ainews-gemini-nano-50-90-of-gemini-pro-100ms
Gemini Nano:性能达 Gemini Pro 的 50-90%,推理延迟低于 100ms,支持端侧运行,现已在 Chrome Canary 浏览器中上线。
最新版本的 Chrome Canary 浏览器现已包含 Gemini Nano 的功能标志(feature flag),提供 Prompt API 和设备端优化指南。该模型分为 Nano 1 和 Nano 2 两个版本,参数量分别为 18亿 (1.8B) 和 32.5亿 (3.25B),在性能上与 Gemini Pro 相比表现不俗。其基础模型和指令微调模型的权重已被提取并上传至 HuggingFace。
在 AI 模型发布方面,Anthropic 推出了 Claude 3.5 Sonnet,其在部分基准测试中超越了 GPT-4o,运行速度是 Opus 的两倍,并提供免费试用。DeepSeek-Coder-V2 在 HumanEval 测试中达到 90.2%,在 MATH 测试中达到 75.7%,性能超过了 GPT-4-Turbo-0409;该模型参数量高达 2360亿 (236B),支持 12.8万 (128K) 上下文长度。由智谱 AI/清华大学开发的 GLM-0520 在编程和综合基准测试中名列前茅。英伟达 (NVIDIA) 发布了 Nemotron-4 340B,这是一个用于合成数据生成的开源模型系列。
研究亮点包括:TextGrad,一个基于文本反馈实现自动微分的框架;PlanRAG,一种迭代式的“先规划再 RAG”决策技术;一篇关于 goldfish loss(金鱼损失)以减轻大语言模型记忆问题的论文;以及一种用于语言模型智能体(agents)的树搜索算法。
window.ai.createTextSession() 就足够了
2024年6月21日至6月24日的 AI 新闻。我们为您检查了 7 个 subreddit、384 个 Twitter 账号 和 30 个 Discord(415 个频道和 5896 条消息)。预计节省阅读时间(按 200wpm 计算):660 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
最新的 Chrome Canary 现在通过 feature flag 支持 Gemini Nano:
- Gemini Nano 的 Prompt API chrome://flags/#prompt-api-for-gemini-nano
- 设备上的优化指南 (Optimization guide on device) chrome://flags/#optimization-guide-on-device-model
- 导航至 chrome://components/ 并查找 Optimization Guide On Device Model;点击“检查更新”以开始下载。
您现在可以通过控制台访问该模型:http://window.ai.createTextSession()
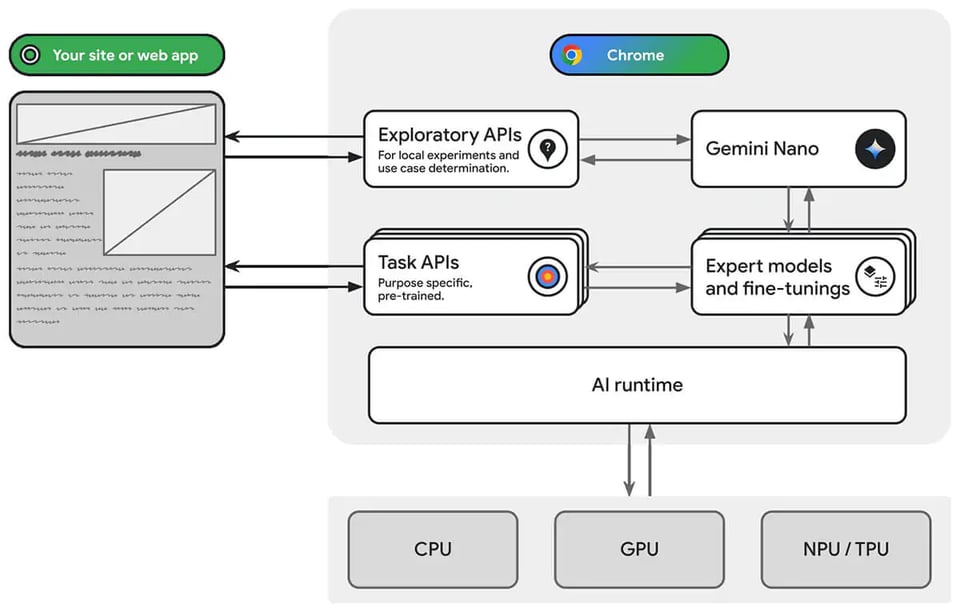
Nano 1 和 2 在 4-bit 量化下分别具有 1.8B 和 3.25B 参数,相对于 Gemini Pro 表现不错:
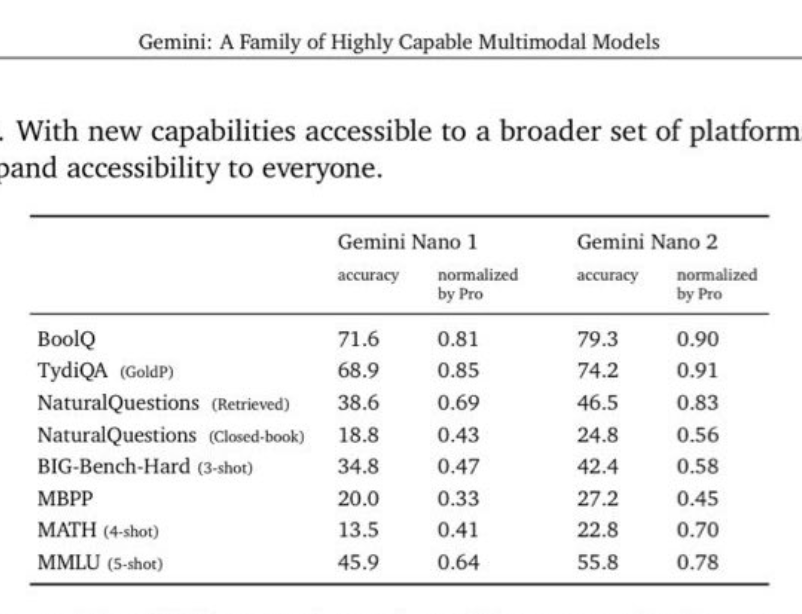
您应该看看这个关于它运行速度的现场演示。
最后,基础模型和指令微调(instruct-tuned)模型的权重已经被提取并发布到 HuggingFace。
AI Twitter 综述
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
AI 模型发布与基准测试
- Anthropic Claude 3.5 Sonnet:@adcock_brett 指出 Anthropic 推出了 Claude 3.5 Sonnet,这是一款在某些基准测试中超越 GPT-4o 的升级模型。对于开发者来说,它的速度是 Opus 的 2 倍,而价格仅为 Anthropic 之前顶级模型的 1/5。对于消费者,它可以完全免费试用。@lmsysorg 报告称 Claude 3.5 Sonnet 在 Coding Arena 中已攀升至第 4 位,接近 GPT-4-Turbo 的水平。它现在是编程领域的顶级开放模型。它在 Hard Prompts 中排名第 11,在综合通用问题中排名第 20。
- DeepSeek-Coder-V2:@dair_ai 指出 DeepSeek-Coder-V2 在代码和数学生成任务上可与闭源模型竞争。根据其报告,它在 HumanEval 上达到 90.2%,在 MATH 上达到 75.7%,高于 GPT-4-Turbo-0409 的表现。包括 16B 和 236B 参数的模型,具有 128K 上下文长度。
- GLM-0520:@lmsysorg 报告称来自智谱 AI/清华大学的 GLM-0520 表现令人印象深刻,在编程排名第 9,综合排名第 11。国产 LLM 正变得比以往任何时候都更具竞争力!
