ainews-somebody-give-andrej-some-h100s-already
赶紧给安德烈(Andrej)整点 H100 吧。
五年前,OpenAI 的 GPT-2 因被认为“过于危险而无法发布”引发了争议。如今,借助 FineWeb 和 llm.c,使用 8 张 A100 GPU,仅需 90 分钟和 20 美元即可训练出一个微型 GPT-2 模型;而完整的 16 亿参数(1.6B)模型预计耗时 1 周,成本约为 2500 美元。该项目因大量使用 CUDA(占比 75.8%)而备受关注,旨在简化训练技术栈。
与此同时,杨立昆(Yann LeCun)与埃隆·马斯克(Elon Musk)在 Twitter 上的辩论突显了卷积神经网络(CNN)在自动驾驶实时图像处理中的重要性,杨立昆强调了科学研究在技术进步中的作用。此外,杨立昆还批评了 AI 末日论,主张对 AI 安全和监管保持审慎乐观。
C+CUDA 就是你所需的一切。
2024年5月27日至5月28日的 AI 新闻。 我们为您检查了 7 个 subreddit、384 个 Twitter 账号 和 29 个 Discord(382 个频道和 4432 条消息)。 预计节省阅读时间(按 200wpm 计算):521 分钟。
五年前,OpenAI 的 GPT-2 被称为“过于危险而无法发布”,引发了其首个争议。
今天,在 FineWeb(上个月发布)的帮助下,你可以在 90 分钟内花费 20 美元的 8xA100 服务器时长训练一个微型 GPT-2。350M 版本已经可以运行(某种程度上),Andrej 估计完整的 1.6B 模型将需要 1 周时间和 2500 美元。
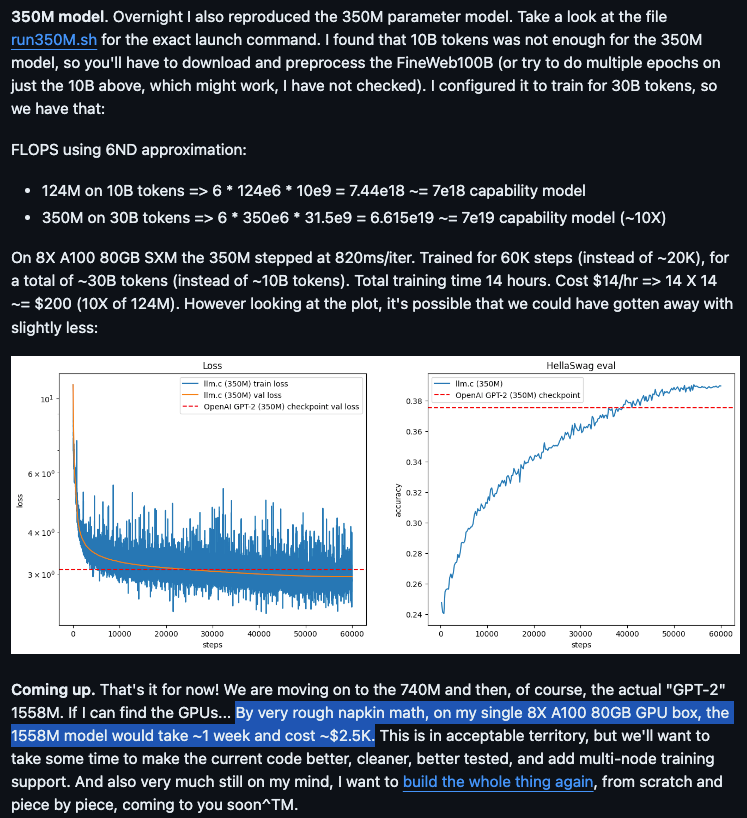
这是从零开始工作 7 周取得的惊人成就,尽管目前该仓库有 75.8% 是 CUDA 代码,这让 “llm.c” 这个名字显得有些名不副实。
Andrej 还在 HN 和 Twitter 上回答了一些问题。其中最有趣的回复之一:
问:完成这项训练任务需要多大的二进制文件集?目前的 PyTorch + CUDA 生态系统极其庞大,操作那些容器镜像非常痛苦,因为它们太大了。我希望这能成为一个更小的训练/微调堆栈的开始?
答:这百分之百是我的意图和希望,我认为我们离删除所有这些内容已经非常接近了。
如果有更多的 H100 可用,成本会更低,速度会更快。有人能帮帮这位新晋的 GPU 穷人(GPU poor)吗?
AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成,从 4 次运行中择优。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
Yann LeCun 与 Elon Musk 的 Twitter 辩论
- 卷积神经网络 (CNNs) 的重要性:@ylecun 指出,1989 年引入的 CNNs 如今被用于所有的驾驶辅助系统,包括 MobilEye、Nvidia、Tesla。技术奇迹建立在通过技术论文分享的多年科学研究之上。
- LeCun 的研究贡献:@ClementDelangue 表示在 @ylecun 和 @elonmusk 之间会选择前者,因为发表突破性研究的科学家是技术进步的基石,尽管他们获得的认可少于企业家。
- Musk 质疑 LeCun 的 CNN 使用情况:@elonmusk 询问 @ylecun,如果没有 ConvNets,Tesla 如何在 FSD 中进行实时摄像头图像理解。@ylecun 回应称 Tesla 使用了 CNNs,因为对于实时高分辨率图像处理来说,Attention 机制太慢了。@svpino 和 @mervenoyann 证实了 Tesla 对 CNN 的使用。
- LeCun 的研究产出:@ylecun 分享自 2022 年 1 月以来他已发表了 80 多篇技术论文,并质疑 Musk 的研究产出。他还提到自己在 Meta 工作,@ylecun 表示这没什么问题。
- Musk 表现得像 LeCun 的老板:@ylecun 开玩笑说 Musk 表现得好像他是自己的老板一样。@fchollet 建议他们通过笼斗(cage fight)来解决,而 @ylecun 则提议进行帆船比赛。
AI 安全与监管讨论
- AI 末日场景:@ylecun 批评了“AI 末日”论调,认为 AI 是由人类设计和建造的,而且如果存在安全的 AI 系统设计,我们就不会有问题。现在担心或通过监管 AI 来防止“生存风险”还为时过早。
- AI 监管与中心化:@ylecun 概述了“末日论者的错觉”,即 AI 末日论者推动少数公司垄断 AI、严格监管、远程关停开关、基础模型构建者的永久责任、禁止开源 AI,并用末日预言恐吓公众。 他们成立个人研究所来推广 AI 安全,从恐惧的亿万富翁那里获得巨额资助,并声称著名科学家也同意他们的观点。
AI 研究与工程讨论
- 在 C/CUDA 中复现 GPT-2:@karpathy 在一个 8X A100 80GB 节点上,仅用 90 分钟和 20 美元的成本,在 llm.c 中复现了 GPT-2 (124M),MFU 达到 60%。他还用约 200 美元在 14 小时内复现了 350M 模型。提供了完整的操作指南。
- 用于算术的 Transformers:@_akhaliq 分享了一篇论文,表明 Transformers 配合正确的 embeddings 可以进行算术运算,通过在单 GPU 上训练一天 20 位数字的数据,在 100 位数字的加法问题上达到了高达 99% 的准确率。
- Gemini 1.5 模型更新:@lmsysorg 公布了 Gemini 1.5 Flash、Pro 和 Advanced 的结果,其中 Pro/Advanced 排名第 2,紧随 GPT-4o 之后,而 Flash 排名第 9,超越了 Llama-3-70b 且接近 GPT-4-0125。Flash 的成本、能力和上下文长度使其成为市场的游戏规则改变者。
- Zamba SSM 混合模型:@_akhaliq 分享了 Zamba 论文,这是一个 7B SSM-Transformer 混合模型,在同等规模下达到了与领先开源权重模型相当的性能。 它是在来自公开数据集的 1T tokens 上训练的。
- 用于将 LLM 训练为嵌入模型的 NV-Embed:@arankomatsuzaki 分享了 NVIDIA 关于 NV-Embed 的论文,该论文改进了将 LLM 训练为通用嵌入模型的技术。它在 MTEB 排行榜上排名第 1。
梗图与幽默
- Musk vs. LeCun 梗图:@svpino 和 @bindureddy 分享了关于 Musk 与 LeCun 辩论的梗图,调侃了这一局面。
- 用 AI Bot 替代 Twitter 上的自己:@cto_junior 开玩笑说要在 Slack 上建立一个 AI 版本的自己来代替参加站会(standups),而不是在 Twitter 上。
AI Reddit 摘要回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 模型与架构
- 01-ai 移除 Yi 模型的自定义许可证:在 /r/LocalLLaMA 中,01-ai 已在 Huggingface 上将其原始 Yi 模型的许可证切换为 Apache-2.0,与其 1.5 系列模型的许可证保持一致。
- InternLM2-Math-Plus 模型发布:发布了一系列升级后的数学专用开源大语言模型,涵盖 1.8B、7B、20B 和 8x22B 尺寸。其中 InternLM2-Math-Plus-Mixtral8x22B 在 MATH(配合 Python)和 GSM8K 基准测试中分别达到了 68.5 和 91.8 分。
- Pandora 世界模型推出:Pandora 是一种混合自回归扩散模型,通过生成视频来模拟世界状态,并允许通过自由文本动作进行实时控制。其目标是实现领域通用性、视频一致性和可控性。
- llama.cpp 添加对 Jamba 架构的支持:在 /r/LocalLLaMA 中,llama.cpp 正在添加对 AI21 Labs 的 Jamba 架构的支持,首批 GGUF 文件已上传,其中包括一个基于 Bagel 数据集微调的模型。
- 针对天文学发布的 AstroPT 模型:AstroPT 是为天文学用例开发的自回归预训练 Transformer,模型参数从 1M 到 2.1B 不等,在 8.6M 个星系观测数据上进行了预训练。代码、权重和数据集均以 MIT 许可证发布。
