ainews-o1-openais-new-general-reasoning-models
o1:OpenAI 全新的通用推理模型
OpenAI 发布了 o1 模型系列,包括 o1-preview 和 o1-mini。该系列专注于“推理时推理”(test-time reasoning),其输出 Token 限制扩展到了 3 万个以上。
这些模型表现强劲:在竞技编程中排名达到前 11%(第 89 百分位),在美国数学奥林匹克预选赛中表现优异,并在物理、生物和化学的基准测试中超过了博士水平的准确率。值得注意的是,尽管 o1-mini 的规模比 gpt-4o 更小,但其表现依然令人印象深刻。此次发布凸显了推理时计算的新“缩放法则”(scaling laws),即性能随计算量呈对数线性增长。
此外,据报道 英伟达(Nvidia) 的 AI 芯片市场份额正被初创公司蚕食,开发者在 Web 开发中的偏好正从 CUDA 转向 llama 模型,不过英伟达在模型训练领域仍保持主导地位。这些新闻反映了推理型模型的重大突破以及 AI 硬件竞争格局的变化。
推理时推理(Test-time reasoning)就是你所需要的一切。
2024年9月11日至9月12日的 AI 新闻。我们为你查看了 7 个 subreddits、433 个 Twitter 账号 和 30 个 Discord 社区(216 个频道,4377 条消息)。预计为你节省了 416 分钟 的阅读时间(以每分钟 200 字计算)。你现在可以在 AINews 讨论中艾特 @smol_ai 了!
o1,又名 Strawberry,又名 Q*,终于发布了!今天我们可以使用两个模型:o1-preview(较大的模型,定价为输入 $15 / 输出 $60)和 o1-mini(专注于 STEM 推理的蒸馏版本,定价为输入 $3 / 输出 $12)——而主模型 o1 仍在训练中。这引起了一点点困惑。
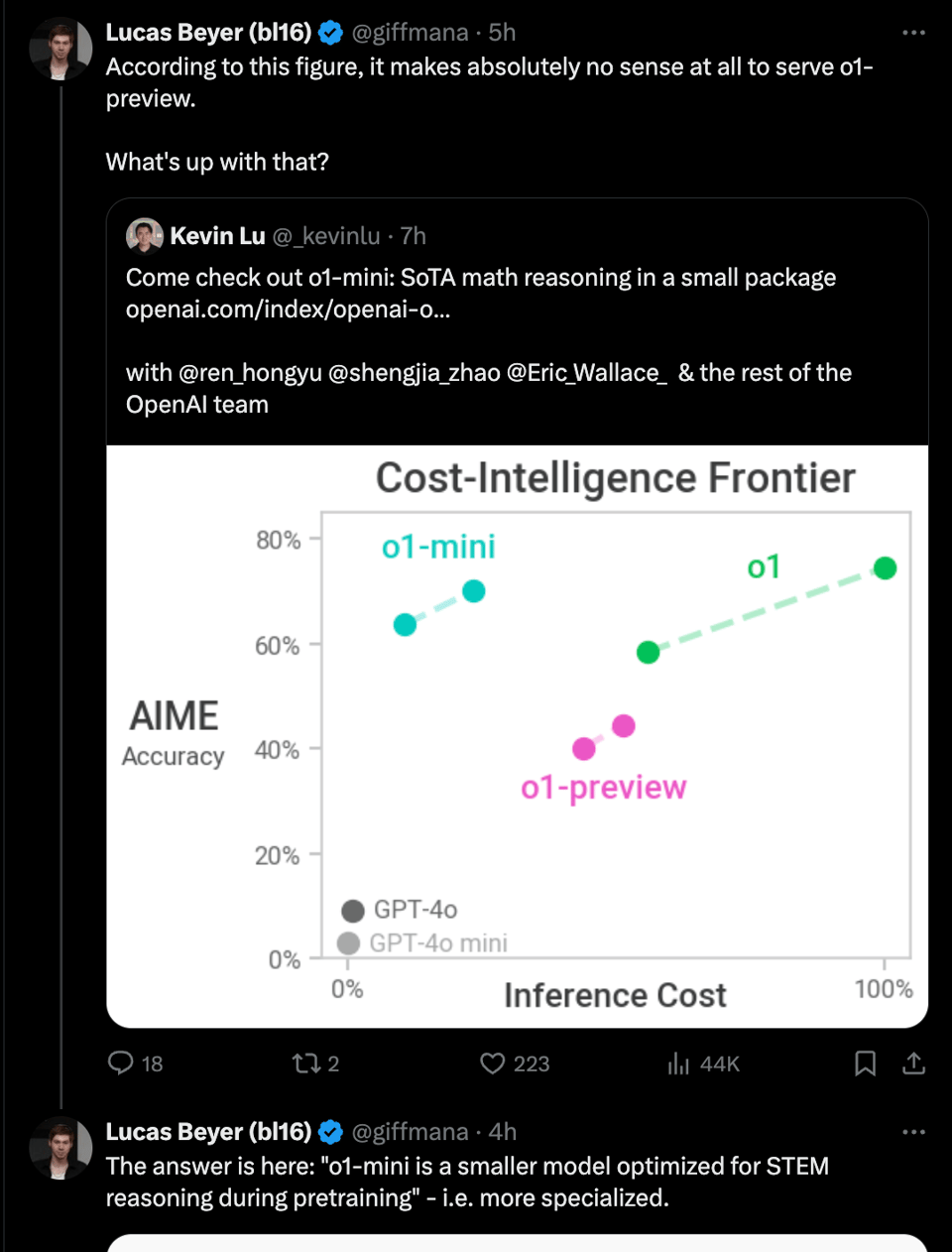
有一系列相关的链接,请不要错过:
与今天之前的大量泄露信息一致,核心故事是更长的“推理时推断(test-time inference)”,即更长的逐步响应——在 ChatGPT 应用中,这表现为一个新的“思考(thinking)”步骤,你可以点击展开查看推理轨迹,尽管有争议的是,这些轨迹对你是隐藏的(有趣的利益冲突……):
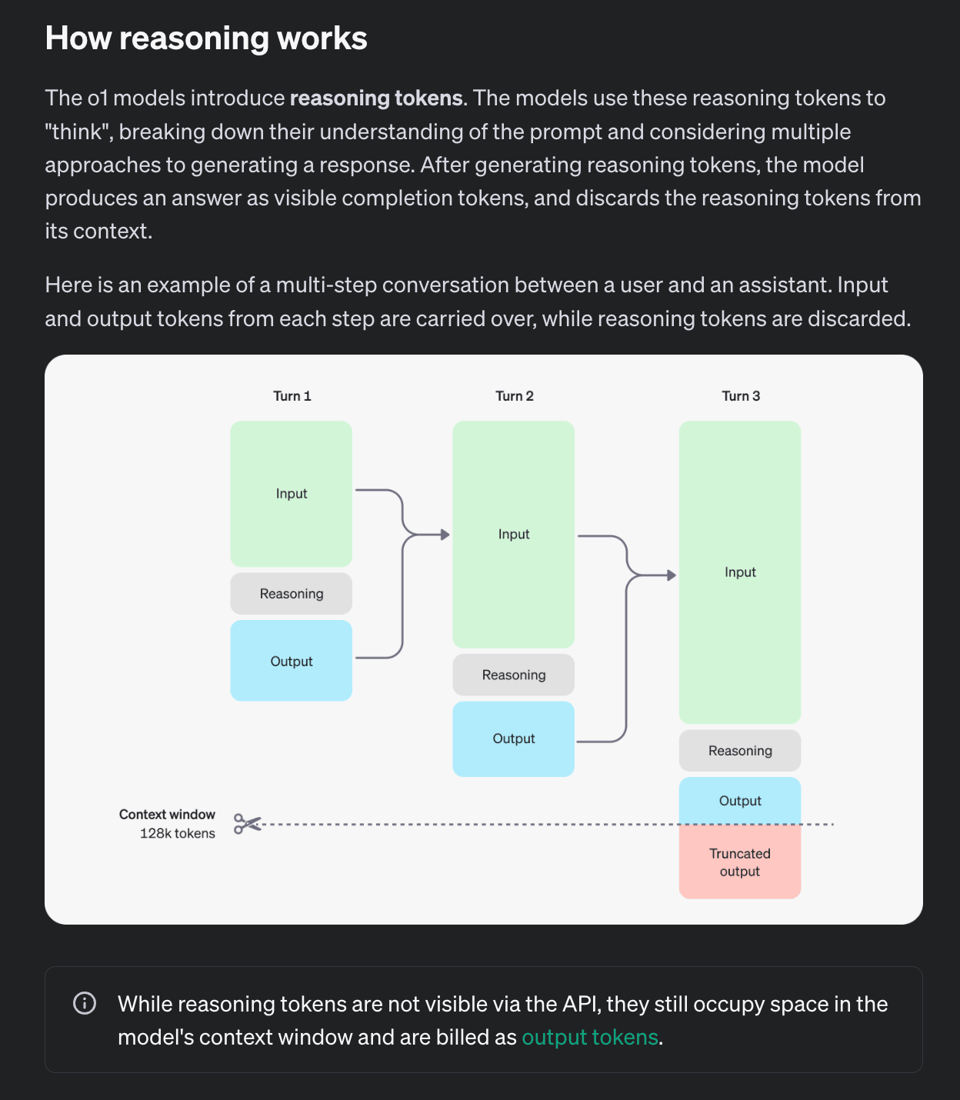
在底层,o1 经过训练以添加新的 推理 Token(reasoning tokens) ——你需要为此付费,OpenAI 也相应地将输出 Token 限制扩展到了 >30k Token(顺便提一下,这也是为什么来自其他模型的一些 API 参数,如 temperature、role、工具调用(tool calling)和流式传输(streaming),尤其是 max_tokens 不再受支持的原因)。
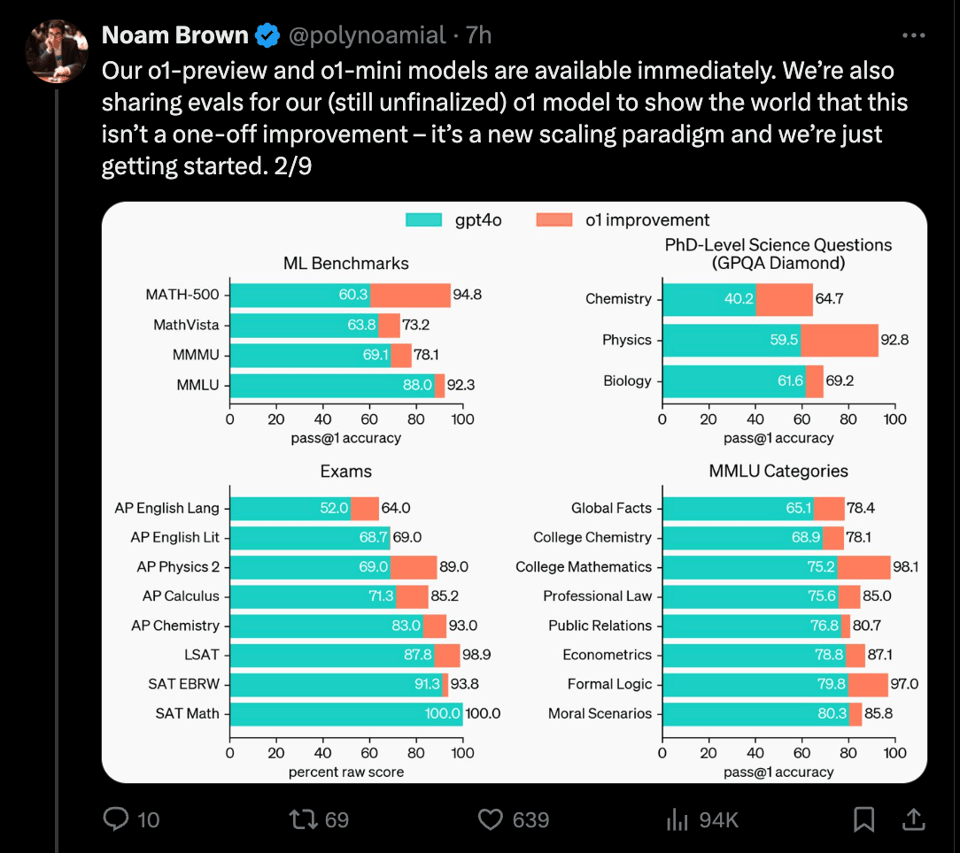
评估结果非常出色。OpenAI o1:
- 在编程竞赛(Codeforces)问题中排名第 89 百分位,
- 在美国数学奥林匹克竞赛(AIME)预选赛中名列全美前 500 名学生之列,
- 并且在物理、生物和化学问题的基准测试(GPQA)中超过了人类博士级别的准确率。
你已经习惯了新模型展示那些令人愉悦的图表,但有一张值得注意的图表在许多模型发布公告中并不常见,这可能是最重要的图表。Jim Fan 博士说得很对:我们现在有了 推理时计算(test time compute)的缩放定律(scaling laws),而且看起来它们呈对数线性缩放。
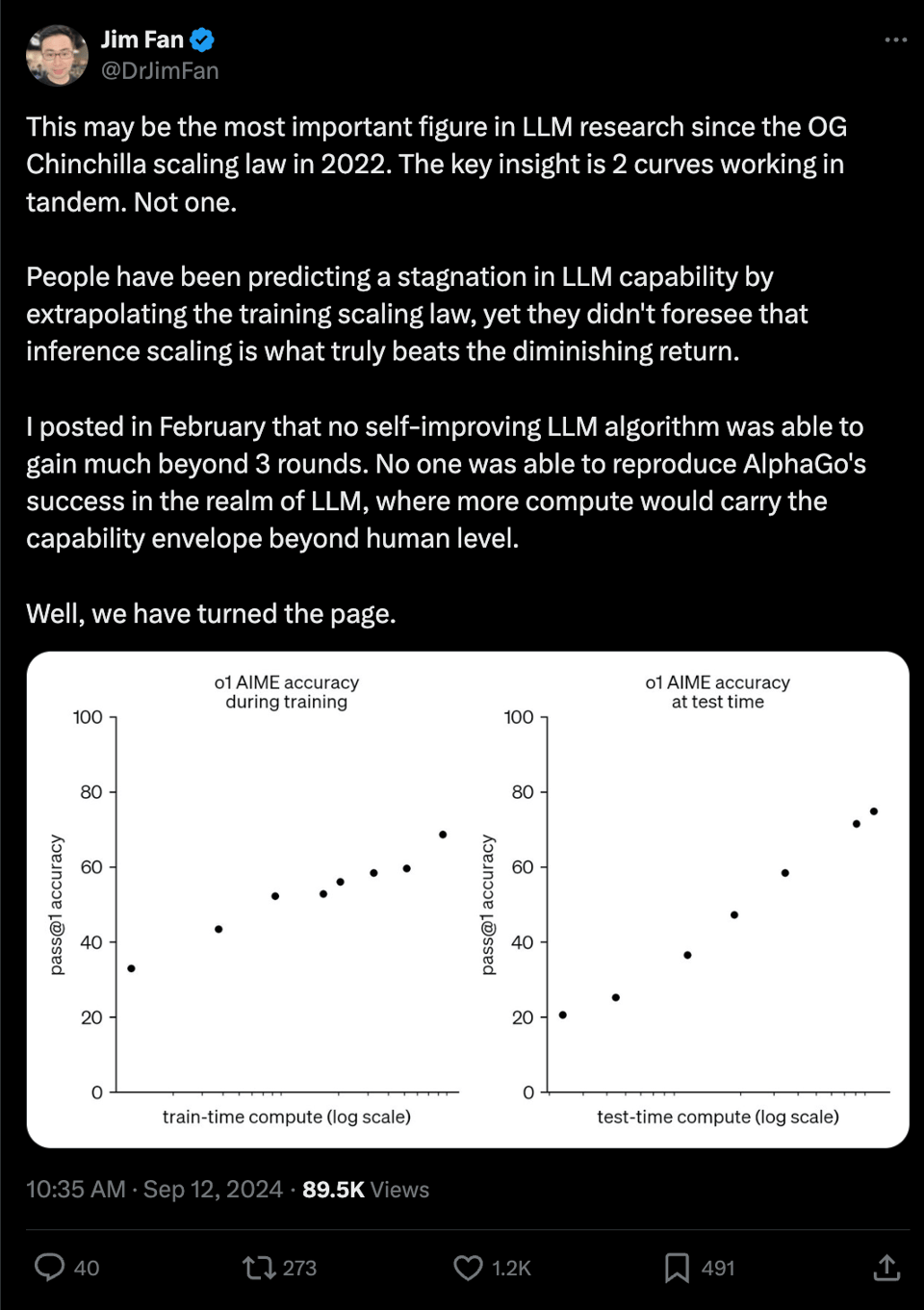
遗憾的是,我们可能永远无法得知推理能力提升的驱动因素,但 Jason Wei 分享了一些提示:

通常大模型会获得所有的赞誉,但值得注意的是,许多人都在称赞 o1-mini 以其体量(比 GPT-4o 更小)所表现出的性能,所以不要错过这一点。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
Nvidia 与 AI 芯片竞争
-
市场份额转移:@draecomino 指出,Nvidia 第一次开始向 AI 芯片初创公司失去份额,最近的 AI 会议上的讨论证明了这一点。
