ainews-rombach-et-al-flux1-prodevschnell-31m-seed
Rombach 等人:发布 FLUX.1 [pro|dev|schnell],Black Forest Labs 获 3100 万美元种子轮融资。
Stability AI 联合创始人 Rombach 推出了 FLUX.1,这是一款全新的文生图模型,包含三个版本:pro(仅限 API)、dev(开源权重,非商业用途)和 schnell(采用 Apache 2.0 协议)。根据 Black Forest Labs 的 ELO 评分,FLUX.1 的表现超越了 Midjourney 和 Ideogram,并计划未来扩展至文生视频领域。
Google DeepMind 发布了 Gemma-2 2B,这是一个拥有 20 亿参数的开源模型。在 Chatbot Arena 排行榜上,它的表现优于 GPT-3.5-Turbo-0613 和 Mixtral-8x7b 等更大规模的模型,并针对 NVIDIA TensorRT-LLM 进行了优化。此次发布还包括安全分类器 (ShieldGemma) 和稀疏自编码器分析工具 (Gemma Scope)。
此外,相关讨论强调了基准测试的差异以及美国政府对开源权重 AI 模型的支持。同时,也有观点对 AI 编程工具在提升生产力方面的实际效果提出了批评。
团队和 3100 万美元就是重现 Stability 所需的一切?
2024年7月31日至8月1日的 AI 新闻。我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 28 个 Discord 服务(335 个频道和 3565 条消息)。预计节省阅读时间(以 200wpm 计算):346 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
今年我们一直在密切关注 Rombach 等人的工作,因为他发布了 Stable Diffusion 3,随后离开了 Stability AI。他在文本生成图像(text-to-image)领域的最新尝试是 FLUX.1,我们非常喜欢在这里展示精美的图片,因此这里展示了它执行各种标准任务的效果,从超现实主义到奇幻风格,再到写实摄影以及长文本 prompting:

这三个变体涵盖了不同的尺寸和许可范围:
- pro:仅限 API
- dev:权重开放(open-weight),非商业用途
- schnell:Apache 2.0
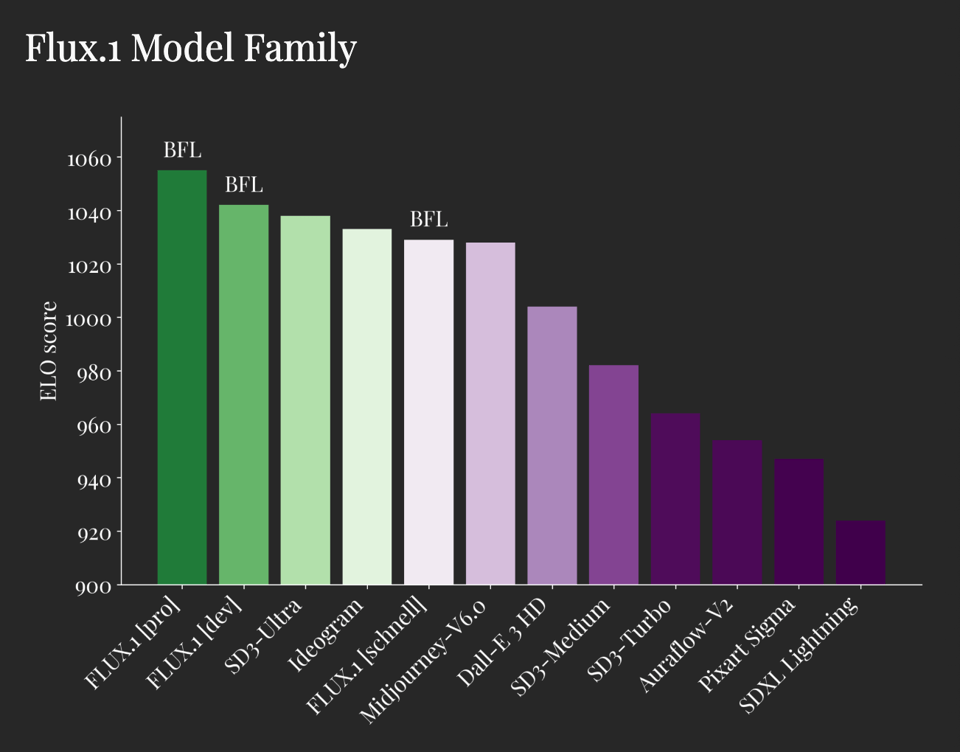
根据 Black Forest Labs 自己的 ELO 评分,所有三个变体都超越了 Midjourney 和 Ideogram:
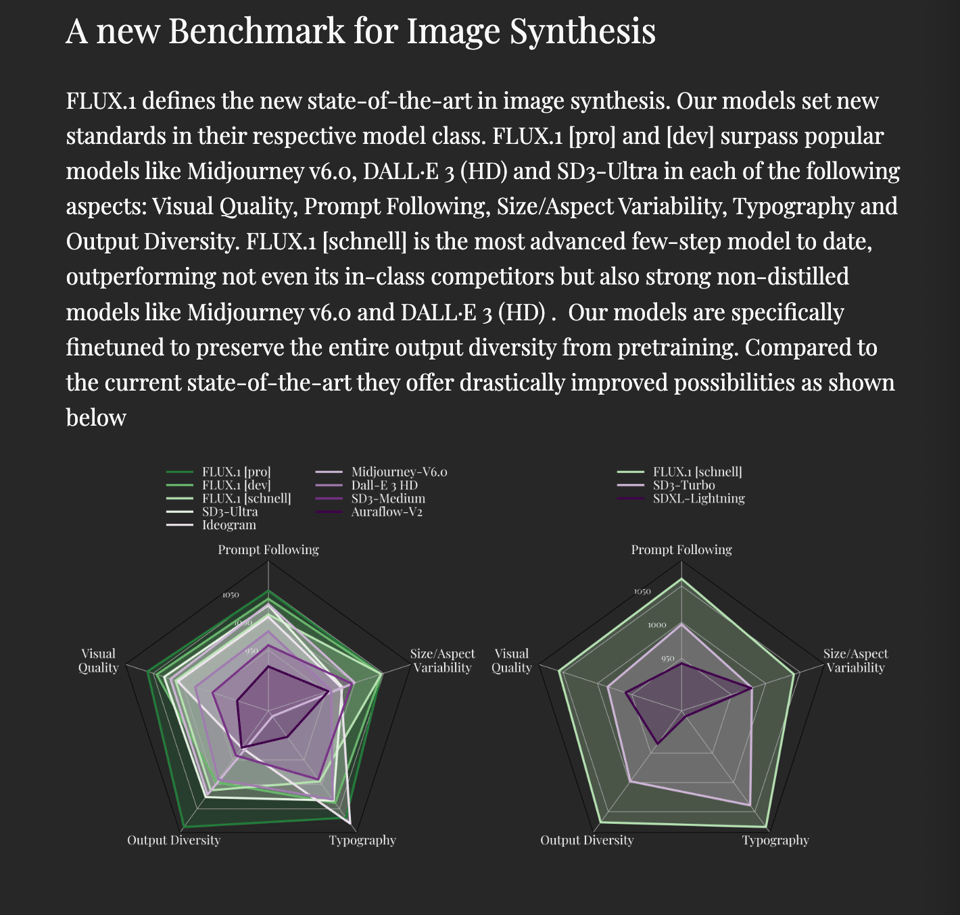
他们还宣布接下来将致力于 SOTA 级别的 Text-to-Video 研究。总而言之,这是我们在过去一年中看到的实力最强、最自信的模型实验室发布之一。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
Gemma 2 发布与 AI 模型进展
Google DeepMind 发布了 Gemma 2,这是一个新的开源 AI 模型系列,其中包括一个 20 亿参数的模型 (Gemma-2 2B),该模型取得了令人印象深刻的性能:
-
@GoogleDeepMind 宣布推出 Gemma-2 2B,这是一款全新的 20 亿参数模型,在其同尺寸模型中提供顶尖性能,并能在各种硬件上高效运行。
-
@lmsysorg 报告称,Gemma-2 2B 在 Chatbot Arena 上获得了 1130 分,表现优于其尺寸 10 倍的模型,并超过了 GPT-3.5-Turbo-0613 (1117) 和 Mixtral-8x7b (1114)。
-
@rohanpaul_ai 强调 Gemma-2 2B 在 Chatbot Arena 上的表现优于所有 GPT-3.5 模型,它通过蒸馏(distillation)技术向大型模型学习,并针对 NVIDIA TensorRT-LLM 进行了优化,适用于各种硬件部署。
-
@fchollet 指出 Gemma 2-2B 是同尺寸中最好的模型,在 lmsys Chatbot Arena 排行榜上超越了 GPT 3.5 和 Mixtral。
此次发布还包括其他组件:
- ShieldGemma:安全分类器,用于检测有害内容,提供 2B、9B 和 27B 三种尺寸。
- Gemma Scope:使用稀疏自编码器 (SAEs) 来分析 Gemma 2 的内部决策过程,拥有超过 400 个 SAEs,覆盖了 Gemma 2 2B 和 9B 的所有层。
AI 模型基准测试与对比
-
@bindureddy 批评了 Human Eval 排行榜,声称其存在刷榜行为,无法准确代表模型性能。他们认为尽管排行榜排名如此,但 GPT-3.5 Sonnet 优于 GPT-4o-mini。
-
@Teknium1 指出了 Gemma-2 2B 在 Arena 分数与 MMLU 表现之间的差异,指出其 Arena 分数高于 GPT-3.5-turbo,但 MMLU 分数仅为 50,而 3.5-turbo 为 70。
开源 AI 与政府立场
-
@ClementDelangue 分享称,美国商务部发布了政策建议,支持强大 AI 模型关键组件的可用性,并认可“权重开放(open-weight)”模型。
-
@ylecun 称赞了支持权重开放/开源 AI 平台的 NTIA 报告,认为现在是时候放弃那些基于虚构风险、扼杀创新的法案了。
AI 在编程与开发中的应用
-
@svpino 讨论了当前 AI 编程工具(如 Cursor, ChatGPT 和 Claude)的局限性,指出它们在编写代码方面并未显著提高生产力。
-
@svpino 强调了“被动 AI(passive AI)”工具的潜力,这些工具在后台运行,无需显式查询即可提供建议并识别代码中的问题。
其他值得关注的 AI 进展
-
@c_valenzuelab 展示了实时视频生成技术,在 11 秒内生成了 10 秒的视频。
-
@mervenoyann 讨论了 SAMv2 (Segment Anything Model 2),它为视频分割引入了一项名为“masklet prediction”的新任务,表现优于之前的 SOTA 模型。
-
@rohanpaul_ai 分享了关于更快的三值推理(ternary inference)的信息,允许 3.9B 模型运行速度与 2B 模型一样快,且仅占用 1GB 内存。
梗与幽默
-
@bindureddy 调侃 Apple Vision Pro 被用户抛弃,可能成为 Apple 历史上最大的败笔。
-
@teortaxesTex 分享了一条关于 “Friend” 噱头的幽默推文。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Google 的 Gemma 2 发布与生态系统
-
Google 刚刚发布了 3 款新的 Gemma 产品 (Gemma 2 2B, ShieldGemma 和 Gemma Scope) (Score: 143, Comments: 30):Google 扩展了其 Gemma AI 阵容,推出了三款新产品:Gemma 2 2B、ShieldGemma 和 Gemma Scope。虽然帖子中未提供这些产品的具体细节,但此次发布表明 Google 正在继续开发和丰富 Gemma 系列的 AI 产品。
