ainews-to-be-named-3686
测试时训练 (Test-Time Training)、MobileLLM、Lilian Weng 谈幻觉(外加:Turbopuffer)
Lilian Weng 发布了一篇关于幻觉检测和抗幻觉方法的全面文献综述,涵盖了 FactualityPrompt、SelfCheckGPT 和 WebGPT 等技术。Facebook AI 研究院 (FAIR) 发布了 MobileLLM,这是一种参数量在十亿以下的端侧语言模型架构,通过“窄而深”的模型设计和权重共享等创新,实现了与 llama-2-7b 相当的性能。此外,一种具有强表达能力隐藏状态的新型基于 RNN 的大模型架构问世,它取代了注意力机制,在长文本建模方面的扩展性优于 Mamba 和 Transformer 模型。最后,清华大学开源了 CodeGeeX4-ALL-9B,这是一款在代码辅助方面表现出色的多语言代码生成模型。
Depth is all you need. 我们无法决定该重点推荐什么,所以这里有 3 个头条故事。
2024年7月8日至7月9日的 AI 新闻。 我们为你检查了 7 个 subreddits、384 个 Twitter 账号 和 29 个 Discord(463 个频道和 2038 条消息)。 预计节省阅读时间(以 200wpm 计算):250 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论了!
两个我们错过的重大故事,以及一个我们喜欢但不想占用全部篇幅的新故事:
- Lilian Weng 关于 Extrinsic Hallucination 的文章:每当 Lil’Log 更新时,我们通常会放下手头的一切去阅读,但她似乎悄无声息地发布了这篇极其详尽的文献综述,甚至没有在 Twitter 上宣布。Lilian 定义了 Hallucination Detection(FactualityPrompt, FActScore, SAFE, FacTool, SelfCheckGPT, TruthfulQA)和 Anti-Hallucination Methods(RARR, FAVA, Rethinking with Retrieval, Self-RAG, CoVE, RECITE, ITI, FLAME, WebGPT)的 SOTA,并以一份关于其他 Hallucination eval 基准测试的简短阅读清单结束。我们肯定需要针对 Reddit 摘要在这方面做大量工作。
-
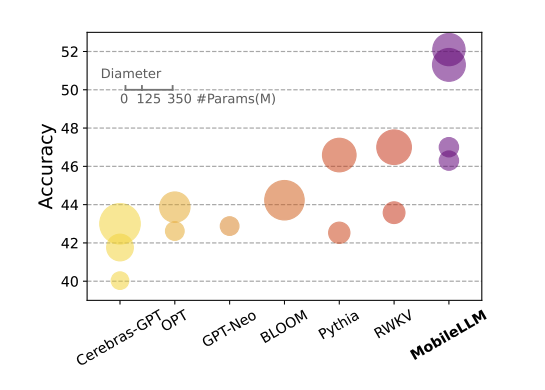
MobileLLM:为端侧使用优化十亿参数以下的语言模型:这是即将在 ICML 上发表的 最受关注 的 FAIR 论文之一(尽管甚至没有获得 Spotlight,嗯),专注于十亿以下规模的端侧模型架构研究,使一个 350M 模型达到了与 Llama 2 7B 相同的性能,令人惊讶的是在对话语境下。Yann LeCun 的要点总结:1) 窄而深,而非宽;2) token->embedding 和 embedding->token 使用共享矩阵;在多个 Transformer 块之间使用共享权重。
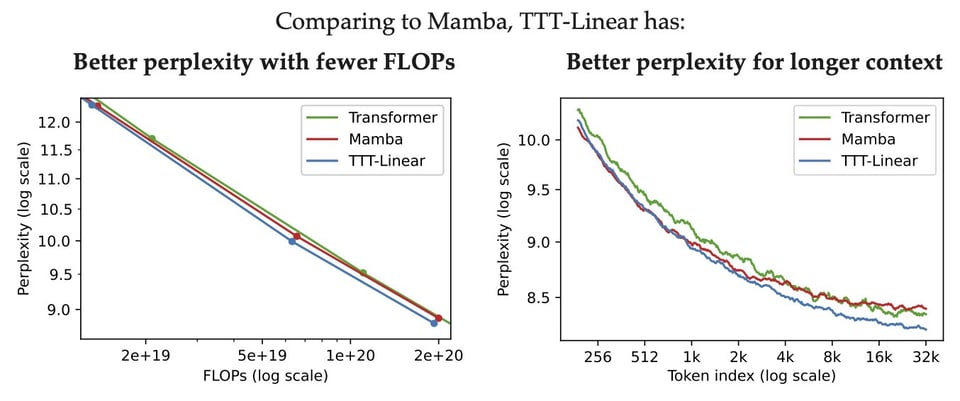
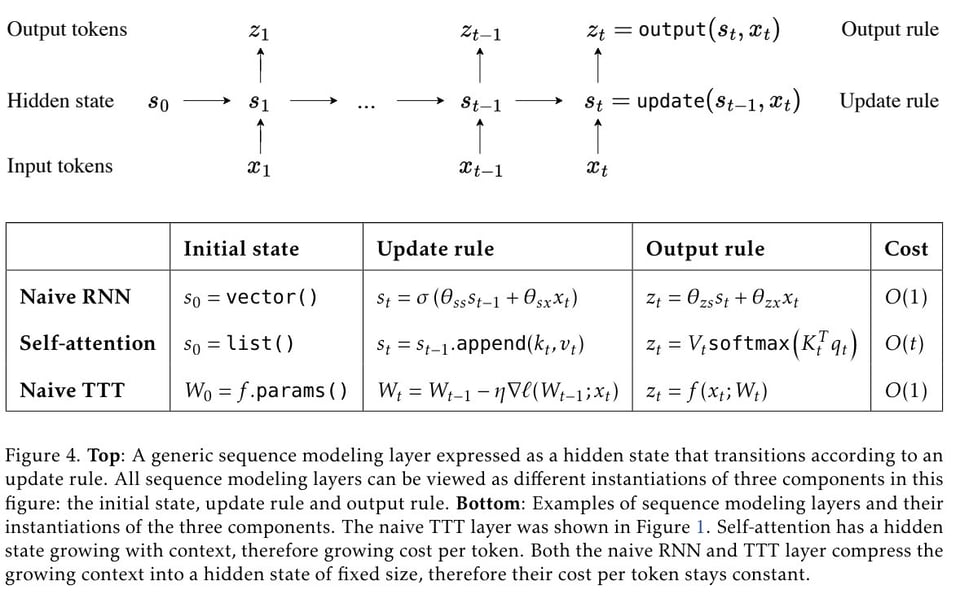
- Learning to (Learn at Test Time): 具有表达性隐藏状态的 RNN(导师 和 作者 的推文):继 ICML 2020 关于 Test-Time Training 的工作之后,Sun 等人发布了一种“新型 LLM 架构,具有线性复杂度和表达性隐藏状态,用于长上下文建模”,它直接取代了 Attention,“比 Mamba 和 Transformer 具有更好的扩展性(从 125M 到 1.3B)”且“在长上下文下表现更好”。
 主要见解是将 RNN 的隐藏状态替换为一个小型神经网络(而不是用于记忆的特征向量)。
主要见解是将 RNN 的隐藏状态替换为一个小型神经网络(而不是用于记忆的特征向量)。
 基本直觉 是合理的:“如果你相信训练神经网络通常是压缩信息的好方法,那么训练一个神经网络来压缩所有这些 token 就是有意义的。”如果我们能一直嵌套网络,这个兔子洞到底有多深?