AI 应用与工具
- 优化 Whisper 以实现快速推理:在 /r/LocalLLaMA 中,有成员分享了通过 SDPA/Flash Attention、投机采样 (speculative decoding)、分块 (chunking) 和蒸馏 (distillation) 等技术将 Whisper 推理速度提升高达 5 倍的技巧。
- 用于文档问答的 Android 应用:Android-Document-QA 是一款 Android 应用,它利用 LLM 回答用户提供的 PDF/DOCX 文档中的问题,并利用各种库进行文档解析、设备端向量数据库等操作。
- 用于本地音乐生成的 MusicGPT:在 /r/MachineLearning 中,MusicGPT 被介绍为一个终端应用,可以在本地运行 Meta 的 MusicGen,通过自然语言提示生成音乐。该应用由 Rust 编写,最终目标是实时生成无限的音乐流。
- 发布新的 Web+LLM 框架:宣布了一个针对与 LLM 和微服务集成的 IO 密集型应用优化的开源 Web 框架,正在寻找早期采用者进行试用并提供反馈。
AI 伦理与安全
- 微软 Recall AI 功能因隐私担忧受到调查:微软新的 Recall AI 功能(通过跟踪用户活动来辅助数字助手)正因隐私担忧受到英国当局的调查,这引发了关于实用 AI 辅助所需数据的辩论。
AI 行业与竞争
- 过去一年 AI 竞争的可视化:来自 LMSYS Chatbot Arena 的可视化图表显示了过去一年中各大 LLM 厂商顶级模型的表现,突显了日益激烈的竞争和不断变化的趋势。
- 关于 OpenAI 股权回收的矛盾说法:一篇文章称数据与 Sam Altman 关于对 OpenAI 股权回收 (equity clawbacks) 知情的声明相矛盾。
AI Discord Recap
摘要之摘要的摘要
LLM 进展与基准测试:
- Llama 3 领跑榜单:来自 Meta 的 Llama 3 在 ChatbotArena 等排行榜上名列前茅,在超过 50,000 场对决中超越了 GPT-4-Turbo 和 Claude 3 Opus 等模型。
- IBM 和 RefuelAI 发布新模型:IBM 的 Granite-8B-Code-Instruct 增强了代码任务的指令遵循能力,而 RefuelAI 的 RefuelLLM-2 则在处理数据密集型任务方面表现出极高的效率。
优化 LLM 推理与训练:
- 前沿量化技术:ZeRO++ 旨在将大型模型在 GPU 上训练期间的通信开销降低 4 倍。
- 内存效率创新:vAttention 系统更动态地管理 KV-cache 内存,提升了 LLM 推理的敏锐度;而 QSolve 引入了 W4A8KV4 量化,以增强基于云端的 GPU 性能。
开源 AI 框架与社区努力:
- Axolotl 吸引开发者关注:支持多种数据格式,助力 LLM 预训练和指令微调。
- LlamaIndex 激发学术好奇心:与 Andrew Ng 合作推出了一门关于构建 Agentic RAG 系统的新课程,预示着 bfloat16 等 AI 扩展技术的进步。
多模态 AI 与生成模型创新:
- Idefics2 8B 在对话领域引起轰动:微调了聊天交互中的话语表现,同时 CodeGemma 1.1 7B 提升了编程任务表现。
- Phi 3 开创基于浏览器的 AI:通过 WebGPU 直接在浏览器中引入强大的 AI 聊天机器人,为注重隐私的交互增强奠定了基础。
LLM Finetuning (Hamel + Dan) Discord
OCR 对决:Google Vision vs. Microsoft Azure:AI 工程师们辩论了 Google Vision OCR 的优缺点,承认其精度但批评了开发者体验。有人建议使用 Microsoft Azure OCR 和 Mindee Doctr,认为它们可能提供更好的易用性,详情见这里。
精选数据:LLM 成功的关键:研讨会讨论强调了使用高质量、精选数据集微调 LLM 的重要性,应用范围从医药应用到技术支持聊天机器人。专家意见指出,需要精确选择数据以最大化 LLM 的有效性,重点关注药物研发、法律、销售和跨学科工作等领域。
Axolotl 的焦虑与优化:用户在 M3 Macs 上运行 Axolotl 的 70B 模型时遇到障碍,本地推理时延迟极高,指出在 Modal 上部署可能是一个解决方案。对 Weights & Biases (WandB) 成本的担忧促使注重经济效益的独立开发者考虑 Aim 和 MLflow 等替代方案 Axolotl 示例。
LLM 评估深度探讨:关于评估 LLM 的会议提供了大量见解,涵盖了产品指标、传统和动态性能指标,以及 LangFuse 和 EvalGen 等工具。通过推荐 Eugene Yan 的资源和可视化微调的实际案例,参与者注意到对 LLM 开发进行细致评估的必要性。
转录纠结与摘要之路:围绕大型会议转录文本的交流阐明了对高效摘要的需求,揭示了 LLM 可能发挥的作用。虽然 Zoom 转录功能即将推出,但 Hamel 鼓励使用 LLM 生成更易读的摘要,这引起了更广泛的社区参与。
Perplexity AI Discord
-
翘首以盼 imfo Alpha 版本发布:@spectate_or 的一条推文链接暗示了即将发布的 imfo alpha,这在工程社区中引发了兴奋,并将其与类似工具进行了比较。
-
AI 任务结构辩论:工程师们讨论了将 AI 任务分类为检索型和变异型,并以“获取 iPhone 15 的重量”等查询为例。针对需要顺序执行的任务,强调了调整的必要性,并指出 “所有步骤几乎是同时发生的。”
-
爬取准确性遇到障碍:成员们表达了在 HTML 解析以实现可靠数据爬取方面面临的挑战,复杂性源于 Apple 和 Docker 发布说明等网站。针对以 JavaScript 为中心的网站,考虑通过 Playwright 进行变通,同时也讨论了 Cloudflare 的相关问题。
