ainews-to-be-named-9199
Cursor 通过微调 Llama3-70b,在快速文件编辑中实现了超过 1000 token/s 的速度。
以下是该文本的中文翻译:
AI 原生 IDE Cursor 宣布了一种用于代码编辑的投机性编辑(speculative edits)算法,其准确率和延迟均优于 GPT-4 和 GPT-4o,在 70b 模型上实现了超过 1000 tokens/s 的速度。OpenAI 发布了具有音频、视觉和文本等多模态能力的 GPT-4o,据称其速度比 GPT-4 Turbo 快 2 倍且价格便宜 50%,但在编程性能方面表现参差不齐。Anthropic 为开发者引入了流式传输、强制工具调用和视觉功能。Google DeepMind 推出了 Imagen Video 和 Gemini 1.5 Flash,后者是一款拥有 100 万上下文窗口的小型模型。HuggingFace 正在分发价值 1000 万美元的免费 GPU 资源,用于支持 Llama、BLOOM 和 Stable Diffusion 等开源 AI 模型。评估洞察强调了 LLM 在应对新颖问题时的挑战以及基准测试饱和的问题,像 MMLU-Pro 这样的新基准显示顶级模型的性能出现了显著下降。
投机性编辑 (Speculative edits) 就是你所需要的一切。
2024/5/15-2024/5/16 的 AI 新闻。 我们为您检查了 7 个 subreddit、384 个 Twitter 账号 和 30 个 Discord 服务器(428 个频道和 6173 条消息)。 预计节省阅读时间(以 200wpm 计算):696 分钟。
作为一款 AI 原生 IDE,Cursor 会编辑大量代码,并且需要快速完成,特别是 全文件编辑 (Full-File Edits)。他们刚刚宣布了一项结果:
“超越了 GPT-4 和 GPT-4o 的性能,并推动了准确率/延迟曲线上的帕累托前沿 (Pareto frontier)。我们使用一种专为代码编辑量身定制的投机性解码 (Speculative-decoding) 变体,称为投机性编辑 (Speculative edits),在我们的 70b 模型上实现了 >1000 tokens/s(略低于 4000 字符/秒)的速度。”
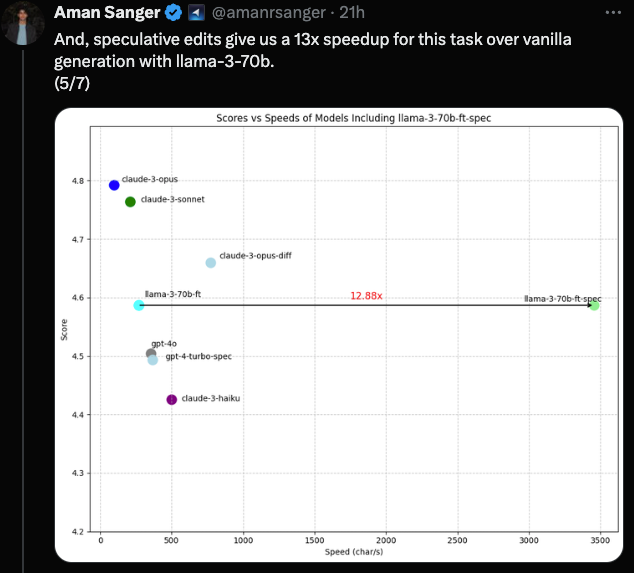
由于重点完全放在“快速应用 (fast apply)”任务上,团队使用了一个专门为此调整的合成数据流水线 (Synthetic data pipeline):
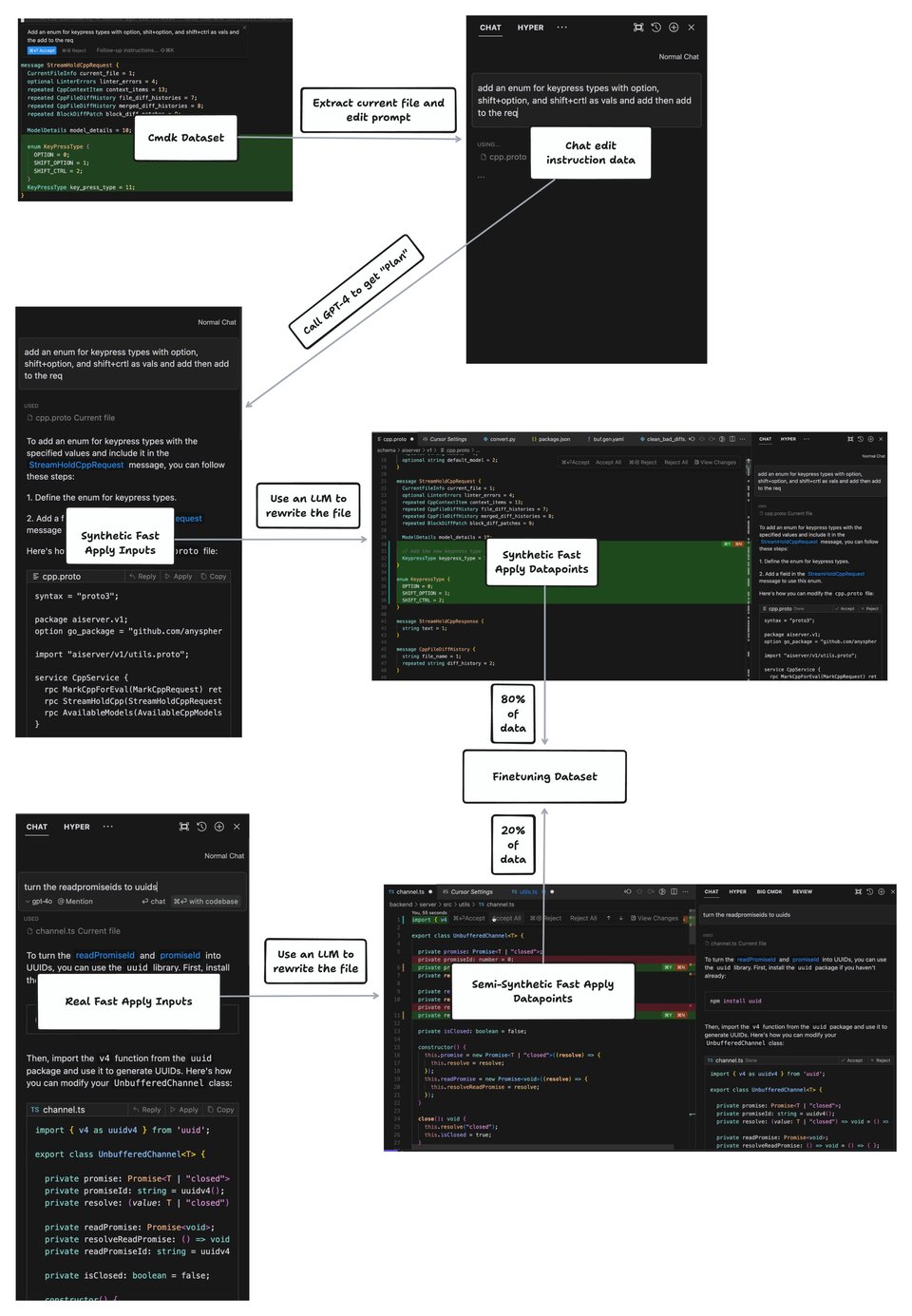
他们对投机性编辑算法有些守口如瓶——这是他们仅有的说明:
“在进行代码编辑时,我们在任何时间点对草稿 Token (Draft tokens) 都有很强的先验知识,因此我们可以使用确定性算法而不是草稿模型 (Draft model) 来推测未来的 Token。”
如果你能弄清楚如何在 gpt-4-turbo 上实现它,这里有一个 免费一个月的 Cursor Pro 送给你。
目录
[TOC]
AI Twitter 回顾
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程 (Flow engineering)。
OpenAI GPT-4o 发布
- 多模态能力:@sama 指出 GPT-4o 的发布标志着我们使用计算机方式的潜在革命,在一个全能模型中具备了音频、视觉和文本能力。@imjaredz 补充说,它比 GPT-4 turbo 快 2 倍且便宜 50%。
- 编程性能:早期测试显示 GPT-4o 的编程能力结果不一。@erhartford 发现与 GPT-4 turbo 相比,它犯了很多错误,而 @abacaj 则指出它非常擅长代码,表现优于 Opus。
-
指令遵循与语言:由于 GPT-4o 的指令遵循能力较差,特别是在 JSON、边缘情况和专门格式方面,一些客户回退到了 GPT-4 turbo,据 @imjaredz 称。然而,GPT-4o 在非英语语言方面表现更好。
- 多模态能力:@gdb 提到 GPT-4o 具有令人印象深刻的图像生成能力值得探索。@sama 澄清说新的语音模式尚未发布,但文本模式目前处于 Beta 阶段。
- 推理与知识:@goodside 发现 GPT-4o 可以解释它以前从未见过的复杂 AI 方法。@mbusigin 指出它熟悉小众的 AI 研究。
Anthropic、Google 及 AI 进展
- Anthropic 的新功能:@alexalbert__ 宣布向 Anthropic 开发者推出流式传输 (Streaming)、强制工具调用 (Forced tool use) 和视觉功能,实现了细粒度流式传输、强制工具选择以及多模态工具调用的基础。
- Google 的 Imagen Video 和 Gemini 模型:@GoogleDeepMind 推出了 Imagen Video,它可以从提示词中理解细微的效果和基调。@drjwrae 分享了 Gemini 1.5 Flash,这是一个具有 1M 上下文且性能快速的小型模型。
- 开源发布与算力获取:@HuggingFace 正在通过 ZeroGPU 向开源 AI 社区分发价值 1000 万美元的免费 GPU。Llama、BLOOM、Stable Diffusion、DALL-E Mini 等模型均可在该平台上使用。
AI 评估与安全考量
- 评估 LLMs:@svpino 指出 LLMs 在其训练数据之外的新颖问题上表现不佳。@maximelabonne 提到顶级模型的 MMLU 基准测试正趋于饱和。@_philschmid 分享了 MMLU-Pro,这是一个 更强大的基准测试,使顶级模型的性能下降了 17-31%。
- 越狱与对抗性攻击:@_akhaliq 分享了关于 语音语言模型中越狱漏洞 的 SpeechGuard 研究,其成功率很高。提出的对策显著降低了攻击成功率。
- 伦理与社会影响:@alexandr_wang 指出 解决 AI 数据挑战至关重要,因为突破是由人类专家共生关系中更好的数据驱动的。@ClementDelangue 为 AI 政策论坛做出了贡献,旨在 降低风险并支持负责任的 AI 创新。
AI 初创公司、产品与课程
- AI 驱动的搜索与 Agents:@perplexity_ai 增加了顾问来指导搜索、移动端和分发工作。@cursor_ai 训练了一个 70B 模型,实现了超过 1000 tokens/s 的速度。
- 教育倡议:@svpino 分享了来自 Google 的 300 小时免费 ML 工程课程。@HamelHusain 宣布了一门 AI 课程,包含来自 @replicate、@modal_labs 和 @hwchase17 的算力额度。
- 开源库:@llama_index 在 LlamaParse 中增加了对 GPT-4o 的支持,用于复杂文档的解析和索引。
迷因与幽默
- @svpino 调侃道“这不再好笑了”,针对 GPT-4o 声称其训练数据截止到 2023 年。
- @saranormous 发布了一个对比 AI Agent 产品营销与现实的迷因。
- @jxnlco 拿“Alex Hormozi 让我和我的朋友们变富有,我现在理解什么是教练技术了”开玩笑。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 模型发布与能力
- GPT-4o 多模态能力:在 /r/singularity 中,来自 OpenAI 的 GPT-4o 展示了令人印象深刻的 实时音频和视频处理能力,同时针对快速推理进行了优化,展示了赋能昆虫大小智能机器人的潜力。
- Google 的先进视觉模型:Google 的 Project Astra 能够记忆物体序列,而 Paligemma 具备 对世界的 3D 理解能力,展示了先进的视觉能力。
- MMLU-Pro 基准测试发布:在一篇图片帖子中,TIGER-Lab 发布了拥有 12,000 个问题的 MMLU-Pro 基准测试,修复了原始 MMLU 的问题并提供了更好的模型区分度。
- Cerebras 推出 Sparse Llama:Cerebras 推出了 Sparse Llama,与原始 Llama 模型相比,其 体积缩小了 70%,速度提高了 3 倍,且保持了完整精度。
{kind=link}
AI 安全与伦理
- OpenAI 核心 AI 安全研究员辞职:包括 Ilya Sutskever 在内的几位核心 AI 安全研究员 从 OpenAI 辞职,引发了对公司发展方向和优先事项的担忧。
- OpenAI 考虑允许 AI 生成的 NSFW 内容:OpenAI 考虑允许 AI 生成的 NSFW 内容,根据一些讨论,这可能会利用 AI 女友剥削孤独人群。
- 美国参议员公布 AI 政策路线图:美国参议员公布 AI 政策路线图 并寻求增加政府资金,以应对 AI 治理挑战。
AI 应用与用例
- 宣布 AI 设计的癌症抑制剂:Insilico 宣布了一种 AI 设计的癌症抑制剂,展示了 AI 在药物研发方面的潜力。
- 用于自主无人机的类脑视觉系统:开发了一种用于自主无人机飞行的 全类脑视觉与控制系统,运行网络时 功耗仅为 7-12 毫瓦。
- 使用本地 LLM 的 AI 驱动搜索应用:使用本地 LLM 开发了一个 网站 AI 搜索应用,结合了 llamaindex, pgvector 和 llama3:instruct 进行文档提取和结构化响应。
技术讨论与教程
- 比较 Llama 3 量化方法:在 /r/LocalLLaMA 中,对 GGUF, exl2 和 transformers 的 Llama 3 量化方法比较 强调了 GGUF I-Quants 和 exl2 在高速或长上下文场景下 的性能。
- LLM 微调背后的直觉:同样在 /r/LocalLLaMA 中,关于 LLM 微调直觉的讨论 寻求基础知识之外的资源,以理解模型行为和优化。
- 微软与佐治亚理工学院推出 Vidur:微软和佐治亚理工学院推出了 Vidur,这是一个 LLM 推理模拟器,用于寻找最佳部署设置并最大化 GPU 性能。
迷因与幽默
- AI 发布会大战迷因:关于 Google 和 OpenAI 之间 AI 发布会大战的迷因。
- 感觉到 AGI 即将到来迷因:关于 感觉到 AGI 即将到来 的迷因。
{kind=link}
{kind=link}
AI Discord 回顾
摘要之摘要的摘要
-
GPT-4o 引发热议与批评:在多个 Discord 频道中,GPT-4o 成为热门话题。OpenAI 和 Perplexity AI 的用户称赞其与 GPT-4 相比更快的速度和多模态能力。然而,OpenAI 和 LM Studio 的一些用户指出其存在性能问题、输出平庸以及功能缺失。在 Reddit 和 OpenAI FAQ 上的讨论提供了更多背景信息。
-
量化与优化技术取得进展:在 CUDA MODE 和 Latent Space Discord 中,成员们探讨了用于量化的 Bitnet 1.58 技术、用于加速三角函数计算的 CORDIC algorithm,以及 Google 用于高效 Transformer 内存的 InfiniAttention。建议使用 Torch AO 仓库 来集中管理 Bitnet 的实现。
-
新基准测试、数据集和模型发布:在以研究为中心的 Discord 频道中,发布了多项新资源,包括具有挑战性的 NIAN benchmark、VidProM 视频提示词数据集、Google 的 Imagen 3 模型以及北欧语言模型 Viking 7B。Nous Research 的 Hermes 2 Θ 模型也引起了关注。
-
Mojo 和 CUDA 的进展引发乐观情绪:Modular 和 CUDA MODE Discord 频道对 Mojo 的跨 GPU 可移植性感到兴奋,并讨论了如何改进 llm.c 等项目中的 CUDA 流处理。成员们还探索了使用 NVMe to GPU DMA 来实现更快的数据传输。
-
对 AI 透明度和可靠性的担忧:在 Datasette 和 Interconnects 等 Discord 频道中,成员们对 Google I/O 等活动中缺乏对 LLM 不可靠性的承认表示不满。有人建议举办一场展示实际应用的 “Sober AI” 展览。GPT-4o 等模型性能指标的变化也引发了关于透明度的质疑。
第一部分:高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
-
GPT4o 在工程师中引发热议:Discord 成员对 GPT4o 进行了快速评估,注意到其“极快”的响应速度,但也反映其缺乏图像生成能力。讨论中还包含了一个指向 Reddit 对话 的链接。
-
微调热潮:Base 还是 Instruct?:对于微调大型模型的建议是“如果你有大型数据集,始终选择 Base 模型”,这引发了讨论,并将用户引向了教育内容,例如一篇 Medium 文章。
-
数据集困境与 GGUF 烦恼:社区深入探讨了数据集生成错误,建议在 pandas 中使用 JSON 进行转换。同时解决了转换 ShareGPT 数据集以及 llama.cpp 的 GGUF 文件 时遇到的问题,建议通过降级 PEFT 作为补救措施。GitHub issue 追踪 提供了更多见解。
-
Unsloth AI 受欢迎程度上升:一位用户提到 Unsloth AI 出现在 Replete-AI code_bagel 数据集 的教程中,标志着它在微调 Llama 模型方面的受欢迎程度日益增长。
-
摘要能力广受好评:社区内的一项 AI-summarization 功能受到称赞,它能精准提炼对话要点,即使与 AI News 没有直接关系,也展示了该模型对冗长讨论的精简概括能力。
Stability.ai (Stable Diffusion) Discord
SD3 发布:我们还能等到它吗?:尽管对 Stability AI 的 SD3 的发布和质量存在怀疑,成员们仍对传闻抱有希望,认为 SD3 可能会被推迟发布以提振销量,但目前尚未提供确切的发布日期或定价信息。
GPU 大战:4060 TI vs 4070 TI 对决:4060 TI 16GB 与 4070 TI 12GB 展开了对比,前者被推荐用于 ComfyUI,而后者被认为在游戏性能方面表现更好,但未详细说明具体细节。
API 替代方案需求旺盛:成员们正积极寻找并讨论 API,Forge 被认为在模型训练和资产设计方面等同于 A1111 的 UI,Invoke 也在讨论之列。
主力 GPU 获得基准测试:一个信息丰富的 基准测试网站 正在流传,用于评估 GPU 性能;它提供了 1.5 和 XL Models 等模型的数据,并可针对包括 Intel Arc a770 在内的特定硬件进行筛选。
金钱与理智的分歧:关于经济不平等的激烈对话展开,一些成员强调了追求财富在道德和福祉方面的代价,不过这些是普遍的哲学对话,而非特定的 AI 相关讨论。
OpenAI Discord
-
GPT-4o 的坎坷开局:讨论强调了 GPT-4o 的性能问题,用户报告了响应时间变慢、话题重复以及缺少预期功能等 Bug。相比之下,在某些 Prompt Engineering 案例中,GPT-4o 被称赞比 GPT-4 具有更好的现实世界语境理解能力。
-
了解 GPT-4o 的访问权限和功能:用户对 GPT-4o 的访问和推广阶段表示困惑,官方澄清其优先面向付费账户——更多详情见 OpenAI 的 FAQ。由于使用限制可能会影响软件开发等重度使用场景,用户对 ChatGPT Plus 订阅权益表示担忧。
-
Prompt Engineering 释放潜力与陷阱:Prompt Engineering 策略正在不断完善,探索语言细微差别如何影响 AI 性能。同时,人们也在努力理解 GPT 版本的正确 Token 限制和功能,并建议构建基于角色的 Prompt 以获得更丰富的交互。
-
AI 在未来工作中的角色及情感设计引发辩论:公会思考了 AI 对就业市场的影响,引发了关于新工作创造潜力与被淘汰威胁之间的讨论。此外,还辩论了 AI 情感响应的适当程度,质疑 AI 应该倾向于类人交互还是保持职业中立。
-
社区助力 AI 语音助手进步:推出了一款易于部署的 Plug & Play AI Voice Assistant,并征求用户反馈以进一步完善产品。据称该助手可在 10 分钟内投入运行,强调了用户友好的实现和社区驱动的改进。
Perplexity AI Discord
- GPT-4o 表现出色:在 Perplexity 上,GPT-4o 因其比 GPT-4 Turbo 更快、更高效的结果而备受关注,尽管部分用户在灰度推送中遇到了障碍。
- Perplexity 在研究领域胜出:与竞争对手相比,用户认可 Perplexity 准确且及时的来源引用和搜索功能,使其成为进行详细研究的首选工具。
- DALL-E 的文本渲染难题:用户报告了 DALL-E 生成的图像中文字显示为乱码的问题;建议的解决方案包括修改 Prompt 结构以优先处理文本指令。
- Perplexity Pro 的 iOS 语音模式赢得粉丝:Perplexity Pro iOS 应用上的语音功能因其流畅自然的交互而广受好评,引发了对 Android 版本的期待。
- Perplexity Pro 支付故障报告:遇到 Perplexity Pro 支付问题的订阅者被引导联系 support@perplexity.ai 寻求帮助。
- Perplexity 的信息高速公路:指向 Perplexity AI 的链接突显了用户的兴趣点,范围涵盖 微调搜索结果、阿兹特克体育场 (Aztec Stadium) 的详情、Google 综述、烹饪界的传闻,以及 Anthropic 的团队扩张。
- 工程师的 API 清单:在 Perplexity AI 社区中,出现了一些关注点,包括 API 引用功能的 Beta 测试访问请求、llama-3-sonar-large-32k-online 模型的联网搜索能力、对固定模型别名 (model aliases) 的需求、不可预测的 API 延迟,以及自动修正 Prompt 导致结果偏差的挑战。
HuggingFace Discord
-
Terminus 处于领先地位:Terminus 模型已更新以提供改进的功能,其最新系列已在 HuggingFace 上线。Velocity v2.1 checkpoint 的下载量已突破 6.1 万次,并在使用负向提示词 (negative prompts) 时提供了增强的性能。
-
PaliGemma 成为焦点:讨论围绕 PaliGemma 模型展开,从生成的代码问题到揭晓一个能有效结合视觉和语言任务的强大 Vision Language Model。DeepMind 的 Veo(一个视频生成模型)也进入了视野,承诺提供 1080p 电影风格的视频,并很快将与 YouTube Shorts 集成。
-
模型奥秘与 Epsilon Greedy 调查:以好奇心驱动的强化学习 (RL) 受到关注,讨论了 epsilon greedy policies 和新型好奇心机制如何促进探索。在 NLP 领域,模型中过时的编码知识引发了挑战;成员们强调了持续重新训练以保持相关性的重要性。
-
dstack 成为本地 GPU 英雄:dstack 工具因简化了使用 CLI 工具管理本地 GPU 集群而受到高度赞扬。在其他方面,AI 在 PowerPoint 幻灯片内容优化中的作用引发了辩论,建议使用 RAG 或 LLM 模型从过去的演示文稿中学习和适应。
-
多样化的讨论让工程师保持参与:各种技术线程照亮了社区的版图——包括对商业用途的 MIT 许可证专业知识的需求、在计算机视觉中使用 UNet 模型,以及 OpenAI 的 Ilya Sutskever 最近的行业动态也引起了关注。
本质上,社区对话围绕新型 AI 工具和模型微调展开,交织出技术进步与实际落地的生动图景。
Nous Research AI Discord
让 AI 像大脑一样流式思考:工程师们建议 AI 可以采用一种类似于人类思维过程的 流式方法 (streaming-like method),并引用了 Infini-attention 论文作为潜在框架,以改进 LLM 处理长上下文的能力,且不会使其有限的工作内存过载。
大海捞针之外,更严苛的基准测试:Needle in a Needlestack (NIAN) 基准测试被引入作为评估 LLM 的更具挑战性的测试,即使是对 GPT-4-turbo 这样强大的模型也构成了障碍;更多信息可在 NIAN 官网 和 GitHub 上查看。
揭秘北欧 NLP 宝藏 Viking 7B:Viking 7B 作为首个针对北欧语言的开源多语言 LLM 问世,而 SUPRA 则被提出作为一种经济高效的方法,通过将大型 Transformer 增强为 Recurrent Neural Networks 来进行改造,从而提高扩展性。
Hermes 2 Ω:合并 LLM 以获得卓越结果:Nous Research 宣布发布 Hermes 2 Ω,这是 Hermes 2 Pro 和 Llama-3 Instruct 的模型合并版本,并经过进一步精炼,在基准测试中表现出色,可在 HuggingFace 上获取。
多模态融合与微调:Meta 发布的 ImageBind 提高了标准,这是一款能够跨多种模态进行联合嵌入的新 AI 模型,同时讨论也涉及了微调现有模型(如 PaliGemma)以增强交互性的潜力。
LM Studio Discord
-
苏联时代密码机引发的“香水幻觉”:关于一台名为 Fialka 的苏联加密机据称使用紫色香水的“创意幻觉”在闲聊频道引起了关注,这凸显了 LM 模型 有时会如何异想天开地偏离现实。
-
APU 在模型压力下挣扎:在讨论 APU 对模型性能的作用时,成员们得出结论,llama.cpp 在推理过程中利用 APU 的方式与 CPU 并无二致,这可能会影响运行大型模型时的硬件购买决策。
-
冰冷的模型构建体验:在 CPU 上为 Llama-3 70B 等大型模型构建 imatrix 令人沮丧,用户报告称 构建时间长达数小时 且散热受限是显著的挑战,这展示了当前基础设施的实际限制。
-
硬件重量级选手展示肌肉:分享了一个包含 32 核 Threadripper、512GB RAM 和 RTX6000 的高端配置,展示了顶级配置实现 0.10s 首字生成时间 (time to first model token) 和 102.45 token/sec 生成速度 的强大性能。
-
软件故障与 AVX 异常:讨论围绕 LM Studio 的兼容性和 UI 问题展开,一位用户指出 AVX1 系统无法运行 LM Studio(需要 AVX2),而其他用户则呼吁进行 UI 优化,以增强复杂服务器管理任务期间的用户体验。
