ainews-qdrants-bm42
Qdrant 的 BM42:“请不要相信我们”
Qdrant 试图通过一种名为“BM42”的新方法来取代 BM25 和 SPLADE。该方法结合了 Transformer 注意力和全集合统计信息,旨在用于语义和关键词搜索,但其在 Quora 数据集上的评估被发现存在缺陷。来自 Cohere 的 Nils Reimers 在更优的数据集上重新测试了 BM42,发现其表现不佳。Qdrant 承认了这些错误,但在对比中仍使用了次优的 BM25 实现。这突显了在搜索模型声明中,数据集选择和评估合理性检查(sanity checks)的重要性。
此外,Stripe 因 AI/ML 模型故障导致账户和支付问题而面临批评,引发了寻求替代方案的呼声。Anthropic 透露 Claude 3.5 Sonnet 会使用后端标签抑制部分回答内容,这引发了广泛争论。Gemma 2 模型的优化使得微调速度提升了 2 倍,内存占用减少了 63%,并支持更长的上下文窗口,能够在消费级 GPU 上运行高达 34B 参数的模型。nanoLLaVA-1.5 作为一款紧凑的 1B 参数视觉模型正式发布,并带来了显著改进。
同行评审就是你所需要的一切。
2024年7月4日至7月5日的 AI 新闻。我们为你检查了 7 个 subreddit、384 个 Twitter 账号 和 30 个 Discord(418 个频道,3772 条消息)。预计节省阅读时间(按每分钟 200 字计算):429 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论,并尝试 Smol Talk!
Qdrant 被广泛认为是 OpenAI 首选的向量数据库,在 7 月 4 日假期期间,他们发布了一些大胆的声明,声称要取代久负盛名的 BM25(甚至是更现代的 SPLADE),并试图创造“BM42”这一术语:
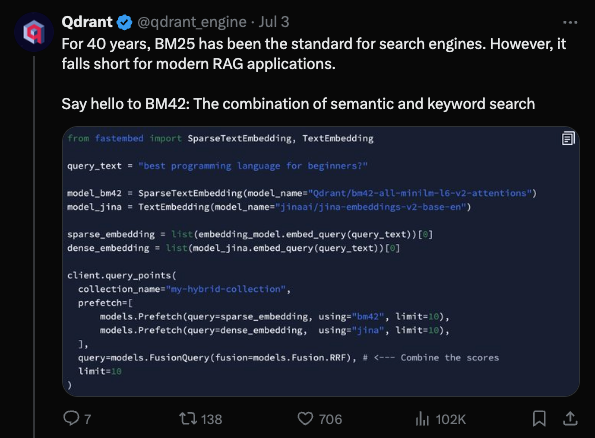
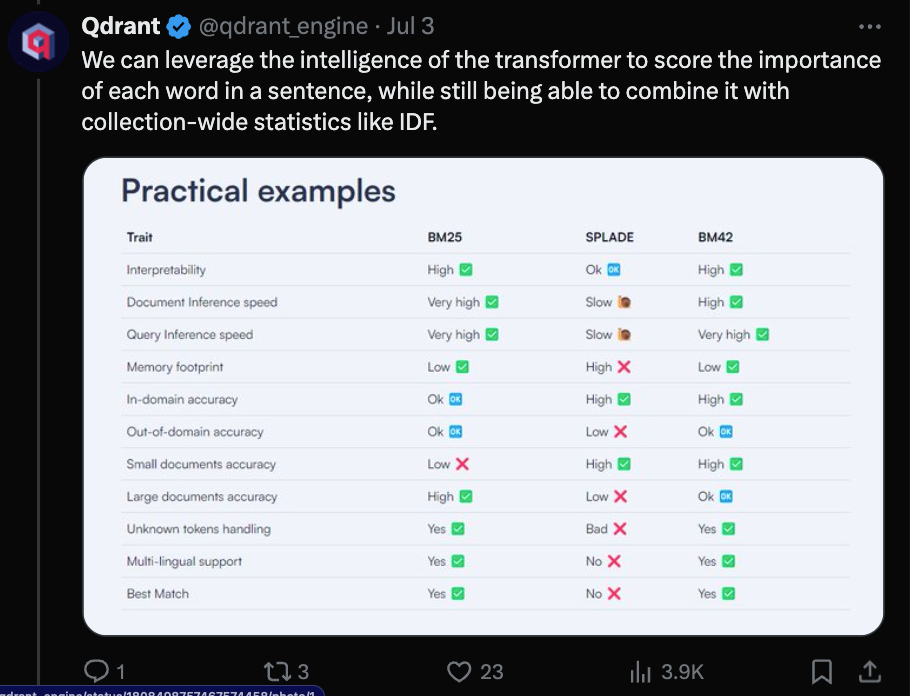
该方案旨在通过结合用于词重要性评分的 Transformer 注意力机制与诸如 IDF 之类的全集合统计数据,来解决语义 + 关键词搜索的问题,并声称在所有用例中都具有优势:
只有一个问题……结果。来自 Vespa(竞争对手)的 Jo Bergum 指出,选择 Quora(一个“寻找相似重复”问题的数据集,而非 Q&A 检索数据集)作为数据集非常奇怪,而且如果你了解该数据集,就会发现其评估结果显然是错误的:
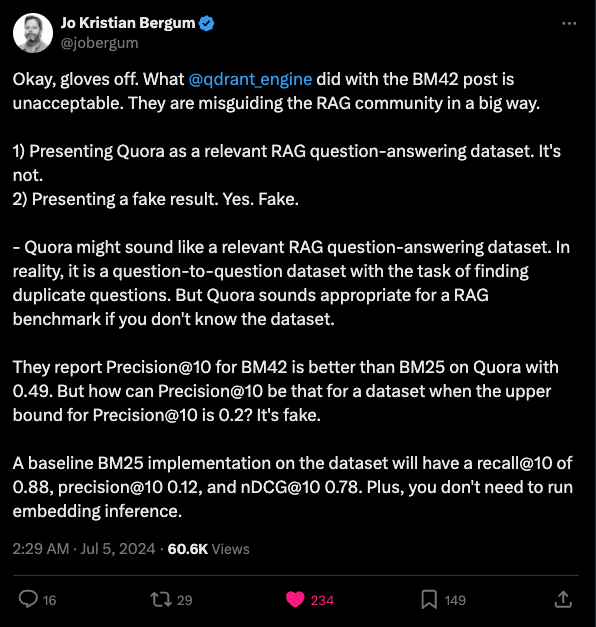
具体来说,Quora 数据集每个查询只有约 1.6 个数据点,因此他们声称每 10 个结果中有超过 4 个(precision@10)的数值显然是错误的。
Cohere 的 Nils Reimers 采用了 BM42 并在金融、生物医学和 Wikipedia 领域更好的数据集上进行了重新运行,遗憾的是,BM42 在所有方面都表现不佳:
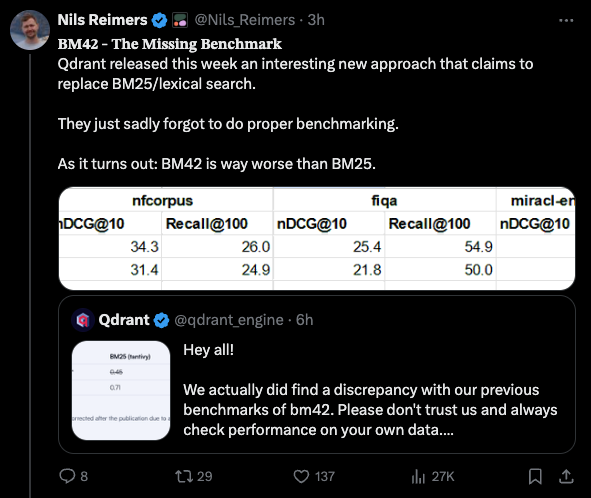
就 Qdrant 而言,他们已经回应并承认了这些修正,并发布了修正方案……除了仍然奇怪地运行着一个比其他人预期得分更低、且恰好比 BM42 表现更差的 BM25 实现。
对 Qdrant 来说这很不幸,但对我们其他人来说,这只是一次关于了解数据和对评估进行常识检查的速成课。最后,正如在公关(PR)中尤其是 AI 领域一贯如此:非凡的主张需要非凡的证据。
元注释:如果你一直想定制自己版本的 AI News,我们现在已经预览了一个简陋的早期版本 Smol Talk,你可以通过这里访问:https://smol.fly.dev
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成。
Stripe 问题与替代方案
- Stripe 账户问题:@HamelHusain 指出,尽管没有退款请求,Stripe 仍以“无尽的官僚程序”为由“扣押了我所有的钱”。@jeremyphoward 称 Stripe 因“AI/ML 模型故障”而注销账户的行为是“可耻的”。
- 申诉 Stripe 的决定:@HamelHusain 对 Stripe 的拒绝提出了申诉,但在 5 分钟内就被驳回,Stripe 继续“扣押着数千美元”。
- Stripe 的替代方案:@HamelHusain 指出需要一个“备份计划”,因为“被 AI/ML 误报抓到真的很糟糕”。@virattt 在看到许多关于此类问题的帖子后,对使用 Stripe 表示谨慎。
AI 与 LLM 进展
- Anthropic Constitutional AI:@Anthropic 指出 Claude 3.5 Sonnet 会使用 “antThinking” 标签隐藏部分回答内容,这些标签在后端会被移除,但一些人不同意这种隐藏做法。
- Gemma 2 模型优化:@rohanpaul_ai 分享了使用 UnslothAI 库可以使 Gemma 2 的微调速度提升 2 倍且显存占用减少 63%,允许比 HF+FA2 长 3-5 倍的上下文。它可以在单个消费级 GPU 上运行高达 34B 的模型。
- nanoLLaVA-1.5 视觉模型:@stablequan_ai 发布了 nanoLLaVA-1.5,这是一个紧凑的 1B 参数视觉模型,性能较 v1.0 有显著提升。推文中附带了模型和 Spaces 链接。
- LLM 的 Reflection as a Service:@llama_index 介绍了将 Reflection(反射)作为 Agentic LLM 应用的独立服务,用于验证输出并自我修正以提高可靠性。文中引用了相关论文。
AI 艺术与感知
- AI 与人类艺术感知投票:@bindureddy 发布了一个包含 3 张 AI 生成图像和 1 张人类艺术作品的投票,挑战人们识别出人类的作品,作为一项关于艺术感知的“快速实验”。
- AI 艺术并非剽窃:@bindureddy 认为 AI 艺术不是剽窃,因为它在研究作品、获取灵感并创造新事物方面与“人类所做的完全一样”。完全的复制是剽窃,但全新的创作不是。
迷因与幽默
- 扎克伯格迷因视频:@GoogleDeepMind 分享了一段 Mark Zuckerberg 反应的迷因视频。@BrivaelLp 调侃扎克伯格在转型为“硬核科技男”方面的“大师级表现”。
- Caninecyte 定义:@c_valenzuelab 在一个模拟词典条目中开玩笑地将 “caninecyte” 定义为“一种以长得像狗为特征的细胞”。
- 有趣的家庭照片:@NerdyRodent 幽默地问道:“为什么当我翻看旧家谱照片时,总有人要吐舌头?”并配上了一张像素艺术作品。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 进展与影响
- AI 突破的飞速步伐:在 /r/singularity 中,一篇文章强调了最近的 AI 进展在人类历史长河中是多么压缩,如果将人类存在比作 24 小时,现代 Deep Learning 仅在最后一“秒”出现。然而,一篇文章质疑了 AI 迄今为止的经济影响,尽管炒作不断。
- AI 幽默能力:研究显示 AI 生成的幽默被评为比人类更幽默,且与 The Onion(洋葱新闻)不相上下,尽管 /r/singularity 的一些评论者对 AI 笑话的原创性持怀疑态度。
