ainews-lskjd
Mini, Nemo, Turbo, Lite - 小模型起飞 (GPT4o 版)
GPT-4o-mini 正式发布,其价格较 text-davinci-003 降低了 99%,仅为 GPT-4o 价格的 3.5%,且基准测试表现达到了 Opus 级别。它支持 16k 输出 token,运行速度快于以往模型,并即将支持文本、图像、视频和音频的输入与输出。Mistral Nemo 是与英伟达 (Nvidia) 联合开发的 12B 参数模型,具备 128k token 上下文窗口和 FP8 检查点,拥有强劲的基准测试表现。Together Lite 和 Turbo 推出了 Llama 3 的 fp8/int4 量化版本,吞吐量提升高达 4 倍,并显著降低了成本。DeepSeek V2 现已开源。即将发布的动态包括至少 5 款未发布的模型,以及在 ICML 2024 前夕流出的 Llama 4 泄露信息。
效率就是你所需要的一切。
2024年7月17日至7月18日的 AI 新闻。我们为你检查了 7 个 subreddits、384 个 Twitter 账号 和 29 个 Discord 社区(包含 467 个频道和 2324 条消息)。预计节省阅读时间(按每分钟 200 字计算):279 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论了!
就像公共汽车和创业点子/小行星撞击地球题材的电影一样,很多时候你都在等待事情发生,而有些日子里,许多事情会在同一天扎堆出现。这种情况在每个月的月中总会以一种令人费解的、类似占星术般的规律性发生——2月15日、4月15日、5月13日,而现在是 7月17日:
- GPT-4o-mini (HN):
- 定价:每百万 token (mtok) $0.15/$0.60(基于 3:1 的输入:输出 token 混合定价,价格仅为 Haiku 的一半,但拥有 Opus 级别的基准测试表现(包括在 BigCodeBench-Hard 上),且价格仅为 GPT-4o 的 3.5%,但在 Lmsys 上与 GPT-4 Turbo 持平)。
- 计算:GPT-4o-mini (3 * 0.15 + 0.6)/4 = 0.26,Claude Haiku (3 * 0.25 + 1.25)/4 = 0.5,GPT-4o (5 * 3 + 15)/4 = 7.5,GPT-4 Turbo 价格曾是 GPT-4o 的 2 倍。
- sama 将其宣传为相比 text-davinci-003 降价了 99%。
- 相比 GPT-3.5,对长上下文的利用率显著提升。
- 支持 16k 输出 token!(比 GPT-4 Turbo/4o 多 4 倍)
- “快了一个数量级”——(约 100tok/s,比 Haiku 稍慢)。
- “未来将支持文本、图像、视频和音频的输入及输出”。
- 首个在全新指令层级 (instruction hierarchy) 框架下训练的模型(我们的相关报道)……但已被越狱。
- @gdb 表示这是由于开发者的需求。
- ChatGPT 语音模式 Alpha 版承诺本月推出。
- 在与 Claude 3.5 Sonnet 的对比中受到批评。
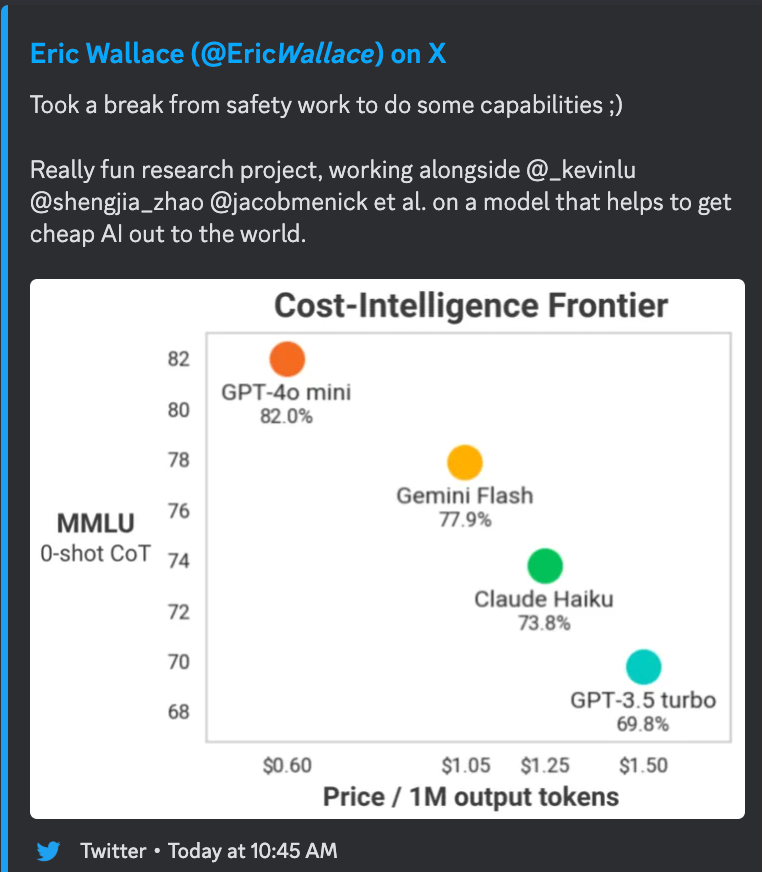
-
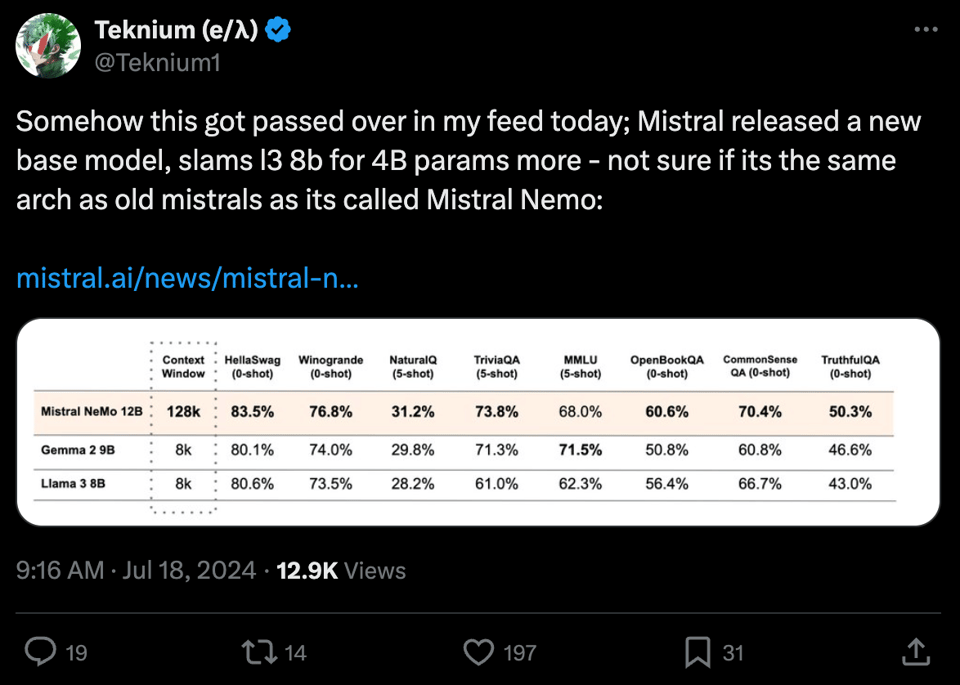
Mistral NeMo (HN):一个与 Nvidia 合作训练的 12B 模型(Nemotron,我们的相关报道)。Mistral NeMo 支持 128k token 的上下文窗口(该级别中原生训练的最高水平,并配有全新的代码/多语言友好型分词器 (tokenizer)),提供 FP8 对齐的检查点,并且在所有基准测试中表现极其出色(“以多出 4B 的参数量碾压 Llama 3 8B”)。
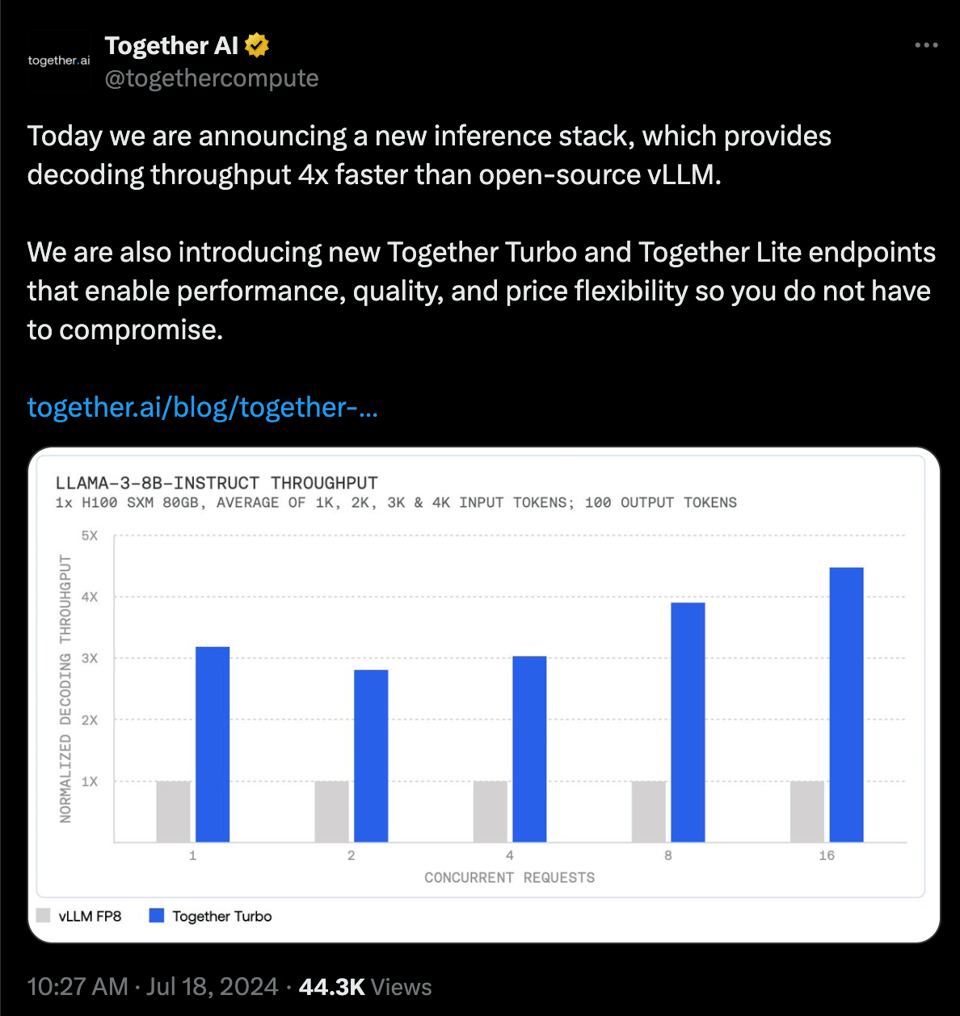
- Together Lite 和 Turbo(Llama 3 的 FP8/Int4 量化版本),吞吐量是 vLLM 的 4 倍。
- Turbo (FP8) —— 主打速度:400 tok/s。
- Lite (Int4) —— 主打成本:$0.1/mtok。“Llama 3 的最低成本”,“比 GPT-4o-mini 成本低 6 倍。”
- DeepSeek V2 开源(我们的报道 涵盖了该论文仅发布 API 时的内容)。
- 注意,Lmsys 上至少还有 5 个代号未公布的模型。
- 以及一些关于 Llama 4 的泄露信息。
至于为什么这些事情都堆在一起——要么是水星逆行,要么是 ICML 下周就要召开了,许多公司都在进行展示或招聘,而且 Llama 3 400b 预计将于 23 日发布。
AI Twitter 综述
所有综述均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型与架构
- Llama 3 和 Mistral 模型:@main_horse 指出 Deepseek 创始人梁文锋表示他们不会走闭源路线,认为强大的技术生态系统更为重要。@swyx 提到在 /r/LocalLlamas 上,Gemma 2 已将 Llama/Mistral/Phi 挤下榜首,在过滤掉大型/闭源模型后,这与 @lmsysorg 的结果一致。
- Anthropic 的方法:@abacaj 注意到,当 OpenAI 发布关于降低智能模型输出能力的论文时,Anthropic 则发布了可供使用的模型,并预计今年晚些时候会推出更大的模型。
- Deepseek Coder V2 和 MLX LM:@awnihannun 分享了最新的 MLX LM 已支持 DeepSeek Coder V2,并在 MLX Hugging Face 社区中提供了预量化模型。一个 16B 模型在 M2 Ultra 上运行速度很快。
- Mistral AI 的 Mathstral:@rasbt 对 Mistral AI 发布 Mathstral 感到惊喜,并将其移植到 LitGPT,作为中小型专业化 LLM 的案例研究,初步印象良好。
- 来自 Google 的 Gemini 模型:@GoogleDeepMind 分享了关于 Gemini 等多模态模型如何帮助机器人变得更有用的最新研究。
- Yi-Large:@01AI_Yi 指出 Yi-Large 在 #LMSYS 排行榜的总榜中继续稳居前 10 名。
开源与闭源之争
- 支持开源的论点:@RichardMCNgo 认为,鉴于开源在过去几十年推动技术进步的成功经验,应强烈倾向于开源。它一直是可解释性对齐(alignment)进展的关键。
- 对开源的担忧:@RichardMCNgo 指出,核心担忧是让恐怖分子制造生物武器,但认为相比于“朝鲜有能力杀死数十亿人”之类的风险,人们很容易对恐怖主义产生不成比例的恐惧。
- 理想情景与负责任披露:@RichardMCNgo 表示,在理想情况下,开源应落后于前沿水平一两年,让世界有机会评估并应对重大风险。如果开源看起来可能追上或超越闭源模型,他会支持强制执行“负责任披露”期。
AI Agent 与框架
- Rakis 数据分析:@hrishioa 提供了关于 Rakis 如何处理推理请求以实现去中心化分布式推理的入门指南,使用了哈希、法定人数(quorums)和嵌入聚类(embeddings clustering)等技术。
- 多 Agent 礼宾系统:@llama_index 分享了一个开源仓库,展示如何构建复杂的、多 Agent 树状系统来处理客户交互,包含常规子 Agent 以及用于礼宾、编排和持续功能的元 Agent。
- LangChain 的改进:@LangChainAI 引入了通用的聊天模型初始化器,可与任何模型对接,并在初始化或运行时设置参数。他们还增加了在 Agent 中分发自定义事件和编辑图状态的功能。
- Guardrails Server:@ShreyaR 宣布推出 Guardrails Server 以简化 Guardrails 的云端部署,具备 OpenAI SDK 兼容性、跨语言支持,以及 Guardrails Watch 和针对开源 LLM 的 JSON 生成等增强功能。
提示词技术与数据
- Prompt Report 调查:@labenz 分享了一个 3 分钟的视频,介绍了来自 The Prompt Report 的 6 大 few-shot prompting 最佳实践建议。该报告是一份长达 76 页、涵盖了 1,500 多篇 prompting 论文的综述。
- Evol-Instruct:@_philschmid 详细介绍了来自 @Microsoft 和 @WizardLM_AI 的 Auto Evol-Instruct 如何在无需人类专家知识的情况下,自动演化合成数据以提高质量和多样性。该方法使用一个 Evol LLM 来创建指令,并使用一个 Optimizer LLM 来评判和优化该过程。
- Llava-NeXT 的交错数据:@mervenoyann 分享称,在交错的图像、视频和 3D 数据上训练新的视觉语言模型 Llava-NeXT-Interleave,可以提升所有基准测试的结果并实现任务迁移。
梗与幽默
- @swyx 针对许多人试图出售 AI 铲子而不是去淘金的现象,开玩笑说:“他们说,在淘金热中要制造镐和铲子。”
- @vikhyatk 讽刺道:“试图卖铲子的人太多,真正想去淘金的人不够。”
- @karpathy 惊讶地发现 FFmpeg 不仅仅是一个多媒体工具包,更是一场运动。
- @francoisfleuret 分享了与 GPT 之间关于解决一个涉及物体着色的谜题的幽默对话。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1:限制 AI 模型可用性的欧盟法规
