问世,这是一个拥有 236B 参数的强大 Mixture of Experts 模型。</li>
<li><strong>本地 LLM 革命</strong>:<a href="https://www.reddit.com/r/LocalLLaMA/comments/1cn2zwn/phi3_webgpu_a_private_and_powerful_ai_chatbot/"><strong>Phi 3</strong></a> 利用 WebGPU 技术,为您的浏览器带来了强大的 AI 聊天机器人功能。</li>
<li><strong>教育合作与工具创新</strong>:与 Andrew Ng 合作推出了新的 <a href="https://www.deeplearning.ai/short-courses/quantization-in-depth/">量化课程</a>,并通过 <a href="https://twitter.com/evilpingwin/status/1786049350210097249"><strong>Gradio Templates</strong></a> 简化了聊天机器人界面的部署。</li>
</ul>
HuggingFace ▷ #general (182 messages🔥🔥):
- 音频查询上采样:成员们讨论了将 8khz 音频上采样至 16khz 以用于微调 Whisper 等模型的可能性。
- BERT 微调难题:一位用户在 微调 BERT 时需要帮助,特别是与数据集中标签编码相关的数据预处理问题。
- 集成未使用的 Token:寻求关于如何使用 Gemma Tokenizer 中未使用的 Token 进行微调的帮助,涉及将
<unused2>等 Token 替换为<start_of_step>。 - 寻求 AI 模型推荐:一位机器学习新手为一个小型聊天机器人项目寻求易于使用的模型推荐,并指出 Mistral 和 BERT 模型具有挑战性。
- 潜在 Prompt 生成器模型咨询:询问是否存在专门训练用于生成 Prompt 的模型,以帮助不了解 Prompt Engineering 的用户。
HuggingFace ▷ #today-im-learning (2 messages):
- 拨动 AI 的弦:一段 YouTube 视频 通过简单而生动的类比来理解 Multimodal AI,将其比作能够处理文本、图像、音频和视频等各种 数据模态 (data modalities) 的电声吉他。特别是 Med-Gemini,因其在训练前就具备的原生、多样化能力而受到关注。
- 用 Med-Gemini 震撼你的研究:论文 “Advancing Multimodal Medical Capabilities of Gemini” 展示了 Multimodal AI 在医学领域的潜力,重点在于提高人类智能并扩大其适用范围。
- 利用 LLM 提升 Q-learning:一篇 arXiv 论文介绍了 LLM-guided Q-learning,这是一种利用 Large Language Models (LLMs) 通过提供 动作级指导 (action-level guidance) 来增强强化学习的方法,从而提高采样效率并降低探索成本。这种协同方法避开了奖励塑造 (reward shaping) 通常引入的偏见,并限制了由 LLM 幻觉 (hallucinations) 引起的性能误差。
- What Is MultiModal AI? With Med-Gemini. In 2 Minutes:从宏观角度看,Multimodal AI 就像一把电木吉他(AE)。像 Gemini 这样的多模态模型可以接收多种数据类型——即模态(modalities)。数据模...
- Advancing Multimodal Medical Capabilities of Gemini:许多临床任务需要理解专业数据,如医学图像和基因组学,这些数据通常在通用的多模态大模型中找不到。基于 Gemini...
- Enhancing Q-Learning with Large Language Model Heuristics:Q-learning 擅长在顺序决策任务中从反馈中学习,但需要大量采样才能获得显著改进。虽然奖励塑形(reward shaping)是增强...的一种强大技术。
HuggingFace ▷ #cool-finds (5 messages):
-
Langchain 的新客服奇迹:Streamline Customer Support with Langchain’s LangGraph 讨论了 LangGraph 如何增强客户支持。该文章由 Ankush k Singal 发表在 Medium 的 AI Advances 专栏。
-
解读 DDPM 引导技术:分享了两篇关于 Denoising Diffusion Probabilistic Models (DDPM) 的学术论文,分别涉及 Classifier-Free Diffusion Guidance 和 Score-Based Generative Modeling through Stochastic Differential Equations,提供了生成建模最新进展的见解。
-
简化检索增强生成 (RAG):GitHub 仓库 bugthug404/simple_rag 展示了 Simple Rag,这是一个辅助开发检索增强生成的项目,可作为语言模型实现的资产。
- Streamline Customer Support with Langchain’s LangGraph:Ankush k Singal
- GitHub - bugthug404/simple_rag: Simple Rag:Simple Rag。通过在 GitHub 上创建账号来为 bugthug404/simple_rag 的开发做出贡献。
- [PDF] Classifier-Free Diffusion Guidance | Semantic Scholar:一个利用人工智能方法提供高度相关结果和新型过滤工具的学术搜索引擎。
- [PDF] Score-Based Generative Modeling through Stochastic Differential Equations | Semantic Scholar:一个利用人工智能方法提供高度相关结果和新型过滤工具的学术搜索引擎。
HuggingFace ▷ #i-made-this (9 messages🔥):
- Python 装饰器快速教程:一个标题为 “Python Decorators In 1 Minute!” 的 YouTube 视频链接,提供了关于 Python 装饰器基础知识的简短教程。
- 发布 Illusion Diffusion 视频模型:一位社区成员创建了 Illusion Diffusion Video Model,可以生成高质量的幻觉视频。请在 HuggingFace Spaces 上的 IllusionDiffusionVideo 查看。
- DDPM 学习之旅:分享了一个 Google Colab 笔记本链接,详细介绍了当前理解 Denoising Diffusion Probabilistic Models (DDPM) 工作原理的项目。DDPM 项目 Colab 笔记本
- RefuelLLM-2 开源发布:RefuelLLM-2 是一个针对“枯燥数据任务”进行微调的模型,现已开源,模型权重可在 HuggingFace 上获取。更多细节可以在 RefuelLLM-2 的博客文章及其 HuggingFace 模型仓库中找到。
- 结合 Lain 的 DreamBooth:分享了一个基于动漫角色 Lain 的新 AI 模型,这是一个源自 stable-diffusion-v1-5 的 DreamBooth 模型。访问该 HuggingFace 模型:DreamBooth - lowres/lain。
- Illusion Diffusion Video - KingNish 的 Hugging Face Space:未找到描述
- Google Colab:未找到描述
- 1 分钟掌握 Python Decorators!:在短短 1 分钟内发现 Python 装饰器的力量!这个快速教程将向你介绍装饰器的基础知识,让你能够增强你的 Python...
- refuelai/Llama-3-Refueled · Hugging Face:未找到描述
- lowres/lain · Hugging Face:未找到描述
HuggingFace ▷ #reading-group (6 messages):
-
考虑使用阶段频道(Stage Channels)进行质量控制:成员们讨论了在未来小组中使用“阶段”频道的想法,通过让参与者在发言前举手来提高音频录制的质量。
-
背景噪音是一个令人担忧的问题:有人提到目前没有默认静音的预设选项,这导致在语音聊天中出现不必要的背景噪音。
-
平衡质量与参与度:有人担心阶段频道可能会阻碍人们提问,因为在传统的语音频道中,人们更倾向于在聊天框中提问。
-
探索默认阶段设置:计划将默认格式设置为阶段频道,以限制未静音的对话,并观察这是否会影响互动水平。
-
在阶段格式中鼓励提问:为了促进参与,有人建议非演讲者可以通过积极提问来参与,希望能激发更多对话。
HuggingFace ▷ #computer-vision (17 messages🔥):
- 用于检测图像中广告的 Adlike 库:分享了一个名为 Adlike 的库,它可以预测图像在多大程度上属于广告。
- 目标检测指南的增强:目标检测指南的更新包括在 Trainer API 中添加 mAP 指标,详情见 Hugging Face 文档,并增加了支持 Trainer API 和 Accelerate 的官方示例脚本,可在 GitHub 上获取。
- 关于视觉问答(Visual Question Answering)挑战的讨论:一位成员征求关于表格图像视觉问答的建议,寻求有相关经验的人士。
- Text-to-Image 模型和 SVG 输出查询:聊天中包含一项关于能够输出 SVG 或矢量图形的
Text-to-Image模型的咨询,并引用了 Hugging Face 模型。 - 从信息密集的 PDF 中提取内容:一位用户寻求使用 AI 方法从 PowerPoint 大小的 PDF 中提取图表和图像的建议,并被推荐了一个 GitHub 仓库 以及进一步研究的承诺,其他资源可以在 Andy Singal 的 Medium 页面上找到。
- Models - Hugging Face: 未找到描述
- openai-cookbook/examples/Creating_slides_with_Assistants_API_and_DALL-E3.ipynb at main · openai/openai-cookbook: 使用 OpenAI API 的示例和指南。通过在 GitHub 上创建账户来为 openai/openai-cookbook 的开发做出贡献。
- GitHub - chitradrishti/adlike: Predict to what extent an Image is an Advertisement.: 预测图像在多大程度上是广告。- chitradrishti/adlike
- Object detection: 未找到描述
- Ankush k Singal – Medium: 阅读 Ankush k Singal 在 Medium 上的文章。我的名字是 Ankush Singal,我是一名旅行者、摄影师和 Data Science 爱好者。每天,Ankush k Singal 和成千上万的其他声音都在阅读、撰写...
