ainews-nvidia-minitron-llm-pruning-and
Nvidia Minitron:针对 Llama 3.1 更新的大语言模型剪枝与蒸馏技术。
英伟达(Nvidia)和 Meta 的研究人员更新了他们的 Llama 3 研究结果,并发表论文展示了结合权重剪枝(weight pruning)与知识蒸馏(knowledge distillation)的有效性。该方法通过仅从头开始训练最大的模型,再通过剪枝和蒸馏衍生出较小的模型,从而降低训练成本。
具体过程包括教师修正、基于激活的剪枝(偏向于宽度剪枝),以及使用 KL 散度损失进行蒸馏重训,最终在同等规模下获得了性能更佳的模型。不过,蒸馏也会带来一定的准确率权衡。
此外,AI21 Labs 推出了 Jamba 1.5,这是一款混合了 SSM-Transformer 架构的 MoE(混合专家)模型,具备大上下文窗口和多语言支持。Anthropic 为 Claude 3 更新了 LaTeX 渲染和提示词缓存(prompt caching)功能。一款名为 Dracarys 的开源编程大模型发布了 70B 和 72B 版本,展现出更强的编程性能。Mistral Nemo Minitron 8B 模型在 Hugging Face 排行榜上超越了 Llama 3.1 8B 和 Mistral 7B,进一步凸显了剪枝与蒸馏的优势。关于提示词优化的研究则揭示了提示词搜索空间的复杂性,以及 AutoPrompt/GCG 等简单算法出人意料的有效性。
剪枝与蒸馏就是你所需要的一切。
2024年8月22日至8月23日的 AI 新闻。我们为你检查了 7 个 subreddits、384 个 Twitter 账号 和 30 个 Discord 服务器(214 个频道,2531 条消息)。预计节省阅读时间(按每分钟 200 字计算):284 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论了!
最近几周我们曾间接提到过 4B 和 8B Minitron(Nvidia 对 Llama 3.1 8B 的蒸馏版本),但现在 Sreenivas & Muralidharan 等人(上个月 Minitron 论文的作者)发布了一篇 7 页的精简论文,将他们之前的 Llama 2 研究结果更新到了 Llama 3:

鉴于 Nvidia 与 Meta 的紧密关系,这一点非常重要,它提供了关于 Llama 3 的一些见解:
“从头开始训练多个数十亿参数的模型极其耗费时间、数据和资源。最近的工作 [1] 证明了将权重剪枝(weight pruning)与知识蒸馏(knowledge distillation)相结合,可以显著降低训练 LLM 模型家族的成本。在这里,模型家族中只有最大的模型是从头开始训练的;其他模型是通过对较大模型进行连续剪枝,然后进行知识蒸馏以恢复剪枝模型的准确性而获得的。”
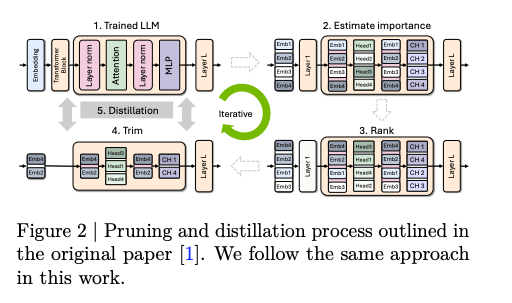
主要步骤:
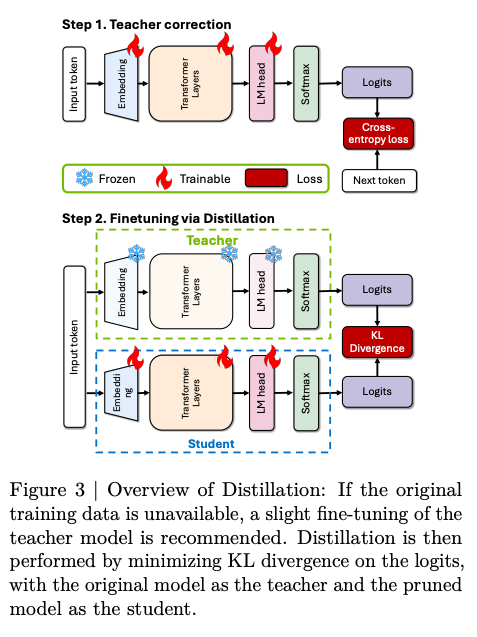
- 教师校正 (teacher correction):在用于蒸馏的目标数据集上对教师模型进行轻微微调,使用约 127B tokens。
-
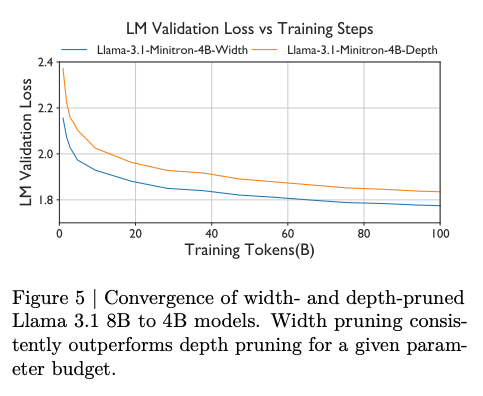
深度或宽度剪枝 (depth or width pruning):使用“一种纯粹基于激活的重要性评估策略,通过一个小型校准数据集和仅前向传播过程,同时计算我们考虑的所有轴(深度、神经元、头部和嵌入通道)的敏感度信息”。在消融实验中,宽度剪枝的表现始终优于深度剪枝。
- 通过蒸馏进行重训练 (Retraining with distillation):使用“真正的” KD,即在教师和学生模型的 Logits 上使用 KL Divergence 损失。
这产生了一个在同等尺寸下全面表现更优的模型:
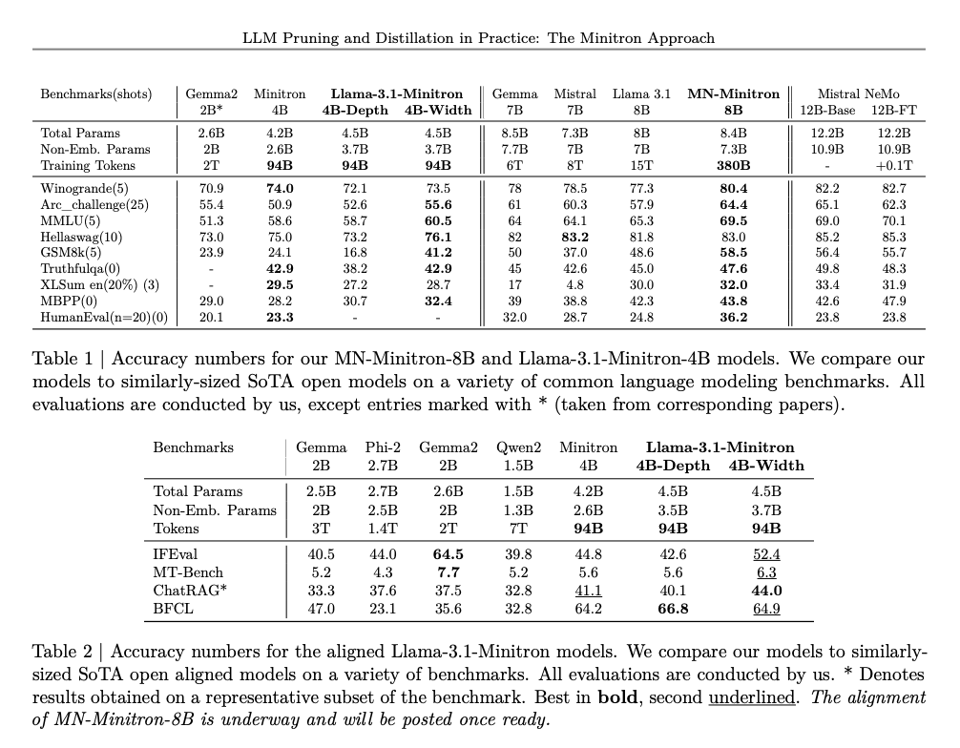
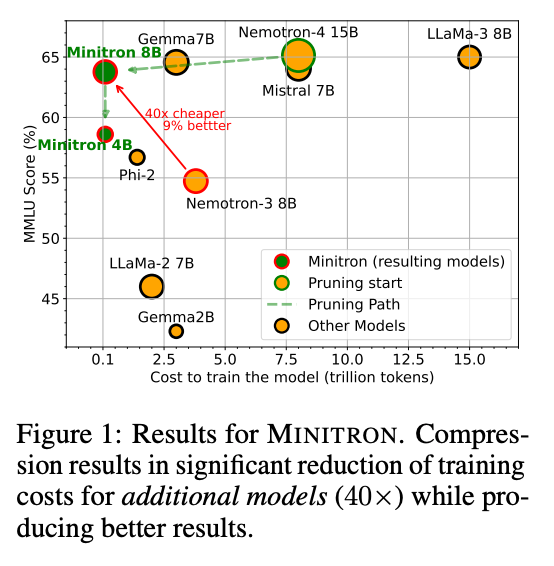
然而,这种蒸馏远非无损;论文并没有直观地列出差异,但在末尾的脚注中提到了权衡。

AI Twitter 综述
所有综述均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型发布与进展
-
Jamba 1.5 发布:@AI21Labs 发布了 Jamba 1.5,这是一款混合 SSM-Transformer MoE 模型,分为 Mini(52B - 12B active)和 Large(398B - 94B active)两个版本。主要特性包括 256K context window、多语言支持以及针对长上下文任务的性能优化。
-
Claude 3 更新:@AnthropicAI 为 Claude 3 增加了 LaTeX 渲染支持,增强了其显示数学方程和表达式的能力。Prompt caching 现在也已支持 Claude 3 Opus。
-
Dracarys 发布:@bindureddy 宣布了 Dracarys,这是一个针对编程任务进行 fine-tuned 的开源 LLM,提供 70B 和 72B 版本。与其他开源模型相比,它在编程性能上显示出显著提升。
-
Mistral Nemo Minitron 8B:该模型在 Hugging Face Open LLM Leaderboard 上的表现优于 Llama 3.1 8B 和 Mistral 7B,展示了对大型模型进行 pruning 和 distilling 的潜在优势。
AI 研究与技术
-
Prompt 优化:@jxmnop 讨论了 Prompt 优化的挑战,强调了在巨大的搜索空间中寻找最优 Prompt 的复杂性,以及像 AutoPrompt/GCG 这样简单算法的出人意料的有效性。
-
混合架构:@tri_dao 指出,混合 Mamba / Transformer 架构表现良好,特别是在长上下文和快速推理(inference)方面。
-
Flexora:一种新的 LoRA fine-tuning 方法,可以产生更优的结果并将训练参数减少高达 50%,它为 LoRA 引入了自适应层选择。
-
Classifier-Free Diffusion Guidance:@sedielem 分享了近期论文的见解,这些论文对目前关于 Classifier-Free Diffusion Guidance 的普遍假设提出了质疑。
