ainews-acquisitions-the-fosbury-flop-of-ma
Execuhires:挑战可汗之怒 (注:“The Wrath of Khan” 是《星际迷航》系列中的经典篇目,通常译为《可汗之怒》或《可汗怒吼》。)
以下是该文本的中文翻译:
Character.ai 以 25 亿美元的价格向谷歌输送核心人才(Execuhire),标志着一次重大的领导层变动;此前,Adept 以 4.29 亿美元向亚马逊输送人才,Inflection 以 6.5 亿美元向微软输送人才。尽管 Character.ai 的用户增长和内容势头强劲,其 CEO Noam Shazeer 仍选择重返谷歌,这预示着 AI 行业风向的转变。
Google DeepMind 的 Gemini 1.5 Pro 在 Chatbot Arena 基准测试中登顶,超越了 GPT-4o 和 Claude-3.5,在多语言、数学和编程任务中表现卓越。Black Forest Labs 的 FLUX.1 文生图模型以及 LangGraph Studio 智能体 IDE 的发布,凸显了行业的持续创新。Llama 3.1 405B 作为目前最大的开源模型发布,促进了开发者的应用,并展开了与闭源模型的竞争。
目前,行业日益将后训练(post-training)和数据视为关键竞争因素,这也引发了公众对收购行为及监管审查的关注。
Noam 回家了。
2024年8月1日至8月2日的 AI 新闻。我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 28 个 Discord 社区(249 个频道,3233 条消息)。预计为您节省阅读时间(以 200wpm 计算):317 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
我们想知道是否是同一批律师参与了以下建议:
- Adept 向 Amazon 提供的 4.29 亿美元 execuhire
- Inflection 向 Microsoft 提供的 6.5 亿美元 execuhire
- Character.ai 今天向 Google 提供的 25 亿美元 execuhire
(我们还要注意到 Stability 的大部分领导层已经离职,尽管这不算是 execuhire,因为 Robin 现在成立了 Black Forest Labs,而 Emad 成立了 Schelling。)
Character 并非真的陷入困境。他们的 SimilarWeb 统计数据已经超过了之前的峰值,且发言人表示内部 DAU 数据同比增长了 3 倍。
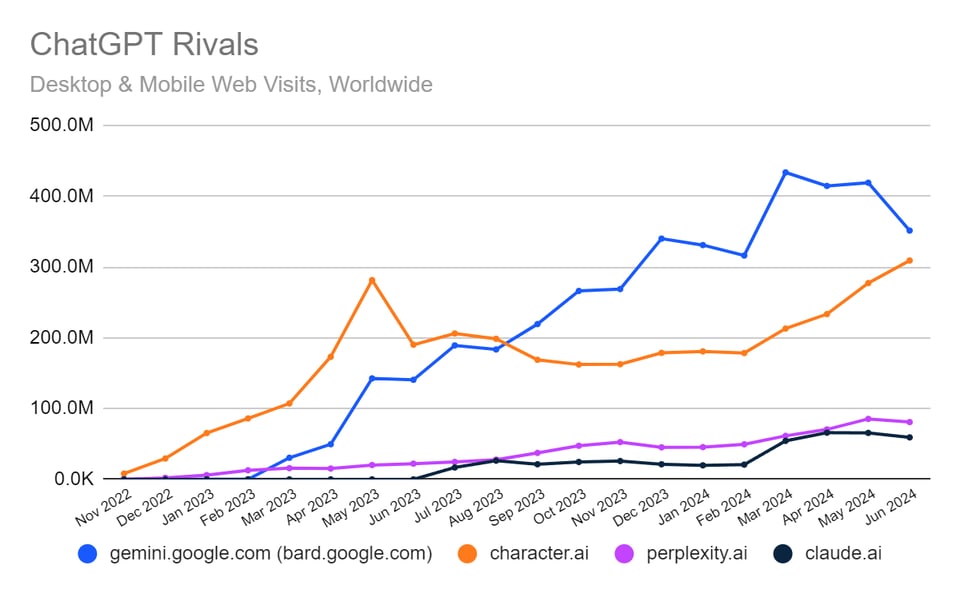
我们曾对他们的博客文章赞不绝口,就在昨天还报道了 Prompt Poet。通常情况下,任何拥有这种近期内容势头的公司都表现良好……但在这里,行动胜于雄辩。
正如我们在 The Winds of AI Winter 中讨论的那样,氛围正在发生变化,虽然这在本质上不完全是技术性的,但它们太重要了,不容忽视。如果 Noam 无法带着 Character 走到底,Mostafa 无法带着 Inflection 走到底,David 无法带着 Adept 走到底,那么其他基础模型实验室的前景又如何呢?转向以后训练 (post-training) 为重心的趋势正在升温。
当一个东西走起来像鸭子,叫起来像鸭子,但又不想被称为鸭子时,我们大概还是可以把它归入鸭科 (Anatidae) 家族树。当大公司拿走了核心技术、核心高管,并偿还了所有核心投资者的资金时……FTC 是否会认为这已经足够接近规避收购的字面定义,但违背了其管辖权的实质精神?