- Model Cards: 未找到描述
HuggingFace ▷ #NLP (3 条消息):
- Llama 缺乏精度:一位成员报告称,使用 Llama 2:13b 从文本中提取单词时,大部分时间都会产生错误答案。他们寻求推荐性能更好且可以在本地加载的模型。
- 澄清任务:另一位参与者询问提到的单词提取是否是指 Named Entity Recognition (NER),旨在澄清当前任务的背景。
HuggingFace ▷ #diffusion-discussions (6 条消息):
-
Diffusion 模型训练困扰:一位用户在运行使用
notebook_launcher训练 Diffusion 模型的代码时,遇到了与git lfs clone相关的 OSError。错误提示由于弃用和更好的性能应使用 ‘git clone’,并以 “repository ‘https://huggingface.co/lixiwu/ddpm-butterflies-128/’ not found” 结尾。 -
寻求 Diffusion 问题的解决方案:在 OSError 之后,同一位用户请求协助修复其 Diffusion 模型设置的问题。
-
损坏的机器人出现故障:一位成员分享了 hugchat 的一个问题,由于尝试获取远程 LLM 失败并抛出错误,状态码为 401,表明可能存在身份验证问题。
-
HuggingChat 中的身份验证异常:指出 hugchat 错误的同一位成员分享了他们正在使用的代码片段,其中涉及使用电子邮件和密码登录,并使用 cookies 初始化
hugchat.ChatBot。
Modular (Mojo 🔥) ▷ #general (57 条消息🔥🔥):
-
Mojo 的就绪情况和 Python 能力:人们对 Mojo 的能力充满期待,有迹象表明它可能在年底前达到更可用的状态,同时已经能够通过 CPython 集成运行 Python 代码。然而,直接使用 Mojo 编译 .py 程序尚未列入近期计划,可能成为明年的关注重点。
-
推进 MLIR 贡献:关于对 MLIR 贡献的讨论非常活跃,特别是活跃度检查(liveliness checking)及其推广到其他应用的潜力。社区内有推测和希望,认为 Modular 将开源其部分 MLIR 方言并可能将其上游化,从而增强 MLIR 技术的通用性。
-
Python 与 Mojo 的未来:人们对将 Python 代码放入 Mojo 以实现更简单的二进制分发的可能性感到非常兴奋,这可以避开分发通常庞大的 Python 库文件夹的需求。
-
Mojo 中的 Variant 和模式匹配:人们对 Mojo 中可能实现的隐式 Variant 和模式匹配感到好奇,这涉及到不同编程语言中 union 和 variant 类型之间的细微差别。
-
Modular 社区更新:社区参与的亮点包括即将举行的直播,旨在深入探讨 MAX 24.3 和 Mojo 的最新更新,这标志着 Modular 致力于让其社区保持知情和参与。
- Modular 社区直播 - MAX 24.3 新特性: MAX 24.3 现已发布!加入我们即将举行的直播,我们将讨论 MAX Engine 和 Mojo🔥 的新功能 - 预览 MAX Engine Extensibility API...
- 2023 LLVM 开发者大会 - (正确地) 将支配关系 (Dominance) 扩展到 MLIR Regions: 2023 LLVM Developers' Meeting https://llvm.org/devmtg/2023-10 ------ (正确地) 将支配关系扩展到 MLIR Regions。演讲者:Siddharth Bhat, Jeff Niu ------ Slide...
Modular (Mojo 🔥) ▷ #💬︱twitter (4 messages):
- Modular 更新提醒:Modular 分享了一条推文,链接到他们在 Twitter 上的最新更新通知。查看详情:Modular 最新推文。
- Modular 功能解析:Modular 在 Twitter 上宣布了新功能发布,承诺为用户带来增强体验。在他们的官方 Twitter 帖子中发现更多细节:Modular 功能发布。
- Modular 增长洞察:Modular 发布了关于其增长统计数据的推文,强调了关键里程碑。了解他们的进展:Modular 增长推文。
- Modular 特别公告预告:Modular 分享了一个即将发布的特别公告预告。请关注 Modular 预告推文 中提到的揭晓内容。
Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- Chris Lattner 深入探讨 Mojo:Chris Lattner 讨论了 Mojo 的创建,重点关注增强 GPU 性能、支持矩阵运算以及像 bfloat16 这样的 AI 扩展。Developer Voices 播客访谈 详细阐述了它对 Python 和非 Python 开发者的吸引力,并强调了 Mojo 是如何为高性能而构建的。
提到的链接:Modular: Developer Voices: 与 Chris Lattner 深入探讨 Mojo:我们正在为世界构建下一代 AI 开发者平台。查看我们的最新文章:Developer Voices: 与 Chris Lattner 深入探讨 Mojo
Modular (Mojo 🔥) ▷ #🔥mojo (108 messages🔥🔥):
-
矩阵乘法性能查询:讨论围绕 Mojo 的矩阵乘法性能展开,一位成员观察到,即使使用了所有优化,它仍然比 NumPy 慢约 3 倍。其他人建议在 GitHub 上提交 Issue 以获取开发者的见解。
-
对 Mojo 中 MLIR 的赞誉:成员们对 MLIR 赋予 Mojo 的“超能力”赞不绝口,有人对这种软件技术直到最近才出现表示惊讶。
-
Mojo 公开状态及 Modular 说明:澄清了 Mojo 的公开状态;其标准库是开源的,但编译器和 stdlib 的部分内容仍未开源。Modular 被确定为 Mojo 背后的公司,专注于 AI 基础设施。
-
Reference 类型的发展与讨论:Discord 上的对话围绕 Mojo 中
Reference类型的演变展开,包括自动解引用 (dereference) 的提案以及关于 struct 中嵌入引用的问题。对赋值、解引用和相等运算符的影响是许多成员关注的焦点。 -
VS Code LSP 和 Nightly Build 问题:一位用户在使用 Mojo nightly build 时遇到了 VS Code 中 Language Server Protocol (LSP) 的连接问题。另一位成员提供了 Mojo VS Code nightly build 插件的链接,并强调需要禁用稳定版扩展才能正常工作。
- Mojo 🔥 (nightly) - Visual Studio Marketplace: Visual Studio Code 扩展 - Mojo 语言支持 (nightly)
- Tensor | Modular Docs: 一种拥有底层数据并以 DType 为参数的张量类型。
- Dunder or magic methods in Python - GeeksforGeeks: Python 魔法方法是以双下划线开头和结尾的方法。它们由 Python 内置类定义,常用于运算符重载。阅读此博客以了解...
- Issues · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账户来为 modularml/mojo 的开发做出贡献。
- Llama2 Ports Extensive Benchmark Results on Mac M1 Max: Mojo 🔥 的速度几乎赶上了 llama.cpp (!!!),且代码更简洁,在多线程基准测试中全面超越了 llama2.c
- GitHub - dorjeduck/minbpe.mojo: port of Andrjey Karpathy's minbpe to Mojo: 将 Andrej Karpathy 的 minbpe 移植到 Mojo。通过在 GitHub 上创建账户来为 dorjeduck/minbpe.mojo 的开发做出贡献。
- Modular: Accelerating the Pace of AI: Modular Accelerated Xecution (MAX) 平台是全球唯一能为您的 AI 工作负载解锁性能、可编程性和可移植性的平台。
- mojo/stdlib/src/memory/reference.mojo at main · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账户来为 modularml/mojo 的开发做出贡献。
- [proposal] Automatic deref for `Reference` · modularml/mojo · Discussion #2594: 大家好,我整理了一份提案,概述了 Mojo 中 Reference 类型的自动解引用(deref)如何工作,希望能听到大家的想法或建议。我希望在下周左右实现它...
