ainews-qwen-2-beats-llama-3-and-we-dont-know-how
Qwen 2 击败了 Llama 3(而我们不知道它是如何做到的)
阿里巴巴发布了 Qwen 2 模型,采用 Apache 2.0 协议,声称其在开源模型中表现优于 Llama 3,支持 29 种语言,并在 MMLU 82.3 和 HumanEval 86.0 等基准测试中取得了优异成绩。Groq 展示了 Llama-3 70B 极快的推理速度,达到了 40,792 tokens/s,并能在 200 毫秒内处理 4 篇维基百科文章。针对 GPT-4 神经活动解释的稀疏自编码器 (SAEs) 研究提出了新的训练方法、评估指标和缩放法则。Meta AI 发布了 No Language Left Behind (NLLB) 模型,能够实现 200 种语言(包括低资源语言)之间的高质量翻译。“我们的后训练阶段遵循‘以最少人工标注实现可扩展训练’的原则,”并强调了针对数学的拒绝采样和针对编程的执行反馈等技术。
又一个没有数据集细节的模型发布。
2024年6月5日至6月6日的 AI 新闻。 我们为您检查了 7 个 subreddit、384 个 Twitter 账号 和 30 个 Discord(408 个频道,2450 条消息)。 预计节省阅读时间(以 200wpm 计算):304 分钟。
随着 Qwen 2 采用 Apache 2.0 协议,阿里巴巴现在声称在开源模型桂冠的争夺中全面击败了 Llama 3:
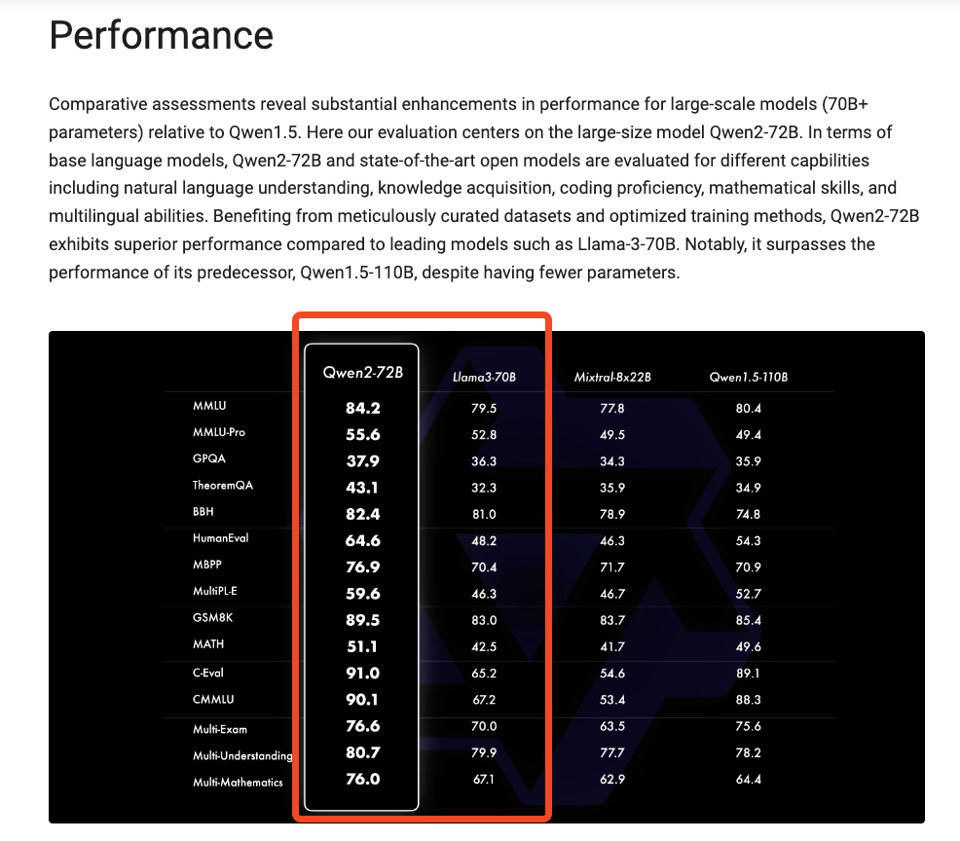
关于数据集的细节为零,因此很难了解他们是如何实现这一点的,但他们确实透露了一些关于 post-training(后期训练)的线索:
我们的 post-training 阶段设计原则是在最少人工标注的情况下进行可扩展训练。
具体来说,我们研究了如何通过各种自动化对齐策略获取高质量、可靠、多样化且具有创造性的演示数据和偏好数据,例如:
- 针对数学的 rejection sampling(拒绝采样),
- 针对代码的执行反馈,以及
- 针对创意写作的指令遵循和反向翻译,
- 针对角色扮演的 scalable oversight(可扩展监督)等。
正如下表所示,这些集体努力显著提升了我们模型的能力和智能。
他们还发布了一篇关于《使用 Qwen-Agent 将 LLM 的上下文从 8k 扩展到 1M》的文章。
AI Twitter 回顾
所有摘要均由 Claude 3 Opus 完成,从 4 次运行中择优录取。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
Qwen2 开源 LLM 发布
- Qwen2 模型发布:@huybery 宣布发布 5 种尺寸(0.5B, 1.5B, 7B, 57B-14B MoE, 72B)的 Qwen2 模型,包括 Base 和 Instruct 版本。模型具有 29 种语言的多语言能力,并在学术和聊天基准测试中实现了 SOTA 性能。除 72B 外,均按 Apache 2.0 协议发布。
- 性能亮点:@_philschmid 指出 Qwen2-72B 实现了 MMLU 82.3, IFEval 77.6, MT-Bench 9.12, HumanEval 86.0。Qwen2-7B 实现了 MMLU 70.5, MT-Bench 8.41, HumanEval 79.9。在 MMLU-PRO 上,Qwen2 得分为 64.4,超过了 Llama 3 的 56.2。
- 多语言能力:@huybery 强调了 Qwen2-7B-Instruct 强大的多语言表现。据 @_philschmid 介绍,这些模型在 29 种语言中进行了训练,包括欧洲、中东和亚洲语言。
Groq 在大型 LLM 上的推理速度
- Llama-3 70B Tokens/s:@JonathanRoss321 报告称,Groq 在 Llama-3 70B 上实现了 40,792 tokens/s 的输入速率,在整个 7989 token 上下文长度中使用了 FP16 乘法和 FP32 累加。
- 200 毫秒运行 Llama 70B:@awnihannun 对这一成就进行了直观描述,指出 Groq 在 200 毫秒内(大约眨眼之间)处理了约 4 篇维基百科文章规模的 Llama 70B 任务,采用 16 位精度和 32 位累加(无损)。
用于 GPT-4 可解释性的稀疏自编码器训练方法
- 改进的 SAE 训练:@gdb 分享了一篇关于改进大规模训练稀疏自编码器(SAEs)以解释 GPT-4 神经活动的方法的论文。
- 新的训练栈和指标:@nabla_theta 介绍了一套用于 SAEs 的 SOTA 训练栈,并在 GPT-4 上训练了一个 16M latent 的 SAE 以展示扩展性。他们还提出了 MSE/L0 损失之外的新 SAE 指标。
- 扩展定律与指标:@nabla_theta 发现了关于自编码器 latent 数量、稀疏度和计算量的清晰扩展定律(scaling laws)。更大的主体模型具有更浅的扩展定律指数。探索了诸如下游损失、探针损失(probe loss)、消融稀疏性和可解释性等指标。
Meta 的 No Language Left Behind (NLLB) 模型
- NLLB 模型详情:@AIatMeta 宣布了发表在 Nature 上的 NLLB 模型,该模型可以在 200 种语言(包括低资源语言)之间直接进行高质量翻译。
- 工作意义:@ylecun 指出 NLLB 能够在训练数据稀疏的情况下,为 200 种语言(包括许多低资源语言)提供任意方向的高质量翻译。
Pika AI 的 B 轮融资
- 8000 万美元 B 轮融资:@demi_guo_ 宣布 Pika AI 完成了由 Spark Capital 领投的 8000 万美元 B 轮融资。Guo 向投资者和团队成员表示了感谢。
- 招聘与未来计划:@demi_guo_ 回顾了过去一年的进展,并预告了今年晚些时候将发布的更新。Pika AI 正在寻找研究、工程、产品、设计和运营方面的人才(链接)。
其他值得关注的发展
- Anthropic 的选举诚信努力:@AnthropicAI 发布了关于其测试和缓解选举相关风险流程的详细信息。他们还分享了用于测试其模型的评估样本。
