ainews-mamba-2-state-space-duality
Mamba-2:状态空间对偶性
Mamba-2 是一种新型的状态空间模型 (SSM),在困惑度(perplexity)和实际运行时间(wall-clock time)方面均优于之前的 Mamba 和 Transformer++ 模型。其特点是状态规模扩大了 8 倍,且训练速度提升了 50%。它引入了状态空间对偶性 (SSD) 的概念,将 SSM 与线性注意力机制联系起来。
FineWeb-Edu 数据集是拥有 15 万亿 token 的 FineWeb 数据集的高质量子集,通过 llama-3-70b 针对教育质量进行了过滤,能够实现更好、更快的 LLM 学习,并有望减少超越 GPT-3 性能所需的 token 数量。此外,使用 1.25 亿参数模型进行基于困惑度的数据剪枝,可以提高下游任务性能,并将预训练步数减少多达 1.45 倍。Video-MME 基准测试则用于评估多模态大模型在不同视觉领域和视频长度下的视频分析能力。
Transformers 是 SSMs。
2024/5/31-2024/6/3 的 AI 新闻。 我们为您查看了 7 个 subreddits、384 个 Twitter 账号 和 29 个 Discord(400 个频道,8575 条消息)。 预计节省阅读时间(按 200wpm 计算):877 分钟。
周末我们收到了 FineWeb 技术报告(我们 一个月前报道过),事实证明,通过更好的过滤和去重,它确实在 CommonCrawl 和 RefinedWeb 的基础上有所改进。
然而,我们将周末的胜利(W)归功于 Mamba 的共同作者们,他们带着 Mamba-2 再次回归。其核心仅有 30 行 Pytorch 代码,在 perplexity 和 wall-clock time 上都优于 Mamba 和 Transformer++。
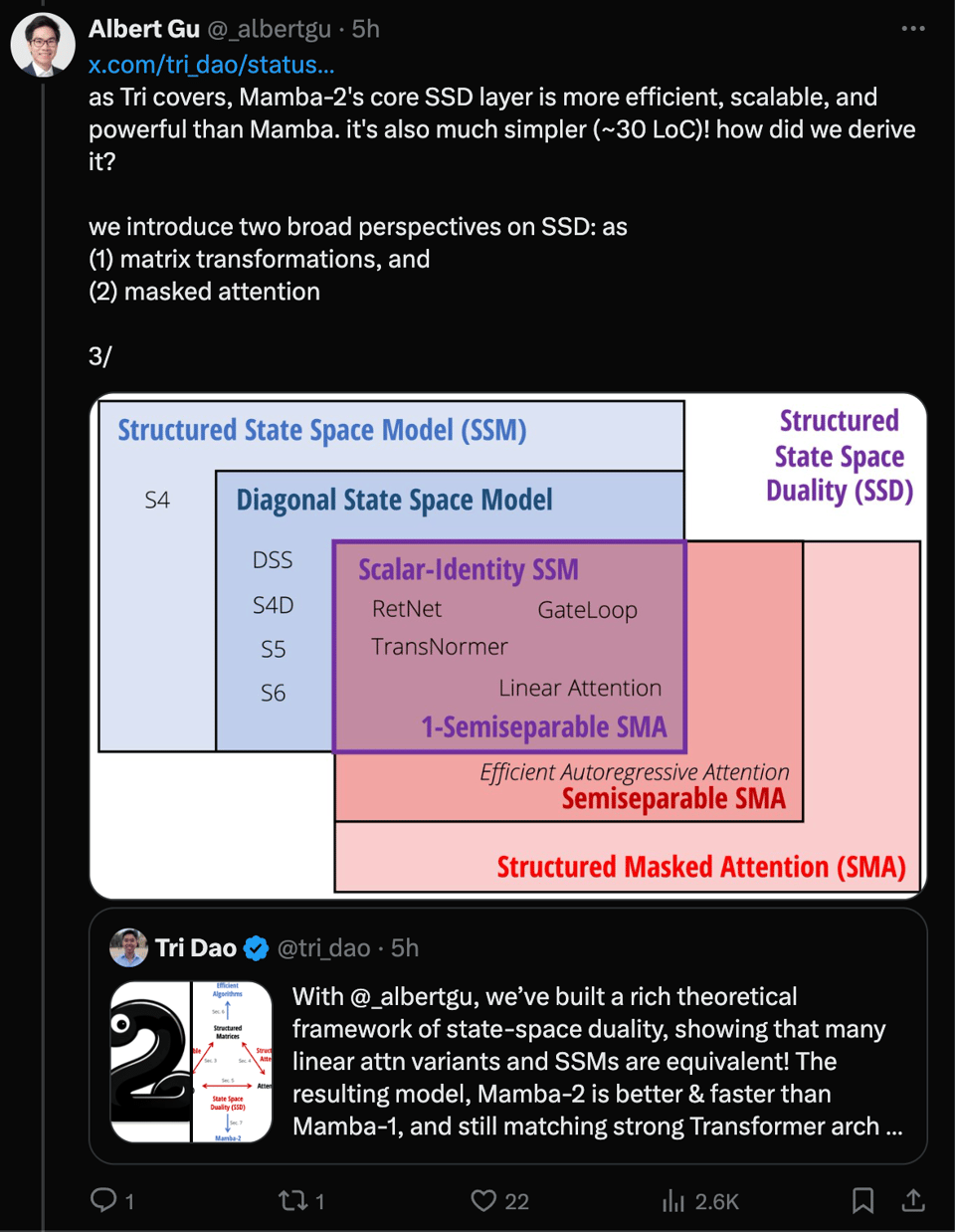
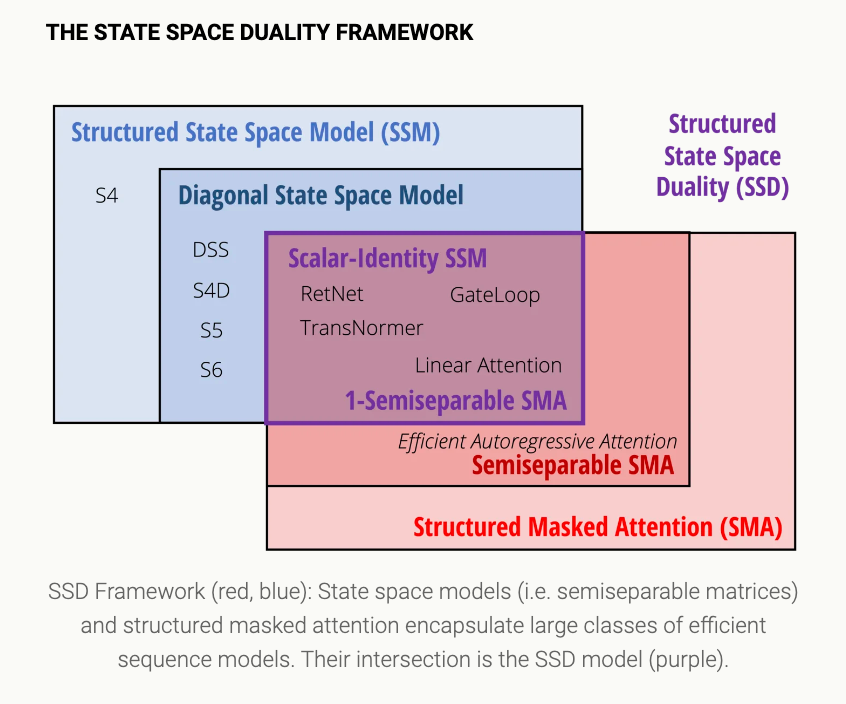
Tri 建议先阅读博客,该博客分 4 个部分介绍了 Mamba-2 的开发:
- 模型 (The Model)
- 理解:SSMs 与 attention 之间有哪些概念上的联系?我们能将它们结合吗?