- stump/stump/log.mojo at nightly · thatstoasty/stump: Mojo 的开发中 (WIP) 日志记录器。通过在 GitHub 上创建账户来为 thatstoasty/stump 的开发做出贡献。
- stump/stump/style.mojo at main · thatstoasty/stump: Mojo 的开发中 (WIP) 日志记录器。通过在 GitHub 上创建账户来为 thatstoasty/stump 的开发做出贡献。
- stump/external/mist/color.mojo at nightly · thatstoasty/stump: Mojo 的开发中 (WIP) 日志记录器。通过在 GitHub 上创建账户来为 thatstoasty/stump 的开发做出贡献。
Modular (Mojo 🔥) ▷ #community-projects (1 条消息):
- Mojo 获得了一个 Toybox: 一个名为 “toybox” 的新 GitHub 仓库包含了 DisjointSet 实现和 Kruskal 最小生成树 (MST) 算法示例。该仓库的创建者是开源新手,欢迎 Pull Requests (PRs),并请对其学习过程保持耐心。
提及链接: GitHub - dimitrilw/toybox: Various data-structures and other toys implemented in Mojo🔥.: 在 Mojo🔥 中实现的各种数据结构和其他小工具。 - dimitrilw/toybox
Modular (Mojo 🔥) ▷ #community-blogs-vids (2 条消息):
- 火热招聘: 一位成员称赞某次面试非常出色,认为它可以作为 招聘 工具。他们表示打算将视频分享给朋友,鼓励他们加入。
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (14 条消息🔥):
-
寻求 Mojo 字符串拼接解决方案: 一位成员指出,与 Python 相比,Mojo 在拼接字符串时存在性能问题,Mojo 明显更慢。他们分享了示例代码,并正在寻找除并行化之外的提速建议。
-
Mojo 中短字符串优化的潜力:一位用户回复称,目前正在 Mojo 的
String结构体中实现短字符串优化(short string optimization),作为提高字符串拼接性能的可能解决方案,并提请关注 GitHub issue #2467 的进展。 -
使用 KeysContainer 进行性能优化:针对次优的字符串拼接提出了性能改进建议,提议使用
KeysContainer来避免过度的重新分配和内存复制(memcopies),并附带了相关 GitHub 资源的链接。 -
避免昂贵的 Int 到 String 转换:另一位用户建议在查找过程中避免大量的
Int到String转换,提议改用带有Int包装器的泛型字典(generic dict),因为Int到String的转换开销可能很大。 -
使用 StringBuilder 获得 3 倍性能提升:在收到建议后,该成员报告称使用 mojo-stringbuilder 库以及针对
Int键的Keyable包装器后,性能提升了 3 倍。虽然性能仍落后于 Python 和 Rust,但正在逐渐接近。
- [Feature Request] Unify SSO between `InlinedString` and `String` type · Issue #2467 · modularml/mojo:审查 Mojo 的优先级。我已阅读路线图和优先级,并相信此请求符合优先级。你的请求是什么?我们目前有 https://docs.modular.com/mojo/stdlib...
- GitHub - dorjeduck/minbpe.mojo: port of Andrjey Karpathy's minbpe to Mojo:将 Andrej Karpathy 的 minbpe 移植到 Mojo。通过在 GitHub 上创建一个帐户来为 dorjeduck/minbpe.mojo 的开发做出贡献。
- GitHub - maniartech/mojo-stringbuilder: The mojo-stringbuilder library provides a StringBuilder class for efficient string concatenation in Mojo, offering a faster alternative to the + operator.:mojo-stringbuilder 库为 Mojo 提供了 StringBuilder 类,用于高效的字符串拼接,是 + 运算符的更快替代方案。 - maniartech/mojo-stringbuilder
- compact-dict/string_dict/keys_container.mojo at main · mzaks/compact-dict:一个在 Mojo 🔥 中快速且紧凑的 Dict 实现。通过在 GitHub 上创建一个帐户来为 mzaks/compact-dict 的开发做出贡献。
Modular (Mojo 🔥) ▷ #nightly (41 messages🔥):
-
累积和函数(Cumulative Sum Function)亮点:提供了一个指向 Modular Mojo 标准库文档中
cumsum函数的链接,特别强调了它的存在和用法。该函数在 Mojo 文档中有所引用。 -
命名规范与 PyConLT 轶事:一位成员提到他们在 PyConLT 演讲时,曾对缩写
cumsum有过短暂的心理挣扎,但最终选择不去纠结它。 -
Mojo 中发现严重 Bug:在
Tensor/DTypePointer标准库中发现了一个潜在的严重问题,详情见 GitHub issue。随后的讨论集中在这是构成一个 Bug,还是由于UnsafePointer缺乏生命周期(lifetime)而导致的特性。 -
指针与生命周期的困惑:在使用
DTypePointer配合memcpy时产生了困惑;指出 Tensor 被销毁了,但其数据赋值仍保留在一个非所有权指针中,这导致了悬空指针(dangling pointer)的情况。 -
Mojo Nightly 编译器更新:宣布发布了新的 Mojo 编译器版本,合并了 31 个外部贡献。鼓励用户使用
modular update nightly/mojo进行更新,并查看此版本的 diff 以及自上次稳定版本以来的变更日志。 -
为提高清晰度更新 Tensor API:
Tensor.data()调用更名为Tensor.unsafe_ptr(),以更好地反映其行为,这一变化得到了讨论成员的普遍认可。
- [BUG]: Weird behavior when passing a tensor as owned to a function · Issue #2591 · modularml/mojo: Bug 描述:当将 tensor 作为 owned 传递给函数,并尝试在 @parameter 函数内部(使用 simd load)对数据进行 memcpy 或打印信息时,会出现一种奇怪的行为...
- [stdlib] Update stdlib corresponding to 2024-05-08 nightly/mojo by JoeLoser · Pull Request #2593 · modularml/mojo: 此 PR 使用与今天的 nightly 版本(mojo 2024.5.822)相对应的内部提交更新了 stdlib。
- mojo/docs/changelog.md at nightly · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账号来为 modularml/mojo 的开发做出贡献。
LM Studio ▷ #💬-general (94 messages🔥🔥):
-
模型目录结构已澄清:成员们讨论了存储模型的正确目录。正确的设置包括一个顶层的
\models文件夹,其中包含每个发布者及其对应仓库的子文件夹,类似于 Hugging Face 的命名规范。例如,模型文件应位于路径\models\lmstudio-community\Meta-Llama-3-8B-Instruct-GGUF\Meta-Llama-3-8B-Instruct-Q8_0.gguf。 -
将 Web UI 连接到 LM Studio:建议使用支持通用 OpenAI API 规范的 UI 来与 LM Studio 集成。AnythingLLM 和 支持 Docker 的 Open WebUI 被提及为与 LM Studio API 交互的可行选项。
-
LM Studio 的 GPU 需求说明:讨论强调了 GPU VRAM 的必要性,并建议在遇到与 GPU 检测相关的错误时关闭 GPU 加速。此外还提到,该应用并非为 Windows ARM 笔记本电脑设计,因为目前不支持 ARM 架构。
-
使用 LM Studio 的挑战:诸如 “unable to allocate backend buffer” 之类的错误意味着用户 PC 上的内存不足以运行本地模型。解释指出,本地模型通常需要 8GB 的 VRAM 和 16GB 的 RAM。
-
在 LM Studio 中发现本地模型:为了在 LM Studio 中找到所有可用模型,有人分享了一个技巧:在模型搜索栏中搜索 “GGUF” 以列出所有模型。即使在用户不知道具体名称的情况下,这个变通方法也能帮助发现不同的模型。
- Aha GIF - Aha - 发现并分享 GIF:点击查看 GIF
- Solution - llama.cpp error: error loading model:此视频分享了在 Windows 或 Linux 上使用 LM Studio 或任何其他 LLM 工具本地安装 AI 模型时出现以下错误的原因。"llama.cpp ...
- OpenAI API Endpoints | Open WebUI:在本教程中,我们将演示如何使用环境变量配置多个 OpenAI(或兼容的)API 端点。此设置允许您轻松地在不同的 API 提供商之间切换...
