ainews-cogvideox-zhipus-open-source-sora
CogVideoX:智谱的开源 Sora
智谱 AI(阿里巴巴旗下的 AI 部门,也是中国第三大 AI 实验室)发布了开源的 5B(50 亿参数)视频生成模型 CogVideoX。该模型可以通过其 ChatGLM 网页端和桌面应用运行,无需本地 GPU。
Meta AI 在发布 Llama 3.1 的同时,宣布了信任与安全研究以及 CyberSecEval 3;目前 Llama 3 405B 已在 Google Cloud Vertex AI 和 Hugging Face x NVIDIA NIM API 上提供无服务器(serverless)服务。
其他更新包括:
- Moondream:一款开源视觉语言模型,提升了 DocVQA(文档视觉问答)和 TextVQA(文本视觉问答)任务的表现。
- Phi-3.5:拥有 16x3.8B 参数的轻量级 MoE(混合专家)聊天模型。
- Together Compute:推出了 Rerank API,采用了 Salesforce 的 LlamaRank 模型用于文档和代码排序。
研究亮点包括:
- 叠加提示(Superposition prompting):无需微调即可用于 RAG(检索增强生成)。
- AgentWrite 流水线:可生成超过 20,000 字的长文本内容。
- 对比研究:结果显示长上下文(Long Context)方法在成本较高的情况下表现优于 RAG。
工具方面包括:AI 模型路由 Not Diamond、AI 命令行界面,以及一款开源的 WebGPU 背景移除工具。
针对 CogVideoX,有评价称:“你甚至不需要 GPU 就能运行它。”
开源 Videogen 就是你所需要的一切。
2024/08/26-2024/08/27 AI 新闻简报。我们为你检查了 7 个 subreddits、384 个 Twitter 账号 和 30 个 Discord 服务器(215 个频道,3433 条消息)。预计节省阅读时间(以 200wpm 计算):369 分钟。你现在可以艾特 @smol_ai 进行 AINews 讨论!
自从 Sora 在 2 月发布以来(我们的报道在此),出现了一系列替代方案的尝试,包括 Kling(未开源)和 Open-Sora(仅约 1B 参数)。智谱 AI(Zhipu AI),实际上是阿里巴巴的 AI 臂膀,也是中国第三大“AI 老虎”实验室,发布了其全新的开源 5B 视频模型 CogVideoX。在这里我们遇到了电子邮件简报的一个经典限制,因为我们无法嵌入视频:
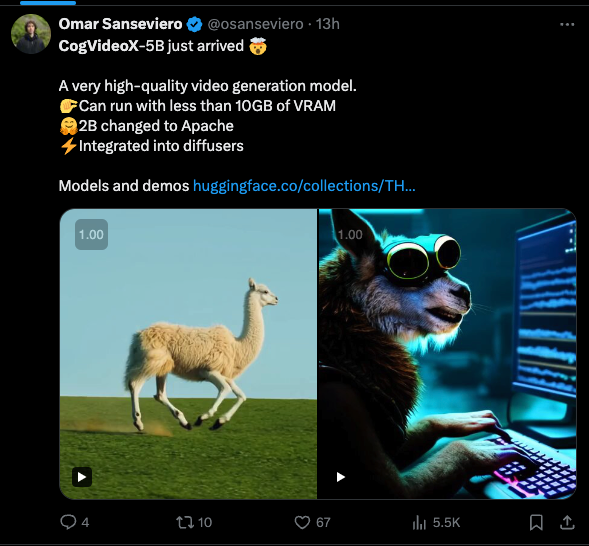
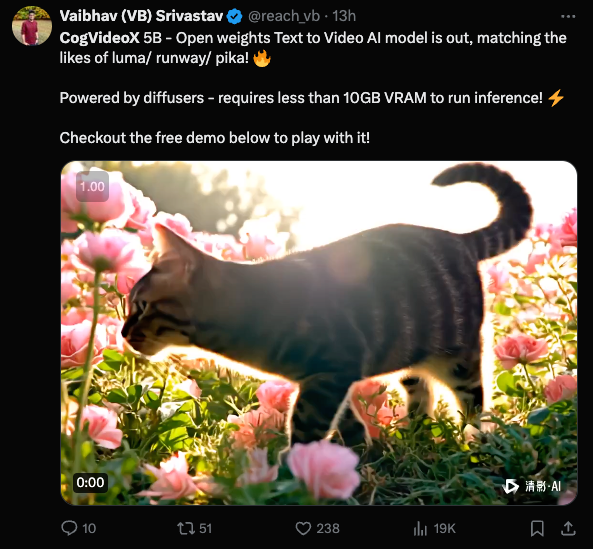
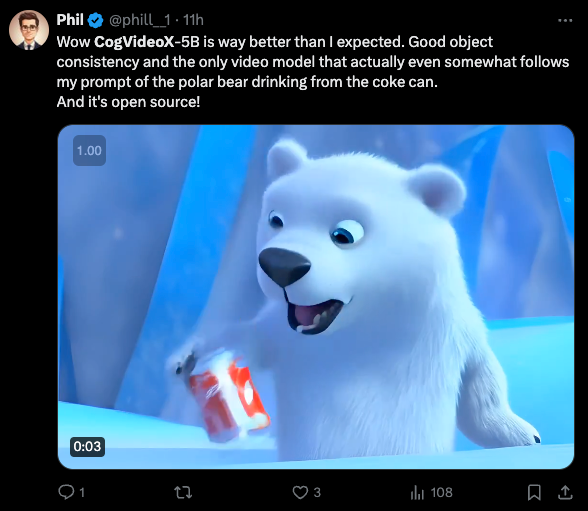
你甚至不需要 GPU 就能运行它 —— 你可以使用 智谱(Zhipu)的在线 ChatGLM Web 应用或桌面应用(可能需要一位懂中文的朋友帮你注册手机号账号)—— 我们第一次尝试就成功运行了。

AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型开发与发布
-
Llama 3 及其他模型更新:@AIatMeta 发布了与 Llama 3.1 发布相关的全新信任与安全研究以及 CyberSecEval 3。@_philschmid 报道称 Llama 3 405B 现已在 Google Cloud Vertex AI 和 Hugging Face x NVIDIA NIM API 上提供 Serverless 服务。
-
Moondream 更新:@vikhyatk 发布了开源视觉语言模型 moondream 的更新,提升了在 DocVQA 和 TextVQA 任务中的性能。
-
Phi-3.5 模型:@rohanpaul_ai 讨论了 Phi-3.5 MoE 聊天模型,这是一款轻量级 LLM,拥有 16x3.8B 参数,通过 2 个专家(experts)使用 6.6B 激活参数。
-
Together Rerank API:@togethercompute 推出了 Together Rerank API,采用 Salesforce 的 LlamaRank 模型,用于改进文档和代码排序。
AI 研究与技术
-
Superposition Prompting:@rohanpaul_ai 分享了关于 Superposition Prompting 的见解,这是一种新颖的 RAG 方法论,无需微调即可加速并增强性能。
-
长文本内容生成:@rohanpaul_ai 讨论了 LongWriter 论文,该论文介绍了用于生成超过 20,000 字连贯输出的 AgentWrite 流水线。
-
RAG vs. 长上下文 (Long Context):@algo_diver 总结了一篇比较检索增强生成 (RAG) 与长上下文 (LC) 方法的研究论文,发现 LC 的表现始终优于 RAG,但成本更高。
AI 工具与应用
-
Not Diamond:@rohanpaul_ai 解释了 Not Diamond,这是一个 AI 模型路由,可自动为给定查询确定最适合的 LLM。
-
命令行中的 AI:@JayAlammar 强调了 AI 在命令行界面中的潜力,能够实现跨多个文件的操作。
-
使用 WebGPU 移除背景:@osanseviero 分享了一个使用 WebGPU 的完全端侧、开源背景移除工具。
AI 行业与商业
-
AI 招聘:@DavidSHolz 宣布 Midjourney 正在为其核心数据团队招聘,强调了在创意能力方面学习和发挥影响力的机会。
-
超大规模企业资本支出:@rohanpaul_ai 报道了超大规模企业(Hyperscaler)在数据中心支出方面的资本支出增加,其中约 50% 用于土地、租赁和建设。
AI 伦理与监管
- 加州 AI 法案 SB 1047:@labenz 讨论了加州 AI 法案 SB 1047 的最新版本,该版本现在的重点是要求前沿公司制定并发布安全计划和协议。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1:用于 AI 开发的高性能硬件解决方案
- Tinybox 终于进入量产阶段 (Score: 83, Comments: 28): Tinybox 是一种用于 AI 开发 的高性能 GPU 集群 解决方案,目前已进入量产阶段。该系统提供配备 NVLink 和 400Gbps 网络 的 8x A100 80GB GPU,与云端替代方案相比,以极具竞争力的价格为机器学习任务提供了一个强大的平台。
