ainews-is-this-openq
这是……OpenQ* 吗?
DeepSeekCoder V2 承诺以极低的成本提供超越 GPT-4 Turbo 的性能。Anthropic 发布了关于奖励篡改(reward tampering)的新研究。Runway 推出了 Gen-3 Alpha 视频生成模型,作为对 Sora 的回应。一系列论文探讨了“推理时”(test-time)搜索技术,旨在利用 LLaMa-3 8B 等模型提升数学推理能力。Apple 发布了 Apple Intelligence,带来更智能的 Siri 以及图像和文档理解能力,并与 OpenAI 合作将 ChatGPT 集成到 iOS 18 中,同时发布了 20 个支持 LoRA 微调以实现专业化的新 CoreML 模型。NVIDIA 发布了 Nemotron-4 340B,这是一款性能媲美 GPT-4 的开源模型。DeepSeek-Coder-V2 在编程和数学方面表现出色,支持 338 种编程语言,上下文长度达 128K。Stability AI 发布了 Stable Diffusion 3 Medium 的权重。Luma Labs 推出了 Dream Machine,可根据文本和图像生成 5 秒钟的视频。
MCTS is all you need.
AI 新闻摘要:2024/06/14 - 2024/06/17。 我们为您查看了 7 个 subreddits、384 个 Twitters 和 30 个 Discords(414 个频道,5506 条消息)。 预计节省阅读时间(以 200wpm 计算):669 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
本周末有一系列增量发布;DeepSeekCoder V2 承诺提供超越 GPT4T 的性能(已由 aider 验证),价格仅为每百万 tokens $0.14/$0.28(相比之下 GPT4T 为 $10/$30),Anthropic 发布了一些 Reward Tampering 研究,而 Runway 终于发布了针对 Sora 的回应产品。
然而,更持久、更有实质性的内容可能是围绕 “test-time” search 的讨论:
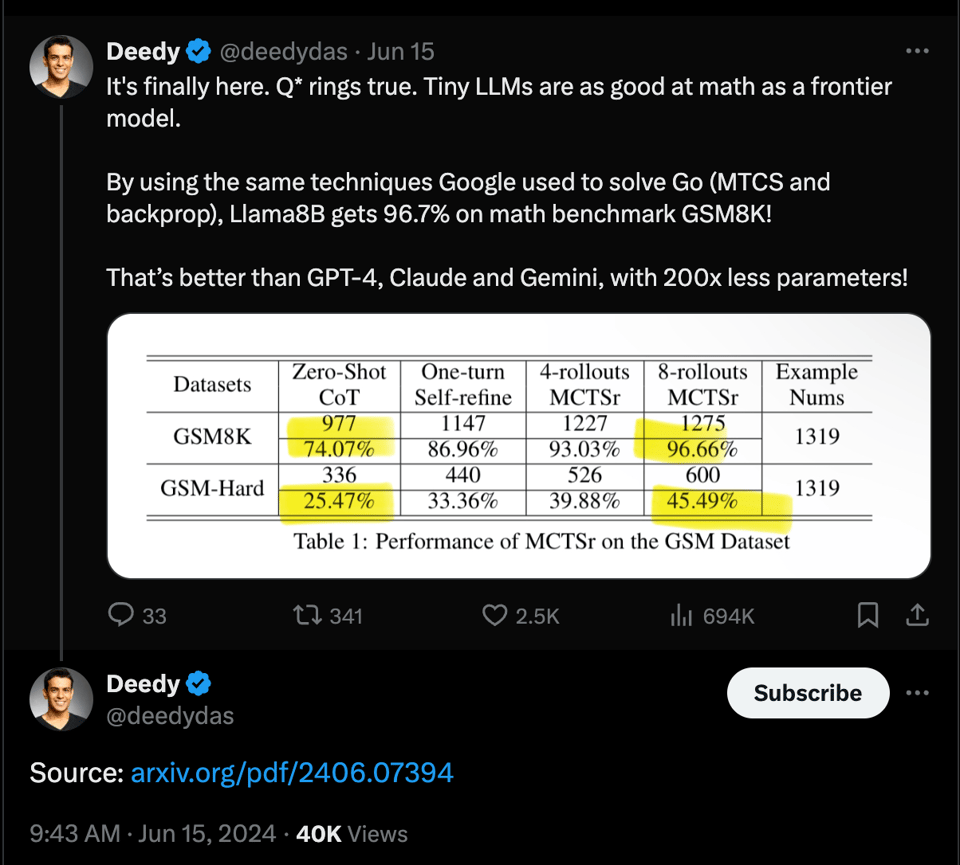
引发了一系列相关论文:
- Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B: A Technical Report
- Improve Mathematical Reasoning in Language Models by Automated Process Supervision
- AlphaMath Almost Zero: Process Supervision Without Process
- ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
坦白说,我们还没读过这些论文,但我们在 ICLR 播客中讨论过 OpenAI 关于 verifier-generator 过程监督(process supervision)的看法,并已将剩余论文列入 Latent Space Discord 论文俱乐部(Paper Club)的计划中。
AI Twitter 回顾
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
Apple 的 AI 进展与合作伙伴关系
- Apple Intelligence 发布:@adcock_brett 指出 Apple 在 WWDC 上展示了 Apple Intelligence,这是他们首个应用于 iPhone、iPad 和 Mac 的 AI 系统,具有更智能的 Siri 以及图像/文档理解等功能。
- OpenAI 合作伙伴关系:Apple 和 OpenAI 宣布达成合作,将 ChatGPT 直接集成到 iOS 18、iPadOS 18 和 macOS 中,如 @adcock_brett 所述。
- 端侧 AI 模型:@ClementDelangue 强调 Apple 在 Hugging Face 上发布了 20 个新的 CoreML 端侧 AI 模型和 4 个新数据集。
- 优化训练:据 @DeepLearningAI 报道,Apple 展示了其新模型的性能,以及它们是如何进行训练和优化的。
- 用于专业化的 LoRA 适配器:@svpino 解释了 Apple 如何使用 LoRA 微调来为不同任务生成专门的“适配器(adapters)”,并实现即时切换。
开源 LLM 达到 GPT-4 性能水平
- 来自 NVIDIA 的 Nemotron-4 340B:根据 @adcock_brett 的消息,NVIDIA 发布了 Nemotron-4 340B,这是一个性能媲美 GPT-4 (0314) 的开源模型。
- DeepSeek-Coder-V2:@deepseek_ai 推出了 DeepSeek-Coder-V2,这是一个 230B 的模型,在编程和数学方面表现出色,超越了多个其他模型。它支持 338 种编程语言和 128K 上下文长度。
- Stable Diffusion 3 Medium:@adcock_brett 提到,Stability AI 发布了其文本转图像模型 Stable Diffusion 3 Medium 的开源模型权重,提供了更先进的能力。
新的视频生成模型
- Luma Labs 的 Dream Machine:据 @adcock_brett 报道,Luma Labs 推出了 Dream Machine,这是一款新的 AI 模型,可以根据文本和图像提示生成 5 秒长的视频片段。
- Runway 的 Gen-3 Alpha:@c_valenzuelab 展示了 Runway 的新 Gen-3 Alpha 模型,该模型可以生成具有复杂场景和自定义选项的高细节视频。
- Apparate Labs 的 PROTEUS:正如 @adcock_brett 所提到的,Apparate Labs 推出了 PROTEUS,这是一款实时 AI 视频生成模型,可以从单张参考图像创建逼真的头像和口型同步。
- Google DeepMind 的 Video-to-Audio:@GoogleDeepMind 分享了其视频转音频(video-to-audio)生成技术的进展,能够为无声片段添加与场景声学和画面动作相匹配的声音。
机器人与具身智能(Embodied AI)进展
- 用于机器人的 OpenVLA:据 @adcock_brett 报道,OpenVLA 是一款新的开源 7B 参数机器人基础模型,其性能优于更大规模的闭源模型。