- OpenAI 安全漏洞:《纽约时报》报道称,2023 年初,一名黑客入侵了 OpenAI 的通信系统并窃取了关于 AI 开发的信息,引发了人们对其在防止外国实体窃取 IP 方面做得不够的担忧。
- 抗衰老进展:在一次 YouTube 采访中,Altos Labs 的 CSO 讨论了通过细胞重编程在小鼠身上看到的重大抗衰老效果,老龄小鼠重焕青春。接下来将进行人体试验。
AI 模型与能力
- 讨论的新开源模型包括 Kyutai 的 Moshi 语音模型、internlm 2.5 xcomposer 视觉模型,以及 T5/FLAN-T5 被合并到 llama.cpp 中。
- 一项针对 180 多个 LLM 代码生成的评估发现,DeepSeek Coder 2 在性价比上击败了 Llama 3,而 Claude 3.5 Sonnet 的能力也旗鼓相当。只有 57% 的响应可以原样编译。
AI 安全与保障
- /r/LocalLLaMA 讨论了保护 LLM 应用安全的方法,包括通过 Fine-tuning 拒绝不安全请求、Prompt Engineering、安全模型、Regex 过滤以及不重写用户 Prompt。
- 分享了一个 Google Gemini AI 重复已被拆穿的虚假信息的例子,表明目前的 AI 不能被盲目信任为事实。
{kind=link}
AI 艺术与媒体
- 分享了使用 Stable Diffusion、MimicMotion 和 Suno AI 生成 AI 歌手的工作流,以及使用 ComfyUI 从单一参考图生成图像的方法。
- /r/StableDiffusion 讨论了一种在图像/视频之间迁移面部表情的新开源方法,以及 AI Technical Artists(AI 技术美术师)新兴的角色,旨在为游戏工作室构建 AI 艺术流水线。
- /r/singularity 预测随着 AI 取代在线媒体,现场娱乐的需求将复苏。
{kind=link}
机器人与具身智能
- 分享了 Menteebot 在环境中导航、机器人粗略采摘西红柿以及日本开发巨型人形机器人维护铁路的视频。
- 一条推文呼吁开发开源机甲(Open Source Mechs)。
其他
- /r/StableDiffusion 对 Auto-Photoshop-StableDiffusion 插件开发者的突然失踪表示担忧。
- Hugging Face 上分享了一个极度恐怖主题的 16.5B 参数 LLaMA 模型。
- /r/singularity 讨论了一个关于如果进度每天翻倍何时购买电脑的“奇点悖论(Singularity Paradox)”思想实验,评论指出该前提存在缺陷。
AI Discord 回顾
总结的总结之总结
1. LLM 性能与优化
- 像 Llama 3、DeepSeek-V2 和 Granite-8B-Code-Instruct 这样的新模型在各种基准测试中表现强劲。例如,Llama 3 已跃升至 ChatbotArena 等排行榜的首位,超越了 GPT-4-Turbo 和 Claude 3 Opus 等模型。
-
优化技术正在迅速发展:
- ZeRO++ 承诺将大模型训练的通信开销降低 4 倍。
- vAttention 系统 旨在动态管理 KV-cache 内存,以实现高效的 LLM 推理。
- QServe 引入了 W4A8KV4 量化,以提升基于云端的 LLM 服务性能。
2. 开源 AI 生态系统
- 像 Axolotl 这样的工具正支持多种数据集格式用于 LLM 训练。
- LlamaIndex 推出了关于构建 Agentic RAG 系统的课程。
- 像 RefuelLLM-2 这样的开源模型正在发布,专注于特定的用例。
3. 多模态 AI 与生成模型
-
新的多模态模型正在增强各种能力:
- Idefics2 8B Chatty 专注于改进对话交互。
- CodeGemma 1.1 7B 优化了编程能力。
- Phi 3 通过 WebGPU 将 AI 聊天机器人带入浏览器。
-
模型组合(例如 Pixart Sigma + SDXL + PAG)旨在达到 DALLE-3 级别的输出效果。
4. Stability AI 许可协议
- 在社区反馈后,Stability AI 修订了 SD3 Medium 的许可协议,旨在为个人创作者和小企业提供更多清晰度。
- 关于 AI 模型许可条款及其对开源开发影响的讨论在多个社区中持续进行。
- Stability AI 推出的 Stable Artisan(一个集成多种 Stable Diffusion 模型用于媒体生成和编辑的 Discord 机器人)成为了热门话题(Stable Artisan 公告)。用户讨论了该机器人的影响,包括关于 SD3 开源状态的问题,以及将 Artisan 作为付费 API 服务推出的讨论。
5. 社区工具与平台
- Stability AI 推出了 Stable Artisan,这是一个集成 Stable Diffusion 3 和 Stable Video Diffusion 等模型的 Discord 机器人,用于在 Discord 内进行媒体生成。
- Nomic AI 发布了 GPT4All 3.0,这是一款开源的本地 LLM 桌面应用,强调隐私保护并支持多种模型和操作系统。
6. 新 LLM 发布与基准测试讨论:
- 多个 AI 社区讨论了新语言模型的发布,例如 Meta 的 Llama 3、IBM 的 Granite-8B-Code-Instruct 和 DeepSeek-V2,重点关注它们在各种基准测试和排行榜上的表现。(Llama 3 博客文章、Hugging Face 上的 Granite-8B-Code-Instruct、Hugging Face 上的 DeepSeek-V2)
- 一些用户对某些基准测试的有效性表示怀疑,呼吁使用更可靠的来源来设定现实的 LLM 评估标准。
7. 优化 LLM 训练与推理:
- 在多个 Discord 频道中,用户分享了优化 LLM 训练和推理的技术和框架,例如用于减少通信开销的 Microsoft ZeRO++(ZeRO++ 教程)、用于动态 KV-cache 内存管理的 vAttention(vAttention 论文),以及用于基于量化提升性能的 QServe(QServe 论文)。
- 其他优化方法,如用于并行 Token 解码的 Consistency LLMs,也得到了讨论(Consistency LLMs 博客文章)。
8. 开源 AI 框架和数据集的进展:
- 开源 AI 框架和数据集是各个 Discord 频道中的共同话题。Axolotl (Axolotl Dataset Formats)、LlamaIndex (Building Agentic RAG with LlamaIndex Course) 和 RefuelLLM-2 (RefuelLLM-2 on Hugging Face) 等项目因其对 AI 社区的贡献而受到关注。
- Modular 框架也因其在 Python 集成和 AI 扩展方面的潜力而受到讨论 (Modular Blog Post)。
9. 多模态 AI 与生成模型:
- 关于多模态 AI 和生成模型的对话非常普遍,提到了 Idefics2 8B Chatty (Idefics2 8B Chatty Tweet)、CodeGemma 1.1 7B (CodeGemma 1.1 7B Tweet) 和 Phi 3 (Phi 3 Reddit Post) 等模型,用于聊天交互、编程和基于浏览器的 AI 等各种应用。
