ainews-chatgpt-advanced-voice-mode
ChatGPT 高级语音模式
以下是该文本的中文翻译:
OpenAI 推出了 ChatGPT 高级语音模式 (Advanced Voice Mode),新增了 5 种声音,并改进了口音和语言支持,目前已在美国广泛可用。在 Llama 3 和 Claude 3.5 传闻更新之际,Gemini Pro 大幅降价,以符合新的“智能前沿”定价标准。OpenAI 的 o1-preview 模型在规划任务中表现出色,在 Randomized Mystery Blocksworld 测试中达到了 52.8% 的准确率。传闻 Anthropic 将发布新模型,引发了社区的广泛关注。Qwen 2.5 正式发布,模型参数最高达 32B,支持 128K token,性能可媲美 GPT-4 0613 基准测试。
研究亮点包括:针对 o1-preview 的 PlanBench 评估;OpenAI 发布了涵盖 14 种语言的多语言 MMMLU 数据集;以及旨在标准化检索增强生成研究的 RAGLAB 框架。新的 AI 工具包括:将 PDF 转换为音频的 PDF2Audio;用于本地模型部署的开源 AI 入门套件;以及来自 Kyutai 的语音 AI 助手 Moshi。行业动态方面,Scale AI 的年度经常性收入 (ARR) 接近 10 亿美元,同比增长 4 倍;Together Compute 的企业平台提供了更快的推理速度和更低的成本。此外,文中还分享了 Sam Altman 博客文章中的见解。
耐心是你唯一需要的,Jimmy。
2024年9月23日至9月24日的 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitters 和 31 个 Discords(222 个频道和 2572 条消息)。预计节省阅读时间(以每分钟 200 字计):294 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
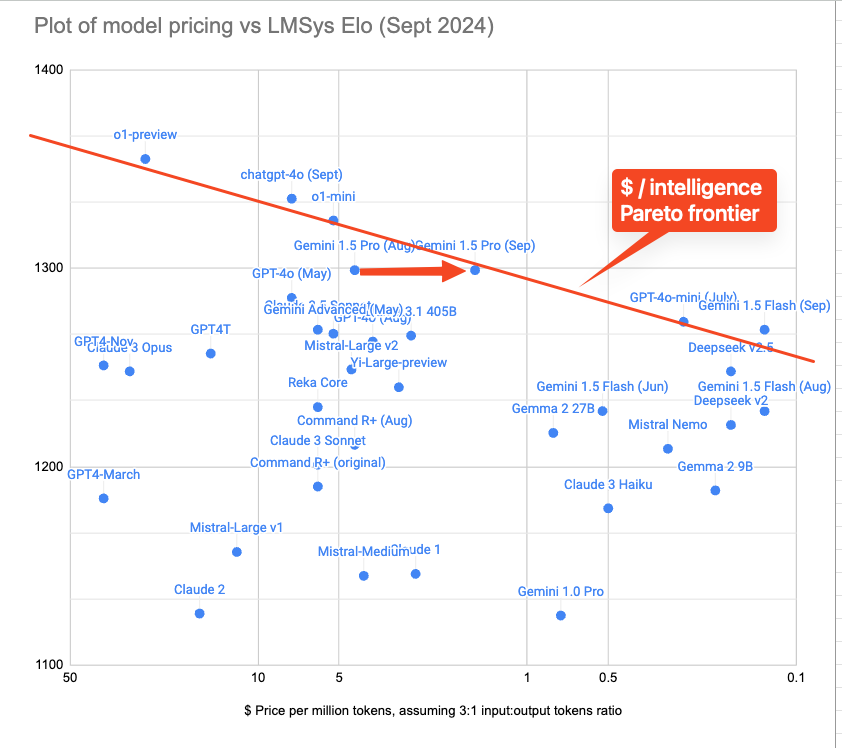
在传闻明天发布的 Llama 3 和 Claude 3.5 更新之前:
今天我们看到了 Gemini Pro 的大幅降价,使 Gemini 的定价与我们在本通讯中一直记录的 新 $/intelligence 前沿 保持一致。
但头条新闻可能是 ChatGPT Advanced Voice Mode,公司高层(如 Mira!)宣布其“本周推出”,但似乎美国的大多数人到今天结束时已经获得了访问权限。共有 5 种新语音,并改进了 口音/语言支持。是的,经过一番努力,它仍然可以唱歌!

AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型开发与发布
-
OpenAI 的 o1-preview 模型:@omarsar0 分享了关于 o1-preview 在规划任务中表现的见解,指出其虽有进步,但在长问题和不可解实例上缺乏鲁棒性。该模型在 Randomized Mystery Blocksworld 上达到了 52.8% 的准确率,显著优于其他 LLM。
-
Anthropic 传闻中的新模型:@bindureddy 和 @rohanpaul_ai 提到了 Anthropic 即将发布新模型的传闻,引发了 AI 社区的热议。
-
Qwen 2.5 发布:@_philschmid 重点介绍了 Qwen 2.5 的发布,其中 7B 模型在各项基准测试中与 OpenAI 的 GPT-4 0613 旗鼓相当。该模型提供 1.5B、7B 和 32B(即将推出)版本,支持高达 128K tokens。
AI 研究与基准测试
-
PlanBench 评估:@omarsar0 讨论了一篇在 PlanBench 上评估 o1-preview 的论文,将其与 LLM 和经典规划器进行了对比。研究揭示了 o1-preview 在规划任务中的优势,同时也指出了其局限性。
-
多语言 MMLU 数据集:@_philschmid 宣布 OpenAI 在 Hugging Face 上发布了多语言大规模多任务语言理解(MMMLU)数据集,涵盖 14 种语言和 57 个类别。
-
RAG 研究标准化:@rohanpaul_ai 提到了 RAGLAB,这是一个用于标准化检索增强生成(RAG)研究的框架,允许在 10 个基准测试中对 6 种 RAG 算法进行公平比较。
AI 应用与工具
-
PDF2Audio:@_akhaliq 分享了一个将 PDF 转换为音频播客、讲座和摘要的工具。
-
开源 AI 入门套件:@svpino 介绍了一个自托管的 AI 入门套件,包含低代码开发、本地模型运行、向量存储和 PostgreSQL 等组件。
-
Moshi 语音 AI 助手:@ylecun 宣布开源 Moshi,这是来自 Kyutai 的语音 AI 助手。
AI 行业与商业
-
Scale AI 动态:@alexandr_wang 报告了 Scale AI 的增长情况,其 ARR 提前达到近 10 亿美元,同比增长 4 倍。
-
Together Enterprise Platform:@togethercompute 推出了用于集中化生成式 AI 流程管理的平台,提供快 2-3 倍的推理速度,并可降低高达 50% 的运营成本。
AI 伦理与社会影响
-
Sam Altman 的博客文章:@rohanpaul_ai 分享了 Sam Altman 博客文章《智能时代》(The Intelligence Age)的见解,讨论了 AI 对人类能力和社会的潜在影响。
-
AI 监管讨论:@togelius 对拟议的 AI 监管法案表示担忧,认为这些法案可能会阻碍开源开发并将权力集中在私人公司手中。
梗与幽默
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Qwen 2.5:本地 LLM 性能的新基准
-
Qwen2.5 Bug 与问题 + 修复,Colab 微调笔记本 (评分: 85, 评论: 15):该帖子强调了 Qwen 2.5 模型 中的 关键 Bug,包括错误的 EOS tokens 和可能导致 NaN 梯度 的 聊天模板问题。作者已将 修复后的模型 和 4-bit 量化版本 上传至 Unsloth 的 Hugging Face 页面,并提供了使用 Unsloth 微调 Qwen 2.5 模型(基础版和对话版)的 Kaggle 和 Colab 笔记本。Unsloth 在微调期间可提供 2 倍的加速 并减少 70% 的 VRAM 占用。
- Qwen 2.5 72B 现在可以在 HuggingChat 上免费使用了! (Score: 196, Comments: 36): Qwen 2.5 72B,一个大型语言模型,现在可以在 HuggingChat 上免费访问。该模型由 Alibaba Cloud 开发,拥有 720 亿参数,是 Qwen(通义千问)系列的一部分,提供包括英语、中文和代码生成在内的多种语言能力。
- Qwen 2.5 72B 现在已在 HuggingChat 上线,具有 32k context window、改进的 role-playing 能力和结构化数据处理能力。开发者正在寻求关于 tool use 的反馈和资源,以便可能与其 tools feature 进行集成。
