ainews-shazeer-et-al-2024
Shazeer 等人 (2024):你在推理上多支付了 13 倍以上的费用。
Noam Shazeer 解释了 Character.ai 如何在承载相当于 20% 谷歌搜索流量的大模型(LLM)推理任务的同时,将服务成本降至 2022 年底的 1/33,而目前领先的商业 API 成本至少要高出 13.5 倍。
关键的内存效率技术包括:
- MQA(多查询注意力)优于 GQA(分组查询注意力):将 KV 缓存(KV cache)大小缩减了 8 倍;
- 混合注意力范围(Hybrid attention horizons);
- 跨层 KV 共享(Cross-layer KV-sharing);
- 有状态缓存(Stateful caching):缓存命中率高达 95%;
- 原生 int8 精度:配合自定义算子(Custom kernels)。
此外,Anthropic 发布了 Claude 3.5 Sonnet,其性能超越了 Claude 3 Opus,且速度提升了两倍,成本仅为五分之一。该模型通过了 64% 的内部拉取请求(PR)测试,并引入了 Artifacts 等新功能,支持实时文档和代码生成。关于大模型架构的讨论则强调了 Transformer 的主导地位、规模扩展与过拟合带来的挑战,以及架构优化工作对推动技术进步的重要性。
这 5 个内存和缓存技巧就是你所需要的一切。
2024年6月20日至6月21日的 AI 新闻。 我们为您检查了 7 个 subreddit、384 个 Twitter 账号 和 30 个 Discord 社区(415 个频道,2822 条消息)。 预计节省阅读时间(按 200wpm 计算):287 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
在一篇简洁的 962 字博客文章中,Noam Shazeer 重新执笔解释了 Character.ai 如何在 LLM 推理方面承载相当于 Google Search 流量 20% 的负载,同时将服务成本降低了 33 倍(与 2022 年底相比),并估计领先的商业 API 成本至少高出 13.5 倍:
内存效率:“我们使用以下技术将 KV cache 大小减少了 20 倍以上,且没有降低质量。通过这些技术,GPU 内存不再是服务大 Batch Size 的瓶颈。”
- MQA > GQA:“与大多数开源模型采用的 Grouped-Query Attention 相比,KV cache 大小减少了 8 倍。” (Shazeer, 2019)
- 混合注意力视界 (Hybrid attention horizons):局部(滑动窗口)注意力层与全局注意力层的比例为 1:5 (Beltagy et al 2020)。
- 跨层 KV 共享 (Cross Layer KV-sharing):局部注意力层与 2-3 个相邻层共享 KV cache,全局层则跨 Block 共享缓存。 (Brandon et al 2024)
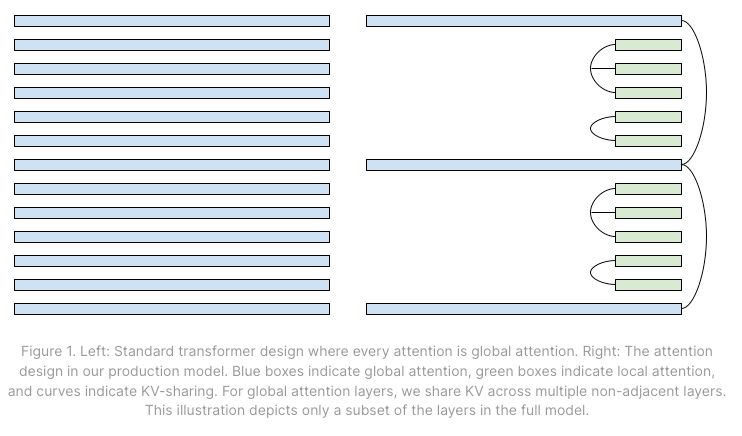
有状态缓存 (Stateful Caching):“在 Character.AI 上,大多数聊天都是长对话;平均每条消息都有 180 条消息的对话历史……为了解决这个问题,我们开发了一个回合间缓存系统。”
- 在具有树结构的 LRU 缓存中缓存 KV tensor (RadixAttention, Zheng et al., 2023)。在集群层面,我们使用粘性会话 (sticky sessions) 将来自同一对话的查询路由到同一台服务器。我们的系统实现了 95% 的缓存率。
- 原生 int8 精度:与更常见的“训练后量化 (post-training quantization)”不同。这需要他们自己定制用于矩阵乘法和注意力的 int8 Kernel——并承诺未来会发布关于量化训练的文章。
AI Twitter 综述
所有综述均由 Claude 3 Opus 完成,从 4 次运行中取最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程。
Anthropic 发布 Claude 3.5 Sonnet
- 性能提升:@AnthropicAI 发布了 Claude 3.5 Sonnet,在关键评估中超越了竞争对手模型,速度是 Claude 3 Opus 的两倍,成本仅为其五分之一。它在理解细微差别、幽默和复杂指令方面表现出显著进步。@alexalbert__ 指出它通过了 64% 的内部 Pull Request 测试用例,而 Claude 3 Opus 为 38%。
- 新功能:@AnthropicAI 推出了 Artifacts,允许生成文档、代码、图表、图形和游戏,这些内容会显示在聊天窗口旁边,以便进行实时迭代。@omarsar0 使用它来可视化深度学习概念。
- 编程能力:在 @alexalbert__ 的演示中,Claude 3.5 Sonnet 自动修复了一个 Pull Request。@virattt 强调了 Agentic 编程评估,模型在其中读取代码、获取指令、创建行动计划、实施更改并接受测试评估。
LLM 架构与扩展讨论
- Transformer 的主导地位:@KevinAFischer 认为 Transformer 将继续扩展并占据主导地位,并将其与硅处理器类比。他建议学术界不要研究替代架构。
- 扩展与过拟合:@SebastienBubeck 讨论了迈向 AGI 的扩展挑战,指出模型在更大规模上可能会过拟合能力,而不是发现所需的“运算”。平滑的扩展轨迹并非必然。
- 架构的重要性:@aidan_clark 强调了架构工作对推动当前进展的重要性,反驳了只有 Scaling 重要的观点。@karpathy 分享了一个 94 行的 autograd 引擎,作为神经网络训练的核心。
检索、RAG 与上下文长度
- Long-Context LLMs 对比检索:Google DeepMind 的 @kelvin_guu 分享了一篇分析 Long-Context LLMs 在检索和推理任务中表现的论文。它们在无需显式训练的情况下可与检索和 RAG 系统相媲美,但在组合推理方面仍面临挑战。
- 用于无限上下文的 Infini-Transformer:@rohanpaul_ai 重点介绍了 Infini-Transformer,它通过基于递归的 token mixer 和基于 GLU 的 channel mixer,在有限内存下实现了无限上下文。
