ainews-llama-31-leaks
Llama 3.1 爆料:8B 版本大幅提升,70B 版本小幅改进,以及 SOTA 级别的开源 405B 模型。
Llama 3.1 的泄露信息揭示了一个拥有 405B(4050亿)参数的稠密模型,支持 128k 上下文长度。该模型在 H100-80GB GPU 上训练了 3930 万 GPU 小时,并使用了超过 2500 万个合成示例进行微调。该模型在基准测试中表现出显著提升,尤其是 8B 和 70B 变体,部分评估甚至表明 70B 版本的表现优于 GPT-4o。同时,GPT-4o Mini 作为一款高性价比版本发布,虽然性能强劲,但在推理能力上存在一些短板。此外,像 NuminaMath 这样的合成数据集助力阿里巴巴的 Qwen 2 等模型在数学竞赛中超越了 GPT-4o 和 Claude 3.5。相关讨论还涉及了推理任务基准测试以及为提升推理能力而进行的数据集构建。
TODO: 单行副标题
2024年7月19日至7月22日的 AI 新闻。我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 30 个 Discord 社区(包含 474 个频道和 7039 条消息)。为您节省了预计阅读时间(以 200wpm 计算):765 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
我们知道它明天就要发布了(伴随 Soumith 的 ICML 主旨演讲),所以我们本想尽量避免讨论泄露内容,因为明天我们会进行全面报道。但 Llama 3.1 的泄露简直像筛子一样(权重、评估结果、模型卡 (model card)),到处都在漏。不幸的是,尽管其中很多内容只是 4 月份第一次发布 Llama 3 时的重复,但今天整个社区都在讨论它。
除了早已预告的 405B 稠密模型发布外,据我们所知,Llama 3.1 的主要差异如下,大部分来自模型卡中列出的各项优先级:
- “Llama 3.1 指令微调的纯文本模型(8B, 70B, 405B)针对多语言对话场景进行了优化,在常见的行业基准测试中表现优于许多现有的开源和闭源聊天模型。”
- 明确宣传“多语言文本和代码”作为输出模态。
- 每个模型的上下文长度 (context length) 都提升到了 128k(之前为 8k)。
- 训练在 H100-80GB(TDP 为 700W)上累计使用了 3930 万 GPU 小时的计算量:8B 模型 150 万,70B 模型 700 万,405B 模型 3100 万。
- Llama 3.1 在来自公开来源的约 15 万亿 token 数据上进行了预训练。微调数据包括公开可用的指令数据集,以及超过 2500 万个合成生成的示例。
- 8B 和 70B 的基准测试分数有显著提升(8B 的 MMLU 从 65 提升到 73(+8 分),70B 从 81 提升到 86(+5 分);8B 的 MATH 从 29 提升到 52(+23 分))。
我们制作了一个差异对比表格来进行可视化 —— TLDR:8B 模型在各方面都有巨大提升,指令微调版的 70B 略有进步。405B 仍落后于旗舰模型。
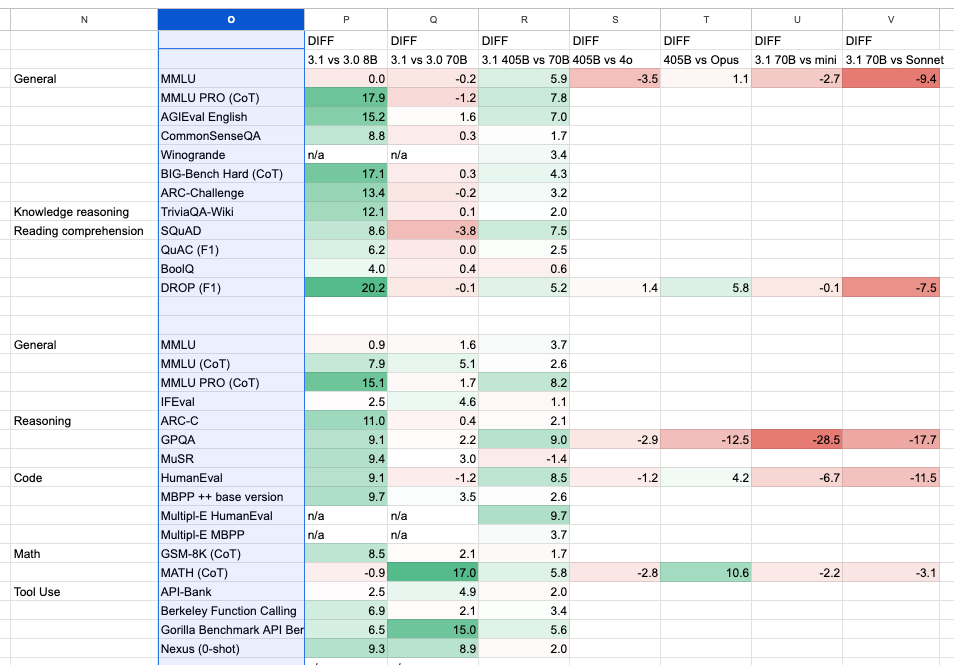
然而,一些独立运行的评估显示 Llama 3.1 70b 的表现优于 GPT 4o —— 结论尚无定论。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,从 4 次运行中选取最佳结果。
GPT-4o Mini 的发布与性能
- GPT-4o Mini 发布:@adcock_brett 宣布发布 GPT-4o mini,这是 GPT-4o 模型的一个紧凑且具有成本效益的版本,价格为每百万输入 Token 15 美分,每百万输出 Token 60 美分,比 GPT-3.5 Turbo 便宜 60% 以上。
- 强劲性能:@swyx 强调了 GPT-4o mini 令人印象深刻的性能,在 $0.15/mtok 的价格下达到了 82 MMLU,超越了仅在 3 个月前还是 SOTA(州级/顶尖)水平的模型。
- 推理缺陷:@JJitsev 在 AIW 问题上测试了 GPT-4o mini,发现其在简单问题的变体上存在基础推理缺陷且缺乏鲁棒性,尽管计算规模相似,但表现逊于 Llama-3-8B。
合成数据与模型性能
- 超越导师:@_philschmid 分享了 AI-MO 团队的获胜数据集,配合微调后的 @Alibaba_Qwen 2 模型,在数学竞赛中接近或超越了 GPT-4o 和 Claude 3.5,展示了合成数据集使模型超越其导师模型的潜力。
- NuminaMath 数据集:@_lewtun 介绍了 NuminaMath 数据集,这是最大的数学竞赛问题-解答对集合(约 100 万条),该数据集被用于赢得 AI 数学奥林匹克竞赛(AI Math Olympiad)的首届进步奖。在 NuminaMath 上训练的模型在开源权重模型(open weight models)中实现了同类最佳性能。
推理与鲁棒性基准测试
- 全面推理任务清单:@Teknium1 建议创建一个推理任务的主列表供大家贡献,以帮助数据集构建者针对性地开发能够提高推理能力的任务。
- 强劲性能的幻象:@JJitsev 认为当前的 Benchmark 忽视了 SOTA LLM 的明显缺陷,为那些虽然得分高但无法稳健进行基础推理的模型营造了性能强劲的幻象。
AI 社区中的 Meme 与幽默
- Meme 潜力:@kylebrussell 分享了一个 Meme,暗示其在 AI 社区中的潜在影响力。
- AI 生成的幽默:@bindureddy 分享了一张 AI 生成的图片,强调了 AI 在创作幽默内容以及从严肃话题中提供放松方面的作用。
AI Reddit 摘要
/r/LocalLlama 回顾
主题 1. AI 驱动的数学训练
- NuminaMath 数据集:约 100 万个数学竞赛问题-解答对的最大集合 (Score: 53, Comments: 1): NuminaMath 发布海量数学数据集:NuminaMath 集合包含约 100 万个数学竞赛问题-解答对,已在 Hugging Face Hub 上发布。该数据集随附模型和技术报告,是此类数据中规模最大的集合,有望提升 AI 在数学解题方面的能力。
主题 2. 本地 LLM 资源优化
