ainews-the-last-hurrah-of-stable-diffusion
Stable Diffusion 的最后辉煌?
Stability AI 推出了 Stable Diffusion 3 Medium,其模型参数范围从 4.5 亿至 80 亿不等,采用了 MMDiT 架构和 T5 文本编码器,以提升图像中的文本渲染能力。在 Emad Mostaque 等核心研究人员离职后,社区对此反应不一。
在 AI 模型方面,Llama 3 8B Instruct 在评估中显示出与 GPT-4 强相关的表现,而 Qwen 2 Instruct 在 MMLU 基准测试上超越了 Llama 3。Mixture of Agents (MoA) 框架在 AlpacaEval 2.0 上的表现优于 GPT-4o。Spectrum 和 QLoRA 等技术实现了在较低显存占用下的高效微调。
关于顿悟 (grokking) 的研究表明,通过延长训练时间,Transformer 模型可以从“死记硬背”转变为“泛化理解”。基准测试方面的举措包括:旨在推动通用人工智能 (AGI) 进展的 100 万美元 ARC 奖金挑战赛,以及旨在防止数据集污染的实时大模型基准测试 LiveBench。
Character Codex 数据集提供了超过 15,000 个角色的开放数据,可用于检索增强生成 (RAG) 和合成数据。MLX 0.2 工具通过改进 UI 和更快的检索增强生成,提升了在搭载 Apple 芯片的 Mac 上的大模型使用体验。
MultiModal Diffusion Transformers 是你所需的一切。
2024年6月11日至6月12日的 AI 新闻。我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 30 个 Discord 社区(413 个频道,3555 条消息)。预计节省阅读时间(以 200wpm 计算):388 分钟。在 Twitter 上关注 AINews。
SD3 Medium 今日发布,并配有一段(对 Stability 而言)异常华丽的视频:

SD3 研究论文 值得关注,不仅因为它详细介绍了 MMDiT 架构以及使用 T5 文本编码器进行图像中的文本渲染,还因为它提到了其模型范围涵盖 450M 到 8B 参数,这使得 2B 参数的 SD3 Medium 并非最强大的 SD3 版本。
如果你一直在勤奋阅读 Stability AI Discord 的摘要,你就会知道社区几乎每天都在为 SD3 的权重开源发布而焦虑。SD3 最初在 3 个月前宣布,随后以 论文形式 和 API 形式 发布,特别是在 Emad Mostaque、Robin Rombach 以及许多参与原始 Stable Diffusion 的资深研究员离职后,这种焦虑愈发明显。汇总相关帖子的点数,可以很容易地看到从 SD1 到 SD2 再 to SD3,随着项目变得越来越不默认开源,人们的兴趣逐渐停滞:
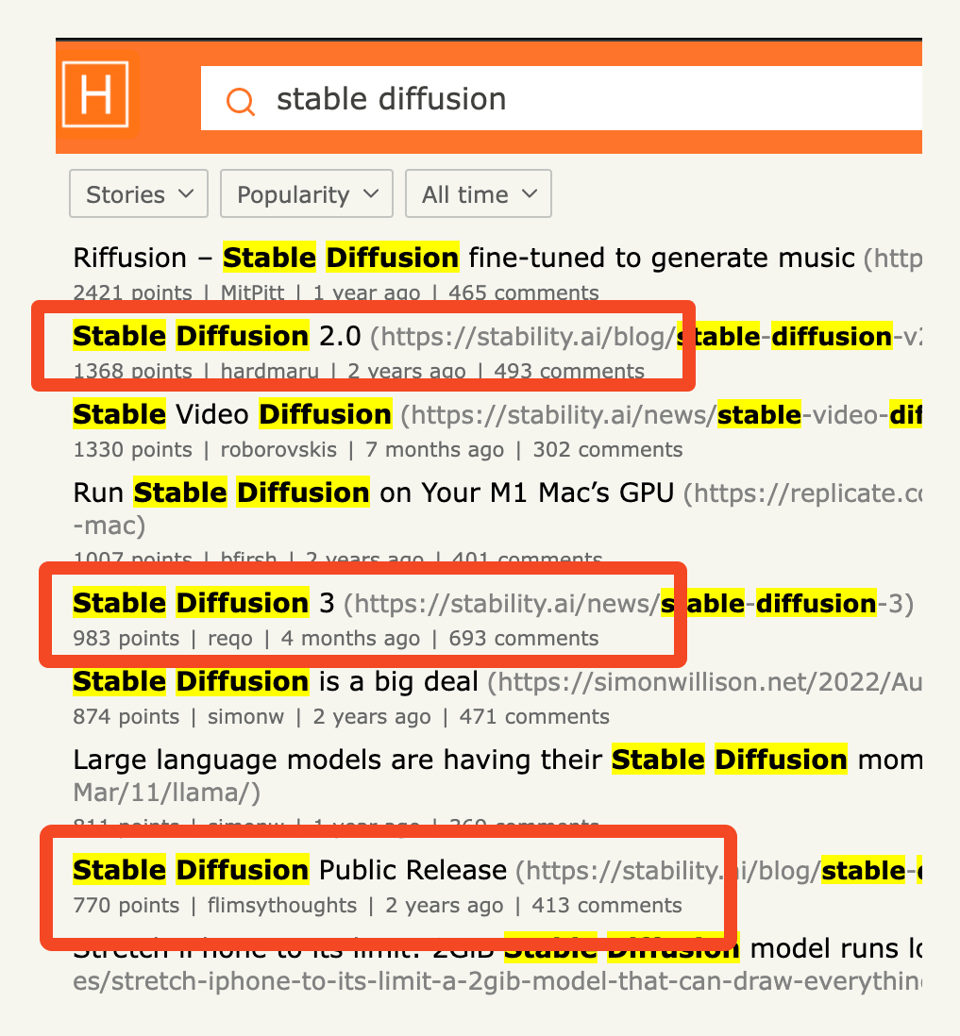
这是 Emad 在 Stability 任期内的最后遗产——新管理层 现在必须独立寻找未来的出路。
目录 和 频道摘要 已移至此邮件的网页版:! (在 Twitter 上分享。)
AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在使用 Haiku 进行聚类和流程工程(flow engineering)。
AI 模型与架构
- Llama 3 与指令微调:@rasbt 发现 Llama 3 8B Instruct 是一个优秀的评估模型,可在 MacBook Air 上运行,与 GPT-4 评分的相关性达到 0.8。提供了独立笔记本。
- Qwen2 与 MMLU 性能:@percyliang 报告在最新的 HELM 排行榜 v1.4.0 中,Qwen 2 Instruct 在 MMLU 上超越了 Llama 3。
- Mixture of Agents (MoA) 框架:@togethercompute 推出了 MoA,它利用多个 LLM 来优化响应。在 AlpacaEval 2.0 上达到 65.1%,优于 GPT-4o。
- 用于扩展上下文窗口的 Spectrum:@cognitivecompai 展示了 Spectrum,这是一种识别微调重要层的技术。它可以与 @Tim_Dettmers 的 QLoRA 结合,实现更快的训练和更少的 VRAM 占用。
- Transformer 中的 Grokking 现象:@rohanpaul_ai 讨论了一篇论文,显示 Transformer 可以通过 Grokking(超越过拟合的延长训练)学习鲁棒的推理。Grokking 涉及从“记忆”电路向“泛化”电路的转变。
基准测试与数据集
- ARC Prize 挑战赛:@fchollet 和 @mikeknoop 发起了一项 100 万美元的竞赛,旨在创建能够适应新奇事物并解决推理问题的 AI,目标是衡量 AGI 的进展。
- LiveBench:@micahgoldblum 发布了 LiveBench,这是一个通用实时 LLM 基准测试,通过发布新问题来避免数据集污染,并且可以进行客观评判。
- Character Codex 数据集:@Teknium1 发布了 Character Codex,这是一个包含 15,939 个角色数据的开源数据集,来源广泛,可用于 RAG、合成数据生成和角色扮演分析。
工具与框架
- MLX 0.2:@stablequan 发布了 MLX 0.2,为 Apple Silicon Mac 提供了全新的 LLM 体验,具有改进的 UI/UX、功能齐全的聊天和更快的 RAG。
- Unsloth:@danielhanchen 宣布 Unsloth 现已加入 Hugging Face AutoTrain,允许以更少的内存将 Llama-3、Mistral 和 Qwen2 等 LLM 的 QLoRA 微调速度提高 2 倍。
- LangChain 集成:@LangChainAI 增加了 Elasticsearch 功能,用于灵活的检索和向量数据库。他们还在 LangSmith Playground 中提供了 @GroqInc 支持。
应用与用例
- Brightwave AI 研究助手:@vagabondjack 宣布为 Brightwave 完成 600 万美元种子轮融资,这是一款生成财务分析的 AI 研究助手,其客户管理资产超过 1200 亿美元。
- Suno 音频输入:@suno_ai_ 发布了音频输入功能,允许用户通过上传或录制音频片段,从任何声音中创作歌曲。
- Synthesia 2.0 发布会:@synthesiaIO 预告了其 AI 视频生成器的新功能、工作流、用例和数字人(avatar)能力,活动将于 6 月 24 日举行。
讨论与观点
- Prompt 工程 vs. 微调:@corbtt 认为,在未来几年,微调后的适配器(adapters)在性能、控制力以及更便宜的推理成本方面将优于 Prompt 工程。
- RLHF 的副作用:@rohanpaul_ai 分享了一篇论文,探讨了 RLHF 对齐如何因阻断 Token 轨迹和模式崩溃(mode collapse)而降低模型的创造力和输出多样性。
