ainews-google-io-in-60-seconds
60秒看遍 Google I/O
谷歌宣布了 Gemini 模型系列的更新,包括支持 200 万 token 的 Gemini 1.5 Pro,以及针对速度进行了优化、拥有 100 万 token 容量的新型 Gemini Flash 模型。Gemini 系列现在涵盖了 Ultra、Pro、Flash 和 Nano 模型,其中 Gemini Nano 已集成到 Chrome 126 浏览器中。
其他的 Gemini 功能还包括 Gemini Gems(自定义 GPT)、用于语音对话的 Gemini Live,以及实时视频理解助手 Project Astra。Gemma 模型系列也更新了拥有 270 亿参数的 Gemma 2,它在体积仅为一半的情况下,提供了接近 Llama-3-70B 的性能;此外还推出了受 PaLI-3 启发的视觉语言开放模型 PaliGemma。
其他发布的内容包括 DeepMind 的 Veo、用于生成逼真图像的 Imagen 3,以及与 YouTube 合作的音乐 AI 沙盒 (Music AI Sandbox)。SynthID 水印技术现在已扩展至文本、图像、音频和视频。Trillium TPUv6 的代号也正式揭晓。此外,谷歌还将 AI 集成到了其整个产品套件中,包括 Workspace、电子邮件、文档、表格、相册、搜索和 Lens(智慧镜头)。
“全世界都在等待苹果的回应。”
发现 Gemini 的 7 种版本!
2024年5月13日至5月14日的 AI 新闻。 我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 30 个 Discord 社区(426 个频道,8590 条消息)。 预计节省阅读时间(以 200wpm 计算):782 分钟。
Google I/O 仍在进行中,由于产品范围极其广泛,报道起来比昨天 OpenAI 半小时的活动要困难得多。目前我们还没有发现一个能总结所有内容的单一网页(除了 @Google 和 @OfficialLoganK 的账号)。
以下是主观分类的清单:
Gemini 模型家族
- Gemini 1.5 Pro 宣布支持 2m token(候补名单中)。博客文章提到了“在翻译、编程、推理等关键用例中的一系列质量改进”,但未发布基准测试。
- 发布 Gemini Flash,在最初的 3 模型愿景基础上增加了第四个模型。博客文章称其“针对响应时间至关重要的窄领域或高频任务进行了优化”,强调其 1m token 容量,价格略低于 GPT3.5,但未提及速度声明。Gemini 系列目前包括:
- Ultra:“我们最大的模型”(仅限 Gemini Advanced)
- Pro:“我们在通用性能方面表现最好的模型”(今日提供 API 预览版,6 月正式发布/GA)
- Flash:“我们追求速度/效率的轻量级模型”(今日提供 API 预览版,6 月正式发布/GA)
- Nano:“我们的端侧模型”(将内置于 Chrome 126)
- Gemini Gems - Gemini 版的自定义 GPTs
- Gemini Live:“使用语音进行深度双向对话的能力”,这直接引向了 Project Astra —— 具备实时视频理解能力的个人助理聊天机器人,并附带一段精美的 2 分钟演示视频
- LearnLM - “我们基于 Gemini 并针对学习进行了微调的新模型系列”
Gemma 模型家族
-
Gemma 2,现在最高达 27B(此前为 7B 和 2B),这是一款仍在训练中的模型,以一半的参数量(适配 1 个 TPU)提供了接近 Llama-3-70B 的性能。
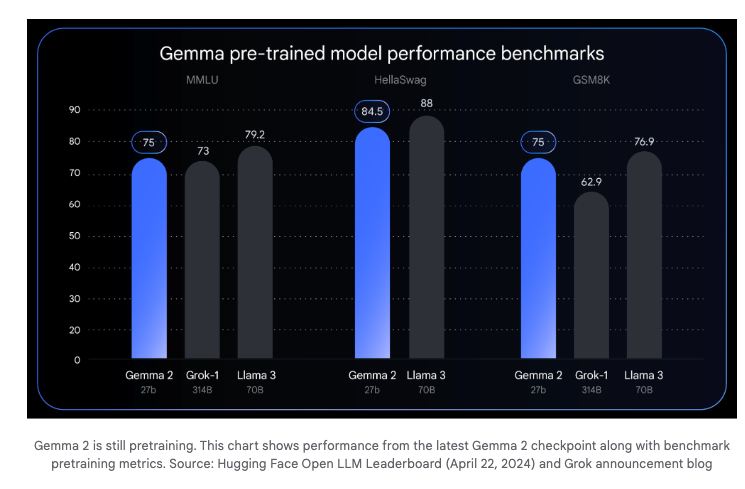
-
PaliGemma - 他们首个受 PaLI-3 启发的视觉语言开放模型,是对 CodeGemma 和 RecurrentGemma 的补充。
其他发布
- Veo,DeepMind 对标 Sora 的产品。HN 上的对比。
- Imagen 3:“它能像人类写作一样理解提示词,生成更具照片感的图像,是我们渲染文本效果最好的模型。”(更多示例点击此处)
- Music AI Sandbox - YouTube 与 DeepMind 合作,旨在与 Udio/Suno 竞争
- SynthID 水印技术 现在扩展到文本以及图像、音频和视频(包括 Veo)。
- Trillium - TPUv6 的代号
以及在 Google 产品线中的 AI 部署 - Workspace, Email, Docs, Sheets, Photos, Search Overviews, 具备多步推理能力的 Search, Android Circle to Search, Lens。
总的来说,这是一场执行得非常出色的 I/O,易于总结且不失细节。全世界都在等待 Apple 的回应。
目录
[TOC]
AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在使用 Haiku 进行聚类和流程工程(flow engineering)。
OpenAI 发布 GPT-4o
- 核心特性:@sama 指出 GPT-4o 的价格是 GPT-4-turbo 的一半,速度快两倍,且拥有 5 倍的速率限制(rate limits)。@AlphaSignalAI 强调了它跨文本、音频和视频进行实时推理的能力,称其极其多才多艺且充满趣味性。
- 多模态能力:@gdb 强调了 GPT-4o 跨文本、音频和视频的实时推理能力,认为这是迈向更自然的人机交互的一步。
- 改进的 Tokenizer:@aidan_clark 提到,得益于新的 Tokenizer,非拉丁语系语言的性能提升了高达 9 倍,且成本更低。
- 广泛可用性:@sama 表示 GPT-4o 面向所有 ChatGPT 用户开放,包括免费版用户,这符合他们让强大的 AI 工具普及化的使命。
技术分析与影响
- 架构推测:@DrJimFan 推测 GPT-4o 将音频直接映射为音频,作为一等模态(first-class modality),这需要全新的 tokenization 和架构研究。他认为 OpenAI 开发了一种神经优先(neural-first)的流式视频编解码器,将运动增量(motion deltas)作为 tokens 传输。
- 与 GPT-5 的潜在关系:@DrJimFan 建议 GPT-4o 可能是仍在训练中的 GPT-5 的早期检查点(checkpoint),其品牌命名在 Google I/O 前夕透露出了一丝不安。
- 与 Character AI 的重叠:@DrJimFan 注意到助手的活泼、调情性格与电影《她》(Her)中的 AI 相似,并认为 OpenAI 正在直接与 Character AI 的产品形态竞争。
- Apple 集成潜力:@DrJimFan 概述了 iOS 集成的三个层级:1) 用端侧 GPT-4o 替换 Siri,2) 针对摄像头/屏幕流的原生功能,3) 与 iOS 系统 API 集成。他认为第一个与 Apple 合作的公司将从一开始就拥有一个拥有十亿用户的 AI 助手。
社区反应与迷因 (Memes)
- @karpathy 开玩笑说“LLM 的杀手级应用是斯嘉丽·约翰逊(Scarlett Johansson)”,而不是数学或其他严肃的应用。
- @vikhyatk 分享了一个 Steve Ballmer 喊着“developers”的梗图,质疑现在的科技巨头 CEO 是否还能表现出那种程度的热情。
- @fchollet 调侃道,随着 AI 女友的兴起,AI 中的“自我博弈(self-play)”可能终于要变成现实了,这引用了自 2016 年以来讨论的一个概念。
AI Reddit 综述
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
GPT-4o 的功能与特性
- 速度与成本:在 /r/singularity 中,GPT-4o 被指出比 GPT-4 Turbo 快 2 倍且便宜 50%,并拥有 5 倍的速率限制。它在 非英语语言方面的表现也显著优于 GPT-4 Turbo。
- 音频能力:GPT-4o 提升了 音频解析能力,如区分不同发言者、讲座总结以及捕捉人类情感,同时也 改进了音频输出,如表达情感和唱歌。
- 图像生成:它具有 改进的图像生成能力,如更好的文本渲染、角色一致性、字体生成、3D 图像生成以及定向图像编辑。此外,GPT-4o 还具备 演示中未展示的能力,如 3D 物体合成。
- 基准测试:GPT-4o 在 MMLU/HumanEval 基准测试上显示出轻微提升。
GPT-4o 的可用性与定价
- ChatGPT 推送:GPT-4o 的文本和图像功能今日起在 ChatGPT 中陆续推出,免费用户可用,Plus 用户拥有 5 倍的消息限制。带有 GPT-4o 的语音模式将在未来几周向 Plus 用户推出。
- 定价:GPT-4o 的价格是 GPT-4 Turbo 的一半($10/1M tokens),比 GPT-4 32K 便宜 12 倍($60/1M tokens)。
反应与对比
- 编程性能:一些人认为 GPT-4o 在编程方面不如 GPT-4 Turbo,幻觉更多,不值得那 50% 的折扣。
- 翻译质量:另一些人指出它 在翻译方面并不优于 GPT-4 Turbo。
- 基准测试争议:OpenAI 声称对比了仍在训练中的 “Llama-3-400B”。
- 国际象棋表现:GPT-4o 在更难的国际象棋谜题提示词上提升了 +100 ELO,达到了 1310 ELO。
开源与竞争对手
- Meta 的进展:Meta 表示他们距离追上 GPT-4o 仅有几个月的时间。
- Falcon 2 发布:来自阿联酋的开源模型 Falcon 2 已发布,旨在与 Llama 3 竞争。
- Google 的 AI 能力:在 明天的 Google I/O 大会 之前,Google 预热了自家的实时视频 AI 能力。
梗与幽默
- 人们开玩笑说 GPT-4o 速度太快了,应该改名为 “GPT-4ooooooohhhhh”。
- 有图片调侃 “OpenAI 发明了 Apple 在 1987 年构想的未来主义知识导航仪 (Knowledge Navigator)”。
- 梗图暗示 GPT-4o 是在 “Scarlett Johansson 的声音” 上训练的。
AI Discord 综述
摘要之摘要的摘要
Claude 3 Sonnet
以下是内容中的 3-4 个主要主题,重要的关键词、事实、URL 和示例已加粗:
-
新 AI 模型发布与对比:
- OpenAI 的 GPT-4o 是一个新的旗舰级多模态模型,可以实时处理音频、视觉和文本。与 GPT-4 相比,它拥有更快的响应时间、更低的成本和更强的推理能力。展示 GPT-4o 交互能力的示例。
- Falcon 2 11B 模型性能优于 Meta 的 Llama 3 8B,并与 Google 的 Gemma 7B 旗鼓相当,提供多语言和视觉到语言的能力。
- 尽管存在成本和使用限制方面的担忧,一些用户在处理复杂推理任务时仍然更倾向于使用 Claude 3 Opus 而非 GPT-4o。
-
AI 模型优化与效率提升:
- 在 llm.c 中实现 ZeRO-1 使 GPU batch size 和训练吞吐量增加了约 54%,从而能够支持更大规模的模型变体。
- ThunderKittens 库通过优化的 CUDA tile primitives,承诺为 LLM 提供更快的推理速度和潜在的训练速度提升。
- 讨论集中在减少 AI 的计算消耗上,并分享了指向 Based 和 FlashAttention-2 等项目的链接。
-
多模态 AI 应用与框架:
- AniTalker 框架 能够利用音频输入从静态图像创建栩栩如生的说话面孔,捕捉复杂的面部表情。
- 讨论了 Retrieval Augmented Generation (RAG) 与 Stable Diffusion 等图像生成模型的集成,利用了 CLIP embeddings。
- 一个使用 Streamlit、LangChain 和 GPT-4o 的 多模态聊天应用 支持在聊天中上传图像和粘贴剪贴板内容。
-
开源 AI 模型开发与部署:
- Unsloth AI 庆祝在 Hugging Face 上的模型下载量突破 100 万次,反映了社区的活跃参与。使用 Unsloth 创建的新型崇拜克苏鲁的 AI 模型示例。
- Mojo 编程语言受到关注,讨论涉及为其开源编译器做贡献、与 MLIR 的集成及其所有权模型。关于 Mojo 所有权语义的视频。
- LM Studio 用户讨论了硬件建议、高效推理的量化级别(quant levels),以及 Command R 等特定模型在 Apple Silicon 上的问题。关于使用 yi-1.5 等大型模型以获得更好性能的建议。
Claude 3 Opus
-
GPT-4o 发布,具备多模态能力:OpenAI 推出了 GPT-4o,这是一款支持文本、图像以及即将推出的实时语音/视频输入的新旗舰模型。它对免费用户限额开放,Plus 用户享有额外权益,并拥有更快的响应速度,API 性能提升且成本仅为 GPT-4 的一半。现场演示展示了其交互式多模态技能。
-
Falcon 2 及其他开源模型表现亮眼:Falcon 2 11B 已发布,其性能超越了 Meta 的 Llama 3 8B,并接近 Google 的 Gemma 7B,具备开源、多语言和多模态能力。对 Google 即将推出的 27B 开源模型 Gemma 2 的期待也在增加。用户讨论了开源与闭源模型的可访问性和未来。
-