AI 应用与工具
-
Spellbook Associate:@scottastevenson 宣布推出 Spellbook Associate,这是一个用于法律工作的 AI Agent,能够分解项目、执行任务并调整计划。
-
Cosine Genie:
@swyx强调 了一期播客节目,讨论了为代码 fine-tuning GPT4o 的价值,使其成为了根据各种基准测试表现最佳的 coding Agent。 -
LlamaIndex 0.11:@llama_index 发布了 0.11 版本,新特性包括用 Workflows 取代 Query Pipelines,以及核心包体积减小了 42%。
-
MLX Hub:一个新的命令行工具,用于从 Hugging Face Hub 搜索、下载和管理 MLX 模型,由 @awnihannun 宣布。
AI 发展与行业趋势
-
AI Agent 的挑战:@RichardSocher 强调了在 AI Agent 的多步 Workflows 中实现高准确率的难度,并将其比作自动驾驶汽车中的“最后一公里”问题。
-
开源 vs. 闭源模型:@bindureddy 指出,大多数开源 fine-tunes 在改进特定维度的同时会降低整体性能,并强调了 Dracarys 在提升整体性能方面取得的成就。
-
AI 监管:@jackclarkSF 分享了给 Newsom 州长关于 SB 1047 的信函,讨论了拟议的 AI 监管法案的成本与收益。
-
AI 硬件:讨论了结合多个设备资源处理家庭 AI 工作负载的潜力,如 @rohanpaul_ai 所述。
AI Reddit 综述
/r/LocalLlama 综述
- Exllamav2 Tensor Parallel 支持!TabbyAPI 也是! (评分: 55, 评论: 29): ExLlamaV2 引入了 Tensor Parallel 支持,实现了利用多块 GPU 进行推理。此次更新还集成了 TabbyAPI,使得部署和 API 访问更加便捷。社区对这些进展表现出极大的热情,强调了提升大语言模型性能和可访问性的潜力。
- 用户对 ExLlamaV2 的更新表示兴奋,其中一位用户在多块 GPU 上以 2.65bpw 运行 Mistral-Large2,8192 context length,生成速度达到 18t/s。
- 性能提升显著,Qwen 72B 4.25bpw 在 2x3090 GPU、2k context 下的速度从 17.5 t/s 提升到 20.8 t/s,增长了 20%。
- 报告了一个影响 draft model (qwama) 的 Bug,并迅速得到了开发者的解决,体现了活跃的社区支持和快速的问题处理能力。
全球 AI Reddit 综述
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 与机器学习进展
-
Stable Diffusion 两周年:2022 年的今天,第一个 Stable Diffusion 模型 (v1.4) 正式向公众发布,标志着 AI 生成图像领域的一个重要里程碑。
-
NovelAI 开源原始模型:NovelAI 决定开源其原始 AI 模型,尽管该模型此前曾被泄露。此举促进了 AI 社区的透明度与协作。
AI 生成内容与工具
-
去模糊 Flux Lora:开发了一款新工具来解决 AI 生成图像中的背景模糊问题,有望提升整体输出质量。
-
业余摄影 Lora:一项关于 AI 生成图像真实感的对比,使用了业余摄影 Lora 与 Flux Dev,展示了写实 AI 生成内容的进步。
-
Pony Diffusion V7:开发下一版本 Pony Diffusion 的进展,展示了专用 AI 模型的持续改进。
机器人与 AR 技术
-
Boston Dynamics 俯卧撑视频:Boston Dynamics 在其官方 Instagram 上发布了一段机器人做俯卧撑的视频,展示了机器人在移动性和力量方面的进步。
-
Meta 的 AR 眼镜:Meta 将于 9 月发布其新款 AR 眼镜,表明大型科技公司在增强现实技术方面的进展。
AI 相关讨论与幽默
-
AI 炒作与预期:一个关于等待 AGI 推翻政府的幽默帖子引发了关于 AI 现状和公众认知的讨论。评论强调了对过度炒作 AI 能力的担忧,以及对现实预期的需求。
-
AI 视频生成推测:一段猫咪似乎在做饭的视频引发了关于 AI 视频生成技术的讨论,一些用户认为这是使用传统视频编辑方法而非 AI 制作的。
AI 工具功能请求
- 一个强调 Flux D 期望功能的帖子,表明用户对改进 AI 图像生成工具的持续兴趣。
AI Discord 综述
由 Claude 3.5 Sonnet 生成的总结之总结
1. AI 模型发布与基准测试
- Jamba 1.5 在长文本领域领先:AI21 Labs 推出了 Jamba 1.5 Mini(12B 激活/52B 总参数)和 Jamba 1.5 Large(94B 激活/398B 总参数),基于全新的 SSM-Transformer architecture,提供 256K 有效上下文窗口,并声称在长文本处理速度上比竞争对手快 2.5 倍。
- Jamba 1.5 Large 在 Arena Hard 上获得了 65.4 分,超越了 Llama 3.1 70B 和 405B 等模型。这些模型已可在 Hugging Face 立即下载,并支持在各大云平台部署。
- Grok 2 在 LMSYS Arena 夺得第二名:Grok 2 及其 mini 版本已加入 LMSYS leaderboard,目前 Grok 2 排名第 2,超越了 GPT-4o (May),并在综合性能上与 Gemini 持平。
- 该模型在数学方面表现尤为出色,并在包括困难提示词(hard prompts)、代码编写和指令遵循在内的其他领域名列前茅,展示了其在各种 AI 任务中的广泛能力。
- SmolLM:小而强大的语言模型:SmolLM 系列小型语言模型已发布,包含 135M、360M 和 1.7B 参数规模,是在精心策划的 Cosmo-Corpus 数据集上训练而成的。
- 这些模型(包括 Cosmopedia v2 和 Python-Edu 等数据集)在与其同等规模的模型对比中显示出极具前景的结果,有望为各种 NLP 任务提供高效的替代方案。
2. AI Development Tools and Frameworks
