ainews-that-openai-demo
那个 GPT-4o 演示
Romain Huet 在 ChatGPT 桌面端演示了 GPT-4o 的一个未发布版本,展示了低延迟语音生成、耳语语调调节、相机模式流式传输视频至 GPT-4o、快速 OCR、用于编程辅助的屏幕共享、剪贴板读取以及基于视觉的代码对话等功能。OpenAI 强调的四个重点投资领域包括:文本智能、效率与成本、模型定制化以及多模态智能体。
谷歌 DeepMind 发布了 9B 和 27B 规模的 Gemma 2 模型,分别在 8T 和 13T token 上进行了训练,采用了 SFT(有监督微调)、蒸馏、RLHF(人类反馈强化学习)和模型合并技术,并针对 TPUv5e 进行了优化,具备强大的性能和安全措施。Meta AI 宣布推出基于 Meta Code Llama 构建的 Meta LLM 编译器,具有增强的代码优化和编译器功能。
Omnimodel is all you need
2024年6月27日至6月28日的 AI 新闻。 我们为您检查了 7 个 subreddit、384 个 Twitter 账号 和 30 个 Discord(417 个频道和 3655 条消息)。 预计节省阅读时间(按每分钟 200 字计算):354 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
Romain Huet 使用未发布版本的 ChatGPT Desktop 演示 GPT-4o 的视频昨天引起了轰动,这基本上是 GPT-4o 发布后的第二次高规格演示(我们的报道见此处),在没有更重大新闻的情况下,这是我们今天的头条首选:
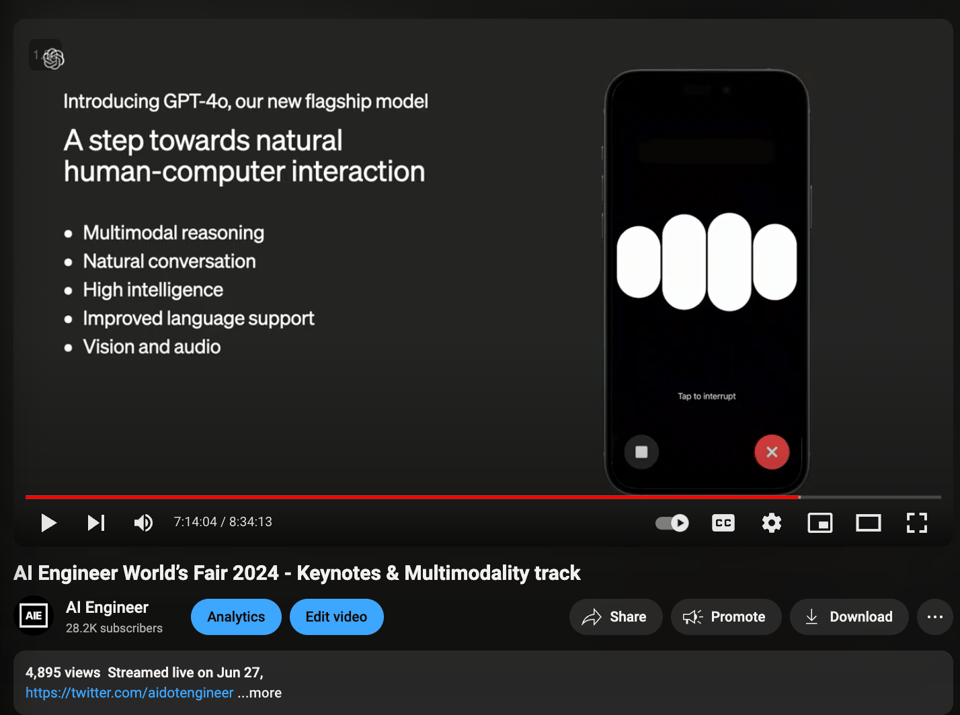
演示从直播的 7:15:50 标记处开始,你应该观看完整视频。
演示的功能包括:
- 低延迟语音生成 (voicegen)
- 调节音调至耳语(甚至更轻的耳语)的指令
- 打断功能
- ChatGPT Desktop 上的相机模式 —— 持续向 GPT-4o 传输视频流
-
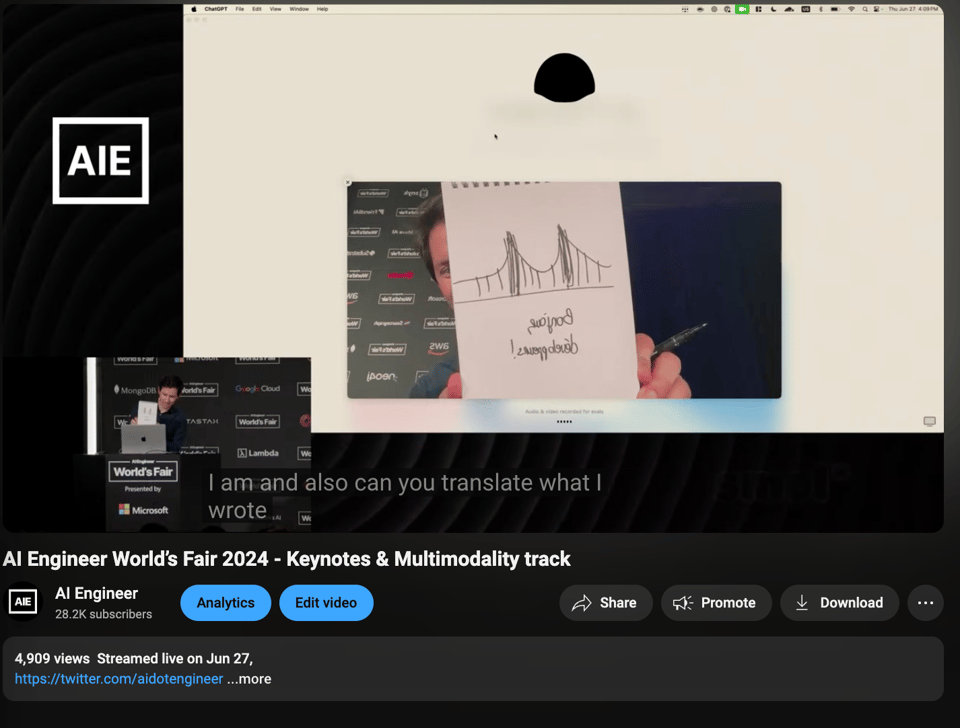
- 配合语音理解,它消除了对“发送”或“上传”按钮的需求
- 快速 OCR:Romain 询问一个随机页码,并展示书中的一页 —— 它几乎瞬间就读出了页面内容!不幸的是,OCR 出现了一点失误 —— 它误读了 “Coca Cola”,但现场演示的条件并不理想。

- 与 ChatGPT 共享屏幕:与 ChatGPT 交谈以描述他的编程问题,并让它根据视觉上下文进行理解
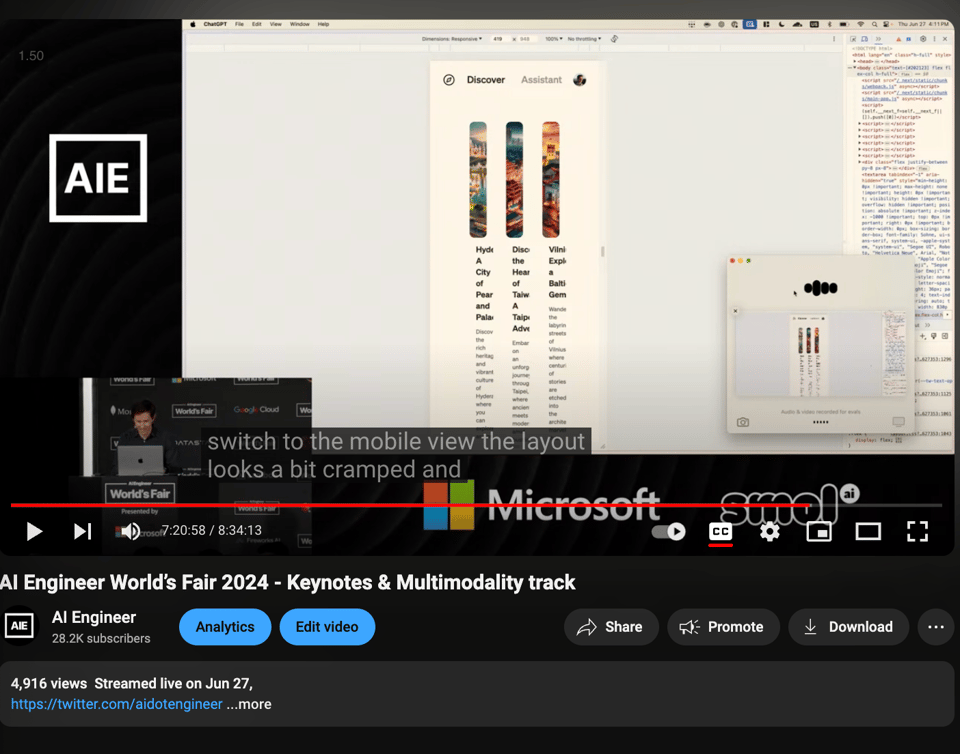
- 读取剪贴板:复制代码,要求对代码进行“单行概述”(此功能目前已在 ChatGPT Desktop 中提供)
- 与 ChatGPT 讨论代码:反复讨论代码中的 Tailwind 类名,依赖视觉(而非剪贴板)
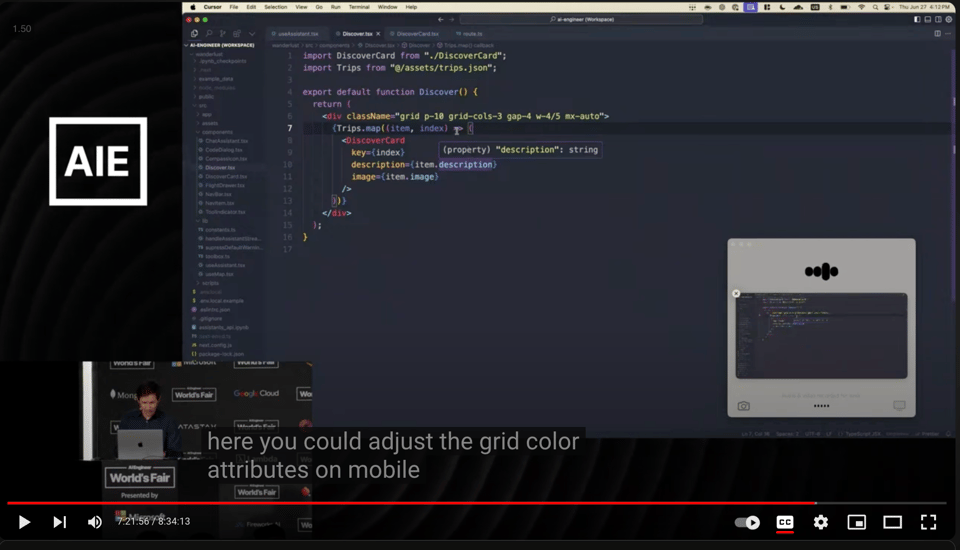
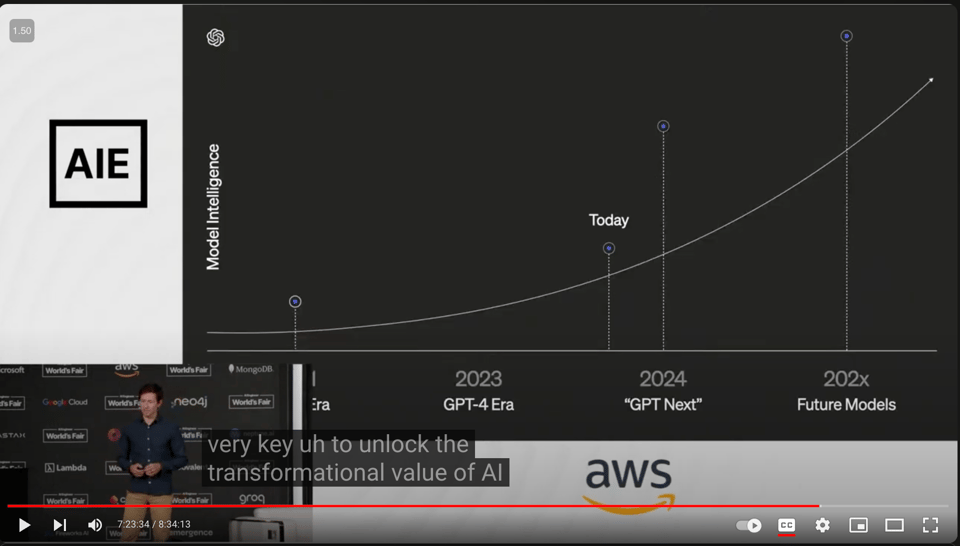
演讲的其余部分讨论了 OpenAI 的 4 个“投资领域”:
- 文本智能(再次使用了 “GPT Next” 而非 “GPT5”……)
-
效率/成本

-
模型定制

-
多模态 Agent
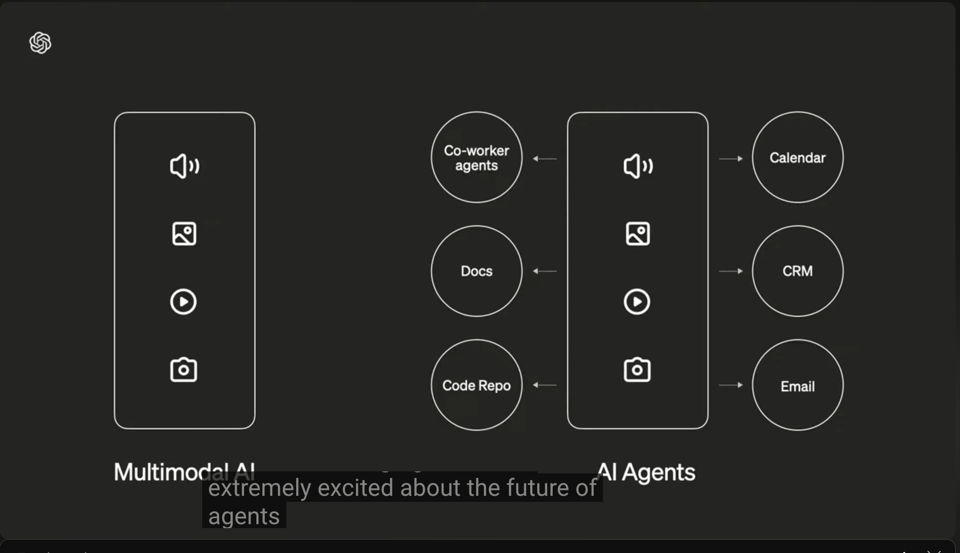 ,包括 Sora 和 Voice Engine 的演示,如果你以前没见过,真的应该去看看。
,包括 Sora 和 Voice Engine 的演示,如果你以前没见过,真的应该去看看。
AI Twitter 摘要回顾
所有摘要由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在尝试使用 Haiku 进行聚类和流程工程(flow engineering)。
Google DeepMind 发布 Gemma 2
- 模型尺寸与训练:@GoogleDeepMind 宣布发布 9B 和 27B 参数尺寸的 Gemma 2,分别在 13T tokens (27B) 和 8T tokens (9B) 上进行训练。使用了 SFT, Distillation, RLHF & Model Merging 技术。在 Google TPUv5e 上完成训练。
- 性能表现:@GoogleDeepMind 9B 版本在同尺寸类别的开源模型中提供了领先的性能。27B 版本的表现超过了某些尺寸是其两倍以上的模型,并针对在单个 TPU 主机上高效运行进行了优化。
- 可用性:@fchollet Gemma 2 已在 Kaggle 和 Hugging Face 上线,使用 Keras 3 编写,并兼容 TensorFlow, JAX 和 PyTorch。
- 安全性:@GoogleDeepMind 遵循了严格的内部安全流程,包括过滤预训练数据、严苛的测试和评估,以识别并缓解潜在的偏见和风险。
Meta LLM Compiler 发布
- 功能特性:@AIatMeta 宣布推出 Meta LLM Compiler,该模型基于 Meta Code Llama 构建,具有额外的代码优化和编译器能力。它可以模拟编译器,预测代码大小的最优 pass,并进行代码反汇编。
- 可用性:@AIatMeta LLM Compiler 7B & 13B 模型已在 Hugging Face 上发布,采用允许研究和商业用途的宽松许可证。
- 潜力:@MParakhin 认为 LLM 替代编译器可能会带来近乎完美的优化代码,扭转数十年来效率下滑的趋势。@clattner_llvm 提到 Mojo 🔥 是过去 15 年编译器研究、MLIR 以及许多其他经验教训的结晶。
Perplexity Enterprise Pro 更新
- 面向学校和非营利机构的降价:@perplexity_ai 宣布为任何学校、非营利组织、政府机构或非营利团体提供 Perplexity Enterprise Pro 的价格优惠。
- 重要性:@perplexity_ai 这些组织在解决社会问题和为儿童提供教育方面发挥着关键作用。Perplexity 希望确保其技术对他们是可触达的。
LangChain 推出 LangGraph Cloud
- 功能特性:@LangChainAI 宣布推出 LangGraph Cloud,这是用于大规模运行容错 LangGraph Agent 的基础设施。它能处理大型工作负载,支持调试和快速迭代,并提供集成的追踪与监控。