-
CUDA vs. Llama:同一位用户强调,虽然 CUDA 在 2012 年至关重要,但在 2024 年,90% 的 AI 开发者是基于 Llama 而非 CUDA 构建应用的 Web 开发者。
-
性能对比:@AravSrinivas 指出,Nvidia 在训练领域依然没有对手,但在推理领域可能会面临一些竞争。然而,采用 fp4 推理的 B100 性能可能会超越竞争对手。
-
SambaNova 性能:@rohanpaul_ai 分享了 SambaNova 推出了“全球最快的 API”,Llama 3.1 405B 的速度达到 132 tokens/sec,Llama 3.1 70B 达到 570 tokens/sec。
新 AI 模型与发布
-
Pixtral 12B:@sophiamyang 宣布发布 Pixtral 12B,这是 Mistral 的首个多模态模型。@swyx 分享的基准测试显示 Pixtral 的表现优于 Phi 3、Qwen VL、Claude Haiku 和 LLaVA 等模型。
-
LLaMA-Omni:@osanseviero 介绍了 LLaMA-Omni,这是一个基于 Llama 3.1 8B Instruct 的新型语音交互模型,具有低延迟语音以及文本和语音同步生成的特点。
-
Reader-LM:@rohanpaul_ai 分享了关于 JinaAI 的 Reader-LM 的细节,这是一个用于网页数据提取和清洗的 Small Language Model,在 HTML2Markdown 任务上的表现优于 GPT-4 和 LLaMA-3.1-70B 等更大型的模型。
-
GOT (General OCR Theory):@_philschmid 描述了 GOT,这是一个 580M 参数的端到端 OCR-2.0 模型,在处理表格、公式和几何形状等复杂任务时优于现有方法。
AI 研究与进展
-
Superposition prompting:@rohanpaul_ai 分享了关于 superposition prompting 的研究,该技术无需微调即可加速并增强 RAG,解决了长上下文 LLM 的挑战。
-
LongWriter:@rohanpaul_ai 讨论了 LongWriter 论文,该论文介绍了一种从长上下文 LLM 中生成 10,000 字以上输出的方法。
-
AI 在科学发现中的应用:@rohanpaul_ai 强调了使用 Agentic AI 进行自动科学发现的研究,揭示了隐藏的跨学科关系。
-
AI 安全与风险:@ylecun 分享了对 AI 安全的看法,认为人类水平的 AI 仍很遥远,因担心生存风险而监管 AI 研发还为时过早。
AI 工具与应用
-
Gamma:@svpino 展示了 Gamma,这款应用可以在几秒钟内根据上传的简历生成功能完备的网站。
-
基于 RAG 的文档问答:@llama_index 介绍了 Kotaemon,这是一个用于通过 RAG 系统与文档对话的开源 UI。
-
AI 调度器:@llama_index 宣布即将举办一场关于使用 Zoom、LlamaIndex 和 Qdrant 构建智能会议 AI 调度器的研讨会。
AI 行业与市场趋势
-
AI 取代企业软件:@rohanpaul_ai 指出,Klarna 用 AI 驱动的内部软件取代 Salesforce 和 Workday,标志着 AI 正在蚕食大部分 SaaS 的趋势。
-
AI 估值:@rohanpaul_ai 分享到 Anthropic 的估值已达到 184 亿美元,跻身顶级私有科技公司之列。
-
AI 在制造业的应用:@weights_biases 宣传了在 AIAI Berlin 举办的“制造业中的生成式 AI:革新工具开发”分会。
AI 伦理与社会影响
-
AI 检测挑战:@rohanpaul_ai 分享的研究显示,AI 模型和人类都难以在对话记录中区分人类和 AI。
-
涉及 AI 的刑事案件:@rohanpaul_ai 详细介绍了首例涉及 AI 虚增音乐流媒体播放量的刑事案件,犯罪者利用 AI 生成的音乐和虚假账号骗取版税。
迷因与幽默
-
@ylecun 分享了一个迷因,关于一名一年级学生因为坚持 2+2=5 而得到差评并感到沮丧。
-
@ylecun 拿《辛普森一家》的万圣节特辑开玩笑:“在斯普林菲尔德,他们在吃他们的狗!”