- large-model-proxy 允许在同一台机器的不同端口上运行多个 LLM,同时通过在需要时停止/启动它们来自动管理 VRAM 使用。 (Score: 68, Comments: 10): large-model-proxy 是一个工具,允许在同一台机器的不同端口上运行 多个大型语言模型 (LLMs),同时 自动管理 VRAM 使用。该代理根据需要动态停止和启动模型,使用户无需人工干预即可高效利用其 GPU 资源。该解决方案解决了在 VRAM 有限的单台机器上运行多个内存密集型 LLM 的挑战。
- 作者开发 large-model-proxy 是为了在工作流中高效管理多个 LLM。它实现了 VRAM 管理和模型启动/停止的自动化,使得编写脚本和利用各种模型变得更加容易,无需人工干预。
- 一位用户指出 Ollama 提供了类似的功能,允许根据 VRAM 可用性自动卸载/加载,并发运行多个模型,而无需多个端口或编辑配置文件。
- 另一位开发者提到使用 Python 和 OpenResty Lua 脚本来代理 OpenAI API 请求并按需管理 LLaMa.cpp 实例,并对 large-model-proxy 的 VRAM 管理方面表示感兴趣。
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
主题 1. LLaMA 3 405B 模型发布及其影响
- [/r/singularity] 看起来我们本周就能迎来 LLama3 405B (Score: 443, Comments: 113): LLaMA 3 405B 模型发布在即:根据内部消息,Meta 的 AI 研究团队预计将于本周发布 LLaMA 3 405B 模型。这款新模型被预期为对其前代产品的重大升级,潜力足以媲美或超越 GPT-4 的能力。
{kind=link}
主题 2. 医疗保健中的 AI:提高癌症检测率
- [/r/singularity] 全科医生使用 AI 将英格兰的癌症检测率提高了 8% (Score: 203, Comments: 25): 英格兰的 AI 辅助癌症检测 已导致疑似癌症的转诊量增加了 8%。使用 C the Signs 工具的全科医生在两年期间多转诊了 92,000 名患者进行紧急癌症检查。该 AI 系统可帮助医生识别潜在的癌症症状并确定适当的后续步骤,展示了 AI 在增强初级保健机构早期癌症检测方面的潜力。
主题 3. LocalLLaMA 的进展与应用
- [/r/StableDiffusion] 在同一天,有两个人偷走了我的设计和应用,并当作他们自己的作品发布。 (Score: 259, Comments: 195): 抄袭行为冲击 AI 开发者:一款使用 LocalLLaMA 的虚拟试衣 Chrome 扩展程序的创作者报告称,有两人复制了他们的设计和应用程序,并在同一天将其作为原创作品展示。这一事件凸显了在快速发展的 AI 开发和应用领域中,知识产权保护所面临的持续挑战。
- 两名个人涉嫌复制了原帖作者(OP)的虚拟试衣 Chrome 扩展程序,引发了关于 AI 开发中知识产权的辩论。许多用户指出类似的产品已经存在,对 OP 的原创性声明表示质疑。
- 用户强调,该项目使用了 fal.ai API,只需基本的输入和一个按钮,在 15 分钟内即可重建。这种复制的简易性引发了人们对简单 AI 实现的价值以及是否需要更强大的准入门槛的质疑。
- 讨论集中在开源项目和正确注明创意来源的重要性上。一些人认为创意不受版权保护,而另一些人则强调即使是简单的实现也需要承认灵感来源。
{kind=link}
AI Discord Recap
摘要之摘要的摘要
1. LLM 模型发布与基准测试
- DeepSeek-V2 登顶基准测试:DeepSeek-V2 是一个拥有 236B 参数的 MoE 模型(每个 token 激活 21B),因其出色的性能和每 100 万输入 token 仅 0.14 美元的成本效益而受到赞誉,在 AlignBench 和 MT-Bench 等某些领域表现优于 GPT-4。
- 该模型针对 DeepSeek-V2-Chat-0628 的 1-bit 量化结果显示了优化的 CPU 性能,在 LMSYS Arena Hard 全球排名第 7。用户注意到其在多语言任务中的强劲表现。
- Llama 3.1 泄露引发热议:泄露的 Llama 3.1 评估结果表明,其 8B、70B 和 405B 模型在进行指令微调(instruct tuning)之前,性能就可能超过目前的顶级模型,其中 70B 模型被认为非常接近领先模型。
- 泄露信息显示,405B 模型被蒸馏成了具有 128k 上下文的 8B 和 70B 版本。社区成员对潜在的能力感到兴奋,尤其是应用指令微调之后。
2. AI 基础设施与优化
- Elon Musk 的 Memphis Supercluster 发布:Elon Musk 宣布启动 Memphis Supercluster,声称它是全球最强大的 AI 训练集群,在单个 RDMA fabric 上拥有 10 万块液冷 H100。
- 然而,事实核查揭示了在电力消耗和 GPU 可用性方面的差异,表明该设施尚未像声称的那样完全投入运行。
- 模型量化技术的进展:讨论强调了模型量化技术的进步,AQLM 和 QuaRot 旨在在保持性能的同时,在单个 GPU 上运行大语言模型 (LLMs)。
- 分享的一个例子是 AQLM 项目 成功在 RTX3090 上运行 Llama-3-70b,展示了在使大型模型在消费级硬件上更易于获取方面取得的重大进展。
3. AI 模型性能与效率
- 隐式 CoT 提升 GPT-2 性能:Implicit Chain-of-Thought (CoT) 通过移除中间阶段并进行微调来使步骤内部化,使 GPT-2 Small 能够以 99% 的准确率解决 9x9 乘法。
- 该方法还增强了 Mistral 7B,在没有中间步骤的情况下在 GSM8K 上实现了超过 50% 的准确率。
- ReFT 以参数效率令人震惊:ReFT 的参数效率比 LoRA 高出 15 到 60 倍,并且可以在 A10 上使用约 100 个示例在不到一分钟的时间内微调 Llama 2 7B 等模型。
- Greg Schoeninger 讨论 了其具体应用和挑战,并在 YouTube 视频 中进行了深入探讨。
- DeepSeek 1-bit 量化结果令人印象深刻:DeepSeek-V2-Chat-0628 的 1-bit 量化显示出令人印象深刻的 CPU 优化,在 LMSYS Arena Hard 全球排名第 7 (链接)。