- 工具特性:@hwchase17 LangGraph Studio 是一个用于测试、调试和分享 LangGraph 应用程序的 IDE。它基于支持多样化控制流的 LangGraph v0.1 构建。
其他值得关注的更新与讨论
- Gemini 1.5 Pro 更新:@GoogleDeepMind 向所有开发者开放了 Gemini 1.5 Pro 的 200 万 token 上下文窗口。Gemini API 现已支持上下文缓存(Context caching)以降低成本。
- 清醒梦体验:@karpathy 分享了一次清醒梦体验,注意到其极其细致和高分辨率的画面,并将其比作类似 Sora 的视频+音频生成模型。
- Anthropic 更新:@alexalbert__ Anthropic 开发者现在可以在 Anthropic Console 的新“使用量和成本”选项卡中查看按金额、token 数量和 API keys 细分的 API 使用情况。
- 蒸馏讨论:@giffmana 和 @jeremyphoward 讨论了蒸馏(distillation)的重要性以及在训练小型高性能模型时的“容量差距诅咒”(curse of the capacity gap)。
AI Reddit 综述
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 模型与架构
- Gemma 2 模型超越 Llama 和 Claude:在 /r/LocalLLaMA 中,根据一份技术报告,Google 的 Gemma 2 27B 模型在 LMSYS 基准测试中击败了 Llama 3 70B。其 9B 变体也 超越了 Claude 3 Haiku。
- 针对小型模型的知识蒸馏(Knowledge distillation):Gemma 2 9B 是 使用 27B 模型作为教师模型进行训练的,这种方法可能是中小型模型的未来趋势,甚至可能使用像 Llama 400B 这样更大的模型作为教师模型。
- 无矩阵乘法(MatMul-free)语言建模:一篇新论文介绍了一种 在保持强劲性能的同时,从语言模型中消除矩阵乘法的方法。它在训练时减少了 61% 的内存占用,在推理时减少了 10 倍,配合定制的 FPGA 硬件,处理模型的功耗仅为 13W。
- Sohu 芯片交付巨大性能:来自 Etched 的专用 Sohu AI 芯片 据称可替代 160 块 H100 GPU,提供 500,000 tokens/sec 的吞吐量。它声称比 Nvidia 的下一代 Blackwell GPU 快 10 倍且更便宜。
AI 应用与用例
- AI 生成的图形小说:在 /r/StableDiffusion 中,一位作者 完全使用 Stable Diffusion 创作了一本图形小说,使用 SD1.5 iComix 制作角色,ControlNet 保持一致性,并使用 Photoshop 进行排版。这是第一本以阿尔巴尼亚语出版的此类小说。
- 利用 AI 重构网站:一个 浏览器扩展使用 OpenAI API 根据提供的提示词重构网站,利用 CSS 变量实现。已在 shadcn.com 和 daisyui.com 上进行了实验。
- 个性化 AI 助手:/r/LocalLLaMA 上的一篇文章详细介绍了 通过 WhatsApp 和 Obsidian 数据扩展个人 Llama 3 8B 模型,以创建一个个性化的 AI 助手。
迷因与幽默
- AI 讨论中的脱节:一段 迷因视频嘲讽了 AI 爱好者与普通大众在讨论该技术时的脱节。
- AI 生成的电影:一段 幽默视频想象了在不久的将来由 AI 批量生产的公式化电影。
- AI 生成动画的进展:一段 威尔·史密斯吃意大利面的迷因视频 展示了 AI 生成逼真人物动画能力的提升,目前仅剩细微的面部和手臂瑕疵。
AI Discord 综述
摘要的摘要之摘要
1. 模型性能优化与基准测试
-
量化(Quantization) 技术如 AQLM 和 QuaRot 旨在单块 GPU 上运行大型语言模型(LLMs)并保持性能。例如:AQLM 项目 实现了在 RTX3090 上运行 Llama-3-70b。
-
通过 动态内存压缩(DMC) 等方法努力 提升 Transformer 效率,在 H100 GPUs 上可能提高高达 370% 的吞吐量。例如:@p_nawrot 的 DMC 论文。
-
关于 优化 CUDA 操作 的讨论,例如融合逐元素操作(element-wise operations),使用 Thrust 库的
transform来实现接近带宽饱和的性能。例如:Thrust 文档。 -
在 AlignBench 和 MT-Bench 等基准测试中进行 模型性能 对比,DeepSeek-V2 在某些领域超越了 GPT-4。例如:DeepSeek-V2 发布公告。
2. 微调挑战与提示工程策略
-
在将 Llama3 模型转换为 GGUF 格式时,存在 保留微调数据 的困难,并讨论了一个 已确认的 Bug。
-
prompt design 的重要性以及正确模板的使用(包括 end-of-text tokens),对微调(fine-tuning)和评估期间模型性能的影响。示例:Axolotl prompters.py。
-
prompt engineering 策略,例如将复杂任务拆分为多个提示词,研究 logit bias 以获得更多控制。示例:OpenAI logit bias guide。
-
教导 LLM 在不确定时使用
<RET>token 进行 information retrieval(信息检索),从而提高在低频查询中的表现。示例:ArXiv paper。
3. 开源 AI 发展与协作
-
发布 StoryDiffusion,这是 Sora 的开源替代方案,采用 MIT 许可证,但权重尚未发布。示例:GitHub repo。
-
发布 OpenDevin,这是一个基于 Cognition 的 Devin 的开源自主 AI 工程师,并举办了 网络研讨会,在 GitHub 上引起了越来越多的关注。
-
呼吁在开源 machine learning paper(机器学习论文)上进行协作,该论文旨在预测 IPO 成功,托管在 RicercaMente。
-
围绕 LlamaIndex 集成的社区努力,包括在更新后遇到的 Supabase Vectorstore 和包导入问题。示例:llama-hub documentation。
4. LLM 创新与训练见解
