ainews-nothing-much-happened-today-7147
今天没发生什么特别的事。
以下是该文本的中文翻译:
OpenAI 的 o1 模型由于其极端的限制以及在思维链(CoT)上进行强化学习(RL)等独特的训练进展,在开源复制方面面临质疑。ChatGPT-4o 在各项基准测试中表现出显著的性能提升。Llama-3.1-405b 的 fp8 和 bf16 版本性能表现相似,但 fp8 具有成本优势。一个新的开源基准测试 “人类最后的考试”(Humanity’s Last Exam) 提供了 50 万美元的奖金来挑战大语言模型(LLM)。模型合并(Model merging) 受益于神经网络的稀疏性和线性模式连接性(linear mode connectivity)。基于嵌入(Embedding)的有毒提示词检测以较低的计算量实现了高准确率。InstantDrag 实现了快速、无需优化的拖拽式图像编辑。LangChain v0.3 发布,改进了依赖管理。自动化代码审查工具 CodeRabbit 能够适应团队的编码风格。视觉搜索的进展整合了多模态数据,以实现更好的产品搜索。专家预测,到 2030 年,AI 将成为软件的默认配置。
宁静是你唯一需要的。
2024/9/16-2024/9/17 的 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitter 账号 和 30 个 Discord(221 个频道,2197 条消息)。预计节省阅读时间(以 200wpm 计算):225 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
鉴于围绕 o1 的极端限制、成本以及缺乏透明度,每个人对于 o1 是否能在开源领域或野外被复制都各有各的看法。正如 /r/localLlama 中讨论的,Manifold 预测市场目前认为开源版本出现的概率为 63%:
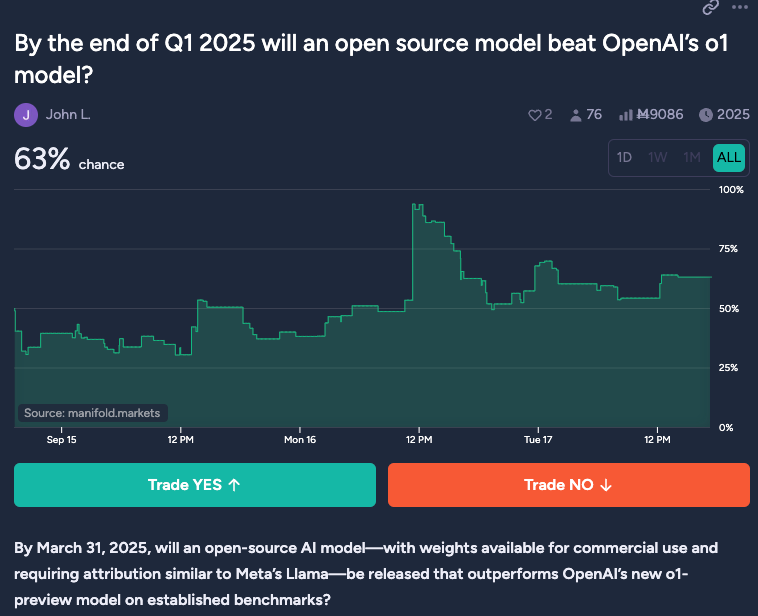
与此同时,以下情况都有可能:
- o1 的许多方面都可以在开源中复制,特别是如果拥有 OpenAssistant 级别的众包推理轨迹(reasoning trace)数据集。
- 也许人们一直在传阅的一些 MCST 论文是相关的,但也可能不相关。
- 在训练层面实现的真正的 RL on CoT 进展,是任何程度的数据集修补(futzing)都无法企及的。
仅凭最后一个原因,模型开发中标准的“达到 OSS 等效水平的时间”曲线在此案例中可能并不适用。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型更新与进展
-
OpenAI 的 o1 模型:@denny_zhou 强调,理论上只要有足够的中间推理 Token,即使深度恒定,Transformer 也可以解决任何问题。这表明扩展 LLM 推理性能具有巨大潜力。
-
性能提升:@lmsysorg 报告了 ChatGPT-4o (20240903) 在各项基准测试中的显著提升,包括整体性能、风格控制、困难提示词(hard prompts)以及多轮交互。
-
模型对比:@lmsysorg 对比了 Llama-3.1-405b 的 bf16 和 fp8 版本,发现在各类别中性能相近,fp8 在显著降低成本的同时,表现与 bf16 非常接近。
-
新兴能力:@svpino 讨论了 GPT-4o 在系统 1(System 1)思维和 OpenAI o1 在系统 2(System 2)思维方面的专业化,并预见未来模型将在单一框架下融合两者。
AI 开发与研究
-
评估挑战:@alexandr_wang 宣布 Scale 与 CAIS 合作推出“人类最后的考试”(Humanity’s Last Exam),这是一个极具挑战性的 LLM 开源基准测试,为最佳问题提供 50 万美元奖金。
-
模型合并:@cwolferesearch 解释了模型合并(model merging)的有效性,将其成功归功于神经网络中的线性模式连接(linear mode connectivity)和稀疏性。
-
AI 安全:@rohanpaul_ai 分享了关于基于 Embedding 的有毒提示词检测的见解,以极低的计算开销实现了高准确率。
-
多模态能力:@_akhaliq 介绍了 InstantDrag,这是一个无需优化的拖拽式图像编辑流水线,增强了图像处理任务中的交互性和速度。
AI 工具与应用
-
LangChain 更新:@LangChainAI 宣布发布适用于 Python 和 JavaScript 的 LangChain v0.3,重点在于改进依赖项并转向对等依赖(peer dependencies)。
-
AI 在代码审查中的应用:@rohanpaul_ai 讨论了使用 CodeRabbit 进行自动化代码审查,强调其能够适应团队编码习惯并提供定制化反馈。
-
AI 在产品搜索中的应用:@qdrant_engine 分享了视觉搜索解决方案的进展,将图像、文本和其他数据集成到统一的向量表示中,以提升产品搜索体验。
行业趋势与观察
-
AI 集成:@kylebrussell 预测到 2030 年,AI 将成为默认配置,软件将实现自我生成,而 Agent 将成为新的应用形式。
-
开源进展:@far__el 暗示了开源 AI 模型的最新进展,表明其可能与闭源模型展开竞争。
-
AI 在时尚界的应用:@mickeyxfriedman 展示了 AI 生成的时尚模特,暗示品牌营销策略可能发生转变。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. 模型压缩与量化方面的进展
- LMSYS 发现 Chatbot Arena 中 bf16 和 fp8 版本的 Llama-3.1-405b 差异极小 (Score: 109, Comments: 34): LMSYS 在其 Chatbot Arena 中对 Llama-3.1-405b 的 bf16 和 fp8 版本进行了对比,发现两者在性能上的差异微乎其微。fp8 模型的胜率仅比 bf16 版本下降了 0.3%,这表明 fp8 quantization 可以在显著减小模型体积和显存需求的同时,对质量的影响几乎可以忽略不计。
- 用户反映不同量化版本在编程性能方面存在显著差异,一些人指出 fp8 在编程任务中的表现不如 q8。Aidan McLau 的一条推文批评了 LMSYS 的评估方法,认为 bf16 在特定提示词下表现更优。
- 讨论强调了像 LMSYS leaderboard 这种基于人类感知的评估方式的局限性。一些用户观察到 q8 和 fp16 在编程方面的差异很小,而另一些用户则在基准测试中报告了相互矛盾的结果。
- 几条评论称赞了 quantization 技术,一位用户成功地将 Llama 3.1 70b 的 IQ2_M 版本 用于编程任务。争论延伸到了各种量化级别(q6_k, q4km)之间的比较及其对模型性能的影响。
- 发布采用 AQLM-PV 压缩的 Llama3.1-70B 权重。 (Score: 249, Comments: 81): Llama3.1-70B 和 Llama3.1-70B-Instruct 模型已使用 AQLM+PV-tuning 进行压缩,将其体积减小至 22GB,从而能够在单张 3090 GPU 上运行。这种压缩导致 MMLU 性能下降了 4-5 个百分点,基础模型的得分从 0.78 降至 0.73,指令微调模型的得分从 0.82 降至 0.78。此外,还发布了一个压缩版的 Llama3.1-8B 模型,它可以作为 Android 应用运行,仅需 2.5GB RAM。
- 压缩后的 Llama3.1-70B 模型与 IQ_2M 量化类似,具有相当的 22GB 体积和 MMLU 分数。用户讨论了运行方法,包括 Transformers, vLLM 和 Aphrodite,一些人在实现过程中遇到了挑战。