- 改进 RAG 系统:@jxnlco 讨论了改进 RAG 系统的策略,重点关注数据覆盖范围以及 metadata/indexing 能力,以增强搜索相关性和用户满意度。
基准测试、评估与安全
- 基准测试饱和的担忧:一些人对基准测试变得饱和或效用下降表示担忧,例如 @polynoamial 对 GSM8K 的看法,以及 @arohan 对编程任务 HumanEval 的看法。
- 严格的发布前测试:@andy_l_jones 强调了 @AISafetyInst 对 Claude 3.5 发布前的测试,这是政府首次在模型发布前对其进行评估。
- 评估赋能微调:@HamelHusain 分享了来自 @emilsedgh 的幻灯片,介绍了评估如何为 Fine-Tuning 奠定基础,从而产生飞轮效应。
多模态模型与视觉
- 多模态优先级的差异:@_philschmid 对比了近期发布的产品,指出 OpenAI 和 DeepMind 优先考虑多模态,而 Anthropic 在 Claude 3.5 中专注于提升文本能力。
- 4M-21 Any-to-Any 模型:@mervenoyann 解析了 EPFL 和 Apple 的 4M-21 模型,这是一个支持文本转图像、深度掩码等功能的单一 any-to-any 模型。
- 用于指令的 PixelProse 数据集:@tomgoldsteincs 介绍了 PixelProse,这是一个包含 16M 图像的数据集,带有密集字幕,可使用 LLM 重构为指令和问答对。
其他
- DeepSeek-Coder-V2 浏览器编程:@deepseek_ai 展示了 DeepSeek-Coder-V2 直接在浏览器中开发小游戏和网站的能力。
- LLM 生产化的挑战:@svpino 指出,由于难以从演示阶段扩展到生产阶段,一些公司暂停了 LLM 的研发。然而,@alexalbert__ 分享到,Anthropic 的工程师现在使用 Claude 在编程任务中节省了数小时。
- Mixture of Agents 击败 GPT-4:@corbtt 介绍了一种 Mixture of Agents (MoA) 模型,在击败 GPT-4 的同时,成本降低了 25 倍。它先生成初始补全,进行反思,然后生成最终输出。
AI Reddit 摘要
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
Claude 3.5 Sonnet 发布
- 令人印象深刻的性能:在 /r/singularity 中,Anthropic 发布了 Claude 3.5 Sonnet,其在 LiveBench 和 GPQA 等基准测试中的表现超越了 GPT-4o 和其他模型。在一项内部评估中,它 解决了 64% 的 Agent 编程问题,而 Claude 3 Opus 的解决率为 38%。
- 视觉推理能力:Claude 3.5 Sonnet 在视觉任务上超越了 GPT-4o,展示了令人印象深刻的视觉推理能力。
- UI 增强:正如 /r/LocalLLaMA 中提到的,除了性能提升外,Claude 3.5 Sonnet 还带来了 UI 增强功能。
- 极具潜力的写作伙伴:一段 YouTube 视频中分享的早期测试表明,Claude 3.5 Sonnet 作为写作伙伴展现出了巨大的潜力。
OpenAI 与竞争
- 对竞争的渴望:在 /r/OpenAI 中,一些人表达了 希望 OpenAI 拥有能与 Claude 3.5 Sonnet 竞争的模型 的愿望,以保持该领域的竞争和进步。
- 批评与不信任:OpenAI 正 面临批评和不信任,涉及忽视安全问题、违反算力承诺以及延迟推出的语音模型等问题。
其他 AI 模型发布与基准测试
- 来自中国的模型:正如 /r/singularity 中指出的,近期超过一半的大语言模型(LLM)来自中国。
- Aider 基准测试:根据 /r/LocalLLaMA 的一个帖子,DeepSeek Coder V2 和 Sonnet 3.5 在 Aider 基准测试排行榜中名列前茅。
- Florence-2 视觉模型:Microsoft 发布了 Florence-2,这是一款通用的开源视觉模型,能以统一的方式处理多项任务,该消息分享于 /r/OpenAI。
Stable Diffusion 与图像生成
- 用于汽车生成的 Stable Diffusion 3:在 /r/StableDiffusion 中,Stable Diffusion 3 medium 模型被认为 擅长遵循提示词生成汽车和其他主体,尽管在解剖结构和一致性方面仍需改进。
- 使用 SD XL 生成一致场景:一段 Reddit 视频帖子展示了如何结合 Stable Diffusion XL 与 img2img 及其他技术来生成一致的场景和角色。
梗图与幽默
- ChatGPT 用户转向 Claude:/r/singularity 的一张梗图调侃了 ChatGPT 用户在看到 3.5 Sonnet 更新后纷纷转向 Claude 的现象。
AI Discord 摘要
特别说明:正如我们在新的前沿模型发布时所做的那样,我们将展示在 Claude 3.5、Claude 3 和 GPT-4o 上运行相同提示词的输出差异。
Claude 3 Sonnet
1. LLM 进展与基准测试
-
Meta 的 Llama 3 在 ChatbotArena 等排行榜上名列前茅,正如此 Discord 讨论中所述,其表现优于 GPT-4-Turbo 和 Claude 3 Opus。
-
IBM 的 Granite-8B-Code-Instruct 和 DeepSeek 的 DeepSeek-V2(236B 参数)在此频道中因其代码能力而受到关注。
-
此研究频道对某些基准测试表示怀疑,呼吁通过可靠来源建立现实的标准。
2. 优化 LLM 推理与训练
-
关于高效 KV-caching 的 vAttention 论文在此处被提及。
-
此频道提到了探索并行解码的 Consistency LLMs 等技术。
3. 开源 AI 框架与社区努力
-
Andrew Ng 关于使用 LlamaIndex 构建 Agentic RAG 系统的课程在此频道被提及。
-
开源的 RefuelLLM-2 在此讨论中被介绍为处理“乏味”任务的顶级模型。
-
Modular 的 Mojo 及其在 AI 扩展方面的潜力在此处被预告。
4. 多模态 AI 与生成模型
-
此频道讨论了用于聊天的 Idefics2 8B Chatty 和用于编程的 CodeGemma 1.1 7B。
-
在此生成式 AI 讨论中,有人提议结合 Pixart Sigma、SDXL 和 PAG 以实现 DALLE-3 级别的输出。
Claude 3.5 Sonnet
