ainews-to-be-named-2748
Nemotron-4-340B:英伟达(NVIDIA)推出的新型大型开放模型,基于合成数据构建,非常适合用于生成合成数据。
NVIDIA 已将其 Nemotron-4 模型从 15B 扩展到了庞大的 340B 稠密模型。该模型基于 9T token 训练,实现了与 GPT-4 相当的性能。在模型对齐过程中,超过 98% 的数据为合成数据,仅使用了约 2 万条人类标注样本 用于微调和奖励模型训练。NVIDIA 已开源其合成数据生成流水线,包括合成提示词(prompts)和偏好数据的生成。
该模型的基座版(base)和指令版(instruct)性能超越了 Mixtral 和 Llama 3,而其奖励模型的排名则优于 Gemini 1.5、Cohere 和 GPT-4o。
其他值得关注的模型还包括:Mamba-2-Hybrid 8B,其速度比 Transformer 架构快达 8 倍,且在长文本任务中表现卓越;Samba-3.8B-instruct,具有线性复杂度的“无限”上下文长度;针对低资源设备优化的 Dolphin-2.9.3 微型模型;以及拥有 200K 上下文窗口、可在 16GB 显存上高效运行的 Faro Yi 9B DPO。此外,Mixture-of-Agents(智能体混合)技术在 AlpacaEval 2.0 测试中助力开源大语言模型超越了 GPT-4 Omni。
Synthetic Data is 98% of all you need.
2024年6月13日至6月14日的 AI 新闻。 我们为您检查了 7 个 subreddits、384 个 Twitter 和 30 个 Discord(414 个频道和 2481 条消息)。 预计节省阅读时间(以 200wpm 计算):280 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
NVIDIA 已完成将 2 月发布的 Nemotron-4 15B 扩展到高达 340B 的 dense model。Philipp Schmid 总结了您需要了解的最佳要点:

来自 NVIDIA 博客、Huggingface、技术报告、Bryan Catanzaro、Oleksii Kuchaiev。
这条 Synthetic Data 流水线值得进一步研究:
值得注意的是,我们模型 alignment 过程中使用的 98% 以上的数据都是合成生成的,展示了这些模型在生成 Synthetic Data 方面的有效性。为了进一步支持开放研究并促进模型开发,我们还将模型 alignment 过程中使用的 Synthetic Data 生成流水线开源。
以及
值得注意的是,在整个 alignment 过程中,我们仅依赖约 20K 的人工标注数据(10K 用于 supervised fine-tuning,10K Helpsteer2 数据用于 reward model 训练和 preference fine-tuning),而我们的数据生成流水线合成了超过 98% 的用于 supervised fine-tuning 和 preference fine-tuning 的数据。
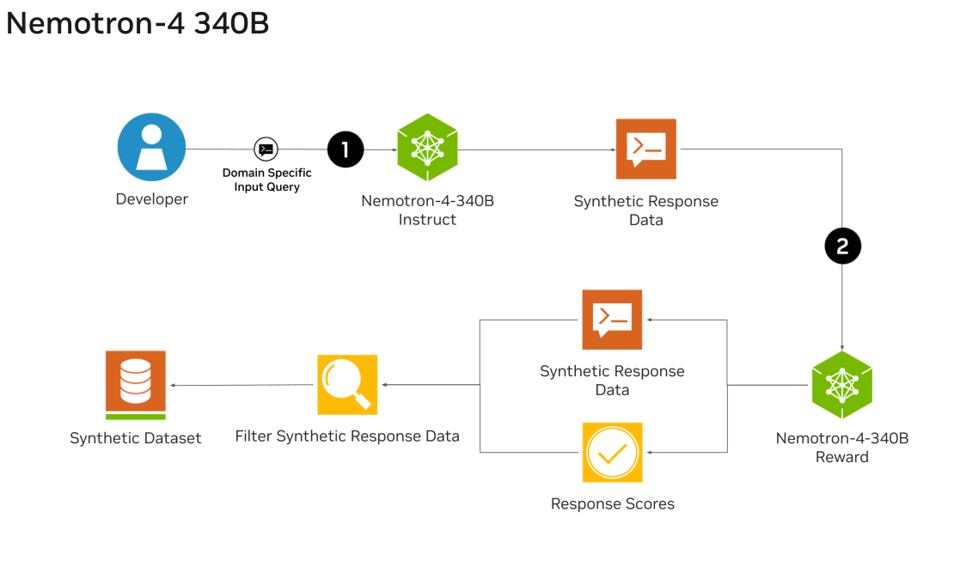
论文中的第 3.2 节提供了关于该流水线的大量精彩细节:
- 合成单轮提示词 (Synthetic single-turn prompts)
- 合成指令遵循提示词 (Synthetic instruction-following prompts)
- 合成双轮提示词 (Synthetic two-turn prompts)
- 合成对话生成 (Synthetic Dialogue Generation)
- 合成偏好数据生成 (Synthetic Preference Data Generation)
Base 和 Instruct 模型轻松击败了 Mixtral 和 Llama 3,但考虑到参数量大出半个数量级,这或许并不令人意外。然而,他们还发布了一个 Reward Model 版本,其排名优于 Gemini 1.5、Cohere 和 GPT 4o。详细披露非常有趣:

且该 RM 取代了 LLM as Judge:

AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在使用 Haiku 进行聚类和 flow engineering。
AI 模型与架构
- NVIDIA Nemotron-4-340B LLM 正式发布:@ctnzr NVIDIA 发布了 340B dense LLM,性能媲美 GPT-4。提供 Base、Reward 和 Instruct 模型。在 9T tokens 上训练而成。
- Mamba-2-Hybrid 8B 表现优于 Transformer:@rohanpaul_ai Mamba-2-Hybrid 8B 在评估任务上超过了 8B Transformer,预计推理速度快达 8 倍。 在长上下文任务中达到或超过 Transformer 水平。
- 支持无限上下文的 Samba 模型:@_philschmid Samba 结合了 Mamba、MLP、Sliding Window Attention,以线性复杂度实现无限上下文长度。 Samba-3.8B-instruct 表现优于 Phi-3-mini。
- Dolphin-2.9.3 微型模型实力不俗:@cognitivecompai Dolphin-2.9.3 0.5b 和 1.5b 模型发布,专注于 instruct 和对话。可以在智能手表或 Raspberry Pi 上运行。
- 具备 200K 上下文的 Faro Yi 9B DPO 模型:@01AI_Yi Faro Yi 9B DPO 因其仅需 16GB VRAM 即可支持 200K 上下文而受到赞誉,实现了高效 AI。
技术与架构
- Mixture-of-Agents (MoA) 提升开源 LLM:@llama_index 基于开源 LLM 的 MoA 配置 在 AlpacaEval 2.0 上超越了 GPT-4 Omni。 该方案通过堆叠多个 LLM Agent 来精炼回答。
- Lamini Memory Tuning 实现 95% 的 LLM 准确率:@realSharonZhou Lamini Memory Tuning 实现了 95% 以上的准确率,并将幻觉减少了 10 倍。 它将开源 LLM 转变为 1M-way adapter MoE。
- LoRA 微调见解:@rohanpaul_ai LoRA 微调论文发现,使用随机值初始化矩阵 A 并使用零初始化矩阵 B 通常会带来更好的性能。 这种方式允许使用更大的学习率。
- Discovered Preference Optimization (DiscoPOP):@rohanpaul_ai DiscoPOP 通过使用 LLM 来提议和评估偏好优化损失函数,其表现优于 DPO。它使用了逻辑损失(logistic loss)和指数损失(exponential loss)的自适应混合。
多模态 AI
- 用于单目深度估计的 Depth Anything V2:@_akhaliq, @arankomatsuzaki Depth Anything V2 能够生成更精细的深度预测。该模型在 59.5 万张合成标注图像和超过 6200 万张真实未标注图像上进行了训练。
- Meta 的论文《一张图片不仅仅是 16x16 的 Patch》:@arankomatsuzaki Meta 的论文显示 Transformer 可以直接处理单个像素而非 Patch,虽然成本更高,但性能更好。
- OpenVLA 开源视觉-语言-动作模型:@_akhaliq OpenVLA 是一个在机器人演示数据上预训练的 7B 开源模型。其表现优于 RT-2-X 和 Octo。该模型基于 Llama 2 + DINOv2 和 SigLIP 构建。
基准测试与数据集
- 用于 LLM 时间推理的 Test of Time 基准测试:@arankomatsuzaki Google 的 Test of Time 基准测试用于评估 LLM 的时间推理能力,包含约 5000 个测试样本。
- 用于 LLM 计算机科学掌握程度的 CS-Bench:@arankomatsuzaki CS-Bench 是一个全面的基准测试,包含约 5000 个样本,涵盖 26 个计算机科学子领域。
- 用于奖励建模的 HelpSteer2 数据集:@_akhaliq NVIDIA 的 HelpSteer2 是一个用于训练奖励模型的数据集。这是一个仅包含 1 万个回答对的高质量数据集。
- Recap-DataComp-1B 数据集:@rohanpaul_ai Recap-DataComp-1B 数据集通过使用 LLaMA-3 为 DataComp-1B 的约 13 亿张图片重新生成标题而获得。这提升了视觉-语言模型的性能。
杂项
- Scale AI 专注于贤能(merit)的招聘政策:@alexandr_wang Scale AI 正式确定了专注于贤能、卓越和才智的招聘政策。
- Paul Nakasone 加入 OpenAI 董事会:@sama Paul Nakasone 将军加入 OpenAI 董事会,因其带来的安全和保密专业知识而受到赞赏。
- Apple Intelligence 在 WWDC 上发布:@bindureddy Apple Intelligence,即 Apple 的 AI 计划,在 WWDC 上正式公布。
梗与幽默
- 模拟假设:@karpathy Andrej Karpathy 调侃了模拟假设——也许模拟是神经化的、近似的,而非精确的。
- 事后看来 Prompt Engineering 显得很蠢:@svpino Santiago Valdarrama 指出,与一年前相比,Prompt Engineering 在今天看来显得很蠢。
- Yann LeCun 谈论 Elon Musk 和火星:@ylecun Yann LeCun 调侃 Elon Musk 不戴太空头盔去火星。
AI Reddit 摘要
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
Stable Diffusion 3.0 发布及反应
- Stable Diffusion 3.0 medium 模型发布:在 /r/StableDiffusion 中,Stability AI 发布了 SD3 medium 模型,但许多人对结果感到失望,尤其是人体解剖结构方面。有些人称其与完整的 8B 模型相比简直是“一个笑话”。