- Gemma 2 以高效训练给人留下深刻印象:Google 的 Gemma 2 模型体积显著更小,且在更少的 token 上进行训练(9B 模型在 8T token 上训练),得益于知识蒸馏(knowledge distillation)和软注意力上限(soft attention capping)等创新,其在基准测试中超越了 Llama3 70B 等竞争对手。
- Gemma-2 的显存效率提升了 QLoRA 微调:新的预量化 Gemma-2 4-bit 模型 承诺下载速度提高 4 倍并减少 VRAM 碎片,充分利用了 QLoRA 微调的效率改进。
- MCTSr 提升奥数解题能力:MCT Self-Refine (MCTSr) 算法将 LLM 与蒙特卡洛树搜索(Monte Carlo Tree Search)相结合,通过系统地优化解决方案,在解决复杂数学问题方面取得了显著成功。
- Adam-mini 优化器的内存效率:Adam-mini 优化器通过利用简化的参数分区方法,以减少高达 50% 的内存使用量,实现了与 AdamW 相当或更好的性能。
5. 安全 AI 与伦理考量
- Rabbit R1 的安全漏洞在 YouTube 上曝光:一段名为 “Rabbit R1 makes catastrophic rookie programming mistake” 的 YouTube 视频揭露了 Rabbit R1 代码库中硬编码的 API 密钥,危及了用户数据安全。
- AI 使用限制警告与政策合规性:成员们强调了过度挑战 AI 边界的风险,警告违反 OpenAI 的使用政策 可能会导致账号封禁或终止。
- 开源 AI 辩论:激烈的讨论权衡了开源 AI 模型的利弊,在潜在的滥用风险与访问民主化以及受限 AI 的经济影响之间寻找平衡,同时考虑了其益处和危险。
6. 实用 AI 集成与社区反馈
- 高显存需求的 AI 视频生成:ExVideo 的成功实现生成了令人印象深刻的视频结果,尽管需要大量的 VRAM (43GB),这展示了 AI 能力与硬件限制之间持续的平衡。
- 跨平台模型实现的问题:在 LM Studio 等平台上集成 Gemma 2 等模型时,需要手动修复和最新更新以确保最佳性能。
- RAG 与 API 限制的挑战:Perplexity 的 RAG 机制 因输出不一致而受到批评,同时 Claude 3 Opus 等模型也存在局限性,表现出在上下文处理和 API 性能方面的挣扎。
7. 数据集与基准测试进展
- REVEAL 数据集基准测试验证器:REVEAL 数据集 对 Chain-of-Thought 推理的自动验证器进行了基准测试,强调了在开放域 QA 设置中验证逻辑正确性的难度。
- 用于鲁棒性测试的 XTREME 和 SPPIQA 数据集:讨论了 XTREME 和 SPPIQA 数据集,分别侧重于评估多语言模型的鲁棒性和多模态问答能力。
- 基于事实的响应生成器的重要性:通过 Glaive-RAG-v1 等数据集强调了对提供可靠、基于事实响应的模型的需求,并探讨了用于质量提升的评分指标。
8. 协作与开发平台
- 使用 LlamaIndex 构建 Agent 服务:工程师可以利用 LlamaIndex notebook 中分享的资源创建向量索引并将其转换为查询引擎,从而增强 AI 服务的部署。
- Featherless.ai 提供无需 GPU 配置的模型访问:Featherless.ai 推出了一个平台,提供对 Hugging Face 上 450 多个模型的固定费率访问,满足社区在模型优先级和使用场景方面的需求。
- LangGraph Cloud 增强 AI 工作流:LangChainAI 推出的 LangGraph Cloud 承诺为 AI Agent 提供强大、可扩展的工作流,并集成了监控和追踪功能以提高可靠性。
PART 1: 高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
-
Gemma-2 变得精简高效:全新的 Gemma-2-27B 和 9B 的预量化 4-bit 版本 现已发布,具有更快的下载速度和更少的 VRAM 碎片,有利于 QLoRA 微调。
-
AI 开发中的操作系统大辩论:社区内关于在 AI 开发中使用 Windows vs. Linux 的优劣展开了积极辩论,涉及 Linux 上的外设兼容性问题,以及尽管 Windows 存在某些限制但用户普遍更倾向于 Linux 的观点。
-
放大镜下的 Hugging Face 评估系统:社区将 Hugging Face 的评估系统比作“流行度竞赛”,并提出了引入高级付费评估的概念,建议“只要用户愿意付费,应允许随时进行评估”。
-
大数据,大麻烦:关于处理 2.7TB Reddit 数据集 的讨论指出,清理这些数据需要巨大的资源,解压后可能会膨胀到“约 15 TB……而得到的数据质量充其量也就一般”。
-
显存极限下的 AI 视频生成:据报道,使用 ExVideo 生成视频内容 效果显著,但它需要高达 43GB 的 VRAM,这凸显了 AI 能力与资源可用性之间不断的权衡。
HuggingFace Discord
-
Gemma 2 表现优于竞争对手:Google 新发布的 Gemma 2 模型已集成到 Transformers 库中,其优势包括尺寸效率——比 Llama3 小 2.5 倍——且 27B 模型在 13T tokens 上进行了强大的训练。诸如知识蒸馏和交替使用局部与全局注意力层等创新旨在增强推理稳定性并减少内存占用,HuggingFace 的博客文章涵盖了详细的 Gemma 2 细节。
-
解读 Elixir 的新文件系统:Elixir 的 FSS 引入了支持 HTTP 的文件系统抽象,并讨论了非扩展性问题。同时,HuggingFace 首个开源的基于图像的检索系统也引起了关注,其中 宝可梦数据集示例 大受欢迎,此外,像 CogVLM2 这样的视觉学习模型项目也备受瞩目。
-
AI 助力多语言应用起飞:U-C4N 的多语言实时航班跟踪应用程序展示了航空与语言的交汇,而 PixArt 的 900M 新变体则在 Spaces 竞技场 中寻求合作。此外,AI 与音乐叙事在 Bandcamp 等平台上的融合打破了流派界限。
-
准备好,Gradio!:Gradio 用户需注意,请务必更新到 3.13 以上版本,以避免分享链接失效。遵守此要求将确保能够持续访问 Gradio 资源,操作非常简单,只需运行
pip install --upgrade gradio。 -