- 人们对压缩更大的模型(如 405B 版本 和 Gemma-2 27B)表现出浓厚兴趣。用户推测了潜在的体积以及与特定硬件(如配备 128GB RAM 的 M3 Max)的兼容性。
- AQLM 量化方法作为一个 开源项目 提供,但目前不支持 GGUF 格式。用户报告推理速度较慢,在 3090 GPU 上约为 7 tokens/秒。
- Hugging Face 优化了 Segment Anything 2 (SAM 2),可在设备端(Mac/ iPhone)实现亚秒级推理! (Score: 83, Comments: 14): Hugging Face 针对设备端推理优化了 Segment Anything 2 (SAM 2),使其能够在 Mac 和 iPhone 上以亚秒级性能运行。这种优化实现了移动设备上的实时分割任务,可能为增强现实、图像编辑和边缘设备上的计算机视觉开启新的应用。
- Hugging Face 正在发布各种尺寸的 SAM 2 Apache 许可证优化模型权重检查点,以及一个用于亚秒级图像标注的 开源应用。他们还为 Medical SAM 等 SAM2 微调模型提供转换指南。
- 开发者计划增加视频支持,并对未来功能的建议持开放态度。这表明 SAM 2 优化项目正在持续开发中,并具有扩展能力的潜力。
- 用户对 Apple 优化其他模型表示出兴趣,特别是提到了 GroundingDino。这表明对更多针对 Apple 硬件优化的端侧 AI 模型存在需求。
主题 2. 开源 LLM 正在缩小与闭源模型的差距
- 开源模型会在 2025 年 Q1 结束前击败 o1 吗? (Score: 111, Comments: 52): 该帖子推测 开源语言模型 是否能通过使用 “System 2” 风格 的方法(如 Monte Carlo Tree Search (MCTS) 和 reflection),在 2025 年 Q1 之前超越 OpenAI 的 GPT-4(此处指代 “o1”)。作者引用了 Noam Brown 的工作,并创建了一个 Manifold market 来衡量公众对这一可能性的看法。
- 开源模型 有可能在 2025 年 Q1 达到 GPT-4 的性能水平,用户提到了 Claude 3.5 的显著进步,以及 reflection 和 thinking magic 进一步增强开源模型的潜力。
- 对 GPT-4 架构的推测表明,它可能是一项 工程成就 而非一个新模型,可能使用了 微调后的现有模型、巧妙的 prompting 以及一个 “critic” LLM 来对回答进行评估。
- 关于时间线的观点各不相同,一些人认为 开源模型 可能在 2025 年底超越 GPT-4,而另一些人指出 OpenAI 可能会进一步改进其模型,保持对开源替代方案的领先地位。
- 发布采用 AQLM-PV 压缩的 Llama3.1-70B 权重。 (Score: 249, Comments: 81): Llama3.1-70B 和 Llama3.1-70B-Instruct 模型已使用 AQLM+PV-tuning 进行压缩,将其大小减小至 22GB,使其能够在单个 3090 GPU 上运行。压缩导致 MMLU 性能 下降了 4-5 个百分点,基础模型的得分从 0.78 降至 0.73,指令模型的得分从 0.82 降至 0.78。此外,还发布了一个压缩后的 Llama3.1-8B 模型,该模型已作为 Android app 运行,仅需 2.5GB RAM。
- 用户将 AQLM+PV-tuning 与 IQ_2M 量化进行了比较,注意到两者在 22GB 大小和 MMLU 得分 上表现相似。该模型的 chat template 已修复,以提高与 vLLM 和 Aphrodite 的兼容性。
- 由于尺寸限制,在 16GB VRAM 系统上运行该模型被证明具有挑战性。70B 模型 仅权重就需要至少 17.5GB,此外还需要额外的内存用于缓存和 embeddings。
- 用户表示有兴趣将 AQLM 压缩应用于其他模型,如 Gemma-2 27B 和 Mixtral。AQLM GitHub 仓库 已分享给那些有兴趣量化自己模型的人。
- 创建开源 o1 模型似乎指日可待! (Score: 173, Comments: 55): 作者报告了在创建一个 开源类 o1 模型 方面取得的 令人鼓舞的结果,该模型使用了在 370 行的小型数据集 上微调的 Q4_K_M 8B 模型。他们提供了 模型、演示 和用于微调的 数据集 的链接,强调了 GPU 受限的用户 很快就能获得类似模型的潜力。
- 用户将该项目与 Matt 的 o1 实验 进行了比较,指出这次尝试确实产生了结果。作者澄清说他们并不是在声称这是一个 SOTA 模型,只是分享一个有趣的实验。
- 讨论集中在需要实现 reinforcement learning 以完全复制 o1 的方法。一些人推测 o1 使用 RL 来为 chain-of-thought 过程寻找最佳措辞和句法结构。
- 几条评论建议运行 热门基准测试 以证明可信度并比较结果。作者已将模型提交至 open llm leaderboard 进行评估,并承认由于数据集较小和 GPU 限制而存在的局限性。
主题 3:LLM 推理(Reasoning)与推理(Inference)技术的发展
-
o1-preview: 一个擅长数学和推理、编程表现平平、写作表现较差的模型 (Score: 87, Comments: 26): o1-preview 模型在复杂推理、数学和科学方面展现了卓越的能力,在处理挑战性提示词的 single-shot 响应中优于其他模型。然而,它在创意写作方面表现不佳,在编程方面表现平平;由于更好的推理速度(inference speed)和准确性权衡,作者在编程任务中更倾向于使用 Sonnet 3.5。尽管推理步骤有时不一致,该模型偶尔仍能提供正确答案。虽然它代表了重大进步,但在推理或数学方面尚未达到 Ph.D. level。
-
论文:Chain of Thought 赋能 Transformers 解决固有的串行问题 (Score: 136, Comments: 27): 来自 Google DeepMind 的 Denny Zhou 声称,正如他们的论文所证明的那样,Large Language Models (LLMs) 在扩展推理时没有性能限制。研究表明,只要能生成足够的中间推理 token,Transformers 就可以解决任何具有固定深度(constant depth)的问题,详情见 arXiv 上的论文。
-
推理阶段 LLM “推理”策略的圣杯 (Score: 39, Comments: 4): 该帖子重点介绍了一个 GitHub 仓库,该仓库汇编了受近期 Reflection models 及其扩展启发的各种推理阶段使用的 LLM “推理”策略。该仓库由第三方创建,地址为 https://github.com/codelion/optillm,提供了一个即插即用的 API(drop-in API),用于测试不同的推理或“思考”方法,并可适配各种本地模型提供商。
- 用户对该仓库表示了兴趣,其中一位指出这些进步超越了常规的微调算法(fine-tuning algorithms)。讨论了该仓库与本地服务器的兼容性,并确认已成功与 oobaboogas textgen 集成。
- 该仓库作为一个透明的 OpenAI API 兼容代理运行,允许与各种工具和框架集成。可以通过在本地服务器中设置 base_url 来使用该代理。
- 与 Patchwork 的集成相比基础模型带来了显著的性能提升。有关此集成的详细信息可以在 仓库的 README 和 wiki 中找到。
主题 4. LLM 评估与可靠性方面的挑战
-
