ainews-gemini-live
**Gemini Live**(通常直接保留英文名称,也可译为 **Gemini 实时对话** 或 **Gemini 实时语音**)。 这是 Google 推出的一项功能,允许用户与 Gemini AI 进行流畅、自然的实时语音对话。
谷歌(Google)在 Pixel 9 发布会期间为 Gemini Advanced 订阅用户在 Android 平台上推出了 Gemini Live,其特点是集成了 Google Workspace 应用和其他谷歌服务。该功能于 2024 年 8 月 12 日开始推出,并计划支持 iOS。
Anthropic 发布了 Genie,这是一个 AI 软件工程系统,在 SWE-Bench 基准测试中实现了 57% 的提升。TII 推出了 Falcon Mamba,这是一个 7B 参数的无注意力机制(attention-free)开源模型,可扩展至长序列。基准测试显示,更长的上下文长度并不总能改善检索增强生成(RAG)。
Supabase 推出了一个由 AI 驱动的 Postgres 服务,被称为“数据库界的 ChatGPT”,且完全开源。Perplexity AI 与 Polymarket 合作,将实时概率预测集成到搜索结果中。
一项教程展示了使用 Qdrant、LlamaIndex 和 Gemini 构建的多模态食谱推荐系统。一位 OpenAI 工程师分享了成功秘诀,强调了调试和努力工作的重要性。线性代数中矩阵与图之间的联系被重点提及,为理解非负矩阵和强连通分量提供了见解。Keras 3.5.0 正式发布,集成了 Hugging Face Hub 以支持模型的保存和加载。
生活中各种每月 20 美元的小额订阅就是你所需的一切。
2024/8/12-2024/8/13 的 AI 新闻。我们为你检查了 7 个 subreddits、384 个 Twitter 账号 和 29 个 Discord(253 个频道和 2423 条消息)。预计节省阅读时间(以 200wpm 计算):244 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
正如在 Google I/O 上所承诺的,Gemini Live 今天在 Android 平台上发布,面向 Gemini Advanced 订阅用户,作为 #MadeByGoogle Pixel 9 发布会的一部分。对那位在台上遭遇了 2 次演示失败的 可怜演示者 表示同情:
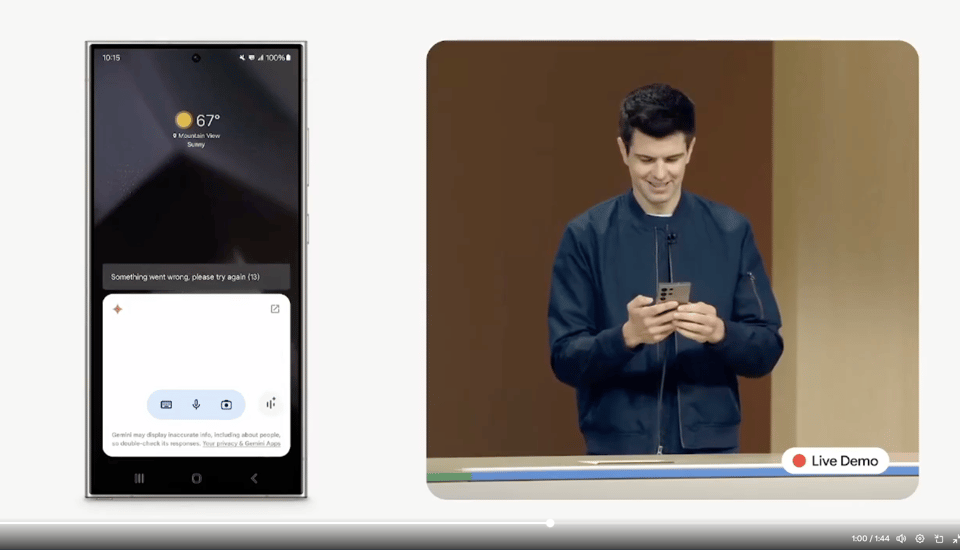
Gemini Live 的媒体评测解禁 结果持谨慎乐观态度。它将拥有 “extensions”(扩展),即与你的 Google Workspace (Gmail, Docs, Drive)、YouTube、Google Maps 以及其他 Google 产品的集成。
重要的是,Google 今天开始推出该功能(尽管截至太平洋时间下午 5 点,我们仍然 无法找到任何人 发布其实测录屏),而 ChatGPT 的 Advanced Voice Mode 发布日期仍不确定。Gemini Live 未来也将面向 iOS 订阅用户推出。
该公司还向现场观众展示了 Gemini Live 在 Pixel Buds Pro 2 上的演示,并向 华尔街日报 (WSJ) 进行了展示。对于关注 Pixel 9 的人来说,还有 Add Me 拍照功能和 Magic Editor 等显著的图像 AI 集成。
https://www.youtube.com/watch?v=KoN_bcDmhR4
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,从 4 次运行中选取最佳结果。
AI 模型进展与基准测试
-
Anthropic 发布了 Genie,这是一个全新的 AI 软件工程系统,在 SWE-Bench 上实现了 30.08% 的 SOTA 性能,比之前的模型提升了 57%。关键点包括推理数据集、具备规划和执行能力的 Agent 系统,以及自我改进能力。@omarsar0
-
TII 发布了 Falcon Mamba,这是一个全新的 7B 开源模型。它是一个 Attention-free 模型,可以扩展到任意序列长度,并且与同尺寸模型相比具有强大的指标表现。@osanseviero
-
研究人员对 13 个流行的开源和商业模型在 2k 到 125k 的上下文长度下进行了基准测试,发现长上下文并不总是有助于检索增强生成 (RAG)。大多数生成模型的性能在超过一定上下文大小后会下降。@DbrxMosaicAI
AI 工具与应用
-
Supabase 推出了一个基于 AI 的 Postgres 服务,被称为“数据库界的 ChatGPT”。它允许用户构建和启动数据库、创建图表、生成 Embeddings 等。该工具 100% 开源。@AlphaSignalAI
-
Perplexity AI 宣布与 Polymarket 建立合作伙伴关系,将选举结果和市场趋势等事件的实时概率预测整合到其搜索结果中。@perplexity_ai
-
分享了一个使用 Qdrant、LlamaIndex 和 Gemini 构建多模态食谱推荐系统的教程,演示了如何摄取 YouTube 视频并对文本和图像块进行索引。@llama_index
AI 工程见解
-
一位 OpenAI 工程师分享了在该领域取得成功的见解,强调了彻底调试和理解代码的重要性,以及努力完成任务的意愿。@_jasonwei
-
