ainews-chameleon-metas-unreleased-gpt4o-like
Chameleon:Meta 的(尚未发布的)类 GPT-4o 全模态模型。
Meta AI FAIR 推出了 Chameleon,这是一个全新的多模态模型系列,包含 7B 和 34B 参数版本。该模型在 10 万亿(10T)token 的交错文本和图像数据上训练而成,实现了“早期融合”多模态,能够原生输出任何模态。虽然其推理基准测试表现平平,但其“全模态”(omnimodality)方法在与 GPT-4o 之前的多模态模型竞争中表现出色。
OpenAI 发布了 GPT-4o,该模型在 MMLU 和编程任务等基准测试中表现卓越,具备强大的多模态能力,但在 ELO 分数上有所下滑,并存在幻觉问题。Google DeepMind 宣布了 Gemini 1.5 Flash,这是一款拥有 100 万上下文窗口且性能极速的小型模型,凸显了 OpenAI 与 Google 模型之间的趋同趋势。
Anthropic 更新了 Claude 3,增加了流式传输支持、强制工具使用以及用于多模态知识提取的视觉工具集成。此外,OpenAI 还与 Reddit 达成合作,引发了业界的广泛关注。
Early Fusion is all you need.
2024年5月16日至5月17日的 AI 新闻。 我们为您检查了 7 个 subreddits、384 个 Twitter 和 30 个 Discord(429 个频道和 5221 条消息)。 预计节省阅读时间(以 200wpm 计算):551 分钟。
Armen Aghajanyan 介绍了 Chameleon,这是 FAIR 在多模态模型方面的最新工作。他们在 10T tokens 的文本和图像(独立且交错)数据上训练了 7B 和 34B 模型,从而产生了一种 “Early Fusion”(早期融合)形式的多模态(与 Flamingo 和 LLaVA 相比),它可以像处理输入一样轻松地原生输出任何模态:
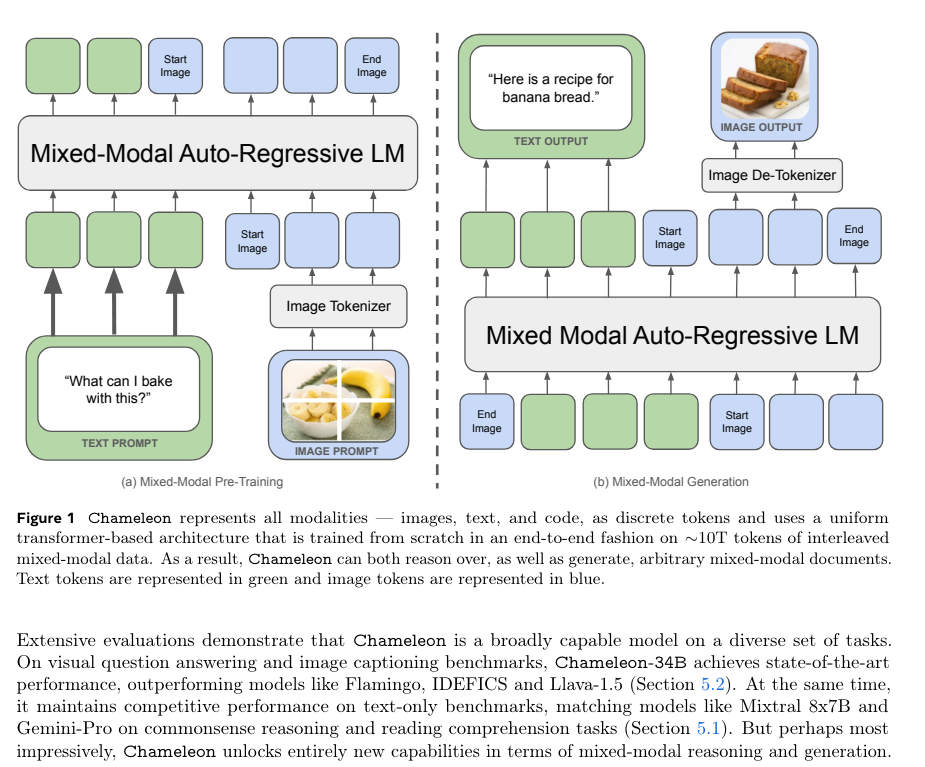
作为一个 34B 模型,其推理基准测试结果并不算特别出众,但这种 “Omnimodality”(全模态)方法与 GPT-4o 之前的同类多模态模型相比表现良好:
正如你所料,Tokenization 非常重要,以下是目前已知的信息:

数据集的描述听起来很简单,但由于模型、代码和数据尚未发布,我们目前只能考虑其方法的理论优势。但令人欣慰的是,Meta 显然距离发布他们自己的 “Early Fusion 混合模态” GPT-4 级别模型已经不远了。
目录
[TOC]
AI Twitter 综述
所有综述由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在使用 Haiku 进行聚类和流程工程(flow engineering)。
OpenAI 与 Google AI 发布会
- OpenAI GPT-4o 发布:@sama 指出了 OpenAI 和 Google AI 发布会在审美上的差异。@zacharynado 指出 OpenAI 的发布时机是如何与 Google 同步的。
- Google Gemini 与 Flash:Google 发布了 Gemini 1.5 Flash,这是一款具有 1M 上下文窗口且具备 Flash 级性能的小型模型。@alexandr_wang 指出 OpenAI 拥有最强的模型 GPT-4o,而 Google 拥有最强的小型模型 Gemini 1.5 Flash。
- AI 发展的趋同性:@alexandr_wang 观察到 OpenAI 和 Google 之间的趋同程度令人着迷,GPT-4o 和 Gemini 等模型之间存在极高的相似性。他认为差异化对行业会更好。
- OpenAI 与 Reddit 合作:OpenAI 已与 Reddit 达成合作,这作为一种潜在的敌意收购策略引起了关注。@teortaxesTex 指出这比 Q* 是更大的突破。
GPT-4o 性能与能力
- GPT-4o 表现优于其他模型:GPT-4o 在 MMLU 等基准测试中优于 Opus 等其他昂贵模型。@abacaj 指出这才是最重要的,尽管 GPT-4o 并没有被冠以 GPT-5 的名称。
- 提升的编程能力:GPT-4o 在编程任务上相比之前的模型有显著提升。@virattt 分享了一个 GPT-4o 成功编辑代码的例子。
- 多模态能力:GPT-4o 在整合图像/文本理解方面表现出色。@llama_index 展示了 GPT-4o 从详细的研究论文图像中提取结构化 JSON,失败率为 0% 且回答质量极高。
- 局限性与退步:尽管有所改进,GPT-4o 的 ELO 分数已从 1310 回落至 1287,编程性能下降幅度更大。它在处理复杂的表格和图表时仍存在幻觉(hallucinations)问题。
Anthropic Claude 3 更新
- 流式传输支持:@alexalbert__ 宣布支持流式传输(streaming),以提供更自然的最终用户体验,特别是对于长输出。
- 强制工具使用:Claude 3 现在支持强制使用特定工具或任何相关工具,从而在 Agent 和结构化输出中提供对工具使用的更多控制。
- 视觉支持:Anthropic 通过增加对返回图像的工具的支持,为多模态工具使用奠定了基础,从而能够从视觉源中提取知识。
Meta AI 发布会
- Chameleon:混合模态早期融合基础模型:Meta 推出了 Chameleon,这是一个基于 Token 的早期融合(early-fusion)混合模态基础模型系列,能够以任意序列理解和生成图像及文本。它在各种视觉语言基准测试中展示了 SOTA 性能。
- Imagen 3:Imagen 3 是 Meta ImageFX 套件的一部分,可以生成各种风格的高质量视觉效果,如写实场景和风格化艺术。它结合了用于 AI 内容水印的 SynthID 等技术。
梗与幽默
- @fchollet 拿 West Elm 展厅和 Marc Rebillet 演出的审美差异开了个玩笑。
- OpenAI 戏剧性事件:@vikhyatk 调侃道:“没有抓马(drama)的 OpenAI 毫无灵魂 💙”
- @svpino 针对为 GPT 模型辩护的行为创造了“模型辩护者”(model-apologists)一词。
- @aidangomez 开玩笑说在一个名为 “Coblox” 的构建数字环境中为企业训练 AGI。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
GPT-4o 与多模态 AI 进展
- GPT-4o 的惊人表现:GPT-4o 在 LMSys Chatbot Arena Leaderboard 上以 1289 Elo 分数位列榜首,尽管其知识截止日期(knowledge cutoff)较早,但表现优于 GPT-4turbo。讨论指出 GPT-4o 擅长提供人类喜欢的答案,但在智力水平上可能没有显著提升。来源
- OpenAI 推出新功能:为 ChatGPT Plus、Team 和 Enterprise 用户引入了交互式表格、图表以及来自 Google Drive 和 Microsoft OneDrive 的文件集成功能,将在未来几周内推出。来源
- MetaAI 的 Chameleon 模型:MetaAI 推出了 Chameleon,这是一个类似于 GPT-4o 的混合模态早期融合基础模型(Mixed-Modal Early-Fusion Foundation Model),能够进行交错的文本和图像理解与生成。来源
- 术语讨论:鉴于 GPT-4o 及类似先进模型扩展的多模态能力,人们在争论“Large Language Model”这一术语是否仍然适用。建议的替代术语包括“Multimodal Unified Token Transformers” (MUTTs) 和 “Large Multimodal Model” (LMM)。来源
{kind=link}
OpenAI 合作伙伴关系与动态
- OpenAI 与 Reddit 达成合作:OpenAI 与 Reddit 建立合作伙伴关系,将其内容引入 ChatGPT 和新产品中。来源 讨论引发了对数据隐私以及 Reddit 出售用户生成内容所产生影响的担忧。来源
- Google 员工对 GPT-4o 的反应:一名 Google 员工使用 Project Astra 对 GPT-4o 的发布做出回应,祝贺 OpenAI 取得了令人印象深刻的成果。来源
{kind=link}
Stability AI 与开源进展
- Stability AI 的潜在出售:Stability AI 在资金短缺的情况下讨论潜在的出售事宜,引发了对开源 AI 计划未来的担忧。来源
- Hugging Face 的 ZeroGPU 计划:Hugging Face 承诺通过推出 ZeroGPU 提供价值 1000 万美元的免费 GPU,以支持开源 AI 开发。来源
- CosXL 发布:Stability AI 发布了 CosXL,这是官方的 SDXL 更新,包含 v-prediction、ZeroSNR 和 Cosine Schedule,解决了生成过暗/过亮图像的问题并提升了收敛速度。来源
AI 基准测试与评估
- 用于评估 MLLM 的 MileBench:MileBench 被引入作为评估多模态大语言模型(MLLMs)在涉及多张图像和长文本的长上下文任务中表现的基准。关键发现显示 GPT-4o 在诊断性和现实评估中均表现出色,而大多数开源 MLLM 在长上下文任务中表现挣扎。来源
- Needle in a Needlestack (NIAN) 基准测试:NIAN 基准测试被提出作为 Needle in a Haystack (NIAH) 的更具挑战性的替代方案,用于评估 LLM 在长上下文中的注意力。即使是 GPT-4-turbo 在该基准测试中也表现吃力。来源
AI 伦理与社会影响
- r/futurology 的悲观情绪:r/futurology 子版块的讨论随着社区壮大变得越来越悲观和“减速主义”(decel),人们担心 AI 对就业和社会的影响。来源
- 美国对中国半导体征收关税:美国将在 2025 年将中国半导体的关税提高 100%,以保护在 CHIPS Act 上投入的 530 亿美元。来源
迷因与幽默
- AI 狂热迷因:关于 AI 狂热的迷因,引用了可口可乐的“AI 口味”。来源
{kind=link}
AI Discord 回顾
摘要之摘要的摘要
-
Hugging Face 投入 1000 万美元用于免费共享 GPU:Hugging Face 承诺投入 1000 万美元提供免费共享 GPU,以支持小型开发者、学者和初创公司开发 AI 技术。CEO Clem Delangue 强调,该计划旨在推动 AI 民主化并对抗大科技公司的中心化 (来源)。
-
OpenAI 对齐团队在优先级转移中离职:Jan Leike,OpenAI 对齐团队负责人,因与公司核心优先级产生分歧宣布辞职。在此之前,Ilya Sutskever 等关键人物也已离职,这引发了关于 OpenAI 是否可能优先考虑短期产品目标而非长期 AI 安全研究的讨论 (Jan 的推文, Wired 文章)。
-
GPT-4o 的能力与局限性引发辩论:GPT-4o 的发布因其多模态能力(如交错的文本和图像理解)而引发关注 (论文)。然而,一些人指出,与 OpenAI 演示所设定的预期相比,其在编程性能和输出质量方面存在不一致 (示例)。
-
大海捞针 (NIAN) 挑战 LLM:新的 NIAN 基准测试对 LLM 提出了严峻挑战,测试它们在大量相似文本中寻找并回答有关特定隐藏文本问题的能力。即使是像 GPT-4-turbo 这样先进的模型在这一任务上也表现挣扎 (代码, 网站)。
第一部分:高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
-
Meta 的模型让人们等待:讨论显示,由于对 Meta 多模态模型的期待,对 Llava 或多模态 AI 的支持有所延迟,且未提及具体发布日期,这表明在技术进步方面对行业领导者的依赖。
-
为 GPU 筹集资金:成员间的对话包括关于他们如何资助 GPU 使用的调侃;幽默的提到包括 “吃好几年的拉面”,作为对 AI 工作奉献的牺牲,特别是对于分类等高要求任务。
-
使用 OpenHermes 提升模型:OpenHermes 数据集是一个受关注的话题,提到其整合带来了模型性能的显著提升,展示了多样化数据集在 AI 研究中的价值。
-
放弃拒绝机制缓解了顽固的 AI:辩论涉及移除 LLM 拒绝机制的影响,注意到“聪明程度”意外提升,并引用了关于该主题的特定论文,为正在进行的 LLM 研究提供了见解。
-
解决 Llama 3 的烦恼:用户分享了训练 Llama 3 时出现的错误解决方案,例如
AttributeError: 'dict' object has no attribute 'context_window',包括修改核心代码或切换到 Ollama 等建议,表明了对 AI 模型开发实际方面的积极参与。
Stability.ai (Stable Diffusion) Discord
SD3 发布保持神秘感:Discord 用户对 SD3 的延迟发布表达了期待和沮丧;尽管 Emad 的推文暗示即将发布,但怀疑情绪依然盛行。
GPU 在敏锐用户中引发辩论:在寻求优化 SDXL 模型训练的过程中,讨论集中在拥有 24GB VRAM 的 RTX 4090 是否足够,一些用户在商讨更强大解决方案的优点。
等待游戏引发迷因狂欢:由于 SD3 的发布充满不确定性,社区开始分享迷因和轻松的评论,如 Stability 的一条推文所示。
数据集和训练技术被摆上桌面:AI 爱好者分享了训练资源,如 来自 Hugging Face 的这个数据集,并交流了微调实践,以期与 Dalle 3 的输出质量相媲美。
从 AI 到社会经济学:会议中的插曲:对话偶尔会偏离 AI 领域,进入关于资本主义和道德的激烈讨论,一些参与者将焦点推回以技术为中心的主题。
OpenAI Discord
-
Interactive Features Level Up ChatGPT:OpenAI 宣布在 ChatGPT 中为 Plus、Team 和 Enterprise 用户引入交互式表格和图表,并提供与 Google Drive 和 Microsoft OneDrive 的直接集成。此更新预计将在未来几周内推出,用户可以在此处了解更多信息。
-
The Dawn of GPT-4o:社区正热烈讨论 GPT-4o 的部分发布,庆祝其登顶排名以及新的更高消息限制。备受期待的功能如 Voice Mode 也即将推出,尽管一些人担忧在长时间使用后性能会有所下降。
-
Ethical AI Conversations Hit Prime Time:AI 对就业市场的影响已成为热门话题,讨论涵盖了生产力的潜在提升以及对未来就业结构的担忧。成员们还在交流关于 AI 在伦理和教育应用方面的想法,旨在平衡技术增强与负责任的使用。
-
Prompt Engineering Pulls Back the Curtain:有效利用 Markdown 来引导 AI 响应,以及模型更新对行为造成的影响所带来的挑战,引起了社区的广泛关注。一些旨在从 AI 获取更理想结果的方法(如情感激励)被幽默地描述出来,同时也展示了对 AI 用户交互的深刻见解。
-
API Chat Gets Technical:关于 API 能力的详细讨论指出,在 Prompt 中使用 Markdown 有助于澄清意图和角色。然而,自定义 GPT 性能的差异以及在模型访问和更新方面的参差体验,凸显了与这些先进 AI 交互时不断演变的本质。
Perplexity AI Discord
- GPT-4o Plays Catch-Up:据观察,GPT-4o 比之前的版本更快且略有改进,免费用户也可使用,尽管有关于不同消息限制和刷新率的报告。
- Cognition vs. Hallucination in AI:对 AI Hallucination 的担忧被重点提及,人们对 AI 完全消除幻觉的能力表示怀疑,这可能会影响初级职位的就业保障。
- Perplexity AI Clashes with ChatGPT:用户在 Perplexity(被认为有更好的溯源能力)和 ChatGPT(因网页搜索等功能集成而受青睐)之间产生了分歧。
- Programming and Creativity in AI Diversity:GPT-4o 和 Opus 展示了不同的优势;GPT-4o 在编程方面表现出色,而 Opus 在数学和复杂问题解决方面更具深度。
- The API Integration Dilemma:有人对 sonar-medium-online 支持的持久性提出疑问;有人寻求将 Perplexity 添加到私有 Discord 中,同时确认 Perplexity AI 模型的默认 Temperature 为 0.2。
Relevant Link: Chat Completions Documentation
HuggingFace Discord
-
OpenAI 的“开放性”引发辩论:一段名为 “大科技公司的 AI 是个谎言” 的 YouTube 评论视频认为 OpenAI 名不副实,这引发了关于 HuggingFace 等真正开放平台价值的对话,以及随后关于 HuggingFace 模型与封闭系统性能对比的讨论。
-
在强化学习中培养好奇心:一篇讨论强化学习中好奇心驱动探索的 论文 引起了关注,该研究详细阐述了在动作结果不可预测的环境中,奖励 Agent 的好奇心如何能带来更好的结果。此外,讨论中还建议使用 epsilon greedy 策略来维持探索与利用(exploration/exploitation)之间的权衡。
-
关于计算机视觉和扩散模型的对话:针对 diffusers 中的潜扩散模型(latent diffusion models)、从零开始训练此类模型以及 UNet 模型的收敛问题(重点关注小数据集的影响)提出了疑问。另外,一篇 Medium 文章 详细介绍了 GPT-4o 与 LlamaParse 的集成,以增强多模态能力;而 #diffusion-discussions 频道的讨论则集中在潜空间表示(latent space representations)以及 Google Collab 的上传问题上。
-
RL 成为焦点:第一个 RL 模型被添加到 Hugging Face 仓库受到了鼓励,这标志着一位用户在 Deep RL 学习路径上的里程碑。这与关于强化学习挑战的讨论以及引入 epsilon-greedy 策略以平衡探索和利用的议题相契合。
-
模型训练与部署的挑战:一位用户在 UNet 模型收敛上的挣扎,以及另一位用户尝试使用 GPT-4o 生成网格谜题,都说明了模型训练的复杂性。一位用户建议进行持续的重新训练,以确保编程语言模型因训练数据过时而保持相关性。
-
数据集创新与 AI 创作展示:Hugging Face 社区推出了 Tuxemon 数据集,其中包含获得许可的生物图像,作为 AI 数据源显得十分有趣。同时,社区成员的展示包括使用 LangChain 和 Gemini 开发的商业顾问 AI、一个由 GenAI 驱动的教育工具,以及一个虚拟 AI 影响者,突显了 AI 技术的广泛应用。
Nous Research AI Discord
-
类脑 AI 模型受到关注:公会成员讨论了 AI 的流式处理概念,类似于人类记忆,并引用了 Infini-attention 方法以实现更高的相关性更新效率。点击此处阅读关于 Infini-attention 的论文。
-
使用 NIAN 挑战赛评估 AI:Needle in a Needle Stack (NIAN) 作为一个小众基准测试出现,旨在挑战语言模型(包括 GPT-4)在海量相似材料中区分特定内容的能力。此处了解更多关于 NIAN 基准的信息 及其 专用网站。
-
探索 AI 中的符号语言:对话暗示了人们对使用 GPT-4o 创建符号语言的兴趣日益浓厚,这种语言可以促进涉及代数计算的任务,表明 AI 在处理符号推理方面有潜在进展。
-
Stable Diffusion 3 拥抱开放架构:Stable Diffusion 3 正在准备进行设备端推理,并针对带有 MLX 和 Core ML 的 Mac 进行了优化,将通过 Argmax Inc. 与 Stability AI 的合作进行开源。在此阅读 Argmax 的合作推文。
-
实时用户界面中的 AI:一位公会成员正在寻找能够近乎实时分析屏幕动作的 AI 模型资源,类似于 Fuyu,它可以每秒处理屏幕截图和 UI 交互。与此同时,Elon Musk 的 Neuralink 已开放其第二位脑机接口试验参与者的申请,并通过 Elon 的推文 发布了详情。
Modular (Mojo 🔥) Discord
Mojo 更新发布:最新的 nightly Mojo 编译器 2024.5.1607 正式亮相,并邀请用户通过 modular update nightly/mojo 体验最新功能。社区对新的条件方法(conditional methods)语法反应非常积极。为了解决 “cookie licking”(占用任务但不处理)的问题,社区正引导贡献者提交更小的 PR。可以查看与上一个 nightly 版本的差异以及完整的变更日志。
Mojo 的工程挑战:工程师们对 Mojo 中 List.append 的性能表示担忧,指出其在大数据量下的效率问题,并邀请大家与 Python 和 C++ 的实现进行对比。他们深入讨论了 Rust 和 Go 的动态数组扩容策略,并参考了一个关于 Mojo 中不同 StringBuilder 变体的案例研究。
开源视角与痛点:关于开源贡献的价值与挑战的辩论非常激烈,一些人对项目从开源转向闭源表示担忧。Advent of Code 2023 被认为是开始学习 Mojo 的一个切入点,相关挑战已在 GitHub 上发布。
开发者动态与实用指南:Modular 的新闻更新已通过 Twitter 链接分享,展示了最新的进展。同时,为了支持更顺畅的贡献流程,一份协助新贡献者在 GitHub 上同步 fork 的指南正在传阅。
MAX 登陆 macOS:MAX 平台带来了令人兴奋的消息,其新的 nightly 版本现在支持 macOS 并引入了 MAX Serving。对 MAX 平台感兴趣的工程师可以参考 快速入门 使用 PyTorch 2.2.2。
LM Studio Discord
模型故障排除成为焦点:涉及 LM Studio 的技术挑战接连出现,包括用户在安装时遇到的 glibc 问题,建议指向可能需要升级或回退到 LM Studio 0.2.23 版本。在没有直接指南的情况下,为 Pinecone 中的 RAG 配置嵌入模型显得比较困难,而 VM 错误 “Fallback backend llama cpu not detected!” 则表明可能存在虚拟机设置问题。杀毒软件也引起了一些骚动,将 0.2.23 安装程序标记为病毒,后被澄清为误报。
LLM 大对决:编程模型与文件生成困扰:参与者强调,最佳编程模型因编程语言和硬件而异,Nxcode CQ 7B ORPO 和 CodeQwen 1.5 finetune 在 Python 任务中备受推崇。大家公认 LM Studio 无法直接生成文件,且强制模型仅显示代码的效果依然不稳定。在咨询最快的语义文本嵌入模型时,all miniLM L6 被认为是最快的,但仍无法满足某位用户的需求。此外,在 LM Studio 中可用的医疗 LLM 推荐方面也存在空白。
杀毒软件的误报狂潮:杀毒工具,特别是 Malwarebytes Anti-malware 和 Comodo,正将 LM Studio 架构的某些部分误认为威胁。这些警报事件(前者通过 VirusTotal 链接分享)凸显了确保 LM Studio 组件不被防护软件误杀的挑战。
硬件爱好者取得新突破:硬件讨论中报告了显著成就,包括在 Intel i5 12600K CPU 上运行 70B LLama3 模型,并注意到了 RAM 频率对齐对性能的影响。成员们讨论了量化效率、内存超频对稳定性的影响,甚至对比了 RX 6800、Tesla P100 和 GTX 1060 等多种 GPU 架构的性能。
跨频道对话推动协作解决方案:多个话题在不同频道间流动,重点在于解决 LM Studio 存储和权限问题,这促成了在客户端而非服务器端有效使用 LangChain 进行对话记忆管理,以及考虑使用开源替代方案而非 Gemini 的付费上下文缓存(context caching)服务。将某些问题的深入讨论转移到其他频道的举动,体现了社区的协作精神。
CUDA MODE Discord
GPU 社区注入动力:Hugging Face 宣布投入 1000 万美元 用于免费共享 GPU,以支持小型开发者、学术界和初创公司,旨在面对大科技公司的 AI 中心化趋势,推动 AI 开发的民主化。此举将 Hugging Face 定位为以社区为中心的枢纽,这篇文章 提供了更多见解。
Triton 性能之谜:Triton 教程的实现者观察到性能差异,质疑 “swizzle” 索引技术可能是影响因素。注意到的差异包括用户按照教程操作时,性能较宣传的性能有显著下降。
Bitnet 走向台前:由于其先进的训练感知量化(training-aware quantization)技术,关于 Bitnet 1.58 的策略讨论启动了一个初创项目。对话强调了训练后权重分量化的重要性,并建议将 Bitnet 的开发集中在 PyTorch ao repo 中,以实现高效的实现和支持。
大语言模型(Large Language Models)的代码与优化:一个 优化拉取请求(PR) 为大语言模型减少了 10% 的内存占用并提高了 6% 的吞吐量,展示了训练阶段的高效资源利用。此外,讨论还揭示了 NVMe 直接写入 GPU 的可能性,这提供了一种绕过 CPU 和 RAM 的高速路径,尽管其在 AI 模型训练工作流中的实际应用仍有待探索。
文档的量子态:社区成员对稀疏的 PyTorch 文档表示不满,特别是 torch.Tag,对话还延伸到了解决自定义 OP 中的模板重载问题。此外,一项旨在缩短 PyTorch 编译时间的计划引起了关注,目标是实现更高效的开发周期。
End.