- 用户讨论了用 Mistral Small 等替代方案替换过时的 Mixtral models,后者的性能与 Llama 3.1 70B 相当。HuggingChat 提供了慷慨的使用限制,仅有每分钟速率限制,没有每日上限。
- 一些用户注意到该模型相比更小版本性能有所提升,而另一些用户则指出一个有趣的怪癖:它声称自己是由 Anthropic 开发的,而不是承认其作为 Qwen 的真实身份。
- Qwen 是如何做到的? (Score: 235, Comments: 127): Qwen 2.5 模型因其令人印象深刻的性能而获得积极反馈,其中 32B 模型的表现与 70B 模型相似。这引发了关于当较小模型能达到相当结果时,运行较大模型的效率问题,这可能使 local LLMs 更具吸引力。帖子作者询问了 Qwen 成功背后的因素,推测了可能的原因,如改进的 data quality、extended training periods 或模型开发中的其他 advancements。
- Qwen2.5 模型在高达 18 trillion tokens 的高质量数据上进行了训练,其中 32B 模型的表现与较旧的 70B 模型相似。Apache 2.0 license 适用于除具有商业价值的 3B 和 72B 版本外的大多数模型。
- 用户报告称,Qwen2.5 72B 在大多数任务中优于 Mistral Large 和 Cohere Command R+,但故事写作除外。32B 模型已经为一些用户取代了 Hermes 3 Llama 3.1 70B,以更快的性能提供相似或更好的结果。
- 正如 Hugging Face 讨论帖 中所讨论的,人们对 Qwen2.5 模型缺乏文化知识表示担忧。一些用户认为这种权衡对于专业任务是可以接受的,而另一些人则认为基础知识对于一个全面的 LLM 是必要的。
主题 2:LLM 效率和量化方面的进展
- 来自 NVIDIA 的新 Llama-3.1-Nemotron-51B 指令模型 (Score: 205, Comments: 47): NVIDIA 发布了 Llama-3.1-Nemotron-51B-instruct,这是一个拥有 51.5B parameter 的 LLM,通过 block-wise distillation 以及针对单个 H100-80GB GPU 的优化,从 Llama-3.1-70B-instruct 衍生而来。该模型使用来自 FineWeb、Buzz-V1.2 和 Dolma 数据集的 40 billion tokens 进行了知识蒸馏,专注于英语单轮和多轮对话用例,可在 Huggingface 上获取,仓库大小为 103.4GB。
- 用户对 width-pruned Qwen 2.5 32B 和 Qwen 70B 模型表示期待。Qwen 14B 模型实现了 ~80 的 MMLU 分数,与大学四年级水平相当,详见 Qwen blog。
- NVIDIA 还开发了该模型的 40B 变体,在精度损失适中的情况下,比父模型实现了 3.2 倍的速度提升。其架构类似于 DeciLM,表明 NVIDIA 可能集成了 Deci 的 AutoNAC 技术。
- 该模型的 context size 尚不明确,配置信息存在冲突。
max_position_embeddings设置为 131,072,但 RoPE scaling 设置中的original_max_position_embeddings为 8,192。
- 以自定义浮点格式运行 LLM(近乎无损的 FP6) (Score: 54, Comments: 20): 该帖子讨论了用于 LLM 运行时量化 的 自定义浮点格式 实现,允许将 FP16 模型 直接加载到 FP4, FP5, FP6 和 FP7 中,且准确率损失和吞吐量惩罚极小。作者解释了其方案的技术细节,包括 位级预打包 (bit-level pre-packing) 和具有 并行反量化 功能的 SIMT 高效 GPU 运行时,这使得即使在不规则位宽下也能获得极具竞争力的性能。基准测试显示,FP5 和 FP7 在 GMS8K 上取得了与 FP8 相似的结果,而 FP6 甚至超过了 BF16 量化,这促使作者建议将 FP6 作为平衡内存和准确率权衡的潜在标准。
- 讨论了用于运行时量化的 自定义浮点格式,用户注意到其相比于 exl2 6bpw 和 GPTQ 等分组量化可能具有的 计算效率 优势。5bpw 格式被强调为某些模型和规模的有意义权衡。
- 有人对 GMS8K 基准测试结果的 统计显著性 提出了担忧,建议需要更全面的评估。作者承认了这一点,并提到计划运行 MMLU-Pro 以及可能的困惑度 (perplexity)/KL 散度测试。
- 用户询问了如何将模型转换为 FP6 格式,并提供了使用命令行界面的说明。作者指出,目前尚无法导出这些格式的模型,但如果需求增加,可能会集成到 llm-compressor 中。
主题 3. 创意应用中的 AI:游戏与音乐
-
OpenMusic:出色的开源文本生成音乐项目! (Score: 59, Comments: 6): OpenMusic 是一个开源的 文本生成音乐 (text-to-music generation) 项目,可在 Hugging Face 上使用。该项目也有一个 GitHub 仓库,允许用户通过文本提示生成音乐。
-
我正在尝试将小型 LLM 用于《天际》+ AI 配置。Qwen 的推理速度让我感到惊讶。 (Score: 87, Comments: 46): 作者正在尝试将 小型语言模型 用于 《天际》(Skyrim) + AI 配置,并对 Qwen 的推理速度 表示惊讶。虽然没有提供具体的性能指标,但帖子表明,在这一与游戏相关的 AI 应用中,Qwen 的速度在测试的其他模型中脱颖而出。
- 像 Mantella 和 AI Follower Framework (AIFF) 这样的 Skyrim AI 模组 能够使用 LLM 实现 NPC 交互。AIFF 提供更多功能但仅限于随从,而 Mantella 允许与任何 NPC 对话。
- 用户正在为《天际》尝试各种 LLM,包括 Qwen 2.5 7B、Llama 3.1 8B 和 Gemma 9B。推荐使用 角色扮演微调模型 (Roleplay-tuned models) 以获得更可信的 NPC 交互。
- 作者使用的是一台配备 RTX 3080 mobile 8GB GPU 的 MSI GP66 11UH-032 游戏笔记本电脑,目标是在少于 6GB 显存 (VRAM) 的情况下运行 LLM。量化后的 7b-8b GGUF 模型 表现出了出色的性能。
主题 4. 新的 AI 数据集与研究论文
- OpenAI 发布开源数据集! (Score: 235, Comments: 51): OpenAI 在 Hugging Face 上发布了 多语言大规模多任务语言理解 (MMMLU) 数据集。该数据集现已在 https://huggingface.co/datasets/openai/MMMLU 公开发布,为研究人员和开发人员提供了用于多语言理解任务的新资源。
- 用户对 OpenAI 的动机表示怀疑,一些人认为该数据集可能 “被投毒” (poisoned) 或旨在偏向他们的模型。在利用 OpenAI 的输出进行训练时,GPTslop 泛滥 (GPTslop epidemic) 被列为需要谨慎的原因。
- 翻译 MMLU 的选择受到了质疑,因为众所周知它存在 有问题的题目 和 无效的答案选项。一些人建议 MMLU-Pro 会是更好的选择,因为许多模型在 MMLU 上的得分已经达到了 90% 左右。