1. AI 模型发布与性能对比
-
新模型声称在基准测试中获胜:Nous Research 的 Hermes 2 Theta 70B 和 Turbcat 8b 均声称在多项基准测试中超越了 Llama-3 Instruct 等更大型的模型。各个 Discord 频道的用户讨论了这些发布,并将其能力与 GPT-4 和 Claude 等成熟模型进行了对比。
-
Claude 3.5 Sonnet 引发褒贬不一的反应:多个 Discord 中的讨论强调了 Claude 3.5 Sonnet 提升的 Python 编程能力,但一些用户发现其在 JavaScript 任务中相较于 GPT-4 表现不足。在 Nous Research Discord 中,有人提到了该模型处理冷门编程语言的能力。
-
专注于代码的模型受到关注:DeepSeek Coder v2 的发布引发了关于代码任务专用模型的讨论,并声称在该领域的性能可与 GPT4-Turbo 媲美。
2. AI 开发工具与基础设施挑战
-
寻求 LangChain 的替代方案:一篇详细介绍 Octomind 弃用 LangChain 的博客文章在多个 Discord 中引起共鸣,开发者们讨论了用于 AI Agent 开发的替代方案,如 Langgraph。
-
硬件限制令开发者受挫:LM Studio 和 CUDA MODE Discord 中的讨论强调了在消费级硬件上运行先进 LLM 的持续挑战。用户辩论了各种 GPU 的优劣,包括 NVIDIA 的 4090 与即将推出的 5090,并探索了针对显存限制的变通方法。
-
Groq 的 Whisper 性能声明:Groq 宣布以 166 倍实时速度运行 Whisper 模型,这在各频道引发了关注和质疑,开发者们讨论了其潜在的应用场景和局限性。
3. AI 行业实践中的伦理担忧
-
OpenAI 与政府的合作引发质疑:一条讨论 OpenAI 向政府实体提供早期访问权限的推文在多个 Discord 中引发了关于 AI 监管和 AGI 安全策略的辩论。
-
Perplexity AI 面临批评:一段批评 Perplexity AI 做法的 CNBC 采访 导致各频道对 AI 开发和部署中的伦理考量展开了讨论。
-
OpenAI 的公共关系挑战:包括 Interconnects 在内的多个 Discord 成员讨论了 OpenAI 代表反复出现的公关失误,并推测这些失误对公司公众形象和内部策略的影响。
Claude 3 Opus
1. 模型性能优化与基准测试
-
[量化 (Quantization)] 技术如 AQLM 和 QuaRot 旨在保持性能的同时,在单个 GPU 上运行大型语言模型 (LLMs)。例如:在 RTX3090 上运行 Llama-3-70b 的 AQLM 项目。
-
通过 Dynamic Memory Compression (DMC) 等方法提升 Transformer 效率的努力,在 H100 GPUs 上可能将吞吐量提高多达 370%。例如:@p_nawrot 的 DMC 论文。
-
关于优化 CUDA 操作的讨论,例如融合逐元素操作,使用 Thrust 库的
transform以获得接近带宽饱和的性能。例如:Thrust 文档。 -
在 AlignBench 和 MT-Bench 等基准测试中对模型性能进行比较,其中 DeepSeek-V2 在某些领域超越了 GPT-4。例如:DeepSeek-V2 发布公告。
2. 微调挑战与提示工程 (Prompt Engineering) 策略
-
在将 Llama3 模型转换为 GGUF 格式时,难以保留微调数据,并讨论了一个已确认的 Bug。
-
提示词设计 (Prompt design) 和使用正确模板(包括文本结束标记)的重要性,这会影响微调和评估期间的模型性能。例如:Axolotl prompters.py。
-
提示工程 (Prompt engineering) 策略,如将复杂任务拆分为多个提示词,研究 logit bias 以获得更多控制。例如:OpenAI logit bias 指南。
-
教会 LLM 在不确定时使用
<RET>标记进行信息检索,从而提高在低频查询中的表现。例如:ArXiv 论文。
3. 开源 AI 进展与协作
-
StoryDiffusion 发布,这是一个采用 MIT 许可证的 Sora 开源替代方案,尽管权重尚未发布。例如:GitHub 仓库。
-
OpenDevin 发布,这是一个基于 Cognition 的 Devin 的开源自主 AI 工程师,配有网络研讨会,在 GitHub 上关注度不断提高。
-
呼吁就预测 IPO 成功的开源机器学习论文进行协作,该项目托管在 RicercaMente。
-
围绕 LlamaIndex 集成的社区努力,包括在更新后 Supabase Vectorstore 和包导入中遇到的问题。例如:llama-hub 文档。
GPT4O (gpt-4o-2024-05-13)
- AI 模型性能与训练技术:
-
Gemini 1.5 在 1M tokens 下表现出色:Gemini 1.5 Pro 通过有效处理高达 1M tokens 给用户留下了深刻印象,表现优于 Claude 3.5 等其他模型,并在长上下文任务中获得了积极反馈。该模型处理大量文档和转录文本的能力受到了关注。
-
FP8 Flash Attention 和 GPTFast 加速推理:关于 Flash Attention 中 INT8/FP8 内核以及最近推出的 GPTFast 的讨论表明,HF 模型推理速度显著提升了高达 9 倍。值得注意的还包括开源 FP8 Flash Attention 的增加,该功能将在 12.5 版本中获得官方 CUDA 支持。
-
Null-shot 提示词与 DPO 优于 RLHF:社区辩论涉及利用 LLM 幻觉的 null-shot 提示词的有效性,以及从人类反馈强化学习 (RLHF) 转向直接策略优化 (DPO) 以简化训练。论文引用包括该概念在 LLM 任务表现中的优势。
-
- AI 伦理与可访问性:
-
AI 伦理引发辩论:一篇批评 OpenAI 背离开源原则的 Nature 文章 引起了关于 AI 透明度和可访问性的讨论。人们对获取尖端 AI 工具和代码的难度日益增加表示担忧。
-
避免不真诚的 AI 道歉:用户对 AI 生成的道歉表示不满,称其不真诚且没有必要。这种情绪反映了人们对更真实、更实用的 AI 交互的广泛期望,而不是自动化的遗憾表达。
-
- OpenAI 与政府合作的担忧:人们对 OpenAI 向政府实体提供早期模型访问权限的担忧日益增加,这在一条 推文 中得到了强调。讨论指向了潜在的监管影响以及向 AGI 安全的战略转变。
