ainews-alphaproof-alphageometry2-almost-reach-imo
AlphaProof + AlphaGeometry2 距离 IMO 金牌仅差 1 分。
“搜索+验证器”(Search+Verifier)突显了 2024 年数学奥林匹克竞赛期间神经符号人工智能(neurosymbolic AI)的进展。Google DeepMind 结合 AlphaProof 和 AlphaGeometry 2 解决了六道国际数学奥林匹克竞赛(IMO)题目中的四道。其中,AlphaProof 是一个采用 AlphaZero 方法微调的 Gemini 模型,而 AlphaGeometry 2 则是在显著增加的合成数据上训练而成,并引入了一种新颖的知识共享机制。尽管成果斐然,人类评委指出 AI 耗费的时间远超人类参赛者。
与此同时,Meta AI 发布了拥有 4050 亿参数的 Llama 3.1 及其较小变体;Mistral AI 则推出了拥有 1230 亿参数和 128k 上下文窗口的 Mistral Large 2,其在编程任务和多语言基准测试中的表现优于 Llama 3.1。这标志着 AI 在数学推理、模型扩展及多语言能力方面取得了重大进展。
Search+Verifier is all you need.
2024年7月24日至7月25日的 AI 新闻。我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 30 个 Discord 服务器(474 个频道和 4280 条消息)。预计节省阅读时间(以 200wpm 计算):467 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
对于神经符号 AI (neurosymbolic AI) 来说,这是一个丰收的月份。当人类齐聚 2024 年夏季奥运会时,AI 在数学奥林匹克竞赛中也取得了巨大进步。本月初,Numina 赢得了首届 AIMO 进步奖,解决了 29/50 道奥数级别的私有集题目。
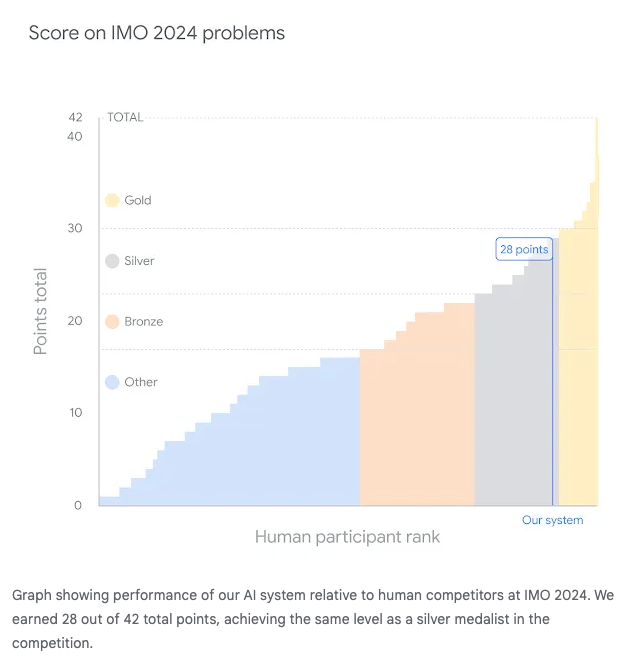
虽然 美国队的 6 名青少年 赢得了第 65 届国际数学奥林匹克竞赛 (IMO),夺回了中国的桂冠,但 Google DeepMind 宣布 他们结合了 AlphaProof 和新版 V2 AlphaGeometry 的新组合解决了 IMO 六道题目中的四道(包括在 19 秒内 解决了第四题)。人类评委(包括 IMO 题目选拔委员会主席)给出了 42 分满分中的 28 分,距离金牌分数线仅差 1 分。
AlphaProof 是一个经过微调的 Gemini 模型,结合了 AlphaZero (论文),它可以在 Lean 中证明数学陈述,并使用 AlphaZero 风格的方法寻找解决方案:
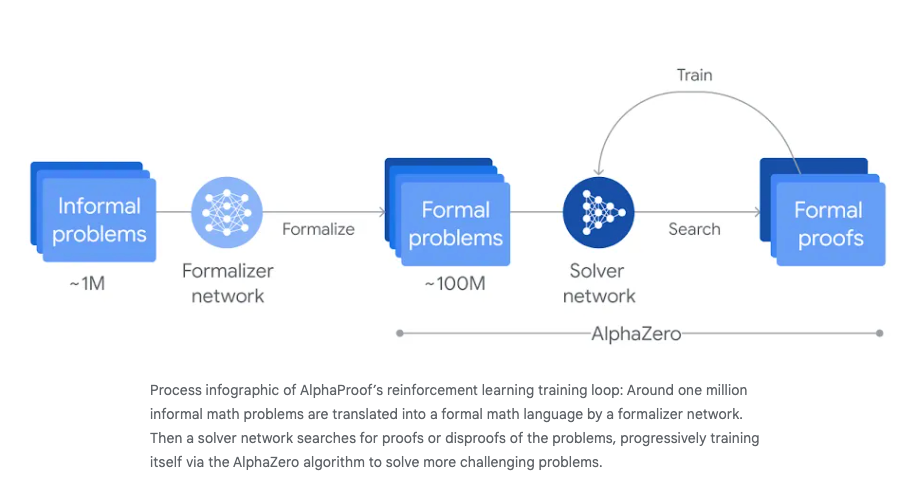
AlphaGeometry 2 是一个神经符号混合系统,其语言模型基于 Gemini,并且 在比其前身多一个数量级的合成数据上从头开始训练。[它] 采用的符号引擎比其前身快两个数量级。当面对新问题时,会使用一种 新颖的知识共享机制,从而实现不同搜索树的高级组合,以应对更复杂的问题。在今年的比赛之前,AlphaGeometry 2 可以解决过去 25 年中 83% 的历史 IMO 几何问题,而其前身的解决率为 53%。
然而,并非一切都尽如人意:IMO 人类评委之一 Tim Gowers 指出:
主要的限制在于,该程序需要比人类选手长得多的时间——对于 某些题目超过了 60 小时——当然,处理速度也比可怜的人类大脑快得多。如果允许人类选手在每道题上花费那样的时间,他们无疑会获得更高的分数。
这与 2022 年 OpenAI 在 Lean 证明器上的工作 类似。
为什么 AI 既能解决 AIMO 问题,却又无法解决 9.11 > 9.9?关于“参差不齐的智能 (Jagged Intelligence)”有 一些 思考,这归结于无处不在的泛化 (generalization) 问题。
尽管如此,对于关于 IMO 中 AI 表现的 预测市场 和 私人赌注 来说,这依然是重大的一天。
Table of Contents 和 Channel Summaries 已移至此邮件的网页版:!
