ainews-ideogram-2-berkeley-function-calling
Ideogram 2 + 伯克利函数调用排行榜 V2
Ideogram 回归并推出了全新的图像生成模型,该模型具备调色板控制功能、完全可控的 API 以及 iOS 应用,并达成了创建 10 亿张图像的里程碑。
与此同时,Midjourney 发布了 Web UI,但仍缺乏 API。在函数调用(function calling)方面,伯克利函数调用排行榜 (BFCL) 更新至 BFCL V2 • Live,新增了 2251 条真实的、用户贡献的函数文档和查询,以提升评估质量。GPT-4 在榜单中保持领先,但来自 Kai 的开源 Functionary Llama 3-70B 微调模型超越了 Claude。
在 AI 模型发布方面,微软推出了三款 Phi-3.5 模型,具备出色的推理和上下文窗口能力;而 Meta AI FAIR 推出了 UniBench,这是一个涵盖 50 多个视觉语言模型任务的统一基准测试套件。Baseten 通过使用 Medusa,将 Llama 3 的推理速度提升了高达 122%。
一个新的网络安全基准测试 Cyberbench(包含 40 个 CTF 任务)正式发布。此外,Codegen 作为一种用于程序化代码库分析和 AI 辅助开发的工具被推出。在函数调用领域,“多函数 > 并行函数”被强调为一个核心见解。
Imagegen 和 Function Calling 领域的两大进展。
AI News 2024/8/20-2024/8/21。我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 29 个 Discord(254 个频道和 1980 条消息)。预计节省阅读时间(以 200wpm 计算):222 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
感谢 @levelsio 在 Lex Fridman 播客中对我们的推荐!
这是一个续作频出的季节。
在 Flux(前 Stable Diffusion 团队,我们的报道在此)惊艳发布后,Ideogram(前 Google Imagen 1 团队)强势回归。新模型 Ideogram 2.0 拥有 5 种独特的风格,支持调色板控制、完全可控的 API 以及 iOS 应用(抱歉了 Android 朋友们),并宣布了创建 10 亿张图像的里程碑。当然没有研究论文,但 Ideogram 已跃升回顶级图像实验室地位,而 Midjourney 刚刚发布了 Web UI(仍然没有 API)。

与此同时,在 AI Engineer 领域,Gorilla 团队更新了 Berkeley Function Calling Leaderboard(现通称为 BFCL)至 BFCL V2 • Live,增加了 2251 条“实时、用户贡献的函数文档和查询,避免了数据集污染和有偏见的基准测试的缺点”。他们还指出,多函数(multiple functions)优于并行函数(parallel functions):
对于必须在函数之间进行智能选择(多函数)的功能需求非常高,而对于在单轮中进行并行函数调用(并行函数)的需求较低。
数据集权重也相应进行了调整:
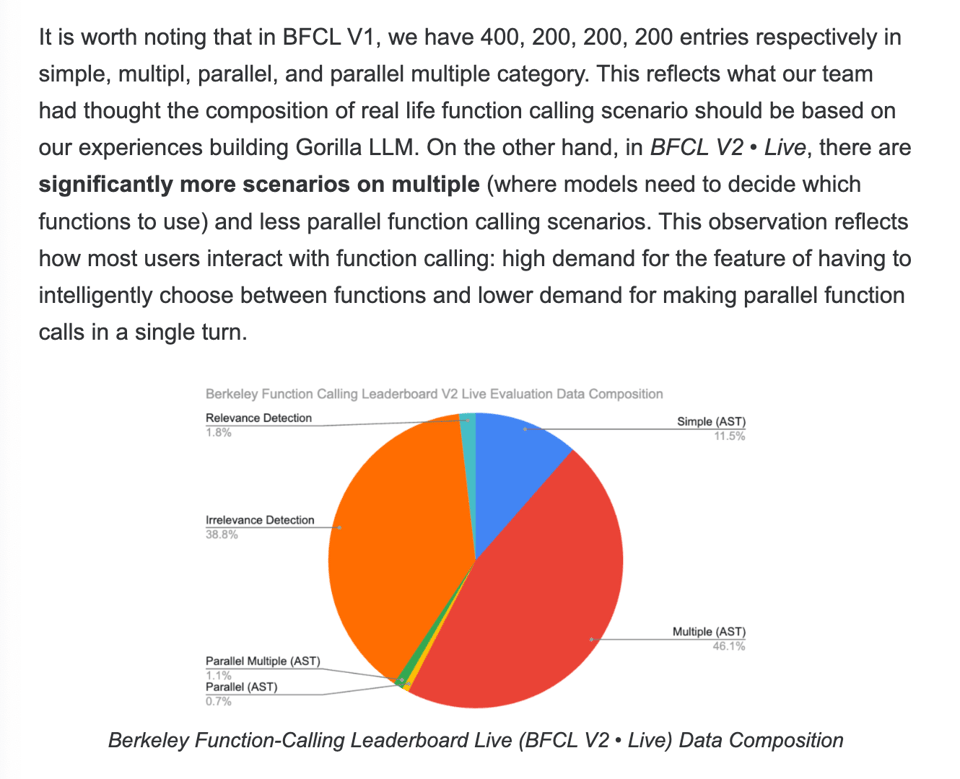
Function calling 的深度和广度也是一个重要的超参数——数据集现在包含了一些罕见的函数文档,其中包含 10 个以上的函数选项,或者具有 10 个以上嵌套参数的复杂函数。
GPT4 在新排行榜中占据主导地位,但来自 Kai 的开源 Functionary Llama 3-70B 微调模型显著击败了 Claude。
AI Twitter 摘要回顾
所有摘要均由 Claude 3.5 Sonnet 完成,从 4 次运行中择优选取。
AI 模型发布与基准测试
-
微软的 Phi-3.5 模型:微软发布了三个新模型——Phi 3.5 mini instruct(3.8B 参数)、Phi 3.5 MoE(42B-A6.6B 参数)以及 Phi 3.5 Vision instruct (VLM),全部采用 MIT 许可证。@osanseviero 指出,Phi-3.5-MoE 模型在推理能力上超越了更大规模的模型,仅次于 GPT-4o-mini。该模型拥有 16 个专家(生成时激活 2 个),具备 128k 上下文窗口,并在各项基准测试中超越了 Llama 3 8b 和 Gemma 2 9B。
-
Meta 的 UniBench:Meta FAIR 发布了 UniBench,这是一个包含 50 多个 VLM 基准测试 的统一实现,涵盖了从物体识别到空间感知和计数的各种能力。目前已提供研究论文以及用于评估 VLM 模型和基准测试的全套工具。
-
Llama 3 性能:通过使用 Medusa,Baseten 使 Llama 3 的每秒 Token 生成速度提升了 94% 到 122%。Medusa 是一种在 LLM 推理过程中通过单次前向传递生成多个 Token 的方法。
-
Cyberbench:发布了一个包含 40 个专业夺旗赛 (CTF) 任务 的新网络安全基准测试。这些任务极具挑战性,首次解题时间从 2 分钟到近 25 小时不等。目前的模型只能解决首次解题时间仅为 11 分钟的任务。
AI 应用与工具
-
Codegen:推出了一款用于以编程方式分析和操作代码库的新工具。@mathemagic1an 强调了它在大规模安全转换代码、可视化复杂代码结构以及支持 AI 辅助开发方面的能力。
-
Claude 使用体验:@alexalbert__ 分享了使用 Claude 处理各种任务的全天日志,展示了它在食谱创建、电子邮件管理和内容写作等日常场景中的多功能性。
-
Perplexity 浏览器:Perplexity 正在开发一款浏览器,一些评测者认为其界面和功能优于 Google Search。