- Tinybox 的规格可在 tinygrad.org 查看,其中提到了 15k tinybox red6 x 7900 XTX 版本。用户讨论了该系统与运行批处理后端的单张 A100 之间的潜在 吞吐量对比。
- 针对是以 1.5 万美元构建类似的 6x 4090 配置 还是选择 2.5 万美元的 Tinybox 展开了辩论。George Hotz (imgeohot) 解释了其中的挑战,包括 PCIe 4.0 信号完整性、多电源供应和散热问题,并引用了一篇详细说明这些问题的 博客文章。
- 一些用户认为 Tinybox 的配置乏善可陈,建议可以用更低的成本构建。其他人则为定价辩护,指出这为 tinygrad 开发 提供了资金,并为企业提供了现成的解决方案。该系统适用于 标准机架 (12U),文档 中提供了导轨信息。
主题 2:开源 RAG WebUI 与本地 LLM 部署进展
- 开源、简洁且可定制的 RAG WebUI,支持多用户并具备合理的默认 RAG 流水线。 (Score: 130, Comments: 43): Kotaemon 是一款开源的 RAG WebUI,为普通用户和高级用户提供简洁的界面、多用户支持 以及可定制的流水线。核心功能包括:带有深色/浅色模式的 极简 UI、多用户管理、带有 混合检索器(hybrid retriever)和重排序(re-ranking) 的默认 RAG 配置、支持浏览器内 PDF 查看的 高级引用支持、多模态 QA 支持,以及诸如问题分解和基于 Agent 推理的 复杂推理方法。该项目旨在具有可扩展性,允许用户集成自定义 RAG 流水线,并在不同的文档和向量数据库提供商之间切换。
- 该项目的 GitHub 仓库 已发布并附带安装说明。用户建议为默认容器添加 volume 以持久化配置,因为 Gradio 应用需要频繁的点选设置。
- UI 的简洁设计 受到称赞,开发者分享称该 主题已在 Hugging Face Hub 上发布,可用于其他项目。主题可以在这里找到。
- 支持 离线功能,用户可以直接使用 Ollama OpenAI 兼容服务器 或 LlamaCPP 本地模型。README 提供了此设置的指南,且该应用从一开始就设计为支持离线工作。
主题 3:分布式 AI 训练与基础设施的创新
- Nous Research 发布关于 DisTrO(互联网分布式训练)的报告 (Score: 96, Comments: 7): Nous Research 发布了一份关于 DisTrO (Distributed Training Over-the-Internet) 的报告,这是一种使用消费级硬件训练大语言模型的新方法。该方法允许通过互联网连接的 多个消费级 GPU 进行分布式训练,这可能使更多的研究人员和爱好者能够参与到 AI 模型开发中。DisTrO 旨在通过利用 分布式计算技术 和 优化节点间的数据传输 来解决训练大模型的挑战。
- DisTrO 被视为一个潜在的 重大突破,一些用户推测它可能是分布式优化器的“圣杯”。它可能会 降低训练成本,无论是对于本地/社区模型还是像 Meta 这样的大型公司。
- 用户表达了怀疑态度,指出在机器学习中,非凡的结果往往伴随着代价。一些人质疑除了缩短训练时间外,对 perplexity(困惑度)和整体模型性能的影响。
- 论文提出了一种可能的 新缩放法则(scaling law),即 模型大小增加而无需增加通信带宽。这可能会导致转向设计 具有更大 VRAM 和更窄互连(interconnects)的 GPU,从而有利于计算密集型工作负载而非 I/O 密集型操作。
Misc AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型开发与发布
-
FLUX 模型展现出惊人的能力:r/StableDiffusion 上的一篇帖子 讨论了关于 FLUX 模型能力的意外发现,作者指出“每一天,我都能在 FLUX 中发现令我大吃一惊的新事物”。他们认为我们距离完全理解其能力还很遥远。
-
Salesforce 发布 xLAM-1b 模型:Salesforce 发布了一个名为 xLAM-1b 的 10 亿参数模型,尽管其体积较小,但在 function calling 方面达到了 70% 的准确率,超越了 GPT-3.5。
-
更新后的 Phi-3 Mini 模型:Rubra AI 发布了更新后的 Phi-3 Mini 模型,具备 function calling 能力,可与 Mistral-7b v3 竞争。
-
Joy Caption 更新:Joy Caption 的更新版本已发布,支持 batching,可实现超快速的 NSFW 自然语言 captioning。
AI 研究与技术
-
DisTrO 分布式优化器:Nous Research 宣布了 DisTrO,这是一系列分布式优化器,在不依赖 amortized analysis 的情况下,将 GPU 间通信减少了 1000 倍至 10,000 倍。这可能会显著加速 AI 训练。
-
AI 驱动的编程演示:一段 使用 Cursor 进行 AI 驱动编程的视频演示 展示了 5 年前难以想象的能力。
AI 安全与伦理担忧
-
OpenAI 的 AGI safety 研究人员流失:据一位前研究人员称,OpenAI 近一半的 AGI safety 工作人员已经离职。这引发了关于 AI safety 研究的重要性和作用的辩论。
-
关于 AI safety 研究的辩论:目前存在大量关于 AI safety 研究是对进步至关重要,还是可能阻碍创新的讨论。一些人认为这对于 alignment 和 interpretability 至关重要,而另一些人则认为现阶段没有必要。
AI 应用
-
TTRPG 地图 LoRA:新版本的 TTRPG 地图 LoRA 发布,展示了 AI 在生成游戏资产和地图方面的潜力。
-
AI 生成的“验证”图像:使用 Flux Dev 配合 “MaryLee” 肖像 LoRA 以及 Runway ML 动画技术,创建了一个 AI 生成的动画“验证”图像。
AI Discord 摘要
由 Claude 3.5 Sonnet 生成的摘要之摘要的摘要
1. LLM 进展与基准测试
- DeepSeek V2 表现超越 GPT-4:DeepSeek-V2 凭借其令人印象深刻的 236B 参数,在 AlignBench 和 MT-Bench 等基准测试中超越了 GPT-4,展示了模型性能的显著提升。
- DeepSeek-V2 公告引发了关于其能力的讨论,特别是在其表现优于现有大语言模型的领域。
- Llama 3.1 刷新速度纪录:Cerebras Systems 宣布其推理服务为 Llama3.1-70B 提供了惊人的 450 tokens/sec,显著领先于传统的 GPU 设置。
