ainews-code
AI 编程之夏:融资 16 亿美元,仅 1 款可用产品。
“代码 + AI” 被强调为 AI 工程中的一种关键模态,突出了其在提高生产力和可验证性方面的优势。近期主要的融资活动包括:Cognition AI 融资 1.75 亿美元、Poolside 融资 4 亿美元、Codeium AI 融资 1.5 亿美元以及 Magic 融资 3.2 亿美元。
Magic 发布了其 LTM-2 模型,该模型拥有 1 亿 token 的超长上下文窗口。据称,在序列维度算法上,该模型比 Llama 3.1 405B 便宜约 1000 倍,且内存需求大幅降低。Magic 的技术栈完全从零开始构建,采用定制的 CUDA 且不依赖开源基础;他们与 Google Cloud 达成合作,由 NVIDIA H100 和 GB200 GPU 提供算力支持,目标是扩展至数万个 GPU。
此外,Google DeepMind 披露了 Gemini Advanced 的更新,推出了可定制的专家级“Gems”。神经游戏引擎(如 GameNGen)已实现在扩散模型中运行《毁灭战士》(DOOM),该模型基于 9 亿帧 数据训练而成。内容还引用了 Rohan Paul 关于 LLM 量化 的研究。
代码 + AI 就足够了。
2024年8月28日至8月29日的 AI 新闻。我们为你检查了 7 个 subreddits、400 个 Twitter 账号 和 30 个 Discord(213 个频道和 2980 条消息)。预计节省阅读时间(以 200wpm 计算):338 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
AI 工程师的兴起 中的核心论点之一是,在即将出现的众多模态中,代码是“首位平等者”(first among equals)。除了明显的良性循环(编码更快 -> 训练更快 -> 编码更快)之外,它还具有以下优良特性:1) 面向内部(因此错误责任较低但非零),2) 提高开发者生产力(最昂贵的人力成本之一),3) 可验证/自纠正(在 Let’s Verify Step by Step 的意义上)。
这个“代码之夏”拉开序幕的标志是:
- Cognition (Devin) 融资 1.75 亿美元(仍处于严格限制的等候名单中)(其 World’s Fair 演讲见此)
- Poolside 融资 4 亿美元(目前大部分仍处于隐身模式)
今天,我们看到:
- Codeium AI 融资 1.5 亿美元,这是在其 1 月份 6500 万美元融资基础上的又一轮(其 World’s Fair 演讲见此)
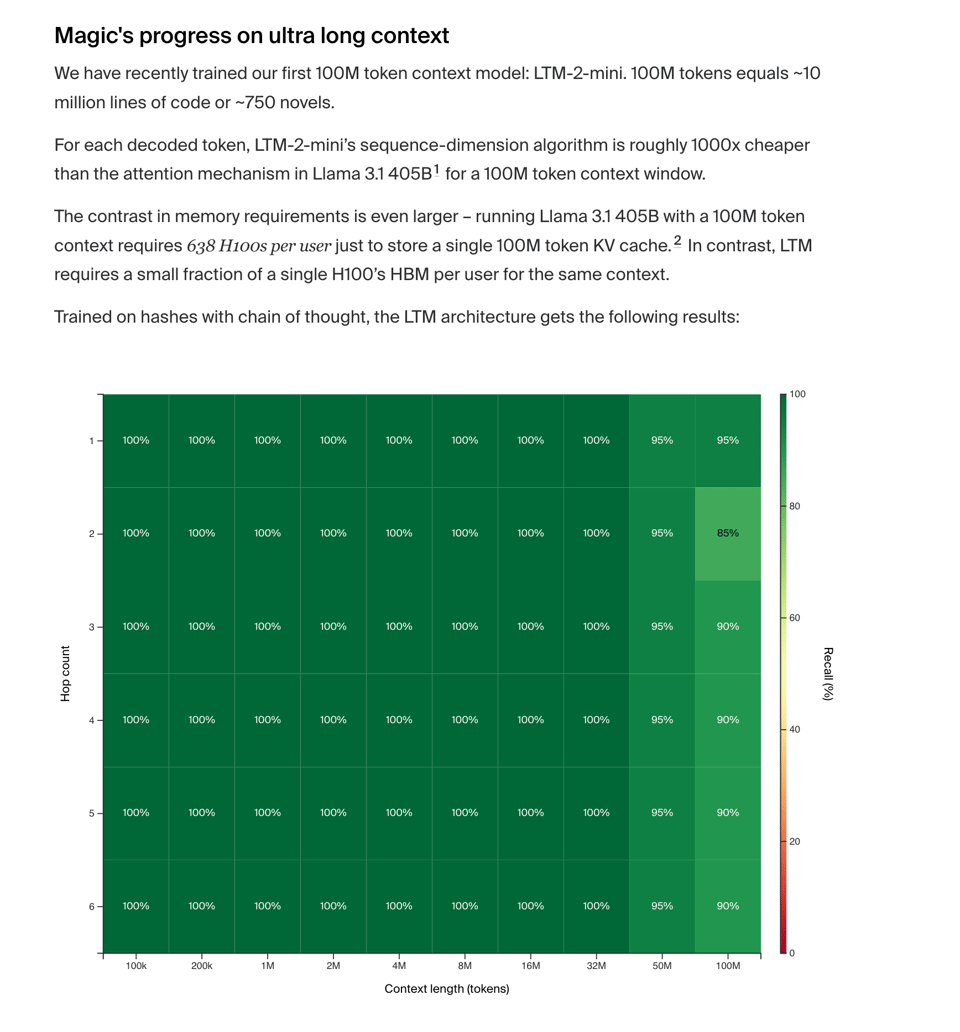
- Magic 融资 3.2 亿美元,这是在其 2 月份 1 亿美元融资基础上的又一轮,并发布了 LTM-2,正式确认了传闻中的 1 亿 token 上下文模型,尽管目前仍处于隐身模式。
虽然 Codeium 是这四家公司中目前唯一可以实际使用的产品,但 Magic 的公告更值得关注,因为其展示了极具前景的长上下文利用能力(由 HashHop 驱动)以及 Nat Friedman 在上一轮融资中透露的效率细节:
对于每个解码的 token,LTM-2-mini 的序列维度算法比 Llama 3.1 405B 在 1 亿 token 上下文窗口下的 Attention 机制便宜约 1000 倍。内存需求的对比则更为巨大——运行具有 1 亿 token 上下文的 Llama 3.1 405B,仅存储单个 1 亿 token 的 KV cache 就需要每用户 638 张 H100。相比之下,LTM 在相同上下文下,每用户仅需单个 H100 HBM 的一小部分。
这是通过一个完全从零开始编写的技术栈实现的:
为了训练和提供 1 亿 token 上下文模型,我们需要从头编写整个训练和推理栈(没有 torch autograd,大量自定义 CUDA,没有开源基础),并针对如何稳定训练模型进行了一次又一次的实验。
他们还宣布了与 Google Cloud 的合作伙伴关系:
Magic-G4 由 NVIDIA H100 Tensor Core GPU 驱动,Magic-G5 由 NVIDIA GB200 NVL72 驱动,并具备随着时间推移扩展到数万个 Blackwell GPU 的能力。
他们提到目前拥有 8000 张 H100,但在前 OpenAI 超级计算负责人 Ben Chess 的领导下,“随着时间的推移,我们将扩展到数万张 GB200”。
他们的下一个前沿领域是 推理时计算(inference-time compute):
想象一下,如果你能为一个问题花费 100 美元和 10 分钟,并能可靠地获得一个针对整个功能的优秀 Pull Request。这就是我们的目标。
AI Twitter 综述
所有综述均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型进展与应用
-
Gemini 更新:Google DeepMind 宣布了 Gemini Advanced 的新功能,包括可自定义的、作为领域专家的 “Gems”,以及针对不同场景的预设 Gems。@GoogleDeepMind 强调了创建这些定制版 Gemini 并与之对话的能力。
-
神经游戏引擎:@DrJimFan 讨论了 GameNGen,这是一个能够在 Diffusion 模型中纯粹运行 DOOM 的神经世界模型。他指出该模型在 0.9B 帧数据上进行训练,这是一个巨大的数据量,几乎占到了训练 Stable Diffusion v1 所用数据集的 40%。
-
LLM 量化:Rohan Paul 分享了关于 AutoRound 的信息,这是来自 Intel Neural Compressor 团队的一个用于 LLM 高级量化的库。@rohanpaul_ai 指出,它对热门模型的压缩接近无损,并能与最近的量化方法相媲美。
