ainews-how-carlini-uses-ai
**Carlini 如何使用 AI** 或 **卡里尼如何使用人工智能**
Groq 的股东净资产在其他公司下跌之际逆势上涨,英特尔首席执行官对此表示担忧。DeepMind 的 Nicholas Carlini 因其大量的 AI 著作而受到关注和争议,其中包括一篇关于 AI 使用的 8 万字论文以及一个针对大语言模型的基准测试。Chris Dixon 对“AI 寒冬”的怀疑论发表了看法,强调了其长期影响。Box 推出了一个 AI API,用于从文档中提取结构化数据,突显了由大语言模型驱动的解决方案的潜力和风险。
近期 AI 领域的发展还包括:Figure AI 推出了先进的人形机器人 Figure 02;OpenAI 为 ChatGPT 推出了具备情感检测功能的“高级语音模式”(Advanced Voice Mode);Google 开源了 Gemma 2 2B 模型,其性能可与 GPT-3.5-Turbo-0613 媲美;Meta AI Fair 发布了用于实时物体追踪的 Segment Anything Model 2 (SAM 2);NVIDIA 展示了 Project GR00T,支持通过 Apple Vision Pro 进行人形机器人远程操作;Stability AI 推出了用于快速生成 3D 资产的 Stable Fast 3D;Runway 则发布了用于 AI 文本生成视频的 Gen-3 Alpha。
保持开放的心态是你唯一需要的。
2024年8月2日至8月5日的 AI 新闻。我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 28 个 Discord 服务区(249 个频道,5970 条消息)。预计节省阅读时间(以 200wpm 计算):685 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
恭喜 Groq 股东的净资产在上涨,而其他人的都在下跌(以及 Intel 的 CEO 在祈祷)。DeepMind 的 Nicholas Carlini 作为最具深度的、具有研究背景的 AI 公开作者之一,正获得越来越多的认可(以及 批评)。今年,他正从其惯常的 对抗性研究领域 扩展开来,发布了其 大语言模型基准测试 (benchmark for large language models),并在本周末凭借一篇 关于他如何使用 AI 的 8 万字长文 引起了轰动,我们理所当然地 使用了 AI 来对其进行总结:
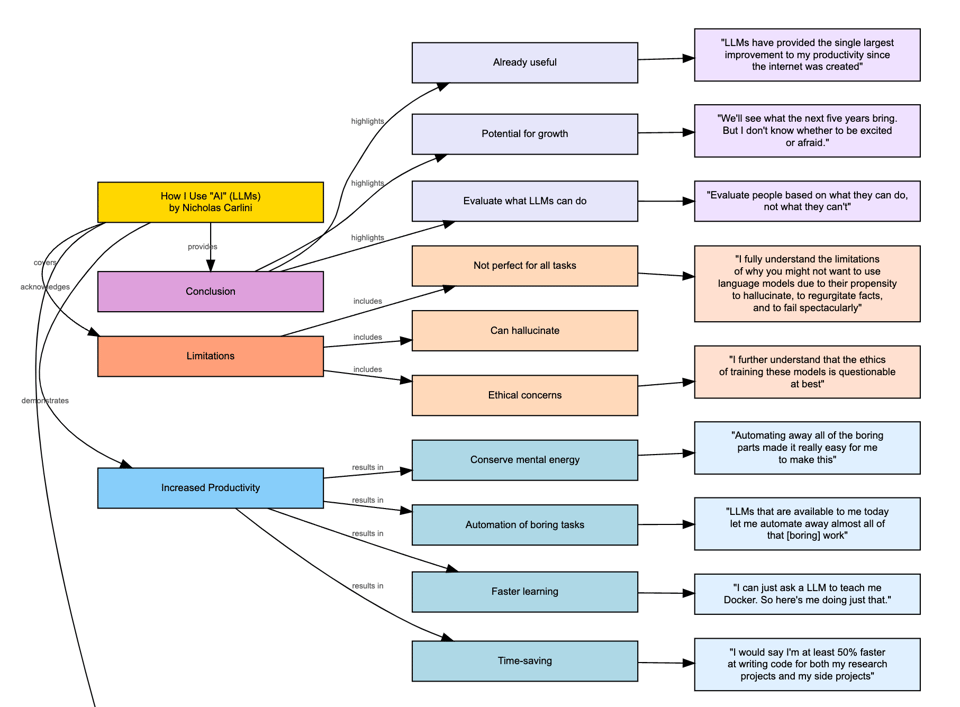
以及使用案例:
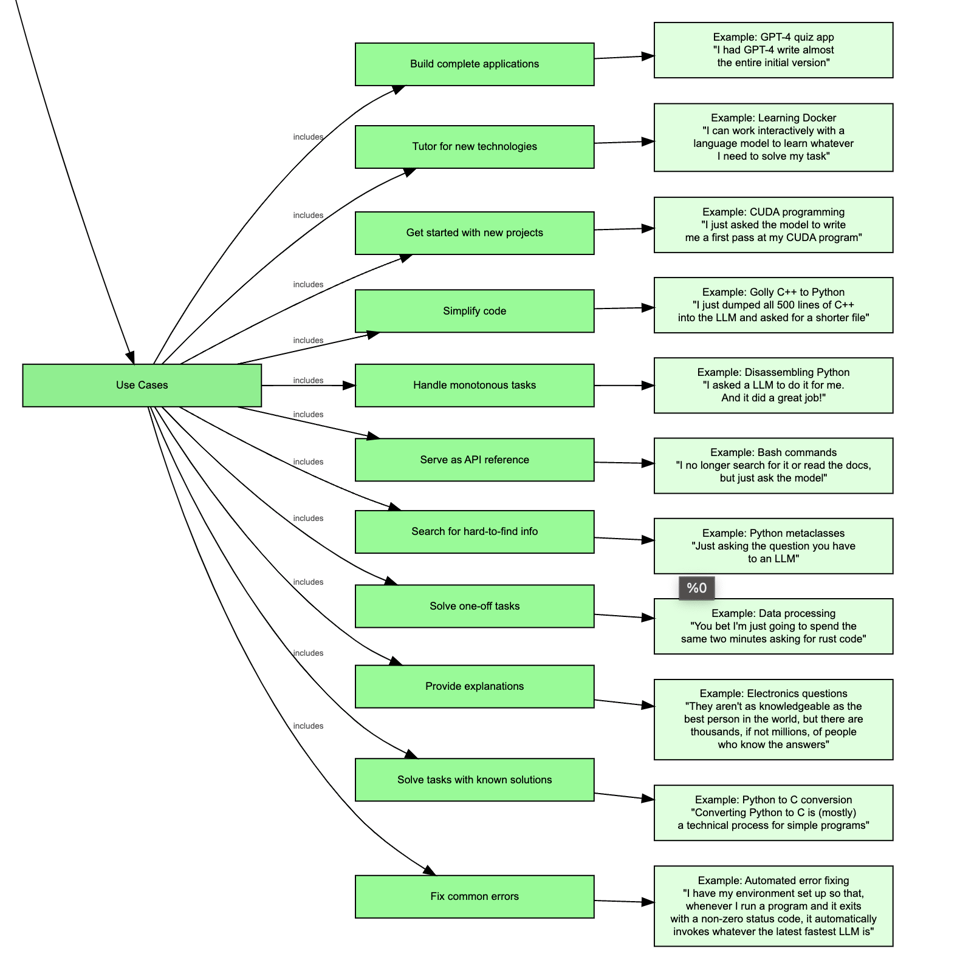
令人印象深刻的是,他说这还不到他所经历的 LLM 使用案例的 “2%”(如果他把所有内容都列出来,那将是 400 万字的作品)。
Chris Dixon 以其 名言 “最聪明的人在周末做的事情,就是十年后其他人在周中会做的事情” 而闻名。当人们在 AI 寒冬将至 的舆论中推波助澜,声称它在工作中尚未产生足够的衡量影响时,他们可能只是过于关注短期利益了。其中的每一个案例至少都值得打磨成工具,甚至可以成立一家初创公司。
新增:我们正在尝试投放一些小巧且得体的广告,专门为 AI Engineers 提供帮助。请点击以支持我们的赞助商,并回复邮件告诉我们您想看到的内容!