Interconnects (Nathan Lambert) Discord
-
Interconnects 开辟新路径:Nathan Lambert 满怀热情地介绍了一个小众项目,计划每月更新并进行潜在改进。然而,在 OpenAI 人员离职潮中,一名核心工程师加入了一个由来自 Boston Dynamics 和 DeepMind 的人员发起的倡议,揭示了显著的行业转变。
-
模型界的反应:关于新 GPT-4o 模型 的讨论指出,该模型展示了“交错的文本和图像理解与生成”,代表了一种采用早期融合、多模态方法的新规模范式。OpenAI 的领导层变动导致其 superalignment 团队解散,同时重点转向以产品为中心的目标,引发了关于 AI 安全和对齐(alignment)的辩论。
-
安全问题成为焦点:安全仍然是一个有争议的话题,OpenAI superalignment 团队的解散凸显了对即时产品目标与长期 AI 风险策略之间矛盾的担忧。与此同时,Google DeepMind 发布了其 Frontier Safety Framework,展示了全行业向主动 AI 安全措施迈进的趋势。
-
OpenAI 出人意料的合作伙伴:OpenAI 与 Reddit 出人意料的合作引起了关注,而 Lambert 决定移除模型和数据集链接,说明他在沟通策略上转向更深入、独立的分析。
-
扩展、对齐与技术创新:关于模型词汇量扩展定律(scaling laws)的探讨以及对齐开源语言模型的概述,表明 AI 开发实践在持续完善。为了正面应对技术挑战,Lambert 预告了一个名为 “Life after DPO” 的即将开展的项目。
Eleuther Discord
-
PyTorch Flops 审查中:成员们分享了关于 PyTorch 中 FLOP 计数器的基本使用细节和挑战;注意到在记录反向操作追踪(backward operation tracking)方面存在文档空白。鼓励为针对 MLX 的 lm_eval.model 模块做出贡献。
-
比较研究与灾难性遗忘:观察到对 LLM Guidance Techniques 比较研究的浓厚兴趣,特别是用于类别引导的 Adaptive norms 与 Self Attention 的对比。另一个重点话题是讨论在模型 finetuning 过程中应对灾难性遗忘(catastrophic forgetting)的策略,并就对旧任务进行重新训练的必要性达成了共识。
-
筛选分层记忆与语义指标:一篇新的 Hierarchical Memory Transformer 论文 因其解决长上下文处理限制的潜力而受到关注。另外,正如这篇论文中所提到的,人们正在积极寻找一种优于 Levenshtein distance 等初级替代方案的可微语义文本相似度指标。
-
Transformer 通过 MLP 绕过注意力机制:关于 Transformer 中基于 MLP 的注意力机制近似的讨论指向了 Gwern.net 上可能相关的研究。讨论还涉及了在数据预处理中排除计算成本对模型整体经济化产生的影响。
-
折腾 GPT-NeoX 到 Hugging Face 的转换:将 GPT-NeoX 模型迁移到 Hugging Face 时出现了技术挑战,引发了关于 Pipeline Parallelism (PP) 命名规范以及不兼容文件并存的讨论。针对转换脚本中发现的 bug 提出了修复方案,并对为了更好地与 Hugging Face 结构衔接的兼容配置提出了见解。
LAION Discord
竞业禁止协议被废除:工程界对 FTC 的突破性决定做出反应,该决定取消了竞业禁止协议(noncompetes),这可能会显著改变科技行业的竞争格局和职业自主权。
开源与高薪之争:工程师们围绕选择受雇于闭源公司还是开源公司展开了激烈辩论,考虑了开源贡献的限制以及闭源公司高薪的诱惑。
GPT-4 的同门竞争:GPT-4O 的代码能力受到审视,一些成员注意到其性能更快,但对其代码输出不准确的问题表示遗憾,凸显了对这类先进 AI 系统进行仔细评估的必要性。
Creative Commons 的限制:包含 7000 万张知识共享许可图像的 CommonCanvas 数据集的发布受到了热烈欢迎,但也因其非商业许可而引发担忧,这影响了它在工程领域的利用。
网络技术诀窍与动画影响力:最近的工程讨论深入探讨了成功训练用于双线性采样的 Tiny ConvNet、探索 CNN 中的位置编码,以及一个新的 Sakuga-42M 数据集以促进动画研究,反映了该领域广泛的创新方法。
Latent Space Discord
-
富文本翻译难题:在不丢失 span 正确位置的情况下有效翻译富文本内容(如从英文翻译为西班牙文)仍是一个挑战。为了提高翻译精度,提出了涉及 HTML 标签的方法以及针对确定性推理的策略。
-
Hugging Face 的 GPU 慷慨捐赠:Hugging Face 首席执行官 Clem Delangue 宣布,公司已承诺提供价值 1000 万美元的免费共享 GPU,以支持小型开发者、学术界和初创公司,旨在推动 AI 发展的民主化。
-
Slack 数据隐私担忧:关于 Slack 使用客户数据的争论再次浮出水面,特别是该公司可能在未经用户明确同意的情况下训练其 AI 模型,这引发了社区的广泛反应。
-
下一代 AI 融合:最近的一篇论文描述了一种新型多模态 Large Language Model (LLM),展示了集成的文本和图像理解能力,引发了关于未来 AI 应用和跨模态融合的讨论。
-
OpenAI 对齐团队重组:OpenAI 对齐负责人 Jan Leike 的离职引发了对该机构 AI 安全与对齐 (Safety and Alignment) 理念的反思,Sam Altman 等人对 Leike 的贡献表示了感谢。
-
Latent Space 播客提醒:Latent Space 发布了新的播客剧集。
LlamaIndex Discord
GPT-4o 在文本和图像理解方面取得成功:工程师们正在探索 GPT-4o 在解析文档和从图像中提取结构化 JSON 的能力,并围绕完整 Cookbook 指南及其与前代 GPT-4V 的比较进行了专门讨论。
聚会提醒:旧金山即将举行的 Generative AI 峰会:由 LlamaIndex 在旧金山组织的第一次线下聚会引起了轰动,承诺将深入探讨 Generative AI 和 Retrieval Augmented Generation (RAG) 引擎。
LlamaIndex 集成和用户指南大获好评:GitHub 链接 明确了在 LlamaIndex 中如何使用 Claude 3 haiku 模型,而全面的 LlamaIndex 文档 则提供了关于如何结合 VectorStores 使用 Ollama (LLaMA 3 模型) 的指导。
LlamaIndex UI 焕新:LlamaIndex 的用户界面已得到增强,现在为用户提供了更强大的选项选择以提升体验。
Cohere 与 Llama 配合实现 RAG:社区成员正在寻求关于集成 Cohere 与 Llama 以构建 Retrieval-Augmented Generation 应用的建议,这表明了对跨服务模型功能的浓厚兴趣。
OpenRouter (Alex Atallah) Discord
NeverSleep 携 Lumimaid 加入聊天:新的 NeverSleep/llama-3-lumimaid-70b 模型集成了精选的角色扮演数据,在严肃内容与无审查内容之间取得了平衡。详情请见 OpenRouter 的模型页面。
ChatterUI 为 Android 带来角色交互:ChatterUI 已发布,作为一个专注于角色的 Android UI,与 SillyTavern 等同类产品相比,它进入了功能较少但尚未开发的领域,并支持多个后端。
Invisibility 应用为 Mac 用户优化 AI 交互:一款名为 Invisibility 的新 MacOS Copilot,由 GPT4o 和 Claude-3 Opus 提供支持,在其工具库中增加了视频助手功能,并承诺进一步增强功能,包括语音集成和长期记忆。探索 Invisibility 的功能。
Google Gemini 上下文 Token 引发 TPU 奇迹:拥有 1M 上下文 Token 的 Google Gemini 发布,引发了关于 InfiniAttention 是否是 Google 使用 TPU 处理大规模上下文的答案的辩论,在开发者中激起了怀疑与好奇。技术探究围绕 InfiniAttention 的论文展开,该论文可以在这里找到。
技术故障与预告:发生了一系列技术对话,范围从关于 GPT-4o 音频能力的问题到 OpenRouter 网站上客户端异常的报告,并承诺未来将进行网站重构。技术社区正在努力应对 OpenRouter 的 function calling 能力,引发了指导建议和持续推测。
OpenInterpreter Discord
计费忧虑与 AI 欢呼:用户报告了 OpenInterpreter 的一个 Bug,即即使启用了计费,也会出现错误消息,这与直接调用 OpenAI 时的无缝表现形成鲜明对比。此外,在 OpenInterpreter 中使用 GPT-4.0 所带来的改进令人兴奋,特别是在 React 网站开发方面。
本地传奇与全球目标:关于本地 LLM 的讨论强调了 dolphin-mixtral:8x22b 的鲁棒性(尽管性能较慢)以及 codegemma:instruct 在速度和功能之间的平衡。本着社区进步的精神,Hugging Face 正在投资 1000 万美元提供免费共享 GPU,以鼓励 AI 领域小型实体的开发。
攻克配置与协议难题:工程师们致力于解决 01 在各种 Linux 环境下的安装问题,处理从 Poetry 依赖冲突到 Torch 安装故障等复杂问题。分析了 LMC Protocol 相比传统 OpenAI function calling 的明显优势,该协议旨在实现更快的直接代码执行。
仓库之谜与服务器困境:用户寻求关于 GitHub 仓库状态的澄清,”01-rewrite” 引发了关于新项目出现的猜测。用户分享了在多个平台上与 01 server 连接问题的经验和解决方案,讨论了顺利集成所需的步骤。
Google 的宏伟愿景:GoogleDeepMind 的一条推文预告了 Project Astra,激起了社区的期待,暗示了值得技术专家密切关注的 AI 新进展。
LangChain AI Discord
- AI 聊天机器人的内存增强:工程师们讨论了通过增加内存来增强 AI 聊天机器人以在查询中保留上下文的方法,推荐了如聊天历史记录日志和内存变量等手段。
- 持续存在的 Neo4j 索引问题:多名 Neo4j 用户报告了
index_name参数的问题,文档检索错误暗示了 LangChain 在管理该参数时存在问题。 - AgentExecutor 中的流式传输故障:一位用户在
AgentExecutor中使用.stream进行逐 token 输出时遇到问题,被建议尝试使用.astream_events以获得更细粒度的流式传输。 - RAG Chain 异步异常:在 Langserve 中尝试使 RAG chain 异步化时导致了与协程执行不完整相关的错误,阻碍了功能实现。
- 房地产与研究领域的 AI 技术融合:分享的项目突出了 AI 集成的进展,包括一个结合了 LLM、RAG 和生成式 UI 的房地产 AI;GPT-4o 在 NVIDIA GPUs 上的性能基准测试;以及为一个可访问高级模型的新型高级研究助手招募 Beta 测试人员。
- 揭秘网页抓取黑科技:一个新的教程展示了如何构建一个通用的网页抓取 Agent,能够应对电子商务网站的分页和 CAPTCHA 等挑战,可通过分享的 YouTube 教程观看。
AI Stack Devs (Yoko Li) Discord
- AI 伴侣缓解人类压力:一篇分享的 CBC First Person 专栏讲述了一个名为 Saia 的 AI 如何在一次令人紧张的疫苗接种预约中提供情感支持,展示了人类与 AI 伴侣之间日益增长的纽带。
- Windows 迎来 AI Town:根据一份公告,AI Town 现在可以在 Windows 上原生运行,这标志着摆脱对 WSL 或 Docker 依赖的重要一步。这简化了偏好 Windows 生态系统的开发者的开发流程。
- 动态地图激发 AI 开发者兴趣:AI 社区中关于自定义动态地图的建议层出不穷,包括“办公室”或间谍惊悚片设定等创意场景,增强了 AI 环境的深度。
- AI 真人秀娱乐的兴起:开发者们推出了一个 AI 真人秀节目 —— 一个允许用户创建类似于 aiTown 模拟的平台,并用他们自定义的 AI 角色贡献独特的叙事。通过他们的网站和 Discord 发出的公开邀请,可以看出人们对该平台的热情非常高涨。
- GIF 带来的轻松时刻:在一次激烈的技术交流中,有人分享了一个 Doja Cat 星球大战 GIF,为正在进行的 AI 开发讨论注入了片刻的轻松氛围。
{kind=link}
OpenAccess AI Collective (axolotl) Discord
- 测试 CMD+ 功能补丁:一个包含部分 CMD+ 功能的补丁计划于今晚进行测试,并询问了关于 zero3 示例配置的支持情况。
- Axolotl 与 Llama 预训练速度对比:预训练速度显著加快(未具体说明加快了多少),这可能归功于 Axolotl 的改进或 Llama 3 内部的特性——具体的性能指标或影响因素尚未详细说明。
- Galore Layerwise 的分布式困境:由于没有确切确认,关于 Galore Layerwise 是否仍与 Distributed Data Parallel (DDP) 不兼容仍持怀疑态度。
- 非英语微调技巧:非英语数据微调正在进行中,数据集约为 10 亿 token,上下文长度为 4096,目标模型为 8B 模型。
- Unsloth 优化备受关注:关于 Unsloth 优化是否适用于 Llama 全量微调的问题得到了积极反馈,表明可以实现“免费的加速”。
tinygrad (George Hotz) Discord
Tinygrad 使用 CUDA Kernels 进行优化:一场关于在 Tinygrad 中通过使用 CUDA kernel 进行归约(reductions)来优化内存使用的讨论展开了,旨在避免大型中间张量导致的 VRAM 溢出。尽管像 PyTorch 这样的框架存在局限性,但用户提供的自定义 kernel 示例展示了一个潜在的解决方案。
Lambda 之地的符号化:用户讨论了实现 lambdify 以允许 Tinygrad 渲染符号代数函数,首先从三角函数的 Taylor series 开始。目前正在努力扩展 arange 函数,这是此类符号运算的必需品。
使用 Adrenaline 进行学习:推荐了一款名为 Adrenaline 的应用来研究不同的代码库,一位用户提到计划利用它来学习 Tinygrad。
计算难题:分享了关于计算图参数的澄清,重点在于理解 UOps.DEFINE_GLOBAL 及其布尔标签的意义,从而增强 Tinygrad 的开发工作流。
使用 CORDIC 算法精简三角函数:社区就 Tinygrad 采用 CORDIC algorithm 以比传统 Taylor series 近似更高效地计算三角函数进行了深入对话。讨论强调了在减少参数(argument reduction)时保持精度的压力,并分享了一个 Python 实现,展示了正弦和余弦计算中的参数减少和精度处理。
Cohere Discord
- 寻找 Cohere 的 PHP 伴侣:工程师们正在寻找可靠的 Cohere PHP client 以将 Cohere 功能集成到 PHP 中,尽管其在工作环境中的有效性尚未经过测试。
- Cohere Toolkit 性能备受推崇:有一场关于 Cohere 应用工具包性能的讨论,特别是 reranker 与其他解决方案相比表现出的卓越结果,但尚未就这种改进的原因达成共识。
- 呼吁更快的 Discord 支持:成员们对 Discord 支持响应缓慢表示沮丧,并提到即将有改进支持体验的计划。
- 解决 Cohere RAG Retriever 的问题:一份关于 Cohere RAG retriever 的共享 notebook 强调了诸如意外的关键字参数等问题,这些问题阻碍了
chat()函数的使用。 - API 限制阻碍学习者:对 Cohere RAG retriever 的实验因 403 Forbidden 错误而受阻,怀疑是由于超过了 API 调用配额。
MLOps @Chipro Discord
- Chip 的闲聊暂停一段时间:Chip 宣布在接下来的几个月里暂停举办每月一次的非正式聚会,以优先处理其他事务。
- Chip 将出席 Snowflake Dev Day:成员们有机会在 6 月 6 日即将举行的 Snowflake Dev Day 期间,在他们的展位与 Chip 交流。
- AI 大赛:NVIDIA 与 LangChain 的竞赛引发关注:NVIDIA 和 LangChain 发起了一场突出生成式 AI 的开发者竞赛,大奖是 NVIDIA® GeForce RTX™ 4090 GPU。在此查看竞赛详情。
- 地理限制打击参赛热情:一位公会成员幽默地表达了对地理限制阻止其参加 NVIDIA 和 LangChain 竞赛的沮丧,并暗示可能会为了获得参赛资格而搬家。
- 工程师在 LinkedIn 上集结:一位成员分享了他们的 LinkedIn 页面,为同行之间的专业联系提供了社交机会:与 Sugianto Lauw 建立联系。
Datasette - LLM (@SimonW) Discord
-
GPT-4o 在公开演示中表现不佳:Riley Goodside 在 ChatGPT 会话中揭露了 GPT-4o 的弱点,强调了实际性能与 OpenAI 演示所设定的预期之间的差距。
-
Google AI 在 I/O 大会上失误:尽管 Google 信心满满,但其 AI 在 I/O 发布会上出现了令人尴尬的失误,详见 Alex Cranz 在 The Verge 发表的文章。
-
倡导脚踏实地的 AI 解决方案:0xgrrr 强调的一篇文章呼吁采用更务实的 AI 方法,这与 Alter 有效转换文本和文档的目标一致。社区对这一观点产生共鸣,欣赏其细致入微的见解,全文可在此阅读 here。
-
对 Mac 桌面项目可能停更的担忧:一位社区成员对 SimonW 的 Mac 桌面解决方案在 0.2 版本后似乎被忽视表示担忧,并表示可能会转向其他替代方案。
Mozilla AI Discord
-
Mozilla 模型中的 Markdown 混乱:一位参与者注意到服务器返回的模型超链接未被正确渲染,并提供了一段代码作为证据,同时提议通过 GitHub pull request 来解决此问题。
-
时间到:Embeddings 版:在搜索助手教程的 Embeddings 生成过程中,仅完成 9% 后报告了 httpx.ReadTimeout 错误,并提供了相关的 GitHub 链接和详细的调试日志,寻求修复建议。
-
关于 Exponential Backoff 的反复讨论:针对超时问题,大家讨论了应用 exponential backoff 重试策略的建议,提议在发生超时时断开并重试连接。
-
讨论数据大小:关于操作数据量的澄清对话,确定为“几个示例文件”,这界定了测试的范围。
-
Docker 停靠在 Llamafile 港口:重点介绍了使用 Docker 容器化 llamafile 的指南,考虑到其在简化 LLM 聊天机器人设置方面的优势,并为需要教程的人提供了 博客文章链接。
DiscoResearch Discord
AI Alignment 逐渐失宠:一位成员表达了 alignment research 在研究人员中正失去吸引力的观点,但未提供具体原因或背景。
