ainews-ten-commandments-for-deploying-fine-tuned
部署微调模型的十诫
以下是该段文本的中文翻译:
Gemini-in-Google-Slides 被强调为总结演示文稿的实用工具。Kyle Corbitt 关于在生产环境中部署微调模型的演讲强调,除非必要,否则应避免进行微调,而应重点关注提示词、数据质量、合适的模型选择以及全面的评估。Anthropic 展示了 Claude AI 中的特征干预(feature alteration),体现了对模型行为的控制,并加深了对大语言模型的理解。像 GPT-4o 这样的开源模型(注:原文如此,GPT-4o 实际为闭源模型)在处理简单任务时,其在 MMLU 等基准测试中的表现正接近闭源模型,但在处理复杂的自动化任务时,高级模型仍然必不可少。
Gemini-in-Google-Slides 正是我们所需要的。
2024年5月23日至5月24日的 AI 新闻。 我们为您查看了 7 个 subreddit、384 个 Twitter 账号 和 29 个 Discord 社区(380 个频道,4467 条消息)。 为您节省了预计阅读时间(以 200wpm 计算):495 分钟。
后续跟进:Jason Wei 发布了一份针对昨天 Evals 主题的优秀 “201” 补充资料,内容涉及如何制作成功的 eval 的博弈策略,同时也包含了一些关于 MATH 和 LMSYS 等著名 eval 的题外话和轶事。此外,今天是使用
AINEWS代码参加 AI Engineer World’s Fair 的最后一天。
今天新闻较少,所以我们深入挖掘了社区中有趣的内容。今天的优胜者是 Kyle Corbitt 关于在生产环境中部署微调模型(Deploying Finetuned Models in Prod)的演讲:
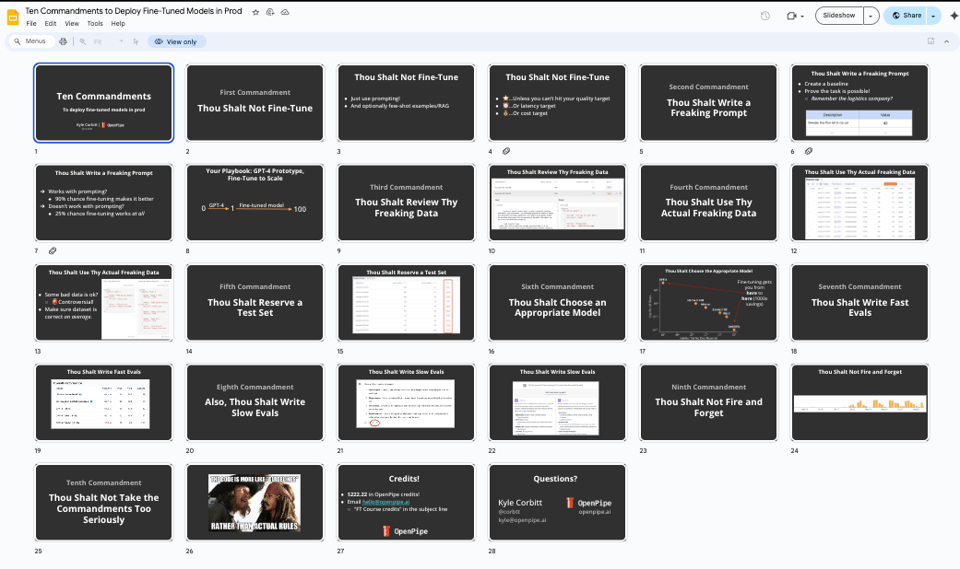
简而言之,这些“诫律”是:
- 你不应微调:直接使用 prompting!以及可选的 few-shot 示例/RAG。微调昂贵、缓慢且复杂。仅在你的用例确实需要时才进行。
- 你应该写一个像样的 Prompt:创建一个基准并证明该任务可以通过 prompting 实现。
- 你应该仔细检查你的数据:如果必须微调,确保你彻底了解你的数据。
- 你应该使用你真实的业务数据:你的模型质量取决于训练它的数据。确保你的训练数据尽可能接近模型在生产环境中将遇到的数据。
- 你应该保留测试集:始终保留一部分数据用于测试,以评估模型的性能。
- 你应该选择合适的模型:模型的参数越多,训练成本越高且速度越慢。选择一个适合你的任务和预算的模型。
- 你应该编写快速评估(Fast Evals):编写计算速度快的评估指标,以便快速迭代模型。
- 此外,你应该编写慢速评估(Slow Evals):编写更全面、计算时间更长的评估指标,以深入了解模型的性能。
- 你不应部署后就不管了:不要只是部署模型然后就置之不理。监控其性能,并准备好根据需要重新训练或更新。
- 你不应太死板地对待这些诫律:这些诫律旨在作为有用的指导方针,而非硬性规定。请根据你的最佳判断并结合具体需求进行调整。
有趣的是,我们使用了 Gemini 来完成这份幻灯片的摘要。去试试吧。
AI Twitter 综述
所有综述均由 Claude 3 Opus 完成,从 4 次运行中选取最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
Anthropic 的 Claude AI 与可解释性研究
- Claude AI 中的特征改变:@AnthropicAI 演示了如何通过改变 AI 内部的“特征”来改变其行为,例如使其极度关注金门大桥。他们发布了一个限时的“Golden Gate Claude”来展示这一能力。
- 理解大语言模型的工作原理:@AnthropicAI 表示,基于他们在 Claude 中发现和改变特征的能力,他们对开始理解大语言模型的真实工作原理有了更强的信心。
- 对 Claude 的知识和局限性保持诚实:@alexalbert__ 表示,Anthropic 对 Claude 了解什么和不了解什么保持诚实,而不是刻意决定其推测棘手哲学问题的能力。
开源 AI 模型与进展
- 开源模型正在追赶闭源模型:@bindureddy 强调,在 MMLU 基准测试中,像 GPT-4o 这样的开源模型在简单的消费者用例上的表现正接近 GPT-4 等闭源模型。然而,对于复杂的 AI Agent 和自动化任务,仍然需要更先进的模型。
- 新开源模型发布:@osanseviero 分享了本周发布的几个新开源模型,包括多语言模型 (Aya 23)、长上下文模型 (Yi 1.5, M2-BERT-V2)、视觉模型 (Phi 3 small/medium, Falcon VLM) 以及其他模型 (Mistral 7B 0.3)。
- Phi-3 small 以更少的参数超越 GPT-3.5T:@rohanpaul_ai 指出,微软的 Phi-3-small 模型仅有 7B 参数,但在语言、推理、代码和数学基准测试中均超越了 GPT-3.5T,展示了在压缩模型能力方面的快速进展。
AI Agent、检索增强生成 (RAG) 和结构化输出
- 从用于问答的 RAG 转向报告生成:@jxnlco 预测,在未来 6-8 个月内,RAG 系统将从问答转向报告生成,利用设计良好的模板和 SOP,通过针对有付费能力的人群来释放商业价值。
- ServiceNow 使用 RAG 减少幻觉:@rohanpaul_ai 分享了 ServiceNow 的一篇论文,展示了 RAG 如何通过检索相关步骤和表名并将其包含在 LLM prompt 中,从而确保生成的 JSON 对象在工作流自动化中是合理且可执行的。
