ainews-mozillas-ai-second-act
Mozilla 的 AI 第二幕
以下是该文本的中文翻译:
Mozilla 在 AIE 世界博览会(AIE World’s Fair)上展示了 llamafile 的详细现场演示,并宣布推出用于向量搜索集成的 sqlite-vec。LlamaIndex 推出了 llama-agents。Anthropic 为 Claude 引入了全新的 UI 功能以及支持 200K 上下文窗口的 Projects(项目)功能。Etched AI 揭晓了一款专用推理芯片,声称其速度可达 每秒 50 万个 token,尽管其基准测试数据遭到了质疑。Sohu 芯片可实现每秒 15 条智能体轨迹。Tim Dettmers 分享了 GPU 推理的理论极限:在 8 个 B200 通过 NVLink 连接运行 70B Llama 模型时,速度约为 每秒 30 万个 token。Deepseek Coder v2 在编程和推理能力上超越了 Gemini 和 GPT-4 的多个变体。PyTorch 纪录片 已发布,但并未引起太多关注。
极速 CPU 推理就是你所需要的一切。
2024/6/25-2024/6/26 AI 新闻。 我们为您检查了 7 个 subreddits、384 个 Twitters 和 30 个 Discords(416 个频道,3358 条消息)。 预计节省阅读时间(按 200wpm 计算):327 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
Mozilla Firefox 市场份额的缓慢下降众所周知,在经历多轮裁员后,其未来的故事非常不确定。然而,在今天的 AIE World’s Fair 开幕主题演讲中,他们强势回归:
{kind=link}

Justine Tunney 亲自带来了非常详细的 llamafile 现场演示及技术讲解,Stephen Hood 宣布了一个非常受欢迎的第二个项目 sqlite-vec,正如你所料,它为 sqlite 增加了向量搜索功能。
您可以在直播中观看完整演讲(从 53 分钟处开始):
https://www.youtube.com/watch?v=5zE2sMka620&t=262s
LlamaIndex 也以发布备受瞩目的 llama-agents 为当天画上句号。
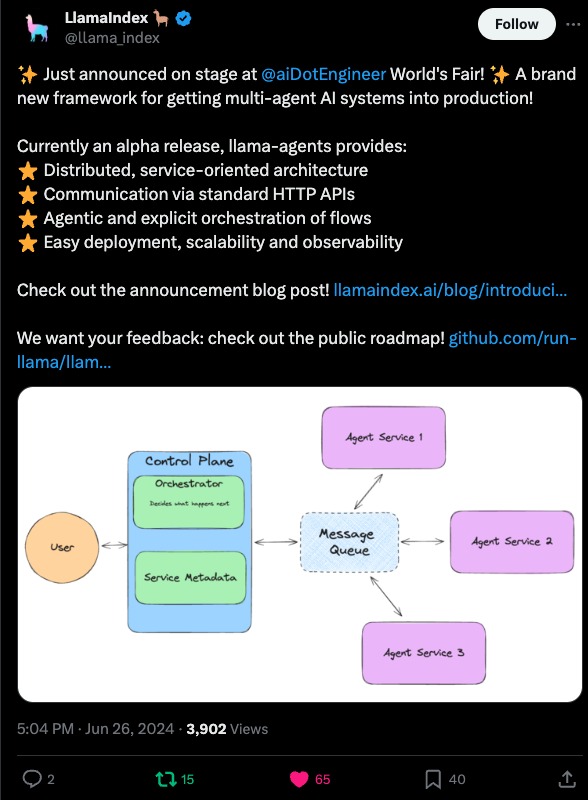
一些道歉:昨天我们漏掉了 Etched 的重大发布(受到质疑),而 Claude Projects 引起了轰动。PyTorch 纪录片发布后反应冷淡(奇怪?)。
AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
Anthropic Claude 更新
- 新 UI 功能:@alexalbert__ 注意到了 Claude UI 的新功能,包括用于收藏对话的侧边栏 (sidebar)、具有 200K context windows 用于文档和文件的可共享项目 (shareable projects),以及用于定制回答的自定义指令 (custom instructions)。
- Anthropic 发布 Projects:@AnthropicAI 推出了 Projects,允许将对话组织成可共享的知识库,并为相关文档、代码和文件提供 200K context window。适用于 Claude Pro 和 Team 用户。
硬件和性能基准测试
- Etched AI 专用推理芯片:@cHHillee 分享了对 Etched 新推理芯片的看法,指出其在芯片效率和性能方面的营销主张可能存在误导性。基准测试声称达到 500k tokens/sec(针对多用户),并能用一台 8x Sohu 服务器取代 160 块 H100,但这些数据可能未针对关键细节进行标准化。基准测试方法论需要更多信息。
- Sohu 芯片实现每秒 15 个 Agent 轨迹:@mathemagic1an 强调,Sohu 上 500k tokens/sec 的速度意味着每秒可处理 15 个完整的 30k token Agent 轨迹,并强调基于这种算力假设进行开发的重要性,以避免被淘汰。
- 理论 GPU 推理极限:@Tim_Dettmers 分享了一个模型,估算在 70B Llama 上进行 8xB200 NVLink 8-bit 推理的理论最大值约为 300k tokens/sec(假设采用类似 OpenAI/Anthropic 的完美实现)。这表明 Etched 的基准测试似乎偏低。
开源模型
- Deepseek Coder v2 击败 Gemini:@bindureddy 声称一个开源模型在推理和代码方面击败了最新的 Gemini,更多关于开源进展的细节即将发布。一份后续推文提供了具体细节——Deepseek Coder v2 在编程和推理方面表现出色,在数学方面击败了 GPT-4 变体,并在真实生产用例中使开源模型位列第三,仅次于 Anthropic 和 OpenAI。
- Sonnet 压倒 GPT-4:@bindureddy 分享到,Anthropic 的 Sonnet 模型在各种工作负载的测试中继续压倒 GPT-4 变体,预示了即将推出的模型将令人印象深刻。
生物 AI 突破
- ESM3 模拟进化以生成蛋白质:@ylecun 分享了 Evolutionary Scale AI 的消息,这是一家使用名为 ESM3 的 98B 参数 LLM 来“编程生物学”的初创公司。ESM3 模拟了 5 亿年的进化过程,生成了一种新型荧光蛋白。博客文章包含更多细节。ESM3 由前 Meta AI 研究员开发。
新兴 AI 趋势与观点
- 数据丰度是 AI 进步的关键:@alexandr_wang 强调,突破“数据墙”需要数据丰度方面的创新。AI 模型会压缩其训练数据,因此持续的进步将取决于新数据,而不仅仅是算法。
- AGI 时代后人类智能的回报:@RichardMCNgo 预测,在 AGI 之后,人类天才的溢价将会增加而非减少,因为只有最聪明的人类才能理解 AGI 正在做什么。
- 多模态 AI 的术语:@RichardMCNgo 指出,将多模态 AI 称为“LLM”正变得奇怪,并征求替代术语的建议,因为模型正在向语言之外扩展。
梗与幽默
- @Teknium1 开玩笑说 OpenAI 在 GPT-4 语音模型更新中难以移除“waifu features”。
- @arankomatsuzaki 幽默地宣布 Noam Shazeer 因在 AI 女友方面的开创性工作而获得图灵奖。
