ainews-pixtral-12b-mistral-beats-llama-to
Pixtral 12B:Mistral 在多模态领域击败 Llama
Mistral AI 发布了 Pixtral 12B,这是一款权重开放的视觉语言模型。该模型以 Mistral Nemo 12B 为文本主干,并配备了一个 4 亿参数的视觉适配器,具有 131,072 个词元的超大词汇量,并支持 1024x1024 像素的图像。此次发布在推出开源多模态模型方面显著领先于 Meta AI。在 Mistral AI 峰会上,官方分享了其架构细节和基准测试表现,展示了强大的 OCR(光学字符识别)和屏幕理解能力。
此外,Arcee AI 宣布推出 SuperNova,这是一款蒸馏自 Llama 3.1 70B 和 8B 的模型,在基准测试中表现优于 Meta 的 Llama 3.1 70B 指令微调版。DeepSeek 发布了 DeepSeek-V2.5,在 HumanEval 编程测试中获得 89 分,在代码任务上超越了 GPT-4-Turbo、Opus 和 Llama 3.1。OpenAI 计划近期将 Strawberry(草莓)作为 ChatGPT 的一部分发布,尽管其具体能力仍存争议。Anthropic 推出了 Workspaces(工作区),旨在通过增强的访问控制功能来管理多个 Claude 部署。
Vision Language Models are all you need.
2024年9月10日至9月11日的 AI News。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 30 个 Discord 服务器(216 个频道和 3870 条消息)。预计节省阅读时间(以 200wpm 计算):411 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
昨晚深夜,Mistral 恢复了往日的风格——与 Mistral Large 2(我们的报道在此)不同,Pixtral 是以 磁力链接的形式发布 的,没有附带论文或博客文章。此时正值 Mistral AI Summit 今日召开,庆祝公司成立一周年。
Huggingface 的 VB 给出了最详尽的解析:
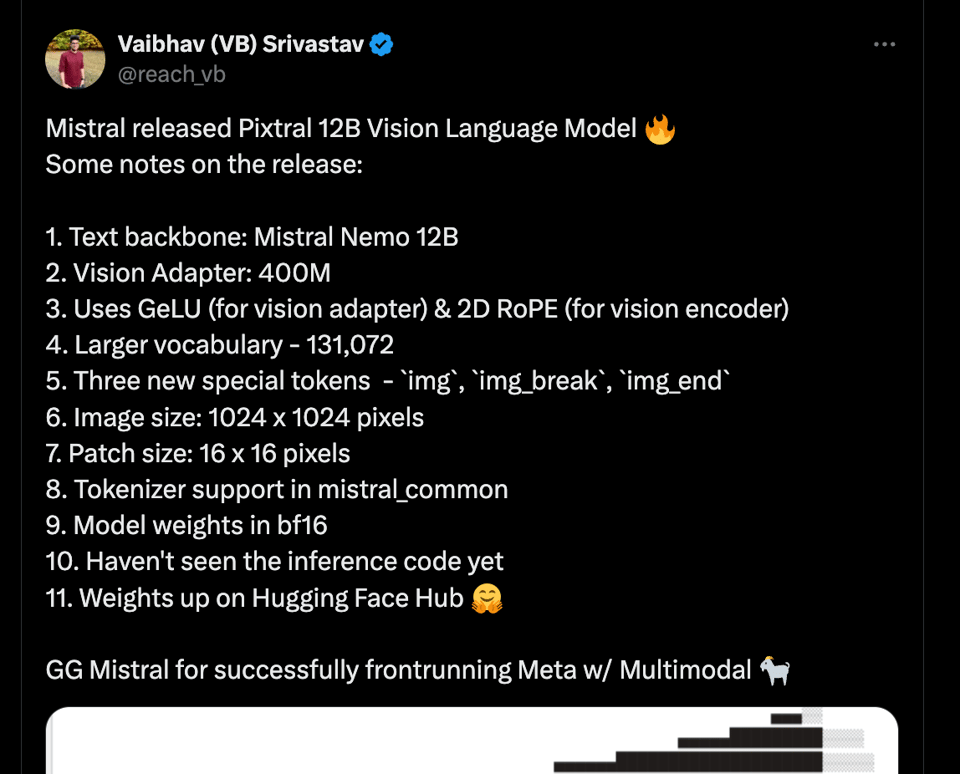
VB 正确地指出,Mistral 在发布权重开放的多模态模型方面击败了 Meta。您可以在 mistral-common 更新 中看到新的 ImageChunk API:

对技术细节感兴趣的朋友可以在这里查看 更多超参数 (hparams)。
在峰会上,Devendra Chapilot 分享了更多关于架构的细节(专为 任意尺寸和交错输入 设计)
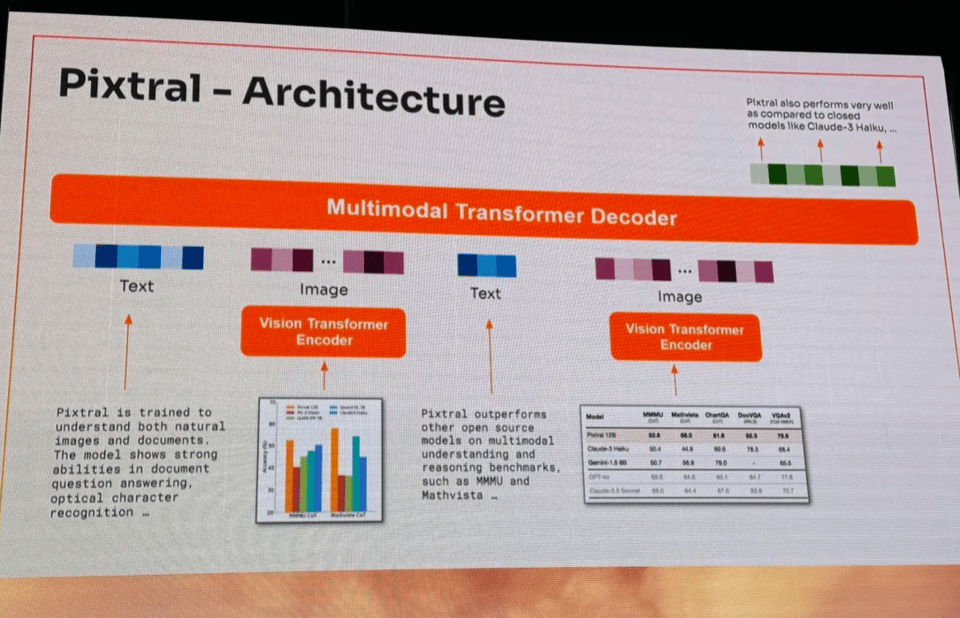
同时展示了令人印象深刻的 OCR 和 屏幕理解 示例(虽然有错误!),以及与开源模型替代方案相比具有优势的 Benchmark 性能(尽管一些 Qwen 和 Gemini Flash 8B 的数据有所偏差):
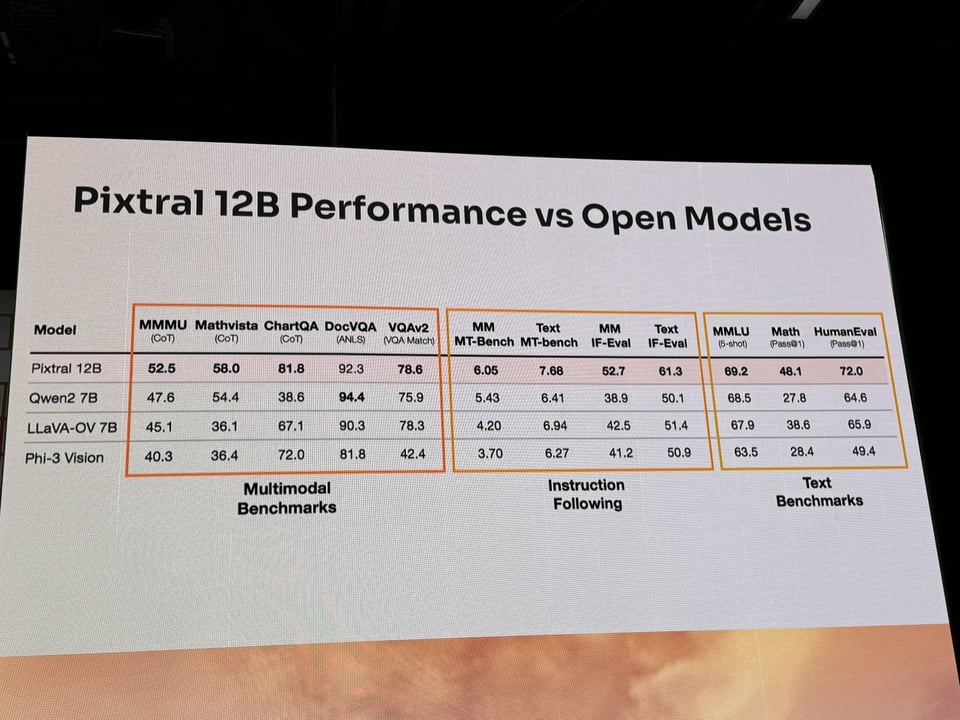
这仍然是一项极其令人印象深刻的成就,对于 Mistral 来说是实至名归的胜利,他们还展示了其 模型优先级 和产品组合。

AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型更新与基准测试
-
Arcee AI 的 SuperNova:@_philschmid 宣布发布 SuperNova,这是一个经过蒸馏推理的 Llama 3.1 70B & 8B 模型。它在各项基准测试中超越了 Meta Llama 3.1 70B instruct,并且是 IFEval 上表现最好的开源 LLM,超过了 OpenAI 和 Anthropic 的模型。
-
DeepSeek-V2.5:@rohanpaul_ai 报告称,新的 DeepSeek-V2.5 模型在 HumanEval 上得分为 89,在编程任务中超越了 GPT-4-Turbo、Opus 和 Llama 3.1。
-
OpenAI 的 Strawberry:@rohanpaul_ai 分享称,OpenAI 计划在未来两周内将 Strawberry 作为其 ChatGPT 服务的一部分发布。然而,@AIExplainedYT 指出关于其能力的报告存在矛盾,有人称其为“对人类的威胁”,而早期测试者则认为“它略好一些的回答不值得等待 10 到 20 秒”。
AI 基础设施与部署
-
Anthropic Workspaces:@AnthropicAI 在 Anthropic Console 中引入了 Workspaces,允许用户管理多个 Claude 部署,设置自定义支出或速率限制,分组 API 密钥,并通过用户角色控制访问权限。
-
SambaNova Cloud:@AIatMeta 强调 SambaNova Cloud 正在为 405B 模型的推理设定新标准,开发者今天即可开始构建。
-
Groq 性能:@JonathanRoss321 声称 Groq 创造了新的速度记录,并计划进一步提升。
AI 开发工具与框架
-
LangChain Academy:@LangChainAI 推出了他们的第一门课程《LangGraph 简介》,教授如何使用基于图的工作流构建可靠的 AI Agent。
-
Chatbot Arena 更新:@lmsysorg 在其排行榜上添加了一个新的“Style Control”按钮,允许用户将其应用于总榜和硬核提示词(Hard Prompts)榜单,以观察排名变化。
-