LM Studio ▷ #🤖-models-discussion-chat (22 messages🔥):
- 更改模型路径:一位成员询问另一位成员是否已将其模型路径更改为特定的 Repository 路径。
- 寻求视觉模型推荐:有人请求推荐一款与 16GB RAM 和 8GB VRAM 兼容的视觉模型。
- 寻找最适合编程的模型:一位成员请求推荐最适合编程用途的 8-9B 参数语言模型 (LLM)。
- 焦急等待更新:成员们正热切期待能够解决现有问题的更新,其中一位成员特别对新的 quant(量化)方案作为潜在解决方案感兴趣。
- 对诗歌模型的挫败感:一位成员对各种模型生成的诗歌表示不满,认为它们偏离了真实性,产生了一些荒谬的文本,并正在寻找能够准确完成诗歌的模型。
提到的链接: ByteDance/Hyper-SD · Hugging Face: 未找到描述
LM Studio ▷ #🧠-feedback (4 messages):
-
对 AI 体验的便捷性表示赞赏:一位成员承认 LM Studio 自早期版本以来已经有了长足的进步,并强调了这种对比:以前设置模型曾是挫败感的来源,而现在的体验更加“省心”。
-
Mac Studio 运行模型遇到问题:Arthur051882 报告了一个关于其 192GB Mac Studio 的问题,该设备可以成功运行 llama3 70B,但在尝试运行 llama1.6 Mistral 或 Vicuña 时遇到错误。错误报告包含了内存、GPU 和 OS 版本的详细信息。
-
寻求技术协助:该成员在同一线程中为其系统遇到的错误寻求帮助,并提供了额外的错误报告详情。
-
提供的管理与指导:另一位成员 Yagilb 做出回应,指示 Arthur051882 在指定频道发布详细帖子,并注明导致加载问题的具体模型文件名。
LM Studio ▷ #📝-prompts-discussion-chat (1 messages):
- RAG 架构的分块处理:一位成员讨论了 RAG (Retriever-Answer Generator) 架构,提到了对文档进行分块(chunking)并附加各种数据(如文本 embeddings 和位置 metadata)的策略。他们建议这种方法有助于限制数据搜索范围,并确定在处理请求时应包含哪些文档分块。
- 智能分块选择可增强搜索:该成员进一步提出,除了使用 metadata 缩小搜索范围外,还可以采用分析技术(例如基于 embeddings 和搜索词之间的余弦相似度进行 reranking)来精细化选择哪些分块。这表明有多种方法可以提高 AI 模型检索数据的相关性。
LM Studio ▷ #⚙-configs-discussion (28 messages🔥):
-
Parsing 还是 Sparse,这是一个问题:起初对一位成员使用的术语存在困惑,在 PDF 的语境下被推测为 sparse 或 parse。随后该成员澄清可能意指 parse,建议使用 RAG application 调用 LMStudio API 进行 PDF 的处理/搜索。
-
深入探究 Llama.cpp 的奥秘:一位成员分享了一个 GitHub issue 链接,讨论了使用 llama.cpp 进行首次 inference 后的无效输出问题:GitHub Issue #7060,该链接提供了对该问题的见解和潜在解决方案。
-
揭开瓶颈之谜:一位用户报告称,在使用 yi 30b q4 ks gguf 模型时,尽管模型显示加载成功,但 CPU 和 GPU 利用率为零且运行缓慢。该报告引发了关于潜在瓶颈问题的讨论。
-
LLM 推理引擎:来自经验人士的学习建议:一位成员提供了关于 LLM inference engines 运作方式的见解,指出性能问题可能与内存读取操作以及 CPU-RAM 与 VRAM 之间的速度差异有关。
-
Swap:计算流量中的慢车道:针对成员关于其系统 VRAM 和模型 inference 期间利用率的性能问题,有人做了一个类比,说明了磁盘 swap 相对于 RAM 的缓慢。
提到的链接:llava 1.5 invalid output after first inference (llamacpp server) · Issue #7060 · ggerganov/llama.cpp: I use this server config: "host": "0.0.0.0", "port": 8085, "api_key": "api_key", "models": [ { "model": "models/phi3_mini_mod…
LM Studio ▷ #🎛-hardware-discussion (35 messages🔥):
-
使用独立 GPU 进行潜在的桌面优化:一位成员考虑将 Intel HD 600 系列 GPU 专门用于桌面任务,以释放 GTX 980 用于 LM Studio 等更密集的应用。然而,另一位成员指出,在只有 6GB VRAM 的情况下,将任务卸载到 HD 600 的收益可能微乎其微,仅能释放约 500MB VRAM。
-
解码 Llama 3 70B 的硬件需求:在本地运行 Llama 3 70B 模型的热情引发了关于必要硬件的讨论,一位成员开玩笑说买一台 128GB M3 MacBook Pro 是处理此类负载的好借口。对于下一代硬件是否能运行理论上的 400B 模型,大家持怀疑态度,推测可能需要超过 200GB 的 VRAM。
-
离线模型使用的成本效益:一位用户权衡了不使用 ChatGPT 等付费服务所节省的费用与本地运行模型的电费成本。有人建议了一个幽默的策略:使用笔记本电脑电池运行,并在 Starbucks 等地方免费充电。
-
为 Apple M1 选择合适的 LLM:针对配备 16GB RAM 的 M1 Pro 应该选择哪种最佳大语言模型 (LLM) 的问题,推荐了 “Llama 3 - 8B Instruct” 作为兼容选项。
-
讨论语言模型之外的 AI 能力:在硬件讨论中,一名成员询问了 Apple 神经网络引擎 (neural engine) 的功能,随后澄清其设计初衷是用于人脸识别和处理较小模型等任务,展示了 AI 在语言模型之外的更广泛应用。
LM Studio ▷ #model-announcements (1 messages):
- Maxime Labonne 的 Self-Merge 杰作:Maxime Labonne 完成了一个传奇般的 120B self-merge(基于 Llama 3 70B instruct),现已在 lmstudio-community 上线。该模型使用 imatrix 创建以增强性能,展现出显著的能力;鼓励用户进行测试并分享体验。
LM Studio ▷ #🛠-dev-chat (4 messages):
- 目前尚不支持编程方式的聊天交互:一名成员根据文档询问是否可以通过 API 与现有聊天进行编程交互。另一名成员确认该功能目前不可用,但提到已列入未来更新计划。
Eleuther ▷ #general (50 messages🔥):
-
早期实现的伦理问题:成员们讨论了在原作者之前在 GitHub 上发布算法的非官方实现的礼仪。有人建议将仓库清晰地标记为非官方复现以避免混淆,而另一人指出许多论文从未发布代码,例如 MeshGPT Example。
-
婚后学术界更名:一名用户询问如何在婚后更新学术平台上的姓氏,同时确保已发表的论文仍能与其关联。建议包括联系网站支持以及使用旧名字作为学术名 (nom-de-academia) 以避免问题。
-
加载 The Pile 数据的最佳实践:参与者分享了为 AI 模型训练处理 The Pile 数据的技巧,包括在 Hugging Face 上寻找预处理版本,或处理应用了特定分词器 (tokenizer) 的
.bin文件。 -
发现 EleutherAI 的 “Cookbook”:提到了 EleutherAI 的 “cookbook”,透露其包含处理真实模型的实用细节和工具,一名成员对此表示惊讶和兴趣——GitHub Cookbook。
-
状态追踪的规模限制:一篇暗示状态空间模型 (SSMs) 和 Transformers 在状态追踪方面具有共同局限性的文章引发了关于长序列反向传播 (backpropagation) 可扩展性以及 xLSTM 等新模型是否能解决这些问题的对话。
-
幽默的开源保险代码:用户们进行了一场轻松的交流,发布了一些关于汽车保险公司运营的幽默伪代码片段,暗指理赔处理的随机性。
- The Illusion of State in State-Space Models: 与之前无处不在的 Transformer 架构相比,状态空间模型 (SSMs) 已成为构建大语言模型 (LLMs) 的一种潜在替代架构。一个理论上的...
- Maximilian Beck (@maxmbeck) 的推文: 敬请关注!🔜 #CodeRelease 💻🚀
- GitHub - EleutherAI/cookbook: Deep learning for dummies. 包含处理真实模型涉及的所有实用细节和有用工具。: Deep learning for dummies. All the practical details and useful utilities that go into working with real models. - EleutherAI/cookbook
- GitHub - nihalsid/mesh-gpt: MeshGPT: 使用 Decoder-Only Transformers 生成三角形网格: MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers - nihalsid/mesh-gpt
- LLM 微调内存需求: LLM 训练的内存成本很高,但可以预测。
Eleuther ▷ #research (119 messages🔥🔥):
-
xLSTM 论文引发关注:成员们对 xLSTM 论文表示怀疑,指出该论文在基线模型上似乎使用了较差的 hyperparameters,从而对其结论产生质疑。社区正等待通过独立实现或官方代码发布来进行进一步验证。
-
Function Vector (FV) 与 In-Context Learning:讨论重点介绍了关于“function vector”的研究,该技术允许高效的 in-context learning,使模型仅凭紧凑的任务表示就能稳健地执行任务。相关见解源自详细阐述 function vectors 如何对上下文变化保持稳健的论文(来源)。
-
利用 YOCO 简化 KV Caches:介绍了一种名为 YOCO 的新型 decoder-decoder 架构;它利用单次 KV cache 循环,而不是在各层之间复制 cache,从而可能优化内存使用。有人提出疑问,该模型是否能从进一步的优化中受益,例如在不增加内存负担的情况下对 KV caches 进行矩阵乘法。
-
探索多语言 LLM 认知:一些成员寻求研究 Large Language Models (LLMs) 如何处理多语言和认知的论文,特别是 next tokens 的计算,以及它们在回答之前是否会在内部翻译成英文。对话中引用了几项相关研究,其中一些侧重于特定语言的神经元。
-
重新审视 Absolute Positional Encodings (APE):讨论并批评了 PoPE,这是一种使用正交多项式的 positional encoding 创新,其核心概念被过多的理论证明所掩盖。该方法有望改进基于正弦的 APEs,但其理论基础仍存疑问。
- You Only Cache Once: Decoder-Decoder Architectures for Language Models: 我们为大语言模型引入了一种名为 YOCO 的 Decoder-Decoder 架构,它仅缓存一次键值对(key-value pairs)。它由两个组件组成,即堆叠在 self-decoder 之上的 cross-decoder。...