[由 Box 赞助] Box 存储文档。Box 还可以从这些文档中 提取结构化数据。这是如何使用 Box AI API 实现的方法。。
swyx 评论:S3 的僵化正是 Box 的机会所在。“多模态 Box” 的理念——放入任何东西,输出结构化数据——使所有数字内容都能被机器读取。特别赞扬这篇博文,因为它还展示了这种方案——就像任何 LLM 驱动的方案一样——可能会意外失败!
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,从 4 次运行中择优。
AI 与机器人进展
-
Figure AI:@adcock_brett 宣布推出 Figure 02,称其为“地球上最先进的人形机器人”,更多细节即将公布。
-
OpenAI:开始向部分用户推送 ChatGPT 的 “Advanced Voice Mode”(高级语音模式),其特点是具有情感检测能力的自然、实时对话 AI。
-
Google:发布并开源了 Gemma 2 2B,在 LMSYS Chatbot Arena 中评分达到 1130 分,尽管体积小得多,但性能与 GPT-3.5-Turbo-0613 和 Mixtral-8x7b 相当。
-
Meta:推出了 Segment Anything Model 2 (SAM 2),这是一个用于在视频帧中进行实时对象识别和跟踪的开源 AI 模型。
-
NVIDIA:Project GR00T 展示了一种扩展机器人数据的新方法,利用 Apple Vision Pro 进行人形机器人远程操作(teleoperation)。
-
Stability AI:推出了 Stable Fast 3D,可在 0.5 秒内从单张图像生成 3D 资产。
-
Runway:宣布其 AI 文本生成视频模型 Gen-3 Alpha 现在可以从图像创建高质量视频。
AI 研究与开发
-
Direct Preference Optimization (DPO):@rasbt 分享了一个从零开始实现的 DPO,这是一种将 Large Language Models (LLM) 与用户偏好对齐的方法。
-
MLX:@awnihannun 建议使用 lazy loading(延迟加载)来降低 MLX 中的峰值内存占用。
-
Modality-aware Mixture-of-Experts (MoE):@rohanpaul_ai 讨论了 Meta AI 关于模态感知 MoE 架构的论文,该架构用于预训练混合模态、早期融合(early-fusion)的语言模型,实现了显著的 FLOPs 节省。
-
Quantization:@osanseviero 分享了五个学习 AI 模型 Quantization(量化)的免费资源。
-
LangChain:@LangChainAI 推出了 Denser Retriever,这是一款企业级 AI 检索器,旨在简化 AI 在应用程序中的集成。
AI 工具与应用
-
FarmBot:@karpathy 将 FarmBot 比作“食物领域的太阳能电池板”,强调了其在后院自动化食物生产的潜力。
-
Composio:@llama_index 提到 Composio 是一个面向生产环境的 AI Agent 工具集,包含超过 100 种适用于各种平台的工具。
-
RAG 部署:@llama_index 分享了关于在 Google Kubernetes Engine 上部署和扩展“与代码对话”应用的全面教程。
-
FastHTML:@swyx 宣布开始使用 FastHTML 开发应用,将 AINews 转化为网站。
AI 伦理与社会影响
-
AI 监管:@fabianstelzer 将当前的 AI 监管努力与奥斯曼帝国历史上对印刷机的限制进行了类比。
-
AI 与失业:@svpino 幽默地评论了关于 AI 取代工作的周期性预测。
迷因与幽默
-
@nearcyan 分享了一个关于 Mark Zuckerberg 公众形象变化的迷因。
-
@nearcyan 开了关于偶像化科技公司 CEO 的玩笑。
-
@lumpenspace 对将 Diffusion(扩散)解释为频域中的 Autoregression(自回归)发表了幽默评论。
AI Reddit 摘要
/r/LocalLlama 回顾
主题 1:LLM 训练中的数据质量与数量之争
- 鉴于这是一个发展如此迅速的领域,你认为 LLM 两年后会发展到什么程度? (Score: 61, Comments: 101):在接下来的两年中,发帖者预计 Large Language Models (LLMs) 将取得重大进展,特别是在模型效率和移动端部署方面。他们专门询问了实现 GPT-4 级别能力所需的参数量 (parameter count) 是否可能减少,以及在智能手机上运行复杂 LLM 的可行性。
- 随着原生数据耗尽,合成数据生成 (Synthetic data generation) 正变得至关重要。Llama 3 论文展示了成功的技术,包括将生成的代码通过 Ground Truth 源运行,以在不引发模型崩溃的情况下增强预测能力。
- 研究人员预计多模态领域将有所增长,模型将整合图像/音频编码器以更好地理解世界。未来的发展可能包括 4D 合成数据(与文本、视频和图片相关的 xyzt 数据)以及改进的上下文处理 (context handling) 能力。
- 模型效率有望显著提高。预测建议 300M 参数模型的表现将超过今天的 7B 模型,并且在加速器硬件和 ASIC 开发的推动下,两年内有望在智能手机上运行 GPT-4 级别能力的模型。
- “我们将耗尽数据”是真的吗? (Score: 61, Comments: 67):该帖子质疑了训练 LLM 数据即将耗尽的观点,理由是互联网包含 64 ZB 的数据,而目前的模型训练仅使用了 TB 级别的数据。根据 Common Crawl 截至 2023 年 6 月的数据,公开可访问的网络包含 约 30 亿个网页和 约 400 TB 的未压缩数据,但这仅代表互联网总数据的一小部分,大量数据存在于私有组织、付费墙后或屏蔽爬取的网站上。作者建议,未来的模型训练可能会涉及购买大量的私营部门数据,而不是使用生成的数据,并指出随着更多国家采用互联网技术和 IoT 使用的扩大,数据量将继续增加。
- 用户认为,免费获取和经济上易于获取的数据可能会耗尽,因为公司意识到了其数据的价值并将其封锁。互联网数据的质量也受到质疑,有人建议从训练数据中移除 Reddit 提高了模型性能。
- 64 ZB 这一数字代表全球总存储容量,而非可用的文本数据。像 GPT-4 这样的当前模型仅在 13 万亿个 token(约 4 万亿个唯一 token)上进行了训练,而据估计,公开可用的高质量文本 token 超过 200 万亿个。
- 互联网数据的很大一部分可能是视频内容,Netflix 在 2022 年占所有互联网流量的 15%。用户讨论了这些数据对语言建模的价值,并建议关注高质量、精选的数据集,而非原始数量。
主题 2:新兴 AI 技术及其现实世界应用
