ainews-microsoft-agentinstruct-orca-3
微软 AgentInstruct + Orca 3
微软研究院(Microsoft Research)发布了其 Orca 系列的第三篇论文 AgentInstruct,介绍了一种生成式教学管线。该管线产生了 2580万条 合成指令用于微调 mistral-7b 模型,并取得了显著的性能提升:AGIEval 提升 40%、MMLU 提升 19%、GSM8K 提升 54%、BBH 提升 38%、AlpacaEval 提升 45%,同时幻觉(hallucinations)减少了 31.34%。
这种合成数据方法延续了 FineWeb 和 苹果重写研究(Apple’s Rephrasing research) 在提升数据集质量方面的成功。此外,腾讯声称已为合成数据生成了 10亿个 多样化的角色(personas)。在 AI Twitter 上,热门讨论包括特朗普集会枪击事件,以及 FlashAttention-3、RankRAG 和 百万专家混合模型(Mixture of A Million Experts) 等近期机器学习研究亮点。
Generative Teaching is all you need.
2024年7月12日至7月15日的 AI 新闻。 我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 29 个 Discord 服务器(465 个频道和 4913 条消息)。 预计节省阅读时间(以 200wpm 计算):505 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
今年 FineWeb 的巨大成功(我们的报道在此,技术报告在此)结合 Apple 的 Rephrasing 研究,基本上证明了在预训练和后训练阶段,数据集质量至少可以有一个数量级的提升。随着内容机构要么诉诸法律,要么寻求合作,研究重点已转向改进合成数据集生成,以延长我们已经压缩或抓取的 Token 的使用寿命。
Microsoft Research 凭借 AgentInstruct: Toward Generative Teaching with Agentic Flows 引起了最新轰动(不要与 Crispino 等人 2023 年的 AgentInstruct 混淆),这是其 Orca 系列论文中的第三篇:
- Orca 1: Progressive Learning from Complex Explanation Traces of GPT-4
- Orca 2: Teaching Small Language Models How to Reason
- Orca Math: Unlocking the potential of SLMs in Grade School Math)
核心概念是由扮演不同角色的多个 Agent 对原始文档进行转换,以提供多样性(针对列出的 17 种能力),然后由更多 Agent 在“内容转换流”(Content Transformation Flow)中生成并完善指令。

该流水线产出了 2200 万条旨在教授这 17 种技能的指令,结合之前 Orca 论文中的 380 万条指令,构成了 “Orca 2.5” —— 这是一个包含 2580 万条指令的合成数据集。作者使用该数据集对 Mistral 7b 进行微调,并报告了以下结果:
- AGIEval 提升 40%,MMLU 提升 19%;GSM8K 提升 54%;BBH 提升 38%;AlpacaEval 提升 45%,摘要任务的幻觉减少了 31.34%(感谢 Philipp 的总结)。
这只是合成数据研究领域的最新进展,最近 腾讯在其相关工作中声称拥有 10 亿个多样化 Persona。
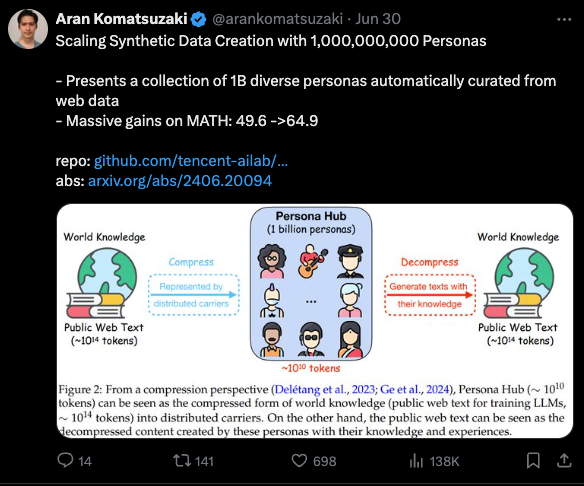
这看起来既显而易见会奏效,但与 FineWeb 相比又极其昂贵且低效,但管它呢,只要有用就行!
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,从 4 次运行中选取最佳结果。
特朗普集会枪击事件
- 枪击细节:@sama 指出,在特朗普集会上,一名枪手在开火前不久,在屋顶上被一名警官发现,并用步枪指向该警官,随后子弹擦过特朗普头部,距离仅一英寸。@rohanpaul_ai 分享了美联社的更新,证实枪手在开火前确实曾用步枪指向该警官。
- 反应与评论:@sama 希望这一时刻能促使减少激进言论并寻求更多团结,并称赞民主党人表现出了风度,抵制了将责任归咎于双方(”both-sides”)的冲动。@zachtratar 认为没有人会在那个距离导演一场子弹距离头部仅一英寸的枪击,因为如果是导演的,风险实在太大。@bindureddy 开玩笑说 AI 总统是无法被暗杀的。
AI 与 ML 研究与进展
- 新模型与技术:@dair_ai 分享了本周的热门 ML 论文,涵盖了 RankRAG、RouteLLM、FlashAttention-3、Internet of Agents、Learning at Test Time 以及 Mixture of A Million Experts 等主题。@_philschmid 强调了最近的 AI 进展,包括 Hugging Face 上的 Google TPU、提升 Transformer 速度的 FlashAttention-3,以及支持在 16GB 显存上训练 7B 模型的 Q-GaLore。
- 实现与应用:@llama_index 在 Beta 版本中实现了 GraphRAG 概念,如图生成和基于社区的检索。@LangChainAI 指出 OpenAI 的 Assistant API 是 Agentic 基础设施的一个例子,具有持久化和后台运行等特性。
- 讨论与见解:@sarahcat21 呼吁对可更新/协作式 AI/ML 以及模型合并(model merging)技术进行更多研究。@jxnlco 正在探索将 Prompting 技术融入 Instructor 文档中,以帮助理解可能性并识别抽象。
编程、API 与开发者工具
- 新 API 与服务:@virattt 推出了一个公开测试版的股市 API,包含 S&P 500 股票 30 多年的数据(包括财务报表),且没有 API 限制。目前正在进行压力测试,随后将发布包含 15,000 多只股票的完整版本,供 AI 金融 Agent 使用。