-
探索高性价比的 AI 模型利用:社区深入探讨了使用 Llama3 和 Claude 等各种 AI 模型的成本效益。一种使用组合系统的方法表明了实现更大成本节约的可能性。
-
强调 API 功能的奇特之处:围绕显示 JSON 对象但缺少功能链接的 API 输出产生了困惑,这可能与缺少 closed beta citations feature(内测引用功能)有关。其他讨论还包括改进视频链接生成的 Prompt,以及对潜在 API 故障的简短询问。
Stability.ai (Stable Diffusion) Discord
值得尝试的新 AI 功能:Stability AI 宣布推出 Stable Assistant,它具备基于 Stable Diffusion 3 构建的编辑功能,并拥有更高的文本生成图像质量,可在此处进行免费试用;此外还推出了搭载 Stable LM 2 12B 的 Beta 版聊天机器人,预示着未来文本生成任务的增强。
教育与 AI 创新融合:由 Stability AI 和 HUG 合作的 Innovation Laboratory 即将开展为期 4 周的课程,旨在指导参与者结合 HUG 的教育方法,利用 Stability AI 的框架训练 AI 模型;报名截止日期为 2024 年 6 月 25 日,可通过此处访问。
GPU 共享成为焦点:AI 工程师讨论了一项基于社区的 GPU 共享提案,以降低计算成本,方案从自定义节点到旨在验证模型训练操作的潜在区块链设置不等。
SD3 的可访问性引发争议:由于成员对 Stable Diffusion 的 SD3 权重无法在本地使用表示不满,争议浮出水面——他们批评 Stability AI 仅限云端的做法,并引发了关于云端依赖和数据隐私问题的辩论。
用户界面对比:一场关于 Stable Diffusion 各种界面优缺点的技术讨论展开,ComfyUI 与 Forge 等更易于使用的替代方案展开竞争;讨论还包括社区技巧、Inpainting(局部重绘)方法以及增强人工智能工作流的方法。
OpenAI Discord
OpenAI 建立安全盾牌:OpenAI 成立了一个 Safety and Security Committee(安全与安保委员会),负责其所有项目的关键安全和安保决策;详细信息可见其官方公告。
AI 在硬件领域大显身手:关于硬件成本的讨论兴起,推测由于 NPUs(神经网络处理单元)的加入,成本将增加 200 至 1000 美元,重点关注其对高端模型的经济影响。
规划 Prompt 蓝图:AI 工程师辩论了 meta-prompting 与 Chain of Thought (CoT) 的优劣,探讨了使用 mermaid 图表来节省 tokens 并提高输出质量的潜力。此外还分享了改进后的 Prompt(如此处),展示了高级 Prompt Engineering 策略的实际应用。
理论付诸代码实践:实际讨论包括 AI 如何原生处理 YAML, XML, and JSON 格式,并建议在 Prompt 中使用这些结构以提高 AI 的理解力和性能,同时分享了指向生成代码和规划的实际 Prompt 应用资源。
交互不一致性引发探究:用户报告了 ChatGPT 的一系列问题,从拒绝抽取塔罗牌到上下文丢失和无响应,突显了对改进和更可预测的 AI 行为的需求。
HuggingFace Discord
语音指令遇见机器人:一段名为 “Open Source Voice-Controlled Robotic Arm” 的演示视频展示了一个语音激活的 AI 机器人手臂。视频提出了通过社区协作实现机器人技术民主化的观点。
跨越模态:关于创建早期多模态空间的贡献指出,可以使用单一模型,也可能使用具有路由功能的堆叠模型。为了深入了解此类实现,分享了一个 源码链接,提供了一个具有实际应用价值的模型示例。
即时深度学习咨询:一位用户就使用 Stanford Cars Dataset 训练模型时遇到的常见痛点咨询了社区,该用户使用 ViT-B_16 仅达到了 60% 的准确率,并深受过拟合困扰。与此同时,另一位成员正在寻求如何改进其深度学习模型的帮助,这表明社区拥有支持新手知识交流的良好环境。
Diffusers 更新:不仅限于生成:Hugging Face 宣布其 Diffusers 库现在支持生成模型之外的任务,例如通过 Marigold 进行深度估计和法线预测。此次更新表明 Diffusion 模型的多功能性及其应用呈现出不断扩大的趋势。
网络安全评估的模型选择:研究人员的分析探讨了各种 Large Language Models 在网络安全背景下的能力。这为 AI 工程师提供了一个视角,去考虑部署 LLM 时固有的安全影响。
稳健的 SDXL 空间重对齐:关于 SDXL 嵌入空间的讨论强调,新对齐的空间默认值为零,而不是编码空间。这些见解反映了将模型重新对齐到新的无条件空间(unconditioned spaces)所涉及的底层复杂性和时间需求,揭示了科学背后的复杂过程。
Gradio 升级版客户端引发关注:Gradio 团队宣布即将举行一场直播活动,深入探讨 Gradio Python 和 JavaScript 客户端的最新功能。此次活动邀请强调了 Gradio 致力于通过增强的界面不断简化 AI 到各种应用程序的集成。
寻找 SFW 数据集的模糊性:社区讨论提到了定位 Nomos8k_sfw 数据集的困难,该数据集与 4x-Nomos8kDAT 模型相关联,这表明该数据集的可用性有限或位置隐蔽。这突显了数据集获取过程中偶尔会遇到的挑战。
发布最新的 AI 叙事工具:Typeface Arc 作为一个综合平台出现,旨在无缝创建 AI 驱动的内容。它包含一个被恰当地称为 “Copilot” 的工具,旨在通过对品牌叙事至关重要的交互式体验来增强内容创作。
LM Studio Discord