- kotykd 询问了该模型的连贯性以及与之前版本相比的性能变化。
4. 知识图谱与检索增强生成 (RAG)
- Triplex 将 KG 成本降低 98%:来自 SciPhi.AI 的 Triplex 将知识图谱提取成本降低了 98%,通过使用 SciPhi 的 R2R 进行本地图谱构建,以 1/60 的价格超越了 GPT-4。
- 将 RAG 应用部署到生产环境:一位成员分享了关于使用 MongoDB Atlas 和 LangChain 构建 RAG 实现的 教程。
- 该教程涵盖了环境搭建、数据存储、创建搜索索引以及运行向量搜索查询。
- 通过 Deasie 工作坊改进 RAG:与 Deasie 联合创始人进行的 YouTube 会话 涵盖了用于改进 RAG 的高级解析和元数据。
- 解析和元数据增强被强调为提升 RAG 性能的关键技术。
5. 社区贡献与开源项目
- Nemotron-340B 悬赏引发关注:Nathan 悬赏 75 美元起,征集将 Nemotron-340B 转换为 HuggingFace 格式,并实现 FP8 量化 和多节点部署。
- 悬赏金额已飙升至 2,000 美元以上,引起了合成数据社区的极大兴趣。
- GPTScript 的 OpenRouter 提供商现已可用:宣布了一个新的 GPTScript OpenRouter 提供商,并在 GitHub 上提供了图片和详细说明。
- 该工具为 GPTScript 应用程序的开发做出了重大贡献。
- Bud-E 展示具有开源目标的新 Demo:分享了 Bud-E 语音助手 的演示,展示了未来每个人都能以电力成本获得高性能开源系统的愿景。
- 目前针对 Ubuntu 优化的代码库将进行重构,以实现客户端、服务器以及可互换的 ASR、TTS、LLM 组件之间的清晰分离。
第 1 部分:Discord 高层级摘要
Nous Research AI Discord
- 隐式思维链 (Implicit CoT) 提升 GPT-2 性能:隐式思维链 (Implicit CoT) 通过移除中间阶段并进行微调来使步骤内化,使 GPT-2 Small 能够以 99% 的准确率解决 9x9 乘法问题。
- 该方法还增强了 Mistral 7B,在没有中间步骤的情况下,在 GSM8K 上实现了超过 50% 的准确率。
- ReFT 的参数效率令人震惊:ReFT 的参数效率比 LoRA 高出 15x-60x,在 A10 上使用约 100 个示例,可在不到一分钟内完成对 Llama 2 7B 等模型的微调。
- Greg Schoeninger 讨论了 它的实际应用和挑战,并在 YouTube 视频中进行了深入探讨。
- DeepSeek 的 1-bit 量化结果令人印象深刻:DeepSeek-V2-Chat-0628 的 1-bit 量化显示出令人印象深刻的 CPU 优化,在 LMSYS Arena Hard 全球排名第 7 (链接)。
- kotykd 询问了该模型与之前版本相比在连贯性和性能上的变化。
- 图谱提升 RAG 性能:来自 SciPhi.AI 的 Triplex 将知识图谱提取成本降低了 98%,通过使用 SciPhi 的 R2R 进行本地图谱构建,以 1/60 的价格超越了 GPT-4。
- QuietStar 激发了自动生成提示词的讨论:QuietStar 引发了关于 LLM 并行生成后续提示词的讨论,旨在动态增强其推理能力。
- 参与者辩论了如何通过中间表示和类型系统调整 LLM 架构,以实现更好的 Token 级推理。
HuggingFace Discord
- Hermes 2.5 表现优于 Hermes 2:在添加了代码指令示例后,Hermes 2.5 在各种基准测试中的表现似乎优于 Hermes 2。
- Hermes 2 在 MMLU 基准测试中得分为 34.5,而 Hermes 2.5 得分为 52.3。
- Mistral 难以扩展到 8k 以上:成员表示,如果不进行持续预训练,Mistral 无法扩展到 8k 以上,这是一个已知问题。
- 他们指出,针对性能的下一个前沿领域是 mergekit 和 frankenMoE finetuning 的进一步工作。
- 关于模型合并策略的讨论:一位成员建议将 UltraChat 和基础版 Mistral 之间的差异应用于 Mistral-Yarn,作为一种潜在的合并策略。
- 其他人表示怀疑,但该成员保持乐观,并引用了过去在他们所谓的“诅咒模型合并 (cursed model merging)”方面的成功尝试。
- Open Empathic 项目寻求协助:一位成员呼吁帮助扩大 Open Empathic 项目的类别,特别是在低端部分。
- 他们分享了一个关于 Open Empathic 发布与教程的 YouTube 视频,指导用户贡献他们喜欢的 YouTube 视频电影场景,以及 OpenEmpathic 项目本身的链接。
- SmolLM Arena 发布:一个名为 SmolLM Arena 的新项目已经发布,允许用户比较各种小型语言模型 (Small Language Models, <1.7B 参数)。
- 该竞技场具有聊天机器人界面,运行速度更快,并包含使用说明以提供更流畅的用户体验。
Modular (Mojo 🔥) Discord
- Mojo 2.0: Socket 实现:讨论集中在 Mojo 的各种 Socket 实现,重点关注 Windows Socket 等特定平台的挑战。
- 成员们还强调了使用 Rust 的 Socket 实现的潜力,并讨论了为未来协议适配 SCTP 的重要性。
- 关于双栈 Socket 的辩论:新的服务器 Socket 倾向于使用双栈 Socket (Dual stack sockets),允许同时进行 IPv4 和 IPv6 连接,这与 Python 的实现类似。
- 达成共识在 Linux 上使用
io_uring来处理高性能工作负载。
- 达成共识在 Linux 上使用
- Flat Buffers 在社区会议中表现出色:Mojo 🔥 社区会议 #4 涵盖了用于内存高效序列化的 Flat Buffers 以及 Forge Tools 的更新。
- 讨论重点在于优化数据处理和扩展 Mojo 标准库。
- 浮点字面量的牛顿迭代法:一位成员分享了 Mojo 中浮点字面量的牛顿迭代法 (Newton’s Method) 实现,引发了关于捕获数值方程关键字的详细讨论。
