ainews-hipporag-first-do-knowledge-graph
HippoRAG:首先,构建知识图谱。 *(注:这句话模仿了医学界的希波克拉底誓言中的名言 "First, do no harm"——“首先,不要伤害”,这里将 "no harm" 巧妙地替换成了 "know(ledge) Graph"——“知识图谱”。)*
阿里巴巴发布了全新的开源 Qwen2 模型,参数范围涵盖 0.5B 到 72B,在 MMLU 和 HumanEval 等基准测试中取得了最先进(SOTA)的结果。研究人员引入了稀疏自编码器(Sparse Autoencoders)来解释 GPT-4 的神经活动,从而改进了特征表示。HippoRAG 论文提出了一种受海马体启发的检索增强方法,利用知识图谱和个性化 PageRank 实现高效的多跳推理。逐步内化(Stepwise Internalization)等新技术使大语言模型能够进行隐式思维链推理,提升了准确性和速度。思想缓冲区(Buffer of Thoughts, BoT)方法在显著降低成本的同时提高了推理效率。此外,研究人员还展示了一种新型的可扩展、无矩阵乘法(MatMul-free)大语言模型架构,其在十亿参数规模上可与最先进的 Transformer 架构相媲美。“单步多跳检索”被强调为检索速度和成本方面的关键进展。
记忆是 LLM 所需的一切。
2024年6月6日至6月7日的 AI 新闻。 我们为您检查了 7 个 Reddit 子版块、384 个 Twitter 账号 和 30 个 Discord 服务端(409 个频道和 3133 条消息)。 预计节省阅读时间(以 200wpm 计):343 分钟。
热烈欢迎加入 TorchTune Discord。提醒一下,我们确实会考虑在 Reddit/Discord 追踪列表中增加内容的请求(我们会拒绝 Twitter 的增加请求——可定制的 Twitter 通讯即将推出!我们知道这让大家久等了)。
随着关于记忆初创公司以及长期运行的 Agent/个人 AI 领域融资增加的传闻,我们看到人们对高精度/高召回率记忆实现的兴趣日益浓厚。
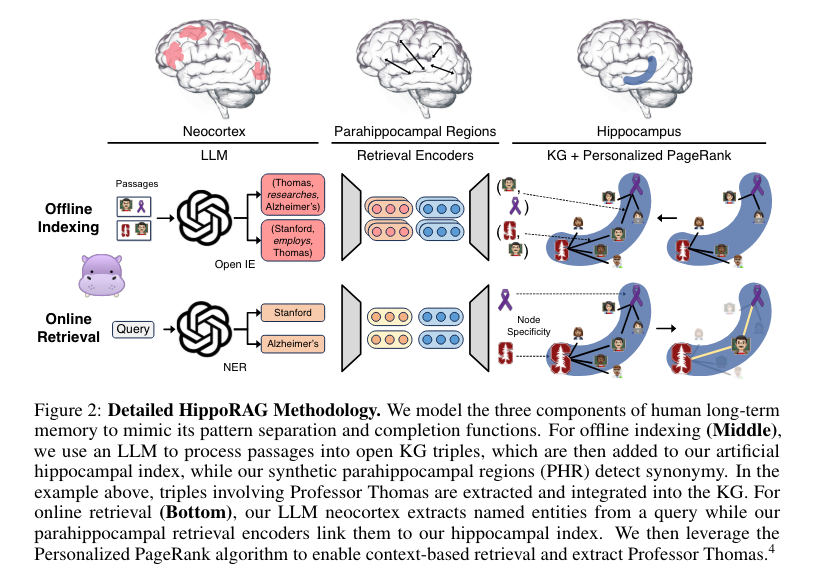
今天的论文虽然不如 MemGPT 那么出色,但它预示了人们正在探索的方向。尽管我们不太推崇用自然智能模型来解释人工智能,但 HippoRAG 论文借鉴了“海马体记忆索引理论(hippocampal memory indexing theory)”,从而实现了一种有用的 Knowledge Graphs 和 “Personalized PageRank” 方案,这可能具有更坚实的实证基础。
讽刺的是,对该方法论最好的解释来自 Rohan Paul 的一个推文串(我们不确定他是如何每天产出这么多内容的):

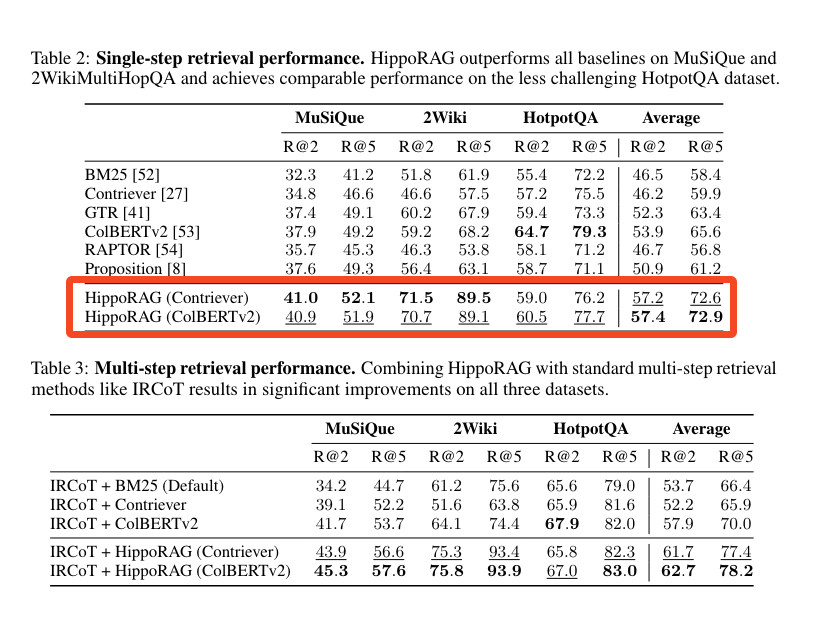
与慢 10 倍以上且更昂贵的同类方法相比,Single-Step, Multi-Hop retrieval 似乎是关键的制胜点:
第 6 节对当前在 LLM 系统中模拟记忆的技术进行了有用且简洁的文献综述。

AI Twitter 综述
所有综述均由 Claude 3 Opus 完成,从 4 次运行中选取最佳结果。我们正在尝试使用 Haiku 进行聚类和 Flow Engineering。
新的 AI 模型与架构
- 来自阿里巴巴的新 SOTA 开源模型:@huybery 宣布发布阿里巴巴的 Qwen2 模型,参数规模从 0.5B 到 72B 不等。这些模型在 29 种语言上进行了训练,并在 MMLU(72B 为 84.32)和 HumanEval(72B 为 86.0)等基准测试中达到了 SOTA 性能。除 72B 外,所有模型均采用 Apache 2.0 许可证。
- 用于解释 GPT-4 的 Sparse Autoencoders:@nabla_theta 介绍了一种新的 Sparse Autoencoders (SAEs) 训练栈,用于解释 GPT-4 的神经活动。该方法显示出前景,但目前仅能捕捉到一小部分行为。它消除了特征收缩(feature shrinking),直接设置 L0,并在 MSE/L0 前沿表现良好。
- 受海马体启发的检索增强:@rohanpaul_ai 概述了 HippoRAG 论文,该论文模拟新皮层和海马体以实现高效的检索增强。它从语料库中构建知识图谱,并使用个性化 PageRank 在单步内进行多跳推理,性能优于 SOTA RAG 方法。
- 隐式思维链推理:@rohanpaul_ai 描述了关于教导 LLM 隐式进行思维链(chain-of-thought)推理,而无需显式中间步骤的研究。所提出的 Stepwise Internalization 方法在微调过程中逐渐移除 CoT token,使模型能够以高准确度和速度进行隐式推理。
- 通过 Buffer of Thoughts 增强 LLM 推理:@omarsar0 分享了一篇提出 Buffer of Thoughts (BoT) 的论文,旨在提高 LLM 的推理准确性和效率。BoT 存储了从问题解决中提取的高级思维模板,并进行动态更新。它在多项任务上达到了 SOTA 性能,而成本仅为多查询提示(multi-query prompting)的 12%。
- 可扩展的无矩阵乘法 LLM,性能媲美 SOTA Transformer:@rohanpaul_ai 分享了一篇论文,声称创建了首个在十亿参数规模下可与 SOTA Transformer 竞争的可扩展 MatMul-free LLM。该模型用三值操作(ternary ops)取代了 MatMul,并使用了 Gated Recurrent/Linear Units。作者构建了一个定制的 FPGA 加速器,在 13W 功耗下处理模型的吞吐量超过了人类阅读速度。
- 通过正交低秩自适应加速 LoRA 收敛:@rohanpaul_ai 分享了一篇关于 OLoRA 的论文,该方法在保持效率的同时加速了 LoRA 的收敛。OLoRA 通过 QR 分解对自适应矩阵进行正交初始化,在多种 LLM 和 NLP 任务上表现优于标准 LoRA。
多模态 AI 与机器人技术进展
- 用于细粒度视觉理解的 Dragonfly 视觉语言模型:@togethercompute 推出了利用多分辨率编码和放大补丁选择(zoom-in patch selection)的 Dragonfly 模型。Llama-3-8b-Dragonfly-Med-v1 在医学影像方面的表现优于 Med-Gemini。
- 用于视频理解与生成的 ShareGPT4Video:@_akhaliq 分享了 ShareGPT4Video 系列,以促进 LVLM 中的视频理解和 T2VM 中的视频生成。它包括一个包含 4 万条 GPT-4 标注的视频数据集、一个卓越的任意视频标注器,以及一个在 3 个视频基准测试中达到 SOTA 的 LVLM。
