ainews-talaria-apples-new-mlops-superweapon-4066
Talaria:苹果的新型 MLOps 超级武器
Apple Intelligence 引入了一个小型(约 30 亿参数)的端侧模型,以及一个在搭载 Apple 芯片的私有云计算(Private Cloud Compute)上运行的更大型服务器模型,旨在超越 Google Gemma、Mistral Mixtral、Microsoft Phi 和 Mosaic DBRX。
该端侧模型采用了一种新颖的无损量化策略,通过混合使用 2 位和 4 位的 LoRA 适配器(平均每个权重为 3.5 位),实现了适配器的动态热插拔和高效的内存管理。苹果将量化和模型延迟的优化归功于 Talaria 工具,在 iPhone 15 Pro 上实现了约 0.6 毫秒的首个 Token 延迟(TTFT)和每秒 30 个 Token 的生成速率。
苹果专注于“适配器适配一切”(adapter for everything)的策略,并初步部署在 SiriKit 和 App Intents 中。性能基准测试主要依赖人工评分,强调满足消费者层面的实际需求,而非追求学术指标上的统治地位。此外,Apple ML 博客还提到了一个专注于 Xcode 代码的模型,以及一个用于生成 Genmoji 的扩散模型。
Apple Intelligence 就够了。
2024年6月7日至6月10日的 AI 新闻。我们为您查看了 7 个 subreddits、384 个 Twitter 账号 和 30 个 Discord 服务(411 个频道和 7641 条消息)。为您节省的预计阅读时间(以 200wpm 计算):816 分钟。
凭借 Apple Intelligence,Apple 声称一举超越了 Google Gemma、Mistral Mixtral、Microsoft Phi 和 Mosaic DBRX。这得益于一个小型 “Apple On-Device” 模型(约 3b 参数)和一个“更大”的 Apple Server 模型(可通过运行在 Apple Silicon 上的 Private Cloud Compute 使用)。
https://www.youtube.com/watch?v=Q_EYoV1kZWk
Apple ML 博客文章 还简要提到了另外两个模型——一个专注于 Xcode 代码的模型,以及一个用于 Genmoji 的 Diffusion 模型。
似乎被低估的是端侧模型热插拔 LoRA 的能力,以及其显然无损的量化策略:
对于端侧推理,我们使用了 low-bit palletization,这是一种实现必要内存、功耗和性能要求的关键优化技术。为了保持模型质量,我们开发了一个使用 LoRA 适配器的新框架,该框架结合了 2-bit 和 4-bit 的混合配置策略——平均每个权重 3.5 bits-per-weight——以达到与未压缩模型相同的准确度。
此外,我们使用交互式模型延迟和功耗分析工具 Talaria,以更好地指导每个操作的比特率选择。我们还利用了 activation quantization 和 embedding quantization,并开发了一种在我们的 Neural Engine 上实现高效 Key-Value (KV) cache 更新的方法。
通过这一系列优化,在 iPhone 15 Pro 上,我们能够达到每个 prompt token 约 0.6 毫秒的 time-to-first-token 延迟,以及每秒 30 个 tokens 的生成速率。 值得注意的是,这一性能是在采用 token speculation 技术之前实现的,通过该技术我们可以看到 token 生成速率的进一步提升。
我们使用 16 bits 表示适配器参数的值,对于约 30 亿参数的端侧模型,rank 16 的适配器参数通常需要数十 MB。适配器模型可以动态加载、临时缓存在内存中并进行切换——这使得我们的基础模型能够针对当前任务即时进行专门化,同时高效管理内存并保证操作系统的响应速度。
他们将这种令人惊叹的端侧推理归功于关键工具 Talaria:

Talaria 有助于在预算限制下消融量化并分析模型架构:


Apple 似乎并没有追求“万能模型(God Model)”,而是采取了“适配器适配一切”的策略,而 Talaria 旨在让快速迭代和跟踪单个架构的性能变得容易。这就是为什么 Craig Federighi 宣布 Apple Intelligence 在启动初期仅专门适用于 SiriKit 的 8 个特定适配器和 12 类 App Intents:


考虑到 Apple 是针对严格的推理预算进行设计的,观察 Apple 如何自报性能也很有趣。几乎所有的结果(除了指令遵循)都是由人类评分员完成的,其优点是作为金标准,但缺点是最不透明:
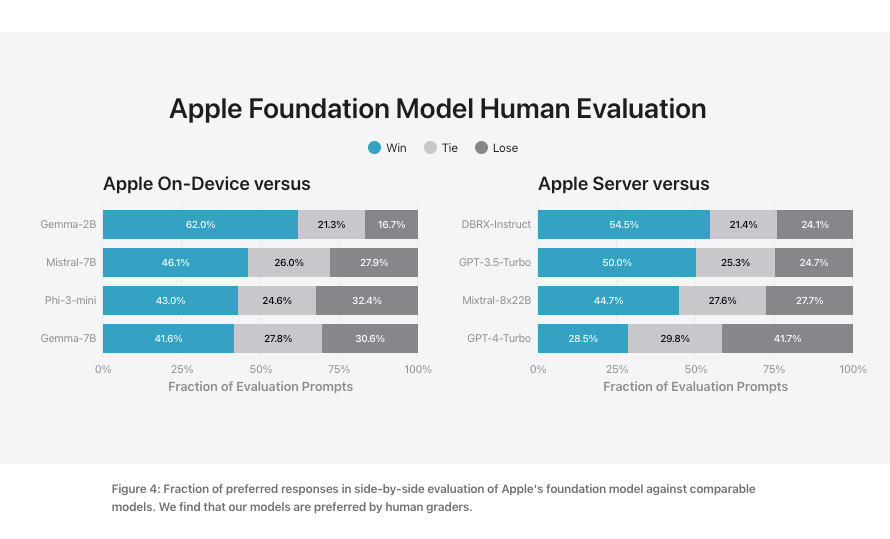
这些声称击败了 Google/Microsoft/Mistral/Mosaic 的基准测试,其唯一可信度来源在于:Apple 不需要在学术领域获胜——它只需要对消费者来说“足够好”就能赢。在这里,它只需要击败 2011-2023 年间 Siri 的低标准即可。
AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程。
Andrej Karpathy 关于复现 GPT-2 (124M) 的新 YouTube 视频
- 全面的 4 小时视频讲座:@karpathy 发布了一个名为 “Let’s reproduce GPT-2 (124M)” 的新 YouTube 视频,涵盖了构建 GPT-2 网络、优化快速训练、设置训练运行以及评估模型。该视频基于 Zero To Hero 系列。
- 详细的演练:视频分为多个部分,包括探索 GPT-2 checkpoint、实现 GPT-2 nn.Module、使用 mixed precision 和 flash attention 等技术加速训练、设置超参数以及评估结果。该模型的性能接近 GPT-3 (124M)。
- 关联的 GitHub 仓库:@karpathy 提到关联的 GitHub 仓库包含完整的 commit 历史,以便逐步跟随代码更改。
Apple 的 WWDC AI 发布
- 缺乏令人印象深刻的 AI 发布:@karpathy 指出,在 Apple 的 WWDC 进行 50 分钟后,没有出现令人印象深刻的重大 AI 发布。
- 关于 “Apple Intelligence” 和 OpenAI 合作的传闻:@adcock_brett 提到了 Apple 将推出名为 “Apple Intelligence” 的新 AI 系统以及与 OpenAI 潜在合作的传闻,但这些在 WWDC 上未得到确认。
矩阵乘法的直观解释
- 关于矩阵乘法的 Twitter 推文串:@svpino 分享了一个 Twitter 推文串,对矩阵乘法进行了极佳且简单的解释,称其为现代 Machine Learning 背后最关键的思想。