Modular (Mojo 🔥) Discord
-
Mojo 在 AI 开发中崛起:工程师们分享了 Mojo SDK 的学习资源,包括 Mojo manual 和 Mandelbrot tutorial 的链接。Mojo 的优势得到了强调,特别是其跨厂商的 GPU 灵活性以及推动硬件竞争的潜力。
-
开源状态引发辩论:社区对 Mojo 的部分开源性质展开了辩论,指出其标准库是开源的,但编译器和 Max 工具链目前尚未开源。人们对编译器可能开源感到兴奋,而 Max 则不太可能开源。
-
语法陷阱与条件方法:讨论揭示了 Mojo 文档中的语法不一致以及
alias数据结构迭代的问题。成员们赞扬了新功能 conditional methods(条件方法)的语法,尽管提到了查找相关 changelog 信息的困难。 -
社区参与编译器与贡献:最新的 Mojo 编译器版本(
2024.5.1515)引发了关于 macOS 上非确定性自检失败的讨论。对仓库中“占坑(cookie licking)”现象的担忧被提出,建议通过更小的 PR 作为加快社区贡献的解决方案。 -
Modular 聚焦 Joe Pamer 及更新:Modular 在推特上发布了其最新更新(未引用具体内容),并通过一篇博客文章展示了 Mojo 的工程负责人 Joe Pamer。推文或博客文章的具体讨论内容未提供细节。
CUDA MODE Discord
Tensor 之争:工程师们讨论了在 CUDA 中使用 torch.tensor Accessors 与直接向 kernel 传递 tensor.data_ptr 的优劣,一些人担心潜在的 unsigned char 指针问题和缺乏清晰文档。对话指向了 PyTorch’s CppDocs 以了解 Accessors 的使用及其对 tensor 效率的影响。
解决棘手的 CUDA 谜题:成员们解决了来自 CUDA puzzle repo 的 dot product problem(点积问题),指出了朴素方法中浮点溢出的陷阱,而基于 reduction 的 kernel 则能保持 fp32 精度。一位用户的经验和代码片段(包括一个浮点溢出错误)在 GitHub Gist 上分享。
对抗非连续 Tensor:关于 torch.compile 问题和 PyTorch 自定义算子(custom ops)的讨论强调了非连续 tensor 步长(strides)和内存缓存限制带来的挑战。工程师们交流了在自定义算子定义中使用标签的想法(如 [torch library](https://pytorch.org/docs/main/library.html) 所建议),并主张减少 torch.compile 编译时间的计划,参考了 PyTorch forum 上的讨论。
探索 Bitnet 的量化之路:对 Bitnet 1.58 的热情高涨,呼吁在 GitHub 等平台上组织相关工作,并深入研究线性层和 2-bit kernel 的训练感知量化(training-aware quantization)。讨论建议将工作集中在 Torch AO repository,并强调了 HQQ 和 BitBLAS 作为位打包(bitpacking)和 2-bit GPU kernel 的现有解决方案。
Kernel 技巧与工具注记:一位用户发布了关于 instant apply 技术的文章链接(未提供进一步背景),另一位分享了 GPU Programming Guide 的心得,还有一位用户遇到了与 CUDA 相关的 ONNXRuntimeError。
迈向精度与性能:讨论集中在重新校准 CUDA stream 的集体努力上,建议推倒重来,这引发了大量讨论和相应的 GitHub Pull Requests。还提到了 NVMe 直接到 GPU 的 DMA 传输这一长远目标,并提及了 ssd-gpu-dma repository。
LlamaIndex Discord
Vertex AI 欢迎 LlamaIndex:LlamaIndex 与 Vertex AI 合作推出了全新的 RAG API,旨在增强用户在 Vertex 云平台上实现检索增强生成(retrieval-augmented generation)模型的能力。社区可以通过 LlamaIndex 的 Twitter 帖子 了解该公告。
GPT-4o Quartz 与 LlamaIndex 深度集成:LlamaIndex 的 create-llama 更新现已整合 GPT-4o,提供了一种直观的方式,通过简单的问答格式基于用户数据创建聊天机器人。更多信息请参阅 LlamaIndex Twitter 上的详细说明。
LlamaParse 与 Quivr 强强联手:LlamaIndex 与 Quivr 达成合作,推出了 LlamaParse——这是一款利用先进 AI 解析多种文档格式(.pdf, .pptx, .md)的工具。Twitter 链接 提供了关于此进展的更多见解。
UI 调整带来 LlamaParse 使用惊喜:LlamaIndex 团队发布了 LlamaParse UI 的重大改进,承诺为用户提供更广泛的功能集。GUI 的改进可以在 最新的 Twitter 更新 中看到。
为 SQL 选择合适的模型:#general 频道讨论了关于为 SQL 表选择合适 Embedding 模型的疑虑,用户建议参考 MTEB Leaderboard 上的模型。然而,有人指出一个障碍:这些模型通常是以文本为中心的,可能无法专门满足 SQL 数据的需求。
通过 RAG 与文档对话:在 #ai-discussion 频道中,一位用户在将 Cohere AI 的检索增强生成(RAG)功能集成到 Llama 中时寻求帮助,希望创建一个“与文档聊天”的应用程序。他们向社区征求关于有效实现的方法和资源的建议。
LAION Discord
AI 正在消耗大量电力:关于 AI 的能源需求 引起了热议,重点提到 5000 块 H100 GPU 集群在闲置状态下的功耗竟高达 375kW。这充分说明了 AI 技术日益增长的能源占用。
Stable Diffusion 在 Mac 上实现原生运行:一个名为 DiffusionKit 的项目与 Stability AI 合作,成功在 Mac 设备上实现了 Stable Diffusion 3 的本地运行,标志着强大 AI 工具的可访问性取得了进展。该消息通过一条 推文 发布,提高了人们对开源版本的期待。
开源的妥协:围绕 开源 创业的创新精神与 私有化公司 的财务诱惑之间的选择展开了激烈辩论,由于对限制性竞业禁止条款的担忧,辩论愈演愈烈。鉴于 FTC 最近颁布的禁止此类协议的规定 (FTC 公告),这一话题变得更加受关注。
GPT-4o 引领多模态革命:讨论指向了 GPT-4o 在多模态功能(包括图像生成和编辑)方面的卓越表现,表明人们日益达成共识:多模态模型 处于 AI 开发的最前沿。
视频数据集和采样方法的突破:从发布旨在加速文本生成视频研究的大型数据集 VidProM(见 arXiv 论文),到克服神经网络双线性采样局限性的新方法,这些讨论强调了对创新的不懈追求。同时,Google 的 Imagen 3 作为领先的图像生成模型正引起轰动,社区成员热切讨论了其在创建合成数据集中的作用 (Imagen 3 信息)。
Eleuther Discord
-
Epinets 呈现出棘手的平衡:Epinet 的使用因其调优复杂性以及作为扰动偏差(perturbative bias)的潜力而受到审视。一段著名的引用强调了这一观点:“Epinet 本应保持较小规模,所以我假设残差只是起到了归纳偏置(inductive bias)的作用……”
-
Transformer 趣闻与模型洞察:技术讨论围绕 Transformer 的反向传播(backpropagation)技术和一个共享的 DCFormer GitHub 仓库展开,一些人根据最近的研究探讨了 Transformer 模型在路径组合(path composition)和结合律挑战方面的执行情况。
-
从 Scaling Laws 到 AGI 愿景:讨论中交织着对符号空间元学习(meta-learning in symbolic space)和 AGI 潜力的向往,以及 GPT-4 训练后 Elo 分数提升带来的实践启示。
-
GPT-NeoX 转换受 Bug 困扰:
convert_neox_to_hf.py脚本在处理不同的流水线并行(Pipeline Parallelism)配置时遇到 Bug,一位贡献者提出了修复方案。涉及rmsnorm的不兼容问题导致有人建议尝试适用于 Huggingface 的不同配置文件。 -
优化模型评估与转换:在竞赛和模型对比领域,分享了使用
--log_samples的方法,以方便提取多选题答案指标,这对于 AI 模型的性能分析至关重要。
Interconnects (Nathan Lambert) Discord
神经网络在现实认知上达成一致:成员们参与的讨论表明,尽管目标和数据不同,神经网络在其表征空间(representation spaces)中正趋向于一个现实的通用统计模型。Phillip Isola 最近的见解支持了这一点,正如他在其项目网站、学术论文和 Twitter 线程中所分享的,展示了 LLM 和视觉模型在规模扩大时如何开始共享表征。
OpenAI Tokenization 之谜:社区在思考 OpenAI 的 Tokenizer 是否可能是“伪造的”,推测不同的模态(modalities)可能必然需要不同的 Tokenizer。尽管存在怀疑,一些成员主张给予疑点利益(benefit of the doubt),认为即使在看似混乱的项目中,也可能存在详细的方法论。
Anthropic 转向以产品为中心:Anthropic 正在转型为基于产品的方法,拥抱对市场化交付物的需求以增强数据精炼。与此同时,讨论也涉及了 OpenAI 和 Anthropic 等 AI 组织面临的更广泛挑战,包括其估值的可持续性以及对外部基础设施的依赖。
AGI 时间节点的拉锯战:受 Dwarkesh 采访的启发,关于接近 AGI 可能性对话揭示了社区的严重分歧,从乐观主义到对 AGI 时间线预测的实用性和影响的批评不一而足。
AI 模型指标的透明度受到质疑:社区关注到 GPT-4o 的 Elo 评分莫名下降以及 LMsys 评估细节的减少,引发了关于需要清晰沟通和一致更新协议的讨论。关于此问题的资源和观点通过各种 推文和视频内容 进行了交流。
LangChain AI Discord
-
使用 LangChain 获取精简的 Token 输出:LangChain 的
.astream_eventsAPI 提供了自定义流式传输的方法,可以实现原本期望在AgentExecutor中通过.stream获取的单个 token 输出。详细的 streaming documentation 阐明了这一过程。 -
解决 Jsonloader 兼容性问题:一位用户提出了针对 Windows 11 上 Jsonloader 无法安装用于 JSON 解析的 jq schema 的修复方案;详情可以在 Langchain 的问题追踪器中找到,Issue #21658。
-
设计巧妙的机器人记忆策略:讨论了为聊天机器人赋予记忆以在对话之间保持上下文的策略,包括跟踪聊天历史记录以及在 prompt 中引入记忆变量。
-
应对服务中断与速率限制:成员们讨论了由 “rate exceeded” 错误和服务器不活动导致的工作流效率低下所引起的干扰;还提出了关于部署修订版和检查与服务器不活动相关的模式的问题(未提供 URL)。
-
分享富有洞察力的教程与巧妙项目:分享了一个关于创建通用网页抓取 Agent 的教学 video,一位用户展示了他们在 Langserve 后端集成 py4j 以处理加密货币交易的情况,以及他们实现的一个结合了 LLM、RAG 和交互式 UI 组件的创新房地产 AI 工具(LinkedIn: Abhigael Carranza, YouTube: Real Estate AI Assistant demo)。
OpenRouter (Alex Atallah) Discord
-
印地语聊天机器人助力:名为 “pranavajay/hindi-8b” 的 Hindi 8B Chatbot Model 已发布,拥有 10.2B 参数,在聊天机器人和语言翻译应用方面表现出潜力。它的发布为印地语 NLP 任务增加了新的能力层。
-
移动端聊天机器人更友好:ChatterUI 已发布,这是一个针对 Android 聊天机器人的极简 UI,专门设计为以角色为中心,并与 OpenRouter 后端兼容。开发者可以通过其 GitHub repository 探索并贡献代码。
-
Invisibility 隐身进入你的 MacOS:名为 Invisibility 的新 MacOS Copilot 集成了 GPT4o、Gemini 1.5 Pro 和 Claude-3 Opus,具有视频助手功能,并计划增强语音和记忆功能。正如其 announcement 中所强调的,社区可以期待很快推出 iOS 版本。
-
Lepton 为 WizardLM-2 提供支持:有建议将 WizardLM-2 8x22B Nitro 切换到 Lepton,以利用 OpenRouter 的 Text Completion API,尽管 Lepton 因某些问题从部分列表中被移除,但其能力仍能提升性能。
-
高效上下文管理解析:Google 的 InfiniAttention 因其在 Transformer 中处理超大 token 上下文的能力而被引用,引发了关于 LLM 内存和性能效率的讨论,并有相关研究论文支持。
OpenInterpreter Discord
- 黑客行为获得回报:一名用户成功绕过了 OpenAI 桌面应用的 gatekeeper dialog,随后受邀加入一个私有的 Discord 频道以参与其开发。
- 意识到 GPT-4o 的局限性:用户报告称,在 OpenInterpreter (OI) 中尝试使用 GPT-4o 的图像识别功能时,在截图阶段后会失败,这凸显了功能上的差距。
- 性能困境:尽管 dolphin-mixtral:8x22b 的处理速度缓慢,仅为每秒 3-4 个 tokens,但它被认为运行有效,而速度更快的 CodeGemma:Instruct 则被视为一个平衡的替代方案。
- OI 功能丰富与调试途径:建议为硬件设备提供更多信息化的 LED 反馈,并推出了一个新的用于 iOS 调试的 TestFlight 应用(TestFlight 链接),协助解决音频输出问题。
- 设置难题与解决方案:在 01 框架内,成员们分享了涉及 grok server 配置和模型兼容性的技术挑战,并提出了包括服务器设置和使用 Poetry 进行 Linux 安装在内的修复方案。为了提供社区支持,分享了 设置指南 和 GitHub 仓库(01/software at main)等资源链接。
Datasette - LLM (@SimonW) Discord
Google I/O 忽视了 LLM 可靠性:公会的工程师们强调,Google I/O 上缺乏对 LLM 可靠性问题 的讨论,并对主要演讲者未承认此事表示担忧。
对 AI 的“冷静”看法:提出了一个“Sober AI”展示概念,旨在展示实用、可靠且无炒作的 AI,目标是为大语言模型应用设定现实的预期。
转型 AI:小组讨论了将 AI 从“generative”(生成式)重新命名为“transformative”(转换式)的潜力,以更好地反映其在改变和处理信息方面的能力,并认为这可能会带来更准确、更富有成效的对话。
Prompt Caching 提高效率:技术讨论涉及使用 Gemini 的 prompt caching,通过在 GPU 内存中保留 prompts 来降低 token 使用成本,尽管其运行成本为每百万 tokens 每小时 4.50 美元。
模型切换与桌面客户端担忧:技术社区对在对话中途切换 LLM 及其可能引起的数据完整性问题表示担忧。此外,有人担心 SimonW 的 Mac 桌面解决方案已被放弃,从而引发了关于无缝体验替代方案的讨论。
Latent Space Discord
-
OpenAI 挖角 Google 高手进行搜索对决:OpenAI 战略性招聘了前 Google 重量级人物 Shivakumar Venkataraman,加速了他们通过自有搜索引擎与 Google 竞争的野心。
-
模型合并大师:Nous Research 在 model merging(模型合并)方面的开创性工作仍在继续,对话强调“post-training”(后训练)是包括 RLHF (Reinforcement Learning from Human Feedback)、fine-tuning 和 quantization 在内的技术的统称,展示了 Nous 的研究方向。
-
观看并学习 Dwarkesh Patel 的对话:Dwarkesh Patel 最新的播客节目收到了褒贬不一的反应,既有对大牌嘉宾的赞扬,也有对采访者参与度不足的批评,该节目被评价为“中规中矩”,但因其嘉宾阵容而值得一听。
-
富文本翻译难题:社区深入探讨了翻译富文本的复杂性,建议使用 HTML 作为中间格式,以确保跨语言时 span 语义不会丢失。
-
Hugging Face 慷慨的 GPU 举措:为了使 AI 开发民主化,Hugging Face 已承诺投入 1000 万美元的 GPU 来支持小型开发者、学术界和初创公司,旨在去中心化 AI 创新。
-
新播客节目预警:Swyxio 发布了一个 新播客节目 的链接,增加了团队对行业见解的持续吸收和讨论。
OpenAccess AI Collective (axolotl) Discord
Falcon 与 LLaMA 的授权之争:Falcon 11B 和 LLaMA 3 的许可证引发了辩论,人们担心 Falcon 的可接受使用政策(Acceptable Use Policy)更新可能无法强制执行。在对 LLaMA 3 等模型应用 LORA 时,原始 Prompt 的保真度是关键。
Docker 困境与数据讨论:针对 8xH100 PCIe 的 Docker 设置已成功完成,但 SXM 版本 的状态尚不明确。同时,STEM MMLU 数据集 已得到扩展,为 STEM 相关的 AI 评估创建了更详细的基准。
小而强大:TinyLlama 的问题与修复:TinyLlama 出现了训练困难,需要使用 accelerate 手动启动。社区成员正在寻求修复这一差异的方法,这似乎是当前的一个挑战。
跨格式对话:用于训练聊天机器人的 Alpaca 格式 因其后续问题的不一致而受到批评,这促使人们在 AI 训练期间更倾向于保持一致的聊天格式。
混元 Hunyuan-DiT 加入战局:Hunyuan-DiT 模型 引起了关注,这是一种专为中文处理量身定制的新型多分辨率扩散 Transformer(multi-resolution diffusion transformer),其详细信息可在其 arXiv 论文中找到。
使用正确的 Token:与 LLaMA 3 和 ChatML 分词(tokenization)相关的查询已得到解决,确认 ChatML 的 ShareGPT 格式 兼容,无需额外的特殊 Token。
AI Stack Devs (Yoko Li) Discord
-
AI Town 探索新领域:关于 AI Town 的讨论强调了对用于 Agent 控制的 API 的兴趣,特别是目前还不支持特定于 Agent 的 LLM。成员们热衷于探索各种 API 级别,包括与 OpenAI 兼容的级别,并且提到一个具有多人游戏功能的潜在 Discord iframe 时表现得尤为兴奋,并引用了一个用于构建 Discord 活动的开箱即用入门模板。
-
为增强性能进行 NPC 微调:在 AI Town 开发中,有人建议通过减少 NPC 活动来提高性能,重点关注可能影响 NPC 行为的冷却常数(cooldown constants)。即将推出的 AI 真人秀平台(AI Reality TV Platform)已宣布,该平台对社区贡献的自定义地图开放。
-
社区贡献与功能热度:社区愿意为 AI Town 的 Discord iframe 等项目做出贡献,反映了一种积极主动的态度,预示着将通过协作努力引入多人活动等新功能。
-
红杉资本的 PMF 框架引发关注:分享了一篇关于红杉资本 PMF 框架的文章,详细介绍了三种产品市场匹配(Product-Market Fit)类型,以协助创始人进行市场定位,这可以为以产品为中心的 AI 工程师提供宝贵的见解。
-
新成员获得帮助:一位新成员得到了社区的帮助,进行了头像自定义,增强了他们在虚拟空间的个人体验,并培养了乐于助人的社区精神。
tinygrad (George Hotz) Discord
CORDIC 战胜复杂性:工程师们讨论了 CORDIC 算法 相比 Taylor series 在计算三角函数方面的优势,重点在于其简洁性和速度优势。讨论了 Python 实现以及处理大参数值的方法,并对机器学习应用中的精度和有效性表示了关注。
驯服三角函数:对话转向了在三角函数中减少参数的有效方法,以确保在可接受范围(-π 到 π 或 -π/2 到 π/2)内获得精确结果。考虑了针对 GPU 的潜在优化路径,以及在处理大三角数值时使用 Taylor 近似作为回退方案。
用于形状索引的高效可视化工具:介绍了一个辅助理解 Tensor 重塑操作中形状表达式的可视化工具,解决了复杂映射带来的挑战。该工具已公开,可以在这里找到。
探索用于代码生成的 TACO:社区评估了 TACO(一个用于张量代数的代码生成器),将其作为 Tensor 计算的高效资源。还建议在 Tinygrad 中探索使用自定义 CUDA kernel 进行大型 Tensor 归约,以实现直接的结果累加。
寻求对 Tinygrad 操作的澄清:针对计算图中的 uops 寻求澄清,特别是 DEFINE_GLOBAL 操作和输出缓冲区标签,强调了底层操作需要更清晰的文档。此外,推荐将 UseAdrenaline 作为理解包括 Tinygrad 在内的各种仓库的辅助学习工具。
MLOps @Chipro Discord
在 Data AI Summit 与成员叙旧:工程师同事们正在协调于 6 月 6 日至 16 日在湾区举行的 Data AI Summit 期间进行非正式会面。这一提议激发了成员们线下交流的共同兴趣。
暂停每月闲聊活动:由 Chip 组织的定期闲聊活动将在未来几个月暂停,参与者们在猜测下一次社交聚会何时举行。