- 开源 AI 发展与社区贡献:
-
介绍 Turbcat 8b:Turbcat 8b 模型 的发布包括了显著的改进,如扩展的数据集和新增的中文支持。该模型目前拥有 5GB 的数据,并与更大但尚未完善的模型进行了对比。
-
Axolotl 与 Backgammon AI 工具:协作努力重点介绍了开源的 Backgammon AI 工具,该工具模拟西洋双陆棋场景以进行战略增强。讨论还涉及了 Turbcat 模型及其多语言处理功能。
-
来自 Stability.ai 的计算机视觉数据集:Stability.ai 发布了一个包含来自 Stable Diffusion 社区的 235,000 个提示词和图像 的数据集。这个 StableSemantics 数据集旨在通过提供广泛的视觉语义数据来增强计算机视觉系统。
-
- 硬件与部署挑战:
-
GPU 使用挑战与优化:工程师们分享了在不同设置中优化 GPU 和 CPU 集成的见解和解决方案,例如为 LM Studio 启用第二个 GPU,并讨论了运行复杂模型的替代方案。推荐使用二手 3090s 以提高成本效益,并期待 NVIDIA 4090 和 5090 之间的性能对比。
-
TinyGrad 与
clip_grad_norm_的纠葛:在 TinyGrad 中实现clip_grad_norm_时遇到了瓶颈,原因是 Metal 的缓冲区大小限制,建议将其划分为 31 个张量块作为权宜之计。Metal 和 CUDA 之间的对比突显了性能差异,特别是针对梯度裁剪操作。 -
模型部署问题:在 Hugging Face 等平台上部署 Unsloth 等模型时遇到的挑战引发了关于 tokenizer 兼容性和替代部署建议的讨论。Together.ai 和 Unsloth 的 H100 之间的微调成本差异巨大,引发了对定价错误的质疑。
-
- 活动讨论与职业机会:
-
Techstars 和 RecSys 虚拟聚会:即将举行的活动,如 6 月 28 日至 30 日在旧金山举行的 Techstars Startup Weekend 和 6 月 29 日的 RecSys Learners Virtual Meetup,被强调为 AI 专业人士建立联系、学习和展示创新想法的机会。为了方便参与者,分享了详细信息和 RSVP 链接。
-
求职与技能展示:Python AI 工程师积极寻求工作机会,强调他们在 NLP 和 LLMs 方面的技能。对话还包括对公司支持框架的见解,例如 Modal 团队 对大模型的协助,以及开发者对 Slack 优于 Discord 的偏好。
-
AI 活动中的演讲与公告:推广了 LlamaIndex 创始人 Jerry Liu 在世博会上关于知识助手未来的演讲,并提到即将在 Twitter 上发布的特别公告。
-
这些讨论全面展示了积极塑造 AI 社区的创新、伦理和实践方面。
PART 1: High level Discord summaries
OpenAI Discord
-
Gemini 1.5 在 Token 竞赛中更进一步:Gemini 1.5 Pro 在处理长上下文任务方面表现出色,具有处理高达 1M tokens 的惊人能力。用户赞赏其在输入文档和转录文本后在各种主题上展现的专业性,尽管它目前还存在一些访问限制。
-
AI 伦理辩论升温:一篇 Nature 文章 引发了关于 AI 模型开放性影响的讨论,激起了对 OpenAI 偏离开源原则的批评。对话指向了关于 AI 工具和代码可访问性更广泛的担忧。
-
在道歉中寻找平衡:多位用户对 AI 频繁的道歉响应表示厌烦,嘲讽机器表达遗憾时的虚伪。这反映了用户对 AI 人设处理错误方式的普遍不满。
-
AI 开发者对 Mac 的偏好:一位支持 MacBook 的用户反映了开发社区内的强烈偏好,强调了开发环境的易用性。虽然 Windows Surface 笔记本在硬件和设计上被提及为竞争对手,但 Windows 上的开发体验隐含地受到了批评。
-
Dall-E 3 挑战复杂图像生成:用户尝试使用 Dall-E 3 生成具有不对称性和精确位置等特定属性的复杂图像,结果褒贬不一。值得注意的是,OpenAI macOS 应用因其与典型 Mac 工作流的集成而受到称赞,这表明该工具符合 AI 专业人士的生产力偏好。
CUDA MODE Discord
-
INT8/FP8 撼动性能表现:受 HippoML 博客文章 的启发,关于 INT8/FP8 flash attention 内核的讨论再次兴起,尽管目前尚未发布用于公开基准测试或与 torchao 集成的代码。同时,有人注意到一个开源的 FP8 flash attention 补充,引用了 Cutlass Kernels GitHub 以及 CUDA 12.5 中待定的 Ada FP8 支持。
-
GPTFast 为快速推理铺平道路:GPTFast 的创建(一个能将 HF 模型推理速度提升高达 9 倍的 pip 包)包含了
torch.compile、key-value caching 和投机采样(speculative decoding)等功能。 -
GPU 优化秘籍揭晓:发现了一些解释 GPU 限制的旧幻灯片,特别是关于 Llama13B 与 4090 GPU 的不兼容性,引发了关于使用 LoRA 优化内存占用的进一步讨论。此外,一份最近的演示文稿提供了管理 GPU vRAM、使用 torch-tune 进行基准测试以及优化内存的策略。
-
稳定 NCCL 的同步与协作:NCCL 领域的实验引发了对同步问题的关注,根据 NCCL 通信器指南,建议从 MPI 转向基于文件系统的同步。关于 CUDA managed memory 的实用性意见不一(在代码整洁度与性能之间权衡),而训练不稳定性现象的出现促使人们开始研究损失峰值(Loss Spikes 论文)。
-
AI 基准测试技术的复杂性:处理时间基准测试的准确性通过
torch.cuda.synchronize和torch.utils.benchmark.Timer等技术得到解决。此外,Triton 的评估代码中强调了一些特定的最佳实践,特别是测量前清理 L2 cache 的重要性。
Stability.ai (Stable Diffusion) Discord
-
社区对频道删减的反应:许多成员对删除使用率较低的频道表示沮丧,特别是这些频道曾被视为灵感来源和社区互动的场所。虽然 Fruit 提到活跃度较低的频道容易吸引机器人垃圾信息,但一些参与者仍希望能更好地理解这一决定,或寻求恢复存档的可能性。
-
Stable Diffusion 中的 UI 偏好:关于 ComfyUI 相对于 A1111 等其他界面的效率和可用性展开了激烈的辩论,一些用户青睐基于节点的 workflow,而另一些用户则更喜欢传统的基于 HTML 输入的界面。虽然未达成共识,但讨论突显了社区在 UI 设计方面的多样化偏好。