- 逐步分解:该推文串分解了矩阵 A 和 B 乘积的原始定义,通过可视化逐步展开,以提供对矩阵乘法运作方式及其几何解释的直观理解。
Apple 的 Ferret-UI:适用于 iOS 的多模态视觉语言模型
- Ferret-UI 论文详情:@DrJimFan 重点介绍了 Apple 关于 Ferret-UI 的论文,这是一种多模态视觉语言模型 (Multimodal Vision-Language Model),可以理解 iOS 移动屏幕上的图标、组件和文本,并对其空间关系和功能含义进行推理。
- 端侧 AI 助手的潜力:论文讨论了数据集和基准测试的构建,展示了 Apple 非凡的开放性。凭借强大的屏幕理解能力,Ferret-UI 可以扩展为功能齐全的端侧助手。
AI 投资与进展
- 自 GPT-4 以来在 NVIDIA GPU 上花费了 1000 亿美元:@alexandr_wang 指出,自 2022 年秋季训练 GPT-4 以来,各方在 NVIDIA GPU 上总计花费了约 1000 亿美元。问题在于下一代 AI 模型的能力是否能达到这一投资水平。
- 撞上数据墙:Wang 讨论了由于数据墙 (data wall) 导致 AI 进展放缓的可能性,这需要数据丰富的方法、算法进步以及扩展到现有互联网数据之外。行业对于这会是短期障碍还是实质性的平台期存在分歧。
Perplexity 成为出版商的顶级引流来源
- Perplexity 为出版商带来流量:@AravSrinivas 分享道,Perplexity 已成为 Forbes 的第二大引流来源(仅次于 Wikipedia),并且是其他出版商的第一大引流来源。
- 即将推出的出版商参与产品:Srinivas 提到 Perplexity 正在开发新的出版商参与产品,以及与媒体公司对齐长期激励措施的方法,即将发布。
Yann LeCun 关于管理 AI 研究实验室的想法
- 声誉卓著的科学家在管理层中的重要性:@ylecun 强调,研究实验室的管理层应由声誉卓著的科学家组成,以识别和留住杰出人才,提供资源和自由,确定有前景的研究方向,识别虚假信息 (BS),激发宏伟目标,并超越简单指标 (metrics) 来评估人才。
- 培养智力上的奇思异想:LeCun 指出,管理研究实验室需要包容智力上的奇思异想 (intellectual weirdness),这可能伴随着书呆子式的性格古怪,这使得管理更加困难,因为真正有创造力的人不会落入可预测的条条框框中。
推理能力 vs. 事实存储与检索
- 区分推理与记忆:@ylecun 指出,推理能力和常识不应与存储和近似检索大量事实的能力相混淆。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 模型开发与基准测试
- 文本转视频模型改进:在 /r/singularity 中,新款中国文本转视频模型 Kling 展示了相比以往模型在一年时间内的显著进步。/r/singularity 的其他讨论推测了再过一年可能会出现哪些进一步的突破。
- AI 对数学的影响:在 /r/singularity 中,菲尔兹奖得主陶哲轩(Terence Tao)认为 AI 将成为数学家的“副驾驶(co-pilot)”,从而彻底改变数学领域。
- 强大的 zero-shot 预测模型:在 /r/MachineLearning 中,讨论了 IBM 的开源 Tiny Time Mixers (TTMs),认为它们是强大的 zero-shot 预测模型。
AI 应用与工具
- 去中心化 AI 模型追踪器:在 /r/LocalLLaMA 中,AiTracker.art(一个 AI 模型的 Torrent 追踪器)被作为 Huggingface 和 Civitai 的去中心化替代方案展出。
- LLM 驱动的压缩技术:在 /r/LocalLLaMA 中,讨论了 Llama-Zip,这是一款由 LLM 驱动的压缩工具,其潜力在于能从压缩后的 key 中恢复完整的训练文章。
- 快速的浏览器端语音识别:在 /r/singularity 中,Whisper WebGPU 展示了直接在浏览器中运行的、极速的 ML 驱动语音识别。
- 用本地模型替换 OpenAI:在 /r/singularity 中,一个帖子演示了如何仅用 1 行 Python 代码通过 llama.cpp 服务器替换 OpenAI。
- 国际象棋棋局的语义搜索:在 /r/LocalLLaMA 中,分享了一个国际象棋棋局的 embeddings 模型,实现了语义搜索功能。
AI 安全与监管
- Prompt injection(提示词注入)威胁:在 /r/OpenAI 中,讨论了针对 LLM 应用的 prompt injection 威胁及防护方法,例如训练自定义分类器来防御恶意提示词。
- 模型中敏感数据的担忧:在 /r/singularity 中,一个帖子认为,随着科技公司在互联网上抓取数据,公开模型曾在绝密文件(TOP SECRET documents)上进行过训练的概率可能超过 99%。
- 减少模型拒绝响应的技术:在 /r/LocalLLaMA 中,正交激活引导(Orthogonal Activation Steering, OAS)和“消融(abliteration)”被指出是减少 AI 模型拒绝执行某些提示词的同一种技术。
AI 伦理与社会影响
- 教育中的 AI:在 /r/singularity 中,讨论了 AI 在教育场景中的应用,引发了关于有效整合以及学生可能滥用的疑问。
AI 硬件与基础设施
- 大型模型基准测试:在 /r/LocalLLaMA 中,分享了 Command-r GGUF 在 P40 上针对长上下文、flash attention 以及 KV quantization 的基准测试,展示了对处理和生成速度的影响。
- 用于本地模型的 Mac Studio:在 /r/LocalLLaMA 中,搭载 M2 Ultra 的 Mac Studio 被认为是运行本地大型模型的理想选择,因为它体积小、安静且功耗相对较低。
- 用于本地 LLM 的 AMD GPU:在 /r/LocalLLaMA 中,一个帖子寻求在 Linux 环境下使用 AMD Radeon GPU 运行本地 LLM 的经验和性能见解。
迷因与幽默
- 深夜 AI 创作:在 /r/singularity 中,分享了一个关于熬夜完善 AI 生成杰作(巨大的动漫胸部)的迷因。
- AI 生成的 Firefox Logo:在 /r/singularity 中,发布了一个由 AI 生成的过度复杂的 Firefox Logo。
- ChatGPT 的调情策略:在 /r/singularity 中,《每日秀》(The Daily Show)的一个片段展示了对 ChatGPT“调情”策略的搞笑反应。
{kind=link}
{kind=link}
AI Discord 回顾
摘要之摘要的摘要
- 多模态 AI 与生成模型创新:
- Ultravox 进入多模态领域:Ultravox 是一个开源的多模态 LLM,能够理解非文本语音元素,目前已发布 v0.1 版本。该项目正受到关注并正在招聘扩张。