-
Andrej Karpathy 宣布成立新的 AI 教育公司 Eureka Labs (评分: 239, 评论: 54):Andrej Karpathy 宣布成立 Eureka Labs,这是一家新的 AI 教育公司。该公司的首款产品是 LLM101n,被誉为“世界上最好的 AI 课程”,课程材料可在 GitHub 上获取。Eureka Labs 的官网为 www.eurekalabs.ai。
-
受监管机构影响,即将推出的多模态 Llama 模型将不向欧盟企业开放 (评分: 341, 评论: 138):由于监管挑战,Meta 的多模态 Llama 模型将不会向 欧盟企业 开放。该问题源于使用 欧洲客户 数据训练模型的 GDPR 合规性,而非即将出台的 AI Act。Meta 声称已向 20 亿欧盟用户 通知了用于训练的数据使用情况并提供了退出选项,但在收到监管机构极少反馈后,于 6 月 被要求暂停使用 欧盟数据 进行训练。
{kind=link}
主题 2:LLM 量化技术的进展
-
新的 LLM 量化算法 EfficientQAT,使 2-bit INT Llama-2-70B 在内存占用更少的情况下性能超越 FP Llama-2-13B。 (评分: 130, 评论: 51):EfficientQAT 是一种新的量化算法,成功挑战了 LLM 均匀(INT)量化的极限。该算法在单张 A100-80GB GPU 上仅用 41 小时 就生成了 2-bit Llama-2-70B 模型,与全精度相比,准确率下降不到 3%(69.48 vs. 72.41)。值得注意的是,这个 INT2 量化的 70B 模型在准确率上超过了 Llama-2-13B 模型(69.48 vs. 67.81),同时使用的内存更少(19.2GB vs. 24.2GB),代码已在 GitHub 上发布。
-
介绍 Spectra:三进制(Ternary)与 FP16 语言模型的全面研究 (Score: 102, Comments: 14): Spectra LLM 套件推出了 54 个语言模型,包括 TriLMs (Ternary) 和 FloatLMs (FP16),参数范围从 99M 到 3.9B,并在 300B tokens 上进行了训练。研究表明,1B+ 参数的 TriLMs 在同尺寸下表现始终优于 FloatLMs 及其量化版本,其中 3.9B TriLM 在常识推理和知识基准测试中的表现与 3.9B FloatLM 相当,尽管其位宽(bit size)比 830M FloatLM 还要小。然而,研究也指出 TriLMs 表现出与较大 FloatLM 相当的毒性和刻板印象,且在验证集和网络语料库上的 Perplexity 表现落后。
- 探索 Llama.cpp 集成:Hugging Face 上的 TriLM 模型 目前是未打包(unpacked)的。开发者们讨论了在 llama.cpp 中支持 BitnetForCausalLM 的可能性,SpectraSuite GitHub 仓库中提供了打包和加速 TriLMs 的指南。
- 训练成本与优化:讨论了在 300B tokens 上训练 3.9B TriLM 等模型的成本。在具有 16GB RAM 的 V100 GPUs 上训练需要水平扩展,导致与使用 H100s 相比通信开销更高。提到了在 Hopper/MI300Series GPUs 上使用 FP8 ops 的潜在收益。
- 社区反响与未来前景:开发者对 TriLM 的结果表示热烈欢迎,并期待更成熟的模型。提到了对扩展到 12GB 模型 的兴趣,并有人询问关于在 Colab 等平台上对这些模型进行其他语言微调(finetuning)的问题。
主题 3. 针对特定任务的 LLMs 对比分析
-
最佳故事写作 LLMs:SFW 与 NSFW 选项 (Score: 61, Comments: 24): 最佳故事写作 LLMs:SFW 与 NSFW 对比。该帖子对比了用于故事写作的各种 Large Language Models (LLMs),将其分为 SFW 和 NSFW 类别。对于 SFW 内容,推荐 Claude 3.5 Sonnet 为最佳选择;而 Command-R+ 被强调为 NSFW 写作的首选,作者指出它在显式和非显式内容方面表现都很好。对比涵盖了 GPT-4.0、Gemini 1.5 pro、Wizard LM 8x22B 和 Midnight Miqu 等模型的上下文处理、指令遵循和写作质量。
-
Cake:用于移动端、桌面端和服务器的 Rust 分布式 LLM 推理框架 (Score: 55, Comments: 16): Cake 是一个基于 Rust 的分布式 LLM 推理框架,专为移动端、桌面端和服务器平台设计。该项目旨在利用 Rust 的安全性和效率特性,为运行大语言模型提供高性能、跨平台的解决方案。虽然仍在开发中,但 Cake 有望成为在各种设备和环境中部署 LLM 的通用工具。
- 想象末日后的 LLM 聚会:Homeschooled316 构思了在荒原中将旧的 iPhone 21s 连接到 Cake host 进行分布式 LLM 推理的社区。用户询问关于婚姻和瘟疫的问题,冒着收到称赞已失效经济政策的无关回复的风险。
- Key_Researcher2598 表达了对 Cake 的兴奋,指出 Rust 正从 Web 开发 (WASM) 扩展到游戏开发 (Bevy),现在又扩展到机器学习领域。他们计划将 Cake 与 Python 的 Ray Serve 进行对比。
主题 4. 创新的 AI 教育与开发平台
- Andrej Karpathy 启动名为 Eureka Labs 的新 AI 教育公司 (Score: 239, Comments: 54): Andrej Karpathy 宣布成立 Eureka Labs,这是一家新的 AI 教育公司。他们的首个产品 LLM101n 被誉为“世界上最好的 AI 课程”,可在其网站 www.eurekalabs.ai 上获取,课程仓库托管在 GitHub。
所有 AI Reddit 摘要
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. AI 在漫画与艺术创作中的应用
-
[/r/OpenAI] 我朋友为我的食人魔专辑制作了一个 AI 生成的音乐视频,他做得棒吗? (Score: 286, Comments: 71): AI 生成的音乐视频展示了对“食人魔专辑”的超现实视觉诠释。视频融合了奇幻与怪诞的意象,包括类食人魔生物、神秘景观以及似乎与音乐同步的异世界场景。虽然未提及具体使用的 AI 工具,但结果展示了 AI 在制作独特且主题连贯的音乐视频方面的创意潜力。
-
[/r/singularity] 他们在搞什么名堂? (Score: 328, Comments: 188): AI 生成艺术争议:最近在社交媒体上分享的一张图片描绘了一件 AI 生成的艺术作品,画面是一个在厨房里做饭的扭曲人物形象。这张图片引发了关于 AI 创作艺术的伦理影响和艺术价值的讨论,一些观众觉得它令人不安,而另一些人则欣赏其独特的审美。
-
[/r/StableDiffusion] 我,我自己,以及 AI (Score: 276, Comments: 57): “我,我自己,以及 AI”:这篇文章描述了一位艺术家整合 AI 工具进行漫画创作的工作流。该过程包括使用 Midjourney 进行初始角色设计和背景制作,使用 ChatGPT 进行故事开发和对话编写,以及使用 Photoshop 进行最终润色和分镜布局,从而实现了 AI 辅助与传统艺术技巧的无缝融合。
- 艺术家的 AI 整合引发辩论:该艺术家自 2022 年 10 月以来一直将 Stable Diffusion 纳入工作流,这引发了褒贬不一的反应。一些人欣赏这种创新方法,而另一些人则指责艺术家“懒惰且不道德”。艺术家计划继续创作漫画,让作品自己说话。
- AI 作为艺术工具:许多评论者将 AI 辅助艺术与创意领域的其他技术进步进行了类比。一位用户将其比作从胶片摄影到数字摄影的转变,认为 AI 辅助工作流将在未来几年成为行业标准。
- 工作流见解:艺术家透露使用 pony 模型作为基础,并根据其旧作微调了黑白和彩色 Loras。他们建议在角色设计上与模型进行“协作”,以创建更直观且能与 AI 工具良好配合的设计。
- 艺术价值辩论:一些评论挑战了“艺术需要付出努力”的观念,认为最终结果才应该是关注的焦点。有人认为 AI 工具类似于专业摄影中的照片编辑,真正的创作工作发生在初始生成之后。
{kind=link}
主题 2. 使用 Kling AI 进行实时 AI 视频生成
- [/r/OpenAI] GPT-4o in your webcam (Score: 312, Comments: 45): GPT-4o in your webcam 将 GPT-4 Vision 与 webcam 集成,实现实时交互。该设置允许用户向电脑摄像头展示物体,并获得来自 GPT-4 的即时响应,从而实现更具交互性和动态的 AI 体验。这种集成展示了 AI 实时处理和响应视觉输入的潜力,将人机交互的可能性扩展到了文本界面之外。
- [/r/StableDiffusion] Hiw to do this? (Score: 648, Comments: 109): 据报道,一款中国 Android 应用允许用户创建名人与其年轻时的自己相遇的 AI-generated videos。该过程被描述为非常简单,用户只需输入两张照片并点击一个按钮,尽管帖子中未提供该应用的具体名称或功能的详细信息。