-
Gemma-2 2b 4bit GGUF / BnB 量化 + 支持 Flash Attention 的 2 倍速微调! (Score: 74, Comments: 10): Google 发布了 Gemma-2 2b,该模型在来自更大 LLM 的 2 万亿 token 蒸馏输出上进行了训练。帖子作者上传了 2b、9b 和 27b 模型的 4bit 量化版本(bitsandbytes 和 GGUF),并开发了一种微调速度提升 2 倍且显存(VRAM)占用减少 63% 的方法,同时为 Gemma-2 整合了 Flash Attention v2 支持。他们提供了各种资源的链接,包括 Colab notebooks、Hugging Face 上的量化模型,以及用于 Gemma-2 instruct 的在线推理聊天界面。
-
Google 低调发布了一个稀疏自编码器(sparse auto-encoder)来解释 Gemma 2 和 9b。这是一个他们整理的 Google Colab,可以帮你入门。超级令人兴奋,我希望 Meta 也能效仿! (Score: 104, Comments: 22): Google 发布了一个用于解释 Gemma 2 和 9b 模型的稀疏自编码器,并提供了一个 Google Colab 笔记本帮助用户入门。此次发布旨在增强这些语言模型的可解释性,可能为提高 AI 开发透明度树立先例,发帖者希望 Meta 等其他公司也能跟进。
- 该稀疏自编码器工具允许可视化每个 token 的层激活,从而可能实现对拒绝移除(refusal removal)、感应头(induction heads)以及模型谎言检测的研究。用户可以探索安全研究中容易实现的目标(low-hanging fruit),并衡量微调对特定概念的影响。
- 该工具为运行时、低成本微调开启了可能性,以提升 AI 模型中的某些情绪或主题。这可以应用于创建动态 AI 体验,例如一个实时对模型撒谎概率进行评分的审讯游戏。
- 用户讨论了如何解读该工具的图表,指出它们显示了可以量化微调效果的 token 概率。以数字字符串表示的特征激活被认为比用于分析目的的可视化仪表板更有用。
主题 2:开源 LLM 的进展与对比
-
Llama-3.1 8B 4-bit HQQ/校准量化模型:相对于 FP16 达到 99.3% 的性能,且推理速度极快 (Score: 156, Comments: 49): Llama-3.1 8B 模型已发布 4-bit HQQ/校准量化版本,在提供 Transformer 最快推理速度的同时,达到了 FP16 99.3% 的相对性能。这款高质量量化模型可在 Hugging Face 上获取,为改进 AI 应用兼顾了效率与性能。
- 只是发张图.. (Score: 562, Comments: 74): 该图片对比了 OpenAI 的模型发布与开源替代方案,突显了开源 AI 开发的飞速进步。它显示虽然 OpenAI 在 2020 年 6 月发布了 GPT-3,在 2022 年 11 月发布了 ChatGPT,但 BLOOM、OPT 和 LLaMA 等开源模型在 2022 年 6 月至 12 月期间接连发布,Alpaca 紧随其后于 2023 年 3 月发布。
- 用户批评 OpenAI 缺乏开放性,评论包括 “OpenAI 完全封闭。真是讽刺。” 并建议将其更名为“ClosedAI”或“ClosedBots”。一些人认为 OpenAI 靠公众炒作和作为该领域先行者的品牌知名度维持。
- Google 的 Gemma 2 受到好评,用户注意到其令人惊讶的质量和个性。一位用户称其 “在许多方面优于 L3”,并表达了对可能具备多模态和更长上下文的 Gemma 3 的期待。
- Mistral AI 因其在资源有限的情况下(相比大公司)取得的快速进展而受到赞赏。用户建议根据团队规模和可用资源进行标准化对比,以突出 Mistral 的成就。
- Google 的 Gemma-2-2B 对比 Microsoft Phi-3:医疗领域 Small Language Models 的比较分析 (Score: 65, Comments: 9):一项针对 Google 的 Gemma-2-2b-it 和 Microsoft 的 Phi-3-4k 模型在医疗领域未经 fine-tuning 表现的比较分析显示。根据 Aaditya Ura 的推文分享,Microsoft 的 Phi-3-4k 以 68.93% 的平均得分胜出,而 Google 的 Gemma-2-2b-it 的平均得分为 59.21%。
- 用户批评了原始分析中的图表颜色选择,强调了数据比较中视觉呈现的重要性。
- 讨论围绕所使用的具体 Phi-3 模型展开,推测其为 3.8B Mini 版本。用户还询问了针对 PubMed 数据集的 fine-tuning 技术。
- 关于在医疗 QA 数据集上评估 small LLMs 的相关性引发了辩论。一些人认为这对于评估医学知识很重要,而另一些人则指出 LLMs 已经被用于回答医疗问题,特别是在医生资源有限的地区。
{kind=link}
主题 3. LLM 的硬件与推理优化
-
哇,SambaNova 在 Llama 405B 上通过其 ASIC 硬件实现了超过 100 tokens/s 的速度,而且无需注册即可使用。 (Score: 247, Comments: 94):SambaNova 在 AI 硬件性能方面取得了突破,利用其 ASIC 硬件在 Llama 405B 模型上实现了每秒超过 100 tokens 的生成速度。该技术现在无需任何注册过程即可供用户使用,有可能使高性能 AI 推理能力的使用变得民主化。
-
发布你运行 Llama 3.1 70B 的 tokens per second (Score: 61, Comments: 124):该帖子请求用户分享他们运行 Llama 3.1 70B 模型的 tokens per second (TPS) 性能基准测试。虽然帖子本身未提供具体的性能数据,但旨在收集和比较来自不同用户和硬件设置运行该大型语言模型的 TPS 指标。
-
70B 我来了! (Score: 216, Comments: 65):帖子作者正准备使用高端 GPU 设置运行 70B 参数模型。他们对即将拥有的处理大型语言模型的能力感到兴奋,正如充满热情的标题“70B 我来了!”所暗示的那样。
- 用户讨论了散热管理,其中一位提到对两块 3090 FE GPU 进行 undervolting 以获得更好的性能。原帖作者使用了一个气流良好的 Meshify 机箱,并在不需要时禁用 3090。
- 性能基准测试被分享,一位用户报告在使用 AWQ 和 LMDeploy 运行 Llama 3.1 70B 模型时达到了 35 tokens per second。另一位推荐了一个用于监控 GDDR6 显存温度的 GitHub 工具。
- 针对 3090 显存过热的担忧被提出,特别是在气候较温暖的地区。一位用户在进行 Stable Diffusion 图像生成时遇到了崩溃,最后不得不拆除机箱侧面板以获得更好的冷却效果。
{kind=link}
{kind=link}
{kind=link}
主题 4. LLM 开发的新工具与框架
