ainews-not-much-happened-today-5059
今天没发生什么特别的事。
以下是该文本的中文翻译:
Anthropic 推出了一种名为“上下文检索”(Contextual Retrieval)的 RAG 技术,通过使用提示词缓存(prompt caching)将检索失败率降低了 67%。Meta 在 Meta Connect 大会前夕预热了多模态 Llama 3。OpenAI 正在为其多智能体研究团队招聘人才,该团队专注于利用其 o1 模型提升 AI 推理能力,而该模型目前引发了褒贬不一的反应。DeepSeek 2.5 被视为 GPT-4 和 Claude 3.5 Sonnet 的高性价比替代方案。文中还重点介绍了用于 3D 资产生成的 3DTopia-XL 和用于图生视频的 CogVideoX 等新模型。此外,分享了通过重读问题以及将检索与提示词缓存相结合来增强推理能力的技术。行业洞察强调了企业采用 AI 的必要性以及对传统机器学习业务的颠覆。LangChainAI 的 LangGraph 模板和 LlamaIndex 的 LlamaParse Premium 等工具增强了智能体应用和多模态内容提取。关于大语言模型评估(evals)和缓存的讨论突出了生产环境中的挑战与改进。一个核心观点是:“不允许开发人员使用 AI 的公司不太可能成功”。
定制化的 AINews 可能很快就是你所需要的一切…
2024年9月19日至9月20日的 AI News。我们为你检查了 7 个 subreddits、433 个 Twitter 账号 和 30 个 Discord 服务(221 个频道和 2035 条消息)。预计节省阅读时间(按 200wpm 计算):258 分钟。你现在可以标记 @smol_ai 来进行 AINews 讨论!
Anthropic 撰写了关于 Contextrual Retrieval 的文章,这是一种利用其 prompt caching 功能的 RAG 技术,结果显示 Reranked Contextual Embedding 和 Contextual BM25 将 top-20-chunk 的检索失败率降低了 67%(5.7% → 1.9%):
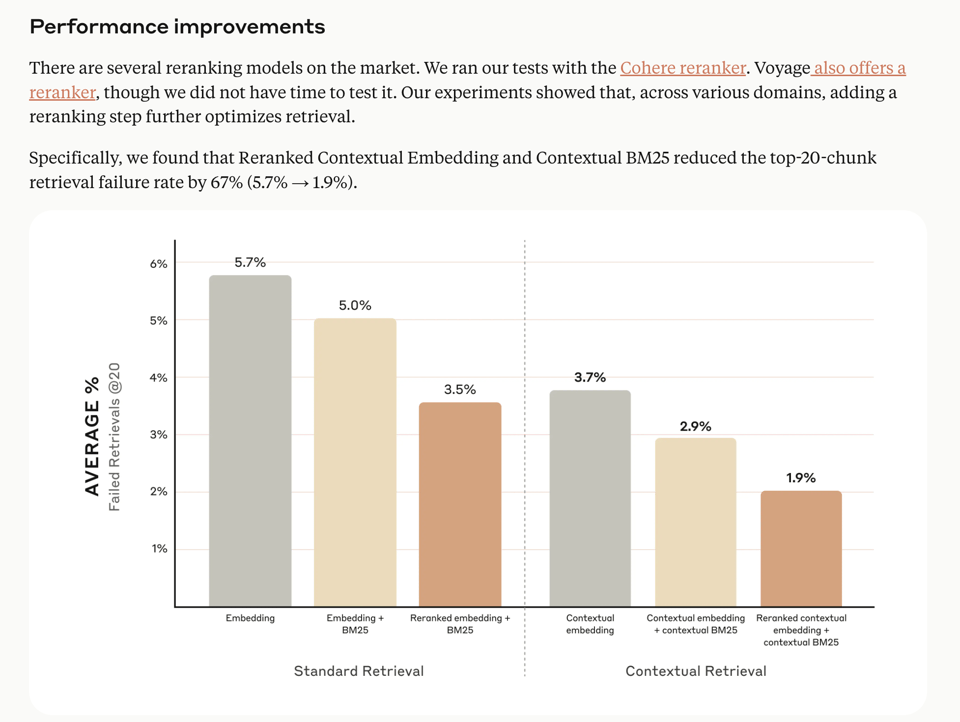
然而,这仅仅是一项 RAG 技术,所以我们觉得它还不值得作为头条新闻。
Meta 团队正在为下周 Meta Connect 上的 multimodal Llama 3 进行大量预热,但在它正式发布之前,我们还不能将其作为头条新闻。
与此同时,如果你一直渴望拥有自己的个人 AINews,或者想为我们提供一些 inference 资金,你现在可以注册我们的 “AINews Plus” 服务,并拥有针对你选择的任何主题的定制化 AI News 服务!
https://youtu.be/iDCUYZgnAjY
如果你在旧金山,本周末的 LLM as Judge Hackathon 见!
AI Twitter 摘要回顾
所有摘要由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 研究与开发
-
OpenAI 的 o1 模型:@polynoamial 宣布 OpenAI 正在为新的 multi-agent 研究团队招聘 ML 工程师,将 multi-agent 视为通往更好 AI 推理能力的路径。@scottastevenson 指出 o1 模型在技术专家中引起了困惑和怀疑,类似于早期对 GPT-3 和 ChatGPT 的反应。@nptacek 观察到 o1 在 prompting 方面感觉不同,需要更多以目标为导向而非指令驱动的方法。
-
AI 模型进展:@rohanpaul_ai 将 DeepSeek 2.5 与 GPT-4 进行了比较,指出其价格比 Claude 3.5 sonnet 便宜 21 倍,比 GPT-4 便宜 17 倍。@_akhaliq 分享了关于 3DTopia-XL 的信息,这是一个使用 Diffusion Transformer 的高质量 3D PBR 资产生成模型。@multimodalart 强调了 CogVideoX 的图生视频能力,特别是对于延时摄影(timelapse)视频。
-
AI 研究洞察:@rohanpaul_ai 讨论了一种强大但简单的 prompting 技术,即要求 LLM 重新阅读问题,这显著提升了不同任务和模型类型的推理能力。@alexalbert__ 分享了关于 Contextual Retrieval 的研究,该技术在结合 prompt caching 时,可将错误的 chunk 检索率降低高达 67%。
AI 行业与应用
-
企业中的 AI:@svpino 表示,不允许开发人员使用 AI 的公司不太可能成功。@scottastevenson 指出 LLM 如何颠覆了传统的 ML 业务,深厚的护城河在几个月内就消失了。
-
AI 工具与平台:@LangChainAI 宣布了 LangGraph Templates,这是一系列用于创建 agentic 应用的参考架构。@llama_index 推出了 LlamaParse Premium,结合了多模态模型的视觉理解能力与长文本/表格内容提取。
-
生产环境中的 AI:@HamelHusain 分享了关于使用 LLM evals 改进 AI 产品的建议,展示了如何创建数据飞轮以从 demo 转向生产就绪的产品。@svpino 讨论了 LLM 应用中缓存(caching)的重要性及挑战,以提高速度和成本效益。
AI 伦理与监管
-
@ylecun 讨论了研究误导信息(misinformation)的科学家的政治倾向,指出科学家通常倾向于左派,因为他们关注事实,而目前误导信息主要来自右派。@ylecun 还分享了一封由行业领袖签署的公开信,敦促欧盟统一 AI 监管,以防止该地区成为技术落后地区。
-
@fchollet 澄清说,ARC-AGI 基准测试并非专门为难倒 LLM 而设计,而是为了突出深度学习的局限性,而 LLM 作为同一范式的一部分也具有这些局限性。
迷因与幽默
AI Reddit 摘要回顾
/r/LocalLlama 摘要回顾
主题 1. Llama 3 多模态:Meta 的下一个重大 AI 发布
-
“Meta 的 Llama 已成为构建 AI 产品的核心平台。下一个版本将是多模态的,并能理解视觉信息。” (Score: 74, Comments: 21):Yann LeCun 在 LinkedIn 上宣布,Meta 的 Llama 3 将是一个具有视觉理解能力的多模态模型。Llama 的下一次发布旨在进一步巩固 Meta 在 AI 产品开发领域的地位。
-
Zuck 正在 IG 上预热 Llama 多模态模型。 (Score: 164, Comments: 42): Mark Zuckerberg 在 Instagram 上暗示了 Llama 的多模态能力。这一进展预计将在下周举行的 Meta Connect 大会上正式揭晓。