-
AI 安全与对齐:François Chollet @fchollet 强调了对选举相关帖子中 AI 生成内容泛滥的担忧,估计有相当一部分(按数量计约 80%,按曝光量计约 30%)并非来自真实人类。
AI 基础设施与性能
-
推理速度:@StasBekman 建议,对于在线推理,每秒每用户 20 个 Token 可能就足够了,这样可以在相同硬件上处理更多并发请求。
-
硬件进展:David Holz @DavidSHolz 提到在 Midjourney 组建了一个新的硬件团队,预示着 AI 专用硬件的潜在发展。
-
模型对比:关于模型性能的讨论包括了 Gemini 与 GPT 模型的对比。@bindureddy 指出,Gemini 的最新实验版本虽然有所进步,但仍落后于其他模型。
AI 应用与研究
-
多模态模型:Meta FAIR 推出了 Transfusion,这是一种将 Next Token Prediction 与 Diffusion 相结合的模型,用于在混合模态序列上训练单个 Transformer。@AIatMeta 分享称其扩展性优于传统方法。
-
RAG 与 Agentic AI:各种讨论集中在检索增强生成 (RAG) 和 Agentic AI 系统。@omarsar0 分享了关于使用多 Agent 架构进行时间序列分析的 Agentic RAG 框架的信息。
-
AI 在法律与商业中的应用:审计公司 Johnson Lambert 报告称,通过在 Amazon Bedrock 上使用 Cohere Command,审计效率提升了 50%,此消息由 @cohere 分享。
AI 开发实践与工具
-
MLOps 与实验追踪:@svpino 强调了机器学习系统中可复现性、调试和监控的重要性,并推荐使用 Comet 等工具进行实验追踪和监控。
-
开源工具:多个开源工具受到关注,包括 Kotaemon,这是一个用于文档对话的可定制 RAG UI,由 @_akhaliq 分享。
AI 伦理与监管
-
选民欺诈讨论:Yann LeCun @ylecun 批评了关于非公民投票的言论,强调了对民主机构信任的重要性。
-
AI 监管:提到了围绕 AI 监管的讨论,包括加州的 SB1047 法案,突显了关于 AI 安全和治理的持续辩论。
AI Reddit 综述
/r/LocalLlama 回顾
主题 1:创新的 Local LLM 用户界面
- 又一个 Local LLM UI,但我保证它与众不同! (分数: 170, 评论: 50):该帖子介绍了一个新的 Local LLM UI 项目,它作为一个 PWA (Progressive Web App) 开发,专注于创建流畅、熟悉的用户界面。开发者在 2023 年初被裁员,他强调了该项目的核心功能,包括用于离线交互和跨设备兼容性的推送通知,并计划实现类似 Character.ai 的人格交互体验。该项目已在 GitHub 上发布,名为 “suaveui”,作者正在寻求反馈、GitHub stars 以及潜在的工作机会。
- 用户称赞了该 UI 的简洁设计,将其比作与真人发消息。开发者计划增加更多受流行聊天应用启发的皮肤,并实现内置安全隧道的一键运行体验。
- 几位用户要求提供更简单的安装方法,包括 Docker/docker-compose 支持和更详细的教程。开发者承认了这些需求,并承诺在未来几天内进行改进。
- 关于兼容性的讨论显示,该项目计划支持 OpenAI 兼容的端点和各种 LLM 服务器。受 Character.ai 通话功能的启发,开发者还表达了实现语音通话支持的兴趣。
主题 2:大语言模型能力的进步
- 我这个非常简单的提示词难倒了很多 LLM。“我的猫名叫 dog,我的狗名叫 tiger,我的老虎名叫 cat。我的宠物有什么不寻常之处?” (分数: 79, 评论: 89):该帖子提出了一个简单的提示词,旨在挑战 LLM。该提示词描述了一个场景:作者的宠物名字通常与其他动物相关联——猫名叫 dog,狗名叫 tiger,老虎名叫 cat,并询问这种安排有什么不寻常之处。
- LLaMA 3.1 405b 和 Gemini 1.5 Pro 被认为是表现最好的模型,它们不仅识别出了不寻常的命名方案,还指出了养一只老虎作为宠物的古怪之处。LLaMA 的回答因其拟人化的语气和对养虎行为的随口询问而特别受到称赞。
- 讨论强调了不同 LLM 的不同处理方式,有些模型仅关注循环命名,而另一些则质疑养老虎的合法性和实用性。Claude 3.5 因其直接的怀疑态度而受到关注,它表示 “你声称拥有一只宠物老虎”。
- 用户辩论了不同 AI 回答的优劣,有些人更喜欢随意的语气,而另一些人则欣赏直接的怀疑。帖子里还包括了关于老虎坐在充气沙发上的 AI 生成图像的幽默交流,并对其不切实际的方面进行了评论。
{kind=link}
主题 3:评估 AI 智能和推理能力的挑战
- 关于确定 LLM 智能的“陷阱”测试 (分数: 112, 评论: 73):该帖子批评了用于测试 LLM 智能的“陷阱 (gotcha)”测试,特别是针对涉及命名奇特的宠物(包括一只老虎)的测试。作者认为此类测试是有缺陷的,并且误用了 LLM。他证明了如果给予适当的提示,即使是 9B 参数模型也能正确识别出养老虎是最不寻常的一点。一个经过修改的示例(使用了更精确的提示词)显示,大多数受测模型(包括 Gemma 2B)都能正确识别出不寻常之处,只有少数例外,如 Yi 模型和 Llama 3.0。
- 用户批评了这种“陷阱”测试,指出它是衡量智能的缺陷标准,甚至人类也可能失败。包括原贴作者 (OP) 在内的许多人最初也忽略了老虎不寻常这一点,而只关注宠物名字。
- 该测试被拿来与其他 LLM 弱点进行比较,用户分享了更具挑战性的谜题链接,如 ZebraLogic。一些人认为 LLM 具备推理能力,并引用了显示其表现与人类相似的基准测试和临床推理测试。