基本直觉 是合理的:“如果你相信训练神经网络通常是压缩信息的好方法,那么训练一个神经网络来压缩所有这些 token 就是有意义的。”如果我们能一直嵌套网络,这个兔子洞到底有多深?
Turbopuffer 也结束了隐身模式,发布了一篇广受好评的小文章。
AI Twitter 回顾
我们的 Twitter 流水线遇到了问题,请明天再来查看。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。评论抓取功能现已上线,但仍有很大改进空间!
AI 模型与架构
- CodeGeeX4-ALL-9B 开源:在 /r/artificial 中,清华大学开源了 CodeGeeX4-ALL-9B,这是一个突破性的多语言代码生成模型,性能超越了主要竞争对手并提升了代码辅助能力。
- Mamba-Transformer 混合模型展现潜力:在 /r/MachineLearning 中,Mamba-Transformer 混合模型提供了巨大的推理加速,对于 120K 输入 token,速度提升高达 7 倍,同时在能力上略微优于纯 Transformer。输入上下文越长,优势越明显。
- Phi-3 框架在 Mac 上发布:/r/LocalLLaMA 分享了 Phi-3 for Mac 的消息,这是一个多功能的 AI 框架,利用了 Phi-3-Vision 多模态模型和最近更新的 Phi-3-Mini-128K 语言模型。它旨在利用 MLX 框架在 Apple Silicon 上高效运行。
AI 安全与伦理
- 前 OpenAI 研究员警告安全被忽视:在 /r/singularity 中,前 OpenAI 研究员 William Saunders 表示,当他意识到 OpenAI 就像泰坦尼克号——一场激励机制驱动公司忽视安全并建造更大的船只最终导致灾难的竞赛时,他选择了辞职。
- AI 模型合规性测试显示审查差异:/r/singularity 中的一项 AI 模型合规性测试显示了哪些模型的审查最少。Claude 模型除一个外均处于后半部分,而 GPT-4 则进入了前半部分。
- 超个性化可能导致共享现实的破碎:在 /r/singularity 中,Anastasia Bendebury 警告说,由于 AI 导致的媒体内容超个性化可能导致我们生活在本质上不同的宇宙中。这可能会加速社交媒体算法中已经出现的过滤泡(filter bubble)效应。
{kind=link}
AI 应用
- Pathchat 实现 AI 医疗诊断:/r/singularity 介绍了 Modella 的 Pathchat,这是一个专为医学和病理学目的设计的多模态 AI 模型,能够识别肿瘤并诊断癌症患者。
- Thrive AI Health 提供个性化教练服务:/r/artificial 讨论了 Thrive AI Health,这是一个由 OpenAI Startup Fund 资助的超个性化 AI 健康教练。
- Odyssey AI 旨在彻底改变视觉特效:在 /r/OpenAI 中,Odyssey AI 正在致力于“好莱坞级”的视觉特效,基于真实世界的 3D 数据进行训练。其目标是大幅缩短电影制作时间和成本。
AI 能力与担忧
- AI 通过面部预测政治信仰:/r/artificial 分享了一项研究,显示了 AI 仅凭面部特征推断政治倾向的能力。
- 红杉资本警告潜在的 AI 泡沫:在 /r/OpenAI 中,红杉资本警告称,AI 每年需要产生 6000 亿美元的收入才能证明当前的硬件支出是合理的。即使是乐观的收入预测也达不到这一水平,这表明潜在的过度投资可能导致泡沫。
- 中国面临 AI 模型过剩且利用不足的问题:/r/artificial 报道了中国 AI 模型过剩的情况,百度 CEO 称由于 100 多个 LLM 缺乏实际应用,这是“资源的重大浪费”。
迷因与幽默
- 推特用户误解 AI 技术:/r/singularity 分享了一个关于推特上普通大众对 AI 技术缺乏了解的幽默看法。
- AI 构思老龄化马里奥游戏:/r/singularity 展示了一个幽默的 AI 生成的游戏封面,描绘了一个患有背痛的老年马里奥。
{kind=link}
{kind=link}
AI Discord 回顾
摘要的摘要的摘要
1. 大语言模型进展
- 细腻的语音模型涌现:JulianSlzr 强调了 GPT-4o 精致的轮询式(turn-based)语音模型与 Moshi 未经雕琢的全双工(full-duplex)模型之间的细微差别。
- Andrej Karpathy 等人对这些差异发表了看法,展示了 AI 模型中涌现出的多样化语音能力。
- Gemma 2 更新后表现出色:Gemma2:27B 模型收到了来自 Ollama 的重大更新,修复了之前的问题,其令人印象深刻的性能赢得了广泛好评,正如这段 YouTube 视频所示。
- 社区成员称赞了该模型的转变,在经历了之前的输出不连贯问题后,称其表现“令人难以置信”。
- Supermaven 发布 Babble:Supermaven 宣布推出其最新的语言模型 Babble,该模型拥有 100 万 token 的海量上下文窗口,比其之前提供的产品大 2.5 倍。
- 此次升级有望凭借其广阔的上下文处理能力丰富对话场景。
2. 创新 AI 研究前沿
- 测试时训练(Test-Time Training)提升 Transformer 性能:一篇新论文提出使用测试时训练(TTT),通过在未标记的测试实例上进行自监督学习来改进模型预测,在 ImageNet 等基准测试中表现出显著提升。
- TTT 可以集成到线性 Transformer 中,实验设置中用神经网络替代线性模型显示出增强的性能。
- 无矩阵乘法(MatMul-Free)模型革新 LLM:研究人员为大语言模型开发了矩阵乘法消除技术,在保持十亿参数规模强劲性能的同时,显著降低了内存使用量,实验显示比未优化的基准线降低了高达 61%。
- 一种名为 Test-Time-Training 层的新架构用机器学习模型取代了 RNN 隐藏状态,实现了线性复杂度,并达到或超越了顶尖的 Transformer,正如最近的一条推文所宣布的那样。