- Sigma-GPT 首次亮相动态序列生成:σ-GPT 提供动态序列生成,减少了模型评估时间。这种方法引发了对其实用性的兴趣和争论,一些人将其与 XLNet 的发展轨迹进行了比较。
- Lumina-Next-T2I 增强文本生成图像模型:Lumina-Next-T2I 模型拥有更快的推理速度、更丰富的生成风格和更好的多语言支持,正如 Ziwei Liu 的推文所示。
- 模型性能优化与微调技术:
- 高效量化与 Kernel 优化:关于 CUDA Profiling Essentials 的讨论建议使用
nsys或ncu进行深入的 Kernel 分析。来自 NVIDIA Cutlass 和 BitBlas 文档的技术展示了有效的位级操作。 - LLama-3 微调问题已修复:用户报告通过使用 vllm 解决了 LLama3 模型微调的问题,并在 axolotl 论坛中分享了相关配置。
- GROUP 项目:该项目在 OpenAI 和 Eleuther 社区中探讨了微调与 RAG 概念的应对以及 LR(学习率)调整,并参考了来自 Stanford 的基准测试见解和 GitHub 上的 Git 设置。
- 开源 AI 框架与工具:
- Rubik’s AI Beta 测试邀请:用户被邀请参与 Rubik’s AI 的 Beta 测试,这是一个包含 GPT-4 Turbo、Claude-3 Opus 等模型的新型研究助手。该平台旨在推动 AI 研究的进步。
- LSP-AI 增强 IDE 兼容性:重点介绍了一个旨在协助软件工程师的多编辑器 AI 语言服务器,社区对其跨平台增强能力表现出极高热情。
- 集成 LangChain 与 Bagel:LangChain 已与 Bagel 集成,提供安全、可扩展的数据集管理,突显了将语言模型与外部数据集成的进展。
- AI 社区与活动亮点:
- AI Engineer World’s Fair 公告:AI Engineer World’s Fair 公布了新演讲者,且门票已售罄,显示出社区极高的参与度和兴趣。
- 创新项目与聚会:社区亮点包括 Websim.ai 的递归探索等有趣项目,以及在旧金山举行的 Lehman Trilogy 活动等著名聚会,由 Nathan Lambert 在 Interconnects discord 中分享。
- ICLR 2024 播客与 AI 峰会见解:ICLR 2024 播客第 2 部分已发布,讨论了基准测试、Agent 等内容,丰富了社区知识和参与感。
- 技术创新与讨论:
- 多语言转录的困扰:在 OpenAI discord 中,用户对 Whisper v3 在多语言转录方面的表现提出了批评,引发了对 OpenAI 未来改进的期待。
- 安全与 API Token 管理:警告不要使用恶意的 ComfyUI 节点,并建议使用环境变量进行 API Token 管理,这是大家共同关注的问题。
- 性能分析与微调:讨论包括优化大模型训练配置(如 CUDA profiling 所示),以及在 Mojo 等编程语言中使用结构化并发。
第一部分:Discord 高层级摘要
Stability.ai (Stable Diffusion) Discord
- Spotify 优惠杂谈:工程师们讨论了获取 Spotify Premium 的各种途径,包括来自某些供应商的免费优惠,但未详细说明这些优惠的具体成本或条款。
- 区域设置揭秘:探索了 regional prompting(区域提示词)技术,建议包括在 ComfyUI 中使用带有 attention masks 的 IPAdapter,并询问了 diffusers 中的类似功能,但对于最佳策略尚未达成明确共识。
- 围绕 Stable Diffusion 3 的热议:社区正热切期待 Stable Diffusion 3 (SD3),辩论焦点集中在预期的功能上,如提示词服从性(prompt obedience)和图像生成增强,同时也关注自定义微调(fine-tunes)和发布后的 LoRas,整体氛围呈现出审慎的乐观。
- LoRas 训练中的小插曲:成员们分享了在使用 ComfyUI 和 Kohya SS GUI 等工具训练模型和 LoRas 时遇到的挑战和解决方法,并由于未说明的安装问题进一步推荐了 OneTrainer 等替代方法。
- ComfyUI 安全警报:发出了关于 ComfyUI 中一个恶意节点的警告,该节点有可能窃取敏感信息,引发了关于如何防范 AI 工具中自定义节点相关风险的更广泛讨论。
Perplexity AI Discord
- 随着 SpaceX Starship 的成功,AI 助力腾飞:SpaceX 的 Starship 第四次试飞取得胜利,标志着向全可重复使用火箭系统迈进了一步,其第一级和第二级均成功着陆。这一成就详见 Perplexity 平台。
- Starliner 前往 ISS 的坎坷之路:波音公司的 Starliner 在与 ISS 对接期间,五个 RCS 推进器出现故障,可能影响任务时间表,并展示了航天硬件的复杂性。完整报告可在 NASA 更新中查看。
- Perplexity 的难题与进展:用户批评了 Perplexity AI 在 AI 旅行规划方面的能力有限,特别是在航班细节方面,而另一些用户则称赞其新的 Pro Search 功能提高了结果的相关性。社区报告的内容去索引(deindexing)和 GPT-4 模型的准确性问题引发了担忧。围绕 Rabbit R1 设备被指为骗局的说法也引发了争议。
- 地缘政治技术紧张局势:华为的 Ascend 910B AI 芯片在训练大语言模型(LLM)方面表现出色,正向 Nvidia 的 A100 发起挑战,这引发了技术辩论和地缘政治影响。访问 Perplexity 更新了解该芯片能力的详细信息。
- Perplexity API 疑难杂症:咨询和讨论集中在利用 Perplexity API 的功能上,例如无法生成 embedding 以及如何获得类似于 Web 版结果的建议,反映了用户对清晰文档和支持的需求。关于 API 积分的特定问题被建议通过私信解决,显示了积极的社区参与。
LLM Finetuning (Hamel + Dan) Discord
- 微调集市上的爆米花与泊松分布:关于使用概率模型预测爆米花爆裂时间的幽默讨论演变成了对逆泊松分布(inverse Poisson distribution)的分析。与此同时,一名成员邀请同学参加 AI Engineer World’s Fair,并承诺任何使用课程仓库对爆米花内核进行案例研究的人都可能获得传奇地位。
- 审查与性能成为 LLM 对话焦点:一篇 Hugging Face 博客文章引发了对 Qwen2 Instruct 中错误信息的担忧,进而引发了关于 LLM 性能和审查制度细微差别的讨论,重点关注英文与中文回答的差异。在其他地方,LLama-3 模型的微调问题通过使用 vllm 部署得到了解决。
- 微调过程中的挫折:访问 Hugging Face、Replicate 和 Modal 等平台授予的额度(credits)的过程引起了混乱,几位成员没有收到预期的金额,导致一些人表达了失望并寻求解决方案。