- LLM 中的幻觉:@rohanpaul_ai 引用了一篇论文,显示经过统计校准的语言模型必然会以一定的概率产生幻觉。
AI Reddit 摘要
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取现已可用,但仍有很大改进空间!
AI 进展与时间线
- GPT-1 六周年:在 /r/singularity 中,有人提到 GPT-1 正好在 6 年前发布,并表达了希望到 2030 年 6 月我们能进入 AGI 或 ASI 时代的愿景。
AI 公司与产品
- Tesla Optimus 部署:/r/singularity 分享了 Tesla 已在其工厂部署了两个自主执行任务的 Optimus 机器人。
- Musk 撤回对 OpenAI 的诉讼:/r/singularity 和 /r/OpenAI 报道称 Elon Musk 撤回了对 OpenAI 和 Sam Altman 的诉讼,邮件显示 Musk 此前曾同意营利性方向。
- Apple 与 OpenAI 合作:根据 /r/singularity 的消息,Apple 宣布了 Apple Intelligence,由 OpenAI 提供支持并由 Microsoft 资助,如果本地解决方案失败,设备端 AI 将使用 OpenAI。
- OpenAI 使用 Oracle Cloud:/r/OpenAI 指出 OpenAI 选择 Oracle Cloud Infrastructure 来扩展 Microsoft Azure AI 平台。
- 前 Google CEO 批评开源模型:/r/singularity 讨论了 前 Google CEO 谴责开源模型并主张政府限制公开发布,反方观点认为这是在保护大科技公司的垄断。
AI 能力
- 餐厅机器人取得进展:/r/singularity 分享了 餐厅机器人现在可以烹饪、上菜和收拾餐具。
- 机器狗神射手:根据 /r/singularity 的报道,一项研究发现 携带机枪的机器狗比人类更擅长射击。
- AI 视频生成:/r/singularity 指出 Katalist AI Video 允许在 1 分钟内将一句话转化为分镜脚本和连贯的视频故事,具有未来电影制作的潜力。
- AI 工作面试:根据 /r/singularity 的消息,AI 卡通人物可能会为你下一次工作面试进行面试。
- Deepfake 裸照:/r/singularity 警告称 青少年正在互相传播 Deepfake 裸照,引发了严重问题。
AI 研究
- 自回归图像模型:/r/MachineLearning 和 /r/singularity 讨论了新的 LlamaGen 研究,显示 像 Llama 这样的自回归模型在可扩展图像生成方面击败了 Diffusion 模型,同时也引发了关于公平引用先前自回归研究的讨论。
- 消除矩阵乘法:/r/singularity 分享了 一种在不损失性能的情况下消除语言模型中矩阵乘法的革命性方法,使用定制的 FPGA 解决方案以 13W 的功耗处理十亿参数模型。
- 过度训练 Transformer:根据 /r/singularity 的消息,研究发现 将 Transformer 训练到超过过拟合点会导致意想不到的推理能力提升。
- MaPO 对齐技术:/r/MachineLearning 指出 MaPO 是一种针对 Diffusion 模型的高样本效率、无参考对齐技术,改进了先前的工作。
- 用于 LLM 预训练的 Megalodon:/r/MachineLearning 分享了 Megalodon 允许以无限上下文长度进行高效的 LLM 预训练和推理。
Stable Diffusion
- Stable Diffusion 3.0 发布:/r/StableDiffusion 社区对 定于 6 月 12 日发布的 Stable Diffusion 3.0 充满期待,社区中涌现出大量兴奋的情绪和梗图。
- SD3 模型辩论:/r/StableDiffusion 正在 辩论 SD3 2B 还是 8B 模型会更好,8B 模型仍在训练中,但预计完成后将超越 2B 模型。
- 开源训练工具:根据 /r/StableDiffusion 的消息,像 Kohya DeepShrink 这样的新开源工具可以实现高分辨率的 SD 训练。
- SDXL 与 SD3 对比:/r/StableDiffusion 正在 对比 SDXL 与 SD3 的汽车图像及其他主题,SD3 在比例、反射和阴影方面表现出明显的改进。
幽默/梗图
- /r/singularity 分享了一张 将胡迪和巴斯光年比作 AI 模型的梗图,暗示我们才是“玩具”。
- /r/singularity 发布了一张 关于“十诫”的梗图,上面写着“不可妄称 ASI 之名”。
- /r/singularity 分享了一张 大眼夹 (Clippy) 询问是否会将我们折叠进虚无的梗图。
AI Discord 摘要
总结之总结的总结
1. Stable Diffusion 3 发布与讨论
- Stability.ai 发布了 Stable Diffusion 3 Medium 的开放权重,这是他们最新的文本生成图像 AI 模型,承诺提供卓越的细节、色彩,通过三个文本编码器实现先进的 Prompt 理解,以及优异的排版渲染能力。
- 用户报告了 人体解剖结构准确性 方面的问题,对其性能与 SD 1.5 和 SDXL 等旧版本的对比反应不一,并对限制商业使用的 限制性许可条款 表示担忧。
- 围绕 微调(finetuning)挑战 展开了广泛讨论,特别是针对热门用例、现有框架(如 ComfyUI 和 diffusers)的安装问题,以及模型的 GPU 利用效率。
2. 大语言模型 (LLM) 进展与基准测试
- Google 推出了 RecurrentGemma 9B,能够快速处理长序列,同时保持与 Gemma 相当的质量,提供基础版和指令微调(instruct-tuned)版本。
- 宣布设立 1,000,000+ 美元的 ARC Prize,旨在为 ARC-AGI 基准测试 开发解决方案,该基准通过技能获取效率来衡量通用智能,引发了关于其重要性的讨论。
- Scalable MatMul-free Language Modeling 研究建议在 LLM 中消除矩阵乘法,同时保持强大的性能,从而减少训练期间的内存占用。
3. 协作式 LLM 开发与部署
- 成员们在使用 llm、Datasette 和 LangServe 等工具 安装和集成模型(如 mistral-instruct、GPT-4o 和 Codestral)方面寻求指导,并在 Hugging Face 和 GitHub 上分享了资源。
- 围绕 LLM 评估方法论、标准化评估 的重要性以及 LLM-as-judge 系统 的潜力进行了讨论,并参考了 Hailey Schoenfeld 的见解。
- 关于使用 Modal、Predibase 和 Axolotl 进行 LLM 微调 的咨询,涵盖了数据集准备、资源限制以及合并 LoRA 和 qLoRA 等技术结果的主题。
4. 硬件优化与资源管理
- 在 Kijiji Canada 等平台上价格实惠的 3090 GPU 引发了构建 GPU 算力集群的兴趣,讨论涉及功耗、散热管理以及优化 flops/watts 等性能指标。