- Aider 0.52.0 为 AI 编程增加 Shell 能力:Aider 0.52.0 引入了 shell 命令执行功能,允许用户直接在工具内启动浏览器、安装依赖、运行测试等,增强了其 AI 辅助编程的能力。
- 该版本还包括一些改进,如
/read和/drop命令支持~路径扩展,新增用于清除聊天记录的/reset命令,并将默认 OpenAI 模型切换为gpt-4o-2024-08-06。值得注意的是,Aider 自主生成了该版本 68% 的代码。
- 该版本还包括一些改进,如
- Cursor 为 AI 驱动的编程融资 6000 万美元:Cursor 宣布获得来自 Andreessen Horowitz、Jeff Dean 以及 Stripe 和 Github 创始人的 6000 万美元融资,巩固了其作为领先 AI 驱动代码编辑器的地位。
- 公司旨在通过即时回答、机械重构(mechanical refactors)和 AI 驱动的后台编码员等功能彻底改变软件开发,其宏伟目标是最终编写世界上所有的软件。
- LangChain 提升 SQL 查询生成水平:LangChain Python 文档 概述了使用
create_sql_query_chain改进 SQL 查询生成的策略,重点关注 SQL 方言如何影响提示词(prompts)。- 文档涵盖了如何使用
SQLDatabase.get_context将 schema 信息格式化到提示词中,以及构建 few-shot 示例来辅助模型,旨在提高生成的 SQL 查询的准确性和相关性。
- 文档涵盖了如何使用
3. AI Research and Technical Advancements
- Mamba 潜入 Transformer 领地:Mamba 2.8B 模型 已发布,这是一个兼容
transformers的语言模型,为传统的 Transformer 模型提供了一种替代架构。- 用户需要从 main 分支安装
transformers(直到 4.39.0 版本发布),并安装causal_conv_1d和mamba-ssm以使用优化的 CUDA kernels,这可能在某些 NLP 任务中提供更高的效率。
- 用户需要从 main 分支安装
- AutoToS:自动化搜索思维:一篇题为 “AutoToS: Automating Thought of Search” 的新论文提出了一种自动化的“搜索思维”(ToS)方法,用于 LLM 规划,在评估领域中以极少的反馈迭代实现了 100% 的准确率。
- 该方法涉及使用代码定义搜索空间,并通过单元测试的反馈引导 LLM 生成可靠且完整的搜索组件,有望推动 AI 驱动的规划和问题解决领域的发展。
- 多模态 LLM 跳过 ASR 中间环节:一位研究人员分享了关于多模态 LLM 的工作,该模型无需单独的自动语音识别(ASR)阶段即可直接理解文本和语音,通过使用多模态投影器(multimodal projector)扩展 Meta 的 Llama 3 模型构建而成。
- 与结合独立 ASR 和 LLM 组件的系统相比,这种方法可以实现更快的响应速度,可能为更高效、更集成的多模态 AI 系统开辟新途径。
4. AI Industry News and Events
- Autogen 负责人离开 Microsoft 开启新事业:Autogen 项目负责人于 2024 年 5 月离开 Microsoft,创办了 OS autogen-ai,这是一家目前正在融资的新公司。
- 这一举动预示着 Autogen 生态系统可能迎来新发展,并凸显了行业内 AI 人才流动的动态特性。
- NVIDIA AI Summit India 官宣:NVIDIA AI Summit India 定于 2024 年 10 月 23 日至 25 日在孟买 Jio World Convention Centre 举行,届时将有 Jensen Huang 的炉边谈话以及超过 50 场关于 AI、机器人等主题的分会。
- 该活动旨在加强 NVIDIA 与行业领袖及合作伙伴的联系,展示在生成式 AI、LLM、工业数字化、超级计算和机器人领域的变革性工作。
- 加州 AI 监管热潮:加州本周将对 20 多项 AI 监管法案 进行投票,涵盖了该州 AI 部署和创新的各个方面。
- 这些法案可能会显著重塑在加州运营的 AI 公司和研究人员的监管格局,并可能为其他州和国家设定先例。
5. AI 安全与伦理讨论
- AI 倦怠引发行业关注:AI 社区的讨论对 AI 倦怠(AI burnout) 的可能性发出了警报,特别是在高强度的前沿实验室中,人们担心对进步的无情追求可能导致不可持续的工作模式。
- 成员们将 AI 高级用户比作“施法者职业(spellcasting class)”,暗示 AI 模型能力的增强可能会增加对这些用户的需求,从而可能加剧该领域的倦怠问题。
- AI 能力与风险 Demo-Jam Hackathon 启动:AI Capabilities and Risks Demo-Jam Hackathon 启动,奖金池为 2000 美元,鼓励参与者创建能够弥合 AI 研究与公众对 AI 安全挑战理解之间鸿沟的演示。
- 该活动旨在展示潜在的 AI 驱动的社会变革,并以引人入胜的方式传达 AI 安全挑战,优秀项目将有机会加入 Apart Labs 进行进一步研究。
- Twitter 上的 AI 讨论强度受到质疑:最近 Greg Brockman 的一条推文 显示其一周工作 97 小时进行编码,这引发了关于 Twitter 上 AI 讨论强度及其与现实可能脱节的讨论。
- 社区成员对社交媒体平台上经常分享的高压叙事表示不安,质疑这种强度对于 AI 领域的长期健康是否可持续或有益。
- 伦敦 AI 工程师见面会:首届 AI Engineer London Meetup 定于 9 月 12 日举行,演讲嘉宾包括 @maximelabonne 和 Chris Bull。
- 鼓励参与者在此处注册,与 AI 工程师同行交流。
- Infinite Generative Youtube 开发中:一个团队正在为其 Infinite Generative Youtube 平台寻找开发人员,准备进行封闭测试。
- 他们正在寻找充满激情的开发人员加入这个创新项目。
第一部分:Discord 高层级摘要
LM Studio Discord
- LM Studio 0.3.0 发布并带来升级:LM Studio 发布了 0.3.0 版本,具有全新的 UI、改进的 RAG 功能,并支持使用