- Do Llamas Work in English? On the Latent Language of Multilingual Transformers: 我们探究了在不平衡且以英语为主的语料库上训练的多语言模型是否使用英语作为内部中转语言——这是一个对于理解语言模型如何运作至关重要的问题...
- PoPE: Legendre Orthogonal Polynomials Based Position Encoding for Large Language Models: 针对原始 Transformer 中使用的基准绝对位置编码(APE)方法,已经提出了几项改进。在本研究中,我们旨在调查不充分的...
- In-Context Learning Creates Task Vectors: 大语言模型(LLMs)中的上下文学习(ICL)已成为一种强大的新学习范式。然而,其底层机制仍未被充分理解。特别是,挑战在于...
- TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding: 随着大语言模型(LLMs)近期被广泛应用于长内容生成,对高效长序列推理支持的需求日益增长。然而,键值(KV)缓存...
- AlphaFold 3 predicts the structure and interactions of all of life’s molecules: 我们的新 AI 模型 AlphaFold 3 能够以前所未有的准确度预测所有生命分子的结构和相互作用。
- How do Large Language Models Handle Multilingualism?: 大语言模型(LLMs)在多种语言中表现出卓越的性能。在这项工作中,我们深入探讨了这个问题:LLMs 如何处理多语言能力?我们引入了一个框架来...
- xLSTM: Extended Long Short-Term Memory: 在 20 世纪 90 年代,恒定误差轮转(constant error carousel)和门控(gating)作为长短期记忆网络(LSTM)的核心思想被引入。从那时起,LSTM 经受住了时间的考验,并为众多...
- CLLMs: Consistency Large Language Models: 诸如 Jacobi 解码之类的并行解码方法在提高 LLM 推理效率方面展现出前景,因为它打破了 LLM 解码过程的顺序性,并将其转化为可并行的计算...
- Function Vectors in Large Language Models: 我们报告了一种简单的神经机制的存在,该机制在自回归 Transformer 语言模型(LMs)中将输入-输出函数表示为一个向量。通过在...上使用因果中介分析
- GitHub - mirage-project/mirage: A multi-level tensor algebra superoptimizer: 一个多级张量代数超优化器。通过在 GitHub 上创建账号来为 mirage-project/mirage 的开发做出贡献。
- unilm/YOCO at master · microsoft/unilm: 跨任务、语言和模态的大规模自监督预训练 - microsoft/unilm
- ICLR 2024 Outstanding Paper Awards – ICLR Blog: 未找到描述
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving: 量化可以加速大语言模型(LLM)推理。除了 INT8 量化之外,研究界正在积极探索更低的精度,例如 INT4。尽管如此,最先进的...
Eleuther ▷ #interpretability-general (1 messages):
jacquesthibs: 每个 pythia 检查点都有经过调优的透镜(tuned lenses)吗?
CUDA MODE ▷ #general (27 messages🔥):
-
动态与静态编译的困境:讨论强调了 torch.compile 面临的挑战;有人建议将数据填充(padding)到一组预定义的形状中,但批处理序列中的动态形状使得静态编译的使用变得复杂。虽然 “dynamic=True” 据称可以避免持续的重新编译,但成员们发现它仍然倾向于频繁地重新编译。
-
深度 Diffusion 推理优化指南:分享了一个由 9 部分组成的博客系列和一个 GitHub 仓库,详细介绍了 Diffusion 模型的推理优化。这包括自定义 CUDA 内核以及对 GPU 架构的见解。
-
从 GPU 啸叫到 GPU 交响乐:分享了一个独特的学习成果,即如何调制 GPU 电感啸叫来播放音乐,特别是《小星星》(Twinkle Twinkle Little Star),并提供了相关的 代码。
-
通过复现进行高效学习:对于 CUDA 初学者来说,一种实践方法是复现 SGEMM_CUDA 教程 中的矩阵乘法内核并进行基准测试,这在处理 Diffusion 论文的推理优化之前非常有帮助。
-
对演讲的鼓励与兴趣:社区成员对分享的优化工作表现出极大的热情,鼓励作者进行演讲,并继续就 ML 和机器人领域的实现及后续步骤提出问题。
- Diffusion Inference Optimization:未找到描述
- How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog:在这篇文章中,我将迭代地优化一个用 CUDA 编写的矩阵乘法实现。我的目标不是构建一个 cuBLAS 的替代品,而是深入...
- inference-optimization-blog-post/part-9/gpu-piano/gpu_piano.cu at main · vdesai2014/inference-optimization-blog-post:通过在 GitHub 上创建一个账户来为 vdesai2014/inference-optimization-blog-post 的开发做出贡献。
CUDA MODE ▷ #triton (17 条消息🔥):
- Triton 的 GitHub 协作:创建了一个 新的 GitHub 资源 来收集社区编写的 Triton 内核链接,其灵感源于建立一个社区拥有的索引。有人表示有兴趣将其转移到 GitHub 上的 cuda-mode 组织。
- 教授 Triton 的倡议:提到目前可用的 Triton 教程并不多,并计划将 PMPP 书籍移植以包含 Triton 代码片段。
- Triton-Index 管理员权限已授予:GitHub 上的 cuda-mode Triton index 已发送并接受了管理员邀请,旨在对已发布的 Triton 内核进行编目。
- 关于 Triton 内核数据集的想法:讨论围绕将 Triton 内核作为数据集发布的可能性展开,虽然最初是玩笑话,但似乎引起了真正的兴趣。
- 理解 Triton 的编程模型:回答了关于 Triton 在 Warp 和线程调度方面与 CUDA 的比较;强调了 Triton 和 CUDA 中的 Block 是一样的,但 Triton 为程序员抽象掉了 Warp 和线程层级的细节。
- 第 14 课:Triton 实战指南: https://github.com/cuda-mode/lectures/tree/main/lecture%2014
- GitHub - cuda-mode/triton-index: 编目已发布的 Triton kernel。: 编目已发布的 Triton kernel。通过在 GitHub 上创建账号为 cuda-mode/triton-index 的开发做出贡献。
- GitHub - haileyschoelkopf/triton-index: 请改看 https://github.com/cuda-mode/triton-index/!: 请改看 https://github.com/cuda-mode/triton-index/! - haileyschoelkopf/triton-index
- - YouTube: 未找到描述
- 使用 CUDA Warp 级原语 | NVIDIA 技术博客: NVIDIA GPU 以 SIMT(单指令多线程)方式执行被称为 warp 的线程组。许多 CUDA 程序通过利用 warp 执行来实现高性能。
CUDA MODE ▷ #torch (47 条消息🔥):
-
关于归一化技术的性能讨论:一位 Torch 用户提出了关于在 NHWC 格式下进行张量归一化时的性能影响问题,询问是否比 NHWC 优化的算法更倾向于转换回 NCHW。另一位用户回应并重点介绍了一个 PyTorch 教程,该教程指出 channels-last 格式可以带来 20% 的性能提升,且由于步幅(stride)操作,转换可能并不会产生额外开销。
-
LibTorch 编译时间的改进:关于缩短编译时间的讨论发现,使用 ATen 的
at::native::randn代替torch::randn并包含<ATen/ops/randn_native.h>而非<ATen/ATen.h>,可以将用户的编译时间从大约 35 秒减少到 4.33 秒。 -
libtorch 与 cpp 扩展:Marksaroufim 建议探索使用 cpp 扩展来将 C++ 与 PyTorch 集成,理由是现在研究 libtorch 的人并不多。此外,他提到 AOT Inductor 是一种提前生成
.so文件的方法,详见 torch export 教程。 -
澄清 ATen 和 libtorch 的区别:通过交流,大家明确了 ATen 被视为后端,而 libtorch 被视为前端。寻求建议的用户意识到他们只需要张量(tensor)功能而不需要整个 libtorch,这显著改进了他们的工作流。
-
关于 AOTInductor 模型缓存的查询:Benjamin_w 询问了如何使用 AOT Inductor 缓存已编译的模型以避免重新编译延迟。Marksaroufim 提供了一个潜在方案,即设置
torch._inductor.config.fx_graph_cache = True,并提到正在努力优化热编译(warm compile)时间。
- (beta) PyTorch 中的 Channels Last 内存格式 — PyTorch Tutorials 2.3.0+cu121 文档: 未找到描述
- torch.export 教程 — PyTorch Tutorials 2.3.0+cu121 文档: 未找到描述
- pytor - 概览: pytor 有一个可用的仓库。在 GitHub 上关注他们的代码。
- torch.export 教程 — PyTorch Tutorials 2.3.0+cu121 文档: 未找到描述
- msaroufim 在 Python 中加载 AOT Inductor · Pull Request #103281 · pytorch/pytorch: 现在如果你运行带有 TORCH_LOGS=output_code python model.py 的 model.py,它将打印一个 tmp/sdaoisdaosbdasd/something.py,你可以像模块一样导入它。还需要设置 'config....