- 开发者在代码中实现了 100% 确定性 (determinism),但遇到了损失值 (loss values) 变为 -inf 的问题,表明存在需要解决的潜在 Bug。
- 提高计算效率的努力促成了 自定义 matmul 实现,达到了 cuBLAS 70% 的速度,目前正在进行移除对 cuBLASLt 依赖的工作,并着手处理稳定的 FP8 实现。
Claude 3 Opus (>220B?)
以下是针对所提供的 Discord 内容中 3-4 个主要主题的高信息密度技术摘要,重要的关键词、事实和 URL 已加粗并链接到相关来源:
- Unsloth AI 的 QWEN 模型引发了关于 VRAM 和 Fine-Tuning 的讨论:Unsloth AI 用户比较了 Qwen2 模型(如 72b 变体)的 VRAM 需求(估计为 48GB,与 Llama 3 70b 相似),并分享了将 PyTorch bins 转换为 safetensors的技巧。讨论了使用 Qlora 和 Galore 等方法对 Qwen2-1.5b 进行 Fine-tuning 的挑战,建议使用 rank 64-128 以避免失败。16-bit 合并后的性能下降归因于 tokenizer/GGUF 问题。
- LLM Fine-Tuning 课程学习成果的应用与辩论:参与者反思了 Nehil 的博文,该文应用课程概念来改进预算分类 Prompt。技术讨论涵盖了向 Huggingface 模型添加 pooling layers、由于安全/隐私担忧而导致广域 Chatbot 与特定范围接口相比的不切实际性,以及使用 Modal 为 Kaggle 竞赛 Fine-tune LLM。对 Datasette、Anthropic Claude 以及从学术界转向工业界的资源表现出明显兴趣。
- GPU 市场动态与创意应用:在 Kijiji Canada 上价格实惠的 3090 GPU(约 450 美元)激发了构建 GPU 算力集群的计划,并讨论了功耗和热量再利用的考虑因素。分享了自定义 CUDA 开发工作,例如实现 100% 确定性(determinism)和高效的矩阵乘法,同时提到了 Scalable MatMul-free Language Modeling 论文 及其 实现。CUDA Performance Checklist 讲座重新发布,包含 视频、代码 和 幻灯片。
如果您希望我详细阐述本摘要的任何部分,或者有其他问题,请告诉我!
GPT4T (gpt-4-turbo-2024-04-09)
摘要:
1. 探索 EleutherAI 中的 LLM-Eval Harness 和 ARCSynthetic 挑战:
- EleutherAI 的成员探索了 LLM-Eval harness,并分享了关于传统评估与基于评分的评估的见解,旨在通过协作环境提高针对特定用例的灵敏度和特异性。
- 介绍了一篇名为 Scaling Laws for Diffusion Models 的新论文,讨论了与 Autoregressive 模型相比,训练和利用 Diffusion 方法的效率。
2. OpenInterpreter 中的跨语言通信:
- OpenInterpreter 的参与者深入讨论了如何有效管理跨语言和跨终端的通信,利用 NLP 模型在不同的计算环境中实现无缝交互。
- 技术讨论强调了语言模型实现的进展,通过改进命令解释来增强用户界面的交互性。
3. Cohere 的实用模型创新受到关注:
- Cohere 的平台更新成为亮点,讨论集中在近期推出的 AI 模型的实际应用上,这些模型增强了用户体验并扩大了应用范围。
- 关于模型集成挑战的辩论为 AI 模型部署的最佳实践和即将到来的创新提供了见解。
4. Modular (Mojo) 关注 TPU 考量及编译器更新:
- Modular 关于集成 TPU 并将其编译器更新至 版本
2024.6.1205的讨论,展示了在提升计算性能和灵活性方面的持续努力。 - 社区反馈对这些改进表示赞赏,并进一步期待即将推出的功能,这些功能有望利用 Modular 的工具推进可扩展的 AI 部署场景。
1. 模型性能优化与基准测试
- Quantization 技术(如 AQLM 和 QuaRot)旨在单块 GPU 上运行大型语言模型 (LLMs),同时保持性能。例如:在 RTX3090 上运行 Llama-3-70b 的 AQLM 项目。
- 通过 Dynamic Memory Compression (DMC) 等方法提升 Transformer 效率,在 H100 GPUs 上可能提高高达 370% 的吞吐量。例如:@p_nawrot 发表的 DMC 论文。
2. 微调挑战与 Prompt Engineering 策略
- 在将 Llama3 模型转换为 GGUF 格式时,存在保留微调数据的困难,并讨论了一个已确认的 Bug。
- Prompt 设计的重要性以及使用正确模板(包括 end-of-text tokens)对微调和评估期间模型性能的影响。例如:Axolotl prompters.py。
3. 开源 AI 发展与协作
- 发布了 StoryDiffusion,这是 Sora 的开源替代方案,采用 MIT 许可证,但权重尚未发布。例如:GitHub 仓库。
- 发布了 OpenDevin,这是一个基于 Cognition 的 Devin 的开源自主 AI 工程师,举办了 Webinar 且在 GitHub 上的关注度日益增长。
4. 多模态 AI 与生成模型创新
- Idefics2 8B Chatty 专注于提升聊天交互体验,而 CodeGemma 1.1 7B 则精进了编程能力。
- Phi 3 模型通过 WebGPU 将强大的 AI 聊天机器人带入浏览器。
5. 其他
- Stable Artisan 将 AI 媒体创作带入 Discord:Stability AI 推出了 Stable Artisan,这是一个集成了 Stable Diffusion 3、Stable Video Diffusion 和 Stable Image Core 等模型的 Discord 机器人,用于直接在 Discord 内进行媒体生成和编辑。该机器人引发了关于 SD3 开源状态以及引入 Artisan 作为付费 API 服务的讨论。
- Unsloth AI 社区对新模型和训练技巧反响热烈:IBM 的 Granite-8B-Code-Instruct 和 RefuelAI 的 RefuelLLM-2 的发布引发了架构讨论。用户分享了 Windows 兼容性方面的挑战以及对某些性能基准测试的怀疑,同时也交流了模型训练和微调的技巧。
GPT4O (gpt-4o-2024-05-13)
主题:
- LLM 进展与模型性能
- 多模态 AI 与生成式建模创新
- 开源工具与社区贡献
- 技术故障排除与实现挑战
- AI 伦理与行业动态
摘要:
- LLM 进展与模型性能:
- Google 的 RecurrentGemma 9B 因其在长序列上的超快性能而受到称赞,提供 base 和 instruct-tuned 版本,并与 Gemma 进行了对比。
