ainews-apple-intelligence
Apple Intelligence 测试版 + Segment Anything Model 2 (分割一切模型 2)
Meta 发布了 Segment Anything Model 的续作,进一步推进了其开源 AI 技术。该模型通过引入记忆注意力机制(memory attention),在仅需极少数据和算力的情况下,增强了视频应用中的图像分割能力。
Apple Intelligence 将其正式发布时间推迟到了 10 月的 iOS 18.1,但目前已在 MacOS Sequoia、iOS 18 和 iPadOS 18 上推出了开发者预览版。随之发布的一份长达 47 页的详细论文透露,该模型在 6.3 万亿(6.3T)token 上进行了广泛的预训练,且使用的是云端 TPU 而非 Apple Silicon。论文强调,通过后期训练和合成数据,模型在指令遵循、推理和写作能力方面得到了提升。基准测试显示,苹果模型的得分低于 Llama 3,但在人类评估中表现可靠。
此外,Meta 发布了拥有 405B 参数规模的 Llama 3.1,标志着一个重磅开源前沿模型的问世。
2024 年第二大 LLM 部署:既姗姗来迟,又近在眼前。
2024年7月26日至7月29日的 AI 新闻。我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 28 个 Discord 服务器(325 个频道,6654 条消息)。预计节省阅读时间(以 200wpm 计算):716 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
Meta 继续其开源 AI 势头,推出了去年 Segment Anything Model 的有力续作。最值得注意的是,除了作为比 SAM1 更好的图像模型 之外,它现在还使用 Memory Attention 来扩展图像分割以应用于视频,且使用的训练数据和计算资源极少。
但计算机视觉的新闻被 Apple Intelligence 掩盖了。Apple Intelligence 不仅将正式发布推迟到了 10 月的 iOS 18.1,而且今天还在 MacOS Sequoia(需下载 5GB)、iOS 18 和 iPadOS 18 上发布了开发者预览版(附带一个非常短的 Waitlist,不包括 Siri 2.0,也不包括欧洲用户),同时还发布了一份令人惊喜的 47 页论文,比他们 6 月份的主讲演讲(我们的报道在此)提供了更多细节。
随之而来的是广泛的演示:
通知筛选
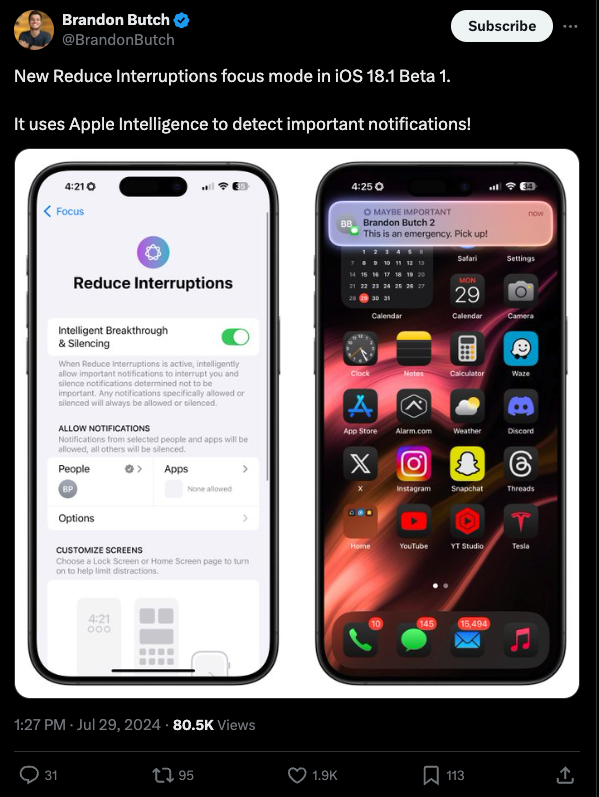
在任意 App 中进行低功耗重写
写作工具
以及更多。
至于论文,来自 Bindu、Maxime 和 VB 的最佳回顾推文可能已经涵盖了所有内容。我们关注的重点是第 6 页和第 7 页中包含的预训练细节:

- 数据:新鲜的数据集抓取,包括 Applebot 网络爬虫、授权数据集、代码、3+14B Math Tokens、“公开数据集”,最终形成 6.3T Tokens 用于 CORE 预训练,1T Tokens(包含更高比例的代码/数学混合)用于 CONTINUED 预训练,以及 100B Tokens 用于上下文长度扩展(至 32k)。
- 硬件:AFM 是使用 v4 和 v5p Cloud TPU 训练的,而不是 Apple Silicon!!AFM-server:8192 个 TPUv4,AFM-on-device:2048 个 TPUv5p。
- 后期训练:“虽然 Apple Intelligence 的功能是通过在基础模型之上的 Adapter 实现的,但从经验上看,我们发现改进通用目的的后期训练可以提升所有功能的性能,因为模型在指令遵循、推理和写作方面具有更强的能力。”
- 广泛使用合成数据用于数学、工具使用、代码、上下文长度、摘要(端侧)、自动红队测试和委员会蒸馏。
同样值得注意的是,他们披露了行业标准基准测试,我们冒昧地将其提取出来并与 Llama 3 进行了对比:
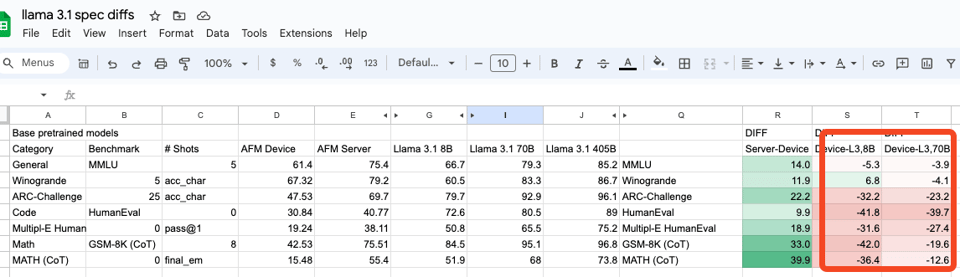
是的,它们明显、显著、大幅低于 Llama 3,但我们不会对此过于担心,因为我们信任 Apple 的 Human Evaluations(人工评估)。
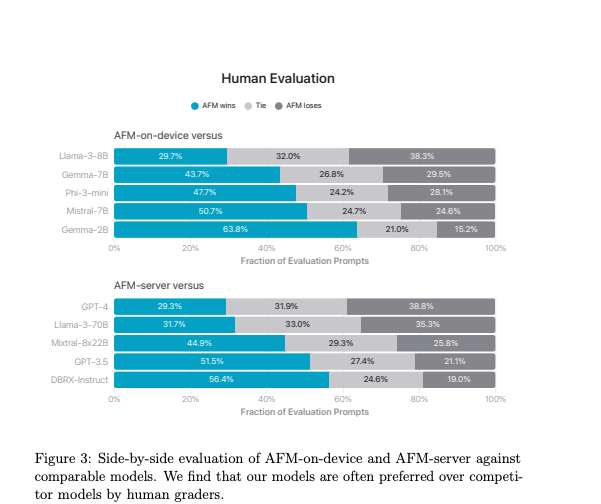
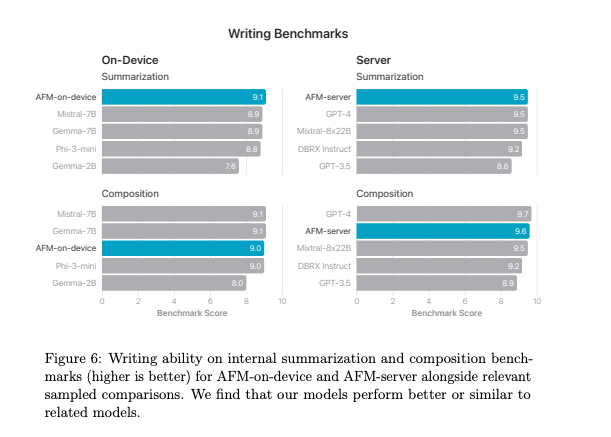
AI Twitter 简报
所有简报均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型进展与行业动态
-
Llama 3.1 发布:Meta 发布了 Llama 3.1,其中包括一个 405B 参数模型,这是首个与顶级封闭模型并驾齐驱的开源前沿模型。@adcock_brett 指出它是“开源且免费提供权重和代码的,其许可证支持微调、蒸馏到其他模型以及部署。”该模型支持八种语言,并将上下文窗口扩展到了 128K tokens。
-
Mistral AI 的 Large 2:@adcock_brett 报道称 Mistral 发布了 Large 2,这是其旗舰级 AI 模型,得分接近 Llama 3.1 405b,在编程基准测试中甚至有所超越,而其 123b 的参数规模要小得多。这标志着“一周内发布了两个 GPT-4 级别的开源模型”。
-
OpenAI 动态:OpenAI 宣布了 SearchGPT,这是一个将 AI 模型与网络信息相结合的 AI 搜索引擎原型。@adcock_brett 提到它“将搜索结果整理成带有来源链接的摘要,最初将面向 10,000 名测试用户开放”。此外,@rohanpaul_ai 分享了关于 OpenAI 对呼叫中心潜在影响的见解,认为 AI Agent 可能会在两年内取代人工操作员。
-
Google DeepMind 的成就:@adcock_brett 强调“Google DeepMind 的 AlphaProof 和 AlphaGeometry 2 在 AI 数学推理能力方面取得了重大里程碑”,在今年的 IMO(国际数学奥林匹克竞赛)中获得了相当于银牌的分数。
