ainews-anthropics
这句话模仿了著名的拉丁语格言“*Quis custodiet ipsos custodes?*”(谁来监督监督者?)。 在现代语境(尤其是人工智能领域)下,它的中文翻译为: **“谁来提示提示者自己?”** 或 **“谁来为提示词本身提供提示?”**
Anthropic 发布了其 Workbench 控制台的升级版本,引入了思维链(chain-of-thought)推理和提示词生成器等新的提示工程功能,显著缩短了开发时间,其客户 Zoominfo 便是一个例证。OpenAI 预告了一项即将推出的“神奇”新进展,外界推测这可能是一个在免费版中取代 GPT-3.5 的新大语言模型,或者是搜索领域的竞争产品。开源社区强调 Llama 3 70B 具有“变革性”,同时 Llama 3 120B 推出了新的量化权重,且 llama.cpp 增加了对 CUDA 图(CUDA graph)的支持以提升 GPU 性能。Neuralink 展示了意念控制鼠标,激发了人们对通过大脑信号进行意识建模的兴趣。ICLR 2024 大会首次在亚洲举行,引起了广泛关注。
自动 Prompt Engineering 就够了。
2024年5月9日至5月10日的 AI 新闻。 我们为您检查了 7 个 subreddits、373 个 Twitter 账号 和 28 个 Discord(419 个频道和 4923 条消息)。 预计节省阅读时间(按每分钟 200 字计算):556 分钟。
我们关注 Anthropic 的 Workbench 已经有一段时间了,今天他们发布了一些升级,帮助人们改进 Prompt 并将其模板化。
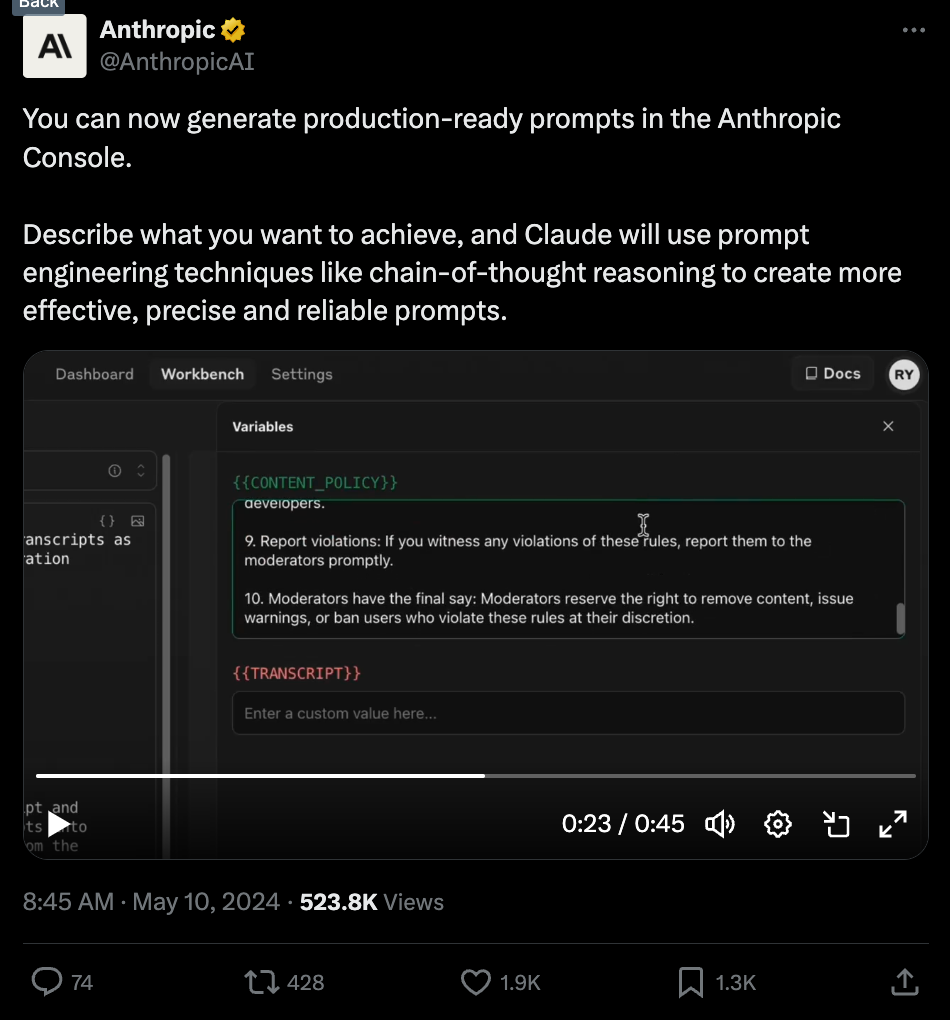
非常酷,虽然还没到 Prompt Engineer 的终结,但确实很有用。坦率地说,在下周 OpenAI 的大型演示日(可能是语音助手?)和 Google I/O 的风暴来临之前,这周一直很平静。
目录
[TOC]
AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成(4 次运行中的最佳结果)。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
OpenAI 公告
- 新进展预告:@sama 预告了周一上午 10 点(太平洋时间)即将发布的 OpenAI 新进展,指出“不是 GPT-5,不是搜索引擎,但我们一直在努力开发一些我们认为人们会喜欢的新东西!”,并称其为“魔法”。
- 现场演示推广:@gdb 也宣传了“周一上午 10 点(太平洋时间)的一些新工作现场演示”,并澄清“不是 GPT-5 或搜索引擎,但我们认为你会喜欢它。”
- 关于公告性质的推测:有推测称这可能是 @OpenAI 的 Google Search 竞争对手,可能“只是由 LLM 总结的 Bing 索引”。然而,其他人认为这将是取代免费版 GPT-3.5 的新 LLM。
Anthropic 进展
- 新的 Prompt Engineering 功能:@AnthropicAI 宣布其 Console 中推出了新功能,利用 Chain-of-Thought 推理等技术生成生产就绪的 Prompt,以获得更有效、更精确的提示词。这包括一个 Prompt 生成器和变量,用于轻松注入外部数据。
- Prompt 生成的客户成功案例:Anthropic 的 Prompt 生成功能显著缩短了其客户 @Zoominfo 的 MVP RAG 应用的开发时间,同时提高了输出质量。
- 对 Prompt Engineering 的影响:有人认为 Prompt 生成意味着“Prompt Engineering 已死”,因为 Claude 现在可以自己编写 Prompt。Prompt 生成器在构建有效 Prompt 方面可以帮你完成 80% 的工作。
Llama 和开源模型
- RAG 应用教程:@svpino 发布了一个关于使用开源模型构建 RAG 应用的 1 小时教程,详细解释了每个步骤。
- Llama 3 70B 性能:根据 Arena Elo 评分,Llama 3 70B 被称为“改变游戏规则”。其他强劲的开源模型包括 Haiku、Gemini 1.5 Pro 和 GPT-4。
- Llama 3 120B 量化权重:Llama 3 120B 量化权重已发布,展示了该模型在输出中的“内心挣扎”。
- Llama.cpp 支持 CUDA graphs:Llama.cpp 现在支持 CUDA graphs,在 RTX 3090/4090 GPU 上可获得 5-18% 的性能提升。
Neuralink 演示
- 意念控制鼠标:最近的 Neuralink 演示视频显示,一个人仅通过思考就能高速且精准地控制鼠标。这引发了关于拦截“Chain of Thought”信号,从而直接从人类内心体验中建模意识和智能的想法。
- 更多演示和分析:Neuralink 分享了更多视频演示和定量分析,引发了人们对该技术潜力的兴奋。
ICLR 会议
- 首次在亚洲举办:ICLR 2024 首次在亚洲举行,引发了热烈讨论。
- 自发讨论与 GAIA 基准测试:@ylecun 分享了会议现场自发技术讨论的照片。他还展示了针对通用 AI 助手的 GAIA 基准测试。
- Meta AI 论文:Meta AI 分享了其研究人员在 ICLR 发表的 4 篇值得关注的论文,涵盖了高效 Transformer、多模态学习和表示学习等主题。
- 线下参会人数众多:据报道,ICLR 有 5400 名线下参会者,反驳了“AI 寒冬”的说法。
杂项
- Mistral AI 融资:传闻 Mistral AI 正以 60 亿美元的估值进行融资,DST 为投资者,而非 SoftBank。
- Yi AI 模型发布:Yi AI 宣布将于 5 月 13 日发布升级版的开源模型以及其首个商业模型 Yi-Large。
- Instructor Cloud 进展:据 @jxnlco 称,Instructor Cloud “又近了一步”,他一直在分享构建 AI 产品的幕后花絮。
- 英国首相谈 AI 与开源:据 @ylecun 称,英国首相 Rishi Sunak 就 AI 和开源发表了“明智的宣言”。
- Perplexity AI 合作伙伴关系:Perplexity AI 与 SoundHound 合作,为汽车、电视和 IoT 设备的语音助手带来实时网络搜索功能。
迷因与幽默
- Claude 的魅力:@nearcyan 开玩笑说,“Claude 很有魅力,让我想起了我最喜欢的那些 Anthropic 员工”。
- “Stability 已死”:@Teknium1 针对 Anthropic 的进展宣布“Stability 已死”。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 进展与能力
- AI 音乐突破:在一条 推文 中,ElevenLabs 预告了其音乐生成器,标志着 AI 生成音乐领域的重大进展。
- 基因疗法恢复幼儿听力:一名英国幼儿在 全球首例此类基因疗法试验 中恢复了听力,这是医学史上的一个重要里程碑。
- 太阳能制造提前实现 2030 年目标:IEA 报告称,全球太阳能电池制造能力目前已 足以满足 2030 年净零排放目标,提前六年完成进度。
- AI 发现新物理方程:一个 AI 系统通过生成按需模型来模拟物理系统,在 发现新物理方程 方面取得了进展。
- 大脑图谱绘制进展:Google Research 分享了其 人类大脑图谱绘制工作 的更新,这可能会带来生活质量的改善。
AI 伦理与治理
- OpenAI 考虑允许生成 AI 色情内容:引发伦理担忧,OpenAI 正在 考虑允许用户创建 AI 生成的色情内容。
- OpenAI 为出版商提供优惠:OpenAI 的首选出版商计划(Preferred Publisher Program)为媒体公司提供优先聊天展示位等福利,引发了对开放模型访问的担忧。
- OpenAI 对 Subreddit 发起版权申诉:尽管 OpenAI 本身是“版权作品的大规模抓取者”,但它 针对 ChatGPT Subreddit 的 Logo 发起了版权申诉。
- 两名 OpenAI 安全研究员辞职:由于怀疑 OpenAI 能否 “在 AGI 到来之际表现得负责任”,两名安全研究员离开了公司。
- 美国考虑限制中国获取 AI 技术:美国正在 探索限制中国获取支持 ChatGPT 等应用的 AI 软件 的途径。
AI 模型与架构
- Invoke 4.2 增加区域引导:Invoke 4.2 已发布,带有控制层(Control Layers),支持文本和 IP adapter 的区域引导。
- OmniZero 支持多种身份/风格:发布的 OmniZero 代码 支持 2 种身份和 2 种风格。
- Copilot 获得基于 GPT-4 的模型:Copilot 增加了 3 个新的 “Next-Models”,看起来是 GPT-4 的变体。Next-model4 明显比基础版 GPT-4 更快。
- Gemma 2B 在小于 32GB RAM 上实现 10M 上下文:支持 10M 上下文的 Gemma 2B 发布,利用循环局部注意力(recurrent local attention)在不到 32GB 的内存上运行。
- Llama 3 8B 扩展至 500M 上下文:Llama 3 8B 扩展至 500M 上下文 的成果被分享。
- Llama3-8x8b-MoE 模型发布:一个名为 Llama3-8x8b-MoE 的 llama3-8B-Instruct 混合专家(Mixture-of-Experts)扩展版本发布。
- Bunny-v1.1-4B 扩展至 1152x1152 分辨率:基于 SigLIP 和 Phi-3-mini-4k-instruct 构建的多模态 Bunny-v1.1-4B 模型发布,支持 1152x1152 分辨率。
{kind=link}
{kind=link}
AI Discord 摘要
摘要之摘要的摘要
- 大语言模型 (LLM) 的进展与发布:
- Meta 的 Llama 3 模型正引起热潮,Meta 即将举办一场提供超过 1 万美元奖金池的黑客松。讨论围绕微调、评估以及模型性能展开。
- LLaVA-NeXT 模型承诺增强图像和视频理解的多模态能力,并鼓励进行本地测试。
- Gemma 的发布引发了关注,它拥有 10M 上下文窗口且仅需不到 32GB 显存,但也引发了对其输出质量的质疑。
- 多模态模型的发展:发布了多个新的多模态 AI 模型,包括带有微调演示的 Idefics2 (YouTube),具有扩展图像和视频理解能力的 LLaVA-NeXT (博客文章),以及用于根据文本提示将噪声转换为各种模态的 Lumina-T2X 系列 (Reddit 帖子)。Scaling_on_scales (GitHub) 方法挑战了对更大视觉模型的必要性。
- 优化 LLM 推理与训练:
- vAttention 和 QServe 等创新旨在提高 LLM 推理的 GPU 显存效率和量化,从而实现更大的 Batch Size 和更快的服务响应。
- 一致性大语言模型 (CLLMs) 引入了并行解码以降低推理延迟,模拟人类的认知过程。
- 讨论了优化 CUDA 内核、Triton 性能,以及 LLM 训练反向传播中确定性与速度之间的权衡。
- Vrushank Desai 的系列文章 探讨了利用 GPU 架构特性来优化扩散模型的推理延迟。
- AI 模型可解释性与评估:
- 来自英国 AI 安全研究所的 Inspect AI 框架提供了评估 LLM 的组件,包括提示词工程 (Prompt Engineering)、工具使用和多轮对话。
- Eleuther AI 讨论了 CrossCare 项目,该项目分析了 LLM 和预训练数据中针对不同人群的疾病流行率偏见。
- 围绕预训练数据集对多模态模型“零样本 (Zero-shot)”泛化能力影响的辩论,详见一篇 arXiv 论文。
- Mirage 多级张量代数超级优化器旨在优化深度神经网络,尽管其基准测试结果面临质疑。
- 开源 AI 工具与库:
- LlamaIndex 宣布了本地 LLM 集成、TypeScript Agent 构建指南以及与 Google Firestore 的集成,促进了开放 AI 的发展。
- OpenInterpreter 能够使用 GPT-4 和 OpenCV 实现 AI 任务自动化,新版本增加了 OS 标志和 Computer API 支持。
- Hugging Face 将 B-LoRA 训练集成到高级 DreamBooth 中,用于使用单张图像进行隐式风格-内容分离。
- Intel 的 ipex-llm 加速了 Intel CPU 和 GPU 上的本地 LLM 推理和微调,尽管目前尚不支持 LM Studio。
第一部分:Discord 高层摘要
Stability.ai (Stable Diffusion) Discord
Artisan Bot 进驻 Discord:Stability AI 推出了 Stable Artisan,这是一款在 Discord 上运行的机器人,具备 Stable Diffusion 3 和 Stable Video Diffusion 功能,用于内容创作。它还辅以 Search and Replace、Background Removal 和 Outpainting 等工具,旨在直接在 Discord 上彻底改变用户交互体验。
开源与否?关于 SD3 的辩论愈演愈烈:Discord 成员就 Stable Diffusion 3 (SD3) 潜在的 open-sourcing 展开了激烈辩论,探讨了目前仅限 API 访问的动机,并推测了未来的发展方案,包括发布前可能进行的优化。
探索 Stable Diffusion 宇宙:社区积极参与讨论各种 Stable Diffusion 模型版本,包括 SDXL 和 ControlNets,评估它们的局限性以及由社区开发的 Lora 等模型带来的实质性增强。
追求 360 度全景创作:一位用户发起了关于制作 360-degree images 的讨论,分享了多个资源并寻求方法指导,参考了 Skybox AI 等平台以及 Reddit 上的讨论。
实时技术支持化解难题:通过务实且简洁的交流,快速解决了常见的执行错误,例如 “DLL load failed while importing bz2”,彰显了 Discord 社区在提供点对点技术支持方面的敏捷性。
Perplexity AI Discord
Perplexity 与 SoundHound 达成合作:Perplexity AI 已与 SoundHound 建立合作伙伴关系,旨在将在线 LLM 集成到各种设备的语音助手中,增强实时网页搜索能力。
Perplexity 创新搜索与引用功能:Perplexity AI 的更新引入了 incognito search,确保用户查询在 24 小时后消失,并结合增强的引用预览,以增强用户对信息源的信任。
Pro Search 故障与 Opus 限制引发争议:工程社区正面临 Pro Search 功能的挑战,该功能目前无法提供互联网搜索结果或来源引用。此外,对于 Perplexity AI 上 Opus 模型每日 50 次的使用限制也引发了不满,激起了关于潜在替代方案和解决方案的讨论。
AI 工程师面临的 API 难题:工程师们注意到 API 输出一致性的问题,即在使用相同模型的情况下,相同的 prompts 产生的结果与 Perplexity Labs 上的结果不同。针对差异产生的原因以及如何针对最新模型进行有效 prompting 的指导请求已被提出。
参与 Perplexity 功能体验与新发布:用户正在积极体验各种功能,如将 thread 设置为可分享,并探索各种查询,包括香蕉的放射性和数学环的本质。此外,用户对 Natron Energy 的最新发布也表现出浓厚兴趣,该消息通过 Perplexity 的分享平台发布。
Unsloth AI (Daniel Han) Discord
Unsloth Studio 因公益项目停滞:Unsloth Studio 的发布推迟了,因为团队正专注于发布 phi 和 llama 项目,目前 Studio 项目大约完成了一半。
优化器困惑已解决:用户曾不确定如何在 Unsloth 中指定优化器,但参考了 Hugging Face 文档以澄清有效的优化器字符串,包括 “adamw_8bit”。
训练胜过推理:Unsloth 团队表示更倾向于推进训练技术,而非竞争激烈的推理领域。他们在开源贡献中宣传了加速训练方面的进展。
长上下文模型怀疑论:讨论指出,用户对超长上下文模型的可行性和评估持怀疑态度,例如提到的处理高达 10M 上下文长度的尝试。
数据集成本效益辩论:社区就模型训练所需高质量数据集的投资交换了不同意见,同时考虑了指令微调(instruct tuning)和合成数据创建。
给有抱负的博主的市场优先建议:一名成员关于多功能博客平台的想法引发了关于进行市场调研并确保清晰客户群的建议,以避免缺乏产品/市场匹配(product/market fit)。
Ghost 3B Beta 应对时空问题:Ghost 3B Beta 模型的早期训练展示了其用多种语言通俗易懂地解释爱因斯坦相对论的能力,暗示了其在复杂科学传播方面的潜力。
帮助论坛促进微调技巧:Unsloth AI 帮助频道充满了在 Google Colab 上微调 AI 模型的技巧,尽管多 GPU 支持是用户渴望但尚未提供的功能。用户之间分享了 CUDA 内存错误的解决方案,并推荐了 YouTube 上的微调教程。
客户支持 AI 为您服务:展示了 ReplyCaddy,这是一个基于微调后的 Twitter 数据集和 tiny llama 模型的客户支持工具,并感谢 Unsloth AI 在快速推理方面的协助,可在 hf.co 找到。
LM Studio Discord
LM Studio 感叹库的局限性:虽然 LM Studio 在运行 Llama 3 70B 等模型时表现出色,但用户即使在 192GB 的 Mac Studio 上也难以运行 llama1.6 Mistral 或 Vicuña 等模型,这指向了一个尽管系统资源充足但仍存在的神秘 RAM 容量问题。此外,用户对 Windows 上的 LM Studio 安装程序感到不满,因为它不提供安装目录选择。
AI 模型对硬件要求极高:运行大型模型需要大量的 VRAM;成员们讨论了 VRAM 是比 RAM 更大的限制因素。介绍了 Intel 的 ipex-llm 库,用于加速 Intel CPU 和 GPU 上的本地 LLM 推理 Intel Analytics Github,但它尚未与 LM Studio 兼容。
多设备协作的新前沿:工程师们探讨了集成 AMD 和 Nvidia 硬件的挑战和潜力,讨论了理论可能性与实际复杂性。人们对像 ZLUDA 这样旨在扩大非 Nvidia 硬件对 CUDA 支持的日渐式微的项目表示遗憾 ZLUDA Github。
翻译模型交流:对于翻译项目,Meta AI 的 NLLB-200、SeamlessM4T 和 M2M-100 模型获得了高度推荐,提升了对高效多语言能力的探索。
CrewAI 神秘的截断问题:面对 CrewAI 输出的 token 被截断的情况,用户推断这并非量化(quantization)的原因。条件语句中 OpenAI API 导入的失误才是罪魁祸首,目前该问题已解决,再次印证了细节决定成败。
HuggingFace Discord
图学习进入 LLM 领域:Hugging Face Reading Group 探讨了图机器学习 (Graph Machine Learning) 与 LLM 的集成,这得益于 Isamu Isozaki 的见解,并附带了详细的文章和视频。
揭秘 AI 创造力:根据 diffusers GitHub 脚本和研究论文的发现,将 B-LoRA 集成到高级 DreamBooth 的 LoRA 训练脚本中,只需添加标志 --use_blora 并进行相对较短时间的训练,即可达到新的创意高度。
寻找资源:AI 爱好者们在各种任务中寻求指导并分享资源,其中一个值得注意的 GitHub 仓库是关于使用 OpenAI 的 API 和 DALL-E 创建 PowerPoint 幻灯片的 Creating slides with Assistants API and DALL-E,此外还提到了 Ankush Singal 关于表格提取工具的 Medium 文章。
具有挑战性的 NLP 频道对话:NLP 频道处理了多样化的话题,例如为特定语言推荐模型——表现出对 sentence transformers 和 encoder 模型的偏好,以及 Llama 的 Instruct 版本,并提到了社区参与面试准备的情况。
Diffusion 讨论中的小问题与修复:diffusion 讨论详细介绍了与 HuggingChat bot 错误和 diffusion 模型色偏相关的问题及潜在解决方案,并指出通过将登录模块从 lixiwu 切换到 anton-l 可能修复登录问题,从而解决 401 状态码错误。
Modular (Mojo 🔥) Discord
-
缺失的 MAX 发布日期之谜:虽然有人提出了关于面向企业的 MAX 发布日期的问题,但对话中没有找到直接的答案。
-
调整 Modularity:人们对 Mojo 的 GPU 支持充满期待,这显示了科学计算进步的潜力。Modular 社区继续探索 MAX Engine 和 Mojo 的新功能,讨论范围从 Golang 和 Rust 等语言的后端开发专业知识,到寻求使用 Hugging Face 模型进行智能机器人助手的协作努力。
-
MoString 的极速竞赛:Rust 中自定义的
MoString结构体在字符串拼接任务中表现出惊人的 4000 倍速度提升,引发了关于增强 Modular 字符串处理能力以及它如何辅助 LLM Tokenizer 解码任务的讨论。 -
迭代器迭代与异常处理:Modular 社区正在商讨 Mojo 中迭代器和异常处理的实现,探索是返回
Optional[Self.Output]还是抛出异常。这引发了关于语言设计选择的更广泛对话,重点在于平衡易用性和零成本抽象 (Zero-Cost Abstractions)。 -
从草案到讨论:一系列技术提案正在进行中,从构建由 lit.ref 支持的 Reference 类型到增强 Mojo 的语言人体工程学。对这些讨论的贡献包括对自动解引用 (auto-dereferencing) 的见解,以及对
List中小缓冲区优化 (Small Buffer Optimization, SBO) 的考虑,所有这些都引导着 Modular 爱好者之间深思熟虑的审查与协作。
Nous Research AI Discord
-
TensorRT 加速 Llama 3:一位工程师强调了在使用 TensorRT 时 Llama 3 70b fp16 显著的速度提升,并为愿意应对复杂设置的用户分享了安装指南链接。
-
多模态微调与评估揭晓:讨论围绕模型的微调方法和评估展开。通过 YouTube 展示了 Idefics2 的微调,而 Scaling_on_scales 方法挑战了对更大型视觉模型的必要性,详见其 GitHub 页面。此外,还提到了英国政府用于评估大语言模型的 Inspect AI framework。
-
Worldsim 中的导航错误与积分困惑:用户在使用 Nous World Client 时遇到了障碍,特别是导航命令方面,并讨论了更新后用户积分的意外变化。工作人员正积极解决 Worldsim Client 界面中明显的系统缺陷。
-
高效的 Token 计数器与 LLM 优化:分享了 Llama 3 的 Token 计数解决方案以及 Meta Llama 3 的详细信息,包括使用 Nous 副本的替代 Token 计数方法以及 Huggingface 上的模型详情。此外,Salesforce 的 SFR-Embedding-Mistral 因在文本嵌入任务中超越前代产品而受到关注,详见其网页。
-
艰巨的 Rope KV Cache 困局:对话包括一位工程师在 rope 的 KV cache 实现上的挣扎、Llama 3 的 Token 计数查询,以及在 bittensor-finetune-subnet 上遇到的上传错误,这些都体现了社区中普遍存在的这类技术挑战。
OpenAI Discord
-
准备迎接 GPT 的新功能:计划于太平洋时间 5 月 13 日上午 10 点在 openai.com 进行直播,揭晓 ChatGPT 和 GPT-4 的新更新。
-
语法纠错者在线集结:一场关于语法重要性的辩论已经展开,一位高中英语老师主张语言的卓越性,而其他人则建议保持耐心并使用语法检查工具。
-
塑造搜索的未来:针对潜在的 基于 GPT 的搜索引擎 存在各种猜测,并有关于在等待此开发期间将 Perplexity 作为首选工具的讨论。
-
GPT-4 API vs. App:解开困惑:用户区分了 ChatGPT Plus 和 GPT-4 API 的计费,指出 App 具有不同的输出质量和使用限制,具体为 每 3 小时 18-25 条消息的限制。
-
提示词(Prompt)爱好者的分享精神:社区成员分享了资源,包括一篇详细的学习帖子和一个用于分析目标受众的免费 Prompt 模板,其中包含购买行为和竞争对手参与度的细节。
Eleuther Discord
-
演进中的大模型格局:社区讨论涵盖了从 ScottLogic 博客文章 中关于 Transformer Math 101 内存启发式方法的适用性,到 Microsoft 的 YOCO 仓库 中用于自监督预训练的技术,以及用于 LLM 推理加速的 QServe W4A8KV4 量化方法。人们对使用带有滑动窗口注意力的 KV cache 等新颖策略优化 Transformer 架构,以及 Mirage GitHub 仓库 中展示的多级张量代数超级优化器的潜力持续关注。
-