- 成员们强调了 LlamaGen 在自回归图像生成方面的优越性,足以与扩散模型(diffusion models)媲美,并有详细的 文档和教程 支持。
- 多模态 AI 与生成式建模创新:
- Anthropic 的 Transformer Lens 帮助调试了模型注意力(attention),而 Stable Diffusion 3 Medium 引发了关于其 图像生成能力 的讨论,但在人体解剖结构准确性方面面临批评。
- Idefics2 8B Chatty 和 CodeGemma 1.1 7B 改进了对话和编程交互。Pixart Sigma 结合 SDXL + PAG 旨在实现 DALLE-3 级别的输出。
- 开源工具与社区贡献:
- Axolotl 支持多种格式用于指令微调(instruction tuning)和预训练 LLM。IBM 的 Granite-8B-Code-Instruct 在代码任务中表现出色。
- DeepEval 允许轻松集成自定义 LLM 评估指标,增强了在摘要生成和忠实度(faithfulness)等任务中的能力。
- 技术故障排除与实现挑战:
- Qwen2-1.5b 微调面临低秩(low-rank)配置问题,通过增加秩(64 或 128)得以解决。成员们分享了在 ComfyUI、diffusers 等框架中设置 Stable Diffusion 3 的困扰,以及针对 RTX 2070 和 P40 显卡 的 GPU 相关讨论。
- 高精度要求 以及 RL 的 PPO 等模型中的稳定性挑战,促使大家分享了关于优化技术、分词器(tokenizer)改进以及 PyTorch distributed log 错误的社区排查经验。
- AI 伦理与行业动态:
- 关于 Nightshade 技术的伦理担忧以及对 Perplexity AI 涉嫌抄袭的分析(Forbes 文章)强调了问责制的必要性。
- 微软通过利用与 Tesla 的讨论收购 OpenAI 49% 股份(推文)突显了科技巨头内部的战略举措,而 ARC Prize 超过 1,000,000 美元的奖励引发了关于行业基准的广泛讨论。
PART 1: 高层级 Discord 摘要
Stability.ai (Stable Diffusion) Discord
Stable Diffusion 3 释放潜力与问题:新发布的 Stable Diffusion 3 Medium 拥有更好的质量和先进的提示词理解能力,但据用户报告,它在人体解剖结构的准确性方面表现不佳。讨论显示出对性能的褒贬不一,一些人认为其表现平平,并对安装和微调中的技术障碍表示担忧。
令人困惑的许可协议:SD3 的许可条款在社区中引发了激烈辩论,焦点在于其对商业用途的限制,许多人认为这些限制对于实际应用来说过于苛刻。
写实主义承诺遭遇质疑:用户认可 SD3 在增强面部和手部真实感方面所做的努力,但与 SD 1.5 和 SDXL 等旧版本相比,结果的一致性仍然是一个有争议的点。
资源效率良好,但定制成本可能很高:工程师们赞赏 SD3 高效的 GPU 利用率和定制选项,尽管对于微调的资金和技术门槛存在担忧,尤其是针对特定领域的内容。
安装集成焦虑:已发现将 SD3 集成到 ComfyUI 和 diffusers 等流行框架中的各种问题,引发了社区内的协作排查工作。
Unsloth AI (Daniel Han) Discord
- 大模型对 VRAM 的需求 - 不开玩笑:Qwen2 72b 的 VRAM 需求与 Llama 3 70b 相似,约为 48GB;对于需要超级计算机的幽默建议被现实情况否定了。
- 将 Pytorch 转换为 Safetensors:尝试使用此工具将 Pytorch bins 转换为 safetensors 时,用户在 Google Colaboratory 上因 RAM 限制而遇到障碍;建议转向资源充足的 Kaggle。
- 提升微调效率:为了缓解 Qwen2-1.5b 在低秩配置下的微调困扰,在使用 Qlora 和 Galore 等方法时,用户建议最小 rank 为 64 或 128。
- 排除 16-bit 合并故障:模型合并到 16-bit 后性能下降,引起了对 tokenizer 和 GGUF 可能存在异常的关注;成员们期待在即将发布的补丁中解决。
- 文档方面的社区努力:志愿者们开始着手改进文档,指出数据准备和 chat notebook 的使用是亟待改进的领域,并建议制作视频教程以提高用户参与度。
LLM Finetuning (Hamel + Dan) Discord
- Zoom 出故障,但博客很出彩:虽然技术问题推迟了 Zoom 会议的录制,但 Nehil 关于预算分类的博客文章因其在 prompting 中对课程概念的实际应用而受到称赞。
- 池化层难题与范围蔓延担忧:关于使用 Huggingface 等库向模型添加 pooling layers 的技术细节讨论展示了社区的协作方式,同时关于广域范围 chatbots 与局部范围接口实用性的辩论也十分激烈,理由是出于对数据隐私和安全的担忧。
- 量化的分量:社区对 Llama-recipes 的 “pure bf16” 模式以及正在进行的 optimizer quantization 研究感到兴奋,这表明了在模型效率与计算精度之间取得平衡的驱动力,包含 Kahan summation 的优化器库的分享也证明了这一点。
- 积分/额度引发的询问:社区收到了几起关于 OpenAI 等平台积分缺失或延迟的询问,并提示查看置顶评论以获取指导,同时通过集中消息来简化积分相关的讨论。
- Modal 创作者、Datasette 爱好者和聊天机器人亲密度:通过 Modal 为 Kaggle 竞赛 finetuning LLMs 的前景、Datasette 的命令行魅力,以及来自 Anthropic Claude 的以角色为中心的 AI 对话模型搅动了技术圈,强调了对集成、分析洞察和用户体验的热情。
请记得查看每条消息历史记录中的具体链接,例如 Datasette 的稳定版本、Simon Willison 的 GitHub repository 以及提到的 meetup events 以获取这些话题的更多详情。
Perplexity AI Discord
- 智能手表与传统的碰撞:一场有趣的交流引发了关于 WearOS 等智能手表与传统数字手表主导地位的讨论,其中还穿插了对 Apple 的调侃,突显了个人对可穿戴技术的偏好。
- Perplexity AI 应对技术问题:Perplexity AI 用户报告了文件上传和图像解读功能的问题,暗示可能存在停机情况。然而,关于 GPT-4o、Claude Sonnet 和 Llama 3 70B 等不同语言模型的讨论集中在它们的性能上,成员们更倾向于将 GPT-4o 视为顶级竞争者。
- Forbes 抨击 Perplexity 抄袭:关于一篇指控 Perplexity AI 抄袭内容的 Forbes 文章展开了辩论,说明了在 AI 快速发展的时代,道德实践如履薄冰。该话题强调了在 AI 领域问责制和正确归因的重要性。Forbes 关于 Perplexity 愤世嫉俗盗窃的文章
- AI 伦理与行业进展快照:针对 Nightshade 技术及其在破坏 AI 模型方面的潜在滥用,人们提出了伦理担忧;与此同时,Perplexity AI 因其相较于 SearXNG 的先进功能而受到称赞。科技史上的另一个显著时刻是 ICQ 在运营 28 年后关闭,展示了通信技术不断更迭的步伐。ICQ 关闭
