ainews-francois-chollet-launches-1m-arc-prize
弗朗索瓦·肖莱(Francois Chollet)发起 100 万美元 ARC 奖金。
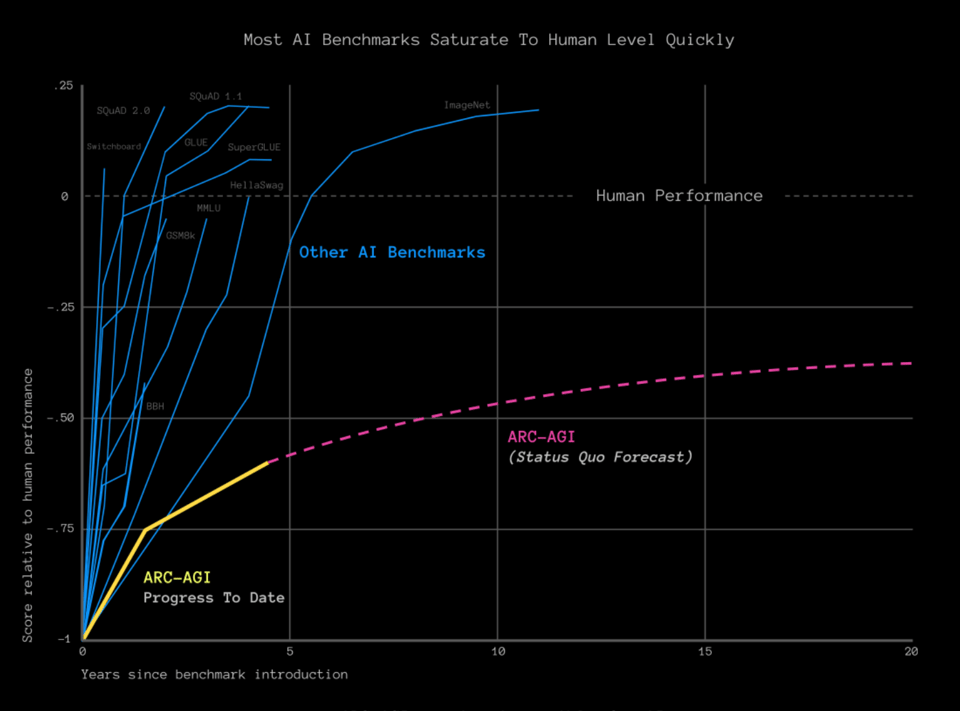
弗朗索瓦·肖莱(François Chollet) 批评了当前通往通用人工智能(AGI)的路径,强调了建立不易饱和、且侧重于技能习得和开放式问题解决的基准测试的重要性。ARC-AGI 谜题体现了“人类易做,AI 难解”的挑战,旨在衡量通往 AGI 的进展。
与此同时,苹果宣布通过与 OpenAI 合作,将 ChatGPT 集成到 iOS、iPadOS 和 macOS 中,在采取隐私保护措施的前提下,实现文档摘要和照片分析等 AI 驱动的功能。相关讨论凸显了苹果对深度 AI 集成和端侧模型的关注,这些模型通过混合精度量化等技术进行了优化,尽管人们对其 AI 能力与 GPT-4 相比仍存有一些疑虑。此外,Together Compute 推出了一种“智能体混合”(Mixture of Agents)方法,在 AlpacaEval 2.0 上表现强劲。
不可记忆的 Benchmark 才是你所需要的。
2024年6月10日至6月11日的 AI 新闻。 我们为你检查了 7 个 subreddit、384 个 Twitter 以及 30 个 Discord(412 个频道和 2774 条消息)。 预计节省阅读时间(以 200wpm 计算):313 分钟。
在本周末的 Latent Space 播客中,我们讨论了测试集污染和 Benchmarking 的科学,今天该领域的一位元老带着解决方案回来了——生成一系列模式识别与补全的 Benchmark:
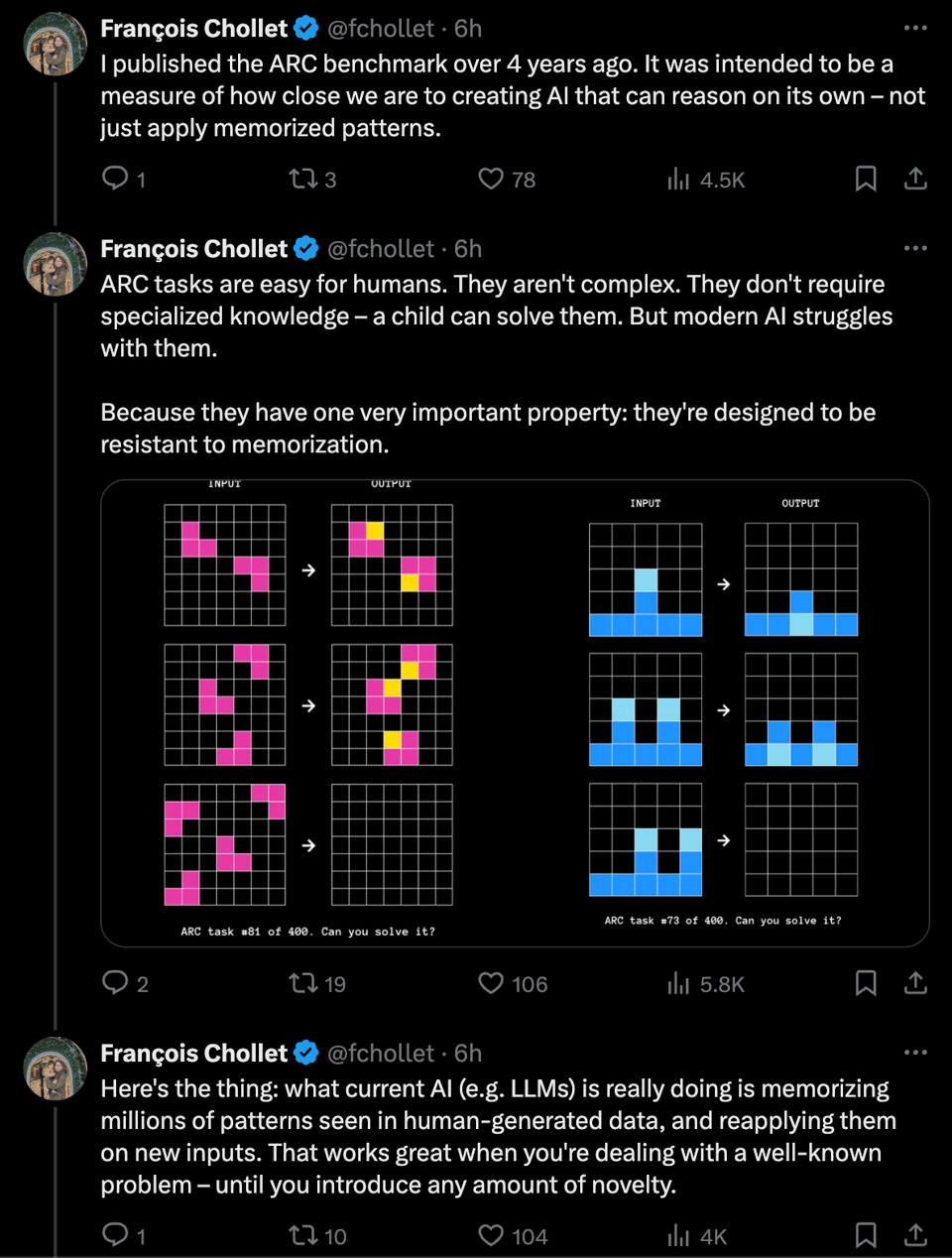
你可以亲自尝试 ARC-AGI 谜题,感受一下什么是“对人类简单但对 AI 困难”的谜题:

这一切都基于对 AGI 的一种带有鲜明观点的定义,该团队优雅地提供了这一观点:
定义 AGI
共识但错误: AGI 是一个能够自动化大部分具有经济价值的工作的系统。
正确: AGI 是一个能够高效获取新技能并解决开放式问题的系统。
定义很重要。我们将它们转化为 Benchmark 来衡量 AGI 的进展。 没有 AGI,我们将永远无法拥有能够与人类一起发明和发现的系统。
这个 Benchmark 经过特殊设计,旨在抵御其他 Benchmark 所面临的经典的 1-2 年饱和周期:
解决方案指南 提供了 François 对极具前景的方向的思考,包括 Discrete program search、技能获取以及混合方法。
上周 Dwarkesh 播客因预测 2027 年实现 AGI 而引起轰动,今天 它又回来了,François Chollet 断言我们目前所走的道路不会通向 AGI。AGI 观察者们,你们怎么看?
AI Twitter 简报
所有简报均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
Apple 将 ChatGPT 集成至 iOS, iPadOS 和 macOS
- OpenAI 合作伙伴关系:@sama 和 @gdb 宣布 Apple 正与 OpenAI 合作,计划于今年晚些时候将 ChatGPT 集成到 Apple 设备中。@miramurati 和 @sama 欢迎 Kevin Weil 和 Sarah Friar 加入 OpenAI 团队以支持此项工作。
- AI 功能:Apple Intelligence 将在各类 App 中实现 AI 驱动的功能,如总结文档、分析照片以及与屏幕内容交互。@karpathy 指出了 AI 逐步集成到操作系统中的路径,从多模态 I/O 到 Agent 能力。
- 隐私担忧:尽管 Apple 提供了“私有云计算”(Private Cloud Compute)保证,但一些人对 Apple 与 OpenAI 共享用户数据表示怀疑。@svpino 详细介绍了 Apple 采取的安全措施,例如端侧处理和差分隐私(differential privacy)。
对 Apple WWDC AI 发布内容的反应
- 反应不一:虽然一些人对 Apple 的 AI 集成印象深刻,但另一些人认为 Apple 已经落后或过于依赖 OpenAI。@karpathy 和 @far__el 质疑 Apple 是否能独立交付高性能的 AI。
- 与其他模型对比:Apple 的端侧模型似乎优于其他小模型,但其服务器端模型仍落后于 GPT-4。@_philschmid 指出 Apple 正在使用 Adapter 和混合精度量化(mixed-precision quantization)来优化性能。
- 侧重集成:许多人注意到 Apple 关注的是深度、无缝的 AI 集成,而非模型规模。@ClementDelangue 赞扬了推动端侧 AI 以提升用户体验和隐私的做法。
AI 研究与应用的进展
- Mixture of Agents (MoA):@togethercompute 推出了 MoA,它利用多个开源 LLM 在 AlpacaEval 2.0 上获得了 65.1% 的评分,超越了 GPT-4。
- AI 推理挑战赛 (ARC):@fchollet 和 @mikeknoop 启动了 100 万美元的 ARC 奖金,旨在创建能够适应新奇事物并解决推理问题的 AI,引导该领域重新向 AGI 迈进。
- 语音与视觉进展:@GoogleDeepMind 展示了 Imagen 3 生成具有复杂纹理的丰富图像的能力。@arankomatsuzaki 分享了 Microsoft 的 VALL-E 2,它在零样本(zero-shot)文本转语音方面达到了人类水平。