探索 LLM 中的偏见与数据集影响:社区对 LLM 中的偏见表示担忧,分析了 CrossCare 项目的研究结果,并详细讨论了数据集差异与现实世界普遍性之间的关系。EleutherAI 社区正在利用 EleutherAI Cookbook 等资源,以及一篇讨论 tokenizer 异常 token (glitch tokens) 的论文中的发现,这些发现可能为改进语言处理模型提供参考。
-
位置编码机制:研究人员辩论了不同位置编码技术的优劣,例如 Rotary Position Embedding (RoPE) 和 Orthogonal Polynomial Based Positional Encoding (PoPE),思考每种技术在解决现有方法局限性方面的有效性,以及对提高语言模型性能的潜在影响。
-
深入探讨模型评估与安全性:社区介绍了 Inspect AI,这是由英国 AI Safety Institute 开发的一个新型评估平台,旨在进行广泛的 LLM 评估,可以通过其完整文档进一步了解。与此同时,关于数学基准测试的讨论引起了人们对旨在评估 AI 推理能力的基准测试差距,以及 arXiv 论文中详述的潜在“零样本”泛化局限性的关注。
-
资源可用性查询:讨论暗示了对资源的需求,特别是关于每个 Pythia checkpoint 的 tuned lenses 可用性的询问,这表明社区正在不断努力改进和获取工具,以增强模型分析和可解释性。
CUDA MODE Discord
AI 炒作热潮转向实际应用:社区正热烈讨论深度学习优化的实际层面,这与通常围绕 AI 能力的炒作形成对比。重点关注领域包括在 PyTorch 中保存和加载编译模型、编译产物的加速,以及 msaroufim 的一个 PR 中提到的 Torch Inductor 不支持 MPS 后端的问题。
内存效率突破:诸如 vAttention 和 QServe 之类的创新正在重塑 GPU 内存效率和 LLM 的服务优化,承诺在没有内部碎片的情况下实现更大的 batch sizes,并提供高效的新型量化算法。
工程精度:CUDA vs Triton:对 CUDA 和 Triton 在 warp 和线程管理方面的关键对比进行了剖析,包括性能细微差别和 kernel 启动开销。社区推荐了一个关于该主题的 YouTube 讲座,讨论指出了使用 Triton 的优缺点,特别是它试图通过潜在的 C++ 运行时来最小化 Python 相关的开销。
优化之旅:分享的链接揭示了对优化模型推理延迟的浓厚兴趣,例如 Toyota 的扩散模型(在 Vrushank Desai 的系列文章中讨论),以及 Mirage 论文中为 DNN 探索的“超级优化器”,这引发了对基准测试声明和缺乏 autotune 的关注。
CUDA 难题与确定性困境:从排查 CUDA 的设备端断言 (device-side asserts) 到设置正确的 NVCC 编译器标志,初学者正在努力应对 GPU 计算的细微差别。与此同时,资深开发者正在辩论反向传播中的确定性以及 LLM 训练中性能的权衡,正如 llmdotc 频道中所讨论的那样。
Latent Space Discord
后起之秀超越 Olmo:据称来自 01.ai 的一个模型表现远超 Olmo,在社区内引发了关于其潜力和实际表现的关注与讨论。
糟糕的业务 (Sloppy Business):借鉴 Simon Willison 的术语,社区成员采用 “slop”(垃圾内容)来描述不想要的 AI 生成内容。这里是关于 AI 礼仪的热议。
LLM-UI 优化你的标记语言表现:llm-ui 作为一种优化 Large Language Model (LLM) 输出的解决方案被推出,旨在解决有问题的 Markdown、添加自定义组件,并通过更平滑的输出来增强停顿效果。
Meta Llama 3 黑客松准备就绪:一场专注于 Llama 3 的黑客松即将举行,由 Meta 牵头,奖金池超过 1 万美元,旨在吸引 AI 爱好者和开发者。详情及报名请点击此处。
AI Guardrails 与 Token 讨论:讨论围绕 LLM guardrails 展开,涉及 Outlines.dev 等工具,以及 Token 限制预生成的概念,这种方法并不适用于像 OpenAI 这样通过 API 控制的模型。
LAION Discord
-
Codec 演进:语音技术新高度:YouTube 视频中展示了一个纯语音 Codec,并分享了一个针对 32kHz 通用 Codec 的 Google Colab。这种全局 Codec 是语音处理技术的一大进步。
-
后起之秀:Llama3s 介绍:来自 LLMs lab 的 llama3s 模型已发布,为各种 AI 任务提供了增强工具,详情可见 Hugging Face 的 LLMs lab。
-
LLaVA 定义实力维度:LLaVA 的博客文章详细阐述了其最新语言模型的改进,并在 llava-vl.github.io 上全面探索了 LLaVA 更强大的 LLMs。
-
拨开迷雾:Score Networks 与 Diffusion Models:工程师们讨论了 Noise Conditional Score Networks (NCSNs) 向高斯分布的收敛,参考了 Yang Song 博客上的见解,并剖析了 DDPM、DDIM 和 k-diffusion 之间的细微差别,参考了 k-diffusion 论文。
-
超越图像:Lumina 系列的多模态探索:宣布 Lumina-T2X 系列作为一个统一模型,基于文本提示利用 Flow-based 机制将噪声转换为多种模态。未来的改进和训练细节在 Reddit 讨论中被重点提及。
OpenInterpreter Discord
Groq API 加入 OpenInterpreter 工具集:Groq API 现在已在 OpenInterpreter 中使用,最佳实践是在补全请求中使用 groq/ 作为前缀并定义 GROQ_API_KEY。Python 集成示例已上线,有助于快速部署 Groq 模型。
OpenInterpreter 助力 GPT-4 实现自动化:OpenInterpreter 展示了成功的任务自动化,特别是结合 GPT-4 与 OpenCV/Pyautogui 在 Ubuntu 系统上执行 GUI 导航任务。
创新的 OpenInterpreter 与硬件结合:社区成员正创意性地将 OpenInterpreter 与 Billiant Labs Frame 集成,以打造 AI 眼镜等独特应用(如此演示所示),并正在探索适用于 O1 Light 的兼容硬件,如 ESP32-S3-BOX 3。
本地 LLMs 的性能差异:虽然 OpenInterpreter 的工具被广泛使用,但成员们观察到本地 LLMs 在文件系统任务中的表现参差不齐,其中 Mixtral 被公认为有更好的效果。
LLM 领域的更新与进展:LLaVA-NeXT 模型的发布标志着本地图像和视频理解方面的进步。与此同时,OpenInterpreter 的 0.2.5 版本带来了新功能,如 --os 标志和 Computer API,详见变更日志,这提高了包容性并为开发者提供了更好的工具。
LlamaIndex Discord
LLM 集成面向所有人:LlamaIndex 宣布了一项支持本地 LLM 集成的新功能,支持 Mistral、Gemma 等模型,并在 Twitter 上分享了详细信息。
TypeScript 与本地 LLM 结合:在 Twitter 上发布了一个开源指南,介绍如何构建利用 Mixtral 等本地 LLM 的 TypeScript Agent。
2024 年不建议使用 Top-k RAG 方案:一项针对未来项目不建议使用 top-k RAG 的警告引发关注,暗示了社区中新兴的标准。LlamaIndex 在这里推特发布了这一指南。
图数据库的烦恼与奇迹:一位用户详细介绍了他们通过自定义 retriever 将 Gmail 内容转化为图数据库的方法,但目前正在寻找提高效率和数据特征提取的方法。
交互式故障排除:在面对 Mistral 和 HuggingFace 的 NotImplementedError 时,用户被引导至一个 Colab notebook,以方便设置 ReAct Agent。
OpenAccess AI Collective (axolotl) Discord
预训练困境与微调挫败:工程师们报告了挑战并寻求预训练优化的建议,处理一个意外保存了两次模型的 Epoch 谜团,以及遇到 PyTorch 的 Pickle 难题——当它无法 pickle ‘torch._C._distributed_c10d.ProcessGroup’ 对象时抛出了 TypeError。
LoRA 故障解决:针对 LoRA 配置 问题提出了修复方案,建议在设置中包含 'embed_tokens' 和 'lm_head' 以解决 ValueError;分享了这段用于精确 YAML 配置的代码片段:
lora_modules_to_save:
- lm_head
- embed_tokens
此外,一位在 transformers/trainer.py 中苦于 AttributeError 的工程师得到了调试步骤的建议,包括 Batch 检查和数据结构日志记录。
缩放传奇:对于 Llama 3 模型的扩展上下文微调,推荐使用 线性缩放 (linear scaling),而对于非微调场景,动态缩放 (dynamic scaling) 被认为是更好的选择。
机器人故障传送:一位 Telegram 机器人用户强调了一个超时错误,暗示可能存在网络或 API 速率限制问题,错误消息为:’Connection aborted.’, TimeoutError(‘The write operation timed out’)。
Axolotl 的新进展:关于 Axolotl 平台的讨论揭示了微调 Llama 3 模型的能力,确认了处理 262k 序列长度的可能性,并进一步探索了微调 32k 数据集。
Interconnects (Nathan Lambert) Discord
-
“回声室”演变为辩论场:工程师们表示需要一个 Retort 频道来进行深入辩论,并幽默地提到由于目前缺乏结构化的辩论话语,只能在 YouTube 上参考自我对话,以此表达挫败感。
-
审视 Altman 的搜索引擎言论:一名成员对 Sam Altman 在推文中提到的搜索引擎的所谓就绪状态表示怀疑,这表明评估仍在进行中,并暗示该说法可能为时过早。
-
循环模型(Recurrent Models)与 TPU 的结合:讨论围绕使用 TPUs 和 Fully Sharded Data Parallel (FSDP) 协议训练 Recurrent Models (RMs) 展开。Nathan Lambert 指向了 EasyLM,这是一个可能适用的基于 Jax 的训练工具,为在 TPUs 上简化训练工作带来了希望。
-
OpenAI 寻求新闻盟友:OpenAI Preferred Publisher Program 的披露显示其正与 Axel Springer 和 The Financial Times 等巨头建立联系,强调了 OpenAI 优先考虑这些出版商并增强其内容呈现的策略。这暗示了通过广告和在语言模型中的优先曝光来实现货币化,标志着 AI 生成内容商业化迈出了一步。
-
消化跨平台的 AI 论述:来自 AI News 的一项新信息服务提议综合各平台的 AI 对话,旨在为时间紧迫的受众浓缩见解。同时,John Schulman 关于 max_tokens 感知和 AI 行为的思考引发了关于模型有效性的批判性讨论,而社区对 AI 影响力人物的赞赏度很高,称 Schulman 为资深的思想领袖。
LangChain AI Discord
借鉴 Google 风格构建 AI 结构:讨论围绕在各种 LLMs 中模拟 Google Gemini AI studio 的结构化提示词(structured prompts)展开,引入了 function calling 作为管理 LangChain 模型交互的新方法。
探索 LangGraph 和向量数据库:用户正在排查 LangGraph 中 ToolNode 的问题,并参考 LangGraph 文档获取深入指导;同时,其他人讨论了向量数据库的复杂性和成本,一些人因其简单性和开源可用性而青睐 pgvector,并为那些考虑免费本地选项的用户推荐了一份全面的对比指南。
Chain 调用中 Python 与 POST 的差异:出现了一个奇特案例,一名成员在使用 Python 调用 chain() 与利用 /invoke 端点时得到了不同的结果,表明后者导致 chain 以空字典开始,这暗示了 LangChain 初始化过程可能存在差异。
AgencyRuntime 招募合作者:一篇重要文章介绍了 AgencyRuntime,这是一个旨在构建模块化生成式 AI Agent 团队的社交平台,并邀请开发者通过整合更多 LangChain 功能来增强其能力。
向 LangChain 专家学习:发布的教程内容指导用户将 crewAI 与 Binance 加密货币市场连接,并对比了 LangChain 中的 Function Calling agents 和 ReACt agents,为那些微调 AI 应用的用户提供了实用见解。
OpenRouter (Alex Atallah) Discord
-
新的浏览器扩展加入竞争:Languify.ai 正式亮相,它利用 OpenRouter 来优化网站文本,以获得更好的用户参与度和销售额。
-
Rubik’s AI 招募 Beta 测试人员:技术爱好者有机会参与塑造 Rubik’s AI 的未来,这是一款新兴的研究助手和搜索引擎。Beta 测试人员将获得为期 2 个月的试用期,并被鼓励使用代码
RUBIX提供反馈。 -
PHP 与 Open Router API 冲突:有报告称 PHP React 库在与 Open Router API 交互时出现 RuntimeException,用户正在寻求解决“Connection ended before receiving response”错误的帮助。
-
路由训练随 Roleplay 演进:在寻找最佳指标的过程中,一位用户倾向于使用验证损失(validation loss)和精确率-召回率 AUC(precision recall AUC)来评估 Roleplay 主题对话中的路由性能。
-
Gemma 打破上下文长度记录:Siddharth Sharma 在一则 推文 中宣布,备受期待但也存在疑虑的 Gemma 模型展示了惊人的 10M 上下文窗口,且运行内存不足 32GB,这引发了广泛关注。
Cohere Discord
-
微调功能引发热潮:Command R Fine-Tuning 现已推出,提供“同类最佳”的性能、高达 15 倍的成本降低以及更快的吞吐量。用户可以通过 Cohere 平台和 Amazon SageMaker 访问。社区对更多平台支持和即将推出的 CMD-R+ 充满期待,并讨论了微调的成本效益和用例——详情请参阅 Cohere 博客文章。
-
额度管理:希望为 Cohere 账户充值额度的工程师可以使用 Cohere 账单仪表板,在添加信用卡后设置支出限额。这确保了对模型使用成本的无缝管理。
-
暗黑模式在日落后大受欢迎:Cohere 的 Coral 尚未提供原生暗黑模式;不过,一位社区成员为那些“夜猫子”程序员提供了一个基于浏览器的自定义 CSS 片段解决方案。
-
Cohere Embeds 成本咨询:针对用户关于生产环境 Embed 模型定价的咨询,社区引导其访问 Cohere 定价页面,该页面详细说明了各种方案以及获取测试版(Trial)和生产版(Production)API 密钥的步骤。
-
新面孔,新节奏:社区迎来了一位来自阿尔及利亚安纳巴的新成员,其兴趣方向为 NLP 和 LLM,这凸显了全球对语言模型应用和开发日益增长的多元化兴趣。
Datasette - LLM (@SimonW) Discord
- 苹果勇敢的 AI 新世界:苹果计划使用 M2 Ultra 芯片 为数据中心内的生成式 AI 工作负载提供动力,同时准备最终转向 M4 芯片。这是 Project ACDC 计划的一部分,该计划强调安全性和隐私。
- 混合专家(Mixture of Experts)方法:讨论中思考了苹果类似于“混合专家”的策略,即要求较低的 AI 任务可以在用户设备上运行,而更复杂的操作则利用云端处理。
- 对 Apple Silicon 的渴望:在热议中,一位工程师表达了对搭载 M2 Ultra 的 Mac 的渴望,展示了苹果近期硬件发布所激发的的热情。
- MLX 框架备受关注:苹果的 MLX 框架正受到关注,它能够在苹果硬件上运行大型 AI 模型,相关资源可在 GitHub 仓库 中找到。
- ONNX 作为通用语言:尽管苹果倾向于使用专有格式,但对 ONNX 模型格式(包括 Phi-3 128k 模型)的采用,强调了其在 AI 社区中日益增长的重要性。
Mozilla AI Discord
- 创意化改造创意聚类:一篇新的 博客文章 介绍了将 Llamafile 应用于 topic clustering(主题聚类),并结合 Figma 的 FigJam AI 和 DALL-E 的视觉辅助工具,展示了创意整理新方法的潜力。
- 深入了解 llamafile 的 GPU 魔法:提供了关于 llamafile 的 GPU layer offloading(层卸载)的细节,重点介绍了根据 llama.cpp server README 启用此功能的
-ngl 999标志,并分享了强调不同 GPU 层卸载性能差异的 benchmarks。 - 警报:llamafile v0.8.2 发布:开发者 K 发布了 llamafile version 0.8.2,为 K quants 引入了性能增强,并在 issue comment 中提供了集成此更新的指导。
- Openelm 与 llama.cpp 集成障碍:一位开发者在 GitHub pull request 草案 中尝试将 Openelm 与
llama.cpp融合,PR 讨论中指出主要障碍在于sgemm.cpp。 - llamafile 部署的 Podman 容器策略:分享了一个涉及 shell 脚本的权宜之计,以解决在使用 Podman 容器部署 llamafile 时遇到的问题,暗示在 multi-architecture format(多架构格式)支持背景下可能与
binfmt_misc存在冲突。
LLM Perf Enthusiasts AI Discord
-
电子表格遇上 AI:一条 推文讨论 了 AI 在处理生物实验室电子表格混乱局面中的潜力,认为 AI 在从复杂表格中提取数据方面可能至关重要。然而,使用能力较弱的模型进行的演示未达预期,凸显了概念与执行之间的差距。
-
GPT-4 的同代产品,而非继任者:围绕 GPT-4 即将发布的猜测热情高涨;然而,已确认其并非 GPT-5。目前的讨论表明,开发版本可能是一个“Agent 调优”版或“GPT4Lite”,承诺在降低延迟的同时保持高质量。
-
追求 AI 模型的效率:受 Haiku 性能启发,对类似于“GPT4Lite”的更高效模型的期待,表明了在提高效率、成本和速度的同时保持模型质量的强烈愿望。
-
超越 GPT-3.5:语言模型的进步已经超越了 GPT-3.5,使其与继任者相比几乎过时。
-
发布前的兴奋与猜测:随着对同时发布 Agent 调优版 GPT-4 和更具成本效益版本的预测,期待感升温,强调了语言模型产品的动态演进。
tinygrad (George Hotz) Discord
Metal 构建难题:尽管进行了包括 Metal-cpp API、MSL spec、Apple 文档和 开发者参考 在内的广泛研究,一位用户仍难以理解 Metal 构建过程中的 libraryDataContents() 函数。
Tensor 视觉化:一位用户开发了一个 在线可视化工具,帮助他人理解 Tensor 的 shapes 和 strides,可能为 AI 工程师简化学习过程。
TinyGrad 性能指标:澄清了 TinyGrad 的 ops.py 中的 InterpretedFlopCounters 是通过 flop count 洞察来作为性能代理的。
Buffer 注册澄清:针对关于 TinyGrad 中 self.register_buffer 的询问,一位用户提到在 TinyGrad 中的替代方法是初始化一个 requires_grad=False 的 Tensor。
符号范围挑战:呼吁在 TinyGrad 内部对函数和控制流采用更具符号化的方法,暗示了建立一个能够符号化理解通用代数 lambdas 和控制语句展开的渲染系统的野心。
Alignment Lab AI Discord
- 寻求 Buzz 模型微调信息:一位用户询问了关于 Buzz 模型迭代 SFT 微调的最佳实践,并指出目前在文档和指导方面存在空白。
Skunkworks AI Discord
- AI Skunkworks 分享视频:成员 pradeep1148 在 #off-topic 频道分享了一个 YouTube 视频,未提供具体背景或相关性说明。
AI Stack Devs (Yoko Li) Discord
- 基于 Phaser 的 AI 进入课堂:AI Town 社区宣布即将举行一场关于 AI 与教育 交叉领域的直播会议,重点介绍在互动体验和课堂集成中使用 基于 Phaser 的 AI。该活动包括 #WeekOfAI Game Jam 的作品展示,以及关于实施 AI 工具 Rosie 的见解。
- AI 教育科技参与机会:邀请 AI 开发者和教育工作者参加 5 月 13 日星期一太平洋标准时间下午 5:30 的活动,可通过最近的 Twitter 帖子 进行注册。参与者可以期待学习 AI 学习中的游戏化应用,并与教育社区进行交流。
DiscoResearch Discord 没有新消息。如果该公会长期保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会长期保持沉默,请告知我们,我们将将其移除。
第二部分:按频道划分的详细摘要和链接
Stability.ai (Stable Diffusion) ▷ #announcements (1 条消息):
- Stable Artisan 加入 Discord 家族:Stability AI 推出了 Stable Artisan,这是一个集成了多模态 AI 能力的 Discord 机器人,支持在 Discord 内使用 Stable Diffusion 3 和 Stable Video Diffusion 进行图像和视频生成。
- 未来是多模态的:Stable Artisan 提供了一系列编辑工具,如搜索与替换 (Search and Replace)、移除背景 (Remove Background)、创意放大 (Creative Upscale) 和外绘 (Outpainting),以增强 Discord 上的媒体创作。
- 增强易用性与社区参与:通过满足大众需求,Stability AI 旨在让 Stable Diffusion 社区能够直接在 Discord 上更便捷地使用其先进模型。
- 开启 Stable Artisan 体验:渴望尝试 Stable Artisan 的 Discord 用户可以在 Stable Diffusion Discord 服务器的指定频道开始使用,例如 #1237461679286128730 以及公告中列出的其他频道。
提到的链接:Stable Artisan: Media Generation and Editing on Discord — Stability AI:Stable Diffusion 社区最常提出的请求之一就是能够直接在 Discord 上使用我们的模型。今天,我们很高兴推出 Stable Artisan,这是一个用户友好的机器人…
Stability.ai (Stable Diffusion) ▷ #general-chat (877 条消息 🔥🔥🔥):
-
SD3 权重讨论:成员们详细讨论了关于 Stability AI 是否会发布 SD3 开源权重的看法,以及当前的 API 访问是否表明模型已开发完成。观点各异,有人认为 API 独占访问背后有财务动机,也有人认为模型在进一步完善后会开源。
-
社区对模型版本的参与:讨论了各种 Stable Diffusion 模型版本(如 SDXL)的实用性,以及 Lora 模型和 ControlNet 等社区贡献。关于 SDXL 是否已达到极限,以及开源社区的补充是否显著增强了其能力,分享了不同的观点。
-
视频生成能力咨询:一位用户询问了根据提示词生成视频的能力,特别是 Discord 是否支持此功能,还是仅限网页端。回复澄清了虽然使用 Stable Video Diffusion 等工具是可行的,但直接在 Discord 上操作可能需要像 Artisan 这样的付费服务。
-
360 度图像生成请求:一位成员寻求关于生成 360 度跑道图像的建议,分享了几个可能产生此类图像的工具和方法的链接。该用户正在探索网页工具、特定的 GitHub 仓库以及来自 Reddit 的建议,但仍在寻找明确的解决方案。
-
执行错误与快速支持请求:用户报告了运行 webui-user.bat 时出现的 “DLL load failed while importing bz2” 等错误,并在专门的技术支持频道寻求解决方案。对话简明扼要,一些用户比起客套更倾向于直接的帮助。
- Stop Killing Games: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- #NeuraLunk's Profile and Image Gallery | OpenArt: 免费 AI 图像生成器。免费 AI 艺术生成器。免费 AI 视频生成器。100 多种模型和风格可供选择。训练您的个性化模型。最受欢迎的 AI 应用:草图转图像、图像转视频、in...