Hugging Face 集成:@multimodalart 分享称,现在可以轻松地将图像添加到 Hugging Face 上的 LoRA 模型库中。
AI 研究与洞察
-
Sigmoid Attention:@rohanpaul_ai 讨论了 Apple 的一篇论文,该论文提出了 Flash-Sigmoid,这是一种硬件感知且内存高效的 Sigmoid Attention 实现,在 H100 GPUs 上相比 FlashAttention2-2 可实现高达 17% 的推理算子加速。
-
Mixture of Vision Encoders:@rohanpaul_ai 分享了关于使用混合视觉编码器(Mixture of Vision Encoders)增强 MLLM 在各种视觉理解任务中性能的研究。
-
引用生成:@rohanpaul_ai 报告了一种用于长文本 QA 引用生成的新方法,提升了性能和可验证性。
行业新闻与趋势
-
Klarna 的技术栈变革:@bindureddy 指出 Klarna 关闭了 Salesforce 和 Workday,取而代之的是由 AI 创建的更简单的技术栈,其运行成本可能比传统的 SaaS 应用程序便宜 10 倍。
-
AI 影响力人物争议:@corbtt 报道了关于 Reflection-70B 模型的争议,称经过调查,他们认为达到声称基准测试水平的模型从未存在过。
-
Mario Draghi 的欧盟报告:@ylecun 分享了 Mario Draghi 对欧洲生产力停滞的分析及解决方法,强调了欧盟与美国之间的竞争力差距。
AI Reddit 摘要
/r/LocalLlama 摘要
抱歉,我们的流水线今天出了点问题,正在修复中。
其他 AI Subreddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 研究与技术
-
AI 唇语识别:一段展示 AI 驱动的唇语识别技术的视频引发了关于其潜在应用和隐私影响的讨论。一些评论者对大规模监控和 Deepfake 的潜力表示担忧,而另一些人则看到了其在无障碍辅助方面的益处。来源
-
中国拒绝签署 AI 核武器禁令:中国拒绝签署一项禁止 AI 控制核武器的协议,引发了对未来 AI 战争的担忧。文章指出,中国希望在相关决策中保留“人为因素”。来源
-
无人驾驶 Waymo 车辆安全性提升:一项研究发现,无人驾驶 Waymo 车辆发生的严重事故远少于人类驾驶的车辆,且大多数事故是由其他车辆的人类驾驶员造成的。这突显了自动驾驶技术的潜在安全优势。来源
AI 模型开发与发布
-
OpenAI 的 GPT-4.5 “Strawberry”:有报告称 OpenAI 可能会在两周内发布名为 “Strawberry” 的新纯文本 AI 模型。据称,该模型在回答前会“思考” 10-20 秒,旨在减少错误。然而,一些测试者发现,与 GPT-4 相比,其改进并不明显。来源
-
OpenAI 研究负责人离职:参与 GPT-4 和 GPT-5 开发的一位 OpenAI 核心研究人员已离职并创办自己的公司,引发了关于 AI 行业人才留存和竞争的讨论。来源
-
Flux 微调改进:开发者通过针对特定层进行微调,在 Flux AI 模型上取得了进展,这可能会提高训练速度和推理质量。这展示了在优化 AI 模型性能方面的持续努力。来源
AI 在娱乐与媒体中的应用
-
James Earl Jones 授权达斯·维达声音版权:演员 James Earl Jones 已签署协议,授权 AI 重塑其标志性的达斯·维达(Darth Vader)配音,突显了 AI 在娱乐行业日益增长的应用,并引发了关于配音行业未来的讨论。来源
-
Domo AI 视频放大工具发布:Domo AI 发布了一款快速视频放大工具,可将视频增强至 4K 分辨率,展示了 AI 驱动的视频处理技术的进步。来源
AI 行业与研究趋势
-
Sergey Brin 对 AI 的关注:Google 联合创始人 Sergey Brin 表示,由于对近期 AI 的进展感到兴奋,他现在每天都在 Google 工作,这表明科技行业领袖对 AI 的高度关注和投入。来源
-
公众对 AI 取代工作的看法:一个梗图(Meme)帖子引发了关于公众对 AI 可能取代工作的态度的讨论,突显了围绕 AI 对就业影响的复杂情绪和担忧。来源
AI Discord 摘要回顾
由 GPT4O-Aug (gpt-4o-2024-08-06) 生成的摘要之摘要的摘要
1. 模型性能与基准测试
- Pixtral 12B 表现优于竞争对手:来自 Mistral 的 Pixtral 12B 在 Mistral 峰会上展示了其在 OCR 任务中优于 Phi 3 和 Claude Haiku 等模型的表现。
- 现场演示强调了 Pixtral 在处理图像尺寸方面的灵活性,引发了关于其与竞争对手相比准确性的讨论。
- Llama-3.1-SuperNova-Lite 在数学方面表现出色:Llama-3.1-SuperNova-Lite 在数学任务中表现优于 Hermes-3-Llama-3.1-8B,在吠陀乘法(Vedic multiplication)等计算中保持了准确性。
- 尽管两个模型都面临挑战,但该模型在处理数字方面的卓越表现得到了关注,SuperNova-Lite 显示出更好的数字完整性。
2. AI 与多模态创新
- Mistral 的 Pixtral 12B 视觉模型:Mistral 发布了视觉多模态模型 Pixtral 12B,该模型拥有 220 亿参数,并针对单 GPU 使用进行了优化。
- 虽然目前仅限于 4K context size,但人们对 11 月份推出的长上下文模型寄予厚望,以增强多模态处理能力。