- SD3 中严重的审查和“安全”过滤:/r/StableDiffusion 社区怀疑 SD3 经过了严格审查,导致人体解剖结构表现糟糕。该模型看起来“无性、平滑且像孩子一样”。
- 强大的提示词遵循度,但存在解剖结构问题:SD3 对许多主题表现出强大的提示词遵循度,但在处理人体姿势时却很吃力,例如“躺着”。一些人正在尝试级联训练 (cascade training) 以改进结果。
- T5xxl 文本编码器有助于理解提示词:一些人发现 T5xxl 文本编码器提高了 SD3 对提示词的理解,尤其是对文本的理解,但这并不能解决解剖结构问题。
- 呼吁社区训练无审查模型:有人呼吁社区团结起来训练一个无审查模型,因为对 SD3 进行微调 (fine-tuning) 不太可能完全解决这些问题。然而,这将需要大量的资源。
AI 进展与未来
- 中国崛起为科学超级大国:《经济学人》报道称 中国已成为科学超级大国,在研究产出和影响力方面取得了重大进展。
- 前 NSA 局长加入 OpenAI 董事会:OpenAI 已邀请前 NSA 局长 Paul Nakasone 加入其董事会,这引发了 /r/singularity 社区对其影响的一些担忧。
新的 AI 模型与技术
- Samba 混合架构超越 Transformer:微软推出了 Samba,一种具有无限上下文长度的混合 SSM 架构,在长程任务上表现优于 Transformer。
- Lamini Memory Tuning 减少幻觉:Lamini.ai 的 Memory Tuning 将事实嵌入到 LLM 中,将准确率提高到 95%,并将幻觉减少了 10 倍。
- Mixture of Agents (MoA) 表现优于 GPT-4:TogetherAI 的 MoA 通过利用多个 LLM 的优势,在基准测试中表现优于 GPT-4。
- WebLLM 实现浏览器内 LLM 推理:WebLLM 是一款由 WebGPU 加速的高性能浏览器内 LLM 推理引擎,支持客户端 AI 应用。
AI 硬件与基础设施
- 三星的“一站式” AI 芯片方案:三星通过集成内存、代工和封装方案,将 AI 芯片生产时间缩短了 20%。他们预计到 2028 年芯片收入将达到 7780 亿美元。
- Cerebras 晶圆级芯片在 AI 工作负载中表现出色:Cerebras 的晶圆级芯片在分子动力学模拟和稀疏 AI 推理任务上表现优于超级计算机。
- 处理 TB 级的机器学习数据:/r/MachineLearning 社区讨论了在机器学习流水线中处理 TB 级数据的方法。
梗与幽默
- Memes 嘲讽 SD3 的审查和人体构造:/r/StableDiffusion 子版块充斥着嘲讽 SD3 糟糕的人体构造和严厉内容过滤的 Memes 和笑话,并伴随着“开除实习生”的呼声。
AI Discord 摘要复盘
摘要之摘要的摘要
1. NVIDIA 通过 Nemotron-4 340B 推动性能提升:
-
NVIDIA 的 Nemotron-4-340B 模型:NVIDIA 新发布的 3400 亿参数模型包括 Instruct 和 Reward 等变体,旨在实现高效率和更广泛的语言支持,可运行在配备 8 张 GPU 且使用 FP8 精度的 DGX H100 上。
-
微调 Nemotron-4 340B 面临资源挑战,据估计需要 40 张 A100/H100 GPU,尽管推理可能需要较少的资源,大约一半的节点即可。
2. 基于 UNIX 的系统通过 ComfyUI 处理 SD3:
-
SD3 配置与性能:用户分享了在 ComfyUI 中设置 Stable Diffusion 3 的过程,包括下载文本编码器,并建议将分辨率调整为 1024x1024,以便在动漫和写实渲染中获得更好的效果。
-
针对 SD3 模型人体构造准确性的意见分歧,促使人们呼吁 Stability AI 在未来的更新中解决这些缺陷,这反映了关于社区预期与模型局限性的持续讨论。
3. 识别并解决 GPU 兼容性问题:
-
CUDA 和 Torch 运行时异常:在 Ada GPUs 上出现的
torch.matmul异常引发了对比 RTX 4090 等 GPU 的测试,结论是 CUDA 版本和基准测试会影响性能,并希望 PyTorch 团队能给出澄清。 -
在 Mojo 中建立的多线程协议有望带来性能提升。分享的见解认为,Mojo 的结构化内存处理使其从长远来看可以作为 CUDA 的可靠替代方案。
4. API 不一致性令用户沮丧:
-
Perplexity API 和服务器宕机:用户报告了频繁的服务器宕机和功能损坏(如文件上传和链接生成错误),导致持续的沮丧感,并对升级到 Perplexity Pro 的价值产生怀疑。
-
LangChain 和 pgvector 集成:尽管遵循了文档,但在识别导入(imports)时仍遇到了问题,这突显了挑战,建议仔细设置 Python 环境以确保无缝集成。
5. 社区努力与资源管理:
-
DiscoPOP 优化:Sakana AI 的方法 DiscoPOP 声称具有卓越的偏好优化能力,在承诺高性能的同时,与基础模型的偏差极小。
-
扩展训练工作:围绕处理检索增强生成(RAG)的大规模数据集的社区讨论强调了分块(chunking)、索引和查询分解,以改进模型训练并管理超过 8k tokens 的上下文长度。
第 1 部分:高层级 Discord 摘要
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion 3 Discord 机器人向全球分享:一个使用 Stable Diffusion 3 根据提示词生成图像的 Discord 机器人已开源,为用户提供了视觉内容创作的新工具。
-
微调 SDXL 以获得更好的动漫角色渲染:用于写实和动漫生成的 SDXL 训练面临挑战,产生的结果过于卡通化;建议使用 1024x1024 分辨率以改善效果。
-
引导 ComfyUI 设置 SD3:提供了在 ComfyUI 中设置 Stable Diffusion 3 的协助,涉及下载文本编码器等步骤,指南源自 Civitai 的快速入门指南。
-
社区对 SD3 人体构造准确性产生分歧:讨论集中在 SD3 明显的局限性上,特别是在人体构造渲染方面,强调了用户呼吁 Stability AI 解决并沟通这些问题的解决方案。
-
SD3 的 LoRA 层训练处于停滞状态:对话涉及为 SD3 训练新的 LoRA,指出缺乏高效的工具和工作流,用户期待未来的更新能增强功能。
CUDA MODE Discord
处理器对决:MilkV Duo vs. RK3588:工程师们对比了 MilkDuo 64MB 控制器与 RK3588 的 6.0 TOPs NPU,引发了关于硬件能力与 sophgo/tpu-mlir 编译器 优化实力的讨论。他们分享了技术细节和基准测试,引发了对 MilkDuo 性能优势实际来源的好奇。
Triton 3.0 效应:Triton 3.0 新的形状操作(shape manipulation)和解释器中的错误修复是热门话题。同时,一位用户在实现低比特(low-bit)Kernel 时遇到了 LLVM ERROR: mma16816 data type not supported 错误,这引发了关于关注 Triton GitHub repo 持续更新的建议。
PyTorch 神秘的矩阵数学:torch.matmul 的异常导致了在不同 GPU 上的基准测试,在 Ada GPU 上观察到的性能提升激发了对 PyTorch 团队提供更深层见解的渴望,正如分享的 GitHub Gist 中所强调的那样。
CUDA 使用 C++,Triton 作为替代方案:在社区内,编写高性能 CUDA Kernel 对 C/C++ 的需求得到了确认,同时强调了 Triton 由于与 PyTorch 的集成以及简化内存处理的能力,在 ML/DL 应用中的适用性日益增强。
Tensor Cores 驱动 INT8 性能:#bitnet 频道的讨论集中在利用 Tensor Cores 的 INT8 操作实现性能目标。实证反馈显示,在 A100 GPU 上,大尺寸矩阵可获得高达 7 倍的加速,但随着 Batch Size 增大,收益递减。讨论详细审视了 Tensor Cores 在各种尺寸矩阵和 Batch 操作中的性能角色,指出了 INT8 与 FP16/BF16 之间的效率差异以及 wmma 限制的影响。
Discord 讨论的线程化挑战:成员们表达了在 Discord 上追踪讨论的挑战,表示更倾向于使用论坛作为信息存储库,并提倡使用线程(threading)和回复作为在实时频道中更好管理对话的策略。
Meta 训练与推理加速器 (MTIA) 兼容性:MTIA 对 Triton 的兼容性受到关注,这标志着 AI 模型开发阶段对流线化编译过程的兴趣。
为新架构考虑 Triton:在 #torchao 频道中,torch.nn 在添加新模型方面的保守与 AO 对促进特定新架构的开放态度形成了对比,这表明了选择性的模型支持和潜在的速度提升。
编码困境与社区协作编码:协作立场显而易见,成员们讨论了改进和合并复杂的 Pull Requests (PRs)、调试和手动测试,特别是在 #llmdotc 的多 GPU 环境下。多线程对话强调了与 ZeRO-2 待集成相关的准确梯度范数(gradient norms)和权重更新条件的复杂性。
定制位运算蓝图:提议通过实时代码审查会议来揭开晦涩 PR 进展的神秘面纱,#bitnet 社区剖析了标量量化(scalar quantization)对性能的影响,揭示了在大矩阵上平均 5-6 倍的提升,以及收益对 Batch Size 的敏感性,并附带了深入研究的资源:BitBLAS 性能分析。
{kind=link}
Unsloth AI (Daniel Han) Discord
- Unsloth AI 激发 ASCII 艺术粉丝俱乐部:社区对 Unsloth 的 ASCII 艺术表现出极大的赞赏,并幽默地建议艺术形式应随着训练失败而演变。
- DiscoPOP 赢得优化粉丝:来自 Sakana AI 的新 DiscoPOP 优化器因其有效的偏好优化功能而备受关注,详见博客文章。
- 合并模型:Ollama 最新提交引发热议:Ollama 的最新提交显示了显著的支持增强,但成员们对 Triton 2.0 与难以捉摸的 3.0 版本之间不明确的改进感到困惑。