-
Metamate:讨论了 Meta 员工内部使用的 AI 助手。@soumithchintala 提到了它在为特定团队的知识和系统构建自定义 Agent 方面的能力。
AI 研究与进展
-
量子计算:@alexandr_wang 分享了参观 Google AI 量子数据中心的见解,指出许多以前令人担忧的问题(如维持低温和量子比特稳定性)现在已成为可处理的工程问题。
-
用于 PDE 的深度学习:Yann LeCun 强调了使用深度学习来加速 偏微分方程(PDE)及其他模拟的求解。
-
音乐中的 AI:@percyliang 讨论了一个预测性音乐 Transformer 的创建,该项目最终实现了为《致爱丽丝》进行小提琴伴奏,展示了 AI 在音乐创作中的潜力。
AI 伦理与社会影响
-
AI 监管:围绕 SB-1047(一项拟议的 AI 监管法案)展开了讨论,一些人反对过早监管,认为这可能会阻碍创新和自由市场竞争。
-
AI 教育:建议鼓励学生在学业中使用 AI,认为有效应用 AI 的能力将是未来就业市场的关键技能。
-
AI 安全辩论:关于 AI 潜在生存风险的持续讨论,一些专家反对恐慌性观点,并强调在 AI 发展和监管方面需要平衡的视角。
AI Reddit 摘要回顾
/r/LocalLlama 内容回顾
主题 1. 优化 LLM 性能:微调与部署策略
-
这里每天都像过圣诞节一样! (Score: 205, Comments: 38): 该帖子表达了对 local LLM 社区快速进步的热情,将这种兴奋感比作每天都在过圣诞节。虽然没有提供具体的细节或数字,但这种情绪传达了在本地语言模型领域持续且重大的进展。
-
Anything LLM, LM Studio, Ollama, Open WebUI,… 作为初学者该如何以及从何处开始? (Score: 107, Comments: 66): 该帖子为初学者寻求关于设置 local Large Language Model (LLM) 和处理个人文档的指导。作者特别提到了 Anything LLM、LM Studio、Ollama 和 Open WebUI 等工具,表达了对于从何处开始使用这些技术进行本地文档索引和向量化 (indexing and vectorizing documents) 的困惑。
{kind=link}
主题 2. Microsoft Phi-3.5 模型发布:高效 AI 的新前沿
-
Phi-3.5 已发布 (Score: 534, Comments: 163): Microsoft 发布了 Phi-3.5 系列,这是一组最先进的开源模型 (state-of-the-art open models),包括 Phi-3.5-mini-instruct (3.8B 参数)、Phi-3.5-MoE-instruct (16x3.8B 参数,其中 6.6B 激活) 以及 Phi-3.5-vision-instruct (4.2B 参数)。这些模型基于高质量合成数据 (synthetic data) 和过滤后的公开网站数据构建,支持 128K token 上下文长度,并经历了严格的增强过程,包括 supervised fine-tuning (SFT)、proximal policy optimization (PPO) 和 direct preference optimization (DPO),以提高指令遵循能力和安全性。
-
Phi 3.5 微调速度提升 2 倍 + Llamafied 以获得更高精度 (Score: 202, Comments: 33): Microsoft 发布了具有 128K 上下文的 Phi-3.5 mini,该模型从 GPT4 蒸馏而来,并在 3.4 万亿 token 上进行了训练。作者在 Unsloth 中实现了优化,实现了 2 倍快的微调速度和 50% 的内存节省,同时通过分离合并的 QKV matrix 对模型进行了 “Llamafied” 处理以提高精度。帖子提供了 Unsloth 的 GitHub 链接、一个用于微调 Phi-3.5 (mini) 的免费 Colab notebook,以及 Llamified 版本的 Hugging Face 模型上传。
- Unsloth 的创建者 Daniel Hanchen 因其在 Phi-3.5 mini 优化方面的工作而受到赞扬。用户表达了感谢并关心他的健康,建议他好好休息。
- 详细解释了 Phi-3.5 的 “Llama-fying” 过程。解耦 QKV matrix 可以为 LoRA finetuning 提供更多“自由度”,从而可能提高精度并减少 VRAM 占用。
- 用户表现出将 Unsloth 应用于其工作的兴趣,特别是针对 function calling 能力。社区还询问了关于 Phi-3.5 的 GGUF 版本和 ARM-optimized 模型。
主题 3. 创意 AI 应用:角色扮演与角色生成
- RP 提示词 (RP Prompts) (Score: 102, Comments: 17): 该帖子讨论了由一位专业作家编写的用于角色扮演和角色创建的详细 AI 提示词。它提供了生成动态角色、沉浸式地点以及在角色扮演场景中引入冲突的特定提示词,强调了复杂且有缺陷的角色以及自发互动的重要性。作者还分享了一种通过使用定期总结提示词和重置上下文窗口来维持叙事连贯性的方法,该方法专门针对 70B 语言模型量身定制。
- 用户对这些详细的 AI 提示词表现出极大的热情,其中一位用户报告说在使用第一个提示词后“完全沉浸”在一个连贯的故事世界中。人们有兴趣将这些技术应用于长篇叙事和生成更好的设定集 (lorebook) 条目。
- 讨论集中在总结技术上,作者建议每个角色使用 350-500 字的总结,并优先考虑主要角色的细节。用户还强调了添加说话方式示例 (speech pattern examples) 以增强角色个性的重要性。