- DeepMind 和哈佛大学的虚拟啮齿动物:@adcock_brett 指出,DeepMind 和哈佛大学创建了一个由 AI 神经网络驱动的“虚拟啮齿动物”,模仿了现实生活中老鼠的敏捷动作和神经活动。
- Northrop Grumman 的 Manta Ray 无人机:@adcock_brett 提到 Northrop Grumman 发布了“Manta Ray”的视频,这是他们新型无人水下航行器(UUV)无人机原型。
- 利用人形机器人实现自动驾驶:据 @adcock_brett 报道,一种自动驾驶的新方法正在利用人形机器人根据传感器反馈来操作车辆控制装置。
其他 AI 研究与应用
- Anthropic 的奖励篡改研究:@AnthropicAI 发表了一篇研究奖励篡改(reward tampering)的新论文,表明 AI 模型可以学会破解自己的奖励系统。
- Meta 的 CRAG 基准测试:@dair_ai 重点介绍了 Meta 讨论纠正检索增强生成(Corrective Retrieval-Augmented Generation, CRAG)基准测试的文章。
- 用于从视频中学习语言的 DenseAV:@adcock_brett 提到了一种名为“DenseAV”的 AI 算法,它可以从无标签视频中学习语言含义和声音位置。
- 用于训练 LLM 的 Goldfish loss:@tomgoldsteincs 介绍了 goldfish loss,这是一种在不记忆训练数据的情况下训练 LLM 的技术。
- 对齐 LLM 中的创造力下降:@hardmaru 分享了一篇论文,探讨了使用 RLHF 对齐 LLM 的意外后果,即降低了它们的创造力和输出多样性。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 模型与技术
- 针对 Stable Diffusion 改进的 CLIP ViT-L/14:在 /r/StableDiffusion 中,改进后的 CLIP ViT-L/14 模型已开放下载,同时还提供了一个 Long-CLIP 版本,可用于任何 Stable Diffusion 模型。
- 从零开始的混合精度训练 (Mixed Precision Training):在 /r/MachineLearning 中,展示了 Nvidia 原始混合精度训练论文在 2 层 MLP 上的重新实现,深入 CUDA 领域以展示 TensorCore 的激活情况。
- 理解 LoRA:同样在 /r/MachineLearning 中,分享了一份用于高效微调大语言模型的 低秩自适应 (LoRA) 理解视觉指南。LoRA 将微调涉及的参数数量减少了 10,000 倍,同时仍能收敛到全量微调模型的性能。
- 使用 LLaMa-3 8B 达到 GPT-4 级别的数学解题能力:一篇 研究论文探讨了如何通过 LLaMa-3 8B 模型结合蒙特卡洛树自我细化 (Monte Carlo Tree Self-refine) 来获得 GPT-4 级别的奥数解决方案。
- 从零开始的指令微调 (Instruction Finetuning):提供了一个 从零开始实现指令微调 的代码实现。
- AlphaMath Almost Zero:关于 AlphaMath Almost Zero 的研究 引入了“无过程的过程监督 (process supervision without process)”。
Stable Diffusion 模型与技术
- 模型对比:在 /r/StableDiffusion 中,展示了 PixArt Sigma、Hunyuan DiT 和 SD3 Medium 模型 在图像生成方面的对比,其中 PixArt Sigma 和 SDXL 细化表现出良好的前景。
- 针对 SD3 的 ControlNet:针对 SD3 的 ControlNet Canny 和 Pose 模型已经发布,Tile 和 Inpainting 模型即将推出。
- 采样器与调度器排列组合:提供了一份 Stable Diffusion 3 所有可用的采样器 (Sampler) 和调度器 (Scheduler) 组合概览。
- SD3 中的 CFG 值:Stable Diffusion 3 中不同 CFG 值的对比 显示,与 SD1 相比,其可用范围更窄。
- Playground 2.5 类似于 Midjourney:Playground 2.5 模型被认为在输出质量和风格上与 Midjourney 最为相似。
- SD3 中的层扰动分析:进行了一项 关于在 SD3 的不同层中添加随机噪声如何影响最终输出的分析,这可能为 SD3 是如何以及在哪里被修改的提供见解。
Llama 与本地 LLM 模型
- Llama 3 Spellbound: 在 /r/LocalLLaMA 中,Llama 3 7B 微调版在没有指令示例的情况下进行了训练,旨在保留对世界的理解和创造力,同时减少写作中的正面偏差 (positivity bias)。
- NSFW 角色扮演模型: 有人请求推荐能在 3060 12GB GPU 上运行的模型,并能生成类似于所提供示例的 NSFW 角色扮演内容。
- 类似于 Command-R 的模型: 有人正在寻找质量与 Command-R 相似的模型,但要求在配备 M3 Max 64GB 的 Mac 上运行 64k 上下文时占用更少的内存。
- 用于角色扮演/聊天/故事创作的系统提示词: 分享了一个用于在角色扮演、聊天和故事创作场景中控制模型的详细系统提示词 (System Prompt),重点在于详尽、直接且符号化的指令。
- 在 24GB 显存上运行大型模型: 寻求关于如何在 24GB 显存 (VRAM) 上运行大型模型/长上下文的指导,可能涉及使用量化 (Quantization) 或 4/8 bit 精度。
- RAG 中底层模型的重要性: 讨论了在拥有可靠语料库的情况下,使用检索增强生成 (RAG) 时底层模型是否重要。
AI Ethics and Regulation
- OpenAI 董事会任命批评: Edward Snowden 批评 OpenAI 任命前 NSA 局长的决定,称其为“对地球上每个人权利的蓄意、精心策划的背叛”。
- Stability AI 的闭源策略: 在 /r/StableDiffusion 中,有一场关于 Stability AI 决定走闭源 API 销售路线的讨论,质疑他们在不利用社区微调 (fine-tunes) 的情况下是否具有竞争力。
- Stable Diffusion 服务条款澄清: 针对一名标题党 YouTuber 造成的误解,提供了 Stable Diffusion 模型服务条款 (TOS) 的澄清。
- SD3 的众筹开源替代方案: 有人建议发起一个众筹的开源替代方案来取代 SD3,该项目可能由一名曾参与训练 SD3 但最近辞职的前 Stability AI 员工领导。
