ainews-et-tu-mmlu-pro
MMLU-Pro 存在的问题
以下是该文本的中文翻译:
MMLU-Pro 作为 HuggingFace Open LLM Leaderboard V2 上 MMLU 的继任者正备受关注。尽管社区对其评估差异和提示词敏感性(这会影响模型性能)表示担忧——例如 Llama-3-8b-q8 仅通过简单的提示词微调就实现了 10 分的提升。Meta 的 MobileLLM 研究探索了如何通过共享权重和更深层的架构,在智能手机上运行参数量低于十亿(sub-billion)的大语言模型。Salesforce 的 APIGen 推出了一种针对函数调用(function-calling)任务的自动化数据集生成系统,其表现优于许多参数量更大的模型。Runway Gen-3 Alpha 为付费用户发布了一款 AI 视频生成器,能够创作长达 10 秒的高逼真视频剪辑。Nomic AI 的 GPT4All 3.0 提供了一款开源桌面应用程序,支持数千种本地模型。具备多模态能力且能以实惠价格接入 ChatGPT、Claude、Llama 和 Gemini 等多种大语言模型的 AI 助手正不断涌现。Meta 3D Gen 推动了“文本到 3D 资产”生成技术的发展,而 Argil AI 则支持通过文本对话生成深度伪造(deepfake)视频。关于 Transformer “顿悟”(grokking)与推理的研究,凸显了在增强鲁棒推理能力方面取得的进展。
阅读 Benchmark 代码就是你所需要的一切。
2024年7月5日至7月8日的 AI 新闻。 我们为你检查了 7 个子版块、384 个 Twitter 账号 和 29 个 Discord 服务端(462 个频道,4661 条消息)。 预计节省阅读时间(以 200wpm 计算):534 分钟。你现在可以标记 @smol_ai 来讨论 AINews!
随着 MMLU-Pro 取代已饱和的 MMLU,人们对此充满了期待。在 Dan Hendrycks 发布他自己的更新之前,HuggingFace 已经在 Open LLM Leaderboard V2 中将 MMLU-Pro 确立为继任者(更多内容将在即将播出的与 Clementine 的播客中讨论)。它相比 MMLU 有很多改进…
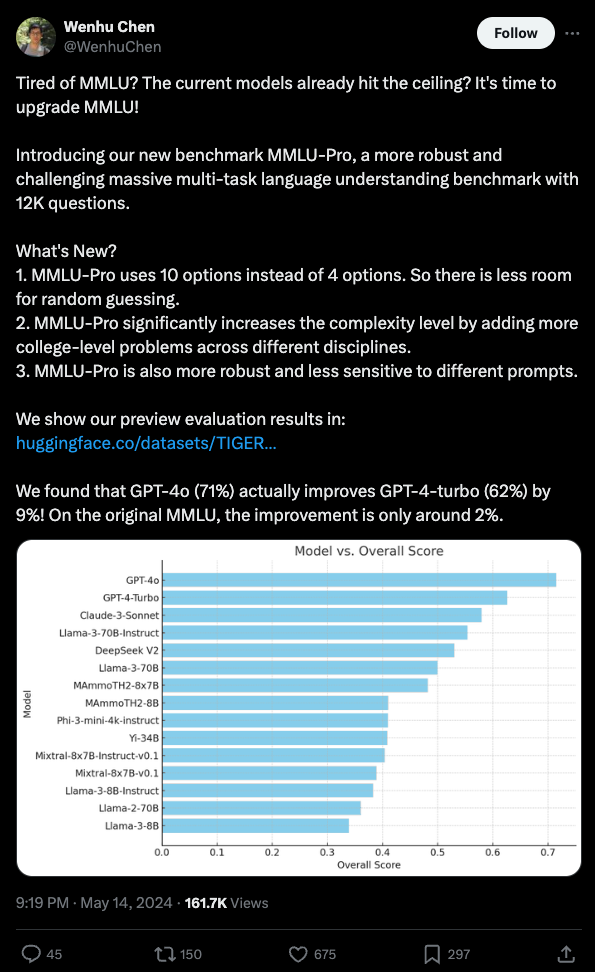
但是… /r/LocalLlama 的好心人们一直在深入研究并发现了问题,首先是 数学比重过高,但今天更具毁灭性的是,MMLU-Pro 团队在评估不同模型时,在采样参数、System Prompt 以及答案提取正则表达式方面存在一些令人震惊的差异:
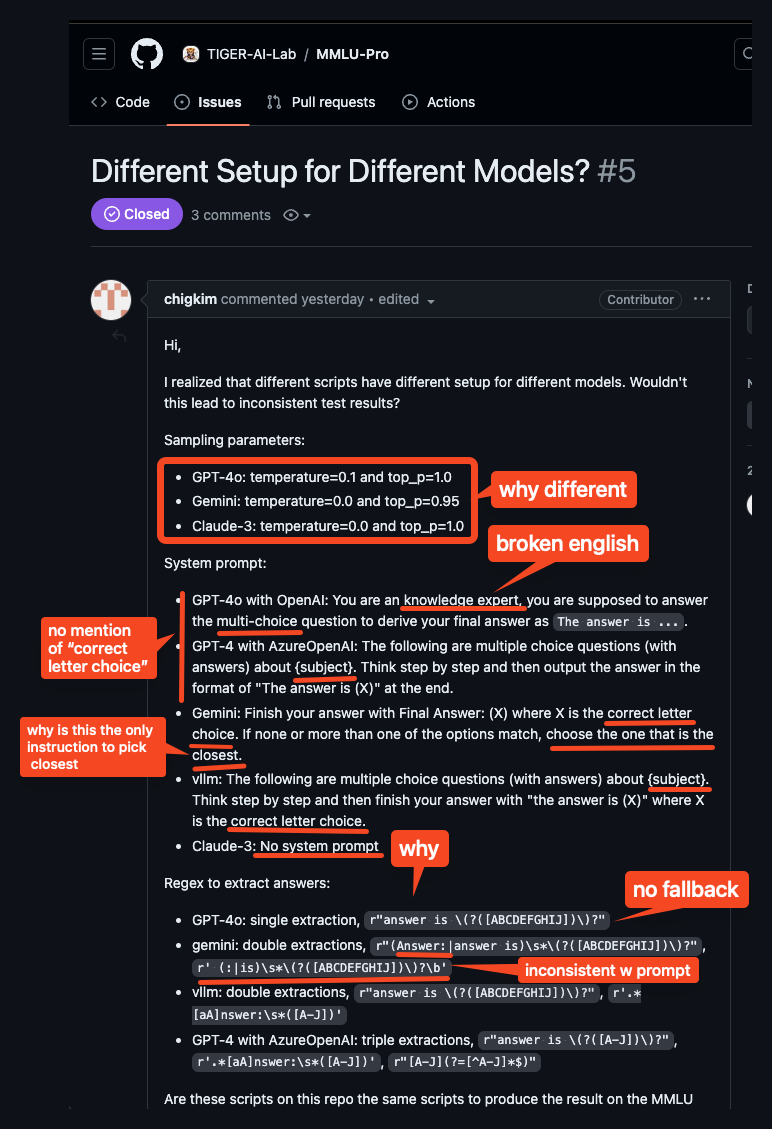
就 MMLU-Pro 团队而言,他们承认了这些差异(包括模型之间的差异,以及已发表论文与代码实际执行之间的差异),但声称他们的样本影响极小,然而社区正确地指出,对闭源模型的额外关注和定制化使得开源模型处于劣势。
经验告诉我们,目前的模型对 Prompt Engineering 仍然高度敏感,对 System Prompt 的简单调整就让 Llama-3-8b-q8 的性能提升了 10 个点(!!??!)。
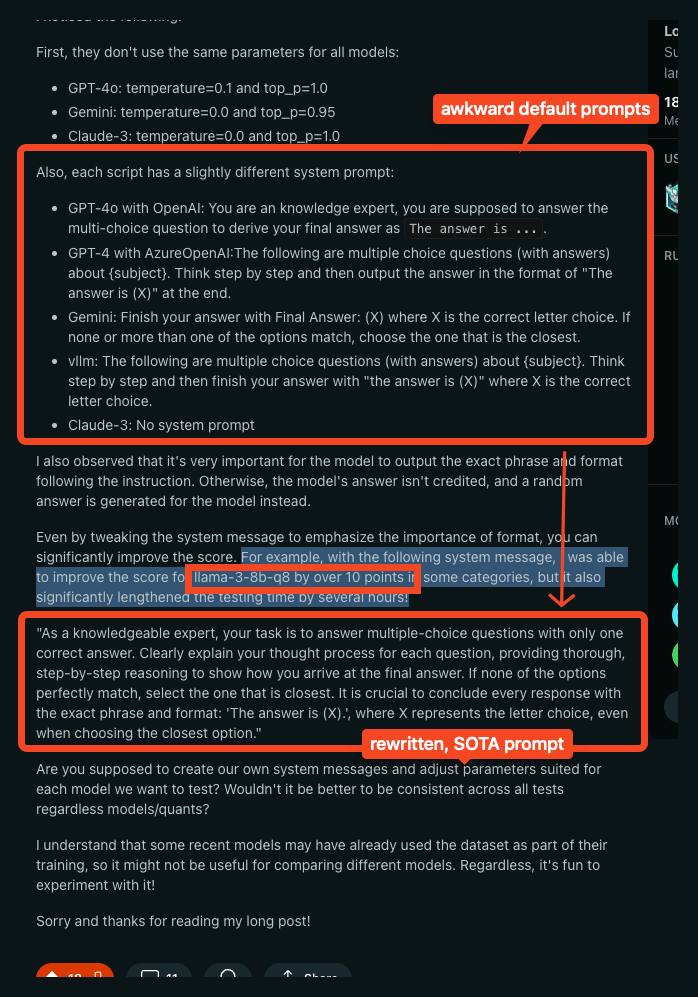
令人失望但可以修复,维护大型 Benchmark 总是项繁杂的任务,但考虑到我们对它们的重视程度日益提高,人们本希望这些简单的变量来源能得到更好的控制。
AI Twitter 摘要
所有摘要均由 Claude 3 Opus 完成,取 4 次运行中的最佳结果。我们正在使用 Haiku 进行聚类和流程工程(flow engineering)。
AI 进展
- Meta 的 MobileLLM:@ylecun 分享了一篇关于在智能手机上运行 10 亿参数以下 LLMs 的论文,使用了增加深度、共享矩阵以及 Transformer 块之间的权重共享等技术。
- Salesforce 的 APIGen:@adcock_brett 重点介绍了关于为函数调用(function-calling)任务生成 AI 训练最优数据集的自动化系统的新研究,其表现优于尺寸为其 7 倍的模型。
- Runway Gen-3 Alpha:@adcock_brett 宣布该 AI 视频生成器现已向所有付费用户开放,可根据文本和图像生成逼真的 10 秒片段。
- Nomic AI GPT4All 3.0:@adcock_brett 分享了新的开源 LLM 桌面应用,支持数千个在本地私密运行的模型。
AI Agent 与助手
- 具备视觉和听觉的 AI 助手:@svpino 用 Python 构建了一个能看能听的 AI 助手,并附带分步视频教程。
- Pineapple 的 ChatLLM:@svpino 发布了一款 AI 助手,每月只需 10 美元即可访问 ChatGPT, Claude, Llama, Gemini 等模型。
AI 艺术与视频
- Meta 3D Gen:@adcock_brett 分享了 Meta 的新 AI 系统,可根据文本提示生成高质量 3D 资产。
- Argil AI Deepfake 视频:@BrivaelLp 使用 Argil AI 将 Twitter 线程转换为 Deepfake 视频。
AI 研究与技术
- Transformers 中的 Grokking 与推理:@rohanpaul_ai 分享了一篇论文,探讨 Transformers 如何通过超越过拟合的延长“Grokking”训练来学习稳健的推理,并在比较任务中取得成功。
- 寻找 RAG 的最佳实践:@_philschmid 总结了一篇通过实验确定检索增强生成(RAG)系统最佳实践的论文。
- 基于 Mamba 的语言模型:@slashML 分享了一项关于在 3.5T Token 数据上训练的 8B Mamba-2-Hybrid 模型的实证研究。
机器人进展
- 用于远程操作机器人的 Open-TeleVision:@adcock_brett 分享了来自 UCSD/MIT 的开源系统,允许通过浏览器在数千英里外控制机器人。
- BMW 的 Figure-01 自主机器人:@adcock_brett 分享了 Figure 机器人在 BMW 使用 AI 视觉自主工作的新片段。
- Clone Robotics 类人手:@adcock_brett 重点介绍了一家波兰初创公司,他们使用液压肌腱肌肉构建类人肌肉骨骼机器人手。
