ainews-cerebras-inference-faster-better-and
Cerebras 推理:更快、更好、且更便宜
Groq 在 2024 年初以极快的大语言模型(LLM)推理速度领跑,Mixtral 8x7B 达到了约 450 tokens/秒,Llama 2 70B 达到了 240 tokens/秒。Cursor 推出了一款专门的代码编辑模型,速度高达 1000 tokens/秒。现在,Cerebras 声称凭借其晶圆级芯片实现了最快的推理速度,在全精度下运行 Llama3.1-8b 的速度为 1800 tokens/秒,Llama3.1-70B 为 450 tokens/秒,同时拥有极具竞争力的定价和慷慨的免费层级。谷歌的 Gemini 1.5 模型在基准测试中展现了显著的提升,尤其是 Gemini-1.5-Flash 和 Gemini-1.5-Pro。针对消费级硬件优化的新型开源模型如 CogVideoX-5B 和 Mamba-2 (Rene 1.3B) 也已发布。Anthropic 的 Claude 现在支持提示词缓存(prompt caching),提升了速度和成本效益。“Cerebras 推理运行 Llama3.1 的速度比 GPU 解决方案快 20 倍,而价格仅为其五分之一。”
Wafer-scale engines are all you need.
2024/8/27-8/28 的 AI 新闻。我们为您检查了 7 个 subreddits、384 个 Twitter 账号 和 30 个 Discord (包含 215 个频道和 2366 条消息)。预计节省阅读时间(按 200wpm 计算):239 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
2024 年超快 LLM 推理简史:
- Groq 在 2 月份占据了新闻头条(这里有很多零散的讨论),它为 Mixtral 8x7B 实现了 ~450 tok/s(为 Llama 2 70b 实现了 240 tok/s)。
- 5 月,Cursor 宣传了一款专门的代码编辑模型(与 Fireworks 合作开发),其速度达到了 1000 tok/s。
现在终于轮到 Cerebras 大放异彩了。全新的 Cerebras Inference 服务 宣称其 Llama3.1-8b 在 全精度 下速度达到 1800 tok/s,价格为 $0.10/mtok;Llama3.1-70B 速度为 450 tokens/s,价格为 $0.60/mtok。毋庸置疑,Cerebras 的全精度定价及其无与伦比的速度,使其突然成为该市场中一个强有力的竞争者。引用他们的营销口号:”Cerebras Inference 运行 Llama3.1 的速度比 GPU 解决方案快 20 倍,而价格仅为 1/5。” —— 从技术上讲这并不完全准确 —— 大多数推理提供商如 Together 和 Fireworks 倾向于引导用户使用其服务的量化版本,其中 FP8 70B 定价为 $0.88/mtok,INT4 70B 定价为 $0.54。虽然 Cerebras 确实更好,但并没有便宜 5 倍,也没有快 20 倍。
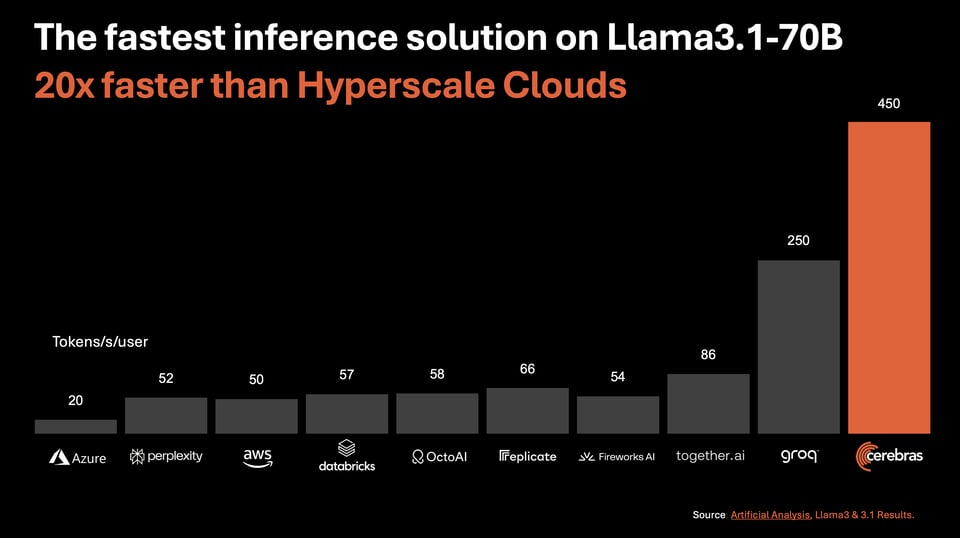
注:还应注意到他们非常慷慨的免费额度,即 每天 100 万个免费 token。
秘密当然在于 Cerebras 的 wafer-scale 芯片(不然你还指望他们说什么呢?)。类似于 Groq 的 LPU 论点,Cerebras 表示将整个模型放入 SRAM 是关键:
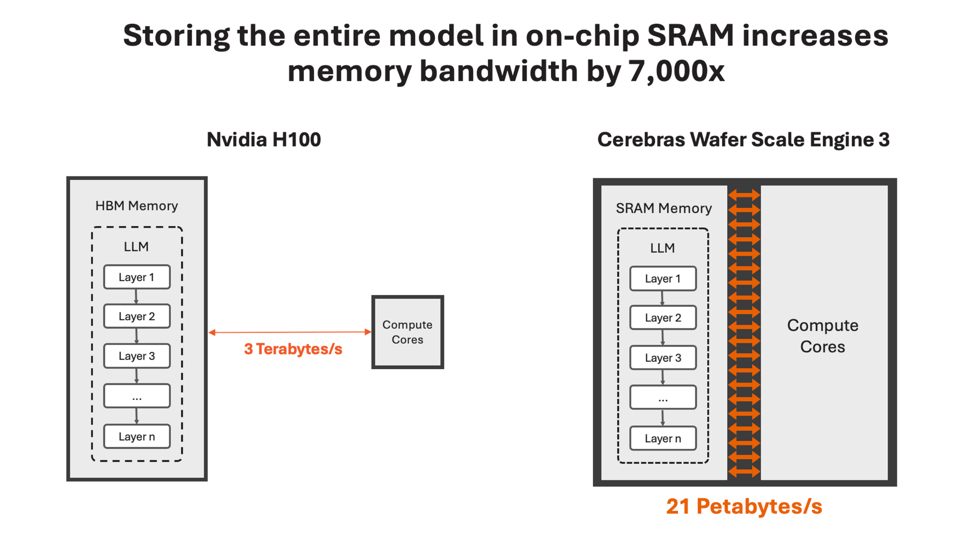
该你们出招了,Groq 和 Sambanova。
今日赞助商:Solaris
Solaris 是位于旧金山的 早期 AI 初创公司办公室,现有新的工位和办公室开放!它曾是受 Nat Friedman、Daniel Gross、Sam Altman、YC 等支持的创始人们的总部。**
Swyx 的评论:我过去 9 个月一直在这里,非常喜欢。如果你正在寻找一个高质量的地方来构建下一个伟大的 AI 初创公司,请在此与创始人预约时间,并告诉他们是我们推荐的。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型更新与基准测试
-
Gemini 1.5 性能:Google 最新的 Gemini 1.5 模型(Pro/Flash/Flash-9b)在基准测试中表现出显著提升,其中 Gemini-1.5-Flash 从总榜第 23 位跃升至第 6 位。新的 Gemini-1.5-Pro 在编程和数学任务中表现出强劲增长。@lmsysorg 分享了来自 2 万多名社区投票的详细结果。
-
开源模型:发布了新的开源模型,包括用于文本生成视频的 CogVideoX-5B,可在不到 10GB 的 VRAM 上运行。@_akhaliq 强调了其高质量和高效率。Rene 1.3B,一个 Mamba-2 语言模型,也已发布,在消费级硬件上表现出色。@awnihannun 指出其在 M2 Ultra 上的速度接近 200 tokens/sec。
-
Cerebras 推理:Cerebras 宣布了一个新的推理 API,声称是 Llama 3.1 模型中最快的,8B 模型速度达到 1,800 tokens/sec,70B 模型速度达到 450 tokens/sec。@AIatMeta 验证了这些令人印象深刻的性能数据。
AI 开发与基础设施
-
Prompt Caching:Jeremy Howard 强调了 Prompt Caching 对于提高性能和降低成本的重要性。@jeremyphoward 指出 Anthropic 的 Claude 现在支持缓存,缓存后的 token 价格便宜 90% 且速度更快。
-
模型合并 (Model Merging):分享了一份全面的模型合并技术时间线,追溯了从 90 年代的早期工作到近期在 LLM 对齐和专业化中应用的发展历程。@cwolferesearch 提供了各个阶段和方法的详细概述。
-