闪电般的机器学习速度:一个超高速的 YouTube 教程制作了关于 10 个关键机器学习算法 的 1 分钟速成课程,非常适合时间紧迫但渴望知识的人。点击此处查看这节快速课程。
LM Studio Discord
Gemma 2 集成虽有小瑕疵:最新的 LM Studio 0.2.26 版本 增加了对 Gemma 2 模型的支持,尽管一些用户报告了集成 bug 和困难。为了解决这些问题,建议手动下载并重新安装配置,并注意某些架构(如 ROCm)仍待支持。
Gemma-2 令人困惑的能力:关于 Gemma-2 上下文限制的信息差异导致了混乱,有报告称限制为 4k,而另一些则称是 8k。此外,推荐支持叙事模型 ZeusLabs/L3-Aethora-15B-V2,而对于 Deepseek coder V2 Lite 等模型,建议用户关注 GitHub pull requests 以获取支持状态的更新。
Snapdragon 在 LM Studio 中表现出色:用户称赞了 Snapdragon X Elite 系统与 LM Studio 的兼容性,指出其在 CPU/内存任务效率上明显优于 i7 12700K,尽管在特定任务中仍逊色于 4090 GPU。
针对多 Agent 框架的精细化讨论:关于模型效能的讨论表明,0.5B 模型 或许可以轻松地在多 Agent 框架中充当用户代理;然而,对于此类低端模型处理编码任务的能力,人们仍持怀疑态度。对于硬件爱好者,关于使用双显卡价值的咨询得到了肯定的回答。
关于 ROCm 兼容性的分歧与 Gemma 2 的首次亮相:在 AMD ROCm 技术预览 频道中,提出了关于 AMD GPU 对 Gemma 2 模型支持的问题,引导用户查看 GitHub 说明 中描述的针对 Windows 新发布的 0.2.26 ROCm “扩展包”。此外,Gemma 2 的发布既伴随着兴奋也伴随着批评,一些用户将其贴上“烂透了”的标签,而另一些用户则急切期待未来更新中承诺的改进。
OpenAI Discord
AI 使用警告:一场讨论强调了测试 AI 极限的风险,并给出了明确警告:违反 OpenAI 的使用政策 可能导致账号被暂停或终止。
开源 AI 辩论:工程社区就 AI 模型的开源进行了辩论;讨论对比了滥用风险与访问民主化,强调了限制访问的经济影响以及为了公共安全进行监管的必要性。
RLHF 训练困扰用户:关于 Reinforcement Learning from Human Feedback (RLHF) 的对话揭示了用户对其偶尔出现的提示以及 OpenAI 处理公开 RLHF 训练的不透明性的困惑。
AI 集成的成功与挑战:成员分享的经验包括使用自定义 GPT 执行特定任务(如生成医疗问题)时遇到的问题,以及将 AI 模型和 API 与其他服务集成以增强功能的成功案例。
Prompt Engineering 见解:成员们交流了 Prompt Engineering 的技巧,建议保持简单和简洁,并探讨了使用 “logit bias” 进行更深层的 Prompt 控制,还简要触及了随机神经网络的准确定性本质。
Stability.ai (Stable Diffusion) Discord
-
自定义风格数据集引发关注:参与者讨论了创建具有自定义风格的数据集,指出无意中生成 NSFW 内容的潜在风险。社区强调了监控图像生成的复杂性,以避免平台封禁。
-
因 Automatic1111 体验不佳转向 Forge:由于 Automatic1111 的问题,用户正在探索 Forge 等替代方案,尽管它也面临自身的内存管理挑战。YouTube 上分享了一个 Stable Diffusion Webui Forge 简易安装 视频作为安装指南。
-
用户请求恢复 Cascade 频道:许多成员表达了恢复 Cascade 频道的愿望,因为它过去有许多富有成效的讨论,这引发了关于公会方向以及可能将重点转向 SD3 的辩论。
-
深入探讨模型训练细节:关于模型训练的对话涉及了 LoRa 训练的细微差别、3m sde exponential 等采样器以及 VRAM 限制。还考察了 ComfyUI、Forge 和 Stable Swarm 等工具的有效性和局限性。
-
Discord 社区呼吁透明度:部分社区成员对删除频道和资源表示不满,促使了关于透明沟通和保留用户生成内容重要性的讨论。
Latent Space Discord
-
Scarlet AI 进军项目管理:用于规划复杂项目的 Scarlet AI 预览版已推出;尽管尚未正式发布,感兴趣的工程师可以在 Scarlet AI Preview 评估其功能。
-
Character.AI 拨入语音功能:Character.AI 推出的全新 Character Calls 功能允许通过电话进行 AI 交互,适用于面试演练和 RPG 场景。该功能在其 移动端应用演示 中进行了展示。
-
Meta 通过 LLM 优化编译器代码:Meta 推出了 Large Language Model Compiler,旨在改进编译器优化任务,其 研究出版物 对细节进行了深入探讨。
-
LangGraph Cloud 的基础设施创新:LangChainAI 推出了 LangGraph Cloud,承诺为 AI Agent 提供具有弹性、可扩展的工作流,并结合了监控和追踪功能;更多见解请参考其 发布博客。
-
Adept 在与 Amazon 合作之际发生领导层变动:有消息称 Adept 正在调整其战略,多位联合创始人将加入 Amazon 的 AGI 团队;更多信息请参阅 GeekWire 文章。
-
OpenAI Demo 即将火热登场:公会成员收到通知,OpenAI Demo 即将举行,建议成员立即访问专门的 OpenAI Demo 频道。
-
GPT-4o 准备重塑桌面端编程:公会讨论了采用 GPT-4o 辅助桌面端编程,并分享了如
Open-Interpreter等可以轻松与本地模型集成的配置。 -
当企鹅更喜欢苹果时:Linux 用户在流媒体方面的困扰引发了一场半幽默半认真的 Mac 优势对比,并引出了 Vesktop——一款提升性能的 Linux 版 Discord 应用,可在 GitHub 上找到。
-
AI 社区的泄露与分享:有关敏感 GPT 定义在 GitHub 等平台流出的讨论,引发了对隐私问题的关注。成员们还交流了学术资料,介绍了 CoALA 框架和语言 Agent 仓库,可在 arXiv 和 GitHub 上找到。
-
对同行演讲的赞赏:成员们对一位同行准备充分的演讲表示赞赏,强调了高质量演示在 AI 领域的重要性。
Nous Research AI Discord
