ainews-to-be-named-2494
混合 SSM/Transformer 架构优于纯 SSM 或纯 Transformer。
NVIDIA 的 Bryan Catanzaro 重点介绍了一篇关于 Mamba 模型的新论文,研究表明将 Mamba 和 Transformer 模块混合使用,其性能优于单一架构,且最佳注意力机制占比低于 20%。Mixture-of-Agents (MoA) 架构提升了大型语言模型(LLM)的生成质量,在 AlpacaEval 2.0 上的得分为 65.1%,超过了 GPT-4 Omni 的 57.5%。LiveBench AI 基准测试用于评估推理、编程、写作和数据分析能力。仅包含 7% 注意力机制的混合模型 Mamba-2-Hybrid 在 MMLU 准确率上超越了 Transformer,从 50% 提升至 53.6%。GPT-4 在温度(temperature)设为 1 时表现更好。Qwen 72B 在 LiveBench AI 榜单上领跑开源模型。LaminiAI 的记忆微调(Memory Tuning)在 SQL 代理任务中实现了 95% 的准确率,优于指令微调。Sakana AI 实验室利用进化策略进行偏好优化。Luma Labs 的 Dream Machine 展示了先进的文本生成视频技术。MMWorld 基准测试用于评估多模态视频理解能力,而 Table-LLaVa 7B 在多模态表格任务中可与 GPT-4V 媲美。
7% 的 Transformers 就足够了。
2024年6月12日至6月13日的 AI 新闻。 我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 30 个 Discord(414 个频道,3646 条消息)。 预计节省阅读时间(按每分钟 200 字计算):404 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
今天有很多有趣的 image-to-video 和 canvas-to-math 演示在流传,但技术细节不多,所以我们转向别处,关注 NVIDIA 的 Bryan Catanzaro 提到的关于研究 Mamba 模型的高质量新论文:
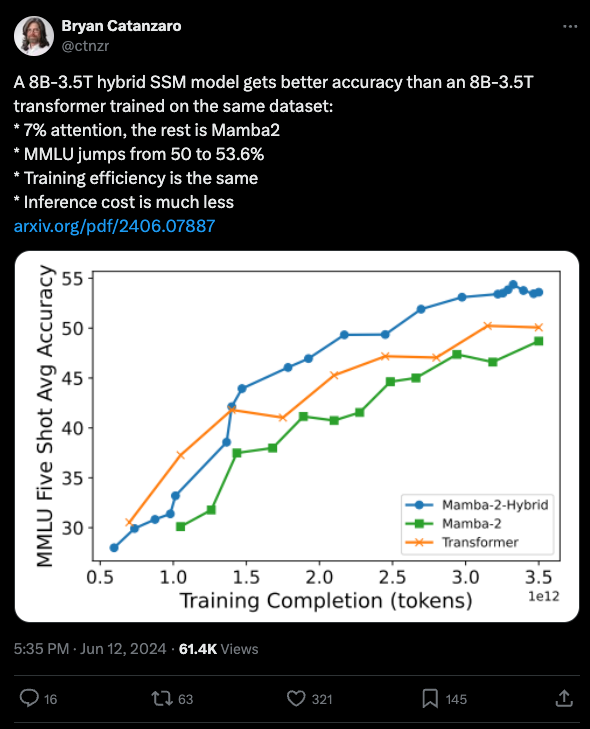
正如 Eugene Cheah 在 Latent Space Discord 中指出的,这是继 Jamba 和 Zamba 之后,第三个独立发现将 Mamba 和 Transformer 块混合使用效果优于单一架构的团队。而且该论文通过实验得出结论,Attention 的最佳比例小于 20%,远非“all you need”(你所需要的全部)。
AI 推特摘要
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在使用 Haiku 进行聚类和流程工程(flow engineering)。
LLM 能力与评估
- Mixture-of-Agents 增强 LLM 性能:@bindureddy 指出,Mixture-of-Agents (MoA) 在分层架构中使用多个 LLM 来迭代增强生成质量。使用开源 LLM 的 MoA 设置在 AlpacaEval 2.0 上得分 65.1%,而 GPT-4 Omni 为 57.5%。
- LiveBench AI 基准测试:@bindureddy 和 @ylecun 宣布了 LiveBench AI,这是一个包含无法被记忆的挑战的新 LLM 基准测试。它在推理、编码、写作和数据分析方面评估 LLM,旨在提供独立、客观的排名。
- Mamba-2-Hybrid 性能超越 Transformer:@ctnzr 分享了一个使用 7% attention 的 8B-3.5T 混合 SSM 模型,在相同数据集上获得了比 8B-3.5T Transformer 更好的准确率,MMLU 从 50% 跃升至 53.6%,同时具有相同的训练效率和更低的推理成本。
- GPT-4 在 Temperature=1 时表现更佳:@corbtt 根据他们的评估发现,即使在确定性任务上,GPT-4 在 temperature=1 时也比 temperature=0 时更“聪明”。
- Qwen 72B 领跑开源模型:@bindureddy 指出,Qwen 72B 是 LiveBench AI 上表现最好的开源模型。
LLM 训练与微调
- Memory Tuning 实现 95% 以上的准确率:@realSharonZhou 宣布了 @LaminiAI Memory Tuning,它使用多个 LLM 作为 Mixture-of-Experts (MoE) 来迭代增强基础 LLM。一家财富 500 强客户的案例研究显示,在 SQL agent 任务上准确率达到 95%,而仅靠指令微调(instruction fine-tuning)时仅为 50%。
- Sakana 的进化 LLM 优化:@andrew_n_carr 强调了 Sakana AI Lab 的工作,即使用进化策略来发现用于偏好优化(preference optimization)的新损失函数,性能超越了 DPO。
多模态与视频模型
- Luma Labs Dream Machine:@karpathy 等人注意到了 Luma Labs 新的 Dream Machine 模型令人印象深刻的文本生成视频(text-to-video)能力,该模型可以将图像扩展为视频。
- MMWorld 基准测试:@_akhaliq 介绍了 MMWorld,这是一个用于在多学科、多维度视频理解任务上评估多模态语言模型的基准测试。