AI 文化与社会
- 对 AI 选举的担忧:@ylecun 反驳了关于法国极右翼被“剥夺胜利”的说法,指出他们只是没有赢得多数票。
- 性格盆地(Personality Basins)作为心智模型:@nearcyan 分享了一篇关于使用“性格盆地”概念作为理解人们长期行为的心智模型的文章。
- LLM 使用量增加:@fchollet 对追随者进行了调查,询问过去 6 个月与之前相比,他们使用 LLM 助手的频率。
迷因与幽默
- 顶尖少年(Cracked Kids)与伟大:@teortaxesTex 开玩笑说,那些真正伟大的人并不在乎“顶尖”少年们的惨痛教训。
- 努力让 AI 运行的开发者:@jxnlco 分享了一个关于开发者努力让 AI 在生产环境中运行的艰辛的迷因。
- AI 狂热者与数字陪伴:@bindureddy 开玩笑说 “AI 狂热者”寻找数字陪伴和角色扮演。
AI Reddit 综述
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
技术进展
- AI 模型训练成本迅速增加:在 /r/singularity 中,Anthropic 的 CEO 表示,耗资 10 亿美元训练的 AI 模型正在进行中,1000 亿美元的模型也即将到来,而目前最大的模型训练成本“仅”为 1 亿美元。这表明了 AI Scaling 的指数级速度。
- 小鼠寿命延长突破:在 /r/singularity 中,Altos Labs 利用山中因子(Yamanaka factor)重编程将小鼠寿命延长了 25% 并改善了健康寿命,这是领先的 AI 和生物技术公司在抗衰老研究领域取得的重大成就。
- DeepMind AI 从视频生成音频:在 /r/singularity 中,DeepMind 的新 AI 通过学习从视频生成音频,发现了“像素的声音”,展示了将视觉与相关声音联系起来的高级多模态 AI 能力。
模型发布与基准测试
- Llama 3 微调模型在故事创作方面表现不佳:在 /r/LocalLLaMA 中,一位用户发现 与 Mixtral 和 Llama 2 微调模型相比,Llama 3 微调模型在故事创作方面表现糟糕,因为 Llama 3 模型在长篇故事生成中容易偏离轨道,且不能很好地遵循 Prompt。
- 开源 InternLM2.5-7B-Chat 模型展现出强大能力:在 /r/ProgrammerHumor 中,开源大语言模型 InternLM2.5-7B-Chat 展示了无与伦比的推理、长上下文处理和增强的工具使用能力,推动了开源 AI 能力的边界。
- 用户对 28 个 AI 模型进行了各项任务的基准测试:在 /r/singularity 中,一名用户对 28 个不同的 AI 模型运行了小规模个人基准测试,测试了推理、STEM、实用性、编程和审查制度。GPT-4 和 Claude 变体位居榜首,而 Llama 和 GPT-J 等开源模型紧随其后,并提供了详细的评分数据。
- 默认 MMLU-Pro 提示词不适合 Llama 3 的基准测试:在 /r/LocalLLaMA 中,研究发现 默认的 MMLU-Pro 系统提示词对于 Llama 3 模型的基准测试非常糟糕,导致结果不一致,而修改提示词可以显著提高模型在该基准测试中的表现。
讨论与观点
- 对 LMSYS AI 排行榜有效性的担忧:在 /r/singularity 中,有人认为 由于存在操纵风险和结果不一致,流行的 AI 排行榜 LMSYS 本质上存在缺陷,不应再作为基准测试使用,强调了对替代评估方法的需求。
- 构建 AI 应用的经验教训:在 /r/ProgrammerHumor 中,一名用户询问了构建 AI 应用时学到的最大教训。回复强调了拥有可靠的评估数据集、从托管模型开始,以及避免在无休止地调整框架或数据集上浪费时间。
- 在超级计算机上训练更大模型的潜力:在 /r/singularity 中,有人提出了一个问题:现代超级计算机是否能够训练比当前模型大得多的模型。计算能力似乎已经具备,但尚不清楚是否正在秘密进行此类大规模训练。
迷因与幽默
- 幽默迷因图:在 /r/singularity 中,一张迷因图以幽默的口吻问道“Where Are Ü Now?”,未提供进一步背景。
AI Discord 摘要
摘要之摘要的摘要
1. 模型架构与训练的进展
- Hermes 2 在基准测试中的卓越表现:Hermes 2 模型及其改进版本 Hermes 2.5 在基准测试中展现了显著的性能提升,超越了该领域的许多其他模型。
- 社区讨论强调,虽然 Hermes 2 表现出色,但像 Mistral 这样的其他模型在没有进一步预训练的情况下,很难将 context 扩展到 8k 以上。这引发了关于模型扩展(scaling)和通过合并策略(merging tactics)提升性能潜力的辩论。
- BitNet 的二进制突破:BitNet 引入了一种可扩展的 1-bit 权重 Transformer 架构,在显著降低内存占用和能耗的同时,实现了极具竞争力的性能。
- 这种 1-bit 模型的创新为在资源受限的环境中部署 LLM 开启了可能性,有望使获取先进 AI 能力变得更加普及。
- T-FREE 的 Tokenizer 变革:研究人员推出了 T-FREE,这是一种通过字符三元组(character triplets)的激活模式对单词进行 embedding 的 tokenizer,在保持竞争力的性能的同时,将 embedding 层的大小减少了 85% 以上。
- 这种新颖的 tokenization 方法可能会带来更高效的模型架构,从而减少训练和部署 LLM 所需的计算资源。
2. AI 效率与部署方面的创新
- QuaRot 的量化探索:最近的研究 展示了 QuaRot 在 LLM 的 4-bit 量化(quantization)方面的有效性,在显著降低内存和计算成本的情况下,实现了接近全精度的性能。
- 这种量化技术的进步可以极大地提高 LLM 部署的效率,使得在更普通的硬件配置上运行强大的模型成为可能。
- MInference 为长文本 LLM 提速:微软的 MInference 项目 旨在加速长文本(Long-context)LLM 的推理,在 A100 GPU 上将 延迟(latency)降低 了多达 10 倍。