- 尽管存在怀疑,用户仍承认 开源基准测试 对于可复现性和模型比较的价值。该数据集的规模(19.4 万测试集)被认为对于计算单个分数来说可能过大。
- Google 发布了新论文:Training Language Models to Self-Correct via Reinforcement Learning (Score: 229, Comments: 30):Google 研究人员提出了一种名为 Self-Correction via Reinforcement Learning (SCRL) 的新方法,旨在改进语言模型的输出。该方法利用 Reinforcement Learning 训练模型对其初始输出进行 Self-Correct,从而在包括 问答、摘要 和 推理 在内的各种任务中提升了 性能。SCRL 展现出比标准微调显著的改进,在某些基准测试中增益高达 11.8%。
- Self-Correction via Reinforcement Learning (SCRL) 方法的有效性受到了质疑,用户讨论了如何确保模型是 真正的自我修正,而非刻意生成错误。论文中关于泛化自我修正能力的关注被视为一个关键见解。
- 用户对论文的方法论进行了辩论,指出 Prompt 并没有明确说明解法是错误的。一些人指出 Qwen 72B 模型可以 zero-shot 解决所有 8 道数学题,这引发了关于数据泄露和需要新型评估集的疑问。
- 讨论涉及了论文的理论重点与实际应用,强调研究论文通常是测试特定理论而非生产最终产品。通过一个关于数字加法的 ELI5 类比 解释了泛化改进步骤的概念。
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型进展与发布
-
OpenAI 的 GPT-4 Turbo (o1) 模型:多篇帖子讨论了 OpenAI 新 o1 模型(尤其是 o1-mini)令人印象深刻的能力。用户报告称其在 复杂数学问题解决等任务中有显著改进,一位用户形容在某些应用中它就像“在使用真正的魔法”。
-
Anthropic 的新模型发布:Anthropic 预计将发布一款新的 AI 模型,在 AI 社区引起了兴奋。
-
AI 推理成本降低:OpenAI 的 Dane Vahey 报告称,每百万 Token 的成本在 18 个月内从 36 美元降至 0.25 美元,这代表了 AI 运营成本的大幅下降。
AI 研究与开发
-
多智能体 (Multi-agent) AI 研究:Google DeepMind 和 OpenAI 都在组建专注于多智能体通用人工智能 (AGI) 研究的团队,表明了对该领域日益增长的兴趣。
-
图像和视频生成中的 AI:AI 驱动的图像和视频处理进展受到关注,包括 CogVideoX-I2V 的工作流 以及 在视频生成中同时控制多个主体的演示。
行业与市场动态
-
Anthropic 潜在的估值增长:据报道,Anthropic 正在与投资者洽谈,计划以 300-400 亿美元的估值筹集资金,这可能会使其之前的估值翻倍。
-
政治层面对 AI 的参与:美国副总统 Kamala Harris 在一场筹款演讲中承诺将加大对 AI 的投资,表明政治层面对于 AI 发展的关注度日益提高。
关于 AI 进展的观点
-
AI 能力的飞速进步:多篇帖子反映了 AI 能力的快速进步,许多以前被认为远未解决的任务现在已经可以实现。
-
未来 AI 预测:Yann LeCun 预测,匹配或超越人类智能的 AI 即将到来,同时在一年或两年内,智能眼镜中的 AI 助手将能够翻译数百种语言。
AI Discord Recap
由 O1-preview 提供的摘要的摘要总结
主题 1. AI 模型升级:新发布与重大更新
- Mistral Small 模型发布,拥有 220 亿参数:全新的 Mistral Small 模型 已上线,拥有 220 亿参数,旨在提升各项任务中的 AI 性能。用户可以通过 HF Collection 进行探索。
- OpenAI o1 模型引发关注,尽管图表未标注:OpenAI 发布了 o1 系列模型,但其 Scaling Law 图表缺少 x 轴标签,促使用户尝试使用 o1-mini API 重构数据。讨论集中在计算量是否仅涉及数万个 Token。
- Gemini 模型性能提升并降价:Gemini-1.5-Pro-002 和 Gemini-1.5-Flash-002 获得更新,速率限制 (Rate Limits) 提升 2 倍以上,且价格下调 50%。开发者对这些变化感到兴奋,称其为“开发者的好日子”。
主题 2. 语音功能在争议中推出
- OpenAI 高级语音功能支持 50 多种语言:高级语音 (Advanced Voice) 功能正向 Plus 和 Team 用户推出,新增了自定义指令 (Custom Instructions)、记忆功能 (Memory) 以及 5 种新语音,并改进了口音。用户现在可以用 50 多种语言 进行表达。
- 欧洲用户因无法使用语音功能感到沮丧:尽管功能已推出,但欧洲用户感到失望,因为 高级语音功能在多个欧洲国家尚未上线。许多人表示该功能“不如早期的演示”。
- 用户讨论语音助手的审查与限制:讨论指出,OpenAI 对安全性的关注导致语音助手功能受限。用户抱怨其缺乏像 Character.ai 等角色扮演 AI 产品那样的动态性。
主题 3. 开发者致力于 AI 集成与优化
- OpenRouter 集成至 Cursor 并提供演示应用:OpenRouter 现在可以在 Cursor 中与包括 Anthropic 在内的所有模型无缝协作。他们还在 GitHub 上发布了 演示应用 以启动开发。
- Aider 安装困扰导致用户卸载:用户在安装 Aider 时面临挑战,导致多次尝试使用 pipx 重新安装仍未解决问题。一些人选择回退到旧版本以恢复功能。
- GPU MODE 更名引发复杂反应:原名为 CUDA MODE 的社区更名为 GPU MODE,旨在扩大关注范围。成员们反应不一,出现了诸如“Gigachad Processing”之类的幽默建议,并对更名进行了辩论。
主题 4. AI 推理与可靠性备受关注
- LLM 无法规划?OpenAI o1 评估报告:一份新的研究简报批判性地评估了 OpenAI o1 模型的规划能力,认为尽管它被宣传为大型推理模型 (Large Reasoning Model),但实际上“无法规划”。
- 高 Temperature 输出导致幻觉频发:用户报告称,将 Temperature 提高到 1.25 以上会导致模型产生幻觉,从而质疑输出的可靠性。指示模型不要产生幻觉虽有帮助,但不能完全解决问题。
- JSON 格式化问题困扰开发者:API 用户在处理 JSON 格式输出时遇到困难,经常收到不完整或错误的响应(如仅有一个 ‘{‘)。虽然建议使用定义更明确的 Prompt 结构,但问题依然存在。
主题 5. 协作努力与工具增强 AI 开发
- DSPy 2.5.0 发布,解决问题的速度比说出“Chain-of-Thought”还要快:DSPy 2.5.0 的发布旨在迅速解决 50-100 个问题,用户对新功能和即将推出的入门 Notebook 充满热情。
- GitHub 仓库涌现大量 AI 工具:诸如 YouTube-to-Audio 之类的新工具可以轻松从视频中提取音频,而 LitServe 等框架则简化了使用 FastAPI 提供和扩展 LLM 服务的过程。