- @willdepue 调侃道,既然现在可以在聊天机器人中搜索历史对话,“AGI 已经解决了”。
AI Reddit 摘要
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 进展
- AI 网站生成:一个新的 AI 系统可以仅通过 URL 或描述输入生成完整的网页,展示了 AI 内容创建能力的进步。视频演示。
- OpenAI Voice Mode 延迟:OpenAI 宣布将高级 Voice Mode 的 alpha 版本发布推迟一个月,以改进安全性和用户体验。计划在秋季向所有 Plus 用户开放。
- 《奇点临近》新书发布:Ray Kurzweil 发布了他 2005 年著作《奇点临近》(The Singularity is Near)的续作,引发了关于 AI 未来的兴奋和讨论。
- AI Agent 猜测:OpenAI 收购了一家远程桌面控制初创公司,引发了关于将其与 ChatGPT 桌面版集成以实现 AI Agent 的猜测。
- AI 生成广告:Toys R Us 使用 SORA AI 系统生成了宣传视频/广告,展示了 AI 在营销中的应用。
{kind=link}
{kind=link}
AI Research
- 新优化器性能超越 AdamW:一篇研究论文介绍了 Adam-mini,这是一种新的优化器,其吞吐量比流行的 AdamW 高出 50%。
- LLM 中消除矩阵乘法:研究人员展示了消除矩阵乘法的 LLM,从而实现了更高效的模型,这对于在消费级硬件上运行大型模型具有重大意义。
- 用 AI 模拟进化:EvolutionaryScale 发布了 ESM3,这是一种生成式语言模型,可以模拟 5 亿年的进化以生成新的功能性蛋白质。
AI Products & Services
- Deepseek Coder V2 数学能力:用户称赞了 Deepseek Coder V2 模型的数学能力,这是一款来自中国的免费模型,表现优于 GPT-4 和 Claude。
- AI 有声读物旁白:一部 AI 旁白的有声读物广受好评,这意味着有声读物旁白现在已成为 AI 解决的问题。
- 新 AI 应用与功能:宣布了几项新的 AI 应用和功能,包括 Tcurtsni(一个“反向指令”聊天应用)、Synthesia 2.0(一个合成媒体平台)以及 Claude 中的 Projects(用于组织聊天和文档)。
{kind=link}
AI Safety & Ethics
- Rabbit 数据泄露:一项安全披露揭示了 Rabbit 的数据泄露,其 R1 模型的所有回复都可以被下载,引发了对 AI 公司疏忽的担忧。
- 幻觉担忧:一篇观点文章认为,“AI 幻觉”这一论点是危险的,因为它掩盖了快速进步的 AI 充斥就业市场的真实风险。
AI Hardware
- AMD MI300X 基准测试:发布并分析了 AMD 新型 MI300X AI 加速芯片的基准测试。
- Sohu AI 芯片声明:一款新的 Sohu AI 芯片发布,声称在 70B 模型上可达到 500K tokens/sec,8 颗芯片相当于 160 块 NVIDIA H100 GPU。
- MI300X vs H100 对比:一项对比显示,在 LLaMA-2 70B 模型上,AMD 的 MI300X 比 NVIDIA 的 H100 慢约 5%,但价格便宜 46%,且显存是其 2.5 倍。
{kind=link}
AI Art
- A8R8 v0.7.0 发布:新版本的 A8R8 Stable Diffusion UI 发布,集成了 ComfyUI 以支持区域提示(regional prompting)及其他更新。
- ComfyUI 新功能:一篇详细文章回顾了 ComfyUI Stable Diffusion 环境中的新功能,如 sampler、scheduler 和 CFG 实现。
- Magnific AI 重光照工具:Magnific AI 新重光照工具的结果与用户的日常工作流进行了对比,发现其质量不足。
- SD 模型对比:对比了不同 Stable Diffusion 模型大小在生成指定身体姿势方面的表现,结果被指出“不佳”。
Other Notable News
- Stability AI 领导层变动:Stability AI 宣布了新任 CEO、董事会成员、融资轮次,以及在扩展企业级工具的同时对开源的承诺。
- AI 流量分析:一篇 帖子 提出了量化主要 AI 系统带宽使用情况的方法,估计 AI 仍仅占整个互联网流量的一小部分。
- 政客分享虚假的 ChatGPT 统计数据:一份新闻报道称,一名加拿大政客分享了由 ChatGPT 生成的不准确统计数据,凸显了使用未经核实的 AI 输出的风险。
- 用于值班的开源 AI Agent:Merlinn 是一款旨在协助值班工程师的开源 AI Slack 机器人,现已 发布。
- 活体皮肤机器人:BBC 报道 了一项关于用活体人类皮肤覆盖机器人的研究,使其更加逼真。
- 基因疗法进展:一条 推文 讨论了基因疗法正从罕见病向常见病领域推进。
- Google AI 活动:有消息称 Google 将在 8 月的活动中展示新的 AI 技术和 Pixel 手机。
- 调低对 AI 发布日期的预期:一篇 帖子 建议对 AI 产品的发布日期持保留态度,因为研发过程存在不确定性。
- AI 终结业余主义:一篇 评论文章 认为,生成式 AI 将使每个人都能创作出专业水准的作品。
AI Discord Recap
摘要的摘要的摘要
Claude 3 Sonnet
1. 🔥 LLM 进展与基准测试
- Meta 的 Llama 3 在排行榜上名列前茅,根据 ChatbotArena 的数据,其表现优于 GPT-4-Turbo 和 Claude 3 Opus。
- 新模型:用于编程的 Granite-8B-Code-Instruct,拥有 236B 参数的 DeepSeek-V2。
- 对某些基准测试持怀疑态度,呼吁可信来源设定现实的评估标准。
2. 🤖 优化 LLM 推理与训练
- ZeRO++ 承诺将 GPU 上的通信开销降低 4 倍。
- vAttention 动态管理 KV-cache 内存以实现高效推理。
- QServe 使用 W4A8KV4 量化 来提升 GPU 上的云端服务性能。
- Consistency LLMs 探索并行 Token 解码以降低延迟。
3. 🌐 开源 AI 框架与社区努力
- Axolotl 支持多种格式的指令微调和预训练。
- LlamaIndex 为一门关于构建 Agentic RAG 系统的课程提供支持。
- RefuelLLM-2 声称是处理“枯燥数据任务”的最佳选择。