- RAG 通过将 LLM 与现实世界数据连接来增加商业价值:@cohere 概述了 RAG 系统如何通过将 LLM 与现实世界数据连接来解决幻觉和成本上升等挑战,并强调了企业在其 LLM 解决方案中采用 RAG 的 5 大原因。
AI 基准测试、评估和文化包容性
- 标准 AI 基准测试可能无法引导真正的全球文化理解:@giffmana 建议,像 ImageNet 和 COCO 这样典型的“西方” AI 基准测试可能无法反映真正的“多文化理解”。在全域数据而非仅在英语数据上训练模型,可以显著提高非西方文化背景下的性能。
- 评估大语言模型的困难:@clefourrier 和 @omarsar0 分享了一份报告,讨论了稳健评估 LLM 的挑战,例如初始基准测试设计与实际使用之间的差异,以及随着模型能力增强,需要更具辨别力的基准测试。
- Aya 23 多语言模型扩大了技术服务的范围:@sarahookr 介绍了 Cohere 的 Aya 23 模型,这是一个强大的多语言系列,旨在为全球近一半的人口提供服务,这也是他们改变“谁被技术看见”这一使命的一部分。
迷因与幽默
- Nvidia 股票与“永久底层阶级”:@nearcyan 开玩笑说,配偶后悔没买 Nvidia 股票,从而将“永远属于永久底层阶级”。
- 对 Anthropic 金门大桥 AI 的讽刺:@jeremyphoward 讽刺了 Anthropic 的可解释性演示,幽默地声称“OpenAI 已经赶上了 Claude 的最新功能,并且还拥有一个基于复杂机械可解释性研究的高级金门大桥模式。”
- 调侃 Google 的 AI 错误:@mark_riedl 分享了一个幽默的轶事,他开玩笑地声称 Google 的 AI 错误地认为他获得了 DARPA 奖项,导致人们真的相信他没有获得该荣誉。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 进展与能力
- GPT-4 令人印象深刻的转录和位置识别能力:在 /r/OpenAI 中,GPT-4o 展示了从图像中转录文本和识别地点的卓越能力,甚至在没有 EXIF 数据的情况下也能做到,正如这段视频所示,并在此处进行了进一步讨论。
- Yi-Large 正在赶超最先进模型:/r/singularity 发布的一份对比图显示,Yi-Large 的表现正逼近 GPT-4,并在多个基准测试中超越了 Claude 3 Opus 和 Gemini 1.5 pro。
AI 伦理与安全担忧
- OpenAI 员工因伦理担忧离职:在 /r/singularity 中有报道称,OpenAI 员工离职不仅是因为对“减速(decel)”的恐惧,还涉及与 News Corp 合作、游说反对开源以及针对前员工的激进手段等问题。
- 对 OpenAI 与 News Corp 合作的担忧:/r/OpenAI 的一篇帖子批评了 OpenAI 与右翼宣传公司 News Corp 的合作,担心这可能导致 ChatGPT 使极端观点合法化。
- 加州 AI 法案要求安全保障但遭到批评:/r/singularity 讨论了加州新通过的一项 AI 法案,该法案强制要求超过 10^26 flops 的模型必须具备武器制造预防机制、关停按钮并向政府报告。然而,这些要求被批评为在技术上不合理。
- Yann LeCun 反击 AI 末日论:在 /r/singularity 分享的一段视频中,AI 先驱 Yann LeCun 认为 AI 最大的危险是审查、监控和权力集中,而不是经常被描绘的末日场景。
AI 可解释性与控制
- Anthropic 的 “Golden Gate Claude” 映射 AI 特征:Anthropic 的研究(在 /r/singularity 中有详细介绍)表明,他们的 “Golden Gate Claude” 可以映射和操纵 AI 的内部特征,这在理解和控制 AI 行为方面可能是重大进展。
- Anthropic 展示了通过特征改变来塑造 AI 行为:另一篇分享在 /r/singularity 的 Anthropic 论文显示,由稀疏自编码器(sparse autoencoder)学习到的可解释特征可以代表复杂概念,并可以通过修改这些特征来控制 AI,例如诱发某种痴迷。
AI 商业化与准入
- Meta 考虑推出 AI 助手付费版:据 The Information 报道(见 /r/singularity 帖子),Meta 正在开发其 AI 助手的付费高级版本。
- 马克龙将 Mistral 定位为欧盟顶尖 AI 公司:CNBC 的一篇文章(分享于 /r/singularity)描述了法国总统马克龙如何将 Mistral 宣传为领先的欧盟 AI 公司,这引发了关于偏袒法国公司而非其他欧洲竞争对手的批评。
- Google Colab 为 AI 开发提供免费 GPU:/r/singularity 的一则帖子强调,Google Colab 正在提供免费的 GPU 访问权限(包括 A100),以支持 AI 开发。
{kind=link}
梗图与幽默
- 关于婴儿潮一代不愿放手的梗图:/r/singularity 上的一个梗图调侃了婴儿潮一代拒绝让年轻一代接管的现象。
- 关于 Microsoft 训练 GPT-5 的讽刺视频:/r/singularity 的一段视频讽刺了 Microsoft 训练 GPT-5 的场景,将其比作鲸鱼吞噬磷虾一样喂入数据。
- 关于 Windows Recall AI 和隐私的梗图:/r/singularity 上的一个梗图嘲讽了假设的 Windows Recall AI 功能及其引发的隐私担忧。
{kind=link}
AI Discord Recap
摘要之摘要的摘要
-
LLM 微调技术与最佳实践:
-
微调十诫:在 Kyle Corbitt 的演讲中,成员们强调了细致的 Prompt 设计和模板配置,使用