讨论了线性代数中矩阵与图之间的联系,强调了这种关系如何提供对非负矩阵和强连通分量的见解。@svpino
-
Keras 3.5.0 发布,具有一流的 Hugging Face Hub 集成,允许直接从 Hub 保存和加载模型。此次更新还包括 Distribution API 的改进,以及支持 TensorFlow、PyTorch 和 JAX 的新算子。@fchollet
AI 伦理与监管
-
围绕 AI 监管及其对创新潜在影响的讨论受到关注,一些人认为过早的监管可能会阻碍有益 AI 应用的进展。@bindureddy
-
有人对 AI “业务战略决策支持”初创公司的有效性表示担忧,认为其价值不易衡量,也难以获得客户信任。@saranormous
AI 社区与活动
-
Google DeepMind 播客宣布了第三季,探讨了 Chatbot 与 Agent 之间的区别、AI 在创意中的角色,以及实现 AGI 后潜在的生活场景等话题。@GoogleDeepMind
-
宣布了由 Andrew Ng 教授的 AI Python for Beginners 课程,旨在帮助有抱负的开发者和专业人士利用 AI 提高生产力并自动化任务。@DeepLearningAI
迷因与幽默
- 分享了各种与 AI 和技术相关的幽默推文和迷因,包括关于 AI 模型名称和能力的笑话。@swyx
本摘要捕捉了所提供推文的主要主题和讨论,重点关注 AI 模型、工具、应用的最新进展,以及对 AI 工程和科技行业的广泛影响。
AI Reddit 摘要
/r/LocalLlama 回顾
主题 1. 高级量化与模型优化技术
-
Llama-3.1 70B 4-bit HQQ/校准量化模型:在 lm-eval 的所有基准测试中,相对于 FP16 的性能达到 99% 以上,且推理速度与 FP16 相当(在 A100 上为 10 toks/sec)。 (评分: 91, 评论: 26): Llama-3.1 70B 模型已通过 HQQ/校准量化 成功量化为 4-bit,在 lm-eval 的所有基准测试中实现了超过 99% 的 FP16 相对性能。该量化版本保持了与 FP16 类似的推理速度,在 A100 GPU 上每秒处理约 10 个 tokens。这一成就展示了在保持性能的同时模型压缩方面取得的重大进展,可能使大型语言模型的部署更加高效。
-
为什么 Unsloth 如此高效? (评分: 94, 评论: 35): Unsloth 在显存有限的情况下处理 32k 文本长度 的摘要任务时,表现出了卓越的效率。用户报告称,使用 Unsloth 在 L40S 48GB GPU 上成功训练了一个模型,而传统的 transformers llama2 结合 qlora、4bit 和 bf16 技术的方法在相同硬件上则无法运行。显著的性能提升归功于 Unsloth 对 Triton 的使用,尽管具体机制对用户来说尚不明确。
-
在 9 天内预训练一个 LLM 😱😱😱 (评分: 216, 评论: 53): Hugging Face 和 Google 的研究人员开发了一种方法,仅使用 16 台 A100 GPU,在短短 9 天 内就预训练了一个拥有 1.3B 参数的语言模型。这项名为 Retro-GPT 的技术将 检索增强语言建模 (retrieval-augmented language modeling) 与 高效的预训练策略 相结合,实现了与训练时间更长的模型相当的性能,有可能彻底改变 LLM 开发的速度和成本效益。
主题 2. LLM 开发的开源贡献
-
一个广泛的 RAG 实现开源集合,包含多种不同策略 (评分: 91, 评论: 20): 该帖子介绍了一个 开源仓库,其中包含 17 种不同检索增强生成 (RAG) 策略 的全面集合,并配有 教程和可视化。作者鼓励社区参与,邀请用户提交 issue、建议额外策略,并将该资源用于学习和参考。
-
来自 TII(阿联酋技术创新研究所)的 Falcon Mamba 7B (评分: 87, 评论: 18): 阿联酋的 技术创新研究所 (TII) 发布了 Falcon Mamba 7B,这是一款开源的 状态空间语言模型 (SSLM),结合了 Falcon 架构与 Mamba 的状态空间序列建模。该模型可在 Hugging Face 上获取,配有模型卡片、集合和 playground,允许用户探索和实验这项新的 AI 技术。
- 用户测试了 Falcon Mamba 7B,报告的结果褒贬不一。一位用户发现它在处理产品需求文档 (PRD) 任务时表现 “非常非常非常差”,响应变得平庸且无组织。
- 该模型的性能受到质疑,尽管声称具有优越性,但一些用户发现它比 Llama 和 Mistral 模型更差。使用各种 prompts 进行的测试结果令人失望。
- 一些用户对 Falcon 模型表示 怀疑,这基于过去的负面体验,暗示 Falcon 系列可能存在性能不佳的模式。
全球 AI Reddit 综述
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型发布与功能
-
关于新 GPT-4 模型的猜测:r/singularity 上的一篇帖子声称 ChatGPT 提到了一个“自上周以来发布的新 GPT-4o 模型”,引发了关于 OpenAI 可能发布新产品的讨论。
-
Flux 图像生成模型:多篇帖子讨论了新 Flux 图像生成模型的能力:
- 令人印象深刻的印象派风景生成,使用了基于 5000 张图像训练的自定义 LoRA。
- 尝试生成符合解剖学结构的裸体图像,使用了自定义 LoRA。