视觉化:OpenAI 与 LLaVA 集成!:工程师现在可以通过在服务器上部署 LLaVA 并利用提供的 Python 视觉模板,在 LM Studio 中利用其视觉能力。
M1 Max 上的快速模型加载:像 MLX 和 EXL2 这样的 AI 模型在 Apple 的 M1 Max 上加载迅速,L3 8bit 仅需 5 秒,表明其性能优于需要 29 秒的 GGUF Q8。
LM Studio 微调的挫败感:尽管是一个强大的环境,但 LM Studio 目前缺乏直接微调模型的能力,爱好者们被引导至专为 Apple Silicon 设计的 MLX 等替代解决方案。
预算还是性能:AI 从业者辩论了各种 Nvidia GPU 的价值主张,考虑了 Tesla P40/P100 等替代方案,并满怀期待地讨论了传闻中的 5090 等 GPU。
Beta 测试的烦恼:在体验新版本时,用户报告了诸如大模型的 Windows CPU 亲和性问题以及 AVX2 笔记本电脑上的错误等问题,这暗示了为 AI 任务配置现代硬件的复杂性。
Unsloth AI (Daniel Han) Discord
-
GPT-2 不受 Unsloth 待见:Unsloth 确认,由于基础架构的根本差异,无法使用其平台对 GPT-2 进行微调。
- Fiery Chat 微调中的挫折:
- 在对包含 50,000 多个邮件条目的 Llama 3 进行微调时,成员们分享了关于构建 Prompt 结构以实现最佳输入输出配对的建议。
- 针对训练后出现的句子重复问题,建议添加 End-Of-Sentence (EOS) Token,以防止模型过拟合或学习效果不佳。
-
视觉模型集成指日可待:成员们正热切期待 Unsloth 下个月支持视觉模型的更新,目前暂且推荐使用 Stable Diffusion 和 Segment Anything 作为当前的解决方案。
-
LoRA Adapter 的协同工作:社区分享了合并和微调 LoRA Adapter 的技巧,强调利用 GitHub 上的 Unsloth 文档等资源,并将模型导出到 HuggingFace。
-
应对 Phi 3 Medium 的注意力跨度:关于 Phi3-Medium 的讨论揭示了其滑动窗口注意力(Sliding Window Attention)会导致在高 Token 计数时效率下降,许多人渴望能有增强功能来处理更大的上下文窗口。
-
ONNX 导出详解:提供了将微调后的模型转换为 ONNX 的指南,参考了 Hugging Face 的 序列化文档,并确认 VLLM 格式兼容转换。
- 迈向低位宽:Unsloth 即将支持 8-bit 模型以及与 Ollama 等环境的集成能力(类似于 OpenAI 的产品),大家对此充满期待。
CUDA MODE Discord
-
Ubuntu 上的 CUDA Toolkit 命令:一位用户建议从 NVIDIA 安装 CUDA Toolkit,通过
nvidia-smi检查安装情况,并提供了在 Ubuntu 上设置的命令,包括通过 Conda 安装:conda install cuda -c nvidia/label/cuda-12.1.0。同时,在设置 PyTorch 2.3 时发现了 Python 3.12 与缺失 triton 安装之间的潜在冲突,这与一个 GitHub Issue 相关。 -
GPT-4o 在处理大型编辑时遇到对手:成员们注意到 GPT-4o 在处理大量代码编辑时表现吃力,而一种新的 fast apply 模型旨在将任务分解为计划和应用阶段以克服这一挑战。为了寻求代码编辑的确定性算法,一位成员提出了使用 vllm 或 trtllm 进行未来 Token 预测(Future Token Prediction)而无需依赖草稿模型的可行性。更多关于此方法的信息可以在 完整博客文章 中找到。
-
SYCL 调试困扰:一位成员询问了调试 SYCL 代码的工具,引发了关于进入 Kernel 代码进行故障排除的讨论。
-
Torchao 的最新进展:torchao 社区庆祝了 PyTorch 合并对 MX 格式(如
fp8/6/4)的支持,这为感兴趣的各方提供了效率提升,部分由一个 GitHub Commit 提供,并符合 MX 规范。 -
理解 DIY 中的 Mixer 模型:成员们剖析了实现细节,例如在 llm.c 中集成
dirent.h,以及为了操作系统兼容性使用#ifndef _WIN32进行保护的重要性。实现了用于在中断时恢复训练的-y 1标志,解决了关于未初始化变量的警告,并探索了 Backward Pass 计算期间的内存优化策略,相关倡议可在 GitHub 讨论 中找到。 -
BitNet 中的激活量化:在 BitNet 频道中得出结论,在激活量化神经网络中直接传递传入梯度可能是错误的。相反,建议使用
tanh等替代函数的梯度,并引用了一篇关于直通估计器 (STE) 性能的 arXiv 论文。
Eleuther Discord
- GPT Agents 无后续学习能力:基于 GPT 的 Agent 在初始训练后不会进行后续学习,但可以引用上传为“知识文件”的新信息,而不会从根本上改变其核心理解。
- Diffusion Models 的效率里程碑:Google DeepMind 推出 EM Distillation 以创建高效的一步生成器 Diffusion Models,Google 的另一项独立研究展示了一个能够生成 1024x1024 高分辨率图像的 8B 参数 Diffusion Model。
- 追求极致的小型化:Super Tiny Language Models 研究专注于在不显著牺牲性能的情况下将语言模型参数减少 90-95%,这为更高效的 NLP 指明了道路。
- 无需猜测的 GPU 性能评估:无需执行即可对 GPU 延迟进行符号建模的方法受到关注,相关的 学术资源 为理论理解和对计算效率的潜在影响提供了指导。
- 与社区共同挑战现状:讨论强调了社区驱动的项目以及在 Prompt 适配研究和实现查询(如 PyTorch 中的 Facenet 模型)等领域中协作解决问题的重要性。
