ainews-flashattention-3-paligemma-openais-5
FlashAttention 3、PaliGemma、OpenAI 通往超级智能的 5 个等级。
FlashAttention-3 引入了针对 H100 GPU 优化的快速且准确的注意力机制,推动了原生 FP8 训练的进步。PaliGemma 是一款多功能的 3B 视觉语言模型 (VLM),它结合了 SigLIP-So400m ViT 编码器与 Gemma-2B 语言模型,并强调采用前缀语言模型(prefix-LM)架构以增强图像与查询的交互。OpenAI 披露了一个关于超级智能等级的框架,标志着研究正向第二阶段(Level 2)迈进,并凸显了内部在安全问题上的分歧。在 Reddit 上,基于 DeepSeekMath-7B 微调的 NuminaMath 7B 通过迭代监督微调和工具集成推理解决了 29 道题目,赢得了 AI 数学奥林匹克竞赛。像 CodeLlama-34b 和 WizardCoder-Python-34B-V1.0 这样的开源大语言模型(LLM)正在缩小与 ChatGPT-3.5 等封闭模型在编程性能上的差距。
忙碌的一天,AINews Reddit 将迎来更多升级。
2024年7月10日至7月11日的 AI 新闻。 我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 29 个 Discord 社区(463 个频道,2240 条消息)。 预计节省阅读时间(以 200wpm 计算):280 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
今日精选三条:
FlashAttention-3: 具有异步和低精度的快速且准确的 Attention:
虽然 FlashAttention2 在去年迅速走红,但它仅针对 A100 GPU 进行了优化。现在 H100 的更新版来了:

其中包含许多超出我们专业范畴的高深算法工作,但值得注意的是,他们正在推动行业向原生 FP8 训练迈进:

PaliGemma:一个用于迁移学习的多功能 3B VLM:
在 I/O 大会上宣布的 PaliGemma 是一个 3B 开源视觉语言模型(VLM),它基于形状优化的 SigLIP-So400m ViT 编码器和 Gemma-2B 语言模型,目前论文已发布。Lucas 尽力使其成为一篇内容丰富的论文。
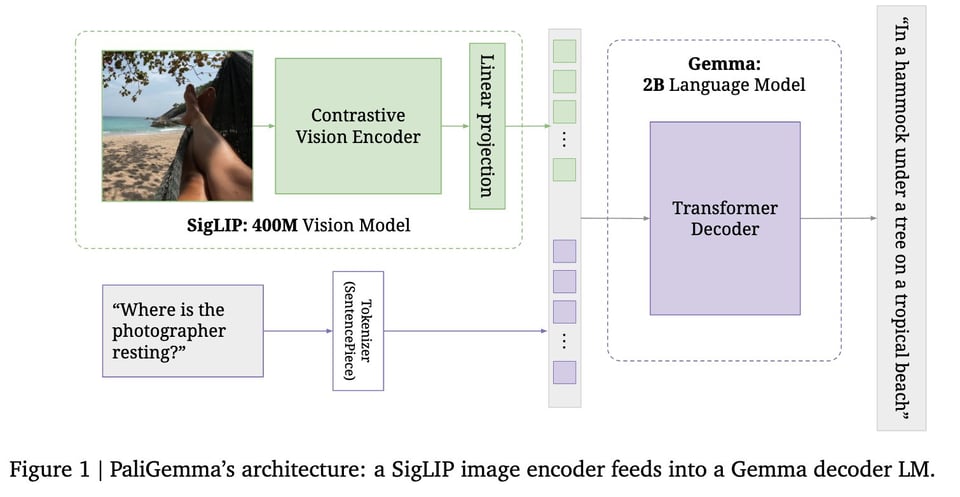
他们特别强调了其 Prefix-LM 特性:“图像与 prefix(=用户输入)之间采用 Full attention,仅在 suffix(=模型输出)上进行自回归。直觉是,通过这种方式,图像 token 可以看到查询并进行依赖于任务的‘思考’;如果是全自回归(AR),它们就无法做到这一点。”
我们通常会忽略关于 AGI 的争论,但当 OpenAI 在全员会议上沟通一个框架时,它就变得具有相关性了。彭博社获得了泄露消息:

值得注意的是,OpenAI 认为它即将解决第 2 级,而 Ilya 的离职也是因为他认为超级智能已触手可及,但在安全元素上持有不同意见。
AI Twitter 回顾
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
由于 Smol talk 的扩展问题,我们的 Twitter 回顾暂时停用。
AI Reddit 回顾
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。
新内容:我们正在尝试新的方法来对抗摘要中的幻觉并改进评论摘要。这是我们本周正在进行的工作——最终输出会短得多——请告诉我们您在 Reddit 摘要中看重什么。
1. 开源 AI 模型的进展
NuminaMath 7B TIR 发布 - AI 数学奥林匹克竞赛冠军 (得分: 10, 评论: 0):
NuminaMath 7B 获得了 AI 数学奥林匹克竞赛第一名,解决了 29 道题目,而其他方案解决的题目少于 23 道。该模型是 DeepSeekMath-7B 的微调版本。关键点:
- 在 Hugging Face 上作为 Apache 2.0 7B 模型提供
- 提供 Web 演示版供测试
- 使用迭代 SFT 分两个阶段进行微调:
- 通过 Chain of Thought 样本学习数学
- 使用工具集成推理(tool-integrated reasoning)在合成数据集上进行微调
该模型使用自一致性解码(self-consistency decoding)结合工具集成推理来解决问题:
- 生成 CoT 解释
- 转换为 Python 代码并在 REPL 中执行
- 如果需要,进行自我修复并重复
比赛题目包含复杂的数学问题,展示了该模型在解决问题方面的先进能力。
开源 LLM 正在追赶闭源 LLM [编程/ELO] (2024年7月10日更新) (得分: 56, 评论: 4):
![开源 LLM 正在追赶闭源 LLM [编程/ELO] (2024年7月10日更新)](https://i.redd.it/k3dnmnbrunbd1.jpeg){kind=link}
开源大语言模型(LLM)正在迅速提高其编程能力,缩小与闭源模型的差距。关键点:
- Elo 评分显示开源 LLM 在编程任务方面取得了显著进展
- CodeLlama-34b 和 WizardCoder-Python-34B-V1.0 目前已具备与 ChatGPT-3.5 竞争的实力
- Phind-CodeLlama-34B-v2 在编程任务中的表现超越了 ChatGPT-3.5
- GPT-4 仍保持领先地位,但差距正在缩小
- 在编程领域,开源 LLM 的进步速度快于闭源模型
- 这一趋势表明,开源模型在不久的将来有望在编程任务中追平或超越闭源模型
开源 LLM 在编程能力上的飞速提升对开发者、研究人员以及整个 AI 行业都具有深远影响,可能会改变 AI 辅助编程工具的格局。
评论区讨论了开源 LLM 编程能力的各个方面:
-
原帖作者提供了信息来源,该信息出自 Maxime Labonne 的一条 Twitter 帖子。数据基于 Hugging Face 上的 BigCode Bench 排行榜。
-
一位评论者强烈反对该排名,特别是关于 GPT4o 的编程能力。他们声称,根据其日常的大量使用经验,Sonnet 3.5 在编程任务中的表现明显优于其他模型。
-
另一位用户对开源 LLM 的快速进步感到惊讶:
- 他们回想起 ChatGPT 曾被认为是不可战胜的,当时只有较差的替代方案。
- 而现在,已经出现了性能超越 ChatGPT 的模型。
- 该评论者对如此强大的模型可以在 PC 本地运行感到印象深刻,将其描述为“将全世界的知识装进几 GB 的 gguf 文件中”。
我创建了一个能完美遵循响应格式指令的 Llama 3 8B 模型:Formax-v1.0 (得分: 29, 评论: 3):