正如我们在早期关于结构化 SSMs 的工作中所阐述的,它们似乎捕捉到了连续、卷积和循环序列模型的本质——全部包裹在一个简单而优雅的模型中。
- 效率:我们能否通过将 Mamba 模型重构为矩阵乘法来加速其训练?
尽管在提高 Mamba 速度方面投入了大量工作,但它的硬件效率仍然远低于 attention 等机制。
- Mamba 和 Mamba-2 之间的核心区别在于其 A 矩阵更严格的对角化:
 利用这个定义,作者证明了 Quadratic Mode (Attention) 和 Linear Mode (SSMs) 之间的等价性(对偶性),并解锁了矩阵乘法。
利用这个定义,作者证明了 Quadratic Mode (Attention) 和 Linear Mode (SSMs) 之间的等价性(对偶性),并解锁了矩阵乘法。
- 理解:SSMs 与 attention 之间有哪些概念上的联系?我们能将它们结合吗?

- 理论 (The Theory)
- 算法 (The Algorithm)
- 系统 (The Systems)
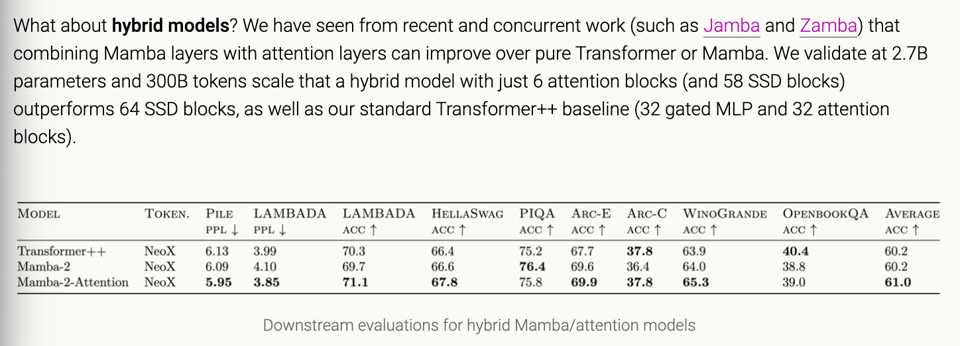
- 他们展示了 Mamba-2 在评估中不仅击败了 Mamba-1 和 Pythia,而且在放入类似于 Jamba 的混合模型架构时,在评估中占据主导地位:
AI Twitter 回顾
所有回顾均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程。
AI 与机器学习研究
-
Mamba-2 状态空间模型:@_albertgu 和 @tri_dao 推出了 Mamba-2,这是一种状态空间模型 (SSM),在 perplexity 和 wall-clock time 上均优于 Mamba 和 Transformer++。它提出了一个连接 SSMs 和 linear attention 的框架,称为状态空间对偶性 (SSD)。Mamba-2 的状态比 Mamba 大 8 倍,训练速度快 50%。(@arankomatsuzaki 和 @_akhaliq)
-
FineWeb 和 FineWeb-Edu 数据集:@ClementDelangue 强调了 FineWeb-Edu 的发布,这是 15 万亿 token 的 FineWeb 数据集的高质量子集,通过使用 Llama 3 70B 模型过滤 FineWeb 以评判教育质量而创建。它能够实现更好、更快的 LLM 学习。@karpathy 指出它有潜力减少超越 GPT-3 性能所需的 token 数量。
-
基于 Perplexity 的数据剪枝:@_akhaliq 分享了一篇关于使用小型参考模型进行基于 perplexity 的数据剪枝的论文。基于 125M 参数模型的 perplexity 进行剪枝提高了下游性能,并减少了高达 1.45 倍的预训练步骤。
-
Video-MME 基准测试:@_akhaliq 介绍了 Video-MME,这是首个评估多模态 LLM 视频分析能力的综合基准测试,涵盖了 6 个视觉领域、视频长度、多模态输入和人工标注。Gemini 1.5 Pro 的表现显著优于开源模型。
AI 伦理与社会影响
-
AI 末日论与奇点论:@ylecun 和 @fchollet 批评 AI 末日论和奇点论是驱动疯狂信仰的“末世邪教”,导致一些人由于对 AI 的恐惧而停止了长期生活规划。@ylecun 认为这些论调让人感到无力,而不是动员人们去寻找解决方案。
-
对 Dr. Fauci 和科学的攻击:@ylecun 谴责共和党国会议员对 Dr. Fauci 的攻击是“可耻且危险的”。Fauci 帮助挽救了数百万人,却被那些将政治置于公共安全之上的人诋毁。对科学和科学方法的攻击是“极其危险的”,并且通过破坏公众对公共卫生的信任,在疫情期间导致了人员死亡。
-
对 Elon Musk 的看法:@ylecun 分享了对 Musk 的看法,喜欢他的汽车、火箭、太阳能/卫星以及在开源/专利方面的立场,但不同意他对科学家的态度、炒作/错误预测、政治观点以及阴谋论,认为这些“对民主、文明和人类福祉是危险的”。他认为 Musk 在其社交平台上“对内容审核的难度和必要性表现得过于天真”。
AI 应用与演示
-
Dino Robotics 机器人厨师:@adcock_brett 分享了 Dino Robotics 机器人厨师制作炸肉排和薯条的视频,该机器人利用物体定位和 3D 图像处理技术,并经过训练以识别各种厨房物品。
-
SignLLM:@adcock_brett 报道了 SignLLM,这是首个用于手语生成的语言多语种 AI 模型,能够根据八种语言的自然语言生成 AI 虚拟人手语视频。
-
Perplexity Pages:@adcock_brett 重点介绍了 Perplexity 的 Pages 工具,用于将研究内容转化为可以在 Google Search 中排名的文章、报告和指南。
-
1X 人形机器人:@adcock_brett 演示了 1X 的 EVE 人形机器人执行拾取衬衫和杯子等链式任务,并提到了内部更新。
-
Higgsfield NOVA-1:@adcock_brett 介绍了 Higgsfield 的 NOVA-1 AI 视频模型,允许企业使用其品牌资产训练自定义版本。
杂项
-
交友建议:@jxnlco 分享了建立社交网络的技巧,如运动、创意表达、烹饪团体餐以及基于共同兴趣联系他人。
-
笔记本电脑推荐:@svpino 赞扬了“完美”但昂贵的 Apple M3 Max,配备 128GB RAM 和 8TB SSD。
-
Nvidia 主旨演讲:@rohanpaul_ai 指出 Nvidia 在 8 年间将数据中心 AI 计算成本降低了 350 倍。@rohanpaul_ai 强调了在集成 RAPIDS cuDF 后,Google Colab 上的 Pandas 速度提升了 50 倍。
-
Python 赞誉:@svpino 称 Python 是“有史以来无可争议的编程语言 GOAT(史上最伟大)”,并且 @svpino 建议教孩子学习 Python。
幽默与迷因
-
Elon Musk 玩笑:@ylecun 向 @elonmusk 开玩笑说 “Elno Muks” 声称正在“给他发垃圾(sh$t)”。
-
获胜迷因:@AravSrinivas 发布了一张“一直赢是什么样子的?”迷因图片。
-
陶器玩笑:@jxnlco 开玩笑说:“烹饪证明。是的,我在一个复古围棋盘上吃饭。”
-
Stable Diffusion 3 迷因:@Teknium1 批评 Stability AI “编造了一个没人听说过的名为 SD3 ‘Medium’ 的新版本”,同时却不发布 Large 和 X-Large 版本。
-
Llama-3-V 争议梗图:@teortaxesTex 发布了关于 Llama-3-V 的 GitHub 和 HF 页面在“被爆出抄袭 @OpenBMB 模型证据后”下线的消息。
AI Reddit 综述