- Hume AI 的 Empathic Voice Interface 2:Hume AI 推出了 Empathic Voice Interface 2 (EVI 2),融合了语言和语音,以增强情感智能应用。
- 该模型现已可用,邀请用户创建需要更深层次情感参与的应用,标志着语音 AI 的进步。
3. 软件工程与 AI 协作
- SWE-bench 凸显 GPT-4 的效率:SWE-bench 结果显示,GPT-4 在 15 分钟以内的任务中表现优于 GPT-3.5,在没有人类基准对比的情况下展示了更高的效率。
- 尽管有所改进,但两个模型在超过四小时的任务上都表现不佳,这表明了问题解决能力的局限性。
- AI 与软件工程集成的挑战:关于 AI 与软件工程集成的讨论反映了日益增长的兴趣,AI 模型虽然展现出潜力,但缺乏细致的人类洞察力。
- AI 在软件工程任务中的作用正在迅速发展,但其在有效性和洞察力方面仍难以与经验丰富的工程师相媲美。
4. 开源 AI 工具与框架
- 对 Modular 的 Mojo 24.5 发布的期待:随着社区会议讨论解决接口清晰度问题,人们对预计在一周内发布的 Mojo 24.5 充满期待。
- 用户热切期待改进产品时间表的沟通,以防止误解并确保为变化做好准备。
- OpenRouter 增强编程工具集成:OpenRouter 提供了 Claude API 的高性价比替代方案,强调了多模型的集中式实验。
- 讨论强调了绕过初始 rate limits 和更低的成本,使其成为开发者的首选。
第一部分:高层级 Discord 摘要
Modular (Mojo 🔥) Discord
- Mojo 用户反馈机会:团队正在积极寻找尚未与 Magic 互动的用户,通过 30 分钟的通话提供反馈,并提供独家周边奖励;感兴趣的人员可以在此预约。关于未来周边获取的咨询得到了积极回应,表明未来可能有更广泛的获取渠道。
- 成员们对开设周边商店以提供更多选择表示了兴趣,反映出社区对额外参与机会的热情。
- Mojo 24.5 版本发布倒计时:备受期待的 Mojo 24.5 版本预计将在一周内发布。近期社区会议讨论了关于条件式 Trait 一致性(conditional trait conformance)导致的用户困惑。成员们特别渴望解决复杂系统中与接口相关的清晰度和可见性问题。
- 讨论强调了在产品时间线上进行更好沟通的必要性,以防止误解并确保用户为变化做好充分准备。
- 对 Mojo 复制行为的担忧:成员们对 Mojo 的隐式复制行为表示担忧,特别是在使用
owned参数约定时,这可能导致大型数据结构发生计划外的复制。对于从 Python 等语言转过来的用户,正在考虑将显式复制设置为默认选项的建议。- 这引发了关于不同编程语言如何管理复制的进一步辩论,用户主张在数据处理方式上应更加透明。
- 所有权语义引发困惑:Mojo 中的所有权语义引发了讨论,因为隐式复制可能导致函数行为发生不可预测的变化,被描述为“幽灵般的远距离作用”(spooky action at a distance)。用户呼吁在 API 变更中提供更好的清晰度,并对
ExplicitlyCopyableTrait 进行更严格的规定,以防止诸如双重释放(double frees)等意外问题。- 几位成员强调了文档和社区指南的重要性,以帮助开发者更有效地应对这些复杂性。
- Mojodojo.dev 受到关注:社区重点介绍了由 Jack Clayton 最初创建的开源项目 Mojodojo.dev,认为它是 Mojo 的重要教育资源。成员们表达了增强该平台的愿望,并受邀贡献以 Mojo 构建的项目为中心的内容。
- Caroline Frasca 强调了扩展博客和 YouTube 频道内容的重要性,以更好地展示 Mojo 开发者的可用项目和资源。
Unsloth AI (Daniel Han) Discord
- Mistral 的 Pixtral 模型亮相:Mistral 推出了 Pixtral 12b,这是一款视觉多模态模型,拥有 220 亿参数,并针对单 GPU 运行进行了优化,尽管其 4K 上下文大小 较为有限。
- 预计 11 月将推出完整的长上下文模型,提升了人们对多模态处理即将推出的功能的期待。
- Gemma 2 表现优于 Llama 3.1:Gemma 2 在多语言任务中始终优于 Llama 3.1,尤其是在瑞典语和韩语等语言方面表现出色。
- 尽管关注点多在 Llama 3,但用户已经认可了 Gemma 2 在高级语言任务中的优势。
- 小数据集的训练效率:用户发现,在模型优化过程中,规模较小且多样化的数据集能显著降低训练损失(training loss)。
- 他们强调质量胜过数量,并指出当数据集经过良好策划且同质化程度较低时,结果会有所改善。
- Unsloth 支持 Flash Attention 2:成员们正在将 Flash Attention 2 与 Gemma 2 集成,但已注意到遇到了一些兼容性问题。
- 尽管面临挑战,但大家乐观地认为最终的调整将解决冲突并提升性能值。
- 在 phi-3.5 上使用 LoRa 的微调挑战:一位用户报告称,在 phi-3.5 模型上应用 LoRa 时,损失下降停滞,最初从 1 降至 0.4 后不再变化。
- 鉴于微调 phi 模型的复杂性,建议包括尝试不同的 alpha 值以进一步优化性能。
OpenAI Discord
- SWE-bench 显示了 GPT-4 相对于 GPT-3.5 的卓越实力:SWE-bench 的表现表明 GPT-4 显著优于 GPT-3.5,尤其是在 15 分钟以内的任务中,标志着效率的提升。
- 然而,由于缺乏人类基准数据,使得将这些结果与人类工程师进行对比评估变得复杂。
- GameNGEN 通过实时模拟突破界限:GameNGEN 令人印象深刻地实时模拟了游戏 DOOM,为世界建模(world modeling)应用开辟了道路。