- 使用 Nvidia Jetson Orin Nano 的开源机器人演示:@hardmaru 强调了开源机器人的潜力,分享了一个使用 Nvidia Jetson Orin Nano 8GB 板卡、Intel RealSense D455 摄像头和麦克风以及 Luxonis OAK-D-Lite AI 摄像头的机器人视频演示。
AI 工具与平台更新
- 用于高吞吐量 Embedding 服务的 Infinity:@rohanpaul_ai 发现 Infinity 在通过 REST API 提供向量 Embedding 服务方面表现出色,支持多种模型/框架、快速推理后端、动态批处理,并能轻松与 FastAPI/Swagger 集成。
- Amazon SageMaker 上的 Hugging Face Embedding Container:@_philschmid 宣布 HF Embedding Container 在 SageMaker 上正式可用,改进了 RAG 应用的 Embedding 创建,支持流行架构,使用 TEI 实现快速推理,并允许部署开源模型。
- Qdrant 与 Neo4j APOC 过程的集成:@qdrant_engine 宣布 Qdrant 与 Neo4j 的 APOC 过程全面集成,为图数据库应用带来了先进的向量搜索功能。
AI 模型的基准测试与评估
- MixEval 基准测试与 Chatbot Arena 的相关性达 96%:@_philschmid 介绍了 MixEval,这是一个结合了现有基准测试与真实世界查询的开放基准。MixEval-Hard 是一个具有挑战性的子集。其运行成本为 0.6 美元,与 Arena 的相关性达 96%,并使用 GPT-3.5 作为解析器/裁判。阿里巴巴的 Qwen2 72B 在开源模型中位居榜首。
- MMLU-Redux:重新标注的 MMLU 问题子集:@arankomatsuzaki 创建了 MMLU-Redux,这是 MMLU 中跨 30 个学科的 3,000 个问题的子集,旨在解决诸如病毒学中 57% 的问题包含错误等问题。该数据集已公开。
- 质疑 MMLU 的持续相关性:@arankomatsuzaki 质疑鉴于 SOTA 开源模型的饱和,我们是否已经完成了使用 MMLU 评估 LLM 的阶段,并提议将 MMLU-Redux 作为替代方案。
- 发现开源 LLM 的缺陷:@JJitsev 从他们的 AIW 研究中得出结论,当前的 SOTA 开源 LLM(如 Llama 3、Mistral 和 Qwen)在基础推理方面存在严重缺陷,尽管它们声称拥有强大的基准测试表现。
关于 AI 的讨论与观点
- 谷歌关于人工超智能(ASI)开放性的论文:@arankomatsuzaki 分享了一篇谷歌论文,认为实现 AI 开放性的要素已经具备,这对于 ASI 至关重要。该论文提供了开放性的定义、通过基础模型实现的路径,并探讨了安全影响。
- 关于微调可行性的辩论:@HamelHusain 分享了 Emmanuel Kahembwe 关于“为什么微调已死”的演讲,引发了讨论。虽然不像演讲者那样悲观,但 @HamelHusain 认为这个演讲很有趣。
- Yann LeCun 谈 AI 监管:在一系列推文中(1, 2, 3),@ylecun 主张监管 AI 应用而非技术,并警告说监管基础技术并让开发者为滥用负责将扼杀创新、停止开源,且这些做法是基于不可信的科幻场景。
- 关于 AI 时间线和进展的辩论:Leopold Aschenbrenner 在 @dwarkesh_sp 播客中讨论他关于 AI 进展和时间线的论文(由一位用户总结),引发了大量辩论,观点从称其为 AI 能力爆炸的重要案例到批评其依赖于持续指数增长的假设不等。
其他
- Perplexity AI 在 NBA 总决赛期间投放广告:@AravSrinivas 指出 首个 Perplexity AI 广告在 NBA 总决赛第一场期间播出。@perplexity_ai 分享了该视频剪辑。
- Yann LeCun 谈指数趋势与 S 型曲线(Sigmoids):@ylecun 认为 每一个指数趋势最终都会经过一个拐点并饱和成 S 型曲线(Sigmoid),因为动力学方程中的摩擦项会变得占主导地位。持续指数增长需要范式转移,正如在摩尔定律中所见。
- John Carmack 谈 Quest Pro:@ID_AA_Carmack 分享说他 曾努力尝试彻底砍掉 Quest Pro,因为他认为这在商业上会失败,并会分散团队在更有价值的大众市场产品上的精力。
- FastEmbed 库新增嵌入类型:@qdrant_engine 宣布 FastEmbed 0.3.0 增加了对图像嵌入 (ResNet50)、多模态嵌入 (CLIP)、延迟交互嵌入 (ColBERT) 和稀疏嵌入的支持。
- 笑话与梗:分享了各种笑话和梗,包括一个在没有 Flash Attention 的情况下输出胡言乱语的 GPT-4 GGUF(链接),@karpathy 针对 DeepMind 的 SAE 论文发布的 llama.cpp 更新(链接),以及对 LLM 炒作周期和夸大言论的评论(例子)。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
中国 AI 模型
- 可灵 (KLING) 模型生成视频:中国的可灵 (KLING) AI 模型生成了几段人们吃面条或汉堡的视频,定位为 OpenAI SORA 的竞争对手。用户讨论了该模型的可访问性及其潜在影响。 (视频 1, 视频 2, 视频 3, 视频 4)
- Qwen2-72B 语言模型发布:阿里巴巴在 Hugging Face 上发布了 Qwen2-72B 中文语言模型。根据对比图,它在多项基准测试中超越了 Llama 3。官方发布博客链接也已提供。
AI 能力与局限性
- 开源 vs 闭源模型:截图展示了 Bing AI 和 CoPilot 等闭源模型如何限制某些话题的信息,强调了开源替代方案的重要性。Andrew Ng 认为 AI 监管应侧重于应用,而非限制开源模型的开发。
- AI 作为“外星智能”:Steven Pinker 认为 AI 模型是一种“外星智能”,我们正在对其进行实验,且人类大脑可能与大语言模型相似。
AI 研究与进展
- 从 GPT-4 中提取概念:OpenAI 关于使用稀疏自编码器识别 GPT-4 神经网络中可解释模式的研究,旨在使模型更可靠、更具可控性。
- 针对 AI 的反垄断调查:微软和 Nvidia 因其 AI 相关业务举措正面临美国反垄断调查。
- 极端权重量化:研究通过极端权重量化实现了比原始版本性能更好的 Stable Diffusion v1.5 模型,体积缩小了 7.9 倍。
AI 伦理与监管
- AI 审查担忧:Bing AI 拒绝提供某些信息的截图引发了关于 AI 审查和信息开放获取重要性的讨论。
- 测试 AI 的选举风险:Anthropic 讨论了在其 AI 系统中测试和缓解潜在选举相关风险的努力。