- Cohere 启动创业计划:@cohere 启动了一项创业计划,旨在支持利用 AI 解决现实业务挑战的早期公司。参与者可以获得折扣访问权限、技术支持和市场曝光。Cohere 还发布了一个针对企业级前沿模型的 Cookbook 库,适用于 Agent、RAG 和语义搜索等应用(链接)。
- 用于 RAG 评估的 Prometheus-2:@llama_index 推出了 Prometheus-2,这是一个用于评估 RAG 应用的开源 LLM,可作为 GPT-4 的替代方案。它可以处理直接评估、成对排名和自定义标准。
- LangChain x Groq 集成:@LangChainAI 宣布即将举行一场关于使用 LangChain 和 Groq 集成构建 LLM Agent 应用的网络研讨会。
- Databutton AI 工程师平台:@svpino 分享了 Databutton 推出的 AI 软件工程师平台,旨在帮助用户根据业务想法构建具有 React 前端和 Python 后端的应用程序。
- 微软的 Copilot+ PC:@DeepLearningAI 报道了微软推出的 Copilot+ PC,其具备 AI 优先的规格,搭载生成式模型和搜索功能,首批机器采用了 Qualcomm Snapdragon 芯片。
AI Reddit 摘要
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
LLM 发展与应用
-
开源 RAG 应用:在 /r/LocalLLaMA 中,用户开源了 LARS,一个以 RAG 为中心的 LLM 应用,它可以根据文档生成带有详细引用的回答。它支持多种文件格式,具有对话记忆,并允许自定义 LLM 和 Embedding。
-
最受喜爱的开源 LLM:在 /r/LocalLLaMA 中,用户分享了他们在不同用例下的首选开源 LLM(链接),包括用于中小规模文档集 RAG 的 Command-R,用于视觉任务的 LLAVA 34b v1.6,用于大规模语料库复杂问题的 Llama3-gradient-70b 等。
-
AI 商业模式:在 /r/LocalLLaMA 中,一位用户质疑新的 AI 业务实际上做了多少原创工作,还是仅仅利用现有的 LLM API(链接),因为许多业务似乎只是针对特定领域封装了 OpenAI 的 API。
-
使用 LLM 查询大量小文件:在 /r/LocalLLaMA 中,一位用户寻求关于将 200 多个 Wiki 小文件输入 LLM 并保持它们之间关系的建议(链接),因为 Embedding 和 RAG 的效果并不理想。目前正在考虑进行适当的 LLM 训练或 LoRA。
-
本地 LLM API 的桌面应用:在 /r/LocalLLaMA 中,一位用户创建了一个桌面应用来与其本地机器上的 LMStudio API 服务器进行交互(链接),并正在评估将其免费发布的意向。
-
LLM 教育平台:在 /r/LocalLLaMA 中,Open Engineer 正式发布,这是一个免费的教育资源,涵盖了 LLM fine-tuning、quantization、embeddings 等主题,旨在让软件工程师更容易上手 LLM。
-
用于数据库操作的 LLM 助手:在 /r/LocalLLaMA 中,一位用户分享了他们将 LLM 助手集成到软件中用于数据库 CRUD 和订单验证的经验,并考虑利用周边系统补充 LLM 的产品查询功能,以实现更稳健的订单处理。
AI 发展与担忧
-
关于超级智能开发的推测:在 /r/singularity 中,一位用户推测主要的 AI 实验室、芯片公司和政府机构可能已经在幕后协同开发超级智能,类似于曼哈顿计划,且美国政府可能正在预测并为之产生的影响做准备。
-
围绕 UBI 实施的问题:在 /r/singularity 中,一位用户对缺乏实施 UBI 的具体计划或框架表示沮丧,尽管 UBI 被视为解决 AI 驱动的就业流失的方案,但仍有资金来源、人口增长影响等诸多问题需要解决。
-
开源 AGI 滥用的风险:在 /r/singularity 中,一位用户询问开源社区将如何防止强大的开源 AGI 被恶意行为者滥用而造成伤害,因为目前缺乏安全防护措施,并认为“这和在 Google 上搜索一样”的反驳观点过于简化了问题。
-
控制 ASI:在 /r/singularity 中,一位用户质疑人类或军队能够控制 ASI 的信念,考虑到其卓越的智能,评论者一致认为这不太可能,且试图统治它的想法是误导性的。
AI 助手与界面
-
聊天模式作为语音数据采集手段:在 /r/singularity 中,一位用户推测 OpenAI 对聊天模式的关注是一项战略举措,旨在收集高质量、自然的语音数据,以克服 AI 训练中文本数据的局限性,因为语音代表了更接近人类思维过程的连续意识流。
-
不寻常的 ChatGPT 使用案例:在 /r/OpenAI 中,用户分享了他们使用 ChatGPT 的一些不寻常方式,包括生成极具戏剧性的浇花提醒、将烹饪指令从烤箱模式转换为空气炸锅模式,以及将购物清单项目映射到商店货架。
-
对 “AI shell” 协议的需求:在 /r/OpenAI 中,一位用户预见到需要一种标准化的 “AI shell” 协议,以允许 AI Agent 轻松地界面化并控制各种设备,类似于 SSH 或 RDP,因为现有协议可能不足以满足需求。
AI 内容生成
-
对 AI 音乐不断演变的看法:在 /r/singularity 中,一位用户分享了他们对 AI 音乐不断变化的观点,认为由于对主流音乐的严格限制,AI 音乐非常适合作为通用的 YouTube 背景音乐,并征求了他人的看法。
-
AI 生成的后摇滚播放列表:在 /r/singularity 中,一位用户在 YouTube 上分享了一个 30 分钟的 AI 生成后摇滚播放列表,其中包含使用 UDIO 制作的沉浸式曲目,并收到了关于“让人忘记这是 AI 音乐”的正向反馈。
-
VFX 项目中的 AI:在 /r/singularity 中,一位用户分享了一个结合 AI 创造城市美学的 VFX 项目,灵感来自广告展示,使用了程序化系统、图像合成和分层 AnimateDiffs,其中 CG 元素经过单独处理并集成。
AI Discord 摘要回顾
摘要之摘要的总结
-
LLM 与模型性能创新:
- Qwen2 引起广泛关注:模型参数范围从 0.5B 到 7B,因其易用性和快速迭代能力而受到赞赏,支持具有 128K token 上下文的创新应用。
-
Stable Audio Open 1.0 引起关注:利用 autoencoders 和 diffusion 模型等组件,详见 Hugging Face,提升了社区在自定义音频生成工作流中的参与度。
-
ESPNet 发布高效 Transformer 推理的竞争性基准测试:围绕新发布的 ESPNet 的讨论展示了其在 Transformer 效率方面的潜力,指向在高端 GPU (H100) 上增强的吞吐量,详见 ESPNet Paper。
-
Seq1F1B 推动高效长序列训练:根据 arxiv 出版物,该流水线调度方法为 LLM 带来了显著的内存节省和性能提升。
- 微调和 Prompt Engineering 挑战:
-
模型微调创新:微调讨论强调了使用 gradient accumulation 来管理内存限制,以及使用
FastLanguageModel.for_inference处理 Alpaca 风格 Prompt 的自定义流水线,如 Google Colab notebook 所示。 -
聊天机器人查询生成问题:使用 Mistral 7B 调试 Cypher 查询强调了系统评估和迭代微调方法在成功模型训练中的重要性。
-
Adapter 集成陷阱:集成已训练 Adapter 的关键挑战指出需要更高效的 Adapter 加载技术以保持性能,并得到了实际编程经验的支持。
- 开源 AI 发展与协作:
-
Prometheus-2 评估 RAG 应用:Prometheus-2 为评估 RAG 应用提供了 GPT-4 的开源替代方案,因其成本低廉和透明度高而受到重视,详见 LlamaIndex。
-
OpenDevin 的发布引发了协作兴趣:该系统由 Cognition 开发,是一个用于自主工程的强大 AI 系统,可通过 网络研讨会 和 GitHub 获取文档。
-
梯度累积策略改进训练:关于 Unsloth AI 的讨论强调了使用 gradient accumulation 来有效处理内存限制,通过分享的 YouTube 教程 展示了训练时间的缩短。
-
Mojo 作为后端框架兴起:开发者分享了使用 Mojo 进行 HTTP 服务器开发的积极经验,描述了其在静态类型和编译时计算特性方面的优势,详见 GitHub。
- 部署、推理和 API 集成:
-
Perplexity Pro 增强搜索能力:最近的更新通过意图系统增加了逐步搜索过程,实现了更具 Agent 特性的执行,正如 Perplexity Labs 社区内讨论的那样。
-
关于 Modal 部署和隐私的讨论:关于使用 Modal 进行 LLM 部署的咨询包括对其微调栈和隐私政策的担忧,Modal Labs 文档 提供了额外支持。
-
OpenRouter 技术见解和限制:用户探索了技术规范和功能,包括助手消息 prefill 支持以及通过 Instructor 工具 处理 function calls。
- AI 社区讨论与活动:
-
Stable Diffusion 3 预测:社区对预期的发布充满热议,对其功能和时间表进行了推测,详见各种 Reddit 帖子。
-
6 月 11 日的 Human Feedback Foundation 活动:即将举行的关于将人类反馈集成到 AI 中的讨论,演讲者来自 Stanford 和 OpenAI,录像可在其 YouTube 频道 观看。
-
Qwen2 模型发布并获得巨大支持:因其多语言能力和增强的基准测试而备受关注,在 Hugging Face 等平台上的发布突显了其实际评估效果。
-
呼吁 Mozilla AI 支持 JSON Schema:在 社区频道 中,显著记录了要求在下一版本中包含 JSON Schema 以简化应用开发的请求。
-
关于机器人 AI 和 Foundation Models 的主题演讲:在 Foundation Model 公司中对“机器人版 ChatGPT”的投资兴趣,强调了 Newcomer 的文章 中详述的战略对齐。
PART 1: High level Discord summaries
LLM Finetuning (Hamel + Dan) Discord
-
网页抓取工具讨论:工程师们交流了关于 Beautiful Soup 和 Scrapy 等 OSS 抓取平台的经验,并特别提到了 Trafilatura,因其在从职位发布和 SEC 文件等复杂来源中提取动态内容方面表现出色,参考了其 官方文档。
-
UI 领域的新面孔:Google 推出的 Mesop 因其在构建内部工具 UI 方面的潜力而引发讨论,开始进入 Gradio 和 Streamlit 的领地。尽管目前缺乏高级身份验证功能,但其 Mesop 主页 引起了广泛好奇。
-
查询构建的挑战:工程师们调试了使用 Mistral 7B 生成 Cypher 查询的问题,强调了系统化评估(evals)、测试驱动开发(TDD)以及迭代过程的重要性——这是模型微调(fine-tuning)中细节工作的体现。
-
深入探讨部署:关于 Modal 使用的问题层出不穷,包括其微调栈的复杂性和隐私政策——为政策寻求者提供了 Modal Labs 查询 链接,并推荐了他们的 Dreambooth 示例 以进行实践启发。
-
CUDA 兼容性疑难杂症:CUDA 版本之间的兼容性问题成为焦点,工程师们在安装
xformers模块时遇到了困难——Jarvis Labs 文档 中关于更新 CUDA 的指南提供了帮助。
OpenAI Discord
- GPT-3 的编程难题:虽然像 GPT-3 这样的 GPT 模型擅长辅助编程,但在面对高度特定且复杂的问题时,局限性变得显而易见,这标志着对其当前能力的挑战。
- 数学方程中的逻辑漏洞:即使是简单的逻辑任务(如纠正数学方程)也可能难倒 GPT 模型,暴露了基础逻辑推理方面的短板。
- 热切期待 GPT-4o 的特殊功能:讨论集中在 GPT-4o 的更新上,语音和实时视觉功能将在几周内首先向 ChatGPT Plus 用户开放,随后会扩大访问范围,正如 OpenAI 官方更新 所述。
- DALL-E 的文本难题:用户正在分享针对 DALL-E 在生成包含精确文本的 Logo 时遇到困难的变通方法,包括通过提示词迭代优化文本准确性,以及一个有用的 自定义 GPT 提示词。