- 为虚构产品进行创意广告概念生成。
AI 生成媒体
- 带有合成语音的 AI 生成视频:一段演示视频展示了将 Flux 生成的图像进行动画处理并配以 AI 生成的语音,尽管评论者指出存在口型同步和语音质量问题。
自动驾驶汽车
- Waymo 自动驾驶汽车问题:一段视频帖子显示 Waymo 自动驾驶汽车在从起点导航时遇到困难,引发了关于当前技术局限性的讨论。
AI 与社会
- AI 伴侣与人际关系:一个具有争议的迷因帖子引发了关于 AI 伴侣对人类关系和社会动态潜在影响的辩论。
AI Discord 综述
由 GPT-4o (gpt-4o-2024-05-13) 生成的摘要之摘要的摘要
1. 模型性能与基准测试
- 无审查模型表现优于 Meta Instruct:一个经过微调以保留原始 Meta Instruct 模型智能的无审查模型已经发布,并在 LLM Leaderboard 2 上超越了原始模型。
- 该模型的表现引发了关于审查与实用性之间权衡的讨论,许多用户赞扬其处理更广泛输入的能力。
- Mistral Large:当前的冠军?:一位成员发现 Mistral Large 2 是目前最好的 LLM,在处理困难的新颖问题上胜过 Claude 3.5 Sonnet。
- 然而,Gemini Flash 在价格上大幅低于 OpenAI 4o mini,但 OpenAI 4o 的价格比 Mistral Large 更便宜。
- Google 的 Gemini Live:正式上线,但并非免费:Gemini Live 现已面向 Advanced Subscribers(高级订阅用户)开放,在 Android 上提供对话式叠加功能以及更多连接的应用。
- 许多用户表示,它比旧的语音模式有所改进,但仅供付费用户使用,且缺乏实时视频功能。
2. GPU 与硬件讨论
- GPU 之战 - A100 vs A6000:成员们讨论了 A100 与 A6000 GPU 的优缺点,其中一位成员指出 A6000 具有极佳的价格/VRAM 比,且与 24GB 显卡相比没有限制。
- 讨论强调了 VRAM 和成本效益对于大型模型训练和推理的重要性。
- Stable Diffusion 安装困扰:一位用户报告了安装 Stable Diffusion 时的困难,遇到了 CUDA 安装问题以及在 Hugging Face 上查找 Token 的问题。
- 另一位用户提供了通过个人资料设置菜单生成 Token 以及正确安装 CUDA 的指导。
- TorchAO 在 Cohere for AI 的演讲:来自 PyTorch Architecture Optimization 的 Charles Hernandez 将在 Cohere For AI 的 ml-efficiency 小组介绍 TorchAO 和量化(quantization)。
- 该活动由 @Sree_Harsha_N 主持,参与者可以通过提供的链接加入 Cohere For AI。
3. 微调与优化技术
- 模型微调技巧与窍门:讨论围绕微调 Phi3 model 以及是否使用 LoRA 或全量微调展开,一位成员建议将 RAG 作为潜在解决方案。
- 用户分享了经验和最佳实践,强调了为不同模型选择正确微调策略的重要性。
- TransformerDecoderLayer 重构 PR:已提交一个重构 TransformerDecoderLayer 的 PR,涉及多个文件,并对 modules/attention.py 和 modules/transformer.py 进行了核心修改。
- 该 PR 实现了 RFC #1211,旨在改进 TransformerDecoderLayer 架构。
- PyTorch 全 FP16:是否可行?:一位用户询问是否可以在 PyTorch core 中使用带有 loss/grad scaling 的全 FP16,特别是在微调来自 Fairseq 的大型模型时。
- 他们尝试使用 torch.GradScaler() 并将模型转换为 FP16,而不使用 torch.autocast(‘cuda’, torch.float16),但遇到了错误 ‘ValueError: Attempting to unscale FP16 gradients.’。
4. AI 平台的 UI/UX 问题
- Perplexity 的 UI/UX 问题:用户报告了多个 UI/UX 问题,包括按钮缺失和提示词输入框消失,导致与平台交互困难。
- 这些 Bug 在 Perplexity 的网页版和 iOS 版中均有报告,引起了用户的极大挫败感,并阻碍了他们有效利用该平台。
- LLM Studio 的 Model Explorer 宕机:多名成员报告称,为 LM Studio Model Explorer 提供支持的 HuggingFace 已宕机。
- 确认该网站已数小时无法访问,多个地区均报告了连接问题。
- Perplexity 网站稳定性担忧:用户报告网站稳定性显著下降,理由包括搜索行为异常、遗忘上下文以及网页和 iOS 版的界面 Bug。
- 这些问题引发了对 Perplexity 提供的可靠性和用户体验的担忧。
5. 开源 AI 框架与社区努力
- Rust GPU 移交给社区所有:此前由 Embark Studios 负责的 Rust GPU 项目现在归 Rust GPU GitHub organization 社区所有。
- 这一转变标志着旨在振兴、统一和标准化 Rust 中 GPU 编程的更广泛战略的开始。