作为一个热衷于 LLM 工作流的人,我发现很难信任 o1 的输出 (Score: 35, Comments: 9): 该帖子批评了 o1 在处理复杂任务(尤其是编程场景)时的输出和工作流方法。作者热衷于 LLM workflows,他观察到 o1 的输出更像是一种工作流结构,而非标准的 Chain of Thought,这可能导致一些问题,例如 LLM 在简单问题上陷入逻辑死胡同,或者通过多个处理步骤丢失功能从而弄乱 Python 方法。帖子认为针对不同类型的任务(如推理 vs 编程)采用定制化工作流至关重要,并暗示 o1 目前对所有任务使用单一工作流的方法可能会有问题,特别是对于复杂的开发工作,这导致作者在编程任务中仍然首选 ChatGPT 4o。
-
新模型可识别并移除数据集中的废话(Slop) (Score: 68, Comments: 18): Exllama 社区开发了一个模型,用于识别和移除公共数据集(包括 HuggingFace 上的数据集)中的“废话(slop)”和说教(moralization)。这一突破允许检测企业废话(corporate slop)、对废话类型进行分类以及分析低质量数据轨迹,从而可能提高 LLM 的对话能力并理解提示词拒绝模式。有关该项目的更多信息可以在 Exllama Discord 服务器上找到,感兴趣的人可以与模型的创建者 Kal’tsit 交流。
-
博士级模型 GPT-o1 在初中数学“陷阱”题上失败,准确率仅为 24.3% (Score: 270, Comments: 78):尽管声称具有博士级智能,GPT-o1 模型在 MathTrap_Public 数据集上的准确率仅为 24.3%,该数据集包含带有“陷阱”的初中数学题。研究人员通过修改 GSM8K 和 MATH 数据集中的问题创建了 MathTrap 数据集,引入了矛盾或不可解的元素,这需要同时理解原始问题和陷阱才能识别。开源模型在 MathTrap_Private 上的表现更差,Reflection-70B 的准确率为 16.0%,Llama-3.1-8B 为 13.5%,Llama-3.1-70B 为 19.4%。
- 博士级数学家和其他用户指出,他们也会犯和 AI 同样的错误,其中一人表示这个问题“从根本上来说毫无趣味”。许多人认为 x=0 处的间断点并非本质问题,极限方法是有效的。
- 用户质疑了研究方法,有人指出该预印本最后修订于 7 月 11 日,并未提及 o1。他们测试了陷阱题,发现 o1 在第一次尝试时就正确识别了所有陷阱,暗示可能存在误导信息。
- 几位评论者批评了 Prompt 设计,认为更合理的提问方式会产生更准确的结果。有人建议这样问:“该函数是周期性的吗?如果是,计算周期;否则,证明不存在周期。请证明你的论点。”
其他 AI Subreddit 摘要
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型进展与基准测试
-
OpenAI 的新 GPT-4o1 模型在 IQ 测试中获得了 120 分,超过了 90% 的人类。然而,在它从未见过的新问题上,其得分接近人类平均水平 100 分。这仍然代表了 AI 推理能力的重大进步。
-
OpenAI 将 o1-mini 模型的速率限制提高了 7 倍,从每周 50 条消息增加到每天 50 条消息。o1-preview 模型也从每周 30 条增加到 50 条。
-
o1 模型在编程基准测试中表现出比 o1-preview 的重大改进,正确率从 62% 跃升至 89%。这代表了复杂代码生成的可靠性提升了 3.5 倍。
-
一些用户报告称 o1-mini 已经取代了 GPT-4 执行编程任务,因为它提供完整的、无上限的响应,无需点击“继续”。
AI 伦理与社会影响
-
亿万富翁 Larry Ellison 建议 AI 驱动的监控系统可以确保“公民表现出最佳行为”,引发了关于隐私担忧和 AI 技术潜在滥用的辩论。
-
关于是该庆祝还是担忧 AI 的飞速进步,目前仍有持续讨论。一些人将其视为令人兴奋的技术进步,而另一些人则对失业和社会影响表示担忧。
AI 开发与研究
-
o1 模型似乎使用了涉及带有内置 Chain of Thought 过程的强化训练的突破,这可能允许能力的大规模扩展。
-
一些研究人员建议 o1 可以被视为一种“原型 AGI”架构,尽管在短期和长期记忆等领域可能仍需要额外的突破才能实现通用人工智能。
AI 工具与应用
-
像 FLUX 这样新的 AI 图像生成工具正在产生令人印象深刻的结果,展示了受《半条命》(Half-Life) 启发的苏联时代场景和抽象超现实主义景观的示例。
-
Quest 3 VR 头显结合 AI 视频生成工具正在开启新型沉浸式内容创作。
AI Discord 摘要
摘要的摘要的摘要
O1-mini
主题 1. AI 模型:新发布与竞争
-
Claude 3.5 对决 GPT-4o:社区在 Claude 3.5 和 GPT-4o 之间摇摆不定,成员们通过测试来确定哪个模型在特定任务中表现更出色。Claude vs GPT-4o 对决 突显了这场持续的竞争。
-
Qwen 2.5 发布更严格的变体:Qwen 2.5 推出了从 0.5B 到 72B 参数的新模型尺寸,全部具备增强的内容过滤功能。用户对 knowledge retention(知识保留)的担忧依然存在。
-
Mistral 的 Pixtral-12B 登场:Pixtral-12B 标志着多模态模型的重大飞跃,提供了可与现有巨头媲美的强大视频和图像生成能力。
主题 2. 创新工具与集成
-
Superflex 实现 Figma 转代码:Superflex 现在允许开发者直接从 Figma 设计 生成前端代码,无缝简化了从设计到开发的流程。
-
OpenRouter 为 Google Sheets 提供 AI 助力:GPT Unleashed for Sheets 集成了 OpenRouter 的“jobs”和“contexts”等功能,实现在电子表格中进行高效的 prompt engineering。
-
Aider 联手 Sonnet 助力编程:Sonnet 3.5 与 O1 Mini 的集成增强了 Aider 处理编程任务的可靠性,用户对其处理快速修复和任务的效率赞誉有加。
主题 3. 训练、优化与技术挑战
-
LM Studio 大幅缩短训练时间:在 LM Studio 中调整 token 和 batch size 将模型训练时间从 5 天 缩短至仅 1.3 小时,展示了显著的 optimization 收益。
-
Tinygrad 面临 AMD 兼容性问题:用户在 AMD 系统上更新 tinygrad 时遇到 AttributeError,引发了关于潜在 kernel version 不匹配和故障排除策略的讨论。
-
CUDA 模式应对存内计算:SK Hynix 在 Hot Chips 2024 上介绍了 AiMX-xPU,通过直接在内存中进行计算来增强 LLM inference,从而提高 power efficiency。
主题 4. AI 安全与伦理担忧
-
Cohere 推出可定制的安全模式:Cohere 的安全模式 在其 Chat API 中允许用户定制模型输出以满足特定的 safety requirements,旨在减轻 liability concerns。
-
Unsloth AI 的审查引发争议:Phi-3.5 模型因过度审查而面临抵制,用户分享了 未审查版本 并讨论了 safety 与 usability 之间的平衡。
-
Jailbreaking Claude 3.5 打开了潘多拉魔盒:针对 Claude 3.5 Sonnet 的成功 越狱 (jailbreak) 引发了关于 model security 以及 bypassing safeguards 伦理影响的讨论。
主题 5. 社区热点与融资动态
-
YOLO Vision 2024 邀请 AI 工程师:由 Ultralytics 在马德里 Google 创业校园举办的 YOLO Vision 2024 邀请 AI 工程师注册参加,通过为活动音乐投票等活动促进 community interaction。