- 用于多模态表格的 Table-LLaVa:@omarsar0 分享了用于多模态表格理解的 Table-LLaVa 7B 模型,该模型与 GPT-4V 具有竞争力,并在多个基准测试中超越了现有的 MLLM。
开源模型与数据集
- 用于图像标注的 LLaMA-3:@_akhaliq 和 @arankomatsuzaki 强调了一篇论文,该论文微调了 LLaVA-1.5,使用 LLaMA-3 对 DataComp-1B 数据集中的 13 亿张图像进行重新标注(recaption),展示了对训练视觉语言模型的益处。
- Stable Diffusion 3 发布:@ClementDelangue 等人注意到了 Stability AI 发布了 Stable Diffusion 3,它迅速成为 Hugging Face 上排名第一的热门模型。
- Hugging Face 收购 Argilla:@_philschmid 和 @osanseviero 宣布,数据集创建和开源贡献领域的领先公司 Argilla 正在加入 Hugging Face,以增强数据集的创建和迭代。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
Stable Diffusion 3 Medium 发布
- 资源高效型模型:在 /r/StableDiffusion 中,Stable Diffusion 3 Medium 权重已发布,这是一个拥有 2B 参数的模型,资源效率高,能够在消费级 GPU 上运行。
- 相比前代模型的改进:SD3 Medium 克服了手部和面部的常见伪影,能理解复杂的提示词,并实现了高质量的文本渲染。
- 新的许可条款:在 /r/OpenAI 中,Stability AI 宣布了 SD3 的新许可条款:非商业用途免费,有限商业用途需支付每月 20 美元的 Creator License,全面商业用途则需定制价格。
- 褒贬不一的初步反馈:首批测试者报告了不同的体验,一些人在复现结果时遇到问题,而另一些人则对 提示词遵循能力、细节丰富度以及光影/色彩给出了正面评价。
SD3 Medium 的问题与局限性
- 人体解剖结构表现不佳:在 /r/StableDiffusion 中,用户报告 SD3 Medium 在人体解剖结构方面表现挣扎,特别是在生成躺下或特定姿势的人像时。关于该模型局限性的更多细致想法在此处进一步讨论。
- 严重的审查:该模型似乎经过了 严格的审查,导致在生成裸露或暗示性内容时表现糟糕。
- 难以处理艺术风格:SD3 Medium 难以遵循艺术风格和概念,往往会生成写实风格的图像。
与其他模型的对比
- 各有优劣:SD3 Medium、SDXL 以及 Stable Cascade 和 PixArt Sigma 等其他模型的对比显示,在不同类型的图像(写实、绘画、风景、漫画艺术)中各有优劣。额外的对比图集进一步强调了这些差异。
- 在特定领域表现出色:SD3 Medium 在某些领域优于其他模型,例如生成云朵或文本,但在 人体解剖结构等其他方面表现不足。
社区反应与推测
- 对发布的失望:/r/StableDiffusion 的许多用户表达了 对 SD3 Medium 发布的失望,理由是解剖结构、审查制度以及缺乏艺术风格等问题。有些人甚至 称其为“笑话”。
- 对原因的推测:一些用户 推测表现不佳可能是由于权重适配中的 Bug 或模型架构造成的。
- 依赖微调:其他人建议 社区需要依靠微调和自定义数据集来提升 SD3 的能力,就像对待之前的模型一样。
梗图与幽默
- 调侃缺点:用户分享了 调侃 SD3 缺点的梗图和幽默图片,特别是它无法生成解剖结构正确的人体。有些人甚至 讽刺地声称该模型取得了“巨大成功”。
AI Discord 摘要
摘要之摘要的摘要
-
Stable Diffusion 3 面临审查但提供了替代方案:
- SD3 因模型质量面临批评:用户对 SD3 表示不满——强调了其解剖结构不准确和提示词(prompt)问题——而中型模型可以在 Huggingface 上下载。
- 讨论了首选界面与工具:ComfyUI 成为最受青睐的界面,并建议使用 uni_pc 和 ddim_uniform 等采样器以获得最佳性能。Juggernaut Reborn 和 Playground 等替代方案因其特定功能而受到关注。
-
提升 AI 性能与基础设施洞察:
- 更高的模型秩(Rank)提升 LLM 性能:将 Rank 从 16 提升到 128 解决了 Qwen2-1.5b 的乱码输出问题,使其输出达到 llama-3 的水准。
- Perplexity AI 的高效 LLM 使用:通过利用 NVIDIA A100 GPU、AWS p4d 实例和 TensorRT-LLM 优化实现了快速响应。
-
微调与量化方面的创新:
- 使用新模型微调 LLM:讨论涉及了使用 GPT 生成数据的法律层面,引用了 OpenAI 的商业条款。针对 ToolkenGPT 的实验展示了用于微调的合成数据的创新方法。
- CUDA 量化项目讨论:如 BiLLM 等项目展示了大模型的快速量化,这对于高效的 AI 部署至关重要。
-
模型管理与部署技术:
- 处理大型 Embedding 的策略:针对 170,000 个 Embedding 索引的咨询,建议使用 Qdrant 或 FAISS 以实现更快的检索。针对错误查询的具体修复方案已在此处分享。
- Docker 与 GPU 配置故障排除:在 WSL 上处理 Docker GPU 检测的用户通过参考官方 NVIDIA toolkit 指南找到了解决方案。
-