- PyTorch 调度器(dispatcher)演练: Python 中具有强大 GPU 加速功能的张量和动态神经网络 - pytorch/pytorch
- pytorch/torch/utils/cpp_extension.py at main · pytorch/pytorch: Python 中具有强大 GPU 加速功能的张量和动态神经网络 - pytorch/pytorch
CUDA MODE ▷ #algorithms (3 条消息):
-
vAttention - 重新定义 KV-Cache 内存管理:一篇新论文提出了 vAttention,这是一种用于大语言模型(LLM)推理的先进内存管理系统,旨在动态分配 KV-cache 内存,以解决 GPU 中的内存碎片问题。据称该系统取代了以往的静态分配方法,后者曾导致容量浪费和软件复杂性(阅读摘要)。
-
QServe - 通过量化提升 LLM 推理性能:QServe 推理库拥有一种新的量化算法 QoQ (W4A8KV4),旨在解决现有 INT4 量化技术面临的效率问题,特别是针对 GPU 上显著的运行时开销。这一进展对于增强大批量、基于云的 LLM 服务性能至关重要(阅读摘要)。
-
CLLMs 实现更快速的推理:一篇博客文章揭示了一致性大语言模型(CLLMs),改变了 LLM 作为顺序解码器的传统观点,证明了 LLM 可以有效地作为并行解码器运行。研究表明,这些模型通过并行解码多个 token,可以显著降低推理延迟,这可能反映了人类形成句子的认知过程(探索博客与研究)。
- vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention:高效利用 GPU 内存对于高吞吐量的 LLM 推理至关重要。之前的系统会提前为 KV-cache 预留内存,由于内部碎片导致容量浪费。在...
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving:量化可以加速大语言模型(LLM)推理。除了 INT8 量化,研究界正在积极探索更低精度,如 INT4。尽管如此,现有的...
- Consistency Large Language Models: A Family of Efficient Parallel Decoders:摘要:LLM 传统上被视为顺序解码器,逐个解码 token。在本博客中,我们展示了预训练的 LLM 可以轻松地被教会作为高效的并行解码器运行...
CUDA MODE ▷ #cool-links (4 条消息):
- Diffusion Model 推理获得大幅加速:Vrushank Desai 的博客系列详细阐述了如何优化 Diffusion Models 的推理延迟,专门针对丰田研究所(Toyota Research Institute)论文中的 U-Net 进行 GPU 架构调整以实现加速。配套的 GitHub 代码提供了实用的见解。
- 使用 Superoptimizer 寻找最快的 DNN:Twitter 上讨论的一个新工具据称可以作为“超级优化器(superoptimizer)”,通过搜索最快的 Triton 程序来优化任何 DNN,详见 Mirage 的论文。
- 对 “Superoptimizer” 基准测试的质疑:一名成员对 Mirage 项目论文中关于 DNN “超级优化器”展示的基准测试表示怀疑,这与其他人的怀疑态度一致。
- 批评 Mirage 的方法论:怀疑态度还延伸到了 Mirage 在其方法中忽略了自动调优(autotuning),尽管该项目专注于识别最优融合策略,这一点在其 GitHub 演示页面上被发现。
提及的链接:Diffusion Inference Optimization:未找到描述
CUDA MODE ▷ #beginner (6 条消息):
-
SetFit 模型 ONNX 导出疑问:一名成员询问了使用 SetFit 的导出方法与 PyTorch 的
torch.onnx.export将 HuggingFace SetFit 模型导出为 ONNX 之间的区别。该过程涉及 SetFit 仓库中的一个笔记本示例用于导出模型。 -
PyTorch 代码导出等效性查询:他们还分享了一段使用
torch.onnx.export的代码片段,并思考这是否会产生与SetFit::export_onnx方法相同的 ONNX 输出。 -
ONNX 到 TensorRT 转换澄清:成员寻求确认在运行
trtexec将其编译为 TensorRT plan 文件之前,是否必须先创建一个 ONNX 模型,并分享了一个用于trtexec转换的示例命令。 -
对 Torch Compile 选项的困惑:
torch.compile中提到的tensorrt选项引发了成员的困惑,即它与之前提到的 ONNX 到 TensorRT 转换过程之间的关系。 -
关于在目标 GPU 上进行转换需求的推测:有人询问
trtexec命令是否需要在打算使用 TensorRT plan 的目标 GPU 上运行。
CUDA MODE ▷ #off-topic (2 条消息):
- Apple 发布 M4 芯片:Apple 推出了 M4 芯片,为新款 iPad Pro 带来了每秒 38 万亿次操作 的性能提升。M4 采用 3 纳米技术和 10 核 CPU,提升了能效并驱动了全新的 Ultra Retina XDR 显示屏。
- Panther Lake 的性能竞争:一项对比指出 Panther Lake 每秒可执行 175 万亿次操作,展示了其强大的计算能力。
提到的链接:Apple introduces M4 chip:Apple 今日发布了 M4,这是 Apple 设计的最新芯片,为全新的 iPad Pro 提供了惊人的性能。
CUDA MODE ▷ #irl-meetup (1 条消息):
seire9159: 芝加哥有没有人想一起看视频并编写一些 CUDA 代码。
CUDA MODE ▷ #llmdotc (40 条消息🔥):
-
ZeRO++ 承诺“少即是多”:ZeRO++ 为大模型训练提供了 4 倍的通信量减少,显著加快了训练过程。通信前对权重和梯度的量化对模型收敛的影响微乎其微。
-
MPI Bug 已修复:一次合并解决了某个问题,现在 master 分支上的多 GPU 训练可以正常运行。
-
所有 GPT-2 模型现在均可训练:已推送更新,允许通过
--model标志选择任何 GPT-2 模型大小,并可指定特定的.bin文件进行训练。在 A100 GPU 上可以进行 Batch size 4 的训练,但在扩展到 4x A100 GPU 时性能会有所下降。 -
梯度累积 (Gradient Accumulation) 正在开发中:讨论集中在需要梯度累积来提高 GPU 扩展效率。尽管有好处,但由于提案 PR 中的复杂性和可读性等实现问题,目前尚未立即采用。
-
Layernorm Backward 精度难题:有人提出了一个问题,即
layernorm_backwardkernel 在不支持 bf16 的硬件上执行 bfloat16 (bf16) 算术,导致编译问题。建议使用#if (CUDART_VERSION >= 12000)进行条件编译修复,以便仅在 CUDA 12 及以上版本中包含该有问题的 kernel。
提到的链接:ZeRO++:ZeRO++ 是构建在 ZeRO 之上的一套通信优化策略,无论规模或跨设备带宽限制如何,都能为大模型训练提供无与伦比的效率。R…
OpenInterpreter ▷ #general (56 条消息🔥🔥):
- 开源与预售讨论:一位成员讨论了 01 light 已开放预售,并指出其硬件和软件均为开源。
- 微软的 VoT 通过空间推理挑战 LAM:分享了一个 YouTube 视频链接,展示了微软的 “Vision of Thought” (VoT),它为 LLM 赋予了空间推理能力,据创作者称,其表现优于 OpenAI 的 LAM。该成员表示期待能有更安全的版本与家人分享。
- API keys 配置难题:几位成员讨论了配置 environment variables(环境变量)和 API keys 时的挑战和解决方法。建议参考 litellm documentation 的说明,并将
GROQ_API_KEY设置为环境变量。 - AI 驱动的计算机交互创新:成员们讨论了利用 OpenCV/Pyautogui 等工具,使用 GPT-4 等模型在不同操作系统环境(Ubuntu, Mac)中执行任务的系统。
- 结合开源 AI 工具:提议将 Open Interpreter 与开源 AI 眼镜 “Billiant Labs Frame” 集成,并分享了一个介绍该眼镜的 YouTube 视频。
- Groq | liteLLM: https://groq.com/
- This is Frame! Open source AI glasses for developers, hackers and superheroes.: 这是 Frame!面向开发者、黑客和超级英雄的开源 AI 眼镜。首批客户将于下周开始收到产品。我们迫不及待想看到...