分布式训练:讨论了分布式社区机器学习(ML)训练的潜力,认为下一个开源 GPT-5 可能会由数百万贡献少量 GPU 算力的人共同构建。@osanseviero 概述了该领域的最新突破和未来可能性。
AI 应用与工具
-
Claude Artifacts:Anthropic 向所有 Claude 用户开放了 Artifacts 功能,包括 iOS 和 Android 应用。@AnthropicAI 分享了该功能的开发过程和广泛采用的情况。
-
AI 驱动的应用:强调了由 LLM 实时创建移动应用的潜力,并展示了使用 Claude 复制简单游戏的示例。@alexalbert__ 演示了这一能力。
-
基于 LLM 的搜索引擎:提到了一个用于 Web 搜索引擎的多智能体(multi-agent)框架,类似于 Perplexity Pro 和 SearchGPT。@dl_weekly 分享了关于此话题更多信息的链接。
AI 伦理与监管
-
AI 监管辩论:关于 AI 监管的讨论仍在继续,一些人认为支持 AI 监管并不一定意味着支持每一项提议的法案。@AmandaAskell 强调了良好初始监管的重要性。
-
OpenAI 的动向:有关 OpenAI 开发名为 “Strawberry” 的强大推理模型以及 “Orion”(GPT-6)计划的报告,引发了关于公司战略及其对竞争潜在影响的讨论。@bindureddy 分享了对这些进展的见解。
其他 AI 见解
-
AI 中的微交易:Andrej Karpathy 提出,启用极小额交易(例如 5 美分)可以释放巨大的经济潜力,并改善数字经济中的价值流动。@karpathy 认为这可能会带来更高效的商业模式和积极的二阶效应。
-
AI 认知研究:强调了研究 AI 认知而非仅仅研究行为对于理解 AI 系统泛化的重要性。@RichardMCNgo 将其类比为心理学中从行为主义的转变。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. 开源文本生成视频 AI:CogVideoX 5B 突破
-
**CogVideoX 5B - 开源权重文本生成视频 AI 模型(运行显存低于 10GB VRAM) 清华 KEG (THUDM)** (Score: 91, Comments: 13):CogVideoX 5B 是由 清华 KEG (THUDM) 开发的开源权重文本生成视频 AI 模型,可在低于 10GB VRAM 的显存下运行,其中 2B 模型 可在 1080TI 上运行,5B 模型 可在 3060 GPU 上运行。该模型系列(包括以 Apache 2.0 协议 发布的 2B 版本)已在 Hugging Face 上线,并附带了 演示空间 (demo space) 和 研究论文。
主题 2. 高效 AI 模型进展:Gemini 1.5 Flash 8B
- Gemini 1.5 Flash 8b, (Score: 95, Comments: 24):Google 发布了 Gemini 1.5 Flash 8B,这是一款新型小型 AI 模型,尽管其参数量仅为 80 亿 (8 billion parameters),但展现出了令人印象深刻的能力。该模型在多项基准测试中达到了 SOTA (state-of-the-art) 性能,包括在某些任务上超越了像 Llama 2 70B 这样的大型模型,同时在推理速度和资源需求方面显著更高效。
- Gemini 1.5 Flash 8B 最初在 6 月份 的 第三版 Gemini 1.5 论文 中被讨论。新版本很可能是原始实验的改进模型,具有更好的基准测试表现。
- Google 公开 80 亿参数量 的做法受到了称赞。目前关于 Google 是否会发布权重存在猜测,但由于 Gemini 模型 通常是闭源的(不同于开源的 Gemma 模型),这被认为不太可能。
- 关于 Google 在 Gemini 中使用 标准 Transformer (standard transformers) 的讨论也随之而起,这让一些期待自定义架构的用户感到惊讶。该模型的性能引发了与 GPT-4o-mini 的对比,暗示了在参数效率方面的潜在进步。
全球 AI Reddit 综述
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型进展与发布
-
Google DeepMind 的 GameNGen:一个由神经网络驱动的游戏引擎,能够以高质量的视觉效果实时交互式地模拟经典游戏 DOOM。这展示了 AI 生成交互式游戏环境的潜力。来源
-
OpenAI 的 “Strawberry” AI:据报道正准备最早于 2024 年秋季发布。OpenAI 已向国家安全官员展示了该 AI,并正利用它开发另一个名为 “Orion” 的系统。关于其能力的细节目前有限。来源 1, 来源 2
-
Google 的 Gemini 1.5 更新:Google 推出了 Gemini 1.5 Flash-8B,这是一个改进版的 Gemini 1.5 Pro,具有更强的代码编写和复杂提示词(Prompt)处理能力,以及增强的 Gemini 1.5 Flash 模型。来源
图像生成与处理中的 AI
机器人与具身智能 (Physical AI)
- Galbot G1:由中国初创公司 Galbot 开发的第一代机器人,旨在执行可泛化的长时间任务。具体能力的细节目前有限。来源
科学突破
- DNA 损伤修复蛋白:科学家发现了一种名为 DNA 损伤响应蛋白 C (DdrC) 的蛋白质,它可以直接阻止 DNA 损伤。它似乎是“即插即用”的,可能在任何生物体中发挥作用,使其成为癌症预防研究中极具前景的候选者。来源
AI 伦理与社会影响
- 媒体中的 AI 生成内容:围绕社交媒体和娱乐行业中 AI 生成内容日益普及的讨论,引发了关于真实性以及创意产业未来的疑问。来源
AI Discord 摘要回顾
由 GPT4O (gpt-4o-2024-05-13) 生成的摘要之摘要的总结
1. LLM 进展与基准测试
- Llama 3.1 API 提供免费访问:Sambanova.ai 提供了一个免费且有速率限制的 API,用于运行 Llama 3.1 405B、70B 和 8B 模型。该 API 与 OpenAI 兼容,并允许用户使用自己微调的模型。