- Modular 预告了 Mojo 的 Python 集成和 AI 扩展。
4. 🖼 多模态 AI 与生成模型创新
- Idefics2 8B Chatty 用于提升聊天交互体验。
- CodeGemma 1.1 7B 优化了编程能力。
- Phi 3 通过 WebGPU 为浏览器带来强大的聊天机器人。
- 结合 Pixart Sigma + SDXL + PAG 旨在实现 DALLE-3 级别的输出,并具备微调潜力。
- 开源的 IC-Light 用于图像重打光技术。
5. 用于 Discord AI 媒体创作的 Stable Artisan
- Stability AI 推出了 Stable Artisan,这是一款集成了 Stable Diffusion 3、Stable Video Diffusion 和 Stable Image Core 的 Discord 机器人,用于 在 Discord 内生成媒体内容。
- 引发了关于 SD3 开源状态以及 Artisan 作为付费 API 服务推出的讨论。
Claude 3.5 Sonnet
-
LLM 在性能和效率方面实现跨越:
-
像 IBM 的 Granite-8B-Code-Instruct 和 RefuelLLM-2 这样的新模型正在突破代码指令和数据任务的界限。Discord 频道中的各个社区正在讨论这些进展及其影响。
-
诸如 Adam-mini 等优化技术正受到关注,有望在保持性能的同时,比 AdamW 减少 45-50% 的显存占用。这在 OpenAccess AI Collective 和 CUDA MODE 的 Discord 频道中引发了讨论。
-
用于高效 KV-cache 内存管理的 vAttention 系统 正在作为 PagedAttention 的替代方案被探索,凸显了 AI 社区对推理优化的持续关注。
-
-
开源 AI 在社区驱动工具的推动下蓬勃发展:
-
Axolotl 因其在 LLM 训练中对多样化数据集格式的支持而日益流行,在 OpenAccess AI Collective 和 HuggingFace 的 Discord 中都有讨论。
-
LlamaIndex 框架正在为构建代理式 RAG 系统的新课程提供支持,在 LlamaIndex 和通用 AI 开发社区中引起了热烈反响。
-
Mojo 在 Python 集成和 AI 扩展方面的潜力是 Modular Discord 的热门话题,讨论集中在它对 AI 开发工作流的影响。
-
-
多模态 AI 突破创意边界:
-
Pixart Sigma、SDXL 和 PAG 的结合正在被探索以实现 DALLE-3 级别的输出,这在 Stability.ai 和通用 AI 社区中得到了讨论。
-
Stable Artisan 是来自 Stability AI 的一款新 Discord 机器人,它集成了 Stable Diffusion 3 和 Stable Video Diffusion 等模型,在多个 Discord 频道中引发了关于 AI 驱动媒体创作的对话。
-
用于图像重光照的开源 IC-Light 项目 正在计算机视觉圈引起关注,展示了图像处理技术中持续的创新。
-
-
AI 硬件竞赛升温:
-
AMD 的 Radeon Instinct MI300X 正在挑战 Nvidia 在 GPU 计算市场的统治地位,尽管面临软件生态系统的挑战。这一直是 CUDA MODE 和硬件导向 Discord 频道的热门话题。
-
Etched 的 Sohu AI 芯片 的发布在 AI 硬件社区引发了辩论,讨论其在运行 Transformer 模型方面超越 GPU 的潜力,并声称可以取代多个 H100 GPU。
-
关于专用 AI 芯片与通用 GPU 的讨论正在进行,各个 Discord 服务器的社区成员正在辩论 AI 硬件加速的未来方向。
-
Claude 3 Opus
1. LLM 性能与基准测试:
- 关于各种 LLM 性能的讨论,例如 Meta 的 Llama 3 在 ChatbotArena 等排行榜上表现优于 GPT-4-Turbo 和 Claude 3 Opus 等模型。
- IBM 的 Granite-8B-Code-Instruct 和 DeepSeek-V2 等新模型展示了在指令遵循和参数量方面的进展。
- 对某些基准测试可信度的担忧,以及对来自权威来源的现实 LLM 评估标准的需求。
2. 硬件进展与优化技术:
- 正在探索 ZeRO++ 和 vAttention 等技术,以优化 GPU 内存使用并减少 LLM 训练和推理过程中的通信开销。
- 量化方面的进展,例如 QServe 引入了 W4A8KV4 量化,以提高云端 LLM 服务中的 GPU 性能。
- 关于 Etched’s Sohu 等专用 AI 芯片潜力的讨论,以及在运行 Transformer 模型时与 GPU 性能的对比。
3. 开源框架与社区努力:
- Axolotl 和 LlamaIndex 等开源框架支持多样化的数据集格式,并助力开发 Agentic RAG 系统。
- 开源模型 RefuelLLM-2 的发布,声称是处理“枯燥数据任务(unsexy data tasks)”的最佳 LLM。
- 社区致力于将 AI 能力集成到 Discord 等平台,例如来自 Stability AI 的 Stable Artisan 机器人,用于多媒体生成和编辑。
4. 多模态 AI 与生成模型:
- 专注于特定任务的新模型,例如用于提升对话交互的 Idefics2 8B Chatty 和用于编程能力的 CodeGemma 1.1 7B。
- 基于浏览器的 AI 聊天机器人进展,例如利用 WebGPU 进行强大交互的 Phi 3 模型。
- 结合 Pixart Sigma、SDXL 和 PAG 等技术,以在生成模型中实现 DALLE-3 级别的输出。
- IC-Light 等开源项目专注于图像重打光(image relighting)等特定任务。
GPT4O (gpt-4o-2024-05-13)
- 模型性能与基准测试:
- Llama3 70B 模型展现潜力:在 300 块 H100 GPU 上托管的新开源 LLM 排行榜显示 Qwen 72B 处于领先地位,尽管更大的模型并不总是等同于更好的性能。分析强调了训练与推理基准测试在范围上的差异。
- 解决小学算术问题:该研究引发了怀疑,指出大型 LLM 中的数据泄漏导致了误导性的高基准测试结果,尽管学习并不完整。文中呼吁进行可靠的评估。
- 训练、优化与实现问题:
- 推动更好的优化器:Adam-mini 优化器提供与 AdamW 相当的性能,但减少了 45-50% 的内存使用。该优化器通过减少每个参数的学习率数量来简化存储。
- 高上下文模型中的内存管理:在消费级 GPU 上加载大型模型(如 Llama3 70B 或 Hermes)的尝试受到显著的 OOM 错误的阻碍,引发了关于有效 GPU VRAM 利用率的讨论。
- AI 伦理与社区辩论:
- AI 数据使用的伦理:LAION Discord 中的辩论强调了数据集中包含 NSFW 内容的争议性,在伦理担忧与无限制数据访问的动力之间寻求平衡。
- 模型投毒担忧:LAION 的讨论集中在伦理影响和潜在的模型投毒上,即在不广泛考虑长期影响的情况下,鼓励在训练和数据集使用中采用有争议的技术。
- 专用 AI 硬件趋势:
- Etched 的 Sohu 芯片号称拥有 10 倍性能:Etched 的新型 Transformer ASIC 芯片声称性能显著优于 Nvidia GPU,并获得了可观的资金支持。然而,CUDA MODE 内部讨论了其实际适应性和缺乏灵活性的问题。
- AMD 的 MI300X 挑战 Nvidia:AMD 的 MI300X 寻求在 GPU 计算市场挑战 Nvidia 的地位,尽管在 Nvidia 的 CUDA 生态系统面前仍显落后。
- AI 应用集成:
- Hugging Face 上的自定义 GPT 应用蓬勃发展:对基于自定义 GPT 的应用兴趣日益浓厚,针对日语语句解释等利基任务的需求依然强劲。社区的协作努力推动了资源和工具包的创建,以简化实现过程。
- AI 辅助工具扩展学术影响力:新的 GPA Saver 平台 利用 AI 进行学术辅助,表明 AI 在流线型教育工具中的集成度不断提高。关于改进 AI 驱动功能的社区讨论强调了其潜力和当前的局限。
第一部分:Discord 高层级摘要
OpenAI Discord
通过快捷键快速访问:适用于 macOS 的 ChatGPT 桌面应用现已发布,具有快速访问的 Option + Space 快捷键,可与电子邮件和图像无缝集成。
语音模式延迟:备受期待的 ChatGPT 高级语音模式(Voice Mode)已推迟一个月,以确保 Alpha 测试前的质量;预计在秋季将推出更多功能,如情绪检测和非语言暗示。
OpenAI 与 Anthropic 的重量级对决:关于 GPTs Agent 在训练后无法学习,以及 Anthropic 的 Claude 凭借技术优势(如更大的 Token 上下文窗口和传闻中的 MoE 架构)领先于 ChatGPT 的讨论正趋于白热化。
AI 定制热潮:爱好者们正利用 Hugging Face 等资源创建自定义 GPT 应用,特别关注日语语句解释等利基任务,同时也对 OpenAI 当前模型更新和功能推出的局限性表示担忧。
GPT-4 桌面应用与性能讨论:用户注意到新的 macOS 桌面应用仅限于 Apple Silicon 芯片,并对 GPT-4 的性能评价褒贬不一,表达了对 Windows 应用支持和响应时间改进的渴望。
HuggingFace Discord
-
显微镜下的 RAG:一场围绕 Retrieval-Augmented Generation (RAG) 技术使用的讨论,强调了在使用 Mamba 等 SSM 时管理文档长度的考量,以及使用 BM25 进行面向关键词的检索。可以在此处找到与 BM25 相关的 GitHub 资源。
-
交互式手势:两个不同的语境都提到了一个基于 Python 的“Hand Gesture Media Player Controller”,并通过 YouTube 演示进行了分享,表明了人们对应用计算机视觉控制界面的兴趣日益增长。
-
PAG 提升 ‘Diffusers’ 库:得益于社区贡献,Perturbed Attention Guidance (PAG) 已集成到
diffusers库中,有望增强图像生成效果,正如 HuggingFace 的核心公告中所宣布的那样。 -
攻克特定语言的知识蒸馏:关于知识蒸馏的咨询非常突出,一名成员提议为单一语言建立蒸馏多语言模型,另一名成员则推荐使用 SpeechBrain 来处理该任务。
-
聚焦 LLMs 和数据集质量:除了 Microsoft 的 Phi-3-Mini-128K-Instruct 模型等进展外,社区还强调了数据集质量的重要性。同时,通过此处和此处引用的论文,探讨了与 LLMs 数据泄露相关的担忧。
-
对 AI 驱动工具的呼声:从对无缝 AI API development 平台的需求(通过反馈调查引用),到识别手写表格中数据的挑战,显然存在对能够简化任务并提高工作流程效率的 AI 驱动解决方案的需求。
LAION Discord
-
AI 伦理成为焦点:出现了关于 AI 训练伦理的对话,一名成员对积极鼓励模型 poisoning 表示担忧。另一名成员辩称 AIW+ 问题的解决方案是不正确的,提到它忽略了某些家庭关系,从而暗示了模糊性和伦理考量。
-
AI 音乐生成达到高潮:讨论涉及使用 RateYourMusic ID 生成歌曲和歌词,一位个人确认了其成功并称结果“非常滑稽”。
-
关于 NSFW 内容的大辩论:关于是否应将 NSFW 内容包含在数据集中的辩论激增,突显了道德担忧与反对过度谨慎的模型安全措施之间的对立。
-
GPU 对决与实用性:成员们交流了对 A6000s, 3090s 和 P40 GPUs 权衡的见解,指出了在应用于 AI 训练时,VRAM、散热要求和模型效率方面的差异。
-
ASIC 芯片进入 Transformer 领域:一个新兴话题是 Etched’s Sohu,这是一种专门用于 Transformer 模型的芯片。其宣传的优势引发了关于其实用性和对各种 AI 模型适应性的讨论,与对其潜在缺乏灵活性的怀疑形成对比。
Eleuther Discord
-
ICML 2024 备受关注的论文:EleutherAI 的研究人员正为 ICML 2024 做准备,提交了关于 classifier-free guidance 和开放基础模型影响的论文。另一项研究深入探讨了语言模型中的记忆现象 (memorization),检查了隐私和泛化等问题。
-
多模态奇迹与聚会盛况:Huggingface 的排行榜已成为寻找顶尖多模态模型的便捷工具;与此同时,ICML 维也纳见面会吸引了一系列热情的计划。混合模型 Goldfinch 也参与了交流,它通过将 Llama 与 Finch B2 层合并以提升性能。
-
引发同行讨论的论文:#research 频道的讨论围绕着从 Synquid 的对比评估到 Hopfield Networks 在 Transformer 中的应用等论文展开。成员们剖析了从多模态学习效率到泛化和 grokking 的实验方法等主题。