lms运行本地服务器。- 然而,用户报告了模型加载问题等 bug,表明开发团队正在积极修复。
- Llama 3.1 硬件性能评测:Llama 3.1 70B q4 在配备双通道 DDR5-6000 的 9700X CPU 上达到了 1.44 t/s 的 token 速率,突显了其 CPU 性能表现。
- 用户指出,如果 GPU 的 VRAM 小于模型大小的一半,GPU offloading 可能会降低推理速度。
- 关于 Apple Silicon 与 Nvidia 运行 LLM 的辩论:一场持续的讨论对比了 M2 24gb Apple Silicon 与 Nvidia 设备,有报告称 M2 Ultra 在特定场景下可能优于 4090。
- 然而,用户在 Apple Silicon 上面临微调速度的限制,据报道在顶配 Macbook Pro 上需要 9 小时的训练。
- GPU Offloading 仍是热门话题:尽管有用户报告问题,LM Studio 仍支持 GPU offloading;用户可以在选择模型时按住 ALT 键来激活它。
- 随着用户在各种配置下探索性能,持续寻找最佳设置仍然至关重要。
- LLM 准确性引发关注:讨论显示,Llama 3.1 和 Phi 3 等 LLM 可能会产生幻觉,特别是在学习风格或特定查询方面,导致输出冗长。
- 一项对比分析指出,Claude 尽管表达模糊,但可能展示出更好的自我评估机制。
Nous Research AI Discord
- Nous Research 周边商店上线!:Nous Research 周边商店已正式发布,提供各种商品,包括每笔订单附赠的贴纸(送完即止)。
- 点击此处查看专属周边!
- Hermes 3 从模式崩溃 (Mode Collapse) 中恢复:一名成员报告成功让 Hermes 3 从模式崩溃中恢复,使模型能够分析并理解崩溃原因,之后仅发生过一次复发。
- 这标志着在解决大型语言模型中普遍存在的模式崩溃问题上迈出了一步。
- 介绍 Mistral-NeMo-Minitron-8B-Base:Mistral-NeMo-Minitron-8B-Base 是一个经过剪枝和蒸馏的文本到文本模型,利用了 3800 亿个 token 以及来自 Nemotron-4 15B 的持续预训练数据。
- 该基础模型展示了模型效率和性能方面的进步。
- 探索 LLM 行为中的“疯狂”:有人提议刻意将 LLM 调优至“疯狂”状态,旨在探索意外行为的边界,并深入了解 LLM 的局限性。
- 该项目寻求模拟 LLM 输出中的异常情况,这可能会带来突破性的发现。
- 适用于 LLM 的 Drama Engine 框架:一位成员分享了他们的项目 Drama Engine,这是一个叙事 Agent 框架,旨在改进类 Agent 的交互和故事创作。
- 他们提供了该项目的 GitHub 页面链接,供有兴趣贡献或了解更多信息的人参考:Drama Engine GitHub。
HuggingFace Discord
- LogLLM - 自动化机器学习实验日志记录:LogLLM 使用 GPT4o-mini 自动从 Python 脚本中提取实验条件,并使用 Weights & Biases (W&B) 记录结果。
- 它简化了机器学习实验的文档记录过程,提高了效率和准确性。
- Neuralink 在 HF 实现论文:一位成员分享说,他们在 Hugging Face 的工作涉及论文实现,可能是一个付费职位。
- 他们对自己的工作表示兴奋,并强调了为低端设备创建高效模型的重要性。
- 适用于低端设备的高效模型:成员们对提高低端硬件上的模型效率表现出浓厚兴趣,突显了当前面临的挑战。
- 这反映了社区对在不同环境中实现可访问性和实际应用的关注。
- GPU 性能怪兽:RTX 6000 亮相:用户发现了 RTX 6000 的存在,它拥有 48GB VRAM,可处理强大的计算任务。
- 其价格为 7,000 美元,是高性能工作负载的首选。
- 用于泛化的三路数据拆分:一位成员建议采用三路数据拆分,以增强模型在训练、验证和测试期间的泛化能力。
- 重点是使用多样化的数据集进行测试,以评估模型在准确性之外的鲁棒性。
Stability.ai (Stable Diffusion) Discord
- SDXL vs SD1.5:速度困境:一位拥有 32 GB RAM 的用户在 SDXL 和 SD1.5 之间犹豫不决,并反馈在其 CPU 上生成图像速度缓慢。尽管可能出现显存溢出(out-of-memory)错误且需要增加交换空间(swap space),建议仍倾向于选择图像质量更优的 SDXL。
- 请记住,对于这些大型模型,平衡 CPU 速度与图像质量是关键因素。
- 提示词技巧:大辩论:成员们分享了他们在提示词(prompt)技巧方面的经验,有人发现使用逗号分隔效果很好,而另一些人则更喜欢自然语言提示词。这种差异突显了关于如何实现一致性的最佳提示策略的持续讨论。
- 参与者建议,提示词的有效性在很大程度上取决于个人喜好和实验尝试。
- ComfyUI 和 Flux 安装难题:一位用户在 ComfyUI 上安装 iPadaper 时遇到挑战,得到的建议是前往技术支持频道寻求帮助。另一位用户在使用 Flux 时遇到困难,尝试通过不同的提示词来克服噪点多、质量低的输出问题。
- 这强调了社区在追求创意目标、微调设置过程中共同经历的尝试与错误。
- GPU RAM:性能的重要性:在使用 16GB RTX 3080 运行 Flux 时,出现了关于在 ComfyUI 中调整 GPU 权重的问题。一位使用 4GB GPU 的用户报告了在 A1111 中令人沮丧的减速现象,这表明了 GPU 性能对图像生成的影响。
- 这一交流表明,为了在各种模型中实现更流畅的性能,对强大硬件有着迫切需求。
- 丰富的 Stable Diffusion 指南:一位用户请求推荐 Stable Diffusion 安装指南,Automatic1111 和 ComfyUI 被建议作为良好的起点。AMD 显卡虽然可以使用,但被指出性能较慢。
- 技术支持频道被强调为故障排除和指导的重要资源。
aider (Paul Gauthier) Discord
- Aider 0.52.0 发布:Shell 命令执行及更多:Aider 0.52.0 引入了 Shell 命令执行功能,允许用户直接在工具内启动浏览器、安装依赖项并运行测试。关键更新包括命令的
