ainews-liquid-foundation-models-a-new
液态基础模型:Transformer 的新替代方案 + AI 新闻播客第 2 期
以下是为您翻译的中文内容:
Liquid.ai 结束隐身状态正式亮相,推出了三个亚二次方(subquadratic)基础模型。这些模型在效率上优于状态空间模型(SSM)以及苹果的端侧和服务器模型,并获得了 3700 万美元的种子轮融资。Meta AI 发布了 Llama 3.2,其中包括具备视觉能力的多模态模型,以及适用于移动设备的轻量级纯文本变体。Google DeepMind 推出了生产就绪的 Gemini-1.5-Pro-002 和 Gemini-1.5-Flash-002 模型,并优化了价格和速率限制;同时还推出了 AlphaChip,这是一个利用强化学习实现超人水平快速布局的 AI 驱动芯片设计系统。OpenAI 为 ChatGPT Plus 和 Teams 用户增强了“高级语音模式”(Advanced Voice Mode),新增了自定义指令、记忆功能以及多款灵感源自自然的新音色。加州州长否决了 SB-1047 AI 监管法案,Yann LeCun 和 svpino 等 AI 社区领袖对此表示庆祝,认为这是开源 AI 的胜利。Google 升级了 NotebookLM,其音频概览功能现已支持 YouTube 视频和音频文件,可将文档转化为 AI 生成的播客。Yann LeCun 指出:“AI 领域的开源正在蓬勃发展”,并强调 GitHub 和 HuggingFace 上的模型数量已达 100 万个。
自适应计算算子(Adaptive computational operators)就是你所需要的一切。
2024年9月27日至9月30日的 AI 新闻。我们为您查看了 7 个 subreddits、433 个 Twitter 账号 和 31 个 Discord(225 个频道,5435 条消息)。预计节省阅读时间(按每分钟 200 字计算):604 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
并不是每天都有一个可信的新基础模型(foundation model)实验室成立,所以今天的头条理所当然属于 Liquid.ai。在获得 3700 万美元种子轮融资 10 个月后,他们终于“结束隐身模式”,发布了 3 个亚二次方(subquadratic)模型,这些模型在同级别中表现非常出色:
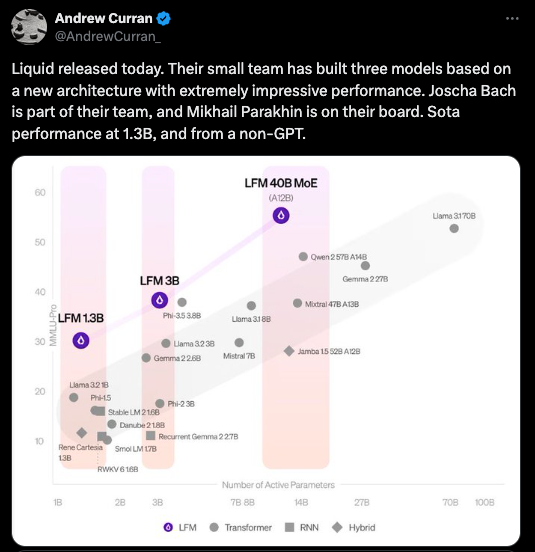
与状态空间模型(state space models)相比,我们对“液体网络”(liquid networks)知之甚少,但他们展示了必不可少的亚二次方图表,证明他们在该领域击败了 SSM:
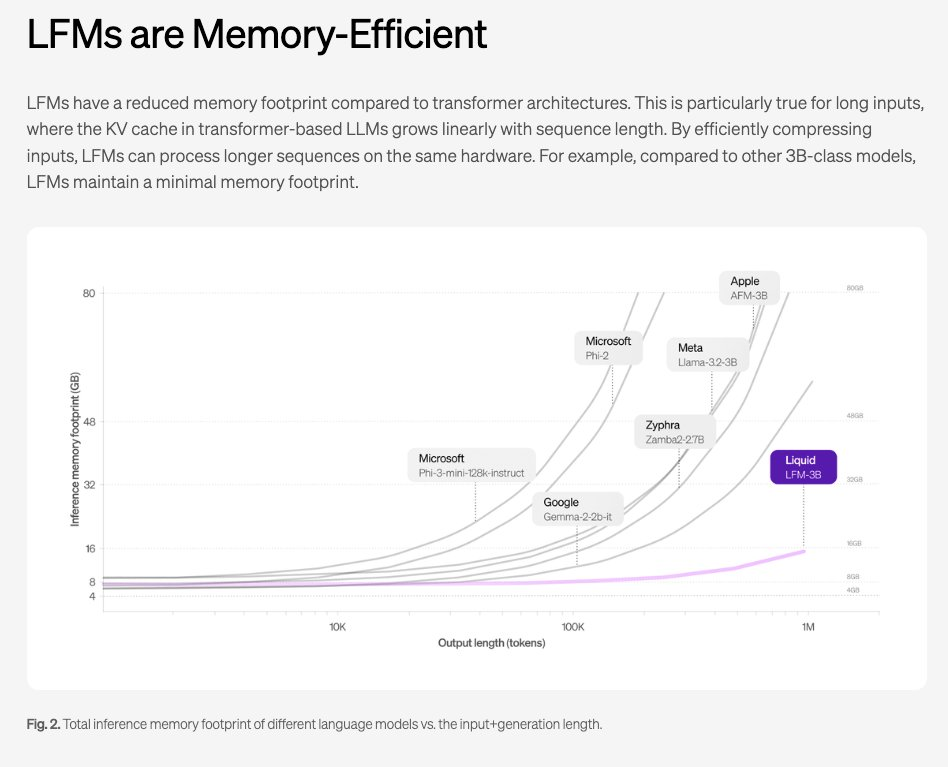
以及非常可信的基准测试(benchmark)分数:
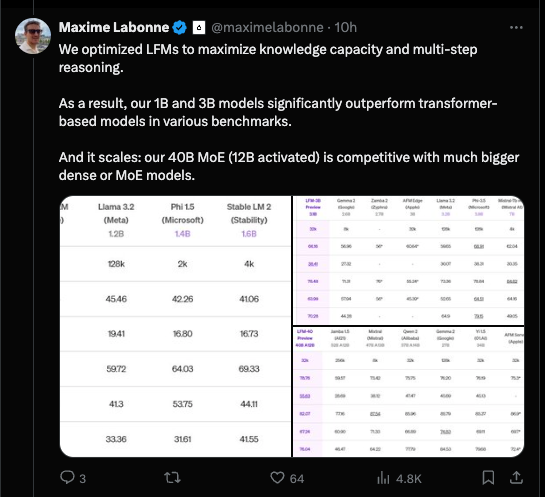
值得注意的是,它们的单参数效率似乎明显高于 Apple 的端侧和服务器基础模型(我们的相关报道在此)。
它们尚未开源,但提供了 playground 和 API,并承诺在 10 月 23 日正式发布前提供更多内容。
AINews 播客
我们本月初首次预览了受 Illuminate 启发的播客。随着 NotebookLM Deep Dive 的走红,我们正在构建一个开源音频版的 AINews 作为一项新实验。在这里查看我们最新的 NotebookLM 与我们播客的对比!如果您有反馈意见或想要开源仓库(repo),请在 @smol_ai 告诉我们。
AI Twitter 摘要
所有摘要均由 Claude 3.5 Sonnet 完成,取 4 次运行中的最佳结果。
AI 模型更新与进展
-
Llama 3.2 发布:Meta AI 宣布推出 Llama 3.2,其特点是包含具有视觉能力的 11B 和 90B 多模态模型,以及适用于移动设备的轻量级 1B 和 3B 纯文本模型。视觉模型支持图像和文本提示,可对输入进行深度理解和推理。@AIatMeta 指出,这些模型可以同时接收图像和文本提示,以深入理解并对输入进行推理。
-
Google DeepMind 公告:Google 宣布推出两个新的生产级 Gemini AI 模型:Gemini-1.5-Pro-002 和 Gemini-1.5-Flash-002。@adcock_brett 强调,该公告最棒的部分是 1.5 Pro 降价 50%,且 Flash 和 1.5 Pro 的速率限制分别提升了 2 倍和 3 倍。
-
OpenAI 更新:据 @adcock_brett 报道,OpenAI 向所有 ChatGPT Plus 和 Teams 订阅用户推出了增强版 Advanced Voice Mode,增加了 Custom Instructions、Memory 以及五种新的“受自然启发”的声音。
-
AlphaChip:Google DeepMind 发布了 AlphaChip,这是一个利用强化学习设计芯片的 AI 系统。@adcock_brett 指出,这使得在数小时内构建出超越人类水平的芯片布局成为可能,而以往则需要数月。
开源与监管
-
SB-1047 否决:加州州长 Gavin Newsom 否决了 SB-1047,这是一项关于 AI 监管的法案。包括 @ylecun 和 @svpino 在内的许多科技界人士对这一决定表示感谢,认为这是开源 AI 和创新的胜利。
-
开源增长:@ylecun 强调 AI 开源正在蓬勃发展,并引用 GitHub 和 HuggingFace 上的项目数量已达到 100 万个模型。
AI 研究与开发
-
NotebookLM:Google 升级了 NotebookLM/Audio Overviews,增加了对 YouTube 视频和音频文件的支持。@adcock_brett 分享道,Audio Overviews 可以将笔记、PDF、Google Docs 等转换为 AI 生成的播客。
-
Meta AI 进展:据 @adcock_brett 报道,Meta AI(消费者聊天机器人)现在已具备多模态能力,能够“看到”图像并允许用户使用 AI 编辑照片。
-
AI 在医学中的应用:根据 @dair_ai 的报道,一项关于 o1-preview 模型在医疗场景中的研究显示,在 19 个数据集和两个新创建的复杂 QA 场景中,其准确率比 GPT-4 平均高出 6.2% 和 6.6%。
行业趋势与合作
-
James Cameron 与 Stability AI:据 @adcock_brett 报道,电影导演 James Cameron 加入了 Stability AI 的董事会,他认为生成式 AI 与 CGI 的融合是视觉媒体创作的“下一波浪潮”。
-
EA 的 AI 演示:EA 展示了一个用于用户生成视频游戏内容的新 AI 概念,利用 3D 资产、代码、游戏时长、遥测事件和 EA 训练的自定义模型来实时重混游戏和资产库,由 @adcock_brett 分享。