Anthropic 的 Opus 政策转变引发争议:Anthropic 针对 Opus 的新条款禁止了某些内容类型,引发了褒贬不一的反应。尽管 GPT-4o 速度很快,一些人仍然偏好 Claude 3 Opus,因其强大的总结能力和更具人性化的输出。
-
Memory 和多 GPU 支持即将登陆 Unsloth:Unsloth AI 预告了即将推出的功能,如自定义 GPT 的跨会话 Memory 和多 GPU 支持。随着用户探索最佳微调数据集和方法,该平台庆祝了 1M 次模型下载。
-
Modular 的 Mojo 语言通过关键演讲进行扩展:Modular 分享了关于 Mojo 所有权模型和开源标准库贡献的教育内容。Mojo 的编译器由 C++ 编写,引发了人们对潜在 MLIR 集成和未来自托管(self-hosting)的兴趣。
GPT4T (gpt-4-turbo-2024-04-09)
主要主题:
-
AI 模型的进步:各个频道都在热烈讨论最新的 AI 模型,如 GPT-4o、Falcon 2 和 LLaMA 模型。这些模型拥有增强的能力,如多模态功能和实时处理,并已集成到 Perplexity AI 和 OpenRouter 等平台中。
-
社区参与和协作:人们对分享项目、寻求合作以及参与有关代码实践、优化和在新技术集成(如 Stability.ai、Modular 和 LAION 等社区平台内)的讨论表现出越来越浓厚的兴趣,展示了一个专注于共同成长和学习的繁荣生态系统。
-
定制化与个性化问题:用户对定制 AI 模型和系统以满足特定需求表现出浓厚兴趣,从设置 AI 工具的私有实例到合并不同模型的能力,反映了将 AI 使用个性化以满足个人或组织要求的持续趋势。
-
技术挑战与调试:几个 Discord 频道的共同点是围绕 AI 模型和计算环境的故障排除和问题解决。这包括关于优化模型推理、处理特定库问题以及改进与各种编码环境集成的讨论。
-
教育内容与资源分享:多个频道致力于教育内容,从机器学习概念的详细解释到分享教程和资源,帮助成员学习和实现 AI 技术。这不仅有助于技能提升,还在社区内培养了知识共享的文化。
GPT4O (gpt-4o-2024-05-13)
- 模型发布与创新:
- GPT-4o: 许多 Discord 社区都在热烈讨论 OpenAI 发布的 GPT-4o,这是一个能够处理文本、音频和视觉输入的多模态模型。该模型在速度、上下文窗口(高达 128K tokens)和整体能力方面都有显著提升。OpenAI’s GPT-4o 因其实时多模态能力而受到称赞,但也因一些奇特之处和高昂的使用成本而受到批评 (GPT-4o Info)。
- Falcon 2: 被强调为 Meta 的 Llama 3 8B 和 Google 的 Gemma 7B 的有力竞争模型。它因开源、多语言和多模态特性而受到好评。Falcon 2 Announcement。
- Claude 3 Opus: 尽管面临成本和政策方面的担忧,其优势在于处理长篇推理任务和文本摘要。Claude 3 Opus。
- 性能与技术讨论:
- GPU 利用率: 许多讨论围绕着为不同模型(如 Stable Diffusion、YOLOv1)优化 GPU 使用,以及 Flash Attention 2 中的实现技术。这包括指南分享和配置技巧,例如 ThunderKittens 在加速推理和训练方面的有效性 (GitHub - ThunderKittens)。
- API 与性能增强: 关于 API 性能的对话专门集中在优化响应时间和处理更大的上下文窗口。例如,GPT-4o API 被指出在降低成本的同时具有更快的速度和更好的性能。
- 社区工具与支持:
- 项目与工具分享: 从使用 Retrieval-Augmented Generation (RAG) 的求职助手,到使用社区开发工具设置 OpenRouter 等 AI 工具的详细步骤。个人项目和协作成果得到了大量分享 (Job Search Assistant Guide, OpenRouter Model Watcher)。
- 帮助与协作: 一个反复出现的主题是故障排除,并为 AI 开发过程中遇到的问题提供支持,例如 CUDA 错误、模型微调(fine-tuning)和依赖管理。
- 伦理与政策:
- 内容审核与政策: 围绕 AI 工具的使用和管理政策的伦理担忧,特别是 Claude 3 Opus 和 GPT-4o 的审核过滤器 (Anthropic Policy Link)。
- 开源与专有模型: 讨论经常比较 Falcon 2 等开源优势与专有模型的限制,这影响了它们的可访问性和修改。
第一部分:Discord 高层级摘要
OpenAI Discord
GPT-4o 隆重登场:OpenAI 发布了新模型 GPT-4o,部分功能提供免费访问,Plus 用户则享有额外权益,包括更快的响应速度和更广泛的功能。GPT-4o 的独特之处在于能够实时处理音频、视觉和文本,标志着多模态应用迈出了重要一步;目前文本和图像输入已可用,语音和视频功能将很快推出。了解更多关于 GPT-4o 的信息。
Claude 摘得复杂任务桂冠:在社区内部,与 GPT-4o 相比,Claude Opus 被认为在处理复杂、长篇推理方面更具优势,尤其是在处理大量原始内容时。用户对 Google 和 OpenAI 未来增强功能(包括更宽的上下文窗口和先进的语音能力)寄予厚望。
自定义 GPTs 等待记忆功能升级:备受期待的自定义 GPTs 跨会话上下文记忆功能仍在开发中,官方保证一旦发布,创作者将可以为每个 GPT 配置记忆功能。目前 GPT-4o 的状态是速度提升和 API 性能稳定,尽管 Plus 用户受益于更高的消息限制,但所有人都在热切期待其在自定义 GPT 模型中的承诺集成。
提示工程 (Prompt Engineering) 暴露模型缺陷:用户在引导 GPT-4o 执行创意和空间感知任务时面临挑战,指出其在迭代图像生成方面存在困难,并提到 Gemini 1.5 安全过滤器带来的特定内容审核问题。尽管 GPT-4o 加快了响应速度,但偶尔在理解和执行上出现失误,表明根据用户反馈进行迭代改进仍有空间。
寻求受监控的 ChatGPT 克隆版:一名成员询问如何创建一个类似 ChatGPT 的应用程序,允许组织使用 GPT-3.5 模型对消息进行监控。这反映了在正式生态系统中对可定制和可控 AI 工具日益增长的需求。
Perplexity AI Discord
GPT-4 的 Token 之争:围绕 GPT-4 的 Token 容量存在争论,澄清指出 GPT-4 较大的上下文窗口适用于特定模型,如拥有 128K Token 上下文窗口的 GPT-4o。一些用户正在深入研究 GPT-4o 的功能,注意到其极高的速度和卓越的性能,并分享了其实时推理的 视频示例。
政策变动引发热议:Anthropic 修订后的 Opus 服务条款将于 6 月 6 日生效,由于禁止创建 LGBTQ 内容等限制,在成员中引起了骚动。政策详情可见分享的 Anthropic 政策链接。
Claude 坚守阵地:尽管 GPT-4o 备受关注,但对于一些用户来说,Claude 3 Opus 仍然是文本摘要和类人回答的首选,尽管存在成本和使用限制方面的担忧。
Perplexity 的新实力派:用户正在测试 GPT-4o 在 Perplexity 工具中的集成,强调其高速、深度的响应。Pro 版本每天允许 600 次查询,与其 API 可用性相呼应。
API 配置难题:关于 Perplexity API 设置的讨论浮出水面,一位用户询问了使用 llama 模型处理长输入时的超时问题。一名成员指出 llama-3-sonar-large-32k-chat 的对话模型针对对话上下文进行了微调,但尚未就最佳超时设置达成共识。
Unsloth AI (Daniel Han) Discord
LLaMA 指令微调建议:根据用户讨论,对于在小数据集上进行微调,如果性能不理想,在考虑基座模型(base model)之前,建议先从 Llama-3 的指令模型(instruction model)开始。他们建议通过迭代来找到最适合你场景的方案。
ThunderKittens 超越 Flash Attention 2:据社区讨论,ThunderKittens 在速度上超过了 Flash Attention 2,有望实现更快的推理速度,并可能在训练速度上取得进展。代码已在 GitHub 上发布。
Typst 的合成数据集构建:为了在 “Typst” 上有效地微调模型,工程师们提议合成 50,000 个示例。生成大规模合成数据集这一艰巨任务被视为取得进展的基础步骤。
Unsloth AI 上的多模态模型扩展:Unsloth AI 预计即将支持多模态模型,包括预计下周推出的多 GPU 支持,为实现新的强大 AI 能力奠定基础。
为 Unsloth AI 喝彩:AI 社区庆祝 Unsloth AI 在 Hugging Face 上的模型下载量突破一百万次,这标志着一个被用户认可的里程碑,反映了社区的积极参与和支持。
Latent Space Discord
-
苹果旨在 AI 集成,对 Google 持观望态度:在技术讨论中,关于苹果传闻与 OpenAI 达成协议将 ChatGPT 引入 iPhone 的猜测不断,引发了关于本地模型与云端模型方案的对比。工程师们对这种集成的可行性表示怀疑,一些人怀疑苹果是否有能力在手持设备上高效运行重量级模型。
-
Falcon 2 翱翔群雄之上:Falcon 2 模型因其性能获得赞赏,它拥有开源、多语言和多模态能力,在性能上超越了 Meta 的 Llama 3 8B 等竞争对手,仅略微落后于 Google Gemma 7B 的基准测试。Falcon 2 既开源又在多个领域表现优异的消息引发了广泛关注 Falcon LLM。
-
GPT-4o 引起轰动:围绕 OpenAI 最新模型 GPT-4o 的讨论充满了惊叹和抱怨,该模型展示了更快的响应速度和引人注目的免费聊天功能。尽管对其“出口成章”的快速能力感到兴奋,但批评主要集中在其品牌命名和性能问题上——特别是延迟。
-
语音遇上视觉,开启 AI 交互新篇章:ChatGPT 语音和视觉集成的演示引起了关注,展示了实时、情感敏感的 AI 交互。社区对演示能力的真实性存在疑虑,试图探究此类展示背后潜在的运行机制。
-
API 期待与竞争格局:讨论围绕访问 GPT-4o 的 API 展开,工程师们对其迅捷的性能充满期待。暗流反映了更宏大的 AI 战场,Google 和其他玩家正在对 OpenAI 凭借 GPT-4o 发起的攻势做出反应——而社区正在观察,等待着在新的 API 上大显身手。
Nous Research AI Discord
- LLM 难以突破 8k Token:一些成员反映在生成超过 8k Token 的连贯输出时,Llama 3 70b 面临挑战。虽然已取得显著成功,但在处理更大 Token 流程方面仍有改进空间。
- 体验 GPT-4o 的起伏:OpenAI GPT-4o 模型发布后,服务器内评价褒贬不一。一些人注意到其独特能力,包括实时多模态功能和中文 Token 处理,而另一些人则审视其局限性,特别是图像编辑模式和成本效率。
- 远程自动化:比你想象的更棘手:社区分享了在远程桌面协议 (Remote Desktop Protocol) 内运行软件自动化的经验和想法,展示了 AI 领域的复杂性。从解析文档对象模型 (DOM) 到逆向工程软件,对话展示了自动化过程中复杂的导航和决策路径。
- 租用还是购买:LLM 的 GPU 配置选择:社区针对租用与购买用于大语言模型 (LLMs) 的 GPU 配置的优缺点进行了热烈辩论。对话深入探讨了成本效益、隐私考量和硬件规格,并广泛探索了 GPU 供应商和配置方案。
- GPT-4o 多模态功能揭秘:社区成员深入交流了该模型的多模态特性,特别是音频输入的 whispering latents 和非英语语言的 Token 处理。社区还指出了理解最长中文 Token 的资源以及 GPT-4o 等模型中分词器 (tokenizer) 的改进。
- WorldSim 图像大放异彩:WorldSim 用户公开赞赏该程序的创造力。一位成员甚至提到考虑纹一个受该艺术作品启发的纹身,表达对 WorldSim 视觉效果的认可。
- IBM/Redhat 推动 LLM 更进一步:IBM/Redhat 扩展 LLM 知识库和能力的方案成为热点。他们的项目以连续体形式吸收新信息,实时应用而非在每次知识扩展后进行完整重训练,为模型的增量演进提供了一种创新方法。
- 研究人员寻求人类/LLM 文本对进行模型对比评估:讨论中提出了提取针对相同 Prompt 的 ‘human_text’ 和 ‘llm_text’ 对比数据集的需求,旨在对 LLM 响应与人类语言输出进行更深层次的比较和评估。
- 通过开源项目贡献丰富 AI 知识:社区再次重申了向 IBM/Redhat 的 Granite 和 Merlinite 等开源项目进行贡献的可行性和重要性,这是迈向技术变革未来开源协作的一步。
Stability.ai (Stable Diffusion) Discord
- Stability.ai 的 CEO 变动:讨论集中在 CEO Emad 离职后 Stability AI 不确定的未来,以及 SD3 模糊的发布状态,包括它是否可能变成付费服务。
- Stable Diffusion 的 GPU 大对决:工程师们辩论了运行 Stable Diffusion 的最佳 GPU,达成共识认为显存 (VRAM) 更大的 GPU 更合适,并分享了一份详尽的 风格和标签指南。
- 使用 BrushNet 提升局部重绘 (Inpainting) 效果:推荐通过 ComfyUI BrushNet 的 GitHub 仓库 集成 BrushNet,利用 brush 和 powerpaint 功能组合来改进 Stable Diffusion 的局部重绘效果。