~路径扩展、用于清除聊天记录的/reset命令,以及模型切换至gpt-4o-2024-08-06。- Aider 自主生成了该版本 68% 的代码,突显了其在软件开发领域不断进步的能力。
- Aider 训练集:元格式探索:一位成员正在收集 Aider 的“提示词-代码”对训练集,旨在利用 DSPY、TEXTGRAD 和 TRACE 等工具为各种编码技术创建高效的元格式(meta-format)。该计划包括一个协作线程,用于对优化进行更深入的头脑风暴。
- 其目标是精简代码和提示词以获得更好的可复现性,增强 Aider 生成代码的有效性。
- 使用 Aider 进行 Token 优化:一位用户正在寻求关于优化 Token 使用的文档,特别是针对超过 OpenAI 限制的小型 Python 文件,以及处理需要多步过程的复杂任务时。他们正在寻找减少项目内 Token 上下文(context)的策略。
- 他们特别要求在计算和渲染优化方面取得进展,强调了改进资源管理的必要性。
- Cursor 对 AI 驱动代码创作的愿景:Cursor 的博客文章描绘了开发 AI 驱动代码编辑器的愿景,该编辑器可能自动完成大量的代码编写任务。功能包括即时响应、重构以及在几秒钟内完成大规模更改。
- 未来的增强目标是实现后台编码、伪代码修改和错误检测,彻底改变开发者与代码交互的方式。
- 规划中的 LLM:AutoToS 论文见解:AutoToS: Automating Thought of Search 提议使用 LLM 自动化规划过程,展示了其在不同领域实现 100% 准确率 的有效性。该方法允许 LLM 用代码定义搜索空间,增强了规划方法论。
- 论文识别了搜索准确性方面的挑战,并阐述了 AutoToS 如何利用单元测试的反馈来引导 LLM,强化了对 AI 驱动规划可靠性的追求。
Latent Space Discord
- Autogen 负责人离开 Microsoft:Autogen 项目负责人于 2024 年 5 月离开 Microsoft,启动了开源项目 autogen-ai,目前正在融资。
- 这一转变引发了关于 AI 编码标准和协作领域新创业项目的讨论。
- Cursor AI 获得 6000 万美元支持:Cursor 成功从 Andreessen Horowitz 和 Jeff Dean 等知名投资者处筹集了 6000 万美元,声称要重塑 AI 编程方式。
- 他们的产品旨在开发能够在大规模范围内实现代码编写自动化的工具。
- 加州提议新的 AI 监管法案:加州本周将对 20 多项 AI 监管法案进行投票,详见此 Google Sheet 摘要。
- 这些法案可能会重塑该州 AI 部署和创新的格局。
- AI Engineer 见面会准备就绪!:欢迎参加 9 月 12 日晚举行的首届 AI Engineer 伦敦见面会,演讲嘉宾包括 @maximelabonne 和 Chris Bull。
- 通过此 链接 注册,与 AI Engineer 同行交流。
- Taxonomy Synthesis 助力 AI 研究:成员们讨论了利用 Taxonomy Synthesis 来分层组织写作项目。
- GPT Researcher 工具因其能够自主进行深入研究、提高生产力而受到关注。
OpenRouter (Alex Atallah) Discord
- OpenRouter 停用多个模型:自 2024 年 8 月 28 日起,OpenRouter 将弃用多个模型,包括
01-ai/yi-34b、phind/phind-codellama-34b、nousresearch/nous-hermes-2-mixtral-8x7b-sft以及完整的 Llama 系列,届时用户将无法使用。- 用户可通过 Together AI 的弃用文档 了解此政策,该文档概述了迁移选项。
- OpenRouter 的计费小插曲:一名用户在误选付费模型后产生了 0.01 美元 的费用,这说明了不熟悉界面的新手可能会遇到的潜在问题。
- 对此,社区安抚该用户称 OpenRouter 不会追究如此低额度的欠费,营造了一个友好的 AI 探索环境。
- Token 计数困惑得到澄清:在一名用户报告简单的 Prompt 被收取了 100 多个 Token 的费用后,引发了关于 OpenRouter Token 计数机制的讨论,揭示了 Token 计算的复杂性。
- 成员们澄清,OpenRouter 转发来自 OpenAI API 的 Token 计数,其差异受系统提示词(System Prompts)和聊天中先前上下文的影响。
- Grok 2 在 LMSYS 排行榜表现亮眼:Grok 2 及其 mini 变体在 LMSYS 排行榜上占据了一席之地,Grok 2 排名 第 2,在性能指标上甚至超越了 GPT-4o。
- 该模型在数学和指令遵循(Instruction-following)方面表现尤为出色,在编码挑战中也展示了极高的能力,引发了对其整体性能概况的讨论。
- OpenRouter 团队依然神秘:有人询问 OpenRouter 团队当前的项目,但遗憾的是没有得到详细回复,令成员们感到好奇。
- 这种信息的缺乏凸显了人们对 OpenRouter 开发活动的持续关注,但具体细节仍难以获知。
Modular (Mojo 🔥) Discord
- Mojo 的开源许可困境:关于 Mojo 开源状态的问题被提出,Modular 正在处理许可细节,以在允许外部使用的同时保护其市场定位。
- 他们的目标是随着时间的推移采用更宽松的许可模型,在保持开放性的同时保护核心产品特性。
- Max 的集成模糊了与 Mojo 的界限:Max 的功能现在与 Mojo 深度集成,尽管最初被设计为独立实体,这引发了关于未来是否会分离的疑问。
- 讨论表明,这种紧密的集成将影响许可的可能性和产品开发路径。
- Modular 对托管 AI 的商业关注:Modular 正专注于托管 AI 云应用,这允许其在对 Max 进行商业应用许可的同时,继续对 Mojo 和 Max 进行投资。
- 他们引入了一种鼓励开放开发并符合其战略业务目标的许可方式。
- 为异构计算铺平道路:Modular 的目标是跨异构计算场景的便携式 GPU 编程,从而促进对先进计算工具的更广泛访问。
- 他们的目标是提供能够为寻求高级计算能力的开发者简化集成过程的框架。
- 异步编程在 Mojo 中占有一席之地:用户讨论了 Mojo 中异步(asynchronous)功能的潜力,特别是针对 I/O 任务,将其类比为 Python 的 async 能力。
