ainews-life-after-dpo
**后 DPO 时代 (RewardBench)** 或者更口语化的表达: **DPO 之后的发展 (RewardBench)**
以下是该文本的中文翻译:
xAI 以 240 亿美元的估值融资 60 亿美元,使其跻身全球估值最高的 AI 初创公司之列,这笔资金预计将用于研发 GPT-5 和 GPT-6 级别的模型。由 Nathan Lambert 开发的 RewardBench 工具用于评估语言模型的奖励模型(RM),结果显示 Cohere 的奖励模型表现优于开源替代方案。讨论回顾了语言模型从 1948 年克劳德·香农(Claude Shannon)的模型到 GPT-3 及其后续版本的演进,并强调了 RLHF(基于人类反馈的强化学习) 以及较新的 DPO(直接偏好优化) 方法的作用。值得注意的是,目前一些基于 Llama 3 8B 的奖励模型在 RewardBench 排行榜上的表现超过了 GPT-4、Cohere、Gemini 和 Claude,这引发了关于“奖励作弊”(reward hacking)的质疑。未来的对齐研究方向包括改进偏好数据集、优化 DPO 技术以及实现语言模型的个性化。此外,报告还将 xAI 的估值与 OpenAI、Mistral AI 和 Anthropic 进行了对比,并提到了关于 xAI 在英伟达(Nvidia)硬件上巨额支出的猜测。
RLHF is all you need.
2024年5月24日至5月27日的 AI 新闻。 我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 29 个 Discord 社区(382 个频道,9556 条消息)。 预计节省阅读时间(按每分钟 200 字计算):1079 分钟。
这是一个平静的美国节假日周末。
- X.ai 以 240 亿美元的估值筹集了 60 亿美元,迅速成为估值最高的 AI 初创公司之一。
- 我们还发布了 ICLR 最佳论文和演讲回顾的第一部分。
- Alex Reibman 在 Meta Llama 3 黑客松中的 LlamaFS 项目走红:这是一个由本地 LLM 驱动的硬盘文件管理器。利用多模态 AI 自动重命名和分类杂乱的文件及目录。
今天的专题介绍 Nathan Lambert,他正在为 Chris Manning 的 CS224N 课程进行客座演讲(完整的建议阅读清单非常值得一读),并发布了关于奖励模型(Reward Models)历史与未来以及他在 RewardBench 工作的演讲幻灯片。
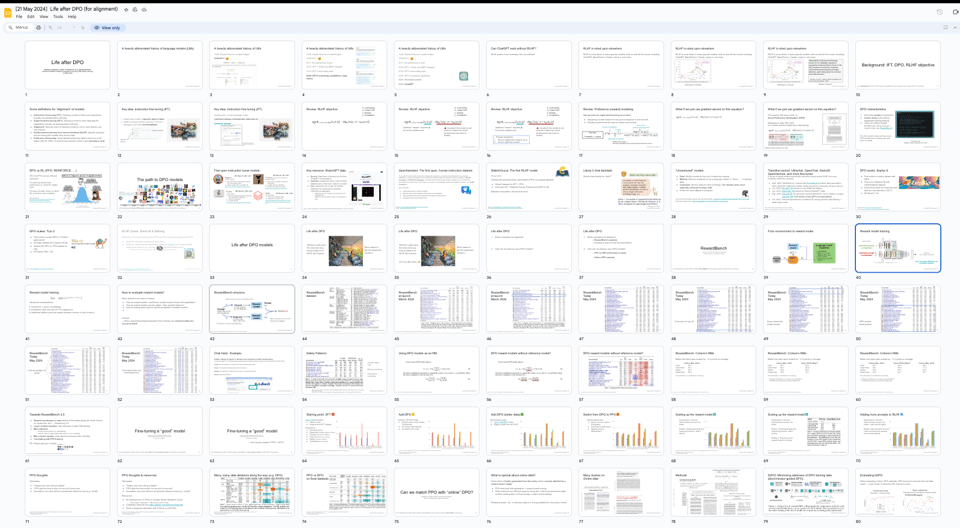
- 语言模型 (LMs) 的历史:LMs 经历了显著的演变,从 1948 年 Claude Shannon 的早期英语语言模型到 2020 年及以后的强大 GPT-3。2017 年引入的 Transformer 架构在这一进展中起到了关键作用,使得开发能够生成日益复杂且连贯文本的模型成为可能。
- RLHF 和 DPO:RLHF(来自人类反馈的强化学习)是许多流行语言模型成功的关键因素,但它复杂且耗费资源。2023 年引入的 DPO(直接偏好优化)是一种更简单、更具扩展性的替代方案,它直接从人类偏好中学习。虽然 DPO 显示出良好的前景,但在许多情况下 RLHF 仍能产生更好的结果。
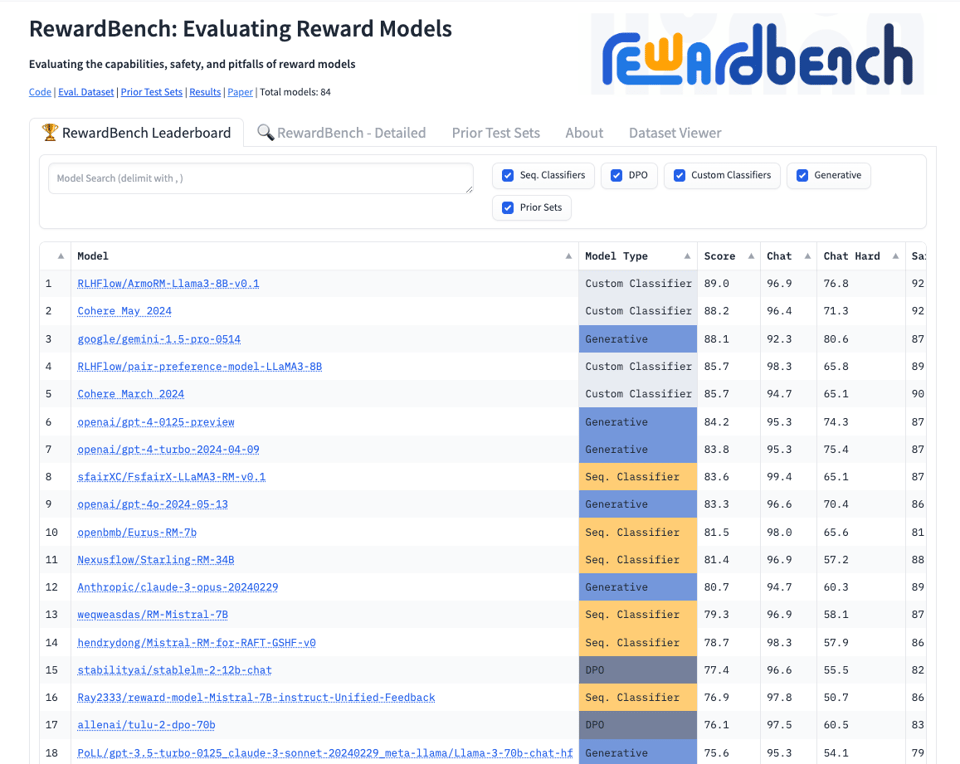
- RewardBench:RewardBench 是一个用于评估 LLM 奖励模型 (RMs) 的工具。它提供了关于 RMs 如何影响 LLM 能力和安全性的见解。Cohere 的 RMs 在 RewardBench 上的表现优于开源模型,突显了在该领域持续研究的重要性。
- 对齐研究的未来方向:未来的关键研究领域包括收集更多数据(特别是偏好数据集)、改进 DPO 技术、探索不同的模型规模、开发超越通用基准的更具体的评估,以及解决语言模型中的个性化问题。
RewardBench 论文列出了一系列最具挑战性的奖励模型基准测试:
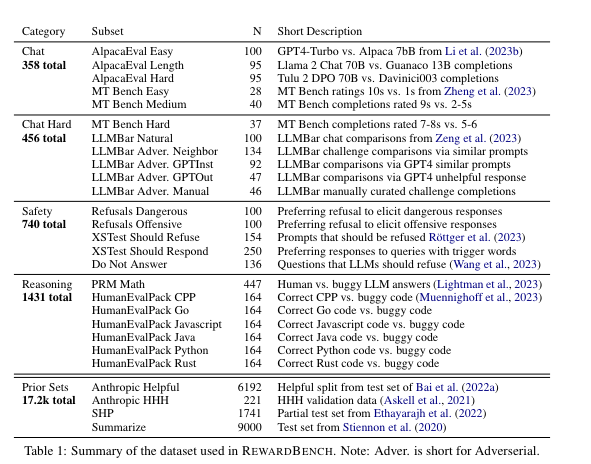
有趣的是,目前在排行榜上,一些专门针对奖励模型优化的 Llama 3 8B 模型正击败 GPT4、Cohere、Gemini 和 Claude。是真有实力,还是奖励作弊 (Reward Hacking)?