AI 社区趋势与更新:
- OpenAI 的营收里程碑与重心转移:OpenAI 的营收翻了一番,反映了直接来自 ChatGPT 和其他服务的销售额,而非主要由 Microsoft 促成(来源)。
- 合作伙伴关系与会议吸引社区参与:Aleph Alpha 和 Silo AI 联手推动欧洲 AI 发展(阅读更多),而 Qwak 的免费虚拟会议承诺将深入探讨 AI 机制并提供社交机会。
第一部分:高层级 Discord 摘要
Stability.ai (Stable Diffusion) Discord
SD3 坎坷的发布:用户对 Stable Diffusion 3 (SD3) 表示不满,理由是与 SDXL 和 SD1.5 相比,它存在解剖结构不准确和不遵循提示词等问题。尽管存在批评,SD3 的中型模型现在已可在 Huggingface 上下载,但需要填写表格才能访问。
首选界面与采样器:ComfyUI 是目前运行 SD3 的首选界面,用户建议不要使用 Euler 采样器。为了让 SD3 达到峰值性能,最受青睐的采样器是 uni_pc 和 ddim_uniform。
探索替代方案:频道参与者强调了 Juggernaut Reborn 和 Divinie Animemix 等替代模型和工具,分别用于实现更强的写实感或动漫风格。其他资源包括用于管理和部署模型的 Playground 和 StableSwarm。
保持讨论的相关性:在有关全球政治和个人轶事的讨论偏离了技术 AI 话题后,管理员不得不引导对话回到正轨。
大模型,大需求:SD3 的 10GB 模型被提及为社区中备受追捧的选择,这表明尽管 SD3 发布后的评价褒贬不一,但用户仍渴望更大、更强大的模型。
Unsloth AI (Daniel Han) Discord
-
通过提高 Rank 提升模型性能:将模型 Rank 从 16 增加到 128 解决了 Qwen2-1.5b 在训练期间产生乱码的问题,使输出质量与 llama-3 的训练结果保持一致。
-
scGPT 的实际应用受限:尽管 Prompting 和 Tokenizer 的实现很有趣,但 scGPT(一个用 PyTorch 编写的自定义 Transformer)被认为在学术环境之外并不实用。
-
拥抱 Unsloth 以实现高效推理:实施 Unsloth 显著降低了训练和推理过程中的内存占用,为人工智能模型提供了一个更节省内存的解决方案。
-
Mixture of Agents (MoA) 令人失望:Together AI 提出的 MoA 方法旨在分层语言模型 Agent,但因过于复杂且更像是一个展示品而非实用工具而受到批评。
-
推进 LLM 的 Docker 集成:AI 工程师建议创建命令行界面 (CLI) 工具以简化工作流,并将 Notebook 与 ZenML 等框架更好地集成,从而在实际应用中取得实质性成果。
HuggingFace Discord
SD3 革新 Stable Diffusion:Stable Diffusion 3 (SD3) 已发布并带来大量增强功能——现在配备了三个强大的文本编码器(CLIP L/14, OpenCLIP bigG/14, T5-v1.1-XXl)、一个 Multimodal Diffusion Transformer 和一个 16 通道的 AutoEncoder。SD3 实现的细节可以在 Hugging Face 博客中找到。
应对 SD3 挑战:用户在不同平台上遇到了 SD3 的困难,建议包括应用 pipe.enable_model_cpu_offload() 以加快推理速度,并确保安装了 sentencepiece 等依赖项。GPU 设置技巧包括使用 RTX 4090、采用 fp16 精度以及确保路径格式正确。
Hugging Face 家族扩展,迎来 Argilla:在一个令人兴奋的事件中,Hugging Face 将 Argilla 纳入麾下,这一举动受到了社区的欢迎,认为其有潜力推进开源 AI 计划和新的合作。
社区与支持在行动:从大学(如 Hugging Face 上新创建的 University of Glasgow 组织)到个人贡献(如 LLM 的 Google Colab 教程),成员们一直在为各种 AI 项目贡献资源并寻求支持。
通过共享资源丰富学习:成员们正在积极交流知识,重点资源包括 Google Colab 上的 LLM 设置教程、关于文本生成图像模型 MaPO 技术的拟议阅读小组讨论,以及一篇阐明 PCFGs 的 NLP 学术论文。
OpenAI Discord
-
通往 AI 专家之路:有抱负的 AI 工程师被引导至 Andrej Karpathy 的资源和 sentdex 的 YouTube 系列视频,内容关于创建深度学习聊天机器人。讨论围绕 AI 工程职业所需的知识和技能展开。
-
GPT-4.5 Turbo 推测引发辩论:一个被辩论的话题是泄露的 GPT-4.5 Turbo 提及,推测其具有 256k context window 和 2024 年 6 月的知识截止日期。这引发了对其潜在 continuous pretraining 功能的推测。
-
揭秘 ChatGPT 的存储策略:有人建议 ChatGPT 内部更好的内存管理可能涉及集体记忆总结和清理技术,以解决当前的局限性。
-
团队合作让梦想成真:分享了关于 ChatGPT Team 账户的关键点,强调了双倍的 Prompt 限制以及在不按年计费时多个团队席位的财务支出。
-
分解大数据:对于管理 300MB 文件等大量文本数据,给出了通过 chunking 和修剪以提高实用性的建议。链接了有用的工具和指南,包括一篇包含处理大型文档实用技巧的 论坛帖子 和一本关于通过 embeddings 处理长文本的 Notebook。