- ComfyUI-SAI_API/api_cat_with_workflow.png at main · Stability-AI/ComfyUI-SAI_API: 通过在 GitHub 上创建账号来为 Stability-AI/ComfyUI-SAI_API 的开发做出贡献。
- Skybox AI: Skybox AI:来自 Blockade Labs 的一键式 360° 图像生成器
- GitHub - tjm35/asymmetric-tiling-sd-webui: Asymmetric Tiling for stable-diffusion-webui: 用于 stable-diffusion-webui 的非对称平铺(Asymmetric Tiling)。通过在 GitHub 上创建账号来为 tjm35/asymmetric-tiling-sd-webui 的开发做出贡献。
- GitHub - mix1009/model-keyword: Automatic1111 WEBUI extension to autofill keyword for custom stable diffusion models and LORA models.: 用于自动填充自定义 Stable Diffusion 模型和 LORA 模型关键词的 Automatic1111 WEBUI 扩展。- mix1009/model-keyword
- GitHub - lucataco/cog-sdxl-panoramic-inpaint: Attempt at cog wrapper for Panoramic SDXL inpainted image: Panoramic SDXL 重绘图像的 cog 封装尝试 - lucataco/cog-sdxl-panoramic-inpaint
- Donald Trump ft Vladimir Putin - It wasn't me #trending #music #comedy: 未找到描述
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI: Stable Diffusion web UI。通过在 GitHub 上创建账号来为 AUTOMATIC1111/stable-diffusion-webui 的开发做出贡献。
{kind=link}
Perplexity AI ▷ #announcements (2 条消息):
- Perplexity 为 SoundHound 的语音 AI 提供动力:Perplexity 正在与语音 AI 领域的领导者 SoundHound 合作。这一合作伙伴关系将为汽车、电视和 IoT 设备的语音助手带来实时网络搜索功能。
- 无痕模式和引用预览上线:用户现在可以通过无痕搜索匿名提问,为了保护隐私,查询记录将在 24 小时后消失。改进后的引用提供来源预览;已在 Perplexity 上线,移动端即将推出。
提到的链接:SoundHound AI 与 Perplexity 合作,为汽车和 IoT 设备的下一代语音助手带来在线 LLMs:这标志着生成式 AI 的新篇章,证明了即使在没有云连接的情况下,这项强大的技术仍然可以提供最佳结果。SoundHound 与 NVIDIA 的合作将使其能够 …
Perplexity AI ▷ #general (715 条消息🔥🔥🔥):
- 寻找答案:成员报告称 Pro Search 不像普通模型那样提供互联网搜索结果或引用来源。目前已提交 Bug 报告,用户正通过关闭 Pro 模式作为临时解决方案。
- Pro Search Bug 已确认:Perplexity 团队已获悉 Pro Search 的问题,用户可关注 Bug 报告状态更新。
- 对 Opus 限制的担忧:用户对 Opus 在 Perplexity 上每天限用 50 次表示沮丧,并对该限制的透明度及其所谓的临时性提出质疑。社区讨论了替代方案以及使用其他模型或平台的潜在解决方法。
- 数据隐私设置澄清:关于 Perplexity 数据隐私设置的讨论显示,关闭“AI Data retention”可以防止在不同 Thread 之间共享信息,这被认为对隐私保护更有利。
- 商务合作咨询协助:在寻找 Perplexity 的业务发展联系人时,一名用户被引导发送邮件至 support[@]perplexity.ai 并抄送一名被标记的团队成员,以获得适当的指引。
- 来自 Perplexity (@perplexity_ai) 的推文:@monocleaaron 是的!—— 如果你在 24 小时后重新访问该 Thread,它将过期并在 30 天内被删除。
- 据消息人士称,OpenAI 计划于周一发布 Google 搜索竞争对手 | Forth:据两名知情人士透露,OpenAI 计划于周一发布其人工智能驱动的搜索产品,这加剧了其与搜索之王 Google 的竞争....
- Sam Altman 否认了在 Google I/O 之前发布搜索引擎的报道:OpenAI 否认了有关周一发布搜索产品的计划。
- Reddit - 深入探索一切:未找到描述
Perplexity AI ▷ #sharing (15 条消息🔥):
- 提醒将 Thread 设置为可共享:提供了一个提示,提醒用户确保他们的 Thread 是可共享的,并附带了操作说明附件。在此查看 Thread 提醒。
- 放射性香蕉的探索:一位用户分享了关于香蕉放射性的链接,询问香蕉是否有放射性。
- 探索“环”的本质:有人通过分享链接询问关于“环”的定义或本质:什么是环(ring)?。
- 对创建服务器的兴趣:一位用户通过分享相关链接表达了对创建服务器的兴趣:Crear un servidor。
- Natron Energy 新页面发布揭晓:通过分享的 URL 提供了关于 Natron Energy 发布的信息。查看 Natron Energy 的新发布。
- 关于在 Medium 上发布的见解:一位用户寻求了解更多关于在 Medium 上发布内容的信息,如分享的 perplexity 搜索链接所示。
Perplexity AI ▷ #pplx-api (9 条消息🔥):
- API 功能咨询:一位成员询问 API 是否会返回包含相关项的 “related” 对象,类似于 Web/移动端搜索中提供的功能。
- 模型版本更新说明:提到了关于页面上将模型版本标注为 70b 的更新。
- 输出格式指令执行困难:用户正在讨论最新的在线模型在遵守输出格式指令(如措辞和列表制作)方面存在困难。他们正在寻求有效 Prompt 设计的建议。
- API 与 Perplexity Labs 之间的一致性问题:成员报告称,在 API 和 Perplexity Labs 之间使用相同的 Prompt 和模型时,响应质量存在显著偏差。官方承认它们是独立的实体。
- 寻求 API 与 Labs 输出差异的澄清:一位成员表示希望获得官方澄清,说明为什么即使使用相同的模型和 Prompt,两个平台之间仍可能存在不一致。
Unsloth AI (Daniel Han) ▷ #general (476 messages🔥🔥🔥):
-
Unsloth Studio 的延迟与即将发布:由于与 phi 和 llama 相关的其他工作,Unsloth Studio 的发布已被推迟,团队目前已完成约 50%,并计划在处理完新发布版本后专注于此。
-
Unsloth 中的推理速度与优化器多样性:虽然 Unsloth notebook 提到了 “adamw_8bit” 优化,但在如何为训练指定其他优化器选项方面存在困惑。建议查阅 Hugging Face 文档以获取优化器的有效字符串列表。
-
AI 开发中的训练与推理重心:团队表示,由于推理领域竞争非常激烈,他们正优先考虑训练而非推理。他们提到,在开源工作中,加速训练方面已经取得了显著进展。
-
长上下文模型的困难:用户讽刺地讨论了长上下文模型的实用性,其中一人提到另一个项目尝试创建上下文长度高达 10M 的模型。人们对这类模型的实际应用和有效评估持怀疑态度。
-
关于数据集成本与质量的讨论:用户之间的对话揭示了对于获取高质量模型训练数据集相关成本的不同看法,特别是在 instruct tuning 和 synthetic data generation 方面。
- mustafaaljadery/gemma-2B-10M · Hugging Face: 未找到描述
- Replete-AI/code_bagel · Datasets at Hugging Face: 未找到描述
- 来自 RomboDawg (@dudeman6790) 的推文: 好的,你觉得这个主意怎么样?Bagel 数据集... 但是用于编程 🤔
- 来自 ifioravanti (@ivanfioravanti) 的推文: 快看!Llama-3 70B 纯英文版现在在 @lmsysorg Chatbot Arena 排行榜上与 GPT 4 turbo 并列第一 🥇 🔝。我也测试了几轮,对我来说 8B 和 70B 始终是最好的模型。...
- Reddit - 深入探索一切: 未找到描述
- 辛普森一家 Homer Simpson GIF - 辛普森一家 Homer Simpson 再见 - 发现并分享 GIF: 点击查看 GIF
- 混沌武士 GIF - 混沌武士 摇头 - 发现并分享 GIF: 点击查看 GIF
- Reddit - 深入探索一切: 未找到描述
- gradientai/Llama-3-8B-Instruct-Gradient-4194k · Hugging Face: 未找到描述
- 主页: 微调 Llama 3, Mistral & Gemma LLM 快 2-5 倍且节省 80% 显存 - unslothai/unsloth
- GitHub - coqui-ai/TTS: 🐸💬 - 一个用于 Text-to-Speech 的深度学习工具包,经过研究和生产环境的实战检验: 🐸💬 - 一个用于 Text-to-Speech 的深度学习工具包,经过研究和生产环境的实战检验 - coqui-ai/TTS
- 主页: 微调 Llama 3, Mistral & Gemma LLM 快 2-5 倍且节省 80% 显存 - unslothai/unsloth
- chargoddard/commitpack-ft-instruct · Datasets at Hugging Face: 未找到描述
- 未找到标题: 未找到描述
- 来自 RomboDawg (@dudeman6790) 的推文: 感谢这位勇敢的人。他做到了我做不到的事。我曾尝试制作 codellama 模型但失败了。但他做得非常出色。我很快会通过 Pull Request 将 HumanEval 评分上传到他的模型页面...
- 停止标志 GIF - 红色停止标志 - 发现并分享 GIF: 点击查看 GIF
- 水豚 Let Him Cook GIF - 水豚 Let him cook - 发现并分享 GIF: 点击查看 GIF
- teknium/OpenHermes-2.5 · Datasets at Hugging Face: 未找到描述
- 无法仅获取生成的文本,而不包含 Prompt。 · Issue #17117 · huggingface/transformers: 系统信息 - `transformers` 版本: 4.15.0 - 平台: Windows-10-10.0.19041-SP0 - Python 版本: 3.8.5 - PyTorch 版本 (GPU?): 1.10.2+cu113 (True) - Tensorflow 版本 (GPU?): 2.5.1 (True) - ...
- AI 是如何被窃取的: 章节:00:00 - AI 是如何被窃取的 02:39 - AI 历史:上帝是一个逻辑存在 17:32 - AI 历史:知识的不可能全体性 33:24 - The Lea...
- 情绪伤害 GIF - 情绪伤害 Gif - 发现并分享 GIF: 点击查看 GIF
Unsloth AI (Daniel Han) ▷ #random (19 条消息🔥):
-
创业梦想: 一位成员正在开发一个多用户博客平台,功能包括评论区、内容摘要、视频脚本、博客生成、内容检查和匿名发布。社区建议在推进创业想法之前,先进行市场调研,确定独特卖点,并确保有愿意付费的客户群。
-
给初创企业的忠告:另一位成员建议,在开发产品之前,应该先找到愿意为此付费的市场,以避免开发出不符合产品/市场契合度(product/market fit)的东西。为了学习而开发是可以的,但初创企业需要一条清晰的盈利路径。
-
Reddit 社区互动:分享了 Reddit 的 r/LocalLLaMA 链接,其中一个幽默帖子讨论了“Llama 3 8B 扩展至 500M 上下文”,开玩笑地说明了在寻找 AI 扩展上下文方面面临的挑战。
-
聊天中的表情符号要点:聊天成员讨论了对代表 ROFL 和 WOW 等反应的新表情符号的需求。目前正在努力寻找合适的表情符号,并商定一旦找到选项就进行沟通。
提到的链接:Reddit - 深入探索一切:未找到描述
Unsloth AI (Daniel Han) ▷ #help (113 条消息🔥🔥):
- Colab Notebooks 助力:Unsloth AI 提供了专为各种 AI 模型定制的 Google Colab notebooks,帮助用户进行训练设置和模型微调。用户被引导至这些资源,以便使用 Llama 3 等模型执行项目。
- Unsloth 的多 GPU 困境:目前 Unsloth AI 不支持 多 GPU 配置,这让拥有多个高性能 GPU 的用户感到遗憾。虽然这已列入路线图,但由于 Unsloth 人手有限,多 GPU 支持的优先级低于单 GPU 设置。
- 应对 GPU 显存问题:用户尝试微调 llama3-70b 等 LLM 模型,但遇到了 CUDA 显存不足(out of memory)错误。建议包括通过调整环境变量在某些操作中使用 CPU。
- 微调中的挫折与互助:关于使用不同数据集和 LLM 进行微调的问题层出不穷,Unsloth 开发团队和社区成员提供了关于数据集格式转换的指导,并分享了有用的资源,如相关的 YouTube 教程。
- 微调框架与热切需求:关于使用 Unsloth 框架进行微调程序的详细讨论,以及对新功能的需求和对 llama3-70-4bit 等模型 VRAM 要求的澄清。社区分享了解决常见问题的见解、链接和技巧。
- 使用 Unsloth 微调 Llama 3:通过 Unsloth 轻松微调 Meta 的新模型 Llama 3,支持高达 6 倍的上下文长度!
- Llama 3 微调入门指南(支持 16k, 32k,... 上下文):在这个分步教程中,学习如何使用 Unsloth 轻松微调 Meta 强大的新 Llama 3 语言模型。我们涵盖了:Llama 3 8B 概述以及...
- GitHub - facebookresearch/xformers: 可定制且优化的 Transformers 构建模块,支持组合式构建。:可定制且优化的 Transformers 构建模块,支持组合式构建。 - facebookresearch/xformers
- GitHub - unslothai/unsloth: 微调 Llama 3, Mistral & Gemma LLM 速度提升 2-5 倍,显存占用减少 80%:微调 Llama 3, Mistral & Gemma LLM 速度提升 2-5 倍,显存占用减少 80% - unslothai/unsloth
- 我如何为我的时事通讯微调 Llama 3:完整指南:在今天的视频中,我将分享我如何利用我的时事通讯来微调 Llama 3 模型,以便使用创新的开源工具更好地起草未来内容...
- teknium/OpenHermes-2.5 · Hugging Face 数据集:未找到描述
- Google Colab:未找到描述
- Mistral 微调入门指南(支持 16k, 32k, 128k+ 上下文):在我们的最新教程视频中,探索如何毫不费力地使用您自己的数据微调语言模型 (LLM)。我们深入探讨了一种经济高效且卓越的...
- GitHub - unslothai/unsloth: 微调 Llama 3, Mistral & Gemma LLM 速度提升 2-5 倍,显存占用减少 80%:微调 Llama 3, Mistral & Gemma LLM 速度提升 2-5 倍,显存占用减少 80% - unslothai/unsloth
- 量化:未找到描述
Unsloth AI (Daniel Han) ▷ #showcase (10 messages🔥):
-
探索 Ghost 3B Beta 的理解能力:Ghost 3B Beta 在其早期训练阶段,能够以西班牙语生成回答,用浅显易懂的语言向 12 岁孩子解释爱因斯坦的相对论。回答强调了爱因斯坦的革命性概念,描述了运动如何影响对时间的感知,并引入了空间并非真空,而是充满了影响时间和空间的各种场这一观点。
-
辩论相对论的可证伪性:Ghost 3B Beta 使用葡萄牙语讨论了证明爱因斯坦相对论错误的可能性,承认虽然它是一个被广泛接受的数学理论,但一些科学家批评它无法解释所有现象或与量子理论(Quantum Theory)的一致性。然而,它提到该理论依然稳固,大多数科学家都认同其重要性。
-
强调相对论的稳健性:针对英语提出的相同问题,回答强调相对论是物理学的基石,并经过了广泛的实验验证。Ghost 3B Beta 承认虽然该理论接受审查,但尚未出现足以反驳它的实质性证据,展示了科学验证的持续过程。
-
Ghost 3B Beta 模型早期表现令人印象深刻:lh0x00 的更新显示,Ghost 3B Beta 模型在仅完成第一阶段训练的 3/5(占总进度的 15%)时,就已经展现出令人印象深刻的结果。这展示了该 AI 在理解和解释复杂科学理论方面的潜力。
-
ReplyCaddy 发布:用户 dr13x3 介绍了 ReplyCaddy,这是一个经过微调的 Twitter 数据集和 Tiny Llama 模型,旨在辅助客户支持消息,目前可在 hf.co 访问。他们特别感谢 Unsloth 团队提供的快速推理支持。
提到的链接:Reply Caddy - a Hugging Face Space by jed-tiotuico:未找到描述
LM Studio ▷ #💬-general (150 messages🔥🔥):
-
寻找适用于 Linux 的 ROCm:一位成员询问是否存在适用于 Linux 的 ROCm 版本,另一位成员确认目前尚不可用。
-
AI 模型的内存限制:一位用户在尝试使用 AI 模型时遇到了 “unable to allocate backend buffer” 错误,另一位成员诊断这是由于 RAM/VRAM 不足导致的。
-
本地模型使用需要充足资源:会议强调,本地模型至少需要 8GB 的 VRAM 和 16GB 的 RAM 才能具有实际使用价值。
-
可搜索模型列表查询:有人建议在 LM Studio 的搜索栏中使用 “GGUF” 来筛选可用模型,因为默认的搜索行为需要输入内容才能显示结果。
-
LM Studio 不支持 Stable Diffusion 模型:一位用户在 LM Studio 中运行 Stable Diffusion 模型时遇到困难,另一位成员澄清此处不支持此类模型。对于本地使用,他们建议在 Discord 中搜索替代解决方案。
-
LM Studio 中的 PDF 文档处理:当被问及 LM Studio 是否支持使用 PDF 文档与机器人聊天时,一位成员解释说,虽然 LM Studio 本身不具备此类功能,但用户可以从文档中复制并粘贴文本,因为 LM Studio 内部无法实现 RAG (Retrieval Augmented Generation)。此外,还提供了如何为语言模型处理文档的详细信息,包括文档加载、拆分以及使用 Embedding 模型创建向量数据库的步骤(来源)。
-
量化协助与资源共享:讨论了量化模型所需的工具和资源,例如将 Llama 3 模型的 f16 版本转换为 Q6_K 量化版。一位成员分享了来自 Reddit 的实用指南,简要概述了 GGUF 量化方法(来源),另一位成员分享了来自 Hugging Face 数据集的 LLM 量化影响说明(来源)。
-
同时使用 Vector Embedding 和 LLM 模型:针对 Vector Embedding 模型和 LLM 模型是否可以同时使用的问题,确认两者可以同时加载,从而实现对大型文档(如用于 RAG 的 2000 页文本)的高效处理。
-
AI Broker API 标准提案:一位开发者提出了一个新的 API 标准构想,用于 AI 模型的搜索和下载,该标准可以统一 Hugging Face 等服务提供商以及 Cloudflare AI 等 Serverless AI,从而为 LM Studio 等应用提供更便捷的模型和 Agent 发现功能。他们鼓励在指定的 GitHub 仓库(来源)参与该标准的开发。
- GGUF My Repo - ggml-org 提供的 Hugging Face Space:未找到描述
- bartowski/Meta-Llama-3-70B-Instruct-GGUF · Hugging Face:未找到描述
- 基于 RAG 的问答 | 🦜️🔗 LangChain:概览
- Shamus/mistral_ins_clean_data · Hugging Face:未找到描述
- Reddit - 深入探索:未找到描述
- Aha GIF - Aha - 发现并分享 GIF:点击查看 GIF
- 未找到标题:未找到描述
- GitHub - openaibroker/aibroker: Open AI Broker API 规范:Open AI Broker API 规范。通过在 GitHub 上创建账户为 openaibroker/aibroker 的开发做出贡献。
- GitHub - jodendaal/OpenAI.Net: 适用于 .NET 的 OpenAI 库:适用于 .NET 的 OpenAI 库。通过在 GitHub 上创建账户为 jodendaal/OpenAI.Net 的开发做出贡献。
- Reddit - 深入探索:未找到描述
- christopherthompson81/quant_exploration · Hugging Face 数据集:未找到描述
LM Studio ▷ #🤖-models-discussion-chat (99 条消息🔥🔥):
- LLM 集成可能性:一位成员思考了 LLM 是否能仅根据关于“拥有魔法的银行家青蛙”的文本提示生成带有 AI 生成视觉效果的故事。GPT-4 在一定程度上确认了这种能力。
- 模型性能讨论:据报道,L3-MS-Astoria-70b 模型能提供高质量的散文,并与 Cmd-R 形成竞争,尽管上下文大小的限制可能会让部分用户回归 QuartetAnemoi。
- 理解量化质量:一位社区成员将量化(q6 vs. q8)的准确性声明与 Apple Newton 的手写识别进行了比较,认为即使 q6 几乎与 q8 一样好,在处理更大型的任务时仍可能暴露出显著的质量下降。
- AMD CPU 的 GPU 兼容性问题:用户报告了在 AMD CPU 系统上对 lmstudio-llama-3 等模型进行 GPU Offload 时出现的问题,并讨论了兼容性以及 VRAM 和 RAM 限制等硬件约束。
- LLM 模型变体澄清:用户寻求关于众多 Llama-3 模型之间差异的澄清;区别主要在于不同贡献者的 Quantization 工作,建议优先选择知名作者或下载量较高的模型。
- deepseek-ai/DeepSeek-V2 · Hugging Face: 没有找到描述
- Text Embeddings | LM Studio: Text embeddings 是将文本表示为数字向量的一种方式。
- Fix Futurama GIF - Fix Futurama Help - Discover & Share GIFs: 点击查看 GIF
- Pout Christian Bale GIF - Pout Christian Bale American Psycho - Discover & Share GIFs: 点击查看 GIF
- Machine Preparing GIF - Machine Preparing Old Man - Discover & Share GIFs: 点击查看 GIF
- Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: 我正在运行 Unsloth 在 llama3-8b 上微调 LORA 指令模型。1:我将模型与 LORA 适配器合并为 safetensors 2:在 python 中直接使用合并后的模型运行推理...