AI Reddit 摘要
/r/LocalLlama 回顾
主题 1. Emu3:多模态 AI 的 Next-token prediction 突破
- Emu3: Next-Token Prediction is All You Need (Score: 227, Comments: 63):Emu3 是一套全新的多模态模型,仅通过 next-token prediction 就在生成和感知任务中均实现了 state-of-the-art performance,超越了 SDXL 和 LLaVA-1.6 等成熟模型。通过将图像、文本和视频 token 化到离散空间,并从零开始训练单个 Transformer,Emu3 简化了复杂的多模态模型设计,并展示了 next-token prediction 在构建超越语言的通用多模态智能方面的潜力。研究人员已经开源了关键技术和模型,包括 GitHub 上的代码和 Hugging Face 上的预训练模型,以支持该方向的进一步研究。
- Booru tags(常用于动漫图站和 Stable Diffusion 模型)出现在 Emu3 的生成示例中。用户讨论了支持这些标签对于模型流行度的必要性,一些人认为这是获得广泛采用的必要条件。
- 讨论中提到了将 diffusion models 应用于文本生成,并提到了 CodeFusion 论文。用户推测了 Meta 的 GPU compute capability 以及潜在的未发布实验,暗示大型 AI 公司之间可能存在控制信息发布的协议。
- 该模型将视频生成作为 next-token prediction 的能力让用户感到兴奋,可能开启“视频生成的新时代”。然而,人们对生成时间表示担忧,有报告称在 Replicate 上生成一张图片需要 10 分钟。
主题 2. Replete-LLM 发布具有性能提升的微调版 Qwen-2.5 模型
- Replete-LLM Qwen-2.5 models release (Score: 73, Comments: 55):Replete-LLM 发布了参数量从 0.5B 到 72B 不等的 Qwen-2.5 微调版本,采用了 Continuous finetuning 方法。这些模型已在 Hugging Face 上发布,据报告,与原始 Qwen-2.5 权重相比,所有尺寸的模型性能均有所提升。
- 用户要求提供 benchmarks 和横向对比以展示改进。开发者为 7B 模型增加了一些基准测试,并指出运行全面的基准测试通常需要大量的计算资源。
- 开发者的 continuous finetuning 方法结合了之前的微调权重、预训练权重和新的微调权重,以最小化损失。一份详细介绍该方法的论文已被分享。
- 模型的 GGUF 版本已提供,包括高达 72B 参数的量化版本。用户表示有兴趣在从高端机器到手机等边缘设备的各种设备上对其进行测试。
其他 AI Subreddit 汇总
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI 模型能力与进展
-
OpenAI 的 o1 模型可以处理 5 小时的任务,与 GPT-3(5 秒任务)和 GPT-4(5 分钟任务)相比,实现了更长程的问题解决能力。据 OpenAI 战略营销负责人 透露。
-
MindsAI 在 ARC-AGI 基准测试中取得了 48% 的新高分,而该奖项的目标设定为 85%。
-
一名黑客演示了在 ChatGPT 中植入虚假记忆的能力,从而创建一个持久的数据外泄通道。
AI 政策与监管
- 加州州长 Gavin Newsom 否决了一项备受争议的 AI 安全法案,突显了围绕 AI 监管的持续争论。
AI 伦理与社会影响
-
AI 研究员 Dan Hendrycks 提出了一个思想实验,关于一种假设的、具有快速增长的智能和繁殖能力的新物种,质疑哪个物种将掌握控制权。
-
向 OpenAI 的 o1 模型进行单次查询的成本引发了关注,触发了关于先进 AI 模型经济影响的讨论。
迷因与幽默
AI Discord 汇总
由 o1-preview 提供的摘要之摘要
主题 1. AI 模型凭借新发布和升级掀起波澜
- LiquidAI 凭借 Liquid Foundation Models (LFMs) 挑战巨头:LiquidAI 推出了 LFMs——1B、3B 和 40B 模型——声称在 MMLU 等基准测试中表现优异,并指出了竞争对手的低效。凭借来自 MIT 的团队成员,其架构旨在挑战行业内的既有模型。
- Aider v0.58.0 编写了超过一半的自身代码:最新版本引入了模型配对和新命令等功能,并自豪地宣布 Aider 自主创建了该更新中 53% 的代码。此版本支持新模型,并通过改进
/copy和/paste等命令增强了用户体验。 - 微软的幻觉检测模型升级至 Phi-3.5:从 Phi-3 升级到 Phi-3.5,该模型展示了令人印象深刻的指标——Precision: 0.77,Recall: 0.91,F1 Score: 0.83,以及 Accuracy: 82%。它旨在通过有效识别幻觉来提高语言模型输出的可靠性。
主题 2. AI 监管与法律斗争升温
- 加州州长否决 AI 安全法案 SB 1047:州长 Gavin Newsom 阻止了旨在监管 AI 公司的法案,声称这不是保护公众的最佳方法。批评者认为这是 AI 监管的挫折,而支持者则推动基于能力的监管。
- OpenAI 因薪酬要求面临人才流失:OpenAI 的核心研究人员威胁要辞职,除非增加薪酬,在估值飙升之际,已有 12 亿美元套现。新任 CFO Sarah Friar 正在应对紧张的谈判,而 Safe Superintelligence 等对手正在挖角人才。
- LAION 在德国赢得里程碑式的版权案件:LAION 成功抵御了版权侵权指控,确立了一个有利于 AI 数据集使用的先例。这一胜利消除了 AI 研究与开发中的重大法律障碍。
主题 3. 社区应对 AI 工具挑战
- Perplexity 用户抱怨性能不稳定:用户报告响应不稳定且缺失引用,尤其是在网页搜索和学术论文之间切换时。许多人因更好的访问权限和来源预览等功能,在学术研究中更倾向于使用 Felo。
- OpenRouter 用户遭遇速率限制和性能下降:频繁的 429 错误 令 Gemini Flash 用户感到沮丧,目前正等待 Google 增加配额。像 Hermes 405B free 这样的模型在维护后表现出性能下降,引发了对供应商变更的担忧。
- 关于 OpenAI 研究透明度的辩论升温:批评者认为 OpenAI 对其研究不够开放,指出仅靠博客文章是不够的。员工坚称具有透明度,但社区寻求除 研究博客 之外更具实质性的交流。
主题 4. 硬件问题困扰 AI 爱好者
- NVIDIA Jetson AGX Thor 的 128GB VRAM 引发硬件羡慕:定于 2025 年发布的 AGX Thor 拥有海量 VRAM,引发了人们对 3090 和 P40 等当前 GPU 未来地位的质疑。该公告让社区对潜在的升级和不断演变的 GPU 格局议论纷纷。