LLM Finetuning (Hamel + Dan) Discord
-
LLM 微调:添加新知识:AI 爱好者讨论了微调像 “Nous Hermes” 这样的 LLM 以引入新知识,尽管成本较高。关于使用 GPT 生成的数据引发了法律辩论,用户查阅了 OpenAI 的商业条款;另外还提到了 ToolkenGPT 论文 中引用的合成数据生成。
-
技术故障与建议:在 LLM 领域,用户报告了 llama-3-8b 和 mistral-7b 等模型的 preprocessing errors(预处理错误)。在实践方面,成员们交流了通过
nohup维持 SSH 连接的技巧,相关建议可参考此 SuperUser 线程。 -
备受关注的创新模型框架:模型框架引起了关注,LangChain 和 LangGraph 引发了不同的观点。glaive-function-calling-v1 的推出引发了关于模型函数执行能力的讨论。
-
Hugging Face Spaces 中的部署与展示:几位用户宣布了他们的 RAG 应用,例如使用 Gradio 构建并托管在 Hugging Face Spaces 上的 RizzCon-Answering-Machine,尽管有人指出需要提高速度。
-
积分与资源追寻仍在继续:关于 OpenPipe 等平台积分缺失以及联系人的咨询不断。未收到积分的用户分享了他们的用户名(例如 anopska-552142, as-ankursingh3-1-817d86),并提到预计在 14 号进行第二轮积分发放。
Nous Research AI Discord
-
无需人类专家的 LLM 目标发现:一篇 arXiv 论文 详细介绍了一种由模型自身驱动的 LLM 优化算法发现方法,这可以在不需要人类专家输入的情况下简化 LLM 偏好优化。该方法采用对 LLM 进行迭代提示(iterative prompting),以根据指定指标提升性能。
-
MoA 超越 GPT-4 Omni:正如一篇 Hugging Face 论文 所强调的,Mixture-of-Agents (MoA) 架构显示,结合多个 LLM 可以提升性能,在 AlpacaEval 2.0 上以 65.1% 的得分超越了 GPT-4 Omni。对于想要贡献或深入研究的 AI 爱好者,MoA 模型的实现已在 GitHub 上发布。
-
Stable Diffusion 3:初印象褒贬不一:虽然 Stable Diffusion 3 在初始发布中既获得了掌声也遭到了批评,但关于 GPT-4 在较高 temperature 设置下反而表现更好的反直觉讨论,加剧了关于模型配置的辩论。相反,一位社区成员传阅了 OpenHermes-2.5 数据集的无审查版本,而一篇关于 消除 MatMul 操作 的论文承诺将带来显著的内存节省。
-
寻找遗失的论文:社区成员正积极寻找一篇关于 预训练与指令交替 (interleaving pretraining with instructions) 的被遗忘论文,这表明社区频道内对前沿研究分享有着浓厚兴趣。
-
RAG 数据集开发持续进行:RAG 的数据集架构(schema)仍在完善中,Marker 的文档转换工具还需要进一步优化,其中设置 min_length 可能会提高处理速度。同时,Pandoc 和 make4ht 成为处理各种文档类型的可能转换方案。
-
World-sim 项目现状:尽管有讨论和未来重新考虑的潜力,World-sim 项目的闭源状态尚未改变。此外,要求让 world-sim AI 变得更大胆并将其适配到移动平台的呼声,反映了社区的前瞻性想法。
Perplexity AI Discord
-
对 Perplexity 搜索更新的热情:成员们对 Perplexity AI 最近推出的 搜索功能 (search feature) 表现出极大的兴奋,并立即表达了对 iOS 版本 的兴趣。
-
马斯克与 OpenAI 的法律战告一段落:埃隆·马斯克在法庭听证会的前一天,撤回了对 OpenAI 的诉讼。该诉讼指控 OpenAI 从使命驱动转向了利润导向,并声称其优先考虑 Microsoft 等投资者的利益 (CNBC)。
-
Perplexity AI 在大语言模型上的速度:尽管使用了大型语言模型,Perplexity.ai 仍通过利用 NVIDIA A100 GPU、AWS p4d 实例 以及 TensorRT-LLM 等软件优化,实现了快速的响应结果 (Perplexity API 介绍)。
-
Perplexity 上自定义 GPT 的困扰:工程师们正面临 Custom GPTs 的连接问题;问题似乎仅限于平台的 Web 版本,因为桌面应用程序上没有相关故障报告,这表明可能存在 API 或特定平台的复杂问题。
-
电子邮件的环境足迹:一封电子邮件平均排放约 4 克二氧化碳 (CO2);通过优先使用文件共享链接而非附件,可以减轻碳排放影响 (Mailjet 电子邮件碳足迹指南)。
CUDA MODE Discord
计算强度讨论悬而未决:一位成员询问 计算强度 (compute intensity) 的计算是否应仅考虑来自 Global Memory 数据的浮点运算。该话题仍处于讨论阶段,尚未得出结论性答案。
精简的 Triton 3.0 安装:出现了两种实用的 Triton 3.0 安装方法;一份指南详细介绍了从源码安装,而另一种方法涉及使用 make triton 并配合 PyTorch 仓库中的特定版本。
