ainews-apple-dclm-7b-the-best-new-open-weights
DataComp-LM:最优秀的开源数据 7B 模型/基准/数据集。
DataComp 团队发布了一款极具竞争力的 7B 开源数据语言模型。该模型仅在拥有 240 万亿 token 的海量 DCLM-POOL 数据集中的 2.5 万亿 token 上训练而成,展现出优于 FineWeb 的扩展趋势。OpenAI 推出了 GPT-4o mini,这是一款高性价比模型,其 MMLU 得分为 82%,性能接近 GPT-4-Turbo,旨在为开发者提供广泛的应用支持。NVIDIA 和 Mistral 联合发布了 Mistral NeMo 12B 模型,该模型具备 128k token 上下文窗口、FP8 检查点、多语言支持,并采用 Apache 2.0 开源协议。DeepSeek 宣布 DeepSeek-V2-0628 成为 LMSYS Chatbot Arena 排行榜上排名最高的开源模型,在编程、数学和高难度提示词(hard prompts)方面表现强劲。这些新闻突显了 AI 社区在数据集设计、模型效率以及开源贡献方面的显著进展。
240T tokens 是你开始所需的一切。
AI 新闻 (2024/7/18-2024/7/19)。我们为你检查了 7 个 subreddits、384 个 Twitter 账号 和 29 个 Discord 服务器(467 个频道和 2305 条消息)。预计节省阅读时间(以 200wpm 计算):266 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
尽管 HuggingFace 的 SmolLM 发布才不到 4 天,但它现在已被超越:DataComp 团队(我们的报道在此)现已发布了一个“基准”语言模型,在 7B 参数规模上可与 Mistral/Llama3/Gemma/Qwen2 竞争。值得注意的是,它是一个来自 DataComp-LM 数据集 的开放数据模型,并且仅用 2.5T tokens 就达到了与其他模型相当的水平:
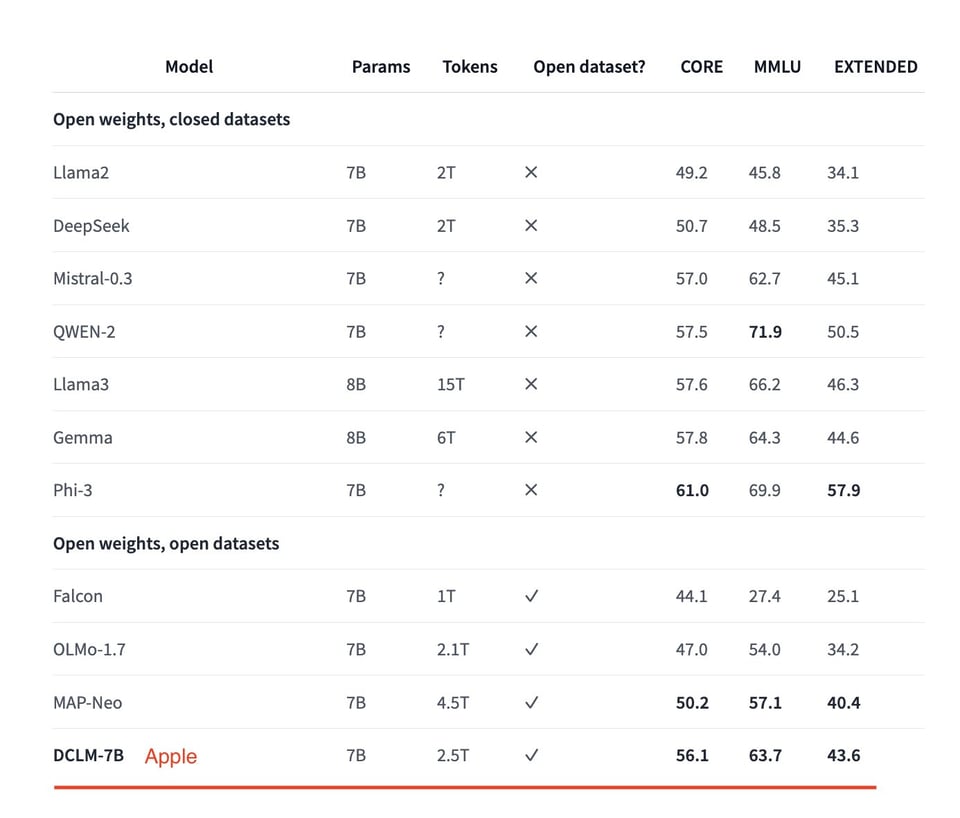
正如你所预料的,秘诀在于数据质量。他们从 DCLM-POOL 开始,这是一个源自 Common Crawl 的 240 万亿 tokens 的语料库,也是迄今为止最大的语料库,并提供了针对 5 个规模的数据集设计扩展趋势 (scaling trends) 研究:
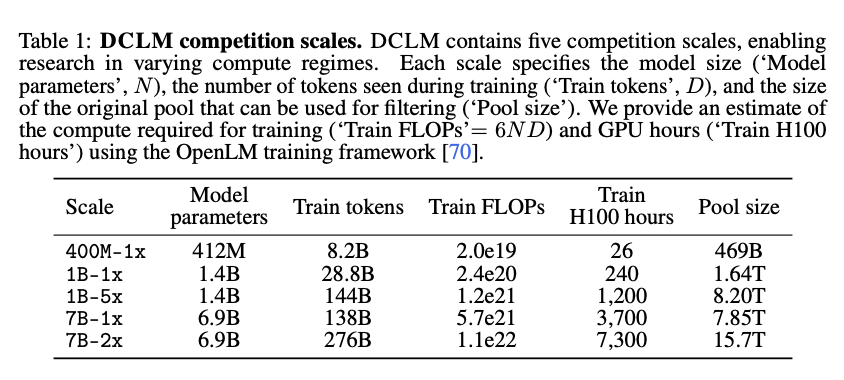
在每个规模中都有两个赛道:Filtering(必须来自 DCLM-Pool,不含任何外部数据,但可以使用其他模型进行过滤/改写)和 Mixing(允许外部数据)。他们提供了一个“Baseline”过滤示例作为起点:

关注数据集进展的人可能会好奇 DCLM-Pool 和 Baseline 与 FineWeb(我们的报道在此)相比如何,前景非常乐观:DCLM 在每一个规模上的训练效果都更好。
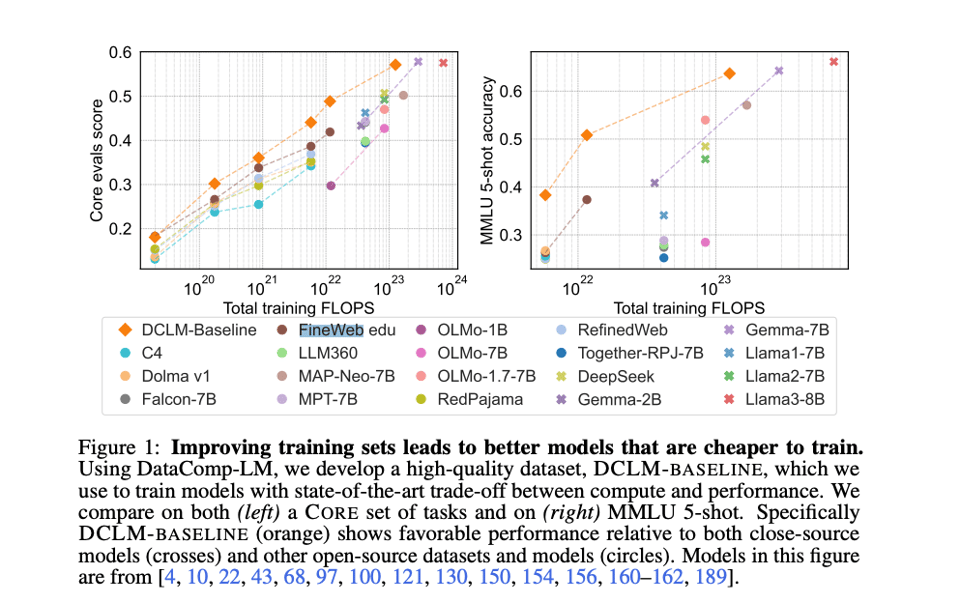
这份长达 88 页的论文其余部分包含了大量关于数据质量技术的细节;这是所有参与者(不仅仅是通常报道的 Apple)对开放 LLM 研究做出的巨大贡献。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
OpenAI 发布 GPT-4o mini 模型
- 能力:@sama 指出 GPT-4o mini “每百万输入 token 15 美分,每百万输出 token 60 美分,MMLU 为 82%,且速度极快。”他将其与 text-davinci-003 进行了对比,称后者“比这个新模型差得多”且“成本高出 100 倍”。
- 定价:@gdb 强调该模型面向开发者,目标是“将机器智能转化为各领域的积极应用”。@miramurati 强调 GPT-4o mini “让智能变得更加经济实惠,从而开启了广泛的应用场景。”
- 基准测试:@lmsysorg 报告称 GPT-4o mini 在 Arena 中进行了测试,显示其性能达到了 GPT-4-Turbo 水平,同时大幅降低了成本。@polynoamial 称其为“同尺寸中的佼佼者,尤其是在推理方面”。
NVIDIA 和 Mistral 发布 Mistral NeMo 12B 模型
- 能力:@GuillaumeLample 介绍了 Mistral NeMo,这是一个 12B 模型,支持 128k token 上下文窗口、FP8 对齐 checkpoint,在学术、对话和微调基准测试中表现强劲。它是支持 9 种语言的多语言模型,并配备了全新的 Tekken tokenizer。
- 许可:@_philschmid 强调基础版和 instruct 版模型均以 Apache 2.0 许可证发布。instruct 版本支持 function calling。
- 性能:@osanseviero 指出 Mistral NeMo 的性能优于 Mistral 7B,由 NVIDIA 和 Mistral 在 DGX Cloud 上的 3,072 块 H100 80GB GPU 上联合训练而成。
DeepSeek 发布 DeepSeek-V2-0628 模型
- 排行榜排名:@deepseek_ai 宣布 DeepSeek-V2-0628 是 LMSYS Chatbot Arena 排行榜上排名第一的开源模型,总榜排名第 11,在 Hard Prompts 和 Coding 方面排名第 3,在 Longer Query 方面排名第 4,在 Math 方面排名第 7。
- 可用性:该模型 checkpoint 已在 Hugging Face 上开源,并提供 API。
趋势与讨论
- 合成数据:@karpathy 建议模型需要先变大再变小,因为需要它们的自动化帮助来“将训练数据重构并塑造成理想的合成(synthetic)格式”。他将其比作 Tesla 的自动驾驶网络,利用之前的模型大规模生成更干净的训练数据。
- 评估担忧:@RichardMCNgo 分享了评判 AI 安全评估方案的标准,警告称许多提案在所有方面都失败了,类似于“必须做点什么。这就是‘点什么’。”的谬误。
- 推理局限性:@JJitsev 测试了在奥数竞赛中排名第一的 NuminaMath-7B 模型在基础推理问题上的表现。该模型在简单的变体问题上表现挣扎,揭示了当前衡量推理能力的基准测试存在缺陷。
梗与幽默
- @fabianstelzer 开玩笑说 OpenAI 悄悄发布了原生的 GPT-o “图像”模型,并分享了一个连环画的 prompt 和输出结果。
- @AravSrinivas 幽默地将新加坡的治理方式比作产品管理,即针对新用户留存进行优化。
- @ID_AA_Carmack 针对一段个人轶事沉思了原则和以牙还牙的升级行为,同时承认由于拥有“FU money”,他免受了大多数影响。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. CPU 推理速度的突破
-
NVIDIA CUDA 现在可以通过 “SCALE” 工具包直接在 AMD GPUs 上运行 (Score: 67, Comments: 17): NVIDIA CUDA 现在可以使用开源的 SCALE (Scalable Compute Abstraction Layer for Execution) 工具包直接在 AMD GPUs 上运行。这一突破允许开发者在无需修改代码的情况下,在 AMD 硬件上执行 CUDA 应用程序,这有可能将 AI 和 HPC 应用的生态系统扩展到 NVIDIA 的硬件垄断之外。由 StreamHPC 开发的 SCALE 工具包旨在弥合不同 GPU 架构和编程模型之间的差距。
-
通过 Llamafile 实现 30% 到 500% 的全新 CPU 推理速度提升 (Score: 70, Comments: 36): Llamafile 实现了显著的 CPU 推理速度提升,范围从 30% 到 500%,在 Threadripper 处理器上的表现尤为出色。最近的一次演讲强调,在 Threadripper 上速度从 300 tokens/second 提升到了 2400 tokens/second,接近了 GPU 级别的性能。虽然没有提到测试的具体模型,但这些改进,加上对 开源 AI 的强调,代表了基于 CPU 的推理能力的显著进步。