- Llama.cpp 开发者对多模态模型和工具调用 (tool calling) 缺乏支持,令用户感到失望。该团队专注于极致的底层效率以及 CPU/CPU+GPU 推理,导致多模态实现需要从零开始重做。
- 用户讨论了 Llama.cpp 与 TabbyAPI、ExllamaV2 和 KTransformers 等其他后端的性能对比。一些人认为通过更好的优化、投机解码 (speculative decoding) 和张量并行 (tensor parallelism),Llama.cpp 的 GPU 性能仍有提升空间。
- 社区对 Llama.cpp 缺乏对 Meta 的 Chameleon 模型支持表示不满,尽管一位 Meta 开发者提供了帮助。一个实现该支持的 Pull Request 未被合并,导致贡献者们感到失望。
主题 2. Qwen2.5 32B:在 GGUF 量化中表现出色
- Qwen2.5 32B GGUF 评估结果 (Score: 78, Comments: 38): 对 Qwen2.5 32B GGUF 模型的评估显示,其在 MMLU PRO 的计算机科学类别中表现强劲,其中 Q4_K_L 量化 (20.43GB) 得分为 72.93,Q3_K_S 量化 (14.39GB) 得分为 70.73,性能损失仅为 3.01%。这两个 Qwen2.5 32B 量化版本的表现都显著优于 Gemma2-27b-it-q8_0 模型 (29GB),后者在同一类别中得分为 58.05。
- Qwen2.5 32B 的量化版本表现令人印象深刻,用户注意到尽管在世界知识和审查 (censorship) 方面可能存在缺陷,但在某些领域有显著改进。
- 用户建议测试 IQ 变体量化,这被认为是 4-bit 以下的 SOTA,通常优于旧的 Q_K 类型量化。对于 24GB VRAM 用户,比较 72B IQ3_XXS (31.85GB) 和 IQ2_XXS (25.49GB) 版本的兴趣很高。
- 围绕 Hugging Face 上官方 Qwen/Qwen2.5 GGUF 文件的讨论指出,官方量化版本的表现往往不如社区创建的版本。
- 手机上的 Qwen 2.5:PocketPal 已添加 1.5B 和 3B 量化版本 (Score: 74, Comments: 34): Qwen 2.5 模型,包括 1.5B (Q8) 和 3B (Q5_0) 版本,已添加到适用于 iOS 和 Android 平台的 PocketPal 移动端 AI 应用中。用户可以通过该项目的 GitHub 仓库提供反馈或报告问题,开发者承诺会抽空解决这些问题。
- 用户表达了对添加 语音转文字 (speech-to-text) 功能和修改 系统提示词 (system prompt) 的兴趣。开发者确认大多数设置都是可自定义的,并分享了可用选项的截图。
- 一位用户询问了 上下文大小 (context size) 设置,引发了关于上下文长度与生成时间参数之间区别的讨论。开发者解释了其放置位置背后的逻辑,并将该问题添加到了 GitHub 仓库中。
- 该应用支持多种 聊天模板 (chat templates) (ChatML, Llama, Gemma) 和模型,用户对比了 Qwen 2.5 3B (Q5)、Gemma 2 2B (Q6) 和 Danube 3 的性能。开发者提供了相关截图。
{kind=link}
主题 3. 欧盟 AI 监管:平衡创新与控制
- 爱立信(Ericsson)发布公开信,由 Meta 协调,探讨欧洲碎片化的监管如何阻碍 AI 机遇 (Score: 87, Comments: 16):爱立信 CEO Börje Ekholm 警告称,碎片化的欧盟监管正在阻碍欧洲的 AI 发展,可能使欧洲人无法享受到其他地区已有的技术进步。信中强调,开放模型(open models)能增强主权和控制力;据估计,生成式 AI(Generative AI)在未来十年内可使全球 GDP 增长 10%。信中敦促制定清晰、一致的规则,以便能够使用欧洲数据进行 AI 训练。点击此处阅读公开信全文。
- 评论者们就欧盟监管对 AI 创新的影响展开辩论,一些人认为这可能导致欧洲在未来 AI 技术上依赖美国。另一些人则主张建立类似于 GDPR 的通用框架,以明确全欧洲的规则并促进投资。
- 讨论集中在 AI 监管的范围上,有建议认为应侧重于禁止监控和歧视等“1984 式的行为”,而不是监管模型本身。发帖者澄清说,问题的核心在于监管用于 AI 训练的数据,而非 AI 的使用。
- 文中分享了 euneedsai.com 的链接,可能为欧洲的 AI 需求和监管环境提供更多背景信息。
- 快速提醒:SB 1047 尚未签署成为法律,如果你住在加州,请给州长留言 (Score: 209, Comments: 57):加州的 SB 1047 是一项受《终结者》启发的 AI “安全”法案,虽然已经通过但尚未签署成为法律。该帖子敦促加州居民通过官方联系页面向州长表达反对意见,在主题中选择“An Active Bill”和“SB 1047”,并选择“Con”(反对)作为立场。
- 批评者认为 SB 1047 是一项监管俘获(regulatory capture)法案,可能会阻碍开放研究,同时让那些在没有安全检查的情况下进行封闭式、利润驱动研究的企业受益。一些人认为该法案可能违宪,但也有人认为它可能是合法的。
- 评论者强调了开源 AI 对研究、通用用途以及通过协作开发实现长期安全的重要性。他们建议在联系官员时提及所在地、选民身份以及开源 AI 带来益处的个人案例。
- 对中国 AI 进步的担忧被作为反对监管的一个理由。文中分享了一个专门的网站 stopsb1047.com,用于提交反对该法案的评论,一些用户反馈已发送了详细的回复。
主题 4. Mistral Small 2409 22B:量化影响分析
- Mistral Small 2409 22B GGUF 量化评估结果 (Score: 106, Comments: 25):该帖子展示了 Mistral Small Instruct 2409 22B 模型的量化评估结果,重点关注 MMLU PRO 基准测试中的计算机科学类别。测试了各种量化级别,令人惊讶的是 Q4_K_L 变体以 60.00% 的准确率优于其他变体,模型大小范围从 9.64GB 到 18.35GB。作者还包含了 Qwen2.5-32B 和 Gemma2-27b 模型的对比结果,并提供了 GGUF 模型、后端、评估工具和所用配置的链接。
- Q4_K_L 量化表现优于 Q5_K_L 引发了讨论,用户推测这可能是由于随机性或层差异造成的。测试在 0 temperature 下运行,Q4_K_L 达到了 60.20% 的准确率(407 道题中答对 245 道)。
- Qwen2.5-32B 的性能受到称赞。用户要求与 Mistral Nemo 12B 进行对比,作者确认已完成评估并稍后发布。
- 讨论涉及了量化效应,有传闻称某些模型的 5-bit 量化表现比 4-bit 更差。一位用户的测试表明,在某些场景下 Q4 变体可能比 Q6 “更聪明”。