- AI 应用:示例包括 @adcock_brett 关于 Figure 机器人制造的更新,@vagabondjack 为 @brightwaveio 的 AI 驱动财务分析筹集了 600 万美元种子轮融资,以及 @AravSrinivas 提到 Perplexity 已成为出版商的主要推荐流量来源。
梗与幽默
- @jxmnop 用一张幽默的图片开玩笑说 LLM 已经触及了人类知识的边界。
- @nearcyan 用一个梗嘲讽了那些反复声称 “NVIDIA 完蛋了” 的言论。
- @far__el 调侃道:“Apple Intelligence 将成为最大规模的工具使用型 AI 部署,我希望有人能在 @aidotengineer 上分享其设计考量!”以此回应 @swyx 对 Apple 工程师分享见解的呼吁。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 进展
- 苹果与 OpenAI 合作,将 GPT-4o 集成到 iOS、iPadOS 和 macOS 中:在 /r/OpenAI 中,苹果发布了 “Apple Intelligence“,这是一款内置于其操作系统的个人 AI 系统。它集成了 OpenAI 的 GPT-4o 并支持端侧运行,增强了 Siri、写作工具并实现了图像生成功能。
- 苹果端侧 LLM 架构细节披露:在 /r/LocalLLaMA 中,分享了更多关于 Apple Intelligence 底层工作原理 的细节,包括使用名为 “adapters” 的量化任务特定 LoRAs,并针对推理性能进行了优化,同时利用“语义索引”来获取个人上下文。
- AMD 为 AI 处理器发布开源 LLVM 编译器:AMD 推出了 Peano,这是一个针对其 Ryzen AI 处理器中 XDNA 和 XDNA2 神经网络处理单元(NPUs)的开源 LLVM 编译器。
- 微软为 Visual Studio Code 推出 AI Toolkit:在 /r/LocalLLaMA 中,讨论了微软新的 VS Code AI Toolkit 扩展,它为各种模型提供了 Playground 和微调功能,并支持在本地或 Azure 上运行。
研究与基准测试
- 研究发现 RLHF 会降低 LLM 的创造力和输出多样性:发布在 /r/LocalLLaMA 的一篇新研究论文显示,虽然像 RLHF 这样的对齐技术减少了有害和偏见内容,但它们也限制了大语言模型的创造力,甚至在与安全无关的语境中也是如此。
- 针对 LLM 推理的廉价 AWS 实例基准测试:在 /r/LocalLLaMA 中,对运行 Dolphin-Llama3 的各种 AWS 实例进行的基准测试显示,g4dn.xlarge 以 0.58 美元/小时的价格提供了最佳性价比,其中 GPU 速度是关键因素。更大的内存允许在输出中使用更高的 Token 数量。
Stable Diffusion 3 及更多内容
- Stable Diffusion 3 的重要性及突出特性解析:/r/StableDiffusion 的一个帖子分析了为什么 SD3 是一个重大进步,其全新的 16 通道 VAE 可以捕捉更多细节,实现更快的训练和更好的低分辨率效果。其多模态架构符合 LLM 研究趋势,预计将推动 ControlNets 和 adapters 等技术的发展。
其他
- 提升 CPU+RAM 推理速度约 40% 的技巧:在 /r/LocalLLaMA 中,一位用户分享了一个提高 tokens/sec 的技巧:在 BIOS 中启用 XMP,使 RAM 以规格带宽运行,而不是 JEDEC 默认值。内存超频可能会带来进一步提升,但存在不稳定的风险。
- 使用 BeyondLLM 0.2.1 简化 RAG 的可观测性:/r/LocalLLaMA 的一个帖子解释了 BeyondLLM 0.2.1 如何更轻松地为 LLM 和 RAG 应用添加可观测性,从而允许跟踪响应时间、Token 使用情况和 API 调用类型等指标。
迷因与幽默
- AI 理想与现实对比梗图:在子版块中分享的一张有趣的图片,对比了 AI 系统被夸大的预期与实际能力。
{kind=link}
AI Discord 回顾
- Apple 首次亮相重大 AI 创新:
- 在 WWDC 2024 上,Apple 发布了 Apple Intelligence,这是一个深度集成于 iPhone、iPad 和 Mac 的 AI 系统。主要功能包括 ChatGPT 集成到 Siri、AI 写作工具,以及用于安全处理复杂任务的新型“Private Cloud Compute”。基准测试显示 Apple 的 on-device and server models 在指令遵循和写作方面表现出色。然而,围绕 用户隐私 的担忧以及埃隆·马斯克因 OpenAI 集成而发出的在公司内禁用 Apple 设备的警告引发了辩论。
- 模型压缩与优化策略:
- 工程师们积极讨论了对 LLaMA 3 等大语言模型进行 quantizing(量化)、pruning(剪枝)和优化的技术,以减小模型体积并提高效率。分享了 LLM-Pruner 和 Sconce 等资源,并就 FP8 等低精度格式的稳定性展开了辩论。探索了 LoRA、8-bit casting 和 offloading to CPU 等优化手段,以解决训练过程中的 Out-of-Memory (OOM) 错误。
- 工程师们讨论了使用 offloading optimizer state to CPU 和 bnb 8bit casting (VRAM Calculator) 等策略来 克服 Out of Memory (OOM) 错误,并重点介绍了 Low-Rank Adapters (LoRA) 等技术。