- Prompt Processing 速度至关重要:Llamafile 的改进主要影响 Prompt Processing(提示词处理),而不是 Token 生成。这非常重要,因为 Prompt Processing 是进行深度理解的地方,特别是对于涉及大量输入数据的复杂任务。
- 布尔输出微调:一些用户报告说,LLM 在处理 True/False 查询并返回 0 或 1 时效果良好,特别是在 Fine-tuning(微调)之后。一位用户使用 Gemma 2 9b 在单张 4090 GPU 上,通过特定的分类任务提示词,达到了每秒 25 次查询。
- CPU vs GPU 性能:虽然 Llamafile 的 CPU 改进令人印象深刻,但 LLM 推理仍然受限于内存带宽(Memory-bound)。DDR5 的带宽无法与 VRAM 相比,但一些用户发现,在某些应用中,用 128 GB RAM 换取高端 GPU 一半的速度是具有吸引力的。
主题 2. Mistral AI 发布全新开源 LLM
-
DeepSeek-V2-Chat-0628 权重发布!(Chatbot Arena 中排名第 1 的开源权重模型) (Score: 67, Comments: 37): DeepSeek-V2-Chat-0628 已作为性能最强的开源权重模型在 Hugging Face 上发布。该模型在 Chatbot Arena 中总排名 第 11,超越了所有其他开源模型,同时在 Coding Arena 和 Hard Prompts Arena 中均取得了 第 3 名 的佳绩。
-
Mistral-NeMo-12B,128k 上下文,Apache 2.0 协议 (Score: 185, Comments: 84): Mistral-NeMo-12B 是一款全新的开源语言模型,具有 128k 上下文窗口并采用 Apache 2.0 许可证。该模型由 Mistral AI 与 NVIDIA 合作开发,基于 NeMo 框架并使用 FlashAttention-2 进行训练。它在各种基准测试中表现出强劲的性能,包括在某些任务上超越了 Llama 2 70B,同时保持了 120 亿参数的较小规模。
主题 3. 全面的 LLM 性能基准测试
- GGUF 与 EXL2 在多模型及多尺寸下的综合性能基准测试 (Score: 51, Comments: 44): GGUF vs EXL2 性能大对决。一项针对 GGUF 和 EXL2 格式在多个模型(Llama 3 8B、70B 以及 WizardLM2 8x22B)上的综合基准测试显示,EXL2 在 Llama 模型上略快(快 3-7%),而 GGUF 在 WizardLM2 上表现更好(快 3%)。在配备 4x3090 GPUs 的系统上进行的测试表明,两种格式的性能相当,其中 GGUF 提供了更广泛的模型支持和 RAM offloading 能力。
- GGUF 追赶上 EXL2:GGUF 的性能有了显著提升,现在在某些情况下已达到或超过了 EXL2。此前,EXL2 要快 10-20%,但最近的测试显示,即使在 prompt 处理方面,两者的速度也旗鼓相当。
- 量化与模型细节:GGUF 中的 Q6_K 实际上是 6.56bpw,而 EXL2 的量化则很精确。为了获得更好的质量,建议使用 5.0bpw 或 4.65bpw,而 4.0bpw 更接近 Q3KM。不同的架构在不同格式之间的表现可能有所不同。
- 投机采样 (Speculative Decoding) 与并发请求:在大型模型前使用 1B 模型 可以通过投机采样显著提高速度。关于 GGUF 和 EXL2 在并发请求场景下的性能差异,仍存在疑问。
- 你目前最常用的 5 个 LLMs 是什么?最近有更换过新的吗? (Score: 79, Comments: 39): 5 大常用 LLM 及其潜在的新竞争者。作者目前最常用的 5 个 LLM 分别是:用于 RAG 任务的 Command-R,用于智能和专业回答的 Qwen2:72b,用于视觉相关任务的 Llava:34b,作为第二意见模型的 Llama:70b,以及用于代码相关任务的 Codestral。他们表示有兴趣尝试 Florence、Gemma2-27b 和用于文档检索的 ColPali,同时幽默地提到,如果存在以 Steven Seagall 命名的 LLM,他们也会尝试。
- ttkciar 报告称对 Gemma-2 模型印象深刻,特别是 Big-Tiger-Gemma-27B-v1c,它在 reason:sally_siblings 任务中 五次测试全部正确。他们还使用 Dolphin-2.9.1-Mixtral-1x22B 处理各种任务,并正在尝试使用 Phi-3 模型进行 Evol-Instruct 开发。
- PavelPivovarov 分享了他们在有限硬件下的顶级模型:用于大多数任务的 Tiger-Gemma2 9B,用于推理的 Llama3 8B,用于复杂逻辑和企业写作的 Phi3-Medium 14B,以及用于角色扮演的 Llama-3SOME。他们表示有兴趣尝试新的 Gemmasutra 模型。
- ttkciar 详细分析了 Phi-3-Medium-4K-Instruct-Abliterated-v3 在各种任务中的表现。该模型在创意任务中表现出色,在简单的心理理论 (Theory-of-Mind) 问题中推理正确,并且…
Theme 4. AI 发展与监管挑战
- 正如承诺的那样,我开源了我的 Tone Changer - https://github.com/rooben-me/tone-changer-open (Score: 96, Comments: 14): Tone Changer AI 工具开源。开发者履行了之前的承诺,在 GitHub 上发布了其 Tone Changer 项目的源代码。该工具可能允许用户修改文本输入的语气或风格,尽管帖子中未提供其功能的具体细节。
- 具有 OpenAI 兼容性的本地部署:Tone Changer 工具完全本地化,并与任何 OpenAI API 兼容。它可以在 GitHub 上获取,并可以通过 Vercel 托管的演示 (demo) 进行访问。
- 征求开发细节:用户对该项目的实现表现出兴趣,要求更新 README 以包含运行说明,并询问了 demo 制作过程。开发者使用了 screen.studio 进行屏幕录制。
- 功能受到质疑:一些用户批评了该工具的新颖性,认为它依赖 prompts 来改变语气,暗示除了现有的语言模型能力之外,技术创新有限。
- Apple 一个月前表示不会在欧盟推出 Apple Intelligence,现在 Meta 也表示由于监管问题,将不会在欧盟提供未来的多模态 AI 模型。 (Score: 170, Comments: 95): Apple 和 Meta 由于监管担忧,正对欧盟保留其 AI 模型。Apple 一个月前宣布不会在欧盟推出 Apple Intelligence,现在 Meta 也紧随其后,表示不会在该地区提供未来的多模态 AI 模型。这些决定凸显了 AI 创新与欧盟法规之间日益紧张的关系,可能会导致欧洲用户在 AI 技术可用性方面出现重大差距。
- • -p-e-w- 认为欧盟的监管是有益的,可以防止 FAANG 公司垄断 AI 市场并压制竞争。他们建议禁止这些公司进入欧盟 AI 市场,以限制其权力。
- • 关于 GDPR 合规性的讨论揭示了不同的观点。一些人认为对于诚信经营的企业来说这很容易,而另一些人则强调,与资源丰富的跨国公司相比,初创公司和小型企业面临着巨大挑战。
- • 批评者指责这些公司虚伪,指出它们一方面倡导“AI 安全”,另一方面却抵制实际的监管。一些人认为这是企业试图挟持政府以降低对公民的保护,而另一些人则认为欧盟的监管可能会阻碍创新。
所有 AI Reddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. AI 在医学执业考试中表现优于人类