- Open Interpreter 实现万物转换:使用 Open Interpreter 将任何类型的数据转换为任何其他格式。
- 通过使用利用 Open Interpreter 强大功能的 ‘Convert Anything’ 工具,这是可以实现的。
- Cohere For AI 研究实验室:Cohere For AI 是一个非营利研究实验室,致力于解决复杂的机器学习问题。
- 他们支持探索未知的基本研究,并专注于为机器学习研究创造更多切入点。
PART 1: Discord 高层级摘要
Unsloth AI (Daniel Han) Discord
- Unsloth Pro 早期访问:目前正向 Unsloth 社区中值得信赖的成员提供 Unsloth Pro 版本的早期访问权限。
- A100 vs A6000 GPU 对决:成员们讨论了 A100 与 A6000 GPU 的优缺点,一位成员指出 A6000 具有极佳的价格/VRAM 比,且与 24GB 显卡相比没有限制。
- 无审查模型登顶排行榜:一个经过调整以保留原始 Meta Instruct 模型智能的无审查模型已发布,并在 LLM Leaderboard 2 上超越了原始模型。
- Dolphin 模型遭受审查困扰:一位成员报告称 Dolphin 3.1 模型无法处理最基本的请求并予以拒绝,这可能是由于其严格的审查制度。
- AI 工程师的微调:讨论围绕微调 Phi3 model 以及是否使用 LoRA 或全量微调展开,一位成员建议将 RAG 作为潜在解决方案。
CUDA MODE Discord
- TorchAO 在 Cohere For AI 的演讲:来自 PyTorch Architecture Optimization 的 Charles Hernandez 将于 CEST 时间 2000 年 8 月 16 日在 Cohere For AI 的 ml-efficiency 小组介绍 TorchAO 和 quantization。
- 本次活动由 @Sree_Harsha_N 主持,参与者可以通过链接 https://tinyurl.com/C4AICommunityApp 加入 Cohere For AI。
- CPU matmul 优化之战:一位用户尝试在 Zig 中编写基于 tiling 的 matmul,但在实现最佳性能方面遇到了困难。
- 他们收到了关于探索 cache-aware 循环重排以及使用 SIMD 指令潜力的建议,并将其性能与 GGML 和 NumPy 进行了对比,后者利用优化的 BLAS 实现获得了极快的运行结果。
- FP16 权重与 CPU 性能:一位用户询问了如何在 CPU 上处理 FP16 权重,并指出最近的模型通常使用 BF16。
- 建议他们将 FP16 权重转换为 BF16 或 FP32,其中 FP32 不会导致精度损失,但可能会导致推理速度变慢;同时建议探索在运行时将 tensor 从 FP16 转换为 FP32 以潜在地提高性能。
- PyTorch 全 FP16:真的可行吗?:一位用户询问在 PyTorch 核心库中是否可以使用带有 loss/grad scaling 的全 FP16 模式,特别是在微调来自 Fairseq 的中大型模型时。
- 他们尝试使用
torch.GradScaler()并将模型转换为 FP16,且不使用torch.autocast('cuda', torch.float16),但遇到了错误 “ValueError: Attempting to unscale FP16 gradients.”。
- 他们尝试使用
- torch.compile: The Missing Manual:一份名为 “torch.compile: The Missing Manual” 的新 PyTorch 文档与一段 YouTube 视频一同被分享。
- 该文档和视频分别可在 https://docs.google.com/document/d/1y5CRfMLdwEoF1nTk9q8qEu1mgMUuUtvhklPKJ2emLU8/edit#heading=h.ivdr7fmrbeab 和 https://www.youtube.com/live/rew5CSUaIXg?si=zwbubwKcaiVKqqpf 获取,提供了关于利用
torch.compile的详细信息。
- 该文档和视频分别可在 https://docs.google.com/document/d/1y5CRfMLdwEoF1nTk9q8qEu1mgMUuUtvhklPKJ2emLU8/edit#heading=h.ivdr7fmrbeab 和 https://www.youtube.com/live/rew5CSUaIXg?si=zwbubwKcaiVKqqpf 获取,提供了关于利用
LM Studio Discord
- Vision Adapters:视觉模型的关键:只有特定的 LLM 模型拥有 vision adapters,其中大多数以 “LLaVa” 或 “obsidian” 命名。
- “VISION ADAPTER” 是视觉模型的关键组件;如果没有它,就会弹出你分享的那个错误。
- Mistral Large:当前的冠军?:一位成员认为 Mistral Large 2 是目前最好的 LLM,在处理困难的新颖问题上胜过 Claude 3.5 Sonnet。
- 然而,该成员也指出 Gemini Flash 在价格上大幅低于 OpenAI 4o mini,但 OpenAI 4o 的价格比 Mistral Large 更便宜。