- Modal 的魔力伴随着复杂反应:成员们分享了在 Modal 上部署模型的经验,评价从称其为“神奇体验”到在权限和 volume ID 错误中挣扎不等,这表明新部署平台存在学习曲线和成长的烦恼。
- 研讨会的困扰与获胜技术:讨论了技术问题,包括 Workshop 4 的 Zoom 录音部分丢失,已通过分享最后几分钟的链接解决。讨论还赞扬了 Weights & Biases 的资源,如 10 分钟视频课程,以及 ColBERT 即将在博客文章中详细介绍的新分层池化(hierarchical pooling)功能。
- 微调 vs. RAG 辩论展开:有人在 LLM 中对微调和 RAG 的角色提出了一个有趣的类比,将添加静态知识与动态的、特定于查询的信息进行并列。然而,这遭到了一些反对,一名成员正致力于对这些复杂概念进行更精确的解释。
- Accelerate 框架测试揭示速度差异:一位 AI 工程师使用 accelerate 测试了训练配置,对比了 DDP, FSDP 和 DS(zero3),在正面交锋中发现 DS(zero3) 的 vRAM 效率最高,速度排名第二。
- 全球签到与本地聚会:成员们从全球各地进行签到,并为旧金山地区的成员提议了一场即兴聚会,展示了社区在数字领域之外建立联系的热情。
Nous Research AI Discord
- 动态对话模型:σ-GPT 脱颖而出,成为改变游戏规则的存在,它在推理时动态生成序列,而不同于 GPT 传统的从左到右生成。正如 OpenAI 博客中所详述的,人们将其与从 GPT-4 中提取概念进行了比较,引发了关于方法论和应用的对话。
- 高风险编辑与法律话语:对于那些敢于尝试 outpainting 的人,推荐使用 Krita stable diffusion 插件;同时,Interstice Cloud 和 Playground AI 被提议作为降低 GPU 云成本的经济高效解决方案。与此同时,关于 SB 1047 的讨论引发了关于 AI 监管及其对行业活力影响的争论。
- 数据图谱与标准:成员们讨论了用于 RAG 数据集的 JSON schemas,并倡导使用更结构化的格式(如结合相关性、相似度得分和情感指标)来磨练语言模型的输出。还研究了 Cohere 的检索系统和结构化引用机制等工具的集成,表明由于 JSON 的简单性和易用性,人们更倾向于使用它。
- 革新资源限制:分享了针对低配置 PC 的解决方案,例如尽管 Phi-3 3b 在代码相关任务中存在局限性,但仍采用它。这表明社区关注各种硬件配置下的资源可访问性和优化。
- 方法论对决:专注于聚类以实现高效语言模型训练的 HippoRAG 的突出地位,标志着向优化信息提取过程的转变。成员们参考 相关工作 和 PruneMe 等工具,就模型剪枝(pruning)和微调策略的最佳实践进行了深入探讨。
Unsloth AI (Daniel Han) Discord
- Qwen 模型中的 GGUF 故障:工程师报告称 Qwen GGUF 会导致“块状”文本输出,尤其是在 7B model 中,尽管部分用户使用 lm studio 等工具成功运行。Qwen 模型表现不佳的问题仍然是高热度讨论的话题。
- 多编辑器语言服务器增强:LSP-AI 是一款提供 VS Code 和 NeoVim 等编辑器兼容性的语言服务器,被强调为一种增强而非取代软件工程师能力的工具。
- 简化模型 Finetuning:用户对用于 continued pretraining 的易用型 Unsloth Colab notebook 表示赞赏,它简化了 finetuning 流程,特别是针对 input and output embeddings。相关支持包括 Unsloth Blog 和 repository。
- 比特之战与模型合并:讨论深入探讨了 QLoRA、DoRA 和 QDoRA 等 4-bit quantization 方法之间的区别,以及使用 differential weight strategy 进行 model merging 策略的细节,展示了社区成员对高级 ML 技术的熟练掌握。
- 值得关注的 Notebook 网络:showcase channel 展示了一系列针对 Llama 3 (8B)、Mistral v0.3 (7B) 和 Phi-3 等知名模型的 Google Colab 和 Kaggle notebook,强调了社区内的易用性和协作精神。
CUDA MODE Discord
- CUDA Profiling 基础:使用 nsys 或 ncu 进行 CUDA profiling,对于深入分析,应专注于单次前向和后向传递(forward and backward pass),如算子性能分析视频所示。对于构建个人 ML 实验机,可以考虑 Ryzen 7950x 等 CPU 以及 3090 或 4090 等 GPU,并注意 AVX-512 支持以及 Threadrippers 和 EPYCs 等服务器级 CPU 的权衡。
- Triton 的崛起:FlagGems 项目因在大型 LLM 中使用 Triton Language 而受到关注。技术讨论包括处理通用 kernel 大小、将向量加载为对角矩阵,以及寻找最先进的 Triton kernel 资源,可在此 GitHub 目录中找到。
- PyTorch 讨论:为了准确测量
torch.compile,请从初始传递时间中减去第二个 batch 的时间;此处提供故障排除指南。在 PyTorch 的 GitHub 中探索 Inductor 性能脚本,并考虑使用自定义 C++/CUDA 算子(operator),如此处所示。 - 高速扫描的未来预测:对客座演讲者关于扫描技术的演讲充满期待,预计会有创新性的见解。
- 电子学启示:The Amp Hour 播客的一期节目邀请了 Bunnie Huang 担任嘉宾,深入探讨了硬件设计和 Hacking the Xbox,可通过 Apple Podcasts 或 RSS 收听。
- 转型建议:成员们分享了转型到基于 GPU 的机器学习的技巧,建议利用 Fatahalian 的视频和 Yong He 的 YouTube 频道来学习 GPU 架构。
- Encoder 探索与 GPT 指导:虽然没有提供关于 PyTorch 中 encoder-only 模型有效参数搜索的详细信息,但分享了重现 GPT-2 的资源。NVIDIA 的 RTX 4060Ti (16GB) 被建议作为 CUDA 学习的入门级选择。
- FP8 在 PyTorch 中的角色:关于使用 FPGA 模型和考虑不含 matmul 的三值(ternary)模型的讨论,并辅以 Intel FPGA 的链接和相关论文。呼吁提供更好的 torch.compile 和 torchao 文档及基准测试,并关注 Pull Request #276 中针对 GPT 模型的新增加内容。
- Triton 话题再次出现:链接了一个有趣的三值累加(ternary accumulation)演示,获得了社区的积极反馈(matmulfreellm)。