-
LLM 的指令预训练表现优异:在大型语料库的预训练中加入 2 亿条指令-响应对 提升了性能,使得轻量级的 Llama3-8B 能够与 Llama3-70B 等重量级模型并驾齐驱。关于高效指令合成器的细节见 Instruction Pre-Training 论文,模型已在 Hugging Face 上可用。
-
MCTSr 与 LLM 融合解决奥数难题:将 Large Language Models 与 蒙特卡洛树搜索 (MCTSr) 相结合,在解决奥林匹克数学竞赛问题上取得了显著成功。该技术的内在机制在 详细研究 中有深入阐述。
-
数据集大爆发:SPPIQA, XTREME, UNcommonsense:Nous Research AI 频道讨论了一系列数据集,包括用于推理的 SPPIQA、用于多语言模型评估的 XTREME,以及用于探索怪诞维度的 UNcommonsense。
-
Hermes 2 Pro 发布,增强函数调用功能:Hermes 2 Pro 70B 模型正式发布,重点改进了函数调用(Function Call)和结构化 JSON 输出,在评估中分别获得 90% 和 84% 的评分。虽然没有提供学术论文,但可以在 NousResearch 的 Hugging Face 探索该模型。
-
辩论 SB 1047 对 AI 的束缚:成员们激烈辩论了加州的 SB 1047 法案是否会阻碍 AI 的增长。一项反对该法案的 运动 警告称,它可能会抑制 AI 蓬勃发展所必需的冒险精神。
Eleuther Discord
-
“诅咒式”复杂度 vs. 实际性能:yoco 架构的 kv cache 策略引发了辩论,批评者认为其偏离了标准的 Transformer 实践且过于复杂。讨论还涵盖了模型中 Attention 和 Feed-forward 层的顺序,一些人提出非标准层顺序可以带来效率提升,而另一些人则对其性能收益持怀疑态度。
-
超越传统认知的 Scaling:围绕 Scaling laws 的讨论质疑了 Challax scaling 模型的统治地位,一些参与者建议将 “Scaling laws” 视为临时性的,更准确地应称为 “Scaling heuristics”。引用了诸如 “Parameter Counts in Machine Learning” 等论文来支持关于不同 Scaling 模型有效性的观点。
-
数据隐私困境:对话探讨了在 privacy-preserving/federated learning 背景下的隐私担忧,其中聚合数据暴露了更广泛的攻击空间。讨论了 AI agents 实施安全行为的潜力,考虑了上下文行为识别以及对隐私泄露的主动响应。
-
LLM 评估与创新:引入了一个新的推理挑战数据集 MMLU-SR,并考虑将其添加到 lm_eval 中,通过修改后的问题探测 LLM 的理解能力。分享了该数据集的 arXiv 论文 链接以及 MedConceptsQA 基准测试添加的 GitHub PR。
-
GPTNeoX 中的 Instruction Tuning 潜力:关于 GPTNeoX 中 Instruction tuning 的咨询(特别是选择性反向传播损失)引发了讨论,引用了一个正在进行的 PR 和一个预处理脚本 “preprocess_data_with_chat_template.py”,标志着定制化训练工作流的积极开发。
CUDA MODE Discord
-
Windows 上的 Triton 困扰:用户报告了在 Windows 上使用
torch.compile时遇到的 Triton 安装问题,导致出现 “RuntimeError: Cannot find a working trilog installation”。这表明 Triton 可能尚未在 Windows 上获得官方支持,因此需要寻找替代安装方法。 -
使用 torch.compile 进行张量修补:Lovely Tensors 的作者遇到了
torch.compile()报错,原因是Tensor.__repr__()在 FakeTensor 上被调用。社区建议利用 torch.compiler fine-grain APIs 来缓解此类问题。同时,NCCL 的一次更新解决了旧版本中的广播死锁(broadcast deadlock)问题,详情见此 PR。 -
装备 CUDA 知识:Stephen Jones 带来了 CUDA 编程的深度概述,涵盖了 波次量化与单波次内核 (wave quantization & single-wave kernels)、并行性以及通过分块 (tiling) 优化 L2 cache 性能等技术。
-
CUDA 好奇心与云端查询:成员们分享了 Vast.ai 和 Runpod.io 等平台,用于在云端 GPU 上探索 CUDA,并建议从
torch.compile开始,逐步过渡到 Triton 或为 Python 编写自定义 CUDA 代码以进行优化。 -
PMPP 出版谜团:一位成员指出 PMPP(第 4 版)书的纸质版缺失了若干页,引发了关于是否有类似经历的询问。
-
torch/aten Ops 列表与 Bug 狩猎:torchao 频道出现了对
FSDP等张量子类所需的torch/aten ops完整列表的需求,讨论了__torch_dispatch__的递归错误,以及 Int4Tensor 的重构 PR。此外,还有关于 GeForce GTX 1650 缺乏原生 bfloat16 支持的提醒。 -
HuggingFace Hub 的喧嚣:off-topic 频道热烈讨论了直接在 HuggingFace Hub 上存储模型架构和预处理代码的 优缺点。关于模型代码和权重存储的最佳实践存在争论,Llama 模型被引用为有效发布策略的案例研究。
-
Gemma 2 成为焦点:Google 推出的 Gemma 2 模型(拥有 27B 和 9B 参数)在基准测试中表现优于竞争对手,社区对其开放性表示赞赏,并期待更小的 2.6B 变体。讨论还集中在架构选择上,如 近似 GeGLU 激活函数 以及 ReLU 与 GELU 之争,并辅以学术研究支持。FP8 支持方面的硬件挑战导致人们提到了 NVIDIA 库的局限性以及 Microsoft 在 FP8-LM 上的工作。Yuchen 的训练见解表明,在针对 H100 GPU 进行优化时,可能存在平台或数据集特定的问题。
Perplexity AI Discord
-