- LLM Studio 的 Model Explorer 宕机:多名成员报告称,为 LM Studio Model Explorer 提供支持的 HuggingFace 出现故障。
- 该网站被确认已连续数小时无法访问,多个地区都报告了连接问题。
- Llama 3.1 性能问题:一位用户报告称,他们的 Llama 3 8B 模型 现在的运行速度仅为 3 tok/s,而最近更新前为 15 tok/s。
- 用户检查了他们的 GPU offload 设置并将其重置为默认值,但问题仍然存在;该问题似乎与最近更新中的更改有关。
- LLM 输出长度控制:一位成员正在寻找限制响应输出长度的方法,因为某些模型即使被指示提供单句回答,也倾向于输出整个段落。
- 虽然可以修改 system prompts,但该成员发现 8B 模型(特别是 Meta-Llama-3.1-8B-Instruct-GGUFI)在遵循精确指令方面表现并非最佳。
OpenAI Discord
- Google 推出 Gemini Live,但并非面向所有人:Gemini Live 现已向 Advanced Subscribers 开放,在 Android 上提供对话式叠加层以及更多连接的应用。
- 许多用户表示,它比旧的语音模式有所改进,但仅供付费用户使用,且缺乏实时视频功能。
- Strawberry:营销天才还是 OpenAI 的新面孔?:关于名为 “Strawberry” 的神秘用户发布一串表情符号的讨论,引发了人们对其与 OpenAI 或 Sam Altman 可能存在联系的猜测。
- 用户评论说,草莓表情符号与 Sam Altman 手持草莓的照片相关联,是一种聪明的营销策略,成功吸引了用户参与对话。
- Project Astra 期待已久的到来:Gemini Live 的发布暗示了 Project Astra,但许多用户对其缺乏进一步进展感到失望。
- 一位用户甚至将其与 Microsoft recall 进行了类比,暗示由于安全担忧,人们对该产品的发布持怀疑态度。
- LLMs:并非万能解决方案:一些用户对 LLMs 是解决所有问题的方案表示怀疑,特别是在处理数学、数据库甚至 waifu 角色扮演等任务时。
- 其他用户强调,tokenization 仍然是一个根本性的弱点,LLMs 需要更具策略性的方法,而不是依靠暴力 tokenization 来解决复杂问题。
- ChatGPT 的网站访问限制:一个持续存在的问题:一位成员询问如何让 ChatGPT 访问网站并获取文章,但另一位成员指出,ChatGPT 可能会被阻止抓取网页内容,或者会对网页内容产生幻觉。
- 一位用户询问是否有人尝试使用 “web browser GPT” 这一术语作为可能的变通方法。
Perplexity AI Discord
- Perplexity 的 UI/UX Bug:用户遇到了 UI/UX 问题,包括按钮缺失和提示词字段消失,导致与平台交互困难。
- 这些 Bug 在 Perplexity 的网页版和 iOS 版上均有报告,引起了用户的极大挫败感,并阻碍了他们有效利用平台。
- Sonar Huge:新模型,新问题:新模型 “Sonar Huge” 取代了 Perplexity Pro 中的 Llama 3.1 405B 模型。
- 然而,用户观察到新模型运行缓慢,且未能遵循用户个人资料中的提示词,引发了对其有效性和性能的担忧。
- Perplexity 的网站稳定性问题:用户报告网站稳定性显著下降,出现了搜索行为异常、丢失上下文以及各种界面 Bug 等问题。
- 这些问题在网页版和 iOS 版上均有观察到,引发了对 Perplexity 提供的可靠性和用户体验的担忧。
- Perplexity 的 Success Team 注意到相关情况:Perplexity 的 Success Team 承认收到了关于平台近期出现的 Bug 和故障的用户反馈。
- 他们表示已意识到报告的问题及其对用户体验的影响,暗示未来可能会有解决方案和改进。
- Perplexity 的功能实现延迟:一位用户对功能实现的漫长等待时间表示沮丧。
- 他们强调了承诺的功能与实际推出速度之间的差异,强调了加快开发和交付以满足用户期望的重要性。
Stability.ai (Stable Diffusion) Discord
- Stability AI 的 SXSW 研讨会提案:Stability AI 首席执行官 Prem Akkaraju 和科技影响力人物 Kara Swisher 将在 SXSW 上讨论开源 AI 模型的重要性以及政府在监管其影响方面的角色。
-
该研讨会将探讨 AI 的机遇与风险,包括岗位取代、虚假信息、CSAM 以及知识产权(IP rights),并可在 PanelPicker® 上查看:[PanelPicker SXSW Conference & Festivals](http://panelpicker.sxsw.com/vote/153232)。
-
- Google Colab 运行时停止工作:一位用户遇到了 Google Colab 运行时过早停止的问题。
- 另一位用户建议切换到 Kaggle,它提供更多资源和更长的运行时,为更长时间的 AI 实验提供了解决方案。
- Stable Diffusion 安装与 CUDA 挑战:一位用户在安装 Stable Diffusion 时遇到了困难,涉及 CUDA 安装以及查找 Hugging Face token 的问题。
- 另一位用户提供了通过 Hugging Face 个人资料设置菜单生成 token 并正确安装 CUDA 的指导,为该用户的挑战提供了解决方案。