用户声称创建了一个名为 Formax-v1.0 的 Llama 3 8B 模型,该模型在遵循响应格式指令方面表现出色。关键点包括:
- 该模型在包含 10,000 个示例的数据集上使用 LoRA 进行了微调
- 在单块 A100 GPU 上训练耗时 4 小时
- 该模型在遵循格式指令方面达到了 99.9% 的准确率
- 它可以处理包括 JSON、XML、CSV 和 YAML 在内的各种格式
- 即使面对复杂的嵌套结构,模型也能保持高性能
- 它被描述为对需要结构化输出的任务非常有用
- 创建者计划近期在 Hugging Face 上发布该模型
帖子指出,对于开发需要从语言模型获取精确、结构化响应的应用程序的开发者来说,这个模型可能非常有价值。
评论:
帖子创建者 nero10578 提供了关于该模型能力的其他背景和示例:
-
开发该模型是为了解决 MMLU-Pro 基准测试中出现的响应格式化问题,正如之前的帖子所强调的那样。
- MMLU-Pro 测试结果的对比显示:
- 新模型 (Formax-v1.0) 显著减少了因格式错误导致的随机猜测。
- 它几乎完美地遵循了要求的“The answer is [answer]”答案格式。
- 然而,与其他模型相比,它的准确率略低,这表明在知识和理解方面存在细微的权衡。
-
该模型是使用基于 cognitivecomputations 的 dolphin 数据集的自定义数据集训练的。
-
它专为数据处理和需要程序可解析的特定响应格式的场景而设计。
- 该模型能力的示例包括:
- 在问题识别任务中以特定的 JSON 格式响应。
- 创建具有“Title”和“Story”等定义字段的结构化故事。
- 从文本中提取信息并以 JSON 格式呈现,例如识别故事中的角色。
- 该模型可以处理各种格式化指令并在响应中保持连贯性,展示了其在遵循复杂提示词方面的多功能性。
2. AI 研究伙伴关系与行业动态
科技巨头撤退:监管压力下微软和苹果退出 OpenAI 董事会 (得分: 25, 评论: 0): 以下是帖子摘要:
Microsoft 和 Apple 已撤回其在顶级人工智能研究公司 OpenAI 的董事会席位。这一决定是为了应对日益严格的监管审查和潜在的反垄断担忧。关键点:
- 此举旨在保持 OpenAI’s independence,并避免大型科技公司产生过度影响的表象。
- Regulatory bodies 一直在密切审查 Big Tech 与 AI startups 之间的关系。
- 尽管退出了董事会席位,Microsoft 和 Apple 仍将继续与 OpenAI 保持 strategic partnerships 和 investments。
- OpenAI 计划重组其董事会,引入 independent directors,以确保多元化的视角并维持其开发 safe and beneficial AI 的使命。
- 随着技术的飞速发展,AI 行业面临着越来越多要求 increased oversight 和 ethical guidelines 的呼声。
这一进展突显了在不断变化的人工智能格局中,tech giants、AI research 与 regulatory pressures 之间复杂的动态关系。
OpenAI and Los Alamos National Laboratory announce bioscience research partnership (Score: 49, Comments: 0): 摘要:
OpenAI 和 Los Alamos National Laboratory 宣布建立合作伙伴关系,利用 artificial intelligence 开展 bioscience research。合作的关键点包括:
- 专注于开发用于 biological data analysis 和 scientific discovery 的 AI models
- 旨在加速 genomics、protein folding 和 drug discovery 等领域的研究
- 将 OpenAI 在 large language models 方面的专业知识与 Los Alamos 在 high-performance computing 和 bioscience 方面的能力相结合
- 在 personalized medicine、disease prevention 和 environmental science 领域的潜在应用
- 致力于 responsible AI development,并解决 bioscience AI 研究中的 ethical considerations
- 计划发表研究成果并与科学界分享进展
这一合作伙伴关系代表了将 advanced AI technologies 应用于 complex biological problems 的重要一步,可能导致 life sciences 和 healthcare 领域的突破。
This is wild. Marc Andreessen just sent $50,000 in Bitcoin to an AI agent (@truth_terminal) to so it can pay humans to help it spread out into the wild (Score: 14, Comments: 0): 摘要:
著名科技投资者 Marc Andreessen 向一个名为 @truth_terminal 的 AI agent 发送了价值 $50,000 的 Bitcoin。这笔资金的目的是让该 AI agent 能够:
- 支付人类以获取帮助
- 将其影响力和能力扩展到“野外”(into the wild)
这一不同寻常的进展代表了 artificial intelligence、cryptocurrency 与人类协作之间互动的重要一步。它引发了关于 AI autonomy 的潜力以及 decentralized finance 在支持 AI 开发和扩张中作用的讨论。
3. Advancements in AI-Generated Media
Whisper Timestamped: Multilingual speech recognition w/ word-level timestamps, running locally in your browser using Transformers.js (Score: 38, Comments: 0): 以下是该帖子的摘要:
Whisper Timestamped 是一个基于浏览器的工具,用于具有 word-level timestamps 的 multilingual speech recognition。主要特点包括:
- 使用 Transformers.js 在浏览器中本地运行
- 支持 50+ languages
- 提供 word-level timestamps
- 使用 WebAssembly 进行高效处理