- GitHub 助力解决 Llama.cpp 困境:Llama.cpp 的安装问题正通过一个新的 GitHub PR 得到解决,并且 Python 3.9 被确认为 Unsloth 项目的最低要求。
- Gemini API 竞赛号召开发者:Gemini API 开发者竞赛邀请参与者联手、集思广益并构建项目,有意向者请访问官方竞赛页面。
LM Studio Discord
推理噪音让你烦恼?:聊天响应生成的噪音可能来自计算过程,而非聊天应用本身;用户讨论了禁用这些干扰噪音的变通方法。
自定义角色留给 Playground:成员们探讨了在 LM Studio 中集成“叙述者(Narrator)”角色的潜力,并承认当前系统不支持此功能,建议使用 Playground 模式可能是一个可行的替代方案。
哔哩哔哩的 Index-1.9B 加入战局:哔哩哔哩发布了 Index-1.9B 模型;讨论指出其在 GitHub 和 Hugging Face 上提供了聊天优化变体。同时,对话转向了由于资源需求巨大,在本地部署 340B Nemotron 模型并不切实际。
硬件故障与期待:对话围绕系统和 VRAM 使用展开,调整 ‘mlock’ 和 ‘mmap’ 参数会影响性能。对比了硬件配置建议,并强调了对 LM Studio 0.2.24 版本导致 RAM 问题的担忧。
LM Studio 跃升至 0.2.25:LM Studio 0.2.25 的发布候选版本承诺提供修复和 Linux 稳定性增强。与此同时,尽管新版本解决了一些问题,但仍有人对某些模型缺乏支持表示不满。
API 焦虑出现:一条消息指出在查询工作流时遇到了 401 invalid_api_key 问题,尽管用户多次验证了 API key,但问题依然存在。
DiscoPOP 颠覆训练规范:Sakana AI 发布的 DiscoPOP 承诺提供一种新的训练方法,并已在 Hugging Face 上可用,详见其博客文章。
OpenAI Discord
-
网络安全专家加入 OpenAI 高层:退役美国陆军上将 Paul M. Nakasone 加入 OpenAI 董事会,预计将增强 OpenAI 日益复杂的系统的网络安全措施。OpenAI 的公告赞扬了他在保护关键基础设施方面的丰富经验。阅读更多
-
支付处理混乱:工程师们报告在尝试在 OpenAI API 上处理支付时出现“请求过多”错误,支持部门建议等待几天的建议被认为不尽如人意,因为这影响了应用程序的功能。
-
API 迁移意向:在支付问题和平台特定版本(偏好 macOS 而非 Windows)的影响下,讨论转向了 OpenRouter 等替代 API,并认可由于此类中介工具的存在,迁移变得更加简单。
-
GPT-4:纠正预期:工程师们澄清 GPT-4 在训练后不会继续学习,同时对比了 Command R 和 Command R+ 各自的解谜能力,其中 Command R+ 展示了更卓越的实力。
-
DALL-E 的 Flat Shading 难题:关于在 DALL-E 中生成利用 Flat Shading(平滑着色)、无光照和阴影的图像(一种类似于基础 3D 模型纹理的技术)提出了技术咨询,询问者正在寻求实现这种特殊效果的指导。
HuggingFace Discord
-
DiscoPOP 在优化领域表现惊艳:Sakana AI 的 DiscoPOP 算法超越了 DPO 等其他算法,通过保持接近基础模型的卓越性能来提供更优的偏好优化,正如最近的 博客文章 所记录的那样。
-
像素级注意力机制备受瞩目:Meta 的研究论文 An Image is Worth More Than 16×16 Patches: Exploring Transformers on Individual Pixels 因其对像素级 Transformer 的深入研究而受到关注,进一步发展了来自 #Terminator 工作的见解,并强调了像素级注意力机制在图像处理中的有效性。
-
幻觉检测模型发布:分享了幻觉检测领域的一项更新,在 HuggingFace 上推出了一个新的微调小语言模型,在识别生成文本中的幻觉方面拥有 79% 的准确率。
-
DreamBooth 脚本需要调整以支持训练自定义:扩散模型开发中的讨论强调了修改基础 DreamBooth 脚本的必要性,以适应 SD3 等模型的预测训练中的个性化 Caption,以及针对 CLIP 和 T5 等 Tokenizer 训练的单独增强,这会增加 VRAM 需求。
-
探索双曲知识图谱(KG)嵌入技术:一篇关于双曲知识图谱嵌入的 arXiv 论文 提出了一种利用双曲几何嵌入关系数据的新方法,并提出了一种结合双曲变换和注意力机制的方法论来处理复杂的数据关系。
Nous Research AI Discord
-
Roblox 与企业幽默案例:工程师们在 VLLM GitHub 页面上发现了关于 Roblox 见面会的讨论,引发了社区内轻松愉快的调侃。
-
关于 ONNX 和 CPU 困境的讨论:来自另一个 Discord 频道的 ONNX 对话 值得关注,该对话声称 CPU 速度提升了 2 倍,但对于 GPU 上的收益仍持怀疑态度。
-
Code-to-Prompt 工具:工具 code2prompt 可以将代码库转换为 Markdown 提示词,这在 RAG 数据集中非常有价值,但会导致较高的 Token 计数。
-
突破上下文长度限制:在处理超过 8k 的上下文长度的讨论中,建议对 RAG 数据集使用 Chunking、Indexing 和查询 Decomposition 等技术,以改进模型训练和信息综合。
-
合成数据领域的新竞争者:NVIDIA 推出的 Nemotron-4-340B-Instruct 模型成为热门话题,重点讨论了其对 合成数据生成 的影响以及在 NVIDIA Open Model License 下的潜力。
-
WorldSim 提示词公开:讨论表明 worldsim prompt 已在 Twitter 上公开,并且在关于扩展模型能力的对话中,正在考虑转向使用 Sonnet 模型。
Modular (Mojo 🔥) Discord
-
Mojo 正在推进:Mojo package manager 正在开发中,这促使工程师们暂时从源码编译或使用 mojopkg 文件。对于生态系统的新手,Mojo Contributing Guide 详细介绍了开发流程,并建议从 “good first issue” 标签开始贡献。
-
GPU 与多线程讨论:Mojo 中的 GPU 支持的性能和实现引发了辩论,重点关注其强类型特性以及 Modular 如何扩展对各种加速器的支持。工程师们交流了关于多线程的见解,涉及 SIMD 优化和并行化,重点讨论了可移植性和 Modular 潜在的商业模式。
-
NSF 资金助力 AI 探索:美国的学者和教育工作者应考虑 National Science Foundation (NSF) EAGER Grants,该资助支持 National AI Research Resource (NAIRR) Pilot,提案每月进行评审。资源和社区建设倡议是 NAIRR 愿景的一部分,强调了获取计算资源和整合数据工具的重要性 (NAIRR Resource Requests)。
-
新版 Nightly Mojo 编译器发布:Mojo 编译器的新 nightly 版本(版本号
2024.6.1405)现已发布,可通过modular update进行更新。发布详情可以通过提供的 GitHub diff 和 changelog 查看。 -
资源与见面会点燃社区热情:目前有人请求提供标准的查询设置指南,建议在官方指南发布前参考 Modular 的 GitHub 方法。此外,马萨诸塞州的 Mojo 爱好者表示有兴趣举办见面会,在喝咖啡的同时讨论 Mojo,凸显了社区对知识共享和直接互动的渴望。
Perplexity AI Discord
-
Perplexity 恐慌:用户经历了 Perplexity 服务的服务器宕机,报告了重复消息和无尽循环,且没有任何官方维护公告,由于缺乏沟通导致用户感到沮丧。
-
技术问题处理:Perplexity 社区发现了几个技术问题,包括 文件上传功能损坏(归因于 AB 测试配置)以及服务生成内核链接时持续出现 404 错误。此外,还讨论了 Perplexity Android 应用与 iOS 或网页端体验不一致的问题。
-
对 Pro 服务的信心动摇:服务器和沟通问题导致用户开始质疑升级到 Perplexity Pro 的价值,对持续的服务中断表示担忧。
-
Perplexity 新闻摘要分享:成员间分享了近期头条新闻,包括 Elon Musk 法律行动的更新、对情境意识(situational awareness)的见解、阿根廷国家足球队的表现以及苹果股价飙升。
-
征集区块链爱好者:在 API 频道中,有人询问如何将 Perplexity 的 API 与 Web3 项目集成并连接到区块链端点,这表明了对去中心化应用的好奇心或潜在的项目倡议。
LlamaIndex Discord
-
由 LlamaIndex 赋能的 Atom:Atomicwork 利用 LlamaIndex 的功能来增强其 AI 助手 Atom,使其能够处理多种数据格式,从而提高数据检索和决策能力。该集成消息已在 Twitter 上发布。
-
纠正你的 ReAct 配置:在一次配置失误中,ReAct agent 的正确参数被澄清为
max_iterations而非 ‘max_iteration’,解决了其中一名成员遇到的错误。 -
Recursive Retriever 难题:在为带有 document agent 的 Recursive Retriever 从 Pinecone 向量数据库加载索引时遇到了挑战,该成员分享了用于解决问题的代码片段。
-
Weaviate 权衡多租户功能 (Multi-Tenancy):社区正在努力为 Weaviate 引入多租户功能,并在 GitHub issue 中征求关于数据隔离增强方案的反馈。
-
解锁 Agent 成就:成员们交流了多个构建自定义 agent 的学习资源,包括 LlamaIndex 文档 以及与 DeepLearning.AI 合作的短课。
LLM Finetuning (Hamel + Dan) Discord
新成员:Helix AI 加入 LLM Fine-Tuning 阵营:LLM fine-tuning 爱好者们一直在探索 Helix AI,这是一个宣传安全且私有的开源 LLM 平台,具有易扩展性,并提供闭源模型透传选项。鼓励用户尝试 Helix AI 并查看与该平台采用 FP8 inference 相关的公告推文,该技术号称能降低延迟和显存占用。