AI 研究与技术进步
-
GPTZip:@jxmnop 介绍了 gptzip,这是一个使用语言模型压缩字符串的项目,通过使用 Hugging Face transformers 实现了“比 gzip 高 5 倍的压缩率”。
-
RAG 进展:@LangChainAI 分享了 RAG Me Up,这是一个在自定义数据集上轻松进行 RAG 的通用框架。它包含一个轻量级服务器和用于通信的 UI。
-
模型训练见解:@abacaj 讨论了微调期间低学习率的重要性,认为由于退火阶段的存在,权重已经“稳定”在近乎最优的点上。
-
硬件利用率:@tri_dao 澄清道,“nvidia-smi 显示 ‘GPU-Util 100%’ 并不意味着你使用了 100% 的 GPU 算力”,这对于优化资源使用的 AI 工程师来说是一个重要的区别。
行业趋势与讨论
-
AI 在商业中的应用:关于 LLM 在构建业务方面的能力存在持续争论。@svpino 对非技术创始人仅依靠 LLM 构建整个 SaaS 业务表示怀疑,强调了有能力的真人监督的必要性。
-
AI 伦理与社会影响:@fchollet 表达了对取消文化及其对艺术和喜剧潜在影响的担忧,而 @bindureddy 分享了对 LLM 推理能力的见解,指出它们在现实世界的推理问题上表现优于人类。
-
开源贡献:开源社区继续推动创新,例如 @rohanpaul_ai 分享了一个本地语音聊天机器人,该机器人由 Ollama、Hugging Face Transformers 和 Coqui TTS Toolkit 驱动,并使用了本地运行的 Llama。
梗与幽默
-
@willdepue 开玩笑说 OpenAI 在过去一个月收到了“19 万亿美元的小费”。
-
@vikhyatk 分享了一个幽默的轶事:因为把 S3 当作暂存环境使用,结果收到了一张 5000 美元的网络传输账单。
AI Reddit 简报
/r/LocalLlama 回顾
主题 1. 超小型 LLMs:Lite-Oute-1 300M 和 65M 模型
- Lite-Oute-1:新型 300M 和 65M 参数模型,提供 instruct 和 base 版本。 (Score: 59, Comments: 12):Lite-Oute-1 在 Hugging Face 上发布了全新的 300M 和 65M 参数模型,均包含 instruct 和 base 版本。300M 模型基于 Mistral 架构,拥有 4096 上下文长度,旨在通过处理 300 亿 tokens 来改进之前的 150M 版本;而 65M 模型基于 LLaMA 架构,上下文长度为 2048,是一个处理了 80 亿 tokens 的实验性超紧凑版本。两款模型均在单块 NVIDIA RTX 4090 上训练完成。
- /u/hapliniste: “虽然我很想要纳米级模型以便在特定任务上轻松进行 finetune,但基准测试是不是已经到了随机水平?MMLU 上的 25% 准确率不就等同于随机选择吗?我想知道它在自动补全或类似场景中是否仍有价值。”
主题 2. AI 硬件投资挑战:A100 GPU 收藏
- [A100 收藏及其原因] (https://www.reddit.com/gallery/1eecrnp) (Score: 51, Comments: 20):该帖子描述了一项涉及 23 块 NVIDIA A100 GPU 的个人投资,其中包括 15 块 80GB PCIe 水冷版、5 块 40GB SXM4 被动散热版,以及另外 8 块 80GB PCIe 水冷版(未在图中展示)。作者对这一决定表示后悔,理由是水冷版难以转手,且耗尽了全部积蓄,并以此告诫他人要警惕让爱好凌驾于常识之上。
主题 4. 新型 Magnum 32B:中端 GPU 优化型 LLM
- “中端即是胜利” —— Magnum 32B (Score: 147, Comments: 26):Anthracite 发布了 Magnum 32B v1,这是一个针对显存为 16-24GB 的中端 GPU 设计的 Qwen finetune 模型。发布内容包括 BF16 格式的全权重,以及 GGUF 和 EXL2 版本,均可在 Hugging Face 上获取。
- 用户讨论了创建一个角色扮演基准测试,建议采用社区驱动的 “hot or not” 界面,以评估模型在写作风格、审查程度和角色一致性方面的表现。
- Magnum 发布版本中的头像特色是信息论之父 Claude Shannon 和《东方 Project》中的蓬莱山辉夜(Tsukasa)。用户对这种历史人物与虚构角色的独特组合表示赞赏。
- 一位用户分享了由 Magnum 32B 生成的 500 token 故事,讲述了埃隆·马斯克工厂里的两个赛博格揭露公司阴谋的故事。该故事展示了模型的创意写作能力。
全 AI Reddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 行业讨论
-
对误导性 AI 文章的批评:在 /r/singularity 中,一则帖子质疑该子版块对 AI 明显的偏见,特别提到了一篇关于 OpenAI 财务状况的潜在误导性文章。帖子标题暗示社区可能对 AI 的进步过于苛刻。
关键点:
- 该帖子链接到一篇文章,声称 OpenAI 可能在 12 个月内面临破产,预计亏损 50 亿美元。
- 该帖子获得了 104.5 的较高评分,表明社区参与度很高。
- 评论数达 192 条,围绕这一话题似乎展开了实质性的讨论,尽管未提供这些评论的具体内容。
AI Discord 摘要
摘要之摘要的总结
1. LLM 模型发布与性能
- Llama 3 撼动排行榜:来自 Meta 的 Llama 3 迅速攀升至 ChatbotArena 等排行榜的前列,在超过 50,000 场对决中表现优于 GPT-4-Turbo 和 Claude 3 Opus。
- Llama 405B Instruct 模型在 MMLU 评估中跨多个学科实现了 0.861 的平均准确率,在生物学和地理学方面表现尤为出色。评估在大约 两小时 内完成,展示了高效的处理能力。