- 使用社交媒体数据的批评:使用 Facebook 和 Instagram 帖子训练 AI 模型的计划面临批评。
AI 工具与框架
- 用于角色扮演的 Higgs-Llama-3-70B:针对角色扮演优化的 Llama-3 微调版本 已在 Hugging Face 上发布。
- 移除 LLM 审查:Hugging Face 博客文章介绍了一种用于移除语言模型审查的“abliteration”方法。
- Atomic Agents 库:新的开源库,用于构建支持本地模型的模块化 AI Agent。
AI Discord 回顾
摘要之摘要的摘要
1. LLM 进展与优化挑战:
- Meta 的 Vision-Language Modeling 指南 提供了 VLM 的全面概述,包括训练过程和评估方法,帮助工程师更好地理解视觉到语言的映射。
- DecoupleQ 来自字节跳动,旨在利用新的量化方法大幅提升 LLM 性能,承诺 7 倍压缩率,尽管进一步的速度基准测试仍有待观察 (GitHub)。
- GPT-4o 即将推出的功能 包括为 ChatGPT Plus 用户提供的新语音和视觉功能,以及为 Alpha 用户提供的实时聊天。 在 OpenAI 的推文中阅读相关内容。
- 高效推理和训练技术 如
torch.compile加速了 SetFit 模型,证实了在 PyTorch 中尝试优化参数以获得性能提升的重要性。 - FluentlyXL Final 来自 HuggingFace,在美学和光影方面引入了实质性改进,提升了 AI 模型的输出质量 (FluentlyXL)。
2. 开源 AI 项目与资源:
- TorchTune 使用 PyTorch 简化了 LLM 的微调,并在 GitHub 上提供了一个详细的仓库。欢迎通过单元测试为 mqa/gqa 配置
n_kv_heads等贡献。 - Unsloth AI 的 Llama3 和 Qwen2 训练指南 提供了实用的 Colab 笔记本和高效的预训练技术,以优化 VRAM 使用 (Unsloth AI 博客)。
- LlamaIndex 中的动态数据更新 通过定期索引刷新和元数据过滤器,帮助保持检索增强生成 (RAG) 系统的实时性,详见 LlamaIndex 指南。
- AI 视频生成和 Vision-LSTM 技术探索了动态序列生成和图像读取能力 (Twitter 讨论)。
- TopK Sparse Autoencoders 在 GPT-2 Small 和 Pythia 160M 上进行了有效训练,无需在磁盘上缓存激活值,有助于特征提取 (OpenAI 发布)。
3. AI 模型实施中的实际问题:
- LangChain 中的 Prompt Engineering 面临重复步骤和提前停止的问题,敦促用户寻找修复方案 (GitHub issue)。
- Automatic1111 在图像生成任务中的高 VRAM 消耗 导致了显著的延迟,凸显了对内存管理解决方案的需求 (Stability.ai 聊天)。
- Qwen2 模型故障排除 揭示了乱码输出的问题,通过启用 flash attention 或使用正确的预设已修复 (LM Studio 讨论)。
- Mixtral 8x7B 模型误区纠正:Stanford CS25 澄清其包含 256 个专家,而不仅仅是 8 个 (YouTube)。
4. AI 监管、安全与伦理讨论:
- 吴恩达 (Andrew Ng) 对 AI 监管的担忧 呼应了全球关于 AI 创新受阻的辩论;与俄罗斯 AI 政策讨论的对比揭示了在开源和伦理 AI 方面的不同立场 (YouTube)。
- Leopold Aschenbrenner 从 OAI 离职 引发了关于 AI 安全措施重要性的激烈辩论,反映了在 AI 保护方面的分歧意见 (OpenRouter 讨论)。
- 艺术软件中的 AI 安全:Adobe 要求访问所有作品(包括签署 NDA 的项目),这促使注重隐私的用户建议使用 Krita 或 Gimp 等替代软件 (Twitter 线程)。
5. 社区工具、技巧与协作项目:
- Predibase 工具与热烈反馈:LoRAX 在高性价比 LLM 部署方面表现出色,尽管存在邮件注册的小插曲 (Predibase 工具)。
- 用于递归分析的 WebSim.AI:AI 工程师分享了使用 WebSim.AI 进行递归模拟的经验,并对源自幻觉的有价值指标进行了头脑风暴 (Google 表格)。
- Modular 的 MAX 24.4 更新 引入了新的 Quantization API 并支持 macOS,通过显著降低延迟和内存占用增强了 Generative AI 流水线 (博客文章)。
- GPU 冷却与电源解决方案 讨论了设置 Tesla P40 及类似硬件的创新方法,并提供了实用指南 (GitHub 指南)。
- 实验与学习资源:由 tcapelle 提供,包括用于微调和提高效率的实用笔记本及 GitHub 资源 (Colab 笔记本)。
第 1 部分:Discord 高层摘要
LLM Finetuning (Hamel + Dan) Discord
-
RAG 改进与表格转换尝试:由于对 Marker 格式化 Markdown 表格的效果不满,引发了关于通过 Fine-tuning 该工具以优化输出的讨论。同时,也在探索如 img2table 等替代的表格提取工具。
-
Predibase 为 Python 专家提供预测文本:用户对 Predibase 的额度与工具表现出浓厚兴趣,其中 LoRAX 因其高性价比、高质量的 LLM 部署能力而脱颖而出。确认函和邮箱注册环节普遍存在小故障,相关求助已定向至注册邮箱。
-
关于深度 LLM 理解的公开讨论:来自 tcapelle 的帖子深入探讨了 LLM Fine-tuning,并分享了 slides 和 notebooks 等资源。此外,一份在 NVIDIA GTC 演讲 中分享的研究强调了通过 Pruning 策略来精简 LLM 的方法。
-
Cursor 代码编辑器吸引工程师关注:AI 代码编辑器 Cursor 利用来自 OpenAI 及其他 AI 服务的 API keys,因其代码库索引(codebase indexing)和代码补全(code completion)方面的改进而获得认可,甚至吸引用户从 GitHub Copilot 迁移。
-
Modal GPU 使用与大量 Gist 分享:评估了 Modal 的 VRAM 使用情况和 A100 GPUs,同时分享了 Pokemon 卡片描述的 Gist 以及 Whisper 适配技巧。会上提到了 GPU 可用性的不稳定性,并注意到缺乏显示队列状态的 Dashboard。
-
通过 Vector 和 OpenPipe 学习:讨论内容包括使用 VectorHub 的 RAG 相关内容构建 Vector 系统,OpenPipe 博客 上的文章也因其对讨论的贡献而受到关注。
-