主题 5. AI 模型大小之争:效率 vs 能力
- 热门观点:Llama3 405B 可能确实太大了 (Score: 104, Comments: 94): Llama3.1-405B 最初在开源模型中处于领先地位,但与 Mistral Large (~120B) 等更高效的模型相比,现在被认为在实际应用中过于庞大。该帖子认为 27-35B 和 120B 模型将成为行业标准,公司会先部署现成的 120B 模型,然后通过微调 30B 模型来降低超过 50% 的成本。在承认 Meta AI 贡献的同时,作者强调需要更多 100B+ 模型,因为它们比更大的模型在训练、微调和托管方面成本更低。
- AI 模型的行业标准引发了辩论,一些人认为公司会使用任何效果最好的模型,而不考虑其大小。405B 模型被认为对研究、蒸馏以及关注数据隐私的大型组织内部使用非常有用。
- 像 Llama 405B 这样的大型模型被视为突破边界以及与传闻中拥有 1.7T 参数的 GPT-4 等模型竞争的重要力量。一些用户认为,创建 SOTA 模型对于研究和收集训练数据具有重要价值。
- 讨论了大型模型的实际应用,一些用户报告称每天通过 API 使用 405B 模型以获得更好的响应。人们对如何在不产生过高成本或复杂性的情况下微调 70B+ 模型的教程表现出浓厚兴趣。
其他 AI Subreddit 综述
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 研究与技术
-
Google Deepmind 通过联合样本选择推进多模态学习:一篇 Google Deepmind 的论文 展示了通过联合样本选择(joint example selection)进行数据策展如何进一步加速多模态学习。该技术可以提高训练大型多模态模型的效率。
-
Microsoft 的 MInference 显著加快了长上下文任务的推理速度:Microsoft 的 MInference 技术 能够在保持准确性的同时,实现多达数百万个 Token 的长上下文任务推理,大幅提升了支持模型的运行速度。这使得处理超长文档或对话变得更加高效。
-
利用 10 亿个网络策划的角色扩展合成数据生成:一篇关于扩展合成数据生成的论文利用 LLM 中的多样化视角,从网络数据策划的 10 亿个角色(personas)中生成数据。这种方法有助于创建更具多样性和代表性的训练数据集。
AI 模型发布与改进
-
Salesforce 的“小巨人” xLAM-1b 模型在函数调用方面超越 GPT 3.5:Salesforce 发布了 xLAM-1b,这是一个 10 亿参数的模型,在函数调用(function calling)中实现了 70% 的准确率,超越了 GPT 3.5。这展示了更小、更高效模型的显著进步。
-
具备函数调用能力的 Phi-3 Mini (六月版):Rubra AI 发布了更新后的 Phi-3 Mini 模型 具备函数调用功能。它具有与 Mistral-7b v3 竞争的实力,并优于基础版 Phi-3 Mini,显示了小型开源模型的快速进展。
-
OmniGen 多模态模型:一篇新的研究论文介绍了 OmniGen,这是一种内置 LLM 和视觉模型的多模态模型,通过 Prompting 提供前所未有的控制力。它可以根据文本指令操作图像,而无需专门的训练。
AI 发展与行业趋势
-
OpenAI 融资轮因需求高涨即将结束:OpenAI 的最新一轮融资即将结束,由于需求极高,他们不得不拒绝了“数十亿美元”的超额认购。这表明投资者对公司未来充满信心。
-
关于 LLM API 与 ML 产品开发的争论:r/MachineLearning 上的一场讨论引发了关注,即 LLM API 的普及导致人们过度关注 Prompt Engineering,而非更基础的 ML 研究与开发。这反映了关于 AI 研发方向的持续争论。
-
不可磨灭的 5D 存储水晶:新技术允许在坚固的水晶中存储高达 360 TB 的数据并保存数十亿年,这可能为长期保存人类知识提供一种方式。
AI Discord 回顾
由 O1-preview 提供的摘要之摘要的总结
主题 1. 新 AI 模型在社区引起轰动
- Qwen 2.5 成为焦点:Unsloth AI 确认支持 Qwen 2.5,用户正积极训练 Qwen2.5-14b。OpenRouter 推出 Qwen2.5 72B,具备增强的代码和数学能力,以及高达 131,072 的 context size。
- Mistral 进军 Multimodal AI:Mistral Pixtral 12B 作为 Mistral 的首个 multimodal 模型首次亮相,现已可在 OpenRouter 上访问。这次发布标志着一个关键时刻,扩展了 Mistral 在多功能 AI 应用领域的产品线。
- Flux 模型点燃 Stability.ai 用户热情:Flux 模型凭借卓越的 prompt adherence 和图像质量给人留下深刻印象,克服了最初的资源障碍。尽管对审美相似性存在一些担忧,但对其性能的乐观情绪依然高涨。
主题 2. 模型微调:胜利与磨难
- LoRA 微调激发创新:HuggingFace 用户建议利用 LoRA 微调基础模型,灵感来自 ipadapter 方法。这可以在不进行大规模重新训练的情况下提升模型性能。
- Phi-3.5-Mini 带来意外挑战:Unsloth AI 用户在微调 Phi-3.5-Mini 时遇到 AttributeError,尽管遵循了推荐的修复方法,仍需处理 LongRopeRotaryEmbedding 问题。社区正在寻找可行的变通方案。
- Quantization 权衡引发辩论:成员们讨论认为,未量化的模型在批处理中可能会提供更好的速度和吞吐量。在决策中,speed、size 和 cost 之间的关键平衡占据了中心位置。
主题 3. AI 工具考验用户耐心
- Aider 与 API 问题搏斗:用户正努力解决 Aider 无法从
.env文件读取的问题,这导致了配置混乱以及 Anthropic API 的过载错误。记录 LLM 对话历史成为首选的排查方法。 - LangChain 的分块输出令人懊恼:LangChain v2.0 用户报告称,在使用 OpenAI streaming 时,function call information 会间歇性地以分块形式输出。对潜在 bug 的怀疑促使人们呼吁修复。
- LM Studio 连接难题获解:在 macOS 上切换到 IPv4 为面临连接困扰的 LM Studio 用户化解了危机。关于调整设置的清晰指导将沮丧转为宽慰。
主题 4. AI 编程助手引发讨论
- O1 模型在代码编辑中受到质疑:Aider 用户对 O1 模型与 Sonnet-3.5 相比的性能表示怀疑,特别是在代码重构任务中。人们仍对未来增强交互能力的改进抱有很高期望。