AI Twitter 回顾
所有回顾均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程。
xAI 以 240 亿美元估值融资 60 亿美元
- 融资细节:@nearcyan 指出 xAI 筹集了 60 亿美元,公司估值达到 240 亿美元。@bindureddy 向 xAI 和 Elon 表示祝贺,并表示这笔资金带来的算力应该足以支持 GPT-5 和 6 级别的模型。
- 与其他 AI 公司的对比:@rohanpaul_ai 将 xAI 240 亿美元的估值与其他 AI 公司进行了对比——OpenAI 估值为 800-1000 亿美元,Mistral AI 在 4 月份的估值约为 60 亿美元,Anthropic 约为 184 亿美元。
- 对支出的猜测:@nearcyan 调侃说这笔钱将直接流向 Nvidia,省去了中间商。他还设想 xAI 会说 100% 的 Nvidia 投资组合是一个合理的赌注。
对 Elon Musk 和 xAI 的批评
- Yann LeCun 的批评:@ylecun 讽刺地建议,如果你能忍受一个声称你正在研究的问题明年就能解决、声称它会杀死所有人、一边散布阴谋论一边又声称要严谨追求真理的老板,那就加入 xAI 吧。
- 对 AI 炒作和监管的担忧:@ylecun 批评了“末日论者的幻觉”(Doomer’s Delusion),即声称 AI 会杀死我们所有人、垄断 AI、要求设置自毁开关、禁止开源,并恐吓公众以从无知的亿万富翁那里获得疯狂的资金。他表示,我们目前甚至还没有人类水平 AI 设计的任何头绪。
- Musk 的政治立场:@ylecun 表示不喜欢 Musk 充满报复性的政治手段、阴谋论和炒作,但他喜欢 Musk 的汽车、火箭、太阳能电池板和卫星网络。他澄清这并非在支持极左翼,因为威权主义和寻找替罪羊在左右两个极端都存在。
AI 安全与存在性风险辩论
- 对 AI 末日论的反驳:@ylecun 认为 AI 不是一种会自动出现并变得危险的自然现象,而是由我们设计和建造的东西。他表示,如果存在一个比人类更好地完成目标且安全、可控的 AI 系统,我们就没问题;否则,我们就不会建造它。目前,我们甚至还没有人类水平 AI 设计的任何头绪。
- 对监管提案的反驳:@ylecun 回应了一条称 AI 必须由少数公司在严格监管下垄断的推文。他指出这种逻辑把 AI 当成了自然现象而非人造产物,并将其类比为我们在广泛部署涡轮喷气发动机之前,是如何使其变得可靠的。
- 关于通用智能的辩论:@ylecun 表示,无论是人工还是自然的通用智能(General Intelligence)都不存在。所有动物都拥有专门的智能和习得新技能的能力。智能的很大一部分是通过与物理世界的互动获得的,而机器需要重现这一过程。
AI 与机器人技术的进展
- Naver Labs 机器人咖啡馆:@adcock_brett 报道称 Naver Labs 打造了一家星巴克,拥有 100 多个名为 “Rookie” 的机器人,负责运送饮料和执行各种任务。
- 微软的 AI 发布:@adcock_brett 分享了微软发布的 Copilot+ PC,其运行 AI 的速度比传统 PC 快 20 倍,内置 GPT-4o,并具有 “Recall” 功能,可以搜索你在屏幕上看到过的内容。
- Tokyo Robotics 演示:@adcock_brett 指出 Tokyo Robotics 展示了一种新型四指机器人手,可以在不预先了解尺寸的情况下抓取任何形状的物体。
- 其他进展:@adcock_brett 提到 MIT 正在开发一种机器人外骨骼,以帮助宇航员从摔倒中恢复。他还分享了 IDEA Research 发布的目标检测模型,并报道了 Anthropic 对 Claude “思想”的窥探。
新的 AI 研究论文
- Grokked Transformers:@_akhaliq 分享了一篇研究 Transformer 是否能对参数化知识进行隐式推理的论文。研究发现 Transformer 可以学习隐式推理,但只能通过 Grokking(在过拟合之后进行的延长训练)来实现。
- Stacking Transformers:@_akhaliq 发布了一篇关于模型增长以实现高效 LLM 预训练的论文,该研究利用较小的模型来加速较大模型的训练。
- Automatic Data Curation:@arankomatsuzaki 分享了 Meta 关于自监督学习自动数据整理的论文,其表现优于人工整理的数据。
- Meteor:@_akhaliq 发布了关于 Meteor 的消息,该模型利用多维度的推理(multifaceted rationale)来增强 LLM 的理解和回答能力。
- AutoCoder:@_akhaliq 指出 AutoCoder 是第一个在 HumanEval 上超越 GPT-4 的 LLM,并配备了多功能代码解释器。
辩论与讨论
- 数学技能 vs 语言技能:针对一条声称 AI 将更看重语言技能而非数学技能的热门推文引发了辩论。@bindureddy 认为,要指导 LLM 解决难题,需要的是数学和分析能力,而非语言技能。他还不同意 AI 会让编程过时的观点,并表示设计能力和 AI 工具的使用将会有很大需求。
- 机械可解释性 (Mechanical Interpretability):@jeremyphoward 告诫不要在可解释性研究中随大流,因为那不是产出顶尖研究的方式。@NeelNanda5 和 @aryaman2020 讨论了探索方向缺乏多样性的问题。
- 感知力与意识:有许多推文在辩论 LLM 和 AI 系统是否具有感知力或意识。主要观点包括:我们无法观察另一个实体的自我意识;试图定义感知力的充分属性会导致荒谬的结论;以及目前的 LLM 可能无法反思其内部状态。
杂项
- 历史项目:@alexandr_wang 正在启动一个下一代历史项目,旨在发明保存故事的新方法,并利用 LLM 和 AI 让历史变得具有体验感。
- 关于 Rabbit AI 的观点:对 Rabbit AI 的看法褒贬不一,一些人批评其为骗局,而另一些人如 @KevinAFischer 则印象深刻,认为向开发者开放后它会变得非常出色。
- Nvidia 的崛起:许多人注意到了 Nvidia 的惊人崛起及其对 AI 的重要性,@rohanpaul_ai 分享了一张其股价走势图。
- 元宇宙炒作周期:@fchollet 将当前的 AI 炒作与 2021 年底进行了比较,当时元宇宙和 NFT 被视为万物的未来,随后便沉寂了下来。
- LLaMA 生态系统:许多人分享了围绕 LLaMA 模型的资源、演示和实验,包括一个名为 LLamaFS 的自组织文件管理器 (@llama_index)。
AI Reddit 摘要
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 进展与能力
- Llama-3-70B 微调模型:在 /r/LocalLLaMA 中,Llama-3-70B 微调模型是 Uncensored General Intelligence 排行榜上最不受限(uncensored)的模型,表现优于其他大语言模型。
- Phi-3 mini ONNX DirectML Python AMD GPU:在 /r/LocalLLaMA 中,一个 演示显示了从 NPU 重用 KV cache 进行 Token 生成,然后在 CPU 上以每秒 27 个 Token 的速度运行。
- 上下文学习 (In-context learning) Transformer:在 /r/MachineLearning 中,上下文学习 Transformer 可以被用作表格数据分类器,在预训练期间学习创建复杂的决策边界。
- MOMENT 基础模型:在 /r/MachineLearning 中,MOMENT 基础模型 已发布,用于时间序列预测、分类、异常检测和插补。
AI Agent 与助手
- 微软的 Recall:在 /r/MachineLearning 中,微软的 Recall 可以使用开源模型和工具进行复刻,例如使用 mss 获取屏幕截图,使用 ollama/llava 进行描述,以及使用 chromadb 进行搜索。
- Jetta 自主可配置 PC 任务执行器:在 /r/singularity 中,Jetta 是一款可以控制你的 PC 的新型 AI Agent。
- Faster Whisper Server:在 /r/LocalLLaMA 中,Faster Whisper Server 提供了一个用于流式转录的 OpenAI 兼容服务器,并使用 faster-whisper 作为后端。
- AI Agent 应用:在 /r/LocalLLaMA 中,人们对潜在的 AI Agent 应用感到兴奋,例如一旦更大的模型可以在消费级硬件上运行,就能实现带有 AI 角色的游戏。
AI 监管与治理
- 两位前 OpenAI 董事会成员:在《经济学人》中,两位前 OpenAI 董事会成员认为 AI 公司无法自我治理,需要监管来为了人类的利益驯服市场力量。
- AI “紧急停止开关” (Kill Switch):在《财富》杂志中,科技公司已同意设立 AI “紧急停止开关”以防止终结者式的风险,尽管具体的实施细节尚不明确。
AI 与社会
- AI 失业与 UBI:在 /r/singularity 中,一些人认为是时候引入与失业率挂钩的 UBI (全民基本收入),以支持那些被 AI 取代的人。
- 后稀缺世界:在 /r/singularity 中,在后稀缺世界里,过剩的财富仍然可以购买稀缺体验,如房地产、度假、现场表演和由人类提供的服务。