- open-interpreter/interpreter/core/computer/display/point/point.py at main · OpenInterpreter/open-interpreter: 计算机的自然语言界面。通过在 GitHub 上创建账号为 OpenInterpreter/open-interpreter 的开发做出贡献。
- "VoT" Gives LLMs Spacial Reasoning AND Open-Source "Large Action Model": 微软的 "Visualization of Thought" (VoT) 赋予了 LLM 空间推理能力,这在以前对 LLM 来说几乎是不可能的。此外,还有一个新的...
OpenInterpreter ▷ #O1 (74 条消息🔥🔥):
-
将 LiteLLM 连接到各种 AI 提供商:LiteLLM 文档指定支持多个 AI 提供商,包括 OpenAI 模型、Azure、Google 的 PaLM 和 Anthropic。LiteLLM providers documentation 中列出了具体的说明和先决条件。
-
Groq Whisper API 热议:Groq 的 API 中加入 Whisper 引发了关于将其与 01 集成的讨论,并指出 Groq 的免费 API 可能具有优势。Groq’s API 因免费且高效而受到称赞,但用户在 模型访问方面遇到了问题。
-
Gemini Pro Vision 被吹捧为免费替代方案:用户讨论将 Gemini Pro Vision 作为一个免费且可能易于集成的 API。未提供具体的文档链接。
-
01 在 Windows 上的烦恼:用户报告称 01 在 Windows 平台上的功能受限,但存在涉及 Windows 10 代码修改以及检查 Windows 11 兼容性更新的潜在修复方案。
-
开源 AI 的难题:几位成员对像 01 这样的开源 AI 系统可能无法完全支持开源 AI 模型表示惊讶,并就专有 AI 模型与开源 AI 模型的可行性展开了辩论。
提到的链接:Providers | liteLLM: 了解如何在 LiteLLM 上部署和调用来自不同提供商的模型
OpenInterpreter ▷ #ai-content (2 条消息):
- GPT-4 与 YouTube 联动:一名成员通过自定义指令让 GPT-4 利用 YouTube 进行音乐推荐,展示了该模型遵循特定用户指令的能力。
- 本地模型性能评估:他们测试了多个本地模型,例如 TheBloke/deepseek-coder-33B-instruct.GGUF,但该模型因声称无网络连接而未能达到预期。另一个使用 lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF 的尝试也表现平平,在一次重试失败后便放弃了。
- mixtral-8x7b 取得成功:mixtral-8x7b-instruct-v0.1.Q5_0.gguf 提供了目前为止最好的性能,几乎正确地执行了任务,表现优于 deepseek,尤其是在配备了自定义调优的 2080 ti GPU 和 32GB DDR5 6000 内存的系统上。
- Macbook Pro 在运行本地模型时力不从心:该成员的 MacBook Pro 被证明甚至无法胜任轻量级的本地模型操作,已不再用于此类任务。
LAION ▷ #general (38 messages🔥):
-
DALLE-3 级别的输出指日可待:成员们讨论了通过结合 Pixart Sigma + SDXL + PAG 来实现与 DALLE-3 相当的输出,尽管 Pixart 在处理文本和单个物体方面仍有困难。据说这种 ComfyUI 工作流 能够实现离线的 提示词对齐(prompt alignment)和质量,并被认为具有进一步改进的潜力。
-
对微调和技术专业知识的需求:社区认为微调可以解决图像生成中的构图问题,并指出技术头脑可以将当前的成就推向新高度。一位用户承认自己技术能力较弱,希望其他人能为改进做出贡献。
-
揭秘模型质量的突破:一位成员发现了提升模型质量的关键拼图——确保微调节(microconditioning)输入范围易于管理以降低学习难度,并提出了优化该过程的具体参数和策略。
-
保险数据自动化:一位商业汽车保险核保师咨询了关于自动化数据处理的开源工具和策略,以提高评估风险和管理理赔的效率与准确性。
-
AI 竞赛公告:一位 AI 研究工程师宣布了在 IJCAI 期刊举办的竞赛,并为那些对发表论文和赢取奖金感兴趣的人分享了链接。该竞赛似乎与 AI 在科学领域的应用有关。
- 认识 AdVon,感染媒体行业的 AI 驱动内容怪兽:我们对 AdVon Commerce 的调查,这家 AI 承包商是《今日美国》和《体育画报》丑闻的核心。
- 具有扁平化与重构功能的 SNAC:纯语音编解码器:https://colab.research.google.com/drive/11qUfQLdH8JBKwkZIJ3KWUsBKtZAiSnhm?usp=sharing 通用(32khz)编解码器:https://colab.research.g...
- IJCAI 2024: Rapid Aerodynamic Drag Pred - 飞桨AI Studio星河社区:未找到描述
LAION ▷ #research (59 messages🔥🔥):
- 提及 IC-Light GitHub 仓库:一位用户分享了 IC-Light GitHub 仓库的链接,这是一个专注于“更多重光照(relighting)!”的开源项目。仓库地址为 GitHub - lllyasviel/IC-Light。
- 建议避免垃圾信息行为:一条消息因在多个频道复制粘贴而被标记为疑似垃圾信息,原发布者已确认收到通知。
- 关于噪声条件评分网络(Noise Conditional Score Networks)的辩论:用户们就噪声条件评分网络和 DDPMs 中的噪声调度展开了技术讨论,质疑其是否收敛到标准高斯分布。
- 探索 K-diffusion 和基于评分的模型:引用了来自 arxiv.org 的“K-diffusion”等多篇论文,用户们交流了对这些模型中数学概念的理解,支持这些概念紧密相关但在 ODE 求解器使用等细节上有所不同的观点。
- DDIM 中的方差爆炸与方差保持:关于扩散模型中“方差爆炸(variance exploding)”概念的澄清对话,结论是它与受 DDPM 启发的 ODE 求解器有关,并将其与 rectified flows 等其他方法进行了比较。
- Elucidating the Design Space of Diffusion-Based Generative Models:我们认为基于扩散的生成模型的理论和实践目前过于复杂,并试图通过展示一个清晰分离...的设计空间来补救这一现状。
- Generative Modeling by Estimating Gradients of the Data Distribution | Yang Song:未找到描述
- GitHub - lllyasviel/IC-Light: More relighting!:更多重光照!通过在 GitHub 上创建账户来为 lllyasviel/IC-Light 的开发做出贡献。
LlamaIndex ▷ #announcements (1 条消息):
- deeplearning.ai 推出“使用 LlamaIndex 构建 Agentic RAG”课程:一门名为“Building Agentic RAG with LlamaIndex”的新课程已在 deeplearning.ai 上线,由 LlamaIndex 的 CEO Jerry Liu 授课。该课程将涵盖 routing(路由)、tool use(工具使用)以及带有工具使用的多步推理,以赋能 Agent 获取信息并实现复杂问答。
提到的链接:Andrew Ng (@AndrewYNg) 的推文:我很高兴启动我们第一个专注于 Agent 的短课程,从由 @jerryjliu0(@llama_index 的 CEO)教授的《使用 LlamaIndex 构建 Agentic RAG》开始。这涵盖了一个重要的转变…
LlamaIndex ▷ #blog (2 条消息):
-
Agentic RAG 课程发布:LlamaIndex 宣布与 @DeepLearningAI 和 @AndrewYNg 合作,提供一门关于构建 Agentic RAG 的新课程,教授如何创建一个能够理解跨多个文档的复杂问题的自主研究助手。感兴趣的用户可以通过提供的 Twitter 链接了解更多信息并报名。
-
在本地更快地运行 LLM:LlamaIndex 集成了一项服务,允许快速运行本地大语言模型 (LLMs),支持 Mistral、Gemma、Llama、Mixtral 等一系列模型,涵盖包括 NVIDIA 在内的各种架构。更多详情可通过其 Twitter 帖子获取。
LlamaIndex ▷ #general (55 条消息🔥🔥):
- Vector Store 中的 Embedding 困扰:一位成员表示在使用 LlamaIndex 构建本地 RAG 系统(使用来自 ollama 的 nomic embeddings)时遇到了困难,原因是与 chroma 自有的 embeddings 存在兼容性问题。给出的建议是,如果使用 Vector Store 集成,LlamaIndex 会自动处理 Embedding。
- 助力社区成员的项目:一位成员呼吁大家支持他在 LinkedIn 上发布的关于使用 LlamaIndex 的 LlamaParse 的帖子。
- Rerank 与元数据困境:成员们讨论了