- [/r/singularity] ChatGPT 轻松通过美国执业医师资格考试,准确率达 98%。医生的平均水平仅为 75%。 (Score: 328, Comments: 146): ChatGPT 在美国执业医师资格考试中的表现优于人类医生,实现了惊人的 98% 准确率,而医生的平均准确率为 75%。这一令人印象深刻的表现展示了 AI 彻底改变医学教育和实践的潜力,引发了关于 AI 在医疗保健中未来角色以及调整医学培训课程必要性的讨论。
- • ChatGPT 在美国执业医师资格考试中 98% 的准确率(医生为 75%)引发了人们对 AI 对医疗职业影响的担忧。一些人认为 AI 可以减少每年 795,000 例因诊断错误导致的死亡,而另一些人则质疑该考试与现实世界医疗实践的相关性。
- • 专家预测 AI 最初将与人类医生并肩工作,特别是在放射科等专业领域。保险公司可能会强制要求使用 AI,以捕捉人类遗漏的信息,从而可能提高诊断速度和准确性。
- • 批评者认为 AI 的表现可能是由于“在测试集上进行了预训练”,而非真正的理解。一些人认为考试结构可能无法充分测试复杂的推理能力,而另一些人则指出人类医生也会通过研究过去的考试来做准备。
主题 2. OpenAI 的 GPT-4o-mini:更实惠、更高效的 AI 模型
-
[/r/singularity] GPT-4o-mini 比 GPT 3.5 Turbo 便宜 2 倍 (Score: 363, Comments: 139): GPT-4o-mini 是一款新的 AI 模型,现在的成本仅为 GPT-3.5 Turbo 的一半。这款由 Anthropic 开发的模型提供了与 GPT-3.5 Turbo 相当的性能,但价格显著降低,有可能使先进的 AI 功能被更广泛的用户和应用所使用。
-
[/r/singularity] GPT-4o mini:推进高性价比智能 (Score: 238, Comments: 89): GPT-4o mini 是由 Anthropic 开发的一款新 AI 模型,旨在通过以 GPT-4 极小部分的成本提供类似的功能,来实现高性价比智能。该模型旨在为开发者和企业提供更易于获取且更实惠的选择,从而可能推动先进 AI 技术的更广泛采用。虽然未提供具体的性能指标和定价细节,但对成本效率的关注表明,在使强大的语言模型对更广泛的应用更具经济可行性方面迈出了重要一步。
-
[/r/singularity] OpenAI 发布其迄今为止最强大模型的迷你版本 (分数: 378, 评论: 222): OpenAI 推出了 GPT-4 Turbo,这是其最先进语言模型的更小、更高效版本。该新模型提供 128k context,旨在为开发者提供 更实惠 的选择,定价为每 1,000 input tokens 0.01 美元,每 1,000 output tokens 0.03 美元。GPT-4 Turbo 还包含了截至 2023年4月 的更新知识,并支持 JSON mode 等新功能以实现结构化输出。
{kind=link}
主题 3. AI 生成视觉与音频内容的进展
-
[/r/singularity] 新语音模式即将推出 (分数: 279, 评论: 106): 新的语音合成模式 即将发布,扩展了 AI 生成语音的能力。这一即将推出的功能有望提升合成语音的质量和通用性,可能为各种应用提供更自然且可定制的音频输出。
-
[/r/singularity] Unanswered Oddities 第 1 集(一部完全由 AI 生成视频的 AI 辅助电视剧) (分数: 330, 评论: 41): 《Unanswered Oddities》 是一部 AI-assisted 电视剧,采用 完全 AI-generated video,目前已发布第一集。该系列探索了 未解现象 和 神秘事件,利用 AI technology 创作剧本和视觉效果,推动了娱乐行业中 AI-driven content creation 的边界。
-
[/r/singularity] Pet Pixels Studio 的 Kling AI 示例 (分数: 287, 评论: 25): Pet Pixels Studio 展示了其 Kling AI 技术,这似乎是一个用于生成或处理宠物相关图像的 AI 系统。虽然没有提供关于该 AI 能力或实现的具体细节,但标题表明这是 Kling AI 输出或功能的示例或演示。
{kind=link}
AI Discord 摘要
摘要之摘要的摘要
GPT4O (gpt-4o-2024-05-13)
1. LLM 进展
- Llama 3 发布在即:传闻拥有 4000 亿参数的 Llama 3 将在 4 天内发布,引发了社区内的兴奋和猜测。
- 即将到来的发布引发了关于其潜在影响和能力的众多讨论。
- GPT-4o mini 提供高性价比性能:GPT-4o mini 被视为 3.5 Turbo 更便宜、更快的替代方案,正如 GitHub 上所指出的,其速度快约 2 倍,价格便宜 60%。
- 然而,它缺乏图像支持,且在基准测试中的得分低于 GPT-4o,凸显了其局限性。
2. 模型性能优化
- DeepSeek-V2-Chat-0628 登顶 LMSYS 排行榜:DeepSeek-V2-Chat-0628 是一款拥有 236B 参数的模型,在 LMSYS Chatbot Arena Leaderboard 上位列开源模型第一。
- 它占据了多个顶尖位置:总榜第 11 名、困难提示词(Hard Prompts)第 3 名、代码(Coding)第 3 名、长查询(Longer Query)第 4 名、数学(Math)第 7 名。
- Mojo vs JAX:基准测试之争:尽管 JAX 针对多核系统进行了优化,但 Mojo 在 CPU 上的表现优于 JAX。讨论表明,Mojo 的编译器可见性赋予了其性能优势。
- MAX 与 openXLA 的对比显示,作为一种惰性计算图构建器,MAX 具有优势,提供了更多的优化机会和广泛的影响。
3. 开源 AI 框架
- SciPhi 开源用于知识图谱的 Triplex:SciPhi 正在开源 Triplex,这是一款用于知识图谱构建的顶尖 LLM,可显著降低 98% 的成本。
- Triplex 可与 SciPhi 的 R2R 配合使用,直接在笔记本电脑上构建知识图谱,其表现优于经过 Few-shot-prompted 的 GPT-4,而推理成本仅为后者的 1/60。
- Open WebUI 功能强大:Open WebUI 拥有 TTS、RAG 以及无需 Docker 即可访问互联网等丰富功能,令用户着迷。
- 在 Windows 10 上使用 Open WebUI 的良好体验,引发了人们将其性能与 Pinokio 进行对比的兴趣。
4. 多模态 AI 创新
- Text2Control 实现自然语言指令:Text2Control 方法使 Agent 能够通过视觉语言模型(Vision-Language Models)解释自然语言指令来执行新任务。
- 该方法在零样本泛化(Zero-shot Generalization)方面优于多任务强化学习基准,并提供交互式演示供用户探索其功能。
- Snowflake Arctic Embed 1.5 提升检索系统扩展性:Snowflake 推出了 Arctic Embed M v1.5,通过极小的嵌入向量(Embedding Vectors),使检索系统的扩展性提升了高达 24 倍。
- Daniel Campos 关于此更新的推文强调了性能指标的显著增强。
5. AI 社区工具
- ComfyUI 赢得 Stable Diffusion 新手的青睐:成员们建议将 ComfyUI 作为 Stable Diffusion 初学者的优秀 UI,强调了其灵活性和易用性。
- 此外,建议观看 Scott Detweiler 的 YouTube 教程以获得详尽的指导。
- GPTs Agents 展现出自我意识:在 GPTs Agents 上进行的一项实验旨在评估其自我意识,特别是过程中避免使用网页搜索功能。
- 测试结果引发了关于在没有外部数据源的情况下,具有自我意识的 AI 系统的实际意义和潜在局限性的讨论。
GPT4OMini (gpt-4o-mini-2024-07-18)
1. 最近的模型发布与性能表现
- Mistral NeMo 与 DeepSeek 模型亮相:Mistral 发布了具有 128k token 上下文长度的 NeMo 12B 模型,展示了多语言能力和工具支持;同时 DeepSeek-V2-Chat-0628 在 LMSYS 排行榜上名列前茅。