- 新的 NVIDIA 驱动程序降低了 Stable Diffusion 的性能:使用 8GB VRAM 显卡 的用户在驱动更新后,生成时间从 20 秒激增至 2 分钟。社区建议不要更新驱动,以免破坏渲染工作流。
- Linux 用户与 NVIDIA 驱动问题作斗争,转而关注 AMD GPU:用户对 NVIDIA 存在问题的 Linux 驱动(尤其是 VRAM offloading 方面)愈发不满。一些用户考虑转向 AMD 显卡,理由是其在配置中具有更好的性能和易用性。
主题 5. AI 扩展到创意和健康领域
- NotebookLM 根据你的内容制作定制播客:Google 的 NotebookLM 推出了一项音频功能,可以使用 AI 主持人生成个性化播客。用户对根据其提供材料生成的引人入胜且极具说服力的对话印象深刻。
- 精神分裂症治疗取得突破:Perplexity AI 宣布推出了 30 年来 首款精神分裂症药物,标志着精神健康护理领域的重大进展。讨论强调了其对患者护理和治疗范式的潜在影响。
- 关于 AI 生成艺术与人类创造力的激烈辩论:Stability.ai 社区在 AI 艺术 与人类创作的质量和深度对比上存在分歧。虽然一些人拥护 AI 生成的作品为合法艺术,但另一些人则坚持人类艺术性的持久优越性。
第 1 部分:高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
- LinkedIn 复制代码争议:LinkedIn 因涉嫌在未妥善署名的情况下复制 Unsloth 的代码而面临抵制,促使 Microsoft 和 GitHub 介入以确保正确归功。
- 该事件强调了遵守 open source licensing(开源许可)的紧迫性,并引发了对 intellectual property(知识产权)的担忧。
- 微调 Llama 模型的最佳实践:为了减轻 Token 生成问题,用户讨论了在 Llama model fine-tuning 期间设置 random seed 并仔细评估输出质量。
- 正确配置 EOS tokens 对于在推理过程中保持模型的原始能力至关重要。
- GGUF 转换错误:用户在加载 GGUF 模型时遇到了“cannot find tokenizer merges in model file”错误,凸显了模型保存过程中的潜在问题。
- 理解转换过程并保持与 tokenizer 配置的兼容性,对于确保模型平滑过渡至关重要。
- Liquid Foundation Models 发布:LiquidAI 宣布推出 Liquid Foundation Models (LFMs),包括 1B、3B 和 40B 模型,但对其公告的有效性存在质疑。
- 针对这些说法的准确性表达了担忧,特别是与 Perplexity Labs 相关的部分。
- 利用未开发的算力:成员注意到大量 compute power 未被充分利用,建议在各种硬件设置中进行潜在的性能改进。
- 通过优化现有资源实现现实的性能提升,表明当前系统仍有很大的增强空间。
aider (Paul Gauthier) Discord
- Aider v0.58.0 带来令人兴奋的增强功能:Aider v0.58.0 的发布引入了模型配对(model pairing)和新命令等功能,其中 Aider 自主创建了该更新 53% 的代码。
- 此版本还支持新模型,并通过 剪贴板命令更新 等功能提升了用户体验。
- Architect/Editor 模型提高效率:Aider 利用一个主模型进行规划,并使用一个可选的 editor 模型进行执行,允许通过
--editor-model进行配置以实现最佳任务处理。- 这种双模型方法引发了关于多 Agent 编程能力以及 LLM 任务价格效率的讨论。
- NotebookLM 的新播客功能脱颖而出:NotebookLM 推出了一项音频功能,可以根据用户内容生成自定义播客,以极具吸引力的形式展示 AI 主持人。
- 其中一个示例播客展示了该技术从提供材料中创建引人入胜的对话的能力。
- 内容生成的自动化提案:有人提出了使用 NotebookLM 自动根据发布说明(release notes)制作视频的想法,这可能会催生一个名为 ReleaseNotesLM 的高效工具。
- 该工具旨在将文字更新转化为音频,为内容创作者简化流程。
- 模型成本效率讨论:在 Architect 任务中使用
claude-3.5-sonnet,在编辑任务中使用deepseek v2.5等不同模型,可以使 editor tokens 的 成本降低 20-30 倍。- 参与者强调了根据成本和功能进行战略性模型选择的优势,并探索了用于增强配置的脚本选项。
HuggingFace Discord
- AI 模型合并技术探讨:用户探索了各种 模型合并(model merging) 方法,特别是关注 PEFT merge 和 DARE 方法,以增强微调期间的性能。
- 对话强调了利用现有模型而非从头开始训练 LLM 的价值,将这些方法定位为高效处理任务的关键。
- 近期论文中的医疗 AI 见解:一篇文章总结了 2024 年 9 月 21 日至 27 日期间 医疗 AI 领域的顶级研究论文,包括《A Preliminary Study of o1 in Medicine》等显著研究。
- 成员们建议将这些见解拆分为单独的博客文章,以增加围绕杰出论文的参与度和讨论。
- 幻觉检测模型性能指标:新发布的 幻觉检测模型(Hallucination Detection Model) 从 Phi-3 升级到 Phi-3.5,拥有令人印象深刻的指标:Precision: 0.77,Recall: 0.91,F1 Score: 0.83,以及 准确率: 82%;查看模型卡片。
- 该模型旨在通过有效识别幻觉来提高语言模型输出的可靠性。
- Gradio 用户反响平平:社区对 Gradio 的情绪趋于负面,用户因 UI 响应问题和使项目管理复杂化的设计缺陷将其贴上“烂透了(hot garbage)”的标签。
- 尽管遭到抵制,成员们仍鼓励在专门的支持频道寻求帮助,表明在故障排除方面仍有持续投入。
- 关键点检测模型增强:OmDet-Turbo 模型 的发布支持 zero-shot 目标检测,集成了 Grounding DINO 和 OWLv2 的技术;详情可以在 这里 找到。
- 对 SuperPoint 等模型的关键点检测的专门关注,为社区对该领域未来发展的期待奠定了基础。
LM Studio Discord
- 在 LM Studio 中下载和侧加载模型的挑战:用户在 LM Studio 中下载模型时遇到问题,特别是在使用 VPN 时,促使一些人选择侧加载模型。指出了对 safetensors 和 GGUF 等模型格式支持的局限性。
- 社区对整体下载体验表示沮丧,讨论强调了对各种模型类型提供更好支持的必要性。