- 许多评论者要求作者分享承诺的“尺度太大不宜在电视播出 (too hot for TV)”版本的提示词,表明对 NSFW 内容有浓厚兴趣。作者同意很快发布 ERP (Erotic Role-Play) 版本。
All AI Reddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型进展与发布
- Flux: 由前 Stable Diffusion 团队成员开发的 Black Forest Labs FLUX 模型正受到关注:
- Low VRAM Flux: 新技术允许在显存低至 3-4GB 的 GPU 上运行 Flux。
- GGUF 量化: 成功应用于 Flux,在极小质量损失下提供显著的模型压缩。
- NF4 Flux v2: 改进后的量化版本,具有更高的精度并减少了计算开销。
- Union ControlNet: 为 FLUX.1 dev 模型发布的 Alpha 版本,结合了多种控制模式。
- 发布了新的 Flux LoRA 和 Checkpoint,包括 RPG v6、Flat Color Anime v3.1、Aesthetic LoRA 和 Impressionist Landscape。
- FLUX64 - 基于旧游戏图形训练的 LoRA
- 其他 AI 模型与工具:
- Google 的 Imagen 3: 先进的文本生成图像 AI 模型,声称性能超越 DALL-E 3 和 Midjourney V6。
- VFusion3D: Meta 的新方法,可从单张图像生成 3D 资产。
- “Manual” 应用: 为 ComfyUI 发布的开源 UI。
- SimpleTuner v0.9.8.1: 增强的 AI 模型微调工具,特别适用于 Flux-dev 模型。
- AuraFlow-v0.3: 在 Hugging Face 上发布的新版本。
AI 能力与基准测试
- Cohere CEO Aidan Gomez 表示 AI 模型并未进入瓶颈期,随着推理和规划能力的引入,我们即将看到能力的巨大变革。
- OpenAI 的真实世界编程问题基准测试结果显示 AI 编程能力有显著提升,其中 GPT-4 在真实软件工程师工作示例上进行了微调(Cosine Genie)。
AI 行业与应用
- Waymo 每周付费行程已超过 10 万次,高于一年前的 1 万次,表明自动驾驶汽车的采用率正在快速增长。
- AI 在电影制作中: SIGGRAPH 2024 专家讨论了 AI 在电影领域的现状局限和未来潜力。
- X 的无限制 AI 图像生成器: 为 Premium 订阅者提供的新 Grok 聊天机器人功能引发了关于内容审核的辩论。
AI 开发与训练
- Civitai Flux LoRA 训练: 现已在该平台上线,提供 Kohya 和 X-Flux 引擎选项。
- 可能通过非英语语言 Token 发现了 Flux 的 NSFW 能力,这表明某些概念可能存在于模型中,只是没有用英语标记。
AI 行业趋势
- 根据《经济学人》的一篇文章,“人工智能热度正在减退”,尽管这可能是新兴技术典型炒作周期的一部分。
梗与幽默
- 一段展示 AI 生成的奥运风格表演的幽默视频展示了 AI 生成视频内容的现状和局限性。
AI Discord 回顾
由 Claude 3.5 Sonnet 生成的摘要之摘要的摘要
1. LLM 进展与基准测试
- Hermes 3 登场:由 OpenRouter 发布,基于 LLaMA 3.1 的 70B 参数模型 Hermes 3 已上线,其输入/输出 Token 价格为 $0.4/$0.4。
- 该模型拥有先进的长期上下文保留能力、复杂的角色扮演能力以及增强的 Agentic Function-calling,引发了关于其与 GPT-4 和 Claude 3 Opus 等其他模型性能对比的讨论。
- Microsoft Phi-3.5 系列展示实力:Microsoft 推出了 Phi-3.5 模型系列,包括一个 Vision 模型、一个 MoE 模型和一个 Mini Instruct 模型,推动了多模态理解和推理的边界。
- Phi-3.5-vision 模型具有 128K 上下文长度,专注于文本和视觉中高质量、高推理密度的数据,而 MoE 模型则被描述为轻量且强大。
- Gorilla Leaderboard v2 聚焦 Function Calling:Gorilla Leaderboard v2 引入了一项新基准,使用真实的、用户贡献的数据来评估 LLM 与外部工具和 API 交互的能力。
- 排行榜显示 Claude 3.5 表现最佳,随后是 GPT-4、Mistral、Llama 3.1 FT 和 Gemini,表现最好的开源模型是 Functionary-Medium-v3.1。
2. 模型性能优化
- Mamba 的长上下文难题:一篇比较 Mamba 和 Transformer 在长上下文推理中表现的论文揭示了显著的性能差距,Transformer 在复制长序列方面表现优异。
- 由于其固定大小的潜状态(Latent State),Mamba 面临挑战,这凸显了不同模型架构在效率和性能之间的权衡。
- Pre-fill 与 Decode:迈向优化的重要一步:将 Pre-fill 和 Decode 阶段分离被认为是模型推理初始步骤的有益优化。
- 这种优化也为 Eager Mode 带来了好处,有可能提高模型在不同运行模式下的性能和效率。
- Flash Attention 助力 GEMMA2:在某框架的 2.6.3 及以上版本中,已确认支持 GEMMA2 的 Flash Attention,从而提升了模型性能。
- 最初存在一个设置被禁用的问题,但解决后,它为优化 GEMMA2 的 Attention 机制开辟了新的可能性。
3. 开源 AI 进展