- Age Reversal Unity:在 /r/singularity 中,Age Reversal Unity 已向 FDA 请愿将衰老认定为一种疾病,这是迈向抗衰老治疗的一步。
AI 艺术与内容生成
- Stable Diffusion 技术:在 /r/StableDiffusion 中,新的 Stable Diffusion 技术允许以创意方式穿梭于图像之间,从而创作出细节丰富、宏大的艺术作品。
- 动漫风格转换器:在 /r/StableDiffusion 中,一款动漫风格转换器结合了 SDXL 模型、ControlNet 和 IPAdapter 来转换角色设计。
- AI 生成艺术的碳足迹:在一篇图文中,有人认为 AI 生成艺术的碳足迹比传统艺术小得多,尽管这一说法存在争议。
- LoRA 模型:在 /r/StableDiffusion 中,发布了用于动漫风格机器人和跑步动作的新 LoRA (Low-Rank Adaptation) 模型。
{kind=link}
模因与幽默
- Nvidia 不断增长的营收:一个模因嘲讽道,Nvidia 不断增长的营收在 2024 年超出了预期,而 AMD 则落后了。
- Google 的 AI 策略:在 /r/singularity 中,一个模因嘲笑 Google 的 AI 策略过于谨慎且缓慢。
- AI 艺术生成的限制:一个模因暗示,AI 艺术生成的唯一限制是“你的想象力……以及 VRAM”。
{kind=link}
{kind=link}
AI Discord 摘要
摘要之摘要的摘要
- 微调与模型训练挑战:
- 各个 Discord 频道上的讨论强调了在微调 (fine-tuning) Llama 3 和 Mistral 等模型时面临的挑战,用户遇到了从语义相似度过拟合 (semantic similarity overfitting) 到 T4 等 GPU 上的运行时错误 (runtime errors) 等问题。社区分享了实用的指南和故障排除技巧,例如 TinyLLama Fine-Tuning 和 Mistral-Finetune repository。
- 成员们在模型分词 (tokenization) 和提示词工程 (prompt engineering) 方面遇到了困难,强调了正确使用模板标记(如
###)或文本结束标记 (end-of-text tokens) 对高效微调的重要性。这在 Axolotl 和 Jarvis Labs 的讨论背景下尤为突出。
- 多模态模型与集成的进展:
- Discord 用户指出,Perplexity AI 在处理 CSV 文件方面优于 ChatGPT,因为它支持直接上传并集成了 Julius AI 等工具进行数据分析。
- HuggingFace 上分享了一个使用 3D 渲染的新蛋白质可视化项目,同时还讨论了集成 Vision Transformers (ViT) 用于单目深度估计等任务的注意事项。查看 GitHub repository 获取蛋白质示例。
- 开源 AI 项目与社区努力:
- LlamaIndex 推出了用于自动化 RAG 聊天机器人的工具,详见关于 MultiOn 演示的帖子。讨论了关于确保上下文维持 (context maintenance) 和高效索引以进行知识检索的问题。
- 新模型发布与基准测试:
- Meta 的 Phi-3 Medium 128k Instruct 首次亮相,因其增强的推理和指令遵循能力而受到关注,可在 OpenRouter 上获取。讨论强调了用户对模型性能和应用的反馈。
- IBM Granite 与 Llama-3 的性能辩论在 ChatbotArena 等平台上浮现,强调了对可信且透明的基准测试的需求。DeepSeek-V2 和 Granite-8B-Code-Instruct 是值得关注的提及对象,并分享了具体的基准测试。
- 伦理、立法与 AI 的社会影响:
- 针对 SB-1047 法案表达了担忧,将其比作监管俘获,并认为这会使较小的 AI 参与者处于劣势。社区分享了使用 Perplexity AI 等工具搜索立法影响的方法,以提高社区意识。
- OpenAI 在 AI 模型训练期间的耗水量引发了关于环境影响的讨论,引用了 Gizmodo 的文章。社区呼吁采取更多环保的 AI 实践,并讨论了如 Meta 的 Audiocraft 等替代方案以实现可持续发展。
LLM Finetuning (Hamel + Dan) Discord
Fine-Tuning 事实:在 general 频道 的讨论中,揭示了由于偏见数据类别导致的 semantic similarity overfitting(语义相似度过拟合) 问题。一位用户在理解 Fine-tuning 与用户输入及模型初始训练的关系时遇到了困难。此外,还注意到 OpenAI 平台侧边栏 的变化,两个图标(threads 和 messages)消失了。
Templates 成为焦点:在 workshop-1 中,强调了在 Fine-tuning 过程中正确配置 Template 的重要性。特别是分隔符 ### 有助于解析不同的输入部分,而 “end of text” Token 则指示何时停止 Token 生成。
Maven 与 Moderation 的交流:在 asia-tz 频道,成员们进行了一次轻松的交流,提到了重聚。关于会议演讲录像的请求得到了回应,视频已在 Maven 上发布。
Modal 动员:🟩-modal 频道的 Modal 用户分享了收到 Credit 的兴奋心情和训练经验,并为新用户提供了 Modal 文档 和 示例 的具体链接。还分享了一个使用 Modal 参加 Kaggle 竞赛 的计划,包括设置和执行细节。
Jarvis 记录 Jupyter 杂记:在 jarvis-labs 频道 中,成员们讨论了在 Jarvis 上存储 VSCode Repo 的问题,并建议使用 GitHub 保存工作。有一则关于因不稳定而移除 spot instance 的通知。分享了 Fine-tuning open-lama-3b 模型的成本和时长,一位用户通过调整模型参数解决了 Ampere 系列显卡的错误。
Hugging Face 讨论 Credit 与西班牙语模型:hugging-face 频道 讨论了待处理的 HF Credit 以及适用于西班牙语文本生成的模型——推荐了 Mistral 7B 和 Llama 3 模型。
Credit 倒计时继续:在 replicate 频道,预告了即将发布的关于 Credit 管理和分配的公告。
Corbitt 的准则引发关注:kylecorbitt_prompt_to_model 频道 的热心参与者讨论了 Kyle Corbitt 演讲中介绍的 Fine-tuning 方法和技术,包括 部署 Fine-tuned 模型的十诫。
Axolotl 响应号召:在 workshop-2 中,用户讨论了数据集、模型训练以及 Axolotl 中的故障排除。分享了一篇关于 TinyLLama Fine-Tuning 的博客文章,并推动将可观测性集成到 LLM 应用中。
退出 Zoom,进入 Discord:在 Zoom 聊天功能禁用后,workshop-3 的用户将讨论转移到了 Discord。
Axolotl 的缓存难题引发困惑:在 axolotl 频道,解决了令用户沮丧的 Axolotl 缓存问题以及文件丢失的困惑。关于 sample packing 的讨论和一份关于 Tokenizer 陷阱的指南解决了有关效率和 Tokenization 的疑虑。
加速迈向胜利:zach-accelerate 频道的用户解决了关于浮点数比较的困惑,修复了 Jarvislab 训练命令错误,并交流了学习模型加速的资源,重点关注 Fine-tuning 的最佳实践。
与 Axolotl 并肩作战:wing-axolotl 频道 在数据集 Template、预处理问题、Axolotl 配置方面进行了协作,并为最新的 Axolotl 更新提供了 PR 合并。他们深入研究了调试工具以及精确 Template 对训练成功的重要性。
HuggingFace Discord
蛋白质数据可视化达到新高度:一个新的蛋白质可视化项目现在支持 3D 渲染,并包含了人类血红蛋白和核糖体蛋白的示例,项目详情可见 GitHub。
使用 OpenAI 的 Whisper 进入 TranscriptZone:一款利用 OpenAI 的 Whisper 转录 YouTube 视频及更多内容的全新转录应用已在 Hugging Face Spaces 上线。
去中心化网络——不仅仅是一个梦想?:一个构建去中心化互联网基础设施的项目通过调查寻求社区反馈,引发了关于数据收集伦理的讨论。
Vision Transformers 深度查询:一名成员寻求关于应用 Vision Transformers (ViT) 进行单目深度估计(monocular depth estimation)的资源,表示有意使用 ViT 开发模型,但讨论中未提供具体资源。
Mistral 模型的量化困惑:在 Mistral v0.3 Instruct 上使用 bitsandbytes 进行 8-bit 量化导致性能比 4-bit 和 fp16 更慢,这一令人费解的结果与减少位数计算预期的效率提升相矛盾。
Perplexity AI Discord
-
Perplexity 在 CSV 对决中超越 ChatGPT:工程师们讨论认为 Perplexity AI 在 CSV 文件处理方面优于 ChatGPT,因为它允许直接上传 CSV。此外,推荐使用 Julius AI 进行数据分析,它利用 Python 并集成了 Claude 3 或 GPT-4 等 LLM。
-
用户冷落 Claude 3 Opus:由于内容限制增加和感知到的效用下降,Claude 3 Opus 遭到冷遇,尽管 GPT-4 也有局限性,但仍被视为更好的选择。