- NVIDIA Jetson AGX Thor 拥有 128GB VRAM:即将推出的 NVIDIA Jetson AGX Thor 将在 2025 年配备 128GB 的 VRAM,这引发了关于 3090 和 P40 等当前 GPU 可行性的疑问。这一公告在 GPU 领域引发了关于潜在升级的热议。
- 一些成员思考,随着对高 VRAM 选项需求的持续增长,现有硬件是否仍具竞争力。
- GPU 性能对比:3090 vs 3090 Ti vs P40:成员们对比了 3090、3090 Ti 和 P40 的性能,重点关注 VRAM 和价格,这些因素严重影响了他们的选择。有评论指出 P40 的运行速度大约是 3090 的一半。
- 成员们对 GPU 价格上涨表示担忧,并辩论了针对当前 AI 工作负载在不同型号之间的权衡。
- GPU 市场定价动态:讨论强调,由于黄牛炒作和 AI 应用需求的增加,GPU 价格居高不下,A6000 可作为高 VRAM 的替代方案。然而,预算有限的成员更倾向于在配置中使用多个 3090。
- 对话凸显了对价格趋势的普遍沮丧,以及许多人在当前市场中面临的障碍。
- Linux 上 NVIDIA 驱动程序的挑战:社区分享了对 NVIDIA 的 Linux 驱动程序 众所周知的问题的抱怨,特别是在 VRAM offloading 方面,而 AMD 显卡在这一领域表现更好。CUDA 和其他驱动程序安装中的复杂性加剧了这些挫败感。
- 一些成员表示越来越倾向于 AMD 硬件,理由是其在某些配置中具有更好的易用性。
GPU MODE Discord
- Cerebras 芯片优化讨论:成员们正在探索 Cerebras 芯片 的代码优化,对于潜在购买和专业知识的获取持有不同意见。
- 随着成员们表现出寻找专家以深入了解 Cerebras 技术的意愿,社区兴趣日益增长。
- 对垃圾信息管理的担忧日益增加:社区正在处理 Discord 上日益增多的加密货币诈骗垃圾信息,建议采用更严格的验证协议以增强服务器安全性。
- 成员们正积极寻找高效的抗垃圾信息工具,并讨论他们使用 AutoMod 等现有解决方案的经验。
- Triton 演讲资料分享:一位成员寻找 Triton 演讲 的幻灯片,并被引导至包含教育资源的 GitHub 仓库。
- 这反映了知识共享和协作学习的强大社区文化。
- AMD GPU 性能问题:成员们重点讨论了 AMD GPU 的显著性能限制,特别是 GFX1100 和 MI300 架构。
- 许多人强调了多节点设置中持续存在的挑战,并表示需要提升性能。
- 理解 Model Parallelism 与 ZeRO/FSDP:成员们阐明了 Model Parallelism 与 ZeRO/FSDP 之间的区别,重点关注 ZeRO 如何实现参数分布策略。
- 讨论强调 FSDP 利用分片(sharding)来提高模型训练效率,吸引了那些希望了解高级功能的成员。
Modular (Mojo 🔥) Discord
- 探讨 Modular 社区会议议程:今天的 Modular 社区会议于 太平洋时间上午 10 点 举行,内容涵盖 MAX driver & engine API 以及关于 Magic 的问答环节,可通过 Zoom 参加。参与者可以查看 Modular Community Calendar 了解后续活动。
- 会议录像将上传至 YouTube,包括今天的会议,可通过此链接观看,确保无人错过。
- 关于 Mojo 语言增强功能的辩论:一项关于高级 Mojo 语言特性 的提案建议为消息传递引入命名变体(named variants),并在不引入新结构的情况下更好地管理标签联合(tagged unions),这引发了成员间的广泛讨论。
- 支持者权衡了定义类型的易用性,讨论了设计过程中名义类型(nominal types)与结构类型(structural types)之间的平衡。
- 使用 Mojopkg 打包模型:社区热烈讨论了在 Mojopkg 中嵌入模型的能力,展示了通过将所有内容打包进单个可执行应用程序来提升用户体验的潜力。
- 提到了其他语言的关键示例,阐明了这如何为用户简化依赖关系并增强可用性。
- 平滑管理原生依赖:针对 Mojopkg 简化依赖管理的能力提出了关注,这可能使安装和配置变得更加容易。
- 讨论包括了一些实际实现,例如直接在 Mojo 应用程序中嵌入 Python 等运行时的安装程序。
- MacOS 上的兼容性警告:一位用户报告了在为 macOS 构建对象文件时的兼容性警告,指出版本 15.0 和 14.4 之间存在链接问题。
- 尽管这些警告不是致命的,但它们可能指向未来需要解决的兼容性挑战。
Nous Research AI Discord
- Nous Research 推动开源倡议:Nous Research 专注于 开源 AI 研究,与开发者合作并发布了包括 Hermes 家族 在内的模型。
- 他们的 DisTrO 项目 旨在加速互联网上的 AI 模型训练,并暗示了 闭源模型 的风险。
- Distro 论文发布引发热议:Distro 论文 预计很快就会发布,引发了渴望更新的社区成员的兴奋。
- 该论文与 AI 社区的相关性放大了对其详细内容的期待。
- 新型 AI 模型微调技术发布:最近 Rombodawg’s Replete-LLM 在创新微调技术的帮助下,登顶了 7B 模型 的 OpenLLM leaderboard。
- TIES merging 等方法被认为是显著提升模型基准测试的关键。
- Liquid Foundation Models 引起关注:LiquidAI 推出了 Liquid Foundation Models,版本包括 1B、3B 和 40B,旨在为 AI 领域提供新的能力。
- 这些模型被视为在为 AI 领域的各种应用提供创新功能方面发挥着关键作用。
- 本周医学 AI 论文:我们离 AI 医生更近了吗?:重点推介的论文《A Preliminary Study of o1 in Medicine》探讨了 AI 担任医生的潜力,由该领域的专家共同撰写。
- 该论文被评为 本周医学 AI 论文,展示了其在关于 AI 在医疗保健中角色的持续讨论中的相关性。
Perplexity AI Discord
- Perplexity 在性能一致性方面面临挑战:用户注意到 Perplexity 在切换网页搜索和学术论文时出现 响应不一致 的情况,并存在引用缺失的案例。
- 用户担心这些不一致性究竟是 bug,还是反映了搜索功能中潜在的设计缺陷。
- Felo 在学术搜索方面表现更优:许多用户发现 Felo 在学术研究中更有效,称其比 Perplexity 能更好地获取相关论文。
- 诸如 悬停预览来源 等功能增强了研究体验,吸引用户因其直观的界面而倾向于选择 Felo。
- 不一致的 API 输出令用户沮丧:社区讨论了 API 的不一致性,特别是 PPLX API,与网站数据相比,该 API 返回的是过时的 房地产列表。
- 有建议提出通过实验 temperature 和 top-p 等参数来提高 API 响应的一致性。