- 逻辑谬误计分板 (Score: 118, Comments: 61):该帖子提议为政治辩论建立一个使用 Large Language Models (LLMs) 的实时逻辑谬误检测系统。该系统将实时分析辩论,识别逻辑谬误,并向观众展示“逻辑谬误计分板”,这有可能提高政治话语的质量,并帮助观众批判性地评估候选人提出的论点。
- 用户对用于现场辩论的实时版本工具表示感兴趣,其中一人建议为所有候选人建立一个“实时胡说八道追踪器 (live bullshit tracker)”。开发者计划在接下来的辩论中运行该系统(如果 Trump 不退出的话)。
- 人们对 AI 准确检测谬误的能力表示担忧,并举例说明了模型判断中的不一致和潜在偏见。一些人建议使用更小的、经过微调的 LLM 或基于 BERT 的分类器,而不是大型预训练模型。
- 该项目因其捍卫民主的潜力而受到赞扬,而其他人则提出了改进建议,如追踪未解决的陈述、对谎言进行分类,以及将 70B 模型蒸馏至 2-8B 以获得实时性能。用户还要求对 Biden 和 Harris 等其他政治家进行分析。
全球 AI Reddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型能力与进展
-
Flux AI 展示了令人印象深刻的文本和图像生成能力:r/StableDiffusion 上的多篇帖子展示了 Flux AI 生成高度详细的产品广告的能力,具有准确的文本放置和品牌一致性。示例包括 Tide PODS 口味珍珠奶茶广告 和 Hot Pockets “Sleepytime Chicken” 包装盒。用户注意到 Flux 与 Midjourney 等其他模型相比,具有更优越的文本生成能力。
-
OpenAI 决定不对 ChatGPT 输出添加水印:OpenAI 宣布他们不会对 ChatGPT 生成的文本实施水印技术,理由是担心对用户产生潜在的负面影响。这一决定引发了关于检测方法、学术诚信以及透明度与用户保护之间平衡的讨论。
AI 伦理与社会影响
-
关于 AI 对就业影响的辩论:r/singularity 上的一篇 高赞帖子 讨论了 AI 对就业的潜在影响,反映了对劳动力中断的持续担忧。
-
AI 驱动的验证与 Deepfakes:r/singularity 的一篇帖子强调了 用于验证目的的 AI 生成图像日益复杂,引发了关于数字身份以及区分真实内容与 AI 生成内容挑战的问题。
AI 在教育与开发中的应用
- AI 导师的潜力:r/singularity 上的一篇 详细帖子 探讨了 AI 导师可能增强儿童学习能力的概念,并与历史上强化教育方法的案例进行了类比。
AI 行业与市场趋势
- Ben Goertzel 谈生成式 AI 的未来:AI 研究员 Ben Goertzel 预测 生成式 AI 市场将继续增长,理由是高价值应用的快速发展。
AI Discord 摘要
摘要之摘要的总结
1. LLM 进展
- Llama 3 性能问题:用户报告了 Llama 3 分词(tokenization)方法的问题,特别是 EOS 和 BOS token 的使用导致了推理挑战。参与者推测,推理中缺失 token 可能会导致训练期间出现分布外(out-of-distribution)上下文,从而促使人们重新评估文档。
- 成员们一致认为有必要重新评估文档以解决这些分词 bug,并强调了准确处理 token 的重要性。
- Claude AI 提供代码修复:成员们讨论了使用 Claude AI 上传
output.json以在没有文件访问权限的情况下进行代码修复的方法,如 这篇 Medium 文章 所述。尽管具有潜力,但人们对这种方法的实证效果仍持怀疑态度。- 人们对这种方法的实证效果仍持怀疑态度,这凸显了需要更多基于证据的结果来验证其效用。
2. 模型性能优化
- 优化 LLM 推理速度:提升 LLM 推理速度的建议包括使用 torch.compile 以及将性能与 vLLM 等工具进行比较。持续的讨论凸显了人们对提高大语言模型效率和性能的兴趣。
- 成员们对在处理大语言模型时增强效率表现出浓厚兴趣,并探索了各种工具和技术。
- Mojo 增强数据处理流水线:讨论强调了 Mojo 在将分析与数据库工作负载集成方面的潜力,通过 JIT 编译和直接文件操作实现更快的数据处理。
- 成员们提到了与 PyArrow 和 Ibis 的兼容性,暗示了 Mojo 框架内强大的数据生态系统具有广阔的前景。
3. 微调挑战
- 微调多语言模型的挑战:用户分享了微调 Llama 3.1 和 Mistral 等模型处理多样化数据集的经验,遇到了由于提示词(prompt)格式可能不正确导致的输出相关性问题。建议敦促恢复到标准提示词格式,以确保正确处理数据集。
- 参与者强调了使用标准格式以避免问题的重要性,凸显了统一提示词格式的必要性。
- LoRA 训练问题:一位用户报告了在使用 SFTTrainer 尝试通过拼接文本和标签来格式化数据集后效果不佳,怀疑可能存在配置错误。澄清指向了正确的列使用方式,但仍未能解决根本问题。
- 澄清指向了正确的列使用方式,但未能解决根本问题,表明需要对数据集配置进行进一步调查。
4. 开源 AI 发展
- DistillKit 介绍:Arcee AI 发布了 DistillKit,这是一个用于从大模型中蒸馏知识以创建更小、更强大模型的开源工具。该工具包结合了传统训练技术与新颖方法,以优化模型效率。
- 该工具包专注于优化模型,使其高效且易于获取,结合了传统训练技术与新颖的蒸馏方法。
- OpenRouter 发布新模型:OpenRouter 推出了令人印象深刻的新模型,包括 Llama 3.1 405B BASE 和 Mistral Nemo 12B Celeste,可以在其 模型页面 查看。Llama 3.1 Sonar 系列的加入进一步扩展了应用能力。
- 新加入的模型迎合了多样化的需求,并根据社区反馈进行持续更新,增强了 OpenRouter 产品的实用性。
5. 多模态 AI 创新
- CatVTON 重新定义虚拟试穿方法:最近的一篇 arXiv 论文 介绍了 CatVTON,这是一种通过直接拼接服装图像显著降低训练成本的方法。这一创新有望实现逼真的服装迁移,彻底改变虚拟试穿技术。
- 该方法消除了对 ReferenceNet 和额外图像编码器的需求,在降低成本的同时保持了逼真的服装迁移效果。
- Open Interpreter 语音识别提议:一位用户提议实现一种母语语音识别方法,以促进英语与当地语言之间的翻译。他们对翻译错误提出了警告,称之为“垃圾进,垃圾出(Garbage in, Garbage out)”。
- 该方法引发了对翻译错误潜在陷阱的担忧,强调了准确输入对确保可靠输出的重要性。
第一部分:Discord 高层级摘要
LM Studio Discord
- LM Studio 遭遇性能问题:多位用户报告了 LM Studio 0.2.31 版本的问题,特别是应用程序启动困难和模型无法正确加载。建议降级到 0.2.29 等早期版本作为潜在的解决方法。
- 用户确认性能不一致的问题仍然存在,敦促社区探索稳定版本以维持工作流。
- 模型下载速度受限:用户在 LM Studio 网站下载时遇到了速度波动,有报告称速度被限制在 200kbps。建议由于典型的 AWS 限速问题,可以稍后重试或等待。