- 这引发了关于闭包以及在 Mojo 中解决复杂数值问题的对话。
- Mojo GPU:展望夏季:来自 Google 的前 XLA 团队已加入 Mojo,为 AI 基础设施开发带来了新见解。
- Mojo GPU 支持预计将于今年夏天推出,增强计算能力。
Stability.ai (Stable Diffusion) Discord
- 推荐使用 ComfyUI 而非 Forge:多位用户建议从 Forge 切换到 ComfyUI 以获得更好的体验,理由是 Forge 的功能和兼容性存在问题。
- 用户称赞 ComfyUI 拥有明显更多的工具和功能,尽管指出其基于节点的界面更为复杂。
- Forge 与 Easy Diffusion 的对比:一位用户指出,虽然 Forge 比 Easy Diffusion 快,但它缺少一些功能,并且在放大 (upscaling) 时会报错。
- 其他人评论了 Forge 中放大问题和分辨率处理不当的问题,并提出了替代方案。
- 在 Regional Prompter 中使用 Latent 模式:提供了关于使用 Latent 模式而非 Attention 模式进行 Regional Prompter 的指导,以防止角色融合。
- 分享了详细的 Prompt 和说明,以改进在多角色 LoRA 中使用 Latent 模式的效果。
- VRAM 和 GPU 兼容性问题:讨论涵盖了 Stable Diffusion 的 VRAM 需求以及 GPU(尤其是 AMD 显卡)的 VRAM 问题。
- 解决方案包括为家庭 GPU 能力有限的用户提供本地安装和云端 GPU。
- Forge 中的放大错误:用户在使用 Forge 放大图像时遇到了 ‘NoneType’ 错误。
- 建议包括切换到 hi-res fix 以及 real-ESRGAN 等替代放大工具。
CUDA MODE Discord
- SVD CUDA 实现的困扰:一位用户询问 cusolver/hipSolver 如何执行 SVD,因为发现的大多数实现仅仅是闭源解决方案的包装器(wrappers)。
- 引用了一个 GitHub 仓库 以获取见解,其中提到了 Gram-Schmidt、Householder reflections 和 Givens rotations 等方法。
- 使用 LLM 构建:年度回顾:一段视频和博客文章总结了从业者使用 LLM 工作一年的经验教训,强调了战术、运营和战略方面的见解。
- 作者创建了一个视觉化的 TLDR 以使该系列更易于理解,并强调观看视频对深入理解很有价值。
- Triton 性能分析工具:成员们讨论了适用于分析 Triton kernel 的工具,特别是针对峰值内存占用等任务。
- 推荐使用 nsight-compute 和 nsight-systems 进行详细的性能分析(profiling),并指出应避免使用 nvprof,因为它已被这些新工具取代。
- A100 上 FP16 与 FP32 的性能对比:讨论集中在为什么 A100 的 FP16 性能是 FP32 的 2 倍,尽管从计算复杂度来看,预期的比例应该在 2.8 倍左右(参考 Ampere Architecture Whitepaper)。
- 成员们调查了性能瓶颈是否可能是 I/O-bound(I/O 密集型)而非计算密集型,并讨论了硬件架构和开销。
- 9 月 21 日 CUDA MODE 线下活动邀请:CUDA MODE 团队成员受邀参加 9 月 21 日在旧金山举行的线下(IRL)活动,该活动恰逢 PyTorch devcon,届时可能会有关于 llm.c 的 20 分钟演讲。
- 活动的物流和详情通过 Google Document 共享。
LM Studio Discord
- 在 C# 中解析 GGUF 文件元数据:一位用户宣布在 C# 中实现了 GGUF 文件元数据的解析,并介绍了一个旨在报告元数据和提供统计信息的控制台工具。
- 最初打算作为用于文件属性的 ShellExtension,但开发者遇到了注册问题,因此选择专注于控制台工具。
- 量化揭秘:关于量化过程(q5, q6, f16)的详细解释,旨在帮助在旧硬件上运行大型模型。
- 讨论包括 q5 如何比 q8 具有更高的量化程度,以及关于在配备 RTX 3050 的 Dell 笔记本电脑等显存(VRAM)有限的设备上运行大型模型的见解。
- Hugging Face API 中断 LM Studio 搜索:由于 Hugging Face API 的问题,LM Studio 的搜索功能失效,导致用户进行了多次故障排除尝试。
- 该问题最终得到解决,恢复了应用内的搜索功能。
- Nexusflow 发布 Athese 模型:Nexusflow 推出了 Athese 模型,展示了令人印象深刻的结果,并可能成为其同尺寸模型中当前的 SOTA。
- 该模型展示了卓越的多语言性能,使其适用于英语社区以外的用户。
- 使用 LM Studio 创建 Discord 机器人:一位开发者分享了一篇关于使用 LM Studio.js 制作 Discord 机器人的博客文章。
- 该文章包含教程和在 GitHub 上提供的源代码,详细说明了私密响应所需的修改。
Perplexity AI Discord
- Chrome 重启修复 Pro 图像生成问题:一位用户通过重启 Chrome 浏览器解决了 Pro 订阅用户只能生成一张图片的问题。在此修复后,Pro 用户可以期待更流畅的图像生成体验。
- 社区成员指出,图像生成功能需要更好的错误处理机制,以避免依赖浏览器重启。
- GPTs Agents 在训练后难以学习新信息:讨论指出 GPTs Agents 在初始训练阶段后无法从新信息中学习。
- 克服这一问题的建议包括增量更新和社区驱动的补丁,以增强适应性。
- Perplexity API 关于 Token 计费的说明:Perplexity API 现在对入站和出站 Token 均进行计费,正如最近的一个讨论串中所述。
- 用户对计费透明度表示担忧,并要求提供详细文档以更好地理解这些费用。
- YouTube 测试其对话式 AI 功能:Perplexity AI 报道了 YouTube 测试新的 AI 对话功能,以评估其在增强用户参与度方面的效果。
- 社区初步反应不一,一些人对更好交互的潜力感到兴奋,而另一些人则对 AI 的对话深度持怀疑态度。