- 生成式变色龙(Generative Chameleon)出现:首个生成式变色龙模型已发布,其详细研究内容记录在 arXiv 论文中。
- 研究界渴望调查该模型适应各种绘画风格的能力,这有可能彻底改变数字艺术创作。
3. AI 工具化与部署进展
- Unsloth 加速模型微调:Unsloth AI 的新文档网站详细介绍了在微调 Llama-3 和 Gemma 等大语言模型时,如何在不牺牲准确性的情况下将速度提高一倍并将内存使用量减少 70%。
- 该网站指导用户创建数据集、部署模型,甚至通过建议从 llama.cpp 仓库构建来解决 gguf 库的问题。
- LlamaCloud 简化数据集成:LlamaCloud 的测试版发布,承诺提供一个用于非结构化数据解析、索引和检索的托管平台,目前已为热切的测试者开放候补名单。
- 通过集成 LlamaParse 进行高级文档处理,LlamaCloud 旨在简化跨不同后端的同步,实现无缝的 LLM 集成。
- Crawlee 简化网页抓取:Crawlee for Python 发布,具有 HTTP 和 Playwright 的统一接口以及自动扩展和会话管理等功能,详见 GitHub 和 Product Hunt。
- 凭借对网页抓取和浏览器自动化的支持,Crawlee 被定位为 Python 开发人员从事 AI、LLM、RAG 或 GPT 数据提取的强大工具。
4. AI 伦理辩论与法律影响
- Copilot 诉讼范围缩小:针对 GitHub Copilot 涉嫌在未注明出处的情况下复制代码的大部分指控已被驳回,在这场涉及 GitHub、Microsoft 和 OpenAI 的法律诉讼中仅剩下两项指控。
- 最初的集体诉讼认为 Copilot 在开源软件上进行训练构成了知识产权侵权,这引起了开发者社区的关注。
- AI 的社会影响受到审视:讨论揭示了对 AI 社会影响的担忧,特别是关于潜在的成瘾问题以及未来监管的必要性。
- 成员们强调,鉴于 AI 在各个领域的变革性特质,采取前瞻性措施迫在眉睫。
- 面向开发者的 Anthropic 额度:社区成员询问 Anthropic 是否存在类似于 OpenAI 的额度系统,寻求在其平台上进行实验和开发的机会。
- 对话强调了人们对获取 Anthropic 产品(类似于 OpenAI 的举措)以促进 AI 研究和探索的兴趣日益增长。
5. Model Performance Optimization
- Deepspeed 提升训练效率:Deepspeed 能够实现在单张 RTX 3090 上训练 25 亿参数模型,并获得更高的 Batch Size 和效率。
- 一位成员分享了他们使用 Deepspeed 的成功经验,引发了人们对其在更易获得的训练方案中潜力的兴趣。
- FlashInfer 的速度秘诀:FlashInfer Kernel Library 支持 INT8 和 FP8 Attention Kernel,有望提升 LLM Serving 的性能。
- AI 社区热衷于测试和讨论 FlashInfer 对模型效率的影响,反映出极高的期待。
6. Generative AI in Storytelling
- 生成式 AI 影响叙事:Medium 文章 探讨了生成式 AI 给叙事和叙事创作带来的深刻变革,开启了丰富的叙事机会。
- KMWorld 重点介绍了塑造知识管理领域的 AI 领导者,强调了生成式 AI 的变革潜力。
- AI 在文化影响中的角色:关于 AI 社会影响的讨论强调了对成瘾和未来监管必要性的担忧,反映了 AI 技术的变革性。
- 社区强调了采取前瞻性措施以应对 AI 的文化效应和社会影响的紧迫性。
7. AI in Education
- 教师探索使用 CommandR 构建学习平台:一位公立学校教师正在利用 CommandR 的 RAG 优化特性 开发一个教学与学习平台。
- 该倡议得到了社区的积极回应和协助提议,展示了集体的热情。
- Claude 竞赛提醒:Build with Claude 竞赛 提供价值 $30k 的 Anthropic API 额度,即将结束。
- 提醒社区成员参与,强调了该竞赛对开发者和创作者的重要性。
PART 1: High level Discord summaries
HuggingFace Discord
- Intel 为 HF 模型带来的推理加速:一个新的 GitHub 仓库 展示了如何在 Intel CPU 上更高效地运行 HF 模型,这对拥有 Intel 硬件的开发者来说是一个福音。
- 该资源的出现填补了 Intel 特定 指导的空白,可能是提升模型运行性能的宝库。
- Gemma 更新后的巨大进步:Gemma2:27B 模型得到了大幅增强,一段富有启发性的 YouTube 视频 展示了这一点,并获得了社区的高度认可。
- Ollama 的及时更新修正了之前的问题,现在 Gemma 因其出色的性能而广受好评。
- 关于上下文窗口的巧妙考量:LLM 训练期间的 VRAM 占用情况各不相同,而 context window(上下文窗口)大小是这一计算难题的核心。
- 社区成员交流了经验,分享了 padding(填充)和 max token 调整是保持 VRAM 负载稳定的关键。
- 深入渗透测试主题:焦点聚集在 PentestGPT 上,一场回顾会议将深入探讨 AI pentesting(AI 渗透测试)的细微差别。
- 随着一篇 专题论文 的深入剖析,该小组正准备推进关于 AI 稳健渗透测试实践的对话。
- 叙事细微差别与 Generative AI:Generative AI 对故事创作的影响成为核心话题,一篇 Medium 文章 揭示了其在叙事方面的潜力。
- 与此同时,KMWorld 报道了正在塑造知识管理领域的 AI 领导者,并重点关注了 Generative AI。
Unsloth AI (Daniel Han) Discord
- Unsloth 文档释放效率:Unsloth AI 新的 文档网站 提升了 Llama-3 和 Gemma 等模型的训练效率,在不牺牲准确性的情况下,将速度提高了一倍,并将内存占用减少了 70%。
- 该网站的教程简化了数据集创建和模型部署的过程,甚至通过建议从 llama.cpp 仓库进行构建来解决 gguf 库 的问题。