- 模型合并讨论:一位用户建议利用 UltraChat 和基础 Mistral 之间的差异来改进 Mistral-Yarn,将其作为一种潜在的模型合并(Model Merging)策略。
- 尽管一些用户表示怀疑,但原用户保持乐观,并引用了以往成功的模型合并尝试,展示了 AI 模型开发的潜在进展。
- 用于换脸的 Flux 真实感:一位用户在尝试 fal.ai 产生卡通化效果后,寻求实现真实换脸的替代方案。
- 另一位用户建议使用 Flux,因为它能够对 logo 进行训练并将其准确放置在图像上,为用户的换脸目标提供了潜在解决方案。
OpenRouter (Alex Atallah) Discord
- Gemini Flash 1.5 降价:Gemini Flash 1.5 的输入 token 成本降低了 78%,输出 token 成本降低了 71%。
- 这使得该模型对更广泛的用户群体来说更加易于获取且负担得起。
- GPT-4o Extended 早期访问启动:GPT-4o Extended 的早期访问已通过 OpenRouter 启动。
- OpenRouter 的更新障碍:OpenRouter 的更新受到了 Gemini 新的 1:4 token 与字符比例的阻碍,这无法清晰地映射到
max_tokens参数验证中。- 一位用户对不断变化的 token 与字符比例表示沮丧,并建议切换到按 token 计费的系统。
- Euryale 70B 停机:一位用户报告 Euryale 70B 对部分用户停机,但对他本人正常,引发了关于故障或错误率的疑问。
- 进一步讨论显示了多次停机情况,包括一次因更新导致的 10 分钟中断,以及可能持续存在的区域可用性问题。
- 模型性能对比:用户对比了 Groq 70b 和 Hyperbolic 的性能,发现相同 prompt 的结果几乎完全一致。
- 这引发了关于 FP8 量化(FP8 quantization) 影响的讨论,一些用户指出它在实践中差异极小,但另一些用户则指出某些供应商可能会出现质量下降的情况。
Modular (Mojo 🔥) Discord
- Mojo 许可证的限制性条款:Mojo License 禁止使用该语言开发用于竞争性活动的应用程序。
- 然而,条款规定该规则不适用于在初始发布后才变得具有竞争性的应用程序,但目前尚不清楚该条款将如何执行。
- Mojo 开源时间表仍不明确:用户询问了 Mojo 编译器开源的时间表。
- 团队确认编译器最终会开源,但没有提供具体时间表,并暗示在能够接受贡献之前可能还需要一段时间。
- Mojo 开发:专注于标准库:目前 Mojo 开发的重点是构建标准库。
- 鼓励用户为标准库做出贡献,而编译器的开发工作虽然在进行中,但尚未开放贡献。
- Stable Diffusion 与 Mojo:内存至关重要:一位用户在 WSL2 中运行 Stable Diffusion Mojo ONNX 示例时遇到了内存压力问题,导致进程被终止。
- 该用户为 WSL2 分配了 8GB 内存,但团队建议将其翻倍,因为 Stable Diffusion 1.5 大约为 4GB,模型及其优化过程都需要更多内存。
- 微软版 Java:往事回顾:一位成员认为“微软版 Java”是不必要的且本可以避免,而另一位成员则反驳说这在当时似乎至关重要。
- 讨论承认了新解决方案的出现以及“微软版 Java”随时间的衰落,强调了它 20 年的运行历程及其在微软市场份额中的相关性。
Cohere Discord
- Cohere For AI 研究实验室扩张:Cohere For AI 是一个专注于复杂机器学习问题的非营利研究实验室。他们正在为机器学习研究创造更多的准入门槛。
- 他们支持探索未知的基本研究。
- Cohere 网站价格变动:一位用户询问了 classify 功能的定价,因为它不再列在定价页面上。
- 未提供回复。
- JSONL 上传失败:用户报告了上传用于 fine-tuning 的 JSONL 数据集时出现的问题。
- Cohere 支持团队承认了该问题,表示正在调查中,并建议暂时使用 API 创建数据集作为替代方案。
- Azure 不支持 JSON 格式化:一位成员询问在 Azure 中使用
response_format进行结构化输出的问题,但遇到了错误。- 已确认 Azure 上尚不支持 JSON 格式化。
- Rerank 概览和代码帮助:一位用户在 Rerank 概览文档中寻求帮助,在使用提供的代码时遇到了问题。
- 该问题与文档过时有关,已提供修订后的代码片段。该用户还被引导至相关文档以供进一步参考。
Torchtune Discord
- TransformerDecoderLayer 重构落地:已提交一个 PR 用于重构 TransformerDecoderLayer,涉及多个文件,并对 modules/attention.py 和 modules/transformer.py 进行了核心更改。
- 此 PR 实现了 RFC #1211,旨在改进 TransformerDecoderLayer 架构,可以在此处找到:TransformerDecoderLayer Refactor。
- RLHF 优选 DPO:有一场关于使用 DPO 或 PPO 测试 HH RLHF 构建器的讨论,对于偏好数据集,DPO 是首选,而 PPO 则与数据集无关。
- 重点在于 DPO,预期损失曲线与普通 SFT 相似,HH RLHF 构建器可能需要调试,这可能会在单独的 PR 中解决。