- 编程经验与技巧:@giffmana 分享了在编写读取 multipart/form-data 的 Python 脚本时,对那些无用的在线资源感到沮丧,发现最有效的还是原始的 RFC2388 规范。@jeremyphoward 展示了 Python 中一种新的 function-cache 装饰器设计,用于组合缓存淘汰策略。
- 开发者讨论:@svpino 预测,随着软件开发和 Machine Learning 的融合,AI 将与数据结构和算法一样,成为未来开发者的基础技能。
幽默、迷因与离题讨论
- 笑话与迷因:@cto_junior 分享了一个结合了 Wagie News 和 4chan 梗的迷因。@lumpenspace 调侃道,鉴于枪手政治倾向的信息相互矛盾,根本无法确定反特朗普情绪是否影响了枪手。
- 离题闲聊:@sarahookr 推荐去里斯本旅游,并分享了一张该城市的照片。@ID_AA_Carmack 讨论了一个漫画分镜,它激发了一个名为 “Corgi Battle Pose” 的独立游戏标题灵感。
AI Reddit 摘要
涵盖 r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity。我们最近改进了抗幻觉措施,但仍在调整过滤、聚类和摘要质量。
主题 1:快速发展中的 AI 研究论文发表滞后
-
[/r/singularity] 由于 AI 发展的速度以及科学出版过程的漫长延迟,大量学术论文暗示 LLM 无法完成它们实际上能做得很好的事情。例如:这是一篇不错的论文,但它使用的是 GPT-3.5。 (Score: 237, Comments: 19): 关于 AI 能力的学术论文迅速过时,这是由于 AI 发展的飞速步伐和漫长的科学出版流程。一个典型的例子是,尽管已经有了像 GPT-4 这样更先进的模型,某篇论文仍在使用 GPT-3.5 来评估 LLM 的能力。这种出版滞后导致已发表的研究与 AI 技术的现状之间存在显著差异。
-
[/r/OpenAI] 本周 AI 头条新闻 (Score: 361, Comments: 57): AI 头条新闻主导科技新闻:本周出现了一系列与 AI 相关的公告,包括 Google 的 Gemini 发布、OpenAI 的 GPT Store 推迟,以及 Anthropic 的 Claude 2.1 发布。AI 发展的飞速步伐引发了人们将其与互联网早期阶段的比较,一些专家认为 AI 的影响可能比网络革命更具变革性和深远意义。
- AI:不仅仅是又一次热潮:评论者将早期互联网怀疑论与当前的 AI 质疑进行了类比。许多人回忆起最初对在线使用信用卡的抵触,强调了观念随时间推移会发生巨大变化。
- AI 彻底改变开发:开发者称赞 AI 是编程的“游戏规则改变者”,一位用户在知识有限的情况下,使用 Anthropic 的 console 创建了一个 native Swift app。其他人指出 AI 能够比传统方法更快地缩小解决方案的范围。
- 互联网泡沫的教训:讨论涉及了 2000 年互联网泡沫崩溃,用户指出像 Amazon 这样的公司当时损失了 90% 的市值。一些人建议 AI 领域可能会出现类似的修正,但认为泡沫尚未达到顶峰。
- AI 的成长的烦恼:批评者指出了当前 AI 应用的问题,例如 Google 的 search highlights 因幻觉(hallucinations)而受到批评。用户强调了负责任地部署 AI 的重要性,以维持该领域的公信力。
{kind=link}
主题 2. AI 对就业的影响:TurboTax 裁员
- [/r/singularity] TurboTax 制造商解雇 1,800 名员工,称其正转向 AI (Score: 303, Comments: 63): TurboTax 和 QuickBooks 背后的公司 Intuit 宣布裁员 7%,即解雇 1,800 名员工。该公司将重组原因归于向人工智能和机器学习的转型,旨在更好地服务客户并推动创新。尽管 Intuit 报告 2023 财年收入为 144 亿美元,比上一年增长了 13%,但仍做出了这一举动。
主题 3. AI 在创意工作流中的集成:ComfyUI GLSL 节点
- [/r/StableDiffusion] 🖼 适用于 ComfyUI 的 OpenGL Shading Language (GLSL) 节点 🥳 (Score: 221, Comments: 21): 适用于 ComfyUI 的 OpenGL Shading Language (GLSL) 节点 已发布,允许用户创建自定义着色器并将其应用于 ComfyUI 工作流中的图像。这一新功能通过 GPU 加速 操作实现实时图像处理,有望增强 ComfyUI 中图像处理任务的效率和能力。GLSL 着色器的集成直接在 ComfyUI 环境中为高级视觉效果和自定义图像变换开辟了可能性。
- 分享了 GitHub 仓库和 ShaderToy 链接:原帖作者 camenduru 提供了 GLSL 节点的 GitHub 仓库 链接,以及一个展示着色器效果潜力的 ShaderToy 示例。
- 兴奋情绪与潜在应用:用户对这一新功能表现出极大的热情,ArchiboldNemesis 强调了其在 遮罩输入 (masking inputs) 方面的潜力,并推测可能实现 “实时 SD 元球 (metaballs)”。另一位用户则思考 ComfyUI 是否会演变成像 TouchDesigner 那样的 可视化编程框架。
- 技术讨论与澄清:一些用户寻求关于 OpenGL 及其与工作流关系的解释。一位评论者澄清说,OpenGL 着色用于 视口渲染 (viewport rendering),不具备光线追踪能力;而另一位则提到 three.js glsl shaders 的知识可以应用于 ComfyUI。
- 未来开发构想:建议包括将 VSCode 及其插件 集成到 ComfyUI 中,或者将 ComfyUI 开发为 VSCode 插件。此外,还有关于当前实现中 实时处理/渲染 能力的疑问。
AI Discord 回顾
摘要的摘要之摘要
1. 推动 LLM 的边界
- 突破性的 LLM 性能提升:微软研究院推出了 AgentInstruct,这是一个自动创建合成数据以对模型进行后期训练的框架,将 Mistral-7b 训练为 Orca-3,在 AGIEval 上实现了 40% 的提升,在 GSM8K 上提升了 54%,在 AlpacaEval 上提升了 45%。
