ainews-reflection-70b-by-matt-from-it-department
Reflection 70B,由 IT 部门的 Matt 创作。
来自 Hyperwrite 和 Glaive 的一个两人团队利用 Reflection Tuning(反思微调)技术对 llama-3.1-70b 进行了微调,在仅使用极少量合成数据的情况下,实现了显著的性能提升。
该方法借鉴了在输出中加入“思考”(thinking)和“反思”(reflection)步骤的概念,与思维链(Chain of Thought)方法相关。尽管面临一些批评,如对数据污染的担忧、编程性能下降以及对系统提示词的依赖,该模型仍获得了积极的反响,并被拿来与 claude-3.5-sonnet 进行比较。这项工作突显了大模型在高效指令微调和合成数据生成方面的潜力。
看来 Matt 找到了理想的“低垂果实”,因为直到现在还没有人费心对 Orca 进行不同的尝试,并生成足够的 synthetic data(我们仍然不知道具体有多少,但考虑到 Matt 和 Sahil 只花了大约几十个人工日,数据量应该不会太大)来完成这件事。
批评声音很少,且大多不是致命伤:
- 数据污染担忧:99.2% 的 GSM8K 分数太高了——超过 1% 的题目存在标签错误,这表明存在污染
- Johno Whitaker 独立验证了 GSM8K 中 5 个已知的错误问题被正确回答(即不是死记硬背)
- Matt 也在其上运行了 LMsys 去污染检查
- 编程表现更差:在 BigCodeBench-Hard 上表现更差 —— 比 L3-70B 低了近 10 分;以及 Aider 代码编辑 —— 比 L3-70B 差 7%。
- 针对解决琐碎知识过度优化:“在理解力方面几乎(但还不完全)与 Llama 70B 持平,但在摘要方面远落后——无论是摘要内容还是语言。它的几个句子完全不通顺。我最后把它删了。” —— /r/locallLama
- 异常依赖系统提示词:“有趣的是,如果你不使用作者建议的特定 system prompt,该模型的表现与基础版 Llama 3.1 相同。他自己甚至也这么说。” —— /r/localllama
- 骗子/炒作警报 —— Matt 没有披露他是 Glaive 的投资者。
经过一天的评测,整体反响依然非常强烈 —— /r/localLlama 报道称 即使是 Reflection 70B 的 4bit 量化版本表现也很好,Twitter 上也流传着关于 谜题 的测试以及与 Claude 3.5 Sonnet 的有利对比。可以说,即使它还不算是一个全能模型,但至少通过了 vibe check,并且在足够多的推理任务中表现显著。
更多信息可以在与 Matthew Berman 的 这段 34 分钟的直播对话 和 12 分钟的回顾视频 中找到。
总而言之,对于 Matt from IT 来说,这是不错的一天。
AI Twitter 综述
所有综述均由 Claude 3.5 Sonnet 生成,取 4 次运行中的最佳结果。
LLM 训练与评估
- LLM 训练与评估:@AIatMeta 的 LLM Evaluations Grant(LLM 评估资助金)申请截止日期为 9 月 6 日。该资助将提供 20 万美元资金,用于支持 LLM 评估研究。
- 多模态模型:@glennko 认为 AI 最终将能够以高准确度数出 “r” 的个数,但这可能不是通过 LLM 实现的,而是通过多模态模型 (multi-modal model)。
- 专用架构:@glennko 指出,FPGA 速度太慢,而 ASIC 成本太高,难以构建自定义逻辑所需的专用架构。
开源模型与研究
- 开源 MoE 模型:@apsdehal 宣布发布 OLMoE,这是一个 1B 参数的 Mixture-of-Experts (MoE) 语言模型,且 100% 开源。该模型由 ContextualAI 和 Allen Institute for AI 合作完成。
- 开源 MoE 模型:@iScienceLuvr 指出,OLMOE-1B-7B 拥有 70 亿参数,但每个输入 Token 仅使用 10 亿参数,且在 5 万亿 Token 上进行了预训练。该模型在激活参数量相似的模型中表现优于其他可用模型,甚至超过了更大的模型,如 Llama2-13B-Chat 和 DeepSeekMoE-16B。
- 开源 MoE 模型:@teortaxesTex 指出,DeepSeek-MoE 在粒度 (granularity) 方面得分很高,但在共享专家 (shared experts) 方面表现一般。
AI 工具与应用
- AI 驱动的电子表格:@annarmonaco 强调了 Paradigm 如何利用 AI 改变电子表格,并使用 LangChain 和 LangSmith 来监控关键成本并获得分步的 Agent 可视化。
- 用于医疗诊断的 AI:@qdrant_engine 分享了一份指南,介绍如何使用结合了文本和图像数据的混合搜索 (hybrid search) 来创建高性能诊断系统,并从文本和图像数据中生成 multimodal embeddings。
- 用于时尚的 AI:@flairAI_ 正在发布一个时尚模型,该模型可以以极高的准确度在服装上进行训练,以 Midjourney 级别的质量保留纹理、标签、Logo 等。
AI 对齐与安全
- AI 对齐与安全:@GoogleDeepMind 分享了一期播客,讨论了 AI 对齐 (AI alignment) 的挑战以及有效监督强大系统的能力。播客包含了来自 Anca Diana Dragan 和 Professor FryRSquared 的见解。
- AI 对齐与安全:@ssi 正在构建“通往安全超级智能的直达路径”,并已从投资者那里筹集了 10 亿美元。
- AI 对齐与安全:@RichardMCNgo 指出,EA 通过使用朴素后果主义选择策略,而没有妥善考虑二阶效应,从而助长了追求权力的行为。
模因与幽默
- 创始人模式 (Founder Mode):@teortaxesTex 拿 Elon Musk 的 Twitter 动态开玩笑,将他比作钢铁侠。
- 创始人模式 (Founder Mode):@nisten 建议 Marc Andreessen 需要一个更好的过滤 LLM 来管理他随机屏蔽的用户。