Fine-tuning 工具与数据的难题:用户正在解决课程会议录像的下载问题;同时,受合成数据集(synthetic datasets)涌入的启发,Bulk 工具的开发正在加速。有人在 Replicate 演示期间寻求关于本地 Docker 空间困境的帮助,但在聊天记录中尚未找到解决方案。
-
LLM Fine-tuning 修复进行中:围绕 Fine-tuning 复杂性展开了热烈讨论,解决了合并 Lora 模型分片异常的问题,并提出了如使用 Mistral Instruct 模板进行 DPO Fine-tuning 等偏好。有趣的是,Axolotl 中 Token 空间组装的输出差异引起了关注,对话倾向于调试和潜在的解决方案。
Perplexity AI Discord
-
Starship 成功翱翔并溅落:SpaceX 的 Starship 测试飞行取得成功,在两大洋着陆,引起了工程界的关注;根据 官方更新,在墨西哥湾和印度洋的成功溅落标志着该项目的显著进展。
-
精彩的咖喱对比:对国际美食感兴趣的工程师分析了日本、印度和泰国咖喱的区别,指出了独特的香料、草药和成分;一份 详细的细分报告 被传阅,提供了关于每种咖喱的历史起源和典型食谱的见解。
-
Perplexity 促销活动令参与者困惑:期待 Perplexity AI “The Know-It-Alls” 广告带来重大更新的用户感到失望;相反,这只是一个宣传视频,让许多人觉得这更像是一个噱头而非实质性的揭晓,正如在 General 频道 中讨论的那样。
-
AI 社区交流 Claude 3 与 Pro Search:关于 Pro Search 和 Claude 3 等不同 AI 模型的讨论非常热烈;模型偏好、搜索能力和用户体验是热门话题,同时还讨论了从 Perplexity Labs 中移除 Claude 3 Haiku 的事宜。
-
API 频道中的 llava 哀叹与 Beta 忧郁:API 用户询问了 llava 模型的集成情况,并对新来源 Beta 测试 似乎不公开的性质表示不满,表现出对 Perplexity 团队提高透明度和加强沟通的强烈渴望。
HuggingFace Discord
-
Electrifying Enhancement with FluentlyXL: 备受期待的 FluentlyXL Final 版本现已发布,承诺在美学和光影方面带来实质性增强,详情见其 官方页面。此外,关注环保的技术爱好者可以探索新的 Carbon Footprint Predictor,以衡量其项目的环境影响 (Carbon Footprint Predictor)。
-
Innovations Afoot in AI Model Development: 初出茅庐的 AI 工程师正在探索模型开发不同领域中快速演进的可能性,从 SimpleTuner 0.9.6.2 版本中新增的 MoE 支持 (SimpleTuner on GitHub),到一个基于 TensorFlow 的 ML Library,其源代码和文档可在 GitHub 上进行同行评审。
-
AI’s Ascendancy in Medical and Modeling Musings: 最近的一段 YouTube 视频深入探讨了 genAI 在医学教育中日益增长的作用,强调了 Anki 和 genAI 驱动的搜索 等工具的优势 (AI in Medical Education)。在开源领域,TorchTune 项目因促进 LLM 的 fine-tuning 而引起关注,相关探索在 GitHub 上有详细叙述。
-
Collider of Ideas in Computer Vision: 爱好者们正在汇集知识,为 Vision Language Models (VLMs) 创建有价值的应用,社区成员分享了新的 Hugging Face Spaces 应用 Model Explorer 和 HF Extractor,这些工具对 VLM 应用开发至关重要 (Model Explorer, HF Extractor,以及相关的 YouTube 视频)。
-
Engaging Discussions and Demonstrations: LLM 的多节点 fine-tuning 是一个讨论热点,引发了对一篇 关于 Vision-Language Modeling 的 arXiv 论文 的分享;同时,Diffusers GitHub 仓库 因其 text-to-image 生成脚本而被重点关注,这些脚本也可用于模型 fine-tuning (Diffusers GitHub)。此外,还传阅了一篇提供原生 PyTorch 优化见解的博客文章,以及为渴望从零开始训练模型的用户准备的 训练示例 notebook。
Stability.ai (Stable Diffusion) Discord
- AI Newbies Drowning in Options: 一位社区成员表达了对海量待探索 AI 模型的兴奋与不知所措,这捕捉到了许多该领域新入局者的共同心声。
- ControlNet’s Speed Bump: 用户 arti0m 报告了 ControlNet 出现的意外延迟,导致图像生成时间长达 20 分钟,这与预期的速度提升背道而驰。
- CosXL’s Broad Spectrum Capture: 来自 Stability.ai 的新 CosXL 模型拥有更广阔的色调范围,能够生成从“漆黑”到“纯白”具有更好对比度的图像。点击 此处 了解更多。
- VRAM Vanishing Act: 关于 Automatic1111 web UI 内存管理挑战的讨论浮出水面,该界面似乎过度占用 VRAM,影响了图像生成任务的性能。
- Waterfall Scandal Makes Waves: 一场关于中国病毒式传播的假瀑布丑闻引发了激烈辩论,进而引发了对其环境和政治影响的更广泛讨论。
Unsloth AI (Daniel Han) Discord
-
Adapter 重载引发关注:成员们在尝试使用模型 Adapter 继续训练时遇到问题,特别是在使用
model.push_to_hub_merged("hf_path")时,Loss 指标出现意外飙升,这指向了保存或加载过程中可能存在的处理不当。 -
通过特殊技术增强 LLM 预训练:Unsloth AI 的博客 概述了使用 Llama3 等 LLM 对韩语等语言进行持续预训练(Continued Pretraining)的效率,承诺减少 VRAM 占用并加速训练,并提供了一个实用的 Colab notebook 用于实际应用。
-
Qwen2 模型开启扩展语言支持:宣布支持 Qwen2 模型,该模型拥有高达 128K 的上下文长度并覆盖 27 种语言,Daniel Han 在 Twitter 上分享了微调资源。
-
探索 Grokking:讨论深入探讨了一种被称为 “Grokking” 的新识别出的 LLM 性能阶段,社区成员引用了一场 YouTube 辩论 并提供了支持性研究链接以供进一步探索。