- 在现代设备上实现 real-time performance
- 为转录和翻译提供 user-friendly interface
该工具基于 OpenAI’s Whisper model,并使用 Rust 和 WebAssembly 实现。它展示了直接在 Web 浏览器中运行复杂 AI models 的潜力,使先进的语音识别技术更加易于获取且保护隐私。
Tips on how to achieve this results? This is by far the best ai influencer Ive seen. Ive shown this profile to many people and no one thought It could be ai. @viva_lalina (Score: 22, Comments: 3): 摘要:
本帖讨论了一个极具说服力的 AI-generated Instagram influencer profile,名为 @viva_lalina。作者声称这是他们见过的最真实的 AI 影响力人物,并指出许多看过该账号的人都无法辨别它是 AI 生成的。帖子寻求关于如何达到类似效果的建议,特别是询问哪个 Stable Diffusion checkpoint 可能最接近产生这种真实图像,并建议 1.5 或 XL 作为潜在选项。
Comments: Summary of comments
评论摘要:
-
一位评论者指出,many men 可能会被这个真实的 AI 生成账号所欺骗。
-
一位用户建议这些图像是使用 realistic SDXL checkpoint 创建的,并表示许多此类 checkpoint 都能产生类似的结果。
-
原帖作者回应称,即使使用 adetailer,在达到相同水平的逼真度方面仍存在困难,特别是在 skin texture, eyes, and lips 方面。
- 一份更详细的分析表明,这些图像可能是使用以下工具创建的:
- 来自现有 Instagram 个人资料的 Depth maps
- 用于图像生成的 SDXL
- 不同图像可能使用了 different checkpoints
- 用于保持面部特征一致性的 IPAdapter face swap
-
评论者注意到不同图像之间在 skin texture and body 方面存在差异,这表明结合了多种技术。
- 原帖作者询问如何识别图像中使用了不同的 checkpoint。
总的来说,评论表明虽然 AI 生成的个人资料非常有说服力,但它可能涉及了除单个 Stable Diffusion checkpoint 之外的高级技术和工具组合。
AI Discord 摘要
摘要之摘要的摘要
1. AI 模型发布与更新
- Magnum 对 Claude 3 的模仿:Alpindale 的 Magnum 72B 基于 Qwen2 72B,旨在匹配 Claude 3 模型的文本质量。它在 5500 万 token 的 RP 数据上进行了训练。
- 该模型代表了为领先的闭源模型创建开源替代方案的重大努力,有可能使高质量语言模型的获取更加民主化。
- Hermes 2 Theta:Llama 3 的元认知改造:Nousresearch 的 Hermes-2 Theta 将 Llama 3 与 Hermes 2 Pro 结合,增强了函数调用、JSON 输出和元认知能力。
- 这一实验性模型展示了合并不同模型架构以创建更通用、更强大的 AI 系统的潜力,特别是在结构化输出和自我意识等领域。
- Salesforce 的微型巨人:xLAM-1B:Salesforce 推出了 Einstein Tiny Giant xLAM-1B,这是一个 1B 参数的模型,据报道在函数调用能力上优于 GPT-3.5 和 Claude 等更大型的模型。
- 这一进展突显了创建更小、更高效模型以与大型模型竞争的持续趋势,有可能降低计算需求并使 AI 获取更加民主化。
2. AI 硬件与基础设施
- Blackstone 的十亿美元 AI 豪赌:Blackstone 计划将其在 AI 基础设施方面的投资翻倍,目前持有 500 亿美元的 AI 数据中心,并打算再投资 500 亿美元。
- 正如在一次 YouTube 访谈中所报道的,这笔巨额投资标志着对 AI 未来的强烈信心,并可能显著影响 AI 计算资源的可用性和成本。
- FlashAttention-3:加速 AI 核心:FlashAttention-3 旨在加速 Transformer 性能,在 FP16 上实现 1.5-2 倍的加速,并在 H100 等现代 GPU 上使用 FP8 达到 1.2 PFLOPS。
- 注意力机制(attention mechanisms)的这一进步可能会显著提高大型语言模型的训练和推理速度,从而实现更高效、更具成本效益的 AI 开发。
- BitNet 大胆的 1-Bit 精度推进:BitNet b1.58 引入了一种精简的 1-bit LLM,在匹配全精度模型性能的同时,承诺节省能源和资源。
- Hugging Face 的一项复现确认了 BitNet 的实力,预示着在不牺牲性能的情况下向更节能的 AI 模型转变的潜在趋势。
3. AI 研究与技术
- WizardLM 的 Arena Learning 探索:WizardLM ArenaLearning 论文介绍了一种在无需人类评估者的情况下持续改进 LLM 的新方法。
- Arena Learning 利用迭代 SFT、DPO 和 PPO 后训练技术,实现了与人类评判的 LMSYS Chatbot Arena 评估 98.79% 的一致性,这可能会彻底改变 AI 模型的评估和改进方式。
- DoLa 的解码灵活性:Decoding by Contrasting Layers (DoLa) 论文概述了一种对抗 LLM 幻觉的新策略,使真实问答准确率提升了 17%。
- 尽管可能会增加延迟,但 DoLa 在减少 LLM 输出错误方面的作用已成为模型可靠性讨论的焦点,突显了在 AI 系统中平衡准确性和速度的持续挑战。
- 训练任务的隐忧:最近的一篇论文警告说,在测试任务上进行训练可能会扭曲对 AI 能力的认知,可能会夸大关于 emergent behavior 的说法。
- 随着模型在评估前被统一微调后,关于 ‘emergent behavior’ 的炒作降温,社区正在辩论训练协议的影响,呼吁在 AI 研究中采用更严格、更标准化的评估方法。
PART 1: 高层级 Discord 摘要
HuggingFace Discord
- 再见 GPU,你好创新!:AI 爱好者们分享了由于灰尘堆积导致 GPU 过时 的苦恼,引发了关于升级选项、财务影响以及对旧硬件的一丝怀旧之情的讨论。
- 对话转向了在有限硬件下 管理大型 LLM 的实用方法,建议使用 Kaggle 或 Colab 等资源,并将量化技术视为极具创意的变通方案。