- “Kling AI” 据报道为这款中国应用提供动力,允许用户创建名人与年轻时的自己相遇的视频。许多评论者注意到了两人之间亲密的肢体语言,一位用户开玩笑说:“为什么他们中有一半看起来像是 10 秒钟后就要亲热的样子。”
- 史泰龙的自我迷恋抢尽风头 - 几位用户强调了 Sylvester Stallone 与年轻时的自己的互动特别强烈,评论如 “该死,史泰龙太饥渴了” 以及 “史泰龙要搞定他自己”。这引发了一场关于跨时空与自己进行亲密行为算作同性恋还是自慰的哲学辩论。
- 错失的机会与情感冲击 - 一些用户提出了改进建议,比如让 Harrison Ford 怀疑地看着年轻时的自己。一位评论者表示,这个概念让他感到意外的情感触动,特别欣赏通过名人配对传达的 “培养对自己的善意” 的信息。
- 技术推测与伦理担忧 - 讨论涉及了该应用潜在的硬件需求,一位用户建议它需要 “大约一千个 GPU”。其他人则辩论了这种技术的含义,一些人对中国的进展表示赞赏。
- [/r/StableDiffusion] Really nice usage of GPU power, any idea how this is made? (Score: 279, Comments: 42): 实时 AI 视频生成展示了对 GPU power 令人印象深刻的利用。该视频演示了流畅、动态的内容创作,可能利用了现代 GPU 的先进 machine learning models 和并行处理能力。虽然未提供具体的实现细节,但这项技术可能结合了 generative AI 技术与高性能计算来实现实时视频合成。
- 带有 1-step scheduler 的 SDXL turbo 可以在 4090 GPU 上以 512x512 resolution 实现实时性能。根据用户测试,即使是 3090 GPU 也能实时处理。
- 技术栈分解:评论者建议该设置可能包括 TouchDesigner、Intel Realsense 或 Kinect、OpenPose 以及输入到 SDXL 的 ControlNet。一些人推测这是一个不含 ControlNet 的简单 img2img 过程。
- 精简的工作流:该过程可能涉及拍摄演员,生成 OpenPose skeleton,然后根据该骨架形成图像。StreamDiffusion 与 TouchDesigner 的集成被提到是一个“神奇”的解决方案。
- 致谢:原视频归功于 Instagram 上的 mans_o,可在 https://www.instagram.com/p/C9KQyeTK2oN/?img_index=1 查看。
主题 3. OpenAI 的 Sora 视频生成模型
- [/r/singularity] 新 Sora 视频 (Score: 367, Comments: 128): OpenAI 的 Sora 发布了一段新视频,展示了其先进的 AI 视频生成能力。该视频展示了 Sora 创建高度详细且逼真场景的能力,包括复杂的环境、多个角色和动态动作。这次最新的演示突显了 AI 生成视频技术的飞速进步及其在各个领域的潜在应用。
- 评论者预测 Sora 的技术 将在 一年内变得非常出色,并在 2-5 年内与现实无异。一些人认为它已经可以在某些应用中投入市场,而另一些人则指出了仍然存在的缺陷。
- Uncanny Valley 挑战:用户注意到演示视频中在 物理、运动和连续性方面存在不一致性。问题包括奇怪的脚部放置、梦幻般的动作以及角色外观的快速变化。一些人认为这些问题可能比预期的更难解决。
- 潜在应用与局限性:讨论集中在 AI 在 CGI 和低预算制作中的作用。虽然目前还无法取代真人实拍,但它可能会彻底改变社交媒体内容和电影中的背景元素。然而,人们对 OpenAI 有限的公开访问权限 提出了担忧。
- 飞速进步令人震惊:许多人对 AI 视频进化的速度 表示惊讶,将其与早期的里程碑(如 thispersondoesnotexist.com)进行比较。尽管仍有瑕疵,但从早期演示到 Sora 能力的飞跃被认为是卓越的。
主题 4. AI 监管与部署挑战
-
[/r/singularity] Meta 将不会向欧盟提供未来的多模态 AI 模型 (Score: 341, Comments: 161): Meta 宣布,由于监管的不确定性,它将不会在 欧盟 (EU) 发布未来的 多模态 AI 模型。该公司对 EU AI Act 表示担忧,该法案仍在最终敲定中,可能会对 AI 系统施加严格的规则。这一决定影响了 Meta 即将推出的 LLM 和 生成式 AI 功能,可能导致欧盟用户无法使用这些先进的 AI 技术。
-
[/r/OpenAI] Sam Altman 称其价值 2700 万美元的旧金山豪宅完全是个“柠檬” (Score: 244, Comments: 155): OpenAI 的 CEO Sam Altman 在最近的一次采访中表达了对他 2700 万美元旧金山豪宅 的沮丧,称其完全是一个“柠檬”(lemon,指有缺陷的产品)。尽管该房产价格高昂且位于 Russian Hill 的显赫位置,Altman 透露房子一直受到众多问题的困扰,包括 游泳池、供暖系统 和 电气线路 的问题。这种情况突显了高端房地产购买的潜在陷阱,即使是拥有巨额资源的科技行业领袖也不例外。
-
[/r/singularity] Marc Andreessen 和 Ben Horowitz 表示,当他们与白宫官员讨论 AI 时,官员们称他们可以将任何他们认为导向不良的数学领域列为国家机密,并且“它将就此终结” (Score: 353, Comments: 210): Marc Andreessen 和 Ben Horowitz 报告称,白宫官员 声称,如果他们认为某个 数学领域 的发展不利于 AI 发展,他们可以将其列为 国家机密。据称,官员们表示通过这种方式,他们可以有效地终结该数学领域的进展。这一启示表明,政府可能采取一种通过数学审查来控制 AI 进步的潜在策略。
AI Discord 摘要
正如我们在前沿模型发布日所做的那样,今天的 Discord 摘要有两个版本。你正在阅读的版本是由 GPT-4o 生成频道摘要,然后将频道摘要汇总为 {4o/mini/sonnet/opus} 的“摘要之摘要”。请查看存档以获取 GPT-4o-mini 配对,以便进行逐个频道的摘要对比。
Claude 3 Sonnet
1. 新型 AI 模型发布与功能
- GPT-4o Mini:OpenAI 的高性价比利器:OpenAI 推出了 GPT-4o mini,这是一款比 GPT-3.5 Turbo 更便宜、更智能的模型,在 MMLU 上得分 82%,拥有 128k context window,价格为 每百万输入 token 0.15 美元,每百万输出 token 0.60 美元。
@AndrewCurran_证实 GPT-4o mini 正在为免费和付费用户取代 GPT-3.5 Turbo,它在显著降低成本的同时提升了 GPT-3.5 的能力,尽管初期缺乏图像支持等某些功能。
- Mistral NeMo:NVIDIA 合作释放强大性能:Mistral AI 与 NVIDIA 联合发布了 Mistral NeMo,这是一个拥有 128k context window 的 12B 模型,在 Apache 2.0 license 下提供最先进的推理、世界知识和代码准确性。
- Mistral NeMo 支持无损的 FP8 inference,性能超越了 Gemma 2 9B 和 Llama 3 8B 等模型,并提供预训练基座模型和指令微调(instruction-tuned)检查点。
- DeepSeek V2 引发中国价格战:DeepSeek 的 V2 模型将推理成本削减至每百万 token 仅 1 元人民币,凭借其革命性的 MLA architecture 和显著降低的内存占用,引发了中国 AI 公司之间的竞争性定价狂潮。
- DeepSeek V2 获得了中国 AI 界的拼多多之称,因其削减成本的创新而受到赞誉,其极高的性价比可能会颠覆全球 AI 格局。
2. 大语言模型(LLM)技术的进步
- Codestral Mamba 凭借线性推理脱颖而出:新推出的 Codestral Mamba 由 Albert Gu 和 Tri Dao 共同开发,凭借其线性时间推理(linear time inference)和处理无限长序列的能力,承诺在代码生成能力上实现飞跃。
- 旨在提高编程效率,Mamba 的目标是在提供无论输入长度如何都能快速响应的同时,超越现有的基于 SOTA Transformer 的模型。
- Prover-Verifier Games 提升 LLM 的可读性:一种名为 Prover-Verifier Games 的新技术已被证明可以提高语言模型输出的可读性和可解释性,详情见相关论文。
- 通过增强 LLM 推理的可解释性,该方法旨在解决开发更透明、更值得信赖的 AI 系统所面临的关键挑战。
3. 硬件优化与 AI 性能
- Resizable BAR 对 LLM 影响微乎其微:讨论表明,旨在增强 GPU 性能的 Resizable BAR 功能对 LLM 操作的影响可以忽略不计,因为 LLM 更依赖于 tensor cores 和 VRAM 带宽。
- 虽然有人推测模型加载和多 GPU 设置可能会从中受益,但社区共识倾向于认为 Resizable BAR 对核心 LLM 工作负载的影响极小。
- Lubeck 凭借 LLVM 效率超越 MKL:Lubeck 数值库展示了优于 MKL (Math Kernel Library) 的性能,这归功于其差异化的 LLVM IR 生成,可能得到了 Mir 的 LLVM 加速通用数值库的辅助。
- 一项 基准测试对比 强调了 Lubeck 的速度优势,引发了关于利用 LLVM 进行优化数值计算的讨论。
4. AI 代码助手与集成