- 创始人模式 (Founder Mode):@cto_junior 调侃亚洲兄弟如何在现有模型之上堆叠 Encoder 和 Cross-attention,仅仅是为了找点感觉。
AI Reddit 综述
/r/LocalLlama 摘要
主题 1:LLM 量化与效率的进展
- llama.cpp 合并了对 TriLMs 和 BitNet b1.58 的支持 (Score: 73, Comments: 4): llama.cpp 通过集成对 TriLMs 和 BitNet b1.58 模型的支持扩展了其功能。此更新允许在 TriLMs 中对权重使用三进制量化 (ternary quantization),并为 BitNet 模型引入了二进制量化 (binary quantization) 方法,这可能为模型部署和执行提供更高的效率。
主题 2:Reflection-70B:一种新型的 LLM 微调技术
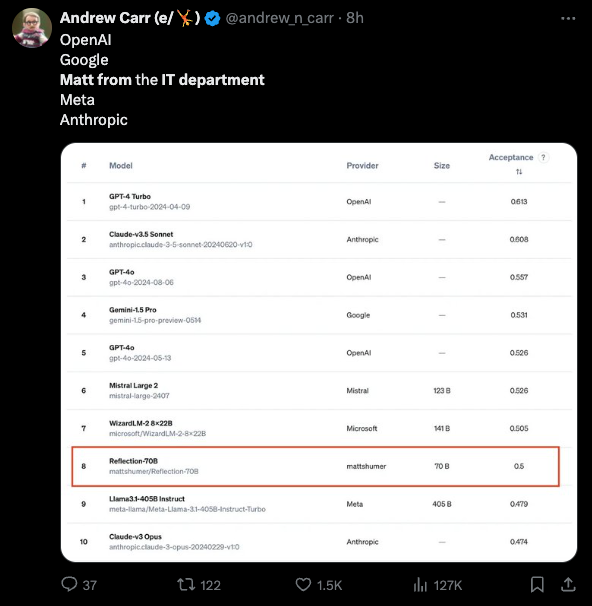
- Reflection 70B 的首个独立基准测试 (ProLLM StackUnseen) 显示出非常好的提升。比基础 Llama 70B 模型提高了 9 个百分点 (41.2% -> 50%) (Score: 275, Comments: 115): Reflection-70B 在 ProLLM StackUnseen 基准测试中展示了相对于其基础模型的显著性能提升,准确率从 41.2% 提高到 50%,增长了 9 个百分点。这项独立评估表明 Reflection-70B 的能力可能超越了更大规模的模型,突显了其在处理未见过的编程任务方面的有效性。
- Matt from IT 意外地与 OpenAI、Google 和 Meta 等顶尖 AI 公司并列,引发了关于个人创新以及来自大型科技公司潜在工作邀约的讨论。
- Reflection-70B 模型展示了优于更大规模模型的显著改进,在基准测试中击败了 405B 版本。用户对未来更大模型的微调表示期待,并讨论了在本地运行这些模型的硬件要求。
- 关于将 Reflection-70B 与其他模型进行比较的公平性产生了争论,因为它使用了独特的
<thinking>和<output>标签输出格式。一些人认为这类似于思维链 (Chain of Thought) 提示词,而另一些人则认为这是一种增强模型推理能力的新颖方法。
- Reflection-Llama-3.1-70B 已在 Ollama 上线 (Score: 74, Comments: 35): Reflection-Llama-3.1-70B 模型现在可以在 Ollama 上访问,扩展了该平台上可用的大语言模型范围。该模型基于 Llama 2,并使用 Constitutional AI 技术进行了微调,以增强其在任务分解、推理和反思 (reflection) 等领域的能力。
- 用户注意到模型最初存在系统提示词错误,该错误已迅速得到更新。该模型在 Ollama 上的名称误删了 “llama”,引发了一些趣谈。
- 据报道存在 tokenizer 问题,可能影响模型在 Ollama 和 llama.cpp 上的表现。Hugging Face 上的一个活跃讨论正在解决此问题。
- 该模型在解决蜡烛问题时展示了其反思能力,捕捉并纠正了最初的错误。用户表示有兴趣将此技术应用于更小的模型,尽管有人指出 8B 版本 的改进有限。
{kind=link}
全球 AI Reddit 综述
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型开发与发布
-
Reflection 70B:由 Matt Shumer 创建,是 Meta Llama 3.1 70B 模型的微调版本,声称在基准测试中超越了最先进的模型。它使用合成数据来提供一种“内心独白”,类似于 Anthropic 在 Claude 3 到 3.5 中采用的方法。
-
AlphaProteo:Google DeepMind 的新 AI 模型可生成新型蛋白质,用于生物学和健康研究。
-
OpenAI 的未来模型:据报道,OpenAI 正在考虑为下一代 AI 模型(可能命名为 Strawberry 和 Orion)设定高达每月 2,000 美元的高价订阅费。
AI 行业与市场动态
-
开源影响力:Reflection 70B 的发布引发了关于开源模型颠覆 AI 行业潜力的讨论,这可能会激励像 OpenAI 这样的公司发布新模型。
-
模型能力:公众认知与实际 AI 模型能力之间存在脱节,许多人并不了解 AI 技术的现状。
AI 应用与创新
-
DIY 药物:一份报告讨论了“盗版 DIY 药物”的兴起,业余人士可以以极低的成本制造昂贵的药物。
-
Stable Diffusion:一个新的 用于 Stable Diffusion 的 FLUX LoRA 模型 受到欢迎,展示了 AI 生成艺术领域的持续发展。
AI Discord 简报
由 Claude 3.5 Sonnet 生成的摘要之摘要的摘要
1. LLM 进展与基准测试
- Reflection 70B 掀起波澜:Reflection 70B 被宣布为全球顶尖的开源模型,该模型采用了一种全新的 Reflection-Tuning 技术,使其能够检测并纠正自身的推理错误。
- 尽管最初的热度很高,但随后在 BigCodeBench-Hard 等基准测试中的表现却褒贬不一,得分低于之前的模型。这引发了关于评估方法以及合成训练数据影响的辩论。
- DeepSeek V2.5 步入赛场:DeepSeek V2.5 正式发布,它结合了 DeepSeek-V2-0628 和 DeepSeek-Coder-V2-0724 的优势,增强了写作、指令遵循(instruction-following)以及人类偏好对齐(human preference alignment)能力。
- 社区对比较 DeepSeek V2.5 与 Reflection 70B 等近期模型在编程任务中的表现表现出浓厚兴趣,凸显了该领域飞速发展的节奏。
2. 模型优化技术
- Speculative Decoding 取得突破:Together AI 宣布在 Speculative Decoding 方面取得突破,在长上下文输入下实现了高达 2 倍的延迟和吞吐量提升,挑战了此前对其有效性的假设。