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 模型发布与更新
-
Stability AI 将于 6 月 12 日发布 SD3 Medium 开放权重:在 /r/StableDiffusion 中,Stability AI 宣布将发布 2B 参数的 SD3 Medium 模型,该模型专为写实摄影、排版、性能优化以及非商业用途下的微调而设计。2B 模型目前在某些指标上优于 8B 版本,且与某些采样方法不兼容。商业权利将通过会员计划提供。
-
Nvidia 和 AMD 揭晓未来 AI 芯片路线图:在 /r/singularity 中,Nvidia 透露了截至 2027 年的计划,其 Rubin 平台将接替 Blackwell,继 OpenAI 模型中使用的 H100 之后,H200 和 B100 芯片也即将推出。AMD 宣布推出拥有 288GB 显存的 MI325X,旨在与 Nvidia 的 H200 竞争,MI350 和 MI400 系列将在未来几年提供重大的推理提升。
AI 能力与局限性
-
AI 生成媒体误导主流新闻:一段被 NBC News 误认为展示真实舞蹈效果的 视频 证明了 AI 生成内容甚至能愚弄大型媒体机构。
-
真正开源 AI 的挑战:一段 视频 指出,开源 AI 并非真正的开源,因为如果没有训练数据、顺序和技术,模型权重是难以捉摸的。由于依赖授权数据,完全开源 LLM 具有很大难度。
-
多模态推理的局限性:在 /r/OpenAI 中,ChatGPT 在图像中标记物体时遇到困难,尽管它能正确识别该物体,这突显了目前 AI 在跨模态推理能力上的差距。
AI 开发工具与技术
-
高质量 Web 数据集在知识和推理方面表现出色:拥有 1.3T token 的 FineWeb 数据集 在知识和推理基准测试中超越了其他开放的 Web 规模数据集。相关的博客文章详细介绍了从 Web 数据创建高质量数据集的技术。
-
书中介绍的新机器学习数学工具:书籍《Tangles》应用了一种新颖的数学方法 来对特征进行分组,以识别数据中的结构和类型,应用范围涵盖从聚类到药物研发。提供开源代码。
-
LLM 的参数化压缩:在 /r/LocalLLaMA 中,一种 简单的参数化压缩方法 在不进行微调的情况下,将 LLaMA 3 70B 的不重要层剪枝至 62B 参数,在基准测试中仅出现轻微的性能下降。
AI 伦理与社会影响
-
披露 AI 对就业影响的伦理困境:/r/singularity 讨论了 是否应该告知朋友 AI 现在可以在几秒钟内完成他们的工作(如书籍封面设计)的困境。传达此类消息的痛苦与隐瞒真相之间的权衡。
-
民意调查衡量对 AI 威胁就业安全的看法:/r/singularity 的一项 投票 衡量了在 AI 自动化的背景下,人们对自己工作在未来 10 年内能否持续的信心。
梗图与幽默
- 梗图讽刺 AI 广泛的职业替代潜力:一张 “所有工作”的梗图 幽默地描绘了 AI 替代广泛职业的能力。
{kind=link}
AI Discord 摘要回顾
摘要之摘要的摘要
-
LLM 进展与多模态应用:
-
来自 IBM 的 Granite-8B-Code-Instruct 增强了代码任务的指令遵循(instruction-following)能力,超越了主要基准测试。Stable Diffusion 3 Medium 版本即将发布,承诺提供更好的写实感和排版能力,计划于 6 月 12 日推出。
-
AI 工程社区讨论了 SD3 的 VRAM 需求,预测在考虑 fp16 优化等潜在缩减方案的情况下,需求约为 15GB。FlashAvatar 承诺使用 Nvidia RTX 3090 实现 300FPS 的数字分身,引发了对高保真头像创建的关注。
-
-
微调技术与挑战:
-
针对克服半精度训练中 tokenizer 问题的建议包括设置
tokenizer.padding_side = 'right',并使用 LoRA 技术来增强微调效果。Axolotl 用户在处理二分类任务时遇到问题,建议使用 Bert 作为替代方案。 -
社区见解强调了使用 Gradio 的 OAuth 进行私有应用访问的有效性,以及
share=True对于快速应用测试的实用性。故障排除包括处理 Kaggle 中的推理设置问题,以及 Axolotl 中损失值(loss values)的差异,并考虑了输入输出预处理等因素。
-
-
开源项目与社区协作:
-
Manifold Research 征集多模态 Transformer 和控制任务方面的合作,旨在构建一个全面的开源通用模型(Generalist Model)。StoryDiffusion 和 OpenDevin 作为新的开源 AI 项目涌现,引发了广泛关注。
-
将 TorchAO 与 LM Evaluation Harness 集成的努力集中在添加量化支持的 API 上。社区倡议(如使 Axolotl 适配 AMD 兼容性)突显了在完善 AI 工具和框架方面的持续努力。
-
-
AI 基础设施与安全:
-
Hugging Face 安全事件 促使官方建议轮换 token 并切换到细粒度访问 token,这影响了用户在 HF Spaces 等处的基础设施。OpenRouter 的讨论提到了亚洲地区的数据库超时问题,导致了服务更新并停用了某些模型,如 Llava 13B 和 Hermes 2 Vision 7B。
-
ZeRO++ 框架在大型模型训练中显著降低了通信开销,助力 LLM 的实现。Paddler 有状态负载均衡器提升了 llama.cpp 的效率,有望优化模型推理服务能力。
-
-
AI 研究与伦理讨论:
-
Yudkowsky 针对 AI 发展的争议性策略引发辩论,其中包括对数据中心进行空袭等激进措施。LAION 社区对此做出反应,讨论了开放协作与防止滥用之间的平衡。
-
关于 Transformer 局限性的新理论:实证证据表明 Transformer 在大定义域上的函数组合方面存在困难,这催生了模型设计的新方法。关于 Embedding 效率的讨论仍在继续,对比了不同 LLM 实现中上下文窗口(context windows)对性能的影响。
-
第一部分:Discord 高层级摘要
HuggingFace Discord
-
HF Spaces 的安全漏洞:在 HF Spaces 发生安全事件后,建议用户轮换所有 token 或密钥,详情见 HuggingFace 的 博客文章。
-
AI 与伦理辩论升温:关于实验室培养神经元分类的辩论引发了对人工智能本质和伦理的深入讨论。同时,HuggingFace 基础设施问题导致了 “MaxRetryError” 问题的解决。
-
Rust 兴起:一名成员合作在 Rust 中实现深度学习书籍 (d2l.ai),并贡献至 GitHub,而其他人则讨论了 Rust 的 Candle 库在效率和部署方面的优势。
-