- 尽管取得了进步,它仍然依赖于现有的游戏机制,这引发了关于 3D 环境原创性的疑问。
- GPT-4o 在基准测试中胜过 GPT-3.5:在处理 SWE-bench 框架中的简单任务时,GPT-4o 的表现比 GPT-3.5 提升了 11 倍。
- 尽管如此,这两个模型在超过四小时的任务上都表现不佳,揭示了它们解决问题能力的局限性。
- AI 在软件工程协作中面临挑战:关于 AI 与软件工程师集成以完成基准测试任务的讨论日益增多,反映出人们对此兴趣激增。
- 虽然 AI 充满前景,但它仍缺乏资深人类工程师那种细致入微的洞察力和效能。
- GAIA 基准测试重新定义了 AI 难度标准:GAIA 基准测试对 AI 系统进行了严格测试,同时允许人类在挑战性任务中获得 80-90% 的分数,这与传统基准测试有显著区别。
- 这表明需要重新进行评估,因为许多现有基准测试甚至对于熟练的从业者来说也变得越来越难以应对。
HuggingFace Discord
- DeepSeek 2.5 结合 238B MoE 的优势:DeepSeek 2.5 的发布集成了 DeepSeek 2 Chat 和 Coder 2 的特性,拥有 238B MoE 模型、128k 上下文长度以及新的编码功能。
- Function calling 和 FIM completion 为聊天和编码任务提供了开创性的新标准。
- AI 变革医疗保健:AI 通过增强诊断、实现个性化医疗以及加速药物研发,改变了医疗保健行业。
- 集成可穿戴设备和 IoT 健康监测有助于疾病的早期发现。
- 韩语词干提取器寻求 AI 助力:一位成员开发了一个韩语词干提取器(lemmatizer),并正在寻求利用 AI 解决词义歧义的方法。
- 他们表达了对 2024 年生态系统进步以获得更好解决方案的希望。
- CSV 仅为图像加载提供 ID:在关于图像加载的讨论中,有人指出 CSV 文件仅包含图像 ID,因此需要获取图像或预先将它们拆分到目录中。
- 与从组织好的文件夹创建 DataLoader 对象相比,这种方法可能会略微增加延迟。
- Multi-agent 系统提升性能:Transformers 现在支持 Multi-agent 系统,允许 Agent 在任务上进行协作,从而提高基准测试中的整体效能。
- 这种协作方法允许对子任务进行专门化处理,从而提高效率。
aider (Paul Gauthier) Discord
- 优化 Aider 的工作流:用户分享了 Aider 的
ask first, code later(先询问,后编码)工作流如何通过使用 plan 模型来增强代码实现的清晰度。- 这种方法改进了上下文并减少了对
/undo命令的依赖。
- 这种方法改进了上下文并减少了对
- Prompt Caching 的优势:Aider 的 Prompt Caching 功能通过对关键文件的策略性缓存,显示出可减少 40% 的 token 使用量。
- 该系统保留了系统提示词(system prompts)等元素,有助于在交互过程中最大限度地降低成本。
- Aider 与其他工具的对比:用户将 Aider 与 Cursor 和 OpenRouter 等其他工具进行了对比,强调了 Aider 提升生产力的独特功能。
- 智能功能(如从 zsh 历史记录自动生成别名和速查表)凸显了 Aider 的能力。
- 探索 OpenRouter 的优势:成员们指出了使用 OpenRouter 优于直接使用 Claude API 的优势,强调了成本降低和绕过初始速率限制(rate limits)。
- OpenRouter 促进了对多个模型的集中实验,使其成为首选。
- Mistral 发布 Pixtral 模型种子:Mistral 以种子(torrent)形式发布了 Pixtral (12B) 多模态模型,适用于图像分类和文本生成。
- 可通过磁力链接
magnet:?xt=urn:btih:7278e625de2b1da598b23954c13933047126238a下载,并支持 PyTorch 和 TensorFlow 等框架。
- 可通过磁力链接
LM Studio Discord
- AI 图像中一致性是关键:用户正在探索在 AI 生成的图像中保持角色一致性 (character consistency) 的技术,即使在更换服装或背景时也是如此。
- 目标是确保角色的面部特征和身体在不同的分镜中保持可辨识性。
- Token 处理中的 GPU 对决:关于 Token 处理的讨论显示,一位用户在 6900XT 上达到了 45 tokens/s,凸显了不同 GPU 型号之间的差异。
- 几位成员建议通过刷 BIOS 来提升性能,同时也对意料之外的结果表示沮丧。
- LM Studio 爱好者聚会:LM Studio 用户正在伦敦组织一场聚会,重点讨论 Prompt Engineering,并向所有用户开放讨论。
- 鼓励参与者寻找带笔记本电脑的非学生群体进行高效交流。
- 聚焦 RTX 4090D:讨论集中在 RTX 4090D 上,这是一款中国特供的 GPU,其特点是与同类产品相比拥有更多 VRAM,但 CUDA 核心较少。
- 尽管游戏性能较低,但由于其显存容量,它可能是 AI 工作负载的战略性选择。
- Surface Studio Pro:升级的挫败感:用户对 Surface Studio Pro 有限的升级选项表示沮丧,并讨论了诸如 eGPU 或 SSD 等增强方案。
- 建议包括投资一台专用的 AI 设备,而不是升级笔记本电脑。
Stability.ai (Stable Diffusion) Discord
- Stable Diffusion 模型展开对决:用户展示了旧模型(如 ‘1.5 ema only’)与新选项之间的性能差异,强调了图像生成质量的进步。