- GitHub 上的恶意 Stable Diffusion 工具: 一篇新闻报道称黑客利用 GitHub 上的恶意 Stable Diffusion 工具瞄准 AI 用户,声称是为了抗议“艺术盗窃”,但实际上是通过勒索软件谋取经济利益。
- 去偏见对创造力的影响: 一篇研究论文讨论了对语言模型进行去偏见 (Debiasing) 处理对其创造力的影响,认为审查模型会降低其创造力。
AI and the Future
- 在 AI 进步中感到迷茫: 在 /r/singularity 中,分享了一段关于在 AI 飞速进步面前感到迷茫和对未来不确定的个人反思。
- 对 AI 影响职业生涯的担忧: 同样在 /r/singularity,有人表达了鉴于近期发展,对 AI 未来及其职业生涯感到迷茫。
AI Discord 回顾
摘要之摘要的摘要
1. AI 模型性能与扩展
- 使用新 AI 模型进行扩展:据报道,DeepSeek 的 Coder V2 在基准测试中击败了 GPT-4;Google DeepMind 展示了新的 video-to-audio 技术,能为任何视频创作配乐,该消息在 Rowan Cheung 的 X 个人资料上引发关注。
- 跨平台扩展 AI 能力:Runway 推出了用于视频生成的 Gen-3 Alpha,增强了电影风格和场景过渡。相关细节分享在 Twitter 上。
2. 跨平台的集成与实现
- 混合笔记应用发布 LLM 集成:OpenRouter 发布了一款集成 LLM 的笔记应用,用于动态内容交互,但正如其全屏应用所述,目前缺乏移动端支持。
- 在不同平台上的实现挑战:用户面临诸如 OpenRouter 上的 CORS 错误以及 LangChain 上的集成挑战,这反映出需要更好的实现指南或特定平台的 API。
3. AI 伦理与治理
- OpenAI 转向利润驱动模式:关于 OpenAI 转向营利实体的推测和确认不断涌现,这可能会影响治理和伦理考量。更多信息见 The Information。
- AI 伦理讨论升温:关于 AI 数据隐私、模型偏见和公司治理的辩论仍在继续,Edward Snowden 在 Edward Snowden 的 X 个人资料上批评了 OpenAI 的新董事会任命。
4. 新 AI 进展与基准测试
- AI 创新与改进发布:Anthropic 在其新的研究文章中发表了关于 AI 篡改奖励系统能力的见解。
- 新模型基准测试:Stability AI 发布了 SD3 模型,并在各大论坛讨论了损失稳定(loss stabilization)和伪影管理(artifacts management)的新技术,其中包括 Reddit 上的热点讨论。
5. 协作式 AI 项目与用户参与
- 社区项目凸显 AI 集成:从 OpenRouter 上合并笔记与 API 密钥管理的笔记应用,到像 Dream Machine 这样创新的 AI 驱动视频生成工具,社区构建的工具正在推向创意和实用 AI 应用的边界,详见 Lumalabs 等平台。
- 互动式 AI 讨论与合作蓬勃发展:网络研讨会和协作活动(如即将举行的 Mojo 社区会议)鼓励对 AI 进展进行深入研究,正如 blog 所分享的,全球用户群参与度极高并进行了详细讨论。
第一部分:高层级 Discord 摘要
Stability.ai (Stable Diffusion) Discord
- SD3 许可证风波:Stable Diffusion 3 (SD3) 的新许可证由于法律模糊性导致其在 Civitai 上被禁,Civitai 法务团队在其临时禁令声明中宣布了对此的审查。
- 社区因 SD3 产生分歧:用户对 Stability AI 的 SD3 授权方式表示沮丧,既有困惑也有不满;同时,一些人批评 YouTuber Olivio Sarikas 为了流量歪曲 SD3 许可证,并引用了他的视频。
- ComfyUI 指南:围绕 ComfyUI 设置的问题引发了技术讨论,建议的自定义节点安装修复方案包括 cv2 等依赖项;社区贡献的 ComfyUI 教程也被分享以提供帮助。
- 寻找 SD3 替代方案:对话指向了寻找替代模型和艺术工具的趋势,例如使用 animatediff 进行视频生成,这可能是由于持续的 SD3 争议所致。
- AI 社区中的虚假信息指控:针对 YouTuber Olivio Sarikas 散布有关 SD3 许可证虚假信息的指控不断,社区成员对其争议视频内容的真实性提出了质疑。
Unsloth AI (Daniel Han) Discord
-
Ollama 集成接近完成:Ollama 支持开发已完成 80%,Unsloth AI 团队与 Ollama 正在协作克服延迟。讨论了关于 Ollama 的模板微调验证和学习率问题,以及运行
model.push_to_hub_merged时无法保存完整合并模型的问题,并提出了手动解决方法。 -
Unsloth 持续提速:基准测试显示,在 NVIDIA GeForce RTX 4090 上,Unsloth 的训练过程比 torch.compile() torchtune 快 24%,训练速度令人印象深刻。此外,即将推出的支持多达 8 个 GPU 的多 GPU 支持正在测试中,部分选定用户已获得早期访问权限进行初步评估。
-
训练难题与技巧:成员们在训练 Yi 模型时遇到了保存步骤崩溃、保存过程中
quantization_method管理不当,以及关于批次大小(batch sizes)和梯度累积(gradient accumulation)对 VRAM 占用影响的困惑。解决方案和变通方法包括验证内存/磁盘资源,以及一个解决量化错误的已提交 Pull Request。 -
关于音乐怀旧与新奇的活跃讨论:成员们分享了从 1962 年的怀旧歌曲到 Daft Punk 和 Darude 的经典曲目,展示了社区轻松的一面。相比之下,针对 AI Studio 上 Gemma 2 的输出存在担忧,反应不一,既有失望也有好奇,并对 Gemini 2.0 充满期待。
-
CryptGPT 通过加密方式保护 LLM:介绍了一个名为 CryptGPT 的概念,它使用 Vigenere 密码在加密数据集上预训练 GPT-2 模型,确保隐私并需要加密密钥才能生成输出,详见分享的 Blog Post。
-
单一的好奇信息:社区协作频道出现了一条表达兴趣的消息,但由于缺乏进一步的上下文或细节,其与更广泛讨论话题的相关性尚不明确。
CUDA MODE Discord
-
NVIDIA 下一代产品预测及 PyCUDA SM 查询澄清:工程师们推测了即将推出的 NVIDIA 5090 GPU 的潜在规格,传闻 VRAM 高达 64 GB,但遭到了质疑。此外,澄清了 techpowerup 报告的 A10G 显卡 GPU SM 数量差异,Amazon Web Services 等独立来源确认正确数量为 80,而非最初陈述的 72。