- Ghost 8B Beta 模型在 lc_winrate 和 AlpacaEval 2.0 胜率等指标上超越了 Llama 3 8B Instruct、GPT 3.5 Turbo 等模型,旨在提供卓越的知识能力、多语言支持和成本效率,详见其文档页面。
- 新基准测试推动 LLM 进步:引入了 InFoBench(Instruction Following Benchmark,指令遵循基准测试),引发了关于其与标准对齐数据集相关性的讨论,以及独特的基准测试是否能突出 LLM 在与 MMLU 高度相关之外的有价值特质。
- WizardArena/ArenaLearning 论文详细介绍了在 Kaggle 竞赛中通过人类偏好评分评估模型的方法,引起了人们对多轮合成交互生成和评估设置的兴趣。
2. 驱动 AI 的硬件创新
- 使用专用硬件加速 AI:MonoNN,一种新型机器学习编译器,通过将整个神经网络容纳到单个 kernel 中来优化 GPU 利用率,解决了传统逐个 kernel 执行方案中的低效问题,详见 论文演示 和 源代码发布。
- 围绕 WebGPU 开发的讨论强调了其快速的迭代周期,但也指出需要更好的工具和分析(profiling),成员们正在探索移植 llm.c transformer kernels 以获取性能洞察,并将更多 ML 工作负载转移到客户端计算。
- 通过量化优化 LLM:关于量化技术的研究显示,压缩模型可能会出现“翻转(flips)”现象——尽管准确率指标相似,但输出会从正确变为错误,这突显了在定量评估之外进行定性评估的必要性。
- 论文“LoQT”提出了一种方法,能够在消费级 24GB GPU 上高效训练高达 7B 参数的量化模型,以不同的方式处理梯度更新,并在预训练和微调中实现了相当的内存节省。
3. 开源驱动 AI 创新
- 协作努力推动进步:OpenArena 项目推出了一个开放平台,让 LLM 相互竞争以提高数据集质量,主要使用 Ollama 模型,但也支持任何兼容 OpenAI 的端点。
- LLM-Finetuning-Toolkit 发布,用于使用单一配置在开源 LLM 上运行实验,该工具构建在 HuggingFace 库之上,并支持评估指标和消融研究。
- 框架简化 LLM 开发:LangChain 社区对流式输出处理进行了积极讨论,涉及
invoke、stream和streamEvents在 langgraph 集成中的应用,以及管理ToolCall弃用和意外的默认工具调用。- LlamaIndex 获得了新功能,例如使用 Neo4j 进行实体去重、使用 LlamaCloud 集中管理数据管道、利用 GPT-4o 解析财务报告、通过 Redis 集成实现多 Agent 工作流,以及发布了高级 RAG 指南。
第一部分:高层级 Discord 摘要
HuggingFace Discord
- NPM 模块支持 Hugging Face Inference:一个支持 Hugging Face Inference 的新 NPM 模块已发布,并邀请社区提供反馈。
- 开发者强调该模型覆盖了 36 个 Large Language Model 提供商,旨在培养协作开发的生态。
- 分布式计算汇聚 Llama3 力量:Llama3 8B 在家庭集群上启动,设备涵盖从 iPhone 15 Pro Max 到 NVIDIA GPU,代码已在 GitHub 开源。
- 该项目旨在进行设备优化,号召社区共同对抗计划性报废。
- LLM-Finetuning-Toolkit 发布:LLM-Finetuning-Toolkit 的首次亮相为跨多种模型的 LLM 实验提供了一种使用单一配置的统一方法。
- 它的独特之处在于集成了评估指标和消融研究(ablation studies),全部构建在 HuggingFace 库之上。
- 混合模型推动 EfficientNetB7 协作:一项训练混合模型的计划将用于特征提取的 EfficientNetB7 与 Huggingface 上的 Swin Transformer 结合进行分类。
- 参与者利用 Google Colab 的计算资源,寻求更简单的实现技术。
- HF Inference API 归属错误引发热议:Copilot 错误地将 HF Inference API 引用为 OpenAI 产品,导致用户在讨论中产生困惑。
- 反应不一,既有像“奶酪冷却”服务器之类的幽默建议,也有对开源文档规范的务实要求。
Unsloth AI (Daniel Han) Discord
- Llama 3 备受期待的发布受阻:传闻 Meta Platforms 原定于 7 月 23 日发布的 Llama 3 (405b) 将会推迟,Reddit 用户议论其可能推迟到今年晚些时候。
- 社区交流中充满了对运营挑战的讨论,尽管有所延迟,大家仍期待微调(fine-tuning)的机会。
- Gemini API 跃升至 2M Token:Google 的 Gemini API 现在为 Gemini 1.5 Pro 提供了 200 万 Token 的上下文窗口,并发布了包括 代码执行 在内的多项功能。
- AI 工程师们辩论了超长上下文的优劣,并推测其在日常场景中对性能的影响。
- MovieChat GitHub 仓库引发数据集讨论:MovieChat 作为一个允许对 10K 帧视频进行对话的工具出现,引发了关于数据集创建的对话。
- 考虑到构建开源数据集的复杂性,用户对其可行性存在争议。
- Ghost 8B Beta 表现亮眼:Ghost 8B Beta 模型因其性能受到赞誉,在 lc_winrate 和 AlpacaEval 2.0 胜率得分等指标上超过了 Llama 3 8B Instruct 和 GPT 3.5 Turbo 等对手。
- 新文档 显示了该模型在多语言支持和成本效益等领域的实力,引发了关于战略贡献的讨论。
- CURLoRA 应对灾难性遗忘:作为微调方法的转变,CURLoRA 使用 CUR 矩阵分解来对抗灾难性遗忘(catastrophic forgetting)并最小化可训练参数。
- AI 专家对这一消息表示赞赏,认为其在各种应用中具有潜力,详见 论文。
Stability.ai (Stable Diffusion) Discord