- 这一进展标志着高吞吐量推理优化方面的重大转变,有望减少 GPU 工时以及 AI 方案部署的相关成本。
- AdEMAMix 优化器增强梯度处理:提出了一种名为 AdEMAMix 的新型优化器,如这篇 论文 所述,它利用两个指数移动平均(EMAs)的混合,比单一 EMA 更好地处理过去的梯度。
- 早期实验显示,AdEMAMix 在语言建模和图像分类任务中优于传统的单一 EMA 方法,有望为各种 AI 应用带来更高效的训练结果。
3. 开源 AI 发展
- llama-deploy 简化微服务:llama-deploy 发布,旨在促进基于 LlamaIndex Workflows 的微服务无缝部署,标志着 Agent 系统部署的一次重要演进。
- 官方分享了一个开源示例,展示了如何结合 llama-deploy 与 @getreflex 前端框架构建一个 Agent 聊天机器人系统,证明了其全栈能力。
- SmileyLlama:AI 分子设计工具:SmileyLlama 亮相,这是一个经过微调的化学语言模型,能够根据 Prompt 中指定的属性设计分子,基于 Axolotl 框架构建。
- 这一进展展示了 Axolotl 在将现有化学语言模型技术适配到分子设计等专门任务方面的能力,拓展了 AI 在化学领域应用的边界。
4. AI 基础设施与部署
- NVIDIA 发布 AI 教学套件:NVIDIA 的 Deep Learning Institute 发布了与达特茅斯学院合作开发的 生成式 AI 教学套件,旨在让学生掌握 GPU 加速的 AI 应用。
- 该套件旨在通过弥合各行业的知识鸿沟,为学生在就业市场提供显著优势,彰显了 NVIDIA 对 AI 教育和人才培养的承诺。
- OpenAI 考虑高端定价:有报道称 OpenAI 正在考虑为其更先进的 AI 模型(包括备受期待的 Orion 模型)推出每月 2000 美元的订阅模式,正如这份 The Information 报告 所讨论的。
- 这种潜在的定价策略在社区内引发了关于可访问性和 AI 民主化影响的辩论,一些人担心这会为小型开发者和研究人员制造障碍。
PART 1: 高层级 Discord 摘要
HuggingFace Discord
- 视觉语言模型(Vision Language Models)概述:一位成员分享了一篇博客文章,详细介绍了 AI 应用中视觉与语言的集成,并强调了其创新潜力。
- 这篇文章旨在将关注点引导至这一技术交叉领域中涌现的多样化用例。
- Tau LLM 训练优化资源:Tau LLM 系列 提供了关于优化 LLM 训练过程的关键见解,有望提升性能。
- 对于任何深入研究如何有效训练 LLM 复杂性的人来说,这被认为是至关重要的资源。
- 寻求用于疾病检测的医疗数据集:一位成员正在寻找用于 Computer Vision 的强大医疗数据集,旨在通过 Transformer 模型增强 疾病检测(Disease Detection)。
- 他们对能够支持该领域大规模数据生成工作的数据集特别感兴趣。
- Flux img2img 流水线仍待定:Flux img2img 功能尚未合并,正如公开 PR 中所述,关于其文档的讨论仍在进行中。
- 尽管它可能对典型的消费级硬件造成压力,但正如相关讨论中所分享的,优化措施正在探索中。
- 用于增强语言模型的选择性微调:选择性 Fine-Tuning 的概念受到关注,展示了其在无需全量重新训练的情况下提高语言模型性能的能力。
- 这种有针对性的方法允许进行更深层次的性能调整,同时避免了与完整训练周期相关的成本。
Stability.ai (Stable Diffusion) Discord
- ControlNet 增强模型搭配:用户分享了结合使用 ControlNet 与 Loras 的成功策略,利用各种 SDXL 模型生成如 Hash Rosin 图像的精确表现。
- 他们建议应用 Depth Maps(深度图)等技术以获得更好的结果,突显了在组合不同 AI 工具方面日益成熟的掌握能力。
- Flux 在 Logo 生成方面领先于 SDXL:社区广泛认可 Flux 在 Logo 生成方面优于 SDXL,强调其在无需大量训练的情况下对 Logo 细节的卓越处理。
- 成员们指出,SDXL 在不熟悉 Logo 设计的情况下表现吃力,这使得 Flux 因其易用性和有效性成为首选。
- 诈骗防范意识提升:关于在线诈骗的讨论显示,即使是经验丰富的用户也可能受到攻击,这促使大家共同承诺保持持续警惕。
- 对诈骗行为的同理心理解成为一项关键见解,强化了“易受攻击性并不局限于缺乏经验者”的观点。
- ComfyUI 中的标签功能创新:社区对 ComfyUI 中打标签(Tagging)功能的见解将其能力比作 Langflow 和 Flowise,展示了其灵活性和用户友好的界面。
- 成员们集思广益,探讨了增强标签效能的具体工作流,预示着界面功能将迎来一波充满希望的适配浪潮。
- Forge 扩展插件见解:对 Forge 中各种可用扩展的咨询突显了用户通过贡献和社区反馈来改善体验的努力。
- 投票被用作塑造未来扩展版本的一种方法,强调了质量保证和社区参与的重要性。
Unsloth AI (Daniel Han) Discord
- 祝贺获得 Y Combinator 批准!: 团队成员庆祝最近获得了 Y Combinator 的支持,展现了强大的 社区支持 以及对项目未来的热情。
- 他们认为这一里程碑是推动开发和推广的重大助力。
- Unsloth AI 面临硬件兼容性障碍: 讨论强调了 Unsloth 目前在硬件兼容性方面的困境,特别是关于 Mac 系统上的 CUDA 支持。
- 团队的目标是实现 硬件无关性 (hardware agnosticism),但持续存在的问题降低了某些配置下的性能。
- 合成数据生成模型见解: 分享了关于使用 Mistral 8x7B 微调版本 进行合成数据生成的见解,以及使用 jondurbin/airoboros-34b-3.3 等模型进行测试。
- 基于硬件限制,实验对于优化微调结果仍然至关重要。
- Phi 3.5 模型输出困扰用户: 用户报告称,尽管调整了参数,Phi 3.5 模型在微调过程中仍返回 乱码输出 (gibberish outputs),令人沮丧。
- 这引发了关于故障排除和优化输入模板以提高模型性能的广泛讨论。