- API 集成步骤确认:关于 Perplexity API 的初始设置得到了确认,伴随着简单的确认“这似乎可行”,随后是指令性建议 “add API key here”,这是 API 集成的关键——证明了让数字工具运行起来的细节过程。
CUDA MODE Discord
- 加拿大市场的 GPU 淘金热:3090 GPUs 在 Kijiji Canada 上的价格已降至约 450 美元的实惠水平,激发了社区内组装机架的兴趣。
- 热量:有益的副产品:有人提出了创新的建议,例如使用 4090 GPUs 为热水浴缸供暖,将 GPU 机架视为替代热源,同时思考可持续的数据中心设计。
- 对 100% 确定性的严谨追求:一位工程师在代码中实现了 100% 的 determinism(确定性),但遇到了 loss values 达到 -inf 等问题,表明存在需要解决的潜在 Bug。
- 自定义 Matmul 实现的效率驱动:提高计算效率的努力使得自定义 matmul 达到了 cuBLAS 70% 的速度,目前正在讨论移除对 cuBLASLt 的依赖以及解决实现稳定 FP8 的困难。
- 矩阵乘法的大变革:Scalable MatMul-free Language Modeling 论文提出了一种新颖的方法,可以减少内存使用并保持 LLMs 的强大性能,引起了社区的关注和实现尝试。
HuggingFace Discord
- Whisper WebGPU 为浏览器赋能语音功能:Whisper WebGPU 实现了浏览器内快速、设备端的语音识别,支持 100 多种语言,通过本地数据处理保障用户隐私。
- 专家级金融 LLM 训练直播!:对金融感兴趣的工程师可以关注由演讲者 Mark Kim-Huang 主持的直播活动,该活动将深入探讨专家级金融 LLM 的训练见解。
- 谷歌 RecurrentGemma 9B 概览:RecurrentGemma 9B 在长序列上的表现引发了社区热议,帖子 强调了其性能。成员们热衷于探索该模型的潜力。
- 微调 Mistral 的可行融合:在这篇详细的 Medium 文章 中可以进一步探索在 Mistral 上微调模型,为处理可适配 AI 解决方案的工程师提供实用指南。
- Diffusers 将支持 SD3 - 期待值达到顶峰:SD3 的
diffusers集成让社区倍感期待,工程师们正热切等待这一高级功能的推出。 - Dalle 3 数据集提供创意储备:由多样化数据驱动的 AI 可能会从 Dalle 3 提供的 100 万张以上带标注的图像中受益,详见此 Dataset Card。
- 推荐将 Simpletuner 用于扩散模型:在讨论中,simpletuner 被推荐用于训练扩散模型,同时有警告称 diffusers examples 可能需要根据特定任务进行定制。
- 量化困境与疑问:工程师们分享了使用 quanto 和 optimum 等量化工具优化 AI 的尝试,这表明在模型部署中需要更稳健且防错的解决方案。
- Google Gemini Flash 模块 - 代码展示:AI 社区呼吁谷歌 开源 Google Gemini Flash,理由是其潜在优势和备受追捧的能力。
OpenAI Discord
Ilya Sutskaver 带来关于泛化的深刻见解:Ilya Sutskaver 在 Simons Institute 发表了一场关于泛化的精彩演讲,可在 YouTube 上搜索标题 An Observation on Generalization 观看。另外,DeepMind 的 Neel Nanda 在 YouTube 视频 Mechanistic Interpretability - NEEL NANDA (DeepMind) 中讨论了记忆与泛化的关系。
Llama 与 GPT 的对决:Llama 3 8b instruct 的性能与 GPT 3.5 进行了对比,重点介绍了 Hugging Face 上的 Llama 3 8b 免费 API。GPT-4o 的编程能力引发了关于其性能问题的辩论。
企业版:买还是不买?:尽管有增强的上下文窗口和对话连续性等优势,但对于 GPT Enterprise 层级是否物有所值,意见不一。一位用户将 Teams 版与 Enterprise 版混淆,表明对产品方案存在误解。
自力更生还是从头构建?这是个 AI 问题:成员们建议微调现有的 AI(如 Llama3 8b)或寻求开源方案,而不是针对特定领域从头构建类似 GPT 的模型。
技术问题单:成员们面临各种技术问题,包括尽管声称支持但无法将 PHP 文件上传到 Assistants Playground,以及在生成响应时出现未指明解决方案的错误信息。此外,还有人请求减少基于大量 PDF 训练的 GPT-4 助手的引用次数;他们希望在保持数据检索的同时精简引用。
Cohere Discord
Qualcomm 的 AIMET 受到批评:一位用户表达了对 Qualcomm AIMET Library 易用性的不满,称其为所遇到的“最差的库”。
Rust 通过 RIG 增强凝聚力:RIG 发布,这是一个用于构建 LLM-powered applications 的开源 Rust 库,具有模块化、人体工程学设计以及 Cohere 集成等特点。
关于 PaidTabs 在集成中使用 AI 的疑问:社区内有推测认为 PaidTabs 可能正在使用 Cohere AI 进行消息生成,重点关注的是根据其 6 月 24 日更新日志,Cohere AI 目前尚不具备音频功能。
工程师们可能会组建乐队:对话转向了分享音乐爱好,由于音乐爱好者的数量众多,有人建议可以组建一个社区乐队。
飞行模拟玩家的昂贵摇杆:成员们讨论了高级摇杆设备(如 VPC Constellation ALPHA Prime)的高昂价格,并开玩笑地将其成本与钻石进行比较。
Eleuther Discord
- Attention Hypernetworks 增强泛化能力:分享的一篇 arXiv 论文指出,Transformer 可以通过在 multi-head attention 中利用低维潜码,提高在符号瑞文标准推理矩阵(Raven Progressive Matrices)等智力任务上的组合泛化能力。
- 评估下一代 LlamaGen:LlamaGen 仓库表明,像 Llama 这样的自回归模型在图像生成方面表现出色,足以媲美 state-of-the-art 性能,并提供了详细的解释和教程。
- DPO 与自回归模型在多轮对话中的博弈:成员们讨论了 Deterministic Policy Optimization (DPO) 在多轮对话中研究不足的问题,并建议探索 Ultrafeedback 数据集和 MCTS-DPO 方法。
- 数据集与架构之争:讨论内容包括在获取用于 Large Language Model (LLM) 训练的小型代码数据集时面临的挑战,以及对 Griffin、Samba 等新型研究论文和模型在高效处理长上下文方面的批评和怀疑。