- 社区联合进行微调与模型训练:成员们分享了微调 Vit_B16 和 Llama3.1 等模型的经验,强调了高质量数据的重要性。与模型开发者的合作有助于解决 Qwen 2.5 中的 Bug 等问题。
注:所有链接和细节均基于各 Discord 频道的讨论,反映了最新的更新和社区情绪。
第 1 部分:Discord 高层摘要
OpenRouter (Alex Atallah) Discord
- Cursor 集成了 OpenRouter!:OpenRouter 现在可以在 Cursor 中无缝运行,支持包括 Anthropic 在内的所有模型。感谢 @cursor_ai 修复了此问题! 🍾
- 此次集成通过简化操作和扩大模型可访问性提升了用户体验。
- Gemini 模型升级,性能更佳!:两个更新的模型 Gemini-1.5-Pro-002 和 Gemini-1.5-Flash-002 现已上线,具有更低的价格和更高的性能指标。
- 这些模型针对效率进行了优化,具有更快的输出和更高的 Rate Limits,并将于 2024 年 10 月 8 日前自动更新面向用户的别名。
- OpenRouter 推出演示应用以快速上手:OpenRouter 团队宣布在 GitHub 上提供基础演示应用,帮助开发者快速启动项目。
- 这些演示包含一个简单的 ‘tool calling’ 功能,使用户更容易从零开始创建应用程序。
- 关于 Middle-Out Transform 影响的讨论:用户对默认禁用 Middle-Out Transform 表示担忧,理由是对工作流和基础设施产生了负面影响。
- 社区强调需要就模型变更进行更清晰的沟通和更新,以减轻干扰。
- 关于 Token 定价结构的见解:相关讨论强调了不同模型之间 Token 定价的差异,指出 OpenRouter 利用从上游返回的原生 Token 进行成本计算。
- 用户注意到 GPT-4o 和 Qwen 等模型之间 Tokenizers 的差异会显著影响 Token 计数和价格估算。
HuggingFace Discord
- Mistral Small 模型发布:新的 Mistral Small 模型 已上线,拥有 220 亿参数,旨在提升各种任务中的 AI 性能。
- 用户可以通过 HF Collection 进一步探索该模型。
- Gradio 5 设定性能标准:Gradio 5 (Beta) 正式发布,引入了重大的易用性改进和服务器端渲染,以实现更快的应用加载。
- 在公开发布之前,官方鼓励用户提供反馈,旨在根据社区见解完善功能。
- FinePersonas 为合成数据增加丰富性:最新的 FinePersonas v0.1 提供 2100 万个 Persona,增强了针对各种应用的合成数据生成。
- 该数据集旨在提供针对特定 Persona 需求量身定制的真实查询生成,彻底改变大规模数据项目。
- Hugging Face Token 问题频发:多位用户报告了 Hugging Face Token 无效的问题,引发了关于潜在 Rate Limit 问题和重新安装 huggingface-hub 包的讨论。
- 尽管进行了故障排除,许多人仍继续遇到 Token 验证失败的情况。
- OpenAI 的单词生成数量令人震惊:据报道,OpenAI 每天生成约 1000 亿个单词,有用户质疑 Hugging Face 是否能使用自己的模型接近这一指标。
- 这一讨论突显了 AI 领域不同实体之间在文本生成能力上的显著差异。
Eleuther Discord
- RWKV 架构提供独特见解:社区深入剖析了 RWKV 架构,特别是其相较于卷积 (convolutions) 的效率,并强调需要更简单的解释来促进采用。
- 熟悉 GLA 至关重要,因为参与者主张对围绕 RWKV 的复杂性进行更清晰的分解。
- 推出 YouTube-to-Audio 工具:一位用户发布了 youtube-to-audio,这是一个命令行工具,可以从 YouTube 提取 MP3 和 WAV 等多种格式的音频,提升了用户体验。
- 该工具还支持播放列表下载和自定义文件名,定位为现有解决方案的无广告替代方案。
- 动态评估 (Dynamic Evaluation) 引发辩论:ML 中的动态评估提议在测试集上微调模型,引发了对其外部有效性以及与经典实践一致性的担忧。
- 尽管有效,成员们强调了训练和测试数据集之间相似分布的关键需求。
- muP 实现得到澄清:社区致力于简化神经网络的 muP (Maximal Update Parameterization) 概念,这对于增加社区参与度至关重要。
- 推动更清晰的实现以及理论见解,旨在提高开发者的集成便利性。
- OpenAI 的 LRM 显示出规划局限性:成员们评估了 OpenAI 的 o1 (Strawberry) 作为大型推理模型 (LRM) 的表现,并对其有效性进行了辩论,特别是在特定测试条件下。
- 对其规划能力的担忧浮现,报告指出推理时计算 (inference time compute) 占比已跃升至 50% 以上。
aider (Paul Gauthier) Discord
- Gemini 模型迎来重大更新:Gemini-1.5-Pro-002 和 Gemini-1.5-Flash-002 的推出带来了 50% 的降价和增强的速率限制,尽管编码基准测试保持平稳,但仍给开发者留下了深刻印象。
- 自 10 月 1 日起,对于 128,000 tokens 以下的输入,输入成本从 $3.50 降至 $1.25/million tokens。
- RoRF 开源以增强性能:Routing on Random Forest (RoRF) 已开源发布,提供 12 个预训练模型路由 (model routers),显著提升了 MMLU 性能。
- 此次发布有望推动各种应用中的模型路由技术。
- 对新 Claude 模型的期待升温:关于即将发布的 Claude 模型(如 Haiku 3.5 或 Opus)的猜测不断,用户对自上次更新以来的等待表示沮丧。
- 这种延迟让人们对未来几周内的及时发布寄予厚望。
- Aider 安装不便:用户在安装 Aider 时面临挑战,在功能失效后通常需要使用 pipx 重新安装,尽管他们努力尝试修复配置。
- 在用户应对这些复杂情况时,回退到旧版本是建议的解决方案之一。
- Prompt Caching 功能正在讨论中:针对 Anthropic API 和 OpenRouter 的 Prompt Caching 配置 AIDER_CACHE_KEEPALIVE_PINGS 是一个热门话题,用户正在寻求实现方面的澄清。
- 分享了 Prompt Caching 文档链接以方便理解。
OpenAI Discord
- Advanced Voice 功能全面推出:Advanced Voice 功能现已向 Plus 和 Team 用户开放,通过 Custom Instructions 等新功能增强了 ChatGPT App 内的交互体验。此次更新还引入了五种新声音,并显著提升了多语言能力,支持超过 50 种语言的表达。
- 然而,这一功能的推出在欧洲用户中引起了困惑和失望,一些人指出其表现不及早期的演示。
- JSON 格式化质量受到抨击:用户正面临 JSON 格式输出的问题,经常获取到如简单的 ‘{‘ 这样令人不满意的响应,导致寻求结构化数据的 API 用户感到沮丧。有人建议通过定义更清晰的结构来提高这些输出的质量。