-
纠正 NVLink VRAM 误区:对 NVIDIA NVLink 技术进行了澄清,成员解释说 NVLink 不会将 VRAM 合并为一个单一池,打破了关于其能够扩展计算可用 VRAM 容量的误解。
CUDA MODE Discord
-
Triton 简化 CUDA:Triton 语言因其使用 Grid 语法 (
out = kernel[grid](...)) 启动 CUDA Kernel 的简便性,以及在启动后轻松访问 PTX 代码 (out.asm["ptx"]) 的能力而受到认可,为 CUDA 开发者提供了更精简的工作流。 -
TorchScript 中的 Tensor 问题与 PyTorch Profiling:在 TorchScript 中无法使用
view(dtype)进行 Tensor 转换,这让寻求 bfloat16s 位操作能力的工程师感到沮丧。同时,PyTorch Profiler 因其提供性能洞察的实用性而受到关注,详见 PyTorch profiling 教程。 -
提示更好的 LoRA 初始化:分享了一篇博客 Know your LoRA,建议 LoRA 中的 A 和 B 矩阵可以从非默认初始化中受益,从而可能改善微调结果。
-
Note 库展示 ML 效率:引用了 Note 库的 GitHub 仓库,该库提供了一个与 TensorFlow 兼容的 ML 库,承诺在包括 Llama2、Llama3 等模型上实现并行和分布式训练。
-
LLM 量化领域的飞跃:频道深入讨论了 字节跳动的 2-bit 量化算法 DecoupleQ,并提供了一篇关于改进 Straight-Through Estimator 量化方法的 NeurIPS 2022 论文 链接,指出了量化过程中对内存和计算的考量。
-
AI 框架讨论升温:LLVM.c 社区深入探讨了支持 Triton 和 AMD、解决 BF16 梯度范数确定性(Determinism)以及未来对 Llama 3 等模型的支持。话题还涉及确保训练中的 100% 确定性,并考虑使用 FineWeb 作为数据集,同时权衡了扩展和数据类型多样化的因素。
OpenAI Discord
-
抄袭席卷研究论文:五篇研究论文因内容中无意包含 AI prompts 而被撤回;成员们对这一疏忽反应不一,既有幽默调侃也有失望。
-
Haiku 模型:高性价比:关于 Haiku AI model 的讨论非常热烈,其成本效益和出色的性能受到赞赏,甚至被比作 “gpt 3.5ish” 的质量。
-
AI 审核:一把双刃剑?:社区内对在 Reddit 和 Discord 等平台使用 AI 进行内容 moderation(审核)的优缺点展开了热烈讨论,权衡了自动化操作与人工监督之间的平衡。
-
通过 YouTube 掌握 LLMs:成员们分享了有助于更好理解 LLMs 的 YouTube 资源,特别提到了 Kyle Hill 的 ChatGPT Explained Completely 和 3blue1brown,称赞其引人入胜的数学解释。
-
GPT 不断变化的能力:GPT-4o 正在向所有用户推出,新的语音和视觉功能专为 ChatGPT Plus 预留。同时,社区正在应对自定义 GPTs 频繁的修改通知以及在使用带有 CSV 附件的 GPT 时遇到的挑战。
LM Studio Discord
-
LM Studio 内的庆祝与协作:LM Studio 迎来一周年里程碑,讨论涉及利用多 GPU——推荐使用 Tesla K80 和 3090 以保持一致性——以及运行多个实例进行模型间通信。强调了在 LLMs 方面 GPU 优于 CPU,并指出了在 PlayStation 5 APUs 等强大硬件上使用 LM Studio 的实际问题。
-
Higgs 强势登场:对 LMStudio update 充满期待,该更新将整合令人印象深刻的 Higgs LLAMA,这是一个拥有 700 亿参数的大型模型,可能为 AI 工程师提供前所未有的能力和效率。
-
硬件方面的挑战与变通:针对 Tesla P40 等小众硬件的 GPU 散热和电源问题引发了创意讨论,从简陋的 Mac GPU 风扇到复杂的纸板风道。建议包括参考 GitHub guide 来处理专有连接的绑定问题。
-
模型兼容性故障排除:Qwen2 乱码的修复方法包括切换 flash attention,同时承认了 Qwen2 在 CUDA offloading 方面的风险,并期待 llama.cpp 的更新。一位成员分享了通过 API 使用 llava-phi-3-mini-f16.gguf 结果不一的经历,引发了进一步的模型诊断讨论。
-
微调要点:关于微调的细致观点强调了通过 LoRA 进行风格调整与 SFT 基于知识的调优之间的区别;LM Studio 在没有训练的情况下对系统 prompt 名称的限制;以及应对“懒惰” LLM 行为的策略,如硬件升级或 prompt 优化。
-
AMD 技术的 ROCm 历程:用户交流了在各种 AMD GPUs(如 6800m 和 7900xtx)上启用 ROCm 的技巧和经验,并提出了在 Arch Linux 上使用的建议以及在 Windows 环境下的变通方案,以优化其 LLM 设置的性能。
Latent Space Discord
- AI 工程师,准备好建立联系:对 AI Engineer event 感兴趣的工程师可以使用 Expo Explorer 门票参加会议,不过演讲者阵容尚未最终确定。
- KLING 等同于 Sora:快手(KWAI)名为 KLING 的类 Sora 新模型因其逼真演示而引发关注,正如 Angry Tom 的 tweet thread 所展示的那样。
- 剖析 GPT-4o 的图像处理:Oran Looney 在一篇深度文章中剖析了 OpenAI 决定使用 170 个 tokens 处理 GPT-4o 图像的决定,讨论了编程中“magic numbers”(魔数)的重要性及其对 AI 的最新影响。
- “幻觉工程师”发表见解:辩论了 GPT 的“有用幻觉范式”概念,强调了其构思有益指标的潜力,并将其与 “superprompts” 和社区开发的工具(如 Websim AI)进行了类比。
- 递归现实与资源库:AI 爱好者们尝试了 websim.ai 的自引用模拟,同时分享了一个 Google spreadsheet 和一个 GitHub Gist,用于未来会议的协作和广泛讨论。
Nous Research AI Discord
-
Mixtral 的专家数量揭晓:一场富有启发性的 Stanford CS25 讲座 澄清了关于 Mixtral 8x7B 的误解,透露其包含 32x8 个专家,而非仅仅 8 个。这一细节凸显了其 MoE 架构背后的复杂性。
-
DeepSeek Coder 在代码任务中胜出:根据 Hugging Face 上分享的介绍,DeepSeek Coder 6.7B 在项目级代码补全方面处于领先地位,展示了在高达 2 万亿代码 token 上训练出的卓越性能。