AI Twitter 回顾
所有总结均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
Llama 3.1 与 Mistral Large 2 发布
-
模型规格:@GuillaumeLample 宣布了 Meta 的 Llama 3.1(包含 405B 参数模型)以及 Mistral AI 的 Mistral Large 2(包含 123B 参数),两者均具备 128k 上下文窗口。Llama 3.1 还包括较小的 8B 和 70B 版本。
-
性能对比:@GuillaumeLample 分享指出,Mistral Large 2 在 HumanEval 和 MultiPL-E 等 编程任务上优于 Llama 3.1 405B,而 Llama 3.1 405B 在 数学方面表现更出色。
-
多语言能力:@GuillaumeLample 强调了 Mistral Large 2 在 Multilingual MMLU 上的强劲表现,显著超越了 Llama 3.1 70B 基础版。
-
许可与可用性:@osanseviero 注意到 Llama 3.1 拥有 更宽松的许可证,允许利用其输出进行训练。正如 @GuillaumeLample 所述,Mistral Large 2 则在 研究许可证 下提供,仅限非商业用途。
-
部署选项:@abacaj 分享称,可以通过 Together API 和 Fireworks 访问 Llama 3.1。根据 @GuillaumeLample 的说法,Mistral Large 2 可以在 Le Chat 上免费测试。
开源 AI 与行业影响
-
生态系统增长:@ClementDelangue 强调了 开源 AI 的快速进步,目前的模型在性能上已足以与闭源替代方案相媲美。
-
计算需求:@HamelHusain 提到,在本地运行 Llama 3.1 405B 需要 大量的硬件资源,例如 8xH100 GPU。
AI 开发与研究
-
训练创新:@GuillaumeLample 透露,Llama 3.1 在训练过程中使用了 大量的合成数据 (synthetic data)。
-
评估挑战:@maximelabonne 讨论了对 标准化基准测试 的需求,并强调了当前评估方法的局限性。
-
新兴研究领域:@LangChainAI 和 @llama_index 分别分享了在 few-shot prompting 和 结构化提取 (structured extraction) 方面的持续工作。
行业趋势与观察
-
模型生命周期:@far__el 创造了“智能毁灭周期 (Intelligence Destruction Cycle)”一词,用来描述 AI 模型快速过时的现象。
-
实施挑战:@nptacek 强调了在模型能力之外,在生产环境中 部署 AI 系统所面临的复杂性。
-
伦理考量:@ylecun 参与了关于 AI 安全 以及大型语言模型对社会影响的持续讨论。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1:开源 AI 模型挑战封闭平台
- Anthropic Claude 随时可能封禁你。 (评分: 84, 评论: 44):据报道,Anthropic 的 Claude AI 在没有明显原因的情况下 封禁了一名用户,这凸显了在其服务条款下可能存在的任意账号限制。作为回应,该用户正将所有任务 转向 Meta 的开源 Llama 3.1 70B 模型,强调了对可访问、不受限的 AI 模型的需求。
- 用户对 开源模型 赶上专有模型表示感激,许多人将 可靠性问题 和 任意的账号限制 作为从 Claude 和 ChatGPT 等闭源 AI 平台转向开源的原因。
- 几位用户报告称在没有解释的情况下被 Claude 封禁,通常是因为使用了 VPN 或在创建账号后几分钟内被封。关于账号停用的透明度和沟通缺乏是普遍的抱怨。
- 讨论强调了 开源 AI 的优势,包括 数据隐私、定制化 以及对公司控制的 独立性。一些用户提到在工作流中切换到了 Mixtral 8x22B 和 Llama 3.1 70B 等模型。
- 随着最新一轮的发布,业界显然正在转向开源模型 (Score: 196, Comments: 96):AI 行业正在向 open models 转型。Meta 发布了 Llama 3 和 Llama 3.1(包括 405B 版本),而 Mistral 也提供了其最新旗舰模型 Mistral Large 2 的下载。Google 凭借 Gemma 2 进入了开源模型领域,Microsoft 继续在 Free Software 许可证下发布高质量的小型模型,Yi-34B 已转为 Apache license。这标志着自 2023 年底以来(当时似乎有可能放弃开源发布)的重大转变。这一趋势表明,尽管 Anthropic 即将发布 Claude 3.5 Opus,但像 OpenAI 这样仅提供封闭模型的厂商可能会面临来自快速进步的开源模型日益激烈的竞争。
- Apple、Nvidia、AMD、Intel、X.ai、Amazon 和其他科技巨头是 AI 发展中潜在的“睡狮”。Amazon 已向 Anthropic 投资 40 亿美元,而据报道 X.ai 正在开发 Grok 3,这是一个融合了图像、视频和音频的 multimodal 模型。
- 向开源模型的转变是由广泛测试和 R&D 的需求驱动的。开源社区提供了宝贵的见解、用例和问题解决方案,在公司和开发者之间建立了共生关系。这种方法在推进 AI 技术方面可能比封闭方法更有效。
- 尽管开源模型进步神速,但一些用户对 Transformer 架构优化的潜在边际收益递减表示担忧。然而,也有人认为进步仍然是指数级的,并引用了 Llama 3.1 8B 超越早期大得多的模型(如 175 billion 参数的 GPT-3.5)作为例子。
Theme 2. 专业 AI 能力的突破
- DeepSeek-Coder-V2-0724 今日发布,在 aider 排行榜位列第二 (Score: 87, Comments: 15):DeepSeek 发布了 DeepSeek-Coder-V2-0724,该模型在编程助手 aider leaderboard 中获得了 第 2 名。新版本在编程任务中表现出更强的性能,使其成为 AI 驱动的编程工具领域中的有力竞争者。
- 用户赞赏 DeepSeek 的频繁更新和性能提升,一些人表示希望其他模型也能有类似的快速迭代,例如 “下个月发布 Llama-3.2,再下个月发布 3.3”。
- DeepSeek-Coder-V2-0724 的 API 被描述为 “极度廉价”,并提供 tools+json 功能。然而,一些用户反映,尽管提示词要求不要这样做,模型仍会生成完整的代码块。
- 社区对该模型在 Hugging Face 上的可用性很感兴趣,开发者指出权重发布可能需要一些时间,类似于之前的版本 (Deepseek-V2-0628)。
- 介绍 InternLM-Step-Prover:在 MiniF2F、Proofnet 和 Putnam 基准测试中达到 SOTA 的数学证明器。 (Score: 68, Comments: 8):InternLM-Step-Prover 在包括 MiniF2F、Proofnet 和 Putnam 在内的数学证明基准测试中实现了 state-of-the-art 的性能,解决了 MiniF2F 中的 3 道 IMO 题目,其中包括一道从未被 ATP 解决过的题目 (IMO1983P6)。该模型及其训练数据集(包含 Lean-Github 数据)已开源,可在 Hugging Face 和 GitHub 上获取,完整研究论文可在 arXiv 查阅。
- 讨论强调了定义 AI 智能的标准在不断变化,用户注意到证明数学定理曾被认为是衡量真正智能的标准,而现在 LLM 已经可以实现。这种转变反映了 Turing test 作为标准被放弃的过程。