- Wizardlm 在 OpenInterpreter 中展现魔力:Wizardlm 8x22B 在 OpenInterpreter 中的表现优于 Llama 405B,更频繁地在第一次尝试时就搞定任务。用户对其效率和效果印象深刻。
- Devin 加倍改进:Devin 现在提供更快、更准确的代码编辑以及改进的企业安全支持。虽然许多人称赞这些更新,但反馈仍然褒贬不一,一些用户对局限性表示沮丧。
主题 5. 社区活动与协作努力
- 黑客松热潮拉开序幕:CUDA MODE 成员正为黑客松做准备,审批流程正在进行,并鼓励通过论坛想法组建团队。有机会让 Wen-mei Hwu 教授在 PMPP book 上签名,这增添了额外的兴奋感。
- OpenAI 征集 Multi-Agent 奇才:OpenAI 正在为一个新的 multi-agent 研究团队招聘 ML 工程师,认为这一领域对于增强 AI 推理至关重要。他们鼓励即使没有 multi-agent 经验的人也积极申请。
- Web AI Summit 2024 即将来临:成员们对即将举行的峰会中的社交机会表示热忱。该活动承诺在热情的参与者之间就 Web AI 主题进行宝贵的交流。
第 1 部分:高层级 Discord 摘要
HuggingFace Discord
- 探索高级 Tokenization 技术:一篇名为 This Title Is Already Tokenized 的新博客文章解释了高级方法,引起了人们对其在现代 NLP 中应用的兴趣。
- 内容详细介绍了 Tokenization 的复杂性,推动了关于其与当前项目相关性的讨论。
- 用于语言模型训练的 Unity ML Agents:观看关于使用 Unity ML Agents 和 sentence transformers 从头开始训练 LLM 的最新 YouTube 视频。
- 本集重点介绍了 Oproof 验证成功,展示了 Tau LLM 系列的关键里程碑。
- 发布新的 GSM8K 推理数据集:一位用户介绍了一个基于 GSM8K 的新推理数据集,旨在用于 AI 模型训练。
- 预计将通过其结构化的挑战增强 AI 的批判性推理能力。
- 分形生成器的新缩放功能:一个分形生成器项目现在通过“Aiming Better”部分实现了缩放功能,允许用户调整网格长度并生成新输出。
- 社区建议包括实现滚轮输入以实现更平滑的交互。
- 使用 LoRA 微调基础模型:有人建议利用 LoRA 微调基础模型,并从 ipadapter 方法论中汲取灵感。
- 这可以通过调整参数而无需进行广泛的重新训练来增强模型性能。
aider (Paul Gauthier) Discord
- Aider 在 API 交互方面遇到困难:用户面临 Aider 无法读取
.env文件的问题,导致配置挑战和 Anthropic API 的重载错误。建议将记录 LLM 的对话历史作为一种潜在的诊断方法。- 在此背景下,进一步调查配置问题对于确保更顺畅的 API 交互至关重要。
- O1 模型与 Sonnet-3.5 的对比:对于 Aider 中
O1模型相对于 Sonnet-3.5 的性能(特别是在编辑和代码重构等任务中)存在怀疑。用户期待能够增强 Aider 与 O1 模型之间交互能力的改进。- 这种对比引发了关于模型集成和在编码任务中可用性的更广泛讨论。
- Chain of Thought 引发辩论:一位成员质疑 Chain of Thought 方法 的有效性,认为先前的训练对性能影响更大。讨论表明,针对结果进行务实的微调对于定制化应用至关重要。
- 这突出了 AI 讨论中的一个共同主题,即通过适当的方法论实现模型性能。
- Anthropic 通过 Contextual Retrieval 增强 LLM 运行:Anthropic 引入了一种 Contextual Retrieval 方法,可改进 Prompt 缓存以实现高效的 LLM 运行。该方法的实现被认为对 Aider 等项目至关重要。
- 总的来说,它强调了持续改进 AI 交互管理以简化功能的必要性。
- Aider 中的函数重命名问题:Aider 尝试重命名函数导致了部分更新,从而引发未定义函数错误,这引起了对其搜索/替换有效性的担忧。用户注意到,尽管有提示,Aider 仅修复了一个 linter 错误实例。
- 增强引用更新功能的必要性显现出来,暗示 Aider 的架构有很大的改进空间。
Unsloth AI (Daniel Han) Discord
- Qwen 2.5 发现 Unsloth 兼容性:用户确认 Unsloth 已支持 Qwen 2.5,尽管 Qwen 团队正在解决聊天模板(chat templates)的 bug。
- “最好是这样,我正在训练 Qwen2.5-14b” 这种情绪表达了对功能支持的紧迫需求。
- 成功微调 Qwen 2.5 等模型:对于在有限数据集上进行文本分类的 LLM 微调,Qwen 2.5 和 BERT 等模型非常理想,一位用户使用 Llama 8.1 8B 达到了 71% 的准确率。
- 成员们正寻求提高这些分数,并分享成功经验与挑战。
- 关键的量化权衡:讨论表明,未量化的模型可能具有更好的速度和吞吐量,特别是在批处理(batch processing)场景中。
- 成员们在决定模型量化时,对速度、尺寸和成本之间的关键权衡进行了辩论。
- AGI 进展引发辩论:有观点认为,实现 AGI 不仅仅是寻找答案,更多的是有效地解释答案,这暗示着未来面临巨大挑战。
- 呼应 80/20 法则,有人指出对 AGI 长达 60 年 的投入表明了其实现路径的艰辛。
- BART 模型的输入机制受到关注:关于 BART 的输入格式出现了疑问,强调它使用 EOS token 而不是预期的 BOS token 来开始生成。
- 计划通过实验进一步分析这种行为的影响。
CUDA MODE Discord
- 修复 Triton 和置信度函数中的 Bug:成员报告了
assert_verbose_allclose的 bug,促使 Pull Request #261 进行修复,旨在增强其在多种场景下的可靠性。- 此外,还出现了关于 KL Divergence 计算在较大输入尺寸下产生意外结果的担忧,表明需要与交叉熵(cross-entropy)等既定函数保持一致。
- 黑客松团队与 CDP 签名会:参与者正在为黑客松做准备,确认了审批情况,并鼓励利用论坛中发布的想法自行组建团队。
- 值得注意的是,活动中有一个让 Wen-mei Hwu 教授在 PMPP 书籍上签名的机会,这增加了额外的参与感。
- Web AI Summit 2024 社交机会:即将举行的 Web AI Summit 2024 令人期待,成员们表达了参加并在 Web AI 话题周围进行社交的兴趣。
- 该峰会为寻求分享该领域见解和经验的参与者提供了宝贵的交流机会。
- 关于 Apple ML 框架和 MLX 平台的见解:Apple 特有的 ML 框架专注于 autodiff 和 JIT 编译等技术,以增强在 Apple silicon 上的性能,这与 PyTorch 的 kernel 开发方法有相似之处。