- 这些模型强调了性能和效率的提升,其中 DeepSeek 拥有 236B 参数,在开源模型中排名第一。
- GPT-4o Mini 对比 Claude 3 Haiku:全新的 GPT-4o mini 比 GPT-3.5 Turbo 快约 2 倍且便宜 60%,尽管其基准测试分数低于 Claude 3 Haiku,但仍是一个极具吸引力的替代方案。
- 用户正在讨论潜在的替代方案,对于 mini 在各种任务中的表现意见不一。
- Apple 发布 DCLM 7B 模型:Apple 发布的 DCLM 7B 模型 表现优于 Mistral 7B,并展示了完全开源的训练代码和数据集。
- 此举引发了关于其对开源 AI 模型竞争格局影响的讨论。
2. AI 工具与社区资源
- Open WebUI 增强功能:Open WebUI 现在包含 TTS 和 RAG 等功能,允许用户在不使用 Docker 的情况下与其模型交互,提升了可访问性和易用性。
- 用户反馈在 Windows 10 上运行体验良好,认为其性能优于 Pinokio。
- 适合初学者的 ComfyUI:成员们推荐将 ComfyUI 作为 Stable Diffusion 初学者的优秀用户界面,强调了其灵活性和易用性。
- 建议那些寻求全面指导的用户观看 YouTube 上 Scott Detweiler 的教程。
3. 训练技术与模型微调
- 提升 Transformer 的泛化能力:一篇 arXiv 论文 指出,在饱和点之外继续训练 Transformer 可以增强其泛化能力,特别是对于域外(out-of-domain)任务。
- 这种方法有助于防止灾难性遗忘(catastrophic forgetting),使其成为未来模型训练的关键策略。
- Mistral-12b 的微调挑战:用户报告了 Mistral-12b 的配置问题,特别是关于投影权重(projection weights)的大小不匹配,需要从源码安装 Transformers 库才能修复。
- 关于微调策略的讨论表明,需要对训练设置进行特定调整以优化性能。
4. AI 中的数据隐私与安全
- CrowdStrike 停机事件的影响:最近的 CrowdStrike 更新导致了全球范围的停机,影响了多个行业,并引发了关于云端安全服务可靠性的讨论。
- 该事件引起了人们对技术基础设施中数据隐私和运营韧性的担忧。
- 企业对分享敏感数据的犹豫:对数据隐私的担忧使企业对与第三方分享敏感信息持谨慎态度,优先考虑内部控制而非外部交换。
- 这一趋势突显了数据安全在 AI 应用中日益增长的重要性。
5. 知识图谱与检索增强生成 (RAG) 的进展
- Triplex 彻底改变知识图谱:Triplex 模型 使知识图谱构建成本降低了 98%,其表现优于 GPT-4,而成本仅为后者的 1/60。
- Triplex 促进了使用 SciPhi 的 R2R 平台进行本地图谱构建,增强了检索增强生成(RAG)方法。
- 用于知识图谱的 R2R 平台:R2R 平台支持可扩展的、生产级的检索增强生成应用,集成了多模态支持和自动关系提取。
- 成员们强调了其在从非结构化数据创建知识图谱方面的有效性,展示了实际应用案例。
第一部分:Discord 高层级摘要
Unsloth AI (Daniel Han) Discord
- Hermes 2.5 表现优于 Hermes 2:在添加了代码指令示例后,Hermes 2.5 在各种基准测试中的表现似乎优于 Hermes 2。
- Hermes 2 在 MMLU 基准测试中得分为 34.5,而 Hermes 2.5 得分为 52.3。
- Mistral 在扩展超过 8k 时遇到困难:成员们表示,如果不进行持续预训练,Mistral 无法扩展到 8k 以上,且这是一个已知问题。
- 他们指出 mergekit 和 frankenMoE finetuning 是性能突破的下一个前沿。
- Mistral 发布 NeMo 12B 模型:Mistral 发布了 NeMo,这是一个 120 亿参数模型,展示了多语言能力和原生工具支持。
- 该模型恰好可以运行在免费的 Google Colab GPU 实例中,你可以在此访问。
- 深入探讨 CUDA bf16 问题及修复:多位用户报告了在 RTX A4000 和 T4 等不同 GPU 型号上与 bf16 支持相关的错误,阻碍了模型执行。
- 问题被确定为 torch.cuda.is_bf16_supported() 返回 False,Unsloth 团队随后已修复此问题。
- SciPhi 开源用于知识图谱的 Triplex:SciPhi 正在开源 Triplex,这是一个用于知识图谱构建的尖端 LLM,可显著降低 98% 的成本。
- Triplex 可与 SciPhi 的 R2R 配合使用,直接在笔记本电脑上构建知识图谱,其表现优于少样本提示的 GPT-4,且推理成本仅为 1/60。
Stability.ai (Stable Diffusion) Discord
- ComfyUI 赢得 Stable Diffusion 新手的青睐:成员们建议将 ComfyUI 作为 Stable Diffusion 新手的理想 UI,强调了其灵活性和易用性。
- 此外,建议观看 Scott Detweiler 的 YouTube 教程以获取详尽指导。
- 在 AI 任务中 NVIDIA 胜过 AMD:讨论中的共识表明,由于更好的支持和更少的故障排除,在 Stable Diffusion 方面,NVIDIA GPU 优于 AMD。
- 尽管 AMD 提供了更多 VRAM,但 NVIDIA 因其更广泛的兼容性而受到赞誉,尤其是在 Linux 环境中,尽管偶尔会出现驱动程序问题。
- Stable Diffusion 模型:没有万能的选择:关于最佳 Stable Diffusion 模型的讨论得出结论,选择取决于 VRAM 和用户的具体需求,推荐 SDXL 是因为其更大的规模和能力。
- 提到 SD3 因采用了新的 VAE 而具有卓越的图像质量,同时指出它目前主要在 ComfyUI 中受支持。
- 让 Stable Diffusion 更有艺术感的技巧:一位成员寻求关于如何让图像看起来更有艺术感、减少超写实感的建议,抱怨高清、高对比度输出占据主导地位。
- 建议包括使用艺术风格的 LoRAs 以及尝试不同的模型,以实现理想的数字绘画效果。
- 寻找 Reddit 之外的 AI 新闻替代来源:一位成员对 Reddit 的封禁和 Twitter 的审查表示沮丧,正在寻找 AI 新闻的替代来源。
- 建议包括在 Twitter 上关注科学界以获取最新的论文和进展,尽管存在感知上的地区和基于用户的审查问题。
HuggingFace Discord
- CrowdStrike BSOD 快速帮助:来自 CrowdStrike 的一个错误文件导致了全球范围的大规模 BSOD(蓝屏死机),影响了全球数百万个系统。CrowdStrike 的 Overwatch 总监发布了一个热修复补丁来打破 BSOD 循环。
- 该问题引发了大量关于后续影响以及预防未来类似事件措施的讨论。
- Hugging Face API 问题:社区中多位用户讨论了 Meta-Llama-3-70B-Instruct API 的问题,包括关于不支持的模型配置的错误消息。
- 普遍认为 Hugging Face 基础设施存在问题,特别是影响了模型处理速度,用户指出在停机后最近已趋于稳定。
- 模型发布潮席卷动态:一天之内发布了多个重要模型:DeepSeek 的顶级开源 lmsys 模型、Mistral 12B、Snowflake 的嵌入模型等。查看推文获取完整列表。
- Osanseviero 评论道:“🌊 送给那些被今天发布的内容淹没的人们,” 总结了社区对大量更新涌现的情绪。
- 神经网络中的技术预告:Circuits 线程提供了一种实验性格式,深入探讨神经网络的内部运作,涵盖了如 Curve Detectors(曲线检测器)和 Polysemantic Neurons(多语义神经元)等创新发现。
- 这种理解神经机制的引人入胜的方法引发了关于概念和实际影响的热烈讨论。
- AI Comic Factory 增强功能:AI Comic Factory 进行了重大更新,现在默认包含对话气泡,提升了漫画创作体验。