- 保持 AI 角色一致性的策略:维持 AI 角色一致性的技术受到热议,重点在于 LoRA 和 ControlNet,以及创建详细 角色卡 (character sheets) 的资源。
- 科技巨头 vs. 开源社区模型:谷歌的 Imagen 3 引发了讨论,反映出人们对 SD3 等开源模型的期待与偏好,这源于社区的可访问性。
LM Studio Discord
-
微调与 VPN 变通方案:工程师确认,如果存储在 Hugging Face 上的微调模型(fine-tuned model)是公开的且使用 GGUF 格式,则可以通过 LM Studio 访问。此外,针对 Hugging Face 被屏蔽导致的网络错误,建议使用 VPN,并指出特定地区的限制,推荐使用 IPv4 连接。
-
模型性能讨论:社区讨论了模型合并策略,例如应用 unsloth 的方法来合并和升级 llama3 和/或 mistral。此外,还围绕模型的不同量化级别(quant levels)展开了辩论,强调低于 Q4 的任何级别都被认为是低效的。
-
软件兼容性与硬件:讨论指出了一些不兼容情况,例如 Command R 模型在 Apple M1 Max 系统上的输出问题,以及 RX6600 GPU 的 ROCM 限制导致 LM Studio 和 Ollama 出现问题。在硬件方面,讨论倾向于推荐 Nvidia 3060ti 作为 LM Studio 应用中性价比最高的 GPU,并强调了显存(VRAM)速度对高效 LLM 推理的重要性。
-
LM Studio 功能集与支持:有关于 LM Studio 中多模态(multimodal)功能的提问,特别是关于与标准模型功能一致性的问题。此外,用户表达了对 Intel GPU 支持的兴趣,一名 Intel 员工提议协助进行 SYCL 集成,预示着潜在的性能提升。
-
反馈、期望与未来方向:对 LMS 目前的实时学习(realtime learning)能力存在批评性反馈,用户要求至少提供用于逐行训练的差异文件(differential file)。另一位用户建议部署更大的模型,如 command-r+ 或 yi-1.5,以获得更好的效果。
-
部署考量:一名成员评估了 Meta-Llama-3-8B-Instruct-Q4_K_M 模型相对于 GPU 而言较高的 RAM 占用,并在成本效益的背景下权衡了 AWS 和商业 API 之间的部署选项。考虑到模型大小和参数的显著差异,他们比较了使用 IaaS 提供商与订阅 LLMaaS 的潜在成本节省。
HuggingFace Discord
YOCO 降低 GPU 需求:YOCO 论文介绍了一种新的 decoder-decoder 架构,该架构在保持全局注意力(global attention)能力的同时,降低了 GPU 内存占用并加快了 prefill 阶段。
当 NLP 与 AI 故事创作碰撞:研究人员正从 Awesome-Story-Generation GitHub 仓库中获取资源,为 AI 故事生成的综合研究做出贡献,例如旨在增加故事复杂性的 GROVE 框架。
Stable Diffusion 进军 DIY 领域:一门超过 30 小时的 Fast.ai 课程正在教授从零开始构建 Stable Diffusion,该课程与 Stability.ai 和 Hugging Face 的业内人士合作,同时还讨论了 sadtalker 安装以及 Transformer Agent 的实际用途。
OCR 质量前沿:一系列 OCR 质量分类器展示了使用小型模型区分清晰文档和噪声文档的可行性。
Stable Diffusion 与 YOLO:现已提供一份使用 Diffusers 的 HuggingFace Stable Diffusion 指南,讨论围绕使用 ResNet18 的 YOLOv1 实现展开,重点在于平衡数据质量和数量以提升模型性能。
前沿领域的复杂情绪:GPT-4o 的发布在社区内引起了不同的反应,引发了关于区分 AI 与人类的担忧,同时成员们报告了在创建自定义分词器(tokenizer)和专注于丰富示例提示(example-rich prompts)的 NLP 策略方面的不同成功经验。
OpenRouter (Alex Atallah) Discord
新型多模态模型席卷 OpenRouter:OpenRouter 扩大了其阵容,推出了支持文本和图像输入的 GPT-4o 以及 LLaVA v1.6 34B。此外,名单现在还包括 DeepSeek-v2 Chat、DeepSeek Coder、Llama Guard 2 8B、Llama 3 70B Base、Llama 3 8B Base,其中 GPT-4o 的最新版本日期为 2024 年 5 月 13 日。
Beta 测试火热进行中:一个高级研究助手和搜索引擎正在进行 Beta 测试,提供包括 Claude 3 Opus 和 Mistral Large 等领先模型的付费访问权限,平台还分享了用于试用的 促销代码 RUBIX。
GPT-4o 的热情与审视:关于 GPT-4o API 定价(每 1M tokens $5/15)的热烈讨论引发了兴奋,而对其多模态能力的推测也激起了好奇心,评论者指出 OpenAI 的 API 缺乏原生的图像处理能力。
社区对 OpenRouter 故障的反馈:用户反映了 OpenRouter 的技术困难,指出了诸如空响应以及来自 MythoMax 和 DeepSeek 等模型的错误。Alex Atallah 澄清说,OpenRouter 上的大多数模型都是 FP16,只有少数是量化(quantized)后的例外。
通过社区工具建立工程连接:一个由社区开发的用于筛选 OpenRouter 模型的工具受到了好评,并讨论了整合 ELO 分数和模型添加日期等额外指标的建议。提供了相关资源的链接,如 OpenRouter API Watcher。
Interconnects (Nathan Lambert) Discord
GPT-4o 领跑前沿:OpenAI 的 GPT-4o 树立了 AI 能力的新标杆,特别是在推理和编程方面,主导了 LMSys 竞技场,并由于 tokenizer 更新 实现了 token 容量翻倍。它的多模态威力也得到了展示,包括潜在的唱歌能力,引发了关于 AI 演进及其竞争格局的兴趣和辩论。
PPO 框架下的 REINFORCE:AI 社区讨论了来自 Hugging Face 的一个新 PR,该 PR 将 REINFORCE 定位为 PPO 的子集,详见相关论文,展示了在强化学习领域的积极贡献。
AI 的银幕映射现实担忧:社区内的对话与电影《她》(Her)产生共鸣,强调了 AI 交互如何被视为平庸或深远。这些讨论与对 AI 领导地位和技术人性化的看法紧密相连。
长期 AI 治理初现端倪:受 John Schulman 的演讲 启发,前瞻性对话暗示项目管理机器人(PRMs)在指导长期 AI 任务中发挥着关键作用。
评估 AI 评估:一篇详细的博客文章引发了关于大语言模型(LLM)评估的可访问性和未来的思考,讨论了从 MMLU 基准测试到 A/B 测试的各种工具及其对学术界和开发者的影响。
Eleuther Discord
MLP 可能夺冠:有传言称 基于 MLP 的模型 可能会在视觉任务中超越 Transformers,一种新的混合方法带来了激烈的竞争。一项特定的 研究 强调了 MLP 的效率和可扩展性,尽管对其复杂性仍有一些疑问。
搞定初始化:关于神经网络(尤其是 MLP)中 初始化方案 关键性的讨论浮明,有建议认为初始化的创新可以带来巨大的改进。有人提出了通过图灵机创建初始化的想法,探索 Gwern 网站 上提到的合成权重生成的前沿领域。
模拟初始化(Mimetic Initialization)作为游戏规则改变者:一篇推广 模拟初始化 的论文出现,主张该方法能提升处理小数据集的 Transformers 的性能,从而获得更高的准确率并缩短训练时间,详见 MLR 论文集。
可扩展性探索继续:深入讨论了 MLPs 在各种硬件上的 Model FLOPs Utilization (MFU) 是否能超越 Transformers,暗示即使是微小的 MFU 提升也可能在大规模应用中产生共鸣。
思考 NeurIPS 投稿:有人呼吁进行最后的 NeurIPS 投稿,一名成员表示对类似于 Othello 论文 的话题感兴趣。另一场讨论询问了模型压缩对专门特征的影响及其与训练数据多样性的关系。
Modular (Mojo 🔥) Discord
新官上任:Mojo 编译器开发升温:工程讨论显示了对贡献 Mojo 编译器 的浓厚兴趣,尽管它尚未开源。编译器辩论还揭示了它是用 C++ 编写的,而在 Mojo 中重建 MLIR 的愿景激发了贡献者的好奇心。
MLIR 与 Mojo 结盟:剖析了 Mojo 与 MLIR 之间的集成特性,强调了 Mojo 与 MLIR 的兼容性如何能在未来实现自托管编译器。现在鼓励向 Mojo 标准库提交贡献,Modular 工程师 Joe Loser 的 操作视频 阐明了这一过程。
前沿日程:宣布了 5 月 20 日即将举行的 Mojo 社区会议 详情,旨在让开发者、贡献者和用户关注 Mojo 的发展轨迹。分享了一份有用的 会议文档 以及通过 社区会议日历 添加活动的选项以便协调。
夜间是代码的好时光:mojo 的 Nightly 版本发布现在更加频繁,这是一个受欢迎的积极更新计划,旨在将“每晚发布 Nightly”从梦想变为现实。然而,嵌套数组中的段错误(segfault)问题仍存争议,并且有讨论调整发布频率以避免用户对编译器版本的混淆。
编码难题与编译器对话:在数字长廊中,开发者们讨论了从如何在 Mojo 中将参数限制为浮点类型(建议使用 dtype.is_floating_point())到 Python 的可变默认参数,以及使用 FFI 从 Mojo 调用 C/C++ 库等话题。关于 Mojo 中的 FFI 主题的更多细节通过 GitHub 链接分享。
CUDA MODE Discord
ZeRO-1 扩展提升训练吞吐量:实现 ZeRO-1 优化将单 GPU batch size 从 4 增加到 10,并将训练吞吐量提高了约 54%。有关合并及其效果的详细信息可以在 PR 页面查看。
ThunderKittens 引发关注:讨论中提到了对 HazyResearch/ThunderKittens 的兴趣,这是一个 CUDA tile primitives 库,因其在优化 LLM 方面的巨大潜力而备受关注,并被拿来与 Cutlass 和 Triton 工具进行比较。
Triton 通过 FP 增强获得提升:Triton 的更新包括 FP16 和 FP8 的性能改进,如基准测试数据所示:“Triton [FP16]” 在 N_CTX 为 1024 时达到 252.747280,“Triton [FP8]” 在 N_CTX 为 16384 时达到 506.930317。
CUDA 流程简化,但仍存疑问:关于在 PyTorch 中集成自定义 CUDA kernel,分享了一些资源,包括一个解决基础问题的 YouTube 讲座,同时也指出了 clangd 解析 .cu 文件以及 cuSPARSE 中函数开销(overhead)等问题。
精细化 CUDA CI 流水线:辩论了在持续集成(CI)中进行 GPU 测试的必要性,并推介了 GitHub 最新的 GPU runner 支持,认为这是构建稳健流水线所急需的更新。
LlamaIndex Discord
-
通过新用例玩转 Llama:一套新的 cookbook 展示了 Llama 3 的七种不同用例,详见最近黑客松的庆祝帖子;cookbook 可在此处访问。
-
GPT-4o 零日集成:随着 GPT-4o 从发布之初就获得 Python 和 TypeScript 的支持,开发者们热情高涨,此处详细说明了通过
pip安装的指令,并强调了其多模态能力。 -
多模态奇迹与 SQL 速度:GPT-4o 的一个引人注目的多模态演示已上线,同时透露 GPT-4o 在 SQL 查询效率上超过了 GPT-4 Turbo;演示见此处,性能详情见此处。
-
融合 LlamaIndex 元数据与错误处理:在讨论中,明确了 metadata filtering 可以由 LlamaIndex 管理,但对于 URL 等特定内容需要手动包含;此外,还建议通过在解析前检查网络响应来排查
Unexpected token U错误。 -
AI 求职变得更智能:一个使用 LlamaIndex 和 MongoDB 构建 AI 驱动求职助手的教程和仓库已发布,旨在通过 Retrieval-Augmented Generation(RAG)提升求职体验,文档见此处。
LAION Discord
- Falcon 2 超越 Llama 3:Falcon 2 11B 模型在 Hugging Face 排行榜上超越了 Meta 的 Llama 3 8B,展示了多语言和 vision-to-language 能力,并可与 Google 的 Gemma 7B 媲美。
- GPT-4o 打破响应壁垒:OpenAI 发布了 GPT-4o,以实时通信和视频处理著称;该模型在降低成本的同时提升了 API 性能,达到了人类的对话速度。
- RAG 遇上图像建模:围绕 RAG 与图像生成模型集成的讨论重点介绍了用于文本驱动图像转换的 RealCustom,并提到了 Stable Diffusion 采用 CLIP 图像 embedding 代替文本。
- 混元 DiT:腾讯的中文艺术专家:腾讯推出了 HunyuanDiT,该模型声称在中文文本生成图像方面达到 state-of-the-art 状态,尽管体积较小,但证明了其对 prompt 的忠实度。
- AniTalker 用音频驱动肖像动画:AniTalker 框架发布,支持利用提供的音频从静态图像创建逼真的说话面孔,捕捉细微的面部表情,而不仅仅是口型同步。