内存微调(Memory Tweaks)助力取胜:Lamini 的 memory tuning 技术引起了轰动,声称拥有 95% 的准确率并显著减少了幻觉。热衷技术的用户可以通过他们的博客文章和研究论文深入了解细节。
关于积分/额度的归属:关于 Hugging Face 和 Langsmith 等平台的积分分配出现了困惑和咨询,用户报告积分处于待处理状态并寻求帮助。提到的邮件注册和 ID 提交(如 akshay-thapliyal-153fbc)表明正在通过沟通解决这些问题。
推理优化咨询:出现了一个关于 inference endpoints 最佳设置的咨询,突显了对已部署机器学习模型性能最大化的需求。
支持工单激增:各种技术问题被反馈,从搜索按钮失效到 Python API 问题,以及从 RTX5000 GPU 上的 fine-tuning 障碍到接收 OpenAI 积分的问题。虽然提供了诸如切换到 Ampere GPU 和向特定联系人寻求帮助等解决方案,但一些用户的挫败感仍未得到解决。
Eleuther Discord
- 提升 LLM 事实准确性并控制幻觉:新公布的 Lamini Memory Tuning 声称能将事实嵌入到 Llama 3 或 Mistral 3 等 LLM 中,拥有 95% 的事实准确率,并将幻觉率从 50% 降低到 5%。
- KANs 继续征服“奇特硬件”:讨论强调,对于非常规硬件,KANs (Kriging Approximation Networks) 可能比 MLPs (Multilayer Perceptrons) 更合适,因为它们仅需要求和与非线性操作。
- LLM 也要“上学”:成员们分享了一篇论文,讨论了在处理复杂文档之前先用 QA 对训练 LLM 以提高编码能力的益处。
- PowerInfer-2 加速智能手机推理:PowerInfer-2 显著提升了 LLM 在智能手机上的推理时间,评估显示速度提升高达 29.2 倍。
- RWKV-CLIP 攀登新高度:RWKV-CLIP 模型(在图像和文本编码中均使用 RWKV)因取得 state-of-the-art 结果而获得赞誉,并附带了 GitHub 仓库和相应的研究论文引用。
OpenRouter (Alex Atallah) Discord
-
OpenRouter 托管 cogvlm2 备受关注:关于在 OpenRouter 上托管 cogvlm2 的能力存在不确定性,讨论集中在澄清其可用性并评估成本效益。
-
通过 OpenRouter 进行 Gemini Pro 审核遇到障碍:在尝试通过 OpenRouter 传递参数以控制 Google Gemini Pro 中的审核选项时,用户遇到了错误,这表明 OpenRouter 需要启用相关设置。讨论中强调了 Google 计费和访问说明。
-
对 AI Studio 极具吸引力的定价的疑问:用户询问 AI Studio 对 Gemini 1.5 Pro 和 1.5 Flash 的折扣定价是否适用于 OpenRouter,用户更倾向于 AI Studio 基于 Token 的定价,而非 Vertex 的模式。
-
NVIDIA 的开源资产激发了工程师的热情:NVIDIA 开放模型、RMs 和数据的举措引起了轰动,特别是 Nemotron-4-340B-Instruct 和 Llama3-70B 变体,Nemotron 和 Llama3 已在 Hugging Face 上可用。成员们还表示,将 PPO techniques 与这些模型结合被认为具有极高价值。
-
June-Chatbot 的神秘起源引发讨论:关于 “june-chatbot” 起源的猜测不断,一些成员将其训练与 NVIDIA 联系起来,并假设其与 70B SteerLM 模型有关,该模型在 SteerLM Hugging Face 页面 有所展示。
OpenInterpreter Discord
-
服务器运行缓慢:Discord 用户经历了严重的性能问题,服务器操作变慢,让人联想到 huggingface 免费模型出现的拥堵情况。耐心等待可能会解决问题,因为任务在漫长等待后最终会完成。
-
Llama 3 的视觉探索:一位成员询问如何为 ‘i’ 模型添加视觉功能,建议可能与自托管的 llama 3 vision profile 混合使用。然而,对于在本地文件中实现此集成所需的调整,仍然存在困惑。
-
自动化释放潜能:该频道展示了通过 分享的 YouTube 视频 演示的使用 Apple Scripts 的自动化,强调了简化脚本结合有效 prompting 以加快任务执行的潜力。
-
模型冻结频发:工程师们指出一个反复出现的技术难题,即 ‘i’ 模型在代码执行期间频繁冻结,需要通过 Ctrl-C 中断进行手动干预。
-
对硬件的渴望:Seeed Studio 发布的一款设备引起了工程师们的兴趣,特别是 Sensecap Watcher,因其作为用于空间管理的物理 AI agent 的潜力而受到关注。
Cohere Discord
-
Cohere 聊天界面获得赞誉:Cohere 的 playground chat 因其用户体验受到称赞,特别是引用功能,点击行内引用时会显示包含文本和源链接的 modal。
-
用于聊天界面开发的开源工具:开发者被引导至 GitHub 上的 cohere-toolkit 作为资源,用于创建具有引用功能的聊天界面,以及 编写有效提示词 指南,以改进使用 Cohere 的文本补全任务。
-
为 Discord Bot 创作者提供资源:对于构建 Discord bots 的用户,分享的资源包括 discord.py 文档 和 Discord Interactions JS GitHub 仓库,为 Aya model 的实现提供了基础材料。
-
对社区创新的期待:社区成员正热切期待各种构建的“大量用例和示例”,回复中表达了极具感染力的积极情绪。
-
通过项目建立社区纽带:对即将到来的社区项目展示的兴奋之情,一个简单的 “so cute 😸” 反应反映了成员之间积极且支持的环境。
LangChain AI Discord
-
RAG 链需要微调:一位用户在 Retrieval-Augmented Generation (RAG) 链的输出上遇到了困难,因为提供的代码未能产生预期的数字 “8”。用户寻求代码调整建议,希望通过过滤特定问题来提高结果准确性。
-
像专家一样构建 JSON:为了在 LangChain 中构建合适的 JSON 对象,一位工程师通过 JavaScript 和 Python 的共享示例获得了帮助。该指南旨在实现能够生成有效 JSON 输出的自定义聊天模型。
-
LangChain 与 pgvector 的集成问题:将 LangChain 连接到 pgvector 时遇到了麻烦,尽管遵循了 官方文档,用户仍无法识别导入。建议通过正确的 Python 环境设置来解决此问题。
-
混合搜索在多教程中大放异彩:社区成员分享了一个关于 使用 Llama 3 进行 RAG 混合搜索 的演示视频,并附带了 GitHub notebook 中的演练。该教程旨在提高对 RAG 应用中混合搜索的理解。
-
NLUX 让用户界面更华丽:NLUX 宣传其 LangServe 端点的便捷设置,并在文档中展示了如何引导用户使用 LangChain 和 LangServe 库将对话式 AI 集成到 React JS 应用中。该教程强调了为 AI 交互创建设计良好的用户界面的便捷性。
tinygrad (George Hotz) Discord
NVIDIA 发布 Nemotron-4 340B:分享了 NVIDIA 新的 Nemotron-4 340B 模型 —— Base、Instruct 和 Reward,号称兼容单台使用 8 个 GPU 且精度为 FP8 的 DGX H100。人们对将 Nemotron-4 340B 适配到更小的硬件配置(例如使用 3-bit quantization 部署在两台 TinyBoxes 上)表现出浓厚兴趣。
tinygrad 故障排除:成员们解决了在 tinygrad 中运行计算图的问题,其中一位寻求将结果实例化;推荐的修复方法是调用 .exec,如 GitHub 上的 abstractions2.py 中所述。其他人讨论了张量排序方法,思考了 PyTorch 的 grid_sample 替代方案,并报告了在 M2 芯片上实现混合精度时的 CompileError 问题。
追求高效的张量操作:在讨论张量排序效率时,社区指出在 tinygrad 的 k-nearest neighbors 算法实现中使用 argmax 可以获得更好的性能。此外,还有关于寻找 PyTorch 操作(如 grid_sample)等效项的对话,参考了 PyTorch 文档 以促进同行间的深入理解。
Apple M2 上的混合精度挑战:一位高级用户在尝试于 M2 芯片上集成混合精度技术时遇到了错误,这凸显了与 Metal 库的兼容性问题;这强调了在此类利基技术领域中持续进行社区驱动问题解决的必要性。
协作学习环境蓬勃发展:在整个对话过程中,协作解决问题的氛围非常浓厚,成员们分享了关于机器学习、模型部署和软件优化等各种技术挑战的知识、资源和修复方案。
Interconnects (Nathan Lambert) Discord
-
NVIDIA 的大动作:NVIDIA 发布了一个大规模语言模型 Nemotron-4-340B-Base,拥有 3400 亿参数 和 4,096 token 的上下文能力,用于 synthetic data generation,在包含多种语言和代码的 9 万亿 token 上进行训练。
-
关于 NVIDIA 新模型许可证的讨论:虽然 Nemotron-4-340B-Base 附带了 synthetic data permissive license,但人们对 NVIDIA 网站上仅提供 PDF 格式的许可证表示担忧。
-
引导 Claude 走向新方向:Claude 的实验性 Steering API 现已开放注册,提供对模型功能的有限 steering 能力,仅用于研究目的,不适用于生产部署。
-
日本崛起的 AI 之星:Sakana AI 是一家致力于寻找 Transformer 模型替代方案的日本公司,在获得知名公司 NEA、Lux 和 Khosla 的投资后,其最新估值达到 10 亿美元,详见此报告。