- GPTs 停滞的启示:人们对 GPTs agents 在训练后无法吸收新信息表示担忧,并澄清 上传的文件仅作为参考“知识”文件,不会改变底层模型。
- 社区交流了 GPTs agents 如何与额外数据交互,确认新输入不会动态重塑基础知识。
- OpenAI 的侧边栏风波:用户注意到 platform.openai.com 侧边栏消失了 两个图标,引发了对界面更改的猜测和评估。
- 侧边栏触发了关于可用性的讨论,提到与 threads 和 messages 相关的图标已经消失。
- ComfyUI 胜过 A1111:ComfyUI 相对于 A1111 的速度优势成为热门话题,社区测试表明 ComfyUI 有 15 倍的性能提升。
- 尽管有速度优势,一些用户批评 ComfyUI 在控制精度上落后于 A1111,这表明在效率和功能之间存在权衡。
- 自定义遮罩组装的焦虑:关于在 ComfyUI 中制作自定义遮罩的复杂过程引发了辩论,参与者指出 SAM inpainting 的性质更为繁琐。
- 社区流传着简化遮罩创建过程的建议,提议集成 Krita 等工具以减轻 ComfyUI 中繁琐的程序。
- 艺术伦理辩论:出现了关于 AI 生成个人肖像的伦理和法律讨论,成员们思考艺术创作中 parody(戏仿)的保护伞作用。
- 社区就 AI 艺术的合法性展开了激烈辩论,涉及对公众人物代表性的担忧,以及在复杂情况下寻求 专业法律咨询 的必要性。
LM Studio Discord
- CUDA 难题与 GPU 指南:用户在解决“No CUDA devices found”错误,主张安装 NVIDIA 驱动程序和 “libcuda1” 软件包。
- 在硬件对话中,Intel Arc a750 的表现不佳受到关注;对于 LM Studio 的精度,建议使用 NVIDIA 3070 或支持 AMD ROCm 的 GPU。
- 多语言编程偏好:Rust vs C++:工程师们交换了对编程语言的看法,引用了 Rust 的内存安全性和 C++ 的历史包袱,并夹杂着一些 Rust Evangelism(Rust 布道)。
- 尽管 Python 在神经网络开发中占据主导地位,但 Rust 和 C++ 社区强调了各自语言的优势以及 llama.cpp 等工具。
- LM Studio:脚本限制与模型之谜:关于 lmstudio.js 的辩论转向其使用 RPC 而非 REST,以及由于 RPC 的模糊性在集成 embedding 支持时面临的挑战。
- AI 爱好者探讨了多 GPU 配置,指出了 PCIe 带宽的影响,并对即将推出的搭载 M4 芯片的 Mac Studio 在 LLM 任务中的表现充满期待。
- Vulkan 和 ROCm:GPU 依赖与革命性运行时:尽管担心其 4-bit 量化限制,但用户对 Vulkan 即将登陆 LM Studio 表示热切期待。
- 同时,ROCm 成为 AMD GPU 用户的核心;对于 Llama 3 等模型至关重要,且其 Windows 支持也正受到关注。
OpenAI Discord
- GPT 替代方案辩论:追求学术卓越:讨论集中在 Copilot 或 Bing AI(据称两者都运行在 GPT-4 上)在学术用途上是否更胜一筹。
- 一位用户在感叹缺乏其他可行选择的同时,提到了 Claude 和 GPT-4o 等替代方案,但仍承认在 ChatGPT 上有支出。
- 微软的多重 CoPilot 难题:成员们剖析了微软在 Word、PowerPoint 和 Outlook 等应用中部署的一系列 CoPilot,并指出 Word CoPilot 在深入研究主题方面的表现。
- 相反,PowerPoint 的助手被贴上了“基础”的标签,主要辅助生成初级的幻灯片。
- DALL-E 在 GPT 指导下的困境:围绕 DALL-E 在遵循 GPT 指令渲染图像时的不可靠性展开了对话,结果要么是 Prompt 文本,要么是损坏的图像链接。
- DALL-E 的这些“小故障”受到了批评,原因是该技术在初始命令下未能恰当地解读 GPT 的引导。
- AI 多语言者:Prompt 语言差异:询问围绕 Prompt 语言对响应质量的影响展开,特别是在 ChatGPT 交互中使用韩语与英语时。
- 核心问题在于,直接使用目标语言的 Prompt 与需要翻译的 Prompt 相比,其有效性如何。
- 用魔法解锁 Android 的全部潜力:分享的“Android 优化大师”指南承诺了通过电池优化、存储管理和高级设置来提升 Android 手机性能的秘诀。
- 该指南通过俏皮的场景吸引了年轻的技术爱好者,使高级 Android 技巧变得易于理解且引人入胜。
Modular (Mojo 🔥) Discord
- 网站担忧与重定向:当 Mojo 网站 宕机时引发了混乱,导致用户发现它并非官方网站。
- 在纠正航向后,用户被引导至 Modular 官方网站,确保了正确的重定向。
- 机器人按部就班带来的困惑:当成员标记多位贡献者时,Modular 的机器人会发出不必要的警告,误将该行为视为具有威胁性的机器人行为。
- 随后展开了关于模式触发器的讨论,成员们要求审查机器人的解释逻辑。
- 推进模块可维护性的提案:提出了一项创建
stdlib-extensions的提案,旨在减轻 stdlib 维护者的工作量,并在 GitHub 上引发了对话。- 社区请求勤奋的贡献者提供反馈,以确保这一改进有助于简化模块管理。
- MAX 许可证文本截断:Max 许可证 文本中的拼写错误引发了关于法律文档细节关注度的讨论。
- 提到了诸如 otherModular 和 theSDK 之类的错误,促使官方迅速进行了修正。
- 加速集成的雄心:成员们询问 Max 如何衔接 AMD 发布的 Unified AI software stack(统一 AI 软件栈),突显了 Modular 日益增长的影响力。
- 引用利益交汇点,用户对 MAX 平台潜在的独家合作伙伴关系表现出极大的热情。
Perplexity AI Discord
- Cloudflare 争议与 API 额度探索:由于 API 位于 Cloudflare 防护之后,成员们正面临访问挑战;同时,另一些人对比 Pro 计划升级中宣传的 5 美元免费额度 的可用性提出质疑。
- 讨论还涉及使用 5 美元额度时的挫败感,用户正通过 社区频道 寻求帮助。