-
11x AI 获得 2400 万美元 A 轮融资:11x AI 从 Benchmark 筹集了 2400 万美元 A 轮 融资,使其年度经常性收入增长了 15 倍,并将客户群扩大到 250 多家客户。
-
Mistral 的战略举措引发讨论:对 微软战略(将 AI 技术与 Mistral 的产品集成)的分析促使社区反思该公司的 竞争方向 以及与其 历史目标 的一致性。
O1-preview
主题 1. 新 AI 模型与发布点燃技术社区
- Qwen 2.5 发布,提供新尺寸和更严格的过滤器:Qwen 2.5 推出了参数量从 0.5B 到 72B 不等的模型,与前代相比引入了更严格的内容过滤。初步测试显示其在主题知识方面存在局限性,引发了对 knowledge retention(知识保留)影响的担忧。
- Mistral-Small-Instruct-2409 隆重登场:Mistral-Small-Instruct-2409 模型拥有 22B parameters,支持 function calls 以及高达 128k tokens 的序列长度。尽管潜力巨大,但它带有非商业使用限制,且建议搭配 vLLM 以获得最佳性能。
- LlamaCloud 展现多模态 RAG 魔法:LlamaCloud 推出了 multimodal capabilities(多模态能力),能够跨非结构化数据类型快速创建端到端的 multimodal RAG pipelines。这一飞跃增强了 marketing decks(营销演示文稿)、legal contracts(法律合同)和 finance reports(财务报告)的工作流。
主题 2. AI 工具获得超能力:丰富的集成
- Google Sheets 通过 OpenRouter 集成获得提升:OpenRouter 与 GPT Unleashed for Sheets 插件联手,提供对 100+ 模型 的免费访问。用户可以为 prompt 分配短代码,极大增强了电子表格内的 AI 输出管理。
- Aider 联手 Sonnet 打造代码魔法:开发者们欢呼雀跃,因为 Aider 集成了 Sonnet 3.5 与 O1 mini,通过可靠的编辑和修复增强了编码任务。用户称赞 Aider 在处理快速代码微调和任务分配方面的高效性。
- Superflex 将 Figma 设计转化为实时代码:Superflex 直接将 Figma designs 转换为前端代码,并无缝集成到现有项目中。该工具加速了开发进程,让设计师的梦想变为现实。
主题 3. 技术故障与解决方案:克服 AI 障碍
- LM Studio 用户苦恼于 GPU 识别失效:尽管设置正确,LM Studio 仍固执地忽略 GPU,转而让 CPU 和 RAM 过载。与抗锯齿设置相关的模糊屏幕促使用户调整配置以获得更平滑的体验。
- Unsloth 微调热潮导致幻觉:微调 ‘unsloth/llama-3-8b-bnb-4bit’ 会导致模型产生幻觉,暗示在保存过程中可能存在数据损坏。社区正在讨论使用
save_method = 'merged_4bit_forced'的影响。 - BitNet 的三进制技巧引发讨论:将 5 个三进制值打包进 8-bit 空间 的做法被证明是聪明但复杂的。围绕使用 Lookup Tables(查找表)来增强该方法的讨论不断升温,挑战着神经网络效率的极限。
主题 4. AI 安全与研究成为焦点
- AI 安全奖学金助力新研究项目:一位社区成员在获得 Open Philanthropy fellowship 后投身于 AI safety,热衷于解决 interpretability(可解释性)和对齐研究。他们正在寻找未来 六个月 的合作机会。
- 傅里叶变换揭示隐藏状态的秘密:深入研究隐藏状态的 Fourier transforms 发现,随着层数加深,状态从均匀分布转向 power law(幂律)。人们对 attention 机制在这一频谱现象中的作用感到愈发好奇。
- LlamaIndex 通过多模态 RAG 处理视觉数据:由于其视觉特性,产品手册一直是一项挑战。LlamaIndex 引入了一个复杂的 indexing pipeline,帮助 LLM 有效地导航和理解包含大量图像的文档。
主题 5. AI 进军商业与创意领域
- Ultralytics 在 YOLO Vision 2024 举办活动:Ultralytics 邀请 AI 爱好者参加 10 月 28 日 在马德里举行的 YOLO Vision 2024。与会者可以在讨论小组期间为自己喜欢的曲目投票,将技术与乐趣融合。
- AdaletGPT 推出用于法律援助的 RAG 聊天机器人:AdaletGPT 推出了基于 OpenAI 和 LangChain 构建的 RAG 聊天机器人,在 adaletgpt.com 提供 AI 驱动的法律支持。用户可以通过友好的界面获取先进的援助。
- Open Interpreter 的智能令用户惊叹:Open Interpreter 因其聪明才智和强大能力而广受赞誉。随着用户探索其潜力,兴奋之情溢于言表,Beta 测试名额需求量极大。
第 1 部分:Discord 高层摘要
Perplexity AI Discord
- O1 Mini 每日限制使用 10 次:用户对 Perplexity 上 O1 Mini 最近限制为每天 10 次表示沮丧,认为与竞争对手相比限制了访问。
- 有推测认为此限制旨在管理服务器成本和营销策略,引发了关于用户体验的质疑。
- Claude 3.5 与 GPT-4o 的对决:随着社区成员权衡在 Claude 3.5 和 GPT-4o 之间选择的优缺点,紧张局势升级,认为测试对于辨别差异至关重要。
- 参与者指出 GPT-4o 可能在特定任务中表现出色,暗示其增强的能力。
- Perplexity AI 的推理功能引发热议:Perplexity 中推出的 Reasoning focus 功能引发了讨论,用户正在 Pro Search 环境中尝试增强的功能。
- 反馈强调了输出质量和推理步骤的改进,展示了显著的升级。
- Minecraft 封禁管理问题解析:在专门页面上发起了一场由社区主导的 Minecraft 封禁管理讨论,征求用户对现有政策的意见。
- 邀请成员分享想法,建议共同努力解决潜在的管理缺陷。
- 微软的策略引发辩论:一篇对微软策略提出质疑的分析文章引起了关注,促使用户审视该公司的竞争方向。
- 讨论鼓励反思微软最近的行动是否与其历史目标一致。
Unsloth AI (Daniel Han) Discord
- Qwen 2.5 推出新模型变体:Qwen 2.5 推出了新的模型尺寸,如 0.5B, 1.5B, 3B, 7B, 14B, 32B 和 72B,与前代相比,所有尺寸都有更严格的内容过滤。
- 据报道,这些模型变体限制了某些主题的知识,引发了对知识保留潜在影响的担忧。
- Mistral-Small-Instruct-2409 发布:Mistral-Small-Instruct-2409 模型拥有 22B 参数,支持 function calls 和高达 128k tokens 的序列,但有非商业使用限制。
- 建议与 vLLM 配合使用,以获得最佳的推理流水线性能。
- 微调模型中的幻觉问题:在对模型 ‘unsloth/llama-3-8b-bnb-4bit’ 进行微调后,用户报告从 Hugging Face 下载的版本存在幻觉,引发了对潜在数据损坏的担忧。
- 这引发了围绕
save_method = 'merged_4bit_forced'的使用及其对模型性能影响的讨论。
- 这引发了围绕
- 优先考虑应用知识而非死记硬背:强调在 LeetCode 等平台中,应用知识胜过单纯对问题的死记硬背,这对于现实场景中的有效编码至关重要。