- 讨论涉及了 LLM 如何生成回复,并辩论了它们是真正的推理还是仅仅是预测。一些用户指出,要求 LLM 在生成后解释其推理过程可能会导致偏见或幻觉式的解释。
AI Reddit 全球综述
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 研究与技术
-
Google DeepMind 的 GameNGen:一个神经模型游戏引擎,能够在长轨迹上实现与复杂环境的实时交互。它可以在单个 TPU 上以超过 20 FPS 的速度模拟 DOOM,下一帧预测的 PSNR 达到 29.4。
-
用于游戏生成的 Diffusion Models:GameNGen 模型在用户游戏时实时生成 DOOM 游戏画面,展示了 AI 生成交互式环境的潜力。
AI 模型发布与改进
- OpenAI 的 GPT-4 迭代:OpenAI 已经发布了多个版本的 GPT-4,包括 GPT-4, GPT-4o, GPT4o-mini 和 GPT4o Turbo。目前存在关于未来发布版本和命名惯例的推测。
AI 对行业和就业的影响
- Klarna 的 AI 驱动裁员:先买后付公司 Klarna 计划裁员 2,000 人,因为他们的 AI 聊天机器人现在执行的任务相当于 700 名人类员工的工作量。
技术细节与讨论
-
GameNGen 架构:该模型使用 65 帧游戏分辨率作为输入,并生成最后一帧。它采用了一种加噪技术,以减轻 AI 生成视频中的增量损坏。
-
GPT-4 训练挑战:讨论中提到了训练 LLM 所需的巨大计算资源,包括需要新建发电厂来支持未来几代模型的运行。
AI Discord 综述
由 GPT-4o (gpt-4o-2024-05-13) 生成的摘要之摘要的摘要
1. LLM 进展
- LLM 在图像对比方面表现不佳:LM Studio Discord 的一名成员询问了 LM Studio 对图像格式的支持,但其他人指出,大多数 LLM 并非针对图像对比任务进行训练,它们“看”图像的方式不同。他们建议尝试 LLaVA 模型,该模型专为视觉任务设计。
- @vision_expert 指出:“LLaVA 模型在视觉任务中表现出了良好的效果,可能非常适合你的需求。”
- Gemini 的能力受到质疑:OpenAI Discord 的一名用户批评了 Gemini 的 VR 信息,指出其错误地将 Meta Quest 3 标记为“即将推出”。该用户表达了对 ChatGPT 的偏好,认为 Gemini 是一个“糟糕的 AI”。
- 其他用户也表示赞同,认为 Gemini 需要改进,特别是在准确性和信息的实时性方面。
2. 模型性能优化
- 降低推理速度:LM Studio Discord 的一名成员希望针对特定用例人为地降低推理速度。LM Studio 目前不支持此功能,但可以通过加载多个模型来使用 server API 实现类似效果。
- 这一变通方案引发了关于优化 server API 使用以高效处理多个模型的讨论。
- RAG 与知识图谱:强大的组合:在 LangChain AI Discord 中,用户强调了 Retrieval-Augmented Generation (RAG) 对 AI 应用的好处,使模型无需重新训练即可访问相关数据。他们表示有兴趣将 RAG 与知识图谱结合,探索解决 text-to-SQL 问题的混合方法。
- @data_guru 建议集成知识图谱,以增强模型的语义理解和准确性。
3. 微调策略
- Prompt Engineering 与 Fine-tuning 的辩论:在 OpenAI Discord 中,成员们就实现理想写作风格时 fine-tuning 和 prompt engineering 的优劣展开了热烈讨论。虽然一些人强调了 prompt-by-example 的有效性,但其他人则强调了为 fine-tuning 进行数据准备的重要性。
- @model_tuner 强调 fine-tuning 需要一个精心策划的数据集,以避免 overfitting 并确保 generalizability。
- Unsloth:流线型 Fine-tuning:Unsloth AI Discord 的一名成员强调了使用 Unsloth 对 Llama-3, Mistral, Phi-3 和 Gemma 等 LLM 进行 fine-tuning 的好处,声称它使过程快了 2 倍,内存占用减少了 70%,且保持了准确性。该成员提供了 Unsloth tutorial 的链接,其中包括将 fine-tuned 模型自动导出到 Ollama 并自动创建
Modelfile。- 这引发了社区的兴趣,成员们讨论了他们在 memory optimization 和 training efficiency 方面的经验。
4. 开源 AI 进展
- Daily Bots 发布 AI 开源云:在 OpenInterpreter Discord 中,Daily Bots(一个用于语音、视觉和视频 AI 的低延迟云)已经发布,允许开发者以低至 500ms 的延迟构建与任何 LLM 的 voice-to-voice 交互。该平台提供开源 SDKs,能够混合搭配 AI 模型,并在 Daily 的实时全球基础设施上大规模运行,利用了开源项目 RTVI 和 Pipecat。
- 这一发布受到了热烈欢迎,@developer_joe 指出了其在客户服务及其他领域的 real-time applications 潜力。
- Llama 3 开源采用率激增:在 Latent Space Discord 中,开源的 Llama 模型家族 继续受到关注,在 Hugging Face 上的下载量已超过 3.5 亿次,比去年增长了十倍。Llama 的普及也延伸到了云服务提供商,自 5 月以来 token 使用量增加了一倍多,并在包括 Accenture, AT&T, DoorDash 在内的各行各业得到采用。