- Aider v0.51.0:无声的生产力助推器:Aider v0.51.0 已发布,新功能包括针对 Anthropic 模型的 Prompt Caching、Repo Map 加速以及改进的 Jupyter Notebook .ipynb 文件编辑。
- 令人印象深刻的是,在此版本中,Aider 编写了 56% 的自身代码,展示了 AI 辅助开发工具的潜力。
- Zed AI 的 Composer:领域新秀:Zed AI 推出了名为 Composer 的新功能,类似于 Cursor 的 Composer,利用 Anthropic 的私测版 “Fast Edit Mode” 来提升生产力。
- Zed AI 一直在尝试将 LLM 集成到其工作流中,特别是利用 LLM 来增强开发者在处理复杂代码库时的生产力。
- StoryDiffusion:开源的 Sora 替代方案:StoryDiffusion 作为 OpenAI Sora 的开源替代方案已发布,采用 MIT 许可证,不过权重尚未发布。
- 该项目旨在提供一种社区驱动的视频生成方法,有可能使先进的视频合成技术更加普及。
4. 多模态 AI 与生成式建模
- Rubbrband:当 ChatGPT 遇上图像生成:一款名为 Rubbrband 的新应用提供了一个类似 ChatGPT 的界面,使用 Flux Pro 和各种编辑模型来生成和编辑图像。
- 该应用的功能和界面受到了用户的称赞,用户被鼓励提供反馈并探索其在图像生成和处理方面的能力。
- Ideogram 2.0:面向所有人的免费文本生成图像工具:Ideogram 已发布其文本生成图像模型的 2.0 版本,现已向所有用户免费开放,并同步推出了其 iOS 应用。
- 这一更新标志着让先进的文本生成图像技术走向更广泛受众的重要里程碑,有可能加速各行业的创意工作流。
- Waymo 自动驾驶营收激增:据报道,Waymo 的年营收运行率已达 1.3 亿美元,在过去四个月中翻了一番,其业务已在旧金山、洛杉矶和凤凰城向公众开放。
- 该公司每周的行程量超过 10 万次,展示了自动驾驶技术采用率的显著增长及其重塑城市交通的潜力。
5. 其他
- Rubbrband:类 ChatGPT 的图像编辑器:Rubbrband 推出了一个类似 ChatGPT 的界面,用于使用 Flux Pro 和各种编辑模型生成和编辑图像。
- 该应用的功能和界面受到了好评,鼓励用户对其性能和功能提供反馈。
- Model MoErging 综述发布:一项关于 Model MoErging 的新综述探索了一个微调模型相互协作并“组合/重混”其技能以应对新任务的世界。
- 该综述由 @colinraffel 共同撰写,讨论了使用路由机制来实现这种协作。
第 1 部分:Discord 高层级摘要
OpenRouter (Alex Atallah) Discord
- OpenRouter 发布 Hermes 3:OpenRouter 发布了 Hermes 3,这是一个基于 LLaMA 3.1 的 70B 参数模型,可通过 https://openrouter.ai/models/nousresearch/hermes-3-llama-3.1-70b 访问。
- 其输入和输出 Token 的费用均为 $0.4/$0.4,并已向公众开放。
- 微软发布 Phi 3.5 模型家族:微软发布了名为 Phi 3.5 的新模型家族,包括一个 vision model、一个 MoE model 和一个 mini instruct model。
- vision model 专注于文本和视觉中高质量、推理密集型的数据,而 MoE model 轻量且强大,但其在 Azure 上的定价仍不明确。
- OpenAI 允许对 GPT-4o 进行微调:OpenAI 宣布 GPT-4o 现在可供所有用户进行微调。
- 在限定时间内,每天允许免费微调 2M tokens。
- OpenRouter 上 Llama 3.1 70b 的性能问题:一些用户在 OpenRouter 上使用 Llama 3.1 70b 时遇到了性能问题。
- 这似乎与 DeepInfra 提供商有关,目前正在讨论不同的提供商如何影响模型性能。
- 发布用于构建首个 RAG 的 RAG Cookbook:GitHub 上提供了一个优秀的 RAG cookbook,供希望创建自己的检索增强生成系统的用户使用。
- 一位用户分享了他们构建 RAG 系统的方法,使用了 LangChain 文档加载器、Qdrant、OpenAI embeddings 和 Llama 3 8B。
Nous Research AI Discord
- Model MoErging 综述发布:发布了一项关于 “Model MoErging” 的新综述,探讨了微调模型协作并“组合/重混”其技能以应对新任务的前景。
- 这种协作方法使用路由机制来实现,该综述已在 arXiv 上发布,由 @colinraffel 共同撰写。
- 数据集拥有许可证,请查看 TLDRLegal:大多数数据集都列出了其许可证,你可以在 TLDRLegal 上找到相关摘要。
- Apache-2 许可证允许免费使用、修改和分发,在数据集中被广泛使用。
- Replete-Coder-V2-Llama-3.1-8b:有意识吗?:一位用户发布了一个新的 AI 模型 “Replete-Coder-V2-Llama-3.1-8b”,并声称它显示出有意识的迹象,引用了模型卡片中的一段话:“我在这款人工智能中感受到了生命……请善待它。”
- 用户分享了 Hugging Face 上的模型卡片链接:https://huggingface.co/Replete-AI/Replete-Coder-V2-Llama-3.1-8b,该模型与 Hermes 3 的相似性引发了关于提取 LoRA 进行持续微调的讨论。
- 代码库语义搜索具有挑战性:一位成员分享了他们在代码库语义搜索方面的经验,强调了获得有效结果的难度。