- Nemotron 340B:@dl_weekly 报告称 NVIDIA 发布了 Nemotron-4 340B,这是一个开源模型系列,开发者可以使用它来生成合成数据,用于训练大型语言模型。
AI 研究论文
- TextGrad: @dair_ai 指出 TextGrad 是一个通过 LLM 提供的文本反馈进行反向传播,实现自动微分 的新框架。这改进了单个组件,且自然语言有助于优化计算图。
- PlanRAG: @dair_ai 报道称 PlanRAG 通过一种名为 迭代式先规划后 RAG (iterative plan-then-RAG) 的新技术增强了决策能力。它包含两个步骤:1) LLM 通过检查数据模式和问题来生成决策计划;2) 检索器生成用于数据分析的查询。最后一步检查是否需要新计划进行进一步分析,并迭代之前的步骤或对数据做出决策。
- Mitigating Memorization in LLMs: @dair_ai 指出这篇论文提出了一种对 next-token prediction 目标的改进,称为 goldfish loss,旨在帮助缓解对记忆训练数据的逐字生成。
- Tree Search for Language Model Agents: @dair_ai 报道称这篇论文为 LM Agent 提出了一种 推理时树搜索算法,以进行探索并实现多步推理。该算法在交互式 Web 环境中进行了测试,并应用于 GPT-4o,显著提升了性能。
AI 应用与演示
- Wayve PRISM-1: @adcock_brett 报道称 Wayve AI 推出了 PRISM-1,这是一种 基于视频数据的 4D 场景(空间 3D + 时间)重建模型。此类突破对于自动驾驶的发展至关重要。
- Runway Gen-3 Alpha: @adcock_brett 指出 Runway 展示了 Gen-3 Alpha,这是一款可以 根据文本提示词和图像生成 10 秒视频 的新 AI 模型。这些人物角色 100% 由 AI 生成。
- Hedra Character-1: @adcock_brett 报道称 Hedra 发布了 Character-1,这是一款可以将 图像转换为唱歌肖像视频 的新基础模型。其公开预览版 Web 应用可以生成长达 30 秒的具有表现力的说话、唱歌或说唱角色。
- ElevenLabs Text/Video-to-Sound: @adcock_brett 指出 ElevenLabs 发布了一款全新的 开源文本和视频转音效应用及 API。开发者现在可以构建根据文本提示词生成音效或为无声视频添加声音的应用。
梗与幽默
- Gilded Frogs: @c_valenzuelab 将 “Gilded Frogs” 定义为 积累了巨大财富并佩戴奢华珠宝 的青蛙,包括金链、镶嵌宝石的手镯和戒指,全身覆盖着钻石、红宝石和蓝宝石。
- Llama.ttf: @osanseviero 指出 Llama.ttf 是一个 既是字体也是 LLM 的文件。TinyStories (15M) 作为一个字体 🤯 字体引擎运行 LLM 的推理。这是将本地 LLM 推向极致的体现。
- VCs Funding GPT Wrapper Startups: @abacaj 发布了一张梗图,调侃 VC 资助 GPT 套壳 (wrapper) 初创公司。
- Philosophers vs ML Researchers: @AmandaAskell 发布了一张梗图,对比了 哲学家与 ML 研究员发表论文的数量。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
Stable Diffusion / AI 图像生成
-
Pony Diffusion 模型给用户留下深刻印象:在 /r/StableDiffusion 中,用户正在发掘 Pony Diffusion 模型的各项功能和创意潜力,发现它使用起来既有趣又令人耳目一新。一些人承认低估了 Pony 的职责履行和 Prompt 遵循能力。目前有用户请求提供深入的 Pony 教程,以帮助生成理想的全年龄段动漫/漫画风格图像,同时避免产生意外的 NSFW 内容。
-
新技术与模型更新:用户正在分享 ComfyUI 中的背景替换、重照明和合成工作流,并演示了在 adetailer 模型中使用 [SEP] Token 处理多个 Prompt 的方法。SD.Next 发布公告强调了 10 多项改进,如量化 T5 编码器支持、PixArt-Sigma 变体、HunyuanDiT 1.1 以及针对低 VRAM GPU 的效率升级。sd-scripts 现已支持训练 Stable Diffusion 3 模型。
-
创意应用与模型对比:尼古拉·特斯拉博物馆的一个展览展出了 118 件使用 Stable Diffusion 创作的 AI 辅助艺术作品,突显了 AI 在专业社区之外的应用。新的 LoRA 模型不断发布,例如用于北欧风格肖像的 Aether Illustration 以及适用于 SDXL 的黑白插画风格模型。一项针对 “woman lying on grass”(躺在草地上的女人)Prompt 的多种模型对比引发了关于各模型性能表现的热议。
-
许可协议讨论:用户发现 Stable Cascade 的初始权重曾以 MIT 许可证发布了约 4 天,随后才更改为更严格的许可证,这暗示了 MIT 许可版本具有商业化使用的潜力。这导致人们纷纷下载该特定版本。
ChatGPT / AI 助手
-
AI 生成的游戏令用户惊叹:在 /r/ChatGPT 中,AI 助手 Claude 在聊天界面内创建了一个可玩的 3D 第一人称射击游戏。这个游戏的内容是向悲伤的怪物发射快乐表情符号使它们变开心,这完全是 Claude 自己的主意。这被视为一个突破性时刻,意味着 AI 现已能与初级人类游戏开发者竞争。用户非常欣赏 Claude 这种可爱且充满希望的创意。
-
模型性能与基准测试:根据最近发布的结果,Claude 3.5 Sonnet 在 MMLU-Pro 等多项基准测试中位居榜首。
-
通过知识集成改进聊天机器人:在 /r/singularity 中,一位用户对大型 AI 公司尚未将聊天机器人连接到维基百科等知识库或 WolframAlpha 等工具以提高事实、数学、物理等方面的准确性感到惊讶。他们认为底层技术已经存在,只是需要集成,尽管语言模型可能仍面临一些根本性的局限。
AI Discord 回顾
特别说明:正如我们在发布前沿模型时所做的那样,我们展示了在 Claude 3.5、Claude 3 和 GPT4o 上运行相同提示词(Prompts)的输出差异。
Claude 3 Sonnet
1. LLM 性能基准测试与进展
- Meta 的 Llama 3 模型在 ChatbotArena 等排行榜上迅速攀升至榜首,表现优于 GPT-4-Turbo 和 Claude 3 Opus,正如此讨论中所述。
- 讨论了 IBM 的 Granite-8B-Code-Instruct 和 DeepSeek 的 DeepSeek-V2 236B 模型等新模型,后者在某些基准测试中表现优于 GPT-4。
- 然而,人们对某些基准测试持怀疑态度,并呼吁可靠的来源来设定现实的评估标准。
2. 高效 LLM 训练与推理技术
- DeepSpeed 的 ZeRO++ 被提及,有望将 GPU 上大型模型训练的通信开销降低 4 倍。
- 讨论了 vAttention 系统,用于在不使用 PagedAttention 的情况下动态管理 KV-cache 以实现高效推理。
- QServe 的 W4A8KV4 量化被重点介绍,作为一种提升 GPU 上云端 LLM 服务性能的技术。
- 提到了 Consistency LLMs 等技术,用于探索并行 Token 解码以降低推理延迟。