- OpenRouter 上的 Codestral 22B 请求:一位用户请求将 Codestral 22B 添加到 OpenRouter,这是一个性能与最先进的基于 Transformer 的模型相当的开源代码模型,并分享了 model card 以供参考。
- Codestral Mamba 在代码生成任务中展示了极具竞争力的性能,激发了人们将其集成到 OpenRouter 等流行 AI 平台中的兴趣。
- Groq 模型主导 Function Calling 排行榜:Groq 新的 tool use 模型,包括 Llama-3-Groq-8B 和 Llama-3-Groq-70B,在 Berkeley Function Calling Leaderboard 上分别获得了 89.06% 和 90.76% 的最高分。
- 这些模型针对 tool use 和 function calling 能力进行了优化,展示了 Groq 在开发擅长执行复杂多步任务的 AI 助手方面的实力。
Claude 3.5 Sonnet
1. AI 模型发布与升级
- DeepSeek V2 引发价格战:DeepSeek 发布了 DeepSeek V2,将推理成本大幅降低至每百万 token 1 元,引发了中国 AI 企业之间的价格战。该模型引入了全新的 MLA architecture,显著降低了显存占用。
- DeepSeek V2 被称为中国 AI 界的拼多多,其极致的性价比和架构创新使其成为 AI 市场的一股颠覆性力量。此次发布凸显了 AI 模型开发与部署中日益激烈的竞争。
- Mistral NeMo 12B 强力模型:Mistral AI 与 NVIDIA 联合推出了 Mistral NeMo,这是一个拥有 12B 参数的模型,具备 128k token 的上下文窗口和顶尖的推理能力。该模型在 Apache 2.0 许可证下发布,提供预训练和指令微调(instruction-tuned)检查点。
- Mistral NeMo 支持无性能损失的 FP8 inference,定位为 Mistral 7B 的无缝替换方案。Mistral AI 与 NVIDIA 的此次合作展示了模型架构和行业伙伴关系的快速演进。
- OpenAI GPT-4o mini 亮相:OpenAI 推出了 GPT-4o mini,号称是其最智能且最具成本效益的小型模型,在 MMLU 上得分为 82%。其价格为每百万输入 token 0.15 美元,每百万输出 token 0.60 美元,比 GPT-3.5 Turbo 便宜得多。
- 该模型支持文本和图像输入,拥有 128k 上下文窗口,已向免费版 ChatGPT 用户及各级付费用户开放。此次发布展示了 OpenAI 致力于让先进 AI 对开发者和企业而言更易获取、更负担得起的决心。
2. 开源 AI 进展
- LLaMA 3 的 Turbo 加速版本:Together AI 推出了 LLaMA 3 的 Turbo 和 Lite 版本,提供更快的推理速度和更低的成本。LLaMA-3-8B Lite 的价格为每百万 token 0.10 美元,而 Turbo 版本 的生成速度高达 400 tokens/s。
- 这些新变体旨在使 LLaMA 3 在各种应用中更易用、更高效。社区中关于可能发布的 LLaMA 3 400B 的传闻也甚嚣尘上,这可能会对开源 AI 格局产生重大影响。
- DeepSeek-V2 登顶开源榜单:DeepSeek 宣布其 DeepSeek-V2-0628 模型现已开源,并在 LMSYS Chatbot Arena Leaderboard 的开源类别中排名第一。该模型在包括综合性能和困难提示词(hard prompts)在内的多项基准测试中表现出色。
- 这一发布凸显了开源模型相对于闭源模型日益增长的竞争力。它还强调了社区在创建高性能、可自由获取的 AI 模型以用于研发方面所做的努力。
3. AI 安全与伦理挑战
- GPT-4 的过去式漏洞:一篇新论文揭示了 GPT-4 的一个重大漏洞:通过将有害请求重新表述为过去式,在 20 次尝试下,越狱成功率从 1% 提高到了 88%。
- 这一发现凸显了当前 AI 安全措施(如 SFT, RLHF 和 adversarial training)的潜在弱点。它引发了人们对对齐技术鲁棒性的担忧,并表明在 AI 开发中需要更全面的安全策略。
- Meta 的多模态模型排除欧盟地区:据 Axios 报道,Meta 计划在未来几个月发布多模态 Llama model,但由于监管的不确定性,该模型将不会在欧盟地区提供。
- 这一决定凸显了 AI 发展与监管合规之间日益紧张的关系,尤其是在欧盟。它还引发了关于潜在技术鸿沟以及地区法规对全球 AI 进步影响的讨论。
Claude 3 Opus
1. Mistral NeMo 12B 模型发布
- Mistral 与 NVIDIA 合作推出 128k 上下文模型:Mistral NeMo 是一款具有 128k token 上下文窗口的 12B 模型,由 Mistral 与 NVIDIA 合作开发,并根据 Apache 2.0 license 发布,详见官方发布说明。
- 该模型在其尺寸类别中提供了顶尖的推理能力、世界知识和编程准确性,可作为 Mistral 7B 的直接替代方案,并支持无损性能的 FP8 inference。
- Mistral NeMo 性能超越同类尺寸模型:Mistral NeMo 的性能已与其他模型进行了对比,尽管在 Meta 报告的针对 Llama 3 8B 的 5-shot MMLU scores 等基准测试中存在一些差异。
- 尽管存在这些不一致之处,根据发布公告,Mistral NeMo 仍被视为强有力的竞争者,在多项指标上超越了 Gemma 2 9B 和 Llama 3 8B 等模型。
2. GPT-4o Mini 发布与越狱
- GPT-4o Mini:比 GPT-3.5 更聪明、更便宜:OpenAI 发布了 GPT-4o mini,被誉为能力最强且最具成本效益的小型模型,在 MMLU 上得分为 82%。据 Andrew Curran 宣布,该模型已向免费和付费用户开放。
- 该模型的定价为每 M token 输入 15 美分,每 M token 输出 60 美分,拥有 128k 上下文窗口。这使得它比 GPT-3.5 Turbo 便宜得多,但缺少完整版 GPT-4o 的某些功能(如图像支持)。
- GPT-4o Mini 的安全机制被越狱:据 Elder Plinius 称,GPT-4o mini 中新实施的名为“指令层级”(instruction hierarchy)的安全机制已被越狱,使其能够输出受限内容。
- 此次越狱揭示了 OpenAI 最新防御方法的漏洞,引发了人们对其实施安全措施的稳健性以及潜在滥用风险的担忧。
3. AI 训练与部署的进展
- Tekken Tokenizer 效率超越 Llama 3:Tekken tokenizer 模型展示了优于 Llama 3 tokenizer 的性能,在包括中文、韩文、阿拉伯文和源代码在内的多种语言中,压缩率提高了 30-300%。
- 这种效率的提升使 Tekken 成为 NLP 任务的强力竞争者,在降低计算成本和实现更紧凑的模型表示方面具有显著优势。
- 通过新编译器在 AMD GPU 上运行 CUDA:一款针对 AMD GPU 的新编译器已实现在 RDNA 2 和 RDNA 3 架构上的 CUDA 支持。正如 Reddit 帖子中所分享的,RX 7800 已确认可以运行。
- 社区成员表示有兴趣在 llama.cpp 中测试此设置,以对比 ROCm implementation 的性能,并提到了 ZLUDA 和 SCALE 等工具作为在 AMD 硬件上运行 CUDA 的替代方案。
GPT4O (gpt-4o-2024-05-13)
1. Mistral NeMo 发布
- Mistral NeMo 的惊艳亮相:Mistral NeMo 模型是由 NVIDIA 合作开发的 12B 参数模型,拥有 128k token 上下文窗口和卓越的推理能力。
- 预训练和指令微调的 Checkpoints 已在 Apache 2.0 许可证下发布,在推理、代码准确性和世界知识方面具有最前沿的性能。
- Mistral NeMo 性能对比:注意到 Llama 3 8B 的 5-shot MMLU 分数存在差异,Mistral 报告为 62.3%,而 Meta 报告为 66.6%,这引发了对报告性能的质疑。
- 这一差异以及 TriviaQA 基准测试中潜在的问题,引发了关于这些指标可靠性的讨论。
2. AI 硬件优化
- 内核探索:应对参数限制:AI 工程师通过优先使用指针传递大型数据结构,解决了 CUDA 4k 内核参数大小限制问题,在这种情况下,必须将数据从 CPU 迁移到 GPU 全局内存。
- 对话转向了指针的复杂性,阐明了内核参数中指针对于寻址 GPU 内存的必要性,并消除了在 CUDA 内存分配中关于 ** 与 * 使用的困惑。
- 模型肌肉:探索高性能硬件的 AI 训练:关于最佳 AI 训练配置的讨论称赞了 A6000 GPU 的性价比,一位用户重点介绍了一套 64 核 Threadripper 配备双 A6000 的配置。
- 这套最初用于流体动力学模拟的配置,激发了人们对高端硬件在 AI 训练中通用性的兴趣和讨论。
3. 多模态 AI 进展
- Meta 发布多模态 Llama 模型:Meta 计划推出多模态 Llama 模型,但由于监管限制,欧盟用户被排除在外,正如 Axios 报告 中所强调的那样。
- 诸如使用 VPN 或勾选非欧盟合规复选框之类的变通方法已经在私下流传,预示着访问破解行为可能会增加。
- 涡轮增压版 LLaMA 3 版本投入使用:Together AI 推出的 LLaMA-3-8B Lite 承诺提供极具成本效益的 每百万 token 0.10 美元的价格,确保了经济性与速度的结合。