- 一位用户指出,根据 2010 年之前的定义,当前的 LLM 将被视为具有智能,而最近的定义使“智能”一词几乎变得毫无意义。ARC (Abstract Reasoning Corpus) 分数的快速进步被引用为一个例子。
- 一些评论认为,不断重新定义 AI 智能可能是由于知识分子对被机器超越的恐惧,导致他们否认并试图推迟承认 AI 的能力。
Theme 3. 无审查 AI 模型与伦理考量
- Mistral Nemo 是未经过滤的 (Score: 131, Comments: 40): Mistral Nemo 是一款高性能且未经过滤的模型,在 UGI 排行榜上优于其他 ~13b 模型,其 instruct 版本比基础模型更少受到过滤。尽管基准测试有限,Mistral 的过往记录表明它将与更大的模型竞争,Cognitive Computations 已经发布了 Dolphin 微调版,这可能会使其更加未经过滤。
- Mistral Nemo 12b 被誉为该尺寸类别中最好的模型,用户报告即使面对“棘手”的提示词也没有拒绝回答。然而,由于其 12b 尺寸,它仍然表现出一些局限性,包括常见的 GPT-isms 以及处理复杂指令的困难。
- 用户将 Mistral Nemo 12b 与更大的模型进行了有利的对比,将其描述为“Gemma 2 27b lite”版本。它在角色扮演场景中表现良好,即使在量化(Q8_0)的情况下也能保持连贯性和角色追踪。
- 该模型被认为非常“开放”,在 temperature 为 0.3 时会产生狂野的结果。它现在已有 GGUF 格式,兼容 llama.cpp,使得硬件有限的用户也可以使用。
- 多模态 Llama 3 将不会在欧盟提供,我们需要感谢这家伙。 (Score: 164, Comments: 78): 该帖子批评了欧盟内部市场专员 Thierry Breton,因为他可能限制了多模态 Llama 3 在欧盟的发布。作者认为 Breton 的行为(包括一条关于 AI 监管的推文)可能导致 Meta 不在欧盟提供多模态版本的 Llama 3,类似于 GPT-4V 目前在该地区无法使用的情况。
- 用户讨论了 EU 限制的实际影响,指出个人仍然可以通过 VPN 或自托管来访问模型。然而,欧盟企业在商业化使用这些模型时可能会面临法律挑战,从而可能导致“AI 殖民地”的局面。
- 值得注意的是,Mark Zuckerberg 讽刺地成为了开放 AI 访问的“救星”,这与 Sam Altman 此前限制开源模型的努力形成了鲜明对比。德国的用户报告称,他们使用 LM Studio 成功下载了 Llama 3.1 模型。
- 批评指向了 Thierry Breton 和欧盟对 AI 监管的方法,一些人称其为“功能失调”,并可能导致欧盟在 AI 发展中落后。用户质疑封锁访问基于欧洲数据训练的模型的有效性。
{kind=link}
全球 AI Reddit 综述
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型发布与基准测试
-
Llama 405B 达到 SOTA 性能:在 /r/singularity 中,一则帖子讨论了 Llama 405B 的成功如何挑战了 OpenAI 拥有专有技术的观念,即在没有使用新颖方法的情况下实现了相当的性能。
-
“AI Explained”频道的 Simple Bench 结果:/r/singularity 上分享了 Llama 405B 与其他模型在一个名为 “Simple Bench” 的私有 100 题基准测试中的对比结果。
-
开源模型超越 GPT-4:/r/singularity 报道了第二个超越 GPT-4 的开源模型,突显了公开可用 AI 的快速进步。
-
Mistral Large 2 发布:据 /r/singularity 报道,Mistral AI 推出了 Mistral Large 2,这是其系列模型中的新成员。
AI 应用与改进
- Udio 1.5 音频质量增强:Udio 发布了 1.5 版本,显著提升了音频质量,该消息分享于 /r/singularity。
AI 生成挑战
-
Stable Diffusion 提示词难题:/r/StableDiffusion 上的一篇幽默帖子展示了在生成特定内容时排除不想要元素的挑战,特别是在角色生成方面。
- 评论建议在正面提示词中使用
rating_safe,在负面提示词中使用rating_questionable, rating_explicit以获得更好的控制。 - 讨论涉及模型偏见、打标系统以及精细提示词工程(prompt engineering)的重要性。
- 评论建议在正面提示词中使用
AI Discord 摘要回顾
摘要之摘要的摘要
1. AI 模型发布与基准测试
- Mistral Large 2 对标 Llama 3.1:Mistral AI 发布了 Mistral Large 2,这是一个拥有 1230 亿参数的模型,具有 128k 上下文窗口,在多语言基准测试中平均领先 Llama 3.1 70B 等竞争对手 6.3%。
- 该模型在 代码生成 (code generation)、数学方面表现出色,并支持多种语言,专为高效的单节点推理 (single-node inference) 而设计。此次发布凸显了开源 AI 模型在与闭源产品竞争中的快速进步。
- DeepMind 的 AlphaProof 在 IMO 中获得银牌:Google DeepMind 宣布其 AlphaProof 系统结合 AlphaGeometry 2,在国际数学奥林匹克竞赛 (International Mathematical Olympiad) 中达到了银牌水平,解决了 6 道题目中的 4 道。
- 这一突破展示了 AI 在形式推理 (formal reasoning) 和数学方面日益增强的能力,尽管它比人类选手花费了更多时间。这一成就引发了关于 AI 对数学研究和教育潜在影响的讨论。
2. AI 搜索与信息检索
- OpenAI 发布 SearchGPT 原型:OpenAI 宣布开始测试 SearchGPT,这是一款全新的 AI 搜索功能,旨在提供快速、相关的答案并带有清晰的来源引用,初期涉及 10,000 名用户。
- 此举标志着 OpenAI 进入搜索市场,可能对传统搜索引擎发起挑战。社区对此表达了兴奋与怀疑并存的态度,并讨论了其对 Perplexity 等现有 AI 驱动搜索工具的影响。
- Reddit 与 Google 的独家协议引发关注:Reddit 实施了一项政策,禁止除 Google 以外的大多数搜索引擎索引其内容,这与两家公司之间每年 6000 万美元 的协议有关。
- 这一决定引发了关于开放互联网实践和数据可访问性的争议,特别是关于其对 AI 训练数据集的影响,以及对信息检索和模型开发的更广泛影响。
3. 开源 AI 与社区努力
- Llama 3.1 引发优化热潮:Meta 发布 Llama 3.1,尤其是 405B 参数版本,促使开源社区讨论并努力优化其在各种硬件设置下的部署和微调 (fine-tuning)。
- 开发者正在探索量化 (quantization)、分布式推理 (distributed inference) 和内存优化等技术,以高效运行这些大型模型。Hugging Face 等平台正在促进这些模型的获取和实现。
- AI 开发的协作工具:支持协作式 AI 开发的新工具和库正在涌现,例如用于管理堆叠拉取请求 (stacked pull requests) 的 stack-pr,以及关于共享优化内核以提高 GPU 效率的讨论。
- 这些举措突显了社区对改进 AI 项目开发工作流和资源利用率的关注。人们对点对点共享优化和缓存以利用模型训练和推理中的集体力量越来越感兴趣。
4. AI 伦理与数据使用