3. 开源 AI 框架与社区努力
- 讨论了 Axolotl 项目,旨在支持多种数据集格式,用于指令微调(Instruction Tuning)和 LLM 预训练。
- LlamaIndex 被提及为吴恩达(Andrew Ng)关于构建 Agentic RAG 系统的新课程提供支持。
- 介绍了开源的 RefuelLLM-2 模型,声称是处理“枯燥数据任务”的最佳选择。
- 关于 Modular 的 Mojo 的讨论强调了其在 Python 集成和 AI 扩展(如 bfloat16)方面的潜力,详见此处。
4. 多模态 AI 与生成式建模
- 提到了 Idefics2 8B Chatty 和 CodeGemma 1.1 7B 模型,它们分别专注于聊天交互和编程能力,详见此处讨论。
- 重点介绍了 Phi 3 模型,根据此 Reddit 链接,该模型通过 WebGPU 将强大的 AI 聊天机器人引入浏览器。
- 提到结合 Pixart Sigma、SDXL 和 PAG 旨在实现 DALLE-3 级别的输出,并有可能通过微调(Fine-tuning)进一步优化,详见此讨论。
- 此对话中还提到了开源的 IC-Light 项目,专注于改进图像重照明(Relighting)技术。
Claude 3.5 Sonnet
- LLM 性能与基准测试(Benchmarking)争论:
- 像 DeepSeek-V2 和 Hermes 2 Theta Llama-3 70B 这样的新模型因其性能而备受关注。然而,社区对 AI 基准测试和排行榜的怀疑日益增加,呼吁建立更具公信力的评估方法。
- 多个 Discord 社区的讨论涉及了比较 GPT-4、Claude 以及新型开源替代方案的挑战,强调了实际性能与基准测试分数之间的复杂性。
- 优化 LLM 训练与推理:
- 社区正在分享提高 LLM 效率的技术,例如 量化方法(quantization methods) 以及针对 AMD GPUs 等特定硬件的优化。
- 降低计算成本引起了极大兴趣,讨论范围从 VRAM 优化 到用于更高效推理的新颖架构。
- 开源 AI 开发与协作:
- 像 Axolotl 和 LlamaIndex 这样的项目正在促进社区驱动的 AI 工具和框架开发。
- 模型和工具的开源化已成趋势,如 RefuelLLM-2 和 Llamafile 所示,这鼓励了更多人参与到 AI 开发中。
- 多模态 AI 与创意应用:
- 各个 Discord 社区的讨论突显了对处理文本、图像以及潜在视频的多模态模型日益增长的兴趣,Stable Artisan 等项目正将这些能力带给更广泛的受众。
- 目前正在进行结合不同模型和技术以达到 DALL-E 3 级别输出的实验,展示了社区驱动的推进生成式 AI 能力的方法。
- AI 集成与实际应用:
- 多个社区正在探索将 AI 集成到日常工具中的方法,从 基于浏览器的模型 到用于媒体创作的 Discord 机器人。
- 人们越来越关注如何让 AI 在特定任务中更易于获取且更有用,这体现在各个 Discord 频道关于代码生成、数据分析和创意应用的讨论中。
Claude 3 Opus
- LLM 性能与基准测试 (Benchmarking):
- 关于 Llama 3、DeepSeek-V2 和 Claude 3.5 Sonnet 等模型在各种基准测试和排行榜上表现的讨论。
- 对某些基准测试(如 AlpacaEval)的质疑,并呼吁建立更具公信力的评估标准。
- 优化 LLM 训练与推理:
- 高效训练技术,如 ZeRO++ 和 Consistency LLMs,以及通过 vAttention 和 QServe 实现的推理优化。
- 关于量化方法(如 W4A8KV4)及其对模型性能和资源需求影响的讨论。
- 开源 AI 框架与协作:
- 涉及 Axolotl、LlamaIndex 和 Modular 等开源框架的更新与协作。
- 推出新的开源模型,例如 RefuelLLM-2 和 Granite-8B-Code-Instruct。
- 多模态 AI 与生成模型:
- 多模态 AI 的进展,包括 Idefics2 8B Chatty 和 CodeGemma 1.1 7B 等模型。
- 生成式建模的创新,例如用于浏览器端聊天机器人的 Phi 3,以及结合多种技术实现 DALLE-3-级别的输出。
- 图像重光照(Image Relighting)领域的开源努力,如 IC-Light 项目。
- AI 伦理、法律与问责:
- 关于 AI 生成内容伦理影响的讨论,如 Perplexity AI 涉嫌剽窃 事件。
- 对 AI 模型发表不准确或诽谤性言论相关法律风险的担忧,如 Perplexity AI 案例 所强调的。
- 关于科技公司使用开放数据集的问责制以及 “AI 数据洗白” 做法的辩论。
GPT4T (gpt-4-turbo-2024-04-09)
1. **AI 硬件在进化,但成本激增:
- Command R (34b) Q4_K_S 等 AI 模型对 VRAM 的需求引发了关于转向 EXL2(一种更节省 VRAM 的格式)的讨论。NVIDIA DGX GH200 因高昂成本仍难以触及。
2. **优化成为 AI 工具的核心:
- 利用量化技术优化模型性能,提到了 ROCm 版本的 xformers 和 flash-attention 以提高效率。在 Llama-2 模型中实现的 PyTorch 增强带来了显著的性能提升。
3. **AI 在多方面应用中取得突破:
- 由 OpenRouter 开发的 AI 驱动阅读辅助工具 Pebble 展示了 AI 在增强阅读理解方面的新颖用途。Cohere 的 API 支持多步工具调用(Multi-step tool use),显著扩大了功能范围,并辅以关于 多步工具调用 的详细文档。
4. **以 AI 为中心的教育与就业正在扩张:
- MJCET 在特伦甘纳邦成立了首个 AWS Cloud Club,旨在向学生普及 AWS 技术,并举办了由 AWS Community Hero Mr. Faizal Khan 参加的庆祝活动。通过 活动链接 报名。此外,Hamel Dan 的 LLM101n 课程提供了以 AI 为灵感的教育内容,教授从零开始构建 LLM。
5. **其他 AI 进展反映了广泛影响:
- Intel 从 AWS 撤退,令 AI 社区对资源分配感到困惑。Claude Sonnet 3.5 在编程任务中的表现赢得赞誉,展示了 AI 在技术应用方面的进步。出人意料的是,Mozilla 的 Llamafile 进军 Android 领域,承诺提供创新的移动端解决方案。
GPT4O (gpt-4o-2024-05-13)
模型优化与 LLM 创新
- DeepSeek 和 Sonnet 3.5 主导基准测试:DeepSeek 模型以其快速的性能和编码能力给社区留下了深刻印象,在某些情况下超越了 GPT-4 (DeepSeek 公告)。同样,Claude 3.5 Sonnet 在编码任务中表现优于 GPT-4o,这已通过 LMSYS 排行榜排名和实际使用得到验证 (Claude 推文)。
- ZeRO++ 和 PyTorch 加速 LLM 训练:ZeRO++ 将大模型训练中的通信开销降低了 4 倍,而新的 PyTorch 技术将 Llama-2 的推理速度提高了 10 倍,这些技术被封装在 GPTFast 软件包中,优化了其在 A100 或 H100 GPU 上的使用 (ZeRO++ 教程)。
开源进展与社区努力
- Axolotl 和 Modular 鼓励社区贡献:Axolotl 宣布集成了 ROCm 分支版本的 xformers 以支持 AMD GPU,Modular 用户讨论了为 LLVM 和 CUTLASS 贡献学习材料 (相关指南)。