- 对话强调了在高需求下载时段需要耐心,并进一步强调了检查连接稳定性的重要性。
- AI 想控制你的电脑!:关于 AI 模型(特别是 OpenInterpreter)是否能获得视觉能力来控制 PC 的讨论引起了关注,这指向了当前 AI 理解能力的局限性。参与者对这种集成可能带来的不可预见行为表示担忧。
- 辩论强调了在本地系统上实施 AI 控制机制之前需要进行仔细考虑。
- 多模态模型引发关注:用户对 AnythingLLM 可用的多模态模型产生了浓厚兴趣,重点讨论了对无审查(uncensored)模型的探索。推荐使用 UGI Leaderboard 等资源进行能力对比。
- 参与者强调了社区驱动探索先进模型以增强功能多样性的重要性。
- 双 GPU 配置引发不同观点:关于双 4090 配置的讨论表明,将模型拆分到多张显卡上可以提高性能,但也提醒用户有效利用这些配置需要一定的编程要求。对于单块 4090 在处理大型模型时的吃力表现,担忧依然存在。
- 成员们在考虑多 GPU 配置时,更倾向于讨论性能与易用性之间的平衡。
HuggingFace Discord
- 深入探讨 Hugging Face 模型特性:用户分享了关于 Hugging Face 上各种模型的见解,例如用于翻译的 MarionMT 和提供语言支持的 TatoebaChallenge。
- 对模型局限性和更好文档必要性的担忧引发了更广泛的讨论。
- 加速 LLM 推理技术:优化 LLM 推理成为热门话题,建议包括使用 torch.compile 以及使用 vLLM 等工具评估性能。
- 成员们对在处理大型语言模型时提高效率表现出浓厚兴趣。
- CatVTON 重新定义虚拟试穿方法:最近的一篇 arXiv 论文 介绍了 CatVTON,这是一种通过直接拼接服装图像显著降低训练成本的方法。
- 这一创新有望实现逼真的服装迁移,彻底改变虚拟试穿技术。
- Diffusers 中 Gradient Checkpointing 的实现:最近的更新现在包含了一种在 Diffusers 中设置 gradient checkpointing 的方法,允许在兼容模块中进行切换。
- 这一增强功能有望优化模型训练期间的内存使用。
- 使用 NLP 识别表格中的关系:成员们正在探索 NLP 方法,根据列描述和名称来确定表格之间的关系。
- 这一探究表明在 NLP 关系建模领域需要进一步的探索。
Stability.ai (Stable Diffusion) Discord
- Flux 模型在 GPU 上表现出色:用户报告 Flux model 的图像生成速度在 1.0 到 2.0 iterations per second 之间,具体取决于 GPU 配置和模型版本。
- 一些用户通过 CPU offloading 或 quantization 技术,在较低 VRAM 的配置上成功生成了图像。
- ComfyUI 安装技巧:讨论围绕在 ComfyUI 上安装 Flux 展开,建议使用
update.py脚本而不是管理器进行更新。- 为新手分享了有用的安装指南,以帮助其顺利配置环境。
- Stable Diffusion 模型对比:参与者详细介绍了不同的 Stable Diffusion models:SD1.5、SDXL 和 SD3,指出各模型的优势,并将 Flux 定位为来自 SD3 team 的新成员。
- 讨论中强调了 Flux 相比传统模型更高的资源需求。
- RAM 与 VRAM 的对决:充足的 VRAM 对 Stable Diffusion performance 至关重要,用户建议至少配备 16GB VRAM 以获得最佳效果,这比对高 RAM 的需求更重要。
- 社区建议,虽然 RAM 有助于模型加载,但它不是影响生成速度的主要因素。
- 动画工具咨询:参与者询问了用于视频内容生成的 Animatediff 等工具,寻求可用方法的最新更新。
- 目前的建议指出,虽然 Animatediff 仍然有用,但针对类似任务可能会出现新的替代方案。
CUDA MODE Discord
- Epoch 8 准确率激增:成员注意到训练过程中 Epoch 8 之后准确率分数出现意外激增,引发了对预期行为的疑问。
- Looks totally normal(看起来完全正常),另一位成员安慰道,表示无需担心。
- CUDA 在 DRL 中的挑战:在为 Deep Reinforcement Learning 创建 CUDA 环境时出现了挫折,建议使用 PufferAI 以获得更好的并行性。
- 参与者强调了设置中涉及的复杂性,强调了对强大 tooling 的需求。
- 寻求 ML 冬季实习:一名用户正在紧急寻找 2025 年 1 月开始的 winter internship,重点关注 ML systems 和 applied ML。
- 该用户强调了之前的实习经历和正在进行的 open source 贡献。
- 对 AI 泡沫破裂的担忧:关于潜在 AI bubble 的猜测开始流传,对于投资的长期潜力存在截然不同的看法。
- 参与者指出,研究成果与盈利之间的滞后时间是一个核心担忧。
- Llama 3 Tokenization 问题:讨论了 Llama 3 在 tokenization 方法上的不一致,特别是关于 EOS 和 BOS token 的使用导致了推理挑战。
- 参与者一致认为需要重新评估文档以解决这些 tokenization bugs。
Unsloth AI (Daniel Han) Discord
- Unsloth 安装问题依然存在:用户在本地安装 Unsloth 时遇到错误,特别是关于 Python compatibility 和 PyTorch 安装,解决方法包括升级 pip。
- 一些用户通过重新连接 Colab runtime 并验证库安装解决了问题。
- 微调多语言模型的挑战:用户分享了使用多样化数据集微调 Llama 3.1 和 Mistral 等模型的经验,由于可能不正确的 prompt 格式遇到了输出相关性问题。
- 建议敦促恢复到标准 prompt 格式以确保正确的数据集处理。
- LoRA 训练在数据集格式上受阻:一名用户报告在尝试使用拼接文本和标签格式化数据集后,其 SFTTrainer 结果不佳,质疑是否存在配置错误。
- 澄清指向了正确的列使用,但未能解决根本问题。
- 加载大型模型的内存问题:在单个 GPU 上加载 405B Llama-3.1 模型导致了内存挑战,促使用户注意到多 GPU 的必要性。
- 这凸显了一个共识,即更大的模型需要更多的计算资源来加载。
- Self-Compressing Neural Networks 优化模型大小:关于 Self-Compressing Neural Networks 的论文讨论了在 loss function 中使用字节大小来实现显著缩减,仅需 3% 的 bits 和 18% 的 weights。
- 该技术声称可以在不需要专门硬件的情况下提高训练效率。
Perplexity AI Discord