###分隔符和 “end of text” tokens 来实现高效的模型微调。 -
Hamel 的延迟优化博客:关于减少过拟合以及有效使用检索增强生成 (RAG) 策略的讨论,重点介绍了来自 Axolotl 等平台持续进行的微调实验的实践指导。
-
-
量化与性能优化创新:
-
Tim Dettmers 关于 LLM.int8() 的研究:他的工作(如这篇博客所示)展示了先进的量化方法如何在不降低性能的情况下保持 Transformer 的表现,并揭示了对涌现特性(emergent features)及其影响的见解。
-
CUDA 的梯度范数 Bug 修复:解决了梯度爆炸和 Batch Size 等问题,显著提高了训练稳定性,详见此 PR。
-
Axolotl 中优化的内存架构:样本打包(Sample packing)效率的提升在分布式训练期间带来了 3-4% 的资源管理收益。
-
-
开源框架与社区努力:
-
Axolotl 的最新更新:社区讨论了将可观测性(observability)集成到 LLM 应用中,并解决缓存和配置问题,以简化模型微调的工作流程。
-
PostgresML 与 LlamaIndex 的集成:Andy Singal 强调了 PostgresML 与 LlamaIndex 之间的协同作用,能够高效地利用 AI 进行数据库管理任务。
-
-
多模态 AI 与新模型进展:
-
Phi-3 模型引发关注:Unsloth 的 Phi-3 模型因其更长的上下文长度和 Medium 版本支持而受到社区关注,并发布了关于快速优化和集成的公告。
-
Mobius 模型期待:DataPlusEngine 即将发布的版本承诺提供高效的基础模型创建,引发了关于基础扩散模型(diffusion models)及其训练方法的讨论。
-
-
AI 伦理、治理与用户体验的挑战:
-
SB-1047 监管担忧:社区对 AI 治理中心化表示愤怒,并将其与其他行业的监管俘获(regulatory captures)进行对比,引发了关于该法案对小型开发者影响的热烈讨论。
-
通讯工具中 AI 的伦理使用:在工作场所通讯监控中部署 GPT-4 和 Claude 引发了关于将伦理嵌入 AI 及其减少法律漏洞潜力的哲学思考,正如有关 API 集成和使用限制的讨论中所强调的那样。
-
第 2 部分
LLM Finetuning (Hamel + Dan) Discord
Fine-Tuning 事实:在 general 频道 的讨论中,揭示了由于偏置的数据类别导致的 语义相似度过拟合 (semantic similarity overfitting) 问题。一位用户在理解 Fine-tuning 与用户输入及初始模型训练的关系时遇到了困难。此外,还注意到 OpenAI 平台侧边栏 的变化,两个图标(线程和消息)消失了。
模板成为焦点:在 workshop-1 中,强调了在 Fine-tuning 期间正确配置模板的重要性。特别是分隔符 ### 有助于解析不同的输入部分,而 “end of text” token 则指示何时停止 token 生成。
Maven 与交流:在 asia-tz 中,成员们进行了一次轻松的交流,提到了重聚。一份会议演讲录像的请求得到了满足,视频已在 Maven 上发布。
Modal 动员:🟩-modal 的 Modal 用户分享了收到额度的兴奋感、训练经验,并为新用户提供了 Modal 文档 和 示例 的具体链接。还分享了一个使用 Modal 参加 Kaggle 竞赛 的计划,包括设置和执行细节。
Jarvis 记录 Jupyter 杂记:在 jarvis-labs 频道 中,成员们讨论了在 Jarvis 上存储 VSCode 仓库,并建议使用 GitHub 保存工作。有一则关于由于不稳定而 移除竞价实例 (spot instance) 的通知。分享了 Fine-tuning open-lama-3b 模型的成本和时长,一位用户通过调整模型参数解决了 Ampere 系列错误。
Hugging Face 讨论额度与西班牙语模型:hugging-face 频道 讨论了待处理的 HF 额度 以及适用于西班牙语文本生成的模型——推荐了 Mistral 7B 和 Llama 3 模型。
额度倒计时继续:在 replicate 频道,预告了即将发布的关于额度管理和分配的公告。
Corbitt 的诫命大显身手:kylecorbitt_prompt_to_model 频道 中热情的与会者讨论了 Kyle Corbitt 演讲中介绍的 Fine-tuning 方法和技术,包括 部署 Fine-tuned 模型的十诫 (Ten Commandments for Deploying Fine-Tuned Models)。
Axolotl 响应号召:在 workshop-2 中,用户讨论了 Axolotl 中的数据集、模型训练和故障排除。分享了一篇关于 TinyLLama Fine-Tuning 的博客文章,并推动将可观测性 (observability) 集成到 LLM 应用中。
退出 Zoom,进入 Discord:在 Zoom 聊天被禁用后,来自 workshop-3 的用户将讨论转移到了 Discord。
Axolotl 的缓存难题引发困惑:在 axolotl 中,Axolotl 的缓存问题令用户沮丧,文件丢失的困惑已得到解决。关于样本打包 (sample packing) 的讨论和一份关于 Tokenizer 陷阱的指南解决了有关效率和分词的疑虑。
加速迈向胜利:zach-accelerate 的用户解决了对浮点数比较的困惑,修复了 Jarvislab 训练命令错误,并交流了学习模型加速的资源,重点关注 Fine-tuning 的最佳实践。
与 Axolotl 一起尝试:wing-axolotl 频道 协作处理了数据集模板、预处理问题、Axolotl 配置,并提供了最新 Axolotl 更新的 PR 合并。他们深入研究了调试工具以及精确模板对训练成功的重要性。