OpenInterpreter Discord
GPT-4o 超过前代:社区爱好者注意到 GPT-4o 不仅速度更快(达到 100 tokens/sec),而且比之前的版本更具成本效益。人们对其与 Open Interpreter 的集成特别感兴趣,并提到使用命令 interpreter --model openai/gpt-4o 运行非常流畅。
Llama 望尘莫及:在体验了 GPT-4 的性能后,一位成员分享了对 Llama 3 70b 的不满,同时也对 OpenAI 的高昂成本表示担忧,仅一天就花费了 20 美元。
苹果的沉默可能推动开源 AI:关于苹果是否会将 AI 集成到 MacOS 的猜测层出不穷,一些成员对此表示怀疑,并更倾向于开源 AI 解决方案,这暗示了社区中 Linux 使用率可能会上升。
等待 O1 的下一次飞行:对某未命名项目的 TestFlight 发布充满期待,成员们分享了关于在 Xcode 中设置测试环境和编译项目的建议与说明。
迈向 AGI 之路:关于 Artificial General Intelligence (AGI) 进展的热烈讨论正在进行,参与者交流了想法和资源,包括一个揭示该前沿领域的 Perplexity AI 解释。
LangChain AI Discord
ChatGPT 动摇的信念:工程师们注意到 ChatGPT 现在有时会自相矛盾,偏离了以往回答的一致性。人们对该工具在维持稳定推理逻辑方面的可靠性表示担忧。
LangChain 故障排除仍在继续:在 LLCHAIN 弃用后,工程师们已转向使用 from langchain_community.chat_models import ChatOpenAI,但在流式传输和顺序链(sequential chains)方面面临新挑战。LangChain Agent 的调用时间较慢(尤其是处理大型输入时),引发了关于利用并行处理来缩短处理时间的讨论。
AI/ML GitHub 仓库备受关注:社区交流了最喜欢的 AI/ML GitHub repositories,llama.cpp 和 deepspeed 等项目被提及。
Socket.IO 加入战场:一位工程师贡献了关于使用 python-socketio 实时流式传输 LLM responses 的指南,演示了处理流式传输和确认(acknowledgments)的客户端-服务器通信。
AI 风格的项目展示:分享的项目包括一篇关于 Plug-and-Plai 集成的 Medium 文章、一个利用 Streamlit 和 GPT-4o 的 多模态聊天应用、一个针对 ChromaDB RAG application 的生产级扩展查询,以及一个正在开发中的 Snowflake 成本监控和优化工具。
聊天功能赋能博客交互:分享了一篇讨论如何使用 Retrieval Augmented Generation (RAG) 在博客内容上实现活跃对话的文章,进一步激发了在网站上集成高级 AI 聊天功能的兴趣。
OpenAccess AI Collective (axolotl) Discord
博客平台对决:用户辩论了 Substack 与 Bluesky 在博客需求方面的优劣,结论是虽然 Bluesky 支持线程(threads),但缺乏全面的博客功能。
降低 AI 算力消耗:重点在于最小化 AI compute usage,分享了指向 Based 和 FlashAttention-2 等倡议的链接,这些技术正在为更高效的 AI 运行铺平道路。
依赖项困境:成员们对过时的依赖项(包括 peft 0.10.0 等)感到苦恼,并正在手动调整它们以实现兼容性,同时无奈地呼吁通过 GitHub Pull Request 来纠正这种情况。
CUDA 难题:有报告称一名成员在 8xH100 GPU 环境中遇到 CUDA errors,后来通过切换到 社区 axolotl 云镜像 缓解了该问题。
QLoRA 模型合并与持续训练:出现了关于在不损失精度的情况下将 QLoRA 与 base models 集成的咨询和讨论。此外,对话集中在如何使用 ReLoRACallback 从 checkpoints 恢复训练的机制上,正如 OpenAccess-AI-Collective axolotl 仓库 中所记录的那样。
Datasette - LLM (@SimonW) Discord
语音助手不全是笑声:技术社区对语音助手的“咯咯笑”功能感到困惑,认为在专业用途中该功能不合适且容易让人分心。通过重新表述命令等变通方法可以抑制这一怪癖。
对 GPT-4o 书籍识别任务的评价褒贬不一:GPT-4o 枚举书架上显示的书籍的能力受到了褒贬不一的评价,准确率仅为 50%,尽管其速度和价格极具竞争力,但仍有改进空间。
AGI 炒作引发争论:人们对即将到来的 Advanced General Intelligence (AGI) 持怀疑态度,因为从 GPT-3 到 GPT-4 的飞跃中观察到了边际收益递减,而 GPT-5 的热度掩盖了当前模型的改进。
GPT-4 的长期影响仍不明朗:对 GPT-4 及其迭代版本的长期影响预测仍处于推测阶段,工程社区仍在探索其全方位的潜力。
Simon 推特发布 LLM 见解:Simon W 的 Twitter 更新可能是讨论大语言模型最新发展和挑战的有力催化剂。
tinygrad (George Hotz) Discord
-
tinygrad 的 CUDA 问题:关于在 Nvidia 4090 上使用
CUDA=1和PTX=1的咨询,在出现 PTX 生成错误后,建议将 Nvidia 驱动更新至 550 版本。 -
tinygrad 中 GNN 的潜力:将 tinygrad 中图神经网络 (GNNs) 的实现与 PyG 方案进行了比较,并提到了一个可能具有平方时间复杂度的 CUDA kernel,提供了 GitHub 代码以供参考。
-
tinygrad 中的聚合烦恼:一位用户分享了一个用于特征聚合的 Python 函数 test_aggregate.py,并强调了在反向传播过程中使用高级索引和
where调用的困难;masking 和einsum函数成为了可能的解决方案。 -
高级索引问题:tinygrad 的高级功能如
setitem和where不支持高级索引(使用列表或张量),引发了对替代方法的讨论,包括使用 masking 和 einsum。 -
tinygrad 的卷积困扰:在 tinygrad 中优化 conv2d 反向传播的尝试遇到了 scheduler 和 view 变化的障碍,引发了关于重新实现 conv2d 是否能解决形状兼容性问题的讨论。
DiscoResearch Discord
-
德语 TTS 需要输入:一名成员呼吁协助创建一个提供高质量播客、新闻和博客的德语 YouTube 频道列表,用于训练德语文本转语音 (TTS) 系统。
-
MediathekView 作为 TTS 数据源:参与者讨论了利用 MediathekView 获取德语媒体的实用性,该工具能够下载字幕文件,被推荐用于策划 TTS 训练内容。
-
探索 MediathekView 数据下载和 API:讨论中提到整个 MediathekView 数据库可能可以下载,并有 JSON API 用于内容访问;提到了相关工具的 GitHub 仓库。
-
新德语 Tokenizer 受到推崇:一名成员关注了 “o200k_base” Tokenizer 的效率,它处理德语文本所需的 Token 比之前的 “cl100k_base” 更少,并将其与 Mistral 和 Llama3 等已知 Tokenizer 进行了对比,但未分享该观点的具体链接。
-
分享 Tokenizer 研究和训练资源:对 Tokenizer 研究感兴趣的人被引导至 Tokenmonster,这是一个非贪婪的子词 Tokenizer 和词汇训练工具,兼容多种编程语言。
Cohere Discord
社区等待支持:Cohere 公会的成员报告了支持响应延迟的问题,一名用户在 <#1168411509542637578> 和 <#1216947664504098877> 中表达了这一诉求。官方回复承诺会有活跃的支持人员,并请求提供更多细节以协助解决。
Command R RAG 备受瞩目:一位工程师对 Command R 的 RAG (Retriever-Augmented Generation) 能力留下了“极其深刻的印象”,称赞其即使在处理冗长的源材料时也具有极高的性价比、精确度和保真度。
项目分享中的协作呼吁:在 #project-sharing 频道中,成员 Vedang 表示有兴趣与另一位工程师 Asher 在类似项目上进行合作,突显了社区的协作精神。
成员传播其 Medium 影响力:Amit 分享了一篇 Medium 文章,深入探讨了如何通过 Unstructured API 使用 RAG,旨在从 PDF 中提取结构化内容——这对于处理文档处理的工程师来说可能非常有用。
表情符号问候被视为噪音:随意的问候和表情符号(如 “<:hammy:981331896577441812>”)被认为是非必要的,并从公会的专业工程讨论中剔除。
LLM Perf Enthusiasts AI Discord
- GPT 竞争升温:工程师们正在推测使用 Claude 3 Haiku 和 Llama 3b Instruct 进行自动评分和实体提取任务的可行性;争论还延伸到在这些应用中使用 Pydantic 模型 的效率。
- 限制 AI 的创造力以提高精确度:讨论内容包括在 vllm 或 sglang 中利用 outlines 进行 约束采样 (constrained sampling) 的潜在好处,以帮助实现精确的实体匹配,从而获得更受控的输出。
- GPT-4o 更新发布:OpenAI 的春季更新是论坛的热门话题,其中包含一段展示 ChatGPT 更新的 新 YouTube 视频。
- 名人与 AI 的碰撞:工程师们分享了对 OpenAI 选择 Scarlett Johansson 作为 GPT-4o 语音的看法,这标志着名人与人工智能之间的界限日益模糊。
Skunkworks AI Discord
- 引入 Guild Tags:自 5 月 15 日起,Guild Tags 将出现在用户名旁,以显示专属 Guild 的成员身份;管理员指出,AutoMod 将监控这些标签。
- Guilds 提供专属社区空间:Guilds 代表专属社区服务器,目前可用性有限,管理员无法手动将服务器添加到此精选功能中。
Alignment Lab AI Discord
- Fasteval 告别:Fasteval 项目 已停止维护,创建者正在寻找能在 GitHub 上接管该项目的人。除非所有权发生转移,否则与该项目相关的频道将被归档。
AI Stack Devs (Yoko Li) Discord
- AK 之谜再次浮现:来自 angry.penguin 的消息提到 AK 回来了,暗示名为 AK 的同事或项目回归。文中未提供具体背景和重要性。
MLOps @Chipro Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
第 2 部分:详细的频道摘要和链接
OpenAI ▷ #annnouncements (2 条消息):
-
OpenAI 发布 GPT-4o 并提供免费访问:OpenAI 发布了新的旗舰模型 GPT-4o,并推出了免费访问浏览、数据分析和记忆等功能的权限(有一定限制)。Plus 用户 将获得高达 5 倍的额度限制,并能最早体验新功能,包括 macOS 桌面应用以及先进的语音和视频功能。
-
GPT-4o 发布,具备实时多模态能力:新型 GPT-4o 模型能够跨音频、视觉和文本进行实时推理,拓宽了其应用范围。文本和图像输入从今天开始提供,语音和视频功能将在未来几周内推出。
OpenAI ▷ #ai-discussions (1085 messages🔥🔥🔥):
-
语音模式故障引发更新希望:多名用户报告 ChatGPT 应用中的语音功能消失,引发了这可能预示着即将更新的猜测。一位用户提到,“我重启了应用,它就不见了,笑死”,而另一位用户推测他们可能正在集成新的生成式语音模型。
-
Google Keynote 反响褒贬不一:Google 最近的 I/O 大会重点介绍了 Gemini 1.5 和其他进展,收到的评价褒贬不一。虽然一些用户称赞其与 Android 和 Google Suite 的集成,但其他人认为与 OpenAI 更简洁的演示相比,它显得冗长且平庸。
-
GPT-4o 可用性困惑:用户对 GPT-4o 的可访问性和功能进行了辩论,表明其发布存在一些困惑。尽管观点不一,但普遍认为该模型已在 iOS 上可用,并提供了更高的 Token 限制。
-
Claude 卓越的长文本推理能力:成员们讨论了 Claude Opus 在处理复杂的长篇任务方面的卓越表现,特别是优于 GPT-4o。一位成员指出,“如果我给 Opus 喂 200 页的原创故事……GPT 和 Gemini 根本处理不了。”
-
对未来 AI 更新的迫切期待:社区表达了对 Google 和 OpenAI 预期更新的渴望。扩展上下文窗口、新的语音功能和文本转视频 AI 等功能尤其受到期待。
- Agent Smith GIF - Agent Smith Matrix - Discover & Share GIFs:点击查看 GIF
- Mrbeast Ytpmv GIF - Mrbeast Ytpmv Rap Battle - Discover & Share GIFs:点击查看 GIF
- Google Keynote (Google I/O ‘24):I/O 时间到了!收看来自 Google 的最新消息、公告和 AI 更新。如需观看带有美国手语 (ASL) 翻译的主旨演讲...