- PyTorch 刚刚发布了自己的 LLM 解决方案 - torchchat (Score: 135, Comments: 28):PyTorch 发布了 torchchat,这是一个用于在服务器、桌面和移动设备等各种设备上本地运行 Large Language Models (LLMs) 的新解决方案。该工具支持 Llama 3.1 等多个模型,提供 Python 和原生执行模式,并包含 eval 和 quantization 功能,GitHub 仓库地址为 https://github.com/pytorch/torchchat。
- 一位用户在 NVIDIA GeForce RTX 3090 上测试了 torchchat 与 Llama 3.1,达到了 26.47 tokens/sec。相比之下,vLLM 最初达到 43.2 tokens/s,在更高 batch sizes 下可达 362.7 tokens/s。
- 讨论集中在性能优化上,包括使用 –num-samples 以在 warmup 后获得更具代表性的指标,使用 –compile 和 –compile-prefill 以启用 PyTorch JIT,以及使用 –quantize 进行模型 quantization。
- 用户询问了对 AMD GPU 的 ROCm 支持、与 Mamba 模型的兼容性,以及与 Ollama 和 llama.cpp 等其他框架的比较。
Reddit AI 动态汇总
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 研究与应用
-
Google DeepMind 的 Diffusion Augmented Agents:来自 Google DeepMind 的一篇新论文 介绍了 Diffusion Augmented Agents,这可能会提升 AI 在复杂环境中的能力。(r/singularity)
-
AI 在前列腺癌检测方面表现优于医生:一项 研究发现 AI 检测前列腺癌的准确率比医生高出 17%,展示了 AI 在医学诊断方面的潜力。(r/singularity)
AI 产品与用户体验
-
ChatGPT 高级语音模式:一段 视频演示 展示了 ChatGPT 的语音模式在模仿航空公司飞行员时,因触发内容准则而突然停止。(r/singularity)
-
OpenAI 改进的对话式 AI:一位 用户报告 称,在 OpenAI 的最新更新中,对话流和教育功能得到了提升,他在 1.5 小时的通勤过程中利用该功能学习了 GitHub 仓库的相关知识。(r/OpenAI)
-
对 AI 可穿戴设备的批评:一篇 帖子批评了 一款新的 AI 可穿戴设备,将其与之前失败的尝试(如 Humane Pin 和 Rabbit R1)进行了比较。用户们讨论了该设备在功能和商业模式上可能存在的问题。(r/singularity)
AI 与数据权利
- Reddit CEO 要求为 AI 数据访问付费:Reddit 的 CEO 表示微软应该为搜索该网站付费,引发了关于数据权利和用户生成内容补偿的讨论。(r/OpenAI)
Discord AI 动态汇总
摘要之摘要的摘要
Claude 3.5 Sonnet
1. 新型 AI 模型与能力
- Llama 3.1 发布引发争论:Meta 发布了 Llama 3.1,包括一个在 15.6 万亿 token 上训练的 4050 亿参数模型,Together AI 的博客文章引发了关于不同供应商实现差异影响模型质量的辩论。
- AI 社区参与了关于结果可能存在“樱桃采摘”(cherry-picking)以及严谨、透明的评估方法论重要性的讨论。Dmytro Dzhulgakov 指出了 Together AI 展示案例中的差异,强调了进行一致性质量测试的必要性。
- Flux 搅动文本生成图像领域:由原 Stable Diffusion 团队成员组成的 Black Forest Labs 推出了 FLUX.1,这是一套全新的最先进文本生成图像模型,其中包括一个在非商业和开源许可下提供的 12B 参数版本。
- FLUX.1 模型因其令人印象深刻的能力而受到关注,用户注意到它在渲染手部和手指等身体末端方面的优势。FLUX.1 的专业版 (pro version) 已经可以在 Replicate 上进行测试,展示了文本生成图像领域的快速发展。
2. AI 基础设施与效率提升
- MoMa 架构提升效率:Meta 引入了 MoMa,这是一种用于混合模态语言建模的新型稀疏早期融合(sparse early-fusion)架构,显著提高了预训练效率,详见其最新论文。
- 根据 Victoria Lin 的说法,MoMa 在文本训练中实现了约 3 倍的效率提升,在图像训练中实现了 5 倍的提升。该架构采用混合专家(MoE)框架,并配有特定模态的专家组,用于处理交错的混合模态 token 序列。
- GitHub 集成 AI 模型:GitHub 宣布了 GitHub Models,这是一项新功能,直接将行业领先的 AI 工具带给其平台上的开发者,旨在弥合编码与 AI 工程之间的鸿沟。
- 这种集成旨在让 GitHub 庞大的开发者群体更容易接触到 AI,从而可能在大规模范围内改变编码与 AI 的交互方式。社区推测此举是否意在通过将 AI 能力集成到开发者的现有工作流中,来与 Hugging Face 等平台竞争。
3. AI 伦理与政策进展
- NTIA 倡导开放 AI 模型:美国国家电信和信息管理局(NTIA)发布了一份报告,支持 AI 模型的开放性,同时建议进行风险监测,以指导美国的政策制定者。
- 社区成员注意到 NTIA 直接向白宫汇报,这使其关于 AI 模型开放性的政策建议具有重大分量。该报告可能会影响美国未来的 AI 监管和政策方向。
- AI 信任中的水印辩论:围绕水印在解决 AI 信任问题上的有效性展开了辩论,一些人认为它仅在机构环境中有效,无法完全防止滥用。
- 讨论表明,需要更好的文化规范和信任机制,而不仅仅是水印,来应对深度伪造(deepfakes)和虚假内容的传播。这突显了在建立 AI 生成内容的信任和真实性方面面临的持续挑战。
PART 1: 高层级 Discord 摘要
HuggingFace Discord
- 神经网络的新型网页模拟器:一个新的 神经网络模拟 工具邀请 AI 爱好者 在线尝试不同的神经网络配置。
- 该模拟器旨在揭示神经网络行为的神秘面纱,为用户提供修改和理解 神经动力学 (neural dynamics) 的交互式体验。
- 可迁移 AI 智慧的蓝图:IBM 详细解析了 知识蒸馏 (Knowledge Distillation),阐明了将庞大的“教师”模型中的见解注入精简的“学生”模型的过程。
- 知识蒸馏 作为一种模型压缩和高效知识迁移的方法脱颖而出,对 AI 可扩展性 (AI scalability) 至关重要。
- 记录模型里程碑的交互式热力图:一个创新的 热力图空间 (heatmap space) 记录了 AI 模型发布 情况,因其可能集成到 Hugging Face 个人资料中而受到社区关注。
- 该工具展示了模型发展趋势的深刻视觉聚合,旨在提高 AI 演进节奏 的可见性和理解。
- 为 Solr 构建语义解析器:一位成员寻求关于教导 大语言模型 (LLM) 解析 Apache Solr 查询的建议,旨在生成包含产品信息的 JSON 响应。
- 在没有现成训练数据集的情况下,挑战在于有条理地引导 LLM 以增强 搜索功能 和用户体验。
Nous Research AI Discord
- Chameleon 架构实现飞跃:由 Chameleon 的创建者开创的一种 新型多模态架构 拥有显著的效率提升,详情可见 学术论文。
- Victoria Lin 在 Twitter 上提供了见解,指出 文本训练提升了约 3 倍,图像训练提升了 5 倍,使 MoMa 1.4B 表现出色 (来源)。