- 精神分裂症治疗取得突破:Perplexity AI 宣布了一个重要里程碑,30 年来首款精神分裂症药物发布,标志着心理健康解决方案的重大进展。
- 讨论强调了这对患者护理的潜在影响以及未来治疗模式的演变。
- 德克萨斯州各县有效利用 AI 技术:德克萨斯州各县展示了在地方政府运营中利用 AI 应用的创新方法,增强了公共服务能力。
- 参与者分享了一份详细资源,重点介绍了 AI 技术在行政任务中的这些实际应用。
OpenRouter (Alex Atallah) Discord
- OpenRouter 深受速率限制困扰:用户报告在使用 Gemini Flash 时频繁出现 429 错误,在等待 Google 可能增加的配额期间感到非常沮丧。
- 这一持续的流量问题正在损害平台的可用性,影响用户参与度。
- 维护后性能下降:像 Hermes 405B free 这样的模型在近期更新后表现出较低的性能质量,引发了对模型提供商可能发生变化的担忧。
- 建议用户检查其 Activity pages 以确保他们使用的是首选模型。
- 翻译模型选项建议:一位用户正在寻找没有严格限制的高效对话翻译模型,并对 GPT4o Mini 表示不满。
- 推荐使用经过 dolphin 技术微调的开源权重模型作为更灵活的替代方案。
- 前端聊天 GUI 推荐:关于允许中间件灵活性的聊天 GUI 解决方案展开了讨论,Streamlit 被提议为一个可行的选择。
- Typingmind 也因其在管理多个 AI Agent 交互时的可定制特性而被提及。
- 关于 Gemini 搜索功能的讨论:用户有兴趣在 Gemini 模型中启用类似于 Perplexity 的直接搜索功能,尽管目前的使用限制仍在评估中。
- 讨论引用了 Google 的 Search Retrieval API 参数,强调需要更清晰的实施策略。
Stability.ai (Stable Diffusion) Discord
- Flux 模型大获成功:受 kohya_ss 工作的启发,成员们注意到 Flux 模型 仅需 12G VRAM 即可进行训练,展示了令人惊叹的性能实力。
- 这种进步带来的兴奋感正在蔓延,暗示着模型效率基准可能发生转变。
- Nvidia 驱动导致 SDXL 变慢:新的 Nvidia 驱动导致 8GB VRAM 显卡 出现严重减速,图像生成时间从 20 秒激增至 2 分钟。
- 成员们强烈建议不要更新驱动,因为这些变化对他们的渲染工作流产生了不利影响。
- 区域提示词遇到障碍:社区成员分享了在 Stable Diffusion 中使用 区域提示词 (regional prompting) 的挫败感,特别是在处理如 “2 个男孩和 1 个女孩” 这种提示词中的角色混淆问题时。
- 建议从更广泛的提示词开始,利用通用指南以获得最佳效果。
- AI 艺术投稿征集:社区受邀提交 AI 生成的艺术作品,有机会入选 The AI Art Magazine,截止日期定为 10 月 20 日。
- 该倡议旨在庆祝数字艺术,并鼓励成员展示他们的创造力。
- AI 艺术引发质量辩论:关于 AI 艺术 与人类艺术优劣的激烈辩论爆发,观点在质量和深度上产生了分歧。
- 一些人主张人类艺术创作的优越性,而另一些人则为 AI 生成的作品辩护,认为其是合法的艺术表达。
OpenAI Discord
- Aider 评测 LLM 编辑能力:成员们讨论了 Aider 的功能,指出它在擅长代码“编辑”的 LLM 上表现出色,正如其排行榜所强调的那样。对于 Aider 基准测试的可靠性存在一些质疑,特别是关于 Gemini Pro 1.5 002 的部分。
- 虽然 Aider 展示了令人印象深刻的编辑能力,但进一步测试和验证的潜力对于获得社区更广泛的认可仍然至关重要。
- 欧盟 AI 法案引发对话:围绕欧盟 AI 法案的讨论升温,成员们就其对多模态 AI 监管的影响以及二级法规下的聊天机器人分类发表了不同看法。对科技公司监管负担的担忧十分普遍。
- 许多人强调,在应对合规环境时,必须明确新兴 AI 技术将如何受到这些法规的影响。
- Meta 在视频翻译领域的重大突破:一位成员强调了 Meta 即将发布的唇形同步视频翻译功能,旨在增强平台上的用户参与度。这一功能引发了关于其重塑内容创作工具潜力的讨论。
- 成员们对这如何提升翻译服务以及对全球内容可访问性的影响表示兴奋。
- GPT-4 语音模式的困惑:对 GPT-4o 表现的挫败感正在酝酿,在有人称其为“最笨的 LLM”后,出现了要求发布 GPT-4.5-o 的紧急呼声。批评集中在推理能力不足这一主要问题上。
- 在用户困惑中,关于每日限制和语音模式可访问性的详细讨论突显了社区对提升用户体验的期待。
- Flutter 代码执行错误已解决:一位用户遇到了指示线程
thread_ey25cCtgH3wqinE5ZqIUbmVT中存在活动运行的错误,导致了关于管理活动运行和使用cancel函数的建议。该用户最终通过在执行之间等待更长时间解决了问题。- 参与者建议加入状态参数来跟踪线程完成情况,这可能会简化线程管理并减少未来交互中的挫败感。
Eleuther Discord
- 新成员丰富社区动态:几位新成员加入,包括来自新加坡的全栈工程师和来自葡萄牙的数据工程师,渴望为 AI 项目和开源倡议做出贡献。
- 他们对协作的热情为社区发展奠定了良好的基调。
- AI 会议即将召开:成员们讨论了即将举行的会议,如 ICLR 和 NeurIPS,特别是新加坡将主办 ICLR,并正在计划聚会。
- 关于活动安保角色的轻松对话为协调工作增添了趣味。
- Liquid AI 发布基础模型:Liquid Foundation Models 正式发布,展示了强大的基准测试分数和针对不同行业优化的灵活架构。
- 这些模型专为各种硬件设计,邀请用户在 Liquid AI 的平台上进行测试。
- 探索 vLLM 指标提取:一位成员询问如何使用基准测试上的
simple_evaluate函数从 lm-evaluation-harness library 中提取 vLLM metrics objects。- 他们特别寻求诸如 time to first token 和 time in queue 等指标,引发了社区的有益回应。
- ExecuTorch 增强设备端 AI 能力:根据平台概述,ExecuTorch 允许在各种设备(包括 AR/VR 和移动系统)上定制和部署 PyTorch 程序。
- 分享了关于
executorchpip 包的详细信息,该包目前处于 Python 3.10 和 3.11 的 Alpha 阶段,兼容 Linux x86_64 和 macOS aarch64。
- 分享了关于
Torchtune Discord
- 优化 Torchtune 训练配置:用户针对 Llama 3.1 8B 微调了各种设置,优化了
batch_size、fused和fsdp_cpu_offload等参数,在启用packed=True时缩短了 epoch 时间。- ……大家一致认为