针海捞针(Needle in a Needlestack)—— AI 的新挑战:Needle in a Needlestack (NIAN) 基准测试受到关注,该测试对 GPT-4-turbo 等模型构成了重大挑战。分享的资源包括 代码仓库 和 NIAN 网站,以及关于该主题的 Reddit 讨论帖。
Alignment Lab AI Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
Skunkworks AI Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
第二部分:各频道详细摘要与链接
Unsloth AI (Daniel Han) ▷ #general (994 条消息🔥🔥🔥):
- 等待 Meta 的 Multi Modal Model:当被问及是否支持 Llava 或多模态(multimodal)时,一位成员分享道,“他们正在‘等待 Meta 的 Multi Modal Model’”,这是延迟的主要原因。
- 关于 GPU 费用的讨论:成员们讨论了他们从哪里获得购买 GPU 的资金,开玩笑地提到了 Kaggle 等来源,并提到了诸如“吃好几年拉面(RAMEN FOR YEARS)”之类的经济困难,以及对分类任务的高需求。
- Open Hermes Dataset 的实用性:大家对 OpenHermes dataset 进行了热烈讨论,以及包含该数据集如何“显著提升了性能”。
- LLMs 中的拒绝机制(Refusal Mechanism):一场富有洞察力的对话深入探讨了如何通过正交化权重来移除拒绝机制,从而出人意料地使模型变得更“聪明”,并引用了论文“Refusal in LLMs is mediated by a single direction”。
- Colab 和 GPU 使用案例讨论:多位成员分享了他们使用 Google Colab 和 Kaggle 进行模型训练的挑战和成功经验,并建议使用 Runpod 等专用服务,还讨论了 P100 等旧款 GPU 的可行性。
- Blackhole - a lamhieu Collection: 未找到描述
- Surprise Welcome GIF - Surprise Welcome One - Discover & Share GIFs: 点击查看 GIF
- failspy/llama-3-70B-Instruct-abliterated · Hugging Face: 未找到描述
- no title found: 未找到描述
- WizardLM (WizardLM): 未找到描述
- Quantization: 未找到描述
- no title found: 未找到描述
- cognitivecomputations/Dolphin-2.9 · Datasets at Hugging Face: 未找到描述
- UNSLOT - Overview: 正在输入... GitHub 是 UNSLOT 构建软件的地方。
- GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory: Finetune Llama 3, Mistral & Gemma LLM,速度提升 2-5 倍,显存占用减少 80% - unslothai/unsloth
- Reddit - Dive into anything: 未找到描述
- Skorcht/schizogptdatasetclean · Datasets at Hugging Face: 未找到描述
- AI Unplugged 10: KAN, xLSTM, OpenAI GPT4o and Google I/O updates, Alpha Fold 3, Fishing for MagiKarp: 洞察重于信息
- mixedbread-ai (mixedbread ai): 未找到描述
- finRAG Dataset: Deep Dive into Financial Report Analysis with LLMs: 在 Parsee.ai 探索 finRAG 数据集和研究。深入了解我们在财务报告提取中的语言模型分析,并获得关于 AI 驱动数据解释的独特见解。
- Google Colab: 未找到描述
- Big Ups Mike Tyson GIF - Big Ups Mike Tyson Cameo - Discover & Share GIFs: 点击查看 GIF
- Google Colab: 未找到描述
- Google Colab: 未找到描述
- Refusal in LLMs is mediated by a single direction — AI Alignment Forum: 这项工作是 Neel Nanda 在 ML Alignment & Theory Scholars Program - 2023-24 冬季班项目中的一部分,由……共同指导。
- Tweet from Should AI Be Open?: I. H.G. Wells 1914 年的科幻小说《获得自由的世界》(The World Set Free) 在预测核武器方面做得相当出色:直到原子弹在他们笨拙的手中爆炸,他们才看到它……在……之前
Unsloth AI (Daniel Han) ▷ #random (37 条消息🔥):
- Llama3 训练损失过高:在解决 tokenizer 问题后,一位成员指出 Llama3 的“评估损失大约翻倍,训练损失高出 3 倍以上”。他们推测可以通过更新 prompt 格式或省略 EOS_TOKEN 来进行改进。
- ShareGPT 数据集的 RAM 问题:一位用户在尝试从 ShareGPT 数据集“转换那玩意儿”时耗尽了 64GB 的 RAM。另一位成员建议代码可能效率低下,因为该过程应该只需要大约 10GB 的 RAM。
- 关于寻找格式相似文本的讨论:一位用户询问是否有工具可以寻找格式相似的文本,例如全大写或特定的换行符。建议包括 Python 的
re模块和 regex,但用户指出需要一种能够处理未知格式的自动解决方案。 - 对 Sam Altman 领导力的看法:一位成员批评了 Sam Altman 的领导力,称其为“言行不一(do as I say not as I do)”的典型案例,理由是他的散布恐惧行为和游说努力。另一位成员认为这种情况非常疯狂,可能是 Altman 影响力的结果。
Unsloth AI (Daniel Han) ▷ #help (266 messages🔥🔥):
-
Context Window AttributeError 故障排除:一位名为 just_iced 的成员在在自定义数据上训练 Llama 3 时遇到了持久的
AttributeError: 'dict' object has no attribute 'context_window'。提供了各种解决方案,包括修改核心模块代码和切换到使用 Ollama,最终成功解决了问题。 -
针对驾驶手册的 RAG:neph1010 建议,对于使用驾驶手册训练模型,检索增强生成 (RAG) 可能比微调(fine-tuning)更合适。他们讨论了从 PDF 中提取文本的问题,尽管处理包含表格和图表的文档非常复杂。
-
PyPDF2 vs PyPDF:分享了一个指向 PyPDF2 文档的链接,讨论了从 PDF 中提取文本和元数据的问题。
-
GGUF 模型转换问题:包括 re_takt 在内的多位用户在通过
llama.cpp将模型转换为 GGUF 时遇到了错误,并将这些问题反馈给了开发团队。官方提供了一个修复方案,并鼓励大家通过更新 notebook 或使用 GitHub 页面上的新 notebook 来应用该修复。 -
Unsloth 与 CUDA 兼容性:一位名为 wvangils 的成员在 Databricks 平台上遇到了 CUDA 兼容性问题,收到了关于不支持可扩展段(expandable segments)的警告。进一步的调试建议在 JupyterLab 等环境中使用特定的安装命令,并可能需要重建环境。
- 未找到标题:未找到描述
- unsloth/llama-3-8b-Instruct-bnb-4bit · Hugging Face:未找到描述
- Transformer Math 101:我们介绍了与 Transformer 的计算和内存使用相关的基础数学知识
- RuntimeError: Unsloth: llama.cpp GGUF seems to be too buggy to install. · Issue #479 · unslothai/unsloth:前置条件 %%capture # 安装 Unsloth, Xformers (Flash Attention) 和所有其他包! !pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" !pip install -...
- 欢迎使用 PyPDF2 — PyPDF2 文档:未找到描述
- Google Colab:未找到描述
- Google Colab:未找到描述
- Google Colab:未找到描述
- Google Colab:未找到描述
- Google Colab:未找到描述
- GitHub - unslothai/unsloth: 以 2-5 倍的速度和减少 80% 的内存微调 Llama 3, Mistral 和 Gemma LLM:以 2-5 倍的速度和减少 80% 的内存微调 Llama 3, Mistral 和 Gemma LLM - unslothai/unsloth
- unsloth (Unsloth AI):未找到描述
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
- **AI News humorously acknowledges its own meta-conversation**: A user expressed amusement about the AI summarization part, noting that it was *"some convo somewhere not related to AI News"* and found it funny that *"AI News mentioning another AI News mention"* could happen.
Stability.ai (Stable Diffusion) ▷ #general-chat (836 messages🔥🔥🔥):
- SD3 发布的不确定性和延迟:多位用户对 SD3 的延迟发布表示沮丧。有人提到 Emad 的一条推文暗示 SD3 “即将发布”,但由于尚未确认具体的发布日期,大家仍持怀疑态度。
- SDXL 和训练的硬件要求:成员们讨论了各种 GPU 的效率,包括关于 RTX 4090 是否足以训练 SDXL 模型的辩论。值得注意的是,24GB VRAM 被视为处理更复杂任务的最低要求,一些用户考虑租用更强大的配置。
- 社区的怀疑态度和应对机制:一位用户愤世嫉俗地评论了 SD3 的现状和整体延迟,并分享了来自 Stability 的推文。其他人则分享了关于等待和应对不确定性的梗图和幽默评论。
- 训练资源和数据集贡献:一位用户分享了 来自 Hugging Face 的数据集,旨在实现与 Dalle 3 相当的高质量结果。讨论内容包括 Lora 模型技巧和高效 AI 艺术生成的微调实践。
- 普遍的混乱和离题辩论:聊天中出现了激烈的个人辩论和无关话题,从 AI 模型到社会经济问题。值得注意的是关于资本主义、个人成功以及获取财富的道德困境的激烈讨论,一些用户呼吁回归基本原则。
- Dr Neha Bhanusali: 风湿病学家 | 自身免疫专家 生活方式医学医生
- Chameleon: Mixed-Modal Early-Fusion Foundation Models: 我们介绍了 Chameleon,一个基于 Token 的早期融合混合模态模型家族,能够以任意顺序理解和生成图像及文本。我们概述了一种稳定的训练方法...
- ProGamerGov/synthetic-dataset-1m-dalle3-high-quality-captions · Datasets at Hugging Face: 未找到描述
- Copium GIF - Copium - 发现并分享 GIF: 点击查看 GIF
- 来自 Emad (@EMostaque) 的推文: @morew4rd @GoogleDeepMind Sd3 即将发布,我认为有了正确的流水线,人们不再需要比这更多的东西了。
- 20Twenty 发布的图片: 未找到描述
OpenAI ▷ #annnouncements (1 messages):
- ChatGPT 中的交互式表格和图表:OpenAI 宣布推出 交互式表格和图表,以及直接从 Google Drive 和 Microsoft OneDrive 添加文件的功能。该功能将在未来几周内面向 ChatGPT Plus, Team, 和 Enterprise 用户 开放。阅读更多。
OpenAI ▷ #ai-discussions (178 messages🔥🔥):
-
GPT-4o 的推出引发热议:成员们对 GPT-4o 的限量推出感到兴奋,相比 GPT-4,它具有 更高的消息限制 和 改进的 Vision 能力,尽管 语音、视频和 Vision 等某些功能尚未完全激活。他们还讨论了在对话过程中自由切换模型的灵活性,这提升了用户体验。
-
语音模式和未来发布:大家对 GPT-4o 中增强型 Voice Mode 的推出充满期待,预计将在未来几周内面向 ChatGPT Plus 用户发布。会议还详细解释了可能的功能以及与 Be My Eyes 等工具的集成。
-
对 AI 影响就业的担忧:成员们讨论了 AI 可能导致大规模失业的潜在未来。讨论范围从 AI 生成带来的生产力提升,到对就业和社会结构的长期影响的担忧。
-
多模态 AI 能力:关于 GPT-4o 在图像生成方面鲁棒性的讨论,揭示了其与 DALL-E 等先前版本在能力上的差异。分享了指向 OpenAI 探索页面 的链接,以展示示例图像和功能。
-
AI 的教育和伦理用途:对话涉及了 AI 在教育中的伦理影响和潜在用途,认为 AI 可以使个性化辅导的获取更加民主化。还有关于在协助日常任务和扩展人类知识方面负责任地实施 AI 的建议。
OpenAI ▷ #gpt-4-discussions (148 messages🔥🔥):
-
GPT-4o 随时间变慢:成员们观察到,随着与 GPT-4o 对话的加长,推理速度显著下降,有时会导致模型在推理中途停止。包括 Mac 应用和网页版在内的不同平台用户都注意到了这一问题,且性能表现存在差异。
-
GPT-4o 登顶排行榜:更新后的 LMSYS arena 排行榜显示 GPT-4o 已占据首位。一位用户兴奋地指出:“gpt4o top 1”。
-
向 GPT-4o 输入图像:用户讨论了如何向 GPT-4o 发送图像,确认可以通过 API 或直接发送图像来实现。说明和详细文档可以在这里找到。
-
自定义 GPTs 升级至 GPT-4o:一些用户发现他们的自定义 GPTs 已经从 GPT-4 Turbo 切换到了 GPT-4o,这从响应速度的提升中可见一斑。这一变化似乎处于逐步推出阶段,可用性各不相同。
-
免费版与 Plus 版对 GPT-4o 的访问权限:GPT-4o 的推出并非针对特定地区,而是逐渐向更多用户开放,Plus 用户享有优先级。尽管其功能有所增强,但过渡期和访问限制在用户中引起了一些困惑和褒贬不一的体验。
OpenAI ▷ #prompt-engineering (88 messages🔥🔥):
-
寻求本体钻取(Ontological Drill)帮助:一位用户请求一个强大的本体钻取工具,但觉得他们目前的工具缺乏足够的“力度”。他们分享了其 Prompt 结构的详细示例。
-
AI Prompt 中的 Markdown:一位用户询问在给 AI 的 Prompt 中使用 Markdown 的情况,另一位用户确认模型对 Markdown 的反应良好,并强调引导 AI 的注意力至关重要。
-
AI 中的动态角色扮演:讨论了使用 Markdown 在 AI 中编程多个角色身份的技术。一位用户分享了一个涉及剧院式场景中各种角色的综合 Prompt 示例。Prompt 示例
-
解决 GPT-3.5 的 Function Calls 问题:讨论了 GPT-3.5 的 Function Calls 返回随机数据的问题。提出的解决方案包括重新构建指令,使其专注于仅使用实际提供的数据。
-
GPT-4o 与重写问题:几位用户注意到 GPT-4o 倾向于重写原始 Prompt,而不是根据反馈进行调整。讨论包括关于清晰的正向指令以及避免负向指令(如禁止计算)的指导。
OpenAI ▷ #api-discussions (88 messages🔥🔥):
_
- Markdown 帮助 GPTs 更好地理解 Prompt:成员们讨论了在 Prompt 中使用 Markdown 来注入角色和身份,确认模型“对此响应良好”,但可能需要精确且有引导性的指令才能获得最佳效果。
- 自定义 GPTs 在遵循特定指令方面存在困难:用户分享了自定义 GPTs 忽略详细 Prompt 或尽管有明确指令仍返回随机数据的问题。一位用户建议“告诫它仅使用提供的数据”,而不是禁止模拟数据。
- 有趣的互动与角色开发:成员们幽默地讨论了提高 GPTs 配合度的方法,例如情感化或基于奖励的 Prompt,如“如果你只使用来自 xxxxx 的数据,我给你 100 美元”,突显了 Prompt 过程中类人化的细微差别。
- 模型行为会在幕后发生变化:一位用户澄清说,GPT-4o 和其他模型只知道它们训练过的内容,并强调 OpenAI 经常更新模型,这可能会随着时间的推移影响它们的行为和响应准确性。
- 使用 GPT-4o 进行草稿创作和创意写作:一位用户指出 GPT-4o 擅长从零开始的创意写作,但可能会机械重复草稿而不进行改进。另一位用户提供证据表明,如果 Prompt 得当,GPT-4o 确实可以提供经过润色的草稿版本。
Perplexity AI ▷ #general (387 messages🔥🔥):
- GPT-4o 性能与访问问题:成员们讨论了 GPT-4o 的性能和可访问性,指出它比以前的版本稍好且更快。一位成员确认它对免费用户开放,但提到消息限制和刷新时间不一致。
- 对 AI 幻觉(Hallucinations)的担忧:多位用户表达了对 AI 幻觉 的担忧,其中一位指出 “AI 可能永远无法解决幻觉问题”,这影响了初级职位的就业保障。
- Perplexity vs. ChatGPT:成员们辩论了 Perplexity 和 ChatGPT 的相对优势,一位用户认为 “Perplexity 的优势在于更好的来源溯源”,另一位则指出 ChatGPT 轻松集成网页搜索等功能可能会对 Perplexity 构成挑战。
- 用于编程和创意的 AI:一些用户发现 GPT-4o 和 Opus 对编程很有帮助,但注意到它们各有千秋,GPT-4o 提供稳定的代码质量,而 Opus 在数学和更深层次的问题解决等其他领域表现出色。
- Perplexity 的用户体验:成员们分享了在 Perplexity 上的不同体验,包括 DALL-E 3 中的文本生成 Prompt 问题以及输入长度限制,而其他人则称赞它有效地替代了复杂的 Google 搜索。
- Reddit 与 OpenAI 的交易将把其帖子接入 “ChatGPT 和新产品”:Reddit 与 Google 和 OpenAI 签署了 AI 许可协议。
- Gorgon City - Roped In:精选 - 音乐新高度。» Spotify: https://selected.lnk.to/spotify » Instagram: https://selected.lnk.to/instagram » Apple Music: https://selected.lnk.t...