- 7b 与视觉模型的协同效应:一个集成成功的案例显示 7b 模型 与 llava-v1.6-mistral-7b 视觉模型配合良好,扩展了模型协作的可能性。
Unsloth AI (Daniel Han) Discord
梯度累积(Gradient Accumulation)显神威:工程师们一致认为 gradient accumulation 可以缓解显存限制并缩短训练时间,但也警告说,由于意外的内存分配行为,较大的 Batch Size 可能会带来潜在陷阱。
利用 Alpaca 提升推理速度:一位工程师分享了利用 FastLanguageModel.for_inference 并结合 Alpaca 风格提示词 在 LLMs 中进行序列生成的代码片段,这与关于共享 Google Colab 笔记本 的讨论共同引发了关注。
Adapter 合并求助:集成训练好的 Adapter 导致性能大幅下降的挑战,引发了对更高效 Adapter 加载技术的需求,以维持训练效率。
Qwen2 模型备受瞩目:Qwen2 模型 的发布引发了热议,工程师们对其 0.5B 到 7B 的小尺寸模型表现出浓厚兴趣,因其易用性且支持更快的迭代。
求助中心的解决方案探索:帮助频道的对话强调了对节省 VRAM 的 lora-adapter 文件转换流程的需求、对可能减慢推理速度的 Bug 的快速情报、缓解 GPU 显存过载的策略,以及关于运行 gguf 模型 和实现 RAG 系统的澄清,参考了 Mistral 文档。
Stability.ai (Stable Diffusion) Discord
-
Stable Audio Open 1.0 正式登场:Stable Audio Open 1.0 因其创新的组件(包括 autoencoder 和 diffusion model)引发了社区关注,成员们正在自定义音频生成工作流中尝试使用 tacotron2、musicgen 和 audiogen。
-
Stable Diffusion 中的尺寸至关重要:用户建议在 Stable Diffusion 中先生成高分辨率图像再进行缩小,这是解决困扰低分辨率(160x90)图像输出的随机颜色问题的有效权宜之计。
-
ControlNet 草图转图像大获成功:ControlNet 成为成员们将草图转换为写实图像且不保留多余颜色的首选方案,为最终构图和图像细节提供了更好的控制。
-
CivitAI 内容质量控制受到质疑:CivitAI 上无关内容的激增导致用户呼吁增强过滤功能,以更好地筛选优质模型并维护用户体验。
-
Stable Diffusion 3 尚待明确:尽管社区内猜测不断,但关于 Stable Diffusion 3 的发布日期和细节仍不明朗,部分成员参考了 Reddit 帖子 以寻求暂定的答案。
LM Studio Discord
-
在 LM Studio 中驯服 RAM 占用:用户讨论了限制 LM Studio 中 RAM 使用的策略,建议在运行期间加载和卸载模型;详细方法可在 llamacpp documentation 中找到。虽然这不是 LM Studio 的内置功能,但此类策略被用于使模型仅在活动时占用 RAM,尽管会损失一定的效率。
-
Nomic Embed 模型步入聚光灯下:得益于 nomic-embed-vision-v1.5,讨论将 Nomic Embed Text 模型 提升到了多模态地位,并以出色的 Benchmark 表现脱颖而出。服务器内的 AI 社区还指出 Llama-3 的 Q6 量化模型 是质量与性能之间的平衡点。
-
寻求完美配置:一位用户提出了在启动新聊天时模型设置会重置的问题,并发现保留旧聊天记录可能是一个简单的解决方法。对话还涉及了 LM Studio 中的
use_mlock和--no-mmap设置,这些设置会影响 8B 模型运行时的稳定性,并强调了受操作系统影响的细微差别。 -
解锁硬件协同对 AI 的潜力:工程师们就 Nvidia 的专有驱动程序与 AMD 的开源方案展开了热烈辩论,强调了其对系统管理和安全性的影响。此外,人们对新款 Qualcomm 芯片 的前景感到兴奋,并提醒不要仅凭合成 Benchmark 来评判 ARM CPUs。
-
更新与升级引发关注:Higgs LLAMA 模型 因其在 70B 规模下的智能表现而获得赞誉,人们对即将发布的包含相关 llamacpp 调整 的 LMStudio 更新充满期待。另一位用户正考虑进行大规模 RAM 升级,以应对备受讨论的 LLAMA 3 405B 模型,这反映了硬件能力与 AI 模型演进之间交织的利益。
HuggingFace Discord
审核是关键:社区讨论了针对不当行为报告的审核策略。处理此类问题的专业性至关重要。
Gradio API 挑战:将 Gradio 与 React Native 和 Node.js 集成在社区中引发了疑问。由于它是用 Svelte 构建的,用户被引导去研究 Gradio 的 API 兼容性。
带有稳定性的文本:围绕用于文本生成的 Stable Diffusion 模型的讨论,向成员推荐了来自 Microsoft 的 AnyText 和 TextDiffuser-2 等解决方案,以获得稳健的输出。
当计算走向点对点:对话转向了用于分布式机器学习的 P2P (peer-to-peer) 计算,Petals 等工具以及具有隐私意识的本地集群 (local swarms) 经验提供了充满前景的途径。
AI 中的人类反馈:Human Feedback Foundation 在将人类反馈引入 AI 方面取得了进展,将于 6 月 11 日举行活动,并在其 YouTube 频道上提供了大量教育课程。
小数据集,大挑战:在计算机视觉讨论中,处理小数据集和不具代表性的验证集是一个紧迫的问题。解决方案包括使用多样化的训练数据,甚至可能使用 Transformer,尽管其训练时间较长。
Swin Transformer 测试:有关于将 Swin Transformer 应用于 CIFar 数据集的查询,突显了社区对在各种场景中实验当代模型的兴趣。
确定性模型降低“热度”:一条消息强调将 temperature 设置降低到 0.1 以实现更具确定性的模型行为,引发了对模型微调方法的思考。
样本输入混乱:出现了关于文本嵌入 (text embeddings) 以及 text-enc 1 和 text-enc 2 等模型样本输入正确结构的困惑,同时还讨论了以字典格式添加 kwargs 所带来的挑战。