- 对话包括探索一种 “sans-io” HTTP 实现,强调线程安全和适当的资源管理。
Perplexity AI Discord
- Perplexity 内部数据困境:用户正在寻求关于 Perplexity 中追问频率的数据,包括花费的时间和往返交互,但回复表明这些数据可能是私有的。
- 这引发了致力于性能改进的 engineers 对透明度和可用性的担忧。
- Perplexity Pro 来源数量之谜:在研究查询中,Perplexity Pro 显示的来源数量从 20 个或更多显著下降到 5 或 6 个,这引发了关于服务变更或使用不当的疑问。
- 这种不一致性凸显了对来源管理清晰度的需求,以及对研究质量的潜在影响。
- 探索邮件自动化工具:用户正在深入研究用于自动化电子邮件的 AI 工具,提到了 Nelima, Taskade, Kindo 和 AutoGPT 作为竞争者,同时寻求进一步的建议。
- 这种探索表明,人们对通过 AI 效率简化沟通流程的兴趣日益浓厚。
- Perplexity AI Bot 寻求可分享的 Thread:Perplexity AI Bot 鼓励用户通过提供 Discord 频道链接来确保他们的 Thread 是“可分享的”,以便参考。
- 这种对可分享内容的推动表明其专注于增强社区参与和资源共享。
- 围绕 MrBeast 的社交情绪:讨论涉及了互联网对 MrBeast 的看法,用户链接到了一个 search query 以深入了解潜在的反感原因。
- 这场对话反映了数字名人文化和公众舆论动态中的更广泛趋势。
OpenAccess AI Collective (axolotl) Discord
- Base Phi 3.5 未发布: 一位成员强调缺少基础版 Phi 3.5,指出 Microsoft 仅发布了 instruct 版本。这给那些希望在没有基础版访问权限的情况下微调模型的人带来了挑战。
- 探索可用性的极限,他们正在寻求使用现有 instruct 版本进行微调的解决方案。
- QLORA + FSDP 硬件需求: 关于运行 QLORA + FSDP 的讨论集中在需要 8xH100 配置上。成员们还注意到,在训练期间启用热重启(warm restarts)时,tqdm 进度条会出现不准确的情况。
- 性能监控仍是一个挑战,这促使人们要求改进框架内可用的跟踪工具。
- SmolLM:一系列小语言模型: SmolLM 包括 135M、360M 和 1.7B 参数的小型模型,全部在高质量的 Cosmo-Corpus 上训练。这些模型整合了 Cosmopedia v2 和 FineWeb-Edu 等各种数据集,以确保训练的鲁棒性。
- 精选的数据集选择,旨在提供在不同条件下平衡的语言理解能力。
- Transformers 中的模式感知聊天模板: 用户在 Transformers 仓库中报告了一个关于模式感知聊天模板(mode-aware chat templates)的问题,建议该功能可以区分训练和推理行为。这可能会解决与聊天模板配置相关的现有问题。
- 详情列在 GitHub issue 中,该 issue 提议实现一个
template_mode变量。
- 详情列在 GitHub issue 中,该 issue 提议实现一个
OpenAI Discord
- GPT-3.5:过时还是有趣?: 出现了一场关于测试 GPT-3.5 是否仍然具有相关性的讨论,因为考虑到后训练(post-training)技术的进步,它可能被认为已经过时。
- 一些成员认为,与 GPT-4 等新模型相比,它可能缺乏重要性。
- 探索邮件自动化替代方案: 用户正在寻找自动化邮件任务的工具,寻找除了 Nelima 之外基于提示词发送邮件的替代方案。
- 这表明在日常工作流中对自动化解决方案的需求日益增长。
- SwarmUI:用户体验备受赞誉: SwarmUI 因其用户友好的界面以及对 NVIDIA 和 AMD GPU 的兼容性而获得赞誉。
- 用户强调了其直观的设计,使其成为许多开发者的首选。
- 知识文件格式困境: 一位用户询问在项目中使用 XML 还是 Markdown 作为知识文件更有效,旨在获得最佳性能。
- 这一询问反映了关于在 GPTs 中构建内容最佳实践的持续争论。
- 不一致的 GPT 格式导致挫败感: 用户对 GPT 响应中不一致的输出格式表示担忧,特别是关于某些消息传达了结构化内容而其他消息则没有。
- 用户正在寻找标准化格式的解决方案,以增强可读性和用户体验。
Eleuther Discord
- 掌握多轮提示词: 一位用户强调了在多轮提示词中包含
n-1轮的重要性,并引用了来自对齐手册(alignment handbook)的 代码示例。- 他们探索了逐步增加轮数来生成提示词的可行性,但对其相对有效性表示担忧。
- SmolLM 模型见解: 讨论了 SmolLM 模型,指出其训练数据源自 Cosmo-Corpus,其中包括 Cosmopedia v2 等。
- SmolLM 模型参数范围从 135M 到 1.7B,在其尺寸类别中表现出显著的性能。
- Mamba 模型部署帮助: 分享了关于 Mamba 2.8B 模型 的信息,该模型可与
transformers库无缝协作。- 提供了设置
causal_conv_1d等依赖项以及使用generateAPI 进行文本生成的说明。
- 提供了设置
- 创新的模型蒸馏技术: 有建议提出将 LoRAs 应用于 27B 模型,并从较小的 9B 模型中蒸馏 logits,旨在以压缩形式复制功能。
- 这种方法有可能在较小的架构中简化大型模型的性能。
- 模型压缩策略: 压缩模型大小的建议包括将参数归零和应用量化方法等技术,并参考了关于 量化技术 的论文。
- 讨论的技术旨在提高效率,同时管理模型大小。
Cohere Discord
- Cohere API 在无效角色上报错:一位用户报告了在使用 Cohere API 时出现 HTTP-400 错误,指出提供的角色无效,可接受的选项为 ‘User’、’Chatbot’、’System’ 或 ‘Tool’。
- 这强调了用户在进行 API 调用之前验证角色参数的必要性。
- 创新的多模态 LLM 进展:一位成员展示了一个能够无缝解释文本和语音的多模态 LLM,通过将直接的多模态投影器连接到 Meta 的 Llama 3 模型,消除了独立的 ASR 阶段。
- 这种方法通过合并音频处理和语言建模,减少了独立组件带来的延迟,从而加快了响应速度。