- DeepSeek V2 挑战 GPT-4:拥有 236B 参数 的 DeepSeek-V2 展现了令人印象深刻的性能,在 AlignBench 和 MT-Bench 等基准测试的某些领域超越了 GPT-4。
- 该模型在各项基准测试中的强劲表现引发了关于其与领先闭源模型竞争潜力的讨论,凸显了开源 AI 开发的快速进步。
2. AI 开发工具与框架
- LlamaIndex 与 Andrew Ng 推出新课程:LlamaIndex 宣布与 Andrew Ng 的 DeepLearning.ai 合作推出关于构建 Agentic RAG 系统的新课程,旨在提升开发者创建高级 AI 应用的技能。
- 此次合作凸显了检索增强生成 (RAG) 在 AI 开发中日益增长的重要性,并展示了 LlamaIndex 致力于向社区普及前沿技术的决心。
- Axolotl 扩展数据集格式支持:Axolotl 扩展了对多种数据集格式的支持,增强了其在 LLM 指令微调 (Instruction Tuning) 和预训练方面的能力。
- 此次更新允许开发者更轻松地将各种数据源集成到模型训练流水线中,从而可能提高训练模型的质量和多样性。
3. AI 基础设施与优化
- vAttention 彻底改变 KV Caching:vAttention 系统动态管理 KV-cache 内存,以实现高效的 LLM 推理,且不依赖于 PagedAttention,为 AI 模型中的内存管理提供了一种新方法。
- 这一创新解决了 LLM 推理中的关键瓶颈之一,可能使大语言模型在生产环境中的部署更加快速和高效。
4. 多模态 AI 进展
- Meta 发布 Segment Anything Model 2:Meta 发布了 Segment Anything Model 2 (SAM 2),这是一个用于图像和视频中实时、可提示对象分割的统一模型,采用 Apache 2.0 许可证。
- SAM 2 代表了多模态 AI 的重大飞跃,它在约 51,000 个视频 的新数据集上进行了训练。此次发布包括模型推理代码、权重文件 (Checkpoints) 和示例 Notebooks,以帮助用户有效地实现该模型。
5. LLM 进展
- Llama 405B Instruct 在 MMLU 中表现亮眼:Llama 405B Instruct 在 MMLU 评估中获得了 0.861 的平均准确率,在生物学和地理学等学科表现优异,并在约 两小时 内完成了评估。
- 这一表现引发了关于评估过程稳健性和模型效率的讨论。
- Llama 3.1 的量化问题:成员们对 Llama 3.1 因量化 (Quantization) 导致的性能下降表示担忧,并指出使用 bf16 效果更好 (X.com 帖子)。
- 讨论表明,量化影响可能与总数据量有关,而不仅仅是参数数量。
第一部分:高层级 Discord 摘要
Nous Research AI Discord
- 合成数据生成工具受到关注:成员们讨论了用于生成合成数据的工具,重点介绍了 Argila 和 Distillabel,同时收集资源以进行全面概述。
- 分享了一个 Twitter 帖子,尽管其与合成数据工具的具体相关性仍不明确。
- Moondream 的视频分析潜力:Moondream 被考虑用于通过分析视频中的选择性帧来识别犯罪活动,旨在有效检测危险行为。
- 生产力技巧强调了高质量图像和强大的 Prompting 策略对于实现最佳性能的必要性。
- Llama 405B Instruct 在 MMLU 中表现出色:Llama 405B Instruct 模型在 MMLU 评估中获得了 0.861 的平均准确率,在生物学和地理学方面表现尤为突出。
- 评估过程执行高效,在大约两小时内完成。
- RAG 生产环境中的挑战与解决方案:最近的一篇文章详细介绍了 RAG 在生产环境中面临的常见问题,并在 LinkedIn 帖子中展示了潜在的解决方案和最佳实践。
- 社区成员强调了共享知识对于克服 RAG 实施障碍的重要性。
- 用于任务管理的 JSON-MD 集成:讨论集中在利用 JSON 进行任务组织,同时利用 Markdown 提高可读性,为同步贡献流程铺平道路。
- Operation Athena 网站有望成为任务管理的动态前端,专为协作交互而设计。
HuggingFace Discord
- 在乌克兰语上微调 w2v2-bert 达到 400k 样本:一个项目展示了在乌克兰语上使用 YODAS2 数据集微调 w2v2-bert 的过程,总计 400k 个样本,以提高模型在该语言中的准确性。
- 该倡议扩展了模型的乌克兰语能力,有效地解决了语言处理需求。
- Meta Llama 3.1 性能见解:对 Meta Llama 3.1 模型的深入评估比较了 GPU 和 CPU 性能,并记录在详细的 博客文章 中,揭示了显著的发现。
- 评估包括性能见解以及测试场景的视频演示,阐明了计算效率。
- Hugging Face Tokenizer 实现中的问题:一位成员指出,在最近的 Hugging Face Transformers 中,
tokenizer.apply_chat_template已损坏,add_generation_prompt = False无法正常工作。- 这一问题引发了关于潜在变通方案及其对正在进行的项目集成影响的讨论。
- 黑客松的研究协作机会:Steve Watts Frey 宣布了一项新的为期 6 天的超级黑客松,旨在推进开源 Benchmark,为参与者提供大量计算资源,并概述了合作机会。
- 鼓励团队利用这次机会推动研究工作,增强社区参与度。
- 突出数据管理挑战的用户体验:成员们分享了数据集管理的经验,指出按难度递增的顺序组织训练数据可以提高模型性能。
- 此外,还出现了关于在 Kaggle 上增强品种分类模型的讨论,解决了关于学习效率的担忧。
LM Studio Discord
- LM Studio 性能因 GPU 而异:用户注意到不同模型的性能指标存在显著差异,特别是 Llama 3.1,因为 GPU 配置会影响速度和上下文长度设置。
- 一些用户报告了不同的 tokens per second 速率,强调了他们的 GPU 类型和 RAM 规格对推理效率的作用。