- 该服务提供极具经济吸引力的价格,每百万 token 仅需 60 美分,吸引了寻求高性价比、高性能 AI 应用解决方案的开发者。
- Google 推出 Gemini 1.5 模型:Google 推出了三个实验性模型:Gemini 1.5 Flash-8B、更强大的 Gemini 1.5 Pro 以及改进后的 Gemini 1.5 Flash,可在 Google AI Studio 进行测试。
- 这些新模型承诺在 coding 和 复杂提示词 方面有所增强,速率限制设定为 每分钟 2 次请求 和 每天 50 次请求,引发了对其潜在能力的关注。
2. 开源 AI 发展
- Intel 首个三进制多模态 LLM 亮相:Intel 推出了 LLaVaOLMoBitnet1B,这是首个能够处理图像和文本并生成连贯响应的三进制多模态 LLM。
- 该模型完全开源并提供训练脚本,鼓励 AI 社区探索三进制建模中的挑战与机遇。
- Microsoft Phi 3.5 在 OCR 领域表现卓越:微软的 Phi 3.5 模型以 MIT 许可证发布,在 OCR 任务中表现出色,特别擅长手写识别和表格数据提取。
- 该模型在各种视觉任务中的文本识别能力引起了 AI 社区的极大兴趣,凸显了其在实际应用中的潜力。
- LocalAI:OpenAI 的开源替代方案:LocalAI 是 Ettore Di Giacinto 发起的一个开源项目,为 OpenAI 提供了一个免费替代方案,带有用于本地推理 LLM、图像和音频生成的 REST API。
- 该平台允许在消费级硬件上运行先进的 AI 模型,无需 GPU,使强大的 AI 能力得以普及。
3. 分布式训练创新
- Nous Research 的 DisTrO 突破:Nous Research 发布了关于 DisTrO 的初步报告,这是一个分布式训练框架,可将 GPU 间的通信大幅减少高达 10,000 倍。
- DisTrO 旨在实现大语言模型的弹性训练,而不依赖于中心化的计算资源,有可能使 AI 研发更加民主化。
- 关于 Nous Research 优化器声明的辩论:AI 社区对 Nous Research 的新优化器表示怀疑,特别是关于其分布式训练能力的声明。
- 讨论中提到了现有的工具如 Petals for Bloom 和 OpenDILo,强调需要更多实质性的证据来支持 Nous 在分布式 AI 训练领域的承诺。
4. 多模态 AI 进展
- Cog-5B 视频模型发布:Cog-5B 视频模型 在 CogVideoX-5b 发布,被誉为视频生成领域最佳的开源权重,并集成了 Diffusers 库。
- 该模型承诺在低于 10GB VRAM 的情况下实现高效推理,展示了结合文本、图像和视频生成能力的多模态 AI 的进步。
- StoryDiffusion:开源版 Sora 替代方案:StoryDiffusion 的推出引起了 AI 社区的兴奋,它是 Sora 的开源替代方案,采用 MIT 许可证,尽管权重尚未发布。
- 这一发展凸显了人们对可与专有解决方案竞争的、易于获取的高质量视频生成模型日益增长的兴趣。
第一部分:高层级 Discord 摘要
Nous Research AI Discord
- DisTrO 算法持续演进:DisTrO 算法正在积极优化中,通过测试不同的变体来优化通信带宽 (communication bandwidth),同时确保收敛性能。
- 成员们指出,像 SWARM 这样的技术可能更适合大型模型。
- 社区渴望合作:成员们对参与 DisTrO 算法的实现表现出浓厚兴趣,强调开放贡献和讨论。
- 团队计划在未来几周内分享完整的代码和细节。
- 围绕 AI 意识的哲学辩论:AI 中感质 (qualia)和意识的影响引发了严肃讨论,呼吁更多的跨学科合作。
- 成员们指出计算机科学家与哲学家之间需要更深层次的合作。
- DisTrO 探索弱设备应用:讨论了在旧手机等弱设备上使用 DisTrO 的可行性,强调了对高效训练方法的需求。
- 虽然 DisTrO 在强硬件上表现出色,但探索其在低性能系统中的效用被认为很有价值。
- Tinybox 正式开放购买:经过 18 个月,Tinybox 现在有了“立即购买”选项,公告称有 13 台可供购买。
- 售价 1.5 万美元的 Tinybox Red 因其在 ML 领域的性价比而受到称赞。
Unsloth AI (Daniel Han) Discord
- 张量转换难题:一位用户在将模型转换为 GGUF 时遇到了关于
embed_tokens.weight的ValueError,这表明 sentence-transformer 和 causalLM 模型之间存在不匹配。- 目前的转换工具缺乏对配对评分 (pair scoring) 的支持,这引发了挫败感。
- Batch Size 优化策略:讨论揭示了一种策略,即不断增加 Batch Size 直到出现显存溢出 (OOM) 错误,从而促使用户调整其训练设置。
- 一位用户计划在完成最新的训练任务后将模型转换为 Ollama 格式。
- Homoiconic AI 项目更新:’Homoiconic AI’ 项目报告了使用 hypernets 进行权重生成的验证损失 (validation loss) 指标有所改善,并旨在实现多模态集成方案。
- 成员们讨论了 In-context learning 如何帮助改进模型权重,并引用了一份进度报告。
- LigerKernel 的抄袭争议:有关 LinkedIn 的 LigerKernel 涉嫌抄袭 Unsloth 核心组件的担忧浮出水面,引发了对其所谓重大改进声明的质疑。
- 社区成员指出抄袭的代码中缺乏原始变量命名。
- LLM 微调中的数据准备:讨论强调许多人希望在没有明确目标或数据集的情况下微调 LLM,这引发了对理解该过程的担忧。
- 成员们表示,在深入研究模型微调之前,扎实的基础知识至关重要。
OpenAI Discord
- 探索 AI 的情感深度:关于 AI 人格 (AI personhood) 的讨论强调,虽然 AI 可以模拟情感,但它并不能真实地体验情感,这在用户产生情感依恋时引发了伦理担忧。
- 参与者质疑将 AI 视为朋友是否会削弱我们对情感本质的理解。
- 推动去中心化 AI:关于 AI 去中心化 的讨论强调了向用户拥有数据的转变,减少企业对 AI 身份和训练数据的控制。
- 人们对 开源模型 (open-source models) 的日益普及持乐观态度,旨在打破当前的中心化系统。
- AI 提供陪伴——某种程度上:尽管 AI 在帮助那些感到孤立的人方面具有潜力,但讨论反映了对 AI 取代真实友谊的怀疑。
- 参与者分享了关于 AI 可能带来的慰藉的个人轶事,特别是在边缘化群体中。
- 对 GPT-4o 推理能力的担忧:GPT-4o 用户表达了对其推理能力的挫败感,称与早期模型相比,它存在事实错误和不一致性。