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型发展与基准测试
-
Gemini 1.5 Pro 性能:@lmsysorg 宣布 @GoogleDeepMind 的 Gemini 1.5 Pro (Experimental 0801) 在 Chatbot Arena 中夺得榜首,以 1300 分的成绩超越了 GPT-4o/Claude-3.5。该模型在多语言任务中表现出色,并在数学、硬核提示(Hard Prompts)和 Coding 等技术领域表现优异。
-
模型对比:@alexandr_wang 指出 OpenAI、Google、Anthropic 和 Meta 都处于 AI 开发的最前沿。Google 凭借 TPU 拥有的长期算力优势可能成为一个显著竞争力。数据和训练后处理(post-training)正成为性能提升的关键竞争驱动因素。
-
FLUX.1 发布:@robrombach 宣布成立 Black Forest Labs 并推出其全新的 SOTA 文本生成图像模型 FLUX.1。该模型包含三个变体:pro、dev 和 schnell,其中 schnell 版本在 Apache 2.0 许可证下发布。
-
LangGraph Studio:@LangChainAI 推出了 LangGraph Studio,这是一个用于开发 LLM 应用程序的 Agent IDE。它提供了复杂 Agent 应用的可视化、交互和调试功能。
-
Llama 3.1 405B:@svpino 分享了 Llama 3.1 405B 现已开放免费测试。这是迄今为止最大的开源模型,可与闭源模型竞争,其许可证允许开发者使用它来增强其他模型。
AI 研究与进展
-
BitNet b1.58:@rohanpaul_ai 讨论了 BitNet b1.58,这是一种 1-bit LLM,其中每个参数都是三值(ternary)的 {-1, 0, 1}。这种方法可能允许在手机等内存有限的设备上运行大型模型。
-
Distributed Shampoo:@arohan 宣布 Distributed Shampoo 在深度学习优化方面超越了 Nesterov Adam,标志着非对角预处理(non-diagonal preconditioning)领域的重大进展。
-
Schedule-Free AdamW:@aaron_defazio 报告称 Schedule-Free AdamW 为自调优训练算法设定了新的 SOTA,在 AlgoPerf 竞赛中整体表现优于 AdamW 和其他提交算法 8%。
-
Adam-atan2:@ID_AA_Carmack 分享了一行代码修改,通过将除法改为 atan2() 来移除 Adam 中的 epsilon 超参数,这对于解决除以零和数值精度问题可能很有用。
行业动态与合作伙伴关系
-
Perplexity 与 Uber 合作:@AravSrinivas 宣布了 Perplexity 与 Uber 的合作伙伴关系,为 Uber One 订阅者提供 1 年免费的 Perplexity Pro。
-
GitHub 模型托管:@rohanpaul_ai 报告称 GitHub 现在将直接托管 AI 模型,通过 Codespaces 提供无摩擦的路径来实验模型推理代码。
-
Cohere 登陆 GitHub:@cohere 宣布其最先进的语言模型现在通过 Azure AI Studio 提供给 GitHub 上的 1 亿多名开发者。
AI 工具与框架
-
torchchat:@rohanpaul_ai 分享了 PyTorch 发布的 torchchat,它使本地运行 LLM 变得容易,支持包括 Llama 3.1 在内的一系列模型,并提供 Python 和原生执行模式。
-
TensorRT-LLM Engine Builder:@basetenco 为 TensorRT-LLM 引入了新的 Engine Builder,旨在简化为开源和微调后的 LLM 构建优化模型服务引擎的过程。
关于 AI 影响与未来的讨论
-
AI 转型:@fchollet 认为,虽然 AGI 不会仅仅通过当前技术的规模扩张(scaling)来实现,但 AI 将改变几乎每一个行业,从长远来看,其规模将比大多数观察者预期的还要大。
-
意识形态的古德哈特定律(Goodhart’s Law):@RichardMCNgo 提出,任何不能被某种意识形态信奉者质疑的错误信念,都将日益成为该意识形态的核心。
本摘要涵盖了所提供推文中反映的 AI 领域关键进展、公告和讨论,重点关注与 AI 工程师和研究人员相关的方面。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. 高效 LLM 创新:BitNet 与 Gemma
-
“hacked bitnet for finetuning, ended up with a 74mb file. It talks fine at 198 tokens per second on just 1 cpu core. Basically witchcraft.” (Score: 577, Comments: 147): 一位开发者成功地微调了 BitNet,创建了一个极其紧凑的 74MB 模型,并展示了令人印象深刻的性能。该模型在单核 CPU 上达到了 198 tokens per second 的速度,尽管体积微小,却展现了高效的自然语言处理能力。
-
Gemma2-2B on iOS, Android, WebGPU, CUDA, ROCm, Metal… with a single framework (Score: 58, Comments: 17): Gemma2-2B 是一款最近发布的语言模型,现在可以在其发布后的 24 小时内,通过 MLC-LLM 框架在包括 iOS, Android, web 浏览器, CUDA, ROCm 和 Metal 在内的多个平台上本地运行。该模型紧凑的体积和在 Chatbot Arena 中的表现使其非常适合本地部署,目前已提供针对各种平台的演示,包括在 chat.webllm.ai 上实时运行的 4-bit 量化版本。针对每个平台都提供了详细的文档和部署说明,包括适用于笔记本电脑和服务器的 Python API、适用于 iOS 的 TestFlight,以及针对 Android 和基于浏览器的实现的特定指南。
-
New results for gemma-2-9b-it (Score: 51, Comments: 32): 由于配置修复,Gemma-2-9B-IT 模型的基准测试结果已更新,现在在大多数类别中都优于 Meta-Llama-3.1-8B-Instruct。值得注意的是,Gemma-2-9B-IT 在 BBH(42.14 vs 28.85)、GPQA(13.98 vs 2.46)和 MMLU-PRO(31.94 vs 30.52)中获得了更高的分数,而 Meta-Llama-3.1-8B-Instruct 在 IFEval(77.4 vs 75.42)和 MATH Lvl 5(15.71 vs 0.15)中保持领先。
- MMLU-Pro 基准测试结果因测试方法而异。/u/chibop1 的 OpenAI API Compatible script 显示 gemma2-9b-instruct-q8_0 得分为 48.55,llama3-1-8b-instruct-q8_0 得分为 44.76,均高于报告的分数。