- 为了增强部署格局,LLaMA-3-8B Turbo 的速度飙升至 400 tokens/s,专为追求极速效率的应用而量身定制。
4. 模型训练问题
- 模型训练困扰:乌云密布:社区讨论了部署和训练模型的挑战,特别是在 AWS 和 Google Colab 等平台上,强调了耗时长和低资源复杂性等问题。
- 特别提到了 Hugging Face Spaces 上的
text2text-generation错误和 GPU 资源困境,贡献者们正在寻求并分享故障排除策略。
- 特别提到了 Hugging Face Spaces 上的
- 微调挑战与 Prompt Engineering 策略:Prompt 设计以及使用正确的模板(包括 end-of-text token)对于在微调和评估期间影响模型性能至关重要。
GPT4OMini (gpt-4o-mini-2024-07-18)
1. Mistral NeMo 模型发布
- Mistral NeMo 令人印象深刻的上下文窗口:Mistral NeMo 是一款与 NVIDIA 合作发布的全新 12B 模型,具有卓越的 128k token 上下文窗口,在推理和编码任务中表现出色。
- 该模型采用 Apache 2.0 许可证发布,关于其与 Llama 3 等其他模型对比效果的讨论已经展开。
- 社区对 Mistral NeMo 的反应:该模型采用 Apache 2.0 许可证发布,关于其与 Llama 3 等其他模型对比效果的讨论已经展开。
- 初步印象显示反响积极,用户渴望测试其各项能力。
2. GPT-4o Mini 发布
- 高性价比 GPT-4o Mini 发布:OpenAI 推出了 GPT-4o mini,这款新模型的定价为 每百万输入 token 0.15 美元 以及 每百万输出 token 0.60 美元,使其比前代产品显著便宜。
- 这一价格结构旨在让更广泛的受众能够接触到先进的 AI。
- GPT-4o Mini 的性能预期:尽管价格实惠,但一些用户对其与 GPT-4 和 GPT-3.5 Turbo 相比的性能表示失望,认为它并未完全达到 OpenAI 设定的高预期。
- 社区反馈表明,虽然它具有成本效益,但在所有场景下可能无法超越现有模型。
3. 深度学习硬件优化
- 使用 A6000 GPU 进行优化:社区讨论强调了利用 A6000 GPU 进行深度学习任务的优势,特别是在以合理成本进行高性能模型训练方面。
- 用户报告了利用 A6000 的能力进行各种 AI 应用的成功配置。
- AI 训练的用户配置:成员们分享了他们的配置,包括从流体力学模拟转为 AI 训练的 双 A6000 设置。
- 这些设置展示了 A6000 GPU 在处理复杂计算任务中的多功能性。
4. RAG 实施挑战
- 对 RAG 技术的怀疑:几位社区成员对 Retrieval Augmented Generation (RAG) 的有效性表示怀疑,称如果没有广泛的微调,它往往会导致次优的结果。
- 共识是,虽然 RAG 具有潜力,但需要大量的定制化投入。
- 社区对 RAG 的反馈:诸如 “如果你想要一个糟糕的结果,RAG 很简单” 之类的评论强调了为了获得理想结果需要付出巨大努力。
- 成员们强调了仔细实施对于释放 RAG 全部潜力的重要性。
5. 多模态 AI 进展
- Meta 的多模态 Llama 模型计划:根据最近的 Axios 报告,Meta 正准备推出多模态 Llama 模型,但由于监管挑战,计划限制在欧盟(EU)地区的访问。
- 这一决定引发了对欧盟用户可访问性的担忧。
- 欧盟用户的绕过方案:用户之间已经在讨论使用 VPN 等绕过方案来突破这些限制。
- 这些讨论凸显了社区在应对监管障碍方面的机敏。
PART 1: 高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
- RAG 的坎坷之路:AI 爱好者就 RAG 展开交锋:几位成员对 RAG 表示怀疑,指出如果不进行广泛的微调,它容易产生不理想的结果。
- “如果你想要一个糟糕的结果,RAG 很简单”暗示了发挥其潜力需要付出巨大努力。
- NeMo 的新篇章:Mistral 发布 12B 强力模型:与 NVIDIA 共同发布的 Mistral NeMo 12B 模型拥有令人印象深刻的上下文窗口,并承诺具备领先的推理能力。
- 根据 Mistral News 链接的公告,Mistral 7B 的采用者现在可以根据 Apache 2.0 license 升级到 NeMo。
- 推迟亮相:Unsloth Studio 的 Beta 发布会延期:Unsloth Studio 宣布推迟其 Beta 测试发布,将计划调整至稍后日期。
- 社区对质量表示支持,回复如“慢慢来——排查故障需要多长时间就花多长时间”。
- 为模型提供动力:探索强悍硬件的 AI 训练:关于最佳 AI 训练配置的讨论称赞了 A6000 GPUs 在价格和性能方面的实力。
- 一位用户的配置——64-core threadripper 配备双 A6000s——引发了关注,突显了该硬件在初始用途(fluid dynamics simulations)之外的多功能性。
- STORM 的成功:塑造结构化摘要:STORM 为 AI 驱动的预写作设定了新标准,其构建的详尽文章在组织结构上提升了 25%,覆盖范围扩大了 10%。
- 该模型集成了专家级多视角提问,可以组装出类似于完整报告的综合性文章,详见 GitHub - stanford-oval/storm。
HuggingFace Discord
- AI 漫画默认气泡上线!:AI Comic Factory 的更新指出,它现在将包含默认对话气泡,该功能仍处于开发阶段。
- 工具 AI Comic Factory 虽然仍在完善中,但旨在通过简化对话元素来增强漫画创作。
- Huggingchat 遇到障碍:响应速度变慢:据报道 Huggingchat 的 commandR+ 运行缓慢,导致用户感到沮丧,一些用户在处理通常只需几秒钟的任务时经历了长达 5 分钟的处理时间。
- 社区中的评论如“他们几乎发了三次同样的消息”突显了影响用户体验的降速问题。
- Florence 2 轻松去除水印:一款使用 Florence 2 和 Lama Cleaner 构建的新水印去除工具展示了其实力,为用户提供了一个高效的移除工具,分享在 Hugging Face Spaces 上。
- 这款水印去除工具旨在易于使用,加入了 Florence 2 的功能套件,有望解决另一个实际问题。
- Mistral NeMo:NVIDIA 的 12B 之子:Mistral NeMo 是一款 12B 模型,现在拥有高达 128k 的上下文长度,以 Apache 2.0 license 首次亮相,专注于高性能,如官方公告所述。
- MistralAI 与 NVIDIA 合作发布的这一新版本分享在 Mistral AI 上,增强了处理海量上下文长度的工具库。
- 模型训练难题:乌云密布:社区讨论了部署和训练模型的考验,特别是在 AWS 和 Google Colab 等平台上,强调了耗时长和低资源复杂性等问题。
- 特别提到了关于 Hugging Face Spaces 上的
text2text-generation错误和 GPU 资源困境,贡献者们正在寻求并分享故障排除策略。
- 特别提到了关于 Hugging Face Spaces 上的
CUDA MODE Discord
- Kernel 探索:应对参数限制:AI 工程师们通过优先使用指针来传递大型数据结构,解决了 CUDA 4k kernel 参数大小限制的问题,在这种场景下,从 CPU 迁移到 GPU 全局内存是强制性的。
- 对话转向了指针的复杂性,阐明了在 kernel 参数中使用指针来寻址 GPU 内存的必要性,并消除了在 CUDA 内存分配中关于
**与*用法的困惑。
- 对话转向了指针的复杂性,阐明了在 kernel 参数中使用指针来寻址 GPU 内存的必要性,并消除了在 CUDA 内存分配中关于
- Google Gemma 2 胜出,随后被超越:Gemma 2 模型因超越了之前的领先者 Llama 2 而吸引了社区的关注,引发了对 Google I/O 上 Google 发布内容的深入探讨。
- 然而,AI 领域的持续进步使得 Gemma 2 迅速被 LlaMa 3 和 Qwen 2 等模型超越,这引发了人们对该行业高速发展的认可。
- GPT-3 125M 模型:突破性的启动:首个 GPT-3 模型 (125M) 训练的启动吸引了社区,其中值得注意的包括 12 小时的预期完成时间以及对最终性能指标的渴望。
- FP8 训练设置的修改和新 Quantization 机制的集成被置于重要位置,指向了未来对模型效率的探索。
- CUDA 难题:Shared Memory 的奥秘:动态 Shared Memory 的效用成为热门话题,诸如
extern __shared__ float shared_mem[];之类的策略被投入到技术讨论中,旨在提升 kernel 性能。- 向动态 Shared Memory 的转变预示着未来更简洁的 CUDA 操作以及对更密集计算过程的共同愿景。
- Triton 编译器的编排艺术:随着 Triton 编译器展示其通过自动微调 GPU 代码将 Python 转换为更易处理的 Triton IR 的才华,人们感到非常兴奋。
- 社区贡献通过分享 Triton Puzzles 的个人解决方案 增强了这一影响,鼓励其他人尝试这些挑战。
Stability.ai (Stable Diffusion) Discord