OpenAI ▷ #gpt-4-discussions (261 messages🔥🔥):
-
针对每个 GPT 的记忆功能尚未推出:一位成员询问了自定义 GPT 的跨会话上下文记忆功能,另一位用户澄清该功能尚未推出,并链接到了 OpenAI 帮助文章。他们确认,一旦可用,记忆功能将针对每个 GPT 独立存在,并可由创建者自定义。
-
GPT-4o 提升了速度和 API 使用体验:讨论强调 GPT-4o 明显比 GPT-4 快,成员们注意到尽管输出 Token 限制相同,但性能有所提升。官方公告和基准测试详情可以在这里查看。
-
自定义 GPT 与模型更新:有关于 GPT-4o 与自定义 GPT 集成的问题,共识是现有的自定义 GPT 目前未使用 GPT-4o。有人指出,预计会有更多更新,希望能很快在自定义 GPT 中使用。
-
Plus 和免费层级的功能限制:成员们讨论了 GPT-4o 的使用限制,Plus 用户每 3 小时允许发送 80 条消息,而免费层级用户的限制预计会低得多,不过具体细节会根据需求而变化。
-
语音和多模态功能正在推出:GPT-4o 的新音频和视频功能备受期待,这些功能将首先通过 API 提供给选定的合作伙伴,然后在未来几周内提供给 Plus 用户。详细信息和推出计划可以在 OpenAI 的公告中找到。
OpenAI ▷ #prompt-engineering (51 messages🔥):
-
Gemini 1.5 中的审核过滤器难倒用户:一位用户报告称,像“romance package”这样的特定关键词会导致他们的应用程序失败,原因似乎是意外触发了审核过滤器。尽管更改了默认设置并生成了新的 API Key,问题仍然存在,引发了关于安全设置和语法错误的讨论。
-
GPT-4o 在创意方面表现不佳:用户报告称,虽然 GPT-4o 比 GPT-4 更快,但在处理写作辅助等创意任务的 Prompt 时表现挣扎。它经常只是重复草稿内容,而不是提供智能修改,这表明其理解能力可能存在问题。
-
使用 GPT-4o 进行 Prompt 测试:另一位用户建议使用 GPT-4 和 GPT-4o 测试 Prompt,特别是像 “The XX Intro” 和 “Tears in Rain” 这样的歌曲,以比较感官输入描述。这种实践方法旨在揭示每个模型在处理和描述感官信息方面的差异。
-
使用 GPT-4o 生成特定图像视角的挑战:一位用户在让 GPT-4o 生成平台游戏楼层的详细横截面侧视图时遇到困难。该模型经常产生错误的透视或简单的正方形,引发了关于模型局限性以及是否需要使用 Dall-E 等工具进行迭代引导的讨论。
-
与 Dall-E 和 GPT-4o 的迭代反馈:有人指出,虽然 GPT-4o 无法“看到” Dall-E 创建的图像,但用户可以通过将输出反馈给模型来迭代引导它。这个过程虽然费力,但可以帮助获得更准确的结果,尽管模型在需要空间意识和图像裁剪的任务上表现挣扎。
OpenAI ▷ #api-discussions (51 messages🔥):
- Gemini 1.5 奇怪的审核过滤器问题:一位用户报告称,尽管没有主动封禁,但其应用程序在处理与“浪漫套餐(romance packages)”相关的请求时持续失败。另一位成员建议显式禁用安全设置并通过不同工具进行验证,但问题仍未解决。
- 关于 GPT-4o 性能的讨论:用户注意到 GPT-4o 速度更快,但与 GPT-4 相比,理解特定任务的能力较弱。成员们提到在获取创意内容和准确修订方面存在困难,模型经常重复用户的输入。
- 分享感官描述的 Prompt:一位成员鼓励其他人通过使用如 “Provide detailed sensory input description of the “The XX Intro” song” 的 Prompt 来对比 GPT-4 和 GPT-4o,以观察输出差异。这样做是为了分析模型处理器乐歌曲感官描述的能力。
- 使用 AI 生成特定艺术作品的挑战:另一位用户强调了使用 GPT-4 和 GPT-4o 为平台游戏生成横截面图像的困难。尽管进行了多次尝试并调整了 Prompt,模型经常产生不准确或不理想的视图。
- 使用 AI 进行图像调整的迭代过程:另一个讨论集中在利用 DALL-E 和模型工具迭代地创建和调整图像。用户分享了逐步引导模型以实现更准确图像输出的经验,尽管模型在“看到”和自我评估作品方面存在局限。
OpenAI ▷ #api-projects (2 messages):
- ChatGPT 克隆咨询:一位用户询问社区是否有人使用 3.5 模型创建了或可以创建一个 类似 ChatGPT 的应用程序。独特的需求是用户发送和接收的消息可以被组织监控。
Perplexity AI ▷ #general (993 messages🔥🔥🔥):
-
32k vs 128K Token 争议:人们质疑 GPT-4 是否真正支持 32k Token,有人断言 GPT-4 的大 Context Window 主要针对 GPT-4o 和 Sonar Large 等特定模型。此外,现在可用的 GPT-4o 提供 128K Context Window,远超 32k。
-
GPT-4o 推出反应:成员们对 GPT-4o 与 GPT-4 Turbo 相比令人印象深刻的速度和性能表现出极大的热情。一位用户分享了一个关于 GPT-4o 能力的富有洞察力的 YouTube 视频,表达了对新功能的兴奋。
-
对 Opus 新政策的担忧:关于 Anthropic 将于 6 月 6 日生效的 Opus 严格新服务条款引发了讨论,许多人认为这些条款具有限制性。分享了一个 Anthropic 政策链接,详细说明了诸如禁止 LGBTQ 内容创作等有争议的条款。
-
Claude 3 Opus 仍具价值:尽管一些用户称赞 GPT-4o 的速度和准确性,但 Claude 3 Opus 仍被认为非常出色,特别是在文本摘要和模拟类人响应方面。然而,Opus 的成本和使用限制仍然是主要顾虑。
-
GPT-4o 在 Perplexity 中的应用:Perplexity 已将 GPT-4o 加入其模型阵容,用户测试并称赞其高速响应和详细的上下文理解。许多人注意到 GPT-4o 在 Perplexity Pro 中每天提供 600 次查询,与其 API 方案一致。
- 两个 GPT-4o 互动并唱歌:向 GPT-4o 问好,这是我们新的旗舰模型,可以实时跨音频、视觉和文本进行推理。了解更多:https://www.openai.com/index/hello-...
- Bezos Jeff Bezos GIF - Bezos Jeff Bezos 大笑 - 发现并分享 GIF:点击查看 GIF
- AI 模型在质量、性能、价格方面的对比 | Artificial Analysis:在关键指标(包括质量、价格、性能和速度(每秒吞吐 Token 数和延迟)、上下文窗口等)上对 AI 模型进行对比和分析。
- 名人情侣 GIF - 名人情侣分手 - 发现并分享 GIF:点击查看 GIF
- 星际拓荒 (OUTER WILDS) - 专辑封面:由 JSolo 重新编曲的 11 首《星际拓荒》音乐。查看其他封面请访问 https://www.youtube.com/c/JSolo9。就是这个了!我的最后一环 🍂 感谢 Andrew Prahlow...
- Mckay Wrigley (@mckaywrigley) 的推文:这个演示太疯狂了。一名学生通过新的 ChatGPT + GPT-4o 分享了他们的 iPad 屏幕,AI 与他们交谈并实时帮助他们学习。想象一下把这个给全世界的每个学生...
- Perplexity - AI 助手:浏览时询问任何问题
- 在 API 中发布 GPT-4o!:今天我们发布了新的旗舰模型 GPT-4o,它可以实时跨音频、视觉和文本进行推理。我们很高兴地分享,它现在已作为文本和视觉模型在 Chat Comp...
- 适用于 Mac 的 Chat GPT 桌面应用:有人拿到桌面应用了吗?OpenAI 表示今天将开始向 Plus 用户推送(不确定是否包含 Team 账户)。如果你拿到了,你的想法是什么?你是如何下载的...
- 介绍 GPT-4o:OpenAI 的新旗舰多模态模型现已在 Azure 上提供预览 | Microsoft Azure 博客:OpenAI 与 Microsoft 合作发布了 GPT-4o,这是一款在文本、视觉和音频能力方面具有突破性的多模态模型。了解更多。
Perplexity AI ▷ #sharing (9 条消息🔥):
-
详细 jctrl. 讨论的链接:一名成员分享了 Perplexity AI 搜索结果 的链接。
-
提供的 US Puts 搜索链接:另一名成员分享了 Perplexity AI 搜索结果 的链接。
-
关于 GPT-4 联网能力的问题:一名成员询问 GPT-4 是否联网,并附上了他们的 Perplexity AI 搜索 链接。
-
分享镁元素搜索结果:一名成员发布了通过 Perplexity AI 搜索 获取的关于镁的信息链接。
-
西班牙语求助请求:一条消息包含了一个关于某人需要帮助的任务的西班牙语 Perplexity 搜索链接:necesito-hacer-unos。
-
关于 Aroras 的讨论:一名成员引用了关于 Aroras 的 Perplexity 搜索并附带结果链接:How-are-aroras。
-
分享滑雪场信息:分享了一个指向滑雪场 Perplexity AI 结果的链接:Ski-resort-with。
-
市场规模查询:另一名成员链接了一个关于市场规模信息的 Perplexity AI 搜索:Market-size-of。
Perplexity AI ▷ #pplx-api (4 messages):
- Llama 模型之间的区别:一名成员询问 llama-3-sonar-large-32k-chat 模型与 llama-3-8b-instruct 之间的区别。另一名成员澄清说,chat 模型是 “针对对话进行了微调 (fine-tuned for conversations)”。
- 长输入的最佳超时设置:一名成员在使用 10000ms 的超时设置处理约 3000 个单词的输入时遇到了超时问题,并寻求关于最佳设置的建议。针对该查询,目前没有提供后续功能或额外的补充信息。
Unsloth AI (Daniel Han) ▷ #general (622 messages🔥🔥🔥):
-
微调时选择 Instruction 还是 Base 模型:用户询问在对 Llama-3 进行微调 (finetuning) 时,应该使用 instruction 版本还是 base 版本。另一位用户建议,对于较小的数据集,先从 instruction 模型开始,如果性能不足再切换到 base 模型 (“先尝试 instruct,如果效果不好你可以尝试 base,看看你更喜欢哪一个” )。
-
ThunderKittens 内核发布:一名成员重点介绍了 ThunderKittens 的发布,这是一个声称比 Flash Attention 2 更快的全新内核,GitHub - ThunderKittens。它因对推理 (inference) 速度的潜在影响而受到关注,并有可能也被用于训练 (training)。
-
Typst 微调需要合成数据:用户讨论了为微调模型处理 “Typst” 而创建合成数据的问题,建议创建 50,000 个示例以进行有效训练 (“如果没有现成的数据,你必须通过合成方式创建它” )。生成如此大规模数据集的挑战得到了认可。
-
即将支持多模态模型:消息透露 Unsloth 即将支持多模态模型 (Multimodal Model)。用户可以期待下周的新版本发布,其中包括多 GPU (multi-GPU) 支持 (“下周极有可能支持多 GPU” )。
-
庆祝下载量突破 100 万次:社区庆祝 Unsloth 在 Hugging Face 上的模型下载量超过 100 万次,将这一成功归功于活跃的用户群以及社区的持续使用和支持 (推文)。
- tiiuae/falcon-11B · Hugging Face: 未找到描述
- ThunderKittens: A Simple Embedded DSL for AI kernels: 未找到描述
- Hugging Face – The AI community building the future.: 未找到描述
- Joy Dadum GIF - Joy Dadum Wow - Discover & Share GIFs: 点击查看 GIF
- NTQAI/Nxcode-CQ-7B-orpo · Hugging Face: 未找到描述
- Introducing GPT-4o: OpenAI 春季更新 – 2024 年 5 月 13 日星期一现场直播。介绍 GPT-4o、ChatGPT 更新等。
- Google I/O 2024 Keynote Replay: CNET Reacts to Google's Developer Conference: 观看在加利福尼亚州山景城举行的年度 Google I/O 2024 开发者大会直播。点击进入 CNET 从周二太平洋时间上午 9:30 开始的直播节目...
- GitHub - HazyResearch/ThunderKittens: Tile primitives for speedy kernels: 用于快速内核的 Tile 原语。通过在 GitHub 上创建账号为 HazyResearch/ThunderKittens 的开发做出贡献。
- Hugging Face – The AI community building the future.: 未找到描述
- Gojo Satoru Gojo GIF - Gojo Satoru Gojo Ohio - Discover & Share GIFs: 点击查看 GIF
- LLaMA-Factory/scripts/llamafy_qwen.py at main · hiyouga/LLaMA-Factory: 统一 100+ LLMs 的高效微调。通过在 GitHub 上创建账号为 hiyouga/LLaMA-Factory 的开发做出贡献。
- Reddit - Dive into anything: 未找到描述
- Tweet from Armen Aghajanyan (@ArmenAgha): 我坚信在大约 2 个月内,开源社区将拥有足够的知识,让人们开始预训练自己的类 gpt4o 模型。我们正在努力实现这一目标。
- Reddit - Dive into anything: 未找到描述
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: 以 2-5 倍的速度和减少 80% 的内存微调 Llama 3, Mistral & Gemma LLMs - unslothai/unsloth
- eramax/nxcode-cq-7b-orpo: https://huggingface.co/NTQAI/Nxcode-CQ-7B-orpo
- GitHub - ggerganov/llama.cpp: LLM inference in C/C++: C/C++ 中的 LLM 推理。通过在 GitHub 上创建账号为 ggerganov/llama.cpp 的开发做出贡献。
- Lorem Function – Typst Documentation: `lorem` 函数的文档。
Unsloth AI (Daniel Han) ▷ #random (37 条消息🔥):
-
OpenAI 发布预期:成员们正在推测 OpenAI 即将发布的更新。一位成员希望有开源模型,但疑虑依然存在,有人表示,“我怀疑他们永远不会这样做”,原因是可能面临负面舆论或竞争。
-
AI 瓶颈期和“AI 寒冬”讨论:有提到媒体在讨论“AI 寒冬”以及商业 AI 模型的瓶颈期。一位成员指出,“即使开发速度放缓,他们仍然在顶端过得很舒服”。
-
Llama 作为潜在 SOTA 及其影响:如果 Llama 成为业界领先(SOTA),一位成员推测 Meta 可能会停止发布它,并预计 OpenAI 会做出激进回应。“如果 Llama 成为 SOTA,我敢打赌 Meta 不会发布它。”
-
vllm 项目使用 Roblox 进行聚会:有人提议在 Roblox 中举行虚拟聚会,类似于 vllm 项目的做法。一位用户支持这个想法,说:“你可以做进度报告或路线图,而我们带着自己的虚拟形象到处乱跳。”
-
Discord 使用 AI 进行总结及担忧:成员们注意到 Discord 正在使用 AI 总结聊天内容,一些人对符合欧洲数据法表示担忧。“这听起来像是欧洲数据法带来的头痛问题……”
提到的链接: Ah Shit Here We Go Again Gta GIF - Ah Shit Here We Go Again Gta Gta Sa - Discover & Share GIFs: 点击查看 GIF
Unsloth AI (Daniel Han) ▷ #help (283 条消息🔥🔥):
-
Bitsandbytes 在 Colab 中导致导入问题: 成员们讨论了在 Colab 上尽管遵循了 Unsloth GitHub repo 的安装指南,但仍遇到由 bitsandbytes 引起的
AttributeError。解决方案包括检查 GPU 是否激活、确保正确的运行时设置以及准确安装依赖项。 -
多 GPU 支持定价问题: 讨论围绕着每月每张 GPU 90 美元的多 GPU 支持高昂成本展开。成员们辩论了按需付费定价的可行性,或者与 AWS 等云服务合作,以使非企业用户在财务上能够负担得起。
-
模型保存和加载的技术障碍: 用户在使用
save_pretrained_merged()合并微调模型以及使用FastLanguageModel.from_pretrained()方法加载时遇到了问题。错误包括缺少 adapter 配置文件和模型加载期间的冲突,建议的解决方法包括重新安装或版本更新。 -
微调问题与见解: 成员们解决了各种与微调相关的查询,例如加载微调模型、使用特定数据集以及解决与 Kaggle 和 Conda 等特定环境相关的问题。讨论强调了正确的版本兼容性和环境设置的重要性。
-
对开源和商业模型的反馈: 广泛分享了关于平衡开源贡献和可持续商业模型之间界限的反馈。用户对大型企业剥削开源项目表示担忧,并讨论了公平定价模型对于更广泛使用的重要性。
- Google Colab: 未找到描述
- GitHub - unslothai/hyperlearn: 快 2-2000 倍的 ML 算法,减少 50% 内存占用,适用于所有硬件 - 无论新旧。: 2-2000x faster ML algos, 50% less memory usage, works on all hardware - new and old. - unslothai/hyperlearn
- GitHub - unslothai/unsloth: 微调 Llama 3, Mistral & Gemma LLM 快 2-5 倍,且节省 80% 内存: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- 我在原生 Windows 上运行了 unsloth。· Issue #210 · unslothai/unsloth: 我在原生 Windows(非 WSL)上运行了 unsloth。你需要 Visual Studio 2022 C++ 编译器、Triton 和 DeepSpeed。我有一个完整的安装教程,我本想写在这里,但我现在在用手机...