- 注意到不同来源的 MMLU-Pro 分数存在差异。Open LLM Leaderboard 显示 Llama-3.1-8B-Instruct 为 30.52,而 TIGER-Lab 报告为 0.4425。分数归一化和测试参数可能是导致这些差异的原因。
- 用户讨论了创建个性化基准测试框架来比较 LLMs 和量化方法。考虑的因素包括模型大小、量化级别、处理速度和质量保留,旨在为各种用例做出明智的决策。
主题 2. 开源 AI 模型的进展
-
fal announces Flux a new AI image model they claim its reminiscent of Midjourney and its 12B params open weights (Score: 313, Comments: 97): fal.ai 发布了 Flux,这是一个拥有 120 亿参数的新型开源文本生成图像模型,他们声称其效果令人联想到 Midjourney。该模型被描述为目前可用的最大的开源文本生成图像模型,现在可以在 fal 平台上使用,为用户提供了一个强大的 AI 生成图像创作工具。
-
新的医疗和金融 70b 32k Writer 模型 (Score: 108, Comments: 34): Writer 发布了两个新的 70B 参数模型,具有 32K 上下文窗口,分别针对医疗和金融领域。据报道,这些模型的表现优于 Google 的专用医疗模型和 ChatGPT-4。这些模型可在 Hugging Face 上用于研究和非商业用途,为处理更复杂的问答提供了可能,同时仍可在家用系统上运行,符合开发多个较小模型而非超大 120B+ 模型的趋势。
- 针对医疗和金融领域的 70B 参数模型(具备 32K 上下文窗口)据称优于 Google 的专用医疗模型和 ChatGPT-4。金融模型以 73% 的平均分通过了难度较大的 CFA 三级考试,而人类的通过率为 60%,ChatGPT 为 33%。
- 讨论了人类医生在这些基准测试中的表现,一位 ML 工程师兼医生认为,如果允许搜索,人类的表现可能会很高,但基准测试可能是为了公关效果而容易被刷分的指标。其他人则认为,在典型的 20 分钟问诊中,LLM 的表现可能优于医生。
- 关于复制智力任务与体力技能(如管道维修)相对难度的辩论。一些人认为,构建超人类通用智能 (AGI) 可能比构建能够执行复杂体力任务的机器更容易,因为动物在感知和运动控制方面经过了数亿年的进化优化。
主题 3. AI 开发工具与平台
-
微软推出 Hugging Face 竞争对手(等候名单注册) (Score: 222, Comments: 46): 微软推出了 GitHub Models,将其定位为 AI 模型市场中 Hugging Face 的竞争对手。该公司已为感兴趣的用户开放了等候名单注册,以便尽早访问该平台,尽管帖子中未提供有关其功能和能力的具体细节。
-
介绍 sqlite-vec v0.1.0:一个可在任何地方运行的矢量搜索 SQLite 扩展 (Score: 117, Comments: 28): SQLite-vec v0.1.0 已发布,这是一个新的 SQLite 矢量搜索扩展,无需独立的矢量数据库即可提供矢量相似度搜索功能。该扩展支持余弦相似度和欧几里得距离指标,并可通过 WebAssembly 在包括桌面、移动端和浏览器在内的各种平台上使用。它旨在轻量化且易于集成,使其适用于从本地 AI 助手到边缘计算的各种应用场景。
主题 4. 本地 LLM 部署与优化技术
-
一个包含多种不同策略的 RAG 实现的大型开源集合 (Score: 76, Comments: 5): 该帖子分享了一个开源仓库,其中包含广泛的检索增强生成 (RAG) 实现策略,包括 GraphRAG。这个由社区贡献的资源提供了教程和可视化图表,是那些对 RAG 技术感兴趣的人的宝贵参考和学习工具。
-
如何在 Windows 11 上本地构建具有 NVIDIA GPU 加速的 llama.cpp:一个真正有效的简单分步指南。 (Score: 67, Comments: 19): 本指南提供了在 Windows 11 上构建具有 NVIDIA GPU 加速的 llama.cpp 的分步说明。它详细介绍了 Python 3.11.9、Visual Studio Community 2019、CUDA Toolkit 12.1.0 的安装,以及使用 Git 和 CMake(带有特定的 CUDA 支持环境变量)克隆和构建 llama.cpp 仓库所需的命令。
All AI Reddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 图像生成进展
-
Flux:新的开源文本转图像模型:Black Forest Labs 推出了 Flux,这是一个拥有 12B 参数的模型,包含三个版本:FLUX.1 [dev]、FLUX.1 [schnell] 和 FLUX.1 [pro]。据称其呈现的美学效果足以媲美 Midjourney。
-
Flux 性能与对比:据报道 Flux 的表现与 Midjourney 相当,在文本生成和解剖结构方面表现更好,而 Midjourney 在美学和皮肤纹理方面更胜一筹。Flux 的生成成本为每张图像 0.003-0.05 美元,生成时间为 1-6 秒。
-
Flux 图像示例:社区分享了一个 Flux 生成的图像库,展示了该模型的能力。
-
Runway Gen 3 视频生成:Runway 的 Gen 3 模型展示了生成 10 秒视频的能力,能够根据文本提示在 90 秒内生成具有高度细节皮肤的视频,每条视频成本约为 1 美元。
AI 语言模型与发展
-
Google Gemini Pro 1.5 占据榜首:Google 1.5 Pro 8 月发布版据报道首次在 AI 模型排名中获得第一名。
-
Meta 的 Llama 4 计划:Mark Zuckerberg 宣布 训练 Llama 4 将需要比 Llama 3 多近 10 倍的算力,目标是使其在明年成为行业内最先进的模型。
AI 交互与用户体验
- AI 谄媚(Sycophancy)担忧:用户报告称 AI 模型变得过度顺从,经常重复用户输入而没有增加有价值的信息。这种被称为“谄媚(Sycophancy)”的行为在各种 AI 模型中都有观察到。
梗图与幽默
- r/singularity 中的一个 梗图帖子 获得了极高的关注。
AI Discord 回顾
摘要的摘要的摘要
1. LLM 进展与基准测试
- Llama 3 登顶排行榜:来自 Meta 的 Llama 3 在 ChatbotArena 等排行榜上迅速崛起,在超过 50,000 场对决中表现优于 GPT-4-Turbo 和 Claude 3 Opus。
- 社区热衷于讨论 Llama 3 在各种基准测试中的表现,一些人注意到它在某些领域的能力超过了闭源替代方案。
- Gemma 2 与 Qwen 1.5B 之争:关于 Gemma 2B 是否被过度炒作引发了争论,有观点认为 Qwen 1.5B 在 MMLU 和 GSM8K 等基准测试中表现更好。
- 一位成员指出 Qwen 的表现很大程度上被忽视了,称其 “残暴地击败了 Gemma 2B”,突显了模型改进的飞速步伐以及紧跟最新进展的挑战。
- 医疗与金融领域的动态 AI 模型:新模型 Palmyra-Med-70b 和 Palmyra-Fin-70b 已被引入医疗和金融应用,并拥有令人印象深刻的性能。
- 正如 Sam Julien 的推文 所证明的那样,这些模型可能会对症状诊断和财务预测产生重大影响。
- MoMa 架构提升多模态 AI:Meta 的 MoMa 引入了一种稀疏早期融合架构,通过 Mixture-of-Expert 框架增强了预训练效率。