文献综述见解与奇特创作:Medium 上总结了一篇 LLM 推理文献综述,此外还分享了 Fast Mobius demo 和 gary4live Max4Live 设备等创意项目,体现了工程严谨性与想象力的融合。
-
实际应用与社区对话:分享了使用 TrOCR 和 MiniCPM-Llama3-V 2.5 等模型进行 OCR 任务的实用指南。讨论还延伸到 LLM 确定性以及增强语言生成和翻译任务的资源建议,特别引用了 Helsinki-NLP/opus-mt-ja-en 作为强大的日译英工具。
-
机器人与 Gradio 的令人兴奋的进展:文章《使用 Lerobot 深入研究 Diffusion Policy》展示了机器人领域的 ACT 和 Diffusion Policy 方法,同时 Gradio 宣布支持动态布局,使用 @gr.render,例如在 Render Decorator 指南 中探索的 Todo List 和 AudioMixer 等多功能应用。
Unsloth AI (Daniel Han) Discord
-
多 GPU 微调进展: 多 GPU 微调正在积极开发中,并讨论了多模态扩展的可行性。分享了对 LoRA 的详细分析,强调了其在特定微调场景中的潜力。
-
训练挑战的技术解决方案: 建议通过设置
tokenizer.padding_side = 'right'来缓解半精度训练中的 tokenizer 问题,并就使用 Kaggle Notebooks 加速 LLM 微调提供了见解。 -
AI 模型实现故障排除: 用户在 GTX 3090 上运行 Phi 3 模型以及在 H100 NVL 上进行 RoPE 优化时遇到困难。社区推荐的修复方案包括 Unsloth 的更新以及对潜在内存报告 Bug 的讨论。
-
模型安全与局限性备受关注: 关于企业因安全顾虑(重点是防止有害内容生成)而犹豫是否使用开源 AI 模型的辩论浮出水面。此外,大家公认 LLM 存在无法在其训练数据之外进行创新的固有局限性。
-
AI 协作工具的持续改进: 社区分享了在 Kaggle 等平台上保存模型和修复安装问题的解决方案。此外,在 Hugging Face 和 Wandb 等平台的微调 Checkpoint 管理优化方面也存在积极协作。
Stability.ai (Stable Diffusion) Discord
-
SD3 Medium 发布倒计时:Stability.ai 宣布 Stable Diffusion 3 Medium 定于 6月12日 发布;感兴趣的用户可以加入等候名单以获取早期访问权限。在台北国际电脑展(Computex Taipei)上的公告强调了该模型在照片级写实感(photorealism)和排版(typography)方面预期的性能提升。
-
关于 SD3 规格的推测:AI 工程社区正热烈讨论 Stable Diffusion 3 可能的 VRAM 需求,预测约为 15GB,同时也有建议提到通过 fp16 优化可能降低这一数字。
-
商业用途需明确说明:用户强烈要求 Stability AI 明确说明 SD3 Medium 商业使用的许可条款,担忧主要源于向带有非商业限制的许可证转型。
-
货币化举措遭遇抵制:免费的 Stable AI Discord 机器人被付费服务 Artisan 取代,引发了社区的不满,凸显了 AI 工具访问趋向货币化的广泛趋势。
-
为优化和微调做好准备:在 SD3 Medium 发布前夕,工程师们正期待社区微调(fine-tunes)流程以及在不同 GPU 上的性能基准测试,Stability AI 确保支持 1024x1024 分辨率优化,包括分块(tiling)技术。
Perplexity AI Discord
-
AI 辅助作业:机遇还是阻碍?:工程师们对 AI 辅助作业的伦理问题分享了不同观点,将其比作在“糖果和羽衣甘蓝”之间做选择,并建议重点教导孩子负责任地使用 AI。
-
引导 Perplexity Pages 的潜力:用户表示需要增强 Perplexity 的 Pages 功能,如导出功能和可编辑标题,以提高可用性,同时对某些模型(如 Opus)的自动选择和配额耗尽表示担忧。
-
增强交互的扩展程序:旨在改进 Perplexity UI 的 Complexity 浏览器扩展程序的发布引起了社区关注,并邀请 Beta 测试人员来提升用户体验。
-
测试 AI 敏感性:讨论强调了 Perplexity AI 处理敏感话题的能力,通过在创建以巴冲突等话题页面时的表现证明了这一点,其令人满意的结果增强了人们对其合规性过滤器的信心。
-
专家级应用的 API 探索:AI 工程师讨论了在 Perplexity API 中针对不同任务的最佳模型使用方案,阐明了小型快速模型与大型准确模型之间的权衡,同时也对潜在的 TTS API 功能表示热衷。参考了 model cards 以获取指导。
CUDA MODE Discord
推测性解码闲谈:工程师们分享了关于 Speculative Decoding 的见解,并提出了添加 Gumbel Noise 和确定性 Argmax 的建议。该主题的录制课程预计在编辑后上传。讨论强调了消融研究(Ablation Studies)在理解采样参数对接受率(Acceptance Rates)影响方面的重要性。
CUDA 迈向云端:讨论了租用 H100 GPU 进行性能分析(Profiling)的事宜,推荐了 cloud-gpus.com 和 RunPod 等供应商。同时,也指出了在不进行大规模 Hack 的情况下收集 Profiling 信息的挑战。
工作与娱乐:宣布成立了一个 Production Kernels 工作组和另一个 PyTorch 性能相关文档 工作组,并邀请大家协作。此外,还给初学者提供了一个小贴士:避免在社区中过度使用 @everyone,以防止不必要的通知骚扰。
技术演讲预告:即将举行的演讲和研讨会包括关于 Tensor Cores 和高性能 Scan 算法的会议。社区还期待邀请 Wen-mei Hwu 教授进行公开问答,以及来自 AMD Composable Kernel 团队的分享。
数据深度探索与开发讨论:#llmdotc 频道的讨论内容非常丰富,包括成功向 Hugging Face 上传 200GB 数据集的细节、LayerNorm 计算优化的提案,以及为了面向未来和更易于集成模型架构而进行的重大代码库重构。
精度与量化:介绍了 AutoFP8 GitHub 仓库,旨在自动转换为 FP8 以提高计算效率。同时,讨论了将 TorchAO 与 LM Evaluation Harness 集成的方案,包括用于改进量化支持的 API 增强。
职场动态解析:Anyscale 正在寻找对 Speculative Decoding 和系统性能感兴趣的候选人。同时,强调了 Chunked Prefill 和 Continuous Batching 实践在预测运营效率方面的重要性。
知识传播:关于 Scan 算法和 Speculative Decoding 的演讲录像将在 CUDA MODE YouTube 频道上发布,为高性能计算的持续学习提供资源。