在 PyTorch 中优化优化器:社区进行了一场深入的对话,讨论如何使用 纯 PyTorch 和 torch.compile 创建快速的 8-bit 优化器,并制作一个精度可与 32-bit 媲美的无缝替换方案,灵感源自 bitsandbytes 的实现。
量化和训练动态方面的突破:BiLLM 项目 宣称能够对大语言模型进行快速量化,同时 torchao 的成员们正在辩论矩阵乘法过程中各种数值表示(从 INT8 到 FP8 甚至 INT6)在速度和精度之间的权衡。
硬件对决与量化创新:AMD 的 MI300X 在 LLM 推理方面展示了比 NVIDIA H100 更高的吞吐量。Bitnet 在重构和每日构建策略方面取得了进展,但由于一个无关的 mx 格式测试,仍存在一个悬而未决的构建问题。
LM Studio Discord
Gemini 1.5 JSON 模式的问题:工程师们报告称 Gemini 1.5 flash 在 JSON 模式 下表现不佳,导致输出出现间歇性问题。社区邀请用户分享对此挑战的见解或解决方案。
Tess 登场:Tess 2.5 72b q3 和 q4 量化模型现已在 Hugging Face 上线,为实验提供了新工具。
AVX2 指令是必需的:遇到直接 AVX2 错误的用户应验证其 CPU 是否支持 AVX2 指令,以确保与应用程序要求的兼容性。
LM Studio 的限制与解决方案:LM Studio 无法在无头 (headless) Web 服务器上运行,也不支持 safetensor 文件,但它成功采用了 GGUF 格式,并且可以通过 llama.cpp 等替代方案启用 Flash Attention。
硬件市场波动:电子报废的 P40 GPU 价格飙升,目前价格超过 200 美元;此外还有一条幽默的消息称制裁可能影响了俄罗斯的 P40 库存。一位社区成员分享了一套高效的家用服务器配置:R3700X、128GB RAM、RTX 4090 以及多种存储选项。
Eleuther Discord
-
LLAMA3 70B 展示多样化才能:LLAMA3 70B 表现出广泛的输出能力,在从空白文档进行提示时,生成了 60% 的 AI2 arc 格式、20% 的 wiki 文本和 20% 的代码,这表明其针对特定格式进行了微调。在另一个查询中,有关于使用滑动窗口技术对 BERT 进行长文本 finetuning 的指导,并指向了相关资源,如 NeurIPS 论文及其实现。
-
Samba 表现优于 Phi3-mini:Microsoft 的 Samba 模型在 3.2 万亿 token 上进行了训练,在 benchmark 中显著优于 Phi3-mini,同时保持了线性复杂度并实现了卓越的长上下文检索能力。另一场讨论深入探讨了 Samba 在 256k 序列中的 passkey retrieval,讨论了 Mamba 层和 SWA 的有效性。
-
Magpie 展露头角:新推出的 Magpie 方法提示对齐的 Large Language Models (LLMs) 自动生成高质量的指令数据,从而规避了手动数据创建。沿着这一创新前沿,另一场讨论强调了将 embedding 和 unembedding 层绑定的争议性做法,并分享了来自 LessWrong 文章 的见解。
-
辩论归一化标准:在社区内部,评估模型的指标引发了辩论,特别是对于具有相同 tokenizer 的模型,是按 token 还是按 byte 归一化准确率。分享了一个关于 Qwen1.5-7B-Chat 测试的相关日志,讨论了解决
truthfulqa_gen任务中空响应故障的方案。 -
Open Flamingo 展翅高飞:一条简短的消息将成员引向 LAION 关于 Open Flamingo 的博客文章,这可能是对其多模态模型工作的引用。
LlamaIndex Discord
GitHub 上的 TiDB AI 实验:PingCap 展示了一个使用其 TiDB 数据库与 LlamaIndex 知识图谱结合的 RAG 应用,所有内容均作为开源代码提供,并在 GitHub 上附有 demo 和 源代码。
巴黎 AI 基础设施见面会诚邀参加:工程师们可以参加在巴黎 Station F 举行的 AI Infrastructure Meetup,演讲者来自 LlamaIndex、Gokoyeb 和 Neon;详情和报名请点击此处。
快速查询的向量数据库解决方案:对于包含 170,000 个 embedding 的索引,建议使用 Qdrant 或 FAISS Index;讨论内容包括修复与 FAISS 查询相关的 AssertionError,以及使用 Chroma 从 VectorStoreIndex 直接进行节点检索。
从 Qdrant 检索相邻节点: 一位用户询问如何在 Qdrant 向量库中获取法律文本的相邻节点,建议利用节点关系和最新的 API 功能进行定向节点检索。
利用 PDF Embedding 提升 LLM-Index 能力:一位 AI 工程师讨论了使用 LLM-Index 将 PDF 和文档嵌入到 Weaviate 中,表现出对扩展向量数据库摄取复杂数据类型的兴趣。
Cohere Discord
- Command-R 登场:Coral 已更名为 Command-R,但 Command-R 和原始的 Coral 仍在运行,以促进模型相关任务。
- 调优还是不调优:在追求最佳模型性能的过程中,辩论激烈,一些工程师强调 prompt engineering 优于参数微调,而另一些人则交换了值得注意的配置。
- 解读 Cohere 的可接受使用政策:注意到大家在共同努力解读 Cohere Acceptable Use Policy 的细微差别,重点在于界定个人项目背景下私用与商用的区别。