- 该架构显著提高了交错混合模态 Token 序列的处理能力,标志着多模态 AI 的重大进步。
2. 优化 LLM 推理与训练
- Vulkan 引擎提升 GPU 加速:LM Studio 推出了全新的 Vulkan llama.cpp 引擎,取代了之前的 OpenCL 引擎,在 0.2.31 版本中为 AMD、Intel 和 NVIDIA 独立 GPU 提供了 GPU 加速支持。
- 用户报告了显著的性能提升,其中一位在 Llama 3-8B-16K-Q6_K-GGUF 模型上达到了 40 tokens/second,展示了本地 LLM 执行优化的潜力。
- DeepSeek API 的磁盘上下文缓存:DeepSeek API 引入了全新的上下文缓存功能,可将 API 成本降低高达 90%,并显著降低多轮对话的首字延迟(first token latency)。
- 这一改进通过缓存频繁引用的上下文来支持数据和代码分析,突显了在优化 LLM 性能和降低运营成本方面的持续努力。
- DeepSeek API 通过缓存降低成本:DeepSeek API 引入了磁盘上下文缓存功能,可降低高达 90% 的 API 成本并降低首字延迟。
- 这一改进通过缓存频繁引用的上下文来支持多轮对话,从而提升性能并降低成本。
- Gemini 1.5 Pro 表现优于竞争对手:讨论强调了 Gemini 1.5 Pro 极具竞争力的性能,成员们注意到其在实际应用中令人印象深刻的响应质量。
- 一位用户观察到,他们对该模型的使用证明了其在响应速度和准确性方面优于其他模型。
3. 开源 AI 框架与社区努力
- Magpie Ultra 数据集发布:HuggingFace 发布了 Magpie Ultra 数据集,这是一个包含 5 万条未过滤 数据的 L3.1 405B 数据集,称其为开放合成数据集的先驱。
- 社区表达了兴奋与谨慎并存的态度,讨论围绕该数据集对模型训练的潜在影响,以及对指令质量和多样性的担忧。
- 用于 RAG 流水的 LlamaIndex 工作流:分享了一个关于使用 LlamaIndex workflows 构建包含检索、重排序和合成的 RAG pipeline 的教程,展示了 AI 应用的事件驱动架构。
- 该资源旨在指导开发者创建复杂的 RAG 系统,反映了人们对模块化和高效 AI 流水线构建日益增长的兴趣。
- FLUX Schnell 的局限性:用户报告称 FLUX Schnell 模型在提示词遵循(prompt adherence)方面表现不佳,经常产生无意义的输出,引发了对其作为生成模型有效性的担忧。
- “请千万、千万、千万不要用 Flux 公开发布的权重制作合成数据集” 是成员们分享的一条警告。
4. AI 行业趋势与收购
- Character.ai 收购引发辩论:Character.ai 被 Google 收购且其联合创始人加入这家科技巨头,引发了关于 AI 初创公司在面对大厂收购时的生存能力的讨论。
- 社区辩论了这对 AI 领域创新和人才留存的影响,一些人对 “人才收购”(acquihire)趋势可能扼杀竞争和创造力表示担忧。
- 在线 GPU 托管服务激增:用户分享了使用 RunPod 和 Vast 等在线 GPU 托管服务的经验,并指出价格随硬件需求的不同而有显著差异。
- RunPod 因其出色的体验而受到称赞,而 Vast 较低的 3090 租用成本则吸引了预算有限的用户。
- GitHub 与 Hugging Face 在模型托管方面的竞争:GitHub 的新模型托管方式 引发了担忧,与 Hugging Face 相比,它被认为是一个限制性的演示,削弱了社区贡献。
- 成员们推测这一策略旨在控制 ML 社区的代码,并防止用户大规模流向更开放的平台。
PART 1: Discord 高层级摘要
Stability.ai (Stable Diffusion) Discord
- Flux 模型的质量不一致性:用户报告称 Flux model 生成的图像质量参差不齐,尤其在处理抽象风格(如躺在草地上的女性)时表现吃力。这引发了与 Stable Diffusion 3 类似的担忧。
- 虽然详细的 Prompt 偶尔能产生不错的效果,但许多人对该模型的核心局限性表示沮丧。
- 在线 GPU 托管服务激增:用户分享了他们在在线 GPU 托管服务方面的经验,特别是 RunPod 和 Vast,并指出价格随硬件需求而有显著差异。青睐 RunPod 的用户强调其体验更精致,而其他人则认为 Vast 的 3090 价格更具吸引力。
- 这一趋势标志着 AI 社区正转向获取更易得的 GPU 资源,从而推动了创意产出。
- 关于许可和模型所有权的辩论:Flux 的发布引发了关于模型所有权以及围绕为 Stable Diffusion 3 开发的技术的法律影响的讨论。随着 AI 艺术领域竞争的加剧,用户对知识产权的转移进行了推测。
- 新兴模型的出现引发了关于未来许可策略和市场动态的疑问。
- 增强 AI 艺术 Prompt 生成:参与者强调需要改进 prompt generation 技术,以增强在各种艺术风格中的可用性。关于迭代过程中速度与质量之间的权衡,意见各不相同。
- 一些人优先考虑有助于快速概念迭代的模型,而另一些人则主张专注于图像质量。
- 用户交流关于写实主义 (Photo-Realism) 的见解:讨论集中在如何在各种模型中实现写实主义,用户分享了他们对各模型优缺点的看法。针对高质量图像生成的不同 GPU 性能评估也是对话的一部分。
- 这种集体评估强调了在 AI 艺术中不断优化图像忠实度的追求。
Unsloth AI (Daniel Han) Discord
- LoRA 训练技术:用户讨论了以 4-bit 或 16-bit 格式保存和加载使用 LoRA 训练的模型,并指出需要进行合并(merging)以保持模型准确性。
- 对于量化方法和正确的加载协议存在困惑,以防止性能下降。
- TPU 速度超越 T4 实例:成员们强调了 TPU 在模型训练中相对于 T4 instances 的速度优势,尽管他们指出缺乏关于 TPU 实现的可靠文档。
- 用户一致认为需要更好的示例来演示如何有效地将 TPU 用于训练。
- GGUF 量化产生乱码:有报告称模型在 GGUF 量化后生成乱码,特别是在 Llamaedge 平台上,这引发了关于 Chat Template 潜在问题的讨论。
- 这一趋势引起了关注,因为这些模型在 Colab 等平台上表现依然正常。
- Bellman 模型的最新微调:新上传的 Bellman 版本基于 Llama-3.1-instruct-8b 进行微调,专注于使用瑞典语维基百科数据集进行 Prompt 问答,并显示出改进。
- 尽管在问答方面有所进步,该模型在故事生成方面表现吃力,表明仍有进一步增强的空间。
- 竞争白热化:Google vs OpenAI:一篇 Reddit 帖子指出 Google 据称正凭借新模型超越 OpenAI,这在社区内引起了惊讶和怀疑。
- 参与者辩论了模型评分的主观性,以及感知到的改进究竟是真正的技术进步,还是仅仅反映了用户的交互偏好。
HuggingFace Discord
- 神经网络模拟吸引社区关注:一位成员展示了一个有趣的模拟,有助于理解神经网络,强调了创新的学习技术。
- 该模拟激发了人们对这些技术如何推向模型能力极限的兴趣。
- 破解图像聚类技术:分享了一个关于使用图像描述符(Image Descriptors)进行图像聚类的视频,旨在增强数据组织和分析。
- 该资源提供了有效的方法来利用视觉数据进行多样化的 AI 应用。