PyTorch 性能解析:号召在即将到来的六月文档马拉松(Docathon)期间改进 PyTorch 的性能文档,重点关注当前实践而非 TorchScript 等已弃用的概念,并推动理清自定义 Kernel 的集成。
LM Studio Discord
-
VRAM 征服者:工程师们正在讨论针对高 Token Prompt 导致低 VRAM 系统响应缓慢的解决方案,并为家庭 AI 装备推荐了如 Nvidia P40 卡等实用的模型硬件。
-
Codestral 夺得编程桂冠:Codestral 22B 在上下文和指令处理方面的卓越表现引发了讨论。同时,解决了 LM Studio 中 Embedding 模型列表的问题,并交流了使用不同模型处理文本生成的经验。
-
缺乏支持的 Whisper:尽管用户强烈要求在 LM Studio 中加入 Whisper 和 Tortoise 增强的音频功能,但关于体积与复杂度的权衡引发了讨论。此外,还揭露了当前版本中的一个 “Stop String” Bug。
-
配置难题:出现了关于从编码到推理等应用的模型配置设置查询,重点关注量化权衡以及在特定 GPU 硬件上推理速度的神秘体验。
-
增强融合探险:成员们思考了如何创建 Visual Studio 插件以实现更智能的编码辅助,借鉴了现有辅助工具的经验,并探讨了使用 Mentat 等模型实现全项目上下文理解的潜力。
注:模型、讨论和 GitHub 仓库的具体链接已在相应频道中提供,可查阅以获取更多技术细节和背景。
Nous Research AI Discord
-
在 Token 世界中蓬勃发展:新发布的 FineWeb-Edu 数据集拥有 1.3 万亿个 Token,据称在 MMLU 和 ARC 等基准测试中表现卓越,详细的技术报告可在此处 访问。
-
电影魔术师资源大爆发:一个包含 3000 个 剧本的数据集 现已面向 AI 爱好者开放,其中包含从 PDF 转换而来的 .txt 格式剧本,并采用 AGPL-3.0 许可证,供模型训练爱好者使用。
-
虚拟舞台指令:使用 Worldsim 进行的策略模拟正围绕乌克兰-俄罗斯冲突展开,展示了其构建详细场景的能力,尽管目前存在一个导致 文本重复 的技术故障,正在审查中。
-
蒸馏困境与线程讨论:研究人员正在交流如何有效地将知识从大模型(如 Llama70b)蒸馏到小模型(如 Llama8b),并建议在管理 AI Agent 任务时使用线程(threading)而非循环(loops)。
-
模型伦理备受关注:社区对 MiniCPM-Llama3-V 涉嫌抄袭 OpenBMB 的 MiniCPM 展开了激烈辩论,在集体关注和证据曝光后,争议模型已从 GitHub 和 Hugging Face 等平台移除。
LLM Finetuning (Hamel + Dan) Discord
-
Axolotl 的挑战:工程师报告了在 Axolotl 的 .yaml 文件中配置二分类(binary classification)时遇到的问题,收到了
ValueError,提示没有对应的 ‘train’ 指令数据。建议的替代方案是部署 Bert 进行分类任务,或者在 Axolotl 缺乏支持时直接使用 TRL。 -
Gradio 的实用性备受赞誉:AI 开发者利用 Gradio 的
share=True参数快速测试和分享应用。讨论还涉及使用 OAuth 进行私有应用访问以及整体分享策略,包括在 HF Spaces 上托管以及处理身份验证和安全性。 -
Modal 之谜与 GitHub 忧虑:由于 近期安全事件 导致 Modal 脚本中缺乏 Hugging Face 的身份验证,用户在下载 Mistral7B_v0.1 等模型时遇到错误。其他挑战还包括 Accelerate 中的
device map = meta,一位用户分享了其在推理机制中的效用。 -
积分结算的关键时刻:截止日期驱动的讨论占据了频道,许多成员担心各平台积分的及时分配。Dan 和 Hamel 介入并进行了说明和安抚,强调了准确填写表格以避免错过平台特定积分的重要性。
-
面向未来的微调:提出了 LLM 训练和微调的可能调整及各种策略,例如将 batch size 保持为 2 的幂次方,使用梯度累积步数(gradient accumulation steps)优化训练,以及大 batch size 在以太网分布式设置中稳定训练的潜力。
OpenAI Discord
-
零交叉与 SGD:持续的争议:关于在优化器改进中追踪梯度中的零交叉(zero crossings)的优缺点的讨论仍在继续,在应用中观察到的结果褒贬不一。另一个热议话题是 SGD 作为基准(baseline)与新优化器进行比较的作用,这表明进展可能取决于学习率(learning rate)的改进。
-
FlashAvatar 引起关注:一种名为 FlashAvatar 的用于创建高保真数字分身的方法引起了特别关注,据 FlashAvatar 项目详情介绍,该方法在 Nvidia RTX 3090 上可实现高达 300FPS 的渲染速度。
-
了解 GPT-4 的怪癖:社区讨论集中在 GPT-4 的内存泄漏和行为上,讨论了“白屏”错误和可能与温度(temperature)设置相关的重复输出实例。还讨论了自定义 GPT 的使用和 API 限制,强调了根据 OpenAI 帮助文章规定的每文件 512 MB 和每文件 500 万个 token 的限制。
-
上下文窗口与 Embedding 有效性的辩论:一场激烈的辩论聚焦于 Embedding 与扩展上下文窗口(context windows)在提升性能方面的有效性。人们还考虑了将 Gemini 纳入流水线的前景,据称这能增强 GPT 的性能。
-
Prompt Engineering 中的困扰:社区成员分享了 ChatGPT 遵循提示词指南方面的挑战,并寻求改进策略。观察发现,在构建复杂提示词时,倾向于使用单个系统消息(system message)。
Modular (Mojo 🔥) Discord
-
Mojo Server 稳定性风波:用户报告 Mojo 语言服务器在 M1 和 M2 MacBook 上的 VS Code 衍生版本(如 Cursor)中崩溃,详情记录在 GitHub issue #2446 中。修复方案已存在于 nightly 构建版本中,且有一个 YouTube 教程涵盖了可以加速代码循环的 Python 优化技术,建议那些寻求提升 Python 性能的用户参考。
-
密切关注 Mojo 的演进:围绕 Mojo 成熟度的讨论集中在其开发进度和开源社区贡献上,如 Mojo 路线图和相应的博客公告所述。其他讨论还包括 Mojo 在数据处理和网络方面的潜力,利用了 DPDK 和 liburing 等框架。
-