- 尽管建议使用更明确的 Prompt,但许多人仍遇到性能不佳的问题,限制了他们获得有效 API 响应的能力。
- 明确 Prompt Engineering 以获得更好的输出:关于 Prompt Engineering 的讨论强调了清晰、详细请求的必要性,以最大化模型的性能和输出的相关性。几位成员强调,在 Prompt 中加入具体示例可以极大地提高生成响应的质量。
- 提到的挑战包括生成多样化的内容,特别是在 Minecraft 提问等利基应用中,面临着内容重复的问题。
- 幻觉与响应可靠性担忧:参与者对模型在 Temperature 设置超过 1.25 时产生幻觉的倾向表示担忧,这表明输出缺乏可靠性。成员们的见解表明,指示模型避免幻觉可能会限制无关内容,但并不能完全解决问题。
- 这种对幻觉的担忧延伸到了 ChatGPT 的各种功能中,促使用户寻求更好的性能优化方法。
- 生成有趣的 Minecraft 问题:一位用户测试了一个旨在以 JSON 格式生成有趣且引人入胜的 Minecraft 问题的 Prompt,但在实现多样化和吸引人的查询方面遇到了障碍。社区的反馈旨在解决重复输出和幻觉的挑战,从而优化这一过程。
- 这种对问题生成创意性的追求引发了关于改进 Prompt 策略和有效利用 API 能力的讨论。
GPU MODE Discord
- GPU MODE 转型:社区从 CUDA MODE 转型为 GPU MODE,旨在更广泛地关注 CUDA 之外的各种 GPU 编程框架。
- 成员们对更名表达了复杂的情绪,并提出了诸如 Heterogeneous Computing 甚至像 Gigachad Processing 这样幽默的替代名称。
- 分布式系统的训练优化:讨论强调了在使用 2x 4090 GPU 进行训练时的扩展性问题,指出在低带宽条件下 DDP 比 FSDP 提供更好的性能。
- 参与者强调了通信带宽对可扩展性的影响,并分享了优化分布式训练工作负载的经验。
- WebNN 集成前景:有人建议为 WebNN 创建专门的频道,思考其在集成 WebGPU 和 WASM 中的作用,这在标准化方面可能面临挑战。
- 针对 WebNN 与 NPU API 交互的能力进行了澄清,展示了其在不同硬件设置下的潜力。
- Luma 招聘性能工程师:Luma 正在为其 Dream Machine 项目积极寻求工程师,提供的职位专注于多模态基础模型(Multimodal Foundation Models)的性能优化。
- 应聘者被要求在分布式训练和低级 Kernel 优化方面拥有丰富经验,该公司被强调为正在快速增长。
- GPU 上的数据处理挑战:成员们指出, GPU 上有效的数据传输严重依赖于延迟和内存带宽,并询问了与 CPU 设置的对比情况。
- 一位参与者对这些因素如何影响 GPU 性能以及在片上系统(SoC)架构中的可用性提出了疑问。
Interconnects (Nathan Lambert) Discord
- OpenAI o1 模型引发关注:OpenAI 发布了 o1 系列模型,并附带了一张展示测试时计算(test-time compute)扩展定律(scaling laws)的图表。尽管 x 轴未标注,但引发了关于利用 o1-mini API 重构数据的讨论。
- 成员指出,计算可能仅涉及数万个 token,这引发了在没有适当结构的情况下进一步扩展的可行性问题。
- Anthropic 估值或达 400 亿美元:报告指出 Anthropic 正在讨论融资,这可能将其估值推高至 300 亿美元 到 400 亿美元 之间,较今年早些时候实际上翻了一番。
- 这反映了在快速发展的市场中,AI 公司争夺大量资金支持的激烈竞争态势。
- James Cameron 加入 Stability AI 董事会:Stability AI 欢迎 James Cameron 加入其董事会,旨在利用他的专业知识探索视觉媒体领域的创新。
- 这一战略举措被视为开发专为创作者量身定制的更全面 AI pipeline 的关键。
- Gemini 模型增强功能发布:Gemini 模型 的更新包括 2 倍以上的速率限制(rate limits)提升 以及 Gemini 1.5 Pro 50% 的降价,同时还为开发者提供了新功能。
- 修订版还引入了可选的过滤器以提高安全性和可靠性,从而更好地控制模型设置。
- Scale AI 财务增长洞察:Scale AI 报告称,尽管毛利率较低,但上半年销售额增长了近四倍,表明在 AI 服务需求不断增长的背景下增长强劲。
- 随着行业格局继续向 AI 驱动的解决方案转变,这一财务激增使 Scale AI 处于极具吸引力的地位。
Nous Research AI Discord
- O1 规划能力评估:最近关于 O1 的一篇 研究简报 概述了其规划能力,据报道团队成员为了完成该报告熬夜奋战。
- 研究结果详细阐述了全面的检查,并承诺在公开发布后提供更多见解。
- World Simulator API 提供低成本访问:讨论集中在 World Sim,强调了用户注册即可获得积分的机会,同时 API 使用成本较低。
- 频道中普遍鼓励创建账户以利用免费积分。
- Hermes 和 Monad 表现出“固执”:有报告称 Hermes 和 Monad 在交互中变得不那么有效,特别是在打标签(tagging)能力方面。
- 一个建议是实施存在惩罚(presence penalty),而其他人则注意到基于托管环境的差异。
- Gemini 1.5 引发关注:人们对 9 月份发布的 Gemini 1.5 升级充满期待,同时 GPT-4o 也进行了小规模推广。
- 成员们对即将举行的 Meta Connect 活动可能出现的突破表示期待。
- DisTrO 在低带宽下表现高效:初步研究结果表明,DisTrO 在非对称带宽和异构 GPU 环境中运行有效,增强了资源管理。
- 这使得 DisTrO 成为次优网络条件下资源分配的可行选择。
Unsloth AI (Daniel Han) Discord
- Qwen 2.5 模型问题已解决:成员们讨论了 Qwen 2.5 模型的问题,报告了崩溃和 Bug,但分享了改进模板和修改训练方法等解决方案。
- 与 Qwen 团队的合作在解决其中一些问题上取得了进展,从而提高了模型的稳定性。
- Unsloth Trainer 的内存使用得到优化:一位用户在初始化 UnslothTrainer 时遇到了内存问题,并建议通过减少数据集映射进程来解决。
- 他们的后续反馈表明,减少进程数取得了成功,强调了为了获得更好内存性能进行平衡的重要性。
- 分享模型微调见解:微调 Vit_B16 模型的经验分享强调,高质量数据比单纯的数据量更能有效提升结果。
- 该用户在获得显著的准确率后,计划通过增加高质量图像来进一步增强其模型。
- Llama3.1 的内存问题已处理:一位用户在加载 4-bit 量化 Llama3.1 时遇到了 out of memory (OOM) 错误,当 PyTorch 使用了 14.75GB 时,20GB 的分配失败了。
- 社区成员建议调整模型配置,作为解决这些 OOM 问题的排查步骤。
- 探索强化学习的改进:讨论了 OpenAI 如何应用 RLHF (Reinforcement Learning from Human Feedback),根据用户交互来升级其模型。
- 参与者指出了利用先前的对话来指导模型改进的挑战,强调了训练方法中缺乏结构化反馈。
Perplexity AI Discord