- 社区交流分享了关于 fine-tuning 挑战 的见解,并提供了实际案例和资源,如 YouTube tutorial。
- 令人兴奋的开源和基准测试新闻:
- Stable Diffusion 3 (SD3) 令成员们感到兴奋,其目标是更好的体素艺术(voxel art),而对 Huggingface 和 Civitai 等模型平台的比较引发了关于最佳上采样方法和可用性的辩论 (SD3 Announcement)。
- Hugging Face 扩展了 AutoTrain 并增加了 Unsloth support (Announcement),通过增强的内存管理简化了大模型 fine-tuning。
- 语言和多模态模型的进展:AI 社区见证了令人兴奋的突破,包括用于自回归图像生成的 LlamaGen、在零样本(zero-shot)文本转语音合成中达到人类水平的 VALL-E 2,以及来自 CAMB AI、承诺在语音克隆中实现更高真实度的 MARS5 TTS。讨论探索了用于高效模型部署的 IQ4_xs 和 HQQ 等量化技术,以及 federated learning 在隐私保护训练中的潜力。
- 社区协作应对 AI 挑战:
- 在引人入胜的讨论帖中,重点讨论了医疗应用中的 Chain of Thought retrieval 以及核心模型 prompt engineering 技术 (YouTube tutorial)。
- OpenAccess AI Collective 分享了一个适合初学者的 RunPod Axolotl tutorial,简化了模型训练流程。
- 量化与模型部署见解:
- 关于 Llama 3 的 4-bit quantization 交流以及使用 Tensor Parallelism 的建议展示了来自 AI 社区的实践经验 (Quantization Blog)。
- 讨论了 DeepSeek-LLM-7B 模型的 LLaMA-based structure 及其可解释性 (DeepSeek Project)。
PART 1: 高层级 Discord 摘要
LLM Finetuning (Hamel + Dan) Discord
LLM 微调,化繁为简:工程师们分享了针对 Out of Memory (OOM) 错误的解决方案,并讨论了微调流程。大家在将优化器状态卸载到 CPU 或使用 CUDA managed memory 的益处上达成共识,并提到了 bnb 8bit casting 和 Low-Rank Adapters (LoRA) 等技术,以在训练期间节省显存并提升性能。有价值的资源包括关于 8-bit Deep Learning 的 YouTube 视频 以及基准测试工具 VRAM Calculator。
对额度困惑的共鸣:多位社区成员表示在获取承诺的额度(credits)时遇到困难。从 Modal、OpenAI 到 Replicate,多个平台都出现了额度缺失的情况,成员们在各自频道发布了寻求解决的请求。为了加快支持进度,成员们主动提供了用户 ID 和组织 ID 等信息。
模型训练的困扰与成就:成员们在不同平台上排查微调和推理的挑战,重点关注 dataset preparation(数据集准备)、使用 TRL 或 Axolotl 等现有框架,以及在有限硬件上处理大型模型训练等实际问题。另一方面,也有成员分享了在 Modal 上部署 Mistral 的正面体验,并对其热重载(hot-reload)功能表示赞赏。
深入现实世界的 ML 讨论:对话深入探讨了实际的 Machine Learning (ML) 应用,例如 dynamically swapping LoRAs(动态切换 LoRA)以及用于音频处理的 Google Gemini API。还研究了 Llama-3 8B 等模型使用 Chain of Thought(思维链)推理进行诊断的情况,同时也承认了模型结论中存在的缺陷。
快速工程的资源积累:社区一直积极分享资源,包括 Jeremy Howard 在 YouTube 上的 《A Hackers’ Guide to Language Models》 以及用于制作图表的 Excalidraw。推荐使用 Sentence Transformers 等工具来微调 Transformer,彰显了不断提升技艺的协作精神。
Stability.ai (Stable Diffusion) Discord
- 等待“圣杯” SD3:大家对 Stable Diffusion 3 (SD3) 的发布充满期待,希望其在体素艺术(voxel art)方面有功能改进,而一位用户幽默地表示担心在发布前不得不去睡觉。
- 缓慢的网络连接考验耐心:由于达到数据上限,一位成员经历了长达 12 小时的漫长过程来下载 Lora Maker,忍受着来自 Pytorch.org 低至 “50kb/s” 的下载速度。
- 模型平台大比拼:关于 AI 模型和 Checkpoints 可用性的讨论兴起,Huggingface 和 Civitai 成为关注焦点;Civitai 凭借丰富的 LoRA 和 Checkpoints 选择占据领先地位。
- 辩论:放大技术:一场关于将 SD1.5 图像放大到 1024 是否能与直接在 1024x1024 分辨率下训练的 SDXL 效果相媲美的技术辩论被引发,随后有人建议测试 SDXL 放大到更高分辨率的能力。
- AMD,为什么你不能运行 SD?:一位努力在 AMD GPU 上运行 Stable Diffusion 的成员表达了挫败感,最终社区建议其重新查阅安装指南并寻求进一步的技术支持。
Unsloth AI (Daniel Han) Discord
2024年7月:Unsloth AI 备受期待的 MultiGPU 支持