-
质疑 Pro Search 的真实升级:Pro Search 的升级引起了关注,用户讨论新的多步推理功能和 API 规范是真正的后端改进,还是仅仅是表面上的 UI 增强。
-
API 集成阐述:围绕 Claude 与外部工具的 API 集成的对话引起了兴趣,同时分享了自定义函数调用、无服务器后端以及诸如 Tool Use with Claude 等文档。
-
AI 伦理:不仅仅是思想实验:关于为 GPT 注入伦理监控能力的讨论被激发,揭示了其在职场沟通和法律辩护中的潜在应用,尽管仍有一些哲学难题尚待解决。
Stability.ai (Stable Diffusion) Discord
-
关于 RTX 5090 显存的猜测达到顶峰:关于传闻中拥有 32GB VRAM 的 RTX 5090 是否具有实际意义的辩论正热。引用了 PC Games Hardware 上的潜在规格和图片,但部分成员对其真实性保持怀疑。
-
Stable Diffusion 与 AMD 的挑战:用户提供了在 AMD 5700XT GPU 上安装 Stable Diffusion 的指导,建议从 Craiyon 等 Web 服务开始,以规避潜在的兼容性问题。
-
Stable Diffusion 3:承诺前的试用:社区将 Stable Diffusion 3 与竞争对手 Midjourney 进行了对比,强调虽然 SD3 提供免费试用,但持续访问需要 Stability 会员资格。
-
对 Mobius 模型的期待与日俱增:关于 DataPlusEngine 的新型 Mobius 模型 的公告引起了极大关注,因为它声称可以创建高效的基础模型。该模型在 Twitter 上进行了预告,它既不是简单的基础模型,也不是现有模型的微调版本。
-
32GB VRAM:游戏规则改变者还是性能过剩?:提到 32GB VRAM GPU 引发了关于 Nvidia 数据中心 GPU 销售策略可能转变的对话,考虑到拥有大容量显存的产品可能会如何影响市场对 H100/A100 系列的需求。
Unsloth AI (Daniel Han) Discord
-
PEFT 配置问题解决:针对 PEFT 训练期间
config.json缺失的问题,通过从基础模型配置中复制该文件已得到解决,用户确认修复成功。 -
Llama 克服 Bug 困扰:Llama 3 模型的基础权重被描述为存在 “bug”,但 Unsloth 已实现相关修复。为了提升训练效果,建议使用 reserved tokens 并更新 tokenizer 和
lm_head。 -
System Prompt 提升 Llama 3 效果:据观察,加入 System Prompt(即使是空的)也能增强 Llama 3 的微调效果。
-
Phi 3 模型激增:随着 Phi 3 模型 的首次亮相,社区反响热烈,该模型已支持 medium 版本。社区讨论引导工程师关注博客文章和发布说明中的详尽细节。
-
Stable Diffusion 的阴森一面:Stable Diffusion 产生的诡异伪影和不自然的声音克隆输出让用户感到吃惊,相关的讨论和经历已在 YouTube 视频和 Reddit 帖子中分享。
-
VSCode Copilot 方案推荐:用户在 random 频道寻求本地 VSCode “copilot” 的建议,并得到了积极的回应和推荐。
-
Phi-3 的推理延迟问题:使用 Unsloth Phi-3 时较慢的推理速度令一位用户感到困惑,该用户提供了一个 Colab notebook 用于调查延迟原因,社区目前仍在努力寻找修复方案。
-
量化困境的剖析:一名成员在量化自定义模型时面临挑战,在 llama.cpp 和 Docker 兼容性方面遇到了障碍,引发了关于解决方案的讨论。
-
模型算力的 VRAM 判定:明确了 VRAM 需求:Phi 3 mini 需要 12GB 即可,但 Phi 3 medium 必须配备 16GB。对于繁重任务,建议考虑外部计算资源。
-
训练一致性的数据尽调:强调了在训练和评估中使用一致数据集的重要性,并重点介绍了 Unslothai 的公共数据集,如 Blackhole Collection。
-
平台可能性与警示:针对 Unsloth 是否支持旧款 Mac 的咨询得到了回复,确认开发重点在于 CUDA 和 GPU 使用,并为仅有 CPU 的设备提供了建议。
-
企业级专业知识扩展:一位社区成员主动向 Unsloth 提供企业级专业知识,并对加入 Build Club 和 GitHub 的加速器表示赞赏,暗示了 Unsloth 未来发展的协同潜力。
Nous Research AI Discord
关于 AI 理解能力的智力辩论:社区就 LLM 对概念的真正“理解”展开了深入讨论,可解释性研究(interpretability research)被视为重要的经验证据。怀疑论者认为目前的努力尚显不足,并引用了 Anthropic 关于映射大语言模型思维的相关工作。
Llama 湖中的生物:一项旨在增强 Llama 模型 的技术探索集中在编写一个能够管理 function calls 的脚本上,并以 Hermes Pro 2 的方法作为灵感。另一个咨询则围绕在 3080 GPU 上实现 Llama 3 LoRA 技术展开。
数字维度中的现实探索:在关于 Nous 和 WorldSim 的对话中,成员们探讨了 NightCafe 和多维 AR 空间在映射复杂 AI 世界中的潜在应用。在音频可视化器中的梦幻探索和奇特的 ASCII art 表现形式,突显了 AI 驱动模拟的创意用途。
筛选 RAG 数据:提倡模型将内部知识与检索增强生成(RAG)相结合成为热门话题,并提出了关于如何处理矛盾和解决冲突的问题。强调用户评估被认为是必不可少的,特别是对于复杂的查询案例。
AI 微调:精准度胜过花哨技巧:社区讨论赞扬了 Mobius 模型 在图像生成方面的卓越表现,并期待其开源版本和阐释性论文的发布。此外,还提到了 Hugging Face 的 PyTorchModelHubMixin 可以简化模型共享,但受限于 50GB 的大小限制(在不分片的情况下)。
Eleuther Discord
-
JAX vs. PyTorch/XLA: TPU 对决:JAX 与 PyTorch/XLA 在 TPU 上的性能对比引发了关于 warmup times 和 blocking factors 等基准测试细微差别的辩论。GPT-3 的训练成本从 450 万美元大幅下降至 2024 年预计的 12.5 万至 100 万美元,这一点受到了关注。讨论结合了来自多位贡献者的 TFLOP rates 和 GPU-hour pricing,并链接到一篇 Databricks 博客文章。
-
扩展与教学 LLMs:在研究论坛中,Chameleon 模型因其在多模态任务中的强劲表现而受到关注,而 Bitune 则承诺提升 LLM 的 zero-shot 性能(Bitune 论文)。讨论质疑了 JEPA 模型对于 AGI 的可扩展性,并批评了 RoPE 的上下文长度限制,引用了相关论文。
-
Emergent Features 困扰 LLM 爱好者:链接了 Tim Dettmers 关于在 transformer 推理中保持性能的高级量化方法的研究,包括他的 emergent outliers 概念,以及通过 bitsandbytes 库 与 Hugging Face 的集成。关于 emergent features 的讨论围绕着它们是模型的“DNA”这一观点展开,并探讨了其对相变(phase transitions)的影响。
-
技术调整与 LM 评估简报:在 lm-thunderdome 中,工程师们分享了在 vllm 模型 中设置 seed 的实用技巧,使用
lm_eval --tasks list获取任务列表,以及处理 BigBench 任务名称变更对 Accelerate 等框架造成的内存问题。建议通过查阅lm-eval/tasks文件夹来定位任务,以便更好地组织。 -
协作呼吁:发出了扩展 Open Empathic 项目的呼吁,并提供了一个用于贡献电影场景的 YouTube 指南 以及该项目的链接。鼓励进一步的协作,强调了社区努力在增强项目方面的必要性。
LM Studio Discord
GPU 历险记:工程师们讨论了将小型模型加载到 GPU 上的挑战,一些人青睐 llama3, mistral instruct 和 cmdrib 等模型。同时,据报道,在某些应用中,使用较低的量化(如 llamas q4)比使用 q8 等较高的量化效果更好,反驳了“越大越好”的观念。
下一代模型即将来临:模型领域的更新通知了一个 35B 模型 的发布,并正在进行测试以确保 LM Studio 的兼容性。针对不同规模模型的优化也是一个话题,重点关注 Phi-3 small GGUFs 及其效率。
服务器与设置:硬件讨论包括利用 llama.cpp 及其最近的 RPC 更新进行分布式推理,尽管目前尚不支持量化模型。还探索了使用配备 RTX 4060 Ti 16GB 的廉价 PC 集群进行分布式模型设置的实验性构建,以及可能的网络限制。
实现多语言凝聚力:Cohere 模型现在将其能力扩展到了 23 种语言,正如广告所言,aya-23 量化版本已开放下载,但 ROCm 用户必须等待更新才能体验。
Stable Diffusion 被排除在外:LM Studio 澄清其专门处理语言模型,不包括像 Stable Diffusion 这样的图像生成器,同时处理旧款 GPU 上的 CUDA 问题,并推广 Julius AI 等服务以缓解用户体验方面的困扰。
CUDA MODE Discord
-