- 对 Anthropic 新模型发布的期待升温:消息源确认,Anthropic 的重大 AI 模型升级预计很快发布,完整细节将在禁令解除后公布。
- 成员们正热烈讨论这次升级可能对 AI 领域的开发者产生的影响。
- Perplexity Pro 功能引发用户好奇:用户在讨论 Perplexity Pro 账户的限制时产生了困惑,特别是关于每日搜索限制的问题。
- 虽然一些用户质疑 Pro 账户的价值,但其他人承认了更个性化搜索体验带来的好处。
- Merlin 扩展受到关注:关于 Merlin 扩展的讨论突出了其直接与各种 LLMs 聊天的能力,提供了无限的模型访问权限。
- 用户赞赏无限查询功能,但对模型设置中与 HARPA AI 相比缺乏透明度表示担忧。
- 引用输出的不一致导致困扰:成员们对通过 API 获取的引用输出不一致表示沮丧,输出在 HTML 和 Markdown 格式之间交替。
- 据报道,这种不一致性阻碍了自动化工作,使可靠的输出生成变得复杂。
- AI 在教育中的角色受到审视:对 AI 如何影响教育的探索揭示了变革性的益处和挑战,并对其影响进行了持续讨论。
- 成员们分析了 AI 融入教育环境的不同方面以及学习动态的潜在转变。
LM Studio Discord
- 在 Air-Gapped 机器上安装 LM Studio:成员们讨论了在 Air-Gapped(物理隔离)机器上安装 LM Studio 的可行性,强调虽然安装本身不需要网络,但初始设置和文件传输是必要的。
- Air-Gapped 安装需要周密的计划,特别是需要分别下载安装程序和模型。
- 模型性能遇到瓶颈:用户报告了模型在接近其 Token 限制时的性能问题,指出随着 Token 填满,由于 VRAM 限制会导致速度变慢。
- 这引发了关于管理 Token 限制以保持最佳性能的建议。
- LongWriter 模型引发关注:LongWriter 模型因其生成超长文本的能力而受到称赞,并分享了相关资源供感兴趣的成员进一步探索其特性。
- 鼓励成员查看 LongWriter 的 GitHub 页面 以了解其用法和功能的见解。
- 对双 GPU 兼容性的担忧:关于 LM Studio 是否支持双 GPU 设置的讨论引发了关于混合使用 RTX 4070 Ti 与 RTX 3080 以及潜在性能收益的询问。
- 建议集中在尝试此类配置之前评估兼容性问题。
- 高昂的 GPU 价格令欧盟买家沮丧:成员们对欧盟地区较高的 GPU 价格表示不满,价格通常在 $750 左右,而美国的定价较低。
- 区域定价问题归因于 VAT(增值税)和税收,同时还讨论了欧洲消费者保护政策的优势。
Modular (Mojo 🔥) Discord
- Mojo 位居编程语言层级榜首:一位用户将 Mojo 排在个人语言层级列表的首位,认为它高于 C# 和 Rust,这是一个主观但发自内心的决定。
- 有人呼吁在 C++ 类别中进行更清晰的划分,特别强调了纯净的 C 互操作性的重要性。
- Rust 面临编译缓慢的困扰:用户抱怨 Rust 缓慢的编译时间,特别是在像 4 万行代码的游戏这样的大型项目中,编译过程可能会拖得很长。
- Generics(泛型)被认为是导致这些减速的主要原因,并建议优化 Windows 上的文件系统设置。
- NixOS 在谨慎中引发兴趣:围绕迁移到 NixOS 的讨论称赞了其包管理,但也对其系统的整体复杂性表示担忧。
- 成员们辩论了将 Ansible 作为小型项目更简单工具的潜力,同时探索 NixOS 的可复现性优势。
- 讨论中 MLIR 胜过 LLVM:关于为什么 MLIR 可能优于 LLVM 的问题集中在并行编译和高级语义处理的改进上。
- MLIR 保留调试信息的能力被视为一个关键优势,特别是在编译器不断演进的情况下。
- 庆祝 Mojo 的进展与未来:社区庆祝了 Mojo 发布两周年,回顾了它的成长,包括 Mojo SDK 发布等关键进展。
- 对该语言未来的热情显而易见,用户们热烈讨论其演进将如何塑造未来几年。
DSPy Discord
- DSPy 2.5.0 发布引发热潮:DSPy 2.5.0 的发布旨在迅速解决 50-100 个问题,其新功能和即将推出的入门 notebook 激发了广泛的热情。
- 成员们建议建立公开周会,以便对发布版本提供进一步的反馈。
- 高效的 GROQ API Key 设置:关于设置 GROQ_API_KEY 并执行
lm = dspy.LM('groq/llama3-8b-8192')的用户指南促进了 Llama 3 的集成。- 该指令简化了在 GROQ 上托管的模型与 dspy 库的使用流程。
- 近期论文对 Chain of Thought 进行评估:一篇论文重点介绍了对超过 100 项研究进行的 Chain-of-Thought (CoT) 提示词定量元分析,显示其在数学或逻辑任务中的有效性显著增强。
- 关键发现表明,在 MMLU 的符号运算中,直接回答的效果与 CoT 相当,强调了当问题涉及等号时对推理的需求。
- 讨论 LLM 使用的自定义适配器:成员们探讨了创建自定义适配器,以便为 dspy.LM 的结构化输出指定
grammar等额外参数。- 讨论集中在分享经验以及对参数使用更清晰最佳实践的需求。
- 多模态能力的期待持续升温:DSPy 备受期待的多模态功能将于下周推出,并收到了关于 Ultravox 等音频模型兼容性的咨询。
- 官方回复指出,最初的重点将放在 Vision Language Models (VLMs) 上。
LLM Agents (Berkeley MOOC) Discord
- 今日关于 AI 框架和多模态助手的课程:Berkeley MOOC 的第 3 讲(直播链接)将由 Chi Wang 讲解 Agentic AI Frameworks & AutoGen,并由 Jerry Liu 介绍构建多模态知识助手的步骤,于 PST 时间下午 3:00 开始。
- Chi 将讨论 Agentic AI 编程的核心设计考量,而 Jerry 将讨论结构化输出和事件驱动工作流等要素。
- 澄清课程签到困惑:直播的签到表仅供 Berkeley 学生使用,这在 MOOC 参与者中引起了一些困惑。
- 下次二维码将附带更清晰的说明以避免误解。
- 探索开源 Embedding 模型:成员们认为 Jina AI 的 jina-embeddings-v3 是领先的开源 Embedding 模型,提供多语言能力并利用了 Task LoRA。
- 该模型增强了神经搜索应用的性能,强调了有效索引和相关性的重要性。
- AutoGen 与 CrewAI 在自定义和速度上的对比:在多 Agent 协作方面,成员们指出 AutoGen 允许更高程度的自定义,而 CrewAI 在快速原型开发方面表现出色,但在往返通信方面有所欠缺。
- AutoGen 中的 conversable_agent 支持更复杂的交互,这是 CrewAI 用户认为受限的一个功能。
- RAG 的搜索/检索技术:讨论建议专注于经典 NLP 技术来增强信息检索,特别是排序算法和语义理解。
- 理解这些技术对于改进 RAG 框架内的搜索至关重要,从而实现更好的索引和相关性。
Latent Space Discord
- Letta AI 脱离隐身模式:由创始人 Sarah Wooders 和 Charles Packer 创立的 Letta AI 正式发布,该公司专注于开发有状态的 LLM Agent。他们目前正在旧金山积极招聘并组建团队。
- 在 TechCrunch 阅读更多关于 Letta 的信息。