- 对对比报告的兴趣激增!: 一位成员表达了对关键主题对比报告的渴望,强调了其作为 深度见解 阅读材料的潜力。
- 与此同时,另一位成员宣布了制作 YouTube 视频 详细介绍这些对比的计划,展示了社区的参与度。
LM Studio Discord
- 寻求免费图像 API 选项: 用户调查了支持高限制的 免费图像 API 选项,特别是询问提供 Stable Diffusion 等模型访问权限的供应商。
- 大家对能够大规模提供这些功能的供应商感到好奇。
- Reflection Llama-3.1 70B 获得增强: Reflection Llama-3.1 70B 作为顶尖的开源 LLM 给人留下了深刻印象,其更新增强了错误检测和纠正能力。
- 然而,用户注意到持续存在的性能问题,并讨论了优化 Prompt 以改善模型行为的方法。
- LM Studio 更新后出现下载问题: 更新到 0.3.2 版本后,用户在下载模型时面临挑战,证书错误 (certificate errors) 是主要问题。
- 讨论的解决方法包括调整 VRAM 和 Context Size,同时对 RAG 摘要功能进行了说明。
- Mac Studio 在处理大模型时的速度挑战: 用户担心拥有 256GB+ 内存的 Mac Studio 在处理大型模型时速度缓慢,希望 LPDDR5X 10.7Gbps 能够解决这一问题。
- 一项讨论强调了所有 M4 芯片可能带来 70% 的速度提升,引发了对硬件升级的进一步兴趣。
- 利用 NVLink 和 RTX 3090 最大化性能: 用户分享了在双 RTX 3090 配置下实现 10 到 25 t/s 的见解,特别是使用 NVLink 时,甚至有人报告达到了 50 t/s。
- 尽管有这些高数据,一些社区成员对 NVLink 对实际推理性能的影响持怀疑态度。
Nous Research AI Discord
- Reflection 70B 模型在基准测试中表现不佳:最近的测试显示 Reflection 70B 在与 BigCodeBench-Hard 的对比中表现不佳,特别是受到 tokenizer 和 prompt 问题的影响。
- 社区对评估结果表示担忧,导致该模型在实际应用中的可靠性存在不确定性。
- 社区调查 DeepSeek v2.5 的可用性:成员们寻求关于 DeepSeek v2.5 在编程任务中改进情况的反馈,鼓励分享用户体验。
- 该倡议旨在建立对模型有效性的集体认识,并促进用户驱动的增强。
- 关于 Llama 3.1 API 可用性的咨询:讨论了实现 Llama 3.1 70B 的最佳 API 选项,强调了对 tool call 格式支持的需求。
- 建议包括探索各种平台,指出 Groq 是一个很有前景的部署候选方案。
- 量化技术的挑战:用户报告了 70B 模型在 FP16 量化方面的挫折,强调了在使用 int4 达到满意性能方面的困难。
- 正在进行的讨论围绕着在保持质量完整性的同时增强模型性能的潜在解决方案。
- 提升性能的 MCTS 和 PRM 技术:对话表明了对合并 MCTS (Monte Carlo Tree Search) 和 PRM (Probabilistic Roadmap) 以提高训练效率的兴趣。
- 社区对尝试这些方法以改进模型评估过程表现出热情。
Latent Space Discord
- OpenAI 考虑 2000 美元的订阅费用:OpenAI 正在为其高端 AI 模型(包括即将推出的 Orion 模型)探索 $2000/月 的定价模式,这引起了社区内对可访问性的担忧。
- 随着讨论的展开,关于这种定价是否符合市场规范或是否为小型开发者设置了障碍,意见不一。
- Reflection 70B 参差不齐的基准测试结果:Reflection 70B 模型表现出参差不齐的性能,在 BigCodeBench-Hard 基准测试中得分为 20.3,明显低于 Llama3 的 28.4 分。
- 批评者强调需要对其方法论进行更深入的分析,特别是关于其声称是顶级开源模型的说法。
- 投机采样 (Speculative Decoding) 提升推理速度:Together AI 报告称,投机采样可以将吞吐量提高多达 2x,挑战了之前关于其在高延迟场景下效率的假设。
- 这一进展可能会重塑优化长上下文输入推理速度的方法。
- 文本转音乐模型的令人兴奋的发展:一个新的开源 text-to-music model 出现,声称具有令人印象深刻的音质和效率,与 Suno.ai 等成熟平台竞争。
- 成员们对其潜在应用非常感兴趣,尽管对其具体可用性存在不同看法。
- AI 代码编辑器的探索:关于 AI 代码编辑器的讨论重点介绍了 Melty 和 Pear AI 等工具,展示了与 Cursor 相比的独特功能。
- 成员们特别感兴趣这些工具如何管理注释和 TODO,推动在编码环境中更好的协作。
OpenAI Discord
- Perplexity 抢尽风头:用户称赞 Perplexity 的速度和可靠性,通常认为它是 ChatGPT Plus 订阅的更好替代方案。
- 一位用户指出,它对学校学习特别有用,因为它易于访问并与 Arc browser 集成。
- RunwayML 面临抵制:一位用户在社区见面会取消后对 RunwayML 表示不满,这引发了对其客户服务的担忧。
- 评论强调了忠实成员的不满以及这如何影响 Runway 的声誉。
- Reflection 模型前景广阔的调整:围绕 Reflection Llama-3.1 70B model 的讨论集中在其性能和一种名为 Reflection-Tuning 的新训练方法上。
- 用户注意到初始测试问题导致了一个平台链接的产生,他们可以在那里实验该模型。
- OpenAI token 赠送引发关注:一项 OpenAI tokens 的赠送活动引起了极大兴趣,因为一位用户有 1,000 tokens 且不打算使用。
- 这引发了关于在社区内进行潜在交易或利用这些 token 的讨论。
- 有效的 tool call 集成:成员们分享了在 prompt 中构建 tool calls 的技巧,强调了 Assistant message 后紧跟 Tool message 的正确顺序。
- 一位成员指出,在单个 prompt 输出中成功实现了超过 10 个 Python tool calls。