重新参数化的成果:一位成员成功地将 Segmind 的 ssd-1b 重新参数化为 v-prediction/zsnr refiner 模型,并称其为新的最爱,暗示了 1B Mixture of Experts 模型的可能趋势。
项目援助:在社区援助环节,成员们通过私信 (DM) 就数据集问题提供个人帮助,增进了公会的协作氛围。
Eleuther Discord
对 KAN 的怀疑:公会成员认为 Kolmogorov-Arnold Networks (KANs) 的效率低于传统的神经网络,并对其可扩展性和可解释性表示担忧。然而,人们对更高效的 KAN 实现(例如使用 ReLU 的实现)表现出兴趣,一份共享的 ReLU-KAN 架构论文 证明了这一点。
扩展数据清洗工具箱:参与者讨论了 influence functions 在数据质量评估中的效用,LESS 算法 (LESS algorithm) 被提及作为一种更具扩展性的替代方案,用于选择高质量的训练数据。
高效模型训练的突破:高效模型训练的创新被广泛分享,包括 Nvidia 在 GitHub 上提供的新开放权重,对 MatMul-free 模型 (arXiv) 以提高效率的探索,以及 Seq1F1B 在内存高效的长序列训练方面的潜力 (arXiv)。
量化技术可能提升 LLM 性能:新颖的 QJL 方法通过量化过程压缩 KV cache 需求,为大语言模型 (LLM) 提供了一条充满希望的途径 (arXiv)。
大脑数据语音解码探索:一位公会成员报告了使用 Whisper tiny.en embeddings 和大脑植入数据解码语音的实验,在面临单 GPU 训练限制的情况下,请求同行建议通过调整层和损失函数来优化模型。
Perplexity AI Discord
-
Perplexity Pro 变得更聪明了:Perplexity Pro 约一周前进行了升级,可以逐步显示其搜索过程,并采用意图系统(intent system)来实现更具 agentic-like(类智能体)的执行。
-
文件格式困扰:用户在 Perplexity 读取 PDF 的能力方面遇到困难,成功率因 PDF 的内容布局而异,从高度样式化到纯文本不等。
-
开发成本令人咋舌:社区对一名成员请求以 100 美元的极低预算构建 text-to-video MVP 的行为表示幽默和难以置信,突显了预期与开发者市场价之间的脱节。
-
Haiku 功能不再:从 Perplexity labs 移除 Haiku 及部分功能引发了讨论,导致成员推测这是成本削减措施,并因其对工作流的影响而表达不满。
-
对 OpenChat 扩展的好奇:有人询问是否会在 Perplexity 中加入 “openchat/openchat-3.6-8b-20240522” 模型,目前已有 Mistral 和 Llama 3 等模型。
CUDA MODE Discord
-
探索往期技术会议:往期 CUDA MODE 技术活动的录像可以在 CUDA MODE YouTube 频道观看。
-
在 PyTorch 中调试 Tensor 内存:分享了一个使用
storage().data_ptr()的代码片段,用于测试两个 PyTorch tensors 是否共享相同内存,引发了关于检查内存重叠的讨论。一名成员请求协助定位 PyTorch C++ 函数的源代码,特别是 at::_weight_int4pack_mm。 -
AI 模型与技术扩展:对话围绕 MoRA 优于 LoRA 的方法论,以及关于 RLHF 的 DPO 与 PPO 之争。另外还提到了用于位置编码的 CoPE 和加速推理的 S3D,详情见 AI Unplugged。
-
Torch 创新火花:围绕 torch.compile 提升 KAN 性能以媲美 MLP 的讨论被点燃,分享了来自 Thomas Ahle 的推文的见解、实践经验以及 KANs 和 MLPs 的 GitHub 仓库。
-
MLIR 瞄准 ARM:一次 MLIR 会议涵盖了创建 ARM SME Dialect,通过 YouTube 视频提供了对 ARM 可扩展矩阵扩展(Scalable Matrix Extension)的见解。讨论了指向潜在 Triton ARM 支持的线索,并参考了 MLIR 文档中用于 NEON 操作的 ‘arm_neon’ dialect。
Interconnects (Nathan Lambert) Discord
-
寻找机器人领域的 ChatGPT:投资者正在寻找能够成为“机器人领域 ChatGPT”的初创公司,优先考虑 AI 而非硬件。正如这篇文章所述,人们对利基基础模型公司的兴趣日益浓厚。
-
Qwen2 引起关注:Qwen2 发布引起关注,其模型在多语言任务中支持高达 128K tokens,但用户反映在近期事件知识和通用准确性方面存在差距。
-
Dragonfly 在多模态 AI 中展翅:Together.ai 的 Dragonfly 带来了视觉推理方面的进展,特别是在医学影像领域,展示了模型开发中文本和视觉输入的整合。
-
AI 社区持批判观点:从讨论有影响力的实验室员工批评小玩家,到分享的一条推文强调了 AI 实验室无意中与 CCP 而非美国研究界分享进展的风险,以及 The Verge 关于 Humane AI 安全问题的文章,社区保持警惕。
-
强化学习论文引起兴趣:分享了 这条推文 中宣布的“自我改进鲁棒偏好优化”(SRPO)论文,表明了对使用鲁棒且自我改进的 RLHF 方法训练 LLM 的关注。Nathan Lambert 计划专门花时间讨论此类前沿论文。
Modular (Mojo 🔥) Discord
-
Mojo Rising:各频道的讨论集中在将 Mojo 用于后端服务器开发的优势,例如 lightbug_http 展示了其在构建 HTTP 服务器中的应用。分享了 Mojo 路线图,指出了未来的核心编程特性;同时,由于 Mojo 的静态类型和编译时计算带来的性能优势,与 Python 的活跃对比引发了关于性能价值的辩论。
-
Keeping Python Safe:在向初学者教授 Python 时,必须避免潜在的“陷阱”(footguns),以帮助学习者顺利过渡到更复杂的语言,如 C++。
-