Perplexity 为公益事业降低成本:Perplexity 为其 Enterprise Pro 产品推出了降价方案,旨在支持学校和非营利组织的社会及教育事业。有关资格和申请的更多信息可以在其 公告 中找到。
-
RAG 挫败感与 API 焦虑:在 Perplexity AI 的讨论中,用户对 RAG(Relevance Aware Generation)机制不稳定的表现感到沮丧,并要求获取更大的模型,如 Gemma 2。此外,用户在使用 Claude 3 Opus 时遇到了限制,理由是使用上限多变且具有约束性。
-
安全第一,修复待定:安全协议已得到处理,引导成员前往 Trust Center 了解有关 数据处理 和 PII 管理 的信息。同时,成员建议使用 “#context” 来改进持续性处理,以解决交互中持续存在的上下文保留问题。
-
功能探索与改进:社区注意力转向探索 Android 14 的增强功能,同时提出了 Minecraft 的机制可能误导儿童 的问题。针对如何过滤 API 结果以获取近期信息的咨询,社区提供了使用特定日期格式的指导。
-
技术深挖与创新亮点:分享的内容包括对 Android 14 的见解、对 Linux 性能 的批评、Robot Skin 的创新用途,以及受牡蛎启发的各种可持续建筑。一个值得注意的分享讨论了对 Minecraft 修复机制 的批评,认为这可能导致误解。
Interconnects (Nathan Lambert) Discord
-
Character.AI 率先推出双向 AI 语音聊天:Character.AI 推出了 Character Calls,实现了与 AI 的语音对话,尽管该体验因 5 秒的延迟和不够流畅的交互而略显逊色。与此同时,行业传闻称亚马逊聘用 Adept 的联合创始人并进行技术授权,使得 Adept 实力削弱,此外还有关于 Adept 拥有毒性工作环境的未经证实的指控。
-
AI Agent 进展落后于炒作曲线:讨论将 AI Agent 的缓慢进展与自动驾驶汽车行业进行了类比,认为炒作超过了实际表现。AI Agent 训练数据的质量和来源(包括对合成数据日益增长的关注)被强调为关键挑战。
-
SnailBot News 节目引发讨论:SnailBot News 最新一期关于 Lina Khan 的节目引发了热议;Natolambert 预告了对 Ross Taylor 和 John Schulman 等知名人物的采访。围绕“请勿在我们的模型输出上进行训练”的数据使用条件的伦理考量也成为了焦点。
-
Scaling 占据 AI 话语权:怀疑论围绕着“仅靠 Scaling(扩展)就能实现 AGI”的信念,正如 AI Scaling Myths 中所指出的,同时还讨论了 LLM 开发者在高质量数据方面所谓的局限性。Nathan Lambert 敦促对这些观点进行批判性审查,并引用了 Substack 讨论 和合成数据的最新进展。
-
对 AI 与全球事务的多样化思考:从 Anthropic CEO 对《最终幻想》的热爱凸显了 AI 领导者人性化的一面,到关于 AI 危机可能比大流行病更复杂的辩论,成员们参与了多样化的对话。一些讨论甚至考虑了智能爆炸如何重塑政治结构,反映了 AI 发展的深远影响。
LlamaIndex Discord
LlamaIndex 助力 Agent 服务:工程师们探索了使用 LlamaIndex 构建 agentic RAG services,讨论了创建 vector indexes 并将其转换为 query engines 的过程。详细步骤和示例可以在最近分享的 notebook 中找到。
Jina 的 Reranking 革命:LlamaIndex 社区对 Jina’s newest reranker 讨论热烈,该工具被誉为他们迄今为止最有效的重排序器。相关细节可见此处。
Vector Retrievers 中的 Node 权重难题:AI 从业者正在解决 LlamaIndex’s embedding challenges,讨论了诸如哪些 node 部分需要进行 embedding,以及模型不匹配导致 vector retrievers 结果不佳等因素。共识倾向于创建简单的测试用例以进行有效的 debugging。
通过 Edges 进行实体链接:增强 entity relationship detection 引发了辩论,重点在于添加受 embedding 逻辑启发的 edges。人们对可能与 Neo4j 合作的技术分享充满期待,预计这将揭示先进的 entity resolution 技术。
Claude 和 OpenAI Keys 出现问题:讨论中提到了需要修复 Claude 因 Bedrock 的 token 限制导致的空响应问题,以及特定情况下的 IndexError;此外还有一个奇怪的环境行为,即代码设置的 OpenAI keys 似乎被覆盖了。工程师们还在探索 batch 和 parallel index loading 的优化,旨在加速大文件处理。
OpenRouter (Alex Atallah) Discord
Gemma 的多语言实力:虽然 Gemma 2 官方仅支持英语,但用户报告其具有出色的多语言能力,并针对其在韩语中的表现进行了具体咨询。
模型迁移热潮:根据公告,包含免费版和标准版的 Gemma 2.9B 模型正在席卷而来,同时多款热门模型降价,包括 Dolphin Mixtral 降价 10%,OpenChat 降价 20%。
OpenRouter 的已知问题:OpenRouter 严密的审核与 AWS 等平台形成对比;与此同时,用户面临着没有企业支持就无法使用 Opus 的困境,并正在解决 Gemini 模型不规范 API 导致的 Status 400 错误。
Passphrase 难题与 API 分配问题已解决:工程师们分享了使用 ssh-add -A 进行无缝 GitHub 身份验证的心得,并讨论了通过观看 Simon Willison 关于 LLM APIs 的概述来获取启发,资源可在 YouTube 及其博客上找到。
AI 偏好调整:采纳 daun.ai 的建议,将默认模型设置为 ‘auto’ 以获得稳定的结果,或者尝试使用 ‘flavor of the week’ 作为备选方案,以确保各项任务的持续生产力。
LAION Discord
-
Gege AI 以新声献唱:音乐创作工具 Gege AI 可以通过少量音频样本模仿任何歌手的声音,引发了关于颠覆音乐产业潜力的幽默评论,以及对 RIAA 反应的猜测。
-