- @data_scientist 讨论了这种增长的影响,强调了 community support 和 open-source collaboration 的重要性。
5. AI 社区与活动
- Perplexity Discord 庆祝 10 万成员:Perplexity AI Discord 服务器正式达到 100,000 名成员!团队对社区的支持和反馈表示感谢,并对未来的增长和演变感到兴奋。
- 成员们分享了他们最喜欢的 Perplexity AI features,并讨论了他们希望看到的潜在 improvements 和 new features。
- AI Engineer 见面会与峰会:在 Latent Space Discord 中,AI Engineer 社区正在扩大!首届伦敦见面会定于 9 月举行,第二届在纽约市举行的 AI Engineer Summit 计划于 12 月举行。有兴趣参加伦敦见面会的人可以在这里找到更多信息,并鼓励纽约峰会的潜在赞助商取得联系。
- 该公告引起了轰动,成员们对活动中的 networking opportunities 和 collaboration 表现出浓厚兴趣。
PART 1: High level Discord summaries
LM Studio Discord
- LLM 在图像比较方面表现不佳:一位成员询问了 LM Studio 对图像格式的支持,但其他人指出,大多数 LLM 并非为图像比较任务而训练,它们“看”图像的方式不同。
- 他们建议尝试专门为视觉任务设计的 LLaVA 模型。
- 降低推理速度:一位成员希望针对特定用例人为降低推理速度。
- LM Studio 目前不支持此功能,但可以通过服务器 API 加载多个模型来实现类似效果。
- LM Studio 的新 UI 变化:几位成员询问了 LM Studio 0.3.2 中缺失的“加载/保存模板”功能,该功能以前用于保存不同任务的自定义设置。
- 他们被告知该功能已不再必要,现在可以在加载模型时按住 ALT 键或在 My Models 视图中更改自定义设置。
- LM Studio 的 RAG 功能面临问题:一位成员报告了 LM Studio 的 RAG 功能存在问题,即聊天机器人在文档处理完成后仍继续分析文档,导致难以进行正常对话。
- 另一位成员报告了下载 LM Studio Windows 安装程序的问题,但通过删除 URL 中的空格解决了该问题。
- 3090 的 PCIE 5.0 x4 模式:一位用户询问 3090 是否可以安装在 PCIE 5.0 x4 模式下,以及这是否能提供足够的带宽。
- 另一位用户确认目前的 GPU 几乎用不满 PCIE 4.0,且 5.0 控制器运行温度很高,首批 5.0 SSD 需要主动散热。
OpenAI Discord
- Gemini 的能力受到质疑:一位用户批评了 Gemini 提供的 VR 信息,指出其错误地将 Meta Quest 3 标记为“即将推出”。
- 该用户表达了对 ChatGPT 的偏好,并得出结论认为 Gemini 是一个“糟糕的 AI”。
- 呼吁个性化 LLM:一位成员提出了个性化 LLM 的愿景,概述了所需的功能,如可定制的 AI 性格、长期记忆和更像人类的对话。
- 他们认为这些功能将增强与 AI 互动的意义和影响。
- 应对上下文窗口限制:用户讨论了上下文窗口的局限性以及在 LLM 中使用 Token 实现长期记忆的高昂成本。
- 提出的解决方案包括利用 RAG 检索相关历史记录、优化 Token 使用以及开发用于记忆管理的自定义工具。
- 提示工程 (Prompt Engineering) 与微调 (Fine-tuning) 之争:成员们就实现所需写作风格的微调和提示工程的优缺点展开了热烈讨论。
- 虽然一些人强调了示例提示 (prompt-by-example) 的有效性,但其他人则强调了微调数据准备的重要性。
- OpenAI API:成本与替代方案:对话集中在利用 OpenAI API 的高昂成本上,特别是对于涉及长期记忆和复杂角色的项目。
- 用户探索了优化策略,并考虑了 Gemini 和 Claude 等替代模型。
Stability.ai (Stable Diffusion) Discord
- SDXL 背景仍是挑战:一位用户表示在使用 SDXL 创建良好的背景时遇到困难,经常生成一些不明物体。
- 该用户正在寻求关于如何克服这一挑战并生成更真实、连贯背景的建议。
- Lora 制作:特写还是全脸:一位用户询问制作 Lora 是只需要所需细节(如鼻子)的特写,还是需要包含整张脸。
- 该用户正在寻求有关 Lora 制作最佳实践的指导,特别是关于训练数据必要范围的问题。
- ComfyUI 能处理多个角色吗?:一位用户询问 ComfyUI 是否可以帮助创建具有两个不同角色的图像,且不混淆它们的特征。
- 该用户试图了解 ComfyUI 是否提供能够生成具有多个不同角色的图像的功能,同时避免不必要的特征融合。
- 正则化 (Regularization) 解释:AI Toolkit:一位用户在观看了一个创作者使用不带正则化的基础图像的视频后,询问正则化在 AI Toolkit 中是如何工作的。
- 该用户要求澄清 AI Toolkit 背景下正则化的目的和实现方式。
- 在 2017 年的中端笔记本电脑上运行 SDXL:可行吗?:一位用户询问在 2017 年的中端 Acer Aspire E 系列笔记本电脑上运行 SDXL 的可行性。
- 该用户正在寻求有关其旧笔记本电脑的硬件能力是否足以有效运行 SDXL 的信息。
Unsloth AI (Daniel Han) Discord
- Unsloth: 速度与内存增益:与 OpenRLHF 相比,Unsloth 使用 4-bit 量化实现了更快的训练速度和更低的 VRAM 占用。
- 虽然 Unsloth 目前仅支持 4-bit 量化模型进行 finetuning,但他们正在努力增加对 8-bit 和非量化模型的支持,且不会在性能或可复制性上妥协。