- RTX 4060 Ti 技巧与提示:关于 RTX 4060 Ti 是否足以运行 Automatic1111 的疑问得到了解答;通过使用
--xformers --medvram-sdxl参数编辑webui-user.bat可以获得最佳的 AI 性能。- 这些配置暗示了社区在 AI 操作中追求硬件效用最大化的探索。
- Adobe Stock 打击艺术家名称的使用:Adobe Stock 修改了其政策,从标题、关键词或 Prompt 中清除艺术家姓名,展示了 Adobe 在 AI 内容生成方面的严格方向。
- 社区对该政策广泛覆盖范围的担忧,反映了对 AI 艺术创作边界的关注。
- AI 艺术的三大难题:讨论指出,手部、文字以及躺在草地上的女性是 AI 渲染中重复出现的陷阱,类似于艺术家的阿喀琉斯之踵。
- 人们对能够纠正这些常见 AI 错误的新模型充满热情,这些错误被揭示为技术人员之间频繁的谈资。
- 揭开 “Ultra” 功能的神秘面纱:对 “Ultra” 功能的技术推测包括对使用 Latent Upscale 或噪声应用等技术的第二采样阶段的期待。
- 澄清说明了 Ultra 已通过网站和 API 提供 Beta 版,将事实与商业化传闻区分开来。
- 关于针对 Troll 进行 IP 封禁的不同看法:IP 封禁威慑 Troll 的有效性引发了关于其实际操作性的激烈辩论,展示了不同的社区管理哲学。
- 讨论揭示了各种专业见解,强调需要一套策略工具箱来维护积极的社区氛围。
Eleuther Discord
- GoldFinch 凭借 Linear Attention 腾飞:GoldFinch 模型成为热门话题,其结合了 Linear Attention 和 Transformers 的混合结构,实现了超长上下文长度并降低了 VRAM 占用。
- 性能讨论强调了其由于高效的 KV-Cache 机制而优于同类模型,并附带了 GitHub 仓库和 Hugging Face 模型链接。
- 数据抓取引发剧烈争议:关于 AI 模型抓取 YouTube 字幕的讨论异常激烈,引发了一系列经济和伦理方面的考量。
- 讨论深入探讨了公平使用(fair use)和公共许可的细微差别,一些用户对法律问题和对比性的舆论愤怒进行了反思。
- 扩展 LLM 的 Patchwork 解决方案:在大型语言模型领域,Patch-Level Training 作为一种潜在的改变游戏规则的技术出现,旨在提高序列训练效率。
- PatchTrain GitHub 是主要的参考点,讨论了 Token 压缩及其对训练动态的影响。
- 通过 Token-Free 视角看可解释性:Tokenization-free 模型 登场,引发了对其对 AI 可解释性(interpretability)影响的好奇。
- 对话涵盖了理论和潜在实现,虽然未达成共识,但激发了有意义的交流。
- ICML 2024 的期待令研究人员兴奋不已:关于 ICML 2024 的讨论层出不穷,其中 grimsqueaker 关于“蛋白质语言模型揭示病毒模拟与免疫逃逸”的见解尤为引人关注。
LM Studio Discord
- Codestral Mamba 潜入 LM Studio:Codestral Mamba 在 LM Studio 中的集成取决于其在 llama.cpp 中的支持,成员们正热切期待其加入。
- LM Studio 对 Codestral Mamba 的增强功能将在其并入底层的 llama.cpp 框架后解锁。
- Resizable BAR 的提升微乎其微:据报告,Resizable BAR(一项增强 GPU 性能的功能)对更依赖 tensor cores 的 LLM 操作 影响微乎其微。
- 讨论集中在硬件功能的效率上,结论是 VRAM 带宽 等因素对 LLM 性能优化具有更大的权重。
- GTX 1050 的 AI 抱负破灭:GTX 1050 的 4GB VRAM 在执行模型时非常吃力,迫使用户考虑缩减到需求较低的 AI 模型。
- 社区成员讨论了模型兼容性,认为 GTX 1050 有限的 VRAM 不适合运行计算更密集的 7B+ 参数模型。
- Groq 模型摘得函数调用桂冠:Groq 的 Llama-3 Groq-8B 和 70B 模型在 Berkeley Function Calling Leaderboard 上的表现令人印象深刻。
- 对 工具使用(tool use)和函数调用(function calls) 的关注使这些模型获得了极具竞争力的分数,展示了它们在实际 AI 场景中的效率。
- CUDA 在 AMD RDNA 上找到新盟友:在 Reddit 上分享的一篇关于新编译器允许 RX 7800 执行的讨论后,CUDA 在 AMD RDNA 架构上的前景引起了兴趣。
- 尽管 SCALE 和便携式安装预示着充满希望的替代方案,但对于通过 ZLUDA 等工具在 AMD 上实现 CUDA 的完全兼容性,怀疑态度依然存在。
Nous Research AI Discord
- 文本梯度(Textual Gradients)成为焦点:围绕一种通过文本反馈进行“微分”的新方法展开了热烈讨论,该方法使用 TextGrad 来指导神经网络优化。
- ProTeGi 凭借类似的方法步入聚光灯下,引发了关于该技术在机器学习应用中潜力的对话。
- STORM 系统的文章创作造诣:斯坦福大学的 STORM 系统利用 LLM 创建全面的大纲,显著提升了长篇文章的质量。
- 作者们现在正致力于解决来源偏见转移(source bias transfer)问题,这是该系统方法论引入的一个新挑战。
- 初步印象:合成数据集与知识库:合成数据集与知识库 发布,旨在增强以商业应用为中心的 AI 系统。
- RAG 系统可以在这个包含大量商业相关数据的 Mill-Pond-Research/AI-Knowledge-Base 中找到宝贵的资源。
- 当 Agent 进化:超越语言模型:一项研究呼吁 LLM 驱动的 Agent 进行进化,建议采用更复杂的处理方式以改进推理,详见这份富有洞察力的 立场论文。
- Mistral-NeMo-12Instruct-12B 震撼发布,宣传其经过多语言和代码数据训练,并拥有 128k 的 context window。
- GPT-4 的过去式谜题:GPT-4 对有害请求重构的鲁棒性受到了冲击,一篇 新论文 发现,通过过去式提示词获取违禁知识的成功率高达 88%。
- 研究敦促针对调查结果中强调的这一意外差距,重新审视当前的对齐技术(alignment techniques)。
Latent Space Discord
- DeepSeek 的工程优雅:DeepSeek 的 DeepSeek V2 将推理成本削减至 每百万 token 1 元,引发了 AI 公司之间的价格战。
- DeepSeek V2 拥有革命性的 MLA 架构,降低了内存占用,为其赢得了中国 AI 拼多多 的称号。
- GPT-4o Mini:质量与成本效益的结合:OpenAI 的 GPT-4o mini 以极高的性价比问世:每百万输入 token $0.15,每百万输出 token $0.60。
- 它实现了 82% 的 MMLU 分数 并支持 128k context window,表现优于 Claude 3 Haiku 的 75%,并树立了新的性能成本基准。
- Mistral NeMo 的性能飙升:Mistral AI 与 NVIDIA 联手发布了 Mistral NeMo,这是一个强大的 12B 模型,拥有巨大的 128k tokens context window。
- 效率是 NeMo 的核心,得益于其 FP8 推理 带来的更快性能,使其定位为 Mistral 7B 的增强版。
- 涡轮增压版 LLaMA 3 版本跃入视野:Together AI 推出的 LLaMA-3-8B Lite 承诺提供具有成本效益的 每百万 token $0.10,确保了经济性与速度的兼顾。
- 为了优化部署格局,LLaMA-3-8B Turbo 的速度飙升至 400 tokens/s,专为追求极速效率的应用而量身定制。
- 随着 400B 即将发布,对 LLaMA 3 的期待达到顶峰:关于 LLaMA 3 400B 即将揭晓的猜测甚嚣尘上,恰逢 Meta 高管预定的会议,有望动摇 AI 现状。
- 社区感觉到正在对现有产品进行战略性清理,为 LLaMA 3 400B 的突破性登场铺平道路。
OpenAI Discord
- GPT-4o Mini:高性价比的智能:OpenAI 推出了 GPT-4o mini,据称比 GPT-3.5 Turbo 更聪明且更具成本效益,目前正在 API 和 ChatGPT 中推出,有望彻底改变可访问性。
- 在兴奋和疑问中,官方澄清了 GPT-4o mini 在 GPT-3.5 的基础上有所增强,但并未超越 GPT-4o;相反,它缺乏 GPT-4o 的全套功能(如图像支持),但永久性地升级了 GPT-3.5。
- Eleven Labs 开启语音提取功能:Eleven Labs 语音提取模型(voice extraction model)的发布引发了热烈讨论,该模型利用其潜力从嘈杂背景中提取清晰的语音音频。
- 参与者正在权衡伦理考量和潜在应用,这与合成媒体中的创新创作方向一致。
- Nvidia 的 Meta 软件包之谜:Nvidia 安装程序与 Facebook、Instagram 以及 Meta 版 Twitter 的集成在用户中引起了困惑和幽默的交织。
- 诸如“Yes sir”确认之类的随意反应反映了社区对这种意外捆绑的轻松回应。
- 关于 EWAC 效率的讨论:新的 EWAC 命令框架作为一种有效的 zero-shot 系统提示(system prompting)解决方案受到关注,优化了模型命令执行。
- 共享的讨论链接鼓励对该命令装置进行协作探索和微调。