- 社区指出,在 AI 任务中 RTX 4060 Ti 的表现优于 7600 和 Quadro P620,强调了 GPU 选择的重要性。
- 分辨率在图像生成中至关重要:建议早期模型的最佳生成分辨率为 512x512,以减少放大时的伪影。
- 用户分享了有效的工作流,建议从较低分辨率开始可以提高最终输出的质量。
- AI 模型及其相似性:由于共享训练数据和技术影响了原创性,人们对各种 LLM 的相似性表示担忧。
- 然而,一些人指出新模型在生成逼真的手部等方面有了显著改进,显示出可喜的进展。
- AI 训练的 GPU 摊牌:社区成员争论 NVIDIA 的 GPU 是 AI 模型训练的首选,主要是因为 CUDA 的兼容性。
- 共识倾向于选择具有 20GB VRAM 的高端 GPU 以获得卓越性能,即使低显存选项可以运行特定模型。
- Reflection LLM 受到审查:被吹捧具有“思考”和“反思”能力的 Reflection LLM,在实际表现与宣传不符方面面临批评。
- API 与开源版本之间的差异引发了用户对其有效性的怀疑。
OpenRouter (Alex Atallah) Discord
- Novita 端点遭遇故障:所有 Novita 端点 面临停机,导致过滤请求出现 403 状态错误 且没有备选方案。
- 问题解决后,所有用户恢复了正常功能。
- 编程工具建议引发讨论:一位用户探索将 AWS Bedrock 与 Litelm 结合进行速率管理,引发了用户对 Aider 和 Cursor 等其他工具的建议。
- 关于这些工具有效性的意见各不相同,引发了关于用户体验和功能的激烈辩论。
- 关于 Hermes 模型定价的推测:用户对 Hermes 3 是否会保持免费表示不确定,预计更新后的端点可能会收取 $5/M 的费用。
- 这引发了关于预期性能提升的讨论,同时也提到了现有的免费替代方案可能仍然可用。
- 洞察 Pixtral 模型的能力:Pixtral 12B 可能主要接受图像输入以产生文本输出,这表明其文本处理能力有限。
- 该模型的表现预计与 LLaVA 相似,侧重于专门的图像任务。
- OpenRouter 与 Cursor 集成的挑战:一些用户在将 OpenRouter 与 Cursor 配合使用时遇到障碍,涉及激活模型功能所需的配置调整。
- 贡献者指出了 Cursor 仓库中存在的问题,特别是与特定模型内的硬编码路由相关的问题。
CUDA MODE Discord
- 使用 cuDNN 优化 Matmul:成员们讨论了各种 matmul 算法(如 Grouped GEMM 和 Split K)的资源,并建议查看 Cutlass 示例。重点仍然是利用现有的优化技术,在机器学习中实现高效的矩阵运算。
- 神经网络量化挑战:一位成员正在重新实现 Post-Training Quantization,并在激活量化过程中面临准确率下降的问题,并在 torch forum 上分享了见解。社区提供了建议,强调了调试对于保持量化模型准确率的重要性。
- Multi-GPU 使用的令人兴奋的进展:分享了关于 Multi-GPU 增强的创新想法,旨在延长上下文长度并提高内存效率,并附带了详细信息。鼓励参与者追求在优化资源利用的同时最小化开销的项目。
- OpenAI RSU 和市场洞察:OpenAI 员工讨论了如果不出售,RSU 将增值到 6-7x,并分享了允许套现的二级交易的复杂性,以及对未来 IPO 的影响。关于这些二级交易对股票定价和估值影响的推测,揭示了对风险投资谈判的见解。
- FP6 已添加到主 API:宣布将 fp6 添加到项目的 README 主文件中,引发了关于与 BF16 和 FP16 集成挑战的讨论。公认需要为用户提供清晰的说明,以确保在不同精度类型之间进行高效的性能管理。
Interconnects (Nathan Lambert) Discord
- OpenAI 经历重大人员离职:OpenAI 遭遇重大人才流失,Alex Conneau 宣布离职创业,而 Arvind 分享了加入 Meta 的兴奋之情。讨论暗示对 GPT-5 的提及可能预示着即将推出的模型,但对这些推测仍持怀疑态度。
- Meta 的巨型 AI 超级计算集群:Meta 即将完成一个拥有 100,000 个 GPU Nvidia H100 的 AI 超级计算集群,用于训练 Llama 4,且未选择 Nvidia 的专有网络设备。这一大胆举措凸显了 Meta 对 AI 的承诺,尤其是在行业竞争加剧的情况下。
- Adobe 的生成式视频举措:Adobe 即将推出其 Firefly Video Model,这标志着自 2023 年 3 月推出以来的重大进展,并计划将其集成到 Creative Cloud 功能中。今年晚些时候的 Beta 版可用性展示了 Adobe 对生成式 AI 驱动的视频制作的关注。
- Pixtral 模型超越竞争对手:在 Mistral 峰会上,据报道 Pixtral 12B 在图像尺寸灵活性和任务性能方面优于 Phi 3 和 Claude Haiku 等模型。活动期间的现场演示展示了 Pixtral 强大的 OCR 能力,引发了关于其与竞争对手相比准确性的辩论。
- Surge AI 的合同挑战:据报道,Surge AI 未能向 HF 和 Ai2 交付数据,直到面临潜在的法律诉讼,这引发了对其在小型合同上可靠性的警惕。担忧集中在他们在延迟期间缺乏沟通,让人对其优先级产生怀疑。
Perplexity AI Discord
- Perplexity Pro 注册活动进入最后阶段:各校区仅剩 5 天时间 来争取 500 个注册量,以解锁一年的免费 Perplexity Pro。请访问 perplexity.ai/backtoschool 参与活动!