- Pro 每日限额下调:Pro 用户注意到其每日搜索限制悄然从 600 次降至 540 次,引发了关于未来变化以及对更高透明度需求的讨论。
- 社区对这一意外变化做出了反应,并讨论了其对日常操作的潜在影响。
- 图像问题与能力对比:用户分享了 Perplexity 的回复错误引用过去图像的问题,这阻碍了对话的连贯性。
- 技术专家们辩论了 Perplexity 相对于 ChatGPT 的优势,特别是在文件处理、图像生成和精准后续跟进等专业领域。
- 令人困扰的 API 模型之谜:一位用户试图通过 API 模拟 Perplexity AI 免费版的结果,但在获取 URL 来源方面遇到困难,从而引发了关于正在使用哪些模型的查询。
- 目标是匹配免费版的能力,这表明需要明确 API 服务中的模型利用和输出情况。
- 分享光谱:从健康到争议:讨论范围广泛,从健康与力量的途径,到理解动态市场力量如坎蒂隆效应 (Cantillon Effect)。
Nous Research AI Discord
- AgentInstruct 的飞跃:AgentInstruct 为将 Mistral-7b 等模型增强为更复杂的版本(如 Orca-3)提供了蓝图,展示了在基准测试上的显著提升。
- 该应用在 AGIEval 和 GSM8K 上分别实现了 40% 和 54% 的提升,在 AlpacaEval 上提升了 45%,为竞争对手树立了新标杆。
- 剥蛋专家的轻松建议:剥蛋技巧意外走红,建议倾向于使用 10 分钟热水浴 来实现完美的剥壳效果。
- 还有人分享了醋溶液魔法,通过酸碱反应展示了无壳蛋的奥秘。
- AI 的 YouTube 戏码:Q-star 泄露:Q-star 的机密细节通过 YouTube 爆料公开,展示了 AGI 发展的希望与风险。
- 来自 OpenAI 代号为 STRAWBERRY 的隐藏宝库的见解揭示了即将推出的 LLM 策略。
- 告别 PDF,拥抱 Markdown:新版本的 Marker 利用高效的模型架构缩短了 PDF 到 Markdown 的转换时间,有助于提升数据集质量。
- 性能提升包括 MPS 上 7 倍的加速 和 10% 的 GPU 性能增长,为快速创建数据集指明了方向。
- 在应用中扩展 LLM 的视野:关于应用集成的讨论显示,检索增强生成 (RAG) 是嵌入教程智能的首选方案。
- 讨论中出现了将 Mixtral 和 Llama 等模型扩展到 1M tokens 的建议,尽管实际使用仍面临挑战。
CUDA MODE Discord
- Warp Speed WebGPU 工作流:探索 WebGPU 开发的用户讨论了其快速迭代周期,但指出工具链和性能分析(profiling)是需要改进的领域。
- 推荐使用类似 dawn 的共享库方法,并提供了一个 livecoding demo 展示了更快的 shader 开发。
- 探究 CUDA Core 的并发性:对 CUDA core 处理过程的深入研究表明,每个 CUDA core 一次可以处理一个线程,一个 A100 SM 可以从 2048 个线程池中同时管理 64 个线程。
- 讨论还集中在 register limitations(寄存器限制)如何影响线程并发,进而影响整体计算效率。
- 使用 cudaMallocManaged 实现高效内存管理:提议使用 cudaMallocManaged 代替 cudaFix,以支持内存有限的设备,特别是为了增强小型 GPU 的集成工作。
- 切换到 cudaMallocManaged 被视为确保性能不受阻碍,同时适配更广泛 GPU 架构的关键。
- 低比特操作的 FSDP 技巧:关于为低比特优化实现 FSDP 支持的讨论集中在优化状态子类(optimization state subclass)中未解决的集合通信操作(collective ops)。
- 讨论了旨在辅助 FSDP 兼容性的开发者指南,以提高开发者参与度并防止潜在的项目流失。
- 基于 WebGPU 的浏览器端 Transformers:成员们讨论了利用 Transformers.js 在浏览器中运行最先进的机器学习任务,发挥 WebGPU 在 ONNX runtime 中的潜力。
- 还强调了在 Windows 上构建 Dawn 相关的挑战,指出了故障排除经验以及 buffer 限制对性能的影响。
Cohere Discord
- OpenArena 雄心勃勃的 AI 对决:一个新的 OpenArena 项目 已启动,挑战 LLM 进行竞争并确保稳健的数据集质量。
- Syv-ai 的仓库 详细说明了申请流程,旨在与各种 LLM 供应商直接接触。
- Cohere 难题:活动访问困局:成员们抱怨 Cohere 活动 链接混淆导致访问问题,通过分享扩散模型(diffusion model)演讲的正确 Zoom 链接 解决了该问题。
- 客座演讲环节 恢复了清晰度,并提供了使用扩散模型创建语谱图(spectrograms)的指导。
- AI 能力训练成本骤降:Andrej Karpathy 对 AI 训练成本的看法 显示成本大幅下降,训练 GPT-2 等模型的门槛显著降低。
- 他阐明了从 2019 年的高成本环境到现在的转变,如今爱好者只需花费极少的费用即可训练类 GPT 模型。
- 使用 NPM 模块实现无缝 LLM 切换:通过 更新的 NPM 模块,开发者可以轻松集成 Cohere,非常适合跨平台 LLM 交互。
- 这种模块化方法为统一使用各种 AI 平台打开了大门,丰富了开发者的工具箱。
- r/localllama 新闻机器人纪事:r/localllama 社区通过一个由 Langchain 和 Cohere 驱动的机器人为 Discord 注入了活力,该机器人可以聚合 Reddit 的热门帖子。
- 这个创新的引擎不仅能进行总结,还能将新闻整理成引人入胜的叙述,专为特定频道定制。
Eleuther Discord
- 伦敦 AI 聚会缺乏技术深度:讨论显示出对伦敦 AI 聚会 (AI meetups in London) 技术深度的不满,建议有兴趣的人去参加 UCL 和 Imperial 的研讨会。
- ICML 和 ICLR 会议被推荐用于有意义的深度交流,尤其是在研究人员的小众聚会中。
- Arrakis:加速机械可解释性 (Mechanistic Interpretability):Arrakis 是一个用于可解释性实验的工具包,旨在增强实验追踪和可视化。