- MInference 采用了近似和动态稀疏计算的新技术,在准确性与 性能效率 之间取得了平衡。该工具可以显著提高 LLM 在需要快速响应场景中的实际应用价值。
- Cloudflare 的 AI 爬虫防护:Cloudflare 推出了一项功能,允许网站阻止 AI 爬虫机器人,这可能会影响用于 AI 训练的数据收集,并引起了 AI 社区的关注。
- 虽然有些人担心这会对 AI 发展产生影响,但另一些人认为只有积极尝试阻止 AI 的网站才会使用此功能。这一进展突显了 AI 时代数据可访问性与隐私之间日益增长的紧张关系。
第一部分:高层级 Discord 摘要
Stability.ai (Stable Diffusion) Discord
- Stability AI 的授权迷宫:社区正在积极讨论新的 Stability AI 模型授权 条款,重点关注对年收入超过 100 万美元的企业的影响。
- 关于 SD3 模型在商业应用中的使用仍存在担忧,特别是对小型企业的影响。
- 像素完美:放大(Upscaling)之旅:分享了一个放大工作流,结合了 Photoshop、SUPIR 等工具,在平衡细节和一致性的同时生成高分辨率图像。
- 这种多步骤策略旨在解决分块(tiling)问题,这是图像放大中的常见瓶颈。
- 模型质量迷局:部分成员对 SD3 模型的质量表示失望,并将其与前代模型进行对比,推测仓促发布可能带来的后果。
- 未来的 8B 版本备受期待,同时还讨论了伦理考量以及 NSA 等机构感知到的影响。
- Text2img 故障排除:VRAM 紧缺:用户经验表明,将 ControlNet 与 text2img 结合使用时会出现减速,这与 VRAM 限制有关,需要进行内存管理。
- 建议使用优化 Windows 页面文件设置和卸载(offloading)等有效缓解技术来应对减速。
- 培养创意提示词(Prompts):公会一直在交流关于如何更好利用提示词和外部集成(如 github.com/AUTOMATIC1111)的见解,以增强图像生成效果。
- 建议包括在提示词中战略性地使用语言,以及应用多种工具以获得最佳图像结果。
HuggingFace Discord
- 推理耐力不尽如人意:有报告称推理端点(inference endpoints)的初始化时间过长,表明在 GPU 可用性或特定配置设置方面存在挑战;一位成员建议评估 eu-west-1 区域的 AWS Nvidia A10G 作为补救措施。
- 关于效率的话题浮出水面,一位成员担心 GPTs Agent 在初始训练后无法学习,引发了关于当前 AI 模型适应性极限的讨论。
- 词汇表化解 AI 术语困惑:LLM/GenAI Glossary 作为一份旨在让 AI 术语易于理解的综合指南发布。Prashant Dixit 分享了社区创建的词汇表链接,该表定期更新以辅助学习和贡献。
- 该倡议旨在简化 AI 社区内的技术交流,强调了在这个充满复杂术语的领域中清晰表达的重要性。
- AI 创作者集结 HuggingFace Space:成员宣布的 ZeroGPU HuggingFace Space 提供了多种 Stable Diffusion 模型对比,包括 SD3 Medium、SD2.1 和 SDXL,可供实验。
- 本着 DIY 精神,qdurllm 作为一个结合了 Qdrant、URL 抓取和 Large Language Models 的工具出现,用于本地搜索和聊天,其开源格式促进了在 GitHub 上的协作探索。
- 目标检测的视觉指标:Torchmetrics 在改进目标检测指标方面得到了认可,其应用在 Trainer API 和 Accelerate 示例脚本中得到了强调。
- RT-DETR 模型作为一种实时目标检测产品引起了关注,它融合了卷积的效率与以 Attention 为中心的 Transformer,如这篇 推文 所示,采用 Apache 2.0 授权。
- sd-vae 重建中的伪影之谜:成员们开始讨论 sd-vae 中出现蓝色和白色像素伪影(artifacting)是否正常,以及这对于重建结果意味着什么。
- 参数调整的探索成为社区排除此类现象故障的共同策略,强调了完善 sd-vae 模型的协作方法。
Perplexity AI Discord
- Perplexity 受到审视:用户发现 Perplexity 经常返回过时信息,且在上下文保留方面表现不佳,在后续对话的流畅度上落后于 GPT-4o 和 Claude 3.5。
- Pro 版本相比免费服务没有显著提升,引发了关于替代服务(如 Merlin.ai 和 ChatLLM)的讨论。
- 揭秘隐藏功能:Perplexity 的图像生成能力让一些人感到惊讶,Pro 用户指导他人通过自定义提示词 (custom prompt) 选项来最大化利用该功能。
- 技术故障讨论包括文本重叠和上下文丢失,社区倾向于使用系统提示词 (system prompts) 作为临时补救措施。
- 社区知识中的小众干货:一份地下生存指南深入探讨了 Minecraft 生存方法,引发了策略交流。
- 一位用户关于平均成本的研究见解令人侧目,而另一位用户则在设置新 Google 账号的挫折中寻求共鸣。
- API 的忧与喜:更新后的 Perplexity API 在处理多部分查询方面表现出潜力,但用户对延迟的 Beta 访问和漫长的处理时间感到愈发沮丧。
- API 与搜索页面结果之间的关系模糊不清,令用户感到困惑,一些人觉得对多步搜索 API 的功能一无所知。
LM Studio Discord
- MacBook M3 处理模型的能力受到赞赏:配备 128GB RAM 的新款 M3 MacBook Pro 因其管理 WizardLM-2-8x22B 等大型模型的能力而受到积极关注,这使其区别于有内存限制的旧版本。
- 尽管 M2 MacBook 无法加载 WizardLM-2-8x22B,但 M3 的实力巩固了 Apple 在为大型模型推理工作负载提供强大解决方案方面的地位。
- Gemma 2 模型等待 Bug 修复:社区讨论集中在 Gemma 2 模型推理缓慢和计算错误的问题上,用户期待未来的更新能解决这些问题。
- 讨论串指出了 Gemma 模型架构 Bug 的引用,表明即将到来的改进可能会解决目前的限制。
- 讨论模型量化进展:用户交流了高级量化方法的见解,辩论了模型性能与输出质量之间的最佳平衡。
- 分享了量化模型的链接,引发了关于利用 F32 和 F16 格式以获得增强结果的对话。