- 成员们讨论了 MLX,这是一个类似 NumPy 的平台,专为 Metal 后端(Metal backends)的最佳性能而设计,增强了与 Apple 硬件能力的兼容性。
- 探索 Modal 的 Serverless 功能:成员们寻求利用 Modal 获取免费 GPU 访问的信息,讨论了其不支持 SSH 的 Serverless 部署,但为新账户提供免费额度。
- 建议探索一个 GitHub 仓库 中的示例,以便在 Modal 上无缝启动 CUDA 工作流。
Perplexity AI Discord
- Perplexity Pro 订阅困惑:新用户对使用 Perplexity Pro 处理优化简历等任务表示困惑,建议 ChatGPT 可能会更有效。
- 关于现有的 Pro 账户持有者在降级订阅后是否可以应用新的 Xfinity 奖励代码的讨论仍在继续。
- o1 Mini 模型表现参差不齐:用户提供了关于 o1 Mini 模型的反馈,报告结果褒贬不一,一些任务生成的响应较为基础且缺乏深度。
- 在与 Claude Sonnet 3.5 进行对比时,用户强烈呼吁改进特定的 Prompting 技术以获得更好的结果。
- AI 模型在编程中的多功能性:几位用户强调了尝试使用最新的 AI 模型进行编程,将 o1 Mini 作为一个选项,但指出其在复杂项目中的局限性。
- 他们强调了互联网搜索能力和实时反馈的必要性,以提升 AI 工具内的编程性能。
- Sonar 与 Llama-3.1 的性能差异:用户报告 llama-3.1-sonar-large-128k-online 模型表现不佳,特别是在响应格式方面,与 Web 端应用的结果相比存在差距。
- 具体问题包括输出质量下降、过早截断以及在遵循 Prompt 指令方面的不一致。
- 获取 Beta 功能访问权限:有关于 return_citations Beta 功能访问权限的咨询,建议联系 api@perplexity.ai 进行申请。
- 用户要求澄清 search_recency_filter 是否处于封闭测试阶段,以及检索近期内容的潜力。
Stability.ai (Stable Diffusion) Discord
- Pony XL 与原始模型的难题:Pony XL 是其前身的一个精炼迭代版本,但引起了关于 Text Encoder 层不匹配以及与其他 Embeddings 混淆模型分类的担忧。
- 一位用户恰当地将围绕 Pony 的热潮比作“郁金香狂热”,建议根据具体项目需求,SDXL 可能会表现得更好。
- Flux 模型展示出强劲性能:Flux 模型现在因克服了初始障碍(特别是资源需求和速度方面)而受到认可,从而在 Prompt 遵循度和图像质量方面建立了声誉。
- 尽管有一些关于生成图像中审美相似性的反馈,社区仍对 Flux 实现顶级性能的能力保持期待。
- SDXL 与旗帜:一个难点:用户报告 SDXL 和 SD3M 在准确渲染国旗等常见符号时表现挣扎,对其可靠性提出质疑。
- 社区建议包括专门训练一个 Lora 模型,旨在提高 SDXL 输出中旗帜的准确性。
- 优化 ComfyUI 以获得更好的工作流:关于高效使用 ComfyUI 的讨论强调了云端工作流,并探索了如 Backblaze 等 Serverless 选项用于模型存储。
- 成员们对在多个 GPU 上最大化利用 VRAM 表现出兴趣,并分享了在处理高负载任务时增强性能的技巧。
- 缺失 Inpainting 模型引发咨询:一位用户对 IOPaint 中缺少 Inpainting 和擦除模型表示沮丧,需要通过命令行访问来解锁这些功能。
- 这引发了关于命令行参数如何影响各种 UI 中模型可用性和操作的更广泛讨论。
Nous Research AI Discord
- 视频放大变得更简单:一位成员建议使用 video2x 通过放大模型处理每一帧来放大视频。
- 另一位成员考虑在放大前降低帧率以减少工作量,尽管对视频质量仍存疑虑。
- 猫咪 AI 革新音乐制作:一位用户展示了他们的猫咪 AI 聊天机器人,用于音乐制作,能够生成 MIDI 文件并推荐合成方法。
- 计划迁移到 Llama 以获得更好的性能,强调其对拍号和音乐风格的理解。
- 对 Forge 技术的兴趣增长:成员们询问了 Forge 的功能,特别是它与 Hermes 和其他模型的关系。
- 链接的 Discord 消息可能揭示了 Forge 在此背景下的能力。
- 探索 Hermes 3 的可访问性:关于访问 Hermes 3 的讨论包括一个指向 OpenRouter 的链接以供探索。
- 参与者分享了关于 Hermes 3 性能和数据处理的看法。
- 关于 AI 意识的哲学思考:一篇关于意识作为智能流形(intelligence manifolds)梯度的奇特论文被提及,引发了对其有效性的怀疑。
- 围绕 AI 对音乐理论等复杂概念的理解程度展开了辩论。
Latent Space Discord
- Hyung Won Chung 的范式转移:Hyung Won Chung 在 MIT 的演讲中介绍了 AI 的范式转移,强调最近推出的 o1 是该领域的重大进展。
- 他表示,由于 AI 理解方面的重大进步,这次演讲正值关键时刻。
- OpenAI 为 multi-agent 团队招聘 ML 工程师:OpenAI 正在为一个新的 multi-agent 研究团队招聘 ML 工程师,认为这个细分领域对于增强 AI 推理至关重要;申请详情点击此处。
- 他们强调,先前在 multi-agent 系统方面的经验并非先决条件,鼓励更广泛的申请。
- Devin 提升了速度和准确性:Devin 最近的增强功能带来了更快、更准确的代码编辑以及改进的企业级安全支持 来源。
- 虽然许多用户对更新表示赞赏,但反馈褒贬不一,一些人对其局限性表示沮丧。
- 新的 RAG 提案减少了检索错误:Anthropic 关于检索增强生成(RAG)的最新提案建议将错误分块检索率降低 67% 链接。
- 对话强调了人们对增强 RAG 有效性策略日益增长的兴趣。
- 关于 GitHub Copilot 模型的疑问:用户提出了关于 GitHub Copilot 所使用模型标准的问题,推测其使用了 GPT-4o,并对性能一致性表示担忧 来源。
- 讨论集中在上下文对各种 AI 工具性能的影响上。
OpenRouter (Alex Atallah) Discord
- 聊天室增强了用户交互:聊天室现在支持可编辑消息,允许用户轻松修改自己的消息或机器人的回复。
- 此次更新包括一个重新设计的统计界面,旨在提升用户参与度。
- Qwen 2.5 树立了新标准:Qwen 2.5 72B 提供了增强的代码和数学能力,具备 131,072 上下文大小。更多信息请点击此处。
- 该模型代表了 AI 能力的重大进步,推高了性能预期。
- Mistral 进入多模态领域:Mistral Pixtral 12B 标志着该公司在多模态 AI 领域的首次亮相,免费版本可在此处访问:此处。