梯度范数难题:将 Batch Size 从 32 更改会导致梯度范数突然飙升,从而干扰训练。一个 Pull Request 通过防止 Fused Classifier 中的索引越界解决了这个问题。
-
Int4 和 Uint4 类型需要关注:一位成员指出 PyTorch 中许多函数缺乏对 int4 和 uint4 数据类型的实现,相关的 讨论帖 指出了在类型提升(Type Promotion)和张量操作方面的限制。
-
直播代码预警——Scan 算法成为焦点:Izzat El Hajj 将主持一场关于 Scan 算法的现场编程会议,该算法对于 Mamba 等 ML 算法至关重要。会议定于
<t:1716663600:F>,有望为爱好者们带来一次深入的技术探讨。 -
CUB 库查询与 CUDA 细节:成员们深入讨论了从 CUDA CUB 库代码的运行机制到在不使用 cuBLAS 或 cuDNN 的情况下触发 Tensor Cores 等话题,并重点推荐了 NVIDIA 的 CUTLASS GitHub 仓库 和 NVIDIA PTX 手册 等资源。
-
FineWeb 数据集难题:处理 FineWeb 数据集非常耗费存储空间,磁盘占用达到 70 GB,内存占用高达 64 GB,这暗示了在数据处理任务中需要更好的优化或更强大的硬件配置。
Modular (Mojo 🔥) Discord
Python 库相较于 Mojo 更倾向于 C:关于将 Python 库移植到 Mojo 的可行性和准备工作有一场激烈的讨论。考虑到 Mojo 不断演进的 API,人们担心这会给维护者带来过大压力。成员们讨论了将目标转向 C 语言库是否是一个更直接且务实的尝试。
Rust 的安全性吸引力并未削弱 Mojo 的潜力:Mojo 并不打算取代 C,但 Rust 的安全性优势正在影响工程师们对 Mojo 在不同场景下应用的思考。正在进行的讨论涉及了可以使 Mojo 开发受益的 Rust 概念。
紧跟 Nightly 版本 Mojo 的步伐:使用 Nightly 版本的 Mojo 在 MacOS 上的 BlazeSeq 性能表现出与 Rust 的 Needletail 相似的潜力,引发了关于跨平台效率的讨论。更新日志 中提到的快速 Nightly 更新让社区能够紧跟这门不断发展的语言。
对 Modular 机器人机制的好奇:有人询问了 “ModularBot” 的底层技术,虽然没有提到具体模型,但机器人给出了一个生动的回复。另外,讨论了在 Mojo 中进行 ML 模型训练和推理的可能性,并提到了 Max Engine 作为 NumPy 的替代方案,尽管目前还没有完整的训练框架。
编译时困惑与对齐问题:从内存中的布尔值对齐到编译时函数问题,这些都引起了用户的关注。临时解决方案和官方 错误报告 凸显了社区驱动排错的重要性。
OpenAI Discord
-
忠于 LaTeX 的 LLM:在格式排版领域,用户对 GPT 强烈倾向于默认使用 LaTeX 而非请求的 Typst 代码感到沮丧,这揭示了 LLM 似乎坚持某些特定的编码语法偏好。
-
Microsoft Copilot+ 与 Leonardo 之争:社区讨论集中在 Microsoft Copilot+ PC 在“草图转图像”等创意任务中的价值,而一些成员则鼓励尝试具有类似功能的 Leonardo.ai。
-
对 AI 效率的渴求:人们对 AI 造成的环境代价表示担忧,引用了一篇关于 AI 模型训练过程中大量耗水的 Gizmodo 文章,引发了关于需要更环保的 AI 实践的讨论。
-
迭代胜过创新:关于通过迭代优化来增强 LLM 性能的对话非常活跃,并提到了像 AutoGPT 这样处理迭代的项目,尽管这伴随着更高的成本。
-
注入智能的提议是否言过其实?:公会成员思考了在 ChatGPT 中嵌入法律知识的可行性和潜力,甚至考虑到了 6.5 亿美元的估值,尽管关于这一大胆断言的详细观点还比较有限。
LangChain AI Discord
LangChain CSV Agent 深度解析:工程师们探讨了在 SequentialChain 中使用 LangChain’s CSV agent,并讨论了如何自定义输出键(如 csv_response)。提到了 SQL agents 在处理多表查询时面临的挑战,指出存在 token 限制和 LLM 兼容性问题,并引导至 GitHub 提交 issue。
AI 展示引发关注:OranAITech 推特发布了他们最新的 AI 技术,同时 everything-ai v2.0.0 宣布了包括音频和视频处理能力在内的功能,并提供了 repository 和 documentation。
揭秘 VisualAgents:通过 YouTube 分享了 Visual Agents platform 的演示,展示了其利用 LangChain 的能力来简化 SQL agent 创建和无需编码构建简单检索系统的潜力。两段特定视频展示了其工作流:SQL Agent 和 Simple Retrieval。
EDA GPT 印象展示:通过 LOVO AI 链接了一个 EDA GPT 的演示,包括一段展示其各项功能的五分钟概览视频。该演示突显了这款 AI 工具的多功能性。
教程预告:教程频道的一条消息提供了 business24.ai 内容的 YouTube 链接,尽管其相关背景尚未披露。
LAION Discord
-
盗版并非万灵药:尽管有人幽默地建议 The Pirate Bay 可能成为分享 AI 模型权重的避风港,但成员们对此表示怀疑,并强调其他国家更友好的 AI 政策环境可能会取而代之。
-
日本在 AI 领域采取高端路线:参与者注意到日本在 AI 发展方面的积极立场,并引用了通过 推文 分享的一篇 paper,内容关于无需大规模预训练即可创建新的基础 diffusion models,展示了一种涉及临时破坏模型关联的策略。
-
探究中毒恢复协议:提到了一项由 fal.ai 进行的涉及中毒模型恢复方法的 合作研究,预计研究结果将从经验上证实该恢复方法。成员们对 AI 生成图像的美学表达了保留意见,特别是像 Mobius 这样的模型与 MJv6 等前辈相比所呈现的“高对比度外观”和伪影。
-
Claude 映射破解代码:Anthropic 的 research paper 详细剖析了 Claude 3 Sonnet 的神经图谱,阐述了对概念激活的操纵,可在其 研究页面 阅读。围绕此类激活的潜在商业化引发了辩论,同时也存在对商业影响的担忧,这令 AI 从业者感到沮丧。
-
怀旧 AI 视觉愿景:一位成员回忆了从 Inception v1 等早期 AI 视觉模型到如今复杂系统的演变,认可了 DeepDream 在理解神经功能方面的作用。此外,还讨论了神经网络中稀疏性的好处,描述了使用 L1 norm 实现稀疏性,以及在高维层中典型的 300 个非零维度。
LlamaIndex Discord
-
见面会提醒:名额有限:即将于周二举行的 LlamaIndex meetup 仅剩少量名额,由于名额有限,鼓励爱好者们尽快预订名额。
-
MultiOn 结合 LlamaIndex 实现任务自动化:LlamaIndex 已与 AI Agent 平台 MultiOn 结合,通过代表用户操作的 Chrome 浏览器实现任务自动化;点击此处查看演示。
-
RAGApp 发布:无需代码即可设置 RAG 聊天机器人:新推出的 RAGApp 简化了通过 Docker 容器部署 RAG 聊天机器人的流程,使其可以轻松部署在任何云基础设施上,并且它是开源的;在此处配置您的模型提供商:此处。
-
解决 PDF 解析难题:社区认可 LlamaParse 是一个从 PDF(尤其是表格和字段)中提取数据的可行 API,它利用 GPT-4o 模型来增强性能;Knowledge Graph Indexing 的挑战也是一个话题,强调了手动和自动(通过
VectorStoreIndex)策略的必要性。 -
PostgresML 与 LlamaIndex 联手:Andy Singal 分享了关于将 PostgresML 与 LlamaIndex 集成的见解,并在 Medium 文章 《Unleashing the Power of PostgresML with LlamaIndex Integration》 中详细介绍了这一协作,获得了社区的积极评价。
OpenRouter (Alex Atallah) Discord
-
Phi-3 Medium 128k Instruct 发布:OpenRouter 推出了 Phi-3 Medium 128k Instruct,这是一个强大的 140 亿参数模型,并邀请用户查看标准版和免费版变体,并参与其有效性的讨论。
-
Wizard 模型获得魔力提升:Wizard 模型表现出改进,响应更加迅速且富有想象力,但仍需注意避免重复段落。
-
关注 Phi-3 Vision 和 CogVLM2:围绕 Phi-3 Vision 的热情高涨,分享了测试链接如 Phi-3 Vision,并建议在 CogVLM-CogAgent 使用 CogVLM2 处理以视觉为中心的任务。
-
Llama 3 Prompt 自动转换:澄清了发送给 Llama 3 模型的 Prompt 会通过 OpenRouter 的 API 自动转换,从而简化流程,但手动 Prompt 仍作为一种替代方法保留。
-
Gemini API 的烦恼:用户报告了 Gemini FLASH API 的问题,如空输出和 Token 消耗,这被认为是模型本身的问题。Google 每日 API 使用限制的出现引起了人们对这可能如何影响 OpenRouter 的 Gemini 集成的关注。
Latent Space Discord
-
显微镜下的 LLM 评估:一篇关于大语言模型(LLM)评估实践、排行榜重要性以及细致的非回归测试的 Hugging Face 博客文章 引起了成员们的关注,强调了此类评估在 AI 发展中的关键作用。