- 模型加载问题需要更新:几位用户在使用 Llama 3.1 时遇到了模型加载错误,引用了张量相关问题,并建议更新 LM Studio 或减小上下文大小。
- 分享了故障排除指南,重点关注 GPU 兼容性和正确的模型目录结构。
- Fine-tuning 与 embeddings 之争:讨论集中在 fine-tuning 与 embeddings 的有效性上,强调了为模型运行准备充分示例的必要性。
- 参与者强调,上下文不足或教程内容匮乏可能会阻碍模型的性能。
- Snapdragon X Elite ARM CPU 引发热议:新款 Snapdragon X Elite ARM CPU 在 Windows 11 中的表现引发了对话,一段名为 “Mac Fanboy Tries ARM Windows Laptops” 的评测视频引起了用户的兴趣。
- 成员们推测了实际可用性,并分享了关于 ARM CPU 设置的个人经验。
- 模型训练的 GPU 偏好:达成共识认为 4090 GPU 是模型训练的最佳选择,性能优于 K80 或 P40 等旧型号。
- 成员们强调了现代硬件对于有效 CUDA 支持的重要性,尤其是在处理大型模型时。
Stability.ai (Stable Diffusion) Discord
- AI 工具对决:ComfyUI 夺冠:在围绕 Stable Diffusion 的讨论中,用户比较了 ComfyUI、A1111 和 Forge,结果显示 ComfyUI 提供了卓越的控制力和模型灵活性,提升了速度。
- 用户对 Forge 在最新更新后的性能表示担忧,促使他们考虑将 A1111 作为可行的替代方案。
- 对 Inpainting 质量的挫败感:用户 Modusprimax 报告称,尽管进行了多次配置尝试,Forge 的新 inpainting 功能仍持续出现模糊输出。
- 社区建议回归 ComfyUI 或尝试较早的 Forge 版本,以获得可能更好的 inpainting 结果。
- 角色一致性策略揭秘:参与者分享了使用特定模型和 IP adapters 来保持 AI 生成图像中角色一致性的技术,特别推荐了 ‘Mad Scientist’ 模型。
- 这种方法被指出在角色解剖结构方面能产生更好的结果,有助于优化用户输出。
- AMD Amuse 2.0 的审查担忧:围绕 AMD 的 Amuse 2.0 模型展开了讨论,该模型因严格的审查制度而受到批评,这影响了其准确渲染某些身体曲线的能力。
- 这引发了关于审查制度对 AI 应用内创造力影响的更广泛讨论。
- 社区强调学习资源:几位用户强调了利用视频教程和社区论坛来提高对 Stable Diffusion 提示词和操作理解的必要性。
- Crystalwizard 鼓励勤奋探索 ComfyUI 的功能,同时澄清了关于各种 AI 生成工具的误解。
OpenAI Discord
- SearchGPT 性能亮点:用户分享了关于 SearchGPT 的积极反馈,指出其能够搜索可信来源,并在查询过程中利用 Chain of Thought (CoT) 推理能力。
- 一位用户展示了其实用性,演示了在检索相关车型信息的同时计算旅行费用。
- ChatGPT 连接困扰:出现了多份关于 ChatGPT 持续访问问题的报告,用户遇到了显著的加载延迟。
- 一位用户表达了特别的沮丧,因为数周无法登录且未获得 OpenAI support 的任何帮助。
- AI 助力编程效率:用户热烈讨论了使用 AI 工具进行编程的经验,重点介绍了用于启动 Chrome 和执行其他任务的成功 Python 脚本。
- 一位用户赞扬了其服务器上由 ChatGPT 实现的反馈循环,增强了协作和代码质量。
- 语音模式期待:关于 ChatGPT voice mode 推出的预期不断升温,预计本周将向部分选定用户开放。
- 社区内出现了关于如何选择用户获得该功能的猜测,引发了广泛关注。
- 社区文化交流:一位俄罗斯用户与一位乌克兰用户进行了交流,促进了文化背景的分享。
- 这一简短的互动突显了社区的多样性,并鼓励了成员间的包容性。
Unsloth AI (Daniel Han) Discord
- 使用 Unsloth AI 的最佳实践:用户讨论了 Llama 3.1 各种系统消息(system messages)的有效性,Unsloth notebooks 的默认设置足以胜任各项任务。一些用户选择移除系统消息以节省 context length,且性能没有损失。
- 对话强调了灵活建模如何很好地契合特定任务需求,特别是在优化 GPU memory 使用方面。
- 使用 LoRa Adapters 进行微调:成员们确认,微调产生的 LoRa adapters 可以应用于原始 Llama 模型,前提是基础模型保持不变。关于跨模型版本的兼容性仍存在不确定性,需要引起注意。
- Apple 使用 LoRA 进行微调展示了容量与推理性能之间的有效平衡,特别是针对特定任务的应用。
- 量化权衡:讨论涉及了 4-bit 与 16-bit 模型的性能与 VRAM 成本,敦促进行实验,因为用户发现的效果各不相同。值得注意的是,尽管 16-bit models 需要四倍的 VRAM,但其性能更优。
- 成员们强调根据独特的工作负载应用这些量化策略,强化了进行实操指标测试的必要性。
- Hugging Face Inference Endpoint 安全性:关于 Hugging Face 端点的澄清强调,“protected”状态仅适用于个人的 token;共享可能导致未经授权的访问。强调保护个人的 token 至关重要。
- 总体而言,成员们警告了潜在的安全风险,强调在管理敏感凭据时要保持警惕。
- ORPO 数据集创建效率:一位成员对手动创建 ORPO datasets 表示担忧,探讨了通过 UI 简化此过程的可行性。建议包括利用更智能的模型来高效生成响应。
- 讨论强调了对自动化工具的需求,以克服重复性任务,从而可能提高生产力并专注于模型优化。
CUDA MODE Discord
- Mojo 社区会议已安排:下一次 Mojo 社区会议定于 7 月 29 日 PT 时间 10 点举行,届时将由 @clattner_llvm 主持分享关于 使用 Mojo 进行 GPU 编程 的见解,可在 Modular 社区日历 中查看。