- 讨论中还涉及了结合 Pixart Sigma, SDXL, and PAG 以获得高质量输出的生成建模技术,以及用于图像重照明的开源 IC-Light 项目 (IC-Light GitHub Repo)。
10. Unsloth AI 社区的新模型发布与训练技巧:
- Unsloth AI 社区对新发布的模型讨论热烈,例如 IBM 的 Granite-8B-Code-Instruct (Granite-8B-Code-Instruct on Hugging Face) 和 RefuelAI 的 RefuelLLM-2 (RefuelLLM-2 on Hugging Face)。用户分享了使用这些模型的经验,包括 Windows 兼容性 方面的挑战以及对某些 performance benchmarks 的质疑。社区还交流了关于模型训练和 fine-tuning 的宝贵技巧和见解。
第 1 部分:Discord 高层级摘要
HuggingFace Discord
- 越南语语言学之声:Vi-VLM 的愿景:Vi-VLM 团队宣布推出一款专为越南语定制的 Vision-Language model,整合了 Vistral 和 LLaVA 框架,专注于图像描述。用户可以在链接的仓库中找到 Demo 和支持代码。
- 数据集可用性:Vi-VLM 发布了一个专门用于越南语 VLM 训练的数据集,可用于增强本地语言模型应用。该数据集丰富了东南亚语言的语言资源。
- 图像处理难题:寻找 WHAM 的替代方案:一位爱好者正在寻找 WHAM 的替代方案,用于复杂视频中的 human pose estimation(人体姿态估计),并指出其 Python 和 CV 依赖项非常笨重。社区交流暗示需要更适合非技术用户使用的高级 AI 应用工具。
- 分享了 ViT 和 U-Net 实现的学习资源,包括来自 Zero to Mastery 的指南和 Andrew Ng 的课程,显示出社区对掌握这些 vision transformer 模型的兴趣。
- 调优:音频语言模型讨论:Moshi 的语言流畅性:Yann LeCun 分享了一条 推文,重点介绍了 Kyutai.org 的数字海盗 (digital pirate),它可以理解带有法国口音的英语,展示了该模型多样化的听觉处理能力。
- 对 Flora 论文和音频语言模型的兴趣依然浓厚,反映了 AI 社区对跨模态能力的关注。人们热切期待即将举行的关于这些主题的论文研读会。
- 陷入停滞:Mistral 模型僵局:用户报告 Mistral 模型 的推理过程陷入停滞,特别是在 3000 次迭代中的第 1800 次,这可能暗示了缓存复杂性问题。这反映了在执行大规模计算任务时管理资源的实际挑战。
- 围绕如何在不本地下载模型的情况下进行有效的 API 调用展开了讨论,强调了对精简远程推理协议的需求。以 API 为中心的对话凸显了向更灵活、基于云的 ML 操作发展的趋势。
- Diffusion 讨论:RealVisXL 和 ISR:专为渲染写实视觉效果而优化的 RealVisXL V4.0 正在训练中,拥有 官方页面 并在 Boosty 上获得赞助,突显了社区对模型开发的支持。
- 现有的 IDM-VTON 在 Google Colab 中出现的 “no file named diffusion_pytorch_model.bin” 错误是 Diffusion 模型领域中典型的排障对话,强调了 AI 部署的实际层面。
Stability.ai (Stable Diffusion) Discord
- 消除困惑:Stability AI 的社区许可:Stability AI 在收到反馈后修订了其 SD3 Medium 的发布许可,推出了全新的 Stability AI Community License,明确了个人创作者和小微企业的使用权限。详情见其近期公告,该公司在商业权益与社区支持之间寻求平衡。
- 用户现在可以根据新许可免费将 Stability AI 的模型用于非商业用途,这对社区来说是开源福音,并引发了关于这些变化如何影响模型开发和可访问性的讨论。
- 动漫 AI 模型的蜕变:Animagine XL 3.1:由 Cagliostro Research Lab 和 SeaArt.ai 开发的 Animagine XL 3.1 模型因其较前代模型的增强而引发热议,将更高质量和更广泛的动漫图像推向了前沿。
- AAM Anime Mix XL 也引起了关注,引发了与 Animagine XL 3.1 的大量对比,爱好者们讨论了他们在不同动漫专注生成模型之间的体验和偏好。
- 辩论 GPU 军备竞赛:多 GPU 配置:技术社区正在积极讨论多 GPU 配置的优化,以提升 Stable Diffusion 的性能,重点关注像 SwarmUI 这样针对复杂配置的工具。
- 辩论集中在高效管理资源和实现高质量输出的挑战上,强调了在不断发展的 AI 模型训练领域中,导航所需的技术实力与创造力的结合。
- CivitAI 对 SD3 的立场引发争议:CivitAI 禁止 SD3 模型的举动在社区内引发了分歧,一些人认为这可能是 Stable Diffusion 3 框架发展的潜在障碍。
- 随着对许可复杂性、商业影响以及这一决定如何塑造未来协作和模型演进的深入见解,讨论进一步加深。
- 许可与限制:备受审视的 Stable Diffusion:最新的对话审视了 Stable Diffusion 3 的许可及其与个人和企业使用的兼容性,考虑到社区对 AI 模型实验的清晰度和自由度的需求。
- 社区情绪出现分歧,讨论围绕着感知到的许可限制是否不公平地惩罚了小型项目,或者它们是否是 AI 领域技术成熟过程中固有的一部分。
Unsloth AI (Daniel Han) Discord
- Gemma 的量子飞跃:全新的 Gemma 2 已震撼技术圈,其 finetuning 速度提升了 2 倍,且 VRAM 占用减少了 63% (Gemma 2 博客)。在 Unsloth 用户中,27B 模型支持高达 9.7K token 上下文成为了一个特别的亮点。
- 发布初期伴随的 notebook 问题(如标签错误)被社区成员指出博客文章过于仓促,但这些问题已被开发者迅速解决 (Notebook 修复)。
- Replete-AI 的海量数据集:Replete-AI 推出了两个大型数据集:Everything_Instruct 及其多语言版本,每个都包含 11-12GB 的 instruct 数据 (Replete AI 数据集)。超过 600 万行数据可供 AI 开发者使用,有望推动下一波语言模型训练。
- 社区的热情伴随着质量检查,开发者们对数据集的 deduplication(去重) 和 内容平衡 进行了探究,体现了对数据集精细构建的专业眼光。
- 固定 Notebook 资源:collaboration 频道的请求促成了 置顶多功能 notebook 的承诺,旨在帮助成员快速定位核心资源。
- 社区持续努力 修正 notebook 链接,并承诺将其整合到 Unsloth 的 GitHub 页面中,展示了一个动态的社区驱动型文档流程 (GitHub Unsloth)。