@user分享道,该 API 提供了入门套件和社区支持,以帮助加速开发。
- Google 发布新款 Gemini 模型:Google 宣布了三个实验性模型:Gemini 1.5 Flash-8B、Gemini 1.5 Pro 以及改进后的 Gemini 1.5 Flash。
@OfficialLoganK强调,Gemini 1.5 Pro 模型在编程和处理复杂提示词方面表现尤为出色。
2. 模型性能优化与基准测试
- OpenRouter 支持 DeepSeek 缓存:OpenRouter 正在增加对 DeepSeek 上下文缓存 (context caching) 的支持,预计可降低高达 90% 的 API 成本。
@user分享了关于这一即将推出的功能的信息,旨在优化 API 的成本效率。
- Hyperbolic 的 BF16 Llama 405B:Hyperbolic 发布了 Llama 3.1 405B 基础模型 的 BF16 变体,补充了 OpenRouter 上现有的 FP8 量化版本。
@hyperbolic_labs在推特上发布了关于该新变体的消息,强调了其在实现更高效模型性能方面的潜力。
3. 开源 AI 发展与协作
- IBM 的 Power Scheduler:IBM 推出了一种名为 Power Scheduler 的新型学习率调度器,它与 Batch Size 和训练 Token 数量无关。
@_akhaliq发推称,该调度器在各种模型大小和架构中始终能取得令人印象深刻的性能。
- 用于实时 AI 的 Daily Bots:Daily Bots 推出了支持 RTVI 标准的语音、视觉和视频 AI 超低延迟云服务。
@trydaily强调,该平台结合了实时 AI 应用的最佳工具,包括与 LLM 的语音对语音交互。
4. 多模态 AI 与生成式建模创新
- GameNGen:神经游戏引擎:GameNGen 是首个完全由神经模型驱动的游戏引擎,能够实现与复杂环境的实时交互。
@user分享道,GameNGen 可以在单个 TPU 上以超过每秒 20 帧的速度模拟 DOOM,其 PSNR 达到 29.4,与有损 JPEG 压缩相当。
- Artifacts 登陆 iOS 和 Android:Anthropic 的项目 Artifacts 已在 iOS 和 Android 上线,允许用户使用 Claude 实时创建简单的游戏。
@alexalbert__强调了这次移动端发布的意义,将 LLM 的能力带到了移动应用中。
5. 微调挑战与提示工程策略
- Unsloth 的持续预训练:Unsloth 的 Continued Pretraining 功能允许以比 Hugging Face + Flash Attention 2 QLoRA 快 2 倍的速度进行 LLM 预训练,且节省 50% 的 VRAM。
@unsloth分享了一个 Colab notebook,用于持续预训练 Mistral v0.3 7b 以学习韩语。
- 使用合成数据进行微调:在模型微调中使用合成数据的趋势日益增强,Hermes 3 等案例凸显了这一点。
- 一位用户提到,合成数据训练需要复杂的过滤流水线,但这种方式正变得越来越流行。
第一部分:Discord 高层级摘要
HuggingFace Discord
- 游戏化家庭训练?:一位成员提议了一个“游戏化家庭训练”基准测试工具,声称是为了其求职申请。
- Triton 配置难题:一位成员遇到了在使用 llama3 instruct 配合 Triton 以及 tensorrt-llm 或 vllm 后端时,响应生成无法停止的问题。
- 直接使用 vllm 托管运行完美,这表明其 Triton 配置可能存在问题。
- Loss 为 0.0 - 日志错误?:讨论集中在模型训练中“Loss 曲线”的重要性。
- 一位成员建议 Loss 为 0.0 可能表示日志错误,并质疑由于舍入原因,Loss 达到绝对 0.0 的完美模型的可行性。
- 在 AMD 上微调 Gemma2b - 实验性的挣扎:一位成员在 AMD 上微调 Gemma2b 模型时遇到困难,将其归因于潜在的日志错误。
- 其他成员指出 ROCm 的实验性质是导致这些困难的一个因素。
- 模型合并策略:UltraChat 和 Mistral:一位成员提议将 UltraChat 与基础 Mistral 之间的差异应用到 Mistral-Yarn 上,作为一种模型合并策略。
- 虽然有些人表示怀疑,但该成员保持乐观,并引用了过去在“被诅咒的模型合并 (cursed model merging)”方面的成功经验。
Unsloth AI (Daniel Han) Discord
- VLLM 在 Kaggle 上可以运行了!:一位用户报告称,使用来自此数据集的 wheels 成功在 Kaggle 上运行了 VLLM。
- 这是使用 VLLM 0.5.4 实现的,该版本被认为相对较新,因为 0.5.5 虽然已经发布但尚未广泛使用。
- Mistral 难以扩展超过 8k:成员们确认,如果不进行持续预训练,Mistral 无法扩展到 8k 以上,且这是一个已知问题。
- 他们还讨论了未来性能增强的潜在途径,包括 mergekit 和 frankenMoE 微调。
- 同构 AI (Homoiconic AI):权重即代码?:一位成员分享了关于 “Homoiconic AI” 的进度报告,该项目使用 hypernet 生成 autoencoder 权重,然后通过 In-context learning 改进这些权重。
- 报告指出,这种“代码即数据 & 数据即代码”的方法可能是推理所必需的,甚至与推理同构。
- Unsloth 的持续预训练能力:一位成员分享了 Unsloth 关于持续预训练的博客文章的链接,强调其持续预训练 LLM 的速度比 Hugging Face + Flash Attention 2 QLoRA 快 2 倍,且显存占用减少 50%。
- 博客文章还提到使用 Colab notebook 对 Mistral v0.3 7b 进行持续预训练以学习韩语。