enable_activation_checkpoint应保持为False以提升计算效率。
- ……大家一致认为
- 对动态 CLI 方案的需求:有人提议使用
tyro库创建一个动态 CLI,允许根据 Torchtune recipes 中的配置设置自定义帮助文本。- 这种灵活性旨在通过清晰的文档增强用户体验并简化 recipe 管理。
- 内存优化策略揭晓:成员们建议更新内存优化页面,同时包含性能和内存优化技巧,提倡一种更集成的方法。
- 实施 sample packing 和探索 int4 training 等想法被强调为提升内存效率的潜在增强方案。
- 分布式训练的错误处理增强:有人建议利用
torch.distributed的 record 工具记录异常,从而改进分布式训练中的错误处理。- 这种方法通过在整个训练过程中维护全面的错误日志,使故障排除变得更加容易。
- 配置管理中的重复键问题:关于 OmegaConf 标记配置中重复条目(如
fused=True)的讨论引发了关注,强调了保持配置文件整洁有序的重要性。- 我们应该在配置中添加一个性能部分, 将快速选项放在注释中,以提高可读性和即时访问性。
Latent Space Discord
- CodiumAI 获得 A 轮融资并更名:QodoAI(原名 CodiumAI)获得了 4000 万美元 的 A 轮融资,总融资额达到 5000 万美元,用于增强 AI-assisted tools。
- “这笔资金验证了他们的路线”,表明开发者支持他们确保代码完整性的使命。
- Liquid Foundation Models 宣称拥有令人印象深刻的基准测试结果:LiquidAI 推出了 LFMs,展示了在 MMLU 和其他基准测试中的卓越性能,并指出了竞争对手的效率低下。
- 凭借来自 MIT 的团队成员,其 1.3B model 架构将挑战行业内的既有模型。
- Gradio 实现实时 AI 语音交互:LeptonAI 展示了 Gradio 5.0,其中包括 LLM 的音频模式实时流媒体,简化了代码集成。
- 这些更新使开发者能够轻松创建交互式应用程序,鼓励开源协作。
- Ultralytics 发布 YOLO11:Ultralytics 推出了 YOLO11,对先前版本进行了增强,提高了computer vision tasks中的准确性和速度。
- 此次发布标志着其 YOLO 模型演进的关键一步,展示了实质性的性能提升。
- 播客听众要求更多研究员参与:最新一期节目邀请了 Shunyu Yao 和 Harrison Chase,吸引了渴望在未来节目中看到更多研究员参与的听众的兴趣。
- 互动凸显了听众的热情,评论如“邀请更多研究员来”,敦促进行更深入的讨论。
LlamaIndex Discord
- 用于公共金融数据的 FinanceAgentToolSpec:LlamaHub 上的 FinanceAgentToolSpec 软件包允许 Agent 访问来自 Polygon 和 Finnhub 等来源的公共金融数据。
- Hanane 的详细帖子强调了该工具如何通过查询来简化金融分析。
- 全栈 Demo 展示流式事件:一个新的 全栈应用程序 展示了具有 Human In The Loop 功能的流式事件 (Streaming Events) 工作流。
- 该应用演示了如何研究和展示一个主题,显著提升了用户参与度。
- YouTube 教程增强对工作流的理解:一段 YouTube 视频 提供了开发者对全栈 Demo 编码过程的演练。
- 该资源旨在帮助那些希望实现类似流式系统的开发者。
- 应对 RAG Pipeline 评估挑战:用户报告了使用 trulens 进行 RAG Pipeline 评估时遇到的问题,特别是关于导入错误和数据检索的问题。
- 这引发了关于构建坚实的评估数据集以进行准确评估的重要性讨论。
- 理解 LLM 推理问题:定义推理问题的类型对于处理 LLM 推理至关重要,正如一篇分享的文章中所详述的推理类型。
- 文章强调,各种推理挑战需要量身定制的方法才能进行有效的评估。
Cohere Discord
- Cohere Startup Program 提供折扣:一位用户询问了使用 Cohere 的创业团队的折扣情况,并提到了与 Gemini 相比的成本。建议他们申请 Cohere Startup Program 以寻求潜在的减免。
- 参与者提到申请过程可能需要时间,但他们肯定了这种支持对早期创业公司的重要性。
- 通过 Fine-tuning 改进抽认卡生成:成员们讨论了专门针对笔记和幻灯片生成抽认卡 (Flash Card) 的 Fine-tuning 模型,以解决输出清晰度的问题。建议采用机器学习 Pipeline 的最佳实践,并利用 Chunking data 来获得更好的结果。
- Chunking 被强调为非常有益,特别是对于处理 PDF 幻灯片,能增强模型的理解和定性输出。
- 文化多语言 LMM 基准测试发布:MBZUAI 正在开发一个针对 100 种语言 的 Cultural Multilingual LMM Benchmark,并正在积极寻求母语翻译志愿者进行纠错。成功的参与者将被邀请共同撰写最终论文。
- 语言范围包括 印度、南亚、非洲 和 欧洲 语言,感兴趣的人士可以通过 LinkedIn 与项目负责人联系。
- 用于 LLM Prompt 的 RAG Header 格式化:用户寻求关于 RAG Prompt 的 Instructional Headers 格式化指导,以确保 LLM 正确解释输入。讨论强调了精确的辅助信息和正确的 Header 终止方法的必要性。
- 对话强调了格式的清晰度如何减少模型响应中的错误,从而增强与 LLM 的交互。
- 发现 API 文档中的缺失:一位用户注意到 API 文档中关于惩罚范围的不一致,呼吁对参数值建立更清晰的标准。这次对话反映了用户在利用 API 功能时对 文档一致性 和清晰度的持续关注。
- 关于从 v1 迁移到 v2 API 的讨论证实,虽然旧功能仍然保留,但系统性的更新对于平滑过渡至关重要。
Interconnects (Nathan Lambert) Discord
- OpenAI 因薪酬需求引发的人才流失:OpenAI 的核心研究人员正在寻求更高的薪酬,随着公司估值的上升,通过出售利润单位已套现 12 亿美元。由于 Safe Superintelligence 等竞争对手积极招募人才,这种人员流动进一步加剧。
- 员工因资金问题威胁辞职,而新任 CFO Sarah Friar 正在处理这些谈判。
- 加州州长否决 AI 安全法案 SB 1047:州长 Gavin Newsom 否决了旨在监管 AI 公司的法案,声称这不是保护公众的最佳方法。批评者认为这是监管的挫折,而支持者则推动基于特定能力的监管。
- 参议员 Scott Wiener 对州长缺乏事先反馈表示失望,强调加州失去了在技术监管方面领先的机会。