- 解码投机采样 (Speculative Decoding):投机采样机制是一个热门话题,有观点认为较小的草稿模型 (draft models) 可能会影响输出分布,除非通过 拒绝采样 (rejection sampling) 等技术进行修正。
- 一个 YouTube 资源 进一步解释了投机采样,暗示了该过程中速度与保真度之间的平衡。
- Bitnet 展现惊人速度:Bitnet 的微调方法 正引起关注,据 Reddit 报道,在单个 CPU 核心上达到了令人印象深刻的 每秒 198 个 token。
- 通过这种微调方法产生了一个紧凑的 74MB 模型,预计将发布开源版本,引发了对其在未来项目中应用的期待 (Twitter 来源)。
- LangChain:是关键还是累赘?:关于在以 OpenAI API 格式使用 Mixtral API 时是否有必要使用 LangChain 产生了争论。
- 一些成员质疑对 LangChain 的需求,认为直接进行 API 交互可能就足够了,这引发了关于工具依赖和 API 惯例的讨论。
- 无需费用的项目参与:社区成员询问了协助一个免费 AI 项目的方法,相关步骤将在预期的 PR 中列出。
- 讨论确认了该项目的免费性质,强调了将在即将发布的 PR 中披露的可执行任务,简化了新贡献者的加入流程。
Unsloth AI (Daniel Han) Discord
- 多 GPU 训练从崩溃到胜利:讨论揭示了 multi-GPU training 的问题,赞扬了修复方案,但也强调了初始设置的麻烦和环境调整。
- 切换到
llamafacs env是某些人成功的关键,而另一些人则选择了更具动手能力的手动 transformers upgrade 方法。
- 切换到
- Unsloth Crypto Runner 揭晓:阐明了 Unsloth Crypto Runner 基于 AES/PKI 的设计细节,解释了其从客户端到服务器的加密通信。
- 当
MrDragonFox强调 GPU 使用的必要性时,社区反响热烈,并透露了 Skunkworks AI 的 open-source 意图。
- 当
- Qwen 持续精炼实现:Qwen2-1.5B-Instruct 的无损持续微调 (Continuous Fine-tuning Without Loss) 引入了代码 FIM 和指令能力的融合,标志着一个技术里程碑。
- 随着用户中呼吁通过教程来解决文档挑战的声音不断回响,社区精神受到鼓舞。
- LoRA 的合并困境:合并 LoRA adapters 成为关注焦点,重点在于将 4-bit 模型合并导致虚假的 16-bit 表示的风险。
- 社区内对这些伪 16-bit models 传播的担忧日益增加,促使大家保持警惕。
Perplexity AI Discord
- Perplexity 与 Uber One 的会员福利:Uber One 会员现在可以免费获得 Perplexity Pro 订阅,有效期至 2024 年 10 月 31 日,提供价值 $200 的增强型回答引擎。
- 要享受此福利,美国和加拿大的用户需要保持其 Uber One 订阅并建立一个新的 Perplexity Pro 账户。更多详情请访问 Perplexity Uber One。
- Perplexity 在 AI 搜索引擎基准测试中夺冠:在一次对比评估中,Perplexity Pro 超越了 Felo.ai 和 Chatlabs 等竞争对手,在 UI/UX 和查询响应方面表现出色。
- 会员对搜索引擎的能力进行了评分,Pro Search 成为最受欢迎的功能,并在 ChatLabs 等平台上被重点介绍。
- Perplexity API 引发困惑:讨论显示用户对 Perplexity API 输出效果不佳感到不满,认为结果质量有所下降。
- 关于问题提示词的猜测不断增加,个人纷纷寻求改进结果的建议,并对 Perplexity References Beta 的访问权限表示好奇。
- Perplexity 优化的 Flask 身份验证:关于 Flask 的讨论强调了安全用户身份验证的必要性,推荐了
Flask-Login等包,以及 一份安全设置指南。- 用户被引导至概述模型创建、用户身份验证路由和加密实践的资源。
- OpenAI 通过 GPT-4o 开启语音未来:OpenAI 推出的 ChatGPT 高级语音模式 (Advanced Voice Mode) 令人印象深刻,自 2024 年 7 月 30 日起为 Plus 订阅者提供逼真的语音交互。
- 该更新允许增强语音功能,如情感语调变化和中断处理,记录在 OpenAI 更新页面上。
OpenAI Discord
- 生动的愿景:GPT-4o 激发图像创新:关于 GPT-4o 图像输出能力的讨论非常热烈,用户将其与 DALL-E 3 进行对比,并分享了激发广泛关注的示例,展示了其栩栩如生且写实的图像效果。
- 尽管 GPT-4o 令人印象深刻的输出赢得了赞誉,但其内容审核端点(moderation endpoint)也遭到了批评,呼应了 DALL-E 3 曾面临的类似担忧。
- 多才多艺的语音:显微镜下的 GPT-4o 语音实力:AI 爱好者测试了 GPT-4o 的语音模型能力,强调了其对口音和情感范围的适应性,以及融合背景音乐和音效的能力。
- 调查结果既有对其潜力的赞赏,也有对其表现不稳定的指出,引发了关于模型局限性和未来改进的讨论。
- 平台难题:寻求精准的 Prompt:AI 工程领域的先行者们交流了关于 prompt engineering 首选平台的见解,将 Claude 3、Sonnet 以及 Artifacts + Projects 视为首选。
- 用于 Prompt 评估的启发式工具成为焦点,其中 Anthropic Evaluation Tool 因其启发式方法被提及,而一个带有脚本的协作式 Google Sheet 则被提议作为一种可共享且高效的替代方案。
- 战略性订阅转变:权衡 Plus 的影响力:社区讨论围绕取消 Plus 订阅的影响展开,透露这样做将导致无法访问自定义 GPTs。
- 讨论还延伸到了 GPT 货币化的前提条件,强调了将大量的后续使用指标和美国本土化作为产生收入机会的标准。
- 图表困境:通过 AI 辅助规划路径:在 AI 图表领域,参与者探讨了擅长制作视觉辅助工具的免费工具,并提到了 ChatGPT —— 尽管其绘图天赋仍存争议。
- 对话还涉及了 LLM 在文本截断方面面临的挑战,建议寻求定性描述可能比要求精确的字符或单词计数更有效。
CUDA MODE Discord
- FSDP 讨论引发热议:一名成员批评 FSDP “有点烂”,引发了关于其可扩展性的辩论,而反方观点则认为它在易用性方面表现出色。
- 话题转向了 FSDP 的场景适用性,表明尽管它具有用户友好的特性,但并非万能的解决方案。
- 分片 LLaMA 的烦恼与 vLLM 的希望:在讨论中出现了在多节点上对 LLaMA 405B 进行分片的挑战,可能的解决方案涉及为更大的上下文窗口增强 vLLM。
- 参与者推荐了量化等方法,一些人避开使用 vLLM,转而引导用户查看 LLaMA 3.1 的增强细节和支持。
- Megatron 的学术魅力:Megatron 论文 激发了成员们讨论分布式训练相关性的兴趣,并得到了 Usenix 论文和解释性的 MIT 讲座视频等资源的支持。
- 关于 Megatron 的论述延伸到了分布式训练的实践见解,参考了学术界认可的资料和 YouTube 传播的内容。