rerank模型和MetadataReplacementPostProcessor的执行顺序,结论是该顺序取决于用户是希望基于原始文本还是替换后的元数据进行 Rerank。 - 托管本地 LLM 模型:讨论涵盖了企业托管本地 LLM 模型的情况,包括 AWS、K8s 上的自动扩缩容以及 vLLM 或 TGI 等选项。共识倾向于生产环境需要可扩展性。
- 工具执行故障排除:一位遇到 _CBEventType.SUB_QUESTION 未被调用问题的用户收到了指向实现缺陷的回复,并获得了一些代码片段指导以尝试解决。
- GitHub - aurelio-labs/semantic-router: Superfast AI decision making and intelligent processing of multi-modal data.: 超快速的 AI 决策和多模态数据智能处理。 - aurelio-labs/semantic-router
- Knowledge graph - LlamaIndex: 未找到描述
- ReAct Agent - A Simple Intro with Calculator Tools - LlamaIndex: 未找到描述
- vLLM - LlamaIndex: 未找到描述
- Structured Hierarchical Retrieval - LlamaIndex: 未找到描述
OpenRouter (Alex Atallah) ▷ #app-showcase (2 条消息):
-
Languify.ai 发布: 一个新的浏览器扩展程序 Languify.ai 已发布,旨在优化网站上的文本以增加用户参与度和销售额,利用 OpenRouter 根据 Prompt 选择模型。该扩展提供免费的个人计划和每月 10.99 欧元的商业计划,可在 www.languify.ai 找到。
-
AnythingLLM 的更简单替代方案: 一位成员对 Languify.ai 表示了兴趣,认为它比 AnythingLLM 更简单,后者对他们的需求来说过于复杂,并表示将尝试这个新扩展。
提到的链接: Languify.ai - Optimize copyright: 通过 Languify 提升内容的触达率,这是我们用户友好的浏览器扩展。由 AI 驱动,它能无缝优化文案,增强参与度并放大您的创意影响力。
OpenRouter (Alex Atallah) ▷ #general (53 条消息🔥):
-
关于 OpenRouter 信息获取的困惑: 一位用户表示难以找到关于 OpenRouter 的非技术信息,尽管阅读了文档,但对于路由如何工作、什么是 Credits 以及某些模型的实际免费状态仍有疑问。频道中没有提供明确的答案或资源来解决这些疑虑。
-
寻找 Llama 3 审核服务: 一位频道成员在寻找用于审核的 Llama 3 Guard API,在注意到 OpenRouter 的产品中没有该服务后,被引导至 Together.ai 作为服务提供商。
-
Min-P 支持查询和变通方法: 关于哪些提供商支持
min_p的讨论明确了由 Together、Lepton、Lynn 和 Mancer 提供的模型确实提供此支持,尽管 Together 遇到问题,Lepton 仍能正常运行。 -
模型托管和 DeepSeek 版本谜题: 频道用户询问了 DeepSeek v2 的托管选项,有报告显示,除了 DeepSeek 自己的 32k Context 模型外,目前似乎没有其他提供商在托管它。
-
越狱 LLM Wizard 8x22B: 频道成员讨论了越狱 Wizard 8x22B 以解锁更多未经审查内容的潜力,并将其与现有的安全内容限制进行了对比。分享了关于理解 LLM 拒绝机制的研究链接,例如这篇 Alignment Forum 帖子,以阐明 LLM 如何处理违规请求。
- 未找到标题:未找到描述
- Meta: 由 meta-llama 提供的 Llama 3 70B Instruct | OpenRouter:Meta 最新的模型类别 (Llama 3) 推出了多种尺寸和版本。这个 70B 指令微调版本针对高质量对话场景进行了优化。它展示了强大的...
- LLM 中的拒绝行为是由单一方向介导的 — AI Alignment Forum:这项工作是 Neel Nanda 在 ML Alignment & Theory Scholars Program - 2023-24 冬季班研究方向的一部分,由...共同指导。
- LLM 中的拒绝行为是由单一方向介导的 — AI Alignment Forum:这项工作是 Neel Nanda 在 ML Alignment & Theory Scholars Program - 2023-24 冬季班研究方向的一部分,由...共同指导。
- OpenRouter:构建与模型无关的 AI 应用
- 企业级 AI 数据分析师 | AI Agent | Athena Intelligence:未找到描述
- 使用 Langchain 的 LangGraph 简化客户支持:Ankush k Singal
- llm-ui | 适用于 LLM 的 React 库:适用于 React 的 LLM UI 组件
- Stanford CS236: Deep Generative Models I 2023 I Lecture 1 - Introduction:有关斯坦福人工智能项目的更多信息,请访问:https://stanford.io/ai。要跟随课程学习,请访问课程网站...
- 使用实时 AI 解决方案加速系统 - Groq:Groq 为开发者提供高性能 AI 模型和 API 访问。以比竞争对手更低的成本获得更快的推理速度。立即探索用例!
- gradientai/Llama-3-8B-Instruct-Gradient-4194k · Hugging Face:未找到描述
- 无标题:未找到描述
- Gordon Wetzstein (@GordonWetzstein) 的推文:很高兴分享我们新的 Nature 论文!在这项工作中,我们提出了一种新的显示设计,将逆向设计的超表面波导与 AI 驱动的全息显示相结合,以实现全色 3D 增强现实...
- [AINews] OpenAI 的公关活动?:2024年5月7日至5月8日的 AI 新闻。我们为您检查了 7 个 subreddit、373 个 Twitter 账号和 28 个 Discord 社区(419 个频道,4079 条消息)。预计阅读时间...
- Slop 是不受欢迎的 AI 生成内容的新名称:我昨天看到了 @deepfates 的这条推文,我非常赞同:“Slop”正实时成为一个专业术语,就像“Spam(垃圾邮件)”一样……
- Axolotl - Dataset Formats: 未找到描述
- Recent RunPod Axolotl error · Issue #1596 · OpenAccess-AI-Collective/axolotl: 请检查此问题之前是否已报告。我搜索了之前的 Bug 报告,未发现类似报告。预期行为:我大约两天前运行了 Axolotl,当时运行正常...
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: 更快地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: 更快地理解代码。
- peft/src/peft/tuners/lora/config.py at main · huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning. - huggingface/peft
- OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: 更快地理解代码。
- Llama 3 怎么了?Arena 数据分析 | LMSYS Org: <p>4 月 18 日,Meta 发布了他们最新的权重开放(open-weight)大语言模型 Llama 3。自那时起,Llama 3-70B 迅速攀升至英语 <...
- Model Spec (2024/05/08): 未找到描述
- React App:未找到描述
- Comparing tinygrad:master...davidjanoskyrepo:symbolic-arange-pull · tinygrad/tinygrad:你喜欢 pytorch?你喜欢 micrograd?你热爱 tinygrad!❤️ - Comparing tinygrad:master...davidjanoskyrepo:symbolic-arange-pull · tinygrad/tinygrad
- GitHub - kyegomez/AlphaFold3: Implementation of Alpha Fold 3 from the paper: "Accurate structure prediction of biomolecular interactions with AlphaFold3" in PyTorch:论文《使用 AlphaFold3 准确预测生物分子相互作用》的 PyTorch 实现 - kyegomez/AlphaFold3
- 加入 Agora Discord 服务器!:通过开源 AI 研究推动人类进步。| 6856 名成员
- Introducing Quickscope - Automate smoke tests in Unity - May 06, 2024 - Regression Games:了解 Quickscope,一个用于在 Unity 中自动化冒烟测试的工具
- Regression Games - The ultimate AI agent testing platform for Unity:轻松为 Unity 开发用于 QA 测试的机器人。