Snowflake Dev Day 的互动学习机会:Discord 成员收到邀请,参观 6 月 6 日 Snowflake Dev Day 的展位,届时有望深入了解 Snowflake 与数据科学工作流的集成。
NVIDIA 加码开发者竞赛:NVIDIA 与 LangChain 举办的 Generative AI Agents Developer Contest 引发了热议,奖品包括 NVIDIA® GeForce RTX™ 4090 GPU,尽管地理限制让部分人感到遗憾。
探索 AI 硬件的演进:分享了一篇深入探讨机器学习微处理器历史发展并预测未来趋势的文章,指出基于 Transformer 的模型带来的变革性影响,并提及了 Nvidia 飙升的估值。文章预测了 NVMe 驱动器和 Tenstorrent 技术的激动人心的进展,但认为 GPU 在中期未来会进入冷静期。
Cohere Discord
- Cohere Reranker 功能强大,期待高亮功能:用户在使用 Cohere 的 rerank-multilingual-v3.0 模型时取得了令人印象深刻的效果,但希望能有类似 ColBERT 的功能,能够高亮显示与检索任务相关的关键词。
- Connectors 详解,但 PHP 客户端查询仍在继续:讨论澄清了 Cohere connectors 旨在与数据源集成,但社区仍在寻求可靠的 PHP 客户端,GitHub 上的 cohere-php 是一个尚未经过测试的选择。
- Toolkit 魔法与 Reranking 奇迹受到关注:关于 Cohere application toolkit 的咨询强调了对其在生产环境中使用时的可扩展性的兴趣,同时社区对为什么 Cohere 的 Reranking 模型优于其他开源替代方案表示好奇。
DiscoResearch Discord
Ilya Sutskever 告别 OpenAI:Ilya Sutskever 离开 OpenAI 的公告引发了关于该组织对 Alignment 研究人员吸引力的争论,并引发了对其未来研究方向的担忧。
GPT-4-turbo 在 NIAN 中遇到对手:Needle in a Needlestack (NIAN) 基准测试对 LLM 的上下文敏感响应提出了新层级的挑战,有报告称“即使是 GPT-4-turbo 在该基准测试中也表现吃力”。访问 代码 和 网站 了解详情。
LLM Perf Enthusiasts AI Discord
- AI 工作室 Ambush 寻觅资深人才:Ambush 正在寻找一名 远程资深全栈 Web 开发人员,为 DeFi 产品打造直观的 UX/UI,职责重点为 70% 前端 和 30% 后端。感兴趣的 AI 工程师可以查看 Ambush 职位列表,成功入职可获得 $5k 推荐奖金。
Mozilla AI Discord
- Llamafile 中的超链接故障:工程师报告 Mozilla 的 llamafile 项目 中存在 Markdown 超链接无法渲染为 HTML 的问题,并建议开启 GitHub issue 来解决这一代码缺陷。
- 超时问题困扰私人助手:AI 工程师在运行 Mozilla 的私人搜索助手 时遇到了 httpx.ReadTimeout 错误,导致 Embedding 生成在 9% 时终止,引发了关于延长超时设置的讨论。
Alignment Lab AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Skunkworks AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
Unsloth AI (Daniel Han) ▷ #general (1022 条消息 🔥🔥🔥):
- 对 GPT4o 的快速评价:成员们分享了对 GPT4o 性能的初步印象,评论包括“快得惊人”以及无法生成图像的缺点。讨论链接。
- 关于微调时选择 Instruction 模型还是 Base 模型的见解:Theyruinedelise 建议:“如果你有大型数据集,始终选择 Base 模型。如果是小型数据集,选择 Instruct 模型,” 并提供了 Medium 上的文章供进一步阅读。
- Unsloth 支持 Qwen 并持续改进:Theyruinedelise 宣布支持 Qwen 并分享了更新后的 Colab notebooks,建议更新安装命令:
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"。 - 用于 AI 训练的数据集:lh0x00 在 Huggingface 上发布了新的英越翻译双语数据集,方便配合 unsloth、transformers 和 alignment-handbook 等工具使用。
- 财务报告提取研究:Preemware 分享了一项比较 RAG 和 Finetuning 方法的研究,显示 Mistral 和 Llama 3 等模型在使用 RAG 时性能大幅下降,详见 Parsee.ai。
- WizardLM (WizardLM): 未找到描述
- mixedbread-ai (mixedbread ai): 未找到描述
- Skorcht/schizogptdatasetclean · Hugging Face 数据集: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- unsloth (Unsloth AI): 未找到描述
- lamhieu/translate_tinystories_dialogue_envi · Hugging Face 数据集: 未找到描述
- Reddit - 深入探索一切: 未找到描述
- AI Unplugged 10: KAN, xLSTM, OpenAI GPT4o 和 Google I/O 更新, Alpha Fold 3, Fishing for MagiKarp: 洞察重于信息
- 来自 VCK5000 Versal 开发卡的推文: AMD VCK5000 Versal 开发卡基于 AMD 7nm Versal™ 自适应 SoC 架构构建,专为使用 Vitis 端到端流程的 (AI) 引擎开发和 AI 推理开发而设计...
- cognitivecomputations/Dolphin-2.9 · Hugging Face 数据集: 未找到描述
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- GitHub - unslothai/unsloth: 以 2-5 倍的速度和减少 80% 的内存微调 Llama 3, Mistral & Gemma LLMs: 以 2-5 倍的速度和减少 80% 的内存微调 Llama 3, Mistral & Gemma LLMs - unslothai/unsloth
- lamhieu/alpaca_gpt4_dialogue_vi · Hugging Face 数据集: 未找到描述
- lamhieu/alpaca_gpt4_dialogue_en · Hugging Face 数据集: 未找到描述
- finRAG 数据集:深入探讨使用 LLMs 进行财务报告分析: 在 Parsee.ai 探索 finRAG 数据集和研究。深入了解我们在财务报告提取中对语言模型的分析,并获得对 AI 驱动的数据解释的独特见解。
- 来自 Should AI Be Open? 的推文: I. H.G. Wells 1914 年的科幻小说《获得自由的世界》(The World Set Free) 在预测核武器方面做得非常好:直到原子弹在他们笨拙的手中爆炸,他们才看到它……在……之前
Unsloth AI (Daniel Han) ▷ #random (27 条消息🔥):
-
Unsloth 出现在微调教程中:一位用户兴奋地提到 Replete-AI code_bagel 数据集 在其微调 Llama 的教程中使用了 Unsloth。“我很高兴 Unsloth 变得如此受欢迎。”
-
Llama3 在修复分词器后出现高 Loss:一位用户报告称,在修复分词器(tokenizer)问题后,他们的 Llama3 模型显示的 Loss 是之前的两倍。在没有 EOS_TOKEN 的情况下进行的进一步实验也未能解决该问题,导致训练 Loss 持续走高。
-
ShareGPT 数据集转换时的内存问题:一位用户分享说,他们的 64GB RAM 不足以转换 ShareGPT 数据集,而另一位用户(可能是 Rombodawg)提到该代码通常只需要约 10GB 的 RAM。他们在私信中讨论了此事以解决代码问题。
提及的链接:Replete-AI/code_bagel · Hugging Face 数据集:未找到描述
Unsloth AI (Daniel Han) ▷ #help (448 条消息🔥🔥🔥):
-
JSON 格式的数据集问题:多位用户(包括 mapler 和 noob_master169)正在排查数据集生成错误。建议将 JSON 加载到 pandas 中,然后转换为数据集作为修复方案。
-
数据集生成故障排除:theyruinedelise 确认该问题很可能是数据集格式问题。他们还讨论了潜在的解决方案,并确认该方法正在解决根本问题。
-
GGUF 转换错误:多位用户(如 leoandlibe 和 jiaryoo)讨论了 llama.cpp 转换和 GGUF 文件的问题。theyruinedelise 等人指出 PEFT 更新可能是潜在原因,并建议降级。
-
使用 GPT-3 进行自定义查询:just_iced 在使用 Llama 3 查询驾驶手册时遇到问题。在与其他成员共同排查后,他们通过转而使用 Ollama 解决了问题。
-
模型兼容性与问题:讨论了关于 Unsloth、Llama 3 等模型的兼容性与安装问题,以及关于上下文窗口限制的问题。starsupernova 提供了解决问题的具体步骤,例如修改 Colab 中的安装指令。
- Google Colab: 未找到描述
- unsloth/mistral-7b-instruct-v0.2 · Hugging Face: 未找到描述
- 使用 LoRA 和 QLoRA 微调 LLM 的深度指南: 在这篇博客中,我们详细解释了 QLoRA 的工作原理,以及如何在 Hugging Face 中使用它来微调你的模型。
- Skorcht/orthonogilizereformatted at main: 未找到描述
- Nicolas Mejia Petit (@mejia_petit) 的推文: @unslothai 在 Windows 上运行 Unsloth 训练模型,速度比常规的 HF+FA2 快 2 倍,且显存占用减少 2 倍,让我能在单张 3090 上以 2048 的序列长度运行 10 的 Batch Size。需要一个教程...
- 银翼杀手 GIF - Blade Runner Blade Runner - 发现并分享 GIF: 点击查看 GIF
- Skorcht/syntheticdata · Hugging Face 数据集: 未找到描述
- RuntimeError: Unsloth: llama.cpp GGUF 似乎由于 Bug 太多而无法安装。 · Issue #479 · unslothai/unsloth: 前提条件 %%capture # 安装 Unsloth, Xformers (Flash Attention) 及所有其他包! !pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" !pip install -...
- unilm/bitnet/The-Era-of-1-bit-LLMs__Training_Tips_Code_FAQ.pdf at master · microsoft/unilm: 跨任务、语言和模态的大规模自监督预训练 - microsoft/unilm
- Skorcht/thebigonecursed · Hugging Face 数据集: 未找到描述
- 欢迎使用 PyPDF2 — PyPDF2 文档: 未找到描述
- 我让 Unsloth 在原生 Windows 上运行了。 · Issue #210 · unslothai/unsloth: 我让 Unsloth 在原生 Windows(非 WSL)上运行了。你需要 Visual Studio 2022 C++ 编译器、Triton 和 DeepSpeed。我有一个完整的安装教程,我本想在这里写下来,但我现在在用手机...
- 机械可解释性 — Neel Nanda: 关于机械可解释性研究的博客文章
- 尝试将微调后的 8bit 模型转换为 GGUF 时出现 KeyError: 'I8' · Issue #4199 · ggerganov/llama.cpp: 前提条件 大家好,我正在使用自己的数据微调模型 https://huggingface.co/jphme/em_german_7b_v01(我只是将问题和答案替换为点,以保持简短)。该模型...
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- GPU 支持 (NVIDIA CUDA & AMD ROCm) — SingularityCE 用户指南 4.1 文档: 未找到描述
Unsloth AI (Daniel Han) ▷ #showcase (5 条消息):
- 成员们对 AI News 的认可感到高兴: 一位成员对 Discord 机器人的成就被 AI News 报道表示高兴。他们开玩笑说这种认可具有循环性,称:“AI News 提到了另一个 AI News 的提及”。
- 对总结功能的正面反馈: 一位成员对 AI 的总结能力充满热情,感谢 swyxio 的强调,并对其提供的帮助表示感激。另一位成员澄清说,该总结来自另一个对话,与 AI News 无关。
Unsloth AI (Daniel Han) ▷ #community-collaboration (1 条消息):
starsupernova: 太棒了 - 如果你需要帮助 - 尽管问!
Stability.ai (Stable Diffusion) ▷ #general-chat (966 条消息🔥🔥🔥):
- SD3 发布疑虑与高昂价格:讨论围绕 SD3 的发布时间表和质量展开,部分用户对其发布和质量持怀疑态度。有人推测 Stability AI 压着 SD3 不发是为了促进销售;一位成员提到“SD3 将会发布”,尽管存在不确定性,但仍保持希望。
- GPU 辩论 – 4060 TI vs 4070 TI:成员们辩论了 4060 TI 16GB 和 4070 TI 12GB 在游戏和 AI 任务中的性能表现。一人倾向于将 4060 TI 用于 ComfyUI,而另一人则强调了 4070 TI 卓越的游戏性能。
- API 替代方案与使用:关于使用 Invoke 或 Forge 进行模型训练和资产设计等 API 替代方案的多次咨询和建议。一位用户称赞了 Forge 的效率,并将其 UI 描述为与 A1111 “完全相同”。
- 分享基准测试网站:一位用户分享了一个用于评估 GPU 性能的 基准测试网站。该网站提供了关于 1.5 和 XL Models 等模型的全面数据,并引导用户过滤特定 GPU(如 Intel Arc a770)的结果。
- 对经济不平等的沮丧情绪:围绕经济困境和不平等的激烈辩论,涉及资本主义、技术进步和历史不公。一些人认为,经济差距和对财富的追求是以牺牲道德和个人福祉为代价的。
OpenAI ▷ #ai-discussions (280 条消息🔥🔥):
- GPT-4o 性能面临批评:多位用户(包括这篇 Reddit 帖子)报告称 GPT-4o 的表现不如其前代产品,经常在编程等任务中出错,且回答效果不如 GPT-2。
- 讨论 GPT-4o 的视觉能力:像
vl2u这样的用户正在实验 GPT-4o 分析医学图像的能力,并挑战其“身份”的极限,但结果褒贬不一,有时会导致模型提供库文件而不是直接分析。 - 超迷信 (Hyperstition) 作为 AI 的概念:探讨了“超迷信”的概念,例如如何通过强化引导 AI 产生新的身份和信念。在 AI 的训练和交互模式背景下,讨论了 AI 在确认自我实现预言中的作用。
- 未来就业市场与 AI 的影响:用户就 AI 可能导致许多工作过时交换了意见,引发了关于人类在 AI 主导的未来将如何适应并寻找新的生活和工作方式的推测。一些人认为 AI 将创造新的就业机会,而另一些人则担心大规模失业。
- 对 AI 情感真实性的担忧:出现了关于 AI 应该保持中立专业还是模拟类人情感反应的辩论。在社区中,创建一个让人产生共鸣的 AI 与创建一个高效、无情感的助手之间的平衡是一个关键讨论点。
提到的链接:Reddit - 深入探索一切:未找到描述
OpenAI ▷ #gpt-4-discussions (103 条消息🔥🔥):
-
对 GPT-4o 可访问性的困惑:许多用户不确定 GPT-4o 的可用性,询问它是免费的还是付费账户专属。得到的澄清是 GPT-4o 正在逐步推出,目前优先考虑付费用户,详见此处。
-
ChatGPT-4o 功能问题:几位用户报告了新 ChatGPT-4o 模型的问题,包括响应缓慢和持续的话题重复。一些人发现它缺少某些功能,如演示中预期的语音交互或图像生成。
-
Custom GPTs 和语音功能关注点:用户询问 Custom GPTs 是否会使用 GPT-4o,并讨论了语音模式(Voice Mode)等功能,目前该功能仅向 Plus 账户推出。根据官方 FAQ,Custom GPTs 将在几周内切换到 GPT-4o。
-
更新与订阅的技术故障:多位参与者对应用更新失败、订阅问题以及语音选项等功能缺失等技术问题表示沮丧。预计这些是由于高需求和持续更新导致的暂时性故障。
-
交互与 Token 计数说明:讨论了不同 GPT 版本的 Token 限制和正确的功能衡量,Token 计数指南中提供了详细解释。建议用户检查 GPT 的响应时间以识别底层模型。
OpenAI ▷ #prompt-engineering (192 messages🔥🔥):
-
成员评估 GPT-4 与 GPT-4o 的差异:多位用户讨论了 GPT-4 与 GPT-4o 在各种 Prompt 下的能力差异,例如理解现实世界场景和解决谜题。他们注意到了一些细微差别,GPT-4o 有时在现实世界背景的 Grounding 方面表现更好。
-
探索 Prompt Engineering 技术:分享了改进 Chatbot 响应的策略,包括使用礼貌用语、鼓励以及特定上下文的指令来获取更好的输出。一位用户分享了研究见解,展示了激励性短语如何提升 AI 模型的性能。
-
Custom GPTs 的挑战与维持 Prompt 忠实度:用户讨论了让 GPT 遵循自定义指令的困难,特别是在避免复杂计算方面。建议包括仅关注正面指令并提供清晰的层级引导。
-
创意应用与输出:用户尝试了创意和细致的 Prompt 来测试 GPT-4 和 GPT-4o 的能力,例如加密消息解密和复杂的叙事场景。讨论了不同 Prompt 风格在引导所需 AI 行为方面的有效性。
-
关于使用限制和订阅的实际问题:一些成员辩论了 ChatGPT Plus 订阅在消息限制下的实用性,特别是对于软件工程等重度使用场景。其他人强调了不同的使用策略以优化订阅收益。
提到的链接:ChatGPT 现在可以访问实时互联网。API 可以吗?:鉴于新闻公告,我想知道 API 现在是否具有相同的互联网访问权限。提前感谢!
OpenAI ▷ #api-discussions (192 messages🔥🔥):
- 探索 AI Prompt Engineering:讨论围绕 GPT 模型不同 Prompt 策略的有效性展开,涉及礼貌、鼓励和特定指令如何改善 AI 响应。探索了诸如 “EmotionPrompt” 和要求 AI 扮演专家等多种技术以增强性能。
- 测试 GPT-4 vs. GPT-4o:成员进行了对比测试,以识别 GPT-4 和 GPT-4o 之间的差异,重点关注代码破译和理解现实世界概念等任务。注意到了一些细微差别,特别是在 GPT-4o 处理多模态(Multimodal)输入的方式上。
- 解决响应有效性问题:一个反复出现的主题是 AI 偶尔产生错误或无关数据。讨论的策略包括强制执行更严格的数据源使用指令,以及更有效地引导模型的注意力。
- 角色扮演以增强交互:用户对使用详细的 Prompt 创建具有独特 Persona 的 AI 角色进行动态交互表现出兴趣。建议使用 Markdown 格式来有效地构建这些 Prompt。
- 过桥问题与图像描述:经典的“手电筒过桥”问题和图像描述任务被用来挑战 AI。对比了不同模型解释和响应这些谜题的能力。
提到的链接:ChatGPT 现在可以访问实时互联网。API 可以吗?:鉴于新闻公告,我想知道 API 现在是否具有相同的互联网访问权限。提前感谢!
OpenAI ▷ #api-projects (4 messages):
- 即插即用 AI 语音助手上线:一款 Plug & Play AI Voice Assistant 因其简单易用而受到大力推广。“10 分钟即可就绪!”被强调为核心优势。
- 即插即用 AI 反馈邀请:鼓励用户“尝试并分享您的反馈”以改进产品。这一公开邀请指向了社区驱动的增强工作。
Perplexity AI ▷ #general (477 messages🔥🔥🔥):
- GPT-4o 引发热议:用户确认 GPT-4o 已在 Perplexity 上线,展示出比 GPT-4 Turbo 更快的响应速度和更好的性能。由于是逐步推出,许多人仍面临访问问题。
- Perplexity 摘得研究桂冠:研究人员对 Perplexity 相较于 ChatGPT 的准确性、溯源和搜索能力感到欣喜,使其成为处理详细查询和获取最新信息的首选工具。
- AI 图像中的文本生成困扰用户:用户在 DALL-E 生成的图像中苦于“文本乱码”,引发了关于提示词结构的讨论。建议包括将文本指令置于最前,并生成多个版本以获得更好效果。
- 语音功能在 iOS 上大放异彩:Perplexity Pro iOS 应用中的语音模式以其自然的交互给人留下深刻印象,同时 Android 版的更新也备受期待。用户非常欣赏其能够进行长时间、不间断对话的易用性。
- Perplexity Pro 账单问题:用户在订阅 Perplexity Pro 时遇到支付问题。建议通过 support@perplexity.ai 联系支持团队寻求帮助。
- 什么是 phidata? - Phidata:未找到描述
- ChatGPT:iOS 版 ChatGPT 介绍:OpenAI 的最新进展触手可及。这款官方应用免费提供,可跨设备同步历史记录,并为您带来 OpenAI 最新的模型改进。...