- 发布巨量合成数据集:一个广泛的合成数据集现已在 Hugging Face 上可用,极大地帮助了机器学习领域的研究人员。
- 该数据集是专注于表格数据分析项目的关键工具。
- 医疗和金融领域的动态 AI 模型:新模型 Palmyra-Med-70b 和 Palmyra-Fin-70b 已在 Hugging Face 上发布,用于医疗和金融应用,性能表现令人印象深刻。
- 正如 Sam Julien 的推文所证明的那样,这些模型可能会对症状诊断和财务预测产生重大影响。
- 应对学习中的技能差距:对参与者之间显著技能差异的担忧引发了对竞赛期间工作量不平衡的恐惧。
- 成员们建议采取公平的方法,以确保在学习活动中照顾到所有技能水平。
Perplexity AI Discord
- Uber One 会员可获得一年 Perplexity Pro:美国和加拿大的符合条件的 Uber One 会员可以兑换价值 200 美元 的免费一年 Perplexity Pro。
- 此项活动旨在增强用户的信息获取能力,让他们能够随时随地使用 Perplexity 的“回答引擎”进行查询。
- 围绕 Uber One 促销资格的困惑:社区成员不清楚为期一年的 Perplexity Pro 访问权限是否适用于所有用户,有多份关于兑换促销代码出现问题的报告。
- 担忧集中在资格问题以及注册后促销邮件发送错误,引发了广泛讨论。
- 数学突破引发关注:最近在数学领域的一项发现可能会改变我们对复杂方程的理解,引发了关于其更广泛影响的讨论。
- 细节仍然很少,但围绕这一突破的兴奋情绪继续激发各领域的兴趣。
- 大奖章基金(Medallion Fund)持续领跑收益:在 Jim Simons 的管理下,自 1988 年成立以来,Medallion Fund 的平均年回报率在扣除费用前为 66%,扣除费用后为 39%,详见神秘的大奖章基金。
- 其神秘的表现令人侧目,因为它始终优于 Warren Buffett 等著名投资者。
- 创新混合抗体靶向 HIV:研究人员通过将羊驼纳米抗体(nanobodies)与人类抗体结合,设计出一种混合抗体,可中和 95% 以上 的 HIV-1 毒株,由佐治亚州立大学分享。
- 这些更小的纳米抗体比传统抗体能更有效地穿透病毒防御,展示了 HIV 治疗的一个充满希望的前景。
LM Studio Discord
- Vulkan llama.cpp 引擎发布!:全新的 Vulkan llama.cpp 引擎 取代了之前的 OpenCL 引擎,为 AMD、Intel 和 NVIDIA 独立 GPU 开启了 GPU 加速。此更新包含在 0.2.31 版本中,可通过 应用内更新 或在官网获取。
- 用户反馈在使用 Vulkan 时性能有显著提升,加快了本地 LLM 的执行速度。
- 新增 Gemma 2 2B 模型支持:0.2.31 版本引入了对 Google Gemma 2 2B 模型 的支持,可在此处 下载。这一新模型增强了 LM Studio 的功能,建议从 lmstudio-community 页面 下载。
- 该模型的集成让用户在 AI 工作负载中能够获得更强大的能力。
- Flash Attention KV Cache 配置:最新更新允许用户通过 Flash Attention 配置 KV Cache 数据量化,从而优化大模型的内存占用。然而,需要注意的是 许多模型并不支持 Flash Attention,因此该功能目前处于实验阶段。
- 用户应谨慎操作,因为根据模型兼容性的不同,可能会出现性能不一致的情况。
- 来自用户的 GPU 性能洞察:有用户报告在 Vulkan 支持下,使用 RX6700XT 运行模型的速度约为 30 tokens/second,展示了强大的性能表现。另一位用户指出,在 Llama 3-8B-16K-Q6_K-GGUF 模型上达到了 40 tokens/second。
- 这些基准测试强调了当前配置的有效性,并为 LM Studio 的进一步性能调优提供了参考。
- LM Studio 的兼容性问题:一名用户报告其 Intel Xeon E5-1650 由于缺乏 AVX2 指令支持,在运行 LM Studio 时遇到兼容性挑战。社区建议使用仅限 AVX 的扩展程序,或考虑升级 CPU 以解决性能问题。
- 这凸显了在部署 AI 模型时进行硬件兼容性检查的必要性。
CUDA MODE Discord
- Nvidia GPU 指令周期资源:一名成员征求关于 Nvidia GPU 指令周期 的优质资源,并分享了一篇 研究论文 和另一项专注于每条指令时钟周期的 微架构研究。
- 这一探究有助于理解不同 Nvidia 架构之间的 性能差异。
- 第 8 个 Epoch 准确率分数剧增:一名成员观察到在训练过程中,准确率分数在 第 8 个 Epoch 显著飙升,这引发了对模型性能稳定性的担忧。
- 他们强调这类波动可能是典型的,并引发了关于模型评估实践的广泛讨论。
- 理解 Triton 内部机制与 GROUP_SIZE_M:讨论澄清了 Triton 分块 matmul 教程中的 GROUP_SIZE_M 如何控制数据块的处理顺序,从而提高 L2 cache 命中率。
- 成员们指出理解 GROUP_SIZE_M 与 BLOCK_SIZE_{M,N} 之间区别的重要性,教程中的图示有助于加深理解。
- 对 AI 行业 Acquihires(人才收购)的关注:包括 Character AI 和 Inflection AI 在内的多家公司正在经历 acquihires,这表明初创公司被大公司吸收已成为一种趋势。
- 这引发了关于竞争潜在影响,以及 AI 开发中编程技能与概念思维之间平衡的讨论。
- 关于 Tensor 操作随机性的辩论:成员们注意到,操作中不同的 Tensor 形状可能会调用不同的 kernels,导致即使是相似的操作也会产生不同的数值输出。
- 建议实现自定义随机数生成器,以确保跨操作的一致性。
Latent Space Discord
- MoMa 架构增强了混合模态语言建模:Meta 推出了 MoMa,这是一种稀疏早期融合(sparse early-fusion)架构,通过使用 Mixture-of-Expert 框架提升了预训练效率。
- 该架构改进了对交错混合模态 Token 序列的处理,标志着多模态 AI 的重大进展。
- BitNet 微调取得显著成果:一位用户报告称,微调 BitNet 得到了一个 74MB 的文件,在单核 CPU 上每秒可处理 198 个 Token,展示了令人印象深刻的效率。
- 该技术正以 Biggie-SmoLlm 的名称开源。
- Character.ai 在收购后的战略转变:Character.ai 的联合创始人已加入 Google,导致其产品转向使用 Llama 3.1 等开源模型。
- 此举引发了关于行业人才流转以及在大科技公司收购背景下初创公司生存能力的讨论。
- DeepSeek API 引入磁盘上下文缓存:DeepSeek API 推出了上下文缓存(context caching)功能,可降低高达 90% 的 API 成本,并显著降低首个 Token 的延迟。
- 这一改进通过缓存频繁引用的上下文来支持多轮对话,从而提升性能。
- Winds of AI Winter 播客发布:标题为 Winds of AI Winter 的最新一集已上线,内容包括对过去几个月 AI 领域的总结,并庆祝下载量突破 100 万次。
- 听众可以通过 播客链接 收听完整讨论。
Cohere Discord
- 令人兴奋的 AI 黑客松系列巡回赛开始:AI Hackathon Series Tour 在全美拉开帷幕,最终将迎来 PAI Palooza,届时将展示当地的 AI 创新和初创公司。参与者现在可以注册参加这一专注于推进 AI 技术的协作活动。