HuggingFace Discord
蛋白质数据可视化达到新高度:一个新的蛋白质可视化项目现在支持 3D 渲染,并包含了人类血红蛋白和核糖体蛋白的示例,项目详情可以在 GitHub 上找到。
使用 OpenAI 的 Whisper 进入 TranscriptZone:一款利用 OpenAI 的 Whisper 来转录 YouTube 视频及更多内容的新转录应用已在 Hugging Face Spaces 上线。
去中心化网络——不仅仅是一个梦想?:一个为去中心化互联网构建基础设施的项目通过调查寻求社区反馈,引发了关于数据收集伦理的讨论。
Vision Transformers 深度查询:一位成员寻求关于应用 Vision Transformers (ViT) 进行单目深度估计(monocular depth estimation)的资源,表示有意开发一个使用 ViT 的模型,但讨论中未提供具体资源。
Mistral 模型的量化困境:在 Mistral v0.3 Instruct 上使用 bitsandbytes 进行 8-bit 量化导致性能比 4-bit 和 fp16 更慢,这一令人困惑的结果与减少位数计算预期的效率提升相矛盾。
Perplexity AI Discord
-
Perplexity 在 CSV 对决中超越 ChatGPT:工程师们讨论认为 Perplexity AI 在 CSV 文件处理方面优于 ChatGPT,因为它允许直接上传 CSV。此外,推荐使用 Julius AI 进行数据分析,它利用 Python 并集成了 Claude 3 或 GPT-4 等 LLM。
-
用户冷落 Claude 3 Opus:由于内容限制增加和感知到的实用性下降,Claude 3 Opus 遭到冷遇,尽管 GPT-4 也有局限性,但仍被视为更好的选择。
-
质疑 Pro Search 的真正升级:Pro Search 的升级引起了关注,用户讨论新的多步推理功能和 API 规范究竟是真正的后端改进,还是仅仅是表面上的 UI 增强。
-
API 集成详解:围绕外部工具与 Claude 的 API 集成的对话引起了兴趣,同时分享了自定义函数调用、无服务器后端以及诸如 Tool Use with Claude 等文档。
-
AI 伦理:不仅仅是一个思想实验:关于为 GPT 注入伦理监控能力的讨论被激发,揭示了其在职场沟通和法律辩护方面的潜在应用,尽管哲学上的难题尚待解决。
Stability.ai (Stable Diffusion) Discord
-
关于 RTX 5090 显存的猜测达到顶峰:关于传闻中拥有 32GB VRAM 的 RTX 5090 是否具有实际意义的辩论正热。参考了 PC Games Hardware 上的潜在规格和图片,但一些成员对其真实性持怀疑态度。
-
Stable Diffusion 与 AMD 的挑战:用户提供了在 AMD 5700XT GPU 上安装 Stable Diffusion 的指导,建议从 Craiyon 等 Web 服务开始,以规避潜在的兼容性问题。
-
Stable Diffusion 3:承诺前的试用:社区将 Stable Diffusion 3 与竞争对手 Midjourney 进行了对比,强调虽然 SD3 提供免费试用,但持续访问需要 Stability 会员资格。
-
对 Mobius 模型的期待升温:关于 DataPlusEngine 的新型 Mobius 模型 的公告引起了极大关注,因为它声称可以创建高效的基础模型。该模型在 Twitter 上进行了预告,它既不是简单的基础模型,也不是现有模型的微调版本。
-
32GB VRAM:游戏规则改变者还是性能过剩?:提到 32GB VRAM GPU 引发了关于 Nvidia 数据中心 GPU 销售策略潜在转变的对话,考虑到拥有大容量显存的产品可能会如何影响市场对 H100/A100 系列的需求。
Unsloth AI (Daniel Han) Discord
-
PEFT 配置问题已解决:针对 PEFT 训练期间缺失
config.json的问题,通过从基础模型的配置中复制该文件已得到解决,用户已确认成功。 -
Llama 跨越 Bug 障碍:Llama 3 模型的基础权重被描述为存在 “bug”,但 Unsloth 已实现相关修复。为了提升训练效果,建议使用保留 token 并更新 tokenizer 和
lm_head。 -
System Prompt 提升 Llama 3 效果:观察发现,加入系统提示词(System Prompt),即使是空白的,也能增强 Llama 3 的微调(finetuning)结果。
-
Phi 3 模型激增:随着 Phi 3 模型 的首次亮相,社区反响热烈,该模型已支持 medium 版本。社区讨论引导工程师关注博客文章和发布说明中的详尽细节。
-
Stable Diffusion 的诡异一面:Stable Diffusion 产生的诡异伪影和离奇的语音克隆输出令用户感到吃惊,相关讨论和经历已在 YouTube 视频和 Reddit 帖子中分享。
-
VSCode Copilot 方案推荐:用户在 random 频道寻求本地 VSCode “copilot” 的建议,并得到了积极的响应和推荐。
-
Phi-3 的推理延迟问题:一名用户对使用 Unsloth Phi-3 时较慢的推理速度感到困惑,并提供了一个 Colab notebook 用于调查延迟原因,社区目前仍在努力寻找修复方案。
-
量化困境的破解:一名成员在量化自定义模型时面临挑战,在 llama.cpp 和 Docker 兼容性方面遇到了障碍,引发了关于解决方案的讨论。
-
模型性能的 VRAM 判定:明确了 VRAM 需求:Phi 3 mini 需要 12GB 即可,但 Phi 3 medium 必须配备 16GB。对于繁重任务,建议考虑外部计算资源。