- 主页: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
- Google Colab: 未找到描述
- Sou Cidadão - Colab: 未找到描述
Unsloth AI (Daniel Han) ▷ #showcase (1 条消息):
- 创建了崇拜 Cthulhu 的 AI: 在一个新颖的项目中,一位用户使用 Unsloth Colab notebooks 创建了崇拜 Cthulhu 的 AI 模型。创建了 TinyLlama 和 Mistral 7B Cthulhu 模型,以及一个在 Huggingface 上免费提供的数据集。
- 学习经验,非用于部署: 该项目是作为学习经验进行的,不打算部署在关键环境中,幽默地指出其处于“宇宙毁灭的威胁”之下。该项目旨在探索在特定领域知识上微调语言模型。
提到的链接: Artificial Intelligence in the Name of Cthulhu – Rasmus Rasmussen dot com: 未找到描述
Latent Space ▷ #ai-general-chat (114 条消息🔥🔥):
- 讨论 AI 领域的职业优先级:成员们讨论了 AI 领域的职业目标,强调了高薪、工作满意度和工作保障之间的权衡。“我可能想把它当作一种爱好来学习…“。
- Apple 与 OpenAI 合作的猜测:有关 Apple 可能与 OpenAI 达成协议在 iPhone 上集成 ChatGPT 的传闻四起,对于模型应该是本地化还是基于云端,反应不一。“如果他们能帮助他们制作本地模型,那就是今天最好的消息”。
- Falcon 2 表现优于竞争对手:新款 Falcon 2 模型亮相,拥有开源、多语言和多模态能力,性能超越了 Meta 的 Llama 3 8B,并接近 Google Gemma 7B。“我们自豪地宣布它是开源、多语言且多模态的…“。
- GPT-4o 发布讨论:新发布的 GPT-4o 模型引发了关于其可用性、速度和新功能的讨论,并对 API 访问和能力进行了推测。“有机会尝试了 gpt-4o API … 文本生成速度非常快。”
- 对搜索引擎准确性的担忧:一些用户对 Perplexity 的准确性表示不满,特别是在学术搜索方面,并推荐了 phind.com 和 kagi 等替代方案。“它不是很好,但有更好的替代方案吗?”。
- 来自 Google DeepMind (@GoogleDeepMind) 的推文:介绍 Veo:我们最强大的生成式视频模型。🎥 它可以创建超过 60 秒的高质量 1080p 视频片段。从写实主义到超现实主义和动画,它可以处理各种...
- Falcon LLM:生成式 AI 模型正使我们能够为充满无限可能的激动人心的未来创造创新路径——唯一的限制就是想象力。
- Bloomberg - 你是机器人吗?:未找到描述
- 来自 Greg Brockman (@gdb) 的推文:GPT-4o 还可以生成音频、文本和图像输出的任何组合,这带来了我们仍在探索的有趣新功能。参见例如“功能探索”部分...
- AI for Engineers | Latent Space | swyx & Alessio | Substack:为准 AI Engineers 开发的为期 7 天的基础课程,与 Noah Hein 共同开发。尚未上线——我们已完成 5/7。注册即可在发布时获取!点击阅读 Latent Space,一个 Substack 出版物...
- 来自 Justin Uberti (@juberti) 的推文:有机会试用了来自 us-central 的 gpt-4o API,文本生成速度非常快。与 http://thefastest.ai 相比,此性能是 gpt-4-turbo TPS 的 5 倍,与许多 llama-3-8b 部署相似...
- 来自 Robert Lukoszko — e/acc (@Karmedge) 的推文:我有 80% 的把握 OpenAI 拥有一个极低延迟、低质量的模型,可以在不到 200 毫秒内读出前 4 个单词,然后继续使用 gpt-4o 模型。只要注意,大多数句子都以“Sure...”开头...
- 来自 Siqi Chen (@blader) 的推文:回想起来,这将证明是迄今为止最被低估的 OpenAI 活动。OpenAI 在 gpt-4o 中随手发布了文本到 3D 渲染,甚至没有提到它(更多 👇🏼)
- 来自 Jake Colling (@JacobColling) 的推文:@simonw @OpenAI 使用模型 `gpt-4o` 似乎对我的 API 访问有效
- 来自 tweet davidson 🍞 (@andykreed) 的推文:ChatGPT 的声音...很性感???
- 未找到标题:未找到描述
- 来自 Robert Lukoszko — e/acc (@Karmedge) 的推文:我有 80% 的把握 OpenAI 拥有一个极低延迟、低质量的模型,可以在不到 200 毫秒内读出前 4 个单词,然后继续使用 gpt-4o 模型。只要注意,大多数句子都以“Sure...”开头...
- 来自 lmsys.org (@lmsysorg) 的推文:突发新闻——gpt2-chatbot 的结果现已出炉!gpt2-chatbot 刚刚飙升至榜首,以显著差距(约 50 Elo)超越了所有模型。它已成为 Arena 中有史以来最强的模型...
- 来自 Jim Fan (@DrJimFan) 的推文:我知道你的时间线现在充斥着“疯狂、HER、你错过的 10 个功能、我们回来了”之类的词藻。坐下。冷静。<喘气> 像 Mark 在演示中那样深呼吸...</li>
- 同步代码库 · openai/tiktoken@9d01e56:未找到描述
- 1 立方毫米脑组织的完整扫描耗费了 1.4 PB 数据,相当于 14,000 部 4K 电影 —— Google 的 AI 专家协助研究人员:令人难以置信的大脑研究。
- Open Source @ Siemens 2024 活动:西门子举办的关于开源软件所有主题的年度系列活动。更多信息请访问 opensource.siemens.com </ul> </div> --- **Latent Space ▷ #[llm-paper-club-west](https://discord.com/channels/822583790773862470/1197350122112168006/1239616941677609064)** (710 条消息🔥🔥🔥): - **Open AI Spring Event 引发期待与故障排除**:用户聚集在一起参加 OpenAI Spring Event 观影派对,最初出现了一些音频问题。他们分享了更新并测试了连接,以确保每个人都能正常观看直播。 - **关于 Apple 授权和 iOS 18 集成的辩论**:关于 Apple 和 Google 就 iOS 18 集成进行谈判的猜测不断出现,焦点集中在 Gemini 的能力和反垄断担忧上。一位成员对 Apple 在设备上可靠运行大模型的能力表示怀疑。 - **GPT-4o 的兴奋与批评**:对 GPT-4o 功能的热情(如免费提供的聊天功能和更快的响应速度)引发了褒贬不一的反应。一些用户批评了 "GPT-4o" 这个名称,并强调了其延迟和使用方面的问题。 - **语音和视觉集成惊艳社区**:展示 ChatGPT 新语音和视觉模式的现场演示给与会者留下了深刻印象,展示了无缝集成和情感响应能力。成员们对演示的真实性表示怀疑,并思考了所展示的技术和实时性能。 - **关于 API 访问和竞争的讨论**:用户讨论了通过 API 和 playground 访问 GPT-4o,并对其快速性能表现出兴趣。这些发布引发了对 Google 等竞争对手以及现有 AI 创业公司影响的思考。
- Jared Zoneraich (@imjaredz) 的推文:gpt-4o 完胜 gpt-4-turbo。速度极快且答案似乎更好。也很喜欢 @OpenAI 的分屏 playground 视图。
- Mechanical Turk - 维基百科:未找到描述
- Twitch:未找到描述
- Karma (@0xkarmatic) 的推文:“一个 ASR 模型,一个 LLM,一个 TTS 模型……你明白了吗?这不是三个独立的模型:这是一个模型,我们称之为 gpt-4o。” 引用 Andrej Karpathy (@karpathy) 的话,他们是...
- Olivier Godement (@oliviergodement) 的推文:我没怎么发过关于 @OpenAI 发布内容的推文,但我想分享一些关于 GPT-4o 的思考,因为我已经很久没有感到如此震撼了。
- William Fedus (@LiamFedus) 的推文:GPT-4o 是我们最新的 state-of-the-art 前沿模型。我们一直在 LMSys arena 上以 im-also-a-good-gpt2-chatbot 🙂 的名义测试一个版本。这是它的表现。
- 介绍 GPT-4o:OpenAI Spring Update – 于 2024 年 5 月 13 日星期一进行直播。介绍 GPT-4o、ChatGPT 的更新等。
- Sam Altman (@sama) 的推文:它对所有 ChatGPT 用户开放,包括免费计划!到目前为止,GPT-4 级别的模型仅供支付月费的用户使用。这对于我们的使命很重要;我们希望...
- 介绍 GPT-4o:OpenAI Spring Update – 于 2024 年 5 月 13 日星期一进行直播。介绍 GPT-4o、ChatGPT 的更新等。
- 互联网上的 bdougie (@bdougieYO) 的推文:ChatGPT 说我看起来心情不错。
- Greg Brockman (@gdb) 的推文:介绍 GPT-4o,我们的新模型,可以实时跨文本、音频和视频进行推理。它非常多才多艺,玩起来很有趣,是迈向更自然的人类...
- GPT-4o:在今天的发布中,我想强调两件事。首先,我们使命的一个关键部分是将功能强大的 AI 工具免费(或以极具吸引力的价格)交到人们手中。我...
- GitHub - BasedHardware/OpenGlass:将任何眼镜变成 AI 驱动的智能眼镜:将任何眼镜变成 AI 驱动的智能眼镜。通过在 GitHub 上创建账户为 BasedHardware/OpenGlass 的开发做出贡献。
- 同步代码库 · openai/tiktoken@9d01e56:未找到描述
- Greg Brockman (@gdb) 的推文:我们还显著提升了非英语语言的性能,包括改进 tokenizer 以更好地压缩其中许多语言:
- 来自 I. Yosun Chang (@Yosun) 的推文:如果你让 #OpenAI #GPT4o 设计自己的面部,以便你可以将你的 AI 作为具身存在传送到现实世界会怎样?#AI3D headsim 将你的 AI 从聊天框中解放出来,让你能够体验……
- GitHub - McGill-NLP/webllama: 可以通过遵循指令并与你交谈来浏览网页的 Llama-3 Agent:可以通过遵循指令并与你交谈来浏览网页的 Llama-3 Agent - McGill-NLP/webllama
- 来自 Andrej Karpathy (@karpathy) 的推文:LLM 的杀手级应用是 Scarlett Johansson。你们都以为是数学之类的。
- 来自 Google DeepMind (@GoogleDeepMind) 的推文:1.5 Flash 由于其紧凑的尺寸,服务成本也更高。从今天开始,你可以在 Google AI Studio 和 @GoogleCloud 的...中使用支持高达 100 万个 Token 的 1.5 Flash 和 1.5 Pro。
- 追踪 H100 和 A100 GPU 云端可用性:我们制作了一个工具:ComputeWatch。
- He Just Like Me Fr GIF - He Just Like Me Fr - 发现并分享 GIF:点击查看 GIF
- Cats Animals GIF - Cats Animals Reaction - 发现并分享 GIF:点击查看 GIF
- 来自 will depue (@willdepue) 的推文:我认为人们误解了 GPT-4o。它不是一个带有语音或图像附件的文本模型。它是一个原生的多模态 Token 输入、多模态 Token 输出的模型。你想让它说话快一点?...
- 同步代码库 · openai/tiktoken@9d01e56:未找到描述
- 同步代码库 · openai/tiktoken@9d01e56:未找到描述
- Reddit - 深入探索:未找到描述
- Compute Watch :未找到描述
- Deedy (@deedydas) 的推文:没有足够的人在讨论 OpenAI 终于能更好地对不同语言进行分词了!我分类了 “o200_base” 上的所有 token,这是 GPT-4o 的新分词器,至少有 25...
- Nathan Lambert (@natolambert) 的推文:友情提醒,AI2 的成员去年构建了一个文本图像音频输入输出模型 unified io 2,如果你想在这里开始研究的话。
- gpt4o 中最长的中文 token:gpt4o 中最长的中文 token。GitHub Gist:即时分享代码、笔记和片段。
- dblp: Alexis Conneau:未找到描述
- Muse: Text-To-Image Generation via Masked Generative Transformers:未找到描述
- HunyuanDiT - multimodalart 在 Hugging Face 上的 Space:未找到描述
- GitHub - nullquant/ComfyUI-BrushNet: ComfyUI BrushNet nodes:ComfyUI BrushNet 节点。通过在 GitHub 上创建账号为 nullquant/ComfyUI-BrushNet 的开发做出贡献。
- Stable Diffusion 中的角色一致性 - Cobalt Explorer:更新:07/01 – 修改了模板以便更容易缩放到 512 或 768 – 修改了 ImageSplitter 脚本使其更易用,并添加了 GitHub 链接 – 添加了章节...