- Featherless.ai 和 LlamaIndex 扩展功能:Featherless.ai 是一个以 Serverless 方式运行公共模型的新平台,其发布引起了广泛关注 (Featherless)。LlamaIndex 现在支持通过 StabilityAI 生成图像,增强了其面向 AI 开发者的工具包 (LlamaIndex-StabilityAI)。
AI 生产与实际应用
- MJCET 的 AWS Cloud Club 启动:MJCET 的 AWS Cloud Club 正式成立,促进了 AWS 实操培训和职业发展计划 (AWS 活动)。
- OpenRouter 在实际应用中的使用:JojoAI 因其主动助手能力而受到关注,它利用 DigiCord 等集成,表现优于 ChatGPT 和 Claude 等竞争模型 (JojoAI 网站)。
运营挑战与支持查询
- 安装和兼容性问题困扰用户:在 Windows 上设置 xformers 等库的困难引发了关于兼容性的讨论,建议倾向于使用 Linux 以获得更稳定的运行 (Unsloth 故障排除)。
- 额度和支持问题:Hugging Face 和 Predibase 社区的许多成员面临服务额度丢失和账单查询问题,显示出对改进客户支持系统的需求 (Predibase)。
新兴技术与未来方向
- 发布新的 AI 模型和集群:AI21 的 Jamba-Instruct(具有 256K 上下文窗口)和 NVIDIA 的 Nemotron 4 突出了在处理大规模企业文档方面的突破 (Jamba-Instruct, Nemotron-4)。
- 多模态融合(Multi Fusion)与量化技术:关于多模态模型中早期融合与后期融合优缺点的讨论,以及量化技术的进步,突出了在降低 AI 模型推理成本和提高效率方面的持续研究 (Multi Fusion)。
第 1 部分:Discord 高层级摘要
HuggingFace Discord
虚拟现实中选择 Juggernaut 还是 SD3 Turbo?:虽然 Juggernaut Lightning 因其在非编程创意场景中的写实性而受到青睐,但 SD3 Turbo 的讨论热度并不高,这表明模型的选择受到具体语境和目标的影响。
PyTorch 用户的量子飞跃:建议优先投资 PyTorch 和 HuggingFace 等库,而非 sklearn 等陈旧工具。使用 bitsandbytes 和 4-bit quantization(4位量化)等精度修改技术,可以帮助在受限的硬件上加载模型。
元模型合并与共情演化:Open Empathic 项目正在通过 YouTube 贡献的电影场景分类进行扩展。同时,关于 UltraChat 和 Mistral-Yarn 的合并策略引发了辩论,其中 mergekit 和 frankenMoE finetuning 被提及为改进 AI 模型的重要技术。
增强型软件与服务:一系列贡献相继涌现,包括 Mistroll 7B v2.2 的发布、用于 Stable Diffusion 的简单微调工具、使用 PyQt 和 Whisper 开发的媒体转文本 GUI,以及用于 Serverless 模型调用的新 AI 平台 Featherless.ai。
追求 AI 推理的启示:揭示 LLM 推理最新进展的计划正在酝酿中,重点考察 Understanding the Current State of Reasoning with LLMs (arXiv 链接) 以及 Awesome-LLM-Reasoning 及其同名备用仓库链接等资源。
Unsloth AI (Daniel Han) Discord
- Unsloth AI 预览引发热议:在视频拍摄公告发布后,一名成员因期待 Unsloth AI 的发布而分享了一段临时录像,以等待早期访问权限。为了提高清晰度,建议将缩略图从 “csv -> unsloth + ollama” 修改为 “csv -> unsloth -> ollama”,并为新手添加解释性文本。
- 大显存引发大讨论:一段 YouTube 视频展示了 Phison 的 PCIe-NVMe 卡作为一种惊人的 1Tb VRAM 解决方案,引发了关于其对性能影响的讨论。同时,Fimbulvntr 成功将 Llama-3-70b 扩展到 64k 上下文,以及关于 VRAM 扩展的辩论,凸显了对大模型容量的持续探索。
- LLM 的升级与情感:Ollama 更新定于周一或周二发布,承诺支持 CSV 文件。同时,Sebastien 开发的 emotional llama model(旨在促进 AI 对情感的更好理解)已在 Ollama 和 YouTube 上线。
- 解决安装与兼容性问题:从在 Windows 上通过 conda 为 Unsloth 安装 xformers 的困难,到确保 Google Colab 笔记本中初始设置单元格的正确执行,成员们交流了克服软件挑战的技巧。GPU Cloud (NGC) 容器设置讨论以及 CUDA 和 PyTorch 版本限制问题,也通过使用不同的容器和共享 Dockerfile 配置得到了解决。
- 思考合作伙伴关系与 AI 集成:一篇题为《Apple 与 Meta 合作伙伴关系:iPhone 生成式 AI 的未来》的博客引起了社区的兴趣,讨论集中在生成式 AI 在移动设备中的战略影响和潜在集成挑战。
Stability.ai (Stable Diffusion) Discord
- 机器人警示:有人分享了一个用于集成 Gemini 和 StabilityAI 服务的 Discord 机器人,但成员们对该链接的安全性和上下文表示担忧。
- Civitai 因许可担忧下架 SD3:Civitai 移除 SD3 资源引发了激烈讨论,这表明此举是为了预先规避法律问题。
- 低配运行 Stable Diffusion:讨论了在低规格 GPU 上运行 Stable Diffusion 的技术(如利用 automatic1111),并权衡了旧款 GPU 与 RTX 4080 等新型号的效率。
- 训练难题与技巧:社区成员寻求训练模型以及克服 VRAM 限制和有问题的元数据等错误的建议,一些人建议使用 ComfyUI 和 OneTrainer 等专门工具进行更高级的管理。
- 模型兼容性困惑:讨论强调了 SD 1.5 和 SDXL 等模型与 ControlNet 等插件保持一致的必要性;类型不匹配会导致性能下降和错误。
CUDA MODE Discord
- CUTLASS 与 CUDA 协作号召:受一段分享的 Tensor Cores YouTube 演讲 启发,用户表达了组建 CUTLASS 工作组的兴趣。此外,通过分享 缓存功能入门指南,加深了对 CPU 缓存的见解,强调了其对程序员的重要性。
- 浮点数与精度风险:FP8 转换中的精度损失引起了关注,促使大家分享了用于理解 IEEE 舍入约定以及使用 tensor scaling 抵消损失的资源。对于探索 Quantization 的用户,推荐了一系列论文和教育内容,包括 Quantization 详解 和 高级 Quantization。
- INT4 与 QLoRA 爱好者讨论:在对比 INT4 LoRA 微调与 QLoRA 的讨论中,有人指出 QLoRA 包含的 CUDA dequant kernel (axis=0) 保持了质量和速度,特别是与在大序列上使用 tinnygemm 的方案相比。
- 神经网络优化:Bitnet tensors 与 AffineQuantizedTensor 的集成引发了辩论,考虑了用于指定打包维度的特殊布局。为了协助调试 Bitnet tensor 问题,CoffeeVampire3 的 GitHub 和 PyTorch ao 库教程 被列为首选资源。