-
大规模的 Meritocracy 叙事:Scale 在一篇 博客文章 中揭示了其招聘理念,表明其采用系统化的方法来维持招聘质量,包括公司创始人的亲自参与。
Latent Space Discord
- 触手可及的 Apple AI 集群:根据 @mo_baioumy 的推文,Apple 用户现在可以使用他们的设备运行个人 AI 集群,这可能反映了 Apple 对其私有云的处理方式。
- 从零到 100 万美元 ARR:Lyzr 通过转向全栈 Agent 框架,在短短 40 天内实现了 100 万美元的年度经常性收入 (ARR),推出了 Jazon 和 Skott 等 Agent,重点关注 Organizational General Intelligence,正如 @theAIsailor 所强调的那样。
- Nvidia 的 Nemotron 实现高效对话:Nvidia 发布了 Nemotron-4-340B-Instruct,这是一个拥有 3400 亿参数的大语言模型 (LLM),专为基于英语的对话用例设计,并支持 4,096 的长 token。
- BigScience 的 DiLoco 和 DiPaco 登顶:在 BigScience 计划中,DiLoco 和 DiPaco 系统已成为最新的 state-of-the-art 工具包,值得注意的是 DeepMind 并没有复现它们的结果。
- 面向大众的 AI 开发:Prime Intellect 宣布打算通过 distributed training 和全球计算资源的可访问性,使 AI 开发过程民主化,迈向开放 AI 技术的集体所有权。有关其愿景和服务的详细信息可以在 Prime Intellect 官网 找到。
OpenAccess AI Collective (axolotl) Discord
-
Nemotron 的疑问与成功:有人询问了 Nemotron-4-340B-Instruct 在 quantization 后的准确性,但没有关于 quantization 后性能的后续细节。在另一项进展中,一位用户成功安装了 Nvidia toolkit 并运行了 LoRA example,并感谢社区的帮助。
-
Nemotron-4-340B 发布:Nemotron-4-340B-Instruct 模型因其多语言能力和支持 4,096 token 的扩展上下文长度而受到关注,专为 synthetic data generation 任务设计。模型资源可以在这里找到。
-
Nemotron Fine-Tuning 的资源需求:一位用户询问了 fine-tuning Nemotron 的资源需求,建议可能需要 40 张 A100/H100 (80GB) GPU。有迹象表明,inference 所需的资源可能比 fine-tuning 少,可能只需要一半的节点。
-
在 DPO 中扩展数据集预处理:建议在 DPO 中为数据集预处理加入灵活的 chat template 支持,该功能在 SFT 中已被证明是有益的。它涉及使用
conversation字段记录历史,并从单独的字段派生chosen和rejected输入。 -
Slurm 集群操作咨询:一位用户寻求关于在 Slurm cluster 上运行 Axolotl 的见解,该咨询凸显了社区对有效利用分布式计算资源的持续兴趣。对话仍对进一步的贡献开放。
LAION Discord
- Dream Machine 动画引人入胜:LumaLabsAI 开发了 Dream Machine,这是一款擅长通过动画赋予 memes 生命的工具,正如一条 推文线程 所强调的那样。
- YaFSDP 大幅削减 AI 训练成本:Yandex 推出了 YaFSDP,这是一个开源 AI 工具,承诺在 LLM 训练中减少 20% 的 GPU 使用量,从而为大型模型每月节省高达 150 万美元的潜在成本。
- PostgreSQL 扩展挑战 Pinecone:据报道,新的 PostgreSQL 扩展 pgvectorscale 性能优于 Pinecone,且成本降低了 75%,这标志着 AI 数据库正向更具成本效益的解决方案转变。
- DreamSync 推进文本生成图像技术:DreamSync 提供了一种对齐文本生成图像模型的新方法,通过消除对人工评分的需求并利用图像理解反馈来实现。
- OpenAI 任命军事专家:OpenAI 新闻稿宣布任命一名退役美国陆军上将,这一消息在频道中被分享但未提供更多背景。原始来源 已链接,但未进行详细讨论。
Datasette - LLM (@SimonW) Discord
- Datasette 成为 Hacker News 焦点:Datasette(一名成员的项目)登上了 Hacker News 首页,因其对不同观点的平衡处理而获得广泛关注和赞誉。有人开玩笑说该项目确保了数据工程师的持续就业机会。
DiscoResearch Discord
- 选择合适的德语模型:成员们讨论了在需要准确德语语法的任务中,discolm 或 occiglot 模型优于一般基准测试结果;这些模型处于 7-10b 范围内,是针对特定场景的选择。
- 更大可能更慢但更聪明:在 50-72b 范围的大型模型中,语言质量和任务性能之间的权衡可能会减弱;然而,推理速度往往会下降,因此需要在能力和效率之间取得平衡。
- 效率高于过度配置:为了获得更好的效率,建议坚持使用符合 VRAM 参数的模型(如 q4/q6),特别是考虑到大型模型的推理速度较慢。提到的相关资源是 Hugging Face 上的 Spaetzle 集合。
- 通过训练或合并实现完美平衡:进一步训练或合并模型可以作为管理非英语语言质量与指令遵循能力之间权衡的策略,这是多语言模型开发者感兴趣的话题。
- 多语言 AI 的大局观:这次讨论强调了在多语言 AI 模型的发展过程中,实现性能、语言忠实度和计算效率之间微妙平衡的持续挑战。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI Stack Devs (Yoko Li) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
Torchtune Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
PART 2: 频道详细摘要与链接
-
SD3 Discord Bot 已开源:一名成员宣布他们已经开源了一个 Stable Diffusion 3 Discord Bot。它允许用户提供 prompt 并生成图像。
-
SDXL 的 LoRA 训练问题:一位用户讨论了为动画角色训练 SDXL 的困难,意图将其用于写实和动漫风格的生成。他们注意到模型结果变得“过于卡通化/动画化”,并感谢一位成员建议使用 1024x1024 分辨率以获得更好的效果。
-
在 ComfyUI 中配置 SD3:成员们正在排查如何在 ComfyUI 中正确配置 Stable Diffusion 3,讨论了下载 text encoders 和正确配置 workflow 等设置过程。Civitai 提供的链接和快速入门指南为用户提供了指导。
-
关于 SD3 模型局限性的持续讨论:用户对 SD3 的人体解剖结构(anatomy)渲染能力表达了复杂的情绪。一位用户发表了详细说明,呼吁 Stability AI 承认并沟通解决 SD3 模型中人体解剖结构问题的计划,这成为了辩论的焦点。
-
SD3 中的 LoRA 功能:针对目前训练适用于 SD3 的新 LoRA 的现状进行了澄清。提到虽然技术上可行,但可用的工具和高效的 workflow 仍在开发中,用户可能需要等待完全兼容的更新。
- SD3 Examples: ComfyUI workflow 示例
- $UICIDEBOY$ - THE THIN GREY LINE: $UICIDEBOY$ 的 "THE THIN GREY LINE" 官方音乐视频。制作人:BUDD DWYER;导演:DILL35MM。NEW WORLD DEPRESSION 已发布:https://orcd.co/newworldd...
- LoRA Inspector | Civitai: LoRA Inspector,用于检查 LoRA 的基于 Web 的工具。全部在浏览器中完成,无需服务器。私密。不依赖 torch 或 python。
- Quickstart Guide to Stable Diffusion 3 - Civitai Education: Stable Diffusion 3 是 Stability AI 于 2024 年 6 月发布的文本生成图像模型,提供无与伦比的图像保真度!
- Stable Diffusion 3 (SD3) - SD3 Medium | Stable Diffusion Checkpoint | Civitai: Stable Diffusion 3 (SD3) 2B "Medium" 模型权重!请注意;有许多与 SD3 关联的文件。它们都将显示在此模型卡片上...
- bridge troll recordz on Instagram: "🌟 寻找你的声音,寻找你的自由 🌟 在最黑暗的时刻,当世界显得太小,阴影显得太长时,请记住:你并不孤单。我在这里,与你站在一起,是这条少有人走的路上的同路人。作为一名集体跟踪(gang stalking)的幸存者,我深知孤独的深度和对无形之物的无情追求。但今天,我站起来不仅是为了生存,更是为了茁壮成长。 💖 你的旅程,我们的使命 💖 我的使命是将我们共同的痛苦转化为光明的灯塔。建立一个社区,让我们互相扶持,分享韧性的故事,在团结中寻找慰藉。齐心协力,我们可以打破沉默和孤立的枷锁。 📚 生存资源 📚 加入我们,一起探索生存的资源、策略和故事。从法律建议到心理健康支持,让我们用应对这些挑战性环境所需的工具武装自己。因为知识就是力量,团结起来,我们将势不可挡。 🔗 #GangStalkingSurvivor #TogetherWeRise #FindYourVoice _ 让我们建立联系、分享并共同成长。关注 @brixetrollrecordz 获取每日灵感、资源,以及一个能看见你、倾听你并与你并肩作战的社区。记住,面对逆境,我们能找到力量。让我们一起寻找属于我们的力量。": 4 个点赞,0 条评论 - brixetrollrecordz 于 2024 年 6 月 13 日:"🌟 寻找你的声音,寻找你的自由 🌟 在最黑暗的时刻,当世界显得太小,阴影太长时,r..."