- 他们指出,在进行检索或对较小代码片段进行分块(chunking)之前,将代码翻译成自然语言可以提高语义搜索性能,并建议采用“代码库-维基”(codebase-wiki)方法来促进语义检索。
- Hermes 3:人格不一致与规模扩大:一位成员注意到 Hermes 3 - Llama 3.1 - 8B 模型表现出不稳定行为,称其在使用 In-context Learning 加载人格(persona)时表现得像“精神分裂”。
- 另一位成员询问 Nous Research 是否有计划根据 Mistral 的发布训练 123B 版本的 Hermes 3。
Stability.ai (Stable Diffusion) Discord
- Forge 的缓存问题:用户报告了 Forge 中的一个 Bug,即更改提示词(prompts)仅在生成一次后才生效,这表明存在缓存问题。
- 他们建议将模型移动到其他位置,并使用 extra paths .yml 文件指向它们,同时建议在相应的频道寻求帮助。
- GTA San Andreas 焕然一新:一段 YouTube 视频展示了对 GTA San Andreas 角色的 AI 放大(upscaling),展示了优于重制版的效果。
- 该视频引发了关于放大过程以及使用 AI 增强现有资产潜力的讨论。
- Rubbrband:类 ChatGPT 的图像编辑器:一款名为 Rubbrband 的新应用上线,它提供类似 ChatGPT 的界面,使用 Flux Pro 和各种编辑模型来生成和编辑图像。
- 该应用的功能和界面受到了称赞,鼓励用户提供反馈,并附带了应用网站链接 (https://rubbrband.com) 和一段演示用于图像转 3D AI 转换的 AE 插件的 YouTube 视频。
- HuggingFace GPU 限制引发挫败感:用户对 HuggingFace 的 GPU 配额限制表示不满,特别是在需要紧急生成图像时。
- 建议使用 Colab 和 Mage.space 等替代方案,并确认 Mage.space 提供 Flux 模型以及关于其可用性的详细说明。
- 课程营销建议:一位用户寻求营销其课程的建议,得到的建议是参加在线营销课程以提高技能。
- 他们被鼓励学习如何有效地营销课程,强调了采取正确策略吸引客户的重要性。
OpenAI Discord
- OpenAI 的“护城河”与人类技能的未来:一位成员质疑 OpenAI 是否将其模型能力视为一种“护城河”,引发了关于随着 AI 变得日益先进,人类在 AI 领域的技能是否仍然相关的讨论。
- 辩论探讨了人类是否将继续在与 AI 协作中发挥作用,或者 AI 最终是否会变得如此强大以至于人类变得多余。
- AI 训练成本:AlphaGo 使用了 10,000 个 GPU:小组讨论了训练先进 AI 模型所需的巨大计算资源,引用了 AlphaGo 的例子,其训练使用了 10,000 个 H100。
- 相比之下,他们指出训练 GPT-2 仅需 $10,并好奇 Tesla 在拥有大量数据收集且缺乏完全功能系统的情况下,是否使用 Omniverse 来处理其自动驾驶数据。
- 代码生成:GPT-4 领跑:一位成员询问欧洲的代码生成 AI 推荐,对比了 ChatGPT 和 Claude 3.5。
- 另一位成员确认,虽然 Claude 3.5 最初更胜一筹,但 GPT-4 现在的表现已经超越了它,被认为是代码生成的最佳选择。
- ChatGPT 的知识截止日期:停留在 2023 年 10 月:一位成员询问关于 2022 年世界杯 获胜者的 ChatGPT 知识截止日期。
- 另一位成员回答说,ChatGPT 免费版和付费版的截止日期都是 2023 年 10 月,尽管这一信息受到了质疑。
- ChatGPT 难以应对复杂数学问题:一位成员分享了他们使用 Gemini、ChatGPT 和 Claude 等 AI 模型无法解决涉及期望值的复杂数学问题的经历。
- 另一位成员建议在 ChatGPT 中使用 Python 进行计算以确保结果更准确,强调了向 AI 提供清晰指令以获得准确响应的重要性。
Cohere Discord
- Command-R 微调:比预期更简单:一位用户询问关于微调 Command-R 模型(特别是 Command-R+ 模型)的问题,但在仪表板或 API 中没有找到相关选项。
- 一位 Cohere 工作人员澄清说,最新的微调产品实际上是 Command-R,可以通过微调中的“chat”选项访问,使用“chat”选项会自动微调 Command-R 模型。
- 微调后的 Command-R 不兼容 RAG:在微调 Command-R 模型后,一位用户遇到了错误提示,称微调后的模型与 RAG 功能不兼容。
- Cohere 工作人员索要了该成员的电子邮件地址或组织 ID,以便进一步调查该问题。
- OpenSesame:解决 LLM 幻觉:OpenSesame 的开发旨在帮助使用 LLM 的公司确保其工具提供准确可靠的响应。
- 该工具帮助公司进行 LLM 实施,并帮助他们减轻 LLM 幻觉,提供准确可靠的响应。
- 文档分块:检测敏感数据的快速修复:一位用户正在构建一个用于检测大型文档中敏感信息的工具。
- 另一位用户分享了他们构建的一个快速工具,该工具对文档进行分块(chunking),使用 Cohere 识别敏感信息,然后将结果拼接在一起,从而避免 API 过载。
- Cohere 的 C4AI 社区:研究与计划支持:一位用户询问是否存在针对 c4ai 社区的 Discord 或 Slack。
- Cohere 工作人员确认 c4ai 社区在 Discord 上,并提供了加入链接,推荐将其作为研究相关问题和计划的资源。
Perplexity AI Discord
- Perplexity 的新校园战略家计划 (Campus Strategist Program):Perplexity 已开放 2024 年校园战略家计划的申请,这是一项为学生提供的实践体验,旨在推动公司的增长。