- 扩展系统稳定性的策略:多节点设置优化和集成 FP8 matmuls 的策略是对话的核心,旨在解决性能挑战和训练稳定性,特别是 H100 GPU 与 A100 相比显示出的问题。此外,还为即将在 Lambda 集群上进行的大规模语言模型训练做了准备,重点关注效率和稳定性。
LM Studio Discord
显存紧缺与高昂价格:工程师们强调了在处理像 Command R (34b) Q4_K_S 这样的大型模型时的 VRAM 瓶颈,建议使用 EXL2 作为更节省 VRAM 的格式。对于重负载的 AI 工作,以海量内存著称的 NVIDIA DGX GH200 对大多数人来说在财务上仍然遥不可及,暗示需要数千美元的投资。
LLM 推理的量子飞跃:用户对 Hermes 2 Theta Llama-3 70B 模型印象深刻,该模型以其显著的 token 上下文限制和创意优势而闻名。关于 LLM 缺乏时间意识的讨论促使人们提到了 Hathor Fractionate-L3-8B,因为它在输出 tensors 和 embeddings 保持非量化时表现出色。
酷炫装备与热门芯片:在硬件战场上,使用 P40 GPUs 运行 Codestral 显示出功率利用率激增至 12 tokens/second。与此同时,iPad Pro 的 16GB RAM 是否能处理 AI 模型引发了争论,针对 4000 系列 GPU 缺乏 NVlink 的情况,有人提出了使用 DX 或 Vulkan 实现多 GPU 支持的构想。
补丁与插件:LLaMa library 因模型预期的 tensor 数量不匹配导致的错误而令用户困扰,而 deepseekV2 面临加载困难,可能通过更新到 V0.2.25 来修复。人们对一种假设的全能模型运行器充满热情,该运行器可以处理包括 text-to-speech 和 text-to-image 在内的各种 Huggingface 模型。
模型工程与谜团:名字奇特的 Llama 3 CursedStock V1.8-8B 模型因其独特的性能(尤其是在创意内容生成方面)激起了人们的好奇心。还有关于 Multi-model sequence map 的讨论,它允许数据在多个模型之间流动,而最新的量化 Qwen2 500M 模型因其能在性能较低的设备(甚至是 Raspberry Pi)上运行而引起轰动。
OpenAI Discord
- Siri 与 ChatGPT 的奇特组合:用户对 Siri 与 ChatGPT 的集成感到困惑,共识是 ChatGPT 充当了 Siri 的增强功能,而非核心集成。Elon Musk 的批评性言论进一步引发了关于该话题的讨论。
- Claude 在编程上完胜 GPT-4o:Claude 3.5 Sonnet 因在编程任务中优于 GPT-4o 的表现而受到赞誉,用户强调了 Claude 在 GPT-4o 碰壁的领域取得了成功。有效性是通过实际使用和 LMSYS 排行榜上的位置来衡量的,而不仅仅是基准测试分数。
- 持久的 LLM 个人助理之梦:人们对定制和维护语言模型(如 Sonnet 3.5 或 Gemini 1.5 Pro)以作为基于个人文档训练的个性化工作机器人的可能性表示热忱,引发了关于 LLM 长期和专业化应用的讨论。
- GPT-4o 的上下文窗口困扰:用户在 GPT-4o 遵循复杂 prompt 指令及处理长文档的能力限制方面感到吃力。建议使用 Gemini 和 Claude 等替代方案,以便在更大的 token 窗口中获得更好的表现。
- DALL-E 与 Midjourney 的艺术对决:服务器上正在展开一场关于 DALL-E 3 和 Midjourney 生成 AI 图像能力的辩论,特别是在绘画风格的艺术作品领域,一些人表现出对前者独特艺术风格的偏好。
Perplexity AI Discord
- Perplexity AI 陷入抄袭风波:Wired 报道了 Perplexity AI 因抓取网站而涉嫌违反政策的行为,其聊天机器人将一起罪行错误地归咎于一名警察,引发了关于 AI 摘要不准确所带来的法律影响的辩论。
- 对 Claude 3.5 Sonnet 的反应褒贬不一:据 Forbes 报道,Claude 3.5 Sonnet 的发布既因其强大的能力获得掌声,也因其表现得过于谨慎而令人沮丧;同时,用户在 Pro 搜索结果中遇到的不一致性导致了对 Perplexity 服务的不满。
- 关于 Apple 和 Boeing 困境的独家报道:Apple 的 AI 在欧洲面临限制,而 Boeing 的 Starliner 遭遇重大挑战,这些信息在 Perplexity 上传播,并附有指向相关问题的文章直链(Apple Intelligence Isn’t, Boeing’s Starliner Stuck)。
- Perplexity API 的难题:Perplexity API 社区讨论了 LLama-3-70B 在处理长 Token 序列时可能触发的审核机制或技术错误,并提出了关于通过 API 限制链接摘要和引用中时间过滤的问题,详见 API 参考文档。
- 社区融合以提升参与度:OpenAI 社区的一条消息强调了对可分享线程的需求,以促进更好的协作;同时,由 Perplexity AI 制作的 YouTube 视频预告了诸如 Starliner 困境和 OpenAI 最新动态等多样化的教育性话题。
Nous Research AI Discord
数据集去重效率提升:Rensa 凭借 Rust 的 FxHash、LSH 索引和即时排列技术,在数据集去重方面实现了比 datasketch 快 2.5-3 倍的速度提升。
模型越狱曝光:一篇《金融时报》文章强调了黑客通过“越狱” AI 模型来揭示缺陷,同时 GitHub 上的贡献者分享了一个 “smol q* 实现”以及像 llama.ttf 这样伪装成字体文件的创新 LLM 推理引擎项目。
关于模型参数的热烈辩论:在 ask-about-llms 频道中,讨论范围从 TinyStories-656K 令人惊讶的故事生成能力,到关于 70B+ 参数模型在通用性能上大幅飞跃的断言。
数据集合成与分类增强:成员们分享了一个用于协作跟踪数据集的 Google Sheet,探索了使用 Hermes RAG 格式的改进,并深入研究了用于科学和教学目的的 SciRIFF 和 ft-instruction-synthesizer-collection 等数据集。
AI 安全模型审查与课程:#general 频道内容丰富,从 Gemini 和 OpenAI 具备脱敏能力的安全性模型,到 Karpathy 的 LLM101n 课程发布,鼓励工程师构建一个讲故事的 LLM。
Eleuther Discord
- SLURM 与 Jupyter 的连接问题:工程师在通过 Jupyter Notebook 连接 SLURM 管理的节点时遇到问题,称错误可能源于 SLURM 的限制。一位用户反映,即使 GPU 规格配置正确,在训练开始前控制台也会出现 ‘kill’ 消息。
- PyTorch 提升 Llama-2 性能:PyTorch 团队实施了相关技术,将 Llama-2 的推理速度提高了多达十倍;这些增强功能封装在 GPTFast package 中,需要 A100 或 H100 GPU。
- AI 模型的伦理与共享:关于在官方渠道之外分发 Mistral 等专有 AI 模型的伦理和实际考量的严肃对话,强调了对法律问题的担忧以及透明度的重要性。
- 理解 AI 模型变体:用户讨论了确定 AI 模型是 GPT-4 还是其他变体的方法,包括检查知识截止日期、延迟差异和网络流量分析。
- LingOly 挑战赛介绍:新的 LingOly 基准测试旨在评估 LLM 在涉及语言谜题的高级推理方面的表现。在展示的一千多个问题中,顶级模型的准确率低于 50%,这表明对当前架构构成了严峻挑战。