- Unsloth vs OpenRLHF:速度与显存效率:一位用户询问了 Unsloth 和 OpenRLHF 之间的区别,特别是关于它们对微调非量化模型的支持。
- 一位成员确认 Unsloth 支持非量化模型,并计划很快增加 8bit 支持,强调其与其他微调方法相比,速度显著更快且显存占用更低。
aider (Paul Gauthier) Discord
- Aider 0.54.0:Gemini 模型与 Shell 命令改进:最新版本的 Aider (v0.54.0) 引入了对
gemini/gemini-1.5-pro-exp-0827和gemini/gemini-1.5-flash-exp-0827模型的支持,并增强了 shell 和/run命令,现在允许在带有 pty 的环境中进行交互式执行。- 新开关
--[no-]suggest-shell-commands允许自定义配置 shell 命令建议,同时大型项目和 monorepo 项目中改进的自动补全功能提升了 Aider 的性能。
- 新开关
- Aider 自动化其自身开发:Aider 在其自身的开发中发挥了重要作用,为本次发布贡献了 64% 的代码。
- 此版本还引入了
--upgrade开关,以便从 PyPI 轻松安装最新的 Aider 版本。
- 此版本还引入了
- Gemini 1.5 Pro 基准测试结果喜忧参半:分享了新 Gemini 1.5 Pro 模型的基准测试结果,显示全量编辑格式(whole edit format)的通过率为 23.3%,差异编辑格式(diff edit format)的通过率为 57.9%。
- 基准测试是使用 Aider 配合
gemini/gemini-1.5-pro-exp-0827模型以及aider --model gemini/gemini-1.5-pro-exp-0827命令运行的。
- 基准测试是使用 Aider 配合
- GameNGen:首个神经游戏引擎:论文介绍了 GameNGen,这是第一个完全由神经模型驱动的游戏引擎,能够在长轨迹上高质量地实时模拟复杂环境。
- 该模型可以在单个 TPU 上以每秒超过 20 帧的速度交互式模拟经典游戏 DOOM,实现的 PSNR 为 29.4,与有损 JPEG 压缩相当。
- OpenRouter:Discord 的替代方案?:一位成员询问 OpenRouter 是否与 Discord 相同。
- 另一位成员确认这两个服务对他们来说都运行良好,并引用了 OpenRouter 的状态页面:https://status.openrouter.ai/ 作为参考。
LM Studio Discord
- LM Studio 0.3.1 发布:LM Studio 的最新版本为 v0.3.1,可在 lmstudio.aido 获取。
- LM Studio 在 Linux 上的问题:一位用户报告称,在没有
--no-sandbox标志的情况下通过 Steam 运行 Linux 版本的 LM Studio 会导致 SSD 损坏。 - 不支持 Snapdragon NPU:一位用户确认 Snapdragon 上的 NPU 在 LM Studio 中无法工作,尽管他们已经在 Snapdragon 上安装了 LM Studio。
- LM Studio 的 AMD GPU 支持:LM Studio 的 ROCM 版本目前仅支持最高端的 AMD GPU,不支持像 6700XT 这样的 GPU,从而导致兼容性问题。
- LM Studio 的安全性测试:一位用户通过提示 LLM 下载程序来测试 LM Studio 的安全性,结果得到了幻觉响应,表明实际上并没有发生下载。
Perplexity AI Discord
- Perplexity Pro 用户陷入上传困境:用户在上传图片和文件时遇到问题,一些用户尽管在某些浏览器中仍能访问,但丢失了 Pro 订阅状态。
- 这个问题引起了 Pro 用户的沮丧,特别是由于缺乏修复的信息和预计时间表,导致出现了一些幽默的回应,比如“this is fine”的 GIF 图。
- Claude 3.5 的每日消息限制:430 条:Claude 3.5 和其他 Pro 模型受每日 430 条消息的限制,但 Opus 除外,其限制为 50 条。
- 虽然有些用户还没达到总限制,但许多人发现他们最接近的一次大约是 250 条消息。
- 图片上传问题——归咎于 AWS Rekognition:无法上传图片归因于达到了 Cloudinary(一种用于图像和视频管理的服务)上的 AWS Rekognition 限制。
- Perplexity 目前正在努力解决此问题,但尚无修复的预计时间表。
- Perplexity 搜索:比 ChatGPT 更好?有待商榷:一些用户声称 Perplexity 的搜索(尤其是 Pro 版)优于其他平台,理由是更好的来源引用和更少的幻觉。
- 然而,其他人认为 ChatGPT 的自定义选项、RAG 和聊天 UX 更先进,而 Perplexity 的搜索较慢且功能较少,特别是在与 ChatGPT 的文件处理和对话上下文相比时。
- Perplexity 的特定领域搜索 Chrome 扩展程序:Perplexity Chrome 扩展程序提供特定领域的搜索功能,允许用户在特定网站内查找信息而无需手动搜索。
- 这一功能因其在寻找特定域名或网站信息方面的优势而受到一些用户的称赞。
Nous Research AI Discord
- DisTrO vs. SWARM:效率考量:虽然 DisTrO 在 DDP 下效率极高,但对于在大量弱设备上训练超大型 LLM(超过 100B 参数)的情况,SWARM 可能是更合适的选择。
- 有成员询问 DisTrO 是否可用于训练这些大型 LLM,并建议了一个使用 10 亿部旧手机、笔记本电脑和台式机的用例,但另一位成员推荐了 SWARM。
- DPO 训练与 AI 预测响应:探索心智理论 (Theory of Mind):一位成员思考了在 DPO 训练中使用 AI 模型预测的用户响应(而非真实响应)的潜在影响。
- 他们认为这种方法可能会提升模型的心智理论 (Theory of Mind) 能力。