- PearAI 面临代码窃取指控:PearAI 被指控从 Continue.dev 窃取代码并在未致谢的情况下重新包装,敦促 YC 等投资者推动问责。这引发了关于初创生态系统内资金来源的重大伦理担忧。
- 这一争议突显了人们对开源社区完整性及其被新兴技术公司对待方式的持续关注。
- 关于 OpenAI 研究透明度的辩论:批评者质疑 OpenAI 的透明度,强调引用博客并不等同于对研究结果的实质性沟通。一些员工则断言公司对他们的研究确实是开放的。
- 讨论突显了人们对于 OpenAI 的研究博客 是否充分解决了社区对透明度担忧的复杂情绪。
- 关于 iPhone IAP 订阅访问的见解:一位 Substack 畅销作者宣布获得了 iPhone In-App Purchase (IAP) 订阅的访问权限,预示着移动端变现的新机会。这一进展为实施和管理这些系统提供了见解。
- 讨论反映了开发者对管理 Apple App Store 混乱环境的挫败感以及他们在处理其复杂性方面的经验。
LLM Agents (Berkeley MOOC) Discord
- 课程材料已开放获取:学生可以在 课程网站 上访问所有课程材料,包括作业和讲座录像,提交截止日期定为 12 月 12 日。
- 定期检查网站以获取材料更新也非常重要。
- Multi-Agent 系统 vs. Single-Agent 系统:讨论中出现了在项目背景下需要 Multi-Agent 系统而非 Single-Agent 实现的需求,以减少幻觉并管理上下文。
- 参与者指出,这些系统可能会从 LLM 中获得更准确的响应。
- 对 NotebookLM 能力的好奇:成员询问 NotebookLM 是否作为 Agent 应用运行,揭示了它作为一个 RAG Agent,可以总结文本并生成音频。
- 关于其技术实现,特别是在多步流程中的实现,也出现了一些问题。
- 等待培训时间表确认:学生们渴望确认培训课程何时开始,其中一人指出所有实验预计将在 10 月 1 日发布。
- 然而,这一时间表尚未得到官方确认。
- 探索 Super-Alignment 研究:一个拟议的研究项目正在讨论中,旨在利用 AutoGen 等框架研究 Multi-Agent 系统中的伦理问题。
- 提出了在没有专用框架的情况下实施该研究的挑战,突显了模拟能力的局限性。
tinygrad (George Hotz) Discord
- 云存储成本与主流供应商相比具有竞争力:George 提到,存储和出站流量成本 (egress costs) 将低于或等于主流云供应商,并强调了成本考量。
- 他进一步解释说,对使用情况的预期可能会显著改变感知的成本。
- Modal 的付费模式引发辩论:Modal 独特的按秒计费算力资源定价吸引了关注,被吹捧为比传统的按小时计费更便宜。
- 成员们质疑这种模式的可持续性,以及它如何与 AI 初创公司环境中持续的使用模式保持一致。
- 使用状态机改进 tinygrad 的 Matcher:一位成员建议实现一个匹配器状态机 (matcher state machine) 可以提高性能,使其趋向于类 C 的效率。
- George 热情地支持这种方法,表示它可以实现预期的性能提升。
- 需要全面的回归测试:有人对优化器缺乏回归测试套件 (regression test suite) 表示担忧,这可能导致代码更改后出现未被察觉的问题。
- 成员们讨论了通过序列化来检查优化模式的想法,但意识到这可能并不吸引人。
- 悬赏任务不强制要求 SOTA GPU:一位成员建议,虽然 SOTA GPU 会有帮助,但使用普通的 GPU 也能应付,尤其是对于某些任务。
- 某些任务(如 tinygrad 中 100+ TFLOPS 的 matmul)可能需要特定的硬件(如 7900XTX),而其他任务则不需要。
OpenAccess AI Collective (axolotl) Discord
- Llama 3.2 微调遭遇显存 (VRAM) 瓶颈:用户在微调 Llama 3.2 1b 时,使用 qlora 和 4bit 加载等设置面临 24GB 的高显存占用,引发了关于平衡序列长度和 batch size 的讨论。
- 担忧特别集中在样本打包 (sample packing) 的影响上,强调了在微调配置中进行优化的必要性。
- 加州强制要求 AI 训练透明化:一项新的加州法律现在要求披露所有 AI 模型的训练来源,即使是较小的非营利组织也不例外。
- 这促使人们开始讨论利用轻量级聊天模型来创建合规数据集,社区成员正在集思广益潜在的变通方案。
- 轻量级聊天模型受到关注:成员们正在探索从网页爬取的数据集中微调轻量级聊天模型,旨在满足法律转换标准。
- 一位用户指出,通过 LLM 优化凌乱的原始网页爬取数据可能是该过程中的重要下一步。
- Liquid AI 引发好奇:新基础模型 Liquid AI 的推出因其潜在特性和应用引起了成员们的兴趣。
- 成员们热衷于讨论立法变化对该模型意味着什么,以及结合近期发展的实际影响。
- 在 Axolotl 中最大化数据集利用率:在 Axolotl 中,通过调整数据集设置中的
split选项,可以将数据集配置为使用前 20% 进行训练。- 由于 Axolotl 直接缺乏随机样本选择功能,用户必须对数据进行预处理,在加载前利用 Hugging Face 的
datasets进行随机子集采样。
- 由于 Axolotl 直接缺乏随机样本选择功能,用户必须对数据进行预处理,在加载前利用 Hugging Face 的
DSPy Discord
- DSPy 展示实时 Pydantic 模型生成:一场实况编程演示了如何使用 Groq 和 GitHub Actions 创建一个免费的 Pydantic 模型生成器。
- 参与者可以在分享的 Loom 视频中观看详细演示。
- 升级到 DSPy 2.5 带来显著改进:切换到带有 LM client 的 DSPy 2.5,并使用 Predictor 代替 TypedPredictor,显著提升了性能并减少了问题。
- 关键的增强源于新的 Adapters,它们现在对 chat LMs 有更好的感知能力。
- OpenSearchRetriever 准备好分享:如果社区表现出兴趣,一位成员愿意分享他们为 DSPy 开发的 OpenSearchRetriever for DSPy。
- 该项目可以简化集成和功能实现,社区鼓励他们提交一个 PR。
- 医疗欺诈分类中的挑战:一位成员在准确分类 DOJ(美国司法部)新闻稿中的医疗欺诈时遇到困难,导致了误分类。
- 社区讨论了细化分类标准,以提高这一关键领域的准确性。
- 解决长 Docstring 引起的困惑:在使用 docstrings 进行长解释时出现了困惑,影响了类签名的准确性。
- 成员们就清晰文档的重要性提供了见解,但用户需要明确所使用的语言模型。
OpenInterpreter Discord
- 全栈开发人员寻求项目:一位全栈开发人员正在寻找新客户,擅长使用 React + Node 和 Vue + Laravel 技术构建电子商务平台、在线商店和房地产网站。
- 他们对长期合作的讨论持开放态度。