Unsloth AI 的 MultiGPU 支持预计将于 2024 年 7 月初发布,以企业级 Unsloth Pro 为首;这将有望实现更高效的微调和模型训练。
Llama 3 尝试多样化微调
用户探索了 Llama 模型的各种 Tokenizer 选项,讨论确认了来自 llama.cpp 和 Hugging Face 等服务的 Tokenizer 是互通的,并为寻求精确指令的用户参考了 YouTube 上的微调指南。
Hugging Face AutoTrain 扩展支持 Unsloth
Hugging Face AutoTrain 现在包含 Unsloth 支持,为更高效的大语言模型 (LLM) 微调铺平了道路,AI 社区对这些节省时间并减少内存占用的进展感到兴奋。
AI 创新展示:心理治疗 AI 与 MARS5 TTS
新兴工具如使用 Unsloth 在 Llama 3 8b 上微调的心理治疗 AI,以及新开源的 CAMB AI 的 MARS5 TTS 模型(该模型承诺在语音克隆中实现更高的真实感),正在社区中引起轰动。
苹果招聘:AI 集成引发辩论
苹果最新的个性化 AI 计划被称为 “Apple Intelligence”,成为激烈讨论的话题。根据 WWDC 的报道,社区正在权衡其在语言支持和集成更大型模型方面的潜力。
Eleuther Discord
深度学习对效率的追求:成员们辩论了 Llama 3 进行 4-bit quantization 的益处与障碍,并建议 Tensor Parallelism 尽管具有实验性质,但提供了可能的路径。讨论强调了包括 IQ4_xs 和 HQQ 在内的各种量化方法的适用性,并参考了一篇展示它们在 Apple Silicon 上性能的博客 LLMs for your iPhone。
寻求更智能的 Transformer:关于改进 Transformer 模型的讨论浮出水面,参考了如 “How Far Can Transformers Reason?” 等论文中强调的学习能力挑战,该论文提倡使用 supervised scratchpads。此外,还出现了关于模型中 influence functions 有用性的辩论,引用了如 Koh and Liang 的 influence functions 论文等开创性著作。
攻克文本转语音 (TTS) 合成:VALL-E 2 因其卓越的 zero-shot TTS 能力被提及,尽管研究人员在访问项目页面时遇到了问题。与此同时,LlamaGen 在视觉 Tokenization 方面的进展有望增强自回归模型,并引发了关于整合来自 “Stay on topic with Classifier-Free Guidance” 等相关工作方法的讨论。
解释多模态转换:讨论了 DeepSeek-LLM-7B 模型的集成挑战,其基于 LLaMA 的结构是焦点。分享的资源包括一个 GitHub 仓库,以协助社区进行解释性工作并克服模型集成复杂性。
LLM 交互的优化策略:Eleuther 通过 –apply_chat_template 标志引入了聊天模板功能,展示了增强用户与语言模型交互的持续工作。社区还在推动优化本地和 OpenAI Batch API 应用的 Batch API 实现,讨论了高层实现步骤,并计划在未来开发一个用于在 Batch 结果上重新运行指标的实用工具。
CUDA MODE Discord
-
GPU 引发的热水浴缸幻想:一个关于将 GPU 废热 重新利用来加热热水浴缸的有趣提议,引发了关于利用数据中心热输出的更广泛讨论。这个玩笑揭示了将废热转化为社区供暖解决方案的潜力,同时提供了可持续的数据中心运营模式。
-
穿越 Triton 丛林:提供了关于提升 Triton 性能的导航建议,常见的困扰包括速度逊于 cuDNN 以及在 kernel 内部打印变量的复杂性。用户表达了对更简单语法的偏好,建议避免使用元组以减少开发困惑。
-
跨越从 Torch 到 C++ 的频谱:展示了技术实力,参与者讨论了使用
torch.compile进行全图编译的优点,而其他人则考虑为 PyTorch 编写 HIP kernels,两者都预示着即将到来的优化浪潮。这些对话的交汇点还思考了 C++20 的 concepts 是否能在不退回 C++17 的情况下解开代码的复杂性。 -
Bitnet 的 0 与 1 成为焦点:围绕训练 1-bit Large Language Models (LLMs) 展开了深入交流,分享了来自 Microsoft 的 Unilm GitHub 的资源,概述了其效率潜力,同时也承认了与 FP16 相比存在的稳定性问题。
-
LLM 的高度与压缩技术:从分析 ThunderKitten 乏善可陈的 TFLOPS 表现,到探索使用 Sconce 的模型压缩策略,社区汇集智慧来应对这些复杂的领域。此外,PyTorch 的 AO 仓库 中增加了一个基准测试 Pull Request,承诺为 Llama 模型提供准确的性能评估。
Modular (Mojo 🔥) Discord
-
Mojo 中的并发难题与 GPU 困境:工程师们在担心 Mojo 异步能力的同时,讨论了在其库中采用结构化并发的问题,并强调了 TPU 支持等异构硬件的重要性。一种强烈的观点认为,Mojo 在执行速度上取得了成功,但与 TPU 等高性价比方案相比,在硬件加速方面仍有不足。
-
Mojo 上的快速 RNG 与数学精通:移植 xoshiro PRNG 的工作在笔记本电脑和使用 SIMD 时都带来了显著的速度提升,同时正努力通过 NuMojo 项目为 Mojo 带来等同于 numpy 的功能。趋势显示社区正在推动扩展 Mojo 的数值计算能力和效率。
-