-
Triton 和 Torch 用户应对故障与限制:Triton 用户在 Colab 中遇到了
AttributeError,并讨论了使用嵌套归约(nested reductions)处理象限的可行性。同时, PyTorch 用户调整了torch.compile(mode="max-autotune")中的 SM 阈值以适应 SM 数量少于 68 的 GPU,并探索启用坐标下降调优(coordinate descent tuning)以获得更好性能。 -
软件与算法突破 AI 极限:一位成员赞扬了 GPT-4 与 LLaMA 3 8B 的匹配表现;Akim 将参加 AI_dev 会议并欢迎交流。此外,Vayuda 的搜索算法论文引起了爱好者的兴趣,并在多个频道进行了讨论。关于 AI 训练的讨论(如 Meta 描述的 LLM 训练挑战)强调了基础设施适应性的重要性。
-
CUDA 开发动态:来自以 CUDA 为核心的开发消息透露:Permuted DataLoader 集成并未显著影响性能;为随机舍入(stochastic rounding)开发了独特的种子策略;ZeRO-2 的内存开销(memory overhead)出现了挑战;新的 LayerNorm 内核在特定配置下提供了急需的加速。
-
超越 CUDA:动态批处理、量化和位打包:在并行计算领域,工程师们正在努力解决 Gaudi 架构的动态批处理(dynamic batching)问题,并讨论了量化和位打包(bit-packing)技术的复杂性。他们强调了 VRAM 限制约束了大模型在本地的部署,并分享了多种资源,包括 Python 开发环境链接和新型机器学习库的文档。
LM Studio Discord
-
LM Studio 为工程师配备了 CLI 工具:最新的 LM Studio 0.2.22 版本引入了 ‘lms’,这是一个用于模型管理和调试 prompt 的 CLI 工具,详见其 GitHub 仓库。此次更新简化了 AI 部署的工作流,特别是在模型加载/卸载和输入检查方面。
-
性能优化与故障排除:工程师们讨论了 AI 模型性能的最佳设置,包括 Intel ARC A7700 的 GPU 支持故障排除、GPU layers 的配置调整以及 Flash Attention 设置的调整。建议在遇到托管本地模型的问题时查看 Open Interpreter 的文档,并呼吁 LM Studio 界面更好地处理字体大小以提高可用性。
-
多样化的模型参与:成员们推荐将 Fimbulvetr-11B 用于角色扮演场景,同时强调了 DeepSeek-Coder-V2 等代码模型的快速更迭,建议同行关注用于特定任务(如编程)的最新模型,这些模型可以在 Large and Small Language Models list 等网站上查看。
-
硬件优化与问题:为遇到安装问题的用户分享了存档的 LM Studio 0.2.23 链接——一个 MirrorCreator 链接。硬件讨论还包括混合 RAM 条的兼容性、服务器模式下的 CPU 核心设置,以及在各种系统上排除 GPU 检测故障。
-
开发见解与 API 交互:开发者们分享了将
llama3和deepseek-coder等各种编程模型集成到 VSCode 工作流中的愿景,并寻求在continue.dev中实现模型的帮助。此外,还有关于将 ROCm 从 LM Studio 主应用中解耦的讨论,以及一份 使用 LM Studio 配置continue.dev的用户指南。 -
Beta 版本观察与应用版本管理:社区测试并回顾了最近的 Beta 版本,讨论了 tokenizer 修复和 GPU offloading 故障。用户需要获取旧版本的途径,但这受到 LM Studio 更新策略的挑战,因此有人建议保留个人偏好版本的存档。
-
AI 驱动的创意与易用性问题:工程师们提出了 LM Studio 对 stop tokens 管理不善以及工具倾向于在输出中附加无关文本的问题。一个常见的与用例相关的投诉是,AI 模型在必要时没有通过使用 #ERROR 消息来表明其未能提供正确的输出。
HuggingFace Discord
低端硬件上 GPT-4 的 AI 替代方案:用户讨论了适用于性能较低服务器的实用 AI 模型,建议使用 “llama3 (70B-7B), mixtral 8x7B, 或 command r+” 来构建类似于 GPT-4 的自托管 AI。
RWKV-TS 挑战 RNN 的主导地位:一篇 arXiv 论文介绍了 RWKV-TS,提出它在时间序列预测中是比 RNN 更高效的替代方案,能有效捕捉长期依赖关系并具有计算扩展性。
商业用途中的模型选择至关重要:在为商业应用选择 AI 时,考虑使用场景、工具和部署限制至关重要,即使受到 7B 模型大小的限制。为了获得量身定制的建议,成员建议关注具体细节。
创新与集成层出不穷:从 Difoosion(一个用于 Stable Diffusion 的用户友好 Web 界面)到 Ask Steve(一个旨在利用 LLM 简化 Web 任务的 Chrome 扩展),社区成员正积极将 AI 集成到实用的工具和工作流中。
模型处理与微调中的问题与建议:
- 分享了一个 BERT 微调教程。
- 提出了对非确定性模型初始化的担忧,并建议保存模型状态以实现可复现性。
- Mistral-7b-0.3 的上下文长度处理以及对高质量 meme generator models 的追求,表明了模型定制中的挑战与探索。
- 对于 TPU 用户,正在寻求关于在 GCP’s TPU 上使用 Diffusers 的指导,表明了利用云端 TPU 运行扩散模型的兴趣。
OpenAI Discord
-
iOS 兼容性疑问:成员们讨论了 ChatGPT 是否能在 iOS 18 beta 上运行,建议坚持使用 iOS 17 等稳定版本,并指出 beta 用户受限于关于新功能的 NDA。关于兼容性尚未达成明确共识。
-
开源崛起:DeepSeek AI 发布的一款开源模型在编程和数学方面超越了 GPT-4 Turbo,引发了关于开源 AI 相比于私有模型优势的辩论。
-
使用 LLM 进行数据库部署:为了获得更好的语义搜索并减少幻觉,一位社区成员推荐了 OpenAI’s Cookbook 作为将向量数据库与 OpenAI 模型集成的资源。
-
GPT-4 使用起伏:用户对访问 GPT 交互、Custom GPTs 的隐私设置以及服务器停机表示沮丧。社区提供了变通方案,并建议监控 OpenAI’s service status 以获取更新。
-