- Torchtune WandB 问题已解决:一位用户在访问 Torchtune 的 WandB 结果时遇到问题,在将该用户添加为团队成员后,访问权限已授予。
- 该用户报告在使用默认 DPO 配置并关闭梯度累积(gradient accumulation)时结果较差,但后来发现它又开始正常工作了,可能是由于延迟或其他因素。
- Torchtune 在 DPO 下的性能:讨论了默认 DPO 配置可能导致 Torchtune 性能不佳的问题。
- 用户建议尝试 SIMPO (Stack Exchange Paired) 并重新开启梯度累积,因为在 batch 中保持平衡的正负样本数量可以显著改善 loss。
- PyTorch Conference:思想的汇聚:关于即将举行的 PyTorch Conference 的讨论,包含网站链接和演讲嘉宾详情。
- 您可以在此处找到有关会议的更多信息:PyTorch Conference。还有人提到以“学术人员”身份混入会议,但这可能只是个玩笑。
OpenAccess AI Collective (axolotl) Discord
- Perplexity Pro 的推理能力:一位用户注意到 Perplexity Pro 的“推理能力变得疯狂地好”,并且能够“字面意义上数清字母”,就像它“抛弃了 tokenizer”一样。
- 他们分享了一个似乎与此主题相关的 GitHub 仓库 链接。
- Llama 3 MoE?:一位用户询问是否有人制作了 Llama 3 的 “MoE” 版本。
- 梯度裁剪 (Grad Clipping) 揭秘:一位用户询问了梯度裁剪的功能,特别是想知道当梯度超过最大值时会发生什么。
- 另一位用户解释说,梯度裁剪本质上是将梯度限制在一个最大值,防止其在训练期间爆炸。
- OpenAI 基准测试 vs 新模型:一位用户对 OpenAI 发布基准测试而不是新模型感到惊讶。
- 他们推测这可能是一个战略举措,旨在引导该领域转向更好的评估工具。
- Axolotl 的功能:一位成员指出 AutoGPTQ 可以完成某些事情,暗示 Axolotl 可能也能做到。
- 他们对 Axolotl 复制这一功能的可能性感到兴奋。
LAION Discord
- Grok 2.0 早期泄露:一位成员分享了一条关于 Grok 2.0 功能和能力 的推文链接,包括使用 FLUX.1 模型生成图像。
- 推文还指出 Grok 2.0 在编程、写作和生成新闻方面表现更好。
- Flux.1 创造了一个拐点:一位成员提到许多 Elon 的粉丝账号预测 X 将使用 MJ(推测指某个模型),暗示 Flux.1 可能在模型使用方面创造了一个拐点。
- 该成员质疑 Flux.1 是否是 Schnellit 的 Pro 模型,考虑到 Elon 的过往经历。
- 开源图像标注工具搜索:一位成员寻求推荐好的开源 GUI,以便快速高效地标注图像。
- 该成员特别提到了单点标注、直线标注和绘制多边形分割掩码(polygonal segmentation masks)。
- Elon 的模型虚张声势:一位成员讨论了 Elon 使用 Grok 开发版本并对权重许可(weight licenses)虚张声势的可能性。
- 该成员认为 Elon 可能会将其称为“红丸(red-pill)”版本。
- 2D 池化 (2D Pooling) 的成功:一位用户对 2D 池化的效果感到惊讶。
- 该用户指出这是由另一位用户推荐的,目前正在验证一种他们认为可能是自己发明的新位置编码(position encoding)的功效。
tinygrad (George Hotz) Discord
- Tensor 过滤性能?:一位用户询问过滤 Tensor 的最快方法,例如
t[t % 2 == 0],目前是通过转换为列表、过滤后再转回列表的方式实现的。- 有建议提到,如果是在 Tensor 的子集上进行计算,可以使用 masking(掩码),但指出目前尚不支持完全相同的功能。
- 超越函数折叠重构优化 (Transcendental Folding Refactor Optimization):一位用户提议进行重构,仅当后端没有针对该
uop的code_for_op时才应用超越函数重写规则。- 该用户实现了一个
transcendental_folding函数并在UOpGraph.__init__中调用,但不确定这如何能实现净减少代码行数,并询问可以删除哪些部分。
- 该用户实现了一个
- CUDA 超时错误 - 已解决:一位用户在使用
CLANG=1运行脚本时收到了RuntimeError: wait_result: 10000 ms TIMEOUT!错误。- 该错误发生在默认运行时,通过使用
CUDA=1得到解决,该问题可能与 ##4562 相关。
- 该错误发生在默认运行时,通过使用
- Nvidia FP8 PR 建议:一位用户对 tinygrad 的 Nvidia FP8 PR 提出了建议。
MLOps @Chipro Discord
- Poe 与 Agihouse 合作举办黑客松:Poe (@poe_platform) 宣布与 Agihouse (@agihouse_org) 合作举办“Previews Hackathon”,以庆祝其扩大发布。
- 该黑客松在 AGI House 举行,邀请创作者构建创新的“聊天内生成式 UI 体验 (in-chat generative UI experiences)”。