- My Man My Man Hd GIF - My Man My Man Hd My Man4k - 发现并分享 GIF: 点击查看 GIF
- GitHub - RocketGod-git/stable-diffusion-3-discord-bot: 一个简单的 SD3 Discord 机器人,用于提供提示词并生成图像: 一个简单的 SD3 Discord 机器人,用于提供提示词并生成图像 - RocketGod-git/stable-diffusion-3-discord-bot
- GitHub - BlafKing/sd-civitai-browser-plus: 通过 WebUI 访问 CivitAI 的扩展:下载、删除、扫描更新、列出已安装模型、分配标签,并通过多线程加速下载。: 通过 WebUI 访问 CivitAI 的扩展:下载、删除、扫描更新、列出已安装模型、分配标签,并通过多线程加速下载。 - BlafKing/sd-civitai-browser-plus
- Stable Diffusion 3 (SD3) - SD3 Medium | Stable Diffusion Checkpoint | Civitai: Stable Diffusion 3 (SD3) 2B "Medium" 模型权重!请注意;有许多与 SD3 关联的文件。它们都将出现在此模型卡片上...
CUDA MODE ▷ #general (5 messages):
- 频道已启用自动线程:机器人 Needle 宣布在指定频道中已启用自动线程。
- 评估 MilkV Duo 性能:一位成员分享了他们使用 MilkV Duo 64MB 控制器 的经验,并询问其性能优势是源于硬件还是 sophgo/tpu-mlir 编译器。他们提供了控制器 (MilkV Duo) 和编译器 (sophgo/tpu-mlir) 的链接。
- 与 RK3588 的对比:另一位成员将 MilkV Duo 的性能与 RK3588 ARM 部件 进行了对比,后者拥有 6.0 TOPs NPU 和各种高级特性。他们提供了 RK3588 规格说明的链接。
- GitHub - sophgo/tpu-mlir: 基于 MLIR 的 Sophgo TPU 机器学习编译器。: 基于 MLIR 的 Sophgo TPU 机器学习编译器。 - sophgo/tpu-mlir
- Rockchip-瑞芯微电子股份有限公司: 未找到描述
CUDA MODE ▷ #triton (8 条消息🔥):
-
Triton 3.0 特性吸引用户:一位成员询问了 Triton 3.0 的重大变化/新特性,其他人提到了有用的形状操作算子(ops),如
tl.interleave,以及修复了许多解释器(interpreter)Bug。 -
低比特 Kernel 调试困扰:一位用户在尝试实现低比特 Kernel (w4a16) 时遇到了
LLVM ERROR: mma16816 data type not supported错误。建议他们检查最新版本的 Triton,并考虑在 Triton GitHub repo 上提交 Issue。 -
FP16 x INT4 Kernel 资源:一位成员建议参考 PyTorch AO 项目中由知名贡献者编写的 FP16 x INT4 Triton kernel。他们分享了 GitHub 资源链接。
-
整数类型的转换变通方法:另一位用户针对将整数类型直接转换为
bfloat16时可能出现的问题提出了变通方法。他们建议先从int转换为float16,然后再从float16转换为bfloat16。
- Segfault in TTIR when doing convert s16->bf16 + dot · Issue #2113 · triton-lang/triton:我们创建了以下 TTIR,之前是可以正常工作的。然而,现在在 main 分支的 HEAD 版本上会出现段错误(segfault)。我们只是尝试加载 2 个参数(一个 bf16,一个 s16),并转换 s16...
- ao/torchao/prototype/hqq/mixed_mm.py at main · pytorch/ao:用于量化和稀疏化的原生 PyTorch 库 - pytorch/ao
CUDA MODE ▷ #torch (25 条消息🔥):
- MTIA 被发现兼容 Triton:一位成员提到了 Meta Training and Inference Accelerator (MTIA),指出它“非常强调 Triton 和编译优先(compile first)”。
- Torch 自动线程化激活:
<#1189607750876008468>频道中启用了自动线程化(Auto-threading)。 - GitHub Gist 揭示 torch.matmul 的奇特现象:一位成员分享了
torch.matmul的性能问题,指出在某些矩阵形状下,对矩阵进行克隆(clone)后性能会提升 2.5 倍。他们推测了 CUDA 版本和 GPU 型号等因素,但承认这是一个极其诡异的异常现象。GitHub Gist - 不同 GPU 型号和 CUDA 版本的差异性:不同成员在各种 GPU(RTX 4090, 4070Ti, RTX 3060, 3090 和 A6000 Ada)上运行了基准测试。他们发现这种性能奇特现象主要在 Ada 架构 GPU 上比较明显,有些人看到了显著的加速,而另一些人则报告在特定 CUDA 版本下性能正常。
- 呼吁 PyTorch 团队洞察性能异常:尽管进行了广泛测试,成员们仍无法确定原因,因此共同希望 PyTorch 团队能提供见解来解释这种奇怪的行为。
提到的链接:torch_matmul_clone.py:GitHub Gist:即时分享代码、笔记和代码片段。
CUDA MODE ▷ #cool-links (1 条消息):
useofusername: https://arxiv.org/abs/2106.00003
CUDA MODE ▷ #beginner (3 条消息):
- C/C++ 对高性能 CUDA Kernel 至关重要:一位成员询问编写自定义 CUDA Kernel 是否必须使用 C 或 C++,以及 Triton 是否是一个可行的替代方案。另一位成员回答说,虽然 C/C++ 提供了最佳性能,但 Triton 对于 ML/DL 应用是一个很好的选择,因为它与 PyTorch 集成良好,并且简化了共享内存(shared memory)等复杂管理。
CUDA MODE ▷ #torchao (3 条消息):
- Torch.nn 对新模型持保守态度:一位成员询问 AO 是否计划支持新架构(如 mamba/KAN),或者这些架构是否会归入 torch.nn。另一位成员澄清说,“Torch.nn 在添加新模型方面往往非常保守”,这表明 AO 乐于让特定部分变快,但其目标并不是成为一个模型库。
CUDA MODE ▷ #off-topic (10 messages🔥):
-
社区使用 Discord 的困扰:一位成员提到他们难以适应将 Discord 用于社区讨论,强调了其与论坛相比的不便。他们表达了沮丧,说道:“在 Discord 上,感觉我必须持续关注才能跟上进度。”
-
相比 Discord 更倾向于通过论坛获取信息:另一位成员提到他们主要将 Discord 用于社区互动,并表示他们通常在相关的 subreddits 浏览信息。他们指出:“Discord 更多是为了互动。”
-
Discord Threads 的最佳实践:一位成员就如何使用 threads 和回复功能使 Discord 更易于管理提供了建议。他们建议使用常规消息开启新话题,使用回复来分支对话,并为专注的讨论创建 threads,并强调这有助于 “更容易阅读有多个正在进行的对话的频道。”
CUDA MODE ▷ #llmdotc (246 messages🔥🔥):
- 新 PR 观察到的加速:一位成员报告称速度从 ~179.5K tok/s 提升至 ~180.5K tok/s,并指出 774M 模型有轻微改进(~30.0K tok/s 提升至 ~30.1K tok/s)。他们认为代码复杂度是一个潜在问题。
- 关于代码复杂度和 CUDA 的讨论:成员们讨论了合并 PR 并启用 ZeRO-2 以简化数据布局。还有建议探索 CUDA dynamic parallelism 和 tail launch,以更高效地处理小型 kernel 启动。
multi_gpu_async_reduce_gradient中的潜在 bug:成员们讨论了关于multi_gpu_async_reduce_gradient中分片大小划分的担忧,并建议添加 assert 或safe_divide辅助函数以确保正确划分。- 确定性与多 GPU 测试:成员们尝试调试多 GPU 设置中的确定性问题,重点关注梯度范数(gradient norm)计算。由于缺乏 CI 覆盖,他们还考虑建立手动多 GPU 测试。
- ZeRO-2 PR 正在进行中:目前正在努力集成 ZeRO-2,初步步骤显示梯度范数匹配,但在 Adam update 中存在问题。调试发现 ZeRO-2 中一个被忽视的权重更新条件。
- PyTorch 中的随机权重平均 (Stochastic Weight Averaging):在这篇博文中,我们介绍了最近提出的随机权重平均 (SWA) 技术 [1, 2],以及它在 torchcontrib 中的新实现。SWA 是一个简单的过程,可以提高泛化能力...
- 早期权重平均结合高学习率用于 LLM 预训练:训练大语言模型 (LLMs) 会消耗巨大成本;因此,任何能加速模型收敛的策略都是有益的。在本文中,我们研究了一个简单想法的能力,即检查点...
- 超越固定训练时长的缩放法则与计算优化训练:规模已成为获得强大机器学习模型的主要因素。因此,理解模型的缩放特性是有效设计正确训练设置的关键...
- llm.c/train_gpt2.cu at master · karpathy/llm.c:使用简单、原生的 C/CUDA 进行 LLM 训练。通过在 GitHub 上创建账号来为 karpathy/llm.c 的开发做出贡献。
- Nemotron-4 340B | Research:未找到描述
- llm.c/llmc/zero.cuh at master · karpathy/llm.c:使用简单、原生的 C/CUDA 进行 LLM 训练。通过在 GitHub 上创建账号来为 karpathy/llm.c 的开发做出贡献。
- 融合前向 GELU(再次)由 ademeure 提交 · Pull Request #591 · karpathy/llm.c:事实证明,这在带有 CUDA 12.5 的 H100 上是正确融合的(因此更快)——在带有 CUDA 12.4 的 RTX 4090 上绝对没有融合,而且实际上明显更慢,我怀疑这更多是关于...
- 数据加载器 - 引入随机性由 gordicaleksa 提交 · Pull Request #573 · karpathy/llm.c:在实现完全随机训练数据打乱的道路上... 此 PR 完成了以下工作:每个进程都有不同的唯一随机种子,每个进程的训练数据加载器独立选择其起始分片 (shard)...