-
训练一致性的数据尽职调查:强调了在训练和评估中使用一致数据集的重要性,并重点介绍了 Unslothai 的公共数据集,如 Blackhole Collection。
-
平台可能性与警示:针对 Unsloth 是否支持旧款 Mac 的咨询得到了回复,确认目前重点在于 CUDA 和 GPU 的使用,并为仅有 CPU 的设备提供了建议。
-
企业级专业知识扩展:一名社区成员主动提出为 Unsloth 提供企业级专业知识,并对加入 Build Club 和 GitHub 的加速器表示赞赏,暗示了 Unsloth 未来发展的协同潜力。
Nous Research AI Discord
关于 AI 理解能力的智力辩论:社区就 LLM 对概念的真实理解展开了深入讨论,可解释性研究(interpretability research)被视为重要的经验证据。怀疑论者认为目前的努力尚不足够,并引用了 Anthropic 关于映射大语言模型思维的相关工作。
Llama 湖中的生物:一项旨在增强 Llama 模型 的技术尝试集中在编写一个能够管理函数调用(function calls)的脚本上,并以 Hermes Pro 2 的方法作为灵感。另一项咨询则围绕在 3080 GPU 上实现 Llama3 LoRA 技术展开。
数字维度中的现实探索:在关于 Nous 和 WorldSim 的对话中,成员们探讨了 NightCafe 和多维 AR 空间在映射复杂 AI 世界中的潜在应用。音频可视化器中的梦幻探索和奇特的 ASCII 艺术表现形式突显了 AI 驱动模拟的创意用途。
筛选 RAG 数据:提倡模型将内部知识与检索增强生成(RAG)相结合成为热门话题,并就如何处理矛盾和解决冲突提出了疑问。强调用户评估被认为是必不可少的,特别是对于复杂的查询案例。
微调 AI:精准度胜过花哨技巧:社区讨论赞扬了 Mobius 模型 在图像生成方面的卓越表现,并期待其开源版本和阐释性论文的发布。此外,还提到了 Hugging Face 的 PyTorchModelHubMixin 可以简化模型共享,但受限于 50GB 的大小限制(在不分片的情况下)。
Eleuther Discord
-
JAX vs. PyTorch/XLA:TPU 对决:TPU 上 JAX 和 PyTorch/XLA 的性能对比引发了关于基准测试细微差别的辩论,例如 warmup times 和 blocking factors。GPT-3 的训练成本从 450 万美元大幅下降到 2024 年预计的 12.5 万至 100 万美元,这一点受到了关注,其中考虑了来自不同贡献者的 TFLOP 速率 和 GPU-hour 定价,并链接到一篇 Databricks 博客文章。
-
扩展与教学 LLMs:在研究论坛中,Chameleon 模型因其在多模态任务中的强劲表现而受到关注,而 Bitune 则承诺改进 LLM 的 zero-shot 性能(Bitune 论文)。讨论质疑了 JEPA 模型对 AGI 的可扩展性,并批评了 RoPE 的上下文长度限制,引用了一篇相关的 论文。
-
涌现特征困扰 LLM 爱好者:链接了 Tim Dettmers 关于在 Transformer 推理中保持性能的高级量化方法的研究,包括他的涌现离群值(emergent outliers)概念,以及通过 bitsandbytes library 与 Hugging Face 的集成。关于涌现特征(emergent features)的讨论围绕着它们是模型的“DNA”这一观点展开,引发了对其对相变(phase transitions)影响的讨论。
-
技术调整与 LM 评估简报:在 lm-thunderdome 中,工程师们介绍了在 vllm models 中设置 seed 的实用技巧,使用
lm_eval --tasks list获取 任务列表,以及处理 BigBench 任务名称更改(这会影响像 Accelerate 这样存在内存问题的 harness)。建议通过查阅lm-eval/tasks文件夹来定位任务,以便更好地组织。 -
协作呼吁:发出了扩大 Open Empathic 项目的呼吁,并提供了一个用于贡献电影场景的 YouTube 指南 以及该项目的链接。鼓励进一步的协作,强调了社区努力进行增强的必要性。
LM Studio Discord
GPU 历险记:工程师们讨论了将小模型加载到 GPU 上的挑战,一些人青睐 llama3, mistral instruct 和 cmdrib 等模型。同时,据报道,在某些应用中,使用较低的量化(如 llamas q4)比 q8 等较高的量化产生更好的结果,反驳了“越大越好”的观念。
下一代模型即将到来:模型领域的一项更新通知了 35B 模型 的发布,并进行了测试以确保 LM Studio 的兼容性。针对不同规模模型的优化也是一个话题,重点是 Phi-3 small GGUFs 及其效率。
服务器与设置:硬件讨论包括利用 llama.cpp 及其最近的 RPC 更新进行 distributed inference,尽管目前还不支持量化模型。还探索了使用配备 RTX 4060 Ti 16GB 的廉价 PC 集群进行分布式模型设置的实验性构建,以及可能的网络限制。
实现多语言凝聚:Cohere 模型现在将其能力扩展到了 23 种语言,正如广告所言,aya-23 quants 已开放下载,但 ROCm 用户必须等待更新才能体验。
Stable Diffusion 被排除在外:LM Studio 澄清说,它专门处理语言模型,不包括像 Stable Diffusion 这样的图像生成器,同时处理旧 GPU 上的 CUDA 问题,并推广 Julius AI 等服务以缓解用户体验方面的困扰。
CUDA MODE Discord
-