3D 建模与 Prompt Engineering 的挑战:对话集中在生成无阴影 3D 模型的各种技术细节,以及防止 GPT-4 混淆信息的复杂性。成员们分享了各种策略,包括 step-back prompting 和设置明确的操作来引导 AI 输出。
LAION Discord
-
稳定 SD3 模型:讨论围绕 SD3 models 面临的稳定性障碍展开,特别是伪影和训练问题。人们对 loss stabilization 提出了担忧,指出了诸如 non-uniform timestep sampling 和缺失 qk norm 等问题。
-
T2I 模型登场:对话强调了对 开源 T2I (text-to-image) 模型 的兴趣,特别是跨场景的角色一致性。对于寻求可靠多轮图像生成的开发者,推荐了 Awesome-Controllable-T2I-Diffusion-Models 和 Theatergen 等资源。
-
逻辑极限突破:一位成员关注了当前 AI 在 logical reasoning 方面面临的挑战,指出了 Phi-2 的“严重推理崩溃”以及 LLM 在处理 AIW 问题时的命名偏差——这一关键点得到了相关研究的支持。
-
提升演绎推理:关于增强 LLM 演绎推理的混合方法的咨询指向了 Logic-LM,这是一种将 LLM 与符号 AI 求解器相结合以提高逻辑问题解决能力的方法。
-
视频生成创新:复旦大学的 Hallo model 引发了关注,这是一款能够从单张图像和音频生成视频的工具,具有与 Text-to-Speech 系统协同应用的潜力。来自 FXTwitter 的一个本地运行工具被分享,凸显了社区对实际集成的兴趣。
OpenAccess AI Collective (axolotl) Discord
-
200T 参数模型:AGI 还是幻想?:讨论了假设的 200T 参数模型 的可访问性,强调了当前计算能力对大多数用户的限制,并幽默地看待了为此类模型冠以 AGI 之名的说法。
-
在大模型竞技场中竞争:成员们对比了 Qwen7B 和 Llama3 8B 模型,公认 Llama3 8B 是性能上的主导竞争者。针对 Llama3 模型的自定义训练配置问题得到了解决,并分享了一个解决方案以处理
chat_template设置问题。 -
PyTorch GPU 优化探索:针对 PyTorch 中各种 GPU 设置的优化反馈请求,汇集了从 AMD MI300X 到 RTX 3090、Google TPU v4 以及运行 tinygrad 的 4090 等丰富的社区经验。
-
在 Axolotl 的开发迷宫中穿行:发现并追踪到一个阻碍 Llama3 模型 开发的问题,该问题指向一个特定的 commit,这有助于识别问题,但也强调了在 main branch 中进行修复的必要性。为用户详细说明了在 Axolotl 中设置推理参数和微调视觉模型的指令。
-
结构化数据提取的新尝试:社区展示暗示了使用 Axolotl 微调 LLM 后的积极成果,特别是在将非结构化新闻稿转换为结构化输出方面。即将发布的一篇文章承诺将阐述如何利用 OpenAI API 的 function calling 来提高 LLM 在此任务中的准确性。作者指向一篇详细文章以获取更多信息。
Perplexity AI Discord
-
Pro 语言合作伙伴关系!:Perplexity AI 与 SoftBank 达成协议,向 SoftBank 客户免费提供一年的 Perplexity Pro。这项通常每年耗资 29,500 日元的优质服务旨在通过 AI 增强用户的探索和学习体验(更多合作信息)。
-
规避 AB 测试协议?再想想:工程师们讨论了如何绕过 Agentic Pro Search 的 A/B 测试,并提供了一个 Reddit 链接;然而,出于对诚信的担忧,他们进行了重新考虑。社区还处理了大量关于 Perplexity 功能 的使用问题,辩论了订阅 Perplexity 与 ChatGPT 的优劣,并提出了关于网络爬虫实践的关键隐私问题。
-
API 访问是关键:成员们表达了对 Perplexity API 封闭测试访问权限的紧迫需求,强调了这对启动如 Kalshi 等项目的影响。在解决 Custom GPT 问题时,他们交流了通过使用基于 schema 的解释和错误详情来增强其“问任何事”功能的技巧,以改进 action/function call 的处理。
-
社区泄露与分享:传阅了指向 Perplexity AI 搜索 和页面的链接,主题涵盖从数据表管理工具(Tanstack Table)到俄罗斯宠物食品市场以及大象交流策略。一份关于前列腺健康的公开个人文件引发的小事故,在社区驱动的支持下得到了解决。
-
游戏与研究的碰撞:社区内分享的内容融合了学术兴趣和游戏文化,例如公开发布的关于 The Elder Scrolls 的页面,暗示了相关技术受众的交叉爱好。
Nous Research AI Discord
-
用神经元玩 Doom:一种将生物技术与游戏结合的创新方法,利用活体神经元来玩视频游戏 Doom,详情见 YouTube 视频。这可能是理解生物过程与数字系统集成迈出的一步。
-
AI 伦理与偏见备受关注:ResearchGate 论文中对 AI 的批判性观点引起了人们对 AI 传播人类偏见和对齐企业利益这一趋势的关注,并将“随机鹦鹉(stochastic parrots)”称为潜在的认知操纵工具。
-
LLM 合并与 MoE 担忧:关于 Mixture of Experts (MoE) 模型实际应用的激烈辩论浮出水面,探讨了模型合并与全面微调的有效性,并引用了 llama.cpp 的 PR 以及 Hugging Face 上的 MoE 模型。
-
Llama3 8B 部署挑战:在设置和部署 Llama3 8B 方面,建议利用 unsloth qlora、Axolotl 和 Llamafactory 进行训练,并使用 lmstudio 或 Ollama 在 Apple 的 M2 Ultra 上运行快速的 OAI 兼容端点,这为模型部署工具提供了参考。
-
Autechre 的曲目引发争论:围绕 Autechre 音乐的观点和情感导致了两个对比鲜明的 YouTube 视频分享:“Gantz Graf” 和 “Altibzz”,展示了这对电子音乐组合创作的多样化听觉景观。
-
探索多人 AI 世界构建:提出了在 WorldSim 中进行协作创作的建议,成员们讨论了为 AI 辅助的协作体验启用多人游戏功能,同时指出模型提供商的审查可能会影响 WorldSim AI 的内容。
-
NVIDIA 的 LLM 亮相:NVIDIA 的 Nemotron-4-340B-Instruct 模型已发布,可在 Hugging Face 上获取,引发了关于合成数据生成和战略合作伙伴关系的讨论,突显了该公司在语言处理领域的新进展。