- 更新后的倒计时器显示为 05:12:11:10,进一步强化了这一行动号召——这是最后的冲刺!
- 学生在 Perplexity 优惠活动中面临差异:虽然提供了免费一个月的 Perplexity Pro 学生优惠,但仅限于美国学生或达到足够注册量的特定校区。
- 德国等其他国家的学生也表达了对不公平待遇的担忧,他们同样希望获得促销优惠。
- 对新 API 功能的期待升温:用户对即将到来的开发者日(dev day)发布的新 API 功能充满期待,特别是 4o 语音和图像生成 功能。
- 此外,还有关于为需求低于全额 Pro 权限的用户创建 hobby tier(兴趣层级)的讨论。
- Neuralink 分享患者更新与 SpaceX 的雄心壮志:Perplexity AI 推广了一段 YouTube 视频,详细介绍了 Neuralink 的首位患者更新 以及 SpaceX 在 2026 年前往火星的目标。
- 该视频深入探讨了这两个项目及其对未来的宏伟目标。
- Bounce.ai 就 API 问题发出紧急支持请求:Bounce.ai 的 CTO Aki Yu 报告了一个影响超过 3,000 名活跃用户 的 Perplexity API 紧急问题,强调需要立即协助。
- 尽管已尝试联系 4 个月,Bounce.ai 仍未收到 Perplexity 团队 的回复,这凸显了支持渠道可能存在的局限性。
Nous Research AI Discord
- Llama-3.1-SuperNova-Lite 在数学方面表现出色:成员们注意到,与 Hermes-3-Llama-3.1-8B 相比,Llama-3.1-SuperNova-Lite 在处理吠陀乘法(Vedic multiplication)等计算时表现更优,且能保持准确性。
- 尽管两个模型都面临挑战,但 SuperNova-Lite 在保持数字完整性方面表现明显更好。
- 模型对比揭示性能差距:测试显示 LLaMa-3.1-8B-Instruct 在数学任务中表现挣扎,而 Llama-3.1-SuperNova-Lite 取得了更好的结果。
- 社区对 Hermes-3-Llama-3.1-8B 的偏好显现,突显了它们在算术能力上的差异。
- 高质量数据增强性能:讨论中的反馈强调,随着参数规模(parameters)的扩大,更高质量的数据能显著提升模型性能。
- 这强调了使用高质量数据集对于实现 LLM 最佳效果的重要性。
- 更好的选择:用于简单任务的小型模型:一位成员询问是否有比 Llama 3.1 8B 更小、适用于基础任务的模型,并提到了 Mistral 7B 和 Qwen2 7B 作为潜在选项。
- 讨论引发了对 3B 参数以下模型更新列表的需求,表明了社区对效率的关注。
- 渴望空间推理创新的更新:人们对空间推理(Spatial Reasoning)及其相关领域是否取得了任何革命性进展感到好奇。
- 成员们积极寻求有关最新创新的见解,这些创新可能会重塑对 AI 推理能力的理解。
Latent Space Discord
- Mistral 展示 Pixtral 12B 模型:在一次受邀参加的会议上,Mistral 发布了 Pixtral 12B 模型。据 Mistral AI 指出,该模型的表现优于 Phi 3 和 Claude Haiku 等竞争对手。
- 该模型支持任意图像尺寸和 interleaving,在有 Jensen Huang 出席的活动中展示了其取得的显著基准测试成绩。
- Klarna 与 SaaS 供应商断绝关系:Klarna 的 CEO 宣布公司正在裁撤其 SaaS 供应商,包括那些曾被认为不可替代的供应商,这引发了关于潜在运营风险的讨论,详见 Tyler Hogge 的报道。
- 与此同时,据报道 Klarna 裁员 50%,这一决定可能受财务挑战驱动。
- Jina AI 发布 HTML 转 Markdown 模型:Jina AI 推出了两个语言模型 reader-lm-0.5b 和 reader-lm-1.5b,专门为高效将 HTML 转换为 Markdown 而优化,提供多语言支持和强劲性能 点击阅读更多。
- 这些模型在保持极小体积的同时,性能超越了更大的模型,简化了可访问内容的转换流程。
- Trieve 获得融资增长:Trieve AI 成功获得了由 Root Ventures 领投的 350 万美元融资,旨在简化各行业的 AI 应用部署,正如 Vaibhav Srivastav 在此处分享的那样。
- 凭借新资金,Trieve 现有系统目前每天为数万名用户提供服务,显示出强劲的市场兴趣。
- Hume 发布 Empathic Voice Interface 2:Hume AI 推出了 Empathic Voice Interface 2 (EVI 2),将语言和语音融合以增强情感智能应用 点击查看。
- 该模型现已面向渴望创建需要深层情感交互应用的开发者开放。
OpenInterpreter Discord
- 在 Open Interpreter 中使用自定义 Python 代码:一位用户询问如何在 Open Interpreter 中利用特定的 Python 代码执行情感分析任务,引发了对数据库进行更广泛自定义查询的兴趣。
- 社区渴望确认在终端应用中使用各种 Python 库(如用于格式化的 rich)的可行性。
- 文档改进引发关注:反馈指出,虽然用户觉得 Open Interpreter 很有吸引力,但文档缺乏组织,阻碍了查阅。
- 有人提议通过协作努力来增强文档,并鼓励提交 Pull Requests 进行改进。
- 桌面应用早期访问临近:用户渴望了解即将推出的桌面应用早期访问的时间线,该应用旨在简化安装过程。
- 社区预计在未来几周内会有更多的 Beta 测试人员加入,旨在提升用户体验。
- 关于 01 Light 的退款和转型:围绕已停产的 01 light 的退款问题爆发了讨论,导致一条泄露的推文确认将转向新的免费 01 app。
- 制造材料的开源也在议程之中,同时配合 01.1 update 进行进一步开发。
- 突出显示来自 JSONL 数据的 RAG 上下文:初步测试运行显示,为 RAG 设计的 JSONL 数据提供上下文具有前景,主要集中在新闻 RSS 订阅源。
- 在完成 NER 流程和数据加载到 Neo4j 后,将开始编写教程,以增强 AI 应用的可用性。
Cohere Discord
- Cohere 的工单支持集成:一位成员计划将 Cohere 与 Link Safe 集成,用于工单支持和文本处理,并对此次合作表示期待。
- 我迫不及待想看到这将如何增强我们目前的工作流程!