- 一些用户认为 GPT-4o 退步了,并正在讨论哪些更新可以恢复其性能。
- YouTube 摘要工具的困境:YouTube 摘要工具的有效性面临挑战,主要是由于平台阻止 Bot 访问转录文本 (transcripts)。
- 虽然有人建议手动获取转录文本,但成员们指出这种方法存在违反 YouTube 服务条款的风险。
HuggingFace Discord
- Hugging Face 中的模型部署挑战:用户报告了在部署 Gemma-7B 模型时因文件缺失和运行时错误导致的问题,并考虑将仓库克隆作为一种变通方法。
- 对话中包含了关于验证模型路径以及使用
.from_pretrained方法来解决配置问题的建议。
- 对话中包含了关于验证模型路径以及使用
- PyTorch Lightning 的 LitServe 提升速度:来自 PyTorch Lightning 的 LitServe 声称其模型服务速度比 FastAPI 快 2 倍,有望提高部署效率。
- 用户热衷于采用这一更新,因为它能显著缩短推理时间。
- StockLlama 发布,用于时间序列预测:StockLlama 利用 Llama 通过自定义 embeddings 进行时间序列预测,旨在提高准确性。
- 这一介绍引起了希望增强预测能力的开发者的兴趣。
- 深入了解 ProteinBERT 结构:关于 ProteinBERT 的讨论阐明了其专注于处理蛋白质序列的局部和全局表示的架构,并分享了 ProteinBERT 论文 链接以供参考。
- 用户表示有兴趣了解这些表示如何有助于有效的分类和回归任务。
- Cog-5B 视频模型发布:Cog-5B 视频模型 现已在 CogVideoX-5b 上线,展示了先进的视频生成能力。
- 对于即将发布的、将增强用户自定义选项的微调脚本,人们的期待正在上升。
LM Studio Discord
- LM Studio 模型加载困扰:用户报告了与系统资源不足相关的模型加载问题,在尝试加载各种模型时遇到了退出错误代码 -1073740791。
- 调整为 CPU-only 设置和修改 guardrails 设置被提出作为潜在的修复方案。
- AMD vs Nvidia:GPU 对决:讨论转向了 Nvidia 和 AMD 在 LLM 任务中的性能差距,目前 Nvidia 处于领先地位。
- 对于追求高效模型性能且预算有限的用户,Nvidia 3060 12GB 被建议作为一个平衡的选择。
- Ollama 的 CPU 瓶颈:在使用 Ollama 运行 LLM 时,有报告称只有一个 CPU 发热,凸显了潜在的单 CPU 性能瓶颈。
- 用户强调了对双 CPU 支持的需求以提高推理速度,尽管这个话题可能存在争议。
- Tinygrad:简化神经网络:新的 Tinygrad 框架因其处理复杂网络的简洁性而受到关注,其特点是包含 ElementwiseOps 等操作。
- 尽管存在局限性,但它因具有简化 LLM 项目工作流的潜力而吸引了注意。
- Cerebras 将推理推向新高度:Cerebras 宣布其推理服务为 Llama3.1-70B 提供惊人的 450 tokens/sec,超越了传统的 GPU 配置。
- 该服务提供了极具经济吸引力的价格,每百万 tokens 仅需 60 美分,吸引了寻求高性价比解决方案的开发者。
aider (Paul Gauthier) Discord
- Aider v0.53.0 引入重大增强:最新发布的 Aider v0.53.0 具有改进的 prompt caching,允许在会话期间有效地缓存 prompts,从而提高编码速度和成本效率。
- 该版本展示了 Aider 编写其自身 59% 代码的能力,强调了其在操作自主性方面的重大飞跃。
- 用户对 Aider 功能的见解:讨论揭示了 Aider 在通过单个 prompt 转换大型代码库时面临的挑战,需要进一步优化以获得有效结果。
- 尽管很有价值,但用户承认 Aider 的输出必须经过严格测试和润色,才能用于实质性项目。
- Gemini 模型性能揭晓:新的 Gemini 1.5 模型已经推出,包括 Gemini 1.5 Pro,旨在为复杂的 prompts 和编码任务提供更好的性能,可在 AI Studio 进行测试。
- 这些模型的 Rate limits 设定为 每分钟 2 次请求 和 每天 50 次请求,促使用户寻求创意性的变通方法来进行性能基准测试。
- Anthropic 发布 Claude 3 的 System Prompts:截至 2024 年 7 月 12 日,Anthropic 已发布其 Claude 3 模型(包括 Claude 3.5 Sonnet)的 system prompts,并承诺随未来变化更新文档。
- 这些 prompts 被视为 LLM 文档中显著的透明度提升,并收集了研究员 Amanda Askell 关于其用法的见解。
- Aider 中的错误处理改进:Aider v0.53.0 改进了错误处理,在未设置变量时提供更清晰的消息,增强了用户的排错体验。
- 最近的 bug 修复还解决了 Windows filenames 的问题,确保在不同系统上实现更顺畅的操作功能。
Stability.ai (Stable Diffusion) Discord
- 对下一代 AI 硬件的期待:成员们热烈讨论了即将发布的具有增强 AI 功能的 Intel CPUs 和 NVIDIA GPUs,引发了对组装新 PC 的兴趣。
- 这些创新将显著提高 AI 任务的性能,为用户的技术升级做好准备。
- Flux 模型的惊人能力:关于 Flux 先进功能的讨论爆发了,包括动态角度和深度透视,这可能会使旧模型过时。
- 随着成员们推测其彻底改变 AI 生成视觉效果的潜力,对其可训练性的担忧也随之增加。
- 对 ZLUDA 开发的担忧:在有报告指出 AMD 已停止资助其开发后,参与者对 ZLUDA 的未来发出了警报。
- 成员们推测,尽管 GitHub 有更新,但持续的法律挑战可能会进一步使 ZLUDA 的进展复杂化。
- SD Next 与 ZLUDA 的集成:一场关于为什么 SD.Next 在使用 ZLUDA 时表现更好的讨论展开了,观点认为其后端架构集成了 A1111 和 Diffusers。
- 这种多后端框架可以增强不同模型之间的兼容性和整体性能。
- Streamdiffusion 和 SDXL Turbo 的挑战:成员们对将 SDXL Turbo 与 Streamdiffusion 集成的困难表示挫败,特别是在 TensorRT 性能方面。
- 对帧率和分辨率兼容性的担忧出现,使其在实际可用性方面受到质疑。
Eleuther Discord