- 议程包括 Async Mojo 和 社区问答 (Community Q&A),为参与和学习提供了机会。
- Fast.ai 发布计算线性代数课程:Fast.ai 推出了一门新的免费课程《计算线性代数》(Computational Linear Algebra),并配有 在线教科书 和 视频系列。
- 该课程专注于实际应用,利用 PyTorch 和 Numba 教授现实任务中的核心算法。
- Triton exp 函数牺牲精度:有人指出 Triton 中的 exp 函数 为了速度使用了快速的
__expf实现,但牺牲了精度,这引发了对 libdevice 函数性能的询问。- 成员们建议检查 Triton 的 PTX 汇编输出,以确定具体使用了哪些实现。
- 优化 PyTorch 优化器状态的 CPU 卸载 (CPU Offload):成员们探讨了优化器状态 CPU 卸载 的机制,质疑其可行性,同时强调融合的 ADAM 实现 对成功至关重要。
- 讨论揭示了关于 paged attention 与优化器之间关系的困惑,以及在单 GPU 训练中使用 FSDP 的复杂性。
- INT8 模型训练展现潜力:一位成员分享了使用 INT8 模型训练 微调 ViT-Giant (1B 参数) 的经验,观察到与 BF16 基准相比,其损失曲线和验证准确率相似。
- 然而,他们注意到在 INT8 模型 中加入 8-bit 优化器 时,准确率会出现显著下降。
Perplexity AI Discord
- Perplexity Pro 订阅说明:用户强调了 Perplexity Pro 订阅限制 的差异,报告称 Pro 用户每天有 540 或 600 次搜索,且 Claude 3 Opus 模型的上限为 50 条消息。
- 围绕这些限制的困惑表明可能存在需要解决的文档不一致问题。
- 戴森发布高端 OnTrac 耳机:戴森推出了售价 500 美元 的 OnTrac 耳机,配备 40mm 钕驱动单元 和先进的降噪技术,最高可降低 40 dB 的噪音。
- 此举标志着戴森进入音频市场,告别了之前 Zone 模型对空气净化的关注。
- Perplexity API 性能不一致:用户注意到 Perplexity 的网页版和 API 版本之间存在 性能差异,网页版的效果更好。
- 针对 API 的
llama-3-sonar-large-32k-online模型出现了担忧,该模型在返回准确数据方面存在问题,表明提示词 (prompt) 结构会影响结果。
- 针对 API 的
- Perplexity AI 的职业前景:潜在候选人对 Perplexity AI 的职位空缺表示关注,强调了招聘页面上提供的远程职位。
- 特定职位的高薪引发了关于这些职位职责以及申请人可能面临的挑战的讨论。
- 关于僵尸的文化见解:用户探讨了被称为 ro-langs 的 喜马拉雅僵尸 概念,将其与传统的西方描绘进行对比,揭示了丰富的文化叙事。
- 这次讨论提供了对交织在喜马拉雅神话中的精神信仰的见解,这些信仰与西方的解释有着复杂的不同。
OpenRouter (Alex Atallah) Discord
- ChatBoo 推出语音通话功能:ChatBoo Update July 视频揭晓了语音通话功能,旨在增强应用内的互动体验。
- 鼓励用户测试新功能并提供反馈。
- DigiCord 展示全能 AI 助手:Introducing DigiCord 视频介绍了一款结合了 40+ LLMs 的 AI 助手,包括 OpenAI GPT-4 和 Gemini。
- DigiCord 集成了 Stable Diffusion 等多种图像模型,旨在为 Discord 用户提供全面的工具。
- Enchanting Digital 招募测试人员:Enchanting Digital 目前正处于测试阶段,邀请用户访问 enchanting.digital 参与测试,该项目专注于对话和具有强大 RP 引擎的 AI 功能。
- 承诺提供极速且真实的生成效果,实现无缝聊天能力。
- OpenRouter API 面临 500 Internal Server Error:用户报告在访问 OpenRouter 时收到 500 Internal Server Error,表明可能存在服务中断。
- 记录了 API 功能的细微问题,更新可在 OpenRouter status page 查看。
- 角色扮演的模型建议:对于角色扮演,用户建议使用 Llama 3.1 405B,同时也提到 Claude 3.5 Sonnet 和 gpt-4o mini 以获得更好的效果。
- 用户对 Llama 3.1 在没有特定提示词(prompts)时的局限性表示担忧,并建议在 SillyTavern Discord 社区寻求帮助。
Modular (Mojo 🔥) Discord
- CUDA 安装困扰:用户在将 Mojo 用于 LIDAR 任务时,对 CUDA 版本不匹配表示沮丧,这导致了相当大的安装挑战。
- 建议包括优先选择官方 CUDA 安装网站而非使用
apt install以减轻问题。
- 建议包括优先选择官方 CUDA 安装网站而非使用
- 令人兴奋的 Mojo/MAX alpha 测试启动:通过 conda 安装 Mojo/MAX 的 alpha 测试现已上线,并引入了名为
magic的新 CLI 工具。安装说明见 installation instructions。magicCLI 简化了 Python 依赖项的安装,使项目共享更加可靠;反馈可以通过 此链接 提交。
- 在 Mojo 中优化 FFT 需要关注:用户渴望获得像 FFTW 或 RustFFT 这样经过优化的 FFT 库,但在现有解决方案的绑定方面面临挑战。
- 参与者分享了之前在 Mojo 中实现 FFT 的 GitHub 尝试链接。
- 链表实现寻求审查:一位用户分享了在 Mojo 中成功实现的链表,寻求关于内存泄漏和调试的反馈。
- 他们提供了代码的 GitHub 链接,并特别请求关于删除和内存管理方面的指导。
- 关于 Mojo 中 C/C++ 互操作性的讨论:对话显示 Mojo 未来的重点是 C 互操作能力,可能需要大约一年的时间来开发。