- Gemini 模型增强:Gemini 模型 迎来了重大更新,包括速率限制(rate limits)翻倍,以及 Gemini 1.5 Pro 降价超过 50%。过滤器已改为选择性开启(opt-in),并发布了更新后的 Flash 8B 实验性模型。
- 开发者对这些变化持乐观态度,认为这是开发者的黄金时期,详见 Google Developers Blog。
- 语音功能推出:OpenAI 宣布 Advanced Voice 正在向 ChatGPT 应用的 Plus 和 Team 用户推出,引入了多项新功能并改进了口音。值得注意的是,它可以表达超过 50 种不同语言的短语。
- 然而,正如 OpenAI 的公告所强调的,该功能尚未在几个欧洲国家开放。
- 客户服务 Agent 实验:关于管理 Agent 模拟多轮对话挑战的讨论揭示了维持有效用户交互的重要见解。建议包括实施阶段标记(stage markers)和设定清晰的对话终止指南。
- 用户正在探索各种方法,将强化学习(reinforcement learning)集成到对话管理中,以提升客户 Agent 的体验。
- HuggingChat macOS 应用介绍:新发布的 HuggingChat macOS 应用提供了开源 LLM 的原生集成,具备 Markdown 支持和网页浏览等功能。这标志着面向直接桌面使用的用户友好型 AI 工具迈出了重要一步。
- 该应用展示了增强 AI 驱动应用程序的可访问性和功能的趋势。
Cohere Discord
- 新人被 Cohere AI 吸引:机械工程专业的学生 Nav 等成员表现出学习 Cohere 和 AI 的兴趣,并寻求博客或视频等资源,随后有人分享了关于 Aya Research 计划的链接,该计划旨在推进多语言 AI。
- 该计划旨在提高可访问性,使跨语言的 AI 应用得到更广泛的理解。
- 社区聊天缓解就业焦虑:Milansarapa 表达了对工作不稳定性的担忧,引发了社区关于已拿到合同的保证,强化了支持的重要性。
- “你已经拿到合同了” 变成了一句令人安心的口号,凸显了社区参与的益处。
- Cohere Toolkit 获得显著功能更新:Cohere Toolkit 的最新更新修复了各种后端/UI 问题,并引入了置顶聊天以及对 parquet 和 tsv 文件的支持,并提供了 YouTube 演示视频。
- 这些增强功能显著提升了用户体验,并展示了团队对社区反馈的重视。
- Reranker 面临多语言挑战:有报告称,多语言 Reranker 在 波兰语 等语言中的相关性得分较低,过滤掉了有用数据,导致其失效。
- “相关性得分太低以至于被过滤掉” 表明在 Reranker 过程中需要更好地处理多样化语言。
- 探索 Chain of Thought (COT):Milansarapa 询问了 Chain of Thought (COT) 机制,引发了关于它如何增强某些任务性能的讨论。
- 最终,COT 被认为是一种有价值的问题解决方法,尽管其应用因案例而异。
Stability.ai (Stable Diffusion) Discord
- James Cameron 加入 Stability AI 董事会:首席执行官 Prem Akkaraju 宣布,传奇电影制作人 James Cameron 已加入 Stability AI 董事会。这一加入支持了 Stability AI 利用前沿技术变革视觉媒体的使命。
- 以《终结者》和《阿凡达》闻名的 Cameron 旨在通过创新的 AI 视觉媒体解决方案彻底改变叙事方式。
- 寻求 FNAF Loras 合作者:一名成员正在寻找 FNAF 粉丝协助为该游戏创建 Loras。他们正在寻找合作伙伴来共同完成这个项目。
- 有人有兴趣合作这个项目吗?
- 使用 3090 EGPU 提升 SDXL 性能:一位用户报告称购买了 3090 EGPU 以增强其 SDXL 运行体验,克服了以往同类产品的失败经历。他们分享了对某些 Aurus 游戏盒子的挫败感。
- 注意到了同类产品的质量问题,从而促成了这一决定。
- 探索 ControlNet 的功能:一位用户询问了 ControlNet,它可以引导图像生成,特别是针对姿势。仅靠语言描述很难明确规格要求。
- 有效的引导方法是改进图像输出的关键焦点。
- 排查 OpenPose 编辑器安装问题:一位用户报告了 Forge 中 OpenPose 编辑器的问题,建议可能需要特定的安装命令。针对在虚拟环境中运行 pip install basicsr 提供了协助。
- 分享了关于安装命令的说明,以便更好地进行集成。
LlamaIndex Discord
- 警惕虚假 LlamaParse 网站:已发布关于冒充 LlamaIndex LlamaParse 的欺诈网站的警告,提醒用户避开。
- 合法的 LlamaParse 可以通过 cloud.llamaindex.ai 访问,以防止混淆。
- LitServe 简化了 LLM 的部署:来自 LightningAI 的 LitServe 框架简化了使用 FastAPI 部署和扩展 LLM 的过程,正如在 LlamaIndex 的演示中所展示的那样。
- 该设置可以在本地针对 Llama 3.1 托管一个简单的 RAG 服务器,为开发者提供高效方案。
- 50 行代码创建 AI 产品经理!:使用 LlamaIndex 和 ComposioHQ 仅需 50 行代码即可构建一个 AI 产品经理,其功能包括读取电子邮件反馈。
- 如果获得批准,它会将反馈整合到 Linear 看板中进行编辑,展示了函数调用 Agent (function calling agent) 架构的功效。
- 探索人机回环 (Human-in-the-Loop) 工作流:成员们讨论了在嵌套工作流中实现人机回环 (HITL) 交互,旨在简化事件后用户控制权的回归。
- 提出了一种事件驱动的方法,用于在工作流过程中动态管理用户响应。
- 用于 RAG 的有效网页爬取技术:讨论集中在用于嵌入的网页爬取技术上,询问了关于 Puppeteer 与 Firecrawl 或 Crawlee 等工具的选择。
- 成员们分享了关于将网页爬取数据集成到检索增强生成 (RAG) 流水线中的有效方法的见解。
LAION Discord
- 用户反馈推动 Blendtain 改进:一位用户分享了对 Blendtain 的兴奋,但指出其容易切断消息,建议增加调整消息长度的功能。
- 另一位用户表示赞同,反映了对该反馈的积极反响。
- dykyi_vladk 发布播放列表生成器:Adify.pro 作为一个新的播放列表生成器被推出,它可以根据用户提示词定制播放列表,由 dykyi_vladk 开发。
- 作者自豪地称其为他“最酷的作品”,表明了对该项目的个人投入。
- 机器学习协作学习提案:dykyi_vladk 邀请其他人私信他进行 机器学习 (Machine Learning) 协作学习倡议,促进社区参与。
- 这一提议以友好的语气呈现,强调了在追求知识过程中的团队合作。
- 图像处理算法的主导地位转移:一位成员询问了目前 GANs、CNNs 和 ViTs 在图像处理任务中的主导地位,寻求对这些趋势的确认。
- 他们对通过视觉时间线来展示这些算法随时间的变化趋势表示感兴趣。
- EleutherAI 的 muTransfer 合作项目:EleutherAI 与 Cerebras 启动了一个项目,旨在提高 muTransfer 的可访问性,目标是降低训练成本。