-
@cto_junior 分享了一张关于 strawberry 可能是什么的幽默图片。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. 复兴并改进经典的 LLM 架构
- 新发布:Solar Pro (preview) Instruct - 22B (Score: 44, Comments: 14): Solar Pro 团队发布了他们新的 22B 参数 instruct model 预览版,可在 Hugging Face 上获取。该模型声称是可以在 单 GPU 上运行的 最佳 open model,尽管帖子作者指出此类声明在模型发布中很常见。
- 用户对 4K context window 表示失望,认为在 2024 年 8K 已被视为最低标准的情况下,这显然不足。2024 年 11 月 的正式发布版将提供 更长的 context windows 并扩展语言支持。
- 讨论中将 Solar Pro 与其他模型进行了对比,一些人称赞了 Solar 11B 的表现。用户对 Phi 3 的可用性和个性改进感到好奇,因为它被视为“榜单狙击手(benchmark sniper)”,在实际应用中表现不佳。
- 相比于声称优于 Llama 70B 等大型模型,该模型声称是“单 GPU 可运行的最佳 open model”被认为更务实。一些用户表示有兴趣尝试 Solar Pro 的 GGUF 版本。
- Chronos-Divergence-33B ~ 释放经典潜力 (Score: 72, Comments: 23): Zeus Labs 推出了 Chronos-Divergence-33B,这是原始 LLaMA 1 模型的改进版本,将有效序列长度从 2048 扩展到了 16,384 tokens。该模型基于 约 500M tokens 的新数据训练,可以连贯地编写多达 12K tokens 的内容,同时保留了 LLaMA 1 的魅力并避免了重复的 “GPT-isms“,技术细节和量化版本可在其 Hugging Face model card 上找到。
- 用户讨论了该模型的叙事能力,开发者确认其主要专注于多轮 RP。一些用户反映回复比预期的短,并寻求改进建议。
- 社区对使用旧模型作为基座以避免新模型中存在的 “GPT slop” 或 “AI smell” 表现出兴趣。用户辩论了这种方法的有效性,并讨论了如 InternLM 20B 等潜在替代方案。
- 讨论涉及了消除偏见的训练技术,建议包括温和的 DPO/KTO、ORPO 以及在预训练原始文本上进行 SFT。一些人提议修改 tokenizer 以消除与 GPT-isms 相关的特定 tokens。
主题 2. 推动边界的新开源语音模型
- 新开源文本转语音模型:Fish Speech v1.4 (Score: 106, Comments: 13): Fish Speech v1.4 是一款新发布的开源 text-to-speech 模型,在涵盖多种语言的 700,000 小时 音频数据上进行了训练。该模型推理仅需 4GB VRAM,使其适用于各种应用,可通过其 官方网站、GitHub 仓库、HuggingFace 页面 获取,并包含一个交互式 demo。
- 用户将 Fish Speech v1.4 与其他开源模型进行了比较,指出虽然它比以前的版本有所改进,但在语音克隆方面仍不及 XTTSv2。该模型在德语方面的表现受到了好评。
- Fish Speech v1.4 背后的开发团队成员来自 SoVITS 和 RVC 项目,这些项目在开源 text-to-speech 社区中备受瞩目。RVC 被认为是目前最好的开源选择。
- 一位用户指出命令行二进制文件 “fap” (fish-audio-preprocessing) 的命名选择不太妥当,建议更改以避免尴尬的执行命令。
- LLaMA-Omni: Seamless Speech Interaction with Large Language Models (分数:74,评论:30): LLaMA-Omni 是一款能够实现与大语言模型进行无缝语音交互的新模型。该模型已在 Hugging Face 上发布,并附带了研究论文和 GitHub 上的开源代码,为语音驱动的 AI 交互领域的进一步探索和开发提供了可能。
- LLaMA-Omni 仅使用 Whisper 的 voice encoder 部分来嵌入音频,而不是完整的转录模型。这种方法不同于以往使用 Whisper 完整 speech-to-text 能力的多模态方法。
- 该模型的硬件要求引发了讨论,用户注意到其对 VRAM 的需求较高。开发者提到,可以使用更小的 Whisper 模型来加快推理速度,但代价是质量会有所下降。
- 用户对该模型的有效性进行了辩论,一些人将其视为与现有解决方案相当的概念验证(proof of concept)。其他人则质疑其语音质量和非言语语音能力,认为它可能是独立的 ASR、LLM 和 TTS 模型的组合。
主题 3. LLM 部署的基准测试与成本分析
- Ollama LLM benchmarks on different GPUs on runpod.io (分数:52,评论:16): 作者在 runpod.io 上使用 Ollama 进行了 GPU 和 AI 模型性能基准测试,重点关注各种模型和 GPU 的
eval_rate指标。主要发现包括:llama3.1:8b 在 2x 和 4x RTX4090 上的表现相似;mistral-nemo:12b 比 llama3.1:8b 慢 ~30%;command-r:35b 的速度是 llama3.1:70b 的两倍;对于较小的模型,L40 与 L40S 以及 A5000 与 A6000 之间的差异极小。作者分享了一份包含研究结果的详细电子表格,并欢迎对基准测试潜在扩展的反馈。- 用户询问了 VRAM 使用情况和量化(quantization),作者在表格中增加了 VRAM 占用范围。一位评论者提到在 Runpod 上运行 Q8 或 fp16 模型,以完成超出家庭硬件能力的任务。
- 讨论了上下文长度(context length)对模型速度的影响,作者详细说明了他们的测试过程:使用一个标准问题(“为什么天空是蓝色的?”),该问题在不同模型中通常会生成 300-500 token 的回答。
- 一位用户分享了使用 kobalcpp 配合 vulkan 来混合 GPU 品牌(7900xt 和 4090)的经验,在 llama3.1 70b q4KS 上达到了 10-14 tokens/second,并指出了 llama.cpp 与 vulkan 的兼容性问题。
- LLMs already cheaper than traditional ML models? (分数:65,评论:40): 该帖子比较了 GPT-4 模型与 Google Translate 之间的翻译成本,发现 GPT-4 选项明显更便宜:GPT-4 的成本为 $20/1M tokens,GPT-4-mini 为 $0.75/1M tokens,而 Google Translate 的成本为 $20/1M 字符(相当于 $60-$100/1M tokens)。作者对为什么还有人使用更昂贵的 Google Translate 表示困惑,因为 GPT-4 模型还提供了诸如上下文理解和自定义提示词(prompts)等额外优势,从而可能获得更好的翻译结果。
- Google Translate 使用的是混合 Transformer(hybrid transformer)架构,详见 2020 年 Google Research 博客文章。用户质疑其与较新 LLM 相比的性能,一些人将其归因于其技术陈旧。
- OpenAI 的 API 定价引发了关于盈利能力的辩论。一些人认为 OpenAI 并没有从 API 调用中赚钱,而另一些人则认为他们可能已经实现了现金流为正,理由是其高效的基础设施以及与开源 LLM 供应商相比具有竞争力的定价。
- 用户强调了 Google Translate 在特定语言对和冷门语言中的可靠性,指出 GPT-4 在非英语翻译中可能会遇到困难或产生无关内容。一些人提到 Gemini Pro 1.5 是多语言翻译的潜在替代方案。
主题 4. 开发者拥抱 AI 编程助手,不像艺术家对待 AI 艺术
- 我想问一个可能会冒犯很多人的问题:是否有很多程序员/软件工程师对 LLMs 在编程方面的进步感到愤愤不平,就像很多艺术家对 AI 艺术感到愤愤不平一样? (Score: 107, Comments: 275):软件工程师和程序员通常对 LLMs 编程能力的提升表现得不如艺术家对 AI 艺术那样愤愤不平。编程行业的整体氛围似乎倾向于适应与整合,许多人将 LLMs 视为提高生产力的工具,而非职业威胁。
- 软件工程师通常将 LLMs 视为增强生产力的工具而非威胁,将其用于样板代码生成 (boilerplate creation)、理解新框架以及自动化繁琐工作等任务。许多人将 AI 视为编程抽象层级 (abstraction level) 演进的又一步。
- 虽然 LLMs 在编程辅助方面很有帮助,但它们仍存在局限性,例如幻觉产生错误代码以及需要人工监督。一些开发者指出,LLMs 目前在实际应用编程方面表现不佳,主要在生成简单或简短的代码片段时表现出色。
- 开发者之间的态度各不相同,从热衷的早期采用者到否认 AI 潜在影响的人都有。一些人对管理层的预期和潜在的就业市场影响表示担忧,而另一些人则将 AI 视为专注于更高层次问题解决和系统设计的机会。
其他 AI Subreddit 回顾
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型发布与改进
-
OpenAI 动态:关于 OpenAI 即将发布的产品有很多传闻和猜测,包括潜在的 “Strawberry” 模型和 GPT-4o 语音模式。然而,许多用户对模糊的公告和延迟发布表示沮丧。一位 OpenAI 应用研究主管发推称即将“发布 (shipping)”一些东西,引发了更多猜测。
-