-
Hopfield 的回归:成员们通过将神经网络中的 self-attention 纳入(异)关联记忆框架,提供了相关见解,并辅以连续现代 Hopfield Networks 及其作为单步 attention 实现的参考文献。
-
稀疏且智能:Sparse Autoencoders (SAEs) 因其从过完备基中挖掘线性特征的能力而备受关注,正如 LessWrong 文章所宣传的那样。此外,值得一提的是一篇关于多语言 LLM 安全性的论文,展示了通过定向中毒优化 (DPO) 实现的跨语言去毒。
CUDA MODE Discord
AMD Radeon MI300X 对标 Nvidia:
尽管 AMD 的软件生态系统 ROCm 仍落后于 Nvidia 的 CUDA,但新款 AMD Radeon Instinct MI300X 的定位是挑战 Nvidia 在 GPU 计算市场的统治地位,详见 Chips and Cheese 的文章。
ASIC 芯片雄心:
Etched 宣布的 Transformer ASIC 芯片旨在比 GPU 更高效地运行 AI 模型,并获得了包括 Bryan Johnson 支持的 1.2 亿美元 A 轮融资,引发了关于专用 AI 芯片未来角色的讨论。
优化调整与 Triton 查询:
工程讨论围绕一个提议的 Adam-mini 优化器展开,该优化器可减少 45-50% 的内存占用,代码已在 GitHub 上发布。此外,社区正在寻求帮助,以便在 python.triton.language.core 中添加 pow 函数,如该 Triton issue 所示。
PyTorch 发布纪录片庆祝:
“PyTorch Documentary Virtual Premiere: Live Stream”的首映引起了关注,展示了 PyTorch 的演变及其社区。用户们反响热烈,并用 山羊 (goat) 表情符号 来表达兴奋之情,可在此处观看。
Intel 寻求在 PyTorch 中集成 GPU 支持:
Intel PyTorch 团队在 GitHub 上发布了 RFC,继续推进原生 PyTorch 对 Intel GPU (XPU) 的支持,标志着 Intel 致力于成为深度学习硬件领域的积极参与者。
AI 基础设施与实践讨论:
社区对话涉及学习率缩放、参考 AdamW 论文 的更新裁剪 (update clipping) 见解、AMD 与 Nvidia 构建方案之间的基础设施选择,以及对 Sohu ASIC 芯片承诺的关注,这些都影响着大型 Transformer 模型的效能。
Perplexity AI Discord
Perplexity API 带来的困扰:工程师们讨论了 Perplexity AI API 间歇性出现的 5xx 错误,强调了通过状态页提高透明度的必要性。此外,还就 API 过滤器和未公开功能进行了辩论,一些用户探究了搜索域名过滤器和引用日期过滤器的存在。
寻找更好的搜索:Perplexity Pro focus search 因其局限性受到批评,而在与 ChatGPT 的对比中,用户注意到了 Perplexity 新的 Agent 式搜索能力,但也批评其在摘要中容易产生幻觉(hallucinate)。
Claude 利用上下文优势:社区热议 Claude 3.5 为 Perplexity Pro 用户提供的 32k token 上下文窗口,并确认了 Android 端支持。用户明显更倾向于 Claude Pro 提供的完整 200k token 窗口。
与 Denis Yarats 洞察创新:Perplexity AI 的 CTO 在一段 YouTube 视频中剖析了 AI 的创新,讨论了它如何彻底改变搜索质量。在相关的对话中,研究人员展示了一种新方法,可能通过从语言模型计算中移除矩阵乘法(matrix multiplication)来改变游戏规则。
分享空间的近期热点:社区分享了大量的 Perplexity AI 搜索结果和页面,包括土卫六(Titan)缺失波浪的证据、中国的探月工程,以及一项关于重力如何影响感知的研究,鼓励他人在平台上探索这些精选搜索。
Latent Space Discord
-
AI World’s Fair 观影会启动:举办 AI Engineer World’s Fair 观影会的热情高涨,该活动在此处直播,重点展示前沿的主旨演讲和代码专题。
-
PyTorch 粉丝的预映之夜:PyTorch 纪录片虚拟首映式备受期待,该片通过创始人及核心贡献者的评论,回顾了该项目的演变和影响。
-
ChatGPT 语音更新推迟:由于语音功能的技术困难,ChatGPT 语音模式(Voice Mode)推迟发布,在 Teknium 的推文发布后引起了轰动。
-
Bee Computer 展现智能活力:AI 工程师活动的参与者对来自 Bee Computer 的新型 AI 可穿戴技术议论纷纷,该技术以其对个人数据的深度理解和主动任务列表而备受推崇。
-
神经视觉效果超出预期:神经科学的一项突破引起了社区关注,即从老鼠皮层活动中重建视觉体验,展示了神经成像技术的惊人进步。
LM Studio Discord
-
LM Studio 的技术故障与技巧:工程师报告了 LM Studio (0.2.25) 的错误,包括加载模型时的 Exit code: -1073740791。对于 Hermes 2 Theta Llama-3 70B,使用 RTX 3060ti 的用户面临“显存不足”(Out of Memory)问题,并考虑使用 NousResearch 的 8b 等替代方案。在 Apple M 芯片上运行 Llama 3 70B 时,由于不同的量化类型(quant types)和设置,也出现了一些问题。
-
RAG 成为焦点:进行了一场关于检索增强生成(RAG)的详细讨论,重点介绍了 NVIDIA 关于 RAG 利用外部数据增强信息生成准确性能力的博客文章。
-
诈骗警告与安全提示:用户注意到指向冒充 Steam 的俄罗斯网站的诈骗链接,并已报告给管理员采取行动。社区对网络钓鱼攻击以及保护个人和项目数据的重要性保持警惕。
-
硬件对话升温:提到了一个使用 8x P40 GPU 完成的配置,引发了关于服务器电源管理(涉及 200 安培电路)以及 LM Studio 在多 GPU 设置下显存(VRAM)报告准确性的进一步讨论。家庭服务器设置产生的噪音也被幽默地比作喷气发动机。
-