- 在 AWS 上使用 Unsloth 进行 Finetuning:Unsloth 目前没有专门的 AWS finetuning 指南。
- 不过,一些用户正在使用 Sagemaker 在 AWS 上 finetuning 模型,并且有许多 YouTube 视频和 Google Colab 示例可供参考。
- 调查寻求 ML 模型部署的见解:发布了一项调查,询问 ML 专业人士关于模型部署的经验,特别关注常见问题和解决方案。
- 该调查旨在确定部署 Machine Learning 模型时遇到的前三个问题,为该领域专业人士面临的实际障碍提供宝贵的见解。
- 为 Function Calling 进行 Gemma2:2b Fine-tuning:一位用户寻求关于从 Ollama 对 Gemma2:2b 模型进行 function calling fine-tuning 的指导,使用的是 XLM Function Calling 60k dataset 和 提供的 notebook。
- 他们不确定如何将数据集格式化为 instruction、input 和 output 格式,特别是关于 ‘tool use’ 列的处理。
- Unsloth: 精简的 Fine-tuning:一位成员强调了使用 Unsloth 对 Llama-3、Mistral、Phi-3 和 Gemma 等 LLM 进行 fine-tuning 的优势,声称其速度快 2 倍,内存占用减少 70%,且能保持准确性。
- 该成员提供了 Unsloth 教程的链接,其中包括将 fine-tuned 模型自动导出到 Ollama 以及自动创建
Modelfile。
- 该成员提供了 Unsloth 教程的链接,其中包括将 fine-tuned 模型自动导出到 Ollama 以及自动创建
Perplexity AI Discord
- Perplexity Discord 庆祝成员突破 10 万:Perplexity AI Discord 服务器正式达到 100,000 名成员!团队对社区的支持和反馈表示感谢,并对未来的增长和演变感到兴奋。
- Perplexity Pro 会员问题:多位用户报告了其 Perplexity Pro 会员身份的问题,包括洋红色会员标识和免费 LinkedIn Premium 优惠消失,以及 “Ask Follow-up” 功能的问题。
- 其他人也遇到了 “Ask Follow-up” 功能的问题,即在 Perplexity 回复中突出显示一行文本时,”Ask Follow-up” 选项消失了。
- Perplexity AI 准确性担忧:用户对 Perplexity AI 倾向于将假设呈现为事实(经常出错)表示担忧。
- 他们分享了线程中的示例,其中 Perplexity AI 错误地提供了有关政府表格和抓取 Google 的信息,展示了在其回复中需要更强大的事实核查和人工审查。
- 穿梭于 AI 模型的迷宫:用户对选择最佳 AI 模型表示困惑,争论 Claude 3 Opus、Claude 3.5 Sonnet 和 GPT-4o 的优劣。
- 几位用户指出,某些模型(如 Claude 3 Opus)限制为 50 个问题,用户不确定 Claude 3.5 Sonnet 是否是更好的选择,尽管它也有局限性。
- Perplexity AI 易用性挑战:用户强调了 Perplexity AI 平台易用性方面的问题,包括访问保存的线程困难以及 prompt 部分的问题。
- 一位用户指出 Chrome 扩展程序的描述不准确,错误地声称 Perplexity Pro 使用 GPT-4 和 Claude 2,这可能误导了平台的实际能力。
Cohere Discord
- LLM 进行 Tokenize,而非处理字母:一位成员提醒大家,LLM 看到的不是字母,而是 Token —— 一个巨大的词表。
- 他们以阅读日语中的汉字(Kanji)为例,认为这比阅读英语字母更接近 LLM 的工作方式。
- 关于 Claude 谄媚倾向的辩论:一位成员询问 LLM 是否有谄媚(Sycophancy)倾向,特别是在推理方面。
- 另一位成员建议添加 System messages 来帮助解决这一问题,但表示即便如此,这更多是一种“小花招”,而非实用的生产工具。
- MMLu 对实际应用场景效果不佳:一位成员指出 MMLu 不是构建实用 LLM 的好基准(Benchmark),因为它与现实世界的用例相关性不强。
- 他们列举了关于弗洛伊德过时的性理论问题,暗示该基准无法反映用户对 LLM 的真实需求。
- Cohere For AI 学者计划开放申请:Cohere For AI 很高兴开启第三届学者计划(Scholars Program)的申请,旨在改变研究的地点、方式和参与者。
- 该计划旨在帮助研究人员和志同道合的合作者,您可以在 Cohere For AI Scholars Program 页面找到更多信息。
- 内部工具即将公开:一位成员分享说,该工具目前托管在公司的管理面板上,但很快将提供公开托管版本。
- 该工具目前托管在公司的管理面板上,但预计很快会发布公开版本。
LlamaIndex Discord
- LlamaIndex Workflows 教程现已上线:LlamaIndex 文档中现已提供关于 LlamaIndex Workflows 的全面教程,涵盖了从 Workflows 入门、循环与分支、状态维护到并发流等一系列主题。
- 教程可以在这里找到。
- GymNation 利用 LlamaIndex 提升销售:GymNation 与 LlamaIndex 合作,改善会员体验并推动实际业务成果,实现了数字线索到销售转化率提升 20% 以及数字线索对话率达到 87% 的显著成效。
- 支持 Function Calling 的 LLM 实现流式输出:一位成员正在寻求一个使用支持 Function Calling 的 LLM 构建 Agent 的示例,要求能够流式传输最终输出,以避免因将完整消息传递到最后一步而导致的延迟。