- Perplexity 的浏览能力遭到质疑:用户报告了在使用 Perplexity 浏览时的参差不齐的体验,指出在获取最新信息方面存在困难,且在使用 Web App 时表现出奇怪的行为。
- 对话强调了模型响应的不一致性,特别是在对于技术应用至关重要的代码查询等任务中。
- Llama 抗体在 HIV 研究中取得突破:佐治亚州立大学的研究人员设计了一种混合抗体,将 Llama 衍生的纳米抗体与人类抗体结合,中和了超过 95% 的 HIV-1 毒株。
- 这种混合方法利用了 Llama 纳米抗体的独特属性,能够更好地进入易逃逸的病毒区域。
- 对模型性能的担忧:Llama 3.1 对比预期:用户发现 Llama 3.1-sonar-large-128k-online 模型在日语测试中表现不佳,提供的结果准确性低于 GPT-3.5。
- 这引发了开发专门针对日语优化的 sonar-large 模型的呼声,以提高输出质量。
- Uber One 订阅引发不满:一位用户批评 Uber One 优惠仅限于 Perplexity 新账号,指出这更多是一种用户获取策略,而非真正的福利。
- 关于通过创建账号来利用促销活动的辩论,提出了 AI 服务中用户管理的重要问题。
- Perplexity 的 API 质量问题:多位用户分享了 Perplexity API 的问题,提到在查询近期新闻时响应不可靠且返回低质量结果。
- 用户对 API 输出感到沮丧,这些输出经常显得被无意义的内容“污染”,从而迫切要求改进模型和 API 的性能。
OpenAI Discord
- OpenAI DevDay 开启巡回活动:OpenAI 将于今年秋季在旧金山、伦敦和新加坡举办 DevDay 巡回活动,提供动手实践环节、演示和最佳实践分享。参与者将有机会与工程师见面,并了解开发者如何利用 OpenAI 进行构建;更多信息请访问 DevDay 官网。
- 参与者将在活动期间与工程师互动,增强技术理解和社区参与。
- AI 全球威胁讨论:关于将 AI 视为全球威胁的看法展开了激烈辩论,重点讨论了政府针对开源 AI 与更优越的闭源模型的行为。随着 AI 能力的扩展,对潜在风险的担忧日益增加。
- 随着关于 AI 影响的观点变得日益两极分化,这一问题得到了强调。
- GPT-4o 图像生成见解:讨论揭示了对 GPT-4o 图像 Token 化能力的见解,图像有可能被表示为 Token。然而,在当前的实现中,实际应用和局限性仍然模糊不清。
- 提到的资源包括 Greg Brockman 的一条推文,讨论了团队在 GPT-4o 图像生成方面的持续工作。
- Prompt Engineering 障碍:用户报告在使用 ChatGPT 进行 Prompt 编写时,在产出高质量结果方面面临持续挑战,这经常导致挫败感。困难在于如何定义什么是高质量输出,这使得交互变得复杂。
- 成员们分享了相关经验,说明了编写清晰、开放式 Prompt 对改善结果的重要性。
- AI 图像生成中的多样性与偏见:关于 AI 生成图像中的种族代表性问题引发了关注,特定的 Prompt 因服务条款准则而遭到拒绝。成员们交流了成功的策略,通过在 Prompt 中明确包含多种族背景来确保多样化的代表性。
- 讨论还揭示了负面提示(Negative Prompting)的影响,即试图限制某些特征反而产生了不理想的结果。建议集中在编写积极、详细的描述以提高输出质量。
Latent Space Discord
- AI 工程师需求激增:随着公司寻求通才技能,特别是能够将 AI 集成到实际应用中的 Web 开发者,对 AI 工程师 的需求正在飞速增长。
- 这种转变凸显了高水平 ML 专业知识的缺口,促使 Web 开发者在 AI 项目中担任关键角色。
- Groq 在 D 轮融资中筹集 6.4 亿美元:Groq 获得了由 BlackRock 领投的 6.4 亿美元 D 轮融资,使其估值提升至 28 亿美元。
- 资金将用于扩大产能并加强下一代 AI 芯片的开发。
- NVIDIA 的抓取伦理备受指责:泄露的信息揭露了 NVIDIA 大规模的 AI 数据抓取行为,每天收集相当于“一个人一生长度”的视频,引发了严重的伦理担忧。
- 这种情况引发了关于此类激进数据获取策略在法律和社区影响方面的辩论。
- 比较 Cody 和 Cursor:讨论强调了 Cody 相比 Cursor 具有更优越的上下文感知能力,Cody 允许用户索引代码库以获得相关的回复。
- 用户欣赏 Cody 的易用性,而认为 Cursor 的上下文管理繁琐且复杂。
- Claude 推出同步文件夹功能:据报道,Anthropic 正在为 Claude 开发 Sync Folder 功能,支持从本地文件夹批量上传,以便更好地进行项目管理。
- 该功能预计将简化 Claude 项目中文件的组织和工作流。
Nous Research AI Discord
- 关于 LLM as Judge 和数据集生成的建议:一位用户询问了有关 LLM as Judge 和合成数据集生成(重点是指令和偏好数据)当前趋势的必读内容,并强调了 WizardLM 的最新两篇论文 作为起点。
- 这次讨论将 LLM 的进步定位为理解模型应用转变的关键。
- 对 Claude Sonnet 3.5 的担忧:用户报告了 Claude Sonnet 3.5 的问题,指出与其前代产品相比,其表现不佳且错误率增加。
- 这引发了人们对近期更新的有效性及其对核心功能影响的质疑。
- DistillKit 介绍:Arcee AI 发布了 DistillKit,这是一个开源工具,用于从大型模型中蒸馏知识以创建更小、更强大的模型。
- 该工具包结合了传统的训练技术与新颖的方法,以优化模型效率。
- 轻松进行高效的 VRAM 计算:分享了一个用于根据 bits per weight 和上下文长度估算 VRAM 需求的 Ruby 脚本,可在 此处 获取。
- 该工具帮助用户确定 LLM 模型中的最大上下文和 bits per weight,简化了 VRAM 计算。
- 创新的 Mistral 7B MoE 化:Mistral 7B MoEified 模型允许将单个层切分为多个专家 (experts),旨在实现连贯的模型行为。
- 这种方法使模型在处理过程中能够平等地共享可用的专家资源。
OpenRouter (Alex Atallah) Discord
- Chatroom 焕然一新:Chatroom 已上线,支持本地聊天保存和简化的 UI,允许在 OpenRouter 进行更好的房间配置。这个翻新后的平台提升了用户体验和易用性。
- 用户可以探索新功能,以增强 Chatroom 内的互动。
- OpenRouter 发布新模型变体:OpenRouter 推出了令人印象深刻的新模型,包括 Llama 3.1 405B BASE 和 Mistral Nemo 12B Celeste,可以在其 模型页面 查看。Llama 3.1 Sonar family 的加入进一步扩展了应用能力。
- 新成员满足了多样化的需求,并根据社区反馈进行持续更新。