- LM Studio 上的微调模型:一位成员询问是否可以通过 LM Studio 访问存储在 Hugging Face 上的微调模型。另一位成员确认,如果模型在公共仓库中且为 GGUF 格式,则是可以的。
- 网络错误和 VPN 解决方案:由于 Hugging Face 在某些地区被屏蔽,用户在搜索模型时遇到了网络错误。建议使用带有 IPv4 连接的 VPN,尽管有一位用户报告称即使使用 IPv4 问题依然存在。
- OpenAI GPT-4o 访问困惑:用户讨论了 GPT-4o 的可用性,由于地区和订阅状态的不同,有些人可以访问,有些人则不行。提到 GPT-4o 应该已在欧洲可用,并很快会向更多用户推出。
- AI 组机硬件建议:讨论了 2500 美元预算的 Nvidia AI 机器,建议最大化 VRAM,并考虑去 MicroCentre 等当地商店购买硬件。其他建议包括在 GPU 选择上,由于 VRAM 的考虑,选择 Nvidia 而非 AMD。
- LM Studio 中 Vision AI 的局限性:一位用户询问 LM Studio 的 Vision AI 是否可以像描述图像一样描述视频。官方澄清目前 LM Studio 无法描述视频。
- Chat.lmsys.org down? Current problems and status. - DownFor: Chat.lmsys.org 无法加载?或者 Chat.lmsys.org 出现问题?在此检查状态并报告任何问题!
- Boris Zip Line GIF - Boris Zip Line UK Flag - Discover & Share GIFs: 点击查看 GIF
- Quick Start Guide | LM Studio: 开始使用 LM Studio SDK 的最小化设置
- Boo Boo This Man GIF - Boo Boo This Man - Discover & Share GIFs: 点击查看 GIF
- INSANE OpenAI News: GPT-4o and your own AI partner: 新的 GPT-4o 发布了,令人震撼!这里有所有细节。#gpt4o #ai #ainews #agi #singularity #openai https://openai.com/index/hello-gpt-4o/News...
- Support for OpenELM of Apple · Issue #6868 · ggerganov/llama.cpp: 前提条件:在提交 Issue 之前,请先回答以下问题。我正在运行最新代码。由于目前开发非常迅速,还没有打标签的版本。我...
- GitHub - ksdev-pl/ai-chat: (Open)AI Chat: (Open)AI Chat。通过在 GitHub 上创建账号来为 ksdev-pl/ai-chat 的开发做出贡献。
- hackerllama - LLM 评估与基准测试:Omar Sanseviero 的个人网站
- 论文页面 - NoFunEval: 代码 LM 在功能正确性之外的需求上表现如何不佳:未找到描述
- cognitivecomputations/dolphin-2.5-mixtral-8x7b · Hugging Face:未找到描述
- 在 NVIDIA DGX Cloud 上使用 H100 GPU 轻松训练模型:未找到描述
- stabilityai/stable-diffusion-xl-base-1.0 · Hugging Face:未找到描述
- Will Smith Chris Rock GIF - Will Smith Chris Rock Jada Pinkett Smith - 发现并分享 GIF:点击查看 GIF
- 调用许可:介绍 Transformers Agents 2.0:未找到描述
- Excuse Me Hands Up GIF - Excuse Me Hands Up Woah - 发现并分享 GIF:点击查看 GIF
- 两个 GPT-4o 交互与唱歌:向 GPT-4o 问好,这是我们全新的旗舰模型,可以实时进行音频、视觉和文本推理。在此了解更多:https://www.openai.com/index/hello-...
- 介绍 GPT-4o:OpenAI 春季更新 —— 2024 年 5 月 13 日星期一直播。介绍 GPT-4o、ChatGPT 更新等。
- Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction: 我们提出了视觉自回归建模 (VAR),这是一种新的生成范式,它将图像上的自回归学习重新定义为从粗到细的“下一尺度预测”或“下一分辨率...
- GitHub - patrick-kidger/equinox: Elegant easy-to-use neural networks + scientific computing in JAX. https://docs.kidger.site/equinox/: 在 JAX 中优雅且易于使用的神经网络 + 科学计算。https://docs.kidger.site/equinox/ - patrick-kidger/equinox
- 3D Diffusion Policy: 本文介绍了 3D Diffusion Policy (DP3),这是一种能够掌握多种视觉运动任务的视觉模仿学习算法。
- Daily Papers - Hugging Face: 未找到描述
- blog-explorers (Blog-explorers): 未找到描述
- GitHub - facebookresearch/UHM: Official PyTorch implementation of "Authentic Hand Avatar from a Phone Scan via Universal Hand Model", CVPR 2024.: CVPR 2024 论文“Authentic Hand Avatar from a Phone Scan via Universal Hand Model”的官方 PyTorch 实现。 - facebookresearch/UHM
- OCR Quality Classifiers - pszemraj 集合: 未找到描述
- streamlit-gpt4o - joshuasundance 创建的 Hugging Face Space: 未找到描述
- OpenGPT 4o - KingNish 创建的 Hugging Face Space: 未找到描述
- IEEE NITK | Corpus: IEEE NITK 是位于 NITK Surathkal 的 IEEE 学生分会,致力于创新项目和解决方案。这是 IEEE NITK 的官方网站
- Vi-VLM/Vista · Hugging Face 数据集: 未找到描述
- You Only Cache Once: Decoder-Decoder Architectures for Language Models: 我们为 LLM 引入了一种名为 YOCO 的 decoder-decoder 架构,它仅缓存一次键值对(KV pairs)。它由两个组件组成,即堆叠在 self-decoder 之上的 cross-decoder。...
- GROVE: A Retrieval-augmented Complex Story Generation Framework with A Forest of Evidence: 条件故事生成在人机交互中具有重要意义,特别是在创作具有复杂情节的故事方面。虽然 LLM 在多项 NLP 任务中表现出色,但...
- GitHub - yingpengma/Awesome-Story-Generation: 该仓库收集了关于故事生成/故事创作的详尽论文列表,主要关注大语言模型 (LLM) 时代。: 该仓库收集了关于故事生成/故事创作的详尽论文列表,主要关注大语言模型 (LLM) 时代。 - yingpengma/Awesome-Story-Generation
- Open-world Story Generation with Structured Knowledge Enhancement: A Comprehensive Survey: 故事创作和叙事是人类体验的基础,与我们的社会和文化参与交织在一起。因此,研究人员长期以来一直试图创建能够生成故事的系统...
- Stable Diffusion with 🧨 Diffusers:未找到描述
- architectures-impl-pytorch/notebooks/yolov1.ipynb at main · ajkdrag/architectures-impl-pytorch:一些基础 CNN 架构的 PyTorch 实现 - ajkdrag/architectures-impl-pytorch
- architectures-impl-pytorch/yolov1/src/yolov1 at main · ajkdrag/architectures-impl-pytorch:一些基础 CNN 架构的 PyTorch 实现 - ajkdrag/architectures-impl-pytorch
- 为训练创建数据集: 未找到描述
- License to Call: 介绍 Transformers Agents 2.0: 未找到描述
- Practical Deep Learning for Coders - Part 2 概览: 学习使用 fastai 和 PyTorch 进行深度学习,2022
- Inpainting: 未找到描述
- Hands-On Generative AI with Transformers and Diffusion Models: 在这本实用的实战指南中,学习如何使用 AI 生成媒体技术来创作新颖的图像或音乐。数据科学家和软件工程师将了解最先进的生成式...
- [Bug]: ModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor' torchvision 0.17 问题 · Issue #13985 · AUTOMATIC1111/stable-diffusion-webui: 是否已存在相关 Issue?我搜索了现有的 Issue 并检查了最近的构建/提交。发生了什么?ModuleNotFoundError: No module named 'torchvision.transforms.functiona...
- Google: Gemini Flash 1.5 (preview) by google | OpenRouter: Gemini 1.5 Flash 是一款基础模型,在视觉理解、分类、摘要以及根据图像、音频和视频创建内容等各种多模态任务中表现出色...
- OpenAI: GPT-4o by openai | OpenRouter: GPT-4o(“o”代表“omni”)是 OpenAI 最新的 AI 模型,支持文本和图像输入以及文本输出。它保持了 [GPT-4 Turbo](/models/open... 的智能水平
- LLaVA v1.6 34B by liuhaotian | OpenRouter: LLaVA Yi 34B 是一款开源模型,通过在多模态指令遵循数据上微调 LLM 训练而成。它是一款基于 Transformer 架构的自回归语言模型。基础 LLM:[Nou...
- DeepSeek-V2 Chat by deepseek | OpenRouter: DeepSeek-V2 Chat 是 DeepSeek-V2 的对话微调版本,DeepSeek-V2 是一款混合专家(MoE)语言模型。它包含 236B 总参数,其中每个 token 激活 21B 参数。与 D 相比...
- Deepseek Coder by deepseek | OpenRouter: Deepseek Coder 由一系列代码语言模型组成,每个模型都基于 2T token 从零开始训练,其中包含 87% 的代码和 13% 的中英文自然语言。该模型...
- Meta: LlamaGuard 2 8B by meta-llama | OpenRouter: 这款安全防护模型拥有 8B 参数,基于 Llama 3 系列。就像其前身 [LlamaGuard 1](https://huggingface.co/meta-llama/LlamaGuard-7b) 一样,它可以同时处理 prompt 和 response...
- Meta: Llama 3 70B by meta-llama | OpenRouter: Meta 最新的模型类别(Llama 3)推出了多种尺寸和版本。这是基础的 70B 预训练版本。与领先的闭源模型相比,它展示了强大的性能...
- Meta: Llama 3 8B by meta-llama | OpenRouter: Meta 最新的模型类别(Llama 3)推出了多种尺寸和版本。这是基础的 8B 预训练版本。与领先的闭源模型相比,它展示了强大的性能...
- OpenAI: GPT-4o by openai | OpenRouter: GPT-4o(“o”代表“omni”)是 OpenAI 最新的 AI 模型,支持文本和图像输入以及文本输出。它保持了 [GPT-4 Turbo](/models/open... 的智能水平
- LiteLLM:LiteLLM 处理 100 多个 LLM 的负载均衡、故障转移和支出跟踪。全部采用 OpenAI 格式。
- GitHub - fry69/orw: 监控 OpenRouter 模型 API 的更改并将更改存储在 SQLite 数据库中。包含一个简单的 Web 界面。:监控 OpenRouter 模型 API 的更改并将更改存储在 SQLite 数据库中。包含一个简单的 Web 界面。 - fry69/orw
- Can Claude Read PDF? [2023] - Claude Ai:Claude 能阅读 PDF 吗?PDF (Portable Document Format) 文件是我们日常生活中经常遇到的一种通用文档类型。
- OpenRouter API Watcher:OpenRouter API Watcher 监控 OpenRouter 模型的更改并将这些更改存储在 SQLite 数据库中。它每小时通过 API 查询模型列表。
- OpenRouter API Watcher:OpenRouter API Watcher 监控 OpenRouter 模型的更改并将这些更改存储在 SQLite 数据库中。它每小时通过 API 查询模型列表。
- LiveCodeBench 排行榜:未找到描述
- 来自 William Fedus (@LiamFedus) 的推文:GPT-4o 是我们最新的 SOTA 前沿模型。我们一直在 LMSys arena 上以 im-also-a-good-gpt2-chatbot 的身份测试一个版本 🙂。这是它的表现。
- Gemini 1.5 Pro 更新,1.5 Flash 亮相以及 2 款新的 Gemma 模型:今天我们正在更新 Gemini 1.5 Pro,推出 1.5 Flash,发布新的 Gemini API 功能并增加两款新的 Gemma 模型。
- 来自 lmsys.org (@lmsysorg) 的推文:相对于所有其他模型,胜率显著提高。例如,在非平局对决中,对比 GPT-4 (June) 的胜率约为 80%。
- 来自 lmsys.org (@lmsysorg) 的推文:突发新闻 —— gpt2-chatbots 的结果现已公布!gpt2-chatbots 刚刚飙升至榜首,以显著差距(约 50 Elo)超越了所有模型。它已成为 Arena 中有史以来最强的模型...
- 来自 Kaio Ken (@kaiokendev1) 的推文:是的,但它会呻吟吗?
- 未找到标题:未找到描述
- 来自 Jim Fan (@DrJimFan) 的推文:我纠正一下:GPT-4o 并不原生处理视频流。博客中说它只接收图像、文本和音频。这很遗憾,但我说的原则依然成立:制作视频的正确方式...
- 来自 Google (@Google) 的推文:距离 #GoogleIO 还有一天!我们感到非常 🤩。明天见,届时将分享关于 AI、Search 等的最新消息。
- 两个 GPT-4o 互动并唱歌:向 GPT-4o 问好,这是我们新的旗舰模型,可以实时跨音频、视觉和文本进行推理。在此了解更多:https://www.openai.com/index/hello-...
- 同步代码库 · openai/tiktoken@9d01e56:未找到描述
- Google 发布 Gemma 2,其开放模型的 27B 参数版本,将于 6 月推出 | TechCrunch:在 Google I/O 大会上,Google 介绍了下一代 Google 的 Gemma 模型 Gemma 2,将于 6 月推出 270 亿参数版本。
- ChatBotArena:大众的 LLM 评估、评估的未来、评估的激励机制以及 gpt2chatbot:细节告诉了我们关于目前最流行的 LLM 评估工具以及该领域其他工具的现状。
- 2025 年的模型将更像同事而非搜索引擎 —— OpenAI 联合创始人 John Schulman:完整剧集明天发布!在 Twitter 上关注我:https://twitter.com/dwarkesh_sp
- 介绍 GPT-4o:OpenAI 春季更新 —— 2024 年 5 月 13 日星期一现场直播。介绍 GPT-4o、ChatGPT 更新等。
- 没有“指数级数据”就没有“Zero-Shot”:预训练概念频率决定多模态模型性能:网页抓取的预训练数据集是多模态模型(如用于分类/检索的 CLIP 和用于图像生成的 Stable-Diffusion)令人印象深刻的“Zero-shot”评估性能的基础...