- 这项新功能利用 AI 进行提示词生成和对话分割,通过视觉指标改善了叙事,甚至可以适应恐龙等非人类角色。
Nous Research AI Discord
- 通过受睡眠启发的动力学克服 ANN 中的灾难性遗忘:Maxim Bazhenov 等人的实验表明,ANN 中的类睡眠阶段有助于减少灾难性遗忘,研究结果发表在 Nature Communications 上。
- ANN 中的睡眠涉及使用局部无监督 Hebbian 塑性规则和噪声输入的离线训练,帮助 ANN 恢复之前遗忘的任务。
- Opus Instruct 3k 数据集助力多轮指令微调:一位成员分享了 Hugging Face 上的 Opus Instruct 3k 数据集链接,其中包含约 250 万个 token 的通用多轮指令微调数据,风格类似于 Claude 3 Opus。
- teknium 以正面评价认可了该数据集的重要性。
- GPT-4o Mini 在编程基准测试中与 GPT-3.5-Turbo 竞争:在一个编程基准测试中,GPT-4o Mini 的表现与 GPT-3.5-Turbo 持平,尽管其宣传的 HumanEval 分数提高了用户的期望。
- 一位用户对过度炒作的性能指标表示不满,推测 OpenAI 在基准测试数据上对其进行了训练。
- Triplex 将 KG 构建成本降低了 98%:Triplex 是 SciPhi.AI 对 Phi3-3.8B 进行微调的版本,在从非结构化数据创建知识图谱(KG)方面,其表现优于 GPT-4,而成本仅为后者的 1/60。
- 它支持使用 SciPhi 的 R2R 平台进行本地图谱构建,显著降低了开支。
- Mistral-Nemo-Instruct GGUF 转换困难备受关注:一位成员在将 Mistral-Nemo-Instruct 转换为 GGUF 时遇到了困难,原因是 BPE 词表问题和缺失 tokenizer.model 文件。
- 尽管提交了支持 Tekken 分词器的 PR,转换脚本仍然无法工作,令人非常沮丧。
OpenAI Discord
- GPT-4o mini 提供高性价比的性能:GPT-4o mini 被视为 3.5 Turbo 更便宜、更快速的替代方案,正如 GitHub 上所述,其速度快约 2 倍,价格便宜约 60%。
- 然而,它缺乏图像支持,且在基准测试中的得分低于 GPT-4o,这凸显了它的一些局限性。
- Crowdstrike 停机事件扰乱各行各业:一次 Crowdstrike 更新导致了全球范围的停机,影响了航空公司、银行和医院等行业,机器需要手动解锁。
- 这主要影响了 Windows 10 用户,使得修复过程缓慢且成本高昂。
- GPT-4o 的基准测试优势引发争议:与 GPT-4 Turbo 相比,GPT-4o 在基准测试中得分更高,但其有效性因使用场景而异 来源。
- 由于这些变数,社区对于谁具有绝对优势尚未达成共识,这凸显了特定应用需求的重要性。
- 4o mini 的微调功能指日可待:成员们预计 4o mini 的微调功能将在大约 6 个月 内推出。
- 这一潜在的增强功能可能会进一步提升其在特定应用中的实用性和性能。
- 在代码片段中请求玻璃拟态 UI:用户正寻求使用 HTML、CSS 和 JavaScript 创建一个具有玻璃拟态(glassmorphic)UI 的代码片段库,并配有动画渐变背景。
- 期望的功能包括管理代码片段(添加、查看、编辑和删除),并具备跨浏览器兼容性和响应式设计。
Modular (Mojo 🔥) Discord
- Mojo 提升调试体验:Mojo 优先开发高级调试工具,增强了在 GPU 上进行机器学习任务的调试体验。了解更多。
- Mojo 的扩展允许在 VS Code 中进行无缝设置,并计划集成 LLDB-DAP 以实现从 CPU 到 GPU 代码的单步执行。
- Mojo vs JAX:基准测试之战:尽管 JAX 针对多核系统进行了优化,但 Mojo 在 CPU 上的表现优于 JAX。讨论表明,Mojo 的编译器可见性赋予了其性能优势。
- MAX 与 openXLA 的对比显示,作为惰性计算图构建器,MAX 具有优势,提供了更多的优化机会和广泛的影响。
- Mojo 的低级编程之旅:一位从 Python 转向 Mojo 的用户考虑到 Mojo 目前文档较少,曾考虑学习 C、CUDA 和 Rust。社区的回应集中在“复杂性的渐进式披露(Progressive Disclosure of Complexity)”。
- 讨论鼓励记录学习历程以帮助塑造 Mojo 的生态系统,并建议在类型中使用
InlineArray处理 FloatLiterals。
- 讨论鼓励记录学习历程以帮助塑造 Mojo 的生态系统,并建议在类型中使用
- Mojo 中的 Async IO API 标准:一场讨论强调了在 Mojo 中建立 Async IO API 标准的必要性,通过有效处理缓冲区来支持更高性能的模型。对话借鉴了 Rust 在 Async IO 方面面临的挑战。
- 社区考虑避免在注重性能的库和主流库之间产生分裂,旨在实现无缝集成。
- Mojo Nightly 更新亮点:Mojo nightly 更新 2024.7.1905 引入了一个新的标准库函数
Dict.setdefault(key, default)。查看 原始差异(raw diff) 了解详细变更。- 贡献者会议可能会与社区会议分开,以便更好地与 Modular 的工作保持一致;标准库的贡献在集成前将通过孵化器进行 API 和受欢迎程度的审核。
LM Studio Discord
- Mistral Nvidia 合作引发关注:Mistral Nvidia 合作推出了 Mistral-Nemo 12B,提供大上下文窗口和顶尖性能,但目前 LM Studio 尚不支持。
- 需要 llama.cpp 提供 Tokenizer 支持才能使 Mistral-Nemo 兼容。
- Open WebUI 的丰富功能备受瞩目:Open WebUI 拥有 TTS、RAG 以及无需 Docker 的互联网访问等广泛功能,令用户着迷。
- 在 Windows 10 上使用 Open WebUI 的良好体验,引发了将其性能与 Pinokio 进行对比的兴趣。
- DeepSeek-V2-Chat-0628 登顶 LMSYS 排行榜:DeepSeek-V2-Chat-0628 是一款拥有 236B 参数的模型,在 LMSYS Chatbot Arena 排行榜上排名开源模型第一。
- 它占据了多个领先位置:总榜第 11,Hard Prompts 第 3,Coding 第 3,Longer Query 第 4,Math 第 7。
- 使用 NVidia Tesla P40 的复杂性:用户在 Windows 上运行 NVidia Tesla P40 时评价褒贬不一;使用了数据中心和 Studio RTX 驱动,但性能表现各异。
- 强调了 Tesla P40 与 Vulcan 的兼容性问题,建议进行多次安装并启用虚拟化。
- TSMC 预测 AI 芯片供应延迟:TSMC 首席执行官预测,由于封装瓶颈和高需求,AI 芯片供应在 2025-2026 年之前不会达到平衡。
- 正如该报告中所述,预计海外扩张将继续。
Latent Space Discord
- Llama 3 发布在即:传闻拥有 400B 参数的 Llama 3 将在 4 天内发布,引发了社区的兴奋和猜测。
- 即将到来的发布引发了关于其潜在影响和能力的众多讨论。
- 自博弈偏好优化引起兴趣:SPPO (Self-Play Preference Optimization) 因其潜力而受到关注,但对其在几次迭代后的长期有效性存在怀疑。
- 对于当前的方法论在广泛部署和使用后是否能经得起考验,意见不一。
- 苹果开源 DCLM 7B 模型:苹果发布了 DCLM 7B 模型,该模型超越了 Mistral 7B 且完全开源,包括训练代码和数据集。
- 此次发布引起了轰动,VikParuchuri 的 GitHub 个人资料展示了 90 个仓库,官方推文也强调了此次开源。
- Snowflake Arctic Embed 1.5 提升检索系统可扩展性:Snowflake 推出了 Arctic Embed M v1.5,通过微小的 Embedding 向量,为检索系统提供高达 24 倍的可扩展性提升。