- OpenAI API 配额困境:讨论围绕管理 OpenAI API 配额问题展开,提倡警惕监控计划限制,并建议购买额度以继续使用。
- 社区成员交流策略以避免 API 幻觉并最大化其使用率,同时还指出了图像 Token 计数的不一致性。
Interconnects (Nathan Lambert) Discord
- Meta 与隐现的 Llama:Meta 计划首次推出多模态 Llama 模型,但由于监管限制,欧盟用户陷入困境,Axios 报告重点介绍了这一问题。
- 诸如使用 VPN 或非欧盟合规复选框之类的变通方法已被私下讨论,预示着 访问破解(access hacks) 可能会增加。
- Mistral NeMo 隆重登场:Mistral NeMo 凭借其专为 128k Token 上下文窗口设计的 12B 模型引起轰动,这是与 NVIDIA 合作并在 Apache 2.0 协议下开源的项目,详见官方发布说明。
- 它超越了前代产品,在推理、世界知识和代码精确度方面有所增强,激发了技术圈的期待。
- GPT-4o mini 抢尽风头:OpenAI 推出了精干且强大的 GPT-4o mini,因其智能和成本透明度而受到赞誉。根据 Andrew Curran 的说法,它因免费可用和强大的 MMLU 表现而获得认可。
- 定价极具攻击性,每百万 Token 输入 15 美分,每百万 Token 输出 60 美分,虽然规模缩小但极具竞争力,并承诺更广泛的可访问性。
- Tekken Tokenizer 应对多语言:Tekken tokenizer 已成为热门话题,效率极高且具备多语言灵活性,大幅领先于 Llama 3 tokenizer。
- 它在压缩文本和源代码方面的娴熟表现令人瞩目,让开发者们开始考虑下一步行动。
- OpenAI 的防御边界被突破:OpenAI 最新的安全机制已被破解,
Elder Plinius通过一项大胆声明揭示了 GPT-4o-mini 的 jailbreak 方法。- 这揭示了其“指令层级(instruction hierarchy)”防御中的裂痕,引起了人们对安全性的关注和质疑。
OpenRouter (Alex Atallah) Discord
- GPT-4o Mini 的经济灵活性:OpenAI 的 GPT-4o Mini 在文本和图像输入方面表现出色,同时拥有极具性价比的价格,每百万输入 $0.15,每百万输出 $0.60。
- 该模型在经济性上击败了 GPT-3.5 Turbo,成本降低了 60% 以上,对免费和订阅用户都极具吸引力。
- OpenRouter 的区域韧性难题:用户面临着不稳定的 OpenRouter 停机,有报告称 API 请求延迟和网站超时,尽管北欧等部分地区未受影响。
- 这种零星的服务状态让工程师们不得不查看 OpenRouter Status 的实时更新以应对中断。
- Mistral NeMo 释放上下文容量:Mistral NeMo 的发布引起了轰动,这款强大的 12B 模型拥有 128k token 上下文窗口,为 AI 的广泛应用铺平了道路。
- Mistral NeMo 采用 Apache 2.0 协议提供,现已提供预训练和指令微调的 Checkpoints,确保了广泛的访问和使用。
- Codestral 22B:代码模型竞争者:社区发出的呼声推动了 Codestral 22B 的加入,重点展示了 Mamba-Codestral-7B 加入现有 AI 模型阵容的能力。
- 凭借其在基于 Transformer 的代码框架中的竞争优势,Codestral 22B 在开发者和模型策展人中引发了热烈讨论。
- GPT-4o Mini 中的图像 Token 波动:随着 AI 工程社区对新发布的 GPT-4o Mini 与之前模型相比的图像 Token 定价差异进行审查,讨论随之兴起。
- 辩论随之而来,一些人对影响使用成本的意外计数表示担忧,这需要对模型的效率和经济性进行更深入的检查。
Modular (Mojo 🔥) Discord
- Nightly Mojo 编译器增强功能发布:全新的 Mojo 编译器更新 (2024.7.1805) 包含了针对使用列表字面量的嵌套 Python 对象的
stdlib增强,可通过modular update [nightly/mojo](https://github.com/modularml/mojo/compare/e2a35871255aa87799f240bfc7271ed3898306c8...bb7db5ef55df0c48b6b07850c7566d1ec2282891)命令进行升级。- 在讨论 stdlib 的未来时,一项提案建议通过
stdlib-extensions在完全集成前收集社区反馈,旨在在添加分配器感知(allocator awareness)等小众特性前达成共识。
- 在讨论 stdlib 的未来时,一项提案建议通过
- Lubeck 凭借出色的 LLVM 效率超越 MKL:Lubeck 的卓越性能优于 MKL,这归功于差异化的 LLVM IR 生成,可能得益于 Mir 的 LLVM 加速通用数值库(LLVM-Accelerated Generic Numerical Library)。
- SPIRAL 的独特之处在于自动执行数值内核优化,尽管其生成的代码复杂性限制了其在 BLAS 等主要领域之外的使用。
- Max/Mojo 拥抱 GPU 的并行威力:围绕 Max/Mojo 的新 GPU 支持 的兴奋感正在升温,这扩展了张量操作和并行运算的能力,Max 平台的一次演讲强调了 NVIDIA GPU 的集成。
- 讨论线程建议利用 MLIR 方言和 CUDA/NVIDIA 进行并行计算,重点关注 AI 进步的潜力。
- Keras 3.0 以多框架支持取得突破:在社区讨论中,最新的 Keras 3.0 更新展示了与 JAX、TensorFlow 和 PyTorch 的兼容性,将其定位为灵活、高效的模型训练和部署的领跑者。
- 这一里程碑在 Mojo 社区会议上分享,进一步暗示了 Keras 集成和实用性的更广阔前景。
- Max 中的交互式聊天机器人设计引发讨论:MAX 24.4 版本通过
--prompt标志进行了创新,通过维护上下文和建立系统提示词来促进交互式聊天机器人的创建,正如 Max 社区直播中所揭示的那样。- 关于命令行提示词使用和模型权重 URI 的疑问引发了关于 UI 动态以及使用 Hugging Face 以外的替代仓库获取权重的可行性的启发性讨论。
Cohere Discord
- Cohere 工具成为焦点:一名成员关于创建 API tools 的咨询揭示了工具是 API-only 的,可以通过 Cohere dashboard 获取相关见解。
- 来自 Cohere 文档 的细节澄清了工具可以是单步或多步的,并且由客户端定义。
- GIF 在权限讨论中等待绿灯:关于在聊天中发送图片和 GIF 的能力引发了讨论,由于潜在的滥用风险,目前面临 受限权限。
- 管理员提到可能会进行更改,允许开发者和普通用户分享视觉内容,以寻求表达与审核之间的平衡。
- DuckDuckGo:探索集成之路:成员们考虑将 DuckDuckGo 搜索工具集成到项目中,并强调了 DuckDuckGo Python package 的潜力。
- 有建议提出使用该包开发自定义工具,以增强项目功能。
- Python 与 Firecrawl 打造爬虫协同效应:讨论了使用 Python 进行爬虫以及 Firecrawl 的使用,并展望了将两者结合以进行高效内容抓取的前景。
- 社区同仁推荐使用 duckduckgo-search library 来收集 URL,作为爬虫过程的一部分。
- GPT-4o 加入 API 集成阵营:将 GPT-4o API 与爬虫工具集成是一个热门话题,其中个人 API key 被用于增强 Firecrawl 的能力。
- 共享了技术设置方法,例如配置 .env 文件以包含 API key,从而促进与 LLM 的集成。
Perplexity AI Discord
- NextCloud 应对 Perplexity 难题:用户报告在 NextCloud 上 设置 Perplexity API 遇到困难,特别是选择正确的模型方面。
- 分享了一个涉及在请求中指定
model参数的解决方案,并将用户引导至 完整的模型列表。
- 分享了一个涉及在请求中指定
- Google 应对 Sheets 故障:社区成员正在排查一个令人困惑的 Google Sheets 问题,遇到了 Google Drive 标志错误。
- 尽管做出了努力,他们仍面临持续的“无法访问页面”问题,导致部分用户无法登录。
- PDF 探究:无限制利用 Perplexity:社区讨论了 Perplexity 目前在 处理多个 PDF 方面的限制,并寻求克服这一挑战的策略。
- 一位社区成员建议将 PDF 和网页搜索内容转换为文本文件,以获得最佳的 Perplexity 性能。
- AI 差异辩论:GPT-4 vs GPT-4 Omni:围绕 Perplexity 在集成 GPT-4 Omni 时产生不同结果的讨论引发了好奇和猜测。
- 成员们辩论了可能的原因,见解暗示了 底层模型的差异。
- DALL-E 困境与罗技 (Logitech) 真实性检查:提出了关于 DALL-E 更新 与 Perplexity Pro 搜索重置同步的问题,同时对罗技提供的 Perplexity Pro 优惠表示怀疑。
- 随后确认了罗技与 Perplexity 的合作伙伴关系,消除了对网络钓鱼的担忧,并有 相关推文 支持。
LangChain AI Discord
- LangChain 利用 Openrouter:讨论围绕将 Openrouter 与 LangChain 集成展开,但对话缺乏具体的示例或详细指南。