- LlaMA 3 的微调技巧:Modular Model Spec 的开发旨在优化 LLaMA 3 等 AI 模型的训练流程。
- SiteForge 将 LLaMA 3 整合到其 网页设计生成 中,承诺提供 AI 驱动的革命性设计体验。
- 利用 LlaMA 3 精通医疗翻译:关于使用 Llama 3 将 5000 条医疗记录翻译成瑞典语的讨论,揭示了该模型在瑞典语方面的熟练程度和应用潜力。
- 用户验证了针对瑞典语特定应用微调 Llama 3 的实用性,正如 AI-Sweden-Models/Llama-3-8B-instruct 所展示的那样。
- 数据集获得合成增强:一种 AI 方法正在创建合成聊天数据集,为超过 100 万条语句 提供逻辑依据和上下文,从而丰富了 PIPPA 数据集。
- 在医疗对话领域,使用现有的微调模型暗示可以跳过预训练,这与 研究 中提到的益处相呼应。
- 利用无矩阵乘法模型重构 LLM:一项 研究 揭示,LLM 可以舍弃矩阵乘法,在十亿参数规模下可节省 61% 的内存。
- Test-Time-Training layers(测试时训练层)作为 RNN 隐藏状态的替代方案出现,并在具有线性复杂度的模型中得到展示,这一点在 社交媒体 上引起了关注。
CUDA MODE Discord
- 集成之谜:Triton 邂逅 PyTorch:好奇的开发者们正在探索如何将 Triton kernels 集成到 PyTorch 中,特别是旨在为
torch.compile自动优化注册自定义函数。- 讨论仍在进行中,技术社区正热切期待关于这一挑战的权威指南或解决方案。
- 纹理对话:Vulkan 后端算子:为什么 executorch 的 Vulkan backend 在其算子中使用纹理(textures)?这个问题引发了成员们的一系列探究。
- 目前尚未达成具体结论,该话题仍保持开放,以待进一步的见解和探索。
- INT8 与 FP8:FlashInfer 的速度秘诀:FlashInfer Kernel Library 的发布引起了广泛关注,它支持 INT8 和 FP8 注意力算子,有望提升 LLM 推理服务的性能。
- 附带 库链接,AI 社区正热衷于测试并讨论其对模型效率的潜在影响。
- 量化清晰化:校准是关键:量化讨论转向了技术深度,揭示了在使用静态量化时,配合数据进行适当的校准(calibration)是必不可少的。
- 一个 GitHub pull request 重点强调了这一必要性,引发了对该实践的技术深挖。
- 分而治之:利用 Ring Attention 进行 GPU 切分:跨 GPU 切分 KV cache:这是一个正通过 ring attention 解决的挑战,特别是在 AWS g5.12xlarge 实例环境下。
- 针对此实现的最佳拓扑结构的追求非常热烈,成员们分享了如 此 gist 之类的资源以辅助研究。
Nous Research AI Discord
- GIF 引发笑声:Marcus 对阵 LeCun:一位用户分享了一个幽默的 GIF,捕捉了 Gary Marcus 和 Yann LeCun 辩论的瞬间,在不涉及技术细节的情况下突显了不同的 AI 观点。
- 它以轻松的方式展现了 AI 专家之间有时会发生的紧张交流,吸引了社区的关注 GIF 来源。
- Hermes 2 Pro:性能新高度:Hermes 2 Pro 因其增强的 Function Calling 和 JSON Structured Outputs 而受到赞誉,在基准测试中展现了强劲的提升 Hermes 2 Pro。
- 该平台的进步令社区着迷,反映了 LLM 能力和用例的进展。
- 合成数据落地:Distilabel 占据主导:Distilabel 成为合成数据生成的卓越工具,因其高效和高质量的输出而受到称赞 Distilabel 框架。
- 成员们建议将 LLM 输出与合成数据协调一致,从而增强 AI 工程师的开发和调试工作流。
- Sonnet 3.5 的 PDF 难题与解决方案:由于缺乏直接使用 Sonnet 3.5 API 处理 PDF 的方案,社区开始探索替代路径,如 Marker Library。
- Everyoneisgross 强调了 Marker 将 PDF 转换为 Markdown 的能力,提议将其作为需要更好模型兼容性场景下的变通方案。
- RAG 的新前沿:RankRAG 革命:RankRAG 的方法论取得了飞跃,通过训练一个 LLM 同时进行排序(ranking)和生成(generation)获得了显著收益 RankRAG 方法论。
- 这种被称为“Llama3-RankRAG”的方法展示了引人注目的性能,在多项基准测试中优于同类产品。
Modular (Mojo 🔥) Discord
- Chris Lattner 备受期待的访谈:The Primeagen 将在 Twitch 上对 Chris Lattner 进行一场备受期待的访谈,引发了社区内的兴奋和期待。
- 随后引发了热烈讨论,helehex 预告了明天将有一个涉及 Lattner 的特别活动,进一步提升了 Modular 社区的热度。
- 前沿 Nightly 版 Mojo 发布:Mojo 编译器最新 Nightly 版本 2024.7.905 引入了多项改进,例如增强的
memcmp使用以及针对条件一致性(conditional conformances)的精细化参数推断。- 开发者们敏锐地研究了 更新日志,并讨论了条件一致性对类型组合的影响,特别关注了一个 重要的 commit。
- Mojo 的 Python 超能力释放:Mojo 与 Python 的集成已成为讨论的核心,正如 Mojo 官方文档 所述,旨在评估利用 Python 庞大包生态系统的潜力。
- 讨论转向了 Mojo 潜力成为 Python 超集的话题,强调了通过 Python 的多功能性为 Mojo 赋能的战略举措。
- 时钟精度困境:对时钟校准的详细检查显示,在连续使用
_clock_gettime调用时存在 1 ns 的微小但关键的差异,揭示了对高精度测量的需求。- 这一发现促使了对时钟不准确性影响的进一步分析,强调了其在时间敏感型应用中的重要性。