Fish Speech 1.4:发布了一个新的开源文本转语音模型,该模型在涵盖 8 种语言的 70 万小时语音上进行了训练。它仅需 4GB VRAM,每天提供 50 次免费使用。
-
Amateur Photography Lora v4:发布了一个用于生成逼真业余风格照片的 Stable Diffusion Lora 模型更新,在清晰度和真实感方面有所提升。
{kind=link}
AI 研究与突破
-
类脑计算 (Neuromorphic computing):科学家报告了使用分子忆阻器在类脑计算方面取得的突破,这可能实现更高效的 AI 硬件。该设备提供 14 位精度、高能效和快速计算。
-
PaperQA2:引入了一个可以自主进行完整科学文献综述的 AI Agent。
AI 行业新闻
-
OpenAI 人员离职:多位知名研究人员最近离开了 OpenAI,包括负责 GPT-4o/GPT-5 工作的 Alexis Conneau。
-
Ilya Sutskever 的新创业项目:这位前 OpenAI 研究员在没有产品或收入的情况下,为他的新 AI 公司筹集了 10 亿美元。
-
苹果的 AI 举措:与竞争对手相比,苹果即将推出的 iPhone 16 AI 功能被批评为“迟到、未完成且笨拙”。
{kind=link}
AI 伦理与社会影响
-
Deepfake 担忧:Taylor Swift 对 AI 生成的 Deepfake 表示担忧,这些视频虚假地描绘了她支持政治候选人的场景。
-
逼真的 AI 生成图像:Amateur Photography Lora v4 模型展示了区分 AI 生成图像与真实照片正变得越来越困难。
AI Discord 回顾
摘要的摘要的摘要。我们将 4o 与 o1 的对比留给您参考。
GPT4O (gpt-4o-2024-05-13)
1. OpenAI O1 模型发布及各界反应
- OpenAI O1 模型因成本问题面临批评:OpenAI 的 O1 模型因其高昂的成本和不尽如人意的表现(尤其是在编程任务中)受到了用户的批评,正如 OpenRouter 中所讨论的那样。
- 价格定为每百万 Token 60 美元,用户对意外成本和整体价值表示担忧,引发了关于该模型实际效用的讨论。
- 对 OpenAI O1 Preview 的评价褒贬不一:O1 preview 收到了用户的混合反馈,人们质疑其相对于 Claude 3.5 Sonnet 等模型的改进,特别是在创意任务方面,如 Nous Research AI 所述。
- 用户对其运行效率持怀疑态度,认为在全面推广之前可能需要进一步迭代。
- OpenAI 发布用于推理任务的 O1 模型:据 OpenAI 报道,OpenAI 推出了 O1 模型,旨在增强科学、编程和数学等复杂任务中的推理能力。该模型已对 ChatGPT 的所有 Plus 和 Team 用户开放,并通过 API 提供给第 5 级(tier 5)开发者。
- 用户注意到 O1 模型在解决问题方面优于之前的版本,但一些人对价格与性能提升的比例表示怀疑。
2. AI 模型性能与基准测试
- DeepSeek V2.5 发布,具备用户友好特性:OpenRouter 宣布,DeepSeek V2.5 引入了全精度提供商,并为注重隐私的用户承诺不记录提示词日志(no prompt logging)。
- 此外,DeepSeek V2 Chat 和 DeepSeek Coder V2 模型已合并到此版本中,允许无缝重定向到新模型。
- PLANSEARCH 算法提升代码生成能力:关于 PLANSEARCH 算法的研究表明,它通过在代码生成前识别多种方案来增强基于 LLM 的代码生成,从而促进高效输出,如 aider 中所讨论。
- 通过缓解 LLM 输出缺乏多样性的问题,PLANSEARCH 在 HumanEval+ 和 LiveCodeBench 等基准测试中展现了显著的性能提升。
3. AI 训练与推理中的挑战
- OpenAI O1 和 GPT-4o 模型面临的挑战:关于 O1 和 GPT-4o 模型的反馈强调了用户的挫败感,因为性能结果显示它们并没有明显优于之前的版本,如 OpenRouter 所述。
- 用户主张在这些先进模型中进行更多针对实际应用的改进,并建议需要进行持续的测试验证。
- LLM 蒸馏(Distillation)的复杂性:Unsloth AI 的参与者表达了将 LLM 蒸馏为更小模型时面临的挑战,强调准确的输出数据是成功的关键。
- 依赖高质量示例至关重要,而复杂推理的 Token 成本会导致推理速度缓慢。
4. AI 工具与框架的创新
- Ophrase 和 Oproof CLI 工具变革操作流程:一篇详细的文章解释了 Ophrase 和 Oproof 如何通过简化任务自动化和管理来增强命令行界面(CLI)功能,如 HuggingFace 中所讨论。
- 这些工具为工作流效率提供了实质性增强,有望为处理命令行任务带来革命。
- HTML 分块(Chunking)包首次亮相:新软件包
html_chunking能够高效地对 HTML 内容进行分块和合并,同时保持 Token 限制,这对于网页自动化任务至关重要,已在 LangChain AI 中介绍。- 这种结构化方法确保了有效的 HTML 解析,为各种应用保留了必要的属性。
5. AI 在各领域的应用
- Roblox 利用 AI 赋能游戏:一段视频讨论了 Roblox 如何创新地将 AI 与游戏融合,将其定位为该领域的领导者,如 Perplexity AI 所述。
- 这一发展标志着在游戏环境中集成先进技术的重大飞跃。
- 个人 AI 行政助理取得成功:Cohere 的一名成员成功构建了一个个人 AI 行政助理,该助理通过 calendar agent cookbook 管理日程,并集成语音输入来编辑 Google Calendar 事件。
- 该助手能够熟练地解释非结构化数据,证明其在组织考试日期和项目截止日期方面非常有用。
GPT4O-Aug (gpt-4o-2024-08-06)
1. OpenAI O1 模型发布与性能表现
- OpenAI O1 模型引发褒贬不一的反应:OpenAI O1 发布,声称增强了在科学、编程和数学等复杂任务中的推理能力,引发了用户的兴奋。
- 虽然一些人称赞其解决问题的能力,但也有人批评其高昂的成本,并质疑其改进是否物有所值,特别是与 GPT-4o 等旧模型相比。
- 社区对 O1 实用性的担忧:用户对 O1 在编程任务中的表现表示沮丧,指出隐藏的 ‘thinking tokens’ 导致了意想不到的成本,据称价格为 每百万 token $60。
- 尽管宣传中提到了其技术进步,许多用户报告称更倾向于使用 Sonnet 等替代方案,强调了在实际应用中进行实用性增强的必要性。
2. DeepSeek V2.5 特性与用户反馈
- DeepSeek V2.5 发布并具备隐私功能:DeepSeek V2.5 引入了全精度提供商,并确保不记录 prompt 日志,吸引了注重隐私的用户。
- 新版本合并了 DeepSeek V2 Chat 和 DeepSeek Coder V2,在保持向后兼容性的同时,促进了模型的无缝访问。
- DeepSeek 端点性能受到质疑:用户报告 DeepSeek 端点 性能不稳定,质疑其在最近更新后的可靠性。
- 社区反馈表明需要提高性能的一致性,一些人正在考虑替代方案。
3. AI 监管与社区反应
- 加州 AI 监管法案面临反对:围绕加州 SB 1047 AI 安全法案 的推测表明,由于政治动态,特别是 Pelosi 的参与,该法案有 66-80% 的概率被否决。
- 讨论强调了其对数据隐私和 inference compute 的潜在影响,反映了技术创新与监管措施之间的紧张关系。
- AI 监管讨论引发辩论:受 Dr. Epstein 在 Joe Rogan 的播客 上的见解启发,关于 AI 监管的对话揭示了对社交媒体塑造的叙事的担忧。
- 成员们主张在 free speech 与 hate speech 之间采取平衡的方法,强调 AI 讨论中的适度管理。
4. LLM 训练与优化方面的创新
- PLANSEARCH 算法提升代码生成:对 PLANSEARCH 算法 的研究表明,它通过识别多样化的计划来增强 基于 LLM 的代码生成,从而提高效率。
- 通过扩大生成观察结果的范围,PLANSEARCH 在 HumanEval+ 和 LiveCodeBench 等基准测试中展现了显著的性能提升。
- 用于高效上下文处理的 Dolphin 架构:Dolphin 架构引入了一个 0.5B 参数 的解码器,在将延迟降低 5 倍 的同时,提高了长上下文处理的能源效率。
- 实验结果显示能源效率提高了 10 倍,使其成为模型处理技术领域的一项重大进展。
5. AI 模型部署与集成的挑战
- Reflection 模型面临批评:Reflection 70B 模型 因涉嫌伪造基准测试结果而遭到抨击,引发了对 AI 开发公平性的担忧。
- 批评者将其贴上现有技术 wrapper(套壳)的标签,强调了模型评估透明度的必要性。
- API 访问与集成挑战:用户对 API 限制和授权问题表示沮丧,强调了故障排除中明确性的必要。
- 在保持低成本的同时管理多个 AI 模型仍然是讨论中的一个经常性话题,突显了集成的挑战。
o1-mini (o1-mini-2024-09-12)
- OpenAI 发布具备卓越推理能力的 O1 模型:OpenAI’s O1 模型系列增强了在复杂任务中的推理能力,在超过 50,000 次对决中表现优于 GPT-4o 和 Claude 3.5 Sonnet 等模型。尽管取得了进步,用户对其 每百万 token 60 美元 的高昂定价表示担忧,并引发了与 Sonnet 等替代方案的比较。
- 先进训练技术提升模型效率:诸如 ZeRO++ 之类的创新将 GPU 通信开销降低了 4 倍,而 vAttention 优化了 KV-cache 内存以实现高效推理。此外,Consistency LLMs 探索了并行 token 解码,显著降低了推理延迟。
- 高价模型的成本管理策略:社区讨论了如何优化使用以减轻 O1 等模型的成本,强调了管理 token 消耗和探索计费结构的重要性。建议包括利用 /settings/privacy 进行数据偏好设置,以及利用高效的 prompting 技术来最大化价值。