创新想法与 SDK 展示:成员们分享了各种想法,从在科幻角色扮演游戏中使用 LLM 作为游戏主持人(game master),到解决 token 预测中大上下文窗口导致的性能不佳问题。这里有一份使用 SDK 构建 Discord 机器人的指南 dev.to,以及关于使用 Python 从 LM Studio 服务器提取数据的问题。
-
Open Interpreter 中的上传障碍:用户对于无法直接将文档或图像上传到 Open Interpreter 终端感到沮丧,这限制了用户与 AI 模型交互及应用场景的扩展。
Modular (Mojo 🔥) Discord
-
使用 Mojo 数据类型绘制路径:工程师们正在尝试使用 Mojo 数据类型进行直接绘图,而无需转换为 Numpy,并利用 Mojo-SDL 等库进行 SDL2 绑定。社区正在讨论 Mojo 图表库所需的功能,重点领域涵盖从高级接口到交互式图表,以及与 Arrow 等数据格式的集成。
-
用于多功能可视化的 Vega IR:数据可视化对交互性的需求得到了强调,Vega 规范被提议作为中间表示(IR),以桥接 Web 和原生渲染。对话涉及了 UW 的 Mosaic 等库的独特方法,以及 D3、Altair 和 Plotly 等主流库。
-
WSL 作为 Windows 进入 Mojo 的门户:已确认 Mojo 可通过 Windows Subsystem for Linux (WSL) 在 Windows 上运行,预计年底前将提供原生支持。Visual Studio Code 与 Linux 目录配合使用的易用性是一个亮点。
-
IQ 与智能之争升温:社区就智能的本质展开了激烈辩论,ARC 测试因其以人为中心的模式识别任务而受到质疑。一些用户认为 AI 在 IQ 测试中表现出色并不代表真正的智能,而意识与记忆(recall)的概念引发了进一步的哲学讨论。
-
编译时特性与 Nightly 版本:Mojo 编译器被曝出多个问题,从类型检查和布尔表达式处理中的 Bug,到编译时对
List和Tensor的处理。各讨论串都鼓励用户报告问题,即使这些问题在 Nightly 版本中已得到解决。此外,还讨论了特定的 Commit、Nightly 版本更新以及引用不可变静态生命周期变量的建议,凝聚社区进行协作调试和改进。
Interconnects (Nathan Lambert) Discord
-
LLM 排行榜的夸耀权受到质疑:Clement Delangue 宣布推出新的开源 LLM 排行榜,并吹嘘使用 300 块 H100 GPU 重新运行 MMLU-pro 评估,这引发了关于此类算力必要性以及大模型有效性的讽刺与批评。
-
RabbitCode 的 API 安全出问题:Rabbitude 发现其存在硬编码 API 密钥,包括 ElevenLabs 等服务的密钥,导致 Azure 和 Google Maps 等服务面临风险,引发了对未经授权数据访问的担忧以及对滥用 ElevenLabs 额度的猜测。
-
ChatGPT 高级语音模式延迟:OpenAI 已将面向 Plus 订阅者的 ChatGPT 高级语音模式发布推迟到秋季,旨在增强内容检测和用户体验,该消息通过 OpenAI 的 Twitter 发布。
-
关于 Imbue 突然成功的传闻:Imbue 突然获得的 2 亿美元融资引起了成员的怀疑,大家探讨了该公司不明确的历史,并将其发展轨迹与 Scale AI 及其子公司在数据标注和远程 AI 项目博士招聘方面的策略进行了比较。
-
音乐行业的 AI 转型:Udio 关于 AI 变革音乐行业潜力的声明与 RIAA 的担忧发生冲突,Udio 断言尽管行业存在阻力,AI 仍将成为音乐创作的必需品。
Stability.ai (Stable Diffusion) Discord
-
挑战 Stability AI 进一步提升:讨论指出,社区对 Stability AI 在 Stable Diffusion 3 (SD3) 上的做法日益担忧,强调需要无审查模型(uncensored models)和更新的许可证,以保持长期竞争力。社区要求提供除猎奇创作之外,更具实际应用价值的现实场景应用。
-
GPU 成本效益策略讨论:GPU 租赁成本对比显示,与 Runpod 相比,使用 Vast 运行 3090 是更经济的选择,据称价格低至每小时 30 美分。
-
辩论:社区驱动 vs. 企业支持:关于开源倡议与企业影响力之间平衡的辩论十分活跃,一些成员认为社区支持至关重要,而另一些成员则引用 Linux 在企业支持下取得的成功,认为这是一条可行的路径。
-
优化机器学习构建:成员们正在分享针对高效 Stable Diffusion 配置的硬件建议,大家一致认为 Nvidia 4090 具有性能优势,并且为了节省成本,双 4090 可能比高 VRAM 的单 GPU 更具优势。
-
对 ICQ 的怀旧与 SDXL 的障碍:老牌即时通讯服务 ICQ 的关闭引发了怀旧交流;同时,社区也报告了运行 SDXL 时面临的挑战,特别是由于 VRAM 不足导致 “cuda out of memory” 错误的成员,正在寻求命令行解决方案的建议。
Nous Research AI Discord
-
推出 Prompt Engineering Toolkit:分享了一个开源的 Prompt Engineering Toolkit,用于配合 Sonnet 3.5 使用,旨在帮助为 AI 应用创建更好的提示词。
-
模型性能引发质疑:微软在 Genstruct 上展示的新原始文本数据增强模型引发了对其有效性的怀疑,展示结果似乎偏离了主题。
-
AI 芯片性能引发热议:新型 “Sohu” AI 芯片引发了关于其高性能推理任务潜力的讨论,并链接到了 Gergely Orosz 的帖子,该帖子暗示尽管硬件在进步,但 OpenAI 并不认为 AGI 即将到来。
-
Imbue AI 发布 70B 模型工具包:Imbue AI 发布了一个 70B 模型工具包,资源包括 11 个 NLP 基准测试、一个专注于代码的推理基准测试以及一个超参数优化器,详见 Imbue 的介绍页面。
-
拥抱搞怪的 AI:一位用户发布了由 Anthropic 的 Claude 生成的梗图(meme)形式的内容,反映了 Claude 对复杂话题的解释,以及它对未经历过天气或存在危机的幽默看法。
LangChain AI Discord
-
简化 AI 对话流:工程师们强调了来自
langchain_community.chat_models的.stream()方法,用于迭代 LangChain 响应;其他人讨论了集成 Zep 以实现 AI 的长期记忆,并考虑在 LangChain 中直接使用BytesIO处理 PDF 而无需临时文件。 -