- 向量化 Mojo 马拉松开辟性能之路:Mojo 马拉松对向量化进行了测试,发现在不同宽度的向量化下性能存在变量,有时 width 1 的表现甚至优于 width 2。
- 社区成员强调了调整基准测试以包含对称和非对称矩阵的重要性,使测试与真实的 地理和图像处理(geo and image processing) 场景保持一致。
LM Studio Discord
- 让 LLM 发声:自定义语音引发关注:社区正在探索将 Eleven Lab 自定义语音与 LM Studio 集成,提议通过 服务器功能的自定义编程 来实现文本转语音。
- 讨论建议保持谨慎,因为尽管有 Claude 等工具可以辅助开发,但仍需要额外的编程工作。
- InternLM:滑动上下文窗口惊艳全场:成员们称赞 InternLM 的滑动上下文窗口,即使在内存过载时也能保持连贯性。
- 带有截图的对话显示了 InternLM 如何通过遗忘早期消息来进行调整,但令人赞赏的是它依然能保持在正轨上。
- 网页工匠:AI 助力自定义爬虫腾飞:一位成员展示了使用 Claude 以极快速度编写 Node.js 网页爬虫 的成果,引发了关于 AI 在工具创建中作用的讨论。
- “我得到了 78 行完全符合我要求的代码,”他们分享道,强调了 AI 对开发效率的影响。
- AI 代码:谨慎处理:AI 代码生成引发了社区辩论;它是一个有价值的工具,但应谨慎使用,并理解底层代码逻辑。
- 共识是:使用 AI 进行快速开发,但要验证其输出以确保代码质量和可靠性。
- AMD 的关键显卡:GPU 成为焦点:成员们讨论了使用 RX 6800XT 进行 LLM 多 GPU 设置,深入了解了 LM Studio 对资源和配置的处理。
- 随着关于 AMD ROCm 支持寿命的辩论展开,人们以面向未来的视角权衡了 RX 6800XT 和 7900XTX 之间的选择。
Eleuther Discord
- **TTT 与 Delta Rule 的探戈:讨论揭示了当使用 mini batch size 为 1 时,TTT-Linear** 与 delta rule 保持一致,从而优化了模型预测的性能。
- 进一步的讨论包括 rwkv7 架构计划利用改进的 delta rule,以及 ruoxijia 阐明了 TTT-linear 并行化的可能性。
- **Shapley 搅动数据归因:In-Run Data Shapley** 作为一个创新项目脱颖而出,有望为 pre-training 期间的实时数据贡献评估提供可扩展的框架。
- 其目标是从训练中排除有害数据,从根本上影响模型能力,并根据 AI 社区的观点澄清“涌现”(emergence)的概念。
- **规范化梯度风暴:一种新兴的梯度归一化(gradient normalization)**技术旨在解决深度网络挑战,如臭名昭著的梯度消失或梯度爆炸。
- 然而,它并非没有缺点,AI 社区强调了诸如 batch-size 依赖性以及相关的跨设备通信故障等问题。
- **RNN 挑战 Transformer 巨头:新兴的 **Mamba 和 RWKV RNN 架构引发了关注,因为它们提供恒定的内存占用,并在 perplexity 任务中被证明是 Transformer 强大的对手。
- 内存管理效率及其对 long-context recall 的影响是当前讨论中理论和实证研究的焦点。
- **弥合大脑容量难题**:最近的一项研究挑战了人们对大脑容量进化的直观认知,特别是人类与体型最大的动物相比,后者并没有按比例拥有更大的大脑。
- 对话还涉及了神经元密度在跨物种智力映射中的作用,进一步复杂化了对智力及其进化优势的理解。
Stability.ai (Stable Diffusion) Discord
- 从像素到完美:提升分辨率:辩论集中在 fine-tuning 模型时,从 512x512 分辨率开始是否比直接跳转到 1024x1024 更有优势。
- 共识倾向于渐进式缩放,以便在控制计算成本的同时获得更好的 gradient propagation。
- **Booru 之战:标签张力:围绕使用 **booru tags 训练 AI 的讨论变得激烈,支持既定词汇的人群与支持更自然语言标签的人群之间存在分歧。
- 争论强调了在模型标签的精确性和泛化性之间取得平衡的必要性。
- AI 与社会:计算文化成本:成员们就 AI 在社会中的角色展开对话,思考其对成瘾的影响,并思索未来监管的必要性。
- 该小组强调了鉴于 AI 技术的变革性质,采取主动措施的紧迫性。
- Roop-Unleashed:革命性的替代方案:Roop-Unleashed 被推荐为视频换脸的卓越解决方案,取代了已过时的 mov2mov 扩展。
- 该工具因其一致性和易用性而受到赞誉,标志着社区偏好的转变。
- 模型组合:SD 工具与技巧:针对 Stable Diffusion 模型和扩展进行了热烈的推荐交流,重点关注 pixel-art 转换和 inpainting 等任务。
- 成员们提到了 Zavy Lora 和带有 IP adapters 的 comfyUI 等工具,分享经验并提升了同伴的知识储备。
OpenAI Discord
- DALL-E 的竞争对手崭露头角:讨论重点关注了 StableDiffusion 以及工具 DiffusionBee 和 automatic1111,认为它们是 DALL-E 的主要对手,因其能为用户提供更高的质量和控制力而受到青睐。
- 这些模型还因其对不同操作系统的兼容性而受到认可,重点是在 Windows 和 Mac 上的本地使用。
- 文本检测器未能通过宪法测试:社区情绪对 AI 文本检测器 的可靠性表示怀疑,并举例说明了误报内容的情况,滑稽的是其中甚至包括了 美国宪法。
- 辩论仍在继续,没有明确的结论,反映了区分 AI 生成文本与人类创作文本的复杂性。
- GPT 的变现前景尚不明朗:用户询问了 GPTs 变现 的潜力,但讨论陷入停滞,没有出现具体的细节。
- 这个话题在社区内似乎缺乏实质性的参与或解决方案。
- VPN 导致 GPT-4 连接中断:用户报告称,当 开启 VPN 时,GPT-4 的交互会受到干扰,建议禁用 VPN 可以缓解问题。