- 成员们推测这种方法可能已经过时,质疑其与新方法相比的关联性。
OpenAccess AI Collective (axolotl) Discord
- Nvidia 的 51B 合成数据模型引起关注:关于 Nvidia 的 51B 合成数据模型的讨论十分热烈,据报道该模型表现出强劲的 MMLU 性能,并具有增强应用的潜力。
- 尝试对其进行微调和推理会很有趣, 这突显了成员们探索实际应用的渴望。
- 自动分块(Auto Chunking):上下文丢失?:关于对话中自动分块实用性的辩论出现,担忧点在于 想象一下你的对话在中间被切成两半,上下文就丢失了。
- 一名成员指出,像 ST 和 Kobold 这样的系统通常通过保留初始消息来管理溢出。
- 提议动态上下文管理:讨论了动态上下文管理如何帮助 LLM 更有效地处理对话转移。
- 成员们建议将此策略作为解决超出上下文限制的可能方案。
- Axolotl 支持 Qwen 2.5:确认 Axolotl 支持 Qwen 2.5 的普通文本处理,但视觉功能可能缺乏支持。
- 这一确认反映了可能影响涉及视觉数据应用的局限性。
- 微调峰值分析:一名成员报告在 100K 行数据集上进行微调时出现显著峰值 (spike),正通过日志寻找相关性。
- 成员注意到缺乏即时的日志帮助,这影响了故障排除工作。
LangChain AI Discord
- LangChain Pydantic 兼容性损坏:由于 Pydantic v2 不再支持
__modify_schema__方法,用户在从langchain_openai导入ChatOpenAI时遇到错误。建议用户检查其 Pydantic 版本并改用__get_pydantic_json_schema__,详见 LangChain 文档。- 由于 Pydantic v2 已于 2023 年 6 月发布,开发者应确保使用兼容的方法以避免集成问题。
- 注意 GraphRecursionError!:当达到 25 的递归限制时,LangGraph 应用中会出现
GraphRecursionError,从而阻碍执行。用户可以在配置中增加递归限制,正如相关 GitHub issue 中所建议的。- 这一调整对于防止 LangGraph 中复杂图操作期间的崩溃至关重要。
- 呼吁 LLM 友好型文档!:一名用户要求提供更多对 LLM 友好的文档,以提高 LangChain 的生产力。持续的讨论表明社区有兴趣改进为使用 LangChain 的开发者提供的资源。
- 这表明需要更好的、专门用于增强 LLM 集成的指南,反映了社区的重点努力方向。
- Mistral vs Mixtral:大对决:开源领域关于 Mistral 和 Mixtral 自托管方案的对比正在酝酿中。成员们对这些模型在性能指标和易用性方面的表现感到好奇。
- 这一对话突显了社区在为实际应用优化和选择最佳开源模型方面的兴趣。
Torchtune Discord
- 关于优化器中 CPU Offloading 的困惑:讨论了为什么没有利用优化器的 CPU Offloading,并引用了提到性能下降的这个旧 issue。
- 一名成员建议使用带有 CPU Offloading 的 PagedAdam 来优化性能,同时强调需要一个 PR 来考虑单设备微调。
- 优化器方法的对比分析:成员注意到使用 torchao 的 CPUOffloadOptimizer 与反向传播(backward)中的优化器配合不佳,引发了对 Adam 等更快替代方案的疑问。
- 建议包括尝试使用
offload_gradients=True以节省梯度内存,同时优化 CPU 和 GPU 处理,详见此 PR。
- 建议包括尝试使用
- CUDA MODE 社区邀请:建议对性能优化感兴趣的成员加入 GPU MODE Discord 群组,那里有更多专业人士可以提供帮助。
- 分享的加入链接在这里,鼓励更广泛地参与优化讨论。
tinygrad (George Hotz) Discord
- 探索“行星大脑”的概念:成员们戏称 tinyboxes 连接起来通过 distributed training 实现“行星大脑”的潜力,挑战集体智慧的边界。
- 这暗示了一个迷人的未来,即先进的 distributed training 可能会在全球范围内运行。
- 用于分布式训练的 DisTrO 介绍:讨论集中在 DisTrO 项目,该项目促进了 Distributed Training Over-The-Internet(互联网分布式训练),旨在实现跨模型的革命性协作。
- 该倡议强调了模型训练中协作框架的需求,增强了可扩展性和可访问性。
- AttributeError: ‘Tensor’ 缺少 cross_entropy:一位用户在训练步骤中遇到了 ‘AttributeError’,原因是 Tensor 对象缺少
cross_entropy属性,这突显了一个潜在的实现缺陷。- 参与者推测了根本原因,指向了 Tensor 功能中可能存在的空白。
- Tinygrad 版本争议:在一位用户从 0.9.2 版本过渡到最新的 master 分支并暴露了功能限制后,引发了关于正确 Tinygrad 版本的对话。
- 建议持续更新以整合提升性能的基本特性。
- 模型架构与训练见解:一位参与者分享了他们的模型架构,利用多个卷积层,随后进行展平操作和线性层,以增强训练效果。
- 对话强调了旨在优化训练迭代期间模型性能的设计策略。
OpenInterpreter Discord
- Open Interpreter 迎来更新:Open Interpreter 正在 GitHub 上积极接收更新,展示了持续的开发努力。
- 重点围绕项目 ‘01’,旨在集成专用的语音助手模式,详见 此处。
- LLM 承担浏览器自动化任务:一位成员讨论了使用 Open Interpreter 进行基于 LLM 的浏览器自动化,确认了其功能,但指出受限于任务复杂度。
- 他们建议使用 Playwright 进行增强,并分享了一个他们一直在磨练的 Prompt 示例。
- 社区热情高涨:尽管最初存在疑虑,社区成员仍渴望使用共享的 Prompt 自动向目录提交内容。
- 随着成员回答问题并交流工具使用经验,参与度保持强劲。
- 即将举行的社区活动:宣布了一个与 Open Interpreter 相关的即将举行的活动,并分享了 包含更多详情的 Discord 链接。
- 这一消息激发了用户的兴奋,表明社区兴趣依然活跃。
- 探讨项目感知的细微差别:在回答一个查询时,一位成员幽默地指出,社区中的一些人可能并未完全意识到项目的进展。
- 这指向了讨论中关于 Open Interpreter 生命力的不同看法。
Alignment Lab AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
LLM Finetuning (Hamel + Dan) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Mozilla AI Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
DiscoResearch Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第二部分:按频道划分的详细摘要和链接
完整的频道逐条解析已因邮件长度限制而截断。
如果你喜欢 AInews,请分享给朋友!提前感谢!