- 此次发布被证明是一个关键时刻,将 Mistral 的产品扩展到了通用的 AI 应用中。
- Hermes 3 转向付费结构:随着 Hermes 3 转向 $4.5/月的付费结构,用户正在重新考虑服务使用选项。更多详情请点击此处。
- 价格变动缺乏通知,引发了社区内关于依赖免费额度的担忧。
- 自定义 API 集成受到关注:有请求提出希望能够使用自定义的兼容 OpenAI 的 API Key 端点,以便更好地与私有 LLM 服务器集成。
- 几位成员对这种灵活性对于未来集成能力的重要性表示赞同。
LlamaIndex Discord
- 令人兴奋的 Opik 合作伙伴关系,助力 RAG 自动日志记录:LlamaIndex 宣布与 Opik 达成合作伙伴关系,将为开发和生产环境自动记录所有 RAG/Agent 调用,简化认证流程。
- 这种自动化简化了复杂多步工作流中的用户体验。
- RAGApp v0.1 发布:无代码多 Agent 应用:团队发布了 RAGApp v0.1,支持在无需任何编码的情况下创建多 Agent 应用程序。
- 用户可以轻松添加 Agent、分配角色、设置 Prompt,并利用各种工具进行应用增强。
- LlamaIndex ID 给 Pinecone 带来麻烦:由于 LlamaIndex 自动生成的 ID,用户在 Pinecone 中面临 ID 控制方面的挑战,导致删除操作变得复杂。
- 社区建议通过手动编辑 ID 和创建节点来更好地管理这些限制。
- Pandas Query Engine 表现异常:Notebook 与 Python 脚本在使用 Pandas Query Engine 时的查询输出存在差异,影响了使用
df.head()时的功能。- 将
df.head()切换为df.head(1)证明可以解决该问题,这表明列数可能会影响查询解析。
- 将
- Graph RAG 面临查询兼容性问题:用户发现了 Graph RAG 中的查询模式问题,提供的模式与检索到的块 (chunks) 不一致。
- 进一步分析显示,在数据获取过程中,GraphRAGQueryEngine 的预期存在不匹配。
OpenAI Discord
- o1 Mini 与 4o 性能对决:用户认为 o1 mini 不如 4o,理由是它缺乏现实世界的经验和智能推理,只是打字速度快但缺乏实质内容。
- 一位用户评论说 o1 感觉与 4o 没有区别, 引发了关于 AI 认知能力的讨论。
- 关于 AI 意识的热烈辩论:一场关于 AI 是否能真正推理还是仅仅是模拟的激烈讨论爆发了,对于意向性持有不同意见。
- 一位成员提出,让 AI 专注于任务完成,而不是类人推理,可能会产生更安全、更高效的结果。
- 澄清 GPT-4 记忆功能:有关于 GPT-4 API Memory 功能的咨询,明确了这些功能仅提供给 ChatGPT Plus 用户。
- 一位用户指出,尽管 ChatGPT 界面缺乏此功能,但使用 Pinecone 等替代方案实现自己的记忆工具非常容易。
- IDE 集成反馈汇总:有建议提出增强集成在 IDE 中的 AI 工具,特别是呼吁增加类似于 ClaudeAI 的实时预览功能。
- 许多用户希望 ChatGPT 增加此功能, 而其他人则建议探索各种 IDE 以获得更好的兼容性。
- 分享并改进 Prompt 使用:一位成员分享了来自 Prompt 指南 的有用 Prompt,强调了其持续的相关性。
- 视觉辅助工具被认为对增强 Prompt 理解很有价值, 突显了它们在有效沟通想法中的作用。
Eleuther Discord
- HyperCloning 加速模型初始化:讨论集中在利用 HyperCloning 使用较小的预训练模型来初始化大型语言模型,旨在提高训练效率。
- 一位成员建议训练一个微型模型,对其进行缩放,并从较大的模型中进行蒸馏,以优化计算资源的使用。
- IDA 在 AI Alignment 中获得关注:用于对齐 AI 系统的 Iterated Distillation and Amplification (IDA) 方法因其迭代有效性而受到认可。
- 一位参与者对“蒸馏”一词表示怀疑,认为它无法代表所需的压缩和信息丢弃。
- 发现关键的 FP8 训练不稳定性:据报告,由于在长时间训练运行中 SwiGLU 激活函数的离群值放大,FP8 训练存在不稳定性。
- 一位听众询问其他激活函数在扩展训练背景下是否会面临类似问题。
- Tokenized SAEs 提升性能:Tokenized SAEs 引入了每个 token 的解码器偏置,增强了 GPT-2 和 Pythia 等模型,促进了更快的训练。
- 该方法解决了训练类别不平衡问题,通过“unigram 重建”能够更好地学习局部上下文特征。
- 对 Gemma 模型中 BOS Token 的担忧:有人担心 Gemma 模型中的 BOS token 在序列中可能只添加一次,从而影响滚动 loglikelihood 计算。
- 同一位成员确认,他们在调试期间发现某些情况下 llh_rolling 中缺失了 BOS token。
LM Studio Discord
- IPv4 切换解决连接问题:一位成员指出,在 MacOS 上切换到 IPv4 通常可以解决连接问题,另一位成员确认“它确实有效”。
- 有关调整 TCP/IP 设置的明确指南可以在这里找到。
- 攻克 LM Studio 连接挑战:成员们在将 LM Studio API 连接到 CrewAI 时遇到了问题,探索了不同的解决方案,但未达成共识。
- 有人建议观看一段有用的 YouTube 视频,以深入了解正确的设置方法。
- 3090 功率限制引发辩论:一位成员分享了关于将 3090 限制在 290W 与降压(undervolting)的见解,并推荐了相关资源以供进一步了解。
- 建议包括查阅文档,各方对每种方法的有效性持有不同意见。
- Windows 与 Linux 电源管理:对比显示,在 Windows 中调整 GPU 电源设置需要手动设置,而 Linux 用户可以通过单个命令进行优化。
- 成员们辩论了跨系统电源管理的易用性,确认 Windows 提供了更快的设置调整。
- RAM 速度与 CPU 推理瓶颈:讨论围绕 RAM 速度和带宽 是否显著阻碍了 CPU 推理展开,并提出了使用 DDR6 主板的建议。
- 成员们分享了对多个 CPU 核心利用不足的沮丧,强调了对当前 CPU 设计效率的担忧。
Modular (Mojo 🔥) Discord
- Mojo LLMs API 引发关注:一位用户表达了对使用基于 Mojo 的 LLMs API 以及 Pythagora(一种旨在通过对话交互构建应用程序的开发工具)的浓厚兴趣。
- 他们提出了关于服务成本的问题,并强调了该服务在软件开发转型中所扮演角色的令人兴奋之处。
- GitHub Discussions 关闭:请记好日期!:Mojo 和 MAX 的 GitHub Discussions 将于 9 月 26 日正式关闭,重要的讨论将被转换为 GitHub Issues。