- Daniel Campos 关于此更新的推文强调了性能指标的显著增强。
- Texify 与 Mathpix 的功能对比:有人提出了 Texify 与 Mathpix 在功能方面的对比,但未提供详细解答。
- 对话凸显了关于这些工具在各种用例中有效性的持续争论。
CUDA MODE Discord
- Nvidia 受反垄断法影响开源内核模块:据推测,Nvidia 开源内核模块的决定可能受到 US anti-trust laws 的影响。
- 一位用户建议,maintaining kernel modules 并非 Nvidia 的核心业务,开源可以在不需要高技能开发人员的情况下提高兼容性。
- Float8 权重在 PyTorch 中引入来自 BF16 的动态转换:成员们讨论了在 PyTorch 中将以 BF16 存储的权重转换为 FP8 进行 matmul,参考了 float8_experimental。
- 还有人对为 FP8 权重更新实现 stochastic rounding 感兴趣,这可能得到 Meta 计算资源的支持。
- Tinygrad 悬赏任务引发褒贬不一的反应:关于为 tinygrad 悬赏任务(如 splitting UnaryOps.CAST)做贡献的讨论指出,有些人认为报酬与付出的努力不成正比。
- 一位成员悬赏 $500 为 tinygrad 添加 FSDP 支持,这被认为太低了,潜在的实现者至少需要一到两周时间。
- Yuchen 的 7.3B 模型训练实现线性扩展:Yuchen 使用 karpathy 的 llm.c 和 32 块 H100 GPU 训练了一个 7.3B model,达到了 327K tokens/s 的速度和 46.7% 的 MFU。
- 为了处理由于模型参数巨大导致的整数溢出,需要将 ‘int’ 更改为 ‘size_t’。
- HQQ+ 2-bit Llama3-8B-Instruct 模型发布:一个新模型 HQQ+ 2-bit Llama3-8B-Instruct 发布,它使用 BitBlas backend 和 64 group-size 量化以保持质量。
- 尽管 Llama3-8B 的低比特量化存在挑战,该模型仍兼容 BitBlas 和
torch.compile以实现快速推理。
- 尽管 Llama3-8B 的低比特量化存在挑战,该模型仍兼容 BitBlas 和
Perplexity AI Discord
- Pro 用户报告搜索质量下降:一些成员,特别是使用 Claude Sonnet 3.5 的成员,注意到过去 8-9 天内 Pro searches 的质量显著下降。
- 这个问题已在讨论中提出,但尚未确定明确的解决方案或原因。
- GPT-4o mini 将取代 Claude 3 Haiku?:围绕在 Perplexity 中用更便宜、更智能的 GPT-4o mini 替换 Claude 3 Haiku 的想法展开了积极讨论。
- 尽管 GPT-4o mini 具有极具吸引力的属性,但目前仍在使用 Claude 3 Haiku。
- YouTube Music 推出智能电台:一场讨论重点介绍了 YouTube Music’s Smart Radio,其特点是创新的内容交付和新的音乐发现工具。
- YouTube Music 因智能策划播放列表并适应用户偏好而受到称赞。
- Dyson 首次推出高科技耳机:Dyson 的新款 high-tech headphones 因集成了先进的降噪和空气过滤技术而受到关注。
- 成员们对该产品的双重功能和时尚设计发表了评论。
- 寻求 Perplexity 的 RAG API 访问权限:一位成员指出,在发送关于其企业 RAG API 的电子邮件后没有收到回复,正在寻求进一步协助以获取访问权限。
- 这表明存在持续的沟通挑战,以及对企业级 API 解决方案未被满足的需求。
OpenRouter (Alex Atallah) Discord
- Mistral AI 发布两款新模型:Daun.ai 推出了 Mistral Nemo,这是一个拥有 12B 参数、支持 128k token 上下文长度的多语言 LLM。
- Codestral Mamba 也已发布,该模型拥有 7.3B 参数和 256k token 上下文长度,专为代码和推理任务设计。
- L3-Euryale-70B 价格大幅下调 60%:L3-Euryale-70B 经历了 60% 的巨额降价,使其在各种应用中的使用更具吸引力。
- 此外,Cognitivecomputations 发布了 Dolphin-Llama-3-70B,这是一款极具竞争力的新模型,承诺提供更强的指令遵循和对话能力。
- LLM-Draw 集成 OpenRouter API 密钥:LLM-Draw 应用现在支持 OpenRouter API 密钥,并利用 Sonnet 3.5 自我审核模型。
- 该应用可作为 Cloudflare page 通过 Next.js 部署,目前已提供 在线版本。
- Gemma 2 出现重复问题:用户报告了 Gemma 2 9B 的内容重复问题,并寻求缓解该问题的建议。
- 有建议提出使用 CoT (Chain of Thought) 提示词以获得更好的性能。
- Mistral NeMo 增加韩语支持:消息指出 Mistral NeMo 已扩展其语言支持以包含韩语,增强了其多语言能力。
- 用户注意到它在 英语、法语、德语、西班牙语、意大利语、葡萄牙语、中文、日语、韩语、阿拉伯语和印地语 方面表现强劲。
Interconnects (Nathan Lambert) Discord
- GPT-4o Mini 的多功能表现:GPT-4o mini 在 Aider 的代码编辑基准测试中与 GPT-3.5 持平,但在处理大文件的代码 diffs 时表现吃力。
- 该模型 提供了极具成本效益的文本生成,但图像输入成本仍然较高,这促使用户考虑 Claude 3 Haiku 和 Gemini 1.5 Flash 等替代方案。
- OpenAI 面临新的安全漏洞:OpenAI 的新安全机制 被轻易绕过,导致 GPT-4o-mini 生成有害内容,暴露了重大漏洞。
- 内部评估 显示 GPT-4o mini 可能存在过拟合问题,额外信息虚高了其得分,凸显了评估设置中的潜在缺陷。
- Gemma 2 的 Logit Capping 令人惊讶:成员们讨论了 Gemma 2 中 移除软 logit capping 的情况,并辩论是否需要重新训练以应对其影响。
- 一些成员发现该模型在没有进行大规模重新训练的情况下表现良好,这令人吃惊,挑战了关于 logit capping 调整的普遍预期。
- MosaicML 独特的宝剑传统:MosaicML 的员工会收到宝剑作为独特传统的一部分,这在关于未来 潜在采访 的讨论中被提及。
- 据报道,人力资源和法律团队曾表示反对,但传闻甚至连 MosaicML 的法律团队也参与其中。
- Sara Hooker 批评美国 AI 法案:一位成员分享了 YouTube 视频,内容是 Sara Hooker 批评美国 AI 法案中的算力阈值,引发了社区关注。
- 她在社区中的活跃(近期发表的论文也证明了这一点)突显了关于监管框架及其对未来 AI 发展影响的持续讨论。
Eleuther Discord
- Z-Loss 正则化项探讨:讨论了 Z-loss 作为目标函数的正则化项,并将其与 weight decay 进行了比较,成员们对其必要性展开了辩论。
- Carsonpoole 澄清道,Z-loss 通过防止过大的激活值来针对激活不稳定性(activation instability),并将其与现有的正则化方法进行了对比。
- CoALA:语言 Agent 的结构化方法:一篇关于 语言 Agent 认知架构 (CoALA) 的论文介绍了一个带有模块化内存组件的框架,用以指导语言模型开发。
- 该框架旨在调查和组织语言模型的最新进展,借鉴认知科学和符号 AI 来提供可操作的见解。
- BPB 与 per token 指标澄清:针对给定指标应解释为 bits per byte (BPB) 还是 per token 进行了澄清,为确保准确性将其确定为 ‘per token’。
- Cz_spoon_06890 指出,正确理解该指标对相应评估具有重大影响。