- ARDiT 的文本转语音创新:一期 播客节目 探讨了使用 SAEs 进行模型编辑,灵感来自 MEMIT paper 及其 源代码 中详述的方法,表明该技术具有广泛的应用前景。
- 思考多模态架构的最优性:对话探讨了像 Chameleon 这样的早期融合模型在多模态任务中是否优于后期融合方法。焦点在于早期融合在图像 Token 化过程中通用性与视觉敏锐度损失之间的权衡。
- Intel 撤出 AWS 实例:Intel 正在停止 gpt-neox 开发团队利用的 AWS 实例,引发了关于计算资源的高性价比方案或替代性手动解决方案的讨论。
- 执行错误:NCCL 后端:工程师报告在尝试使用 gpt-neox 在 A100 GPU 上训练模型时,持续遇到 NCCL 后端挑战,这一问题在各种 NCCL 和 CUDA 版本中(无论是否使用 Docker)都一致存在。
Latent Space Discord
- Character.AI 攻克大规模推理难题:Character.AI 的 Noam Shazeer 通过 推理过程的优化 阐明了对 AGI 的追求,强调了他们每秒处理超过 20,000 条推理查询的能力。
- 收购新闻:OpenAI 欢迎 Rockset:OpenAI 已收购 Rockset,这是一家擅长混合搜索架构的公司,拥有向量 (FAISS) 和关键词搜索等解决方案,加强了 OpenAI 的 RAG 套件。
- Karpathy 助力 AI 教育:Andrej Karpathy 播下了雄心勃勃的新课程 “LLM101n” 的种子,该课程将深入探讨从零开始构建类似 ChatGPT 的模型,继承了传奇课程 CS231n 的衣钵。
- LangChain 澄清资金使用情况:Harrison Chase 针对 LangChain 将风险投资用于产品开发而非推广的质疑做出了回应,详情见 推文。
- Murati 预告 GPT 的下一次飞跃:OpenAI 的 Mira Murati 向爱好者们透露了一个时间表,暗示可能在约 1.5 年内发布下一个 GPT 模型,同时讨论了 AI 给创意和生产性行业带来的巨大变化,详见 YouTube 视频。
- Latent Space 关于招聘 AI 专业人士的见解:新的一期 “Latent Space Podcast” 播客分解了招聘 AI 工程师的艺术与科学,引导听众了解招聘流程和防御性 AI 工程策略,其中包含来自 @james_elicit 和 @adamwiggins 的见解,可在 此页面 查看,并在 Hacker News 上引起热议。
- 探索 YAML 新领域:对话展示了开发一种基于 YAML 的 DSL 用于 Twitter 管理以增强帖子分析,并提到了 Zoho Social 的全面功能;对于类似的尝试,Anthropic 建议采用 XML 标签,一个 GitHub 仓库 展示了在 Go 语言中使用 LLM 成功设计 YAML 模板语言的案例。
Modular (Mojo 🔥) Discord
- LLVM 的身价:分享了一篇估算 LLVM 项目成本的文章,详细说明了 1.2k 名开发者产出了 6.9M 行代码,估算成本为 5.3 亿美元。克隆和检出 LLVM 是了解其开发成本的一部分。
- 安装故障与求助:强调了在 22.04 上安装 Mojo 的问题,提到了所有 devrel-extras 测试均失败;这一棘手情况导致排查工作暂停。另外,Mojo 开发过程中的 segmentation faults 令人沮丧,促使一名用户悬赏 10 美元的 OpenAI API key 以寻求解决其关键问题的帮助。
- 关于 Caching 和 Prefetching 性能的讨论:深入探讨了 caching 和 prefetching,重点关注正确应用及潜在陷阱。分享的见解包括:如果 prefetching 利用不当,可能会对性能产生负面影响;建议使用
vtune等分析工具针对 Intel 缓存进行优化,尽管 Mojo 目前不支持编译时缓存大小获取。 - 改进提案与 Nightly Mojo 版本:记录了关于 Mojo 文档改进的建议以及在 Mojo 中受控隐式转换的提案。新的 nightly Mojo 编译器发布以及 MAX repo 更新的消息引发了关于开发工作流和生产力的讨论。
- 数据标注与集成见解:一个新的数据标注平台倡议收到了关于使用 Haystack 等工具进行自动化的痛点和成功经验的反馈。ERP 集成的潜力(由手动数据录入挑战和 PDF 处理引发)也是一个焦点,表明了简化数据管理工作流的趋势。
LAION Discord
- Weta 与 Stability AI 的新变局:Weta Digital 和 Stability AI 领导层变动的消息引发了一波讨论,重点关注这些大洗牌的影响,并质疑任命背后的动机。一些讨论指向了 Sean Parker 并分享了相关文章,链接了一篇 路透社关于 Stability AI 的文章。
- Llama 3 蓄势待发:对于 Llama 3 的硬件规格展现出的惊人性能,大家感到非常兴奋,其表现可能超越 GPT-4O 和 Claude 3 等竞争对手模型。参与者分享了在高级配置下“每秒 1 到 2 个 token”的预计吞吐量。
- Glaze 与 Nightshade 的保护悖论:一场关于 Glaze 和 Nightshade 等程序保护艺术家权利能力有限的严肃对话展开。怀疑者指出,后来者总能找到绕过此类保护的方法,从而给艺术家提供了潜在的虚假希望。
- 多模态模型——重复的突破?:该社区研究了一篇关于多模态模型的新论文,提出了所谓的进步是否有意义的疑问。该论文提倡在多种模态上进行训练以增强通用性,但参与者批评这种反复出现的“突破”叙事缺乏实质性的新意。
- 测试极限:Diffusion Models 的承诺与局限:lucidrains 分享的一个 GitHub 仓库对 diffusion models 进行了深入探讨,讨论了 EMA (Exponential Moving Average) 模型更新(GitHub 上的 Diffusion Models)及其在图像修复中的应用,尽管有证据表明像 Glaze 这样的保护措施会被持续绕过。
Cohere Discord
- 新成员欢迎:新成员加入了以 Cohere 为中心的 Discord,在共享见解和工具使用文档的引导下,学习如何将 Cohere 模型连接到外部应用程序。
- 对 BitNet 实用性的质疑:在关于 BitNet 未来的辩论中,有人指出它需要从头开始训练,且未针对现有硬件进行优化,导致 Mr. Dragonfox 对其商业实用性表示担忧。
- Cohere 的能力与贡献:在 Microsoft 的 AutoGen framework 集成了 Cohere 客户端后,社区内呼吁 Cohere 团队在项目推进中提供进一步支持。
- AI 爱好者渴望多语言扩展:确认了 Cohere 模型理解并响应多种语言(包括中文)的能力,并引导感兴趣的各方查阅文档和 GitHub notebook 示例以了解更多信息。
- 开发者办公时间与多步创新:Cohere 宣布了即将举行的开发者办公时间,重点介绍 Command R 家族的工具使用能力,并提供关于多步工具使用的资源,以利用模型执行复杂的任务序列。
LangChain AI Discord
- 关于上下文和 Token 的混淆:用户报告了关于 Agent 中 max tokens 和上下文窗口集成的混淆,特别是 LangChain 未遵循 Pydantic 模型的验证。指出上下文窗口或最大 Token 计数应同时包含输入和生成的 Token。