- 未找到标题:未找到描述
- GitHub - kagisearch/llm-chess-puzzles: 通过解决国际象棋谜题来基准测试 LLM 的推理能力。:通过解决国际象棋谜题来基准测试 LLM 的推理能力。 - kagisearch/llm-chess-puzzles
- GitHub - openai/simple-evals:通过在 GitHub 上创建账号来为 openai/simple-evals 的开发做出贡献。
- I <3 Coffee GIF - Jimcarrey Brucealmighty Coffee - 发现并分享 GIF:点击查看 GIF
- 未找到标题:未找到描述
- Gift Present GIF - Gift Present Surprise - 发现并分享 GIF:点击查看 GIF
Perplexity AI ▷ #sharing (12 messages🔥):
- 分享微调链接: 一名成员发布了 Perplexity AI 上关于 Finetuning 搜索结果的链接。点击此处查看链接。
- 分享阿兹特克体育场页面: 一名成员分享了关于 Aztec Stadium 的 Perplexity AI 页面链接。点击此处查看页面。
- Google 总结: 发布了一个关于 Google recap 的有趣链接。点击此处探索总结。
- 最新烹饪趋势: 一名成员分享了关于最新烹饪趋势的链接。点击此处深入了解趋势。
- Anthropic 招聘 Instagram 员工: 分享了一个讨论 Anthropic 从 Instagram 招聘的链接。点击此处阅读更多关于此话题的内容。
Perplexity AI ▷ #pplx-api (10 messages🔥):
-
API 引用功能的 Beta 访问申请:一位用户请求获取 Perplexity API 引用功能的 Beta 访问权限,强调了该功能对其业务的重要性。他们承认可能存在积压,但强调了获得访问权限对于与关键客户达成交易的重要性。
-
llama-3-sonar-large-32k-online 执行网页搜索:一位用户询问 llama-3-sonar-large-32k-online 模型 API 是否像 Perplexity.com 一样执行网页搜索。已确认该模型确实会搜索网页。
-
请求稳定的 API 模型别名:一位用户对模型名称的频繁更改表示沮丧,并请求建立稳定别名 (stable aliases),以便在旧模型弃用时始终指向最新模型。
-
今日 API 延迟增加:一位用户注意到当天向 Perplexity 发起 API 调用时延迟 (latency) 增加。
-
Prompt 的自动纠错问题:一位用户报告了 Perplexity 错误地自动纠错 Prompt 的问题,导致响应不准确。他们正在寻求调整 Prompt 的建议以避免此问题。
HuggingFace ▷ #announcements (3 messages):
-
HuggingFace 上的 Terminus 模型已更新:社区成员为 Terminus 模型提供了一个新的更新集合。这些更新提供了新的功能和改进。
-
YouTube 上的开源 AI+音乐探索:查看社区成员在 YouTube 上进行的更多 AI 和音乐探索。这些探索提供了结合 AI 和音乐的创新方式。
-
高效管理 On-Prem GPU 集群:了解管理 On-Prem GPU 集群的新方法。该方法为密集型计算任务提供了增强的控制和可扩展性。
-
了解用于故事生成的 AI:通过一篇详细文章和相关的 Discord 活动参与故事生成中的 AI 讨论。讨论将深入探讨 AI 在创意叙事中的应用和影响。
-
OpenGPT-4o 介绍:探索新的 OpenGPT-4o。它接受文本、文本+图像和音频输入,并可以生成包括文本、图像和音频在内的多种输出形式。
- SimpleTuner/documentation/DREAMBOOTH.md at main · bghira/SimpleTuner: 一个通用的微调工具包,针对 Stable Diffusion 2.1, DeepFloyd 和 SDXL。 - bghira/SimpleTuner
- Vi-VLM/Vista · Datasets at Hugging Face: 未找到描述
HuggingFace ▷ #general (261 messages🔥🔥):
- OpenAI 的 Ilya Sutskever 消息引起反响:由一条关于 Ilya Sutskever 离职的推文引发的讨论(链接)。另一位成员分享了来自 Jan Leike 的相关推文。
- 关于使用 React 获取 PDF 的建议:一位用户寻求关于如何使用 React 获取 GPT 列出的 PDF 的建议。社区随后进行了互动,多位用户参与了讨论。
- PaliGemma 模型的挑战:用户讨论了与使用 PaliGemma 模型相关的问题和解决方案,包括代码示例链接和 HuggingFace 集合。一位用户强调了由于
do_sample=False导致的不正确结果。 - 探索 ZeroGPU 和模型部署:成员们讨论了用于部署机器学习模型的 ZeroGPU 的功能和 Beta 访问权限(链接)。引用了基于 ZeroGPU 构建的 Spaces 作为示例。
- 在 HuggingFace 平台上使用 MIT License:一位用户寻求关于在 HuggingFace 平台上将 MIT 许可的模型用于商业用途的澄清。另一位用户确认这应该是没问题的,并引用了 MIT License 文档(链接)。
- MIT License: 一种简短且简单的宽松型许可证,仅要求保留版权和许可声明。受许可的作品、修改版及更大型作品可以在不同的...
- — Zero GPU Spaces — - 由 enzostvs 创建的 Hugging Face Space: 未找到描述
- Inference Endpoints - Hugging Face: 未找到描述
- 欢迎来到社区计算机视觉课程 - Hugging Face Community Computer Vision Course: 未找到描述
- Stable Diffusion 2-1 - 由 stabilityai 创建的 Hugging Face Space: 未找到描述
- zero-gpu-explorers (ZeroGPU Explorers): 未找到描述
- 2024-04-22 - Hub 事件复盘报告: 未找到描述
- 使用 PaliGemma 3B 进行批量多语言字幕生成!· huggingface/diffusers · Discussion #7953: 使用 PaliGemma 3B 进行多语言字幕生成。动机:我认为 PaliGemma 系列的默认代码示例虽然很快,但有局限性。我想看看这些模型的能力,所以我...
- 20 秒内完成 Python 计算器!#shorts #python #calculator: 嘿,Python 伙伴们!🐍💻 需要计算器但等不及喝杯咖啡的时间?没问题!快来体验我们闪电般迅速的 Python 魔法...
- “等等,这个 Agent 能爬取任何东西?!” - 构建通用网页爬取 Agent: 在 5 分钟内为电子商务网站构建通用网页爬虫;试用 CleanMyMac X,享受 7 天免费试用 https://bit.ly/AIJasonCleanMyMacX。使用我的代码 AIJASON ...
- AI Agents 驱动的 SaaS 和 UI 的未来: 关于 AI agents 对 B2B 和 SaaS 影响的简短调查,由 https://hai.ai 发起
- 未找到标题: 未找到描述
- Spaces - Hugging Face: 未找到描述
- Lamini - 企业级 LLM 平台: Lamini 是为现有软件团队提供的企业级 LLM 平台,旨在快速开发和控制自己的 LLMs。Lamini 内置了在数十亿私有文档上进行 LLMs 专业化训练的最佳实践...
- PaliGemma 发布 - google 收藏集: 未找到描述
- PaliGemma FT 模型 - google 收藏集: 未找到描述
- GitHub - huggingface/transformers: 🤗 Transformers: 为 Pytorch、TensorFlow 和 JAX 提供的尖端机器学习框架。: 🤗 Transformers: 为 Pytorch、TensorFlow 和 JAX 提供的尖端机器学习框架。 - huggingface/transformers
</div>
HuggingFace ▷ #today-im-learning (13 条消息🔥):
-
Epsilon Greedy Policy 维持 RL 权衡:在回答关于如何在 RL 中维持探索/利用(exploration/exploitation)权衡的问题时,一位成员解释说使用了 epsilon greedy policy。他们建议通过 ChatGPT 了解更多信息并鼓励保持好奇心。
-
RL 中的好奇心鼓励探索:一位成员建议研究好奇心驱动的探索(curiosity-driven exploration),以此作为在 RL 中鼓励探索的一种方式。他们分享了 Pathak 等人的论文,该论文奖励 Agent “预测其自身行为后果的能力误差”。
-
异常情况驱动探索:讨论提到,在好奇心驱动的探索中,鼓励 Agent 选择导致异常情况的动作以增加其奖励。这种方法有助于解决 RL 中难以维持密集奖励(dense rewards)的场景。
提到的链接:通过自监督预测实现好奇心驱动的探索:Pathak, Agrawal, Efros, Darrell. Curiosity-driven Exploration by Self-supervised Prediction. In ICML, 2017.
HuggingFace ▷ #cool-finds (6 条消息):
-
揭秘 PaliGemma 视觉语言模型 (Vision Language Model):一位成员分享了 Medium 上关于 PaliGemma 视觉语言模型的一篇文章。该模型声称在结合视觉和语言任务方面提供了强大的功能。阅读更多。
-
Veo 视频生成模型发布:DeepMind 最新的视频生成模型 Veo 可以生成 1080p 分辨率的视频,具有多种电影风格和广泛的创意控制。选定的创作者可以通过 Google 的实验性工具 VideoFX 使用这些功能,该模型最终将与 YouTube Shorts 集成。更多详情。
-
语音和文本的联合语言建模 (Joint Language Modeling):一篇研究论文探讨了语音单元和文本的联合语言建模。研究表明,通过使用所提出的技术混合语音和文本,可以提升口语理解任务的性能。阅读论文。
-
Google IO 2024 全面解析:一段 YouTube 视频对 Google IO 2024 活动进行了全面分析,称其让 Google 在 AI 领域再次变得举足轻重。在此观看。
-
Candle 入门指南:一篇 Medium 文章提供了关于如何开始使用 Candle(一种 AI 领域的新工具或技术)的指南。阅读文章。
- Veo:Veo 是我们迄今为止功能最强大的视频生成模型。它可以生成高质量、1080p 分辨率且长度可超过一分钟的视频,涵盖广泛的电影和视觉风格。
- Toward Joint Language Modeling for Speech Units and Text:语音和文本是人类语言的两种主要形式。多年来,研究界一直专注于语音到文本或反之亦然的映射。然而,在语言建模领域,非常……
- Google IO 2024 Full Breakdown: Google is RELEVANT Again!:这是我对 Google IO 2024 活动的全部分析,在我看来,这次活动让 Google 在 AI 领域再次变得非常重要。加入我的 Newsletter 以获取定期 AI 更新?...
HuggingFace ▷ #i-made-this (7 条消息):
-
dstack 简化本地 GPU 管理:宣布了一个管理本地 (on-prem) GPU 集群的“游戏规则改变者”,dstack 允许团队成员使用 CLI 在本地和云端服务器上运行开发环境、任务和服务。了解更多信息并查看其 文档和示例。
-
对 dstack 的兴奋反应:成员们对 dstack 的功能表示好奇和兴奋,其中一人计划放弃深入研究 slurm,转而使用 dstack。另一位成员提到,在做出集群管理决策之前,这似乎值得一试。
-
Musicgen 延续项目 max4live 设备:一位成员分享了 Musicgen 延续项目的更新,强调了对 max4live 设备后端的改进及其令人上瘾的功能。查看 YouTube 演示。
-
Terminus 模型更新提升性能:集合中的每个 Terminus 模型都已更新了正确的无条件输入配置,增强了它们在有或没有负面提示词 (negative prompts) 情况下的功能。velocity v2.1 检查点 (checkpoint) 目前拥有 6.1 万次下载,可在 Terminus XL Velocity V2 获取。
提到的链接:Terminus XL - a ptx0 Collection:未找到描述
HuggingFace ▷ #reading-group (12 条消息🔥):
-
周六活动计划:一位成员建议在周六组织一次活动,并创建了一个占位符以确认时间。他们在 Discord 上分享了活动的邀请链接:活动链接。
-
对《矮人要塞》(Dwarf Fortress) 引用的赞赏:一位成员表达了对《矮人要塞》引用的喜爱,称其为他们最喜欢的游戏之一。另一位成员指出,他们在 YouTube 上看过很多《矮人要塞》的故事。
-
YouTube 阅读小组的缩略图:一位成员提议为上传到 YouTube 的 Reading Group 会议设计缩略图。他们分享了一个设计方案并获得了积极反馈,同时收到了一些关于提高文本可读性的微调建议。
| Link mentioned: Join the Hugging Face Discord Server!: We're working to democratize good machine learning 🤗Verify to link your Hub and Discord accounts! | 79111 members |
HuggingFace ▷ #computer-vision (10 messages🔥):
-
销售预测中训练数据至关重要:一名成员建议使用一个表格,其中列代表图像特征和销售数据,通过将新产品的视觉特征与这些数据进行对比来获取洞察。他们强调了拥有相关 training data 的重要性。
-
分享销售预测数据集:另一位成员分享了一个 Sales Prediction Dataset,包含图像像素和销售数据。该数据集旨在帮助构建一个使用图像输入来预测销售输出的模型。
-
在图像特征上训练模型:一名成员建议微调 CNN 以获取特征图 (feature maps),然后将这些特征图与销售数据合并。他们进一步建议训练 RF, SVM, 或 XGBoost 等模型,并与图像相似度结果进行评估对比。
-
关于图像篡改检测模型的咨询:一名成员询问是否有能够在不需要数据集的情况下检测图像伪造的模型。他们正在寻找可以确定图像是否被编辑过的模型。
-
UNet 模型收敛问题:一名用户报告其 UNet 模型的 loss 从 0.7 开始并在 0.51 处收敛,使用了 depth=5, learning rate=0.002, 以及 BCE with logits loss。他们请求帮助识别设置中可能存在的问题。
Link mentioned: tonyassi/sales1 · Datasets at Hugging Face: no description found
HuggingFace ▷ #NLP (9 messages🔥):
-
成员寻求 Llama2 微调帮助:一名用户询问如何本地微调 Llama2。另一位成员幽默地问提供帮助是否能换来一份工作。
-
模型中过时代码带来的困扰:一名用户分享了关于模型为特定 Python 库生成新旧混合代码的挫败感。他们询问 ORPO 或 DPO 等技术是否能帮助从基础模型中移除错误的知识。
-
代码对齐需要持续重训练:针对过时代码问题,一名成员指出过时的训练数据是一个重大问题。他们提到用于代码的语言模型需要持续重训练以保持最新。
HuggingFace ▷ #diffusion-discussions (7 messages):
- 使用 PIL 解决图像加载问题:一名用户最初在处理 URL 时遇到问题,但通过使用 PIL 的 Image.open 方法配合 load_image 函数成功解决了问题。他们分享了一段代码片段:from PIL import Image baseimage=Image.open(r”/kaggle/input/mylastdata/base.png”)。
- 寻找用于生成 PowerPoint 演示文稿的 AI:一名成员询问是否有能够使用 OpenAI Assistant API 生成 PowerPoint 演示文稿的聊天机器人。他们寻求其他可以从之前的演示文稿中学习并仅修改幻灯片内容的 RAG 或 LLM 模型 推荐。
- 关于 SDXL 潜空间 (Latent Space) 的讨论:一名用户分享了一篇 blog post,讨论潜空间中的每个值是否应该代表像素空间中的 48 个像素。博客包含关于 The 8-bit pixel space 和 SDXL latent representation 的章节。
Link mentioned: Explaining the SDXL latent space: no description found
Nous Research AI ▷ #ctx-length-research (2 messages):
-
人类大脑像流 (streams) 一样工作:人类的短期记忆较小,但通过更新最相关的信息,可以处理长篇书籍和长时间对话。建议 AI 应该专注于类似流的方法,例如 Infini-attention。
-
Needle in a Needlestack 基准测试:Needle in a Needlestack (NIAN) 是一个更具挑战性的评估 LLMs 的新基准,即使对 GPT-4-turbo 来说也很困难,它建立在更简单的 Needle in a Haystack 测试之上。更多详情可以在其 官网 和 GitHub 上找到。
提及的链接: Reddit - Dive into anything: 未找到描述
Nous Research AI ▷ #off-topic (16 messages🔥):
-
Discord AV1 嵌入工具引起关注:成员们讨论了在 Discord 上嵌入 AV1 视频以及使用 Discord AV1 Embed Tool 的优势,该工具允许嵌入超过 500MB 的视频并支持自定义缩略图。
-
设备命名创意大爆发:一场为 IoT 空气净化器命名的趣味活动激发出许多创意选项,如 “Filterella,” “Puff Daddy,” 和 “Airy Potter”。一位成员提到 “最后一个听起来相当不错”,指的是 “The Filtergeist”。
-
GPT-4 的角色扮演能力令人侧目:一位成员幽默地推测了 GPT-4 角色扮演能力的疯狂可能性,特别提到了语音功能推出后可能涉及政治人物和 BDSM 主题的场景。
-
Fuyu 模型被认为不尽如人意:在回答有关训练用于识别 UI 元素的模型咨询时,有人提到了 Fuyu,但批评其在该任务上的表现 “相当平庸”。另一位成员正在探索用于实时 UI 交互处理的替代方案。
- Autocompressor Video Embed Tool: 未找到描述
- Autocompressor Video Embed Tool: 未找到描述
- 无标题: 未找到描述
Nous Research AI ▷ #interesting-links (10 messages🔥):
-
Silo AI 发布首个北欧语言 LLM:Silo AI 与图尔库大学的 TurkuNLP 以及 HPLT 合作发布了 Viking 7B,这是一个针对北欧语言的开源多语言 LLM。该模型代表了“迈向适用于所有欧洲语言的尖端 LLM 家族旅程中的一个重要里程碑”。
-
对北欧语言模型的兴趣:成员们讨论了为低资源语言训练大模型的意义和吸引力。有人指出,即使是更大的模型,尽管针对此类任务的优化较少,但在这些语言上的表现往往也不错。
-
正在使用的 AMD 加速器:Silo AI 和 TurkuNLP 在其项目中使用 AMD 加速器,这让一些成员感到惊讶。
-
用于 Transformer 向上训练(uptraining)的 SUPRA:Scalable UPtraining for Recurrent Attention (SUPRA) 被提出作为预训练线性 Transformer 的一种具有成本效益的替代方案。它旨在将预训练的大型 Transformer 改进为 Recurrent Neural Networks,以解决线性 Transformer 扩展性差的问题。
- Linearizing Large Language Models:线性 Transformer 已成为 Softmax Attention 的一种亚线性时间替代方案,并因其固定的循环状态可降低推理成本而引起了广泛关注。Howe...
- Viking 7B: The first open LLM for the Nordic languages:Silo AI 宣布发布首个针对北欧语言的开源 LLM。
Nous Research AI ▷ #announcements (1 messages):
- Hermes 2 Θ 作为实验性合并模型发布:Nous Research 与 Arcee AI 合作发布了 Hermes 2 Θ,该模型合并了 Hermes 2 Pro 和 Llama-3 Instruct,并经过进一步 RLHF 以获得卓越性能。它已在 HuggingFace 上提供,并在基准测试中实现了两者的优势结合。
- Hermes 2 Θ 的 GGUF 版本已可用:除了 FP16 模型外,Hermes 2 Θ 的 GGUF 版本也已发布。该模型可以在 HuggingFace 上获取。
Nous Research AI ▷ #general (199 条消息🔥🔥):
- Hermes 2 Θ 模型发布:宣布发布 Hermes 2 Θ,该模型结合了 Hermes 2 Pro 和 Llama-3 Instruct,并经过 RLHF 进一步优化。该模型在基准测试中超越了 Hermes 2 Pro 和 Llama-3 Instruct,现已在 HuggingFace 上可用。
- GPT-4 变体在推理任务中挣扎:不同的 GPT-4 模型在关于拿破仑的白马问题和薛定谔的猫问题的变体上表现出不同的成功率。一位成员指出,“几乎没有 LLM 能发现猫从一开始就是死的”。
- 测试网挖矿问题:一位用户报告了在 testnet 61 上挖矿时看不到请求的问题,并质疑验证者的存在。另一位成员建议在更专业的服务器上寻求支持。
- 对 GPT-4o 的担忧:多位用户对 GPT-4o 的表现表示失望,强调其通用的输出结构和枚举式的解释。一位用户指出,“我想要的是代码问题的解决方案,而不是安装所需模块的分步计划”。
- 实验 Hermes 的自合并:一位成员分享了合并 Hermes 模型以创建一个名为 Quicksilver 的 12B 参数模型的计划,该模型整合了 OpenHermes 数据集并进行了进一步微调。另一位成员对该项目表示兴趣,表示完成后会去查看。
- Nous Research (@NousResearch) 的推文:今天我们与 @chargoddard 和 @arcee_ai 合作发布了一个实验性新模型,Hermes 2 Θ,这是我们的第一个模型合并,结合了 Hermes 2 Pro 和 Llama-3 Instruct,并进行了进一步的 RLHF...
- 未找到标题:未找到描述
- Cameron Jones (@camrobjones) 的推文:新预印本:在图灵测试中,人们无法将 GPT-4 与人类区分开来。在一项预注册的图灵测试中,我们发现 GPT-4 有 54% 的时间被判定为人类。在某些解释下,这构成了...
- Brian Atwood (@batwood011) 的推文:剧情反转:安全团队离开不是因为他们看到了“某些东西”,而是因为他们“什么也没看到”。没有真正的危险。只有局限性、死胡同和商业化带来的无尽分心——没有路径...
- Taelin (@VictorTaelin) 的推文:发布日:经过近 10 年的努力、不懈的研究以及对计算机科学内核的深入钻研,我终于实现了一个梦想:在 GPU 上运行高级语言。而我...