LangChain 中的可视化探索:关于在 Streamlit 中实时可视化 Agent 思考过程的讨论涉及了使用
StreamlitCallback,但也指出了在不使用回调的情况下管理流式响应的空白。 -
排除不可见的故障:有关于 LangSmith 在环境设置正确的情况下仍无法追踪执行的咨询,建议是检查追踪配额。
-
扩展容器化测试:一位社区成员为 testcontainers-python 贡献了 Ollama 支持,方便了 LLM 端点测试,详见其 GitHub issue 和 pull request。
-
认知手艺与出版物:分享了一篇关于在 LangChain 中结合工具调用进行少样本提示(few-shot prompting)的 Medium 文章,以及一段探索 ARC AGI 挑战的 YouTube 视频,题为“Claude 3.5 也挣扎?!百万美元挑战”。
LlamaIndex Discord
-
寻求上下文清晰度的聊天机器人:一位工程师询问了如何有效地直接从 LlamaIndex 聊天机器人框架的聊天响应中检索上下文,并分享了实现细节及遇到的挑战。
-
即将进行的 Pull Request 审查:一名成员分享了一个 GitHub PR 待审查,旨在为 LlamaIndex 中的 Neo4J 数据库添加查询过滤功能;另一名成员确认需要处理积压的任务。
-
消除多余通知:讨论了如何抑制 Openailike 类中关于缺失机器学习库的不必要通知,并澄清此类消息并非错误。
-
使用 LLM 优化 SQL 查询:用户间的对话强调了在使用 RAG SQL 层时,微调语言模型对于提高 SQL 查询精确度的好处,并建议使用高质量训练数据以获得更好性能。
-
平衡混合搜索:解答了关于 LlamaIndex 中混合搜索实现的问题,重点在于调整
alpha参数以平衡搜索结果中元数据和文本的相关性。 -
使用 LlamaIndex 增强 RAG:分享了一篇文章,重点介绍了使用 LlamaIndex 和 DSPy 构建优化后的检索增强生成(RAG)系统的方法,为 AI 工程师提供了见解和实践步骤。
-
开源贡献奖励:发起了一项针对开源项目 Emerging-AI/ENOVA 的反馈征集,该项目旨在增强 AI 部署、监控和自动扩展,参与者有机会获得 50 美元的礼品卡。
OpenInterpreter Discord
-
Claude-3.5-Sonnet 成为焦点:最新的 Anthropic 模型正式命名为
claude-3-5-sonnet-20240620,结束了成员们对名称的困惑。 -
确认 MoonDream 的视觉限制:虽然人们对 OpenInterpreter (OI) 适配基于 MoonDream 的视觉模型很感兴趣,但目前的对话确认其与 OI 不兼容。
-
多行输入异常与视觉命令错误:在使用
-ml进行多行输入以及执行interpreter --os --vision命令时出现了技术问题。一名用户验证了其 API key 但仍面临错误,另一名成员报告称因尝试直接将文件拖入终端而被封禁。 -
01:OI 的语音界面,并非到处有售:01 作为 OI 的语音界面,无法在西班牙购买;爱好者们被引导至 GitHub 上的开源开发套件以寻求 DIY 替代方案。
-
构建你自己的 01:从开源套件 DIY 组装 01 的教程将会增多,其中一个计划在 7 月发布,这暗示了社区致力于在商业销售限制之外确保更广泛的获取途径。
Cohere Discord
对 Cohere 学者计划的好奇:一名成员询问了今年学者计划的状态,但随后没有关于此话题的进一步信息或讨论。
计费 Preamble Token 受到关注:一位用户分享了一个涉及 API 调用 preamble token 的实验,提出了一个可能通过利用不计费的 preamble 使用来规避费用、降低成本的漏洞。
使用 Rust 为 LLM 进行设计:宣布发布 Rig,这是一个用于创建 LLM 驱动应用程序的 Rust 库,并邀请开发者参与有奖反馈计划以探索和审查该库。
AI 使用中的伦理考量浮出水面:针对 SpicyChat AI(一个提供 NSFW 机器人托管服务的平台)提出了担忧,认为其通过盈利性使用可能违反了 Cohere 的 CC-BY-NA 许可,并声称通过 OpenRouter 规避了这一限制。
Hongyu Wang 关于 1Bit LLM 的学习活动:宣布了一场由 Hongyu Wang 主持的题为《1Bit LLM 时代》的在线演讲,并邀请通过提供的 Google Meet 链接参加。
OpenAccess AI Collective (axolotl) Discord
-
Adam 优化器瘦身:工程师们讨论了一篇介绍 Adam-mini 的 arXiv 论文,强调其内存占用比 AdamW 减少了 45% 到 50%。它通过使用更少的学习率,并利用受 Transformer 的 Hessian 结构启发的参数块学习来实现这一目标。
-
训练陷阱与 CUDA 难题:一位工程师寻求关于在训练期间实现输出文本掩码(类似于
train_on_input)的建议,而另一位工程师提出了 CUDA 错误问题,建议启用CUDA_LAUNCH_BLOCKING=1以识别模型训练期间的非法内存访问。 -
梯度累积——是友是敌?:增加梯度累积的影响引发了热烈讨论;一些人认为这可以通过减少优化器的运行次数来缩短训练时间,而另一些人则担心这可能导致步长变慢并增加总训练时间。
-
余弦调度与 QDora 探索:关于在 Hugging Face 平台上创建具有非零最小值的余弦学习率调度器的问题被提出,同时社区对在 PEFT 中启用 QDora 的拉取请求(Pull Request)表现出明显的兴奋。
-
叙事引擎与 Mistral 谜团:展示了 Storiagl,一个使用自定义 LLM 构建故事的平台;而另一位工程师报告了 Mistral7B 的重复文本生成问题,尽管设置了高 Temperature 仍在寻求解决方案。
LLM Finetuning (Hamel + Dan) Discord
Prompting 在语言学习中更胜一筹:包括 Eline Visser 在内的研究人员表明,在使用单本语法书学习 Kalamang 语言时,对大语言模型 (LLM) 进行 Prompting 的表现优于微调。这一“Prompting 胜出”的发现详见 Jack Morris 的推文,并在学术论文中进行了进一步阐述。
在线观看 AI 工程师世界博览会:AI Engineer World’s Fair 2024 正在直播,重点关注主题演讲和 CodeGen 赛道,可通过 YouTube 观看;更多详情请见 Twitter。