- 该库与 tuned-lens 等工具集成,以提高 mechinterp 研究效率。
- 探索模型的时间相关性:将时间相关性引入 LLM 的兴趣日益增长,因为传统的 timestamp 方法缺乏有效性。
- 目前的讨论集中在时间敏感型数据集的文献和用于提升训练的 Benchmark 等途径。
- 量化怪癖:表象之下另有乾坤:针对一篇关于量化翻转 (quantization flips)的论文提出了担忧,该论文解释了压缩模型尽管准确率指标相同,但行为可能不同。
- 这引发了关于在定量评估之外进行严格定性评估必要性的对话。
- 挖掘 lm-eval 的潜力:一项技术咨询引导出了将自定义 Transformer-lens 模型与 lm-eval 的 Python API 集成的指南,详见此文档。
- 然而,一些成员仍在摸索 lm-evaluation-harness 中自定义函数和指标的复杂性。
tinygrad (George Hotz) Discord
- MonoNN 优化 GPU 工作负载:新型机器学习编译器 MonoNN 的引入引起了关注,它采用针对整个神经网络的单算子 (single kernel) 方法,可能提高 GPU 效率。相关论文和源代码已发布。
- 社区考虑了 MonoNN 方法在减少逐算子 (kernel-by-kernel) 执行开销方面的潜在影响,这与正在进行的关于 tinygrad kernel overhead 问题的讨论相呼应。
- MLX 胜过 tinygrad:在 beautiful_MNIST 基准测试中,MLX 以更好的速度和准确性占据了上风,引起了社区对 mlx 的 tinygrad commit 的关注。
- 这一发现引发了关于改进 tinygrad 性能的进一步讨论,目标是解决开销和效率低下的问题。
- 针对 tinygrad 的 avg_pool2d 的改进建议:社区请求增强
avg_pool2d以支持count_include_pad=False,这是 Stable Diffusion 训练评估中的一个功能,并提出了模仿 PyTorch 实现的潜在解决方案。- 讨论围绕 MLPerf 等基准测试对该功能的需求展开,并出现了使用现有池化操作的变通方案建议。
- 关于 Tinygrad 张量索引 (Tensor Indexing) 的讨论:成员们交流了 tinygrad 中张量索引的细微差别,将其与其他框架进行比较,并演示了掩码 (masking) 等操作如何提高性能。
- 一位成员引用了 tinygrad 文档来阐明该工具包中这种特定张量操作的执行和效率优势。
- PR 策略与文档动态:成员们达成共识,建议将增强功能、Bug 修复和功能实现分成独立的 Pull Request (PR),以简化审核流程,这在处理 FID 的
interpolate函数时表现得很明显。- 成员们强调了保持示例最新且可运行的重要性,讨论了在 tinygrad 文档中测试和验证代码块的策略。
Latent Space Discord
- Leaderboard Levels Up: Open LLM Leaderboard V2 Excitement: 排行榜升级:Open LLM Leaderboard V2 引发热议。Latent Space 关于 Open LLM Leaderboard V2 的新一期节目引发了讨论,社区成员分享了他们的热情。
- 该播客链接到了一个新发布版本,为听众提供了关于最新 LLM 排名的见解。
- Linking Without Hallucinating: Strategies to Combat Misinformation: 链接不幻觉:打击误导信息的策略。讨论围绕 SmolAI 消除 Reddit 链接幻觉的创新方法展开,重点关注 pre-check and post-proc(预检查和后处理)方法。
- 讨论了技术和结果,强调了可靠链接在增强 LLM 使用方面的重要性。
- Unknown Entrants Stir LMSys: New Models Spark Curiosity: 未知参赛者搅动 LMSys:新模型引发好奇。关于 LMSys arena 中新模型背后实体的猜测四起,伴随着各种不同的观点。
- 关于 Command R+ jailbreaks(越狱)及其影响的传闻也是热议的一部分,反映在社区对话中。
- Composing with Cursor: The Beta Buzz: 使用 Cursor 创作:Beta 版热潮。Cursor 的新 Composer 功能在社区中引起了轰动,用户们急于讨论其 UX 对比和 Beta 版发布。
- 价格和实用性成为关注的话题,旁观者分享了积极反应并思考了订阅模式。
- Microsoft’s Spreadsheet Savvy: Introducing SpreadsheetLLM: 微软的电子表格智慧:推出 SpreadsheetLLM。微软凭借 SpreadsheetLLM 引起了轰动,这项创新旨在利用 SheetCompressor 编码框架改进 LLM 对电子表格的处理。
- 对话转向了其将 LLM 适配到电子表格数据的潜力,对其论文中详述的细致方法感到兴奋。
OpenAccess AI Collective (axolotl) Discord
- Open Source Tools Open Doors: 开源工具开启新大门。用户 le_mess 创建了一个名为 OpenArena 的数据集创建工具的 100% 开源版本,扩展了模型训练灵活性的视野。
- OpenArena 最初是为 OpenRouter 设计的,现在正利用 Ollama 来提升其能力。
- Memory Usage Woes in ORPO Training: ORPO 训练中的内存使用困扰。xzuyn 注意到 ORPO 训练期间内存使用量激增,尽管最大序列限制为 2k,但仍导致了 out-of-memory 错误。
- 对话指出,Tokenization(分词)后长序列截断时丢失消息可能是罪魁祸首。
- Integrating Anthropic Prompt Know-How: 集成 Anthropic 的 Prompt 诀窍。Axolotl 改进的 Prompt 格式从 Anthropic 的官方 Claude 中汲取了灵感(由 Kalomaze 讨论),其特点是使用特殊 Token 来清晰划分对话轮次。