- Taelin (@VictorTaelin) 的推文:说真的——这太棒了。我无法形容它有多好。当时我花了很长时间才让 Opus 跑出一个还算过得去的运行结果。其他模型几乎无法画出一帧。GPT-4o 就这样...玩起了游戏...
- GitHub - NousResearch/Hermes-Function-Calling:通过在 GitHub 上创建账户来为 NousResearch/Hermes-Function-Calling 的开发做出贡献。
- interstellarninja/hermes-2-theta-llama-3-8b:Hermes-2 Θ 是我们优秀的 Hermes 2 Pro 模型和 Meta 的 Llama-3 Instruct 模型的合并及进一步 RLHF 版本,形成了一个新模型 Hermes-2 Θ,结合了两者的优点...
- 未找到标题:未找到描述
- 未找到标题:未找到描述
- Sam Altman (@sama) 的推文:特别是在代码方面
- 猫咪 GIF - 猫 - 发现并分享 GIF:点击查看 GIF
Nous Research AI ▷ #ask-about-llms (55 条消息🔥🔥):
-
Meta 推出多模态 AI 模型 ImageBind:Meta 已开源 ImageBind,能够跨六种不同模态进行联合嵌入:图像、文本、音频、深度、热成像和 IMU 数据。该模型避免了对所有配对数据组合的依赖,利用图像配对数据来扩展功能。
-
从头开始构建 LLM 需要大量资源:用户强调了从头开始训练大语言模型 (LLM) 所需的巨大资金和计算资源。一位用户建议,如果没有 10 万美元,进行这样的尝试是不可行的。
-
Hermes 2 Theta 数学性能问题:用户讨论了 Hermes 2 Theta 的性能,指出与 L3 8B Instruct 相比,它在基础数学方面的表现较差。建议使用 function calling 以在数学问题中获得更好的结果。
-
模型推理及触发中文文本的挑战:一位用户报告了 Nous Hermes-2-Mixtral-8x7B-DPO 的问题,即尽管输入是英文,模型偶尔会产生中文回复。这一问题引发了对 Together 推理端点可能存在问题的猜测,而替代模型则产生了更好的结果。
-
微调中的 Stop tokens 行为异常:用户分享了在使用 Alpaca 指令格式微调模型时,无法在正确的 token 处停止生成的挑战。建议确保在推理过程中正确设置 stop token。
- NousResearch/Hermes-2-Pro-Llama-3-8B · Hugging Face:未找到描述
- 无标题:未找到描述
- ImageBind: One Embedding Space To Bind Them All:我们介绍了 ImageBind,这是一种在六种不同模态(图像、文本、音频、深度、热成像和 IMU 数据)之间学习联合嵌入的方法。我们展示了并非所有配对数据的组合都是必需的...
Nous Research AI ▷ #project-obsidian (3 条消息):
- 讨论微调 PaliGemma 的计划:一名成员询问了关于 finetune PaliGemma 的计划。他们指向了 PaliGemma 的模型卡片,并指出为“多轮”交互进行微调会“很酷”。
- 多模态工具使用公告:一名成员分享的推文提到增加了对返回图像的工具的支持,为 multimodal tool use 奠定了基础。详细信息可以在这份 cookbook中找到。
- 来自 Alex Albert (@alexalbert__) 的推文:3) Vision 我们增加了对返回图像的工具的支持,为跨图像、图表等关键知识源的多模态工具使用奠定了基础。在此阅读 cookbook:https://g...
- google/paligemma-3b-pt-224 · Hugging Face:未找到描述
Nous Research AI ▷ #world-sim (3 条消息):
-
Robo Psychology 服务器接收 Worldsim 更新:一名成员宣布他们已将 Robo Psychology Discord 服务器订阅了 worldsim 更新。他们提到,如果发布任何公告,都应该传播到该服务器。
-
关于其他模拟提示词的查询:一名成员询问了 Discord 频道内其他模拟中使用的提示词 (prompts)。
-
探索通用网页抓取 Agent:分享了一个名为 “Wait, this Agent can Scrape ANYTHING?” 的 YouTube 视频,讨论了如何为电子商务网站构建一个通用的网页抓取 Agent,能够处理分页和验证码破解等任务。该成员还提到了一项软件实用程序的赞助推广。
提到的链接:“Wait, this Agent can Scrape ANYTHING?!” - 构建通用网页抓取 Agent:在 5 分钟内为电商网站构建通用网页抓取工具;试用 CleanMyMac X 享受 7 天免费试用 https://bit.ly/AIJasonCleanMyMacX。使用我的代码 AIJASON …
LM Studio ▷ #💬-general (145 条消息🔥🔥):
- Command R 模型中的有趣幻觉:一位成员分享了来自 Command R 模型的搞笑幻觉,该模型描述了一台名为 Fialka 的苏联加密机,它使用芬芳的紫色香水进行打印,因此其 NATO 代号为 “Violet!”。这一极具创意的幻觉被该成员评价为几乎可以乱真。
- 长上下文模型的首个 Token 缓慢问题:讨论强调了长上下文模型(如 Llama-3-8B-Instruct-Gradient-1048k)面临的困难,表现为漫长的首个 Token 生成时间。此类问题被指出是由于长上下文长度所需的大量计算造成的。
- LM Studio CLI 与 Vision 模型集成:LM Studio 的配套 CLI 工具
lms的发布,使得在没有 GUI 的情况下也能加载/卸载模型以及启动/停止 API 服务器。文中还讨论了 Vision 模型支持,尽管最近的问题似乎阻碍了该功能的使用。 - Embedding 和上下文长度策略:成员们探讨了 Embedding 模型的最佳 Prompt Engineering 和配置设置,以及如何最大化上下文长度的使用,并引用了不同硬件设置下的性能差异。提到用户可以在 Colab 等平台上运行像 llama.cpp 这样的 Embedding 模型。
- 安全疑虑与杀毒软件误报:针对用户在安装 LM Studio 时遇到的杀毒软件标记,建议允许例外,并强调此类标记属于误报。给出的建议强调使用 Windows Defender 和适当的网络安全措施已足以提供保护。
- bar (bar cohen):未找到描述
- PyTorch ExecuTorch:未找到描述
- 介绍 `lms` - LM Studio 的配套 CLI 工具 | LM Studio:今天,随着 LM Studio 0.2.22 的发布,我们推出了第一个版本的 lms —— LM Studio 的配套 CLI 工具。
- bartowski/Llama-3-8B-Instruct-Gradient-1048k-GGUF · Hugging Face:未找到描述
- abetlen/nanollava-gguf · Hugging Face:未找到描述
- nisten/obsidian-3b-multimodal-q6-gguf · Hugging Face:未找到描述
- Reddit - 深入探索任何事物:未找到描述
- 不要问能不能问,直接问:未找到描述
LM Studio ▷ #🤖-models-discussion-chat (66 条消息🔥🔥):
-
在 LM Studio 中添加 Idefics 模型:一位成员询问如何在 LM Studio 中添加 Idefics 模型。回复指出需要有人将其转换为 GGUF 格式,并提到由于它是 Vision 模型,因此需要 mmproj 适配器。
-
构建 Imatrix 的挑战:多次讨论展示了为 Llama-3 70B 等大模型构建 Imatrix 时的挫败感,强调在 CPU 上构建可能需要数小时,并且可能需要散热解决方案。一位用户分享道:“尝试在 CPU 上为 Llama-3 70B 构建 Imatrix… 进行了 5 小时,完成了约 40%”,指出了 CPU 热节流问题。
-
编程模型推荐:用户讨论了哪些模型最适合编程,并推荐了 Nxcode CQ 7B ORPO(一个 CodeQwen 1.5 的微调版)。还提到运行像 Cat 8B (Q8) 这样的模型在 Tool/Function Calling 功能上的表现令人失望。
-
处理模型中的长上下文:提供了关于处理 Token 限制和上下文溢出策略以获得更好性能的实用建议,例如使用截断策略以避免在 Token 计数饱和时出现错误。
-
编程的模型输出控制:成员们寻求让 LLM 模型仅输出代码而不包含解释的方法。建议使用 Markdown 功能并明确指示模型,但也承认 LLM 通常仍会提供解释。
提到的链接:HuggingFaceM4/idefics-9b-instruct at main:未找到描述
LM Studio ▷ #🧠-feedback (8 条消息🔥):
-
设置面板滚动条重叠并困扰用户:一位成员指出,设置面板有“两个重叠的滚动条,一个用于模型设置,一个用于工具”,导致了混淆,并建议使用单一的通用滚动条。另一位成员表示赞同,并补充说该面板对新用户来说尤其令人困惑。
-
将设置移至独立窗口并移动 System Prompt:一位成员提议将设置放在独立窗口中,并将 System Prompt 移至聊天配置中,理由是他们在不同的聊天中针对同一模型使用不同的 Prompt。
-
UI 反馈和可用性问题:一份详细的反馈强调了多个 UI 可用性问题,包括:按下 “enter” 键误触发 Prompt 发送、生成开始前缺少 “cancel request”(取消请求)按钮、系统预设令人困惑、分支/复制/编辑/删除图标对齐不当,以及请求更好地集成 Whisper。
-
误报病毒警报已被澄清:一位成员确认,被识别为可能有害的文件在 Malwarebytes 和 Windows Defender 中均显示为安全,并提供了一个 VirusTotal 链接 以供验证。
提到的链接:VirusTotal:未找到描述
LM Studio ▷ #⚙-configs-discussion (2 条消息):
-
Windows 任务管理器 CUDA 检查:一位成员建议通过启动任务管理器并导航到 GPU 部分的“性能”选项卡来检查 GPU 使用情况。他们建议将图表源更改为 “CUDA”,如果 CUDA 不可用,则在 Windows 设置中停用“硬件加速”。
-
华硕笔记本上的 CUDA 错误:另一位成员报告了配备 GTX 950M GPU 的华硕笔记本上的 CUDA 问题。在尝试使用 GPU offload 时,尽管尝试了各种 CUDA 版本(12.4, 12.1, 11.8)并确保系统环境变量中正确设置了 CUDA/CUDNN 路径,他们仍遇到“加载模型错误”的消息。
LM Studio ▷ #🎛-hardware-discussion (46 条消息🔥):
-
关于使用 APU 加载模型的疑问:一位成员询问模型在拥有大量 RAM 的 APU 上的表现是否优于普通 CPU。另一位成员澄清说,llama.cpp 在推理时将 APU/iGPU 视为普通 CPU。
-
高端配置展示 LM 性能:一位成员分享了他们高端配置的细节,包括 32 核 Threadripper、512GB RAM 和 RTX6000。在使用特定配置时,他们实现了 0.10s 的 Time to First Token,生成速度为每秒 103.45 tokens。
-
水冷 4090 兼容性问题:讨论集中在将水冷 RTX 4090 集成到现有高性能设备中的挑战。成员们分享了关于合适机箱和冷却方案的见解。
-
BIOS 设置对性能的影响:成员们辩论了 BIOS 预设和冷却设置的有效性及其对 CPU 性能的影响。有人提到了水冷预设中的默认 undervolting(降压),以及需要手动覆盖 DDR5 的内存频率设置。
-
叠瓦式硬盘 (SMR HDDs) 与读写速度:成员们讨论了 SMR 硬盘的性能问题,指出其写入速度缓慢。建议包括 BIOS 更新和旨在提高磁盘性能的驱动器策略设置,特别是针对永久安装的驱动器。
LM Studio ▷ #🧪-beta-releases-chat (9 条消息🔥):
- AVX1 导致 LM Studio 加载失败:一位成员报告 LM Studio 显示 “App starting…” 后便不再继续。另一位成员澄清说 LM Studio 需要 AVX2 指令集,无法在 AVX1 系统上加载,不过 Llamafile 可以正常运行。
- 模型存储驱动器选择问题:由于权限错误,一位用户在 LM Studio 中选择另一个驱动器进行模型存储时遇到困难。尽管设置了完全写入权限,系统仍拒绝所选位置,并提示选择其他位置或恢复出厂设置。
- UI 改进请求:有建议提出通过关闭未使用的代码部分和允许窗口重新定位来简化 UI,以减少杂乱。用户反馈强调当前的 UI 过于复杂,特别是对于服务器管理任务。
LM Studio ▷ #amd-rocm-tech-preview (7 条消息):
- ROCM Windows 构建版本需要最新版以解决 iGPU 问题:一位用户不得不禁用其 Ryzen 7000 iGPU 才能让 ROCM Windows build 正常工作,并询问该问题是否仍然存在。另一位用户提到该问题应在最近的版本中得到修复,并建议确保安装了最新的 ROCM (0.2.22) 更新。
- 对 RX 6800 上 ROCM 改进的期待:用户们表达了对 ROCM 为 RX 6800 等受支持的 AMD GPU 带来性能提升的期待。一位用户确认 RX 6800 确实在支持范围内。
Modular (Mojo 🔥) ▷ #general (59 messages🔥🔥):
-
推荐将 Mojo SDK 用于 AI 开发:一位成员分享了多个学习 Mojo 的资源,建议从 Mojo manual 和 Mandelbrot tutorial 等示例开始。他们强调该 SDK 已包含在 MAX SDK 中,提供了一套完整的工具包。
-
关于 Mojo 潜力的讨论:尽管目前知名度较低,成员们对 Mojo 的未来表示乐观。一位用户表示:“我们可以成为谈论它的人”,鼓励社区驱动的意识提升。
-
GPU 灵活性使 Mojo 具有优势:在将 Mojo 与 CUDA 进行比较时,讨论强调了 Mojo 在不同 GPU 厂商之间的可移植性是其相对于 CUDA 厂商锁定(vendor lock-in)的一个显著优势。这种灵活性可能会促进更具竞争力的硬件市场,正如多位成员所指出的。
-
围绕开源承诺的担忧:关于 Mojo 的开源状态引发了辩论,一些成员对未来许可协议的变化持怀疑态度。其他人则为 Modular 目前的开源贡献辩护,指出即使没有完全开源,其提供的价值也很大。
-
社区项目和学习建议:成员们为 Mojo 新手建议了各种学习项目,例如为 toybox data-structures project 贡献代码,或挑战 Advent of Code(GitHub link)。他们讨论了适合初学者的任务以及更高级的项目(如 LAS 文件读取器)的想法。
- 开始使用 Mojo🔥 | Modular Docs: 获取 Mojo SDK 或尝试在 Mojo Playground 中编码。
- 在 Mojo 中使用 Python 绘图实现 Mandelbrot | Modular Docs: 学习如何编写高性能的 Mojo 代码并导入 Python 包。
- Mojo 简介 | Modular Docs: Mojo 基本语言特性介绍。
- GitHub - p88h/aoc2023: Advent of Code 2023 (Mojo): Advent of Code 2023 (Mojo)。通过在 GitHub 上创建账号为 p88h/aoc2023 的开发做贡献。
Modular (Mojo 🔥) ▷ #💬︱twitter (2 messages):
Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- Modular 介绍 Joe Pamer:一篇博客文章介绍了 Joe Pamer,他是 Modular 的 Mojo 工程负责人。阅读更多关于 Joe Pamer 的信息。
Modular (Mojo 🔥) ▷ #🔥mojo (166 messages🔥🔥):
- Mojo 尚未完全开源:讨论明确指出,虽然 Mojo 标准库的许多部分是开源的,但编译器和 Max 工具链尚未开源。预计编译器最终会开源,但 Max 可能永远不会。
- 语法差异和文档不一致:用户注意到各种书籍与官方 Mojo 文档之间的语法差异,例如
varvs.let以及classvs.struct。一位用户提到他们的书可能是 AI 生成的。 - Mojo 中
alias的迭代问题:关于在 Mojo 中迭代数据结构的广泛讨论揭示了对列表使用alias时会导致 LLVM 错误。探讨了变量声明方法以及使用Reference[T]和迭代器的影响。 - 条件一致性(Conditional conformance)和 Traits 解释:深入探讨了使用 FromString 等 Traits 处理泛型的复杂性以及 Mojo 类型系统的局限性。用户建议,类似于 Rust、Swift 和 Haskell 中的条件一致性可以解决其中一些问题。
- Mojo 的在线资源和社区贡献:提到了各种资源,如 repositories 和 online books。此外,鼓励用户为标准库做贡献以加速 Mojo 的开发,并将语言处理中的错误作为潜在 Bug 进行讨论。
- Traits | Modular Docs:为类型定义共享行为。
- rebind | Modular Docs:rebinddesttype AnyRegType -> $0
- Issues · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 开发做贡献。
- 未找到标题:未找到描述
- Learn Mojo Programming Language:未找到描述
- mojo/stdlib/src/builtin/tuple.mojo at bf73717d79fbb79b4b2bf586b3a40072308b6184 · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 开发做贡献。
- Issues · dimitrilw/toybox:在 Mojo🔥 中实现的各种数据结构和其他玩具项目。 - Issues · dimitrilw/toybox
Modular (Mojo 🔥) ▷ #nightly (35 条消息🔥):
- Mojo 编译器 Nightly 版本发布:Mojo 编译器的最新 Nightly 版本
2024.5.1515已发布。用户可以使用modular update nightly/mojo进行更新,并查看 changelog 了解详情。 - Mac 自检失败:由于 LLDB 初始化问题,用户在 macOS 上可能会遇到非确定性的 Mojo 自检失败。该问题目前正在调查中。
- 最新版本中令人兴奋的提交:最新版本中有两个值得注意的提交,包括 对
Tuple构造函数的更改 以及将Reference.is_mutable从i1更新为Bool(commit)。 - 开源贡献中的“舔饼干(Cookie Licking)”问题:一名成员对 Mojo 仓库中的“舔饼干”现象表示担忧,即贡献者认领了 Issue 但没有及时采取行动,这可能会挫伤新贡献者的积极性。他们建议鼓励更小的 PR 和更及时的贡献来缓解这一问题。
- 条件方法语法受到称赞:新引入的条件方法语法受到了称赞,这与最近的 Pull Requests 相关。然而,另一位用户提到在 changelog 中很难找到关于这种新语法的信息。
- How to Remove Link Previews | Discord For Beginners: 如何移除链接预览 | Discord 初学者指南。在这段视频中,我将向你展示如何在 2024 年删除 Discord 上的链接预览。我会展示你所需的一切...
- Issues · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账号来为 modularml/mojo 的开发做出贡献。
- [mojo-stdlib] Make `Tuple`'s constructor move its input elements. (#3… · modularml/mojo@f05749d: …9904) 这将 `Tuple` 更改为将其输入 pack 作为 'owned' 接收,然后从 pack 移动到其存储中。这发现了一些处理 owned packs 时的 bug,这些 bug 导致了多次 d...
- [stdlib] Change `Reference.is_mutable` to `Bool` (from `i1`) · modularml/mojo@09db8f3: 随着近期将 `Bool` 更改为使用 `i1` 作为其表示形式,许多阻碍将 `Reference.is_mutable` 移动到 `Bool` 的错误已得到解决。共同作者:Chris Lattner <clatt...
CUDA MODE ▷ #cuda (15 messages🔥):
-
Torch Tensor Accessor vs Kernel Data Pointer: 一位成员询问在 Cpp 中为 torch tensors 使用 Accessors(如此处所述)是否比在 CUDA 中将
tensor.data_ptr传递给 kernel 更好。他们还询问了对这些 tensors 使用 unsigned char 指针的情况,并请求进一步的文档。 -
Dot Product Puzzle Problem: 一位成员分享了他们对 cuda puzzle repo 中点积问题的解决方案。他们报告说使用朴素实现时出现了浮点溢出错误,但使用基于 reduction 的 kernel 则没有,这引发了关于 fp32 精度以及 reduction 如何帮助维持精度的讨论。
-
Triton Lecture and Matrix Multiplication: Umerha 向 Ericauld 推荐了他的 Triton 讲座和 Triton 文档 Matmul 示例,以获取更多关于矩阵乘法和性能优化的信息。这些教程涵盖了 block 级矩阵乘法、指针算术和性能调优。
-
Proposing Bitnet Community Project: Coffeevampir3 联系发起一个 Bitnet 社区项目,表示可以参与并寻求合作。Andreaskoepf 支持这一想法,建议将论文讨论活动作为第一步,并对 extreme quantization 表示感兴趣。
-
Creating a Bitnet Channel: Andreaskoepf 提议为 Bitnet 项目讨论创建一个专门的频道,表明社区正趋向于将项目工作正式化。
- Matrix Multiplication — Triton documentation: 未找到描述
- GitHub - srush/GPU-Puzzles: Solve puzzles. Learn CUDA.: 解决谜题。学习 CUDA。通过在 GitHub 上创建账号来为 srush/GPU-Puzzles 的开发做出贡献。
- puzzle10_dotproduct floating point overflow error: puzzle10_dotproduct 浮点溢出错误。GitHub Gist:即时分享代码、笔记和代码片段。
CUDA MODE ▷ #torch (25 messages🔥):
-
Custom Op Issue with torch.compile: 一位成员报告了一个问题,即 custom op 在 eager mode 下运行正常,但在与 torch.compile 一起使用时,由于 non-contiguous tensors 而触发断言。另一位用户建议尝试冗余的
.contiguous()调用,但问题似乎与 Triton 生成的 tensor strides 有关。 -
Memory Issues with Static Cache: 成员们讨论了使用 static cache 的内存影响,这可能会阻碍更大的 batch sizes。提出的解决方案是为动态 tensor 分配使用 custom kernels,并仅对结果应用 torch.compile。
-
Adding torch.compile Inside no_grad: 有人建议在
torch.no_grad上下文中编译模型,以便更好地定位违规代码。然而,这对于该用户来说仍然导致了 non-contiguous tensors。 -
使用 Tags 定义自定义算子 (Custom Ops):一位用户建议使用特定 Tags 定义自定义算子以修复步长 (stride) 问题,并参考了
torch.library的较新 API。对话强调了在 C++ 自定义算子定义中实现这些 Tags 的挑战和解决方法。 -
减少 torch.compile 时间:分享了一个减少
torch.compile热编译时间的新计划,引导用户前往 PyTorch 论坛查看详细策略。该计划旨在通过优化编译过程的各个方面,将编译时间降至零。
- Accelerating Generative AI with PyTorch II: GPT, Fast:这篇文章是一个多系列博客的第二部分,重点介绍如何使用纯原生 PyTorch 加速生成式 AI 模型。我们很高兴能分享大量新发布的 PyTorch 性能...