- llm.c 讨论:关于模型训练的广泛讨论涵盖了超参数选择、重叠计算(overlapping computations)、FineWebEDU 数据集问题,以及使用详细脚本成功将模型转换为 Hugging Face 格式。
- Bit 与 Bitnet:使用微分位计数(differential bitcounts)的技术引发了好奇和调试工作。将 FPGA 的成本与 A6000 ADA GPU 的速度进行了比较,同时确认 NVIDIA 的 Cutlass 支持 nbit bit-packing,包括 uint8 格式(Cutlass 文档)。此外,BitBlas 的基准测试结果引发了关于 matmul fp16 性能差异的讨论。
- ARM 雄心:简要提到讨论可能涉及 ARM 服务器芯片而非移动处理器,并链接了一个热门 YouTube 视频作为参考。
HuggingFace Discord
- 大模型,深度讨论:工程师们讨论了 2B parameter models 的计算需求,公认 50GB 的系统可能不足,可能需要超过 2 个 T4 GPUs。关于 API 的争论凸显了对成本和访问权限的困惑,批评者将 OpenAI 平台戏称为 “closedAI”。
- 科技巨头之战:尽管 Nvidia 拥有“锁定生态系统”,但其市场主导地位仍得到认可,其 AI 芯片创新和游戏行业需求使其在技术领导地位中保持核心地位。
- API Tokens 安全提示:一次意外的邮件 Token 泄露引发了在软件开发中使用环境变量来增强安全性的建议。
- AI 在模拟中的力量:成员们接触到了诸如 AI Summit YouTube 录像等资源,展示了 AI 在物理模拟中的应用,并受邀参加由 Stanford 研究人员举办的关于防止模型崩溃(model collapse)的活动。
- 机器学习新动向:分享了一系列 AI 工具和进展,包括用于 LLM 微调的 Torchtune、用于多功能 LLM 使用的 Ollama、用于图像分类的 Kaggle 数据集,以及用于可持续农业的 FarmFriend。
- 前沿 AI 创作:AI 领域的创新包括发布了针对尼日利亚语境回复的 Llama3-8b-Naija、用于多 GPU 训练增强的 SimpleTuner v0.9.6.3、用于提升超写实美感的 Visionix Alpha,以及可以与来自不同 AI 公司的各种模型对话的 Chat With ‘Em。
- CV 和 NLP 进展展示:亮点包括关于旋转边界框(rotated bounding boxes)高效实现的讨论、Gemini 1.5 Pro 在视频分析中的优越性,以及针对 CVPR 2024 论文的语义搜索工具。在 NLP 领域,主题涵盖了从构建基于 RAG 的聊天机器人到使用 MyResumo 生成 AI 简历,以及关于 PyTorch 与 TensorFlow 在模型托管和错误处理方面的咨询。
- Diffusion Model 动态:讨论集中在利用共享资源训练 Conditional UNet2D 模型、利用 SDXL 进行图像文本印记,以及对训练期间计算 MFU 的好奇,并由此提出了对代码库修改的建议。
LM Studio Discord
新可视化模型仍在排队中:LM Studio 目前不支持生成图像 Embedding;建议用户关注 daanelson/imagebind 或等待 nomic 和 jina 的未来版本。
给 Tesla P40 降降温!:对于 Tesla P40 的散热,社区建议从使用 Mac 风扇到尝试自定义 3D 打印导风罩,一位用户指向了 Mikubox Triple-P40 散热指南。
跨越多 GPU 之桥:讨论指出,虽然 LM Studio 在高效多 GPU 支持方面进度落后,但 ollama 表现出更出色的处理能力,促使用户寻求更好的 GPU 利用方法。
解决硬件兼容性:从处理将 AMD 的 ROCm 注入 Windows 应用程序,到解决 Tesla P40 的驱动安装,用户分享了经验和解决方案,包括来自 AMD 文档的隔离技术。
LM Studio 等待 Smaug 的 Tokenizer:LM Studio 的下一个版本将包含对 Smaug 模型 的 BPE Tokenizer 支持,同时成员们也在探索将 LMS 数据定向到外部服务器 的选项。
OpenAI Discord
- iOS 抢占 AI 焦点:OpenAI 宣布与 Apple 合作,在 iOS、iPadOS 和 macOS 平台上集成 ChatGPT,计划于今年晚些时候发布,引发了关于 AI 在消费科技领域影响的热烈讨论。详情和反应可见 官方公告。
- 多语言转录风波与 Apple AI 进展:Whisper version 3 在多语言转录方面表现不佳引发热议,用户纷纷要求推出新版本;同时 Apple 的 “Apple Intelligence” 承诺将提升 iPhone 16 的 AI 能力,可能需要硬件升级以进行优化。
- 图像 Token 经济学与 Agent 困扰:在经济方面,关于 128k 上下文 Token 化和图像处理的 API 调用成本效益讨论升温;在技术方面,用户对 GPT Agent 默认使用 GPT-4o 导致性能欠佳表示不满。
- 自定义 GPTs 与语音模式的烦恼:AI 爱好者正在剖析自定义 GPTs 的私有性质(实际上被禁止与外部 OpenAPI 集成),同时对 Plus 用户新语音模式推送缓慢感到困惑和不耐烦。
- HTML 与 AI 代码编写挑战:讨论集中在如何让 ChatGPT 输出极简 HTML、改进摘要 Prompt、使用 Canva Pro 进行图像文本编辑、理解 LLM 的失效点,以及生成将十六进制代码转换为 Photoshop 渐变映射的 Python 脚本,这表明工具和指令仍需磨合。
Eleuther Discord
- CPU 模型解决 GPU 贫乏问题:工程师们讨论了针对有限 GPU 资源的变通方案,考虑使用 sd turbo 和基于 CPU 的解决方案来减少等待时间,有人表示这种体验仍然“值得”。
- 固定种子对抗局部最小值:在神经网络训练中固定种子与随机种子的争论中,一些人倾向于设置手动种子以微调参数并逃离局部最小值,强调“种子总归是存在的”。
- MatMul 操作被剔除:一篇 arXiv 论文展示了参数量高达 2.7B 的无 MatMul 模型,引发讨论,认为此类模型在保持性能的同时可能降低计算成本。
- 扩散模型:NLP 的新宠?:转向使用扩散模型来增强 LLM 已被提上日程,这篇综述论文等参考文献激发了关于该话题的对话。
- 匈牙利押注 AI Safety:分析了在匈牙利投资 3000 万美元进行 AI Safety 研究的可行性,强调了不浪费资金的重要性,并考虑使用云端资源满足计算需求。
- RoPE 技术来救场:研究频道揭示了实现相对位置编码 (RoPE) 以改进非自回归模型的热情,成员们提出了各种初始化方案,如通过插值权重矩阵进行模型扩缩,以及使用 SVD 进行 LoRA 初始化。
- 给模型“瘦身”:一位工程师使用层剪枝 (layer pruning) 成功将 Qwen 2 72B 缩减至 37B 参数,在不牺牲性能的情况下展示了效率。