- Runway AI 训练数据争议:一次泄密显示,Runway 的 AI 视频生成工具 是在从 YouTube 抓取的内容和盗版电影上训练的,引发了关于 AI 训练中数据使用的伦理问题。
- 这一发现引发了 AI 社区关于使用公开但可能受版权保护的内容训练 AI 模型的激烈辩论,凸显了在平衡创新与知识产权方面的持续挑战。
- Condé Nast 对 Perplexity 采取法律行动:Condé Nast 向 AI 搜索引擎 Perplexity 发出了停止侵权函,要求其停止在 AI 回答中使用来自 Condé Nast 出版物的内容。
- 这一法律行动强调了传统媒体公司与 AI 驱动平台之间在内容使用权方面日益紧张的关系,可能为 AI 公司如何使用和引用已出版材料设定先例。
第一部分:Discord 高层级摘要
Unsloth AI (Daniel Han) Discord
- Discord AI 训练中的数据隐私担忧:关于在 GDPR 法规下使用 Discord 日志 进行 AI 训练的担忧浮出水面,表明重复使用公开数据可能仍需获得许可。
- 参与者一致认为,尽管公开消息看起来可以随意获取,但忽视隐私权可能会导致严重的违规行为。
- Llama 3 的微调挑战:用户报告了在微调 Llama 3 时遇到的 Out-Of-Memory (OOM) 错误和推理质量问题,强调了数据集清洗(sanitization)的必要性。
- 建议包括切换到 instruct 模型以提高响应质量,并解决数据集中格式不一致的问题。
- Batching 对推理速度的重要性:参与者强调,有效地对数据进行 batching 可以显著提高推理速度,并指出不使用 HF transformers 可能会阻碍性能。
- 讨论指出,由于 batching 管理不当,许多用户的平均速度仅为 30-100 tokens/sec,体感极慢。
- 推理过程缓慢原因解析:一位参与者解释了 autoregressive inference process(自回归推理过程)如何导致响应生成变慢,因为它需要按顺序计算每个 token。
- 这种顺序生成因其低效而受到批评,引发了对改进实时应用方法的呼吁。
- AI 就业保障辩论升温:关于 AI 可能导致的职位取代(特别是软件工程领域)引发了讨论,揭示了对于这些影响紧迫性的不同看法。
- 参与者反映了对 AI 融入职场的焦虑与接受,并对立法如何应对快速演变的现状提出了质疑。
LM Studio Discord
- LM Studio 0.2.28 支持 Llama 3.1:最新版本的 LM Studio 0.2.28 对于有效利用 Llama 3.1 至关重要,因为用户在旧版本中遇到了限制。
- 升级对于获取新功能至关重要,尤其是因为 auto-updater 缺少此版本。
- 了解 LLaMA 的预训练数据集:LLaMA 模型的预训练数据集包含 50% 通用知识、25% 数学推理、17% 代码和 8% 多语言内容,这对它的整体性能至关重要。
- 这一数据混合的重要性通过一份 数据混合摘要 进行了分享。
- Beta 1 面临性能问题:用户报告 Beta 1 存在严重的 CPU 飙升,导致聊天交互过程中性能迟缓,甚至有用户遇到了崩溃。
- 用户的普遍情绪是希望在预期的 Beta 2 发布之前解决这些性能瓶颈。
- Mistral Large 模型发布:Mistral Large 现已发布,其特点是采用 imatrix 设计进行尺寸管理,能力可扩展至 70GB。
- 鼓励用户通过其 Hugging Face 页面 尝试此模型,它承诺提供强大的性能。
- 针对 LLM 优化 GPU 配置:讨论强调了各种 GPU 配置,特别是 P40 与 RTX 3090 等较新模型的对比,揭示了在速度和散热管理方面的显著差异。
- 值得注意的是,用户记录了在 P40 上运行 Llama 3.1 的速度为 3.75 tokens/s,但散热问题需要冷却方案才能维持性能。
HuggingFace Discord
- Llama 3.1 登场:备受期待的 Llama 3.1 现已发布,增强了社区最喜爱的 AI 聊天模型。可以在 官方博客 探索其功能,并通过 此链接 使用。
- 感兴趣的用户可以参考 GitHub 上的 Hugging Face recipes 获取实现细节。
- Hugging Face 在中国访问受阻:讨论强调了在中国访问 Hugging Face 的挑战,由于该网站被封锁,导致一些开发者不得不依赖 VPN 来获取模型。
- 建议包括与中国监管机构协商以恢复访问,以及推广本地化内容。
- Dolphin 2.9.3 模型革新 AI:由 Eric Hartford 策划的新发布的 Dolphin 2.9.3 Mistral Nemo 12b 模型 具有 128K 上下文 和 8192 序列长度。
- 这一增强源自 Mistral-Nemo-Base-2407 模型,有望带来性能提升。
- 开源悬赏计划蓬勃发展:成员们分享了几个 开源悬赏计划,鼓励为实现各种模型做出贡献。
- 此类计划不仅为完成的工作提供报酬,还促进了技能发展和协作。
- 使用量化 Diffusers 进行优化:通过 Quanto 支持 量化 Diffusers 模型 的新功能可减少 50% 的内存占用,详见 此 GitHub PR。
- 此外,Orig PixArt Sigma 权重文件大小 显著下降,从 2.44GB 降至 587MB,提升了模型获取和处理速度。
Nous Research AI Discord
- Hermes 2 Theta 70B 超越 Llama-3:Nous Research 发布了 Hermes 2 Theta 70B,它超越了 Llama-3 Instruct 设定的基准,并与 GPT-4 的性能持平。该模型具备 function calling 和 feature extraction 等功能。
- 此次发布反映了模型架构的重大进展,表明在多功能 AI 应用中具有竞争优势。
- Mistral Large 2 革新 AI:2024 年 7 月 24 日,Mistral AI 推出了 Mistral Large 2,拥有 1230 亿参数 和 128,000 token 的上下文窗口。该模型在 code generation 和 mathematics 方面表现出色,略胜 Llama 3.1。
- 该模型的推出是 AI 应用规模化的进步,可能已接近 GPT-4 等领先基准的水平。
- Reddit 的新索引政策:Reddit 更新政策以屏蔽除 Google 之外的大多数搜索引擎,这引发了与 Google 达成的 6000 万美元 协议相关的争议。此举阻止了未经授权的索引,引发了对开放互联网实践的质疑。
- 成员们辩论了限制数据访问的影响,表达了对快速演变的数字格局中内容可用性的担忧。
- Condé Nast 对 Perplexity 采取法律行动:Condé Nast 向 Perplexity 发出了 停止侵权函 (cease-and-desist),要求停止从其出版物中使用内容。在 Perplexity 估值上升之际,这加剧了传统媒体与 AI 驱动的搜索引擎之间的紧张关系。
- 这一举动反映了 AI 驱动的信息检索时代下,内容所有权和使用权的广泛问题。
- LLaMA 3.1 受到质疑:用户报告 LLaMA 3.1 instruct 模型 的结果令人失望,在知识基准测试中表现不如 LLaMA 3.0。讨论集中在 RoPE 对性能的影响上,认为它可能有害。
- 成员们指出,关闭 RoPE 可能会带来更好的结果,特别是对于较小的模型,这指明了潜在的优化方向。
Modular (Mojo 🔥) Discord
- Modular 发布新 Git 工具 - stack-pr:Modular 推出了一款名为 stack-pr 的新开源工具,旨在管理 GitHub 上的堆叠式 Pull Requests (PR),目标是为开发者简化集成流程。