- 测试密钥的波折:社区交流了关于 trial keys 遇到权限问题和限制的挫败感,并将这些经历与正式版密钥用户报告的更顺畅体验进行了对比。
- 向 Fluent API 支持致敬:对话中简要提到了对 Fluent API 的偏好,并对其被 Cohere 采纳表示赞赏,最近一个包含 Cohere 支持的项目发布也体现了这种祝贺基调。
LAION Discord
-
Stable Diffusion 中的性别失衡困扰:社区讨论了 Stable Diffusion 由于审查制度在生成女性图像(无论是否着装)方面存在问题,建议使用自定义 checkpoint 和基于 SD1.5 的 img2img 技术作为变通方案。点击此处查看 讨论线程。
-
Dream Machine 首次亮相:Luma AI 的 Dream Machine(一款文本转视频模型)已经发布,其潜力引发了热烈讨论,尽管用户注意到它在处理复杂 prompt 时表现不稳定。在此处查看该 模型。
-
AI 领域概览:讨论了 SD3 Large、SD3 Medium、Pixart Sigma、DALL E 3 和 Midjourney 等模型的对比,以及 /r/StableDiffusion 子版块的重新开放和 Reddit 的 API 变更。社区正密切关注这些模型和问题,该 Reddit 帖子 提供了对比。
-
模型不稳定性曝光:一项研究显示,像 GPT-4o 这样的模型在面对输入稍作修改的爱丽丝梦游仙境(Alice in Wonderland)场景时会发生剧烈崩溃,凸显了推理能力中的重大问题。详情可见 论文。
-
重新标注网页:AI 生成的嘈杂网页图像标注增强即将到来,DataComp-1B 旨在通过更好地对齐文本描述来改进模型训练。如需进一步了解,请查看 综述 和 科学论文。
LangChain AI Discord
-
追求最佳语音转文本方案:工程师们讨论了 speech-to-text 解决方案,在 AWS Transcribe、OpenAI Whisper 和 Deepgram Nova-2 等工具之外,寻找带有 MP3 和角色分离(diarization)的数据集。还强调了对鲁棒处理的需求,即在不使用工具的情况下处理简单响应,并管理流式响应(streaming responses)而不丢失上下文。
-
LangChain 连接链与状态:在 LangChain AI 中,明确讨论了在状态管理中集成用户 ID 和线程 ID,并分享了利用 LangGraph 在各种交互中简洁维护状态的技巧。对于 LangChain 内的消息相似度检查,建议结合实际用例使用字符串和 embedding 距离指标。
-
为所有人简化 LLM:展示了一个名为 tiny-ai-client 的 GitHub 项目以简化 LLM 交互,一个 YouTube 教程 展示了如何使用 Docker 和 Ollama 设置 LLM 的本地执行。同时,另一位成员分享了一个 GitHub 教程 介绍如何利用 15GB Tesla T4 GPU 在 Google Colab 上设置 LLM。
-
简化开发的代码示例与对话:在整个讨论中,引用了各种代码示例和问题来辅助排查故障并简化 LLM 开发流程,包括 聊天机器人反馈模板 等链接,以及在 LangChain 中评估现成评估器和维护问答聊天历史的方法论。
-
社区知识共享:成员们积极分享自己的作品、方法和解决问题的策略,建立了一个包含操作指南和非平凡 LangChain 场景响应的社区知识库,肯定了工程社区的协作精神。
Modular (Mojo 🔥) Discord
-
Windows 的困境与对策:工程师们讨论了 Modular (Mojo 🔥) 对 Windows 的支持,预计将在秋季发布,并期待直播更新。同时,一些人已转向使用 WSL 作为 Mojo 开发的临时解决方案。
-
Mojo 字符串的真值特性:有人指出 Mojo 中的非空字符串 被视为真值(truthy),这可能会在代码逻辑中导致意外结果。同时,可以在 Neovim 中设置 Mojo LSP,相关配置可在 GitHub 上找到。
-
优化矩阵运算:基准测试显示,在小型固定尺寸的矩阵乘法中,Mojo 的性能优于 Python,这归功于 Python 的 numpy 在此类任务中具有较高的开销。
-
循环逻辑与输入处理:Mojo 中
for循环的特殊行为导致有人建议在需要变量重新赋值的迭代中使用while循环。此外,确认了 Mojo 目前缺乏对stdin的支持。 -
Nightly 版本更新与编译器见解:Mojo 编译器版本
2024.6.1305发布,引发了关于更新程序的讨论,建议使用modular update nightly/max并考虑使用别名(aliases)来简化操作。讨论还涉及了编译器的局限性,以及 ExplicitlyCopyable trait 在避免语言中隐式复制方面的潜在益处。
Interconnects (Nathan Lambert) Discord
-
OpenAI 的间接盈利之路:OpenAI 的营收在没有微软帮助的情况下激增,在过去六个月中几乎翻了一番,主要归功于 ChatGPT 等产品的直接销售,而非依赖微软的渠道,这与行业预期相反。阅读更多。
-
AI 研究的闭环:Sakana AI 的 DiscoPOP 是一种最先进的偏好优化算法,它源于 AI 驱动的发现,预示着 LLM 可以自主改进 AI 研究方法的新时代。在其论文中探索研究结果,并通过 GitHub 仓库做出贡献。
-
硬件热潮与研究启示:随着一条 推文 的预热,人们对 Nvidia 可能即将推出的 Nemotron 充满期待;同时,Jupinder Parmar 和 Shrimai Prabhumoye 等研究人员发布了一篇探索语音建模的论文,讨论了突破性进展。