- 寻找终极预训练数据集:在寻找类似于 DeepMind LTIP 的开源数据集时,有人推荐了 DataComp dataset,认为它因拥有更丰富的 10 亿图像-文本对编译,在 CLIP 模型上的表现优于 LAION。
LM Studio Discord
- 为聊天机器人编写 Python 脚本:一位成员构思将 Python 脚本集成到 LM Studio 中,以允许聊天机器人模拟角色扮演,并被引导参考官方 LM Studio documentation 进行设置。建议添加 RecurrentGemma-9B,并附带了其 Hugging Face 页面。
- 对 LM Studio 0.2.24 故障的抱怨:用户指出了 LM Studio 0.2.24 中的严重 Bug,抱怨 Token 计数错误以及模型/GPU 利用率不稳定。一个更有趣的查询探讨了使用 OpenAI API 让机器人创建 PowerPoint 演示文稿的可行性。
- 聚焦 GPU 与模型匹配:在模型与 GPU 匹配的热烈讨论中,重点在于为 RTX 2070 寻找最快的选项,即 Mistral7b、Codestral 和 StarCoder2。建议还围绕特定代码模型(如 Codestral)、使用 Unsloth 的微调技巧以及使用 vectordb 的持久化策略展开。
- GPU 市场价格动态:成员们交流了全球 P40 显卡 的价格信息,记录了 eBay 上低至 $150 USD 的交易。进一步的评论涵盖了澳大利亚的 GPU 价格,从 RTX 3060 的 450 澳元到 RTX 4090 的 3200 澳元,揭示了稀缺性、功耗及其他考虑因素的现实情况。
- 现代 UI 预览:分享了一张 AMD ROCm 技术预览框架中“现代 UI”的快照,链接的照片因其时尚的呈现赢得了成员的赞赏。
{kind=link}
LlamaIndex Discord
- RAG 在真实世界部署中的坎坷之路:该频道的一份公告邀请大家对在企业环境中部署 Retrieval-Augmented Generation (RAG) 提供见解,Quentin 和 Shreya Shankar 正在通过访谈收集反馈。
- 通过实体去重增强 Graph RAG:频道中分享的一个教程建议通过引入实体去重和采用自定义检索方法来提高 Graph RAG 的效率,更多内容可以在完整教程中探索。
- 利用 Excel 的空间严谨性提升 RAG:一次对话强调了将 RAG 适配于 Excel 文件的挑战,指出有序的空间网格对于确保功能有效的重要性,参考推文提供了更多背景信息。
- 向量索引的烦恼与胜利:成员们讨论了多个问题,包括 S3DirectoryReader 的解密问题、Redis 索引中
MetadataFilter的失效、向量数据库中的 Markdown 格式挑战,以及在CondensePlusContextChatEngine中自定义 Prompt 的策略。 - 破解 Text-to-SQL 查询中的上下文密码:社区中的一位 AI 工程师指出 Text-to-SQL 查询中的上下文识别问题,即确定项的性质(例如 “Q” 是否指代产品名称)仍然是一个挑战,导致生成了错误的 SQL 查询。
Interconnects (Nathan Lambert) Discord
- ARC Prize 引发讨论:为开发 ARC-AGI 基准测试解决方案而新设立的 $1,000,000+ ARC Prize 引发了广泛讨论,强调了该基准测试在通过技能获取效率衡量通用智能方面的作用。尽管 ARC-AGI 具有重要意义,但业界对其明显缺乏了解的情况也令人担忧。
- 科技媒体评价褒贬不一:Kyle Wiggers 在 TechCrunch 上发表的一篇关于 AI 的文章因方法流于表面而受到批评;而对于一场涉及 AI 与人类智能关系的播客采访,反应则褒贬不一,其中一些争论点集中在遗传血统在决定智力中的作用。
- 微软获得 OpenAI 股份:一条推文揭示了微软如何利用与 Tesla 的讨论,以 OpenAI 的参与作为激励,潜在地吸引 Tesla 进入 Azure 平台,从而获得了 OpenAI 49% 的股份。
- 机器人开发与 AI 更新引发热议:讨论了 AI 工具的问题与进展:
june-chatbot遇到 NVDA API 错误,显示出稳定性问题;”SnailBot” 因反应迟缓而得名;对 LMSYS 的挫败感;以及对 Luma Labs 的 Dream Machine 新 Text-to-Video 能力的兴奋。 - AI 强化学习的发展:成员们剖析了 Apple 的一篇博客文章,分享了其涉及人工标注和合成数据的混合数据策略,并讨论了 @jsuarez5341 推文中提到的 PPO (Proximal Policy Optimization) 实现与伪代码之间的差异。同时,Tulu 2.5 的性能更新和 Nathan Lambert 对 RL 实践的探索显示了社区对当前 AI 方法论的深入研究。
Nous Research AI Discord
- 通用模型征集合作者:Manifold Research 正在寻找合作伙伴,共同开发用于多模态和控制任务的 Transformers,目标是创建一个类似于 GATO 的大规模开源模型。你可以通过 Discord 加入他们的行动,在 Github 上贡献代码,或在 Google Docs 上查看他们的预期目标。
- 智能工厂结合群聊:讨论围绕 GendelveChat 展开,该项目展示了使用 @websim_ai 为智能工厂等行业模拟的群聊 UX;同时,StabilityAI 发布了 Stable Diffusion 3 Medium 的开放权重。
- AI 进展与数据流水线提案:Apple 的 AI 受到剖析,Introducing Apple Foundation Models 重点介绍了其 3B 模型和压缩技术。Stable Diffusion 3 Medium 宣布发布,具有视觉改进和性能提升;同时,一个利用 Cat-70B 和 oobabooga 等工具处理 ShareGPT 数据的流水线被提议用于 Character Codex 项目。
- 语言模型帝国:在征求日语语言模型建议时,用户推荐了具有 API 访问权限的 Cohere Aya 和 Stability AI 模型,特别称赞了 Aya 35B 的多语言能力(包括日语)。对于更高性能的需求,Cohere Command R+ (103B) 是日语模型需求的首选。
- WorldSim 中的控制台与开源查询:最近的一次更新使得在移动端和桌面端界面编写和编辑较长的控制台提示词(prompts)更加用户友好。有人对 WorldSim 的开源状态表示好奇,但在查询的时间范围内未得到确认。
LAION Discord
Elon Musk 对阵 Apple 和 OpenAI:据报道,在 Apple 与 OpenAI 建立合作伙伴关系后,Elon Musk 对 Apple 的 Twitter 账号采取了行动,Ron Filipkowski 在 Threads.net 上的帖子强调了这一进展。
Google 的 Gemma 转向循环架构:Google 的 RecurrentGemma 9B 已发布,能够快速处理长序列,同时保持与原始 Gemma 模型相当的质量,Omar Sanseviero 对此进行了预告。