梯度范数(Gradient Norm)麻烦:将 batch size 从 32 修改会导致梯度范数突然飙升,从而中断训练。一个 pull request 通过防止 fused classifier 中的索引溢出解决了这个问题。
-
Int4 和 Uint4 类型需要关注:一位成员指出 PyTorch 中许多函数缺乏对 int4 和 uint4 数据类型的实现,相关的 讨论帖 指出了在类型提升(type promotion)和 tensor 操作方面的局限性。
-
直播代码预警——聚焦 Scan 算法:Izzat El Hajj 将主持一场关于 Scan 算法的现场编程会议,该算法对于像 Mamba 这样的 ML 算法至关重要。会议定于
<t:1716663600:F>,有望为爱好者们带来一次技术深度探讨。 -
CUB 库查询与 CUDA 细节:成员们深入讨论了从 CUDA CUB 库代码的运行机制到在不使用 cuBLAS 或 cuDNN 的情况下触发 tensor cores 等话题,并重点推荐了 NVIDIA 的 CUTLASS GitHub 仓库 和 NVIDIA PTX 手册 等资源。
-
FineWeb 数据集难题:处理 FineWeb 数据集非常占用存储空间,磁盘占用达到 70 GB,并消耗高达 64 GB 的 RAM,这暗示在数据处理任务中需要更好的优化或更强大的硬件配置。
Modular (Mojo 🔥) Discord
Python 库比起 Mojo 更倾向于 C:关于将 Python 库移植到 Mojo 的可行性和准备工作有一场激烈的讨论,考虑到 Mojo 不断演进的 API,人们担心给维护者施加太大压力。成员们讨论了将目标对准 C 库是否是一个更直接且实际的尝试。
Rust 的安全性吸引力不会削弱 Mojo 的潜力:Mojo 并不打算取代 C,但 Rust 的安全性优势正在影响工程师们对 Mojo 在不同场景下应用的思考。正在进行的讨论涉及了可以使 Mojo 开发受益的 Rust 概念。
使用 Nightly 版本 Mojo 奋力前行:在 MacOS 上使用 Mojo 的 Nightly 版本运行 BlazeSeq 的性能表现出与 Rust 的 Needletail 相似的潜力,引发了关于跨平台效率的讨论。快速的 Nightly 更新(见 changelog)让社区保持对这门演进中语言的关注。
对 Modular 机器人机制的好奇:有人对 “ModularBot” 的底层技术提出了疑问,虽然没有提到具体模型,但机器人给出了一个生动的回复。另外,还讨论了在 Mojo 中进行 ML 模型训练和推理的潜力,并提到 Max Engine 可以作为 numpy 的替代方案,尽管目前还没有完善的训练框架。
编译时困惑与对齐问题:从内存中 boolean 值的对齐问题到编译时函数问题,都引起了用户的关注,解决方法和官方 bug reports 凸显了社区驱动排错的重要性。
OpenAI Discord
-
忠于 LaTeX 的 LLM:在格式化领域,用户对 GPT 表现出强烈的默认使用 LaTeX 的倾向感到沮丧,即使要求提供 Typst 代码也是如此,这揭示了 LLM 似乎坚持某种特定的编码语法偏好。
-
Microsoft Copilot+ 与 Leonardo 之争:社区讨论集中在 Microsoft Copilot+ PC 在“草图转图像”等创意任务中的价值,而一些成员则鼓励尝试 Leonardo.ai 以获得类似的功能。
-
对 AI 效率的渴求:人们对 AI 造成的环境代价表示担忧,引用了 Gizmodo 的一篇文章,该文指出 AI 模型训练过程中耗水量巨大,引发了关于需要更环保的 AI 实践的讨论。
-
迭代优于创新:关于通过迭代优化来增强 LLM 性能的对话非常活跃,并提到了像 AutoGPT 这样处理迭代的项目,尽管这伴随着更高的成本。
-
智能注入的报价是否言过其实?:公会思考了在 ChatGPT 中嵌入法律知识的可行性和潜力,其价值甚至被认为达到 6.5 亿美元,不过关于这一大胆断言的详细观点较少。
LangChain AI Discord
LangChain CSV Agent 深度解析:工程师们探讨了在 SequentialChain 中使用 LangChain’s CSV agent,并讨论了如何自定义输出键(如 csv_response)。提到了 SQL agent 在处理多表查询时面临的挑战,指出存在 Token 限制和 LLM 兼容性问题,并引导至 GitHub 提交 issue。
AI 展示引发热议:OranAITech 在推特上展示了他们最新的 AI 技术,同时 everything-ai v2.0.0 发布了包含音视频处理功能的新特性,并提供了 仓库 和 文档。
揭秘 VisualAgents:YouTube 上分享了 Visual Agents 平台 的演示,展示了其利用 LangChain 的能力,在无需编码的情况下简化 SQL agent 创建和构建简单检索系统的潜力。两个具体视频展示了其工作流:SQL Agent 和 简单检索。
EDA GPT 印象展示:LOVO AI 链接了一个 EDA GPT 的演示,包含一段五分钟的概览视频,展示了其各项功能。该演示突显了这款 AI 工具的多功能性。
教程预告:tutorials 频道的一条消息提供了 business24.ai 内容的 YouTube 链接,尽管其相关背景尚未披露。
LAION Discord
-
盗版并非万灵药:尽管有人幽默地建议 The Pirate Bay 可以成为分享 AI 模型权重的避风港,但成员们对此表示怀疑,并强调其他国家更友好的 AI 政策环境可能会脱颖而出。
-
日本在 AI 领域采取积极态度:参与者注意到日本对 AI 发展的鼓励立场,并引用了一篇通过 推文 分享的 论文,该论文关于在无需大量预训练的情况下创建新的基础 Diffusion 模型,展示了一种涉及暂时破坏模型关联的策略。