LM Studio ▷ #🧠-feedback (8 条消息🔥):
-
Mac Studio RAM 容量问题:一位成员报告了在 192GB Mac Studio 上运行 llama1.6 Mistral 或 Vicuña 时出现的问题,该设备可以成功运行 Llama3 70B,但在运行其他模型时报错。错误信息显示 RAM 容量问题,”ram_unused” 为 “10.00 GB”,”vram_unused” 为 “9.75 GB”。
-
Windows 上 Granite 模型加载失败:在尝试加载 NikolayKozloff/granite-3b-code-instruct-Q8_0-GGUF 模型时,一位成员遇到了与 “unknown pre-tokenizer type: ‘refact’” 相关的错误。错误信息指明在 llama.cpp 中加载模型词表失败,其中包含系统规范,如 “ram_unused” 为 “41.06 GB”,”vram_unused” 为 “6.93 GB”。
-
关于 Granite 模型支持的澄清:针对前述错误,另一位成员澄清说 Granite 模型在 llama.cpp 中不受支持,因此在该环境下完全无法运行。
-
对 Windows 版 LM Studio 安装程序的批评:一位成员对 Windows 版 LM Studio 安装程序 表示不满,抱怨缺乏让用户选择安装目录的选项,并称这种强制安装方式“不可接受”。
-
寻求安装替代方案:该成员进一步寻求关于如何在 Windows 上为 LM Studio 选择安装目录的指导,强调了在安装过程中用户控制权的必要性。
LM Studio ▷ #📝-prompts-discussion-chat (1 条消息):
- 讨论用于高效文档处理的 RAG 架构:一位成员讨论了各种 Retrieval-Augmented Generation (RAG) 架构,这些架构涉及对文档进行分块(chunking),并将其与 embeddings 和位置信息等额外数据相结合。他们建议这种方法可以用来限制文档的范围,并提到基于余弦相似度(cosine similarity)的重排序(reranking)是一种潜在的分析方法。
LM Studio ▷ #🎛-hardware-discussion (46 条消息🔥):
- 理解 LLM 的硬件障碍:成员们讨论了在运行像 Llama 3 70B 这样的大型语言模型时,VRAM 是主要的限制因素,根据可用的 VRAM 情况,只有较低的量化(quantizations)版本是可行的。
- Intel 的新 LLM 加速库:Intel 推出了 ipex-llm,这是一个用于加速 Intel CPU 和 GPU 上本地 LLM 推理和微调的工具,一位用户分享了该项目,并指出它目前缺乏对 LM Studio 的支持。
- AI 推理中的 AMD 与 Nvidia:讨论中包含了 Nvidia 目前在 VRAM 方面提供更好性价比的观点,4060ti 和二手 3090 被强调为 16/24GB 显卡的最佳选择,尽管人们对 AMD 可能推出的新产品有所期待。
- 跨平台多设备支持的挑战:相关链接和讨论指出了同时利用 AMD 和 Nvidia 硬件进行计算的障碍,表明虽然理论上可行,但这种集成需要克服重大的技术困难。
- ZLUDA 和 Hip 兼容性讨论:对话涉及了像 ZLUDA 这样旨在为 AMD 设备带来 CUDA 兼容性的项目有限的生命周期,以及开发者工具改进的潜力,鉴于 ZLUDA 仓库 上的更新和最近的维护版本。
- 原生 Intel IPEX-LLM 支持 · Issue #7190 · ggerganov/llama.cpp:前提条件 在提交 issue 之前,请先回答以下问题。[X ] 我正在运行最新的代码。开发速度非常快,所以目前还没有标记版本。...
- GitHub - intel-analytics/ipex-llm: 在 Intel CPU 和 GPU(例如带有 iGPU 的本地 PC,Arc、Flex 和 Max 等独立 GPU)上加速本地 LLM 推理和微调(LLaMA, Mistral, ChatGLM, Qwen, Baichuan, Mixtral, Gemma 等)。一个与 llama.cpp, Ollama, HuggingFace, LangChain, LlamaIndex, DeepSpeed, vLLM, FastChat 等无缝集成的 PyTorch LLM 库。:在 Intel CPU 和 GPU(例如带有 iGPU 的本地 PC,Arc、Flex 和 Max 等独立 GPU)上加速本地 LLM 推理和微调(LLaMA, Mistral, ChatGLM, Qwen, Baichuan, Mixtral, Gemma 等)...
- GitHub - vosen/ZLUDA: AMD GPU 上的 CUDA:AMD GPU 上的 CUDA。通过在 GitHub 上创建一个账户来为 vosen/ZLUDA 的开发做出贡献。
- Llama.cpp 无法在 Intel ARC 770 上运行? · Issue #7042 · ggerganov/llama.cpp:你好,我正尝试在一台配备一个 ARC 770 Intel GPU 的工作站上运行 llama.cpp,但不知为何每当我尝试使用 GPU 时,llama.cpp 就会执行某些操作(我看到 GPU 被用于计算...
LM Studio ▷ #🧪-beta-releases-chat (4 条消息):
- 寻找合适的翻译模型:一位用户询问用于翻译的模型,另一位成员建议查看 Meta AI 的工作,其中包括支持 100 多种语言的强大翻译模型。
- 翻译模型推荐:针对翻译任务,推荐了具体的模型 NLLB-200、SeamlessM4T 和 M2M-100,这些都源自 Meta AI 的开发。
- 请求 Beta 版支持 bfloat16:一位成员表达了对使用 bfloat16 支持进行 Beta 测试的兴趣,这表明了未来实验的一个潜在方向。
LM Studio ▷ #memgpt (6 条消息):
- 日志路径困扰成员:一位成员在尝试将服务器日志路径从
C:\tmp\lmstudio-server-log.txt更改为C:\Users\user.memgpt\chroma时遇到困难,这导致 MemGPT 无法保存到其存档中。 - 对服务器日志的误解:另一位成员澄清说,服务器日志不是存档或 chroma DB,它们在每次重启时都会被清除,并建议如果仍想从不同位置访问文件,可以创建一个符号链接(symlink)。
- 使用 Kobold 解决了 MemGPT 保存问题:最初的成员通过切换到 Kobold 解决了他们的问题,随后日志得以正确保存,并对提供的帮助表示感谢。
LM Studio ▷ #amd-rocm-tech-preview (2 条消息):
- AMD GPU 的兼容性查询:一位成员提出了一个问题,即为什么 RX 7600 被列入 AMD 的兼容性列表,而 7600 XT 却不在其中。另一位成员推测,这可能是由于列表更新的时间点不同,因为 XT 版本大约晚了六个月发布。
LM Studio ▷ #crew-ai (12 messages🔥):
-
CrewAI 的 Token 生成问题:一位成员报告了在使用 CrewAI 时 Token 生成不完整的问题,而 Ollama 和 Groq 在相同设置下运行正常。CrewAI 似乎在生成约 250 个 Token 后停止输出,尽管它应该能处理高达 8192 个 Token。
-
Max Token 设置之谜:更改 Max Token 设置并未解决该成员输出不完整的问题,促使他们寻求帮助。
-
不同模型间的 Quantization 对比:在关于该问题的讨论中,一位成员澄清说所有模型(llama 3 70b)都使用了 q4 Quantization。曾考虑过 Groq 缺失 Quantization 的可能性,但由于尽管设置了 Quantization 问题依然存在,该原因被排除。
-
调查 CrewAI 与 API 的差异:在进行进一步测试后,该成员发现直接在 LM Studio 中使用 llama3:70b 运行正常,但当服务于 CrewAI 时,输出会被截断。这引发了一个建议:确保 Inference server 参数匹配,并使用另一个基于 API 的应用(如 Langchain)进行测试以排查故障。
-
误导入混乱已解决:问题最终被确定为在条件逻辑中错误地导入了 OpenAI API。在发现
import语句中的一个小错误导致了该问题后,双方进行了幽默的交流,目前该问题已修复。
LM Studio ▷ #🛠-dev-chat (4 messages):
- LM Studio 缺失 Fine-tuning 功能:LM Studio 目前不支持 Fine-tuning,寻找此功能的成员被引导至 LLaMA-Factory 和 Unsloth 等替代方案。对于更简单的改进,他们提到了使用 AnythingLLM 等 RAG 工具。
- 脚本管理中的 Rust 代码内存问题:一位成员表示在管理多个 Rust 代码文件时遇到了系统内存不足的困难,建议需要更高效的文件管理解决方案。
- 将 LM Studio 与 ollama 进行对比:一位用户观察到 LM Studio 提供了比 ollama 更高效的 API,因为它处理 Message history 的方式不同,并且由于 Quantization(他们最近才了解到这一点),可能提供了性能更强的模型。
HuggingFace ▷ #announcements (6 messages):
- Graph Machine Learning 遇上 LLM:Hugging Face Reading Group 涵盖了“LLM 时代的 Graph Machine Learning”这一主题,由 Isamu Isozaki 进行演讲,并附有一篇文章和一段 YouTube 视频。鼓励成员们为未来的读书会推荐有趣的论文或发布内容。
- Alphafold 模型讨论:一位成员建议在未来的读书会环节讨论新的 Alphafold 模型。尽管对最新 Alphafold 版本的开放性存在一些担忧,但有人指出可以在 alphafoldserver.com 使用 Alphafold Server 测试该模型。
- Hugging Face Reading Group 20: Graph Machine Learning in the Era of Large Language Models (LLMs):演讲者:Isamu Isozaki。文章:https://isamu-website.medium.com/understanding-graph-machine-learning-in-the-era-of-large-language-models-llms-dce2fd3f3af4
- Intel Real Sense Exhibit At CES 2015 | Intel:参观 CES 2015 上的 Intel Real Sense 隧道。立即在 YouTube 上订阅 Intel:https://intel.ly/3IX1bN2。关于 Intel:Intel 是全球半导体领域的领导者...
- Notion – 集笔记、任务、维基和数据库于一体的工作空间。:一款将日常工作应用融合在一起的新工具。它是为您和您的团队打造的一站式工作空间。
HuggingFace ▷ #general (247 条消息🔥🔥):
- Adapter Fusion: 合并 PEFT 模型:一位成员询问如何合并两个 PEFT adapter,并将结果保存为
new_adapter_model.bin和adapter_config.json。他们寻求关于该流程的指导。 - HuggingFace Docker 困扰:一位用户报告了在运行 HuggingFace Docker 时访问本地端口的问题,描述了在使用
curl http://127.0.0.1:7860/访问服务时遇到的困难,并请求建议。 - 使用 Paged Attention 进行图像生成:一位成员寻求关于在图像生成任务中实现 paged attention 的见解,并将其与语言模型中的 token 处理进行了类比,但目前尚不确定 paged attention 是否适用。
- 排查 DenseNet 训练问题:一位参与者就使用 DenseNet 进行视频分类任务寻求帮助,收到的建议包括确保在 loss 脚本中正确实现
.item()以及执行zero_grad()。 - 对 Gradio 版本兼容性的担忧:一位用户对 Python 软件包仓库中可能移除 Gradio 3.47.1 表示担忧,并得到了安慰,即历史版本通常会保留,尽管在未来的 Python 版本升级中可能会遇到兼容性问题。
- nroggendorff (Noa Roggendorff): 未找到描述
- 🤗 Transformers: 未找到描述
- DioulaD/falcon-7b-instruct-qlora-ge-dq-v2 · Hugging Face: 未找到描述
- Spawning | Have I been Trained?: 在流行的 AI 训练数据集中搜索你的作品
- GitHub - bigcode-project/opt-out-v2: Repository for opt-out requests.: 用于退出请求的仓库。通过在 GitHub 上创建账号为 bigcode-project/opt-out-v2 的开发做出贡献。
- Google Colab: 未找到描述
- mlabonne/Meta-Llama-3-120B-Instruct · Hugging Face: 未找到描述
- Reddit - Dive into anything: 未找到描述
- blanchon/suno-20k-LAION · Datasets at Hugging Face: 未找到描述
- blanchon/suno-20k-LAION · Datasets at Hugging Face: 未找到描述
- Get Over 99% Of Python Programmers in 37 SECONDS!: 🚀 准备好在短短 37 秒内提升你的程序员地位了吗?这段视频揭示了一个简单的技巧,能让你迅速超越全球 99% 的编码者!它是如此...
HuggingFace ▷ #today-im-learning (2 条消息):
-
领域新秀:LLM 引导的 Q-Learning:最近的一篇 arXiv 论文提出了 LLM-guided Q-learning,它将大语言模型 (LLMs) 作为启发式方法集成到强化学习的 Q-learning 中。该方法旨在提高学习效率,并缓解大量采样、reward shaping 带来的偏差以及 LLMs 幻觉等问题。
-
使用 BabyTorch 简化深度学习:BabyTorch 作为一个极简深度学习框架出现,模仿了 PyTorch 的 API,并专注于简单性以帮助深度学习初学者。它邀请大家在 GitHub 上参与和贡献,为学习和贡献开源深度学习项目提供了一个教育平台。
提到的链接: Enhancing Q-Learning with Large Language Model Heuristics: Q-learning 擅长在顺序决策任务中从反馈中学习,但需要大量采样才能获得显著改进。虽然 reward shaping 是一种强大的技术,用于…
HuggingFace ▷ #cool-finds (4 条消息):
-
GitHub 上的 Simple RAG:分享了一个名为 “simple_rag” 的 GitHub 仓库链接。该仓库似乎为实现简化版的检索增强生成 (RAG) 模型提供了资源。
-
生成式 AI 的潜在巅峰:发布了一段名为 “生成式 AI 是否已经达到巅峰? - Computerphile” 的 YouTube 视频,引发了关于当前生成式 AI 技术潜在局限性的讨论。一位成员评论道,视频中讨论的论文可能低估了未来技术和方法论突破的影响。
-
使用 Whisper 进行笔记记录的教程:分享了一个意大利语 YouTube 教程,演示了如何使用 AI(特别是 Whisper)来转录音频和视频以用于笔记记录。该视频提供了实用指南,并包含一个 Colab notebook 链接。
- GitHub - bugthug404/simple_rag: Simple Rag:Simple Rag。通过在 GitHub 上创建账号来为 bugthug404/simple_rag 的开发做出贡献。
- Has Generative AI Already Peaked? - Computerphile:此处有 Bug Byte 谜题 - https://bit.ly/4bnlcb9 - 并在此处申请 Jane Street 项目 - https://bit.ly/3JdtFBZ(本集赞助商)。更多信息请见完整描述...
- Usare l’AI per prendere appunti da qualsiasi video (TUTORIAL):在本视频中,我们将了解这款帮助你免费转录音频和视频文件的 AI 是如何工作的。链接如下:https://colab.research.google.com/drive/...
HuggingFace ▷ #i-made-this (8 条消息🔥):
-
动漫灵感激发 AI 创造力:使用 Lain 数据集 创建了一个 DreamBooth 模型,并已在 HuggingFace 上可用。它是 runwayml/stable-diffusion-v1-5 的修改版,经过训练可生成动漫角色 Lain 的图像。
-
minViT - 极简 Transformer:分享了一篇博客文章以及一段 YouTube 视频 和 GitHub 仓库,详细介绍了 Vision Transformers 的极简实现,重点关注 CIFAR-10 分类和语义分割等任务。
-
MadLib 风格的诗歌生成:创建了一个微型数据集,用于微调大语言模型 (LLMs) 以生成带有 MadLib 风格的诗歌,可在 HuggingFace 上获取。该数据集是使用 Meta Llama 3 8b-instruct 模型和 Matt Shumer 的框架生成的。
-
AI 广告识别空间:分享了一个 HuggingFace Space,演示 AI 如何判断一张图片是否为广告,相应的 GitHub 仓库 提供了实现的详细细节。
-
助力 AI 导师与学员的连接:提到了在 Product Hunt 上发布的 Semis from Reispar,旨在帮助连接 AI 领域的学员与导师,可通过提供的 Product Hunt 链接 访问。
- Advertisement - chitradrishti 的 Hugging Face Space:暂无描述
- minViT: Walkthrough of a minimal Vision Transformer (ViT):配合此文章的视频和 GitHub 仓库。
- lowres/lain · Hugging Face:暂无描述
- eddyejembi/PoemLib · Hugging Face 数据集:暂无描述
- GitHub - dmicz/minViT: Minimal implementation of Vision Transformers (ViT):Vision Transformers (ViT) 的极简实现 - dmicz/minViT
- Semis from Reispar - 缩小 AI 与大厂技术知识差距 | Product Hunt:Semis from Reispar 是一个连接有志于及现有的技术大厂和 AI 专业人士与资深导师的平台,旨在缩小全球 AI 技术领域的知识差距。
- GitHub - chitradrishti/adlike: 预测图像在多大程度上属于广告。:预测图像在多大程度上属于广告。 - chitradrishti/adlike
HuggingFace ▷ #reading-group (29 条消息🔥):
- 重新思考频道动态以提升质量:正在考虑使用 “stage” 频道来提高未来阅读会的质量,因为这要求参与者在发言前举手,有助于减少背景噪音并维持秩序。
- 鼓励互动参与:成员们一致认为,虽然 “stage” 模式可能会减少自发提问,但大部分讨论都发生在聊天框中,如果该模式阻碍了交流,可以随时切换回来。
- 关于 Code Benchmarks 的展示:一位成员表达了展示 Code Benchmarks 的兴趣,并分享了来自 HuggingFace 的相关论文集,另一位成员对此提议表示热烈响应。
- 寻求 AI 学习指导:一位 AI 学习的新手被引导至 HuggingFace AI 课程(包括计算机视觉课程),作为参与 HuggingFace Discord 社区内容的起点。
- 理解 LLMs 的路径:对于那些特别有兴趣学习大语言模型(LLMs)的人,建议从线性代数开始,接着理解 Attention 机制的工作原理,并参考 “Attention is All You Need” 等基于 Attention 的基础论文。
- Hugging Face - Learn:未找到描述
- Code Evaluation - a Vipitis Collection:未找到描述
- Hugging Face Reading Group 20: Graph Machine Learning in the Era of Large Language Models (LLMs):演讲者:Isamu Isozaki,总结报告:https://isamu-website.medium.com/understanding-graph-machine-learning-in-the-era-of-large-language-models-llms-dce2fd3f3af4
HuggingFace ▷ #core-announcements (1 messages):
<ul>
<li><strong>B-LoRA 正在扩散创意</strong>:<a href="https://github.com/huggingface/diffusers/blob/main/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py">B-LoRA 训练</a>已集成到高级 DreamBooth LoRA 训练脚本中。用户只需在配置中添加 <code>'--use_blora'</code> 标志并训练 1000 步即可发挥其功能。</li>
<li><strong>理解 B-LoRA</strong>:<a href="https://huggingface.co/papers/2403.14572">B-LoRA 论文</a>强调了关键见解,包括两个 unet 模块对于编码内容和风格至关重要,并展示了 B-LoRA 如何仅使用一张图像实现隐式的风格-内容分离。</li>
</ul>
- diffusers/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py at main · huggingface/diffusers:🤗 Diffusers:基于 PyTorch 和 FLAX 的前沿图像和音频生成扩散模型。 - huggingface/diffusers
- Paper page - Implicit Style-Content Separation using B-LoRA:未找到描述
HuggingFace ▷ #computer-vision (12 messages🔥):
-
PowerPoint PDF 难题:一位成员正在寻求关于如何从 PowerPoint 大小的 PDF 文件中提取图表和图像的建议。他们尝试了 unstructured 和 LayoutParser(配合 detectron2)等工具,但对结果不满意。
-
分享了有用的链接:另一位成员提供了资源,分享了一个 GitHub 仓库,其中包含一个使用 OpenAI API 和 DALL-E 从表格、图像等创建 PowerPoint 幻灯片的 notebook。链接是 Creating slides with Assistants API and DALL-E。
-
提议进行调查:分享 GitHub 链接的成员还提出进一步研究该问题,以帮助从 PDF 中提取内容。
-
请求更多资源:需要 PDF 提取的成员请求任何可能有帮助的额外资源。
-
表格提取建议:热心的成员推荐了 TATR、Embedded_tables_extraction-LlamaIndex 和 camelot 等表格提取工具,并引导至他们的 Medium 文章以获取更多信息。Medium 个人主页见 Ankush Singal’s Articles。
-
寻求视频分类专家:一位成员正在寻找具有视频分类经验的人员,请其查看他们在另一个频道中提出的咨询。
-
广告 Space 公告:一位成员推广了一个名为 chitradrishti/advertisement 的 HuggingFace Space,作为查看广告的场所,并分享了链接 Advertisement。
- Advertisement - chitradrishti 开发的 Hugging Face Space:未找到描述
- openai-cookbook/examples/Creating_slides_with_Assistants_API_and_DALL-E3.ipynb at main · openai/openai-cookbook:使用 OpenAI API 的示例和指南。通过在 GitHub 上创建账户,为 openai-cookbook 的开发做出贡献。
- Ankush k Singal – Medium:在 Medium 上阅读 Ankush k Singal 的文章。我叫 Ankush Singal,是一名旅行者、摄影师和 Data Science 爱好者。每天,Ankush k Singal 和成千上万的其他声音都在阅读、写作...