- 模型合并:一种有争议的策略:一位成员提议将 UltraChat 和 Mistral 基础模型之间的差异合并到 Mistral-Yarn 中作为一种潜在策略,并引用了以往类似成功的案例。
- 尽管其他人表示怀疑,该成员仍对这种“诅咒式模型合并” (cursed model merging) 技术的有效性保持乐观。
- Hermes 3 与 Llama 3.1:正面交锋:一位成员分享了 Hermes 3 和 Llama 3.1 的对比,强调了 Hermes 3 在通用能力方面具有竞争力的表现,甚至更胜一筹。
- 提供了基准测试链接,展示了 Hermes 3 相对于 Llama 3.1 的优缺点。
- 使用合成数据进行微调:训练的未来?:成员们讨论了在微调模型中使用合成数据的趋势,并以 Hermes 3 和传闻中的“草莓模型” (strawberry models) 为例。
- 虽然并非总是推荐,但合成数据训练已势头强劲,尤其是在 Hermes 3 等模型中,但这需要复杂的过滤流水线。
OpenRouter (Alex Atallah) Discord
- OpenRouter API 短暂降级:OpenRouter 经历了 5 分钟的 API 性能下降,但随后发布了补丁,目前已恢复正常。
- Llama 3.1 405B BF16 端点上线:Llama 3.1 405B (base) 已更新 BF16 端点。
- Hyperbolic 部署 BF16 Llama 405B Base:Hyperbolic 发布了 Llama 3.1 405B 基础模型 的 BF16 变体。
- 这是对 OpenRouter 上现有 FP8 量化版本 的补充。
- LMSys 排行榜相关性受到质疑:一位用户质疑 LMSys 排行榜 的相关性,认为它可能已经过时。
- 他们指出像 Gemini Flash 这样的新模型表现异常出色。
- OpenRouter DeepSeek 缓存即将推出:OpenRouter 正在努力增加对 DeepSeek 上下文缓存 (context caching) 的支持。
- 该功能预计可降低高达 90% 的 API 成本。
Eleuther Discord
- 免费 Llama 3.1 405B API:一位成员分享了 Sambanova.ai 的链接,该网站提供运行 Llama 3.1 405B、70B 和 8B 的免费、限速 API。
- 该 API 兼容 OpenAI,允许用户上传自己的微调模型,并提供入门套件和社区支持以加速开发。
- TRL.X 已弃用:一位成员指出 TRL.X 已严重过时,且很长时间没有更新。
- 另一位成员询问它是否仍在维护,或者是否有替代方案。
- 模型训练数据——私有还是公开?:一位成员询问人们使用什么样的数据来训练大型语言模型。
- 他们想知道人们是使用私有数据集还是像 Alpaca 这样的公开数据集,然后应用自定义 DPO 或其他无监督技术来提高性能,还是仅仅在非指令微调模型上进行 N-shot 基准测试。
- 逆向蒙特卡洛树搜索:一位成员建议训练一个模型来逆向执行蒙特卡洛树搜索 (Monte Carlo Tree Search)。
- 他们提议利用图像识别和生成技术来生成最优树搜索选项,而不是去识别它。
- 计算机视觉研究:论文反馈:一位成员分享了他们正在进行的计算机视觉扩散模型项目,并正在寻求对其论文草案的反馈。
- 他们提到大规模测试成本高昂,并请求帮助寻找可以审阅其工作的人员。
LlamaIndex Discord
- LlamaIndex 是否支持 GPT-4o-mini?: 一位用户询问
llama_index.llms.openai是否支持使用gpt-4o-miniOpenAI 模型。- 另一位成员确认目前不支持该模型,并分享了支持的模型列表:
gpt-4,gpt-4-32k,gpt-4-1106-preview,gpt-4-0125-preview,gpt-4-turbo-preview,gpt-4-vision-preview,gpt-4-1106-vision-preview,gpt-4-turbo-2024-04-09,gpt-4-turbo,gpt-4o,gpt-4o-2024-05-13,gpt-4-0613,gpt-4-32k-0613,gpt-4-0314,gpt-4-32k-0314,gpt-3.5-turbo,gpt-3.5-turbo-16k,gpt-3.5-turbo-0125,gpt-3.5-turbo-1106,gpt-3.5-turbo-0613,gpt-3.5-turbo-16k-0613,gpt-3.5-turbo-0301,text-davinci-003,text-davinci-002,gpt-3.5-turbo-instruct,text-ada-001,text-babbage-001,text-curie-001,ada,babbage,curie,davinci,gpt-35-turbo-16k,gpt-35-turbo,gpt-35-turbo-0125,gpt-35-turbo-1106,gpt-35-turbo-0613,gpt-35-turbo-16k-0613。
- 另一位成员确认目前不支持该模型,并分享了支持的模型列表:
- LlamaIndex 的 OpenAI 库需要更新: 一位成员报告在运行 LlamaIndex 时遇到了与
gpt-4o-miniOpenAI 模型相关的错误。- 建议他们更新
llama-index-llms-openai库以解决此问题。
- 建议他们更新
- Pydantic v2 导致 LlamaIndex 出错,但正在修复中: 一位成员遇到了与 LlamaIndex
v0.11和pydantic v2相关的问题,LLM 会对pydantic结构产生幻觉。- 他们分享了 GitHub 上的 issue 链接,并表示修复程序正在开发中。
- 使用 OpenAILike 解决 GraphRAG 身份验证错误: 一位成员在使用 GraphRAG 配合自定义网关与 OpenAI API 交互时遇到了身份验证错误。
- 问题追溯到 GraphRAG 实现内部进行的直接 OpenAI API 调用,建议他们使用
OpenAILike类来解决此问题。