- 该工具支持更小的贡献,通过在 PR 评估过程中实现更平滑的更新,从而使 Code Reviews 受益。
- 对 AI 应用中 Posits 的兴趣:关于 Posits 在 AI 中作用的讨论显示了对 Gosit 和 llvm-xposit 等实现的兴趣,未来可能会集成到 MLIR 中。
- 然而,成员们指出,从传统的浮点系统过渡到 Posits 可能会面临重大挑战。
- 开源 Mojo 矩阵乘法:一位成员宣布开源其在 Mojo 中的矩阵乘法实现,并邀请其他人分享在各自配置下的性能基准测试。
- 该倡议旨在促进围绕所使用的性能指标的技术讨论和协作。
- 关于 SIMD 比较的讨论:社区参与了关于 SIMD 比较的讨论,争论是否应同时保留逐元素(element-wise)和总计比较结果,以适应各种功能。
- 社区正努力确保 SIMD 性能保持强劲,同时不损害其与列表行为的集成,特别是针对数据库。
- 推出具有增强能力的 Llama 3.1:Meta 发布了 Llama 3.1 模型,现在具有 128K 上下文长度并支持八种语言,推动了开放智能进步的边界。
- 该模型提供了与领先的闭源模型相匹配的独特能力,扩展了潜在的 AI 应用。
Perplexity AI Discord
- Perplexity AI 计划停机警报:Perplexity 宣布在 <t:1722060000:R> 进行 10 分钟的计划停机,以进行必要的数据库维护,从而提高系统可靠性。
- 团队对用户在这一关键维护期间的耐心表示感谢。
- Mistral Large 2 在 AI 领域取得进展:2024 年 7 月 24 日,Mistral AI 推出了 Mistral Large 2,拥有 1230 亿参数和 128,000 token 上下文窗口,在多语言 MMLU 基准测试中显著优于 Llama 3.1 70B。
- Mistral Large 2 表现出比竞争对手平均高出 6.3% 的提升,特别是在代码生成和数学方面。
- Reddit 对搜索引擎施加限制:Reddit 最近的举动阻止了大多数搜索引擎索引其内容,仅因一项价值 6000 万美元的年度协议而授予 Google 访问权限。
- 这一决定引发了关于 AI 模型爬取和训练中数据访问影响的辩论。
- Condé Nast 质疑 AI 搜索做法:Condé Nast 已向 Perplexity 发出停止并终止函,指控其未经批准使用其出版物,这表明媒体与 AI 内容使用之间的紧张关系正在升级。
- 随着 AI 工具的激增并寻求将信息变现,这一法律行动使内容权利的复杂性成为焦点。
- 报告 Microsoft Teams 连接器错误:一位用户在尝试将 Perplexity Connector ZIP 文件上传到 Microsoft Teams 时遇到了未指定的错误消息。
- 这引发了社区内关于成功集成经验和潜在变通方法的咨询。
OpenRouter (Alex Atallah) Discord
- Llama 405B 降价 10%:根据 OpenRouterAI 的公告,Llama 405B 的价格已降低 10%,这是市场持续竞争策略的一部分。
- 这一趋势表明,在 AI 模型产品的激进定价策略中,用户选择存在一种过滤机制。
- Middle-out transform 将默认关闭:从 8 月 1 日开始,middle-out transform 将默认关闭,从其历史设置转为增强用户控制。
- 依赖此功能的用户应参考 文档 以相应地调整其请求。
- 流量激增导致数据库压力:OpenRouter 经历了 5 倍的流量激增,导致在 东部时间晚上 10:05 进行计划内停机以进行数据库升级。
- 据报道,升级后的服务已迅速恢复在线,但由于反复出现的数据库问题,仍存在未解决的性能担忧。
- Llama 3.1 表现不稳定:报告指出 Llama 3.1 的输出不一致,特别是在高上下文负载期间,部分回答偏离主题。
- 用户注意到更换供应商有时会提高输出质量,这表明推理引擎的有效性可能存在问题。
- Mistral Large 2 展示了多语言实力:Mistral Large 2 在多种语言中表现出色,在包括英语、西班牙语和中文在内的语言中展现了强大的能力。
- 这一表现使其成为多语言语言处理领域的重要竞争者。
OpenAI Discord
- OpenAI 测试 SearchGPT 原型:OpenAI 推出了 SearchGPT,这是一个旨在通过快速、相关的答案和清晰的来源引用来增强搜索能力的原型,最初向选定用户推出以获取反馈。更多信息请访问 OpenAI 的 SearchGPT 页面。
- 测试期间的用户反馈对于在 SearchGPT 完全集成到 ChatGPT 之前进行改进至关重要。
- Mistral 模型下载时间长:用户报告 Mistral Large 模型的下载时间很长,其中一位用户指出下载耗时 2.5 小时,在 MacBook Pro 上达到了 18 tk/s 的性能。尽管下载缓慢,但 MacBook Pro M2 Max 配合 96GB RAM 的能力引发了对未来改进的期待。
- 对网络升级的期待显而易见,一位用户计划在 12 月将速度提升至 1 Gbps,这对于优化下载时间至关重要。
- 用户对 GPT-4o 的表现感到沮丧:升级到 GPT-4o 后,用户表示失望,指出频繁出现错误且缺乏来源引用,一位用户感叹道:“我觉得那位睿智的朋友早已离去,只剩下一个愚蠢的双胞胎兄弟。”
- 对 SearchGPT API 的担忧表明,普通访问可能需要 数月 时间,用户优先考虑功能改进而非 API 细节。
- 聊天机器人记忆功能的挑战:开发者讨论了在实现聊天机器人记忆创建、编辑和删除的 function calls 时的困难,目前的准确率约为 60%。为了改进记忆存储决策,清晰的指导被认为是必要的。
- 建议包括在保存重要事件的同时保存用户偏好,同时强调记忆输入指令需要具体化。
- OpenAI 文件上传问题:一位用户在尝试向 OpenAI 上传 txt 文件 时遇到了 400 错误,理由是不支持的文件扩展名,并引用了 OpenAI 文档。
- 尽管遵循了使用 Python 和 FastAPI 上传文件的详细文档,该用户在处理与文件上传失败相关的 vector store 配置时仍面临挑战。
Stability.ai (Stable Diffusion) Discord
- Stable Video 4D 颠覆视频生成:Stability AI 推出了 Stable Video 4D,这是一款开创性的 video-to-video 生成模型,可在约 40 秒内从单个输入视频创建动态多视角视频。
- 该工具能够生成 8 个视角下的 5 帧画面,为追求高质量视频制作的用户增强了创作流程。
- Stable Assistant 获得新功能:Stable Assistant 现在新增了 Inpaint 和 Erase 工具,允许用户在 3 天免费试用期内轻松清理生成内容并进行迭代。
- 这些更新支持对输出进行微调,满足了用户在创意工作流中对精确度的需求。
- 关于模型性能的激烈辩论:围绕模型效率的讨论非常热烈,部分成员声称某款模型性能优于 SDXL,而另一些成员则注意到来自 Kolors 和 Auraflow 等模型的日益激烈的竞争。
- 讨论强调了在模型性能格局快速变化的背景下,保持关注最新发布版本的重要性。
- 掌握 Lora 训练以获得更佳输出:社区成员交流了关于 Lora 训练最佳实践的见解,重点讨论了针对不同特征应使用完整图像还是裁剪图像。
- 这一讨论突出了构建详细训练数据集以有效提升结果的关键策略。
- 深入探讨 Inpainting 技术:用户探索了各种 inpainting 方法,并建议利用 img2img 流程和相关的教程资源以获得最佳效果。
- 社区强调,使用上下文丰富的 Prompt 对于将物体成功融入场景至关重要。
Eleuther Discord