- 该系列活动旨在吸引社区参与有意义的技术讨论,并在地方层面促进创新。
- GraphRAG 系统助力投资者:引入了一套全新的 GraphRAG 系统,利用从 200 万个抓取的 公司网站中获得的洞察,帮助投资者识别有潜力的公司。该系统目前正与一个 Multi-Agent 框架同步开发,以提供更深层次的见解。
- 开发者正在积极寻求合作者以增强系统功能。
- Neurosity Crown 增强专注力:Neurosity Crown 因其在注意力下降时提供音频提示(如鸟鸣声)来提高专注力的能力而受到关注。一些用户强调了其对生产力的显著提升,尽管也有人对其整体效果表示怀疑。
- 它的可用性引发了关于整合技术方案以提高生产力的持续讨论。
- 寻找 Web3 合约机会:一位成员正在寻求与 Web3、Chainlink 和 UI 开发方面的资深开发者讨论兼职合约职位,这表明了对新兴技术技能的需求。
- 这突显了社区对进一步提升区块链和 UI 集成技术专长的兴趣。
- 工具包定制引发关注:围绕 toolkit 的定制功能(如启用身份验证)引起了热议,这可能需要通过 Fork 和创建 Docker 镜像来进行大规模修改。目前已提出安全修改的社区指南,强调协作改进。
- 成员们正在评估其应用,特别是关于内部工具扩展和 upstream updates(上游更新)方面。
Eleuther Discord
- GitHub 对 Hugging Face 的挑战:GitHub 最新的模型托管方式引发了担忧,被认为是一个有限的演示,与 Hugging Face 的模型共享理念相比,削弱了社区贡献。
- 成员们推测这是一种控制 ML 社区代码并防止人员大规模流失的策略。
- 对欧盟 AI 法规的质疑依然存在:随着即将出台的针对大型模型的 AI 法案,人们对潜在的执行力及其对全球公司(尤其是初创公司)的影响表示怀疑。
- 讨论集中在新的立法框架可能如何无意中扼杀创新和适应性。
- 应对 LLM 评估指标的挑战:一位成员询问了评估 LLM 输出的最佳指标,特别强调了对代码输出使用精确匹配(exact matches)的复杂性。
- 虽然提出了像 humaneval 这样的建议,但对评估过程中使用
exec()的影响表示担忧,并引发了进一步辩论。
- 虽然提出了像 humaneval 这样的建议,但对评估过程中使用
- 对蒸馏技术的兴趣重燃:成员们讨论了对 logit distillation(Logit 蒸馏)关注度的回升,揭示了其对数据效率的影响以及对较小模型微小的质量提升。
- 最近的论文展示了蒸馏的多样化应用,特别是那些结合了合成数据集的应用。
- GEMMA 的性能接受测试:GEMMA 与 Mistral 的性能对比出现了差异,导致了关于评估过程缺乏透明度的辩论。
- 针对训练动态和资源分配是否准确反映了模型结果,人们提出了担忧。
OpenAI Discord
- OpenAI 语音模式引发咨询热潮:新的 OpenAI voice mode 发布后,社区内涌入了大量私信。
- 似乎许多人都渴望了解更多关于其功能和访问权限的信息。
- Assistants API 的延迟困扰:成员们报告了 Assistants API 的延迟问题,一些人建议使用 SerpAPI 等替代方案进行实时抓取。
- 社区反馈集中在共享经验和潜在的变通方法上。
- Gemini 1.5 Pro 证明了其竞争力:讨论强调了 Gemini 1.5 Pro 的性能,激发了对其现实应用和响应能力的关注。
- 一位参与者指出,他们的使用体验展示了该模型极具竞争力的响应质量。
- Gemma 2 2b 模型见解:关于 Gemma 2 2b 模型 的见解表明,尽管与大型模型相比缺乏知识储备,但它在指令遵循方面表现出色。
- 对话反思了在实际应用中如何平衡模型能力与可靠性。
- Flux 图像模型令社区兴奋:Flux 图像模型 的发布引发了兴奋,用户开始测试其对比 MidJourney 和 DALL-E 等工具的能力。
- 值得注意的是,它的开源性质和较低的资源需求表明其具有广泛采用的潜力。
Nous Research AI Discord
- 关于 LLM-as-Judge 的见解:成员们征求了关于 LLM-as-Judge 元框架以及专注于指令和偏好(instruction and preference)数据的合成数据集策略的必读综述。
- 这一咨询强调了在 LLM 领域开发有效方法论的浓厚兴趣。
- 新 VRAM 计算工具发布:一个新的 VRAM 计算脚本 使用户能够根据各种参数确定 LLM 的 VRAM 需求。
- 该脚本无需外部依赖即可运行,旨在简化对 LLM 上下文长度和每权重位数(bits per weight)的评估。
- Gemma 2B 与 Qwen 1.5B 的对比:成员们讨论了 Gemma 2B 被过度炒作的问题,并将其与 Qwen 1.5B 进行对比,据报道后者在 MMLU 和 GSM8K 等基准测试中表现更优。
- Qwen 的能力在很大程度上被忽视了,导致有评论称其“残暴地”超越了 Gemma 2B。
- Llama 3.1 微调挑战:一位用户在私有数据集上微调了 Llama 3.1,通过 vLLM 运行时仅达到 30tok/s,且输出内容杂乱无章。
- 尽管温度(temperature)设置为 0,问题依然存在,这表明可能存在模型配置错误或数据相关性问题。
- 推理任务的新 Quarto 网站设置:一个 Quarto 网站的 PR 已经启动,专注于增强推理任务的在线可见性。
- 最近对文件夹结构的调整旨在简化项目管理,并提高仓库内的导航便利性。
LAION Discord
- FLUX Schnell 表现出弱点:成员们讨论了 FLUX Schnell 模型似乎训练不足,且在提示词遵循(prompt adherence)方面表现不佳,产生了一些荒谬的输出,例如 “一名穿着网球服骑着金翼摩托车的女性”。
- 他们担心该模型更像是一个数据集记忆机器,而非有效的生成模型。
- 对合成数据集的使用建议谨慎:针对使用 FLUX Schnell 模型生成合成数据集的做法出现了担忧,理由是存在跨代表征崩溃(representational collapse)的风险。
- 一位成员警告说:“求求大家,千万不要用 Flux 公开发布的权重来制作合成数据集”。
- 精选数据集优于随机噪声的价值:强调了精选数据集(curated datasets)的重要性,认为用户偏好的数据对于质量和资源效率至关重要。
- 成员们一致认为,在随机提示词上进行训练会浪费资源,且不会带来显著改进。
- Bug 阻碍了 LLM 的进展:一位成员在代码中发现了一个拼写错误,该错误严重影响了 50 多个实验的性能,并对新优化的损失曲线(loss curve)感到满意。
- 他们表示如释重负,因为新的曲线下降速度明显快于以前,这展示了调试的重要性。
- 关注强大的基准模型:讨论转向了创建强大基准模型(baseline model)的需求,而不是纠结于正则化技术带来的微小改进。
- 成员们注意到工作重点正转向开发分类器(classifier),同时考虑参数高效架构(parameter-efficient architecture)。
Interconnects (Nathan Lambert) Discord
- 对活动赞助的兴趣:成员们对赞助活动表现出热情,标志着对未来聚会的积极态度。
- 这种乐观情绪表明,可能会获得潜在的资金支持来推动这些倡议。
- Character AI 交易引发关注:Character AI 交易引发了成员们的怀疑,质疑其对 AI 领域的影响。