OpenRouter (Alex Atallah) Discord
- 最新模型创新投放市场:OpenRouter 发布了新的 AI 模型,包括 Mistral 7B Instruct v0.3 和 Hermes 2 Pro - Llama-3 8B,同时保证之前版本如 Mistral 7B Instruct v0.2 仍可访问。
- 对 Max Loh 网站模型的好奇:用户对 Max Loh 网站 上使用的模型表示好奇,并有兴趣识别 OpenRouter 上可用的所有无审查模型。
- OCR 能力展示:Gemini 的 OCR 能力成为热门话题,用户称其在读取西里尔字母和英文文本方面具有卓越能力,超越了 Claude 和 GPT-4o 等竞争模型。
- OpenRouter Token 经济学:社区澄清了在 OpenRouter 上 0.26 美元可获得 1M 输入 + 输出 Token,讨论强调了每次聊天交互如何重新计算 Token 使用量,这可能会增加成本。
- 尖端 Vision 模型的成本:关于在 Azure 上使用 Phi-3 Vision 的成本展开了激烈讨论,一些成员认为 Llama 定价的 0.07 美元/M 太贵,尽管其他服务提供商也有类似的费率。
Nous Research AI Discord
- 翻译的苦恼:讨论涉及了在控制歌词语调以保留原始艺术意图的情况下翻译歌曲的挑战。其独特的困难在于平衡意义的忠实度与音乐性和艺术表达。
- AI 渗透 Greentext:成员们尝试使用 LLM 生成 4chan greentexts,分享了他们对 AI 叙事能力的着迷——尤其是构思一个醒来后发现 AGI 已经实现的世界的场景。
- 哲学性的 Phi 与逻辑受限的 LLM:围绕 Phi 模型的训练数据 构成展开了辩论,提到了“经过严格过滤的公开数据和合成数据”。此外,有报告显示 LLM 在交互过程中难以处理逻辑和自我修正,引发了对模型推理能力的担忧。
- 为机器消化塑造数据:AI 爱好者交流了关于创建 DPO 数据集和调整数据集格式以进行 DPO 训练的资源和见解。Hugging Face 的 TRL 文档 和 DPO Trainer 成为关键参考,此外还有一篇详细介绍根据偏好数据训练语言模型的 论文。
- 为 RAG 财富连接思想:协作氛围浓厚,成员们分享了在 RAG 相关项目上共同努力的意向。这包括 GitHub 上的情感和语义密度平滑 Agent 项目(带有 TTS),以及将现有项目移植到 SLURM 以增强计算管理的意图。
LangChain AI Discord
LangChain 中的无限循环问题:工程师们正在排查 LangChain agent 在调用工具时进入持续循环的问题;其中一个解决方案讨论涉及优化 Agent 的触发条件,以防止无限的工具调用循环。
详情请看!LangChain 0.2.2 中的 16385-token 错误:用户反馈 LangChain 0.2.2 版本中存在 token 限制错误,尽管模型支持高达 128k tokens,但系统却错误地应用了 16385-token 的限制,这引发了社区对该差异的调查。
SQL Prompt 编写咨询:关于带有 few-shot 示例的 SQL agent prompt 模板请求已得到解答,为工程师提供了在 LangChain 中更有效地构建查询的资源。
消失的自定义参数:Langserve 中的 custom kwargs:部分用户遇到通过 Langserve 发送用于 Langsmith 日志记录的自定义 “kwargs” 在到达时丢失的问题,该问题目前正在寻求解决方案。
应用展示:分享了使用 LangChain 开发的多样化应用,包括药物研发 (drug discovery) 框架、节省成本的日志记录措施、飞行模拟器增强功能,以及关于 Agent 流程中路由逻辑 (routing logic) 的教程。
Modular (Mojo 🔥) Discord
-
Mojo 用户的 Python 版本警示:提醒 Mojo 用户遵守支持的 Python 版本(3.8 到 3.11),因为 3.12 仍不受支持。通过使用 deadsnakes 仓库进行 Python 更新,解决了 Mojo 中的相关问题。
-
AI 驱动的游戏创新:工程师们讨论了开放世界游戏中基于 NPC 智能的订阅模式前景,并为智能设备引入特殊的 AI 功能,这可能导致 AI 推理 (inference) 在本地运行。他们还探讨了可以实现 AI 驱动自定义世界生成的开放世界游戏。
-
Mojo 精通:Mojo 允许循环依赖 (Circular dependencies),因为模块可以相互定义。
Intable和Stringable等 Traits 是原生可用的。虽然 lambda 函数尚未成为 Mojo 的功能,但目前使用回调 (callbacks) 作为替代方案。 -
性能先锋:在 Mojo 中,32 字节时观察到显著的 50 倍速度提升,但超过该长度后遇到了缓存限制。k-means 算法的基准测试显示出波动性,这是由于内存分配和矩阵计算的差异造成的,建议针对 AVX512 操作优化内存对齐。
-
Nightly 版本小结:最新的 Mojo 编译器版本 (2024.5.2805) 带来了新功能,包括
tempfile.{mkdtemp,gettempdir}和String.isspace()的实现,详细变更见当前更新日志和原始差异 (raw diff)。通过引用实现的结构共享 (Structural sharing) 也因其在 Mojo 编程中潜在的效率提升而受到关注。
Latent Space Discord
-
调试功能升级:工程师们称赞了 cursor 解释器模式 (interpreter mode),强调其在调试场景中具有比传统搜索功能更先进的代码导航能力。
-
消息助推器:Microsoft Copilot 集成到 Telegram 引起了关注,它能够通过游戏技巧和电影推荐等功能丰富聊天体验。
-