- 扎实掌握算法和数据结构(如 linked lists 和 hashmaps)对于实际应用至关重要。
- KTO 在 RLHF 圈子中占据主导地位:在强化学习中,由于 KTO 作为一个“点赞、点踩”数据集的简单性,人们更倾向于选择它而非 ORPO。
- 虽然认识到 RLHF 方法可以简化模型,但强调了测试所有可用选项的必要性。
aider (Paul Gauthier) Discord
- O1 模型在实际应用中表现滞后:用户对 O1 模型的表现表示失望,指出它们在 playground 场景中表现出色,但在 Aider 等实际应用中由于 system prompts 的限制而表现不佳。
- 虽然 O1 模型展现了潜力,但其有效部署仍是一个问题,促使开发者寻找替代方案。
- Sonnet 与 Aider 协作:社区讨论显示,用户主张将 Sonnet 3.5 与 O1 mini 集成以增强编码任务,理由是其在编辑和修复方面的可靠性更高。
- 许多人称赞 Aider 能高效处理快速的代码修复,展示了结合这些工具的优势。
- 关于编程 RAG 的辩论:讨论强调了在编程中 RAG 方法相对于在特定代码库上进行 fine-tuning 的有效性,许多人主张采用定制化方法以获得更好的结果。
- 人们对大型代码库中检索机制失效表示担忧,强调了改进策略的必要性。
- 使用 Aider 设置 Azure API Key:一位用户详细介绍了将 Aider 与 Azure OpenAI 集成所需的配置步骤,强调了结构化 JSON 请求对功能实现的重要性。
- 推荐了 LiteLLM 文档等额外资源,以有效处理 Azure API keys。
- Superflex 将 Figma 转换为代码:Superflex 的发布改变了游戏规则,允许开发者直接从 Figma 设计生成前端代码,简化了工作流程。
- 该工具能将设计平滑地集成到现有项目中,使其成为现代 Web 开发中极具吸引力的选择。
LM Studio Discord
- GPU 性能故障排除:尽管在 Settings -> System Resources 中进行了正确设置,用户仍对 LM Studio 未利用其 GPU 表示沮丧。导致屏幕模糊的问题与 anti-aliasing 设置有关,从而引发了对配置调整的建议。
- 活跃的对话强调了常见的故障排除步骤,这些步骤可以增强 GPU 利用率并减少用户界面中的模糊视觉效果。
- 训练时间大幅缩短:一位用户训练了一个 100k 参数的模型,通过调整 tokens 和 batch size,时间从 5 天 缩短到了 1.3 小时。社区成员讨论了 data loader 中的瓶颈,强调了高效配置对训练效率的重要性。
- 对话阐明了通过参数调整优化模型训练时长的实际解决方案。
- LM Studio 的新功能引发热议:LM Studio 最近新增的文档集成功能引发了积极反馈,证明了社区对该功能的长期需求。用户渴望测试更新版本并利用改进的功能。
- 这一功能强调了设计上的简洁性如何吸引缺乏深厚 IT 背景的用户,使高级功能变得更加易于使用。
- 关于双 GPU 配置的讨论:用户探索了双 4060 Ti 配置的优势,旨在不消耗过多功率的情况下最大化 VRAM。这种实用的配置引发了关于使用相同 GPU 以简化设置和管理能效优势的辩论。
- 讨论表明,在 GPU 配置中优化成本效益和性能的趋势日益增长。
- VRAM 对 LLM 性能至关重要:针对处理强大的 LLM 时对 VRAM 的关键需求,人们提出了担忧,并深入探讨了各种 GPU 在 token 生成速率方面的能力。成员们分享的个人经验表明,许多强大的模型超出了当前可用显卡的 VRAM 限制。
- 对 VRAM 的强调引发了关于 GPU 进步如何更好地支持 LLM 训练和推理需求的深入对话。
HuggingFace Discord
- API 文档得到提升:Hugging Face Inference API docs 进行了关键更新,现在包含更清晰的速率限制(rate limits)、增强的代码示例以及专门的 PRO 专区。
- 此次改版旨在随着数据集供应的持续增加来优化用户体验,使部署更加直观。
- 100 万个模型倒计时:社区推测很快将达到 100 万个模型,统计数据显示每周有 40K 个新模型上线。
- 随着参与者对比不同模型仓库的增长率,预测即将迎来这一里程碑,兴奋之情溢于言表。
- 数据集创建新工具:DataCraft 作为一种使用自然语言生成合成数据集(synthetic datasets)的无代码工具被推出,旨在简化数据创建的挑战。
- 该工具结合了最佳实践,为希望构建高效 AI 数据集的用户增强了易用性。
- 参与 Gradio Office Hours:成员受邀参加正在进行的 Gradio office hours,这是一个讨论功能、增强功能和社区反馈的开放论坛。
- 该环节为直接与专家分享见解和解决 Gradio 相关问题提供了沃土。
- LLaMA3 设置挑战:一位用户在下载 LLaMA3 模型时寻求帮助,表达了他们在当前 PyTorch 设置中遇到的困难并请求指导。
- 关于实现选择的困惑随之而来,揭示了大家对模型操作中异构工具有效性的共同需求。
OpenAI Discord
- GPT-4o 在 GeoGuessr 中表现惊人:成员们对 GPT-4o 在 GeoGuessr 中的表现感到惊讶,尽管它仍落后于专家级玩家。值得注意的是,它与 o1-mini 模型的预期速度有所偏差。
- 这种表现引发了人们对其在游戏之外的潜在改进和应用的关注。
- 微调任务触及硬限制:一位用户对他们的微调(fine-tuning)任务超过硬限制(hard limit)表示沮丧,在剩余 $19.91 配额的情况下产生了 $24.31 的费用。有人猜测这可能与折扣有关。
- 讨论集中在微调操作中的成本管理策略。
- 高级语音模式(Advanced Voice Mode)可用性待定:多位成员反映虽然使用了 Plus,但仍无法访问 Advanced Voice Mode,预计将在 秋末 开放。这引发了关于推送时间的疑问。
- 这种期待反映了用户对语音功能进步的浓厚兴趣。
- 探索 Ideogram/Midjourney 的自动提示词:一位成员分享了 Ideogram/Midjourney 的自动提示词(auto prompt),鼓励大家反馈并评价其可用性,并强调这是免费分享的。
- 这种资源交换的启动展示了社区的协作精神。
- 关于官方库的讨论:提到 官方库(official libraries) 引起了兴趣,但随后没有进行深入交流。这为未来讨论潜在资源留下了空间。
- 这种模糊性为寻求更多细节的用户留下了澄清的空间。
OpenRouter (Alex Atallah) Discord
- OpenRouter 与 Google Sheets 集成:OpenRouter 已被整合进 GPT Unleashed for Sheets 插件中,根据用户需求,该功能现已免费开放。
- 我个人也非常喜欢使用 OR,并期待随着更多用户采用这一集成功能,能获得有益的反馈。
- 令人兴奋的功能提升 Google Sheets 性能:Google Sheets 插件中新增的 ‘jobs’(任务)、’contexts’(上下文)和 ‘model presets’(模型预设)等功能简化了 Prompt Engineering。
- 这些增强功能允许用户为提示词分配短代码,从而优化 AI 输出管理。
- OpenRouter 遭遇 API 停机:多名用户报告了访问 OpenRouter 时出现的间歇性问题,特别是
o1模型,导致了对 Rate Limits(速率限制)的困惑。- 一位用户注意到瑞士地区出现了临时停机,但确认功能在不久后已恢复。
- Gemini 在图像生成一致性方面表现不佳:关于 Gemini 的图像生成能力存在争议,其官方网站与 OpenRouter 上的表现存在差异。