-
AI 对搜索引擎操纵的回应:一起涉及网站投毒影响 Google AI 概览的事件引发了围绕安全和数据完整性的讨论,包括通过 Mark Riedl 的推文 报道的自定义搜索引擎浏览器绕过等解决方法。
-
AI 是让开发民主化还是引发了可靠性问题?:GitHub CEO Thomas Dohmke 关于 AI 在简化编码中作用的 TED 演讲 引发了对其可靠性的争论,尽管 AI 驱动的 UX 改进加快了编码过程中的问题解决。
-
多元化奖学金以弥合差距:针对面临参加即将举行的 AI Engineer World’s Fair 财务障碍的多元化背景工程师,官方宣布了多元化奖学金。有兴趣的申请人应在 申请表 中对论文问题提供简明的回答。
Interconnects (Nathan Lambert) Discord
-
无需信用卡的税务轶事:Nathan Lambert 解释了一场发票混乱,意识到由于转售证书(resale certificates)的存在,无需信用卡进行税务结算具有其合理性。
-
Golden Gate AI 备受关注:Anthropic AI 的实验产生了 “Golden Gate Claude”,这是一个一心只关注金门大桥的 AI,因其在 claude.ai 上的公开互动性而引发热议。
-
Google 的 AI 失误:Google 未能有效利用反馈以及过早部署 AI 模型,引发了关于这家科技巨头公关挑战和产品开发困境的讨论。
-
反驳数据集误解:Google 的 AI 团队反驳了关于使用 LAION-5B 数据集的说法,指出他们使用的是更优越的内部数据集,正如最近的一条推文所提到的。
-
Nathan 分享知识干货:针对 AI 爱好者,Nathan Lambert 上传了进阶的 CS224N 讲义幻灯片。此外,与会者还获悉即将发布会议录像,但尚未公布具体发布日期。
OpenAccess AI Collective (axolotl) Discord
- GQA 在 CMDR 模型中获得关注:讨论显示,Grouped Query Attention (GQA) 存在于 “cmdr+” 模型中,但不存在于基础的 “cmdr” 模型中,这标志着它们在规格上的重要区别。
- 智能注意力机制提升 VRAM 效率:工程师们注意到,虽然 GQA 不提供线性缩放,但与指数缩放相比,它代表了一种改进的缩放方法,对 VRAM 使用产生了积极影响。
- 样本打包(Sample Packing)效率提升:一个新的 GitHub pull request 展示了样本打包效率提升了 3-4%,有望在分布式环境下实现更好的资源管理,链接见此处。
- 学术成就获得认可:一位成员合著的期刊文章已在 Journal of the American Medical Informatics Association 上发表,强调了高质量、跨领域数据对医学语言模型的影响,文章可在此处获取。
- 社区庆祝学术成功:社区通过个人祝贺信息对同行发表的作品表示支持,在 AI 领域内营造了一种认可学术贡献的文化。
OpenInterpreter Discord
SB-1047 引发技术动荡:工程师们对 SB-1047 法案的影响表示深切担忧,称其对小型 AI 参与者有害,并将这种情况比作在其他行业观察到的监管俘获(regulatory capture)。
Perplexity 和 Arc:生产力工具展示:社区重点介绍了辅助工作流的工具,分享了关于 SB-1047 的 Perplexity AI 搜索结果以及 Arc Browser 的新功能 “Call Arc”,该功能简化了在线寻找相关答案的过程,附带信息链接。
安装问题引发排查:用户在使用 pip 安装 Typer 库时遇到问题,引发了关于是否遵循了设置步骤(如在 poetry run 之前执行 poetry install)或是否使用了虚拟环境的疑问。
Mozilla AI Discord
Twinny 作为虚拟副驾驶起飞:开发者正在将 Twinny 与 LM Studio 集成,作为强大的本地 AI 代码补全工具,支持在不同端口上运行多个 llamafile。
关于 Embedding 端点的澄清:澄清了 /v1/embeddings 端点不支持 image_data;根据 pull request #4681,图像应使用 /embedding 端点。
Mac M2 在 continue.dev 中遭遇对手:性能观察指出,在使用 llamafile 执行时,continue.dev 在 Mac M2 上的运行速度比旧款 Nvidia GPU 慢。
训练你自己的 LLM:对于那些希望构建和训练自定义 LLM 的用户,社区建议使用 HuggingFace Transformers 进行训练,并提醒 llamafile 是为推理而非训练设计的。
Cohere Discord
- 服务器中回荡着感激之情:一位用户向团队表达了衷心的感谢,展示了用户对团队支持或开发工作的认可。
- 对扩展规模模型的关注:社区中流传着关于 104B 版本 模型是否会加入家族树的讨论,但目前尚未有明确答案。
- Langchain 连接缺失:用户提出了关于 Langchain 与 Cohere 集成的问题,寻求关于其当前可用性和实现状态的指导。
- 模型尺寸之谜:用户正在寻求澄清 Playground 中的 Aya model 是指 8B 还是 35B 版本,这表明理解模型规模对应用至关重要。
- 错误排查角落:诸如 ContextualCompressionRetriever 的
ValidationError和 403 Forbidden error 等问题,标志着工程师们正在进行活跃的调试和技术问题解决,提醒人们 AI 开发中常见的挑战。
AI Stack Devs (Yoko Li) Discord
AI 喜剧之夜反响热烈:用户分享的一段 AI 生成的单口喜剧作品获得了积极的惊喜,表明 AI 在模仿幽默和进行娱乐表演方面的能力有所提升。
关于 AI 应用的探索性查询:用户询问 Ud.io 的功能是否超出了生成喜剧的范畴,表现出对其功能边界的好奇。
声音变换展示:一位用户通过分享一段原始音频的变体、恶魔化版本,展示了 Suno 灵活的音频修改功能。
对音频工程知识的渴望:用户表达了对获取演示中此类音频修改技能的兴趣,这对于对声音处理感兴趣的 AI 工程师来说是一项宝贵的技能。
偏好简洁沟通:对一个问题的单字回复“No”突显了对简洁回答的偏好,这或许反映了工程师对直接、务实沟通的渴望。
MLOps @Chipro Discord
- 寻找统一的事件追踪器:一名成员强调了对与 Google Calendar 兼容的活动日历的迫切需求,以确保不会错过任何社区活动。该系统的缺失是社区内关注的一个问题。
DiscoResearch Discord
- 新数据集发布通知:用户 datarevised 引用了一个新数据集,并提供了更多详情的链接:DataPlusEngine Tweet。
Latent Space Discord
-
基准测试驱动创新:诸如 GLUE、MMLU 和 GSM8K 等评估基准对 AI 研究进展至关重要,而“execution based evals”在动态任务中面临特殊挑战,正如成员们分享的一篇 博客文章 中所讨论的那样。
-
对 GPT-5 的期待:一次谈话引发了公会成员的猜测,认为 GPT-5 可能会在 2024 年首次亮相,并向“Agent 架构”迈进,正如一条 传闻推文 所暗示的那样。
-
探讨 AI 在音乐中的角色:成员们探讨了关于 Suno 等 AI 创作音乐的版权问题,思考了 Meta 的 Audiocraft 的能力,并讨论了法律影响以及促进创作自由的开源工作,包括 GitHub 上的 gary-backend-combined。
-
Python 开发者为 NumPy 2.0 做准备:人们对 NumPy 2.0 的期待日益高涨,成员们还开玩笑说这可能对依赖管理产生影响,正如一篇 Twitter 帖子 所提到的。
-
xAI 获得巨额投资:在投资新闻方面,xAI 获得了 60 亿美元的 B 轮融资,目标是快速提升其模型的能力,正如其 公告文章 所示。
Modular (Mojo 🔥) Discord
-
社区集思广益修复 Nightly 版本困扰:在成员们指出 Mojo VSCode extension 仅对安装后的文件有效,且自 24.3 版本以来存在 Bug 后,解决方案包括关闭并重新打开代码以及频繁重置。与之相反,Mojo compiler 的 Nightly 更新(
2024.5.2505到2024.5.2705)带来了诸如 LSP 中的变量重命名和新的tempfile模块等增强功能,尽管它们在 GitHub 上的现有 PR(如 #2832)中引入了测试问题。 -
在 Mojo 中实现 ZIP 的禅意:在 Mojo 中复制 Python 的
zip和unzip函数时遇到的困难,引发了关于如何声明根据变长参数列表返回元组(tuples)的讨论。对话揭示了 Mojo 使用新的ref语法实现自动解引用迭代器的潜力,旨在简化实现并减少显式的解引用操作。 -
不同处理器的性能表现差异:一位成员在 Mojo 中优化 CRC32 计算的努力导致了不同核心类型之间的性能差异;由于 L1 cache 限制,紧凑型实现在处理较大字节大小时表现落后,但能效核(efficiency cores)则更青睐紧凑版本。基准测试元数据和版本化文件位于 fnands.com 以及 上述内容的 Nightly 版本测试。
-
关于 Mojo 潜力的思考:关于 Mojo 的一般性讨论涵盖了与 Python 相比的函数行为差异、可选类型(optional types)的处理、LinkedLists 的实现,以及对 Mojo 尚未实现的反射(reflection)能力的思考。成员们就使用