- Flash Attention 优化 VRAM 但不减少耗时:Flash Attention 有助于实现线性 VRAM 占用,特别是在推理期间,但它并不能降低时间复杂度,时间复杂度仍为平方级。一位成员观察到,在长缓存和单查询(single query)的情况下使用 Flash Attention 实际上可能会因为并行化降低而减慢性能。
- 讨论了 KV-Cache 等策略的影响,其随序列长度线性增加,在不显著改变计算时间的情况下影响 VRAM。
- 关于模型提供商推理成本的辩论:成员们认为,像 Mistral 这样的大规模模型推理应该免费提供,并强调了利用单层或 MoE 框架的效率。有人担心,由于复杂性增加,批量推理(batch inference)的低效可能会抵消 MoE 带来的好处。
- 讨论涉及对 Meta 运营策略的极少了解,挑战了那些似乎为了优化代码行数而忽略的运营效率。
- 对 Meta 的 Scaling Laws 的审查:用户质疑 Meta 的 Scaling Laws 是否受到数据叠加(data superposition)的影响,建议通过指数函数实现最佳数据量的非线性缩放。这引发了关于计算和理解与模型性能相关的最佳数据量的对话。
- 提到了 Chinchilla 推广到每个参数 20 个 token 的情况,揭示了缩放感知虽然看似扭曲,但在更深层次上是合理的。
- 探索 Awesome Interpretability 仓库:Awesome Interpretability in Large Language Models GitHub 仓库是专注于 LLM 可解释性的研究人员的重要汇编。它是深入研究大型语言模型行为复杂性的关键资源。
- 参与 NDIF 计划可以获取 Llama3-405b 以进行大胆的实验,参与者将获得大量的 GPU 资源和支持——这是一个记录在 这里 的开展有意义研究合作的新机会。
- 在外部 API 上进行 MMLU 评估:一位成员正在寻求关于使用反映 OpenAI 设置的外部 API 测试 MMLU 性能的指导,特别是关于模型评估过程中的 log_probs。提到了一个相关的 GitHub PR,该 PR 引入了一个旨在实现 API 模块化的超类。
- 出现了关于计算模型评估所需 VRAM 的担忧,强调了理解 VRAM 能力对实验结果的影响。
CUDA MODE Discord
- NCCL 重叠挑战:一位用户在参考 NCCL Issue #338 进行训练设置时,对在反向传播(backward pass)期间实现 计算重叠(computation overlap) 表示担忧。他们指出,实现讲座中建议的内容比预期的要复杂得多。
- 这突显了在训练中有效利用 NCCL 优化 GPU 工作负载时面临的持续挑战。
- 引入 Flute 矩阵乘法:一位成员分享了 Flute 的仓库,该项目专注于针对查找表量化(lookup table-quantized)的 LLM 进行 快速矩阵乘法。这旨在提升 LLM 处理应用的性能。
- 该工具可能有助于简化需要高效矩阵处理的模型操作,这对于大规模部署至关重要。
- 使用 CUDA 工具分析 Triton Kernels:你可以像分析其他 CUDA kernel 一样,使用 Nsight Compute 等工具对 Triton kernels 进行详细的性能分析(profiling)。Nsight Compute 提供了全面的分析能力来优化 GPU 吞吐量。
- 对于旨在提高 GPU 应用性能和效率的开发者来说,这款性能分析工具必不可少。
- FP16 执行的内存限制:一位用户对以 FP16 精度运行模型时内存不足表示沮丧,这突显了开发者面临的一个常见问题。这引发了关于探索优化内存使用的替代方案的讨论。
- 解决这一问题对于提高在内存受限环境中部署大型模型的可行性至关重要。
- 使用 BnB 探索量化技术:另一位用户建议研究使用 bitsandbytes (BnB) 库的 量化(quantization) 技术,作为内存问题的潜在变通方案。这引发了一些困惑,部分人对量化概念本身提出了疑问。
- 理解量化的影响对于利用模型效率至关重要,尤其是在大型语言模型中。
Interconnects (Nathan Lambert) Discord
- DeepMind AI 在 IMO 2024 中获得银牌:最近的讨论集中在 Google DeepMind AI 在 IMO 2024 中获得银牌,根据 Google 的博客,它达到了“银牌标准”。
- 怀疑者对标准的清晰度提出了质疑,认为 Google 可能影响了挑战题目以展示其 AI 的性能。
- Runway AI 的训练数据源曝光:一次泄露透露,Runway 的 AI 视频生成工具 是在抓取的 YouTube 内容和盗版电影上训练的,这引发了伦理担忧。
- 这一争议引发了激烈的讨论,暗示了关于内容创作者受影响程度的激烈辩论。
- OpenAI 凭借 SearchGPT 进入搜索市场:OpenAI 宣布测试 SearchGPT,旨在提供快速回答,最初将涉及 10,000 名用户。
- 来自此次测试的反馈预计将影响其在 ChatGPT 中的集成,引发了人们对 AI 搜索功能改进的期待。
- 现代架构书籍推荐:在寻找关于 Diffusion 和 Transformers 的资源时,一位社区成员为机器学习课程寻求书籍推荐,强调了对更具针对性的阅读材料的需求。
- 其中一个建议是 rasbt 的书《Building LLMs from scratch》,但成员们正在寻找更多关于现代架构的综合性著作。
- 理解 LLAMA 3.1 退火(Annealing):讨论集中在 LLAMA 3.1 技术报告上,特别是将学习率降低到 0 如何有助于在不越过最佳点的情况下进行训练。
- 这种策略可以通过精细的预训练策略提升模型在排行榜上的表现。
Latent Space Discord
- OpenAI 的 SearchGPT 原型亮相:OpenAI 宣布推出 SearchGPT 原型,旨在增强现有选项之外的搜索能力,首先从选定的用户群体开始收集反馈。
- 这一初始阶段旨在将该原型集成到 ChatGPT 进行实时运行之前收集见解。
- AI 在国际数学奥林匹克竞赛中大放异彩:由 Google DeepMind 开发的混合 AI 系统在国际数学奥林匹克竞赛 (IMO) 中获得了银牌水平的表现,利用 AlphaProof 和 AlphaGeometry 2 解决了 6 道题目中的 4 道。
- 这一成就突显了 AI 在应对复杂数学挑战方面的重大进展,尽管其耗时比人类参赛者更长。
- OpenAI 用于更安全 AI 的基于规则的奖励:OpenAI 发布了 基于规则的奖励 (RBRs),旨在通过对齐行为来提高 AI 安全性,而无需大量的人工数据收集。
- 这种方法允许使用更少的手动标记示例对安全协议进行更快速的调整,从而促进更具适应性的安全模型。
- LLM 凭借评分注释晋升为裁判:Databricks 引入了 评分注释 (Grading Notes),通过创建结构化的评估量表来提高 LLM 在裁判角色中的可靠性。
- 这些注释的加入通过为专业评估中的 LLM 提供明确指南,增强了特定领域的应用。
- AI 训练中的合成数据面临批评:最近的一篇论文对 AI 训练中过度依赖合成数据表示担忧,警告称这可能导致多代之后的模型崩溃 (model collapse)。
- 专家强调保持训练输入的多样性,以维护信息质量并减轻性能下降。
LlamaIndex Discord
- 结构化提取功能发布:新版本在任何 LLM 驱动的 ETL、RAG 或 Agent 流水线中实现了结构化提取功能,全面支持异步和流式处理功能。
- 用户现在可以定义一个 Pydantic 对象,并使用
as_structured_llm(…)将其附加到他们的 LLM 上,以实现流线型实现。
- 用户现在可以定义一个 Pydantic 对象,并使用