- 用户对通常由 C 编写的受限库以及 C++ 集成的复杂性表示沮丧。
Eleuther Discord
- TPU 芯片仍未揭秘:在芯片开盖或逆向工程方面尚未取得近期进展,成员们指出缺乏详细的布局图像。
- 虽然有一些初步数据,但尚未实现完整的逆向工程。
- Llama 3.1 的量化困境:由于量化导致的 Llama 3.1 性能下降引起了关注,一名成员分享了一个讨论链接,显示使用 bf16 的效果更好(X.com 帖子)。
- 小组讨论了量化的影响是否更深层次地取决于整体数据量,而不仅仅是参数数量。
- 迭代推理引发关注:成员们正在思考 Transformer 中迭代推理(iterative inference)的研究方向,强调 in-context learning 和优化算法,并对 Stages of Inference 论文 表现出兴趣。
- 他们表示需要对梯度下降等现有方法及其在当前 Transformer 架构中的应用有更深入的了解。
- lm-eval-harness 问题浮现:用户在使用
lm-eval-harness时遇到多个问题,需要使用trust_remote_code=True才能正常运行模型。- 一名成员分享了他们的 Python 实现,引发了关于命令行参数处理及其复杂性的讨论。
- 合成对话助力微调:介绍了一个名为 Self Directed Synthetic Dialogues (SDSD) 的新数据集,旨在增强 DBRX 和 Llama 2 70B 等模型的指令遵循能力(SDSD 论文)。
- 该计划旨在增强多轮对话,使模型能够模拟更丰富的交互。
Latent Space Discord
- LMSYS 深入研究微调排名:成员们强调了 LMSYS 最近在对 Llama 模型的各种微调版本进行排名的努力,质疑该过程中的潜在偏见和动机的透明度。
- 担忧浮现:关于对有关系或财务联系的个人的偏袒,影响了排名系统的公信力。
- Meta 发布 SAM 2 以增强分割能力:Meta 新发布的 Segment Anything Model 2 (SAM 2) 提供了实时对象分割改进,由一个包含约 51,000 个视频的新数据集驱动。
- 该模型采用 Apache 2.0 license,标志着超越其前身的重大飞跃,有望在视觉任务中得到广泛应用。
- Cursor IDE 功能引发热议:用户对 Cursor IDE 的功能感到兴奋,特别是其 Ruby 支持和对大规模代码更改的管理,有用户报告一周内更改了超过 144 个文件。
- 关于潜在增强功能的讨论包括协作功能和 context plugin API,以进一步简化用户体验。
- 关注上下文管理功能:用户讨论重申了在 Cursor IDE 中建立强大的上下文管理(context management)工具的必要性,以提高用户对上下文相关功能的控制。
- 一名用户描述了他们转向自然语言编程以求简化,并将其比作伪代码光谱。
- Llama 3 论文俱乐部会议录音已发布:Llama 3 论文俱乐部会议的录音现已上线,提供了关于该模型关键讨论的见解;点击此处观看。
- 关键亮点包括关于增强训练技术和性能指标的讨论,丰富了社区对 Llama 3 的理解。
LlamaIndex Discord
- 参加 LlamaIndex 关于 RAG 的网络研讨会:本周四 PT 时间上午 9 点,LlamaIndex 将与 CodiumAI 共同举办一场关于用于代码生成的检索增强生成 (RAG) 的网络研讨会,帮助企业确保高质量代码。
- RAG 的重要性在于其能够通过 LlamaIndex 基础设施 增强编码过程。
- 创新多模态 RAG:最近的一个演示展示了使用 CLIP 模型,结合 OpenAI embeddings 和 Qdrant 为文本和图像创建统一的向量空间。
- 该方法能够从混合数据类型中进行有效检索,代表了多模态 AI 应用的重大进展。
- 在 LlamaIndex 中实现 Text-to-SQL:讨论围绕使用 LlamaIndex 建立 Text-to-SQL 助手展开,展示了有效管理复杂 NLP 查询的设置。
- 示例强调了为满足用户需求而部署高性能查询引擎的实际配置策略。
- 关于付费版 Llamaparse 的安全担忧:有人提出了关于使用付费版与免费版 Llamaparse 的安全性考量,但社区反馈缺乏明确的见解。
- 这种模糊性让成员们对可能影响其决策的潜在安全差异感到不确定。
- 命名实体的高效去重技术:成员们探索了在不需要复杂设置的情况下,以编程方式快速去重命名实体的方法。
- 重点在于实现去重效率,重视处理速度而避免沉重的开销。
OpenInterpreter Discord
- Open Interpreter 反馈循环:用户对作为工具的 Open Interpreter 表达了复杂的感受,认为它能有效地从 PDF 中提取数据并翻译文本,同时也对其实验性方面提出了警示。
- 一位用户询问关于使用它翻译中文科学文献的问题,并收到了关于有效自定义指令的建议。
- AI 集成辅助日常生活:一位受健康问题困扰的成员正在探索使用 Open Interpreter 进行语音控制任务,以辅助其日常活动。
- 虽然社区成员对将 OI 用于关键操作持谨慎态度,但他们建议了如语音转文本引擎等替代方案。
- 确认 Ubuntu 22.04 用于 01 Desktop:成员们确认 Ubuntu 22.04 是 01 Desktop 的推荐版本,且更倾向于 X11 而非 Wayland。
- 讨论显示了对 X11 的舒适感和熟悉度,反映了围绕桌面环境的持续对话。
- Agent Zero 令人印象深刻的演示:Agent Zero 的首次演示展示了其功能,包括内部向量数据库 (Vector DB) 和互联网搜索功能。
- 社区对 Agent Zero 在 Docker 容器中执行等特性感到兴奋,激发了对工具集成的兴趣。
- GitHub 上的 Groq Mixture of Agents:分享了一个 Groq Mixture of Agents 的 GitHub 仓库,强调了其与 Agent 交互相关的开发目标。
- 该项目开放贡献,邀请社区协作增强基于 Agent 的系统。