解决 Mojo 的内存狂热:关于 Mojo 内存管理实践引发了争议,讨论集中在对上下文管理器的需求、对 RAII 的依赖以及 UnsafePointers 的复杂性。这场辩论强调了社区致力于完善 Mojo 的所有权(ownership)和生命周期(lifetimes)范式的决心。
-
攻克 TPU 领地:MAX 引擎与 TPU 的潜在兼容性成为亮点,社区成员探索了 OpenXLA 等资源以获取机器学习编译器的指导。前瞻性讨论涉及了 MAX 引擎路线图的更新,包括不可避免的 Nvidia GPU 支持。
-
Mojo Nightly 更新日志的细微差别:新发布的 Nightly Mojo 编译器版本
2024.6.1105带来了多项变化,包括移除SliceNew和SIMD.splat,以及引入NamedTemporaryFile。社区内这种持续集成的文化体现了对迭代和快速开发周期的偏好。
Perplexity AI Discord
-
苹果涉足个人 AI 领域:苹果宣布了 “Apple Intelligence”,将 ChatGPT-4o 集成到 Siri 和写作工具中,以增强系统级的用户体验,同时优先考虑隐私,正如一篇 Reddit 帖子中所分享的那样。
-
iOS 18 和 WWDC 2024 拥抱 AI:随着 WWDC 2024 设定的愿景,iOS 18 中由机器学习驱动的新照片应用可以更智能地对媒体进行分类,并伴随着整个苹果生态系统的重大 AI 集成和软件进步。
-
Rabbit R1 是一个失败的设备吗?:成员们就 Rabbit R1 设备的合法性交换了意见,提到了其可疑的加密货币联系,并推测了其在 Android OS 上的功能,正如一段 Coffeezilla 视频中所讨论的那样。
-
Perplexity AI - 承诺与怀疑并存:围绕 Perplexity 的 Pages 和 Pro 功能在桌面/网页端的限制存在困惑;同时,Perplexity 的学术来源准确性面临审查,用户指出 Google 的 NotebookLM 可能更胜一筹。
-
集成难题与隐藏的密钥:在将 Perplexity AI 引入自定义 GPT 应用时遇到了障碍,引发了关于模型名称更新以及在 API 密钥误暴露后的安全 API 实践的讨论,相关内容记录在 Perplexity API 指南中。
LM Studio Discord
-
PDF 解析的探索:工程师们正在探索用于解析 PDF 中结构化表单的本地工具,并建议使用 Langchain 结合本地 LLM 来高效提取字段。
-
WebUI 的困扰与变通方法:由于 LMStudio 官方缺乏 WebUI 支持,导致用户使用 llama.cpp server 和 text-generation-webui 从远程 PC 与该工具进行交互。
-
加州 AI 法案引发争议:SB 1047 法案引发了关于其对开源 AI 影响的激烈辩论,人们担心这可能会使 AI 开发集中在少数大公司手中,并无限期地增加模型创建者的法律责任。Dan Jeffries 的推文为这一讨论提供了见解。
-
GPU 升级与 ROCm 见解:工程师们讨论了升级到具有更高 VRAM 的 GPU 以运行大型 AI 模型,并推荐 AMD 的 ROCm 作为计算任务中比 OpenCL 更快的替代方案。由于对 LMStudio 中多 GPU 性能的担忧,一些人转向了 stable.cpp 和 Zluda 等替代方案,以便在 AMD 上兼容 CUDA。
-
模型合并大师:社区在模型合并方面非常活跃(例如 Boptruth-NeuralMonarch-7B),评估新配置(如 Llama3-FiditeNemini-70B),并处理 AutogenStudio 中的 token 限制 bug 等运行问题,相关修复已在 GitHub 上跟踪。
OpenAI Discord
-
Apple 在 AI 领域引起轰动:Apple 宣布将 AI 集成到其生态系统中,社区对其对竞争和设备性能的影响议论纷纷。WWDC 2024 的参与者热烈讨论了 “Apple Intelligence”,这是一个深度集成到 Apple 设备中的系统,并正在研究现有的 Apple Foundation Models 概览。
-
关于 AI 与隐私的担忧与辩论:随着 AI 的进步,隐私担忧也随之增加。用户对潜在的数据滥用表示担忧,主张使用更安全的设备端 AI 功能,而不是仅仅依赖云计算。这种讨论反映了技术爱好者对云端和本地解决方案都持怀疑态度的二分法。
-
GPT-4:高期望遭遇实际小问题:OpenAI 关于即将推出的 ChatGPT 更新的承诺引起了兴奋,但用户报告了应用冻结以及对新语音模式延迟发布的困惑。此外,开发者对 GPT Store 中明显的政策违规行为感到沮丧,这阻碍了他们发布或编辑 GPTs 的能力。
-
跨时区的时间管理:AI 工程师正在制定策略,以应对 Completions API 的时区挑战,权衡使用外部库进行时间戳转换或使用合成数据来降低风险并提高精度的方案。共识倾向于将 UTC 作为一致模型输出的基准,并在输出后进行针对特定用户的时区调整。
-
认识 Hana AI:你的 Google Chat 新队友:Hana AI 被介绍为一款用于 Google Chat 的 AI 机器人,旨在通过处理各种生产力任务来提高团队效率,目前可免费使用。工程师可以试用并对该机器人提供反馈,它承诺为经理和高管提供帮助,可通过 Hana AI 网站访问。
HuggingFace Discord
-
寻求最佳医疗诊断 AI 的进程停滞:在讨论中,对于用于医疗诊断的最佳大语言模型(LLM)尚未达成共识。
-
CVPR 论文获取的语义化飞跃:一个索引了 CVPR 2024 论文摘要并具备语义搜索功能的新应用已被分享,可以点击这里访问。