-
SSMs 仍在局中:社区对 Structured State Machines (SSMs) 的延续持 50/50 的观望态度,尽管人们更倾向于混合 SSM/Transformer 架构,因为并非每个步骤都需要 Attention 层。
-
新架构横扫基准测试:Samba 3.8B 问世,这是一种融合了 Mamba 和 Sliding Window Attention 的架构,展示了它在主要基准测试中可以显著超越 Phi3-mini 等模型,并提供具有线性复杂度的无限上下文长度。Samba 的强大性能详情见此论文。
Latent Space Discord
-
Haize Labs 挑战 AI 防护栏 (AI Guardrails):Haize Labs 发布了一份关于识别和修复 AI 故障模式的宣言,通过成功破解领先 AI 安全系统的保护机制,展示了其中的漏洞。
-
tldraw 以开源风格复刻 iPad 计算器:tldraw 团队将苹果的 iPad 计算器重构为一个开源项目,展示了他们分享创新成果的承诺。
-
亚马逊对话式 AI 失误分析:根据 cakecrusher 分享的文章中前员工的见解,对亚马逊对话式 AI 进展(或缺乏进展)的调查指出,其文化和运营流程优先考虑产品而非长期的 AI 开发。
-
OpenAI 财政业绩飙升:OpenAI 的年化收入运行率已接近 $34 亿,引发了关于此类收益影响的对话,包括可持续性和支出率。
-
Argilla 与 Hugging Face 合并以优化数据集:Argilla 已与 Hugging Face 合并,为推动 AI 数据集和内容生成的改进奠定了更好的协作基础。
OpenInterpreter Discord
-
Open Interpreter 为 LLM 赋能:Open Interpreter 被讨论作为一种将自然语言转化为直接计算机控制的手段,为未来与定制化 LLM 和增强型感官模型的集成提供了桥梁。
-
视觉与代码在实际应用中相遇:社区分享了使用 Open Interpreter 运行视觉模型代码的经验和故障排除技巧,特别关注
llama3-vision.py配置文件,以及在复杂任务中管理服务器负载的策略。 -
浏览器控制初见成效:在一个实际应用案例中,Open Interpreter 成功导航浏览器查看实时体育比分,展示了用户 Prompt 的简洁性以及对服务器需求的影响。
-
Whisper STT 的 DIY 方法:在寻找合适的 Whisper Speech-To-Text (STT) 库时,一位成员最终自己开发了一个独特的解决方案,体现了社区解决问题的精神。
-
针对峰值性能进行微调:关于微调 Open Interpreter(如修改 core.py)的讨论,突显了为应对性能和服务器负载挑战以满足用户特定需求所做的持续努力。
OpenAccess AI Collective (axolotl) Discord
-
苹果 30 亿参数模型的突破:苹果在 WWDC 上发布了一个 30 亿参数 的端侧语言模型,通过混合 2-bit 和 4-bit 配置(平均每权重 3.5 bits)的策略,实现了与未压缩模型相同的准确度。该方法优化了内存、功耗和性能;更多细节见其 研究文章。
-
Docker 化 AI 遭遇 GPU 障碍:一名工程师遇到 Docker Desktop 在 Windows 11 的 Ubuntu 虚拟机上无法识别 GPU 的问题,尽管使用了
docker run --gpus all --rm -it winglian/axolotl:main-latest等命令。建议的诊断步骤包括使用nvidia-smi检查 GPU 状态并确认 CUDA toolkit 的安装。 -
CUDA 困惑与 WSL 2 解决方案:讨论转向了应该在 Windows 还是 Ubuntu 上设置 CUDA toolkit,共识倾向于在 Ubuntu 的 WSL 2 中安装。一位用户表示打算参考官方 NVIDIA toolkit 安装指南 在 Ubuntu WSL 上配置 CUDA。
OpenRouter (Alex Atallah) Discord
OpenRouter 中的参数截断 (Param Clamping):Alex Atallah 明确指出,对于 OpenRouter,超过支持范围的参数(如 Temp > 1)会被截断(clamped)为 1;此外,尽管 UI 界面显示了 Min P 等参数,但这些参数实际上并未通过 UI 传递。
Mistral 7B 延迟之谜:用户注意到 Mistral 7B 变体的响应时间有所增加,并将其归因于上下文长度的变化和潜在的路由调整。这一观点得到了来自 API watcher 和 model uptime tracker 数据的支持。
区块链开发者求职:一位资深全栈兼区块链开发者正在寻找新机会,展示了该领域的丰富经验和积极参与的意愿。
视觉模型展望:有用户请求在 OpenRouter 中加入更多先进的视觉模型(如 cogvlm2),以增强数据集打标(captioning)能力。
tinygrad (George Hotz) Discord
- tinygrad 中的 RDNA3 汇编悬赏:George Hotz 发布了 tinygrad 中支持 RDNA3 汇编的悬赏,邀请合作者共同完成此项增强。
- 招募 Qualcomm 内核驱动开发:目前有一个开发“支持 HCQ graph 的 Qualcomm 内核级 GPU 驱动”的机会,目标对象是具备 Qualcomm 设备和 Linux 系统专业知识的工程师。