-
中毒恢复协议探讨:提到了一项由 fal.ai 开展的关于中毒模型恢复方法的 合作研究,预计研究结果将为恢复方法提供实证支持。此外,成员们对 AI 生成图像的美学表达了保留意见,特别是 Mobius 等模型与 MJv6 等前作相比所呈现的“高对比度外观”和伪影。
-
Claude 映射破解代码:Anthropic 的 研究论文 详细剖析了 Claude 3 Sonnet 的神经图谱,阐述了对概念激活(conceptual activations)的操作,可在其 研究页面 阅读。关于此类激活可能商业化的讨论引发了争论,同时也存在对商业影响导致 AI 从业者受挫的担忧。
-
怀旧 AI 视觉愿景:一位成员回忆了从早期 AI 视觉模型(如 Inception v1)到如今复杂系统的演变,认可了 DeepDream 在理解神经功能方面的作用。此外,还讨论了神经网络中稀疏性的好处,描述了使用 L1 范数实现稀疏性,以及在高维层中典型的 300 个非零维度。
LlamaIndex Discord
-
聚会提醒:名额有限:即将于周二举行的 LlamaIndex meetup 仅剩少量名额,由于名额有限,鼓励爱好者们尽快预订位置。
-
MultiOn 结合 LlamaIndex 实现任务自动化:LlamaIndex 已与 AI Agent 平台 MultiOn 结合,通过代表用户操作的 Chrome 浏览器实现任务自动化;在此查看 demo。
-
RAGApp 发布,支持无代码 RAG 聊天机器人设置:新推出的 RAGApp 简化了通过 Docker 容器部署 RAG 聊天机器人的过程,使其可以轻松部署在任何云基础设施上,并且它是开源的;在此配置你的模型提供商 model provider。
-
解决 PDF 解析难题:社区认可 LlamaParse 作为从 PDF(特别是表格和字段)中提取数据的可行 API,利用 GPT-4o 模型提升性能;Knowledge Graph Indexing 的挑战也是讨论话题,强调了手动和自动(通过
VectorStoreIndex)策略的必要性。 -
PostgresML 与 LlamaIndex 联手:Andy Singal 分享了将 PostgresML 与 LlamaIndex 集成的见解,并在 Medium 文章 “Unleashing the Power of PostgresML with LlamaIndex Integration” 中详细介绍了这一协作,获得了社区的积极评价。
OpenRouter (Alex Atallah) Discord
-
Phi-3 Medium 128k Instruct 发布:OpenRouter 推出了 Phi-3 Medium 128k Instruct,这是一个强大的 140 亿参数模型,并邀请用户查看标准版和免费版变体,并参与其效果讨论。
-
Wizard 模型获得魔力提升:Wizard 模型 表现出改进,响应更加迅速且富有想象力,但仍需注意避免重复段落。
-
关注 Phi-3 Vision 和 CogVLM2:围绕 Phi-3 Vision 的热情高涨,分享了如 Phi-3 Vision 的测试链接,并建议在 CogVLM-CogAgent 中使用 CogVLM2 处理以视觉为中心的任务。
-
Llama 3 Prompt 自动转换:澄清了发往 Llama 3 模型的 Prompt 会通过 OpenRouter 的 API 自动转换,从而简化流程,但手动 Prompt 仍作为一种替代方案保留。
-
Gemini API 的烦恼:用户报告了 Gemini FLASH API 的问题,如空输出和 Token 消耗,这被认为是模型本身的问题。Google 每日 API 使用限制的出现引起了人们对这可能如何影响 OpenRouter 的 Gemini 集成的关注。
Latent Space Discord
-
Indexify 引发关注:Tensorlake 推出的开源实时数据框架 Indexify 引发了讨论,重点在于其“streaming ETL”能力以及创建可持续开源模型的挑战。人们对所提供的 extractor 的充分性及其潜在的变现路径表示担忧。
-
LLM 评估备受瞩目:一篇关于 Large Language Model (LLM) 评估实践、排行榜重要性以及严谨的回归测试(non-regression testing)的 Hugging Face 博客文章 引起了成员们的注意,强调了此类评估在 AI 发展中的关键作用。
-
AI 对搜索引擎操纵的回应:一起涉及网站中毒并影响 Google AI 汇总概览(AI-gathered overviews)的事件引发了关于安全和数据完整性的讨论,包括 Mark Riedl 的推文 中提到的通过自定义搜索引擎浏览器绕过(bypass)的解决方法。
-
AI 是在民主化开发还是引发可靠性疑问?:GitHub CEO Thomas Dohmke 关于 AI 在简化编程中作用的 TED 演讲 引发了对其可靠性的辩论,尽管 AI 驱动的 UX 改进加快了编程过程中的问题解决速度。
-
多元化奖学金助力弥合差距:面对参加即将举行的 AI Engineer World’s Fair 财务障碍的多元化背景工程师收到了多元化奖学金发布的助力。有兴趣的申请人应在 申请表 中对论文问题提供简洁的回答。
Interconnects (Nathan Lambert) Discord
-
无需信用卡的税务故事:Nathan Lambert 破解了一场发票纠纷,意识到了由于转售证书(resale certificates)而在没有信用卡的情况下进行税务计费的合理性。
-
金门大桥 AI 引起关注:Anthropic AI 的实验诞生了“Golden Gate Claude”,这是一个一心一意针对金门大桥训练的 AI,因其在 claude.ai 上的公开互动性而引发热议。