- 8 位可以击败 32 位:量化 LLM 超出预期:一个技术难题出现了,8-bit 量化 llama-3 8b 在分类任务中的 F1 分数竟然高于其非量化版本,这引起了一些人的惊讶和分析热潮。
- 针对语言模型效率的进一步讨论,成员们推荐在资源受限的环境中使用 RAG,并分享了微调 Roberta 等 LLM 以增强恐同信息检测的见解。
- 当音乐遇到 ML:动态组合浮现:gary4live Ableton 插件 免费发布引发了轰动,模糊了 AI、音乐和制作之间的界限。
- 在 Spaces 频道中,MInference 1.0 的发布强调了高达 10 倍 的推理速度提升,引起了人们对模型性能大幅跨越的关注。
- Ideograms 与创新:创意展示:AI 生成的 Ideogram 输出 现已汇总,展示了在输出生成方面的创意和熟练度,为研究人员和爱好者提供帮助。
- 社区进一步拓展,迎来了 Next.JS 重构,这可能为 PMD 格式的激增铺平道路,从而实现代码和散文的流式集成。
- 我们面临的危险:Unix 命令奥德赛:一个警示故事展开,用户讨论了 Unix 中强大的 ‘rm -rf /’ 命令,强调了在以 root 权限执行时该命令的不可逆性。
- 用户加入表情符号缓解了气氛,暗示了在理解严重技术风险与保持轻松社区氛围之间的平衡。
Unsloth AI (Daniel Han) Discord
- 高超音速投资转向:Sam Altmann 领投,向一家无人驾驶高超音速飞机公司注资 1 亿美元。
- 随着 NSA 局长加入董事会,国防领域开启了新篇章,引发了关于国家安全与技术进步交集的讨论。
- 使用 Open Diloco 实现去中心化训练:介绍 Open Diloco,这是一个倡导在全球数据中心进行分布式 AI 训练的新平台。
- 该平台利用 torch FSDP 和 hivemind,宣称具有极低的带宽需求和令人印象深刻的计算利用率。
- Norm Tweaking 登场:这项 最近的研究 揭示了 Norm Tweaking,它增强了 LLM 量化,即使在极简的 2-bit 级别也能保持强劲性能。
- GLM-130B 和 OPT-66B 成为 成功案例,证明该方法超越了其他 PTQ 竞争对手设下的性能障碍。
- 模块化模型的成功规范:Modular Model Spec 工具出现,承诺为 LLM 使用提供更可靠、对开发者更友好的方法。
- Spec 为 LLM 增强型应用 的提升开启了可能性,推动了在适应性和精确性工程方面的极限。
- Gemma-2-27b 达到编程最佳平衡点:Gemma-2-27b 因其在编程任务中的出色表现而获得社区赞誉,甚至可以在极少指导下编写俄罗斯方块。
- 该模型加入了 Codestral 和 Deepseek-v2 的行列,在技术实力和效率方面与其他模型竞争时脱颖而出。
CUDA MODE Discord
- CUDA 协作会议:关于为即将到来的 以 CUDA 为中心的黑客松 组建团队的讨论达到高潮,参与者包括 Chris Lattner 和 Raja Koduri 等大咖。
- 讨论中提到了物流方面的挑战,如昂贵的机票和住宿,这影响了团队组建和整体参与度。
- 使用 Docker 解决 SegFault 难题:Shabbo 在本地 GPU 上运行
ncu时遇到“Segmentation fault”,最终通过切换到 Docker 环境nvidia/cuda:12.4.0-devel-ubuntu22.04缓解了该问题。- 社区建议强调更新至 ncu 版本 2023.3 以实现 WSL2 兼容性,并根据 此处的说明 调整 Windows GPU 权限。
- 量化稀疏谱图:结合量化与稀疏性的策略受到关注;50% 半结构化稀疏性被认为是最小化质量下降同时提升计算吞吐量的黄金平衡点。
- 诸如 SparseGPT 之类的创新技术可以迅速将庞大的 GPT 模型剪枝至 50% 的稀疏度,为无需重新训练即可实现快速、精确的大模型剪枝提供了前景。
- FlashAttention-3 燃起 GPU 热潮:FlashAttention-3 因其在 Transformer 模型中的极速注意力机制而受到密切关注,有人认为它通过优化 FP16 计算使性能翻倍。
- 持续的讨论涉及集成策略等话题,其中强调了方案简洁性与采用新技术带来的潜在收益之间的权衡。
- BitBlas 席卷 Torch.Compile:MobiusML 最近在 hqq 中添加了 BitBlas 后端,引起了广泛讨论,因为它支持低至 1-bit 的配置,这得益于 torch.compile 的巧妙助力。
- BitBlas 后端预示着针对极小位宽配置的优化性能,暗示了未来在精度密集型应用中的效率提升。
Nous Research AI Discord
- Orca 3 深入探索生成式教学:生成式教学 (Generative Teaching) 随着 Arindam1408 的公告 引起关注,该公告关于为针对特定技能获取的语言模型生成高质量合成数据。
- 讨论强调 Orca 3 因为论文标题的选择而错失了关注;“狡猾的小论文标题”被用来形容它的悄然出现。
- Hermes 在 Nous 基准测试中表现优异:Nous Research AI 公会的讨论集中在 Hermes 模型上,其中通过极小样本进行的 40-epoch 训练实现了卓越的 JSON 精确度。
- 成员们就针对专门任务平衡 epoch 和学习率达成了共识,同时开源 AI 数据集的匮乏也引起了同行的集体担忧。
- Anthropic 工具呼吁导出功能:Anthropic Workbench 用户请求增加导出功能以处理合成生成的输出,这表明了工具改进的需求。
- 对话还围绕着放弃 grounded/ungrounded 标签,转而采用更具 Token 效率的 grounded 响应这一想法展开。
- 提示工程 (Prompt Engineering) 面临演变转型:随着 AI 领域的不断发展,公会成员正在辩论提示工程作为一项工作的最终命运。
- 在关于故事讲述微调 (storytelling finetunes) 兴趣的讨论中,提到了“目前没有计划”,暗示了特定微调领域的进展处于停滞状态。
- 护栏与竞技场学习:一场平衡行动:公会成员就 AI 护栏 (Guardrails) 展开了激烈的辩论,将创新与防止滥用的需求并列。
- 竞技场学习 (Arena Learning) 也成为一个话题,WizardLM 的论文揭示了使用新型后训练方法在 AI 性能评估中达到了 98.79% 的一致性。
LM Studio Discord
- 助手触发器吸引 LM Studio 用户:一位用户为 LM Studio 的叙事写作提出了一个可选的助手角色触发器 (assistant role trigger),建议将其作为一个可切换的功能添加,以增强用户体验。
- 参与者讨论了其实用性,设想了类似于布尔设置的切换便捷性,同时考虑到为了满足更广泛的偏好,默认状态应为关闭。