用户对 Gege AI 和 GPT-4 模型感到沮丧:用户报告了注册 Gege AI 的困难,并伴有关于社交信用的调侃;另一些人则对 GPT-4 和 4O 模型 的表现表示失望,认为它们过于刻板,在编程任务上不如 GPT-3.5 等早期版本。
-
Adam-mini 优化器减少内存浪费:根据讨论中提到的一篇最新论文,Adam-mini 优化器提供与 AdamW 相当或更好的性能,同时通过划分参数并为每个 block 分配单一学习率,可减少 45-50% 的内存消耗。
-
Gemma 27B:怀疑与雄心并存:虽然新的 Gemma 27B 模型据报道显示出了一些有前景的性能提升,但成员们因其高置信区间而保持谨慎,质疑其相对于之前版本的整体优势。
-
转向 Claude 以获得更顺畅的体验:鉴于 OpenAI’s models 的问题,一些成员选择了 Claude,因为它具有卓越的 artifacts 功能以及与 Hugging Face libraries 更好的集成,报告称其体验比 GPT-4 模型更顺畅。
LangChain AI Discord
-
Bedrock 让工程师感到困惑:工程师们分享了在将 csv_agent 和 pandas_dataframe_agent 与 Bedrock 集成时遇到的挑战,以及在使用
ChatPromptTemplate.fromMessages配合 Sonnet 3.5 model 和 Bedrock 时遇到的错误,这表明可能存在兼容性问题。 -
LangGraph 发布,Human-in-the-Loop 功能遭遇困境:LangGraph 引入了 Human-in-the-loop 功能,特别是 “Interrupt” 和 “Authorize”,但在人工审批后恢复执行时出现了反序列化错误,正如 LangChain Blog 中所讨论的。
-
JSONL 编辑工具的改进以及使用 Matryoshka Embeddings 的 RAG:社区成员传阅了一个用于编辑 JSONL 数据集的工具 (uncensored.com/jsonl),并分享了关于使用 Matryoshka Embeddings 构建 RAG 以提高检索速度和内存效率的见解,并附带了 Colab tutorial。
-
Dappier 创造 AI 内容变现机会:TechCrunch 报道的 Dappier platform 为创作者提供了一个市场,通过 RAG API 授权内容用于 AI 训练,这为专有数据持有者标志着一条新的收入来源。
-
Testcontainers Python SDK 助力 Ollama:Testcontainers Python SDK 现在支持 Ollama,增强了通过 Ollama 运行和测试 Large Language Models (LLMs) 的便利性,该功能在 4.7.0 版本中可用,并附带了使用示例 (pull request #618)。
Modular (Mojo 🔥) Discord
-
Mojolicious 与 Mojo 之间的混淆已解决:当一名用户请求 Mojo 代码示例却收到基于 Perl 的 Mojolicious 示例时引起了混淆;但随后澄清了该请求是关于 Modular 的 AI 开发语言 Mojo 的信息,该语言因其类 Python 的增强能力和类 C 的稳健性而备受推崇。
-
陷入 REPL 网络陷阱:有报告称 Mojo REPL 存在异常,它会静默连接然后毫无预警地关闭,这引发了关于可能开启一个 GitHub issue 以识别并解决这个神秘连接难题的讨论。
-
Nightly 版本笔记:新编译器和 Graph API 切片:Modular 最新的 nightly 版本 ‘2024.6.2805’ 包含一个具有 LSP 行为调整的新编译器,并建议使用
modular update nightly/mojo;开发者还需要注意增加了 “跨维度的整数型字面量切片”,并建议通过 issues 记录新功能请求以便追溯。 -
SDK 遥测技巧与 MAX 回归:分享了关于在 Mojo SDK 中禁用遥测的指导,并提供了一个有用的 FAQ link;MAX nightly builds 再次运行,欢迎试用 Llama3 GUI Chatbot 并通过给出的 Discord link 提供反馈。
-
会议标记与社区资料:社区正在为下一次 Mojo Community meeting 做准备,计划在未指定的 当地时间 举行,详情可通过 Zoom 和 Google Docs 获取;此外,还向加拿大和美国的节日庆祝者表达了亲切问候。同时,点击 Modular.com 即可通过 Modverse Weekly - Issue 38 保持信息同步。
Torchtune Discord
- 社区模型获准加入:Torchtune 团队表达了对社区贡献模型的兴趣,鼓励成员分享自己的实现并增强库的通用性。
- 调试文本补全难题:Torchtune 文本补全中的一个令人困惑的问题被追踪到是由数据集错误插入的句末(EOS)token 引起的,详情见 GitHub 讨论。
- PreferenceDataset 备受青睐:对于强化学习应用,PreferenceDataset 成为优于文本补全数据集的选择,能更好地对齐“首选”输入-响应对的奖励。
- 预训练机制澄清:讨论澄清了预训练机制,特别是它涉及用于 token 预测的完整文档,而不是处理碎片化的输入-输出对。
- EOS Token:加还是不加?:社区对在 Torchtune 的文本补全数据集中引入 add_eos 标志进行了讨论并达成一致,解决了近端策略优化(PPO)实现中的一些问题。
LLM Finetuning (Hamel + Dan) Discord
新一代数据科学 IDE 预警:工程师们讨论了 Positron,这是一个前瞻性的数据科学 IDE,已在 #general 频道分享,暗示其对社区的潜在价值。
摘要生成障碍赛:出现了一个关于从患者记录中生成结构化摘要的技术咨询,重点在于如何使用 Llama 模型避免幻觉;社区正在征集 Prompt Engineering 和微调策略。
LLAMA 部署风波:如 #🟩-modal 频道所述,将 LLAMA 部署到 Streamlit 时出现了本地环境未见的错误;另一位成员通过调整数据集路径解决了 Tinyllama 的 FileNotFoundError。
额度归属问题:多位成员报告了关于各种应用额度缺失的问题,包括在 #fireworks 和 #openai 频道的请求,强调需要解决涉及 kishore-pv-reddy-ddc589 等标识符和组织 ID org-NBiOyOKBCHTZBTdXBIyjNRy5 的问题。