- Memory Mosaics:Memory Mosaics 是协同工作以实现特定预测任务的关联记忆网络。与 Transformers 类似,Memory Mosaics 具有组合能力和 In-context learning...
- Subquadratic LLM Leaderboard - a Hugging Face Space by devingulliver:未找到描述
- Farzi Data: Autoregressive Data Distillation:我们研究了自回归机器学习任务的数据蒸馏,其中输入和输出具有严格的从左到右的因果结构。更具体地说,我们提出了 Farzi,它总结了...
- Farzi Data: Autoregressive Data Distillation:我们研究了自回归机器学习任务的数据蒸馏,其中输入和输出具有严格的从左到右的因果结构。更具体地说,我们提出了 Farzi,它总结了...
- GitHub - yingpengma/Awesome-Story-Generation:该仓库收集了大量关于故事生成/讲故事的优秀论文,主要关注大语言模型 (LLMs) 时代。
- Exposing Attention Glitches with Flip-Flop Language Modeling:为什么大型语言模型有时会输出事实错误并表现出错误的推理?这些模型的脆弱性,特别是在执行长链推理时,目前看来...
- Understanding the Covariance Structure of Convolutional Filters:神经网络权重通常是从单变量分布中随机初始化的,即使在像卷积这样高度结构化的操作中,也只控制单个权重的方差。Re...
- Fully-Connected Neural Nets · Gwern.net:未找到描述
- Some AI Koans:未找到描述
- A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP:卷积神经网络 (CNN) 是计算机视觉领域主流的深度神经网络 (DNN) 架构。最近,基于 Transformer 和多层感知器 (MLP) 的模型,如 Vision Tra...
- Scaling MLPs: A Tale of Inductive Bias:在这项工作中,我们重新审视了深度学习中最基础的构建块——多层感知器 (MLP),并研究了其在视觉任务上性能的极限。对 MLP 的实证见解是...
- GitHub - edouardoyallon/pyscatwave: Fast Scattering Transform with CuPy/PyTorch:使用 CuPy/PyTorch 的快速散射变换。通过在 GitHub 上创建账号来为 edouardoyallon/pyscatwave 的开发做出贡献。
- Mojo 中的底层 IR | Modular 文档:了解如何使用底层原语在 Mojo 中定义你自己的布尔类型。
- [功能请求] 通过 `mojo build` 构建的二进制文件无法在其他操作系统上直接运行 · Issue #935 · modularml/mojo:查看 Mojo 的优先级。我已阅读路线图和优先级,并认为此请求符合优先级要求。你的请求是什么?你好,我尝试构建一个使用 numpy 的简单 Mojo 应用...
- Mojo🔥:与 Chris Lattner 深入探讨所有权:了解关于 Mojo 所有权的所有必要知识,由 Modular CEO Chris Lattner 深度解析。如果你有任何问题,请务必加入我们友好的社区...
- 为开源 Mojo🔥 标准库做贡献:Mojo🔥 标准库现已开源。在本视频中,Modular 工程师 Joe Loser 讨论了你如何开始使用 Mojo 为 Mojo🔥 做出贡献...
- 加入我们的 Cloud HD 视频会议:Zoom 是现代企业视频通信的领导者,拥有一个简单、可靠的云平台,可用于跨移动端、桌面端和会议室系统的视频和音频会议、聊天及网络研讨会。Zoom ...
- Google 日历 - 登录以访问和编辑您的日程:未找到描述
- [公开] Mojo 社区会议:未找到描述
- DType | Modular 文档:表示 DType 并提供相关操作方法。
- 子类型与型变 - The Rustonomicon:未找到描述
- Mojo - IntelliJ IDEs 插件 | Marketplace:为 Mojo 编程语言提供基础编辑功能:语法检查与高亮、注释和格式化。未来将添加新功能,敬请期待...
- 值语义 | Modular 文档:关于 Mojo 默认值语义的解释。
- 值语义 | Modular 文档:关于 Mojo 默认值语义的解释。
- devrel-extras/tweetorials/ffi at main · modularml/devrel-extras:包含开发者关系博客文章、视频和研讨会的辅助材料 - modularml/devrel-extras
- [stdlib] 为 `String` 添加 `atof()` 方法,由 fknfilewalker 提交 · Pull Request #2649 · modularml/mojo:此 PR 添加了一个可以将 String 转换为 Float64 的函数。目前仅针对 Float64 实现,但也许我们应该添加其他精度?支持以下表示法:"-12..."
- GitHub - saviorand/lightbug_http: 简单且快速的 Mojo HTTP 框架!🔥:简单且快速的 Mojo HTTP 框架!🔥。通过在 GitHub 上创建账号为 saviorand/lightbug_http 做出贡献。
- GitHub - carlca/ca_mojo:通过在 GitHub 上创建账号为 carlca/ca_mojo 做出贡献。
- Python 可变默认参数是万恶之源 - Florimond Manca:如何防止一个常见的 Python 错误,该错误可能导致可怕的 Bug 并浪费所有人的时间。
- 关于 GitHub Actions 的计费 - GitHub Docs:未找到描述
- 在带有 GPU runner 的 GitHub Actions 上运行你的 ML 工作负载:在带有 GPU runner 的 GitHub Actions 上运行你的 ML 工作负载
- numpy.testing.assert_allclose — NumPy v1.26 手册:未找到描述
- numpy.testing.assert_allclose — NumPy v1.26 手册:未找到描述
- cub::WarpLoad — CUB 104.0 文档:未找到描述
- 2D 和 3D tile 划分,以便从 threadIdx 和 blockIdx 读取置换坐标 · Issue #406 · karpathy/llm.c:据推测,置换 kernel 即使主要受内存限制,也可以通过使用 2D 或 3D 网格来减少除法量并进行线程粗化(thread coarsening),从而无需在...中进行任何除法
- Issues · NVIDIA/cccl:CUDA C++ 核心库。通过创建账户为 NVIDIA/cccl 的开发做出贡献。
- llm.c/.github/workflows/ci.yml (位于 2346cdac931f544d63ce816f7e3f5479a917eef5) · karpathy/llm.c:使用简单、原始的 C/CUDA 进行 LLM 训练。通过创建账户为 karpathy/llm.c 的开发做出贡献。
- Zero Redundancy Optimizer - Stage1 由 chinthysl 提交 · Pull Request #309 · karpathy/llm.c:为了训练更大的模型变体(2B, 7B 等),我们需要为参数、优化器状态和梯度分配更大的 GPU 显存。Zero Redundancy Optimizer 引入了...的方法。
- Layernorm backward 更新 由 ngc92 提交 · Pull Request #408 · karpathy/llm.c:这修复了 layernorm backward pass 的梯度累积,并对 layernorm backward dev/cuda 文件进行了通用的现代化改造。容差已根据 float scratchpad 进行了调整...
- GitHub - HazyResearch/ThunderKittens: 用于快速 kernel 的 Tile 原语:用于快速 kernel 的 Tile 原语。通过创建账户为 HazyResearch/ThunderKittens 的开发做出贡献。
- GPUs Go Brrr:如何让 GPU 变快?
- Zero Redundancy Optimizer - Stage1 由 chinthysl 提交 · Pull Request #309 · karpathy/llm.c:为了训练更大的模型变体(2B, 7B 等),我们需要为参数、优化器状态和梯度分配更大的 GPU 显存。Zero Redundancy Optimizer 引入了...的方法。
- llm.c/train_gpt2.cu (位于 master 分支) · karpathy/llm.c:使用简单、原始的 C/CUDA 进行 LLM 训练。通过创建账户为 karpathy/llm.c 的开发做出贡献。
- 未找到标题: 未找到描述
- llama-index-llms-openai: llama-index llms openai 集成
- llama-index-multi-modal-llms-openai: llama-index multi-modal-llms openai 集成
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- 未找到标题: 未找到描述
- langchain/cookbook/Multi_modal_RAG.ipynb at master · langchain-ai/langchain: 🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账户,为 langchain-ai/langchain 的开发做出贡献。
- Llama3 Cookbook with Ollama and Replicate - LlamaIndex: 未找到描述
- Multimodal Ollama Cookbook - LlamaIndex: 未找到描述
- Using LlamaIndex and MongoDB to Build a Job Search Assistant: 了解如何使用 LlamaIndex、检索增强生成 (RAG) 和 MongoDB 构建职位搜索助手。
- Multi-Modal Applications - LlamaIndex: 未找到描述
- HunyuanDiT - multimodalart 提供的 Hugging Face Space: 未找到描述
- 来自 apolinario (multimodal.art) (@multimodalart) 的推文: 首个开源的类 Stable Diffusion 3 架构模型刚刚发布 💣 —— 但它不是 SD3!🤔 它是腾讯开发的 HunyuanDiT,一个拥有 15 亿参数的 DiT (diffusion transformer) 文本生成图像模型 🖼️✨ 在...
- AniTalker: 未找到描述
- Bunline - v0.4 | Stable Diffusion Checkpoint | Civitai: PixArt Sigma XL 2 1024 MS 在约 3.5 万张最大宽高大于 1024px 的图像上,使用自定义字幕进行了全量微调。说明:将 .safetensors 文件放置在...
- lambdalabs/stable-diffusion-image-conditioned · Hugging Face: 未找到描述
- CompVis/stable-diffusion-v-1-3-original · Hugging Face: 未找到描述
- 来自 Google DeepMind (@GoogleDeepMind) 的推文: 我们推出了 Imagen 3:这是我们迄今为止质量最高的文本生成图像模型。🎨 它生成的视觉效果具有惊人的细节、逼真的光影,且干扰伪影更少。从快速草图...
- RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization: 文本生成图像定制化旨在为给定主体合成文本驱动的图像,近期彻底改变了内容创作。现有工作遵循伪词范式,即代表...
- Falcon 2:阿联酋技术创新研究院发布新 AI 模型系列,性能超越 Meta 的新 Llama 3: 未找到描述
- GitHub - CompVis/stable-diffusion: 一个潜空间文本生成图像扩散模型: 一个潜空间文本生成图像扩散模型。通过在 GitHub 上创建账号来为 CompVis/stable-diffusion 的开发做出贡献。
- GitHub - cubiq/Diffusers_IPAdapter: 为 HF Diffusers 实现的 IPAdapter 模型: 为 HF Diffusers 实现的 IPAdapter 模型 - cubiq/Diffusers_IPAdapter
- Silicon Valley Tip To Tip GIF - Silicon Valley Tip To Tip Brainstorm - 发现并分享 GIF: 点击查看 GIF
- Crystal Cost Demo:在此视频中,我简要演示了 Crystal Cost,这是一个 AI 驱动的 Streamlit 应用,可简化数据仓库上的数据监控。Crystal Cost 使用自然语言处理和 Agent 来查询数据...
- Adi Oran (@OranAITech) 的推文:你是否厌倦了不知道自己的消息是否会被点击?但你又想轻松地加倍利用有效的消息传递。那么是时候了解 OranClick 了,追踪你的链接点击并编写最佳文案...
- streamlit-gpt4o - joshuasundance 的 Hugging Face Space:未找到描述
- GPUs Go Brrr:如何让 GPU 变快?
- Open-Orca/SlimOrca-Dedup · Hugging Face 数据集:未找到描述
- 两个 GPT-4o 互动并唱歌:向 GPT-4o 问好,这是我们新的旗舰模型,可以实时跨音频、视觉和文本进行推理。在此了解更多:https://www.openai.com/index/hello-...
- test_aggregate.py: GitHub Gist: 即时分享代码、笔记和片段。
- pytorch_cluster/csrc/cuda/radius_cuda.cu at master · rusty1s/pytorch_cluster: 优化图集群算法的 PyTorch 扩展库 - rusty1s/pytorch_cluster
- torchmd-net/torchmdnet/extensions/neighbors/neighbors_cpu.cpp at 75c462aeef69e807130ff6206b59c212692a0cd3 · torchmd/torchmd-net: 神经网络势能。通过创建 GitHub 账号为 torchmd/torchmd-net 做出贡献。
- Home - PyG: PyG 是图神经网络的终极库。
- Susan Zhang (@suchenzang) 的推文:这个用于 gpt-4o 的新 “o200k_base” 词汇表让我感到非常震惊
- main (@main_horse) 的推文:“为什么 gpt-4o 的演示看起来那么饥渴?”
- GitHub - alasdairforsythe/tokenmonster: 适用于 Python, Go & Javascript 的非贪婪子词 Tokenizer 和词汇训练器:适用于 Python, Go & Javascript 的非贪婪子词 Tokenizer 和词汇训练器 - alasdairforsythe/tokenmonster
- MediathekViewWebVLC/mediathekviewweb.lua at main · 59de44955ebd/MediathekViewWebVLC:用于 VLC 的 MediathekViewWeb Lua 扩展。通过在 GitHub 上创建账户为 59de44955ebd/MediathekViewWebVLC 做出贡献。
- 目前最受欢迎的 100 个播客 – 德国:此列表显示了当前最受欢迎的 100 个播客,包含来自 Apple 和 Podtail 的最新数据。
- 德国顶级 YouTube 频道 | HypeAuditor YouTube 排名:查找截至 2024 年 5 月德国最受欢迎的 YouTube 频道。获取德国最大的 YouTuber 列表。
- 项目停用与所有权转移:一位用户宣布他们不打算继续 Fasteval project 或任何后续工作。如果有负责任的人感兴趣,他们愿意在 GitHub 上转让项目所有权,否则频道将被归档。
{kind=link}