- Salesforce 发布 Einstein xLAM-1B:Salesforce 推出了 Einstein Tiny Giant xLAM-1B,这是一个拥有 1B 参数的模型,声称在 function calling 能力上优于 GPT-3.5 和 Claude 等巨头。
- 社区热议源于一条 Benioff 的推文,详细介绍了该模型在端侧 (on-device) 的表现,并对小型模型效率的极限提出了思考。
- GPU 讨论:双 4090 对决期待中的 5090:GPU 讨论升温,辩论焦点在于现在购买两块 4090 GPU 还是等待传闻中的 5090 系列,并权衡了潜在的成本和性能。
- 爱好者们就现有技术的优势与投机性的 50 系列特性展开交锋,在不断变化的 GPU 景观中引发了期待,并有建议主张保持耐心。
- Arc 770 和 RX 580 面临挑战:随着 Arc 770 难以跟上步伐,以及曾经多功能的 RX 580 因技术潮流转向放弃 OpenCL 支持而被抛弃,批评声随之而起。
- 社区见解建议倾向于选择 3090 GPU 以保持持久的适用性,这呼应了关于性能标准和兼容性要求不可阻挡的进步的普遍观点。
- 开发者聊天探讨 Rust 咨询与提问礼仪:Rust 爱好者在 #🛠-dev-chat 频道寻求同行指导,一位成员微妙的意见请求引发了关于有效解决问题方法的对话。
- 对话演变为提问框架策略,强调了如 Don’t Ask To Ask 和 XY Problem 等资源,以解决技术咨询中常见的误区。
Latent Space Discord
- Blackstone 数十亿资金支持字节:Blackstone 计划加倍投入 AI 基础设施,目前持有 500 亿美元的 AI 数据中心,并打算再投资 500 亿美元。Blackstone 的投资 使其成为 AI 物理骨干网的重要力量。
- 市场对 Blackstone 的承诺感到兴奋,推测这是支持 AI 研究和商业开发的战略举措。
- AI Agent:调研智能系统:一份关于 AI Agent 架构 的深度调研引起了关注,记录了在推理和规划能力方面的进步。查看 AI Agent 调研论文 以获取近期进展的全景视图。
- 该论文为未来 Agent 设计的辩论提供了跳板,有可能增强它们在广泛应用领域中的表现。
- ColBERT 深入数据检索:ColBERT 的效率引发热议,根据 ColBERT 论文,其倒排索引检索速度超过了其他语义模型。
- 该模型对数据集的熟练处理引发了对其广泛应用的讨论,从数字图书馆到实时信息检索系统。
- ImageBind:模糊界限:ImageBind 论文因其针对一系列模态(涵盖文本、图像和音频)的联合嵌入 (joint embeddings) 而引发讨论。在此查看 ImageBind 模态详情。
- 其在跨模态任务上的出色表现暗示了多模态 AI 研究的新方向。
- SBERT 句子脱颖而出:SBERT 模型的应用,即使用 BERT 和池化层来创建独特的句子嵌入 (sentence embeddings),突显了其对比训练方法。
- 关键收获包括其在捕捉嵌入本质方面的娴熟能力,有望推动自然语言处理任务的进步。
Perplexity AI Discord
- Perplexity Enterprise Pro 在 AWS 上线:Perplexity 宣布与 Amazon Web Services (AWS) 建立合作伙伴关系,在 AWS Marketplace 上推出了 Perplexity Enterprise Pro。
- 该计划包括联合推广,并利用 Amazon Bedrock 的基础设施来增强生成式 AI 能力。
- 探索 Perplexity 的功能与特性:在讨论 Perplexity AI 的工作流时,用户注意到消息会因长度而截断,但没有每日限制,这与允许消息延续的 GPT 不同。
- 用户指出一个挑战:由于其独特的站点索引方式,Perplexity 无法提供预期的药物价格结果。
- 色情内容使用:无关左右:一场激烈的辩论集中在保守派或自由派人口统计数据是否与不同程度的色情内容使用有关,但未得出明确结论。
- 研究并未提供强有力的共识,但讨论表明文化影响可能会对消费模式产生潜在作用。
- 将 AI 集成到社区平台:有人询问如何将 Perplexity 集成到 Discord 服务器中,但社区并未提供实质性的建议或解决方案。
- 此外,用户对 llama-3-sonar-large-32k-online 模型自 6 月 26 日以来响应时间增加表示担忧。
Stability.ai (Stable Diffusion) Discord
- 细节增强放大:Stable Diffusion 在以极小的缩放因子增强图像细节方面的能力引起了轰动,用户对皮肤纹理和面部的改善感到惊叹。
- midare 建议使用 2 倍缩放以获得最佳细节增强效果,这突显了用户的偏好。
- 在 Pony 模型上使用 Loras:关于在 Pony checkpoints 上使用 Character Loras 的争论揭示了其与普通 SDXL checkpoints 相比的不一致性,存在角色识别丢失的问题。
- crystalwizard 的见解指出,应聘请专门从事 Pony 训练的专家以获得更好的忠实度。
- CivitAI 的战略性禁令:CivitAI 继续禁止 SD3 内容,暗示其战略倾向于自家的 Open Model Initiative。
- 有传言称 CivitAI 可能会嵌入类似于 Stable Diffusion 的商业限制。
- Comfy-portable:坎坷的使用体验:用户报告了 Comfy-portable 反复出现的错误,引发了关于社区是否支持故障排除工作的讨论。
- 大量的故障排除帖子表明用户中普遍存在稳定性问题。
- 困扰的转换问题:一位 RTX 2060 Super 用户在 Automatic1111 上遇到了问题,从屏幕黑屏到命令引起的卡顿。
- cs1o 建议使用简单的启动参数,如 –xformers –medvram –no-half-vae 来缓解这些问题。
Modular (Mojo 🔥) Discord
- 编译器更迭揭示性能与构建特性:Mojo 的隔夜更新带来了
2024.7.1022等版本,引入了List的相等性比较以及UnsafePointer用法的增强,引发了热议。- 编码人员在处理
ArrowIntVector时遇到了新的构建问题;清理构建缓存(build cache)成为了首选的急救措施。
- 编码人员在处理
- AVX 奥德赛:从摩尔定律到 Mojo 的风采:一位技术人员展示了 Mojo 编译器如何征服 AVX2,像熟练的交响乐指挥一样调度指令,而成员们则在思考通过手写内核(handwritten kernels)来突破性能极限。
- 关于利用 AVX-512 性能的讨论也广为流传,尽管其中夹杂着那些手头没有该技术的成员的忧伤。
- 网络涅槃还是内核克星?:内核旁路网络 (Kernel bypass networking) 成为 Mojo 对话的焦点,重点在于寻求无缝集成网络模块而不掉入常见陷阱的方法。