- 问题追溯到 GraphRAG 实现内部进行的直接 OpenAI API 调用,建议他们使用
- 构建多 Agent 自然语言转 SQL 聊天机器人: 一位成员寻求关于使用 LlamaIndex 工具构建多 Agent 系统以驱动 NL-to-SQL-to-NL 聊天机器人的指导。
- 建议他们考虑使用 workflows 或 reAct agents,但未给出最终定论。
Torchtune Discord
- QLoRA 与 FSDP1 不兼容: 用户讨论了 QLoRA 是否与 FSDP1 兼容以进行分布式微调(finetuning),结果确定它们不兼容。
- 如果未来需要这种兼容性,这是一个需要考虑的开发点。
- Torch.compile 与 Liger Kernels 在 Torchtune 中的对比: 一位用户质疑 Liger kernels 在 Torchtune 中的价值,一位成员回应称他们更倾向于使用
torch.compile。 - 全模型编译与逐层编译的性能对比: 讨论集中在
torch.compile应用于整个模型与应用于单个层时的性能表现。 - 激活检查点(Activation Checkpointing)的影响: 发现 Activation Checkpointing (AC) 会显著影响编译性能。
- 平衡编译粒度下的速度与优化: 讨论涉及模型编译的粒度,不同层级会影响性能和优化潜力。
- 目标是在速度和优化之间找到合适的平衡点。
OpenAI Discord
- GPT-4 会自信地产生幻觉: 一位成员讨论了 GPT-4 即使在被纠正后仍会自信地提供错误答案的挑战。
- 他们建议在提示词中加入具体的网络搜索指令,使用像 Perplexity 这样预配置的 LLM,或者设置一个带有网络搜索指令的自定义 GPT。
- Mini 模型对比 GPT-4: 一位成员指出,在某些场景下,Mini 模型比 GPT-4 更便宜且表现更好。
- 他们认为这主要是人类偏好的问题,且所使用的基准测试(benchmark)并不能反映人们真正关心的使用场景。
- SearchGPT 对比 Perplexity: 一位成员询问了 Perplexity 相比 SearchGPT 的优势。
- 另一位成员回答说他们还没试过 Perplexity,但认为 SearchGPT 很准确、偏见极小,且非常适合复杂的搜索。
- AI 是否有意识?: 一位成员讨论了 AI 体验类似人类情感的想法,认为将此类体验归因于 AI 可能是一种误解。
- 他们表示,将理解 AGI 视为需要类人情感可能是一个不切实际的期望。
- Orion 模型访问权限担忧: 一位成员对将 Orion-14B-Base 和 Orion-14B-Chat-RAG 等 Orion 模型的访问权限限制在私营部门的潜在后果表示担忧。
- 他们认为这可能会加剧不平等、扼杀创新并限制更广泛的社会效益,可能导致技术进步仅为精英利益服务的未来。
Interconnects (Nathan Lambert) Discord
- Google 发布了三个新的 Gemini 模型:Google 发布了三个实验性的 Gemini 模型:Gemini 1.5 Flash-8B、Gemini 1.5 Pro 和 Gemini 1.5 Flash。
- 这些模型可以在 Aistudio 上进行访问和实验。
- Gemini 1.5 Pro 专注于 Coding 和复杂 Prompts:Gemini 1.5 Pro 模型被强调在 coding 和 complex prompts 方面具有改进的能力。
- 原始的 Gemini 1.5 Flash 模型也得到了显著提升。
- API 可用性担忧与 Benchmark 怀疑:存在关于 API 可用性 的讨论,一位用户对其功能缺失表示沮丧。
- 该用户还提到他们尝试在 RewardBench 上评估 8B 模型,但认为这是一个虚假的 benchmark。
- SnailBot 为短链接提供及时通知:当使用 livenow.youknow 缩短链接时,SnailBot 会在用户收到电子邮件之前通过 Discord 发出通知。
- 然而,该用户也注意到 SnailBot 未能识别 URL 的更改,这表明该工具存在局限性。
- 开源数据可用性与代码授权趋势并行:一位用户预测,关于数据可用性的开源辩论将遵循与代码授权现状类似的轨迹。
Cohere Discord
- Cohere API 错误与 Token 计数:一位用户报告在使用 Langchain 和 Cohere TypeScript 对 Cohere API 进行后续调用时出现 404 错误。
- 错误消息显示为 “non-json” 响应,这表明 Cohere API 返回了一个 404 页面而不是 JSON 对象。该用户还询问了关于 Cohere API 的 token 计数问题。
- Aya-23-8b 推理速度:一位用户询问 Aya-23-8b 模型是否能在 500 毫秒内完成约 50 个 token 的推理。
- 模型 quantization 被建议作为实现更快推理速度的潜在解决方案。
- 波斯语旅游景点 App:一款结合了 Cohere AI 和 Google Places API 的 Next.js 应用上线,用于推荐波斯语的旅游景点。
- 该应用具有详细的信息,包括描述、地址、坐标和照片,均采用高质量的波斯语。
- 应用功能与特性:该应用利用 Cohere AI 和 Google Places API 的强大功能,提供准确且引人入胜的波斯语旅游建议。
- 用户可以探索具有详细信息的旅游景点,包括描述、地址、坐标和照片,所有内容均以高质量的波斯语格式呈现。
- 社区反馈与分享:社区的几位成员表达了试用该应用的兴趣,称赞其功能和创新方法。
- 该应用已在 GitHub 和 Medium 上公开分享,邀请社区提供反馈和协作。
Modular (Mojo 🔥) Discord
- Mojo 编译器消除了循环导入 (Circular Imports):Mojo 是一种编译型语言,因此它可以在编译前扫描每个文件并确定 struct 的形状,从而解决循环导入问题,因为它拥有实现
to_queue所需的所有函数。- Python 处理循环导入的方式不同,因为它在编译期间按顺序运行所有内容,这会导致 Mojo 编译器可以避免的潜在问题。