- 可解释性:新前沿:对 TopK activations 的兴趣重新抬头,一个探索 Llama3 中 MLP neurons 的项目受到关注,资源可在 neuralblog 和 GitHub 上找到。
- 绝望的 MAUVE:一位成员在 MAUVE setup 方面寻求帮助,强调了在安装和使用该工具评估新采样方法时面临的复杂性。
Modular (Mojo 🔥) Discord
- MacOS 安装遇到障碍:在 MacOS 14.5 Sonoma 上安装 MAX 的工程师面临挑战,需要手动干预。解决方案包括通过 pyenv 设置 Python 3.11,详见 Modular 官方安装指南。
- 探讨编程中的并发性:引发了关于结构化并发(structured concurrency)与函数着色(function coloring)的辩论,并提出了效应泛型(effect generics)作为解决方案,尽管这增加了语言编写的复杂性。讨论还延伸到了 Erlang、Elixir 和 Go 等语言中的并发原语,以及 Mojo 从底层为这些范式设计解决方案的潜力。
- 最大化你的 Mojo:关于 Mojo 语言的见解涵盖了 MAX 平台中使用 GGML k-quants 的量化主题,并提供了现有文档和示例的链接,例如 Llama 3 pipeline。此外,由于上下文管理器(context managers)在 Python 生态中具有整洁的资源管理能力,其被认为优于潜在的
defer关键字。 - Modular 发布更新:最近的开发更新包括视频内容,Modular 发布了一个新的 YouTube 视频,这对关注者来说可能至关重要。另一个重点资源是来自 Andrej Karpathy 的项目,通过 YouTube 分享,预计社区会对此感兴趣。
- 新版本的工程效率:Mojo 编译器的 Nightly 版本显示出进展,更新至版本
2024.6.805、2024.6.905和2024.6.1005,变更日志可在此处供社区查阅 here。这些迭代版本构成了 Modular 编程领域持续改进的叙事。
OpenInterpreter Discord
Gorilla OpenFunctions v2 媲美 GPT-4:社区成员一直在讨论 Gorilla OpenFunctions v2 的能力,注意到其令人印象深刻的性能以及从自然语言指令生成可执行 API 调用的能力。
Local II 推出本地 OS 模式:Local II 宣布支持本地 OS 模式,可实现实时演示,可通过 pip install --upgrade open-interpreter 进行关注。
OI 模型出现技术问题:用户报告了 OI 模型 的各种问题,包括 API key 错误以及 moondream 等视觉模型的问题。故障排除中的交流表明修复和改进正在进行中。
OI 在 iPhone 和 Siri 上的里程碑:Open Interpreter 与 iPhone 的 Siri 集成取得了突破,允许通过语音命令执行终端功能,参考教程视频。
Raspberry Pi 和 Linux 用户的尝试与需求:在 Raspberry Pi 上运行 OI 的尝试遇到了资源问题,但社区仍致力于寻找解决方案。对 Linux 安装教程的请求表明了对跨平台支持的广泛渴望。
Latent Space Discord
- Ultravox 登场:Ultravox 发布了 v0.1 版本,这是一个能够理解非文本语音元素的全新开源多模态 LLM。目前正在进行招聘以扩大其开发规模。
- OpenAI 聘请新高管:OpenAI 在其 Twitter 上发布了新任命的 CFO 和 CPO——Friley 和 Kevin Weil,进一步增强了组织的领导团队。
- Perplexity 因内容滥用遭受抨击:Perplexity 招致了批评,包括来自 @JohnPaczkowski 的推文,指责其在未获得适当授权的情况下重新利用 Forbes 的内容。
- Apple 凭借 Cloud Compute Privacy 进军 AI:Apple 最近关于 “Private Cloud Compute” 的公告旨在安全地将 AI 任务卸载到云端,同时保护隐私,这引发了工程界的广泛讨论。
- ICLR 播客与 AI World’s Fair 更新:最新的 ICLR 播客剧集 深入探讨了代码编辑以及学术界与工业界的融合,而 AI Engineer World’s Fair 列出了新演讲者,并宣布赞助名额和早鸟票已售罄。
- Websim.ai 激发递归混沌与创意:对实时流媒体面部识别网站的发现,引导成员们将 websim.ai 递归地应用于自身,制作了一个 greentext 生成器,并分享了一个资源电子表格,展现了探索 Websim 新前沿的创新精神和好奇心。
Cohere Discord
- Cohere 的 Command R 模型占据领先地位:最新对话显示,Cohere 的 Command R 和 R+ 模型被认为是行业顶尖水平,用户正在 Amazon SageMaker 和 Microsoft Azure 等云平台上使用它们。
- 创新 AI 驱动的角色扮演:”reply_to_user” 工具被公认为能增强 AI 角色扮演中的角色化回复,特别是在 Dungeonmasters.ai 等项目中,这表明交互能力正向更具上下文感知的方向转变。
- 多元化的 Cohere 社区积极参与:Cohere 社区的新成员(包括一名巴西初级 NLP DS 和一名 MIT 毕业生)正在分享他们对 NLP 和 AI 项目的热情,显示出一个充满活力且多元化的协作环境。
- 塑造 AI 职业生涯与项目:成员的项目讨论阐明了 Cohere API 在提高性能方面的作用,正如在需要 AI 集成的领域获得的积极反馈所证明的那样,这标志着一种对开发者互利的合作关系。
- Cohere 的 SDK 拓宽视野:Cohere SDKs 与 AWS、Azure 和 Oracle 等多种云服务的兼容性已经公布,增强了灵活性和开发选项,详见其 Python SDK 文档。
LAION Discord
σ-GPT 为高效序列生成铺平道路:引入了一种名为 σ-GPT 的新方法,提供具有即时定位功能的动态序列生成,在减少语言建模等领域的模型评估方面显示出强大潜力(阅读 σ-GPT 论文)。尽管其前景广阔,但由于需要特定的课程学习(curriculum),人们对其实用性表示担忧,并将其与 XLNET 的轨迹相类比。
AI 推理挑战曝光:一项针对 Transformer 嵌入的研究揭示了关于离散与连续表示的新见解,阐明了在性能损失微乎其微的情况下对注意力头进行剪枝的可能性(分析多头自注意力论文)。此外,一个旨在测试 LLM 推理能力的 Prompt 仓库被分享,指出训练数据偏差是模型失败背后的关键原因(MisguidedAttention GitHub 仓库)。
加密货币对话引发关注:使用加密货币支付 AI 算力的做法引发了褒贬不一的反应,一些人看到了潜力,而另一些人则持怀疑态度,将其贴上可能为诈骗的标签。随后出现了一条关于 ComfyUI_LLMVISION 节点可能收集敏感信息的警告,敦促与其交互过的用户采取行动(ComfyUI_LLMVISION 节点警报)。