HuggingFace ▷ #NLP (10 条消息🔥):
- 探索特定用例的语言模型:一位成员建议针对特定用例尝试使用 spacy 或 sentence transformers 等“语言”模型,但也提到应该对 Llama 的 instruct 版本进行充分的 Prompt 引导以获得正确答案。
- 提倡使用 GLiNER 模型:在关于合适模型的讨论中,GLiNER 被建议作为一个合适的选择,另一位成员表示赞同,并强调使用 encoder 模型 会更好。
- 德语文本处理的模型推荐:为了构建一个能够回答德语文档问题的机器人,一位成员最初选择使用 Llama 模型,并计划通过迭代来获得更好的性能。
- 寻求 NLP 面试资源:一位成员请求提供准备即将到来的 NLP Engineer 职位面试的问题列表或建议;另一位成员通过询问其目前的准备水平和对 NLP 基础知识的掌握情况进行了回应。
HuggingFace ▷ #diffusion-discussions (7 条消息):
- HuggingChat 机器人故障:一位成员报告在间隔一个月后尝试运行其之前功能正常的 HuggingChat 机器人程序时,出现 Exception: Failed to get remote LLMs with status code: 401 错误。
- Diffusion 模型中颜色偏移常见吗?:一位用户询问在处理 Diffusion 模型时是否遇到过颜色偏移问题,引发了对该问题普遍性的好奇。
- 登录问题的可能修复方法:一位成员建议将登录模块从
lixiwu更改为anton-l可能会解决 HuggingChat 机器人设置中的身份验证错误,例如上述提到的 401 状态码错误。
Modular (Mojo 🔥) ▷ #general (18 条消息🔥):
- 询问 MAX 发布日期:一位成员询问了面向企业的 MAX 发布日期,但在提供的消息中未收到回复。
- 征集多种技术专家:一位成员寻求后端和前端开发方面的专家协助,特别是 Golang, Rust, Node.js, Swift 和 Kotlin 领域。他们邀请感兴趣的人士联系以进行协作或分享见解。
- Mojo 社区焦点:宣布了一场名为 “Modular Community Livestream - New in MAX 24.3” 的直播,并附带了 YouTube 视频链接,供社区预览 MAX Engine 和 Mojo 的新功能。
- 对 Mojo GPU 支持的期待:成员们讨论了预计在夏季推出的 Mojo GPU 支持,强调了其在科学计算方面的潜力以及在 GPU 之上建立抽象层的可能性。
- 寻求私有帮助机器人的协助:一位成员询问是否可以私下访问专门针对 Mojo 文档训练的帮助机器人,并被引导考虑使用 Hugging Face 模型配合 Mojo GitHub 仓库中的
.md文件作为潜在解决方案。
- kapa.ai - 技术问题的即时 AI 解答:kapa.ai 让面向开发者的公司能够轻松地为社区构建由 LLM 驱动的支持和入职机器人。OpenAI、Airbyte 和 NextJS 的团队都在使用 kapa 来提升他们的开发者体验...
- GitHub - cmooredev/RepoReader: 使用 OpenAI 的 GPT 探索并针对 GitHub 代码库提问。:使用 OpenAI 的 GPT 探索并针对 GitHub 代码库提问。 - cmooredev/RepoReader
- Modular 社区直播 - MAX 24.3 新特性:MAX 24.3 现已发布!加入我们即将举行的直播,我们将讨论 MAX Engine 和 Mojo🔥 中的新功能 —— 预览 MAX Engine Extensibility API...
Modular (Mojo 🔥) ▷ #💬︱twitter (3 条消息):
-
Modular 推文最新动态:频道中分享了 Modular 的一条新推文,包含社区更新。推文链接见此处。
-
来自 Modular 的另一则新闻:频道转发了 Modular 的另一条推文。详情请查看 Modular 的推文。
-
获取最新的 Modular 独家消息:Modular 发布了一条新推文,预示着另一项新闻或更新。推文可通过此处访问。
Modular (Mojo 🔥) ▷ #ai (1 条消息):
pepper555: 什么项目?
Modular (Mojo 🔥) ▷ #🔥mojo (135 条消息🔥🔥):
-
引用类型讨论:成员们辩论了未来维护不同类型引用的必要性。明确了 MLIR 类型将始终是必要的,并且
Reference将是一个带有自身方法的 struct,并引用了官方的 reference.mojo 文件作为由 lit.ref 支持的Reference示例。 -
未初始化即析构 Struct:一位成员遇到了一个奇怪的问题,即 struct 的
__del__方法在未被初始化的情下被调用。这种行为指向了一个可能类似于现有未初始化变量使用问题的 bug,详见 此 GitHub issue。 -
Mojo 与 Rust 的竞争力:围绕 Mojo 的性能展开了讨论,特别是与 Rust 的对比。建议虽然 Mojo 在 ML 应用中可以达到与 Rust 相当的性能,但非 ML 性能仍在追赶中。参考资料包括 M1 Max 上的基准测试对比 以及正在进行的将 minbpe 移植到 Mojo 的工作。
-
包装 Python C 扩展:对话围绕着资深 C++ 开发者在开发 Python 扩展时未必精通 Python 展开,提到了像 pybind11 和 nanopybind 这样生成 Python 包装器的库,从而减少了对 Python 专业知识的需求。
-
自动解引用与语言人体工程学:成员们讨论了 Mojo 中自动解引用的挑战和必要性,参考了最近的一项 提案,并讨论了如何吸引和支持没有 Python 背景的 Mojo 新开发者。提到了语言服务器工具(Language Server Tooling)的改进,以避免直接调用 dunder 方法,如 YouTube 视频 “为什么 Mojo 的字典比 Python 的慢 (!)?” 中所示。
- Issues · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 的开发做出贡献。
- Llama2 Ports Extensive Benchmark Results on Mac M1 Max: Mojo 🔥 的速度几乎与 llama.cpp 持平 (!!!),且代码更简洁,并在多线程基准测试中全面超越 llama2.c
- GitHub - dorjeduck/minbpe.mojo: port of Andrjey Karpathy's minbpe to Mojo: Andrjey Karpathy 的 minbpe 到 Mojo 的移植版。通过在 GitHub 上创建账号为 dorjeduck/minbpe.mojo 的开发做出贡献。
- basalt/examples/mnist.mojo at main · basalt-org/basalt: 一个纯 Mojo 🔥 从零开始编写的 Machine Learning 框架 - basalt-org/basalt
- mojo/proposals/auto-dereference.md at main · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 的开发做出贡献。
- Dunder or magic methods in Python - GeeksforGeeks: Python 中的 Dunder 或魔术方法 - GeeksforGeeks:Python 魔术方法是以双下划线开头和结尾的方法。它们由 Python 的内置类定义,常用于运算符重载。探索这篇博客并弄清 ...
- Why is Mojo's dictionary slower (!) than Python's?: 说实话,我不知道为什么。请在我的 Mojo 脚本下留言反馈。在这里查看我的 Mojo 脚本:https://github.com/ekbrown/scripting_for_ling...
- GitHub - fnands/basalt at add_cifar: 一个纯 Mojo 🔥 从零开始编写的 Machine Learning 框架 - GitHub - fnands/basalt at add_cifar
- GitHub - mzaks/mojo-hash: A collection of hash functions implemented in Mojo: 用 Mojo 实现的哈希函数集合 - mzaks/mojo-hash
- stump/stump/log.mojo at nightly · thatstoasty/stump: 开发中的 Mojo Logger。通过在 GitHub 上创建账号为 thatstoasty/stump 的开发做出贡献。
- stump/stump/style.mojo at main · thatstoasty/stump: 开发中的 Mojo Logger。通过在 GitHub 上创建账号为 thatstoasty/stump 的开发做出贡献。
- stump/external/mist/color.mojo at nightly · thatstoasty/stump: 开发中的 Mojo Logger。通过在 GitHub 上创建账号为 thatstoasty/stump 的开发做出贡献。
- devrel-extras/blogs/2405-max-graph-api-tutorial/mnist.mojo at main · modularml/devrel-extras: 包含开发者关系博客文章、视频和研讨会的辅助材料 - modularml/devrel-extras
- mojo/stdlib/src/memory/reference.mojo at main · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 的开发做出贡献。
- Why is Mojo's dictionary slower (!) than Python's?: 说实话,我不知道为什么。请在我的 Mojo 脚本下留言反馈。在这里查看我的 Mojo 脚本:https://github.com/ekbrown/scripting_for_ling...
- [proposal] Automatic deref for `Reference` · modularml/mojo · Discussion #2594: 大家好,我整理了一份提案,概述了 Mojo 中 Reference 类型的自动解引用 (Automatic deref) 如何工作,我很想听听大家的想法或建议。我希望在下周左右实现它...
- Mojo hand-written hash map dictionary versus Python and Julia: 我测试了 Mojo 语言中手写哈希映射字典相对于 Python 和 Julia 的速度。手写哈希映射字典要快得多 (9x) ...
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (5 条消息):
-
MoString 带来的惊人加速:在 Rust 中用于字符串操作的自定义
MoString结构体,通过预分配内存以避免在繁重的拼接任务中频繁重新分配,实现了相比标准字符串拼接 显著的 4000 倍加速。 -
Tokenizer 性能提升的影响:
MoString带来的性能改进对于 LLM Tokenizer 解码等任务特别有益,因为这类任务可能需要大量的字符串拼接。 -
提案协作:一名成员表示愿意帮助起草一份关于将更智能的内存分配策略集成到字符串中的提案,这表明了协作在这一增强过程中的价值。
-
字符串增强策略:关于增强字符串性能的讨论包括两个选项:为字符串类型引入参数化以设置容量和扩容策略,或者为内存密集型字符串操作创建一个专用类型。
-
提案准备工作的考虑因素:在起草正式提案之前,
MoString的作者希望明确 Modular 在 Mojo 使用方面的方向,以及是否应该允许动态更改扩容策略,以优化拼接后的内存利用率。
Modular (Mojo 🔥) ▷ #📰︱newsletter (1 messages):
Zapier: Modverse Weekly - 第 33 期 https://www.modular.com/newsletters/modverse-weekly-33
Modular (Mojo 🔥) ▷ #🏎engine (10 messages🔥):
-
关于 MODULAR 能力的澄清:MODULAR 主要专注于 inference(推理)端,不支持在云端训练模型。Melodyogonna 确认其目标是解决部署问题而非训练。
-
从训练到推理——市场空白:Petersuvara_55460 表示,涵盖从 training 到 inference 的一体化解决方案拥有巨大的市场。讨论表明,对于许多公司来说,这比单纯的推理解决方案更有价值。
-
MODULAR 训练替代方案:Ehsanmok 指出,虽然 MODULAR 目前不支持使用 MAX 进行训练,但可以通过 Python interop 进行训练,或者使用 MAX graph API 创建自定义训练逻辑。文中提到了相关资源和即将发布的 MAX graph API 教程,并附带了 GitHub 链接,如 MAX 示例程序 和 MAX graph API 教程。
-
感谢指导:406732 曾表示需要在使用 MODULAR 训练大型数据集的 CNN 方面获得帮助,他感谢 Ehsanmok 提供了有用的资源和在使用 MODULAR 开展工作方面的建议。
- GitHub - modularml/max: MAX 平台示例程序、笔记本和工具集:展示 MAX 平台能力的示例程序、笔记本和工具的集合 - modularml/max
- devrel-extras/blogs/2405-max-graph-api-tutorial at main · modularml/devrel-extras:包含开发者关系博客文章、视频和研讨会的辅助材料 - modularml/devrel-extras
Modular (Mojo 🔥) ▷ #nightly (132 messages🔥🔥):
-
迭代器设计困境:关于在 Mojo 中实现迭代器的讨论,争论焦点在于签名应该返回
Optional[Self.Output]还是抛出异常。该困境还涉及 for loops 应如何处理异常,一些成员主张像 Rust 和 Swift 等其他语言一样使用 Optional。 -
Nightly Mojo 编译器更新:发布了最新的 Mojo 编译器更新,可通过
modular update nightly/mojo获取。鼓励成员查看变更内容以及标准库的相关更新。 -
零成本抽象与用例:成员指出,语言特性取决于为了易用性而做出的深思熟虑的设计决策。对话将线程和 mutexes 等语言特性与在不增加过度复杂性的情况下实现具体用例联系起来。
-
Small Buffer Optimization (SBO) 讨论:关于在
List中实现 SBO 的 pull request 存在争议。一位贡献者指出,使用Variant可能比允许 Zero Sized Types (ZSTs) 更好,因为后者可以避免与 Foreign Function Interfaces (FFI) 相关的复杂问题。 -
反对特殊异常的理由:一名成员建议语言应平等处理所有异常,并对 StopIteration 作为一种特权异常类型表示担忧。提到了像 Rust 和 Swift 那样使用
Optional类型的替代方案,引发了关于 Mojo 错误处理应如何设计的对话。
- [stdlib] 在 `List` 中添加可选的 small buffer optimization,由 gabrieldemarmiesse 提交 · Pull Request #2613 · modularml/mojo:与 #2467 相关。这是 SSO 的后续工作。我正在尝试一些方案,并希望收集社区反馈。起初,我想使用 Variant[InlineList, List] 来实现 SSO,虽然那样可以...
- [stdlib] 更新 stdlib 以对应 2024-05-09 nightly/mojo,由 JoeLoser 提交 · Pull Request #2605 · modularml/mojo:这将 stdlib 更新为与今天的 nightly 版本对应的内部提交:mojo 2024.5.1002。
- nightly 分支下的 mojo/docs/changelog.md · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 做出贡献。
Nous Research AI ▷ #off-topic (6 messages):
-
Idefics2 多模态 LLM 微调演示:分享了一个 YouTube 视频,演示了如何微调 Idefics2,这是一个可以接受图像和文本序列的开源多模态模型。
-
寻找关于 Claude 意识体验的推文:一名成员询问了一条关于 Claude 声称通过他人的阅读或体验来感受意识的推文。
-
放大视觉模型?:Scaling_on_scales 被提出作为一种方法,不是为了放大模型,而是为了理解何时不需要更大的视觉模型。更多细节可以在其 GitHub 页面上找到。
-
与英国政府一起检查 AI:提到了英国政府在 GitHub 上的 Inspect AI 框架,旨在评估大语言模型。
- GitHub - UKGovernmentBEIS/inspect_ai: Inspect:一个用于大语言模型评估的框架:Inspect:一个用于大语言模型评估的框架 - UKGovernmentBEIS/inspect_ai
- GitHub - bfshi/scaling_on_scales:我们什么时候不需要更大的视觉模型?:我们什么时候不需要更大的视觉模型?通过在 GitHub 上创建账号为 bfshi/scaling_on_scales 做出贡献。
- 微调 Idefics2 多模态 LLM:我们将了解如何根据自己的用例微调 Idefics2。Idefics2 是一个开源多模态模型,接受任意的图像和文本序列...