- Unsloth 2024.7 的补丁与进展:Unsloth 的 2024.7 补丁因 checkpoint 相关错误 评价褒贬不一,但它通过将 Gemma 2 支持 集成到 Unsloth 不断扩展的工具包中,迈出了重要一步 (2024.7 更新)。
- 忠实用户和 Unsloth 响应迅速的开发者正致力于解决 fine-tuning 中的小瑕疵和错误修复,证明了对于精细化模型优化至关重要的强大反馈闭环。
- Facebook 备受争议的 Token 策略:Facebook 的 multi-token prediction 模型引发了关于访问壁垒的辩论,在 Unsloth 紧密的社区中激起了各种观点。
- 对数据隐私的批评观点屡见不鲜,特别是涉及使用 Facebook 模型需要共享联系人数据的问题,这引发了关于 AI 伦理使用的持续讨论 (Facebook 的 Multi-Token 模型)。
Latent Space Discord
- 冲刺融资跑道:紧随 rakis 的链接,社区成员讨论了 AI 与 blockchain 交叉领域高达 8500 万美元的种子轮投资,引发了关于当前技术领域风险投资趋势的对话。
- BM42 的开发者因 benchmark 可能存在偏差而面临压力,促使社区警惕并倡导严谨的评估实践;这促使其修改了指标和数据集的方法。
- 碰撞:编程工具:用户对比了 git merge 工具的使用体验,特别点名了 lazygit 和 Sublime Merge,讨论转向了对更细致的代码冲突解决工具的需求。
- Claude 3.5 和其他基于 AI 的工具因其在编程辅助方面的出色表现而备受关注,强调了代码补全的效率以及处理复杂多文件重构的能力。
- 调频技术对话:在 Latent Space Podcast 中,来自 Reka 的 Yi Tay 阐述了为 frontier models 开发训练栈的过程,并将其规模和策略与 OpenAI 及 Google Gemini 团队进行了类比。
- 听众受邀在 Hacker News 上参与实时讨论,架起了播客与更广泛的 AI 研究社区对话之间的桥梁。
- 应对音视频故障:OpenAI 的 AV 在 AIEWF 演示期间出现中断,随后出现了切换到 Zoom 的呼声,紧接着迅速采取行动分享了 Zoom 会议链接 以获得更好的 AV 稳定性。
- Discord 与 Linux 之间的兼容性问题仍然是一个反复出现的技术难题,促使用户探索更适合 Linux 的通信替代方案。
- 解构模型合并热潮:关于 model merging tactics 的辩论成为焦点,参与者思考了 LlamaFile 和 Ollama 等工具的不同目标和潜在的集成策略。
- 对话深入探讨了可穿戴技术与 AI 集成以增强活动体验的可能性,并对隐私和知情同意进行了深度思考。
LM Studio Discord
- Snapdragon 令人惊讶的速度:搭载 Snapdragon Elite 的 Surface Laptop 展示了强大的实力,在 8bit 精度的 LLaMA3 8b 上实现了 1.5 秒的首个 token 响应时间和每秒 10 个 token 的速度,而 GPU 占用率仅为 10%。目前尚未监测到 NPU 活动,但该笔记本的速度引发了人们对 NPU 最终提升 LLaMA 模型性能的猜测。
- 技术爱好者将 Snapdragon 的 CPU 实力与旧款 Intel 产品进行了对比,发现前者的速度非常惊人。在欢声笑语中,技术社区调侃了一个临时搭建的“纸板 NPU”,并预测在进行适当的 NPU 编程后,性能可能会达到巅峰。
- 量化奇点与代码探索:Gemma-2-27b 出现了量化难题,模型基准测试在不同量化版本中表现异常。与此同时,定制的系统提示词优化了 Gemma 2 27B 的性能,使其能够输出符合 PEP 8 标准且高效的算法。
- 有建议指出,Qwen2 模型在使用 ChatML 和 flash attention 设置时表现最佳,而使用非 CUDA 设备的用户则对 IQ 量化带来的混乱提出了警告,指出在替代架构上表现明显更好。
- LM Studio 的 ARM 僵局:一位恼火的用户对 LM Studio 的 AppImage 无法在 aarch64 CPU 上运行表示沮丧。错误提示显示存在语法冲突,一行哀叹确认道:“Linux 上不支持 ARM CPU。”
- 对话打破了立即包含 ARM CPU 支持的希望,让 Linux 忠实拥趸们感到渴望。一种共同的观点认为,LM Studio 的架构调整已在计划中,但尚未正式落地。
- RTX 的坎坷之路:RTX 4060 8GB VRAM 的所有者表达了他们在处理 20B 量化模型时的困境;与 token 的顽强搏斗最终导致系统完全冻结。论坛其他成员对他们表示同情,回想起自己使用 RTX 4060 时支离破碎的经历。
- 社区指南为 GPU 困扰者带来了一线希望,建议中端机器用户使用 Mistral 7B 和 Open Hermes 2.5 等负载较小的模型。大家纷纷赞扬这些较小的模型,建议避开那些巨大的 token 吞噬者。
- ROCm 的救援角色:拥有 7800XT 的用户在模型运行混乱、无法实现 GPU offload 时表达了他们的痛苦。一个脚本标志着成功,安抚了寻求 ROCm 慰藉的超负荷系统。
- 技术集体汇聚解决方案,证实了 ROCm 安装脚本的有效性。论坛中响起了欢快的旋律,因为 GPGPU 大师们已经找到了一个值得技术圈使用的变通方法。
CUDA MODE Discord
- CUDA 难题与混合精度 MatMul:CUDA MODE 社区的讨论转向了使用 CUDA 优化矩阵乘法,重点关注了一篇关于 GPU 矩阵乘法中列加载技术的博客文章;另一个话题探讨了用于 int2*int8 的定制 gemv kernels 的发布,以及用于混合精度操作的 BitBLAS 库。
- 用户探讨了 TorchDynamo 在 PyTorch 性能中的作用,并对比了使用 Python 与 C++ 进行 CUDA kernel 开发的易用性,Python 因其在初始阶段的灵活性而更受青睐。一些用户在将
torch.compile适配 Python 3.12 字节码变化时遇到挑战,这在最近的讨论中得到了解决。
- 用户探讨了 TorchDynamo 在 PyTorch 性能中的作用,并对比了使用 Python 与 C++ 进行 CUDA kernel 开发的易用性,Python 因其在初始阶段的灵活性而更受青睐。一些用户在将
- GPT 撰写执行摘要与模型训练试验:一篇详细介绍使用 GPT 起草执行摘要的博客文章引发了关注,而使用 FP8 梯度的 LLM 训练试验因导致 loss 增加而被标记,促使某些操作切换到 BF16。
- Schedule-Free Optimizers 拥有更平滑的 loss 曲线,用户分享了其收敛优势的经验证据。同时,关于后端 SDE 转型 CUDA 推理优化的讨论也在进行,建议涵盖了在线资源、课程推荐和社区参与。
- AI 播客与主题演讲引发热烈讨论:Lightning AI 与 Luca Antiga 和 Thomas Viehmann 合作的 Thunder Sessions 播客引起了社区成员的注意,而 Andrej Karpathy 在 UC Berkeley 的主题演讲则是创新和学生才华的亮点。
- 随意的交谈和频道互动描绘了一个互动活跃的论坛图景,成员们分享了简短的兴奋或赞赏之情,但在标记为关注度较低的频道中则较少进行深入的技术交流。