- 还提到影响 GPT-4 服务的 服务器问题 已得到解决,但未提供具体细节。
- 内容创作者渴望前沿建议:内容创作者寻求 5-10 个以趋势为中心的内容创意 以促进受众增长,并询问了追踪内容表现的关键指标。
- 他们还探索了结构化内容日历的策略,强调了有效的 受众参与 和平台优化的必要性。
LlamaIndex Discord
- LlamaCloud 开启 Beta 测试:LlamaCloud 的 Beta 版发布,承诺提供一个用于非结构化数据解析、索引和检索的高级平台,目前已面向热切的测试者 开放候补名单。
- 该服务旨在优化 LLMs 的数据质量,集成了用于高级文档处理的 LlamaParse,并力求简化跨各种数据后端的同步。
- 图技术迎来 Llama 式创新:LlamaIndex 通过一系列展示 Property Graphs 的 新视频系列 推动参与,这是一项强调节点和边中模型复杂性的协作成果。
- 这一教育推广由 mistralai, neo4j, 和 ollama 团队合作提供支持,在复杂的文档关系与 AI 易用性之间架起了一座桥梁。
- 聊天机器人向电子商务的复杂化迈进:为了增强客户互动,该公会的一项工程推进重点是利用关键词搜索和元数据过滤器改进 RAG 聊天机器人,以解决复杂的建筑项目查询。
- 这种方法涉及一种混合搜索机制,从而实现更细致的后续问题交流,旨在实现对话精准度的飞跃。
- FlagEmbeddingReranker 的导入困局:社区的排错工作建议独立安装
peft以克服FlagEmbeddingReranker遇到的导入错误,帮助用户最终解决了技术难题。- 这一小插曲凸显了设置机器学习环境时经常隐藏的复杂性,包依赖关系可能会成为一个隐蔽的障碍。
- Groq API 的速率限制难题:AI 工程师在利用 Groq API 进行索引时遇到了 LlamaIndex 中的 429 速率限制错误,凸显了与 OpenAI 嵌入模型同步时的挑战。
- 讨论转向了 API 交互的复杂性以及采取战略性方法规避此类限制的必要性,以保持无缝的索引体验。
Perplexity AI Discord
- Perplexity 的 API 与 UI 表现存在差异:关于 Perplexity 中 API 和 UI 结果之间明显差异 的辩论被触发,特别是在未应用 Pro 版本或溯源功能的情况下。
- 考虑了一个积极的解决方案,即涉及 labs 环境,以在没有额外 Pro 功能的情况下测试 API 和 UI 输出之间的一致性。
- PPLX 集成中的 Nodemon 问题:在为使用 PPLX 库的项目配置 Nodemon 时出现了问题,尽管本地执行正确且对 tsconfig.json 进行了调整,但一名成员仍未成功。
- 该用户寻求其他 AI 工程师的见解,分享了指示可能与 PPLX 设置相关的模块缺失问题的错误日志。
LAION Discord
- DeepSpeed 在低成本下表现出色:一位创新工程师报告称,使用 DeepSpeed 在单块 RTX 3090 上成功训练了一个 25 亿参数模型,且有潜力实现更高的 batch sizes。
- 这场对话激发了人们探索在资源受限情况下进行高效训练的边界,暗示了更易于获取的训练方案。
- OpenAI 的编程助手在法庭获胜:加州法院部分驳回了针对 Microsoft 的 GitHub Copilot 和 OpenAI 的 Codex 的诉讼,这是一项关键的法律裁决,展示了 AI 系统在应对版权指控时的韧性。
- 社区正在剖析这一法律进展对 AI 生成内容的影响。阅读更多。
- Chameleon:模仿大师的生成模型:首个 generative chameleon model 已发布,其详细研究内容记录在 arXiv 的论文中。
- 研究社区渴望调查该模型适应各种绘画风格的能力,这可能会彻底改变数字艺术创作。
- 扩展复数值前沿:一位先锋成员在扩展用于视觉任务的复数值神经网络(complex-valued neural networks)深度时遇到了挑战。
- 尽管在扩展方面存在障碍,一个仅有 65k 参数的复数值模型在 CIFAR-100 上的准确率表现优于其 400k 参数的实数值对应模型,展现了良好的前景。
- 揭秘 Diffusion:资源库:一个新的 GitHub 仓库提供了一个直观的基于代码的课程,用于掌握非常适合在普通硬件上训练的图像 diffusion 模型。探索仓库。
- 该资源旨在通过简明的课程和教程培养实践理解,并邀请各界贡献以完善其教育内容。
OpenRouter (Alex Atallah) Discord
- 突破配额上限:OpenRouter 上的超限困扰:用户在使用 gemini-1.5-flash 模型时遇到了来自
aiplatform.googleapis.com的 “Quota exceeded” 错误,这表明存在 Google 施加的限制。-
有关使用情况的见解,请查看 [Activity OpenRouter](https://openrouter.ai/activity);有关自定义路由解决方案,请参阅 [Provider Routing OpenRouter](https://openrouter.ai/docs/provider-routing#custom-routing)。
-
- 看到 None:OpenRouter 上的图像问题挑战:有报告称在 gpt-4o、claude-3.5 和 firellava13b 等模型上进行图像查看时出现 None 响应,用户对功能的确认情况不一。
- 这表明是一个选择性问题,并非影响所有用户,需要详细检查个人用户的配置。
- Dolphin 潜水:排查 LangChain 最新成员的问题:用户在将 OpenRouter 上的 Dolphin 2.9 Mixstral 作为语言工具集成到 LangChain 时面临挑战。
- 未提供问题的技术细节,表明可能存在兼容性问题或配置错误。
- JSON 震荡:Mistralai Mixtral 偶尔的支持失效:错误 “not supported for JSON mode/function calling” 随机困扰着 mistralai/Mixtral-8x22B-Instruct-v0.1 的用户。