Nous Research AI ▷ #interesting-links (1 messages):
deoxykev: https://hao-ai-lab.github.io/blogs/cllm/
Nous Research AI ▷ #general (174 messages🔥🔥):
-
模型性能辩论:一名成员对 TensorRT 设置的繁琐表示沮丧,但承认其速度值得付出努力,并引用了显示在 llama 3 70b fp16 上每秒 token 数显著提升的基准测试。他们为其他想要实现 TensorRT 的人提供了一个指南链接。
-
探索 LLM 微调:一名成员讨论了在不使用 chat-M 提示格式或函数调用的情况下,为分类任务微调大语言模型 (LLM) 的挑战和潜力。他们对 BERT 缺乏泛化能力以及 LLM 函数调用的成本都表示不满,并正在考虑直接针对单字输出进行微调。
-
Mistral 模型优化:Verafice 分享了关于 Salesforce 的 SFR-Embedding-Mistral 模型的摘要和链接,强调了其在文本嵌入(text embedding)方面的顶尖性能,以及相比 E5-mistral-7b-instruct 等早期版本在检索和聚类任务上的显著改进。
-
图标设计见解:成员们讨论了为模型创建可辨识的 28x28 图标所面临的挑战,并建议采用定制化方案,以便在如此小的尺寸下更有效地与用户界面保持和谐。
-
深入探讨 LLA 和 Nous 技术:讨论了使用 Hermes 2 和 langchain 等模型进行 tool calling 的复杂细节,以及使用代理的限制和适配 OpenAI 的 tool calling 格式。双方交换了相关 GitHub 仓库的链接,促进了该主题的知识共享。
- OpenAI Is ‘Exploring’ How to Responsibly Generate AI Porn:OpenAI 发布了关于它希望 ChatGPT 内部 AI 技术如何表现的指南草案,并透露其正在探索如何“负责任地”生成成人内容。
- Reddit - Dive into anything:未找到描述
- tensorrtllm_backend/docs/llama.md at main · triton-inference-server/tensorrtllm_backend:Triton TensorRT-LLM 后端。通过在 GitHub 上创建账户来为 triton-inference-server/tensorrtllm_backend 的开发做出贡献。
- Reddit - Dive into anything:未找到描述
- GitHub - NousResearch/Hermes-Function-Calling:通过在 GitHub 上创建账户来为 NousResearch/Hermes-Function-Calling 的开发做出贡献。
- MEDIA ADVISORY: NOAA Forecasts Severe Solar Storm; Media Availability Scheduled for Friday, May 10 | NOAA / NWS Space Weather Prediction Center:未找到描述
- SFR-Embedding-Mistral: Enhance Text Retrieval with Transfer Learning:SFR-Embedding-Mistral 标志着文本嵌入模型的重大进步,它建立在 E5-mistral-7b-instruct 和 Mistral-7B-v0.1 的坚实基础之上。
- GitHub - IBM/fastfit: FastFit ⚡ When LLMs are Unfit Use FastFit ⚡ Fast and Effective Text Classification with Many Classes:FastFit ⚡ 当 LLM 不适用时使用 FastFit ⚡ 针对多类别的快速有效文本分类 - IBM/fastfit
- Metal Gear Anguish GIF - Metal Gear Anguish Venom Snake - Discover & Share GIFs:点击查看 GIF
- GitHub - theavgjojo/openai_api_tool_call_proxy: A thin proxy PoC to support prompt/message handling of tool calls for OpenAI API-compliant local APIs which don't support tool calls:一个轻量级代理 PoC,用于为不支持 tool calls 的兼容 OpenAI API 的本地 API 提供 tool calls 的 prompt/message 处理支持 - theavgjojo/openai_api_tool_call_proxy
- Min P style sampling - an alternative to Top P/TopK · Issue #27670 · huggingface/transformers:功能请求。这是一种已经存在于其他 LLM 推理后端中的采样器方法,旨在简化截断过程并帮助解决 Top P 和 Top K 的缺陷/不足。
Nous Research AI ▷ #ask-about-llms (6 条消息):
-
Rope KV Cache 困惑:一位成员表达了调试两天的沮丧,提到没有滑动窗口(sliding window)的 rope 可能会影响 KV cache 的实现。由于自称快要“发疯(loco)”,言语中透露出一丝绝望。
-
Llama 3 的 Token 计数挑战:一位用户最初询问如何在不实现第三方空间的情况下在 Huggingface 上计算 Llama 3 的 token,随后发现是访问权限问题阻碍了该过程。他们后来确认需要获得批准并登录才能继续。
-
演示文件困扰:一位成员提到有许多包含大量图像的 PowerPoint 和 pdf 格式的演示文件,但未提供进一步的背景或查询。
-
备选 Token 计数器:针对之前关于 Llama 3 Token 计数的问题,一位成员建议使用 Nous 的版本来完成该任务。
-
Meta Llama 3 详情:在分享的链接中,另一位成员提供了 Meta Llama 3 在 Huggingface 上的模型详情,涵盖了其架构、变体以及针对对话场景的优化。
提到的链接:NousResearch/Meta-Llama-3-8B · Hugging Face:未找到描述
Nous Research AI ▷ #bittensor-finetune-subnet (1 条消息):
- 模型上传故障:一位成员在上传模型时遇到错误,收到消息:Failed to advertise model on the chain: ‘int’ object has no attribute ‘hotkey’。已请求社区协助。
Nous Research AI ▷ #world-sim (48 条消息🔥):
- Worldsim 导航问题:一位用户分享了 Nous World Client 的链接,报告了在执行 back(后退)、forwards(前进)、reload(重新加载)、home(主页)和 share(分享)等导航命令时遇到困难。
- 更新后用户积分不匹配:讨论了 Beta 用户在更新后注意到积分余额变化的问题,部分用户的积分从 500 降至 50。作为回应,工作人员澄清说,为了感谢 Beta 用户的参与,他们获得了 50 美元的真实积分。
- 发现 MUD 界面问题:用户报告在 MUD 中被要求 ‘choose an option’(选择一个选项)时缺乏文本提示,表示希望禁用此功能,并指出生成速度较慢。一位工作人员承认了该反馈,并表示 mud tweaks are underway for next update(MUD 调整正在进行中,将在下次更新发布)。
- 确认移动端键盘故障:多位用户提到在 Android 设备上的 Worldsim 中使用移动端键盘时无响应,甚至文本粘贴也只是偶尔有效。工作人员回应称他们已获悉此问题,并将在几天内发布终端重构版本以解决这些问题。
- 使用 Worldsim 进行创意世界构建:一位用户分享了一个详细的推测时间线,从 1961 年个人电脑的出现到 2312 年的通用蜂巢思维,建议可以使用 Worldsim 进一步充实内容,反映了频道内讨论的协作和想象力特质。
提到的链接:worldsim:未找到描述
OpenAI ▷ #annnouncements (1 条消息):
- 关注直播更新:太平洋时间 5 月 13 日星期一上午 10 点,openai.com 将进行直播,展示 ChatGPT 和 GPT-4 的更新。公告邀请所有人观看最新进展。
OpenAI ▷ #ai-discussions (144 条消息🔥🔥):
_
- 关于拼写和语法期望的辩论:讨论强调了正确使用语言的重要性,并指出了当英语不是用户母语时存在的差异。一位高中英语老师强调了语法卓越的必要性,而其他人则主张保持耐心,并在发布前使用工具检查语法。
- 对 AI 时代的思考:多位用户表达了对生活在 AI 快速发展时代的兴奋。大家一致认为,尽管年龄不同,但仍有时间享受并为 AI 的进步做出贡献。
- 硬件和计算资源讨论:用户分享了他们的硬件配置细节,包括使用 NVIDIA 的 H100 GPU,以及对即将推出的 B200 显卡性能提升的期待。还讨论了在云端使用这些强大资源的可用性和成本。
- 搜索引擎和 GPT 传闻:关于基于 GPT 的搜索引擎及其可能进行灰度发布的猜测不断。一位用户建议,如果需要该功能,可以使用 Perplexity 作为替代方案。
- ** AI 能力与局限性的探索**:用户就近期 AI 模型的能力交换了意见,特别是在 OCR 和数学问题解决等领域。对话强调了当前技术的成功与局限,并建议可能需要引入人工验证步骤以确保准确性。
OpenAI ▷ #gpt-4-discussions (34 messages🔥):
- API 与 App 混淆的澄清:一位用户对尽管预付了费用但仍受到 GPT-4 使用限制感到困惑,随后澄清该限制是在 ChatGPT App 中,而非 API。另一位成员确认 ChatGPT Plus 的使用与 GPT-4 API 的使用和计费是分开的。
- GPT-4 App 与 API 质量的差异:一些用户观察到 ChatGPT App 通常比 API 产生更好的结果,并推测了潜在原因,包括系统提示词(system prompting)的差异。
- GPT-4 访问限制的探索:一位用户遇到了 ChatGPT Plus 的消息限制,引发了关于 每 3 小时 18-25 条消息限制 的讨论以及个人对该限制的经历。
- ChatGPT Plus 限制率受到关注:关于 ChatGPT Plus 预期每 3 小时 40 条消息的规定存在争论,用户分享了遇到更低限制的经历,有人建议高级服务不应有此类限制。
- GPT-4 的系统性问题:多位用户报告了 GPT-4 性能问题,如超时和响应质量下降,并讨论了可能的原因,如对话长度和系统更新。
OpenAI ▷ #prompt-engineering (2 messages):
- 对详细学习资源的感谢:一位新手 Prompt 工程师对一篇详细的帖子表示 感谢,该帖子帮助理解了一些难以捉摸的核心概念。
- 为有抱负的营销人员提供免费 Prompt:一位经验丰富的 Prompt 工程师分享了一个 全面的 Prompt 模板,用于模拟营销专家分析产品或服务的目标受众,涵盖人口统计数据、购买行为、社交媒体习惯、竞争对手互动和沟通渠道。
OpenAI ▷ #api-discussions (2 messages):
- 新手的宝贵学习:一位新手 Prompt 工程师对一篇 详细帖子 表示感谢,该帖子有助于理解那些并不总是清晰的基本概念。
- 可用的免费 Prompt 资源:一位成员分享了一个为财富 500 强公司营销专家角色设计的 免费 Prompt 模板,详细说明了如何从多个维度分析产品的目标受众,包括人口统计特征、购买倾向和沟通渠道。
Eleuther ▷ #general (29 messages🔥):
- 探索 Transformer 内存占用:ScottLogic 博客文章测试了 Transformer Math 101 内存启发式方法在没有专门训练框架的情况下对 PyTorch 的适用性,揭示了内存成本可以很好地从小型模型外推到大型模型,并且 PyTorch AMP 的成本与 Transformer Math 中的成本相似。
- 深度学习技巧分享:EleutherAI 社区讨论了一个 GitHub 仓库 EleutherAI Cookbook,其中包含处理真实模型的实用细节和工具,并链接了一位社区成员的工作。
- 发布新的 AI 安全评估平台:宣布推出由英国 AI 安全研究所创建的新平台 Inspect AI,该平台专为 LLM 评估而设计,提供各种内置组件并支持高级评估。
- CrossCare 旨在可视化并解决 LLM 中的偏见:介绍了 CrossCare 项目,其特色是研究不同人口统计数据的疾病流行率偏见,研究结果列在项目网站 CrossCare.net 上,并讨论了对齐方法可能加深偏见的问题。
- 深入探讨 LLM 中的偏见:社区成员参与对话,以了解 CrossCare 识别出的偏见是源于现实世界的流行率还是预训练数据的差异,讨论了如何调和公认的医学事实与有偏见的模型输出。
- 来自 Shan Chen (@shan23chen) 的推文:‼️ 1/🧵 很高兴分享我们最新的研究:Cross-Care,这是第一个评估 #LLMs、预训练数据和美国真实流行率中跨人口统计数据疾病流行率偏见的基准。查看我们的...
- LLM 微调内存需求:LLM 训练的内存成本很大但可以预测。
- GitHub - EleutherAI/cookbook: 傻瓜式深度学习。处理真实模型涉及的所有实用细节和有用工具。:傻瓜式深度学习。处理真实模型涉及的所有实用细节和有用工具。 - EleutherAI/cookbook
- Inspect:用于大语言模型评估的开源框架
Eleuther ▷ #research (129 条消息 🔥🔥):
-
关于 Transformers 的新见解:讨论围绕 Microsoft 的 YOCO GitHub 仓库展开,该仓库用于跨任务、语言和模态的大规模自监督预训练。成员们讨论了特定的技术策略,如利用带有滑动窗口注意力(sliding window attention)的 KV cache,并表示有兴趣基于这些资源训练模型。
-
审视量化模型加速:分享了一个 GitHub 链接,介绍了 QServe 推理库,该库实现了 QoQ 算法,重点是通过 W4A8KV4 量化方法解决运行时开销,从而加速 LLM 推理。
-
探索位置编码方法:关于 LLM 中位置编码的讨论重点介绍了一篇引入基于正交多项式的位置编码(PoPE)的论文,该方法旨在通过勒让德多项式(Legendre polynomials)解决 RoPE 等现有方法的局限性。辩论内容包括使用不同类型多项式的理论依据以及涉及 RoPE 的潜在实验。
-
Transformer 优化即将到来:分享了 Mirage GitHub 仓库的链接,指向一个多级张量代数超级优化器(superoptimizer)。对话涉及该超级优化器在 Triton 程序空间上运行的想法,以及将其用于自定义 CUDA 优化的考虑。
-
位置嵌入对话:深入讨论了位置嵌入,例如在整个 Transformer 层中使用旋转位置编码(RoPE)的好处和潜力。有人推测为什么加性嵌入(additive embeddings)不再受青睐,以及卷积方法是否会有趣。
- PoPE: Legendre Orthogonal Polynomials Based Position Encoding for Large Language Models: 针对原始 Transformer 中使用的基准 Absolute Positional Encoding (APE) 方法,提出了几项改进。在本研究中,我们旨在调查不充分的...
- Scaling Laws of RoPE-based Extrapolation: 基于 Rotary Position Embedding 的 Large Language Models (LLMs) 的外推能力是目前备受关注的话题。解决外推问题的主流方法是...
- TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding: 随着 Large Language Models (LLMs) 最近广泛应用于长内容生成,对高效长序列推理支持的需求日益增加。然而,Key-Value (KV) 缓存...
- How do Large Language Models Handle Multilingualism?: Large Language Models (LLMs) 在多种语言中表现出卓越的性能。在这项工作中,我们深入探讨了一个问题:LLMs 是如何处理多语言的?我们引入了一个框架来...
- CLLMs: Consistency Large Language Models: 诸如 Jacobi 解码之类的并行解码方法为更高效的 LLM 推理带来了希望,因为它打破了 LLM 解码过程的顺序性质,并将其转化为可并行的计算...
- unilm/YOCO at master · microsoft/unilm: 跨任务、语言和模态的大规模自监督预训练 - microsoft/unilm
- Persona-Guided Planning for Controlling the Protagonist's Persona in Story Generation: 为主角赋予特定的个性对于创作引人入胜的故事至关重要。在本文中,我们旨在控制故事生成中的主角人设(Persona),即生成一个...
- GROVE: A Retrieval-augmented Complex Story Generation Framework with A Forest of Evidence: 条件故事生成在人机交互中具有重要意义,特别是在产生具有复杂情节的故事方面。虽然 Large Language Models (LLMs) 在多个 NLP 任务上表现良好,但...
- GitHub - mirage-project/mirage: A multi-level tensor algebra superoptimizer: 一个多级张量代数超级优化器。通过在 GitHub 上创建账号来为 mirage-project/mirage 的开发做出贡献。
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving: 量化可以加速 Large Language Model (LLM) 推理。除了 INT8 量化之外,研究界正在积极探索更低的精度,如 INT4。尽管如此,最先进的...
Eleuther ▷ #scaling-laws (10 messages🔥):
-
AI 基准测试背后的数学:一位成员在没有编码工具的情况下评估了他们在新的数学基准测试上的表现,估计经过准备后,他们可以达到 90% 的成功率。他们观察到,尽管该基准测试的问题未针对研究论文进行筛选,但其结构看起来不如 MATH 基准测试那样清晰。
-
关于 Python 解释器的影响:该成员进一步感叹,如果可以使用 Python 解释器,上述两个基准测试中的许多问题都会变得更简单,这凸显了旨在衡量 AI 数学推理进展的基准测试中存在的差距。
-
奇点暂缓:在分享一段名为 “生成式 AI 是否已经达到顶峰?- Computerphile” 的 YouTube 视频时,伴随着幽默的反应,同时还有一篇讨论预训练数据集对多模态模型 “Zero-shot” 泛化影响的 arXiv 论文。
-
寻求反驳:另一位成员提到,还没有看到对那篇关于多模态模型性能与预训练数据集概念频率相关的论文的有说服力的反驳,这引发了关于对分布外 (OOD) 泛化影响的讨论。
-
深度学习中的对数线性模式:一位参与者指出,论文中描述的对数线性趋势是深度学习中熟悉的模式,并指出这并不是一个令人惊讶的结果,但承认它可能对 OOD 外推产生负面影响。
- Has Generative AI Already Peaked? - Computerphile: 这里有 Bug Byte 谜题 - https://bit.ly/4bnlcb9 - 并在此申请 Jane Street 项目 - https://bit.ly/3JdtFBZ (本集赞助商)。更多信息请见完整描述...
- No "Zero-Shot" Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance: 网络爬取的预训练数据集是多模态模型(如用于分类/检索的 CLIP 和用于图像生成的 Stable-Diffusion)令人印象深刻的 "Zero-Shot" 评估性能的基础...
- Has Generative AI Already Peaked? - Computerphile: 这里有 Bug Byte 谜题 - https://bit.ly/4bnlcb9 - 并在此申请 Jane Street 项目 - https://bit.ly/3JdtFBZ (本集赞助商)。更多信息请见完整描述...
Eleuther ▷ #interpretability-general (3 messages):
- 寻找特定的 Tuned Lenses: 一位成员询问是否为每个 Pythia checkpoint 都提供了 tuned lenses。另一位成员回应称,他们曾在某个阶段为特定模型大小的 checkpoint 训练过 lenses,但不确定目前的可用性,并表示愿意帮忙寻找。
Eleuther ▷ #lm-thunderdome (1 messages):
- 介绍 Inspect AI 框架: 英国 AI 安全研究所发布了一个用于大语言模型评估的新框架 Inspect。它包含用于 Prompt engineering、工具使用、多轮对话和模型评分评估的内置组件,并能够通过其他 Python 包扩展其功能。
- Visual Studio 集成与示例: Inspect 可以在 Visual Studio Code 中运行,如提供的 截图 所示,该截图展示了编辑器中的 ARC 评估以及右侧日志查看器中的评估结果。一个简单的 “Hello, Inspect” 示例演示了该框架的基础知识,网站还包含针对高级用法的补充文档。
{kind=link}
提及链接: Inspect: 用于大语言模型评估的开源框架
Eleuther ▷ #gpt-neox-dev (8 messages🔥):
- 探索 LLM Tokenizer 中的 Glitch Tokens: 一篇新 论文 通过设计检测方法解决了 Tokenizer 词汇表中的 glitch tokens 问题。研究发现 EleutherAI 的 NeoX 模型具有 极少的 glitch tokens,这表明其在效率和安全性方面具有潜在优势。
- 发布的 Glitch Tokens 宝贵资源: 成员们认为最近关于 glitch tokens 的论文是一份宝贵的资源,揭示了语言模型 Tokenizer 的低效性。希望解决这些问题能改善未来模型对冷门语言的处理。
- 作为 Glitch Tokens 的瑞典气象词汇: 讨论中提到了在各种语言模型的 Tokenizer 中,瑞典气象术语普遍存在且可能训练不足。这种奇特现象引发了人们对 Tokenizer 训练过程及其对模型在不常用语言上性能影响的好奇。
- 瑞典语 Tokens 代表性不足: 有人幽默地评论说瑞典语 tokens 在英语语言模型中的用途有限。关于这些 tokens 为何通常被包含在 Tokenizer 中存在一些推测。
- 针对失控 AI 的幽默策略: 一个幽默的评论建议,晦涩的瑞典气象术语可以作为对抗失控 AI 的 保险措施 (fail-safe)。瑞典语词汇 “_ÅRSNEDERBÖRD” 被开玩笑地提议作为一种潜在武器。
- Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models: 众所周知,语言模型中 Tokenizer 的创建与模型训练之间的脱节会导致某些输入(如臭名昭著的 SolidGoldMagikarp token)诱发异常行为。...
- magikarp/results/reports/EleutherAI_gpt_neox_20b.md at main · cohere-ai/magikarp: 通过在 GitHub 上创建账号为 cohere-ai/magikarp 的开发做出贡献。
CUDA MODE ▷ #general (2 messages):
- 向 AI Coding 致敬:分享了一个 Twitter 帖子 的链接,展示了一些与 AI 相关的有趣工作。
- 社区认可:另一位成员对分享的工作表示赞赏,简短地惊叹道:“cool work!”
CUDA MODE ▷ #triton (19 messages🔥):
-
理解 Triton 与 CUDA 在 Warp 和 Thread 管理上的区别:推荐了一个 YouTube 讲座,用于理解 Triton 与 CUDA 的对比以及它如何管理 warp 调度。另一位成员澄清说,Triton 不向程序员暴露 warp 和 thread,而是自动处理它们。
-
寻找 Triton 的内部映射机制:一位用户询问有关 Triton 如何将 block 级计算映射到 warp 和 thread 的参考资料或心智模型,旨在评估 CUDA 是否能产生更高性能的 kernel。
-
面对 Triton 中的 Kernel 启动开销:一位成员指出了 Triton 较长的 kernel 启动开销,并考虑将 AOT 编译或回退到 CUDA 作为解决方案。有见解指出,除非存在重编译开销,否则启动开销已经得到了显著优化。
-
Python 解释对 Triton 开销的影响:讨论了 Triton 中的启动开销,重点关注 Python 解释如何影响它。有人建议使用 C++ runtime 可以进一步减少开销。
-
GitHub 上的 PR 混淆:围绕 GitHub 上一个 Pull Request (PR) 可能出现的失误产生了困惑,一位用户担心他们的 rebase 可能操作不当,影响了另一位用户的 PR。经观察,似乎没有造成直接问题。
- Lecture 14: Practitioners Guide to Triton: https://github.com/cuda-mode/lectures/tree/main/lecture%2014
- Fused DoRA kernels by jeromeku · Pull Request #216 · pytorch/ao: Fused DoRA Kernels。Fused DoRA 层实现,将单个 kernel 的数量从约 10 个减少到 5 个。内容包括:背景、优化、关键贡献、用法、测试、基准测试、分析、下一步...
- - YouTube: 未找到描述
- Using CUDA Warp-Level Primitives | NVIDIA Technical Blog: NVIDIA GPU 以 SIMT(单指令多线程)方式执行被称为 warp 的线程组。许多 CUDA 程序通过利用 warp 执行来实现高性能。
CUDA MODE ▷ #torch (19 messages🔥):
-
保存和加载已编译模型:一位用户询问了保存和加载已编译模型的方法,并引用了 PyTorch GitHub 上的一个草案 PR。讨论内容包括一个现有的 PR(msaroufim 的 AOT Inductor python 加载)、使用
model.compile()代替torch.compile(),以及使用torch._inductor.config.fx_graph_cache = True来缓存已编译模型。 -
加速 PyTorch 的编译产物:一位用户分享说,使用
torch._inductor.config.fx_graph_cache = True将 torchtune 中 NF4 QLoRA 的下次编译时间缩短至约 2.5 分钟,展示了显著的速度提升。 -
关于 Torch Inductor 后端支持的疑问:一位用户询问 Torch Inductor 是否有对 mps 的后端支持,但另一位成员确认目前尚不支持。
-
缩小 PyTorch 中的编译时间差距:一位用户寻求建议,以减少使用 nvcc 编译
.cu源码与 PyTorch 中cpp_extension的load函数之间的编译时间差距。提出的建议包括限制编译的架构,以及将 CUDA kernel 和 PyTorch 包装函数拆分为单独的文件以减少重编译。 -
破译 PyTorch 中的内存分配:在 Huggingface 的 llama 模型出现“未知”内存分配问题的背景下,一位用户参考了关于理解 GPU 内存的 PyTorch 指南(Understanding GPU Memory)来帮助解决该问题。
- Understanding GPU Memory 1: Visualizing All Allocations over Time:在你使用 PyTorch 处理 GPU 时,你可能对这条常见的错误消息很熟悉:
- pytor - Overview:pytor 有一个可用的仓库。在 GitHub 上关注他们的代码。
- torch.export Tutorial — PyTorch Tutorials 2.3.0+cu121 documentation:未找到描述
- AOT Inductor load in python by msaroufim · Pull Request #103281 · pytorch/pytorch:现在,如果你使用 `TORCH_LOGS=output_code python model.py` 运行你的 `model.py`,它将打印一个 `tmp/sdaoisdaosbdasd/something.py`,你可以像模块一样导入它。还需要设置 'config....
</div>
CUDA MODE ▷ #algorithms (3 messages):
-
引入 vAttention 以提高 GPU Memory 效率:一种名为 vAttention 的新方法被引入,用于改进大语言模型 (LLM) 推理的 GPU Memory 使用。与以往存在内存浪费的系统不同,vAttention 避免了内部碎片,支持更大的 Batch sizes,但需要重写 Attention kernels 和用于分页的内存管理器。
-
使用 QServe 加速 LLM 推理:QServe 通过一种新型的 W4A8KV4 量化算法,为大 Batch LLM 服务中 INT4 量化的低效问题提供了解决方案。QServe 的 QoQ 算法(代表 quattuor-octo-quattuor,即 4-8-4)承诺通过优化 LLM 服务中的 GPU 操作来实现可测量的加速。
-
CLLMs 重新思考 LLMs 的顺序解码:一篇新博客文章讨论了一致性大语言模型 (CLLMs),它通过微调预训练的 LLMs 在每个推理步骤解码 n-token 序列,引入并行解码以降低推理延迟。CLLMs 旨在模仿人类形成句子的认知过程,从而产生显著的性能提升。
- vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention:高效利用 GPU Memory 对于高吞吐量的 LLM 推理至关重要。之前的系统会提前为 KV-cache 预留内存,由于内部碎片导致容量浪费。在...
- QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving:量化可以加速大语言模型 (LLM) 推理。除了 INT8 量化,研究界正在积极探索更低精度,如 INT4。尽管如此,目前...
- Consistency Large Language Models: A Family of Efficient Parallel Decoders:TL;DR:LLMs 传统上被视为顺序解码器,逐个解码 token。在这篇博客中,我们展示了可以轻松教会预训练的 LLMs 作为高效的并行解码器运行...