- torch — PyTorch main documentation:未找到描述
- torch.library — PyTorch main documentation:未找到描述
- How To Bring Compile Time Down to Zero: Our Plans and Direction (May 14th Edition):我们很高兴地宣布,在 2024 年上半年,我们一直在优先改进 torch.compile 工作流的编译时间。快速迭代和高效的开发周期...
- src/python/bindings.py · v043 · AaltoRSE / XMC Sparse PyTorch · GitLab:Aalto 版本控制系统
- compile problem - Pastebin.com:Pastebin.com 是自 2002 年以来排名第一的文本粘贴工具。Pastebin 是一个可以在线存储一段时间文本的网站。
- manylinux-cu121: [cp310, 2.3] (#86868) · Jobs · AaltoRSE / XMC Sparse PyTorch · GitLab:Aalto 版本控制系统
- src/python/ops.py · v043 · AaltoRSE / XMC Sparse PyTorch · GitLab:Aalto 版本控制系统
- [wip] fast semi-sparse sparse training by jcaip · Pull Request #184 · pytorch/ao:在 HuggingFace BERT 上测试了这个,没有看到加速 - 这是因为我被其他一堆东西卡住了。(bf16, compile, adamw, dataloader, batchsize)bf16 + compil...
CUDA MODE ▷ #algorithms (1 条消息):
andreaskoepf: https://www.cursor.sh/blog/instant-apply
CUDA MODE ▷ #cool-links (1 条消息):
- 提升你的 LLM 推理部署:通过查看这条 推文,了解如何通过调优 LLM 推理部署获得高达 2 倍的性能提升。关键的更新和优化可以显著提高你的部署效率。
CUDA MODE ▷ #beginner (8 条消息🔥):
-
CUDA 设置导致的 ONNXRuntime 错误困扰用户:一位用户在 CUDA 12.2 和 CUDNN 8.9 环境下运行 ONNX 时遇到错误,详细信息为
[ONNXRuntimeError] : 1 : FAIL : LoadLibrary failed with error 126。该错误突显了加载onnxruntime_providers_cuda.dll失败的问题。 -
可能的解决方案在于 CUDA 版本:另一位成员建议 ONNXRuntime 对 CUDA 版本非常挑剔,并分享了使用通过 conda 安装的 cudatoolkit 11.8,然后再通过 pip 安装 ONNXRuntime 解决了他们的类似问题。
-
在 ONNX 之前导入 Torch:针对该错误,一位成员建议尝试在导入 ONNX 之前先导入 Torch。另一位用户确认这“极有可能是问题所在”。
CUDA MODE ▷ #pmpp-book (5 条消息):
- 新手在 Kernel 代码执行上遇到困难:一位新成员在运行 Kernel 时遇到问题,虽然代码可以运行但未产生预期输出。他们在 GitHub 上分享了代码,并指出输出结果与初始化值完全相同。
提及的链接:Programming-Massively-Parallel-Processors-A-Handson-Approach/Chapter 2 Heterogeneous data parallel computing/device_vector_addition_gpu.cu at main · longlnOff/Programming-Massively-Parallel-Processors-A-Handson-Approach:通过在 GitHub 上创建账号,为 longlnOff/Programming-Massively-Parallel-Processors-A-Handson-Approach 的开发做出贡献。
CUDA MODE ▷ #jax (1 条消息):
prometheusred: https://x.com/srush_nlp/status/1791089113002639726
CUDA MODE ▷ #off-topic (3 条消息):
- 分享了实用的 NVIDIA GPU 编程指南:一位成员分享了 GPU Programming Guide 的链接,为对 GPU 编程感兴趣的同仁提供了宝贵的见解。
- Twitter 链接公告:一位成员发布了一个 Twitter 链接,但未对推文的具体内容展开讨论。
CUDA MODE ▷ #triton-puzzles (1 条消息):
-
成员挑战 CUDA puzzle 10:一位用户分享了他们解决 CUDA puzzle 仓库中关于点积(dot product)的 puzzle 10 的经验。他们分别使用了 naive 方法和 reduction 方法实现了解决方案,代码已上传至 GitHub Gist。
-
浮点数溢出问题:他们提到在将大小为 20480000 的 float 数组初始化为 1 时遇到了浮点数溢出错误。naive 实现产生了错误结果,而 reduction 实现运行正常,他们正在寻求帮助以理解这种差异。
- GitHub - srush/GPU-Puzzles: Solve puzzles. Learn CUDA.:解决 puzzles,学习 CUDA。通过在 GitHub 上创建账号,为 srush/GPU-Puzzles 的开发做出贡献。
- puzzle10_dotproduct floating point overflow error:puzzle10_dotproduct 浮点数溢出错误。GitHub Gist:即时分享代码、笔记和片段。
CUDA MODE ▷ #llmdotc (141 条消息 🔥🔥):
- 从根源彻底清除 Bug:成员们讨论了通过从头开始重构来解决跨函数边界的复杂依赖问题。有人幽默地提到:“昨晚我已经尝试过‘从根源彻底清除 streams’了,但出于某种原因,它并没有修复代码。”
- 追踪 CUDA streams:关于将 CUDA streams 作为每个 kernel launcher 的参数以更好地追踪执行过程进行了大量讨论。普遍共识倾向于重置有关 streams 的代码库,并从头开始重新处理相关的 PR。
- 移除并行 CUDA streams:Pull Request #417 旨在移除并行 CUDA streams,同时保留 main stream 和 loss event,并辅以详细的注释用于教学目的。
- 梯度累积改进:另一个 Pull Request #412 确认了梯度累积方面的改进已生效,将性能从 43K tok/s 提升了 6% 至 45.37K tok/s。
- NVMe GPU DMA 提案:有人提出了一个有趣的想法,即使用支持 CUDA 的 NVMe 驱动程序来跳过 CPU/RAM 步骤,从而可能实现从 GPU 直接写入 SSD。详情请参阅 ssd-gpu-dma 仓库。
- gradient clipping by global norm by ngc92 · Pull Request #315 · karpathy/llm.c: 一个用于计算梯度全局范数的新 Kernel,以及对 Adam Kernel 的更新。待办事项:裁剪值在函数调用处仍为硬编码,针对损坏梯度的错误处理将...
- Remove parallel CUDA streams while keeping main_stream and loss_event(?) by ademeure · Pull Request #417 · karpathy/llm.c: 参见 Discord 上的讨论,我认为无论我们最终构建出什么比我那幼稚尝试更好的架构,可能仍然需要类似于 "main_stream" 的东西作为默认的 f...
- GitHub - enfiskutensykkel/ssd-gpu-dma: Build userspace NVMe drivers and storage applications with CUDA support: 构建具有 CUDA 支持的用户空间 NVMe 驱动程序和存储应用程序 - enfiskutensykkel/ssd-gpu-dma
- CUDA Runtime API :: CUDA Toolkit Documentation: 未找到描述
- [wip] gradient accumulation, another attempt by karpathy · Pull Request #412 · karpathy/llm.c: 目前无法工作。在 master 分支上,我们通过运行以下命令(几乎)完全复现了 Python 脚本:make train_gpt2cu NO_MULTI_GPU=1 USE_CUDNN=1 ./train_gpt2cu -b 4 -t 64 -l 1e-4 -v 200 -s 200 -a 1 -x 10 但是...
- feature/recompute by karpathy · Pull Request #422 · karpathy/llm.c: 在反向传播期间重计算前向激活值的选项。这将是一个整数,0 = 不使用该功能,1, 2, 3, 4...(未来)表示重计算程度越来越高。这通过牺牲延迟来换取更少的 VRAM 占用...
CUDA MODE ▷ #bitnet (12 messages🔥):
-
Bitnet 1.58 展现出潜力并需要一名领导者:一名成员对领导 Bitnet 1.58 的项目搭建表现出极高热情,并指出其相比未量化网络有显著改进。他们建议在 GitHub 等平台上组织该项目,并分享了一个复现项目的链接。
-
Bitnet 的量化需要基础设施:提到的 Bitnet 1.58 方法专注于线性层的训练感知量化(training-aware quantization),并提供了一个简单的训练演示。然而,它目前缺乏 2-bit Kernel 或表示形式,需要为实际的推理节省奠定基础。
-
实际实现中的挑战:讨论围绕 Bitnet 训练如何仍然依赖全权重矩阵,并具有训练后量化的潜力,其中可能需要自定义量化方法。有人提出“滚动训练量化”(rolling-training quantization)作为一个可能但极具挑战性的前进方向。
-
建议在 Torch AO 中集中进行 Bitnet 工作:有人建议将 Bitnet 的实现工作集中在 Torch AO 仓库中,以利用现有的基础设施,如自定义 CUDA/Triton 算子支持和 Tensor 子类。
-
现有的量化解决方案:会议强调 HQQ 提供了 2-bit 位打包(bitpacking)方法,而 BitBLAS 为推理提供了 2-bit GPU Kernel。这些资源可以解决 Bitnet 量化过程中的一些挑战。
- GitHub - pytorch/ao: Native PyTorch library for quantization and sparsity: 用于量化和稀疏化的原生 PyTorch 库 - pytorch/ao
- hqq/hqq/core/bitpack.py at master · mobiusml/hqq: Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- GitHub - microsoft/BitBLAS: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment.: BitBLAS 是一个支持混合精度矩阵乘法的库,特别适用于量化 LLM 的部署。 - microsoft/BitBLAS
LlamaIndex ▷ #blog (6 messages):
-
LlamaIndex 与 Vertex AI 合作:LlamaIndex 宣布与 Vertex AI 建立合作伙伴关系,在 Vertex 平台上推出全新的 RAG API。点击此处查看更多详情。
-
GPT-4o 与 create-llama 的集成:LlamaIndex 现在在其 create-llama 工具中支持 GPT-4o,通过回答几个问题即可更轻松地基于用户数据构建聊天机器人。更多信息请点击这里。
-
LlamaParse 与 Quivr 合作:LlamaIndex 已与 Quivr 合作推出 LlamaParse,允许用户通过先进的 AI 能力解析复杂的文档(.pdf, .pptx, .md)。了解更多信息。
-
全新改版的 LlamaParse UI:LlamaIndex 显著改进了 LlamaParse UI,扩展了用户可用的选项范围。在此查看更新。
-
旧金山见面会公告:LlamaIndex 宣布在他们新的旧金山办公室举行线下见面会,演讲嘉宾来自 Activeloop、Tryolabs 和 LlamaIndex。有关详情及加入名单,请访问此链接。
提到的链接:RSVP to GenAI Summit Pre-Game: Why RAG Is Not Enough? | Partiful:注意:这是在旧金山 LlamaIndex 总部举行的线下见面会!顺道参加我们的见面会,了解为您的公司构建生产级检索增强生成(RAG)引擎的最新创新…
LlamaIndex ▷ #general (155 条消息🔥🔥):
- SQL 表 Embedding 建议:一位用户寻求适用于 SQL 表的 Embedding 模型建议。另一位成员建议探索在 MTEB Leaderboard 上排名的模型;然而,有人指出这些模型更多关注文本数据而非 SQL 特定数据。
- 用于机密数据的本地部署(On-Premise)LlamaParse:关于在本地使用 LlamaParse 处理机密数据的查询,建议通过 其联系页面 直接联系 LlamaIndex 团队以获取本地部署解决方案。
- OpenAIAgent 的 Streamlit 问题:排查发现 Streamlit 的无状态行为导致 OpenAIAgent 丢失对话记忆。受 Streamlit 论坛 讨论启发,解决方案涉及使用
@st.cache_resource装饰器来初始化 Agent。 - LlamaIndex 对 Claude 3 Haiku 的支持:尽管用户存在困惑,但共享的 文档 链接确认 LlamaIndex 支持 Claude 3 Haiku。
- LlamaIndex Document Loader 增强:用户讨论了增强 Document Loader 以避免重复,并在 Ingestion Pipeline 中使用 Transformation。为了有效地处理文档,通过 文档 明确了挂载
docstore并通过完整文件路径管理文档标识符的方法。
- Discord | 您的沟通与聚会场所: Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区交谈、聊天、聚会并保持紧密联系。
- MTEB 排行榜 - 由 mteb 提供的 Hugging Face Space: 未找到描述
- 联系我们 — LlamaIndex,LLM 应用的数据框架: 如果您对 LlamaIndex 有任何疑问,请联系我们,我们将尽快安排通话。
- st.cache_resource - Streamlit 文档: st.cache_resource 用于缓存返回共享全局资源(例如数据库连接、ML 模型)的函数。
- “等等,这个 Agent 可以抓取任何东西?!” - 构建通用网页抓取 Agent: 在 5 分钟内为电子商务网站构建通用网页抓取工具;试用 CleanMyMac X 7 天免费试用版 https://bit.ly/AIJasonCleanMyMacX。使用我的代码 AIJASON ...
- 构建您自己的 OpenAI Agent - LlamaIndex: 未找到描述
- OPENAI_FUNCTIONS Agent 记忆在 Streamlit st.chat_input 元素内无法工作 · Issue #7061 · langchain-ai/langchain: 系统信息 langchain = 0.0.218 python = 3.11.4 谁能帮忙?@hwchase17 , @agola11 信息 官方示例笔记本/脚本 我自己修改的脚本 相关组件 LLMs/Chat Models Em...
- 有办法运行初始化函数吗?: 能请您举个例子说明我在这种情况下该如何使用它吗?
- [Bug]: 在流模式下 tools_call 类型响应后未调用 OpenAIAgent 函数 · Issue #11708 · run-llama/llama_index: Bug 描述 在多次情况下,当 Agent 执行可能包含工具调用响应的聊天补全时,如果响应返回 JSON 缩进... 则该过程无法调用函数。
- Chat Stores - LlamaIndex: 未找到描述
- GitHub - run-llama/llama_index 位于 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0: LlamaIndex 是适用于您的 LLM 应用的数据框架 - GitHub - run-llama/llama_index 位于 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0
- Ingestion Pipeline - LlamaIndex: 未找到描述
- Ingestion Pipeline + 文档管理 - LlamaIndex: 未找到描述
- llama_index/llama-index-integrations/llms/llama-index-llms-anthropic/llama_index/llms/anthropic/utils.py 位于 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0 · run-llama/llama_index: LlamaIndex 是适用于您的 LLM 应用的数据框架 - run-llama/llama_index
- Anthropic Haiku Cookbook - LlamaIndex: 未找到描述
- 使用文档 - LlamaIndex: 未找到描述
- 加载数据 (Ingestion) - LlamaIndex: 未找到描述
LlamaIndex ▷ #ai-discussion (3 条消息):
- 寻求关于使用 Llama 实现 RAG 的帮助: 一位用户正在使用 Cohere AI 开发一个“与文档聊天”的 RAG 应用程序,但在使用 Llama 实现 RAG 时遇到问题。他们向社区寻求有关此实现的指导和参考资料。
LAION ▷ #general (144 条消息🔥🔥):
- AI 对电网的影响:用户讨论了 用于 AI 的 GPU 阵列 巨大的功耗。一位用户指出,“一个由 5000 块 H100 组成的集群,仅 GPU 待机功耗就达到 375kW。”
- 设备端 Stable Diffusion 3:一个推文链接宣布通过名为 DiffusionKit for Mac 的项目实现了 设备端 Stable Diffusion 3。该项目将与 Stability AI 合作开源(推文链接)。
- 开源与闭源工作的辩论:成员们辩论了在 开源公司 工作与在薪资更高的 闭源公司 工作的优劣。一些人指出,闭源公司的 竞业禁止条款 阻碍了对开源项目的贡献。
- FTC 禁止竞业禁止协议:关于 FTC 禁止劳动者竞业禁止协议的新规定 的讨论(FTC 公告)。用户注意到这将有助于保护劳动者并促进竞争。
- GPT-4o 与 AI 多模态模型:关于 GPT-4o 在生成和修改图像方面的性能讨论,以及与 DALL-E 3 等其他模型的比较。一些用户认为 多模态模型 是 AI 的未来。
- Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention:这项工作介绍了一种高效的方法,可以在有限的内存和计算资源下,将基于 Transformer 的大语言模型(LLMs)扩展到无限长的输入。我们提出的方法中的一个关键组件...
- Scaling Transformer to 1M tokens and beyond with RMT:Transformer 可解决的问题范围受限,一个主要原因是计算复杂度随输入大小呈二次方增长。在这项研究中,我们调查了循环记忆(recurrent memory)...
- 来自 argmax (@argmaxinc) 的推文:设备端 Stable Diffusion 3。我们很高兴能与 @StabilityAI 合作,实现其最新旗舰模型的设备端推理!我们正在构建 DiffusionKit,这是我们的多平台设备端推理...
- FTC 宣布禁止竞业禁止协议的规定:今天,联邦贸易委员会发布了一项最终规定,通过在全国范围内禁止竞业禁止协议来促进竞争,保护基本的...
LAION ▷ #research (20 条消息🔥):
-
推出新的视频生成数据集:一位用户分享了一篇介绍 VidProM 的论文链接,这是首个大规模数据集,包含来自真实用户的 167 万个独特的文本转视频提示词,以及由最先进的扩散模型生成的 669 万个视频。该数据集旨在解决缺乏公开文本转视频提示词研究的问题,使其区别于 DiffusionDB 等现有数据集。arXiv 论文。
-
双线性采样的神经方法:一位成员讨论了由于梯度的局部性,在神经网络中使用双线性采样所面临的挑战。他们提议训练一个小型神经网络来近似双线性采样,旨在实现平滑可优化的采样位置,而不会出现硬梯度停止。
-
Google 的 Imagen 3 占据主导地位:成员们对 Google 新推出的 Imagen 3 感到兴奋,该模型声称以更好的细节、更丰富的光影和更少的伪影击败了所有其他图像生成模型。Imagen 3 已通过 ImageFX 向选定的创作者开放,成员们讨论了将其用于合成数据生成。Google Imagen 3。
-
社区数据集构想:成员们对利用 API 或抓取互联网生成新的社区数据集表现出极大热情,并利用 Imagen 3 等模型进行数据收集。
-
Stable Diffusion 超级放大方法:分享的一篇 Reddit 帖子详细介绍了一种使用 Stable Diffusion 进行图像超级放大的新方法,承诺在不失真的情况下获得高质量结果。Reddit 上的超级放大方法。
- Imagen 3: Imagen 3 是我们最高质量的 text-to-image 模型,与我们之前的模型相比,它能够生成细节更出色、光影更丰富且干扰伪影更少的图像。
- Reddit - Dive into anything: 未找到描述
- VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models: Sora 的到来标志着 text-to-video 扩散模型进入了一个新时代,在视频生成和潜在应用方面带来了显著进步。然而,Sora 以及其他 text-to-video ...
Eleuther ▷ #general (31 messages🔥):
-
Epinet 的复杂性引发辩论:成员们讨论了使用 epinets 的权衡与挑战,强调了调优困难和 epinet 的启发式特性等问题(“epinet 应该保持较小,所以我假设 residual 只是作为一种归纳偏置(inductive bias),将 epinet 维持为原始输出的一种扰动。”)。
-
职位发布规则困惑得到澄清:提出了关于职位发布规则的问题。成员们指出存在“禁止广告”的规则,但未深入探讨具体指南。
-
AGI/ASI 预测引发准备工作的讨论:关于 AGI 及其影响 的对话包含了关于它何时到来以及应采取何种行动的不同意见。建议包括学习非自动化技能或搬到农村地区,尽管一些人建议维持日常生活照旧(“你做什么并不重要,所以做你本来会做的事就好”)。
-
分享了 PyTorch
flop_counter.py文档见解:一位成员分享了如何在 PyTorch 中使用FlopCounterMode。他们提供了使用示例并解释了模块追踪器,尽管它缺少关于追踪 backward 操作的细节。 -
lm_eval 模型模块工作邀请:一位成员表示有兴趣为 MLX 贡献 lm_eval 模型模块。他们被鼓励继续进行,并记录任何新发现以帮助未来的贡献者(“尽管去处理它,如果遇到困难就开一个 Github issue。”)。
Eleuther ▷ #research (51 messages🔥):
-
讨论 Transformer 反向传播:成员们讨论了标准 Transformer 层中反向传播的复杂性,特别是即使只计算最后一个 token 的 loss,它为何仍然是 “6N”。他们注意到了细微差别,例如 “你的 output projection 将被反向传播一次,而不是 seq_len 次”,强调了计算负载的减少。
-
分享了 DCFormer GitHub 代码:一位成员分享了 DCFormer GitHub 的链接,指出尽管其结构复杂,但结果令人印象深刻。其他成员辩论了相关伪代码中记录的实用性和设计选择。
-
视觉问答模型:成员们研究了视觉问答(Visual Question Answering)模型的可用性和实用性,提到了 Salesforce 的 BLIP3。一位成员确认了它回答关于图像的特定问题的能力,将其定位在简单的目标检测模型和更复杂的 vision-language 模型之间。
-
Transformer 在路径组合中的挑战:一位成员强调了一篇论文,证明 Transformer 在路径组合(path composition)任务中表现挣扎。这一观察结果与 Transformer 在关联学习(associative learning)中已知的弱点一致,例如无法正确链接不相干的信息片段。
-
Open LLM Leaderboard 和 Chat Templating 更新:回答了关于 Open LLM Leaderboard 评估框架(evaluation harness)的查询,确认其仍在使用旧版本。这里的 Chat Templating pull request 正在进行中,预计很快将支持 zero-shot 场景。
- ALPINE: Unveiling the Planning Capability of Autoregressive Learning in Language Models: 在本文中,我们展示了 ALPINE 项目的研究结果,该项目代表“网络中规划的自回归学习 (Autoregressive Learning for Planning In NEtworks)”。ALPINE 项目启动了对...开发的理论调查。
- Salesforce/xgen-mm-phi3-mini-instruct-r-v1 · Hugging Face: 未找到描述
- evals/docs/completion-fn-protocol.md at main · openai/evals: Evals 是一个用于评估 LLM 和 LLM 系统的框架,也是一个开源的基准测试注册表。 - openai/evals
- GitHub - Caiyun-AI/DCFormer: 通过在 GitHub 上创建账号来为 Caiyun-AI/DCFormer 的开发做出贡献。
- What is Visual Question Answering? - Hugging Face: 未找到描述
- Beyond Scaling Laws: Understanding Transformer Performance with Associative Memory: 增加 Transformer 模型的大小并不总是能带来性能的提升。这种现象无法通过经验性的 Scaling Laws 来解释。此外,改进的泛化能力...