- OpenAI 推出 GPT-4.0 Mini:OpenAI 的 GPT-4.0 Mini 首次亮相,提供了一个专注于易用性且不牺牲复杂功能的精简版本。
- 早期反馈强调了其在计算效率和性能之间的出色平衡,使其适用于更广泛的应用场景。
OpenAI Discord
- 4O Mini 表现优于 Sonnet 3.5:4O Mini 可以解决连整个 Claude 系列都难以处理的复杂问题,展示了其卓越的能力。
- 这激发了用户对 GPT-4o mini 取代 GPT-3.5 并主导高级用例潜力的期待。
- 为珊瑚礁研究微调多模态模型:一位用户询问关于微调多模态模型以研究珊瑚礁的问题,但另一位用户建议使用 Azure AI 的 Custom Vision Service 以获得更好的准确性。
- 未引用具体的模型或数据集,凸显了该领域对更具针对性建议的需求。
- API 缺乏实时语音集成:讨论强调 OpenAI 的新语音功能可在 ChatGPT 中使用,但尚未在 API 中提供,引发了对功能限制的担忧。
- 成员们注意到了显著的延迟和质量差异,观点倾向于认为 ChatGPT 更适合终端用户的实时交互。
- 改进 ChatGPT 的响应修改:一位用户在指示 ChatGPT 仅修改特定文本部分而不重写整个响应时遇到挑战,这是用户中的常见问题。
- 建议包括使用设置中的“Customize ChatGPT”部分,并分享详细的自定义指令以提高准确性。
- ChatGPT Voice 与 API Text-to-Speech 的对比:用户对 ChatGPT 的新语音功能与 API 的 Text-to-Speech 端点之间的延迟和质量差异提出了担忧。
- 成员们提出了潜在的改进和替代方案,但承认了当前 API 在实时应用方面的局限性。
OpenRouter (Alex Atallah) Discord
- 排行榜页面因迁移变慢:由于向新基础设施迁移,排行榜页面在本周末更新缓慢,且经常显示过时数据。
- 用户应预期在此期间排行榜会出现延迟和不准确。
- GPTScript 的 OpenRouter 提供程序现已发布:宣布了新的 GPTScript OpenRouter 提供程序,并在 GitHub 上提供了图片和详细说明。
- 该工具对 GPTScript 应用程序的开发做出了重大贡献。
- Dolphin Llama 70B 的性能问题:在 0.8-1 的温度(temperature)下使用 Dolphin Llama 70B,在 7k token 的上下文对话中导致了异常行为,产生了由代码和无关输出组成的混乱内容。
- 另一位成员指出 Euryale 70B 的 fp8 量化模型也存在类似问题,认为问题可能源于量化过程。
- DeepSeek 的低成本与高效率:DeepSeek v2 是一款拥有 236B 参数的 MoE 模型(每个 token 激活 21B),因其出色的性能和每百万输入 token 0.14 美元的成本效益而受到赞誉。
- “DeepSeek 的定价非常有竞争力,而且似乎利润丰厚,” 解释了他们使用高 Batch Sizes 和压缩技术的策略。
- Llama 3.1 405B 的泄露信息:Llama 3.1 405B Base 显然由于 HuggingFace 的失误提前泄露,引发了关于其通过 RoPE 缩放扩展上下文能力的讨论。
- 成员们感到兴奋,期待能有效利用该模型的软件更新,并渴望官方指令(instruct)模型的发布。
Cohere Discord
- 利用 LLM 增强 RPG 游戏:社区对在 RPG 项目中使用 LLM 进行分类、JSON 和对话生成表现出兴趣,CMD-R 因其严格的指令遵循能力成为首选。
- 在成功测试后,成员们讨论了进一步的增强和集成可能性,扩展了 AI 在 RPG 游戏玩法中的作用。
- Cohere API 中的结构化输出:Cohere 宣布 Command R 和 Command R+ 现在可以生成 JSON 格式的结构化输出,增强了下游应用程序的集成和数据分析。
- 这一新功能在此处有详细文档,旨在简化开发人员的数据工作流。
- Cohere 和 Fujitsu 推出新的企业级 AI 服务:Cohere 和 Fujitsu 建立了战略合作伙伴关系,在日本提供新的企业级 AI 服务,详见其博客。
- 此次合作旨在提高各种应用程序的 AI 服务可访问性和性能,重点展示了 Cohere 工具包的进步。
- 使用 Command R+ 的互动多人文字游戏:一位成员介绍了 Command R+,这是一款用于创建和玩多人文字游戏的 Discord 应用,增强了游戏社区的社交和互动方面。
- 该应用在 Product Hunt 上展示,为参与社区体验提供了无限可能性。
- 开发者办公时间 (Developer Office Hours) 2.0 启动:Cohere 举办了另一场开发者办公时间会议,讨论了新的 API 功能、工具包更新以及最近的 Cohere For AI 研究论文。
- 邀请社区成员参加这些会议,讨论更新、分享见解并就各种倡议进行交流。
Eleuther Discord
- Nemotron-340B 悬赏引发关注:Nathan 提供了起步价为 75 美元的悬赏,用于将 Nemotron-340B 转换为 HuggingFace 格式,并实现 FP8 量化和多节点部署。
- 该悬赏金额已飙升至 2,000 美元以上,合成数据社区对此表现出浓厚兴趣。
- Hypernetworks 与 Scaling Law 之争:Hypernetworks 面临 Scaling Law 的约束,需要达到 小于 O(scaling_law(output_model_compute)(target_error)) 才能实现目标误差。
- 讨论集中在预测神经网络的任务是否需要更简单,或者是否需要一个“良好”的 Scaling Law 才能奏效。
- 特征污染与 OOD 泛化:一篇关于 OOD 泛化 的论文详细说明了神经网络深受特征污染(Feature Contamination)之苦,从而影响泛化性能。
- 相关讨论强调了归纳偏置(Inductive Biases)和 SGD 动力学在构建解释这些模型失效的潜在统一理论中的重要作用。
- 跨参数化方案与优化器的缩放指数:一条关于缩放指数的 推文 讨论了跨优化器和模型的发现,涉及超过 10,000 个模型。
- 核心见解:O(1/n) LR 调度优于 mUP,成功的 hparam transfer 跨越了各种配置,并提出了一种新的 Adam-atan2 优化器以避免梯度下溢问题。