- 聊天内 UI 是未来:Poe Previews Hackathon 鼓励开发者创建创新且实用的“聊天内生成式 UI 体验”,强调了生成式 AI 中用户体验的重要性。
- 黑客松希望在竞争环境中展示参与者的创造力和技能。
- 虚拟试穿功能加速训练:一位成员分享了构建虚拟试穿功能的经验,指出通过存储提取的特征可以有效加速训练运行。
- 该功能使用在线预处理并将提取的特征存储在文档存储表中,从而在训练期间实现高效检索。
- 灵活的虚拟试穿功能:一位成员询问了为虚拟试穿功能提取的具体特征。
- 该成员详细说明了该通用的方法,成功适配了各种规模的模型,展示了其在处理计算需求和模型复杂性方面的灵活性。
LangChain AI Discord
- Llama 3.1 8b 支持结构化输出:一位用户确认 Llama 3.1 8b 可以通过 tool use 产生结构化输出,并已直接使用 llama.cpp 进行了测试。
- RAG 在处理技术图像时遇到困难:一位用户正在寻求关于从电气图、地图和电压曲线等图像中提取信息以用于技术文档 RAG 的建议。
- 他们提到传统方法遇到了困难,强调需要捕获那些文本中不存在但专家可以视觉解读的信息。
- Next.js POST 请求被误解为 GET:一位用户在从运行在 EC2 上的 Next.js Web 应用向同一 EC2 实例上的 FastAPI 端点发送 POST 请求时遇到了 405 Method Not Allowed 错误。
- 他们观察到,尽管在 Next.js 代码中明确使用了 POST 方法,请求仍被错误地解释为 GET 请求。
- AWS pip install 问题已解决:一位用户通过专门为 Unix 环境安装软件包,解决了 AWS 系统上的 pip install 问题。
- 问题源于虚拟环境在 pip install 过程中错误地模拟了 Windows,导致了该问题。
- Profundo 发布以自动化研究:Profundo 自动化数据收集、分析和报告,使每个人都能对感兴趣的主题进行深度研究。
- 它最大限度地减少错误并提高生产力,让用户能够专注于做出明智的决策。
OpenInterpreter Discord
- Open Interpreter in Obsidian: 一个新的 YouTube 系列将演示如何在 Obsidian 笔记应用中使用 Open Interpreter。
- 该系列将重点介绍 Open Interpreter 插件如何让你控制你的 Obsidian vault,这可能对人们处理知识的方式产生重大影响。这是第 0 集的链接。
- AI Agents in the Enterprise: #general 频道的一位用户询问了在大型组织内监控和治理 AI Agent 的挑战。
- 该用户邀请任何在企业内部从事 AI Agent 相关工作的人分享他们的经验。
- Screenless Personal Tutor for Kids: #O1 频道的一位成员提议使用 Open Interpreter 为儿童创建一个无屏幕的私人导师。
- 该成员请求反馈,并询问是否有其他人有兴趣在这个项目上进行协作。
- Convert Anything Tool: “Convert Anything” 工具可以使用 Open Interpreter 将任何类型的数据转换为任何其他格式。
- 该工具利用了 Open Interpreter 的强大功能,在各个领域都有巨大的应用潜力。
Alignment Lab AI Discord
- SlimOrca Without Deduplication: 一位用户询问了一个移除了 soft prompting 且没有 deduplication 的 SlimOrca 版本,最好包含代码。
- 他们还询问是否有人实验过在有或没有 deduplication,以及有或没有 soft prompting 的数据上进行 fine-tuning (FT)。
- Fine-tuning with Deduplication: 该用户询问了使用 soft prompting 与不使用 soft prompting 进行 fine-tuning (FT) 的效果。
- 他们还询问了在 deduplicated data 与 non-deduplicated data 上进行 fine-tuning (FT) 的效果。
LLM Finetuning (Hamel + Dan) Discord
- Building an Agentic Jupyter Notebook Automation System: 一位成员提议构建一个 Agentic 系统来自动化 Jupyter Notebook,旨在创建一个以现有 notebook 为输入、修改单元格并生成多个变体的流水线。
- 他们寻求有关库、cookbook 或开源项目的建议,这些可以作为该项目的起点,并从 Devin 等类似工具中汲取灵感。
- Automated Notebook Modifications and Validation: 该系统应该能够智能地替换 Jupyter Notebook 中的特定单元格,并根据这些修改生成不同的 notebook 版本。
- 至关重要的是,该系统应具备 Agentic 特性,使其能够验证其输出并迭代优化修改,直到达到预期的结果。
Mozilla AI Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。
第 2 部分:按频道划分的详细摘要和链接
完整的频道细分内容已为邮件版缩减。
如果您喜欢 AInews,请分享给朋友!提前致谢!