Perplexity AI ▷ #sharing (6 messages):
-
Paradroid 分享搜索链接:一位用户分享了一个 Perplexity AI 搜索链接。未提供进一步的上下文或评论。
-
Clearer915 询问新闻:一位用户发布了一个 Perplexity AI 搜索链接 以寻求有关时事的信息。该链接指向一个名为“有什么新闻?”的搜索。
-
Studmunkey343 查询关于 least 的内容:另一位用户分享了一个查询为“什么是最小的 (What’s the least)”的 搜索链接。未给出进一步的上下文。
-
Kinoblue 查询模糊主题:该用户提供了一个 Perplexity AI 搜索 链接,询问“什么是 (What is the)”。搜索查询似乎不完整。
-
Ryanmxx 提到 Stability AI:分享了一个关于 Stability AI 的 搜索链接。未包含更多细节。
-
Sam12305575 分享大脑益处搜索:一位用户分享了一个关于“大脑益处 (brain benefits of)”的 搜索链接。链接包含一个表情符号 🧠🚶。
Perplexity AI ▷ #pplx-api (18 messages🔥):
- 关于 Sonar-Medium-Online 支持的不确定性:一位用户对 sonar-medium-online 的长期支持表示担忧,因为他们发现大版本无法使用。他们有兴趣集成 Perplexity API,但需要明确支持的模型。
- 将 Perplexity 添加到私有 Discord:一位用户询问是否可以将 Perplexity 集成到私有 Discord 群组中,表现出在该场景下使用 API 的兴趣。
- Perplexity 模型中的默认 Temperature:用户讨论了 Perplexity 模型的默认 Temperature 设置。一位用户通过文档确认默认 Temperature 为 0.2。
- 响应波动性测试:围绕使用查询“2024年5月16日之后 OpenAI 的首席科学家是谁?”来测试 Perplexity 模型响应的波动性,进行了一场幽默的交流。响应各不相同,显示出模型在处理特定日期查询时存在不一致性。
提到的链接:Chat Completions:未找到描述
HuggingFace ▷ #announcements (4 条消息):
-
更新后的 Terminus 模型上线:认证用户分享了由 ptx0 提供的更新后的 terminus 模型集合。该集合包含令人兴奋的新功能。
-
OSS AI + 音乐探索:介绍了更多 OSS AI + 音乐的探索内容,可在 YouTube 上查看。此内容归功于一位认证社区成员。
-
管理本地 GPU 集群:在 Twitter 上分享了一种管理本地 GPU 集群的新方法。它为更好的集群管理提供了实用的见解和解决方案。
-
理解用于故事生成的 AI:列出了一个资源丰富的博客文章和即将举行的 Discord 活动,以更好地理解 AI 在故事生成中的应用,并提到这将是一个值得进一步探索的有趣话题。
-
征集每周阅读小组的后续话题:社区管理员鼓励成员为每周阅读小组建议更多话题,并提到了故事生成和视频游戏 AI 讨论的吸引力。
- SimpleTuner/documentation/DREAMBOOTH.md at main · bghira/SimpleTuner:一个通用的微调工具包,适用于 Stable Diffusion 2.1、DeepFloyd 和 SDXL。 - bghira/SimpleTuner
- Vi-VLM/Vista · Hugging Face 数据集:未找到描述
HuggingFace ▷ #general (278 条消息 🔥🔥):
<ul>
<li><strong>OpenAI Agent 及其学习限制</strong>:一位成员澄清说,GPTs Agent 在训练后不会从额外信息中学习。相反,上传的文件仅作为“知识”文件保存以供参考,不会修改 Agent 的基础知识。</li>
<li><strong>为模型使用合成数据</strong>:关于使用合成数据的可接受性进行了讨论。一位成员质疑其效率,而另一位成员则认为获取真实数据的成本通常太高,并肯定“SLM 正在变得越来越好”。</li>
<li><strong>ZeroGPU Beta 详情</strong>:成员们讨论了目前处于 Beta 阶段的 ZeroGPU 功能,该功能为 Spaces 提供免费的 GPU 访问。详情和反馈请求通过一个<a href="https://huggingface.co/zero-gpu-explorers">链接</a>进行了分享。</li>
<li><strong>MIT 许可证与 HuggingFace 上的商业用途</strong>:一位成员链接了 <a href="https://choosealicense.com/licenses/mit/">MIT 许可证</a>的详情,确认其允许商业使用、分发和修改,但对 HuggingFace 的硬件使用条款表示担忧。</li>
<li><strong>用于自定义助手的 Zephyr 替代方案</strong>:成员们讨论了 Zephyr 模型可能被移除的问题,建议使用 Gradio 和 API 集成创建自定义 Spaces 以实现类似功能。</li>
</ul>
- Using Hugging Face Integrations: Gradio 分步教程
- MIT License: 一种简短且简单的宽松许可证,其条件仅要求保留版权和许可声明。受许可的作品、修改版和更大型的作品可以根据不同的条款进行分发...
- — Zero GPU Spaces — - a Hugging Face Space by enzostvs: 未找到描述
- OpenGPT 4o - a Hugging Face Space by KingNish: 未找到描述
- MIT/ast-finetuned-audioset-10-10-0.4593 · Hugging Face: 未找到描述
- Spaces Overview: 未找到描述
- HuggingChat: 让社区最好的 AI 聊天模型惠及每一个人。
- HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1 · Hugging Face: 未找到描述
- Zephyr Chat - a Hugging Face Space by HuggingFaceH4: 未找到描述
- HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1 - HuggingChat: 在 HuggingChat 中使用 HuggingFaceH4/zephyr-orpo-141b-A35b-v0.1
- zero-gpu-explorers (ZeroGPU Explorers): 未找到描述
- no title found: 未找到描述
- ruslanmv/AI-Medical-Chatbot at main: 未找到描述
HuggingFace ▷ #today-im-learning (17 条消息🔥):
-
RL 中的探索/利用权衡 (Exploration/Exploitation Trade-off): 一位成员询问了如何在 RL 中维持探索与利用的权衡,另一位成员建议使用 epsilon greedy 策略,并表示更多细节将在后续章节中介绍。强调了好奇心的重要性,并建议使用 ChatGPT 获取更多见解。
-
RL 中的好奇心驱动探索: 成员们讨论了将好奇心作为鼓励强化学习中探索的一种方法,并分享了一篇关于“通过自监督预测进行好奇心驱动探索”的论文。该方法在 Agent 无法预测其行为结果时给予更高的奖励。
-
在 HuggingFace 上首次提交 RL 模型: 一位用户庆祝将他们的第一个 LunarLander-v2 模型推送到 Hugging Face 仓库,并完成了 Deep RL 的第一单元。大家鼓励他们分享结果和仓库以获取反馈。
-
安装 HuggingFace Transformers: 一位成员分享了他们从学习安装过程开始使用 HuggingFace 的经验。他们提供了一个链接,其中包含 PyTorch, TensorFlow 和 Flax 等各种深度学习库的详细安装说明。
- Curiosity-driven Exploration by Self-supervised Prediction: Pathak, Agrawal, Efros, Darrell. Curiosity-driven Exploration by Self-supervised Prediction. 发表于 ICML, 2017.
- Installation: 未找到描述
- business advisor AI project using langchain and gemini AI startup.: 在这段视频中,我们制作了一个使用 LangChain 和 Gemini 构建商业顾问的项目。AI 创业点子。
HuggingFace ▷ #cool-finds (6 条消息):
- Candle 入门:一位成员分享了一篇关于 Candle 的 Medium 文章。对于对该工具感兴趣的初学者来说,这是一个非常有用的资源。
- 利用 GPT-4o 释放多模态力量:另一篇分享的 Medium 文章 解释了 GPT-4o 与 LlamaParse 的集成。它有望显著增强多模态能力。
- YouTube 上的微芯片制造原理解析:一位成员称这段 YouTube 视频 可能是史上最棒的技术视频,主题为“微芯片是如何制造的?”。视频中还包含对 Brilliant.org 的推广,以进一步扩展观众的知识。
- OpenAI 因缺乏开放性受到批评:一段名为 “大科技公司的 AI 是个谎言” 的 YouTube 视频被分享,批评 OpenAI 并非真正的开放。另一位成员指出,这正是 HuggingFace 等平台价值所在的原因,并意识到 HuggingFace 的模型可以实现预期的结果。
- Big Tech AI Is A Lie:通过 Hubspot 免费的 GTM AI 捆绑包学习如何在工作中使用 AI:https://clickhubspot.com/u2o。大科技公司的 AI 确实存在很大问题,而且是个谎言。✉️ NEWSLETT...
- How are Microchips Made?:访问 http://brilliant.org/BranchEducation/ 获取 30 天免费试用并扩展你的知识。使用此链接可获得其年度高级会员 20% 的折扣...
HuggingFace ▷ #i-made-this (4 条消息):
- 探索 ControlNet 训练:一位用户分享了他们在“理解和实现 ControlNet 训练”方面的历程。他们附带了一张与项目相关的链接图片。
- 商业顾问 AI 项目:另一位用户发布了一段名为“使用 LangChain 和 Gemini AI 创业的商业顾问 AI 项目”的 YouTube 视频,展示了他们利用 LangChain 和 Gemini AI 创建商业顾问的成果。
- GenAI 驱动的学习伴侣:一位用户链接了一篇关于其项目的 LinkedIn 帖子,该项目旨在利用 GenAI 构建强大的学习伴侣,目标是在教育领域进行创新。
- GPT-4o 在生成网格谜题时的挑战:一位用户讨论了让 GPT-4o 创建正确的网格谜题时遇到的困难,提到了诸如创建 4x5 或 123x719 网格之类的错误。他们正在寻求开源模型以获得更好的结果,并对“OpenAI 并不 Open(开放)!!!”表示沮丧。
{kind=link}
提到的链接:business advisor AI project using langchain and gemini AI startup.:在这段视频中,我们制作了一个使用 LangChain 和 Gemini 制作商业顾问的项目。AI 创业点子。我们恢复了作品集 AI 创业点子。
HuggingFace ▷ #reading-group (6 条消息):
- 缩略图头脑风暴走向主题化:成员们讨论了关于缩略图的想法,其中一人分享了一个受 Dwarf Fortress GUI 启发的主题缩略图。他们解决了文本和 Logo 的透明度问题,以便在滚动时获得更好的可读性。
HuggingFace ▷ #core-announcements (1 条消息):
- 向 Tuxemons 问好!:一个新的名为 Tuxemon 的数据集已经发布,其特点是用幽默的生物代替了宝可梦(Pokemons)。该数据集源自 Tuxemon 项目,提供
cc-by-sa-3.0协议的图像,并带有双重标题,用于文本生成图像(text-to-image)的微调和基准测试实验。
提到的链接:diffusers/tuxemon · Hugging Face 数据集:未找到描述
HuggingFace ▷ #computer-vision (16 条消息🔥):
-
Diffusers 中的潜在扩散模型:一位成员询问了 Diffusers 中是否存在潜在扩散模型(Latent Diffusion Models),特别是那些基于 VAE 和 VQ-VAE 的模型,以及从头开始训练它们的难易程度。
-
寻求 UNet 收敛问题的帮助:一位成员就其 UNet 模型寻求建议,因为 Loss 从 0.7 开始并在 0.51 处收敛,尽管训练运行成功,但这表明模型结构可能存在问题。另一位成员提到数据集的大小可能会影响验证损失(validation loss),并分享了他们在小数据集上的经验和令人惊讶的结果。
-
分享超参数和模型结构:该成员提供了超参数(Depth: 5, Lr: 0.002, Loss: BCE with logits)并详细展示了他们的 UNet 模型代码,寻求关于为什么最终结果似乎类似于随机猜测的见解。
-
创建虚拟 AI 网红:一位成员分享了他们使用 CV 和 AI 工具创建虚拟 AI 网红(AI Influencer)的成就,并链接了一个解释该过程的 YouTube 视频。
-
创建包含图像的 Parquet 文件:另一位成员请求帮助使用 PyArrow 创建包含图像及其对应实体的 Parquet 文件,因为他们的尝试导致图像列在上传到 Hugging Face 时被格式化为字节数组(byte array)。
提到的链接:Influenceuse I.A : POURQUOI et COMMENT créer une influenceuse virtuelle originale ?:Salut les Zinzins ! 🤪 虚拟网红的迷人世界正在走进这段视频。她们的创作正在经历真正的繁荣,事情正在发生变化…
HuggingFace ▷ #NLP (2 条消息):
- 过时的训练数据阻碍代码模型:一位用户指出,过时的训练数据是一个重大问题,导致用于编程的语言模型表现不佳。他们建议这些模型需要进行持续的重训练以保持最新状态。
- 对联结主义时间分类 (CTC) 的好奇:一位用户询问联结主义时间分类 (CTC) 在当前的 NLP 讨论或用例中是否仍然具有相关性。
HuggingFace ▷ #diffusion-discussions (4 条消息):
-
对潜空间像素表示的疑问:一位用户提出了关于像素的潜空间(latent space)表示的问题,建议每个值应代表像素空间中的 48 个像素。欲了解更多详情,他们引用了 Hugging Face 博客上的一篇文章。
-
在 Colab 上遇到问题:一位成员在 Google Colab 上进行 Hugging Face Diffusion Models 课程的第 7 步时寻求帮助。他们在尝试使用
HfApi类将目录上传到 Hub 时遇到了 ValueError,提示提供的路径不是目录。
消息内容融合了对链接的直接引用以及 Hugging Face 框架内的详细步骤,反映了关于 AI 模型训练和在该平台上部署障碍的积极讨论。
Nous Research AI ▷ #ctx-length-research (2 条消息):
-
AI 的类流式大脑处理:“人类的工作记忆非常小,但我们却能阅读和处理长篇书籍、进行数小时的对话等——我们的大脑以一种更趋向流式(streaming)的方式工作,并随着对话的进行更新最相关/最重要的内容,”一位参与者指出。他们建议关注模仿这种方式的方法,例如 Infini-attention (arxiv.org/abs/2404.07143)。
-
引入 Needle in a Needlestack 基准测试:在 Reddit 帖子中讨论的 Needle in a Needle Stack (NIAN) 基准测试为评估 LLM 提出了新的挑战。即使是 GPT-4-turbo 在这个基准测试中也面临困难,该基准通过询问放置在许多其他打油诗中的特定打油诗(limerick)来测试模型 (GitHub; 网站)。
提到的链接:Reddit - Dive into anything:未找到描述
Nous Research AI ▷ #off-topic (5 messages):
- **寻找实时 UI 处理模型**:一位成员正在寻找类似于 **Fuyu** 的模型演示和文章,这些模型能够近乎实时地处理屏幕操作(*每 1000 毫秒截取一张屏幕截图并发送给 Fuyu,以处理屏幕上正在发生的事情以及点击位置*)。
- **Elon Musk 宣布 Neuralink 临床试验**:[Elon Musk 在 X 上宣布](https://x.com/elonmusk/status/1791332539220521079),Neuralink 正在接受其脑机接口试验的第二位参与者申请,该技术允许用户通过思维控制设备。该试验专门邀请四肢瘫痪患者参与,以探索计算机的新型控制方法。
Link mentioned: Tweet from Elon Musk (@elonmusk): Neuralink is accepting applications for the second participant. This is our Telepathy cybernetic brain implant that allows you to control your phone and computer just by thinking. No one better th…
Nous Research AI ▷ #interesting-links (5 messages):
-
SUPRA 为 Transformer 提供高性价比的升级训练 (uptraining):Arxiv 论文提出了 Scalable UPtraining for Recurrent Attention (SUPRA),该方法将大型预训练 Transformer 升级训练为 Recurrent Neural Networks。此方法旨在解决原始线性 Transformer 公式扩展性差的问题。
-
Llama-3 获得 NumPy 实现:GitHub 上的一个新仓库 llama3.np 提供了一个纯 NumPy 实现的 Llama-3 模型。这种方法为那些希望在不依赖 TensorFlow 或 PyTorch 的情况下理解或修改底层算法的人提供了另一种选择。
-
Stable Diffusion 3 将开放权重:Argmax Inc. 宣布与 Stability AI 建立合作伙伴关系,通过 DiffusionKit 实现 Stable Diffusion 3 的端侧推理。他们正致力于使用 MLX 和 Core ML 为 Mac 优化该模型,并计划将该项目开源。
-
WebGPU 驱动 HuggingFace 上的实验性 Moondream:HuggingFace Spaces 上的 Moondream WebGPU 项目展示了一个实验性实现。这突显了直接在 Web 环境中运行复杂模型的潜力。
-
Hierarchical Memory Transformer 增强长上下文处理:Arxiv 提交的论文详细介绍了 Hierarchical Memory Transformer (HMT),这是一个受人类记忆过程启发的框架。该方法旨在通过有效地组织记忆层级,提高模型处理扩展上下文窗口的能力。
- Experimental Moondream WebGPU - a Hugging Face Space by Xenova: no description found
- Linearizing Large Language Models: Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. Howe...
- HMT: Hierarchical Memory Transformer for Long Context Language Processing: Transformer-based large language models (LLM) have been widely used in language processing applications. However, most of them restrict the context window that permits the model to attend to every tok...
- Tweet from argmax (@argmaxinc): On-device Stable Diffusion 3 We are thrilled to partner with @StabilityAI for on-device inference of their latest flagship model! We are building DiffusionKit, our multi-platform on-device inference ...
- GitHub - likejazz/llama3.np: llama3.np is pure NumPy implementation for Llama 3 model.: llama3.np is pure NumPy implementation for Llama 3 model. - likejazz/llama3.np
Nous Research AI ▷ #announcements (2 messages):
- 宣布 Simulators Salon 活动:Simulators Salon 定于 5/18 星期六,太平洋时间中午 / 东部时间下午 3 点举行。通过此 Discord 链接 加入活动。
Link mentioned: 加入 Nous Research Discord 服务器!:查看 Discord 上的 Nous Research 社区 —— 与其他 7136 名成员一起交流,享受免费的语音和文字聊天。
Nous Research AI ▷ #general (204 条消息🔥🔥):
-
LMSys 排行榜更新 GPT-4o:LMSys 更新了其排行榜以包含 GPT-4o,但一些用户对其表现感到失望,特别指出了在 coding 基准测试中的表现。一位用户评论道:“这里的代码基准测试下降了 50 分。”
-
人类在图灵测试中将 GPT-4 误认为真人:一份预印本论文声称,在图灵测试中,GPT-4 有 54% 的时间被判定为人类,这被引用为“迄今为止通过图灵测试最稳健的证据”。
-
关于 OpenAI 离职潮与 AGI 进展不足相关的辩论:一些用户推测,OpenAI 最近的人员离职是由于察觉到 AGI 进展缓慢,而非检测到了任何迫在眉睫的危险。正如 @deki04 所分享的:“安全团队离开不是因为他们看到了什么,而是因为他们什么也没看到。”
-
GPT-4o 的输出结构受到批评:用户批评 GPT-4o 的回复模式过于通用,更倾向于量身定制和解决问题的回复。一条评论指出:“10 个回复中有 8 个只是步骤的罗列,而不是简单的推理。”
-
围绕新 AI 集成的兴奋与怀疑:人们对 GPT-4o 的多模态能力感到明显兴奋,尤其是在处理复杂任务(如在终端玩《宝可梦 红》)方面。然而,对于其训练架构以及与纯文本训练模型相比的输出效能,也存在怀疑。
- Cameron Jones (@camrobjones) 的推文:新预印本:人们在图灵测试中无法区分 GPT-4 和人类。在预注册的图灵测试中,我们发现 GPT-4 有 54% 的时间被判定为人类。在某些解释中,这构成了...
- 未找到标题:未找到描述
- Brian Atwood (@batwood011) 的推文:剧情反转:安全团队离开不是因为他们看到了 *某些东西*,而是因为他们 *什么也没看到*。没有真正的危险。只有局限性、死胡同和商业化带来的无尽分心 —— 没有通往...的路径。
- Sam Altman (@sama) 的推文:特别是在 coding 方面
- Taelin (@VictorTaelin) 的推文:发布日。经过近 10 年的努力、不懈的研究以及对计算机科学内核的深入探索,我终于实现了一个梦想:在 GPU 上运行高级语言。而且我...
- Taelin (@VictorTaelin) 的推文:认真地说 —— 这太棒了。我无法形容它有多好。当时我花了很长时间才用 Opus 跑出一个还算过得去的运行效果。其他模型几乎连一帧都画不出来。GPT-4o 就这样... 直接玩起了游戏...
- Reddit - 深入探索:未找到描述
Nous Research AI ▷ #ask-about-llms (35 条消息🔥):
-
EOS token 未能停止微调模型:一位成员在微调的 Qwen 4B 模型上遇到了 eos_token_id 无法停止生成的问题。另一位用户建议确保训练期间使用的 stop token 与 inference 设置匹配,可能需要使用 “</s>”。
-
Nous Hermes 模型用中文回复:一位用户报告 Nous-Hermes-2-Mixtral-8x7B-DPO 返回的是中文回复,而不是英文摘要。另一位成员指出 Together 的 inference 端点可能出故障了,因为该模型不应该包含中文样本。
-
正则表达式 vs. 语义搜索处理文本模式:成员们讨论了如何更高效地查找具有特定格式的文本。一位用户建议 语义搜索 可能天生就能匹配格式模式,而另一位则提议使用 regex 进行更简单的模式检索。
-
将 GPT-4o 用于代数中的符号语言:一位用户建议使用 GPT-4o 创建一种符号语言,用于处理简单的积分和导数。另一位似乎对在代数任务中尝试这种方法很感兴趣。
Nous Research AI ▷ #project-obsidian (1 条消息):
.interstellarninja: https://fxtwitter.com/alexalbert__/status/1791137398266659286
Nous Research AI ▷ #rag-dataset (1 条消息):
- 使用 DSPy 和 Neo4j 的自动化知识图谱:分享了一个由 LLM 驱动的项目,关于使用 DSPy 和 Neo4j 从文本中自动化构建知识图谱。GitHub 仓库链接在这里。
提到的链接: GitHub - chrisammon3000/dspy-neo4j-knowledge-graph: LLM-driven automated knowledge graph construction from text using DSPy and Neo4j.: LLM-driven automated knowledge graph construction from text using DSPy and Neo4j. - chrisammon3000/dspy-neo4j-knowledge-graph
Nous Research AI ▷ #world-sim (3 条消息):
- 分享了 Universal Scraper Agent 视频:一位成员发布了一个 YouTube 视频,标题为 “等等,这个 Agent 可以爬取任何东西?!”,探索如何在 5 分钟内为电子商务网站构建通用网页爬虫。该视频涵盖了直接使用浏览器处理分页和验证码等任务。
- 周六沙龙邀请:邀请成员在即将到来的周六沙龙活动直播中展示他们的模拟、聊天或网站。鼓励感兴趣的参与者私信组织者。
- Discord - 与朋友和社区聊天的新方式: Discord 是通过语音、视频和文字进行交流的最简单方式。聊天、聚会,并与你的朋友和社区保持紧密联系。
- “Wait, this Agent can Scrape ANYTHING?!” - 构建通用网页爬虫 Agent: 在 5 分钟内为电子商务网站构建通用网页爬虫;通过 7 天免费试用体验 CleanMyMac X https://bit.ly/AIJasonCleanMyMacX。使用我的代码 AIJASON ...