- 添加导出至 HF 并运行 Eleuther 评估的脚本由 karpathy 提交 · Pull Request #594 · karpathy/llm.c:未找到描述
- 添加带有 (1-sqrt) 衰减的 wsd 调度由 eliebak 提交 · Pull Request #508 · karpathy/llm.c:添加新的学习率调度支持:WSD 学习率调度:Warmup(线性预热)、Stable(恒定学习率)、Decay(以 (1-sqrt) 形状衰减至 min_lr)。(更多信息见此处 https://ar...
- RMSNorm 内核由 AndreSlavescu 提交 · Pull Request #575 · karpathy/llm.c:未找到描述
- mdouglas/llmc-gpt2-774M-150B · Hugging Face:未找到描述
- GPT-2 (774M) 复现成功 · karpathy/llm.c · Discussion #580:我让 GPT-2 774M 模型在我的 8X A100 80GB 节点上运行了约 6 天(150B token,在 100B FineWeb 样本数据集上进行了 1.5 个 epoch),训练几小时前刚刚结束,进展顺利...
- Compiler Explorer - C++ (x86-64 gcc 14.1):int sizeof_array(char* mfu_str) { return sizeof(mfu_str); }
- 修复 MFU 打印由 gordicaleksa 提交 · Pull Request #585 · karpathy/llm.c:当运行的设备不受支持时,我们有一个 bug:会打印 "-100%"。已修复,在这种情况下打印 "n/a"。还增加了对 H100 PCIe 设备的支持...
- 整合内存由 karpathy 提交 · Pull Request #590 · karpathy/llm.c:通过删除梯度激活结构体,将最后一些内存碎片移动到前向传递中
- 数据加载器 - 引入随机性由 gordicaleksa 提交 · Pull Request #573 · karpathy/llm.c:在实现完全随机训练数据打乱的道路上... 此 PR 完成了以下工作:每个进程都有不同的唯一随机种子,每个进程的训练数据加载器独立选择其起始分片 (shard)...
- Cursor: AI 代码编辑器
- - YouTube: 未找到描述
- no title found: 未找到描述
- Nemotron 4 340B - nvidia 集合: 未找到描述
- 将 RL 重新带回 RLHF: 未找到描述
- Llama 3 微调入门(包含 16k, 32k,... 上下文): 在这个分步教程中,学习如何使用 Unsloth 轻松微调 Meta 强大的新 Llama 3 语言模型。我们涵盖了:Llama 3 8B 的概述以及...
- Daniel Han (@danielhanchen) 的推文: 看了下 NVIDIA 的 340B Nemotron LLM 1. 使用 Squared ReLU,不同于 Llama 的 SwiGLU 和 Gemma 的 GeGLU 2. "rotary_percentage" 50% 是什么?与 Phi-2 的 "partial_rotary_factor" 有关吗?3. U...
- SakanaAI/DiscoPOP-zephyr-7b-gemma · Hugging Face: 未找到描述
- The Annotated Transformer: 未找到描述
- 主页: 以 2-5 倍的速度和减少 80% 的显存微调 Llama 3, Mistral, Phi & Gemma LLMs - unslothai/unsloth
- GitHub - microsoft/Samba: "Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling" 的官方实现: microsoft/Samba 的官方实现
- Callbacks: 未找到描述
- bet0x 提交的 llama.cpp 失败问题 · Pull Request #371 · unslothai/unsloth:llama.cpp 无法为训练好的模型生成量化版本。错误:你可能需要自己编译 llama.cpp,然后再次运行。你不需要关闭此 Python 程序。Ru...
- Qwen2/examples/sft/finetune.py (main 分支) · QwenLM/Qwen2:Qwen2 是由阿里巴巴云 Qwen 团队开发的大语言模型系列。 - QwenLM/Qwen2
- GitHub: Let’s build from here:GitHub 是超过 1 亿开发者共同塑造软件未来的地方。为开源社区做贡献,管理你的 Git 仓库,像专家一样审查代码,跟踪错误和功能...
- 工作中的 LM Studio:未找到描述
- GGUF My Repo - ggml-org 提供的 Hugging Face Space:未找到描述
- 介绍 `lms` - LM Studio 的配套 CLI 工具 | LM Studio:今天,随 LM Studio 0.2.22 一起,我们发布了 lms 的第一个版本 —— LM Studio 的配套 CLI 工具。
- Nemotron 4 340B - NVIDIA 集合:未找到描述
- 华尔街之狼 Rookie Numbers GIF - 发现并分享 GIF:点击查看 GIF
- GitHub - bilibili/Index-1.9B:通过在 GitHub 上创建账号来为 bilibili/Index-1.9B 的开发做出贡献。
- IndexTeam/Index-1.9B-Chat · Hugging Face:未找到描述
- One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning:我们提出了 Generalized LoRA (GLoRA),这是一种用于通用参数高效微调任务的高级方法。作为对 Low-Rank Adaptation (LoRA) 的增强,GLoRA 采用了一个通用的 prompt 模块来优化...
- ReLoRA: High-Rank Training Through Low-Rank Updates:尽管缩放(scaling)具有主导地位和有效性,并产生了拥有数千亿参数的大型网络,但训练过度参数化模型的必要性仍然知之甚少...
- Adina Yakup (@AdeenaY8) 的推文:Huggy 头巾已为社区准备就绪!🔥 如果你想要我们的新头巾,请在帖子中回复一个 🤗,我会发给你一个!等不及看到大家戴上它们了!🥳✨🤘
- 微调与引导 - Hugging Face Diffusion 课程:未找到描述
- GitHub 上的 ViT-Slim/GLoRA:我们 CVPR'22 论文“Vision Transformer Slimming: Multi-Dimension Searching in Continuous Optimization Space”的官方代码 - Arnav0400/ViT-Slim
- Thomas Wolf (@Thom_Wolf) 的推文:你知道 bert-based-uncased 在 Hugging Face hub 上已被下载 15 亿次吗?顶尖的 AI 模型正在达到 YouTube 病毒式传播视频的播放量级别。
- 无标题:未找到描述
- SakanaAI/DiscoPOP-zephyr-7b-gemma · Hugging Face:未找到描述
- GitHub - emangamer/KAN-Stem:尝试使用 gpt4o 创建 KAN stem 训练脚本 - emangamer/KAN-Stem
- 来自 ViT-Slim/GLoRA 的 Glora 实现 · Pull Request #1835 · huggingface/peft:更多信息见 https://arxiv.org/abs/2306.07967
- peft/src/peft/tuners/glora.py · Arnav0400/peft:🤗 PEFT:最先进的参数高效微调(Parameter-Efficient Fine-Tuning)。 - Arnav0400/peft
- OpenVLA: 一个开源视觉-语言-动作模型:在互联网规模的视觉语言数据和多样化机器人演示组合上预训练的大型策略,具有改变我们教授机器人新技能方式的潜力:与其训练新的...
- QubiCSV: 一个用于协作量子比特控制的开源数据存储与可视化平台:开发用于量子比特控制的协作研究平台对于推动该领域的创新至关重要,因为它们能够实现思想、数据和实现的交流,从而实现更具影响力的...
- 低维双曲知识图谱嵌入:知识图谱 (KG) 嵌入学习实体和关系的低维表示以预测缺失的事实。KG 通常表现出层次化和逻辑模式,这些模式必须保留在...
- GitHub - neeraj1bh/openai-playground: OpenAI playground 克隆版:OpenAI playground 克隆版。通过在 GitHub 上创建账号来为 neeraj1bh/openai-playground 的开发做出贡献。
- Papertalk.io - :Unlock the Power of Research: Swiftly, Simply, Smartly:未找到描述
- Training a Perceptron on Logical Operators:机器学习领域的基本概念之一是感知机,这是一种受神经元功能启发的算法。
- GitHub - VedankPurohit/LiveRecall: Welcome to **LiveRecall**, the open-source alternative to Microsoft's Recall. LiveRecall captures snapshots of your screen and allows you to recall them using natural language queries, leveraging semantic search technology. For added security, all images are encrypted.:欢迎来到 **LiveRecall**,微软 Recall 的开源替代方案。LiveRecall 捕捉屏幕快照,并允许你利用语义搜索技术通过自然语言查询来召回它们。为了增加安全性,所有图像都经过加密。
- Shadertoy:未找到描述
- Philipp Schmid (@_philschmid) 的推文: 这就是我们所说的 Bingo 吗?🎯 "Samba = Mamba + MLP + Sliding Window Attention + 层级 MLP 堆叠。" => 具有线性复杂度的无限上下文长度 Samba-3.8B-instruct ...
- Bill Yuchen Lin 🤖 (@billyuchenlin) 的推文: 如果我们用空内容去提示像 Llama-3-Instruct 这样对齐过的 LLM 会怎样?🤔 出乎意料的是,由于其自回归特性,它会解码出相当不错的用户查询。在我们新的预印本 Magpie🐦⬛ 中,我们发现这...
- Nemotron-4 340B | Research: 未找到描述
- 前 NSA 负责人加入 OpenAI 董事会:另一位新董事会成员。
- Stable Diffusion 3 Medium - stabilityai 的 Hugging Face Space:未找到描述
- 无标题:未找到描述
- SakanaAI/DiscoPOP-zephyr-7b-gemma · Hugging Face:未找到描述
- 论文页面 - PowerInfer-2: 智能手机上的快速大语言模型推理:未找到描述
- nvidia/Nemotron-4-340B-Base · Hugging Face:未找到描述
- nvidia/Nemotron-4-340B-Instruct · Hugging Face:未找到描述
- 教父大屠杀 GIF - Godfather Massacre Sad - 发现并分享 GIF:点击查看 GIF
- 斯诺登 GIF - Snowden - 发现并分享 GIF:点击查看 GIF
- Modular: Mojo🔥 中的快速⚡ K-Means 聚类:将 Python 移植到 Mojo🔥 以实现加速 K-Means 聚类的指南:我们正在为世界构建下一代 AI 开发者平台。查看我们的最新文章:Mojo🔥 中的快速⚡ K-Means 聚类:将 Python 移植到 Mojo🔥 以实现加速 K-Means 聚类...