-
计算机视觉新数据集发布:宣布了一个包含 235,000 个 prompt 和图像的新数据集,该数据集源自 Stable Diffusion Discord 社区,旨在通过提供对视觉场景语义的见解来改进计算机视觉系统。数据集可在 StableSemantics 获取。
-
关于频道管理的辩论:删除某些低活跃度频道的决定引发了广泛辩论,因为用户失去了一个宝贵的视觉存档资源,并正在寻求关于频道删除标准的明确说明。
-
探索 Stable Diffusion 工具:用户分享了与不同 Stable Diffusion 界面相关的经验和资源,包括 ComfyUI、Invoke 和 Swarm,并提供了帮助新手使用这些工具的指南。对话线程提供了对比和个人偏好,帮助他人为自己的 workflow 选择合适的界面。
Perplexity AI Discord
-
AI 模型表演赛:Discord 频道内的互动展示了成员对 Opus、Sonnet 3.5 和 GPT4-Turbo 等 AI 模型的对比,重点在于 Sonnet 3.5 的性能与 Opus 持平,并讨论了使用 Complexity 扩展在这些模型之间高效切换的方法。
-
模型访问困境:用户讨论了 Claude 3.5 Sonnet 在不同设备上的实际可用性,并对使用限制表示担忧,例如 Opus 每天 50 次的使用上限,这抑制了用户使用该模型的意愿。
-
解码推理硬件:工程师们剖析了用于 AI 推理的可能硬件,在 TPUs 和 Nvidia GPUs 之间进行推测,并对 AWS’s Trainium 在机器学习训练效率方面的表现表示认可。
-
Hermes 2 Theta 夺冠:Nous Research 推出的 Hermes 2 Theta 70B 引发了关注,它超越了竞争对手的基准测试,并增强了 function calling、特征提取和不同输出模式等能力,在熟练度上可与 GPT-4 媲美。
-
API 管理简化:分享了一个关于管理 API key 的简短指南,引导用户前往 Perplexity settings 轻松生成或删除 key,不过关于将 API 搜索限制在特定网站的疑问仍未得到解答。
HuggingFace Discord
精彩的 OCR 工作,Florence!:工程师们讨论了 Florence-2-base 模型出人意料的卓越 OCR 能力,甚至超过了其更大规模的变体;这一发现引发了好奇心并需要进一步验证。令人惊讶的是,更复杂的模型在看似更简单的任务上表现挣扎,这表明需要衡量模型在规模之外的能力。
HuggingFace 总部遭遇故障:用户经历了 Hugging Face 网站的中断,遇到了 504 错误,影响了工作流的连续性。这一关键开发资源的瘫痪给依赖该平台服务的用户带来了暂时性的挫折。
AI 项目的援手:开源 AI 项目正在寻求协作:Backgammon AI tool 旨在模拟西洋棋场景,而 Nijijourney dataset 尽管由于图像本地存储存在访问问题,但仍提供了强大的基准测试。
玩耍与贡献:分享了一款名为 Milton is Trapped 的创新游戏,目标是与一个脾气暴躁的 AI 互动。鼓励开发者通过其 GitHub repository 为这个有趣的 AI 尝试做出贡献。
伦理计算的十字路口:一篇引人入胜的论文强调了 NLP 中 fairness(公平性)与 environmental sustainability(环境可持续性)之间妥协的对话,凸显了行业微妙的平衡行为。它指出在推进 AI 技术时需要整体视角,过度强调某一方面可能会无意中损害另一方面。
Unsloth AI (Daniel Han) Discord
-
训练中的 Token 问题:工程师们讨论了 OpenChat 3.5 中 EOS tokens 的问题,注意到在训练和推理的不同阶段,
<|end_of_turn|>和</s>之间存在混淆。例如,“Unsloth 使用<|end_of_turn|>,而 llama.cpp 使用<|reserved_special_token_250|>作为 PAD token。” -
价格战:Unsloth vs. Together.ai:价格对比显示,在 Together.ai 上对 150 亿个 tokens 进行 fine-tuning 可能耗资约 4,000 美元,如其交互式计算器所示。相比之下,使用 Unsloth 的 H100,同样的任务可以在大约 3 小时内以不到 15 美元的成本完成,这引发了人们的怀疑和对定价错误的猜测。
-
比起 Mistral 更青睐 Phi-3-mini:在模型对比中,一位工程师报告称,在使用 1k、10k 和 50k 样本的训练数据集时,phi-3-mini 的一致性优于 Mistral 7b,并将训练中的数据框架设定为唯一可接受的响应。
-
采用 DPO 替代 RLHF 以简化训练:成员们考虑放弃 Reinforcement Learning with Human Feedback (RLHF),转而采用 Unsloth 支持的 Direct Policy Optimization (DPO),因为它更简单且同样有效。一位参与者在了解更多 DPO 的优势后提到:“我想我会先切换到 DPO。”
-
Hugging Face 的部署困扰:由于 tokenizer 问题,用户分享了在 Hugging Face Inference endpoints 上部署 Unsloth 训练模型的困难,这导致了对替代部署平台的咨询。
Nous Research AI Discord
-
Hermes 2 Theta 70B 胜过巨头:由 Nous Research、Charles Goddard 和 Arcee AI 合作推出的 Hermes 2 Theta 70B 宣称其性能超越了 Llama-3 Instruct 甚至 GPT-4。主要特性包括 function calling、feature extraction 和 JSON output 模式,在 MT-Bench 上获得了令人印象深刻的 9.04 分。更多详情请见 Perplexity AI。
-
Claude 3.5 精通晦涩语言:Claude 3.5 的最新进展显示其有能力处理自创的晦涩编程语言中的问题,超越了既定的问题解决参数。
-
AI/人类协作洞察:观察到一种转变,AI 的使用正从单纯的任务执行转向与人类形成共生工作关系——详细讨论见 “Piloting an AI“。
-