- 询问视频 Benchmark 示例:一位成员询问了关于 video benchmarks 的高质量示例,重点关注 spatial awareness(空间感知)和生成模型等任务,随后引发了关于标准评估方法的建议。
- 虽然针对判别任务提出了 action recognition(动作识别),但生成任务目前明显缺乏成熟的 benchmarks。
- 关于 RLHF 库的讨论:频道内讨论了 TRL/TRLX 是否仍是 Reinforcement Learning from Human Feedback (RLHF) 的首选,由于担心 TRLX 已经过时,许多人推荐使用 TRL。
- 成员们表达了对替代方案的渴望,但在最近的讨论中尚未出现新的选择。
- Llama 3.1 的免费 API 访问:一位成员分享了来自 SambaNova 的 Llama 3.1 405B 免费 API 链接,强调了其在提升可访问性方面的潜力。
- 简要介绍了 SambaNova 的服务细节,这可能会增强使用其平台的 AI 项目。
- 关于 Gemini 误导性陈述的指控:社区就 Jamba 作者对 Gemini 的指控展开了辩论,据称 Gemini 在没有进一步测试的情况下被限制在 128k,这引发了争议。
- 辩护者认为作者的措辞并没有误导,并评论道 “他们无法复现超过 128k 的结果”。
- 学习率缩放的见解:分享了关于在使用 Adam 优化器时,针对 batch sizes 调整学习率必须进行 sqrt scaling(平方根缩放)的见解,并引用了多篇论文。
- 小组探讨了实验中的方法论差异,并对提议方法的可行性提出了疑问。
CUDA MODE Discord
- Liger Kernel 欢迎新贡献者:新成员加入了 Liger Kernel 社区并渴望做出贡献,重点关注 Triton 及其功能,其中包括一家来自华盛顿特区、对训练效率感兴趣的初创公司。
- 分享了贡献指南以促进积极协作,标志着对该项目的兴趣日益浓厚。
- Triton 实现对比:开发者发现 Triton 的实现比 PyTorch 更难,但比纯 CUDA 更容易,这呈现出一种独特的权衡。
- 利用 torch.compile 等工具可以提升性能,使这种转换变得物有所值。
- Encoder 风格 Transformer 的支持计划:社区正在探索对 BERT 等 encoder-only Transformer 的支持,并创建了一个 Issue 来跟踪功能开发。
- 存在复用层的潜力,表明在 Liger Kernel 框架内增强现有模型的协作努力。
- 呼吁开发融合算子 (Fused Kernel):讨论集中在建立一个“融合算子库 (fused kernel zoo)”,以简化在当前框架之外添加高效 kernel 的过程。
- 成员们认为 PyTorch 和 Triton 之间的协同作用可以产生最佳结果,并邀请大家提交 kernel 请求。
- 低比特优化技术的见解:用户专注于用于微调 4-bit 优化 模型的数据集,并指出 Alpaca 数据集在性能上面临挑战。
- 推荐将 Chatbot Arena 数据集 作为潜在解决方案,强调了其全面性,但也承认其复杂性。
Perplexity AI Discord
- Perplexity 应用出现性能缓慢:许多用户反映 Perplexity app 自今天早上以来响应时间变慢,导致用户感到沮丧。
- 投诉内容包括搜索结果不可靠以及对平台近期表现的普遍不满。
- 全面出现文件上传失败:多名用户尝试上传图片时遇到 file upload failed 错误,一些 Pro 订阅用户也对此类问题表示失望。
- 虽然有报告称 PDF 上传正常,但用户仍在等待图片上传故障的修复。
- 澄清 GPT 模型的用量限制:据报告,Claude 3.5 模型的每日消息限制为 430 条(所有 Pro 模型共用),但 Opus 除外,其限制为 50 条。
- 用户指出,即使在高强度使用下也很少达到限制,有人提到他们最接近的一次大约是 250 条消息。
- 波音更换 737 的计划:波音更换 737 的计划被强调为在需求增长背景下提高机队效率和可持续性的战略举措。
- 他们的目标是通过一款在性能和环境影响方面优于现有模型的新飞机来满足市场需求。
- 在聊天机器人中集成 Perplexity AI 的挑战:一位用户尝试将 Perplexity AI 集成到希伯来语事实核查聊天机器人中,但面临响应内容过短且缺少 links(链接)和 images(图片)的问题。
- 他们指出,来自 API 的响应与 Perplexity 搜索网站上的响应显著不同,并提到链接经常导致 404 errors。
OpenRouter (Alex Atallah) Discord
- API 性能下降事件短暂影响服务:出现了一段约 5 分钟的 API degradation(API 性能下降)时期,影响了服务可用性。目前已推出补丁,该事件似乎已完全 recovered(恢复)。
- 响应团队在 API 性能下降期间迅速识别了问题,确保了最小程度的中断。这种主动的方法突显了快速响应在维护服务完整性方面的重要性。
- 团队努力获得认可!:一位成员对团队的贡献表示感谢,称:Thank you team! 这种认可彰显了相关人员的协作精神和辛勤工作。
- 此外,分享的一条 tweet 展示了 AI 协作方面的重大进展。该推文强调了社区努力在推动 AI 技术发展中的重要性。
- OpenRouter 模型定价和费用说明:一位用户询问 OpenRouter 显示的每个 token 价格是否包含服务费。已澄清所列价格基于 OpenRouter 积分,不包括添加积分时产生的任何额外费用。
- 还有人对活动页面当前显示为 $0 表示担忧,这可能会误导用户。增强 model pricing(模型定价)的可见性对于改善用户体验至关重要。
- DisTrO 为分布式训练带来新希望:一位成员强调了 Nous Research 发布的一份关于 DisTrO (Distributed Training Over-the-Internet) 的初步报告,该技术提高了分布式训练效率。它有望大幅减少 GPU 间的通信,从而实现更具弹性的大型模型训练。
- 社区讨论集中在其对未来分布式训练策略的影响上。成员们表示渴望进一步探索这种创新方法。
- 讨论 Gemini 模型的激动人心更新:讨论了即将发布的全新 Gemini 1.5 Flash 和 Pro 模型,引发了对其潜在功能和性能的兴奋。用户推测这些更新可能旨在与 GPT-4 等现有模型竞争。
- 官方渠道的推文概述了计划发布的细节,引发了对新模型预期功能和增强的关注。社区成员正密切关注进展。
tinygrad (George Hotz) Discord
- Tinybox 在欧洲的运输挑战:讨论围绕 Tinybox 目前在欧洲无法购买的问题展开,尤其是对英国买家的影响。成员们建议联系客服获取运费报价,同时有消息称该产品在法国和意大利已售罄。