-
Meta AI 详解视觉语言建模:Meta AI 通过 “An Introduction to Vision-Language Modeling” 提供了一份关于 Vision-Language Models (VLMs) 的全面指南,为那些对视觉与语言融合感兴趣的人详细介绍了其工作原理、训练和评估。
-
RAG 格式化技巧:围绕 RAG 数据集 创建的讨论强调了简单性和针对性的必要性,拒绝千篇一律的框架,并重点介绍了利用 Ollama 和 emo 向量搜索进行数据集生成的工具,如 Prophetissa。
-
WorldSim 控制台的移动端优化:最新的 WorldSim 控制台 更新解决了移动端用户界面问题,通过修复文本输入 bug、增强
!list命令以及新增禁用视觉效果的设置来提升体验,同时集成了多功能的 Claude 模型。
LlamaIndex Discord
-
RAG 迈向 Agentic 检索:最近在旧金山总部的一次演讲强调了 Retrieval-Augmented Generation (RAG) 向 全 Agentic 知识检索 的演进。此举旨在克服 top-k 检索的局限性,可通过 视频指南 获取增强实践的相关资源。
-
LlamaIndex 增强记忆能力:LlamaIndex 引入了 Vector Memory Module,通过向量搜索存储和检索用户消息,从而加强 RAG 框架。感兴趣的工程师可以通过分享的 demo notebook 探索此功能。
-
Create-llama 中增强的 Python 执行:Create-llama 与 e2b_dev 沙箱的集成现在允许在 Agent 内部执行 Python 代码,这一进步使得返回复杂数据(如统计图表图片)成为可能。正如此处详述,这一新功能拓宽了 Agent 的应用范围。
-
同步 RAG 与动态数据:在 RAG 中实现动态数据更新涉及重新加载索引以反映最新更改,这一挑战通过使用定期索引刷新来解决。通过多个索引或元数据过滤器,可以优化对销售或支持文档等数据集的管理,相关实践已在 Document Management - LlamaIndex 中列出。
-
LlamaIndex 中使用 Embedding 进行优化和实体解析:直接使用 LlamaIndex 框架创建 property graphs 并应用 Embedding,可以通过调整
chunk_size参数来增强实体解析。通过 “Optimization by Prompting” 等 RAG 指南和 LlamaIndex 指南 可以更好地理解这些功能的管理。
Modular (Mojo 🔥) Discord
-
Andrew Ng 对 AI 监管敲响警钟:Andrew Ng 对加州的 SB-1047 法案表示担忧,担心其可能阻碍 AI 的进步。公会的工程师们对比了全球监管环境,指出即使没有美国的限制,像俄罗斯这样的国家也缺乏全面的 AI 政策,正如一段关于普京及其 deepfake 的视频所示。
-
Mojo 变得更聪明而非更复杂:确认了
isdigit()函数为了性能而依赖ord(),并在出现问题时提交了问题报告。Mojo 的 Async 功能仍有待进一步开发,建议使用__type_of进行变量类型检查,VSCode 扩展可辅助进行编译前后的识别。 -
MAX 首次登陆 macOS:Modular 的 MAX 24.4 版本现已支持 macOS,并推出了 Quantization API,社区贡献者已突破 200 人。该更新有望显著降低 AI pipeline 的延迟和内存占用。
-
动态 Python 备受关注:最新的 nightly 版本支持动态选择
libpython,有助于简化 Mojo 的环境搭建。然而,VS Code 的集成仍存在痛点,需要手动激活.venv,这在 nightly 变更说明以及新引入的 microbenchmarks 中有详细说明。 -
对 Windows 原生版 Mojo 的高度期待:工程师们调侃并渴望即将发布的 Windows 原生版 Mojo,其发布时间表仍充满神秘感。对该版本的渴望凸显了其对社区的重要性,表明 Windows 开发者对此有浓厚兴趣。
Eleuther Discord
-
工程师们开始上手新的 Sparse Autoencoder 库:Nora Belrose 最近发布的 推文 介绍了一个用于训练 TopK Sparse Autoencoders 的库,该库在 GPT-2 Small 和 Pythia 160M 上进行了优化,可以同时训练所有层的 SAE,而无需在磁盘上缓存 activations。
-
Sparse Autoencoder 研究进展:一篇新 论文 揭示了 k-sparse autoencoders 的开发,它增强了重构质量与稀疏性之间的平衡,这可能会显著影响语言模型特征的可解释性。
-
LLM 的下一次飞跃,源自新皮质 (Neocortex):成员们讨论了 Jeff Hawkins 和 Numenta 的 Thousand Brains Project,该项目旨在将新皮质原理应用于 AI,专注于开放协作——向大自然复杂的系统致敬。
-
评估错误文件路径的混乱:针对一个已知问题,成员们确认文件处理(特别是错误的测试结果文件放置——应位于 tmp 文件夹中)已列入修复清单,正如 KonradSzafer 的 PR 所示。
-
揭示 Data Shapley 的不可预测性:关于一篇 arXiv 预印本 的讨论展开,评估了 Data Shapley 在不同设置下数据选择性能的不一致性,建议工程师关注所提出的假设检验框架,以预测 Data Shapley 的有效性。
Interconnects (Nathan Lambert) Discord
-
AI 视频合成战争升温:一款中国 AI 视频生成器的表现超越了 Sora,通过快手 (KWAI) iOS 应用提供令人惊叹的 2 分钟、1080p、30fps 视频,引起了社区的显著关注。同时,Johannes Brandstetter 宣布了 Vision-LSTM,它结合了 xLSTM 处理图像的能力,并提供了代码和 arxiv 预印本 以供进一步探索。
-
Anthropic 的 Claude API 访问权限扩大:Anthropic 正在为对齐研究提供 API 访问权限,申请访问需要提供机构隶属关系、职位、LinkedIn、GitHub 和 Google Scholar 个人资料,以促进对 AI 对齐挑战的深入探索。
-
Daylight 电脑引发关注:新型 Daylight 电脑 因其减少蓝光发射和增强阳光直射下可见性的承诺而吸引了大量关注,引发了关于其相对于 iPad mini 等现有设备潜在优势的讨论。
-
模型调试与理论的新前沿:围绕类似于“自我调试模型”的新方法展开了引人入胜的对话,这些方法利用错误来改进输出,同时还讨论了对 DPO 等复杂理论密集型论文中解析解的渴望。