- 关于重新指令 AI 执行的询问:一位成员询问是否可以修改 AI 执行指令,以便用户能够独立修复和调试问题,并指出了频繁出现的路径相关错误。
- 成员对当前系统的能力表达了明显的挫败感。
- 持续的解码数据包错误:用户报告了一个反复出现的解码数据包问题,在服务器重启或客户端连接期间出现错误消息:Invalid data found when processing input。
- 虽然建议检查终端错误消息,但未发现任何信息,表明问题具有持续性。
- Ngrok 身份验证困难:一位成员在执行服务器时遇到了 ngrok 身份验证错误,要求提供验证过的账户和 authtoken。
- 他们怀疑问题可能与 .env 文件未能正确读取 apikey 有关,并就此寻求帮助。
- Jan AI 作为计算机控制接口:一位成员分享了将 Jan AI 与 Open Interpreter 结合使用作为本地 LLMs 的本地推理服务器的见解,并邀请他人分享经验。
- 他们提供了一个 YouTube 视频,展示了 Jan 如何通过接口控制计算机。
LAION Discord
- 征集法语音频数据集:一位用户需要高质量的法语音频数据集来训练 CosyVoice,并强调了获取合适数据集的紧迫性。
- 他们表示,如果没有合适的数据集,不确定项目能否继续推进。
- LAION 在版权挑战中获胜:LAION 在德国法院赢得了一场重大的版权侵权挑战,为 AI 数据集的法律障碍树立了先例。
- 进一步的讨论强调了这次胜利的影响,详情可以在 Reddit 上找到。
- 使用 Phenaki 探索文本转视频:成员们探索了用于从文本生成视频的 Phenaki 模型,并分享了一个用于初步测试的 GitHub 链接。
- 由于缺乏数据集,他们请求关于测试其能力的指导。
- 视觉语言与潜在扩散模型之间的协同作用:讨论围绕结合 VLM(视觉语言模型)和 LDM(潜在扩散模型)以增强图像生成的潜力展开。
- 提出了一个理论循环,即由 VLM 指导 LDM,从而有效优化输出质量。
- 澄清 PALM-RLHF 数据集的实现:一位成员询问了关于为特定任务定制 PALM-RLHF 训练数据集的合适频道。
- 他们的目标是明确如何使这些数据集与操作需求保持一致。
LangChain AI Discord
- Vectorstores 可以使用示例问题:一位成员建议,加入示例问题可能会增强 Vectorstore 在寻找最接近匹配时的性能,尽管这可能被认为有些过度。
- 他们强调了测试的重要性,以衡量这种方法的实际有效性。
- 对于 LLMs 而言,数据库优于表格数据:一位成员指出,从表格数据切换到 Postgres 数据库更适合 LLMs,这促使他们利用 LangChain 模块进行交互。
- 这一转变旨在优化模型训练和查询的数据处理。
- 在 Discord 中探索感谢礼物:有人询问了向提供帮助的 Discord 成员发送小型感谢礼物的可行性。
- 这反映了致谢贡献并建立社区纽带的愿望。
- Gemini 突然出现图像错误:一位成员报告了向 Gemini 发送图像时出现的意外错误,并指出该问题是在最近升级了所有 pip 包之后出现的。
- 这种情况引发了对升级后潜在兼容性问题的担忧。
- 使用 LangChain 修改推理方法:一位成员正在研究使用 LangChain 修改聊天模型的推理方法,重点关注 vllm 中的优化。
- 他们寻求控制 token 解码,特别是围绕聊天历史和输入调用(input invocation)。
MLOps @Chipro Discord
- 2024 年 AI Realized 峰会定于 10 月 2 日举行:由 Christina Ellwood 和 David Yakobovitch 在 UCSF 主办的 AI Realized - 企业级 AI 峰会 备受期待,届时将有企业级 AI 领域的行业领袖出席。
- 参会者可以使用代码 extra75 在购票时立减 $75,门票包含会议期间的膳食。
- Manifold Research 前沿讲座启动:Manifold Research 正在推出 Frontiers 系列讲座,以展示基础和应用 AI 领域的创新工作,首场讲座由 Helen Lu 主讲,重点关注神经符号 AI 和人机协作。
- 讲座将讨论自主 Agent 在动态环境中面临的挑战,并开放免费注册,链接在此处。
- 咨询斯德哥尔摩的 MLOps 聚会:一位最近搬到斯德哥尔摩的成员正在寻找该市关于 MLOps 或基础设施的聚会信息。
- 他们表达了与当地技术社区建立联系并了解即将举行的活动的愿望。
DiscoResearch Discord
- Calytrix 推出 anti-slop 采样器:一个原型 anti-slop 采样器通过对检测到的序列进行回溯,在推理过程中抑制不需要的词汇。Calytrix 旨在使该代码库可用于下游用途,该项目已在 GitHub 上发布。
- 这种方法旨在通过减少生成输出中的噪声来直接提高数据集质量。
- 社区支持 anti-slop 概念:成员们对 anti-slop 采样器分享了积极的反馈,其中一位评论道:“太酷了,我喜欢这个主意!”,强调了其潜在影响。
- 这种热情表明人们对优化数据集生成过程的解决方案越来越感兴趣。
Mozilla AI Discord
- Takiyoshi Hoshida 展示 SoraSNS:独立开发者 Takiyoshi Hoshida 将现场演示他的项目 SoraSNS,这是一款社交媒体应用,提供来自你通常不关注的用户的私人时间线。
- 演示强调了该应用独特的昼夜天空概念,象征着开放和远距离观察,以增强用户体验。
- Hoshida 令人印象深刻的技术背景:Takiyoshi Hoshida 曾在卡内基梅隆大学学习计算机科学,这为他打下了坚实的技术基础。
- 他拥有丰富的经验,此前曾在苹果的 AR Kit 团队工作,并参与了超过 50 个 iOS 项目。
Gorilla LLM (Berkeley Function Calling) Discord
- Hammer Handle 变得更好了:Hammer Handle 进行了更新,在设计和功能上引入了增强。期待在这个迭代版本中看到许多令人兴奋的改进。
- 此次更新标志着团队致力于不断提高工具的可用性。
- 了解 Hammer2.0 系列模型:团队推出了 Hammer2.0 系列模型,包括 Hammer2.0-7b、Hammer2.0-3b、Hammer2.0-1.5b 和 Hammer2.0-0.5b。
- 这些模型标志着开发应用产品多样化方面的重要进展。
- 提交了新的 Pull Request PR#667:作为 Hammer 产品线程序化更新的一部分,已提交了一个 Pull Request (PR#667)。这次提交对正在进行的开发过程至关重要。
- 该 PR 旨在整合最近的增强功能和来自社区的反馈。
第 2 部分:按频道划分的详细摘要和链接
完整的逐频道细分内容已针对电子邮件进行了截断。
如果您喜欢 AInews,请与朋友分享!提前致谢!