低成本训练 GPT-2:Andrej Karpathy 展示了一种经济高效的方法,仅需 20 美元即可在 90 分钟内训练 GPT-2,并在 GitHub 上详细介绍了该过程。
-
Agents 和 Copilots 的角色区分:在 Microsoft Build 进行分类后,关于 Copilots 和 Agents 之间的区别展开了辩论,并引用了 Kanjun Qiu 对该话题的见解。
-
AI 播客交付前沿发现:发布了一期聚焦 ICLR 2024 的播客,讨论了 ImageGen、Transformers、Vision Learning 等领域的突破,并期待即将发布的关于 LLM Reasoning 和 Agents 的见解。
LlamaIndex Discord
-
金融极客们,尽情享用 FinTextQA:FinTextQA 是一个旨在改进长文本金融相关问答系统的新数据集;它包含跨越 6 种不同问题类型 的 1,262 个带有来源属性的问答对。
-
完善 Prompt 结构:有人咨询了关于构建最佳系统角色 Prompt 的资源,并从 LlamaIndex 的模型中汲取了灵感。
-
聊天历史保存策略:社区讨论了在 LlamaIndex 中保存聊天历史的技术,考虑为 NLSQL 和 PandasQuery 引擎定制 Retriever,以维护查询和结果的记录。
-
API 函数管理探索:针对拥有超过 1000 个函数的庞大 API 提出了管理策略,倾向于使用层级路由(hierarchical routing)并将函数划分为更易于管理的子组。
-
LlamaIndex 的 RAG 系统复杂性辩论:剖析了 RAG 系统中与元数据相关的技术挑战,在为了获得最佳信息检索准确性而嵌入较小还是较大的语义分块(semantic chunks)方面,意见存在分歧。
LAION Discord
AI 的弦外之音:成员们对 SOTA AGI 模型的古怪言论付诸一笑,其中一个模型的自我训练断言——“它为我们训练了一个模型”——戳中了大家的笑点。马斯克对 CNNs 的嘲讽——调侃道“我们这些天不怎么使用 CNN 了”——引发了一连串的反讽回复,并对作为行业新宠的 Vision Transformer 模型表示了认可。
人工智能艺术家的水印烦恼:Corcelio 的 Mobius 艺术模型 正在通过多样化的 Prompt 挑战极限,但尽管它在创造力上超越了以往的模型,却仍会留下水印。图像生成系统产生“不当”内容的能力引发了伦理困境,触发了关于社区准则和系统控制设置的辩论。
合成视觉寻求改进:为了解决 SDXL 无法生成“正在阅读的眼睛”图像的问题,一名成员请求协作帮助,利用 DALLE 构建一个合成数据库,希望在这一细微的视觉任务中磨练 SDXL 的能力。
生成式水印中的模式与谜题:公会内部的观察指出,生成模型产生水印是一个反复出现的主题,这表明可能存在训练不足(undertraining),这在工程师中既被认为有趣又值得关注。
埃隆对 CNN 的白眼引发 AI 调侃:埃隆·马斯克的推文在社区中引起了涟漪,引发了关于 CNN 在当今变革性 AI 方法论中已过时的笑话,以及可能向 Transformer 模型转型的讨论。
tinygrad (George Hotz) Discord
无需基准测试的 GPU 延迟预测?:工程师们讨论了在不运行 Kernel 的情况下,通过考虑数据移动和操作时间来对 GPU 延迟进行符号化建模的可能性,尽管占用率(occupancy)和异步操作等复杂性被认为是潜在的干扰因素。人们还期待 AMD 开源 MES,并推测量化交易公司正在使用周期精确(cycle accurate)的 GPU 模拟器进行深入的 Kernel 优化。
使用 Autotuner 进行优化:社区探索了 AutoTVM 和 Halide 等 Kernel 优化工具,注意到它们在性能改进方面的不同方法;George Hotz 强调了 TVM 对 XGBoost 的使用,并强调了缓存仿真(cache emulation)对于准确建模的重要性。
GPU 中的延迟隐藏机制:有人指出,GPU 利用运行并发 Wavefronts/Blocks 的能力采用了多种延迟隐藏策略,从而使延迟建模变得更加复杂和细微。
Tinygrad 中的 Buffer 创建讨论:#learn-tinygrad 频道有成员询问在调度中使用后支配者分析(post dominator analysis)以提高图融合(graph fusion)效率,以及从数组创建 LazyBuffer 的问题,并建议在此类场景中使用 Load.EMPTY -> Load.COPY。
代码清晰度与协助:针对 Tinygrad 中的 Buffer 分配和 LazyBuffer 创建进行了详细讨论,一名成员提出提供代码指针(code pointers)以进一步澄清和理解。
AI Stack Devs (Yoko Li) Discord
-
Elevenlabs 语音进入 AI Town:通过集成 Elevenlabs 的文本转语音(text-to-speech)功能,AI Town 推出了一项新特性,让对话不仅能被阅读,还能被听到。目前约有一秒的轻微延迟,这对实时使用构成了挑战。实现过程涉及将文本转换为音频以及在前端管理音频播放。
-
将科学辩论引入 AI 聊天:分享了一个利用 AI 聊天机器人模拟科学辩论的概念,旨在促进用户参与并展示科学讨论的统一性。
-
新增音频窃听功能以增强沉浸感:AI Town 的 Zaranova 分支现在通过为环境对话生成音频来模拟“窃听”,这可能会增强平台的互动性。
-
协作开发集结:社区对贡献并可能将新功能(如文本转语音)合并到 AI Town 主项目表现出浓厚兴趣。
-
解决用户体验问题:有用户反映对话关闭速度过快,导致无法舒适阅读,这暗示 AI Town 需要在用户界面和无障碍体验方面进行改进。
Cohere Discord
-
精简日志:一名成员开发了新的流水线来移除冗余日志以降低成本。他们推荐使用一个工具来选择“详细日志(verbose logs)”流水线以实现此目标。