- 推出用于高效数据提取的 LlamaExtract:披露了 LlamaExtract 的早期预览版,这是一款用于从非结构化文档中提取结构化数据的托管服务。
- 该服务从文档中推断出 人工可编辑的 Schema,允许用户自定义结构化提取的标准。
- OpenAI 调用重复的困惑:用户对在
MultiStepQueryEngine中看到重复的 OpenAI 调用表示担忧,引发了关于 Arize 日志问题的讨论。- 澄清确认这些并非实际的重复调用,结构化文本提取的工作仍在继续推进。
- RAG 聊天机器人更新计划分享:一位用户分享了升级其早期使用 LlamaIndex 构建的 RAG 聊天机器人的计划,并为开发者提供了 GitHub 仓库 链接。
- 他们强调,既然 RAG 现在如此流行,他们非常渴望增强聊天机器人的功能。
- 监控 Llama Agent 的文章获得好评:成员们讨论了一篇题为《监控 Llama Agent:利用 LlamaIndex 和 Portkey 解锁可见性》的文章,链接见 此处。
- 一位成员评论说这是一篇 很棒的文章,强调了它对社区的重要性。
Cohere Discord
- Cohere 与 OpenAI 相比表现出色:Cohere 提供专注于通过 API 进行自然语言处理的语言模型解决方案 (language model solutions),允许开发者创建诸如对话式 Agent 和摘要生成器之类的工具。欲了解全面信息,请访问 Cohere API 文档。
- 他们的定价基于使用量,无需订阅,这使其与市场上的其他竞争对手区别开来。
- 撰写研究论文的指导:成员们讨论了撰写研究论文的技巧,强调了大学导师对学术界新人的作用。他们指出 Cohere For AI 社区 是一个可以获得协作支持的资源。
- 该社区提供必要的指导,帮助加强新作者学术研究的早期阶段。
- 理解 Langchain 的 optional_variables:关于 Langchain 的 ChatPromptTemplate 中 ‘optional_variables’ 的澄清浮出水面,强调了其允许 Prompt 中存在非必需变量的功能。这种灵活性对于创建自适应用户查询至关重要。
- 然而,关于它与 ‘partial_variables’ 的区别也产生了困惑,后者同样提供了在 Prompt 设计中处理可选元数据的功能。
OpenAccess AI Collective (axolotl) Discord
- Mistral Large 2 树立了新标杆:据报道,Mistral Large 2 以 1230 亿参数 (123 billion parameters) 和 128k 上下文窗口 (context window) 超越了 4050 亿参数的模型,使其适用于长上下文应用。
- 该模型支持多种语言和编程语言,专为高效的单节点推理而设计,引发了对其性能潜力的期待。
- 探索多 Token 预测 (Multi-token Predictions):成员们对多 Token 预测表示好奇,指出其在使字节级模型在训练期间更可行、更高效方面的潜力。
- 成员们对数据集中可能用于指定 Token 预测的注释感到兴奋,这与相关论文中讨论的方法论一致。
- 训练数据修改策略:讨论围绕通过掩盖不增加价值的简单词汇来提高训练效率展开,类似于 Microsoft Rho 论文中的概念。
- 成员们考虑了增强训练数据的策略,例如分析困惑度点 (perplexity spots) 并使用标签增强上下文,以提升训练效果。
- 对 Mistral 发布版本的困惑:关于 Mistral Large 与 Mistral Large 2 的发布细节存在困惑,成员们对开源状态和改进声明提出了质疑。
- 一些人对与 Claude 3.5 等现有模型相比的相对性能指标,以及该模型最终是否会开源表示担忧。
- 使用 FSDP 和 Zero3 加载 405B 的挑战:一位用户报告了在使用 QLoRA 配合 FSDP 或 Zero3 加载 405B 模型时遇到困难。
- 他们对导致这些加载失败的具体问题表示不确定。
tinygrad (George Hotz) Discord
- 内核共享增强 GPU 效率:成员们讨论了在搜索最优内核后,通过点对点 (p2p) 内核共享来提高 GPU 效率的潜力。
- 之前的讨论强调了 p2p 搜索和共享 tinygrad 缓存的有效性。
- 需要支持多次反向传播 (Backpropagation):社区强调了在 tinygrad 中需要一种一致的方法来进行多次反向传播,以实现神经网络势能 (neural network potentials)。
- 虽然有些人认为为 backward 调用合并损失 (combining losses) 就足够了,但许多人寻求一种能够为复杂的梯度计算保留计算图 (computation graph) 的解决方案。
- 随机张量生成给出重复结果:一位用户报告了 get_random_sum() 由于 TinyJit 的输出覆盖行为而重复返回相同输出的问题。
- 建议在重复调用之前使用
.numpy()可以解决此问题,从而确保输出的唯一性。
- 建议在重复调用之前使用
- NumPy 转换过程中的优化:一位用户报告通过在张量转换方法中移除
.to('CLANG'),将 NumPy 转换时间从 6 秒缩短至 3 秒。- 虽然出现了关于正确性的疑问,但他们验证了生成的 NumPy 数组仍然是准确的。
OpenInterpreter Discord
- Mistral-Large-Instruct-2407 提供速度优势:Mistral-Large-Instruct-2407 (128B) 比 405B 模型大约小 3 倍,从而减少了 inference time(推理时间)。
- 这种规模的缩减可能会吸引那些寻求 efficient models(高效模型)的用户。
- Llama 3.1 最大输出 Token 查询:一位成员询问了 Llama 3.1 的 maximum output tokens(最大输出 Token 数),表明社区需要更多相关信息。
- 了解这些限制可以优化用户使用 Llama 3.1 的体验。
- 对过时的 Ubuntu 安装说明的担忧:讨论中提到 Ubuntu 的安装指南 可能已经过时。
- 有人指出目前的说明 已经不再适用。
- 为优化而微调 GPT-4o-mini:有人提出了关于在 Open Interpreter 框架内微调 GPT-4o-mini 以获得更好性能的问题。
- 这一讨论反映了用户对利用现有 free fine-tuning quota(免费微调配额)的兴趣。
- Deepseek coder 展示了令人期待的更新:Deepseek coder 最近的 update 引起了关注,并分享了极具前景的性能规格。
- Deepseek 每百万 Token 14-28 美分 的性价比被强调为一个显著优势。
Torchtune Discord
- Llama 3.1 接近完成测试:成员们表示正在完成 Llama 3.1 补丁的最终测试,重点是在单节点上集成 405B QLoRA。一位参与者指出在保存如此大模型的 checkpoints 时遇到了困难。
- 目前的工作反映了重大进展,但在处理更重型模型时的内存管理方面仍面临挑战。
- 探索 Llama 3/3.1 的多 GPU 生产环境挑战:有人询问了 Llama 3/3.1 70B 的分布式生成问题,并指出目前的功能原生不支持此操作;成员们建议查看一个 GitHub 仓库 以寻找变通方法。此外,单 GPU 适配也存在问题,用户被引导将模型量化为 int4。
- 持续的讨论表明,虽然多 GPU inference 支持目前不是优先级,但 torchchat 库正在进行相关开发。
- Snowflake 增强了微调内存管理:一位成员强调了一篇 blog post,概述了微调 Llama 3.1 的内存优化,指出在 A100 上使用 bfloat16 的峰值占用为 66GB。他们分享说,由于缺乏 FP8 内核,被迫做出了这一选择。