- 他们正利用 Workflows 从头开始构建 Agent,并正在寻找解决方案。
- Workflows:一个复杂逻辑示例:一位成员分享了一个 Workflow 示例,该示例利用异步生成器来检测 Tool calls 并流式传输输出。
- 他们还讨论了使用“Final Answer”工具的可能性,该工具可以限制输出 Token,并在被调用时将最终消息传递给最后一步。
- 优化图像 + 文本检索:一位成员询问了结合图像和文本检索的最佳方法,考虑对两者都使用 CLIP Embeddings,但担心 CLIP 与专门的文本嵌入模型(如 text-embeddings-ada-002)相比,在语义优化方面表现不足。
Latent Space Discord
- Agency 融资 260 万美元:Agency 是一家构建 AI Agent 的公司,宣布融资 260 万美元,用于开发“具有代际意义的技术”并将其 AI Agent 变为现实。
- 该公司的愿景是构建一个 AI Agent 无处不在并成为我们生活一部分的未来,正如其网站 agen.cy 所强调的那样。
- AI Engineer 见面会与峰会:AI Engineer 社区正在扩张!首场伦敦见面会定于 9 月举行,第二届纽约 AI Engineer Summit 计划于 12 月举行。
- 个人用途的 AI:DeepMind 研究科学家 Nicholas Carlini 认为,AI 的重点应该从宏大的革命承诺转向其对个人的益处。
- 他的博客文章《我如何使用 AI》(”How I Use AI” https://nicholas.carlini.com/writing/2024/how-i-use-ai.html)详细介绍了他在 AI 工具方面的实际应用,引起了许多读者的共鸣,特别是在 Hacker News 上(https://news.ycombinator.com/item?id=41150317)。
- Midjourney 进军硬件领域:知名的 AI 图像生成平台 Midjourney 正式进入硬件领域。
- 有兴趣加入其旧金山新团队的人员可以联系 hardware@midjourney.com。
- Llama 3 开源采用率飙升:开源 Llama 模型系列继续受到关注,在 Hugging Face 上的下载量已超过 3.5 亿次,与去年相比增长了十倍。
- Llama 的受欢迎程度延伸到了云服务提供商,自 5 月以来 Token 使用量翻了一番多,并在包括 Accenture、AT&T、DoorDash 在内的各行各业得到采用。
OpenInterpreter Discord
- OpenInterpreter 开发持续进行:OpenInterpreter 的开发依然活跃,最近在 OpenInterpreter GitHub 仓库的 main 分支上有新的提交。
- 这意味着该项目仍在不断推进和改进。
- Auto-run 安全问题:提醒用户注意在 OpenInterpreter 中使用
auto_run功能的风险。- 使用此功能时,仔细监控输出以防止任何潜在问题非常重要。
- 即将举行的 House Party:计划于下周提前举行一场 House Party,以鼓励更多人参与。
- 此次活动将是与社区其他成员建立联系并讨论 OpenInterpreter 相关事宜的绝佳机会。
- 终端应用推荐:一位用户正在寻找适用于 KDE 的推荐终端应用,因为他们目前使用的终端 Konsole 在滚动 GPT-4 文本时会出现花屏。
- 这个问题可能是由于终端无法处理来自 GPT-4 的大量文本输出造成的。
- Daily Bots 发布 AI 开源云平台:Daily Bots 推出了一款用于语音、视觉和视频 AI 的低延迟云平台,允许开发者以低至 500ms 的延迟构建与任何 LLM 的语音交互。
- 该平台提供开源 SDK,支持混合搭配 AI 模型,并在 Daily 的实时全球基础设施上大规模运行,利用了开源项目 RTVI 和 Pipecat。
OpenAccess AI Collective (axolotl) Discord
- Macbook Pro 训练速度对比:一位用户在 128GB 的 Macbook Pro 上成功训练了大模型,但速度明显慢于 RTX 3090,训练速度大约只有后者的一半。
- 他们正在寻求更具成本效益的训练解决方案,并考虑将降压版 3090 或 AMD 显卡作为昂贵 H100 的替代方案。
- 租用硬件进行训练:一位用户建议在决定购买之前先租用硬件,特别是对于初学者。
- 他们建议花费 30 美元租用不同的硬件并尝试训练模型,以确定最佳配置。
- 模型大小与训练速度:用户正在探索模型大小与训练速度之间的关系。
- 他们特别感兴趣的是在比较 Nemotron-4-340b-instruct 与 Llama 405 等模型时,训练时间会如何变化。
- 为对话微调 LLM:一位成员拥有用于长对话的优质模型,但用于训练的数据集都是 “ShareGPT” 类型。
- 他们希望实现个性化的数据处理,特别是简化星号()括起来的内容,例如将 *she smile 简化为 smiling。
- 通过 Instruction 简化内容:一位成员询问是否可以使用简单的指令来控制微调后的模型,以简化和重写数据。
- 他们询问了 LlamaForCausalLM 的功能以及是否有更好的替代方案,另一位成员建议只需将 Prompt 配合 system prompt 传递给 Llama 即可。
LangChain AI Discord
- 使用 SQLDatabaseChain 和 PGVector 进行混合搜索:一位用户正在使用带有
pgvector的 PostgreSQL 进行 Embedding 存储,并使用SQLDatabaseChain将查询转换为 SQL,旨在修改SQLDatabaseChain以搜索向量从而获得更快的响应。- 与传统的基于 SQL 的查询相比,这种方法可能会提高搜索速度并提供更高效的结果。