- Mistral 发布视觉模型:Mistral 推出了一个新的视觉模型,引发了对其功能和即将开展项目的兴趣。
- 成员们推测 C4AI 推出视觉模型的可能性,并将其与需要更多时间开发的 Maya 项目联系起来。
- 人类监督的长期需求:成员们一致认为,在 AI 的进步过程中,人类监督仍然至关重要,主张采用可靠的方法而非单纯追求机器智能。
- 让我们专注于使现有的东西变得可靠,而不是追求理论上的能力。
- Discord FAQ 机器人初具规模:正在努力为 Cohere 创建一个 Discord FAQ 机器人,以简化社区内的沟通。
- 讨论还开启了举办虚拟黑客松活动的可能性,鼓励创新想法。
- 询问 Aya-101 的状态:Aya-101 是否已达到生命周期终点(End-of-life)? 这一问题引发了关于向性能可能超越竞争对手的新模型过渡的猜测。
- 一位成员将其称为潜在的 Phi-killer,引起了大家的好奇。
Eleuther Discord
- lm-evaluation-harness 指导请求:一位用户寻求使用 lm-evaluation-harness 在 swe-bench 数据集上评估 OpenAI gpt4o 模型的帮助。
- 他们欢迎任何指导,并表示实践建议能显著帮助他们的评估过程。
- Pixtral 模型发布:社区分享了新发布的 Pixtral-12b-240910 模型权重(checkpoint),暗示其部分与 Mistral AI 最近的更新保持一致。
- 用户可以在发布说明中找到下载详情和磁力链接,以及指向 Mistral Twitter 的链接。
- RWKV-7 展现潜力:RWKV-7 被视为潜在的 Transformer 杀手,其特点是具有源自 DeltaNet 的恒等加低秩(identity-plus-low-rank)转移矩阵。
- arXiv 上展示了一项关于优化序列长度并行化的相关研究,增强了该模型的吸引力。
- 多节点训练的陷阱:一位用户对慢速以太网链路下的多节点训练表示担忧,特别是关于 8xH100 机器之间的 DDP 性能。
- 讨论表明训练可能会受到速度限制,并且跨节点使用 DDP 的效率可能低于预期。
- 数据集分块实践:一位成员询问将数据集拆分为 128-token 块 是否为标准做法,暗示这一决定往往源于直觉而非实证研究。
- 回复指出许多从业者可能会忽视分块对模型性能的潜在影响,凸显了理解上的空白。
LlamaIndex Discord
- LLM 时代的 RAG Maven 课程:查看名为 Search For RAG in the LLM era 的 Maven 课程,包含客座讲座和现场代码演示。
- 参与者可以与行业资深人士一起练习代码示例,以增强学习体验。
- 构建 RAG 的快速教程:现已提供使用 LlamaIndex 构建检索增强生成(RAG)的简明教程。
- 该教程专注于有效地实现 RAG 技术。
- Kotaemon:构建基于 RAG 的文档问答系统:学习使用 Kotaemon 构建基于 RAG 的文档问答系统,这是一个用于与文档聊天的开源 UI。
- 本次会议涵盖了可定制 RAG UI 的设置以及如何组织 LLM 和 embedding 模型。
- AI 调度器动手研讨会:参加 9 月 20 日在 AWS Loft 举行的研讨会,使用 Zoom、LlamaIndex 和 Qdrant 构建用于智能会议的 AI 调度器。
- 参与者将使用 Zoom 的转录 SDK 创建一个专注于会议效率的 RAG 推荐引擎。
- 探索用于索引的任务队列设置:发起了一场关于使用 FastAPI 和 Celery 后端 创建构建索引任务队列的讨论,重点关注文件和索引信息的数据库存储。
- 鼓励参与者查看可能满足这些要求的现有设置。
LangChain AI Discord
- 查询生成的 POC 开发:一位成员正在使用 LangGraph 开发用于 查询生成 的 POC,面临着随着表数量增加而导致的 Token 大小增加的挑战。
- 他们正在利用 RAG 创建 Schema 的向量表示以进行查询构建,并对增加更多 LLM 调用感到犹豫。
- OppyDev 重大更新发布:OppyDev 团队宣布了一项重大更新,增强了该 AI 辅助编码工具在 Mac 和 Windows 上的可用性,并支持 GPT-4 和 Llama。
- 用户可以通过限时促销代码获得 一百万免费 GPT-4 Token;详情可按需获取。
- 构建 RAG 应用的见解:关于在存入向量数据库之前,是否保留 RAG 应用中通过 Web Loader 检索到的文本中的 换行符 引起了讨论。
- 确认保留 换行符 是可以接受的,这能确保文本格式保持完整。
- OppyDev 中的实时代码审查功能:最新的 OppyDev 更新包括一个 带颜色编码的可编辑 Diff 功能,用于实时代码更改监控。
- 此次升级显著增强了开发人员有效跟踪和管理代码修改的能力。
Torchtune Discord
- Torchtune 缺乏 FP16 支持:一位成员指出 Torchtune 不支持 FP16,需要额外的工作来保持与混合精度模块的兼容性,而 bf16 被认为是更优的替代方案。
- 缺乏支持可能会给使用旧型号 GPU 的用户带来问题。
- Qwen2 接口分词怪癖:Qwen2 接口允许
eos_id为None,这导致在encode方法中添加它之前需要进行检查,引发了对其意图的疑问。- 由于代码的另一部分没有执行此检查,指示存在疏忽,从而产生了潜在的 Bug。
- None EOS ID 处理问题:关于在
eos_id设置为None时允许add_eos=True的担忧被提出,这暗示了 Qwen2 模型分词过程中行为不一致。- 这种不一致可能会困扰用户并破坏预期功能。
- 关于 padded_collate 功效的疑问:一位成员质疑 padded_collate 的实用性,指出它在任何地方都没有被使用,同时指出了关于 input_ids 和 labels 序列长度缺失逻辑的问题。
- 这引发了后续询问,即 padded_collate 逻辑是否已正确合并到 PPO Recipe 中。
- PPO Recipe 需要澄清:围绕 PPO Recipe 中的
padded_collate逻辑是否完整展开了讨论,一位成员表示他们已经集成了一部分。- 这进一步引发了关于 input_ids 和 labels 之间长度通常匹配的讨论。
DSPy Discord