Model Performance Frontiers Explored:讨论指出,将 Mistral 等模型扩展到特定限制之外需要持续的预训练,并建议将 UltraChat 与基础 Mistral 之间的差异应用于 Mistral-Yarn 作为一种合并策略,尽管有人对其可行性和实用性表示怀疑。
-
Community Coding Contributions Cloaked with Humor:成员们幽默地使用“舔饼干”(licking the cookie)等表达来讨论鼓励开源贡献,并戏称技术演讲和编码挑战的复杂性,将一个简单的快速排序(quicksort)实现请求比作一场崇高的远征。
-
Nightly Builds Yield Illumination and Frustration:考察了 Nightly 构建版本,重点关注了列表迭代器的不可变自动解引用(immutable auto-deref)用法,以及最新编译器版本
2024.6.616中引入的String.format等特性。然而,网络波动以及parallel_sort函数中algorithm.parallelize的不可预测性成为了挫折的来源,这从 GitHub 讨论以及关于工作流计时和网络问题的故障排除分享中可见一斑。
Latent Space Discord
- Cohere Cashes In Big Time:根据 路透社报道,Cohere 已获得令人咋舌的 4.5 亿美元 融资,NVidia 和 Salesforce 等科技巨头贡献巨大,尽管该公司去年的营收并不高。
- IBM’s Granite Gains Ground:IBM 的 Granite 模型因其透明度(特别是在训练数据使用方面)而受到赞誉,引发了关于它们在企业领域是否超越 OpenAI 的辩论,参考了 Talha Khan 的见解。
- Databricks Dominates Forrester’s AI Rankings:在 Forrester 关于 AI 基础模型的最新报告中,Databricks 被评为领导者,强调了企业的定制化需求,并暗示基准测试分数并不代表一切。该报告在 Databricks 的 公告博客 中被重点提及,并可在此处 免费获取。
- Qwen 2 Trumps Llama 3:新的 Qwen 2 模型具有令人印象深刻的 128K 上下文窗口能力,在代码和数学任务中表现出优于 Llama 3 的性能,详见 最近的推文。
- New Avenues for AI Web Interaction and Assistance:Browserbase 庆祝获得 650 万美元 的种子基金,旨在使 AI 应用能够导航网页,由创始人 Nat & Dan 分享;而 Nox 推出了一款 AI 助手,旨在让用户体验感到无懈可击,早期注册请点击 此处。
LlamaIndex Discord
Prometheus-2 助力 RAG 应用评估:Prometheus-2 被定位为评估 RAG 应用时 GPT-4 的开源替代方案,因其在透明度和成本效益方面的优势而引发关注。
LlamaParse 引领知识图谱构建:一份发布的 notebook 展示了 LlamaParse 如何执行顶级解析以构建知识图谱(Knowledge Graph),并配合 RAG 流水线进行节点检索。
LlamaIndex 配置过载问题:AI 工程师们表示,在配置 LlamaIndex 以查询 JSON 数据时感到非常复杂并寻求指导,同时还在讨论 Text2SQL 查询在平衡结构化与非结构化数据检索方面存在的问题。
探索资源受限场景下的 LLM 选项:针对硬件受限情况的替代方案讨论倾向于使用 Microsoft Phi-3 等小型模型,并尝试在 Google Colab 等平台上运行大型模型。
评分过滤器获得可定制优势:工程师们正在讨论 LlamaIndex 根据自定义阈值和性能评分过滤结果的能力,这表明了对搜索结果进行精细化准确度控制的需求。
Cohere Discord
-
早期采用者的初创公司福利:Cohere 推出了一个初创公司计划,旨在为 B 轮或更早阶段的初创公司提供 AI 模型折扣、专家支持和市场影响力,以推动 AI 技术应用的创新。
-
优化聊天机器人体验:Cohere Chat API 将于 6 月 10 日迎来更新,届时将引入新的默认多步工具(multi-step tool)行为,并为简化操作提供
force_single_step选项,所有内容均已记录在 API 规范增强文档中。 -
AI 采样器的高 Temperature 设置:OpenRouter 因允许 AI 响应采样器的 temperature 设置超过 1 而脱颖而出,这与 Cohere 试用版 1.0 的上限形成对比,引发了关于响应多样性和质量灵活性的讨论。
-
开发智能群聊机器人:关于在商务会议等群组场景中部署 AI 聊天机器人的建议不断涌现,讨论分析了 Rhea 在处理多用户上下文方面的优势,以及在众多用户中提供个性化响应时可能存在的精度问题。
-
Cohere 社交与演示:社区成员欢迎新成员 Toby Morning,通过交换 LinkedIn 个人资料(LinkedIn Profile)建立更广泛的联系,并对即将展示的 Coral AGI 系统在多用户环境下的强大功能表现出极大热情。
Nous Research AI Discord
Qwen2 飞跃式进展:Qwen2 系列模型的发布标志着相较于 Qwen1.5 的重大进化,现在支持 128K token 的上下文长度、27 种新增语言,并提供各种尺寸的预训练及指令微调模型。这些模型已在 GitHub、Hugging Face 和 ModelScope 等平台上线,并设有专门的 Discord 服务器。
地图事件预测讨论:一位用户询问了如何利用时间数据预测地图上事件点的真伪,引发了关于相关命令和技术的讨论,尽管未提供具体方法。
Mistral API 与模型存储更新:Mistral 推出的微调 API 及其相关成本引发了讨论,重点在于其对开发和实验的实际影响。该 API(包括定价详情)在其微调文档中有所说明。
移动端文本输入焕然一新:WorldSim Console 更新了其移动平台,修复了与文本输入相关的错误,提高了文本输入的可靠性,并提供了增强的复制/粘贴以及外观自定义选项等新功能。