- 社区对未来的运输方案进行了推测,重点关注潜在的新配色版本,尽管 George 否认近期会发布蓝色版本。
- 探索使用 Tinygrad 进行 BERT 训练:一位成员表现出利用 Tinygrad 预训练大型 BERT 模型的兴趣,并讨论了高性能设置所需的必要支持。关于使用 Tinygrad 还是 Torch 存在争论,参与者指出 Torch 的优化更好。
- 对话强调了现有的硬件需求,提到使用 64 张 Hopper 卡 的配置才能进行有效的模型训练。
- Tinybox 销售更新:George 分享说已经售出了约 40 台 Tinybox,库存还有 60 台。销售额增长带来的兴奋感因正在进行的国际运输谈判而有所减弱。
- 成员们讨论了新配色版本的可能性,尽管 George 否定了蓝色版本,但大家仍表达了好奇。
- 使用 Tinygrad 时的运行时错误:一名用户在处理超过 3500 篇维基百科文章时,在 Tinygrad 中转换 Tensor 时遇到了
RecursionError。该问题在处理较小数据集时似乎消失了,这引发了对该函数处理大数据量输入能力的担忧。- 社区建议创建一个最小可复现示例进行调试;大家对协作排查这些运行时问题很感兴趣。
- 确认 Tinygrad 版本 0.9.2:一名用户确认他们正在运行 Tinygrad 版本 0.9.2,这可能与 Tensor 转换过程中遇到的
RecursionError问题有关。该版本的 LazyOp 功能被提及为讨论中问题的潜在因素。- 社区正致力于故障排除,包括是否需要更新或确定该错误是否为特定版本所致。
Interconnects (Nathan Lambert) Discord
- 英特尔发布 LLaVaOLMoBitnet1B:英特尔推出了首个三元多模态 LLM —— LLaVaOLMoBitnet1B,该模型可以处理图像和文本并生成连贯的响应。该模型完全开源,并提供了训练脚本,以探索三元建模中的挑战和机遇。
- 社区对其在未来 AI 应用(特别是多模态交互)中使用这种结构的意义感到好奇。
- OpenAI 旨在通过 Orion AI 实现复杂推理:据 The Information 报道,OpenAI 据传正在开发名为 Orion 的新模型,旨在增强复杂推理能力,同时寻求额外投资。这一举措旨在加强其在竞争激烈的聊天机器人领域的地位。
- 成员们正密切关注这一进展,期待可能重塑 AI 辅助问题解决能力的潜在突破。
- 对 Nous Research 优化器的质疑:成员们对 Nous Research 新优化器的真实性表示怀疑,主要集中在其关于分布式训练能力的声明上。讨论引用了现有的工具如 Petals for Bloom 和 OpenDILo,进一步加剧了怀疑。
- 社区呼吁提供更多实质性证据来支持 Nous 的承诺,强调了对 AI 工具开发透明度的关注。
- Cerebras 在推理速度上遥遥领先:Cerebras 声称其推理 API 在 8B 模型上达到了 1,800 tokens/s 的速度,在 70B 模型上达到了 450 tokens/s,显著优于竞争对手。这一公告在渴望推理技术快速进步的社区中引起了轰动。
- 成员们对这种速度可能给实时 AI 应用和市场竞争力带来的影响感到兴奋。
- 谷歌 Gemini 1.5 模型引起关注:谷歌推出了实验性模型:Gemini 1.5 Flash-8B 和 Gemini 1.5 Pro,增强了代码任务处理能力。现在可以通过 Google’s AI Studio 访问,鼓励社区进行亲身体验。
- 成员们热衷于测试这些新模型,讨论表明由于其独特的功能,项目方法可能会发生转变。
OpenAccess AI Collective (axolotl) Discord
- 评估 lm eval 指标:对于多选题,使用的指标是目标预测准确率,即判断模型的最高 logit 是否与正确选项一致。
- 成员们强调了模型评估中的细微差别,讨论了答案略有不同的场景。
- Tokenizer v3 规范引发困惑:成员们对 tokenizer v3 表示困惑,并分享了 nemo 仓库中之前相关讨论的链接。
- 大家一致认为需要正确的配置来支持多角色功能。
- Deepseek V2 monkey-patch 见解:成员们讨论了使用 monkey-patching 来覆盖 Deepseek V2 注意力模型的 forward 方法,并分享了相关代码片段。
- 对比了 Java 与 Python 中 monkey-patching 的经验,展示了实现中的复杂性。
- FSDP 的 RAM 资源需求受到质疑:关于 FSDP (Fully Sharded Data Parallel) 是否需要大量系统 RAM 才能有效运行的担忧被提出。
- 这引发了关于有效运行 FSDP 所需的最佳系统资源的讨论。
- AI 评分 vs 人类评分深度解析:一位成员利用 llm-as-judge 进行评分,并质疑 AI 评判与人类评分相比的准确性。
- 进一步询问了是否进行了评估该准确性的测试,强调了指标验证的必要性。
Modular (Mojo 🔥) Discord
- 征集关于 Magic 的用户反馈:团队正在为 magic 功能征集 5 名参与者进行 30 分钟的反馈会议,并提供独家 swag 作为奖励。
- 参与者可以在此预约以贡献见解,并优先获得设计阶段的 swag。
- ClassStruct 允许使用可变参数:Mojo 中的 ClassStruct 支持动态参数化,允许在不创建独立 struct 的情况下进行变体,并以发动机尺寸的
car示例进行了说明。- 这种效率允许开发者根据编译时参数定义 struct 字段,增强了灵活性。
- Struct 字段影响性能:编译具有大量字段的 struct 会显著降低性能,据报道 100 个字段需要 1.2 秒来编译。
- 这种性能延迟暗示了底层数据结构在超过特定字段阈值时存在调整大小的问题。
- Mojo 的类型推断遇到瓶颈:Mojo 在类型推断方面面临挑战,特别是关于泛型,使其与 Rust 强大的推断系统相比不够便捷。
- 参与者指出 Mojo 的泛型和类型类可能会限制灵活性,引发了对开发者体验的担忧。
- Mojo 与 Luma:类型系统对决:讨论对比了 Mojo 与 Luma,指出虽然 Luma 拥有更强的类型推断,但 Mojo 提供了像类型类这样独特但有限制的元素。
- 共识认为 Mojo 正在进化,可能会更接近 Rust 的能力,暗示了未来可能支持效应系统等功能。
LlamaIndex Discord
- 为 Pinecone 的 RAG-a-thon 做好准备!:我们将于 10 月 11 日至 13 日在帕洛阿尔托的 500GlobalVC 办公室举办第二届 RAG-a-thon,奖金超过 7,000 美元!