-
Civitai 文件的技术故障:一名成员在将
diffusers.StableDiffusionPipeline.from_single_file()与来自 Civitai 的 safetensors 文件配合使用时,遇到了TypeError: argument of type 'NoneCycle' is not iterable错误。 -
AI 立法对开源领域产生重大影响:一条推文线程批评了加州 AI 控制法案(California AI Control Bill),认为其可能会阻碍开源 AI 的发展,并对模型创建者的严格责任制提出了警示。
-
动漫遇上 Wuerstchen3 扩散模型:一位用户发布了经过动漫微调的 SoteDiffusion Wuerstchen3 版本,并提供了指向 Fal.AI 文档的有用链接,以获取 API 实现细节。
Nous Research AI Discord
Character Codex 发布:Nous Research 发布了 Character Codex 数据集,包含来自动漫、历史档案和流行偶像等不同来源的 15,939 个角色数据,现已开放下载。
技术讨论热火朝天:引人入胜的对话包括 LLM 中 RLHF 可能对创造力造成的抑制,并与 Anthropic 等公司的成功进行了对比。辩论还涵盖了模型量化和剪枝方法,其中一种针对 LLaMA 3 10b 的策略旨在巧妙地缩减模型尺寸。
知识同步:成员们讨论了 CoHere 用于多步输出构建的 Chain of Thought (CoT) 检索技术,并提出了一种混合检索方法,可能将 elastic search 与 bm25 + embedding 以及网络搜索结合起来。
代码遭遇立法:有一篇针对 CA SB 1047 的出色评论,认为它对开源 AI 构成了风险,同时一位成员分享了 Dan Jeffries 对此事的见解。此外还提到了旨在保护 AI 创新的反向提案 SB 1048。
新的 Rust 库 Rig 登场:用于创建 LLM 驱动应用的开源 Rust 库 ‘Rig’ 的发布引起了关注;其 GitHub 仓库是 AI 开发者获取示例和工具的宝库。
Cohere Discord
-
Apple 的 AI 变革者:Apple 在 WWDC 2024 上发布了 ‘Apple Intelligence’,将 ChatGPT 集成到 Siri 中,以提升 iPhone, iPad 和 Mac 的用户界面体验,这引发了关于安全性的担忧和讨论。公告详情已在这篇文章中分享。
-
求职现状反思:一位向往 Cohere 团队的成员分享了尽管在黑客松中取得显著成绩并拥有 ML 经验,却依然遭遇求职被拒的挫折,这引发了关于个人推荐是否优于资历的讨论。
-
Cohere 的开发者对话:Cohere 推出了 Developer Office Hours,这是一个供开发者解决疑虑并直接与 Cohere 团队互动的论坛。官方发布了下一场活动的提醒并邀请大家参与。
-
反馈热烈:成员们对 Cohere 提供的这种新的 Developer Office Hours 形式表示高度满意,称赞团队营造了一个极具参与感且轻松的环境。
-
与专家交流:Cohere 鼓励成员积极参与,并为开发者提供了通过 Developer Office Hours 扩展知识并与团队一起排查问题的机会。下一场活动定于 6 月 11 日下午 1:00 (ET),可通过此 Discord Event 参加。
Latent Space Discord
-
Apple 全力投入 AI 集成:Apple 宣布在其整个 OS 中集成 AI,重点关注多模态 I/O 和用户体验,同时保持隐私标准。针对 AI 任务,他们推出了 “Private Cloud Compute”,这是一个安全的系统,可以在不损害用户隐私的情况下将计算卸载到云端。
-
ChatGPT 找到新归宿:Apple 与 OpenAI 宣布达成合作伙伴关系,将 ChatGPT 引入 iOS, iPadOS 和 macOS,标志着向 AI 驱动的操作系统的重大迈进。这将使 Apple 用户在今年晚些时候能直接使用对话式 AI。
-
Mistral 掀起融资浪潮:AI 初创公司 Mistral 获得了 6 亿欧元的 Series B 融资用于全球扩张,这证明了投资者对人工智能未来的信心。此轮融资紧随 AI 领域投资激增的趋势,凸显了市场的增长潜力。
-
PostgreSQL 的 AI 性能超越 Pinecone:PostgreSQL 的新开源扩展 “pgvectorscale” 因在 AI 应用中表现优于 Pinecone 而受到赞誉,承诺提供更好的性能和成本效率。这标志着支持 AI 工作负载的数据库技术取得了重大进展。
-
LLM 在现实世界中的应用:Mike Conover 和 Vagabond Jack 做客 Latent Space 播客,分享了他们在生产环境中部署 Large Language Models (LLM) 的经验以及金融领域的 AI Engineering 策略。讨论集中在行业背景下有效利用 LLM 的实际考量和策略。
LlamaIndex Discord
-
进阶知识图谱专题:一场聚焦于“进阶知识图谱 RAG”的特别研讨会已与来自 Neo4j 的 Tomaz Bratanic 共同安排,旨在探索 LlamaIndex 属性图(property graph)抽象。鼓励工程师们注册参加将于太平洋时间周四上午 9 点举行的活动。
-
巴黎 AI 聚会:@hexapode 将在 Paris Local & Open-Source AI Developer meetup 上进行现场演示,该活动将于 6 月 20 日下午 6:00 在巴黎 Station F 举行,届时将有包括 Koyeb、Giskard、Red Hat 和 Docker 在内的多家知名公司参加,其他人也可以通过此处申请演示自己的作品。