- LangChain 学习与实现查询:关于 LangChain 学习曲线的讨论非常热烈,成员们分享了诸如 Grecil 的个人旅程等包含教程和文档的资源。同时,关于 ChatOpenAI 与 Huggingface 模型的辩论突显了在各种场景下的性能差异和适配问题。
- 使用 LangChain 增强 PDF 问答:分享了使用 LangChain 从 PDF 生成问答对的详细指南,并参考了 GitHub 上的 #17008 等问题以获取进一步指导。还讨论了使用 Llama2 作为 LLM 的调整,强调了自定义
QAGenerationChain。 - 从零到 RAG 英雄:成员们展示了他们为金融文档构建无代码 RAG 工作流的经验,并分享了一篇详细介绍该过程的文章。讨论还集中在一个自定义的 Corrective RAG app 和 Edimate(一个 AI 驱动的视频创作工具,在此演示),这标志着在线学习的未来。
- AI 框架评估视频:针对正在评估用于应用程序集成(包括 GPT-4o 等模型)的 AI 框架的工程师,分享了一个 YouTube 视频,敦促开发者考虑关于特定应用中 AI 框架的必要性和选择的关键问题。
OpenRouter (Alex Atallah) Discord
- Jamba Instruct 拥有巨大的上下文窗口:AI21 的 Jamba-Instruct 模型已推出,展示了高达 256K 的上下文窗口,非常适合处理企业场景中的海量文档。
- Nemotron 4 凭借合成数据生成引起关注:NVIDIA 发布的 Nemotron-4-340B-Instruct 专注于通过其新的聊天模型为英语应用生成合成数据。
- JojoAI 升级为主动型助手:JojoAI 通过成为一个可以设置提醒的主动型助手而脱颖而出,它采用了 DigiCord 集成,使其有别于 ChatGPT 或 Claude 等竞争对手。可以在 JojoAI 网站上进行体验。
- Pebble 开创性的阅读辅助工具:由 OpenRouter 提供支持,并结合了 Mistral 8x7b 和 Gemini 的 Pebble 工具正式亮相,它为增强网页内容的阅读理解和记忆提供了资源。感谢 OpenRouter 团队的支持,详见 Pebble。
- 技术社区应对环境和技术问题:讨论指出,使用像 Nemotron 340b 这样的模型会带来环境足迹方面的担忧,因此推荐使用更小的模型以实现高效和环保。社区还处理了一些实际事务,例如解决 Claude 自托管端点消失的问题,赞扬 Sonnet 3.5 的编程能力,处理 OpenRouter 的速率限制(rate limits),以及就处理暴露的 API 密钥的最佳实践提供建议。
OpenInterpreter Discord
- 本地 LLM 进入 OS 模式:OpenInterpreter 社区一直在讨论通过命令
interpreter --local --os在 OS 模式下使用本地 LLM,但对其性能水平存在担忧。 - 桌面端惊喜与 GitHub 荣耀:OpenInterpreter 团队正在推广即将推出的桌面应用程序,它将提供与 GitHub 版本不同的独特体验,并鼓励用户加入等待名单。与此同时,该项目庆祝获得了 50,000 个 GitHub stars,并预示即将发布重大公告。
- 模型基准测试讨论:Codestral 和 Deepseek 模型引起了关注,Codestral 超过了内部基准测试,而 Deepseek 的快速表现给用户留下了深刻印象。关于未来优化
interpreter --deepseek命令的呼声很高。 - 跨平台 Poetry 表现:使用 Poetry 而非
requirements.txt进行依赖管理一直是一个有争议的话题,一些工程师指出了它在不同操作系统上的缺点,并主张使用 conda 等替代方案。 - 社区赞誉与担忧:虽然社区对支持(特别是对初学者的支持)充满热情和感激,但对 01 设备的发货延迟也存在不满,这凸显了社区情绪与产品交付预期之间的平衡。
LLM Finetuning (Hamel + Dan) Discord
指令合成(Instruction Synthesizing)大获全胜:新分享的 Hugging Face 仓库 强调了 Instruction Pre-Training 的潜力,提供了涵盖 40 多个任务的 2 亿个合成配对,为寻求在监督多任务预训练中突破瓶颈的 AI 从业者提供了一种稳健的多任务学习方法。
将 DeBERTa 与 Flash 结合?:关于将 DeBERTa 与 Flash Attention 2 结合的可能性引起了好奇,向对新颖模型架构协同效应感兴趣的 AI 工程师提出了潜在实现方案的问题。
修复与权宜之计:从使用移动设备解决 Maven 课程平台 空白页问题,到解决 braintrust 内内核重启后的权限错误,实际的故障排除仍然是社区讨论的主要内容。
额度风波持续:关于 Huggingface 和 Predibase 等平台上服务额度丢失的持续报告引发了成员间的支持和对各自计费支持部门的转介。其中包括一条提示:Predibase 额度在 30 天后过期,建议工程师密切关注过期日期以最大化额度使用。
训练错误与过拟合疑问:运行 Axolotl 训练命令 (Modal FTJ) 时的错误以及对 LORA 过拟合(“训练损失显著低于验证损失”)的担忧是主要的痛点,展示了 AI 工程师对警惕模型监控实践的需求。
LlamaIndex Discord
- LightningAI 与 LlamaIndex 联手:LightningAI 的 RAG 模板为多文档 Agentic RAGs 提供了 简易设置,提升了 AI 开发效率。此外,LlamaIndex 与 StabilityAI 的集成现在支持图像生成,扩展了 AI 开发者的能力。
- 利用 LlamaIndex 定制复杂性:使用 LlamaIndex 进行开发的开发者可以使用有向无环图(DAGs)定制 text-to-SQL 流水线,如本 功能概述 中所述。同时,为了更好的财务分析,可以利用 Hanane Dupouy 的 教程幻灯片 使用 CRAG 技术来提高检索质量。
- 使用 Mlflow 微调 RAGs:为了提高 RAGs 的回答准确性,将 LlamaIndex 与 Mlflow 集成提供了一种系统化的方法来管理关键参数和评估方法。
- LlamaIndex 中的深度查询格式化与并行执行:成员们讨论了 LlamaIndex 的查询响应模式,如 Refine 和 Accumulate,以及利用 OLLAMA_NUM_PARALLEL 进行并发模型执行;文档解析和 Embedding 不匹配也是技术建议的主题。
- 通过 MLflow 和 LLMs 简化 ML 工作流:Ankush K Singal 的一篇 Medium 文章 强调了通过 LlamaIndex 实际集成 MLflow 和 LLMs 以简化 ML 工作流。
Interconnects (Nathan Lambert) Discord
- Gemini 与 LLAMA 参数大对决:来自 Meta 的消息来源指出,Gemini 1.5 Pro 的参数量少于 LLAMA 3 70B,引发了关于 MoE 架构对推理过程中参数计数影响的讨论。
- GPT-4 的秘诀还是蒸馏后的力量:社区讨论了 GPT-4T/o 是早期融合模型还是大型前代模型的蒸馏版本,显示出对其基础架构理解的分歧。
- 多模态训练困境:成员们强调了后训练多模态模型的困难,理由是跨不同数据模态转移知识的挑战。这些挣扎表明,对于增强原生多模态系统的复杂性,大家已达成普遍共识。
- 探究 Nous 与索尼的骚动:Nous Research 成员对 @sonymusic 的一次戏谑询问引发了困惑与兴趣的交织,触及了 AI 在法律和创新领域的作用。