Mojo 与 MAX 编排前向与反向传播:在 Max 引擎中,成员们正在剖析实现前向传播(forward pass)以保留反向传播(backward pass)所需输出的细节,并对缺乏反向计算文档表示担忧。社区对 Mojo 中的条件一致性(conditional conformance)功能感到兴奋,这将增强标准库的功能。
-
Nightly 更新亮点:nightly Mojo 编译器 (2024.6.305) 的持续更新引入了新功能,例如全局
UnsafePointer函数变为方法。关于 C 语言中char类型的讨论最终确认了其实现定义(implementation-defined)的性质。同时,有人提出了改进变更日志(changelog)一致性的建议,指向了一个风格指南建议,并讨论了将 Tensor 移出标准库的过渡。 -
性能追求者:性能爱好者正在进行数据处理时间基准测试,发现 Mojo 的速度超过了 Python,但落后于编译型语言,相关讨论记录在 PR#514 草案中。这一发现引发了关于自定义 JSON 解析的提案,灵感来自 C# 和 Swift 的实现。
Eleuther Discord
-
BERT 不适合 lm-eval 任务:BERT 在进行 lm-eval 测试时表现不佳,因为像 BERT 这样的 encoder 模型并非为生成式文本任务而设计。目前正在寻找 Hugging Face 上最小的 decoder 模型,以便进行能耗分析。
-
Llama-3-8b 性能中无法解释的差异:一位用户报告了 llama-3-8b 在 gsm8k 分数上的不一致性,其测得的 62.4 分与官方公布的 79.6 分之间存在显著差距。有人建议旧的 commit 可能是罪魁祸首,检查 commit hash 可能会澄清问题。
-
Few-shot 设置导致结果差异巨大:gsm8k 分数的差异可能进一步归因于排行榜上使用的 ‘fewshot=5’ 配置,这可能与其他人的实验设置有所偏离。
-
协作与讨论激发创新:提到了 Manifold Research 征集 multimodal transformers 和控制任务的合作者,并分享了对标准 RLHF 偏差的见解。讨论还深入探讨了 transformer 的局限性,并参与了数据依赖型 positional embeddings 的挑战。
-
破解黑盒:人们对即将于 7 月举行的 mechanistic interpretability 黑客松表现出浓厚兴趣,邀请大家利用周末时间剖析神经网络。分享了一篇关于 backward chaining circuits 的论文摘要,旨在吸引更多人才参与合作。
-
视觉与多模态可解释性成为焦点:AI Alignment Forum 的文章阐明了视觉和多模态 mechanistic interpretability 的基础建设,强调了涌现的分割图(segmentation maps)和 “dogit lens”。然而,也有观点表示需要对 score models 本身的电路进行进一步研究,并指出目前文献中存在空白。
OpenRouter (Alex Atallah) Discord
亚洲地区的数据库困扰:OpenRouter 用户报告了在亚洲地区的数据库超时问题,主要集中在首尔、孟买、东京和新加坡。官方已实施修复,其中包括回滚部分延迟优化以解决此问题。
OpenRouter 因 API 故障受到指责:尽管进行了补丁修复,用户仍持续遇到 504 Gateway 错误,部分用户通过使用欧洲 VPN 暂时绕过了该问题。用户建议增加特定供应商的运行时间统计(uptime statistics),以提高服务问责制。
模型退役与建议:由于使用率低且成本高,OpenRouter 正在退役 Llava 13B 和 Hermes 2 Vision 7B (alpha) 等模型,并建议切换到 FireLlava 13B 和 LLaVA v1.6 34B 等替代方案。
无缝 API 切换:正如在 Playground 中所见,OpenRouter 的标准化 API 简化了在不同模型或供应商之间的切换,无需修改代码,这为工程师提供了更简便的管理方式。
流行度优于基准测试:OpenRouter 倾向于基于实际应用对语言模型进行排名,详细列出模型使用情况而非传统的基准测试,以提供务实的视角,具体可见 OpenRouter Rankings。
LAION Discord
-
AI 伦理风口浪尖:围绕 Eliezer Yudkowsky 限制 AI 发展的激进策略展开了激烈的辩论和愤怒,其中要求采取包括摧毁数据中心在内的激进行动引发了分歧对话。点击此处深入了解这一争议。
-
Mobius 模型大显身手:新款 Mobius 模型以“灭霸闻着一朵黄色小玫瑰”等提示词迷倒了社区,展示了该模型的灵气和多功能性。可以在 Hugging Face 上寻找灵感或一睹这些有趣的生成结果。
-
法律乱象消耗资源:一场讨论详细说明了伪法律诉讼如何浪费精力和资金,温哥华的一起伪法律索赔案例成为了前车之鉴。点击此处查看这些荒谬行为的详情。
-
医疗 AI 挑战赛招募:Alliance AI4Health 医疗创新挑战赛呼吁创新者走在前沿,提供 5000 美元奖金以激励医疗 AI 解决方案的开发。未来的医疗先锋可以在此处找到起跑点。
-
研究揭示 AI 新见解:Phased Consistency Model (PCM) 的发布挑战了 LCM 的设计局限,详情见此处;同时,一篇新论文阐述了文本生成图像模型的效率飞跃,被称为“应用于图像生成的 1.58 bits 论文”,可在 arXiv 上探索。SSMs 在速度领域发起反击,Mamba-2 超越了前代产品并可与 Transformers 媲美,点击此处阅读全文。
LlamaIndex Discord
-
LlamaIndex 中图与文档的结合:LlamaIndex 推出了对构建知识图谱 (Knowledge Graphs) 的一流支持,并集成了手动定义实体和关系的工具包,提升了文档分析能力。现在可以使用知识图谱构建自定义 RAG 流程,相关资源包括 neo4j 集成和 RAG 流程示例。
-
研讨会中的记忆与模型:即将举行和已录制的网络研讨会展示了 AI 前沿,Julian Saks 和 Kevin Li 讨论了用于长期自主 Agent 记忆的“memary”,另一场会议则聚焦于与 MultiOn 的 Div 讨论“Web Agents 的未来”。点击此处注册研讨会,并在此处在线观看往期会议。
-
并行处理的分歧:工程师们讨论了 OpenAI Agent 进行并行函数调用的能力,LlamaIndex 的文档澄清了这一功能,尽管真正的并行计算仍难以实现。讨论涵盖了 TypeScript 中的持久化以及针对文档集的基于 RAG 的分析,相关示例链接在文档中。
-
GPT-4o 在专业文档提取方面表现出色:最近的研究显示,GPT-4o 在文档提取方面显著超越了其他工具,平均准确率达到 84.69%,预示着金融等各行业的潜在变革。
-
寻求语义 SQL 协同:公会思考了语义层 (Semantic Layers) 与 SQL Retrievers 的融合,以潜在地增强数据库交互,这一话题仍有待探索,并可能启发未来的集成和讨论。