- 据澄清,Gemini 的聊天机器人使用 Imagen 模型进行图像生成,而 OpenRouter 使用的是 Google Vertex AI。
- Mistral API 价格大幅下调:最新公告显示 Mistral API 大幅降价,Large 2 模型降至 $2,使其成为一个极具竞争力的选择。
- 这一转变正在影响用户对于 API 调用所选模型的决策。
CUDA MODE Discord
- 探索 Metal Puzzles 与协作:Metal Puzzles GitHub 仓库通过协作解谜促进 Metal 编程学习,鼓励社区参与。
- 提议进行一场直播解谜活动,成员们的热情预示着新手对此的兴趣日益浓厚。
- Triton LayerNorm 遭遇一致性瓶颈:一名成员报告称,在 Triton LayerNorm 中使用 Tensor Parallelism > 1 会导致非确定性梯度累积,从而影响其 MoE 训练。
- 他们正在联系 Liger 团队,以寻求潜在的见解和替代实现方案。
- FP8 实现端到端功能修复:最近的实现更新已成功恢复了前向和反向传播的 FP8 端到端能力,推进了 AI 工作流的功能性。
- 未来的任务将包括多 GPU 支持和性能测试,以确保与现有技术的收敛。
- SK Hynix 推动内存计算创新:在 Hot Chips 2024 上,SK Hynix 展示了其专为高效 LLM 推理量身定制的内存计算(In-memory Computing)技术 AiMX-xPU 和 LPDDR-AiM。
- 该方法通过直接在内存中进行计算,显著降低了功耗和延迟。
- BitNet 的三元打包特性:讨论揭示了将 5 个三元值(ternary values)打包进 8 位空间优于传统方法,尽管实现复杂,但提升了效率。
- 成员们考虑将 Lookup Tables(查找表)作为打包方法的可能增强手段,推动进一步探索。
Nous Research AI Discord
- NousCon 细节确认:NousCon 的地点详情已确认于当晚发出,引发了关于未来活动举办地(包括 NYC)的讨论。
- 一位用户询问了未来活动对社区参与的更广泛影响。
- 对 Hermes 3 Unleashed 的兴趣:一位新成员表示希望将 AI 模型 Hermes 3 用于业务咨询,并寻求联系方式。
- 另一位用户建议联系特定成员以获取建议。
- InstantDrag 成为关注焦点:InstantDrag 被强调为一种现代的基于拖拽的图像编辑解决方案,因其在无需掩码或文本提示的情况下提高速度而受到关注。
- 开发者将其与 DragGAN 进行了对比,展示了更快工作流的潜力。
- LLM 推理性能极限探索:Denny Zhou 的一条推文指出,如果给予足够的中间推理 Token(Intermediate Reasoning Tokens),Transformer 理论上可以解决任何问题。
- 这与一篇被 ICLR 2024 接收的论文相关联,强调了 Constant Depth(固定深度)在 Transformer 能力中的重要性。
- Claude 3.5 越狱方法揭晓:一名成员成功创建了针对 Claude 3.5 Sonnet 的 Jailbreak(越狱),据报道该模型特别难以攻破。
- 虽然受到了之前作品的启发,但他们强调了自己的独特方法和功能性。
Latent Space Discord
- Luma Labs 发布 Dream Machine API:Luma Labs 宣布发布 Dream Machine API,使开发者能够以极少的工具投入利用领先的视频生成模型。
- 这一举措旨在让视频创作变得触手可及,允许用户直接投入到创意开发中。
- 11x AI 筹集 2400 万美元 A 轮融资:11x AI 成功从 Benchmark 获得了 2400 万美元 A 轮融资,其今年年度经常性收入增长了 15 倍,服务客户超过 250 家。
- 该团队计划构建 LLM-powered systems,旨在变革数字市场进入(go-to-market)策略。
- AI 对就业市场的冲击:一份报告预测,明年美国和墨西哥将有 6000 万个工作岗位受到 AI 影响,未来十年的预测可能会增加到美国的 7000 万个和墨西哥的 2600 万个。
- 虽然某些工作转型可能不会导致失业,但仍有大量职位面临相当大的风险,这凸显了劳动力适应的必要性。
- Claude 3.5 系统提示词流传:Claude 3.5 Projects + Artifacts 系统提示词通过一个 gist 被分享,在有兴趣探索 AI 应用的用户中获得了关注。
- 该提示词的相关性因其在多个平台上的讨论而受到关注,表明了它在当前 AI 评估中的重要性。
- Yann LeCun 展示基于 ZIG 的推理栈:Yann LeCun 介绍了一个新的基于 ZIG 的推理栈,旨在优化高性能 AI 推理,能够在各种硬件上高效运行深度学习系统。
- 这个开源项目标志着它脱离了隐身模式,展示了在 AI 性能方面的显著进步。
Eleuther Discord
- 基础模型在生物技术领域砥砺前行:一位成员展示了他们在 biotech 领域 foundation models 的工作,重点关注序列和表格数据的 large scale representation learning,强调了 AI 与生物技术应用日益增长的交集。
- 这突显了利用 AI technologies 彻底改变传统生物技术流程的兴趣日益浓厚。
- AI Safety 奖学金引发关注:一位成员分享了在获得 Open Philanthropy 职业转型奖学金后转向 AI safety 的经历,表达了参与 interpretability 和 alignment 研究的热情。
- 他们邀请其他人分享研究项目,以便在接下来的六个月内进行潜在的合作。
- 解决 TensorRT-LLM 构建问题:关于在 T4 显卡上构建 TensorRT-LLM 的问题浮出水面,特别是引用了与 workspace size 相关的错误,并寻求故障排除建议。
- 解决该问题的一个建议是使用
IBuilderConfig::setMemoryPoolLimit()来增加 workspace size。
- 解决该问题的一个建议是使用
- 通过傅里叶变换解释隐藏状态:讨论重点关注隐藏状态的 Fourier transforms,揭示了随着层深度增加,从均匀性到幂律 (power law) 的趋势。
- 有人提出疑问,attention 机制是否在最终隐藏状态的 power spectrum 形成中发挥了作用。
- Pythia Checkpoints 受到关注:社区成员强调 Pythia suite 是探测规模和架构对模型行为影响的强大资源,鼓励更广泛的探索。
- 成员们表达了通过 Pythia repository 分析不同架构的兴趣,以确认与模型训练效果相关的观察结果。
Stability.ai (Stable Diffusion) Discord
- SSH 密钥更新后连接失败:一名成员在更新 SSH 密钥后,其部署的 pods 遇到了 SSH 连接问题,询问是否有任何配置调整可以解决此问题。
- “我进不去了!” 引发了关于通过详细配置检查来寻找可能修复方案和替代方案的讨论。
- Stable Diffusion 模型无法加载:另一位用户在按照 安装指南 操作后仍遇到“模型加载失败”错误,陷入安装困境。
- 社区建议通过分享具体的错误日志来寻求帮助,以便进行针对性的故障排除。
- ComfyUI 面临白屏困境:更新后,一位用户报告 ComfyUI 出现 白屏 问题,导致其 GUI 尝试中断。
- 提出了一种修复方法:完全卸载 ComfyUI 并使用更新脚本重新启动。
- Control Net 需要强大的数据集:成员们讨论了训练有效 Control Net 的 数据集要求,强调需要高质量数据。
- 建议包括探索 新型数据集增强 方法以提升训练效果。