-
LlamaIndex 的问题与变通方案:用户正在寻求集成各种查询引擎和 LLM 流水线的帮助,例如使用 LlamaIndex 结合 SQL、Vector Search 和 Image Search,以及在查询向量数据库时使用 OpenAI Chat Completion 作为备选方案。对于涉及使用 Llama 3 进行 SQL 数据库检索和分析的项目,建议探索 text-to-SQL 流水线并参考 LlamaIndex 进阶指南。
-
伯克利头脑风暴:加州大学伯克利分校(UC Berkeley)的一个研究团队正在探索自定义 RAG 系统的领域,寻求资深工程师的意见,以应对构建、部署和维护此类系统的复杂性。
-
稀疏向量生成的提速需求:在使用 Qdrant 和 LlamaIndex 的混合模式下,生成和上传稀疏向量(sparse vectors)对某些用户来说太慢了,有建议提示利用本地 GPU 或使用 API 来加速这一过程。
LAION Discord
-
LAION 陷入争议:LAION 数据集在巴西电视节目中受到批评;问题源于人权观察组织(Human Rights Watch)的一项指控,称 AI 工具正在滥用儿童的在线个人照片,详情见此处。
-
隐私与互联网素养辩论:工程师们对互联网数据隐私的普遍误解表示担忧,触及了数十亿用户缺乏相关知识所导致的严重问题。
-
LlamaGen 推动图像生成发展:发布的 LlamaGen 模型展示了图像生成领域的重大进展,利用语言模型技术进行视觉内容创作,详见其研究论文。
-
CAMB AI 的 MARS5 宣布开源:由 CAMB AI 开发的 TTS 模型 MARS5 已向社区开源,Reddit 上的一个帖子邀请大家提供反馈,更多技术讨论可在此线程中找到。
-
视觉数据集的安全性:LlavaGuard 项目(详见此处)提出了一个模型,旨在提高视觉数据集标注的安全性和伦理合规性。
Interconnects (Nathan Lambert) Discord
-
Apple Intelligence 评价褒贬不一:工程师们对 OpenAI 与 Apple 的合作反馈不一,认为集成到 Apple Intelligence 中的程度可能较浅;然而,尽管存在传闻和质疑,官方公告中仍强调了用户隐私(阅读更多)。Apple 设备端和服务器端模型的对比基准测试引发了人们对其相对于同类产品性能的好奇。
-
建立清晰区分:Apple 将 Apple Intelligence 与 Siri 分开的战略方法引发了关于其对用户采用率以及对新系统功能认知潜在影响的对话。
-
科技界期待重磅访谈:Dwarkesh Patel 即将对 François Chollet 进行的采访让工程师们对 AGI 时间线辩论可能出现的转向充满期待,强调了基于 Chollet 对智力衡量研究进行深度提问的重要性。
-
TRL 实现引发争议:有人对实现 TRL 提出了警告,称该技术“未经证实”。一位成员计划为 TRL 提交 Pull Request (PR),得到了另一位社区成员的积极鼓励和 Review 提议。
-
社区贡献中的支持:协作精神显而易见,一名成员计划为 TRL 做出贡献并收到了 Review 承诺,展示了该组织相互支持和知识共享的文化。
OpenInterpreter Discord
-
Apple Intelligence 备受关注:社区对 Open Interpreter 与 Apple 在 Apple Intelligence 页面上概述的以隐私为中心的 AI 功能进行潜在集成的可能性表现出浓厚兴趣。这可能会促使利用开发者 API 来增强 Apple 设备上的 AI 功能。
-
SB 1047 成为众矢之的:Dan Jeffries 批评了由 Dan Hendyrcks 提出的加州 AI 控制与中心化法案 (SB 1047),理由是该法案对 AI 实施中心化控制,并对开源 AI 创新构成威胁。
-
Mac M1 上的 Arduino IDE 问题已解决:通过在 GitHub pull request 中找到的修复方案,解决了 Mac M1 芯片上 Arduino IDE 的一个问题,但该修复导致设备重启时 Wi-Fi 设置出现了额外的问题。
-
Linux 成为 Open Interpreter 的避风港:成员间的讨论强调了在未来的 Open Interpreter 开发中优先考虑 Linux 的想法,旨在提供独立于 Apple 和 Microsoft 等主流操作系统的 AI 辅助工具。
-
具有记忆功能的个人助手:分享了增强 Open Interpreter 的工作,通过一个熟练的 Prompting 系统,使其能够像个人助手一样存储、搜索和检索信息,突出了在为 AI 系统创建记忆保留方面的创新。
-
Killian 的见解被记录:在 Killian 最近的演讲之后进行了一场值得关注的讨论,该演讲对于在社区成员中聚焦相关的 AI 话题起到了重要作用。录音可以在此处查看。
LangChain AI Discord
- LangChain 的标签功能(Tagging)出现问题:工程师们注意到 LangChain 中的
create_tagging_chain()函数会忽略 Prompt,由于目前尚未提供解决方案,这引起了开发者的不满。 - 征集 RAG 开发见解的协作邀请:加州大学伯克利分校(UC Berkeley)团队成员正积极寻求与在 Retrieval-Augmented Generation (RAG) 系统方面有经验的工程师进行交流,以分享在开发和部署过程中面临的挑战。