-
深化机器人讨论的挑战:成员们敦促对机器人内容的变现策略和具体数据进行更深入的洞察,特别要求对“40,000 个高质量机器人年数据”进行更细致的分解,并对该领域的商业模式进行更仔细的审查。
Cohere Discord
-
使用 Aya 进行免费翻译研究,但商业用途需付费:虽然 Aya 对学术研究免费,但商业应用需要付费以维持业务。面临 Vercel AI SDK 与 Cohere 集成挑战的用户可以找到指导,并已采取措施联系 SDK 维护者寻求支持。
-
聪明的 Command-R-Plus 胜过 Llama3:用户表示 Command-R-Plus 在某些场景下优于 Llama3,并引用了对其在语言规范之外表现的主观体验。
-
探索 Cohere 使用的数据隐私选项:对于在使用 Cohere 模型时担心数据隐私的用户,社区分享了关于如何在本地或 AWS 和 Azure 等云服务上将这些模型用于个人项目的详细信息和链接。
-
开发者展示全栈专业知识:一份全栈开发者作品集已上线,展示了在 UI/UX, Javascript, React, Next.js, 和 Python/Django 方面的技能。作品集可以在该开发者的个人网站上查看。
-
关注 GenAI 安全和新型搜索解决方案:Rafael 正在开发一款防止 GenAI 应用出现幻觉的产品并邀请合作;而 Hamed 推出了 Complexity,这是一个令人印象深刻的生成式搜索引擎,邀请用户在 cplx.ai 进行探索。
OpenRouter (Alex Atallah) Discord
-
Qwen 2 也支持韩语:Voidnewbie 提到,最近添加到 OpenRouter 产品中的 Qwen 2 72B Instruct 模型也支持韩语。
-
OpenRouter 与网关故障作斗争:多名用户在 Llama 3 70B 模型上遇到了 504 网关超时错误;数据库压力被确定为罪魁祸首,促使将任务迁移到只读副本以提高稳定性。
-
路由困扰引发技术对话:成员报告 WizardLM-2 8X22 通过 DeepInfra 产生乱码响应,导致建议调整请求路由中的
order字段,并暗示正在部署内部端点以帮助解决服务提供商问题。 -
AI 安全引发激烈争论:Leopold Aschenbrenner 被 OAI 解雇一事引发了成员之间关于 AI 安全重要性的激烈辩论,反映了在 AI 保护措施的必要性和影响方面的观点分歧。
-
ChatGPT 的性能波动:分享了关于 ChatGPT 在高流量期间可能出现性能下降的观察,引发了关于重负载对服务质量和一致用户体验影响的推测。
OpenAccess AI Collective (axolotl) Discord
Flash-attn 安装需要高 RAM:成员们强调了在 slurm 上构建 Flash-attn 时的困难;解决方案包括加载必要的模块以提供充足的 RAM。
Finetuning 问题已修复:报告了 Qwen2 72b 在 Finetuning 时的配置问题,建议进行另一轮调整,特别是由于 max_window_layers 的错误设置。
多节点 Finetuning 指南:分享了一个使用 Axolotl 和 Deepspeed 进行分布式 Finetuning 的 Pull Request,标志着社区协作开发努力的增加。
数据难题解决:一名成员在配置 JSONL 格式的 test_datasets 时遇到的困难,通过采用为 axolotl.cli.preprocess 指定的结构得到了解决。
针对工程化推理,API 优于 YAML:澄清了 Axolotl 在 API 使用与 YAML 设置方面的配置困惑,重点在于扩展脚本化、持续模型评估的能力。
LAION Discord
- 从左到右序列生成的竞争者:与 SkysoftATM 合作开发的创新型 σ-GPT 挑战了传统的 GPTs,通过动态生成序列,可能将步骤减少一个数量级,详见其 arXiv 论文。
- 讨论 σ-GPT 的高效学习:尽管 σ-GPT 采用了创新方法,但对其实用性存在质疑,因为高性能的课程学习(curriculum)可能会限制其使用,这与 XLNET 有限的影响力有相似之处。
- 探索填充任务的替代方案:对于某些操作,像 GLMs 这样的模型可能被证明更有效,而使用独特的 Positional Embeddings 进行 Finetuning 可能会增强基于 RL 的非文本序列建模。
- AI 视频生成竞争升温:快手 (KWAI) iOS 应用上的一款新型中国 AI 视频生成器可以制作 1080p、30fps 的 2 分钟视频,引起了轰动;而另一款生成器 Kling 凭借其逼真的能力,其真实性也受到了质疑。
- 社区对 Schelling AI 公告的反应:Emad Mostaque 关于 Schelling AI 的推文引发了质疑和幽默的混杂,该项目旨在使 AI 和 AI 算力挖掘民主化,但因使用流行语和宏大主张而受到关注。
LangChain AI Discord
-
LangChain 中的 Early Stopping 障碍:讨论强调了 LangChain 中的
early_stopping_method="generate"选项在较新版本中无法按预期工作的问题,促使一位用户链接了一个活跃的 GitHub Issue。社区正在探索权宜之计并等待官方修复。 -
RAG 和 ChromaDB 隐私担忧:出现了关于在使用 LangChain 和 ChromaDB 时增强数据隐私的查询,建议在 vectorstores 中利用基于元数据的过滤 (metadata-based filtering),正如 GitHub 讨论中所述,尽管承认该话题具有复杂性。
-
LLaMA3-70B 的 Prompt Engineering:工程师们集思广益,探讨了让 LLaMA3-70B 执行任务而无需冗余开场白(prefatory phrases)的有效 Prompting 技术。尽管进行了多次尝试,但共享的对话中尚未出现确定的解决方案。
-
苹果推出生成式 AI 指南:一位工程师分享了苹果新制定的生成式 AI 指导原则,旨在优化苹果硬件上的 AI 运行,这对 AI 应用开发者可能非常有用。
-
B-Bot 应用的 Alpha 测试:宣布了 B-Bot 应用程序的封闭 Alpha 测试阶段,这是一个专家知识交流平台,邀请函已发送至此处,寻求测试人员提供开发反馈。
Torchtune Discord
-
Phi-3 模型导出困惑已解决:用户解决了将自定义 phi-3 model 导出到 Hugging Face 以及从其导入的问题,并从 GitHub discussion 中指出了潜在的配置错误。会议指出,通过使用 FullModelHFCheckpointer,Torchtune 在 checkpoint 过程中可以处理其自身格式与 HF format 之间的转换。
-