- CivitAI 悬赏包寻求建议:一位成员询问关于发布一个包含 49 个项目、约 4000 张图像的角色包 CivitAI 悬赏,寻求合理的 Buzz 报酬建议。
- “什么样的报价才合理?” 引发了关于悬赏定价策略的讨论。
LlamaIndex Discord
- LlamaCloud 发布多模态 RAG 功能:最近发布的 LlamaCloud 多模态功能 使用户能够跨非结构化数据格式快速创建 端到端多模态 RAG 流水线,显著增强了工作流(详情点击此处)。
- 该工具包支持各种应用,包括 营销幻灯片、 法律合同 和 财务报告,从而简化了复杂的数据处理。
- LlamaIndex 与 Neo4j 无缝集成:社区成员探索了如何使用 LlamaIndex 检索存储在 Neo4j 中作为节点属性的 embeddings,建议通过属性图索引进行连接以实现有效查询。
- 讨论认为,一旦检索到节点,解析其属性以获取 embeddings 应该是一项简单的任务,并链接到了 Neo4j Graph Store - LlamaIndex。
- 解决 LlamaIndex 包中的循环依赖问题:在
llama-index-agent-openai和llama-index-llms-openai之间检测到循环依赖问题,促使成员们集思广益潜在解决方案,包括创建一个 openai-utils 包。- 关于这些修复时间表的问题激增,需要社区贡献以迅速解决依赖问题。
- 使用 GPT-4o 导航图像坐标:一位用户强调了使用 GPT-4o 进行 图像坐标提取 的挑战,特别是由于其网格叠加方法,在对齐标签和获取准确坐标方面存在困难。
- 社区鼓励提供反馈,以提高检测实体进行图像裁剪的精度,强调了涉及空间识别的技术难度。
- 多模态 RAG 与产品手册挑战:产品手册 已被证明对 RAG 技术来说非常困难,因为它们主要是视觉化的,需要复杂的 索引流水线 才能让 LLM 有效地导航。
- 讨论强调需要处理产品手册中典型的分步视觉效果和图表的方法。
Interconnects (Nathan Lambert) Discord
- Mistral 发布新功能:Mistral 推出了多项功能,包括在 La Plateforme 上的免费层级,旨在供开发者进行 API 实验。
- 这些更新还包括降价以及对 Mistral Small 的增强,使其对用户更具吸引力。
- Transformer 受益于中间生成:研究表明,在 Transformer 中加入“思维链”(chain of thought)可以显著增强其计算能力。
- 这种方法有望提高在标准 Transformer 难以应对的推理任务上的性能。
- 揭秘 Gemini 模型:关于未发布的 Gemini 模型(如 potter-v1 和 dumbledore-v1)的令人兴奋的见解已经出现,暗示了包括 gemini-test 和 qwen2.5-72b-instruct 在内的强大阵容。
- 社区对这些新模型议论纷纷,标志着模型开发的一个关键时刻。
- 共同庆祝 Newsletter 读者:一位成员分享了“伟大的 Newsletter 读者派对”的邀请,通过分享阅读创造了社区参与的机会。
- 这一举措旨在建立联系,并培养参与者对精选内容的喜爱。
- 对主流媒体依赖的批评:一场讨论强调了仅依靠主流媒体获取新闻的弊端。
- 成员们表达了对探索更多样化和替代性来源的愿望。
LangChain AI Discord
- 探索 LangChain 中的聊天历史管理:成员们讨论了 LangChain 中 Chat Message History Management 的复杂性,特别是关于在 PostgresChatMessageHistory 中存储 UI 消息的问题。
- 大家一致认为,UI 特有的消息必须存放在单独的表中,因为现有系统缺乏组合事务支持。
- 设定开源贡献目标:一位成员表达了为开源项目做出重大贡献的雄心,同时寻求赞助以保持独立。
- 他们请求社区就实现这些有影响力的贡献的途径提供见解。
- 迁移到现代 LLMChain 实现:反馈建议从旧版的 LLMChain 迁移到更新的模型,以获得更好的参数清晰度和流式传输(streaming)能力。
- 更新的实现允许更轻松地访问原始消息输出,强调了保持更新的重要性。
- AdaletGPT 推出 RAG 聊天机器人:adaletgpt.com 的一名后端开发人员推出了一个利用 OpenAI 和 LangChain 的 RAG 聊天机器人,邀请用户在 adaletgpt.com 进行体验。
- 他们鼓励社区咨询,并承诺会以“我将竭尽全力为您服务”的态度提供支持。
- 针对本地业务集成的 AI 解决方案:一位成员表示准备向本地企业推广 AI 解决方案,并询问有效的实施策略。
- 他们专门寻求了关于如何吸引可能不熟悉 AI 的企业主的建议。
tinygrad (George Hotz) Discord
- Tinygrad 遇到 AMD 相关问题:用户在尝试将 tinygrad 从 0.9.0 升级到 0.9.2 时在 AMD 平台上遇到了 AttributeError,这表明 struct_kfd_ioctl_criu_args 可能存在内核版本问题。
- 调查参考了 tinygrad/extra/hip_gpu_driver/test_kfd_2.py 文件以及解决该问题的 pull request #5917。
- 监控 VRAM 分配峰值:用户寻求关于识别 VRAM 分配峰值 原因的建议,引发了关于有效内存使用监控工具的讨论。
- 社区成员强调了理解这些峰值对于优化 Tinygrad 性能的重要性。
- 调查 Tinygrad Tensor 错误:另一位成员报告了在 Tinygrad 中进行 Tensor 操作时遇到的错误,并链接到了一个 公开 issue 以获取更多细节。
- 这突显了调试 Tinygrad 过程中持续存在的挑战以及社区协作的必要性。
- Diffusers 分支集成 Tinygrad:讨论围绕一个利用 Tinygrad 的 Diffusers fork 展开,该分支避开了 Torch,旨在采用一种不直接复制的新方法。
- 社区成员对这一举措表示热烈欢迎,认为这是对 Tinygrad 生态系统的潜在增强。
- NotebookLM 制作引人入胜的 Tinygrad 播客:NotebookLM 团队发布了一个 8 分钟的播客,通过生动的比喻来阐明 Tinygrad 的概念,并有效地推介了 tinybox。
- 这种方法展示了教育他人了解 Tinygrad 原理和应用的创新方式。
Cohere Discord
- Cohere 推出测试版安全模式 (Safety Modes):Cohere 宣布在其 Chat API 中启动 Safety Modes 测试版,允许用户根据安全需求自定义模型输出。
- 这可能允许用户实施安全检查并减轻责任顾虑。
- Cohere 优化市场策略:Cohere 战略性地专注于特定的用例,以在拥挤的 LLM 市场中航行,避免过度饱和。
- 成员们讨论了务实的商业选择的价值,这些选择强调了模型应用中的清晰度和实用性。
- 关于微调模型的咨询:一位用户询问在微调期间是否可以跳过最后的
<|END_OF_TURN_TOKEN|>,以便更顺畅地继续推理。- 他们提出了一个训练数据的 POC 示例,强调了微调聊天模型的潜在好处。
- Sagemaker Client 问题反馈:一位用户报告在访问端点时,从 Sagemaker 客户端收到了
input_tokens=-1.0和output_tokens=-1.0。- 这引发了对端点设置过程中可能存在配置错误的担忧。
- Sagemaker 查询的支持渠道:有人建议原帖作者联系 support@cohere.com 以寻求有关 Sagemaker 计费问题的帮助。
- 该用户表示他们将通过检查用户账户来进一步调查此事。
DSPy Discord