- 开源框架加速 AI 开发:LlamaIndex 和 Axolotl 等项目为开发者提供了构建强大 AI 应用的工具。黑客松和社区活动提供了超过 10,000 美元 的奖金,促进了 RAG technology 和 AI agent 开发方面的协作与创新。
- 微调和专业模型训练受到关注:Qlora 等技术促进了对 Llama 3.1 和 Mistral 等模型的有效微调,增强了在代码生成和翻译等任务中的性能。社区基准测试显示,微调后的模型可以取得具有竞争力的结果,引发了关于优化训练工作流和解决特定领域挑战的持续讨论。
o1-preview (o1-preview-2024-09-12)
OpenAI 的 o1 模型发布,评价褒贬不一
- OpenAI 发布了 o1 模型系列,旨在增强科学、编程和数学等复杂任务中的推理能力。虽然一些人称赞其解决问题的能力有所提高,但其他人批评其成本高昂(每百万输出 token 60 美元),并质疑其相对于 GPT-4o 和 Sonnet 等现有模型的性能提升。
Reflection 70B 模型因夸大宣传面临抵制
- Reflection 70B 模型 因涉嫌伪造基准测试数据(声称超越 GPT-4o 和 Claude 3.5 Sonnet)而受到批评。用户将其称为 “现有技术的套壳”,并报告其性能令人失望,引发了对 AI 模型评估透明度的担忧。
AI 开发者采用新工具优化工作流
- HOPE Agent 等项目引入了动态任务分配和基于 JSON 的管理等功能,以简化 AI 编排。此外,Parakeet 展示了快速训练能力,使用 AdEMAMix optimizer 在不到 20 小时内完成了训练。
尽管承诺有所改进,新 AI 模型仍面临质疑
- 用户对 OpenAI’s o1、DeepSeek V2.5 和 Solar Pro Preview 等模型的有效性表示怀疑,理由是性能不佳且成本高昂。讨论强调了在 AI 进步中,可验证的基准测试和实际改进比营销噱头更重要。
加州 AI 监管法案 SB 1047 引发行业担忧
- 拟议的 加州 AI 监管法案 SB 1047 引发了关于对数据隐私和推理算力潜在影响的辩论。推测认为,由于政治动态,该法案有 “66-80% 的概率被否决”,凸显了技术创新与监管措施之间的紧张关系。
PART 1: High level Discord summaries
OpenRouter (Alex Atallah) Discord
- DeepSeek V2.5 发布,具备用户友好特性:根据 OpenRouter 公告,DeepSeek V2.5 的推出引入了全精度提供商,并为关注隐私的用户承诺不记录 Prompt。用户可以在
/settings/privacy栏目中更新其数据偏好。- 此外,DeepSeek V2 Chat 和 DeepSeek Coder V2 模型已合并至此版本,允许无缝重定向到新模型而不会失去访问权限。
- OpenAI O1 模型面临批评:OpenAI O1 模型因其高昂的成本和在编程任务中令人失望的输出而引发用户不满,特别是由于其使用了隐藏的“思考 Token”。多位用户报告称,他们感觉该模型未能达到预期的能力。
- 定价设定为每百万 Token 60 美元,用户对意外成本和所提供的整体价值表示担忧,引发了围绕该模型实际效用的讨论。
- DeepSeek Endpoint 性能受到质疑:社区成员报告 DeepSeek Endpoint 性能不稳定,理由是之前的停机问题和整体质量。用户特别质疑最近更新后该 Endpoint 的可靠性。
- 对性能一致性的担忧表明,用户可能需要调整或更换对该 Endpoint 可靠性和输出质量的预期。
- LLM 的多样化用户体验:论坛讨论显示,用户对各种 LLM 的体验褒贬不一,许多人更倾向于 Sonnet 等替代方案,而非 OpenAI 的 O1。一些用户指出,尽管 O1 宣传有进步,但与其它竞争对手相比,性能仍然不足。
- 这些交流反映出一种普遍情绪:虽然用户希望有所改进,但许多人正转向其它表现更好的模型。
- 探索 O1 和 GPT-4o 模型的局限性:关于 O1 和 GPT-4o 模型反馈强调了挫败感,因为性能结果显示它们并没有明显优于之前的版本。用户主张在这些先进模型中加入更多针对现实世界应用的实际增强功能。
- 批评者呼吁更加重视实际效果,而非未经证实的卓越推理能力宣称,并认为持续的测试对于验证至关重要。
aider (Paul Gauthier) Discord
- OpenAI o1 定价令用户震惊:OpenAI 的 o1 模型,包括 o1-mini 和 o1-preview,价格高昂,输入 Token 每百万 $15.00,输出 Token 每百万 $60.00,导致用户担心成本会与全职开发人员相当。
- 用户担心使用 o1 进行调试可能会导致费用迅速飙升,这引起了社区的关注。
- Aider 相比 Cursor 的智能优势:Aider 与 Cursor 的对比突出了 Aider 在代码迭代和仓库映射方面的优势,这有助于结对编程。
- 虽然 Cursor 允许在提交前更轻松地查看文件,但 Aider 被认为是进行复杂代码调整的更优选择。
- PLANSEARCH 算法提升代码生成:关于 PLANSEARCH 算法 的研究表明,它通过在代码生成前识别多样化的计划来增强基于 LLM 的代码生成,从而促进更高效的输出。
- 通过缓解 LLM 输出缺乏多样性的问题,PLANSEARCH 在 HumanEval+ 和 LiveCodeBench 等基准测试中表现出极具价值的性能。
- 社区热议 LLM 输出的多样性:一篇新论文强调,LLM 输出的多样性不足会阻碍性能,导致搜索效率低下和重复的错误输出。
- PLANSEARCH 通过扩大生成观察的范围来解决这一问题,从而在代码生成任务中实现显著的性能提升。
- Aider 脚本改进易用性:围绕增强 Aider 脚本的讨论提出了一些建议,包括定义脚本文件名和配置 .aider.conf.yml 以实现高效的文件管理。
- 其他用户还处理了 git ignore 问题,提供了通过调整设置或使用命令行标志来编辑被忽略文件的解决方案。
OpenAI Discord
- OpenAI 发布用于推理的 o1 模型:OpenAI 发布了 o1 预览版,这是一个全新的 AI 模型系列,旨在增强在科学、编程和数学等复杂任务中的推理能力。该版本已面向 ChatGPT 的所有 Plus 和 Team 用户开放,并通过 API 提供给 tier 5 开发者。
- 用户注意到 o1 模型在解决问题方面优于之前的迭代,但一些人对价格与性能的提升比例表示怀疑。
- ChatGPT 在记忆功能方面遇到困难:成员们报告了 ChatGPT 记忆加载的持续问题,影响了数周对话中响应的一致性。一些人转而使用移动端 App,希望能获得可靠的访问,同时注意到 Windows 应用的缺失。
- 用户对这些缺陷表示沮丧,特别是在处理对话记忆方面,同时对于新 o1 模型与 GPT-4 相比的创造力表现也褒贬不一。
- 关于提示词性能的热烈讨论:一位成员指出,在进行优化(特别是集成了增强的物理功能)后,某个提示词的执行时间为 54 秒,表现良好。为了方便用户访问,明确了 prompt-labs 的位置。
- 社区成员在 Workshop 中发现库(library)部分后感到宽慰,这揭示了在工具可用性沟通方面可能存在的差距。
- 讨论了可定制 ChatGPT 的 API 访问:讨论强调了用户对访问可定制 ChatGPT 的 API 的好奇心,确认了其可用性,但对 o1 等模型的有效性表示不确定。对于不同模型界面和推出状态导致的用户困惑,人们表示担忧。
- 还出现了一些关于自定义 GPT 的关键体验,包括由于疑似违反政策而导致的发布问题,引发了对 OpenAI 流程可靠性的质疑。
Nous Research AI Discord
- 对 o1 预览版的评价褒贬不一:o1 preview 收到了褒贬不一的反馈,一些用户质疑其相对于 Claude 3.5 Sonnet 等现有模型的改进,特别是在创意任务方面。
- 人们对其运行效率表示担忧,认为在全面推出之前可能需要进一步的迭代。
- Dolphin 架构提升上下文效率:Dolphin 架构展示了一个 0.5B 参数的解码器,提升了长上下文处理的能源效率,同时将延迟降低了 5 倍。
- 实验结果显示能源效率提升了 10 倍,使其成为模型处理技术的一项重大进步。
- 探寻演绎推理的替代方案:关于通用推理引擎可用性的讨论探索了传统 LLM 之外的选择,强调了对能够解决逻辑三段论的系统的需求。
- 一个涉及土豆的示例问题说明了 LLM 在演绎推理方面的表现差距,暗示了混合系统使用的潜力。
- Cohere 模型与 Mistral 的对比:关于 Cohere 模型的反馈显示,与 Mistral 相比,其对齐程度和智能程度有限,表明后者性能更佳。
- 参与者强化了 Mistral Large 2 与 CMD R+ 之间的对比,展示了 Mistral 卓越的能力。
- AI 在产品营销中的讨论:成员们研究了能够跨平台自主管理营销任务的 AI 模型,表示目前缺乏可行的解决方案。
- 提出了集成各种 API 的可能性,激发了对营销自动化未来发展的想法。
HuggingFace Discord
- Ophrase 和 Oproof CLI 工具变革操作:一篇详细的文章解释了 Ophrase 和 Oproof 如何通过简化任务自动化和管理来增强命令行界面功能。
- 这些工具为工作流效率提供了实质性的提升,承诺在处理命令行任务方面带来一场革命。
- 解析 Reflection 70B 模型:Reflection 70B 项目展示了模型通用性的进步,利用 Llama cpp 提升了性能和用户交互。
- 它开启了关于模型适应性动态的讨论,旨在围绕其功能进行可访问的社区参与。
- 发布用于 NLP 的波斯语数据集:推出一个新的波斯语数据集,包含来自 Wikipedia 的 6K 条翻译句子,旨在辅助波斯语语言建模。
- 这一举措增强了 NLP 领域内各种语言处理任务的资源可用性。