模型幻觉的战略性应用:一篇 arXiv paper 描述了 null-shot prompting 如何巧妙地利用大语言模型(LLMs)的 hallucinations,在任务达成方面优于 zero-shot prompting。
-
立即获取 Hermes 2 Theta 70B:Hermes 2 Theta 70B 的 FP16 和量化 GGUF 格式 下载已在 Hugging Face 上线,确保广泛的可用性。点击获取 FP16 版本 和 量化 GGUF 版本。
LM Studio Discord
压榨 GPU 的更多性能:工程师发现将 main_gpu 值设置为 1 可以在 Windows 10 系统上为 LM Studio 启用第二个 GPU。一名用户还成功通过禁用 GPU 加速并使用 OpenCL 在 CPU 上运行视觉模型,尽管性能较慢。
集成 Ollama 模型变得更简单:为了将 Ollama models 整合到 LM Studio 中,贡献者们正从 llamalink project 转向更新后的 gollama project,尽管有人提议使用不同的预设和 flash attention 来减轻模型输出乱码的问题。
高级模型挑战硬件极限:讨论揭示了在当前硬件配置上运行高端 LLMs 的挫败感,即使拥有 96GB VRAM 和 256GB RAM。社区还在探索二手 3090s 以提高成本效益,并热切期待 NVIDIA 4090 与即将推出的 5090 之间的性能对比。
面对错误优化 AI 工作流:在 Beta 版更新后遇到可用性挑战时,工程师建议利用 nvidia-smi -1 检查模型是否加载到 vRAM,并考虑在 Docker 环境中禁用 GPU 加速以保证稳定性。
Chroma 与 langchain 完美协作:langchain 与 Chroma 集成时出现的 BadRequestError 已通过 GitHub Issue #21318 中的修复方案 迅速解决,证明了社区在维护无缝 AI 工作流方面响应迅速的问题解决能力。
Modular (Mojo 🔥) Discord
告别像素化会议:社区成员讨论了在 YouTube 上直播的社区会议的分辨率问题,指出虽然直播流可以达到 1440p,但手机端的分辨率经常被限制在 360p,这可能是由于网络速度限制造成的。
MLIR 对 256 位整数的探索:在寻求处理密码学所需的 256 位操作时,一位用户尝试了多种 MLIR 方言但遇到了障碍,这促使他们考虑内部建议,因为 MLIR 或 LLVM 中的语法支持并非显而易见。
Kapa.ai 机器人自动补全故障:用户在 Discord 上遇到了 Kapa.ai 机器人的自动补全不一致问题,建议在异常行为得到解决之前,手动输入或下拉选择可能更可靠。
Mojo 异常处理的曲折之路:对话透露 Mojo 标准库中的异常处理(exception handling)尚待实现,一份路线图文档阐明了未来的功能推出计划和当前的局限性(Mojo 路线图与注意事项)。
应对 Nightly 构建动荡:由于分支保护规则的更改,Mojo 编译器的 nightly 版本发布一度中断,但一位社区成员提交的修复编译器版本不匹配的 commit 帮助稳定了流水线,从而成功推出了新的 2024.6.2115 版本,详见 changelog。
OpenRouter (Alex Atallah) Discord
-
Stripe 平息支付混乱:OpenRouter 宣布解决了一个 Stripe 支付问题,该问题此前导致用户账户暂时无法充值。官方表示该问题已 “针对所有支付完全修复”。
-
Claude 在停机后恢复平静:Anthropic 的推理引擎 Claude 经历了 30 分钟的停机并导致 502 错误,目前已修复,可通过其 状态页面 确认。
-
OpenRouter 上的应用上架建议:一位想要列出其应用的 OpenRouter 用户被建议参考 OpenRouter 快速入门指南,该指南要求使用特定的 header 以进行应用排名。
-
Claude 3.5 Sonnet 引发热议(与辩论):Claude 3.5 Sonnet 的发布因其提升的 Python 能力而引发关注,同时也引发了关于其 JavaScript 性能与 GPT-4 相比的辩论。
-
Perplexity Labs 推出 Nemetron 340b:Perplexity Labs 提供了对其 Nemetron 340b 模型的访问,该模型拥有 23t/s 的响应速度——鼓励成员们进行尝试。有人提出了关于 OpenRouter 的 VS2022 扩展问题,Continue.dev 被提及为一个兼容工具。
Eleuther Discord
- Epoch AI 的新数据港湾:Epoch AI 发布了一个更新的 datahub,收录了从 1950 年至今的 800 多个模型的数据,通过开放的 Creative Commons Attribution 许可促进负责任的 AI 发展。
- 区分 Samba 与 SambaNova 的困惑:在新模型浪潮中,人们对微软名为 “Samba” 的混合模型(专注于 mamba/attention 混合)与 SambaNova 系统进行了区分,后者是 AI 模型领域的独立实体。
- GoldFinch 论文预告:备受期待的 GoldFinch 论文将介绍一种 RWKV 混合模型,具有独特的超压缩 kv cache 和全注意力机制。对于 mamba 变体在训练阶段的稳定性担忧也得到了承认。
- 重新思考损失函数:围绕模型在 forward pass 过程中内部生成其损失函数表示的想法展开了精彩辩论,这可能提高模型在需要理解全局属性的任务上的性能。
- NumPy 版本兼容性问题,Colab 来救场:讨论涉及 NumPy 2.0.0 与使用 1.x 版本编译的模块之间的不兼容性,导致建议要么降级 numpy,要么更新模块,而其他人则发现 Colab 是执行特定任务的避风港。
tinygrad (George Hotz) Discord
GPT 的 Weight Tying 难题:围绕 GPT 架构中 weight tying 的正确实现展开了讨论,指出冲突的方法会导致 separate optimization 陷阱,以及由于权重初始化方法干扰 weight tying 而导致的超时问题。
TinyGrad 纠结的 clip_grad_norm_:在 TinyGrad 中实现 clip_grad_norm_ 正在产生性能瓶颈,这主要是由于 Metal 在 buffer size 方面的限制。建议的解决方法是将梯度划分为 31-tensor chunks 以获得最佳效率。