- Triton 教程的分块 Matmul 矩阵:针对 Triton 教程中
GROUP_SIZE_M参数的疑问浮出水面,讨论了其在优化缓存中的作用。- 辩论包括将
GROUP_SIZE_M设置得过高如何导致效率低下,探索了硬件设计选择的微妙平衡。
- 辩论包括将
- Llama 3.1:混乱与 TorchChat 指引:用户表示需要一个 10 行的 Python 代码片段来简化 Llama 3.1 模型 的使用,因为现有的 推理脚本 被认为过于复杂。
- 作为回应,PyTorch 发布了 TorchChat 作为指南,为运行 Llama 3.1 提供了急需的参考实现。
Stability.ai (Stable Diffusion) Discord
- Stable Fast 3D 的闪电发布:Stability AI 发布了 Stable Fast 3D,这是一款能够在短短 0.5 秒内将单张图像转换为详细 3D 资产的新模型,推向了 3D 重建技术的极限。该模型对游戏和 VR 领域具有重大意义,重点在于速度和质量。探索技术细节。
- “Stable Fast 3D 惊人的处理时间为 3D 框架中的快速原型设计开辟了先河。” 用户还可以受益于可选的 remeshing 等额外功能,这些功能仅增加极少的时间,却能广泛适用于各种行业。
- SD3 成为焦点:社区讨论围绕 Stable Diffusion 3 (SD3) Medium 的利用展开,解决了加载错误并探索了模型的能力。分享的解决方案包括获取所有组件以及利用 ComfyUI workflows 等工具来实现更顺畅的操作。
- 通过社区支持和适配各种可用的 UI,用户成功解决了如 ‘AttributeError’ 等挑战,确保了使用 SD3 时更无缝的创作体验。
- 解决 VAE 难题:社区解决了一个常见问题:由于 VAE 设置,图像在渲染过程中变红。通过协作努力,找到了减轻该问题的故障排除方法。
- 应用 ‘–no-half-vae’ 命令成为同行推荐的修复方案,简化了艺术家的工作流,使他们在应对特定硬件解决方案时能准确地创作图像。
- 拨开 Creative Upscaler 的迷雾:社区共同努力澄清了关于提及“Creative Upscaler”的困惑,明确其并非 Stability AI 的项目。成员们交流了其他的放大(upscaling)建议。
- 受欢迎的技术包括 ERSGAN 的应用和采用 Transformer 技术,并从各种社区贡献的资源中汇集了针对提示词挑战的建议。
- Flux:下一代图像生成模型:Black Forest Labs 发布的 Flux 模型备受期待,社区对其在图像呈现和高效参数使用方面的增强议论纷纷。该公告展示了潜力,有望改变 text-to-image 领域。
- 关于该模型 GPU 效率的讨论强调了 Nvidia 4090 可获得最佳性能,并特别赞赏了该模型在渲染手部和手指等身体末端部位方面的卓越能力。
LM Studio Discord
- 退出代码揭示兼容性冲突:LM Studio 用户报告了如 6 和 0 的退出代码,引发了关于系统兼容性和调试迷宫的讨论。
- 这一困境已升级为围绕特定系统的特性以及可能需要更新 LM Studio 版本的讨论。
- Gemma 2 故障引发 GPU 困扰:运行 Gemma 2 2B 模型时出现了挑战,特别是在陈旧的硬件上,这促使用户呼吁发布新版本的 LM Studio。
- 社区的反应包括同情以及分享规避硬件障碍的策略。
- LLaMA:Embedding 之谜:在询问 LLaMA 在 LM Studio 中的集成情况时,爱好者们通过 LLM2Vec 等项目探索了 Embedding 能力。
- 这最终促成了关于文本编码器(text encoders)前瞻性解决方案的深入对话,以及对 Embedding 演进的兴奋。
- 深入探索 LM Studio:成员们揭示了 LM Studio 中的 Bug,从 GPU offloading 的异常到可能与 VPN/DNS 配置有关的棘手网络错误。
- 同行们协助定位问题并提出了可能的补丁,营造了解决技术难题的协作氛围。
- 对 LM Studio 功能的愿景:讨论深入到了对未来 LM Studio 功能的憧憬,用户渴望增加 TTS voices 和 RAG 支持的文档交互等功能。
- 在这些愿景中,Hugging Face 以及 Papers with Code 上的 Visual Question Answering (VQA) 方法引起了关注。
Eleuther Discord
- 水印之困:AI 的认证焦虑:成员们讨论了水印在 AI 信任问题中的作用,指出其有效性有限,并建议建立文化规范至关重要。
- 令人担忧的是,如果没有更广泛的信任机制,水印可能无法阻止滥用和虚假内容的传播。
- NTIA 的开放 AI 倡导:政策影响力巅峰:NTIA 报告 促进了 AI 模型的开放性,并建议进行勤勉的风险监测以指导政策制定者。
- 观察人士指出,由于 NTIA 直接向白宫汇报,其政策建议具有很大分量,预示着 AI 监管可能发生转变。
- GitHub 的模型混搭:将 AI 与代码集成:GitHub 推出的 GitHub Models 方便了在开发者工作流中直接访问 AI 模型。
- 随后引发了讨论,争论这究竟是挑战 Hugging Face 等竞争对手的策略,还是 GitHub 服务产品的自然演进。
- 转发双重下降:缩放法则受到审视:AI 研究人员讨论了 Scaling Laws 实验中验证对数似然(validation log-likelihood)的异常,特别是当具有 1e6 序列的模型表现不佳时。
- 这引发了对 BNSL 论文 的引用,揭示了类似的模式,并激发了对数据集大小影响的好奇。
- Prompt 过量生成的谜团:lm-eval 意外的倍数:lm-eval 在 gpqa_main 等基准测试中使用的 Prompt 数量超过了指定的数量,这一行为引发了技术咨询和调试工作。
- 澄清结果显示,lm-eval 中的进度条考虑了
num_choices * num_docs,从而解释了感知到的差异,并有助于理解工具行为。
- 澄清结果显示,lm-eval 中的进度条考虑了
Interconnects (Nathan Lambert) Discord
- Grok 的增长:xAI 不太可能收购 Character AI:关于 xAI 收购 Character AI 以增强其 Grok 模型的传闻一直在流传,但 Elon Musk 否认了这些说法,称该信息不准确。
- 社区思考了 Musk 言论背后的真相,并提到了此前官方否认后又确认收购的先例。
- Black Forest Labs 诞生于 Stable Diffusion 的根基:Stable Diffusion 的创始团队推出了 Black Forest Labs,专注于先进的生成模型,引起了轰动。
- Black Forest Labs 的 Flux 展示了强大的创造力,早期测试者可以在 fal 上进行尝试,预示着生成式领域潜在的变革。
- GitHub Models 将开发者与 AI 实力结合:GitHub 通过推出 GitHub Models 在 AI 领域引起关注,向其庞大的开发者群体提供强大的 AI 工具。
- 这一新套件旨在为开发者普及 AI 使用,可能在大规模范围内改变编程与 AI 的交互方式。
- Apple Intelligence 为科技未来带来转折:Apple 最新的 AI 进展承诺将应用程序更无缝地编织在一起,增强日常科技互动。