- 这些见解通过分享处理大型模型架构的技术,为更高效的 AI 部署奠定了基础。
- RFC 提议升级 Transformer 模块以支持 Cross Attention:一项 RFC 提案寻求修改 TransformerDecoderLayer,以便在多模态应用中支持 cross attention。由于 pull request 中详述的更改,这将对现有的自定义构建器产生重大影响。
- 成员们被提醒需要进行更新,并强调了为了保持兼容性,这些更改具有全面性。
- 分布式生成脚本的实验:一位用户建议,对于精通 FSDP 集成技术的人,可以将现有的 generate.py 改编为 generate_distributed.py。他们建议利用分布式微调方案(recipes)以实现更平滑的过渡。
- 这种方法可以简化多 GPU 实现,并在旨在最大化分布式环境效率的过程中增强协作努力。
LAION Discord
- Mistral Large 2 树立了新的 AI 标杆:Mistral Large 2 拥有 128k 上下文窗口,支持十几种语言,并具备 1230 亿参数 (123 billion parameters),用于增强 AI 应用。
- 单节点推理 (Single-node inference) 能力允许在长上下文任务中实现极高的吞吐量。
- DFT Vision Transformer 重塑图像处理:新型 DFT Vision Transformer 在每个模块中采用 傅里叶变换 (Fourier transform)、MLP 和逆傅里叶变换,在不产生数据瓶颈的情况下提升图像质量。
- 该架构还高效集成了 全图像归一化层 (image-wide norm layers),在整个过程中保持详细信息。
- 复数成为核心:DFT Vision Transformer 完全使用 复数参数 (complex number parameters) 运行,增强了网络内的 计算动态 (computational dynamics)。
- 这使得它能与 旋转位置编码 (rotary position encoding) 有效融合,从而优化整体性能。
- 旋转位置编码提升训练速度:切换到 旋转位置编码 (rotary position encoding) 显著改善了 损失曲线的下降率,对训练产生了积极影响。
- 参与者发现这种增强效果非常 令人满意,证实了该方法的有效性。
- 精简设计提升性能:DFT Vision Transformer 采用由等尺寸模块组成的 直线流水线 (straight pipeline) 结构,最后以全局平均池化 (global average pool) 和线性层 (linear layer) 结束。
- 这确保了 图像永远不会被下采样 (downsampled),在整个处理过程中保留了所有信息。
DSPy Discord
- SymbolicAgentLearner 将 RAG 与符号学习相结合:一名成员使用 DSPy 开发了 SymbolicAgentLearner,它集成了 检索增强生成 (RAG) 和符号化技术,用于问答和引用生成。
- SymbolicLearningProcedure 类支持多跳检索和自动添加引用,显著增强了信息的丰富度。
- 共享 GitHub 仓库的计划:为了回应大家的兴趣,有成员提到计划创建一个 新的公共 GitHub 仓库,以便与更广泛的社区分享开发成果。
- 目前现有的代码库仍为私有,但这一转变旨在增加可访问性和协作。
- litellm 代理实现完美集成:成员们报告在所有模型中使用了 litellm 代理 (litellm proxy),指出通过重定向 OpenAI 的
api_base与 DSPy 集成时效果 非常出色。- 该解决方案简化了模型交互,增强了 DSPy 的易用性。
- 跨模型的 Function calling 需要额外努力:一名成员成功实现了跨多种模型的 函数调用 (function calling),尽管这需要额外的变通步骤。
- 讨论了所采用的具体方法但未详述,强调了实现跨模型功能所需的努力。
- DSPy 处理新闻分类的新方法:一个新实施的 新闻分类系统 使用 DSPy 和 OpenAI 的 GPT-3.5-turbo,通过思维链 (Chain of Thought) 机制将文章分类为 “虚假”或“真实”。
- 该方法采用 ColBERTv2 进行检索,并使用 MIPRO 进行优化,展示了用于评估误导信息有效性的自定义 F1 分数 (F1 score)。
LangChain AI Discord
- LangChain Agents 在一致性方面面临挑战:用户对使用开源模型的 LangChain agents 表示沮丧,理由是 性能不一致 以及工具选择不当。
- 多位测试者在评估本地 LLMs 时报告了类似令人失望的结果。
- 社区探索 Multi Agents 功能:一位用户寻求关于实现 multi agents 的指导,引发了社区对感兴趣的特定功能的讨论。
- 这次交流引发了关于这些 agents 的潜在应用和配置的进一步问题。
- 咨询在 Database Agents 中使用 ConversationSummary:一位用户想知道是否可以将 ConversationSummary 与他们自己的 database agent 集成,并寻求实现建议。
- 他们对建议持开放态度,特别是如果直接使用存在挑战的话。
- LangChain 和 Ollama 发布了一个有用的视频:一位成员推荐了一个名为 ‘Fully local tool calling with Ollama’ 的 YouTube 视频,讨论了本地 LLM 工具及其用法。
- 该视频旨在澄清 工具选择,并坚持认为如果设置正确,agents 可以稳定运行;点击此处观看。
- LangGraph 寻找持久化选项:一位用户请求关于 LangGraph persistence 潜在增强功能的更新,希望超出现有的 SqliteSaver 选项。
- 社区成员对可以改进数据处理的替代存储解决方案表现出兴趣。
AI Stack Devs (Yoko Li) Discord
- 对 AI Raspberry Pi 感到兴奋:在最近的一次交流中,一位用户对 AI Raspberry Pi 项目表示热烈欢迎,引发了对其细节的好奇。
- 对更多细节的请求表明,人们对其在低成本 AI 部署中的能力和应用可能感兴趣。
- 咨询更多细节:一位成员针对 AI Raspberry Pi 的讨论请求更多信息,表示 这很酷,告诉我们更多。
- 这表明社区围绕使用 Raspberry Pi 的创新 AI 项目进行了积极参与,可能希望探索技术细节。
Alignment Lab AI Discord 没有新消息。如果该频道长期没有活动,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长期没有活动,请告知我们,我们将将其移除。
LLM Perf Enthusiasts AI Discord 没有新消息。如果该频道长期没有活动,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长期没有活动,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长期没有活动,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长期没有活动,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期没有活动,请告知我们,我们将将其移除。
第 2 部分:按频道划分的详细摘要和链接
完整的频道细分内容已针对电子邮件进行截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!