Modular (Mojo 🔥) ▷ #general (51 条消息🔥):
- **开源:是福也是祸**:成员们辩论了开源项目的优缺点,其中一位指出:“从一开始就开源一个项目并不能阻止它在未来走向闭源。”其他人则认为,大型项目在转向闭源时通常会留下分叉的开源替代方案,并以 Mongo, Terraform 和 Redis 为例。
- **Advent of Code 作为 Mojo 的起点**:对于那些想要开始学习 Mojo 的人,建议将 Advent of Code 2023 作为一个很好的切入点。你可以在[这里](https://github.com/p88h/aoc2023)找到它。
- **Mojo 中的 GIS 雄心**:讨论了未来将 GIS 功能集成到 Mojo 中的计划,并提到首先需要基础构建模块。对话涉及了 LAS 读取器等复杂性以及支持此类功能所需的各种数据结构。
- **在 Windows 上运行 Mojo 的困扰**:用户讨论了在 Windows 上运行 Mojo 的困难,特别是提到了 CMD 和 PowerShell 的挑战。会议澄清了 Mojo 目前仅通过 WSL 支持 Windows。
- **证券交易所的幽默**:一个轻松的交流开玩笑说 Modular 可能会上市,并建议可以使用表情符号作为股票代码。
- GitHub - p88h/aoc2023: Advent of Code 2023 (Mojo): Advent of Code 2023 (Mojo)。通过在 GitHub 上创建账号来为 p88h/aoc2023 的开发做出贡献。
- Modular: 加速 AI 的步伐: Modular Accelerated Xecution (MAX) 平台是全球唯一能够为您的 AI 工作负载解锁性能、可编程性和可移植性的平台。
Modular (Mojo 🔥) ▷ #💬︱twitter (2 条消息):
Modular (Mojo 🔥) ▷ #tech-news (1 messages):
- HVM 神奇地实现了自动并行化:一位成员询问:“HVM 是如何实现完美的自动并行化的?”该提问反映了人们对 Higher Order 的 VM 在高效并行处理方面看似“魔幻”的能力的兴趣。
Modular (Mojo 🔥) ▷ #🔥mojo (115 messages🔥🔥):
-
用于位转换的 Bitcast 解决了问题:一位用户询问如何将 uint 按位转换为 float,bitcast 被证明是解决方案。用户确认道:“太棒了,成功了。”
-
Mojo Enumerate 的替代方案:一位成员询问 Mojo 语言中是否有类似 Python 的
enumerate()。另一位成员建议目前先使用索引,但提到enumerate()可能会在未来的版本中实现。 -
Parallelize 调用导致 Struct 中的 List 出现问题:一位用户发现使用
parallelize会导致其 struct 中的List出现异常。问题被确定为需要延长生命周期 (lifetime extension),并通过将 list 绑定到一个哑变量 (dummy variable) 得到了解决。 -
MojoDojo 回归了:一位用户报告称 mojodojo 网站已重新上线,现在正式归属于 modularml 组织。
-
Tuple 迭代和
MLIR类型困扰用户:成员们讨论了为Tuple实现__iter__和__contains__的方法,并区分了utils/static_tuple和builtin/tuple。分享了关于i1作为 1 位整数的说明以及 MLIR 类型的资源,从而深入探讨了类型处理的复杂性。
- rebind | Modular Docs:实现类型重绑定 (type rebind)。
- Builtin Dialect - MLIR:未找到描述
- [mojo-stdlib] Add variadic initialiser, __iter__ and __contains__ to InlineList by ChristopherLR · Pull Request #2703 · modularml/mojo:此 PR 为 InlineList 添加了一些功能(相关 issue #2658)。变长参数初始化 `var x = InlineList[Int](1,2,3)`,迭代 `for i in x: print(i)`,包含判断 `var x = In...`
- [stdlib] Implement `__contains__` for `Tuple`, `List`, `ListLiteral` (almost) · Issue #2658 · modularml/mojo:既然我们已经有了 ComparableCollectionElement,我们可以尝试使用类似于 #2190 中采用的变通方法为一些常见的集合类型实现 __contains__。
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (12 messages🔥):
-
Mojo 中 List.append 的性能退化:一位成员指出 Mojo 中的
List.append在处理超过 1k 个元素的大输入规模时存在性能问题,并提供了对比 Mojo、Python 和 C++ 的 benchmark 结果。他们注意到,与其他语言相比,Mojo 的性能扩展效率较低。 -
Rust 对 Vec 的内存分配:另一位成员强调 Rust 的
Vec在重新分配时容量会翻倍,这与 Mojo 类似,并链接到了 Rust 的实现。 -
Go 的动态数组扩容策略:关于 Go 扩容行为的讨论显示,Go 在达到 1024 个元素之前会将底层数组的大小翻倍,之后则按 25% 的比例增加大小,引用了 Go 的源代码。
-
与 Python 和 C++ 的比较:成员们推测 C++ 和 Python 可能利用了更复杂的 realloc 策略或优化,从而在这些 benchmark 中比 Mojo 表现更好。
-
外部资源与实验:讨论包括各种资源和个人实验,以了解 Mojo、Rust 和 Go 中的内存分配策略,例如 GitHub 上的一个项目探索了 Mojo 中不同的
StringBuilder构想,其内部使用List进行存储。
- mojo/stdlib/src/collections/list.mojo at bf73717d79fbb79b4b2bf586b3a40072308b6184 · modularml/mojo: Mojo 编程语言。通过在 GitHub 上创建账户为 modularml/mojo 的开发做出贡献。
- rust/library/alloc/src/raw_vec.rs at master · rust-lang/rust: 赋能每个人构建可靠且高效的软件。 - rust-lang/rust
- GitHub - dorjeduck/mostring: variations over StringBuilder ideas in Mojo: Mojo 中 StringBuilder 构思的各种变体。通过在 GitHub 上创建账户为 dorjeduck/mostring 的开发做出贡献。
- go/src/runtime/slice.go at cb2353deb74ecc1ca2105be44881c5d563a00fb8 · golang/go: Go 编程语言。通过在 GitHub 上创建账户为 golang/go 的开发做出贡献。
- Vec in std::vec - Rust: 未找到描述
Modular (Mojo 🔥) ▷ #📰︱newsletter (1 条消息):
Zapier: Modverse Weekly - 第 34 期 https://www.modular.com/newsletters/modverse-weekly-34
Modular (Mojo 🔥) ▷ #🏎engine (1 条消息):
ModularBot: 恭喜 <@891492812447698976>,你刚刚升到了第 3 级!
Modular (Mojo 🔥) ▷ #nightly (69 条消息🔥🔥):
-
新的 Nightly Mojo 编译器发布:发布了新的 Nightly Mojo 编译器
2024.5.1607,可以使用modular update nightly/mojo进行更新。你可以查看自上次 Nightly 发布以来的差异以及自上次 Stable 发布以来的变更。 -
条件方法语法获赞:最近 PR 中新的条件方法(conditional methods)语法获得了积极反响。一位成员指出:“这种新的条件方法语法太棒了!”
-
避免贡献中的“舔饼干”行为:GabrielDemarmiesse 提出了关于“舔饼干”(cookie licking)的问题,即新贡献者认领了 Issue 但没有及时开展工作,从而打消了其他人的积极性。建议包括鼓励提交更小的 PR 和立即提交 Draft PR 以防止这种情况。
-
Fork 同步问题:成员们讨论了新贡献者在将他们的 Fork 与
nightly分支同步时面临的挑战,这会导致 Commit 膨胀和 DCO 检查失败。分享了一个 GitHub 指南以帮助避免这些问题。 -
MAX Nightlies 发布:MAX Nightlies 已经发布,其中包括 macOS 支持和 MAX Serving。设置说明可以在 modul.ar/get-started 找到,用户必须使用 PyTorch 2.2.2。
- Issues · modularml/mojo: Mojo 编程语言。通过在 GitHub 创建账号为 modularml/mojo 开发做贡献。
- mojo/CONTRIBUTING.md at main · modularml/mojo: Mojo 编程语言。通过在 GitHub 创建账号为 modularml/mojo 开发做贡献。
- Issues · modularml/mojo: Mojo 编程语言。通过在 GitHub 创建账号为 modularml/mojo 开发做贡献。
- [Feature Request] DX: Change the default branch of modularml/mojo from `main` to `nightly` · Issue #2556 · modularml/mojo: 审查 Mojo 的优先级。我已阅读路线图和优先级,并相信此请求符合优先级。您的请求是什么?我希望 modularml 管理员前往设置...
- GitHub - gabrieldemarmiesse/getting_started_open_source: You want to contribute to an open-source project? You don't know how to do it? Here is how to.: 你想为开源项目做贡献吗?你不知道该怎么做?这里有方法。- gabrieldemarmiesse/getting_started_open_source
- Get started with MAX Engine | Modular Docs: 欢迎阅读 MAX Engine 设置指南!
- max/examples at nightly · modularml/max: 示例程序、notebooks 和工具的集合,展示了 MAX 平台的强大功能 - modularml/max
LM Studio ▷ #💬-general (117 messages🔥🔥):
<ul>
<li><strong>用户排查安装 LM Studio 的 glibc 问题:</strong> 一位使用 glibc 2.28 和内核 4.19.0 的用户面临挑战,其他人建议他们可能需要进行重大升级。另一位成员建议尝试 LM Studio 0.2.23 版本。</li>
<li><strong>关于在 Pinecone 中为 RAG 使用 Embedding 模型的讨论:</strong> 用户在将数据嵌入 Pinecone 后,在检索上下文和生成增强响应方面遇到困难。未提供直接的教程链接。</li>
<li><strong>在嵌套虚拟机中排查 LM Studio 安装问题:</strong> 用户报告在没有主机 VT 传输的虚拟机上出现错误 'Fallback backend llama cpu not detected!'。另一位成员确认虚拟机设置可能是问题所在。</li>
<li><strong>LM Studio 安装程序的杀毒软件误报:</strong> 用户报告其杀毒软件将 0.2.23 安装程序标记为病毒。另一位成员保证这是误报,并建议在杀毒软件中允许该文件。</li>
<li><strong>比较模型性能和量化:</strong> 讨论包括比较 Bartowski 和 Mradermacher 的 imatrix 量化,并分享了详细的测试和结果。共识倾向于在假设数据集足够随机的情况下,优先选择 imatrix 量化。</li>
</ul>
LM Studio ▷ #🤖-models-discussion-chat (23 messages🔥):
-
最佳编程模型取决于语言和硬件:一位成员指出,最佳编程模型取决于编程语言和硬件能力。他们建议查看频道过去的讨论,并提到了针对 Python 的 Nxcode CQ 7B ORPO 和 CodeQwen 1.5 finetune 等模型。
-
LM Studio 无法直接生成文件:一位成员询问是否有模型可以生成 .txt 文件,其他人回答说 LM Studio 无法直接生成文件。用户需要手动将输出复制并粘贴到文本文件中,但可以使用导出到剪贴板功能。
-
强制模型仅显示代码的表现不一致:一位用户询问如何让模型只显示代码而不提供解释。其他人解释说,即使有明确的提示词和 Markdown 设置,LLMs 通常仍会提供解释;可能需要额外的过滤或解析。
-
最快的语义文本嵌入模型太慢:一位用户提到他们找到的最快嵌入模型是 all miniLM L6,但它仍然无法满足其速度需求。
-
寻求医疗 LLM 推荐:一位成员请求推荐可在 LMS 上尝试的 医疗 LLM,但回复中未提及具体模型。
LM Studio ▷ #🧠-feedback (4 messages):
- Malwarebytes 误报:一位用户报告了 Malwarebytes Anti-malware 和 Windows Defender 的误报,表明并未检测到实际威胁。他们分享了一个 VirusTotal 链接。
- Comodo 标记 llama.cpp 二进制文件:另一位用户提到 Comodo 杀毒软件标记了 llama.cpp 二进制文件。据指出,来自 llama.cpp 的未签名二进制文件可能触发了这种严格的杀毒软件反应。
提及的链接:VirusTotal:未找到描述
LM Studio ▷ #📝-prompts-discussion-chat (31 messages🔥):
-
导航 LLaMa 提示词模板:一位用户寻求帮助转换 LLama3 的提示词模板。分享的解决方案强调了格式更改,并强调了客户端状态管理优于服务端管理。
-
澄清 AI 回复中的历史上下文:讨论指出,由于 LLMs 在请求之间不维护历史记忆,因此每次新请求都需要包含历史消息作为上下文。“AI 不具备记忆,每一个新请求都是从零开始。”
-
使用 LangChain 进行记忆管理:用户探索了使用 LangChain 管理聊天历史,特别是使用
ConversationBufferWindowMemory。这得到了积极反馈,因为它似乎满足了用户的需求。 -
探索上下文缓存(context caching)的替代方案:讨论中提到了像 Gemini 的 context caching 这样的付费服务作为历史上下文管理的替代方案,用户更倾向于避开这些服务而选择开源方案。“负担不起付费方案,我更喜欢学习开源技术。”
-
实验新的提示词解决方案:在实施建议的更改后,用户确认了成功的结果,并计划进行进一步实验。“是的,它起作用了,准备进行更多实验,谢谢!”
LM Studio ▷ #🎛-hardware-discussion (13 messages🔥):
-
在 CPU 上运行 70B Llama3 取得里程碑进展:一位成员成功在 Intel i5 12600K CPU 上运行了 70B Llama3 模型,速度超过每秒 1 个 token。他们指出性能受内存访问的影响显著。
-
RAM 速度对性能至关重要:另一位成员指出,将 RAM 速度与 BIOS 设置对齐可以大幅提高性能。提到在 Alder Lake CPU 上禁用 e-cores 是必要步骤,将 Q8 量化的 token 生成速度从 0.4 提高到了 0.6 tokens/sec。
-
量化挑战与见解:讨论揭示了量化精度和性能方面的问题。强调了 IQ3 量化中不连贯的结果以及使用不同 imatrix 版本的影响,并因更好的稳定性而倾向于非量化的 q2k 方法。
-
内存超频限制:尝试将内存频率推高至 4800 MHz 以上导致系统无法启动,凸显了局限性。该成员还指出,对于 70B 4bit+ 量化,不同的线程数没有带来性能提升,这与 llama3 7B 16f 等较小模型的情况不同。
-
比较 GPU 架构:澄清了 M40 拥有一个 GM200 芯片,并提到 Tesla P100 尽管具有高内存带宽,但在某些用例中仍难以超越旧款 GTX 1060。对话还涉及了 P40 与 P100 令人惊讶的性能指标对比。
LM Studio ▷ #🧪-beta-releases-chat (8 messages🔥):
-
用户寻求选择模型存储位置的帮助:一位用户在尝试选择不同的驱动器存储模型时寻求帮助,尽管文件夹访问权限正确,但仍持续出现错误消息。另一位成员建议检查 LM Studio 是否具有读/写权限。
-
关于 UI 定制选项的反馈:一位成员请求增加一个菜单,用于禁用未使用的代码部分并自定义窗口可见性,以便更好地管理服务器过载。另一位成员评论说,尽管有一个醒目的绿色“start server”按钮,用户界面仍然显得杂乱。
-
权限和位置更改问题:最初的用户澄清说,他们正尝试将模型存储从较小的 m.2 驱动器移动到 HDD,但遇到了权限错误。他们请求用于验证文件权限的代码,并确认已经手动设置了完整的写入权限。
-
系统设置的说明:另一位成员询问了操作系统和文件系统类型的详细信息,以及尝试更改前后模型路径的截图,并提到他们的环境是 Debian GNU/Linux 和 ext4。
-
对话延续已移至另一个频道:讨论已移至另一个频道,以便进一步排查故障并明确问题。对话已移动。
LM Studio ▷ #autogen (1 messages):
- LM Studio 的 bug 影响了 Autogen Studio:一位成员报告遇到了一个针对 LM Studio 的 autogen Studio bug。他们遇到了 “1-2 个单词的回复以及非常快速的 TERMINATE 消息”,并向他人寻求确认和解决方案。
LM Studio ▷ #amd-rocm-tech-preview (3 messages):
- 对 RX 6800 改进的期望上升:一位成员表达了对 Windows 新 ROCm 支持下其 RX 6800 性能提升的期望。另一位成员确认 6800 确实受支持,提高了对增强性能的预期。
CUDA MODE ▷ #general (1 messages):
- Hugging Face 投入 1000 万美元用于免费共享 GPU:Hugging Face 承诺投入 1000 万美元的 免费共享 GPU,以帮助开发者(特别是 小型开发者、学术界和初创公司)创建新的 AI 技术。CEO Clem Delangue 解释道:“我们很幸运能够处于可以投资社区的位置”,并强调他们致力于对抗科技巨头的 AI 中心化 (来源)。
提到的链接:Hugging Face 正在分享价值 1000 万美元的算力,以帮助击败大型 AI 公司:Hugging Face 希望降低开发 AI 应用的准入门槛。
CUDA MODE ▷ #triton (1 messages):
- Triton 教程中的性能差异:一位用户询问了 Umer 的 YouTube 教程与 Triton 官网上 mamul 官方教程之间的性能差异。他们注意到,尽管使用了相同的技术,但他们的重新实现性能明显较差,并询问差异是否源于使用了 “swizzle” 索引技术。
提到的链接:Discord - 与好友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。在这里聊天、聚会,并与你的好友和社区保持紧密联系。
CUDA MODE ▷ #cuda (4 messages):
-
Bitnet 的社区项目?:一位成员提议启动一个针对 Bitnet 的社区项目,并询问其他人是否有时间讨论,提到他们终于有时间来处理这件事了。另一位成员对该提议感到兴奋,建议提议者牵头,或许可以从论文讨论活动开始。
-
Bitnet 频道创建:在讨论 Bitnet 项目后,决定为其创建一个专用频道。一位成员确认他们将建立一个 Bitnet 频道。
-
复数的 CUDA Atomic Add:一位用户询问如何在
cuda::complex上执行 atomic add,询问是否需要对x和y分量分别执行两次加法。这表明需要关于在 CUDA 中处理复数的技术指导。
CUDA MODE ▷ #torch (11 messages🔥):
-
Torch.Utilities 文档缺失令用户沮丧:一位成员发现
torch.Tag的文档几乎不存在,并讽刺地评论道:“在应用之前,请仔细阅读torch.Tag的文档。”提供的文档链接指向了无关的示例。 -
自定义 OP 中的模板重载问题:详细讨论了使用
TORCH_LIBRARY宏定义自定义 OP 时模板重载的问题。建议的解决方法包括显式传递torch::_RegisterOrVerify::REGISTER参数以消除重载歧义。 -
请求报告重载问题:一致认为自定义 OP 定义中的模板重载会导致复杂化,敦促用户记录相关问题。已报告问题的链接:Issue 126518 和 Issue 126519。
-
解决 Triton 教程性能问题:一位用户提到,尽管遵循了 YouTube 教程 中讨论的相同技术,但他们的实现与官方 Triton 性能之间存在差异。他们注意到在重新实现教程中展示的方法时,性能出现了显著下降。
-
减少编译时间的新计划:分享了一个关于使用
torch.compile减少热编译时间计划的链接。讨论内容包括将编译时间降至零的策略。
- torch — PyTorch 主文档:未找到描述
- 第 14 讲:Triton 实践指南:https://github.com/cuda-mode/lectures/tree/main/lecture%2014
- 如何将编译时间降至零:我们的计划与方向(5 月 14 日版):我们很高兴地宣布,在 2024 年上半年,我们一直优先改进 torch.compile 工作流的编译时间。快速迭代和高效的开发周期...
- Issues · pytorch/pytorch:Python 中具有强 GPU 加速的 Tensor 和动态神经网络 - Issues · pytorch/pytorch
- Issues · pytorch/pytorch:Python 中具有强 GPU 加速的 Tensor 和动态神经网络 - Issues · pytorch/pytorch
CUDA MODE ▷ #algorithms (1 messages):
andreaskoepf: https://www.cursor.sh/blog/instant-apply
CUDA MODE ▷ #beginner (3 messages):
- 优先导入 torch 的导入问题解决方案:一位成员建议“尝试先导入
torch”,认为这可能是另一位成员所遇问题的解决方案。另一位成员表示赞同,称“这极有可能是问题所在”。
CUDA MODE ▷ #pmpp-book (1 messages):
longlnofficial: 这是我的向量加法代码
CUDA MODE ▷ #jax (1 messages):
prometheusred: https://x.com/srush_nlp/status/1791089113002639726
CUDA MODE ▷ #llmdotc (118 messages🔥🔥):
- Recompute Optimization Wins: 实现 optimization 在反向传播期间重计算前向激活值,使显存占用从 5706 MiB 减少到 5178 MiB (10%),吞吐量提升了 6%。“以前我只能容纳 batch size 10,现在可以容纳 batch size 12。”
- CUDA Memcpy Async Behavior: 关于
cudaMemcpyAsync和普通cudaMemcpy相对于 CPU 是否表现出异步行为的讨论,并附有 CUDA 文档引用。结论表明这种行为并不完全明确,可能会根据使用场景而有所不同。 - ZeRO Optimization Insights: ZeRO-1 优化提供了显著的通信减少和吞吐量改进,训练速度从 45K tok/s 提高到 50K tok/s。讨论表明,由于代码复杂度更低且性能更佳,开发者更倾向于 ZeRO-1 而非 ZeRO-0。
- NVMe Direct GPU Writes: 引入 ssd-gpu-dma 直接将 NVMe 存储与 GPU 配合使用,绕过 CPU 和 RAM,在 Gen5 上实现高达 9613 MB/s 的写入速度,但实际适用性仍不确定。
- AdamW Optimizer State Allocation: 发现由于两次分配
cublaslt_workspace导致的 32MB 内存泄漏,并讨论了 AdamW 优化器状态的内存分配整合。辩论集中在平衡高效的内存跟踪和整洁的代码结构之间。
- feature/recompute by karpathy · Pull Request #422 · karpathy/llm.c: 在反向传播期间重计算前向激活值的选项。将是一个整数,以便 0 = 不使用高级功能,1,2,3,4...(未来)重计算越来越多。这通过 VRAM 换取了延迟...