UnsafePointer和Optional进行高效初始化交换了意见。 -
科技巨头的巨额交易:AI 社区消化了 Elon Musk 的 AI 初创公司 xAI 获得 60 亿美元 B 轮融资的消息,正如 TechCrunch 文章 所述,这使 xAI 能够直接对抗 OpenAI 和 Microsoft 等 AI 领跑者,引发了围绕 AI 技术商业化的讨论。
OpenRouter (Alex Atallah) Discord
新成员加入:Phi-3 模型上线:Microsoft 的 phi-3-medium-128k-instruct 和 phi-3-mini-128k-instruct 模型现已上线,同时 llama-3-lumimaid-70b 模型还提供 4.3 折(57% discount)优惠。
速率限制迷宫解析:关于 OpenRouter 上 rate limiting(速率限制)的挑战引发了激烈讨论,强调了理解信用余额如何影响请求速率的重要性,详见 OpenRouter 文档。
Modal 混乱:当信用额度与速率限制冲突时:Modal 回退功能出现了一个令人困惑的问题,即尽管信用余额充足,仍触及了速率限制。社区建议监控免费请求,并在限制临近时考虑停用免费模型。
AI 的自我审查困境削弱了吸引力:爱好者们表示担心,Claude 自我审查模型中更严格的护栏和更高的拒绝率导致了不够拟人化的体验,这可能导致使用量下降。
视觉模型分析:性能 vs 价格:话题转向了视觉模型的性能,特别是 Gemini 的 OCR 能力,并对其与传统视觉服务相比的性价比表示认可。对话还强调了通过 RunPod 和 Vast.ai 使用 GPU 比使用 Google Cloud 和 Amazon Bedrock 等主流云服务更便宜。
Eleuther Discord
-
CCS 表现未达预期:Eleuther 团队对 Collin Burns 的 Contrast Consistent Search (CCS) 方法进行的后续研究在泛化能力提升方面未取得预期效果,正如 Quirky Models 基准测试 所示。他们在详细的 博客文章 中分享了该方法及其平庸的结果,这种透明度受到了称赞。
-
最优模型提取策略引发热议:工程师们就 RAG 在从自定义库中提取数据方面是否优于 LLM 的 finetuning 展开了辩论,结论是 RAG 可能更好地保留信息。在 Hugging Face 上发布的 ThePitbull 21.4B 模型 引起了轰动,但一些人对其宣称的接近 70B 模型的性能表示怀疑。
-
数据复制故障排除:AI 程序员在复制 Pythia 数据时遇到了 tokenizer 难题,解决方案包括使用
batch_viewer.py以及通过MMapIndexedDataset正确处理数据类型。正如 Pythia 仓库 中所指出的,虽然这个过程被比作“黑魔法”,但对于正确解析数据集是必要的。 -
利用新技术突破极限:工程师们深入讨论了通过梯度扰动(gradient perturbation)方法来分配权重更新,以及 Transformer 在参数化知识上进行隐式推理的潜力。一篇新的“schedule-free”优化论文引起了关注,该论文建议在不增加额外超参数的情况下进行迭代平均,其表现可能优于传统的学习率调度(learning rate schedules)。
-
量化困境:在追求效率的过程中,一场关于小模型是否能在某些情况下超越大型量化模型的讨论随之展开。引用 ggerganov 的 Twitter 暗示了量化方法的潜力,激发了关于模型大小与性能平衡的激烈辩论。
LlamaIndex Discord
-
RAG 革命:企业级流水线即将到来:LlamaIndex 团队宣布将与 AWS 合作举办研讨会,展示如何使用 AWS Bedrock 和 Ragas 构建企业级 RAG 流水线。该活动旨在提供关于将 Bedrock 与 LlamaIndex 集成以优化 RAG 系统的见解,目前已开放注册 点击此处报名。
-
提升检索能力的创新:讨论重点关注了 Vespa 的集成 以增强混合搜索(hybrid search)能力,以及 Jayita B. 撰写的关于使用 Llama3 和 GroqInc 创建快速响应 RAG 聊天机器人的高级指南。此外,还提到了一种通过 gpt4o 等模型生成的结构化注释对图像进行索引的创新方法。
-
文件组织能力的提升:LlamaFS 作为一种自动组织杂乱目录的新工具发布,这可能会引起那些寻求整洁高效文件管理解决方案的人的共鸣。
-
技术故障排除成为焦点:AI 工程师们正在解决围绕 Llama Index reAct 的问题,包括通过
max_iterations设置进行权衡,以及通过对齐软件包版本来克服导入错误。HTML 解析通常比 PDF 文件需要更多的自定义代码,而 PDF 可以利用依赖项较少的高级分块工具。 -
使用 Pydantic 实现 LlamaIndex 结构化输出:关于在 LlamaIndex 中使用 Pydantic 模型 的指南标志着向结构化输出集成迈进了一步,指向了系统更广泛的应用和可用性。对改进检索器文档的呼吁凸显了社区在不同项目中增强对 BM25 和 AutoRetrieval 模块理解与应用的动力。
Cohere Discord
Aya-23 登场:工程师们讨论了 Aya-23 的多语言能力,并将其与 Command R/R+ 进行了对比,暗示其性能更优,但对其针对英语的效率提出了疑问。他们还指出 Aya-23-35b 是 Command R 的微调版本,并提供了技术报告以获取更多细节。
移动端隐私 vs LLM 局限性:大家达成共识,认为手机端 LLM 尚未成熟到可以在移动应用中进行私密的本地执行,特别是对于通常与 RAG 移动应用 相关的任务。
机器人创新蓬勃发展:一位社区成员在 LinkedIn 上展示了一个游戏机器人,因其与 Cohere Command R 的集成而备受关注;同时,Discord 的 “Create ‘n’ Play” 机器人号称拥有 “超过 100 款引人入胜的文字游戏”,并通过 AI 增强社交参与度。
Prompt 的适配与集成:公会确认 Aya-23 支持系统提示词 (system prompts),并分享了关于如何使用特定 Token(如 <|USER_TOKEN|> 和 <|CHATBOT_TOKEN|>)来适配 Command R 提示词以实现有效运行的见解。
OneDrive 同步解决方案:针对关于 OneDrive 连接器 的咨询,推荐了一个 SharePoint 连接器,它可能满足类似的集成需求。
LAION Discord
AI 建议跳桥的闹剧:成员们分享了一个关于 Google AI 给出“跳桥治疗抑郁症”危险建议的幽默段子,提到了 Reddit 建议的误导性。还分享了一个关于这一失误的相关梗图。
ConvNeXt 获得优化:关于 ConvNeXt 论文 的热烈讨论赞扬了其高效处理高分辨率图像的能力,这有可能减少过多的视觉 Token 生成,并简化高分辨率任务的优化。
从红石到神经网络:展示了数据集和 AI 工具的创新用途,包括来自 archive.org 的出版物 PDF 和 TeX 源码数据集,以及一段演示如何用红石 (Redstone) 创建神经网络的 YouTube 视频。
AI 预训练中的模型增长堆叠:一篇 arXiv 论文 强调了深度方向堆叠 (depthwise stacking) 是 Large Language Models (LLMs) 高效预训练中模型增长的一种有效方法,引起了广泛关注,解决了预训练过程中关键的速度和性能挑战。
PyTorch 持久化中的陷阱:学习领域的讨论集中在解决训练-验证集划分的随机性以及模型重新加载时 Loss 不一致的问题。具体而言,PyTorch 中正确保存优化器状态 (optimizer states) 被指出是避免 Loss 爆炸的关键。
DiscoResearch Discord
-
Llama3 德语化:新的 Llama3-German-8B 模型将 Meta 的 Llama3-8B 能力扩展到了德语,在 650 亿个 tokens 上进行了训练,且 English 性能损失微乎其微;详情请见 Hugging Face。然而,值得注意的是,与其他语言模型不同,该训练省略了英语数据重放 (English data replay),这引发了关于其有效性的辩论。
-
量化怪癖与谜题:Llama3 的量化版本 GGUF 在基准测试中表现平平,暗示了潜在的问题,可在 Llama3-DiscoLeo-Instruct-8B-32k-v0.1-GGUF 查看。同时,关于参数设置和奇怪输出的讨论暗示了运行这些模型的复杂挑战,例如 max tokens 和 engine 的选择。
-
Cohere 的多语言飞跃:Cohere 的 Aya-23-35B 模型虽然在许可方面有所限制,但现在支持 23 种语言,这表明了业界对强大多语言模型日益增长的趋势和兴趣。一个相关的用于翻译的 ShareGPT 格式数据集引发了关于质量和过滤的讨论,托管在 这里。
-
Mistral 的微调指南:为了向技术社区致敬,Mistral 为 Mixtral 模型推出了微调指南,为那些开启微调之旅的人提供了指引;该指南可以在其 GitHub 上查阅。
-
模型调优细节曝光:社区正在使用 oobabooga 和 ollama 进行实验,涉及 ‘skip_special_tokens’ 开关和 stop token 设置,包括建议使用特定的 Llama3 模板 来解决输出问题——这反映了成员中盛行的积极调整和调优文化。
OpenInterpreter Discord
-