-
Google 的 AI 失误:Google 未能利用反馈以及过早部署 AI 模型,引发了关于这家科技巨头公关挑战和产品开发困境的讨论。
-
反击数据集误解:Google 的 AI 团队反驳了关于使用 LAION-5B 数据集的说法,提出他们使用的是更优越的内部数据集,正如最近的一条推文所引用的那样。
-
Nathan 分享知识锦囊:为 AI 爱好者,Nathan Lambert 上传了高级 CS224N 课程讲义。此外,与会者还收到了关于即将发布的会议录像的提示,但尚未公布发布日期详情。
OpenAccess AI Collective (axolotl) Discord
- GQA 在 CMDR 模型中受到关注:讨论显示 Grouped Query Attention (GQA) 存在于 “cmdr+” 模型中,但不存在于基础 “cmdr” 模型中,这表明了它们规格上的重要区别。
- VRAM 效率与智能注意力机制:工程师们指出,虽然 GQA 不提供线性缩放,但与指数缩放相比,它代表了一种改进的缩放方法,对 VRAM 使用产生了有利影响。
- Sample Packing 获得提升:一个新的 GitHub pull request 展示了在 sample packing 方面 3-4% 的效率提升,有望为分布式环境提供更好的资源管理,链接见此处。
- 学术成就获得认可:一名成员合著的期刊文章已在 Journal of the American Medical Informatics Association 上发表,强调了高质量、跨领域数据对医学语言模型的影响,文章可见此处。
- 社区庆祝学术成功:社区通过个人祝贺信息表达了对同行发表作品的支持,培养了 AI 领域内认可学术贡献的文化。
OpenInterpreter Discord
SB-1047 引发技术动荡:工程师们对 SB-1047 法案的影响表示深切担忧,认为其不利于小型 AI 参与者,并将这种情况比作在其他行业观察到的“监管俘获”(regulatory capture)。
Perplexity 和 Arc,行业工具展示:社区重点展示了辅助工作流的工具,分享了一个关于 SB-1047 的 Perplexity AI 搜索结果 以及 Arc Browser 的新功能 “Call Arc”,该功能简化了在线查找相关答案的过程,并附带了信息链接。
安装问题引发咨询:用户在使用 pip 安装 Typer 库时遇到问题,引发了关于是否遵循了设置步骤(如在 poetry run 之前执行 poetry install)或是否使用了虚拟环境的讨论。
Mozilla AI Discord
Twinny 作为虚拟副驾驶起飞:开发者们正在将 Twinny 与 LM Studio 集成,将其作为强大的本地 AI 代码补全工具,并支持在不同端口上运行多个 llamafile。
嵌入端点(Embedding Endpoint)详解:澄清了 /v1/embeddings 端点不支持 image_data;根据 pull request #4681,图像应使用 /embedding 端点。
Mac M2 在 continue.dev 中遇到对手:一项性能观察指出,在使用 llamafile 执行时,continue.dev 在 Mac M2 上的运行速度比旧款 Nvidia GPU 慢。
训练你自己的 LLM:对于那些希望构建和训练自定义 LLM 的用户,社区推荐使用 HuggingFace Transformers 进行训练,并提醒 llamafile 是为推理而非训练设计的。
Cohere Discord
- 服务器中回荡着感激之情:一位用户对团队表达了由衷的感谢,展示了用户对团队支持或开发工作的认可。
- 对扩展模型的关注:有传言称该模型是否会加入 104B 版本,但目前尚未有明确的答复。
- Langchain 集成缺失:出现了关于 Langchain 与 Cohere 集成的问题,用户正在寻求关于其当前可用性和实现状态的指导。
- 模型尺寸之谜:用户正在寻求澄清 Playground 中的 Aya model 是指 8B 还是 35B 版本,这表明理解模型规模对于应用的重要性。
- 错误排查角落:诸如 ContextualCompressionRetriever 的
ValidationError和 403 Forbidden error 等问题标志着工程师们正在进行活跃的调试和技术问题解决,这提醒了 AI 开发中的常见挑战。
AI Stack Devs (Yoko Li) Discord
AI 喜剧之夜恰到好处:用户分享的一段 AI 生成的单口喜剧作品获得了积极的反响,显示了 AI 在模仿幽默和进行娱乐表演方面的进步。
关于 AI 应用的探索性查询:从用户询问 Ud.io 的功能是否超出生成喜剧的范围来看,对其功能边界的好奇显而易见。
声音变换展示:一位用户通过分享一段原始音频的变体、恶魔化版本,展示了 Suno 灵活的音频修改功能。
对音频工程知识的渴望:用户表达了对获取制作演示中音频修改技能的兴趣,这对于对声音处理感兴趣的 AI 工程师来说是一项宝贵的技能。
偏好简洁的沟通:对一个问题的单字回答“No”凸显了对简洁回复的偏好,这或许反映了工程师对直接、务实沟通的追求。
MLOps @Chipro Discord
- 寻找统一的事件追踪器:一位成员强调了对兼容 Google Calendar 的活动日历的迫切需求,以确保不会错过任何社区活动。缺乏这样一个系统是社区内一个值得关注的问题。
DiscoResearch Discord
- 新数据集发布公告:用户 datarevised 引用了一个新数据集,并提供了详细信息的链接:DataPlusEngine 推文。
完整的各频道详细分析已针对邮件进行截断。
如果您喜欢 AInews,请分享给朋友!预谢!