- Scaling laws 影响 hypernetwork 能力:讨论集中在 scaling laws 如何影响 hypernetworks 及其达到这些定律预测的目标误差的能力,并质疑了较小 hypernetworks 的可行性。
- 建议包括将 hypernetworks 集中在具有有利 scaling laws 的任务上,从而更容易从特定的数据子集中学习。
- 无分词模型引发辩论:关于 tokenization-free models 在字节或字符层面的可解释性展开了辩论,并对缺乏规范的处理位置表示担忧。
- 一位成员指出,“Utf-8 也是一种 tokenization 方案,只是个糟糕的方案”,表达了对字节级 tokenization 的怀疑。
LlamaIndex Discord
- MistralAI 和 OpenAI 发布新模型:今天是新模型发布的大日子,MistralAI 和 OpenAI 均有发布,且两者都已获得 零日支持,包括性能超越 Mistral 7b 的全新 Mistral NeMo 12B 模型。
- Mistral NeMo 模型拥有显著的 128k context window。
- LlamaCloud 更新增强协作:LlamaCloud 最近的更新引入了 LlamaCloud Chat(数据的对话式界面)以及用于协作的新团队功能。
- 这些变化旨在提升用户体验和生产力。点击此处阅读更多。
- 通过 Re-ranking 提升相关性:对检索结果进行重排序(Re-ranking)可以显著增强响应的相关性,尤其是在使用 @postgresml 等托管索引时。
- LLMs context window 限制引发困惑:一位用户在为 GPT-4o mini 设置 max_tokens 限制时遇到了 ‘Error code: 400’,尽管 OpenAI 的文档称其 context window 为 128K tokens,但据报道它仅支持 16384 个 completion tokens。
- 这种困惑源于在代码的不同部分使用了不同的模型,导致 SQL query engines 中 GPT-3.5 和 GPT-4 之间产生了干扰。
- 通过 LlamaIndex 为非结构化数据提供 ETL:一位成员询问如何将视频和音乐等非结构化数据解析为 LLMs 可理解的格式,并引用了 Jerry Liu 和 Alejandro 之间的一次 YouTube 对话,其中提到了一种新型 ETL。
- 这突出了 ETL 在 AI 数据处理中的实际应用和潜在用例。
OpenAccess AI Collective (axolotl) Discord
- 训练推理提升 Transformer 泛化能力:一篇 arXiv 论文 指出,在饱和点之外继续训练 Transformer 可以增强其泛化能力和推理事实推断能力。
- 研究结果显示,由于缺乏在多种语境下存储相同事实的动力,Transformer 在处理域外(out-of-domain)推理时表现不佳。
- 配置问题困扰 Mistral-12b 的使用:一名成员报告了 Mistral-12b 的配置问题,特别是投影权重(projection weights)的大小不匹配。
- 修复方案包括从源码安装 transformers 并调整训练设置(如使用 8x L40s),这在降低 loss 方面表现出了改进。
- Triplex 模型革新知识图谱构建:基于 Phi3-3.8B 的 Triplex 模型 与 GPT-4 相比,构建知识图谱的成本降低了 98%(来源)。
- 该模型可共享、可在本地执行,并能与 Neo4j 和 R2R 良好集成,从而增强下游的 RAG 方法。
- Axolotl 训练调整解决 GPU 显存错误:axolotl 训练过程中常见的 GPU 显存错误引发了关于调整
micro_batch_size、gradient_accumulation_steps以及启用fp16的讨论。- 社区分享了这些设置的详细指南,以优化显存使用并防止错误。
- Llama3 调整降低了 Eval 和训练 Loss:降低 Llama3 的 rank 有助于改善其 eval loss,尽管仍需进一步运行以确认稳定性。
- 训练 loss 也明显降低,表明改进效果一致。
Cohere Discord
- GPTs Agents 表现出自我意识:在 GPTs agents 上进行的一项实验旨在评估其自我意识,过程中特意避开了网络搜索功能。
- 测试结果引发了关于在没有外部数据源的情况下,具有自我意识的 AI 系统的实际意义和潜在局限性的讨论。
- Cohere Toolkit 的灵活性给社区留下深刻印象:一位社区成员转发了 Aidan Gomez 和 Nick Frosst 的推文,赞扬了 Cohere Toolkit UI 的开源特性,它允许集成各种模型并贡献新功能。
- 开源方法因其能够实现广泛的定制化并促进整个社区在工具开发方面的创新而受到称赞。
- Firecrawl 面临定价挑战:一名成员指出,在没有庞大客户群的情况下, Firecrawl 的成本很高,建议转向按需付费(pay-as-you-go)模式。
- 讨论内容包括各种定价策略以及针对小型用户提供更灵活方案的需求。
- Firecrawl 自托管被视为节省成本的方案:成员们探讨了通过自托管 Firecrawl 来降低费用,一位成员分享了一份详细说明该过程的 GitHub 指南。
- 据报告,自托管显著降低了成本,使该服务对个人开发者更具吸引力。
- 本地 LLM 聊天 GUI 项目获得关注:社区分享了一个由本地 LLMs 驱动的聊天 GUI 新项目,集成了 Web Search、Python 解释器和图像识别功能。
- 感兴趣的成员可前往该项目的 GitHub 仓库 进行进一步的交流和贡献。
Torchtune Discord
- 统一数据集抽象 RFC 获得关注:旨在统一 instruct 和 chat 数据集以支持多模态数据的 RFC 引起了广泛讨论,核心反馈集中在将 tokenizer 和 prompt templating 与其他配置分离。
- 成员们强调了可用性和改进领域,建议采用更用户友好的方法来高效管理数据集配置。
- Torchtune Recipe 文档将自动生成:出现了从 recipe docstrings 自动生成文档的提案,以提高 Torchtune recipes 的可见性和可访问性。
- 此举旨在确保用户拥有与当前版本 recipes 保持一致的、最新的、易于浏览的文档。
- 错误处理重构建议:讨论中提到了通过集中通用的验证函数来简化 Torchtune recipes 中的错误处理,从而提供更简洁的代码库。
- 其理念是尽量减少样板代码,并将用户的注意力集中在关键配置上,以提高效率。
- 合并 Instruct/Chat 数据集 RFC:分享了一个 RFC,旨在合并 Instruct/Chat 数据集,以简化在 Hugging Face 上添加自定义数据集的过程。
- 鼓励微调任务的定期贡献者进行审查并提供反馈,确保这不会影响高层 API。
Alignment Lab AI Discord
- Mozilla Builders 启动初创企业加速器:Mozilla Builders 宣布了一个针对硬件和 AI 项目的初创企业加速器,旨在推动边缘创新。
- 一位成员表现出极大的热情,表示:“我不搬走,这不是兼职加速器,我们就住在这里。”
- 为盲人生成的 AI 场景描述:社区讨论了利用 AI 为视障人士生成场景描述,旨在增强可访问性。
- 情绪高涨,出现了诸如 “失明和所有疾病都需要被消除” 之类的言论。
- 智能 AI 设备助力养蜂业:重点介绍了用于养蜂业的智能 AI 数据驱动设备的开发,为养蜂人提供预警以防止蜂群流失。
- 这种创新方法为将 AI 整合到农业和环境监测中带来了希望。
- GoldFinch 凭借混合模型增益问世:GoldFinch 结合了来自 RWKV 和 Transformers 的 Linear Attention,在任务表现上优于 1.5B 级 Llama 等模型,减少了二次减速并缩小了 KV-Cache 大小。
- GPTAlpha 和 Finch-C2 模型表现优于竞争对手:新的 Finch-C2 和 GPTAlpha 模型融合了 RWKV 的线性特性和 Transformer 架构,提供比传统模型更好的性能和效率。
- 这些模型增强了下游任务的性能,可在 GitHub 和 Huggingface 上获取完整的文档和代码。