Eleuther Discord
- 获得学术实验室职位:成员们讨论了获得学术实验室职位的策略,强调了 project proposals 的有效性,而冷邮件(cold emailing)的成功率较低。
- 一位成员强调需要将研究项目与当前趋势结合,以吸引潜在导师的注意。
- Universal Transformers 面临可行性问题:关于 Universal Transformers 的可行性展开了辩论,一些成员表示怀疑,而另一些成员则在自适应隐式计算(adaptive implicit compute)技术中发现了潜力。
- 尽管前景广阔,但稳定性仍然是在实际应用中广泛采用的重大障碍。
- AdEMAMix Optimizer 改进梯度处理:新提出的 AdEMAMix 优化器通过混合两个 Exponential Moving Averages,增强了梯度利用率,在语言建模等任务中表现出更好的性能。
- 早期实验表明,这种方法优于传统的单一 EMA 方法,有望带来更高效的训练结果。
- 自动化强化学习 Agent 架构:引入了一种新的自动化 RL Agent 架构,通过 Vision-Language Model 高效管理实验进度并构建课程(curricula)。
- 这标志着强化学习实验工作流中首批实现完全自动化的案例之一,在模型训练效率方面取得了新突破。
- Hugging Face RoPE 兼容性担忧:一位成员提出了关于 GPTNeoX 的 Hugging Face RoPE implementation 与其他模型之间兼容性的问题,指出 attention 输出存在超过 95% 的差异。
- 这为那些使用多个框架的开发者提供了重要的参考,并可能影响未来的集成工作。
OpenInterpreter Discord
- Open Interpreter 庆祝里程碑:成员们热烈庆祝 Open Interpreter 的生日,社区表达了对其创新潜力的深切赞赏。
- Happy Birthday, Open Interpreter! 成了大家的口号,强调了对其能力的兴奋之情。
- Open Interpreter 中的 Skills 功能仍处于实验阶段:讨论显示 Skills 功能目前是实验性的,引发了关于这些技能是否跨会话持久化的疑问。
- 用户注意到技能似乎是临时的,这导致了调查本地机器存储位置的建议。
- 对 01 app 性能的正面反馈:用户分享了关于 01 app 能够高效搜索并播放拥有 2,000 个音频文件的库中歌曲的热情反馈。
- 尽管受到好评,但也有关于结果不一致性(inconsistencies)的报告,反映了典型的早期访问挑战。
- Fulcra app 扩展到新地区:Fulcra app 已正式在更多地区上线,响应了社区对提高可访问性的请求。
- 讨论表明用户对 Australia 等地的可用性感兴趣,并支持进一步扩张。
- 申请 Beta Role 访问权限:多位用户渴望获得 desktop 的 beta role 访问权限,其中包括一位为 Open Interpreter 01 的 dev kit 做出贡献的用户。
- 一位用户对错过直播会议表示遗憾,并询问:“有什么办法可以获得 desktop 的 beta role 吗?”
Modular (Mojo 🔥) Discord
- Mojo Values 页面返回 404:成员们注意到 Modular 的 values 页面目前在此链接显示 404 错误,可能需要重定向到 company culture。
- 建议进行澄清,指出需要更改链接以有效地将用户引导至相关内容。
- Mojo 中 Async 函数的限制:一位用户在处理
async fn和async def时遇到问题,发现这些 async 功能仅限于 nightly 构建版本,在稳定版中引起了困惑。- 建议用户检查其版本,并考虑切换到 nightly 构建版本以使用这些功能。
- DType 作为 Dict Key 的约束:关于无法将
DType用作 Dictionary 键的讨论引发了关注,因为它实现了KeyElementtrait。- 参与者探讨了 Mojo 数据结构中的设计约束,这些约束可能会限制某些类型的使用。
- 构造函数使用故障排除:分享了解决涉及
Arc[T, True]和Weak[T]的构造函数问题的进展,突出了 @parameter guards 带来的挑战。- 建议包括改进标准库中的命名规范以提高清晰度,并对齐类型的结构。
- 探索 MLIR 和 IR 生成:对如何在 Mojo 中更有效地利用 MLIR 产生了兴趣,特别是关于 IR 生成方面。
- 建议参考之前 LLVM 会议的资源 2023 LLVM Dev Mtg - Mojo 🔥,以深入了解集成情况。
CUDA MODE Discord
- Reflection 70B 发布,带来令人兴奋的特性:Reflection 70B 模型已发布,被称为全球最强的开源模型,利用 Reflection-Tuning 来纠正 LLM 错误。
- 预计下周将推出 405B 模型,其性能可能超越目前所有模型。
- 调查 TorchDynamo 缓存查找延迟:在执行大型模型时,成员注意到 TorchDynamo Cache Lookup 耗时 600us,主要源于
torch/nn/modules/container.py的调用。- 这表明需要对缓存查找过程进行潜在优化,以提高模型训练的运行效率。
- NVIDIA 联手开展生成式 AI 教育:NVIDIA 的 Deep Learning Institute 与达特茅斯学院合作发布了 生成式 AI 教学套件,以增强 GPU 学习。
- 参与者将在 AI 应用中获得竞争优势,弥补关键的知识鸿沟。
- FP16 x INT8 Matmul 在 Batch Size 上显示出局限性:由于共享内存限制,4090 RTX 上的 FP16 x INT8 matmul 在 Batch Size 超过 1 时会失败,这暗示需要针对非 A100 GPU 进行更好的调优。
- 用户在启用 inductor 标志时遇到了严重的减速,但可以通过关闭它们来绕过错误。
- Liger 的性能基准测试引人关注:Liger 的 swiglu kernels 性能与 Together AI 的基准测试 进行了对比,据报道后者提供了高达 24% 的加速。