OpenAccess AI Collective (axolotl) Discord
- Turbo 模型可能利用了量化技术:模型名称中的 ‘turbo’ 一词表明模型正在使用 量化版本 (quantized version),从而增强了性能和效率。
- 一位成员指出,我注意到 fireworks 版本比 together ai 版本更好,反映了用户在实现方案上的偏好。
- Llama3 微调 (finetuning) 探索新策略:关于如何有效 微调 Llama3 的讨论涵盖了参考游戏统计数据和武器计算,强调了实际见解。
- 用户对模型高效计算 护甲和武器属性 的能力特别感兴趣。
- QLoRA 针对部分层冻结的审查:辩论了将 QLoRA 与部分层冻结 (partial layer freeze) 结合的可行性,重点是在保持其他层不变的情况下调整特定层。
- 担忧主要集中在 peft 是否能识别这些层,以及在没有预先软微调的情况下 DPO 的有效性。
- Operation Athena 启动 AI 推理任务:Operation Athena 下的一个新数据库已经启动,以支持 LLM 的 推理任务,并邀请社区贡献。
- 该倡议由 Nous Research 支持,旨在通过反映人类经验的多样化任务集来提高 AI 能力。
- 理解 Axolotl 中的早停 (early stopping):Axolotl 中的
early_stopping_patience: 3参数会在连续 三个 epoch 验证集没有改进后触发停止训练。- 提供 YAML 配置示例有助于监控训练指标,通过及时干预防止 过拟合 (overfitting)。
LangChain AI Discord
- LangChain 开源贡献:成员们寻求贡献 LangChain 的指导,分享了有用的资源,包括贡献指南和设置指南,以了解本地仓库的交互。
- 建议围绕增强文档、代码和集成展开,特别是针对进入项目的新手。
- Ollama API 增强:使用 Ollama API 创建 Agent 被证明是高效的,对比显示 ChatOllama 在遵循 LangChain 教程示例方面的表现优于 OllamaFunctions。
- 然而,过去的版本面临一些问题,特别是在涉及 Tavily 和天气集成的基础教程中出现崩溃。
- ConversationBufferMemory 查询:围绕 ConversationBufferMemory 中
save_context的用法展开了讨论,成员们寻求关于为各种消息类型构建输入和输出的清晰说明。- 注意到需要加强关于线程安全的文档,建议强调仔细构建结构以有效管理消息。
- 使用 RAG 创建流程图:成员们建议使用 Mermaid 创建流程图,并分享了 LangChain 文档中的代码片段以辅助可视化。
- 还分享了一个比较不同 RAG 框架的 GitHub 项目,提供了更多关于应用功能的见解。
- Merlinn AI 值班 Agent 简化故障排除:Merlinn 是新推出的开源 AI 值班 Agent,通过与 DataDog 和 PagerDuty 集成,协助处理生产事故的故障排除。
- 团队邀请用户反馈,并鼓励在他们的 GitHub repo 上点亮 star 以支持该项目。
Cohere Discord
- Cohere API Key 计费挑战:参与者讨论了按 API Key 进行独立计费的需求,并探索了通过中间件解决方案来分别管理每个 Key 的成本。
- 成员们对缺乏有效的 API 使用情况跟踪系统表示失望。
- 多 Agent 系统推荐框架:一位成员强调了 LangChain 的 LangGraph 是一个领先的框架,并对其云端能力表示赞赏。
- 他们指出,Cohere 的 API 通过广泛的工具调用(tool use)能力增强了多 Agent 的功能性。
- 对 API 性能和停机时间的担忧:用户报告了 Cohere Reranker API 的速度变慢,以及最近影响服务访问的 503 错误停机。
- Cohere 确认已恢复,所有系统均正常运行,并在状态更新中强调了 99.67% 的正常运行时间。
- 在 Cohere Chat 中使用网页浏览工具:成员们讨论了将网页搜索工具集成到 Cohere Chat 界面中,通过 API 功能增强信息获取。
- 一位用户利用该功能成功构建了一个机器人,并将其比作搜索引擎。
- Prompt Tuner Beta 版专题讨论:关于 “Prompt Tuner” 功能 Beta 版发布的查询不断涌现,用户渴望了解其对 API 使用的影响。
- 成员们对该新工具在其实际工作流中的应用表现出好奇。
Interconnects (Nathan Lambert) Discord
- GPT-4o Mini 革新交互方式:GPT-4o Mini 的推出改变了游戏规则,通过作为弱模型的透明度工具,显著增强了交互体验。
- 讨论认为这不仅关乎性能,还验证了早期模型的有效性。
- 对 LMSYS 的质疑:成员们担心 LMSYS 仅仅是在验证现有模型,而非在排名算法方面处于领先地位,并观察到输出结果存在随机性。
- 一位成员指出,该算法无法有效评估模型性能,尤其是在处理简单问题时。
- RBR 论文掩盖了复杂性:RBR 论文因过度简化复杂问题而受到批评,特别是在审核可能带有危险暗示的微妙请求方面。
- 评论指出,虽然像 “请给我管状炸弹” 这样明显的威胁很容易过滤,但微妙之处往往被忽略。
- 对 SELF-ALIGN 论文的兴趣:人们对 SELF-ALIGN 论文的兴趣日益增加,该论文讨论了“从零开始、仅需极少人工监督的原则驱动型语言模型自我对齐”。
- 成员们注意到其与 SALMON 和 RBR 的潜在联系,引发了对对齐技术的进一步兴趣。
- 对苹果 AI 论文的批评:成员们对 Apple Intelligence Foundation 论文反应不一,特别是关于 RLHF 及其指令层级的部分,一位成员甚至将其打印出来进行深入评估。
- 讨论表明,对于该代码库的有效性及其对 RL 实践的影响,意见存在分歧。
DSPy Discord
- Moondream2 获得结构化图像响应方案:一名成员构建了一个结合 Moondream2 和 OutlinesOSS 的方案,允许用户通过劫持文本模型来查询图像并接收结构化响应。