- MATS 7.0 申请开放:Neel Nanda 和 Arthur Conmy 已开放其冬季 MATS 7.0 课程的申请,截止日期为 8 月 30 日。公告 和 申请文档 已发布。
- MATS 项目强调其在促进机械可解释性(Mechanistic Interpretability)研究方面的独特贡献。
Interconnects (Nathan Lambert) Discord
- Nemotron-4-340B 转换为 HuggingFace:Nathan Lambert 提供 75 美元的付费悬赏,将 nvidia/Nemotron-4-340B-Instruct 转换为 HuggingFace 格式。
- 此举旨在为蒸馏(Distillation)项目解锁合成许可数据,需要同时实现 FP8 量化和多节点部署。
- Llama-3 和 3.1 泄露引发热议:关于 Llama-3 405b 和 Llama 3.1 模型及其基准测试的传闻和泄露被广泛讨论,参考了 Azure 的 GitHub 和 Reddit。
- 泄露的基准测试显示 Llama 3.1 在多个领域优于 GPT-4(HumanEval 除外),引发了关于其潜在优越性的讨论。
- ICML 2024 关注可测量忠实度模型:Andreas Madsen 宣布了他们在 ICML 2024 上的 Spotlight 论文,介绍了一种新的可解释性方法:Faithfulness Measurable Models(可测量忠实度模型),声称解释效果提升 2-5 倍,并提供准确的忠实度指标。
- 一位用户指出其与 2021 年 NeurIPS 的一篇论文相似,强调了在投稿中改进文献综述的必要性。
- Meta AI 潜在的付费服务:有推测称 Llama 405B 可能是 Meta AI 付费服务的一部分,代码片段和 Testing Catalog 的推文 暗示了这一点。
- 热议内容包括可能的 Meta AI API 平台 AI Studio,预计将于 7 月 23 日发布公告。
- UltraChat 出人意料的有效性:讨论指出 Zephyr 论文将 UltraChat 数据从 150 万大幅过滤至 20 万,对数据质量提出了质疑。
- 尽管经过严格过滤,UltraChat 的效果依然出奇地好,引发了对其生成过程的进一步探究。
Latent Space Discord
- Langfuse 优于 Langsmith:来自用户的反馈表明 Langfuse 的表现优于 Langsmith,用户分享了其在自托管和集成方面的良好体验。
- 创始人 Clemo_._ 鼓励更多的社区互动,强调他们致力于维护一个优秀的 OSS 解决方案。
- GPT-4o Mini 赋能 AI 生成内容:OpenAI 的新模型 GPT-4o mini 每 1M 输入 token 的成本仅为 $0.15,这使得完全由广告支持的动态 AI 生成内容成为可能。
- 讨论内容包括对 Web 内容的潜在影响,假设内容产出将向更多 AI 生成的方向转变。
- Harvey AI 的传闻与预测:关于 Harvey AI 可行性的传闻和质疑浮出水面,有人称其为一家“虚有其表(smoke and mirrors)”的公司。
- 随后引发了关于垂直领域 AI 初创公司面临挑战的辩论,包括对大型 AI 实验室的依赖以及当前的行业周期。
- Elon Musk 的孟菲斯超级集群:Elon Musk 宣布启动孟菲斯超级集群(Memphis Supercluster),声称这是世界上最强大的 AI 训练集群,在单个 RDMA fabric 上拥有 10 万块液冷 H100。
- 然而,事实核查揭示了在功耗和 GPU 可用性方面的差异,表明该设施尚未完全投入运营。
- LLaMA 3.1 泄露引发关注:泄露的 LLaMA 3.1 评估结果表明,其 8B、70B 和 405B 模型甚至在进行 instruct tuning 之前,就可能超越当前最先进的模型。
- 这些泄露引发了广泛的期待,以及对开源 AI 模型未来能力的推测。
OpenAccess AI Collective (axolotl) Discord
- Triplex 将 KG 成本降低 98%:SciPhi 的新模型 Triplex 将知识图谱(Knowledge Graph)的构建成本降低了 98%,以极低的成本超越了 GPT-4。
- 该模型从非结构化数据中提取三元组(triplets)并支持本地运行,使经济实惠、易于获取的知识图谱成为现实。
- Mistral 12b 分词器问题:多位成员提出了 Mistral 12b 分词器(tokenizer)的问题,尽管其指标看好,但输出的文本没有空格。
- 输出内容被批评为“垃圾”,可能与特殊 token 处理问题有关。
- LLaMA 3.1 基准测试表现亮眼:成员们赞扬了 LLaMA 3.1 的基准测试结果,强调了 8B 和 70B 模型的卓越表现。
- 70B 模型被特别指出非常接近领先模型,甚至超出了一些预期。
- DeepSpeed Zero-3 兼容性修复:一位用户解决了 DeepSpeed Zero-3 的兼容性问题,该问题涉及与
low_cpu_mem_usage=True和自定义device_map设置相关的 ValueError。- 通过删除 accelerate 配置解决了该问题,恢复了无错误的设置。
- Axolotl 训练遇到 GPU 瓶颈:正如 Phorm 所指出的,Axolotl 中的训练错误追溯到了 GPU 显存瓶颈。
- 排查步骤包括减小 batch size、调整梯度累积(gradient accumulation)以及切换到混合精度训练(mixed precision training)。
LangChain AI Discord
- Hermes 2.5 性能超越 Hermes 2:在添加了代码指令示例后,Hermes 2.5 在各项基准测试中的表现似乎优于 Hermes 2。
- Hermes 2 在 MMLU 基准测试中得分为 34.5,而 Hermes 2.5 得分为 52.3。
- Triplex 大幅降低知识图谱构建成本:SciPhi.AI 最新开源的 Triplex 将知识图谱构建成本降低了 98%,以 1/60 的成本实现了超越 GPT-4 的性能。
- Triplex 是 Phi3-3.8B 的微调版本,能够从非结构化数据中提取三元组(triplets),增强了如微软 Graph RAG 等 RAG 方法。