- AI 实验室的怀疑论者质疑 Apple Intelligence 的突破性地位,而其他人则将其视为科技实用性的重要倍增器。
- 拒绝采样在 Open Instruct 中找到归宿:Open Instruct 采用了 Rejection Sampling(拒绝采样),这是一种通过避免常见陷阱来微调训练的方法。
- 此举可能标志着模型训练效率的提高,也是 AI 训练领域方法论的一大进步。
Latent Space Discord
- Llama 3.1 触及质量辩论的敏感神经:Together AI 博客通过强调由于推理提供商不同的实现实践导致的性能差异,引发了关于 Llama 3.1 的辩论,引起了对模型一致性的关注。
- Dmytro Dzhulgakov 提醒社区注意潜在的结果挑选(cherry-picking)行为,并强调了模型评估中清晰方法论的重要性,在此推文线程中引发了广泛讨论。
- Sybill 为 AI 增强型销售筹集数百万美元:Sybill 获得了强劲的 1100 万美元 A 轮融资,用于完善其针对销售代表的 AI 个人助理,支持者包括 Greystone Ventures 等知名机构(公告详情)。
- AI 销售工具领域正随着 Sybill 的解决方案迸发创新火花,该方案通过克隆销售代表的声音来设计更相关的后续跟进。
- Black Forest Labs 凭借 FLUX.1 取得突破:由前 Stable Diffusion 专家组成的 Black Forest Labs 推出了其突破性的文本生成图像模型 FLUX.1,其中包括一个强大的 12B 参数版本(查看公告)。
- FLUX.1 的专业版目前已在 Replicate 上线试用,展示了相对于该领域其他模型的优势。
- LangGraph Studio 为 Agentic 应用开启新视野:LangChain 推出了 LangGraph Studio,旨在简化 Agentic 应用的创建和调试,推动 IDE 创新(公告推文)。
- 这个以 Agent 为核心的 IDE 结合了 LangSmith,提升了 LLM 领域开发者的效率和团队协作。
- Meta MoMa 变革混合模态建模:Meta 的新型 MoMa 架构采用 Mixture-of-Experts 方法,加速了混合模态语言模型的预训练阶段(附带论文)。
- 该架构专为有效处理和理解混合模态序列而设计,标志着该领域迈出了一大步。
LlamaIndex Discord
- 异步进展加速 BedrockConverse:BedrockConverse 集成了新的异步方法,解决了 pull request #14326 中提到的未决问题,特别是 #10714 和 #14004。
- 社区表示赞赏,强调了该贡献在提升 BedrockConverse 用户体验方面的重大影响。
- LongRAG 论文见解:由 Ernestzyj 撰写的 LongRAG 论文介绍了一种索引更大文档块的技术,以发挥长上下文 LLM 的潜力。
- 这种方法开启了新的可能性,简化了检索增强生成(RAG)过程,引起了社区的兴趣。
- Workflows 在 LlamaIndex 中大显身手:新引入的 llama_index 中的 workflows 赋能了事件驱动的多 Agent 应用的创建。
- 社区对这一创新表示赞赏,认为它为复杂的编排提供了一种易读且 Pythonic 的方法。
- 稳定代码库的难题:讨论围绕确定 LlamaIndex 的稳定版本展开,明确了引导用户通过 pip 安装是保证稳定性的手段。
- “稳定”一词成为焦点,将稳定性与 PyPI 上提供的最新版本联系起来,引发了进一步辩论。
- 使用 DSPy 和 LlamaIndex 进行 Prompt 实验:成员们评估了 DSPy 的 Prompt 优化与 LlamaIndex 重写功能的对比。
- 社区对这两个工具之间的对比探索表现出极大的热情,并考虑将它们应用于提高 Prompt 性能。
Cohere Discord
- Embed with Zest: Content Structures Clarified: 在一场技术讨论中,Nils Reimers 澄清说 embedding 模型会自动移除换行符和特殊符号,强调了文本预处理并非必不可少。
- 这一发现表明模型在处理噪声数据方面具有鲁棒性,允许 AI 工程师专注于模型应用,而非繁琐的文本预处理。
- Citations Boost Speed; Decay Dilemmas: 一位敏锐的用户指出,在 Cohere Cloud 上使用乌克兰语/俄语时,高 citation_quality 设置会导致响应变慢,并注意到从 fast 切换到 accurate 解决了字符问题。
- 虽然获得了稳定的输出,但响应速度的权衡已成为工程师之间潜在优化讨论的话题。
- Arabic Dialects in LLMs: A Linguistic Leap: 当 LLM Aya 在各种阿拉伯语方言中生成准确文本时,社区表达了惊讶,并对在以英语为主的 prompt 环境下的方言训练提出了疑问。
- 社区在 LLM 处理方言方面的经验强化了先进上下文理解的概念,激发了对训练机制的好奇。
- Devcontainer Dilemma: Pydantic Ponders: AI 工程师在设置 Cohere toolkit 仓库时遇到了瓶颈,Pydantic 验证错误导致设置中止,暴露出
Settings类中缺失字段(如 auth.enabled_auth)的问题。- 团队迅速做出回应,承诺即将修复,展示了在工具包维护和可用性方面的敏捷性与承诺。
- “Code and Convene”: AI Hackathon Series: 社区成员热烈讨论参加在 Google 举办的 AI Hackathon Series Tour,这是一场为期 3 天 的 AI 创新与竞赛。
- 该巡回赛旨在展示 AI 进展和创业项目,最终以 PAI Palooza 告终,这是一个展示新兴 AI 初创公司和项目的盛会。
LangChain AI Discord
- Pydantic Puzzles in LangChain Programming: 由于 Pydantic 版本不匹配导致 ValidationError,在配合 LangChain 工作时引起了类型不一致的困惑。
- 输入不匹配和验证导致执行失败,突显了冲突,强调了 api_version 协调的必要性。
- API Access Angst for LangSmith Users: 一位用户在尝试使用 LangSmith 部署 LLM 时遇到了
403 Forbidden错误,提示可能存在 API key 配置错误。- 社区讨论围绕 key 的正确设置展开,并寻求通过各种 LangChain 渠道获得帮助。
- Streaming Solutions for FastAPI Fabulousness: 一位用户提出了一种在 LangChain 应用中使用 FastAPI 进行异步流式传输的模式,提倡使用 Redis 进行平滑的消息代理。
- 这将保持当前的同步操作,同时赋能 LangChain Agent 实时分享结果。
- Jump-Start Resources for LangChain Learners: 讨论深入探讨了掌握 LangChain 的可用资源,强调了有效学习的替代方案和仓库。
- 成员们交换了 GitHub 示例和各种 API 文档,以便更好地应对常见的部署和集成难题。