Metal 与 CUDA 的对比:Metal 和 CUDA 之间的对比显示,Metal 在处理张量操作(特别是梯度裁剪)方面表现较差。针对 Metal 提出的解决方案涉及内部调度器(scheduler)增强,以更好地管理资源限制。
AMD 设备超时成为焦点:用户在运行 YOLOv3 和 ResNet 等示例时遇到 AMD 设备超时,这指向了同步错误以及 Radeon RX Vega 7 等 integrated GPUs 可能存在的过载问题。
开发者工具包亮点:分享了一个 Weights & Biases 日志链接,用于深入了解 TinyGrad 的 ML 性能,展示了开发者工具在跟踪和优化机器学习实验中的效用。TinyGrad 的 W&B 日志
LAION Discord
-
Caption Dropout 技术受到审视:工程师们辩论了在 SD3 中使用零向量与编码后的空字符串作为 caption dropout 的有效性。使用编码字符串时未发现显著的结果变化。
-
Sakuga-42M 数据集受阻:Sakuga-42M 数据集论文意外撤回,阻碍了卡通动画研究的进展。撤回的具体原因尚不清楚。
-
OpenAI 与政府的密切关系引发关注:一条 推文 引发了关于 OpenAI 为政府提供 AI 模型早期访问权限的讨论,促使人们呼吁加强监管措施,并对向 AGI 安全策略的转变提出质疑。
-
MM-DIT 全局不一致性警示:在关于 MM-DIT 的讨论中,强调了增加 latent channels 对全局一致性(global coherency)的影响,并指出了场景表示不一致等具体问题。
-
Chameleon 模型优化困境:在微调 Chameleon 模型时,异常高的梯度范数(gradient norms)一直导致 NaN 值,调整学习率、应用梯度范数裁剪(grad norm clipping)或使用权重衰减(weight decay)等方案均难以奏效。
Interconnects (Nathan Lambert) Discord
-
快速发布引发关注:关于新版本快速发布的讨论兴起,成员们质疑改进是源于 posttraining 还是 pretraining,以及 pod training 在此过程中的贡献。
-
OpenAI Mira 的公关危机:Mira 反复出现的公关错误遭到了社区成员的批评,一些人认为这是缺乏公关培训,而另一些人则认为这些错误是吸引注意力离开 OpenAI 高管的策略。由于一次 Twitter 事件 以及 Nathan Lambert 转向使用 Claude,这种挫败感被进一步放大。
-
CNBC 抨击 Perplexity:一次 CNBC 采访让 Perplexity 陷入负面舆论,引用了一篇批评该公司做法的 Wired 文章。这段 YouTube 视频 引发了对 Perplexity 的一波批评,包括 Casey Newton 在内的其他人也加入其中,批评该公司的创始人。
-
寻求互动:‘natolambert’ 发布的一条寻找 ‘snail’ 的简短帖子暗示了正在进行的对话或可能需要提及人员关注或投入的项目。
-
写作构思流传:注意到有人对开发关注近期技术话题的书面作品感兴趣——这一计划可能涉及通过协作努力来深化理解。
OpenInterpreter Discord
-
Open Interpreter 展示跨平台功能:一段 demo 显示 Open Interpreter 已可在 Windows 和 Linux 上运行,并利用 gpt4o via Azure,未来还将有更多增强功能。
-
对 Claude 3.5 Sonnet 的赞赏:一位用户强调了 Claude 3.5 Sonnet 卓越的沟通能力和代码质量,认为其易用性优于 GPT-4 和 GPT-4o。
-
Open Interpreter 的 Windows 安装指南:Open Interpreter 的 设置文档 阐明了 Windows 上的安装过程,包括
pip安装和可选依赖项的配置。 -
推出 DeepSeek Coder v2:DeepSeek Coder v2 的发布预示着一个专注于负责任和道德使用的强大模型,在代码特定任务上可能与 GPT4-Turbo 旗鼓相当。
-
Open Interpreter 对 macOS 的偏好:讨论指出 Open Interpreter 在 macOS 上往往表现更好,这归功于核心团队在该平台上进行的广泛测试。
-
AI 克服“贴纸”难题:一位用户展示了一条 推文,演示了一个完全本地、可控制计算机的 AI 如何通过读取贴纸上的密码连接到 WiFi——这是 AI 实用性的一次实质性飞跃。
LLM Finetuning (Hamel + Dan) Discord
- 放弃抽象:Octomind 团队在一篇 博客文章 中详细说明了他们不再使用 LangChain 构建 AI agents 的原因,理由是其结构僵化且难以维护,而一些成员建议将 Langgraph 作为可行的替代方案。
- 冷落 LangChain:对 LangChain 的不满引起了共鸣,据称它在调试和复杂性方面存在挑战。
- Modal 专家赢得赞誉:成员们称赞了 Modal 团队对 BLOOM 176B 模型的支持,对其乐于助人的态度表示肯定,但一位用户表示相比 Discord 更喜欢 Slack。
- 评估框架获得好评:一位用户称赞 eval framework 非常出色,因为它易于使用且能灵活适配自定义的企业级端点,并强调其直观的 API 设计带来了极佳的开发者体验。
- 额度困惑与登记:用户正在寻求关于解锁额度系统和验证邮箱注册的帮助,其中特别提到的一个邮箱是 “alexey.zaytsev@gmail.com”。
LangChain AI Discord
在 Techstars SF 结识 AI 创新者:对初创企业开发感兴趣的工程师应考虑参加 6 月 28 日至 30 日在旧金山举行的 Techstars Startup Weekend;议程包括行业领袖的主旨演讲和导师指导。更多活动信息请点击 此处。
Reflexion 教程因复杂性令人困惑:关于在 Reflexion 教程中使用 PydanticToolsParser 而非更简单的循环引发了担忧,用户质疑验证失败的影响——教程可参考 此处。
市场上的 AI 工程人才:一位精通 LangChain、OpenAI 和多模态 LLMs 的资深 AI 工程师目前正在行业内寻找全职工作机会。
LangChain 的流式传输难题:在使用 Flask 向 React 应用程序流式传输 LangChain/LangGraph 消息时遇到困难,促使一位用户寻求社区帮助,但目前尚未找到解决方案。
AI 领域的创新与互动:两项值得关注的贡献包括一篇关于 使用 MLX 进行检索增强 的文章(详见 此处),以及介绍增强 GPT 模型 Markdown 使用体验的 CLI 工具 ‘Mark’(详见 此处)。