- 为了确保有价值的讨论得以保留,随着社区集中化其沟通方式,成员可以标记组织者以请求进行转换。
- Packed Structs:Mojo 的兼容性疑问:聊天中强调了对 Mojo 缺乏 packed structs 支持的担忧,这使得将 bitflags 作为
__mlir_type.i1列表处理变得复杂。- 尽管对其可靠性仍存疑虑,但人们希望 LLVM 能通过字节对齐(byte alignment)来解决这一问题。
- 对可变位宽整数的需求:成员们讨论了为 TCP/IP 实现可变位宽整数(variable bit width integers)的问题,特别是对 UInt{1,2,3,4,6,7,13} 等类型的需求。
- 虽然提出了位运算符和掩码(bitwise operators and masks)作为替代方案,但它们被认为不够易用(ergonomic),因此希望 Mojo 能提供原生支持。
- Mojo 的功能请求堆积:出现了一项功能请求,允许在没有类型参数的情况下使用空列表,以便更好地与 Mojo 中的 Python 兼容,此外还有其他语法咨询。
- 显式 trait 实现的提及很常见,并有请求要求提供关于定义具有多个 trait 的 generic struct 的更清晰指南。
Torchtune Discord
- 输入位置系统得到简化:最近的 PR 移除了 input_pos 的自动设置,以简化 generation/cacheing logic。
- 此举旨在通过消除在各个类中寻找默认设置的过程,来防止用户产生困惑。
- 内存优化备受关注:讨论强调了正在开发中的内存优化(如 activation offloading),并鼓励使用 chunked cross entropy。
- 成员们承认,之前被否定的方法现在正被重新评估,以用于 mem opt tutorial。
- 通过批大小提升生成效率:重点集中在生成效率上,强调 generate script 在执行期间仅支持 bsz 1。
- 成员们在考虑提高批大小的缺点的同时,也在思考循环遍历批次的简单性。
- 关于生成过程子方法的辩论:围绕引入 sample 和 batched_sample 等子方法展开了激烈辩论,旨在改进生成方法。
- 观点各异,一些人倾向于方法分离,而另一些人则更喜欢类似于 gpt-fast 实践的精简方法。
- 保持 Generate Recipe 简洁的挑战:一位成员对在用户报告的与较大批大小相关的问题中保持 generate recipe 的简单性表示紧迫感。
- 目前正在努力简化逻辑,这被认为对于 generate functionalities 的清晰度至关重要。
OpenInterpreter Discord
- Wizardlm 在任务表现上超越了 Llama:实验表明 microsoft/Wizardlm 8x22B 的表现始终优于 llama 405B,在第一次尝试时成功完成任务的频率更高。
- 成员们对 Wizardlm 在各种任务中的效率印象深刻,引发了对其潜在更广泛应用的讨论。
- O1 目前缺乏实用功能:参与者指出 O1 仍处于开发阶段,目前没有任何可用于部署的功能。
- 他们对它无法与应用程序交互表示担忧,强调了进一步增强的必要性。
- 提议讨论 O1 的功能:有人呼吁针对 O1 的功能进行专门讨论,旨在澄清其潜在用例并收集见解。
- 为了最大限度地提高参与度,鼓励成员分享他们的空闲时间,特别是 GMT 时区。
- Firebase/Stripe 集成困难:一位用户报告了他们的 FarmFriend 项目在集成 Firebase 和 Stripe 时遇到的持续问题,特别是在处理 CORS 和身份验证域名方面。
- 他们描述在服务配置中遇到了“死循环”,并寻求有此类集成维护经验的人员提供帮助。
tinygrad (George Hotz) Discord
- 替换 CLANG dlopen 的悬赏:关于用 mmap 替换 CLANG dlopen 的悬赏讨论出现了,这可能需要像这个 pull request 中所示的那样手动处理重定位。
- “此时我非常好奇谁会拿到这个悬赏” 凸显了对该任务的竞争兴趣。
- Tinygrad 与 Intel GPU 的兼容性:一位用户询问 Tinygrad 是否支持多个 Intel GPU(类似于其对 AMD 和 NVIDIA GPU 的支持),并得到了积极反馈。
- 建议是进一步调查兼容性,表明对 Intel 硬件的兴趣日益增长。
- 排查 IPMI 凭据问题:报告的 IPMI 问题指向可能错误的凭据,引发了关于重置凭据最佳方法的讨论。
- 建议包括使用显示器和键盘进行设置,并确保 web BMC 密码与显示的密码匹配。
- 对 GPU 设置连接的困惑:关于在 GPU 设置中应使用 HDMI 还是 VGA 出现了一个问题,明确的共识是在初始连接期间仅需使用 VGA。
- 这种困惑凸显了硬件配置实践中常见的疏忽。
- 关于 ShapeTrackers 可合并性的本科论文:一位用户表示有兴趣在 Lean 中解决两个任意 ShapeTrackers 的可合并性问题,作为其本科论文,并询问了悬赏状态。
- 他们注意到该任务似乎尚未完成,为项目的新贡献提供了机会。
Cohere Discord
- Cohere Discord:学习之地:成员们对加入 Cohere Discord 社区表示兴奋,鼓励营造一个学习 AI 和 Cohere 产品的协作氛围。
- 向新人发送了 “欢迎!” 消息,为知识共享营造了积极的环境。
- 获取试用密钥并开始 Hack:一位成员建议使用每月提供 1000 次免费调用 的试用密钥,强调通过项目进行实践学习。
- 另一位成员表示赞同,称应用是最好的学习方式,并提到他们将在完成毕业设计后进一步探索。
- Rerank Multilingual v3 在英语处理上的困难:一位成员报告了使用 rerank_multilingual_v3 时的差异,指出英语查询的分数低于 0.05,而使用 rerank_english_v3 时分数为 0.57 和 0.98。
- 这种不一致性正对他们的 RAG 结果 产生负面影响,导致相关分块被意外过滤。
- 使用 Curl 命令测试 Rerank 模型:另一位成员建议使用 curl 命令切换模型进行测试,提议使用诸如 ‘what are the working hours?’ 和 ‘what are the opening times?’ 之类的查询。
- 这可以实现模型之间更好的性能对比。
- 对新闻简报的兴趣:一位成员提到他们是通过 classify newsletter 被吸引到社区的,展示了其在社区参与中的重要性。
- 另一位成员表示希望看到更多新闻简报,表明对社区持续更新和信息的需求。
LAION Discord
- 寻求快速的 Whisper 解决方案:一名成员请求帮助以最大化 Whisper 的速度,重点是针对超大规模数据集的转录任务使用多 GPU。