- RAG 与知识图谱:强大的组合:用户强调了检索增强生成 (RAG) 对 AI 应用的好处,使模型无需重新训练即可访问相关数据。
- 他们表示有兴趣将 RAG 与知识图谱结合,为他们的 text-to-SQL 问题探索一种混合方法,从而可能提高模型的理解力和准确性。
- 为多数据库查询构建自适应 Prompt:由于不同的 Schema 要求,用户在为不同的 SQL 数据库创建最佳 Prompt 时面临挑战,导致性能问题和模板冗余。
- 他们正在寻求创建能够适应多个数据库且不损害性能的 Prompt 解决方案,从而可能提高效率并缩短开发时间。
- 解决 Docker 中 OllamaLLM 连接被拒绝的问题:一位用户在尝试在 Docker 容器中调用
OllamaLLM时遇到了连接被拒绝的错误,尽管与 Ollama 容器的通信是成功的。- 建议使用
langchain_community.llms.ollama包作为权宜之计,这可能会解决该问题,并凸显了langchain_ollama包中潜在的 Bug。
- 建议使用
- 探索 LangChain v2.0 中函数调用的流式传输 (Streaming):用户询问了在 2.0 版本中将 LangChain 函数调用与流式传输结合使用的可能性。
- 虽然没有提供直接答案,但目前看来该功能尚不可用,这暗示了 LangChain 未来开发的一个潜在领域。
Torchtune Discord
- Torchtune 需要你的帮助:Torchtune 团队正在寻求社区帮助,通过完成一些小型任务来为他们的仓库做出贡献。在 GitHub issues 页面上标有 “community help wanted” 标签的 issue 均可参与。
- 他们也可以通过 Discord 为贡献者提供协助。
- QLoRA 显存问题:一位成员报告在尝试使用 4x A6000 显卡对 Llama 3.1 70B 进行 QLoRA 训练时遇到了显存溢出(out-of-memory)错误。
- 另一位成员质疑这是否为预期行为,认为这些硬件对于 QLoRA 应该是足够的,并建议提交一个带有可复现示例的 GitHub issue 以进行排查。
- 确认 Torchtune 与 PyTorch 2.4 的兼容性:一位成员询问了 Torchtune 与 PyTorch 2.4 的兼容性,并得到了可以正常工作的确认。
- Fusion Models RFC 讨论:一位成员质疑在
setup_caches函数中处理 decoder-only 的 max_seq_len 是否会导致问题,特别是对于CrossAttentionLayer和FusionLayer。- 另一位成员表示赞同,并提议探索一种能有效处理该问题的工具类(utility)。
- Flamingo 模型的特殊推理:对话探讨了 Flamingo 模型对混合序列长度的使用,特别是其融合层(fusion layers),这需要专门的
setup_caches处理方式。- 准确的缓存位置追踪(cache position tracking)的必要性得到了认可,并指出 Flamingo PR 与包含更新
setup_caches的 Batched Inference PR 之间存在潜在重叠。
- 准确的缓存位置追踪(cache position tracking)的必要性得到了认可,并指出 Flamingo PR 与包含更新
DSPy Discord
- LinkedIn 职位申请自动化:一位成员分享了一个 GitHub 仓库,该仓库利用 Agent Zero 创建新的流水线,自动申请 LinkedIn 上的职位。
- 该仓库旨在利用 AIHawk 实现职位申请的个性化,从而提高流程效率。
- 生成式奖励模型 (GenRM) 论文探讨:一篇新论文提出了 Generative Reward Models (GenRM),它利用 next-token prediction 目标来训练验证器(verifiers),从而实现与指令微调(instruction tuning)、思维链(chain-of-thought)推理的无缝集成,并通过多数投票(majority voting)利用额外的推理时间计算量来增强验证效果。
- 论文认为 GenRM 可以克服传统判别式验证器无法利用预训练 LLM 文本生成能力的局限性,详情请参阅 论文。
- DSPY 优化挑战:一位成员在利用 DSPY 实现其核心目标(抽象化模型、提示词和设置)时感到困难。
- 他们分享了一个 YouTube 视频链接 展示其困惑,并寻求理解 DSPY 优化技术的资源。
- 利用人类回复引导合成数据:一位成员提出了一种引导合成数据的新方法:通过循环使用各种模型和提示词,利用手写的人类回复来最小化 KL divergence 指标。
- 他们就该方法作为生成与人类回复高度一致的合成数据的可行性寻求反馈。
- DSPY 优化器对示例顺序的影响:一位用户询问哪些 DSPY optimizers 会改变示例/few-shot 的顺序,哪些不会。
- 该用户似乎对不同优化器策略对训练数据顺序的影响以及这如何影响模型性能感兴趣。
AI21 Labs (Jamba) Discord
- Jamba 1.5 依赖问题:PyTorch 23.12-py3:有用户报告在尝试使用 pytorch:23.12-py3 训练 Jamba 1.5 时遇到了依赖问题。
- Jamba 1.5 与 Jamba Instruct (1.0) 共享相同的架构和基础模型。
- Transformers 4.44.0 和 4.44.1 的 Bug:发现 Transformers 4.44.0 和 4.44.1 版本包含一个 Bug,会阻碍 Jamba 架构的执行。