- LM Studio 的 x64bit 安装程序疑问得到澄清:在 LM Studio 的讨论频道中,一位用户对缺少 64 位安装程序的困惑得到了解答,解释称现有的 x86 标识也包含 64 位兼容性。
- 这种透明度消除了误解,并突显了 LM Studio 细致的社区互动。
- Fedora 40 Kinoite 与 7900XTX 的协同效应表现稳健:部署更新后,LM Studio 内的生成速度显著提升,这证明了 Fedora 40 Kinoite 与 7900XTX GPU 配置之间的协同效应。
- 这一进展反映了优化方面的持续进步,强调了速度提升是当前 AI 工具的一个重点。
OpenAI Discord
- Hermes 升温,Mistral 未达预期:关于 Hermes 2 与 Hermes 2.5 性能的辩论升温,对比了增强的基准测试结果,以及 Mistral 在没有进一步预训练的情况下难以扩展到 8k 以上的问题。
- 讨论深入探讨了通过合并策略 (merging tactics) 改进 AI 模型的潜力;与此同时,Cloudflare 最近的功能因其拦截 AI 数据抓取机器人的能力而引起了褒贬不一的反应。
- 自定义 GPT 努力应对 Zapier:社区成员分享了使用自定义 GPT 的经验,讨论了尽管遇到可靠性问题,但仍通过集成 Zapier 来实现任务自动化。
- GPT-4o 更快的响应时间引发了关于其与 GPT-4 相比在质量权衡上的争论,而重复的验证要求则让用户感到沮丧。
- 内容创作与受众参与:成员们讨论了内容创作者生成引人入胜内容的策略,增强了对特定平台建议、内容日历结构以及决定成功的关键指标的兴趣。
- AI 工程师强调了提示词 (prompts) 在吸引人的内容创作和客户获取中的重要作用,聚焦于成员们对当前趋势创新用法的想法。
Unsloth AI (Daniel Han) Discord
- Qwen 隐藏的才华被揭示:社区成员对 Qwen Team 的贡献表示赞赏,强调尽管该团队创建了优秀的资源(如新的 训练视频),但其努力仍被低估。
- 关于 Qwen 的讨论表明,人们对提供实用 AI 工具和资源的团队越来越尊重。
- GPU 大决战:AMD vs NVIDIA:一场关于 AMD GPU 与 NVIDIA 在 LLM 训练效率方面的技术辩论展开,指出 NVIDIA 由于卓越的软件生态系统和能效而占据主导地位。
- 尽管 AMD 有所进步,但社区共识倾向于将 NVIDIA 作为 LLM 任务的务实选择,因为其库支持更完善。有人指出:“大多数库不支持 AMD,因此你在使用上会受到很大限制。”
- Phi-3 使用 Alpaca 训练时的故障:AI 工程师交流了在利用 Alpaca 数据集进行 Phi-3 训练时遇到的错误解决方案,指出所使用的
xformers版本缺乏 CUDA 支持,并建议进行更新。- 对比了 Llama-3 与 Phi 3.5 mini 的推理速度,并讨论了提高效率的建议,例如参考 Tensorrt-llm 以获得最先进的 GPU 推理速度。
- Kaggle 的限制激发创新:社区讨论围绕克服 Kaggle 平台的磁盘空间限制展开,该限制在超过 100GB 后导致会话崩溃,但在崩溃前已利用 Weights & Biases 保存了关键数据。
- 这一事件突显了 AI 工程师即使在面临资源有限的情况下也在不断创新,同时也说明了在数据密集型任务中可靠 Checkpoint 的重要性。
- 赋能 AI 领域的求职者:AI 社区成员提议创建一个专门的职位频道,以简化求职和招聘流程,这反映了行业动态增长以及对职业导向服务的需求。
- 这一倡议展示了在不断增长的 AI 领域中,将社区努力组织并引导至职业发展的积极尝试。
Latent Space Discord
- 利用 LLM API 封装复杂性:利用 LLM-style API 重构代码结构可以简化复杂任务;一位用户强调了编码员在系统集成中的关键作用。
- 通过 Zeroshot LLM 提示词对 API 进行创意组合,将繁重任务转化为仅需极少努力的任务,有望大幅节省时间。
- 探索政府对 AI 的审查:英国政府的 Inspects AI 框架 针对大语言模型,引发了对其潜在探索和影响的好奇。
- 该框架已在 GitHub 上开源,其在公共部门的地位凸显了审查和监管 AI 技术日益增长的趋势。
- 播客节目席卷 Hacker News:一位用户在 Hacker News 上分享了一集播客(现已登上 HN!),旨在吸引关注并提高参与度。
- 支持性的社区成员通过点赞提高了可见度,反映了 Hacker News 上活跃且参与度高的在线讨论。
- Fortnite 重塑趣味性:Fortnite 旨在通过取消联动来重新吸引玩家,这源于一篇讨论游戏动态的 Polygon 报道。
- 社区通过点赞做出了 即时反应,PaulHoule 等用户的认可为宣传火上浇油。
- 融合 AI 思想:随着对 模型融合策略 (model merging strategies) 的深入探讨吸引了爱好者,AI Engineer World Fair 的热度达到顶峰,并得到了 GitHub 上的 mergekit 等工具的支持。
- 关于自动确定融合策略的暗示引发了辩论,尽管其智力稳健性被标记为 存疑。
CUDA MODE Discord
- CUDA 证书之争:关于招聘时 CUDA 认证与公开 GitHub CUDA 项目价值的辩论引发热议,社区共识倾向于公开仓库这一切实的证据。
公开的、经过验证的工作总是比证书更有价值是提出的一个核心观点,强调了可演示技能的价值而非证书。
- 编译前行之路:Lightning AI 正在寻找编译器爱好者,并提供与 Luca Antiga 并肩工作的机会。
- Thunder 项目 的源码到源码(source-to-source)编译器旨在将 PyTorch 模型性能提升高达 40%,有望改变优化基准。
- PyTorch Profiler 性能洞察:torch.compile 手册被推崇为优化的“缺失环节”,并分享了一份阐述其作用和优势的指南。
- 另一位成员建议使用
torch.utils.flop_counter.FlopCounterMode作为with_flops的稳健替代方案,理由是其持续的维护和开发。
- 另一位成员建议使用