- Mojo 编译器优化 Struct 大小:Mojo 编译器知道指针的大小,这使得它无需查看
Queue就能计算出List的形状。- Mojo 使用
Arc或其他类型的指针来打破循环导入链。
- Mojo 使用
- Mojo 对顶级语句 (Top Level Statements) 的潜力:Mojo 目前没有顶级语句,但预计它们将通过在
main开始之前按导入顺序运行顶级代码来处理循环导入。- 这将确保循环导入得到正确且高效的解决。
- Mojo 异常的性能曲线:一位用户观察到 Mojo 的性能在约 1125 个字段时急剧上升,推测可能是 smallvec 或 arena 发生了溢出。
- 另一位用户建议,原因可能是单个文件包含 1024 个参数。
- Mojo 命名返回槽 (Named Return Slots) 解析:Mojo 支持命名返回槽,允许使用类似
fn thing() -> String as result: result = "foo"的语法。- 该功能似乎旨在用于被调用方帧 (callee frame) 内的 “placement new”,尽管语法可能会发生变化。
Latent Space Discord
- Google 发布全新 Gemini 模型:Google 发布了三个实验性 Gemini 模型:Gemini 1.5 Flash-8B、Gemini 1.5 Pro 以及显著改进的 Gemini 1.5 Flash 模型。
- 用户可以在 aistudio.google.com 探索这些模型。
- Anthropic 的 Claude 3.5 Sonnet:编程利器:Anthropic 于 6 月发布的 Claude 3.5 Sonnet 已成为编程任务的强力竞争者,表现优于 ChatGPT。
- 这一进展可能标志着 LLM 领导地位的转变,Anthropic 有可能占据领先地位。
- Artifacts 席卷移动端:Anthropic 的创新项目 Artifacts 已在 iOS 和 Android 上线。
- 此次移动端发布允许使用 Claude 创建简单的游戏,将 LLM 的力量带入移动应用。
- Cartesia 的 Sonic:端侧 AI 革命:专注于普及 AI 的 Cartesia 推出了其首个里程碑:Sonic,全球最快的生成式语音 API。
- Sonic 旨在将 AI 带到所有设备上,促进与世界之间保护隐私且快速的交互,有望改变机器人、游戏和医疗领域的应用。
- Cerebras 推理:速度之王:Cerebras 推出了其推理解决方案,展示了 AI 处理速度的显著提升。
- 该解决方案由定制硬件和内存技术驱动,速度高达 1800 tokens/s,在速度和设置简易性方面均超越了 Groq。
OpenInterpreter Discord
- OpenInterpreter 获得新的指令格式:一位成员建议将
interpreter.custom_instructions设置为使用str(" ".join(Messages.system_message))的字符串而非列表,以潜在地解决一个问题。- 这一更改可能会改进 OpenInterpreter 对自定义指令的处理。
- Daily Bots 发布,专注于实时 AI:Daily Bots 是一个用于语音、视觉和视频 AI 的超低延迟云平台,现已发布并专注于实时 AI。
- Daily Bots 是开源的并支持 RTVI 标准,旨在将实时 AI 的最佳工具、开发者体验和基础设施整合到一个平台中。
- Bland 的 AI 电话拨打 Agent 结束隐身状态:Bland 是一款听起来像真人一样的可定制 AI 电话拨打 Agent,已筹集 2200 万美元 A 轮融资,现已结束隐身状态。
- Bland 可以使用任何语言或声音交谈,针对任何用例进行设计,并能 24/7 全天候同时处理数百万个电话,且不会产生幻觉。
- Jupyter Book 元数据指南:一位成员分享了关于使用 Python 代码向 notebook 添加元数据的 Jupyter Book 文档链接。
- 该文档提供了如何向 Jupyter Book 中的各类内容(如代码、文本和图像)添加元数据的指导。
- OpenInterpreter 开发持续进行:一位成员确认 OpenInterpreter 的开发仍在进行中,并分享了 GitHub 上 OpenInterpreter 主仓库的链接。
- 提交历史记录显示了活跃的开发进展和来自社区的贡献。
OpenAccess AI Collective (axolotl) Discord
- Axolotl 在 Apple Silicon (M3) 上的运行情况: 一位用户确认 Axolotl 可以在 Apple Silicon 上使用,特别是 M3 芯片。
- 他们提到在 128GB RAM 的 Macbook 上运行没有出现任何错误,但未提供关于训练速度或是否需要进行自定义设置的细节。
- IBM 推出 Power Scheduler:一种新的学习率方法: IBM 推出了一种名为 Power Scheduler 的新型学习率调度器,它与 batch size 和训练 token 数量无关。
- 该调度器是在对学习率、batch size 和训练 token 之间的相关性进行广泛研究后开发的,揭示了它们之间的幂律关系(power-law relationship)。该调度器在各种模型规模和架构中始终保持令人印象深刻的性能,甚至超越了 state-of-the-art 的小型语言模型。来自 AK (@_akhaliq) 的推文
- Power Scheduler:适用于所有配置的单一学习率: 这种创新的调度器允许为任何给定的 token 计数、batch size 和模型规模预测最佳学习率。
- 通过使用公式
lr = bsz * a * T ^ b!,可以在不同配置下实现使用单一学习率。来自 Yikang Shen (@Yikang_Shen) 的推文
- 通过使用公式
- QLora FSDP 参数争议: 关于在 QLora FSDP 示例中正确设置