- Mistral 模型现已登陆 Azure:Mistral Large 和 Mistral Nemo 模型现在可以通过 Azure 访问,增强了它们在云环境中的实用性。此举旨在为用户提供更好的基础设施和性能。
- 用户可以利用 Azure 的能力,轻松访问高性能 AI 模型。
- Gemini Pro 经历价格大调整:Google Gemini 1.5 Flash 的价格将在 12 日减半,使其在与 Yi-Vision 和 FireLLaVA 等对手的竞争中更具优势。这一转变可能会促进更多用户参与自动标注(automated captioning)。
- 社区反馈在塑造这一转变中起到了至关重要的作用,因为用户渴望更经济的选择。
- Multi-AI Answers 发布:Multi-AI answer 网站 在 OpenRouter 的支持下正式在 Product Hunt 上线。他们的团队鼓励社区进行 点赞(upvotes)和建议,以完善服务。
- 发布期间的社区贡献体现了用户参与在开发过程中的重要性。
Modular (Mojo 🔥) Discord
- Mojo 加速数据处理流水线:讨论强调了 Mojo 在将分析与数据库工作负载集成方面的潜力,通过 JIT 编译和直接文件操作实现更快的数据处理。
- 成员们提到了与 PyArrow 和 Ibis 的兼容性,暗示了 Mojo 框架内强大的数据生态系统有着广阔的前景。
- Elixir 令人困惑的错误处理:成员们讨论了 Elixir 的挑战,即库返回错误原子(error atoms)或抛出异常,导致错误处理不规范。
- 一段由 Chris Lattner 和 Lex Fridman 参与的 YouTube 视频 详细阐述了异常与错误的区别,提供了进一步的背景信息。
- Mojo 调试器缺乏支持:一位成员确认 Mojo 调试器目前无法在 VS Code 中工作,并引用了一个现有的 GitHub issue 以寻求调试支持。
- 调试工作流似乎依赖于 print 语句,表明需要改进调试工具。
- Mojo SIMD 的性能问题:有关 Mojo 在大型 SIMD 列表上操作性能的担忧浮出水面,这些操作在某些硬件配置上可能会出现延迟。
- 有建议称,使用符合 CPU 处理能力的 SIMD 大小可以提高性能。
- 缺少 MAX Engine 对比文档:一位用户报告称,很难找到将 MAX Engine 与 PyTorch 和 ONYX 进行对比的文档,特别是在 ResNet 等模型上。
- 该查询凸显了寻求对比数据的用户在可用资源方面的空白。
Eleuther Discord
- Claude AI 提供代码修复:成员们讨论了通过开启 Claude AI 的新对话并上传
output.json,使其能够直接提供代码修复而无需文件访问权限,详见这篇 Medium 文章。- 尽管潜力巨大,但对于这种方法的经验有效性仍持怀疑态度。
- 通过架构增强性能:新的架构,特别是针对用户特定音频分类的架构,可以通过contrastive learning等策略来维持用户不变特征,从而显著提高性能。
- 此外,还讨论了针对 3D data 调整架构,以确保在变换下的性能。
- 音乐生成的最新技术 (SOTA):关于音乐生成的 SOTA 模型的咨询包括了围绕正在进行的 AI 音乐生成诉讼的讨论,成员们更倾向于本地执行而非外部依赖。
- 这次对话反映了在音乐生成应用中增加控制权的日益增长的趋势。
- 关于 RIAA 和厂牌的见解:审查了 RIAA 与音乐厂牌之间的关系,强调了它们如何影响艺术家报酬和行业结构,并要求更直接的补偿方式。
- 艺术家相对于行业利润获得的版税微乎其微,这引发了担忧,暗示了对自我推广的推动。
- 用于高效 Embedding 管理的 HDF5:关于使用 HDF5 从大型 embedding 数据集中加载批次的讨论仍在继续,反映了在简化数据管理技术方面的持续努力。
- 这表明 AI 社区对高效数据利用有着持久的兴趣。
LangChain AI Discord
- Ollama 内存错误记录:一位用户报告了一个 ValueError,表明在调用检索链时模型内存不足,尽管在使用 aya (4GB) 和 nomic-embed-text (272MB) 等模型时 GPU 使用率较低。
- 这引发了关于高性能设置中资源分配和内存管理的疑问。
- 混合 CPU 和 GPU 资源:讨论集中在 Ollama 在重负载期间是否有效地利用了 CPU 和 GPU,用户注意到预期的回退到 CPU 的情况并未如期发生。
- 用户强调了理解回退机制以防止推理瓶颈的重要性。
- LangChain 内存管理见解:分享了关于 LangChain 如何处理内存和对象持久化的见解,重点是评估跨会话内存效率的输入。
- 确定适合内存存储的信息的查询成为了测试不同模型响应的试验场。
- SAM 2 Fork:CPU 兼容性实践:一位成员发起了一个兼容 CPU 的 SAM 2 model Fork,展示了提示分割和自动掩码生成,并期望实现 GPU compatibility。
- 有关此项工作的反馈正在其 GitHub 仓库中积极征集。
- 快速启动你的 AI 语音助手:一段名为 “8 分钟创建自定义 AI 语音助手!- 由 ChatGPT-4o 驱动” 的教程视频指导用户为其网站构建语音助手。
- 创建者提供了一个 演示链接,供潜在用户在注册服务前进行实际体验。
LlamaIndex Discord
- 使用 LlamaIndex 构建 ReAct Agents:您可以利用 LlamaIndex workflows 从头开始创建 ReAct agents,以增强内部逻辑的可视化。
- 这种方法允许您“拆解”逻辑,确保对 Agentic 系统有更深入的理解和控制。
- 面向 AI 工程师的 Terraform 助手:使用 LlamaIndex 和 Qdrant Engine 为有志于成为 AI 工程师的人员开发 Terraform 助手,指南提供在 此处。
- 该教程提供了在 DevOps 领域集成 AI 的实用见解和框架。
- 使用 LlamaExtract 自动提取工资单:LlamaExtract 通过自动化的 Schema 定义和元数据提取,实现对工资单的 高质量 RAG。
- 这一过程显著增强了工资单文档的数据处理能力。
- 扩展 RAG 应用教程:Benito Martin 概述了如何在 Google Kubernetes 上部署和扩展您的聊天应用,并在 此处 强调了实用策略。
- 该资源详细解决了 RAG 应用生产化方面内容稀缺的问题。
- 创新的 GraphRAG 集成:GraphRAG 与 LlamaIndex 的集成增强了 智能问答 能力,正如一篇 Medium 文章 中所讨论的。
- 这种集成利用 知识图谱(knowledge graphs) 来提高 AI 响应的上下文关联性和准确性。
Interconnects (Nathan Lambert) Discord
- 湾区活动引发热议:成员们表达了对 湾区(Bay Area) 即将举行的活动的更新需求,一些人提到了个人缺席的情况。
- 持续的关注暗示了对当地聚会更好沟通的需求。
- Noam Shazeer 缺乏认可:讨论围绕自 2002 年以来一直是 Google 关键人物的 Noam Shazeer 缺少 Wikipedia 页面 展开。