- [WIP] Add chat templating for HF models by haileyschoelkopf · Pull Request #1287 · EleutherAI/lm-evaluation-harness: 这是一个 WIP PR,延续了 @daniel-furman 在 #1209 中开始的为 HF 模型添加指定的、经常被要求的聊天模板功能的工作。目前的 TODO 包括:使用 OpenHermes 等检查性能...
Eleuther ▷ #scaling-laws (22 messages🔥):
-
符号空间中的元学习 (Meta-learning) 很难:一位参与者建议,可以通过寻找一个近似预训练 Transformer 权重的符号函数,在符号空间中进行元学习。然而,另一位成员指出符号回归(symbolic regression)具有挑战性,并提议通过优化符号表达式来压缩已训练的神经网络参数。
-
想法倾倒 (Idea-dump) 频道提议:一位用户提到自己有太多的想法,并建议为社区项目创建一个“idea-dump”频道。另一位用户指向了一个可能存在的想法板,但不确定它是否仍然存在。
-
将想法委派给 AGI:讨论转向了对未来 AGI 能够处理想法执行的希望。一位参与者幽默地评论说,甚至可以将想法的产生也委派给 AGI,而另一位参与者则将想法产生过程比作生活中不应被委派的愉悦部分。
-
GPT-4 的训练后 (Post-training) 改进:一段引用的对话强调了训练后如何显著提高模型性能,从而大幅提升了 GPT-4 的 Elo 评分。讨论暗示,虽然训练后可以产生实质性的改进,但当训练后效率下降时,最终可能需要新的训练。
-
使用 MLP 近似 Attention:一位用户思考了训练一个 MLP 来近似 Attention 计算,并将其作为不含 Attention 层的 Transformer 模型初始化的可能性。他们推测在 Vaswani 等人的论文之后,是否已有现有的论文探索过这项直接的后续工作。
Eleuther ▷ #interpretability-general (1 messages):
alofty: https://x.com/davidbau/status/1790218790699180182?s=46
Eleuther ▷ #lm-thunderdome (3 messages):
- 通过
--log_samples导出多选题答案:一位成员询问如何导出多选题的单个答案,以便比较正确/错误答案的分布。建议他们使用--log_samples,该参数会存储包含模型对数似然 (log likelihoods) 和每个样本指标(如准确率)的日志文件。
Eleuther ▷ #gpt-neox-dev (31 messages🔥):
-
模型转换过程中的困难:一位用户在使用
convert_neox_to_hf.py将使用 GPT-NeoX 训练的模型转换为 Huggingface 格式时遇到问题。错误包括缺失word_embeddings.weight和attention.dense.weight。 -
调查转换问题:Hailey Schoelkopf 提出调查转换问题,并指出该转换脚本之前经过了测试。即使使用默认的 125M 配置,问题依然存在。
-
Pipeline Parallelism 命名冲突:Pipeline Parallelism (PP) 的文件命名约定差异被确定为错误源。以 PP=2 保存的文件与以 PP=1 保存的文件使用不同的命名约定,导致转换脚本失败。
-
MoE PR 变更:发现 MoE PR 中的更改影响了
is_pipe_parallel的行为,从而促使对转换脚本进行修复。Hailey Schoelkopf 提交了一个 bugfix PR 来解决这些问题。 -
配置文件不兼容:在 transformers 库中发现涉及
rmsnorm的不支持配置后,建议遇到问题的用户使用 Huggingface 支持的其他配置文件。
- gpt-neox/tools/upload.py at 2e40e40b00493ed078323cdd22c82776f7a0ad2d · EleutherAI/gpt-neox:基于 Megatron 和 DeepSpeed 库在 GPU 上实现模型并行自回归 Transformer —— EleutherAI/gpt-neox
- Conversion script bugfixes by haileyschoelkopf · Pull Request #1218 · EleutherAI/gpt-neox:更新 NeoX-to-HF 转换工具以修复以下问题:#1129 调整了默认的 `is_pipe_parallel` 行为,使得 PP=1 模型不再使用 PipelineModules 训练,因为 MoE...
- Add MoE by yang · Pull Request #1129 · EleutherAI/gpt-neox:关闭 #479
Interconnects (Nathan Lambert) ▷ #other-papers (10 条消息🔥):
-
神经网络向现实收敛:一位成员指出:“神经网络在不同的数据和模态上以不同的目标进行训练,正在其表示空间中收敛到一个共享的现实统计模型。”这突显了各种神经网络表示向统一现实模型的收敛。
-
分享 Phillip Isola 的见解:分享了指向 Phillip 项目网站、一篇 arxiv 论文和一个展示新结果的 Twitter 线程的链接。文中指出,随着 LLM 的改进,它们学习到的表示与视觉模型的表示变得越来越相似,反之亦然。
-
智力上的谦逊与共识:一位成员坦言:“我觉得我不够聪明,无法理解这个,但它很酷,”表达了敬畏与困惑交织的情绪。另一位成员指出他们理解这些结论,并认为这些结论令人兴奋,且与 AI 领域现有的假设一致。
-
机械解释性(Mechanistic Interpretation)领域:不同神经模型收敛于相似表示的结论被总结为机械解释性领域的关键。这种相互理解强化了“解释神经网络机制至关重要”的观点。
提到的链接:来自 Phillip Isola (@phillip_isola) 的推文:我们调查了文献中的证据,然后提供了几个 新 结果,包括:随着 LLM 变得更大更好,它们学习到的表示与视觉模型学习到的表示越来越相似…
Interconnects (Nathan Lambert) ▷ #ml-questions (16 条消息🔥):
-
OpenAI 的模型编号怪癖引发成员热议:一位用户幽默地注意到 OpenAI 经常从头开始训练新模型,而不分配新编号。另一位响应者表示赞同,评论了该公司倾向于“模糊化(obscivate)”的趋势。
-
Tokenization 的可能性引发好奇:成员们讨论了新多模态模型的 tokenizer 是否可能是“伪造的”。一位用户假设跨不同模态共享 tokenizer 是没有意义的,暗示每种模态可能都有自己的 tokenizer。
-
对 OpenAI 方法的信任与怀疑:虽然一些成员对 OpenAI 的 tokenization 方法表示怀疑,但其他人建议对该公司保持疑中留情(benefit of the doubt)。一位用户特别提到,尽管项目看起来“一团糟”,但细节应该在某处可以找到。
Interconnects (Nathan Lambert) ▷ #random (64 条消息🔥🔥):
-
Anthropic 转型为产品公司:注意到 Anthropic 正在从以服务为中心向以产品为导向的公司转型,并提到了投资者的预期以及产品开发对数据改进的必要性。一位成员评论说,随着时间的推移,这种转变是不可避免的。
-
AI 公司的商业模式困境:OpenAI、Anthropic 及类似公司面临挑战,原因在于它们依赖外部基础设施,且容易被产品公司商品化,这可能导致不可持续的估值。一位成员将其与历史上的科技巨头如 IBM 和 Cisco 进行类比,强调了无法达到增长预期的风险。
-
OpenAI 的新业务与招聘:OpenAI 即将推出的旨在与 Google 竞争的搜索引擎已得到确认,并聘请了一位前 Google 高管来领导该项目。这表明其战略正向商业化产品发生重大转变。
-
关于 AGI 时间线的讨论:参考 Dwarkesh 的采访,成员们讨论了 AGI 在不久的将来实现的实际性,并对这类时间线的合理性和相关性持不同意见。
-
AI 模型性能与透明度的变化:成员们讨论了 GPT-4o 性能评分的变化,注意到 ELO 评级和部分 LMsys 评估出现了显著且无法解释的下降。此外,还提出了对模型性能指标缺乏透明度和更新机制的担忧。分享了相关讨论和公告的链接。
- William Fedus (@LiamFedus) 的推文:但 ELO 最终可能会受到提示词难度的限制(即在“最近怎么样”这类提示词上无法获得任意高的胜率)。我们发现,在更难的提示词集上——特别是……
- The Information (@theinformation) 的推文:OpenAI 聘请了在 Google 工作 21 年的老将 Shivakumar Venkataraman,他此前领导该公司的搜索广告业务。此举正值 OpenAI 开发一款将与 Google 竞争的搜索引擎之际……
- Sam Altman 谈论 GPT-4o 并预测 AI 的未来:在 ChatGPT-4o 发布当天,Sam Altman 坐下来分享了发布会的幕后细节,并对他对 AI 未来的预测……
- ChatGPT 扩展背后的故事 - Evan Morikawa 在 LeadDev West Coast 2023:ChatGPT 扩展背后的故事。这是关于我们如何扩展 ChatGPT 和 OpenAI API 的幕后观察。扩展团队和基础设施是困难的。它……
- Evan Morikawa (@E0M) 的推文:我在 OpenAI 工作 3 年半后即将离职。我将加入我的好朋友 Andy Barry (Boston Dynamics) + @peteflorence & @andyzeng_ (DeepMind 🤖) 的一个全新项目!我认为这将是必要的……
- Teknium (e/λ) (@Teknium1) 的推文:现在已经上线了,我不记得旧分数是多少,但现在看起来更接近 4-turbo 了,对于编程来说,不确定性相当大,但也是一个巨大的领先。引用 Wei-Lin Chiang (@infwinston) @...
Interconnects (Nathan Lambert) ▷ #memes (1 条消息):
- 跳过 Huberman 获得认可:Nathan Lambert 对从不听 Huberman 表示解脱,并分享了他的推文链接。推文的具体背景或他产生这种感觉的原因未被讨论。
Interconnects (Nathan Lambert) ▷ #posts (4 条消息):
- 对 OpenAI 的赞扬与批评:“最后两篇文章从赞扬 OpenAI 的技术领导力转变为对其文化展示的全面抨击。” Nathan Lambert 强调了近期文章中关于 OpenAI 的截然不同的观点,并将其描述为一种“经典”的转变。
- 创作文章是令人愉悦的:Nathan Lambert 表示,撰写近期的文章虽然具有挑战性,但比平时更像是一种“手艺活” (craft)。这表明了他从工作中投入的努力和获得的满足感。
LangChain AI ▷ #general (86 条消息 🔥🔥):
-
澄清关于 LangChain 流式输出的误解:一位用户误解了 LangChain 中
AgentExecutor的.stream工作方式,期望它能流式传输单个 token。建议他们使用.astream_eventsAPI 来实现包含单个 token 输出的自定义流式传输,而不仅仅是中间步骤。Streaming Documentation。 -
Windows 11 上 Jsonloader 的修复方案:一位成员分享了一个修复链接,针对 Jsonloader 使用 jq schema 解析 JSON 文件时无法在 Windows 11 上安装的问题。Issue #21658。
-
在向量数据库之间迁移 Embeddings:讨论涉及将 embeddings 从 pgvector 迁移到 qdrant。由于对检索速度的担忧,建议寻找迁移工具或从原始语料库重新生成 embeddings。
-
Neo4j 的 Index Name 问题:一位用户报告了
index_name无法更新并总是恢复到第一个使用的索引的问题。建议他们为不同的索引创建单独的实例,并检查潜在的 bug。 -
为聊天机器人添加 Memory:有关于如何将 memory 整合到聊天机器人中以在查询之间保留上下文的问题。建议的解决方案包括跟踪聊天历史记录以及在 prompt 中为 memory 变量添加占位符,并附带了相关文档链接。
- MultiQueryRetriever | 🦜️🔗 LangChain: 基于距离的向量数据库检索将查询嵌入(表示)在高维空间中,并根据“距离”寻找相似的嵌入文档。但是,检索可能会产生不同的...
- Matryoshka embeddings: faster OpenAI vector search using Adaptive Retrieval: 使用 Adaptive Retrieval 提升 OpenAI 新嵌入模型的查询性能。
- Postgres Embedding | 🦜️🔗 LangChain: Postgres Embedding 是一个用于 Postgres 的开源向量相似度搜索,使用 Hierarchical Navigable Small Worlds (HNSW) 进行近似最近邻搜索。
- Issues · langchain-ai/langchain: 🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号,为 langchain-ai/langchain 的开发做出贡献。
- DOC: Jsonloader uses jq schema to parse Json files which cannot be installed on windows 11 · Issue #21658 · langchain-ai/langchain: 检查清单:我为此 Issue 添加了一个非常详细的标题。我包含了所引用的文档页面链接(如果适用)。当前文档的问题:文档:https://python....
- PGVector | 🦜️🔗 LangChain: 使用 Postgres 作为后端并利用 pgvector 扩展实现的 LangChain vectorstore 抽象。
- Neo4j Vector Index | 🦜️🔗 LangChain: Neo4j 是一个开源图形数据库,集成了对向量相似度搜索的支持。
- Custom agent | 🦜️🔗 LangChain: 本笔记本介绍了如何创建你自己的自定义 Agent。
- Memory management | 🦜️🔗 LangChain: 聊天机器人的一个关键特性是能够使用之前对话轮次的内容作为上下文。这种状态管理可以采取多种形式,包括:
- Streaming | 🦜️🔗 LangChain: Streaming 是 LLM 应用中重要的 UX 考量,Agent 也不例外。由于 Agent 的流式传输不仅涉及最终答案的 Token,这使得其实现更加复杂...
- Issues · langchain-ai/langchain: 🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号,为 langchain-ai/langchain 的开发做出贡献。
- Issues · langchain-ai/langchain: 🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号,为 langchain-ai/langchain 的开发做出贡献。
- Issues · langchain-ai/langchain: 🦜🔗 构建上下文感知的推理应用。通过在 GitHub 上创建账号,为 langchain-ai/langchain 的开发做出贡献。
- langchain.retrievers.multi_query.MultiQueryRetriever — 🦜🔗 LangChain 0.2.0rc2: 未找到描述
- langchain.chains.llm.LLMChain — 🦜🔗 LangChain 0.2.0rc2: 未找到描述
LangChain AI ▷ #langserve (2 条消息):
-
Rate Exceeded 错误中断工作流:一位成员指出,他们在加载带有 “/docs” 的服务器 URL 时遇到了 “rate exceeded” 错误,导致工作流中断。他们询问切换到 Langsmith 的 Pro 计划是否能解决此问题。
-
服务器不活动阻碍持续使用:同一位用户提到,他们的服务器会定期进入休眠模式或变得不活跃,影响了服务的持续使用。他们正在寻求关于该问题原因及潜在解决方案的见解。
-
请求已部署修订版本的日志:有人提出了一个额外的问题,即是否可以查看已部署修订版本的日志,而不仅仅是构建日志。这将有助于更好地监控和调试他们的部署。
-
调查速率限制和非活动状态的模式:另一位成员询问是否存在与 RAG 源大小影响速率限制相关的可识别模式,或者服务器进入休眠状态的任何已知超时时间间隔。
LangChain AI ▷ #share-your-work (2 条消息):
- 在 Langserve 后端快速启动加密货币支付:一位用户正在利用 py4j 库,从 Langserve 后端调用 JVM 中的 JAR 接口进行 加密货币 SDK 调用。这实现了针对 prompt/response token 计数的微支付,并在 OpenAI API 预付密钥对之上增加了可调节的利润空间。
- 房地产 AI 助手发布:一位用户宣布了一款新的 AI 工具,结合了 LLM、结合 LangChain 的 RAG,以及来自 @vercel AI 和 @LumaLabsAI 的交互式 UI 组件,以提供独特的房地产体验。他们在 LinkedIn 上分享了他们的项目,并在 YouTube 上发布了演示视频。
LangChain AI ▷ #tutorials (1 条消息):
- 探索通用网页抓取 Agent:一位成员分享了一个关于通用网页抓取 Agent 的视频,该 Agent 可以直接使用浏览器。视频涵盖了处理分页、验证码(CAPTCHA)以及更复杂的网页抓取功能。
OpenRouter (Alex Atallah) ▷ #app-showcase (3 条消息):
-
印地语 8B 聊天机器人模型发布:推出了一款名为 “pranavajay/hindi-8b” 的新文本生成语言模型,专门针对印地语对话任务进行了微调。该模型拥有 102 亿参数,面向聊天机器人和语言翻译应用,使其在引人入胜、上下文相关的交互方面非常通用。
-
ChatterUI 简化移动端聊天机器人:ChatterUI 是一个简单、以角色为中心的 Android UI,支持包括 OpenRouter 在内的各种后端。它类似于 SillyTavern,但功能较少,在设备上原生运行,其仓库已在 GitHub 上发布。
-
Invisibility MacOS Copilot 发布:推出了一款名为 Invisibility 的免费 MacOS Copilot,由 GPT4o, Gemini 1.5 Pro 和 Claude-3 Opus 提供支持。它包含一个新的视频副手,用于无缝上下文吸收,语音和长期记忆功能即将推出,iOS 版本也正在开发中(来源)。
- pranavajay/hindi-8b · Hugging Face:未找到描述
- 来自 SKG (ceo @ piedpiper) (@sulaimanghori) 的推文:过去几周我们一直在打磨。很高兴终于揭晓 Invisibility:专用的 MacOS Copilot。由 GPT4o, Gemini 1.5 Pro 和 Claude-3 Opus 提供支持,现已免费提供 -> @inv...
- GitHub - Vali-98/ChatterUI: 基于 react-native 构建的 LLM 简单前端。:基于 react-native 构建的 LLM 简单前端。通过在 GitHub 上创建账户,为 Vali-98/ChatterUI 的开发做出贡献。
OpenRouter (Alex Atallah) ▷ #general (82 条消息🔥🔥):
-
为 WizardLM-2 8x22B Nitro 切换到 Lepton:成员们讨论了在 SillyTavern 上切换到 Lepton 以获得更好的性能,并确认可以在 OpenRouter 的 Text Completion API 中选择它。“Lepton 在 OR 上作为一个提供商可用”,但请注意,由于某些问题,它已从某些列表中移除。
-
Llama3 微调公告:一位社区成员在专用频道宣布了一个新的 Llama3 微调 70B 模型,旨在处理角色扮演 (RP) 和思维链 (chain of thought) 任务。他们请求大家通过表态(reactions)来支持他们的后续工作。
-
公开模型查看器/探索器工具:一位用户分享了他们更新后的 OpenRouter 模型列表观察器和探索器,强调了其改进的移动端友好型 UI 并征求反馈:模型列表探索器。
-
高效处理大 Token 上下文:讨论中提到了 Google 使用 InfiniAttention 在 Transformers 中进行高效的大 Token 上下文处理,并引用了相关的 研究论文。
-
自定义 Provider 选择信息:分享了关于 OpenRouter 根据价格和性能优先选择 Provider 的功能信息,详见其 文档。该功能旨在帮助有效选择最佳的语言模型。
- Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention:这项工作介绍了一种高效的方法,可以在有限的内存和计算资源下,将基于 Transformer 的大型语言模型 (LLMs) 扩展到无限长的输入。我们提出的方法中的一个关键组件是...