fsdp_use_orig_params的讨论。- 一些成员认为它应该始终设置为
true,而另一些成员则不确定,并认为这可能不是一个严格的要求。
- 一些成员认为它应该始终设置为
- 模型训练中的异常 Token 行为: 一位成员询问,如果其数据集中的 token 与预训练数据集相比具有异常含义,模型是否应该识别出来。
- 该成员建议,出现频率高于正态分布的 token 可能是有效训练的一个指标。
DSPy Discord
- DSPy 的 “ImageNet 时刻”: DSPy 的 “ImageNet” 时刻归功于 @BoWang87 实验室在 MEDIQA 挑战赛中的成功,其中基于 DSPy 的解决方案以 12.8% 和 19.6% 的显著优势赢得了两项临床 NLP 竞赛。
- 这一成功导致 DSPy 的采用率大幅增加,类似于 CNN 在 ImageNet 上表现出色后变得流行。
- NeurIPS HackerCup:DSPy 的下一个 “ImageNet 时刻”?: NeurIPS 2024 HackerCup 挑战赛被视为 DSPy 潜在的 “ImageNet 时刻”,类似于卷积神经网络在 ImageNet 上脱颖而出后获得显赫地位。
- 该挑战赛为 DSPy 提供了一个展示其能力并可能获得更大规模采用的机会。
- 用于代码生成的 DSPy 优化器: DSPy 正被用于代码生成,最近的一次演讲涵盖了它在 NeurIPS HackerCup 挑战赛中的应用。
- 这表明 DSPy 不仅对 NLP 有效,对代码生成等其他领域也同样有效。
- DSPy 入门: 对于对 DSPy 感兴趣的人,@kristahopsalong 最近在 Weights & Biases 上发表了关于 DSPy 编程入门的演讲,涵盖了其优化器以及使用 2023 HackerCup 数据集的动手演示。
- 这次演讲为任何有兴趣了解更多关于 DSPy 及其在编程中应用的人提供了一个很好的起点。
- 修改 OpenAI Base URL 和模型: 一位用户想要将 OpenAI 的 base URL 和模型更改为其他的 LLM(如 OpenRouter API),但找不到实现方法。
- 他们提供了演示其尝试的代码片段,其中包括在
dspy.OpenAI中设置api_base和model_type参数。
- 他们提供了演示其尝试的代码片段,其中包括在
tinygrad (George Hotz) Discord
- Tinygrad 发货至欧洲: Tinygrad 现在提供发货至欧洲的服务!如需索取报价,请发送电子邮件至 support@tinygrad.org,并注明您的地址和所需的机箱。
- Tinygrad 致力于让发货尽可能便捷,并将尽最大努力为您提供所需的机箱!
- Tinygrad CPU 错误:”No module named ‘tinygrad.runtime.ops_cpu’“: 一位用户报告在 CPU 上运行 Tinygrad 时遇到 “ModuleNotFoundError: No module named ‘tinygrad.runtime.ops_cpu’” 错误。
- 回复建议使用设备 “clang”、”llvm” 或 “python” 来在 CPU 上运行,例如:
a = Tensor([1,2,3], device="clang")。
- 回复建议使用设备 “clang”、”llvm” 或 “python” 来在 CPU 上运行,例如:
- 在 Tinygrad 中获取设备数量: 一位用户询问是否有比使用
tensor.realize().lazydata.base.realized.allocator.device.count更简单的方法来获取 Tinygrad 中的设备数量。- 该用户发现
from tinygrad.device import Device和Device["device"].allocator.device.count提供了一个更直接的解决方案。
- 该用户发现
LAION Discord
- LAION-aesthetic 数据集链接已断开:一位成员请求获取 LAION-aesthetic 数据集的 Hugging Face 链接,因为 LAION 官网上的链接已失效。
- 另一位成员建议查看 Hugging Face 上的 CaptionEmporium 数据集,将其作为潜在的替代方案或相关数据源。
- LAION-aesthetic 数据集链接替代方案:LAION-aesthetic 数据集是一个用于图像描述(captioning)的数据集。
- 该数据集包含审美评判的各个方面,对于图像描述和图像生成模型可能具有很高的价值。
Gorilla LLM (Berkeley Function Calling) Discord
- 在自定义 API 上进行 Llama 3.1 基准测试:一位用户请求关于使用自定义 API 对 Llama 3.1 进行基准测试的建议,特别是针对私有托管的 Llama 3.1 endpoint 及其推理流水线(inference pipeline)。
- 他们正在寻求关于如何有效评估其推理流水线相对于 Llama 3.1 endpoint 性能的指导。
- Gorilla 的 BFCL 排行榜与模型处理器优化:一位用户提出了一个问题,即他们为函数调用(function-calling)功能实施的某些优化是否会被认为对 BFCL Leaderboard 上的其他模型不公平。
- 他们担心 BFCL Leaderboard 对模型处理器(model handler)优化的立场,因为这些优化可能无法推广到所有模型,特别是涉及系统提示词(system prompts)、聊天模板(chat templates)、带约束解码的束搜索(beam search with constrained decoding)以及输出格式化。
Alignment Lab AI Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
PART 2: 按频道划分的详细摘要和链接
完整的频道细分内容已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!预谢!