- 成员们反思道“Wikipedia 有时很荒谬”,强调了对有影响力的专业人士这种讽刺性的忽视。
- 对 30 Under 30 奖项有效性的质疑:一位成员批评 30 Under 30 奖项更多是为了迎合圈内人而非真正的功绩,暗示是“特殊类型的人”在寻求这种认可。
- 这引起了成员们的共鸣,他们指出这些奖项赋予的认可通常是表面上的。
- 关于使用 Nemotron 生成合成数据的辩论:一场关于利用 Nemotron 重新制作 合成数据(synthetic data) 以微调 Olmo 模型的激烈讨论展开。
- 讨论中提出了对 Nemotron 名称可能被挪用的担忧,并对 AI2 的发展轨迹提出了批评。
- 在噪声环境中 KTO 优于 DPO:Neural Notes 采访 讨论了 KTO 在处理噪声数据时优于 DPO 的优势,表明其具有显著的性能提升。
- 来自 UCLA 的适配报告称,KTO 在人类偏好测试中以 70-30% 的优势领先于 DPO。
LAION Discord
- 合成数据集引发争议:成员们辩论了 合成数据集(synthetic datasets) 与原始数据集的有效性,指出它们可以加速训练,但可能面临对齐不齐和质量下降的风险。
- 成员们对偏见表示担忧,呼吁更有目的地创建数据集,以避免生成数十亿张无用的图像。
- FLUX 模型性能评价两极分化:用户对 FLUX 模型生成艺术输出的能力持不同看法;一些人称赞其能力,而另一些人则表示失望。
- 讨论指出更好的参数设置可以增强其性能,但对其艺术创作的整体实用性仍持怀疑态度。
- CIFAR-10 验证准确率达到 80%:在 CIFAR-10 数据集上仅使用 36k 参数 就实现了 80% 的验证准确率,将复数参数的实部和虚部作为独立部分处理。
- 对架构和 Dropout 实现的调整解决了之前的问题,从而得到了一个更稳健的模型,几乎消除了过拟合。
- 模型训练中的伦理问题:围绕在受版权保护的图像上进行训练的伦理影响,讨论变得激烈,引发了对合成数据集中 版权洗白(copyright laundering) 的担忧。
- 一些人提出,虽然合成数据具有优势,但更严格的审查可能会对社区内的训练实践施加监管。
- Stable Diffusion 数据集可用性受质疑:一位用户对 Stable Diffusion 数据集 的不可用表示沮丧,这阻碍了他们的进展。
- 同行澄清说,使用 Stable Diffusion 并不严格需要该数据集,并提供了替代解决方案。
DSPy Discord
- 为 ChatmanGPT Stack 添加 Coding Agent:一名成员正在为 ChatmanGPT Stack 寻求 Coding Agent 推荐,并建议将 Agent Zero 作为潜在选择。
- 寻找有效的补充以增强编程交互。
- Golden-Retriever 论文概览:分享的 Golden-Retriever 论文链接详细介绍了它如何通过改进传统 LLM 微调的挑战(特别是通过基于反思的问题增强步骤)来高效导航工业知识库。
- 该方法通过在检索文档前澄清术语和上下文来提高检索准确性。更多信息请阅读 Golden-Retriever 论文。
- Voice Lounge 中的 Livecoding:一名成员宣布回归,并提到在 Voice Lounge 进行 Livecoding 会话,预示着即将开展协作编程。
- 成员们期待在这种互动式设置中通力合作。
- AI NPC 响应与巡逻:正在计划使用 Oobabooga API 在 C++ 游戏中开发 AI 角色进行玩家互动,重点是巡逻和响应功能。
- 必要的组件包括修改 ‘world’ 节点和扩展 NPC 类。
- 轻松导出 Discord 聊天记录:一名用户使用 DiscordChatExporter 工具成功将 Discord 频道导出为 HTML 和 JSON,生成了 463 个线程文件。
- 该工具简化了聊天记录的组织,便于未来参考。查看 DiscordChatExporter。
OpenInterpreter Discord
- Open Interpreter 在本地 LLM 上运行!:一名用户使用 LM Studio 作为服务器,成功将 Open Interpreter 与本地 LLM 集成,并获得了 OI 系统提示词的访问权限。
- 他们发现这种集成既有趣又富有启发性,为本地部署铺平了道路。
- 排查 Hugging Face API 集成问题:用户在 Open Interpreter 中设置 Hugging Face API 集成时遇到挑战,尽管参考了文档,仍遇到各种错误。
- 一名用户对获得的支持表示感谢,希望能解决他们的集成问题。
- 执行截图命令变得繁琐:用户质疑为什么 Open Interpreter 会生成大量代码而不是直接执行截图命令,这引发了关注。
- 使用 ‘screencapture’ 命令的变通方法确认了功能性,缓解了一些挫败感。
- 提议多语言语音识别:一名用户提议实现一种母语语音识别方法,以促进英语与当地语言之间的翻译。
- 他们对翻译错误提出了警告,称之为 垃圾进,垃圾出 (Garbage in, Garbage out)。
- Electra AI 在 Linux AI 领域展现潜力:一名成员展示了 Electra AI,这是一个内置 AI 功能且免费使用的 Linux 发行版,强调了其集成的潜力。
- 他们指出 Electra AI 提供三种版本:Lindoz、Max 和 Shift——全部免费提供。
Cohere Discord
- Cohere 支持解决 CORS 问题:为了解决计费页面的 CORS 问题,社区成员建议发送邮件至 support@cohere.com 寻求帮助,并在咨询中包含组织详情。
- 该支持渠道旨在解决阻碍用户支付服务费用的问题。
- GenAI 训练营寻求 Cohere 见解:Andrew Brown 正在探索 Cohere 在免费 GenAI 训练营中的潜力,该训练营旨在今年覆盖 5 万名参与者。
- 他强调需要文档之外的见解,特别是关于 Cohere 的跨云能力 (cloud-agnostic capabilities)。
- 保持一致性进行模型基准测试:一名成员询问在对多个模型进行基准测试时如何保持验证子集的一致性,强调了受控比较的重要性。
- 讨论强化了维持一致验证集以提高比较准确性的必要性。
- 在 Azure 模型上激活 Rerank:Cohere 宣布 Azure 模型现已支持 Rerank,并具有集成到 RAG 应用的潜力,详见此 博客文章。
- 成员们表现出更新工具包以供 Azure 用户使用 Rerank 的兴趣。
- 澄清 Cohere 模型混淆:一名支付了 Cohere API 费用的用户发现只有 Coral 模型可用,并对如何访问 Command R 模型感到困惑。
- 作为回应,一名成员澄清说 Coral 实际上就是 Command R+ 的一个版本,以缓解用户的疑虑。
tinygrad (George Hotz) Discord