- 该模板适用于 Claude/Anthropic 格式,可以在这里找到,引发了关于其可读性和灵活性的分歧。
- RAG Dataset Creation Faces Scrutiny: RAG 数据集创建面临审查。nafnlaus00 对 Chromium 在渲染 RAG 模型数据集抓取所需的 JavaScript 站点时的安全性表示担忧。
- 建议包括探索替代的抓取解决方案,如 firecrawl 或 Jina API,以应对这些潜在的漏洞。
- Weighted Conversations Lead Learning: 加权对话引导学习。Tostino 提出了一种利用训练数据的创新方法,涉及权重调整,以引导模型学习远离不理想的输出。
- 这种高级微调可以通过专注于问题区域来优化模型,从而提升学习曲线。
Interconnects (Nathan Lambert) Discord
- AI 推理的草莓地 (Strawberry Fields of AI Reasoning):OpenAI 正在开发一种名为 Strawberry 的新推理技术,人们将其与斯坦福大学的 STaR (Self-Taught Reasoner) 进行比较。社区内部人士认为,其能力与 Reuters 详细报道的一篇 2022 年论文中所概述的内容相吻合。
- 该技术对推理基准测试的预期影响,引发了对其相较于现有系统可能具备的优势的审视,重点关注产品名称、核心功能和发布日期。
- LMSYS Arena 的神秘模型参赛者:LMSYS chatbot arena 因 column-r 和 column-u 等新选手的加入而热闹非凡。根据 Jimmy Apples 的消息,推测这些模型是 Cohere 的杰作。
- Twitter 用户 @btibor91 进一步引发了关注,他指出有四个新模型正准备发布,包括 eureka-chatbot 和 upcoming-gpt-mini,据称其中一些模型的训练方是 Google。
- 评估 Mistral-7B 的指令强度:鉴于 Orca3/AgentInstruct 论文 的发现,AI 社区正在讨论 Mistral-7B 的指令微调 (instruct-tuning) 效果,并试图确定底层指令微调数据集的强度。
- 讨论评估了当前数据集是否符合鲁棒性标准,并将 Mistral-7B 的基准测试结果与其他模型的表现进行了对比。
- InFoBench 引发基准测试辩论:最近公开的 InFoBench (Instruction Following Benchmark) 引发了关于其价值与既有对齐数据集对比的讨论,对其在现实世界中的相关性评价褒贬不一。
- 怀疑者和支持者就 InFoBench 以及 EQ Bench 等独特基准测试是否真正突出了语言模型的重要特质(考虑到它们与 MMLU 等成熟基准测试的相关性)展开了激烈交锋。
- 加州 AI 立法迷宫:加州 AI 法案 SB 1047 的通过引发了一场立法冲突,AI 安全专家和风险投资家在关键投票前就该法案的影响展开辩论。
- 参议员 Scott Wiener 将这场冲突描述为“喷气机帮对阵鲨鱼帮 (Jets vs Sharks)”,揭示了 Fortune 文章 中记录的极化观点,该文章可通过 Archive.is 获取以供更广泛的审阅。
LangChain AI Discord
- JavaScript 的权衡:LangChain 的三大函数:用户剖析了 LangChain JS 中
invoke、stream和streamEvents的复杂性,讨论了它们在 langgraph 中流式输出的效果。- 出现了一项提议,建议使用 Agent 来处理数据收集和 API 交互等各种任务。
- Gemini API 的 Base64 困扰:寻觅、解码、失败:尽管 File API 上传是唯一有文档记录的方法,但用户在 Gemini Pro API 中使用 Base64 时遇到了令人困惑的“无效输入”障碍。
- 社区的指导指出,文档需要进一步明确,并对在 API 中使用 Base64 进行更详细的阐述。
- ToolCall 的更迭:从 LangChain Legacy 到 OpenAIToolCall:
ToolCall现已废弃,引导用户使用其继任者OpenAIToolCall,后者引入了用于排序的index功能。- 社区思考了包更新以及如何处理自动模式下无意触发的默认工具调用。
- 幻觉风险:聊天机器人凭空生成查询:有报告称 HuggingFace 模型出现幻觉,引发了围绕 LLM 生成的聊天机器人随机问答对的讨论。
- 社区提供了替代方案,包括转向 OpenAI 模型或 FireworksAI 模型,尽管经过微调的 Llama 模型似乎对典型的重复惩罚具有抵抗力。
- 嵌入模型的卓越表现:OpenAI 模型备受关注:关于最佳 OpenAI 嵌入模型的讨论达到高潮,引发了关于理解和利用嵌入向量 (embedding vectors) 的最佳模型的探讨。
- 普遍共识倾向于将
text-embedding-ada-002作为 LangChain 中向量嵌入的首选模型。
- 普遍共识倾向于将
LlamaIndex Discord
- LlamaIndex 的去重之舞:LlamaIndex 知识图谱正在进行节点去重(node deduplication),在相关文章中提供了新见解和解释,强调了知识建模的重要性。
- 在执行 NebulaGraphStore 集成时出现了技术困难,详见 GitHub Issue #14748,这指向了方法预期上的潜在不匹配。
- 公式与财务的融合:结合 SQL 和 PDF Embedding 引发了关于集成数据库和文档的讨论,讨论由 LlamaIndex 的 SQL 集成指南中的示例引导。
- 提到的
NLSQLTableQueryEngine问题引发了关于正确方法的辩论,因为 Manticore 的查询语言与 MySQL 的经典语法有所不同。
- 提到的
- Redis 重新思考多 Agent 工作流:@0xthierry 的 Redis 集成 促进了生产级工作流的构建,为 Agent 服务通信创建了一个网络,详见热门讨论帖。
- 多 Agent 系统 的效率是一个核心主题,Redis Queue 作为 Broker(代理),反映了架构流线化的趋势。
- 更细的数据分块,更精准的 Embedding:根据基础策略文档中关于最佳分块和重叠设置的建议,将数据切分为更小的尺寸提升了 LlamaIndex Embedding 的精度。