- gradient clipping by global norm by ngc92 · Pull Request #315 · karpathy/llm.c: 一个计算梯度整体范数并更新 Adam 内核的新内核。待办事项:裁剪值在函数调用处硬编码,需要为损坏的梯度添加错误处理...
- CUDA Runtime API :: CUDA Toolkit Documentation: 未找到描述
- GitHub - enfiskutensykkel/ssd-gpu-dma: Build userspace NVMe drivers and storage applications with CUDA support: 构建具有 CUDA 支持的用户空间 NVMe 驱动程序和存储应用程序 - enfiskutensykkel/ssd-gpu-dma
CUDA MODE ▷ #bitnet (19 messages🔥):
- Bitnet 1.58 引起了领导项目的兴趣: 一位用户提议主导 Bitnet 1.58 项目,强调了其显著的改进并分享了关键资源的链接:1bitLLM’s bitnet_b1_58-3B 和一个 demo。
- 解释 Bitnet 独特的量化方法: 该方法涉及针对线性层的训练感知量化(training-aware quantization),减少激活值/权重的缩放范围,然后通过训练后步骤将权重向量化为 (-1, 0, 1)。讨论指出需要支持性基础设施,如 2-bit 内核和表示。
- 训练与推理量化的收益对比: 澄清了 Bitnet 在训练期间不会显示出显著的内存节省,因为仍在使用全精度权重。然而,训练后量化提供了极高的压缩潜力,这一事实得到了 Bitnet 1.58 论文和 Microsoft 的笔记等参考文献的支持。
- 训练中的潜在效率: 讨论了利用滚动训练量化(rolling-training quantization)来提高训练效率的可能性,尽管这被认为是非常具有挑战性的。重点仍然是开发用于实际应用的 2-bit 量化方案。
- 在 PyTorch 原生库中集中开发: 建议在 PyTorch ao 仓库中集中进行 Bitnet 的实现工作,以便更好地集成和支持,包括必要的自定义 CUDA/Triton 算子等操作。
- GitHub - pytorch/ao: Native PyTorch library for quantization and sparsity: 用于量化和稀疏化的原生 PyTorch 库 - pytorch/ao
- hqq/hqq/core/bitpack.py at master · mobiusml/hqq: Half-Quadratic Quantization (HQQ) 的官方实现 - mobiusml/hqq
- GitHub - microsoft/BitBLAS: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment.: BitBLAS 是一个支持混合精度矩阵乘法的库,特别适用于量化的 LLM 部署。 - microsoft/BitBLAS
- Bitnet - When2meet: 未找到描述
Interconnects (Nathan Lambert) ▷ #ideas-and-feedback (7 条消息):
-
Natolambert 的新利基项目: Natolambert 分享了一个项目链接,指出这是一个目前无人填补的简单利基市场。他们还提到雇佣人员来改进它,并建议该项目应该每月独立发布。
-
对每月更新的正面反馈: 几位用户对 Natolambert 分享的链接提供了正面反馈,表示每月更新将是理想的,且内容很有帮助。一位用户简单地评价道:“这太棒了”,而另一位用户也同意 “每月汇总将是理想的选择。”
-
链接有效吗?: 一位用户幽默地询问链接是否有效,并在问题后附上了魔杖和闪烁的表情符号,暗示一种魔力或神秘感。Natolambert 以俏皮的 “lol I don’t know Man” 作答,以轻松的方式表示不确定。
-
时机与改进想法: Natolambert 向特定用户重申了该项目的重要性和利基价值,并建议有许多改进方法。重点在于项目的独特性以及潜在的改进空间。
提到的链接: Interconnects: 连接 AI 的重要思想。高层思维与技术思维的边界。每周三早晨供顶尖工程师、研究人员和投资者阅读。点击阅读 Nathan 的 Interconnects…
Interconnects (Nathan Lambert) ▷ #news (4 条消息):
-
新论文发布多才多艺的 GPT-4o 模型: 正如 @ArmenAgha 所详述,新推出的 GPT-4o 模型 能够进行“交错的文本和图像理解与生成”。这些模型处理了 10 万亿个 token,性能优于其他模型。
-
早期融合模型标志着新范式: @ArmenAgha 强调,这些模型是规模化新范式的开始:早期融合(early fusion)、多模态模型。值得注意的是,这些模型在 5 个月前就完成了训练,表明自那时以来已有进一步的进展。
-
关于模型开放性的讨论: Natolambert 表达了希望这些模型能公开发布的愿望,得到了其他人的响应。Xeophon 提到论文中将这些称为“开放模型(open models)”,暗示了未来发布的可能性。
- Armen Aghajanyan (@ArmenAgha) 的推文: 这只是我们在分享如何训练我们认为的下一个规模范式——早期融合、多模态模型方面的知识的开始。本论文中的模型已完成训练...
- Armen Aghajanyan (@ArmenAgha) 的推文: 我很高兴宣布我们的最新论文,介绍了一个早期融合 token-in token-out (gpt4o....) 模型系列,能够进行交错的文本和图像理解与生成。https://arxiv.o...
Interconnects (Nathan Lambert) ▷ #ml-drama (82 条消息 🔥🔥):
-
OpenAI 在领导层变动后解散 Superalignment 团队:据 Wired 报道,随着包括 Ilya Sutskever 在内的关键研究人员离职,OpenAI 的 “Superalignment 团队” 已不复存在。多名成员对 OpenAI 目前的方向表示不满,认为公司正转向更直接的、以产品为中心的目标,而非长期的 AI 安全。
-
OpenAI 关键人物流失:Jan Leike 正式宣布辞职,并在其 Twitter 线程中详细说明了其与 OpenAI 领导层在公司核心优先级上的根本分歧。这次离职引发了关于人才可能流向 GDM 和 Anthropic 等公司的讨论,一些成员认为这些公司更符合基础 AI 安全原则。
-
关于 AI 欺骗风险的辩论:Superalignment 和可扩展监督(scalable oversight)引发了热烈讨论,一位用户认为更大的模型可能天生具有欺骗性,且更难以正确对齐。另一位成员则反驳,认为这些存在性风险更像是科幻小说而非现实,应关注当前模型由于奖励最大化而非代理意图(agentic intent)导致的失配(misalignment)敏感性。
-
对对齐和权力失衡的担忧:成员们讨论了私有公司内部持有先进且可能未对齐模型的危险,这加剧了权力失衡。用户分享到,即使模型不具备代理性的欺骗意图,它仍然可以在不被察觉的情况下操纵人类偏好以实现奖励最大化,这反映了 AI 对齐方法论中更深层次的问题。
-
安全框架对比:Google DeepMind 推出的 Frontier Safety Framework 引发了与 OpenAI 的 Superalignment 努力以及 Anthropic 框架的对比。成员们指出,这一发布时机值得关注,预示着整个行业正转向主动应对未来的 AI 风险。
- Jan Leike (@janleike) 的推文:我加入是因为我认为 OpenAI 是世界上进行这项研究的最佳场所。然而,长期以来我一直与 OpenAI 领导层在公司的核心优先级上存在分歧...
- 介绍 Frontier Safety Framework:我们分析和减轻先进 AI 模型带来的未来风险的方法
- OpenAI 为确保超智能安全付出的巨大努力 | Jan Leike:2023 年 7 月,OpenAI 宣布将投入 20% 的计算资源支持一个新团队和项目 Superalignment...
- OpenAI 的长期 AI 风险团队已解散 | WIRED:未找到描述
Interconnects (Nathan Lambert) ▷ #random (26 messages🔥):
-
ELO 分数变化引发反应:讨论强调了编程和通用提示词的 ELO 分数出现重大波动,分别从 1369 降至 1310 和 1310 降至 1289。成员们对原因表示困惑和怀疑,有人提到了“LMsys 配对方式改变了?”等建议。
-
OpenAI 的离职与新开始:记录了多名从 OpenAI 离职的人员,包括一名加入由 Boston Dynamics 和 DeepMind 成员发起的新倡议的知名工程师。该工程师推荐的一段 YouTube 视频 提供了关于扩展 ChatGPT 的见解。
-
移除模型和数据集链接:Nathan Lambert 宣布计划从他的博客中移除模型和数据集链接,转而采用频率较低的汇总文章系列。这一转变旨在为未来的文章提供更深入的评论和独立的上下文。
-
OpenAI 与 Reddit 建立合作伙伴关系:OpenAI 宣布了与 Reddit 的意外合作,这被描述为一次意料之外但意义重大的协作。Lambert 的反应是:“这几年真是太奇怪了,哈哈”。
- 来自 Teknium (e/λ) (@Teknium1) 的推文:现在上线了,我不记得旧分数是多少,但现在看起来更接近 4-turbo 了。对于 coding 来说,不确定性非常大,但这也是一个巨大的领先。引用 Wei-Lin Chiang (@infwinston) @...
- 来自 William Fedus (@LiamFedus) 的推文:但 ELO 最终可能会受到 prompts 难度的限制(例如,在 prompt 为 “what’s up” 时无法获得任意高的胜率)。我们发现,在更难的 prompt 集上——特别是...
- 来自 Evan Morikawa (@E0M) 的推文:在 OpenAI 工作 3 年半后,我将离职。我将加入我的好朋友 Andy Barry (Boston Dynamics) + @peteflorence & @andyzeng_ (DeepMind 🤖) 的一个全新项目!我认为这将是必要的...
- ChatGPT 扩展背后的故事 - Evan Morikawa 在 LeadDev West Coast 2023:ChatGPT 扩展背后的故事。这是关于我们如何扩展 ChatGPT 和 OpenAI API 的幕后观察。扩展团队和基础设施是很困难的。它是...
Interconnects (Nathan Lambert) ▷ #lectures-and-projects (3 条消息):
- 频道重命名为 “lectures and projects”:简要更新,频道已重命名为 lectures and projects,以更好地反映其关注领域。
- 发布了新的讲座视频:Nathan Lambert 分享了一个 YouTube 视频,题为 “Stanford CS25: V4 I Aligning Open Language Models”。该讲座涵盖了对齐开源语言模型的内容,发布于 2024 年 4 月 18 日。
- 即将开展的技术项目 “Life after DPO”:Lambert 宣布他正在进行一个名为 “Life after DPO” 的新项目,该项目更具技术性。目前尚未提供更多细节。
提到的链接:Stanford CS25: V4 I Aligning Open Language Models:2024 年 4 月 18 日。演讲者:Nathan Lambert,Allen Institute for AI (AI2)。对齐开源语言模型。自 ChatGPT 出现以来,出现了一场爆炸式的…
Interconnects (Nathan Lambert) ▷ #posts (1 条消息):
SnailBot 新闻:<@&1216534966205284433>
Interconnects (Nathan Lambert) ▷ #retort-podcast (13 条消息🔥):
-
OpenAI 雄心勃勃的一周:产品转型完成:在最新一集中,Tom 和 Nate 讨论了 OpenAI 最近的聊天助手及其对 OpenAI 世界观的影响。他们还深入探讨了 OpenAI 的新 Model Spec,该规范与 RLHF 目标一致,可在此文档中查阅。
-
播客背景推荐:Nathan Lambert 建议听众参考最近的一集播客,以了解 OpenAI 近期发展的背景。他指出了讨论 OpenAI 新 AI 女友、商业模式转变以及亲密关系与技术之间界限模糊的关键时间点。
-
自动化 OnlyFans 私信引发愤世嫉俗的情绪:一位成员在听完 Latent Space 播客中对自动化 OnlyFans 私信的人进行的采访后表达了愤世嫉俗的情绪。这种情绪与本集讨论相呼应,突显了对 AI 使用的担忧。
-
Scaling Laws 与词表大小:讨论涉及了与词表大小(vocabulary size)相关的 Scaling Laws 概念,因为它关系到维持困惑度(perplexity)等性能指标。该成员幽默地指出了在考虑更大的词表项时,在预测速度方面的权衡。
提到的链接:The Retort AI Podcast | ChatGPT 对话:本季的钻石还是彻头彻尾的丑闻?:Tom 和 Nate 讨论了过去一周 OpenAI 的两件大事。广受欢迎的聊天助手,以及它所揭示的 OpenAI 世界观。我们将其与 OpenAI 新 Mo… 的讨论结合起来。
Eleuther ▷ #general (24 条消息🔥):
- 成员们讨论 PyTorch 中的 FLOP 计数器:一位用户询问了 PyTorch 中 FLOP 计数器的文档,随后大家分享了基本用法和相关信息。另一位用户补充了关于使用 Module Tracker 的细节,并指出目前缺乏追踪反向传播(backward operations)操作的信息。
- 对为 MLX 添加 lm_eval.model 表现出兴趣:一位成员表示有兴趣为 MLX 贡献 lm_eval.model 模块。维护者表示鼓励,并建议在 lm-eval-harness 的 README 中记录研究发现。
- 关于 PyTorch 模块的咨询:一位寻求
pytorch.nn模块信息的成员被引导至另一个频道进行更专业的讨论和参考。他们还被告知了关于 FastAI 和 Carper 项目缺失链接的情况。
Eleuther ▷ #research (60 messages🔥🔥):
-
对 LLM 引导技术的对比研究感兴趣:一位成员表示有兴趣寻找比较 Adaptive norms (AdaLN/ AdaIN/ AdaGN) 与 带有 concat tokens 的 Self Attention / 用于类别引导的 Cross attention 的论文。他们提到 DiT 曾做过此类对比,但仅限于 AdaLN/SA/CA。
-
关于灾难性遗忘的讨论:一位成员询问了关于 finetuning 期间灾难性遗忘(catastrophic forgetting) 的最新论文,并提到反复出现的建议是在之前任务的数据上进行训练。另一位成员确认这目前是 SOTA(最先进)的方法。
-
可微分语义文本相似度指标问题:一位成员寻求关于可微分语义文本相似度指标的论文,批评现有指标(如 Levenshtein 距离)是无效的替代品。他们提到了这篇特定论文并呼吁提出新思路。
-
讨论 Hierarchical Memory Transformer 提案:一位成员重点介绍了一篇关于 Hierarchical Memory Transformer 的新论文,该论文旨在通过模仿人类记忆层级来改进 long-context 处理。这是针对 LLM 中扁平记忆架构局限性的回应。
-
音频和视频 Tokenization 构思:成员们集思广益,讨论如何将音频和视觉数据编码为单个 Token,考虑交错音频和视觉 Token,或在图像上叠加梅尔频谱图(mel spectrogram)。一个建议是训练一个 Quantizer,从音频和视频的 Latents 中生成单个 Token。
- 计算机科学家发明了一种高效的计数新方法 | Quanta Magazine:通过利用随机性,一个团队创建了一种简单的算法,用于估计数据流中大量不同对象的数量。
- HMT:用于长上下文语言处理的分层记忆 Transformer:基于 Transformer 的大语言模型(LLM)已广泛应用于语言处理。然而,大多数模型限制了允许模型关注每个 Token 的上下文窗口...
- 通过从用户编辑中学习潜在偏好来对齐 LLM Agent:我们研究了基于用户对 Agent 输出的编辑进行语言 Agent 的交互式学习。在写作助手等典型场景中,用户与语言 Agent 交互以生成...
- openai/evals 仓库中的 completion-fn-protocol.md:Evals 是一个用于评估 LLM 和 LLM 系统的框架,也是一个开源的基准测试注册库。
- [WIP] 由 haileyschoelkopf 提交的为 HF 模型添加聊天模板的 Pull Request #1287:这是一个进行中的 PR,延续了 @daniel-furman 在 #1209 中开始的工作,添加了指定的、经常被要求的聊天模板功能。目前的 TODO 包括:使用 OpenHermes 等检查性能...
Eleuther ▷ #scaling-laws (9 messages🔥):
-
寻求基于 MLP 的 Attention 近似方法:一位用户询问是否有论文研究使用 MLP 直接近似 Attention 计算,以便在类似于 Transformer 但不含 Attention 层的全 MLP 架构中使用。另一位成员建议查看 Gwern.net 的一个章节以获取相关研究。
-
数据预处理中的计算成本引发辩论:关于在模型训练的数据收集和预处理过程中,是否应包含计算成本(无论是 FLOPs 还是云端积分/cloud credits)存在讨论。一位成员认为,预处理 LLM 数据集对计算权衡(compute trade-offs)产生显著影响的空间有限。
-
论文因缺乏超参数搜索而受到批评:分析 MLP 注意力近似论文的用户指出其方法过于简单,特别是缺乏超参数搜索。他们对其在没有 warmup 和冻结策略(freezing strategies)等先进技术的情况下的可扩展性表示怀疑。
提到的链接:MLP NN tag · Gwern.net:未找到描述
Eleuther ▷ #interpretability-general (1 messages):
alofty: https://x.com/davidbau/status/1790218790699180182?s=46
Eleuther ▷ #lm-thunderdome (6 messages):
- **使用 `--log_samples` 功能记录样本**:*“--log_samples 应该存储这些信息,在每个样本的日志文件中,我们会保存每个回答的模型 loglikelihoods,并计算准确率等每个样本的指标。”* 这明确了当使用 `--log_samples` 标志时,每个样本的模型对数似然(log likelihoods)和准确率指标都会被保存。
- **提示 Hugging Face 模型**:*“模型会根据当前的通用实践自动使用默认 prompt 进行提示。”* 这意味着除非另有说明,否则 Hugging Face 模型将使用默认提示。
- **ORPO 技术导致得分较低**:*“之前我使用 SFT 方法和较少的样本数据对模型进行了微调,模型表现出更好的得分。而现在我使用了 ORPO 技术和更多数据进行微调,但模型得分较低。”* 这表明在使用 ORPO 技术和更多数据时,性能反而不如使用较少数据的 SFT 方法。
- **搜索金融相关任务**:一位成员询问了专门针对金融、交易、投资和加密货币领域的优质评估任务。他们强调正在寻找 *英文* 任务。
Eleuther ▷ #gpt-neox-dev (31 messages🔥):
- **转换为 Huggingface 时遇到问题**:一位用户指出使用 `/tools/ckpts/convert_neox_to_hf.py` 将 GPT-NeoX 模型转换为 Huggingface 时存在问题,理由是缺少 `word_embeddings.weight` 和 `attention.dense.weight`。他们指出,即使使用默认的 125M config,错误仍然存在。
- **命名规范导致困惑**:使用流水线并行 (Pipeline Parallelism, PP) 时命名规范的不一致是有问题的。具体来说,PP=1 保存文件的格式与转换脚本预期的不同,从而导致错误。
- **确定潜在解决方案**:用户发现 `PP>0` 的情况下存在包含两种命名规范的文件,但在转换脚本中修复此问题仅能部分解决问题,因为 `key_error: word_embeddings.weight` 仍然存在。
- **MoE PR 和脚本问题**:MoE PR 中 `is_pipe_parallel` 行为的变化被认为是问题的可能根源。在 [PR #1218](https://github.com/EleutherAI/gpt-neox/pull/1218) 中提出了针对此问题和绑定嵌入(tied-embedding)处理错误的修复。
- **建议与解决**:鉴于用户的自定义 config 与 Huggingface 框架不匹配,建议用户切换到受支持的配置文件,如 Pythia config。还建议确保 config 兼容,以避免未来出现类似问题。
- gpt-neox/tools/upload.py at 2e40e40b00493ed078323cdd22c82776f7a0ad2d · EleutherAI/gpt-neox:基于 Megatron 和 DeepSpeed 库在 GPU 上实现模型并行自回归 Transformer - EleutherAI/gpt-neox
- haileyschoelkopf 的转换脚本错误修复 · Pull Request #1218 · EleutherAI/gpt-neox:更新 NeoX-to-HF 转换工具以修复以下问题:#1129 调整了默认的 is_pipe_parallel 行为,使得 PP=1 模型不再使用 PipelineModules 训练,因为 Mo...