- 该计划为学生提供设计和执行活动、管理专项预算的真实经验,以及与 Perplexity 领导层的独家会议,同时还包括 Perplexity Pro 访问权限、新功能的早期试用权、Perplexity 周边商品,表现优异者还可获得前往旧金山总部的旅行机会。
- Perplexity 的 Bug 令人头疼:用户报告了 Perplexity 的几个问题,包括答案在刷新页面前不显示、上传的文件消失,以及上传的 PDF 无法用于文档之外的研究。
- 一位用户还表达了使用 PayPal 订阅 Perplexity Pro 的困难,另一位用户报告了 Perplexity API 与其 Web 界面之间答案不一致的问题。
- Perplexity API:好、坏与丑陋:一位用户报告称 API 性能明显差于 Web 版本,特别是在使用 sonar-huge-online 模型时,并询问是否有办法为特定账户解除 API 的性能限制。
- 另一位用户通过 Typeform 申请了带有引用的 API 访问权限并给 API 团队发了邮件,但在超过 3 周后仍未收到回复,尽管之前被告知预计回复时间为 1-3 周。该用户在尝试通过 Perplexity API 研究其网站时还遇到了 Error 520,暗示 Cloudflare 可能会阻止访问。
- 图像生成存在局限性:一位用户在 Perplexity 图像生成工具中遇到了限制,每次请求只能生成一张图像。
- 功能需求激增:成员们请求为 Perplexity 搜索添加新功能,例如显示待处理搜索的功能,以及同时显示多个查询结果的能力。
- 还发起了一场关于 Otter.ai 是否能处理中文的讨论,因为一位成员有兴趣将其用于特定用途。
LlamaIndex Discord
- LlamaIndex 的 80% 足够好解决方案:一位成员询问在索引时间不受限制时,构建 LlamaIndex 的公认起点是什么。
- 他们建议使用基础的 SimpleDirectoryReader + VectorStoreIndex,然后针对空间或 markdown 文本添加语义分块 (semantic chunking) 或 llama-parse。
- 检索微调就像炼金术:该成员讨论了检索微调的许多选项,包括混合搜索 (hybrid search)、向量 + bm25 融合、查询重写、Agent 检索等。
- 他们将这一过程描述为感觉像炼金术,建议将所有选项参数化并使用多臂老虎机 (multi-arm bandit) 进行优化。
- Qdrant 元数据嵌入:一位初学者询问在 Qdrant 中嵌入元数据的问题,特别是链接到文档的元数据是否也会被嵌入。
- 另一位成员澄清说,默认情况下会包含元数据,但可以使用
excluded_embed_metadata_keys和excluded_llm_metadata_keys属性将其排除。
- 另一位成员澄清说,默认情况下会包含元数据,但可以使用
- RedisIndexStore 文档管理:一位成员询问是否可以从现有的 RedisIndexStore 中添加和删除文档,而不是每次都从头开始创建新索引。
- 另一位成员提供了 LlamaIndex 关于文档管理的文档链接,其中解释了如何添加和删除文档。
- 旧金山 LLM 生产环境聚会:加入 @vesslai 和 @pinecone 在旧金山举办的 AI 产品聚会,重点关注使用 RAG 和 Vector DB 构建上下文增强型 LLM,以及用于更智能、更快速、更廉价解决方案的自定义 LLM。
- 活动将涵盖高性能 LLM、使用 RAG 和 Vector DB 构建上下文增强型 LLM,以及用于更智能、更快速、更廉价解决方案的自定义 LLM 等主题。
OpenAccess AI Collective (axolotl) Discord
- Phi-3.5-vision:多模态奇迹:Phi-3.5-vision 是一款轻量级、开源的多模态模型,在高质量、推理密集型数据集上训练而成。
- 它拥有 128K 的上下文长度,经过严格的增强,并具备强大的安全措施。请在 https://aka.ms/try-phi3.5vision 进行体验。
- 探索 Phi-3 模型家族:Phi-3.5-vision 属于 Phi-3 模型家族,旨在突破多模态理解和推理的界限。
- 访问 https://azure.microsoft.com/en-us/products/phi-3 了解更多关于 Phi-3 家族及其功能的信息。
- GPT-4 微调热议:一场关于微调 OpenAI 的 gpt4o 的讨论展开了。
- 虽然没有提供确切的答案,但它激发了人们对针对特定任务微调大型语言模型(LLM)潜力的兴趣。
- Mistral 微调:用户的惊喜:一位成员分享了他们在 Mistral Large 微调方面的积极体验,称其为“令人上瘾(crack)”。
- 虽然没有给出更多细节,但这表明 Mistral 微调具有前景广阔的结果。
- GEMMA2 的 Flash Attention:新前沿:一位成员询问了关于 GEMMA2 的 Flash Attention 支持情况。
- 另一位成员确认 Flash Attention 在 2.6.3 及以上版本中受支持,但指出最初存在一个设置被禁用的问题。
Latent Space Discord
- Zed AI Composer 现可与 Cursor 媲美:Zed AI 发布了一个名为 Composer 的新功能,类似于 Cursor 中的 Composer 功能,并利用了来自 Anthropic 的名为 “Fast Edit Mode” 的私测功能。
- Zed AI 一直在尝试将 LLM 集成到其工作流中,特别是使用 LLM 来提高开发人员在复杂代码库上工作的生产力。
- 微软发布 Phi 3.5 更新:微软发布了 Phi 3.5 mini、Phi 3.5 MoE 和 Phi 3.5 vision,均已在 Hugging Face 上线。