- LangGraph’s Blueprints Unveiled: 分享了一种创新的 LangGraph 设计模式,旨在用户友好地集成到 web-chats 和即时通讯机器人等应用中,并提供了一个展示集成过程的 GitHub 示例。
- 此外,还发出了测试 Rubik’s AI 新功能的 Beta 邀请,通过特别促销活动提供包括 GPT-4o 和 Claude 3 Opus 在内的顶级模型。
OpenRouter (Alex Atallah) Discord
- 数字排毒饮食:Moye 方法:Moye Launcher 的极简设计通过刻意降低应用的可访问性来促进数字健康,倡导向减少屏幕时间的行为转变。
- 开发者针对导致过度使用的三个因素(如自动点击和缺乏问责制),旨在通过设计和用户反馈培养专注应用使用的习惯。
- 闪耀的人格:Big-agi 的大动作:Big-agi 的“人格创建器”允许用户根据 YouTube 输入快速生成角色档案,而 BEAM 功能则合并了多个模型的输出,增加了响应的多样性。
- 尽管如此,Big-agi 仍因缺失服务器保存和同步功能而感到局促,这阻碍了原本流畅的模型交互体验。
- Msty 融合记忆与网页掌控力:Msty 与 Obsidian 的集成以及网页连接功能因其易用性而获得用户好评,但因其健忘的参数持久性而面临批评。
- 尽管 Msty 仍需打磨,但一些用户因其精美的界面交互能力而考虑转向使用它。
- Llama 405B 走 FP16 钢丝:OpenRouter 缺少 Llama 405B 的 FP16 路径,而 Meta 推荐的 FP8 量化被证明更有效率。
- 虽然 SambaNova Systems 提供类似服务,但它们受限于最大 4k 的上下文限制以及成本高昂的 bf16 托管。
- OpenRouter 的 Beta 版保证 API 门户:OpenRouter 预告了 API 集成 Beta 版,欢迎通过支持邮件进行速率限制(rate limit)微调,并将 OpenAI 和 Claude API 串联到用户项目中。
- 虽然其网站有时会遇到区域性问题,但 OpenRouter 状态页面 就像一座灯塔,引导用户度过运行风暴。
OpenInterpreter Discord
- Open Interpreter 陷入慢车道:对于 Ben Steinher 延迟回复的担忧正在增加,他错过了 7 月中旬的回复截止日期。
- 尽管有所延迟,社区仍称赞了一个关于 Groq 配置文件贡献的新 PR,认为这是支持 Open Interpreter 的有效方式,并重点介绍了 MikeBirdTech 提交的 GitHub PR。
- 技术人员关注无障碍讨论:一场无障碍圆桌会议定于 8 月 22 日举行,旨在激发讨论和参与,并公开邀请社区分享见解。
- 在解决了最初的时区混乱后,人们对即将举行的 House Party 活动充满期待,参与者可前往 活动链接。
- 模型选择令人困惑:关于使用 ‘01 –local’ 时是否需要 OpenAI API key 以及正确的模型字符串产生了讨论,这表明需要更清晰的指南。
- 探究性的帖子仍在继续,询问 OpenInterpreter 是否可以保存和调度工作流,社区尚未给出答案。
- iKKO 耳机放大 AI 可能性:关于在 iKKO ActiveBuds 上集成 OpenInterpreter 的讨论正在升温,将高分辨率音频与 AI 结合,详见 iKKO 官网。
- 01 的发货更新在社区内引发了紧迫感,随着 8 月的流逝,更新信息的呼声仍未得到回应。
- 带有视觉的耳机:摄像头讨论:出现了一个为耳机配备摄像头的创新想法,通过在与 LLM 对话期间捕捉视觉上下文来增强交互。
- 社区成员思考了这一集成,考虑通过点击功能激活摄像头,以增强 HCI 体验。
Modular (Mojo 🔥) Discord
- Mojo 线程支持缺失:在关于 Mojo 能力的讨论中,一位成员澄清说 Mojo 目前并不直接向用户开放线程支持。
- 有人提到,在编译环境中,利用 fork() 是实现多线程的一种变通方法。
- MAX 与 Mojo 的打包公告:官方透露了即将到来的 MAX 和 Mojo 打包变更,从
modularCLI 的 0.9 版本开始,下载 MAX 和 Mojo 将不再需要身份验证。- Mojo 将与 MAX nightly 构建版本合并,公告建议转向新的
magicCLI 以实现无缝的 Conda 集成。
- Mojo 将与 MAX nightly 构建版本合并,公告建议转向新的
- 层级图表引发困惑:成员们对一张层级图表表示困惑,争论其表示是否准确,并批评其未能反映预期的“抽象层级”。
- 一些人主张用火焰表情符号简化视觉效果,表示希望有一个清晰且有效的沟通工具。
- CrazyString 中的 Unicode 支持:CrazyString gist 已更新,引入了基于 Unicode 的索引,并实现了完全的 UTF-8 兼容性。
- 对话涉及了 Mojo 字符串的小字符串优化(small string optimization)以及更新后带来的易用性提升。
- M1 Max 上的 Max 安装难题:一位成员在 Mac M1 Max 设备上尝试安装 max 时遇到挑战,社区成员介入并提供了潜在的修复方案。
- 一份共享资源建议使用特定的 Python 安装变通方案来解决安装问题。
OpenAccess AI Collective (axolotl) Discord
- Axolotl 引入自动停止算法:针对关于在损失停滞(loss plateaus)或验证损失激增时停止训练的询问,Axolotl 引入了早停(early stopping)功能。
- 社区成员就手动终止运行同时保存当前 LoRA adapter 状态的能力进行了简短交流。
- SharedGPT 的掩码学习飞跃:一位成员为 SharedGPT 的每一轮对话提出了一个“输出掩码(output mask)”字段,旨在通过选择性输出掩码进行针对性训练。
- 这一创新引发了关于其通过处理输出错误来精炼学习潜力的讨论。
- 聊天模板需要更清晰:由于难以理解新的聊天模板(chat templates),成员们呼吁提供更好的文档以帮助理解和自定义。
- 一位成员主动分享了关于该主题的个人笔记,并建议由社区驱动更新官方文档。
- Pad Token 重复问题:训练问题讨论中提到了频繁出现的
<pad>token 重复现象,暗示了采样方法的低效。- 对话贡献了一个技巧:确保 pad token 在标签中被遮蔽(cloaked),以防止循环冗余。
- Gemma2 使用 Eager 优于 Flash:出现了一个针对 Gemma2 模型训练的推荐技巧,建议使用
eager而非flash_attention_2以巩固稳定性和性能。- 提供了实践指导和代码示例,演示如何在
AutoModelForCausalLM中设置eagerattention。
- 提供了实践指导和代码示例,演示如何在
DSPy Discord
- 围绕 DSPy 和符号学习(Symbolic Learning)展开热烈讨论:成员们对将 DSPy 与符号学习器集成充满期待,推测其具有突破性的潜力。
- 参与者预期这种结合将为 AI 能力带来实质性的进步,表现出乐观态度。
- 自适应 Agent 成为焦点:Microsoft Research 博客将自适应 AI Agent 推向台前,展示了一篇具有前景的职场应用文章。
- 见解指出游戏行业是 AI 进步的催化剂,现在正体现在 ChatGPT 和 Microsoft Copilots 等工具中。