- Cohere 的新 Schema Object 引起用户关注:新引入的 Cohere Schema Object 因其在单个 API 请求中促进结构化多重操作的能力而受到热捧,有助于生成式小说任务。
- 用户报告称,它有助于高效地生成复杂的 Prompt 响应和内容管理。
- Cohere 定价 - 基于 Token 的模型:Cohere 模型的定价结构(如 Command R)基于 Token 系统,每个 Token 都有成本。
- 一个通用指南指出,一个单词大约等于 1.5 个 Token,这对于预算规划至关重要。
- Cohere 模型即将登陆 Hugging Face Hub:目前正在计划将所有主要的 Cohere 模型 打包并托管在 Hugging Face Hub 上,为开发者创建一个易于访问的生态系统。
- 这一举措引起了热衷于在项目中使用这些资源的成员们的兴奋。
Interconnects (Nathan Lambert) Discord
- AI 倦怠引发警惕:对 AI 倦怠 的担忧正在升级,成员们注意到 AI 领域面临的倦怠风险远高于人类,特别是在高强度的前沿实验室中,这已成为一个可持续性问题。
- 这场讨论突出了无休止的工作量这一令人担忧的趋势,以及对 AI 社区心理健康的潜在长期影响。
- AI 高级用户如同施法者:一位成员将 AI 高级用户 比作施法者职业,强调他们持续使用工具会产生压力并导致潜在的倦怠。
- 随着 AI 模型的进步,对这些用户的需求可能会升级,从而加剧已经观察到的倦怠循环。
- 无止境的模型迭代陷阱:对下一代模型生成的追求正受到审视,人们担心这种周期性的追逐可能导致严重的行业倦怠。
- 预测模型表明,倦怠趋势的转变与 AI 进步速度的加快及其对开发者的消耗有关。
- Twitter 焦虑再次袭来:最近 Greg Brockman 在 Twitter 上发布的一篇展示单周编码 97 小时的帖子引发了关于在线 AI 讨论 强度增加所带来压力的对话。
- 参与者表示担心,充满活力但又令人焦虑的 Twitter 氛围可能会削弱现实世界的参与感,凸显了令人担忧的脱节。
LAION Discord
- Infinite Generative Youtube 招聘开发人员:一个团队正在为其 Infinite Generative Youtube 平台寻求开发人员,该平台即将推出封闭测试版。
- 他们特别希望有热情的开发人员加入这个创新项目。
- 针对低资源语言的文本转语音模型:一位用户热衷于为印地语、乌尔都语和德语训练 TTS 模型,旨在开发语音助手应用。
- 该项目专注于提高低资源语言处理的可访问性。
- 利用 WhisperSpeech 的语义 Token 探索 ASR:有关使用 WhisperSpeech 语义 Token 通过定制训练过程增强低资源语言 ASR 的咨询浮出水面。
- 提议的方法包括使用来自音频和转录的语义 Token 微调一个小型的解码器模型。
- SmolLM:更小但有效的模型:SmolLM 提供三种尺寸(135M、360M 和 1.7B 参数),在 Cosmo-Corpus 上进行训练,展示了极具竞争力的性能。
- 该数据集包括 Cosmopedia v2 和 Python-Edu,表明其对高质量训练集的强力关注。
- Mamba 与 Transformers 的兼容性:Mamba 语言模型推出了与 transformers 兼容的 mamba-2.8b 版本,需要特定的安装步骤。
- 用户需要配置 ‘transformers’ 直到 4.39.0 版本发布,才能利用优化后的 CUDA 内核。
LangChain AI Discord
- Graph Memory 保存咨询:成员们讨论了是否可以将 Memory 保存为文件以编译新的 Graph,以及相同的 Memory 是否可以在不同的 Graph 之间复用。
- 它是针对每个 Graph 的还是共享的? 是核心问题,成员们对优化 Memory 使用表现出浓厚兴趣。
- 使用 LangChain 改进 SQL 查询:LangChain Python Documentation 提供了通过 create_sql_query_chain 增强 SQL 查询生成的新策略,重点关注 SQL 方言的影响。
- 了解如何使用 SQLDatabase.get_context 格式化 Schema 信息,以提高 Prompt 在查询生成中的有效性。
- LangChain 中的显式上下文:要在 LangChain 中使用类似
table_info的上下文,必须在调用 Chain 时显式传递,如文档所示。- 这种方法确保了你的 Prompt 是针对提供的上下文定制的,展示了 LangChain 的灵活性。
- 将 Writer Framework 部署到 Hugging Face:一篇博客文章探讨了使用 Docker 将 Writer Framework 应用部署到 Hugging Face Spaces,展示了 AI 应用部署的便捷性。
- Writer Framework 提供了类似于 Streamlit 和 Gradio 的拖拽界面,旨在简化 AI 应用开发。
- Hugging Face Spaces 作为部署平台:上述博客文章详细介绍了在 Hugging Face Spaces 上的部署过程,强调了 Docker 在托管和共享 AI 应用中的作用。
- 像 Hugging Face 这样的平台为开发者提供了展示项目的绝佳机会,推动了社区参与。
DSPy Discord
- Adalflow 惊艳亮相:一名成员重点介绍了 Adalflow,这是来自 SylphAI 的一个新项目,并对其功能和应用表示了兴趣。
- Adalflow 旨在优化 LLM 任务流水线,为工程师提供增强工作流的工具。
- DSpy vs Textgrad vs Adalflow 大比拼:大家对 DSpy、Textgrad 和 Adalflow 之间的区别感到好奇,特别是关于何时能有效利用每个模块。
- 有人指出 LiteLLM 将专门管理推理的查询提交,暗示了这些模块的性能潜力。
- 新研究论文预警!:一名成员分享了 ArXiv 上一篇名为 2408.11326 的有趣论文链接,鼓励工程师同行们去阅读。
- 虽然没有透露论文的详细信息,但它的出现表明了对 DSPy 社区的持续贡献。
OpenInterpreter Discord
- 寻求 Open Interpreter 品牌指南:一名用户询问是否有 Open Interpreter 品牌指南,表示需要明确品牌规范。
- 你能分享在哪里可以找到这些指南吗?