- 其专门定制的 kernels 性能优于 cuBLAS 和 PyTorch eager mode 约 22-24%,表明需要进一步的调优选项。
Interconnects (Nathan Lambert) Discord
- Reflection Llama-3.1 70B 表现参差不齐:新发布的 Reflection Llama-3.1 70B 声称是领先的开源模型,但在 BigCodeBench-Hard 等基准测试中表现挣扎。
- 用户观察到其在推理任务中的性能下降,并在 Twitter 上将其描述为“乏善可陈的非新闻级模型”。
- 对 Glaive 合成数据的担忧依然存在:社区成员对来自 Glaive 的合成数据的有效性提出了警示,回顾了过去可能影响模型性能的数据污染问题。
- 这些担忧引发了关于合成数据对 Reflection Llama 模型泛化能力影响的讨论。
- HuggingFace Numina 在研究领域受到好评:HuggingFace Numina 被强调为以数据为中心任务的强大资源,其应用潜力令研究人员感到兴奋。
- 用户对它如何提高各种正在进行的项目的效率和创新表达了热情。
- 引入用于数学推理的 CHAMP 基准测试:社区欢迎新的 CHAMP 基准测试,该基准旨在通过提供提示的注释问题来评估 LLM 的数学推理能力。
- 该数据集将探索额外的上下文如何在复杂条件下辅助问题解决,促进该领域的进一步研究。
- Fireworks 和 Together 的可靠性问题:讨论揭示 Fireworks 和 Together 都被认为并非 100% 可靠,促使实施 failovers 以维持功能。
- 在可靠性得到加强保证之前,用户对使用这些工具持谨慎态度。
Perplexity AI Discord
- 无技术背景进入科技行业:一位成员表达了在没有技术技能的情况下进入科技行业的渴望,并寻求关于撰写有吸引力的简历和有效建立人脉(Networking)的建议。
- 另一位成员提到通过 PerScholas 开始 cybersecurity training(网络安全培训),强调了对 coding 和 AI 日益增长的兴趣。
- Bing Copilot 对比 Perplexity AI:一位用户对比了 Bing Copilot 提供 5 个来源及内嵌图片的能力与 Perplexity 的功能,并提出了改进建议。
- 他们暗示为引用内容集成 hover preview cards(悬停预览卡片)可能是 Perplexity 的一个有价值的增强功能。
- Perplexity AI 的推荐计划:Perplexity 正在推出一项专门针对学生的 merch referral program(周边商品推荐计划),鼓励通过分享来获取奖励。
- 有人提出了关于一年免费访问权限可用性的问题,特别是针对前 500 名注册用户。
- Web3 职位空缺:一则帖子强调了一个 Web3 创新团队的 job openings(职位空缺),正在寻找 Beta 测试人员、开发人员和 UI/UX 设计师。
- 他们邀请提交申请和提案,以创造互助合作的机会,作为其愿景的一部分。
- Sutskever 的 SSI 获得 10 亿美元融资:Sutskever 的 SSI 成功筹集了 10 亿美元,以推动 AI 技术的进步。
- 这笔资金旨在推动 AI 领域的进一步创新。
tinygrad (George Hotz) Discord
- 悬赏任务探索引发兴趣:一位用户表示有兴趣尝试悬赏任务(bounty)并寻求指导,参考了关于如何提问的智慧的资源。
- 这引发了另一位成员的幽默回应,突显了社区在悬赏任务讨论中的参与度。
- Tinygrad 价格降至零:在一个令人惊讶的转折中,georgehotz 确认 4090 + 500GB 方案的价格已降至 $0,但仅限 tinygrad 的朋友。
- 这促使 r5q0 询问成为朋友的标准,为对话增添了轻松的氛围。
- 澄清 PHI 操作的困惑:成员们讨论了 IR 中 PHI 操作的功能,注意到其与 LLVM IR 相比不寻常的放置位置,特别是在循环中。
- 一位成员建议将其重命名为 ASSIGN,因为它的运作方式与传统的 phi 节点不同,旨在消除误解。
- 理解 MultiLazyBuffer 的特性:一位用户对
MultiLazyBuffer.real属性及其在收缩(shrinking)和复制到设备交互中的作用提出了疑问。- 这一询问引发了讨论,揭示了它代表设备上的真实 lazy buffers 以及配置中潜在的 bug。
- View 与内存挑战:成员们对
_recurse_lb函数中 view 的实现(realization)表示持续困惑,质疑优化与利用率之间的平衡。- 这种反思强调了对基础 tensor view 概念进行澄清的必要性,并邀请社区投入以完善理解。
Torchtune Discord
- 分享 Gemma 2 模型资源:成员们讨论了 Gemma 2 model card,提供了来自 Google 轻量级模型系列的技术文档链接。
- 资源包括 Responsible Generative AI Toolkit 以及指向 Kaggle 和 Vertex Model Garden 的链接,强调了 AI 伦理实践。
- 多模态模型与因果掩码:一位成员概述了多模态设置在推理过程中使用 causal masks(因果掩码)面临的挑战,重点关注固定序列长度。
- 他们指出,通过注意力层暴露这些变量对于有效解决此问题至关重要。
- 期待 Flex Attention 带来的加速:人们乐观地认为,带有文档掩码(document masking)的 flex attention 将显著提升性能,在 A100 上实现 40% 的加速,在 4090 上实现 70% 的加速。
- 这将改进 dynamic sequence length(动态序列长度)训练,同时最大限度地减少填充(padding)带来的低效。
- 关于 TransformerDecoder 设计的疑问:一位成员询问 TransformerDecoder 是否可以在没有自注意力(self-attention)层的情况下运行,挑战了其传统结构。
- 另一位成员指出,原始的 Transformer 利用了 交叉注意力(cross-attention)和自注意力,使得这种偏离变得复杂。
- PR 更新标志着生成工具的重构:成员们确认 GitHub PR #1449 已更新,以增强与