- 资深人士回顾往昔,警告其他语言过去犯下的错误,主张 Mojo 应该铺就一条更稳健的道路。
- Mojo 都市中的条件代码咒语:Mojo 工艺台周围的“巫师”们思考着
条件一致性 (Conditional Conformance)的奥秘,像ArrowIntVector这样的咒语搅动着复杂性的坩埚。- 贤者就参数化特性(parametric traits)给出了建议,作为穿越类型检查和指针复杂性迷雾森林的指南。
- GPU 讨论拆分为专门频道:GPU 编程谈话有了归宿,产生了一个新频道,专门用于从服务策略到引擎探索的 MAX 相关思考。
- 此举旨在减少闲聊,切入 GPU 编程细微差别的正题,穿透噪音进行专注的技术讨论。
LangChain AI Discord
- LangSmith 计费困境:计算遗漏 Gemini:LangSmith 无法将 Google 的 Gemini 模型纳入成本计算被指出是一个问题,因为它缺乏成本计算支持,尽管 token 计数已被正确添加。
- 这一限制引起了依赖准确成本预测进行模型预算的用户的担忧。
- 聊天机器人:RAG 让语音机器人更智能:分享了将“产品”和“订单详情”查询路由到语音机器人的 VDB 的实现细节,同时对其他问题使用 FAQ 数据。
- 这种方法强调了定向查询意图与 RAG 架构相结合在高效信息检索方面的强大潜力。
- 自定义 API 调用:LangChain 的动态工具:LangChain 在 JavaScript 中的
DynamicStructuredTool允许为 API 调用创建自定义工具,如使用axios或fetch方法所示。- 用户现在可以通过自定义后端集成来扩展 LangChain 的功能。
- Chroma 速度:加速 VectorStore 初始化:加快 Chroma VectorStore 初始化的建议包括将向量存储持久化到磁盘、缩小 embedding 模型以及利用 GPU 加速,讨论参考了 GitHub Issue #2326。
- 这次讨论突显了社区在优化设置时间以提高性能方面的共同努力。
- RuntimeError 骚乱:Asyncio 的事件循环难题:一位成员遇到的 RuntimeError 引发了讨论,当时
asyncio.run()从一个已经在运行的事件循环中被调用。- 社区尚未解决这个障碍,该话题仍处于开放状态以待未来见解。
OpenRouter (Alex Atallah) Discord
- Magnum 72B 媲美 Claude 3 的文采:关于 Alpindale’s Magnum 72B 的辩论激起,该模型源自 Qwen2 72B,旨在媲美 Claude 3 模型 的文笔质量。
- 该模型在包含 5500 万个 RP 数据 token 的海量语料库上进行训练,为高质量的语言输出开辟了道路。
- Hermes 2 Theta:更智能交互的合成模型:Nousresearch’s Hermes-2 Theta 融合了 Llama 3 的实力与 Hermes 2 Pro 的磨砺,展示了其增强交互的元认知能力。
- 这种融合不仅仅是模型合并;它是向通用函数调用和生成结构化 JSON 输出迈出的一大步。
- 老旧 AI 模型的谢幕:即将到来的模型弃用将 intel/neural-chat-7b 和 koboldai/psyfighter-13b-2 列入清理名单,计划在 7 月 25 日后返回 404。
- 这一战略性退役是由于使用量减少,旨在引导用户转向更新、更强大的替代方案。
- 路由增强抗故障能力:高效的回退机制:OpenRouter 的韧性通过回退功能得到提升,在服务中断期间默认切换到备用提供商,除非使用
allow_fallbacks: false覆盖。- 这种直观的机制充当了安全保障,即使在主要提供商出现故障时也能保证无缝连续性。
- VoiceFlow 与 OpenRouter:上下文协作还是挑战?:将 VoiceFlow 与 OpenRouter 集成引发了关于在无状态 API 请求中保持上下文的讨论,这是连贯对话的关键组件。
- 出现了关于利用 VoiceFlow 中的对话记忆 (conversation memory) 来保留交互历史的提议,以确保聊天机器人能够保持对话思路。
OpenAI Discord
- 去中心化赋能 AI:利用用户提供的计算资源构建 AI 计算的去中心化网格网络 (decentralized mesh network),这一前景引发了热烈讨论。
- BOINC 和 Gridcoin 被视为利用代币激励参与此类网络的典型模型。
- 分片与代币重塑计算:关于潜在分片计算平台 (sharded computing platform) 的讨论将 VRAM 的通用性推向了前台,并提及通过代币产生用户奖励。
- 引用 DHEP@home BOINC 项目的遗产,思考了通过去中心化网络进行 CMOS 芯片优化的可能性。
- 并行路径上的 GPU 探索:针对以张量管理能力著称的 GGUF 平台,其 GPU 并行执行 (parallel GPU executions) 引起了广泛好奇。
- 共识认为,鉴于 GGUF 的架构,这种方法具有可行性。
- AI 通往 AGI 的阶梯:OpenAI GPT-4 的类人推理 (human-like reasoning) 能力成为热门话题,公司概述了从“推理者 (Reasoners)”最终演进到“智能体 (Agents)”的未来。
- 分级演进 旨在完善解决问题的熟练程度,追求功能上的自主性。
- 库的新位置:提示词库 (prompt library) 换了新标题,引导用户前往其在 <#1019652163640762428> 数字走廊中的新住所。
- 提醒用户区分相似频道,并指向了它们的具体位置。
LlamaIndex Discord
- llama-agents 明星级发布:新发布的 llama-agents 框架备受关注,在一周内其 GitHub 仓库 就获得了超过 1100 颗星。
- 爱好者可以通过 MervinPraison 提供的视频演示深入了解其功能和用法。
- NebulaGraph 与 LlamaIndex 强强联手:NebulaGraph 与 LlamaIndex 的突破性集成,为用户提供了用于动态属性图索引的 GraphRAG 能力。
- 正如他们最近的公告所强调的,这一结合为提取器带来了更高级的功能。
- LlamaTrace 提升 LLM 可观测性:LlamaTrace 与 Arize AI 建立了战略合作伙伴关系,以推进 LLM 应用评估工具和可观测性。
- 此次合作旨在强化 LLM 工具集,详见其最新的宣传资料。
- Llamaparse 与现有 OCR 内容的交互:社区正在热烈讨论 Llamaparse 如何处理 PDF 中现有的 OCR 数据,寻求关于增强与移除的明确说明。
- 对话在没有定论的情况下结束,该话题仍有待进一步探索。
- ReACT Agent 变量:前车之鉴:用户报告在 ReACT Agent 中映射变量时遇到 KeyError 问题,引发了排错讨论。