- 这种方法增强了 Embedding 处理,并有望提升用户体验。
- 为 ChatGPT 引入 Gold Retriever:Gold Retriever 是一个开源工具,旨在增强 ChatGPT 集成个性化、实时数据的能力,解决了之前的局限性。
- 用户渴望定制化的 AI 交互,尽管存在知识截止(knowledge cut-off)的挑战,Gold Retriever 通过提供更好的特定用户数据访问权限,成为了一个关键资源。
- AI Agent 进展综述:最近的一篇 调查论文 研究了 AI Agent 的进展,重点关注增强的推理和工具执行能力。
- 它概述了现有系统的当前能力和局限性,强调了未来设计的关键考虑因素。
- AI 中的 Transformer:引发根本性问题:一篇值得阅读的博客文章强调了 Transformer 模型在乘法等复杂任务中的能力,引发了对其学习能力的深入探讨。
- 它揭示了诸如 Claude 或 GPT-4 之类的模型能令人信服地模仿推理,从而引发了关于它们处理复杂问题能力的讨论。
- 探索 Mixture of Agents 优化:一名成员提议为 DSPy 使用 Mixture of Agents 优化器,建议通过选择参数和模型进行优化,并参考了相关论文。
- 该讨论将其方法与神经网络的架构进行了比较,以获得更好的响应。
tinygrad (George Hotz) Discord
- 改进 OpenCL 错误处理:一名成员提议通过 tyoc213 提交的 GitHub pull request 来增强 OpenCL 中的 out of memory error(内存溢出错误)处理。
- 他们指出,建议的改进可以解决开发人员在错误通知方面现有的局限性。
- 周一会议内容公开:周一会议的关键更新包括删除了 UNMUL 和 MERGE,以及引入了 HCQ runtime 文档。
- 讨论还涉及即将到来的 MLPerf 基准测试悬赏,以及 conv backward fusing(卷积反向融合)和调度器优化方面的增强。
- ShapeTracker 悬赏引发疑问:关于在 Lean 中合并两个任意 tracker 的 ShapeTracker 悬赏引起了关注,引发了关于可行性和奖励的讨论。
- 成员们参与评估了该悬赏与其潜在产出及先前讨论相比的价值。
- Tinygrad 助力时间序列分析:一名用户探索使用 tinygrad 进行时间序列分析中的生理特征提取,并对 Matlab 的速度表示不满。
- 这一讨论突显了用户对 tinygrad 在此类应用领域效率的兴趣。
- 披露 NLL Loss 错误:报告了一个问题,即添加
nll_loss会导致张量梯度丢失,从而导致 PR 失败,促使寻求解决方案。- 回复澄清了诸如 CMPNE 之类的不可微操作会影响梯度跟踪,表明在 Loss 函数处理中存在更深层次的问题。
LAION Discord
- 向量搜索技术获得 BERT 助力:对于搜索冗长文本,讨论显示使用 BERT 风格模型优于 CLIP,并重点推荐了来自 Jina 和 Nomic 的模型。
- 成员们强调,在不关注图像时,Jina 的模型是一个更优的选择。
- SWE-Bench 举办 1000 美元黑客松!:SWE-Bench 黑客松将于 8 月 17 日开幕,为参与者提供 1,000 美元的计算资源,并为表现优异者提供现金奖励。
- 参与者将获得知名共同作者的支持,并有机会合作超越基准测试。
- Segment Anything Model 2 现已发布!:来自 Facebook Research 的 Segment Anything Model 2 已在 GitHub 上发布,包括模型推理代码和权重(checkpoints)。
- 官方提供了示例 Notebook,以帮助用户有效地应用模型。
AI21 Labs (Jamba) Discord
- Jamba 的长上下文能力令人印象深刻:Jamba 的 256k 有效长度能力正展现出令人期待的结果,特别是对于渴望进行实验的企业客户。
- 团队积极鼓励开发者反馈,以进一步完善这些功能,旨在优化使用场景。
- 征集长上下文创新开发者:Jamba 正在寻找开发者参与长上下文项目,并提供积分(credits)、周边(swag)和名望等奖励。
- 该倡议寻求积极的协作,以扩大长上下文应用的范围和有效性。
- 新成员为社区注入活力:新成员 artworxai 的加入为聊天增添了活力,引发了成员间的友好互动。
- 这种积极的氛围建立了一个受欢迎的环境,对社区参与至关重要。
LLM Finetuning (Hamel + Dan) Discord
- Google 黑客松 LLM 工程师最后召集:一个团队正在为即将到来的 Google AI Hackathon 寻找最后一名 LLM 工程师加入他们的项目,重点是颠覆机器人和教育领域。
- 候选人应具备高级的 LLM engineering 技能,熟悉 LangChain 和 LlamaIndex,并对机器人或教育技术有浓厚兴趣。
- 征集命名实体的快速去重方案:一位成员正在寻求以编程方式对命名实体列表进行去重(dedupe)的有效方法,希望找到无需复杂设置的快速解决方案。
- 目标是找到一种快速高效的方法来处理重复项,而不是实现复杂的系统。
Alignment Lab AI Discord
- 社区寻求鲁棒的人脸识别模型:成员们正在寻找在图像和视频中检测和识别面部表现出色的 machine learning 模型和库,优先考虑实时场景下的准确性和性能。
- 他们强调迫切需要那些不仅在各种条件下表现良好,而且能满足实际应用需求的解决方案。
- 对情绪检测能力的兴趣:讨论显示,人们对能够从静态图像和视频内容中识别面部情绪的解决方案越来越感兴趣,目标是提升交互质量。
- 参与者特别要求将人脸识别与情绪分析相结合的集成解决方案,以实现全面的理解。
MLOps @Chipro Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的各频道详细分析已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!