-
讨论部署方案:成员们讨论了用于 reranking 和查询提取(query extraction) 的云端/本地部署方案,在没有提供更多背景的情况下寻求最佳集成实践的见解。
-
金融 RAG 微调:有人咨询了微调 Cohere 模型以回答金融问题的可能性,特别提到了使用 SEC 备案文件与 RAG(检索与生成)系统的集成。
-
Aya23 模型的限制性使用:会议澄清了 Aya23 模型严格用于研究目的,不可用于商业用途,这影响了它们在初创公司环境中的部署。
-
机器人玩游戏:一名成员推出了由 Cohere Command R 驱动的游戏机器人 Create ‘n’ Play,其特点是拥有“超过 100 款基于文本的游戏”,旨在促进 Discord 上的社交互动。该项目的开发情况和目的可以在这篇 LinkedIn 帖子中找到。
OpenAccess AI Collective (axolotl) Discord
-
推理与训练的现实:对话强调了 AI 训练中的性能数据,特别是关于“仅推理(inference only)”话题的简单查询如何迅速演变为关注训练计算需求的复杂领域。
-
FLOPS 决定训练速度:讨论中的一个关键点是,AI 模型训练在实践中受限于每秒浮点运算次数(FLOPS),特别是在采用 teacher forcing 等技术增加有效 batch size 时。
-
期待用于 FP8 的 Hopper 显卡:社区对 Hopper 显卡在 FP8 原生训练方面的潜力表现出极大热情,凸显了利用尖端硬件提升训练吞吐量的浓厚兴趣。
-
消除 fschat 的版本混淆:由于错误的版本标识,成员们被建议通过重新安装来解决 fschat 问题,这体现了该集体生态系统中对细节的严谨关注。
-
当 CUTLASS 更胜一筹时:讨论明确了设置
CUTLASS_PATH的重要性,强调了 CUTLASS 在优化深度学习至关重要的矩阵运算中的作用,突出了该组织对优化算法效率的关注。
Interconnects (Nathan Lambert) Discord
-
Apache 欢迎 YI 和 YI-VL 模型:YI 和 YI-VL(多模态 LLM)模型现在采用 Apache 2.0 许可证,正如 @_philschmid 的推文所庆祝的那样;它们在这次许可更新中加入了 1.5 系列。
-
Gemini 1.5 挑战王座:Gemini 1.5 Pro/Advanced 已攀升至排行榜第 2 位,并有超越 GPT-4o 的野心,而 Gemini 1.5 Flash 则自豪地占据了第 9 位,险胜 Llama-3-70b,正如 lmsysorg 的推文所宣布的那样。
-
OpenAI 董事会蒙在鼓里:一位前 OpenAI 董事会成员透露,董事会事先并未获悉 ChatGPT 的发布,而是像公众一样通过 Twitter 才得知消息。
-
Toner 对 OpenAI 领导层投下重磅炸弹:OpenAI 前董事会成员 Helen Toner 在 TED 播客节目中指责 Sam Altman 营造了有毒的工作环境且行为不诚实,并敦促“对 AI 公司进行外部监管”。
-
社区对 OpenAI 的爆料感到震惊:针对 Helen Toner 的严重指控,社区表达了震惊,并对行业可能发生重大变革的前景充满期待,Natolambert 甚至发问 Toner 是否会“从字面意义上拯救世界?”
Datasette - LLM (@SimonW) Discord
- 专家认可的常用 LLM 排行榜:chat.lmsys.org 上的排行榜受到了用户的关注和认可,被认为是比较各种大语言模型(LLM)性能的可靠资源。
Mozilla AI Discord
- 保护本地 AI 端点至关重要:一位成员强调了保护 AI 模型本地端点的重要性,建议使用 DNS SRV 记录和公钥来确保经过验证且值得信赖的本地 AI 交互,并开玩笑说未经证实的模型可能会导致意外购买乡村音乐或喂松鼠的风险。
- 故障排除警报:发现 Llamafile 错误:一位运行 Hugging Face llamafile(具体为
granite-34b-code-instruct.llamafile)的用户报告了一个“未知参数:–temp”的错误,这表明模型部署过程的实施阶段可能存在问题。 - 关注正在运行的模型:在一次澄清中指出,无论本地
localhost:8080运行的是什么模型(如 tinyllama),它都将是默认模型,聊天补全请求中的model字段对操作无关紧要。这表明所使用的 llamafiles 采用的是单模型运行范式。
提到的链接:granite-34b-code-instruct.llamafile
OpenInterpreter Discord
- 请求 R1 更新:一位成员表达了对 R1 未来发展的期待,并幽默地提到如果它达不到预期,可能会变成一个“漂亮的镇纸”。
- 社区寻求明确答复:社区内对 R1 相关的更新有着共同的好奇心,成员们正在积极寻求和分享信息。
- 等待支持团队的关注:向 OI 团队咨询的一封电子邮件正在等待回复,这表明需要改进沟通或支持机制。
AI21 Labs (Jamba) Discord
- 发现一座“鬼城”:一位成员提出担忧,认为该服务器似乎无人管理,这可能意味着管理员的疏忽,或者是故意采取的放任自流的态度。
- 通知未能发出:在服务器中尝试使用 @everyone 标签失败,这表明权限受限或存在技术故障。
MLOps @Chipro Discord
- LLM 用于后端自动化的咨询未获回应:一位成员好奇课程是否涵盖使用 Large Language Models (LLM) 自动化后端服务的内容,但该问题尚未得到解答。该咨询旨在寻求有关 LLMs 在自动化后端流程中实际应用的见解。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
完整的各频道详细分析已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!预谢!