链接救急与 Predibase 谜题:在 #freddy-gradio 频道,一个失效链接被迅速修复;而 #predibase 频道关于 Predibase 额度过期的提问目前仍未得到解答。
OpenInterpreter Discord
-
安全且开放:Open Interpreter 应对安全挑战:讨论了 Open Interpreter 的安全措施,例如在执行代码前需要用户确认以及使用 Docker 进行沙箱隔离,强调了社区反馈对项目安全的重要性。
-
速度与技能:代码模型竞技场:工程师们对比了各种代码模型,认可 Codestral 的卓越性能,而 DeepSeek Coder 虽然运行速度更快,但有效性约为 70%。DeepSeek Coder-v2-lite 以其极速执行和编码效率脱颖而出,潜力可能超越 Qwen-1.5b。
-
资源效率咨询:量化版 SMOL 模型:由于 RAM 限制,有人咨询以量化格式运行 SMOL 多模态模型的问题,突显了 AI 系统在有限资源环境下的适应性挑战。
-
API 密钥泄露:Rabbit R1 的安全疏忽:一段 YouTube 视频 揭露了一个重大的安全疏忽,发现 Rabbit R1 在其代码库中硬编码了 API 密钥,这对用户数据安全构成了严重威胁。
-
修改 OpenInterpreter 以支持本地运行:一位 AI 工程师概述了使用非 OpenAI 供应商本地运行 OpenInterpreter 的过程,并在 GitHub issue 评论 中详细说明了调整方法。除了订阅费之外,人们还对额外的 API 相关成本表示了担忧。
tinygrad (George Hotz) Discord
tinygrad 获得新的移植福利:一个支持微调(finetuning)的新 port 已完成,标志着 tinygrad 项目的进展。
FPGA 在人形机器人领域取得胜利:一个为期 8 个月的项目利用 FPGA-based systems 研发出了高能效的人形机器人,这被认为比目前因高功耗而消耗电池寿命的 GPU 系统更具成本效益。
Shapetracker 的零成本 reshape 革命:tinygrad 中的 Shapetracker 允许在不改变底层内存数据的情况下进行张量变形(tensor reshaping),这在 Shapetracker explanation 中有详细说明,成员们讨论了其相对于传统内存步长(memory strides)的优化。
模型存储的新旧结合:根据 George Hotz 的说法,在 tinygrad 中,权重由 safetensors 处理,计算由 pickle 处理,这表明了当前模型存储的方法论。
对 Shapetracker 血统的好奇:参与者思考 Shapetracker 背后的概念是原创的,还是从现有的深度学习编译器中汲取的灵感,同时赞赏其无需数据复制即可进行优化的能力。
Cohere Discord
- 实习咨询点燃网络:一名学生将其在 LLMs and Reinforcement learning 方面的学术重点与现实应用相结合,向 Cohere 员工咨询公司的企业文化和项目。平台上的互动表明,在竞争 AI 领域的实习机会时,展示强大的公开项目组合已达成共识。
- Cohere 的功能请求:Cohere 用户对潜在的新功能表现出好奇,促使大家提出可以增强平台产品的建议。
- AI 博客自动化的愿景:围绕为博客和社交媒体内容生成设置 AI-powered automations 展开了讨论,并将咨询引导至专门的协助渠道。
- AI Agent 成果发布:一名成员展示了一个名为 Data Analyst Agent 的 AI 项目,该项目使用 Cohere and Langchain 构建,并通过 LinkedIn post 进行了推广。
OpenAccess AI Collective (axolotl) Discord
-
Gemma2 通过 Pull Request 获得 Sample Packing:提交了一个 GitHub pull request 以将 Gemma2 与 sample packing 集成。由于需要 Hugging Face 的修复,该 PR 目前处于待定状态,详情见 PR 内部。
-
27b 模型表现平平:尽管参数量有所增加,但 27b model 在基准测试中的表现与 9b model 相比并不理想,这表明可能存在扩展或架构效率低下的问题。
AI Stack Devs (Yoko Li) Discord
- Featherless.ai 推出固定费率模型访问:Featherless.ai 推出了一个平台,以极具竞争力的价格提供对 Hugging Face 上 450 多个模型的访问,基础层级起价为每月 10 美元,无需 GPU 设置或下载。
- 订阅升级:每月 10 美元的 Feather Basic 计划允许访问最高 15B 的模型,而每月 25 美元的 Feather Premium 计划允许访问最高 72B 的模型,并增加了私密和匿名使用等福利。
- 社区对模型推出的影响:Featherless.ai 正在征求社区对平台模型优先级的意见,强调了目前 AI 角色本地应用以及语言微调(finetuning)和 SQL 模型使用等专门任务的受欢迎程度。
Datasette - LLM (@SimonW) Discord
- 对 Chatbot Elo 演变的好奇:用户请求获取超出提供的六周 JSON 数据集之外的更长时间跨度的 chatbot elo ratings 数据,表达了对聊天机器人竞技场(chatbot arena)不断演变的竞争格局的兴趣。
- 观察 Elo 竞赛:从 5 月 19 日开始,注意到领先的聊天机器人在 elo 评分中的“梯队”正在缩短,表明竞争领域非常激烈。
MLOps @Chipro Discord
- Feature Stores 成为关注焦点:一场名为“使用 Featureform 和 Databricks 构建企业级 Feature Store”的精彩网络研讨会将于 7 月 23 日上午 8 点(太平洋时间)举行。Simba Khadder 将探讨特征工程的复杂性、Databricks 的利用以及处理大规模数据的路线图,最后设有问答环节。报名参加以深入了解 Feature Store。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的频道细分内容已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!