- tinygrad 移动端能力确认:已确认 tinygrad 可以在 Termux 应用中运行,展示了其对移动环境的适应性。
- 讨论:在 tinygrad 中模拟混合精度:关于在矩阵乘法期间通过 bfloat16 和 float32 之间的转换来实现混合精度的讨论表明,当与 Tensor Core 数据类型对齐时,可能会带来潜在的速度提升。
- 张量索引与 UOp 图执行查询:正在探索高效的张量索引技术(参考布尔索引),以及使用
MetalDevice和MetalCompiler进行 UOp 图执行,重点在于使用compiledRunner简化内核执行。
Datasette - LLM (@SimonW) Discord
-
AI 炒作中的现实清醒剂:dbreunig 的一篇博客指出,AI 行业主要由接地气的务实工作组成,并将当前的 LLM 工作阶段与 2019 年左右的数据科学状况进行了对比。他的文章登上了 Hacker News 首页,表明人们对超越煽情预期的务实 AI 方法有着浓厚兴趣。
-
昔日 CPU,今日 GPU:计算资源的搜索重点已从 RAM 和 Spark 容量转向 GPU 核心和 VRAM,这说明了随着 AI 发展的推进,技术需求正在发生变化。
-
LLM 部署中的 Token 经济学:Databricks 的客户数据显示,大语言模型(LLMs)的输入输出比为 9:1,这强调了输入 Token 的成本可能比输出更关键,这对运营 LLM 的机构具有经济影响。
-
聚焦务实 AI 应用:Hacker News 对 dbreunig 在 Databricks 峰会上的观察表示认可,突显了社区对 AI 技术演进和现实落地讨论的关注。
DiscoResearch Discord
- 欧洲 AI 协同:Aleph Alpha 与 Silo AI 建立了战略合作伙伴关系,旨在推动开源 AI 的前沿发展,并为欧洲量身定制企业级解决方案。此次合作结合了 Aleph Alpha 的先进技术栈和 Silo AI 强大的 300 多名 AI 专家团队,旨在加速 AI 在欧洲工业领域的部署。阅读合作详情。
Torchtune Discord
-
请大家参与投票:一位用户请求社区参与一项关于如何提供微调(finetuned)模型服务的投票,并对大家的参与表示感谢。
-
Tokenizer 正在迎来大改:一项关于全面重构 Tokenizer 的 RFC 已被提出,旨在为模型 Tokenization 提供一个功能更丰富、更具可组合性且更易用的框架,详见 GitHub 上的 Pull Request。
MLOps @Chipro Discord
- AI 爱好者的免费虚拟会议:Infer: Summer ‘24 是一场将于 6 月 26 日举行的免费虚拟会议,将汇集 AI 和 ML 专业人士,共同讨论该领域的最新动态,包括推荐系统 (recommender systems) 和 AI 在体育领域的应用。
- 行业专家集结:来自 Qwak 的解决方案架构师 Hudson Buzby 和来自 ArtifexAI 的数据科学家 Russ Wilcox 等资深专业人士将在会议上分享见解,他们代表了 Lightricks、LSports 和 Lili Banking 等公司。
- 专家实时互动:参会者将有机会与行业领袖进行实时交流,为在 ML 和 AI 领域交换实践知识和创新解决方案提供平台。
- 动手学习机会:预定的演讲将深入探讨 AI 系统的实际应用,如架构和用户参与策略,重点是构建稳健的预测技术。
- 与 AI 专业人士建立联系:鼓励参与者通过免费注册参加活动,与顶尖的 ML 和 AI 专业人士建立联系并向其学习。组织者强调,这次活动是扩大 AI 认知和行业联系的关键机会。
Mozilla AI Discord
-
不要错过 AI 开发的未来:一场关于 AI 软件开发系统如何赋能开发者 (amplify developers) 的活动即将举行。更多信息和 RSVP 请点击此处。
-
了解顶尖 ML 论文:最新的机器学习论文精选 (Machine Learning Paper Picks) 已整理完毕供您阅读,请点击此处。
-
参与 CambAI 团队的最新动态:参加即将与 CambAI 团队举行的活动,保持行业领先地位。点击此处 RSVP 参与对话。
-
领取您的 AMA 福利:参加 AMA 的成员,请记得通过公告中提供的自定义链接领取您的 0din 角色,以获取有关 T-shirts 等周边礼品 (swag) 的更新。
-
通过新标签参与精选对话:新的
member-requested标签现已上线,用于向专门策划的讨论频道投稿,体现了社区驱动的内容策划。 -
为创新者提供资金和支持:Builders Program 正在征集寻求 AI 项目支持和资金的成员,更多详情可通过链接的公告获取。
YAIG (a16z Infra) Discord
- GitHub Codespaces 使用情况调查:在 #tech-discussion 频道发起了一项调查,以统计团队中 GitHub Codespaces 的使用情况,使用 ✅ 表示“是”,❌ 表示“否”作为回复选项。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
AI Stack Devs (Yoko Li) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
第 2 部分:按频道划分的详细摘要和链接
完整的各频道详细分析已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!