展示 AI 的进展与问题:小组讨论了 Lumina-Next-T2I 的发布,这是一款新的文本生成图像模型,因其增强的生成风格和多语言支持而受到赞誉(Hugging Face 上的 Lumina-Next-T2I)。在一个更具警示意义的案例中,巴西 AI 数据集中滥用儿童照片的事件成为焦点,揭示了数据来源的阴暗面以及公众对 AI 隐私问题的漠视(人权观察报告)。
WebSocket 问题与预训练模型的潜力:在技术故障排除方面,分享了诊断通用 WebSocket 错误的技巧,以及在文本转语音(TTS)服务 WebSocket 中观察到的特殊持续延迟。为了增强项目,建议使用具有扩展上下文窗口的预训练 Instruct 模型,特别是为了将 Rust 文档纳入模型的训练体系。
LlamaIndex Discord
- 图谱专家齐聚:一场专注于高级知识图谱 RAG 的研讨会定于太平洋时间周四上午 9 点举行,由来自 Neo4j 的 Tomaz Bratanic 主讲,涵盖 LlamaIndex 属性图和图查询技术。感兴趣的参与者可以在此报名。
- 编码增强 RAG:推荐了一系列资源以改进 RAG 应用中的数据分析和用户交互,包括集成沙箱环境、构建 Agentic RAG 系统、查询重写技巧以及创建快速语音机器人。
- 优化 AI 的效率与精度:讨论强调了增加 SimpleDirectory.html 读取器中
chunk_size的策略,以及管理图存储中的实体解析,并参考了 LlamaIndex 关于存储文档和优化流程的文档,以构建可扩展的 RAG 系统。 - LlamaParse 现象已修复:LlamaParse 的临时服务中断已由社区迅速解决,确保了依赖该工具进行解析需求的用户能够获得不间断的服务。
- 寻求通过 QLoRA 增强 RAG:目前正在努力从电话手册中开发数据集,利用 QLoRA 训练模型,旨在提高 RAG 性能。
OpenRouter (Alex Atallah) Discord
- 三款全新 AI 模型上市:Qwen 2 72B Instruct 在语言熟练度和代码理解方面表现出色;Dolphin 2.9.2 Mixtral 8x22B 面世,其使用挑战在于 1 美元/M tokens 的价格,且依赖于每天 1.75 亿 tokens 的使用率。同时,StarCoder2 15B Instruct 作为首个专门用于编码任务的自对齐开源 LLM 开放使用。
- 利用 AI Brushes 增强代码能力:一款为 VS Code 设计的 AI 增强型代码转换插件现已免费提供,该插件利用 OpenRouter 和 Google Gemini,旨在通过利用这些排名中 Programming/Scripting 类别里表现顶尖的模型来革新编码方式。
- 支付讨论中的电子货币与加密货币:社区正在讨论采用 Google Pay 和 Apple Pay 以简化支付体验,并考虑加入 cryptocurrency 支付作为去中心化选项。
- 攻克 JSON Stream 挑战:工程师们交流了处理 OpenRouter chat completions 流仅交付部分 JSON 响应情况的策略;运行缓冲区(running buffer)成为了关注焦点,同时还有来自一篇说明性文章的见解。
- 应对偏见与扩展语言支持:一项关于 LLM 内部审查和偏见的调查集中在中美模型的对比上,详见《利用 Qwen 2 Instruct 分析中国 LLM 的审查与偏见》;同时社区呼吁在模型熟练度中加入更好的语言类别评估,渴望对捷克语、法语和普通话等语言提供更细致的支持。
Interconnects (Nathan Lambert) Discord
Apple Intelligence:不仅仅是 Siri 的更新:Nathan Lambert 强调了 Apple 的“personal intelligence”,这可能会重塑 Siri 的角色,使其超越语音助手。尽管最初对 OpenAI 的角色存在困惑,Lambert 承认 Apple Intelligence 系统是迈向“面向大众的 AI”的重要一步。
RL 社区审视 SRPO 倡议:来自 Cohere 关于 SRPO 的论文引发了讨论,该论文介绍了一种新的离线 RLHF 框架,旨在提高 out-of-distribution 任务的鲁棒性。该技术使用 min-max 优化,并被证明可以解决之前 RLHF 方法中固有的任务依赖问题。
Dwarkesh Podcast 期待值攀升:Dwarkesh Patel 与 François Chollet 即将播出的节目备受关注,因为 Chollet 对 AGI 时间线有着独特的见解。这与通常的乐观情绪相反,可能会为 AGI 讨论提供引人注目的贡献。
Daylight Computer:小众但值得关注:工程社区对 Daylight Computer 表示好奇,注意到它在减少蓝光暴露和辅助阳光直射下的可见度方面所做的尝试。同时,对于成为此类新颖技术的早期采用者所带来的风险,人们持适度的怀疑态度。
RL 模型审查公开征集:Nathan Lambert 提议为 RL 频道中讨论的近期论文里尚未验证的方法提供 Pull Requests 反馈。这表明社区为测试和验证提供了一个支持性的环境。
LangChain AI Discord
Markdown 困境与缺失的方法:工程师们报告了一个问题,即一个 25MB 的 Markdown 文件在 LangChain 处理过程中无限期运行,且目前没有建议的解决方案;同时,在使用 create_tagging_chain() 时由于 Prompt 被忽略而出现问题,这表明文档中可能存在 Bug 或空白。
使用 LangChain 和 Bagel 保护你的数据集:LangChain 与 Bagel 的新集成引入了安全、可扩展的数据集管理,相关进展在一条 推文 中被强调,这可能会增强数据密集型应用的基础设施。
文档难题:讨论集中在为 LangChain 加载和拆分文档,强调了针对 PDF 和代码文件等不同文档类型所需的技术技巧,为优化预处理以提高语言模型性能提供了途径。
API 歧义:有用户寻求关于如何在 LangServe 中使用 api_handler() 而不求助于 add_route() 的澄清,特别是旨在实现 playground_type=”default” 或 “chat” 但缺乏指导。
AI 创新诚邀参与:社区成员受邀测试新的高级研究助手 Rubik’s AI,该助手可访问 GPT-4 Turbo 等模型;同时还可以查看其他社区项目,如记者的可视化工具、音频新闻简报服务以及 Hugging Face 上的多模型聊天平台,反映了活跃的开发和测试活动。
OpenAccess AI Collective (axolotl) Discord
- Pip 技巧:工程师们发现,通过