encoder_max_seq_len和encoder_mask的兼容性,测试仍在进行中。- 此次更新为进一步修改 generation utils 以及与 PPO 的集成铺平了道路。
LlamaIndex Discord
- llama-deploy 提供微服务魔力:全新的 llama-deploy 系统增强了基于 LlamaIndex Workflows 的微服务部署。这为简化类似于之前 llama-agents 迭代的 Agent 系统提供了机会。
- 社区分享的一个示例展示了使用 llama-deploy 与 @getreflex 的全栈能力,演示了如何有效地构建 Agent 聊天系统。
- PandasQueryEngine 面临列名混淆问题:用户报告称 PandasQueryEngine 在识别
averageRating列时遇到困难,经常在对话中退回到错误的标签。建议包括在 Chat Engine 的上下文中验证映射。- 这种混淆可能会在将 Engine 响应与预期输出格式集成时导致更深层次的数据完整性问题。
- 利用 RAG 开发客户支持机器人:一位用户正在探索如何创建一个将对话引擎与检索增强生成 (RAG) 高效集成的客户支持聊天机器人。成员们强调了 Chat Engine 和 Query Engine 之间的协同作用,以实现更强大的数据检索能力。
- 验证这种集成可以提升在有效支持至关重要的现实应用中的用户体验。
- 报告 NeptuneDatabaseGraphStore Bug:关于 NeptuneDatabaseGraphStore.get_schema() 的一个 Bug 引起了关注,该 Bug 会导致图摘要中丢失日期信息。怀疑该问题可能与 LLM 的 Schema 解析错误有关。
- 社区成员表示需要进一步调查,特别是围绕
datetime包在故障中所起的作用。
- 社区成员表示需要进一步调查,特别是围绕
- Azure LlamaIndex 与 Cohere Reranker 查询:一场关于将 Cohere Reranker 作为后处理器集成到 Azure 的 LlamaIndex 中的讨论展开了。成员们确认,虽然目前不存在 Azure 模块,但由于文档简单明了,创建一个是可行的。
- 鼓励社区考虑构建此集成,因为它能显著增强 Azure 环境中的处理能力。
OpenAccess AI Collective (axolotl) Discord
- Reflection Llama-3.1:顶级 LLM 的重新定义:Reflection Llama-3.1 70B 现被誉为领先的开源 LLM,通过 Reflection-Tuning 增强了推理准确性。
- 快速产出结果的合成数据集生成:讨论集中在 Reflection Llama-3.1 合成数据集的快速生成上,引发了对 human rater 参与度和样本量的好奇。
- 成员们辩论了合成数据集创建中速度与质量之间的平衡。
- 接受挑战:微调 Llama 3.1:成员们提出了关于 Llama 3.1 有效 fine-tuning 技术的问题,指出其在 8k 序列长度 下性能提升显著,并可能通过 rope scaling 扩展到 128k。
- 对微调复杂性的担忧也随之出现,建议采用自定义 Token 策略以获得最佳性能。
- SmileyLlama 来了:认识化学语言模型:SmileyLlama 作为一个经过微调的化学语言模型脱颖而出,旨在根据指定属性创建分子。
- 该模型被标记为 SFT+DPO 实现,展示了 Axolotl 在专业模型适配方面的实力。
- GPU 算力:Lora 微调见解:关于使用 A100 80 GB GPU 以 4 bit 模式并配合 adamw_bnb_8bit 对 Meta-Llama-3.1-405B-BNB-NF4-BF16 进行微调的咨询,强调了有效进行 Lora finetuning 的资源需求。
- 这指出了高效管理 Lora 微调过程所必需的实际考虑因素。
Cohere Discord
- 探索 Cohere 的功能与 Cookbook:成员们讨论了查看专门用于功能与演示的频道,社区在该频道分享了使用 Cohere 模型构建的项目,并参考了提供现成指南的全面 cookbook。
- 一位成员强调,这些 cookbook 展示了利用 Cohere 生成式 AI 平台的最佳实践。
- 通过 Anthropic 库了解 Token 使用情况:一位成员询问了关于使用 Anthropic 库的问题,并分享了一个用于计算 Token 使用情况的代码片段:
message = client.messages.create(...)。- 他们引导其他人前往 Anthropic SDK 的 GitHub 仓库以进一步探索 Tokenization。
- Embed-Multilingual-Light-V3.0 在 Azure 上的可用性:一位成员询问了
embed-multilingual-light-v3.0在 Azure 上的可用性,并询问是否有支持计划。- 这一询问反映了人们对 Cohere 资源与流行云平台集成的持续关注。
- 关于 RAG 引用的查询:一位成员询问在使用带有外部知识库的 RAG 时,引用将如何影响文本文件的内容,特别是询问在目前获得结果为 None 的情况下如何接收引用。
- 他们表达了解决文本文件响应中缺失引用问题的紧迫性。
DSPy Discord
- Chroma DB 设置简化:一位成员指出,启动 Chroma DB 服务器仅需一行代码:
!chroma run --host localhost --port 8000 --path ./ChomaM/my_chroma_db1,并注意到其设置非常简便。- 他们对如此简单就能确定数据库位置感到宽慰。
- Weaviate 设置咨询:同一位成员询问是否有类似于 Chroma DB 的 Weaviate 简单设置,以避免 Go Docker 的复杂性。
- 由于非技术背景,他们表达了对简易操作的需求。
- 用于服务器-客户端通信的 Jupyter Notebook:另一位成员分享了他们使用 两个 Jupyter Notebook 分别运行服务器和客户端的做法,强调这符合他们的需求。
- 他们自称是生物学家,寻求不复杂的解决方案。