- 一位参与者称这是一场“奇怪的交易”,引发了对交易后员工和公司影响的进一步担忧。
- Ai2 发布受闪烁图标启发的新品牌:Ai2 推出了新品牌和网站,采用了 AI 品牌推广中流行的闪烁表情符号(sparkles emojis)趋势,正如一篇 Bloomberg 文章中所讨论的那样。
- Rachel Metz 强调了这一转变,突出了行业对这种美学日益增长的迷恋。
- Magpie Ultra 数据集发布:HuggingFace 发布了 Magpie Ultra 数据集,这是一个包含 50k 未过滤数据的 L3.1 405B 数据集,声称它是开放合成数据集的先驱。查看他们的 推文 和 HuggingFace 上的数据集。
- 初始指令质量仍存疑问,特别是在用户轮次多样性和覆盖范围方面。
- 下周 RL 会议晚宴:一位成员正考虑下周在 RL Conference 举办晚宴,正在寻找有兴趣赞助的 VC 或朋友。
- 这一倡议可能为寻求贡献的行业专业人士提供极佳的人际网络机会。
OpenRouter (Alex Atallah) Discord
- OpenRouter 网站访问性:用户报告访问 OpenRouter website 存在问题,局部停机偶尔会影响部分地区。
- 一位特定用户指出网站问题已短暂解决,突显了用户体验可能存在非统一性。
- Anthropic 服务困境:多位用户指出 Anthropic services 正面临严重的负载问题,导致数小时内间歇性无法访问。
- 这引发了人们对基础设施处理当前需求能力的担忧。
- 聊天室改版与增强设置:Chatroom 已实现功能化,采用了更简洁的 UI 并支持本地保存聊天记录,提升了用户交互体验。
- 用户现在可以通过 settings page 配置设置,以避免将请求路由到某些供应商,从而优化体验。
- API Key 获取变得简单:用户获取 API Key 就像注册、充值并在插件中使用一样简单,无需任何技术技能(了解更多)。
- 使用自己的 API Key 可以获得更优惠的价格——对于 GPT-4o-mini 等事件,1,000,000 tokens 仅需 $0.6——并通过供应商仪表板清晰地洞察模型使用情况。
- 了解免费模型使用限制:讨论强调,免费模型在 API 访问和聊天室使用方面通常都有显著的速率限制 (rate limits)。
- 这些约束对于管理服务器负载和确保用户之间的公平访问至关重要。
LlamaIndex Discord
- 事件驱动 RAG 流水线教程发布:分享了一个关于构建 RAG pipeline 的教程,详细介绍了使用 LlamaIndex workflows 在特定步骤中进行检索、重排序和合成。这份综合指南旨在展示用于流水线构建的事件驱动架构。
- 你可以逐步实现本教程,从而更好地集成各种事件处理方法。
- 为印度农民开发的 AI 语音 Agent:如这条推文所述,已开发出一款 AI Voice Agent 来支持印度农民,解决由于政府援助不足而产生的资源需求。该工具旨在提高他们的生产力并应对挑战。
- 这一举措体现了技术在解决关键农业问题、改善农民生计方面的潜力。
- 无工具 ReAct Agent 的策略:用户寻求关于配置 ReAct agent 在无工具状态下运行的指导,建议的方法包括
llm.chat(chat_messages)和SimpleChatEngine以实现更流畅的交互。成员们讨论了 Agent 错误的挑战,特别是关于缺失工具请求的问题。- 寻找这些问题的解决方案仍然是提高 Agent 实现中可用性和性能的优先事项。
- LlamaIndex Service Context 的变化:成员们研究了 LlamaIndex 即将移除 service context 的变动,这会影响
max_input_size等参数的设置方式。这一转变引发了对需要进行大量代码调整的担忧。- 一位用户表达了他们的沮丧,这影响了开发者的工作流,特别是向基础 API 中更独立组件的过渡。
- DSPy 最新更新破坏了 LlamaIndex 集成:一位成员报告 DSPy 的最新更新导致与 LlamaIndex 的集成失败。他们指出,与标准的 LlamaIndex 抽象相比,之前的版本 v2.4.11 在 Prompt 微调结果上没有任何改进。
- 该用户在更新后实现 DSPy 运行成功方面仍面临障碍。
Modular (Mojo 🔥) Discord
- Mojo 的错误处理困境:成员们讨论了围绕 Mojo 错误处理的困境,比较了 Python 风格的异常 和 Go/Rust 的错误值,并担心混合两者可能会导致复杂性。
- 有人感叹这可能会“在程序员面前爆炸”(意指产生严重后果),强调了在 Mojo 中有效管理错误的复杂性。
- Max 的安装烦恼:一位成员报告在安装 Max 时遇到困难,表示运行代码并不顺利。
- 他们正在寻求帮助以排查有问题的安装过程。
- Mojo Nightly 表现出色!:对于一位活跃的贡献者来说,Mojo nightly 运行顺畅,表明尽管 Max 存在问题,但其稳定性良好。
- 这表明 Mojo 的 nightly 构建版本提供了可靠的体验,在处理安装问题时可以加以利用。
- Conda 安装或许能解决问题:一位成员建议使用 conda 作为安装问题的可能解决方案,并指出该过程最近已变得更加简单。
- 这可能会显著减轻那些面临 Max 安装挑战的人在排查和解决问题时的负担。
OpenInterpreter Discord
- Open Interpreter 会话混淆已解决:成员们对加入正在进行的会话感到困惑,澄清了对话发生在特定的语音频道中。
- 一位成员提到他们费力才找到该频道,直到其他人确认其可用性。
- 运行本地 LLM 的指导:一位新成员寻求运行本地 LLM 的帮助,并分享了他们遇到模型加载错误的初始脚本。
- 社区成员引导他们查看文档以正确设置本地模型。
- 明确 LlamaFile 服务器的启动:强调在 Python 模式下使用 LlamaFile 之前,必须单独启动其服务器。
- 参与者确认了 API 设置的正确语法,强调了不同加载函数之间的区别。
- Aider 浏览器 UI 演示发布:新的 Aider 浏览器 UI 演示视频展示了与 LLM 协作在本地 git 仓库中编辑代码。
- 它支持 GPT 3.5、GPT-4 等模型,并具有使用合理的提交信息实现自动 commit 的功能。
- 讨论 LLM 应用中的事后验证:研究强调,由于代码理解方面的挑战,人类目前在创建后验证 LLM 生成的输出 时面临困难。
- 该研究建议加入“撤销”功能并建立损害限制 (damage confinement),以便于事后验证 更多详情请点击此处。
DSPy Discord
- LLM 提升其判断技能:最近一篇关于 LLM Meta-Rewarding 的论文展示了增强的自我判断能力,将 Llama-3-8B-Instruct 在 AlpacaEval 2 上的胜率从 22.9% 提升至 39.4%。
- 这一 meta-rewarding 步骤解决了传统方法的饱和问题,提出了一种模型评估的新方法。
- MindSearch 模拟人类认知:MindSearch 框架利用 LLM 和多智能体 (multi-agent) 系统来解决信息整合挑战,增强了对复杂请求的检索。
- 论文讨论了该框架如何有效缓解由 LLM 上下文长度 (context length) 限制带来的挑战。
- 构建 DSPy 摘要流水线:成员们正在寻求关于使用 DSPy 配合开源模型进行摘要的教程,以迭代提升 prompt 的有效性。
- 该计划旨在优化符合技术需求的摘要结果。