Latent Space Discord
Latent Space 中的 AI 迷局与动荡:一段 AI 反向图灵测试 视频浮出水面,展示了先进的 AI 试图在它们中间辨别出人类,引发了广泛关注。与此同时,llama3-V 被指控涉嫌挪用 MiniCPM-Llama3-V 2.5 的学术成果,正如 GitHub 上所记录的那样。
软件的未来与精英影响力:工程师们深入探讨了名为 “The End of Software”(软件的终结)的挑衅性 Google Doc 文档的影响,同时讨论了 Anthropic 的 Dario Amodei 在决定推迟聊天机器人 Claude 发布后,入选《时代》周刊百大人物。此外,一篇关于 LLM 应用运营方面的 O’Reilly 文章也因其对一年来构建这些模型的洞察而受到审视。
AI 活动成为行业枢纽:最近宣布的 AI Engineering World Forum (AIEWF)(详情见 推文)引发了期待,活动包括新的演讲者、Fortune 500 强中的 AI 专场,以及涵盖各种 LLM 主题和行业领导力的官方活动。
Zoom 解决技术故障:一个 Zoom 会议为在直播流中遇到技术中断的成员解了围。他们通过共享的 Zoom 链接 进入会议,继续进行讨论。
LangChain AI Discord
RAG 系统拥抱历史数据:社区成员讨论了将历史数据集成到 RAG 系统中的策略,建议优化处理 CSV 表格和扫描文档的方法以提高效率。
游戏聊天机器人表现更强:关于游戏推荐聊天机器人结构的辩论引出了一条建议:反对将 LangGraph Chatbot agent 拆分为多个 agent,而是倾向于使用统一的 agent 或预先策划的数据集以保持简洁。
LangChain 与 OpenAI 的对决:比较 LangChain 与 OpenAI agents 的对话指出,LangChain 在编排 LLM 调用方面具有适应性,强调应根据用例需求来决定是选择抽象层还是直接使用 OpenAI。
对话式 AI 主题在媒体中走红:社区中出现的出版物包括在 Google Colab 上使用 Hugging Face 和 LangChain 探索 LLMs,以及 LangChain 中对话式 agent 日益增长的重要性。关键资源包括 Medium 上的探索指南 和 Ankush k Singal 对对话式 agent 的深入探讨。
JavaScript 遇到 LangServe 障碍:一段代码片段分享了 JavaScript 社区在处理 LangServe 中的 RemoteRunnable 类时遇到的困难,表现为与消息数组处理相关的 TypeError。
tinygrad (George Hotz) Discord
Tinygrad 向 Haskell 迈进:讨论强调了一位成员因 Python 的局限性而对将 tinygrad 翻译成 Haskell 感兴趣,而另一位成员建议专门为 tinygrad 的 uop end 开发一种新语言。
AI 中自动调优的演进:社区批评了像 TVM 这样的旧式自动调优方法,强调需要创新来解决块大小(block size)和流水线(pipelining)调优中的缺点,以提高模型准确性。
用泰勒级数重新思考 exp2:包括 georgehotz 在内的用户研究了 Taylor series(泰勒级数)在改进 exp2 函数 方面的适用性,讨论了类似 CPU 的范围缩减和重构方法的潜在益处。
期待 tinygrad 的量子飞跃:George Hotz 兴奋地宣布 tinygrad 1.0 计划在 NVIDIA 和 AMD 上训练 GPT-2 的速度超过 PyTorch,并发布了一篇 推文 强调了即将推出的功能,如 FlashAttention,并提议放弃 numpy/tqdm 依赖。
NVIDIA 乏善可陈的展示引发不满:Nvidia 首席执行官 黄仁勋(Jensen Huang)的 COMPUTEX 2024 主题演讲 视频 提高了人们对革命性发布的期望,但最终至少让一位社区成员感到非常失望。
OpenAccess AI Collective (axolotl) Discord
- Yuan2.0-M32 展示其专业实力:新款 Yuan2.0-M32 模型凭借其 Mixture-of-Experts 架构脱颖而出,并与其 Hugging Face 仓库及配套研究论文一同展示。
- llama.cpp 故障排除:用户正在定位 llama.cpp 中的 Tokenization 问题,引用了具体的 GitHub issues(#7094 和 #7271),并建议在 Finetuning 过程中进行仔细验证。
- Axolotl 适配 AMD:针对 AMD 兼容性修改 Axolotl 的工作已经展开,并在 GitHub 上发布了实验性 ROCm 安装指南。
- 明确 Axolotl 的非加密货币领域属性:在社区的一次澄清中,重申 Axolotl 专注于训练 Large Language Models,明确表示不涉及加密货币。
- 使用 wandb 追踪 QLoRA 训练:成员们正在交流如何实现 wandb 以监控 QLoRA 训练期间的参数和 Loss,并参考了现有的 wandb 项目和特定的
qlora.yml配置。
Cohere Discord
AI 协作公开招募:Manifold Research 正在寻找合作伙伴,共同构建受 GATO 启发的开源“Generalist”模型,目标是涵盖视觉、语言等领域的 Multimodal 和控制任务。
Cohere 社区故障排查:Cohere Chat API 文档中一个失效的 Dashboard 链接被发现并标记,社区成员已介入确认并着手修复。
AI 模型 Aya 23 获得好评:一位用户分享了对 Cohere Aya 23 模型的成功测试,并表示希望分发其代码以供同行评审。
社区标签升级揭晓:Discord 更新后的标记机制引发了社区的热议和期待,成员们分享了标签说明链接。
支持网络已激活:对于遇到聊天记录消失或其他问题的用户,提供了 Cohere 支持团队邮箱 support@cohere.com 或服务器指定支持频道的重定向指引。
OpenInterpreter Discord
-
Whisper 助力 OI:将 Whisper 或 Piper 集成到 Open Interpreter (OI) 的工作正在进行中;旨在减少冗余并提高语音启动速度。目前尚无在非 Ubuntu 系统上成功安装 OI 的报告;一次在 MX Linux 上的尝试因 Python 问题而失败。
-
Agent 决策困惑已澄清:对 OI 内部的“Agent-like decisions”进行了澄清,并指向了代码库中的特定部分——带有默认系统消息中 Prompt 的 LLM。
-
寻找市场营销人员:小组讨论了对 Open Interpreter 进行市场推广的需求,此前该工作由个人负责。
-