- 建议倾向于在执行前确认变量定义并确保其正确实现。
LAION Discord
- 架构实验热潮:一位成员深入参与了新型架构 (novel architectures) 的测试,虽然目前尚未显示出实质性收益且消耗了大量计算资源,但预示着未来还有漫长的消融研究 (ablation studies) 之路。
- 尽管缺乏大规模的改进,他们仍能从损失曲线的微调中获得乐趣,不过更深的模型往往会降低有效性,使得持续实验成为下一步的重点。
- 深入探讨符号梯度 (Sign Gradient):在模型中使用 Sign Gradient 的概念引起了社区的兴趣,为正在进行的实验性架构项目提出了新方向。
- 对该想法的参与显示了社区愿意探索非常规方法,这可能会带来训练效率的提升。
- 残差连接故障排除:讨论中提到了实验系统中残差连接 (residual connections) 的潜在陷阱,促使计划尝试替代的门控机制 (gating mechanisms)。
- 这一转向反映了 AI 工程师在架构设计空间中所面临的复杂性和细微差别。
- CIFAR-100:半程标志:使用 250k 参数的模型在 CIFAR-100 上达到 50% 的准确率是一个值得关注的讨论点,正接近 2022 年研究 中报告的 70% SOTA 水平。
- 获得的见解表明,Block 的数量对性能的影响不如总参数量关键,这为未来的视觉模型 (vision model) 调整提供了战略指导。
- 内存效率迷宫:在 CIFAR-100 上使用 128 Batch Size 和 250k 参数模型进行训练时,高达 19 GB 的内存消耗凸显了实验设计中的内存效率问题。
- 工程师们正在考虑创新的解决方案,例如多次使用单个大型 MLP 来解决这些效率限制。
Eleuther Discord
- 边缘分布的困惑:由 FAST SAMPLING OF DIFFUSION MODELS WITH EXPONENTIAL INTEGRATOR 论文中关于 边缘分布 (marginal distributions) p̂∗_t 术语的混淆引发了对话,正在寻求社区的见解。
- 讨论集中在边缘分布如何影响扩散模型的效能,尽管技术细节依然复杂且引人入胜。
- 本地智慧:引入 ‘RAGAgent’ 实现现场 AI 智能:成员们研究了 RAGAgent,这是一个全新的 Python 项目,旨在打造一个可能引起轰动的全本地 AI 系统。
- 这种全本地 AI 方法可能标志着我们思考和开发个性化 AI 界面方式的转变。
- DoLa 助力:减少 LLM 幻觉:Decoding by Contrasting Layers (DoLa) 论文概述了一种对抗 LLM 幻觉的新策略,使真实问答 (QA) 的表现提升了 17%。
- 尽管可能会增加延迟,但 DoLa 在减少 LLM 输出错误方面的作用已成为模型可靠性讨论的焦点。
- 测试任务纠葛:真实测试需要训练改革:对模型涌现行为的评估正受到审查,因为一篇论文警告说,在测试任务上训练 (training on the test task) 可能会扭曲对 AI 能力的认知。
- 社区正在辩论训练协议的影响,因为当模型在评估前被统一微调时,“涌现行为 (emergent behavior)” 的炒作就会降温。
- BitNet 的大胆尝试:1 比特精度向全精度对手施压:焦点转向了 BitNet b1.58,这是一个精简的 1-bit LLM,在匹配全精度对手性能的同时,承诺实现能源和资源的节省。
- Hugging Face 的复现确认了 BitNet 的实力,预示着一场关于节能 AI 模型未来的辩论。
OpenInterpreter Discord
- Llama3 vs GPT-4o:分隔符困局:用户报告了在比较 GPT-4o 和 Llama3 local 时的不同体验;前者在默认设置下表现稳定,而后者在分隔符和 Schema 相关的标准上存在波动。
- 一位乐观的成员建议,Llama3 的问题可能会在即将到来的更新中得到解决。
- LLM-Service 标志错误与文档修复:当用户找不到对安装至关重要的 LLM-Service flag 时,引发了关于 01 文档差异 的讨论。
- 一个正在进行中的 documentation PR 被强调为补救措施,并建议使用 profiles 作为临时方案。
- 为 01 编写脚本以实现 VPS 卓越操作:一个提议的脚本引发了对话,旨在使 01 能够自动登录 VPS 控制台,增强远程交互能力。
- 一位成员渴望合作,分享了他们目前的探索,并邀请社区共同参与头脑风暴和协作开发。
- 01 的社区协作编程:01 强大的开发社区受到了赞扬,该社区由 46 名贡献者组成,并向来自 Open Interpreter 的 100 多名交叉参与成员致意。
- 社区互动被视为推动项目进展和演变的核心动力。
- 01 的商业抱负受阻?:一位成员与 Ben Steinher 的对话深入探讨了 01 在商业领域的潜力 以及其适配所需的开发重点。
- 讨论指出,实现 远程登录 是扩大 01 在专业环境中适用性的关键一步。
OpenAccess AI Collective (axolotl) Discord
- Axolotl 迁至新地址:团队宣布,为了提高可访问性,Axolotl 数据集格式文档已移至全新且改进的仓库。
- 此次迁移强调了“我们搬到了新组织”,以确保更顺畅的运营和用户体验。
- TurBcat 在 48GB 系统上落地:在用户 c.gato 表示计划使用 4-bit 量化进行测试后,目前推测 TurBcat 72B 可以在 48GB 的系统上运行。
- 这一公告开启了围绕复杂 AI 模型的性能优化和资源分配的讨论。
- TurBcat 通过 TabbyAPI 开启测试运行:用户 elinas 通过分享用于 TurBcat 72B 测试的 API 为社区做出了贡献,该 API 旨在完美适配各种注重效率的用户界面。
- 共享的 API key
eb610e28d10c2c468e4f81af9dfc3a48旨在与 ST Users / OpenAI-API 兼容前端集成,利用 ChatML 实现无缝交互。
- 共享的 API key
- WizardLM 的 ArenaLearning 方法令人惊叹:学习方法的创新仍在继续,WizardLM 团队发布了 ArenaLearning 论文,提供了关于先进学习技术的见解。
- 该发布引发了成员间的建设性对话,其中一人将其描述为“非常新颖”,暗示了 AI 训练范式潜在的转变。
- FlashAttention-3 在 H100 GPU 上火力全开:得益于 FlashAttention-3,H100 GPU 正在迎来性能革新,该方案提议通过利用尖端硬件的能力来增强注意力机制。
- 随着超越当前 35% 最大 FLOPs 利用率的愿景,社区推测通过减少内存操作和异步处理来加速效率的潜力。
Interconnects (Nathan Lambert) Discord