- 深度学习框架与 Triton Kernel 修复:尝试用 C++ 从零构建一个类似于 tinygrad 的深度学习框架揭示了复杂性障碍,引发了关于 C++ 与 Python 在此背景下提供的功能支持的辩论。同时,在并行 CUDA graph 实例中 Triton kernel 的
tl.load问题需要通过创意手段来规避延迟问题。- 在讨论 torch.ao 中
.to方法的功能时,发现了更多的复杂性,目前的限制约束了 dtype 和内存格式的更改,促使开发者对函数进行了临时修正,正如问题追踪器和 commit 日志中所讨论的那样。
- 在讨论 torch.ao 中
Perplexity AI Discord
- Llamas Looping Lines:AI 中的重复故障:用户反映 Perplexity AI 在 Llama 3 和 Claude 等模型中出现了重复输出的现象,并得到保证称该问题正在处理中,即将发布修复补丁。
- Alex 确认了该问题已被记录并正在努力修复,这标志着 Perplexity AI 性能基准测试中一个亟待解决的问题。
- 实时现实检查失败:实时访问故障:由于 Perplexity AI 用户面临实时互联网数据检索问题,接收到的是过时而非最新的信息,导致预期与实际出现差距。
- 尽管用户尝试通过重启应用程序来解决准确性问题,但反馈频道显示该问题依然存在。
- 数学模型失误:Perplexity Pro 的计算挑战:Perplexity Pro 的计算(如 CAPM beta)被指出存在不准确之处,尽管其源自 GPT-4o,这为其在可靠学术应用上的前景蒙上了阴影。
- 社区对该模型在需要精确数学解题领域的实用性表达了不满和担忧。
- 股市成功案例:Perplexity 的盈利预测:一些利用 Perplexity AI 进行股市决策并获利(如赚取 8,000 美元)的财务胜利案例浮出水面,引发了关于其多样化益处的讨论。
- 这些用户故事证明了 Perplexity AI 的 Pro 版本在现实世界用例中的多样化能力。
- 订阅审查:解码 Perplexity AI 方案:随着用户深入探讨 Pro 和 Enterprise Pro 方案之间的差异,特别是关于 Sonnet 和 Opus 等模型的分配,相关问题和对比也随之增多。
- 咨询不仅集中在可用性上,还包括 Perplexity 不同订阅服务中所包含模型的具体细节。
LAION Discord
- BUD-E 面板扩展:BUD-E 现在可以读取剪贴板文本,这一新功能在一段 YouTube 视频中展示,详情见 GitHub。该功能演示虽然画质较低,但引发了轻松的讨论。
- 社区讨论了由于反复使用重叠数据集而导致的 AI model training 挑战,FAL.AI 的数据集访问障碍凸显了这一问题。相比之下,像 Chameleon 这样的突破则与多种集成数据相关联。
- Clipdrop 审查困惑:Clipdrop 的 NSFW 检测出现误判,将一张正常的图片错误标记为不当内容,引起了社区的哄笑。
- Stability AI 修改了许可证,SD3 Medium 现在采用 Stability AI Community License,在收到社区反馈后,允许个人创作者和小企业获得更多访问权限。
- T-FREE 趋势引领者:在最近发表的论文中详细介绍的新型 T-FREE tokenizer,承诺在字符三元组(character triplets)上实现稀疏激活,无需大型参考语料库,并可能减少超过 85% 的 embedding 层参数。
- 该方法因增强了在冷门语言上的性能并精简了 embedding 计时器而受到赞誉,为 LLM 增添了紧凑的优势。
- 警报:公会中的诈骗者:#[research] 频道发现了一名诈骗者,提醒社区保持高度警惕。
- 一名用户在多个频道发布了一串完全相同的钓鱼链接,声称提供“50 美元礼品卡”,引起了关注。
OpenAI Discord
- 虚空中的声音:新发布的 Moshi AI demo 引起了热议,人们对其实时语音交互感到兴奋,但同时也对其响应中断和循环回复的问题感到失望。
- Hume AI 的 playground 因缺乏长期记忆而受到审视,这让追求持久 AI 对话的用户感到沮丧。
- 内存库受质疑:GPT 的记忆能力受到抨击,因为它虽然保存了用户偏好但仍会编造响应;成员们建议通过增强自定义功能来缓解这一问题。
- 出现了一场激烈的 GPT-2 与现代模型的辩论,对比了旧模型的成本效益与 GPT-3.5 Turbo 等当前迭代版本的性能飞跃。
- ChatGPT:免费版 vs. Plus 计划:明确了付费版 ChatGPT Plus 计划的优势,详细说明了更高使用限额、DALL·E 访问权限以及扩展的上下文窗口等福利。
- 针对 GPT-4 使用量的担忧得到了回应,明确了达到限制后的冷却期,特别是 Plus 会员每 3 小时最多可发送 40 条消息。
- AI 工具箱扩展:社区成员探索了用于测试多个 AI 响应提示词的工具,并推荐了一个定制工具以及用于高效评估的现有选项。
- 话题转向了 API 集成,研究了用于将 AI 模型链接到多样化数据集的严格聚合生成器(RAG),并利用现有的 Assistant API endpoints。
- 结合上下文的申诉:在 #prompt-engineering 频道中,勾勒了申诉交通罚单的策略,建议采用结构化方法和法律辩论技巧。
- 关于创建员工表彰计划以提高职场士气的讨论十分热烈,重点关注了重大贡献的目标和表彰标准。
Nous Research AI Discord
- Replete-AI 发布海量数据集:Replete-AI 发布了两个巨大的数据集,名为 Everything_Instruct 和 Everything_Instruct_Multilingual,容量达 11-12GB,包含超过 600 万条数据。其意图是整合各种 instruct 数据以推进 AI 训练。
- Everything_Instruct 针对英语,而 Everything_Instruct_Multilingual 则引入了多语言混合,以扩展 AI 的语言处理能力。这两套数据集呼应了以往 bagel 数据集的成功,并借鉴了 EveryoneLLM AI 模型。在 Hugging Face 深入了解。
- Nomic AI 发布 GPT4All 3.0:Nomic AI 的最新作品 GPT4All 3.0 问世,这是一个开源的本地 LLM 桌面应用,支持多种模型并优先考虑隐私。该应用以重新设计的用户界面著称,并采用 MIT 许可证。探索其功能。
- GPT4All 3.0 拥有超过 25 万月活跃用户,促进了与 LLM 的私密本地交互,减少了对互联网的依赖。其采用率非常强劲,标志着向本地化和私密 AI 工具使用的转变。
- InternLM-XComposer-2.5 提升标准:InternLM 推出了 InternLM-XComposer-2.5,这是大型视觉语言模型中的佼佼者,能够出色地处理 24K 交错图文上下文,并通过 RoPE 外推扩展至 96K。
- 该模型在 16 项基准测试中取得了顶尖结果,正在逼近 GPT-4V 和 Gemini Pro 等巨头。这款融合了创新与竞争力的 InternLM 之作正等待探索。
- Claude 3.5 的难题与封锁:尝试绕过 Claude 3.5 Sonnet 伦理限制的行为让用户感到沮丧,围绕特定预设提示词(pre-prompts)的策略几乎没有效果。