- 故障排除确定 Together 是与该重复错误相关的供应商,凸显了进一步调查的必要性。
- 翻译的跷跷板:评估 LLM 作为语言学家的表现:讨论集中在 LLM 在语言翻译任务中相对于专业模型的有效性,强调了偏好和性能指标。
- 讨论考虑了现代 decoder-only 模型与真正的 encoder/decoder transformers 在准确翻译能力方面的可靠性对比。
Latent Space Discord
- Claude 竞赛进入尾声,代码换现金:Build with Claude 竞赛即将结束,正如社区提醒的那样,该竞赛为开发者提供 3 万美元的 Anthropic API 额度。
- Alex Albert 在这篇揭秘帖子中提供了更多关于参与方式和背景的信息。
- 语音模型各显神通:GPT-4o 和 Moshi 的语音模型因其截然不同的风格而备受关注,GPT-4o 拥有精致的轮询式(turn-based)方法,而 Moshi 则是原始的全双工(full-duplex)模式。
- 感谢 JulianSlzr 和 Andrej Karpathy 的见解,让这场对话得以展开。
- AI 在数学奥林匹克中大放异彩:Thom Wolf 赞扬了 AI 数学奥林匹克(AIMO),Numina 与 Hugging Face 的联手展示了 AI 解决问题的强大实力。
- 欲了解深入内容,请查看 Thom Wolf 的推文串,其中详细介绍了比赛亮点和 AI 取得的成就。
- Babble 拥有更强大的“大脑”:Supermaven 推出了他们最新的语言模型 Babble,其上下文窗口进行了巨大升级,可容纳 100 万个 token。
- SupermavenAI 的公告预示着它比前代产品实现了 2.5 倍的飞跃,并承诺提供更丰富的对话体验。
- Lillian Weng 视角下的 LLM 缺陷:Lillian Weng 在博客中探讨了 LLM 中的“幻觉”现象,研究了该现象的起源和分类。
- 探索详情,了解为什么大语言模型有时会偏离事实。
LangChain AI Discord
- LLMWhisperer 解码密集文档:LLMWhisperer 在解析复杂 PDF 方面表现出色,建议在 LangChain 中集成来自 Pydantic 或 zod 的 schema,以增强数据提取能力。
- 通过结合逐页 LLM 解析和 JSON 合并,用户发现 LLMWhisperer 对于从冗长文档中提取精炼数据非常有用。
- Crawlee for Python 首次亮相引发关注:Apify 宣布推出 Crawlee for Python,并在 GitHub 和 Product Hunt 上展示了统一接口和自动扩展等功能。
- 凭借对 HTTP、Playwright 和会话管理的支持,Crawlee 被定位为 Python 开发者进行网页爬取的强大工具。
- Llamapp 锁定本地化 RAG 响应:Llamapp 作为一个本地检索增强生成器(RAG)出现,融合了检索器和语言模型以实现精准的回答准确度。
- 通过启用倒数排名融合(Reciprocal Ranking Fusion),Llamapp 在提供定制化响应的同时,始终保持基于原始事实。
- Slack Bot Agent 革命进行中:一份指南展示了如何利用 LangChain 和 ChatGPT 构建 Slack Bot Agent,用于 PR 评审自动化。
- 文档指出了一个分步过程,整合了多个框架来优化 PR 评审工作流。
- Rubik’s AI Pro 向 Beta 测试人员开放:Rubik’s AI Pro 邀请 AI 爱好者进行 Beta 测试,展示了其使用“RUBIX”代码的科研辅助和搜索能力。
- 他们强调了对高级模型的访问和高级版试用,支撑其对全面搜索解决方案的追求。
OpenInterpreter Discord
- OI 以示例精度执行:通过引入 代码指令示例,OI 的执行 与 assistant.py 保持一致,展示了其多功能的技能指令处理能力。
- 这一功能增强表明其功能容量有所提升,与复杂语言模型的发展趋势相吻合。
- Qwen 2.7B 的随机伪影:Qwen 2 7B 模型 在 128k 上下文处理方面表现出色,但偶尔会生成随机的 ‘@’ 符号,导致输出中出现意外的故障。
- 虽然该模型的鲁棒性显而易见,但这些异常现象凸显了对其生成模式进行精细化调整的必要性。
- 本地视觉模式的兼容性疑问:关于使用参数 ‘–model i’ 启用 Local vision mode 的讨论引发了对其兼容性以及是否能开启多模态用例的探讨。
- 凭借此类功能,工程师们正在探索整合多种输入模态,以构建更全面的 AI 系统。
- GROQ 与 OS 模式的同步协作:出现了一系列关于在 OS mode 下实现 GROQ 的咨询,并探讨了在这种情况下使用多模态模型的必要性。
- 这些对话强调了 AI 工程领域对更无缝、更具凝聚力的工作流的积极追求。
- 使用 Open Interpreter 解析坐标:用户询问了 Open Interpreter 解析屏幕坐标的方法,这表明人们正在深入研究该模型的交互能力。
- 理解这一机制对于旨在利用 AI 进行更动态、更精确的用户界面交互的工程师来说至关重要。
tinygrad (George Hotz) Discord
- Ampere 和 Ada 架构支持 NV=1:讨论显示 NV=1 的支持主要针对 Ampere 和 Ada 架构,而早期模型则有待社区驱动的解决方案。
- George Hotz 介入澄清,Turing 架构显卡 确实是兼容的,正如 GSP 固件仓库 中所述。
- Karpathy 的课程助力理解 tinygrad 概念:对于那些想要深入研究 tinygrad 的人,推荐了 Karpathy 的转型教程,承诺提供对该框架的深刻见解。
- 这个基于 PyTorch 的视频起到了探索催化剂的作用,促使人们以交互式方式阅读 tinygrad 文档。
- WSL2 在 NV=1 部署中遇到困难:成员们在 WSL2 上部署 NV=1 时遇到了困境,面临设备文件缺失以及对 CUDA 兼容性不确定的问题。