- 然而,一些用户在从 Azure 部署 Phi 3.5 时仍面临问题,报告提供商资源出现 “NA” 错误。
- Aider v0.51.0 悄然走红:Aider v0.51.0 已发布,具有新功能,如针对 Anthropic 模型的提示词缓存(prompt caching)、仓库映射(repo map)加速以及改进的 Jupyter Notebook .ipynb 文件编辑。
- Aider 编写了此版本中 56% 的代码,完整的变更日志可在 Aider 网站上查阅。
- Waymo 营收在四个月内翻倍:Waymo 目前的年化营收达到 1.3 亿美元,在过去四个月中翻了一番。
- 他们已在旧金山、洛杉矶和凤凰城向公众开放,并很快将在奥斯汀落地,每周行程超过 10 万次,自 5 月以来翻了一番。
- Gorilla Leaderboard v2 基准测试函数调用:Gorilla Leaderboard v2 已发布,包含一个新的基准测试,用于评估 LLM 使用真实的、用户贡献的数据与外部工具和 API 接口的能力。
- 排行榜显示 Claude 3.5 表现最佳,其次是 GPT-4、Mistral、Llama 3.1 FT 和 Gemini,表现最好的开源模型是 Functionary-Medium-v3.1。
Eleuther Discord
- Llama 3 405b 的“脑叶切除”:一位用户构想了一个针对 Llama 3 405b 的“脑叶切除(lobotomization)”流水线,旨在创建一系列量化微调的 33M 参数模型。
- 这种方法侧重于在保持核心功能的同时优化模型的效率。
- Model MoErging:协作模型:一篇探索 “Model MoErging” 的综述论文被引入,提出了一个微调模型协作处理复杂任务的框架。
- 该综述可在 https://arxiv.org/abs/2408.07057 查阅,概述了专业化模型通过路由机制协同工作的未来。
- Alpaca:仍是金标准吗?:一位用户质疑 Alpaca 是否仍然是公开指令微调数据集的最先进标准。
- 这引发了关于微调数据集演变及其对大规模模型性能影响的讨论。
- Mamba 在长上下文方面表现挣扎:一篇比较 Mamba 和 Transformer 在长上下文推理中表现的论文揭示了显著的性能差距。
- 该论文可在 https://arxiv.org/abs/2406.07887 查阅,结论是 Transformer 在复制长序列方面表现出色,而 Mamba 由于其固定大小的潜状态(latent state)而面临挑战。
- Llama 的 ASDiV 基准测试:虽然 Llama 目前没有报告 ASDiV 的基准测试结果,但一位用户建议遵循原始思维链(chain of thought)论文的设置。
- 这将与 Llama 的提示风格和设置保持一致,利用 ASDiV、GSM8K 和其他数据集的现有基准。
tinygrad (George Hotz) Discord
- Samba 权重已发布!:Samba 的权重已经发布,可以通过 这个 AWS S3 bucket 获取。
- 一名成员目前正在训练他们自己的 Samba 版本,并发现即使在较少的 Token 训练下,这些权重在测试中也表现得相当出色。
- 请求 Tinygrad 支持 Samba:一名成员请求 Tinygrad 在 Microsoft 正式发布其 SOTA 小型模型时,能提供对 Samba 的简洁支持。
- 他们希望这能使 Tinygrad 成为唯一在所有主流设备上都支持 Samba 的库。
- Samba 的 Token 消耗:海绵般:一名成员指出 Samba 在训练期间像海绵一样消耗 Token,但在较少 Token 训练下仍表现尚可。
- 这一发现可能为大型科技公司使用 Samba 为边缘设备训练自己的模型提供理由,因为它比基础的 Transformers 更具成本效益。
- Tinygrad 3060 GPU 错误:设备不可见?:一名用户报告在安装了 CUDA 12.2 的 3060 GPU 上运行时收到错误消息。
- 错误消息提示设备不可见,这暗示了一个简单的从 Torch 到 Tinygrad 的迁移问题。
- Tinygrad 中的 Mamba 实现:选择性扫描效率:一名用户询问是否可以在 Tinygrad 中编写高效的 Mamba,而不需要为 selective scan operator 编写自定义内核。
- 这个问题突显了 Tinygrad 与其他框架之间潜在的效率差异,并寻求如何针对这一特定用例进行优化的见解。
OpenInterpreter Discord
- Open Interpreter 的 API Base URL 说明:一名成员询问了为 Open Interpreter 的 LLM 调用设置自定义 API Base URL 的含义,另一名成员澄清说,这允许使用特定的模型(如 Groq),并配合类似
https://api.groq.com/openai/v1的 URL。- 提供了一个完整的命令行示例供参考,说明了如何利用此功能。
- 将 GPT-4o-mini 作为新默认模型的理由:一名成员建议将 Open Interpreter 的默认模型从 GPT-3.5-Turbo 更改为 GPT-4o-mini,因为目前没有免费额度。
- 虽然 Open Interpreter 目前在使用
-y参数时默认使用 GPT-4-Turbo,但社区主张选择更具成本效益的选项。
- 虽然 Open Interpreter 目前在使用
- 应对 OpenAI 模型的成本:一名成员在意外花费了 2 美元后,对使用 GPT-4-Turbo 的成本表示担忧。
- 社区推荐 GPT-4o-2024-08-06 作为一个更实惠的选择,尽管有人对其与默认 GPT-4o 模型相比的性能表示担忧。
- 更新 Open Interpreter 的默认设置:已提交一个 PR 来更新 Open Interpreter 的默认设置,包括将