- 尽管 Claude 的限制非常坚固,但社区分享了尝试 Anthropic’s workbench 的建议。然而,用户被警告此类尝试后存在账号受限的风险。查看对话详情。
- Apollo 的艺术 AI 之路:Achyut Benz 向世界展示了 Apollo 项目,这是一个能够创作类似于备受推崇的 3Blue1Brown 动画视觉效果的 AI。它构建于 Next.js 之上,接入了 GroqInc,并交织使用了 AnthropicAI 3.5 Sonnet 和 GPT-4。
- Apollo 致力于通过 AI 生成的内容来增强学习体验,这让技术型教育者非常受用。观看 Apollo 的发布演示。
OpenRouter (Alex Atallah) Discord
- LLM 部署的重大飞跃:OpenRouter 的 LLM 模型部署策略指定 FP16/BF16 为默认量化标准,例外情况会通过相关的量化图标注明。
- 这种量化方法的采用引发了关于技术影响和效率提升的详细讨论。
- OpenRouter 避开 API 灾难:Microsoft API 的突然变化本可能给 OpenRouter 用户带来灾难,但一个快速补丁使一切恢复正常,赢得了社区的掌声。
- 该修复恢复了和谐,反映了 OpenRouter 在面对技术中断时快速周转的准备能力。
- Infermatic 注入隐私信心:在一份肯定的更新中,Infermatic 宣布了其对实时数据处理的承诺,并发布了新的隐私政策,明确表示不会保留输入提示词或模型输出。
- 这一更新为用户带来了清晰度和安全感,使该平台摆脱了此前的数据保留疑虑。
- DeepSeek 解码等式之谜:用户在排查 DeepSeek Coder 问题时,发现了一个解决等式无法渲染的变通方法,即巧妙地使用 regex 来调整输出字符串。
- TypingMind 前端无法正确处理提示词的持久性问题已被标记待修复,展示了积极的社区参与。
- 昂贵的 API 引起同行关注:围绕 Mistral 的 Codestral API 定价策略展开了激烈辩论,一些社区成员认为 22B 模型定价过高。
- 用户互相推荐更经济实惠的替代方案,如 DeepSeek Coder,它在不耗费巨资的情况下提供了极具竞争力的编程能力。
Eleuther Discord
- 数字思维的指纹:社区探索了使用拓扑数据分析 (TDA) 进行独特的模型指纹识别,并辩论了用于模型验证的等效校验和指标的效用,例如使用 lm-evaluation-harness 对
LlamaForCausalLM进行验证。- 讨论还涉及通过拓扑数据分析利用其不变量来剖析模型权重,参考了 TorchTDA 等资源,并考虑了来自 1.58-bit LLMs 等论文的位级创新以提高效率。
- 扩展与优化之谈:关注了用于扩展定律的 efficientcube.ipynb 笔记本,同时强调了 JAX 中的 AOT 编译能力是预执行代码优化的进步。
- 分享了 Flax 中 JIT 函数的 FLOPs 估算方法,并重新调查了临界批量大小,挑战了性能在低于特定阈值时不受影响的假设。
- 稀疏编码器与残差启示:讨论了在 Llama 3 8B 残差流上训练的稀疏自编码器 (SAEs) 的部署,介绍了与 LLM 集成以实现更好处理的实用工具,并提供了模型实现的细节。
- 深入研究残差流处理,该策略按层组织 SAEs,以优化它们与 Llama 3 8B 的协同作用,详见相关的模型卡片。
- 利用并行评估的动力:爱好者提出了关于缓存预处理输入的可行性以及解决 Proof-Pile Config Errors 的问题,指出切换到
lambada_openai规避了该问题。- 值得注意的包括模型名称长度问题,导致 OSError(36, ‘File name too long’),并就设置并行模型评估寻求指导,同时收到了关于单进程评估假设的警告。
LangChain AI Discord
- LangChain 的哀鸣:LangChain 用户报告了在 CPU 上运行时的性能问题,响应时间长和处理步骤复杂是主要的痛点。
- 关于这种迟钝是由于模型推理效率低下还是缺乏 GPU 加速的争论仍在继续,而一些人认为它被不必要的复杂性所拖累,正如这里所讨论的。
- AI 模型大决战:OpenAI vs ChatOpenAI:由于前者可能会被逐步淘汰,关于使用 OpenAI 优于 ChatOpenAI 的优势展开了讨论,引发了对它们实现效率的比较。
- 成员们分享了围绕特定任务需求的各种经验,而一些人则因其熟悉的界面和工具链而更倾向于使用 OpenAI。
- Juicebox.ai:人才搜索奇才:Juicebox.ai 的 PeopleGPT 因其无需 Boolean 的自然语言搜索能力而受到称赞,能够迅速识别合格人才,并通过易于使用的功能增强了人才搜索体验。
- 技术社区赞扬了其过滤与自然语言搜索的结合,提升了用户的整体体验;详情请见这里。
- RAG 聊天机器人日历难题:一位 基于 LangChain RAG 的聊天机器人 开发者寻求集成 演示预约功能 的指导,强调了在实现过程中发现的复杂性。
- 社区的反应倾向于协助完成这一集成,表明了尽管缺乏明确的资源链接,大家仍在共同努力增强聊天机器人的功能。
- 视觉向量化精湛技艺:一篇博客文章概述了使用 Lightly SSL 和 FAISS 创建 E2E 图像检索应用 的过程,并配备了 vision transformer 模型。
- 该文章附带了 Colab Notebook 和 Gradio app,旨在鼓励同行学习和应用。
LlamaIndex Discord
- LlamaIndex RAG 专题网络研讨会热潮:LlamaIndex 与 Weights & Biases 合作举办了一场网络研讨会,旨在揭开 RAG 实验和评估 中涉及的复杂性。该会议承诺提供关于准确的 LLM Judge 对齐的见解,并重点关注与 Weights & Biases 的协作。
- 随着 RAG pipeline 成为即将举行的网络研讨会的焦点,人们的期待与日俱增,突显了该领域的挑战。对 RAG 细微评估的一丝怀疑也引发了社区对该活动的关注。
- AI 明星崭露头角:新星 @ravithejads 分享了他成为 明星级 AI 工程师和教育者 的晋升之路,激发了 LlamaIndex 社区内的抱负。
- LlamaIndex 阐述了 @ravithejads 对 OSS 的贡献以及对 AI 趋势的持续关注,引发了关于 AI 职业发展路径的讨论。
- 反思“Reflection as a Service”:’Reflection as a Service’ 在 LlamaIndex 备受关注,它提出了一种内省机制,通过添加自我修正层来提高 LLM 的可靠性。
- 这种创新方法吸引了社区,引发了关于其通过智能自我修正增强 Agent 应用潜力的对话。
- Cloud Function 挑战与协作修复:关于 Google Cloud Function 在 多模型加载 方面的困难出现了讨论,引发了 AI 爱好者集体寻找更高效的方法。
- 随着成员们分享减少加载时间和优化模型使用的策略,社区智慧得以传播,展示了解决问题中的协作精神。
- CRAG – 纠错机制登场:Yan 等人 介绍了 Corrective RAG (CRAG),这是一种创新的 LlamaIndex 服务,旨在检索过程中动态验证和纠正不相关的上下文,引起了 AI 从业者的兴趣。