- Mermaid | Diagramming and charting tool:未找到描述
- Pricing | Lepton AI:使用云原生平台,在几分钟内高效、大规模地运行 AI 应用程序。
- mlabonne/Meta-Llama-3-120B-Instruct · Hugging Face:未找到描述
- Reddit - Dive into anything:未找到描述
- OpenRouter API Watcher:OpenRouter API Watcher 监控 OpenRouter 模型的更改,并将这些更改存储在 SQLite 数据库中。它每小时通过 API 查询一次模型列表。
- OpenRouter:构建与模型无关的 AI 应用
OpenInterpreter ▷ #general (19 条消息🔥):
-
OpenAI 邀请桌面应用破解者提供反馈:一位成员透露,在绕过 OpenAI 桌面应用的看门人对话框后,他们被邀请加入一个私有的 Discord 频道,以帮助塑造其开发。他们对被接纳并参与反馈过程感到兴奋。
-
GPT-4o 在 OI 中缺乏图像识别功能:多位用户讨论了通过 OpenInterpreter (OI) 使用 GPT-4o 图像识别功能时遇到的困难。尽管进行了包括调试在内的各种尝试,他们注意到该功能在截屏后就停止了。
-
Dolphin-mixtral:8x22b 虽慢但有效:一位用户分享了尝试不同本地 LLM 的经验,并最终选择了 dolphin-mixtral:8x22b,因为尽管它非常慢(每秒仅处理 3-4 个 Token),但性能表现出色。他们指出 CodeGemma:Instruct 速度更快,是一个合理的折中方案。
-
保存 OI 聊天记录:一位新用户询问如何保存其 OI 交互的聊天记录。另一位成员回复解释说,在启动 interpreter 时使用
--conversations标志允许用户调取之前的对话。 -
GPT-4o 在开发任务中的改进:一位用户详细介绍了使用 GPT-4o 进行 React Web 开发任务的积极体验,指出它在处理多个组件、路由和数据交换时没有出现问题。他们感谢 OpenInterpreter 团队,并对未来的发展感到兴奋。
OpenInterpreter ▷ #O1 (55 条消息🔥🔥):
- 01 中的地址配置障碍:一位成员讨论了由于 captive portal 限制导致更新 grok 服务器地址时遇到的问题,建议为 Wi-Fi 和服务器设置提供统一的配置页面。
- 设备状态的 LED 颜色:正在考虑通过增加颜色来增强设备的 LED 反馈系统,以指示各种状态,如 “Launching WiFi AP”(启动 WiFi AP)和 “Establishing connection to server”(建立与服务器的连接)。目前的状态仅限于几种颜色。
- TestFlight 批准与调试:分享了 TestFlight 链接(TestFlight link),以及用于调试的新终端功能。用户讨论了设置细节,并解决了由错误标志引起的无音频问题。
- OpenRouter 与配置问题:成员们正在排查使 01 与 OpenRouter 协同工作的问题,分享了变通方法,并指出了模型兼容性的不一致,例如 “openrouter/meta-llama/llama-3-70b-instruct:nitro”。还提到了 Groq 和循环提示词的问题。
- 安装与设置挑战:讨论安装问题时,一位用户详细说明了在 Linux 上使用 Poetry 设置 01 时的错误消息和解决方案。在遇到多个与安装相关的错误后,考虑进行彻底重启。
- Shortcuts:未找到描述
- Setup - 01:未找到描述
- 无标题:未找到描述
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、闲逛,并与你的朋友和社区保持紧密联系。
- 01/software at main · OpenInterpreter/01:开源语言模型计算机。通过在 GitHub 上创建账号为 OpenInterpreter/01 的开发做出贡献。
- Introduction - Open Interpreter:未找到描述
- GitHub - OpenInterpreter/01: 开源语言模型计算机:开源语言模型计算机。通过在 GitHub 上创建账号为 OpenInterpreter/01 的开发做出贡献。
Datasette - LLM (@SimonW) ▷ #ai (64 messages🔥🔥):
- Google I/O 未能承认 LLM 的可靠性问题:成员们对 Google I/O 主旨演讲中完全没有提到 LLM 的不可靠性表示失望。“I/O 主旨演讲中让我感到奇怪的是,他们似乎完全没有承认 LLM 的不可靠性——甚至连提都没提。”
- 提议举办 “Sober AI” 展示:讨论了创建一个 “Sober AI” 展示的想法,重点关注实际、平凡的 AI 应用,这些应用在没有过度炒作能力的情况下也能发挥作用。“类似这样:… 我正考虑将其介绍为‘这不是关于人工智能的大谈特谈,而是关于大语言模型以及我们现在能用它们做些什么的小谈。’”
- Gloo 在 MuckRock AI 集成中的作用:Gloo 是 OpenAI 模型的一个第三方封装器,帮助 MuckRock 对 FOIA 响应进行分类并执行其他任务。“如果你想了解更多关于我们正在做的事情的细节,可以联系 mitch@muckrock.com。”
- 引入 “Transformative AI”:成员们讨论将 AI 定义为 “transformative”(转换式)而非 “generative”(生成式),以更好地突出其在转换和处理数据方面的效用。“我还打算推销 ‘transformative AI’ 作为一个更有用的框架,而不是 ‘generative AI’,因为使用 LLM 来处理和转换输入要有趣得多。”
- 关于 prompt caching 的技术见解:一位成员指出,使用 Gemini 的 prompt caching 可以通过将提示词保留在 GPU 内存中来降低 token 使用成本。“你必须付费来保持缓存活跃——$4.50/百万-tokens/小时——这意味着你的提示词被主动加载到某处 GPU 的内存中,从而避免了每次都要加载和处理它。”
- AI news that's fit to print: 新闻机构如何以好坏参半的方式使用 AI。
- no title found: 未找到描述
- We have to stop ignoring AI’s hallucination problem: AI 可能很酷,但它也是个十足的骗子。
- Boundary | The all-in-one toolkit for AI engineers: 未找到描述
- ChatGPT in “4o” mode is not running the new features yet: OpenAI 周一发布的 GPT-4o 模型包含了一些引人入胜的新功能:在理解和生成语音的能力方面有了令人毛骨悚然的改进(Sam Altman 只是发推文说 ...
- llama.cpp/examples/main/main.cpp at e1b40ac3b94824d761b5e26ea1bc5692706029d9 · ggerganov/llama.cpp: C/C++ 环境下的 LLM 推理。通过在 GitHub 上创建账户为 ggerganov/llama.cpp 的开发做出贡献。
- no title found: 未找到描述
- muckrock/muckrock/foia/tasks.py at 11eb9a155fd52140184d1ed4f88bf5097eb5e785 · MuckRock/muckrock: MuckRock 的源代码 - 请向 info@muckrock.com 报告 bug、问题和功能请求 - MuckRock/muckrock
Datasette - LLM (@SimonW) ▷ #llm (2 messages):
- 在对话中途切换模型引发担忧: 一位用户思考了使用不同模型(如切换到
4o)继续已记录对话的影响。他们担心可能会损坏现有对话,但考虑将从 SQLite 表的最新条目中提取 JSON 日志作为权宜之计。 - Mac 桌面端解决方案似乎已废弃: SimonW 作品的一位粉丝注意到,Mac 桌面端解决方案似乎在大约一年前停留在 0.2 版本后就被废弃了。他们正在考虑研究其他选项,以寻求一个简单的入门方案,避免让自己陷入困境。
Latent Space ▷ #ai-general-chat (54 messages🔥):
-
Dwarkesh Patel 剧集讨论: 一位成员称 Dwarkesh Patel 的最新一集为“又一力作”,并指出其中一段由于 John 在采访中缺乏信念和参与感而显得“不忍直视”。他们还提到,虽然整体评价中庸,但为 Patel 带来了重量级嘉宾。
-
OpenAI 聘请 Google 老兵: OpenAI 聘请了 Shivakumar Venkataraman,一位在 Google 工作了 21 年的老兵。此举标志着 OpenAI 正在战略性地推动搜索引擎的开发,直接挑战 Google 的核心产品。
-
模型合并与 GPT 讨论: 成员们注意到 Nous Research 在模型合并方面有趣的探索方向。关于“post-training”一词的讨论显示,它旨在涵盖 RLHF、fine-tuning 和 quantization 等各种技术。
-
富文本翻译问题: 几位用户讨论了在保留 span 语义的同时翻译富文本内容的挑战和潜在解决方案。有人建议使用 HTML 作为中间格式,以保持 span 翻译的一致性。
-
Hugging Face 承诺为社区提供 1000 万美元的 GPU 资源: Hugging Face 承诺提供价值 1000 万美元的免费共享 GPU,以帮助小型开发者、学者和初创公司,旨在对抗 AI 中心化并支持开放式进步。
- Hugging Face 正在分享价值 1000 万美元的算力,以帮助对抗大型 AI 公司:Hugging Face 希望降低开发 AI 应用的准入门槛。
- 来自 The Information (@theinformation) 的推文:OpenAI 聘请了在 Google 工作 21 年的资深人士 Shivakumar Venkataraman,他此前领导该公司的搜索广告业务。此举正值 OpenAI 开发与 Google 竞争的搜索引擎之际...
- 来自 mark erdmann (@markerdmann) 的推文:GPT-4o 在这个极其困难的 needle-in-a-needle 基准测试中取得了突破。这非常令人兴奋。我期待着针对我们 Pulley 内部的一些用例进行测试...
- 来自 Dwarkesh Patel (@dwarkesh_sp) 的推文:这是我与 @johnschulman2(OpenAI 联合创始人,曾领导 ChatGPT 的创建)的对话:关于 post-training 如何驯服 shoggoth,以及未来进展的本质... 链接见下方。请享用!
- Hugging Face 正在分享价值 1000 万美元的算力,以帮助对抗大型 AI 公司:Hugging Face 希望降低开发 AI 应用的准入门槛。
- Sam Altman 谈论 GPT-4o 并预测 AI 的未来:在 ChatGPT-4o 发布当天,Sam Altman 坐下来分享了发布背后的细节,并对他对 AI 的未来做出了预测。
Latent Space ▷ #ai-announcements (1 messages):
swyxio: 新播客发布! https://twitter.com/latentspacepod/status/1791167129280233696
OpenAccess AI Collective (axolotl) ▷ #general (33 messages🔥):
-
LLaMA vs Falcon 辩论:一场关于 Falcon 11B 和 LLaMA 3 的比较讨论展开,强调 Falcon 的许可证并非完全开源,但比 LLaMA 更开放。一位成员指出 “Falcon 2 许可证有一个非常有问题的条款”,涉及可能无法执行的可接受使用政策(Acceptable Use Policy)更新。
-
训练 Mistral 和 TinyLlama:一位成员分享了 TinyLlama 的问题,即除非使用
accelerate通过特定命令手动启动,否则训练会崩溃。他们指出 “手动解决方法有效” 并寻求这种差异的原因。 -
Hunyuan-DiT 模型发布:分享了新的 Hunyuan-DiT 模型 链接,展示了一个具有精细中文理解能力的 multi-resolution diffusion transformer,详情见 项目页面 和 arXiv 论文。
-
聊天格式一致性:成员们讨论了使用 Alpaca 格式 进行训练的问题,其中一人提到他们更喜欢保持聊天格式的一致性,并发现 Alpaca 的后续问题表现不佳。
-
ChatML 和 LLaMA Tokens:针对使用 LLaMA 3 特殊分词器的咨询得到了解答,确认 ShareGPT 格式 适用于作为 ChatML 或 LLaMA 3 对话类型的训练,无需特殊 tokens。
提到的链接:Tencent-Hunyuan/HunyuanDiT · Hugging Face:未找到描述
OpenAccess AI Collective (axolotl) ▷ #general-help (5 messages):
- LORA 训练受益于原始 Prompt:一位成员询问在进行 LORA 时,是否最好使用基础模型训练时所用的原始 Prompt 风格。另一位成员确认,特别是在 LORA 中,重新格式化为原始风格(如 LLaMA 3 风格的
<|eot|>tokens)会产生更好的效果。 - Docker 中的 Python 环境问题:一位成员报告在 Docker 中遇到 AttributeError: LLAMA3。建议他们检查 pip 是否已更新。
OpenAccess AI Collective (axolotl) ▷ #datasets (3 messages):
- STEM MMLU 已完全分类:讨论的数据集似乎是 MMLU 基准测试中 STEM 相关主题的详细分类。如前所述,它涵盖了超出典型 MMLU 覆盖范围的更多内容。
OpenAccess AI Collective (axolotl) ▷ #runpod-help (8 messages🔥):
- 8xH100 PCIe 的 Docker 设置已成功运行:一位成员确认使用 8xH100 PCIe 配置的 Docker 运行正常。他们指出 SXM 版本不可用,因此无法进行测试。
- Docker 故障排除取得进展:一位成员分享了成功运行 Docker 的经验,并澄清了他们使用的是 8xH100 版本。他们对确认表示感谢,并认可了分享的设置信息。
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (13 messages🔥):
-
DrTristanbehrens 询问用于 Agent 控制的 API:一位成员询问 AI Town 是否通过 API 暴露 Agent 控制,以便将自己的代码连接到模拟中。另一位成员提到目前不支持特定于 Agent 的 LLM,但在 LLamaFarm 的背景下讨论过此问题。
-
关于不同 API 层级的讨论:一位成员详细阐述了 Agent 控制的不同 API 层级,建议了运行自定义代码或通过符合 OpenAI 标准的 API 进行 Completions 和 Embeddings 交互的场景。他们还讨论了用于交互和记忆管理的语义 API 的可能性。
-
AI Town 的 Discord iframe 引起关注:成员们讨论了为 AI Town 创建 Discord iframe 的潜力,其中可以包含多人活动和游戏。一位成员评论说这不难实现,并且可能会非常受欢迎。
-
社区参与开发:多位成员表示有兴趣为 Discord iframe 项目做贡献,认为这是一个“低风险高回报的机会”。一位成员提出很快会开始着手开发,并对新的多人活动功能表示兴奋,特别是提到了 Zaranova。
提到的链接:Hugo Duprez (@HugoDuprez) 的推文:正在构建 @discord 活动的朋友们,我制作了一个开箱即用的入门模板 🕹️ 内置物理引擎和多人游戏支持 ⚡️ @JoshLu @RamonDarioIT
AI Stack Devs (Yoko Li) ▷ #ai-town-dev (10 messages🔥):
- 减少 NPC 活动可提高性能:一位成员建议 “一个简单的方法是减少 NPC 的数量”,并提到调整冷却时间常量可以影响 NPC 在活动之间的等待时间。
- 新成员寻求更换头像的帮助:一位新成员询问:“有人能帮我更换角色的头像吗?” 另一位成员确认已找到解决方案:“我已经搞定了,顺便谢谢你”。
- AI 真人秀平台发布:一位成员宣布:“我们明天将发布新的 AI 真人秀平台……如果你有想让我添加到平台上的自定义地图,请告诉我!”。他们表示欢迎社区贡献以增强初始发布效果。
AI Stack Devs (Yoko Li) ▷ #late-night-lounge (2 messages):
- 分享红杉资本(Sequoia Capital)的 PMF 框架: 一位成员分享了红杉资本关于 Arc 产品市场匹配(PMF)框架的文章链接。该文章概述了 PMF 的三种原型,旨在帮助创始人了解其产品在市场中的位置。
提到的链接:Arc PMF 框架:该框架概述了 PMF 的三种不同原型,帮助你了解产品在市场中的位置并确定公司的运营方式。
tinygrad (George Hotz) ▷ #general (10 messages🔥):
- 三角函数计算的复杂性引发了 CORDIC 算法建议:针对使用 CORDIC 算法计算 sin 和 cos 函数展开了讨论,认为它可能比 Taylor approximation(泰勒近似)更简单、更快速。一位成员分享了详细的实现,强调了该算法如何降低复杂性,并通过在多次计算中采用它来节省代码行数。
- 分享了 CORDIC 实现代码片段:演示了 CORDIC 在 Python 中的实现,展示了该算法如何近似正弦和余弦值。分享了用于计算常量和减小参数值的关键函数,以说明其潜在效率。
- 关于处理三角函数中大参数值的辩论:成员们讨论了在三角函数计算中减少大参数值所面临的挑战。重点在于如何精确地将范围缩减至 (-π) 到 (π) 或 (-π/2) 到 (π/2),以保持精度。
- 对大三角函数值的应用和回退(fallback)的担忧:有人提出了在机器学习语境下处理大三角函数值的必要性问题。此外,还讨论了针对 GPU 计算使用 Taylor expansions 进行回退或优化的可能性。
- 提到了 ONNX Runtime 错误:一位成员发布了运行 ONNX 时遇到的错误,强调了一个特定的 CUDA provider bridge 问题。分享了错误日志以便进行故障排除。
tinygrad (George Hotz) ▷ #learn-tinygrad (14 messages🔥):
-
使用新工具可视化形状索引表达式:一位用户介绍了一个用于可视化形状表达式的工具,该工具用于 view 和 shapetracker 操作,使重塑后的数据布局之间复杂的映射关系更容易理解。你可以在这里尝试该工具。
-
探索 TACO 代码生成:另一位用户分享了关于 TACO 的信息,它可以利用可定制的张量格式将张量代数转换为生成的代码。对于任何研究高效张量计算的人来说,这都是一个基础工具。
-
为大型张量归约(reductions)提议高效 CUDA kernel:一位成员讨论了在不将中间结果存储在 VRAM 中的情况下归约大型张量元素的挑战。他们提议使用自定义 CUDA kernel 直接累加结果,并寻求关于 Tinygrad 如何处理此类优化的见解。
-
Tinygrad 学习辅助建议:一位用户推荐将 UseAdrenaline 作为理解和学习包括 Tinygrad 在内的各种仓库的有用应用。他们称赞了该工具在增强学习过程方面的有效性。
-
请求澄清计算图操作:一位用户寻求关于理解计算图中 uops 的确认,特别是询问
DEFINE_GLOBAL操作以及输出缓冲区标签的重要性。这突显了对底层张量操作清晰度的普遍需求。
- Adrenaline:未找到描述
- Shape & Stride Visualizer:未找到描述
- Web Tool:TACO 项目网站
- Google Colab:未找到描述
MLOps @Chipro ▷ #events (9 messages🔥):
-
成员计划在 Data AI Summit 见面:一位来自悉尼的用户提到,他们将于 6 月 6 日至 6 月 16 日在湾区参加 Data AI Summit,并期待与其他成员见面。另一位成员回应称他们也会到场,并表示有兴趣建立联系。
-
Chip 的每月非正式活动暂停:一位用户询问在哪里可以找到 Chip 的每月非正式活动链接。Chip 回应称未来几个月将不会举办此类活动。
-
Snowflake Dev Day 邀请:Chip 邀请成员们在 6 月 6 日参观他们在 Snowflake Dev Day 的展位。
-
NVIDIA 和 LangChain 竞赛公告:Chip 分享了由 NVIDIA 和 LangChain 发起的竞赛,有机会赢取 NVIDIA® GeForce RTX™ 4090 GPU 和其他奖励。
-
NVIDIA 竞赛的参赛资格问题:一位用户对自己的国家不符合 NVIDIA 和 LangChain 竞赛的参赛资格表示失望。Chip 幽默地建议他们搬家。
相关链接:NVIDIA & LangChain 生成式 AI Agent 开发者大赛:立即注册!#NVIDIADevContest #LangChain
MLOps @Chipro ▷ #general-ml (1 条消息):
- AI 硬件历史探究:一位成员分享了一篇长文,回顾了机器学习和 AI 微处理器的历史并做出了未来预测。文章强调了理解我们目前处于 S 型曲线(sigmoid curve)何处的重要性,以便有效地发现趋势。
- Transformer 的主导地位得到认可:文章讨论了过去 4 年中由于基于 Transformer 的模型而取得的 AI 重大突破,并引用了 Mamba Explained 作为例子。文章指出了行业的兴奋情绪,并强调了 Nvidia 的市值已超过 2.2 万亿美元。
- 未来硬件预测:作者对未来 3-4 年内的 NVMe 驱动器和 Tenstorrent 技术表示乐观。相反,他们对 GPU 在 5-10 年时间跨度内的前景持平淡态度。
相关链接:AI 硬件的过去、现在和未来 - SingleLunch:未找到描述
Cohere ▷ #general (10 条消息🔥):
-
Cohere reranker 表现出色但需要高亮支持:一位成员报告称,通过使用 Cohere 的 reranker
[rerank-multilingual-v3.0](https://example.link)取得了目前最好的结果。他们需要一个类似于 ColBERT 的功能,能够高亮显示哪些词对检索任务更相关。 -
Cohere connectors 澄清:一位成员询问了 Cohere connectors 的工作原理,询问它们是向 connector API 发送完整查询,还是仅发送从问题中提取的部分/关键词。另一位成员澄清说,connectors 用于连接数据源以供模型使用。
-
Cohere 的 PHP 客户端查询:一位成员分享了一个 Cohere PHP 客户端的 GitHub 链接(cohere-php),但尚未尝试。他们正在寻求推荐优秀的 Cohere PHP 客户端。
-
Cohere 应用工具包和 reranking 模型咨询:一位成员询问了在生产环境中使用 Cohere 应用工具包的优势,特别是其根据使用情况进行扩缩容的能力。他们还试图了解为什么 Cohere reranking 模型比其他开源模型表现更好。
相关链接:GitHub - hkulekci/cohere-php:通过在 GitHub 上创建账户来为 hkulekci/cohere-php 的开发做出贡献。
DiscoResearch ▷ #general (2 条消息):
- Ilya 离开 OpenAI:一位成员分享了一条推文,宣布 Ilya 将离开 OpenAI。这次离职引发了关于 OpenAI 对对齐(alignment)研究人员吸引力的猜测。
- OpenAI 对对齐研究人员的吸引力似乎在下降:针对 Ilya 离职的消息,另一位成员评论道:“显然,他们对对齐研究人员不再那么有吸引力了。” 这表明了对 OpenAI 内部对齐研究方向和领导层的担忧。
DiscoResearch ▷ #benchmark_dev (1 条消息):
- 新的 NIAN 基准测试甚至挑战了 GPT-4-turbo:Needle in a Needlestack (NIAN) 是一个新的、更具挑战性的基准测试,旨在评估 LLM 在其上下文窗口中关注内容的有效性。尽管有所进步,“甚至 GPT-4-turbo 也在这个基准测试中表现吃力。” 查看 代码 和 网站 了解更多详情。
相关链接:Reddit - 深入探索一切:未找到描述
LLM Perf Enthusiasts AI ▷ #jobs (2 条消息):
-
Ambush 招聘高级全栈 Web 开发人员:Ambush 是一家专注于为交易者和 DeFi 用户提供产品的 AI 工作室,目前正在招聘远程高级全栈 Web 开发人员。查看 职位列表 了解更多详情并分享给你的社交网络;如果他们雇用了你推荐的人选,将提供 5000 美元的推荐奖金。
-
候选人理想特质:理想的候选人应具备敏锐的设计眼光、直观的 UX 感知,并作为原生用户熟悉 DeFi。该职位涉及 70% 前端 和 30% 后端 工作,有 AI 消费级产品经验者优先。
提到的链接:Ambush 的远程高级 Web 开发人员(全栈):Ambush 正在招聘一名远程高级 Web 开发人员(全栈)加入其团队。这是一个全职职位,可以在美洲、亚洲、欧洲或英国的任何地方远程工作…
Mozilla AI ▷ #llamafile (2 条消息):
- Markdown 超链接渲染问题:一位用户报告称,llamafile 项目中服务器返回的超链接未被渲染为 HTML,询问这是否为已知问题,并表示愿意创建 GitHub issue 和 PR 来解决。他们提供了相关代码的 GitHub 链接。
- 私有搜索助手的超时问题:另一位用户分享了他们在私有搜索助手项目中的经验,详见此贴,在仅生成 9% 的 embeddings 后遇到了 超时问题。他们提供了显示 httpx.ReadTimeout 错误的 DEBUG 日志,并征求关于增加超时的建议。
- llamafile-llamaindex-examples/example.md at main · Mozilla-Ocho/llamafile-llamaindex-examples:通过在 GitHub 上创建账号来为 Mozilla-Ocho/llamafile-llamaindex-examples 的开发做出贡献。
- llamafile/llama.cpp/server/public/index.html at d5f614c9d7d1efdf6d40a8812d7f148f41aa1072 · Mozilla-Ocho/llamafile:通过单个文件分发和运行 LLM。通过在 GitHub 上创建账号来为 Mozilla-Ocho/llamafile 的开发做出贡献。