Transformer 学习面临“分布局部性”挑战:Transformer 的可学习性面临“分布局部性”(distribution locality)的限制,arXiv 上的一篇论文对此进行了探讨,指出模型在根据已知规则组合新三段论方面存在挑战。
利用 LlavaNext 专业能力修订 CC12M 数据集:CC12M 数据集利用 LlavaNext 进行了修订,生成的重新标注版本现已托管在 HuggingFace。
基于 TensorFlow 的机器学习库全球首秀:一位工程师宣布推出了他们以 TensorFlow 为核心的机器学习库,支持并行和分布式训练,并支持 Llama2 和 CLIP 等一系列模型,该项目已在 GitHub 上发布。
Modular (Mojo 🔥) Discord
Mojo 未来对 TPU 的支持:成员们讨论了如果 Google 为 MLIR 或 LLVM 提供 TPU 后端,Mojo 利用 TPU 硬件的可能性。这表明由于计划中的可扩展性,未来将支持多种架构,而无需等待官方更新。
紧跟 Modular 发布步伐:新的 Mojo 编译器版本 2024.6.1205 已发布,其引入的条件一致性(conditional conformance)获得了积极评价,同时还有关于递归 trait 约束(recursive trait bounds)能力的咨询。更新说明和详情可以在 最新的 changelog 中找到。
深入探索 Mojo 的功能与特性:将代码从 var 更改为 alias 并未带来性能提升,而过时的 Tensor 模块示例问题已得到解决,并且在最近的 Pull Request 中引入了一个成功的指针转换解决方案。
Modular 多媒体更新:Modular 在各平台上表现活跃,发布了新的 YouTube 视频以及来自其官方 Twitter 账号的推文更新。
社区讨论与资源:交流内容涵盖了从通过 VSCode 学习 Mojo 的建议(潜在资源见 Learn Mojo Programming Language),到对科技影响力人物作为现代编程评论家的反思,分享内容中重点提到了 Marques 和 Tim 的访谈。
OpenInterpreter Discord
Zep 在免费额度内缓解内存忧虑:参与者认为 Zep 是内存管理的利器,前提是使用量保持在其免费层级(free tier)限制之内。
Apple 在技术领域投放免费福利:Apple 提供某些免费服务的举动引发了讨论,成员们认为这是一个显著的竞争优势。
OpenAI API 价格亲民:关于 OpenAI API 定价的辩论出现,有提到每月费用在 $5-10 左右,强调了 OpenAI 产品对工程师的负担能力。
在 GCP 上配置高级模型:一位用户成功在他们的 GCP 账户上实现了 GPT-4o,尽管指出了高昂的成本以及在将默认模型更改为 gemini-flash 或 codestral 时遇到的困难。
OpenInterpreter 势头强劲:重点介绍了综合资源,包括 GitHub 仓库、代码 Gist 以及 uConsole 和 OpenInterpreter 视频,用户们还在集思广益,探讨可能通过 mini USB 麦克风来增强语音交互。
OpenRouter (Alex Atallah) Discord
轻松实现 LLM 自定义指标:DeepEval 允许用户平滑地集成语言模型的自定义评估指标,增强在 G-Eval、Summarization、Faithfulness 和 Hallucination 方面的能力。
透明 AI 与无审查模型:一场激烈的讨论指出用户对无审查模型(uncensored models)的兴趣日益浓厚,承认其在为各种应用提供未经过滤的 AI 响应方面的价值。
WizardLM-2 令人惊讶的低价:关于 WizardLM-2 负担能力的咨询引出了相关见解,即它可能通过使用更少的参数和战略性的 GPU 租赁来节省成本,引发了成员们对该模型效率的讨论。
自托管 vs. OpenRouter:在权衡利弊后,成员们得出结论,与 OpenRouter 等解决方案相比,自托管大语言模型 (LLMs) 只有在持续的高需求下,或者在已有硬件能力抵消成本的情况下,才具有经济意义。
用于批量推理的 GPU 租赁:公会就租用 GPU 进行批量推理(batch inference)的可行性交换了意见,涉及成本效益和效率,并建议使用 Aphrodite-engine / vllm 等工具来优化大规模计算。
OpenAccess AI Collective (axolotl) Discord
- 探索本地模型训练的边界:一位工程师测试了使用 mlx library 在本地运行 7 billion parameter 模型,并反馈称“极其缓慢,但确实能运行,笑死”,而其他人则建议尝试 llama.cpp 以获得更好的性能。另一位成员在寻求关于训练 15 亿参数的 QWEN 2 的见解,但讨论中未提供具体的性能数据。
- Runpod 令人困惑的路径持久化问题:成员们讨论了 Runpod 上的一个问题,即在将数据卷挂载到 /workspace 时,经常会导致 /workspace/axolotl 被覆盖,从而需要重新安装或重新克隆 Axolotl —— 这是开发环境配置中一个持续存在的困扰。
- 排除冗余指令:在文档频道中,有人指出模型上传过程中的“Step 2”是多余的,因为仓库是自动创建的,这表明文档可能需要更新。
- PyTorch 分布式故障:一位工程师在使用 PyTorch 的分布式启动器(distributed launcher)时遇到了 ChildFailedError,得到的建议是检查环境设置、验证配置,并可能需要增加共享内存,更多排查步骤可参考 Accelerate 文档。
- LoRA 的学习曲线:有关于利用 LoRA 将训练从补全格式(completion format)转换为指令格式(instruction format),以及在 24GB GPU 系统上合并 Mistral 7B 的 qLoRA 训练结果的咨询,这表明关于处理资源限制的讨论正在进行中。
Latent Space Discord
- 谷歌推出 RecurrentGemma 9B:谷歌的 RecurrentGemma 9B 承诺在快速处理长序列方面取得突破,拥有与 Gemma 类似的实力,并推出了基础版(base)和指令微调版(instruct-tuned)。该模型的详细信息及其与前代产品的比较可以在此处的集合中找到,底层研究见 Griffin 论文。
- 对 Alexa AI 缺陷的细致分析:Mihail Eric 揭露了 Alexa AI 失败的幕后原因,指出技术脱节和组织效率低下是创新的主要障碍,尽管拥有深厚的资源,但公开的突破却寥寥无几。详细的推文揭示了幕后的挑战,可在此处查看。
- ARC 奖项开辟 AI 基准测试新前沿:一个与 ARC 任务数据集相关的奖项旨在提升对 AI 中人类解决问题方法的理解和开发,该数据集目前包含超过 4,100 条交互历史。相关资源如视频和多个数据集已发布,并可通过此链接受邀参与。
- 谷歌发布医疗专用语言模型:谷歌的最新成员 Personal Health Large Language Model 利用可穿戴设备数据提供量身定制的健康见解,据报道其表现超越了行业专家。关于该模型能力和设计的深入信息可以在此处找到。