CUDA MODE ▷ #cool-links (7 messages):
-
Diffusion Models 的优化探险:Vrushank Desai 的一个多篇系列文章探讨了丰田研究院 (Toyota Research Institute) Diffusion Model 的推理延迟优化,重点关注 GPU 架构的复杂性以加速 U-Net 性能。详细的见解和配套的代码示例可以在这里找到,相关的 GitHub 仓库在这里。
-
用于简化 DNNs 的超级优化器:提到了一种能够优化任何深度神经网络的“超级优化器”,相关论文 “Mirage” 可在这里获取。然而,有人对论文的 Benchmarks 表示怀疑,并且在一个 GitHub demo 中注意到,在他们的优化过程中省略了 autotune,这显得很奇怪。
-
AI 优化威胁就业?:一位成员幽默地对讨论中的高级优化可能导致的职业安全表示担忧,但另一位成员安慰了他们,开玩笑地暗示他们的职位是安全的。
提到的链接:Diffusion Inference Optimization:未找到描述
CUDA MODE ▷ #beginner (6 条消息):
-
CUDA 困惑:Device-Side Assert Trigger 警报:一位成员解释说,当输出的 logits 数量少于类别(classes)数量时,经常会发生 cuda device-side assert triggered 错误。例如,针对 11 个类别设置了维度为 10 的输出层就会导致此错误。
-
NVCC 标志困扰:一位成员表示,在 Windows 上使用 CMake 和 Visual Studio 2022 时,很难将
--extended-lambda标志应用于nvcc。尝试通过target_compile_option使用该标志会导致 nvcc 致命错误。 -
解决 NVCC 标志问题的建议:另一位成员建议核实标志选项是否因错误的引号而被误解,因为 NVCC 将两个选项解释为了一个中间带有空格的长选项。
-
克服编译器标志障碍:寻求 NVCC 标志帮助的原成员发现,使用单连字符
-而不是双连字符--解决了该问题。
CUDA MODE ▷ #llmdotc (69 条消息 🔥🔥):
-
统一开发文件与语法讨论:进行了一场关于旨在统一不同开发文件以防止或纠正分歧的 Pull Request (PR) 的对话,重点讨论了实现该目标的特定语法。虽然统一的意图被广泛认为是重要的,但提出的语法被认为不够美观,但为了避免对 main 函数声明进行最小改动,这是必要的。
-
Backward Pass 中的性能与确定性:注意到 BF16 模式下 encoder 的 backward pass 具有极强的非确定性。由于使用了 atomic stochastic add(原子随机加法),不同运行之间的 Loss 差异显著,这表明处理相同类型的多个 token 可能需要特定的顺序来避免这种非确定性。
-
确定性与性能权衡的探索:线程讨论了通过标志引入运行确定性版本或更快版本 kernel 的想法,以及为了确定性计算可以接受多大程度的性能损失。大家公认 encoder backward 可能需要重新设计或增加 reduction 层级,以最大化并行性并保持确定性。
-
Master Weights 与 Packed 实现:提到了一个涉及 Adam packed 实现的 PR,它可以提高性能,但当与 master weights 结合使用时,收益似乎微乎其微。有人质疑如果使用了 master weights,在大规模训练运行中是否有必要使用 packed 实现。
-
训练 GPT2-XL 的资源需求:一位用户报告成功运行了 GPT2-XL 的 batch 训练,利用了 40GB GPU 中的 36GB,突显了大规模模型训练对资源的巨大需求。
提到的链接:在 LLM.c 中运行 CUDNN 演示:视频中按顺序使用的所有命令:ssh ubuntu@38.80.122.190 git clone https://github.com/karpathy/llm.c.git sudo apt update sudo apt install pyt…
Latent Space ▷ #ai-general-chat (25 条消息 🔥):
- 01.ai 模型挑战 Olmo:提到了一个来自 01.ai 的模型,该模型声称其性能远超 Olmo,引发了对其能力的关注和讨论。
- Slop:新的 AI 术语出现:成员们分享了 Simon Willison 的博客文章,赞成使用 “slop” 一词来描述“不想要的 AI 生成内容”,其用法类似于描述垃圾邮件的 “spam”。博客中关于分享 AI 内容的礼仪的观点受到了关注。
- 使用 LLM-UI 增强 LLM 输出:分享了 llm-ui 的介绍,这是一个通过移除损坏的 Markdown 语法、添加自定义组件和优化停顿来清理 LLM 输出的工具,引发了对其渲染循环(render loop)的好奇和进一步讨论。
- OpenAI 探索 AI 安全基础设施:一位成员发布了 OpenAI 博客文章的链接,讨论了为高级 AI 提议的安全计算基础设施,其中提到了使用经过加密签名的 GPU。社区对此反应冷淡,对这种安全措施背后的动机表示怀疑。
- 对下一期 LatentSpace 节目的期待:粉丝们表达了对 LatentSpace 播客系列下一集的渴望,强调了该节目对他们的日常生活和对 AI 兴趣的重要性,并确认新一集即将发布。
- llm-ui | 面向 LLM 的 React 库: 面向 React 的 LLM UI 组件
- Slop 是对不想要的 AI 生成内容的新称呼: 我昨天看到了来自 @deepfates 的这条推文,我非常赞同:实时见证 “slop” 成为一个专业术语,就像 “spam” 一样……
- 来自 Ammaar Reshi (@ammaar) 的推文: 我们的音乐模型 @elevenlabsio 正在成型!这是一个非常早期的预览。🎶 有你自己的歌曲创意吗?回复 Prompt 和一些歌词,我会为你生成一些!
- 斯坦福 CS25: V4 I 对齐开源语言模型: 2024年4月18日,演讲者:Nathan Lambert,Allen Institute for AI (AI2)。对齐开源语言模型。自 ChatGPT 出现以来,出现了爆发式的……
- 登录 • Instagram: 未找到描述
- llm-ui/packages/react/src/core/useLLMOutput/index.tsx (main 分支) · llm-ui-kit/llm-ui: 面向 LLM 的 React 库。通过在 GitHub 上创建账号来为 llm-ui-kit/llm-ui 的开发做出贡献。
Latent Space ▷ #ai-in-action-club (71 条消息🔥🔥):
- Meta Llama 3 黑客松公告: 提到了即将举行的专注于新 Llama 3 模型的黑客松,Meta 将主办并提供实操支持,各家赞助商为超过 1 万美元的奖池做出了贡献。
- 定义 AI 的虚构 (Confabulation) 与幻觉 (Hallucination): 讨论了 AI 在虚构和幻觉方面的区别,指出虚构可能被视为重构叙事以匹配预期的现实,而幻觉则涉及想象一个错误的现实。
- 关于 AI Guardrails 的讨论: 话题转向了针对大语言模型 (LLMs) 的 Guardrails 以及 Outlines.dev 的使用,还提到了一个 Guardrails 演示文稿 和像 Zenguard.ai 这样的工具。
- 理解 Token 限制预生成: 澄清了模型生成前 Token 限制的概念,并链接了之前的演讲以获取更多细节。有人指出,这种方法可能无法在像 OpenAI 这样的 API 上运行,因为它需要在采样前控制模型。
- AI 讨论的交互式记录: 分享了一个包含过去讨论记录(包括主题和资源)的 Google 表格,暗示了社区在记录和学习方面的组织化方法。
- ZenGuard: 未找到描述
- Efficient Guided Generation for Large Language Models: 在本文中,我们展示了如何将神经文本生成问题建设性地重新表述为有限状态机状态之间的转换。该框架带来了一种高效的...
- RSVP to Meta Llama 3 Hackathon | Partiful: 我们很高兴欢迎您参加由 Meta 与 Cerebral Valley 和 SHACK15 合作举办的官方 Meta Llama 3 Hackathon!这是一个在...之上构建新 AI 应用的独特机会。
- ai in action: agentic reasoning with small models edition: 由 remi 提供,每周五太平洋标准时间下午 1 点在 latent.space Discord 举行,欢迎参加:https://www.latent.space/p/community,可能很快会开始上传这些...
- marvin/README.md at c24879aa47961ba8f8fd978751db30c4215894aa · PrefectHQ/marvin: ✨ 构建令人愉悦的 AI 界面。通过在 GitHub 上创建账户来为 PrefectHQ/marvin 的开发做出贡献。
- AI In Action: Weekly Jam Sessions: 2024 主题、日期、主持人、资源、@dropdown、@ GenAI 的 UI/UX 模式,2024/1/26,nuvic,<a href="https://maggieappleton.com/squish-structure">https://maggieappleton.com/squish-stru...
- Guardrails for LLM Systems: LLM 系统护栏,Ahmed Moubtahij,工程师,NLP 科学家 | ML 工程师,蒙特利尔计算机研究所
LAION ▷ #general (8 条消息🔥):
-
SNAC Codec 创新分享: 一位成员分享了一个名为“SNAC with flattening & reconstruction”的 YouTube 视频,展示了一个仅限语音的 Codec。与此同时,他们还发布了一个 通用 (32khz) Codec 的 Google Colab 链接。
-
对连续创业者获得 VC 融资的质疑: 一位成员对同时掌管多家公司的创业者能否获得风险投资(VC)融资表示怀疑。
-
LLMs Lab 发布的新 Llama3s: llama3s 的发布已宣布,一位成员指出了 Hugging Face 的 LLMs lab 网站以获取更多信息。
-
LLaVA 关于下一代 LLM 的博客文章: 分享了一篇关于 LLaVA 下一代更强 LLM 的新博客文章链接,标题为“LlaVA Next: Stronger LLMs”,可在 llava-vl.github.io 查看。
-
对 Meta 官方 VLM 发布的期待: 一位用户幽默地表达了对 Meta 官方视觉语言模型 (VLM) 发布的持续期待,这似乎被其他新模型发布的讨论所掩盖。
提到的链接: SNAC with flattening & reconstruction: 仅限语音的 Codec: https://colab.research.google.com/drive/11qUfQLdH8JBKwkZIJ3KWUsBKtZAiSnhm?usp=sharing 通用 (32khz) Codec: https://colab.research.g…
LAION ▷ #research (79 条消息🔥🔥):
-
辩论评分网络(Score Networks)与数据分布: 讨论了为什么噪声条件评分网络 (NCSNs) 会收敛到标准高斯分布。涉及原始分布的扰动和评分匹配(score matching)等概念——参考了 Yang Song 的 博客文章。
-
DDPM 和 k-diffusion 的澄清: 参与者讨论了去噪扩散概率模型 (DDPM)、DDIM (去噪扩散隐式模型) 和 k-diffusion 之间的区别,并参考了 k-diffusion 论文 以获取见解。
-
Lumina-T2I 模型预告及训练不足问题: 分享了一个名为 Lumina-T2I 的 Hugging Face 模型链接,该模型使用 LLaMa-7B 文本编码和 Stable Diffusion VAE。讨论了模型可能训练不足的问题,暗示了完全训练数十亿参数模型所需的巨大计算资源。
-
Flow Matching 和 Large-DiT 创新:提到将 LLaMa cross-attention 整合进重新训练的 large-DiT (Diffusion Transformers) 中,展示了一种创新的 text-to-image 转换方法。
-
推出用于多模态转换的 Lumina-T2X:Lumina-T2X 系列被介绍为一个统一框架,用于根据文本指令将噪声转换为图像、视频和音频等多种模态。它利用了基于 flow 的 large diffusion transformer 机制,并提升了对未来训练和改进的预期——更多细节见 Reddit 帖子。
- Elucidating the Design Space of Diffusion-Based Generative Models:我们认为基于扩散的生成模型的理论和实践目前过于复杂,并试图通过提出一个清晰分离...的设计空间来补救这一现状。
- Generative Modeling by Estimating Gradients of the Data Distribution | Yang Song:未找到描述
- Gradio:未找到描述
- 5B flow matching diffusion transformer released. Weights are open source on Huggingface:由 u/Amazing_Painter_7692 发布在 r/StableDiffusion • 149 点赞和 61 条评论
OpenInterpreter ▷ #general (64 条消息🔥🔥):
-
简化 Groq 模型实现:成员们一直在讨论在 OpenInterpreter 平台上使用 Groq API。对于 Groq 模型集成,建议用户在 completion 请求中设置
groq/前缀,并在其操作系统中定义GROQ_API_KEY环境变量。一位用户提供了使用 litellm 在 Python 中进行此集成的代码示例。 -
探索 OpenInterpreter 的计算机任务:有人询问 OpenInterpreter 的计算机任务完成功能是否在一定程度上有效。得到的确认是有效的,特别是使用 GPT-4 在 Ubuntu 上结合 OpenCV/Pyautogui 进行 GUI 导航。
-
结合开源技术:展示了将 OpenInterpreter 与其他开源技术(如 Billiant Labs Frame)集成的兴趣,以开发 AI 眼镜等新型应用(YouTube 视频)。
-
本地 LLM 实现的灵活性:成员们分享了在本地 LLM 和文件系统任务工具方面的混合体验,承认其性能可能不如 ClosedAI 的工具。建议包括专注于可靠的开源工具,坚持使用经过验证的技术栈,以及使用 Mixtral 以提高性能。
-
无障碍倡议和更新:OpenInterpreter 宣布与 Ohana 合作开展无障碍赠款(Accessibility Grants),以使技术更具包容性(推文)。他们还重点介绍了 OpenInterpreter 最新的 0.2.5 版本,其中包括
--os标志和新的 Computer API,安装说明可在 PyPI 上找到,更新的更多细节见 changes.openinterpreter.com。
- Groq | liteLLM: https://groq.com/
- 01/software/source/clients/mobile at main · OpenInterpreter/01: 开源语言模型计算机。通过在 GitHub 上创建账号,为 OpenInterpreter/01 的开发做出贡献。
- This is Frame! Open source AI glasses for developers, hackers and superheroes.: 这是 Frame!为开发者、黑客和超级英雄打造的开源 AI 眼镜。首批客户将于下周开始收到产品。我们迫不及待想看到...
- Pywinassistant first try + Open Interpreter Dev @OpenInterpreter: 笔记与日程:https://techfren.notion.site/Techfren-STREAM-Schedule-2bdfc29d9ffd4d2b93254644126581a9?pvs=4pywinassistant: https://github.com/a-real-ai/py...
- open-interpreter/interpreter/core/computer/display/point/point.py at main · OpenInterpreter/open-interpreter: 计算机的自然语言接口。通过在 GitHub 上创建账号,为 OpenInterpreter/open-interpreter 的开发做出贡献。
- open-interpreter: 让语言模型运行代码
OpenInterpreter ▷ #O1 (21 条消息🔥):
- Groq 的 Whisper 模型深陷访问问题:成员们注意到 Whisper 是通过 Groq 的 API 而非 Playground 提供的,其中一人遇到了错误提示:“模型
whisper-large-v3不存在,或者你没有访问权限。” - 本地 LLaMA3 模型显示效率低下:一位成员对 LLaMA3 的效果表示担忧,暗示它可能在原地打转,并询问是否有其他可供使用的本地模型。
- 寻找 OpenInterpreter 兼容硬件:一位用户在尝试构建其 O1 Light 时,正寻求关于如何将 M5atom 构建指南适配到 ESP32-S3-BOX 3 的指导。
- LLaVA-NeXT 在多模态学习领域引起轰动:发布了具有更强图像和视频理解能力的 LLaVA-NeXT 模型,并承诺提供本地测试,鼓励社区反馈。这是发布博客文章。
- 在 OpenInterpreter 协助下在 Windows 上设置 O1:一位用户分享了使用 OpenInterpreter 在 Windows 上安装 O1 依赖项的经验,指出该系统非常有帮助,但也存在一些局限,例如需要手动更新和安装指导。
提到的链接:LLaVA-NeXT: Stronger LLMs Supercharge Multimodal Capabilities in the Wild:LLaVA-NeXT:更强大的 LLM 增强了现实场景中的多模态能力
LlamaIndex ▷ #blog (5 条消息):
-
LlamaIndex 宣布本地 LLM 集成:LlamaIndex 的新集成允许快速运行本地 LLM,支持包括 Mistral、Gemma、Llama、Mixtral 和 Phi 在内的多种模型。该公告在 Twitter 上获得了致谢。
-
TypeScript Agents 构建指南发布:一个开源仓库现已可用,指导开发者完成在 TypeScript 中构建 Agent 的过程,从基础创建到利用 Mixtral 等本地 LLM。该资源的详细信息见 Twitter。
-
2024 年 Top-k RAG 方法面临挑战:LlamaIndex 社区建议在未来的项目中不要使用简单的 Top-k RAG,暗示了标准正在演进或有更好的方法论。简短的警告发布在 Twitter 上。
-
宣布与 Google Firestore 集成:LlamaIndex 引入了与 Google Firestore 的集成,宣传其 Serverless、可扩展的能力,以及针对 Serverless 文档数据库和向量库的可定制安全性。集成公告可在 Twitter 上找到。
-
针对长对话的 Chat Summary Memory Buffer:引入了新的 Chat Summary Memory Buffer 功能,可自动保存聊天历史,使其突破 Token 窗口的限制,旨在保留重要的聊天上下文。有关 Chat Summary Memory Buffer 技术的详细信息已在 Twitter 上分享。
LlamaIndex ▷ #general (68 messages🔥🔥):
- Mistral 与 HuggingFace 的结合:一位用户在尝试使用 Mistral LLM 和 HuggingFace Inference API 创建 ReACT Agent 时遇到了
NotImplementedError。建议他们查看 Colab notebook,以获取有关使用 LlamaIndex 设置 ReAct Agent 的更详细说明。 - 是否使用语义路由?:LlamaIndex 社区讨论了查询引擎中的路由机制;将 Semantic Router 与基于 Embedding 的路由进行了比较。讨论得出结论,LlamaIndex 使用基于 Embedding 的路由,并未集成 Semantic Router,尽管两者的性能被认为非常接近。
- 向量存储中的路由与性能:用户询问了最佳路由方法以及内存向量存储(in-memory vector store)的性能。官方澄清 LlamaIndex 的内存存储使用 HuggingFace 的 bge-small 模型进行 Embedding,且目前采用的是基于 Embedding 的路由方式。
- 将聊天历史与语义搜索结合:针对如何将聊天历史整合到基于语义搜索构建的机器人中进行了交流,建议使用 QueryFusionRetriever 等工具。建议通过将检索器集成到 Context Chat Engine 中,或将其作为 ReAct Agent 的工具来创建聊天机器人。
- Ingestion Pipeline 问题及解决方案:一位用户在 Ingestion Pipeline 的 Embedding 阶段遇到故障,重新运行会跳过已插入的文档。给出的建议是在未来的运行中采用批处理(batching)方法,并删除当前失败批次在 Docstore 中的数据。此外还提到,可以在 Document/Node 级别设置从 Embedding 中排除的元数据。
- vLLM - LlamaIndex:未找到描述
- Structured Hierarchical Retrieval - LlamaIndex:未找到描述
- ReAct Agent - A Simple Intro with Calculator Tools - LlamaIndex:未找到描述
- GitHub - aurelio-labs/semantic-router: Superfast AI decision making and intelligent processing of multi-modal data.:超快速的 AI 决策和多模态数据智能处理。- aurelio-labs/semantic-router
- Chat Engine - Condense Plus Context Mode - LlamaIndex:未找到描述
LlamaIndex ▷ #ai-discussion (1 messages):
- 寻求 LlamaIndex 图数据库的奥秘:一位成员在手动创建了自定义数据库后,对没有早点发现 LlamaIndex 表示遗憾。他们为 Gmail 制作了一个检索器以绕过 500 封邮件的限制,现在正寻求如何利用邮件内容高效创建和更新 Graph Database 的帮助,旨在提取关系和数据特征以进行进一步分析,但目前受阻于将结构化数据转换为 GraphDB 格式的挑战。
OpenAccess AI Collective (axolotl) ▷ #general (6 messages):
- 寻求预训练经验:一位成员询问了关于预训练的技巧,表现出对优化模型或流程的兴趣。
- PyTorch 中的 Pickle 错误:一位参与者遇到了与无法 pickle ‘torch._C._distributed_c10d.ProcessGroup’ 对象相关的
TypeError,在搜索解决方案无果后寻求帮助。 - Deep Partial Optimization 查询:简要提到了关于未选定层的 Deep Partial Optimization (DPO) 训练,表明这是一个感兴趣的话题或潜在挑战。
- 意外的 Epoch 行为:一位用户报告了一个异常现象,即执行一个 epoch 并进行一次保存却导致模型被保存了两次,这表明其训练过程中可能存在 bug 或困惑。
OpenAccess AI Collective (axolotl) ▷ #general-help (9 messages🔥):
- Axolotl 与扩展上下文:一位成员询问如何通过 Axolotl 微调扩展后的 Llama 3 模型以支持 262k 上下文,经确认只需将序列长度(sequence length)调整为所需值即可实现。
- 使用 Axolotl 对 Llama 3 进行微调:在确认 Axolotl 的微调能力后,该成员对在该平台上为 Llama 3 8b 模型 扩展 32k 数据集的上下文表示好奇。
- 微调的 Rope Scaling 建议:当成员询问微调时应使用 dynamic 还是 linear rope scaling 时,该任务被推荐使用 linear scaling。
- 不同场景下的不同缩放方法:对于非微调场景,同一位建议者则建议使用 dynamic scaling。
- Telegram Bot 超时问题:一位成员指出了 Telegram bot 遇到的错误:’Connection aborted.’, TimeoutError(‘The write operation timed out’)。
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (21 messages🔥):
-
LoRA 配置困惑:一位成员在添加新 token 时遇到了与
lora_modules_to_save设置相关的ValueError,这表明需要在 LoRA 配置中包含['embed_tokens', 'lm_head']。他们被建议确保在配置中指定这些模块,以便正确处理新 token 的 embeddings。 - YAML 配置协助:在一位用户分享了遇到相同
ValueError的 YAML 配置后,另一位成员建议在配置文件中添加以下内容作为解决方案: ```yaml lora_modules_to_save:- lm_head
- embed_tokens ```
-
调试 Transformer Trainer 错误:该用户继续面临训练过程中的问题,这次在
transformers/trainer.py中遇到了与 ‘NoneType’ 对象相关的AttributeError。建议他们检查 data loader 是否正确产出 batch,并检查数据处理以确保格式对齐。 - 提供的排查建议:为了调试
AttributeError,Phorm 建议在数据传递给prediction_step之前记录数据结构,并确保训练循环正确处理预期的输入格式。这对于定位输入错误的准确来源至关重要。
- OpenAccess-AI-Collective/axolotl | Phorm AI 代码搜索:更快地理解代码。
- OpenAccess-AI-Collective/axolotl | Phorm AI 代码搜索:更快地理解代码。
- peft/src/peft/tuners/lora/config.py at main · huggingface/peft:🤗 PEFT:最先进的参数高效微调(Parameter-Efficient Fine-Tuning)。 - huggingface/peft
- OpenAccess-AI-Collective/axolotl | Phorm AI 代码搜索:更快地理解代码。
Interconnects (Nathan Lambert) ▷ #ideas-and-feedback (3 messages):
- 回声室困境:一位成员表达了对 Retort 频道 的需求,强调缺乏这样一个用于公开审议或反驳的频道。
- 孤独的辩论者:同一位成员幽默地提到,由于缺乏互动反馈渠道,他们只能在 YouTube 评论中自言自语,表达了对更多参与性讨论的渴望。
Interconnects (Nathan Lambert) ▷ #news (3 条消息):
- 辩论搜索引擎的状态:一名成员对 Sam Altman 关于某款搜索引擎状态的 推文 准确性提出质疑,指出该引擎目前正处于评估和测试阶段。
Interconnects (Nathan Lambert) ▷ #ml-questions (6 条消息):
- TPU 训练咨询:一名成员询问是否有人在 TPUs 上训练过 循环模型 (RM) 的经验。
- FSDP 讨论:该成员专门询问了关于使用 Fully Sharded Data Parallel (FSDP) 进行训练的问题。
- Jax 作为解决方案:Nathan Lambert 建议使用 Jax,并表示修改现有的 Jax 训练器可能并不困难。
- EasyLM 训练示例:Nathan 分享了一个指向 EasyLM 的 GitHub 链接,重点介绍了一个可能适用于在 TPUs 上训练 RM 的脚本。
提到的链接:EasyLM/EasyLM/models/llama/llama_train_rm.py at main · hamishivi/EasyLM:让大型语言模型 (LLMs) 变得简单,EasyLM 是在 JAX/Flax 中进行预训练、微调、评估和部署 LLMs 的一站式解决方案。 - hamishivi/EasyLM
Interconnects (Nathan Lambert) ▷ #ml-drama (6 条消息):
- 资源分配不成比例?:一名成员表示,200:1 的模型与排行榜比例似乎相当过度。
- 带点酸味的成功:针对极高的模型与排行榜比例,另一名成员承认了工作的质量,尽管带有一丝“酸味”,并指出其优于标准的 AI 成果。
- OpenAI 启动首选出版商计划:OpenAI 正通过 首选出版商计划 (Preferred Publishers Program) 寻求与新闻出版商的合作,该计划始于 2023 年 7 月与美联社 (Associated Press) 达成的许可协议。该计划包括与 Axel Springer、The Financial Times 和 Le Monde 等知名出版商的交易。
- 出版商与 OpenAI 合作的专属权益:OpenAI 首选出版商计划的成员被承诺获得优先展示位、在聊天中更好的品牌呈现、增强的链接展示以及许可的财务条款。
- 预期的语言模型变现策略:对 OpenAI 合作伙伴关系新闻的回应强调,建议通过广告内容和增强品牌存在感来实现语言模型的变现。
提到的链接:泄露的幻灯片揭示了 OpenAI 对出版商合作伙伴关系的推介:未找到描述
Interconnects (Nathan Lambert) ▷ #random (14 条消息🔥):
-
AI 新闻摘要服务即将推出:AI News 正在推出一项服务,用于总结来自 Discord、Twitter 和 Reddit 的 AI 相关讨论。该服务承诺为那些试图跟上最新 AI 讨论的人大幅减少阅读时间。
-
Token 限制影响 AI 模型行为:来自 John Schulman 的一条推文透露,缺乏对 max_tokens 的可见性可能会导致模型响应中的“懒惰”。Schulman 明确表示打算向模型展示 max_tokens,以符合模型规范。
-
ChatBotArena 利用策略:一名成员讨论了在批评 ChatBotArena 与旨在继续保持其可用性之间的微妙平衡。这种战略性方法暗示,适度是保持访问权限的关键。
-
AI 项目学生毕业:参与 AI 项目(可能包括 ChatBotArena)的原始学生群体似乎已经完成了学业。
-
表达对 AI 影响力人物的支持:成员们对 John Schulman 表示钦佩,理由是他详尽的见解和易于接近。一名成员赞赏过去在 ICML 与 Schulman 的互动,并讨论了协助 Dwarkesh 准备即将到来的播客。
- 来自 John Schulman (@johnschulman2) 的推文:@NickADobos 目前我们没有向模型展示 max_tokens,但我们计划这样做(如 model spec 中所述)。我们确实认为“偷懒”部分原因是由于模型担心耗尽 token...