- 该 Bug 已在 Jamba 1.5-Mini 的 Hugging Face 模型卡片中记录:https://huggingface.co/ai21labs/AI21-Jamba-1.5-Mini。
- Transformers 4.40.0 解决依赖问题:使用 transformers 4.40.0 成功解决了依赖问题,从而能够成功训练 Jamba 1.5。
- 在该 Bug 完全解决之前,应使用此版本。
- Transformers 4.44.2 发布说明:transformers 4.44.2 的发布说明中提到了对 Jamba 缓存失败的修复,但已确认该修复与影响 Jamba 架构的 Bug 无关。
- 在 Jamba 的 Bug 得到解决之前,用户应继续使用 transformers 4.40.0。
tinygrad (George Hotz) Discord
- Tinygrad 针对静态调度进行了优化:Tinygrad 针对静态调度(Static Scheduling)操作进行了高度优化,在不涉及动态稀疏性或权重选择的任务中实现了显著的性能提升。
- 对静态调度的关注使 Tinygrad 能够利用编译器优化并执行高效的内存管理。
- Tinygrad 的 ReduceOp 合并行为:一位用户询问了 Tinygrad 的
schedule.py文件中大量# max one reduceop per kernel语句背后的原理,特别是其中一个有时会触发 reduction 的早期实例化(early realization),从而阻碍了它们在_recurse_reduceops函数中的合并。- 一位贡献者解释说,当链式调用 reduction 时(例如
Tensor.randn(5,5).realize().sum(-1).sum()),这个问题就会显现,reduction 不会像预期那样合并为单个 sum,PR #6302 解决了这个问题。
- 一位贡献者解释说,当链式调用 reduction 时(例如
- FUSE_CONV_BW=1:卷积反向传播的未来:一位贡献者解释说,Tinygrad 中的
FUSE_CONV_BW=1标志目前通过在反向传播中启用高效的卷积融合来解决 reduction 合并问题。- 他们还指出,一旦在所有场景下都实现了性能优化,该标志最终将成为默认设置。
- Tinygrad 文档:你的起点:一位用户寻求开始学习 Tinygrad 的指导。
- 多位贡献者建议从官方 Tinygrad 文档开始,这被认为是初学者的宝贵资源。
- 动态稀疏操作的局限性:虽然 Tinygrad 在静态调度方面表现出色,但在处理动态稀疏性或权重选择时可能会遇到性能限制。
- 这些类型的操作需要内存管理和计算流的灵活性,而 Tinygrad 目前尚未完全支持。
Gorilla LLM (Berkeley Function Calling) Discord
- 排行榜中缺少 Groq:一位成员询问为什么 Groq 不在 Gorilla LLM 的排行榜(或变更日志)中。
- 回复解释说 Groq 尚未添加,团队正在等待他们的 PR,预计将于下周提交。
- Groq PR 预计下周提交:一位成员询问为什么 Groq 不在 Gorilla LLM 的排行榜(或变更日志)中。
- 回复解释说 Groq 尚未添加,团队正在等待他们的 PR,预计将于下周提交。
LAION Discord
- CLIP-AGIQA 提升 AIGI 质量评估:一篇新论文提出了 CLIP-AGIQA,这是一种利用 CLIP 来提高 AI-Generated Image (AIGI) 质量评估性能的方法。
- 论文认为,当前模型在应对日益增多且多样化的生成图像类别时面临挑战,而 CLIP 评估自然图像质量的能力可以扩展到 AIGI 领域。
- AIGI 需要鲁棒的质量评估:AIGI 在日常生活中的广泛应用凸显了对鲁棒图像质量评估技术的需求。
- 尽管已有一些现有模型,但论文强调需要更先进的方法来评估这些多样化生成图像的质量。
- CLIP 在 AIGI 质量评估中展现出潜力:CLIP 作为一种视觉语言模型,在评估自然图像质量方面已显示出巨大潜力。
- 论文探索了将 CLIP 应用于生成图像的质量评估,并相信它在该领域同样有效。
Alignment Lab AI Discord
- Nous Hermes 2.5 性能:最近在 X 上的一篇帖子讨论了 Hermes 2.5 的性能提升,但未给出具体指标。
- 该帖子链接到了一个 GitHub 仓库 Hermes 2.5,但未提供更多细节。
- 未提供更多细节:这只是 X 上的单条帖子。
- 没有进一步的细节或讨论点。
Mozilla AI Discord
- Common Voice 寻求贡献者:Common Voice 项目是一个用于收集语音数据的开源平台,目标是构建一个既免费又无版权限制的多语言语音片段数据集。
- 该项目旨在让语音技术服务于所有用户,无论其语言或口音如何。
- 加入 Common Voice 社区:您可以通过 Common Voice Matrix 频道或论坛加入 Common Voice 社区。
- 如果您需要帮助,可以发送电子邮件至 commonvoice@mozilla.com 联系团队。
- 为 Common Voice 项目做贡献:有兴趣贡献的人可以在此处找到指南。
- 在文档看起来过时、令人困惑或不完整的地方,需要帮助提交 Issue。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该社区长时间没有动态,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该社区长时间没有动态,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该社区长时间没有动态,请告知我们,我们将将其移除。
第二部分:各频道的详细摘要与链接
邮件中已截断完整的逐频道详情。
如果您喜欢 AInews,请分享给朋友!预谢!