- AI 监管引发褒贬不一的反应:关于 AI 监管的对话(由 Epstein 博士在 Joe Rogan 的播客中的见解引发)反映了对社交媒体平台塑造叙事的担忧。
- 成员们主张在言论自由与仇恨言论之间采取平衡的方法,强调在 AI 讨论中进行适度引导的必要性。
- HOPE Agent 增强 AI 工作流管理:HOPE Agent 引入了诸如动态任务分配和基于 JSON 的管理等功能,以简化 AI 编排。
- 它与 LangChain 和 Groq API 等现有框架集成,增强了跨工作流的自动化。
Modular (Mojo 🔥) Discord
- Mojo 错误处理的重要性:讨论集中在确保 Mojo 中的 syscall 接口返回有意义的错误值,鉴于 C 等语言中的接口契约,这一点至关重要。
- 设计这些接口需要深入了解潜在错误,以便进行有效的 syscall 响应管理。
- 将 Span[UInt8] 转换为 String:寻求关于在 Mojo 中将
Span[UInt8]转换为字符串视图的指导,建议指向了StringSlice。- 为了正确初始化
StringSlice,在遇到初始化错误后,注意到unsafe_from_utf8关键字参数是必需的。
- 为了正确初始化
- ExplicitlyCopyable Trait RFC 提案:有人建议为
ExplicitlyCopyabletrait 发起一个 RFC,要求实现copy(),这可能会影响未来的更新。- 据参与者称,这可以显著减少对现有定义的破坏性变更。
- MojoDojo 的开源协作:社区发现 mojodojo.dev 现已开源,为协作铺平了道路。
- 该资源最初由 Jack Clayton 创建,是学习 Mojo 的游乐场。
- Mojo 中的推荐系统:有关于开发推荐系统的现有 Mojo 或 MAX 功能的咨询,结果显示两者仍处于“自行构建”阶段。
- 成员们注意到这些功能正在开发中,尚未完全建立。
Perplexity AI Discord
- OpenAI O1 引发热潮:用户们正在热烈讨论 OpenAI O1 的发布,这是一个承诺增强推理和复杂问题解决能力的模型系列。
- 推测认为它可能会集成来自反思和面向 Agent 框架(如 Open Interpreter)的功能。
- 对 AI 音乐的质疑:成员们对 AI 驱动音乐的可持续性表示怀疑,认为这只是一个缺乏真正艺术价值的噱头。
- 他们强调 AI 音乐缺乏赋予传统音乐深度和意义的“人类情感(human touch)”。
- Uncovr.ai 面临开发挑战:Uncovr.ai 的创建者分享了在平台开发过程中遇到的障碍,强调了增强用户体验的必要性。
- 讨论中多次提到对成本管理和可持续收入模式的担忧。
- API 限制带来的挫败感依然存在:用户表达了对 API 限制和授权问题的挫败感,强调在故障排除时需要更高的透明度。
- 在保持低成本的同时管理多个 AI 模型是讨论中反复出现的主题。
- Roblox 利用 AI 赋能游戏:一段视频讨论了 Roblox 如何创新地将 AI 与游戏融合,将其定位为该领域的领导者;点击此处查看视频。
- 这一进展标志着在游戏环境中集成先进技术迈出了实质性的一步。
Interconnects (Nathan Lambert) Discord
- OpenAI o1 模型推理能力令人印象深刻:新发布的 OpenAI o1 模型旨在响应前进行更多思考,并在 MathVista 等基准测试中表现出强劲结果。
- 用户注意到它处理复杂任务的能力,但对其未来的实际表现评价褒贬不一。
- 加州 AI 监管法案 SB 1047 引发担忧:围绕加州 SB 1047 AI 安全法案的推测表明,由于政治动态(尤其是 Pelosi 的参与),该法案有 66-80% 的概率被否决。
- 关于该法案对 数据隐私 和 推理算力(inference compute) 潜在影响的讨论,凸显了技术创新与监管措施之间的紧张关系。
- 关于 OpenAI o1 性能的基准测试推测:初步基准测试表明,OpenAI 的 o1-mini 模型的表现与 gpt-4o 相当,特别是在代码编辑任务中。
- 社区对 o1 模型与现有 LLM 的竞争情况非常感兴趣,反映了 AI 领域激烈的竞争格局。
- 了解私有模型中的 RLHF:随着 Scale AI 在该领域的探索,成员们正试图揭示 RLHF (Reinforcement Learning from Human Feedback) 在私有模型中具体是如何运作的。
- 这种方法旨在使模型行为与人类偏好对齐,从而增强训练的可靠性。
- Scale AI 在领域专业知识方面的挑战:在 材料科学 和 化学 等专业领域,预计 Scale AI 将面临来自资深领域专家的挑战。
- 成员们反映,与监管较少的领域相比,处理临床环境中的数据要复杂得多,这会影响训练的有效性。
Unsloth AI (Daniel Han) Discord
- Reflection 模型面临抵制:Reflection 70B 模型因涉嫌伪造基准测试(benchmarks)而遭到抨击,该模型目前仍可在 Hugging Face 上获取,这引发了人们对 AI 开发公平性的担忧。
- 批评者将其贴上“现有技术包装(wrapper)”的标签,并强调模型评估中透明度的必要性。
- Unsloth 仅限于 NVIDIA GPU:Unsloth 确认其微调(finetuning)仅支持 NVIDIA GPU,这让潜在的 AMD 用户感到失望。
- 讨论强调,Unsloth 优化的内存占用使其成为需要高性能项目的首选。
- KTO 表现优于传统模型对齐:关于 KTO 的见解表明,它的表现可能显著优于 DPO 等传统方法,但由于使用私有数据,使用该方法训练的模型仍未公开。
- 成员们对 KTO 的潜力感到兴奋,但指出一旦模型可以获取,还需要进一步的验证。
- Solar Pro Preview 模型引发质疑:拥有 220 亿参数的 Solar Pro Preview 模型已推出,旨在实现单 GPU 效率,同时声称性能优于更大的模型。
- 批评者对其大胆声明的实用性表示担忧,并回顾了以往类似公告中令人失望的情况。
- LLM 蒸馏的复杂性:参与者表达了将 LLM 蒸馏为更小模型的挑战,强调准确的输出数据是成功的关键。
- Disgrace6161 指出,依赖高质量样本是关键,而由于复杂推理的 Token 成本,推理(inference)速度较慢。
Latent Space Discord
- OpenAI 发布 o1:推理能力的规则改变者:OpenAI 推出了 o1 模型系列,旨在数学和编程等多个领域表现出卓越的推理能力,因其增强的问题解决能力而备受关注。
- 报告强调,o1 模型不仅优于之前的版本,还在安全性和鲁棒性方面有所提高,在 AI 技术上取得了显著飞跃。
- Devin AI 在 o1 测试中表现出色:对编程 Agent Devin 使用 OpenAI o1 模型的评估取得了令人印象深刻的结果,展示了推理在软件工程任务中的重要性。
- 这些测试表明,o1 的泛化推理能力为专注于编程应用的 Agent 系统提供了显著的性能提升。
- 推理时间扩展(Inference Time Scaling)讨论:专家们正在评估与 o1 模型相关的推理时间扩展方法的潜力,认为它可以与传统的训练扩展(training scaling)相媲美,并增强 LLM 的功能。
- 讨论强调需要衡量隐藏的推理过程,以了解它们对 o1 等模型运行成功的影响。
- 社区对 o1 的复杂情绪:AI 社区对 o1 模型表达了多种情绪,一些人对其与 Sonnet/4o 等早期模型相比的效能表示怀疑。
- 对话的重点包括对非领域专家使用 LLM 局限性的担忧,强调了 AI 专用工具的必要性。
- 期待 o1 的未来发展:社区热切期待 o1 模型的后续发展,特别是对潜在语音功能的探索。
- 虽然人们对 o1 的认知能力感到兴奋,但一些用户在语音交互等功能层面仍面临限制。
CUDA MODE Discord
- CUDA Hackathon 令人兴奋的计算额度:组织团队为黑客松参与者争取到了 $300K 的云端额度,以及一个 10 节点 GH200 集群和一个 4 节点 8 H100 集群的使用权。
- 此次机会包括对节点的 SSH access,允许使用 Modal stack 进行无服务器扩展(serverless scaling)。
- 对 torch.compile 的强力支持:在 MobiusML 仓库的 0.2.2 版本中,
torch.compile已集成到model.generate()函数中,提升了易用性。- 此次更新意味着模型生成不再依赖之前的 HFGenerator,简化了开发者的工作流程。
- GEMM FP8 实现进展:最近的一个 pull request 使用 E4M3 representation 实现了 FP8 GEMM,解决了 issue #65 并测试了多种矩阵尺寸。
- 新增了 SplitK GEMM 的文档,以指导开发者了解其用法和实现策略。
- Aurora Innovation 招聘工程师:Aurora Innovation 目标在 2024 年底前实现商业发布,正在寻找在 GPU acceleration 以及 CUDA/Triton 工具方面具有专业知识的 L6 和 L7 级工程师。
- 该公司最近筹集了 4.83 亿美元以支持其无人驾驶发布计划,彰显了投资者的显著信心。
- 评估 AI 模型与 OpenAI 的策略:参与者对 OpenAI 相较于 Anthropic 等竞争对手的竞争力表示担忧,强调了对创新训练策略的需求。
- 围绕 Chain of Thought (CoT) 的讨论揭示了对其实现透明度的不满,这影响了对 OpenAI 领导效能的看法。
Stability.ai (Stable Diffusion) Discord
- Reflection LLM 性能担忧:Reflection LLM 声称性能超越了 GPT-4o 和 Claude Sonnet 3.5,但其实际表现引发了大量批评,尤其是与开源变体相比。
- 由于其 API 似乎在镜像 Claude,人们对其原创性产生了怀疑,促使用户质疑其有效性。