- Sci Scope 发布用于 Arxiv 洞察:Sci Scope 是一个新工具,使用 LLM 对最新的 Arxiv 论文进行分类和总结,可在 Sci Scope 免费使用。用户可以订阅 AI 研究的 每周摘要,增强对文献的关注。
- 讨论了如何确保输出的 真实性 并减少摘要中的幻觉,反映了对 AI 生成内容可靠性的担忧。
- 为客户需求定制 DSPy:一位成员询问如何将 针对特定客户的定制 集成到 DSPy 为聊天机器人生成的提示词中,希望避免硬编码客户数据。他们考虑使用 后处理步骤 进行动态适配,并征求关于更好实现策略的反馈。
- 这种交流体现了小组内的协作精神,成员们通过分享见解和解决方案积极互相支持。
tinygrad (George Hotz) Discord
- 在 tinygrad 中探索音频模型:一位用户寻求关于如何使用 tinygrad 运行音频模型的指导,特别是希望了解仓库中现有的 Whisper 示例之外的内容。
- 这一询问引发了关于在 tinygrad 中探索音频应用潜在切入点的建议。
- 学习的哲学方法:一位成员引用了 “千里之行,始于足下”,强调了直觉在学习过程中的重要性。
- 这种观点鼓励了对社区内资源的深思熟虑式探索。
- 链接到有用的资源:另一位成员分享了 Eric S. Raymond 编写的 smart questions FAQ 链接,概述了在线寻求帮助的礼仪和策略。
- 该资源可作为撰写有效查询并最大限度获得社区帮助的指南。
OpenAccess AI Collective (axolotl) Discord
- Mistral 的 Pixtral 奠定多模态基础:Mistral 的 Pixtral 正在推进 multi-modal support(多模态支持)的工作,呼应了 AI 能力的最新发展。
- 考虑到当今的技术进步,这是一个具有先见之明的举动。
- Axolotl 项目获得新的消息结构:Axolotl 项目中关于新消息结构的 pull request 旨在增强消息的表示方式,以支持改进的功能。
- 欲了解更多信息,请参阅 New Proposed Message Structure 的详细信息。
- LLM 模型进行速度与性能测试:最近的一段 YouTube 视频 评估了截至 2024 年 9 月领先的 LLM 模型在速度和性能方面的表现,重点关注 tokens per second。
- 测试强调了 latency(延迟)和 throughput(吞吐量),这是生产环境中任何性能评估的关键指标。
LAION Discord
- AI 开发者为 NYX 模型寻找合作伙伴:一位 AI 开发者宣布正在开发拥有超过 6000 亿参数的 NYX 模型,并正在积极寻找合作伙伴。
- 如果你具备 AI 方面的专业知识且时区相近以便有效协作,让我们聊聊吧!
- 关于训练大模型的咨询:一位开发者询问了用于训练 600B 参数模型的训练资源,并提到了在 15 万亿 tokens 上训练的 LLaMA-405B。
- 好奇心集中在此类超大模型的数据来源方法论上,表明了对底层流程的浓厚兴趣。
LLM Finetuning (Hamel + Dan) Discord
- Literal AI 在易用性方面表现出色:用户称赞 Literal AI 具有直观的界面,增强了 LLM 应用的可访问性和用户体验。
- 这反映了在 LLM 技术竞争日益激烈的格局中,对用户友好型工具日益增长的需求。
- 可观测性提升 LLM 生命周期健康度:强调了 LLM 可观测性的重要性,因为它使开发者能够快速迭代并有效地处理调试过程。
- 利用日志可以提升较小模型的性能,同时降低成本,推动高效的模型管理。
- 监控 prompt 防止回归:在部署新版本的 prompt 之前,持续跟踪 prompt 的表现对于防止回归(regressions)至关重要。
- 这种主动评估保护了 LLM 应用免受潜在故障的影响,并增加了部署信心。
- LLM 监控确保生产环境可靠性:强大的日志记录和评估机制对于监控生产环境中的 LLM 性能至关重要。
- 实施有效的分析使团队能够保持监督并增强应用的稳定性。
- 集成 Literal AI 非常简便:Literal AI 支持跨应用的轻松集成,允许用户接入完整的 LLM 生态系统。
- 提供自托管选项,以满足欧盟用户和管理敏感数据的用户需求。
Mozilla AI Discord
- Ground Truth Data 在 AI 中的关键作用:一篇新博客文章强调了 Ground Truth Data 的重要性,它能提升 AI 应用中的 模型准确性 (model accuracy) 和可靠性,并敦促读者参与正在进行的讨论 加入讨论。
- Ground Truth Data 被认为是推动 AI 系统在不同语境下性能提升的核心要素。
- Mozilla 开启校友资助申请:Mozilla 邀请之前的 Mozilla Fellowship 参与者申请针对 可信 AI (trustworthy AI) 和更健康互联网倡议的 项目资助,这反映了在 AI 领域进行 结构性变革 (structural changes) 的努力。
- “互联网,尤其是人工智能 (AI),正处于一个转折点。” Hailey Froese 的这句话强调了在该领域进行变革性努力的号召。
Gorilla LLM (Berkeley Function Calling) Discord
- 评估脚本错误困扰用户:用户在运行
openfunctions_evaluation.py并带有--test-category=non_live参数时遇到了 ‘No Scores’ 问题,指定文件夹中没有生成结果。- 尝试使用新的 API 凭据重新运行 未能成功,导致了进一步的复杂情况。
- API 凭据已更新但问题依旧:在设置中,用户在
function_credential_config.json中添加了四个新的 API 地址,希望能解决问题。- 尽管进行了这些更改,评估期间仍然出现错误,证实了凭据更新无效。
- Urban Dictionary API 超时问题:在评估过程中,出现了与 Urban Dictionary API 相关的 连接错误 (Connection Error)(涉及术语 ‘lit’),表明存在超时问题。
- 怀疑网络问题 是用户面临连接困难的根源。
Alignment Lab AI Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的频道细分内容已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!