- Agent Zero 登场:用户测试版 AI 的尝试:Agent Zero 作为首个经过用户测试的生产版本亮相,展示了其 AI 实力。
- 反馈暗示 AI 正在向职业环境中占据更多样化角色的方向转变。
- LLM 通过 Meta-Rewarding 实现自我提升:一篇 arXiv 论文揭示了一种新的 Meta-Rewarding 技术,增强了 LLM 的自我判断能力,从而提升其性能。
- 据报道,在 AlpacaEval 2 上胜率显著提高,表明 Llama-3-8B-Instruct 等模型也从中受益。
- MindSearch 论文探讨基于 LLM 的多 Agent 框架:发表在 arXiv 上的一篇论文介绍了 MindSearch,它使用 LLM 驱动的 Agent 在网络搜索中模拟人类认知过程。
- 该研究解决了信息检索挑战,旨在改进现代搜索辅助模型。
tinygrad (George Hotz) Discord
- NVIDIA 获得纳税人资金:一条消息对 NVIDIA 获得公共资金表示热议,详细说明了纳税人投资的价值。
- 这一话题引发了关于投资优先级及其对技术发展影响的对话。
- George Hotz 强调 Discord 规范:George Hotz 提醒了服务器规则,将注意力集中在 tinygrad 开发上。
- Hotz 的提醒是号召社区保持专业且切题的对话。
- Argmax 拖慢了 GPT-2 的速度:对 GPT-2 性能的深入研究发现,embedding 结合
argmax显著限制了执行速度,如 Issue #1612 所示。- 效率低下追溯到 O(n^2) 复杂度问题,引发了关于更高效算法方案的讨论。
- Embedding 悬赏:Qazalin 的任务:出现了关于提升 tinygrad 中 embeddings 性能的悬赏讨论,专门针对名为 Qazalin 的用户。
- 悬赏引起了轰动,并激励其他贡献者在 tinygrad 中寻找不同的优化机会。
- Cumsum 难题:Issue #2433 解决了
cumsum函数 O(n) 复杂度的挑战,激发了开发者的创新思维。- George Hotz 召集人马,提倡通过实际实验来发现可能的优化策略。
LAION Discord
- 多语言 ChatGPT 的语音绝技:一位成员展示了 ChatGPT Advanced Voice Mode,它能熟练地用乌尔都语朗诵诗歌,并用包括希伯来语、挪威语和格鲁吉亚语在内的多种语言讲故事。
- 此次展示还包括了摩洛哥阿拉伯语 (Moroccan Darija)、阿姆哈拉语、匈牙利语、克林贡语等冷门方言的叙述,令工程社区惊叹不已。
- Black Forest Labs 的惊艳亮相:Black Forest Labs 的发布引发了热烈反响,其使命专注于媒体领域的创新生成模型。
- 该计划以 FLUX.1 拉开序幕,这款模型承诺将提升视觉生成的创造力、效率和多样性。
- FLUX.1 模型首秀令人印象深刻:社区将目光转向了 FLUX.1,这款新模型在 Hugging Face 上的首次亮相赢得了广泛赞誉。
- 讨论集中在这一模型如何潜在地改变生成式学习的格局,其特性被形容为“令人耳目一新”且“非常出色”。
- 创新的激活函数尝试:AI 爱好者们深入研究了在复数值激活(complex-valued activations)上使用各种归一化和激活函数的实验,并称这些练习“挺有意思!”。
- 这种实践探索促进了心得分享,并探讨了在复杂领域的潜在应用。
- 被过度炒作的正则化难题:一位用户引用 一篇 Medium 文章 指出,像数据增强 (data augmentation) 和 Dropout 这样广泛使用的方法在显著抑制过拟合方面表现乏力。
- 通过探究各种正则化技术 (regularization techniques) 的有效性,社区开始思考超越传统技巧的方法,以推进机器学习模型的发展。
Torchtune Discord
- 使用 Top_p 达到性能巅峰:一位成员发现将 top_p=50 设置为符合其性能标准的参数,并获得了显著的效果。
- 他们将 0.8 在线模型与自己的模型进行了对比,注意到在线变体具有更优的结果。
- 使用 Generate Recipe 享受调试乐趣:澄清了 generate recipe 主要是为调试目的而设计的,旨在实现对模型的准确刻画。
- 与基准测试的任何差异都应促使提交 Issue,评估确认了该 Recipe 的有效性。
- FSDP2 的新特性融合:一位成员分享道,FSDP2 现在同时支持 NF4 tensor 的量化和 QAT,增强了其通用性。
- 虽然 QAT Recipe 看起来是兼容的,但使用 FSDP2 进行编译可能会遇到挑战,这标志着一个潜在的优化领域。
- 精准合并 PR:一个即将合并的 PR 被标记为依赖于前一个 PR,其中 PR #1234 正在审查中,从而为序列化改进铺平了道路。
- 这预示着微调数据集的增强,重点关注 grammar 和 samsum,推进了 Torchtune 的系统化演进。
MLOps @Chipro Discord
- Data Phoenix 举办 AI 网络研讨会:Data Phoenix 团队宣布了一场名为“利用 LLM 和生成式 AI 增强推荐系统”的网络研讨会,主讲人为 Andrei Lopatenko,定于 PDT 时间 8 月 8 日上午 10 点举行。
- 此次研讨会旨在揭示 LLM 和 Generative AI 如何变革个性化引擎,并已开放 研讨会注册。
- dlt 通过工作坊提升 ELT 技能:一场关于 使用 dlt 进行 ELT 的 4 小时工作坊将为数据爱好者传授构建稳健 ELT 流水线的知识,完成后可获得“dltHub ELT Engineer”认证。
- 该课程定于 2024 年 8 月 15 日 16:00 GMT+2 在线举行,从 dlt 基础知识开始,可以在此处注册。
- 会议展示了 NLP 和 GenAI 的主导地位:两场机器学习会议都重点强调了 NLP 和 GenAI,掩盖了关于 高斯过程 (Gaussian Processes) 和 孤立森林 (Isolation Forest) 等模型的演讲。
- 这一趋势凸显了社区向 NLP 和 GenAI 技术的强烈倾斜,使得一些小众模型的讨论显得黯然失色。
- 社区审视 GenAI 的 ROI:一场热烈的辩论质疑了 GenAI 的 ROI(投资回报率) 是否能达到业内某些人设定的高度预期。
- 对话指出了预期与现实之间的差距,强调需要对回报保持理性的预期。
LLM Finetuning (Hamel + Dan) Discord
- LangSmith 额度难题:Digitalbeacon 报告了在添加付款方式后无法访问 LangSmith 额度的问题,他使用的电子邮件地址与其组织 ID 93216a1e-a4cb-4b39-8790-3ed9f7b7fa95 不同。
- Danbecker 建议联系支持部门解决额度相关问题,暗示需要直接通过客服解决。
- LangSmith 付款方式混乱:Digitalbeacon 询问了在更新付款方式后,即使及时提交了表格,LangSmith 余额仍为零的问题。
- 这种情况表明可能存在系统故障或用户操作失误,需要进一步调查或支持干预。
Alignment Lab AI Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
第二部分:分频道详细摘要与链接
完整的逐频道细分内容已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!