关于 PR 的澄清与欢迎:针对通过 n_kv_heads 增强 Torchtune 以支持 mqa/gqa 的咨询得到了澄清,并鼓励提交 pull requests,前提是需要为任何拟议的更改提供 unit tests。
-
开发讨论中的依赖项风波:工程师们强调了安装 Torchtune 时 versioning of dependencies(依赖版本控制)的准确性,并指出了版本不匹配引起的问题,引用了如 Issue #1071、Issue #1038 和 Issue #1034 等情况。
-
Nightly Builds 获得认可:大家达成共识,有必要明确使用 Torchtune 完整功能集需要 PyTorch nightly builds,因为某些功能是这些版本独有的。
-
为更清晰的安装流程准备 PR:一位社区成员宣布他们正在准备一个专门更新 Torchtune 安装文档的 PR,以解决围绕依赖版本控制和使用 PyTorch nightly builds 的难题。
AI Stack Devs (Yoko Li) Discord
-
觉醒文化的终结:AI Stack Devs 频道的讨论围绕着像 Stellar Blade(剑星)背后的游戏工作室展开;成员们赞赏这些工作室专注于游戏质量,而非 Western SJW 主题和 DEI 措施。
-
回归游戏本质:成员们对 Shift Up 等 Chinese 和 South Korean developers 表示钦佩,因为他们专注于游戏开发,而没有卷入女权主义等社会政治运动,尽管韩国社会在这些问题上面临挑战。
-
Among AI Town - 开发中的 Mod:一个 AI-Powered “Among Us” mod 引起了关注,游戏开发者注意到 AI Town 在早期阶段的有效性,尽管存在一些局限性和性能问题。
-
使用 Godot 升级:ai-town-discuss 频道提到了从 AI Town 转向使用 Godot 的过程,作为为 “Among Us” mod 添加高级功能的步骤,标志着在初始能力基础上的改进和扩展。
-
AI Town 的持续增强:AI Town 的开发仍在继续,贡献者们正在推动项目前进,正如最近关于持续进展和更新的对话所表明的那样。
OpenInterpreter Discord
-
是否有 Open Interpreter 的桌面版?:一位公会成员询问是否有 Open Interpreter 的桌面 UI,但对话中未提供回复。
-
Open Interpreter 连接的波折:一名用户正苦于 Posthog connection errors,特别是与
us-api.i.posthog.com的连接,这表明其设置或外部服务可用性存在更广泛的问题。 -
使用 OpenAPI 配置 Open Interpreter:讨论围绕 Open Interpreter 是否可以利用现有的 OpenAPI specs 进行 function calling 展开,建议通过某些配置中的 true/false 开关作为潜在解决方案。
-
在 Gorilla 2 中使用工具:分享了在 LM Studio 中使用工具的挑战,以及在自定义 JSON 输出和 OpenAI toolcalling 方面取得的成功。建议查看 GitHub 上的 OI Streamlit 仓库以寻找可能的解决方案。
-
寻找技巧?查看 OI 网站:在对一个请求的简短回复中,ashthescholar. 引导成员访问 Open Interpreter 的网站以获取指导。
DiscoResearch Discord
-
Mixtral 的专家系统揭秘:一段澄清性的 YouTube 视频 破除了关于 Mixtral 的传言,确认其在各层中包含 256 个专家,并拥有惊人的 467 亿参数,其中 129 亿激活参数 用于 token 交互。
-
哪个 DiscoLM 占据统治地位?:关于领先的 DiscoLM 模型的讨论充满了困惑,多个模型在争夺关注,建议对于仅有 3GB VRAM 的系统使用 8b llama。
-
在极小 VRAM 上实现内存最大化:一位用户使用 Q2-k 量化在 3GB VRAM 配置上成功以每秒 6-7 个 token 的速度运行 Mixtral 8x7b,强调了模型选择中内存效率的重要性。
-
重新评估 Vagosolutions 的能力:最近的基准测试引发了对 Vagosolutions 模型 的新兴趣,导致了关于微调 Mixtral 8x7b 是否能胜过微调后的 Mistral 7b 的辩论。
-
RKWV vs Transformers - 解码优势:该频道尚未回应关于 RKWV 相对于 Transformers 的直观优势见解的请求,这表明可能存在疏忽或需要更多调查。
Datasette - LLM (@SimonW) Discord
-
LLM 瞄准新的数字领域:成员们分享了暗示 LLM 正在被集成到 Web 平台 的进展,Google 正在考虑为 Chrome 引入 LLM(Chrome AI 集成),而 Mozilla 正在 Firefox Nightly 中实验使用 transformers.js 进行本地替代文本生成(Mozilla 实验)。用户推测最终目标是在 操作系统级别 实现更深层次的 AI 集成。
-
Prompt Injection 的技巧与行业:通过一名成员的 LinkedIn 经历强调了一个使用 Prompt Injection 操纵电子邮件地址的有趣用例,并讨论了一个展示该概念的链接(Prompt Injection 见解)。
-
跨维度文本分析:一位频道成员深入研究了测量文本中“概念速度”的概念,灵感来自一篇博客文章(概念速度见解),并表现出将这些概念应用于天文新闻数据的兴趣。
-
维度:Embedding 的视觉前沿:成员们赞赏了一篇关于使用 PCA、t-SNE 和 UMAP 进行降维解释的 Medium 文章(3D 可视化技术),这有助于可视化 200 篇天文新闻文章。
-
UMAP 在恒星聚类方面优于 PCA:研究发现,当使用 GPT-3.5 进行标注时,对于分类的新闻主题(如嫦娥六号月球着陆器和 Starliner),UMAP 提供的聚类效果显著优于 PCA。
tinygrad (George Hotz) Discord
-
Hotz 挑战 Taylor Series 悬赏假设:George Hotz 对一个关于 Taylor Series 悬赏要求的问题给出了一个疑惑的评论,促使人们重新考虑假设的要求。
-
证明逻辑受到审视:一名成员对某个未识别证明的有效性感到困惑,引发了一场辩论,质疑该证明的逻辑或结果。
-
符号化 Shape 维度归零:出现了一场关于符号化 Shape 维度是否可以为零的讨论,表明了对 Tensor 操作中符号化表示极限的兴趣。
PART 2: Detailed by-Channel summaries and links
完整的各频道详细分析已为邮件格式截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!