- 这是一个在协作环境中展示创新想法并获得宝贵经验的绝佳机会。
- Llama 3.1-8b 打破速度记录:需要超快速响应?Llama 3.1-8b 提供每秒 1800 tokens 的速度,使其成为目前最快的 LLM,详情讨论见此处。
- 达到这种速度对于需要快速响应的应用至关重要,尤其是在复杂系统中。
- 使用 LlamaIndex 构建 Serverless RAG 应用:通过 Wassim Chegham 的这份综合指南,学习如何使用 LlamaIndex 和 Azure OpenAI 创建 Serverless RAG 应用程序 指南链接。
- 它涵盖了 RAG 架构,并展示了如何利用您自己的业务数据来改进 AI 驱动的响应。
- Neo4j 无法建立关系:一位用户报告称,在使用 Neo4j Desktop 复现 LlamaIndex 的属性图教程时遇到困难,关系未能正确提取。
- 他们澄清说自己严格遵守了教程,怀疑其 Neo4j 设置可能与默认预期不符。
- 使用 LlamaParse 增强数据提取:一位用户讨论了 LlamaParse 在转换表格数据时因扫描问题可能出现的问题,并寻求集成图像提取的解决方案。
- 出现了关于处理结合了图像的多个表格时的 chunking 策略问题。
Latent Space Discord
- DisTrO 变革分布式训练:Nous Research 的 DisTrO 将 GPU 间的通信大幅减少了高达 10,000 倍,促进了具有韧性的 LLM 训练。
- 该框架促进了共享的 AI 研究工作,规避了对中心化实体的依赖,从而增强了安全性和竞争力。
- Phi 3.5 在 OCR 任务中表现出色:微软的 Phi 3.5 在 OCR 方面表现卓越,特别是在手写识别和表格数据提取方面,且采用了宽松的 MIT 许可证。
- 该模型在文本识别方面的出色表现引起了社区的极大兴趣和讨论。
- Cerebras 打破推理速度记录:Cerebras 宣布了一项推理服务,其 8B 模型的速度达到了 1,800 tokens/s,表现优于 NVIDIA 和 Groq。
- 在其 WSE-3 芯片的支持下,Cerebras 还在推动 Llama 模型的竞争性定价,引发了关于其经济可行性的激烈讨论。
- Google 发布 Gemini 1.5 模型:Google 推出了 Gemini 1.5 系列,包括一个较小的变体和一个强大的 Pro 模型,在编程和处理复杂 Prompt 方面表现出色。
- 随着开发者评估它们的相对性能和优势,这些发布引发了与 GPT-4o-mini 等模型的比较。
- Anthropic 的 Artifacts 引起关注:Anthropic 推出了 Artifacts,其开发见解和方法论引起了许多人的兴趣。
- 对于此次及时发布背后的原因出现了一些疑虑,有人猜测对话中可能存在潜在的付费推广。
OpenInterpreter Discord
- 用于聊天的 Streamlit Python 服务器:一名成员介绍了一个简单的 Streamlit Python 服务器,用于在 Web 浏览器中创建聊天界面,促进了快速实现。
- 这引起了另一名成员的兴趣,并表示打算进一步探索该解决方案。
- 使用 Open Interpreter 配置 Telegram Bot:一名成员分享了他们使用 Open Interpreter 设置 Telegram Bot 的配置(包括必要的 API key 设置)时遇到了问题。
- 他们面临图像显示问题,引发了关于故障排除和潜在修复方案的有价值讨论。
- 利用 Cython 提升 Black-Scholes 模型效率:分享了一个使用 Cython 实现 Black-Scholes 模型 的示例,强调了针对期权定价的优化计算。
- 这展示了如何在 Cython 中定义高效函数,从而增强 Jupyter notebooks 的整体性能。
- 采用克隆声音的每日播客启动:Mike 和 Ty 幽默地尝试使用来自 ElevenLabs 的 voice cloning 技术创建每日播客,为社区带来了欢笑。
- 他们的俏皮话展示了将语音合成技术融入引人入胜的内容中的创新想法。
- 分享首次见面会品牌文档:一名成员通过 Canva 展示了 01 project 的品牌文档链接。
- 该文档包含了设计见解,并承诺很快会在其 GitHub 仓库中发布更全面的更新。
Torchtune Discord
- Llama 3.1 在 CPU 上运行吃力:一位用户报告称,即使在高端 AWS 服务器上,Llama 3.1 8B 在 CPU 上的推理速度也极慢(<0.05 tok/s),凸显了巨大的性能差距。
- 对话中承认,CPU 配置天生比 GPU 配置慢,尤其是在使用 Ollama 时。
- 值得考虑的优化框架:成员们建议使用 Ollama 或 vLLM 来部署模型,因为与 Torchtune 相比,这些框架为推理提供了更好的优化。
- 分享了一个关于如何将 Ollama 与自定义 checkpoints 配合使用的实用教程,以帮助新手。
- 关于 LoRA 模型加载的咨询:一位用户询问
from_pretrained()是否能正确从本地 checkpoints 加载 LoRA 微调权重,揭示了用户对模型集成的普遍关注。- 提供了一个关于将 LoRA adapters 加载到 HF 的讨论链接以进行澄清。
- AWS 实例成本讨论:讨论了 AWS 实例的成本,指出 AWS c7a.24xlarge 的运行费用可能在每小时 $5 左右,引发了关于性价比的讨论。
- 建议探索 Runpod 等替代方案,尽管监管限制被指出是某些用户的限制因素。
- CPU 服务器的性能挑战:用户表示由于成本效益和对项目满意的响应时间,他们更倾向于使用 CPU 服务器。
- 然而,也有人指出,较低的 CPU 性能会严重影响推理速度,迫使用户重新考虑使用优化框架。
Cohere Discord
- 对请求限制的担忧:成员们对超过 1k requests 的阈值表示担忧,尤其是在测试场景中。
- 一名成员怀疑如何能达到这 1k 的限制,认为这似乎难以触及。
- 间歇性的 Model Not Found 错误:一名成员报告遇到了 ‘model not found’ 错误,认为这与模型的版本控制有关,因为 reranker 现在已更新至 v3。
- 这在持续更新中引发了潜在的稳定性担忧。
- 关于 Production Key 403 的澄清:对 production key 403 的含糊提及导致了困惑,促使其他成员请求提供上下文。
- 缺乏清晰度表明需要改进关于 key 引用方面的沟通。
- Langchain 与 Cohere TypeScript 的 404 错误:出现了一个问题,即最初使用 Langchain 配合 Cohere TypeScript 的调用是成功的,但随后的调用却导致了 404 error。
- 这表明集成中可能存在配置错误或不稳定性。
LangChain AI Discord