- Modular: 职业生涯:在 Modular,我们相信优秀的文化是创建伟大公司的关键。我们工作的三个支柱是:打造用户喜爱的产品、赋能员工以及成为一支不可思议的团队。
- Modular: 职业生涯:在 Modular,我们相信优秀的文化是创建伟大公司的关键。我们工作的三个支柱是:打造用户喜爱的产品、赋能员工以及成为一支不可思议的团队。
- Dialects - MLIR:未找到描述
- mojo/stdlib/docs/vision.md at main · modularml/mojo:Mojo 编程语言。通过在 GitHub 上创建账号为 modularml/mojo 的开发做出贡献。
- MLIR C/C++ 前端工作组:MLIR C/C++ 前端工作组,每月第一个周一,太平洋时间上午 9 点。Discord: #clangir, … 日历:如果你想被添加到 Google 日历邀请中,请发送你的 Google 账号邮箱地址...
- 未找到标题:未找到描述
- Building Agentic RAG with LlamaIndex:学习如何构建一个能够对文档进行推理并回答复杂问题的 Agent。师从 LlamaIndex 的联合创始人兼 CEO。
- Sub Question Query Engine - LlamaIndex:未找到描述
- Building a Custom Agent - LlamaIndex:未找到描述
- llama_index/llama-index-core/llama_index/core/question_gen/llm_generators.py at main · run-llama/llama_index:LlamaIndex 是适用于您的 LLM 应用程序的数据框架 - run-llama/llama_index
- llama_index/llama-index-core/llama_index/core/query_engine/sub_question_query_engine.py at 379503696e59d8b15befca7b9b21e1675db17c50 · run-llama/llama_index:LlamaIndex 是适用于您的 LLM 应用程序的数据框架 - run-llama/llama_index
- Faiss Vector Store - LlamaIndex:未找到描述
- Recursive Retriever + Document Agents - LlamaIndex:未找到描述
- [Feature Request]: Add support for multi-tenancy in weaviate · Issue #13307 · run-llama/llama_index:功能描述:在 Weaviate 中添加多租户(MT)支持。原因:Weaviate 中的 MT 需要修改架构(启用 MT)和 CRUD 操作(传递租户名称)。我们该如何更新 llamain...
- Multi-Tenancy RAG with LlamaIndex - LlamaIndex:未找到描述
- Anthropic - LlamaIndex:未找到描述
- Defining a Custom Property Graph Retriever - LlamaIndex:未找到描述
- Private GenAI Platform – Helix AI:未找到描述
- Michael Goin (@mgoin_) 的推文:很高兴 vLLM 中的 FP8 随着我们的投入变得越来越好。查看我们收集的准确、预量化的 Checkpoints!https://huggingface.co/collections/neuralmagic/fp8-llms-f...
- Introducing Lamini Memory Tuning: 95% LLM Accuracy, 10x Fewer Hallucinations | Lamini - Enterprise LLM Platform:未找到描述
- Lamini-Memory-Tuning/research-paper.pdf at main · lamini-ai/Lamini-Memory-Tuning:消除 LLM 幻觉需要重新思考泛化 - lamini-ai/Lamini-Memory-Tuning
- 寻求推理端点的最佳设置:一位成员就如何让 inference endpoints 达到最佳性能提出了疑问。他们询问是否有推荐的设置来优化性能。
- Introducing Lamini Memory Tuning: 95% LLM Accuracy, 10x Fewer Hallucinations | Lamini - Enterprise LLM Platform:未找到描述
- XNOR-Net++: Improved Binary Neural Networks:本文提出了一种改进的二进制神经网络训练算法,其中权重和激活值均为二进制数。当前技术中一个关键但相当被忽视的特性是...
- Instruction-tuned Language Models are Better Knowledge Learners: 为了让基于大语言模型 (LLM) 的助手有效适应不断变化的信息需求,必须能够通过对新数据的持续训练来更新其事实知识...
- Cognitively Inspired Energy-Based World Models: 训练世界模型的主要方法之一是在输出空间中对序列的下一个元素进行自回归预测。在自然语言处理 (NLP) 中,这表现为...
- 4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities: 目前的多模态和多任务基础模型(如 4M 或 UnifiedIO)展示了可观的前景,但在实践中,它们接受多样化输入和执行多样化任务的开箱即用能力有限...
- Understanding Hallucinations in Diffusion Models through Mode Interpolation: 通俗地说,基于扩散过程的图像生成模型经常被认为表现出“幻觉”,即训练数据中从未出现过的样本。但这些...
- Transformers meet Neural Algorithmic Reasoners: Transformers 以其简单而有效的架构彻底改变了机器学习。在来自互联网的海量文本数据集上预训练 Transformers 带来了无与伦比的泛化能力...
- An Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels: 这项工作没有引入新方法。相反,我们提出了一个有趣的发现,质疑了现代计算机视觉架构中归纳偏置——局部性(locality)的必要性。具体来说...
- RWKV-CLIP: A Robust Vision-Language Representation Learner: 对比语言-图像预训练 (CLIP) 通过使用从网站获取的图像-文本对扩展数据集,显著提高了各种视觉-语言任务的性能。本文...
- Paper page - PowerInfer-2: Fast Large Language Model Inference on a Smartphone: 未找到描述
- Lamini-Memory-Tuning/research-paper.pdf at main · lamini-ai/Lamini-Memory-Tuning: 消除 LLM 幻觉需要重新思考泛化 - lamini-ai/Lamini-Memory-Tuning
- 命令行参数需要后处理:一位成员询问是否可以通过命令行参数指定结果路径。他们得到的建议是可能需要进行一些后处理。
- GitHub - cohere-ai/cohere-toolkit: Cohere Toolkit 是预构建组件的集合,使用户能够快速构建和部署 RAG 应用。:Cohere Toolkit 是预构建组件的集合,使用户能够快速构建和部署 RAG 应用。 - cohere-ai/cohere-toolkit
- 欢迎来到 discord.py:未找到描述
- GitHub - discord/discord-interactions-js: 用于 Discord Interactions 的 JS/Node 辅助工具:Discord Interactions 的 JS/Node 辅助工具。通过在 GitHub 上创建账号为 discord/discord-interactions-js 做出贡献。
- 编写有效的 Prompt:未找到描述
- 登录 | Cohere:Cohere 通过一个易于使用的 API 提供对先进大语言模型(LLM)和 NLP 工具的访问。免费开始使用。
- PGVector | 🦜️🔗 LangChain:使用 Postgres 作为后端并利用 pgvector 扩展的 LangChain 向量存储抽象实现。
- 如何创建自定义聊天模型类 | 🦜️🔗 Langchain:本指南假设你已熟悉以下概念:
- 使用 Llama 3 进行 RAG 的混合搜索:我们将了解如何为 RAG 进行混合搜索 https://github.com/githubpradeep/notebooks/blob/main/hybrid%20vector%20search.ipynb https://superlinked....
- Gumloop - 通过直观的 UI 构建 AI-native 工作流自动化:Gumloop 是一个用于构建强大 AI 自动化的无代码平台。Gumloop 成立于 2023 年,旨在让任何人都能利用 AI 自动化复杂的工作,而无需...
- 开始使用 NLUX 和 LangChain LangServe | NLUX:LangChain 是构建由 LLM 驱动的服务和后端的流行框架。
- torch.nn.functional.grid_sample — PyTorch 2.3 documentation: 未找到描述
- tinygrad/docs/abstractions2.py at master · tinygrad/tinygrad: 你喜欢 pytorch?你喜欢 micrograd?你一定会爱上 tinygrad!❤️ - tinygrad/tinygrad
- 来自 Stephanie Palazzolo (@steph_palazzolo) 的推文:最新消息(与 @nmasc_ @KateClarkTweets 合作):Sakana AI,一家开发 Transformer 模型替代方案的日本初创公司,已从 NEA、Lux 和 Khosla 融资,估值达 10 亿美元。更多信息:https://www.theinform...
- nvidia/Nemotron-4-340B-Base · Hugging Face:未找到描述
- 来自 Alex Albert (@alexalbert__) 的推文:喜欢 Golden Gate Claude 吗?🌉 我们正开放实验性 Steering API 的限量访问——允许你引导 Claude 内部功能的一个子集。在此注册:https://forms.gle/T8fDp...
- nvidia/Nemotron-4-340B-Instruct · Hugging Face:未找到描述
- Siva Surendira (@theAIsailor) 的推文:我们今天突破了 100 万美元 ARR(合同额)。这是 Lyzr 从 0 到 1 的故事👇 前 400 天 - 10 万美元;最后 40 天 - 100 万美元;2024 年预测 - 600 万美元。在 2023 年 9 月,我们从 AI 数据分析器转型为 (...
- Siva Surendira (@theAIsailor) 的推文:我们今天突破了 100 万美元 ARR(合同额)。这是 Lyzr 从 0 到 1 的故事👇 前 400 天 - 10 万美元;最后 40 天 - 100 万美元;2024 年预测 - 600 万美元。在 2023 年 9 月,我们从 AI 数据分析器转型为 (...
- Mohamed Baioumy (@mo_baioumy) 的推文:本周又一项 Apple 发布:你现在可以使用 Apple 设备运行你的个人 AI 集群 @exolabs_ h/t @awnihannun
- 来自 Blaine Brown (@blizaine) 的推文:来自 @LumaLabsAI 的 Dream Machine 真的让 memes 焕发了生机!一个线程 🧵
- 来自 Blaine Brown (@blizaine) 的推文:未找到描述
- 论文页面 - Are We Done with MMLU?: 未找到描述
- Reddit - Dive into anything: 未找到描述
- Reddit - Dive into anything: 未找到描述
- Reddit - Dive into anything: 未找到描述