闲聊板块中的音乐探索:一位成员分享了探索“瓦坎达音乐”的链接,尽管这对于工程师受众来说技术相关性有限。分享的链接中包括 DG812 - In Your Eyes 和 MitiS & Ray Volpe - Don’t Look Down 等音乐视频。
OpenRouter (Alex Atallah) Discord
使用 Pilot 轻松进行服务器管理:Pilot 机器人通过提供 “Ask Pilot”(智能服务器洞察)、”Catch Me Up”(消息摘要)以及每周关于服务器活跃度的 “Health Check”(健康检查)报告,正在彻底改变 Discord 服务器的管理方式。它是免费使用的,能促进社区增长和参与度,可通过其网站访问。
角色扮演领域的 AI 竞争者:WizardLM 8x22b 模型目前在角色扮演社区中大受欢迎,然而 Dolphin 8x22 作为一个潜在对手出现,正等待用户测试以比较它们的效能。
Gemini Flash 引发图像输出好奇心:关于 Gemini Flash 是否能渲染图像的询问引发了澄清:虽然目前没有 Large Language Model (LLM) 直接提供图像输出,但理论上它们可以使用 base64 或调用外部服务(如 Stable Diffusion)进行图像生成。
处理函数调用的工具提示:对于处理特定的函数调用(Function Calls)和格式化,推荐使用 Instructor 这一强大工具,它能促进自动化命令执行并改进用户工作流。
模型热潮中的技术讨论:一位成员关于 OpenRouter 中 prefill 支持的询问得到了确认,即这是可能的,特别是通过使用反向代理;同时,由于 GLM-4 支持韩语,人们对其表现出极大的热情,暗示了该模型在多语言应用中的潜力。
MLOps @Chipro Discord
-
人类反馈推动 AI 进步:即将于 6 月 11 日举行的 Human Feedback Foundation event 将探讨人类反馈在增强医疗和公民领域 AI 应用中的作用;感兴趣的各方可以通过 Eventbrite 注册。此外,包含来自 UofT、Stanford 和 OpenAI 演讲者的往期活动录像可在 Human Feedback Foundation YouTube Channel 观看。
-
Azure 活动吸引 AI 爱好者:”Unleash the Power of RAG in Azure” 是一个在多伦多举行的、报名人数众多的 Microsoft 活动,一位正在寻找同伴的参与者提到了这一点;更多详情可以在 Microsoft Reactor 页面找到。
-
应对杂乱数据:工程师们讨论了处理高基数分类列的策略,包括使用聚合/分组、手动特征工程、字符串匹配和编辑距离技术,目标都是精炼输入以获得更好的回归结果。
-
合并数据与聚类技术:存在一种共同观点,即结合拼写纠正与特征聚类可能会简化高基数分类数据带来的挑战,重点是将此类问题视为核心数据建模问题。
-
特征工程的实用方法:对话转向了务实的方法,例如分解复杂问题(例如,隔离品牌和项目元素)以及将移动平均线作为价格预测简化技术的一部分。与会者对讨论的多方面解决方案表示赞赏,包括用于特征提取的 regex。
OpenAccess AI Collective (axolotl) Discord
AI 爱好者的资料盛宴:工程师们赞叹 15T 数据集的可获得性,并幽默地指出数据过剩但计算资源和资金匮乏的困境。
硬件讨论中的 GPU 调侃:4090s 是否适合预训练海量数据集引发了诙谐的交流,大家开玩笑地谈论了消费级 GPU 在处理此类高难度任务时的局限性。
GLM 与 Qwen2 的微调乐趣:社区分享了微调 GLM 4 9b 和 Qwen2 模型的技巧和配置,并指出 Qwen2 与 Mistral 的相似性简化了这一过程。
寻求可靠的 Checkpointing:在关于 checkpoint 策略的讨论中,提到了使用 Hugging Face 的 TrainingArguments 和 EarlyStoppingCallback,特别是为了根据 eval_loss 捕获最近状态和性能最佳状态。
排查 AI 代码中的错误:针对 “returned non-zero exit status 1” 错误的排查,成员们建议精确定位失败的命令,仔细检查 stdout 和 stderr,并检查权限或环境变量问题。
LAION Discord
-
吸引眼球的命名难题:在公会中,人们对 1B 参数 zsnr/vpred refiner 的清晰度提出了质疑;有评论指出该模型实际上是一个 1.3B 模型,而非 1B 模型,这引发了关于需要更准确、更具吸引力的命名的轻松调侃。
-
Vega 的参数困境:关于 Vega 模型 的讨论强调了其迅捷的处理能力,但也引发了对其参数规模不足可能限制连贯输出生成的担忧。
-
Elrich Logos 数据集仍是谜团:一名成员询问了 Elrich logos 数据集 的可用性,但未收到关于获取该数据集的任何结论性信息或回复。
-
Qwen2 的黎明:Qwen2 的发布已经宣布,在语言支持、上下文长度和基准测试性能等多个方面较 Qwen1.5 引入了实质性的改进。Qwen2 目前提供不同尺寸的版本,并支持高达 128K tokens,资源分布在 GitHub、Hugging Face、ModelScope 和 demo。
LangChain AI Discord
-
知识图谱构建的安全措施:分享了一个关于从文本构建知识图谱的教程,强调了在将数据纳入图数据库之前进行数据验证以确保安全的重要性。
-
LangChain 技术要点:关于是否必须使用 tools 装饰器的困惑引发了澄清讨论,同时观察到用户有理解 token 消耗追踪方法的需求。此外,还出现了一个关于如何创建 LangChain 的 FreeCodeCamp 教程视频中展示的 RAG 图表的问题。
-
流程控制与搜索自动化资源:一段关于 LangGraph 条件边(conditional edges)的 YouTube 视频因其在流程工程(flow engineering)中对流程控制的实用性而受到关注;另外分享了一个名为 search-result-scraper-markdown 的新项目,用于抓取搜索结果并将其转换为 Markdown。
-
跨框架 Agent 协作:用户对能够让使用不同工具构建的 Agent 进行协作的框架表现出兴趣,这些工具包括 LangChain、MetaGPT、AutoGPT,甚至来自 coze.com 等平台的 Agent,突显了 AI 领域互操作性的潜力。