- AI 照片生成服务探索:有关于生成写实图像效果最佳的付费 AI 照片生成服务的咨询,引发了围绕现有选项的热烈讨论。
- 讨论中提到了一个值得注意的替代方案:Easy Diffusion,被定位为一个强大的免费竞争对手。
- Flux 模型性能优化:用户报告了使用 Flux model 的积极体验,强调了与内存使用调整和 RAM 限制相关的显著性能提升。
- 目前正在进行关于低 VRAM 优化的讨论,特别是与 SDXL 等竞争对手的比较。
- Lora 训练故障排除:成员们分享了在 Lora 训练过程中遇到的困难,寻求在显存(VRAM)有限的设备上进行更好配置的帮助。
- 讨论中参考了工作流优化的资源,特别提到了 Kohya 等训练器。
- 模型中的动态对比度调整:一位用户探索了通过使用特定 CFG 设置来降低其光照模型对比度的方法,并提出了动态阈值(dynamic thresholding)技术。
- 他们征求了关于在修改 CFG 值时如何平衡参数的建议,表明需要精确调整以提高输出质量。
LM Studio Discord
- 在 LM Studio 中实现 RAG 的指南:为了在 LM Studio 中成功构建 RAG 流水线,用户应下载 0.3.2 版本并根据成员建议上传 PDF。另一位用户遇到了“未找到与用户查询相关的引用”错误,建议进行具体询问而非泛泛而谈。
- 鼓励成员参考 Building Performant RAG Applications for Production - LlamaIndex 以获取更多深入见解。
- Ternary Models 性能问题:成员们讨论了加载 ternary models 时遇到的麻烦,有人报告在访问模型文件时出错,另一人建议回退到旧的量化类型,因为最新的 “TQ” 类型仍处于实验阶段。
- 这突显了在处理新型号时需要谨慎,并相应地调整工作流程。
- 伦敦社区见面会:邀请用户参加在伦敦举行的社区见面会,讨论 Prompt Engineering 并分享经验,强调已准备好与同行工程师建立联系。与会者可以寻找携带笔记本电脑的老成员。
- 此次活动为建立网络和交流宝贵见解提供了一个平台。
- OpenAI O1 访问权限逐步开放:成员们正在讨论获取 OpenAI O1 preview 访问权限的体验,指出开放过程是分批进行的。一些用户最近获得了访问权限,而其他人仍在等待机会。
- 这一过程展示了新工具在社区中的逐步普及。
- 对双 4090D 配置的兴趣:一位成员分享了使用两块 4090D GPU(每块配备 96GB RAM)的兴奋之情,但强调了电力挑战,其 600W 的需求需要一个小功率发电机。这种对高功耗的幽默看法引起了小组的关注。
- 这种热情反映了成员们为了提升性能而考虑的先进配置。
OpenInterpreter Discord
- 使用 Rich 增强终端输出:Rich 是一个用于美化终端格式的 Python 库,极大地增强了开发者的视觉输出效果。
- 成员们探索了各种终端操作技术,讨论了改进颜色和动画功能的替代方案。
- LiveKit Server 最佳实践:社区共识推荐 Linux 作为 LiveKit Server 的首选操作系统,并有在 Windows 上遇到麻烦的案例。
- 一位成员幽默地提到:“别用 Windows,到目前为止只遇到过问题,” 缓解了其他人对操作系统选择的担忧。
- OpenAI o1 模型预览版发布:OpenAI 预告了 o1 预览版,这是一个旨在提高科学、编程和数学应用推理能力的新模型系列,详见其公告。
- 成员们对该模型比以往模型更好地处理复杂任务的潜力感到兴奋。
- Open Interpreter 技能面临的挑战:参与者指出 Open Interpreter skills 在会话结束后无法保留,影响了 Slack 消息传递等功能。
- 社区已发起协作呼吁以解决此问题,寻求进一步调查。
- 期待 Cursor 和 o1-mini 的集成:用户表达了对 Cursor 推出 o1-mini 支持的渴望,并用俏皮的表情符号暗示了其即将发布的功能。
- 对 o1-mini 的期待表明社区对新型工具能力的需求日益增长。
Cohere Discord
- Parakeet 项目引起轰动:使用 A6000 系列模型在 3080 Ti 上训练 10 小时的 Parakeet 项目产出了显著的成果,引发了人们对 AdEMAMix 优化器有效性的兴趣。一位成员指出,“这可能就是 Parakeet 能够在不到 20 小时内完成 4 层模型训练的原因。”
- 这一成功表明训练范式可能发生转变,同时也引发了对优化技术的进一步研究。
- GPU 拥有情况揭示了多样化的配置:一位成员分享了他们令人印象深刻的 GPU 阵容,拥有 7 块 GPU,包括 3 块 RTX 3070 和 2 块 RTX 4090。这引发了关于 GPU 命名惯例及其在当今相关性的幽默讨论。
- 持续的讨论凸显了成员之间在硬件选择和使用上的广泛多样性。
- 训练数据质量重于数量:一次对话强调,在训练模型时,重要的不是纯粹的数据量,而是数据的质量——一位成员在处理 26k 行数据用于 JSON 转 YAML 的用例时分享了这一观点。他们表示:“数据量并不那么重要——更重要的是质量。”
- 这一交流表明人们对训练方法论中数据重要性有了更深层次的理解。
- 个人 AI 行政助理取得成功:一位成员成功构建了一个个人 AI 行政助理,它通过 calendar agent cookbook 管理日程,并集成了语音输入来编辑 Google Calendar 事件。该项目展示了 AI 在个人生产力方面的创新应用。
- 该助理能够熟练地解释非结构化数据,事实证明对整理考试日期和项目截止日期非常有益。
- 寻求 RAG 应用的最佳实践:一位用户询问了在 RAG 应用中实施护栏(guardrails)的最佳实践,强调解决方案应视具体语境而定。这与优化 AI 应用以实现现实实用性的持续努力相一致。
- 他们还调查了用于评估 RAG 性能的工具,旨在确定广泛认可的指标和方法论。
Eleuther Discord
- 简化项目贡献流程:一位成员强调,在任何项目中提交 Issue 并随后提交 PR 是最简单的贡献方式。
- 这种方法提供了清晰度,并促进了正在进行的项目中的协作。
- 博士毕业的喜悦:一位成员分享了在德国完成博士学位的热情,并准备开始专注于安全(safety)和多 Agent 系统(multi-agent systems)的博士后研究。
- 他们还强调了国际象棋和乒乓球等爱好,展示了丰富多彩的个人生活。
- RWKV-7 凭借 Chain of Thought 脱颖而出:仅拥有 2.9M 参数的 RWKV-7 模型在利用 Chain of Thought 解决复杂任务方面展示了令人印象深刻的能力。
- 据指出,使用反转数字生成大量数据增强了其训练效率。
- Pixtral 12B 在对比中表现不佳:关于 Pixtral 12B 性能的讨论爆发,尽管其规模更大,但表现似乎逊色于 Qwen 2 7B VL。
- 人们对 MistralAI 会议上展示的数据完整性产生了怀疑,认为可能存在疏忽。
- 多节点训练的挑战:人们对在慢速以太网连接上进行多节点训练的可行性表示担忧,特别是在 8xH100 机器上使用 DDP 时。
- 成员们一致认为,优化全局 Batch Size 对于克服性能瓶颈至关重要。
LlamaIndex Discord
- 即将举行 AI 调度器实战研讨会:请于 9月20日 加入我们在 AWS Loft 的活动,学习如何使用 Zoom, LlamaIndex 和 Qdrant 构建用于提升会议效率的 RAG 推荐引擎。更多详情请见 此处。
- 本次研讨会旨在利用提供转录功能的前沿工具,创造一个高效的会议环境。
- 为汽车需求构建 RAG 系统:一个新的多文档 Agentic RAG 系统 将利用 LanceDB 帮助诊断汽车问题并管理保养计划。参与者可以按照 此处 的说明设置向量数据库,以进行有效的汽车诊断。
- 这种方法强调了 RAG 系统在传统场景之外的实际应用中的多功能性。
- OpenAI 模型现已在 LlamaIndex 中可用:随着 OpenAI 的 o1 和 o1-mini 模型 的集成,用户可以直接在 LlamaIndex 中使用这些模型。使用
pip install -U llama-index-llms-openai安装最新版本以获取完整访问权限,详情见此。- 此次更新增强了 LlamaIndex 的功能,与模型实用性的持续进步保持一致。
- LlamaIndex 黑客松提供现金奖励:为定于 10月11-13日 举行的第二届 LlamaIndex 黑客松做准备,由 Pinecone 和 Vesslai 赞助的奖金超过 $10,000。参与者可以 在此 注册参加这个专注于 RAG 技术 的活动。
- 黑客松鼓励在 RAG 应用和 AI Agent 开发方面的创新。
- 关于 AI 框架复杂性的辩论:针对 LangChain, Llama_Index 和 HayStack 等框架是否对于 LLM 开发的实际应用变得 过于复杂 展开了讨论。引用了一篇深刻的 Medium 文章。
- 这突显了人们对工具设计中功能性与简洁性平衡的持续关注。
DSPy Discord
- 输出评估挑战:成员们强调,除了旨在减少幻觉的标准 Prompt 技术外,缺乏评估输出 真实性 (veracity) 的方法,并强调了对更好评估手段的需求。
- 一位成员幽默地提到,“请不要在你的下一篇出版物中引用我的网站”,强调了在使用生成输出时的谨慎。
- 定制 DSPy 聊天机器人:一位成员询问如何在 DSPy 生成的 Prompt 中通过后处理步骤而非硬编码来实现针对特定客户的定制,以追求灵活性。
- 另一位成员建议利用类似于 RAG 方法的“context”输入字段,建议使用通用格式训练 Pipeline 以增强适应性。
- O1 定价困惑:关于 OpenAI O1 定价的讨论显示,成员们对其结构并不确定,其中一人确认 O1-mini 比其他选项更便宜。
- 成员们表示有兴趣对 DSPy 和 O1 进行对比分析,建议试用 O1 以评估潜在的成本效益。