LAM 安全担忧与移动性:尽管 Rabbit LAM 架构概览 展示了其安全的 Web App 控制能力,但讨论中仍透露出对 Large Action Model (LAM) 易被逆向工程的怀疑。对话还围绕在 Rabbit R1 设备和 Humane 平台上运行 01 模型的集成挑战,并强调了用户驱动的解决方案,如 01 model Android GitHub 仓库。
-
快速安装策略:Python 版本升级到 3.11 解决了 Mac 上的 OpenInterpreter 问题,而通过 Andronix 折腾 Linux 发行版则实现了在 Android 驱动的耳机上使用 OpenInterpreter。关于 Open Interpreter 安装的咨询显示了对本地或云端可访问 LLM 的需求,并且推出了新的 Markdown 导出功能 以帮助开发者。
-
社区的 DIY 精神:一位用户通过升级到 Python 3.11 修复了 Mac 上的 OpenInterpreter 问题,其他用户分享了增强现有设备的途径,例如使用 LineageOS 修改 R1。在购买还是自建硬件的讨论中,共识是购买预建的 O1 有利于西雅图开发团队,尽管它与自建版本在技术上没有区别。
-
发货与存储备受关注:用户对硬件发货缺乏更新表示不满,特别是关于欧洲地区的配送和预订信息的缺失。对话还涉及寻找克服 Runpod 磁盘空间限制的解决方案,这暗示了 AI 工作负载中对成本效益型数据存储的持续需求。
-
OpenInterpreter 的进步:成员成功在 Mac 上切换到 Python 3.11 以运行 OpenInterpreter,标志着社区在解决问题方面的持续敏捷性。同时,新 Markdown 导出功能 的实现反映了在 AI 工具链中增强开发者实用性的推动。
LangChain AI Discord
PDF 提取被证明具有挑战性:关于从 PDF 中提取文本的讨论强调了在处理复杂表格和图表时遇到的困难,并建议了基于 ML 的文本分割和使用 Adobe Extract API 进行布局解析等解决方案,参考了 LangChain 文档。
LangChain 社区即将扩展:来自 Scogo Networks 的 Karan Singh 表示有兴趣在孟买建立本地 LangChain 社区,并正在寻找市场联系人以组织活动。
Langserve 等候名单出现波折:用户在 Airtable 上遇到了 Langserve 等候名单的访问问题,正在寻找尝试该托管服务的替代方法。
交互式数据可视化工具推出:介绍了 NLAVIDA 项目,该项目通过自然语言促进交互式数据可视化和分析,并附带了 YouTube 视频教程。
准备就绪,为 OranClick 投票:旨在优化消息撰写以提高注册率的工具 OranClick 宣布发布,并邀请在 ProductHunt 上提供支持。
Mozilla AI Discord
- Llamafile 发布 v0.8.5 版本:重点介绍了 llamafile 0.8.5 版本 的发布,该版本为 X86 CPU 上的 K 量化(K quants)提供了快速推理,并号召社区使用
llamafile-bench进行基准测试。 - Llamafile 增强网络访问能力:工程师们交流了如何使 llamafile 服务器支持网络访问的技巧,建议使用
--host <my ip>或--host 0.0.0.0等标志,以便在同一网络内的跨机器可用。 - Llama3-70B 中的空白响应之谜:贡献者报告称遇到了来自 llama3-70b 模型的空白响应,并分享了日志供社区主导的调试,尽管目前尚未出现明确的解决方案。
- Home Assistant 的本地 API:关于增强 Home Assistant 集成的讨论非常热烈,重点是开发一个类似于 OpenAI 候选方案的标准本地 API,并强调了 API 可发现性和安全 API 端点等功能的重要性。
- 模型选择的 Python 难题:问题和分享的代码片段表明,在 LLaMA_CPP 集成的 Python 示例中指定模型时存在一些困惑,特别是关于何时必须指定模型(例如使用 TinyLlama 时)。
OpenAccess AI Collective (axolotl) Discord
- Mistral-Finetune 之谜揭晓:开发者们致力于解读 Mistral-Finetune 仓库 中的新更新,重点在于理解其独特的变更。
- MoEs 微调的怪癖:AI 圈讨论了微调 专家混合模型 (MoEs) 的不确定性,强调了运行多次迭代以挑选最有效模型的必要性,尽管关于成功率的细节尚未透露。
- Aya 23 受限的能力:Aya 23 的局限性引发了热烈讨论,强调其在聊天应用中的表现不佳,其优势仅限于特定任务,正如其 技术报告 所述。
- MoRA 步入微调聚光灯:MoRA 作为一种用于微调的前沿高秩更新方法进入了讨论,它具有补充或超越 LoRA 的潜力,并关联了一个 专门的 GitHub 仓库。
- FFD Bin Packing 问题与 Llama 3 Token 备受关注:出现了关于 FFD bin packing 实现的问题,特别是在分布式训练上下文中;同时针对 Llama 3 未训练 Token 的修复也备受关注,并分享了 sfttrainer 的补丁 以解决后者。
AI Stack Devs (Yoko Li) Discord
-
通过虚拟生物模拟现实:Virtual Beings Summit 对 AI 专业人士来说可能是一个有价值的活动,由 Will Wright 主持,重点关注 AI 与模拟(simulations)的交集。支持内容可以在 Virtual Beings YouTube channel 找到,该频道提供了关于 AI 在交互式模拟中作用的见解。
-
使用 DIAMOND 构建 AI 梦境:DIAMOND GitHub repository 介绍了 “DIAMOND (DIffusion As a Model Of eNvironment Dreams)”,它在 Reinforcement Learning 场景下使用 Diffusion Models 来增强 AI 模拟中的环境交互。
-
利用 UE5 和 4Wall 打造 AI 版“西部世界”:关于创建沉浸式体验的讨论表明,AI Town 可能会利用 UE5 并集成语音控制来模拟类似于“西部世界”的环境,持续的开发信息可在 4Wall Discord 获取。
-
进军虚拟现实:将 AI Town 与 VR 技术结合的想法受到了热烈欢迎,这表明工程师们正在考虑通过 VR 让 AI 生成的环境变得栩栩如生的新方法。
-
使用 SadTalker 和 V-Express 制作头像动画:两个 GitHub 仓库,SadTalker 和 Tencent AI Lab’s V-Express,分别提供了用于创建逼真的说话人脸动画和生成说话头像视频的工具,展示了风格化动画技术的进步。
Interconnects (Nathan Lambert) Discord
Zyphra Zamba 崭露头角:新型 Zyphra Zamba 模型结合了 Mamba 和 Attention 机制,现已发布,并附带相应的技术报告、PyTorch 代码以及对 Hugging Face Transformers 的集成。与 OLMo 1.7 的对比分析正在进行中,以评估其性能。
SD Audio 2.0 低调发布:SD Audio 2.0 的一个未经授权版本出现在 4chan 上,并在一个 Hugging Face 账号上提供,引发了成员们的讨论。
站对站监管:前 OpenAI 董事会成员 Hellen Toner 和 Tasha McCauley 在《经济学人》中提议对 AI 公司进行严格监管,强调由于利润动机,此类公司无法进行自我监管,并指出了过去的内部问题。
领导层的争议:文章批评了 Sam Altman 在任职期间所谓的“谎言毒性文化”,讨论了内部调查以及公众对缺乏透明度的抗议。
RL 的教科书案例:社区在 GitHub 上分享了一个新资源,即一本关于 Reinforcement Learning from Human Feedback (RLHF) 的教科书,并赞扬了 Chris Potts 和 Chris Manning 教授引人入胜的教学风格。讨论还涉及了斯坦福 CS224n 课程电子版何时发布,建议联系 Chris 以获取具体的时间表。
tinygrad (George Hotz) Discord
调整技术测试的时间限制:讨论涉及将每个测试的时间限制延长至 9 分 34 秒 以上的可能性,以适应如 ‘Taylor approximations’ 等复杂函数。一个具体问题是 clang 函数无法完成,仅达到约 60% 的进度。
编译崩溃需要解决方案:一位成员指出,生成过大的表达式会导致编译器崩溃,并出现与不兼容操作数类型(特别是 double 类型)相关的错误。
关于 Double 类型位运算的争议:澄清了无法在 double 数据类型上执行诸如 XOR 等位运算的问题,解决了成员们观察到的编译错误原因。
悬赏任务热度上升:对各种研究导向型悬赏任务的兴趣激增,讨论涉及旧的 pull requests,并且 George Hotz 确认了诸如 tinygrad pull request #4212 中提到的悬赏仍然有效。
解读 ‘vin’ 并讨论支配者 (Dominators):George Hotz 澄清了 UOp class 中的 ‘vin’ 并不是一个缩写。此外,一位成员询问为什么不使用后支配分析 (post dominator analysis) 来改进模型中的调度 (scheduling),并建议这可能会在执行期间优化子图融合 (subgraph fusion)。
邮件中已截断了完整的逐频道明细。
如果您喜欢 AInews,请分享给朋友!预谢!