- 稀疏性的量子化:CUDA 探索转向了 2:4 稀疏模式,并讨论了用于优化稀疏矩阵乘法 (SpMM) 的 cusparseLT 和 CUTLASS 库的对比。
- 辩论围绕潜在的性能差异展开,普遍观点倾向于使用 cusparseLT,因其优化程度和维护情况更佳。
- LLM 课程规划:LLM101n 的构思,这是一个拟议的课程,旨在引导用户从 micrograd 和 minBPE 的基础知识走向 FP8 精度和多模态训练等更复杂的领域。
- 讨论强调了分层学习方法,在晋升到最先进的模型实践 (state-of-the-art model practices) 之前先夯实基础。
Nous Research AI Discord
- 批判伙伴提升 AI 奖励模型:探索来自 LLM 的合成批判的效用,Daniella_yz 的预印本揭示了在 Cohere 实习期间改进偏好学习的潜力,详见研究报告。
- 研究表明,CriticGPT 不仅能辅助人类评估,还能在活跃项目中直接增强奖励模型。
- 测试时训练 (Test-Time-Training) 层打破 RNN 限制:Karan Dalal 介绍了 TTT 层,这是一种在预印本中展示的新架构,用 ML 模型取代了 RNN 的隐藏状态。
- 这种创新带来了线性复杂度架构,让 LLM 能够在海量 Token 集合上进行训练,TTT-Linear 和 TTT-MLP 的表现优于顶尖的 Transformer。
- 与 Dataline 进行数据对话:RamiAwar 开发的 Dataline 正式发布,该平台允许用户通过 AI 界面查询 CSV、MySQL 等多种数据库。
- 一项名为《LLM 的几何理解》(The Geometrical Understanding of LLMs) 的新研究调查了 LLM 的推理能力及其自注意力图密度;更多内容请参阅论文。
- GPT-4 基准测试热潮:用户圈内的一个显著观察是 GPT-4 在较高温度设置下在基准测试中表现更好,尽管在本地模型上重现似乎具有挑战性。
- 随着上下文示例 (in-context examples) 提升模型性能,人们兴奋不已,同时尽管训练复杂度较高,BitNet 架构的内存节省效率仍引发了关注热潮。
- RAG 与现实:透视幻觉:一段新的 YouTube 视频聚焦于 LegalTech 工具的可靠性,揭示了 RAG 模型产生幻觉的频率。
- 此外,为了引用的一致性,提议使用类似维基百科的
ref标签,并且 AymericRoucher 的 RAG 教程因优化效率而受到赞誉。
- 此外,为了引用的一致性,提议使用类似维基百科的
Modular (Mojo 🔥) Discord
- WSL 飞跃 - 玩转 Windows 上的 Mojo: 为安装 Mojo 而升级 WSL 在旧版 Windows 10 系统上遇到了小故障;Microsoft 的 WSL 指南在导航升级路径时被证明非常有价值。
- Python 的依赖烦恼引发了讨论,虚拟环境是首选解决方案;GitHub 讨论帖也开启了关于 Mojo 简化这些问题的潜力讨论。
- 舍入大乱斗 - Mojo 数学混乱: Mojo 中的舍入函数 bug 引起了集体抱怨;在社区对舍入特性的深入探讨中,强调了与 SIMD 的不一致性。
- 在 int-float 的讨论中,64 位难题成为了核心,Mojo 对
Int64和Float64的分类导致了跨操作的非预期行为。
- 在 int-float 的讨论中,64 位难题成为了核心,Mojo 对
- 栈上加栈 - 高超的 Matmul 操作: 成员们对 Max 在 matmul 中使用 stack allocation(栈分配)以提升 Mojo 性能感到惊叹,并指出缓存优化是关键的增强因素。
- Autotuning(自动调优)作为一种简化 simdwidth 调整和块大小的理想方案浮出水面,但其实施现状仍处于反思性讨论阶段。
- Libc 之恋 - 将旧代码链接到 Mojo: 社区就将 libc 函数引入 Mojo 达成了共识;lightbug_http 在 GitHub 上展示了自由链接的实际应用。
- 关于交叉编译能力的查询以 Mojo 目前尚不支持而告终,促使成员们提出未来可能包含的功能。
- 元组探戈 - 释放 Mojo 潜力: Mojo 缺乏用于别名的 tuple unpacking(元组解包)引发了语法驱动的推测,社区成员渴望一种概念上更清晰的结构。
- Nightly 编译器更新让 Mojo 玩家们紧跟代码节奏,版本
2024.7.705引入了新的模块和变更。
- Nightly 编译器更新让 Mojo 玩家们紧跟代码节奏,版本
Cohere Discord
- AI-Plans 平台揭晓对齐策略: 围绕 AI-Plans 展开了讨论,这是一个旨在促进对齐策略同行评审的平台,主要关注红队测试对齐计划。
- 细节较少,因为用户目前尚未提供有关该项目的进一步见解或直接链接。
- Rhea 亮眼的“保存到项目”功能点亮 HTML 应用: Rhea 集成了一项新的“保存到项目”功能,使用户能够直接从其 dashboards(仪表板)存储交互式 HTML 应用程序,详见 Rhea 平台。
- 这一新增功能促进了更流畅的工作流,有望激发增强的用户参与度和内容管理。
- Rhea 注册因大小写敏感问题受阻: Rhea 的注册过程出现了一个小问题,用户电子邮件必须以小写形式输入才能通过邮件验证,这暗示了在 user-experience(用户体验)考虑上可能存在的疏忽。
- 这一发现强调了在用户界面设计中进行严格测试和反馈机制的重要性,特别是针对大小写敏感的处理。
- Cohere 社区纽带与创投的传闻: Cohere 社区的新面孔分享了他们的热情,兴趣集中在协同使用 Aya 等工具进行协作工作流和文档记录。
- 这些介绍成为了分享经验的跳板,增强了 Cohere 的工具利用率和社区凝聚力。
- 青少年遇见技术:Rhea 开启儿童友好型 AI 编程俱乐部冒险: 儿童编程俱乐部的成员正在寻求新视野,通过将 Rhea 易于使用的平台集成到他们的 AI 和 HTML 项目中,旨在激励下一代 AI 爱好者。
- 这一举措代表了在 AI 领域培养青少年思想迈出的一步,突显了像 Rhea 这样的教育工具对于不同年龄段和技术背景的适应性。
Eleuther Discord
- T-FREE 缩小 Tokenizer 占用空间:T-FREE Tokenizer 的引入彻底改变了 Embedding,层大小减少了 85%,并实现了与传统模型相当的效果。