- GitHub 交流引发期待:一位成员在 GitHub 上回复了 Prashant 关于正在进行的讨论,并可以关注后续的潜在反应。
- 请继续关注这次互动可能产生的任何后续反应。
- 展示 CodeBlueprint 与 Aider:一位成员分享了一个链接,展示了他们新的编码模式 CodeBlueprint with Aider,展示了其集成潜力。
- 这一展示可能为在编码实践中采用新工具提供见解。
- Ruff 检查遇到错误:Prashant 报告在执行
ruff check . --fix-only时遇到 TOML 解析错误,提示未知字段indent-width。- 此错误突显了需要解决的潜在配置不匹配问题。
- 引入 GPT-4 Vision API 封装器:一个新的 Pull Request 添加了 GPT-4 Vision API wrapper,简化了 DSPy 仓库中的图像分析请求。
- 在
visionopenai.py中引入 GPT4Vision 类应该会简化开发者的 API 交互。
- 在
- 社区渴望贡献和悬赏:成员们表达了贡献的热情,其中一人询问是否有可参与的悬赏 (bounties)。
- 尽管承认需要进行更改,但讨论期间未透露有关悬赏的具体细节。
LAION Discord
- 图像合成技术表现出色:成员们讨论了基础的 compositing(合成)技术是图像生成的有效选择,建议使用 Pillow 等库来增强效果。
- 不建议使用带有集成文本的图像进行训练,以实现海报级的视觉效果。
- 后期处理提升质量:涉及 GIMP 等工具的有效工作流可以通过后期处理技术显著提高图像的准确性和效果。
- 在后期处理中完成 相比仅依赖初始方法能产生最佳效果。
- Nouswise 增强创意流程:Nouswise 被强调为一个个人搜索引擎,在从 reading(阅读)到 curation(策展)的各个创意阶段提供可信的答案。
- 它的功能简化了 searching(搜索)和 writing(写作)的方法,提升了整体生产力。
- 寻求 Whisper speech 见解:一位成员询问了关于 Whisper speech 技术的经验,引发了查看特定频道以获取进一步指导的建议。
- 社区讨论允许分享见解和集体知识,并提供相关资源链接。
- StyleTTS-ZS 项目资源征集:一位成员为 StyleTTS-ZS 项目请求计算资源支持,该项目旨在实现高效的高质量 zero-shot 文本转语音合成。
- 该项目的详细信息已发布在 GitHub 上,鼓励社区协作开发。
OpenInterpreter Discord
- Open Interpreter 给用户留下深刻印象:Open Interpreter 因其巧妙的设计赢得了赞誉,增强了社区对其功能的兴奋感。
- 成员们表达了探索其潜力的渴望,并围绕其功能展开了持续讨论。
- Beta 测试兴趣高涨:成员们询问了 Open Interpreter 的 beta testers 名额,表明了对贡献开发的持续热情。
- 此类询问反映了对协助工具进步和改善用户体验的浓厚兴趣。
- 本周五 Human Device Discord 活动:Human Device 即将举行的活动定于本周五,鼓励参与者通过 Discord 链接 加入。
- 该活动旨在让用户参与有关创新技术和产品的讨论。
- Tool Use 播客聚焦语音智能:Tool Use 的最新一期节目展示了 Killian Lucas 讨论语音智能的进展以及 01 Voices 脚本的能力。
- 听众可以深入了解语音 Agent 如何在群组对话中无缝交互。
- Deepgram 走向开源:一位成员宣布创建了 Deepgram 的开源和本地版本,激发了社区对更易用工具的热情。
- 这一举措强调了社区在开发有效的语音智能解决方案方面的参与。
Torchtune Discord
- Eleuther Eval Recipe 的使用限制:关于 Eleuther eval recipe 及其在 generation(生成)和 multiple choice (mc) 任务中的表现出现了担忧,特别是关于生成任务的 cache(缓存)对后续任务执行的影响。
- 其他用户确认该 recipe 运行异常,暗示可能存在与 cache management 相关的潜在问题。
- 缓存重置的必要性:用户讨论了缺乏适当的缓存重置可能是问题的根源,特别是在 model generation 之后切换任务时。
- 一位成员指出他们在生成后重置缓存的习惯,但强调这仅是为新一轮生成做准备,并未实现完全重置。
- MM 评估期间 Batch Size 不一致:讨论指出在模型评估期间(特别是使用缓存时)存在未达到预期 Batch Size 的问题。
- 预计当另一位用户尝试未来的多模型评估时,这一挑战将再次出现。
Modular (Mojo 🔥) Discord
- 社区对 RISC-V 支持的好奇:成员们正在询问支持 RISC-V 的计划,但目前该架构尚无计划。
- 这种兴趣可能会引发未来关于替代架构兼容性的讨论。
- 零拷贝互操作性缺乏 Mojo-Python 集成:由于目前无法从 Python 导入或调用 Mojo 模块,实现零拷贝数据互操作性面临挑战。
- 讨论中提到了 Mandelbrot 示例 如何通过
numpy_array.itemset()低效地利用内存。
- 讨论中提到了 Mandelbrot 示例 如何通过
- Mandelbrot 示例突显了 Mojo 的潜力:关于 Mandelbrot 集 的教程展示了 Mojo 在集成 Python 可视化工具的同时,能够执行高性能代码。
- 该教程说明了 Mojo 适合利用 Python 库为不规则应用构建快速解决方案。
- LLVM Intrinsics 现在支持在 Comptime 使用:Mojo 扩展了对 comptime LLVM intrinsics 的支持,重点针对整数的
ctlz和popcount等函数。- 未来的发展取决于 LLVM 对这些 intrinsics 进行常量折叠(constant fold)的能力,从而为更广泛的类型支持开辟道路。
OpenAccess AI Collective (axolotl) Discord
- Shampoo 在 Transformers 中未受重视:一位成员指出 Transformers 和 Axolotl 中都缺少 Shampoo,并认为它提供了被忽视的实质性好处。
- Shampoo 在大规模、可预测的方式下简直就是免费的午餐,这表明其潜力可能值得进一步探索。
- Shampoo 缩放定律 vs Adam:关于 语言模型的 Shampoo 缩放定律 的讨论揭示了与 Adam 的对比分析,并引用了 Kaplan et al 的图表。
- 该图表展示了 Shampoo 有效的缩放特性,表明对于大型模型,它是比 Adam 更优的选择。
MLOps @Chipro Discord
- Ultralytics 邀请社区参加 YOLO Vision 2024!:Ultralytics 将于 <t:1727424000:F> - <t:1727458200:t> 在马德里的 Google Campus for Startups 举办 YOLO Vision 2024 🇪🇸,并邀请 AI 工程师注册参加。
- 与会者可以通过在讨论环节为音乐投票来参与互动,旨在增强社区交流!
- 为 YOLO Vision 2024 的音乐投票!:YOLO Vision 2024 的注册参与者可以对讨论期间播放的音乐进行投票,为活动增添独特的互动环节。
- 这一举措鼓励与会者参与,旨在营造活跃的活动氛围。
Alignment Lab AI Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
PART 2: 按频道详细摘要及链接
完整的频道细分内容已为邮件格式截断。
如果您喜欢 AInews,请分享给朋友!预先感谢!