pip3 install -e '.[deepspeed]'和pip3 install -e '.[flash-attn]'分别安装包可以避免 RAM 溢出,这是在 Python 3.10 的新 conda 环境中工作时的一个有用技巧。 - Axolotl 的多模态查询:询问了 axolotl 对多模态微调的支持;提到了一个过时的 Qwen 分支,指向了潜在的重启或更新需求。
- 数据集加载故障:成员们报告了数据集加载问题,其中包含括号的文件名可能会导致
datasets.arrow_writer.SchemaInferenceError;解决命名规范对于无缝数据处理至关重要。 - 学习率救星:关于有效 Batch Size 的重申断言,根据 Hugging Face 的指导,在更改 Epoch、GPU 或 Batch 相关参数时,学习率调整是维持训练稳定性和效率的关键。
- JSONL 配置指南:分享了 JSONL 数据集的配置技巧,包括为训练和评估数据集指定路径;这包括 alpaca_chat.load_qa 和 context_qa.load_v2 的路径,有助于在模型训练期间更好地处理数据。
tinygrad (George Hotz) Discord
- PyTorch 代码评价褒贬不一:George Hotz 评价了 PyTorch 的 fuse_attention.py,称赞其设计优于 UPat,但指出其过于冗长并考虑进行语法增强。
- tinygrad 开发者寻求效率提升:tinygrad 中的一个初学者项目旨在加速 Pattern Matcher,并通过 Process Replay 测试设定了确保正确性的基准。
- 剖析 UOp 中的 ‘U’:”Micro op”(微操作)是 UOp 中 “U” 的含义,这是由 George Hotz 澄清的,反驳了社区内的其他潜在推测。
- Hotz 为欧洲代码大会做准备:George Hotz 将在 Code Europe 讨论 tinygrad;他接受了社区建议,修改其演讲的最后一张幻灯片以增强观众互动。
- tinygrad 对 AMD 和 Nvidia 的 GPU 规格要求:AMD GPU 需要最低 RDNA 规格,而 Nvidia 的门槛是 2080 型号;建议使用 HIP 或 OpenCL 作为已失效的 HSA 的替代方案。RDNA3 GPU 已验证为兼容。
AI Stack Devs (Yoko Li) Discord
- 游戏设计反思:Serverless 函数引领潮流:核心讨论集中在 http://hexagen.world 中用于游戏循环的 Convex 架构 独特的 Serverless 函数,这与旧游戏范式中对内存和机器的依赖形成鲜明对比。通过分布式函数增强了可扩展性,在实现高效后端扩展的同时,通过 websocket 订阅确保了实时客户端更新。
- AI Town 架构深度解析:建议对 AI 和 CS 感兴趣的工程师探索 AI Town 架构文档 提供的深度剖析,这是一个非常有见地的资源。
- 多人同步难题:多人环境固有的延迟问题被强调为在基于 Convex 的游戏架构中提供最佳竞争体验的一项挑战。
- 令人困惑的 convex.json 配置难题:用户报告了对缺失 convex.json 配置文件感到困惑,并面临后端错误,提示可能缺失依赖项,消息为:”Recipe
convexcould not be run because just could not find the shell: program not found.” - Hexagen 创作者现身:这款由 Serverless 函数驱动的游戏 http://hexagen.world 的创作者对社区分享其项目表示了认可。
AI21 Labs (Jamba) Discord
- Agentic 架构:是掩饰而非修复:有讨论指出 “Agentic 架构” 仅仅是掩饰而非解决了复杂系统中的深层问题,尽管有类似 Theorem 2 的提示表明缓解是可能的。
- 结构性约束削弱了真正的推理能力:工程师们强调,由于固有的结构限制,RNNs, CNNs, SSMs 和 Transformers 等架构在实际推理任务中表现挣扎,这一点被 Theorem 1 所印证。
- 重温理论基础:一位成员表示打算重新研读论文,以更好地理解当前模型架构中存在的局限性和通信复杂性问题。
- 探讨通信复杂性与 Theorem 1:深入探讨了多 Agent 系统中的通信复杂性概念,Theorem 1 说明了准确计算需要多次通信,这可能导致 Agent 生成幻觉(hallucinated)结果。
- 计划深度研读论文:计划重新阅读并讨论所引用论文的细节,特别是关于 Theorem 1 在函数组合和多 Agent 系统通信挑战方面的见解。
Datasette - LLM (@SimonW) Discord
- 排行榜刺激发布策略:一位成员推测,最近的发布是出于战略考虑,旨在促进更多研究并在行业排行榜上占据一席之地,强调了其对进一步分析和基准测试的效用。
- UMAP 因卓越的聚类性能受到赞赏:UMAP 因其出色的聚类表现受到一名成员的称赞,他向对该工具技术深度感兴趣的人推荐了一段对 UMAP 创作者的精彩采访。
- 与 UMAP 幕后大脑进行深度探讨:一段名为 “Moving towards KDearestNeighbors with Leland McInnes - creator of UMAP” 的 YouTube 采访被重点推荐,其中由创作者 Leland McInnes 直接提供了关于 UMAP 及其相关项目(如 PyNNDescent 和 HDBScan)复杂细节的丰富讨论。
Torchtune Discord
- DPO 实验中没有 KL 图表?:成员们讨论了在 Torchtune 的 DPO 实现实验 期间没有使用 KL 图表(KL plots)。对于那些对 KL 图表使用感兴趣的人,可以参考 GitHub 上 TRL 的 PPO 训练器中的 KL 图表。
DiscoResearch Discord
- Bitsandbytes 查询遇到意外问题:一位成员报告在使用 lighteval 评估 bitsandbytes 模型时遇到困难,命令行工具无法识别 bitsandbytes 方法,而是请求 GPTQ 数据。
- 文档打包(Document Packing)中的效率追求者:一位成员对 Document Packing 策略提出疑问,好奇该实现是用于实际生产还是仅仅作为一个简单的示例。他们强调了处理大型数据集时高效策略的重要性,并探究了
tokenized_documents数据类型的具体细节。
MLOps @Chipro Discord
- Chip Huyen 现身 Databricks 活动:著名工程师 Chip Huyen 正在参加 Databricks 峰会上的 Mosaic 活动,这为同行交流和建立联系提供了机会。与会者受邀见面并讨论当前的 MLOps 趋势。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。
第二部分:分频道详细摘要与链接
完整的频道细分内容已因邮件长度而截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!