- LlamaIndex AI 社区一致认为,
chunk_size为 512 且重叠(overlap)为 50 时,能优化细节捕捉和检索准确率。
- LlamaIndex AI 社区一致认为,
- 带有 LlamaIndex 特色的高级 RAG:想要深入了解 Agent 模块,LlamaIndex 指南提供了全面的教程,如 @kingzzm 关于利用 LlamaIndex 查询流水线(query pipelines) 的教程所示。
- RAG 工作流 的复杂性被分步拆解,从发起查询到面向 AI 工程师的查询引擎微调。
OpenInterpreter Discord
- GUI 之光:OpenInterpreter 升级:在 OpenInterpreter 中集成完整的 GUI 增加了可编辑消息、分支、自动运行代码和保存功能。
- 对探索这些功能的视频教程的需求表明了社区的高度兴趣。
- OS 探索:OpenAI 的潜在尝试:在 Sam Altman 领导下的 OpenAI 可能正在酝酿自己的 OS,这一推文暗示引发了广泛猜测。
- 随着社区成员拼凑近期招聘职位中的线索,悬念不断增加。
- Phi-3.1:承诺与精度:Techfren 对 Phi-3.1 模型潜力的分析揭示了其令人印象深刻的尺寸能力比。
- 然而,讨论显示它偶尔在精确执行
<INST>时遇到困难,引发了关于增强功能的讨论。
- 然而,讨论显示它偶尔在精确执行
- 从 Internlm2 到 Raspi5:紧凑型突破:“Internlm2 smashed”因其在 Raspi5 系统上的表现而受到关注,这对于紧凑型计算需求来说前景广阔。
- 重点在于探索适用于新型 IoT 应用的 multi-shot 和 smash 模式。
- Ray-Ban 的数字越狱:社区的狂欢:越狱 Meta Ray-Ban 的可能性让社区兴奋不已并充满期待。
- 破解该硬件的愿景引发了对新功能机会的关注热潮。
LLM Finetuning (Hamel + Dan) Discord
- Agents Assemble in LLM:一位用户解释了在 LLMs 中添加 Agent 以增强 chat pipelines 模块化的方法,利用 JSON 输出执行诸如 fetching data 和 API interaction 等任务。
- 分享的 指南 展示了包含 Input Processing 和 LLM Interpretation 的步骤,强调了模块化组件的优势。
- OpenAI API Keys: The Gateway for Tutorials:聊天机器人项目教程需要 API keys,社区中有人请求分享 key 以协助教程的创作。
- 该成员未提供更多背景,但强调了完成并发布指南对 key 的临时需求。
- Error Quest in LLM Land:成员们表达了在处理来自 modal 和 axolotl 的陌生错误时的困扰,表示需要在 Slack 等平台上寻求社区帮助。
- 虽然未详细说明错误的具体性质,但对话暗示需要更好的渠道来解决这些技术问题。
- Navigating Through Rate Limit Labyrinths:一位在 Langsmith evaluation 期间面临 token 速率限制的用户通过调整 max_concurrency 设置找到了解决方法。
- 讨论还涉及了在脚本运行中引入延迟的策略,旨在避开服务提供商施加的速率限制。
- Tick Tock Goes the OpenAI Clock:讨论透露 OpenAI credits 将于 9 月 1 日到期,用户在询问后澄清了截止日期。
- 对话幽默地暗示要发起一份 请愿书 来延长额度有效期,表明用户在既定到期日之后仍依赖这些资源。
LAION Discord
- Hugging Face Hits the Green Zone:Hugging Face 宣布在拥有 220 人团队的情况下实现盈利,同时保持其大部分平台免费且开源。
- CEO Clement Delangue 兴奋地指出:‘这并不是我们的目标,因为我们银行里有很多钱,但看到 @huggingface 最近盈利了还是挺兴奋的,我们有 220 名团队成员,而且我们的大部分平台对社区都是免费和开源的!’
- Cambrian-1’s Multimodal Vision:介绍了 Cambrian-1 系列,这是一系列专注于视觉的新型多模态 LLM,可在 GitHub 上获取。
- 这一扩展有望拓宽 AI 模型在学习语境中整合图像的视野。
- MagViT2 Dances with Non-RGB Data:围绕 MagViT2 与非 RGB 运动数据(特别是 24x3 数据集)的潜在兼容性展开了讨论。
- 虽然对话简短,但提出了关于 AI 模型中非标准数据格式预处理需求的问题。
- Choreographing Data for AI Steps:非 RGB 运动数据的预处理技术引起了关注,以确保它们能与现有的 AI 模型和谐协作。
- 这些技术的细节仍有待在进一步讨论中明确。
DiscoResearch Discord
- OpenArena 开启 LLM 竞赛:OpenArena 的发布启动了一个新的 LLM 对决平台,通过第三方模型评审来增强数据集的完整性。
- OpenArena 主要整合了 Ollama 模型,并与任何基于 OpenAI 的端点兼容,扩展了其在 AI 领域的潜在应用。
- WizardLM 论文聚焦 Arena Learning:WizardLM 论文 详细介绍了“Arena Learning”的概念,为 LLM 评估建立了一种新方法。
- 这种基于模拟的方法侧重于细致的评估和持续的离线模拟,通过监督微调和强化学习技术来增强 LLM。
Alignment Lab AI Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
AI Stack Devs (Yoko Li) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
Torchtune Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
第 2 部分:频道详细摘要与链接
完整的各频道详细分析已因邮件长度而截断。
如果您喜欢 AInews,请分享给朋友!预谢!