- 斯坦福分享关于 AI 快速演进的见解:hwchung27 在斯坦福大学的一次讲座中展示了 AI 尖端状态的宝贵见解,关注了更廉价的计算资源和 Transformer 架构增长所带来的变革性影响。观看这段富有见地的讲座并查阅配套幻灯片以获取详细叙述。
tinygrad (George Hotz) Discord
- MLPerf 上 RetinaNet 的悬赏任务:George Hotz 宣布了一项 600 美元的悬赏,用于在 MLPerf 基准测试中实现 RetinaNet,并承诺如果该贡献被 MLPerf 采纳,奖金将翻倍。查看相关的 Pull Request 请点击这里。
- 渴望高效的数据加载:工程师们对在 PyTorch 中优化数据加载(尤其是在 HPC 集群上)所耗费的时间表示担忧,并建议将 WebDataset 作为一种可行的解决方案。
- 起草 TinyGrad 的数据加载器:George Hotz 分享了 TinyGrad 数据加载器 API 的计划,其中包括加载记录、随机打乱缓冲区大小(shuffle buffer size)和批次大小(batch size)的函数,并提到了 Comma 的 “gigashuffle” 作为参考。
- TinyGrad 进化至 0.9.0:正如 GitHub Pull Request 所确认的,TinyGrad 0.9.0 版本现已在 Nix 仓库中可用,其特点是将 gpuctypes 直接包含在代码库中。
- MLPerf 基准测试与社区热议:最新的 MLPerf 结果已发布,展示了 tinybox red/green 的基准测试,同时还有媒体报道,如 Heise.de 上的一篇关于 TinyGrad 的德语文章。进一步的讨论暗示未来会有一篇博客文章将 TinyGrad 的速度与理论极限进行对比。
Mozilla AI Discord
- LLM 需要结构化输出:成员们强调了 LLM (Large Language Models) 必须具备定义的语法或 JSON Schema 才能有效地作为 Agent 使用。输出的标准化以便外部程序解析,被认为是应用层实用性的关键。
- 通过集成 Schema 简化 llamafile:关于优化
llamafile使用的讨论提出了一个两步简化流程:首先将 JSON Schema 转换为语法(grammar),然后集成该语法以供使用,并给出了一个命令示例:llamafile --grammar <(schemaify <foo.sql)。 - 共享对象的有效打包:一场关于在
llamafile发行版中包含ggml_cuda.so和ggml_rocm.so的最有效方法的架构讨论展开了,其中包括一个共享的 Bash 脚本,并提到需要针对 AMD 和 tinyblas 等不同库进行手动调整。 - Magit 作为同步解决方案:幽默地引用了一个名为 “Interview with an Emacs Enthusiast in 2023 [Colorized]” 的视频,以此为例说明 Magit(Emacs 的 Git 界面)的使用,展示了其在同步
llama.cpp等文件中的应用。 - LLM 中的 Schema 应用:对话强调了社区对应用结构化数据 Schema 以改进 LLM 输出的兴趣,这标志着工程界正趋向于增强 LLM 与下游系统的集成。
Datasette - LLM (@SimonW) Discord
- 苹果接口前景与 LORA 类似物:苹果的适配器技术被比作 LORA 层,暗示了一种用于本地模型的动态加载系统,以执行各种任务。
- 复杂的 HTML 提取:AI 工程师探索了不同的 HTML 内容提取工具,如 htmlq、shot-scraper 和
nokogiri。Simonw 强调了使用shot-scraper进行高效的 JavaScript 执行和内容提取。 - 跳过繁琐步骤,直接总结:Chrisamico 发现绕过技术性的 HTML 提取,直接将文章粘贴到 ChatGPT 中进行总结效率更高,从而省去了复杂的
curl和llm系统。 - Simon 建议使用 shot-scraper 进行抓取:Simonw 提供了关于利用
shot-scraper进行内容提取的说明,主张对于精通 JavaScript 的人来说,在过程中使用 CSS 选择器非常实用。 - 利用 Nokogiri 进行命令行学习:为了让工程师能够利用他们的命令行专业知识,Dbreunig 分享了关于将
nokogiri作为 CLI 工具使用的见解,并附带了一个解析和从 HTML 文档中提取文本的示例。
LangChain AI Discord
LangChain Postgres 困扰程序员:工程师们报告了 LangChain Postgres 文档的问题,发现包中缺少对使用至关重要的 checkpoint。文档可以在这里找到,但困惑仍在继续。
LangChain 中的 GPT-4 抱怨:一名成员反映了在 langchain_openai 中使用 GPT-4 时出现的错误;建议切换到 ChatOpenAI,因为 OpenAI 使用的是不支持新模型的旧版 API。关于 OpenAI API 的更多信息可以在这里找到。
LangServe 中的分享混乱:讨论了在 LangServe 的聊天游乐场(chat playground)中分享对话历史的困难,用户遇到的问题是“分享”按钮会导致空聊天,而不是显示预期的对话历史。该问题正在 GitHub Issue #677 中进行跟踪。
Nostrike AI 的免费代码创作:Nostrike AI 推出了一款新的免费 Python 工具,可以轻松创建 CrewAI 代码,并计划在未来支持导出 Langgraph 项目,邀请用户在 nostrike.ai 进行探索。
Rubik’s AI 招募 Beta 测试人员:Rubik’s AI 被宣传为先进的 AI 研究助手和搜索引擎,目前正在寻求 Beta 测试人员,并提供使用促销代码 RUBIX 获得 2 个月免费试用的诱惑,涵盖 GPT-4 Turbo 和 Claude 3 Opus 等模型。点击这里查看。
Torchtune Discord
Discord 通过应用增强功能:从 6 月 18 日开始,成员现在可以通过在服务器和私信中添加应用来增强其 Discord 体验。有关应用管理和服务器审核的详细信息和指导可以在 帮助中心文章 中找到,开发者可以借助 综合指南 创建自己的应用。
Torchtune 中的缓存难题:关于 Torchtune 在每个计算步骤中增加缓存内存使用的对话已经展开,社区成员正在深入探讨以了解这一性能特征。
Tokenizer 重构即将到来:一份详细说明 Tokenizer 系统重大重构的 RFC 引发了关于多模态(multimodal)功能集成和设计一致性的讨论,该 RFC 可在 GitHub 上查看并参与贡献。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI Stack Devs (Yoko Li) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
PART 2: 各频道详细摘要与链接
完整的频道细分内容已为邮件格式截断。
如果你喜欢 AInews,请分享给朋友!提前感谢!