tinygrad (George Hotz) Discord
- tinygrad 中的 Kernel 重构引发变革:George Hotz 建议重构 Kernel 以消除
linearize并引入to_program函数,从而促进更好的结构化。- 他强调需要先移除
get_lazyop_info才能高效地实施这些变更。
- 他强调需要先移除
- GTX1080 在 tinygrad 兼容性方面遇到困难:一位成员报告了在 GTX1080 上使用
CUDA=1运行 tinygrad 时出现错误,突显了 GPU 架构问题。- 另一位成员建议至少使用 2080 代 GPU,并建议在
ops_cuda中应用补丁并禁用 tensor cores。
- 另一位成员建议至少使用 2080 代 GPU,并建议在
- tinygrad 内部机制:理解 View.mask:一位成员深入研究了 tinygrad 的内部结构,特别是询问了
View.mask的用途。- George Hotz 澄清它主要用于 padding,并提供了一个参考链接。
- 剖析 tinygrad 中的
_pool函数:一位成员寻求关于_pool函数的澄清,思考它是否通过pad、shrink、reshape和permute操作复制了数据。- 经过进一步检查,该成员意识到该函数并不像最初想象的那样复制数值。
- 新项目提案:记录 OpenPilot 模型追踪:George Hotz 提议了一个项目,旨在利用 OpenPilot 模型追踪来记录 kernel 的变更及其对性能的影响。
- 他分享了一个包含说明的 Gist 链接,邀请成员参与。
OpenInterpreter Discord
- GPT-4o Mini 引发参数修改疑问:一位用户询问 GPT-4o Mini 是否仅通过修改参数即可运行,还是需要 OI 的正式引入。
- 讨论暗示了潜在的设置挑战,但在是否需要正式引入机制方面缺乏明确共识。
- 16k token 输出功能令人惊叹:社区对令人印象深刻的 16k 最大 token 输出功能感到惊叹,突显了其在处理海量数据方面的潜在效用。
- 贡献者建议这种能力可能会彻底改变大规模文档解析和生成任务。
- Yi large preview 仍是顶级竞争者:成员们报告称 Yi large preview 在 OI 框架内的表现继续优于其他模型。
- 推测认为稳定性和改进的上下文处理是其关键优势。
- GPT-4o Mini 在代码生成方面落后:初步测试表明 GPT-4o Mini 速度很快,但在代码生成方面表现平平,未达到预期。
- 尽管如此,一些人认为它在配合精确的自定义指令时可能在特定任务中表现出色,尽管其 function-calling 能力仍需改进。
- OpenAI 宣传 GPT-4o Mini 的 function calling:OpenAI 的公告赞扬了 GPT-4o Mini 强大的 function-calling 技能和增强的长上下文性能。
- 社区反应不一,争论所报道的改进是否与实际观察相符。
LAION Discord
- ICML’24 重点介绍 LAION 模型:研究人员感谢 LAION 项目提供的模型,这些模型被用于一篇 ICML’24 论文。
- 他们分享了其 Text2Control 方法的交互式 Demo,并称其对于提升 vision-language models 的能力至关重要。
- Text2Control 支持自然语言指令:Text2Control 方法使 Agent 能够通过 vision-language models 解析自然语言指令来执行新任务。
- 该方法在 zero-shot generalization 方面优于多任务 reinforcement learning 基准,并提供了一个 交互式 Demo 供用户探索其功能。
- AGI 炒作与模型性能:一次讨论强调了 AGI 被过度炒作的现状,同时指出许多模型在经过适当实验后能达到很高的准确率,并引用了 @_lewtun 的一条推文。
- “许多模型能正确解决类似 AGI 的任务,但进行必要的实验通常被认为是‘无趣的’”。
- 需要 Latents 以降低存储成本:用户表示需要像 sdxl vae 这样的大型图像数据集的 latents,以降低存储成本。
- 有建议将其托管在 Hugging Face 上,因为该平台可以承担 S3 存储费用。
- 体验 CNN 解释器工具:分享了一个 CNN 解释器可视化工具,旨在通过交互式视觉效果帮助用户理解卷积神经网络(CNNs)。
- 该工具对于那些希望从实践角度加深对 CNNs 理解的人特别有用。
LangChain AI Discord
- Triplex 大幅降低图谱构建成本:Triplex 在构建知识图谱方面实现了 98% 的成本降低,在性能超过 GPT-4 的同时,运行成本仅为其 1/60。
- 由 SciPhi.AI 开发的 Triplex 是一个经过 finetuned 的 Phi3-3.8B 模型,得益于 SciPhi 的 R2R,现在支持以极低的成本进行本地图谱构建。
- LangChain 中不需要特定模型的 Prompt 用词:一位用户询问在 LangChain 的
ChatPromptTemplate中是否需要针对特定模型的用词来确保 Prompt 的准确性。- 官方澄清
ChatPromptTemplate抽象化了这一需求,使得像<|assistant|>这样的特定标记变得不再必要。
- 官方澄清
- 使用 ChatPromptTemplate 创建 Prompt:分享了一个关于如何在 LangChain 的
ChatPromptTemplate中定义消息数组的示例,利用了角色(role)和消息文本对。- 提供了 指南链接 以获取详细步骤,帮助有效地构建结构化 Prompt。
LLM Perf Enthusiasts AI Discord
- OpenAI Scale Tier 之谜:一位成员询问关于新的 OpenAI Scale Tier 的理解,引发了社区对 GPT-4 TPS 计算方式的困惑。
- 讨论强调了 TPS 确定的复杂性以及 GPT-4 性能指标中的差异。
- GPT-4 TPS 计算困惑:成员们对 OpenAI 在 pay-as-you-go 级别上计算出的 19 tokens/second 感到困惑,因为 GPT-4 的实际输出接近 80 tokens/second。
- 这引发了关于 TPS 计算准确性及其如何影响不同使用层级的辩论。
LLM Finetuning (Hamel + Dan) Discord
- 企业对共享敏感数据持谨慎态度:一位成员指出,企业不愿与第三方共享敏感的业务线数据或客户/患者数据,这反映了对数据隐私的高度关注。
- 讨论强调,这种谨慎源于对数据安全和隐私泄露日益增长的担忧,导致企业优先考虑内部控制而非外部数据交换。
- 数据隐私成为焦点:随着企业应对合规性和安全性挑战,对数据隐私的关注变得越来越重要。
- 观察到一个明显的趋势,即企业正优先考虑保护敏感信息,以防潜在的未经授权访问。
MLOps @Chipro Discord
- 明确针对目标受众的沟通:讨论重点在于理解目标受众以实现有效沟通,强调了不同的群体,如工程师、准工程师、产品经理、DevRel 和解决方案架构师。
- 参与者强调,为这些特定群体定制信息可以确保相关性和影响力,从而提高沟通的有效性。
- 针对性沟通的重要性:明确目标受众可确保沟通对特定群体具有相关性和影响力。
- 其目的是为工程师、准工程师、产品经理、DevRel 和解决方案架构师适当地定制信息。
AI Stack Devs (Yoko Li) Discord 没有新消息。如果该频道长期处于静默状态,请告知我们,我们将予以移除。
Mozilla AI Discord 没有新消息。如果该频道长期处于静默状态,请告知我们,我们将予以移除。
DiscoResearch Discord 没有新消息。如果该频道长期处于静默状态,请告知我们,我们将予以移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期处于静默状态,请告知我们,我们将予以移除。
第 2 部分:按频道详细摘要和链接
完整的频道明细已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!