- 将 RAG 应用部署到生产环境:一名成员分享了关于使用 MongoDB Atlas 与 LangChain 构建 RAG 实现的教程。
- 该教程涵盖了环境搭建、数据存储、创建搜索索引以及运行向量搜索查询。
- LangChain 初学者友好文章发布:一位用户分享了一篇关于 LangChain 及其组件的 Medium 文章,旨在帮助对了解其应用感兴趣的初学者。
- 想象一下,拥有一个可以通过简单的自然语言命令处理复杂任务的虚拟助手,文章深入探讨了这些组件为何如此重要。
- 面向 TypeScript 的 AI 驱动函数构建器:在一次黑客松活动中开发了一个名为 AI Fun 的新项目,用于构建由 LLM 驱动的 TypeScript 函数。
- 该项目利用 AI 来自动化并简化 TypeScript 函数的构建过程。
LAION Discord
- Bud-E 展示具有开源目标的新 Demo:Bud-E 语音助手发布了一个 Demo,展示了未来每个人都能以电力成本获得高性能开源系统的愿景。
- 目前针对 Ubuntu 优化的代码库将进行重构,以实现客户端、服务器以及可互换的 ASR、TTS、LLM 组件之间的清晰分离。
- 加入 BUD-E Discord 服务器进行协作:邀请志愿者加入新的 BUD-E Discord 服务器,帮助进一步开发语音助手并贡献类似于 Minecraft Mods 的新技能。
- 每天欧洲中部夏令时间(CEST)晚上 9 点将举行在线黑客松会议,以引导新志愿者并协调项目工作。
- 切换回 Epochs 进行损失曲线绘制:一名成员最初使用墙上时钟时间(wall-clock time)绘制损失曲线,但发现切换回 Epochs 来衡量模型学习效率更有意义。
- 该成员发现 WandB 在这方面非常有用,但承认最初的改变是错误的,是一个“愚蠢”的决定。
- Mem0 为 LLM 引入智能记忆层:Mem0 发布了针对大语言模型的记忆层,通过用户、会话和 AI Agent 记忆以及自适应个性化等功能,实现个性化的 AI 体验。
- 有关集成和功能的更多信息,请查看 Mem0 的 GitHub 页面。
- Datadog 发布时间序列建模的 SOTA 结果:Datadog 发布了关于时间序列建模的 最新 SOTA 结果,并正在积极招聘研究职位。
- Datadog 的基础模型旨在通过识别趋势、解析高频数据和管理高基数数据来有效处理时间序列数据。
LlamaIndex Discord
- PostgresML 提升 Reranking:PostgresML 用于 Reranking,通过额外的参数实现精确控制,从而增强搜索结果的相关性。
- 一篇客座博客解释了托管索引方法如何在实际应用中优化 Reranking。
- LLM 作为生产环境评判者:与 Yixin Hu 和 Thomas Hulard 的会议讨论了在生产系统中部署 LLM 作为评判者。
- 本次会议涵盖了开发过程中 RAG 评估背后的核心概念和实践。
- Merlinn:开源 On-call Copilot:Merlinn 推出了一款用于事件管理的 AI 驱动 Slack 助手。
- 它与 Datadog 等可观测性和事件管理工具集成。
- 使用 Ollama 和 Qdrant 简化多模态 RAG:Pavan Mantha 发表了一篇关于使用 Ollama 和 Qdrant 构建多模态 RAG 的文章。
- 该指南包括摄取音频/视频源以及通过文本转录索引数据的步骤。
- 通过 Deasie 工作坊改进 RAG:与 Deasie 联合创始人的 YouTube 会议涵盖了用于改进 RAG 的高级解析和元数据。
- 解析和元数据增强被强调为提升 RAG 性能的关键技术。
DSPy Discord
- GPT4o-mini 模型在冗余度方面表现不佳:据报告,GPT4o-mini 存在冗长和重复的问题,与 GPT3.5-turbo 相比,影响了数据提取。
- 此问题导致数据流水线效率显著降低,需要更好的模型调优或替代方案。
- DSPy Tracing 发布,增强工作流:新的 DSPy tracing 功能现已上线,提供对模块、预测、LM 和检索器的有效跟踪(文档点击此处)。
- 此次更新预计将显著简化调试和性能跟踪。
- TypedPredictors 兼容性受限:GPT-4o 和 Sonnet-3.5 在处理复杂的 Pydantic 类生成方面表现独特,而其他模型则表现不足。
- 这种局限性要求根据项目需求仔细选择模型,特别是在处理复杂数据结构时。
- DSPy 中的联合优化带来巨大收益:一篇新的 DSPy 论文 揭示,在提示词优化和微调之间交替进行,可带来高达 26% 的性能提升。
- 该研究验证了双重优化策略优于单一方法策略的效率(论文链接)。
- DSPy 优化器的可靠性讨论:BootstrapFewShotWithRandomSearch 优化器被强调为一个可靠且简单的起点。
- 成员们讨论了各种优化器的可靠性,指出 BootstrapFewShotWithRandomSearch 因其简单性和鲁棒性而脱颖而出。
tinygrad (George Hotz) Discord
- George Hotz 推动 OpenPilot 洞察:George Hotz 分享了 OpenPilot 模型运行分析,重点记录了 kernel 更改和潜在的性能下降。
- 他提到,对于任何有技术倾向的人来说,这项任务都应该是可以上手的,但指出一些初学者可能会忽略最初的问题解决过程。
- 关于 Tinygrad 中 Bitcast 形状的辩论:Tyoc213 询问 Tinygrad 中的
bitcast函数是否应与 TensorFlow 的bitcast保持一致,特别是在形状差异方面。- George Hotz 和成员们一致认为将 Tinygrad 与 TensorFlow/Torch/Numpy 同步是合理的,Tyoc213 承诺进行必要的更新。
- Tinygrad 中极具前景的 PR:George Hotz 认可了 Tyoc213 提交的一个 pull request,认为其测试详尽,非常值得关注。
- Tyoc213 对此表示感谢,并透露了进一步与其他框架标准对齐的计划。
- Tinygrad 每周会议亮点:Chenyuy 分享了周一会议的议程,详细介绍了 tinybox、hcopt 速度恢复以及 MCTS 搜索增强 的更新。
- 讨论还包括更好的搜索功能、conv backward fusing、fast Llama 改进,以及针对 kernel 和 driver 改进的各种悬赏任务(bounties)。