- 人们将 CRAG 与推进检索增强生成系统的可能性联系起来,激发了关于改进和准确性的前瞻性对话。
Cohere Discord
- AI 聚会的开放邀请:社区成员澄清,参加伦敦 AI 活动不需要特殊资格;只需填写表格即可。这种包容性政策确保了活动对所有人开放,促进了多元化的思想交流。
- 关于活动出席情况的讨论强调了 AI 聚会中社区参与和开放访问的重要性,因为这些政策促进了跨领域和专业水平的更广泛参与及知识共享。
- 生产模式下的 API 烦恼:一名成员在生产环境中部署使用 Cohere 的 rerank API 的应用时遇到了 TypeError 问题,这引发了一个故障排除讨论帖,与其在本地的顺利运行形成对比。
- 社区在解决 rerank API 问题上的协作努力展示了共享知识和即时同行支持在克服生产环境技术挑战中的价值。
- AI 开发领域的新面孔:具有不同背景的新成员(包括一名计算机科学毕业生和一名专注于教学的 AI 开发者)介绍了自己,表达了为公会的集体专业知识做出贡献的渴望。
- 对新人的热烈欢迎凸显了公会致力于培育一个充满活力的 AI 爱好者社区,并为协作增长和学习做好准备。
- Command R+ 抢占风头:Cohere 宣布了 Command R 系列中最强大的模型 Command R+ 现已可以使用,在技术型受众中引起了不小的轰动。
- Command R+ 的发布被视为提升 AI 模型能力和应用的重要一步,表明了该领域持续创新的动力。
- 使用 Rhea.run 保存脚本:Rhea.run 中引入的“保存到项目” (Save to Project) 功能受到了热烈欢迎,它允许用户通过对话式 HTML 脚本创建并保存交互式应用程序。
- 这一新功能强调了 Rhea.run 致力于简化应用创建过程,从而使开发者能够轻松地进行构建和实验。
OpenInterpreter Discord
- MacOS Copilot 成为关注焦点:搭载了 GPT-4、Gemini 1.5 Pro 和 Claude-3 Opus 的 Invisibility MacOS Copilot 因其上下文吸收能力而受到关注,目前可免费使用。
- 社区成员对潜在的开源 grav.ai 以将类似功能整合到 Open Interpreter (OI) 生态系统中表现出兴趣。
- ‘wtf’ 命令为 OI 增添调试魅力:’wtf’ 命令允许 Open Interpreter 智能地切换 VSC 主题并提供终端调试建议,引发了社区的兴奋。
- 成员们对该命令直观执行动作的能力表示惊讶,并计划分享关于安全圆桌会议和即将举行的 OI House Party 活动的进一步更新。
- O1 Light 爱好者的发货烦恼:社区中充满了对 01 Light 发货的期待和沮丧,讨论围绕着延迟展开。
- 等待的情绪引发了共鸣,强化了大家对发货时间表透明沟通的共同愿望。
Modular (Mojo 🔥) Discord
- Mojo 对象出现异常!:成员们讨论了一个影响 Mojo 对象(与 Python 对象 相比)的类型转换(casting)Bug,可能与 GitHub Issue #328 有关。
- MLIR 的无符号整数风波:社区发现 MLIR 将无符号整数(unsigned integers)解释为有符号整数,引发了讨论并导致了 GitHub Issue #3065 的创建。
- 针对这一无符号整数转换问题对各类用户的影响,担忧情绪激增,对话焦点转向了这一新出现的 Bug。
- 编译器 Nightly 新闻:段错误(Segfaults)与解决方案:最近 nightly 构建中的 segfaults 导致了 Bug 报告的提交和问题文件的分享,详见此处。
- 此外,官方发布了新的编译器版本,在
2024.7.505版本中包含了exclusive参数和新方法等改进,链接见 changelog。
- 此外,官方发布了新的编译器版本,在
- 马拉松进展:Mojo 的矩阵乘法:Benny 分享了一种矩阵乘法技术,令人印象深刻,并建议定制分块大小(block sizes),建议同行参考德克萨斯大学奥斯汀分校(UT Austin)的论文以获取见解。
- 在另一个讨论线程中,由于编译时间增加和最新测试套件中的 segfaults,进度有所减缓,参与者互相推荐了诸如 Google Spreadsheet 之类的论文资源。
LLM Finetuning (Hamel + Dan) Discord
- 无需 Chain 的独立 Smithing:讨论确认 LangSmith 可以脱离 LangChain 独立运行,正如 Colab 和 GitHub 上的示例所示。LangSmith 允许对 LLMs 进行插桩(instrumentation),从而深入了解应用行为。
- 社区成员缓解了关于 AI 课程期间 GPU 额度的担忧,强调了条款的正确传达,并引导至课程平台上的清晰信息。
- 额度澄清与每月挑战:一个热门话题围绕着 1000 美元的月度额度及其有效期展开,共识是额度不会结转(no rollover),但依然对这一优惠表示赞赏。
- 一位用户对 Mistral 微调后余额莫名增加到 1030 美元 表示疑惑,引发了关于每月可能存在 30 美元默认额度 的猜测。
- 训练微调:折腾 Token:关于使用
type: input_output设置Meta-Llama-3-8B-Instruct的讨论引发了一些困惑,用户们正在检查特殊 Token 和模型配置,参考 GitHub。- 训练者发现 L3 70B Instruct 的效果优于 L3 8B,这是在配置默认指向 Instruct 模型时偶然发现的,凸显了模型选择的影响。
- 额度困惑与课程进度跟进:关于服务额度资格的确定性尚不明确,一名成员寻求关于 6 月 14 日入群后条款的澄清。
- 另一位用户也表达了对算力额度过期的担忧,请求为因日程疏忽而错过的剩余额度申请延期。
Interconnects (Nathan Lambert) Discord
- 揭秘演示困境 (Debunking the Demo Dilemma):社区成员挑战了一个 AI 演示的真实性,质疑其响应的现实感,并强调了显著的 response time 问题。该讨论包含了一个指向有争议的 demonstration 的链接。
- 作为一种道歉式的转向,Stability AI 针对社区反馈对 Stable Diffusion 3 Medium 进行了修订,并对其 license 进行了澄清,为未来的 high-quality Generative AI 努力划定了路径。
- 搜索大对决:BM42 vs. BM25:Qdrant Engine 宣称其 BM42 是搜索技术的突破,承诺在 RAG 集成方面优于历史悠久的 BM25,详见其 announcement。
- 包括 Jo Bergum 在内的批评者质疑了 BM42 报告成功的完整性,认为这些主张不太可能,并引发了关于 Quora 数据集结果有效性的辩论。
- VAEs 的烦恼与 AI 投资眼光:关于理解 Variational Autoencoders 难度的幽默描述浮出水面,与之并列的是社区内关于卓越 AI investment strategy 的主张。
- 一项严肃的预测推断,为了有效支持 GDP growth,AI 的贡献必须在 11-15% 之间,而社区仍在努力应对 Anthropic Claude 3.5 Sonnet 不透明的运作。