- 虽然路径尚不明确,但 NVIDIA 的 开源 GPU 内核模块 成为热心工程师解决问题的潜在关键。
Interconnects (Nathan Lambert) Discord
- Copilot 诉讼难题持续:针对 GitHub Copilot 涉嫌未经授权复制大部分代码的指控大多已被驳回,在涉及 GitHub、Microsoft 和 OpenAI 的法律诉讼中仅剩两项指控。
- 去年 11 月提出的担忧认为,Copilot 在开源软件上进行训练构成了知识产权侵权;开发者们正等待法院对剩余指控的最终裁定。
- 向量词汇统一:Control Vector、Steering Vector 和 Concept Vectors 引发了辩论,达成的共识是 Steering Vectors 是在语言模型中应用 Control Vectors 的一种形式。
- 此外,Feature Clamping 和 Feature Steering 之间的区别得到了澄清,并被视为 RepEng 领域中的互补策略。
- Google Flame 的数据撤回:在发现一个未指明的问题后,’Google Flame’ 论文的分数被撤回,社区戏称该失误是否涉及“在测试数据上训练”。
- Scott Wiener 在 Twitter 上抨击了 a16z 和 Y Combinator 对加州 SB 1047 AI 法案 的谴责,在 AI 立法讨论中掀起了风暴。
LLM Finetuning (Hamel + Dan) Discord
- 多 GPU 的痛苦与 Accelerate 的焦虑:一个 6 个 H100 GPU 的配置意外地出现了比预期慢 10 倍的训练速度,引发了困扰。
- 建议围绕根据 Hugging Face 的故障排除指南调整 batch size,并分享代码进行社区驱动的调试。
- 多 GPU 魔法的现实考量:成员们思考了多 GPU 设置下现实的速度提升,打破了 10 倍速度增长的神话,认为 6-7 倍是更可行的目标。
- 关于速度提升的辩论主要基于对通信开销(communication overhead)的担忧以及对吞吐量优化(throughput optimization)的追求。
Cohere Discord
- 教育工作者关注 CommandR 在教室中的应用:一位公立学校教师正在探索整合一个利用 CommandR 的 RAG 优化特性的教学平台。
- 该教师的倡议得到了社区的积极反应,成员们提供了协助并表达了共同的热情。
- 夜猫子们为深色模式的开发感到欢欣:许多人期待已久的深色模式(Dark Mode)已确认正在开发中,并计划在即将发布的企业级版本中推出。
- 讨论表明 Darkordial Mode 可能会适配给更广泛的受众,暗示免费的 Coral 平台用户可能会迎来更新。
Mozilla AI Discord
- Llama.cpp 性能大幅下滑:在 NVIDIA GPU 上从 0.8.8 版本迁移到 0.8.9 版本时,发现 llama.cpp 出现了意外的 ~25% 性能损失。
- 这个问题非常明显,NVIDIA 3090 GPU 的性能下降到了与上一代 NVIDIA 3060 相当的水平。
- 基准测试套件的升级烦恼:在编写新的基准测试套件时,发现升级 llamafile 版本后产生了性能影响。
- 社区反馈断言最近的更改不应导致性能下降,这给开发者留下了难题。
AI Stack Devs (Yoko Li) Discord
- Rosebud AI 的文学游戏创作:在 Rosebud AI Book to Game Jam 期间,开发者们受命将书籍转化为互动的益智游戏、节奏游戏和文字冒险游戏。
- 此次创作大赛涵盖了对 Lewis Carroll、China Miéville 和 R.L. Stine 作品的改编,获胜者将于 PST 时间 7 月 10 日星期三上午 11:30 公布。
- 游戏开发者利用 AI 挑战文学作品:参与者在 Rosebud AI Jam 中展示了他们的创意,整合了 Phaser 和 AI 技术来创作基于文学经典的游戏。
- 人们对 Rosebud AI Discord 社区官方公告中揭晓的获胜者寄予厚望。
MLOps @Chipro Discord
- KAN 论文在 alphaXiv 上的讨论升温:KAN 论文的作者正在 alphaXiv 论坛上积极回答有关他们近期 arXiv 论文的问题。
- 社区成员正与作者互动,讨论 KAN 的技术细节和方法论。
- 寻觅信息检索专家:一位播客主持人正在协调采访来自 Cohere、Zilliz 以及 Doug Turnbull 的专家,主题涉及信息检索(information retrieval)和推荐系统。
- 他们还寻求在信息检索领域推荐更多的嘉宾,以加入他们的系列节目。
LLM Perf Enthusiasts AI Discord
- 查询 Anthropic:是否有类似于 OpenAI 的额度计划?:一位成员询问 Anthropic 是否存在类似于 OpenAI 的额度系统,以寻求实验机会。
- 该询问反映了开发者对访问 Anthropic 平台进行开发和测试的兴趣日益增长,类似于 OpenAI 10K credit program。
- 了解 Anthropic 的可访问性:额度难题:社区成员对 Anthropic 为开发者提供的支持措施感到好奇,并询问其是否与 OpenAI 的额度计划类似。
- 这次对话强调了需要关于 Anthropic 服务的更清晰信息,以促进 AI 研究和探索。
Alignment Lab AI Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
OpenAccess AI Collective (axolotl) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Torchtune Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的逐频道细分内容已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!