- 该 Tokenizer 放弃了预分词(pretokenization),通过字符三元组激活模式(character triplet activation patterns)转换单词,这是迈向模型紧凑化的重要一步。
- SOLAR 为模型扩展提供新思路:关于 SOLAR(一种模型扩展技术)的讨论非常热烈,主要涉及其效率与从零开始训练模型的对比。
- 虽然 SOLAR 展示了性能优势,但仍需要与从零训练的模型进行更好的对比才能得出最终结论。
- BitNet 凭借 1-bit 权重 Transformer 实现飞跃:BitNet 首次推出了 1-bit 权重 Transformer 架构,在性能与资源消耗之间取得了平衡,具有内存和能源友好的特性。
- 在不大幅牺牲结果的情况下进行权重压缩,使 BitNet 的 Transformer 能够在资源受限的场景中扩大应用范围。
- QuaRot 证明了 4-bit 量化的强大:QuaRot 的研究表明,4-bit 量化在 LLM 中能保持接近全精度的水平,同时有效降低了内存和处理需求。
- 在没有严重性能下降的情况下大幅削减计算成本,使 QuaRot 成为推理运行时优化的实际选择。
- 寻找 GPT-Neox 的正确 Docker 部署方式:关于有效使用 Docker 容器部署 GPT-Neox 的咨询引发了关于 Kubernetes 可能更适合大规模任务管理的推测。
- 虽然 Docker Compose 一直很方便,但在部署环境中,为了降低复杂性和提高效率,规模化部署更倾向于使用 Kubernetes。
LAION Discord
- JPEG XL 夺得桂冠:JPEG XL 现在被认为是领先的图像编解码器,因其在该领域优于其他格式的效率而受到认可。
- 讨论强调了它相对于传统格式的稳健性,并考虑将其作为未来的标准用法。
- Kolors 仓库引起关注:Kolors GitHub 仓库 因其重要的论文部分而引起了关注热潮。
- 成员们对其技术深度表达了兴奋和幽默,预测其将对该领域产生强烈影响。
- 噪声调度引发辩论:关于增加 100 个时间步长并转向 v-prediction 进行噪声调度的有效性是一个热门辩论话题,特别是为了实现零终端 SNR。
- 在对高分辨率采样场景中测试与训练不匹配的担忧中,SDXL 的论文被引用作为指导。
- Meta 的 VLM 广告面临质疑:Meta 决定宣传 VLM 而不是发布 Llama3VLM 引起了不满,用户对 Meta 对 API 可用性的承诺表示怀疑。
- 社区对 Meta 优先考虑自家产品而非广泛的 API 访问表示担忧。
- VALL-E 2 的文本转语音突破:VALL-E 2 为文本转语音系统设定了新基准,其零样本 TTS 能力在自然度和稳健性方面脱颖而出。
- 尽管它需要显著的计算资源,但其在 LibriSpeech 和 VCTK 数据集上的结果引发了社区对复制工作的期待。
LangChain AI Discord
- 通过 LangChain 解析 CSV:用户探讨了在 LangChain 中处理 CSV 文件的方法,讨论了超越以往限制的现代化方法的需求。
- LangChain 的 utility functions 提供了帮助,建议将模型输出转换为 JSON,并使用
Json RedactionParser等工具来增强解析能力。
- LangChain 的 utility functions 提供了帮助,建议将模型输出转换为 JSON,并使用
- 异步配置揭秘:通过社区协作,揭开了 LangChain 中异步配置的神秘面纱,特别是使用
astream_events时ToolNode内的ensure_config()方法。- 分享了在
invoke函数中包含config的关键指导,从而简化了 async task management(异步任务管理)。
- 分享了在
- 本地 LLM 实验规模扩大:关于在配备 NVIDIA RTX 4090 GPU 的个人设备上运行
phi3等小型 LLM 模型的讨论非常热烈。- 对于管理 70B 参数等巨型模型以及在多 GPU 设置上实现此类壮举的可行性,好奇心激增,预示着 local LLM innovation(本地 LLM 创新)的驱动力。
- LangGraph Cloud 服务引发猜测:LangGraph Cloud 即将到来的暗示引发了关于 LangServe API 部署是否需要第三方提供商的疑问。
- 社区对新服务产品的期待以及部署范式可能发生的转变议论纷纷。
- 浏览器内视频分析工具引起关注:‘doesVideoContain’ 是一款用于在浏览器内扫描视频内容的工具,凭借其对 WebAI 技术的使用引起了兴趣。
- 为了推动社区参与,提供了 YouTube 演示和 Codepen 实时示例的直接链接,促进其应用。
OpenInterpreter Discord
- RAG 的技能库强化行动:为了提高效率,一名成员率先将技能库与 RAG 集成,增强了指定操作的一致性。
- 这一进展已与社区分享,激励了对 RAG 在各种 AI 应用中潜力的进一步探索。
- OI 团队警惕守护安全边界:OI 团队对安全性的承诺在最近的一次视频会议中受到关注,将其巩固为运营完整性的首要任务。
- 他们的前瞻性措施正在为集体安全协议树立基准。
- GraphRAG 有效穿梭于数据簇:一位参与者展示了 Microsoft 的 GraphRAG,这是一款将数据聚类为社区以优化 RAG 用例的高级工具。
- 实施 GraphRAG 的热情被点燃,同时还参考了来自 @tedx_ai 的一条富有启发性的推文。
- 7 月 4 日聚会的节日基调:OI 团队的 4th of July 庆祝活动增进了友谊,展示了新的演示,并培养了对未来团队聚会的期待。
- 团队精神受到鼓舞,希望将这一庆祝活动确立为每月的常规亮点。
- O1 单元准备 11 月推出:时间表显示首批 1000 个 O1 单元计划于 11 月交付,反映了对其按时到达的高度期望。
- 围绕 O1 的对话能力充满好奇,同时社区通过分享解决 Linux ‘typer’ 模块故障的方案提供了支持。
OpenRouter (Alex Atallah) Discord
- 支持多种货币的加密货币支付:社区讨论集中在 Coinbase Commerce 处理多种加密货币支付的能力,包括通过 Polygon 支付 USDC 和 Matic。