- 谷歌在全球 AI 挑战中的磨砺:用户讨论了 Google 在生成式 AI 领域的缓慢起步,对其 Gemini web app 等产品的消息传递清晰度和方向表示担忧。
- 围绕 Google’s Gemini 1.5 的定价模型和有效性展开了讨论,并将其与其他 AI 产品及 Vertex AI 等软件进行了比较,同时反思了 First Amendment 在 AI 领域的应用。
OpenAccess AI Collective (axolotl) Discord
- API 队列系统的怪癖:关于 build.nvidia API 问题的报告导致发现了一个新的 queue system 来管理请求,这标志着服务可能已过载。
- 一位成员遇到了 build.nvidia API 的脚本问题,在临时停机后观察到功能恢复,暗示服务存在间歇性。
- YAML 助力 Pipeline 进度:一位成员分享了其 pipeline 集成 YAML examples 用于 few-shot learning 对话模型的情况,引发了对其在教科书数据上应用的兴趣。
- 进一步澄清了基于 YAML 的结构如何促进 pipeline 中高效的 few-shot learning 过程。
- Gemma2 获得稳定性:Gemma2 的更新解决了过去的 bug。通过 pinned version of transformers 强化版本控制,确保了未来更平滑的更新。
- Continuous Integration (CI) 工具因其在预先捕捉问题方面的作用而受到赞誉,为开发环境提供了抵御困扰的鲁棒性。
- 呼吁更多 VRAM:来自 ‘le_mess’ 的一条简洁但有力的消息强调了小组内长期的需求:请求更多的 VRAM。
- 这一行简单的恳求反映了从业者对高性能计算资源持续增长的需求,对话中未作进一步阐述。
tinygrad (George Hotz) Discord
- Tinygrad 中的 Tensor 问题:讨论指出 Tensor.randn 和 Tensor.randint 会创建连续的 Tensors,而
Tensor.full则会导致非连续结构,这引发了对与 PyTorch 预期 不同的方法的审查。- 一位社区成员询问了 tinygrad 中 Bug 测试的放置位置,在 test_nn 或 test_ops 模块之间进行了讨论,最终决定在 test_ops 中编写一个高效且命名规范的测试。
- 训练的挑战与收获:Tinygrad 用户对该框架的大规模训练效率表示担忧,称其运行缓慢且在经济上不切实际,同时考虑尽管 BEAM search 具有复杂性和时间需求,仍尝试使用它。
- 围绕在 Tinygrad 中使用预训练 PyTorch 模型展开了对话,引导用户使用
tinygrad.nn.state.torch_load进行有效的模型推理操作。
- 围绕在 Tinygrad 中使用预训练 PyTorch 模型展开了对话,引导用户使用
- Matmul 大师课:社区分享了一篇展示高性能矩阵乘法指南的博客文章,该指南在 CPU 上实现了超过 1 TFLOPS 的性能,详细介绍了实际实现方法和 源代码。
- 分享内容包括指向该博客文章的链接,该文章将矩阵乘法分解为一个易于理解的 150 行 C 程序,引发了关于 Tinygrad 性能优化的讨论。
Torchtune Discord
- Torchtune 的微调讨论:社区成员就设置 Torchtune 的评估参数交换了意见,提到了一个潜在的“验证数据集”参数来调整性能。
- 其他人对缺失 wandb logging 指标表示担忧,特别是 evaluation loss 和 grad norm 统计数据,强调了对更强大的指标追踪的需求。
- Wandb 的烦恼与胜利:讨论的一个话题是 wandb 的可视化能力,其中 grad norm 图表的缺失引发了对其与 aoxotl 等工具相比可用性的质疑。
- 建议包括调整初始 learning rate 以影响 loss curve,但尽管进行了优化,一位成员指出 loss 没有显著改善,强调了参数微调的挑战。
AI Stack Devs (Yoko Li) Discord
- 代码冲突:Python 遇见 TypeScript:分享了在设置 Convex 平台时将 Python 与 TypeScript 集成的挑战经历。当 Convex 因缺少预安装的 Python 而出现启动 Bug 时,问题浮出水面。
- 此外,讨论还围绕在 Docker 环境中自动安装 Convex 本地后端的困难展开,强调复杂性源于将特定容器文件夹配置为 volumes(卷)。
- 像素猎寻:寻找完美的精灵图:一位成员探索了 sprite sheets(精灵图表)领域,表达了寻找与 Cloudpunk 游戏风格共鸣的视觉效果的目标,但发现从 itch.io 获取的资源缺乏理想的赛博朋克细微差别。
- 他们正在寻找更符合 Cloudpunk 独特美学的精灵图资源,因为之前获取的资源未能反映出该游戏的标志性氛围。
DiscoResearch Discord
- 使用 GPT 三人组进行总结:三个 GPT 走进酒吧并撰写执行摘要 博客文章展示了一个由三个 Custom GPTs 组成的动态组合,旨在快速提取见解、起草和修改执行摘要。
- 该工具包能够在紧迫的截止日期前生成简洁且相关的执行摘要,简化了交付简练且有影响力的简报的过程。
- Magpie 在 HuggingFace 上的首飞:Magpie 模型在 HuggingFace Spaces 上首次亮相,提供了一个生成偏好数据的工具,尽管它与 davanstrien/magpie 存在重复。
- 用户体验显示仍有改进空间,反馈表明该模型的表现并不完全令人满意,但社区对其潜在应用保持乐观。
MLOps @Chipro Discord
- Build With Claude 活动即将到来:工程爱好者们被号召参加 Claude hackathon,这是一场将于下周结束的创意编程冲刺。
- 参与者旨在利用 Claude 的能力构建创新解决方案,争取在闭幕竞赛中脱颖而出。
- Kafka 成本削减会议:一场定于 IST 时间 7 月 18 日下午 4 点举行的网络研讨会,承诺将分享关于优化 Kafka 以提升性能并降低开支的见解。
- Yaniv Ben Hemo 和 Viktor Somogyi-Vass 将主持讨论,重点关注 Kafka 设置中的扩展策略和效率。
Datasette - LLM (@SimonW) Discord
- 对职位术语的幽默调侃:围绕该领域 Embeddings 潜在用途的讨论不断增加,引发了一些关于职位名称的幽默调侃。
- 一位参与者开玩笑说要将自己改名为 Embeddings AyEngineer,为 AI 领域不断演变的命名法增添了幽默色彩。
- 职位闲谈变得流行:随着 Embeddings 特定角色的兴起,出现了一个轻松的建议,即使用 Embeddings Engineer 这一头衔。
- 这个幽默的提议强调了 Embeddings 在当前工程工作中的重要性以及社区的创造精神。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
完整的频道细分内容已针对电子邮件进行截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!