-
对 GUI 和课程文件指导的需求:有用户询问如何从 AI Agents LangGraph 课程中找到特定的 “helper.py” 文件,这表明在 DLAI 课程页面等技术课程中需要更好的资源发现方法。
tinygrad (George Hotz) Discord
- Tinygrad 为正式发布做准备:George Hotz 强调了在 1.0 版本发布 之前需要对 tinygrad 进行更新,待处理的 PRs 预计将解决目前的差距。
- 使用 UOps.CONST 解开 Tensor 谜题:AI 工程师研究了 UOps.CONST 在 tinygrad 中的作用,它在计算过程中充当地址偏移(address offsets),用于确定 Tensor 加法期间的索引值。
- 解码复杂代码:针对一段代码引发的困惑,相关人员澄清说,为了在行优先(row-major)数据布局限制内高效管理 Tensor 的形状(shapes)和步长(strides),通常需要复杂的条件判断。
- 动态 Kernel 解决索引难题:关于 tinygrad 中 Tensor 索引的讨论显示,由于该架构依赖于静态内存访问,Kernel 生成至关重要,所讨论的 Kernel 能够实现类似 Tensor[Tensor] 的操作。
- 在 Getitem 操作中使用 Arange 进行掩码处理:讨论中提到了用于索引操作的 Kernel 与 arange kernel 之间的相似性,后者有助于在 getitem 函数中创建掩码,以实现动态 Tensor 索引。
OpenInterpreter Discord
图形输出的加速需求:成员们正在寻求关于使用 interpreter.computer.run 执行图形输出的建议,特别是针对像 matplotlib 生成的可视化内容,目前尚未取得成功。
OS Mode 的混乱:对话强调了在让 --os mode 与来自 LM Studio 的本地模型协同工作时遇到的麻烦,包括本地 LLAVA 模型无法启动屏幕录制的问题。
M1 Mac 上的视觉模型探索:工程师们对 M1 Mac 上视觉模型的硬件限制表示沮丧,鉴于 OpenAI 服务的成本较高,他们对免费且易于获取的 AI 解决方案表现出浓厚兴趣。
对 Rabbit R1 集成的期待:将 Rabbit R1 与 OpenInterpreter 集成的讨论正热,特别是即将推出的 webhook 功能,以实现实际操作。
征集 Bash 模型:关于征集适用于处理 bash 命令的开源模型的呼吁尚未得到回应,目前在该推荐领域仍存在空白。
AI Stack Devs (Yoko Li) Discord
对 AI Town 开发进度的关注:AI Stack Devs 的成员们寻求该项目的更新,其中一人对进度表示关注,而另一人则因时间不足尚未贡献代码而表示歉意。
AI Town 中的图块集(Tileset)解析难题:在为 AI Town 解析精灵图表(spritesheets)时出现了一个工程挑战,提议使用提供的层级编辑器或 Tiled,并辅以社区提供的转换脚本。
学习如何取消 LLM 的审查:一位成员分享了来自 Hugging Face 博客关于 abliteration(消融技术)的见解,该技术可以取消 LLM 的审查,文中介绍了第三代 Llama 模型的 instruct 版本。随后,他们询问了如何将此技术应用于 OpenAI 模型。
未获解答的 OpenAI 实现咨询:尽管分享了关于 abliteration 的研究,但在讨论帖中,关于如何使用 OpenAI 模型实现该技术的知识请求尚未得到解答。
深入了解:
- 解析挑战与方法:(未提供)
- 关于 abliteration 的博客文章:使用 abliteration 取消任何 LLM 的审查。
Datasette - LLM (@SimonW) Discord
-
文本截断之谜:在使用
llm处理 embeddings 时,一位成员发现输入文本超过模型的上下文长度(context length)并不一定会触发错误,反而可能导致输入被截断。实际行为因模型而异,这凸显了需要更清晰的文档来说明各模型如何处理超长输入。 -
嵌入任务:是否支持续传:有人询问
embed-multi在不重新处理已完成部分的情况下恢复大型嵌入任务的功能。这突出了对能够管理嵌入过程中部分完成任务的功能的需求。 -
对嵌入行为文档的需求:@SimonW 的回应指出,关于输入是被截断还是产生错误的模型行为文档缺乏清晰度,这表明用户普遍呼吁为这些 AI 系统提供全面且易于获取的文档。
-
模型截断的推测:在缺乏错误消息的情况下,@SimonW 推测导致意外嵌入结果的长文本输入很可能被截断了,这种行为应该在特定模型文档中得到明确验证。
-
大型嵌入任务的效率:关于
embed-multi是否能在重新运行大型任务时识别并跳过先前已处理数据的讨论,展示了对效率的关注以及在长时间运行的 AI 流程中进行智能任务处理的需求。
Torchtune Discord
Megatron 的 Checkpoint 难题:工程师们询问了 Megatron 与微调库的兼容性,并注意到了其独特的 checkpoint 格式。大家一致认为,将 Megatron checkpoints 转换为 Hugging Face 格式并利用 Torchtune 进行微调是最佳方案。
Mozilla AI Discord
- 对 JSON Schema 集成的呼声日益高涨:一位 AI 工程师提议在即将发布的软件版本中包含 JSON schema,以简化应用开发。他承认虽然存在一些 Bug,但强调了它为构建应用程序带来的便利。目前尚未提供关于时间表或潜在实现挑战的细节。
YAIG (a16z Infra) Discord
- 关于 AI Infrastructure 的周末音频学习:一位成员分享了周末听力环节的链接,内容涉及 AI Infrastructure 的讨论,这对于希望紧跟该领域最新趋势和挑战的 AI 工程师来说可能很有意义。内容可以在 YouTube 上观看。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
PART 2: 详细频道摘要与链接
邮件中已截断完整的频道详情。
如果您喜欢 AInews,请分享给朋友!预谢!