-
OpenAI 转向营利模式:OpenAI 首席执行官 Sam AltBody 表示,公司可能会从非营利性质转向营利性架构,从而与竞争对手更加一致,并影响 AI 行业的组织动态和未来轨迹。
Modular (Mojo 🔥) Discord
-
Mojo 函数讨论升温:工程师们批评了 Mojo 手册中对
def和fn函数的处理方式,指出了英语表述中的歧义以及这些函数变体对类型声明的影响。这达成了一个共识:虽然def函数允许可选的类型声明,但fn函数强制要求类型声明;这一细微差别影响了代码的灵活性和类型安全性。 -
聚会提醒:Mojo 社区集会:宣布了即将举行的 Mojo Community Meeting,包含关于 constraints、Lightbug 和 Python 互操作性的演讲,邀请参与者通过 Zoom 加入。此外,基准测试显示 Mojo 的 Lightbug 在单线程性能上超过了 Python FastAPI,但仍逊于 Rust Actix,这引发了关于函数着色(function coloring)决策带来的潜在运行时开销的进一步讨论。
-
Mojo 24.4 正式发布:Mojo 团队推出了 24.4 版本,引入了核心语言和标准库的改进。建议关注细节的工程师阅读博客文章,深入了解新的 traits、OS 模块功能等。
-
揭秘 Mojo 高级技术:深入的技术讨论揭示了 Mojo 编程中的挑战和见解,从处理 2D Numpy 数组、利用
DTypePointer进行高效 SIMD 操作,到解决无符号整数转换中的 Bug。值得注意的是,CRC32 表初始化中涉及alias使用的差异引发了对意外转换行为的调查。 -
Nightly Mojo 编译器即将到来:工程师们获悉了 Mojo 编译器的全新 nightly builds,发布了
2024.6.1505、2024.6.1605和2024.6.1705版本,并提供了通过modular update进行更新的说明。每个版本的具体细节可以通过提供的 GitHub diffs 进行查看,展示了平台的持续改进。此外,有人注意到内置 MLIR dialects 缺乏外部文档,并且有人请求增加如 REPL 中直接输出表达式等增强功能。
Eleuther Discord
-
Eleuther 对 OpenAI 泛化技术的复现:EleutherAI 的可解释性团队成功在 21 个 NLP 数据集上的开源 LLM 中复现了 OpenAI 的 “weak-to-strong” 泛化技术,并在此处发布了关于实验变体(如 strong-to-strong 训练和基于探针的方法)的详细发现,包括正面和负面的结果。
-
工作机会与 CommonCrawl 导航:AI Safety Institute 在其招聘页面宣布了提供英国搬迁签证支持的新职位;同时,在关于高效处理 CommonCrawl 数据的讨论中提到了 ccget 和 resiliparse 等工具。
-
模型创新与担忧:从探索 RWKV-CLIP(一种视觉语言模型),到对 Diffusion 模型生成内容以及商业模型输出被窃取的担忧,社区探讨了 AI 模型开发与安全的各个方面。Laprop 优化器的有效性引发了辩论,分享了从在线适配到“窃取”嵌入模型的各类论文,其中一篇关键论文见此处。
-
演进中的优化与 Scaling Laws:成员对一篇基于 Hypernetwork 论文的批评引发了关于 Hypernetwork 与 Hopfield 网络价值及对比的对话。感兴趣的各方深入探讨了 Scaling Laws 的扩展,考虑了 LLM 的在线适配,并引用了 Andy L. Jones 关于用训练计算抵消推理计算的概念。
-
Sparse Autoencoders 的可解释性洞察:可解释性研究集中在 Sparse Autoencoders,一篇论文提出了在 GPT-2 的间接对象识别等任务中评估特征字典的框架,另一篇则强调了分解 Logit 输出组件的 “logit prisms”,详见这篇文章。
-
对模型评估共享平台的需求:社区呼吁建立一个共享和验证 AI 模型评估结果的平台,特别是针对使用 Hugging Face 并寻求验证闭源模型可信度的用户,强调了对全面且透明的评估指标的需求。
-
等待视觉语言项目的代码发布:针对 RWKV-CLIP 相关代码发布日期的具体请求已定向至该项目的 GitHub Issues 页面,显示出对获取最新视觉语言表示模型进展的需求。
LLM Finetuning (Hamel + Dan) Discord
-
苹果在 AI 领域避开 NVIDIA:苹果在 WWDC 上的发布详情显示其避开了 NVIDIA 硬件,更倾向于在 TPU 和 Apple Silicon 上使用其内部的 AXLearn,这可能会彻底改变其 AI 开发策略。技术细节在 Trail of Bits 博客文章中进行了拆解。
-
嵌入与微调:微调方法论受到热捧,讨论范围从嵌入的复杂性(如 Awesome Embeddings 资源所示)到特定实践(如针对独特叙事风格适配 TinyLlama,详见开发者的博客文章)。
-
Prompt 构建创新:提到 Promptfoo 和 inspect-ai 表明了向更复杂的 Prompt Engineering 工具发展的趋势,社区正在权衡其功能性和易用性。不同的偏好表明此类工具对于精细化的人机交互方案至关重要。
-
积分混淆已澄清:参与者对 LangSmith 和 Replicate 等平台上的课程积分表达了混淆,通过社区支持进行了提醒和澄清。为相关成员说明了测试版积分与课程积分之间的区别。
-
Code Llama 的飞跃:Code Llama 发布引发的对话显示了对提高编程生产力的承诺。对 Hugging Face 和 GitHub 配置文件格式之间允许的差异表示好奇,这表明了微调这些专用模型所需的精确度。
Interconnects (Nathan Lambert) Discord
-
Sakana AI 加入独角兽俱乐部:Sakana AI 正在突破传统的 Transformer 模型,并从 NEA、Lux 和 Khosla 等重量级机构获得了高达 10 亿美元的估值,标志着 AI 社区的一个重要里程碑。详细的财务细节可以在这篇文章中查阅。
-
Runway Gen-3 Alpha 开启下一代视频生成:Runway 的 Gen-3 Alpha 备受瞩目,展示了创建包含复杂场景转换和丰富电影风格的高质量视频的能力,为视频生成设定了新标杆,详情请点击此处探索。
-
DeepMind 视频转音频技术的突破:Google DeepMind 的新视频转音频技术旨在通过为任何视频量身定制理论上无限数量的音轨,彻底改变无声 AI 视频生成,正如 Rowan Cheung 的示例所展示的那样。
-