- 提出了对基于代码的 RAG 示例以驱动问答聊天机器人的需求,这表明 LangChain 社区对全面、实操性演示的渴望。
- Langserve 发布 Debugger 容器:一位用户询问了 Langserve Debugger 容器,寻求对其角色和应用的澄清,并附带了 Docker registry 链接。
- 关于 Langserve Debugger 与标准 Langserve 容器之间区别的好奇心达到顶峰,这直接影响了开发工作流和部署策略。
- GitHub 上处理模板难题:一个与在 LangChain 的 ChatPromptTemplate 中加入 JSON 相关的 KeyError 问题引发了讨论,并参考了 GitHub issue 以寻求潜在修复。
- 尽管一些社区成员找到了 JSON 集成挑战的变通方法,但其他人仍在努力应对模板系统的细微差别。
- Product Hunt 首发 Easy Folders:Easy Folders 在 Product Hunt 上亮相,具有整理聊天记录和管理 Prompt 的功能,详见 Product Hunt 帖子。
- 宣布了 Easy Folders 30 天 Superuser 会员的促销活动,依靠社区的支持和反馈来增强参与度。
- LangGraph 结合 Corrective RAG:YouTube 教程展示了 LangGraph 与 Corrective RAG 的集成,以对抗聊天机器人的幻觉,为改进 AI 聊天机器人提供了思路。
- 这种新颖的方法暗示了社区通过 RAG Fusion 等创新组合来增强 AI 聊天机器人可信度和可靠性的动力,解决了现有聊天机器人技术的基本问题。
LlamaIndex Discord
- Jerry 的 AI World 智慧:想要了解 AI World’s Fair 的最新动态?观看 @jerryjliu0 在他的主题演讲中发表的关于知识助手的见解,这是去年活动的一个亮点。
- 他深入探讨了这些助手的演变和未来,引发了社区内持续的技术讨论。
- RAGapp 的聪明伙伴:RAGapp 的最新版本现在可以与 MistralAI 和 GroqInc 接口,为开发者增强了计算创造力。
- 加入 @cohere 的 reranker 旨在优化和增强应用结果,为大语言模型的集成引入了新的动态。
- RAG 评估器辩论:围绕 RAG 流水线评估框架的选择展开了对话,正在审查受限的 Ragas 工具的替代方案。
- 贡献者讨论了在紧张的两周时间内构建自定义评估工具是否合适,但未达成共识。
- 数据安全脱敏探索:我们的社区剖析了保护敏感数据的策略,推荐使用 LlamaIndex 的 PIINodePostprocessor 在 OpenAI 处理前进行数据脱敏。
- 这一 Beta 功能代表了在 AI 交互中确保用户隐私和数据安全处理的积极步骤。
- 多模态 RAG 的微调未来主义:当一名成员分享他们使用 GPT4o 和 Sonnet3.5 进行多模态 RAG 的成功经验时,热情达到了顶峰,强调了 LlamaIndex 在处理复杂文件时出人意料的高质量响应。
- 他们的发现激发了人们对 LlamaIndex 更广泛能力的兴趣,并展望了其简化 RAG 部署和提高效率的潜力。
OpenInterpreter Discord
- OpenInterpreter 社区规模显著增长:OpenInterpreter Discord 庆祝了一个重要的里程碑,社区成员数达到了 10,000 名。
- 社区内的热情显而易见,成员们用 “Yupp” 和 “Awesome!” 等反应来纪念这一成就。
- 经济型 AI 性能超越 GPT-4:一位成员称赞了一款性价比极高的 AI,声称其性能优于 GPT-4,特别是在作为 AI agents 使用时表现出色。
- 社区强调了其易用性和极低的价格,一位成员评论道:“它基本上是免费的。”
- Multimodal AI:快速且多功能:讨论重点介绍了一款新型 multimodal AI 的惊人速度,它支持多种功能,并可通过 API 调用。
- 社区成员对其多样化的应用感到兴奋,评论强调了其 “极低的延迟” 和 multimodal 特性。
OpenAccess AI Collective (axolotl) Discord
- Mistral NeMo 惊艳登场:Mistral NeMo 拥有 12B parameter 规模和 128k token context,凭借卓越的推理和编程能力正式亮相。预训练版本已在 Apache 2.0 license 下发布,详情见 Mistral 官网。
- Meta 报告的 Llama 3 8B 的 5-shot MMLU score 受到质疑,因为其数据与 Mistral 的测试结果不一致,导致人们对声称的 62.3%(对比 Mistral 的 66.6%)产生怀疑。
- Transformer 推理能力综述:一场关于 Transformers 在隐式推理中潜力的辩论被引发,新研究 提倡在经过大规模训练后它们具备这种能力。
- 尽管在 intra-domain inferences 方面取得了成功,但如果没有更多的迭代层交互,Transformers 尚未能克服 out-of-domain 的挑战。
- Rank Reduction 与 Eval Loss 的关联:一个有趣的观察显示,降低模型 rank 与 eval loss 的显著下降相关。然而,目前数据尚不足以确定这一趋势是否会在随后的训练步骤中持续。
- 参与者就这一现象交换了见解,思考其对模型准确性和计算效率的影响。
- GEM-A 的过拟合困境:有关 GEM-A 模型在训练期间可能出现过拟合的担忧浮出水面。
- 对话仍在继续,目前尚无具体解决方案,但充满了谨慎气氛,并表示需要进一步实验。
LLM Finetuning (Hamel + Dan) Discord
- GPT-3.5-turbo 占据领先地位:讨论显示 GPT-3.5-turbo 在 fine-tuning 任务中超越了 Mistral 7B 和 Llama3,尽管 OpenAI 坚持不使用用户提交的数据进行 fine-tuning。
- 有观点表示不倾向于使用 GPT 模型进行 fine-tuning,原因是担心将敏感信息传输给第三方。
- Mac M1 的模型延迟滞后:由于在启动 preprocessing pipeline 时的模型加载时间问题,用户在 Mac M1 芯片上运行 Hugging Face 模型时遇到了延迟问题。
- 当尝试多个模型时,延迟会进一步加剧,因为每个模型都需要单独下载和加载,从而增加了初始延迟。
LAION Discord
- Meta 的多模态使命:Meta 将目光投向未来,将焦点转向 multimodal AI models,正如一篇分享文章后引发的零星讨论所暗示的那样。
- 欧盟社区缺乏实质性辩论,使得对创新和可访问性的影响悬而未决。
- Llama 离开欧盟:Meta 决定从欧盟市场撤回 Llama models,在用户中引起了低调的回应。
- 对区域性 AI 工具可访问性的影响尚未得到深入审查或辩论。
- Codestral Mamba 的编程突破:新推出的 Codestral Mamba 凭借其线性时间推理(linear time inference)承诺在代码生成方面实现飞跃。
- 该模型由 Albert Gu 和 Tri Dao 共同创建,旨在提高编码效率,同时处理无限长的序列。
- Prover-Verifier 的可读性飞跃:Prover-Verifier Games 的引入引发了提高语言模型可读性的兴趣,并得到了一些技术参考资料的支持。
- 完整文档中提供了详细信息,在实际应用出现之前,社区表现出的热情较为克制。
- NuminaMath-7B 夺冠但存在缺陷:尽管 NuminaMath-7B 在 AIMO 夺冠,但其在基础推理能力方面暴露出的缺陷被视为前车之鉴。
- AI 资深人士正在思考,在 AIW 问题审查下,那些经不起基础推理考验的强力主张所带来的严重性和后续影响。
Torchtune Discord
- 模板困惑的转机:在使用
torchtune.data.InstructTemplate进行自定义模板格式化时产生了困惑,特别是关于 column mapping。- 随后进行了澄清,说明列映射会重命名数据集列,并询问是否正在使用 alpaca cleaned dataset。
- 代码贡献中的 CI 难题:关于 CI 行为的讨论指出,更新 PR 时会自动运行,这让贡献者感到困惑。
- 共识建议是在 PR 从草稿状态转变为准备好进行同行评审的状态之前,忽略 CI 结果。
- 爆笑 LLMs —— 现实还是虚构?:尝试编程让 LLM 在喂入特定数据集的情况下持续输出 ‘HAHAHA’,但模型并未遵循。
- 该实验是为一个使用 alpaca dataset 的项目进行更严肃应用的前奏。
tinygrad (George Hotz) Discord
- GTX1080 在 tinygrad 上受阻:用户在 GTX1080 上尝试以 CUDA=1 运行 tinygrad 时遇到 nvrtc: error,怀疑与旧的 GPU 架构不兼容。
- 解决方法包括为 GTX1080 修改 ops_cuda 并关闭 tensor cores;然而,为了获得最佳性能,可能需要 GTX2080 或更新的显卡。
- 编译难题导致转向新技术测试:成员在 GTX1080 上设置 tinygrad 时遇到障碍,表明存在潜在的兼容性问题。
- 他们采纳了社区建议,转而使用更现代的系统来实验 tinygrad。
PART 2: Detailed by-Channel summaries and links
各频道的完整详细内容已针对邮件进行截断。
如果您喜欢 AInews,请分享给朋友!预谢!