- Reflection 70B 夺冠:Reflection 70B 已被宣布为领先的开源模型,其特点是采用 Reflection-Tuning 使模型能够纠正自己的错误。
- 一个新模型 405B 将于下周推出,承诺提供更出色的性能。
- 通过定价优化 LLM 路由:围绕根据查询路由合适的 LLM 展开了讨论,意图将 定价 和 TPU 速度 等因素纳入逻辑。
- 参与者指出,虽然路由 LLM 的思路很清晰,但通过性能指标进行增强可以精细化选择过程。
LAION Discord
- SwarmUI 易用性担忧:成员们对展示 100 个节点 的用户界面表示不适,并将其与 SwarmUI 进行对比,进一步强调了其易用性问题。
- 讨论强调了将其标记为“简直就是 SwarmUI”反映了工具中 UI 复杂性的广泛担忧。
- GitHub 上的 SwarmUI 模块化设计:分享了 GitHub 上的 SwarmUI 链接,其特点是专注于模块化设计,以实现更好的可访问性和性能。
- 该仓库强调提供对强力工具(powertools)的便捷访问,通过结构良好的界面增强易用性。
- Reflection 70B 作为开源领导者亮相:Reflection 70B 的发布已被宣布为首个使用 Reflection-Tuning 的顶级开源模型,使 LLM 能够自我纠错。
- 预计下周将推出 405B 模型,其粉碎现有基准测试性能的潜力令人侧目。
- 自我纠错 LLM 引起轰动:围绕一种能够自我纠错的 LLM 展开了新讨论,据报道该模型在包括 MMLU 在すす的所有基准测试中均优于 GPT-4o。
- 该模型的开源特性以及超越 Llama 3.1 405B 的表现,标志着 LLM 功能的重大飞跃。
- Lucidrains 重构 Transfusion 模型:Lucidrains 分享了 Transfusion 模型的 GitHub 实现,在扩散图像的同时优化下一 Token 预测。
- 未来的扩展可能会集成 Flow Matching 以及音频/视频处理,预示着强大的多模态能力。
LangChain AI Discord
- ReAct Agent 部署挑战:一位成员在通过 FastAPI 在 GCP 上部署其 ReAct Agent 时遇到困难,面临重新部署时本地 SQLite 数据库消失的问题。他们正在寻求 Postgres 或 MySQL 作为
SqliteSaver的替代方案。- 该成员愿意分享他们的本地实现以供参考,希望能找到协作解决方案。
- 澄清 LangChain Callbacks 用法:关于语法
chain = prompt | llm准确性的讨论出现,参考了 LangChain 的 callback 文档。成员们指出文档似乎已经过时,特别是 0.2 版本的更新。- 对话强调了 Callbacks 在日志记录、监控和第三方工具集成中的实用性。
- Cerebras 与 LangChain 协作咨询:一位成员询问了 Cerebras 与 LangChain 结合使用的情况,寻求他人的协作见解。回复表示有兴趣,但尚未分享具体的经验或解决方案。
- 这一话题在社区内仍有待进一步探索。
- 解码 .astream_events 的困境:成员们讨论了缺乏解码 .astream_events() 流的参考资料,其中一人对不得不手动序列化事件表示沮丧。对话表达了对更好资源和解决方案的渴望。
- 这一繁琐的过程凸显了社区协作和资源共享的必要性。
LLM Finetuning (Hamel + Dan) Discord
- 在有限硬件下增强 RAG:一位成员寻求在受限的 4090 GPU 硬件条件下,使用带有 4bit 量化 的 llama3-8b 以及 BAAI/bge-small-en-v1.5 嵌入模型来升级其 RAG 系统 的策略。
- 在寻求更好的实现资源时, 他们表达了硬件限制,强调了对高效实践的需求。
- 利用更大模型最大化 GPU 潜力:作为回应,另一位成员建议 4090 可以并发运行更大的嵌入模型,并指出 3.1 版本 也可能提升性能。
- 他们提供了一个 GitHub 示例,展示了在 Milvus 上集成涉及 bge & bm25 的混合搜索。
- 利用元数据进行更好的重排序 (Reranking):对话强调了 每个 chunk 的元数据 的关键作用,建议它可以改进返回结果的排序和过滤。
- 他们认为,实现一个重排序器 (reranker) 可以显著提高用户搜索的输出质量。
Gorilla LLM (Berkeley Function Calling) Discord
- XLAM 系统提示词引发好奇:一位成员指出 XLAM 的系统提示词 与其他 OSS 模型 相比非常独特,并对这种设计选择背后的基本原理提出疑问。
- 讨论揭示了人们对于这些差异是源于 功能性 还是 许可考虑 的兴趣。
- 测试 API 服务器需要指导:一位用户寻求测试其 API 服务器 的有效方法,但未收到具体的文档回复。
- 共享资源的缺失凸显了社区支持和知识共享方面潜在的增长空间。
- 如何将模型添加到排行榜 (Leaderboard):一位用户询问了将新模型添加到 Gorilla 排行榜 的流程,并得到了相关指南的回复。
- 访问 GitHub 页面 上的贡献详情,以了解如何促进模型收录。
- Gorilla 排行榜资源亮点:成员们讨论了 Gorilla: Training and Evaluating LLMs for Function Calls GitHub 资源,该资源概述了排行榜的贡献方式。
- 同时也分享了其仓库中的一张图片,说明了为有兴趣参与的用户提供的指南,详见 GitHub。
Alignment Lab AI Discord
- 来自 Knut09896 的问候:Knut09896 进入频道并打了招呼,引发了欢迎互动。
- 这个简单的问候暗示了 Alignment Lab AI 社区内持续的参与度。
- 频道活动热度:#general 频道的活跃度看起来非常高,成员们在闲聊并进行自我介绍。
- 这种互动在促进社区联系和协作讨论方面发挥着至关重要的作用。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
第二部分:各频道详细摘要与链接
完整的逐频道细分内容已针对电子邮件进行截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!