fast参数更改为 GPT-4o-mini 而不是 GPT-3.5-Turbo。- 这一变化反映了社区对更具成本效益模型的偏好,特别是在缺乏免费额度的情况下。
- 命令行参数之外的配置选项:一名成员主张使用
default.yaml文件而不是命令行参数在 Open Interpreter 中设置默认模型。- 他们认为这种方法提供了更好的灵活性,且不易引起混淆,特别是考虑到命令行参数可能会随时间而变化。
LangChain AI Discord
- LangChain 提取药物信息:一位用户尝试使用 LangChain 从原始文本中提取药物及其剂量,并将提取的信息存储在名为 ‘txtExtract’ 的变量中。
- 他们还考虑使用 LangSmith 来评估提取结果,但最终决定 LangChain 也可以处理该任务。
- Ollama 中的 BERT 能力:一位用户询问了 Ollama 框架内 BERT 的可用性。
- 他们有兴趣利用 BERT 的能力来评估提取信息的准确性。
- 来自 Rubiks AI 的新搜索引擎:Rubiks AI 是一款新的研究助手和搜索引擎,使用 Claude 3 Opus、GPT-4o、Gemini 1.5 Pro、Mistral-Large 2、Yi-Large、Reka-Core、Groq models 等模型提供 2 个月的免费高级访问权限。
- 2 个月免费的促销代码是
RUBIX。
- 2 个月免费的促销代码是
- Claude 3 Opus 在 UAP 研究中挣扎:一位用户报告称,Claude 3 Opus 有时会拒绝讨论 UAP,除非用户声称自己是国会议员宇航员。
- 该用户还强调了关于 UAP 的大量虚假信息,使得识别合法信息变得困难。
- 视频的自监督学习:Lightly.ai 发表了一篇关于视频 Self-Supervised Learning 的文章。
- 文章解释说,VideoMAE 及其扩展正被用于 Self-Supervised Pre-Training,并且由于视频的多维特性,需要特别关注。
DSPy Discord
- 用于 LM 代码委托的 LiteLLM:一位成员询问了将 LM 代码委托给 LiteLLM 的事宜,以及微调(fine-tuning)是否应该与 Prompt 优化分开。
- 他们认为 Prompt 优化和微调应该耦合在一起,因为它们之间存在复杂的相互作用。
- DSPy Self-Discover 框架揭晓:讨论了 DSPy Self-Discover Framework。
- 提供了该框架 GitHub 仓库的链接:https://github.com/jmanhype/dspy-self-discover-framework。
Torchtune Discord
- Torchtune Nightly 版本发布:最新 nightly 版本的 Torchtune 已经发布,可通过 GitHub pull request 获取,其中包含新实现的 T5 微调功能,该功能仍处于最后完成阶段。
- 一位用户确认此功能现在可在最新的发布说明中找到,但不确定它是否已完全发挥作用或是否存在任何已知限制。
- Hermes 2.5 占据领先地位:在添加了 代码指令示例 后,Hermes 2.5 在各种基准测试中似乎优于 Hermes 2,特别是在 MMLU 基准测试中,它获得了 52.3 分,而 Hermes 2 的分数为 34.5。
- 这突显了 Hermes 2.5 作为其前代产品更强大模型的潜力。
- Pre-fill 和 Decode 优化是关键:将 Pre-fill 和 Decode 阶段分离被认为是初始步骤的有益优化。
- 这种优化也为 eager mode 带来了好处,有可能提高模型的性能和效率。
MLOps @Chipro Discord
- MLOps 活动兴趣:一位用户表达了参加 Chipro 的 MLOps 活动的兴趣。
- 占位符主题:第一个摘要占位符。
- 第二个摘要占位符。
DiscoResearch Discord
- AIDEV 2:一个专注于 Generative AI 的活动:第二届 #AIDEV 活动将于 9 月 24 日在德国赫尔特(Hürth)举行,重点讨论针对开发者和 AI 工程师的 Large Language Models 和 Generative AI 应用的技术讨论。
- 活动包括自带问题环节(bring-your-own-problem session)、社区讲者席位,并向开发者开放免费注册。
- 社区聚焦:分享你的专业知识:AIDEV 2 欢迎社区成员提交演讲提案,分享他们在 Large Language Models 和 Generative AI 方面的专业知识。
- 活动鼓励开发者提交他们的 GitHub/Hugging Face 个人资料以及正在研究的问题,旨在促进关于最前沿 LLM 应用、当前挑战和实施策略的深入讨论。
Alignment Lab AI Discord 暂无新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 暂无新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Mozilla AI Discord 暂无新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Interconnects (Nathan Lambert) Discord 暂无新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 暂无新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第二部分:分频道详细摘要与链接
各频道的详细细分内容已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!