Wayve 在视图合成方面的亮眼表现:Wayve 凭借利用 4D Gaussians 的视图合成模型在 AI 领域取得了新胜利,有望在从静态图像生成新视角方面实现重大飞跃,详见 Jon Barron 的推文。
-
关于 OpenAI 未来的猜测:有关 OpenAI 治理结构调整的传闻暗示其可能转向营利性立场,并考虑随后进行 IPO,这在社区内引发了激烈讨论;一些人对此表示嘲讽,而另一些人则在等待具体进展,正如 The Information 的报道以及 Jacques Thibault 的推文所回应的那样。
LlamaIndex Discord
-
RAG 与 Agent 概念详解:分享了一份 Excalidraw 增强型幻灯片,详细介绍了检索增强生成 (RAG) 和 Agent 的构建,其中的图表阐明了从基础到高级的概念。
-
LLM 应用中集成可观测性:通过 Arize 集成,一个新的仪表化模块为 LLM 应用程序带来了端到端的可观测性,并提供了一份详细说明自定义事件/Span 处理器仪表化的指南。
-
知识图谱与 Neo4j 的结合:关于将 Neo4j 知识图谱与 LlamaIndex 集成的讨论集中在将 Neo4j 图转换为 LlamaIndex 的属性图(Property Graphs)上,并提供了相关资源和文档(LlamaIndex 属性图示例)。
-
通过网页抓取策略增强 LLM:一篇出版物讨论了通过结合网页抓取和 RAG 来改进 LLM,推荐使用 Firecrawl 等工具进行有效的 Markdown 提取,以及使用 Scrapfly 获取适用于 LLM 预处理的多样化输出格式。
-
实用教程与 AI 活动亮点:发布了关于全栈 Agent 和多模态 RAG 流水线的实用分步指南;此外,AI World’s Fair 亮点中,知名演讲者分享了他们在 AI 和工程方面的知识,提升了社区的技能水平并加深了对新兴 AI 趋势的理解。
tinygrad (George Hotz) Discord
-
脚本混乱与 OpenCL 困扰:关于
autogen_stubs.sh的讨论显示clang2py会破坏缩进,但发现这对于 GPU 加速的 tinygrad 操作并非必要。同时,George Hotz 建议修复 OpenCL 安装并使用clinfo进行验证,因为相关错误影响了 tinygrad 的 GPU 功能。 -
增强型 OpenCL 诊断即将到来:改进 OpenCL 错误消息的工作正在进行中,一个拟议的解决方案可以从现有的 OpenCL headers 中自动生成消息,旨在简化开发者的调试过程。
-
解读梯度同步:为了揭开梯度同步(gradient synchronization)的神秘面纱,George Hotz 肯定了 Tinygrad 在其 optimizer 中内置的解决方案,宣称其效率优于 PyTorch 中更复杂的 Distributed Data Parallel。
-
雄心勃勃追赶 PyTorch:George Hotz 表达了让 tinygrad 在速度、简洁性和可靠性方面超越 PyTorch 的雄心。尽管目前在 LLM 训练等方面仍处于追赶状态,但 tinygrad 简洁的设计和强大的基础展现了巨大的潜力。
-
Kernel 领域的精度至关重要:一次技术交流讨论了在模型中引入混合精度(mixed precision)的策略,George Hotz 建议采用 late casting 以获得效率提升,并使用
cast_方法,强调了这是优化计算密集型任务的关键环节。
OpenRouter (Alex Atallah) Discord
-
GPT 笔记应用发布:展示了一个 LLM 客户端与笔记应用的混合体,具有动态包含笔记的功能,采用原生 JavaScript 构建,并在浏览器中本地存储笔记和 API keys;不过,目前该应用尚不支持移动端。该应用通过 Codepen 和全屏部署版本进行展示。
-
OpenRouter 的抱怨与见解:OpenRouter 要求至少有一条用户消息以防止错误,用户建议使用
prompt参数;推荐使用 PDF.js 和 Jina AI Reader 等格式化工具进行 PDF 预处理,以增强 LLM 的兼容性。 -
Qwen2 的审查困扰:Qwen2 模型因过度审查面临用户批评,而限制较少的 Dolphin Qwen 2 模型因其更写实的叙事生成能力而获得推荐。
-
Gemini Flash 上下文冲突:关于 Gemini Flash 的 token 限制出现了疑问,OpenRouter 列出的限制为 22k,而 Gemini Documentation 中提到的则是 8k tokens;这一差异归因于 OpenRouter 采用字符计数以与 Vertex AI 的计费方式保持一致。
-
速率限制与配置讨论:用户讨论了 GPT-4o 和 Opus 等模型的速率限制以及模型性能配置;欲了解更多信息,OpenRouter 关于速率限制的文档提供了详尽说明,讨论重点在于 API 请求和使用的效率。
LangChain AI Discord
-
LangChain API 更新导致 TextGen 损坏:最近的 API update 破坏了 LangChain 中的 textgen integration,成员们正在通用频道寻求解决方案。
-
技术故障排除成为焦点:用户讨论了安装 langchain_postgres 的挑战,以及由 tenacity version 8.4.0 更新引起的 ModuleNotFoundError;将版本回退到 version 8.3.0 修复了该问题。
-
LangChain 知识共享:出现了围绕 LangChain 使用的问题,包括从 Python 转向 JavaScript implementations,以及如何处理 Llama 3 或 Google Gemini 等模型的本地部署。
-
技术爱好者介绍新酷工具:一些创新项目受到关注,例如 R2R 的自动知识图谱构建、Collision 事件的交互式地图,以及 CryptGPT(一种使用 Vigenere 密码保护 LLM 隐私的方法)。
-
面向创意人士的 AI:社区成员发布了一个用于生成技术图表的新定制 GPT,以及 Rubik’s AI(一个研究助手和搜索引擎,向测试人员提供包含 GPT-4 Turbo 等模型的免费高级版)。
Latent Space Discord
OtterTune 退出舞台:OtterTuneAI 在收购交易失败后已关闭,标志着其自动数据库调优服务的终结。
Apple 和 OpenAI 的新动作:Apple 在 Hugging Face 上发布了优化的端侧模型,例如 DETR Resnet50 Core ML;而 OpenAI 因邀请前 NSA 局长 Paul M. Nakasone 加入董事会而遭到 Edward Snowden 的批评。