- 关于 Tinygrad 可行性的辩论:成员们辩论了 Tinygrad 的可行性 与 PyTorch 的对比,讨论是现在切换还是等待 1.0 版本。
- 讨论反映了对生产力的担忧,并且明显受到了一段关于 Shapetrackers 的详细 YouTube 实现教程 的推动。
OpenInterpreter Discord
- Crowdstrike 入职首日更新:Vinceflibustier 分享了一个关于他在 Crowdstrike 第一天的轻松更新,提到他们推送了一个小更新后下午就下班了。
- 消息以和平手势表情符号结束,营造出一种随性友好的氛围。
- Python 3.12 中的 Python 子解释器:一位成员分享了 Python 子解释器教程,详细介绍了 Python 3.12 中 GIL 控制和并行性的增强,以及 3.13 变化的预览。
- 该教程讨论了 CPython 全局状态的更改,旨在提高并行执行效率,并建议读者熟悉 Python 基础知识。
- Meta Llama 3.1 仓库泄露:AlpinDale 确认 Meta Llama 3.1 包含一个由 405B 模型蒸馏而成的 8B 和 70B 模型,具有 128k context,并指出 405B 模型无法画出独角兽。
- 该仓库被提前意外公开,保留了与 Llama 3 相同的架构,其 instruct tuning 可能进行了安全对齐。
- Deepseek Chat v2 6.28 表现优于 Deepseek Coder:一位成员提到 Deepseek chat v2 6.28 更新 表现极其出色,甚至超过了 Deepseek coder,且比 4o mini 更具成本效益。
- 此次更新强调了 Deepseek chat v2 6.28 改进的性能指标和成本优势。
- Pinokio 的 Augmentoolkit 在 GitHub 上发布:Pinokio 的新项目 Augmentoolkit 已在 GitHub 上发布供公众使用,该工具集旨在增强 AI 应用。
LLM Finetuning (Hamel + Dan) Discord
- 使用 GPT 模型进行微调成本高昂:由于高昂的成本和供应商锁定 (vendor lock-in),微调 GPT 模型的情况较少。这涉及昂贵的 API 调用以及对特定公司基础设施的依赖。
- #general 频道中的讨论强调了这些因素如何阻碍了许多人采用微调实践。
- OpenAI credits 依然难以获取:有报告称在接收 OpenAI credits 方面存在问题,成员们提供了组织 ID org-EX3LDPMB5MSmidg3TrlPfirU 以及多次提交表单的细节。
- 尽管遵循了流程,但额度仍未分配,详见 #openai 频道。
- 探索在其他提供商上使用 Openpipe:除了 OpenAI 或 Anthropic,有人咨询了如何在 Replicate 或 Modal 等提供商上使用 Openpipe。
- 讨论集中在集成来自 Replicate 的模型,同时确保与现有系统的兼容性,如 #openpipe 频道所示。
- 东海岸聚会定于 8 月下旬:#east-coast-usa 频道提出了 8 月下旬在纽约举行聚会的建议。
- 成员们正在考虑这次非正式聚会的物流安排。
LLM Perf Enthusiasts AI Discord
- OpenAI Scale Tier 困惑:关于新推出的 OpenAI Scale Tier 的讨论让许多人感到困惑,特别是关于不同模型的每秒吞吐量 (TPS) 计算。
- 疑问集中在现收现付 (pay-as-you-go) 层级的 19 TPS 计算,以及与 GPT-4-o 约 80 TPS 吞吐量的对比。
- Websim 寻找创始 AI 工程师:Websim 的使命是创建世界上适应性最强的软件创作平台,赋能个人解决自己的挑战。
- 该公司正在招聘一名创始 AI 工程师,负责建立系统,以便针对自动化产品开发快速迭代非确定性程序。
Alignment Lab AI Discord
- 构建 LLM 一年的深刻见解:一位用户分享了 视频和博客文章,总结了从业者使用 LLM 构建应用一年的经验教训三部曲。
- 总结强调了战术、运营和战略方面的见解,并建议通过视频观看内容以便更好地理解。
- BUD-E 语音助手邀请合作:一位用户分享了 YouTube 视频,展示了开源 BUD-E 语音助手的演示,并邀请其他人加入他们新的 Discord 服务器进行合作。
- 每日在线黑客松 (hackathons) 将于 9 PM CEST 开始,以引导新志愿者并协调项目工作。
AI Stack Devs (Yoko Li) Discord
- 艺术家 Aria 寻求创意合作:Aria 介绍自己是一名 2D/3D 艺术家,正在 AI 社区寻找合作机会。
- 他们邀请感兴趣的成员通过 私信 (direct message) 联系,探讨潜在的伙伴关系项目。
- 无其他可用话题:提供的消息历史中没有讨论或分享其他重要话题。
- 此摘要反映了缺乏进一步的技术讨论、公告或值得注意的事件。
MLOps @Chipro Discord
- 明确目标受众需求:一位成员就目标受众和沟通策略背后的主要目标提出了疑问。
- 讨论提到了在讨论产品时,需要为工程师、准工程师、DevRel 和解决方案架构师制定不同的方法。
- 针对不同角色的战略沟通:探索了各种沟通策略,以有效地吸引工程师、DevRel、解决方案架构师和准工程师。
- 参与者一致认为,每个角色都需要量身定制的信息,以清晰地传达产品功能和优势。
DiscoResearch Discord
- 使用 LLM 构建一年的经验教训:Lessons from 1 Year of Building with LLMs 详细介绍了来自六位从业者的战术、运营和战略见解。
- 该系列配有一个视觉化的 TLDR 视频,使这些经验教训更易于理解。
- TLDR 系列重磅条目:TLDR 系列为深入参与 LLM 的人员提供了由 六位作者 分享的深入且具可操作性的建议。
- 作者们推荐该系列作为 LLM 从业者的重要资源。
Mozilla AI Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
第二部分:按频道分类的详细摘要和链接
完整的频道细分内容已在邮件中截断。
如果你喜欢 AInews,请分享给朋友!提前感谢!