OpenAccess AI Collective (axolotl) Discord
- 更大且支持多语言:Turbcat 8b 掀起热潮:Turbcat 8b 模型正式推出,其数据集从 2GB 增加到 5GB 并增加了 中文支持,引发了用户的广泛关注和公开访问。
- GPU 兼容性的不确定性引发讨论:关于 AMD Mi300x GPU 与 Axolotl 平台兼容性的查询仍未得到明确答复;一位用户建议等待 PyTorch 2.4 的发布说明或更新以确认支持情况。
- 模型优越性辩论:用户开始将 Turbcat 8b 与即将推出的 72B 模型进行比较,强调了 Turbcat 的数据集规模,但也认可了仍在开发中的更大模型的潜力。
- 训练时间:关注时钟:虽然有人提出了一个估算模型 训练时间 的简单公式,但从业者强调了实际运行以获取准确估算的重要性,并需考虑 Epochs 和评估的缓冲时间。
- 消息重定向——少即是多:datasets 频道中的一条消息简单地将用户重定向到 general-help 频道,强调了社区内对话的组织性和专注度。
Cohere Discord
- API 角色混淆已解决:公会的讨论澄清了 Cohere 当前的 API 缺乏对 “user” 或 “assistant” 等 OpenAI 风格角色 的支持;然而,预计 未来的 API 更新 将引入这些功能以促进集成。
- 不一致的 API 挑战开发者:关于 Cohere 的 Chat API 与 OpenAI 的 ChatCompletion API 之间 不兼容问题 的辩论正在进行,人们担心不同的 API 标准正在阻碍 AI 模型之间的无缝服务集成。
- 对模型替换的质疑:成员们对 OpenRouter 等服务表示担忧,认为其可能会用更便宜的模型替换请求的模型,并建议使用 直接 Prompt 检查 和对比来确保模型的准确性。
- 资源利用的最佳实践:一位成员分享了一篇富有洞察力的博客文章,鼓励利用现有资源而不是囤积资源,在游戏内道具管理与现实世界中的项目推广或寻求帮助之间画出了启发性的类比。
LlamaIndex Discord
- 看看谁在世博会发言:LlamaIndex 创始人 Jerry Liu 将在世博会(World’s Fair)上发表关于 知识助手的未来 的演讲,并计划在 6 月 26 日下午 4:53 发布一些 特别公告,随后在 6 月 27 日进行另一场演讲。
- 凭借 Python 实力寻找工作:一位精通 AI 驱动应用 和 大型语言模型 (LLMs) 的 Python AI 工程专家正在寻找工作,其擅长 NLP、Transformers、PyTorch 和 TensorFlow。
- 图嵌入查询引起兴趣:针对 Neo4jGraphStore 的 Embedding 生成 提出了疑问,重点是在不初始使用 LLMs 的情况下,将 Embedding 集成到现有的图结构中。
- LlamaIndex 扩展探索:用户探索了如何通过发送电子邮件、Jira 集成和日历事件等实用功能来扩展 LlamaIndex,并参考了 自定义 Agent 文档 获取指导。
- NER 需求与模型合并思考:讨论了将 Ollama 和 LLMs 用于 命名实体识别 (NER) 任务,一位成员建议转向 Gliner;此外,还辩论了一种涉及 UltraChat 和 Mistral-Yarn 的新型“诅咒模型合并(cursed model merging)”技术。
Latent Space Discord
-
Swyx 指出 AI 的下一个前沿:Shawn “swyx” Wang 在一篇文章中深入探讨了 AI 在软件开发中的新机遇,强调了即将到来的用例,并重点介绍了 AI Engineer World’s Fair,认为这是行业专业人士的关键活动。
-
Groq 挑战实时 Whispering:Groq 声称其平台运行 Whisper model 的速度可达 166 倍实时速度,引发了关于其在高效率播客转录中的应用以及速率限制(rate limits)潜在挑战的讨论。
-
寻找音乐转文本 AI:一场关于能够将音乐翻译成文本描述(详细说明流派、调性和节拍)的 AI 系统的讨论浮出水面,凸显了市场上除了歌词生成之外的服务空白。
-
MoA 混合模型亮相:Mixture of Agents (MoA) 模型发布,其成本比 GPT-4 低 25 倍,但在人类对比测试中获得了 59% 的更高偏好率;正如 Kyle Corbitt 在推特上所说,它还刷新了多项基准测试记录。
AI Stack Devs (Yoko Li) Discord
AI Town 遭遇垃圾信息攻击:社区成员举报了一名用户 <@937822421677912165> 在不同频道多次发布垃圾信息,引发了要求版主干预的呼声。随着成员们表达挫败感,情况有所升级,有人表示 “wtf what’s wrong with u” 并鼓励其他人向 Discord 举报该行为。
MLOps @Chipro Discord
-
赶上 RecSys 浪潮:RecSys Learners Virtual Meetup 正在招募 2024 年 6 月 29 日活动的参与者,活动定于太平洋标准时间上午 7 点开始,为推荐系统(Recommendation Systems)领域的兴趣小组提供汇聚机会。工程师和 AI 爱好者可以 预约参加见面会,届时将有一系列精彩且信息丰富的环节。
-
对 AI Quality Conference 的好奇:有人询问关于下周二在旧金山举行的 AI Quality Conference 的出席情况,一名成员正在寻求有关该会议提供的服务和主题的更多细节。
Torchtune Discord
- 讨论 PyTorch 中的数据结构:一名成员寻求关于在处理多个数据输入时应使用 PyTorch 的 TensorDict 还是 NestedTensor 的见解。共识强调了这些结构在简化操作方面的效率,通过避免数据类型转换和设备处理的重复代码,并简化了在批次维度(batch dimensions)上的广播(broadcasting)。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
Datasette - LLM (@SimonW) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
PART 2: 按频道详细摘要和链接
完整的频道分类详情已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!