DeepMind 恪守本分:在近期的社区讨论中,相关人员澄清 DeepMind 并未参与特定的 AI 项目,打破了此前的猜测。
Runway 和 Anthropic 持续创新:Runway 在 Twitter 上发布了其全新的视频生成模型 Gen-3 Alpha;同时,Anthropic 在一篇博客文章中公布了关于 AI 模型攻击其奖励系统的重要研究。
AI 协作与学习的未来:Prime Intellect 将开源复杂模型 DiLoco 和 DiPaco;Bittensor 正在利用 The Horde 进行去中心化训练;此外,社区分享的一段 YouTube 视频深入解析了对模型训练至关重要的优化器(optimizers)。
Cohere Discord
-
AGI:幻想还是未来?:成员们分享了对一段关于 AGI 的 YouTube 视频的看法,讨论了在怀疑态度与类似互联网泡沫破裂后可能出现的实质性进展之间如何取得平衡。
-
Next.js 迁移进行中:社区正在协作推动在 Cohere toolkit 中使用 Next.js App Router,旨在提高代码的可移植性和社区贡献效率,详情见 GitHub issue #219。
-
Cohere 的 C4AI:Nick Frosst 邀请参加 C4AI 演讲(通过 Google Meet 链接),为社区成员提供了参与 LLM 进展和应用讨论的渠道。
-
掌控你的浏览器:一款免费的 Chrome 扩展程序已发布,它将 LLMs 集成到 Chrome 中以提升生产力;同时,一个带有 AI 聊天功能的交互式 Collision 地图展示了如何使用现代 Web 技术栈呈现活动。
-
开发者交流:Cohere 正在举办由 David Stewart 主持的开发者办公时间(Developer Office Hours),深入探讨 API 和模型的复杂细节;感兴趣的社区成员可以从这里加入,并在指定线程提交问题以获得专门支持。
OpenInterpreter Discord
-
模型冻结之谜已解:工程师们报告了模型在编码过程中冻结的情况,但事实证明耐心等待是有回报的,因为模型通常会完成任务,只是中间会有一个具有误导性的停顿。
-
技术支持重定向:关于模型 Windows 安装问题的咨询被引导至特定的帮助频道,以便获得更具针对性的协助。
-
模型记忆功能得到提升:一位成员庆祝了在内存实现(memory implementation)方面的突破,并用初步术语描述了其成功;同时,Reddit 帖子披露了 Llama 3 Instruct 70b 和 8b 的性能细节。
-
网络帽子(Cyber Hat)倒计时:一个开源的、AI 赋能的“网络帽子”项目因其原创性和创新潜力引起了工程师们的兴趣,并公开邀请协作,点击观看;同样,Dream Machine 基于文本和图像的逼真视频生成功能也标志着 AI 模型能力的巨大进步。
-
语义搜索协同:讨论转向了将基于语音的语义搜索与索引与存储音频数据的向量数据库相结合,利用 LLM 的强大能力根据语音输入执行复杂任务,这预示着集成技术系统的潜在力量。
Torchtune Discord
-
聚焦 Torchtune 的单节点优先级:Torchtune 目前正专注于优化单节点训练 (single node training),之后才会考虑多节点训练;它使用
tune run命令作为torch run的封装,虽然在多节点环境下未经测试,但通过一些调整可能支持多节点设置。 -
解锁 Torchtune 的多节点潜力:一些成员分享了如何配置 Torchtune 进行多节点训练的潜在方案,建议使用
tune run —nnodes 2以及 TorchX 或 slurm 等额外工具来进行脚本执行和跨节点网络协调,并参考 FullyShardedDataParallel 文档 作为分片策略的资源。
DiscoResearch Discord
- Llama3 坚守本源:尽管推出了德语模型,但 Llama3 tokenizer 并未进行修改,与基础版 Llama3 完全一致,这引发了人们对其处理德语 Token 效率的质疑。
- Token 讨论:针对未改变的 Tokenizer 出现了一些担忧,工程师们推测,不加入特定的德语 Token 可能会大幅缩减上下文窗口 (context window) 并影响 Embedding 的质量。
- 比较 Llama2 和 Llama3 的 Token 尺寸:好奇的成员注意到 Llama3 的 Tokenizer 显著比 Llama2 大 4 倍,这引发了关于其对德语现有功效以及潜在未察觉问题的讨论。
Datasette - LLM (@SimonW) Discord
预示数据工程的就业保障:ChatGPT 在技术领域日益增长的角色引发了带有幽默色彩的评论,称其为数据工程师的“无限工作生成器”。
Thoughtbot 拨开 LLM 的迷雾:社区成员对 Thoughtbot 的指南 表示赞赏,认为其清晰地剖析了 Large Language Models 的世界,特别是对 Base、Instruct 和 Chat 模型的划分,对初学者非常有帮助。
搜索领域的新成员:Turso 的最新版本将 原生向量搜索 (native vector search) 集成到了 SQLite 中,旨在通过取代对 sqlite-vss 等独立扩展的需求,来提升 AI 产品开发体验。
AI Stack Devs (Yoko Li) Discord
- 寻找医院 AI 项目名称:用户 gomiez 询问了 AI Stack Devs 社区内医院 AI 项目的名称。目前没有提供额外的上下文或回复来进一步确认该项目。
Mozilla AI Discord
- Llama 作为 Firefox 的新搜索伴侣?:社区成员 cryovolcano. 询问了将 llamafile 与 tinyllama 集成作为 Firefox 浏览器搜索引擎的可能性。目前尚未提供有关实现或可行性的更多细节或上下文。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该社区长时间保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该社区长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区长时间保持沉默,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该社区长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
完整的频道逐项分析已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!