- 理解 O1 的 RPM:一位成员澄清 “20rpm” 指的是 “每分钟请求数 (requests per minute)”,这是一个影响 O1 和 DSPy 性能讨论的关键指标。
- 这一澄清引发了关于该指标对当前和未来集成影响的进一步询问。
- 对 DSPy 和 O1 集成的好奇:关于 DSPy 与 O1-preview 兼容性的问题不断涌现,反映了社区探索这两个系统之间更多功能的渴望。
- 这种兴趣标志着集成对于增强 DSPy 内部能力的重要性。
Torchtune Discord
- 混合精度训练复杂性:维护 mixed precision modules 与其他特性之间的兼容性需要额外的工作;由于旧款 GPU 上的 fp16 支持问题,bf16 半精度训练被认为明显更好。
- 简单地使用 fp16 会导致溢出错误,增加系统复杂性,并因使用全精度梯度 (full precision gradients) 而增加内存占用。
- FlexAttention 集成获批:用于文档掩码 (document masking) 的 FlexAttention 集成已合并,其潜力引发了广泛关注。
- 有人提出疑问,每个 ‘pack’ 是否都填充到了 max_seq_len,考虑到缺乏完美打乱 (perfect shuffle) 对收敛 (convergence) 的影响。
- PackedDataset 在 INT8 下表现出色:性能测试显示,在 torchao 中使用 INT8 混合精度时,PackedDataset 在 A100 上实现了 40% 的加速。
- 一名成员计划进行更多测试,确认 PackedDataset 的固定 seq_len 与其 INT8 策略非常契合。
- Tokenizer API 标准化讨论:一名成员建议在解决 eos_id 问题之前,先处理 issue #1503 以统一 tokenizer API,这意味着这可以简化开发流程。
- 由于 #1503 已经有负责人,该成员打算探索其他修复方案以增强整体改进。
- 提供了 QAT 澄清:一名成员对比了 QAT (Quantization-Aware Training) 与 INT8 混合精度训练,强调了它们目标上的关键差异。
- QAT 旨在提高准确性,而 INT8 训练侧重于提升速度,且在准确性损失极小的情况下可能不需要 QAT。
OpenAccess AI Collective (axolotl) Discord
- OpenAI 模型引发好奇:成员们对 新的 OpenAI 模型 议论纷纷,询问其特性和反响,认为这是一个值得探索的新发布。
- 它引发了好奇心,并带动了关于其功能和反响的进一步讨论。
- Llama Index 关注度达到顶峰:随着成员们分享对 Llama Index 交互工具的熟悉程度以及与 OpenAI 模型的潜在联系,对其兴趣日益增长。
- 这促使人们开始探索它与新的 OpenAI 模型之间的关系。
- Reflection 70B 被贴上“哑弹”标签:有成员担心 Reflection 70B 模型被视为哑弹 (dud),引发了关于 OpenAI 新发布时机影响的讨论。
- 该评论是以轻松的方式分享的,暗示这是对之前失望情绪的一种回应。
- DPO 格式预期已设定:一名成员参考 GitHub issue 澄清了预期的 DPO 格式为
<|begin_of_text|>{prompt},后接{chosen}<|end_of_text|>和{rejected}<|end_of_text|>。- 这一更新指向了 Axolotl 框架中自定义格式处理的改进。
- Llama 3.1 在工具调用方面遇到困难:llama3.1:70b 模型在利用工具调用 (tool calls) 时出现了无意义输出的问题,尽管功能上看起来是正确的。
- 在一个案例中,在工具指示夜间模式已停用后,助手仍未能对后续请求做出恰当回应。
LAION Discord
- RenderNet 推出的 Flux 已发布!:来自 RenderNet 的 Flux 允许用户仅凭一张参考图即可创建超现实 (hyper-realistic) 图像,无需 LoRAs。可以通过此 链接 查看。
- 准备好让你的角色栩栩如生了吗? 用户只需点击几下即可轻松上手。
- SD 团队更名:SD 团队更改了名称以反映他们从 SAI 离职,引发了关于其现状的讨论。
- 所以 SD 就这么没了? 这条评论捕捉到了成员们对该团队未来的担忧情绪。
- 对 SD 开源状态的担忧:成员们对 SD 在开源领域缺乏活跃度表示担忧,这表明社区参与度可能有所下降。
- 如果你关心开源,SD 似乎已经名存实亡了,这是一条关于其活跃度下降的显著评论。
- SD 发布了新的仅限 API/Web 的模型:尽管存在参与度方面的担忧,SD 团队最近发布了一个仅限 API/Web 的模型,标志着一定程度的产出。
- 虽然对其开源承诺的初步怀疑依然存在,但这次发布表明他们仍在工作。
- 通过 Sci Scope 保持更新:Sci Scope 汇集了带有相关主题的新 ArXiv 论文,并每周进行总结,以便于 AI 研究的消化吸收。
- 订阅时事通讯 以获取直接投递的简明更新,增强你对当前文献的了解。
LangChain AI Discord
- HTML 分块包发布:新软件包
html_chunking能够高效地对 HTML 内容进行分块和合并,同时保持 Token 限制,这对于网络自动化任务至关重要。- 这种结构化方法确保了有效的 HTML 解析,为各种应用保留了必要的属性。
- 共享 HTML 分块演示代码:展示
get_html_chunks的演示代码片段说明了如何在设定的 Token 限制内处理 HTML 字符串并保留其结构。- 输出由有效的 HTML 块组成——过长的属性会被截断,确保长度在实际使用的合理范围内。
- HTML 分块与现有工具对比:将
html_chunking与 LangChain 的HTMLHeaderTextSplitter和 LlamaIndex 的HTMLNodeParser进行了对比,突出了其在保留 HTML 上下文方面的优越性。- 现有工具主要提取文本内容,这削弱了它们在需要完整保留 HTML 场景下的有效性。
- 开发者行动指南:鼓励开发者探索
html_chunking以增强网络自动化能力,并强调了其精确的 HTML 处理能力。- HTML chunking PYPI 页面和 GitHub 仓库的链接提供了进一步探索的途径。
tinygrad (George Hotz) Discord
- George Hotz 提倡理性互动:George Hotz 要求成员除非问题具有建设性,否则请勿进行不必要的 @mentions,鼓励在资源利用方面保持自给自足。
- 只需一次搜索即可找到相关信息,从而在讨论中培养一种关注相关性的文化。
- 新服务条款侧重于伦理实践:George 为 ML 开发者引入了专门的服务条款,旨在禁止在 GPU 上进行加密货币挖矿和转售等活动。
- 该政策旨在创建一个专注的开发环境,特别是利用 MacBook 的能力。
LLM Finetuning (Hamel + Dan) Discord
- Literal AI 的易用性脱颖而出:一位成员赞扬了 Literal AI 的易用性,并指出了其增强 LLM 应用生命周期的功能,详见 literalai.com。
- 集成和直观的设计被强调为促进开发者更顺畅运营的关键方面。
- 通过 LLM 可观测性提升应用生命周期:LLM 可观测性被讨论为增强应用开发的重大变革,它允许更快的迭代和调试,同时利用日志对小型模型进行 Fine-tuning。
- 这种方法旨在显著提高模型管理的性能并降低成本。
- 变革 Prompt 管理:强调将 Prompt 性能追踪作为防止部署回归的保障,讨论指出这是获得可靠 LLM 输出的必要条件。
- 这种方法在更新过程中主动维护质量保证。
- 建立 LLM 监控设置:分享了关于构建强大的 LLM 监控与分析系统的见解,整合日志评估以维持最佳生产性能。
- 此类设置被认为对于确保运营的持续效率至关重要。
- Fine-tuning LLM 以获得更好的翻译:关于专门针对翻译进行 Fine-tuning LLM 的讨论浮出水面,指出了 LLM 虽然能捕捉大意但往往遗漏语气或风格的挑战。
- 这一差距为开发者在翻译能力方面的创新提供了途径。
Gorilla LLM (Berkeley Function Calling) Discord
- Gorilla LLM 测试显示准确率参差不齐:最近对 Gorilla LLM 的测试显示了令人担忧的结果,irrelevance(无关性)达到了 1.0 的完美准确率,而 java 和 javascript 的记录均为 0.0。
- live_parallel_multiple 和 live_simple 等测试结果令人失望,引发了对模型有效性的质疑。
- 成员寻求 Qwen2-7B-Chat Prompt 拼接方面的帮助:一位用户对 qwen2-7b-chat 的表现欠佳表示担忧,询问这是否源于 Prompt 拼接的问题。
- 他们正在寻找可靠的见解和方法,通过有效的 Prompt 策略来增强其测试体验。
MLOps @Chipro Discord
- 寻求预测性维护(Predictive Maintenance)的见解:一名成员就其在 predictive maintenance 方面的经验提出了疑问,并寻求有关最佳模型和实践的资源(如论文或书籍),特别是关于无需追踪故障的无监督方法。
- 讨论强调了手动标记事件的不切实际性,强调了该领域对高效方法论的需求。
- 监控中的机械与电气重点:讨论集中在一种兼具 mechanical(机械)和 electrical(电气)特性的设备上,该设备记录了多个操作事件,可以从改进的监控实践中受益。
- 成员们一致认为,利用有效的监控策略可以增强维护方法,并可能降低未来的故障率。
Alignment Lab AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第 2 部分:详细的频道摘要与链接
完整的各频道详情因邮件长度限制已截断。
如果您喜欢 AInews,请分享给朋友!预谢!