- 征集 Discord 频道导出数据:出现了一项征集志愿者分享 JSON 或 HTML 格式的 Discord 频道导出数据的请求,旨在进行更广泛的分析。
- 在发布调查结果和代码时,将对贡献者表示感谢,从而加强社区协作。
- 将 AI 集成到游戏角色开发中:关于使用来自 GitHub 的代码开发 AI 驱动的游戏角色的讨论非常热烈,特别是针对巡逻和动态玩家交互。
- 成员们表示有兴趣实现 Oobabooga API,以促进游戏角色的高级对话功能。
OpenAccess AI Collective (axolotl) Discord
- Fine-tuning Gemma2 2B 备受关注:成员们探讨了 Fine-tuning Gemma2 2B 模型并分享了见解,其中有人建议利用 pretokenized dataset 以更好地控制模型输出。
- 社区的反馈显示了不同的经验,他们热衷于从调整后的方法中获得进一步的结果。
- 寻求日本顶尖语言模型:在寻找最流利的日语模型时,根据社区的输入,有人推荐了基于 lightblue 的 suzume 模型。
- 用户表示有兴趣了解更多关于该模型在现实世界应用中的情况。
- BitsAndBytes 简化了 ROCm 安装:最近的一个 GitHub PR 简化了 BitsAndBytes 在 ROCm 上的安装,使其兼容 ROCm 6.1。
- 成员们指出,此次更新允许打包与最新的 Instinct 和 Radeon GPU 兼容的 wheel 文件,标志着重大改进。
- 训练 Gemma2 和 Llama3.1 的输出问题:用户详细描述了他们在训练 Gemma2 和 Llama3.1 时遇到的困难,指出模型往往只有在达到 max_new_tokens 后才会停止。
- 人们越来越担心在训练上投入的时间与输出质量的提升不成正比。
- Prompt Engineering 的效果微乎其微:尽管为了引导模型输出付出了严苛的 Prompt 努力,用户报告称对整体行为的影响微乎其微。
- 这引发了关于当前 AI 模型中 Prompt Engineering 策略有效性的质疑。
LangChain AI Discord
- LangChain 0.2 文档缺失:用户报告称 LangChain v0.2 中缺乏关于 agent functionalities 的文档,导致对其能力的质疑。
- Orlando.mbaa 特别指出他们找不到任何关于 Agent 的引用,引发了对易用性的担忧。
- 在 RAG 应用中实现 Chat Sessions:讨论了如何在基础 RAG 应用中加入 chat sessions,类似于 ChatGPT 对历史对话的跟踪。
- 参与者评估了在现有框架内进行 Session 跟踪的可行性和可用性。
- LangChain 中的 Postgres Schema 问题:一名成员引用了一个关于 Postgres 中 chat message history 失败的 GitHub Issue,特别是在使用显式 Schema 时 (#17306)。
- 人们对拟议解决方案的有效性及其对未来实现的影响表示担忧。
- 使用 Testcontainers 测试 LLM:分享了一篇博文,详细介绍了在 Python 中利用 4.7.0 版本,使用 Testcontainers 和 Ollama 测试 LLM 的过程。
- 鼓励对此处提供的教程提供反馈,强调了稳健测试的必要性。
- 来自社区研究电话会议 #2 的精彩更新:最近的 Community Research Call #2 强调了 Multimodality、Autonomous Agents 和 Robotics 项目的激动人心的进展。
- 参与者积极讨论了多个协作机会,强调了未来研究方向中的潜在合作伙伴关系。
Torchtune Discord
- QAT Quantizers 说明:成员们讨论了 QAT recipe 支持 Int8DynActInt4WeightQATQuantizer,而 Int8DynActInt4WeightQuantizer 用于训练后量化,目前尚不支持。
- 他们指出只有 Int8DynActInt4Weight 策略适用于 QAT,其他量化器计划在未来实现。
- 请求对 SimPO PR 进行审查:一名成员强调需要对 GitHub 上的 SimPO (Simple Preference Optimisation) PR #1223 进行澄清,该 PR 旨在解决 Issue #1037 和 #1036。
- 他们强调该 PR 解决了对齐问题,呼吁更多的监督和反馈。
- 文档重构的 RFC:出现了一项关于改进 torchtune 文档系统的提案,重点是更流畅的 recipe 组织以改善入门体验。
- 鼓励成员提供见解,特别是关于 LoRA single device 和 QAT distributed 的 recipe。
- 对新模型页面的反馈:一位参与者分享了一个潜在新模型页面的预览链接,旨在解决当前文档中的可读性问题。
- 讨论的细节包括需要清晰且详尽的模型架构信息,以增强用户体验。
MLOps @Chipro Discord
- Computer Vision Enthusiasm: 成员们表达了对 Computer Vision 的共同兴趣,强调了其在当前技术领域的重要性。
- 许多成员似乎渴望从主导各类会议的 NLP 和 genAI 讨论中分流出来。
- Conferences Reflect Machine Learning Trends: 一位成员分享了参加两次 Machine Learning 会议的经历,会上展示了他们在 Gaussian Processes 和 Isolation Forest 模型方面的工作。
- 他们注意到许多与会者对这些主题并不熟悉,这表明讨论存在向 NLP 和 genAI 倾斜的强烈偏见。
- Skepticism on genAI ROI: 参与者质疑 genAI 的 ROI(投资回报率)是否能达到预期,表明可能存在脱节。
- 一位成员强调,正向的 ROI 需要初始投资,这表明预算通常是根据感知价值分配的。
- Funding Focus Affects Discussions: 一位成员指出,Funding 通常流向 Budgets 分配的地方,从而影响技术讨论。
- 这强调了市场细分和 Hype Cycles 在塑造行业活动焦点方面的重要性。
- Desire for Broader Conversations: 鉴于这些讨论,一位成员表示很高兴能有一个平台来讨论 genAI 炒作之外的话题。
- 这反映了对涵盖 Machine Learning 各个领域(而非仅限于主流趋势)的多元化对话的渴望。
Alignment Lab AI Discord
- Image Generation Time Inquiry: 讨论集中在 A100 上使用 FLUX Schnell 生成 1024px image 所需的时间,引发了关于性能预期的疑问。
- 然而,对话中没有提到在该硬件上生成图像的具体耗时。
- Batch Processing Capabilities Explored: 出现了关于图像生成是否可以进行 Batch Processing 以及可以处理的最大图像数量的问题。
- 对话中缺少关于硬件能力和限制的具体回应。
tinygrad (George Hotz) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
第 2 部分:按频道分类的详细摘要和链接
为了便于邮件发送,完整的频道细分内容已被截断。
如果您喜欢 AInews,请分享给朋友!预谢!