- 高效处理至关重要,讨论中强调了对 batching(批处理)的需求。
- Whisper-TPU:一个快速的选择:Whisper-TPU 被强调为转录需求中一个显著的快速替代方案,迎合了需要高速处理的用户。
- 它处理高要求任务的潜力引起了讨论者的兴趣。
- 探索 Transfusion 架构的使用:人们对利用 Transfusion 架构进行多模态应用产生了好奇,暗示了其创新的能力。
- Transfusion 的 GitHub 仓库展示了其预测 tokens 和扩散图像的潜力。
- Diffusion 与 AR 训练的挑战:结合 diffusion 和 AR 训练 的实验揭示了显著的稳定性挑战,凸显了一个关键的集成障碍。
- 社区正在积极寻求有效的策略来增强这些训练方法的稳定性。
- 询问 Qwen-Audio 训练的不稳定性:讨论中提到了 Qwen-Audio 论文中的训练不稳定性,并将其与多模态设置中的问题联系起来。
- 成员们表示打算重新审视该论文,以明确这些挑战及其相关性。
Interconnects (Nathan Lambert) Discord
- Qwen 2.4 对比 o1-mini 令人失望:新发布的 qwen2.4-math-72b-instruct 在使用代码执行和 n=256 生成的 ensemble 方法测试中,未能超越 o1-mini。
- 这一结果凸显了在没有反思型 CoT 的情况下,很难在 AIME 等指标上实现公平比较。
- 欧盟暂停 Llama 多模态发布:一位开发者提到,他们的团队热衷于创建一个 多模态版本的 Llama,但由于监管的不确定性,他们不会在欧盟发布。
- 这一决定反映了人们对碎片化的技术监管可能扼杀欧洲 AI 创新的广泛担忧。
- 社区担忧欧盟的反技术立场:围绕欧盟被感知的反技术情绪展开了讨论,成员们认为监管虽然初衷良好,但诱发了巨大的不确定性。
- 呼吁制定更清晰的法规,以更好地平衡技术领域的创新与安全。
- OpenAI 扩展视频的见解:OpenAI 的扩展视频表明,与人类能力相比,带有 RL 的模型现在在发现 CoT 步骤方面更具优势。
- 提出的关键点包括基础设施在算法性能中的重要性,以及 self-critique(自我批判)作为一项重大进展的出现。
LangChain AI Discord
- LangChain v2.0 中的分块输出问题:用户报告称 LangChain v2.0 在使用 OpenAI streaming 时,会间歇性地以分块形式输出 function call 信息,这暗示可能存在 bug。
- 这种情况引发了对函数调用期间配置设置和输出格式稳定性的担忧。
- Ell 与 LangChain 的对比:讨论强调了 Ell 和 LangChain 之间的区别和比较,显示了社区对评估 AI 框架可靠性的兴趣。
- 参与者正在细致地检查框架,以确定当前项目有效的模型集成方案。
- 澄清 LangGraph 支持渠道:关于去哪里咨询 LangGraph 问题的询问表明,社区对适当的支持渠道存在困惑。
- 这表明需要为探索各种工具和库的用户提供更明确的支持途径。
- 新 Agent 平台 Beta 测试招募:一份公告邀请 Beta 测试人员参与一个使用原生 tokens 启动 Agent 的新平台,预示着创新的机会。
- 该平台旨在增强 Agent 的部署方法,引发了围绕集成策略的热议。
- OpenAI Assistants 文档请求:成员们请求根据最新文档使用其自定义 OpenAI assistants 的指导,展示了对 API 变化的适应。
- 随着社区成员应对版本修订,理解新 Assistants API 功能的重要性被反复强调。
OpenAccess AI Collective (axolotl) Discord
- Moshi 模型发布引发关注:Moshi 模型 已作为一款 speech-text foundation model(语音-文本基础模型)发布,它采用了一种全新的文本转语音方法,支持 full-duplex spoken dialogue(全双工语音对话)。
- 这一进展显著增强了 conversational dynamics(对话动态)和 speech recognition(语音识别)能力。
- GRIN MoE 以极少参数实现卓越性能:GRIN MoE 模型表现出色,仅凭 6.6B active parameters(激活参数)就实现了高性能,尤其在编程和数学任务中表现优异。
- 该模型采用 SparseMixer-v2 进行梯度估计,通过规避标准的 expert parallelism(专家并行)方法挑战了技术极限。
- Mistral Small 发布引发关注:关于 Mistral Small 的讨论确认了它是一个 instruction-only(仅指令)版本,成员们对此反应不一。
- 参与者指出 memory intensity(内存占用)问题是困扰多位用户的一个显著限制。
DSPy Discord
- DSPy 中的 Bootstrapping 概念澄清:一位成员澄清了 DSPy 中的 bootstrapping 用于在 pipeline 中生成中间示例,确保成功的预测能捕获完整的流程轨迹。
- 强调了即使 LLM 具有非确定性,只要最终结果正确,中间步骤也应该是有效的。
- MathPrompt 论文引起兴趣:一位成员分享了一篇关于 MathPrompt 的研究论文,认为它有潜力扩展对增强数学推理的理解,并提供了论文链接。
- 这一参考资料可能为针对数学任务的更强大的 prompt engineering 策略铺平道路。
- TypedPredictors JSON 技巧:一位成员分享了 TypedPredictors 的新技巧,展示了如何模拟 JSON 解析来优化输出预处理,从而增强数据处理能力。
- 该方法包括删除多余文本、处理无效转义序列以及记录来自其 GitHub Gist 的错误。
LLM Finetuning (Hamel + Dan) Discord
- 金融科技初创公司寻找 LLM 工程师:一家金融科技初创公司正在寻找一名资深的 LLM Engineer,参与为期一周的冲刺,旨在利用 LLama 3.1 或 Qwen2 模型增强其多语言 real-time translation service(实时翻译服务)。
- 该计划有望显著改善跨语言障碍处理数百万笔金融交易的方式。
- Qwen 2.5 的多语言潜力:一位参与者建议探索 Qwen 2.5 的 multilingual capabilities(多语言能力),认为它可能非常符合项目目标。
- 这一建议指出了在选择 LLM 的同时增强 Whisper model 的方向,以进一步提高翻译准确性。
Alignment Lab AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第 2 部分:各频道详细摘要与链接
为了便于邮件阅读,完整的频道明细已被截断。
如果您喜欢 AInews,请分享给朋友!预谢!