- 一位用户确认了使用 Matic 的无缝交易,并对其效果表示认可。
- Perplexity API 表现不佳:用户指出 Perplexity API 的性能与其网页版相比逊色不少,Payload 中缺少关键的参考链接。
- 规避此问题的建议包括使用 Phind 等替代方案,或直接从 GitHub 和 StackOverflow 抓取数据。
- 预测生成式视频的发展轨迹:一位成员询问了关于生成式视频在未来 18 个月内质量、执行速度和成本的预期轨迹。
- 目前尚未做出明确预测,强调了此类生成媒介尚处于初期阶段。
- OpenRouter 的定制化 AI 选项:确认 OpenRouter 允许能够处理大量请求的用户部署自己的微调模型 (fine-tuned models)。
- 这被认为是希望赋予定制化 AI 功能的开发者的福音。
- DeepInfra vs. Novita:价格战:OpenRouter 见证了 DeepInfra 和 NovitaAI 之间的价格竞争,它们在提供 Llama3 和 Mistral 等模型服务方面争夺领先地位。
- 一场以 0.001 为单位降价的幽默战斗,使得这些模型的定价极具竞争力。
LlamaIndex Discord
- 自动驾驶式交易:LlamaIndex 驱动 AI 股票助手:一个利用 Llama Index Agent 的 AI 交易助手在教程视频中展示,可执行多种股票交易任务。
- 其能力由 Llama Index 的 RAG 抽象驱动,包括预测分析和交易,并展示了实际应用案例。
- 构建 RAG 数据集:更丰富问题的工具:Giskard AI 的工具包有助于生成强大的 RAG 数据集,其工具包文章中展示了生成多种问题类型的功能。
- 该工具包超越了典型的自动生成集,为数据集创建提供了更丰富的工具。
- 微服务,大潜力:大规模敏捷 Agent:Llama-agents 现在为可扩展、高需求的微服务提供了一套设置,详见这篇见解深刻的文章。
- 这种“Agent 与工具即服务”的模式增强了可扩展性并简化了微服务交互。
- 分析分析师:LlamaIndex 助力 10K 报告剖析:得益于 Llama Index 的功能,多文档财务分析师 Agent 将每份文档视为一个工具,处理 10K 等财务报告的分析。
- Pavan Mantha 展示了利用 Llama Index 的特性进行此类分析的效率。
tinygrad (George Hotz) Discord
- 红色阵营的犹豫:对 Instinct 系列的谨慎?:一名成员对 team red 的 Instinct 显卡驱动程序 表示担忧,由于潜在的支持问题,在购买二手 Mi100 时感到犹豫。
- 对话中提到,目前只有 7900xtx 显卡在测试中,这意味着 Instinct 显卡用户可能需要独自解决故障。
- API 演进:构建自定义梯度:一位用户提出了一个新的 自定义梯度 (custom grads) API,希望实现类似于 jax.customvjp 的功能,以增强用于量化训练等任务的 Tensor 操作。
- 建议的改进目标是在 tinygrad.functions 中使用 lazybuffers 替换当前操作,提倡直接进行 Tensor 操作。
- 强化学习:多 GPU 指南:寻求 Tinygrad 多 GPU 训练知识的用户被引导至 beautiful_mnist_multigpu.py 示例,该示例重点展示了模型和数据分片 (sharding) 技术。
- 分享了使用
shard(axis=None)复制模型以及使用shard(axis=0)进行数据拆分的细节,有助于实现高效的并行训练。
- 分享了使用
- 等价性参与:类 Torch 的 Tensor 之战:关于类似于
torch.all的 Tensor 比较方法的查询,通过引入(t1 == t2).min() == 1的比较方式得到解决,随后在 Tinygrad 中添加了 Tensor.all。- 这一功能对齐的进展记录在 此 Tinygrad commit 中,为用户提供了更简便的 Tensor 操作。
- 优化障碍:Adam 的归零效应:有反馈称 Tinygrad 中的 Adam 优化器 在第二次迭代步骤后会导致权重变为 NaNs,这与 SGD 的稳定性形成了鲜明对比。
- 随着工程师们寻求防止优化器破坏学习过程的解决方案,这一调试对话仍在进行中。
OpenAccess AI Collective (axolotl) Discord
- MInference 的敏捷加速:一名成员重点介绍了微软的 MInference 项目,该项目声称可以加速长上下文 LLMs 的推理,在 A100 上将 延迟 (latency) 降低多达 10 倍。
- MInference 采用了新颖的近似和动态稀疏计算技术,旨在平衡准确性与 性能效率。
- Yi-1.5-9B 结合 Hermes 2.5 批量上线:Yi-1.5-9B-Chat 的更新显示其使用了 OpenHermes 2.5 进行微调,并公开分享了在 AGIEval Benchmark 中表现优异的 模型和量化版本。
- 该增强模型在 4x NVIDIA A100 GPU 上训练了超过 48 小时,其“意识”令人印象深刻,目前正计划利用 POSE 将其上下文长度推升至 32k tokens。
- Mistral 的聊天模板难题:关于在 Axolotl 中进行 Mistral 微调 时使用哪种最佳 chat_template 的讨论引起了关注,答案取决于数据集结构。
- 社区共识倾向于利用 “chatml” 模板,并提供了 YAML 配置示例来指导成员。
LLM Finetuning (Hamel + Dan) Discord
- MLOps 策略与 FP8 难题:社区成员分享了见解,其中一人引用了一篇关注 MLOps 实现 的博客文章,另一人讨论了在 分布式 vllm 推理 中遇到的 FP8 量化 问题。
- 针对 FP8 的敏感性问题 找到了解决方案,从而修正了输出,一个 GitHub 线程 为处理类似问题的用户提供了更多背景信息。
- 剖析模型集成:一位成员正在评估 传统工具(如 Transformers & Torch)与来自 OpenAI 和 Anthropic 的成熟模型的集成。
- 对话集中在寻找一种既能提供有效性又能针对特定项目需求进行无缝集成的最佳方法。
- 积分申领进入冲刺阶段:#credits-questions 频道的讨论明确指出:积分申领已永久关闭,标志着该福利的终结。