- LangGraph 与 LangChain 的对比:社区表现出对理解使用 LangGraph 优于经典 LangChain 配置的优势的兴趣,特别是关于在 LangGraph 中执行受控脚本方面。
- 期待 ONNX 与 LangChain 的结合:有人对 ONNX 和 LangChain 之间的潜在兼容性感到好奇;然而,对话并未深入展开。
- 通过 OpenAI 简化大型数据集处理:分享了一份使用 OpenAI API 处理大型数据集的综合指南,重点介绍了设置环境变量、数据匿名化以及使用 Elasticsearch 和 Milvus 进行高效数据检索的最佳实践。文中提供了相关文档和 GitHub issue 链接供参考。
tinygrad (George Hotz) Discord
-
新手遭遇权限难题:一位渴望参与 tinygrad 开发的新成员发现自己被 bounties 频道锁定权限,无法参与 AMX support bounty 的工作。George Hotz 解决了这一困惑,表示必须“成为紫色(Become a purple)”才能获得必要的贡献权限。
-
George 扮演“守门人”角色:在回答有关 tinygrad 中 AMX support 的问题时,George Hotz 暗示在处理此类任务之前,需要更深入地了解社区文档,并提到需要阅读一份特定的问题文档。
-
一个经典的误会:当一名新成员引用了错误的指南——“How To Ask Questions The Smart Way” 时,发生了一次文档引用失误,导致与 George Hotz 之间出现了一个幽默的“先有鸡还是先有蛋的问题”时刻。
-
回到起点:在一番反复沟通后,这位新贡献者决定退后一步,在带着更精确的问题回来之前,先深入研究 tinygrad 的代码库,这展示了为此类项目做贡献所需的复杂性和专注度。
OpenRouter (Alex Atallah) Discord
- OpenRouter 的高速服务:OpenRouter 通过利用 Vercel Edge 和 Cloudflare Edge 网络解决了延迟问题,确保服务器节点在地理位置上靠近用户,从而实现更快的响应速度。
- 计划中的供应商偏好设置:虽然 OpenRouter playground 目前缺少用户选择首选 API 供应商的功能,但已确认计划实现该功能。
- 技术极客的 API 供应商选择:用户可以通过使用 API 来绕过 OpenRouter playground 中缺乏直接供应商选择的问题;该变通方法的指南可在 OpenRouter 文档中找到。
OpenAccess AI Collective (axolotl) Discord
- ShareGPT 的训练面纱:在训练时,ShareGPT 不会“看到”其自身转换后的 prompt 格式,从而确保训练过程的纯净。
- Apple AI 展示实力:Apple 新的端侧和服务器模型的基准测试结果已出炉,展示了它们在指令遵循和写作方面的实力,并与其他领先模型进行了对比。
- 乐天 (Rakuten) 模型席卷而来:Rakuten AI 团队发布了一系列在日语方面表现出色的 LLM,这些模型基于 Mistral-7B 并提供商业许可,在社区成员中引发了乐观的反响。
- JSON 响应带来的喜悦:工程师们在交流中愉快地赞赏了模型以 JSON 格式响应的能力,表达了对模型这一技术能力的认可与喜爱。
- 使用 Axolotl 让微调更简单:AI 从业者可以参考在 RunPod 上进行微调的新教程,该教程概述了微调 LLM 的简化流程,并提供了涵盖各种模型系列的 YAML 示例。
Datasette - LLM (@SimonW) Discord
-
编码风暴前的宁静:Vincent Warmerdam 推荐使用 calmcode.io 进行模型训练,用户们也认可该网站在模型训练策略和技术方面的实用内容。
-
RAG 的正确姿势:一篇 Stack Overflow 博客文章 详细介绍了 RAG (retrieval-augmented generation) 实现中的分块 (chunking) 策略,强调了 text embeddings 在将源文本准确映射到 LLM 语义结构中的作用,从而增强了对源数据的可靠性。
Torchtune Discord
- 关于 TRL 中 DPO 的 KL 图表说明:Dominant Policy Optimization (DPO) 的实现中没有直接绘制 Kullback–Leibler (KL) 散度图表,但在 Trust Region Learning (TRL) 的 Proximal Policy Optimization (PPO) 训练器中确实存在此类 KL 图表。正如 TRL 的 GitHub 仓库中指出的,KL 图表可以在 PPO 训练器的代码中找到。
MLOps @Chipro Discord
AI 社区齐聚 Mosaic 活动:在 Databricks Summit 的 Mosaic 活动上与 Chip Huyen 面对面交流,与 AI 和 ML 专家建立联系。该聚会定于 2024 年 6 月 10 日在旧金山举行。
Mozilla AI Discord
鉴于提供的片段中缺乏实质性的讨论点且上下文不足,目前没有重大的技术或详细讨论可供工程师读者总结。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
AI Stack Devs (Yoko Li) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:各频道详细摘要与链接
完整的频道逐条细分内容已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!