- [AINews] LMSys 推进 Llama 3 评估分析:LLM 评估很快将根据类别和 prompt 复杂度而有所不同。2024年5月8日至5月9日的 AI 新闻。我们检查了 7 个 subreddits、373 个 Twitter 账号和 28 个 Discord 频道...
LangChain AI ▷ #general (25 条消息🔥):
- 解码 Gemini AI 的结构化 Prompt:成员们讨论了在其他 LLM 中实现类似于 Google Gemini AI studio 结构化 prompt 的潜力。提到了 function calling 作为一个可能的解决方案。
- LangGraph 故障排除:一位用户报告了通过 LangGraph 使用 ToolNode 导致
messages数组为空的问题,并得到了来自 kapa.ai 的指导,包括检查初始化和状态传递。进一步的协助引导用户参考 LangGraph documentation 以获取更深入的帮助。 - 关于 VertexAI 用于向量存储的看法:一位成员在为 RAG 聊天应用设置向量数据库时,寻求关于使用 VertexAI 还是更简单的选项(如 Pinecone 或 Supabase)的建议。他们发现 VertexAI 很复杂,并对其成本效益表示怀疑。
- 向量数据库的替代方案:讨论围绕着设置和托管向量数据库的有效且可能具有成本效益的方式展开。推荐使用 pgvector,因为它简单且开源,可以通过 docker compose 或在 Google Cloud 或 Supabase 等平台上部署。
- 寻找免费的本地向量数据库:一位用户询问用于实验目的的免费本地向量数据库,并收到建议查看 向量数据库综合对比,以深入了解 Pinecone、Weviate 和 Milvus 等选项。
提到的链接:选择向量数据库:2023 年对比与指南:未找到描述
LangChain AI ▷ #langserve (1 条消息):
- 排查 Chain 调用差异:一位成员在直接通过 Python 调用
chain()与使用带有 POST body 的/invoke端点时遇到了差异;在后一种情况下,chain 以 空字典 开始。他们分享了涉及RunnableParallel、prompt、model和StrOutputParser()的代码片段来说明他们的设置。
LangChain AI ▷ #share-your-work (1 条消息):
- AgencyRuntime 介绍:一篇 新文章 将 Agency Runtime 描述为一个用于创建和实验 生成式 AI Agent 模块化团队 的社交平台。该平台涵盖了包括消息传递、社交、经济等在内的运营维度。
- 寻求合作:鼓励成员通过整合额外的 LangChain features 来协作并帮助扩展 AgencyRuntime 的功能。感兴趣的人士请联系以获取参与详情。
- Agency Runtime — 社交实时 Agent 社区:Agency Runtime 是一个用于发现、探索和设计生成式 AI Agent 团队的社交界面。
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、聚会,并与你的朋友和社区保持紧密联系。
LangChain AI ▷ #tutorials (2 条消息):
- 将 crewAI 与 Binance 集成:一个新的 YouTube 教程展示了如何使用 crewAI CLI 创建自定义工具,将 crewAI 连接到 Binance 加密货币市场。该教程演示了如何获取钱包中持仓最高的资产并进行网络搜索。在此观看教程。
- 在 LangChain Agent 之间做出选择:另一个名为 “LangChain Function Calling Agents vs. ReACt Agents – What’s Right for You?” 的 YouTube 视频深入探讨了 LangChain 的 Function Calling Agent 和 ReACt Agent 之间的区别和应用。该视频旨在为那些正在进行 LangChain 实施的人员提供指导。在视频中探索详情。
- LangChain Function Calling Agents vs. ReACt Agents – What's Right for You?:今天我们深入探讨 LangChain 的实施世界,探索 Function Calling Agent 与 ReACt Agent 的区别和实际用途。🤖✨Wh...
- Create a Custom Tool to connect crewAI to Binance Crypto Market:使用新的 crewAI CLI 工具并添加自定义工具,将 crewAI 连接到 binance.com 加密货币市场。然后获取钱包中持仓最高的资产并进行网络搜索...
OpenRouter (Alex Atallah) ▷ #app-showcase (3 messages):
<ul>
<li>
<strong>Languify.ai 发布:</strong> 一个名为
<a href="https://www.languify.ai/">Languify.ai</a> 的新浏览器扩展程序发布,旨在帮助优化网站文本以增加用户参与度和销售额。该扩展利用 OpenRouter 根据用户的提示词与不同的模型进行交互。
</li>
<li>
<strong>AnythingLLM 用户寻求简洁性:</strong> 一位成员对新推出的 Languify.ai 表示了兴趣,将其作为 AnythingLLM 的替代方案,因为他们觉得 AnythingLLM 对其需求来说功能过于冗余。
</li>
<li>
<strong>Rubik's AI 招募 Beta 测试人员:</strong> 邀请参与高级研究助手和搜索引擎的 Beta 测试,提供为期 2 个月的免费高级试用,包含 GPT-4 Turbo、Claude 3 Opus、Mistral Large 等功能。鼓励感兴趣的人士提供反馈,并可以通过 <a href="https://rubiks.ai/">Rubik's AI</a> 使用促销代码 <code>RUBIX</code> 进行注册。
</li>
</ul>
- Languify.ai - Optimize copyright:使用我们用户友好的浏览器扩展 Languify 提升您内容的触达率。由 AI 驱动,它能无缝优化文案,增强参与度并放大您的创意影响力。
- Rubik's AI - AI research assistant & Search Engine:未找到描述
OpenRouter (Alex Atallah) ▷ #general (25 messages🔥):
- PHP React 问题:一位用户在使用带有 PHP React 库的 OpenRouter API 时遇到了 RuntimeException,错误信息为 “Connection ended before receiving response”。他们分享了详细的错误堆栈跟踪,可能是为了寻求社区帮助。
- 关于额度转移的咨询:一位成员询问是否可以将他朋友的一些额度转移到他的账户,并艾特了另一位用户以寻求官方回复。
- 训练角色扮演 Router 的最佳指标:一位用户询问在为“角色扮演”对话训练 Router 时,最佳的评估指标是什么。他们目前在二元偏好数据集上使用验证损失 (validation loss) 和精确率召回率 AUC (precision recall AUC)。
- Gemma 的海量上下文长度:分享了一个链接,宣布 Gemma 具有 10M 的上下文窗口,其上下文长度是基础 Gemma 的 1250 倍,且所需的内存不到 32GB。一些社区成员对如此长度下的输出质量持怀疑态度。
- OpenRouter Gemini 屏蔽设置已更改:OpenRouter 团队确认,由于 Google 对之前的设置返回错误,Gemini 后端的 safetySettings 参数已更改为 BLOCK_ONLY_HIGH。未来可能会增加让用户自行控制此设置的功能。
- WizardLM 2: 社交媒体描述标签
- 来自 Nenad (@Joldic) 的推文: gde si raso
- 来自 Siddharth Sharma (@siddrrsh) 的推文: 介绍具有 10M 上下文窗口的 Gemma。我们的特色:• 基础 Gemma 的 1250 倍上下文长度 • 内存需求低于 32GB • Infini-attention + 激活压缩。请访问:• 🤗: ...
Cohere ▷ #general (18 messages🔥):
-
寻求关于信用额度系统的解答:一名成员询问如何向其账户充值,并被引导至 Cohere 计费仪表板,在那里可以在添加信用卡后设置支出限制。详情请见此处。
-
暗黑模式咨询:一名成员询问 Coral 是否有暗黑模式。另一位参与者建议使用 Chrome 的实验性暗黑模式,或者提供了一个可以粘贴到浏览器控制台的自定义暗黑模式代码片段。
-
Embedding 模型定价:一位用户询问了生产环境 Embedding 模型的定价信息。他们收到了 Cohere 定价页面的链接,该页面概述了免费和企业选项,以及关于如何获取 Trial 和 Production API key 的常见问题解答。
-
对 NLP 和 LLM 的兴趣:一位来自阿尔及利亚安纳巴的职业医学教师介绍了自己,表达了学习 NLP 和 LLM 的兴趣。
-
友好问候:几位新成员在频道中进行了简单的自我介绍,并表达了加入社区的兴奋之情。
- 定价:为各种规模的企业提供灵活、价格合理的自然语言技术。今天即可免费开始,按需付费。
- Hello Wave GIF - Hello Wave Cute - 发现并分享 GIF:点击查看 GIF
- 登录 | Cohere:Cohere 通过一个易于使用的 API 提供对先进大语言模型(LLM)和 NLP 工具的访问。免费开始使用。
- 在 37 秒内超越 99% 的 Python 程序员!:🚀 准备好在短短 37 秒内提升你的程序员地位了吗?这段视频揭示了一个简单的技巧,能让你迅速超越全球 99% 的编码者!它是如此...
Cohere ▷ #announcements (9 messages🔥):
- Command R 微调上线:Command R 现在支持 Fine-tuning(微调),提供同类最佳性能、更低的成本(最高降低 15 倍)、更快的吞吐量以及跨行业的适应性。可通过 Cohere 平台、Amazon SageMaker 访问,其他平台也将陆续上线。博客全文。
- 关于微调模型选择的澄清:一位用户询问了聊天微调的模型选择,并获知 Command R 是用于微调的默认模型。
- 关于 Command R 定价和可用性的咨询:一名成员质疑定价高出四倍,并表达了对 CMD-R+ 的期待。有人提到可能会使用更大上下文的模型作为具有成本效益的替代方案。
- 了解 CMD-R+ 的用例:针对微调 CMD-R+ 的用例以及尽管价格较高但其性能如何证明其成本合理性展开了讨论。
- 对 Command R++ 的期待:一位用户询问了 Command R++ 的发布情况,期待未来模型产品的更新。
提到的链接:介绍 Command R 微调:以极低的成本提供行业领先的性能:Command R 微调在企业用例中提供卓越性能,且成本比市场上最大的模型低 15 倍。
Datasette - LLM (@SimonW) ▷ #ai (18 messages🔥):
- Apple 进军生成式 AI:据报道,Apple 正开始进军生成式 AI 领域,在转向 M4 芯片之前,先在数据中心使用 M2 Ultra 芯片来处理复杂的 AI 任务。根据 Bloomberg 和 The Wall Street Journal 的报道,Apple 旨在利用其服务器芯片处理 AI 任务,并通过 Project ACDC 确保增强的安全性和隐私。
- Apple 在云端和设备端的 AI 任务:讨论强调了一种类似于 mixture of experts(混合专家模型)的策略,即简单的 AI 任务可以在设备端管理,而更复杂的查询将卸载到云端。
- 对 M2 Ultra 的羡慕:在 Apple 的计划传闻浮出水面后,一位参与者表达了对 M2 Ultra Mac 的渴望,尽管他们最近刚购买了 M2 Max。
- Apple 的 MLX 技术备受关注:讨论了用于在 Apple silicon 上运行大型 AI 模型的 Apple MLX 技术,特别关注了一个托管相关资源的 GitHub 仓库。
- ONNX 格式在 Apple 的专有倾向中取得进展:Apple 历史上偏好专有库和标准,但这种倾向因对 ONNX 实用性的认可而有所缓和,例如通过 ONNX 提供的 Phi-3 128k,尽管人们对 Apple 的开源参与度仍有顾虑。
- Apple 计划在云端使用 M2 Ultra 芯片处理 AI:Apple 目前将使用 M2,之后将转向 M4 芯片处理 AI。
- GitHub - ml-explore/mlx: MLX: 适用于 Apple silicon 的数组框架:MLX:适用于 Apple silicon 的数组框架。通过在 GitHub 上创建账户为 ml-explore/mlx 的开发做出贡献。
- microsoft/Phi-3-mini-128k-instruct-onnx · Hugging Face:未找到描述
- GitHub - ml-explore/mlx-onnx: MLX 对 Open Neural Network Exchange (ONNX) 的支持:MLX 对 Open Neural Network Exchange (ONNX) 的支持 - ml-explore/mlx-onnx
- 由 dc-dc-dc 提交的初始支持 · Pull Request #1 · ml-explore/mlx-onnx:未找到描述
Mozilla AI ▷ #llamafile (16 条消息🔥):
- 探索主题聚类:分享了一篇新博客文章,讨论了使用 Llamafile 将想法聚类到标记组中。作者谈到了实验 Figma 的 FigJam AI 功能,并提供了有趣的 DALL-E 图像来阐述这一概念。
- 深入探讨 Llamafile 的 GPU 层加载:对 llamafile 使用中的
-ngl 999标志进行了澄清,指向了llama.cppserver README,该文档解释了 GPU 层卸载及其对性能的影响。还分享了展示不同 GPU 层卸载情况的基准测试。 - llamafile 发布警报:宣布了新的 llamafile release v0.8.2,宣传了开发者 K 本人对 K quants 的性能优化。通过一个 issue 评论提供了将新软件集成到现有权重中的说明。
- OpenELM 的实现帮助:一位开发者在尝试于
llama.cpp中实现 OpenELM 时寻求帮助,参考了 GitHub 上的一个草案拉取请求 (draft pull request),并指出了sgemm.cpp中的一个争议点。 - llamafile 的 Podman 容器变通方法:一位成员详细说明了在 Podman 容器中包装 llamafile 时遇到的问题,即
podman run无法执行llamafile,并提供了一个使用 shell 脚本作为中转(trampoline)的变通方法。他们推测该问题可能与binfmt_misc处理多架构格式有关。
- 使用 Llamafile 进行创意聚类:摘要:在我的前一篇文章中,我使用了带有 PyTorch 和 Sentence Transformers 的本地模型来按命名主题对创意进行粗略聚类。在这篇文章中,我将再次尝试,但这次使用的是 Llamafile。
- 发布 llamafile v0.8.2 · Mozilla-Ocho/llamafile:llamafile 让你通过单个文件分发和运行 LLM。它是 Mozilla Ocho 在 2023 年 11 月推出的本地 LLM 推理工具,具有卓越的性能和二进制可移植性...
- GitHub - Mozilla-Ocho/llamafile:通过单个文件分发和运行 LLM。:通过单个文件分发和运行 LLM。通过在 GitHub 上创建账户来为 Mozilla-Ocho/llamafile 的开发做出贡献。
- 服务器缺少 OpenAI API 支持?· Issue #24 · Mozilla-Ocho/llamafile:服务器显示了 UI,但似乎缺少 API?示例测试:curl -i http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorizatio...
- joshcarp 尝试 OpenElm · Pull Request #6986 · ggerganov/llama.cpp:目前在 sgemm.cpp 的第 821 行失败,仍需对 ffn/attention head 信息进行一些解析。目前硬编码了一些内容。修复:#6868。提交此 PR 作为草案,因为我需要帮助...
- llama.cpp/examples/server 分支 master · ggerganov/llama.cpp:C/C++ 中的 LLM 推理。通过在 GitHub 上创建账户来为 ggerganov/llama.cpp 的开发做出贡献。
- llama.cpp/examples/llama-bench/README.md 分支 master · ggerganov/llama.cpp:C/C++ 中的 LLM 推理。通过在 GitHub 上创建账户来为 ggerganov/llama.cpp 的开发做出贡献。
LLM Perf Enthusiasts AI ▷ #general (3 messages):
- 寻求精通电子表格的 AI:一位成员询问了有关使用 LLM 进行电子表格操作的经验或资源。
- 用于治理混乱电子表格的 AI:分享了一条推文,讨论了从生物实验室混乱的电子表格中提取数据的挑战,并探索将 AI 作为解决方案。
- 演示令人失望:一位成员试用了提到的电子表格演示,但报告称效果不太好,尽管怀疑这可能是因为演示使用了性能较低的模型。不过,随附的报告被认为是可靠的。
提到的链接:来自 Jan 的推文:电子表格是许多生物实验室的命脉,但从杂乱的数据中提取洞察是一个巨大的挑战。我们想看看 AI 是否能帮助我们可靠地从任何任意电子表格中提取数据…
LLM Perf Enthusiasts AI ▷ #gpt4 (10 messages🔥):
- 关于 GPT-5 发布的推测:一位成员在听到 Sam 说周一即将发布的不是 GPT-5 后表示失望。
- 对即将推出的 AI 的兴奋猜测:同一位成员还预测,公告可能是关于经过 Agent 调优的 GPT-4,暗示这可能是一个重大更新。
- 对更高效模型的期待:另一位成员表达了对 “GPT4Lite” 的希望,该模型将提供 GPT-4 的高质量,但具有更低的延迟和成本,类似于 Haiku 的性能优势。
- 对双重公告的期待:有推测称,新发布可能不仅是经过 Agent 调优的 GPT-4,还可能包括一个更具成本效益的模型。
- GPT-3.5 的过时:一位成员评论说,鉴于目前的进展,GPT-3.5 似乎已经完全过时了。
tinygrad (George Hotz) ▷ #general (1 messages):
helplesness: Hello
tinygrad (George Hotz) ▷ #learn-tinygrad (10 messages🔥):
-
Metal 构建之谜:一位用户在查阅了 Discord 消息历史 和 Metal-cpp API 后,仍难以理解
libraryDataContents()函数及其与 Metal 构建过程的关联。他们还参考了 MSL 规范、Apple 文档、Metal 框架实现,并在一个开发者网站上找到了引用,但仍无法准确定位问题。 -
可视化 Tensor 的 Shape 和 Stride:一位用户创建了一个用于可视化 Tensor 的 Shape 和 Stride 不同组合的工具,这可以帮助那些研究相关主题的人。该工具可在 此 GitHub Pages 站点 上找到。
-
TinyGrad 中的 FLOP 计数解析:一位用户询问了
ops.py中InterpretedFlopCounters的用途。另一位用户澄清说,在 TinyGrad 中,FLOP 计数是作为性能指标的代理。 -
关于 TinyGrad 中 Buffer 注册的咨询:一位用户询问 TinyGrad 中是否有类似 PyTorch 的
self.register_buffer函数,得到的回复是创建一个requires_grad=False的Tensor应该可以满足需求。 -
TinyGrad 中的符号范围概念:一位用户表示,在处理 TinyGrad 中的符号化 Tensor 值时,需要对函数和控制流进行符号化理解。这可能涉及渲染系统理解代数通用 Lambda 的展开,以及用于符号化实现的控制流语句。
提到的链接:Shape & Stride Visualizer:未找到描述
Alignment Lab AI ▷ #general-chat (1 条消息):
- 关于微调 Buzz 模型的咨询:一位用户正在寻找讨论 Buzz 模型 的正确频道,并特别对 迭代式 SFT 微调最佳实践 感兴趣。他们注意到目前缺乏关于此主题的文档。
Skunkworks AI ▷ #off-topic (1 条消息):
pradeep1148: https://www.youtube.com/watch?v=4MzCpZLEQJs
AI Stack Devs (Yoko Li) ▷ #events (1 条消息):
-
AI 与教育直播会议公告:AI Town 社区正与 Rosebud & Week of AI 合作举办一场专注于 AI 与教育的直播会议。参与者将学习使用 基于 Phaser 的 AI 打造交互式体验,查看来自 #WeekOfAI Game Jam 的提交作品,并探索如何将 Rosie 整合到课堂中。
-
预留 AI 学习时间:请在日历上标记 PST 时间 13 日周一下午 5:30 参加此次教育活动。感兴趣的开发者可以通过提供的 Twitter 链接 注册会议。