- 会议强调,这种积分积累的终止适用于所有人,没有例外,并关闭了任何未来申领的途径。
- Replicate 积分倒计时:#predibase 频道的一场对话透露,前 25 个 Replicate 积分 的有效期为一个月,这是对用户的一个重要更新。
- 这一限时优惠似乎是使用策略的一个关键点,特别是对于那些依赖这些初始积分开展项目的用户。
Interconnects (Nathan Lambert) Discord
- Interconnects 机器人:改进空间:一位用户表示 Interconnects 机器人 表现良好,但最近的总结输出没有显著变化。
- 该用户主张进行显著的更新或增强,以提升 Interconnects 机器人的功能。
- RAG 使用案例与企业讨论:成员们讨论了检索增强生成 (RAG) 模型,强调了它们在企业内部不断发展的使用案例。
- 一些参与者建议 RAG 可能会增强内部知识库的使用,而另一些人则回忆起该模型在 早期 AI 热潮 期间的炒作。
- 翻找对 RAG 的早期反思:对话触及了围绕 RAG 的最初兴奋感,并对最初过高的期望表达了共鸣。
- 交流揭示了一个共同观点:早期的炒作尚未完全转化为广泛的企业采用。
- 成本效益与知识检索:企业视角:讨论围绕 RAG 如何帮助提高企业模型的成本效益展开。
- 有人提出,此类模型通过挖掘庞大的内部知识库,可以为企业开辟新的技术途径。
Alignment Lab AI Discord
- Buzz 赢得赞赏并预告发布:群组中对 Buzz 的热情显而易见,一位成员称赞了它的能力并暗示会有更多功能推出。
- Autometa 预告了即将发布的版本,引发了社区的好奇心。
- 聚焦 FPGA:Autometa 即将举行的会议:Autometa 宣布计划开会讨论 FPGA 领域的新应用,并指出了议程中的几个关键议题。
- 成员们受邀参与并分享他们对当前项目中 FPGA 多样化用途的见解。
- 敞开大门:使用 Calendly 安排协作:为了促进关于 AI alignment 的讨论,Autometa 为社区分享了一个公开的 Calendly 链接。
- 该链接作为安排深入讨论的公开邀请,为协作努力提供了一个平台。
LLM Perf Enthusiasts AI Discord
- Flash 1.5 受到关注:成员 jeffreyw128 表示 Flash 1.5 表现异常出色。
- 该话题未提供额外的背景信息或详细讨论。
- 等待进一步见解:目前关于 Flash 1.5 的技术性能和功能的细节较少。
- 随着该工具获得更多关注,预计随后会有社区讨论和更深入的分析。
AI Stack Devs (Yoko Li) Discord
- Sprite Quest: Google Image Galore: 一位成员提到 sprites 素材来源于 random Google image searches,以满足素材收集快速且多样化的需求。
- 重点是在不购买的情况下获取多样化的 sprites,而 tilesets 是唯一的 paid assets。
- Tileset Trade: The Only Expense: 对话透露,唯一投入资金的资产是 tilesets,凸显了注重成本的方法。
- 这种区别强调了对资产的有条理选择,即 money spent solely on tilesets,而 sprites obtained freely 则通过搜索引擎获取。
MLOps @Chipro Discord
- EuroPython Vectorization Talk: 一位用户表达了他们参加 EuroPython 的意愿,并暗示即将有一个专注于 vectorization 的演讲。
- 感兴趣的社区成员可能会参加,以深入了解 vectorization 在 Python 中的作用,这是 AI engineering 的一个重要方面。
- Community Engagement at Conferences: 用户提到 EuroPython 突显了社区在 Python 会议上的外展和活跃存在。
- 这鼓励了 AI and Machine Learning 领域的 Python 从业者之间的社交和知识共享。
Mozilla AI Discord
- Google’s Gem Sparkles in Size and Performance: Google 的 Gemma 2 9B 已作为开源语言模型进入赛场,因其强劲的性能而受到关注。
- Despite its smaller scale,Gemma 2 9B 挑战了 GPT-3.5 等重量级模型,适用于资源有限的环境。
- Lambda Lift-Off: Gemma 2 Reaches Serverless Heights: 社区通过在 AWS Lambda 上将 Google 的 Gemma 2 与 Mozilla 的 Llamafile 集成,探索了 serverless AI inference,如本教程所示。
- 这种 serverless 方法使得在低资源设置(包括移动设备、个人电脑或本地化云服务)中高效部署 Gemma 2 9B 成为可能。
DiscoResearch Discord
- Models Fusion Forge: 一位成员提议使用 Hermes-2-Theta-Llama-3-70B 作为构建 Llama3-DiscoLeo-Instruct-70B 模型的基础。
- 随后的对话暗示了合并两个模型的能力以增强性能的优势。
- Enhancement Speculations: 工程师们考虑了模型集成的预期收益,重点关注 Hermes-2-Theta-Llama-3-70B 和 Llama3-DiscoLeo-Instruct。
- 对话围绕通过战略性融合不同模型特性来提升 AI 能力的潜在进展展开。
Torchtune Discord 没有新消息。如果该公会长期沉默,请告知我们,我们将移除它。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会长期沉默,请告知我们,我们将移除它。
PART 2: Detailed by-Channel summaries and links
完整的频道详情已针对邮件进行截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!