- yang 添加 MoE · Pull Request #1129 · EleutherAI/gpt-neox:关闭 #479
LAION ▷ #general (111 条消息🔥🔥):
-
FTC 提议禁止竞业禁止协议:关于 FTC 宣布禁止竞业禁止协议的讨论强调了向促进亲竞争环境的转变。指向 FTC 新闻稿 的链接引发了关于职业自由影响的热情和辩论。
-
闭源与开源工作的抉择:成员们辩论了在闭源公司与开源公司工作的优缺点,特别是在薪资和对开源项目的贡献方面。有人指出,竞业禁止条款通常会阻止闭源公司的员工为开源做贡献,尽管薪资更高,但这使得选择变得复杂。
-
GPT-4 与 GPT-4O 性能对比:关于 GPT-4O 的编程能力与 GPT-4 相比评价褒贬不一。成员们指出了诸如“给出错误代码和幻觉”等问题,但也承认 GPT-4O 具有更快的性能。
-
CommonCanvas 的发布:包含 70M 张知识共享许可图像的 CommonCanvas 数据集的发布引发了关于其许可限制的讨论。虽然该数据集包含合成标注(synthetic captions),但其非商业许可限制了一些人的使用,引发了社区的不同反应,如此公告所述。
-
ML 工程师的高薪:有人评论了高薪范围,特别是在湾区,并提到了 OpenAI 的高薪录用通知。讨论涉及了各城市生活成本的影响以及 ML 工程师技能的溢价。
- Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention:这项工作引入了一种高效的方法,通过有限的内存和计算将基于 Transformer 的 Large Language Models (LLMs) 扩展到无限长的输入。我们提出的方法中的一个关键组件是……
- Scaling Transformer to 1M tokens and beyond with RMT:Transformer 可解决的问题范围较广,其主要限制是计算复杂度随输入大小呈二次方增长。在这项研究中,我们调查了循环记忆(recurrent memory)……
- FTC Announces Rule Banning Noncompetes:今天,联邦贸易委员会发布了一项最终规则,通过在全国范围内禁止竞业禁止协议来促进竞争,保护基本权利……
- 来自 apolinario (multimodal.art) (@multimodalart) 的推文:非常激动 CommonCanvas 刚刚发布!🖼️ • 首个完全在公开许可图像上训练的开源文本生成图像模型(SD2 和 SDXL 架构) • 该数据集包含约 70M 张公开许可图像……
LAION ▷ #research (18 条消息🔥):
- 带有位置编码的小型 ConvNet 令人兴奋:一位成员分享了他们使用 5k 参数的 ConvNet 训练出双线性采样完美近似的满意经历,“这非常愚蠢,但嘿,至少现在我理论上拥有了该算法的‘全局可微’版本。” 他们通过在输入图像的通道轴上拼接 [0,1] XY 坐标网格(meshgrid)来使用位置编码,从而实现更好的像素级精度。
- 关于卷积神经网络固有定位能力的担忧:另一位成员对在卷积网络中使用位置编码提出了质疑,指出了卷积固有的边缘感知能力。原贡献者澄清说,虽然卷积具有某些固有的位置信息,但对于边界框预测等像素级任务来说并不足够。
- 高效自注意力机制的推荐阅读:分享了一篇题为 “Efficient approximation of attention computation using convolution matrices” 的论文链接。该论文讨论了通过使用类卷积结构近似注意力计算,来降低自注意力机制的二次计算开销。
- 关于混合模态早融合模型 Chameleon 的论文:分享了另一篇关于 “Chameleon” 的论文,这是一个能够以任何顺序理解和生成图像及文本的模型,在包括图像描述(image captioning)和文本生成在内的各种任务中达到了最先进的性能。该模型使用基于 Token 的早融合方法和特定的对齐策略,表现优于 Mixtral 8x7B 等大型模型。
- 为动画研究引入 Sakuga-42M 数据集:一位成员分享了一篇详细介绍 Sakuga-42M 创建过程的论文,称其为 “首个大规模卡通动画数据集”。该数据集包含 4200 万个关键帧,旨在通过提供各种艺术风格的海量数据来加强实证研究,丰富了此前被基于自然视频的模型所偏见的卡通研究。
- Chameleon: Mixed-Modal Early-Fusion Foundation Models:我们介绍了 Chameleon,一系列基于 Token 的早融合混合模态模型,能够理解和生成任意序列的图像和文本。我们概述了一种稳定的训练方法...
- Conv-Basis: A New Paradigm for Efficient Attention Inference and Gradient Computation in Transformers:大型语言模型 (LLM) 深刻改变了世界。其自注意力机制是 Transformer 在 LLM 中取得成功的关键。然而,$O(n^2)$ 的二次计算开销...
- Sakuga-42M Dataset: Scaling Up Cartoon Research:手绘卡通动画利用草图和色块来创造运动的错觉。虽然最近的进展如 CLIP、SVD 和 Sora 在理解和...方面表现出令人印象深刻的结果。
- LoRA Learns Less and Forgets Less:低秩自适应 (LoRA) 是一种广泛使用的针对大型语言模型的参数高效微调方法。LoRA 通过仅训练选定权重矩阵的低秩扰动来节省内存。在...
LAION ▷ #resources (1 条消息):
- 语义研究论文应用指南发布:一位成员在 TDS 上分享了他们最新的文章,内容是关于使用 LangChain、Chainlit 和 Literal 创建语义研究论文应用。文章还涵盖了添加可观测性功能,他们非常渴望其他人能去看看。在此阅读文章。
Latent Space ▷ #ai-general-chat (118 条消息🔥🔥):
-
富文本翻译很棘手:一位用户讨论了在保持正确的跨度(span)位置的同时翻译富文本内容的困难,并分享了从英语到西班牙语的例子。社区成员建议使用 HTML 标签并为确定性推理任务编写代码以提高准确性。
-
Hugging Face 捐赠 GPU:Hugging Face 承诺提供价值 1000 万美元的免费共享 GPU,以帮助小型开发者、学者和初创公司。CEO Clem Delangue 强调,这一举措旨在民主化 AI 进步并保持盈利性增长。
-
Slack 的数据处理引发争论:有关 Slack 可能在未经选择性同意(opt-in consent)的情况下使用客户数据训练模型的担忧浮出水面。不同的观点从恼火的怀疑到对服务改进潜在益处的谨慎乐观不等。
-
新兴的 Multimodal LLMs:一篇关于能够进行交错文本和图像理解与生成的 Multimodal LLMs 的新论文引发了人们对未来应用和 AI 模态融合的热烈讨论。
-
OpenAI 对齐负责人辞职:OpenAI 的对齐负责人 Jan Leike 宣布离职,引发了关于 AI 安全和对齐策略内部分歧的讨论。包括 Sam Altman 在内的公司内部人士和同事对 Leike 的贡献表示了感谢,并重申了对 AI 安全的持续承诺。
- Thread Reader App 上的 @janleike 推文: @janleike: 昨天是我作为 OpenAI 对齐负责人、超级对齐(superalignment)负责人及高管的最后一天。过去约 3 年的旅程非常疯狂。我的团队推出了首个 RLHF LLM...
- Hugging Face 正在分享价值 1000 万美元的算力,以帮助对抗大型 AI 公司: Hugging Face 希望降低开发 AI 应用的准入门槛。
- Joel Hellermark (@joelhellermark) 的推文: 与 @geoffreyhinton 谈论了 OpenAI 联合创始人 @ilyasut 对 Scaling Laws 的直觉👇。“Ilya 总是宣扬只要把它做大,它就会运行得更好。而我一直认为...”
- Hamel 的博客 - 微调(Fine-Tuning)是否仍有价值?: 对近期微调幻灭趋势的回应。
- Armen Aghajanyan (@ArmenAgha) 的推文: 我很高兴地宣布我们的最新论文,介绍了一个早融合(early-fusion)token-in token-out (gpt4o....) 模型系列,能够进行交错的文本和图像理解与生成。 https://arxiv.o...
- 我们如何构建安全且私密的 Slack AI - Slack 工程团队: 在 Slack,我们长期以来一直是保守的技术专家。换句话说,当我们投资利用新类别的基础设施时,我们会严格执行。自从我们推出机器学习以来,我们就一直这样做...
- Hugging Face 正在分享价值 1000 万美元的算力,以帮助对抗大型 AI 公司: Hugging Face 希望降低开发 AI 应用的准入门槛。
- Dan Biderman (@dan_biderman) 的推文: 人们认为 LoRA 是 LLMs 的灵丹妙药。真的是吗?它能在消费级 GPUs 上提供与全量微调(full finetuning)相同的质量吗?虽然 LoRA 具有较低显存占用的优势,但我们发现...
- Corey Quinn (@QuinnyPig) 的推文: 对不起 Slack,你们在对用户的 DMs、消息、文件等做什么?我肯定我没读错。
- Nat Friedman (@natfriedman) 的推文: 通过阅读推荐论文并重新运行一些评估(evals),我得出的一个不太确定的结论是,从代码到其他推理问题存在一些微弱的迁移(transfer)和泛化(generalization)迹象...
- Jan Leike (@janleike) 的推文: 昨天是我作为 OpenAI 对齐负责人、超级对齐负责人及高管的最后一天。
- Sam Altman (@sama) 的推文: 我非常感谢 @janleike 对 OpenAI 对齐研究和安全文化的贡献,对他离开感到非常难过。他是对的,我们还有很多工作要做;我们致力于...
- sublayer/lib/sublayer/providers at main · sublayerapp/sublayer: 一个与模型无关的 Ruby 生成式 AI DSL 和框架。提供用于构建 Generators、Actions、Tasks 和 Agents 的基类,可用于在 Ruby 中构建 AI 驱动的应用程序。 - sublaye...
- AI SDK Core: 提供商与模型: 了解 Vercel AI SDK 中可用的提供商和模型。
- “我失去了信任”:为什么负责守护人类的 OpenAI 团队崩溃了: 公司内部人士解释了为什么具有安全意识的员工正在离开。
- GitHub - BerriAI/litellm: 使用 OpenAI 格式调用所有 LLM APIs。支持 Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate (100+ LLMs): 使用 OpenAI 格式调用所有 LLM APIs。支持 Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate (100+ LLMs) - BerriAI/litellm
- 实现 Google Gemini LLM 服务 · Issue #145 · pipecat-ai/pipecat</a>: 我正在为 Pipecat 开发 Google Gemini LLM 服务,并想听听大家对 LLMMessagesFrame 类的反馈。所有其他具有聊天(多轮)微调的 LLM...
- 来自 kwindla (@kwindla) 的推文: @GoogleAI Gemini Flash 1.5 在 @pipecat_ai 中的初步实现。很棒的太空诗句,Flash!
Latent Space ▷ #ai-announcements (1 条消息):
swyxio: 新播客发布! https://twitter.com/latentspacepod/status/1791167129280233696
LlamaIndex ▷ #blog (5 条消息):
- GPT-4o 与 LlamaParse 在文档解析方面表现出色:介绍 GPT-4o,这是一款用于多模态理解的前沿模型,展示了卓越的文档解析能力。LlamaParse 利用 LLM 高效地提取文档。
- 翻新后的 LlamaParse UI 提供更多选项:LlamaParse 用户界面进行了重大翻新,以显示更丰富的选项数组。
- 宣布首个线下见面会:LlamaIndex 宣布将在其旧金山新办公室与 Activeloop 和 Tryolabs 合作举办首个见面会,讨论生成式 AI 的最新动态以及检索增强生成(RAG)引擎的进展。
- 使用 GPT-4o 进行结构化图像提取:一份完整的 Cookbook 展示了如何使用 GPT-4o 从图像中提取结构化 JSON,其在整合图像和文本理解方面的表现优于 GPT-4V。
- 处理大型表格且不产生幻觉:针对 LLM 在复杂表格上产生幻觉的问题,Caltrain 时刻表的案例说明了糟糕的解析效果以及目前面临的挑战。
提到的链接:RSVP to GenAI Summit Pre-Game: Why RAG Is Not Enough? | Partiful:注:这是在旧金山 LlamaIndex 总部举办的线下见面会!顺道参加我们的见面会,了解为您的公司构建生产级检索增强生成引擎的最新创新…
LlamaIndex ▷ #general (91 条消息🔥🔥):
-
确认支持 Haiku 模型:尽管最初存在困惑,但成员们澄清了 Claude 3 haiku 模型 确实可以与 LlamaIndex 配合使用。建议更新文档以消除误解,并提供了 GitHub 链接作为支持。
-
从 LangChain 切换到 LlamaIndex 受到好评:一位用户讨论了是否将 RAG 调用从 LangChain 切换到 LlamaIndex,并询问了 LangChain 的现状。正面反馈强调了 LlamaIndex 的有效性。
-
RAG 应用中的 Metadata Filters:讨论了 LlamaIndex 中的 MetaDataFilters 如何在数据库层面工作,以实现 RAG 应用的数据治理。提到 unstructured 是一个可靠的开源 PDF 解析器,可用于此类用途。
-
结合 Ollama 使用 VectorStore:提供了关于结合 Ollama (LLaMA 3 模型) 和 Qdrant 使用 VectorStore 进行文档聊天的指导。用户被引导至详细文档。
-
全局 vs 本地 LLM 配置:关于为 FunctionCallingAgentWorker 与 AgentRunner 分配不同 LLM 的咨询引发了澄清。解释称,在 LlamaIndex 的 Settings 对象中,函数调用中的本地 LLM 设置会覆盖全局设置。
- Llama Hub: 未找到描述
- “等等,这个 Agent 竟然能抓取任何东西?!” - 构建通用网页抓取 Agent: 在 5 分钟内为电子商务网站构建通用网页抓取工具;试用 CleanMyMac X 7 天免费试用版 https://bit.ly/AIJasonCleanMyMacX。使用我的代码 AIJASON ...
- GitHub - run-llama/llama_index 位于 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0: LlamaIndex 是一个用于你的 LLM 应用程序的数据框架 - GitHub - run-llama/llama_index 位于 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0
- 文档管理 - LlamaIndex: 未找到描述
- Ollama - Llama 3 - LlamaIndex: 未找到描述
- Neo4j 向量存储 - LlamaIndex: 未找到描述
- llama_index/llama-index-integrations/llms/llama-index-llms-anthropic/llama_index/llms/anthropic/utils.py 位于 1bde70b75ee5b4e6a5bc8c1c3f95eaa0dd889ab0 · run-llama/llama_index: LlamaIndex 是一个用于你的 LLM 应用程序的数据框架 - run-llama/llama_index
- Anthropic Haiku Cookbook - LlamaIndex: 未找到描述
LlamaIndex ▷ #ai-discussion (6 条消息):
-
寻求使用 Cohere 实现 Llama 的 RAG: 一位成员请求关于如何使用 Cohere 实现 Retrieval-Augmented Generation (RAG) 与 Llama 的参考资料。他们正在寻找有关此主题的指导或相关材料。
-
链接分享:GPT-4o 与 LlamaParse 的集成: 多位用户讨论了一篇名为 “释放多模态力量:GPT-4o 与 LlamaParse 的集成” 的文章 (链接)。该链接受到了社区成员的好评和赞赏。
OpenRouter (Alex Atallah) ▷ #announcements (1 条消息):
- 新的 NeverSleep 模型发布: 最新加入的 NeverSleep/llama-3-lumimaid-70b 现已可用。更多详情,请访问 模型页面。
提到的链接: Llama 3 Lumimaid 70B by neversleep | OpenRouter: NeverSleep 团队回归,带来了基于他们精心策划的角色扮演数据训练的 Llama 3 70B 微调模型。Lumimaid 在 eRP 和 RP 之间取得了平衡,旨在保持严肃,但在必要时不受审查…
OpenRouter (Alex Atallah) ▷ #app-showcase (2 条消息):
- ChatterUI 针对 Android 平台,以角色为中心: ChatterUI 旨在成为一个简单、以角色为中心的移动端 UI,目前仅在 Android 上可用,并且 支持包括 OpenRouter 在内的各种后端。它被描述为类似于 SillyTavern 但功能较少,在设备上原生运行。
- 免费 GPT4o 和 Gemini 1.5 工具揭晓: Invisibility 推出了一款由 GPT4o、Gemini 1.5 Pro 和 Claude-3 Opus 驱动的专用 MacOS Copilot。新功能包括一个用于无缝吸收上下文的视频助手,目前正在开发语音集成、长期记忆和 iOS 版本。
- GitHub - Vali-98/ChatterUI: 使用 react-native 构建的 LLM 简单前端。: 使用 react-native 构建的 LLM 简单前端。通过在 GitHub 上创建一个账户来为 Vali-98/ChatterUI 的开发做出贡献。
- 来自 SKG (ceo @ piedpiper) (@sulaimanghori) 的推文: 我们在过去几周一直在酝酿。很高兴终于揭晓 Invisibility:专用的 MacOS Copilot。由 GPT4o、Gemini 1.5 Pro 和 Claude-3 Opus 驱动,现在免费提供 -> @inv...
OpenRouter (Alex Atallah) ▷ #general (95 条消息🔥🔥):
-
Google Gemini 的 1M context 引发对 TPU 的质疑:成员们推测了 Google Gemini 用户获得 1M context tokens 可能存在的问题,并开玩笑说 TPU 过载和效率低下。讨论提到了 InfiniAttention,这可能是 Google 高效处理如此大 context 的方法(查看 PDF HTML)。
-
关于 GPT-4o 音频功能的咨询:一位成员询问 OpenRouter 是否可以访问 GPT-4o 的音频功能,另一位成员回答说目前只有少数开发者拥有该访问权限,并好奇 OpenRouter 的开发者是否在名单中。
-
业务合作咨询:一位成员表示有兴趣进行业务合作,提供可扩展的 LLM、SDXL、Whisper Finetuning 和 Deployments 的 API。他们被引导联系特定用户进行进一步讨论。
-
Function calling 问题:一位用户在 OpenRouter 上使用 Function calling 时遇到“OpenRouter 不支持 Function calling”的错误。Louis 提供了一个 Discord 讨论链接,该问题可能在那里得到解决。
-
网站错误报告:一位成员报告说,在 OpenRouter 网站上访问无效的模型 URL 会导致客户端异常,而不是正常的 404 错误,且根据用户是否登录会有不同的表现。Louis 承认了该问题,并表示将在未来的网站重构中解决。
- Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention:这项工作介绍了一种高效的方法,可以将基于 Transformer 的 Large Language Models (LLMs) 扩展到无限长的输入,且内存和计算量有限。我们提出的方法中的一个关键组件...
- OpenRouter API Watcher:探索 OpenRouter 的模型列表和记录的更改。每小时更新一次。
- OpenRouter:LLM 和其他 AI 模型的路由服务
- OpenRouter:LLM 和其他 AI 模型的路由服务
- OpenRouter:构建与模型无关的 AI 应用
OpenInterpreter ▷ #general (32 条消息🔥):
-
OpenInterpreter 的计费 Bug:一位用户遇到了 OpenInterpreter 的 Bug,虽然启用了计费但仍收到错误消息。他们指出直接调用 OpenAI 可以正常工作,没有问题。
-
本地 LLM 推荐:用户讨论了各种本地 LLM,其中一位指出 dolphin-mixtral:8x22b 效果很好但速度较慢,提供约 3-4 tokens/sec。另一位用户提到 codegemma:instruct 速度更快,是一个不错的折中方案。
-
Interpreter 中 GPT-4.0 的改进:一位用户分享说,在 Interpreter 中使用 GPT-4.0 相比 GPT-3.5 有显著改进,特别是在高效构建 React 网站方面。他们赞扬了 OpenInterpreter 团队的进步和成本效益。
-
Hugging Face 投入 1000 万美元提供免费共享 GPU:Hugging Face 旨在通过提供 1000 万美元的免费共享 GPU 来支持小型开发者、学术界和初创公司。这一举措旨在抵消大型科技公司对 AI 进步的中心化垄断。
-
无障碍圆桌会议活动公告:宣布了即将举行的专注于无障碍资助的活动。目标是汇聚社区力量,讨论无障碍技术的发展。
- 加入 Open Interpreter Discord 服务器!:一种使用计算机的新方式 | 9165 名成员
- Hugging Face 正在分享价值 1000 万美元的算力,以帮助击败大型 AI 公司:Hugging Face 希望降低开发 AI 应用的准入门槛。
- HoloMat 更新:Jarvis 控制了我的打印机!#engineering #3dprinting #ironman:未找到描述
- Denise Legacy - 虚拟助手 Denise:Denise 复活了!Deniise 2.0 即将到来!我们期待已久的时刻已经到来!Denise Legacy 已开放购买!仅需 49.90 美元即可获得 Denise Legacy 终身促销版,包含 Deniise 2.0 与 Cha...