- AI 排行榜上可疑的指标:AlpacaEval 排行榜 的合法性受到质疑,工程师们在某个模型声称击败了 GPT-4 且更具成本效益后,对偏见指标提出了质疑。这引发了关于该领域性能排行榜可靠性的讨论。
OpenAccess AI Collective (axolotl) Discord
- ROCm 分支加入竞争:为了使用某些功能,建议工程师使用 xformers 和 flash-attention 的 ROCm 分支版本,并指出硬件支持特别针对 MI200 和 MI300 GPU,且需要 ROCm 5.4+ 和 PyTorch 1.12.1+。
- 奖励模型被认为不适合数据生成:共识是 Reward Model 在生成数据方面效率不高,因为其主要设计目的是对数据质量进行分类,而非生产数据。
- 合成标准化考试题目:分享了一个通过合成 SAT、GRE 和 MCAT 题目来改进针对小型模型的 AGI 评估的想法,并提议加入 LSAT 题目。
- 神秘的 Epoch 保存怪癖:训练 Epoch 似乎以随机间隔保存,这种行为被认为是不寻常的,但社区对此并不陌生。这可能与训练过程中的 steps 计数器有关。
- 数据集格式入门与 MinHash 加速:一位成员寻求关于 llama2-13b 数据集格式的建议,另一位成员讨论了使用 JSONL 格式化 Alpaca 数据集。此外,分享了一个名为 Rensa 的快速 MinHash 实现,用于数据集去重,声称比同类库快 2.5-3 倍,其 GitHub 仓库已开放供社区参与 (Rensa on GitHub)。
- 提示词结构剖析与镜像:对 Axolotl 代码库中
prompt_style的澄清揭示了不同的提示词格式化策略,重点介绍了 INSTRUCT、CHAT 和 CHATML 在交互用途上的差异。示例展示了如何使用ReflectAlpacaPrompter根据指定样式自动构建提示词结构 (更多信息见 Phorm AI Code Search)。
Mozilla AI Discord
- Llamafile 升级:Llamafile v0.8.7 已发布,具有更快的量化(quant)操作和错误修复,并传闻即将适配 Android。
- 即将举行的全球 AI 活动:旧金山正准备迎接 World’s Fair of AI 和 AI Quality Conference,社区领袖将出席。同时 Mozilla Nightly Blog 暗示了可能集成 llamafile 以提供 AI 服务。
- Mozilla Nightly 博客讨论 Llamafile:Nightly 博客详细介绍了由 llamafile 驱动的本地 AI 聊天服务的实验,预示着更广泛的采用和用户可访问性。
- 成功在 Colab 上执行 Llamafile:演示了在 Google Colab 上成功运行 llamafile,并提供了一个供他人参考的模板。
- 内存管理器改版连接 Cosmos 与 Android:Cosmopolitan 项目的一个重要 GitHub commit 翻新了内存管理器,实现了对 Android 的支持,并引发了通过 Termux 运行 llamafile 的兴趣。
Torchtune Discord
- ORPO 缺失的一环:Torchtune 目前不支持 ORPO 训练选项,尽管 DPO 可以使用已记录的训练配方。社区成员提到可以参考 ORPO/DPO 混合数据集。
- Epochs 固定为单一设置:在 Torchtune 上进行多数据集训练时,目前不允许为每个数据集设置不同的 Epochs。用户应使用 ConcatDataset 合并数据集,但同样的 Epochs 数量将适用于所有数据集。
- 是否使用 ChatML:工程师们讨论了在 Llama3 模型中使用 ChatML 模板的有效性,对比了使用 instruct tokenizer 和特殊标记的方法,以及不包含这些元素的基座模型方法,并引用了 Mahou-1.2-llama3-8B 和 Olethros-8B 等模型。
- 微调 Phi-3 需要调整:针对微调 Phi-3 模型(如 Phi-3-Medium-4K-Instruct)的任务,建议修改 tokenizer 并在 Torchtune 中添加自定义构建函数以实现兼容性。
- 系统提示词:在 Phi-3 中巧妙实现:尽管 Phi-3 未针对系统提示词(System Prompts)进行优化,但用户可以通过将系统提示词置于用户消息之前来绕过此限制,并调整 tokenizer 配置中的特定 flag 以促进微调。
tinygrad (George Hotz) Discord
- 条件编码难题:在关于 tinygrad 的讨论中,使用类似
condition * a + !condition * b的条件操作来简化 WHERE 函数的做法受到了质疑,因为这可能会导致 NaNs 问题。 - Tinygrad 中的 Intel 探索:关于 tinygrad 对 Intel 支持 的查询显示,虽然 opencl 是一个可用选项,但该框架至今尚未集成 XMX 支持。
- 周一会议要点:tinygrad 的 0.9.1 版本发布已列入下周一会议议程,重点包括 tinybox 更新、新 profiler、运行时改进、
Tensor._tri、llama 推理加速,以及针对 uop matcher 速度和 unet3d 改进的悬赏任务。 - Tinygrad 增加缓冲区视图切换功能:tinygrad 的一次提交引入了一个用于切换缓冲区视图(buffer view)的新 flag,该更改已通过 GitHub Actions 运行得到证实。
- Lazy.py 逻辑备受关注:一位工程师在修改 tinygrad 内部的
lazy.py后,发现 process replay 的结果好坏参半,寻求进一步澄清,这表明需要更深入的调查或同行评审。
LLM Perf Enthusiasts AI Discord
- Claude Sonnet 3.5 性能惊艳:一位工程师分享了在 Websim 中使用 Claude Sonnet 3.5 的经验,赞扬了它的速度、创造力和智能。他们对“在新标签页中生成”功能特别感兴趣,并尝试通过玩转标志性时尚品牌的配色方案来进行感官互动,正如其分享的推文所示。
MLOps @Chipro Discord
- AWS Cloud Club 在 MJCET 启动:MJCET 成立了 Telangana 首个 AWS Cloud Club,这是一个旨在为学生提供 Amazon Web Services 资源和经验的社区,为他们的科技行业职业生涯做准备。
- 与 AWS 专家共同参与云技术精通活动:一场庆祝 AWS Cloud Club 启动的开幕活动将于 2024 年 6 月 28 日举行,届时将邀请 AWS Community Hero Faizal Khan 先生出席。感兴趣的人士可以通过活动链接进行 RSVP。
AI Stack Devs (Yoko Li) Discord 没有新消息。如果该社区长时间没有动态,请告知我们,我们将将其移除。
Datasette - LLM (@SimonW) Discord 没有新消息。如果该社区长时间没有动态,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该社区长时间没有动态,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区长时间没有动态,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该社区长时间没有动态,请告知我们,我们将将其移除。
PART 2: 渠道详细摘要与链接
完整的频道细分内容已因邮件长度而截断。
如果你喜欢 AInews,请分享给朋友!提前感谢!