Claude 竞赛征集创意:2024 年 6 月的 Build with Claude 竞赛已宣布,邀请工程师展示他们在 Claude 方面的专业知识,详见官方指南。
额度问题协助:有人针对额度表单问题提供协助,要求直接私信相关的电子邮件地址,以便高效解决问题。
模型卸载(Offloading)技术辩论:社区观察到,与 FairScale 的 Fully Sharded Data Parallel (FSDP) 相比,DeepSpeed (DS) 似乎拥有更有效的细粒度卸载策略。此外,寻求优化设置的成员正在考虑这些卸载策略在 LLama 70B 上的实用性。
Mozilla AI Discord
-
Mozilla Builders 计划倒计时:提醒成员在 7 月 8 日早期申请截止日期前提交 Mozilla Builders Program 的申请。如需支持和更多信息,请查看 Mozilla Builders Program 页面。
-
通过 Firefox 和 llamafile 体验 90 年代怀旧风:Firefox 集成了 llamafile 作为 HTTP 代理,允许用户在复古的 Web 体验中探索 LLM 权重;演示视频可在 YouTube 上观看。
-
创建你自己的聊天宇宙:用户可以通过此处访问的共享 Notebook,将 llamafile 与 Haystack 和 Character Codex 融合,创建沉浸式聊天场景。
-
清理 Notebook 中的 CUDA 杂讯:为了保持 Jupyter Notebook 的整洁,建议使用 Haystack 的工具函数来处理 CUDA 警告。
-
NVIDIA 股价坐上过山车:在 AIEWF 的演讲之后,NVIDIA 的市值大幅下跌,引发了 MarketWatch 和 Barrons 等媒体对该公司财务表现催化剂的各种分析。
tinygrad (George Hotz) Discord
- Tinygrad 探索 FPGA 加速:有传闻称 tinygrad 正在利用 FPGA 作为后端,George Hotz 暗示可能会实现一种 加速器设计(accelerator design)。
- Groq 校友推出面向高效 AI 的 Positron:前 Groq 工程师推出了 Positron,目标直指 AI 硬件市场。其产品如 Atlas Transformer Inference Server,声称比 DGX-H100 等竞争对手在单位成本下拥有 10 倍的性能提升。
- FPGA 在定制化 AI 与 HDL 中的角色:讨论集中在配备 DSP 模块和 HBM 的 FPGA 未来发展,这可能允许创建特定于模型的 HDL。不过也有人指出,Positron 的方法是通用的,并不绑定于特定的 FPGA 品牌。
- 纪录片致敬 PyTorch 对 AI 的影响:社区分享了一部 YouTube 纪录片,重点介绍了 PyTorch 的开发历程及其对 AI 研究和工具链的影响。
AI Stack Devs (Yoko Li) Discord
- Angry.penguin 晋升版主:用户 angry.penguin 被提升为版主(Moderator)以解决频道的垃圾信息(spam)问题。他以积极主动的态度自愿参与,并立即清理了现有的垃圾信息。Yoko Li 授权 angry.penguin 负责这些新职责和垃圾信息控制措施。
- 告别垃圾信息:新任版主 angry.penguin 宣布成功实施了反垃圾信息措施,确保频道的讨论环境现在已针对破坏性的垃圾信息攻击加强了防御。成员们会发现后续的讨论环境更加整洁、专注。
DiscoResearch Discord
- 德语 Encoder 在 Hugging Face 上线:AI 工程师可能会对新发布的 German Semantic V3 和 V3b 编码器感兴趣,可在 Hugging Face 上获取。V3 针对知识库应用,而 V3b 则强调高性能,具有 Matryoshka Embeddings 和 8k token 上下文能力等创新特性。
- 无 GGUF 格式下德语 Encoder 的微调步骤:尽管有人询问,但 German V3b encoder 目前还没有 GGUF 格式;不过,对于有兴趣进行微调的用户,建议使用 UKPLab 的 sentence-transformers 微调脚本。
- Encoder 适配 GGUF 的可能性:在一番困惑之后,一名成员通过与 Ollama 对比进行了澄清,确认像 German V3 这样的编码器确实可以适配 GGUF 格式,这可能涉及使用双嵌入器(dual embedders)来增强性能。
OpenRouter (Alex Atallah) Discord
- AI 领域新玩家加入:OpenRouter 引入了 01-ai/yi-large 模型,这是一个专门用于知识搜索、数据分类、拟人化聊天机器人和客户服务的全新语言模型;该模型支持多语言能力。
- 参数显示故障已修复:OpenRouter 模型页面上的“推荐参数”选项卡之前存在数据显示问题,目前已 修复,确保工程师现在能看到准确的配置选项。
- AI 助力学术:新推出的 GPA Saver 利用 AI 提供学术辅助,包括聊天助手、快速测验解答器等工具;早期采用者使用代码 BETA 可获得折扣。
- 简化集成体验:用户对 OpenRouter 简化 AI 模型集成 流程表示感谢,这对于 GPA Saver 平台的创建起到了关键作用。
LLM Perf Enthusiasts AI Discord 无新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
MLOps @Chipro Discord 无新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
Datasette - LLM (@SimonW) Discord 无新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
Torchtune Discord 无新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 无新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 无新消息。如果该公会长期沉寂,请告知我们,我们将将其移除。
PART 2: Detailed by-Channel summaries and links
邮件中已截断完整的频道细分内容。
如果您喜欢 AInews,请分享给朋友!预谢!