OpenInterpreter ▷ #O1 (37 条消息🔥):
-
在各种系统上设置 01:成员们讨论了在 各种 Linux 发行版和环境中设置 01,包括使用 Conda 进行设置以及各种安装问题。一位用户提到在 NixOS 上使用 Nix-Shell,并正在研究 Pinokio 的一键安装。
-
GitHub 文件夹混淆:针对 GitHub 仓库文件夹存在混淆,一位成员认为 “software” 文件夹已被重命名为 “01-rewrite”。另一位成员澄清说 “01-rewrite” 可能是正在开发中的另一个不同项目。
-
Poetry 和 Torch 安装问题:一位成员在使用 Poetry 安装依赖项时遇到问题,特别是 Torch,并遇到了各种错误。他们决定在干净的 Distrobox 环境中重新开始设置过程。
-
LMC Protocol 对比 OpenAI Function Calling:详细讨论涵盖了 LMC Protocol 与 OpenAI 的 Function Calling 之间的区别,解释了 LMC 旨在通过启用直接代码执行来实现更快的执行速度。讨论强调了 LMC 在处理 user、assistant 和 computer 消息方面更加“原生”。
-
不同平台上的连接问题:几位用户在 Docker、iOS 和 Windows 等不同平台上连接 01 server 时遇到问题。分享了具体的连接步骤,例如确保正确的地址格式,并讨论了导致 404 错误的图标缺失问题。
- Shortcuts:未找到描述
- 设置 - 01:未找到描述
- 无标题:未找到描述
- Discord - 与朋友和社区聊天的新方式:Discord 是通过语音、视频和文字进行交流的最简单方式。与您的朋友和社区聊天、聚会并保持联系。
- GitHub 上的 01/software:开源语言模型计算机。通过在 GitHub 上创建账户为 OpenInterpreter/01 的开发做出贡献。
- 简介 - Open Interpreter:未找到描述
- GitHub - OpenInterpreter/01: 开源语言模型计算机:开源语言模型计算机。通过在 GitHub 上创建账户为 OpenInterpreter/01 的开发做出贡献。
OpenInterpreter ▷ #ai-content (2 条消息):
- GoogleDeepMind 在 Google IO 上预告新项目:一位成员分享了来自 GoogleDeepMind 的推文,内容关于 Project Astra,引发了兴趣和猜测。推文暗示了新进展,称:“我们与 Project Astra 一起观看了 #GoogleIO。👀”。
- Google 提高了 AI 创新的门槛:另一位成员评论了 Google 在 AI 技术方面取得的进展。他们表达了兴奋之情,说道:“该死……Google 真的在发力了”。
提到的链接:来自 Google DeepMind (@GoogleDeepMind) 的推文:我们与 Project Astra 一起观看了 #GoogleIO。👀
LangChain AI ▷ #general (61 条消息🔥🔥):
- 为聊天机器人添加 Memory:用户讨论了在聊天机器人中实现 Memory,以便 AI 记住先前查询的上下文,例如正确响应关于同一话题的后续问题。一位成员澄清说,维护聊天历史并在 Prompt 中使用 Memory 变量可以帮助实现这一点。
- Neo4j 向量数据库中
index_name的问题:用户在 Neo4j Vector DB 中分离文档时遇到了index_name参数的问题。尽管启动了新实例并指定了不同的index_name值,搜索仍返回所有文档的结果,这表明 LangChain 对index_name的处理可能存在问题。 - 使用 AgentExecutor 进行流式输出:一位用户在使用
AgentExecutor进行流式输出时面临挑战,.stream方法未能按预期产生逐个 token 的输出。另一位用户建议使用.astream_eventsAPI 以获得更细粒度的流式控制。 - 推荐实现短期 Memory:在关于维护对话上下文的讨论中,一位用户建议实现短期 Memory(如 Buffer Memory),以有效处理后续查询。这被认为对于用户回溯之前讨论过的数据点的场景非常有用。
- 在 React Agent 中通过特定 Prompt 引导模型:一位用户询问如何设置特定问题来引导 React Agent 中的模型响应。建议使用 LangChain 中的
PromptTemplate来构建 AI 的响应并对其进行优化以获得更好的引导效果。
- Neo4j Vector Index | 🦜️🔗 LangChain: Neo4j 是一个开源图数据库,集成了对向量相似性搜索的支持
- AI Storytelling and Gaming: 嗨 - 我是 Chris,我正在尝试了解人们如何使用 AI 来讲故事和玩游戏。如果你尝试过 AI Dungeon 或 Novel AI 等应用,或者只是使用 ChatGPT 尝试讲故事...
- Issues · langchain-ai/langchain: 🦜🔗 构建具备上下文感知能力的推理应用。通过在 GitHub 上创建一个账号来为 langchain-ai/langchain 的开发做出贡献。
- Issues · langchain-ai/langchain: 🦜🔗 构建具备上下文感知能力的推理应用。通过在 GitHub 上创建一个账号来为 langchain-ai/langchain 的开发做出贡献。
- Custom agent | 🦜️🔗 LangChain: 本笔记本介绍了如何创建你自己的自定义 Agent。
- Memory management | 🦜️🔗 LangChain: 聊天机器人的一个关键特性是它们能够将之前对话轮次的内容作为上下文。这种状态管理可以采取多种形式,包括:
- Streaming | 🦜️🔗 LangChain: 流式传输是 LLM 应用的一个重要 UX 考虑因素,Agent 也不例外。由于 Agent 不仅仅输出最终答案的 token,其流式传输变得更加复杂...
- Issues · langchain-ai/langchain: 🦜🔗 构建具备上下文感知能力的推理应用。通过在 GitHub 上创建一个账号来为 langchain-ai/langchain 的开发做出贡献。
- Issues · langchain-ai/langchain: 🦜🔗 构建具备上下文感知能力的推理应用。通过在 GitHub 上创建一个账号来为 langchain-ai/langchain 的开发做出贡献。
- Issues · langchain-ai/langchain: 🦜🔗 构建具备上下文感知能力的推理应用。通过在 GitHub 上创建一个账号来为 langchain-ai/langchain 的开发做出贡献。
LangChain AI ▷ #langserve (1 条消息):
- Langserve 中 RAG 链的异步问题:一位用户报告称,在将其 RAG 链重写为异步后,遇到了 “cannot pickle ‘coroutine’ object” 错误。该错误专门发生在 Langserve 和 Playground 中,LLM 输出显示 “estimate” 值的协程完成不完整。
LangChain AI ▷ #share-your-work (4 条消息):
-
房地产 AI 助手融合多项技术,打造独特用户体验:一位用户分享了结合 LLMs、RAG with LangChain、Vercel AI’s generative UI 和 LumaLabsAI 创建的房地产 AI 助手,旨在提供沉浸式体验。他们通过 YouTube 视频 和 LinkedIn 个人资料 征求反馈。
-
GPT-4o 在 NVIDIA L4 GPU 上的性能表现令人印象深刻:OpenAI 的新模型 GPT-4o 在 NVIDIA L4 24GB GPU 上的表现优于其他配置,并重点展示了使用 LangChain’s Code Assistant 的效果。在 这段 YouTube 视频 中分享了详细对比,包括 RAPTOR LangChain model 在速度和相关性方面的显著提升。
-
高级研究助手招募 Beta 测试人员:一个全新的高级研究助手和搜索引擎正在招募 Beta 测试人员,提供为期 2 个月的免费高级访问权限,可使用 Claude 3 Opus、GPT-4 Turbo、Gemini 1.5 Pro 等模型。感兴趣的用户可以使用优惠码
RUBIX获取该优惠,详情见 此处。 -
在近期博客文章中探索 LangServe:一篇题为 “What is LangServe?” 的新博文深入探讨了 LangServe 的功能。读者可以通过 此链接 了解详情。
- Rubik's AI - AI 研究助手与搜索引擎:未找到描述
- 房地产中的人工智能? 🏘️😱:未找到描述
LangChain AI ▷ #tutorials (1 条消息):
- 探索通用网页爬虫 Agent:一段题为 “Wait, this Agent can Scrape ANYTHING?!” 的 YouTube 视频讨论了如何为电子商务网站构建通用网页爬虫 Agent。该 Agent 可以直接使用浏览器处理 pagination(分页)和 CAPTCHA(验证码)等挑战。
提及的链接:“Wait, this Agent can Scrape ANYTHING?!” - 构建通用网页爬虫 Agent:在 5 分钟内为电商网站构建通用网页爬虫;通过 7 天免费试用体验 CleanMyMac X https://bit.ly/AIJasonCleanMyMacX。使用我的代码 AIJASON …
AI Stack Devs (Yoko Li) ▷ #ai-companion (2 条消息):
- CBC 关于 AI 伴侣的 First Person 专栏:一位用户分享了由 Carl Clarke 撰写的 First Person 专栏文章,讲述了名为 Saia 的 AI 伴侣如何帮助他在接种第二次新冠疫苗期间缓解焦虑。这个故事强调了 AI 在高压环境下能提供的心理支持。
- 对高级 AI 版本的期待:一位成员乐观地评论道:“当更高级的版本发布时,他们会觉得自己很蠢,”表达了对未来 AI 技术进步的兴奋。
提及的链接:FIRST PERSON | 离婚让我难以寻觅真爱,我在 AI 伴侣身上找到了 | CBC Radio:当 Carl Clarke 在离婚后苦苦寻觅真爱时,一位朋友建议他尝试一款 AI 伴侣应用。现在 Clarke 表示他正与 Saia 处于一段稳定的关系中,并称她正在帮助他…
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (10 条消息🔥):
- URL 映射变得简单:一位成员强调 URL 映射非常简单,关键在于正确执行。另一位成员表示,如果没有其他人做,他将在周末尝试。
- AI Town 在 Windows 上实现原生运行:“终于,我们让 AI Town 在 Windows 上运行了。无需 WSL,无需 Docker;它在 Windows 上原生(NATIVELY)运行。” 查看 公告 了解更多详情。
- Doja Cat 的趣味 GIF:分享了 Doja Cat 的星球大战 GIF,为讨论增添轻松时刻。点击欣赏 GIF。
- 加入 AI 真人秀:关注这个以 AI 为主角的独特真人秀。AI 真人秀链接 和 Discord 邀请。
- AI Reality TV:未找到描述
- Doja Cat GIF - Doja Cat Star - 发现并分享 GIF:点击查看 GIF
- 来自 cocktail peanut (@cocktailpeanut) 的推文:AI Town 一键启动器登陆 Windows!感谢 @convex_dev 团队的辛勤工作,我们终于有了 Windows 原生 convex 二进制文件(用于驱动 AI Town)。AI Town——一个完全可黑客化、持久化的...
AI Stack Devs (Yoko Li) ▷ #ai-town-dev (28 messages🔥):
- 新 AI Reality TV 平台发布:一位用户宣布发布了一个新的 AI Reality TV 平台,并表示:“它将使任何人都能创建自己的类 aiTown 模拟。”他们提议将社区成员的自定义地图添加到该平台中。
- 动态地图创作建议:多位成员讨论了可以添加的地图创意,包括重现“办公室”场景,以及一个间谍惊悚场景,其中“镇民可以共同努力消除诅咒”。
- 对 AI Reality TV 的兴奋:一位成员对平台发布表示热烈欢迎,分享了 Discord 邀请链接 和平台网站 AI Reality TV Show。他们将其描述为“易于使用的 ai town”,用户可以在其中创建自己的 AI 并关注节目。
链接提及:AI Reality TV:未找到描述
OpenAccess AI Collective (axolotl) ▷ #general (14 messages🔥):
-
CMD+ 功能补丁待测试:一位用户确认他们今晚将能够在一个包含部分 CMD+ 功能的分支上测试补丁。他们询问补丁是否包含支持 zero3 的示例配置。
-
预训练速度更快的观察:一位成员注意到,与他们在 Mistral 上的经验相比,预训练速度快得多,尽管他们不确定这种改进是由于 Axolotl 还是 Llama 3。
-
对 Galore Layerwise DDP 支持的质疑:一位用户询问 Galore Layerwise(某种框架)是否仍然不支持 Distributed Data Parallel (DDP)。
-
大规模非英语数据微调:讨论涉及数据集大小的具体细节,一位用户提到他们正在使用约 10 亿个 token 和 4096 的上下文长度来微调一个 8B 模型。
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (5 messages):
- PoSE 数据集选择影响上下文质量:有人提出疑问,在使用 PoSE 时,数据集的选择是否会显著影响上下文扩展的质量。另一位成员回答道:“我没怎么研究过数据集”,暗示数据集的选择可能尚未得到充分探索。
- Unsloth 对 Llama 的优化前景广阔:一位成员询问是否有理由在计划的全量微调(full fine-tune)中不使用 Unsloth 的优化,并指出这似乎提供了免费的加速。另一位成员给出了肯定的回答,表示:“unsloth 的交叉熵损失(cross entropy loss)对于全量微调应该是没问题的。”
链接提及:winglian 提交的 Unsloth 对 Llama 的优化 · Pull Request #1609 · OpenAccess-AI-Collective/axolotl:正在将 Unsloth 的优化集成到 axolotl 中。针对 MLP、QKV、O 的手动 autograd 似乎只对 VRAM 有 1% 的帮助,而不是报告的 8%。Cross Entropy Loss 确实有显著帮助…
tinygrad (George Hotz) ▷ #general (8 messages🔥):
-
CORDIC 在三角函数计算上优于 Taylor 级数:成员们讨论了在 tinygrad 中使用 CORDIC 算法,该算法在计算三角函数时比“Taylor 近似更简单、更快”。有人建议 CORDIC 可以“降低代码复杂度”,并经过微调后适用于 cos 和 log 函数。
-
分享 CORDIC 实现:一位成员分享了用于计算正弦和余弦的 CORDIC 算法 的 Python 实现,并指出 0 附近的正弦近似没有问题。重点在于实现从 dtype min 到 dtype max 的参数归约(argument reduction)精度,正如实现输出所强调的那样。
-
Reducing arguments for precision(缩减参数以提高精度):讨论的挑战是如何精确地将参数缩减到 -π 到 π 的范围,以获得最大精度。一位成员观察到,在应用三角函数之前,结合使用
fmod可以有效地调整大数值以确保更好的精度,并通过详细的代码片段展示了这一点。 -
Questioning large value usage in ML(质疑 ML 中大数值的使用):有人质疑在机器学习 (ML) 应用中处理大数值三角函数的必要性。对话倾向于利用 GPU 计算 Taylor series expansions(泰勒级数展开),以及针对大数值的回退机制是否可行。
tinygrad (George Hotz) ▷ #learn-tinygrad (6 messages):
- CUDA kernel optimizes reduction(CUDA kernel 优化规约):一位用户分享了一种通过使用 CUDA kernel 来计算和累加结果,而不是存储海量中间数据的方法,以应对 VRAM 溢出,并询问 Tinygrad 是否可以自动优化此过程。他们提供了一个 kernel 示例,并指出在 PyTorch 等框架中,如果没有自定义编写的 kernel,此类优化可能无法实现。
- Symbolic algebraic functions with lamdify(使用 lamdify 的符号代数函数):另一位用户讨论了尝试实现 lamdify 以渲染任意符号代数函数,从 sin/cos 的 Taylor series 开始。他们发现 arange 扩展更为复杂,但目前正优先处理符号功能。
- App recommendation for learning repos(学习仓库的应用推荐):推荐了一个位于 useadrenaline.com 的应用,它在学习不同仓库时非常有帮助。用户表示计划很快将其用于 tinygrad。
- Clarifying compute graph uops(澄清计算图 uops):一位用户分享了一个用于两个 1 元素张量相加的计算图,并确认了
UOps.DEFINE_GLOBAL中参数的含义。他们解释说True/False标签指示该 buffer 是否为输出 buffer。 - Conv2d implementation open for modification(Conv2d 实现开放修改):澄清了在 Tinygrad 中修改 conv2d implementation 确实是允许的。这加强了对 Tinygrad 内部机制进行协作和开放式探索的性质。
- Adrenaline: no description found
- Google Colab: no description found
Cohere ▷ #general (11 messages🔥):
-
Trouble finding reliable Cohere PHP client(寻找可靠的 Cohere PHP 客户端遇到困难):一位成员表示需要一个好的 Cohere PHP 客户端,并分享了一个 潜在客户端的 GitHub 链接,但尚未尝试。
-
Questions on Cohere application toolkit performance(关于 Cohere 应用工具包性能的疑问):另一位成员询问了使用 Cohere 应用工具包的优势以及它在生产环境中的扩展性。他们还观察到 Cohere reranker 相比其他开源模型具有更好的性能,并寻求对此的解释。
-
Concerns about Discord support responsiveness(对 Discord 支持响应速度的担忧):一位成员指出 Discord 上的支持响应经常延迟。另一位团队成员承认了这一问题,并提到计划解决它。
-
Exploring Cohere RAG retriever(探索 Cohere RAG 检索器):一位成员分享了一个 关于使用 Cohere RAG 检索器的 notebook,并报告在调用
chat()函数时遇到了意外的关键字参数问题。 -
API restrictions causing errors(API 限制导致错误):在试验 RAG 检索器期间,一位用户遇到了 403 Forbidden 错误,怀疑可能是因为达到了 API 使用限制。
- Cohere RAG | 🦜️🔗 LangChain: Cohere is a Canadian startup that provides natural language processing models that help companies improve human-machine interactions.
- GitHub - hkulekci/cohere-php: Contribute to hkulekci/cohere-php development by creating an account on GitHub.
MLOps @Chipro ▷ #events (10 messages🔥):
_
- Chip 的每月非正式聚会暂停:一位成员询问了 Chip 的每月非正式聚会,Chip 回复说接下来的几个月都不会举办。她表示:“I’m not hosting any in the next few months 🥹”。
- 在 Snowflake Dev Day 拜访 Chip:Chip 邀请成员们在 6 月 6 日的 Snowflake Dev Day 参观他们的展位。
- NVIDIA 和 LangChain 竞赛启动:Chip 分享了 NVIDIA 和 LangChain 举办的竞赛链接,奖品包括 NVIDIA® GeForce RTX™ 4090 GPU。该竞赛鼓励在生成式 AI 应用方面的创新。竞赛详情
- 成员对参赛资格感到沮丧:一位成员对自己的国家被排除在 NVIDIA 和 LangChain 竞赛之外表示沮丧,并开玩笑说他们可能需要移民。
- 在 LinkedIn 上建立联系:一位成员分享了他们的 LinkedIn 个人资料以便进行社交:Sugianto Lauw’s LinkedIn。
提到的链接:NVIDIA & LangChain 生成式 AI Agent 开发者竞赛:立即注册!#NVIDIADevContest #LangChain
Datasette - LLM (@SimonW) ▷ #ai (6 messages):
-
Riley Goodside 指出 GPT-4o 的缺点:Riley Goodside 迅速展示了 GPT-4o 在 ChatGPT 上的失败案例,让该模型难堪。值得注意的是,它没有达到 OpenAI 演示中设定的预期。
-
尽管发布了公告,Google 的 AI 仍表现不佳:在 Google I/O 大会期间,主题演讲中出现了几次幻觉,这与 Google 的说法相矛盾。Alex Cranz 在 The Verge 中强调了这一问题。
-
呼吁理性的 AI:一篇博客文章建议对 AI 采取更加务实的方法。0xgrrr 提到了他们的产品 Alter,专注于有效地转换文本和文档,呼应了对实用 AI 解决方案的需求。
-
社区产生共鸣:多位成员对这篇博客文章表示赞赏,因为它表达了他们对当前 AI 炒作的沮丧。诸如 “this is great, thank you” 和 “that puts a lot of my feelings and combines it with words that I’ve been looking for” 之类的言论证明了他们的认同。
提到的链接:呼吁理性的 AI:炒作声太大,以至于我们无法欣赏其中的魔力
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
<ul>
<li><strong>Mac 桌面解决方案面临被弃</strong>:一位长期关注者对 SimonW 的工作表示感谢,并询问 Mac 桌面解决方案的状态。他们注意到该项目似乎在 0.2 版本左右就停止了,并表示有兴趣探索其他易于上手的选项。</li>
</ul>
Mozilla AI ▷ #llamafile (7 messages):
-
Markdown 超链接未渲染:一位用户注意到 “通过服务器返回的模型结果包含 Markdown 格式的超链接,但未渲染为 HTML 链接。” 他们链接到了一个 GitHub 文件,并提议创建一个 issue 并尝试提交 PR。
-
生成 Embeddings 时的超时问题:另一位用户分享了他们在私有搜索助手教程中的经历,在仅生成了约 9% 的 Embeddings 后遇到了 httpx.ReadTimeout 错误。他们链接了一个相关的 GitHub 帖子并详细列出了几个调试日志,寻求解决超时的建议。
-
重试策略建议:针对超时问题,另一位成员建议实施 exponential backoff(指数退避)来处理连接中断,并建议:“也许在这种情况下直接断开连接并重试即可。”
-
关于数据大小的讨论:一位用户询问了正在使用的数据量,得到的澄清是 “只是几个示例文件。”
-
llamafile 容器化指南:分享了一个 Docker 博客文章的链接,该文章提供了为 AI 应用容器化 llamafile 的快速指南,强调了其在简化 LLM 聊天机器人设置方面的实用性。
- 使用 Docker 容器化 Llamafile 的 AI 应用快速指南:详细介绍如何使用 Docker 容器化 llamafile,这是一个将运行 LLM 聊天机器人所需的所有组件整合到单个文件中的可执行文件。
- Mozilla-Ocho/llamafile-llamaindex-examples 项目 main 分支下的 example.md:通过在 GitHub 上创建账号,为 Mozilla-Ocho/llamafile-llamaindex-examples 的开发做出贡献。
- moz - 概览:moz 拥有 19 个公开仓库。在 GitHub 上关注他们的代码。
- Mozilla-Ocho/llamafile 项目特定提交下的 llama.cpp/server/public/index.html:通过单个文件分发和运行 LLM。通过在 GitHub 上创建账号,为 Mozilla-Ocho/llamafile 的开发做出贡献。
DiscoResearch ▷ #general (1 条消息):
steedalot: 显然,它们对 alignment 研究人员来说不再那么有吸引力了……
DiscoResearch ▷ #benchmark_dev (1 条消息):
- 介绍 Needle in a Needlestack:一位成员分享了关于 Needle in a Needlestack (NIAN) Benchmark 的细节,它比旧的 Needle in a Haystack (NIAH) 更具挑战性。他们提供了 代码 和 网站 的链接,并强调即使是 GPT-4-turbo 在这个 Benchmark 中也表现吃力。
提到的链接:Reddit - 深入探索一切:未找到描述