Gemini 运行遇到问题:关于在 Open Interpreter 上运行 Gemini 的咨询被提出,因为提供的文档似乎已过时。
-
OI 的移动端布局:关于创建将 OI 服务器连接到 iPhone 的 App 的讨论非常活跃,目前已有 GitHub 代码和 iOS 版本的 TestFlight 链接。iOS 上的 TTS 功能已确认,而 Android 版本正在开发中。
-
聚焦 Loyal-Elephie:用户 cyanidebyte 提到了 Loyal-Elephie,但未提供具体背景。
Interconnects (Nathan Lambert) Discord
-
Hugging Face 发生安全漏洞:未经授权的访问损害了 Hugging Face 的 Spaces 平台上的密钥,建议用户更新密钥并使用 fine-grained access tokens(细粒度访问令牌)。完整详情请参阅此 安全更新。
-
AI2 主动更新令牌:针对 Hugging Face 事件,AI2 正作为预防措施刷新其令牌。不过,Nathan Lambert 报告称他的令牌已自动更新,从而减轻了手动操作的必要。
-
Phi-3 模型加入行列:Phi-3 Medium (14B) 和 Small (7B) 模型已添加到 @lmsysorg 排行榜,其表现分别与 GPT-3.5-Turbo 和 Llama-2-70B 相当,但同时也提醒不要仅针对学术基准(benchmarks)优化模型。
-
VLM 社区的抄袭指控:有讨论称 Llama 3V 是一个抄袭模型,据称是在 MiniCPM-Llama3-V 2.5 的框架上进行了细微改动。包括 Chris Manning 的批评和一篇现已删除的 Medium 文章在内的链接,引发了关于 VLM 社区诚信的讨论。
-
捐赠赌注(Donation-Bets)受到青睐:Dylan 将一场关于模型性能的输掉的赌注转化为慈善机会,在成员中引发了“捐赠赌注”的趋势,成员们认为这既能支持公益事业,也能提升个人声誉。
Mozilla AI Discord
-
Mozilla 支持本地 AI 创新:Mozilla Builders Accelerator 现已开放申请,目标是 Local AI 领域的创新者,提供高达 100,000 美元的资金、导师指导以及在 Mozilla 网络上展示突破性项目的舞台。立即申请,将个人设备转变为本地 AI 的强大动力源。
-
使用 Paddler 增强 llama.cpp:工程师们正考虑将 Paddler(一个有状态负载均衡器)与 llama.cpp 集成,以简化 llamafile 的操作,这可能提供更高效的模型推理服务能力。
-
采样缓慢引发对 JSON Schema 的质疑:由于服务器问题,AI 工程师遇到了采样速度变慢的情况,并确定了 JSON Schema 验证存在问题,引用了 llama.cpp 仓库中的一个特定 issue。
-
API 端点兼容性处理:可用性讨论显示,OpenAI 兼容的聊天端点
/v1/chat/completions适用于本地模型;然而,模型特定的角色(roles)需要进行调整,而这些调整以前是由 OpenAI 的处理流程完成的。 -
努力实现模型接口的统一:尽管由于不同模型的特性存在固有挑战,但大家仍在共同努力维护各种模型和供应商之间的统一接口,这需要为 Mistral-7b-instruct 等模型提供定制化的预处理解决方案。
DiscoResearch Discord
-
Spaetzle 令参与者感到困惑:成员们讨论了 Spaetzle 模型的细节,并澄清实际上存在多个模型而非单一实体。一篇相关的 AI 生成的 Medium 文章强调了微调预训练 LLM 的不同方法,其中包括 phi-3-mini-instruct 和 phoenix 等名称。
-
对 Replay Buffer 实现的期待:一篇关于 InstructLab 的文章描述了一种可能与 Spaetzle 密切相关的 Replay Buffer 方法;然而,该方法至今尚未实现。围绕这一概念的兴趣正在酝酿,预示着未来的潜在发展。
-
破译德语数字:有人征求关于德语手写识别模型的建议,Kraken 被推荐为一个选项,并附带了一个调查链接,可能用于进一步的研究或信息收集。
-
模型基准测试与策略分享:微调方法的有效性是一个核心话题,一位成员表示打算研究 InstructLab 的相关材料。虽然在 Spaetzle 的背景下提到了这些模型,但并未提供具体的模型基准测试数据。
Datasette - LLM (@SimonW) Discord
- Claude 3 的分词困扰:工程师们发现 Claude 3 缺乏专用的 tokenizer(分词器)令人费解,而这是语言模型预处理的关键工具。
- Nomic 模型查询:关于如何使用 nomic-embed-text-v1 模型 存在困惑,因为它没有出现在
llm models命令输出的 gpt4all models 列表中。 - SimonW 的插件转向:对于 embedding 任务,SimonW 建议切换到 llm-sentence-transformers 插件,该插件似乎对 Nomic 模型 提供了更好的支持。
- 参考发布说明进行专业嵌入:关于 nomic-embed-text-v1 模型 的详细安装和使用说明,可以在 llm-sentence-transformers 的 0.2 版本发布说明 中找到。
AI21 Labs (Jamba) Discord
- Jamba Instruct 与 Mixtral 旗鼓相当:在讨论中,Jamba Instruct 的性能被比作 Mixtral 8x7B,使其成为近期备受关注的 GPT-4 模型的强力竞争对手。
- 函数组合:AI 的阿喀琉斯之踵:一篇分享的 LinkedIn 帖子 揭示了当前机器学习模型(如 Transformer 和 RNN)的局限性,指出了 function composition(函数组合)面临的挑战,并提到 Jamba 参与了相关的 SSM 实验。
MLOps @Chipro Discord
- 参与黑客松,创新医疗健康:Alliance AI4Health 医疗创新挑战赛黑客松/创意赛 正在征集参与者,开发 AI 驱动的医疗解决方案。该活动提供超过 $5k 的奖金,旨在激发医疗技术领域的突破性进展。点击注册。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该社区长时间保持沉默,请告知我们,我们将将其移除。
AI Stack Devs (Yoko Li) Discord 没有新消息。如果该社区长时间保持沉默,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该社区长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
完整的各频道详细内容已针对邮件进行截断。
如果您喜欢 AInews,请分享给朋友!预谢!