- Flutter 协作引发关注:为了改进 Flutter 应用开发,在 fritzlandry 发起询问后,社区提议进行协作,以填补共享专业知识方面的空白。
- 这一响应可能会促成富有成效的伙伴关系,增强 Flutter 在工程项目中的应用。
- vllm 的 RAG 能力受到关注:针对使用 vllm 运行 Retrieval-Augmented Generation (RAG) 的可能性展开了讨论,并提到了可用于 Embedding 和问答任务的模型。
- 这显示了多模型方法的增长,促使工程师不断拓展 vllm 的应用边界。
- 寻求 LLM 工作流构建工具:对现有 LLM workflow builders 的呼吁凸显了在用户工作流中推动自动化的需求,旨在寻找创新解决方案。
- 这反映了对能够有效整合 LLM 能力的工具的需求日益增长。
- 本地 Embedding 模型更受青睐:对 Pinecone 等云端选项的不满促使了对本地 Embedding 模型推荐的咨询,因为用户渴望优化性能。
- 讨论指向了最大化模型效率,强调本地设置优于云端依赖。
- 仪表板价值受到质疑:对仪表板有效性的担忧浮出水面,用户对 Claude 和 GPT 等模型在处理复杂任务时出现的错误表示沮丧。
- 这一对话强调了 AI 输出准确性的必要性,推动了对用户体验的改进。
Gorilla LLM (Berkeley Function Calling) Discord
- 排行榜模型必须可访问:列在 leaderboard 上的模型必须是公开可访问的,无论是开源还是通过 API 进行推理。
- 该要求规定,即使使用了注册或 Token,端点也应对公众开放。
- 无公开访问权限的基准测试限制:虽然可以使用 BFCL 对模型进行基准测试,但只有公开可访问的模型才能显示在排行榜上,这形成了一个显著的区别。
- 这一限制影响了哪些模型可以被展示,而哪些模型仅能被评估。
- Function Calling 功能导致性能下降:直接在 GPT-4-1106-Preview 中使用 System Prompt 可达到 85.65 的准确率,而启用 Function Calling 后准确率降至 79.65。
- 这种差异引发了关于 Function Calling 与模型整体性能之间关系的疑问,促使进一步调查。
- BFCL 优化策略受到审查:一位用户对他们针对 Function Calling 功能的优化策略表示担忧,质疑其是否符合 BFCL 指南。
- 他们询问像 System Prompt 更新之类的优化是否会被视为无法在所有模型中推广的不公平做法。
- 寻求 Llama 3.1 的基准测试指导:一位用户正在寻求关于 Llama 3.1 基准测试 的建议,特别是使用其公司托管的自定义 API 端点。
- 他们正在寻找如何顺利启动基准测试过程的有效指导。
DSPy Discord
- 社区解决 DSPy 输出截断问题:一位成员报告 DSPy 输出被截断,怀疑是 Token 限制;他们通过在初始化期间调整 max_tokens 并使用 your_lm.inspect_history() 检查 Prompt 解决了此问题。
- 原贴确认社区的建议有效解决了他们的问题,展示了成员间良好的协作。
- 类型支持错误难倒用户:一位成员在导入时遇到错误
module is installed, but missing library stubs or py.typed,询问 DSPy 是否支持 Python 的类型提示(Typing),这反映了文档的缺失。- 目前尚未提供后续跟进或解决方案,表明库内对类型支持仍存在不确定性。
- 对使用 DSPy 进行文本评分的兴趣日益增长:一位用户询问如何使用 DSPy 根据 BLEU 或 ROUGE 等指标对生成的文本进行评分,反映了社区对评估文本性能的推动。
- 遗憾的是,没有成员回复,使得他们在文本评分方面的经验和见解无从得知。
LLM Finetuning (Hamel + Dan) Discord
- 需要 Hamel 签到:一名成员在频道中询问 Hamel 是否在场,这表明关于 LLM finetuning 的潜在讨论即将展开。
- 未提供更多背景信息,但成员们正等待 Hamel 直接就相关项目发表见解。
- 关于 LLM 模型的讨论:对话暗示了 Hamel 到场对于讨论通过微调技术增强 LLM 性能的重要性。
- 成员们可能对模型优化策略和学习增强方案感兴趣。
MLOps @Chipro Discord
- 参加 LLM 可观测性工具网络研讨会:本周六,8 月 31 日 东部时间上午 11:30,一场网络研讨会将涵盖超过 60 种 LLM 可观测性工具,以评估其监控有效性。在此处注册会议。
- 参与者将获得关于可观测性基础、工具选择以及为了更好管理模型而进行的 LLM 集成策略的见解。
- 测试 ML 监控平台的炒作:即将举行的网络研讨会旨在批判性地评估众多的 ML 监控工具 是否满足从业者在模型 monitoring 和 debugging 方面的真实需求。期待通过实操评估来筛选营销辞令。
- 重点将放在实用性和用户友好性上,确保工具能带来真正的收益。
- 生产环境中的机器学习项目训练营:一个名为“Machine Learning in Production”的直播训练营现已开放,旨在提升有效部署 ML 模型的实操技能。感兴趣的参与者可以在此处找到更多详情 here。
- 该课程承诺为现实应用中的有效 ML 管理提供必要的工具和知识。
LAION Discord
- LAION-aesthetic 链接问题:一名成员报告称 LAION 网站上指向 LAION-aesthetic 的链接已失效,并请求提供来自 Hugging Face 的替代链接。
- 对有效链接的任何更新都将不胜感激,这凸显了社区对可靠资源的持续需求。
- 请求可用的 LAION-aesthetic 资源:讨论强调了拥有一个可用的 LAION-aesthetic 链接的重要性,这对于用户访问数据模型至关重要。
- 成员们对网站失效表示沮丧,并敦促尽快提供解决方案以提高可用性。
Mozilla AI Discord
- 准备参加与 Ettore Di Giacinto 的 LocalAI AMA:两小时后参加与 Ettore Di Giacinto 进行的 LocalAI AMA,探索其作为 OpenAI 开源替代方案的功能,其特点是拥有用于本地推理的 REST API。
- LocalAI 能够在消费级硬件上本地生成 LLM、图像和音频,无需 GPU。
- LocalAI 活动参与链接:LocalAI 活动的参与链接现已可用;点击此处加入直接参与。
- 让你关于该项目的问题得到解答,并了解它如何集成到你的工作流中。
Alignment Lab AI Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
由于邮件篇幅限制,完整的频道分类详情已被截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!