- tinygrad 0.9.2 引入了令人兴奋的特性:最近发布的 tinygrad 0.9.2 带来了显著的更新,如 faster gemv、kernel timing 以及 CapturedJit 的改进。
- 其他讨论包括对 ResNet 的增强和高级索引技术,这标志着性能优化迈出了重要一步。
- 在 Aurora 超级计算机上评估 tinygrad:成员们讨论了在 Aurora 超级计算机上运行 tinygrad 的可行性,重点关注与 Intel GPU 的兼容性。
- 虽然存在 OpenCL 支持,但有人对该平台上的性能限制和效率提出了疑问。
- CUDA 性能相比 CLANG 令人失望:成员们注意到 CUDA 的测试运行速度比 CLANG 慢,这引发了对可能存在的效率问题的调查。
- 这种差异引发了关于 CUDA 执行完整性的重要问题,特别是在 test_winograd.py 中。
- 自定义 tensor kernel 引发讨论:一位用户分享了在 tensor 上执行自定义 kernel 的兴趣,并参考了一个 GitHub 文件 进行指导。
- 这反映了 tinygrad 内部 tensor 操作的持续增强,展示了社区在实际实现中的参与度。
- Bounties 激励 tinygrad 特性贡献:社区开始讨论针对 tinygrad 改进的 bounties(悬赏),例如 fast sharded llama 和 AMX 的优化。
- 这一举措鼓励开发者积极参与增强框架,旨在实现更广泛的功能。
Torchtune Discord
- PPO 训练 Recipe 现已上线:团队引入了一个端到端的 PPO 训练 recipe,将 RLHF 与 Torchtune 集成,详见 GitHub pull request。
- 快去看看并尝试一下吧!
- Qwen2 模型支持已添加:Qwen2 模型支持 现已包含在训练 recipe 中,7B 模型 已在 GitHub pull request 中提供。
- 预计即将推出 1.5B 和 0.5B 版本!
- LLAMA 3 在生成时遇到问题:用户使用自定义配置成功运行了 LLAMA 3 8B INSTRUCT 模型,在 20.62 GB 内存占用下,以 12.25 tokens/sec 的速度在 27.19 秒 内生成了一个时间查询。
- 然而,存在 文本重复 10 次 的问题,目前正在审查一个 pull request 以解决意外的结束 token 问题。
- 呼吁为 LLAMA 3 提供调试模式:针对 LLAMA 3 生成输出中不显示 所有 token 的调试模式缺失问题,引发了关注。
- 一位成员建议在生成脚本中添加一个参数可以解决此问题。
- 模型简介(Model Blurbs)维护焦虑:成员们对保持 model blurbs 更新表示担忧,担心维护工作量可能过大。
- 有人提议使用 model card 或白皮书中的快照作为最小化的简介方案。
OpenAccess AI Collective (axolotl) Discord
- bitsandbytes 在 ROCm 上的安装已简化:最近的一个 PR 实现了在 ROCm 上打包 bitsandbytes 的 wheel 文件,为用户简化了安装过程。
- 该 PR 更新了 ROCm 6.1 的编译过程,以支持最新的 Instinct 和 Radeon GPU。
- 构建 AI 营养师需要数据集:一位成员正在开发 AI Nutritionist,并考虑微调 GPT-4o mini,但正在寻找合适的营养数据集,如 USDA FoodData Central。
- 建议包括从 FNDDS 编译潜在数据集,尽管尚不清楚其是否在 Hugging Face 上可用。
- 寻找 FFT 和基准测试:一位成员表示有兴趣寻找 FFT 或 LORA/QLORA 来对 27b model 进行实验,提到在 9b model 上效果良好,但在更大的模型上遇到了挑战。
- Caseus 建议针对 Gemma 2 27b 的 QLORA 版本在调整 learning rate 并使用最新的 flash attention 后可能会奏效。
- 关于 L40S GPUs 性能的咨询:一位成员询问是否有人在 L40S GPUs 上训练或部署过模型,寻求有关其性能的见解。
- 该咨询突显了人们对 L40S GPUs 在 AI 模型训练中的效率和能力的关注。
- 关于 AI 训练中 DPO 替代方案的讨论:一位成员质疑 DPO 是否仍是 AI 训练中的最佳方法,并建议 orpo、simpo 或 kto 等替代方案可能更优。
- 这引发了关于 AI 模型训练中各种方法有效性的不同意见交流。
MLOps @Chipro Discord
- Triton Conference 报名现已开启!:将于 2024 年 9 月 17 日 在 Meta Campus, Fremont CA 举行的 Triton Conference 报名现已开启!请通过 此 Google Form 报名以预留名额。
- 参会是免费的,但名额有限,因此建议尽早报名。
- 报名所需信息:参与者必须提供其 email、name、affiliation 和 role 进行报名。其他可选问题包括饮食偏好,如素食、纯素、犹太洁食和无麸质。
- 专业提示:收集参会者希望从会议中获得什么收获!
- 会议报名的 Google 登录:系统会提示参会者登录 Google 以保存报名表单的进度。所有回复将发送至参与者提供的电子邮箱。
- 别忘了:为确保安全,参与者绝不应通过 Google Forms 提交密码。
Mozilla AI Discord
- Llamafile 提升离线 LLM 访问:Llamafile 的核心维护者报告了在单个文件中实现离线、可访问的 LLM 方面的重大进展。
- 这一举措提高了可访问性,并简化了用户与大型语言模型的交互。
- 社区对 8 月项目充满期待:围绕 August 正在进行的项目引发了热烈讨论,鼓励社区成员展示他们的工作。
- 参与者有机会在 Mozilla AI 空间内参与并分享他们的贡献。
- sqlite-vec 发布会即将举行:即将举行的 sqlite-vec 发布会将允许参与者讨论功能并与核心维护者交流。
- 演示和讨论即将展开,为最新进展的深入交流创造了机会。
- 令人兴奋的机器学习论文研讨会已排期:即将举行的讲座将涵盖 Communicative Agents 和 Extended Mind Transformers 等主题,并邀请杰出演讲者。
- 这些活动有望为机器学习领域的尖端研究和协作机会提供宝贵的见解。
- Local AI AMA 承诺提供开源见解:已安排的与核心维护者的 Local AI AMA 将提供关于这个可自托管的 OpenAI 替代方案的见解。
- 本次会议邀请参与者探索 Local AI 的功能并直接解答他们的疑问。
Alignment Lab AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第二部分:按频道详细摘要及链接
完整的逐频道细分内容已针对电子邮件进行缩减。
如果您喜欢 AInews,请分享给朋友!预谢!