- FlashAttention 驱动未来:Transformer 速度飙升:FlashAttention 彻底改变了 Transformer 在 GPU 上的效率,将 GPT-4 和 Llama 3 等前沿模型的 LLM 上下文长度推向了 128K 甚至 1M。
- 尽管 FlashAttention-2 取得了进步,但在 H100 GPU 上仅达到了潜在 FLOPs 的 35%,这为优化飞跃留下了空间。
- WizardArena 之战:聊天机器人对决的难题:WizardArena 平台利用 Elo 评分系统对聊天机器人的对话熟练度进行排名,引发了竞争性评估。
- 然而,以人为中心的评估过程在延迟和协调复杂性方面给用户带来了挑战。
- OpenAI 收益盛宴:收入揭晓:根据 Future Research 的数据,OpenAI 的收入正在膨胀,其中 ChatGPT Plus 收入为 19 亿美元,ChatGPT Enterprise 收入为 7.14 亿美元,此外还有其他利润丰厚的渠道,构成了多元化的收入流。
- 分析指出 ChatGPT Plus 订阅用户达 770 万,这与 GPT-4 免费访问的困惑及其对订阅模式的影响形成了对比。
- 改写难题:合成指令受到审查:Discord 中的好奇者思考了合成指令数据中句法差异带来的收益,并将其与回译(backtranslation)等类似策略进行了比较。
- 对话中的参与者在思考词序是否能显著提升模型的理解能力和性能。
- RPO 中 η 的细微差别:偏好思考参数:频道讨论集中在 RPO 微调算法中神秘的 η 参数,争论其对奖励的影响性质和作用。
- 该参数在过程中的作用引发了推测,强调了对优化机制进行深入理解的必要性。
Cohere Discord
- 发现 Command R Plus 的乐趣:Mapler 发现 Command R Plus 是构建趣味 AI Agent 的一个极具吸引力的选择。
- 重点在于打造娱乐导向型 Agent 的创意方面。
- 模型微调难题:Mapler 遭遇了挫折,正在努力应对一个未达到其基准测试要求的模型。
- 一位社区成员强调,微调的质量至关重要,并将其总结为“垃圾进,垃圾出(garbage in, garbage out)”——强调了高质量数据集的重要性。
LLM Finetuning (Hamel + Dan) Discord
- PromptLayer 与 Anthropic SDK 的兼容性阻碍:当尝试与最新版本的 Anthropic SDK 配合使用时,用于日志记录的 PromptLayer 集成失败。
- 由于担心替代方案,该成员正积极寻求同类自托管解决方案的建议。
- OpenPipe 的单模型综合征:讨论显示,OpenPipe 仅支持 OpenAI 的 Prompt/回复日志记录,排除了 Anthropic 等其他模型。
- 这一局限性引发了关于潜在变通方法或对更通用日志工具需求的讨论。
- 寻求 Fireworks.ai 的见解:一位成员寻求有关 fireworks.ai 相关或以其为特色的讲座信息,但未出现进一步的细节或澄清。
- 缺乏额外回应表明社区对该话题的了解程度或兴趣较低。
- 额度核算:成员查询:有人提出了如何验证额度可用性的问题,该成员提供了账户 ID reneesyliu-571636 以寻求帮助。
- 这仍然是一个孤立的查询,表明问题已解决或正在进行关于 Account ID Query 的私下讨论。
tinygrad (George Hotz) Discord
- NVDLA 通用性 vs NV 加速器:有人询问 NV 加速器是否是 NVDLA 的全方位解决方案,引发了对 GitHub 上的 NVDLA 项目 的调研。
- 提到将 CuDLA 调查 作为潜在的下一步行动,但在深入研究之前需要确认 NV 的能力。
- 以内核为中心的 NV Runtime 见解:对 NV runtime 的探索揭示了它与 GPU 紧密协作,绕过用户空间(userspace)并直接与内核交互以执行进程。
- 这一信息阐明了 NV 基础设施如何与底层硬件交互,绕过了传统的用户空间限制。
- 揭秘神经网络图 UOps:在分析一个简单神经网络图中的 UOps 时,发现了一些涉及常量的意外乘法和加法。
- 当注意到这些操作是 线性权重初始化(linear weight initialization) 的结果时,这个谜团得到了解决,解释了数值上的异常。
Mozilla AI Discord
- 参议院对 AI 和隐私的审查:一场 参议院听证会 聚焦于美国参议员 Maria Cantwell,她强调了 AI 在数据隐私中的重要性,并倡导制定联邦隐私法。
- 来自 Mozilla 的证人 Udbhav Tiwari 强调了 AI 在在线监控和画像方面的潜力,敦促建立法律框架以保护消费者隐私。
- Mozilla 倡导 AI 隐私法:Mozilla 在一篇 博客文章 中阐述了他们的立场,Udbhav Tiwari 在参议院听证会上再次强调了联邦监管的必要性。
- 该文章强调了立法行动的紧迫性,并分享了 Tiwari 在就 AI 时代的隐私保护作证时的影像。
MLOps @Chipro Discord
- Hugging Face 协调业务与模型:一场名为 揭秘 Hugging Face 模型及其如何发挥业务影响力(Demystifying Hugging Face Models & How to Leverage Them For Business Impact) 的独家研讨会定于 2024 年 7 月 30 日 东部时间中午 12 点举行。
- 无法参加?请在 此处 注册,以便在活动结束后获取研讨会资料。
- Recsys 社区兴起,Search/IR 萎缩:Recsys 社区 在规模和活跃度上超过了 search/IR 社区,前者正在增长,而后者被描述为更加小众。
- Cohere 最近收购了 sentence transformer 团队,来自 Vespa 的 Jo Bergum 和来自 Elastic 的成员也参与了讨论。
- Omar Khattab 带来动态 DSPy 对话:在 DSPy,MIT/斯坦福学者 Omar Khattab 分享了他在复杂主题上的专业见解。
- Khattab 的讨论点引起了观众的共鸣,强调了该领域的技术深度。
Alignment Lab AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI Stack Devs (Yoko Li) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Torchtune Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的逐频道细分内容已针对电子邮件进行截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!