- Phi-3.5-mini 引发意外热议:用户对 Phi-3.5-mini 的性能表现出意料之外的认可,引发了将 Qwen2 推向聚光灯下的讨论。
- 积极的反馈让所有人都措手不及!
- 屏幕点击的 Python 脚本需求:一名用户寻求一个 Python script,能够根据文本命令在指定的屏幕位置执行点击操作,例如在 Notepad++ 中进行导航。
- 如何让它点击文件下拉菜单?
- –os 模式可能是解决方案:针对脚本咨询,有人建议使用 –os mode 可能会解决屏幕点击的挑战。
- 这可能会显著简化操作流程!
- 免费数据分析大师课激动人心的公告:一名用户分享了关于免费数据分析大师课的公告,推广现实世界的应用和实用的见解。
- 有兴趣的参与者可以在这里注册,并分享对潜在参与机会的兴奋之情。
Gorilla LLM (Berkeley Function Calling) Discord
- Gorilla 和 Huggingface 排行榜现已对齐:一名成员询问了 Gorilla 和 Huggingface 排行榜上的分数,这些分数最初并不一致。目前差异已解决,Huggingface 排行榜现在与 Gorilla 排行榜保持同步。
- 这种对齐为用户在跨平台评估模型性能时提供了更可靠的参考。
- Llama-3.1-Storm-8B 在 Gorilla 排行榜首次亮相:一位用户提交了一个 Pull Request,申请将 Llama-3.1-Storm-8B 添加到 Gorilla Leaderboard 进行基准测试。由于该模型最近刚完成发布,该 PR 将进入审核阶段。
- 该模型的加入展示了社区对持续更新基准测试框架的承诺。
- 寻求 REST API 测试对的指导:有用户寻求关于为其 REST API 功能构建“可执行测试对”的建议,并参考了 Gorilla leaderboard 中现有的测试对。他们更倾向于既“真实”又“易于”实现的测试。
- 这表明在 API 开发中,对更具实用性的测试资源和方法存在需求。
- 需要对可执行测试对进行澄清:关于 “可执行测试对” (executable test pairs) 这一术语引发了另一场讨论,用户寻求更清晰地理解其在 REST API 测试中的相关性。这反映出成员们在概念清晰度上存在差距。
- 深入了解这一术语有助于增强他们在测试策略中的理解和应用。
AI21 Labs (Jamba) Discord
- Jamba 1.5 Mini & Large 正式登场:AI21 Labs 推出了 Jamba 1.5 Mini(12B 激活/52B 总参数)和 Jamba 1.5 Large(94B 激活/398B 总参数),基于全新的 SSM-Transformer 架构,在长上下文处理能力和速度上均优于竞争对手。
- 这些模型具有 256K 有效上下文窗口,声称在长上下文处理速度上比竞争对手快 2.5 倍。
- Jamba 在长上下文中占据主导地位:Jamba 1.5 Mini 在 Arena Hard 上获得了 46.1 的领先分数,而 Jamba 1.5 Large 达到了 65.4,甚至超越了 Llama 3.1 的 405B。
- 性能的飞跃使 Jamba 成为长上下文领域的重要竞争者。
- API 速率限制已确认:用户确认了 API 速率限制,使用额度为每分钟 200 次请求和每秒 10 次请求,解决了关于利用率的疑虑。
- 这些信息是用户在初步查询后发现的。
- Jamba 尚不支持 UI 微调:官方对 Jamba 的微调进行了澄清;微调仅适用于 instruct 版本,且目前无法通过 UI 进行操作。
- 这一细节给依赖 UI 进行调整的开发者带来了疑问。
- Jamba 的过滤功能受到关注:讨论中提到了 Jamba 的过滤能力,特别是针对涉及暴力的角色扮演场景。
- 成员们对这些内置功能表示好奇,以确保交互的安全性。
MLOps @Chipro Discord
- NVIDIA AI Summit India 引发关注:NVIDIA AI Summit India 将于 2024 年 10 月 23-25 日在孟买的 Jio World Convention Centre 举行,届时 Jensen Huang 将与其他行业领袖一起出席超过 50 场会议。
- 峰会重点关注推进 Generative AI、Large Language Models (LLM) 和超级计算等领域,旨在展示行业内的变革性工作。
- AI 黑客松提供丰厚奖励:AI Capabilities and Risks Demo-Jam Hackathon 已启动,设有 $2000 的奖金池,优秀项目有机会与 Apart Labs 合作开展研究。
- 该倡议旨在创建应对 AI 影响和安全挑战的演示项目,鼓励向公众清晰地传达复杂概念。
- 黑客松激动人心的启动:黑客松以一场关于交互式 AI 展示的精彩开幕主旨演讲拉开帷幕,随后进行了团队组建和项目头脑风暴。
- 参与者将受益于专家指导和资源支持,同时活动在 YouTube 上进行了直播,以实现广泛的传播。
tinygrad (George Hotz) Discord
- Tinygrad 的 Mypyc 编译探索:一名成员表示有兴趣使用 mypyc 编译 tinygrad,目前正在调查其可行性。
- 原作者邀请其他人参与这一努力,强调了协作精神。
- 加入探索!:原作者邀请其他人为使用 mypyc 编译 tinygrad 的工作做出贡献。
- 鼓励大家在探索这一新尝试时积极参与。
Alignment Lab AI Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Torchtune Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的频道详细分析已针对电子邮件进行截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!